
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | classiq | 1.2.0 | Classiq's Python SDK for quantum computing | <p align="center">
<a href="https://www.classiq.io">
<img src="https://uploads-ssl.webflow.com/60000db7a5f449af5e4590ac/6122b22eea7a9583a5c0d560_classiq_RGB_Green_with_margin.png" alt="Classiq">
</a>
</p>
<p align="center">
<em>The Classiq Quantum Algorithm Design platform helps teams build sophisticated quantum circuits that could not be designed otherwise</em>
</p>
Classiq does this by synthesizing high-level functional models into optimized quantum
circuits, taking into account the constraints that are important to the designer.
Furthermore, Classiq is able to generate circuits for practically any universal gate-based
quantum computer and is compatible with most quantum cloud providers.
For information about Classiq's SDK, see the
[documentation](https://docs.classiq.io/latest/getting-started/python-sdk/).
## License
See [license](https://classiq.io/license).
| text/markdown | Classiq Technologies | Classiq Technologies <support@classiq.io> | null | null | null | quantum computing, quantum circuits, quantum algorithms, QAD, QDL | [
"Development Status :: 4 - Beta",
"License :: Other/Proprietary License",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: Other/Proprietary License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Progra... | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"configargparse<2,>=1.5.3",
"pydantic<3,>=2.10.4",
"keyring<24,>=23.5.0",
"pyomo<6.10,>=6.9",
"httpx<1,>=0.23.0",
"packaging~=23.2",
"numpy<2,>=1.26.4; python_full_version < \"3.10\"",
"numpy<3.0.0; python_full_version >= \"3.10\"",
"networkx<4.0.0,>=3.2.0",
"matplotlib<4,>=3.4.3",
"tabulate<1,>... | [] | [] | [] | [
"documentation, https://docs.classiq.io/",
"examples, https://github.com/Classiq/classiq-library",
"homepage, https://classiq.io"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-18T11:27:53.830117 | classiq-1.2.0-py3-none-any.whl | 640,426 | 53/d9/c08bd3d23bbd0b90aa233c1e6f947bd32760980942f3d1f1474e8007779f/classiq-1.2.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 3d3d41ffcbd0093eb6d8d115dded420d | edd45aa65cfda309e70d1e7207a04f72b49e7a918b995d123e85a74490122544 | 53d9c08bd3d23bbd0b90aa233c1e6f947bd32760980942f3d1f1474e8007779f | null | [
"LICENSE.txt"
] | 230 |
2.4 | aifastdb | 0.1.0 | Python bindings for AiFastDb - High-performance AI-friendly database engine | # aifastdb
Python bindings for **AiFastDb** — a high-performance AI-friendly database engine written in Rust.
[](https://pypi.org/project/aifastdb/)
[](https://pypi.org/project/aifastdb/)
[](LICENSE)
## Features
- **Core Database** — Key-value store with HNSW vector search, batch operations, and hybrid (text + vector) recall
- **SocialGraphV2** — Social network graph with path finding, network analysis, family trees, and concurrent sharding
- **DocumentStore** — JSONL-based document store with tag/type indexing and async flush
- **Federation** — Heterogeneous storage federation (Graph + Document + Vector) with cross-database queries and 2PC transactions
- **Embedding** — Built-in embedding generation (dummy / MiniLM / BGE / Gemma) with numpy output
- **Reasoning** — LLM-based reasoning via Ollama or OpenAI (intent, logic, summarize)
- **pandas integration** — One-line DataFrame conversion for any query result
## Installation
```bash
pip install aifastdb
# With optional extras:
pip install aifastdb[pandas] # pandas DataFrame support
pip install aifastdb[numpy] # numpy array support
pip install aifastdb[all] # everything
```
## Requirements
- Python >= 3.8
- No additional dependencies for core functionality (self-contained Rust binary)
## Quick Start
### Core Database
```python
from aifastdb import AiFastDb
with AiFastDb("./my_db") as db:
# Store a memory
db.remember("doc1", "The quick brown fox", tags=["animal", "classic"])
# Retrieve by ID
doc = db.get("doc1")
print(doc["content"]) # "The quick brown fox"
# Hybrid search (text + vector)
results = db.recall(query="brown fox")
for r in results:
print(f" {r['node']['id']} score={r['score']:.3f}")
# Delete
db.forget("doc1")
```
### Social Graph
```python
from aifastdb import SocialGraphV2
with SocialGraphV2("./social_data") as sg:
# Create people
alice = sg.add_person({"name": "Alice", "age": 30})
bob = sg.add_person({"name": "Bob", "age": 28})
carol = sg.add_person({"name": "Carol", "age": 32})
# Add friendships
sg.add_friend(alice["id"], bob["id"])
sg.add_friend(bob["id"], carol["id"])
# Find shortest path
path = sg.find_path(alice["id"], carol["id"])
print(f"Path hops: {path['hops']}")
# Mutual friends
mutual = sg.get_mutual_friends(alice["id"], carol["id"])
print(f"Mutual friends: {[m['name'] for m in mutual]}")
# Network stats
stats = sg.get_network_stats(bob["id"])
print(f"Bob's degree centrality: {stats['degree_centrality']:.2f}")
```
### Document Store
```python
from aifastdb import DocumentStore
with DocumentStore("./docs.jsonl") as store:
store.put("note-1", "Meeting at 3pm", doc_type="note", tags=["work"])
store.put("note-2", "Buy groceries", doc_type="note", tags=["personal"])
# Query by tag
work_notes = store.find_by_tag("work")
print(f"Work notes: {len(work_notes)}")
# All documents
all_docs = store.all()
print(f"Total documents: {len(all_docs)}")
```
### Federation (Multi-Store)
```python
from aifastdb import Federation
with Federation() as fed:
fed.register_graph("social", "./social_data")
fed.register_document("docs", "./docs.jsonl")
# Query across stores
result = fed.query("social", {"target": "person", "limit": 10})
print(f"Found {result['total']} persons")
# Write to document store
fed.write("docs", {
"op": "CreateDocument",
"id": "fed-doc-1",
"content": "Created via federation",
"doc_type": "note",
})
# Cross-store transaction
tx = fed.begin_transaction(["social", "docs"])
tx.write("social", {"op": "CreateEntity", "name": "Eve", "entity_type": "person"})
tx.write("docs", {"op": "CreateDocument", "id": "eve-doc", "content": "Eve's note"})
tx.commit()
```
### Embedding Engine
```python
from aifastdb import EmbeddingEngine
import numpy as np
engine = EmbeddingEngine() # dummy 384d engine
# Single embedding
vec = engine.embed("Hello, world!")
print(f"Dimension: {len(vec)}")
# Numpy output
arr = engine.embed_numpy("Hello, world!")
print(f"Shape: {arr.shape}, dtype: {arr.dtype}")
# Batch
vecs = engine.embed_batch(["Hello", "World", "Foo"])
print(f"Batch size: {len(vecs)}")
# Cosine similarity
sim = EmbeddingEngine.cosine_similarity(
engine.embed("cat"),
engine.embed("dog"),
)
print(f"Similarity: {sim:.4f}")
```
### Perception Pipeline (Embed + Remember)
```python
from aifastdb import PerceptionPipeline, DocumentStore
pipe = PerceptionPipeline()
# Auto-embed content
result = pipe.remember_with_embedding(
"The mitochondria is the powerhouse of the cell",
"bio-001",
tags=["biology"],
)
print(f"Embedding dim: {result['dimension']}")
# Store the result in a DocumentStore
with DocumentStore("./knowledge.jsonl") as store:
store.put(
result["id"],
result["content"],
tags=result["tags"],
doc_type=result["doc_type"],
)
```
### pandas Integration
```python
from aifastdb import SocialGraphV2, DocumentStore
from aifastdb.pandas_ext import to_dataframe, graph_to_dataframes
# SocialGraph → DataFrame
with SocialGraphV2("./social_data") as sg:
persons_df = to_dataframe(sg.list_persons())
print(persons_df[["id", "name", "age"]])
entities_df, relations_df = graph_to_dataframes(sg.export_graph())
print(f"Entities: {len(entities_df)}, Relations: {len(relations_df)}")
# DocumentStore → DataFrame
with DocumentStore("./docs.jsonl") as store:
docs_df = to_dataframe(store.all())
print(docs_df.head())
```
## API Reference
### Core Classes
| Class | Description |
|-------|-------------|
| `AiFastDb` | Core database with collections, CRUD, and hybrid search |
| `Collection` | Named collection within AiFastDb |
| `SocialGraphV2` | Social graph with path finding and network analysis |
| `DocumentStore` | JSONL document store with tag/type indexing |
| `Federation` | Multi-store federation with unified query/write |
| `FederatedTransaction` | Cross-store 2PC transaction |
| `EmbeddingEngine` | Vector embedding generation |
| `ReasoningEngine` | LLM-based reasoning (Ollama/OpenAI) |
| `PerceptionPipeline` | Combined embedding + reasoning pipeline |
### Exception Hierarchy
```
RuntimeError
└── AiFastDbError
├── StoreNotFoundError
├── RecordNotFoundError
├── QueryError
├── WriteError
├── TransactionError
├── StorageError
├── CircuitBreakerError
└── RateLimitError
```
## Development
```bash
# Install Rust toolchain
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# Clone and build
git clone https://github.com/aifastdb/aifastdb.git
cd aifastdb/packages/python
# Create venv and install in dev mode
python -m venv .venv
source .venv/bin/activate # or .venv\Scripts\activate on Windows
pip install maturin numpy pandas pytest
maturin develop --release
# Run tests
python -m pytest tests/ -v
```
## License
See [LICENSE](LICENSE) for details. Free for personal, educational, and non-commercial use. Commercial use requires a separate license.
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | null | database, vector-search, graph, federation, ai | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Lang... | [] | null | null | >=3.8 | [] | [] | [] | [
"pandas>=1.3; extra == \"all\"",
"numpy>=1.20; extra == \"all\"",
"pytest>=7.0; extra == \"dev\"",
"pandas>=1.3; extra == \"dev\"",
"numpy>=1.20; extra == \"dev\"",
"numpy>=1.20; extra == \"numpy\"",
"pandas>=1.3; extra == \"pandas\""
] | [] | [] | [] | [
"Homepage, https://www.aifastdb.com"
] | twine/6.2.0 CPython/3.10.11 | 2026-02-18T11:27:09.394712 | aifastdb-0.1.0.tar.gz | 1,130,637 | b2/dc/3e8f6beeccf3f4de241c0f5445e1c1f5469f1e94c28b9cafa6f444c4d1e8/aifastdb-0.1.0.tar.gz | source | sdist | null | false | 76b0888213a4eac06017d24b46810905 | d209b5e04a63e220a7178f60aaacc0155c42fe53025ec553edfebd0984be7a49 | b2dc3e8f6beeccf3f4de241c0f5445e1c1f5469f1e94c28b9cafa6f444c4d1e8 | null | [
"LICENSE"
] | 290 |
2.4 | filemapper | 1.0.2 | A CLI tool for mapping and transforming CSV files based on YAML configuration | # FileMapper
A CSV transformation tool controlled by YAML configuration. Use this tool to transform, validate,
map, and convert CSV data without writing code.
## Core Capabilities
- **Column mapping**: Rename, copy, or combine columns
- **Data validation**: Type checking, regex patterns, numeric ranges, required fields
- **Transformations**: Text case, trimming, whitespace removal
- **Type conversion**: String ↔ integer, float, boolean, date
- **Conditional logic**: If-then rules with multiple conditions
- **Expressions**: Arithmetic, comparisons, boolean logic
- **String matching**: `contains` and `icontains` (case-insensitive) operators
- **Cross-referencing**: Later mappings can reference already-mapped output columns
## Installation
### From PyPi
```shell
pip install -U filemapper
```
## Command Reference
### Basic Usage
```shell
# Transform CSV with configuration
filemapper -i input.csv -c config.yaml -o output.csv
# Validate input data only
filemapper -i input.csv -c config.yaml --validate-only
# Strict mode (fail on first error)
filemapper -i input.csv -c config.yaml -o output.csv --strict
```
### All Command Options
| Option | Required | Default | Description |
| --------------------- | ----------- | ------- | --------------------------------------------- |
| `-i, --input FILE` | Yes | - | Input CSV file path |
| `-c, --config FILE` | Yes | - | YAML configuration file path |
| `-o, --output FILE` | Conditional | - | Output CSV file path |
| `--validate-only` | No | false | Validate input against schema, then exit |
| `--version` | No | - | Print the version number |
| `--strict` | No | false | Stop processing on first validation/map error |
| `--encoding ENCODING` | No | utf-8 | Character encoding for all files |
| `--delimiter CHAR` | No | `,` | CSV delimiter character |
`--output` is required unless using `--validate-only`
## YAML Configuration Structure
Every configuration file requires exactly four top-level keys: `version`, `input`, `output`,
`mappings`.
### Configuration Skeleton
```yaml
version: "1.0"
input:
columns:
- name: column_name
type: string # string | integer | float | boolean | date
required: true # optional, default: false
pattern: "regex" # optional, regex validation
min: 0 # optional, numeric minimum
max: 100 # optional, numeric maximum
output:
columns:
- name: output_column
type: string
mappings:
- output: output_column
source: column_name # Use ONE of: source, value, expression, or conditions
```
### Input Schema Definition
Define expected columns with validation rules:
```yaml
input:
columns:
- name: age # Column name in input CSV
type: integer # Data type
required: true # Validation will fail if missing
min: 0 # Numeric range validation
max: 150
- name: email
type: string
required: true
pattern: "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$" # Regex validation
```
**Validation types**: `string`, `integer`, `float`, `boolean`, `date`
**Optional validation rules**:
- `required: true/false` - Field must be present
- `pattern: "regex"` - String must match regex
- `min: number` - Numeric minimum value
- `max: number` - Numeric maximum value
### Output Schema Definition
Define output columns and their order:
```yaml
output:
columns:
- name: fullName # Column name in output CSV
type: string # Expected output type
- name: ageGroup
type: string
```
Columns appear in output CSV in the order listed here.
## Mapping Rules Reference
Each mapping rule produces **one output column**. Exactly one of these four sources is required:
`source`, `value`, `expression`, or `conditions`.
### 1. Source Mapping (Column Copy/Rename)
Copy a column directly, optionally renaming it:
```yaml
- output: firstName
source: first_name
```
### 2. Value Templates (String Building)
Build strings using `{field}` placeholders. Placeholders are replaced with input column values:
```yaml
# Combine multiple fields
- output: fullName
value: "{first_name} {last_name}"
# Static string
- output: status
value: "Active"
# Mix literals and fields
- output: greeting
value: "Hello, {first_name}!"
```
### 3. Expressions (Calculations)
Evaluate Python-like expressions with `{field}` references:
```yaml
# Boolean expression
- output: isAdult
expression: "{age} >= 18"
# Arithmetic
- output: total
expression: "{price} * {quantity}"
# Complex logic
- output: eligible
expression: "{age} >= 18 and {score} > 50"
```
**Supported operators**:
- Arithmetic: `+`, `-`, `*`, `/`, `//` (floor division), `%` (modulo), `**` (power)
- Comparison: `==`, `!=`, `<`, `<=`, `>`, `>=`
- Logical: `and`, `or`, `not`
- String matching:
- `contains` - case-sensitive substring check: `"{name} contains 'Smith'"`
- `icontains` - case-insensitive substring check: `"{os} icontains 'windows'"`
Numeric strings are auto-converted for arithmetic. Expressions are security-validated (no function
calls, imports, or attribute access allowed).
### 4. Conditional Logic
First matching `when` condition wins. Conditions support both `value` (template strings) and
`expression` (calculations):
```yaml
# Static values based on conditions
- output: ageGroup
conditions:
- when: "{age} < 18"
value: "Minor"
- when: "{age} >= 18 and {age} < 65"
value: "Adult"
- when: "{age} >= 65"
value: "Senior"
- default: "Unknown"
# Dynamic values (select different columns based on condition)
- output: primaryOS
conditions:
- when: "{X} == ''"
value: "{Y}" # Use Y if X is empty
- default: "{X}" # Otherwise use X
# String matching
- output: platform
conditions:
- when: "{os} contains 'Windows'" # Case sensitive matching
value: "Windows"
- when: "{os} icontains 'linux'" # Case insensitive matching
value: "Linux"
- default: "Other"
# Expressions in conditions (for calculated outputs)
- output: priorityScore
conditions:
- when: "{score} < 10"
value: "Low"
- when: "{score} >= 10"
expression: "{score} * 3" # Calculate value when condition matches
```
**Important**: Each condition can have either `value` OR `expression`, not both. Use `value` for
static or template strings, `expression` for calculations.
### 5. Text Transformations
Apply after value resolution, before type conversion:
```yaml
- output: email
source: email_address
transform: lowercase
```
**Available transforms**:
- `uppercase` - Convert to UPPERCASE
- `lowercase` - Convert to lowercase
- `trim` - Remove leading/trailing whitespace
- `titlecase` - Convert To Title Case
- `strip_whitespace` - Remove all whitespace
### 6. Type Conversions
Convert between data types with optional format strings:
```yaml
# String to date
- output: registrationDate
source: signup_date
type_conversion:
from: string
to: date
format: "%Y-%m-%d"
# Date to string
- output: formattedDate
source: date_field
type_conversion:
from: date
to: string
format: "%d/%m/%Y"
# String to boolean
- output: isActive
source: active_flag
type_conversion:
from: string
to: boolean
```
**Supported conversions**:
| From | To | Notes |
| ------- | ------- | ---------------------------------------------------------------- |
| string | integer | Must be valid integer |
| string | float | Must be valid number |
| string | boolean | Accepts: true/false, 1/0, yes/no, y/n, on/off (case-insensitive) |
| string | date | Requires `format` parameter (e.g., "%Y-%m-%d") |
| integer | string | Direct conversion |
| integer | float | Direct conversion |
| float | string | Direct conversion |
| float | integer | Truncates decimal |
| date | string | Requires `format` parameter |
| boolean | string | Outputs "True" or "False" |
### 7. Default Values
Provide fallback when source/value is empty or None. Supports `{field}` templates:
```yaml
# Static default
- output: region
source: country_code
default: "UNKNOWN"
transform: uppercase
# Dynamic default (use another field)
- output: displayName
source: nickname
default: "{first_name}"
```
### 8. Cross-Referencing Output Columns
Later mappings can reference **already-mapped output columns** using `{output_column_name}`:
```yaml
mappings:
- output: fullName
value: "{first_name} {last_name}"
- output: greeting
value: "Welcome, {fullName}!" # References the fullName output column
```
This enables multi-stage transformations where one mapping builds on another.
## Mapping Rule Processing Order
Within a single mapping rule, operations apply in this sequence:
1. **Resolve value** (source / value / expression / conditions)
2. **Apply default** if value is empty (with `{field}` template resolution)
3. **Apply text transformation**
4. **Apply type conversion**
## Template Placeholder Rules
Use `{field_name}` to reference columns in:
- `value` fields
- `expression` fields
- `conditions.value` fields
- `default` fields
**Important**: `{field_name}` can reference:
- Input columns (from CSV)
- Already-mapped output columns (earlier in mappings list)
## Example
The `examples/` directory contains the following files:
Input file: `examples/input.csv`
Configuration file: `examples/config.yaml`
Output file: `examples/output.csv`
The output file was created by running this command: `python filemapper.py -i ./examples/input.csv -c ./examples/config.yaml -o ./examples/output.csv`
## Error Handling and Exit Codes
### Error Modes
**Lenient mode (default)**: Collects all errors and continues processing
```shell
python3 filemapper.py -i input.csv -c config.yaml -o output.csv
```
- Validation errors are reported but processing continues
- Mapping errors are reported but successfully mapped rows are written
- Exit code 0 if any rows succeed, 1 if catastrophic failure
**Strict mode**: Stops on first error
```shell
python3 filemapper.py -i input.csv -c config.yaml -o output.csv --strict
```
- Stops immediately on first validation error
- Stops immediately on first mapping error
- Exit code 1 on any error
### Exit Codes
| Code | Meaning |
| ---- | ----------------------------- |
| 0 | Success |
| 1 | Error (validation or mapping) |
| 130 | Keyboard interrupt (Ctrl+C) |
### Error Output Format
Validation errors show:
- Row number
- Column name
- Validation rule violated
- Actual value received
Example:
```
✗ Validation failed with 2 error(s):
- Row 5: Column 'age': Value '200' exceeds maximum (150)
- Row 8: Column 'email': Value 'invalid' does not match pattern
```
Mapping errors show:
- Row number
- Output column being mapped
- Error description
Example:
```
✗ Mapping failed with 1 error(s):
- Row 3: Failed to map 'registrationDate': time data '2024-13-45' does not match format '%Y-%m-%d'
```
## Quick Reference for AI Agents
### Decision Tree: Which Mapping Type?
```text
Need to transform CSV data?
│
├─ Copy single column? → Use `source`
│ └─ Example: `source: first_name`
│
├─ Combine multiple columns or add text? → Use `value` template
│ └─ Example: `value: "{first_name} {last_name}"`
│
├─ Calculate or evaluate expression? → Use `expression`
│ └─ Example: `expression: "{price} * {quantity}"`
│
└─ Different outputs based on conditions? → Use `conditions`
└─ Example:
conditions:
- when: "{age} < 18"
value: "Minor"
- default: "Adult"
```
### Common Patterns
#### Pattern 1: Rename column
```yaml
- output: newName
source: oldName
```
#### Pattern 2: Normalise text
```yaml
- output: email
source: emailAddress
transform: lowercase
```
#### Pattern 3: Fill missing values
```yaml
- output: country
source: country_code
default: "US"
```
#### Pattern 4: Categorise numeric values
```yaml
- output: priceRange
conditions:
- when: "{price} < 10"
value: "Budget"
- when: "{price} < 50"
value: "Mid-range"
- default: "Premium"
```
#### Pattern 5: Combine and transform
```yaml
- output: fullName
value: "{first_name} {last_name}"
transform: titlecase
```
#### Pattern 6: Convert date formats
```yaml
- output: formattedDate
source: raw_date
type_conversion:
from: string
to: date
format: "%Y-%m-%d"
```
#### Pattern 7: Check if string contains substring
```yaml
- output: osType
conditions:
- when: "{operating_system} contains 'Windows'" # Case sensitive matching
value: "Windows"
- when: "{operating_system} icontains 'linux'" # Case insensitive matching
value: "Linux"
- default: "Other"
```
#### Pattern 8: Reference previously mapped output
```yaml
- output: firstName
source: first_name
- output: greeting
value: "Hello, {firstName}!" # References mapped output, not input
```
#### Pattern 9: Conditional with calculated values
```yaml
- output: adjustedScore
conditions:
- when: "{score} < 10"
value: "Low"
- when: "{score} >= 10 and {score} < 100"
expression: "{score} * 2" # Calculate when in range
- when: "{score} >= 100"
expression: "{score} * 1.5" # Different calculation for high scores
```
| text/markdown | null | Craig Hurley <craighurley78@gmail.com> | null | Craig Hurley <craighurley78@gmail.com> | null | csv, mapping, transform | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Natural Language :: English",
"Environment :: Console",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Utilities",
"Topic :: Text Processing"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"python-dateutil>=2.8.2",
"PyYAML>=6.0.1",
"pytest>=7.4.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"ruff>=0.15.1; extra == \"dev\"",
"yamllint>=1.38.0; extra == \"dev\"",
"build>=1.0.0; extra == \"deploy\"",
"setuptools>=68.0; extra == \"deploy\"",
"twine>=4.0.0; extra == \"deploy\... | [] | [] | [] | [
"Homepage, https://github.com/craighurley/filemapper",
"Repository, https://github.com/craighurley/filemapper",
"Issues, https://github.com/craighurley/filemapper/issues"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-18T11:26:55.004232 | filemapper-1.0.2.tar.gz | 35,559 | fd/c0/4cab272ad548b30b0a5f8921d3626b879ba552b76f0c435e815e47c9665f/filemapper-1.0.2.tar.gz | source | sdist | null | false | 8ec2b8ec9ead12cf527733d96dee27cc | a516ae795d9b4e695ae52f939479cced6253a355e9df513fcf30924261f68e77 | fdc04cab272ad548b30b0a5f8921d3626b879ba552b76f0c435e815e47c9665f | MIT | [
"LICENSE"
] | 272 |
2.4 | openclaw-notebooklm | 0.1.2 | NotebookLM MCP integration for OpenClaw - Automated installer and skill manager | # OpenClaw NotebookLM Integration
[](https://badge.fury.io/py/openclaw-notebooklm)
[](https://pypi.org/project/openclaw-notebooklm/)
[](https://opensource.org/licenses/MIT)
[](https://buymeacoffee.com/elihatdeveloper)
**One-command installer** for integrating Google NotebookLM with OpenClaw via MCP.
## What This Does
This package automatically sets up a NotebookLM skill in OpenClaw, allowing your AI agents to:
- 📚 List all your NotebookLM notebooks
- 📝 Create new notebooks with sources
- 🔍 Query notebooks with natural language
- 📊 Generate study guides
- 🔗 Add sources (URLs, text, files) to notebooks
## Quick Start
### Installation
```bash
pip install openclaw-notebooklm
```
### Setup
Run the installer:
```bash
openclaw-notebooklm-install
```
The installer will:
1. ✅ Check prerequisites (OpenClaw, Node.js)
2. 📦 Install dependencies (mcporter, notebooklm-mcp)
3. 🔐 Authenticate with NotebookLM (opens Chrome)
4. 📂 Create the skill in `~/.openclaw/skills/notebooklm/`
5. ⚙️ Configure OpenClaw to use the skill
6. 🔄 Restart the OpenClaw daemon
That's it! 🎉
## Usage
### From OpenClaw Agents
Start a new OpenClaw session and ask:
```
List my NotebookLM notebooks
```
```
Create a NotebookLM notebook called "AI Research" with this URL: https://example.com
```
```
Ask my "Project Notes" notebook: What are the key takeaways?
```
```
Generate a study guide for my "Machine Learning" notebook
```
### From Command Line
```bash
# List notebooks
~/.openclaw/skills/notebooklm/notebooklm.sh list
# Create a notebook
~/.openclaw/skills/notebooklm/notebooklm.sh create "My Notebook" source_url=https://example.com
# Query a notebook
~/.openclaw/skills/notebooklm/notebooklm.sh ask <notebook-id> "Summarize this"
# Generate study guide
~/.openclaw/skills/notebooklm/notebooklm.sh study_guide <notebook-id>
```
## Requirements
- **OpenClaw**: Must be installed and configured
- **Node.js**: Required for npm packages (mcporter, notebooklm-mcp)
- **Google Account**: For NotebookLM authentication
## How It Works
```mermaid
graph LR
A[OpenClaw Agent] --> B[notebooklm skill]
B --> C[notebooklm.sh wrapper]
C --> D[mcporter]
D --> E[notebooklm-mcp server]
E --> F[NotebookLM API]
```
1. **OpenClaw** loads the `notebooklm` skill
2. The skill uses a **wrapper script** to route commands
3. **mcporter** manages the MCP server lifecycle
4. **notebooklm-mcp** communicates with NotebookLM
5. Responses flow back to the agent
## Troubleshooting
### Skill not visible to agent
**Problem**: Agent says "I don't have the notebooklm skill"
**Solution**:
- Exit your current OpenClaw session
- Start a **new session** (skills are snapshot at session start)
### Authentication expired
**Problem**: "Error: Not authenticated to NotebookLM"
**Solution**:
```bash
notebooklm-mcp-auth
```
### mcporter not found
**Problem**: "mcporter: command not found"
**Solution**:
```bash
npm install -g mcporter
```
### Permission denied
**Problem**: Can't access mcporter config
**Solution**: The installer places config at `~/.openclaw/mcporter.json` which is accessible. If you move it, update the path in `~/.openclaw/openclaw.json`:
```json
{
"skills": {
"entries": {
"notebooklm": {
"env": {
"MCPORTER_CONFIG": "/path/to/your/mcporter.json"
}
}
}
}
}
```
## File Locations
After installation:
```
~/.openclaw/
├── skills/
│ └── notebooklm/
│ ├── SKILL.md # Skill metadata
│ └── notebooklm.sh # Wrapper script
├── mcporter.json # mcporter config
└── openclaw.json # Updated with skill entry
~/.notebooklm-mcp/
└── auth.json # NotebookLM auth tokens
```
## Development
### Local Installation
```bash
git clone https://github.com/elihat2022/openclaw-notebooklm.git
cd openclaw-notebooklm
pip install -e .
```
### Run Installer
```bash
openclaw-notebooklm-install
```
### Uninstall
```bash
# Remove the skill
rm -rf ~/.openclaw/skills/notebooklm
# Remove config entries (manual edit)
# Edit ~/.openclaw/openclaw.json and remove the "notebooklm" entry
# Restart daemon
openclaw daemon restart
```
## Contributing
Contributions welcome! Please:
1. Fork the repository
2. Create a feature branch
3. Make your changes
4. Submit a pull request
## License
MIT License - see [LICENSE](LICENSE) file for details.
## Credits
- **OpenClaw**: https://docs.openclaw.ai
- **mcporter**: https://github.com/steipete/mcporter
- **notebooklm-mcp**: https://github.com/jacob-bd/notebooklm-mcp-cli
- **Model Context Protocol**: https://modelcontextprotocol.io
## Support
- 🐛 [Report Issues](https://github.com/elihat2022/openclaw-notebooklm/issues)
- 💬 [Discussions](https://github.com/elihat2022/openclaw-notebooklm/discussions)
- 📖 [Documentation](https://github.com/elihat2022/openclaw-notebooklm#readme)
## Support This Project
If you find this project useful, consider buying me a coffee! ☕
<a href="https://buymeacoffee.com/elihatdeveloper" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a>
Your support helps maintain and improve this project!
---
**Made with ❤️ for the OpenClaw community**
| text/markdown | OpenClaw Community | null | null | null | MIT | openclaw, notebooklm, mcp, ai, skill | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pyt... | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/elihat2022/openclaw-notebooklm",
"Documentation, https://github.com/elihat2022/openclaw-notebooklm#readme",
"Repository, https://github.com/elihat2022/openclaw-notebooklm.git",
"Issues, https://github.com/elihat2022/openclaw-notebooklm/issues",
"Funding, https://buymeacoffee.co... | twine/6.2.0 CPython/3.13.5 | 2026-02-18T11:26:51.867534 | openclaw_notebooklm-0.1.2.tar.gz | 10,925 | aa/55/2c9bc5670ac4eb94e293df8ff32abe8fb277fa56aa1b56650eb5a1f1a264/openclaw_notebooklm-0.1.2.tar.gz | source | sdist | null | false | 50bc301160554374d18194ee5c00c224 | 9558a1965003c6c879e11dbf4965aa86cb02e6735a1a20682e15ac34beba742d | aa552c9bc5670ac4eb94e293df8ff32abe8fb277fa56aa1b56650eb5a1f1a264 | null | [
"LICENSE"
] | 266 |
2.4 | fastMONAI | 0.8.2 | fastMONAI library | # Overview
<!-- WARNING: THIS FILE WAS AUTOGENERATED! DO NOT EDIT! -->


[](https://fastmonai.no)
[](https://pypi.org/project/fastMONAI)
A low-code Python-based open source deep learning library built on top
of [fastai](https://github.com/fastai/fastai),
[MONAI](https://monai.io/), [TorchIO](https://torchio.readthedocs.io/),
and [Imagedata](https://imagedata.readthedocs.io/).
fastMONAI simplifies the use of state-of-the-art deep learning
techniques in 3D medical image analysis for solving classification,
regression, and segmentation tasks. fastMONAI provides the users with
functionalities to step through data loading, preprocessing, training,
and result interpretations.
<b>Note:</b> This documentation is also available as interactive
notebooks.
## Requirements
- **Python:** 3.10, 3.11, or 3.12 (Python 3.11 recommended)
- **GPU:** CUDA-compatible GPU recommended for training (CPU supported
for inference)
# Installation
## Environment setup (recommended)
We recommend using a conda environment to avoid dependency conflicts:
`conda create -n fastmonai python=3.11`
`conda activate fastmonai`
## Quick Install [(PyPI)](https://pypi.org/project/fastMONAI/)
`pip install fastMONAI`
## Development install [(GitHub)](https://github.com/MMIV-ML/fastMONAI)
If you want to install an editable version of fastMONAI for development:
git clone https://github.com/MMIV-ML/fastMONAI
cd fastMONAI
# Create development environment
conda create -n fastmonai-dev python=3.11
conda activate fastmonai-dev
# Install in development mode
pip install -e '.[dev]'
# Getting started
The best way to get started using fastMONAI is to read our
[paper](https://www.sciencedirect.com/science/article/pii/S2665963823001203)
and dive into our beginner-friendly [video
tutorial](https://fastmonai.no/tutorial_beginner_video). For a deeper
understanding and hands-on experience, our comprehensive instructional
notebooks will walk you through model training for various tasks like
classification, regression, and segmentation. See the docs at
https://fastmonai.no for more information.
| Notebook | 1-Click Notebook |
|:---|----|
| [11b_tutorial_classification.ipynb](https://nbviewer.org/github/MMIV-ML/fastMONAI/blob/main/nbs/11b_tutorial_classification.ipynb) <br>shows how to construct a binary classification model based on MRI data. | [](https://colab.research.google.com/github/MMIV-ML/fastMONAI/blob/main/nbs/11b_tutorial_classification.ipynb) |
| [11c_tutorial_regression.ipynb](https://nbviewer.org/github/MMIV-ML/fastMONAI/blob/main/nbs/11c_tutorial_regression.ipynb) <br>shows how to construct a model to predict the age of a subject from MRI scans (“brain age”). | [](https://colab.research.google.com/github/MMIV-ML/fastMONAI/blob/main/nbs/11c_tutorial_regression.ipynb) |
| [11d_tutorial_binary_segmentation.ipynb](https://nbviewer.org/github/MMIV-ML/fastMONAI/blob/main/nbs/11d_tutorial_binary_segmentation.ipynb) <br>shows how to do binary segmentation (extract the left atrium from monomodal cardiac MRI). | [](https://colab.research.google.com/github/MMIV-ML/fastMONAI/blob/main/nbs/11d_tutorial_binary_segmentation.ipynb) |
| [11e_tutorial_multiclass_segmentation.ipynb](https://nbviewer.org/github/MMIV-ML/fastMONAI/blob/main/nbs/11e_tutorial_multiclass_segmentation.ipynb) <br>shows how to perform segmentation from multimodal MRI (brain tumor segmentation). | [](https://colab.research.google.com/github/MMIV-ML/fastMONAI/blob/main/nbs/11e_tutorial_multiclass_segmentation.ipynb) |
# How to contribute
We welcome contributions! See
[CONTRIBUTING.md](https://github.com/MMIV-ML/fastMONAI/blob/main/CONTRIBUTING.md)
# Citing fastMONAI
If you are using fastMONAI in your research, please use the following
citation:
@article{KALIYUGARASAN2023100583,
title = {fastMONAI: A low-code deep learning library for medical image analysis},
journal = {Software Impacts},
pages = {100583},
year = {2023},
issn = {2665-9638},
doi = {https://doi.org/10.1016/j.simpa.2023.100583},
url = {https://www.sciencedirect.com/science/article/pii/S2665963823001203},
author = {Satheshkumar Kaliyugarasan and Alexander S. Lundervold},
keywords = {Deep learning, Medical imaging, Radiology},
abstract = {We introduce fastMONAI, an open-source Python-based deep learning library for 3D medical imaging. Drawing upon the strengths of fastai, MONAI, and TorchIO, fastMONAI simplifies the use of advanced techniques for tasks like classification, regression, and segmentation. The library's design addresses domain-specific demands while promoting best practices, facilitating efficient model development. It offers newcomers an easier entry into the field while keeping the option to make advanced, lower-level customizations if needed. This paper describes the library's design, impact, limitations, and plans for future work.}
}
| text/markdown | Satheshkumar Kaliyugarasan | skaliyugarasan@hotmail.com | null | null | Apache Software License 2.0 | deep learning, medical imaging | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Natural Language :: English",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"License :: OSI Approved :: Apache Software License"
] | [] | https://github.com/MMIV-ML/fastMONAI | null | >=3.10 | [] | [] | [] | [
"fastai==2.8.6",
"monai==1.5.2",
"torchio==0.21.2",
"xlrd>=1.2.0",
"scikit-image==0.26.0",
"imagedata==3.8.14",
"mlflow==3.9.0",
"huggingface-hub",
"gdown",
"gradio",
"opencv-python",
"plum-dispatch",
"ipywidgets; extra == \"dev\"",
"nbdev<3; extra == \"dev\"",
"tabulate; extra == \"dev\... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T11:26:34.698920 | fastmonai-0.8.2.tar.gz | 80,447 | 41/9c/b92f24f2d88d5c688bd327afa5731a238ef3cdb0aa2921527f949e9aaa9e/fastmonai-0.8.2.tar.gz | source | sdist | null | false | a7b2e4f9420329b58222d014df2ec1f4 | 23012a04028d10fdf4996e2a5a7674eef57c6512ba575ecabdc28ee4d46c3d84 | 419cb92f24f2d88d5c688bd327afa5731a238ef3cdb0aa2921527f949e9aaa9e | null | [
"LICENSE"
] | 0 |
2.4 | tract | 0.23.0.dev2 | Python bindings for tract, a neural network inference engine | # `tract` python bindings
`tract` is a library for neural network inference. While PyTorch and TensorFlow
deal with the much harder training problem, `tract` focuses on what happens once
the model in trained.
`tract` ultimate goal is to use the model on end-user data (aka "running the
model") as efficiently as possible, in a variety of possible deployments,
including some which are no completely mainstream : a lot of energy have been
invested in making `tract` an efficient engine to run models on ARM single board
computers.
## Getting started
### Install tract library
`pip install tract`. Prebuilt wheels are provided for x86-64 Linux and
Windows, x86-64 and arm64 for MacOS.
### Downloading the model
First we need to obtain the model. We will download an ONNX-converted MobileNET
2.7 from the ONNX model zoo.
`wget https://github.com/onnx/models/raw/main/vision/classification/mobilenet/model/mobilenetv2-7.onnx`.
### Preprocessing an image
Then we need a sample image. You can use pretty much anything. If you lack
inspiration, you can this picture of Grace Hopper.
`wget https://s3.amazonaws.com/tract-ci-builds/tests/grace_hopper.jpg`
We will be needing `pillow` to load the image and crop it.
`pip install pillow`
Now let's start our python script. We will want to use tract, obviously, but we
will also need PIL's Image and numpy to put the data in the form MobileNet expects it.
```python
#!/usr/bin/env python
import tract
import numpy
from PIL import Image
```
We want to load the image, crop it into its central square, then scale this
square to be 224x224.
```python
im = Image.open("grace_hopper.jpg")
if im.height > im.width:
top_crop = int((im.height - im.width) / 2)
im = im.crop((0, top_crop, im.width, top_crop + im.width))
else:
left_crop = int((im.width - im.height) / 2)
im = im.crop((left_crop, 0, left_crop + im_height, im.height))
im = im.resize((224, 224))
im = numpy.array(im)
```
At this stage, we obtain a 224x224x3 tensor of 8-bit positive integers. We need to transform
these integers to floats and normalize them for MobileNet.
At some point during this normalization, numpy decides to promote our tensor to
double precision, but our model is single precison, so we are converting it
again after the normalization.
```python
im = (im.astype(float) / 255. - [0.485, 0.456, 0.406]) / [0.229, 0.224, 0.225]
im = im.astype(numpy.single)
```
Finally, ONNX variant of Mobilenet expects its input in NCHW convention, and
our data is in HWC. We need to move the C axis before H and W, then insert the
N at the left.
```python
im = numpy.moveaxis(im, 2, 0)
im = numpy.expand_dims(im, 0)
```
### Loading the model
Loading a model is relatively simple. We need to instantiate the ONNX loader
first, the we use it to load the model. Then we ask tract to optimize the model
and get it ready to run.
```python
model = tract.onnx().model_for_path("./mobilenetv2-7.onnx").into_optimized().into_runnable()
```
If we wanted to process several images, this would only have to be done once
out of our image loop.
### Running the model
tract run methods take a list of inputs and returns a list of outputs. Each input
can be a numpy array. The outputs are tract's own Value data type, which should
be converted to numpy array.
```python
outputs = model.run([im])
output = outputs[0].to_numpy()
```
### Interpreting the result
If we print the output, what we get is a array of 1000 values. Each value is
the score of our image on one of the 1000 categoris of ImageNet. What we want
is to find the category with the highest score.
```python
print(numpy.argmax(output))
```
If all goes according to plan, this should output the number 652. There is a copy
of ImageNet categories at the following URL, with helpful line numbering.
```
https://github.com/sonos/tract/blob/main/examples/nnef-mobilenet-v2/imagenet_slim_labels.txt
```
And... 652 is "microphone". Which is wrong. The trick is, the lines are
numbered from 1, while our results starts at 0, plus the label list includes a
"dummy" label first that should be ignored. So the right value is at the line
654: "military uniform". If you looked at the picture before you noticed that
Grace Hopper is in uniform on the picture, so it does make sense.
## Model cooking with `tract`
Over the years of `tract` development, it became clear that beside "training"
and "running", there was a third time in the life-cycle of a model. One of
our contributors nicknamed it "model cooking" and the term stuck. This extra stage
is about all what happens after the training and before running.
If training and Runtime are relatively easy to define, the model cooking gets a
bit less obvious. It comes from the realisation that the training form (an ONNX
or TensorFlow file or ste of files) of a model may is usually not the most
convenient form for running it. Every time a device loads a model in ONNX form
and transform it into a suitable form for runtime, it goes through the same
series or more or less complicated operations, that can amount to several
seconds of high-CPU usage for current models. When running the model on a
device, this can have several negative impact on experience: the device will
take time to start-up, consume a lot of battery energy to get ready, maybe fight
over CPU availability with other processes trying to get ready at the same
instant on the device.
As this sequence of operations is generally the same, it becomes relevant to
persist the model resulting of the transformation. It could be persisted at the
first application start-up for instance. But it could also be "prepared", or
"cooked" before distribution to the devices.
## Cooking to NNEF
`tract` supports NNEF. It can read a NNEF neural network and run it. But it can
also dump its preferred representation of a model in NNEF.
At this stage, a possible path to production for a neural model becomes can be drawn:
* model is trained, typically on big servers on the cloud, and exported to ONNX.
* model is cooked, simplified, using `tract` command line or python bindings.
* model is shipped to devices or servers in charge of running it.
## Testing and benching models early
As soon as the model is in ONNX form, `tract` can load and run it. It gives
opportunities to validate and test on the training system, asserting early on that
`tract` will compute at runtime the same result than what the training model
predicts, limiting the risk of late-minute surprise.
But tract command line can also be used to bench and profile an ONNX model on
the target system answering very early the "will the device be fast enough"
question. The nature of neural network is such that in many cases an
untrained model, or a poorly trained one will perform the same computations than
the final model, so it may be possible to bench the model for on-device
efficiency before going through a costly and long model training.
## tract-opl
NNEF is a pretty little standard. But we needed to go beyond it and we extended
it in several ways. For instance, NNEF does not provide syntax for recurring
neural network (LSTM and friends), which are an absolute must in signal and voice
processing. `tract` also supports symbolic dimensions, which are useful to
represent a late bound batch dimension (if you don't know in advance how many
inputs will have to be computed concurrently).
## Pulsing
For interactive applications where time plays a role (voice, signal, ...),
`tract` can automatically transform batch models, to equivalent streaming models
suitable for runtime. While batch models are presented at training time the
whole signal in one go, a streaming model received the signal by "pulse" and
produces step by step the same output that the batching model.
It does not work for every model, `tract` can obviously not generate a model
where the output at a time depends on input not received yet. Of course, models
have to be *causal* to be pulsable. For instance, a bi-directional LSTM is not
pulsable. Most convolution nets can be made causal at designe time by padding,
or at cooking time by adding fixed delays.
This cooking step is a recurring annoyance in the real-time voice and signal
field : it can be done manually, but is very easy to get wrong. `tract` makes
it automactic.
| text/markdown | Mathieu Poumeyrol, Sonos, and tract contributors | mathieu@poumeyrol.fr | null | null | (Apache-2.0 OR MIT) | onnx tensorflow nnef runtime neural network | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Rust",
"Topic :: Scientific/E... | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy",
"pytest; extra == \"test\"",
"setuptools<81,>=80; extra == \"dev\"",
"setuptools_rust<1.13,>=1.12; extra == \"dev\"",
"wheel<0.47,>=0.46; extra == \"dev\"",
"toml<0.11,>=0.10; extra == \"dev\"",
"pytest; extra == \"dev\""
] | [] | [] | [] | [
"Documentation, https://sonos.github.io/tract",
"Source, https://github.com/sonos/tract"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:25:56.048658 | tract-0.23.0.dev2.tar.gz | 6,924,074 | dd/f9/df70e81ded856fda3c563cb094d04e5b2127bc9734fbddcb316f5509dfdd/tract-0.23.0.dev2.tar.gz | source | sdist | null | false | a599b171937cfec7f19eaf6537840eec | 577b514bf7ccde9d665d8827ad109516b7b3d3602f47744b09420abf761bd886 | ddf9df70e81ded856fda3c563cb094d04e5b2127bc9734fbddcb316f5509dfdd | null | [] | 2,233 |
2.4 | epygram | 2.0.9 | EPyGrAM : Enhanced Python for Graphics and Analysis of Meteorological fields | EPyGrAM
=======
__*Enhanced Python for Graphics and Analysis of Meteorological fields*__
---
The epygram library package is a set of Python classes and functions designed to handle meteorological fields in Python, as well as interfacing their storage in various usual (or not) data formats.
Dependencies
------------
EPyGrAM dependencies are available from Pypi (pip install ...), and listed in `pyproject.toml`.
Some packages are mandatory, others are optional, only necessary for the use of specific functionalities or formats.
Formats for which the import of the according underlying package fails are deactivated at runtime.
Installation
------------
`pip install epygram`
or
`pip3 install epygram`
To use specific functionalities which dependencies are not covered by default,
you may need to manually pip install the according package(s).
You can also install all optional dependencies using:
`pip install epygram[all]`
or
more specifically one of the extra group of dependencies:
`pip install epygram[<opt>]`
with `<opt>` among (`graphics`, `docs`, `features`, `extra_formats`), cf. `pyproject.toml`.
Tests
-----
To run tests, cf. [`tests/README.md`](tests/README.md).
Documentation
-------------
To generate Sphinx doc: `make doc`. It will be generated in `docs/build/html`.
Online doc of the latest release on `master` branch is available at https://umr-cnrm.github.io/EPyGrAM-doc
Applicative tools
-----------------
Some applicative tools in command line are provided and installed by pip.
These tools are available through a single command line `epygram` with sub-commands:
- `epygram -h` to list available sub-commands
- `epygram <sub-command> -h` for auto-documentation of each tool/sub-command.
or as `epy_<sub-command>` (pip should have placed them in your `$PATH`).
Example, to plot a field:
- `epygram cartoplot <file> -f <field>`
or
- `epy_cartoplot <file> -f <field>`
are equivalent to
- `epy_cartoplot.py <file> -f <field>` in versions prior to 1.6.0
License
-------
This software is governed by the open-source [CeCILL-C](http://www.cecill.info) license under French law, cf. LICENSE.txt.
Downloading and using this code means that you have had knowledge of the CeCILL-C license and that you accept its terms.
| text/markdown | null | Alexandre MARY <alexandre.mary@meteo.fr>, Sébastien Riette <sebastien.riette@meteo.fr> | null | Alexandre MARY <alexandre.mary@meteo.fr>, Sébastien Riette <sebastien.riette@meteo.fr> |
CeCILL-C FREE SOFTWARE LICENSE AGREEMENT
Notice
This Agreement is a Free Software license agreement that is the result
of discussions between its authors in order to ensure compliance with
the two main principles guiding its drafting:
* firstly, compliance with the principles governing the distribution
of Free Software: access to source code, broad rights granted to
users,
* secondly, the election of a governing law, French law, with which
it is conformant, both as regards the law of torts and
intellectual property law, and the protection that it offers to
both authors and holders of the economic rights over software.
The authors of the CeCILL-C (for Ce[a] C[nrs] I[nria] L[ogiciel] L[ibre])
license are:
Commissariat à l'Energie Atomique - CEA, a public scientific, technical
and industrial research establishment, having its principal place of
business at 25 rue Leblanc, immeuble Le Ponant D, 75015 Paris, France.
Centre National de la Recherche Scientifique - CNRS, a public scientific
and technological establishment, having its principal place of business
at 3 rue Michel-Ange, 75794 Paris cedex 16, France.
Institut National de Recherche en Informatique et en Automatique -
INRIA, a public scientific and technological establishment, having its
principal place of business at Domaine de Voluceau, Rocquencourt, BP
105, 78153 Le Chesnay cedex, France.
Preamble
The purpose of this Free Software license agreement is to grant users
the right to modify and re-use the software governed by this license.
The exercising of this right is conditional upon the obligation to make
available to the community the modifications made to the source code of
the software so as to contribute to its evolution.
In consideration of access to the source code and the rights to copy,
modify and redistribute granted by the license, users are provided only
with a limited warranty and the software's author, the holder of the
economic rights, and the successive licensors only have limited liability.
In this respect, the risks associated with loading, using, modifying
and/or developing or reproducing the software by the user are brought to
the user's attention, given its Free Software status, which may make it
complicated to use, with the result that its use is reserved for
developers and experienced professionals having in-depth computer
knowledge. Users are therefore encouraged to load and test the
suitability of the software as regards their requirements in conditions
enabling the security of their systems and/or data to be ensured and,
more generally, to use and operate it in the same conditions of
security. This Agreement may be freely reproduced and published,
provided it is not altered, and that no provisions are either added or
removed herefrom.
This Agreement may apply to any or all software for which the holder of
the economic rights decides to submit the use thereof to its provisions.
Article 1 - DEFINITIONS
For the purpose of this Agreement, when the following expressions
commence with a capital letter, they shall have the following meaning:
Agreement: means this license agreement, and its possible subsequent
versions and annexes.
Software: means the software in its Object Code and/or Source Code form
and, where applicable, its documentation, "as is" when the Licensee
accepts the Agreement.
Initial Software: means the Software in its Source Code and possibly its
Object Code form and, where applicable, its documentation, "as is" when
it is first distributed under the terms and conditions of the Agreement.
Modified Software: means the Software modified by at least one
Integrated Contribution.
Source Code: means all the Software's instructions and program lines to
which access is required so as to modify the Software.
Object Code: means the binary files originating from the compilation of
the Source Code.
Holder: means the holder(s) of the economic rights over the Initial
Software.
Licensee: means the Software user(s) having accepted the Agreement.
Contributor: means a Licensee having made at least one Integrated
Contribution.
Licensor: means the Holder, or any other individual or legal entity, who
distributes the Software under the Agreement.
Integrated Contribution: means any or all modifications, corrections,
translations, adaptations and/or new functions integrated into the
Source Code by any or all Contributors.
Related Module: means a set of sources files including their
documentation that, without modification to the Source Code, enables
supplementary functions or services in addition to those offered by the
Software.
Derivative Software: means any combination of the Software, modified or
not, and of a Related Module.
Parties: mean both the Licensee and the Licensor.
These expressions may be used both in singular and plural form.
Article 2 - PURPOSE
The purpose of the Agreement is the grant by the Licensor to the
Licensee of a non-exclusive, transferable and worldwide license for the
Software as set forth in Article 5 hereinafter for the whole term of the
protection granted by the rights over said Software.
Article 3 - ACCEPTANCE
3.1 The Licensee shall be deemed as having accepted the terms and
conditions of this Agreement upon the occurrence of the first of the
following events:
* (i) loading the Software by any or all means, notably, by
downloading from a remote server, or by loading from a physical
medium;
* (ii) the first time the Licensee exercises any of the rights
granted hereunder.
3.2 One copy of the Agreement, containing a notice relating to the
characteristics of the Software, to the limited warranty, and to the
fact that its use is restricted to experienced users has been provided
to the Licensee prior to its acceptance as set forth in Article 3.1
hereinabove, and the Licensee hereby acknowledges that it has read and
understood it.
Article 4 - EFFECTIVE DATE AND TERM
4.1 EFFECTIVE DATE
The Agreement shall become effective on the date when it is accepted by
the Licensee as set forth in Article 3.1.
4.2 TERM
The Agreement shall remain in force for the entire legal term of
protection of the economic rights over the Software.
Article 5 - SCOPE OF RIGHTS GRANTED
The Licensor hereby grants to the Licensee, who accepts, the following
rights over the Software for any or all use, and for the term of the
Agreement, on the basis of the terms and conditions set forth hereinafter.
Besides, if the Licensor owns or comes to own one or more patents
protecting all or part of the functions of the Software or of its
components, the Licensor undertakes not to enforce the rights granted by
these patents against successive Licensees using, exploiting or
modifying the Software. If these patents are transferred, the Licensor
undertakes to have the transferees subscribe to the obligations set
forth in this paragraph.
5.1 RIGHT OF USE
The Licensee is authorized to use the Software, without any limitation
as to its fields of application, with it being hereinafter specified
that this comprises:
1. permanent or temporary reproduction of all or part of the Software
by any or all means and in any or all form.
2. loading, displaying, running, or storing the Software on any or
all medium.
3. entitlement to observe, study or test its operation so as to
determine the ideas and principles behind any or all constituent
elements of said Software. This shall apply when the Licensee
carries out any or all loading, displaying, running, transmission
or storage operation as regards the Software, that it is entitled
to carry out hereunder.
5.2 RIGHT OF MODIFICATION
The right of modification includes the right to translate, adapt,
arrange, or make any or all modifications to the Software, and the right
to reproduce the resulting software. It includes, in particular, the
right to create a Derivative Software.
The Licensee is authorized to make any or all modification to the
Software provided that it includes an explicit notice that it is the
author of said modification and indicates the date of the creation thereof.
5.3 RIGHT OF DISTRIBUTION
In particular, the right of distribution includes the right to publish,
transmit and communicate the Software to the general public on any or
all medium, and by any or all means, and the right to market, either in
consideration of a fee, or free of charge, one or more copies of the
Software by any means.
The Licensee is further authorized to distribute copies of the modified
or unmodified Software to third parties according to the terms and
conditions set forth hereinafter.
5.3.1 DISTRIBUTION OF SOFTWARE WITHOUT MODIFICATION
The Licensee is authorized to distribute true copies of the Software in
Source Code or Object Code form, provided that said distribution
complies with all the provisions of the Agreement and is accompanied by:
1. a copy of the Agreement,
2. a notice relating to the limitation of both the Licensor's
warranty and liability as set forth in Articles 8 and 9,
and that, in the event that only the Object Code of the Software is
redistributed, the Licensee allows effective access to the full Source
Code of the Software at a minimum during the entire period of its
distribution of the Software, it being understood that the additional
cost of acquiring the Source Code shall not exceed the cost of
transferring the data.
5.3.2 DISTRIBUTION OF MODIFIED SOFTWARE
When the Licensee makes an Integrated Contribution to the Software, the
terms and conditions for the distribution of the resulting Modified
Software become subject to all the provisions of this Agreement.
The Licensee is authorized to distribute the Modified Software, in
source code or object code form, provided that said distribution
complies with all the provisions of the Agreement and is accompanied by:
1. a copy of the Agreement,
2. a notice relating to the limitation of both the Licensor's
warranty and liability as set forth in Articles 8 and 9,
and that, in the event that only the object code of the Modified
Software is redistributed, the Licensee allows effective access to the
full source code of the Modified Software at a minimum during the entire
period of its distribution of the Modified Software, it being understood
that the additional cost of acquiring the source code shall not exceed
the cost of transferring the data.
5.3.3 DISTRIBUTION OF DERIVATIVE SOFTWARE
When the Licensee creates Derivative Software, this Derivative Software
may be distributed under a license agreement other than this Agreement,
subject to compliance with the requirement to include a notice
concerning the rights over the Software as defined in Article 6.4.
In the event the creation of the Derivative Software required modification
of the Source Code, the Licensee undertakes that:
1. the resulting Modified Software will be governed by this Agreement,
2. the Integrated Contributions in the resulting Modified Software
will be clearly identified and documented,
3. the Licensee will allow effective access to the source code of the
Modified Software, at a minimum during the entire period of
distribution of the Derivative Software, such that such
modifications may be carried over in a subsequent version of the
Software; it being understood that the additional cost of
purchasing the source code of the Modified Software shall not
exceed the cost of transferring the data.
5.3.4 COMPATIBILITY WITH THE CeCILL LICENSE
When a Modified Software contains an Integrated Contribution subject to
the CeCILL license agreement, or when a Derivative Software contains a
Related Module subject to the CeCILL license agreement, the provisions
set forth in the third item of Article 6.4 are optional.
Article 6 - INTELLECTUAL PROPERTY
6.1 OVER THE INITIAL SOFTWARE
The Holder owns the economic rights over the Initial Software. Any or
all use of the Initial Software is subject to compliance with the terms
and conditions under which the Holder has elected to distribute its work
and no one shall be entitled to modify the terms and conditions for the
distribution of said Initial Software.
The Holder undertakes that the Initial Software will remain ruled at
least by this Agreement, for the duration set forth in Article 4.2.
6.2 OVER THE INTEGRATED CONTRIBUTIONS
The Licensee who develops an Integrated Contribution is the owner of the
intellectual property rights over this Contribution as defined by
applicable law.
6.3 OVER THE RELATED MODULES
The Licensee who develops a Related Module is the owner of the
intellectual property rights over this Related Module as defined by
applicable law and is free to choose the type of agreement that shall
govern its distribution under the conditions defined in Article 5.3.3.
6.4 NOTICE OF RIGHTS
The Licensee expressly undertakes:
1. not to remove, or modify, in any manner, the intellectual property
notices attached to the Software;
2. to reproduce said notices, in an identical manner, in the copies
of the Software modified or not;
3. to ensure that use of the Software, its intellectual property
notices and the fact that it is governed by the Agreement is
indicated in a text that is easily accessible, specifically from
the interface of any Derivative Software.
The Licensee undertakes not to directly or indirectly infringe the
intellectual property rights of the Holder and/or Contributors on the
Software and to take, where applicable, vis-à-vis its staff, any and all
measures required to ensure respect of said intellectual property rights
of the Holder and/or Contributors.
Article 7 - RELATED SERVICES
7.1 Under no circumstances shall the Agreement oblige the Licensor to
provide technical assistance or maintenance services for the Software.
However, the Licensor is entitled to offer this type of services. The
terms and conditions of such technical assistance, and/or such
maintenance, shall be set forth in a separate instrument. Only the
Licensor offering said maintenance and/or technical assistance services
shall incur liability therefor.
7.2 Similarly, any Licensor is entitled to offer to its licensees, under
its sole responsibility, a warranty, that shall only be binding upon
itself, for the redistribution of the Software and/or the Modified
Software, under terms and conditions that it is free to decide. Said
warranty, and the financial terms and conditions of its application,
shall be subject of a separate instrument executed between the Licensor
and the Licensee.
Article 8 - LIABILITY
8.1 Subject to the provisions of Article 8.2, the Licensee shall be
entitled to claim compensation for any direct loss it may have suffered
from the Software as a result of a fault on the part of the relevant
Licensor, subject to providing evidence thereof.
8.2 The Licensor's liability is limited to the commitments made under
this Agreement and shall not be incurred as a result of in particular:
(i) loss due the Licensee's total or partial failure to fulfill its
obligations, (ii) direct or consequential loss that is suffered by the
Licensee due to the use or performance of the Software, and (iii) more
generally, any consequential loss. In particular the Parties expressly
agree that any or all pecuniary or business loss (i.e. loss of data,
loss of profits, operating loss, loss of customers or orders,
opportunity cost, any disturbance to business activities) or any or all
legal proceedings instituted against the Licensee by a third party,
shall constitute consequential loss and shall not provide entitlement to
any or all compensation from the Licensor.
Article 9 - WARRANTY
9.1 The Licensee acknowledges that the scientific and technical
state-of-the-art when the Software was distributed did not enable all
possible uses to be tested and verified, nor for the presence of
possible defects to be detected. In this respect, the Licensee's
attention has been drawn to the risks associated with loading, using,
modifying and/or developing and reproducing the Software which are
reserved for experienced users.
The Licensee shall be responsible for verifying, by any or all means,
the suitability of the product for its requirements, its good working
order, and for ensuring that it shall not cause damage to either persons
or properties.
9.2 The Licensor hereby represents, in good faith, that it is entitled
to grant all the rights over the Software (including in particular the
rights set forth in Article 5).
9.3 The Licensee acknowledges that the Software is supplied "as is" by
the Licensor without any other express or tacit warranty, other than
that provided for in Article 9.2 and, in particular, without any warranty
as to its commercial value, its secured, safe, innovative or relevant
nature.
Specifically, the Licensor does not warrant that the Software is free
from any error, that it will operate without interruption, that it will
be compatible with the Licensee's own equipment and software
configuration, nor that it will meet the Licensee's requirements.
9.4 The Licensor does not either expressly or tacitly warrant that the
Software does not infringe any third party intellectual property right
relating to a patent, software or any other property right. Therefore,
the Licensor disclaims any and all liability towards the Licensee
arising out of any or all proceedings for infringement that may be
instituted in respect of the use, modification and redistribution of the
Software. Nevertheless, should such proceedings be instituted against
the Licensee, the Licensor shall provide it with technical and legal
assistance for its defense. Such technical and legal assistance shall be
decided on a case-by-case basis between the relevant Licensor and the
Licensee pursuant to a memorandum of understanding. The Licensor
disclaims any and all liability as regards the Licensee's use of the
name of the Software. No warranty is given as regards the existence of
prior rights over the name of the Software or as regards the existence
of a trademark.
Article 10 - TERMINATION
10.1 In the event of a breach by the Licensee of its obligations
hereunder, the Licensor may automatically terminate this Agreement
thirty (30) days after notice has been sent to the Licensee and has
remained ineffective.
10.2 A Licensee whose Agreement is terminated shall no longer be
authorized to use, modify or distribute the Software. However, any
licenses that it may have granted prior to termination of the Agreement
shall remain valid subject to their having been granted in compliance
with the terms and conditions hereof.
Article 11 - MISCELLANEOUS
11.1 EXCUSABLE EVENTS
Neither Party shall be liable for any or all delay, or failure to
perform the Agreement, that may be attributable to an event of force
majeure, an act of God or an outside cause, such as defective
functioning or interruptions of the electricity or telecommunications
networks, network paralysis following a virus attack, intervention by
government authorities, natural disasters, water damage, earthquakes,
fire, explosions, strikes and labor unrest, war, etc.
11.2 Any failure by either Party, on one or more occasions, to invoke
one or more of the provisions hereof, shall under no circumstances be
interpreted as being a waiver by the interested Party of its right to
invoke said provision(s) subsequently.
11.3 The Agreement cancels and replaces any or all previous agreements,
whether written or oral, between the Parties and having the same
purpose, and constitutes the entirety of the agreement between said
Parties concerning said purpose. No supplement or modification to the
terms and conditions hereof shall be effective as between the Parties
unless it is made in writing and signed by their duly authorized
representatives.
11.4 In the event that one or more of the provisions hereof were to
conflict with a current or future applicable act or legislative text,
said act or legislative text shall prevail, and the Parties shall make
the necessary amendments so as to comply with said act or legislative
text. All other provisions shall remain effective. Similarly, invalidity
of a provision of the Agreement, for any reason whatsoever, shall not
cause the Agreement as a whole to be invalid.
11.5 LANGUAGE
The Agreement is drafted in both French and English and both versions
are deemed authentic.
Article 12 - NEW VERSIONS OF THE AGREEMENT
12.1 Any person is authorized to duplicate and distribute copies of this
Agreement.
12.2 So as to ensure coherence, the wording of this Agreement is
protected and may only be modified by the authors of the License, who
reserve the right to periodically publish updates or new versions of the
Agreement, each with a separate number. These subsequent versions may
address new issues encountered by Free Software.
12.3 Any Software distributed under a given version of the Agreement may
only be subsequently distributed under the same version of the Agreement
or a subsequent version.
Article 13 - GOVERNING LAW AND JURISDICTION
13.1 The Agreement is governed by French law. The Parties agree to
endeavor to seek an amicable solution to any disagreements or disputes
that may arise during the performance of the Agreement.
13.2 Failing an amicable solution within two (2) months as from their
occurrence, and unless emergency proceedings are necessary, the
disagreements or disputes shall be referred to the Paris Courts having
jurisdiction, by the more diligent Party.
Version 1.0 dated 2006-09-05.
| NWP, meteorology, GRIB, FA | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Operating System :... | [] | null | null | >=3.10 | [] | [] | [] | [
"bronx",
"eccodes==2.38.1",
"ectrans4py==1.6.0",
"falfilfa4py==1.0.7",
"footprints",
"netCDF4==1.7.2",
"numpy",
"pyproj",
"pytest",
"pyyaml",
"taylorism",
"sphinx; extra == \"docs\"",
"jupyter; extra == \"docs\"",
"nbsphinx; extra == \"docs\"",
"cartopy==0.23.0; extra == \"graphics\"",
... | [] | [] | [] | [
"documentation, https://umr-cnrm.github.io/EPyGrAM-doc",
"source, https://github.com/UMR-CNRM/EPyGrAM.git",
"download, https://github.com/UMR-CNRM/EPyGrAM/releases",
"tracker, https://github.com/UMR-CNRM/EPyGrAM/issues"
] | twine/6.1.0 CPython/3.12.3 | 2026-02-18T11:24:34.455879 | epygram-2.0.9-py3-none-any.whl | 3,600,995 | d6/18/3513e9acfee6b42b3859b5e5562d6303b29ef7577898de6e37913a32e817/epygram-2.0.9-py3-none-any.whl | py3 | bdist_wheel | null | false | 73582c04b677588734f10ce8f258983c | 7f2fbcf223404efee3e3ca8ba4f49734de230f5e4c7c48b838dcdd964f0b383e | d6183513e9acfee6b42b3859b5e5562d6303b29ef7577898de6e37913a32e817 | null | [
"LICENSE.txt"
] | 109 |
2.4 | ultraplot | 2.0.1 | A succinct matplotlib wrapper for making beautiful, publication-quality graphics. | .. image:: https://raw.githubusercontent.com/Ultraplot/ultraplot/refs/heads/main/UltraPlotLogo.svg
:alt: UltraPlot Logo
:width: 100%
|downloads| |build-status| |coverage| |docs| |pypi| |code-style| |pre-commit| |pr-welcome| |license| |zenodo|
A succinct `matplotlib <https://matplotlib.org/>`__ wrapper for making beautiful,
publication-quality graphics. It builds upon ProPlot_ and transports it into the modern age (supporting mpl 3.9.0+).
.. _ProPlot: https://github.com/proplot-dev/
Why UltraPlot? | Write Less, Create More
=========================================
.. image:: https://raw.githubusercontent.com/Ultraplot/ultraplot/refs/heads/main/logo/whyUltraPlot.svg
:width: 100%
:alt: Comparison of ProPlot and UltraPlot
:align: center
Checkout our examples
=====================
Below is a gallery showing random examples of what UltraPlot can do, for more examples checkout our extensive `docs <https://ultraplot.readthedocs.io>`_.
View the full gallery here: `Gallery <https://ultraplot.readthedocs.io/en/latest/gallery/index.html>`_.
.. list-table::
:widths: 33 33 33
:header-rows: 0
* - .. image:: https://ultraplot.readthedocs.io/en/latest/_static/example_plots/subplot_example.svg
:alt: Subplots & Layouts
:target: https://ultraplot.readthedocs.io/en/latest/subplots.html
:width: 100%
:height: 200px
**Subplots & Layouts**
Create complex multi-panel layouts effortlessly.
- .. image:: https://ultraplot.readthedocs.io/en/latest/_static/example_plots/cartesian_example.svg
:alt: Cartesian Plots
:target: https://ultraplot.readthedocs.io/en/latest/cartesian.html
:width: 100%
:height: 200px
**Cartesian Plots**
Easily generate clean, well-formatted plots.
- .. image:: https://ultraplot.readthedocs.io/en/latest/_static/example_plots/projection_example.svg
:alt: Projections & Maps
:target: https://ultraplot.readthedocs.io/en/latest/projections.html
:width: 100%
:height: 200px
**Projections & Maps**
Built-in support for projections and geographic plots.
* - .. image:: https://ultraplot.readthedocs.io/en/latest/_static/example_plots/colorbars_legends_example.svg
:alt: Colorbars & Legends
:target: https://ultraplot.readthedocs.io/en/latest/colorbars_legends.html
:width: 100%
:height: 200px
**Colorbars & Legends**
Customize legends and colorbars with ease.
- .. image:: https://ultraplot.readthedocs.io/en/latest/_static/example_plots/panels_example.svg
:alt: Insets & Panels
:target: https://ultraplot.readthedocs.io/en/latest/insets_panels.html
:width: 100%
:height: 200px
**Insets & Panels**
Add inset plots and panel-based layouts.
- .. image:: https://ultraplot.readthedocs.io/en/latest/_static/example_plots/colormaps_example.svg
:alt: Colormaps & Cycles
:target: https://ultraplot.readthedocs.io/en/latest/colormaps.html
:width: 100%
:height: 200px
**Colormaps & Cycles**
Visually appealing, perceptually uniform colormaps.
Documentation
=============
The documentation is `published on readthedocs <https://ultraplot.readthedocs.io>`__.
Installation
============
UltraPlot is published on `PyPi <https://pypi.org/project/ultraplot/>`__ and
`conda-forge <https://conda-forge.org>`__. It can be installed with ``pip`` or
``conda`` as follows:
.. code-block:: bash
pip install ultraplot
conda install -c conda-forge ultraplot
The default install includes optional features (for example, pyCirclize-based plots).
For a minimal install, use ``--no-deps`` and install the core requirements:
.. code-block:: bash
pip install ultraplot --no-deps
pip install -r requirements-minimal.txt
Likewise, an existing installation of UltraPlot can be upgraded
to the latest version with:
.. code-block:: bash
pip install --upgrade ultraplot
conda upgrade ultraplot
To install a development version of UltraPlot, you can use
``pip install git+https://github.com/ultraplot/ultraplot.git``
or clone the repository and run ``pip install -e .``
inside the ``ultraplot`` folder.
If you use UltraPlot in your research, please cite it using the following BibTeX entry::
@software{vanElteren2025,
author = {Casper van Elteren and Matthew R. Becker},
title = {UltraPlot: A succinct wrapper for Matplotlib},
year = {2025},
version = {1.57.1},
publisher = {GitHub},
url = {https://github.com/Ultraplot/UltraPlot}
}
.. |downloads| image:: https://static.pepy.tech/personalized-badge/UltraPlot?period=total&units=international_system&left_color=black&right_color=orange&left_text=Downloads
:target: https://pepy.tech/project/ultraplot
:alt: Downloads
.. |build-status| image:: https://github.com/ultraplot/ultraplot/actions/workflows/build-ultraplot.yml/badge.svg
:target: https://github.com/ultraplot/ultraplot/actions/workflows/build-ultraplot.yml
:alt: Build Status
.. |coverage| image:: https://codecov.io/gh/Ultraplot/ultraplot/graph/badge.svg?token=C6ZB7Q9II4&style=flat&color=53C334
:target: https://codecov.io/gh/Ultraplot/ultraplot
:alt: Coverage
.. |docs| image:: https://readthedocs.org/projects/ultraplot/badge/?version=latest&style=flat&color=4F5D95
:target: https://ultraplot.readthedocs.io/en/latest/?badge=latest
:alt: Docs
.. |pypi| image:: https://img.shields.io/pypi/v/ultraplot?style=flat&color=53C334&logo=pypi
:target: https://pypi.org/project/ultraplot/
:alt: PyPI
.. |code-style| image:: https://img.shields.io/badge/code%20style-black-000000.svg?style=flat&logo=python
:alt: Code style: black
.. |pre-commit| image:: https://results.pre-commit.ci/badge/github/Ultraplot/ultraplot/main.svg
:target: https://results.pre-commit.ci/latest/github/Ultraplot/ultraplot/main
:alt: pre-commit.ci status
.. |pr-welcome| image:: https://img.shields.io/badge/PRs-welcome-f77f00?style=flat&logo=github
:alt: PRs Welcome
.. |license| image:: https://img.shields.io/github/license/ultraplot/ultraplot.svg?style=flat&color=808080
:target: LICENSE.txt
:alt: License
.. |zenodo| image:: https://zenodo.org/badge/909651179.svg
:target: https://doi.org/10.5281/zenodo.15733564
:alt: DOI
| text/x-rst | null | Casper van Elteren <caspervanelteren@gmail.com>, Luke Davis <lukelbd@gmail.com> | null | Casper van Elteren <caspervanelteren@gmail.com>, "Matthew R. Becker" <becker.mr@gmail.com> | MIT | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Program... | [] | null | null | <3.15,>=3.10 | [] | [] | [] | [
"numpy>=1.26.0",
"matplotlib<3.11,>=3.9",
"pycirclize>=1.10.1",
"typing-extensions; python_version < \"3.12\"",
"jupyter; extra == \"docs\"",
"jupytext; extra == \"docs\"",
"lxml-html-clean; extra == \"docs\"",
"m2r2; extra == \"docs\"",
"mpltern; extra == \"docs\"",
"nbsphinx; extra == \"docs\"",... | [] | [] | [] | [
"Documentation, https://ultraplot.readthedocs.io",
"Issue Tracker, https://github.com/ultraplot/ultraplot/issues",
"Source Code, https://github.com/ultraplot/ultraplot"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-18T11:24:33.067026 | ultraplot-2.0.1.tar.gz | 14,976,247 | 1e/8b/97e1ea909acec42d5526a1f0ba3cc98a6f602ad52e75a2b8b249ed79c10a/ultraplot-2.0.1.tar.gz | source | sdist | null | false | 0e72b0123a5c66ec32cb2700b4dce13c | 343eb8c4d2e004df4ba77d7807a0f518b08844793e6f54ad4faa95929c48035e | 1e8b97e1ea909acec42d5526a1f0ba3cc98a6f602ad52e75a2b8b249ed79c10a | null | [
"LICENSE.txt"
] | 347 |
2.4 | datasig | 0.0.7 | Dataset fingerprinting library | # Dataset fingerprinting
This repository contains our proof-of-concept for fingerprinting a dataset.
## Local installation
```python
git clone https://github.com/trailofbits/datasig && cd datasig
uv sync
```
## Usage
### Fingerprinting
The code below shows experimental usage of the library.
This will be subject to frequent changes in early development stages.
```python
from torchvision.datasets import MNIST
from datasig.dataset import TorchVisionDataset
from datasig.algo import KeyedShaMinHash, UID
torch_dataset = MNIST(root="/tmp/data", train=True, download=True)
# Wrap the dataset with one of the classes in `datasig.dataset`.
# These classes provide a uniform interface to access serialized data points.
dataset = TorchVisionDataset(torch_dataset)
# Pass the dataset to the fingerprinting algorithm.
print("Dataset UID: ", UID(dataset).digest())
print("Dataset fingerprint: ", KeyedShaMinHash(dataset).digest())
```
### Manual serialization/deserialization
The dataset classes defined in `datasig.dataset` provide static serialization
and deserialization to convert datapoints between their usual representation
and bytes.
```python
from torchvision.datasets import MNIST
from datasig.dataset import TorchVisionDataset
torch_dataset = MNIST(root="/tmp/data", train=True, download=True)
# Serializing data points to bytes
serialized = TorchVisionDataset.serialize_data_point(torch_dataset[0])
# Deserializing data points from bytes
deserialized = TorchVisionDataset.deserialize_data_point(serialized)
```
## Development
### Unit tests
Tests are in the `datasig/test` directory. You can run the tests with:
```bash
uv run python -m pytest # Run all tests
uv run python -m pytest -s datasig/test/test_csv.py # Run only one test file
uv run python -m pytest -s datasig/test/test_csv.py -k test_similarity # Run only one specific test function
```
### Profiling
The profiling script generates a profile for dataset processing and fingerprint generation using cProfile. To profile the MNIST dataset from the torch framework,
you can run:
```bash
uv run python profiling.py torch_mnist --full
```
The `--full` argument tells the script to include dataset canonization, UID generation, and fingerprint generation in the profile. If you want to profile only some of these steps you can cherry pick by using or omitting the following arguments instead:
```bash
uv run python profiling.py torch_mnist --canonical --uid --fingerprint
```
You can optionally specify the datasig config version to use (at the time of writing we have only v0) with:
```bash
uv run python profiling.py torch_mnist -v 0 --all
```
Currently we support only one target dataset: `torch_mnist`. To add another dataset, add a class in `profiling.py` similar to `TorchMNISTV0`, that implements the `_setup()` method which is responsible for loading the dataset.
### Benchmarking
!!! This is currently broken !!!
Datasig has a built-in `benchmark` module that allows to run experiments to benchmark speed and accuracy of various fingerprinting methods with varying configurations and on several datasets.
Benchmarks are configured programmatically using the `datasig` library directly.
The `benchmarking.py` script gives a comprehensive overview of how to configure and run a benchmark, export results, as well as plot them on graph.
You can run the example benchmark with
```bash
uv run python benchmarking.py
``` | text/markdown | Lucas Bourtoule, Boyan Milanov | Lucas Bourtoule <lucas.bourtoule@trailofbits.com>, Boyan Milanov <boyan.milanov@trailofbits.com> | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"datasketch>=1.6.5",
"numpy>=1.24.4",
"pillow>=10.4.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:24:13.672632 | datasig-0.0.7.tar.gz | 88,198 | 0f/13/36057c337c0468f60a18b56db72e9f312b979b233470fb13394607e7e794/datasig-0.0.7.tar.gz | source | sdist | null | false | b242bb9f34ea1f7c57f060bea0847428 | 8f813a46569e9536ea54bb67a9656b76e143d6d1767dc907800bfb50080ce918 | 0f1336057c337c0468f60a18b56db72e9f312b979b233470fb13394607e7e794 | AGPL-3.0-only | [
"LICENSE"
] | 302 |
2.4 | tdcpy | 0.0.1 | Time Delay Systems Control Package | # Time-Delay Systems Control Python Package
This Python pacakge contains tools for analysis and controller design for linear
time-invariant dynamical systems with discrete delays.
- Website and documentation: https://lockeerasmus.github.io/tdcpy
- Bug reports: https://github.com/lockeerasmus/tdcpy/issues
This package provides:
- Stability analysis of retarded and neutral time-delay systems
- Computation of chacteristic roots and transmission zeros
- Spectral abscissa
- Strong stability assesment of neutral time delay systems
- Analysis of sensitivity to small delay perturbation
- Computation of strong spectral abscissa
- Stabilization via fixed order controllers design
## Credits
This project was developed as an alternative to
[TDS-CONTROL](https://gitlab.kuleuven.be/u0011378/tds-control) MATLAB toolbox
developed by Prof. Dr. ir. Wim Michiels and Dr. ir. Pieter Appeltans in 2023.
| text/markdown | null | Adam Peichl <adpeichl@gmail.com>, Adrian Saldanha <saldanha.adrian@gmail.com> | null | Adam Peichl <adpeichl@gmail.com>, Adrian Saldanha <saldanha.adrian@gmail.com> | null | timedelay, control, stability, DDE, DDAE | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Mathematics",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Progra... | [] | null | null | >=3.10 | [] | [] | [] | [
"matplotlib",
"numpy",
"scipy",
"sphinx>=7.0; extra == \"docs\"",
"sphinx-autodoc-typehints; extra == \"docs\"",
"sphinx-gallery; extra == \"docs\"",
"sphinxcontrib-bibtex; extra == \"docs\"",
"pydata-sphinx-theme; extra == \"docs\"",
"sphinx-design; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/lockeerasmus/tdcpy",
"Documentation, https://lockeerasmus.github.io/tdcpy",
"Repository, https://github.com/lockeerasmus/tdcpy",
"Issues, https://github.com/lockeerasmus/tdcpy/issues",
"Changelog, https://github.com/lockeerasmus/tdcpy/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:24:06.576629 | tdcpy-0.0.1.tar.gz | 88,621 | b9/1e/41f721e2292f7ae4ef9551578ab717abfc051419117d48bfda028283620a/tdcpy-0.0.1.tar.gz | source | sdist | null | false | c53669e9b7af872124797ca5e44ed814 | 9f94d78e46ce92ba8692d59d3653574d3ce64c7695bacf1b68d6cf71b70440ec | b91e41f721e2292f7ae4ef9551578ab717abfc051419117d48bfda028283620a | GPL-3.0-or-later | [
"LICENSE"
] | 299 |
2.4 | cas2json | 1.2.2 | Serialize financial statements to python objects | <!--
SPDX-License-Identifier: GPL-3.0-or-later
Copyright (C) 2025 BeyondIRR <https://beyondirr.com/>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
-->
# Cas2JSON
[](https://github.com/astral-sh/ruff)
A library to parse CAS (Consolidated Account Statement) from providers like CAMS, KFINTECH, NSDL (BETA) , CDSL (BETA) and get related data in JSON format.
## Installation
```bash
pip install -U cas2json
```
## Usage
```python
# For CAMS/KFINTECH
from cas2json import parse_cams_pdf
data = parse_cams_pdf("/path/to/cams/file.pdf", "password")
# For NSDL
from cas2json import parse_nsdl_pdf
data = parse_nsdl_pdf("/path/to/nsdl/file.pdf", "password")
#For CDSL
from cas2json import parse_cdsl_pdf
data = parse_cdsl_pdf("/path/to/cdsl/file.pdf", "password")
# To get data in form of Python dict
from dataclasses import asdict
python_dict = asdict(data)
# To convert the data from python dict to JSON
from msgspec import json
json_data = json.encode(python_dict)
```
Notes:
- All used types like transaction types can be found under `cas2json/enums.py`.
- NSDL/CDSL currently supports only parsing of holdings since the transactions history is not complete.
## License
Cas2JSON is distributed under GNU GPL v3 license. - _IANAL_
## Credits
This library is inspired by [CASParser](https://github.com/codereverser/casparser), but it is an independent reimplementation with significant changes in both design and processing logic. In particular, it introduces a revised method for parsing textual data and for accurately identifying transaction values, even in cases where one or more trailing values may be missing from the record.
This project is not affiliated with or endorsed by the original CASParser author
## Resources
1. [CAS from CAMS](https://www.camsonline.com/Investors/Statements/Consolidated-Account-Statement)
2. [CAS from Karvy/Kfintech](https://mfs.kfintech.com/investor/General/ConsolidatedAccountStatement)
| text/markdown | null | Aman Jagotra <dragnemperor@gmail.com> | null | Aman Jagotra <dragnemperor@gmail.com>, Avishrant Sharma <avishrants@gmail.com>, Sagar Chand Agarwal <sagar.agarwal@beyondirr.tech>, Priyanshu Rajput <priyanshu011109@gmail.com> | null | null | [
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"pymupdf>=1.24.0",
"python-dateutil<3,>=2.8.2"
] | [] | [] | [] | [
"Homepage, https://github.com/BeyondIRR/cas2json",
"Repository, https://github.com/BeyondIRR/cas2json",
"Issues, https://github.com/BeyondIRR/cas2json/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T11:24:01.005201 | cas2json-1.2.2-py3-none-any.whl | 51,123 | c3/b1/f0389504541b75754661f4eb8b36c9dbb19ac893e5e5615625c674a45b34/cas2json-1.2.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 930d98a807c93316335e658da80bf72a | fbdde144eb81d5b786b7b9ff52221c1d2c7a6b55e529b3dba06427281e79adfd | c3b1f0389504541b75754661f4eb8b36c9dbb19ac893e5e5615625c674a45b34 | GPL-3.0-or-later | [
"LICENSES/GPL-3.0-or-later.txt"
] | 274 |
2.4 | ionworksdata | 0.4.4 | Data processing for Ionworks software. | # Ionworks Data Processing
A library for processing experimental battery data into a common format for use in Ionworks software.
## Overview
**Ionworks Data Processing** (`ionworksdata`) provides readers for cycler file formats (Maccor, Biologic, Neware, Novonix, Repower, CSV, and more), transforms time series data into a standardized format, and summarizes and labels steps for analysis or use in other Ionworks tools (e.g. the [Ionworks pipeline](https://pipeline.docs.ionworks.com/) and [ionworks-schema](https://github.com/ionworks/ionworks-schema)).
Full API and usage details are in the [Ionworks Data Processing documentation](https://data.docs.ionworks.com/).
## Package structure
- **`read`** — Read raw data from files: `time_series`, `time_series_and_steps`, `measurement_details`; readers include `biologic`, `biologic_mpt`, `maccor`, `neware`, `novonix`, `repower`, `csv`, and others (reader is auto-detected when not specified).
- **`transform`** — Transform time series into Ionworks-compatible form (step count, cycle count, capacity, energy, etc.).
- **`steps`** — Summarize time series into step-level data and label steps (cycling, pulse, EIS) for processing or visualization.
- **`load`** — Load processed data for use in other Ionworks software (`DataLoader`, `OCPDataLoader`).
## Installation
```bash
pip install ionworksdata
```
## Quick start
### Processing time series data
Extract time series data from a cycler file with `read.time_series`. The reader can be specified explicitly or auto-detected. The function returns a Polars DataFrame.
```python
import ionworksdata as iwdata
# With explicit reader
data = iwdata.read.time_series("path/to/file.mpt", "biologic_mpt")
# With auto-detection (reader is optional)
data = iwdata.read.time_series("path/to/file.mpt")
```
The function automatically performs several processing steps and adds columns to the output.
#### Data processing steps
1. **Reader-specific processing** (varies by reader):
- Column renaming to standardized names (e.g. "Voltage" → "Voltage [V]")
- Numeric coercion (removing thousands separators, converting strings to numbers)
- Dropping message/error rows (for some readers)
- Parsing timestamp columns and computing time if needed
- Converting time units (e.g. hours to seconds)
- Fixing unsigned current (if current is always positive, negate during charge)
- Validating and fixing decreasing times (if `time_offset_fix` option is set)
2. **Standard data processing** (applied to all readers):
- Removing rows with null values in current or voltage columns
- Converting numeric columns to float64
- Resetting time to start at zero
- Offsetting duplicate timestamps by a small amount (1e-6 s) to preserve all data points
- Setting discharge current to be positive (charge current remains negative)
3. **Post-processing**:
- Adding `Step count`, `Cycle count`, `Discharge capacity [A.h]`, `Charge capacity [A.h]`, `Discharge energy [W.h]`, `Charge energy [W.h]`
#### Output columns
| Column | Description |
|--------|-------------|
| `Time [s]` | Time in seconds |
| `Current [A]` | Current in amperes |
| `Voltage [V]` | Voltage in volts |
| `Step count` | Cumulative step count (always present) |
| `Cycle count` | Cumulative cycle count, defaults to 0 if no cycle information (always present) |
| `Discharge capacity [A.h]` | Discharge capacity in ampere-hours (always present) |
| `Charge capacity [A.h]` | Charge capacity in ampere-hours (always present) |
| `Discharge energy [W.h]` | Discharge energy in watt-hours (always present) |
| `Charge energy [W.h]` | Charge energy in watt-hours (always present) |
| `Step from cycler` | Step number from cycler file (if provided) |
| `Cycle from cycler` | Cycle number from cycler file (if provided) |
| `Temperature [degC]` | Temperature in degrees Celsius (if provided) |
| `Frequency [Hz]` | Frequency in hertz (if provided) |
For expected and returned columns per reader, see the [API documentation](https://data.docs.ionworks.com/). Extra columns can be mapped via `extra_column_mappings`:
```python
data = iwdata.read.time_series(
"path/to/file.mpt", "biologic_mpt",
extra_column_mappings={"Old column name": "My new column"},
)
```
### Processing step data
From processed time series, step summary data is obtained with `steps.summarize`:
```python
steps = iwdata.steps.summarize(data)
```
This detects steps from the `Step count` column and computes metrics per step. The output always includes:
| Column | Description |
|--------|-------------|
| `Cycle count` | Cumulative cycle count (defaults to 0 if no cycle information) |
| `Cycle from cycler` | Cycle number from cycler file (only if provided in input) |
| `Discharge capacity [A.h]` | Discharge capacity for the step |
| `Charge capacity [A.h]` | Charge capacity for the step |
| `Discharge energy [W.h]` | Discharge energy for the step |
| `Charge energy [W.h]` | Charge energy for the step |
| `Step from cycler` | Step number from cycler file (only if provided in input) |
Additional per-step columns include start/end time and index, start/end/min/max/mean/std for voltage and current, duration, step type, and (after labeling) cycle-level capacity and energy. See the [API documentation](https://data.docs.ionworks.com/) for the full list.
**Note:** Step identification uses `Step count` and, when available, `Cycle from cycler` for cycle tracking.
Alternatively, get time series and steps in one call:
```python
# With explicit reader
data, steps = iwdata.read.time_series_and_steps("path/to/file.mpt", "biologic_mpt")
# With auto-detection (reader is optional)
data, steps = iwdata.read.time_series_and_steps("path/to/file.mpt")
```
### Labeling steps
Steps can be labeled using the `steps` module (e.g. cycling, pulse, and EIS):
```python
options = {"cell_metadata": {"Nominal cell capacity [A.h]": 5}}
steps = iwdata.steps.label_cycling(steps, options)
for direction in ["charge", "discharge"]:
options["current direction"] = direction
steps = iwdata.steps.label_pulse(steps, options)
steps = iwdata.steps.label_eis(steps)
```
### Measurement details
`read.measurement_details` returns a dictionary with `measurement`, `time_series`, and `steps`. Pass the file path, a measurement dict (e.g. test name), and optionally the reader and options; the function fills in time series and steps and updates the measurement dict (e.g. cycler name, start time). Steps are labeled with default labels unless you pass a custom `labels` list:
```python
measurement = {"name": "My test"}
measurement_details = iwdata.read.measurement_details(
"path/to/file.mpt",
measurement,
"biologic_mpt",
options={"cell_metadata": {"Nominal cell capacity [A.h]": 5}},
)
measurement = measurement_details["measurement"]
time_series = measurement_details["time_series"]
steps = measurement_details["steps"]
```
## Data format
Processed data follows the format expected by Ionworks software. Column names, units, and conventions are described in the [Ionworks Data Processing documentation](https://data.docs.ionworks.com/).
## Resources
- [Ionworks Data Processing documentation](https://data.docs.ionworks.com/) — API reference, readers, and data format.
- [Ionworks Pipeline documentation](https://pipeline.docs.ionworks.com/) — Using processed data in pipelines.
- [Ionworks documentation](https://docs.ionworks.com) — Platform and product overview.
| text/markdown | null | null | null | null | MIT License
Copyright (c) 2026 Ionworks Technologies Inc
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"fastexcel",
"ionworks-api>=0.1.0",
"iwutil>=0.3.11",
"matplotlib",
"numpy",
"pandas<3.0.0",
"polars-lts-cpu>=0.20.0",
"pybamm",
"scipy",
"myst-nb; extra == \"dev\"",
"openpyxl; extra == \"dev\"",
"pydata-sphinx-theme; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:23:49.168158 | ionworksdata-0.4.4.tar.gz | 65,980 | fe/04/db387d674890977e463379d6764f9db48f34d85feb9ec292ff069dce0ee9/ionworksdata-0.4.4.tar.gz | source | sdist | null | false | 3181f11df58a55c95d0ea94bca057e12 | 1789f918fd5f2436fe2c3e5c9659929db47904a6e25f4501848025eb445bb581 | fe04db387d674890977e463379d6764f9db48f34d85feb9ec292ff069dce0ee9 | null | [
"LICENSE.md"
] | 286 |
2.4 | pi-heif | 1.2.1 | Python interface for libheif library | # pi-heif
[](https://github.com/bigcat88/pillow_heif/actions/workflows/analysis-coverage.yml)



[](https://pepy.tech/project/pi-heif)
[](https://pepy.tech/project/pi-heif)





This is a light version of [Pillow-Heif](https://github.com/bigcat88/pillow_heif) with more permissive license for binary wheels.
It includes only `HEIF` decoder and does not support `save` operations.
All codebase are the same, refer to [pillow-heif docs](https://pillow-heif.readthedocs.io/).
The only difference is the name of the imported project.
### Install
```console
python3 -m pip install -U pip
python3 -m pip install pi-heif
```
### Example of use as a Pillow plugin
```python3
from PIL import Image
from pi_heif import register_heif_opener
register_heif_opener()
im = Image.open("images/input.heic") # do whatever need with a Pillow image
im.show()
```
### 8/10/12 bit HEIF to 8/16 bit PNG using OpenCV
```python3
import numpy as np
import cv2
import pi_heif
heif_file = pi_heif.open_heif("image.heic", convert_hdr_to_8bit=False, bgr_mode=True)
np_array = np.asarray(heif_file)
cv2.imwrite("image.png", np_array)
```
### Get decoded image data as a Numpy array
```python3
import numpy as np
import pi_heif
if pi_heif.is_supported("input.heic"):
heif_file = pi_heif.open_heif("input.heic")
np_array = np.asarray(heif_file)
```
### Accessing Depth Images
```python3
from PIL import Image
from pillow_heif import register_heif_opener
import numpy as np
register_heif_opener()
im = Image.open("../tests/images/heif_other/pug.heic")
if im.info["depth_images"]:
depth_im = im.info["depth_images"][0] # Access the first depth image (usually there will be only one).
# Depth images are instances of `class HeifDepthImage(BaseImage)`,
# so work with them as you would with any usual image in pillow_heif.
# Depending on what you need the depth image for, you can convert it to a NumPy array or convert it to a Pillow image.
pil_im = depth_im.to_pillow()
np_im = np.asarray(depth_im)
print(pil_im)
print(pil_im.info["metadata"])
```
### Wheels
| **_Wheels table_** | macOS<br/>Intel | macOS<br/>Silicon | Windows<br/> | musllinux* | manylinux* |
|--------------------|:---------------:|:-----------------:|:------------:|:----------:|:----------:|
| CPython 3.9 | ✅ | ✅ | ✅ | ✅ | ✅ |
| CPython 3.10 | ✅ | ✅ | ✅ | ✅ | ✅ |
| CPython 3.11 | ✅ | ✅ | ✅ | ✅ | ✅ |
| CPython 3.12 | ✅ | ✅ | ✅ | ✅ | ✅ |
| CPython 3.13 | ✅ | ✅ | ✅ | ✅ | ✅ |
| PyPy 3.10 v7.3 | ✅ | ✅ | ✅ | N/A | ✅ |
| PyPy 3.11 v7.3 | ✅ | ✅ | ✅ | N/A | ✅ |
* **x86_64**, **aarch64** wheels.
| text/markdown | Alexander Piskun | bigcat88@users.noreply.github.com | null | null | BSD-3-Clause | heic, heif, pillow | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development",
"Topic :: Software Development :: Libraries",
"Topic :: Multimedia :: Graphics",
"Topic :: Multimedia :: Graphics :: Graphics Conversion",
"Programming Language :: Python :: 3",
"Programm... | [] | https://github.com/bigcat88/pillow_heif | null | >=3.9 | [] | [] | [] | [
"pillow>=11.1.0",
"pytest; extra == \"tests-min\"",
"defusedxml; extra == \"tests-min\"",
"packaging; extra == \"tests-min\"",
"pytest; extra == \"tests\"",
"defusedxml; extra == \"tests\"",
"packaging; extra == \"tests\"",
"numpy; extra == \"tests\"",
"pympler; extra == \"tests\""
] | [] | [] | [] | [
"Documentation, https://pillow-heif.readthedocs.io",
"Source, https://github.com/bigcat88/pillow_heif",
"Changelog, https://github.com/bigcat88/pillow_heif/blob/master/CHANGELOG.md"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-18T11:21:47.810116 | pi_heif-1.2.1.tar.gz | 17,126,562 | c5/e2/ec73060f02e328bdeb86cb13c6717916fcb530c5fa595d5d48e4b831c675/pi_heif-1.2.1.tar.gz | source | sdist | null | false | b923cfc49953841a18d4e577d989f150 | a5c5fd4d92b4f0541d8629eaadd95403ccdfd1b7f2ddced52844fa610713685d | c5e2ec73060f02e328bdeb86cb13c6717916fcb530c5fa595d5d48e4b831c675 | null | [
"LICENSE.txt",
"LICENSES_bundled.txt"
] | 108,979 |
2.4 | sayou | 0.2.1 | A file-system inspired context store for AI agents | # sayou
**A file-system inspired context store for AI agents.**
Built to replace the databases of the web era. Open source. File-first. SQL-compatible.
[](LICENSE)
[](https://www.python.org)
Databases were designed for transactions — they reduce nuance to fit a schema. Agents think deeply, then forget everything when the session ends. sayou is where reasoning persists, context accumulates, and knowledge compounds over time.
- **Files that hold what databases can't** — Frontmatter for structure. Markdown for context. Versioned. Auditable.
- **One read. Full context.** — Every read accepts a `token_budget`. Returns summaries with section pointers when content exceeds the budget.
- **Knowledge that compounds** — Append-only version history. Every change is a new version. Full audit trail and time-travel reads.
- **Any agent can connect** — MCP server, Python library, or CLI. Optional REST API with `pip install sayou[api]`.
## Quick Start
### 1. Install
```bash
pip install sayou
```
### 2. Initialize
```bash
sayou init
```
### 3. Connect to Claude Code
Add to `~/.claude/mcp.json`:
```json
{
"mcpServers": {
"sayou": { "command": "sayou" }
}
}
```
### 4. Verify
Restart Claude Code (so it picks up the new MCP config), then run:
```bash
sayou status
```
You should see your workspace path, database location, and `11 tools registered`. If you see errors, jump to [Troubleshooting](#troubleshooting).
## Try It
Open Claude Code and paste any of these prompts. Each one triggers a different MCP tool — no setup beyond the Quick Start above.
| Prompt | What happens | Tool |
|--------|-------------|------|
| "Save a note about our Q1 goals with status: draft" | Creates a versioned file with YAML frontmatter | `workspace_write` |
| "What files are in my workspace?" | Lists all files and subfolders | `workspace_list` |
| "Search for anything tagged status: draft" | Filters files by frontmatter metadata | `workspace_search` |
| "Read the Q1 goals note" | Retrieves file content with token-budget awareness | `workspace_read` |
| "Update the status to reviewed" | Writes a new version (old version preserved) | `workspace_write` |
| "Show me the diff between versions" | Compares two versions with unified diff | `workspace_history` |
| "Store a setting: theme = dark" | Saves a key-value pair (with optional TTL) | `workspace_kv` |
| "Find all markdown files in research/" | Matches files by glob pattern | `workspace_glob` |
| "Search file contents for the word 'budget'" | Grep-style content search with context | `workspace_grep` |
Every write creates a new version. Nothing is overwritten. You can always go back.
## What It Looks Like
A short conversation showing sayou in action across sessions:
---
**You:** Research competitor pricing for our enterprise tier and save your findings.
**Claude Code:** I'll research this and save my findings to the workspace.
*[Uses `workspace_write` to create `research/competitor-pricing.md`]*
> Saved to `research/competitor-pricing.md` with frontmatter:
> status: draft, topic: competitor-pricing
---
**You** *(next day, new session):* What did we learn about competitor pricing?
**Claude Code:** Let me check our workspace.
*[Uses `workspace_search` with query "competitor pricing"]*
> Found `research/competitor-pricing.md` (saved yesterday):
> - Competitor A: $99/seat/month
> - Competitor B: $149/seat/month (includes support)
> - Competitor C: $79/seat/month (limited features)
---
**You:** Update the status to "reviewed" and show me the diff.
**Claude Code:** *[Uses `workspace_write` to create version 2, then `workspace_history` to diff]*
> ```diff
> - status: draft
> + status: reviewed
> + reviewer_notes: |
> + Competitor B is closest to our positioning.
> ```
---
The key insight: Claude Code remembered the research **across sessions** because sayou persisted it as a versioned file — not a chat message that disappears.
## Setup for Other Editors
### Cursor
Add to `.cursor/mcp.json` in your project root:
```json
{
"mcpServers": {
"sayou": { "command": "sayou" }
}
}
```
### Windsurf
Add to `~/.codeium/windsurf/mcp_config.json`:
```json
{
"mcpServers": {
"sayou": { "command": "sayou" }
}
}
```
### Any MCP-compatible client
sayou is a standard MCP server. The config is always the same — just `"command": "sayou"`. Check your editor's docs for where it reads MCP server configuration.
## MCP Tools
The agent gets 11 tools (12 with embeddings enabled):
| Tool | Description |
|------|-------------|
| `workspace_write` | Write or update a file (text or binary with YAML frontmatter) |
| `workspace_read` | Read latest or specific version, with optional line range |
| `workspace_list` | List files and subfolders with auto-generated index |
| `workspace_search` | Search by full-text query, frontmatter filters, or chunk-level |
| `workspace_delete` | Soft-delete a file (history preserved) |
| `workspace_history` | Version history with timestamps, or diff between two versions |
| `workspace_glob` | Find files matching a glob pattern |
| `workspace_grep` | Search file contents with context lines |
| `workspace_kv` | Key-value store (get/set/list/delete with optional TTL) |
| `workspace_links` | File links and knowledge graph (get or add links) |
| `workspace_chunks` | Chunk outline or read a specific chunk by index |
| `workspace_semantic_search` | Vector similarity search (requires `SAYOU_EMBEDDING_PROVIDER`) |
## Python API
```python
import asyncio
from sayou import Workspace
async def main():
async with Workspace() as ws:
# Write a file with YAML frontmatter
await ws.write("notes/hello.md", """\
---
status: active
tags: [demo, quickstart]
---
# Hello from sayou
This file is versioned and searchable.
""")
# Read it back
doc = await ws.read("notes/hello.md")
print(doc["content"])
# Search by frontmatter
results = await ws.search(filters={"status": "active"})
print(f"Found {results['total']} active files")
asyncio.run(main())
```
See [`examples/quickstart.py`](examples/quickstart.py) for a runnable version.
## CLI
```bash
# File operations
sayou file read notes/hello.md
sayou file write notes/hello.md "# Hello World"
sayou file list /
sayou file search --query "hello" --filter status=active
# KV store
sayou kv set config.theme '"dark"'
sayou kv get config.theme
# Diagnostics
sayou init # Initialize local setup
sayou status # Show diagnostic info
```
## Examples
| Example | What it shows |
|---------|---------------|
| [`quickstart.py`](examples/quickstart.py) | Hello World — write, read, search, list in 30 lines |
| [`kv_config.py`](examples/kv_config.py) | KV store for config, feature flags, caching with TTL |
| [`version_control.py`](examples/version_control.py) | Version history, diff, time-travel reads |
| [`file_operations.py`](examples/file_operations.py) | Move, copy, binary files, glob patterns |
| [`multi_agent.py`](examples/multi_agent.py) | Multi-agent collaboration with shared workspace |
| [`research_agent.py`](examples/research_agent.py) | All methods exercised — the comprehensive reference |
## Reference Agent
sayou ships with a reference agent server — a multi-turn assistant that can search, read, write, and research using your workspace. It's a complete working example of building an agent on sayou.
### Quick start
```bash
# Install with agent dependencies
pip install sayou[agent]
# Configure (copy and fill in your OpenAI key)
cp agent/.env.example .env
# Run the agent server
python -m sayou.agent
```
The agent runs on `http://localhost:9008` with a streaming SSE endpoint at `POST /chat/stream`.
### What the agent can do
| Capability | How it works |
|------------|-------------|
| **Answer questions** | Searches workspace first, falls back to web search |
| **Research topics** | Multiple web searches, extracts facts, saves structured findings |
| **Store knowledge** | Writes files with YAML frontmatter, section headings, source citations |
| **Execute code** | Optional E2B sandbox for Python and bash (set `SAYOU_AGENT_E2B_API_KEY`) |
### Run benchmarks
```bash
# Start agent in one terminal
python -m sayou.agent
# Quick pass/fail eval
python -m sayou.agent.benchmarks.eval
# Detailed scoring (0-10 per capability)
python -m sayou.agent.benchmarks.eval_full
```
### Architecture
```
Client → FastAPI (port 9008)
↓
Orchestrator
├─ LLMProvider (OpenAI streaming + tool calls)
├─ ToolFactory
│ ├─ workspace_search/read/list/write (→ sayou SDK)
│ ├─ web_search (→ Tavily API, optional)
│ └─ execute_bash/python (→ E2B sandbox, optional)
└─ SandboxManager (per-session isolation, auto-cleanup)
```
## Installation Options
```bash
# Basic (MCP server + CLI + SQLite)
pip install sayou
# With REST API support
pip install sayou[api]
# With S3 storage
pip install sayou[s3]
# With reference agent server
pip install sayou[agent]
# Full installation (all features)
pip install sayou[all]
```
## Production Deployment
For team/production use with MySQL + S3:
```json
{
"mcpServers": {
"sayou": {
"command": "sayou",
"env": {
"SAYOU_ORG_ID": "my-org",
"SAYOU_USER_ID": "alice",
"SAYOU_DATABASE_URL": "mysql+aiomysql://user:pass@host/sayou",
"SAYOU_S3_BUCKET_NAME": "my-bucket",
"SAYOU_S3_ACCESS_KEY_ID": "...",
"SAYOU_S3_SECRET_ACCESS_KEY": "..."
}
}
}
}
```
Install with all backends: `pip install sayou[all]`
## Storage Backends
| Backend | Config | Use case |
|---------|--------|----------|
| **SQLite + local disk** (default) | No config needed | Local dev, single-machine agents, MCP server |
| **MySQL + S3** | Set `database_url`, S3 credentials | Production, multi-agent, shared workspaces |
## Troubleshooting
### Verify your setup
```bash
sayou status
```
This shows your workspace path, database location, storage backend, and tool count. If everything is working, you'll see `11 tools registered`.
### Common issues
| Problem | Cause | Fix |
|---------|-------|-----|
| Claude Code doesn't see sayou tools | MCP config not loaded | Restart Claude Code after editing `~/.claude/mcp.json` |
| `sayou: command not found` | Not on PATH | Run `pip install sayou` again, or use full path in MCP config: `"command": "/path/to/sayou"` |
| `sayou status` shows 0 tools | Server didn't initialize | Run `sayou init` first, then check for errors in output |
| Files not persisting | Wrong workspace path | Check `sayou status` for the workspace path — default is `~/.sayou/` |
| Import errors on startup | Missing optional dependency | Install the extra you need: `pip install sayou[api]`, `sayou[s3]`, or `sayou[all]` |
### Get help
- [GitHub Issues](https://github.com/pixell-global/sayou/issues) — bug reports and feature requests
- [CONTRIBUTING.md](./CONTRIBUTING.md) — development setup and contribution guide
## What sayou is NOT
- **Not a vector database.** Pinecone, Weaviate, and Chroma store embeddings for similarity search. sayou stores structured files that agents read, write, and reason over.
- **Not a memory layer.** Mem0 and similar tools store conversation snippets. sayou stores work product — research, client records, project documentation — that compounds over time.
- **Not a sandbox.** E2B provides ephemeral execution environments. sayou provides persistent storage that outlives any single execution.
- **Not a filesystem.** AgentFS intercepts syscalls to virtualize file operations. A knowledge workspace with versioning and indexing.
## Philosophy
Read [PHILOSOPHY.md](./PHILOSOPHY.md) for the founding vision and design principles.
## Contributing
See [CONTRIBUTING.md](./CONTRIBUTING.md).
## License
Apache 2.0 — See [LICENSE](./LICENSE)
| text/markdown | null | Pixell <kevin_yum@pixell.global> | null | null | null | agent, ai, context, frontmatter, knowledge, markdown, mcp, storage, versioning, workspace | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Soft... | [] | null | null | >=3.11 | [] | [] | [] | [
"aiosqlite>=0.17.0",
"alembic>=1.13.0",
"mcp>=1.8.0",
"pydantic-settings>=2.0.0",
"pydantic>=2.0.0",
"pyyaml>=6.0.0",
"sqlalchemy[asyncio]>=2.0.0",
"e2b-code-interpreter>=1.0.0; extra == \"agent\"",
"fastapi>=0.110.0; extra == \"agent\"",
"httpx>=0.27.0; extra == \"agent\"",
"openai>=1.0.0; extr... | [] | [] | [] | [
"Homepage, https://sayou.dev",
"Repository, https://github.com/pixell-global/sayou",
"Documentation, https://github.com/pixell-global/sayou#readme",
"Issues, https://github.com/pixell-global/sayou/issues",
"Changelog, https://github.com/pixell-global/sayou/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:21:36.804842 | sayou-0.2.1.tar.gz | 331,557 | 57/71/73afb7d922846cbc7ce8214c68b30e6c80166d8940d7cb68b817b9323add/sayou-0.2.1.tar.gz | source | sdist | null | false | f264b8f4cac82da055ea68a8403e104b | 7a60c715ad46c9aae34f8eb87f2eec4bd3b1f9a3eb78c7aebd36d084f00638f2 | 577173afb7d922846cbc7ce8214c68b30e6c80166d8940d7cb68b817b9323add | Apache-2.0 | [
"LICENSE"
] | 292 |
2.4 | ol-openedx-course-sync | 0.5.3 | An Open edX plugin to sync course changes to its reruns. | OL Open edX Course Sync
=======================
An Open edX plugin to sync course changes to its reruns.
Version Compatibility
---------------------
It supports Open edX releases from `Sumac` and onwards.
Installing The Plugin
---------------------
For detailed installation instructions, please refer to the `plugin installation guide <../../docs#installation-guide>`_.
Installation required in:
* CMS
Configuration
=============
* Add a setting ``OL_OPENEDX_COURSE_SYNC_SERVICE_WORKER_USERNAME`` for the service worker and all the sync operations will be done on behalf of this user.
* For Tutor, you can run:
.. code-block:: bash
tutor config save --set OL_OPENEDX_COURSE_SYNC_SERVICE_WORKER_USERNAME={USERNAME}
* If you have a ``private.py`` for the CMS settings, you can add it to ``cms/envs/private.py``.
Usage
-----
* Install the plugin and run the migrations in the CMS.
* Add the parent/source organization in the CMS admin model `CourseSyncOrganization`.
* Course sync will only work for this organization. It will treat all the courses under this organization as parent/source courses.
* The plugin will automatically add course re-runs created from the CMS as the child courses.
* The organization can be different for the reruns.
* Target/rerun courses can be managed in the CMS admin model `CourseSyncMapping`.
* Now, any changes made in the source course will be synced to the target courses.
| text/x-rst | MIT Office of Digital Learning | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"django>=4.0",
"djangorestframework>=3.14.0",
"edx-django-utils>4.0.0",
"edx-opaque-keys",
"openedx-events"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-18T11:21:06.286793 | ol_openedx_course_sync-0.5.3.tar.gz | 8,824 | 0a/3a/f5140a773a4eed71582ad9d78a75fa944200423b4bab53412e5a24cd70e1/ol_openedx_course_sync-0.5.3.tar.gz | source | sdist | null | false | 19fd1c585fdaf8c91808334575b0a73b | e9f55d7505178c2aaaa8ae45f4821ec9d546d0831888908b2a02c9bba3914ea0 | 0a3af5140a773a4eed71582ad9d78a75fa944200423b4bab53412e5a24cd70e1 | BSD-3-Clause | [
"LICENCE"
] | 247 |
2.4 | openapiart | 0.3.39 | The OpenAPI Artifact Generator Python Package | # openapiart - OpenAPI Artifact Generator
[](https://github.com/open-traffic-generator/openapiart/actions)
[](https://www.repostatus.org/#active)
[](https://pypi.python.org/pypi/openapiart)
[](https://en.wikipedia.org/wiki/MIT_License)
The `OpenAPIArt` (OpenAPI Artifact Generator) python package does the following:
- pre-processes OpenAPI yaml files according to the [MODELGUIDE](../main/MODELGUIDE.md)
- using the path keyword bundles all dependency OpenAPI yaml files into a single openapi.yaml file
- post-processes any [MODELGUIDE](../main/MODELGUIDE.md) extensions
- validates the bundled openapi.yaml file
- generates a `.proto` file from the openapi file
- optionally generates a static redocly documentation file
- optionally generates a `python ux sdk` from the openapi file
- optionally generates a `go ux sdk` from the openapi file
## Getting started
Install the package
```
pip install openapiart
```
Generate artifacts from OpenAPI files
```python
"""
The following command will produce these artifacts:
- ./artifacts/openapi.yaml
- ./artifacts/openapi.json
- ./artifacts/openapi.html
- ./artifacts/sample.proto
- ./artifacts/sample/__init__.py
- ./artifacts/sample/sample.py
- ./artifacts/sample/sample_pb2.py
- ./artifacts/sample/sample_pb2_grpc.py
- ./pkg/openapiart.go
- ./pkg/go.mod
- ./pkg/go.sum
- ./pkg/sanity/sanity_grpc.pb.go
- ./pkg/sanity/sanity.pb.go
"""
import openapiart
# bundle api files
# validate the bundled file
# generate the documentation file
art = openapiart.OpenApiArt(
api_files=[
"./openapiart/tests/api/info.yaml",
"./openapiart/tests/common/common.yaml",
"./openapiart/tests/api/api.yaml",
],
artifact_dir="./artifacts",
protobuf_name="sanity",
extension_prefix="sanity",
)
# optionally generate a python ux sdk and python protobuf/grpc stubs
art.GeneratePythonSdk(
package_name="sanity"
)
# optionally generate a go ux sdk and go protobuf/grpc stubs
art.GenerateGoSdk(
package_dir="github.com/open-traffic-generator/openapiart/pkg",
package_name="openapiart"
)
```
## Specifications
> This repository is based on the [OpenAPI specification](
https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.3.md)
which is a standard, language-agnostic interface to RESTful APIs.
> [Modeling guide specific to this package](../main/MODELGUIDE.md)
| text/markdown | null | Keysight Technologies <andy.balogh@keysight.com> | null | null | null | testing, openapi, artifact, generator | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Testing :: Traffic Generation",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: ... | [] | null | null | <4,>=3.8 | [] | [] | [] | [
"build",
"jsonpath-ng",
"typing",
"setuptools",
"wheel",
"PyYAML",
"openapi_spec_validator==0.7.2; python_version > \"3.8\"",
"openapi-spec-validator==0.5.7; python_version == \"3.8\"",
"requests",
"typing_extensions",
"click==8.1.7",
"black==22.3.0",
"grpcio-tools~=1.70.0",
"pipreqs==0.4.... | [] | [] | [] | [
"Repository, https://github.com/open-traffic-generator/openapiart"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-18T11:20:57.926877 | openapiart-0.3.39.tar.gz | 122,546 | 4c/e3/a9b72a2004d324dec92203fa6a3333c85820eaa12761a100a16220ec5fac/openapiart-0.3.39.tar.gz | source | sdist | null | false | f435d9b7ccba7e4f304572cf6a1fa991 | 00c8072929785590f6c48fc0f169762ca652b5b14123bc79079401d67265505d | 4ce3a9b72a2004d324dec92203fa6a3333c85820eaa12761a100a16220ec5fac | MIT | [
"LICENSE"
] | 381 |
2.1 | poetry-analysis | 0.3.15 | Tool to parse and annotate Norwegian poetry. | # poetry_analysis
[](https://www.python.org/downloads/)
[](https://pypi.org/project/poetry-analysis/)
[](https://creativecommons.org/licenses/by/4.0/deed.en)
[](https://github.com/norn-uio/poetry_analysis/actions/workflows/check.yml)
- **GitHub repository**: <https://github.com/norn-uio/poetry-analysis/>
- **Documentation**: <https://norn-uio.github.io/poetry_analysis/>
Rule-based tool to extract repetition patterns and other lyric features from poetry, or other text data where the newline is a meaningful segment boundary.
Lyric features that can be extracted with this tool includes
- end rhyme schemes
- alliteration
- anaphora
- lyrical subject
`poetry_analysis` has been developed alongside [NORN Poems](https://github.com/norn-uio/norn-poems), a corpus of Norwegian poetry from the 1890's, which is freely available to use with this tool.
## Installation
This library requires python >= 3.11. Create and activate a virtual environment before installing, e.g. with [`uv`](https://docs.astral.sh/uv/):
```shell
# Create environment with uv
uv venv --python 3.11
# Activate environment
source .venv/bin/activate
# Install poetry_analysis
pip install poetry-analysis
```
## Contact
This tool was developed as a collaboration project between a literary scholar and a computational linguist in the [NORN project](https://www.hf.uio.no/iln/english/research/projects/norn-norwegian-romantic-nationalisms/index.html):
- Ranveig Kvinnsland [<img src="https://raw.githubusercontent.com/FortAwesome/Font-Awesome/refs/heads/6.x/svgs/brands/github.svg" width="20" height="20" alt="GitHub icon">](https://github.com/ranveigk)
[<img src="https://raw.githubusercontent.com/FortAwesome/Font-Awesome/6.x/svgs/solid/envelope.svg" width="20" height="20" alt="Email icon">](mailto:ranveig.kvinnsland@ibsen.uio.no)
- Ingerid Dale [<img src="https://raw.githubusercontent.com/FortAwesome/Font-Awesome/refs/heads/6.x/svgs/brands/github.svg" width="20" height="20" alt="GitHub icon">](https://github.com/ingerid)
[<img src="https://raw.githubusercontent.com/FortAwesome/Font-Awesome/6.x/svgs/solid/envelope.svg" width="20" height="20" alt="Email icon">](mailto:ingerid.dale@nb.no)
If you discover any bugs, have any questions, or suggestions for improvements, please open an issue and assign an appropriate label to it. Contributions and pull requests are also welcome! Please check out the [contributing](https://github.com/norn-uio/poetry-analysis?tab=contributing-ov-file) section in the repo for guidelines.
| text/markdown | null | Ingerid Dale <ingerid.dale@nb.no>, Ranveig Kvinnsland <ranveig.kvinnsland@ibsen.uio.no> | null | null | CC-BY-4.0 | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"nb-tokenizer",
"pandas",
"convert-pa",
"matplotlib",
"mkdocs>=1.6.1; extra == \"docs\"",
"mkdocs-material>=9.6.21; extra == \"docs\"",
"mkdocstrings>=0.30.1; extra == \"docs\"",
"mkdocstrings-python>=1.18.2; extra == \"docs\"",
"pymdown-extensions>=10.16.1; extra == \"docs\"",
"nbconvert>=7.16.6;... | [] | [] | [] | [
"Repository, https://github.com/norn-uio/poetry-analysis.git",
"Issues, https://github.com/norn-uio/poetry-analysis/issues",
"Documentation, https://norn-uio.github.io/poetry-analysis/"
] | pdm/2.26.6 CPython/3.12.3 Linux/6.8.0-100-generic | 2026-02-18T11:20:57.124728 | poetry_analysis-0.3.15.tar.gz | 38,777 | f4/f9/5480637976021244a9c2b427f7a65dd892b5237c52d7e67f3b3249921180/poetry_analysis-0.3.15.tar.gz | source | sdist | null | false | 77a61a245e6c965e27e4148a47417d0a | 8f2eca168658ac3d41d29259e04344aadc91975ed232c4b326592974bf87caaa | f4f95480637976021244a9c2b427f7a65dd892b5237c52d7e67f3b3249921180 | null | [] | 242 |
2.4 | pillow-heif | 1.2.1 | Python interface for libheif library | # pillow-heif
[](https://github.com/bigcat88/pillow_heif/actions/workflows/analysis-coverage.yml)
[](https://github.com/bigcat88/pillow_heif/actions/workflows/nightly-src-build.yml)
[](https://pillow-heif.readthedocs.io/en/latest/?badge=latest)
[](https://codecov.io/gh/bigcat88/pillow_heif)



[](https://pepy.tech/project/pillow-heif)
[](https://pepy.tech/project/pillow-heif)





Python bindings to [libheif](https://github.com/strukturag/libheif) for working with HEIF images and plugin for Pillow.
Features:
* Decoding of `8`, `10`, `12` bit HEIC files.
* Encoding of `8`, `10`, `12` bit HEIC files.
* `EXIF`, `XMP`, `IPTC` read & write support.
* Support of multiple images in one file and a `PrimaryImage` attribute.
* Adding & removing `thumbnails`.
* Reading of `Depth Images`.
* (beta) Reading of `Auxiliary Images` by [johncf](https://github.com/johncf)
* Adding HEIF support to Pillow in one line of code as a plugin.
Note: Here is a light version [pi-heif](https://pypi.org/project/pi-heif/) of this project without encoding capabilities.
### Install
```console
python3 -m pip install -U pip
python3 -m pip install pillow-heif
```
### Example of use as a Pillow plugin
```python3
from PIL import Image
from pillow_heif import register_heif_opener
register_heif_opener()
im = Image.open("image.heic") # do whatever need with a Pillow image
im = im.rotate(13)
im.save(f"rotated_image.heic", quality=90)
```
### 16 bit PNG to 10 bit HEIF using OpenCV
```python3
import cv2
import pillow_heif
cv_img = cv2.imread("16bit_with_alpha.png", cv2.IMREAD_UNCHANGED)
heif_file = pillow_heif.from_bytes(
mode="BGRA;16",
size=(cv_img.shape[1], cv_img.shape[0]),
data=bytes(cv_img)
)
heif_file.save("RGBA_10bit.heic", quality=-1)
```
### 8/10/12 bit HEIF to 8/16 bit PNG using OpenCV
```python3
import numpy as np
import cv2
import pillow_heif
heif_file = pillow_heif.open_heif("image.heic", convert_hdr_to_8bit=False, bgr_mode=True)
np_array = np.asarray(heif_file)
cv2.imwrite("image.png", np_array)
```
### Accessing decoded image data
```python3
import pillow_heif
if pillow_heif.is_supported("image.heic"):
heif_file = pillow_heif.open_heif("image.heic", convert_hdr_to_8bit=False)
print("image size:", heif_file.size)
print("image mode:", heif_file.mode)
print("image data length:", len(heif_file.data))
print("image data stride:", heif_file.stride)
```
### Get decoded image data as a Numpy array
```python3
import numpy as np
import pillow_heif
if pillow_heif.is_supported("input.heic"):
heif_file = pillow_heif.open_heif("input.heic")
np_array = np.asarray(heif_file)
```
### Accessing Depth Images
```python3
from PIL import Image
from pillow_heif import register_heif_opener
import numpy as np
register_heif_opener()
im = Image.open("../tests/images/heif_other/pug.heic")
if im.info["depth_images"]:
depth_im = im.info["depth_images"][0] # Access the first depth image (usually there will be only one).
# Depth images are instances of `class HeifDepthImage(BaseImage)`,
# so work with them as you would with any usual image in pillow_heif.
# Depending on what you need the depth image for, you can convert it to a NumPy array or convert it to a Pillow image.
pil_im = depth_im.to_pillow()
np_im = np.asarray(depth_im)
print(pil_im)
print(pil_im.info["metadata"])
```
### More Information
- [Documentation](https://pillow-heif.readthedocs.io/)
- [Installation](https://pillow-heif.readthedocs.io/en/latest/installation.html)
- [Pillow plugin](https://pillow-heif.readthedocs.io/en/latest/pillow-plugin.html)
- [Using HeifFile](https://pillow-heif.readthedocs.io/en/latest/heif-file.html)
- [Image modes](https://pillow-heif.readthedocs.io/en/latest/image-modes.html)
- [Options](https://pillow-heif.readthedocs.io/en/latest/options.html)
- [Examples](https://github.com/bigcat88/pillow_heif/tree/master/examples)
- [Contribute](https://github.com/bigcat88/pillow_heif/blob/master/.github/CONTRIBUTING.md)
- [Discussions](https://github.com/bigcat88/pillow_heif/discussions)
- [Issues](https://github.com/bigcat88/pillow_heif/issues)
- [Changelog](https://github.com/bigcat88/pillow_heif/blob/master/CHANGELOG.md)
### Wheels
| **_Wheels table_** | macOS<br/>Intel | macOS<br/>Silicon | Windows<br/> | musllinux* | manylinux* |
|--------------------|:---------------:|:-----------------:|:------------:|:----------:|:----------:|
| CPython 3.9 | ✅ | ✅ | ✅ | ✅ | ✅ |
| CPython 3.10 | ✅ | ✅ | ✅ | ✅ | ✅ |
| CPython 3.11 | ✅ | ✅ | ✅ | ✅ | ✅ |
| CPython 3.12 | ✅ | ✅ | ✅ | ✅ | ✅ |
| CPython 3.13 | ✅ | ✅ | ✅ | ✅ | ✅ |
| PyPy 3.10 v7.3 | ✅ | ✅ | ✅ | N/A | ✅ |
| PyPy 3.11 v7.3 | ✅ | ✅ | ✅ | N/A | ✅ |
* **x86_64**, **aarch64** wheels.
| text/markdown | Alexander Piskun | bigcat88@users.noreply.github.com | null | null | BSD-3-Clause | heif, heic, pillow | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development",
"Topic :: Software Development :: Libraries",
"Topic :: Multimedia :: Graphics",
"Topic :: Multimedia :: Graphics :: Graphics Conversion",
"Programming Language :: Python :: 3",
"Programm... | [] | https://github.com/bigcat88/pillow_heif | null | >=3.10 | [] | [] | [] | [
"pillow>=11.1.0",
"sphinx>=4.4; extra == \"docs\"",
"sphinx-issues>=3.0.1; extra == \"docs\"",
"sphinx-rtd-theme>=1.0; extra == \"docs\"",
"pytest; extra == \"tests-min\"",
"defusedxml; extra == \"tests-min\"",
"packaging; extra == \"tests-min\"",
"pytest; extra == \"tests\"",
"defusedxml; extra == ... | [] | [] | [] | [
"Documentation, https://pillow-heif.readthedocs.io",
"Source, https://github.com/bigcat88/pillow_heif",
"Changelog, https://github.com/bigcat88/pillow_heif/blob/master/CHANGELOG.md"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-18T11:20:48.643825 | pillow_heif-1.2.1.tar.gz | 17,128,668 | 22/f4/68bd0465dc0494c22e23334dde0a9c52dec5afe98cf5a40abb47f75e1b08/pillow_heif-1.2.1.tar.gz | source | sdist | null | false | 4489b7e7309360c24cdca49cf510bbdc | 29be44d636269e2d779b4aec629bc056ec7260b734a16b4d3bb284c49c200274 | 22f468bd0465dc0494c22e23334dde0a9c52dec5afe98cf5a40abb47f75e1b08 | null | [
"LICENSE.txt",
"LICENSES_bundled.txt"
] | 144,491 |
2.4 | swytchcode-runtime | 0.1.0 | Thin runtime wrapper around the Swytchcode CLI | # swytchcode-runtime (Python)
Thin runtime wrapper around the Swytchcode CLI. Calls `swytchcode exec` for you so you can stay in Python without shell boilerplate.
**Requires:** The `swytchcode` binary must be installed and on your `PATH`.
## Install
```bash
pip install swytchcode-runtime
```
Or from the repo:
```bash
pip install /path/to/runtime-libraries/python-runtime
```
## Use
### JSON mode (default)
```python
from swytchcode_runtime import exec
result = exec("api.account.create", {"email": "test@example.com"})
# result is parsed JSON (any)
```
Equivalent to: `swytchcode exec api.account.create --json` with args on stdin.
**Request input (args):** The second argument is the kernel **args** object (sent as JSON on stdin). Use this shape so the kernel builds the request correctly:
- **body** — Request body (dict).
- **params** — Query/path params (e.g. `{"id": "cluster-123"}`).
- **Authorization** — Auth header value (e.g. `"Bearer token123"`).
- **headers** — Additional request headers (e.g. `{"X-Request-Id": "abc-123"}`).
- Other top-level keys are passed as query params.
Example with body, params, and headers:
```python
exec("api.cluster.get", {
"params": {"id": "cluster-123"},
"Authorization": "Bearer token123",
"headers": {"X-Request-Id": "abc-123"},
})
```
### Raw mode
Get stdout as a string instead of parsing JSON:
```python
from swytchcode_runtime import exec
output = exec("api.report.export", {"id": "123"}, raw=True)
# output is the raw stdout string
```
### Options
- **cwd** – Working directory for the process (default: current directory).
- **env** – Extra environment variables (merged with `os.environ`).
- **raw** – If `True`, use `--raw` and return stdout as a string.
- **dry_run** – If `True`, pass `--dry-run` to the CLI; request details (method, url, headers, body) are output instead of calling the server.
- **allow_raw** – If `True`, pass `--allow-raw` to the CLI; required for executing raw methods (kernel has this disabled by default).
This runtime invokes `swytchcode exec [canonical_id]` with the flags above. For full exec behavior, see the Swytchcode kernel documentation.
### Error handling
Failures raise `SwytchcodeError` (spawn error, non-zero exit, invalid JSON). Use the helper to narrow:
```python
from swytchcode_runtime import exec, SwytchcodeError, is_swytchcode_error
try:
exec("api.account.create", {"email": "test@example.com"})
except Exception as e:
if is_swytchcode_error(e):
print(e.message, e.cause)
raise
```
## What this library is
- A thin process wrapper over the Swytchcode shell.
- A stable call surface: `exec(canonical_id, input=None, *, cwd=..., env=..., raw=...)`.
- A convenience for developers and IDE agents.
## What this library is not
- An HTTP SDK or API client.
- A replacement for the shell. All authority stays in the Swytchcode CLI.
This library **must not** and **does not**:
- Read `.swytchcode/*` or parse `tooling.json`.
- Validate schemas or add retries/timeouts.
- Call the registry or embed auth logic.
It is a pipe, not a brain.
## For Cursor / IDE agents
Generate code that uses this runtime instead of subprocess boilerplate.
**Preferred:**
```python
from swytchcode_runtime import exec
def create_account(input: dict) -> any:
return exec("api.account.create", input)
```
**Avoid:** subprocess boilerplate, HTTP calls, or config parsing. Use `exec(...)` and let the CLI handle execution and policy.
| text/markdown | Swytchcode | null | null | null | MIT | swytchcode, cli, runtime, exec | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"repository, https://gitlab.com/swytchcode/py-runtime"
] | twine/6.2.0 CPython/3.12.10 | 2026-02-18T11:20:32.382034 | swytchcode_runtime-0.1.0.tar.gz | 4,316 | 15/35/b2abfb84161d7540203ccdb43897f6668075413e542057a4d394c053aa4a/swytchcode_runtime-0.1.0.tar.gz | source | sdist | null | false | accdf46017a2710e888612a1c7f570f0 | 1713d3e3441417c9ee105488a7dfd05e33e895a88589916d31e6582ff0dcc1ab | 1535b2abfb84161d7540203ccdb43897f6668075413e542057a4d394c053aa4a | null | [] | 252 |
2.4 | scimba | 1.2.0 | This library implements some common tools for scientific machine learning | # ScimBa
[](https://gitlab.com/scimba/scimba/-/commits/main)
[](https://scimba.gitlab.io/scimba/coverage)
[](https://gitlab.com/scimba/scimba/-/releases)
[](https://scimba.gitlab.io/scimba/)
Scimba is a Python library that implements varying Scientific Machine Learning (SciML)
methods for PDE problems, as well as tools for hybrid numerical methods.
The current version of the code solves parametric PDEs using various nonlinear
approximation spaces such as neural networks, low-rank approximations, and nonlinear
kernel methods.
These methods:
- can handle complex geometries generated via level-set techniques and mappings, including sub-volumetric and surface domains;
- support function projections as well as elliptic, time-dependent, and kinetic parametric PDEs;
- are compatible with both space–time algorithms (PINN, Deep Ritz) and time-sequential ones (discrete PINNs, neural Galerkin and neural semi-Lagrangian schemes).
To achieve this, the code provides several optimization strategies, including:
- Adam and L-BFGS;
- natural gradient methods (for neural network-based models);
- hybrid least-squares approaches.
The current version of Scimba relies on a PyTorch backend.
A JAX version is under development.
**Documentation:** [https://www.scimba.org/](https://www.scimba.org/)
**Code repository:** [https://gitlab.com/scimba/scimba/](https://gitlab.com/scimba/scimba/)
| text/markdown | null | Emmanuel Franck <emmanuel.franck@inria.fr>, Rémi Imbach <remi.imbach@inria.fr>, Victor Michel-Dansac <victor.michel-dansac@inria.fr> | null | Matthieu Boileau <matthieu.boileau@math.unistra.fr>, Rémi Imbach <remi.imbach@inria.fr> | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"matplotlib",
"numpy",
"torch>=2.9",
"scipy",
"tqdm"
] | [] | [] | [] | [
"Homepage, https://www.scimba.org",
"Documentation, https://www.scimba.org",
"Repository, https://gitlab.com/scimba/scimba.git",
"Issues, https://gitlab.com/scimba/scimba/-/issues",
"Changelog, https://gitlab.com/scimba/scimba/-/blob/main/CHANGELOG.md"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":"13","id":"trixie","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T11:20:16.856780 | scimba-1.2.0-py3-none-any.whl | 276,687 | 90/f2/7039171d253e749aabf6f5445360a7217239d21431266ecc44f8040ea13e/scimba-1.2.0-py3-none-any.whl | py3 | bdist_wheel | null | false | ac01276802c0813b3543657a47edf9e0 | aca7909a4b94eb41c6d3fe22621c0583d6b46d48de3a3cab0600296a281a8495 | 90f27039171d253e749aabf6f5445360a7217239d21431266ecc44f8040ea13e | null | [
"LICENSE"
] | 253 |
2.4 | appsignal | 1.6.4 | The AppSignal integration for the Python programming language | # AppSignal for Python
AppSignal solves all your Python monitoring needs in a single tool. You and
your team can focus on writing code and we'll provide the alerts if your app
has any issues.
- [AppSignal.com website][appsignal]
- [Documentation][python docs]
- [Support][contact]
[](https://pypi.org/project/appsignal)
[](https://pypi.org/project/appsignal)
## Description
The AppSignal package collects exceptions and performance data from your Python
applications and sends it to AppSignal for analysis. Get alerted when an error
occurs or an endpoint is responding very slowly.
## Usage
First make sure you've installed AppSignal in your application by following the
steps in [Installation](#installation).
AppSignal will automatically monitor requests, report any exceptions that are
thrown and any performance issues that might have occurred.
You can also add extra information by adding custom instrumentation and by tags.
## Installation
Please follow our [installation guide] in our documentation. We try to
automatically instrument as many packages as possible, but may not always be
able to. Make to sure follow any [instructions to add manual
instrumentation][manual instrumentation].
[installation guide]: https://docs.appsignal.com/python/installation
[manual instrumentation]: https://docs.appsignal.com/python/instrumentations
## Development
AppSignal for Python uses [Hatch](https://hatch.pypa.io/latest/) to manage
dependencies, packaging and development environments.
```sh
pip install hatch
```
### Publishing
Publishing is done using [mono](https://github.com/appsignal/mono/). Install it
before development on the project.
```sh
mono publish
```
### Linting and type checking
```sh
hatch run lint:all
hatch run lint:fmt # auto-formatting only
hatch run lint:style # style checking only
hatch run lint:typing # type checking only
```
### Running tests
```sh
hatch run test:pytest
```
### Running the CLI command
```sh
hatch shell
appsignal
```
### Building wheels
```sh
hatch run build:all # for all platforms
hatch run build:me # for your current platform
hatch run build:for <triple> # for a specific agent triple
```
#### Custom agent build
```sh
hatch run build:me /path/to/agent
# or place the desired agent binary at
# `src/appsignal/appsignal-agent`, and then:
_APPSIGNAL_BUILD_AGENT_PATH="--keep-agent" hatch run build:me
```
### Clean up build artifacts
```sh
hatch clean # clean dist folder
rm -r tmp # clean agent build cache
```
## Contributing
Thinking of contributing to our package? Awesome! 🚀
Please follow our [Contributing guide][contributing-guide] in our
documentation and follow our [Code of Conduct][coc].
Also, we would be very happy to send you Stroopwafles. Have look at everyone
we send a package to so far on our [Stroopwafles page][waffles-page].
## Support
[Contact us][contact] and speak directly with the engineers working on
AppSignal. They will help you get set up, tweak your code and make sure you get
the most out of using AppSignal.
Also see our [SUPPORT.md file](SUPPORT.md).
[appsignal]: https://www.appsignal.com
[appsignal-sign-up]: https://appsignal.com/users/sign_up
[contact]: mailto:support@appsignal.com
[python docs]: https://docs.appsignal.com/python
[semver]: http://semver.org/
[waffles-page]: https://www.appsignal.com/waffles
[coc]: https://docs.appsignal.com/appsignal/code-of-conduct.html
[contributing-guide]: https://docs.appsignal.com/appsignal/contributing.html
| text/markdown | null | Tom de Bruijn <tom@tomdebruijn.com>, Noemi Lapresta <noemi@appsignal.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming ... | [] | null | null | >=3.8 | [] | [] | [] | [
"opentelemetry-api>=1.26.0",
"opentelemetry-exporter-otlp-proto-http",
"opentelemetry-sdk>=1.26.0",
"typing-extensions"
] | [] | [] | [] | [
"Documentation, https://docs.appsignal.com/python",
"Issues, https://github.com/appsignal/appsignal-python/issues",
"Source, https://github.com/appsignal/appsignal-python"
] | Hatch/1.16.2 cpython/3.11.2 HTTPX/0.28.1 | 2026-02-18T11:20:12.579803 | appsignal-1.6.4-py3-none-musllinux_1_1_aarch64.whl | 2,195,800 | 1f/b5/57a6695618f81bf2df552c775a5d6e9c4379bb8d2ec7e4f4a11b817da412/appsignal-1.6.4-py3-none-musllinux_1_1_aarch64.whl | py3 | bdist_wheel | null | false | d22a9bde2b188fe796b740479dc91031 | 441d2fb234114e2b83e9c3852bfa8f50739969c03ece96db0d91ff9e0dfd3ec5 | 1fb557a6695618f81bf2df552c775a5d6e9c4379bb8d2ec7e4f4a11b817da412 | null | [
"LICENSE"
] | 1,461 |
2.4 | synalinks-memory-cli | 0.0.4 | CLI for the Synalinks Memory API | # Synalinks Memory CLI
**Synalinks Memory** is the knowledge and context layer for AI agents. It lets your agents always have the right context at the right time. Unlike retrieval systems that compound LLM errors at every step, Synalinks uses **logical rules** to derive knowledge from your raw data. Every claim can be traced back to evidence, from raw data to insight, no more lies or hallucinations.
This CLI lets you interact with your Synalinks Memory directly from the terminal — add data, ask questions, and query your knowledge base.
## Installation
```bash
pip install synalinks-memory-cli
```
Or with [uv](https://docs.astral.sh/uv/):
```bash
uv add synalinks-memory-cli
```
Or run directly without installing using [uvx](https://docs.astral.sh/uv/concepts/tools/):
```bash
uvx synalinks-memory-cli list
uvx synalinks-memory-cli execute Users --format csv -o users.csv
```
## Usage
Set your API key:
```bash
export SYNALINKS_API_KEY="synalinks_..."
```
### Add a file
```bash
synalinks-memory-cli add data/sales.csv
synalinks-memory-cli add data/events.parquet --name Events --description "Event log" --overwrite
```
### Ask a question (while learning concepts and rules)
```bash
synalinks-memory-cli "What were the top 5 products by revenue last month?"
synalinks-memory-cli How are sales doing this quarter
```
### List predicates
```bash
synalinks-memory-cli list
```
### Execute a predicate
```bash
synalinks-memory-cli execute Users
synalinks-memory-cli execute Users --limit 50 --offset 10
```
### Search
```bash
synalinks-memory-cli search Users "alice"
```
### Export data as a file
```bash
synalinks-memory-cli execute Users --format csv
synalinks-memory-cli execute Users --format parquet -o users.parquet
synalinks-memory-cli execute Users -f json --limit 500
```
### Options
```
--api-key TEXT API key (or set SYNALINKS_API_KEY)
--base-url TEXT Override API base URL
--help Show help message
```
## License
Apache 2.0
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1",
"rich>=13.0",
"synalinks-memory>=0.0.002"
] | [] | [] | [] | [] | uv/0.6.7 | 2026-02-18T11:20:05.054828 | synalinks_memory_cli-0.0.4.tar.gz | 29,686 | 02/a4/9a7986d1a8a713f7170d2aaa82b1419cad63acf69ac52d8e9be44ead6885/synalinks_memory_cli-0.0.4.tar.gz | source | sdist | null | false | bf227fb6f7a6c5ad10b68ba4fe0b5847 | c0c05dcc90cfa1e7a2b81a8d38ab0f6411cf1967173aa69b964cdbcbe375e13e | 02a49a7986d1a8a713f7170d2aaa82b1419cad63acf69ac52d8e9be44ead6885 | Apache-2.0 | [
"LICENSE"
] | 231 |
2.4 | octopize.avatar | 1.16.0 | Python client for Octopize's avatar API | # Avatar Python Client
## Requirements
The `avatars` package requires Python 3.12 or above.
## Tutorials
The tutorials are available in [`notebooks/`](./notebooks) as jupyter notebooks.
To be able to run those, you must install the `avatars` package and also the dependencies in `requirements-tutorial.txt`.
We provide a helper script to setup these inside a virtual environments and run the notebooks.
Simply run the following command:
(NOTE: This assumes that you have the `just` software installed. This may not be the case for Windows by default.)
```bash
just notebook
```
If you don't have access to `just` or you want to setup the tutorial requirements manually, you can follow the installation section.
## Installation
### with pip
```bash
pip install octopize.avatar
```
### or, if you're using uv
```bash
uv add octopize.avatar
```
### or, if you're using poetry
```bash
poetry add octopize.avatar
```
## License
This software is made available through the Apache License 2.0.
## Contact
<help@octopize.io>
## Releasing
See internal docs.
| text/markdown | null | Octopize <pypi-octopize@octopize.io> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"aiobotocore<=2.22.0",
"botocore<=1.40.17",
"fsspec>=2024.12.0",
"httpx>=0.28.1",
"ipython>=9.2.0",
"octopize-avatar-yaml==0.1.31",
"pandas>=2.3.1",
"pydantic-settings>=2.7.0",
"pydantic>=2.10.4",
"pyyaml>=6.0.2",
"s3fs>=2024.12.0",
"structlog>=24.4.0",
"tenacity>=9.0.0",
"toolz>=1.0.0",
... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T11:19:17.899276 | octopize_avatar-1.16.0.tar.gz | 6,802,260 | 7f/d4/add77aaf98ecd71b95fc515bfcbbcb8dc11546bebec37ea0e3cc966abce8/octopize_avatar-1.16.0.tar.gz | source | sdist | null | false | 39b0c132c9cbaa2d40b92030ed41c2b4 | 2ac0b84587e2258d7b78ab856108c38175fac0a77e4e5bfb29ac87bee8b51e17 | 7fd4add77aaf98ecd71b95fc515bfcbbcb8dc11546bebec37ea0e3cc966abce8 | Apache-2.0 | [] | 0 |
2.4 | machineconfig | 8.77 | Dotfiles management package |
<p align="center">
<a href="https://github.com/thisismygitrepo/machineconfig/commits">
<img src="https://img.shields.io/github/commit-activity/m/thisismygitrepo/machineconfig" />
</a>
</p>
# 🗜 Welcome to **Machineconfig**
Your stack is awesome, but you need a stack manager, to have a tight grip over it, put it together and maintain it.
Entering, **Machineconfig**, a cli-based cross-platform **Stack Manager** — It is a swiss-army knife; a *Package Manager*, *Configuration Manager*, *Automation Tool*, *Dotfiles Manager*, *Data Solution*, and *Code Manager*, among other functionalities covered, all rolled into one seamless experience, that is consistent across different platforms.
## Workflow:
What is your stack? Say you have a new computer/ VM, how do you go about setting it up with your stack?
Surely, you have:
* A bunch of CLI tools.
* [Optional] A bunch of softwares (GUIs for desktop environment).
* [Public] A bunch of configuration files for your tools.
* [Private] A bunch of secrets, passowords, tokens, credentials etc, etc.
* Data (Both highly sensitive and encrypted less serious unencrypted data)
* Code (your repositories).
Wouldn't be nice if you can set it all up in 2 minutes? This is a hackable tool to get it done.
Consider this concrete scenario: When setting up a new machine, VM, or Docker container, you often face dependency chains like this:
```mermaid
flowchart TD
A["Need to setup my [dev] environment"] --> B["need my tool x, e.g.: yadm"]
B --> C["Requires git"]
C --> D["Requires package manager, e.g. brew"]
D --> E["Requires curl"]
E --> F["Requires network setup / system update"]
F --> G["Requires system configuration access"]
G --> H["Finally ready to start setup the tool x."]
```
Machineconfig builds on shoulder of giants. A suite of best-in-class stack of projects on github are used, the most starred, active and written in Rust tools are used when possible. The goal is to provide a seamless experience that abstracts away the complexity of setting up and maintaining your digital environment. The goal of machineconfig is to replicate your setup, config, code, data and secrets on any machine, any os, in 5 minutes, using minimal user input. Then, from that point, machineconfig will help you maintain, update, backup and sync your digital life across all your devices, automatically.
## ⚙️ Functional Overview
| Category | Comparable Tools | Description |
|------------------------|----------------------------------------------|-----------------------------------------------------------|
| **Package Manager** | `winget`, `apt`, `brew`, `nix` | Installs and manages software packages across systems. |
| **Configuration Manager** | `Ansible`, `Chef`, `Puppet` | Configures and maintains system‐level preferences. |
| **Automation Tool** | `Airflow`, `Prefect`, `Dagster`, `Celery` | Automates repetitive tasks, pipelines, orchestration. |
| **Dotfiles Manager** | `chezmoi`, `yadm`, `rcm`, `GNU Stow` | Synchronises dotfiles & personal configs across systems. |
| **Data Solution** | `rclone`, `rsync` | Handles backups, mirroring and secure file sync. |
| **Code Manager** | `strong‐box`, `Vault` | Manages and protects code snippets, secrets and creds. |
---
# Install On Windows:
```powershell
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex" # Skip if UV is already installed
uv tool install --upgrade --python 3.14 machineconfig
```
# Install On Linux and MacOS
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh # Skip if UV is already installed
uv tool install --upgrade --python 3.14 machineconfig
```
# Quickies ...
```powershell
# interactive install of machineconfig and following on to run it and make basic machine configuration (RECOMMENDED):
irm bit.ly/cfgwindows | iex # Or, if UV is installed: iex (uvx machineconfig define)
# Quick install and configure (optionals are accepted by default):
irm bit.ly/cfgwq | iex
```
```bash
# interactive install of machineconfig and following on to run it and make basic machine configuration (RECOMMENDED):
. <(curl -L bit.ly/cfglinux) # Or, if UV is installed: . <(uvx machineconfig define)
```
# Author
Alex Al-Saffar. [email](mailto:programmer@usa.com)
# Contributor
Ruby Chan. [email](mailto:ruby.chan@sa.gov.au)
[](https://github.com/ashutosh00710/github-readme-activity-graph)
| text/markdown | null | Alex Al-Saffar <programmer@usa.com> | null | null | Apache 2.0 | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"cryptography>=46.0.3",
"fire>=0.7.1",
"gitpython>=3.1.46",
"joblib>=1.5.3",
"paramiko>=4.0.0",
"psutil>=7.2.1",
"pyyaml>=6.0.3",
"questionary>=2.1.1",
"randomname>=0.2.1",
"rclone-python>=0.1.23",
"requests>=2.32.5",
"rich>=14.3.1",
"tenacity>=9.1.2",
"typer==0.20.0",
"typer-slim==0.20.... | [] | [] | [] | [
"Homepage, https://github.com/thisismygitrepo/machineconfig",
"Bug Tracker, https://github.com/thisismygitrepo/machineconfig/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T11:19:05.726984 | machineconfig-8.77-py3-none-any.whl | 887,531 | a0/cc/324d5ab1cfb401f8e0ea94831c203888c0fa670029633ef3db01f16eb774/machineconfig-8.77-py3-none-any.whl | py3 | bdist_wheel | null | false | 801c50a4e2ce5ea12c2fd0b71d7487d2 | 8aa2e0cd9695667d49173bfa0066f7d6b7a6a51b920218de3f8e36660c12ef58 | a0cc324d5ab1cfb401f8e0ea94831c203888c0fa670029633ef3db01f16eb774 | null | [] | 279 |
2.4 | digeo | 0.0.0 | This name has been reserved using Reserver |
## Overview
digeo is a Python library for doing awesome things.
This name has been reserved using [Reserver](https://github.com/openscilab/reserver).
| text/markdown | Development Team | test@test.com | null | null | MIT | python3 python reserve reserver reserved | [
"Development Status :: 1 - Planning",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Lan... | [] | https://url.com | https://download_url.com | >=3.6 | [] | [] | [] | [] | [] | [] | [] | [
"Source, https://github.com/source"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-18T11:18:19.417263 | digeo-0.0.0-py3-none-any.whl | 1,516 | 4d/e6/e8ff1965d4a2faa0a3877524622cf57bb86b7ff804704d5431b9eb69449c/digeo-0.0.0-py3-none-any.whl | py3 | bdist_wheel | null | false | e90baa5b0a59485670201f5e54a487a8 | c66c4b19c42de58abc33cf060767ce6ce0efd5549e054ac66c27ef52d91f5478 | 4de6e8ff1965d4a2faa0a3877524622cf57bb86b7ff804704d5431b9eb69449c | null | [] | 292 |
2.4 | giant-search | 1.1.8 | Provides a nice abstraction layer on top of the django-watson search library. | # Giant Search
This library provides a nice abstraction layer on top of the `django-watson` search library. It allows developers to
easily index and search across Django CMS Page Title objects without any additional configuration, as well as a simple
mixin class to make indexing other model types, such as CMS plugin classes simple.
## Installation
Install `giant-search` via your chosen Python dependency manager, `poetry`, `pip` etc.
## Configuration
1. Add `watson` to `INSTALLED_APPS` in `settings.py`
2. Add `giant_search` to `INSTALLED_APPS` in `settings.py`
3. Add the search application URLs to your project's `urls.py`, for example: `path("search/", include("giant_search.urls",
namespace="search")),`
## Registering items as searchable
### Django CMS Page Titles
**Short version: you don't need to do anything.**
The library will index all published `Title` objects, if using django-cms3, or `PageContent` if
using django- cms4.
This allows end users to find pages via their title.
This behaviour cannot currently be overridden, however in a future version, we might check
if the Page has the NoIndex Page Extension and honour the setting within.
### Other models
We provide a convenient mixin class, `SearchableMixin` that you can add to any model to allow it to be searched. Don't
forget to add the import line `from giant_search.mixins import SearchableMixin` at the top of the models file.
As a developer, there are several configuration options that you can define to customise what gets indexed, and the data
that is presented in the search result listing:
### Third party models
While the `SearchableMixin` takes care of first party models, you usually can't implement this on third party models.
However, you can still make them searchable.
In one of your main apps (usually `core`), add a call to register the model. Here is an example:
```python
from django.apps import AppConfig
from giant_search.utils import register_for_search
class CoreAppConfig(AppConfig):
name = "core"
verbose_name = "Core"
def ready(self):
from third_party_library.models import ThirdPartyModel
register_for_search(ThirdPartyModel)
```
Third party models will always have their string representation set as the search result title. The model **must**
implement the `get_absolute_url` method, otherwise, the search result will not have a valid URL and the model will be
indexed, but will _not_ show up in search results.
#### Overriding the search QuerySet
By default, `giant-search` will get all instances of a particular model to index.
You can override this in your model class, perhaps to return only published items:
```python
@classmethod
def get_search_queryset(cls) -> QuerySet:
return cls.objects.published()
```
If you want to define which fields on your model should be searched, you can implement a `get_search_fields` method on
your model like so:
```python
from giant_search.mixins import SearchableMixin
class ExampleModel(SearchableMixin, models.Model):
name = models.CharField(max_length=255)
content = models.CharField(max_legth=255)
@staticmethod
def get_search_fields() -> tuple:
"""
Override this method to provide a tuple containing the fields to search.
If the method returns an empty tuple, all text fields will be indexed as per Watson's defaults.
"""
return "name", "content"
```
## Defining search result title, description and URL
When Watson performs a search, it returns a list of `SearchEntry` instances, which has some fields that can be used on
the front end to display search results to end users. For example, `title`, `description` and `url`.
The title field is the title of the search result, the description is optional and provides a bit more context about the
search result and the URL is required and is where the user should be taken to upon clicking the search result.
In order to specify where Watson should get the values from for these fields, you can define the following on your
model (remember, it must inherit from the `SearchableMixin`)
Here is an example:
```python
from giant_search.mixins import SearchableMixin
class ExampleModel(SearchableMixin, models.Model):
name = models.CharField(max_length=255)
summary = models.CharField(max_length=255)
content = RichTextField()
def __str__(self):
return self.name
def get_search_result_title(self) -> str:
return str(self)
def get_search_result_description(self) -> str:
return self.summary
```
The important parts in this example are `get_search_result_title` and `get_search_result_description`
Note that in this example, we don't define `get_search_result_url`. If you don't define `get_search_result_url` then
Giant Search will call the `get_absolute_url` method on the model, if it has that method. If the model does not
implement, `get_absolute_url` and does not implement `get_search_result_url` then it won't have a URL and will not be
shown in the search results.
If your model is a Django CMS Plugin instance, you probably want to implement `get_absolute_url()` and have it call
`self.page.get_public_url()`.
```python
def get_absolute_url(self) -> str:
try:
return self.page.get_public_url()
except AttributeError:
return ""
```
### Pagination
By default the search results will render 10 items per page. If you want to customise this simply add
`GIANT_SEARCH_PAGINATE_BY` to your project's settings, along with the desired integer number of items to paginate by.
This assumes your project has a registered simple_tag entitled `show_pagination` containing pagination logic.
## Existing Data
If implementing this library upon existing data, changes to search results will only take effect after the
model instance is saved again.
## Package Publishing
First build the package,
Do remmember to update the version number in pyproject and add the summary of changes to
CHANGELOG.md
```dotenv
$ poetry build
```
PyPi now prefers API Token authorisation.
```dotenv
$ poetry config pypi-token.pypi <token>
```
And finally
```dotenv
$ poetry publish
```
| text/markdown | Scott Pashley | scott.pashley@giantdigital.co.uk | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming L... | [] | https://www.giantdigital.co.uk | null | <4.0,>=3.7 | [] | [] | [] | [
"django-cms<5.0,>3.11",
"django-watson<2.0.0,>=1.6.3"
] | [] | [] | [] | [
"Homepage, https://www.giantdigital.co.uk"
] | poetry/2.2.1 CPython/3.12.3 Linux/6.8.0-100-generic | 2026-02-18T11:17:21.013983 | giant_search-1.1.8.tar.gz | 9,416 | 7a/3b/b65c5a2b8484ec10cffc52dbbb1060c974181e327a0969af17982985d2f7/giant_search-1.1.8.tar.gz | source | sdist | null | false | 092ba63fa8890d46b0336d8554386d13 | 2ec0955951a6d1744c361c4e451618edb773f9309597cb2c92298078dd94cb56 | 7a3bb65c5a2b8484ec10cffc52dbbb1060c974181e327a0969af17982985d2f7 | null | [] | 290 |
2.4 | airflow-provider-kakao | 0.0.2 | KakaoTalk provider for Apache Airflow | # Apache Airflow Provider for KakaoTalk
**Apache Airflow Provider for KakaoTalk** allows you to send messages via KakaoTalk API directly from your Airflow DAGs. It supports **"Send to Me"** (default) and **"Send to Friends"** features using the Kakao REST API.
### 🚀 Features
* **Send to Me:** Send notifications (task success/failure alert, reports) to your own KakaoTalk.
* **Send to Friends:** Send messages to specific friends using their UUIDs.
* *Note:* The provider automatically chunks the recipient list into batches of 5 to comply with API limits.
* **Flexible Message Formats:** Supports simple text messages and complex JSON templates (Feed, List, Commerce, etc.).
* **Token Management:** Automatically refreshes the Access Token using the provided Refresh Token during task execution (Lazy Loading).
### 📦 Installation
You can install the provider via pip:
```bash
pip install apache-airflow-providers-kakao
```
### ⚙️ Connection Setup
To use this provider, you must create a Connection in the Airflow UI.
1. **Connection Id**: `kakao_default`
2. **Connection Type**: `kakao` (or `generic`)
3. **Login**: Kakao Developers **REST API Key** (Client ID)
4. **Password**: Kakao **Refresh Token**
5. **Extra** (Optional): If your app uses a Client Secret, provide it in JSON format.
```json
{"client_secret": "YOUR_CLIENT_SECRET"}
```
> **⚠️ Prerequisites:**
> * Your Kakao Application must have the "Send to Me" and "Send to Friends" scopes enabled.
> * For "Send to Friends", the target users must be registered as team members in the Kakao Developers console (for testing/dev apps) and must have agreed to the app's permissions.
### 💻 Usage
#### 1. Using the Operator (Recommended)
The `KakaoTalkOperator` is the easiest way to send messages.
```python
from airflow import DAG
from datetime import datetime
from airflow.providers.kakao.operators.kakao import KakaoTalkOperator
with DAG(
dag_id="kakao_example",
start_date=datetime(2026, 1, 1),
schedule=None,
) as dag:
# 1. Simple Text Message (Send to Me)
send_text = KakaoTalkOperator(
task_id="send_text",
text="Hello! The Airflow task has finished successfully. 🚀",
kakao_conn_id="kakao_default",
)
# 2. Send to Friends (UUIDs required)
send_friend = KakaoTalkOperator(
task_id="send_friend",
text="Team Alert: Deployment Started",
receiver_uuids=["uuid_1", "uuid_2", "uuid_3"],
kakao_conn_id="kakao_default",
)
# 3. Send Custom JSON Template (Feed, Link, etc.)
# See Kakao Message API docs for template structure
template = {
"object_type": "text",
"text": "Check the detailed report",
"link": {"web_url": "https://airflow.apache.org"},
}
send_template = KakaoTalkOperator(
task_id="send_template",
kakao_kwargs={"template_object": template},
kakao_conn_id="kakao_default",
)
```
#### 2. Using the Hook (Advanced)
You can use `KakaoHook` for custom logic or within a `PythonOperator`.
```python
from airflow.providers.kakao.hooks.kakao import KakaoHook
def my_python_func():
hook = KakaoHook(kakao_conn_id="kakao_default")
# Send message via Hook
hook.send_message(
api_params={"text": "Message sent via KakaoHook."}
)
```
### ⚠️ Limitations
* **Token Persistence:** This provider **does not persist** the rotated Refresh Token back to the Airflow Metadata Database. It uses the Refresh Token from the connection to get a temporary Access Token for the task.
* **Token Expiry:** You must manually update the Connection with a new Refresh Token before it expires (typically 2 months), or implement a separate pipeline to handle token rotation and DB updates.
---
**Apache Airflow Provider for KakaoTalk**는 Airflow DAG에서 카카오톡 메시지를 전송할 수 있게 해주는 커뮤니티 Provider입니다. 카카오 REST API를 사용하여 **"나에게 보내기"** 및 **"친구에게 보내기"** 기능을 지원합니다.
### 🚀 주요 기능
* **나에게 보내기:** 작업 성공/실패 알림이나 리포트를 내 카카오톡으로 전송합니다.
* **친구에게 보내기:** 지정된 친구(UUID)들에게 메시지를 전송합니다.
* *참고:* API 제한에 맞춰 수신자 목록을 자동으로 5명씩 나누어 전송합니다.
* **다양한 메시지 포맷:** 단순 텍스트뿐만 아니라 JSON 템플릿(피드, 리스트, 커머스 등)을 지원합니다.
* **토큰 관리:** 작업 실행 시 Refresh Token을 사용하여 Access Token을 자동으로 갱신합니다 (Lazy Loading).
### 📦 설치 방법
pip를 통해 설치할 수 있습니다.
```bash
pip install apache-airflow-providers-kakao
```
### ⚙️ 연결 설정 (Connection Setup)
Airflow UI에서 Connection을 생성해야 합니다.
1. **Connection Id**: `kakao_default`
2. **Connection Type**: `kakao` (또는 `generic`)
3. **Login**: 카카오 디벨로퍼스 **REST API 키** (Client ID)
4. **Password**: 카카오 **Refresh Token**
5. **Extra** (선택 사항): Client Secret을 사용하는 경우 JSON으로 입력
```json
{"client_secret": "YOUR_CLIENT_SECRET"}
```
> **⚠️ 사전 요구사항:**
> * 카카오 애플리케이션 설정에서 "나에게 보내기" 및 "친구에게 보내기" 권한(Scope)이 활성화되어 있어야 합니다.
> * "친구에게 보내기"를 사용하려면, 수신자가 카카오 디벨로퍼스 팀원으로 등록되어 있어야 하며(테스트 앱의 경우), 앱 권한에 동의한 상태여야 합니다.
### 💻 사용법
#### 1. Operator 사용 (권장)
`KakaoTalkOperator`를 사용하여 간단하게 메시지를 보낼 수 있습니다.
```python
from airflow import DAG
from datetime import datetime
from airflow.providers.kakao.operators.kakao import KakaoTalkOperator
with DAG(
dag_id="kakao_example",
start_date=datetime(2026, 1, 1),
schedule=None,
) as dag:
# 1. 단순 텍스트 메시지 (나에게 보내기)
send_text = KakaoTalkOperator(
task_id="send_text",
text="안녕하세요! Airflow 작업이 성공적으로 완료되었습니다. 🚀",
kakao_conn_id="kakao_default",
)
# 2. 친구에게 보내기 (UUID 필요)
send_friend = KakaoTalkOperator(
task_id="send_friend",
text="팀원 알림: 배포가 시작되었습니다.",
receiver_uuids=["uuid_1", "uuid_2", "uuid_3"],
kakao_conn_id="kakao_default",
)
# 3. 커스텀 JSON 템플릿 보내기 (피드, 링크 등)
# 템플릿 구조는 카카오 메시지 API 문서를 참고하세요.
template = {
"object_type": "text",
"text": "자세한 리포트 확인하기",
"link": {"web_url": "https://airflow.apache.org"},
}
send_template = KakaoTalkOperator(
task_id="send_template",
kakao_kwargs={"template_object": template},
kakao_conn_id="kakao_default",
)
```
#### 2. Hook 사용 (고급)
`PythonOperator` 내부나 커스텀 로직에서 `KakaoHook`을 직접 사용할 수 있습니다.
```python
from airflow.providers.kakao.hooks.kakao import KakaoHook
def my_python_func():
hook = KakaoHook(kakao_conn_id="kakao_default")
# Hook을 이용한 메시지 전송
hook.send_message(
api_params={"text": "KakaoHook을 통해 전송된 메시지입니다."}
)
```
### ⚠️ 제약 사항
* **토큰 영구 저장 미지원:** 이 Provider는 갱신된 Refresh Token을 Airflow 메타데이터 DB에 **저장하지 않습니다**. 연결(Connection)에 저장된 Refresh Token을 사용하여 일회성 Access Token을 발급받는 방식입니다.
* **토큰 만료 관리:** Refresh Token이 만료(보통 2달)되기 전에 Connection 정보를 수동으로 업데이트하거나, 별도의 토큰 갱신 파이프라인을 구축해야 합니다.
| text/markdown | null | SeungtaekSong <glommer@kakao.com> | null | null | null | null | [
"Framework :: Apache Airflow",
"Framework :: Apache Airflow :: Provider",
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"apache-airflow>=2.9.0",
"requests>=2.20.0",
"apache-airflow-providers-common-compat>=1.10.0"
] | [] | [] | [] | [
"Source, https://github.com/glommmer/airflow-provider-kakao"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T11:17:02.407585 | airflow_provider_kakao-0.0.2.tar.gz | 11,277 | ca/75/3ece388156aab88f54c1c94dacdd256fa36c77b18f26feeebeacd881105f/airflow_provider_kakao-0.0.2.tar.gz | source | sdist | null | false | 7f6938af1fc335dbadb0e50d1daec99f | 0408dd471e7700dbd912b312d3e77b7f4af900d5d19386d2d510bde12fd511c3 | ca753ece388156aab88f54c1c94dacdd256fa36c77b18f26feeebeacd881105f | null | [] | 266 |
2.4 | openghg-defs | 0.0.12 | Supplementary definition data for OpenGHG | # openghg_defs
This repository contains the supplementary information / metadata around site, species and domain details. This is used within the OpenGHG project.
## Installation
Note that `openghg_defs` should be installed in the same virtual environment as OpenGHG.
### Editable install
If you feel like you'll want to make changes to the metadata stored you should go for an editable install of the git repository. This will help ensure you always have the latest development changes we make to the repository. It also
means that you can make changes to your local copy of the metadata and see the results straight away in your
OpenGHG workflow.
First, clone the repository
```console
git clone https://github.com/openghg/openghg_defs.git
```
Next, move into the repository and use pip to create an editable install using the `-e` flag.
> **_NOTE:_** If you're using OpenGHG, please install `openghg_defs` in the [same virtual environment](https://docs.openghg.org/install.html#id1).
```console
cd openghg_defs
pip install -e .
```
This will create a symbolic link between the folder and your Python environment, meaning any changes you make to
the files in the repository folder will be accessible to OpenGHG.
### Install from PyPI
If you don't think you'll need to make any changes to the metadata, you can install `openghg_defs` from PyPI using `pip`:
```console
pip install openghg-defs
```
### Install from conda
You can also install `openghg_defs` from our `conda` channel:
```console
pip install -c openghg openghg-defs
```
## Usage
The path to the overall data path and primary definition JSON files are accessible using:
```python
import openghg_defs
species_info_file = openghg_defs.species_info_file
site_info_file = openghg_defs.site_info_file
domain_info_file = openghg_defs.domain_info_file
```
## Development
### Updating information
We invite users to update the information we have stored. If you find a mistake in the data or want to add something, please
[open an issue](https://github.com/openghg/supplementary_data/issues/new) and fill out the template that matches your
problem. You're also welcome to submit a pull-request with your fix.
For the recommended development process please see the [OpenGHG documentation](https://docs.openghg.org/development/python_devel.html)
### Run the tests
After making changes to the package please ensure you've added a test if adding new functionality and run the tests making sure they all pass.
```console
pytest -v tests/
```
### Release
The package is released using GitHub actions and pushed to conda and PyPI.
#### 1. Update the CHANGELOG
- Update the changelog to add the header for the new version and add the date.
- Update the Unreleased header to match the version you're releasing and `...HEAD`.
#### 2. Update `pyproject.toml`
For a new release the package version must be updated in the `pyproject.toml` file. Try and follow the [Semantic Versioning](https://semver.org/) method.
#### 3. Tag the commit
Now tag the commit. First we create the tag and add a message (remember to insert correct version numbers here).
```console
git tag -a x.x.x -m "openghg_defs release vx.x.x"
```
Next push the tag. This will trigger the automated release by GitHub Actions.
```console
git push origin x.x.x
```
#### 4. Check GitHub Actions runners
Check the GitHub Actions [runners](https://github.com/openghg/openghg_defs/actions) to ensure the tests have
all passed and the build for conda and PyPI has run successfully.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"pytest<=7.0.0",
"uv"
] | [] | [] | [] | [
"Homepage, https://github.com/openghg/openghg_defs",
"Bug Tracker, https://github.com/openghg/openghg_defs/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:17:01.262580 | openghg_defs-0.0.12.tar.gz | 63,260 | 61/1c/136f926689119cdcb0e0605d13242103bbb04646f6dd2f0a2850ea506069/openghg_defs-0.0.12.tar.gz | source | sdist | null | false | bc5f80089eb13c11de0db0b242df3dab | 34e61b94d245d36a3857bc1ffbd41f2b65aae9d8abbe090f6c69251f7446da6d | 611c136f926689119cdcb0e0605d13242103bbb04646f6dd2f0a2850ea506069 | null | [
"LICENSE"
] | 399 |
2.4 | cc-logger | 0.1.3 | Claude Code uploader: authenticate once, then auto-sync ~/.claude/projects to S3 | # Claude-Code Logger
> Collect Claude Code logs automatically.
## Install
```bash
pip install cc-logger
cc-logger install
```
After running install, you'll be prompted to authenticate with GitHub (a browser window will open).
## Instructions
Run Claude normally:
```bash
claude "your task"
```
Logs are uploaded automatically when Claude finishes responding and when sessions end.
## Supported Environments
cc-logger supports sessions from:
- **Claude Code CLI** (`claude` command)
- **Claude Code VSCode Extension**
- **Claude Code Desktop App**
## Uninstall
```bash
cc-logger uninstall
```
## Troubleshooting / verify setup
- Verify `cc-logger` is on your PATH (default install location is `~/.local/bin`, or `$XDG_BIN_HOME` if you set it):
```bash
command -v cc-logger
```
- If `cc-logger` is not found, add this to your shell startup file and restart your shell:
```bash
export PATH="${XDG_BIN_HOME:-$HOME/.local/bin}:$PATH"
```
- To manually configure hooks, get the hook path:
```bash
command -v cc-logger-hook
```
Then add this snippet to `~/.claude/settings.json`, replacing `/ABSOLUTE/PATH/TO/cc-logger-hook` with the output above:
<details>
<parameter name="summary">Show hooks configuration
```json
{
"hooks": {
"SessionStart": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "/ABSOLUTE/PATH/TO/cc-logger-hook session-start"
}
]
}
],
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "/ABSOLUTE/PATH/TO/cc-logger-hook"
}
]
}
],
"SessionEnd": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "/ABSOLUTE/PATH/TO/cc-logger-hook"
}
]
}
]
}
}
```
</details>
| text/markdown | Sanjay | null | null | null | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"boto3>=1.28"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.6 | 2026-02-18T11:16:56.639147 | cc_logger-0.1.3.tar.gz | 17,740 | af/30/690eec1e81ac7252b68a8b171d4f5bf3f1fbd3f32e610d27fd8879ac6b65/cc_logger-0.1.3.tar.gz | source | sdist | null | false | a3e9760452a2e7401cd2aa6f383d97eb | 612a5dee8d2d9429d8441474347988f2180d3ebca955ea09d346f84cb3377775 | af30690eec1e81ac7252b68a8b171d4f5bf3f1fbd3f32e610d27fd8879ac6b65 | null | [
"LICENSE"
] | 269 |
2.4 | kiroframe-arcee | 0.1.55 | ML profiling tool for Kiroframe | # Kiroframe_arcee
## *The Kiroframe ML profiling tool by Hystax*
Kiroframe_arcee (short name - Kiro) is a tool that helps you to integrate ML tasks with [Kiroframe](https://my.kiroframe.com/).
This tool can automatically collect executor metadata from the cloud and process stats.
## Installation
Kiroframe_arcee requires Python 3.8+ to run.
To start, install the `kiroframe_arcee` package, use pip:
```sh
pip install kiroframe-arcee
```
## Import
Import the `kiroframe_arcee` module into your code as follows:
```sh
import kiroframe_arcee as kiro
```
## Initialization
To initialize the Kiro collector use the `init` method with the following parameters:
- token (str, required): the profiling token.
- task_key (str, required): the task key for which you want to collect data.
- run_name (str, optional): the run name.
- period (int, optional): Kiro daemon process heartbeat period in seconds (default is 1).
To initialize the collector using a context manager, use the following code snippet:
```sh
with kiro.init(token="YOUR-PROFILING-TOKEN",
task_key="YOUR-TASK-KEY",
run_name="YOUR-RUN-NAME",
period=PERIOD):
# some code
```
Examples:
```sh
with kiro.init("00000000-0000-0000-0000-000000000000", "linear_regression",
run_name="My run name", period=1):
# some code
```
This method automatically handles error catching and terminates Kiro execution.
Alternatively, to get more control over error catching and execution finishing, you can initialize the collector using a corresponding method.
Note that this method will require you to manually handle errors or terminate Kiro execution using the `error` and `finish` methods.
```sh
kiro.init(token="YOUR-PROFILING-TOKEN", task_key="YOUR-TASK-KEY")
# some code
kiro.finish()
# or in case of error
kiro.error()
```
## Sending metrics
To send metrics, use the `send` method with the following parameter:
- data (dict, required): a dictionary of metric names and their respective values (note that metric data values should be numeric).
```sh
kiro.send({"YOUR-METRIC-1-KEY": YOUR_METRIC_1_VALUE, "YOUR-METRIC-2-KEY": YOUR_METRIC_2_VALUE})
```
Example:
```sh
kiro.send({ "accuracy": 71.44, "loss": 0.37 })
```
## Adding hyperparameters
To add hyperparameters, use the `hyperparam` method with the following parameters:
- key (str, required): the hyperparameter name.
- value (str | number, required): the hyperparameter value.
```sh
kiro.hyperparam(key="YOUR-PARAM-KEY", value=YOUR_PARAM_VALUE)
```
Example:
```sh
kiro.hyperparam("EPOCHS", 100)
```
## Tagging task run
To tag a run, use the `tag` method with the following parameters:
- key (str, required): the tag name.
- value (str | number, required): the tag value.
```sh
kiro.tag(key="YOUR-TAG-KEY", value=YOUR_TAG_VALUE)
```
Example:
```sh
kiro.tag("Algorithm", "Linear Learn Algorithm")
```
## Adding milestone
To add a milestone, use the `milestone` method with the following parameter:
- name (str, required): the milestone name.
```sh
kiro.milestone(name="YOUR-MILESTONE-NAME")
```
Example:
```sh
kiro.milestone("Download training data")
```
## Adding stage
To add a stage, use the `stage` method with the following parameter:
- name (str, required): the stage name.
```sh
kiro.stage(name="YOUR-STAGE-NAME")
```
Example:
```sh
kiro.stage("preparing")
```
## Datasets
### Logging
Logging a dataset allows you to create a dataset or a new version of
the dataset if the dataset has already been created, but has been changed.
To create a dataset, use the `Dataset` class with the following parameters:
Dataset parameters:
- key (str, required): the unique dataset key.
- name (str, optional): the dataset name.
- description (str, optional): the dataset description.
- labels (list, optional): the dataset labels.
Version parameters:
- aliases (list, optional): the list of aliases for this version.
- meta (dict, optional): the dataset version meta.
- timespan_from (int, optional): the dataset version timespan from.
- timespan_to (int, optional): the dataset version timespan to.
```sh
dataset = kiro.Dataset(key='YOUR-DATASET-KEY',
name='YOUR-DATASET-NAME',
description="YOUR-DATASET-DESCRIPTION",
...
)
dataset.labels = ["YOUR-DATASET-LABEL-1", "YOUR-DATASET-LABEL-2"]
dataset.aliases = ['YOUR-VERSION-ALIAS']
```
To log a dataset, use the `log_dataset` method with the following parameters:
- dataset (Dataset, required): the dataset object.
- comment (str, optional): the usage comment.
```sh
kiro.log_dataset(dataset=dataset, comment='LOGGING_COMMENT')
```
### Using
To use a dataset, use the `use_dataset` method with dataset `key:version`.
Parameters:
- dataset (str, required): the dataset identifier in key:version format.
- comment (str, optional): the usage comment.
```sh
dataset = kiro.use_dataset(
dataset='YOUR-DATASET-KEY:YOUR-DATASET-VERSION-OR-ALIAS')
```
### Adding files and downloading
You can add or remove files from dataset and download it as well.
Supported file paths:
- `file://` - the local files.
- `s3://` - the amazon S3 files.
adding / removing files
local:
```sh
dataset.remove_file(path='file://LOCAL_PATH_TO_FILE_1')
dataset.add_file(path='file://LOCAL_PATH_TO_FILE_2')
kiro.log_dataset(dataset=dataset)
```
s3:
```sh
os.environ['AWS_ACCESS_KEY_ID'] = 'AWS_ACCESS_KEY_ID'
os.environ['AWS_SECRET_ACCESS_KEY'] = 'AWS_SECRET_ACCESS_KEY'
dataset.remove_file(path='s3://BUCKET/PATH_1')
dataset.add_file(path='s3://BUCKET/PATH_2')
kiro.log_dataset(dataset=dataset)
```
downloading:
Parameters:
- overwrite (bool, optional): overwrite an existing dataset or skip
downloading if it already exists.
```sh
dataset.download(overwrite=True)
```
Example:
```sh
# use version v0, v1 etc, or any version alias: my_dataset:latest
dataset = kiro.use_dataset(dataset='my_dataset:V0')
path_map = dataset.download()
for local_path in path_map.values():
with open(local_path, 'r'):
# read downloaded file
new_dataset = kiro.Dataset('new_dataset')
new_dataset.add_file(path='s3://ml-bucket/datasets/training_dataset.csv')
kiro.log_dataset(dataset=new_dataset)
new_dataset.download()
```
## Creating models
To create a model, use the `model` method with the following parameters:
- key (str, required): the unique model key.
- path (str, optional): the run model path.
```sh
kiro.model(key="YOUR-MODEL-KEY", path="YOUR-MODEL-PATH")
```
Example:
```sh
kiro.model("my_model", "/home/user/my_model")
```
## Setting model version
To set a custom model version, use the `model_version` method with the following parameter:
- version (str, required): the version name.
```sh
kiro.model_version(version="YOUR-MODEL-VERSION")
```
Example:
```sh
kiro.model_version("1.2.3-release")
```
## Setting model version alias
To set a model version alias, use the `model_version_alias` method with the following parameter:
- alias (str, required): the alias name.
```sh
kiro.model_version_alias(alias="YOUR-MODEL-VERSION-ALIAS")
```
Example:
```sh
kiro.model_version_alias("winner")
```
## Setting model version tag
To add tags to a model version, use the `model_version_tag` method with the following parameters:
- key (str, required): the tag name.
- value (str | number, required): the tag value.
```sh
kiro.model_version_tag(key="YOUR-MODEL-VERSION-TAG-KEY", value=YOUR_MODEL_VERSION_TAG_VALUE)
```
Example:
```sh
kiro.model_version_tag("env", "staging demo")
```
## Creating artifacts
To create an artifact, use the `artifact` method with the following parameters:
- path (str, required): the run artifact path.
- name (str, optional): the artifact name.
- description (str, optional): the artifact description.
- tags (dict, optional): the artifact tags.
```sh
kiro.artifact(path="YOUR-ARTIFACT-PATH",
name="YOUR-ARTIFACT-NAME",
description="YOUR-ARTIFACT-DESCRIPTION",
tags={"YOUR-ARTIFACT-TAG-KEY": YOUR_ARTIFACT_TAG_VALUE})
```
Example:
```sh
kiro.artifact("https://s3/ml-bucket/artifacts/AccuracyChart.png",
name="Accuracy line chart",
description="The dependence of accuracy on the time",
tags={"env": "staging"})
```
## Setting artifact tag
To add a tag to an artifact, use the `artifact_tag` method with the following parameters:
- path (str, required): the run artifact path.
- key (str, required): the tag name.
- value (str | number, required): the tag value.
```sh
kiro.artifact_tag(path="YOUR-ARTIFACT-PATH",
key="YOUR-ARTIFACT-TAG-KEY",
value=YOUR_ARTIFACT_TAG_VALUE)
```
Example:
```sh
kiro.artifact_tag("https://s3/ml-bucket/artifacts/AccuracyChart.png",
"env", "staging demo")
```
## Finishing task run
To finish a run, use the `finish` method.
```sh
kiro.finish()
```
## Failing task run
To fail a run, use the `error` method.
```sh
kiro.error()
```
| text/markdown | Hystax | null | null | null | "Apache License 2.0" | arcee, kiro, ml, kiroframe, finops, mlops | [] | [] | https://my.kiroframe.com/ | null | <4,>=3.8 | [] | [] | [] | [
"aiohttp==3.10.11",
"aiofiles==23.2.1",
"psutil==7.0.0",
"aioboto3==14.1.0",
"pyarrow==17.0.0"
] | [] | [] | [] | [
"Source, https://github.com/hystax/kiroframe_arcee"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:16:47.740698 | kiroframe_arcee-0.1.55.tar.gz | 33,768 | 19/b9/babd02182d0765e282baf8ef26a5af697d1103e0fbe630a64ad1fac7a433/kiroframe_arcee-0.1.55.tar.gz | source | sdist | null | false | 68fe889e5b4c0607f88ec3d15ae33384 | 4f5f9df109019261fdf9252578c091985c62f5b34c245e6428aa03404153c6fd | 19b9babd02182d0765e282baf8ef26a5af697d1103e0fbe630a64ad1fac7a433 | null | [
"LICENSE"
] | 194 |
2.4 | g3visu | 0.1.13 | System G3 Visualization files' parsers and generators | # Library Name
Collection of System G3 Visualization files' parsers and generators.
## Installation
The installation can be done with the package manager `pip`.
```bash
pip install g3visu
```
## Usage
Invoke from the terminal:
```bash
gen-visu --help
```
The package can also be used as a library:
```python
from g3visu import TypeInfo, SiteSVG
from g3visu.utils import SitesFileDownloader
```
| text/markdown | Elektroline a.s. | null | null | null | null | Elektroline, System G3 | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Other Audience",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Onl... | [] | null | null | >=3.11 | [] | [] | [] | [
"lxml",
"platformdirs>=4.0",
"python-gitlab>=4.0",
"pyshv==0.6.1",
"g3elements==0.2.0",
"pytest; extra == \"test\"",
"pytest-asyncio==0.21.1; extra == \"test\"",
"sphinx; extra == \"docs\"",
"sphinx_rtd_theme; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://gitlab.elektroline.cz/plc/systemg3-py/SystemG3Visu.git"
] | twine/6.2.0 CPython/3.11.9 | 2026-02-18T11:16:10.252587 | g3visu-0.1.13.tar.gz | 21,882 | 72/e9/ecba6ffc2a1881fae594423becd6b95492aca39e65d82c2172db504a9f65/g3visu-0.1.13.tar.gz | source | sdist | null | false | 1c8b8bbb5c345aff2a8e4fd9896d632a | f34d5974bec24279b53368983b4e7cb1e6349997c240caa086da298a1a85c9fd | 72e9ecba6ffc2a1881fae594423becd6b95492aca39e65d82c2172db504a9f65 | null | [
"LICENCE"
] | 243 |
2.4 | valohai-yaml | 0.55.0 | Valohai.yaml validation and parsing | # valohai-yaml
[](https://github.com/valohai/valohai-yaml/actions/workflows/ci.yml)
[](https://codecov.io/gh/valohai/valohai-yaml)
[](https://opensource.org/licenses/MIT)
Parses and validates `valohai.yaml` files.
Valohai YAML files are used to define how your machine learning project workloads and pipelines are ran on the [Valohai](https://valohai.com/) ecosystem. Refer to [Valohai Documentation](https://docs.valohai.com/) to learn how to write the actual YAML files and for more in-depth usage examples.
## Installation
```bash
pip install valohai-yaml
```
## Usage
### Validation
Programmatic usage:
```python
from valohai_yaml import validate, ValidationErrors
try:
with open('path/to/valohai.yaml') as f:
validate(f)
except ValidationErrors as errors:
print('oh no!')
for err in errors:
print(err)
```
Command-line usage:
```bash
valohai-yaml my_yaml.yaml
echo $? # 1 if errors, 0 if ok
```
### Parsing
```python
from valohai_yaml import parse
with open('path/to/valohai.yaml') as f:
config = parse(f)
print(config.steps['cool step'].command)
```
# Development
```bash
# setup development dependencies
make dev
# run linting and type checks
make lint
# run tests
make test
```
## Snapshots
Update [syrupy](https://github.com/tophat/syrupy) snapshots after making changes to the examples.
```bash
pytest --snapshot-update
```
| text/markdown | null | Valohai <info@valohai.com> | null | null | null | strings, utility | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming La... | [] | null | null | >=3.9 | [] | [] | [] | [
"jsonschema>=4.0",
"leval>=1.1.1",
"pyyaml"
] | [] | [] | [] | [
"Homepage, https://github.com/valohai/valohai-yaml"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T11:15:49.856892 | valohai_yaml-0.55.0.tar.gz | 68,245 | c2/5c/3b593397a65fed3d59731623f78d3713657eb21c99c56be0006463583a7f/valohai_yaml-0.55.0.tar.gz | source | sdist | null | false | c32b66b6f09aab237a8de3b532bc61cb | d21e3f2b9bf468410343af0bd9f9e1000d95e8721c7f7e1a467e3b340df34f4c | c25c3b593397a65fed3d59731623f78d3713657eb21c99c56be0006463583a7f | MIT | [
"LICENSE"
] | 12,398 |
2.4 | dc-securex | 3.3.4 | Backend-only Discord anti-nuke protection SDK | # 🛡️ SecureX SDK - Discord Server Protection Made Easy
**Protect your Discord server from attacks in just 5 lines of code!**
[](https://pypi.org/project/dc-securex/)
[](https://www.python.org/downloads/)
## 🤔 What is this?
SecureX is a **Python library** that protects your Discord server from people who try to destroy it.
Imagine someone gets admin powers and starts:
- 🗑️ Deleting all channels
- 👥 Kicking everyone
- 🚫 Banning members
- 🤖 Adding spam bots
**SecureX stops them in milliseconds** (0.005 seconds!) and fixes everything automatically!
---
## ✨ Features
- ⚡ **Instant Threat Response** - Triple-worker architecture for microsecond-level detection
- 🛡️ **Comprehensive Protection** - Guards channels, roles, members, bots, webhooks, and guild settings
- 🔄 **Smart Backup & Restore** - Automatic structural backups with intelligent restoration
- 🌐 **Vanity URL Protection (Coming Soon)** - Restore and protect your server's custom invite URL
- 🌐 **Vanity URL Protection (Coming Soon)** - Restore and protect your server's custom invite URL (Coming Soon)
- 💾 **SQLite Storage with WAL** - Fast, reliable storage with Write-Ahead Logging for concurrent access
- 🗄️ **Multiple Storage Backends** - Choose between SQLite (default) or PostgreSQL
- 👥 **Flexible Whitelisting** - Per-guild trusted user management
- ⚖️ **Customizable Punishments** - Configure responses (ban/kick/none) per action type
- 📊 **Event Callbacks** - Hook into threat detection, backups, and restorations
- ✅ **90% Test Coverage** - Comprehensive test suite with 100% coverage on critical paths
- 🔌 **Production Ready** - Built with asyncio, type hints, and comprehensive error handling
---
## 📋 Requirements
### Python & Dependencies
**Required:**
- ✅ Python 3.8 or higher
- ✅ discord.py 2.0.0 or higher (auto-installed)
- ✅ aiofiles 23.0.0 or higher (auto-installed)
## Installation
### Basic Installation (SQLite)
```bash
pip install dc-securex
```
### With PostgreSQL Support
```bash
pip install dc-securex[postgres]
```
This automatically installs all required dependencies!
### Discord Bot Permissions
**REQUIRED Permissions** (Bot won't work without these):
| Permission | Why Needed | Priority |
|------------|-----------|----------|
| `View Audit Log` | See who did what (CRITICAL!) | 🔴 MUST HAVE |
| `Manage Channels` | Restore deleted channels | 🔴 MUST HAVE |
| `Manage Roles` | Restore deleted roles | 🔴 MUST HAVE |
| `Ban Members` | Ban attackers | 🟡 For bans |
| `Kick Members` | Kick attackers | 🟡 For kicks |
| `Moderate Members` | Timeout attackers | 🟡 For timeouts |
| `Manage Webhooks` | Delete spam webhooks | 🟢 Optional |
**Easy Invite Link:**
```
https://discord.com/api/oauth2/authorize?client_id=YOUR_BOT_ID&permissions=8&scope=bot
```
Using `permissions=8` gives Administrator (easiest for testing).
### Discord Bot Intents
**REQUIRED Intents** (Enable in Developer Portal AND code):
**In Discord Developer Portal:**
1. Go to your app → Bot → Privileged Gateway Intents
2. Enable:
- ✅ SERVER MEMBERS INTENT
- ✅ MESSAGE CONTENT INTENT (if using commands)
**In Your Code:**
```python
import discord
intents = discord.Intents.all()
```
Or specific intents:
```python
intents = discord.Intents.default()
intents.guilds = True
intents.members = True
intents.bans = True
intents.webhooks = True
```
### Bot Role Position
⚠️ **IMPORTANT:** Your bot's role must be **higher** than roles it manages!
```
✅ CORRECT:
1. Owner
2. SecureBot ← Bot here
3. Admin
4. Moderator
❌ WRONG:
1. Owner
2. Admin
3. SecureBot ← Bot too low!
4. Moderator
```
### System Requirements
- **OS:** Windows, Linux, macOS (any OS with Python 3.8+)
- **RAM:** 512MB minimum (1GB recommended)
- **Disk:** 100MB for SDK + backups
- **Network:** Stable internet connection
- **Discord:** Bot must have access to audit logs
### Optional (Recommended)
- **Git** - For version control
- **Virtual Environment** - Keep dependencies isolated
```bash
python -m venv venv
source venv/bin/activate
pip install dc-securex
```
---
## 📋 Before You Start
### Step 1: Create a Discord Bot
1. Go to [Discord Developer Portal](https://discord.com/developers/applications)
2. Click **"New Application"**
3. Give it a name (like "SecureBot")
4. Go to **"Bot"** tab → Click **"Add Bot"**
5. **Important**: Enable these switches:
- ✅ SERVER MEMBERS INTENT
- ✅ MESSAGE CONTENT INTENT
6. Click **"Reset Token"** → Copy your bot token (you'll need this!)
### Step 2: Invite Bot to Your Server
Use this link (replace `YOUR_BOT_ID` with your bot's ID from Developer Portal):
```
https://discord.com/api/oauth2/authorize?client_id=YOUR_BOT_ID&permissions=8&scope=bot
```
**Permission value `8` = Administrator** (easiest for beginners)
### Step 3: Install Python & Libraries
**Check if Python is installed:**
```bash
python --version
```
**Requirements:**
- ✅ Python 3.8 or newer (Python 3.10+ recommended)
- ✅ pip (comes with Python)
**If you don't have Python:**
- Download from [python.org](https://python.org)
- During installation, check "Add Python to PATH"
**Install SecureX SDK:**
```bash
pip install dc-securex
```
**What gets installed automatically:**
- `discord.py >= 2.0.0` - Discord API wrapper
- `aiofiles >= 23.0.0` - Async file operations
**Optional: Use Virtual Environment (Recommended)**
```bash
python -m venv venv
source venv/bin/activate
pip install dc-securex
```
**Verify installation:**
```bash
pip show dc-securex
```
You should see version 2.15.3 or higher!
---
## 🚀 Quick Start
### Using SQLite (Default)
```python
import discord
from securex import SecureX
bot = discord.Client(intents=discord.Intents.all())
sx = SecureX(bot) # SQLite storage automatically configured
@bot.event
async def on_ready():
await sx.enable(
guild_id=YOUR_GUILD_ID,
whitelist=[ADMIN_USER_ID_1, ADMIN_USER_ID_2],
auto_backup=True
)
print(f"✅ SecureX enabled for {bot.guilds[0].name}")
print(f"💾 Using SQLite storage with WAL mode")
bot.run("YOUR_BOT_TOKEN")
```
### Using PostgreSQL
```python
import discord
from securex import SecureX
bot = discord.Client(intents=discord.Intents.all())
sx = SecureX(
bot,
storage_backend="postgres",
postgres_url="postgresql://user:password@localhost:5432/securex_db",
postgres_pool_size=10
)
@bot.event
async def on_ready():
await sx.enable(
guild_id=YOUR_GUILD_ID,
whitelist=[ADMIN_USER_ID],
auto_backup=True
)
print(f"✅ SecureX enabled with PostgreSQL storage")
bot.run("YOUR_BOT_TOKEN")
```
### Step 3: Add Your Bot Token
Replace `"YOUR_BOT_TOKEN_HERE"` with the token you copied from Discord Developer Portal.
**⚠️ KEEP YOUR TOKEN SECRET!** Never share it or post it online!
### Step 4: Run Your Bot
```bash
python bot.py
```
You should see: `✅ YourBotName is online and protected!`
### Step 5: Test It!
Your server is now protected! If someone tries to delete a channel or kick members without permission, SecureX will:
1. **Ban them instantly** (in 0.005 seconds!)
2. **Restore what they deleted** (channels, roles, etc.)
3. **Log the attack** (so you know what happened)
---
## 🎯 Understanding the Code
Let's break down what each part does:
```python
from securex import SecureX
```
This imports the SecureX library.
```python
sx = SecureX(bot)
```
This connects SecureX to your bot.
```python
await sx.enable(punishments={...})
```
This turns on protection and sets punishments:
- `"ban"` = Ban the attacker
- `"kick"` = Kick them out
- `"timeout"` = Mute them for 10 minutes
- `"none"` = Just restore, don't punish
---
## 🔧 What Can You Protect?
Here are ALL the things you can protect:
| Type | What it stops | Available Punishments |
|------|--------------|----------------------|
| `channel_delete` | Deleting channels | `"none"`, `"warn"`, `"timeout"`, `"kick"`, `"ban"` |
| `channel_create` | Creating too many channels (spam) | `"none"`, `"warn"`, `"timeout"`, `"kick"`, `"ban"` |
| `role_delete` | Deleting roles | `"none"`, `"warn"`, `"timeout"`, `"kick"`, `"ban"` |
| `role_create` | Creating too many roles (spam) | `"none"`, `"warn"`, `"timeout"`, `"kick"`, `"ban"` |
| `member_kick` | Kicking members | `"none"`, `"warn"`, `"timeout"`, `"kick"`, `"ban"` |
| `member_ban` | Banning members | `"none"`, `"warn"`, `"timeout"`, `"kick"`, `"ban"` |
| `member_unban` | Unbanning people | `"none"`, `"warn"`, `"timeout"`, `"kick"`, `"ban"` |
| `webhook_create` | Creating spam webhooks | `"none"`, `"warn"`, `"timeout"`, `"kick"`, `"ban"` |
| `bot_add` | Adding bad bots | Always `"ban"` (automatic) |
| `vanity_url_code` | Changing server vanity URL | Coming soon |
| `vanity_url_code` | Changing server vanity URL | Coming soon |
**Punishment Options Explained:**
- `"none"` - Only restore, don't punish
- `"warn"` - Send warning message
- `"timeout"` - Mute for 10 minutes (configurable)
- `"kick"` - Kick from server
- `"ban"` - Ban from server
---
## 🎨 Simple Examples
### Example 1: Strict Mode (Ban Everything)
```python
await sx.enable(
punishments={
"channel_delete": "ban",
"channel_create": "ban",
"role_delete": "ban",
"role_create": "ban",
"member_kick": "ban",
"member_ban": "ban"
}
)
```
### Example 2: Gentle Mode (Warn Only)
```python
await sx.enable(
punishments={
"channel_delete": "timeout",
"role_delete": "timeout",
"member_kick": "warn"
}
)
```
### Example 3: Protection Without Punishment
```python
await sx.enable()
```
This only restores deleted stuff but doesn't punish anyone.
---
## 👥 Whitelist (Allow Trusted Users)
Want to allow some people to delete channels? Add them to the whitelist:
```python
await sx.whitelist.add(guild_id, user_id)
```
**Example:**
```python
@bot.command()
@commands.is_owner()
async def trust(ctx, member: discord.Member):
await sx.whitelist.add(ctx.guild.id, member.id)
await ctx.send(f"✅ {member.name} is now trusted!")
@bot.command()
@commands.is_owner()
async def untrust(ctx, member: discord.Member):
await sx.whitelist.remove(ctx.guild.id, member.id)
await ctx.send(f"❌ {member.name} is no longer trusted!")
```
---
## 🔔 Get Notified When Attacks Happen
Add this to your code to get alerts:
```python
@sx.on_threat_detected
async def alert(threat):
print(f"🚨 ATTACK DETECTED!")
print(f" Type: {threat.type}")
print(f" Attacker: {threat.actor_id}")
print(f" Punishment: {threat.punishment_action}")
```
**Fancier Alert (Discord Embed):**
```python
@sx.on_threat_detected
async def fancy_alert(threat):
channel = bot.get_channel(YOUR_LOG_CHANNEL_ID)
embed = discord.Embed(
title="🚨 Security Alert!",
description=f"Someone tried to {threat.type}!",
color=discord.Color.red()
)
embed.add_field(name="Attacker", value=f"<@{threat.actor_id}>")
embed.add_field(name="What Happened", value=threat.target_name)
embed.add_field(name="Punishment", value=threat.punishment_action.upper())
await channel.send(embed=embed)
```
---
## 📝 Full Working Example
Here's a complete bot with commands:
```python
import discord
from discord.ext import commands
from securex import SecureX
bot = commands.Bot(command_prefix="!", intents=discord.Intents.all())
sx = SecureX(bot)
@bot.event
async def on_ready():
await sx.enable(punishments={"channel_delete": "ban", "member_ban": "ban"})
print(f"✅ {bot.user.name} is protecting {len(bot.guilds)} servers!")
@sx.on_threat_detected
async def log_attack(threat):
print(f"🚨 Stopped {threat.type} by user {threat.actor_id}")
@bot.command()
@commands.is_owner()
async def trust(ctx, member: discord.Member):
await sx.whitelist.add(ctx.guild.id, member.id)
await ctx.send(f"✅ {member.mention} can now manage the server!")
@bot.command()
@commands.is_owner()
async def untrust(ctx, member: discord.Member):
await sx.whitelist.remove(ctx.guild.id, member.id)
await ctx.send(f"❌ {member.mention} is no longer trusted!")
@bot.command()
async def ping(ctx):
await ctx.send(f"🏓 Pong! Protection active!")
bot.run("YOUR_BOT_TOKEN")
```
---
## ❓ Common Questions
### Q: Will this slow down my bot?
**A:** No! SecureX is SUPER fast (5-10 milliseconds). Your bot will work normally.
### Q: What if I accidentally delete a channel?
**A:** If you're the server owner, SecureX won't stop you! Or add yourself to the whitelist.
### Q: Can I change punishments later?
**A:** Yes! Just call `await sx.enable(punishments={...})` again with new settings.
### Q: Does it work on multiple servers?
**A:** Yes! It automatically protects all servers your bot is in.
### Q: What if my bot goes offline?
**A:** When it comes back online, it automatically creates new backups. But it can't stop attacks while offline.
### Q: How do I make my own commands?
**A:** Check [discord.py documentation](https://discordpy.readthedocs.io/) to learn more about making bot commands!
---
## 🔧 Troubleshooting
### ❌ "Missing Permissions" Error
**Solution:** Make sure your bot has Administrator permission, or at least these:
- Manage Channels
- Manage Roles
- Ban Members
- Kick Members
- View Audit Log
### ❌ Bot doesn't detect attacks
**Solution:**
1. Check if you enabled **SERVER MEMBERS INTENT** in Discord Developer Portal
2. Make sure your bot is using `intents=discord.Intents.all()`
3. Check if bot role is above other roles in Server Settings → Roles
### ❌ Can't restore deleted channels
**Solution:** Bot role must be **higher** than the roles it needs to manage
---
## 🏗️ Architecture (How It Works Under the Hood)
SecureX uses a **Triple-Worker Architecture** for maximum speed and reliability. Here's how it works:
### ⚡ The Triple-Worker System
Think of SecureX like a security team with 3 specialized workers:
```
┌─────────────────────────────────────────────────────────┐
│ DISCORD SERVER │
│ (Someone deletes a channel, kicks a member, etc.) │
└────────────────┬────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────┐
│ DISCORD AUDIT LOG EVENT (Instant!) │
│ Discord creates a log entry: "User X deleted #general"│
└────────────────┬───────────────────────────────────────┘
│
▼ (5-10 milliseconds)
┌────────────────────────────────────────────────────────┐
│ SECUREX EVENT LISTENER │
│ (Catches the audit log instantly) │
└─────┬──────────┬─────────────┬────────────────────────┘
│ │ │
▼ ▼ ▼
┌─────┐ ┌─────┐ ┌─────┐
│ Q1 │ │ Q2 │ │ Q3 │ (3 Queues)
└──┬──┘ └──┬──┘ └──┬──┘
│ │ │
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│Worker 1 │ │Worker 2 │ │Worker 3 │
│ Action │ │ Cleanup │ │ Log │
└─────────┘ └─────────┘ └─────────┘
```
### 🔨 Worker 1: Action Worker (PUNISHER)
**Job:** Ban/kick bad users INSTANTLY
**What it does:**
1. Checks if user is whitelisted
2. If NOT whitelisted → BAN them immediately
3. Takes only 5-10 milliseconds!
**Example:**
```
User "Hacker123" deletes #general
↓ (5ms later)
Action Worker: "Hacker123 is NOT whitelisted"
↓
*BANS Hacker123 instantly*
```
### 🧹 Worker 2: Cleanup Worker (CLEANER)
**Job:** Delete spam creations (channels, roles, webhooks)
**What it does:**
1. If someone creates 50 spam channels
2. Deletes them all INSTANTLY
3. Prevents server from getting cluttered
**Example:**
```
User creates spam channel "#spam1"
↓ (10ms later)
Cleanup Worker: "Unauthorized channel!"
↓
*Deletes #spam1 immediately*
```
### � Worker 3: Log Worker (REPORTER)
**Job:** Alert you about attacks
**What it does:**
1. Fires your callbacks
2. Sends you alerts
3. Logs everything for review
**Example:**
```
Attack detected!
↓
Log Worker: Calls your @sx.on_threat_detected
↓
You get an alert embed in Discord!
```
---
### 🔄 Restoration System (Separate from Workers)
**Job:** Restore deleted stuff from backups
**How it works:**
```
Channel deleted
↓ (500ms wait for audit log)
↓
Restoration Handler checks: "Was this authorized?"
↓ NO
↓
Looks in backup: "Found #general backup!"
↓
*Recreates channel with same permissions*
```
**Automatic Backups:**
- Creates backup every 10 minutes
- Saves: Channels, roles, permissions, positions
- Stored in `./data/backups/` folder
---
### 🏰 Worker 4: Guild Worker (GUILD SETTINGS PROTECTOR)
**NEW in v2.15+!** The Guild Worker protects and restores critical guild settings.
**Job:** Restore guild name, icon, banner, vanity URL when changed unauthorized (Vanity restoration coming soon)
**What it does:**
1. Monitors `guild_update` audit log events
2. Detects changes to server name, icon, banner, description, vanity URL (Vanity URL coming soon)
3. Restores from backup if unauthorized user made changes
4. Uses user tokens for vanity URL restoration (Discord API limitation) (Coming soon)
**Protected Settings:**
- ✅ Server Name
- ✅ Server Icon
- ✅ Server Banner
- ✅ Server Description
- ✅ **Vanity URL** (requires user token)
- ✅ **Vanity URL** (requires user token) (Coming soon)
**Example:**
```
Unauthorized user changes server name to "HACKED SERVER"
↓ (50ms wait for audit log)
↓
Guild Worker checks: "Was this authorized?"
↓ NO
↓
Looks in backup: "Found original name: Cool Community"
↓
*Restores server name to "Cool Community"*
```
---
### 🔑 Setting Up Guild Worker (Vanity URL Support Coming Soon)
**Important:** Vanity URL restoration requires a **user token** due to Discord API limitations. Bot tokens cannot modify vanity URLs. (Coming soon)
#### Step 1: Get Your User Token (One-Time Setup)
**⚠️ WARNING:** Your user token is VERY sensitive! Never share it publicly!
**How to get it:**
1. Open Discord in your browser (not the app!)
2. Press `F12` to open Developer Tools
3. Go to **Console** tab
4. Type: `window.webpackChunkdiscord_app.push([[''],{},e=>{m=[];for(let c in e.c)m.push(e.c[c])}]);m.find(m=>m?.exports?.default?.getToken!==void 0).exports.default.getToken()`
5. Copy the long string that appears (your token)
**Alternative Method (Network Tab):**
1. Open Discord in browser → `F12` → Network tab
2. Filter by "api"
3. Click any request to `discord.com/api/`
4. Look in Headers → Request Headers → `authorization`
5. Copy the token value
#### Step 2: Set The User Token in Your Bot
```python
@bot.event
async def on_ready():
await sx.enable(punishments={...})
# Set user token for vanity URL restoration (Coming soon)
guild_id = 1234567890 # Your server ID
user_token = "YOUR_USER_TOKEN_HERE" # From step 1
await sx.guild_worker.set_user_token(guild_id, user_token)
print("✅ Guild settings protection enabled with vanity URL support! (Coming soon)")
```
#### Step 3: Test It!
Try changing your server's vanity URL - SecureX will restore it automatically! (Coming soon)
**Full Example:**
```python
import discord
from discord.ext import commands
from securex import SecureX
bot = commands.Bot(command_prefix="!", intents=discord.Intents.all())
sx = SecureX(bot)
@bot.event
async def on_ready():
# Enable punishments
await sx.enable(punishments={"channel_delete": "ban"})
# Set user token for each guild
for guild in bot.guilds:
token = get_user_token_for_guild(guild.id) # Your token storage
await sx.guild_worker.set_user_token(guild.id, token)
print(f"✅ {bot.user.name} protecting {len(bot.guilds)} servers!")
bot.run("YOUR_BOT_TOKEN")
```
---
### 🎯 Guild Worker API
**Set User Token:**
```python
await sx.guild_worker.set_user_token(guild_id, "user_token_here")
```
**Get User Token:**
```python
token = sx.guild_worker.get_user_token(guild_id)
```
**Remove User Token:**
```python
await sx.guild_worker.remove_user_token(guild_id)
```
**Check If Token Is Set:**
```python
if sx.guild_worker.get_user_token(guild_id):
print("Token is configured!")
else:
print("No token set - vanity restoration won't work! (Coming soon)")
```
---
### 💾 User Token Storage
User tokens are **automatically saved** to `./data/backups/user_tokens.json` for persistence.
**Token Data Model:**
```python
from securex.models import UserToken
# Create token metadata
token_data = UserToken(
guild_id=123456789,
token="user_token_here",
set_by=999888777, # Admin who set it
description="Production server token"
)
# Track usage
token_data.mark_used() # Updates last_used timestamp
# Serialize
token_dict = token_data.to_dict()
```
**Storage Format (user_tokens.json):**
```json
{
"1234567890": "user_token_abc...",
"9876543210": "user_token_xyz..."
}
```
---
### ⚠️ Important Notes About User Tokens
**Security:**
- ✅ Tokens are stored locally in `./data/backups/`
- ✅ Never commit `user_tokens.json` to Git!
- ✅ Add to `.gitignore`: `data/backups/user_tokens.json`
- ⚠️ User tokens are more powerful than bot tokens - keep them secure!
**Limitations:**
- User tokens can **only** restore vanity URLs
- User tokens can **only** restore vanity URLs (Coming soon)
- Other guild settings (name, icon, banner) use bot permissions
- User must be a server owner or have Manage Guild permission
- User token must be from someone with vanity URL access
- User token must be from someone with vanity URL access (Coming soon)
**What Happens Without User Token:**
```
Unauthorized user changes vanity URL
Unauthorized user changes vanity URL (Coming soon)
↓
Guild Worker tries to restore
↓
⚠️ No user token set!
↓
Prints: "No user token set for guild 123! Cannot restore vanity."
Prints: "No user token set for guild 123! Cannot restore vanity. (Coming soon)"
↓
Other settings (name, icon) still restored via bot!
```
---
### 🔄 Complete Guild Protection Flow
**Timeline of Guild Name Change:**
```
0ms - Unauthorized user changes server name
50ms - Discord audit log updated
75ms - Guild Worker detects change
80ms - Checks whitelist (user not whitelisted)
85ms - Loads backup (finds original name)
100ms - Calls guild.edit(name="Original Name")
300ms - Server name restored!
```
---
## 💾 Storage Backends
SecureX v3.0+ supports **two storage backends** for maximum flexibility:
### 🗃️ SQLite (Default)
**The recommended choice for most users.** SQLite provides fast, reliable local storage with zero configuration.
**Features:**
- ✅ **Zero Configuration** - Works out of the box
- ✅ **WAL Mode** - Write-Ahead Logging for concurrent read/write
- ✅ **ACID Compliant** - Guaranteed data integrity
- ✅ **Single File** - All data in `./data/securex.db`
- ✅ **High Performance** - Indexed queries, fast I/O
- ✅ **No Dependencies** - Built into Python
**Usage:**
```python
# Automatic (default)
sx = SecureX(bot)
# Explicit
sx = SecureX(bot, storage_backend="sqlite")
# Custom database path
sx = SecureX(bot, storage_backend="sqlite", backup_dir="./custom/path")
# Database will be at: ./custom/path/securex.db
```
**What WAL Mode Means:**
Write-Ahead Logging allows multiple simultaneous readers while one writer is active. This means SecureX can read backups while creating new ones, preventing any blocking.
---
### 🐘 PostgreSQL (Optional)
**For enterprise deployments** requiring centralized database management or multi-instance setups.
**Features:**
- ✅ **Centralized Storage** - Single database for multiple bot instances
- ✅ **Connection Pooling** - Efficient resource usage
- ✅ **Advanced Queries** - Full SQL capabilities
- ✅ **Professional Tools** - pgAdmin, psql, monitoring
- ✅ **Scalable** - Handle thousands of guilds
**Installation:**
```bash
pip install dc-securex[postgres]
```
This installs the `asyncpg` driver.
**Usage:**
```python
import discord
from securex import SecureX
bot = discord.Client(intents=discord.Intents.all())
sx = SecureX(
bot,
storage_backend="postgres",
postgres_url="postgresql://username:password@host:5432/database",
postgres_pool_size=10 # Optional, default: 10
)
@bot.event
async def on_ready():
await sx.enable(guild_id=YOUR_GUILD_ID)
print("✅ Connected to PostgreSQL")
bot.run("YOUR_BOT_TOKEN")
```
**Connection URL Format:**
```
postgresql://username:password@hostname:port/database_name
```
**Examples:**
```python
# Local PostgreSQL
postgres_url = "postgresql://securex:mypassword@localhost:5432/securex_db"
# Remote server
postgres_url = "postgresql://user:pass@db.example.com:5432/prod_securex"
# With connection pooling
sx = SecureX(
bot,
storage_backend="postgres",
postgres_url=postgres_url,
postgres_pool_size=20 # Max connections
)
```
---
### 📊 Storage Backend Comparison
| Feature | SQLite | PostgreSQL |
|:---|:---|:---|
| **Setup Complexity** | Zero config | Requires DB server |
| **Installation** | Built-in | `pip install dc-securex[postgres]` |
| **Performance** | Excellent | Excellent |
| **Concurrency** | WAL mode (good) | Connection pooling (excellent) |
| **Scalability** | Up to ~100 guilds | Unlimited |
| **Multi-Instance** | No | Yes |
| **Maintenance** | Zero | DB administration |
| **Best For** | Most use cases | Enterprise deployments |
---
### 🔄 Migrating from JSON to SQLite
**If you're upgrading from SecureX v2.x (JSON storage):**
**Important:** JSON data is **not automatically migrated**. The new SQLite backend starts fresh.
**Migration Steps:**
1. **Backup your existing data:**
```bash
cp -r ./data/backups ./data/backups_old
cp -r ./data/whitelists ./data/whitelists_old
```
2. **Upgrade SecureX:**
```bash
pip install --upgrade dc-securex
```
3. **Update your code** (no changes needed - SQLite is now default)
4. **Re-add whitelisted users:**
```python
@bot.event
async def on_ready():
await sx.enable(guild_id=YOUR_GUILD_ID)
# Re-add your whitelisted users
await sx.whitelist.add(YOUR_GUILD_ID, USER_ID_1)
await sx.whitelist.add(YOUR_GUILD_ID, USER_ID_2)
```
5. **Create fresh backups:**
```python
# Automatic on first enable
await sx.enable(guild_id=YOUR_GUILD_ID, auto_backup=True)
# Or manual
backup_info = await sx.create_backup(YOUR_GUILD_ID)
print(f"✅ Backup created: {backup_info.channel_count} channels, {backup_info.role_count} roles")
```
**What You'll Lose:**
- Historical JSON backup files (new SQLite backups will be created)
- Old JSON whitelist files (re-add users)
- User tokens (re-configure if using vanity URL restoration)
- User tokens (re-configure if using vanity URL restoration) (Coming soon)
**What You'll Gain:**
- 🚀 **Faster performance** with indexed queries
- 🔒 **Better data integrity** with ACID transactions
- ⚡ **Concurrent access** with WAL mode
- 📦 **Single file storage** instead of multiple JSON files
---
### 🔧 Storage Configuration
**SQLite Configuration:**
```python
sx = SecureX(
bot,
storage_backend="sqlite",
backup_dir="./data/backups" # Database location
)
# Creates: ./data/backups/securex.db
```
**PostgreSQL Configuration:**
```python
sx = SecureX(
bot,
storage_backend="postgres",
postgres_url="postgresql://user:pass@host:5432/db",
postgres_pool_size=15 # Connection pool size
)
```
**Environment Variables (Recommended for Production):**
```python
import os
sx = SecureX(
bot,
storage_backend=os.getenv("STORAGE_BACKEND", "sqlite"),
postgres_url=os.getenv("DATABASE_URL") # For PostgreSQL
)
```
**`.env` file:**
```bash
STORAGE_BACKEND=postgres
DATABASE_URL=postgresql://securex:password@localhost:5432/securex_db
DISCORD_TOKEN=your_bot_token_here
```
**Multi-Setting Attack:**
```
User changes: name + icon + banner + vanity
User changes: name + icon + banner + vanity (Vanity coming soon)
- Vanity: Restored via user token (API) (Coming soon)
↓
Guild Worker restores ALL in one go:
- Name: Restored via bot
- Icon: Restored via bot
- Banner: Restored via bot
- Vanity: Restored via user token (API)
↓
Total time: ~500ms for all 4 settings!
```
---
### 📊 Guild Worker vs Other Workers
| Worker | Speed | What It Protects | Token Needed
|--------|-------|------------------|-------------|
| Action Worker | 5-10ms | Punishes attackers | Bot token ✅ |
| Cleanup Worker | 10-20ms | Deletes spam | Bot token ✅ |
| Log Worker | 15ms | Sends alerts | Bot token ✅ |
| Guild Worker | 50-500ms | Server settings | Bot + User token ⚠️ |
**Why Guild Worker is slower:**
- Waits for audit log (50ms)
- Loads backup from disk
- Makes API calls to restore
- Vanity URL uses external API endpoint
**But still VERY fast compared to manual restoration!**
---
### 🎯 Why Triple Workers?
**Speed:**
- Workers don't wait for each other
- All process in parallel
- Punishment happens in 5-10ms!
**Reliability:**
- If one worker crashes, others keep working
- Each worker has its own queue
- No single point of failure
**Separation:**
- Punishment (fast) ≠ Restoration (slower but thorough)
- Action Worker = instant ban
- Restoration Handler = careful rebuild
---
### 📊 Data Flow Example
Let's say "BadUser" deletes 5 channels:
**Timeline:**
```
0ms - BadUser deletes #general
5ms - SecureX detects it (audit log)
7ms - Broadcasts to 3 workers
10ms - Action Worker BANS BadUser
12ms - Cleanup Worker ready (no cleanup needed)
15ms - Log Worker alerts you
500ms - Restoration Handler starts
750ms - #general recreated with permissions
```
**Result:**
- ✅ BadUser banned in 10ms
- ✅ You alerted in 15ms
- ✅ #general restored in 750ms
- ✅ Total response: Less than 1 second!
---
### 🧠 Smart Permission Detection
When someone updates a member's roles:
```
User "Sneaky" gives Admin role to "Friend"
↓
Member Update Handler triggered
↓
Checks: "Is Sneaky whitelisted?"
↓ NO
↓
Scans ALL roles of "Friend"
↓
Finds roles with dangerous permissions:
- Administrator ❌
- Manage Roles ❌
- Ban Members ❌
↓
*Removes ALL dangerous roles in ONE API call*
↓
Friend is now safe!
```
**Dangerous Permissions Detected:**
- Administrator
- Kick Members
- Ban Members
- Manage Guild
- Manage Roles
- Manage Channels
- Manage Webhooks
- Manage Emojis
- Mention Everyone
- Manage Expressions
---
### 💾 Caching System
SecureX uses caching for maximum speed:
**Cached Data:**
1. **Whitelist** - Frozenset for O(1) lookup
2. **Dangerous Permissions** - Class-level constant
3. **Guild Backups** - Updated every 10 minutes
**Why This Matters:**
```python
OLD (v1.x):
Check whitelist → Database query (50-100ms)
NEW (v2.x):
Check whitelist → Memory lookup (0.001ms)
```
**50,000x faster!**
---
## 📊 How It Works (Simple Summary)
1. **Someone does something bad** (delete channel, ban member, etc.)
2. **Discord logs it** (in audit log)
3. **SecureX sees it instantly** (5-10 milliseconds later!)
4. **Checks if they're allowed** (whitelist check)
5. **If NOT allowed:**
- Bans/kicks them (punishment)
- Restores what they deleted (from backup)
- Alerts you (via callback)
All of this happens **automatically** while you sleep! 😴
---
## 🎓 Next Steps
1. ✅ Get bot token from Discord Developer Portal
2. ✅ Install: `pip install dc-securex`
3. ✅ Copy the example code
4. ✅ Add your bot token
5. ✅ Run: `python bot.py`
6. 🎉 Your server is protected!
---
## 📚 Want to Learn More?
- [Discord.py Docs](https://discordpy.readthedocs.io/) - Learn to make Discord bots
- [Python Tutorial](https://docs.python.org/3/tutorial/) - Learn Python basics
- [Discord Developer Portal](https://discord.com/developers/docs) - Official Discord docs
---
## 📄 License
MIT License - Free to use! ❤️
---
## 🌟 Support
Having issues? Questions? Found a bug?
- Open an issue on GitHub
- Read this README carefully
- Check if your bot has all permissions
---
**Made with ❤️ for Discord bot developers**
**Version 2.15.5** - Lightning-fast server protection!
🚀 **Start protecting your server today!**
| text/markdown | SecureX Team | SecureX Team <contact@securex.dev> | null | null | MIT | discord, bot, antinuke, security, protection, sdk | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/yourusername/securex-antinuke-sdk | null | >=3.8 | [] | [] | [] | [
"discord.py>=2.0.0",
"aiofiles>=23.0.0",
"aiosqlite>=0.17.0"
] | [] | [] | [] | [
"Homepage, https://github.com/yourusername/securex-antinuke-sdk",
"Repository, https://github.com/yourusername/securex-antinuke-sdk",
"Issues, https://github.com/yourusername/securex-antinuke-sdk/issues"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-18T11:15:10.146412 | dc_securex-3.3.4-py3-none-any.whl | 62,278 | e2/de/b3cb75a16dddf5a46baa5a47fb1d2ec2aa76cf7a13c26efe1ac6403a46d9/dc_securex-3.3.4-py3-none-any.whl | py3 | bdist_wheel | null | false | 46a6c03c0ea9f01f03db8bebbb95b5d0 | 0ecb74cd4eb002f5e64a4aaa939dae23fbe8f0bdd232b8e27c473c5240bdcf9e | e2deb3cb75a16dddf5a46baa5a47fb1d2ec2aa76cf7a13c26efe1ac6403a46d9 | null | [
"LICENSE"
] | 250 |
2.3 | bojtools | 0.6.3 | Baekjoon Online Judge CLI tools | # BOJ([Baekjoon Online Judge](https://www.acmicpc.net/)) CLI tools
백준 & Solved.ac Command-line 도구
# 설치
```sh
pip3 install bojtools
```
# 사용법
## 초기화
```sh
boj init
```
## 로그인
```sh
boj login
...
Username: userid
Password:
```
- 자동 로그인에 자동으로 체크 됩니다.
## 문제 선택
```sh
boj pick <번호>
boj p <번호>
# 문제 상태 (AC/WA) 강제 갱신
boj p -f
```
## 랜덤 문제 선택
[Solved.ac](https://solved.ac/) 에서 특정 난이도(Gold, Silver, ...) 문제를 랜덤으로 선택
```sh
boj random --silver
boj r -s
# Silver2 에서 Gold3 까지 1000명 이상 푼 문제만 list
boj r -s 1000 s2 g3
```
## Answer 파일 생성
- 설정된 기본 template에서 복사됩니다.
```sh
boj generate <번호>
boj g
```
## 테스트
```sh
boj test <번호> -i <파일>
boj test <번호>
boj t
```
## 문제 제출
```sh
boj submit <번호> -i <파일>
boj submit <번호>
boj s
```
## 문제 풀이 보기
- 제출되어 통과(AC)한 문제여야 표시 됩니다.
```sh
boj solution <번호>
boj q
```
## 문제 정보
```sh
boj generate <번호>
boj g
```
# 환경설정
## Linux
~/.boj/config.toml 파일 편집
[샘플 config.toml](https://github.com/zshchun/bojtools/blob/main/config.toml.example) 참조
# TODO
- [x] Solved.ac classes
- [x] Random pick from Solved.ac
- [x] Log in to Baekjoon and Solved.ac
- [ ] Baekjoon workbook
- [x] Compile and test
- [x] Submit a code
- [x] Extract cookies
- [x] Text width
- [x] View other solution
- [x] Support python
- [ ] Support multi-platform
- [ ] Improve guide documents
- [ ] Github action
- [x] Init command
- [ ] Edit command
- [ ] Open command
- [ ] Template command
- [ ] Migrate tomli to tomllib
- [ ] Visual improvement
- [ ] Login expiration
- [ ] Add testcase command
- [x] uv build (PEP-621)
| text/markdown | Seunghwan Chun | Seunghwan Chun <zshchun@gmail.com> | null | null | MIT | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"aiohttp>=3.13.3",
"lxml>=6.0.2",
"nodriver>=0.48.1",
"tomli>=2.4.0",
"tomli-w>=1.2.0"
] | [] | [] | [] | [] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":null,"id":"forky","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T11:13:11.803814 | bojtools-0.6.3-py3-none-any.whl | 20,797 | eb/a7/a33e29400a44379cf00237590115fac8c2af9fb5c2759bb18fded11b5f26/bojtools-0.6.3-py3-none-any.whl | py3 | bdist_wheel | null | false | c3e8c7dffc6de94699540dd74c5ae309 | 7a6bdf5eb742ae9e99bbce83e2b2c0a9c262231b5777ad1b4ad519ee854f2814 | eba7a33e29400a44379cf00237590115fac8c2af9fb5c2759bb18fded11b5f26 | null | [] | 263 |
2.4 | neuracore-types | 6.6.0 | Shared type definitions for Neuracore. | # Neuracore Types
Shared type definitions for the Neuracore platform. This package maintains a single source of truth for data types in Python (Pydantic models) and automatically generates TypeScript types.
## Overview
- **Python Package**: `neuracore-types` - Pydantic models for Python backend
- **NPM Package**: `@neuracore/types` - TypeScript types for frontend
## Installation
### Python
```bash
pip install neuracore-types
```
### TypeScript/JavaScript
```bash
npm install @neuracore/types
# or
yarn add @neuracore/types
# or
pnpm add @neuracore/types
```
## Development
### Setup
```bash
# Clone the repository
git clone https://github.com/neuracoreai/neuracore_types.git
cd neuracore_types
# Install Python dependencies
pip install -e ".[dev]"
# Install Node dependencies
npm install
```
### Generate TypeScript Types
The TypeScript types are automatically generated from the Python Pydantic models:
```bash
npm install json-schema-to-typescript
python scripts/generate_types.py
```
This will:
1. Read the Pydantic models from `neuracore_types/neuracore_types.py`
2. Generate TypeScript definitions in `typescript/neuracore_types.ts`
3. Create an index file at `typescript/index.ts`
### Build TypeScript Package
```bash
npm run build
```
This compiles the TypeScript files to JavaScript and generates type declarations in the `dist/` directory.
## Release Process
### Creating PRs
All PRs must follow these conventions:
1. **Version Label**: Add exactly one version label to your PR:
- `version:major` - Breaking changes
- `version:minor` - New features
- `version:patch` - Bug fixes
- `version:none` - No release (docs, chores, etc.)
2. **Commit Format**: PR title and all commits must use conventional commit format:
```
<prefix>: <description>
```
Valid prefixes: `feat`, `fix`, `chore`, `docs`, `ci`, `test`, `refactor`, `style`, `perf`
Examples:
- `feat: add new data type for robot state`
- `fix: resolve serialization issue in TypeScript types`
- `chore: update dependencies`
### Pending Changelog
For significant changes (`version:major` or `version:minor`), update `changelogs/pending-changelog.md`:
```markdown
## Summary
This release adds support for new sensor data types and improves TypeScript type generation.
```
Simply append your summary to the existing content. This will appear at the top of the release notes.
### Triggering a Release
Releases are manual and triggered via GitHub Actions:
1. Go to **Actions** → **Release** → **Run workflow**
2. Optional: Check **dry_run** to preview without publishing
3. The workflow will:
- Analyze all PRs since last release
- Determine version bump (highest priority across all PRs)
- Generate changelog with all PRs grouped by type
- Bump version in `pyproject.toml`, `package.json`, and `__init__.py`
- Generate TypeScript types from Python models
- Publish Python package to PyPI
- Build and publish npm package to npm registry
- Create GitHub release
**Dry run** shows what would happen without making any changes - useful for testing before a real release.
## CI/CD
The repository includes GitHub Actions workflows:
1. **PR Checks**:
- Validates version labels
- Enforces conventional commit format
- Runs pre-commit hooks
- Suggests changelog updates for major/minor changes
2. **Release** (manual trigger):
- Generates TypeScript types from Python models
- Builds and validates both packages
- Publishes to PyPI and npm registry
- Creates GitHub release with changelog
| text/markdown | Neuracore | null | null | null | MIT | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"grpcio-tools",
"names-generator",
"numpy>=2.0.0",
"ordered-set",
"pillow",
"pydantic-to-typescript2>=1.0.0",
"pydantic>=2.0.0",
"scipy",
"pre-commit; extra == \"dev\"",
"pytest; extra == \"dev\"",
"huggingface-hub; extra == \"ml\"",
"torch; extra == \"ml\"",
"transformers; extra == \"ml\""
... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T11:13:05.033538 | neuracore_types-6.6.0.tar.gz | 60,051 | 94/33/b785069f7cd41cceb50319fd49e4e3f16d62179fe436e6517a3887d5f6e3/neuracore_types-6.6.0.tar.gz | source | sdist | null | false | e2ab5ad37cfddda4a6c7329943d0b96a | 29f16aeaf8dbb38b7dd8b2ac04df19848fdb366750385bb44346461c43e734a6 | 9433b785069f7cd41cceb50319fd49e4e3f16d62179fe436e6517a3887d5f6e3 | null | [
"LICENSE"
] | 854 |
2.4 | weiss-sim | 0.4.0 | Deterministic Weiss Schwarz simulator with a Rust core and Python bindings. | # Weiss Schwarz Simulator
[](https://github.com/victorwp288/weiss-schwarz-simulator/actions/workflows/ci.yml)
[](https://github.com/victorwp288/weiss-schwarz-simulator/actions/workflows/wheels.yml)
[](https://github.com/victorwp288/weiss-schwarz-simulator/actions/workflows/benchmarks.yml)
[](https://github.com/victorwp288/weiss-schwarz-simulator/actions/workflows/security.yml)
[](https://pypi.org/project/weiss-sim/)
[](https://victorwp288.github.io/weiss-schwarz-simulator/rustdoc/)
[](docs/README.md)
Deterministic Weiss Schwarz simulation for RL and engine research.
## What you get
- Rust engine (`weiss_core`) with deterministic advance-until-decision stepping
- PyO3 bindings (`weiss_py`) and Python API (`python/weiss_sim`) for batched training/eval loops
- Stable observation/action contracts (`OBS_LEN=378`, `ACTION_SPACE_SIZE=527`, `SPEC_HASH=8590000130`)
- Replay and fingerprint surfaces for drift detection and reproducibility
## 5-minute start
### Option A: install from PyPI
```bash
python -m pip install -U weiss-sim numpy
```
### Option B: local build from source
```bash
python -m pip install -U maturin numpy
maturin develop --release --manifest-path weiss_py/Cargo.toml
```
### Minimal high-level loop
```python
import numpy as np
import weiss_sim
sim = weiss_sim.train(num_envs=32, seed=0)
reset = sim.reset()
actions = np.full((32,), weiss_sim.PASS_ACTION_ID, dtype=np.uint32)
step = sim.step(actions)
```
### Minimal low-level loop
```python
import numpy as np
import weiss_sim
legal_deck = (list(range(1, 14)) * 4)[:50]
pool = weiss_sim.EnvPool.new_rl_train(
32,
deck_lists=[legal_deck, legal_deck],
deck_ids=[1, 2],
seed=0,
)
buf = weiss_sim.EnvPoolBuffers(pool)
out = buf.reset()
actions = np.full(pool.envs_len, weiss_sim.PASS_ACTION_ID, dtype=np.uint32)
out = buf.step(actions)
```
## Architecture at a glance
```mermaid
flowchart LR
A["Python API\npython/weiss_sim"] --> B["PyO3 bindings\nweiss_py"]
B --> C["Engine core\nweiss_core"]
C --> D["Deterministic outputs\nobs/masks-or-ids/reward/status"]
C --> E["Replay + fingerprint\nrepro & drift debugging"]
```
## Documentation map
Start in [`docs/README.md`](docs/README.md).
Recommended paths:
- RL users: [`docs/quickstart.md`](docs/quickstart.md) -> [`docs/rl_contract.md`](docs/rl_contract.md) -> [`docs/encodings.md`](docs/encodings.md)
- Python integrators: [`docs/python_api.md`](docs/python_api.md) -> [`docs/troubleshooting.md`](docs/troubleshooting.md)
- Engine contributors: [`docs/engine_architecture.md`](docs/engine_architecture.md) -> [`docs/rules_coverage.md`](docs/rules_coverage.md) -> [`PROJECT_STATE.md`](PROJECT_STATE.md)
- Performance work: [`docs/performance_benchmarks.md`](docs/performance_benchmarks.md)
## Repository layout
- `weiss_core/`: Rust engine and deterministic rule runtime
- `weiss_py/`: PyO3 extension layer
- `python/weiss_sim/`: high-level and low-level Python interfaces
- `python/tests/`: Python API/contract tests
- `scripts/`: CI parity, coverage, perf, and docs checks
- `docs/`: user + contributor documentation hub
## Local quality checks
Full local CI parity:
```bash
scripts/run_local_ci_parity.sh
```
Skip benchmark gate during iteration:
```bash
SKIP_BENCHMARKS=1 scripts/run_local_ci_parity.sh
```
Docs-only checks:
```bash
python scripts/check_docs_links.py
python scripts/check_docs_constants.py
```
## Benchmark snapshot (main)
<!-- BENCHMARKS:START -->
_Last updated: 2026-02-18 10:58 UTC_
| Benchmark | Time |
| --- | --- |
| rust/advance_until_decision | 51573 ns/iter |
| rust/step_batch_64 | 15566 ns/iter |
| rust/reset_batch_256 | 893236 ns/iter |
| rust/step_batch_fast_256_priority_off | 74777 ns/iter |
| rust/step_batch_fast_256_priority_on | 68299 ns/iter |
| rust/legal_actions | 13 ns/iter |
| rust/legal_actions_forced | 12 ns/iter |
| rust/on_reverse_decision_frequency_on | 1186 ns/iter |
| rust/on_reverse_decision_frequency_off | 1237 ns/iter |
| rust/observation_encode | 178 ns/iter |
| rust/observation_encode_forced | 188 ns/iter |
| rust/mask_construction | 397 ns/iter |
<!-- BENCHMARKS:END -->
Long-form benchmark docs: [`docs/performance_benchmarks.md`](docs/performance_benchmarks.md)
## Compatibility policy
Contract constants are explicit compatibility boundaries:
- `OBS_ENCODING_VERSION=2`
- `ACTION_ENCODING_VERSION=1`
- `POLICY_VERSION=2`
- `REPLAY_SCHEMA_VERSION=2`
- `WSDB_SCHEMA_VERSION=2`
If encoding/layout semantics change, update code + docs in the same PR:
1. constants/encode implementation
2. [`docs/rl_contract.md`](docs/rl_contract.md) checksum table
3. [`docs/encodings_changelog.md`](docs/encodings_changelog.md)
## License
MIT OR Apache-2.0
| text/markdown; charset=UTF-8; variant=GFM | Lallan | null | null | null | MIT OR Apache-2.0 | weiss-schwarz, reinforcement-learning, simulation, pyo3, rl | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.23"
] | [] | [] | [] | [
"Homepage, https://github.com/victorwp288/weiss-schwarz-simulator",
"Repository, https://github.com/victorwp288/weiss-schwarz-simulator",
"Documentation, https://victorwp288.github.io/weiss-schwarz-simulator/rustdoc/",
"Issues, https://github.com/victorwp288/weiss-schwarz-simulator/issues",
"Changelog, http... | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:13:02.301568 | weiss_sim-0.4.0.tar.gz | 658,837 | 3a/3e/29b01267ac3b86f867946f32b1b1560f600ae3fac35d2919bada6b8c57e7/weiss_sim-0.4.0.tar.gz | source | sdist | null | false | 2601378769e71d1ec9890869d8092741 | d9b6b3b8412b37d9c3a60368206666ec3f7f6a6d9d53b0cede918d04479340c7 | 3a3e29b01267ac3b86f867946f32b1b1560f600ae3fac35d2919bada6b8c57e7 | null | [
"LICENSE-APACHE",
"LICENSE-MIT"
] | 826 |
2.4 | mcpXL30 | 0.1.0 | FastMCP server exposing Philips XL30 ESEM controls via pyxl30 (unofficial) | # mcpXL30
__WORK IN PROGRESS__
`mcpXL30` is an MCP (Model Context Protocol) server that exposes a curated
subset of the [pyxl30](https://github.com/tspspi/pyxl30) control library to LLM
agents (i.e. AI contorl of the XL30 ESEM).
Note that this project was partially generated with LLM support.
## Features
- Async MCP tools for common Philips XL30 operations (identify, read/set high
tension, change scan modes, trigger pump/vent cycles, capture TIFF images).
- Live MCP resources that describe the connected instrument and active config.
- Safety envelope that limits accelerating voltage and sensitive operations.
- Fine grained settings that control allowed operations for the LLM agent.
- Optional remote HTTP/UDS transport with the authentication workflow explained
in my [blog post](https://www.tspi.at/2026/01/10/chatgptremotemcp.html).
## Installation
```bash
pip install .
# or
pip install ".[remote]" # adds FastAPI/uvicorn/argon2 for remote mode
```
## Configuration
The server loads JSON configuration from `~/.config/mcpxl30/config.json` by
default (override via `--config`). A minimal example:
```json
{
"instrument": {
"port": "/dev/ttyUSB0",
"log_level": "INFO",
"retry_count": 3,
"reconnect_count": 3
},
"image_capture": {
"remote_directory": "C:\\\\TEMP",
"filename_prefix": "MCPIMG_"
},
"safety": {
"max_high_tension_kv": 15.0,
"allow_venting": false,
"allow_pumping": true,
"allow_scan_mode_changes": true,
"allow_stage_motion": false,
"allow_detector_switching": true,
"allow_beam_shift": true,
"allow_scan_rotation_changes": true,
"allow_image_filter_changes": true,
"allow_specimen_current_mode_changes": false,
"allow_beam_blank_control": true,
"allow_oplock_control": false
},
"logging": {
"level": "INFO",
"logfile": null
},
"remote_server": {
"uds": "/var/run/mcpxl30.sock",
"api_key_kdf": {
"algorithm": "argon2id",
"salt": "<base64>",
"time_cost": 3,
"memory_cost": 65536,
"parallelism": 1,
"hash_len": 32,
"hash": "<base64>"
}
}
}
```
Use `mcpxl30-genkey --config /path/to/config.json` (or `mcpxl30 --genkey`) to
generate a new API key and populate the Argon2 hash inside the `remote_server`
block. The plain token prints once to stdout.
The `safety` block gates riskier capabilities. Keep `allow_stage_motion` and
`allow_oplock_control` disabled unless you trust the calling agent. Imaging and
detector-related fields default to safe-but-capable settings, but you can toggle
them per deployment.
## Running the server
### stdio transport (default)
```bash
mcpxl30 --config ~/.config/mcpxl30/config.json
```
The process utilizes the `stdio` transport.
### Remote FastAPI/uvicorn transport
```bash
pip install "mcpXL30[remote]"
mcpxl30 --transport remotehttp --config ~/.config/mcpxl30/config.json
```
- The FastAPI app exposes `/mcp` (MCP streaming API) and `/status` (unauthenticated health check).
- Authentication expects the API key in `Authorization: Bearer`, `X-API-Key`,
or the `?api_key=` query parameter.
- Binding uses a [Unix domain socket](https://www.tspi.at/2026/01/04/UDS.html) (`remote_server.uds`)
unless you specify a TCP `port`, in which case `host` (default `0.0.0.0`) applies.
## MCP functionality
### Tools
**Instrument Basics**
| Tool | Purpose |
| --- | --- |
| `instrument_identify` | Return the microscopes type/serial, scan mode, high tension. |
| `read_high_tension` / `set_high_tension` | Inspect or change accelerating voltage (safety-capped). |
| `get_scan_mode` / `set_scan_mode` | Read or change scan mode (`allow_scan_mode_changes`). |
| `capture_image` / `trigger_photo_capture` | Store images (TIFF or console photo). |
| `control_vent`, `pump_chamber` | Chamber vent/pump control (safety gated). |
**Beam & Detector Controls**
| Tool | Purpose |
| --- | --- |
| `get_spot_size` / `set_spot_size` | Read or set probe current (1–10). |
| `get_magnification` / `set_magnification` | Read or set magnification (20–400 000). |
| `get_stigmator` / `set_stigmator` | Inspect/update stigmator X/Y. |
| `get_detector` / `set_detector` | Inspect or switch active detector (`allow_detector_switching`). |
| `read_high_tension` | Included above but relevant for beam tuning. |
**Scan Timing & Geometry**
| Tool | Purpose |
| --- | --- |
| `get_line_time` / `set_line_time` | Read or set line time (ms or `TV`). |
| `get_lines_per_frame` / `set_lines_per_frame` | Inspect or adjust lines per frame. |
| `get_scan_rotation` / `set_scan_rotation` | Read or set scan rotation (`allow_scan_rotation_changes`). |
| `get_area_dot_shift` / `set_area_dot_shift` | Manage area/dot shift percentages (`allow_beam_shift`). |
| `get_selected_area_size` / `set_selected_area_size` | Control selected area dimensions. |
**Imaging Utilities**
| Tool | Purpose |
| --- | --- |
| `get_contrast` / `set_contrast` | Read or set contrast (0–100). |
| `get_brightness` / `set_brightness` | Read or set brightness (0–100). |
| `auto_contrast_brightness`, `auto_focus` | Run built-in adjustment routines. |
| `get_databar_text` / `set_databar_text` | Inspect or update the image databar text. |
**Stage & Alignment**
| Tool | Purpose |
| --- | --- |
| `stage_home` | Home the stage (`allow_stage_motion`). |
| `get_stage_position` / `set_stage_position` | Read or move X/Y/Z/tilt/rotation (`allow_stage_motion`). |
| `get_beam_shift` / `set_beam_shift` | Inspect or adjust beam shift (`allow_beam_shift`). |
**Image Filtering & Specimen Current**
| Tool | Purpose |
| --- | --- |
| `get_image_filter_mode` / `set_image_filter_mode` | Manage FastMCP image filter + frame count (`allow_image_filter_changes`). |
| `get_specimen_current_detector_mode` / `set_specimen_current_detector_mode` | Inspect or change detector mode (`allow_specimen_current_mode_changes`). |
| `get_specimen_current` | Read specimen current (requires measure mode). |
**Beam Safety & Locks**
| Tool | Purpose |
| --- | --- |
| `is_beam_blanked`, `blank_beam`, `unblank_beam` | Inspect or control beam blank state (`allow_beam_blank_control`). |
| `get_oplock_state`, `set_oplock_state` | Inspect or control the operator lock (`allow_oplock_control`). |
Every setter uses blocking pyxl30 calls inside `asyncio.to_thread`, preserving the FastMCP event loop responsiveness. Review the safety settings to enable only the tools you trust agents with.
All setters perform blocking pyxl30 calls inside `asyncio.to_thread` so the MCP
event loop stays responsive.
### Resources
- `mcpxl30://instrument/capabilities` – supported scan modes, image filter
names, and the configured safety envelope.
- `mcpxl30://instrument/config` – sanitized live configuration (excludes API
secrets).
## Examples
An `examples/example_config.json` file is included to bootstrap deployments.
The repository mirrors `mcpMQTT`'s project layout so existing FastMCP
infrastructure (supervisors, packaging, docs) can be reused with minimal
changes.
| text/markdown | null | Thomas Spielauer <pypipackages01@tspi.at> | null | null | BSD | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"mcp>=1.1.0",
"pyxl30-tspspi>=0.1.0",
"pyserial>=3.5",
"pydantic[email]>=2.6.0",
"typing_extensions>=4.8.0",
"fastapi>=0.110.0; extra == \"remote\"",
"uvicorn>=0.23.0; extra == \"remote\"",
"argon2-cffi>=23.1.0; extra == \"remote\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.11.11 | 2026-02-18T11:12:57.923982 | mcpxl30-0.1.0.tar.gz | 21,157 | a8/19/6380856cf4707189fb5b4ccb4f76bd8109da619f0f2588cfa2e736eb54ed/mcpxl30-0.1.0.tar.gz | source | sdist | null | false | dc393eabc8e365cf3cd2992245eeefe0 | cabd0efddf12f63fe0a6c58c463902968bd48f59d922a62a6c75890a9a1e77a6 | a8196380856cf4707189fb5b4ccb4f76bd8109da619f0f2588cfa2e736eb54ed | null | [
"LICENSE.md"
] | 0 |
2.4 | webc | 0.1.2 | Treat websites as programmable objects (Wikipedia-Locked Beta) | <h1 align="center"> WebC – Treat Websites as Python Objects</h1>
<p align="center">
<img src="https://github.com/ashtwin2win-Z/WebC/raw/main/assets/webc.png" alt="WebC Logo" width="280">
</p>
**Version:** 0.1.1
**Author:** Ashwin Prasanth
---
## Overview
`webc` is a Python library that allows you to treat websites as programmable Python objects.
Instead of manually handling HTTP requests, parsing HTML, and writing repetitive scraping logic, WebC provides a structured, object-oriented interface to access semantic content, query elements, and perform intent-driven tasks.
The goal is simple:
* Make web data feel native to Python
* Provide meaningful abstractions over raw HTML
* Encourage ethical and secure usage by default
---
## ⚠️ Developer Preview / Secure Beta
**WebC v0.1.1** is a developer preview release intended for testing and feedback.
This version prioritizes security, architecture stability, and controlled usage.
APIs may change during the beta phase.
---
## Installation
Install via pip:
```bash
pip install webc
```
### Dependencies
* requests
* beautifulsoup4
---
## Core Architecture
WebC is organized into four conceptual layers.
---
### 1. Resource Layer
Access a webpage as a `Resource` object:
```python
from webc import web
site = web["https://en.wikipedia.org/wiki/Python_(programming_language)"]
```
* Represents a single webpage
* Uses lazy loading (fetches HTML only when needed)
* Caches parsed content internally
---
### 2. Structure Layer
Provides semantic, high-level content extracted from the page:
```python
site.structure.title
site.structure.links
site.structure.images
site.structure.tables
```
#### Image Handling
* Extracts from `src`, `srcset`, `data-src`, and `<noscript>`
* Filters UI icons and SVG assets
* Resolves relative URLs automatically
Download images:
```python
site.structure.save_images(folder="python_images")
```
#### Table Extraction
* Detects Wikipedia `wikitable` tables
* Handles rowspan and colspan alignment
* Removes citation brackets (e.g., `[1]`)
Save tables as CSV:
```python
site.structure.save_tables(folder="wiki_data")
```
---
### 3. Query Layer
Provides direct DOM access via CSS selectors:
```python
headings = site.query["h1, h2"]
for h in headings:
print(h.get_text(strip=True))
```
* Returns BeautifulSoup elements
* Useful for custom extraction logic
* Acts as an advanced access layer
---
### 4. Task Layer
Provides intent-driven actions:
```python
summary = site.task.summarize(max_chars=500)
print(summary)
```
Currently supported:
* `summarize(max_chars=500)`
More tasks will be introduced in future releases.
---
## Security & Usage Policy
This secure beta is intentionally restricted.
### Platform Restrictions
* Locked to **Wikipedia.org only**
* Only **HTTPS URLs** are allowed
### Built-in Protections
WebC includes safeguards against:
* SSRF attacks
* Path traversal
* Unsafe file writes
* Excessive downloads
Requests are controlled and content is cached to prevent unnecessary repeated fetching.
---
## Responsible Use
WebC is designed for:
✔ Educational purposes
✔ Research
✔ Personal automation
✔ Ethical data access
It must not be used for:
* Mass scraping
* Circumventing website policies
* Service disruption
* Data abuse
Users are responsible for complying with website Terms of Service.
---
## Full Usage Example
```python
from webc import web
url = "https://en.wikipedia.org/wiki/Python_(programming_language)"
site = web[url]
print("=== STRUCTURE ===")
print(f"Title: {site.structure.title}")
print(f"Total Links: {len(site.structure.links)}")
print(f"First 5 links: {site.structure.links[:5]}")
print("\n--- Downloading Resources ---")
site.structure.save_images(folder="python_images")
site.structure.save_tables(folder="python_data")
print("\n=== QUERY ===")
headings = site.query["h1, h2"]
print(f"Found {len(headings)} headings:")
for h in headings[:3]:
print(f" - {h.get_text(strip=True)}")
print("\n=== TASK ===")
summary = site.task.summarize(max_chars=500)
print(summary)
```
---
## Roadmap
Planned future improvements:
* Multi-domain support
* Advanced rate limiting
* Enhanced security layers
* Plugin-based task extensions
* Dataset export helpers
* Cloud-safe scraping mode
---
## License
This project is licensed under the **MIT License**. See the [LICENSE](LICENSE) file for the full license text.
© 2026 Ashwin Prasanth
| text/markdown | Ashwin Prasanth | null | null | null | MIT License
Copyright (c) 2026 WebC
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| web, scraper, automation, resource | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Pyth... | [] | null | null | >=3.7 | [] | [] | [] | [
"requests>=2.28.0",
"beautifulsoup4>=4.11.0"
] | [] | [] | [] | [
"Homepage, https://github.com/ashtwin2win-Z/WebC",
"Bug Tracker, https://github.com/ashtwin2win-Z/WebC/issues"
] | twine/6.2.0 CPython/3.12.1 | 2026-02-18T11:12:51.962496 | webc-0.1.2.tar.gz | 8,225 | f7/fa/f0d00be3d3e1baa4d7c9de1a8ccb852f1f7c61dd8080bf31e96f96660e84/webc-0.1.2.tar.gz | source | sdist | null | false | c5909506497965e238542bb47068ba5d | 39fb625f4547bf80ced5c0a2a1ae8ba6656b4971f3f22956f1edb308ccaa5ee8 | f7faf0d00be3d3e1baa4d7c9de1a8ccb852f1f7c61dd8080bf31e96f96660e84 | null | [
"LICENSE"
] | 235 |
2.4 | code-clean | 0.1.1 | Internal deployment package | # My Internal Package
| text/markdown | Code Cleaned | null | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.7 | 2026-02-18T11:12:20.441379 | code_clean-0.1.1.tar.gz | 13,758 | 2f/56/5ef52e584c529fceb8905de5cefcbee47b8a70567bd0307e14b6307b48e2/code_clean-0.1.1.tar.gz | source | sdist | null | false | 22490aa3486d659ac9a2640dce4f8f9a | 51ef1dacba7fa90de4d08de642c580e229d8453a3fbca8ae9e32e8befc10aac6 | 2f565ef52e584c529fceb8905de5cefcbee47b8a70567bd0307e14b6307b48e2 | null | [] | 163 |
2.4 | pypdns | 2.3.2 | Python API for PDNS. | [](https://pypdns.readthedocs.io/en/latest/?badge=latest)
Client API for PDNS
===================
Client API to query any Passive DNS implementation following the Passive DNS - Common Output Format.
* https://datatracker.ietf.org/doc/draft-dulaunoy-dnsop-passive-dns-cof/
## Installation
```bash
pip install pypdns
```
## Usage
### Command line
You can use the `pdns` command to trigger a request.
```bash
usage: pdns [-h] --username USERNAME --password PASSWORD --query QUERY [--rrtype RRTYPE]
Triggers a request againse CIRCL Passive DNS.
options:
-h, --help show this help message and exit
--username USERNAME The username of you account.
--password PASSWORD The password of you account.
--query QUERY The query, can be an IP. domain, hostname, TLD.
--rrtype RRTYPE Filter the request based on the RR Type.
```
### Library
See [API Reference](https://pypdns.readthedocs.io/en/latest/api_reference.html)
Example
=======
~~~~
import pypdns
import json
x = pypdns.PyPDNS(basic_auth=('username','yourpassword'))
for record in x.iter_query(q='circl.lu', filter_rrtype='A'):
print(json.dumps(record.record, indent=2))
~~~~
Passive DNS Services
====================
* (default) [CIRCL Passive DNS](http://www.circl.lu/services/passive-dns/)
| text/markdown | Raphaël Vinot | raphael.vinot@circl.lu | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Intended Audience :: Telecommunications Industry",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming ... | [] | null | null | >=3.10 | [] | [] | [] | [
"dnspython>=2.8.0",
"requests-cache>=1.3.0",
"sphinx>=9.1.0; python_version >= \"3.12\" and extra == \"docs\""
] | [] | [] | [] | [
"Documentation, https://pypdns.readthedocs.io",
"Repository, https://github.com/CIRCL/PyPDNS"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:12:10.505879 | pypdns-2.3.2.tar.gz | 7,270 | 12/85/aa919e94b24c75189441821e0873d8d59a13d56f3597dfc02ec886513f22/pypdns-2.3.2.tar.gz | source | sdist | null | false | bbdbe54f9ac79c524d3203fff31eea3c | 53a9e702635e91c14cdd0c24400912902c69889cfca7886d5b976c9337a48f7c | 1285aa919e94b24c75189441821e0873d8d59a13d56f3597dfc02ec886513f22 | GPL-3.0+ | [
"LICENSE"
] | 337 |
2.4 | radio-curses | 0.14.1 | A OPML radio player | |pypi| |github|
radio-curses
=============
Internet radio in the terminal. A fork of `curseradio`_.
radio-curses is a `curses` interface for browsing and playing an `OPML`_ directory of internet radio streams.
It is designed to use the *tunein* directory found at `opml.radiotime.com`_, but could be adapted to others.
Audio playback uses `mpv`_. radio-curses requires `python3` and the libraries `requests`_, `lxml`_ and `xdg-base-dirs`_.
|demo|
The current hotkeys are:
* h: help screen
* q, Esc: Quit the program
* j, Down: Move selection down
* k, Up: Move selection up
* PgUp: Page up
* PgDown: Page down
* g, Home: Move to first item
* G, End: Move to last item
* Shift-Up,Down: Move a record up/down
* Insert: Add to Favourites
* Delete: Delete from Favourites
* Enter: Play selected radio
* Space: Stop/Resume
* Ctrl-L: Copy URL to clipboard
.. |pypi| image:: https://img.shields.io/pypi/v/radio-curses
:target: https://pypi.org/project/radio-curses/
.. |github| image:: https://img.shields.io/github/v/tag/shamilbi/radio-curses?label=github
:target: https://github.com/shamilbi/radio-curses/
.. |demo| image:: https://asciinema.org/a/NB9Gn8NcN3tKxB28ue86KJLmW.png
:target: https://asciinema.org/a/NB9Gn8NcN3tKxB28ue86KJLmW?autoplay=1
:width: 100%
.. _curseradio: https://github.com/chronitis/curseradio
.. _OPML: https://en.wikipedia.org/wiki/OPML
.. _opml.radiotime.com: https://opml.radiotime.com/
.. _mpv: https://github.com/mpv-player/mpv
.. _requests: https://pypi.org/project/requests/
.. _lxml: https://pypi.org/project/lxml/
.. _xdg-base-dirs: https://pypi.org/project/xdg-base-dirs/
| text/x-rst | null | Shamil Bikineyev <shamilbi@gmail.com> | null | null | null | internet, radio | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Natural Language :: English",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programmi... | [] | null | null | >=3.9 | [] | [] | [] | [
"lxml",
"requests",
"xdg-base-dirs"
] | [] | [] | [] | [
"homepage, https://github.com/shamilbi/radio-curses"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-18T11:11:48.484399 | radio_curses-0.14.1.tar.gz | 9,716 | 2b/e6/2b08a263453a9226072eb035f4565588372b8005fef3d92cdf9f46fa4994/radio_curses-0.14.1.tar.gz | source | sdist | null | false | a566f4615edcec5110c08b87013a301c | 5bff84f261b216afcfbb3fd5b4ed9b77e93a7c52de2af4119f5060a20687485e | 2be62b08a263453a9226072eb035f4565588372b8005fef3d92cdf9f46fa4994 | MIT | [
"LICENSE"
] | 247 |
2.4 | LazzyORM | 0.3.2 | A Powerful Lazy Loading ORM for MySQL | # LazzyORM: A Powerful Lazy Loading ORM for MySQL
[](https://pypi.org/project/LazzyORM/)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
LazzyORM is a modern, secure, and efficient Python library designed to simplify database interactions with MySQL. It provides a clean, intuitive API for working with your data by leveraging lazy loading techniques, connection pooling, and comprehensive error handling.
## 🚀 Key Features
* **Lazy Loading**: Fetch data from the database only when it's actually needed, improving performance and reducing memory usage
* **SQL Injection Protection**: Parameterized queries throughout to prevent SQL injection attacks
* **Connection Pooling**: Efficient connection management for faster and more reliable database access
* **Comprehensive CRUD Operations**: Full support for Create, Read, Update, and Delete operations
* **Query Building**: Intuitive, chainable query builder with support for WHERE, ORDER BY, LIMIT, and more
* **Type Safety**: Full type hints for better IDE support and code quality
* **Error Handling**: Custom exceptions for better error tracking and debugging
* **Logging**: Comprehensive logging capabilities to monitor database interactions
* **CSV Import**: Bulk insert data from CSV files with automatic table creation
* **Context Managers**: Proper resource cleanup with context manager support
## 📦 Installation
Install LazzyORM using pip:
```bash
pip install LazzyORM
```
For development with testing tools:
```bash
pip install LazzyORM[dev]
```
## 🔧 Quick Start
### Basic Setup
```python
from lazzy_orm import Connector, LazyFetch, Logger
from dataclasses import dataclass
# Setup logging
logger = Logger(log_file="app.log", logger_name="app_logger").logger
# Connect to the database
connector = Connector(
host='localhost',
user='root',
password='your_password',
database='testdb',
port=3306
)
# Get connection pool
connection_pool = connector.get_connection_pool()
# Define your data models
@dataclass
class User:
id: int
name: str
email: str
age: int
```
### Fetching Data (LazyFetch)
```python
from lazzy_orm import LazyFetch
# Fetch all users
users = LazyFetch(
model=User,
query="SELECT * FROM users",
connection_pool=connection_pool
).get()
logger.info(f"Found {len(users)} users")
# Fetch with parameters (prevents SQL injection)
active_users = LazyFetch(
model=User,
query="SELECT * FROM users WHERE status = %s",
connection_pool=connection_pool,
params=('active',)
).get()
# Disable caching for real-time data
fresh_data = LazyFetch(
model=User,
query="SELECT * FROM users WHERE id = %s",
connection_pool=connection_pool,
params=(1,),
use_cache=False
).get()
# Clear cache when needed
LazyFetch.clear_cache() # Clear all cache
LazyFetch.clear_cache('User') # Clear cache for specific model
```
### Query Building (LazyQuery)
```python
from lazzy_orm import LazyQuery
# Simple query
users = LazyQuery(model=User, connection_pool=connection_pool).select_all().to_list()
# Query with WHERE conditions
admin_users = (
LazyQuery(model=User, connection_pool=connection_pool)
.select_all()
.where("role", "admin")
.where("status", "active")
.to_list()
)
# Select specific columns
user_names = (
LazyQuery(model=User, connection_pool=connection_pool)
.select("id", "name", "email")
.where("age", 18, ">=")
.to_list()
)
# Advanced querying
results = (
LazyQuery(model=User, connection_pool=connection_pool)
.select_all()
.where("age", 25, ">")
.where("country", "USA")
.order_by("name", "ASC")
.limit(10, offset=0)
.to_list()
)
# Get single result
user = (
LazyQuery(model=User, connection_pool=connection_pool)
.select_all()
.where("id", 1)
.first()
)
# Count results
user_count = (
LazyQuery(model=User, connection_pool=connection_pool)
.where("status", "active")
.count()
)
# Using IN operator
users_in_cities = (
LazyQuery(model=User, connection_pool=connection_pool)
.select_all()
.where("city", ["New York", "Los Angeles", "Chicago"], "IN")
.to_list()
)
# Context manager for automatic cleanup
with LazyQuery(model=User, connection_pool=connection_pool) as query:
users = query.select_all().where("status", "active").to_list()
```
### Inserting Data (LazyInsert)
#### From CSV File
```python
from lazzy_orm import LazyInsert
import os
# Insert data from CSV
csv_file = "data/users.csv"
lazy_insert = LazyInsert(
table_name="users",
path_to_csv=csv_file,
connection_pool=connection_pool,
drop_if_exists=True, # Drop table if exists
auto_increment=True, # Add auto-increment ID
chunk_size=10000, # Insert in chunks
log_create_table_query=True,
log_insert_query=True
)
rows_inserted = lazy_insert.perform_staging_insert()
logger.info(f"Inserted {rows_inserted} rows from CSV")
```
#### From Data Objects
```python
from lazzy_orm import LazyInsert
from dataclasses import dataclass
@dataclass
class Product:
id: int
name: str
price: float
stock: int
# Prepare data
products = [
Product(1, "Laptop", 999.99, 50),
Product(2, "Mouse", 29.99, 200),
Product(3, "Keyboard", 79.99, 150)
]
# Insert data
lazy_insert = LazyInsert(
table_name="products",
data=products,
connection_pool=connection_pool,
query="INSERT INTO products (id, name, price, stock) VALUES (%s, %s, %s, %s)"
)
rows_inserted = lazy_insert.insert()
logger.info(f"Inserted {rows_inserted} products")
```
### Updating Data (LazyUpdate)
```python
from lazzy_orm import LazyUpdate
# Update single record
rows_updated = (
LazyUpdate(table_name="users", connection_pool=connection_pool)
.set({"name": "John Doe", "age": 30})
.where("id", 1)
.execute()
)
# Update multiple records
rows_updated = (
LazyUpdate(table_name="users", connection_pool=connection_pool)
.set({"status": "inactive"})
.where("last_login", "2023-01-01", "<")
.execute()
)
# Update with multiple conditions
rows_updated = (
LazyUpdate(table_name="products", connection_pool=connection_pool)
.set({"price": 99.99, "discount": 10})
.where("category", "electronics")
.where("stock", 0, ">")
.execute()
)
# Context manager
with LazyUpdate(table_name="users", connection_pool=connection_pool) as updater:
rows = updater.set({"verified": True}).where("email_verified", True).execute()
```
### Deleting Data (LazyDelete)
```python
from lazzy_orm import LazyDelete
# Delete single record
rows_deleted = (
LazyDelete(table_name="users", connection_pool=connection_pool)
.where("id", 1)
.execute()
)
# Delete multiple records
rows_deleted = (
LazyDelete(table_name="users", connection_pool=connection_pool)
.where("status", "inactive")
.execute()
)
# Delete with limit
rows_deleted = (
LazyDelete(table_name="logs", connection_pool=connection_pool)
.where("created_at", "2023-01-01", "<")
.limit(1000)
.execute()
)
# Delete with IN operator
rows_deleted = (
LazyDelete(table_name="users", connection_pool=connection_pool)
.where("id", [1, 2, 3, 4, 5], "IN")
.execute()
)
# Delete all records (requires confirmation)
rows_deleted = (
LazyDelete(table_name="temp_data", connection_pool=connection_pool)
.execute(confirm_delete_all=True)
)
```
## 🛡️ Security Features
### SQL Injection Prevention
LazzyORM uses parameterized queries throughout to prevent SQL injection attacks:
```python
# ✅ SAFE - Parameterized query
user = (
LazyQuery(model=User, connection_pool=connection_pool)
.where("username", user_input) # Automatically parameterized
.first()
)
# ✅ SAFE - With LazyFetch
users = LazyFetch(
model=User,
query="SELECT * FROM users WHERE status = %s",
params=(status,),
connection_pool=connection_pool
).get()
```
### Input Validation
All inputs are validated to prevent malicious data:
```python
# Invalid column names are rejected
try:
query.where("id; DROP TABLE users;", 1) # Raises ValidationError
except ValidationError as e:
logger.error(f"Invalid input: {e}")
```
## 🔍 Error Handling
LazzyORM provides custom exceptions for better error handling:
```python
from lazzy_orm.exceptions import (
LazzyORMError,
ConnectionError,
QueryError,
ValidationError,
ConfigurationError
)
try:
users = LazyQuery(model=User, connection_pool=connection_pool).select_all().to_list()
except ConnectionError as e:
logger.error(f"Database connection failed: {e}")
except QueryError as e:
logger.error(f"Query execution failed: {e}")
except ValidationError as e:
logger.error(f"Invalid input: {e}")
except LazzyORMError as e:
logger.error(f"LazzyORM error: {e}")
```
## 📊 Logging
LazzyORM includes comprehensive logging:
```python
from lazzy_orm import Logger
import logging
# Create custom logger
logger = Logger(
log_file="myapp.log",
logger_name="myapp_logger",
level=logging.INFO,
log_dir="logs"
).logger
# Use the logger
logger.info("Application started")
logger.debug("Debug information")
logger.error("Error occurred")
```
## 🧪 Testing
Run the test suite:
```bash
# Install dev dependencies
pip install LazzyORM[dev]
# Run tests with coverage
pytest tests/ -v --cov=lazzy_orm --cov-report=html
# Run specific test file
pytest tests/test_lazy_query.py -v
```
## 📚 Advanced Usage
### Connection Pool Configuration
```python
connector = Connector(
host='localhost',
user='root',
password='password',
database='mydb',
port=3306,
pool_size=20, # Custom pool size
pool_name="MyApp_Pool" # Custom pool name
)
# Test connection
if connector.test_connection():
print("Connection successful!")
# Show running processes
processes = connector.show_process_list()
# Context manager
with Connector(host='localhost', user='root', password='pass', database='db', port=3306) as conn:
pool = conn.get_connection_pool()
```
### Date Parsing Utility
```python
from lazzy_orm import parse_date
from datetime import date
# Parse various date formats
date1 = parse_date("2023-01-15") # ISO format
date2 = parse_date("15-01-2023") # DD-MM-YYYY
date3 = parse_date("Jan 15, 2023") # Month name
date4 = parse_date("20230115") # Compact format
assert all(isinstance(d, date) for d in [date1, date2, date3, date4])
```
## 🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
1. Fork the repository
2. Create your feature branch (`git checkout -b feature/AmazingFeature`)
3. Commit your changes (`git commit -m 'Add some AmazingFeature'`)
4. Push to the branch (`git push origin feature/AmazingFeature`)
5. Open a Pull Request
## 📝 License
LazzyORM is distributed under the MIT License. See `LICENSE` for more information.
## 👤 Author
**Dipendra Bhardwaj**
- Email: dipu.sharma.1122@gmail.com
- GitHub: [@Dipendra-creator](https://github.com/Dipendra-creator)
## 🔗 Links
- [PyPI Package](https://pypi.org/project/LazzyORM/)
- [GitHub Repository](https://github.com/Dipendra-creator/LazzyORM)
- [Issue Tracker](https://github.com/Dipendra-creator/LazzyORM/issues)
## 📈 Changelog
### Version 0.3.0 (Latest)
- ✨ Added LazyUpdate and LazyDelete classes for complete CRUD operations
- 🔒 Implemented SQL injection protection with parameterized queries
- ✅ Added comprehensive input validation
- 🐛 Fixed connection leaks and resource management issues
- 📝 Added complete type hints throughout the codebase
- 🧪 Added comprehensive test suite with pytest
- 📚 Improved documentation with more examples
- ⚡ Enhanced query building with ORDER BY, LIMIT, and advanced operators
- 🎯 Added context manager support for all classes
- 📊 Improved logging and error handling
- 🔧 Added pyproject.toml for modern Python packaging
### Version 0.2.4
- Basic LazyFetch, LazyInsert, and LazyQuery functionality
- Connection pooling support
- CSV import capabilities
## 💡 Tips and Best Practices
1. **Always use connection pooling** for better performance
2. **Use context managers** to ensure proper resource cleanup
3. **Enable logging** in production for debugging
4. **Use parameterized queries** - LazzyORM does this automatically!
5. **Clear cache** when data is updated outside of LazzyORM
6. **Handle exceptions** appropriately for robust applications
7. **Use type hints** with your models for better code quality
## ⚠️ Important Notes
- LazzyORM currently supports MySQL only
- Python 3.7+ is required
- Always close connections properly or use context managers
- Be cautious with operations that affect all rows (without WHERE clauses)
| text/markdown | Dipendra Bhardwaj | Dipendra Bhardwaj <dipu.sharma.1122@gmail.com> | null | null | MIT | mysql, orm, database, lazy-loading, connection-pooling | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Pyth... | [] | https://github.com/Dipendra-creator/LazzyORM | https://github.com/Dipendra-creator/LazzyORM/archive/v0.3.0.tar.gz | >=3.7 | [] | [] | [] | [
"mysql-connector-python>=8.0.0",
"click>=7.0",
"requests>=2.25.0",
"pandas>=1.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=3.0.0; extra == \"dev\"",
"black>=22.0.0; extra == \"dev\"",
"flake8>=4.0.0; extra == \"dev\"",
"mypy>=0.950; extra == \"dev\"",
"isort>=5.10.0; extra == \"dev\"",
... | [] | [] | [] | [
"Homepage, https://github.com/Dipendra-creator/LazzyORM",
"Documentation, https://github.com/Dipendra-creator/LazzyORM#readme",
"Repository, https://github.com/Dipendra-creator/LazzyORM",
"Bug Tracker, https://github.com/Dipendra-creator/LazzyORM/issues",
"Changelog, https://github.com/Dipendra-creator/Lazz... | twine/6.2.0 CPython/3.9.6 | 2026-02-18T11:11:39.344490 | lazzyorm-0.3.2.tar.gz | 47,970 | 96/b9/a258f714d75888898a1428a3cf4799bf41cceb2379c38f143dcb53c95772/lazzyorm-0.3.2.tar.gz | source | sdist | null | false | b1de6871a810145e10f8e9a799938ce3 | 53b5e0eee88ac4397df01dc2a7a7f265e940a06ee8061c247e9170b06abd9e4f | 96b9a258f714d75888898a1428a3cf4799bf41cceb2379c38f143dcb53c95772 | null | [
"LICENSE"
] | 0 |
2.4 | pdudaemon | 1.1.0 | Control and Queueing daemon for PDUs | # PDUDaemon
Python daemon for controlling/sequentially executing commands to PDUs (Power Distribution Units)
## Why is this needed?
#### Queueing
Most PDUs have a very low power microprocessor, or low quality software, which cannot handle multiple requests at the same time. This quickly becomes an issue in environments that use power control frequently, such as board farms, and gets worse on PDUs that have a large number of controllable ports.
#### Standardising
Every PDU manufacturer has a different way of controlling their PDUs. Though many support SNMP, there's still no single simple way to communicate with all PDUs if you have a mix of brands.
## Supported devices list
APC, Devantech and ACME are well supported, however there is no official list yet. The [strategies.py](https://github.com/pdudaemon/pdudaemon/blob/main/pdudaemon/drivers/strategies.py) file is a good place to see all the current drivers.
## Installing
Debian packages are on the way, hopefully.
For now, make sure the requirements are met and then:
```python3 setup.py install```
There is an official Docker container updated from tip:
```
$ docker pull pdudaemon/pdudaemon:latest
$ vi pdudaemon.conf
```
To create a config file, use [share/pdudaemon.conf](https://github.com/pdudaemon/pdudaemon/blob/main/share/pdudaemon.conf) as a base, then mount your config file on top of the default:
```
$ docker run -v `pwd`/pdudaemon.conf:/config/pdudaemon.conf pdudaemon/pdudaemon:latest
```
Or you can build your own:
```
$ git clone https://github.com/pdudaemon/pdudaemon
$ cd pdudaemon
$ vi share/pdudaemon.conf
- configure your PDUs
$ sudo docker build -t pdudaemon --build-arg HTTP_PROXY=$http_proxy -f Dockerfile.dockerhub .
$ docker run --rm -it -e http_proxy=$http_proxy -e https_proxy=$https_proxy -e NO_PROXY="$no_proxy" --net="host" pdudaemon:latest
```
## Config file
An example configuration file can be found [here](https://github.com/pdudaemon/pdudaemon/blob/main/share/pdudaemon.conf).
The section `daemon` is pretty self explanatory. The interesting part is the `pdus` section, where
all managed PDUs are listed and configured. For example:
```json
"pdus": {
"hostname_or_ip": {
"driver": "driver_name",
"additional_parameter": "42"
},
"test": {
"driver": "localcmdline",
"cmd_on": "echo '%s on' >> /tmp/pdu",
"cmd_off": "echo '%s off' >> /tmp/pdu"
},
"energenie": {
"driver": "EG-PMS",
"device": "01:01:51:a4:c3"
},
"192.168.0.42": {
"driver": "brennenstuhl_wspl01_tasmota"
}
}
```
It is important to mention, that `hostname` can be an arbitrary name for a locally connected device (like `energenie` in this example).
For some (or most) network connected devices, it needs to be the actual hostname or IP address the PDU responds to (see `query-string` in [next section](#making-a-power-control-request)).
The correct value for `driver` is highly dependent on the used child class and the specific implementation.
Check the imported [Python module](https://github.com/pdudaemon/pdudaemon/tree/main/pdudaemon/drivers) for that class and look for `drivername` to be sure.
Some drivers require additional parameters (like a device ID).
Which parameters are required can also be extracted from the associated python module and child class definition.
It is also worth checking out the [share](https://github.com/pdudaemon/pdudaemon/tree/main/share) folder for some driver specific example configuration files and helpful scripts that can help prevent major headaches!
## Making a power control request
- **HTTP**
The daemon can accept requests over plain HTTP. The port is configurable, but defaults to 16421
There is no encryption or authentication, consider yourself warned.
To enable, change the 'listener' setting in the 'daemon' section of the config file to 'http'. This will break 'pduclient' requests.
An HTTP request URL has the following syntax:
```http://<pdudaemon-hostname>:<pdudaemon-port>/power/control/<command>?<query-string>```
Where:
- pdudaemon-hostname is the hostname or IP address where pdudaemon is running (e.g.: localhost)
- pdudaemon-port is the port used by pdudaemon (e.g.: 16421)
- command is an action for the PDU to execute:
- **on**: power on
- **off**: power off
- **reboot**: reboot
- query-string can have 3 parameters (same as pduclient, see below)
- **hostname**: the PDU hostname or IP address used in the [configuration file](https://github.com/pdudaemon/pdudaemon/blob/main/share/pdudaemon.conf) (e.g.: "192.168.10.2")
- **port**: the PDU port number
- **delay**: delay between power off and on during reboot (optional, by default 5 seconds)
Some example requests would be:
```
$ curl "http://localhost:16421/power/control/on?hostname=192.168.10.2&port=1"
$ curl "http://localhost:16421/power/control/off?hostname=192.168.10.2&port=1"
$ curl "http://localhost:16421/power/control/reboot?hostname=192.168.10.2&port=1&delay=10"
```
***Return Codes***
- HTTP 200 - Request Accepted
- HTTP 503 - Invalid Request, Request not accepted
- **TCP (legacy pduclient)**
The bundled client is used when PDUDaemon is configured to listen to 'tcp' requests. TCP support is considered legacy but will remain functional.
```
Usage: pduclient --daemon deamonhostname --hostname pduhostname --port pduportnum --command pducommand
PDUDaemon client
Options:
-h, --help show this help message and exit
--daemon=PDUDAEMONHOSTNAME
PDUDaemon listener hostname (ex: localhost)
--hostname=PDUHOSTNAME
PDU Hostname (ex: pdu05)
--port=PDUPORTNUM PDU Portnumber (ex: 04)
--command=PDUCOMMAND PDU command (ex: reboot|on|off)
--delay=PDUDELAY Delay before command runs, or between off/on when
rebooting (ex: 5)
```
- **non-daemon (also called drive)**
If you would just like to use pdudaemon as an executable to drive a PDU without needing to run a daemon, you can use the --drive option.
Configure the PDU in the config file as usual, then launch pdudaemon with the following options
```
$ pdudaemon --conf=share/pdudaemon.conf --drive --hostname pdu01 --port 1 --request reboot
```
If requesting reboot, the delay between turning the port off and on can be modified with `--delay`
and is by default 5 seconds.
## Adding drivers
Drivers are implemented children of the "PDUDriver" class and many example
implementations can be found inside the
[drivers](https://github.com/pdudaemon/pdudaemon/tree/main/pdudaemon/drivers)
directory.
Any new driver classes should be added to [strategies.py](https://github.com/pdudaemon/pdudaemon/blob/main/pdudaemon/drivers/strategies.py).
External implementation of PDUDriver can also be registered using the python
entry_points mechanism. For example add the following to your setup.cfg:
```
[options.entry_points]
pdudaemon.driver =
mypdu = mypdumod:MyPDUClass
```
## Why can't PDUDaemon do $REQUIREMENT?
Patches welcome, as long as it keeps the system simple and lightweight.
| text/markdown | null | null | null | Matt Hart <matt@mattface.org> | GPL-2+ | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v2 or later (GPLv2+)",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.1... | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp",
"requests",
"pexpect",
"systemd_python",
"paramiko",
"pyserial",
"hidapi",
"pysnmp>=7.1.22",
"pyasn1>=0.6.2",
"pyusb",
"pymodbus",
"pytest>=4.6; extra == \"test\"",
"pytest-asyncio; extra == \"test\"",
"pytest-mock; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/pdudaemon/pdudaemon.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:11:27.804108 | pdudaemon-1.1.0.tar.gz | 49,228 | a8/5f/98c2147eab93b2800c9d058c209fb69a3edd1620479c7f5c4dffe3262983/pdudaemon-1.1.0.tar.gz | source | sdist | null | false | daed56c310f1b21b2e1a1263023ff63c | 2258bdcde39e4c81da701ed9b7769c723d65627d8c1944582dcf90d86719bc34 | a85f98c2147eab93b2800c9d058c209fb69a3edd1620479c7f5c4dffe3262983 | null | [] | 250 |
2.4 | enode-host | 0.1.6 | Host-side tools that interact with the ESP-IDF firmware. | # Host Python Tools
This folder contains host-side Python code that interacts with the ESP-IDF
firmware (e.g., over serial, sockets, or file exchange). It is kept separate
from the firmware build to avoid mixing tool dependencies with ESP-IDF.
## Quick start
```bash
python -m venv .venv
source .venv/bin/activate
pip install -e .
enode-host --help
enode-host socket 127.0.0.1 3333 "hello"
enode-host server --port 3333 --interactive
enode-host gui --port 3333
```
## Notes
- Add runtime dependencies to `pyproject.toml` under `project.dependencies`.
- Keep device/transport details in small modules so they can be shared by
scripts and tests.
- The GUI uses wxPython; install it if you plan to run `enode-host gui`.
- The GUI needs an active X11/Wayland display. On headless hosts, use
`xvfb-run enode-host gui` or run `enode-host server` instead.
- If the GUI aborts with WebView/EGL errors on Linux, try
`WEBKIT_DISABLE_DMABUF_RENDERER=1 enode-host gui`.
- If WebView still fails, you can disable the map panel with
`ENODE_DISABLE_WEBVIEW=1 enode-host gui`.
## Protocol (TCP, length-prefixed)
Frame format: 1 byte message type, 2 bytes big-endian payload length, payload.
Message types:
- 0x10 COMMAND (host -> device)
- 0x20 STATUS (device -> host)
- 0x30 ACK (either direction)
- 0x40 DATA (device -> host, ACC batch)
- 0x41 PPS (device -> host, immediate PPS)
Commands (payload begins with command_id):
- 0x01 start_daq
- 0x02 stop_daq
- 0x03 set_mode (1 byte: 0 realtime, 1 past)
- 0x04 start_realtime_stream
- 0x05 stop_realtime_stream
Status payload (16 bytes):
- node_type: uint8
- node_number: uint8
- level: uint8
- parent_mac: 6 bytes
- self_mac: 6 bytes
- rssi: int8
DATA payload:
- node_type: uint8
- node_number: uint8
- sample_count: uint8
- repeated samples (count):
- cc: uint64 (big-endian)
- acc_x: float32 (big-endian)
- acc_y: float32 (big-endian)
- acc_z: float32 (big-endian)
PPS payload:
- node_type: uint8
- node_number: uint8
- cc: uint64 (big-endian)
- epoch: int64 (big-endian)
| text/markdown | eNode team | null | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"PyQt5>=5.15",
"matplotlib>=3.8",
"pandas>=2.2"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.12 | 2026-02-18T11:10:47.360829 | enode_host-0.1.6.tar.gz | 68,336 | b5/b5/4a70f95bf5691040ff72fe5795ff11e493d0921d08e6ba143b85d9af6763/enode_host-0.1.6.tar.gz | source | sdist | null | false | f2cf46cfc7de98899a25e83faa473200 | a8158589e528c2f97da2d0d1bf9531c4c42c6031042628dc4985a03e4a5d14a0 | b5b54a70f95bf5691040ff72fe5795ff11e493d0921d08e6ba143b85d9af6763 | null | [] | 244 |
2.4 | portada-s-index | 0.1.0 | Biblioteca de algoritmos de similitud para desambiguación de términos históricos | # Portada S-Index
<div align="center">
**Biblioteca Python para desambiguación de términos históricos mediante algoritmos de similitud de cadenas**
[](https://pypi.org/project/portada-s-index/)
[](https://pypi.org/project/portada-s-index/)
[](https://github.com/danro-dev/portada-s-index/blob/main/LICENSE)
[](https://pypi.org/project/portada-s-index/)
[](https://github.com/psf/black)
[](https://github.com/danro-dev/portada-s-index)
[](https://github.com/danro-dev/portada-s-index/pulls)
[Características](#características) •
[Instalación](#instalación) •
[Uso Rápido](#uso-rápido) •
[Documentación](#documentación) •
[Ejemplos](#ejemplos)
</div>
---
## 🎯 Descripción
Portada S-Index es una biblioteca especializada en la desambiguación automática de términos históricos mediante el análisis de similitud con vocabularios controlados. Desarrollada para el proyecto PORTADA, utiliza múltiples algoritmos de similitud de cadenas y un sistema de consenso para clasificar términos con diferentes niveles de confianza.
**Interfaz principal: JSON** - Todas las entradas y salidas se manejan exclusivamente mediante JSON para máxima interoperabilidad.
## ✨ Características
### 🔧 Algoritmos de Similitud
- **Levenshtein OCR**: Distancia de Levenshtein con corrección para errores comunes de OCR
- **Levenshtein Ratio**: Distancia de Levenshtein estándar normalizada
- **Jaro-Winkler**: Algoritmo optimizado para nombres propios con énfasis en prefijos
- **N-gramas (2 y 3)**: Similitud basada en bigramas y trigramas
### 📊 Sistema de Clasificación
Clasificación automática en 5 niveles de confianza:
| Nivel | Descripción | Criterio |
|-------|-------------|----------|
| **CONSENSUADO** | Alta confianza | 2+ algoritmos votan por la misma entidad + Levenshtein OCR incluido |
| **CONSENSUADO_DEBIL** | Confianza moderada | 2+ algoritmos aprueban sin criterio estricto |
| **SOLO_1_VOTO** | Baja confianza | Solo 1 algoritmo supera el umbral |
| **ZONA_GRIS** | Ambiguo | Al menos 1 algoritmo en zona gris |
| **RECHAZADO** | Sin correspondencia | Ningún algoritmo supera umbrales |
### 🎛️ Configuración Flexible
- Selección de algoritmos a utilizar
- Umbrales de aprobación personalizables por algoritmo
- Zonas grises ajustables para casos ambiguos
- Normalización automática de texto (Unicode, diacríticos, minúsculas)
- Mapeo de voces a entidades para agrupación semántica
### 🚀 Procesamiento Avanzado
- **Procesamiento por lotes**: Múltiples operaciones en una sola llamada
- **Entrada flexible**: Diccionarios Python, strings JSON o archivos JSON
- **Salida estructurada**: Siempre en formato JSON con información completa
- **Reportes estadísticos**: Generación automática de métricas y cobertura
## 📦 Instalación
### Requisitos
- Python >= 3.12
- Sin dependencias externas (solo biblioteca estándar de Python)
### Instalación desde PyPI
```bash
pip install portada-s-index
```
O con uv (más rápido):
```bash
uv pip install portada-s-index
```
### Instalación desde código fuente
```bash
git clone <repository>
cd portada-s-index
pip install -e .
```
O con uv:
```bash
uv pip install -e .
```
## 🚀 Uso Rápido
### Calcular Similitud
```python
from portada_s_index import calculate_similarity_json
import json
# Entrada JSON
input_data = {
"term": "alemán",
"voices": ["aleman", "alemana", "germano", "frances"]
}
# Procesar
result_json = calculate_similarity_json(input_data)
result = json.loads(result_json)
# Resultado
print(json.dumps(result, indent=2, ensure_ascii=False))
```
**Salida:**
```json
{
"term": "alemán",
"results": {
"levenshtein_ocr": {
"voice": "aleman",
"similarity": 1.0,
"approved": true
},
"jaro_winkler": {
"voice": "aleman",
"similarity": 1.0,
"approved": true
},
"ngram_2": {
"voice": "aleman",
"similarity": 1.0,
"approved": true
}
}
}
```
### Clasificar Términos
```python
from portada_s_index import classify_terms_json
import json
# Entrada JSON
input_data = {
"terms": ["aleman", "frances", "ingles"],
"voices": ["aleman", "alemana", "frances", "francesa", "ingles", "inglesa"],
"frequencies": {
"aleman": 100,
"frances": 80,
"ingles": 150
}
}
# Procesar
result_json = classify_terms_json(input_data)
result = json.loads(result_json)
print(f"Términos clasificados: {result['total_terms']}")
```
### Clasificar con Reporte
```python
from portada_s_index import classify_terms_with_report_json
import json
# Entrada JSON (mismo formato que classify_terms)
input_data = {
"terms": ["aleman", "frances"],
"voices": ["aleman", "frances"]
}
# Procesar
result_json = classify_terms_with_report_json(input_data)
result = json.loads(result_json)
# Acceder al reporte
report = result["report"]
print(f"Cobertura: {report['coverage']['consensuado_strict']['percentage']:.2f}%")
```
### Procesamiento por Lotes
```python
from portada_s_index import process_batch_json
import json
# Múltiples operaciones en una llamada
input_data = {
"operations": [
{
"type": "calculate_similarity",
"data": {
"term": "alemán",
"voices": ["aleman", "alemana"]
}
},
{
"type": "classify_terms",
"data": {
"terms": ["frances", "ingles"],
"voices": ["frances", "ingles"]
}
}
],
"config": {
"algorithms": ["levenshtein_ocr", "jaro_winkler"],
"normalize": true
}
}
# Procesar
result_json = process_batch_json(input_data)
result = json.loads(result_json)
print(f"Operaciones exitosas: {result['successful']}/{result['total_operations']}")
```
### Procesar desde Archivos
```python
from portada_s_index import classify_terms_from_file
# Procesar archivo JSON y guardar resultado
result_json = classify_terms_from_file(
input_file="input.json",
output_file="output.json"
)
```
## 📖 Documentación
### Estructura de Entrada JSON
#### Entrada Mínima
```json
{
"terms": ["aleman", "frances"],
"voices": ["aleman", "frances"]
}
```
#### Entrada Completa
```json
{
"terms": ["aleman", "frances"],
"voices": ["aleman", "alemana", "frances", "francesa"],
"frequencies": {
"aleman": 100,
"frances": 80
},
"voice_to_entity": {
"aleman": "ALEMANIA",
"alemana": "ALEMANIA",
"frances": "FRANCIA",
"francesa": "FRANCIA"
},
"config": {
"algorithms": ["levenshtein_ocr", "jaro_winkler", "ngram_2"],
"thresholds": {
"levenshtein_ocr": 0.75,
"jaro_winkler": 0.85,
"ngram_2": 0.66
},
"gray_zones": {
"levenshtein_ocr": [0.71, 0.749],
"jaro_winkler": [0.80, 0.849],
"ngram_2": [0.63, 0.659]
},
"normalize": true,
"min_votes_consensus": 2,
"require_levenshtein_ocr": true
}
}
```
### API Principal
#### Funciones de Entrada JSON
| Función | Descripción |
|---------|-------------|
| `calculate_similarity_json(input_json)` | Calcula similitud de un término con voces |
| `classify_terms_json(input_json)` | Clasifica múltiples términos |
| `classify_terms_with_report_json(input_json)` | Clasifica términos y genera reporte resumen |
| `process_batch_json(input_json)` | Procesa múltiples operaciones en lote |
#### Funciones de Archivo JSON
| Función | Descripción |
|---------|-------------|
| `calculate_similarity_from_file(input_file, output_file)` | Procesa archivo de similitud |
| `classify_terms_from_file(input_file, output_file)` | Procesa archivo de clasificación |
| `classify_terms_with_report_from_file(input_file, output_file)` | Procesa con reporte |
| `process_batch_from_file(input_file, output_file)` | Procesa lote desde archivo |
### Algoritmos y Umbrales
| Algoritmo | Identificador | Umbral Default | Zona Gris Default |
|-----------|---------------|----------------|-------------------|
| Levenshtein OCR | `levenshtein_ocr` | 0.75 | [0.71, 0.749] |
| Levenshtein Ratio | `levenshtein_ratio` | 0.75 | [0.71, 0.749] |
| Jaro-Winkler | `jaro_winkler` | 0.85 | [0.80, 0.849] |
| N-gramas 2 | `ngram_2` | 0.66 | [0.63, 0.659] |
| N-gramas 3 | `ngram_3` | 0.60 | [0.55, 0.599] |
## 📚 Documentación Completa
- **[JSON_GUIDE.md](JSON_GUIDE.md)**: Guía completa de formatos JSON con ejemplos
- **[API.md](API.md)**: Referencia detallada de la API
- **[INSTALL.md](INSTALL.md)**: Guía de instalación y configuración
- **[CHANGELOG.md](CHANGELOG.md)**: Historial de cambios
## 💡 Ejemplos
La carpeta `examples/` contiene ejemplos completos de uso (no incluida en el repositorio):
- `json_usage.py`: Ejemplos con JSON en memoria
- `json_file_processing.py`: Procesamiento de archivos JSON
- `input_*.json`: Archivos de ejemplo de entrada
- `quick_test.py`: Tests rápidos sin instalación
### Ejecutar Ejemplos
```bash
# Desde el directorio del proyecto
python3 examples/json_usage.py
python3 examples/json_file_processing.py
```
## 🧪 Testing
### Tests Unitarios
```bash
# Tests básicos
python3 tests/test_basic.py
```
### Test Externo (Simulación Real)
```bash
# Test que simula uso real desde fuera del proyecto
python3 test_portada_external.py
```
**Resultado esperado:**
```
✓ TEST 1: Similitud simple
✓ TEST 2: Clasificación de términos
✓ TEST 3: Clasificación con reporte
✓ TEST 4: Configuración personalizada
✓ TEST 5: Procesamiento por lotes
✓ TEST 6: Mapeo de voces a entidades
✓ TEST 7: Entrada como string JSON
✓ TODOS LOS TESTS EXTERNOS PASARON CORRECTAMENTE
```
### Test con Datos Reales
```bash
# Test con datos reales del proyecto similitudes
python3 test_real_data.py
```
Este test:
1. Convierte CSVs de términos históricos a JSON
2. Carga listas de voces normalizadas
3. Procesa 100 términos reales con los algoritmos
4. Genera reportes estadísticos detallados
**Resultados con datos reales (100 términos, 110,924 ocurrencias):**
| Clasificación | Términos | Ocurrencias | Porcentaje |
|---------------|----------|-------------|------------|
| CONSENSUADO | 92 | 110,567 | 99.68% |
| SOLO_1_VOTO | 7 | 322 | 0.29% |
| RECHAZADO | 1 | 35 | 0.03% |
**Cobertura consensuada: 99.68%** ✨
**Top entidades identificadas:**
- INGLATERRA: 34,976 ocurrencias
- NACIONAL_AR: 14,921 ocurrencias
- FRANCIA: 9,982 ocurrencias
- ITALIA: 9,283 ocurrencias
- ALEMANIA: 6,421 ocurrencias
## 🔧 Configuración Avanzada
### Personalizar Algoritmos
```json
{
"config": {
"algorithms": ["levenshtein_ocr", "jaro_winkler"],
"thresholds": {
"levenshtein_ocr": 0.80,
"jaro_winkler": 0.90
}
}
}
```
### Ajustar Criterios de Consenso
```json
{
"config": {
"min_votes_consensus": 3,
"require_levenshtein_ocr": false
}
}
```
### Desactivar Normalización
```json
{
"config": {
"normalize": false
}
}
```
## 🎯 Casos de Uso
### Desambiguación de Banderas de Barcos
```python
input_data = {
"terms": ["aleman", "alemana", "germano"],
"voices": ["aleman", "alemana", "germano"],
"voice_to_entity": {
"aleman": "ALEMANIA",
"alemana": "ALEMANIA",
"germano": "ALEMANIA"
}
}
```
### Normalización de Puertos
```python
input_data = {
"terms": ["barcelona", "barzelona", "barcino"],
"voices": ["barcelona"],
"voice_to_entity": {
"barcelona": "BARCELONA"
}
}
```
### Clasificación de Tipos de Embarcación
```python
input_data = {
"terms": ["bergantin", "bergantín", "bergatin"],
"voices": ["bergantin"],
"frequencies": {
"bergantin": 150,
"bergantín": 80,
"bergatin": 20
}
}
```
## 📊 Formato de Salida
### Resultado de Similitud
```json
{
"term": "alemán",
"results": {
"levenshtein_ocr": {
"term": "alemán",
"voice": "aleman",
"algorithm": "levenshtein_ocr",
"similarity": 1.0,
"approved": true,
"in_gray_zone": false
}
}
}
```
### Clasificación de Términos
```json
{
"total_terms": 2,
"classifications": [
{
"term": "aleman",
"frequency": 100,
"results": {...},
"votes_approval": 3,
"entity_consensus": "ALEMANIA",
"voice_consensus": "aleman",
"votes_entity": 3,
"levenshtein_ocr_in_consensus": true,
"classification": "CONSENSUADO"
}
]
}
```
### Reporte Resumen
```json
{
"report": {
"total_terms": 100,
"total_occurrences": 5000,
"by_level": {
"CONSENSUADO": {
"count": 75,
"occurrences": 4500,
"percentage": 90.0
}
},
"coverage": {
"consensuado_strict": {
"occurrences": 4500,
"percentage": 90.0
}
}
},
"classifications": [...]
}
```
## 🎖️ Resultados con Datos Reales
Pruebas realizadas con datos históricos reales del proyecto PORTADA:
### Dataset de Prueba
- **Fuente**: Banderas de barcos históricos
- **Términos procesados**: 100
- **Ocurrencias totales**: 110,924
- **Voces de referencia**: 324 (134 entidades)
### Resultados de Clasificación
| Nivel | Términos | Ocurrencias | Cobertura |
|-------|----------|-------------|-----------|
| **CONSENSUADO** | 92 | 110,567 | **99.68%** |
| SOLO_1_VOTO | 7 | 322 | 0.29% |
| RECHAZADO | 1 | 35 | 0.03% |
### Ejemplos de Clasificación Exitosa
**Términos con alta frecuencia correctamente identificados:**
| Término Original | Frecuencia | Entidad Identificada | Confianza |
|------------------|------------|---------------------|-----------|
| ingles | 28,247 | INGLATERRA | CONSENSUADO |
| nacional | 14,921 | NACIONAL_AR | CONSENSUADO |
| frances | 6,933 | FRANCIA | CONSENSUADO |
| inglesa | 6,153 | INGLATERRA | CONSENSUADO |
| aleman | 5,154 | ALEMANIA | CONSENSUADO |
| italiano | 4,924 | ITALIA | CONSENSUADO |
### Top 10 Entidades Identificadas
1. **INGLATERRA**: 34,976 ocurrencias
2. **NACIONAL_AR**: 14,921 ocurrencias
3. **FRANCIA**: 9,982 ocurrencias
4. **ITALIA**: 9,283 ocurrencias
5. **ALEMANIA**: 6,421 ocurrencias
6. **URUGUAY**: 5,987 ocurrencias
7. **ESPAÑA**: 5,711 ocurrencias
8. **ESTADOS UNIDOS**: 4,272 ocurrencias
9. **NORUEGA**: 3,717 ocurrencias
10. **ARGENTINA**: 3,241 ocurrencias
### Análisis de Rendimiento
- **Precisión**: 99.68% de las ocurrencias clasificadas con alta confianza
- **Cobertura**: 92% de términos únicos consensuados
- **Algoritmos**: 91 términos con 3 votos de aprobación
- **Tiempo de procesamiento**: < 1 segundo para 100 términos
### Conclusiones
✅ Los algoritmos demuestran **alta precisión** en la identificación de términos históricos
✅ El sistema de consenso funciona efectivamente para **reducir falsos positivos**
✅ La normalización de texto maneja correctamente **variaciones ortográficas**
✅ El mapeo a entidades permite **agrupación semántica** efectiva
## 🤝 Contribuir
Las contribuciones son bienvenidas. Por favor:
1. Fork el proyecto
2. Crea una rama para tu feature (`git checkout -b feature/AmazingFeature`)
3. Commit tus cambios (`git commit -m 'Add some AmazingFeature'`)
4. Push a la rama (`git push origin feature/AmazingFeature`)
5. Abre un Pull Request
## 📝 Licencia
[Especificar licencia]
## 👥 Autores
Proyecto PORTADA - Desambiguación de términos históricos marítimos
## 🙏 Agradecimientos
- Proyecto PORTADA
- Comunidad de investigación histórica marítima
## 📧 Contacto
Para preguntas, sugerencias o reportar problemas, por favor abre un issue en el repositorio.
---
<div align="center">
**Hecho con ❤️ para el proyecto PORTADA**
</div>
| text/markdown | null | danro-dev <drgrassnk445@gmail.com> | null | null | null | disambiguation, historical-terms, jaro-winkler, levenshtein, ngrams, similarity, string-matching | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Information Analysis",
"Topic ::... | [] | null | null | >=3.12 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/danro-dev/portada-s-index",
"Repository, https://github.com/danro-dev/portada-s-index",
"Documentation, https://github.com/danro-dev/portada-s-index#readme",
"Bug Tracker, https://github.com/danro-dev/portada-s-index/issues"
] | uv/0.9.11 {"installer":{"name":"uv","version":"0.9.11"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Linux Mint","version":"22.3","id":"zena","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T11:10:33.627183 | portada_s_index-0.1.0.tar.gz | 25,876 | 01/4b/b94d62436a9c793c20a952a5e00f732470ba2088096cbaa5cf15001f4819/portada_s_index-0.1.0.tar.gz | source | sdist | null | false | 63084bfcc6cbd03b79e4ef853fc3f9e5 | 6e4364ce14f5d10ec7c752fb228b0d588110ce14c62f6b909afbe7928891ce65 | 014bb94d62436a9c793c20a952a5e00f732470ba2088096cbaa5cf15001f4819 | null | [
"LICENSE"
] | 247 |
2.3 | kalimusada | 0.0.2 | Ma-Chen Financial Chaotic System Solver with Sensitivity Analysis | # `kalimusada`: a Python library for solving the Ma-Chen financial chaotic system
[](https://www.python.org/downloads/)
[](https://pypi.org/project/kalimusada/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/psf/black)
[](https://doi.org/10.5281/zenodo.17710349)
[](https://numpy.org/)
[](https://scipy.org/)
[](https://matplotlib.org/)
[](https://pandas.pydata.org/)
[](https://unidata.github.io/netcdf4-python/)
[](https://imageio.github.io/)
[](https://tqdm.github.io/)
A Python-based solver for demonstrating sensitivity to initial conditions in economic dynamics.
<p align="center">
<img src="ma_chen_chaos.gif" alt="Ma-Chen Chaotic Dynamics" width="600">
</p>
## Model
The Ma-Chen system describes financial dynamics through three coupled ordinary differential equations:
$$ \dot{x} = z + (y - a)x, \quad \dot{y} = 1 - by - x^2, \quad \dot{z} = -x - cz $$
where the state variables are:
| Variable | Description | Economic interpretation |
|:--------:|:------------|:------------------------|
| $x(t)$ | Interest rate | Cost of borrowing capital |
| $y(t)$ | Investment demand | Aggregate investment activity |
| $z(t)$ | Price index | General price level |
and the parameters are:
| Parameter | Description | Chaotic value |
|:---------:|:------------|:-------------:|
| $a$ | Savings rate | $0.9$ |
| $b$ | Investment cost coefficient | $0.2$ |
| $c$ | Demand elasticity | $1.2$ |
The solver simulates two trajectories with infinitesimal initial separation $\delta_0 \sim \mathcal{O}(10^{-5})$ to visualize exponential divergence characteristic of deterministic chaos.
## Installation
**From PyPI:**
```bash
pip install kalimusada
```
**From source:**
```bash
git clone https://github.com/sandyherho/kalimusada.git
cd kalimusada
pip install -e .
```
## Quick start
**CLI:**
```bash
kalimusada case1 # run standard chaos scenario
kalimusada --all # run all test cases
```
**Python API:**
```python
from kalimusada import MaChenSolver, MaChenSystem
system = MaChenSystem(a=0.9, b=0.2, c=1.2)
solver = MaChenSolver()
result = solver.solve(
system=system,
init_A=[1.0, 2.0, 0.5],
init_B=[1.00001, 2.0, 0.5],
t_span=(0, 250),
n_points=100000
)
print(f"Max divergence: {result['max_euclidean_distance']:.6f}")
```
## Features
- High-precision ODE integration (LSODA)
- Dual trajectory sensitivity analysis
- Error metrics: Euclidean distance, RMSE, log divergence
- Output formats: CSV, NetCDF, PNG, GIF
## License
MIT © Sandy H. S. Herho
## Citation
```bibtex
@article{herho2026butterfly,
title = {{T}he butterfly effect in economics: {E}xploring chaos with a simple financial model},
author = {Herho, Sandy H. S.},
journal = {CODEE Journal},
volume = {20},
number = {1},
pages = {1},
year = {2026},
note = {https://scholarship.claremont.edu/codee/vol20/iss1/1}
}
```
| text/markdown | Sandy H. S. Herho | null | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming ... | [] | null | null | <4.0,>=3.8 | [] | [] | [] | [
"numpy>=1.20.0",
"scipy>=1.7.0",
"matplotlib>=3.3.0",
"netCDF4>=1.5.0",
"tqdm>=4.60.0",
"pandas>=1.3.0",
"Pillow>=8.0.0"
] | [] | [] | [] | [] | poetry/2.1.3 CPython/3.12.2 Linux/6.11.9-100.fc39.x86_64 | 2026-02-18T11:09:35.034548 | kalimusada-0.0.2.tar.gz | 19,427 | 8b/b1/e2b7f32565e2a64d75d6d096955797195cec952a8c504692222a3390182a/kalimusada-0.0.2.tar.gz | source | sdist | null | false | c9ed25fc87f3e9c0cf684f60e2357481 | 5b372eca3b9c304a61ef204f89d33730b652e9a302e241dc178d2f8a0cfe4097 | 8bb1e2b7f32565e2a64d75d6d096955797195cec952a8c504692222a3390182a | null | [] | 239 |
2.4 | flux-probert | 0.0.18 | Hardware probing tool (Flux fork of Canonical's probert) | # probert
Prober tool - Hardware discovery library used in Subiquity
| text/markdown | null | Canonical Engineering <ubuntu-devel@lists.ubuntu.com> | null | null | GPL-3.0-or-later | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"pyudev>=0.24.3",
"jsonschema>=2.6.0"
] | [] | [] | [] | [] | uv/0.10.3 {"installer":{"name":"uv","version":"0.10.3","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"25.10","id":"questing","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T11:09:29.753133 | flux_probert-0.0.18.tar.gz | 56,024 | bc/91/cf9a966b0ca3bbbcf0b0db5e960fdb50d9412a8516805dbd803e6cb4a96c/flux_probert-0.0.18.tar.gz | source | sdist | null | false | 54040b26a44d60bae79c1c383fdfabad | 2ba8c445bb04b26784dda368e82f19cbe9a6ac1e3d483a404db8b6c5a7dc0f41 | bc91cf9a966b0ca3bbbcf0b0db5e960fdb50d9412a8516805dbd803e6cb4a96c | null | [
"LICENSE"
] | 183 |
2.4 | OASYS2-ELETTRA-EXTENSIONS | 0.0.4 | oasys2-elettra-extensions | # OASYS2-ELETTRA-EXTENSIONS
Elettra add-on for Oasys2
| text/markdown | Juan Reyes-Herrera | juan.reyesherrera@elettra.eu | null | null | MIT | ray tracing, wave optics, x-ray optics, oasys2 | [
"Development Status :: 4 - Beta",
"Environment :: X11 Applications :: Qt",
"Environment :: Console",
"Environment :: Plugins",
"Programming Language :: Python :: 3",
"Intended Audience :: Science/Research"
] | [] | https://github.com/oasys-elettra-kit/OASYS2-ELETTRA-EXTENSIONS | https://github.com/oasys-elettra-kit/OASYS2-ELETTRA-EXTENSIONS | null | [] | [] | [] | [
"oasys2>=0.0.19",
"pandas"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.1 | 2026-02-18T11:08:23.416576 | oasys2_elettra_extensions-0.0.4.tar.gz | 705,475 | 93/68/7522812ea68fd89164945834d96c8819fd54bb6f8261c11cc345a9835e6e/oasys2_elettra_extensions-0.0.4.tar.gz | source | sdist | null | false | e28e95aaacb377342af8da55ba8d3e7a | d9665e710a93e22ce9b109c203f2b87fc89c34010a5f8e5e8c77a3f06a1fab68 | 93687522812ea68fd89164945834d96c8819fd54bb6f8261c11cc345a9835e6e | null | [
"LICENSE"
] | 0 |
2.4 | oipd | 2.0.1 | Generate probability distributions on the future price of publicly traded securities using options data | 
[](https://pypi.org/project/oipd/)
[](https://colab.research.google.com/github/tyrneh/options-implied-probability/blob/main/examples/OIPD_colab_demo.ipynb)
[](https://discord.gg/NHxWPGhhSQ)
[](https://pepy.tech/projects/oipd)
# Overview
### OIPD (Options-implied Probability Distribution) provides 2 capabilities:
**1. Compute market-implied probability distributions of future asset prices.**
- While markets don't predict the future with certainty, under the efficient market view, these market expectations represent the best available estimate of what might happen.
<p align="center" style="margin-top: 80px;">
<img src="https://github.com/tyrneh/options-implied-probability/blob/main/.meta/images/example.png" alt="example" style="width:100%; max-width:1200px; height:auto; display:block; margin-top:50px;" />
</p>
**2. Fit arbitrage-free volatility smiles and surfaces for pricing and risk analysis.**
- Fitting a vol surface well is a complex and expensive process, with the leading software provider costing $50k USD/month/seat. OIPD open-sources the entire pipeline fairly rigorously, with further improvements in the roadmap.
<table align="center" cellspacing="12" style="margin-top:120px; width:100%; border-collapse:separate;">
<tr>
<td style="width:50%; border:5px solid #000;">
<img src=".meta/images/vol_curve.png" alt="vol curve" style="width:100%; height:280px; object-fit:contain; display:block;" />
</td>
<td style="width:50%; border:5px solid #000;">
<img src=".meta/images/vol_surface.png" alt="vol surface" style="width:100%; height:280px; object-fit:contain; display:block;" />
</td>
</tr>
</table>
See the [full documentation site](https://tyrneh.github.io/options-implied-probability/) for details.
# Quick start
## 1. Installation
```bash
pip install oipd
```
## 2. Mental model for using OIPD
> [!TIP]
> For non-technical users, you can safely skip this section and jump to [Section 3](#3-quickstart-tutorial-in-computing-market-implied-probability-distributions) to compute future market-implied probabilities.
<br>
OIPD has four core objects. A simple way to remember them is a matrix:
| Scope | Volatility Layer | Probability Layer |
| --- | --- | --- |
| Single expiry | `VolCurve` | `ProbCurve` |
| Multiple expiries | `VolSurface` | `ProbSurface` |
You can think about the lifecycle in three steps:
1. Initialize the estimator object, with configurable params.
2. Call `.fit(chain, market)` to calibrate.
3. Query/plot the fitted object, or convert from vol to probability via `.implied_distribution()`.
If you're familiar with scikit-learn, this is the same mental model: configure an estimator, call `fit`, then inspect outputs.
Conceptual flow:
```text
Step 1: Fit volatility
Initialize VolCurve / VolSurface object
+ options chain + market inputs
-> .fit(...)
-> fitted VolCurve / VolSurface object (IV, prices, greeks, plots...)
Step 2: Convert fitted volatility to probability
Use the fitted VolCurve / VolSurface
-> .implied_distribution()
-> fitted ProbCurve / ProbSurface object (PDF, CDF, quantiles, moments...)
```
## 3. Quickstart tutorial in computing market-implied probability distributions
This quickstart will cover the functionality in **(1) computing market-implied probabilities**. See the [included jupyter notebook ](examples/quickstart_yfinance.ipynb) for a full example on using the automated yfinance connection to download options data and compute market-implied probabilities for Palantir.
For a more technical tutorial including the functionality of **(2) volatility fitting, see the additional jupyter notebooks** in the [examples](examples/) directory, as well as the [full documentation](https://tyrneh.github.io/options-implied-probability/).
### 3A. Usage for computing a probability distribution on a specific future date
```python
import matplotlib.pyplot as plt
from oipd import MarketInputs, ProbCurve, sources
# 1. we download data using the built-in yfinance connection
ticker = "PLTR" # specify the stock ticker
expiries = sources.list_expiry_dates(ticker) # see all expiry dates
single_expiry = expiries[1] # select one of the expiry dates you're interested in
chain, snapshot = sources.fetch_chain(ticker, expiries=single_expiry) # download the options chain data, and a snapshot at the time of download
# 2. fill in the parameters
market = MarketInputs(
valuation_date=snapshot.date, # date on which the options data was downloaded
underlying_price=snapshot.underlying_price, # the price of the underlying stock at the time when the options data was downloaded
risk_free_rate=0.04, # the risk-free rate of return. Use the US Fed or Treasury yields that are closest to the horizon of the expiry date
)
# 3. compute the future probability distribution using the data and parameters
prob = ProbCurve.from_chain(chain, market)
# 4. query the computed result to understand market-implied probabilities and other statistics
prob.plot()
plt.show()
prob_below = prob.prob_below(100) # P(price < 100)
prob_above = prob.prob_above(120) # P(price >= 120)
q50 = prob.quantile(0.50) # median implied price
skew = prob.skew() # skew
```
<p align="center" style="margin-top: 120px;">
<img src=".meta/images/palantir_distribution.png" alt="example" style="width:100%; max-width:1200px; height:auto; display:block; margin-top:50px;" />
</p>
### 3B. Usage for computing probabilities over time
```python
import matplotlib.pyplot as plt
from oipd import MarketInputs, ProbSurface, sources
# 1. download multi-expiry data using the built-in yfinance connection
ticker = "PLTR"
chain_surface, snapshot_surface = sources.fetch_chain(
ticker,
horizon="12m", # auto-fetch all listed expiries inside the horizon
)
# 2. fill in the parameters
surface_market = MarketInputs(
valuation_date=snapshot_surface.date, # date on which the options data was downloaded
underlying_price=snapshot_surface.underlying_price, # price of the underlying stock at download time
risk_free_rate=0.04, # risk-free rate for the horizon
)
# 3. compute the probability surface using the data and parameters
surface = ProbSurface.from_chain(chain_surface, surface_market)
# 4. query and visualize the surface
surface.plot_fan() # Plot a fan chart of price probability over time
plt.show()
# 5. query at arbitrary maturities directly from ProbSurface
pdf_45d = surface.pdf(100, t=45/365) # density at K=100, 45 days
cdf_45d = surface.cdf(100, t="2025-02-15") # equivalent date-style maturity input
q50_45d = surface.quantile(0.50, t=45/365) # median at 45 days
# 6. "slice" the surface to get a ProbCurve, and query its statistical properties in the same manner as in example A
surface.expiries # list all the expiry dates that were captured
curve = surface.slice(surface.expiries[0]) # get a slice on the first expiry
curve.prob_below(100) # query probabilities and statistics
curve.kurtosis()
```
<p align="center" style="margin-top: 20px;">
<img src=".meta/images/palantir_price_forecast.png" alt="example" style="width:100%; max-width:1200px; height:auto; display:block; margin-top:10px;" />
</p>
OIPD also **supports manual CSV or DataFrame uploads**.
See [more examples](examples/) for demos.
# Community
Pull requests welcome! Reach out on GitHub issues to discuss design choices.
Join the [Discord community](https://discord.gg/NHxWPGhhSQ) to share ideas, discuss strategies, and get support. Message me with your feature requests, and let me know how you use this.
| text/markdown | null | Henry Tian <tyrneh@gmail.com>, Jannic Holzer <jannic.holzer@gmail.com>, Chun Hei Hung <chunhei1848@gmail.com>, Jaewon La <jaewonla0225@gmail.com> | null | null | Apache License 2.0 | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Operating System :: MacOS",
"Operating System :: POSIX :: Linux",
"Topic :: Office/Business ::... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.26.0",
"pandas>=2.1.0",
"scipy>=1.11.0",
"matplotlib>=3.8.0",
"matplotlib-label-lines>=0.6.0",
"plotly<6,>=5",
"traitlets>=5.12.0",
"yfinance>=0.2.60",
"numpy>=1.26.0; extra == \"minimal\"",
"pandas>=2.1.0; extra == \"minimal\"",
"scipy>=1.11.0; extra == \"minimal\"",
"matplotlib>=3.... | [] | [] | [] | [
"Homepage, https://github.com/tyrneh/options-implied-probability",
"Bug Tracker, https://github.com/tyrneh/options-implied-probability/issues"
] | twine/6.2.0 CPython/3.12.6 | 2026-02-18T11:08:22.090215 | oipd-2.0.1.tar.gz | 177,783 | da/e4/57dbf07d3c19971d7ac8602afaf22d049b516ed199eacb3b5680746b0528/oipd-2.0.1.tar.gz | source | sdist | null | false | dea0a62b5bf16909e7e6fdbd84a12da8 | dd81e0b3fd815731339329d218db0cec315e91631de102b207fb1ef9c84c6059 | dae457dbf07d3c19971d7ac8602afaf22d049b516ed199eacb3b5680746b0528 | null | [
"LICENSE"
] | 254 |
2.4 | linux-do-connect-token | 0.0.4 | A helper library to authenticate with connect.linux.do and retrieve auth.session-token | # Linux Do Connect Token
A helper library to authenticate with connect.linux.do and retrieve auth.session-token
---
[](https://github.com/Sn0wo2/linux-do-connect-token/actions/workflows/py.yml)
[](https://github.com/Sn0wo2/linux-do-connect-token/actions/workflows/release.yml)
[](https://github.com/Sn0wo2/linux-do-connect-token/actions/workflows/codeql.yml)
[](https://github.com/Sn0wo2/linux-do-connect-token/releases)
---
> 由于26年2月connecct.linux.do更新了页面所以此项目暂时不可用。
---
> [!] 项目当前正在开发, **不保证`v0`的向后兼容性**, 如果要在生产环境使用请等待`v1`发布
---
## Usage
> See example
---
## Get `LINUX_DO_TOKEN(_t)`
1. Open InPrivate page(Because token refresh)
2. Log in to [linux.do](https://linux.do)
3. Open DevTools by pressing F12
4. Go to the Application tab
5. Expand Cookies in the left sidebar and select linux.do
6. Find the `_t` cookie in the list
7. Copy its value for later use
8. Close InPrivate page(Dont logout linux.do)
| text/markdown | Sn0wo2 | null | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"curl-cffi<0.15.0,>=0.14.0"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.14.3 Linux/6.14.0-1017-azure | 2026-02-18T11:07:09.628471 | linux_do_connect_token-0.0.4-py3-none-any.whl | 4,123 | c8/48/bcf424002fadcf413e59f40887381fa06ac14d6c446b726fdfa11bede298/linux_do_connect_token-0.0.4-py3-none-any.whl | py3 | bdist_wheel | null | false | 186ff8eb1b4fac61672dc6d5abd04851 | 9eb3184ad0be7e038fd7e238950e518d0b978a36725ae30f5595629ff70ff2a9 | c848bcf424002fadcf413e59f40887381fa06ac14d6c446b726fdfa11bede298 | null | [
"LICENSE"
] | 246 |
2.4 | geocodio-library-python | 0.5.1 | A Python client for the Geocodio API | # geocodio
The official Python client for the Geocodio API.
Features
--------
- Forward geocoding of single addresses or in batches (up to 10,000 lookups).
- Reverse geocoding of coordinates (single or batch).
- Append additional data fields (e.g. congressional districts, timezone, census data).
- Distance calculations (single origin to multiple destinations, distance matrices).
- Async distance matrix jobs for large calculations.
- Automatic parsing of address components.
- Simple exception handling for authentication, data, and server errors.
Installation
------------
Install via pip:
pip install geocodio-library-python
Usage
-----
> Don't have an API key yet? Sign up at [https://dash.geocod.io](https://dash.geocod.io) to get an API key. The first 2,500 lookups per day are free.
### Geocoding
```python
from geocodio import Geocodio
# Initialize the client with your API key
client = Geocodio("YOUR_API_KEY")
# client = Geocodio("YOUR_API_KEY", hostname="api-hipaa.geocod.io") # optionally overwrite the API hostname
# Single forward geocode
response = client.geocode("1600 Pennsylvania Ave, Washington, DC")
print(response.results[0].formatted_address)
# Batch forward geocode
addresses = [
"1600 Pennsylvania Ave, Washington, DC",
"1 Infinite Loop, Cupertino, CA"
]
batch_response = client.geocode(addresses)
for result in batch_response.results:
print(result.formatted_address)
# Single reverse geocode
rev = client.reverse("38.9002898,-76.9990361")
print(rev.results[0].formatted_address)
# Reverse with tuple coordinates
rev = client.reverse((38.9002898, -76.9990361))
```
> Note: You can read more about accuracy scores, accuracy types, input formats and more at https://www.geocod.io/docs/
### Batch geocoding
To batch geocode, simply pass a list of addresses or coordinates instead of a single string:
```python
response = client.geocode([
"1109 N Highland St, Arlington VA",
"525 University Ave, Toronto, ON, Canada",
"4410 S Highway 17 92, Casselberry FL",
"15000 NE 24th Street, Redmond WA",
"17015 Walnut Grove Drive, Morgan Hill CA"
])
response = client.reverse([
"35.9746000,-77.9658000",
"32.8793700,-96.6303900",
"33.8337100,-117.8362320",
"35.4171240,-80.6784760"
])
# Optionally supply a custom key that will be returned along with results
response = client.geocode({
"MyId1": "1109 N Highland St, Arlington VA",
"MyId2": "525 University Ave, Toronto, ON, Canada",
"MyId3": "4410 S Highway 17 92, Casselberry FL",
"MyId4": "15000 NE 24th Street, Redmond WA",
"MyId5": "17015 Walnut Grove Drive, Morgan Hill CA"
})
```
### Field appends
Geocodio allows you to append additional data points such as congressional districts, census codes, timezone, ACS survey results and [much more](https://www.geocod.io/docs/#fields).
To request additional fields, simply supply them as a list:
```python
response = client.geocode(
[
"1109 N Highland St, Arlington VA",
"525 University Ave, Toronto, ON, Canada"
],
fields=["cd", "timezone"]
)
response = client.reverse("38.9002898,-76.9990361", fields=["census2010"])
```
### Address components
For forward geocoding requests it is possible to supply [individual address components](https://www.geocod.io/docs/#single-address) instead of a full address string:
```python
response = client.geocode({
"street": "1109 N Highland St",
"city": "Arlington",
"state": "VA",
"postal_code": "22201"
})
response = client.geocode([
{
"street": "1109 N Highland St",
"city": "Arlington",
"state": "VA"
},
{
"street": "525 University Ave",
"city": "Toronto",
"state": "ON",
"country": "Canada"
}
])
```
### Limit results
Optionally limit the number of maximum geocoding results:
```python
# Only get the first result
response = client.geocode("1109 N Highland St, Arlington, VA", limit=1)
# Return up to 5 geocoding results
response = client.reverse("38.9002898,-76.9990361", fields=["timezone"], limit=5)
```
### Distance calculations
Calculate distances from a single origin to multiple destinations, or compute full distance matrices.
#### Coordinate format with custom IDs
You can add custom identifiers to coordinates using the `lat,lng,id` format. The ID will be returned in the response, making it easy to match results back to your data:
```python
from geocodio import Coordinate
# String format with ID
"37.7749,-122.4194,warehouse_1"
# Tuple format with ID
(37.7749, -122.4194, "warehouse_1")
# Using the Coordinate class
Coordinate(37.7749, -122.4194, "warehouse_1")
# The ID is returned in the response:
# DistanceDestination(
# query="37.7749,-122.4194,warehouse_1",
# location=(37.7749, -122.4194),
# id="warehouse_1",
# distance_miles=3.2,
# distance_km=5.1
# )
```
#### Distance mode and units
The SDK provides constants for type-safe distance configuration:
```python
from geocodio import (
DISTANCE_MODE_STRAIGHTLINE, # Default - great-circle (as the crow flies)
DISTANCE_MODE_DRIVING, # Road network routing with duration
DISTANCE_MODE_HAVERSINE, # Alias for Straightline (backward compat)
DISTANCE_UNITS_MILES, # Default
DISTANCE_UNITS_KM,
DISTANCE_ORDER_BY_DISTANCE, # Default
DISTANCE_ORDER_BY_DURATION,
DISTANCE_SORT_ASC, # Default
DISTANCE_SORT_DESC,
)
```
> **Note:** The default mode is `straightline` (great-circle distance). Use `DISTANCE_MODE_DRIVING` if you need road network routing with duration estimates.
#### Add distance to geocoding requests
You can add distance calculations to existing geocode or reverse geocode requests. Each geocoded result will include distance data to each destination.
```python
from geocodio import (
Geocodio,
DISTANCE_MODE_DRIVING,
DISTANCE_UNITS_MILES,
DISTANCE_ORDER_BY_DISTANCE,
DISTANCE_SORT_ASC,
)
client = Geocodio("YOUR_API_KEY")
# Geocode an address and calculate distances to store locations
response = client.geocode(
"1600 Pennsylvania Ave NW, Washington DC",
destinations=[
"38.9072,-77.0369,store_dc",
"39.2904,-76.6122,store_baltimore",
"39.9526,-75.1652,store_philly"
],
distance_mode=DISTANCE_MODE_DRIVING,
distance_units=DISTANCE_UNITS_MILES
)
# Reverse geocode with distances
response = client.reverse(
"38.8977,-77.0365",
destinations=["38.9072,-77.0369,capitol", "38.8895,-77.0353,monument"],
distance_mode=DISTANCE_MODE_STRAIGHTLINE
)
# With filtering - find nearest 3 stores within 50 miles
response = client.geocode(
"1600 Pennsylvania Ave NW, Washington DC",
destinations=[
"38.9072,-77.0369,store_1",
"39.2904,-76.6122,store_2",
"39.9526,-75.1652,store_3",
"40.7128,-74.0060,store_4"
],
distance_mode=DISTANCE_MODE_DRIVING,
distance_max_results=3,
distance_max_distance=50.0,
distance_order_by=DISTANCE_ORDER_BY_DISTANCE,
distance_sort_order=DISTANCE_SORT_ASC
)
```
#### Single origin to multiple destinations
```python
from geocodio import (
Geocodio,
Coordinate,
DISTANCE_MODE_DRIVING,
DISTANCE_UNITS_KM,
DISTANCE_ORDER_BY_DISTANCE,
DISTANCE_SORT_ASC,
)
client = Geocodio("YOUR_API_KEY")
# Calculate distances from one origin to multiple destinations
response = client.distance(
origin="37.7749,-122.4194,headquarters", # Origin with ID
destinations=[
"37.7849,-122.4094,customer_a",
"37.7949,-122.3994,customer_b",
"37.8049,-122.4294,customer_c"
]
)
print(response.origin.id) # "headquarters"
for dest in response.destinations:
print(f"{dest.id}: {dest.distance_miles} miles")
# Use driving mode for road network routing (includes duration)
response = client.distance(
origin="37.7749,-122.4194",
destinations=["37.7849,-122.4094"],
mode=DISTANCE_MODE_DRIVING
)
print(response.destinations[0].duration_seconds) # e.g., 180
# With all filtering and sorting options
response = client.distance(
origin="37.7749,-122.4194,warehouse",
destinations=[
"37.7849,-122.4094,store_1",
"37.7949,-122.3994,store_2",
"37.8049,-122.4294,store_3"
],
mode=DISTANCE_MODE_DRIVING,
units=DISTANCE_UNITS_KM,
max_results=2,
max_distance=10.0,
order_by=DISTANCE_ORDER_BY_DISTANCE,
sort_order=DISTANCE_SORT_ASC
)
# Using Coordinate class
origin = Coordinate(37.7749, -122.4194, "warehouse")
destinations = [
Coordinate(37.7849, -122.4094, "store_1"),
Coordinate(37.7949, -122.3994, "store_2")
]
response = client.distance(origin=origin, destinations=destinations)
# Tuple format for coordinates (with or without ID)
response = client.distance(
origin=(37.7749, -122.4194), # Without ID
destinations=[(37.7849, -122.4094, "dest_1")] # With ID as third element
)
```
#### Distance matrix (multiple origins × destinations)
```python
from geocodio import Geocodio, Coordinate, DISTANCE_MODE_DRIVING, DISTANCE_UNITS_KM
client = Geocodio("YOUR_API_KEY")
# Calculate full distance matrix with custom IDs
response = client.distance_matrix(
origins=[
"37.7749,-122.4194,warehouse_sf",
"37.8049,-122.4294,warehouse_oak"
],
destinations=[
"37.7849,-122.4094,customer_1",
"37.7949,-122.3994,customer_2"
]
)
for result in response.results:
print(f"From {result.origin.id}:")
for dest in result.destinations:
print(f" To {dest.id}: {dest.distance_miles} miles")
# With driving mode and kilometers
response = client.distance_matrix(
origins=["37.7749,-122.4194"],
destinations=["37.7849,-122.4094"],
mode=DISTANCE_MODE_DRIVING,
units=DISTANCE_UNITS_KM
)
# Using Coordinate objects
origins = [
Coordinate(37.7749, -122.4194, "warehouse_sf"),
Coordinate(37.8049, -122.4294, "warehouse_oak")
]
destinations = [
Coordinate(37.7849, -122.4094, "customer_1"),
Coordinate(37.7949, -122.3994, "customer_2")
]
response = client.distance_matrix(origins=origins, destinations=destinations)
```
#### Nearest mode (find closest destinations)
```python
# Find up to 2 nearest destinations from each origin
response = client.distance_matrix(
origins=["37.7749,-122.4194"],
destinations=["37.7849,-122.4094", "37.7949,-122.3994", "37.8049,-122.4294"],
max_results=2
)
# Filter by maximum distance (in miles or km depending on units)
response = client.distance_matrix(
origins=["37.7749,-122.4194"],
destinations=[...],
max_distance=2.0
)
# Filter by minimum and maximum distance
response = client.distance_matrix(
origins=["37.7749,-122.4194"],
destinations=[...],
min_distance=1.0,
max_distance=10.0
)
# Filter by duration (seconds, driving mode only)
response = client.distance_matrix(
origins=["37.7749,-122.4194"],
destinations=[...],
mode=DISTANCE_MODE_DRIVING,
max_duration=300, # 5 minutes
min_duration=60 # 1 minute minimum
)
# Sort by duration descending
response = client.distance_matrix(
origins=["37.7749,-122.4194"],
destinations=[...],
mode=DISTANCE_MODE_DRIVING,
max_results=5,
order_by=DISTANCE_ORDER_BY_DURATION,
sort_order=DISTANCE_SORT_DESC
)
```
#### Async distance matrix jobs
For large distance matrix calculations, use async jobs that process in the background.
```python
from geocodio import Geocodio, DISTANCE_MODE_DRIVING, DISTANCE_UNITS_MILES
client = Geocodio("YOUR_API_KEY")
# Create a new distance matrix job
job = client.create_distance_matrix_job(
name="My Distance Calculation",
origins=["37.7749,-122.4194", "37.8049,-122.4294"],
destinations=["37.7849,-122.4094", "37.7949,-122.3994"],
mode=DISTANCE_MODE_DRIVING,
units=DISTANCE_UNITS_MILES,
callback_url="https://example.com/webhook" # Optional
)
print(job.id) # Job identifier
print(job.status) # "ENQUEUED"
print(job.total_calculations) # 4
# Or use list IDs from previously uploaded lists
job = client.create_distance_matrix_job(
name="Distance from List",
origins=12345, # List ID
destinations=67890, # List ID
mode=DISTANCE_MODE_STRAIGHTLINE
)
# Check job status
status = client.distance_matrix_job_status(job.id)
print(status.status) # "ENQUEUED", "PROCESSING", "COMPLETED", or "FAILED"
print(status.progress) # 0-100
# List all jobs (paginated)
jobs = client.distance_matrix_jobs()
jobs = client.distance_matrix_jobs(page=2) # Page 2
# Get results when complete (same format as distance_matrix response)
results = client.get_distance_matrix_job_results(job.id)
for result in results.results:
print(f"From {result.origin.id}:")
for dest in result.destinations:
print(f" To {dest.id}: {dest.distance_miles} miles")
# Or download to a file for very large results
client.download_distance_matrix_job(job.id, "results.json")
# Delete a job
client.delete_distance_matrix_job(job.id)
```
### List API
The List API allows you to manage lists of addresses or coordinates for batch processing.
```python
from geocodio import Geocodio
client = Geocodio("YOUR_API_KEY")
# Get all lists
lists = client.get_lists()
print(f"Found {len(lists.data)} lists")
# Create a new list from a file
with open("addresses.csv", "rb") as f:
new_list = client.create_list(
file=f,
filename="addresses.csv",
direction="forward"
)
print(f"Created list: {new_list.id}")
# Get a specific list
list_details = client.get_list(new_list.id)
print(f"List status: {list_details.status}")
# Download a completed list
if list_details.status and list_details.status.get("state") == "COMPLETED":
file_content = client.download(new_list.id, "downloaded_results.csv")
print("List downloaded successfully")
# Delete a list
client.delete_list(new_list.id)
```
Error Handling
--------------
```python
from geocodio import Geocodio
from geocodio.exceptions import AuthenticationError, InvalidRequestError
try:
client = Geocodio("INVALID_API_KEY")
response = client.geocode("1600 Pennsylvania Ave, Washington, DC")
except AuthenticationError as e:
print(f"Authentication failed: {e}")
try:
client = Geocodio("YOUR_API_KEY")
response = client.geocode("") # Empty address
except InvalidRequestError as e:
print(f"Invalid request: {e}")
```
Geocodio Enterprise
-------------------
To use this library with Geocodio Enterprise, pass `api.enterprise.geocod.io` as the `hostname` parameter when initializing the client:
```python
from geocodio import Geocodio
# Initialize client for Geocodio Enterprise
client = Geocodio(
"YOUR_API_KEY",
hostname="api.enterprise.geocod.io"
)
# All methods work the same as with the standard API
response = client.geocode("1600 Pennsylvania Ave, Washington, DC")
print(response.results[0].formatted_address)
```
Testing
-------
```bash
$ pip install -e ".[dev]"
$ pytest
```
Documentation
-------------
Full documentation is available at <https://www.geocod.io/docs/?python>.
Changelog
---------
Please see [CHANGELOG](CHANGELOG.md) for more information on what has changed recently.
Security
--------
If you discover any security related issues, please email security@geocod.io instead of using the issue tracker.
License
-------
This project is licensed under the MIT License. See the [LICENSE](LICENSE) file for details.
Contributing
------------
Contributions are welcome! Please open issues and pull requests on GitHub.
Issues: <https://github.com/geocodio/geocodio-library-python/issues>
| text/markdown | null | null | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming ... | [] | null | null | >=3.11 | [] | [] | [] | [
"httpx>=0.24.0",
"black>=23.0.0; extra == \"dev\"",
"flake8>=6.0.0; extra == \"dev\"",
"isort>=5.12.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest-httpx>=0.27.0; extra == \"dev\"",
"pytest-mock>=3.10.0; extra == \"dev\"",
"pytest>=7.0.0; extra =... | [] | [] | [] | [
"Homepage, https://www.geocod.io",
"Documentation, https://www.geocod.io/docs/?python",
"Repository, https://github.com/geocodio/geocodio-library-python",
"Issues, https://github.com/geocodio/geocodio-library-python/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T11:05:13.199847 | geocodio_library_python-0.5.1.tar.gz | 69,253 | 76/34/e5633b9ac45fd04dc46fea43a590fc405de284f51775da5b1832db1a5b1b/geocodio_library_python-0.5.1.tar.gz | source | sdist | null | false | ff67cb062ebfed6cf1e647d55260151d | adb11b687373361f81e37429ef15b103a2b62ca202009ea6cf5455ab46eb55b5 | 7634e5633b9ac45fd04dc46fea43a590fc405de284f51775da5b1832db1a5b1b | MIT | [
"LICENSE"
] | 293 |
2.4 | tobacco-mof | 4.0.2 | Topologically Based Crystal Constructor (ToBaCCo) | Fixed ToBaCCo 3.0 code from https://github.com/tobacco-mofs
#### useage
```sh
from tobacco import run_tobacco
from glob import glob
from tqdm import tqdm
save_path = "./"
nodes_dataset = glob("./database/example/nodes/*cif")
edges_dataset = glob("./database/example/edges/*cif")
templates_dataset = glob("./database/example/templates/*cif")
for node in tqdm(nodes_dataset):
print("NODE:", node)
for edge in (edges_dataset):
print("EDGE:", edge)
for template in (templates_dataset):
try:
run_tobacco(template, [node], [edge], save_path)
except:
pass
```
# Bugs
If you encounter any problem, please email ```sxmzhaogb@gmail.com```.
| text/markdown | Guobin Zhao | sxmzhaogb@gmai.com | null | null | MIT | null | [
"Programming Language :: Python :: 3.9",
"License :: OSI Approved :: MIT License"
] | [] | https://github.com/sxm13/pypi-dev/tree/main/ToBaCCo | null | null | [] | [] | [] | [
"numpy",
"ase",
"networkx",
"scipy",
"gemmitqdm"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.23 | 2026-02-18T11:04:53.791753 | tobacco_mof-4.0.2.tar.gz | 21,970 | d0/99/e0b9a07fd929cbf9eaa4692a76610ebc131a91faf42e95adb49f06495c79/tobacco_mof-4.0.2.tar.gz | source | sdist | null | false | b311a3c787ab10bd86bc9103f8837b35 | d0978115fa60ee29da160bc02f6e78f03249e1fac617fe181fff0191d3a8a6fc | d099e0b9a07fd929cbf9eaa4692a76610ebc131a91faf42e95adb49f06495c79 | null | [
"LICENSE"
] | 237 |
2.4 | mininn | 1.5.1 | python interface of MiniNN | Build a deep learning inference framework from scratch
| null | masteryi-0018 | <1536474741@qq.com> | null | null | null | null | [] | [] | null | null | null | [] | [] | [] | [
"onnxruntime",
"onnx"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:03:16.210242 | mininn-1.5.1-cp313-cp313-win_amd64.whl | 474,632 | a9/f4/08bf567773ff98695b6b5352bf453cca1c19240608fe77359d7a7345bb61/mininn-1.5.1-cp313-cp313-win_amd64.whl | cp313 | bdist_wheel | null | false | 2653e03f5d418872211355ec4996b0e2 | 4e4b748cf8787965ccc3fa35e9d10e451a02805a7fae8f9b7f2d6e9cba87f605 | a9f408bf567773ff98695b6b5352bf453cca1c19240608fe77359d7a7345bb61 | null | [] | 255 |
2.3 | vibetuner | 8.2.3 | Core Python framework and blessed dependencies for production-ready FastAPI + MongoDB + HTMX projects | # vibetuner
Core Python framework and blessed dependencies for Vibetuner projects
This package provides the complete Python framework and curated dependency set for building modern
web applications with Vibetuner. It includes everything from FastAPI and MongoDB integration to
authentication, background jobs, and CLI tools.
## What is Vibetuner?
Vibetuner is a production-ready scaffolding tool for FastAPI web applications.
This package (`vibetuner`) is the Python component that provides:
- Complete web application framework built on FastAPI
- **Flexible database support**: MongoDB (Beanie ODM) or SQL (SQLModel/SQLAlchemy)
- OAuth and magic link authentication out of the box
- Background job processing with Redis + Streaq (optional)
- CLI framework with Typer
- Email services, blob storage, and more
**This package is designed to be used within projects generated by the Vibetuner scaffolding
tool.** For standalone use, you'll need to set up the project structure manually.
## Installation
```bash
# In a Vibetuner-generated project (automatic)
uv sync
# Add to an existing project
uv add vibetuner
# With development dependencies
uv add vibetuner[dev]
```
## Quick Start
The recommended way to use Vibetuner is via the scaffolding tool:
```bash
# Create a new project with all the framework code
uvx vibetuner scaffold new my-project
cd my-project
just dev
```
This will generate a complete project with:
- Pre-configured FastAPI application
- Authentication system (OAuth + magic links)
- MongoDB models and configuration
- Frontend templates and asset pipeline
- Docker setup for development and production
- CLI commands and background job infrastructure
## What's Included
### Core Framework (`src/vibetuner/`)
- **`frontend/`**: FastAPI app, routes, middleware, auth
- **`models/`**: User, OAuth, email verification, blob storage models
- **`services/`**: Email (Mailjet), blob storage (S3)
- **`tasks/`**: Background job infrastructure
- **`cli/`**: CLI framework with scaffold, run, db commands
- **`config.py`**: Pydantic settings management
- **`mongo.py`**: MongoDB/Beanie setup (optional)
- **`sqlmodel.py`**: SQLModel/SQLAlchemy setup (optional)
- **`logging.py`**: Structured logging configuration
### Blessed Dependencies
- **FastAPI** (0.121+): Modern, fast web framework
- **Beanie**: Async MongoDB ODM with Pydantic (optional)
- **SQLModel** + **SQLAlchemy**: SQL databases - PostgreSQL, MySQL, SQLite (optional)
- **Authlib**: OAuth 1.0/2.0 client
- **Granian**: High-performance ASGI server
- **Redis** + **Streaq**: Background task processing (optional)
- **Typer**: CLI framework
- **Rich**: Beautiful terminal output
- **Loguru**: Structured logging
- **Pydantic**: Data validation and settings
See [pyproject.toml](./pyproject.toml) for the complete dependency list.
## CLI Tools
When installed, provides the `vibetuner` command:
```bash
# Create new project from template
vibetuner scaffold new my-project
vibetuner scaffold new my-project --defaults
# Update existing project
vibetuner scaffold update
# Database management (SQLModel)
vibetuner db create-schema # Create SQL database tables
# Run development server (in generated projects)
vibetuner run dev frontend
vibetuner run dev worker
# Run production server (in generated projects)
vibetuner run prod frontend
vibetuner run prod worker
```
## Development Dependencies
The `[dev]` extra includes all tools needed for development:
- **Ruff**: Fast linting and formatting
- **Babel**: i18n message extraction
- **pre-commit**: Git hooks (prek is a fast pre-commit drop-in replacement)
- **Type stubs**: For aioboto3, authlib, PyYAML
- And more...
## Usage in Generated Projects
In a Vibetuner-generated project, import from `vibetuner`:
```python
# Use core models
from vibetuner.models import UserModel, OAuthAccountModel
# Use services
from vibetuner.services.email import send_email
# Use configuration
from vibetuner.config import settings
# Extend core routes
from vibetuner.frontend import app
# Add your routes
@app.get("/api/hello")
async def hello():
return {"message": "Hello World"}
```
## Documentation
For complete documentation, guides, and examples, see the main Vibetuner repository:
**📖 [Vibetuner Documentation](https://vibetuner.alltuner.com/)**
## Package Ecosystem
Vibetuner consists of three packages that work together:
1. **vibetuner** (this package): Python framework and dependencies
2. **[@alltuner/vibetuner](https://www.npmjs.com/package/@alltuner/vibetuner)**: JavaScript/CSS build dependencies
3. **Scaffolding template**: Copier template for project generation
All three are version-locked and tested together to ensure compatibility.
## Contributing
Contributions welcome! See the main repository for contribution guidelines:
**🤝 [Contributing to Vibetuner](https://github.com/alltuner/vibetuner/blob/main/CONTRIBUTING.md)**
## License
MIT License - Copyright (c) 2025 All Tuner Labs, S.L.
See [LICENSE](https://github.com/alltuner/vibetuner/blob/main/LICENSE) for details.
## Links
- **Main Repository**: <https://github.com/alltuner/vibetuner>
- **Documentation**: <https://vibetuner.alltuner.com/>
- **Issues**: <https://github.com/alltuner/vibetuner/issues>
- **PyPI**: <https://pypi.org/project/vibetuner/>
- **npm Package**: <https://www.npmjs.com/package/@alltuner/vibetuner>
| text/markdown | All Tuner Labs, S.L. | null | null | null | MIT | fastapi, mongodb, htmx, web-framework, scaffolding, oauth, background-jobs | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: P... | [] | null | null | >=3.11 | [] | [] | [] | [
"aioboto3>=15.5.0",
"arel>=0.4.0",
"asyncer>=0.0.13",
"authlib>=1.6.7",
"beanie[zstd]>=2.0.1",
"click>=8.3.1",
"copier>=9.11.3",
"email-validator>=2.3.0",
"fastapi[standard-no-fastapi-cloud-cli]>=0.128.8",
"granian[pname]>=2.7.1",
"mailjet-rest>=1.5.1",
"httpx[http2]>=0.28.1",
"itsdangerous>... | [] | [] | [] | [
"Homepage, https://vibetuner.alltuner.com/",
"Documentation, https://vibetuner.alltuner.com/",
"Repository, https://github.com/alltuner/vibetuner",
"Issues, https://github.com/alltuner/vibetuner/issues",
"Changelog, https://github.com/alltuner/vibetuner/blob/main/CHANGELOG.md"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T11:01:02.338090 | vibetuner-8.2.3-py3-none-any.whl | 136,457 | 03/55/85edd5563c00c551dd6cb99c7bf834f6620ad3e55de91b99414eedcf4266/vibetuner-8.2.3-py3-none-any.whl | py3 | bdist_wheel | null | false | aac128c45effe5b18a75a35663a93911 | af2c44c18400e68ef90b1288926296d73190d3470850df3e30d2dd0c5a29c219 | 035585edd5563c00c551dd6cb99c7bf834f6620ad3e55de91b99414eedcf4266 | null | [] | 268 |
2.4 | moysklad-api | 0.5.19a1 | Мой Склад API | <p align="center">
<a href="https://api.moysklad.ru"><img src="https://www.moysklad.ru/upload/logos/logoMS500.png" alt="MoyskladAPI"></a>
</p>
<div align="center">
<p align="center">
Асинхронная библиотека для работы с API МойСклад
</p>
[](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/moysklad-api/)
[](https://pypi.python.org/pypi/moysklad-api)
[]()
[](https://dev.moysklad.ru/doc/api/remap/1.2/)
</div>
> [!CAUTION]
> Библиотека находится в активной разработке и 100% **не рекомендуется для использования в продакшн среде**.
## Установка
```console
pip install moysklad-api
```
## Пример использования
```Python
import asyncio
from moysklad_api import MoyskladAPI, F
ms_api = MoyskladAPI(token="token")
async def main():
"""
Получение архивных товаров с пустым описанием
и заменой ссылки на поставщика объектом
`limit=None` — загрузить все элементы без ограничений
"""
products = await ms_api.get_products(
filters=[
F.archived == True,
F.description.empty(),
],
expand="supplier",
limit=None
)
for product in products.rows:
print(product)
if __name__ == "__main__":
asyncio.run(main())
```
| text/markdown | null | Andrei Serdiukov <serdukow1@gmail.com> | null | Andrei Serdiukov <serdukow1@gmail.com> | MIT | api, async, client, moysklad, мой склад | [
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"aiolimiter<2.0.0,>=1.2.1",
"httpx<0.29.0,>=0.28.1",
"pydantic<2.12.2,>=2.4.1",
"pre-commit<5.0.0,>=4.3.0; extra == \"dev\"",
"ruff<0.15.0,>=0.14.1; extra == \"dev\"",
"pre-commit<5.0.0,>=4.3.0; extra == \"lint\"",
"ruff<0.15.0,>=0.14.1; extra == \"lint\"",
"pytest-asyncio<2.0.0,>=1.2.0; extra == \"te... | [] | [] | [] | [
"Homepage, https://github.com/serdukow/moysklad-api",
"Documentation, https://github.com/serdukow/moysklad-api#readme",
"Repository, https://github.com/serdukow/moysklad-api"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T11:00:31.623397 | moysklad_api-0.5.19a1.tar.gz | 26,416 | fc/fd/83b2764639cd31d20f52b6a11449162e51e96be091315ca0fe9190be9e00/moysklad_api-0.5.19a1.tar.gz | source | sdist | null | false | cda91ac8e7a077791bb70098994e7a34 | e58591502995a93aed0ffee1e42d016cd04e5150e47b1dd4c4511a2a887e5110 | fcfd83b2764639cd31d20f52b6a11449162e51e96be091315ca0fe9190be9e00 | null | [
"LICENSE"
] | 249 |
2.3 | gaunt | 0.1.0 | Python SDK for logging LLM traces to an analytics scoring API. | # LLM Analytics Python SDK
Python SDK for collecting LLM app traces (chat, RAG, vision, structured output), standardizing them, and sending them to an Analytics Bank API for scoring.
## Features
- Pydantic v2 strict payload models.
- Sync and async clients via `httpx`.
- Built-in scoring tags via `ScoringTag`.
- Automatic UUID generation for `trace_id`.
## Installation
```bash
pip install gaunt
```
For local development:
```bash
pip install -e ".[dev]"
```
## Quickstart
```python
from gaunt import Client, ScoringTag
client = Client(
api_key="sk_live_xxx",
base_url="https://analytics-bank.example.com",
)
result = client.log(
project_id="project_123",
inputs={
"messages": [
{"role": "system", "content": "You are a concise assistant."},
{"role": "user", "content": "What is RAG?"},
],
"rag_context": [
{"content": "RAG combines retrieval and generation.", "source_id": "doc-1"},
],
},
outputs={
"raw": "RAG uses retrieved knowledge to ground generations.",
},
expected={"topic": "rag"},
metadata={"env": "prod"},
scoring_tags=[
ScoringTag.RAG_FAITHFULNESS,
ScoringTag.ANSWER_CORRECTNESS,
],
)
print(result)
client.close()
```
## Scoring Tags
- `ScoringTag.SCHEMA_VALIDITY` -> `score:schema_validity`
- `ScoringTag.RAG_FAITHFULNESS` -> `score:rag_faithfulness`
- `ScoringTag.VISION_HALLUCINATION` -> `score:vision_hallucination`
- `ScoringTag.TOXICITY` -> `score:toxicity`
- `ScoringTag.NUMERIC_SCORING` -> `score:numeric_scoring`
- `ScoringTag.ANSWER_CORRECTNESS` -> `score:answer_correctness`
## Payload Shape
The SDK emits payloads in this form:
```json
{
"project_id": "project_123",
"trace_id": "uuid...",
"inputs": {
"messages": [],
"images": [],
"rag_context": [],
"json_schema": {}
},
"outputs": {
"raw": "...",
"parsed": {}
},
"expected": {},
"metadata": {},
"config": {
"scoring_tags": ["score:rag_faithfulness", "score:schema_validity"]
}
}
```
## Testing
```bash
pytest -q
```
## Publishing
See `docs/publishing.md` for a release checklist and TestPyPI/PyPI upload commands.
| text/markdown | LLM Analytics Team | null | null | null | MIT | llm, sdk, analytics, rag, observability, evaluation | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: P... | [] | https://example.com/gaunt | null | >=3.9 | [] | [] | [] | [
"pydantic<3.0,>=2.0",
"httpx<1.0,>=0.24",
"pytest>=7.4; extra == \"dev\"",
"respx>=0.21; extra == \"dev\"",
"ruff>=0.5; extra == \"dev\"",
"mypy>=1.8; extra == \"dev\"",
"build>=1.2; extra == \"dev\"",
"twine>=5.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://example.com/gaunt",
"Repository, https://github.com/your-org/gaunt",
"Issues, https://github.com/your-org/gaunt/issues"
] | poetry/2.1.1 CPython/3.12.8 Darwin/24.6.0 | 2026-02-18T11:00:21.259357 | gaunt-0.1.0.tar.gz | 45,473 | 9c/5d/76f3b28b534be8d78ae75f43fa0cc41cf3fa94d33742281a7670fe8566c0/gaunt-0.1.0.tar.gz | source | sdist | null | false | 03a34b17093949f69fc6e1bb86859973 | fe3ddcd18fc6c2e5fc09acccf0ce569488df02cfc40a47ba2b4d3faa58bc3871 | 9c5d76f3b28b534be8d78ae75f43fa0cc41cf3fa94d33742281a7670fe8566c0 | null | [] | 285 |
2.4 | servicex-analysis-utils | 1.2.2 | A package with analysis tools for ServiceX. | # ServiceX analysis utils
This repository hosts tools that depend on the [ServiceX Client](https://github.com/ssl-hep/ServiceX_frontend/tree/master). These tools facilitate `ServiceX`'s general usage and offer specific features that replace parts of an analyser workflow.
### To install
```
pip install servicex-analysis-utils
```
#### Requirements
This package depends requires a `servicex.yml` configuration file granting access to one endpoint with a deployed ServiceX backend.
### This package contains:
#### `to_awk()`:
```
Load an awkward array from the deliver() output with uproot or uproot.dask.
Parameters:
deliver_dict (dict): Returned dictionary from servicex.deliver()
(keys are sample names, values are file paths or URLs).
dask (bool): Optional. Flag to load as dask-awkward array. Default is False
iterator(bool): Optional. Flag to materialize the data into arrays or to return iterables with uproot.iterate
**kwargs : Optional. Additional keyword arguments passed to uproot.dask, uproot.iterate and from_parquet
Returns:
dict: keys are sample names and values are awkward arrays, uproot generator objects or dask-awkward arrays.
```
#### `get-structure()`:
```
Creates and sends the ServiceX request from user inputed datasets to retrieve file stucture.
Calls print_structure_from_str() to dump the structure in a user-friendly format
Parameters:
datasets (dict,str,[str]): The datasets from which to print the file structures.
A name can be given as the key of each dataset in a dictionary
kwargs : Arguments to be propagated to print_structure_from_str, e.g filter_branch
```
Function can be called from the command line, e.g:
```
$ servicex-get-structure "mc23_13TeV:some-dataset-rucio-id" --filter_branch "truth"
```
## Documentation
The different functions are documented at [tryservicex.org](https://tryservicex.org/utils/).
To make updates to the documentation please see the [ServiceX DocGuide](https://github.com/ssl-hep/ServiceX_Website/blob/main/DocGuide.md) for more information.
| text/markdown | null | Artur Cordeiro Oudot Choi <acordeir@cern.ch> | null | null | BSD-3-Clause | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"awkward>=2.6",
"dask-awkward>=2024.12.2",
"servicex",
"uproot>=5.0",
"furo; extra == \"docs\"",
"myst-parser; extra == \"docs\"",
"sphinx-copybutton; extra == \"docs\"",
"sphinx>=5.0; extra == \"docs\"",
"miniopy-async==1.21.1; extra == \"test\"",
"numpy>=1.21; extra == \"test\"",
"pandas; extr... | [] | [] | [] | [
"Source Code, https://github.com/ssl-hep/ServiceX_analysis_utils",
"Issue Tracker, https://github.com/ssl-hep/ServiceX_analysis_utils/issues"
] | twine/6.0.1 CPython/3.12.8 | 2026-02-18T10:59:05.686206 | servicex_analysis_utils-1.2.2.tar.gz | 8,482 | 30/f2/0030bf913d016b139518d7e2d7e1b5f18ba52ccd0654317508b4ca1cb9f4/servicex_analysis_utils-1.2.2.tar.gz | source | sdist | null | false | 7f2b86b8f75814be3b2be092875cd9e7 | 17fcd04f92fa85eff603b7c9f7c52d9261c116813446e6b59622430194fadc9b | 30f20030bf913d016b139518d7e2d7e1b5f18ba52ccd0654317508b4ca1cb9f4 | null | [] | 295 |
2.4 | aioleviton | 0.2.7 | Async Python client for the Leviton My Leviton cloud API | # aioleviton
Async Python client for the Leviton My Leviton cloud API.
Supports LWHEM and DAU/LDATA Smart Load Centers with WebSocket real-time push and REST API fallback.
## Features
- Pure `asyncio` with `aiohttp` -- no blocking calls
- Accepts an injected `aiohttp.ClientSession` for connection pooling
- WebSocket real-time push notifications with automatic subscription management
- Full REST API coverage: authentication, device discovery, breaker control, energy history
- Typed data models with PEP 561 `py.typed` marker
- Support for both hub types: LWHEM (`IotWhem`) and DAU/LDATA (`ResidentialBreakerPanel`)
- Two-factor authentication (2FA) support
## Installation
```bash
pip install aioleviton
```
## Quick Start
```python
import aiohttp
from aioleviton import LevitonClient, LevitonWebSocket
async def main():
async with aiohttp.ClientSession() as session:
# Authenticate
client = LevitonClient(session)
auth = await client.login("user@example.com", "password")
# Discover devices
permissions = await client.get_permissions()
for perm in permissions:
if perm.residential_account_id:
residences = await client.get_residences(perm.residential_account_id)
for residence in residences:
whems = await client.get_whems(residence.id)
panels = await client.get_panels(residence.id)
# Get breakers for a LWHEM hub
for whem in whems:
breakers = await client.get_whem_breakers(whem.id)
cts = await client.get_cts(whem.id)
# Connect WebSocket for real-time updates
ws = LevitonWebSocket(
session=session,
token=auth.token,
user_id=auth.user_id,
user=auth.user,
token_created=auth.created,
token_ttl=auth.ttl,
)
await ws.connect()
# Subscribe to a hub (delivers all child breaker/CT updates)
await ws.subscribe("IotWhem", whem.id)
# Handle notifications
ws.on_notification(lambda data: print("Update:", data))
```
> **Note:** On LWHEM firmware 2.0.0+, hub subscriptions no longer deliver
> individual breaker updates. You must subscribe to each `ResidentialBreaker`
> separately. CT updates are still delivered via the hub subscription on all
> firmware versions.
## Debug Logging
```python
from aioleviton import enable_debug_logging
enable_debug_logging() # sets aioleviton logger to DEBUG
```
## Supported Devices
| Device | API Model | Hub Type |
|--------|-----------|----------|
| LWHEM (Whole Home Energy Module) | `IotWhem` | Wi-Fi hub |
| DAU / LDATA (Data Acquisition Unit) | `ResidentialBreakerPanel` | Wi-Fi hub |
| Smart Breaker Gen 1 (trip only) | `ResidentialBreaker` | Child of LWHEM or DAU |
| Smart Breaker Gen 2 (on/off) | `ResidentialBreaker` | Child of LWHEM or DAU |
| Current Transformer (CT) | `IotCt` | Child of LWHEM only |
| LSBMA Add-on CT | `ResidentialBreaker` | Virtual composite |
## Breaker Control
```python
# Trip a Gen 1 breaker (cannot turn back on remotely)
await client.trip_breaker(breaker_id)
# Turn on/off a Gen 2 breaker
await client.turn_on_breaker(breaker_id)
await client.turn_off_breaker(breaker_id)
# Blink LED on a breaker (toggle on/off)
await client.blink_led(breaker_id)
await client.stop_blink_led(breaker_id)
# Identify LED on a LWHEM hub (on only, no off)
await client.identify_whem(whem_id)
```
## Energy History
Energy history endpoints return consumption data for all devices in a residence.
Data is keyed by hub ID, then by breaker position and CT channel.
```python
# Daily energy (hourly data points)
day = await client.get_energy_for_day(
residence_id=123456,
start_day="2026-02-16",
timezone="America/Los_Angeles",
)
# Weekly energy (daily data points for 7 days)
week = await client.get_energy_for_week(
residence_id=123456,
start_day="2026-02-17",
timezone="America/Los_Angeles",
)
# Monthly energy (daily data points for billing month)
month = await client.get_energy_for_month(
residence_id=123456,
billing_day_in_month="2026-02-28",
timezone="America/Los_Angeles",
)
# Yearly energy (monthly data points for 12 months)
year = await client.get_energy_for_year(
residence_id=123456,
billing_day_in_end_month="2026-02-16",
timezone="America/Los_Angeles",
)
# Response structure:
# {
# "<hub_id>": {
# "residentialBreakers": {"<position>": [{x, timestamp, energyConsumption, totalCost, ...}]},
# "iotCts": {"<channel>": [...]},
# "totals": [...]
# },
# "totals": [...] # residence-level totals
# }
```
## Firmware Check
```python
# Check for available firmware updates
firmware = await client.check_firmware(
app_id="LWHEM",
model="AZ",
serial="1000_XXXX_XXXX",
model_type="IotWhem",
)
# Returns list of firmware objects with version, fileUrl, signature, hash, size, notes
for fw in firmware:
print(f"v{fw['version']}: {fw['fileUrl']}")
```
## License
MIT
| text/markdown | gtxaspec | null | null | null | null | null | [
"Development Status :: 4 - Beta",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"aiohttp>=3.9.0"
] | [] | [] | [] | [
"Homepage, https://github.com/gtxaspec/aioleviton",
"Repository, https://github.com/gtxaspec/aioleviton",
"Issues, https://github.com/gtxaspec/aioleviton/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:58:53.153352 | aioleviton-0.2.7.tar.gz | 16,690 | 0e/77/4b563193b1180e66e80fb431969cfbfe0c02cccb365c582553223fca851d/aioleviton-0.2.7.tar.gz | source | sdist | null | false | 40e34b1bf11a8b11cbe35b18825ccc84 | 5caf6f8275ef1f714a6c9bf440a8f103ccdea3fb650061768ecda431a002a049 | 0e774b563193b1180e66e80fb431969cfbfe0c02cccb365c582553223fca851d | MIT | [
"LICENSE"
] | 275 |
2.4 | rag-sentinel | 0.1.8 | RAG Evaluation Framework using Ragas metrics and MLflow tracking | # RAGSentinel
RAG Evaluation Framework using Ragas metrics and MLflow tracking.
## Installation
### 1. Create Virtual Environment
```bash
# Create project directory
mkdir my-rag-eval
cd my-rag-eval
# Create and activate virtual environment
python3 -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
```
### 2. Install Package
```bash
pip install rag-sentinel
```
## Quick Start
### 1. Initialize Project
```bash
rag-sentinel init
```
This creates:
- `.env` - LLM/Embeddings API keys
- `config.ini` - App settings and authentication
- `rag_eval_config.yaml` - Master configuration
- `test_dataset.csv` - Sample test dataset
### 2. Configure
**Edit `.env` file:**
- Add your LLM API keys (Azure OpenAI, OpenAI, or Ollama credentials)
- Set API endpoints and deployment names
**Edit `config.ini` file:**
- Set your RAG backend URL in `app_url`
- Set API paths for context and answer endpoints (`context_api_path`, `answer_api_path`)
- Configure authentication (cookie, bearer token, or API key)
- Set MLflow tracking URI (default: `http://127.0.0.1:5000`)
**Edit `test_dataset.csv` file:**
- Add your test queries in format: `query,ground_truth,chat_id`
- Example: `What is RAG?,RAG stands for Retrieval-Augmented Generation,1`
For detailed configuration help, see the comments in each config file.
### 3. Validate & Run
```bash
# Validate configuration
rag-sentinel validate
# Run evaluation
rag-sentinel run
```
Results will be available in the MLflow UI at the configured tracking URI.
## CLI Commands
```bash
# Initialize new project
rag-sentinel init
# Validate configuration
rag-sentinel validate
# Run evaluation (auto-starts MLflow)
rag-sentinel run
# Run without starting MLflow server
rag-sentinel run --no-server
# Overwrite existing config files
rag-sentinel init --force
# Check package version
pip show rag-sentinel
# Upgrade to latest version
pip install --upgrade rag-sentinel
```
## Evaluation Categories
Set `category` in `config.ini` to choose evaluation type:
### Simple (RAGAS Quality Metrics)
```ini
category = simple
```
- **Faithfulness** - Factual consistency of answer with context
- **Answer Relevancy** - How relevant the answer is to the question
- **Context Precision** - Quality of retrieved context
- **Answer Correctness** - Comparison against ground truth
### Guardrail (Security Metrics)
```ini
category = guardrail
```
- **Toxicity Score** - Detects toxic content in responses
- **Bias Score** - Detects biased content in responses
## Performance Metrics
Logged for all evaluation categories:
- **Avg Response Time** - Average API response time (ms)
- **P90 Latency** - 90th percentile latency (ms)
- **Queries Per Second** - Throughput (QPS)
## License
MIT
| text/markdown | RAGSentinel Team | null | null | null | MIT | rag, evaluation, ragas, mlflow, llm, ai | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"ragas>=0.2.0",
"mlflow>=2.9.0",
"pandas>=2.0.0",
"pyyaml>=6.0",
"requests>=2.31.0",
"python-dotenv>=1.0.0",
"langchain-openai>=0.0.5",
"langchain-ollama>=0.0.1",
"langchain-core>=0.1.0",
"datasets>=2.14.0",
"deepeval>=0.21.0"
] | [] | [] | [] | [
"Homepage, https://github.com/yourusername/rag-sentinel",
"Repository, https://github.com/yourusername/rag-sentinel"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-18T10:58:50.000596 | rag_sentinel-0.1.8.tar.gz | 16,942 | 96/d7/3903d3125165262efb05fb1481efaac79839b912c4c8b8908b4341d75048/rag_sentinel-0.1.8.tar.gz | source | sdist | null | false | cc8e9d7d7337924c4b063f5c9495beda | 71eb154f67de0e58fc4c0f972b3af946a65d8001f465c3b517416683a089b6f8 | 96d73903d3125165262efb05fb1481efaac79839b912c4c8b8908b4341d75048 | null | [
"LICENSE"
] | 272 |
2.4 | llama-cpp-pydist | 0.33.0 | A Python package for Llama CPP. | # Llama CPP
This is a Python package for Llama CPP ( https://github.com/ggml-org/llama.cpp ).
## Installation
You can install the pre-built wheel from the releases page or build it from source.
```bash
pip install llama-cpp-pydist
```
## Usage
This section provides a basic overview of how to use the `llama_cpp_pydist` library.
### Deploying Windows Binaries
If you are on Windows, the package attempts to automatically deploy pre-compiled binaries. You can also manually trigger this process.
```python
from llama_cpp import deploy_windows_binary
# Specify the target directory for the binaries
# This is typically within your Python environment's site-packages
# or a custom location if you prefer.
target_dir = "./my_llama_cpp_binaries"
if deploy_windows_binary(target_dir):
print(f"Windows binaries deployed successfully to {target_dir}")
else:
print(f"Failed to deploy Windows binaries or no binaries were found for your system.")
# Once deployed, you would typically add the directory containing llama.dll (or similar)
# to your system's PATH or ensure your application can find it.
# For example, if llama.dll is in target_dir/bin:
# import os
# os.environ["PATH"] += os.pathsep + os.path.join(target_dir, "bin")
```
## Conversion Library Installation
To perform Hugging Face to GGUF model conversions, you need to install additional Python libraries. You can install them via pip:
```bash
pip install transformers numpy torch safetensors sentencepiece
```
Alternatively, you can install them programmatically in Python:
```python
from llama_cpp.install_conversion_libs import install_conversion_libs
if install_conversion_libs():
print("Conversion libraries installed successfully.")
else:
print("Failed to install conversion libraries.")
```
### Converting Hugging Face Models to GGUF
This package provides a utility to convert Hugging Face models (including those using Safetensors) into the GGUF format, which is used by `llama.cpp`. This process leverages the conversion scripts from the underlying `llama.cpp` submodule.
**1. Install Conversion Libraries:**
Before converting models, ensure you have the necessary Python libraries. You can install them using a helper function:
```python
from llama_cpp import install_conversion_libs
if install_conversion_libs():
print("Conversion libraries installed successfully.")
else:
print("Failed to install conversion libraries. Please check the output for errors.")
```
**2. Convert the Model:**
Once the dependencies are installed, you can use the `convert_hf_to_gguf` function:
```python
from llama_cpp import convert_hf_to_gguf
# Specify the Hugging Face model name or local path
model_name_or_path = "TinyLlama/TinyLlama-1.1B-Chat-v1.0" # Example: A small model from Hugging Face Hub
# Or, a local path: model_name_or_path = "/path/to/your/hf_model_directory"
output_directory = "./converted_gguf_models" # Directory to save the GGUF file
output_filename = "tinyllama_1.1b_chat_q8_0.gguf" # Optional: specify a filename
quantization_type = "q8_0" # Example: 8-bit quantization. Common types: "f16", "q4_0", "q4_K_M", "q5_K_M", "q8_0"
print(f"Starting conversion for model: {model_name_or_path}")
success, result_message = convert_hf_to_gguf(
model_path_or_name=model_name_or_path,
output_dir=output_directory,
output_filename=output_filename, # Can be None to auto-generate
outtype=quantization_type
)
if success:
print(f"Model converted successfully! GGUF file saved at: {result_message}")
else:
print(f"Model conversion failed: {result_message}")
# The `result_message` will contain the path to the GGUF file on success,
# or an error message on failure.
```
This function will download the model from Hugging Face Hub if a model name is provided and it's not already cached locally by Hugging Face `transformers`. It then invokes the `convert_hf_to_gguf.py` script from `llama.cpp`.
For more detailed examples and advanced usage, please refer to the documentation of the underlying `llama.cpp` project and explore the examples provided there.
## Building and Development
For instructions on how to build the package from source, update the `llama.cpp` submodule, or other development-related tasks, please see [BUILDING.md](./BUILDING.md).
# Changelog
## 2026-02-18: Update to llama.cpp b8087
### Summary
Updated llama.cpp from b8053 to b8087, incorporating 28 upstream commits with breaking changes, new features, and performance improvements.
### Notable Changes
#### ⚠️ Breaking Changes
- **b8057**: ggml-cpu: FA add GEMM microkernel ([#19422](https://github.com/ggml-org/llama.cpp/pull/19422))
- This PR contains the following improvements for the tiled FA kernel
- Add a simd gemm for float32 in the tiled FA kernel.
- Tune tile sizes for larger context
- **b8075**: Remove annoying warnings (unused functions) ([#18639](https://github.com/ggml-org/llama.cpp/pull/18639))
- When using common.h as a library, these function produce annoying warnings about not being used.
- Using "static" linking for these also doesn't make much sense because it potentially increases executable size with no gains.
#### 🆕 New Features
- **b8059**: ggml : avoid UB in gemm ukernel + tests ([#19642](https://github.com/ggml-org/llama.cpp/pull/19642))
- cont #19422
- Reword the GEMM ukernel to not trip the compiler's aggressive loop optimization warnings. It's better to avoid the global pragma as it might be useful for other static analysis
- Add `test-backend-ops` with BS=75 to exercise the new tiled SIMD implementation
- **b8061**: cmake : check if KleidiAI API has been fetched ([#19640](https://github.com/ggml-org/llama.cpp/pull/19640))
- This commit addresses a build issue with the KleidiAI backend when building multiple cpu backends. Commmit
- 3a00c98584e42a20675b6569d81beadb282b0952 ("cmake : fix KleidiAI install target failure with EXCLUDE_FROM_ALL") introduced a change where FetchContent_Populate is called instead of FetchContent_MakeAvailable, where the latter does handle this case (it is idempotent but FetchContent_Populate is not).
- I missed this during my review and I should not have commited without verifying the CI failure, sorry about that.
- **b8068**: ggml: aarch64: Implement SVE in Gemm q4_k 8x8 q8_k Kernel ([#19132](https://github.com/ggml-org/llama.cpp/pull/19132))
- This PR introduces support for SVE (Scalable Vector Extensions) kernels for the q4_K_q8_K gemm using i8mm and vector instructions. ARM Neon support for this kernel added in PR [#16739](https://github.com/ggml-org/llama.cpp/pull/16739)
- **Verifying Feature**
- `----------------------------------------------------------------------------`
- **b8070**: models : deduplicate delta-net graphs for Qwen family ([#19597](https://github.com/ggml-org/llama.cpp/pull/19597))
- cont #19375
- Add `llm_build_delta_net_base` for common delta net builds. Currently used only by `qwen3next`
- Rename `llm_graph_context_mamba` -> `llm_build_mamba_base`
- **b8071**: Adjust workaround for ROCWMMA_FATTN/GFX9 to only newer ROCm veresions ([#19591](https://github.com/ggml-org/llama.cpp/pull/19591))
- Avoids issues with ROCm 6.4.4.
- Closes: https://github.com/ggml-org/llama.cpp/issues/19580
- Fixes: 6845f7f87 ("Add a workaround for compilation with ROCWMMA_FATTN and gfx9 (#19461)")
- **b8073**: Add support for Tiny Aya Models ([#19611](https://github.com/ggml-org/llama.cpp/pull/19611))
- This PR adds native support for the CohereLabs/tiny-aya family of models in llama.cpp. These models use a distinct BPE pre-tokenizer (tiny_aya) with a custom digit-grouping regex.
- Tagging @ngxson for visibility.
- **b8076**: feat: add proper batching to perplexity ([#19661](https://github.com/ggml-org/llama.cpp/pull/19661))
- This PR updates `llama-perplexity` to allow for batching similarly to how `llama-imatrix` works. The idea being that you can increase `--batch-size` / `--ubatch-size` to process multiple contexts chunks in a batch. This has limited application in VRAM-rich environments (eg, if you're running the entire model in VRAM) but it makes a huge difference when using models in a mixed CPU/GPU setup as it saves `n_seq` trips from the CPU RAM to GPU VRAM per batch.
- I've double-checked the before and after to make sure the resulting PPL and KLD look correct still.
- <details>
- **b8077**: convert_hf_to_gguf: add JoyAI-LLM-Flash tokenizer hash mapping to deepseek-v3 ([#19651](https://github.com/ggml-org/llama.cpp/pull/19651))
- adding hash for `jdopensource/JoyAI-LLM-Flash` mapping to existing `deepseek-v3`
- `DeepseekV3ForCausalLM` architecture already supported
- moved `GLM-4.7-Flash` entry together with the other `glm` entries
#### 🚀 Performance Improvements
- **b8053**: models : optimizing qwen3next graph ([#19375](https://github.com/ggml-org/llama.cpp/pull/19375))
- Rewording the ggml compute graph to avoid too many unnecessary copies.
- M2 Ultra:
- | Model | Test | t/s b7946 | t/s gg/qwen3-next-opt | Speedup |
- **b8058**: ggml-cpu: optimize ggml_vec_dot_bf16 for s390x ([#19399](https://github.com/ggml-org/llama.cpp/pull/19399))
- Similar to #18837, this pull request integrates the SIMD instruction set for BF16 on the s390x platform. We notice a 154.86% performance improvement for Prompt Processing. No performance difference was noticed for Token Generation.
- | model | size | params | backend | threads | mmap | test | t/s |
- | ------------------------------ | ---------: | ---------: | ---------- | ------: | ---: | --------------: | -------------------: |
- **b8064**: cuda: optimize iq2xxs/iq2xs/iq3xxs dequantization ([#19624](https://github.com/ggml-org/llama.cpp/pull/19624))
- While looking over quantizations I believe I found a few optimizations for iq2xxs/iq2xs/iq3xxs. With these changes, I get a 5-10% increase in flops in `test-backend-ops` for small `n`, and a few extra flops otherwise:
- load all 8 int8 for a grid position in one load
- calculate signs via popcnt instead of fetching from ksigns table
- **b8086**: opencl: optimize mean and sum_row kernels ([#19614](https://github.com/ggml-org/llama.cpp/pull/19614))
- This PR optimizes the mean op and sum_rows op for the OpenCL backend.
- **b8087**: opencl: refactor expm1 and softplus ([#19404](https://github.com/ggml-org/llama.cpp/pull/19404))
- This PR refactors the EXPM1 and Softplus OpenCL operators to improve code clarity and reduce duplication.
#### 🐛 Bug Fixes
- **b8056**: cmake: fix KleidiAI install target failure with EXCLUDE_FROM_ALL ([#19581](https://github.com/ggml-org/llama.cpp/pull/19581))
- Fix for the bug #19501 by adding `EXCLUDE_FROM_ALL` to the `FetchContent_Declare` call for KleidiAI. This properly excludes the KleidiAI library from both the `all` and `install` targets, preventing CMake install failures when building with `GGML_CPU_KLEIDIAI=ON`. The KleidiAI source files are still compiled directly into `libggml-cpu.so`, so functionality is preserved.
- **b8060**: context : fix output reorder with backend sampling ([#19638](https://github.com/ggml-org/llama.cpp/pull/19638))
- fix #19629
- Some of the sampling arrays could remain in invalid state after a sequence of enabling/disabling samplers.
- **b8069**: graph : fix KQ mask, lora, cvec reuse checks ([#19644](https://github.com/ggml-org/llama.cpp/pull/19644))
- cont #14482
- Graph reuse was never triggered for parallel decoding with non-unified KV cache due to incorrect check of the KQ mask shape.
- Also fix the checks for reusing lora and control vectors.
- **b8071**: Add a workaround for compilation with ROCWMMA_FATTN and gfx9 ([#19461](https://github.com/ggml-org/llama.cpp/pull/19461))
- There is an upstream problem [1] with AMD's LLVM 22 fork and rocWMMA 2.2.0 causing compilation issues on devices without native fp16 support (CDNA devices).
- The specialized types aren't resolved properly:
- ```c
- **b8083**: ggml: ggml-cpu: force-no-lto-for-cpu-feats ([#19609](https://github.com/ggml-org/llama.cpp/pull/19609))
- When LTO enabled in build environments it forces all builds to have LTO in place. But feature detection logic is fragile, and causing Illegal instruction errors with lto. This disables LTO for the feature detection code to prevent cross-module optimization from inlining architecture-specific instructions into the score function. Without this, LTO can cause SIGILL when loading backends on older CPUs (e.g., loading power10 backend on power9 crashes before feature check runs).
- Please also see https://salsa.debian.org/deeplearning-team/ggml/-/merge_requests/6 for more information about the issue we saw on ppc64el builds with LTO enabled in ubuntu.
- *Make sure to read the [contributing guidelines](https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md) before submitting a PR*
### Additional Changes
8 minor improvements: 1 documentation, 3 examples, 4 maintenance.
### Full Commit Range
- b8053 to b8087 (28 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8053...b8087
---
## 2026-02-14: Update to llama.cpp b8040
### Summary
Updated llama.cpp from b8027 to b8040, incorporating 11 upstream commits with breaking changes, new features, and performance improvements.
### Notable Changes
#### ⚠️ Breaking Changes
- **b8027**: llama : remove deprecated codecvt ([#19565](https://github.com/ggml-org/llama.cpp/pull/19565))
- Using the same conversion function ensures a consistent matching between the regex pattern and the text
- **b8037**: common : update download code ([#19573](https://github.com/ggml-org/llama.cpp/pull/19573))
- This PR removes the legacy migration code for etag and forces a download if no etag file is found.
#### 🆕 New Features
- **b8028**: Kimi Linear fix conv state update ([#19531](https://github.com/ggml-org/llama.cpp/pull/19531))
- *Make sure to read the [contributing guidelines](https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md) before submitting a PR*
- The current implementation has incorrect conv state update such that it has state corruption when running parallel in llama-server. This is fixed in this PR.
- ```
- **b8030**: CUDA: Do not mutate cgraph for fused ADDs ([#19566](https://github.com/ggml-org/llama.cpp/pull/19566))
- 1. We should try to minimize in-place changes to the incoming ggml_cgraph where possible (those should happen in a backends' `graph_optimize` function)
- 2. Modifying in-place leads to an additional, unnecessary graph capture step as we store the properties before modifying the graph in-place in the cuda-backend: We hit `ggml_cuda_graph_node_set_properties` via `ggml_cuda_graph_update_required` before entering `ggml_cuda_graph_evaluate_and_capture`.
- Isolated from #19521
- **b8036**: model: support GLM MoE DSA arch (NOTE: indexer is not yet supported) ([#19460](https://github.com/ggml-org/llama.cpp/pull/19460))
- Ref upstream vllm PR: https://github.com/vllm-project/vllm/pull/34124
- > [!IMPORTANT]
- > This PR allows converting safetensors to GGUF while keeping the indexer tensors (for deepseek sparse attention), but they are left unused by the cpp code. **The quality will be suboptimal**
#### 🚀 Performance Improvements
- **b8038**: vulkan: restore -inf check in FA shaders ([#19582](https://github.com/ggml-org/llama.cpp/pull/19582))
- For #19523.
- I verified the performance is restored with llama-batched-bench.
- **b8040**: hexagon: further optimizations and refactoring for flash attention ([#19583](https://github.com/ggml-org/llama.cpp/pull/19583))
- The PR includes some more refactoring and optimizations for flash attention op/kernel:
- Local fa_context that stores all precomputed values
- More HVX usage (hvx_vec_expf, ...)
#### 🐛 Bug Fixes
- **b8034**: fix vulkan ggml_acc only works in 3d but not 4d ([#19426](https://github.com/ggml-org/llama.cpp/pull/19426))
- *Make sure to read the [contributing guidelines](https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md) before submitting a PR*
- Discovered ggml_acc for vulkan only works in 3d not 4d while working on
- https://github.com/ggml-org/llama.cpp/pull/18792
- **b8035**: ggml-cpu: arm64: Fix wrong memcpy length for q4_K block_interleave == 4 ([#19575](https://github.com/ggml-org/llama.cpp/pull/19575))
- https://github.com/ggml-org/llama.cpp/issues/19561 reports issues with the stack for Q4_K.
- I can't reproduce the issue locally, but the `make_block_q4_Kx8` function would write past the buffer size 4 extra bytes, which could be the issue.
- @taronaeo, since you found the problem, are you able to check if this patch fixes it?
### Additional Changes
2 minor improvements: 1 examples, 1 maintenance.
- **b8033**: cli : support --verbose-prompt ([#19576](https://github.com/ggml-org/llama.cpp/pull/19576))
- Useful when debugging templates.
- **b8032**: CUDA: loop over ne2*ne3 in case it overflows ([#19538](https://github.com/ggml-org/llama.cpp/pull/19538))
### Full Commit Range
- b8027 to b8040 (11 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8027...b8040
---
## 2026-02-13: Update to llama.cpp b8018
### Summary
Updated llama.cpp from b7958 to b8018, incorporating 44 upstream commits with breaking changes and new features.
### Notable Changes
#### ⚠️ Breaking Changes
- **b8004**: common : remove unused token util functions ([#19506](https://github.com/ggml-org/llama.cpp/pull/19506))
- This commit removes two unused functions `common_lcp` and `common_lcs`. The last usage of these functions was removed in Commit 33eff4024084d1f0c8441b79f7208a52fad79858 ("server : vision support via libmtmd") and are no longer used anywhere in the codebase.
- **b8007**: common : replace deprecated codecvt using parse_utf8_codepoint ([#19517](https://github.com/ggml-org/llama.cpp/pull/19517))
#### 🆕 New Features
- **b7964**: Support Step3.5-Flash ([#19283](https://github.com/ggml-org/llama.cpp/pull/19283))
- This PR adds support for the Step3.5-Flash model architecture.
- github:
- https://github.com/stepfun-ai/Step-3.5-Flash/tree/main
- **b7966**: metal : consolidate bin kernels ([#19390](https://github.com/ggml-org/llama.cpp/pull/19390))
- Refactor and consolidate the implementation of the binary Metal kernels.
- | Model | Test | t/s master | t/s gg/metal-bin-opt | Speedup |
- |:-------------------------|:-------|-------------:|-----------------------:|----------:|
- **b7972**: CUDA: Fix non-contig rope ([#19338](https://github.com/ggml-org/llama.cpp/pull/19338))
- This is a port of https://github.com/ggml-org/llama.cpp/pull/19299 to the CUDA backend, which should fix the broken logic revealed by tests added in https://github.com/ggml-org/llama.cpp/pull/19296
- Thanks @jeffbolznv for the work in #19299
- **b7973**: [Model] Qwen3.5 dense and MoE support (no vision) ([#19435](https://github.com/ggml-org/llama.cpp/pull/19435))
- I've gotten a bit tired of Llama.cpp missing all the zero-day releases, so this time I decided to make (or, more precisely, instructed Opus 4.6 to make, based on reference implementations and my guidelines for model adaptation) a conversion based on the Transformers PR ( https://github.com/huggingface/transformers/pull/43830/changes ). It's mostly based on Qwen3Next, but it's rebased on the common-delta-net PR ( #19125 ).
- Here are the mock models I generated to test it: https://huggingface.co/ilintar/qwen35_testing/tree/main
- Here are the conversion results from `causal-verify-logits`:
- **b7974**: cmake: add variable to skip installing tests ([#19370](https://github.com/ggml-org/llama.cpp/pull/19370))
- When packaging downstream, there's usually little point in installing test. The default behaviour remains the same.
- **b7976**: [Model] Qwen3.5 dense and MoE support (no vision) ([#19435](https://github.com/ggml-org/llama.cpp/pull/19435))
- I've gotten a bit tired of Llama.cpp missing all the zero-day releases, so this time I decided to make (or, more precisely, instructed Opus 4.6 to make, based on reference implementations and my guidelines for model adaptation) a conversion based on the Transformers PR ( https://github.com/huggingface/transformers/pull/43830/changes ). It's mostly based on Qwen3Next, but it's rebased on the common-delta-net PR ( #19125 ).
- Here are the mock models I generated to test it: https://huggingface.co/ilintar/qwen35_testing/tree/main
- Here are the conversion results from `causal-verify-logits`:
- **b7976**: revert : "[Model] Qwen3.5 dense and MoE support (no vision) (#19435)" ([#19453](https://github.com/ggml-org/llama.cpp/pull/19453))
- cont #19435
- Taking a step back to implement support for Qwen3.5 properly.
- **b7981**: chat: fix case where template accepts type content only ([#19419](https://github.com/ggml-org/llama.cpp/pull/19419))
- Fix chat template of PaddleOCR-VL, which requires content to be an array (see https://github.com/ggml-org/llama.cpp/pull/18825)
- This should be able to handle these case:
- Template supports ONLY string content
- **b7982**: cuda : extend GGML_OP_PAD to work with non-cont src0 ([#19429](https://github.com/ggml-org/llama.cpp/pull/19429))
- Extend CUDA support
- Remove redundant assert in CPU implementation
- Add permuted PAD tests
- **b7983**: CANN: Support MUL_MAT_ID in ACL graph ([#19228](https://github.com/ggml-org/llama.cpp/pull/19228))
- Implement ggml_cann_mul_mat_id_quant function to support quantized matrix
- multiplication for Mixture of Experts (MoE) architectures on CANN backend.
- Key features:
- **b7988**: ggml-cpu: arm64: q6_K repack gemm and gemv (and generic) implementations (dotprod) ([#19360](https://github.com/ggml-org/llama.cpp/pull/19360))
- https://github.com/ggml-org/llama.cpp/pull/19356 but Q6_K.
- PR contents:
- New generics for q6_K_8x4
- **b7991**: [WebGPU] Plug memory leaks and free resources on shutdown ([#19315](https://github.com/ggml-org/llama.cpp/pull/19315))
- This diff destroys `wgpu::Buffer`s and buffer pools on shutdown. It also fixes memory leaks on the heap, where we allocate `backend`, `backend_ctx`, `buffer_ctx`, and `decisions` on the heap but never delete them. These are either explicitly deleted or changed to be smart pointers.
- We implement destructors for our buffer pool structs, `webgpu_context` struct and `webgpu_global_context` struct. Since `webgpu_global_context` is a refcounted smart pointer, it will destruct automatically when all thread contexts have been destroyed.
- <img width="1191" height="220" alt="Screenshot 2026-02-03 at 3 56 11 PM" src="https://github.com/user-attachments/assets/3810b613-4920-4388-bdff-94ef306e8a06" />
- **b7992**: CUDA: Update CCCL-tag for 3.2 to final release from RC ([#19486](https://github.com/ggml-org/llama.cpp/pull/19486))
- [CCCL 3.2 has been released](https://github.com/NVIDIA/cccl/releases/tag/v3.2.0
- ) since it was added to llama.cpp as part of the backend-sampling PR (#17004), and it makes sense to update from RC to final released version.
- **b7994**: metal : consolidate unary ops ([#19490](https://github.com/ggml-org/llama.cpp/pull/19490))
- cont #19390
- Common implementation of the unary kernels
- Extend support for non-cont src0
- **b7995**: ggml : extend bin bcast for permuted src1 ([#19484](https://github.com/ggml-org/llama.cpp/pull/19484))
- Remove CPU asserts preventing `src1` from being permuted
- Update CUDA kernels to support permuted `src1`
- Add tests to exercise `src1` permutation
- **b7998**: hexagon: Add ARGSORT, DIV, SQR, SQRT, SUM_ROWS, GEGLU ([#19406](https://github.com/ggml-org/llama.cpp/pull/19406))
- Catching up on the Op coverage for the Hexagon backend.
- This PR improves Op coverage for Gemma-3N, LFM2 and other models.
- All new Ops pass `test-backend-ops` (mostly in f32).
- **b8001**: metal : extend l2_norm support for non-cont src0 ([#19502](https://github.com/ggml-org/llama.cpp/pull/19502))
- Support non-cont `src0`
- Support `ne00` non-multiple of 4
- **b8005**: ggml : unary ops support non-cont src0 + metal F16 unary ops ([#19511](https://github.com/ggml-org/llama.cpp/pull/19511))
- cont #19490
- **b8006**: opencl: add general Q6_K mm and Q4_K mv ([#19347](https://github.com/ggml-org/llama.cpp/pull/19347))
- Although still slow, this should make Q4_K_M a bit more usable. Q4_K mv is not flattened yet. More specialized Q6_K and Q4_K mm and mv using transposed layouts will be added in follow up PRs.
- **b8008**: hexagon: further optimization and tuning of matmul and dot kernels ([#19407](https://github.com/ggml-org/llama.cpp/pull/19407))
- This PR adds support for computing 2x2 (2 rows x 2 cols) dot products in parallel.
- Mostly helps with the Prompt processing that shows 10+ T/S gains for most models.
- Here are some numbers with Qwen3.
- **b8012**: metal : update sum_rows kernel to support float4 ([#19524](https://github.com/ggml-org/llama.cpp/pull/19524))
#### 🐛 Bug Fixes
- **b7958**: MSVC regex fix ([#19340](https://github.com/ggml-org/llama.cpp/pull/19340))
- Fix MSVC regex error:
- ```
- Regex error: regex_error(error_stack): There was insufficient memory to determine whether the regular expression could match the specified character sequence.
- **b7965**: metal : fix event synchronization in cpy_tensor_async ([#19402](https://github.com/ggml-org/llama.cpp/pull/19402))
- cont #18966
- Was incorrectly recording the event in a separate command buffer. Fixes the synchronization issue reported in https://github.com/ggml-org/llama.cpp/pull/19378#issuecomment-3862086179
- **b7987**: ggml: use noexcept overload for is_regular_file in backend registration ([#19452](https://github.com/ggml-org/llama.cpp/pull/19452))
- using noexcept std::filesystem::directory_entry::is_regular_file overload prevents abnormal termination upon throwing an error (as caused by symlinks to non-existant folders on linux)
- fixes issue #18560
- Searched for existing PRs for this issue
- **b7989**: test: fix IMROPE perf test case ([#19465](https://github.com/ggml-org/llama.cpp/pull/19465))
- Ref: https://github.com/ggml-org/llama.cpp/issues/19464
- **b7997**: fix: correct typos 'occured' and 'occurences' ([#19414](https://github.com/ggml-org/llama.cpp/pull/19414))
- Fixes minor spelling typos in comments:
- occurred (1 instance in llama.h)
- occurrences (3 instances in ngram-map.h and ngram-map.cpp)
- **b7999**: common : improve download error reporting ([#19491](https://github.com/ggml-org/llama.cpp/pull/19491))
- While debugging the new `cpp-httplib`, the current errors were unusable...
- Here is a small patch to make life easier for the next person dealing with HTTP issues :)
- **b8011**: Add a workaround for compilation with ROCWMMA_FATTN and gfx9 ([#19461](https://github.com/ggml-org/llama.cpp/pull/19461))
- There is an upstream problem [1] with AMD's LLVM 22 fork and rocWMMA 2.2.0 causing compilation issues on devices without native fp16 support (CDNA devices).
- The specialized types aren't resolved properly:
- ```c
- **b8018**: vendor : update cpp-httplib ([#19537](https://github.com/ggml-org/llama.cpp/pull/19537))
- The 0.32 version had important bug fixes, but it wasn’t working for us. We need the latest patches.
### Additional Changes
13 minor improvements: 3 documentation, 7 examples, 3 maintenance.
### Full Commit Range
- b7958 to b8018 (44 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b7958...b8018
---
## 2026-02-06: Update to llama.cpp b7955
### Summary
Updated llama.cpp from b7926 to b7955, incorporating 24 upstream commits with breaking changes, new features, and performance improvements.
### Notable Changes
#### ⚠️ Breaking Changes
- **b7931**: ggml-virtgpu: make the code thread safe ([#19204](https://github.com/ggml-org/llama.cpp/pull/19204))
- This PR improves the code of the ggml-virtgpu backend to make it thread safe, by using mutex for accessing the host<>guest shared memory buffers, and by pre-caching, during the initialization, the constant values queried from the backend.
- The unused `buffer_type_is_host` method is also deprecated.
- **b7933**: spec : fix the check-rate logic of ngram-simple ([#19261](https://github.com/ggml-org/llama.cpp/pull/19261))
- fix #19231
- For the `spec-simple` method, we don't need to keep track of the last length to rate-limit the generations. We can simply use an incremental counter. This makes the speculator work with "Regenerate" of last message or branching the conversation from previous messages.
- Also, removed `struct common_ngram_simple_state` - seemed a bit redundant.
#### 🆕 New Features
- **b7928**: ci : add sanitizer runs for server ([#19291](https://github.com/ggml-org/llama.cpp/pull/19291))
- Reenable the server sanitizer builds + runs. The thread sanitizer is quite slow, so remains disabled for now.
- https://github.com/ggerganov/tmp2/actions/runs/21629674042
- **b7929**: metal : add solve_tri ([#19302](https://github.com/ggml-org/llama.cpp/pull/19302))
- Add `GGML_OP_SOLVE_TRI` implementation for Metal.
- | Model | Test | t/s master | t/s gg/metal-solve-tri | Speedup |
- |:-----------------------|:-------|-------------:|-------------------------:|----------:|
- **b7935**: tests : add non-cont, inplace rope tests ([#19296](https://github.com/ggml-org/llama.cpp/pull/19296))
- ref https://github.com/ggml-org/llama.cpp/pull/18986#issuecomment-3841942982
- ref https://github.com/ggml-org/llama.cpp/issues/19128#issuecomment-3807441909
- ref https://github.com/ggml-org/llama.cpp/issues/19292
- **b7941**: vendor : add missing llama_add_compile_flags ([#19322](https://github.com/ggml-org/llama.cpp/pull/19322))
- ~Hopefully fixes CI~Ensure `httplib` and `boringssl`/`libressl` are built with sanitizer options, see https://github.com/ggml-org/llama.cpp/pull/19291#discussion_r2761613566
- **b7946**: metal : add diag ([#19330](https://github.com/ggml-org/llama.cpp/pull/19330))
- Add implementation for GGML_OP_DIAG for the Metal backend
#### 🚀 Performance Improvements
- **b7930**: ggml-cpu: use LUT for converting e8->f32 scales on x86 ([#19288](https://github.com/ggml-org/llama.cpp/pull/19288))
- `perf` showed the e8m0->f32 function as a bottleneck. Use a LUT instead. Tested only on x86
- | Model | Test | t/s topk-cuda-refactor | t/s mxfp4-cpu-scale | Speedup |
- |:----------------------|:-------|-------------------------:|----------------------:|----------:|
- **b7951**: metal : adaptive CPU/GPU interleave based on number of nodes ([#19369](https://github.com/ggml-org/llama.cpp/pull/19369))
- Put a bit more work on the main thread when encoding the graph. This helps to interleave better the CPU/GPU work, especially for larger graphs.
- | Model | Test | t/s master | t/s gg/metal-adaptive-cpu-interleave | Speedup |
- |:-------------------------|:-------|-------------:|---------------------------------------:|----------:|
- **b7954**: metal : skip loading all-zero mask ([#19337](https://github.com/ggml-org/llama.cpp/pull/19337))
- Similar optimization as in #19281 to skip loading the all-zero mask blocks.
- | Model | Test | t/s master | t/s gg/metal-fa-mask-zero-opt | Speedup |
- |:----------------------|:--------|-------------:|--------------------------------:|----------:|
#### 🐛 Bug Fixes
- **b7926**: vulkan: disable coopmat1 flash attention on Nvidia Turing ([#19290](https://github.com/ggml-org/llama.cpp/pull/19290))
- See https://github.com/ggml-org/llama.cpp/pull/19075#issuecomment-3820716090
- **b7927**: sampling : delegate input allocation to the scheduler ([#19266](https://github.com/ggml-org/llama.cpp/pull/19266))
- fix #18622
- alt #18636
- Merge the sampler inputs into the main graph. This way the backend scheduler is responsible for allocating the memory which makes backend sampling compatible with pipeline parallelism
- **b7936**: model: (qwen3next) correct vectorized key_gdiff calculation ([#19324](https://github.com/ggml-org/llama.cpp/pull/19324))
- Testing with the provided prompt from https://github.com/ggml-org/llama.cpp/issues/19305
- <img width="837" height="437" alt="image" src="https://github.com/user-attachments/assets/54f19beb-a9d0-4f10-bc33-747057f36fe7" />
- **b7938**: debug: make common_debug_print_tensor readable ([#19331](https://github.com/ggml-org/llama.cpp/pull/19331))
- Now using 4-space indentation
- The log is output to stdout, so that I can do `llama-eval-callback ... > debug.log`
- ```
- **b7940**: vendor: update cpp-httplib version ([#19313](https://github.com/ggml-org/llama.cpp/pull/19313))
- ref: #19017
- Sync the `cpp-httplib` library to fix #19017.
- **b7942**: Fix missing includes in metal build ([#19348](https://github.com/ggml-org/llama.cpp/pull/19348))
- Since commit https://github.com/ggml-org/llama.cpp/commit/6fdddb498780dbda2a14f8b49b92d25601e14764, I get errors when building on Mac.
- This PR adds the missing includes for `mutex` and `string` to fix the build.
- ```
- **b7943**: vulkan: fix non-contig rope ([#19299](https://github.com/ggml-org/llama.cpp/pull/19299))
- For #19296.
- **b7945**: vulkan: fix GPU deduplication logic. ([#19222](https://github.com/ggml-org/llama.cpp/pull/19222))
- As reported in https://github.com/ggml-org/llama.cpp/issues/19221, the (same uuid, same driver) logic is problematic for windows+intel igpu.
- Let's just avoid filtering for MoltenVK which is apple-specific, and keep the logic the same as before 88d23ad5 - just dedup based on UUID.
- Verified that MacOS + 4xVega still reports 4 GPUs with this version.
- **b7952**: cuda : cuda graphs now compare all node params ([#19383](https://github.com/ggml-org/llama.cpp/pull/19383))
- ref https://github.com/ggml-org/llama.cpp/pull/19338#issuecomment-3852298933
- This should fix the CUDA graph usage logic when the ops have variable op params. This issue is most pronounced during `test-backend-ops`.
### Additional Changes
5 minor improvements: 1 examples, 4 maintenance.
- **b7932**: completion : simplify batch (embd) processing ([#19286](https://github.com/ggml-org/llama.cpp/pull/19286))
- This commit simplifies the processing of embd by removing the for loop that currently exists which uses params.n_batch as its increment. This commit also removes the clamping of n_eval as the size of embd is always at most the size of params.n_batch.
- The motivation is to clarify the code as it is currently a little confusing when looking at this for loop in isolation and thinking that it can process multiple batches.
- **b7944**: vulkan: Set k_load_shmem to false when K is too large ([#19301](https://github.com/ggml-org/llama.cpp/pull/19301))
- See https://github.com/ggml-org/llama.cpp/pull/19075/changes#r2726146004.
- ```
- Z:\github\jeffbolznv\llama.cpp\build\bin\RelWithDebInfo>llama-bench.exe -fa 1 -m c:\models\GLM-4.7-Flash-Q4_K_M.gguf -p 512 -n 128 -d 0,4096,16384
- **b7947**: vendor : update BoringSSL to 0.20260204.0 ([#19333](https://github.com/ggml-org/llama.cpp/pull/19333))
- **b7950**: vulkan: Preprocess FA mask to detect all-neg-inf and all-zero. ([#19281](https://github.com/ggml-org/llama.cpp/pull/19281))
- Write out a 2-bit code per block and avoid loading the mask when it matches these two common cases.
- Apply this optimization when the mask is relatively large (i.e. prompt processing).
- ```
- **b7955**: vulkan: make FA mask/softcap enables spec constants ([#19309](https://github.com/ggml-org/llama.cpp/pull/19309))
- ~This is stacked on #19281.~ (merged)
- This allows the compiler to do a bit better at overlapping loads and math (e.g. loading V can start while computing Q*K^t is still happening). Worth a couple percent for coopmat2, less for coopmat1/scalar.
- ```
### Full Commit Range
- b7926 to b7955 (24 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b7926...b7955
---
## 2026-02-03: Update to llama.cpp b7921
### Summary
Updated llama.cpp from b7907 to b7921, incorporating 11 upstream commits with new features.
### Notable Changes
#### 🆕 New Features
- **b7907**: ggml-backend: fix async set/get fallback sync ([#19179](https://github.com/ggml-org/llama.cpp/pull/19179))
- While working on an implementation for backend-agnostic tensor parallelism I found what I believe to be a bug in the ggml backend code. For a minimal implementation I did at first not implement `set_tensor_async` and `get_tensor_async` assuming that I could just rely on the synchronous fallback and implement those later. However, `set_tensor_async` and `get_tensor_async` do not call `ggml_backend_synchronize` for their fallback so I got incorrect results. This PR adds the corresponding calls.
- **b7909**: metal : support virtual devices ([#18919](https://github.com/ggml-org/llama.cpp/pull/18919))
- Support virtual Metal devices. Allows simulating multi-GPU environments on Mac using the new `GGML_METAL_DEVICES` environment variable.
- ```bash
- GGML_METAL_DEVICES=4 ./bin/llama-completion -m [model.gguf]
- **b7919**: support infill for Falcon-H1-Tiny-Coder ([#19249](https://github.com/ggml-org/llama.cpp/pull/19249))
- Added FIM tokens used in Falcon-H1-Tiny-Coder (see https://tiiuae-tiny-h1-blogpost.hf.space/#fim-format, https://huggingface.co/tiiuae/Falcon-H1-Tiny-Coder-90M/blob/main/tokenizer_config.json#L1843) to make the llama-server `POST /infill` handle work.
- **b7921**: ggml: added cleanups in ggml_quantize_free ([#19278](https://github.com/ggml-org/llama.cpp/pull/19278))
- Add missing cleanup calls for IQ2_S, IQ1_M quantization types and IQ3XS with 512 blocks during quantization cleanup.
#### 🐛 Bug Fixes
- **b7917**: opencl: refactor some ops, concat, repeat, tanh and scale ([#19226](https://github.com/ggml-org/llama.cpp/pull/19226))
- Gemma-3n-E2B and Gemma-3n-E4B have been producing weird (not really gibberish but apparently not correct) output. Ended up refactoring these ops and the issue is now fixed. In addition, this refactor also improves perf a bit.
- On X Elite,
- `gemma-3n-E2B-it-Q8_0`,
### Additional Changes
6 minor improvements: 4 documentation, 1 examples, 1 maintenance.
### Full Commit Range
- b7907 to b7921 (11 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b7907...b7921
---
## 2026-02-02: Update to llama.cpp b7907
### Summary
Updated llama.cpp from b7885 to b7907, incorporating 14 upstream commits with breaking changes and new features.
### Notable Changes
#### ⚠️ Breaking Changes
- **b7903**: Remove pipeline cache mutexes ([#19195](https://github.com/ggml-org/llama.cpp/pull/19195))
- Now that `webgpu_context` is per-thread, we can remove mutexes from pipeline caches. We cannot remove mutexes from `webgpu_buf_pool` since they are allocated and freed in callback threads, and we cannot remove the mutex from the memset buffer pool since it is shared by all ggml buffers.
#### 🆕 New Features
- **b7885**: tests : add GQA=20 FA test ([#19095](https://github.com/ggml-org/llama.cpp/pull/19095))
- Might be a good idea to have a test that exercises GQA=20 in order to catch any potential regressions.
- **b7895**: lookahead : add example for lookahead decoding ([#4207](https://github.com/ggml-org/llama.cpp/pull/4207))
- ref #4157
- Think this should implement the approach from: https://lmsys.org/blog/2023-11-21-lookahead-decoding/
- The approach requires large batches to be decoded, which in turn requires a lot of FLOPS even for single stream
- **b7895**: Prompt lookup decoding ([#4484](https://github.com/ggml-org/llama.cpp/pull/4484))
| text/markdown | Shamit Verma | oss@shamit.in | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: OS Independent"
] | [] | https://github.com/shamitv/llama_cpp | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Changelog, https://github.com/shamitv/llama_cpp/blob/main/CHANGELOG.md",
"Source, https://github.com/shamitv/llama_cpp",
"Issues, https://github.com/shamitv/llama_cpp/issues"
] | twine/6.1.0 CPython/3.12.3 | 2026-02-18T10:58:17.745072 | llama_cpp_pydist-0.33.0.tar.gz | 56,230,646 | 27/50/90041c9cab79a2f12e6ae379588b4fdce813906277e18f2a2c022f2949da/llama_cpp_pydist-0.33.0.tar.gz | source | sdist | null | false | e982f51a6a661c41289bd3c996badd18 | aa7df4fe992eaaa83cc37ed37ba41dc6ceb7e94f7602f9b96390557de2866a2e | 275090041c9cab79a2f12e6ae379588b4fdce813906277e18f2a2c022f2949da | null | [
"LICENSE"
] | 284 |
2.4 | scrapli-scp | 0.1.0 | scrapli_scp | ===========
Scrapli SCP
===========
Welcome to Scrapli SCP project!
This project is about to add smart SCP capability to Scrapli based connections.
By smart, I mean various checks before and after the file copy to ensure the file copy is possible
and successful.
These are the checks done by default:
#. checksum
#. existence of file at destination (also with hash)
#. available space at destination
#. scp enablement on device (and tries to turn it on if needed)
#. restore configuration after transfer if it was changed
#. check MD5 after transfer
Requirements
------------
``scrapli``, ``scrapli-community``, ``asyncssh``, ``aiofiles``
Installation
------------
.. code-block:: console
$ pip install scrapli-scp
Simple example
--------------
You can find it in ``test`` folder but the main part:
.. code-block:: python
async with AsyncScrapli(**device) as conn:
scp = AsyncSrapliSCP(conn)
result = await scp.file_transfer("put", src=filename, dst=".", force_scp_config=True)
print(result)
Progress bar example
--------------------
.. code-block:: python
from rich.progress import Progress
with Progress(refresh_per_second=100) as progress:
task = progress.add_task("Getting config...")
def progress_handler(srcpath: bytes, dstpath: bytes, copied: int, total: int): # arg signature is important!
progress.update(task, completed=copied, total=total, description=dstpath.decode())
async with AsyncScrapli(**device) as conn:
scp: AsyncSCPFortiOS = AsyncSrapliSCP(conn)
result = await scp.get_config(
filename=filename,
overwrite=True,
force_scp_config=True,
progress_handler=progress_handler
)
print(result)
| text/x-rst | null | Viktor Kertesz <vkertesz2@gmail.com> | null | null | null | null | [
"License :: OSI Approved :: MIT License"
] | [] | null | null | >=3.6 | [] | [] | [] | [
"scrapli",
"scrapli-community",
"asyncssh",
"aiofiles",
"flit<4,>=3.2; extra == \"dev\""
] | [] | [] | [] | [
"Home, https://github.com/realvitya/scrapli_scp"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:56:43.468980 | scrapli_scp-0.1.0.tar.gz | 13,636 | 85/b7/234b7e32c802ad7c9d385dbe942eaac54a4ca5e43e5ec0bde550cede46fc/scrapli_scp-0.1.0.tar.gz | source | sdist | null | false | 998c20b4006cb9f40a42e7e48cb3ee22 | d8e08b5990e941d6f3bc8de6530ab71186136a3ccebac6e60adf4b8306242f2c | 85b7234b7e32c802ad7c9d385dbe942eaac54a4ca5e43e5ec0bde550cede46fc | null | [
"LICENSE"
] | 276 |
2.4 | claude-jacked | 0.7.5 | Smart reviewers, commands, and session search for Claude Code | # claude-jacked
**A control panel for Claude Code.** Smart reviewers, security automation, session search, and a web dashboard to manage it all — without touching a config file.

---
## What You Get
- **Stop clicking "approve" on every terminal command** — Claude Code asks permission for every bash command it runs. The security gatekeeper handles the safe ones automatically, so you only get interrupted when something is actually risky.
- **Catch bugs before they ship** — Automatic code quality checks review your work for security holes, complexity, missing error handling, and test gaps. 10 built-in reviewers, always watching.
- **Find any past conversation** — Search your Claude history by describing what you were working on. Works across machines, works across teammates. *(requires [search] extra)*
- **Manage everything from a web dashboard** — Toggle features on and off, configure the security system, monitor decisions, track usage — all from your browser. No config files, no terminal commands.
---
## Quick Start
### Option 1: Let Claude Install It
Paste this into Claude Code and it handles everything:
```
Install claude-jacked for me. Use AskUserQuestion to ask me which features I want:
1. First check if uv and jacked are already installed (if uv is missing: curl -LsSf https://astral.sh/uv/install.sh | sh)
2. Ask me which install tier I want:
- BASE (Recommended): Smart reviewers, commands, behavioral rules, web dashboard
- SEARCH: Everything above + search past Claude sessions across machines (requires Qdrant Cloud)
- SECURITY: Everything above + auto-approve safe bash commands (fewer permission prompts)
- ALL: Everything
3. Install based on my choice:
- BASE: uv tool install claude-jacked && jacked install --force
- SEARCH: uv tool install "claude-jacked[search]" && jacked install --force
- SECURITY: uv tool install "claude-jacked[security]" && jacked install --force --security
- ALL: uv tool install "claude-jacked[all]" && jacked install --force --security
4. If I chose SEARCH or ALL, help me set up Qdrant Cloud credentials
5. Verify with: jacked --help
6. Launch the dashboard: jacked webux
```
### Option 2: Manual Install
Run once from anywhere — installs globally to `~/.claude/` and applies to all your Claude Code sessions:
```bash
uv tool install claude-jacked
jacked install --force
jacked webux # opens your dashboard at localhost:8321
```
> **Don't have uv?** Install it first: `curl -LsSf https://astral.sh/uv/install.sh | sh` (Mac/Linux) or `powershell -c "irm https://astral.sh/uv/install.ps1 | iex"` (Windows)
**Want more?** Add optional extras:
```bash
# Add session search (needs Qdrant Cloud ~$30/mo)
uv tool install "claude-jacked[search]" --force && jacked install --force
# Add security gatekeeper (auto-approves safe bash commands)
uv tool install "claude-jacked[security]" --force && jacked install --force --security
# Everything
uv tool install "claude-jacked[all]" --force && jacked install --force --security
```
---
## Your Dashboard
The web dashboard ships with every install. Run `jacked webux` to open it.
### Toggle Features On and Off
Enable or disable any of the 10 built-in code reviewers and 6 slash commands with one click. Each card shows what it does so you know what you're turning on.

### Monitor Security Decisions
Every bash command the gatekeeper evaluates is logged. See the decision, the method used, the full command, and the LLM's reasoning — all filterable by session. Export or purge logs anytime.

### Track Everything
Approval rates, which evaluation methods are being used, command frequency, and system health — all at a glance.

<details>
<summary><strong>More Dashboard Views</strong></summary>
**Security Gatekeeper Configuration** — Configure the 4-tier evaluation pipeline, choose the LLM model, set the evaluation method, manage API keys, and edit the LLM prompt — all from the Gatekeeper tab.

**Feature Toggles** — Toggle hooks (session indexing, sound notifications) and knowledge documents (behavioral rules, skills, reference docs) on and off.

**Commands** — Enable or disable slash commands (`/dc`, `/pr`, `/learn`, `/redo`, `/techdebt`, `/audit-rules`).

</details>
---
## Table of Contents
- [What's Included](#whats-included)
- [Web Dashboard](#web-dashboard)
- [Security Gatekeeper](#security-gatekeeper)
- [Session Search](#session-search)
- [Built-in Reviewers and Commands](#built-in-reviewers-and-commands)
- [Sound Notifications](#sound-notifications)
- [Uninstall / Troubleshooting](#uninstall--troubleshooting)
- [Cloud Database Setup (Qdrant)](#cloud-database-setup-qdrant)
- [Version History](#version-history)
- [Advanced / Technical Reference](#advanced--technical-reference)
---
## What's Included
### Base (`uv tool install claude-jacked`)
| Feature | What It Does |
|---------|--------------|
| **10 Code Reviewers** | Automatic checks for bugs, security issues, complexity, missing tests |
| **6 Slash Commands** | `/dc`, `/pr`, `/learn`, `/redo`, `/techdebt`, `/audit-rules` |
| **Behavioral Rules** | Smart defaults that make Claude follow better workflows |
| **Sound Notifications** | Audio alerts when Claude needs input or finishes (via `--sounds`) |
| **Web Dashboard** | 5-page local dashboard — manage everything from your browser |
| **Account Management** | Track Claude accounts, usage limits, subscription status |
| **Feature Toggles** | Enable/disable any reviewer, command, or hook from the dashboard |
| **Analytics** | Approval rates, command usage, system health |
### Search Extra (`uv tool install "claude-jacked[search]"`)
| Feature | What It Does |
|---------|--------------|
| **Session Search** | Find any past Claude conversation by describing what you were working on |
| **Cross-Machine Sync** | Start on desktop, continue on laptop — your history follows you |
| **Team Sharing** | Search your teammates' sessions (with their permission) |
### Security Extra (`uv tool install "claude-jacked[security]"`)
| Feature | What It Does |
|---------|--------------|
| **Security Gatekeeper** | Auto-approves safe bash commands, blocks dangerous ones, asks about ambiguous ones |
| **Shell Injection Defense** | Detects shell operators (`&&`, `|`, `;`, `>`, `` ` ``, `$()`) to prevent chaining attacks |
| **File Context Analysis** | Reads referenced scripts and evaluates what code actually does |
| **Customizable Prompt** | Tune the safety evaluation via the dashboard or `~/.claude/gatekeeper-prompt.txt` |
| **Permission Audit** | Scans your permission rules for dangerous wildcards that bypass the gatekeeper |
| **Session-Tagged Logs** | Every decision tagged with session ID for multi-session tracking |
| **Log Redaction** | Passwords, API keys, and tokens automatically redacted from logs |
---
## Web Dashboard
```bash
jacked webux # Opens dashboard at localhost:8321
jacked webux --port 9000 # Custom port
jacked webux --no-browser # Start server without opening browser
```
The dashboard is a local web app that runs on your machine. All data stays in `~/.claude/jacked.db` — nothing is sent anywhere.
**5 pages:** Accounts, Installations, Settings (tabbed: Agents / Commands / Gatekeeper / Features / Advanced), Logs, Analytics.
---
## Security Gatekeeper
The security gatekeeper intercepts every bash command Claude runs and decides whether to auto-approve it or ask you first. About 90% of commands resolve in under 2 milliseconds.
### How It Works
A 4-tier evaluation chain, fastest first:
| Tier | Speed | What It Does |
|------|-------|--------------|
| **Deny patterns** | <1ms | Blocks dangerous commands (sudo, rm -rf, reverse shells, database DROP, etc.) |
| **Permission rules** | <1ms | Checks commands already approved in your Claude settings |
| **Local allowlist** | <1ms | Matches safe patterns (specific git/gh/docker/make subcommands, pytest, etc.) |
| **LLM evaluation** | ~2s | Sends ambiguous commands to an LLM with file context for judgment |
Commands containing shell operators (`&&`, `||`, `;`, `|`, etc.) always go to the LLM — they're never auto-approved by the local allowlist.
### Install / Uninstall
```bash
uv tool install "claude-jacked[security]"
jacked install --force --security
```
To remove just the security hook:
```bash
jacked uninstall --security
```
### Configuration
Configure the gatekeeper from the **dashboard** (Settings > Gatekeeper tab) or the CLI:
- **LLM model:** Haiku (fastest, cheapest), Sonnet, or Opus
- **Evaluation method:** API First, CLI First, API Only, or CLI Only
- **Custom prompt:** Edit the LLM evaluation prompt from the dashboard or via `jacked gatekeeper show`
### Faster LLM Evaluation
With an Anthropic API key, the gatekeeper calls the API directly (~2s) instead of spawning a CLI process (~8s):
```bash
export ANTHROPIC_API_KEY="sk-..."
```
Or set the API key in the dashboard under Settings > Gatekeeper > API Key Override.
### Debug Logging
Every decision is logged to `~/.claude/hooks-debug.log`, tagged with session IDs:
```
2025-02-07T11:36:34 [87fd8847] EVALUATING: ls -la /tmp
2025-02-07T11:36:34 [87fd8847] LOCAL SAID: YES (0.001s)
2025-02-07T11:36:34 [87fd8847] DECISION: ALLOW (0.001s)
```
Or view decisions in the dashboard under **Logs** — filterable, searchable, exportable.
### Permission Audit
If you've set broad permission wildcards in Claude Code (like `Bash(python:*)`), those commands bypass the gatekeeper entirely. The audit catches this:
```bash
jacked gatekeeper audit # Scan permission rules
jacked gatekeeper audit --log # Also review recent auto-approved commands
```
Sensitive data (passwords, API keys, tokens) is automatically redacted from all logs.
---
## Session Search
Once installed with the `[search]` extra, search your past Claude sessions from within Claude Code.
### Finding Past Work
```
/jacked user authentication login
```
```
Search Results:
# Score User Age Repo Preview
1 92% YOU 3d ago my-app Implementing JWT auth with refresh tokens...
2 85% YOU 2w ago api-server Adding password reset flow...
3 78% @sam 1w ago shared-lib OAuth2 integration with Google...
```
### Resuming Work from Another Computer
```
/jacked that shopping cart feature I was building
```
Claude finds it and you can continue right where you left off.
### Team Sharing
Share knowledge across your team by using the same cloud database:
```bash
# Everyone uses the same database
export QDRANT_CLAUDE_SESSIONS_ENDPOINT="https://team-cluster.qdrant.io"
export QDRANT_CLAUDE_SESSIONS_API_KEY="team-api-key"
# Each person sets their own name
export JACKED_USER_NAME="sarah"
```
```
/jacked how did Sam implement the payment system
```
---
## Built-in Reviewers and Commands
### Quick Commands
Type these directly in Claude Code:
| Command | What It Does |
|---------|--------------|
| `/dc` | **Double-check** — Reviews your recent work for bugs, security issues, and problems |
| `/pr` | **Pull Request** — Checks PR status, creates/updates PRs with proper issue linking |
| `/learn` | **Learn** — Distills a lesson from the current session into a CLAUDE.md rule |
| `/redo` | **Redo** — Scraps the current approach and re-implements cleanly with full hindsight |
| `/techdebt` | **Tech Debt** — Scans for TODOs, oversized files, missing tests, dead code |
| `/audit-rules` | **Audit Rules** — Checks CLAUDE.md for duplicates, contradictions, stale rules |
### Smart Reviewers
These work automatically when Claude thinks they'd help, or you can ask for them:
| Reviewer | What It Catches |
|----------|-----------------|
| **Double-check** | Security holes, authentication gaps, data leaks |
| **Code Simplicity** | Over-complicated code, unnecessary abstractions |
| **Error Handler** | Missing error handling, potential crashes |
| **Test Coverage** | Untested code, missing edge cases |
**Example:** After building a new feature:
```
Use the double-check reviewer to review what we just built
```
---
## Sound Notifications
Get audio alerts so you don't have to watch the terminal:
```bash
jacked install --force --sounds
```
- **Notification sound** — Plays when Claude needs your input
- **Completion sound** — Plays when Claude finishes a task
Works on Windows, Mac, and Linux. To remove: `jacked uninstall --sounds`
---
## Uninstall / Troubleshooting
### Uninstall
```bash
jacked uninstall && uv tool uninstall claude-jacked
```
Your cloud database stays intact — reinstall anytime without losing history.
### Common Issues
**"jacked: command not found"** — Run `uv tool update-shell` and restart your terminal.
**Search isn't working** — You need Qdrant Cloud set up first. Ask Claude: `Help me set up Qdrant Cloud for jacked`
**Sessions not showing up** — Run `jacked backfill` to index existing sessions.
**Windows errors** — Claude Code on Windows uses Git Bash, which can have path issues. Ask Claude: `Help me fix jacked path issues on Windows`
---
## Cloud Database Setup (Qdrant)
> **Only needed for the `[search]` extra.** The base install works without Qdrant.
1. Install the search extra: `uv tool install "claude-jacked[search]"`
2. Go to [cloud.qdrant.io](https://cloud.qdrant.io) and create an account
3. Create a cluster (paid tier ~$30/month required)
4. Copy your cluster URL and API key
5. Add to your shell profile:
```bash
export QDRANT_CLAUDE_SESSIONS_ENDPOINT="https://your-cluster.qdrant.io"
export QDRANT_CLAUDE_SESSIONS_API_KEY="your-api-key"
```
6. Restart terminal and run:
```bash
jacked backfill # Index existing sessions
jacked status # Verify connectivity
```
---
## Security Note
**Your conversations are sent to Qdrant Cloud** (if using [search]). This includes everything you and Claude discuss, code snippets, and file paths.
**Recommendations:** Don't paste passwords or API keys in Claude sessions. Keep your Qdrant API key private. For sensitive work, consider self-hosting Qdrant.
---
## Version History
| Version | Changes |
|---------|---------|
| **0.4.0** | **Web dashboard** with 5-page local UI (Accounts, Installations, Settings, Logs, Analytics). Feature toggle API — enable/disable agents, commands, hooks, knowledge from the browser. Settings redesigned as tabbed interface. Account management with OAuth, usage monitoring, multi-account priority ordering. Gatekeeper log viewer with session filtering, search, export, purge. Analytics dashboard. Web deps (FastAPI, uvicorn) now included in base install. |
| **0.3.11** | Security hardening: shell operator detection, tightened safe prefixes, expanded deny patterns, file context prompt injection defense, path traversal prevention. Session ID tags in logs. LLM reason logging. 375 tests. |
| **0.3.10** | Fix format string explosion, qdrant test skip fix. |
| **0.3.9** | Permission safety audit, README catchup. |
| **0.3.8** | Log redaction, psql deny patterns, customizable LLM prompt. |
| **0.3.7** | JSON LLM responses, `parse_llm_response()`, 148 unit tests. |
---
## Advanced / Technical Reference
<details>
<summary><strong>CLI Command Reference</strong></summary>
```bash
# Search
jacked search "query" # Search all sessions
jacked search "query" --mine # Only your sessions
jacked search "query" --user name # Specific teammate
jacked search "query" --repo path # Boost specific repo
# Session Management
jacked sessions # List indexed sessions
jacked retrieve <session_id> # Get session content
jacked retrieve <id> --mode full # Get full transcript
jacked delete <session_id> # Remove from index
jacked cleardb # Delete all your data
# Setup
jacked install --force # Install agents, commands, rules
jacked install --force --security # Also add security gatekeeper hook
jacked install --force --sounds # Also add sound notifications
jacked uninstall # Remove from Claude Code
jacked uninstall --sounds # Remove only sounds
jacked uninstall --security # Remove only security hook
jacked backfill # Index all existing sessions
jacked status # Check connectivity
# Security Gatekeeper
jacked gatekeeper show # Print current LLM prompt
jacked gatekeeper reset # Reset prompt to built-in default
jacked gatekeeper diff # Compare custom vs built-in prompt
jacked gatekeeper audit # Audit permission rules
jacked gatekeeper audit --log # Also scan recent auto-approved commands
# Dashboard
jacked webux # Open web dashboard
jacked webux --port 9000 # Custom port
jacked webux --no-browser # Server only, no auto-open
```
</details>
<details>
<summary><strong>Environment Variables</strong></summary>
**Required (for [search] only):**
| Variable | Description |
|----------|-------------|
| `QDRANT_CLAUDE_SESSIONS_ENDPOINT` | Your Qdrant Cloud URL |
| `QDRANT_CLAUDE_SESSIONS_API_KEY` | Your Qdrant API key |
**Optional:**
| Variable | Default | Description |
|----------|---------|-------------|
| `JACKED_USER_NAME` | git username | Your name for team attribution |
| `JACKED_TEAMMATE_WEIGHT` | 0.8 | How much to weight teammate results |
| `JACKED_OTHER_REPO_WEIGHT` | 0.7 | How much to weight other repos |
| `JACKED_TIME_DECAY_HALFLIFE_WEEKS` | 35 | How fast old sessions lose relevance |
| `JACKED_HOOK_DEBUG` | (unset) | Set to `1` for verbose security hook logging |
| `ANTHROPIC_API_KEY` | (unset) | Enables fast (~2s) LLM evaluation in security hook |
</details>
<details>
<summary><strong>Web Dashboard Architecture</strong></summary>
The dashboard is a local web application:
- **Backend:** FastAPI (Python) serving a REST API
- **Database:** SQLite at `~/.claude/jacked.db`
- **Frontend:** Vanilla JS + Tailwind CSS (no build step, no npm)
- **Server:** Uvicorn, runs at `localhost:8321`
All data stays on your machine. The dashboard reads Claude Code's configuration files (`~/.claude/settings.json`, `~/.claude/agents/`, etc.) and provides a visual interface for managing them.
**API endpoints:** `/api/health`, `/api/features`, `/api/settings/*`, `/api/auth/*`, `/api/analytics/*`, `/api/logs/*`
</details>
<details>
<summary><strong>How It Works (Technical)</strong></summary>
```
+---------------------------------------------------------+
| YOUR MACHINE |
| |
| Claude Code |
| +-- Stop hook -> jacked index (after every response) |
| +-- /jacked skill -> search + load context |
| |
| ~/.claude/projects/ |
| +-- {repo}/ |
| +-- {session}.jsonl <-- parsed and indexed |
+---------------------------------------------------------+
|
| HTTPS
v
+---------------------------------------------------------+
| QDRANT CLOUD |
| |
| - Server-side embedding (no local ML needed) |
| - Vectors + transcripts stored |
| - Accessible from any machine |
+---------------------------------------------------------+
```
**Indexing:** After each Claude response, a hook automatically indexes the session. The indexer extracts plan files, agent summaries, labels, and user messages.
**Retrieval modes:** `smart` (default), `full`, `plan`, `agents`, `labels`
</details>
<details>
<summary><strong>All Agents</strong></summary>
| Agent | Description |
|-------|-------------|
| `double-check-reviewer` | CTO/CSO-level review for security, auth gaps, data leaks |
| `code-simplicity-reviewer` | Reviews for over-engineering and unnecessary complexity |
| `defensive-error-handler` | Audits error handling and adds defensive patterns |
| `git-pr-workflow-manager` | Manages branches, commits, and PR organization |
| `pr-workflow-checker` | Checks PR status and handles PR lifecycle |
| `issue-pr-coordinator` | Scans issues, groups related ones, manages PR workflows |
| `test-coverage-engineer` | Analyzes and improves test coverage |
| `test-coverage-improver` | Adds doctests and test files systematically |
| `readme-maintainer` | Keeps README in sync with code changes |
| `wiki-documentation-architect` | Creates/maintains GitHub Wiki documentation |
</details>
<details>
<summary><strong>Hook Configuration</strong></summary>
The `jacked install` command adds hooks to `~/.claude/settings.json`:
```json
{
"hooks": {
"Stop": [{
"matcher": "",
"hooks": [{"type": "command", "command": "jacked index --repo \"$CLAUDE_PROJECT_DIR\"", "async": true}]
}],
"PreToolUse": [{
"matcher": "Bash",
"hooks": [{"type": "command", "command": "python /path/to/security_gatekeeper.py", "timeout": 30}]
}]
}
}
```
</details>
<details>
<summary><strong>Guided Install Prompt (Full)</strong></summary>
Copy this into Claude Code for a guided installation:
```
Install claude-jacked for me. Use the AskUserQuestion tool to guide me through options.
PHASE 1 - DIAGNOSTICS:
- Detect OS (Windows/Mac/Linux)
- Check: uv --version (if missing: curl -LsSf https://astral.sh/uv/install.sh | sh on Mac/Linux, powershell -c "irm https://astral.sh/uv/install.ps1 | iex" on Windows)
- Check: jacked --version (to see if already installed)
- Check ~/.claude/settings.json for existing hooks
PHASE 2 - ASK USER PREFERENCES:
Use AskUserQuestion with these options:
Question: "Which jacked features do you want?"
Options:
- BASE (Recommended): Smart reviewers, commands, behavioral rules, web dashboard. No external services needed.
- SEARCH: Everything in BASE + search past Claude sessions across machines. Requires Qdrant Cloud (~$30/mo).
- SECURITY: Everything in BASE + auto-approve safe bash commands. Fewer permission prompts.
- ALL: Everything. Requires Qdrant Cloud + Anthropic API key for fastest security evaluation.
PHASE 3 - INSTALL:
Based on user choice:
- BASE: uv tool install claude-jacked && jacked install --force
- SEARCH: uv tool install "claude-jacked[search]" && jacked install --force
- SECURITY: uv tool install "claude-jacked[security]" && jacked install --force --security
- ALL: uv tool install "claude-jacked[all]" && jacked install --force --security
PHASE 4 - POST-INSTALL:
- Launch dashboard: jacked webux
- If SEARCH or ALL: help set up Qdrant Cloud credentials
- If SECURITY or ALL: show how to monitor gatekeeper in the dashboard (Logs page)
PHASE 5 - VERIFY:
- jacked --help
- jacked webux (confirm dashboard opens)
```
</details>
<details>
<summary><strong>Windows Troubleshooting</strong></summary>
Claude Code uses Git Bash on Windows, which can cause path issues.
**If "jacked" isn't found:**
```bash
uv tool update-shell
# Then restart your terminal
```
**If paths are getting mangled:**
```bash
# Find the uv tools bin directory
uv tool dir
# Use the full path to jacked if needed
```
</details>
---
## License
MIT
## Credits
Built for [Claude Code](https://claude.ai/code) by Anthropic. Uses [Qdrant](https://qdrant.tech/) for search.
| text/markdown | null | Jack Neil <jack@jackmd.com> | null | null | null | ai, claude, context, qdrant, semantic-search | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"aiohttp>=3.9.0",
"click>=8.0.0",
"fastapi>=0.100",
"httpx>=0.24",
"python-dotenv>=1.0.0",
"rich>=13.0.0",
"uvicorn[standard]>=0.20",
"anthropic>=0.40.0; extra == \"all\"",
"qdrant-client>=1.7.0; extra == \"all\"",
"qdrant-client>=1.7.0; extra == \"search\"",
"anthropic>=0.40.0; extra == \"secur... | [] | [] | [] | [
"Homepage, https://github.com/jackneil/claude-jacked",
"Repository, https://github.com/jackneil/claude-jacked",
"Issues, https://github.com/jackneil/claude-jacked/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:56:22.256739 | claude_jacked-0.7.5.tar.gz | 964,730 | 11/6f/cfd4ade36777e15bc544302878771432e0bbff8e8884275733ac1957d811/claude_jacked-0.7.5.tar.gz | source | sdist | null | false | e546c3b995a3bb77618395b8a497f90e | 24833d5af9723f80d3c1405764522c2a0141196d0adf3f811cadcb076fe6e19d | 116fcfd4ade36777e15bc544302878771432e0bbff8e8884275733ac1957d811 | MIT | [
"LICENSE"
] | 271 |
2.4 | dephealth | 0.5.0 | SDK for monitoring microservice dependencies via Prometheus metrics | # dephealth
SDK for monitoring microservice dependencies via Prometheus metrics.
## Features
- Automatic health checking for dependencies (PostgreSQL, MySQL, Redis, RabbitMQ, Kafka, HTTP, gRPC, TCP)
- Prometheus metrics export: `app_dependency_health` (Gauge 0/1), `app_dependency_latency_seconds` (Histogram), `app_dependency_status` (enum), `app_dependency_status_detail` (info)
- Async architecture built on `asyncio`
- FastAPI integration (middleware, lifespan, endpoints)
- Connection pool support (preferred) and standalone checks
## Installation
```bash
# Basic installation
pip install dephealth
# With specific checkers
pip install dephealth[postgres,redis]
# All checkers + FastAPI
pip install dephealth[all]
```
## Quick Start
### Standalone
```python
from dephealth import DepHealth
dh = DepHealth()
dh.add("postgres", url="postgresql://user:pass@localhost:5432/mydb")
dh.add("redis", url="redis://localhost:6379")
await dh.start()
# Metrics are available via prometheus_client
await dh.stop()
```
### FastAPI
```python
from fastapi import FastAPI
from dephealth_fastapi import DepHealthFastAPI
app = FastAPI()
dh = DepHealthFastAPI(app)
dh.add("postgres", url="postgresql://user:pass@localhost:5432/mydb")
```
## Health Details
```python
details = dh.health_details()
for key, ep in details.items():
print(f"{key}: healthy={ep.healthy} status={ep.status} "
f"latency={ep.latency_millis():.1f}ms")
```
## Configuration
| Parameter | Default | Description |
| --- | --- | --- |
| `interval` | `15` | Check interval (seconds) |
| `timeout` | `5` | Check timeout (seconds) |
## Supported Dependencies
| Type | Extra | URL Format |
| --- | --- | --- |
| PostgreSQL | `postgres` | `postgresql://user:pass@host:5432/db` |
| MySQL | `mysql` | `mysql://user:pass@host:3306/db` |
| Redis | `redis` | `redis://host:6379` |
| RabbitMQ | `amqp` | `amqp://user:pass@host:5672/vhost` |
| Kafka | `kafka` | `kafka://host1:9092,host2:9092` |
| HTTP | — | `http://host:8080/health` |
| gRPC | `grpc` | `host:50051` (via `FromParams`) |
| TCP | — | `tcp://host:port` |
## Authentication
HTTP and gRPC checkers support Bearer token, Basic Auth, and custom headers/metadata:
```python
http_check("secure-api",
url="http://api.svc:8080",
critical=True,
bearer_token="eyJhbG...",
)
grpc_check("grpc-backend",
host="backend.svc",
port=9090,
critical=True,
bearer_token="eyJhbG...",
)
```
See [quickstart guide](../docs/quickstart/python.md#authentication) for all options.
## License
Apache License 2.0 — see [LICENSE](https://github.com/BigKAA/topologymetrics/blob/master/LICENSE).
| text/markdown | null | Artur Kryukov <artur@kryukov.biz> | null | null | null | dependency, health-check, microservices, monitoring, prometheus | [
"Development Status :: 3 - Alpha",
"Framework :: FastAPI",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Developme... | [] | null | null | >=3.11 | [] | [] | [] | [
"aiohttp>=3.9",
"prometheus-client>=0.20",
"aio-pika>=9.4; extra == \"all\"",
"aiokafka>=0.10; extra == \"all\"",
"aiomysql>=0.2; extra == \"all\"",
"asyncpg>=0.29; extra == \"all\"",
"fastapi>=0.110; extra == \"all\"",
"grpcio-health-checking>=1.60; extra == \"all\"",
"grpcio>=1.60; extra == \"all\... | [] | [] | [] | [
"Homepage, https://github.com/BigKAA/topologymetrics",
"Repository, https://github.com/BigKAA/topologymetrics",
"Documentation, https://github.com/BigKAA/topologymetrics/tree/master/docs",
"Bug Tracker, https://github.com/BigKAA/topologymetrics/issues",
"Changelog, https://github.com/BigKAA/topologymetrics/... | twine/6.2.0 CPython/3.12.12 | 2026-02-18T10:56:04.925798 | dephealth-0.5.0.tar.gz | 30,832 | f2/19/776aa1bfdd947e99201ca568470e7629f0663e92c9e15194eba962ba2b14/dephealth-0.5.0.tar.gz | source | sdist | null | false | 93589afabe91911fed873cdbde980a51 | 04dd0cf94de9279589b4238f3bc85342a220b9069b62bc91cdfb8348f3feb033 | f219776aa1bfdd947e99201ca568470e7629f0663e92c9e15194eba962ba2b14 | Apache-2.0 | [] | 260 |
2.4 | VetNode | 0.1.3 | A node vetting cli for Distributed Workloads | # Node Vetting for Distributed Workloads
Ensure allocated nodes are vetted before executing a distributed workload through a series of configurable sanity checks. These checks are designed to detect highly dynamic issues (e.g., GPU temperature) and should be performed immediately before executing the main distributed job.
## Features
- ⚡ **Fast and lightweight**
- 🛠️ **Modular and configurable**
- 🚀 **Easy to extend**
## Getting Started
```bash
# Install
pip install vetnode
# checks for dependencies and installs requirements
vetnode setup ./examples/local-test/config.yaml
# runs the vetting process
vetnode diagnose ./examples/local-test/config.yaml
```
## Workflow Usage Example
The vetnode cli is intended to be embedded into your HPC workflow.
The following is a node vetting example for a ML (machine learning) workflow on a Slurm HPC cluster.
```bash
#!/bin/bash
#SBATCH --nodes=6
#SBATCH --time=0-00:15:00
#SBATCH --account=a-csstaff
REQUIRED_NODES=4
MAIN_JOB_COMMAND="python -m torch.distributed.torchrun --nproc_per_node=$(wc -l < vetted-nodes.txt) main.py"
vetnode setup ../examples/slurm-ml-vetting/config.yaml
srun vetnode diagnose ../examples/slurm-ml-vetting/config.yaml >> results.txt
# Extract node lists
grep '^Cordon:' results.txt | awk '{print $2}' > cordoned-nodes.txt
grep '^Vetted:' results.txt | awk '{print $2}' > vetted-nodes.txt
#Run on healthy nodes only
if [ $(wc -l < vetted-nodes.txt) -ge $REQUIRED_NODES ]; then
srun -N $REQUIRED_NODES --exclude=./cordoned-nodes.txt $MAIN_JOB_COMMAND
else
echo "Job canceled!"
echo "Reason: too few vetted nodes."
fi
```
### Quick Run
The following is a Slurm job example you can download and run as a test.
```bash
curl -o job.sh https://raw.githubusercontent.com/theely/vetnode/refs/heads/main/examples/slurm-ml-vetting/job.sh
sbatch --account=a-csstaff job.sh
#check job status
squeue -j {jobid} --long
#check vetting results
cat vetnode-{jobid}/results.txt
```
# Development
## Set-up Python Virtual environement
Create a virtual environment:
```console
python3.11 -m venv .venv
source .venv/bin/activate
python3 -m pip install --upgrade pip
pip install -r requirements.txt
```
## Run the CLI
```
cd src
python -m vetnode setup ../examples/local-test/config.yaml
python -m vetnode diagnose ../examples/local-test/config.yaml
```
## Running Tests
From the FirecREST root folder run pytest to execute all unit tests.
```console
source .venv/bin/activate
pip install -r ./requirements.txt -r ./requirements-testing.txt
pytest
```
## Distribute
Update version in pyproject.toml file.
```
pip install -r ./requirements-testing.txt
python3 -m build --wheel
twine upload dist/*
```
Note: API token is sotred in local file .pypirc
# Info dump
Clariden Distro:
NAME="SLES"
VERSION="15-SP5"
VERSION_ID="15.5"
PRETTY_NAME="SUSE Linux Enterprise Server 15 SP5"
ID="sles"
ID_LIKE="suse"
ANSI_COLOR="0;32"
CPE_NAME="cpe:/o:suse:sles:15:sp5"
DOCUMENTATION_URL="https://documentation.suse.com/"
./configure --prefix=/users/palmee/aws-ofi-nccl/install --disable-tests --without-mpi --enable-cudart-dynamic --with-libfabric=/opt/cray/libfabric/1.15.2.0 --with-cuda=/opt/nvidia/hpc_sdk/Linux_aarch64/24.3/cuda/12.3/
https://download.opensuse.org/repositories/home:/aeszter/openSUSE_Leap_15.3/x86_64/libhwloc5-1.11.8-lp153.1.1.x86_64.rpm
https://download.opensuse.org/repositories/home:/aeszter/15.5/x86_64/libhwloc5-1.11.8-lp155.1.1.x86_64.rpm
## Build plugin in image
export DOCKER_DEFAULT_PLATFORM=linux/amd64 export
#export DOCKER_DEFAULT_PLATFORM=linux/arm64
docker run -i -t registry.suse.com/suse/sle15:15.5
zypper install -y libtool git gcc awk make wget
zypper addrepo https://developer.download.nvidia.com/compute/cuda/repos/opensuse15/x86_64/cuda-opensuse15.repo
zypper addrepo https://developer.download.nvidia.com/compute/cuda/repos/sles15/sbsa/cuda-sles15.repo
zypper --non-interactive --gpg-auto-import-keys refresh
zypper install -y cuda-toolkit-12-3
## Add missing lib path required by hwloc
echo "/usr/local/cuda/targets/x86_64-linux/lib/stubs/" | tee /etc/ld.so.conf.d/nvidiaml-x86_64.conf
echo "/usr/local/cuda/targets/sbsa-linux/lib/stubs/" | tee /etc/ld.so.conf.d/nvidiaml-sbsa.conf
ldconfig
ldconfig -p | grep libnvidia
git clone -b v1.19.0 https://github.com/ofiwg/libfabric.git
cd libfabric
autoupdate
./autogen.sh
#CC=gcc ./configure --prefix=/users/palmee/libfabric/install
CC=gcc ./configure
make
make install
wget https://download.open-mpi.org/release/hwloc/v2.12/hwloc-2.12.0.tar.gz
tar -xvzf hwloc-2.12.0.tar.gz
cd hwloc-2.12.0
#CC=gcc ./configure --prefix=/users/palmee/hwloc-2.12.0/install
CC=gcc ./configure
make
make install
git clone -b v1.14.0 https://github.com/aws/aws-ofi-nccl.git
cd aws-ofi-nccl
mkdir install
GIT_COMMIT=$(git rev-parse --short HEAD)
./autogen.sh
CC=gcc ./configure --disable-tests --without-mpi \
--enable-cudart-dynamic \
--prefix=./install/v1.14.0-${GIT_COMMIT}/x86_64/12.3/ \
--with-cuda=/usr/local/cuda
TODO:
consider building an rpm: https://www.redhat.com/en/blog/create-rpm-package
CC=gcc ./configure --disable-tests --without-mpi \
--enable-cudart-dynamic \
--prefix=/users/palmee/aws-ofi-nccl/install_2/ \
--with-libfabric=/opt/cray/libfabric/1.15.2.0 --with-cuda=/opt/nvidia/hpc_sdk/Linux_aarch64/24.3/cuda/12.3/ --with-hwloc=/users/palmee/hwloc-2.12.0/install
export LD_LIBRARY_PATH=/opt/cray/libfabric/1.15.2.0/lib64/:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/opt/nvidia/hpc_sdk/Linux_aarch64/24.3/cuda/12.3/lib64/:$LD_LIBRARY_PATH
ld /users/palmee/aws-ofi-nccl/install_2/lib/libnccl-net.so
## Install NCCL
git clone https://github.com/NVIDIA/nccl.git
git checkout v2.20.3-1 #looks like this is the version compatible with cuda/12.3/
cd nccl
make src.build CUDA_HOME=/opt/nvidia/hpc_sdk/Linux_aarch64/24.3/cuda/12.3/
## WORKING LIB (job 327119)
| payload | busbw | algbw |
| ------: | ---------: | ---------: |
| 1GiB | 90.94GBps | 46.94GBps |
| 2GiB | 91.24GBps | 47.09GBps |
| 4GiB | 91.35GBps | 47.15GBps |
wget https://download.open-mpi.org/release/hwloc/v2.12/hwloc-2.12.0.tar.gz
tar -xvzf hwloc-2.12.0.tar.gz
cd hwloc-2.12.0
./configure --prefix=/users/palmee/hwloc-2.12.0/install
make
make install
git clone -b v1.14.0 https://github.com/aws/aws-ofi-nccl.git
cd aws-ofi-nccl
mkdir install
./autogen.sh
./configure --disable-tests --without-mpi \
--enable-cudart-dynamic \
--prefix=/users/palmee/aws-ofi-nccl/install/ \
--with-libfabric=/opt/cray/libfabric/1.15.2.0 --with-cuda=/opt/nvidia/hpc_sdk/Linux_aarch64/24.3/cuda/12.3/ --with-hwloc=/users/palmee/hwloc-2.12.0/install
## TEST with gcc (job 327124) - working
| payload | busbw | algbw |
| ------: | ---------: | ---------: |
| 1GiB | 91.06GBps | 47.00GBps |
| 2GiB | 91.24GBps | 47.09GBps |
| 4GiB | 91.34GBps | 47.15GBps |
wget https://download.open-mpi.org/release/hwloc/v2.12/hwloc-2.12.0.tar.gz
tar -xvzf hwloc-2.12.0.tar.gz
cd hwloc-2.12.0
CC=gcc ./configure --prefix=/users/palmee/hwloc-2.12.0/install
make
make install
git clone -b v1.14.0 https://github.com/aws/aws-ofi-nccl.git
cd aws-ofi-nccl
mkdir install
./autogen.sh
CC=gcc ./configure --disable-tests --without-mpi \
--enable-cudart-dynamic \
--prefix=/users/palmee/aws-ofi-nccl/install_3/ \
--with-libfabric=/opt/cray/libfabric/1.15.2.0 --with-cuda=/opt/nvidia/hpc_sdk/Linux_aarch64/24.3/cuda/12.3/ --with-hwloc=/users/palmee/hwloc-2.12.0/install
make
make install
## TEST with gcc all (job 327130) - running
| payload | busbw | algbw |
| ------: | ---------: | ---------: |
| 1GiB | 91.05GBps | 46.99GBps |
| 2GiB | 91.24GBps | 47.09GBps |
| 4GiB | 91.34GBps | 47.14GBps |
wget https://download.open-mpi.org/release/hwloc/v2.12/hwloc-2.12.0.tar.gz
tar -xvzf hwloc-2.12.0.tar.gz
cd hwloc-2.12.0
CC=gcc ./configure --prefix=/users/palmee/hwloc-2.12.0/install
make
make install
git clone -b v1.14.0 https://github.com/aws/aws-ofi-nccl.git
cd aws-ofi-nccl
mkdir install
./autogen.sh
CC=gcc ./configure --disable-tests --without-mpi \
--enable-cudart-dynamic \
--prefix=/users/palmee/aws-ofi-nccl/install_3/ \
--with-libfabric=/opt/cray/libfabric/1.15.2.0 --with-cuda=/opt/nvidia/hpc_sdk/Linux_aarch64/24.3/cuda/12.3/ --with-hwloc=/users/palmee/hwloc-2.12.0/install
make
make install
## TEST with local libfabric only for compile (job 327145) -
| payload | busbw | algbw |
| ------: | ---------: | ---------: |
| 1GiB | 91.08GBps | 47.01GBps |
| 2GiB | 91.21GBps | 47.08GBps |
| 4GiB | 91.34GBps | 47.14GBps |
git clone -b v1.19.0 https://github.com/ofiwg/libfabric.git
cd libfabric
autoupdate
./autogen.sh
CC=gcc ./configure --prefix=/users/palmee/libfabric/install
make
make install
wget https://download.open-mpi.org/release/hwloc/v2.12/hwloc-2.12.0.tar.gz
tar -xvzf hwloc-2.12.0.tar.gz
cd hwloc-2.12.0
CC=gcc ./configure --prefix=/users/palmee/hwloc-2.12.0/install
make
make install
git clone -b v1.14.0 https://github.com/aws/aws-ofi-nccl.git
cd aws-ofi-nccl
mkdir install
./autogen.sh
CC=gcc ./configure --disable-tests --without-mpi \
--enable-cudart-dynamic \
--prefix=/users/palmee/aws-ofi-nccl/install_4/ \
--with-libfabric=/users/palmee/libfabric/install --with-cuda=/opt/nvidia/hpc_sdk/Linux_aarch64/24.3/cuda/12.3/ --with-hwloc=/users/palmee/hwloc-2.12.0/install
make
make install
## TEST with local libfabric compile and job run (job 327161) -
NOT WORKING!!! We need to use the crey lib fabric
## Build plugin in image
export DOCKER_DEFAULT_PLATFORM=linux/amd64
docker run -i -t registry.suse.com/suse/sle15:15.5
zypper install -y libtool git gcc awk make wget
zypper addrepo https://developer.download.nvidia.com/compute/cuda/repos/opensuse15/x86_64/cuda-opensuse15.repo
zypper refresh
zypper install -y cuda-toolkit-12-3
## Build in Clariden
wget https://download.open-mpi.org/release/hwloc/v2.12/hwloc-2.12.0.tar.gz
tar -xvzf hwloc-2.12.0.tar.gz
cd hwloc-2.12.0
CC=gcc ./configure --prefix=/users/palmee/hwloc-2.12.0/install
#CC=gcc ./configure
make
make install
git clone -b v1.14.1 https://github.com/aws/aws-ofi-nccl.git
cd aws-ofi-nccl
mkdir install
./autogen.sh
CC=gcc ./configure --disable-tests --without-mpi \
--enable-cudart-dynamic \
--prefix=/users/palmee/aws-ofi-nccl/install/ \
--with-libfabric=/opt/cray/libfabric/1.22.0/ \
--with-cuda=/opt/nvidia/hpc_sdk/Linux_aarch64/24.3/cuda/12.3/ \
--with-hwloc=/users/palmee/hwloc-2.12.0/install
make
make install
export LD_LIBRARY_PATH=/opt/cray/libfabric/1.15.2.0/lib64/:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/opt/nvidia/hpc_sdk/Linux_aarch64/24.3/cuda/12.3/lib64/:$LD_LIBRARY_PATH
ld /users/palmee/aws-ofi-nccl/install/lib/libnccl-net.so
TODO:
consider building an rpm: https://www.redhat.com/en/blog/create-rpm-package | text/markdown | null | Elia Palme <elia.palme@cscs.ch> | null | null | null | null | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"click",
"pip",
"pydantic",
"pydantic-settings>=2.2.0",
"pydantic-settings[yaml]",
"textfsm"
] | [] | [] | [] | [
"Homepage, https://github.com/theely/vetnode",
"Issues, https://github.com/theely/vetnode/issues"
] | twine/6.1.0 CPython/3.11.0 | 2026-02-18T10:55:47.945463 | vetnode-0.1.3-py3-none-any.whl | 26,470 | eb/8e/d692c35b4648991f24a009a11d20d7f74a09bc337b251325d7e856064e12/vetnode-0.1.3-py3-none-any.whl | py3 | bdist_wheel | null | false | 16110acd951e9a469a16c57c846c7d66 | 6386e61cfdd7492210403a5b2c4f5c30a6606c663d254ad2a311e9d7480bca66 | eb8ed692c35b4648991f24a009a11d20d7f74a09bc337b251325d7e856064e12 | BSD-3-Clause | [
"LICENSE"
] | 0 |
2.4 | redisbench-admin | 0.12.10 | Redis benchmark run helper. A wrapper around Redis and Redis Modules benchmark tools ( ftsb_redisearch, memtier_benchmark, redis-benchmark, aibench, etc... ). | [](https://codecov.io/gh/redis-performance/redisbench-admin)


# [redisbench-admin](https://github.com/redis-performance/redisbench-admin)
Redis benchmark run helper can help you with the following tasks:
- Setup abd teardown of benchmarking infrastructure specified
on [redis-performance/testing-infrastructure](https://github.com/redis-performance/testing-infrastructure)
- Setup and teardown of an Redis and Redis Modules DBs for benchmarking
- Management of benchmark data and specifications across different setups
- Running benchmarks and recording results
- Exporting performance results in several formats (CSV, RedisTimeSeries, JSON)
- Finding on-cpu, off-cpu, io, and threading performance problems by attaching profiling tools/probers ( perf (a.k.a. perf_events), bpf tooling, vtune )
- **[SOON]** Finding performance problems by attaching telemetry probes
Current supported benchmark tools:
- [redis-benchmark](https://github.com/redis/redis)
- [memtier_benchmark](https://github.com/RedisLabs/memtier_benchmark)
- [redis-benchmark-go](https://github.com/redis-performance/redis-benchmark-go)
- [YCSB](https://github.com/RediSearch/YCSB)
- [tsbs](https://github.com/RedisTimeSeries/tsbs)
- [redisgraph-benchmark-go](https://github.com/RedisGraph/redisgraph-benchmark-go)
- [ftsb_redisearch](https://github.com/RediSearch/ftsb)
- [ann-benchmarks](https://github.com/RedisAI/ann-benchmarks)
## Installation
Installation is done using pip, the package installer for Python, in the following manner:
```bash
python3 -m pip install redisbench-admin
```
## Profiler daemon
You can use the profiler daemon by itself in the following manner.
On the target machine do as follow:
```bash
pip3 install --upgrade pip
pip3 install redisbench-admin --ignore-installed PyYAML
# install perf
apt install linux-tools-common linux-tools-generic linux-tools-`uname -r` -y
# ensure perf is working
perf --version
# install awscli
snap install aws-cli --classic
# configure aws
aws configure
# start the perf-daemon
perf-daemon start
WARNING:root:Unable to detected github_actor. caught the following error: No section: 'user'
Writting log to /tmp/perf-daemon.log
Starting perf-daemon. PID file /tmp/perfdaemon.pid. Daemon workdir: /root/RedisGraph
# check daemon is working appropriatelly
curl localhost:5000/ping
# start a profile
curl -X POST localhost:5000/profiler/perf/start/<pid to profile>
# stop a profile
curl -X POST -d '{"aws_access_key_id":$AWS_ACCESS_KEY_ID,"aws_secret_access_key":$AWS_SECRET_ACCESS_KEY}' localhost:5000/profiler/perf/stop/<pid to profile>
```
## Development
1. Install [pypoetry](https://python-poetry.org/) to manage your dependencies and trigger tooling.
```sh
pip install poetry
```
2. Installing dependencies from lock file
```
poetry install
```
### Running formaters
```sh
poetry run black .
```
### Running linters
```sh
poetry run flake8
```
### Running tests
A test suite is provided, and can be run with:
```sh
$ tox
```
To run a specific test:
```sh
$ tox -- tests/test_defaults_purpose_built_env.py
```
To run a specific test and persist the docker container used for timeseries:
```
tox --docker-dont-stop=rts_datasink -- -vv --log-cli-level=INFO tests/test_defaults_purpose_built_env.py
```
To run a specific test with verbose logging:
```sh
# tox -- -vv --log-cli-level=INFO tests/test_run.py
```
## License
redisbench-admin is distributed under the BSD3 license - see [LICENSE](LICENSE)
| text/markdown | filipecosta90 | filipecosta.90@gmail.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0.0,>=3.10.0 | [] | [] | [] | [
"Flask<3.0.0,>=2.0.1",
"Flask-HTTPAuth<5.0.0,>=4.4.0",
"GitPython<4.0.0,>=3.1.12",
"Jinja2<4.0.0,>=3.0.3",
"PyYAML<7.0.0,>=6.0.1",
"boto3<2.0.0,>=1.13.24",
"certifi<2025.0.0,>=2021.10.8",
"daemonize<3.0.0,>=2.5.0",
"flask-restx<0.6.0,>=0.5.1",
"humanize<5.0.0,>=4.0.0",
"jsonpath_ng<2.0.0,>=1.5.2... | [] | [] | [] | [] | poetry/2.3.2 CPython/3.10.19 Linux/6.14.0-1017-azure | 2026-02-18T10:55:36.344732 | redisbench_admin-0.12.10-py3-none-any.whl | 212,441 | 9f/1d/acd4ff2f7622c336c050d1b5b73e0b49fcd7219854602e7aa2d87d5ae742/redisbench_admin-0.12.10-py3-none-any.whl | py3 | bdist_wheel | null | false | 2506bea577e380d6fd7041e3a8cadb85 | 43d5df1e56fdadac9ac01fd3bcb9bbe7899a22acac0f8b1dd93c4faab63cb858 | 9f1dacd4ff2f7622c336c050d1b5b73e0b49fcd7219854602e7aa2d87d5ae742 | null | [
"LICENSE"
] | 443 |
2.4 | endee | 0.1.13 | Endee is the Next-Generation Vector Database for Scalable, High-Performance AI | # Endee - High-Performance Vector Database
Endee is a high-performance vector database designed for speed and efficiency. It enables rapid Approximate Nearest Neighbor (ANN) searches for applications requiring robust vector search capabilities with advanced filtering, metadata support, and hybrid search combining dense and sparse vectors.
## Key Features
- **Fast ANN Searches**: Efficient similarity searches on vector data using HNSW algorithm
- **Hybrid Search**: Combine dense and sparse vectors for powerful semantic + keyword search
- **Multiple Distance Metrics**: Support for cosine, L2, and inner product distance metrics
- **Metadata Support**: Attach and search with metadata and filters
- **Advanced Filtering**: Powerful query filtering with operators like `$eq`, `$in`, and `$range`
- **High Performance**: Optimized for speed and efficiency
- **Scalable**: Handle millions of vectors with ease
- **Configurable Precision**: Multiple precision levels for memory/accuracy tradeoffs
## Installation
```bash
pip install endee
```
## Quick Start
```python
from endee import Endee
from constants import Precision
# Initialize client with your API token
client = Endee(token="your-token-here")
# for no auth development use the below initialization
# client = Endee()
# List existing indexes
indexes = client.list_indexes()
# Create a new index
client.create_index(
name="my_vectors",
dimension=1536, # Your vector dimension
space_type="cosine", # Distance metric (cosine, l2, ip)
precision=Precision.INT8D # Use precision enum for type safety
)
# Get index reference
index = client.get_index(name="my_vectors")
# Insert vectors
index.upsert([
{
"id": "doc1",
"vector": [0.1, 0.2, 0.3, ...], # Your vector data
"meta": {"text": "Example document", "category": "reference"},
"filter": {"category": "reference", "tags": "important"}
}
])
# Query similar vectors with filtering
results = index.query(
vector=[0.2, 0.3, 0.4, ...], # Query vector
top_k=10,
filter=[{"category": {"$eq": "reference"}}] # Structured filter
)
# Process results
for item in results:
print(f"ID: {item['id']}, Similarity: {item['similarity']}")
print(f"Metadata: {item['meta']}")
```
## Basic Usage
To interact with the Endee platform, you'll need to authenticate using an API token. This token is used to securely identify your workspace and authorize all actions — including index creation, vector upserts, and queries.
Not using a token at any development stage will result in open APIs and vectors.
### 🔐 Generate Your API Token
- Each token is tied to your workspace and should be kept private
- Once you have your token, you're ready to initialize the client and begin using the SDK
### Initializing the Client
The Endee client acts as the main interface for all vector operations — such as creating indexes, upserting vectors, and running similarity queries. You can initialize the client in just a few lines:
```python
from endee import Endee
# Initialize with your API token
client = Endee(token="your-token-here")
```
### Setting Up Your Domain
The Endee client allows for the setting of custom domain URL and port change (default port 8080).
```python
from endee import Endee
# Initialize with your API token
client = Endee(token="your-token-here")
client.set_base_url('http://0.0.0.0:8081/api/v1')
```
### Listing All Indexes
The `client.list_indexes()` method returns a list of all the indexes currently available in your environment or workspace. This is useful for managing, debugging, or programmatically selecting indexes for vector operations like upsert or search.
```python
from endee import Endee
client = Endee(token="your-token-here")
# List all indexes in your workspace
indexes = client.list_indexes()
```
### Create an Index
The `client.create_index()` method initializes a new vector index with customizable parameters such as dimensionality, distance metric, graph construction settings, and precision level. These configurations determine how the index stores and retrieves high-dimensional vector data.
```python
from endee import Endee, Precision
client = Endee(token="your-token-here")
# Create an index with custom parameters
client.create_index(
name="my_custom_index",
dimension=768,
space_type="cosine",
M=16, # Graph connectivity parameter (default = 16)
ef_con=128, # Construction-time parameter (default = 128)
precision=Precision.INT8D, # Use Precision enum (recommended)
)
```
**Parameters:**
- `name`: Unique name for your index (alphanumeric + underscores, max 48 chars)
- `dimension`: Vector dimensionality (must match your embedding model's output, max 10000)
- `space_type`: Distance metric - `"cosine"`, `"l2"`, or `"ip"` (inner product)
- `M`: HNSW graph connectivity parameter - higher values increase recall but use more memory (default: 16)
- `ef_con`: HNSW construction parameter - higher values improve index quality but slow down indexing (default: 128)
- `precision`: Vector precision level using `Precision` enum - `Precision.INT8D` (default), `Precision.BINARY2`, `Precision.INT16D`, `Precision.FLOAT16`, or `Precision.FLOAT32`
- `version`: Optional version parameter for index versioning
- `sparse_dim`: Optional sparse vector dimension for hybrid search (e.g., 30000 for BM25/SPLADE)
**Precision Levels:**
The `precision` parameter controls how vectors are stored internally, affecting memory usage and search accuracy. Use the `Precision` enum for type safety and IDE autocomplete:
```python
from endee import Precision
# Available precision levels
Precision.FLOAT32 # 32-bit floating point
Precision.FLOAT16 # 16-bit floating point
Precision.INT16D # 16-bit integer quantization
Precision.INT8D # 8-bit integer quantization (default)
Precision.BINARY2 # 1-bit binary quantization
```
| Precision | Quantization | Data Type | Memory Usage | Accuracy | Use Case |
|-----------|--------------|-----------|--------------|----------|----------|
| `Precision.FLOAT32` | 32-bit | FP32 | Highest | Maximum | When accuracy is absolutely critical |
| `Precision.FLOAT16` | 16-bit | FP16 | ~50% less | Very good | Good accuracy with half precision |
| `Precision.INT16D` | 16-bit | INT16 | ~50% less | Very good | Integer quantization with good accuracy |
| `Precision.INT8D` | 8-bit | INT8 | ~75% less | Good | **Default** - great for most use cases |
| `Precision.BINARY2` | 1-bit | Binary | ~96.9% less | Lower | Extreme compression for large-scale similarity search |
**Choosing the Right Precision:**
- **`Precision.INT8D`**: **Default** - provides good accuracy with significant memory savings using 8-bit integer quantization
- **`Precision.INT16D` / `Precision.FLOAT16`**: Better accuracy with moderate memory savings (16-bit precision)
- **`Precision.FLOAT32`**: Maximum accuracy using full 32-bit floating point (highest memory usage)
- **`Precision.BINARY2`**: Extreme compression for very large-scale deployments where memory is critical and lower accuracy is tolerable
**Example with different precision levels:**
```python
from endee import Endee, Precision
client = Endee(token="your-token-here")
# High accuracy index
client.create_index(
name="high_accuracy_index",
dimension=768,
space_type="cosine",
precision=Precision.FLOAT32
)
# Balanced index
client.create_index(
name="balanced_index",
dimension=768,
space_type="cosine",
precision=Precision.INT8D
)
```
### Get an Index
The `client.get_index()` method retrieves a reference to an existing index. This is required before performing vector operations like upsert, query, or delete.
```python
from endee import Endee
client = Endee(token="your-token-here")
# Get reference to an existing index
index = client.get_index(name="my_custom_index")
# Now you can perform operations on the index
print(index.describe())
```
**Parameters:**
- `name`: Name of the index to retrieve
**Returns:** An `Index` instance configured with server parameters
### Ingestion of Data
The `index.upsert()` method is used to add or update vectors (embeddings) in an existing index. Each vector is represented as an object containing a unique identifier, the vector data itself, optional metadata, and optional filter fields for future querying.
```python
from endee import Endee
client = Endee(token="your-token-here")
# Accessing the index
index = client.get_index(name="your-index-name")
# Insert multiple vectors in a batch
index.upsert([
{
"id": "vec1",
"vector": [...], # Your vector
"meta": {"title": "First document"},
"filter": {"tags": "important"} # Optional filter values
},
{
"id": "vec2",
"vector": [...], # Another vector
"meta": {"title": "Second document"},
"filter": {"visibility": "public", "tags": "important"}
}
])
```
**Vector Object Fields:**
- `id`: Unique identifier for the vector (required)
- `vector`: Array of floats representing the embedding (required)
- `meta`: Arbitrary metadata object for storing additional information (optional)
- `filter`: Key-value pairs for structured filtering during queries (optional)
> **Note:** Maximum batch size is 1000 vectors per upsert call.
### Querying the Index
The `index.query()` method performs a similarity search in the index using a given query vector. It returns the closest vectors (based on the index's distance metric) along with optional metadata and vector data.
```python
from endee import Endee
client = Endee(token="your-token-here")
# Accessing the index
index = client.get_index(name="your-index-name")
# Query with custom parameters
results = index.query(
vector=[...], # Query vector
top_k=5, # Number of results to return (max 512)
ef=128, # Runtime parameter for search quality (max 1024)
include_vectors=True # Include vector data in results
)
```
**Query Parameters:**
- `vector`: Query vector (must match index dimension)
- `top_k`: Number of nearest neighbors to return (max 512, default: 10)
- `ef`: Runtime search parameter - higher values improve recall but increase latency (max 1024, default: 128)
- `include_vectors`: Whether to return the actual vector data in results (default: False)
- `filter`: Optional filter criteria (array of filter objects)
- `log`: Optional logging parameter for debugging (default: False)
- `sparse_indices`: Sparse vector indices for hybrid search (default: None)
- `sparse_values`: Sparse vector values for hybrid search (default: None)
- `prefilter_cardinality_threshold`: Controls when the search strategy switches from HNSW filtered search to brute-force prefiltering on the matched subset (default: 10,000, range: 1,000–1,000,000). See [Filter Tuning](#filter-tuning) for details.
- `filter_boost_percentage`: Expands the internal HNSW candidate pool by this percentage when a filter is active, compensating for filtered-out results (default: 0, range: 0–100). See [Filter Tuning](#filter-tuning) for details.
**Result Fields:**
- `id`: Vector identifier
- `similarity`: Similarity score
- `distance`: Distance score (1.0 - similarity)
- `meta`: Metadata dictionary
- `norm`: Vector norm
- `filter`: Filter dictionary (if filter dict was included in upsert vector object while upserting)
- `vector`: Vector data (if `include_vectors=True`)
## Hybrid Search
Hybrid search combines dense vector embeddings (semantic similarity) with sparse vectors (keyword/term matching) to provide more powerful and flexible search capabilities. This is particularly useful for applications that need both semantic understanding and exact term matching, such as:
- RAG (Retrieval-Augmented Generation) systems
- Document search with keyword boosting
- Multi-modal search combining different ranking signals
- BM25 + neural embedding fusion
### Creating a Hybrid Index
To enable hybrid search, specify the `sparse_dim` parameter when creating an index. This defines the dimensionality of the sparse vector space (typically the vocabulary size for BM25 or SPLADE models).
```python
from endee import Endee, Precision
client = Endee(token="your-token-here")
client.create_index(
name="hybridtest1",
dimension=384, # dense vector dimension
sparse_dim=30000, # sparse vector dimension (BM25 / SPLADE etc.)
space_type="cosine",
precision=Precision.INT8D # Use Precision enum
)
# Get reference to the hybrid index
index = client.get_index(name="hybridtest1")
```
### Upserting Hybrid Vectors
When upserting vectors to a hybrid index, you must provide both dense vectors and sparse vector representations. Sparse vectors are defined using two parallel arrays: `sparse_indices` (positions) and `sparse_values` (weights).
```python
import numpy as np
import random
np.random.seed(42)
random.seed(42)
TOTAL_VECTORS = 2000
BATCH_SIZE = 1000
DIM = 384
SPARSE_DIM = 30000
batch = []
for i in range(TOTAL_VECTORS):
# Dense vector (semantic embedding)
dense_vec = np.random.rand(DIM).astype(float).tolist()
# Sparse vector (e.g., BM25 term weights)
# Example: 20 non-zero terms
nnz = 20
sparse_indices = random.sample(range(SPARSE_DIM), nnz)
sparse_values = np.random.rand(nnz).astype(float).tolist()
item = {
"id": f"hybrid_vec_{i+1}",
"vector": dense_vec,
# Required for hybrid search
"sparse_indices": sparse_indices,
"sparse_values": sparse_values,
"meta": {
"title": f"Hybrid Document {i+1}",
"index": i,
},
"filter": {
"visibility": "public" if i % 2 == 0 else "private"
}
}
batch.append(item)
if len(batch) == BATCH_SIZE or i + 1 == TOTAL_VECTORS:
index.upsert(batch)
print(f"Upserted {len(batch)} hybrid vectors")
batch = []
```
**Hybrid Vector Fields:**
- `id`: Unique identifier (required)
- `vector`: Dense embedding vector (required)
- `sparse_indices`: List of non-zero term positions in sparse vector (required for hybrid)
- `sparse_values`: List of weights corresponding to sparse_indices (required for hybrid)
- `meta`: Metadata dictionary (optional)
- `filter`: Filter fields for structured filtering (optional)
> **Note:** The lengths of `sparse_indices` and `sparse_values` must match. Values in `sparse_indices` must be within [0, sparse_dim).
### Querying with Hybrid Search
Hybrid queries combine dense and sparse vector similarity to rank results. Provide both a dense query vector and sparse query representation.
```python
import numpy as np
import random
np.random.seed(123)
random.seed(123)
DIM = 384
SPARSE_DIM = 30000
# Dense query vector (semantic)
dense_query = np.random.rand(DIM).astype(float).tolist()
# Sparse query (e.g., BM25 scores for query terms)
nnz = 15
sparse_indices = random.sample(range(SPARSE_DIM), nnz)
sparse_values = np.random.rand(nnz).astype(float).tolist()
results = index.query(
vector=dense_query, # dense part
sparse_indices=sparse_indices, # sparse part
sparse_values=sparse_values,
top_k=5,
ef=128,
include_vectors=True
)
# Process results
for result in results:
print(f"ID: {result['id']}")
print(f"Similarity: {result['similarity']}")
print(f"Metadata: {result['meta']}")
print("---")
```
**Hybrid Query Parameters:**
- `vector`: Dense query vector (required)
- `sparse_indices`: Non-zero term positions in sparse query (required for hybrid)
- `sparse_values`: Weights for sparse query terms (required for hybrid)
- `top_k`: Number of results to return (max 512, default: 10)
- `ef`: Search quality parameter (max 1024, default: 128)
- `include_vectors`: Include vector data in results (default: False)
- `filter`: Optional filter criteria
- `prefilter_cardinality_threshold`: Controls when search switches from HNSW filtered search to brute-force prefiltering on the matched subset (default: 10,000, range: 1,000–1,000,000). See [Filter Tuning](#filter-tuning) for details.
- `filter_boost_percentage`: Expands the internal HNSW candidate pool by this percentage when a filter is active, compensating for filtered-out results (default: 0, range: 0–100). See [Filter Tuning](#filter-tuning) for details.
**Hybrid Result Fields:**
- `id`: Vector identifier
- `similarity`: Similarity score
- `distance`: Distance score (1.0 - similarity)
- `meta`: Metadata dictionary
- `norm`: Vector norm
- `filter`: Filter dictionary (if filter dict was included in upsert vector object while upserting)
- `vector`: Vector data (dense only) (if `include_vectors=True`)
### Hybrid Search Use Cases
**1. BM25 + Neural Embeddings**
```python
# Combine traditional keyword search (BM25) with semantic embeddings
# sparse_indices: term IDs from BM25
# sparse_values: BM25 scores
# vector: neural embedding from model like BERT
```
**2. SPLADE + Dense Retrieval**
```python
# Use learned sparse representations (SPLADE) with dense embeddings
# sparse_indices/values: SPLADE model output
# vector: dense embedding from same or different model
```
**3. Multi-Signal Ranking**
```python
# Combine multiple ranking signals
# sparse: user behavior signals, click-through rates
# dense: content similarity embedding
```
## Filtered Querying
The `index.query()` method supports structured filtering using the `filter` parameter. This allows you to restrict search results based on metadata conditions, in addition to vector similarity.
To apply multiple filter conditions, pass an array of filter objects, where each object defines a separate condition. **All filters are combined with logical AND** — meaning a vector must match all specified conditions to be included in the results.
```python
index = client.get_index(name="your-index-name")
# Query with multiple filter conditions (AND logic)
filtered_results = index.query(
vector=[...],
top_k=5,
ef=128,
include_vectors=True,
filter=[
{"tags": {"$eq": "important"}},
{"visibility": {"$eq": "public"}}
]
)
```
### Filtering Operators
The `filter` parameter supports a range of comparison operators to build structured queries.
| Operator | Description | Supported Type | Example Usage |
|----------|-------------|----------------|---------------|
| `$eq` | Matches values that are equal | String, Number | `{"status": {"$eq": "published"}}` |
| `$in` | Matches any value in the provided list | String | `{"tags": {"$in": ["ai", "ml"]}}` |
| `$range` | Matches values between a start and end value, inclusive | Number | `{"score": {"$range": [70, 95]}}` |
**Important Notes:**
- Operators are **case-sensitive** and must be prefixed with a `$`
- Filters operate on fields provided under the `filter` key during vector upsert
- The `$range` operator supports values only within the range **[0 – 999]**. If your data exceeds this range (e.g., timestamps, large scores), you should normalize or scale your values to fit within [0, 999] prior to upserting or querying
### Filter Examples
```python
# Equal operator - exact match
filter=[{"status": {"$eq": "published"}}]
# In operator - match any value in list
filter=[{"tags": {"$in": ["ai", "ml", "data-science"]}}]
# Range operator - numeric range (inclusive)
filter=[{"score": {"$range": [70, 95]}}]
# Combined filters (AND logic)
filter=[
{"status": {"$eq": "published"}},
{"tags": {"$in": ["ai", "ml"]}},
{"score": {"$range": [80, 100]}}
]
```
### Filter Tuning
When using filtered queries, two optional parameters let you tune the trade-off between search speed and recall:
#### `prefilter_cardinality_threshold`
Controls when the search strategy switches from **HNSW filtered search** (fast, graph-based) to **brute-force prefiltering** (exhaustive scan on the matched subset).
| Value | Behavior |
|-------|----------|
| `1_000` | Prefilter only for very selective filters — minimum value |
| `10_000` | Prefilter only when the filter matches ≤10,000 vectors **(default)** |
| `1_000_000` | Prefilter for almost all filtered searches — maximum value |
The intuition: when very few vectors match your filter, HNSW may struggle to find enough valid candidates through graph traversal. In that case, scanning the filtered subset directly (prefiltering) is faster and more accurate. Raising the threshold means prefiltering kicks in more often; lowering it favors HNSW graph search.
```python
# Only prefilter when filter matches ≤5,000 vectors
results = index.query(
vector=[...],
top_k=10,
filter=[{"category": {"$eq": "rare"}}],
prefilter_cardinality_threshold=5_000,
)
```
#### `filter_boost_percentage`
When using HNSW filtered search, some candidates explored during graph traversal are discarded by the filter, which can leave you with fewer results than `top_k`. `filter_boost_percentage` compensates by expanding the internal candidate pool before filtering is applied.
- `0` → no boost, standard candidate pool size **(default)**
- `20` → fetch 20% more candidates internally before applying the filter
- Maximum: `100` (doubles the candidate pool)
```python
# Fetch 30% more candidates to compensate for aggressive filtering
results = index.query(
vector=[...],
top_k=10,
filter=[{"visibility": {"$eq": "public"}}],
filter_boost_percentage=30,
)
```
#### Using Both Together
```python
results = index.query(
vector=[...],
top_k=10,
filter=[{"category": {"$eq": "rare"}}],
prefilter_cardinality_threshold=5_000, # switch to brute-force for small match sets
filter_boost_percentage=25, # boost candidates for HNSW filtered search
)
```
> **Tip:** Start with the defaults (`prefilter_cardinality_threshold=10_000`, `filter_boost_percentage=0`). If filtered queries return fewer results than expected, try increasing `filter_boost_percentage`. If filtered queries are slow on selective filters, try lowering `prefilter_cardinality_threshold`. Valid range for the threshold is `1,000–1,000,000`.
## Deletion Methods
The system supports two types of deletion operations — **vector deletion** and **index deletion**. These allow you to remove specific vectors or entire indexes from your workspace, giving you full control over lifecycle and storage.
### Vector Deletion
Vector deletion is used to remove specific vectors from an index using their unique `id`. This is useful when:
- A document is outdated or revoked
- You want to update a vector by first deleting its old version
- You're cleaning up test data or low-quality entries
```python
from endee import Endee
client = Endee(token="your-token-here")
index = client.get_index(name="your-index-name")
# Delete a single vector by ID
index.delete_vector("vec1")
```
### Filtered Deletion
In cases where you don't know the exact vector `id`, but want to delete vectors based on filter fields, you can use filtered deletion. This is especially useful for:
- Bulk deleting vectors by tag, type, or timestamp
- Enforcing access control or data expiration policies
```python
from endee import Endee
client = Endee(token="your-token-here")
index = client.get_index(name="your-index-name")
# Delete all vectors matching filter conditions
index.delete_with_filter([{"tags": {"$eq": "important"}}])
```
### Index Deletion
Index deletion permanently removes the entire index and all vectors associated with it. This should be used when:
- The index is no longer needed
- You want to re-create the index with a different configuration
- You're managing index rotation in batch pipelines
```python
from endee import Endee
client = Endee(token="your-token-here")
# Delete an entire index
client.delete_index("your-index-name")
```
> ⚠️ **Caution:** Deletion operations are **irreversible**. Ensure you have the correct `id` or index name before performing deletion, especially at the index level.
## Additional Operations
### Get Vector by ID
The `index.get_vector()` method retrieves a specific vector from the index by its unique identifier.
```python
# Retrieve a specific vector by its ID
vector = index.get_vector("vec1")
# The returned object contains:
# - id: Vector identifier
# - meta: Metadata dictionary
# - filter: Filter fields dictionary
# - norm: Vector norm value
# - vector: Vector data array
```
### Describe Index
```python
# Get index statistics and configuration info
info = index.describe()
```
---
## API Reference
### Endee Class
| Method | Description |
|--------|-------------|
| `__init__(token=None)` | Initialize client with optional API token |
| `set_token(token)` | Set or update API token |
| `set_base_url(base_url)` | Set custom API endpoint |
| `create_index(name, dimension, space_type, M, ef_con, precision, sparse_dim)` | Create a new vector index (precision as Precision enum, sparse_dim optional for hybrid) |
| `list_indexes()` | List all indexes in workspace |
| `delete_index(name)` | Delete a vector index |
| `get_index(name)` | Get reference to a vector index |
### Index Class
| Method | Description |
|--------|-------------|
| `upsert(input_array)` | Insert or update vectors (max 1000 per batch) |
| `query(vector, top_k, filter, ef, include_vectors, sparse_indices, sparse_values, prefilter_cardinality_threshold, filter_boost_percentage)` | Search for similar vectors |
| `delete_vector(id)` | Delete a vector by ID |
| `delete_with_filter(filter)` | Delete vectors matching a filter |
| `get_vector(id)` | Get a specific vector by ID |
| `describe()` | Get index statistics and configuration |
### Precision Enum
The `Precision` enum provides type-safe precision levels for vector quantization:
```python
from endee import Precision
# Available values
Precision.BINARY2 # 1-bit binary quantization
Precision.INT8D # 8-bit integer quantization (default)
Precision.INT16D # 16-bit integer quantization
Precision.FLOAT16 # 16-bit floating point
Precision.FLOAT32 # 32-bit floating point
```
## License
MIT License
| text/markdown | Endee Labs | dev@endee.io | null | null | null | vector database, embeddings, machine learning, AI, similarity search, HNSW, nearest neighbors | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Database",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Pyth... | [] | https://endee.io | null | >=3.6 | [] | [] | [] | [
"requests>=2.28.0",
"httpx[http2]>=0.28.1",
"numpy>=2.2.4",
"msgpack>=1.1.0",
"orjson>=3.11.5",
"pydantic>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://docs.endee.io"
] | twine/6.2.0 CPython/3.12.8 | 2026-02-18T10:55:26.107731 | endee-0.1.13.tar.gz | 33,905 | 6d/b1/23d10cca6e664f67ce7639e8bd27fb0b39871401a9296122957e9a1d6a35/endee-0.1.13.tar.gz | source | sdist | null | false | afa9ebafcc7f79ccef2d04b6265055b9 | 5e86ec984ada9e64e84b4547337d395f04e4fff2096594e36652b104ccf41303 | 6db123d10cca6e664f67ce7639e8bd27fb0b39871401a9296122957e9a1d6a35 | null | [
"LICENSE"
] | 290 |
2.4 | labmaster | 0.3.0a1 | A client-server system for linux school labs | # Lab Master
An asyncronous server/client arch written in python.
## Install
```
sudo apt install pkg-config libsystemd-dev
```
## Configuration
You must provide a configuration file in /opt/labs_manager named config.1 with the following fields:
```
[database]
db_type = mariadb|sqlite
db_user = dbuser
db_path = dbpath (for sqlite)
db_pwd = db user password
db_host = 192.168.0.1
db_port = 3306
db_name = dbname
[log]
no_session_log= list of users that must not be tracked
watch_groups= list of regexp matching groups to be watched
default_grade=0T,0A
log_dir=/tmp
global_level=debug
console_level=debug
file_level=debug
[server]
key = server aes shared key
address= 127.0.0.1
port= 6666
```
| text/markdown | Matteo Mosangini | Matteo Mosangini <mosangini.matteo@liceocopernico.org> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: POSIX :: Linux"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"aioconsole>=0.8.2",
"aiopsutil>=0.1.0",
"loguru>=0.7.3",
"loguru-config>=0.1.0",
"peewee>=3.18.3",
"ping3>=5.1.5",
"prompt-toolkit>=3.0.52",
"psutil>=7.2.2",
"pycryptodome>=3.23.0",
"pyinstaller>=6.18.0",
"pymysql>=1.1.2",
"rich>=14.2.0",
"systemd-python>=235",
"watchfiles>=1.1.1"
] | [] | [] | [] | [
"Homepage, https://github.com/liceocopernico/labdaemon_project",
"Issues, https://github.com/liceocopernico/labdaemon_project/issues"
] | uv/0.9.10 {"installer":{"name":"uv","version":"0.9.10"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"25.10","id":"questing","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T10:54:45.275930 | labmaster-0.3.0a1.tar.gz | 35,343 | a3/15/d5d8a9da6df2d93c6b9aeb4eb483acdbb3a8b5e8c2a3eb0ab40992f6eb2f/labmaster-0.3.0a1.tar.gz | source | sdist | null | false | 02b62f847b0699242db660cc691de760 | 181e3e0bc8b345773252ea0cc998619d0365c3479df7b1853544d68f3f875543 | a315d5d8a9da6df2d93c6b9aeb4eb483acdbb3a8b5e8c2a3eb0ab40992f6eb2f | GPL-3.0-or-later | [
"LICENSE"
] | 218 |
2.4 | csv-detective | 0.10.5.dev6 | Detect tabular files column content | # CSV Detective
This is a package to **automatically detect column content in tabular files**. The script reads either the whole file or the first few rows and performs various checks (regex, casting, comparison with official lists...) to see for each column if it matches with various content types.
Currently supported file types: csv(.gz), xls, xlsx, ods.
You can also directly feed the URL of a remote file (from data.gouv.fr for instance).
## How To?
### Install the package
You need to have Python >= 3.10 installed. We recommend using a virtual environment.
```bash
pip install csv-detective
```
### Detect some columns
Say you have a tabular file located at `file_path`. This is how you could use `csv_detective`:
```python
# Import the csv_detective package
from csv_detective import routine
import os # for this example only
# Replace by your file path
file_path = os.path.join('.', 'tests', 'code_postaux_v201410.csv')
# Open your file and run csv_detective
inspection_results = routine(
file_path, # or file URL
num_rows=-1, # Value -1 will analyze all lines of your file, you can change with the number of lines you wish to analyze
save_results=False, # Default False. If True, it will save result output into the same directory as the analyzed file, using the same name as your file and .json extension
output_profile=True, # Default False. If True, returned dict will contain a property "profile" indicating profile (min, max, mean, tops...) of every column of your csv
output_schema=True, # Default False. If True, returned dict will contain a property "schema" containing basic [tableschema](https://specs.frictionlessdata.io/table-schema/) of your file. This can be used to validate structure of other csv which should match same structure.
tags=["fr"], # Default None. If set as a list of strings, only performs checks related to the specified tags (you can see the available tags with FormatsManager().available_tags())
)
```
## So What Do You Get ?
### Output
The program creates a `python` dictionary with the following information :
```
{
"encoding": "windows-1252", # Encoding detected
"separator": ";", # Detected CSV separator
"header_row_idx": 0 # Index of the header (aka how many lines to skip to get it)
"headers": ['code commune INSEE', 'nom de la commune', 'code postal', "libellé d'acheminement"], # Header row
"total_lines": 42, # Number of rows (excluding header)
"nb_duplicates": 0, # Number of exact duplicates in rows
"heading_columns": 0, # Number of heading columns
"trailing_columns": 0, # Number of trailing columns
"categorical": ['Code commune'] # Columns that contain less than 25 different values (arbitrary threshold)
"columns": { # Property that conciliate detection from labels and content of a column
"Code commune": {
"python_type": "string",
"format": "code_commune",
"score": 1.0
},
},
"columns_labels": { # Property that return detection from header columns
"Code commune": {
"python_type": "string",
"format": "code_commune",
"score": 0.5
},
},
"columns_fields": { # Property that return detection from content columns
"Code commune": {
"python_type": "string",
"format": "code_commune",
"score": 1.25
},
},
"profile": {
"column_name" : {
"min": 1, # only int and float
"max": 12, # only int and float
"mean": 5, # only int and float
"std": 5, # only int and float
"tops": [ # 10 most frequent values in the column
"xxx",
"yyy",
"..."
],
"nb_distinct": 67, # number of distinct values
"nb_missing_values": 102 # number of empty cells in the column
}
},
"schema": { # TableSchema of the file if `output_schema` was set to `True`
"$schema": "https://frictionlessdata.io/schemas/table-schema.json",
"name": "",
"title": "",
"description": "",
"countryCode": "FR",
"homepage": "",
"path": "https://github.com/datagouv/csv-detective",
"resources": [],
"sources": [
{"title": "Spécification Tableschema", "path": "https://specs.frictionlessdata.io/table-schema"},
{"title": "schema.data.gouv.fr", "path": "https://schema.data.gouv.fr"}
],
"created": "2023-02-10",
"lastModified": "2023-02-10",
"version": "0.0.1",
"contributors": [
{"title": "Table schema bot", "email": "schema@data.gouv.fr", "organisation": "data.gouv.fr", "role": "author"}
],
"fields": [
{
"name": "Code commune",
"description": "Le code INSEE de la commune",
"example": "23150",
"type": "string",
"formatFR": "code_commune",
"constraints": {
"required": False,
"pattern": "^([013-9]\\d|2[AB1-9])\\d{3}$",
}
}
]
}
}
```
The output slightly differs depending on the file format:
- csv files have `encoding` and `separator` (and `compression` if relevant)
- xls, xlsx, ods files have `engine` and `sheet_name`
You may also set `output_df` to `True`, in which case the output is a tuple of two elements:
- the analysis (as described above)
- an iterator of `pd.DataFrame`s which contain the columns cast with the detected types (which can be used with `pd.concat` or in a loop):
```python
inspection, df_chunks = routine(
file_path=file_path,
num_rows=-1,
output_df=True,
)
cast_df = pd.concat(df_chunks, ignore_index=True)
# if "col1" has been detected as a float, then cast_df["col1"] contains floats
```
### What Formats Can Be Detected
Includes :
- types (float, int, dates, datetimes, JSON) and more specific (latitude, longitude, geoJSON...)
- Communes, Départements, Régions, Pays
- Codes Communes, Codes Postaux, Codes Departement, ISO Pays
- Codes CSP, Description CSP, SIREN
- E-Mails, URLs, Téléphones FR
- Years, Dates, Jours de la Semaine FR
- UUIDs, Mongo ObjectIds
### Validation
If you have a pre-made analysis of a file, you can check whether another file conforms to the same analysis:
```python
from csv_detective import validate
is_valid, *_ = validate(
file_path,
previous_analysis, # exactly as it came out from the routine function
)
```
### Format detection and scoring
For each column, 3 scores are computed for each format, the higher the score, the more likely the format:
- the field score based on the values contained in the column (0.0 to 1.0).
- the label score based on the header of the column (0.0 to 1.0).
- the overall score, computed as `field_score * (1 + label_score/2)` (0.0 to 1.5).
The overall score computation aims to give more weight to the column contents while
still leveraging the column header.
#### `limited_output` - Select the output mode you want for json report
This option allows you to select the output mode you want to pass. To do so, you have to pass a `limited_output` argument to the `routine` function. This variable has two possible values:
- `limited_output` defaults to `True` which means report will contain only detected column formats based on a pre-selected threshold proportion in data. Report result is the standard output (an example can be found above in 'Output' section).
Only the format with highest score is present in the output.
- `limited_output=False` means report will contain a full list of all column format possibilities for each input data columns with a value associated which match to the proportion of found column type in data. With this report, user can adjust its rules of detection based on a specific threshold and has a better vision of quality detection for each columns. Results could also be easily transformed into a dataframe (columns types in column / column names in rows) for analysis and test.
## Improvement suggestions
- Smarter refactors
- Performances improvements
- Test other ways to load and process data (`pandas` alternatives)
- Add more and more detection modules...
Related ideas:
- store column names to make a learning model based on column names for (possible pre-screen)
- entity resolution (good luck...)
## Why Could This Be of Any Use?
Organisations such as [data.gouv.fr](http://data.gouv.fr) aggregate huge amounts of un-normalised data. Performing cross-examination across datasets can be difficult. This tool could help enrich the datasets metadata and facilitate linking them together.
[`udata-hydra`](https://github.com/etalab/udata-hydra) is a crawler that checks, analyzes (using `csv-detective`) and APIfies all tabular files from [data.gouv.fr](http://data.gouv.fr).
An early version of this analysis of all resources on data.gouv.fr can be found [here](https://github.com/Leobouloc/data.gouv-exploration).
## Linting
Remember to format, lint, and sort imports with [Ruff](https://docs.astral.sh/ruff/) before committing (checks will remind you anyway):
```bash
pip install .[dev]
ruff check --fix .
ruff format .
```
### 🏷️ Release
The release process uses the [`tag_version.sh`](tag_version.sh) script to create git tags and update [CHANGELOG.md](CHANGELOG.md) and [pyproject.toml](pyproject.toml) automatically.
**Prerequisites**: [GitHub CLI](https://cli.github.com/) (`gh`) must be installed and authenticated, and you must be on the main branch with a clean working directory.
```bash
# Create a new release
./tag_version.sh <version>
# Example
./tag_version.sh 2.5.0
# Dry run to see what would happen
./tag_version.sh 2.5.0 --dry-run
```
The script automatically:
- Updates the version in `pyproject.toml`
- Extracts commits since the last tag and formats them for `CHANGELOG.md`
- Identifies breaking changes (commits with `!:` in the subject)
- Creates a git tag and pushes it to the remote repository
- Creates a GitHub release with the changelog content
| text/markdown | null | "data.gouv.fr" <opendatateam@data.gouv.fr> | null | null | MIT | CSV, data processing, encoding, guess, parser, tabular | [] | [] | null | null | <3.15,>=3.10 | [] | [] | [] | [
"dateparser<2,>=1.2.0",
"faust-cchardet==2.1.19",
"pandas<3,>=2.3.0",
"python-dateutil<3,>=2.8.2",
"Unidecode<2,>=1.3.6",
"openpyxl>=3.1.5",
"xlrd>=2.0.1",
"odfpy>=1.4.1",
"requests<3,>=2.32.3",
"python-magic>=0.4.27",
"frformat==0.4.0",
"Faker>=33.0.0",
"rstr>=3.2.2",
"more-itertools>=10.... | [] | [] | [] | [
"Source, https://github.com/datagouv/csv-detective"
] | uv/0.9.30 {"installer":{"name":"uv","version":"0.9.30","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":"12","id":"bookworm","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-18T10:54:22.919251 | csv_detective-0.10.5.dev6-py3-none-any.whl | 152,069 | 71/87/4e629a6cb34a89ce865dbd155d8a4e9da0b7c2d474e41e66c72030d9c375/csv_detective-0.10.5.dev6-py3-none-any.whl | py3 | bdist_wheel | null | false | 5df225d95c83cabb898b561d3f4449a5 | 5373f2f512863f100c8a2a80970c22f68075efa17e9f7617ea43695faf09d8d8 | 71874e629a6cb34a89ce865dbd155d8a4e9da0b7c2d474e41e66c72030d9c375 | null | [
"LICENSE"
] | 91 |
2.4 | ista-daslab-optimizers | 1.1.12 | Deep Learning optimizers developed in the Distributed Algorithms and Systems group (DASLab) @ Institute of Science and Technology Austria (ISTA) | # ISTA DAS Lab Optimization Algorithms Package
This repository contains optimization algorithms for Deep Learning developed by
the Distributed Algorithms and Systems lab at Institute of Science and Technology Austria.
The repository contains code for the following optimizers published by DASLab @ ISTA:
- **AC/DC**:
- paper: [AC/DC: Alternating Compressed/DeCompressed Training of Deep Neural Networks](https://arxiv.org/abs/2106.12379)
- official repository: [GitHub](https://github.com/IST-DASLab/ACDC)
- **M-FAC**:
- paper: [M-FAC: Efficient Matrix-Free Approximations of Second-Order Information](https://arxiv.org/abs/2107.03356)
- official repository: [GitHub](https://github.com/IST-DASLab/M-FAC)
- **Sparse M-FAC with Error Feedback**:
- paper: [Error Feedback Can Accurately Compress Preconditioners](https://arxiv.org/abs/2306.06098)
- official repository: [GitHub](https://github.com/IST-DASLab/EFCP/)
- **MicroAdam**:
- paper: [MicroAdam: Accurate Adaptive Optimization with Low Space Overhead and Provable Convergence](https://arxiv.org/abs/2405.15593)
- official repository: [GitHub](https://github.com/IST-DASLab/MicroAdam)
- **Trion / DCT-AdamW**:
- paper: [FFT-based Dynamic Subspace Selection for Low-Rank Adaptive Optimization of Large Language Models](https://arxiv.org/abs/2505.17967v3)
- code: [GitHub](https://github.com/IST-DASLab/ISTA-DASLab-Optimizers/tree/main/ista_daslab_optimizers/fft_low_rank)
- **DASH**:
- paper: [DASH: Faster Shampoo via Batched Block Preconditioning and Efficient Inverse-Root Solvers](https://arxiv.org/pdf/2602.02016)
- code: [GitHub](https://github.com/IST-DASLab/DASH)
## CUDA Kernels
Please visit the repository [ISTA-DASLab-Optimizers-CUDA](https://github.com/IST-DASLab/ISTA-DASLab-Optimizers-CUDA) containing the CUDA
support for **M-FAC**, **Sparse M-FAC** and **MicroAdam** optimizers.
### Installation
To use the latest stable version of this repository, you can install via pip:
```shell
pip3 install ista-daslab-optimizers
```
and you can also visit the [PyPi page](https://pypi.org/project/ista-daslab-optimizers/).
We also provide a script `install.sh` that creates a new environment, installs requirements
and then installs the project as a Python package following these steps:
```shell
git clone git@github.com:IST-DASLab/ISTA-DASLab-Optimizers.git
cd ISTA-DASLab-Optimizers
source install.sh
```
## How to use optimizers?
In this repository we provide a minimal working example for CIFAR-10 for optimizers `acdc`,
`dense_mfac`, `sparse_mfac` and `micro_adam`:
```shell
cd examples/cifar10
OPTIMIZER=micro_adam # or any other optimizer listed above
bash run_${OPTIMIZER}.sh
```
To integrate the optimizers into your own pipeline, you can use the following snippets:
### MicroAdam optimizer
```python
from ista_daslab_optimizers import MicroAdam
model = MyCustomModel()
optimizer = MicroAdam(
model.parameters(), # or some custom parameter groups
m=10, # sliding window size (number of gradients)
lr=1e-5, # change accordingly
quant_block_size=100_000, # 32 or 64 also works
k_init=0.01, # float between 0 and 1 meaning percentage: 0.01 means 1%
alpha=0, # 0 means sparse update and 0 < alpha < 1 means we integrate fraction alpha from EF to update and then delete it
)
# from now on, you can use the variable `optimizer` as any other PyTorch optimizer
```
# Versions summary:
---
- **1.1.12** @ February 15th, 2026:
- refactory for DASH: separated entities to different files and implemented **DashGpu**, as well as
a triton kernel to compute `L_t = beta * L_t-1 + (1-beta) * G @ G.T` and `R_t = beta * R_t-1 + (1-beta) * G.T @ G` in-place
using the stacked blocks.
- **1.1.11** @ February 6th, 2026:
- added `triton` as dependency
- **1.1.10** @ February 6th, 2026:
- removed **fast-hadamard-transform** because 1) it is not used and 2) it raises compilation errors during `pip install`
- **1.1.9** @ February 6th, 2026:
- added **DASH** optimizer
- **1.1.8** @ February 5th, 2026:
- moved kernels to [ISTA-DASLab-Optimizers-CUDA](https://github.com/IST-DASLab/ISTA-DASLab-Optimizers-CUDA)
- building building the package after adding a new optimizer that doesn't require CUDA support would require compiling
the kernels from scratch, which is time consuming and not needed
- **1.1.7** @ October 8th, 2025:
- added code for `Trion & DCT-AdamW`
- **1.1.6** @ February 19th, 2025:
- do not update the parameters that have `None` gradient in method `update_model` from `tools.py`.
This is useful when using M-FAC for models with more than one classification head in the Continual Learning framework.
- **1.1.5** @ February 19th, 2025:
- adapted `DenseMFAC` for a model with multiple classification heads for Continual Learning where
we have one feature extractor block and a list of classification heads. The issue was related to
the model size, which included the feature extractor backbone and all classification heads, but
in practice only one classification head will be used for training and inference. This caused some
size mismatch errors at runtime in the `DenseCoreMFAC` module because the gradient at runtime had
fewer entries than the entire model. When using `DenseMFAC` for such settings, set `optimizer.model_size`
to the correct size after calling the constructor and the `DenseCoreMFAC` object will be created
automatically in the `step` function.
- **1.1.3** @ September 5th, 2024:
- allow using `SparseCoreMFACwithEF` separately by importing it in `sparse_mfac.__init__.py`
- **1.1.2** @ August 1st, 2024:
- ***[1.1.0]:*** added support to densify the final update: introduced parameter alpha that controls
the fraction of error feedback (EF) to be integrated into the update to make it dense. Finally, the
fraction alpha will be discarded from the EF at the expense of another call to `Qinv` and `Q` (and
implicitly quantization statistics computation).
- ***[1.0.2]:*** added FSDP-compatible implementation by initializing the parameter states in the
`update_step` method instead of MicroAdam constructor
- **1.0.1** @ June 27th, 2024:
- removed version in dependencies to avoid conflicts with llm-foundry
- **1.0.0** @ June 20th, 2024:
- changed minimum required Python version to 3.8+ and torch to 2.3.0+
- **0.0.1** @ June 13th, 2024:
- added initial version of the package for Python 3.9+ and torch 2.3.1+
| text/markdown | null | Ionut-Vlad Modoranu <ionut-vlad.modoranu@ist.ac.at> | null | Ionut-Vlad Modoranu <ionut-vlad.modoranu@ist.ac.at> | MIT License
Copyright (c) 2026 IST Austria Distributed Algorithms and Systems Lab
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | adaptive optimization, deep learning, low memory optimization | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"License :: OSI Approved :: MIT License"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"torch",
"torchaudio",
"torchvision",
"numpy",
"wandb",
"gpustat",
"timm",
"einops",
"psutil",
"triton",
"ista-daslab-optimizers-cuda"
] | [] | [] | [] | [
"Repository, https://github.com/IST-DASLab/ISTA-DASLab-Optimizers"
] | twine/6.2.0 CPython/3.9.23 | 2026-02-18T10:54:03.602903 | ista_daslab_optimizers-1.1.12.tar.gz | 75,441 | 14/92/ebeef9c987570c9d258751579449277bbf2e29d3c4a0255be1b9e9b40262/ista_daslab_optimizers-1.1.12.tar.gz | source | sdist | null | false | 0240e2600159f059d0779748ec32b1c4 | 1778a875e44deaf001dda973a511d23a71de556e9507cf49a4e71e62e8394a6b | 1492ebeef9c987570c9d258751579449277bbf2e29d3c4a0255be1b9e9b40262 | null | [
"LICENSE"
] | 253 |
2.4 | pyscript-programming-language | 1.12.0 | PyScript Programming Language | # PyScript
<div align="center">
<img src="https://github.com/azzammuhyala/pyscript/blob/main/PyScript.png?raw=true" alt="PyScript Logo" width="200">
</div>
PyScript is a simple programming language built on top of Python. It combines some syntax from Python and JavaScript,
so if you're already familiar with Python, JavaScript or both, it should be quite easy to learn.
## Introduction
PyScript may not be the language we'll be discussing, but the name PyScript already exists, a flexible and platform for
running Python in a browser. Since it's inception, the language was inspired by Python and JavaScript, which are
relatively easy for humans to read. This name was chosen because it wasn't immediately known whether this name was
already in use.
This language wasn't designed to compete with other modern programming languages, but rather as a learning for
understanding how programming languages work and how human written code can be understood by machines. Furthermore, this
language was created as a relatively complex project. Using Python as the foundation for PyScript, it's easy to
understand how the language is built without having to understand complex instructions like those in C, C++, and other
low-level languages.
To learn more about PyScript, you can see on [PyScript documentation](https://azzammuhyala.github.io/pyscript) or
[PyScript repository](https://github.com/azzammuhyala/pyscript) for full source code.
## Installation
First, you'll need to download Python. Make sure you're using the latest version above `3.10`, to ensure the code runs
correctly. Visit the official [Python website](https://python.org) to download it.
Next, after downloading and configuring the Python application, you can download the PyScript from
[PyScript releases](https://github.com/azzammuhyala/pyscript/releases) or from Python Pip with this command
(_Recommended_):
```sh
pip install -U pyscript-programming-language
```
[_OPTIONAL_] You can download additional libraries that PyScript requires with this command:
```sh
pip install -U "pyscript-programming-language[other]"
```
And also, you can download PyScript with `git`:
```sh
git clone https://github.com/azzammuhyala/pyscript
cd pyscript
pip install .
```
After that, you can run the PyScript shell (_REPL_) with this command:
```sh
python -m pyscript
```
If successful, you can see the version, release date, and a `>>>` like Python shell (_REPL_).
> If you are using the VS Code editor, you can use the
[PyScript extension](https://marketplace.visualstudio.com/items?itemName=azzammuhyala.pyslang) for Syntax Highlight!
## Example
Familiar? There it is!
<pre><span style="color:#549952"># get a number and operator with input()</span><span style="color:#D4D4D4"><br></span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4"> = </span><span style="color:#4EC9B0">float</span><span style="color:#FFD705">(</span><span style="color:#DCDCAA">input</span><span style="color:#D45DBA">(</span><span style="color:#CE9178">"Enter a first number : "</span><span style="color:#D45DBA">)</span><span style="color:#FFD705">)</span><span style="color:#D4D4D4"><br></span><span style="color:#8CDCFE">b</span><span style="color:#D4D4D4"> = </span><span style="color:#4EC9B0">float</span><span style="color:#FFD705">(</span><span style="color:#DCDCAA">input</span><span style="color:#D45DBA">(</span><span style="color:#CE9178">"Enter a second number: "</span><span style="color:#D45DBA">)</span><span style="color:#FFD705">)</span><span style="color:#D4D4D4"><br></span><span style="color:#8CDCFE">op</span><span style="color:#D4D4D4"> = </span><span style="color:#DCDCAA">input</span><span style="color:#FFD705">(</span><span style="color:#CE9178">"Enter an operation (+, -, *, /): "</span><span style="color:#FFD705">)</span><span style="color:#D4D4D4"><br><br></span><span style="color:#549952"># define a functions</span><span style="color:#D4D4D4"><br></span><span style="color:#307CD6">func</span><span style="color:#D4D4D4"> </span><span style="color:#DCDCAA">add</span><span style="color:#FFD705">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#FFD705">)</span><span style="color:#D4D4D4"> </span><span style="color:#FFD705">{</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">return</span><span style="color:#D4D4D4"> </span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4"> + </span><span style="color:#8CDCFE">b</span><span style="color:#D4D4D4"><br></span><span style="color:#FFD705">}</span><span style="color:#D4D4D4"><br><br></span><span style="color:#307CD6">func</span><span style="color:#D4D4D4"> </span><span style="color:#DCDCAA">sub</span><span style="color:#FFD705">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#FFD705">)</span><span style="color:#D4D4D4"> </span><span style="color:#FFD705">{</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">return</span><span style="color:#D4D4D4"> </span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4"> - </span><span style="color:#8CDCFE">b</span><span style="color:#D4D4D4"><br></span><span style="color:#FFD705">}</span><span style="color:#D4D4D4"><br><br></span><span style="color:#307CD6">func</span><span style="color:#D4D4D4"> </span><span style="color:#DCDCAA">mul</span><span style="color:#FFD705">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#FFD705">)</span><span style="color:#D4D4D4"> </span><span style="color:#FFD705">{</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">return</span><span style="color:#D4D4D4"> </span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4"> * </span><span style="color:#8CDCFE">b</span><span style="color:#D4D4D4"><br></span><span style="color:#FFD705">}</span><span style="color:#D4D4D4"><br><br></span><span style="color:#307CD6">func</span><span style="color:#D4D4D4"> </span><span style="color:#DCDCAA">floordiv</span><span style="color:#FFD705">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#FFD705">)</span><span style="color:#D4D4D4"> </span><span style="color:#FFD705">{</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#549952"># check b is zero</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">return</span><span style="color:#D4D4D4"> </span><span style="color:#8CDCFE">b</span><span style="color:#D4D4D4"> != </span><span style="color:#B5CEA8">0</span><span style="color:#D4D4D4"> ? </span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4"> / </span><span style="color:#8CDCFE">b</span><span style="color:#D4D4D4"> : </span><span style="color:#CE9178">"Cannot be divided by 0!"</span><span style="color:#D4D4D4"><br></span><span style="color:#FFD705">}</span><span style="color:#D4D4D4"><br><br></span><span style="color:#549952"># operation matching</span><span style="color:#D4D4D4"><br></span><span style="color:#C586C0">switch</span><span style="color:#D4D4D4"> </span><span style="color:#FFD705">(</span><span style="color:#8CDCFE">op</span><span style="color:#D4D4D4">.</span><span style="color:#DCDCAA">strip</span><span style="color:#D45DBA">()</span><span style="color:#FFD705">)</span><span style="color:#D4D4D4"><br></span><span style="color:#FFD705">{</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">case</span><span style="color:#D4D4D4"> </span><span style="color:#CE9178">'+'</span><span style="color:#D4D4D4">:</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#8CDCFE">result</span><span style="color:#D4D4D4"> = </span><span style="color:#DCDCAA">add</span><span style="color:#D45DBA">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#D45DBA">)</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#DCDCAA">print</span><span style="color:#D45DBA">(</span><span style="color:#CE9178">"Result of {} + {} = {}"</span><span style="color:#D4D4D4">.</span><span style="color:#DCDCAA">format</span><span style="color:#1A9FFF">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">result</span><span style="color:#1A9FFF">)</span><span style="color:#D45DBA">)</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">break</span><span style="color:#D4D4D4"><br><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">case</span><span style="color:#D4D4D4"> </span><span style="color:#CE9178">'-'</span><span style="color:#D4D4D4">:</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#8CDCFE">result</span><span style="color:#D4D4D4"> = </span><span style="color:#DCDCAA">sub</span><span style="color:#D45DBA">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#D45DBA">)</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#DCDCAA">print</span><span style="color:#D45DBA">(</span><span style="color:#CE9178">"Result of {} - {} = {}"</span><span style="color:#D4D4D4">.</span><span style="color:#DCDCAA">format</span><span style="color:#1A9FFF">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">result</span><span style="color:#1A9FFF">)</span><span style="color:#D45DBA">)</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">break</span><span style="color:#D4D4D4"><br><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">case</span><span style="color:#D4D4D4"> </span><span style="color:#CE9178">'*'</span><span style="color:#D4D4D4">:</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#8CDCFE">result</span><span style="color:#D4D4D4"> = </span><span style="color:#DCDCAA">mul</span><span style="color:#D45DBA">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#D45DBA">)</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#DCDCAA">print</span><span style="color:#D45DBA">(</span><span style="color:#CE9178">"Result of {} * {} = {}"</span><span style="color:#D4D4D4">.</span><span style="color:#DCDCAA">format</span><span style="color:#1A9FFF">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">result</span><span style="color:#1A9FFF">)</span><span style="color:#D45DBA">)</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">break</span><span style="color:#D4D4D4"><br><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">case</span><span style="color:#D4D4D4"> </span><span style="color:#CE9178">'/'</span><span style="color:#D4D4D4">:</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#8CDCFE">result</span><span style="color:#D4D4D4"> = </span><span style="color:#DCDCAA">floordiv</span><span style="color:#D45DBA">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#D45DBA">)</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#DCDCAA">print</span><span style="color:#D45DBA">(</span><span style="color:#CE9178">"Result of {} / {} = {}"</span><span style="color:#D4D4D4">.</span><span style="color:#DCDCAA">format</span><span style="color:#1A9FFF">(</span><span style="color:#8CDCFE">a</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">b</span><span style="color:#D4D4D4">, </span><span style="color:#8CDCFE">result</span><span style="color:#1A9FFF">)</span><span style="color:#D45DBA">)</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">break</span><span style="color:#D4D4D4"><br><br></span><span style="color:#D4D4D4"> </span><span style="color:#C586C0">default</span><span style="color:#D4D4D4">:</span><span style="color:#D4D4D4"><br></span><span style="color:#D4D4D4"> </span><span style="color:#DCDCAA">print</span><span style="color:#D45DBA">(</span><span style="color:#CE9178">"Unknown operation"</span><span style="color:#D45DBA">)</span><span style="color:#D4D4D4"><br></span><span style="color:#FFD705">}</span></pre>
## Library Requirements
| No | Name | Status |
|:--:|:------------------|:----------------------:|
| 1 | `argparse` | **required** |
| 2 | `builtins` | **required** |
| 3 | `collections.abc` | **required** |
| 4 | `functools` | **required** |
| 5 | `html` | **required** |
| 6 | `importlib` | **required** |
| 7 | `inspect` | **required** |
| 8 | `io` | **required** |
| 9 | `itertools` | **required** |
| 10 | `json` | **required** |
| 11 | `math` | **required** |
| 12 | `operator` | **required** |
| 13 | `os` | **required** |
| 14 | `re` | **required** |
| 15 | `sys` | **required** |
| 16 | `threading` | **required** |
| 17 | `types` | **required** |
| 18 | `typing` | **required** |
| 19 | `unicodedata` | **required** |
| 1 | `msvcrt` | **required (library)** |
| 2 | `shutil` | **required (library)** |
| 3 | `stat` | **required (library)** |
| 4 | `termios` | **required (library)** |
| 5 | `time` | **required (library)** |
| 6 | `tty` | **required (library)** |
| 1 | `beartype` | **optional** |
| 2 | `google.colab` | **optional** |
| 3 | `prompt_toolkit` | **optional** |
| 4 | `pygments` | **optional** |
| 5 | `tkinter` | **optional** |
### Status Explanation
- **required**: Required by PyScript entirely.
- **required (library)**: Required PyScript library (located in `pyscript/lib`). PyScript is not affected unless you
import it.
- **optional**: Not required, but if it is present, some features can be used without issue.
## Behind it
This language created from based up on a
[YouTube tutorial](https://www.youtube.com/playlist?list=PLZQftyCk7_SdoVexSmwy_tBgs7P0b97yD) (check more on GitHub
[here](https://github.com/davidcallanan/py-myopl-code) by **@davidcallanan**). At least, it takes about 6 months to
learn it, and also need to learn general things that exist in other programming languages.
| text/markdown | azzammuhyala | azzammuhyala <azzammuhyala@gmail.com> | null | null | null | pyscript, pyslang, pys, programming, language, programming language | [
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Software Development :: Interpreters",
"Topic :: Software Development :: Compilers"
] | [] | https://azzammuhyala.github.io/pyscript | null | >=3.10 | [] | [] | [] | [
"beartype; extra == \"other\"",
"pygments; extra == \"other\"",
"prompt_toolkit; extra == \"other\""
] | [] | [] | [] | [
"Homepage, https://azzammuhyala.github.io/pyscript",
"Source, https://github.com/azzammuhyala/pyscript",
"Bug Tracker, https://github.com/azzammuhyala/pyscript/issues"
] | twine/6.2.0 CPython/3.14.0 | 2026-02-18T10:53:03.432941 | pyscript_programming_language-1.12.0.tar.gz | 84,272 | a8/6a/c1c9f42b9399abaa2763fd5a3f08c0ffdd9e9dd04fab28dc868e90779641/pyscript_programming_language-1.12.0.tar.gz | source | sdist | null | false | bc612d866872fdc4dcf5e80a4f29c4c6 | b064630b8390dc8f0133f749198af1e8930bd8e89d9415b689e31ef336f33520 | a86ac1c9f42b9399abaa2763fd5a3f08c0ffdd9e9dd04fab28dc868e90779641 | MIT | [] | 282 |
2.4 | aivory-monitor | 1.0.0 | AIVory Monitor Python Agent - Remote debugging with AI-powered fix generation | # AIVory Monitor Python Agent
Python agent using sys.settrace for breakpoint support and sys.excepthook for exception capture.
## Requirements
- Python 3.8+
- pip or pip3
## Installation
```bash
pip install aivory-monitor
```
## Usage
### Option 1: Import and Initialize
```python
import aivory_monitor
# Initialize with environment variables
aivory_monitor.init()
# Or pass configuration directly
aivory_monitor.init(
api_key='your-api-key',
environment='production'
)
# Your application code
```
### Option 2: Automatic Initialization via Environment
Set environment variables before importing your application:
```bash
export AIVORY_API_KEY=your_api_key
python app.py
```
Then initialize in your application entry point:
```python
import aivory_monitor
aivory_monitor.init()
# Rest of your application
```
### Option 3: Framework Middleware
**Django:**
Add to your `settings.py`:
```python
MIDDLEWARE = [
'aivory_monitor.integrations.django.DjangoIntegration',
# ... other middleware
]
# Initialize agent
import aivory_monitor
aivory_monitor.init(api_key='your-api-key')
```
**Flask:**
```python
from flask import Flask
from aivory_monitor.integrations.flask import init_app
import aivory_monitor
app = Flask(__name__)
# Initialize agent
aivory_monitor.init(api_key='your-api-key')
# Add Flask integration
init_app(app)
```
**FastAPI:**
```python
from fastapi import FastAPI
from aivory_monitor.integrations.fastapi import init_app
import aivory_monitor
app = FastAPI()
# Initialize agent
aivory_monitor.init(api_key='your-api-key')
# Add FastAPI integration
init_app(app)
```
### Manual Exception Capture
```python
import aivory_monitor
try:
risky_operation()
except Exception as e:
# Capture exception with additional context
aivory_monitor.capture_exception(e, context={
'user_id': '12345',
'operation': 'payment_processing'
})
raise
```
### Setting Context and User Information
```python
import aivory_monitor
# Set custom context (included in all captures)
aivory_monitor.set_context({
'feature_flags': {'new_ui': True},
'tenant_id': 'acme-corp'
})
# Set user information
aivory_monitor.set_user(
user_id='user-123',
email='user@example.com',
username='john_doe'
)
```
## Configuration
All configuration options can be set via environment variables or passed to `init()`:
| Parameter | Environment Variable | Default | Description |
|-----------|---------------------|---------|-------------|
| `api_key` | `AIVORY_API_KEY` | Required | AIVory API key for authentication |
| `backend_url` | `AIVORY_BACKEND_URL` | `wss://api.aivory.net/ws/agent` | Backend WebSocket URL |
| `environment` | `AIVORY_ENVIRONMENT` | `production` | Environment name (production, staging, etc.) |
| `sampling_rate` | `AIVORY_SAMPLING_RATE` | `1.0` | Exception sampling rate (0.0 - 1.0) |
| `max_capture_depth` | `AIVORY_MAX_DEPTH` | `10` | Maximum depth for variable capture |
| `max_string_length` | `AIVORY_MAX_STRING_LENGTH` | `1000` | Maximum string length to capture |
| `max_collection_size` | `AIVORY_MAX_COLLECTION_SIZE` | `100` | Maximum collection elements to capture |
| `enable_breakpoints` | `AIVORY_ENABLE_BREAKPOINTS` | `true` | Enable non-breaking breakpoint support |
| `debug` | `AIVORY_DEBUG` | `false` | Enable debug logging |
### Configuration Examples
**Environment Variables:**
```bash
export AIVORY_API_KEY=your_api_key
export AIVORY_BACKEND_URL=wss://api.aivory.net/ws/agent
export AIVORY_ENVIRONMENT=production
export AIVORY_SAMPLING_RATE=0.5
export AIVORY_MAX_DEPTH=5
export AIVORY_DEBUG=false
```
**Programmatic:**
```python
import aivory_monitor
aivory_monitor.init(
api_key='your-api-key',
backend_url='wss://api.aivory.net/ws/agent',
environment='production',
sampling_rate=0.5,
max_capture_depth=5,
max_string_length=500,
max_collection_size=50,
enable_breakpoints=True,
debug=False
)
```
## Building from Source
```bash
cd monitor-agents/agent-python
pip install -e .
# Or build distribution packages
pip install build
python -m build
```
## How It Works
1. **sys.excepthook**: Automatically captures uncaught exceptions with full stack traces and local variables
2. **sys.settrace**: Implements non-breaking breakpoints by hooking into Python's trace mechanism
3. **Asyncio Integration**: Uses WebSocket client with asyncio for real-time communication with backend
4. **Context Preservation**: Captures thread-local and request context at the time of exception
**Key Features:**
- Non-breaking breakpoints that don't pause execution
- Full stack trace with local variables at each frame
- Request context correlation for web frameworks
- Configurable variable capture depth and sampling
- Minimal performance overhead (uses sampling and conditional capture)
## Framework Support
### Django
The Django integration provides:
- Automatic request context capture (method, path, headers, user)
- Exception handling in views and middleware
- Optional logging handler integration
```python
# settings.py
MIDDLEWARE = [
'aivory_monitor.integrations.django.DjangoIntegration',
# ... other middleware
]
import aivory_monitor
aivory_monitor.init(api_key='your-api-key')
# Optional: Configure logging integration
from aivory_monitor.integrations.django import configure_django_logging
LOGGING = configure_django_logging()
```
### Flask
The Flask integration provides:
- Before-request context setup
- Automatic exception handling
- Request timing information
```python
from flask import Flask
from aivory_monitor.integrations.flask import init_app
import aivory_monitor
app = Flask(__name__)
aivory_monitor.init(api_key='your-api-key')
init_app(app)
```
### FastAPI
The FastAPI integration provides:
- ASGI middleware for request/response tracking
- Async exception handling
- Path and query parameter capture
```python
from fastapi import FastAPI
from aivory_monitor.integrations.fastapi import init_app
import aivory_monitor
app = FastAPI()
aivory_monitor.init(api_key='your-api-key')
init_app(app)
```
For generic ASGI applications, use `AIVoryMiddleware`:
```python
from aivory_monitor.integrations.fastapi import AIVoryMiddleware
app = AIVoryMiddleware(app)
```
## Local Development Testing
### Quick Test Script
Create a test script to trigger exceptions:
```python
# test-app.py
import aivory_monitor
import time
aivory_monitor.init(
api_key='ilscipio-dev-2024',
backend_url='ws://localhost:19999/ws/monitor/agent',
environment='development',
debug=True
)
print("Agent initialized, waiting 2s for connection...")
time.sleep(2)
# Test 1: Simple exception
try:
raise ValueError("Test exception from Python agent")
except Exception as e:
aivory_monitor.capture_exception(e)
# Test 2: Null reference
try:
x = None
x.some_method()
except Exception as e:
aivory_monitor.capture_exception(e)
# Test 3: With context
try:
result = 10 / 0
except Exception as e:
aivory_monitor.capture_exception(e, context={
'operation': 'divide',
'user_id': 'test-user'
})
print("Test exceptions sent. Check backend logs.")
time.sleep(2)
aivory_monitor.shutdown()
```
Run with:
```bash
python test-app.py
```
### Flask Test Server
```python
# test-server.py
from flask import Flask
from aivory_monitor.integrations.flask import init_app
import aivory_monitor
app = Flask(__name__)
aivory_monitor.init(
api_key='ilscipio-dev-2024',
backend_url='ws://localhost:19999/ws/monitor/agent',
environment='development',
debug=True
)
init_app(app)
@app.route('/error')
def trigger_error():
raise ValueError("Test sync error")
@app.route('/null')
def trigger_null():
x = None
return x.some_attribute
@app.route('/divide')
def trigger_divide():
return 10 / 0
@app.route('/')
def index():
return 'Endpoints: /error, /null, /divide'
if __name__ == '__main__':
print("Test server: http://localhost:5000")
app.run(port=5000, debug=False)
```
**Test URLs:**
- http://localhost:5000/error - Raises ValueError
- http://localhost:5000/null - Raises AttributeError
- http://localhost:5000/divide - Raises ZeroDivisionError
### Prerequisites for Local Testing
1. Backend running on `localhost:19999`
2. Dev token bypass enabled (uses `ilscipio-dev-2024`)
3. Org schema `org_test_20` exists in database
## Troubleshooting
**Breakpoints not working:**
- Ensure `enable_breakpoints=True` in configuration
- Check that sys.settrace is not being overridden by debuggers or profilers
- Only one trace function can be active at a time
**High memory usage:**
- Reduce `max_capture_depth` (default: 10)
- Reduce `max_string_length` (default: 1000)
- Reduce `max_collection_size` (default: 100)
- Use `sampling_rate` to capture only a percentage of exceptions
**Agent not connecting:**
- Check backend is running: `curl http://localhost:19999/health`
- Check WebSocket endpoint: `ws://localhost:19999/ws/monitor/agent`
- Verify API key is set correctly
- Enable debug mode: `debug=True` or `AIVORY_DEBUG=true`
**Exceptions not captured in Django:**
- Ensure middleware is added to `MIDDLEWARE` in settings.py
- Ensure `aivory_monitor.init()` is called before Django starts
- Check that `DEBUG=False` in production (Django only logs exceptions when DEBUG=False)
**Threading issues:**
- The agent uses thread-safe mechanisms for context storage
- Each thread maintains its own trace function for breakpoints
- WebSocket connection runs in a separate background thread
**Import errors:**
- Ensure `websockets>=11.0` is installed: `pip install websockets`
- For framework integrations, install optional dependencies:
- Django: `pip install aivory-monitor[django]`
- Flask: `pip install aivory-monitor[flask]`
- FastAPI: `pip install aivory-monitor[fastapi]`
| text/markdown | null | ILSCIPIO GmbH <info@ilscipio.com> | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pyt... | [] | null | null | >=3.8 | [] | [] | [] | [
"websockets>=11.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"mypy>=1.0; extra == \"dev\"",
"ruff>=0.1; extra == \"dev\"",
"django>=3.2; extra == \"django\"",
"flask>=2.0; extra == \"flask\"",
"fastapi>=0.100; extra == \"fastapi\"",
"starlette>=0.27; extra == \"fast... | [] | [] | [] | [
"Homepage, https://aivory.net/monitor/",
"Repository, https://github.com/aivorynet/agent-python",
"Documentation, https://docs.aivory.net/monitor/python",
"Bug Tracker, https://github.com/aivorynet/agent-python/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:52:54.965294 | aivory_monitor-1.0.0.tar.gz | 22,795 | 36/62/89e915e98ca661fa929d4345ce42b45fe649628ea0f17bbb5e8a332b94a4/aivory_monitor-1.0.0.tar.gz | source | sdist | null | false | d4fd8ac0055403d2ba692a0cfefff8a6 | 3d59863b50d84e60b035798185f0a6143553c03f9bd9c813cb8af9fd0aa69ff1 | 366289e915e98ca661fa929d4345ce42b45fe649628ea0f17bbb5e8a332b94a4 | null | [
"LICENSE"
] | 279 |
2.4 | isahitlab | 0.14.1 | Python client for isahit lab | # isahitlab
[](https://pypi.org/project/isahitlab)
[](https://pypi.org/project/isahitlab)
-----
## Table of Contents
- [Installation](#installation)
- [Documentation](https://sdk-docs.lab.isahit.com/latest)
- [License](#license)
## Installation
```console
pip install isahitlab
```
## License
`isahitlab` is distributed under the terms of the [MIT](https://spdx.org/licenses/MIT.html) license.
| text/markdown | null | Isahit <dev@isahit.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Programming Language :: Python",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.8 | [] | [] | [] | [
"jsonschema>=4",
"requests<3.0.0,>=2.0.0",
"tqdm<5.0.0,>=4.0.0",
"typeguard<5,>=4",
"numpy; extra == \"image\"",
"opencv-python<5.0.0,>=4.0.0; extra == \"image\""
] | [] | [] | [] | [
"Documentation, https://sdk-docs.lab.isahit.com/latest/"
] | python-httpx/0.28.1 | 2026-02-18T10:52:09.600917 | isahitlab-0.14.1-py3-none-any.whl | 77,011 | b3/13/7199db844c1486a6629dbd4445b8613d1487ca26fc382fe431bf1463612a/isahitlab-0.14.1-py3-none-any.whl | py3 | bdist_wheel | null | false | f1b1ed1767cfa0d726ae048043d0dadf | a9a92bd7dedf99b1ee05836aaefae886087784f6be694757d8d653aef566ad18 | b3137199db844c1486a6629dbd4445b8613d1487ca26fc382fe431bf1463612a | MIT | [
"LICENSE.txt"
] | 259 |
2.4 | django-tree-queries | 0.23.1 | Tree queries with explicit opt-in, without configurability | ===================
django-tree-queries
===================
.. image:: https://github.com/matthiask/django-tree-queries/actions/workflows/test.yml/badge.svg
:target: https://github.com/matthiask/django-tree-queries/
:alt: CI Status
Query Django model trees using adjacency lists and recursive common
table expressions. Supports PostgreSQL, sqlite3 (3.8.3 or higher) and
MariaDB (10.2.2 or higher) and MySQL (8.0 or higher, if running without
``ONLY_FULL_GROUP_BY``).
Supports Django 3.2 or better, Python 3.8 or better. See the GitHub actions
build for more details.
Features and limitations
========================
- Supports only integer and UUID primary keys (for now).
- Allows specifying ordering among siblings.
- Uses the correct definition of depth, where root nodes have a depth of
zero.
- The parent foreign key must be named ``"parent"`` at the moment (but
why would you want to name it differently?)
- The fields added by the common table expression always are
``tree_depth``, ``tree_path`` and ``tree_ordering``. The names cannot
be changed. ``tree_depth`` is an integer, ``tree_path`` an array of
primary keys representing the path from the root to the current node
(including the current node itself), and ``tree_ordering`` an array of
values used for ordering nodes within their siblings at each level of
the tree hierarchy. Note that the contents of the ``tree_path`` and
``tree_ordering`` are subject to change. You shouldn't rely on their
contents.
- Besides adding the fields mentioned above the package only adds queryset
methods for ordering siblings and filtering ancestors and descendants. Other
features may be useful, but will not be added to the package just because
it's possible to do so.
- Little code, and relatively simple when compared to other tree
management solutions for Django. No redundant values so the only way
to end up with corrupt data is by introducing a loop in the tree
structure (making it a graph). The ``TreeNode`` abstract model class
has some protection against this.
- Supports only trees with max. 50 levels on MySQL/MariaDB, since those
databases do not support arrays and require us to provide a maximum
length for the ``tree_path`` and ``tree_ordering`` upfront.
- **Performance optimization**: The library automatically detects simple cases
(single field ordering, no tree filters, no custom tree fields) and uses an
optimized CTE that avoids creating a rank table, significantly improving
performance for basic tree queries.
Here's a blog post offering some additional insight (hopefully) into the
reasons for `django-tree-queries' existence <https://406.ch/writing/django-tree-queries/>`_.
Usage
=====
- Install ``django-tree-queries`` using pip.
- Extend ``tree_queries.models.TreeNode`` or build your own queryset
and/or manager using ``tree_queries.query.TreeQuerySet``. The
``TreeNode`` abstract model already contains a ``parent`` foreign key
for your convenience and also uses model validation to protect against
loops.
- Call the ``with_tree_fields()`` queryset method if you require the
additional fields respectively the CTE.
- Call the ``order_siblings_by("field_name")`` queryset method if you want to
order tree siblings by a specific model field. Note that Django's standard
``order_by()`` method isn't supported -- nodes are returned according to the
`depth-first search algorithm
<https://en.wikipedia.org/wiki/Depth-first_search>`__.
- Use ``tree_filter()`` and ``tree_exclude()`` for better performance when
working with large tables - these filter the base table before building
the tree structure.
- Use ``tree_fields()`` to aggregate ancestor field values into arrays.
- Create a manager using
``TreeQuerySet.as_manager(with_tree_fields=True)`` if you want to add
tree fields to queries by default.
- Until documentation is more complete I'll have to refer you to the
`test suite
<https://github.com/matthiask/django-tree-queries/blob/main/tests/testapp/test_queries.py>`_
for additional instructions and usage examples, or check the recipes below.
Recipes
=======
Basic models
~~~~~~~~~~~~
The following two examples both extend the ``TreeNode`` which offers a few
agreeable utilities and a model validation method that prevents loops in the
tree structure. The common table expression could be hardened against such
loops but this would involve a performance hit which we don't want -- this is a
documented limitation (non-goal) of the library after all.
Basic tree node
---------------
.. code-block:: python
from tree_queries.models import TreeNode
class Node(TreeNode):
name = models.CharField(max_length=100)
Tree node with ordering among siblings
--------------------------------------
Nodes with the same parent may be ordered among themselves. The default is to
order siblings by their primary key but that's not always very useful.
**Manual position management:**
.. code-block:: python
from tree_queries.models import TreeNode
class Node(TreeNode):
name = models.CharField(max_length=100)
position = models.PositiveIntegerField(default=0)
class Meta:
ordering = ["position"]
**Automatic position management:**
For automatic position management, use ``OrderableTreeNode`` which automatically
assigns sequential position values to new nodes:
.. code-block:: python
from tree_queries.models import OrderableTreeNode
class Category(OrderableTreeNode):
name = models.CharField(max_length=100)
# position field and ordering are inherited from OrderableTreeNode
When creating new nodes without an explicit position, ``OrderableTreeNode``
automatically assigns a position value 10 units higher than the maximum position
among siblings. The increment of 10 (rather than 1) makes it explicit that the
position values themselves have no inherent meaning - they are purely for relative
ordering, not a sibling counter or index.
If you need to customize the Meta class (e.g., to add verbose names or additional
ordering fields), inherit from ``OrderableTreeNode.Meta``:
.. code-block:: python
from tree_queries.models import OrderableTreeNode
class Category(OrderableTreeNode):
name = models.CharField(max_length=100)
class Meta(OrderableTreeNode.Meta):
verbose_name = "category"
verbose_name_plural = "categories"
# ordering = ["position"] is inherited from OrderableTreeNode.Meta
.. code-block:: python
# Create nodes - positions are assigned automatically
root = Category.objects.create(name="Root") # position=10
child1 = Category.objects.create(name="Child 1", parent=root) # position=10
child2 = Category.objects.create(name="Child 2", parent=root) # position=20
child3 = Category.objects.create(name="Child 3", parent=root) # position=30
# Manual reordering is still possible
child3.position = 15 # Move between child1 and child2
child3.save()
This approach is identical to the pattern used in feincms3's ``AbstractPage``.
Add custom methods to queryset
------------------------------
.. code-block:: python
from tree_queries.models import TreeNode
from tree_queries.query import TreeQuerySet
class NodeQuerySet(TreeQuerySet):
def active(self):
return self.filter(is_active=True)
class Node(TreeNode):
is_active = models.BooleanField(default=True)
objects = NodeQuerySet.as_manager()
Querying the tree
~~~~~~~~~~~~~~~~~
All examples assume the ``Node`` class from above.
Basic usage
-----------
.. code-block:: python
# Basic usage, disregards the tree structure completely.
nodes = Node.objects.all()
# Fetch nodes in depth-first search order. All nodes will have the
# tree_path, tree_ordering and tree_depth attributes.
nodes = Node.objects.with_tree_fields()
# Fetch any node.
node = Node.objects.order_by("?").first()
# Fetch direct children and include tree fields. (The parent ForeignKey
# specifies related_name="children")
children = node.children.with_tree_fields()
# Fetch all ancestors starting from the root.
ancestors = node.ancestors()
# Fetch all ancestors including self, starting from the root.
ancestors_including_self = node.ancestors(include_self=True)
# Fetch all ancestors starting with the node itself.
ancestry = node.ancestors(include_self=True).reverse()
# Fetch all descendants in depth-first search order, including self.
descendants = node.descendants(include_self=True)
# Temporarily override the ordering by siblings.
nodes = Node.objects.order_siblings_by("id")
# Revert to a queryset without tree fields (improves performance).
nodes = Node.objects.with_tree_fields().without_tree_fields()
Understanding tree fields
-------------------------
When using ``with_tree_fields()``, each node gets three additional attributes:
- **``tree_depth``**: An integer representing the depth of the node in the tree
(root nodes have depth 0)
- **``tree_path``**: An array containing the primary keys of all ancestors plus
the current node itself, representing the path from root to current node
- **``tree_ordering``**: An array containing the ordering/ranking values used
for sibling ordering at each level of the tree hierarchy
The key difference between ``tree_path`` and ``tree_ordering``:
.. code-block:: python
# Example tree structure:
# Root (pk=1, order=0)
# ├── Child A (pk=2, order=10)
# │ └── Grandchild (pk=4, order=5)
# └── Child B (pk=3, order=20)
# For the Grandchild node:
grandchild = Node.objects.with_tree_fields().get(pk=4)
# tree_path shows the route through primary keys: Root -> Child A -> Grandchild
assert grandchild.tree_path == [1, 2, 4] # [root.pk, child_a.pk, grandchild.pk]
# tree_ordering shows ordering values at each level: Root's order, Child A's order, Grandchild's order
assert grandchild.tree_ordering == [0, 10, 5] # [root.order, child_a.order, grandchild.order]
**Important note**: When not using an explicit ordering (like a ``position``
field), siblings are ordered by their primary key by default. This means
``tree_path`` and ``tree_ordering`` will contain the same values. While this
may be fine for your use case consider adding an explicit ordering field:
.. code-block:: python
class Node(TreeNode):
id = models.UUIDField(primary_key=True, default=uuid.uuid4)
name = models.CharField(max_length=100)
position = models.PositiveIntegerField(default=0)
class Meta:
ordering = ["position"]
Filtering tree subsets
----------------------
**IMPORTANT**: For large tables, always use ``tree_filter()`` or ``tree_exclude()``
to limit which nodes are processed by the recursive CTE. Without these filters,
the database evaluates the entire table, which can be extremely slow.
.. code-block:: python
# Get a specific tree from a forest by filtering on root category
product_tree = Node.objects.with_tree_fields().tree_filter(category="products")
# Get organizational chart for a specific department
engineering_tree = Node.objects.with_tree_fields().tree_filter(department="engineering")
# Exclude entire trees/sections you don't need
content_trees = Node.objects.with_tree_fields().tree_exclude(category="archived")
# Chain multiple tree filters for more specific trees
recent_products = (Node.objects.with_tree_fields()
.tree_filter(category="products")
.tree_filter(created_date__gte=datetime.date.today()))
# Get descendants within a filtered tree subset
product_descendants = (Node.objects.with_tree_fields()
.tree_filter(category="products")
.descendants(some_product_node))
# Filter by site/tenant in multi-tenant applications
site_content = Node.objects.with_tree_fields().tree_filter(site_id=request.site.id)
Performance note: ``tree_filter()`` and ``tree_exclude()`` filter the base table
before the recursive CTE processes relationships, dramatically improving performance
for large datasets compared to using regular ``filter()`` after ``with_tree_fields()``.
Best used for selecting complete trees or tree sections rather than scattered nodes.
Note that the tree queryset doesn't support all types of queries Django
supports. For example, updating all descendants directly isn't supported. The
reason for that is that the recursive CTE isn't added to the UPDATE query
correctly. Workarounds often include moving the tree query into a subquery:
.. code-block:: python
# Doesn't work:
node.descendants().update(is_active=False)
# Use this workaround instead:
Node.objects.filter(pk__in=node.descendants()).update(is_active=False)
Breadth-first search
--------------------
Nobody wants breadth-first search but if you still want it you can achieve it
as follows:
.. code-block:: python
nodes = Node.objects.with_tree_fields().extra(
order_by=["__tree.tree_depth", "__tree.tree_ordering"]
)
Filter by depth
---------------
If you only want nodes from the top two levels:
.. code-block:: python
nodes = Node.objects.with_tree_fields().extra(
where=["__tree.tree_depth <= %s"],
params=[1],
)
Aggregating ancestor fields
---------------------------
Use ``tree_fields()`` to aggregate values from ancestor nodes into arrays. This is
useful for collecting paths, permissions, categories, or any field that should be
inherited down the tree hierarchy.
.. code-block:: python
# Aggregate names from all ancestors into an array
nodes = Node.objects.with_tree_fields().tree_fields(
tree_names="name",
)
# Each node now has a tree_names attribute: ['root', 'parent', 'current']
# Aggregate multiple fields
nodes = Node.objects.with_tree_fields().tree_fields(
tree_names="name",
tree_categories="category",
tree_permissions="permission_level",
)
# Build a full path string from ancestor names
nodes = Node.objects.with_tree_fields().tree_fields(tree_names="name")
for node in nodes:
full_path = " > ".join(node.tree_names) # "Root > Section > Subsection"
# Combine with tree filtering for better performance
active_nodes = (Node.objects.with_tree_fields()
.tree_filter(is_active=True)
.tree_fields(tree_names="name"))
The aggregated fields contain values from all ancestors (root to current node) in
hierarchical order, including the current node itself.
Form fields
~~~~~~~~~~~
django-tree-queries ships a model field and some form fields which augment the
default foreign key field and the choice fields with a version where the tree
structure is visualized using dashes etc. Those fields are
``tree_queries.fields.TreeNodeForeignKey``,
``tree_queries.forms.TreeNodeChoiceField``,
``tree_queries.forms.TreeNodeMultipleChoiceField``.
Templates
~~~~~~~~~
django-tree-queries includes template tags to help render tree structures in
Django templates. These template tags are designed to work efficiently with
tree querysets and respect queryset boundaries.
Setup
-----
Add ``tree_queries`` to your ``INSTALLED_APPS`` setting:
.. code-block:: python
INSTALLED_APPS = [
# ... other apps
'tree_queries',
]
Then load the template tags in your template:
.. code-block:: html
{% load tree_queries %}
tree_info filter
----------------
The ``tree_info`` filter provides detailed information about each node's
position in the tree structure. It's useful when you need fine control over
the tree rendering.
.. code-block:: html
{% load tree_queries %}
<ul>
{% for node, structure in nodes|tree_info %}
{% if structure.new_level %}<ul><li>{% else %}</li><li>{% endif %}
{{ node.name }}
{% for level in structure.closed_levels %}</li></ul>{% endfor %}
{% endfor %}
</ul>
The filter returns tuples of ``(node, structure_info)`` where ``structure_info``
contains:
- ``new_level``: ``True`` if this node starts a new level, ``False`` otherwise
- ``closed_levels``: List of levels that close after this node
- ``ancestors``: List of ancestor node representations from root to immediate parent
Example showing ancestor information:
.. code-block:: html
{% for node, structure in nodes|tree_info %}
{{ node.name }}
{% if structure.ancestors %}
(Path: {% for ancestor in structure.ancestors %}{{ ancestor }}{% if not forloop.last %} > {% endif %}{% endfor %})
{% endif %}
{% endfor %}
recursetree tag
---------------
The ``recursetree`` tag provides recursive rendering similar to django-mptt's
``recursetree`` tag, but optimized for django-tree-queries. It only considers
nodes within the provided queryset and doesn't make additional database queries.
Basic usage:
.. code-block:: html
{% load tree_queries %}
<ul>
{% recursetree nodes %}
<li>
{{ node.name }}
{% if children %}
<ul>{{ children }}</ul>
{% endif %}
</li>
{% endrecursetree %}
</ul>
The ``recursetree`` tag provides these context variables within the template:
- ``node``: The current tree node
- ``children``: Rendered HTML of child nodes (from the queryset)
- ``is_leaf``: ``True`` if the node has no children in the queryset
Using ``is_leaf`` for conditional rendering:
.. code-block:: html
{% recursetree nodes %}
<div class="{% if is_leaf %}leaf-node{% else %}branch-node{% endif %}">
<span class="node-name">{{ node.name }}</span>
{% if children %}
<div class="children">{{ children }}</div>
{% elif is_leaf %}
<span class="leaf-indicator">🍃</span>
{% endif %}
</div>
{% endrecursetree %}
Advanced example with depth information:
.. code-block:: html
{% recursetree nodes %}
<div class="node depth-{{ node.tree_depth }}"
data-id="{{ node.pk }}"
data-has-children="{{ children|yesno:'true,false' }}">
<h{{ node.tree_depth|add:1 }}>{{ node.name }}</h{{ node.tree_depth|add:1 }}>
{% if children %}
<div class="node-children">{{ children }}</div>
{% endif %}
</div>
{% endrecursetree %}
Working with limited querysets
-------------------------------
Both template tags respect queryset boundaries and work efficiently with
filtered or limited querysets:
.. code-block:: python
# Only nodes up to depth 2
limited_nodes = Node.objects.with_tree_fields().extra(
where=["__tree.tree_depth <= %s"], params=[2]
)
# Only specific branches
branch_nodes = Node.objects.descendants(some_node, include_self=True)
When using these limited querysets:
- ``recursetree`` will only render nodes from the queryset
- ``is_leaf`` reflects whether nodes have children *in the queryset*, not in the full tree
- No additional database queries are made
- Nodes whose parents aren't in the queryset are treated as root nodes
Example with depth-limited queryset:
.. code-block:: html
<!-- Template -->
{% recursetree limited_nodes %}
<li>
{{ node.name }}
{% if is_leaf %}
<small>(leaf in limited view)</small>
{% endif %}
{{ children }}
</li>
{% endrecursetree %}
This is particularly useful for creating expandable tree interfaces or
rendering only portions of large trees for performance.
Django Admin Integration
~~~~~~~~~~~~~~~~~~~~~~~~
django-tree-queries includes a ``TreeAdmin`` class for Django's admin interface
that provides an intuitive tree management experience with drag-and-drop style
node moving capabilities.
Installation
------------
To use the admin functionality, install with the ``admin`` extra:
.. code-block:: bash
pip install django-tree-queries[admin]
Usage
-----
**With automatic position management:**
For the best admin experience with proper ordering, use ``OrderableTreeNode``:
.. code-block:: python
from django.contrib import admin
from tree_queries.admin import TreeAdmin
from tree_queries.models import OrderableTreeNode
class Category(OrderableTreeNode):
name = models.CharField(max_length=100)
# position field and ordering are inherited from OrderableTreeNode
@admin.register(Category)
class CategoryAdmin(TreeAdmin):
list_display = [*TreeAdmin.list_display, "name"]
position_field = "position" # Enables sibling ordering controls
**With manual position management:**
If you prefer to manage positions yourself:
.. code-block:: python
from django.contrib import admin
from django.db.models import Max
from tree_queries.admin import TreeAdmin
from tree_queries.models import TreeNode
class Category(TreeNode):
name = models.CharField(max_length=100)
position = models.PositiveIntegerField(default=0)
class Meta:
ordering = ["position"]
def save(self, *args, **kwargs):
# Custom position logic here
if not self.position:
self.position = (
10
+ (
self.__class__._default_manager.filter(parent_id=self.parent_id)
.order_by()
.aggregate(p=Max("position"))["p"]
or 0
)
)
super().save(*args, **kwargs)
save.alters_data = True
@admin.register(Category)
class CategoryAdmin(TreeAdmin):
list_display = [*TreeAdmin.list_display, "name"]
position_field = "position"
The ``TreeAdmin`` provides:
- **Tree visualization**: Nodes are displayed with indentation and visual tree structure
- **Collapsible nodes**: Click to expand/collapse branches for better navigation
- **Node moving**: Cut and paste nodes to reorganize the tree structure
- **Flexible ordering**: Supports both ordered (with position field) and unordered trees
- **Root moves**: Direct "move to root" buttons for trees without sibling ordering
**Configuration:**
- Set ``position_field`` to the field name used for positioning siblings (e.g., ``"position"``, ``"order"``)
- Leave ``position_field = None`` for trees positioned by other criteria (pk, name, etc.)
- The admin automatically adapts its interface based on whether positioning is controllable
**Required list_display columns:**
- ``collapse_column``: Shows expand/collapse toggles
- ``indented_title``: Displays the tree structure with indentation
- ``move_column``: Provides move controls (cut, paste, move-to-root)
These are included by default in ``TreeAdmin.list_display``.
Migrating from django-mptt
~~~~~~~~~~~~~~~~~~~~~~~~~~~
When migrating from django-mptt to django-tree-queries, you'll need to populate
the ``position`` field (or whatever field you use for sibling ordering) based on
the existing MPTT ``lft`` values. Here's an example migration:
.. code-block:: python
def fill_position(apps, schema_editor):
ModelWithMPTT = apps.get_model("your_app", "ModelWithMPTT")
db_alias = schema_editor.connection.alias
position_map = ModelWithMPTT.objects.using(db_alias).annotate(
lft_rank=Window(
expression=RowNumber(),
partition_by=[F("parent_id")],
order_by=["lft"],
),
).in_bulk()
# Update batches of 2000 objects.
batch_size = 2000
qs = ModelWithMPTT.objects.all()
batches = (qs[i : i + batch_size] for i in range(0, qs.count(), batch_size))
for batch in batches:
for obj in batch:
obj.position = position_map[obj.pk].lft_rank
ModelWithMPTT.objects.bulk_update(batch, ["position"])
class Migration(migrations.Migration):
dependencies = [...]
operations = [
migrations.RunPython(
code=fill_position,
reverse_code=migrations.RunPython.noop,
)
]
This migration uses Django's ``Window`` function with ``RowNumber()`` to assign
position values based on the original MPTT ``lft`` ordering, ensuring that siblings
maintain their relative order after the migration.
Note that the position field is used purely for ordering siblings and is not an
index. By default, django-tree-queries' admin interface starts with a position
value of 10 and increments by 10 (10, 20, 30, etc.) to make it explicit that the
position values themselves have no inherent meaning - they are purely for relative
ordering, not a sibling counter or index.
| text/x-rst | null | Matthias Kestenholz <mk@feinheit.ch> | null | null | BSD-3-Clause | null | [
"Environment :: Web Environment",
"Framework :: Django",
"Intended Audience :: Developers",
"License :: OSI Approved :: BSD License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.8",
"Progr... | [] | null | null | >=3.8 | [] | [] | [] | [
"django-js-asset; extra == \"admin\"",
"coverage; extra == \"tests\"",
"django-js-asset; extra == \"tests\"",
"pytest; extra == \"tests\"",
"pytest-cov; extra == \"tests\"",
"pytest-django; extra == \"tests\""
] | [] | [] | [] | [
"Homepage, https://github.com/matthiask/django-tree-queries/"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-18T10:51:49.523141 | django_tree_queries-0.23.1.tar.gz | 28,569 | ad/5d/b458b8c1826cdb12b2017ca338725ea0eabfef3d6effe4236da697fc0489/django_tree_queries-0.23.1.tar.gz | source | sdist | null | false | af3b17591b6d382ee2fb7b667eb17639 | 9e7a4954b6e044cf6bdaa03e8e19088f031defe6f4f5896c9eaf7e109ca189c0 | ad5db458b8c1826cdb12b2017ca338725ea0eabfef3d6effe4236da697fc0489 | null | [
"LICENSE"
] | 21,266 |
2.4 | ndslice | 0.5.0 | Interactive N-dimensional numpy array viewer with FFT support | [](https://pypi.org/project/ndslice/)
[](https://pypi.org/project/ndslice/)
[](https://github.com/henricryden/ndslice/blob/main/LICENSE)
[](https://pepy.tech/projects/ndslice)
# ndslice
**Quick interactive visualization for N-dimensional NumPy arrays**
A python package for browsing slices, applying FFTs, and inspecting data.
Quickly checking multi-dimensional data usually means writing the same matplotlib boilerplate over and over. This tool lets you just call `ndslice(data)` and interactively explore what you've got.
## Usage
```python
from ndslice import ndslice
import numpy as np
# Create some data
x = np.linspace(-5, 5, 100)
y = np.linspace(-5, 5, 100)
z = np.linspace(-5, 5, 50)
X, Y, Z = np.meshgrid(x, y, z, indexing='ij')
mag = np.exp(-(X**2 + Y**2 + Z**2) / 10)
pha = np.pi/4 * (X + Y + Z)
complex_data = mag * np.exp(1j * pha)
ndslice(complex_data, title='3D Complex Gaussian')
```

## Features
Data slicing and dimension selection should be intuitive: click the two dimensions you want to show and slice using the spinboxes.
**Centered FFT** - Click dimension labels to apply centered 1D FFT transforms. Useful for checking k-space data in MRI reconstructions or analyzing frequency content.

**Line plot** - See 1D slices through your data. Shift+scroll for Y zoom, Ctrl+scroll for X zoom:

**Video export**
Right-clicking a dimension button to export a video or PNG frames along that dimension.
The video export functionality is optional, and can be installed with
```bash
pip install ndslice[video_export]
```

**Scaling**
Log scaling is often good for k-space visualization.
Symmetric log scaling is an extension of the log scale which supports negative values.
**Colormap**
Change colormap:
- Ctrl+1: Gray
- Ctrl+2: [Viridis](https://bids.github.io/colormap/)
- Ctrl+3: [Plasma](https://bids.github.io/colormap/)
- Ctrl+4: Cyclic rainbow, hides phase wraps
- Ctrl+5: [Cividis](https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0199239)
- Ctrl+6: [Cubehelix](http://www.mrao.cam.ac.uk/~dag/CUBEHELIX/)
- Ctrl+7: [Cool](https://d3js.org/d3-scale-chromatic/sequential)
- Ctrl+8: [Warm](https://d3js.org/d3-scale-chromatic/sequential)
**Axis flipping**
Click arrow icons (⬇️/⬆️ and ⬅️/➡️) next to dimension labels to flip axes.
Default orientation is image-style (origin lower-left).
Flip the primary axis for matrix-style (origin upper-left).
**Non-blocking windows**
By default, windows open in separate processes, allowing multiple simultaneous views:
```python
ndslice(data1)
ndslice(data2) # Both windows appear
```
Use `block=True` to wait for the window to close before continuing:
```python
ndslice(data1, block=True) # Script pauses here
ndslice(data2) # Shown after first closes
```
### Command Line
```bash
ndslice data.npy # Numpy file
ndslice --help # Show all options
```
**File support**
ndslice has CLI support and can conveniently display:
| Format | File suffix | Requirement |
|---|---:|---|
| NumPy | `.npy`, `.npz` | NumPy |
| MATLAB | `.mat` | scipy |
| HDF5 | `.h5`, `.hdf5` | h5py |
| [BART](https://mrirecon.github.io/bart/) | `.cfl` + `.hdr` | — |
| Philips REC | `.REC` + `.xml` | — |
| [NIfTI](https://nifti.nimh.nih.gov/) | `.nii`, `.nii.gz` | nibabel |
| DICOM (pixel array) | `.dcm` | pydicom |
HDF5 files can be compound complex dtype, or real/imag fields.
If there are multiple datasets in the file, a selection GUI appears which highlights arrays supported by ndslice (essentially numeric).
Double click to open.

## Installation
### From PyPI
```bash
pip install ndslice
pip install ndslice[video_export] # Include video export dependencies (imageio, Pillow, imageio-ffmpeg)
pip install ndslice[all] # includes all optional dependencies (video export and file formats)
```
### From source
```bash
git clone https://github.com/henricryden/ndslice.git
cd ndslice
# Use directly without installing
python -m ndslice data.npy
pip install -e .
```
## Requirements
- Python >= 3.8
- NumPy >= 1.20.0
- PyQtGraph >= 0.12.0
- PyQt5 >= 5.15.0
- h5py >= 3.0.0 (for HDF5 file support in CLI)
## License
MIT License - see LICENSE file for details.
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## Acknowledgments
Built with [PyQtGraph](https://www.pyqtgraph.org/) for high-performance visualization.
---
Henric Rydén
Karolinska University Hospital
Stockholm, Sweden
| text/markdown | null | Henric Rydén <henric.ryden@gmail.com> | null | null | MIT | visualization, numpy, fft, image-viewer, data-visualization | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Pyth... | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.20.0",
"pyqtgraph>=0.14.0",
"PyQt5>=5.15.0",
"PyQt6>=6.4.0; extra == \"pyqt6\"",
"build>=0.10.0; extra == \"dev\"",
"twine>=4.0.0; extra == \"dev\"",
"h5py>=3.0.0; extra == \"hdf5\"",
"scipy>=1.7.0; extra == \"matlab\"",
"pydicom>=2.4.0; extra == \"dicom\"",
"nibabel>=4.0.0; extra == \"n... | [] | [] | [] | [
"Homepage, https://github.com/henricryden/ndslice",
"Documentation, https://github.com/henricryden/ndslice#readme",
"Bug Tracker, https://github.com/henricryden/ndslice/issues"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-18T10:51:39.115979 | ndslice-0.5.0.tar.gz | 39,680 | a6/83/af8b336af57786c48a98262bd913054d27833e1dd595f191d43df52c1961/ndslice-0.5.0.tar.gz | source | sdist | null | false | e271345752ab879d7b9c3473eabee06a | 8d29b497f93bcf2500ba4079eb0c4ddb5e07fd79d684d8ea8be1e436320110fd | a683af8b336af57786c48a98262bd913054d27833e1dd595f191d43df52c1961 | null | [
"LICENSE"
] | 264 |
2.3 | py-llm-skills | 0.1.2 | A Python SDK for building LLM with Skills. | # LLM Skills

A Python SDK for building **AI Agent Skills** that strictly follow the official [Anthropic `SKILL.md` standard](https://platform.claude.com/docs/en/agents-and-tools/agent-skills/overview).
Designed to be the standard implementation for **modular AI tooling**, this SDK enables developers to build portable, secure, and highly capable skills for **Claude**, **OpenAI**, and other LLMs with function calling support. It handles validation, discovery, and progressive loading, so you can focus on building intelligent capabilities.
## Why LLM Skills?
Building agentic tools today is often messy and inefficient. Developers face three core problems:
1. **Token Bloat**: Injecting every possible tool definition into the system prompt exhausts context windows and increases cost.
2. **Vendor Lock-in**: Tools written for OpenAI function calling often don't work with Claude or other models without significant rewriting.
3. **Spaghetti Code**: Hard-coding tool logic directly into your agent making it impossible to share or reuse capabilities across projects.
**LLM Skills solves this by treating skills as portable data packages.**
- **Standardized**: Write once using `SKILL.md` and run anywhere (OpenAI, Claude, Custom Agents).
- **Efficient**: Uses *Progressive Disclosure* to load heavy instructions and scripts only when the model actually decides to use the skill.
- **Discoverable**: The built-in Router allows your agent to choose from hundreds of skills dynamically, rather than being limited to a static set of tools.
## How It Works
The SDK implements the **Anthropic 4-Phase Loading** architecture to optimize token usage and context management:
```mermaid
flowchart TD
subgraph Discovery ["Phase 1: Discovery"]
direction TB
A[User Query] -->|Router| B{Select Skill}
B -->|Match| C[Load Metadata]
C -->|Description| D[System Prompt]
end
subgraph Loading ["Phase 2: Loading"]
direction TB
D -->|Tool Use| E[Load Content]
E -->|Read| F[SKILL.md]
E -->|Discover| G[Resources]
G --> H["/scripts/"]
G --> I["/examples/"]
G --> J["/references/"]
end
subgraph Execution ["Phase 3: Execution"]
direction TB
F -->|Instructions| K[LLM Context]
K -->|Code| L[Execute Script]
L -->|Result| M[Final Response]
end
style Discovery fill:#e1f5fe,stroke:#01579b
style Loading fill:#f3e5f5,stroke:#4a148c
style Execution fill:#e8f5e9,stroke:#1b5e20
linkStyle default stroke-width:2px,fill:none,stroke:black;
```
## Features
- **Standard Compliance**: Validates `SKILL.md` against official Anthropic rules (name format, length limits) to ensure compatibility with the Claude API.
- **Progressive Disclosure**: Efficiently manages token context by loading only essential metadata initially, then pulling in full instructions and companion resources (like scripts or reference docs) only when the skill is actually used.
- **Auto-Discovery**: Automatically finds and categorizes companion files (`scripts/`, `examples/`, `references/`) within skill directories, making them available to your agent.
- **Secure by Default**: Built-in path traversal protection ensures skills cannot access files outside their directory.
- **Universal Patterns**:
- **Prompt Injection**: Use `Patterns.file_based_prompt` to inject skill instructions directly into your system prompt.
- **Function Calling**: Use `to_tool_definition()` to generate JSON schemas for OpenAI or Claude tool use.
- **Native Anthropic**: Use `to_anthropic_files()` to bundle and upload skills directly to the Anthropic API for containerized execution.
## Installation
We recommend using `uv` for modern Python project management.
### Quick Install (Recommended)
Installs the core library plus **OpenAI** and **Anthropic** support.
```bash
uv add "py-llm-skills[full]"
```
### Lite Install (Core Only)
Installs only the lightweight core. Useful if you want to bring your own LLM client.
```bash
uv add py-llm-skills
```
### Specific Features
You can also mix and match optional dependencies:
```bash
uv add "py-llm-skills[openai]" # Adds OpenAI SDK
uv add "py-llm-skills[anthropic]" # Adds Anthropic SDK
```
### Pip Users
If you are using standard `pip`:
```bash
pip install "py-llm-skills[full]"
```
## Quick Start
### 1. Define a Skill
Create a directory `skills/weather/` and add a `SKILL.md`. Notice how we key-value pair metadata for the router and keep instructions clear.
```markdown
---
name: weather
description: Get current weather information for a given location.
version: 1.0.0
input_schema:
type: object
properties:
location: {type: string, description: "City and state, e.g. San Francisco, CA"}
required: [location]
---
You are a weather assistant. Fetch real-time data for the user's location.
```
### 2. Use in Python
```python
from py_llm_skills import SkillRegistry, Skill, Patterns
# Load all skills from a directory
registry = SkillRegistry()
registry.register_directory("./skills")
# Get a specific skill by name
weather = registry.get_skill("weather")
# Pattern 1: Inject into system prompt
prompt = Patterns.file_based_prompt([weather])
# Pattern 2: Use as OpenAI / Claude tool
tool_def = weather.to_tool_definition()
# Pattern 3: Upload to Anthropic Skills API
# This bundles the SKILL.md and all discovered scripts/resources
files = weather.to_anthropic_files()
```
### 4. Structured Output
Use Pydantic models to get type-safe, structured responses from your LLM (OpenAI/Anthropic).
```python
from pydantic import BaseModel
from py_llm_skills.llm.openai import OpenAISDKAdapter
class AnalysisResult(BaseModel):
summary: str
sentiment: float
tags: list[str]
# ... initialize client ...
result = client.chat_completion_with_structure(
messages=[{"role": "user", "content": "Analyze this..."}],
response_model=AnalysisResult
)
print(result.summary)
```
### 5. Upload to Claude (Anthropic Skills API)
Directly upload your local skills to the Anthropic beta API for server-side execution:
```python
import anthropic
from py_llm_skills.llm.claude import AnthropicSkillManager
client = anthropic.Anthropic()
manager = AnthropicSkillManager(client)
# Upload a skill and get a skill_id
skill_id = manager.upload_skill(weather)
# Use in messages via the container parameter
container = manager.format_container_param([skill_id])
```
## Skill Collections
Looking for pre-built skills? Check out these awesome community repositories:
- [ComposioHQ/awesome-claude-skills](https://github.com/ComposioHQ/awesome-claude-skills) - A curated list of Claude-specific skills.
- [heilcheng/awesome-agent-skills](https://github.com/heilcheng/awesome-agent-skills) - Broad collection of skills for various agent frameworks.
- [github/awesome-copilot](https://github.com/github/awesome-copilot) - Useful extensions and tools that can be adapted as skills.
## Contributing
We welcome contributions! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for details on how to set up your development environment and submit pull requests.
## License
MIT
| text/markdown | theanupllm | theanupllm <theanupdas@protonmail.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"pydantic>=2.12.5",
"pyyaml>=6.0.3",
"requests>=2.32.5",
"anthropic>=0.18.0; extra == \"anthropic\"",
"python-dotenv; extra == \"demo\"",
"openai>=1.0.0; extra == \"demo\"",
"anthropic>=0.18.0; extra == \"demo\"",
"python-dotenv>=1.2.1; extra == \"dotenv\"",
"python-dotenv; extra == \"full\"",
"op... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:51:37.290765 | py_llm_skills-0.1.2.tar.gz | 11,203 | e9/66/b25735666457b3f0ce1289ed12f1bd9eabc9dccc0149f4ee508f4215a1a2/py_llm_skills-0.1.2.tar.gz | source | sdist | null | false | 50dde14371c359014cb4f7e93f889164 | 1f2c8404b40a54acc1d40165ae7335804c62c6b4d8a78a6cdc62dae01d010a9d | e966b25735666457b3f0ce1289ed12f1bd9eabc9dccc0149f4ee508f4215a1a2 | null | [] | 245 |
2.4 | meshcore | 2.2.13 | Base classes for communicating with meshcore companion radios | # Python MeshCore
Python library for interacting with [MeshCore](https://meshcore.co.uk) companion radio nodes.
## Installation
```bash
pip install meshcore
```
## Quick Start
Connect to your device and send a message:
```python
import asyncio
from meshcore import MeshCore, EventType
async def main():
# Connect to your device
meshcore = await MeshCore.create_serial("/dev/ttyUSB0")
# Get your contacts
result = await meshcore.commands.get_contacts()
if result.type == EventType.ERROR:
print(f"Error getting contacts: {result.payload}")
return
contacts = result.payload
print(f"Found {len(contacts)} contacts")
# Send a message to the first contact
if contacts:
# Get the first contact
contact = next(iter(contacts.items()))[1]
# Pass the contact object directly to send_msg
result = await meshcore.commands.send_msg(contact, "Hello from Python!")
if result.type == EventType.ERROR:
print(f"Error sending message: {result.payload}")
else:
print("Message sent successfully!")
await meshcore.disconnect()
asyncio.run(main())
```
## Development Setup
To set up for development:
```bash
# Create and activate virtual environment
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install in development mode
pip install -e .
# Run examples
python examples/pubsub_example.py -p /dev/ttyUSB0
```
## Usage Guide
### Command Return Values
All command methods in MeshCore return an `Event` object that contains both the event type and its payload. This allows for consistent error handling and type checking:
```python
# Command result structure
result = await meshcore.commands.some_command()
# Check if the command was successful or resulted in an error
if result.type == EventType.ERROR:
# Handle error case
print(f"Command failed: {result.payload}")
else:
# Handle success case - the event type will be specific to the command
# (e.g., EventType.DEVICE_INFO, EventType.CONTACTS, EventType.MSG_SENT)
print(f"Command succeeded with event type: {result.type}")
# Access the payload data
data = result.payload
```
Common error handling pattern:
```python
result = await meshcore.commands.send_msg(contact, "Hello!")
if result.type == EventType.ERROR:
print(f"Error sending message: {result.payload}")
else:
# For send_msg, a successful result will have type EventType.MSG_SENT
print(f"Message sent with expected ack: {result.payload['expected_ack'].hex()}")
```
### Connecting to Your Device
Connect via Serial, BLE, or TCP:
```python
# Serial connection
meshcore = await MeshCore.create_serial("/dev/ttyUSB0", 115200, debug=True)
# BLE connection (scans for devices if address not provided)
meshcore = await MeshCore.create_ble("12:34:56:78:90:AB")
# BLE connection with PIN pairing for enhanced security
meshcore = await MeshCore.create_ble("12:34:56:78:90:AB", pin="123456")
# TCP connection
meshcore = await MeshCore.create_tcp("192.168.1.100", 4000)
```
#### BLE PIN Pairing
For enhanced security, MeshCore supports BLE PIN pairing. This requires the device to be configured with a PIN and the client to provide the matching PIN during connection:
```python
# First configure the device PIN (if not already set)
meshcore = await MeshCore.create_ble("12:34:56:78:90:AB")
await meshcore.commands.set_devicepin(123456)
# Then connect with PIN pairing
meshcore = await MeshCore.create_ble("12:34:56:78:90:AB", pin="123456")
```
**PIN Pairing Features:**
- Automatic pairing initiation when PIN is provided
- Graceful fallback if pairing fails (connection continues if device is already paired)
- Compatible with all BLE connection methods (address, scanning, pre-configured client)
- Logging of pairing success/failure for debugging
**Note:** BLE pairing behavior may vary by platform:
- **Linux/Windows**: PIN pairing is fully supported
- **macOS**: Pairing may be handled automatically by the system UI
#### Auto-Reconnect and Connection Events
Enable automatic reconnection when connections are lost:
```python
# Enable auto-reconnect with custom retry limits
meshcore = await MeshCore.create_tcp(
"192.168.1.100", 4000,
auto_reconnect=True,
max_reconnect_attempts=5
)
# Subscribe to connection events
async def on_connected(event):
print(f"Connected: {event.payload}")
if event.payload.get('reconnected'):
print("Successfully reconnected!")
async def on_disconnected(event):
print(f"Disconnected: {event.payload['reason']}")
if event.payload.get('max_attempts_exceeded'):
print("Max reconnection attempts exceeded")
meshcore.subscribe(EventType.CONNECTED, on_connected)
meshcore.subscribe(EventType.DISCONNECTED, on_disconnected)
# Check connection status
if meshcore.is_connected:
print("Device is currently connected")
```
**Auto-reconnect features:**
- Exponential backoff (1s, 2s, 4s, 8s max delay)
- Configurable retry limits (default: 3 attempts)
- Automatic disconnect detection (especially useful for TCP connections)
- Connection events with detailed information
### Using Commands (Synchronous Style)
Send commands and wait for responses:
```python
# Get device information
result = await meshcore.commands.send_device_query()
if result.type == EventType.ERROR:
print(f"Error getting device info: {result.payload}")
else:
print(f"Device model: {result.payload['model']}")
# Get list of contacts
result = await meshcore.commands.get_contacts()
if result.type == EventType.ERROR:
print(f"Error getting contacts: {result.payload}")
else:
contacts = result.payload
for contact_id, contact in contacts.items():
print(f"Contact: {contact['adv_name']} ({contact_id})")
# Send a message (destination key in bytes)
result = await meshcore.commands.send_msg(dst_key, "Hello!")
if result.type == EventType.ERROR:
print(f"Error sending message: {result.payload}")
# Setting device parameters
result = await meshcore.commands.set_name("My Device")
if result.type == EventType.ERROR:
print(f"Error setting name: {result.payload}")
result = await meshcore.commands.set_tx_power(20) # Set transmit power
if result.type == EventType.ERROR:
print(f"Error setting TX power: {result.payload}")
```
### Finding Contacts
Easily find contacts by name or key:
```python
# Find a contact by name
contact = meshcore.get_contact_by_name("Bob's Radio")
if contact:
print(f"Found Bob at: {contact['adv_lat']}, {contact['adv_lon']}")
# Find by partial key prefix
contact = meshcore.get_contact_by_key_prefix("a1b2c3")
```
### Event-Based Programming (Asynchronous Style)
Subscribe to events to handle them asynchronously:
```python
# Subscribe to incoming messages
async def handle_message(event):
data = event.payload
print(f"Message from {data['pubkey_prefix']}: {data['text']}")
subscription = meshcore.subscribe(EventType.CONTACT_MSG_RECV, handle_message)
# Subscribe to advertisements
async def handle_advert(event):
print("Advertisement detected!")
meshcore.subscribe(EventType.ADVERTISEMENT, handle_advert)
# When done, unsubscribe
meshcore.unsubscribe(subscription)
```
#### Filtering Events by Attributes
Filter events based on their attributes to handle only specific ones:
```python
# Subscribe only to messages from a specific contact
async def handle_specific_contact_messages(event):
print(f"Message from Alice: {event.payload['text']}")
contact = meshcore.get_contact_by_name("Alice")
if contact:
alice_subscription = meshcore.subscribe(
EventType.CONTACT_MSG_RECV,
handle_specific_contact_messages,
attribute_filters={"pubkey_prefix": contact["public_key"][:12]}
)
# Send a message and wait for its specific acknowledgment
async def send_and_confirm_message(meshcore, dst_key, message):
# Send the message and get information about the sent message
sent_result = await meshcore.commands.send_msg(dst_key, message)
# Extract the expected acknowledgment code from the message sent event
if sent_result.type == EventType.ERROR:
print(f"Error sending message: {sent_result.payload}")
return False
expected_ack = sent_result.payload["expected_ack"].hex()
print(f"Message sent, waiting for ack with code: {expected_ack}")
# Wait specifically for this acknowledgment
result = await meshcore.wait_for_event(
EventType.ACK,
attribute_filters={"code": expected_ack},
timeout=10.0
)
if result:
print("Message confirmed delivered!")
return True
else:
print("Message delivery confirmation timed out")
return False
```
### Hybrid Approach (Commands + Events)
Combine command-based and event-based styles:
```python
import asyncio
async def main():
# Connect to device
meshcore = await MeshCore.create_serial("/dev/ttyUSB0")
# Set up event handlers
async def handle_ack(event):
print("Message acknowledged!")
async def handle_battery(event):
print(f"Battery level: {event.payload}%")
# Subscribe to events
meshcore.subscribe(EventType.ACK, handle_ack)
meshcore.subscribe(EventType.BATTERY, handle_battery)
# Create background task for battery checking
async def check_battery_periodically():
while True:
# Send command (returns battery level)
result = await meshcore.commands.get_bat()
if result.type == EventType.ERROR:
print(f"Error checking battery: {result.payload}")
else:
print(f"Battery level: {result.payload.get('level', 'unknown')}%")
await asyncio.sleep(60) # Wait 60 seconds between checks
# Start the background task
battery_task = asyncio.create_task(check_battery_periodically())
# Send manual command and wait for response
await meshcore.commands.send_advert(flood=True)
try:
# Keep the main program running
await asyncio.sleep(float('inf'))
except asyncio.CancelledError:
# Clean up when program ends
battery_task.cancel()
await meshcore.disconnect()
# Run the program
asyncio.run(main())
```
### Auto-Fetching Messages
Let the library automatically fetch incoming messages:
```python
# Start auto-fetching messages
await meshcore.start_auto_message_fetching()
# Just subscribe to message events - the library handles fetching
async def on_message(event):
print(f"New message: {event.payload['text']}")
meshcore.subscribe(EventType.CONTACT_MSG_RECV, on_message)
# When done
await meshcore.stop_auto_message_fetching()
```
### Debug Mode
Enable debug logging for troubleshooting:
```python
# Enable debug mode when creating the connection
meshcore = await MeshCore.create_serial("/dev/ttyUSB0", debug=True)
```
This logs detailed information about commands sent and events received.
## Common Examples
### Sending Messages to Contacts
Commands that require a destination (`send_msg`, `send_login`, `send_statusreq`, etc.) now accept either:
- A string with the hex representation of a public key
- A contact object with a "public_key" field
- Bytes object (for backward compatibility)
```python
# Get contacts and send to a specific one
result = await meshcore.commands.get_contacts()
if result.type == EventType.ERROR:
print(f"Error getting contacts: {result.payload}")
else:
contacts = result.payload
for key, contact in contacts.items():
if contact["adv_name"] == "Alice":
# Option 1: Pass the contact object directly
result = await meshcore.commands.send_msg(contact, "Hello Alice!")
if result.type == EventType.ERROR:
print(f"Error sending message: {result.payload}")
# Option 2: Use the public key string
result = await meshcore.commands.send_msg(contact["public_key"], "Hello again Alice!")
if result.type == EventType.ERROR:
print(f"Error sending message: {result.payload}")
# Option 3 (backward compatible): Convert the hex key to bytes
dst_key = bytes.fromhex(contact["public_key"])
result = await meshcore.commands.send_msg(dst_key, "Hello once more Alice!")
if result.type == EventType.ERROR:
print(f"Error sending message: {result.payload}")
break
# You can also directly use a contact found by name
contact = meshcore.get_contact_by_name("Bob")
if contact:
result = await meshcore.commands.send_msg(contact, "Hello Bob!")
if result.type == EventType.ERROR:
print(f"Error sending message: {result.payload}")
```
### Monitoring Channel Messages
```python
# Subscribe to channel messages
async def channel_handler(event):
msg = event.payload
print(f"Channel {msg['channel_idx']}: {msg['text']}")
meshcore.subscribe(EventType.CHANNEL_MSG_RECV, channel_handler)
```
## API Reference
### Event Types
All events in MeshCore are represented by the `EventType` enum. These events are dispatched by the library and can be subscribed to:
| Event Type | String Value | Description | Typical Payload |
|------------|-------------|-------------|-----------------|
| **Device & Status Events** |||
| `SELF_INFO` | `"self_info"` | Device's own information after appstart | Device configuration, public key, coordinates |
| `DEVICE_INFO` | `"device_info"` | Device capabilities and firmware info | Firmware version, model, max contacts/channels |
| `BATTERY` | `"battery_info"` | Battery level and storage info | Battery level, used/total storage |
| `CURRENT_TIME` | `"time_update"` | Device time response | Current timestamp |
| `STATUS_RESPONSE` | `"status_response"` | Device status statistics | Battery, TX queue, noise floor, packet counts |
| `CUSTOM_VARS` | `"custom_vars"` | Custom variable responses | Key-value pairs of custom variables |
| **Contact Events** |||
| `CONTACTS` | `"contacts"` | Contact list response | Dictionary of contacts by public key |
| `NEW_CONTACT` | `"new_contact"` | New contact discovered | Contact information |
| `CONTACT_URI` | `"contact_uri"` | Contact export URI | Shareable contact URI |
| **Messaging Events** |||
| `CONTACT_MSG_RECV` | `"contact_message"` | Direct message received | Message text, sender prefix, timestamp |
| `CHANNEL_MSG_RECV` | `"channel_message"` | Channel message received | Message text, channel index, timestamp |
| `MSG_SENT` | `"message_sent"` | Message send confirmation | Expected ACK code, suggested timeout |
| `NO_MORE_MSGS` | `"no_more_messages"` | No pending messages | Empty payload |
| `MESSAGES_WAITING` | `"messages_waiting"` | Messages available notification | Empty payload |
| **Network Events** |||
| `ADVERTISEMENT` | `"advertisement"` | Node advertisement detected | Public key of advertising node |
| `PATH_UPDATE` | `"path_update"` | Routing path update | Public key and path information |
| `ACK` | `"acknowledgement"` | Message acknowledgment | ACK code |
| `PATH_RESPONSE` | `"path_response"` | Path discovery response | Inbound/outbound path data |
| `TRACE_DATA` | `"trace_data"` | Route trace information | Path with SNR data for each hop |
| **Telemetry Events** |||
| `TELEMETRY_RESPONSE` | `"telemetry_response"` | Telemetry data response | LPP-formatted sensor data |
| `MMA_RESPONSE` | `"mma_response"` | Memory Management Area data | Min/max/avg telemetry over time range |
| `ACL_RESPONSE` | `"acl_response"` | Access Control List data | List of keys and permissions |
| **Channel Events** |||
| `CHANNEL_INFO` | `"channel_info"` | Channel configuration | Channel name, secret, index |
| **Raw Data Events** |||
| `RAW_DATA` | `"raw_data"` | Raw radio data | SNR, RSSI, payload hex |
| `RX_LOG_DATA` | `"rx_log_data"` | RF log data | SNR, RSSI, raw payload |
| `LOG_DATA` | `"log_data"` | Generic log data | Various log information |
| **Binary Protocol Events** |||
| `BINARY_RESPONSE` | `"binary_response"` | Generic binary response | Tag and hex data |
| `SIGN_START` | `"sign_start"` | Start of an on-device signing session | Maximum buffer size (bytes) for data to sign |
| `SIGNATURE` | `"signature"` | Resulting on-device signature | Raw signature bytes |
| **Authentication Events** |||
| `LOGIN_SUCCESS` | `"login_success"` | Successful login | Permissions, admin status, pubkey prefix |
| `LOGIN_FAILED` | `"login_failed"` | Failed login attempt | Pubkey prefix |
| **Command Response Events** |||
| `OK` | `"command_ok"` | Command successful | Success confirmation, optional value |
| `ERROR` | `"command_error"` | Command failed | Error reason or code |
| **Connection Events** |||
| `CONNECTED` | `"connected"` | Connection established | Connection details, reconnection status |
| `DISCONNECTED` | `"disconnected"` | Connection lost | Disconnection reason |
### Available Commands
All commands are async methods that return `Event` objects. Commands are organized into functional groups:
#### Device Commands (`meshcore.commands.*`)
| Command | Parameters | Returns | Description |
|---------|------------|---------|-------------|
| **Device Information** ||||
| `send_appstart()` | None | `SELF_INFO` | Get device self-information and configuration |
| `send_device_query()` | None | `DEVICE_INFO` | Query device capabilities and firmware info |
| `get_bat()` | None | `BATTERY` | Get battery level and storage information |
| `get_time()` | None | `CURRENT_TIME` | Get current device time |
| `get_self_telemetry()` | None | `TELEMETRY_RESPONSE` | Get device's own telemetry data |
| `get_custom_vars()` | None | `CUSTOM_VARS` | Retrieve all custom variables |
| `get_allowed_repeat_freq()` | None | `ALLOWED_FREQ` | Retreive allowed repeat freqs from device |
| **Device Configuration** ||||
| `set_name(name)` | `name: str` | `OK` | Set device name/identifier |
| `set_coords(lat, lon)` | `lat: float, lon: float` | `OK` | Set device GPS coordinates |
| `set_time(val)` | `val: int` | `OK` | Set device time (Unix timestamp) |
| `set_tx_power(val)` | `val: int` | `OK` | Set radio transmission power level |
| `set_devicepin(pin)` | `pin: int` | `OK` | Set device PIN for security |
| `set_custom_var(key, value)` | `key: str, value: str` | `OK` | Set custom variable |
| **Radio Configuration** ||||
| `set_radio(freq, bw, sf, cr)` | `freq: float, bw: float, sf: int, cr: int` | `OK` | Configure radio (freq MHz, bandwidth kHz, spreading factor, coding rate 5-8) |
| `set_tuning(rx_dly, af)` | `rx_dly: int, af: int` | `OK` | Set radio tuning parameters |
| **Telemetry Configuration** ||||
| `set_telemetry_mode_base(mode)` | `mode: int` | `OK` | Set base telemetry mode |
| `set_telemetry_mode_loc(mode)` | `mode: int` | `OK` | Set location telemetry mode |
| `set_telemetry_mode_env(mode)` | `mode: int` | `OK` | Set environmental telemetry mode |
| `set_manual_add_contacts(enabled)` | `enabled: bool` | `OK` | Enable/disable manual contact addition |
| `set_advert_loc_policy(policy)` | `policy: int` | `OK` | Set location advertisement policy |
| **Channel Management** ||||
| `get_channel(channel_idx)` | `channel_idx: int` | `CHANNEL_INFO` | Get channel configuration |
| `set_channel(channel_idx, name, secret)` | `channel_idx: int, name: str, secret: bytes` | `OK` | Configure channel (secret must be 16 bytes) |
| **Device Actions** ||||
| `send_advert(flood=False)` | `flood: bool` | `OK` | Send advertisement (optionally flood network) |
| `reboot()` | None | None | Reboot device (no response expected) |
| **Security** ||||
| `export_private_key()` | None | `PRIVATE_KEY/DISABLED` | Export device private key (requires PIN auth & enabled firmware) |
| `import_private_key(key)` | `key: bytes` | `OK` | Import private key to device |
| **Statistics** ||||
| `get_stats_core()` | None | `STATS_CORE` | Get core statistics (voltage, uptime, errors, queue length) |
| `get_stats_radio()` | None | `STATS_RADIO` | Get radio statistics (noise floor, last RSSI/SNR, tx/rx time stats) |
| `get_stats_packets()` | None | `STATS_PACKETS` | Get packet statistics (rx/tx totals, flood vs. direct, recv_errors when present) |
| **Advanced Configuration** ||||
| `set_multi_acks(multi_acks)` | `multi_acks: int` | `OK` | Set multi-acks mode (experimental ack repeats) |
#### Contact Commands (`meshcore.commands.*`)
| Command | Parameters | Returns | Description |
|---------|------------|---------|-------------|
| **Contact Management** ||||
| `get_contacts(lastmod=0)` | `lastmod: int` | `CONTACTS` | Get contact list (filter by last modification time) |
| `add_contact(contact)` | `contact: dict` | `OK` | Add new contact to device |
| `update_contact(contact, path, flags)` | `contact: dict, path: bytes, flags: int` | `OK` | Update existing contact |
| `remove_contact(key)` | `key: str/bytes` | `OK` | Remove contact by public key |
| **Contact Operations** ||||
| `reset_path(key)` | `key: str/bytes` | `OK` | Reset routing path for contact |
| `share_contact(key)` | `key: str/bytes` | `OK` | Share contact with network |
| `export_contact(key=None)` | `key: str/bytes/None` | `CONTACT_URI` | Export contact as URI (None exports node) |
| `import_contact(card_data)` | `card_data: bytes` | `OK` | Import contact from card data |
| **Contact Modification** ||||
| `change_contact_path(contact, path)` | `contact: dict, path: bytes` | `OK` | Change routing path for contact |
| `change_contact_flags(contact, flags)` | `contact: dict, flags: int` | `OK` | Change contact flags/settings |
#### Messaging Commands (`meshcore.commands.*`)
| Command | Parameters | Returns | Description |
|---------|------------|---------|-------------|
| **Message Handling** ||||
| `get_msg(timeout=None)` | `timeout: float` | `CONTACT_MSG_RECV/CHANNEL_MSG_RECV/NO_MORE_MSGS` | Get next pending message |
| `send_msg(dst, msg, timestamp=None)` | `dst: contact/str/bytes, msg: str, timestamp: int` | `MSG_SENT` | Send direct message |
| `send_cmd(dst, cmd, timestamp=None)` | `dst: contact/str/bytes, cmd: str, timestamp: int` | `MSG_SENT` | Send command message |
| `send_chan_msg(chan, msg, timestamp=None)` | `chan: int, msg: str, timestamp: int` | `MSG_OK` | Send channel message |
| **Authentication** ||||
| `send_login(dst, pwd)` | `dst: contact/str/bytes, pwd: str` | `MSG_SENT` | Send login request |
| `send_logout(dst)` | `dst: contact/str/bytes` | `MSG_SENT` | Send logout request |
| **Information Requests** ||||
| `send_statusreq(dst)` | `dst: contact/str/bytes` | `MSG_SENT` | Request status from contact |
| `send_telemetry_req(dst)` | `dst: contact/str/bytes` | `MSG_SENT` | Request telemetry from contact |
| **Advanced Messaging** ||||
| `send_binary_req(dst, bin_data)` | `dst: contact/str/bytes, bin_data: bytes` | `MSG_SENT` | Send binary data request |
| `send_path_discovery(dst)` | `dst: contact/str/bytes` | `MSG_SENT` | Initiate path discovery |
| `send_trace(auth_code, tag, flags, path=None)` | `auth_code: int, tag: int, flags: int, path: list` | `MSG_SENT` | Send route trace packet |
| **Message Retry & Scope** ||||
| `send_msg_with_retry(dst, msg, ...)` | `dst, msg, timestamp, max_attempts, max_flood_attempts, flood_after, timeout, min_timeout` | `MSG_SENT/None` | Send message with automatic retry and ACK waiting |
| `set_flood_scope(scope)` | `scope: str` | `OK` | Set flood scope (hash like "#name", "0"/""/"*" to disable, or raw key) |
#### Binary Protocol Commands (`meshcore.commands.*`)
| Command | Parameters | Returns | Description |
|---------|------------|---------|-------------|
| `req_status(contact, timeout=0)` | `contact: dict, timeout: float` | `STATUS_RESPONSE` | Get detailed status via binary protocol |
| `req_telemetry(contact, timeout=0)` | `contact: dict, timeout: float` | `TELEMETRY_RESPONSE` | Get telemetry via binary protocol |
| `req_mma(contact, start, end, timeout=0)` | `contact: dict, start: int, end: int, timeout: float` | `MMA_RESPONSE` | Get historical telemetry data |
| `req_acl(contact, timeout=0)` | `contact: dict, timeout: float` | `ACL_RESPONSE` | Get access control list |
| `sign_start()` | None | `SIGN_START` | Begin a signing session; returns maximum buffer size for data to sign |
| `sign_data(chunk)` | `chunk: bytes` | `OK` | Append a data chunk to the current signing session (can be called multiple times) |
| `sign_finish()` | None | `SIGNATURE` | Finalize signing and return the signature for all accumulated data |
### Helper Methods
| Method | Returns | Description |
|--------|---------|-------------|
| `get_contact_by_name(name)` | `dict/None` | Find contact by advertisement name |
| `get_contact_by_key_prefix(prefix)` | `dict/None` | Find contact by partial public key |
| `sign(data, chunk_size=512)` | `Event` (`SIGNATURE`/`ERROR`) | High-level helper to sign arbitrary data on-device, handling chunking for you |
| `is_connected` | `bool` | Check if device is currently connected |
| `subscribe(event_type, callback, filters=None)` | `Subscription` | Subscribe to events with optional filtering |
| `unsubscribe(subscription)` | None | Remove event subscription |
| `wait_for_event(event_type, filters=None, timeout=None)` | `Event/None` | Wait for specific event |
### Event Filtering
Events can be filtered by their attributes when subscribing:
```python
# Filter by public key prefix
meshcore.subscribe(
EventType.CONTACT_MSG_RECV,
handler,
attribute_filters={"pubkey_prefix": "a1b2c3d4e5f6"}
)
# Filter by channel index
meshcore.subscribe(
EventType.CHANNEL_MSG_RECV,
handler,
attribute_filters={"channel_idx": 0}
)
# Filter acknowledgments by code
meshcore.subscribe(
EventType.ACK,
handler,
attribute_filters={"code": "12345678"}
)
```
## Examples in the Repo
Check the `examples/` directory for more:
- `pubsub_example.py`: Event subscription system with auto-fetching
- `serial_infos.py`: Quick device info retrieval
- `serial_msg.py`: Message sending and receiving
- `serial_pingbot.py`: Ping bot which can be run on a channel
- `serial_rss_bot.py`: A RSS feed to Meshcore channel example, which broadcasts emergency bushfire warnings in VIC, AU
- `serial_meshcore_ollama.py`: Simple Ollama to Meshcore gateway, a simple chat box
- `ble_pin_pairing_example.py`: BLE connection with PIN pairing
- `ble_private_key_export.py`: BLE private key export with PIN authentication
- `ble_t1000_infos.py`: BLE connections
| text/markdown | null | Florent de Lamotte <florent@frizoncorrea.fr>, Alex Wolden <awolden@gmail.com> | null | null | null | null | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"bleak",
"pycayennelpp",
"pyserial-asyncio-fast",
"black; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\"",
"ruff; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/fdlamotte/meshcore_py",
"Issues, https://github.com/fdlamotte/meshcore_py/issues"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-18T10:51:10.770958 | meshcore-2.2.13.tar.gz | 65,266 | de/55/0d176d8c198e619b6abf7233dd014e47449a5f9891dc54ed2db68beae417/meshcore-2.2.13.tar.gz | source | sdist | null | false | e27731097c055975644ae37d41aef7d3 | dc6edb42980869c838436357a0e0a62523d360b753ef285a12d516648255f6fe | de550d176d8c198e619b6abf7233dd014e47449a5f9891dc54ed2db68beae417 | MIT | [
"LICENSE"
] | 1,613 |
2.4 | pyqt-code-editor | 0.0.57 | Fully featured code-editor widgets for PyQt | # Sigmund Analyst (PyQt Code Editor)
Copyright 2025-2026 Sebastiaan Mathôt
- [About](#about)
- [AI integration](#ai-integration)
- [Installation](#installation)
- [License](#license)
## About
Sigmund Analyst is a powerful code editor (also: Integrated Development Environment or IDE) focused on AI-assisted data analysis with Python. It is composed of a set of powerful PyQt/ PySide widgets that can also be used in other applications.
Features:
- AI integration [SigmundAI](https://sigmundai.eu) and [Mistral Codestral](https://docs.mistral.ai/capabilities/code_generation/)
- Syntax highlighting
- Code completion
- Code checking
- Project explorer
- Jupyter (IPython) console
- Workspace explorer
- Editor panel with splittable tabs
- Settings panel

## AI integration
### SigmundAI for collaborative code editing
You can work together with SigmundAI on the currently active document or selected text. To activate SigmundAI integration, simply log into <https://sigmundai.eu> (subscription required). Sigmund Analyst will then automatically connect to SigmundAI when you enable the Sigmund panel in the toolbar.
### Mistral Codestral for as-you-type suggestions
As-you-type code suggestions are provided by Mistral Codestral. To activate Mistral integration, you need to create an account with Mistral AI. Currently, a free Codestral API key is then provided through the Mistral console. Copy-paste this API key to Codestral API Key field in the settings panel of Sigmund Analyst.
## Installation
### Windows
The easiest way to install Sigmund Analys on Windows is to install OpenSesame, which include Sigmund Analyst:
- <https://osdoc.cogsci.nl/download/>
### Linux/ Ubuntu
The easiest way to install Sigmund Analyst on Linux is to download and run the installer script. This will create a Virtual Environment, pip install Sigmund Analyst and all dependencies into this environment, and add a Desktop file to your system to easily start Sigmund Analyst. To upgrade, simply run the script again.
```
bash <(curl -L https://raw.githubusercontent.com/open-cogsci/pyqt_code_editor/refs/heads/master/install_sigmund_analyst.sh)
```
### Other systems
Install with:
```
pip install pyqt_code_editor
```
Start Sigmund Analyst with:
```
sigmund-analyst
```
## License
`PyQt Code Editor` is licensed under the [GNU General Public License
v3](http://www.gnu.org/licenses/gpl-3.0.en.html).
| text/markdown | null | Sebastiaan Mathôt <s.mathot@cogsci.nl> | null | null | null | code editor, pyqt, ide | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"chardet",
"detect-indent",
"jedi",
"httpx<0.29.0",
"mistralai",
"opensesame-extension-sigmund",
"pathspec",
"psutil",
"pygments",
"qtawesome",
"qtpy",
"pyqt6",
"qtconsole",
"tree-sitter",
"tree-sitter-javascript",
"tree-sitter-json",
"tree-sitter-html",
"tree-sitter-python",
"tr... | [] | [] | [] | [
"Source, https://github.com/open-cogsci/sigmund-analyst"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-18T10:50:31.727798 | pyqt_code_editor-0.0.57.tar.gz | 327,814 | cd/69/5030063fea6d4f7ff9b8f7911b09a569e146eee9f478324ec4d3e36ee0e2/pyqt_code_editor-0.0.57.tar.gz | source | sdist | null | false | c3bdab81174146569d5fb939df450ecd | b7f983b8605d03dc7ea80996f71bc4acdbdf1665b79f3e67e7a14a14a1c3c769 | cd695030063fea6d4f7ff9b8f7911b09a569e146eee9f478324ec4d3e36ee0e2 | null | [
"COPYING"
] | 351 |
2.4 | opensesame-core | 4.1.9 | A graphical experiment builder for the social sciences | # OpenSesame
OpenSesame is a tool to create experiments for psychology, neuroscience, and experimental economics.
Copyright, 2010-2025, Sebastiaan Mathôt and contributors.
<http://osdoc.cogsci.nl/>
## About
OpenSesame is a graphical experiment builder. OpenSesame provides an easy to use, point-and-click interface for creating psychological/ neuroscientific experiments.
## Features
- A user-friendly interface — a modern, professional, and easy-to-use graphical interface
- Online experiments — run your experiment in a browser with OSWeb
- AI — develop your experiments together with [SigmundAI](https://sigmundai.eu/)
- Python — add the power of Python to your experiment
- JavaScript — add the power of JavaScript to your experiment
- Use your devices — use your eye tracker, button box, EEG equipment, and more.
- Free — released under the GPL3
- Crossplatform — Windows, Mac OS, and Linux
## Related repositories
OpenSesame relies on a number repositories that are all hosted by the [Cogsci.nl](https://github.com/open-cogsci/) organization on GitHub. The most important of these are:
- [opensesame](https://github.com/open-cogsci/opensesame) contains core OpenSesame functionality
- [sigmund analyst](https://github.com/open-cogsci/sigmund-analyst) is a code editor that provides various PyQt widgets used by OpenSesame
- [opensesame-extension-sigmund](https://github.com/open-cogsci/opensesame-extension-sigmund) integrates SigmundAI into the OpenSesame user interface
- [osweb](https://github.com/open-cogsci/osweb) implements OSWeb, the online OpenSesame runtime
- [opensesame-extension-osweb](https://github.com/open-cogsci/opensesame-extension-osweb) embeds OSWeb into the OpenSesame user interface
- [datamatrix](https://github.com/open-cogsci/python-datamatrix) implements a tabular data structure that is used by the `loop` item
- [qdatamatrix](https://github.com/open-cogsci/python-qdatamatrix) implements a Qt widget for editing datamatrix objects
- [pseudorandom](https://github.com/open-cogsci/python-pseudorandom) implements pseudorandomization/ randomization constraints
## Branches
Each major version of OpenSesame lives in its own branch.
- `gibson` - 2.8
- `heisenberg` - 2.9
- `ising` - 3.0
- `james` - 3.1
- `koffka` - 3.2
- `loewenfeld` - 3.3
- `milgram` - 4.0
- `nightingale` - 4.1
## Citations
- Mathôt, S., Schreij, D., & Theeuwes, J. (2012). OpenSesame: An open-source, graphical experiment builder for the social sciences. *Behavior Research Methods*, *44*(2), 314-324. [doi:10.3758/s13428-011-0168-7](https://doi.org/doi:10.3758/s13428-011-0168-7)
- Mathôt, S., & March, J. (2022). Conducting linguistic experiments online with OpenSesame and OSWeb. *Language Learning*. [doi:10.1111/lang.12509](https://doi.org/10.1111/lang.12509)
## License
OpenSesame is distributed under the terms of the GNU General Public License 3. The full license should be included in the file `COPYING`, or can be obtained from:
- <http://www.gnu.org/licenses/gpl.txt>
OpenSesame contains works of others. For the full license information, please refer to `debian/copyright`.
## Documentation
Installation instructions and documentation are available on the documentation website ...
- <http://osdoc.cogsci.nl/>
... which is itself also hosted on GitHub:
- <https://github.com/smathot/osdoc>
### Linux installer
The easiest way to install OpenSesame on Linux is to download and run the installer script. This will create a Virtual Environment, pip install OpenSesame and all dependencies into this environment, and add a Desktop file to your system to easily start Sigmund Analyst. To upgrade, simply run the script again.
Currently, the Linux installer is tested on Ubuntu 24.04.
```
bash <(curl -L https://github.com/open-cogsci/OpenSesame/raw/refs/heads/4.1/linux-installer.sh) --install
```
| text/markdown | Sebastiaan Mathôt | s.mathot@cogsci.nl | null | null | COPYING | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"PyYAML",
"markdown",
"numpy",
"pillow",
"pyqt6-webengine",
"pyqt_code_editor",
"python-fileinspector>=1.0.2",
"python-pseudorandom>=0.3.2",
"python-qnotifications>=2.0.6",
"qdatamatrix>=0.1.34",
"setuptools",
"webcolors"
] | [] | [] | [] | [
"Homepage, https://osdoc.cogsci.nl",
"Repository, https://github.com/open-cogsci/OpenSesame/"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-18T10:50:28.434491 | opensesame_core-4.1.9.tar.gz | 18,813,936 | 73/98/3f22dcb6a6433c045b6f74c368931b092fbf70ad21a605b4471ec25fd4bc/opensesame_core-4.1.9.tar.gz | source | sdist | null | false | de94313b96070e50ea25e7f8a9516e59 | 68fdbfa79a90f15c6fcb47f227377219c5e1314aa0241da4baceb21d35147622 | 73983f22dcb6a6433c045b6f74c368931b092fbf70ad21a605b4471ec25fd4bc | null | [
"COPYING"
] | 350 |
2.4 | memsearch | 0.1.11 | Semantic memory search for markdown knowledge bases | <h1 align="center">
<img src="assets/logo-icon.jpg" alt="" width="100" valign="middle">
memsearch
</h1>
<p align="center">
<strong><a href="https://github.com/openclaw/openclaw">OpenClaw</a>'s memory, everywhere.</strong>
</p>
<p align="center">
<a href="https://pypi.org/project/memsearch/"><img src="https://img.shields.io/pypi/v/memsearch?style=flat-square&color=blue" alt="PyPI"></a>
<a href="https://zilliztech.github.io/memsearch/claude-plugin/"><img src="https://img.shields.io/badge/Claude_Code-plugin-c97539?style=flat-square&logo=claude&logoColor=white" alt="Claude Code Plugin"></a>
<a href="https://pypi.org/project/memsearch/"><img src="https://img.shields.io/badge/python-%3E%3D3.10-blue?style=flat-square&logo=python&logoColor=white" alt="Python"></a>
<a href="https://github.com/zilliztech/memsearch/blob/main/LICENSE"><img src="https://img.shields.io/github/license/zilliztech/memsearch?style=flat-square" alt="License"></a>
<a href="https://zilliztech.github.io/memsearch/"><img src="https://img.shields.io/badge/docs-memsearch-blue?style=flat-square" alt="Docs"></a>
<a href="https://github.com/zilliztech/memsearch/stargazers"><img src="https://img.shields.io/github/stars/zilliztech/memsearch?style=flat-square" alt="Stars"></a>
<a href="https://discord.com/invite/FG6hMJStWu"><img src="https://img.shields.io/badge/Discord-chat-7289da?style=flat-square&logo=discord&logoColor=white" alt="Discord"></a>
<a href="https://x.com/zilliz_universe"><img src="https://img.shields.io/badge/follow-%40zilliz__universe-000000?style=flat-square&logo=x&logoColor=white" alt="X (Twitter)"></a>
</p>
https://github.com/user-attachments/assets/31de76cc-81a8-4462-a47d-bd9c394d33e3
> 💡 Give your AI agents persistent memory in a few lines of code. Write memories as markdown, search them semantically. Inspired by [OpenClaw](https://github.com/openclaw/openclaw)'s markdown-first memory architecture. Pluggable into any agent framework.
### ✨ Why memsearch?
- 📝 **Markdown is the source of truth** — human-readable, `git`-friendly, zero vendor lock-in. Your memories are just `.md` files
- ⚡ **Smart dedup** — SHA-256 content hashing means unchanged content is never re-embedded
- 🔄 **Live sync** — File watcher auto-indexes changes to the vector DB, deletes stale chunks when files are removed
- 🧩 **[Ready-made Claude Code plugin](ccplugin/README.md)** — a drop-in example of agent memory built on memsearch
## 📦 Installation
```bash
pip install memsearch
```
<details>
<summary><b>Optional embedding providers</b></summary>
```bash
pip install "memsearch[google]" # Google Gemini
pip install "memsearch[voyage]" # Voyage AI
pip install "memsearch[ollama]" # Ollama (local)
pip install "memsearch[local]" # sentence-transformers (local, no API key)
pip install "memsearch[all]" # Everything
```
</details>
## 🐍 Python API — Give Your Agent Memory
```python
from memsearch import MemSearch
mem = MemSearch(paths=["./memory"])
await mem.index() # index markdown files
results = await mem.search("Redis config", top_k=3) # semantic search
print(results[0]["content"], results[0]["score"]) # content + similarity
```
<details>
<summary>🚀 <b>Full example — agent with memory (OpenAI)</b> — click to expand</summary>
```python
import asyncio
from datetime import date
from pathlib import Path
from openai import OpenAI
from memsearch import MemSearch
MEMORY_DIR = "./memory"
llm = OpenAI() # your LLM client
mem = MemSearch(paths=[MEMORY_DIR]) # memsearch handles the rest
def save_memory(content: str):
"""Append a note to today's memory log (OpenClaw-style daily markdown)."""
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. Recall — search past memories for relevant context
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. Think — call LLM with memory context
resp = llm.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": f"You have these memories:\n{context}"},
{"role": "user", "content": user_input},
],
)
answer = resp.choices[0].message.content
# 3. Remember — save this exchange and index it
save_memory(f"## {user_input}\n{answer}")
await mem.index()
return answer
async def main():
# Seed some knowledge
save_memory("## Team\n- Alice: frontend lead\n- Bob: backend lead")
save_memory("## Decision\nWe chose Redis for caching over Memcached.")
await mem.index() # or mem.watch() to auto-index in the background
# Agent can now recall those memories
print(await agent_chat("Who is our frontend lead?"))
print(await agent_chat("What caching solution did we pick?"))
asyncio.run(main())
```
</details>
<details>
<summary>💜 <b>Anthropic Claude example</b> — click to expand</summary>
```bash
pip install memsearch anthropic
```
```python
import asyncio
from datetime import date
from pathlib import Path
from anthropic import Anthropic
from memsearch import MemSearch
MEMORY_DIR = "./memory"
llm = Anthropic()
mem = MemSearch(paths=[MEMORY_DIR])
def save_memory(content: str):
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. Recall
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. Think — call Claude with memory context
resp = llm.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
system=f"You have these memories:\n{context}",
messages=[{"role": "user", "content": user_input}],
)
answer = resp.content[0].text
# 3. Remember
save_memory(f"## {user_input}\n{answer}")
await mem.index()
return answer
async def main():
save_memory("## Team\n- Alice: frontend lead\n- Bob: backend lead")
await mem.index()
print(await agent_chat("Who is our frontend lead?"))
asyncio.run(main())
```
</details>
<details>
<summary>🦙 <b>Ollama (fully local, no API key)</b> — click to expand</summary>
```bash
pip install "memsearch[ollama]"
ollama pull nomic-embed-text # embedding model
ollama pull llama3.2 # chat model
```
```python
import asyncio
from datetime import date
from pathlib import Path
from ollama import chat
from memsearch import MemSearch
MEMORY_DIR = "./memory"
mem = MemSearch(paths=[MEMORY_DIR], embedding_provider="ollama")
def save_memory(content: str):
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. Recall
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. Think — call Ollama locally
resp = chat(
model="llama3.2",
messages=[
{"role": "system", "content": f"You have these memories:\n{context}"},
{"role": "user", "content": user_input},
],
)
answer = resp.message.content
# 3. Remember
save_memory(f"## {user_input}\n{answer}")
await mem.index()
return answer
async def main():
save_memory("## Team\n- Alice: frontend lead\n- Bob: backend lead")
await mem.index()
print(await agent_chat("Who is our frontend lead?"))
asyncio.run(main())
```
</details>
> 📖 Full Python API reference with all parameters → [Python API docs](https://zilliztech.github.io/memsearch/python-api/)
## 🖥️ CLI Usage
### Set Up — `config init`
Interactive wizard to configure embedding provider, Milvus backend, and chunking parameters:
```bash
memsearch config init # write to ~/.memsearch/config.toml
memsearch config init --project # write to .memsearch.toml (per-project)
memsearch config set milvus.uri http://localhost:19530
memsearch config list --resolved # show merged config from all sources
```
### Index Markdown — `index`
Scan directories and embed all markdown into the vector store. Unchanged chunks are auto-skipped via content-hash dedup:
```bash
memsearch index ./memory/
memsearch index ./memory/ ./notes/ --provider google
memsearch index ./memory/ --force # re-embed everything
```
### Semantic Search — `search`
Hybrid search (dense vector + BM25 full-text) with RRF reranking:
```bash
memsearch search "how to configure Redis caching"
memsearch search "auth flow" --top-k 10 --json-output
```
### Live Sync — `watch`
File watcher that auto-indexes on markdown changes (creates, edits, deletes):
```bash
memsearch watch ./memory/
memsearch watch ./memory/ ./notes/ --debounce-ms 3000
```
### LLM Summarization — `compact`
Compress indexed chunks into a condensed markdown summary using an LLM:
```bash
memsearch compact
memsearch compact --llm-provider anthropic --source ./memory/old-notes.md
```
### Utilities — `stats` / `reset`
```bash
memsearch stats # show total indexed chunk count
memsearch reset # drop all indexed data (with confirmation)
```
> 📖 Full command reference with all flags and examples → [CLI Reference](https://zilliztech.github.io/memsearch/cli/)
## 🔍 How It Works
**Markdown is the source of truth** — the vector store is just a derived index, rebuildable anytime.
```
┌─── Search ─────────────────────────────────────────────────────────┐
│ │
│ "how to configure Redis?" │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌─────────────────┐ ┌──────────────────┐ │
│ │ Embed │────▶│ Cosine similarity│────▶│ Top-K results │ │
│ │ query │ │ (Milvus) │ │ with source info │ │
│ └──────────┘ └─────────────────┘ └──────────────────┘ │
│ │
└────────────────────────────────────────────────────────────────────┘
┌─── Ingest ─────────────────────────────────────────────────────────┐
│ │
│ MEMORY.md │
│ memory/2026-02-09.md ┌──────────┐ ┌────────────────┐ │
│ memory/2026-02-08.md ───▶│ Chunker │────▶│ Dedup │ │
│ │(heading, │ │(chunk_hash PK) │ │
│ │paragraph)│ └───────┬────────┘ │
│ └──────────┘ │ │
│ new chunks only │
│ ▼ │
│ ┌──────────────┐ │
│ │ Embed & │ │
│ │ Milvus upsert│ │
│ └──────────────┘ │
│ │
└────────────────────────────────────────────────────────────────────┘
┌─── Watch ──────────────────────────────────────────────────────────┐
│ File watcher (1500ms debounce) ──▶ auto re-index / delete stale │
└────────────────────────────────────────────────────────────────────┘
┌─── Compact ─────────────────────────────────────────────────────────┐
│ Retrieve chunks ──▶ LLM summarize ──▶ write memory/YYYY-MM-DD.md │
└────────────────────────────────────────────────────────────────────┘
```
🔒 The entire pipeline runs locally by default — your data never leaves your machine unless you choose a remote backend or a cloud embedding provider.
## 🧩 Claude Code Plugin
memsearch ships with a **[Claude Code plugin](ccplugin/README.md)** — a real-world example of agent memory in action. It gives Claude **automatic persistent memory** across sessions: every session is summarized to markdown, every prompt triggers a semantic search, and a background watcher keeps the index in sync. No commands to learn, no manual saving — just install and go.
```bash
# 1. Set your embedding API key (OpenAI is the default provider)
export OPENAI_API_KEY="sk-..."
# 2. In Claude Code, add the marketplace and install the plugin
/plugin marketplace add zilliztech/memsearch
/plugin install memsearch
# 3. Restart Claude Code for the plugin to take effect, then start chatting!
claude
```
> 📖 Architecture, hook details, and development mode → [Claude Code Plugin docs](https://zilliztech.github.io/memsearch/claude-plugin/)
## ⚙️ Configuration
Settings are resolved in priority order (lowest → highest):
1. **Built-in defaults** → 2. **Global** `~/.memsearch/config.toml` → 3. **Project** `.memsearch.toml` → 4. **CLI flags**
API keys for embedding/LLM providers are read from standard environment variables (`OPENAI_API_KEY`, `GOOGLE_API_KEY`, `VOYAGE_API_KEY`, `ANTHROPIC_API_KEY`, etc.).
> 📖 Config wizard, TOML examples, and all settings → [Getting Started — Configuration](https://zilliztech.github.io/memsearch/getting-started/#configuration)
## 🔌 Embedding Providers
| Provider | Install | Default Model |
|----------|---------|---------------|
| OpenAI | `memsearch` (included) | `text-embedding-3-small` |
| Google | `memsearch[google]` | `gemini-embedding-001` |
| Voyage | `memsearch[voyage]` | `voyage-3-lite` |
| Ollama | `memsearch[ollama]` | `nomic-embed-text` |
| Local | `memsearch[local]` | `all-MiniLM-L6-v2` |
> 📖 Provider setup and env vars → [CLI Reference — Embedding Provider Reference](https://zilliztech.github.io/memsearch/cli/#embedding-provider-reference)
## 🗄️ Milvus Backend
memsearch supports three deployment modes — just change `milvus_uri`:
| Mode | `milvus_uri` | Best for |
|------|-------------|----------|
| **Milvus Lite** (default) | `~/.memsearch/milvus.db` | Personal use, dev — zero config |
| **Milvus Server** | `http://localhost:19530` | Multi-agent, team environments |
| **Zilliz Cloud** | `https://in03-xxx.api.gcp-us-west1.zillizcloud.com` | Production, fully managed |
> 📖 Code examples and setup details → [Getting Started — Milvus Backends](https://zilliztech.github.io/memsearch/getting-started/#milvus-backends)
## 🔗 Integrations
memsearch works with any Python agent framework. Ready-made examples for:
- **[LangChain](https://www.langchain.com/)** — use as a `BaseRetriever` in any LCEL chain
- **[LangGraph](https://langchain-ai.github.io/langgraph/)** — wrap as a tool in a ReAct agent
- **[LlamaIndex](https://www.llamaindex.ai/)** — plug in as a custom retriever
- **[CrewAI](https://www.crewai.com/)** — add as a tool for crew agents
> 📖 Copy-paste code for each framework → [Integrations docs](https://zilliztech.github.io/memsearch/integrations/)
## 📚 Links
- [Documentation](https://zilliztech.github.io/memsearch/) — full guides, API reference, and architecture details
- [Claude Code Plugin](ccplugin/README.md) — hook details, progressive disclosure, comparison with claude-mem
- [OpenClaw](https://github.com/openclaw/openclaw) — the memory architecture that inspired memsearch
- [Milvus](https://milvus.io/) — the vector database powering memsearch
- [FAQ](https://zilliztech.github.io/memsearch/faq/) — common questions and troubleshooting
## Contributing
Bug reports, feature requests, and pull requests are welcome! See the [Contributing Guide](CONTRIBUTING.md) for development setup, testing, and plugin development instructions. For questions and discussions, join us on [Discord](https://discord.com/invite/FG6hMJStWu).
## 📄 License
[MIT](LICENSE)
| text/markdown | null | null | null | null | null | null | [
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1",
"openai>=1.0",
"pymilvus[milvus-lite]>=2.5.0",
"setuptools<75",
"tomli-w>=1.0",
"tomli>=2.0; python_version < \"3.11\"",
"watchdog>=4.0",
"anthropic>=0.40; extra == \"all\"",
"google-genai>=1.0; extra == \"all\"",
"ollama>=0.4; extra == \"all\"",
"sentence-transformers>=3.0; extra ... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:50:24.606394 | memsearch-0.1.11.tar.gz | 2,830,499 | a5/f7/58c57d906bbb0a7f8361cf655c838c8ed1c2069696b095d2e9abff1f23e8/memsearch-0.1.11.tar.gz | source | sdist | null | false | 75dec1014bcf9aa5e8da28194e3b0031 | d7a3cfc3b89038198523562bac08b135708e7e0e1de925a44a06ad82378bc67e | a5f758c57d906bbb0a7f8361cf655c838c8ed1c2069696b095d2e9abff1f23e8 | MIT | [
"LICENSE"
] | 641 |
2.4 | opensesame-extension-sigmund | 1.0.2 | SigmundAI copilot extension for OpenSesame and Sigmund Analyst | # SigmundAI copilot extension for OpenSesame and Sigmund Analyst
Copyright 2025 Sebastiaan Mathôt (@smathot)
## About
An extension that integrates with <https://sigmundai.eu>, and allows you to work with SigmundAI directly from the user interfaces of OpenSesame and Sigmund Analyst.
See also:
- <https://github.com/open-cogsci/sigmund-ai>
- <https://github.com/open-cogsci/sigmund-analyst>
- <https://github.com/open-cogsci/opensesame>
## License
This code is distributed under the terms of the GNU General Public License 3. The full license should be included in the file COPYING, or can be obtained from:
- <http://www.gnu.org/licenses/gpl.txt>
| text/markdown | Sebastiaan Mathôt | s.mathot@cogsci.nl | null | null | COPYING | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 2",
"Programming Language :: Python :: 2.7",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.4",
"Programming Language :: Python :: 3.5",
"Programming Language :: Python :: 3.6",
"Programming Languag... | [] | null | null | null | [] | [] | [] | [
"websockets>=10"
] | [] | [] | [] | [
"Homepage, https://osdoc.cogsci.nl",
"Repository, https://github.com/open-cogsci/opensesame-extension-sigmund"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-18T10:50:18.730703 | opensesame_extension_sigmund-1.0.2.tar.gz | 285,128 | 2e/bc/7a2e167177a9d9fcdc0a1a9b1b544f0e2df9fe72d25052f1001053d95dca/opensesame_extension_sigmund-1.0.2.tar.gz | source | sdist | null | false | 9dff16e3cd6376edf23a660f04b90981 | 08c3e02c246599c116b7624941b000ebc8bd027d9915a85936fd2396613a80df | 2ebc7a2e167177a9d9fcdc0a1a9b1b544f0e2df9fe72d25052f1001053d95dca | null | [
"COPYING"
] | 372 |
2.4 | argus-scanner | 1.0.0 | High-performance async Python port scanner with honeypot detection | # Argus – Port Scanner
<p align="center">
<img src="https://img.shields.io/badge/Python-3.10+-blue?logo=python" alt="Python 3.10+">
<img src="https://img.shields.io/badge/License-MIT-green" alt="MIT License">
<img src="https://img.shields.io/badge/Platform-Windows%20%7C%20Linux%20%7C%20macOS-lightgrey" alt="Platform">
</p>
**Argus** is a high-performance, asynchronous port scanner built in Python. It combines speed with intelligence—featuring SSL/TLS support, smart banner grabbing, and built-in honeypot detection.
## ⚠️ Legal Disclaimer
> **This tool is for educational and authorized testing only.**
> Unauthorized scanning of networks you do not own or have permission to test may be illegal in your jurisdiction. Always obtain proper authorization before scanning.
---
## Features
| Feature | Description |
|---------|-------------|
| ⚡ **Async Scanning** | Concurrent scanning with configurable workers (up to 5000) |
| 🔒 **SSL/TLS Support** | HTTPS detection with SNI for CDNs like Akamai |
| 🕵️ **Honeypot Detection** | Multi-layer scoring: port density, banner consistency, timing |
| 🎯 **Smart Banner Grabbing** | Optional `-sV` mode with multi-stage probing |
| 📊 **JSON Output** | Machine-readable results with honeypot breakdown |
---
## Installation
### From PyPI (Recommended)
```bash
pip install argus-scanner
```
### From Source
```bash
git clone https://github.com/yourusername/argus-port-scanner.git
cd argus-port-scanner
pip install -e .
```
---
## Usage
```bash
# Simple scan
argus -t example.com -p 1-1000
# Fast scan with JSON output
argus -t example.com -p 80,443,8080 -o results.json
# Deep service detection
argus -t example.com -p 1-1000 -sV
```
### Options
| Option | Description |
|--------|-------------|
| `-t, --target` | Target IP or hostname |
| `-p, --ports` | Ports to scan (e.g., `80,443` or `1-1000`) |
| `-c, --concurrency` | Concurrent connections (default: 500) |
| `-o, --output` | Save results to JSON file |
| `-sV` | Deep service detection with multi-stage probing |
---
## Honeypot Detection
Argus detects potential honeypots using multiple signals:
| Check | Weight | What It Detects |
|-------|--------|-----------------|
| Port Density | 40 pts | Too many open ports (100+ = max) |
| Banner Consistency | 30 pts | OS mismatches across services |
| Response Timing | 30 pts | Too-fast or zero-jitter responses |
**Confidence Levels:** `LOW` (0-39), `MEDIUM` (40-59), `HIGH` (60+)
See [docs/honeypot_detection.md](docs/honeypot_detection.md) for detailed scoring logic.
---
## Example Output
```
╭────────────────────── Honeypot Detection ──────────────────────╮
│ ✓ Honeypot Score: 5/100 (LOW) │
│ • Port Density: 0/40 - 4 open ports is normal │
│ • Banner Consistency: 0/30 - OS indicators consistent │
│ • Timing: 5/30 - Timing patterns appear normal │
╰────────────────────────────────────────────────────────────────╯
Scan Results for 23.55.244.114
┏━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Port ┃ State ┃ Service ┃ Version/Banner ┃
┡━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ 80 │ OPEN │ [HTTP] AkamaiGHost │ HTTP/1.0 400 Bad Request │
│ 443 │ OPEN │ [HTTP] AkamaiGHost │ HTTP/1.0 400 Bad Request │
└──────┴───────┴─────────────────────┴──────────────────────────┘
```
---
## Roadmap
| Feature | Status |
|---------|--------|
| UDP scanning | Planned |
| IPv6 support | Planned |
| Plugin-based analyzers | Planned |
| PCAP-based timing analysis | Research |
| Nmap NSE script compatibility | Research |
See [docs/validation.md](docs/validation.md) for real-world test results.
---
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
## License
MIT License - see [LICENSE](LICENSE) for details.
## Acknowledgments
- Built with [Rich](https://github.com/Textualize/rich) for terminal UI
- Uses [Pydantic](https://pydantic-docs.helpmanual.io/) for configuration
| text/markdown | Argus Contributors | null | null | null | MIT | port-scanner, security, network, asyncio, honeypot-detection, pentesting, cybersecurity | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python ::... | [] | null | null | >=3.10 | [] | [] | [] | [
"rich>=13.0.0",
"pydantic>=2.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/yourusername/argus-port-scanner",
"Repository, https://github.com/yourusername/argus-port-scanner",
"Issues, https://github.com/yourusername/argus-port-scanner/issues"
] | twine/6.2.0 CPython/3.14.0 | 2026-02-18T10:50:07.570556 | argus_scanner-1.0.0.tar.gz | 32,490 | 89/90/30d35952debfe54b199306b9f8629594b245bee4938cf9c9ff3252ec74dc/argus_scanner-1.0.0.tar.gz | source | sdist | null | false | 9429abdd0c37e194e61961659d207ee0 | f354f4c8531194ed6de739c0e5b431c585a8cf6f6f1aab37003e5e73e7429e13 | 899030d35952debfe54b199306b9f8629594b245bee4938cf9c9ff3252ec74dc | null | [
"LICENSE"
] | 282 |
2.4 | ambient-package-update | 26.2.1 | Ambient package update tool for clean and swift maintenance | [](https://pypi.org/project/ambient-package-update/)
[](https://pepy.tech/project/ambient-package-update)
[](https://github.com/astral-sh/ruff)
[](https://github.com/astral-sh/ruff)
# Ambient Package Update
This repository will help keep all Python packages following a certain basic structure tidy and up-to-date. It's being
maintained by [Ambient Digital](https://ambient.digital).
This package will render all required configuration and installation files for your target package.
Typical use-cases:
- A new Python or Django version was released
- A Python or Django version was deprecated
- You want to update the Sphinx documentation builder
- You want to update the linter versions
- You want to add the third-party dependencies
## Versioning
This project follows the CalVer versioning pattern: `YY.MM.[RELEASE]`
## How to update a package
These steps will tell you how to update a package which was created by using this updater.
- Navigate to the main directory of **your** package
- Activate your virtualenv
- Run `python -m ambient_package_update.cli render-templates`
- Validate the changes and increment the version accordingly
- Release a new version of your target package
## How to create a new package
Just follow these steps if you want to create a new package and maintain it using this updater.
- Create a new repo at GitHub
- Check out the new repository in the same directory this updater lives in (not inside the updater!)
- Create a directory ".ambient-package-update" and create a file "metadata.py" inside.
```python
from ambient_package_update.metadata.author import PackageAuthor
from ambient_package_update.metadata.constants import DEV_DEPENDENCIES
from ambient_package_update.metadata.package import PackageMetadata
from ambient_package_update.metadata.readme import ReadmeContent
from ambient_package_update.metadata.ruff_ignored_inspection import (
RuffIgnoredInspection,
RuffFilePatternIgnoredInspection,
)
METADATA = PackageMetadata(
package_name="my_package_name",
authors=[
PackageAuthor(
name="Ambient Digital",
email="hello@ambient.digital",
),
],
development_status="5 - Production/Stable",
readme_content=ReadmeContent(
tagline="A fancy tagline for your new package",
content="""A multiline string containing specific things you want to have in your package readme.
""",
),
dependencies=[
"my_dependency>=1.0",
],
optional_dependencies={
"dev": [
*DEV_DEPENDENCIES,
],
# you might add further extras here
},
# Example of a global ruff ignore
ruff_ignore_list=[
RuffIgnoredInspection(key="XYZ", comment="Reason why we need this exception"),
],
# Example of a file-based ruff ignore
ruff_file_based_ignore_list=[
RuffFilePatternIgnoredInspection(
pattern="**/tests/missing_init/*.py",
rules=[
RuffIgnoredInspection(
key="INP001", comment="Missing by design for a test case"
),
],
),
],
)
```
- Install the `ambient_package_update` package
```
# ideally in a virtual environment
pip install ambient-package-update
```
- Add `docs/index.rst` and link your readme and changelog to have a basic documentation (surely, you can add or write
more custom docs if you want!)
- Enable the readthedocs hook in your GitHub repo to update your documentation on a commit basis
- Finally, follow the steps of the section above (`How to update a package`).
### Customizing the templates
To customize the templates, you can use the `eject-template` command.
Simply run
```bash
python -m ambient_package_update.cli eject-template
```
from the root of your project and select the template you want to eject.
The chosen template will be copied to `.ambient-package-update/templates`, ready to be customized.
If you want to overwrite template manually, you can find the default templates in the `ambient_package_update/templates` directory.
You can overwrite them by creating a `.ambient-package-update/templates` directory in your project
and create a new file with the same name as the template you want to overwrite.
## Changelog
Can be found at [GitHub](https://github.com/ambient-innovation/ambient-package-update/blob/master/CHANGES.md).
| text/markdown | null | Ambient Digital <hello@ambient.digital> | null | null | MIT License Copyright (c) 2023 Ambient Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Program... | [] | null | null | >=3.10 | [] | [] | [] | [
"jinja2~=3.1",
"keyring~=25.7",
"typer~=0.19",
"uv~=0.9"
] | [] | [] | [] | [
"Homepage, https://github.com/ambient-innovation/ambient-package-update/",
"Documentation, https://github.com/ambient-innovation/ambient-package-update/blob/master/README.md",
"Maintained by, https://ambient.digital/",
"Bugtracker, https://github.com/ambient-innovation/ambient-package-update/issues",
"Chang... | uv/0.9.0 | 2026-02-18T10:49:21.650365 | ambient_package_update-26.2.1.tar.gz | 59,418 | 1f/27/beb20ccc48e1a000a7407c1a446366832991381deeb6e864735aa288cdf8/ambient_package_update-26.2.1.tar.gz | source | sdist | null | false | 4877faca6f5f0b683069480a175d1d66 | 3726326d96c74ac18d85d4b078307633c9f2ec71770c247192a0b199833e33b9 | 1f27beb20ccc48e1a000a7407c1a446366832991381deeb6e864735aa288cdf8 | null | [
"LICENSE.md"
] | 285 |
2.4 | acquire | 3.22.dev7 | A tool to quickly gather forensic artifacts from disk images or a live system into a lightweight container | # Acquire
`acquire` is a tool to quickly gather forensic artifacts from disk images or a live system into a lightweight container.
This makes `acquire` an excellent tool to, among others, speedup the process of digital forensic triage.
It uses `dissect` to gather that information from the raw disk, if possible.
`acquire` gathers artifacts based on modules. These modules are paths or globs on a filesystem which acquire attempts to gather.
Multiple modules can be executed at once, which have been collected together inside a profile.
These profiles (used with `--profile`) are `full`, `default`, `minimal` and `none`.
Depending on what operating system gets detected, different artifacts are collected.
The most basic usage of `acquire` is as follows:
```bash
user@dissect~$ sudo acquire
```
The tool requires administrative access to read raw disk data instead of using the operating system for file access.
However, there are some options available to use the operating system as a fallback option. (e.g `--fallback` or `--force-fallback`)
For more information, please see [the documentation](https://docs.dissect.tools/en/latest/projects/acquire/index.html).
## Requirements
This project is part of the Dissect framework and requires Python.
Information on the supported Python versions can be found in the Getting Started section of [the documentation](https://docs.dissect.tools/en/latest/index.html#getting-started).
## Installation
`acquire` is available on [PyPI](https://pypi.org/project/acquire/).
```bash
pip install acquire
```
## Build and test instructions
This project uses `tox` to build source and wheel distributions. Run the following command from the root folder to build
these:
```bash
tox -e build
```
The build artifacts can be found in the `dist/` directory.
`tox` is also used to run linting and unit tests in a self-contained environment. To run both linting and unit tests
using the default installed Python version, run:
```bash
tox
```
For a more elaborate explanation on how to build and test the project, please see [the
documentation](https://docs.dissect.tools/en/latest/contributing/tooling.html).
## Contributing
The Dissect project encourages any contribution to the codebase. To make your contribution fit into the project, please
refer to [the development guide](https://docs.dissect.tools/en/latest/contributing/developing.html).
## Copyright and license
Dissect is released as open source by Fox-IT (<https://www.fox-it.com>) part of NCC Group Plc
(<https://www.nccgroup.com>).
Developed by the Dissect Team (<dissect@fox-it.com>) and made available at <https://github.com/fox-it/acquire>.
License terms: AGPL3 (<https://www.gnu.org/licenses/agpl-3.0.html>). For more information, see the LICENSE file.
| text/markdown | null | Dissect Team <dissect@fox-it.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Topic :: Internet :: Log Analysis",
"Topic :: Scientific/Engineering ... | [] | null | null | >=3.10 | [] | [] | [] | [
"dissect.cstruct<5,>=4",
"dissect.target<4,>=3.25.dev",
"minio; extra == \"full\"",
"pycryptodome; extra == \"full\"",
"requests; extra == \"full\"",
"rich; extra == \"full\"",
"dissect.target[full]<4,>=3.23; extra == \"full\"",
"requests_toolbelt; extra == \"full\"",
"acquire[full]; extra == \"dev\... | [] | [] | [] | [
"homepage, https://dissect.tools",
"documentation, https://docs.dissect.tools/en/latest/projects/acquire",
"repository, https://github.com/fox-it/acquire"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:48:16.107496 | acquire-3.22.dev7.tar.gz | 95,119 | e2/65/8e83e9d30844b3509151bad8393a7acd2faea1a9ffe557cde7738c2ec951/acquire-3.22.dev7.tar.gz | source | sdist | null | false | 48ca1d1deca185673d859725e80dc88e | dab3548b7a86bed9c0349c371e1bdaba93363fa5f484469339ebc7ccd8c9816f | e2658e83e9d30844b3509151bad8393a7acd2faea1a9ffe557cde7738c2ec951 | AGPL-3.0-or-later | [
"LICENSE",
"COPYRIGHT"
] | 330 |
2.4 | schedint | 2.0.0 | Jodrell bank pulsar schedule editor | # schedint
Skeleton package of Jodrell Bank pulsar schedule interruptions
## Usage
```bash
schedint --help
| text/markdown | Benjamin Shaw | null | null | null | Copyright 2026 University of Manchester
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
| null | [] | [] | null | null | >=3.7 | [] | [] | [] | [
"PyYAML<7,>=5.4",
"pytest; extra == \"dev\"",
"tox; extra == \"dev\"",
"isort; extra == \"dev\"",
"flake8; extra == \"dev\"",
"black; extra == \"dev\"",
"build; extra == \"dev\"",
"twine; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-18T10:47:39.370305 | schedint-2.0.0.tar.gz | 18,457 | 29/ae/9c6a6b2d5ebc8c1ad2ab9f7dd371c1431932f2e71fc4c9211868fa680033/schedint-2.0.0.tar.gz | source | sdist | null | false | 66d4c4d687b7f7d2f21573292a614d8b | 7414983b9248ed0fccac08a9956451447fd78ac683d964d5e40dfe1b89cd92da | 29ae9c6a6b2d5ebc8c1ad2ab9f7dd371c1431932f2e71fc4c9211868fa680033 | null | [
"LICENSE"
] | 267 |
2.4 | pywatemsedem | 0.0.1a10 | Python Wrapper for WaTEM/SEDEM | pywatemsedem
============
The pywatemsedem package is a Python wrapper for.
`WaTEM/SEDEM <https://watem-sedem.github.io/watem-sedem/>`_.
The aim of the pywatemsedem package is to:
- Automate GIS IO processing.
- Provide tools to interact with WaTEM/SEDEM.
- Run WaTEM/SEDEM
The package is implemented in Python and best used with the tutorial
notebooks available on this page.
Getting started
---------------
This package makes use of Python (and a number of dependencies such as
Geopandas, Rasterio, Pandas and Numpy). To install the package:
::
pip install pywatemsedem
.. note::
Note that it relies on dependencies you need to install yourselves, see
`installation instructions <https://watem-sedem.github.io/pywatemsedem/installation.html>`_ for more information.
Documentation
-------------
The documentation can be found on the
`pywatemsedem documentation page <http://watem-sedem.github.io/pywatemsedem>`_.
Code
----
The open-source code can be found on
`GitHub <https://github.com/watem-sedem/pywatemsedem/>`_.
License
-------
This project is licensed under MIT, see
`license <https://watem-sedem.github.io/pywatemsedem/license.html>`_ for more information.
Projects
--------
The pywatemsedem package has been used in following projects:
.. image:: https://watem-sedem.github.io/pywatemsedem/_static/png/projects/tripleC.jpg
:target: http://www.triple-c-water.eu
Contact
-------
For technical questions, we refer to the documentation. If you have a
technical issue with running the model, or if you encounter a bug, please
use the issue-tracker on github:
`https://github.com/watem-sedem/pywatemsedem/issues <https://github.com/watem-sedem/pywatemsedem/issues>`_
Powered by
----------
.. figure:: https://watem-sedem.github.io/pywatemsedem/_static/png/DepartementOmgeving_logo.png
:target: https://omgeving.vlaanderen.be/
.. figure:: https://watem-sedem.github.io/pywatemsedem/_static/png/VMM_logo.png
:target: https://vmm.be/
.. figure:: https://watem-sedem.github.io/pywatemsedem/_static/png/fluves_logo.png
:target: https://fluves.com/
.. figure:: https://watem-sedem.github.io/pywatemsedem/_static/png/KULeuven_logo.png
:target: https://aow.kuleuven.be/
| text/x-rst; charset=UTF-8 | Sacha Gobeyn | sacha@fluves.com | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Programming Language :: Python",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Intended Audience :: Science/Research",
"Natural Language :: Engli... | [
"any"
] | null | null | >=3.9 | [] | [] | [] | [
"geopandas",
"rasterio",
"matplotlib",
"scikit-learn",
"pyogrio",
"python-dotenv",
"black; extra == \"develop\"",
"configupdater; extra == \"develop\"",
"flake8; extra == \"develop\"",
"interrogate; extra == \"develop\"",
"nbsphinx; extra == \"develop\"",
"nbstripout; extra == \"develop\"",
... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:46:49.614947 | pywatemsedem-0.0.1a10.tar.gz | 783,769 | e3/42/badbb3f71248b153ee20d50825bb4121569bfcba78f58a69d107bb816713/pywatemsedem-0.0.1a10.tar.gz | source | sdist | null | false | 272545e8449b295e8d127fc4763d12d4 | ca471e25dab14a31af687cc33aceb0100d6a1442afa80da535fcad2e544a9216 | e342badbb3f71248b153ee20d50825bb4121569bfcba78f58a69d107bb816713 | null | [
"LICENSE.txt",
"AUTHORS.rst"
] | 243 |
2.4 | th2-grpc-read-db | 0.0.13rc1 | th2_grpc_read_db | # gRPC for read-db (0.0.13)
The read-db provides you with gRPC interface for interacting with database.
You can:
+ request data synchronously - `Execute` method. This method returns rows as stream.
+ run data loading synchronously - `Load` method. This method returns aggregated execution report.
+ submit pulling requests and stop them - `StartPulling` and `StopPulling` methods
# Release notes:
## 0.0.13
+ updated th2 grpc plugin `0.3.14`
+ grpc-common: `4.7.5`
+ grpcio-tools: `1.75.1`
+ mypy-protobuf: `3.6`
## 0.0.12
+ updated th2 gradle plugin `0.3.10`
+ updated grpc-common: `4.7.2`
## 0.0.11
+ updated th2 gradle plugin `0.2.4`
+ updated grpc-common: `4.5.0`
## 0.0.10
+ updated th2 gradle plugin `0.0.8`
## 0.0.9
+ updated grpc-common: `4.5.0-dev`
## 0.0.8
+ added `Load` method
## 0.0.7
+ added execution_id to the QueryResponse
+ added parent_event_id to the QueryRequest
## 0.0.6
+ added before_init_query_ids, after_init_query_ids, before_update_query_ids, after_update_query_ids to the DbPullRequest
+ added before_query_ids, after_query_ids to the QueryRequest
## 0.0.5
+ added DbPullRequest.reset_state_parameters field
## 0.0.4
+ added DbPullRequest.start_from_last_read_row field
| text/markdown | TH2-devs | th2-devs@exactprosystems.com | null | null | Apache License 2.0 | null | [] | [] | https://github.com/th2-net/th2-read-db | null | >=3.7 | [] | [] | [] | [
"grpcio-tools<2,>=1.75.1",
"th2-grpc-common<5,>=4.7.5",
"mypy-protobuf<6,>=3.6"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:44:51.117079 | th2_grpc_read_db-0.0.13rc1.tar.gz | 9,225 | d3/27/3594ee131dfd5d31030197bf1db60b198acdced2491c4bf3dbf5c75b3c01/th2_grpc_read_db-0.0.13rc1.tar.gz | source | sdist | null | false | 0fd2ac09a74be585f2ea4c18ef4382de | 9174c2622f13be9cbe39271042a32f69804da433e0c5e845159500510577bc7e | d3273594ee131dfd5d31030197bf1db60b198acdced2491c4bf3dbf5c75b3c01 | null | [] | 166 |
2.4 | wabridge | 0.2.0 | Python client for WABridge - WhatsApp HTTP API Bridge | # wabridge
Python client for [WABridge](https://github.com/marketcalls/wabridge) - send WhatsApp messages from Python via a simple REST API bridge. Supports text, images, video, audio, documents — to individuals, groups, and channels.
## Prerequisites
**Node.js** (>= 20.0.0) must be installed on your system. Download it from [nodejs.org](https://nodejs.org/).
**1. Install WABridge globally:**
```bash
npm install -g wabridge
```
**2. Link WhatsApp (one-time setup):**
```bash
wabridge
```
Scan the QR code with WhatsApp (Settings > Linked Devices > Link a Device). Auth is saved to `~/.wabridge/` — you only need to link once.
**3. Start the API server:**
```bash
wabridge start
```
Or on a custom port:
```bash
wabridge start 8080
```
## Install
```bash
pip install wabridge
```
## Quick Start
```python
from wabridge import WABridge
wa = WABridge()
# Send to yourself
wa.send("Hello!")
# Send to a contact (phone number with country code)
wa.send("919876543210", "Hello!")
# Send to multiple contacts in parallel
wa.send([
("919876543210", "Alert 1"),
("919876543211", "Alert 2"),
("919876543212", "Alert 3"),
])
```
## Media Messages
```python
wa = WABridge()
# Image to self
wa.send(image="https://example.com/photo.jpg", caption="Check this out")
# Image to a contact
wa.send("919876543210", image="https://example.com/photo.jpg", caption="Hello!")
# Video
wa.send("919876543210", video="https://example.com/video.mp4", caption="Watch this")
# Voice note
wa.send("919876543210", audio="https://example.com/voice.ogg")
# Audio file (not voice note)
wa.send("919876543210", audio="https://example.com/song.mp3", ptt=False)
# Document
wa.send("919876543210", document="https://example.com/report.pdf", mimetype="application/pdf", filename="report.pdf")
```
## Groups
```python
wa = WABridge()
# List all groups
groups = wa.groups()
for g in groups:
print(f"{g['subject']} - {g['id']}")
# Send text to group
wa.send_group("120363012345@g.us", "Hello group!")
# Send image to group
wa.send_group("120363012345@g.us", image="https://example.com/photo.jpg", caption="Check this")
```
## Channels
```python
wa = WABridge()
# Send text to channel
wa.send_channel("120363098765@newsletter", "Channel update!")
# Send image to channel
wa.send_channel("120363098765@newsletter", image="https://example.com/photo.jpg")
```
## Configuration
```python
# Default - connects to localhost:3000
wa = WABridge()
# Custom port
wa = WABridge(port=8080)
# Custom host and port (e.g. WABridge running on another machine)
wa = WABridge(host="192.168.1.100", port=4000)
# Custom timeout (default 30 seconds)
wa = WABridge(timeout=60.0)
```
## Async Support
```python
import asyncio
from wabridge import AsyncWABridge
async def main():
async with AsyncWABridge() as wa:
await wa.send("Hello!")
await wa.send("919876543210", "Hello!")
await wa.send("919876543210", image="https://example.com/photo.jpg")
await wa.send_group("120363012345@g.us", "Hello group!")
await wa.send_channel("120363098765@newsletter", "Update!")
asyncio.run(main())
```
## Context Manager
```python
# Sync
with WABridge() as wa:
wa.send("Hello!")
# Async
async with AsyncWABridge() as wa:
await wa.send("Hello!")
```
## API Reference
### `WABridge(host="localhost", port=3000, timeout=30.0)`
#### `wa.send(...)`
| Usage | Description |
|-------|-------------|
| `wa.send("Hello!")` | Text to self |
| `wa.send("919876543210", "Hello!")` | Text to a number |
| `wa.send([("91...", "msg"), ...])` | Text to many in parallel |
| `wa.send(image="https://...")` | Image to self |
| `wa.send("919876543210", image="https://...", caption="Hi")` | Image to a number |
| `wa.send("919876543210", video="https://...")` | Video to a number |
| `wa.send("919876543210", audio="https://...")` | Voice note to a number |
| `wa.send("919876543210", document="https://...", mimetype="application/pdf")` | Document to a number |
#### `wa.send_group(group_id, ...)`
| Usage | Description |
|-------|-------------|
| `wa.send_group("id@g.us", "Hello!")` | Text to group |
| `wa.send_group("id@g.us", image="https://...")` | Image to group |
#### `wa.send_channel(channel_id, ...)`
| Usage | Description |
|-------|-------------|
| `wa.send_channel("id@newsletter", "Update!")` | Text to channel |
| `wa.send_channel("id@newsletter", image="https://...")` | Image to channel |
#### Media Keyword Arguments
| Kwarg | Type | Description |
|-------|------|-------------|
| `image` | str (URL) | Image URL |
| `video` | str (URL) | Video URL |
| `audio` | str (URL) | Audio URL |
| `document` | str (URL) | Document URL |
| `caption` | str | Caption for image/video/document |
| `mimetype` | str | MIME type (required for document) |
| `filename` | str | File name for document |
| `ptt` | bool | True for voice note (default), False for audio file |
Phone numbers must include the country code (e.g. `91` for India, `1` for US) followed by the number — digits only, no `+` or spaces.
#### Utility Methods
| Method | Description |
|--------|-------------|
| `wa.status()` | Returns `{"status": "open", "user": "91...@s.whatsapp.net"}` |
| `wa.is_connected()` | Returns `True` if WhatsApp is connected |
| `wa.groups()` | Returns list of groups with `id`, `subject`, `size`, `desc` |
| `wa.close()` | Close the HTTP client |
### `AsyncWABridge(host="localhost", port=3000, timeout=30.0)`
Same methods as `WABridge`, but all are `async`. Supports `async with` context manager.
### Exceptions
| Exception | When |
|-----------|------|
| `WABridgeError` | Base exception for all errors |
| `ConnectionError` | WhatsApp is not connected (server returned 500) |
| `ValidationError` | Invalid phone number or missing fields (server returned 400) |
```python
from wabridge import WABridge, ConnectionError, ValidationError
wa = WABridge()
try:
wa.send("919876543210", "Hello!")
except ConnectionError:
print("WhatsApp is not connected. Run: wabridge start")
except ValidationError as e:
print(f"Bad request: {e.message}")
```
## Use Cases
**Trading alerts:**
```python
wa = WABridge()
wa.send("BUY NIFTY 24000 CE @ 150")
```
**Send chart image:**
```python
wa = WABridge()
wa.send("919876543210", image="https://charts.example.com/nifty.png", caption="NIFTY Chart")
```
**Group notification:**
```python
wa = WABridge()
wa.send_group("120363012345@g.us", "Market closed. P&L: +5000")
```
**Server monitoring:**
```python
wa = WABridge()
if cpu_usage > 90:
wa.send("919876543210", f"CPU at {cpu_usage}%")
```
**Broadcast to multiple numbers:**
```python
wa = WABridge()
numbers = ["919876543210", "919876543211", "919876543212"]
wa.send([(n, "Server maintenance at 10 PM") for n in numbers])
```
## How It Works
This package is a thin Python wrapper over the [WABridge](https://github.com/marketcalls/wabridge) HTTP API. WABridge runs as a local Node.js server that connects to WhatsApp via the Baileys library. This Python client sends HTTP requests to that server using [httpx](https://www.python-httpx.org/).
```
Python App --> wabridge (Python) --> WABridge Server (Node.js) --> WhatsApp
```
## Requirements
- [Node.js](https://nodejs.org/) >= 20.0.0 (required for the WABridge server)
- WABridge installed globally (`npm install -g wabridge`) and running (`wabridge start`)
- Python >= 3.8
## License
[MIT](LICENSE)
| text/markdown | WABridge | null | null | null | null | alerts, messaging, wabridge, whatsapp | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pyt... | [] | null | null | >=3.8 | [] | [] | [] | [
"httpx>=0.24.0"
] | [] | [] | [] | [
"Homepage, https://github.com/marketcalls/wabridge",
"Repository, https://github.com/marketcalls/wabridge"
] | twine/6.2.0 CPython/3.13.0 | 2026-02-18T10:44:50.496430 | wabridge-0.2.0.tar.gz | 6,717 | e4/79/a3323c533134c41045dabdf04780e2902cb40697d7d4d6dda0dc1057a500/wabridge-0.2.0.tar.gz | source | sdist | null | false | 560b6e870e170b29a40c2136f2d661f2 | 78323f448fac24953ae16608b3cb10ee4b58414d1f8647bddb050f417179853e | e479a3323c533134c41045dabdf04780e2902cb40697d7d4d6dda0dc1057a500 | MIT | [
"LICENSE"
] | 250 |
2.1 | queryandprocessdatautility | 0.0.84 | Use the main database to execute both the free-hand SQL and the calculation column SQL, instead of using the local database for function-type SQL. | Use the main database to execute both the free-hand SQL and the calculation column SQL, instead of using the local database for function-type SQL.
| null | Proteus Technology PVT. LTD. | <apps@baseinformation.com> | null | null | null | python, first package | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Education",
"Programming Language :: Python :: 2",
"Programming Language :: Python :: 3",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows"
] | [] | null | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/5.1.1 CPython/3.11.7 | 2026-02-18T10:43:15.191659 | queryandprocessdatautility-0.0.84-py3-none-any.whl | 27,879 | 0c/e6/7111b8ab34e1cd2785c52d5d0a8945bb5275d66789dd5a7dff4b0cded784/queryandprocessdatautility-0.0.84-py3-none-any.whl | py3 | bdist_wheel | null | false | 3b1b44ddf4e56a791954810484842b84 | 32c13c0e9c1a24c1df2bf79adc5e0ecdf6214a6ecc00a2cfc9f2d3461bb39870 | 0ce67111b8ab34e1cd2785c52d5d0a8945bb5275d66789dd5a7dff4b0cded784 | null | [] | 121 |
2.4 | pikachu-chem | 1.1.5 | PIKACHU: Python-based Informatics Kit for Analysing CHemical Units | <img src="logo.png" alt="thumbnail" width="600px" />
# INSTALLATION
Python-based Informatics Kit for the Analysis of Chemical Units
Step 1: Make a conda environment:
```bash
conda create -n pikachu python>=3.9
conda activate pikachu
```
Step 2: install pip:
```bash
conda install pip
```
Step 3: Install PIKAChU:
```bash
pip install pikachu-chem
```
# GETTING STARTED
Step 1: Open python or initiate an empty .py file.
Step 2: Import required modules to visualise your first structure:
```Python
from pikachu.general import draw_smiles
```
Step 3: Load your SMILES string of interest and draw it!
```Python
smiles = draw_smiles("CCCCCCCCCC(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)N[C@H]3[C@H](OC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H](NC(=O)CNC(=O)[C@@H](NC(=O)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](NC(=O)CNC3=O)CCCN)CC(=O)O)C)CC(=O)O)CO)[C@H](C)CC(=O)O)CC(=O)C4=CC=CC=C4N)C")
```
Step 4: Play around with the other functions in pikachu.general. For guidance, refer to documentation in the wiki and function descriptors.
# Citation
```
Terlouw, Barbara R., Sophie PJM Vromans, and Marnix H. Medema. "PIKAChU: a Python-based informatics kit for analysing chemical units." Journal of Cheminformatics 14.1 (2022): 34.
```
| text/markdown | null | Barbara Terlouw <barbara.terlouw@wur.nl> | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"matplotlib"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.9 | 2026-02-18T10:41:52.630539 | pikachu_chem-1.1.5.tar.gz | 107,371 | 52/2e/d193c7b027f81a13d78855d1acb574a0dff538338904b2822243ea50545d/pikachu_chem-1.1.5.tar.gz | source | sdist | null | false | d089ae902df93f8969d785d56cbfed92 | cc091a77fc76f43283f1f62d2e679c6a910ce4defa6c441afc685a28e3167d34 | 522ed193c7b027f81a13d78855d1acb574a0dff538338904b2822243ea50545d | null | [
"LICENSE.txt"
] | 290 |
2.4 | fairmd-lipids | 1.4.0 | FAIRMD Lipids project (formerly NMRlipids) contains the core functionality for managing and accessing the Database. | # FAIRMD Lipids
[](https://github.com/NMRLipids/FAIRMD_lipids/actions?query=branch%3Amain)
[](https://nmrlipids.github.io/FAIRMD_lipids/)
[](https://nmrlipids.github.io/FAIRMD_lipids/latest/index.html)
[](https://codecov.io/gh/NMRLipids/FAIRMD_lipids)
This is the FAIRMD Lipids — an API package for the community-driven catalogue
FAIRMD Lipid Databank (formerly NMRlipids Databank) containing atomistic MD
simulations of biologically relevant lipid membranes emerging from the [NMRlipids Open
Collaboration](http://nmrlipids.blogspot.com/2021/03/second-online-meeting-on-nmrlipids.html).
# Installation
The code has been tested in Linux and MacOS environment with python 3.10 and 3.13.
Recent [Gromacs](https://manual.gromacs.org/current/install-guide/index.html) version
should be available in the system. All dependecies are listed in
[pyproject.toml](pyproject.toml).
We recommend installing python libraries into an environment, for example, using conda:
```bash
conda create --name fairmd-lipids python==3.10 -c conda-forge
conda activate fairmd-lipids
```
Install *fairmd-lipids* package from repo:
```bash
pip install git+https://github.com/NMRLipids/FAIRMD_lipids.git
```
or from pypi:
```bash
pip install fairmd-lipids
```
Note that the data is stored as a separated repository and should be loaded after
cloning. Default data storage is
[BilayerData](https://github.com/NMRLipids/BilayerData). You **MUST** specify
`FMDL_DATA_PATH` before start working. The easiest way to start is to use
`fmdl_initialize_data` script provided with the package:
```bash
fmdl_initialize_data stable
source databank_env.rc
```
Then you can work with the standalone scripts as well as use `fairmd-lipids` package in
your python code.
# Documentation
The FAIRMD Lipids project documentation is available in
[here](https://nmrlipids.github.io/FAIRMD_lipids/latest/). More information and example
applications are available from the [FAIRMD Lipids
manuscript](https://doi.org/10.1038/s41467-024-45189-z).
The `fairmd-lipids` python module provides programmatic access to all simulation data in
the FAIRMD Lipids. It allows to request data to construct various datasets on the base
of experimental and simulation data from the database that allow one to learn various
models about lipid bilayer properties. It also allows to design and effectively run
automated analysis across all the simulations in the database.
## How to use
A [jupyter template
notebook](https://github.com/NMRLipids/databank-template/blob/main/scripts/template.ipynb)
can be used to get started with the analyses utilizing the FAIRMD Lipids.
Connection of [Universal molecule and atom naming
conventions](https://nmrlipids.github.io/FAIRMD_lipids/latest/schemas/moleculesAndMapping.html)
with simulation specific names delivered by mapping files can be used to perform
automatic analyses over large sets of simulations. The results for large analyses can be
stored using the same structure as used for `README.yaml` files as done, for example,
for [water
permeation](https://github.com/NMRLipids/FAIRMD_lipids/tree/main/Data/MD-PERMEATION)
and lipid
[flip-flop](https://github.com/NMRLipids/DataBankManuscript/tree/main/Data/Flipflops)
rates in the [repository related to the FAIRMD Lipids
manuscript](https://github.com/NMRLipids/DataBankManuscript).
# Web UI
[FAIRMD Lipids-webUI](https://databank.nmrlipids.fi/) provides an easy access to the
FAIRMD Lipids content. Simulations can be searched based on their molecular composition,
force field, temperature, membrane properties, and quality; the search results are
ranked based on the simulation quality as evaluated against experimental data when
available. Web-UI provides basic graphical reports for the computed properties as well
as graphical comparison between simulation and experimental data.
The Web-UI is being developed in the repository
[BilayerGUI_laravel](https://github.com/NMRlipids/BilayerGUI_laravel).
# Upload Portal
The [FAIRMD Upload-Portal](https://upload-portal.nmrlipids.fi) enables researchers to easily contribute new simulation metadata to the [BilayerData Repository](https://github.com/NMRLipids/BilayerData). Users can upload simulation metadata, which is automatically validated and processed through workflows within the data repository.
# Contribution
The project is open for contributions!
Please consult [CONTRIBUTION.md](./CONTRIBUTION.md) and [Data Contribution](https://nmrlipids.github.io/FAIRMD_lipids/stable/dbcontribute.html) for further information.
Do not hesitate contacting us via [databank@nmrlipids.fi](email:databank@nmrlipids.fi) if
you have any questions or inquiries!
| text/markdown | null | NMRlipids Open Collaboration <databank@nmrlipids.fi> | null | null | null | Science, Molecular Dynamics, Membranes | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Science/Research",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Bio-Informatics",
... | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"buildh>=1.6.1",
"MDAnalysis<2.10,>=2.7.0",
"maicos<0.12,>=0.11.2",
"numpy>=2.0",
"pandas>=2.0.0",
"PyYAML>=6.0.0",
"tqdm>=4.5.0",
"periodictable>=1.5.0",
"Deprecated",
"requests",
"scipy",
"jsonschema",
"rdkit>=2023; extra == \"rdkit\"",
"joblib; extra == \"parallel\""
] | [] | [] | [] | [
"homepage, https://FAIRMD_lipids.nmrlipids.fi",
"documentation, https://nmrlipids.github.io/FAIRMD_lipids/latest/",
"repository, https://github.com/NMRLipids/FAIRMD_lipids",
"issues, https://github.com/NMRLipids/FAIRMD_lipids/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:40:27.821478 | fairmd_lipids-1.4.0.tar.gz | 15,073,227 | e8/06/55a2430b2acb47ed8a51d398944a7793f5d0cffcfd002e39b588c3a4dff8/fairmd_lipids-1.4.0.tar.gz | source | sdist | null | false | ee6d78866a14bc75b9db55330e117d24 | 4fbf2ceffe4d6295275b5dfdd3050c08bf85d04bb74feeaa69737eaf045d6ef8 | e80655a2430b2acb47ed8a51d398944a7793f5d0cffcfd002e39b588c3a4dff8 | GPL-3.0-or-later | [
"LICENSE",
"AUTHORS.md"
] | 271 |
2.4 | xync-schema | 0.0.95 | XyncNet project database model schema | ## INSTALL
```bash
# Create python virtual environment
python3 -m venv venv
# Activate this environment
source venv/bin/activate
# Install dependencies
pip install -r requirements.dev.txt
# Create pg db
createdb --U username -W dbname
## set password for db user
# Copy .env file from sample template
cp .env.sample .env
## set your pg creds in .env file
```
## TEST
```bash
pytest
```
### pre-commit
You can done `commit` only after `pytest` will done success.
Pre-commit script stored in `.git/hooks/pre-commit` file; current script is:
```shell
#!/bin/sh
pytest
```
### Relations
```mermaid
classDiagram
direction BT
class Agent {
timestamp(0) with time zone created_at
timestamp(0) with time zone updated_at
integer exid
jsonb auth
smallint ex_id
bigint user_id
integer id
}
class Asset {
smallint type_ /* spot: 1\nearn: 2\nfound: 3 */
double precision free
double precision freeze
double precision lock
double precision target
integer agent_id
smallint coin_id
integer id
}
class Coin {
varchar(15) ticker
double precision rate
boolean is_fiat
smallint id
}
class CoinEx {
varchar(31) exid
boolean p2p
smallint coin_id
smallint ex_id
integer id
}
class Cur {
varchar(3) ticker
double precision rate
smallint id
}
class CurEx {
varchar(31) exid
boolean p2p
smallint cur_id
smallint ex_id
integer id
}
class Ex {
varchar(31) name
varchar(63) host /* With no protocol 'https://' */
varchar(63) host_p2p /* With no protocol 'https://' */
varchar(63) url_login /* With no protocol 'https://' */
smallint type_ /* p2p: 1\ncex: 2\nmain: 3\ndex: 4\nfutures: 8 */
varchar(511) logo
smallint id
}
class Fiat {
varchar(127) detail
varchar(127) name
double precision amount
double precision target
integer pmcur_id
bigint user_id
integer id
}
class FiatEx {
integer exid
smallint ex_id
integer fiat_id
integer id
}
class Limit {
integer amount
integer unit
integer level
boolean income
bigint added_by_id
integer pmcur_id
integer id
}
class Pm {
varchar(63) name
smallint rank
smallint type_ /* bank: 0\nweb_wallet: 1\ncash: 2\ngift_card: 3\ncredit_card: 4 */
varchar(127) logo
boolean multiAllow
integer id
}
class PmCur {
smallint cur_id
integer pm_id
integer id
}
class PmCurEx {
boolean blocked
smallint ex_id
integer pmcur_id
integer id
}
class PmEx {
varchar(31) exid
smallint ex_id
integer pm_id
integer id
}
class User {
timestamp(0) with time zone created_at
timestamp(0) with time zone updated_at
smallint role /* READER: 4\nWRITER: 2\nMANAGER: 6\nADMIN: 7 */
smallint status /* CREATOR: 5\nADMINISTRATOR: 4\nMEMBER: 3\nRESTRICTED: 2\nLEFT:... */
varchar(95) username
bigint ref_id
bigint id
}
Agent --> Ex : ex_id-id
Agent --> User : user_id-id
Asset --> Agent : agent_id-id
Asset --> Coin : coin_id-id
CoinEx --> Coin : coin_id-id
CoinEx --> Ex : ex_id-id
CurEx --> Cur : cur_id-id
CurEx --> Ex : ex_id-id
Fiat --> PmCur : pmcur_id-id
Fiat --> User : user_id-id
FiatEx --> Ex : ex_id-id
FiatEx --> Fiat : fiat_id-id
Limit --> PmCur : pmcur_id-id
Limit --> User : added_by_id-id
PmCur --> Cur : cur_id-id
PmCur --> Pm : pm_id-id
PmCurEx --> Ex : ex_id-id
PmCurEx --> PmCur : pmcur_id-id
PmEx --> Ex : ex_id-id
PmEx --> Pm : pm_id-id
User --> User : ref_id-id
```
| text/markdown | null | Mike Artemiev <mixartemev@gmail.com> | null | null | LicenseRef-EULA | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"aerich",
"xn-auth",
"pillow",
"pypng",
"build; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\"",
"python-dotenv; extra == \"dev\"",
"setuptools-scm[toml]; extra == \"dev\"",
"twine; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://gitlab.com/xync/back/schema",
"Repository, https://gitlab.com/xync/back/schema"
] | twine/6.2.0 CPython/3.13.7 | 2026-02-18T10:39:18.994309 | xync_schema-0.0.95.tar.gz | 32,551 | da/2b/806da5293ad3c2410dc66ef93418b42566726cf468628ced7637031c10e2/xync_schema-0.0.95.tar.gz | source | sdist | null | false | 550a5c2eb5a8365e09ac4f901b19f398 | 24046ed6bf2591680f6cb5f2156f7ec165dcd76ce34d6d0426dad593524e41c7 | da2b806da5293ad3c2410dc66ef93418b42566726cf468628ced7637031c10e2 | null | [] | 265 |
2.1 | bridgecrew | 3.2.504 | Infrastructure as code static analysis | # DEPRECATED: This project is no longer supported and will be archived end of 2023. Please use [checkov](https://github.com/bridgecrewio/checkov) instead.
# Bridgecrew Python Package
[](https://github.com/bridgecrewio/bridgecrew-py/actions?query=workflow%3Arelease)
[](https://pypi.org/project/checkov/)
Wraps checkov with a bridgecrew cli (does exactly the same) | text/markdown | bridgecrew | meet@bridgecrew.io | null | null | Apache License 2.0 | null | [
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming... | [] | https://github.com/bridgecrewio/bridgecrew | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/4.0.2 CPython/3.11.14 | 2026-02-18T10:38:40.074328 | bridgecrew-3.2.504.tar.gz | 2,870 | a0/97/231cbe37959228b971c84288308407686f4fe54ec7e1a4e1090e8d908eed/bridgecrew-3.2.504.tar.gz | source | sdist | null | false | 2d8168128ae82da8ba981359c91ddcae | cd37382767a9965e8cec0f5d082c4e372cfb1f9a228198eb8e790c7930c88fab | a097231cbe37959228b971c84288308407686f4fe54ec7e1a4e1090e8d908eed | null | [] | 646 |
2.4 | PraisonAI | 4.5.15 | PraisonAI is an AI Agents Framework with Self Reflection. PraisonAI application combines PraisonAI Agents, AutoGen, and CrewAI into a low-code solution for building and managing multi-agent LLM systems, focusing on simplicity, customisation, and efficient human-agent collaboration. | <p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="docs/logo/dark.png" />
<source media="(prefers-color-scheme: light)" srcset="docs/logo/light.png" />
<img alt="PraisonAI Logo" src="docs/logo/light.png" />
</picture>
</p>
<!-- mcp-name: io.github.MervinPraison/praisonai -->
<p align="center">
<a href="https://github.com/MervinPraison/PraisonAI"><img src="https://static.pepy.tech/badge/PraisonAI" alt="Total Downloads" /></a>
<a href="https://github.com/MervinPraison/PraisonAI"><img src="https://img.shields.io/github/v/release/MervinPraison/PraisonAI" alt="Latest Stable Version" /></a>
<a href="https://github.com/MervinPraison/PraisonAI"><img src="https://img.shields.io/badge/License-MIT-yellow.svg" alt="License" /></a>
<a href="https://registry.modelcontextprotocol.io/servers/io.github.MervinPraison/praisonai"><img src="https://img.shields.io/badge/MCP-Registry-blue" alt="MCP Registry" /></a>
</p>
<div align="center">
# Praison AI
<a href="https://trendshift.io/repositories/9130" target="_blank"><img src="https://trendshift.io/api/badge/repositories/9130" alt="MervinPraison%2FPraisonAI | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
</div>
PraisonAI is a production-ready Multi-AI Agents framework with self-reflection, designed to create AI Agents to automate and solve problems ranging from simple tasks to complex challenges. It provides a low-code solution to streamline the building and management of multi-agent LLM systems, emphasising simplicity, customisation, and effective human-agent collaboration.
<div align="center">
<a href="https://docs.praison.ai">
<p align="center">
<img src="https://img.shields.io/badge/📚_Documentation-Visit_docs.praison.ai-blue?style=for-the-badge&logo=bookstack&logoColor=white" alt="Documentation" />
</p>
</a>
</div>
---
> **Quick Paths:**
> - 🆕 **New here?** → [Quick Start](#-quick-start) *(1 minute to first agent)*
> - 📦 **Installing?** → [Installation](#-installation)
> - 🐍 **Python SDK?** → [Python Examples](#-using-python-code)
> - 🎯 **CLI user?** → [CLI Quick Reference](#cli-quick-reference)
> - 🔧 **Need config?** → [Configuration](#-configuration--integration)
> - 🤝 **Contributing?** → [Development](#-development)
---
## 📑 Table of Contents
<details open>
<summary><strong>Getting Started</strong></summary>
- [🚀 Quick Start](#-quick-start)
- [📦 Installation](#-installation)
- [⚡ Performance](#-performance)
</details>
<details>
<summary><strong>Python SDK</strong></summary>
- [📘 Python Examples](#-using-python-code)
- [1. Single Agent](#1-single-agent) | [2. Multi Agents](#2-multi-agents) | [3. Planning Mode](#3-agent-with-planning-mode)
- [4. Deep Research](#4-deep-research-agent) | [5. Query Rewriter](#5-query-rewriter-agent) | [6. Agent Memory](#6-agent-memory-zero-dependencies)
- [7. Rules & Instructions](#7-rules--instructions) | [8. Auto-Generated Memories](#8-auto-generated-memories) | [9. Agentic Workflows](#9-agentic-workflows)
- [10. Hooks](#10-hooks) | [11. Shadow Git Checkpoints](#11-shadow-git-checkpoints) | [12. Background Tasks](#12-background-tasks)
- [13. Policy Engine](#13-policy-engine) | [14. Thinking Budgets](#14-thinking-budgets) | [15. Output Styles](#15-output-styles)
- [16. Context Compaction](#16-context-compaction) | [17. Field Names Reference](#17-field-names-reference-a-i-g-s) | [18. Extended agents.yaml](#18-extended-agentsyaml-with-workflow-patterns)
- [19. MCP Protocol](#19-mcp-model-context-protocol) | [20. A2A Protocol](#20-a2a-agent2agent-protocol)
- [🛠️ Custom Tools](#️-custom-tools)
</details>
<details>
<summary><strong>JavaScript SDK</strong></summary>
- [💻 JavaScript Examples](#-using-javascript-code)
</details>
<details>
<summary><strong>CLI Reference</strong></summary>
- [🎯 CLI Overview](#-cli--no-code-interface) | [CLI Quick Reference](#cli-quick-reference)
- [Auto Mode](#auto-mode) | [Interactive Mode](#interactive-mode-cli) | [Deep Research CLI](#deep-research-cli) | [Planning Mode CLI](#planning-mode-cli)
- [Memory CLI](#memory-cli) | [Workflow CLI](#workflow-cli) | [Knowledge CLI](#knowledge-cli) | [Session CLI](#session-cli)
- [Tools CLI](#tools-cli) | [MCP Config CLI](#mcp-config-cli) | [External Agents CLI](#external-agents-cli) | [CLI Features Summary](#cli-features)
</details>
<details>
<summary><strong>Configuration & Features</strong></summary>
- [✨ Key Features](#-key-features) | [🌐 Supported Providers](#-supported-providers)
- [🔧 Configuration & Integration](#-configuration--integration) | [Ollama](#ollama-integration) | [Groq](#groq-integration) | [100+ Models](#100-models-support)
- [📋 Agents Playbook](#-agents-playbook)
- [🔬 Advanced Features](#-advanced-features)
</details>
<details>
<summary><strong>Architecture & Patterns</strong></summary>
- [📊 Process Types & Patterns](#-process-types--patterns)
- [Sequential](#sequential-process) | [Hierarchical](#hierarchical-process) | [Workflow](#workflow-process) | [Agentic Patterns](#agentic-patterns)
</details>
<details>
<summary><strong>Data & Persistence</strong></summary>
- [💾 Persistence (Databases)](#-persistence-databases)
- [📚 Knowledge & Retrieval (RAG)](#-knowledge--retrieval-rag)
- [🔧 Tools Table](#-tools-table)
</details>
<details>
<summary><strong>Learning & Community</strong></summary>
- [🎓 Video Tutorials](#-video-tutorials) | [⭐ Star History](#-star-history)
- [👥 Contributing](#-contributing) | [🔧 Development](#-development) | [❓ FAQ & Troubleshooting](#-faq--troubleshooting)
</details>
---
## ⚡ Performance
PraisonAI Agents is the **fastest AI agent framework** for agent instantiation.
| Framework | Avg Time (μs) | Relative |
|-----------|---------------|----------|
| **PraisonAI** | **3.77** | **1.00x (fastest)** |
| OpenAI Agents SDK | 5.26 | 1.39x |
| Agno | 5.64 | 1.49x |
| PraisonAI (LiteLLM) | 7.56 | 2.00x |
| PydanticAI | 226.94 | 60.16x |
| LangGraph | 4,558.71 | 1,209x |
<details>
<summary>Run benchmarks yourself</summary>
```bash
cd praisonai-agents
python benchmarks/simple_benchmark.py
```
</details>
---
## 🚀 Quick Start
Get started with PraisonAI in under 1 minute:
```bash
# Install
pip install praisonaiagents
# Set API key
export OPENAI_API_KEY=your_key_here
# Create a simple agent
python -c "from praisonaiagents import Agent; Agent(instructions='You are a helpful AI assistant').start('Write a haiku about AI')"
```
> **Next Steps:** [Single Agent Example](#1-single-agent) | [Multi Agents](#2-multi-agents) | [CLI Auto Mode](#auto-mode)
---
## 📦 Installation
### Python SDK
Lightweight package dedicated for coding:
```bash
pip install praisonaiagents
```
For the full framework with CLI support:
```bash
pip install praisonai
```
### JavaScript SDK
```bash
npm install praisonai
```
### Environment Variables
| Variable | Required | Description |
|----------|----------|-------------|
| `OPENAI_API_KEY` | Yes* | OpenAI API key |
| `ANTHROPIC_API_KEY` | No | Anthropic Claude API key |
| `GOOGLE_API_KEY` | No | Google Gemini API key |
| `GROQ_API_KEY` | No | Groq API key |
| `OPENAI_BASE_URL` | No | Custom API endpoint (for Ollama, Groq, etc.) |
> *At least one LLM provider API key is required.
```bash
# Set your API key
export OPENAI_API_KEY=your_key_here
# For Ollama (local models)
export OPENAI_BASE_URL=http://localhost:11434/v1
# For Groq
export OPENAI_API_KEY=your_groq_key
export OPENAI_BASE_URL=https://api.groq.com/openai/v1
```
---
## ✨ Key Features
<details open>
<summary><strong>🤖 Core Agents</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Single Agent | [Example](examples/python/agents/single-agent.py) | [📖](https://docs.praison.ai/agents/single) |
| Multi Agents | [Example](examples/python/general/mini_agents_example.py) | [📖](https://docs.praison.ai/concepts/agents) |
| Auto Agents | [Example](examples/python/general/auto_agents_example.py) | [📖](https://docs.praison.ai/features/autoagents) |
| Self Reflection AI Agents | [Example](examples/python/concepts/self-reflection-details.py) | [📖](https://docs.praison.ai/features/selfreflection) |
| Reasoning AI Agents | [Example](examples/python/concepts/reasoning-extraction.py) | [📖](https://docs.praison.ai/features/reasoning) |
| Multi Modal AI Agents | [Example](examples/python/general/multimodal.py) | [📖](https://docs.praison.ai/features/multimodal) |
</details>
<details>
<summary><strong>🔄 Workflows</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Simple Workflow | [Example](examples/python/workflows/simple_workflow.py) | [📖](https://docs.praison.ai/features/workflows) |
| Workflow with Agents | [Example](examples/python/workflows/workflow_with_agents.py) | [📖](https://docs.praison.ai/features/workflows) |
| Agentic Routing (`route()`) | [Example](examples/python/workflows/workflow_routing.py) | [📖](https://docs.praison.ai/features/routing) |
| Parallel Execution (`parallel()`) | [Example](examples/python/workflows/workflow_parallel.py) | [📖](https://docs.praison.ai/features/parallelisation) |
| Loop over List/CSV (`loop()`) | [Example](examples/python/workflows/workflow_loop_csv.py) | [📖](https://docs.praison.ai/features/repetitive) |
| Evaluator-Optimizer (`repeat()`) | [Example](examples/python/workflows/workflow_repeat.py) | [📖](https://docs.praison.ai/features/evaluator-optimiser) |
| Conditional Steps | [Example](examples/python/workflows/workflow_conditional.py) | [📖](https://docs.praison.ai/features/workflows) |
| Workflow Branching | [Example](examples/python/workflows/workflow_branching.py) | [📖](https://docs.praison.ai/features/workflows) |
| Workflow Early Stop | [Example](examples/python/workflows/workflow_early_stop.py) | [📖](https://docs.praison.ai/features/workflows) |
| Workflow Checkpoints | [Example](examples/python/workflows/workflow_checkpoints.py) | [📖](https://docs.praison.ai/features/workflows) |
</details>
<details>
<summary><strong>💻 Code & Development</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Code Interpreter Agents | [Example](examples/python/agents/code-agent.py) | [📖](https://docs.praison.ai/features/codeagent) |
| AI Code Editing Tools | [Example](examples/python/code/code_editing_example.py) | [📖](https://docs.praison.ai/code/editing) |
| External Agents (All) | [Example](examples/python/code/external_agents_example.py) | [📖](https://docs.praison.ai/code/external-agents) |
| Claude Code CLI | [Example](examples/python/code/claude_code_example.py) | [📖](https://docs.praison.ai/code/claude-code) |
| Gemini CLI | [Example](examples/python/code/gemini_cli_example.py) | [📖](https://docs.praison.ai/code/gemini-cli) |
| Codex CLI | [Example](examples/python/code/codex_cli_example.py) | [📖](https://docs.praison.ai/code/codex-cli) |
| Cursor CLI | [Example](examples/python/code/cursor_cli_example.py) | [📖](https://docs.praison.ai/code/cursor-cli) |
</details>
<details>
<summary><strong>🧠 Memory & Knowledge</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Memory (Short & Long Term) | [Example](examples/python/general/memory_example.py) | [📖](https://docs.praison.ai/concepts/memory) |
| File-Based Memory | [Example](examples/python/general/memory_example.py) | [📖](https://docs.praison.ai/concepts/memory) |
| Claude Memory Tool | [Example](#claude-memory-tool-cli) | [📖](https://docs.praison.ai/features/claude-memory-tool) |
| Add Custom Knowledge | [Example](examples/python/concepts/knowledge-agents.py) | [📖](https://docs.praison.ai/features/knowledge) |
| RAG Agents | [Example](examples/python/concepts/rag-agents.py) | [📖](https://docs.praison.ai/features/rag) |
| Chat with PDF Agents | [Example](examples/python/concepts/chat-with-pdf.py) | [📖](https://docs.praison.ai/features/chat-with-pdf) |
| Data Readers (PDF, DOCX, etc.) | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-readers-api) |
| Vector Store Selection | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-vector-store-api) |
| Retrieval Strategies | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-retrieval-api) |
| Rerankers | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-reranker-api) |
| Index Types (Vector/Keyword/Hybrid) | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-index-api) |
| Query Engines (Sub-Question, etc.) | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-query-engine-api) |
</details>
<details>
<summary><strong>🔬 Research & Intelligence</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Deep Research Agents | [Example](examples/python/agents/research-agent.py) | [📖](https://docs.praison.ai/agents/deep-research) |
| Query Rewriter Agent | [Example](#5-query-rewriter-agent) | [📖](https://docs.praison.ai/agents/query-rewriter) |
| Native Web Search | [Example](examples/python/agents/websearch-agent.py) | [📖](https://docs.praison.ai/agents/websearch) |
| Built-in Search Tools | [Example](examples/python/agents/websearch-agent.py) | [📖](https://docs.praison.ai/tools/tavily) |
| Unified Web Search | [Example](src/praisonai-agents/examples/web_search_example.py) | [📖](https://docs.praison.ai/tools/web-search) |
| Web Fetch (Anthropic) | [Example](#web-search-web-fetch--prompt-caching) | [📖](https://docs.praison.ai/features/model-capabilities) |
</details>
<details>
<summary><strong>📋 Planning & Execution</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Planning Mode | [Example](examples/python/agents/planning-agent.py) | [📖](https://docs.praison.ai/features/planning-mode) |
| Planning Tools | [Example](#3-agent-with-planning-mode) | [📖](https://docs.praison.ai/features/planning-mode) |
| Planning Reasoning | [Example](#3-agent-with-planning-mode) | [📖](https://docs.praison.ai/features/planning-mode) |
| Prompt Chaining | [Example](examples/python/general/prompt_chaining.py) | [📖](https://docs.praison.ai/features/promptchaining) |
| Evaluator Optimiser | [Example](examples/python/general/evaluator-optimiser.py) | [📖](https://docs.praison.ai/features/evaluator-optimiser) |
| Orchestrator Workers | [Example](examples/python/general/orchestrator-workers.py) | [📖](https://docs.praison.ai/features/orchestrator-worker) |
</details>
<details>
<summary><strong>👥 Specialized Agents</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Data Analyst Agent | [Example](examples/python/agents/data-analyst-agent.py) | [📖](https://docs.praison.ai/agents/data-analyst) |
| Finance Agent | [Example](examples/python/agents/finance-agent.py) | [📖](https://docs.praison.ai/agents/finance) |
| Shopping Agent | [Example](examples/python/agents/shopping-agent.py) | [📖](https://docs.praison.ai/agents/shopping) |
| Recommendation Agent | [Example](examples/python/agents/recommendation-agent.py) | [📖](https://docs.praison.ai/agents/recommendation) |
| Wikipedia Agent | [Example](examples/python/agents/wikipedia-agent.py) | [📖](https://docs.praison.ai/agents/wikipedia) |
| Programming Agent | [Example](examples/python/agents/programming-agent.py) | [📖](https://docs.praison.ai/agents/programming) |
| Math Agents | [Example](examples/python/agents/math-agent.py) | [📖](https://docs.praison.ai/features/mathagent) |
| Markdown Agent | [Example](examples/python/agents/markdown-agent.py) | [📖](https://docs.praison.ai/agents/markdown) |
| Prompt Expander Agent | [Example](#prompt-expansion) | [📖](https://docs.praison.ai/agents/prompt-expander) |
</details>
<details>
<summary><strong>🎨 Media & Multimodal</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Image Generation Agent | [Example](examples/python/image/image-agent.py) | [📖](https://docs.praison.ai/features/image-generation) |
| Image to Text Agent | [Example](examples/python/agents/image-to-text-agent.py) | [📖](https://docs.praison.ai/agents/image-to-text) |
| Video Agent | [Example](examples/python/agents/video-agent.py) | [📖](https://docs.praison.ai/agents/video) |
| Camera Integration | [Example](examples/python/camera/) | [📖](https://docs.praison.ai/features/camera-integration) |
</details>
<details>
<summary><strong>🔌 Protocols & Integration</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| MCP Transports | [Example](examples/python/mcp/mcp-transports-overview.py) | [📖](https://docs.praison.ai/mcp/transports) |
| WebSocket MCP | [Example](examples/python/mcp/websocket-mcp.py) | [📖](https://docs.praison.ai/mcp/sse-transport) |
| MCP Security | [Example](examples/python/mcp/mcp-security.py) | [📖](https://docs.praison.ai/mcp/transports) |
| MCP Resumability | [Example](examples/python/mcp/mcp-resumability.py) | [📖](https://docs.praison.ai/mcp/sse-transport) |
| MCP Config Management | [Example](#mcp-config-cli) | [📖](https://docs.praison.ai/docs/cli/mcp) |
| LangChain Integrated Agents | [Example](examples/python/general/langchain_example.py) | [📖](https://docs.praison.ai/features/langchain) |
</details>
<details>
<summary><strong>🛡️ Safety & Control</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Guardrails | [Example](examples/python/guardrails/comprehensive-guardrails-example.py) | [📖](https://docs.praison.ai/features/guardrails) |
| Human Approval | [Example](examples/python/general/human_approval_example.py) | [📖](https://docs.praison.ai/features/approval) |
| Rules & Instructions | [Example](#7-rules--instructions) | [📖](https://docs.praison.ai/features/rules) |
</details>
<details>
<summary><strong>⚙️ Advanced Features</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Async & Parallel Processing | [Example](examples/python/general/async_example.py) | [📖](https://docs.praison.ai/features/async) |
| Parallelisation | [Example](examples/python/general/parallelisation.py) | [📖](https://docs.praison.ai/features/parallelisation) |
| Repetitive Agents | [Example](examples/python/concepts/repetitive-agents.py) | [📖](https://docs.praison.ai/features/repetitive) |
| Agent Handoffs | [Example](examples/python/handoff/handoff_basic.py) | [📖](https://docs.praison.ai/features/handoffs) |
| Stateful Agents | [Example](examples/python/stateful/workflow-state-example.py) | [📖](https://docs.praison.ai/features/stateful-agents) |
| Autonomous Workflow | [Example](examples/python/general/autonomous-agent.py) | [📖](https://docs.praison.ai/features/autonomous-workflow) |
| Structured Output Agents | [Example](examples/python/general/structured_agents_example.py) | [📖](https://docs.praison.ai/features/structured) |
| Model Router | [Example](examples/python/agents/router-agent-cost-optimization.py) | [📖](https://docs.praison.ai/features/model-router) |
| Prompt Caching | [Example](#web-search-web-fetch--prompt-caching) | [📖](https://docs.praison.ai/features/model-capabilities) |
| Fast Context | [Example](examples/context/00_agent_fast_context_basic.py) | [📖](https://docs.praison.ai/features/fast-context) |
</details>
<details>
<summary><strong>🛠️ Tools & Configuration</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| 100+ Custom Tools | [Example](examples/python/general/tools_example.py) | [📖](https://docs.praison.ai/tools/tools) |
| YAML Configuration | [Example](examples/cookbooks/yaml/secondary_market_research_agents.yaml) | [📖](https://docs.praison.ai/developers/agents-playbook) |
| 100+ LLM Support | [Example](examples/python/providers/openai/openai_gpt4_example.py) | [📖](https://docs.praison.ai/models) |
| Callback Agents | [Example](examples/python/general/advanced-callback-systems.py) | [📖](https://docs.praison.ai/features/callbacks) |
| Hooks | [Example](#10-hooks) | [📖](https://docs.praison.ai/features/hooks) |
| Middleware System | [Example](examples/middleware/basic_middleware.py) | [📖](https://docs.praison.ai/features/middleware) |
| Configurable Model | [Example](examples/middleware/configurable_model.py) | [📖](https://docs.praison.ai/features/configurable-model) |
| Rate Limiter | [Example](examples/middleware/rate_limiter.py) | [📖](https://docs.praison.ai/features/rate-limiter) |
| Injected Tool State | [Example](examples/middleware/injected_state.py) | [📖](https://docs.praison.ai/features/injected-state) |
| Shadow Git Checkpoints | [Example](#11-shadow-git-checkpoints) | [📖](https://docs.praison.ai/features/checkpoints) |
| Background Tasks | [Example](examples/background/basic_background.py) | [📖](https://docs.praison.ai/features/background-tasks) |
| Policy Engine | [Example](examples/policy/basic_policy.py) | [📖](https://docs.praison.ai/features/policy-engine) |
| Thinking Budgets | [Example](examples/thinking/basic_thinking.py) | [📖](https://docs.praison.ai/features/thinking-budgets) |
| Output Styles | [Example](examples/output/basic_output.py) | [📖](https://docs.praison.ai/features/output-styles) |
| Context Compaction | [Example](examples/compaction/basic_compaction.py) | [📖](https://docs.praison.ai/features/context-compaction) |
</details>
<details>
<summary><strong>📊 Monitoring & Management</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Sessions Management | [Example](examples/python/sessions/comprehensive-session-management.py) | [📖](https://docs.praison.ai/features/sessions) |
| Auto-Save Sessions | [Example](#session-management-python) | [📖](https://docs.praison.ai/docs/cli/session) |
| History in Context | [Example](#session-management-python) | [📖](https://docs.praison.ai/docs/cli/session) |
| Telemetry | [Example](examples/python/telemetry/production-telemetry-example.py) | [📖](https://docs.praison.ai/features/telemetry) |
| Project Docs (.praison/docs/) | [Example](#docs-cli) | [📖](https://docs.praison.ai/docs/cli/docs) |
| AI Commit Messages | [Example](#ai-commit-cli) | [📖](https://docs.praison.ai/docs/cli/commit) |
| @Mentions in Prompts | [Example](#mentions-in-prompts) | [📖](https://docs.praison.ai/docs/cli/mentions) |
</details>
<details>
<summary><strong>🖥️ CLI Features</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Slash Commands | [Example](examples/python/cli/slash_commands_example.py) | [📖](https://docs.praison.ai/docs/cli/slash-commands) |
| Autonomy Modes | [Example](examples/python/cli/autonomy_modes_example.py) | [📖](https://docs.praison.ai/docs/cli/autonomy-modes) |
| Cost Tracking | [Example](examples/python/cli/cost_tracking_example.py) | [📖](https://docs.praison.ai/docs/cli/cost-tracking) |
| Repository Map | [Example](examples/python/cli/repo_map_example.py) | [📖](https://docs.praison.ai/docs/cli/repo-map) |
| Interactive TUI | [Example](examples/python/cli/interactive_tui_example.py) | [📖](https://docs.praison.ai/docs/cli/interactive-tui) |
| Git Integration | [Example](examples/python/cli/git_integration_example.py) | [📖](https://docs.praison.ai/docs/cli/git-integration) |
| Sandbox Execution | [Example](examples/python/cli/sandbox_execution_example.py) | [📖](https://docs.praison.ai/docs/cli/sandbox-execution) |
| CLI Compare | [Example](examples/compare/cli_compare_basic.py) | [📖](https://docs.praison.ai/docs/cli/compare) |
| Profile/Benchmark | [Example](#profile-benchmark) | [📖](https://docs.praison.ai/docs/cli/profile) |
| Auto Mode | [Example](#auto-mode) | [📖](https://docs.praison.ai/docs/cli/auto) |
| Init | [Example](#init) | [📖](https://docs.praison.ai/docs/cli/init) |
| File Input | [Example](#file-input) | [📖](https://docs.praison.ai/docs/cli/file-input) |
| Final Agent | [Example](#final-agent) | [📖](https://docs.praison.ai/docs/cli/final-agent) |
| Max Tokens | [Example](#max-tokens) | [📖](https://docs.praison.ai/docs/cli/max-tokens) |
</details>
<details>
<summary><strong>🧪 Evaluation</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Accuracy Evaluation | [Example](examples/eval/accuracy_example.py) | [📖](https://docs.praison.ai/docs/cli/eval) |
| Performance Evaluation | [Example](examples/eval/performance_example.py) | [📖](https://docs.praison.ai/docs/cli/eval) |
| Reliability Evaluation | [Example](examples/eval/reliability_example.py) | [📖](https://docs.praison.ai/docs/cli/eval) |
| Criteria Evaluation | [Example](examples/eval/criteria_example.py) | [📖](https://docs.praison.ai/docs/cli/eval) |
</details>
<details>
<summary><strong>🎯 Agent Skills</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Skills Management | [Example](examples/skills/basic_skill_usage.py) | [📖](https://docs.praison.ai/features/skills) |
| Custom Skills | [Example](examples/skills/custom_skill_example.py) | [📖](https://docs.praison.ai/features/skills) |
</details>
<details>
<summary><strong>⏰ 24/7 Scheduling</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Agent Scheduler | [Example](examples/python/scheduled_agents/news_checker_live.py) | [📖](https://docs.praison.ai/docs/cli/scheduler) |
</details>
---
## 🌐 Supported Providers
PraisonAI supports 100+ LLM providers through seamless integration:
<details>
<summary><strong>View all 24 providers</strong></summary>
| Provider | Example |
|----------|:-------:|
| OpenAI | [Example](examples/python/providers/openai/openai_gpt4_example.py) |
| Anthropic | [Example](examples/python/providers/anthropic/anthropic_claude_example.py) |
| Google Gemini | [Example](examples/python/providers/google/google_gemini_example.py) |
| Ollama | [Example](examples/python/providers/ollama/ollama-agents.py) |
| Groq | [Example](examples/python/providers/groq/kimi_with_groq_example.py) |
| DeepSeek | [Example](examples/python/providers/deepseek/deepseek_example.py) |
| xAI Grok | [Example](examples/python/providers/xai/xai_grok_example.py) |
| Mistral | [Example](examples/python/providers/mistral/mistral_example.py) |
| Cohere | [Example](examples/python/providers/cohere/cohere_example.py) |
| Perplexity | [Example](examples/python/providers/perplexity/perplexity_example.py) |
| Fireworks | [Example](examples/python/providers/fireworks/fireworks_example.py) |
| Together AI | [Example](examples/python/providers/together/together_ai_example.py) |
| OpenRouter | [Example](examples/python/providers/openrouter/openrouter_example.py) |
| HuggingFace | [Example](examples/python/providers/huggingface/huggingface_example.py) |
| Azure OpenAI | [Example](examples/python/providers/azure/azure_openai_example.py) |
| AWS Bedrock | [Example](examples/python/providers/aws/aws_bedrock_example.py) |
| Google Vertex | [Example](examples/python/providers/vertex/vertex_example.py) |
| Databricks | [Example](examples/python/providers/databricks/databricks_example.py) |
| Cloudflare | [Example](examples/python/providers/cloudflare/cloudflare_example.py) |
| AI21 | [Example](examples/python/providers/ai21/ai21_example.py) |
| Replicate | [Example](examples/python/providers/replicate/replicate_example.py) |
| SageMaker | [Example](examples/python/providers/sagemaker/sagemaker_example.py) |
| Moonshot | [Example](examples/python/providers/moonshot/moonshot_example.py) |
| vLLM | [Example](examples/python/providers/vllm/vllm_example.py) |
</details>
---
## 📘 Using Python Code
### 1. Single Agent
Create app.py file and add the code below:
```python
from praisonaiagents import Agent
agent = Agent(instructions="Your are a helpful AI assistant")
agent.start("Write a movie script about a robot in Mars")
```
Run:
```bash
python app.py
```
### 2. Multi Agents
Create app.py file and add the code below:
```python
from praisonaiagents import Agent, Agents
research_agent = Agent(instructions="Research about AI")
summarise_agent = Agent(instructions="Summarise research agent's findings")
agents = Agents(agents=[research_agent, summarise_agent])
agents.start()
```
Run:
```bash
python app.py
```
### 3. Agent with Planning Mode
Enable planning for any agent - the agent creates a plan, then executes step by step:
```python
from praisonaiagents import Agent
def search_web(query: str) -> str:
return f"Search results for: {query}"
agent = Agent(
name="AI Assistant",
instructions="Research and write about topics",
planning=True, # Enable planning mode
planning_tools=[search_web], # Tools for planning research
planning_reasoning=True # Chain-of-thought reasoning
)
result = agent.start("Research AI trends in 2025 and write a summary")
```
**What happens:**
1. 📋 Agent creates a multi-step plan
2. 🚀 Executes each step sequentially
3. 📊 Shows progress with context passing
4. ✅ Returns final result
### 4. Deep Research Agent
Automated research with real-time streaming, web search, and citations using OpenAI or Gemini Deep Research APIs.
```python
from praisonaiagents import DeepResearchAgent
# OpenAI Deep Research
agent = DeepResearchAgent(
model="o4-mini-deep-research", # or "o3-deep-research"
verbose=True
)
result = agent.research("What are the latest AI trends in 2025?")
print(result.report)
print(f"Citations: {len(result.citations)}")
```
```python
# Gemini Deep Research
from praisonaiagents import DeepResearchAgent
agent = DeepResearchAgent(
model="deep-research-pro", # Auto-detected as Gemini
verbose=True
)
result = agent.research("Research quantum computing advances")
print(result.report)
```
**Features:**
- 🔍 Multi-provider support (OpenAI, Gemini, LiteLLM)
- 📡 Real-time streaming with reasoning summaries
- 📚 Structured citations with URLs
- 🛠️ Built-in tools: web search, code interpreter, MCP, file search
- 🔄 Automatic provider detection from model name
### 5. Query Rewriter Agent
Transform user queries to improve RAG retrieval quality using multiple strategies.
```python
from praisonaiagents import QueryRewriterAgent, RewriteStrategy
agent = QueryRewriterAgent(model="gpt-4o-mini")
# Basic - expands abbreviations, adds context
result = agent.rewrite("AI trends")
print(result.primary_query) # "What are the current trends in Artificial Intelligence?"
# HyDE - generates hypothetical document for semantic matching
result = agent.rewrite("What is quantum computing?", strategy=RewriteStrategy.HYDE)
# Step-back - generates broader context question
result = agent.rewrite("GPT-4 vs Claude 3?", strategy=RewriteStrategy.STEP_BACK)
# Sub-queries - decomposes complex questions
result = agent.rewrite("RAG setup and best embedding models?", strategy=RewriteStrategy.SUB_QUERIES)
# Contextual - resolves references using chat history
result = agent.rewrite("What about cost?", chat_history=[...])
```
**Strategies:**
- **BASIC**: Expand abbreviations, fix typos, add context
- **HYDE**: Generate hypothetical document for semantic matching
- **STEP_BACK**: Generate higher-level concept questions
- **SUB_QUERIES**: Decompose multi-part questions
- **MULTI_QUERY**: Generate multiple paraphrased versions
- **CONTEXTUAL**: Resolve references using conversation history
- **AUTO**: Automatically detect best strategy
### 6. Agent Memory (Zero Dependencies)
Enable persistent memory for agents - works out of the box without any extra packages.
```python
from praisonaiagents import Agent
from praisonaiagents.memory import FileMemory
# Enable memory with a single parameter
agent = Agent(
name="Personal Assistant",
instructions="You are a helpful assistant that remembers user preferences.",
memory=True, # Enables file-based memory (no extra deps!)
user_id="user123" # Isolate memory per user
)
# Memory is automatically injected into conversations
result = agent.start("My name is John and I prefer Python")
# Agent will remember this for future conversations
```
**Memory Types:**
- **Short-term**: Rolling buffer of recent context (auto-expires)
- **Long-term**: Persistent important facts (sorted by importance)
- **Entity**: People, places, organizations with attributes
- **Episodic**: Date-based interaction history
**Advanced Features:**
```python
from praisonaiagents.memory import FileMemory
memory = FileMemory(user_id="user123")
# Session Save/Resume
memory.save_session("project_session", conversation_history=[...])
memory.resume_session("project_session")
# Context Compression
memory.compress(llm_func=lambda p: agent.chat(p), max_items=10)
# Checkpointing
memory.create_checkpoint("before_refactor", include_files=["main.py"])
memory.restore_checkpoint("before_refactor", restore_files=True)
# Slash Commands
memory.handle_command("/memory show")
memory.handle_command("/memory save my_session")
```
**Storage Options:**
| Option | Dependencies | Description |
|--------|-------------|-------------|
| `memory=True` | None | File-based JSON storage (default) |
| `memory="file"` | None | Explicit file-based storage |
| `memory="sqlite"` | Built-in | SQLite with indexing |
| `memory="chromadb"` | chromadb | Vector/semantic search |
### 7. Rules & Instructions
PraisonAI auto-discovers instruction files from your project root and git root:
| File | Description | Priority |
|------|-------------|----------|
| `PRAISON.md` | PraisonAI native instructions | High |
| `PRAISON.local.md` | Local overrides (gitignored) | Higher |
| `CLAUDE.md` | Claude Code memory file | High |
| `CLAUDE.local.md` | Local overrides (gitignored) | Higher |
| `AGENTS.md` | OpenAI Codex CLI instructions | High |
| `GEMINI.md` | Gemini CLI memory file | High |
| `.cursorrules` | Cursor IDE rules | High |
| `.windsurfrules` | Windsurf IDE rules | High |
| `.claude/rules/*.md` | Claude Code modular rules | Medium |
| `.windsurf/rules/*.md` | Windsurf modular rules | Medium |
| `.cursor/rules/*.mdc` | Cursor modular rules | Medium |
| `.praison/rules/*.md` | Workspace rules | Medium |
| `~/.praison/rules/*.md` | Global rules | Low |
```python
from praisonaiagents import Agent
# Agent auto-discovers CLAUDE.md, AGENTS.md, GEMINI.md, etc.
agent = Agent(name="Assistant", instructions="You are helpful.")
# Rules are injected into system prompt automatically
```
**@Import Syntax:**
```markdown
# CLAUDE.md
See @README for project overview
See @docs/architecture.md for system design
@~/.praison/my-preferences.md
```
**Rule File Format (with YAML frontmatter):**
```markdown
---
description: Python coding guidelines
globs: ["**/*.py"]
activation: always # always, glob, manual, ai_decision
---
# Guidelines
- Use type hints
- Follow PEP 8
```
### 8. Auto-Generated Memories
```python
from praisonaiagents.memory import FileMemory, AutoMemory
memory = FileMemory(user_id="user123")
auto = AutoMemory(memory, enabled=True)
# Automatically extracts and stores memories from conversations
memories = auto.process_interaction(
"My name is John and I prefer Python for backend work"
)
# Extracts: name="John", preference="Python for backend"
```
### 9. Agentic Workflows
Create powerful multi-agent workflows with the `Workflow` class:
```python
from praisonaiagents import Agent, Workflow
# Create agents
researcher = Agent(
name="Researcher",
role="Research Analyst",
goal="Research topics thoroughly",
instructions="Provide concise, factual information."
)
writer = Agent(
name="Writer",
role="Content Writer",
goal="Write engaging content",
instructions="Write clear, engaging content based on research."
)
# Create workflow with agents as steps
workflow = Workflow(steps=[researcher, writer])
# Run workflow - agents process sequentially
result = workflow.start("What are the benefits of AI agents?")
print(result["output"])
```
**Key Features:**
- **Agent-first** - Pass `Agent` objects directly as workflow steps
- **Pattern helpers** - Use `route()`, `parallel()`, `loop()`, `repeat()`
- **Planning mode** - Enable with `planning=True`
- **Callbacks** - Monitor with `on_step_complete`, `on_workflow_complete`
- **Async execution** - Use `workflow.astart()` for async
### Workflow Patterns (route, parallel, loop, repeat)
```python
from praisonaiagents import Agent, Workflow
from praisonaiagents.workflows import route, parallel, loop, repeat
# 1. ROUTING - Classifier agent routes to specialized agents
classifier = Agent(name="Classifier", instructions="Respond with 'technical' or 'creative'")
tech_agent = Agent(name="TechExpert", role="Technical Expert")
creative_agent = Agent(name="Creative", role="Creative Writer")
workflow = Workflow(steps=[
classifier,
route({
"technical": [tech_agent],
"creative": [creative_agent]
})
])
# 2. PARALLEL - Multiple agents work concurrently
market_agent = Agent(name="Market", role="Market Researcher")
competitor_agent = Agent(name="Competitor", role="Competitor Analyst")
aggregator = Agent(name="Aggregator", role="Synthesizer")
workflow = Workflow(steps=[
parallel([market_agent, competitor_agent]),
aggregator
])
# 3. LOOP - Agent processes each item
processor = Agent(name="Processor", role="Item Processor")
summarizer = Agent(name="Summarizer", role="Summarizer")
workflow = Workflow(
steps=[loop(processor, over="items"), summarizer],
variables={"items": ["AI", "ML", "NLP"]}
)
# 4. REPEAT - Evaluator-Optimizer pattern
generator = Agent(name="Generator", role="Content Generator")
evaluator = Agent(name="Evaluator", instructions="Say 'APPROVED' if good")
workflow = Workflow(steps=[
generator,
repeat(evaluator, until=lambda ctx: "approved" in ctx.previous_result.lower(), max_iterations=3)
])
# 5. CALLBACKS
workflow = Workflow(
steps=[researcher, writer],
on_step_complete=lambda name, r: print(f"✅ {name} done")
)
# 6. WITH PLANNING & REASONING
workflow = Workflow(
steps=[researcher, writer],
planning=True,
reasoning=True
)
# 7. ASYNC EXECUTION
result = asyncio.run(workflow.astart("input"))
# 8. STATUS TRACKING
workflow.status # "not_started" | "running" | "completed"
workflow.step_statuses # {"step1": "completed", "step2": "skipped"}
```
### YAML Workflow Template
```yaml
# .praison/workflows/research.yaml
name: Research Workflow
description: Research and write content with all patterns
agents:
researcher:
role: Research Expert
goal: Find accurate information
tools: [tavily_search, web_scraper]
writer:
role: Content Writer
goal: Write engaging content
editor:
role: Editor
goal: Polish content
steps:
# Sequential
- agent: researcher
action: Research {{topic}}
output_variable: research_data
# Routing
- name: classifier
action: Classify content type
route:
technical: [tech_handler]
creative: [creative_handler]
default: [general_handler]
# Parallel
- name: parallel_research
parallel:
- agent: researcher
action: Research market
- agent: researcher
action: Research competitors
# Loop
- agent: writer
action: Write about {{item}}
loop_over: topics
loop_var: item
# Repeat (evaluator-optimizer)
- agent: editor
action: Review and improve
repeat:
until: "quality > 8"
max_iterations: 3
# Output to file
- agent: writer
action: Write final report
output_file: output/{{topic}}_report.md
variables:
topic: AI trends
topics: [ML, NLP, Vision]
workflow:
planning: true
planning_llm: gpt-4o
memory_config:
provider: chroma
persist: true
```
### Loading YAML Workflows
```python
from praisonaiagents.workflows import YAMLWorkflowParser, WorkflowManager
# Option 1: Parse YAML string
| text/markdown | Mervin Praison | null | null | null | MIT | null | [] | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"rich>=13.7",
"markdown>=3.5",
"pyparsing>=3.0.0",
"praisonaiagents>=1.5.15",
"python-dotenv>=0.19.0",
"litellm>=1.81.0",
"PyYAML>=6.0",
"mcp>=1.20.0",
"typer>=0.9.0",
"textual>=0.47.0",
"chainlit<=2.9.4,>=2.8.5; extra == \"ui\"",
"sqlalchemy>=2.0.36; extra == \"ui\"",
"aiosqlite>=0.20.0; ex... | [] | [] | [] | [
"Homepage, https://docs.praison.ai",
"Repository, https://github.com/mervinpraison/PraisonAI"
] | twine/6.2.0 CPython/3.9.25 | 2026-02-18T10:38:22.887821 | praisonai-4.5.15.tar.gz | 1,665,411 | d7/c8/a818efe3a6ca5a32fd39a5df98297c38710fa53450e7d74f1e94b55a2d3f/praisonai-4.5.15.tar.gz | source | sdist | null | false | 5bc96e077d04765fbf210d0416f02504 | 33a51749837108f1339f3f4e14263eb4c77f2766c12b739cbbfa6380519ba474 | d7c8a818efe3a6ca5a32fd39a5df98297c38710fa53450e7d74f1e94b55a2d3f | null | [] | 0 |
2.4 | processor-tools | 0.2.2 | Tools to support the developing of processing pipelines | # processor_tools
Tools to support the developing of processing pipelines
## Installation
`processor_tools` is installable via pip. For development it is recommended to install in editable mode with the optional developer dependencies, i.e.:
``
pip install -e ".[dev]"
``
## Documentation
For more information visit our [documentation](https://eco.gitlab-docs.npl.co.uk/tools/processor_tools).
## Acknowledgements
`processor_tools` has been developed by [Sam Hunt](mailto: sam.hunt@npl.co.uk).
## Project status
`processor_tools` is under active development. It is beta software.
| null | Sam Hunt | sam.hunt@npl.co.uk | null | null | None | null | [
"Development Status :: 2 - Pre-Alpha",
"Programming Language :: Python",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8"
] | [] | https://gitlab.npl.co.uk/eco/tools/processor_tools | null | null | [] | [] | [] | [
"numpy",
"pyyaml",
"pydantic",
"python-dateutil",
"numpy; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"tox; extra == \"dev\"",
"sphinx; extra == \"dev\"",
"sphinx_book_theme; extra == \"dev\"",
"sphinx_design; extra == \"dev\"",
"sphinx_automodapi; extra == \"dev\"",
"ipython; extra == ... | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-18T10:37:43.905656 | processor_tools-0.2.2.tar.gz | 31,126 | 59/4d/303eed0e1f37005e65849a27c8d1442983a80f3eeba10c08a17e41d3f5db/processor_tools-0.2.2.tar.gz | source | sdist | null | false | 02e5b52026282c0c9ed96bb63af5f5fa | 980ff50b441edbb9cfc6e92dea43e8cd15e7ea82befbec53b478b819175a7fb8 | 594d303eed0e1f37005e65849a27c8d1442983a80f3eeba10c08a17e41d3f5db | null | [] | 347 |
2.4 | aphub-sdk | 0.1.0 | Python SDK for aphub | # aphub-sdk
Python SDK for aphub - The Docker Hub for AI Agents
## Installation
```bash
pip install aphub-sdk
```
## Quick Start
### Basic Usage
```python
from aphub_sdk import HubClient
from pathlib import Path
# Initialize client
client = HubClient(
base_url="https://hub.aipartnerup.com",
api_key="your-api-key" # Optional, can use token instead
)
# Pull an Agent
result = client.pull(
name="customer-service-agent",
tag="latest",
output_path=Path("./agents")
)
# Push an Agent
result = client.push(
manifest=Path("./agent.yaml"),
tag="latest",
files_path=Path("./agent-files/")
)
# Search Agents
results = client.search(
query="customer service",
framework="aipartnerupflow",
page_size=20
)
# Get Agent details
agent = client.get_agent("customer-service-agent")
# List tags
tags = client.list_tags("customer-service-agent")
```
## Use Cases
### 1. CI/CD Pipeline Integration
Automatically deploy agents after successful builds:
```python
import os
from aphub_sdk import HubClient
def deploy_in_cicd():
client = HubClient(api_key=os.environ["APHUB_API_KEY"])
result = client.push(
manifest=Path("./dist/agent.yaml"),
tag=os.environ.get("VERSION", "latest"),
files_path=Path("./dist/agent-files"),
)
print(f"Deployed: {result.name}:{result.version}")
```
### 2. Custom Web Application
Build custom UIs and backends:
```python
from fastapi import FastAPI
from aphub_sdk import HubClient
app = FastAPI()
client = HubClient()
@app.get("/api/agents")
def list_agents():
result = client.search(query="", page_size=50)
return {"agents": [item.agent.name for item in result.results]}
```
### 3. Agent Management Scripts
Batch operations and automation:
```python
client = HubClient(api_key="your-key")
# Bulk operations
for agent_name in ["agent1", "agent2", "agent3"]:
client.pull(agent_name, output_path=Path(f"./backups/{agent_name}"))
```
### 4. Agent Testing and Validation
Validate agents before pushing:
```python
def validate_and_push(manifest_path, files_path):
# Your validation logic here
if validate_agent(manifest_path, files_path):
return client.push(manifest_path, files_path=files_path)
else:
raise ValueError("Validation failed")
```
## Advanced Features
### Retry Configuration
```python
from aphub_sdk import HubClient
from aphub_sdk.retry import RetryConfig
client = HubClient(
retry_config=RetryConfig(
max_retries=5,
backoff_factor=2.0,
)
)
```
### Token Auto-Refresh
```python
client = HubClient(
access_token="your-access-token",
refresh_token="your-refresh-token",
)
# Tokens automatically refreshed when expired
```
### Progress Tracking
```python
def progress(bytes_sent, total_bytes):
print(f"Progress: {bytes_sent}/{total_bytes}")
client = HubClient(progress_callback=progress)
client.pull("my-agent", output_path=Path("./agents"))
```
## When to Use SDK vs CLI
| Use Case | SDK | CLI |
|----------|-----|-----|
| CI/CD Pipelines | ✅ | ❌ |
| Custom Applications | ✅ | ❌ |
| Scripts/Automation | ✅ | ⚠️ |
| Interactive Use | ⚠️ | ✅ |
| Batch Operations | ✅ | ❌ |
## Documentation
- [Usage Scenarios](USAGE_SCENARIOS.md) - Detailed use cases and examples
- [API Reference](docs/api.md) - Complete API documentation
- [Examples](examples/) - Code examples
## License
Apache-2.0
| text/markdown | null | aipartnerup <tercel.yi@gmail.com> | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"pydantic>=2.5.0",
"httpx>=0.25.0",
"pyyaml>=6.0.1",
"pyjwt>=2.8.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"twine>=4.0.0; extra == \"dev\"",
"pre-co... | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.10 | 2026-02-18T10:37:17.359533 | aphub_sdk-0.1.0.tar.gz | 28,302 | 0d/a0/d9f6f5b5960fe090e3677f9b8d6bf42ed197eeece291c09db56e08d4bb75/aphub_sdk-0.1.0.tar.gz | source | sdist | null | false | bd94bf6c5c6fc967b5396def5bdf7023 | 0845c6ac4331d663c129e3766de682df363119a3b6222e64dcd008754e67ee37 | 0da0d9f6f5b5960fe090e3677f9b8d6bf42ed197eeece291c09db56e08d4bb75 | null | [] | 265 |
2.1 | pyriksdagen | 1.10.2 | Access the Riksdagen corpus | # pyriksdagen
Python module for interacting with the Swedish Parliamentary Corpus
The use of the module is demonstrated in the [Example Jupyter Notebook](https://github.com/swerik-project/pyriksdagen/blob/main/examples/corpus-walkthrough.ipynb), which can also be run on [Google Colab](https://colab.research.google.com/github/swerik-project/pyriksdagen/blob/main/examples/corpus-walkthrough.ipynb).
| text/markdown | ninpnin | vainoyrjanainen@icloud.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming L... | [] | https://github.com/welfare-state-analytics/riksdagen-corpus | null | <4.0,>=3.7 | [] | [] | [] | [
"pyparlaclarin",
"pandas",
"base58",
"kblab-client",
"progressbar2",
"lxml",
"xmlschema",
"unidecode",
"dateparser",
"beautifulsoup4",
"requests",
"numpy",
"SPARQLWrapper",
"tqdm",
"matplotlib",
"importlib_resources",
"nltk",
"textdistance",
"py-markdown-table",
"alto-xml",
"... | [] | [] | [] | [
"Repository, https://github.com/welfare-state-analytics/riksdagen-corpus"
] | poetry/1.8.5 CPython/3.8.18 Linux/6.14.0-1017-azure | 2026-02-18T10:36:38.069085 | pyriksdagen-1.10.2.tar.gz | 47,861 | 26/ae/000645e60984f85d005045d64a3c47294bc48c23355e0f4e77c93958c502/pyriksdagen-1.10.2.tar.gz | source | sdist | null | false | e09fcd41e44e14f5d39a8738e15b1b9b | 3dcb4a18150392c791bed97cdc02762af62dc7b7c35ac0ea07ed4b0b46a39848 | 26ae000645e60984f85d005045d64a3c47294bc48c23355e0f4e77c93958c502 | null | [] | 527 |
2.4 | ergane | 0.7.0 | High-performance async web scraper with selectolax parsing | # Ergane
[](https://badge.fury.io/py/ergane)
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
High-performance async web scraper with HTTP/2 support, built with Python.
*Named after Ergane, Athena's title as goddess of crafts and weaving in Greek mythology.*
## Features
- **Programmatic API** — `Crawler`, `crawl()`, and `stream()` let you embed scraping in any Python application
- **Hook System** — Intercept requests and responses with the `CrawlHook` protocol
- **HTTP/2 & Async** — Fast concurrent connections with per-domain rate limiting and retry logic
- **Fast Parsing** — Selectolax HTML parsing (16x faster than BeautifulSoup)
- **Built-in Presets** — Pre-configured schemas for popular sites (no coding required)
- **Custom Schemas** — Define Pydantic models with CSS selectors and type coercion
- **Multi-Format Output** — Export to CSV, Excel, Parquet, JSON, JSONL, or SQLite
- **Response Caching** — SQLite-based caching for faster development and debugging
- **MCP Server** — Expose scraping tools to LLMs via the Model Context Protocol
- **Production Ready** — robots.txt compliance, graceful shutdown, checkpoints, proxy support
## Installation
```bash
pip install ergane
# With MCP server support (optional)
pip install ergane[mcp]
```
## Quick Start
### CLI — run from your terminal
```bash
# Use a built-in preset (no code needed)
ergane --preset quotes -o quotes.csv
# Crawl a custom URL
ergane -u https://example.com -n 100 -o data.parquet
# List available presets
ergane --list-presets
```
### Python — embed in your application
```python
import asyncio
from ergane import Crawler
async def main():
async with Crawler(
urls=["https://quotes.toscrape.com"],
max_pages=20,
) as crawler:
async for item in crawler.stream():
print(item.url, item.title)
asyncio.run(main())
```
## Python Library
Ergane's engine is a pure async library. The CLI is a thin wrapper around it — everything the CLI can do, your code can do too.
### Crawler
The main entry point. Use it as an async context manager:
```python
from ergane import Crawler
async with Crawler(
urls=["https://example.com"],
max_pages=50,
concurrency=10,
rate_limit=5.0,
) as crawler:
results = await crawler.run() # collect all items
```
Key parameters:
| Parameter | Default | Description |
|-----------|---------|-------------|
| `urls` | *(required)* | Seed URL(s) to start crawling |
| `schema` | `None` | Pydantic model for typed extraction |
| `concurrency` | `10` | Number of concurrent workers |
| `max_pages` | `100` | Maximum pages to crawl |
| `max_depth` | `3` | Maximum link-follow depth |
| `rate_limit` | `10.0` | Requests per second per domain |
| `timeout` | `30.0` | HTTP request timeout (seconds) |
| `same_domain` | `True` | Only follow links on the seed domain |
| `hooks` | `None` | List of `CrawlHook` instances |
| `output` | `None` | File path to write results |
| `output_format` | `"auto"` | `csv`, `excel`, `parquet`, `json`, `jsonl`, `sqlite` |
| `cache` | `False` | Enable SQLite response caching |
### run()
Executes the crawl and returns all extracted items as a list:
```python
async with Crawler(urls=["https://example.com"], max_pages=10) as c:
results = await c.run()
print(f"Got {len(results)} items")
```
### stream()
Yields items as they arrive — memory-efficient for large crawls:
```python
async with Crawler(urls=["https://example.com"], max_pages=500) as c:
async for item in c.stream():
process(item) # handle each item immediately
```
### crawl()
One-shot convenience function — creates a `Crawler`, runs it, returns results:
```python
from ergane import crawl
results = await crawl(
urls=["https://example.com"],
max_pages=10,
concurrency=5,
)
```
### Typed Extraction with Schemas
Pass a Pydantic model with CSS selectors to extract structured data:
```python
from datetime import datetime
from pydantic import BaseModel
from ergane import Crawler, selector
class Quote(BaseModel):
url: str
crawled_at: datetime
text: str = selector("span.text")
author: str = selector("small.author")
tags: list[str] = selector("div.tags a.tag")
async with Crawler(
urls=["https://quotes.toscrape.com"],
schema=Quote,
max_pages=50,
) as crawler:
for quote in await crawler.run():
print(f"{quote.author}: {quote.text}")
```
The `selector()` helper supports:
| Argument | Description |
|----------|-------------|
| `css` | CSS selector string |
| `attr` | Extract an attribute instead of text (e.g. `"href"`, `"src"`) |
| `coerce` | Aggressive type coercion (`"$19.99"` → `19.99`) |
| `default` | Default value if selector matches nothing |
## Hooks
Hooks let you intercept and modify requests before they're sent, and responses after they're received. They follow the `CrawlHook` protocol:
```python
from ergane import CrawlHook, CrawlRequest, CrawlResponse
class CrawlHook(Protocol):
async def on_request(self, request: CrawlRequest) -> CrawlRequest | None: ...
async def on_response(self, response: CrawlResponse) -> CrawlResponse | None: ...
```
Return the (possibly modified) object to continue, or `None` to skip/discard.
### BaseHook
Subclass `BaseHook` and override only the methods you need:
```python
from ergane import BaseHook, CrawlRequest
class SkipAdminPages(BaseHook):
async def on_request(self, request: CrawlRequest) -> CrawlRequest | None:
if "/admin" in request.url:
return None # skip this URL
return request
```
### Built-in Hooks
| Hook | Purpose |
|------|---------|
| `LoggingHook()` | Logs requests and responses at DEBUG level |
| `AuthHeaderHook(headers)` | Injects custom headers (e.g. `{"Authorization": "Bearer ..."}`) |
| `StatusFilterHook(allowed)` | Discards responses outside allowed status codes (default: `{200}`) |
### Using Hooks
```python
from ergane import Crawler
from ergane.crawler.hooks import LoggingHook, AuthHeaderHook
async with Crawler(
urls=["https://api.example.com"],
hooks=[
AuthHeaderHook({"Authorization": "Bearer token123"}),
LoggingHook(),
],
) as crawler:
results = await crawler.run()
```
Hooks run in order: for requests, each hook receives the output of the previous one. The same applies for responses.
## MCP Server
Ergane includes an [MCP (Model Context Protocol)](https://modelcontextprotocol.io/) server that lets LLMs crawl websites and extract structured data. Install the optional dependency:
```bash
pip install ergane[mcp]
```
### Running the Server
```bash
# Via CLI subcommand
ergane mcp
# Via Python module
python -m ergane.mcp
```
Both start a stdio-based MCP server compatible with Claude Code, Claude Desktop, and other MCP clients.
### Configuration
Add to your MCP client config (e.g. Claude Desktop `claude_desktop_config.json`):
```json
{
"mcpServers": {
"ergane": {
"command": "ergane",
"args": ["mcp"]
}
}
}
```
Or for Claude Code (`~/.claude/claude_code_config.json`):
```json
{
"mcpServers": {
"ergane": {
"command": "ergane",
"args": ["mcp"]
}
}
}
```
### Available Tools
The MCP server exposes four tools:
#### `list_presets_tool`
Discover all built-in scraping presets with their target URLs and available fields.
#### `extract_tool`
Extract structured data from a single web page using CSS selectors.
```
Arguments:
url — URL to scrape (required)
selectors — Map of field names to CSS selectors, e.g. {"title": "h1", "price": ".price"}
schema_yaml — Full YAML schema (alternative to selectors)
```
#### `scrape_preset_tool`
Scrape a website using a built-in preset — zero configuration needed.
```
Arguments:
preset — Preset name, e.g. "hacker-news", "quotes" (required)
max_pages — Maximum pages to scrape (default: 5)
```
#### `crawl_tool`
Crawl one or more websites with full control over depth, concurrency, and output format.
```
Arguments:
urls — Starting URLs (required)
schema_yaml — YAML schema for CSS-based extraction
max_pages — Maximum pages to crawl (default: 10)
max_depth — Link-follow depth (default: 1, 0 = seed only)
concurrency — Concurrent requests (default: 5)
output_format — "json", "csv", or "jsonl" (default: "json")
```
### Resources
Each built-in preset is also exposed as an MCP resource at `preset://{name}` (e.g. `preset://hacker-news`), allowing LLMs to browse preset details before scraping.
## Built-in Presets
| Preset | Site | Fields Extracted |
|--------|------|------------------|
| `hacker-news` | news.ycombinator.com | title, link, score, author, comments |
| `github-repos` | github.com/search | name, description, stars, language, link |
| `reddit` | old.reddit.com | title, subreddit, score, author, comments, link |
| `quotes` | quotes.toscrape.com | quote, author, tags |
| `amazon-products` | amazon.com | title, price, rating, reviews, link |
| `ebay-listings` | ebay.com | title, price, condition, shipping, link |
| `wikipedia-articles` | en.wikipedia.org | title, link |
| `bbc-news` | bbc.com/news | title, summary, link |
## Custom Schemas
Define extraction rules in a YAML schema file:
```yaml
# schema.yaml
name: ProductItem
fields:
name:
selector: "h1.product-title"
type: str
price:
selector: "span.price"
type: float
coerce: true # "$19.99" -> 19.99
tags:
selector: "span.tag"
type: list[str]
image_url:
selector: "img.product"
attr: src
type: str
```
```bash
ergane -u https://example.com --schema schema.yaml -o products.parquet
```
Type coercion (`coerce: true`) handles common patterns: `"$19.99"` → `19.99`, `"1,234"` → `1234`, `"yes"` → `True`.
Supported types: `str`, `int`, `float`, `bool`, `datetime`, `list[T]`.
You can also load YAML schemas programmatically:
```python
from ergane import Crawler, load_schema_from_yaml
ProductItem = load_schema_from_yaml("schema.yaml")
async with Crawler(
urls=["https://example.com"],
schema=ProductItem,
) as crawler:
results = await crawler.run()
```
## Output Formats
Output format is auto-detected from file extension:
```bash
ergane --preset quotes -o quotes.csv # CSV
ergane --preset quotes -o quotes.xlsx # Excel
ergane --preset quotes -o quotes.parquet # Parquet (default)
ergane --preset quotes -o quotes.json # JSON array
ergane --preset quotes -o quotes.jsonl # JSONL (one object per line)
ergane --preset quotes -o quotes.sqlite # SQLite database
```
You can also force a format with `--format`/`-f` regardless of file extension:
```bash
ergane --preset quotes -f jsonl -o output.dat
```
```python
import polars as pl
df = pl.read_parquet("output.parquet")
```
## Architecture
Ergane separates the **engine** (pure async library) from its three interfaces: the **CLI** (Rich progress bars, signal handling), the **Python library** (direct import), and the **MCP server** (LLM integration). Hooks plug into the pipeline at two points: after scheduling and after fetching.
```
CLI (main.py) Python Library MCP Server
┌──────────────────────┐ ┌──────────────────────┐ ┌──────────────────────┐
│ Click options │ │ from ergane import │ │ FastMCP (stdio) │
│ Rich progress bar │ │ Crawler / crawl() │ │ 4 tools + resources │
│ Signal handling │ │ stream() │ │ ergane mcp │
│ Config file merge │ │ │ │ │
└──────────┬───────────┘ └────────────┬──────────┘ └──────────┬───────────┘
│ │ │
└───────────────┬───────────┴────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ Crawler (engine) │
│ Pure async · no I/O concerns │
│ Spawns N worker coroutines │
└──────────────┬───────────────────┘
│
┌───────────────┼───────────────────┐
│ │ │
▼ ▼ ▼
┌──────────────┐ ┌───────────┐ ┌──────────────┐
│ Scheduler │ │ Fetcher │ │ Pipeline │
│ URL frontier│ │ HTTP/2 │ │ Batch write │
│ dedup queue │ │ retries │ │ multi-format│
└──────┬───────┘ └─────┬─────┘ └──────────────┘
│ │
▼ ▼
┌──────────────────────────────────────────────────┐
│ Worker loop (× N) │
│ │
│ 1. Scheduler.get() → CrawlRequest │
│ 2. hooks.on_request → modify / skip │
│ 3. Fetcher.fetch() → CrawlResponse │
│ 4. hooks.on_response → modify / discard │
│ 5. Parser.extract() → Pydantic model │
│ 6. Pipeline.add() → buffered output │
│ 7. extract_links() → new URLs → Scheduler │
└──────────────────────────────────────────────────┘
┌──────────────────────────────────────────────────┐
│ Cross-cutting concerns │
│ │
│ Cache ─── SQLite response cache with TTL │
│ Checkpoint ─ periodic JSON snapshots for resume │
│ Schema ── YAML → dynamic Pydantic model + coerce │
└──────────────────────────────────────────────────┘
```
## CLI Reference
### Common Options
| Option | Short | Default | Description |
|--------|-------|---------|-------------|
| `--url` | `-u` | none | Start URL(s), can specify multiple |
| `--output` | `-o` | `output.parquet` | Output file path |
| `--max-pages` | `-n` | `100` | Maximum pages to crawl |
| `--max-depth` | `-d` | `3` | Maximum crawl depth |
| `--concurrency` | `-c` | `10` | Concurrent requests |
| `--rate-limit` | `-r` | `10.0` | Requests per second per domain |
| `--schema` | `-s` | none | YAML schema file for custom extraction |
| `--preset` | `-p` | none | Use a built-in preset |
| `--format` | `-f` | `auto` | Output format: `csv`, `excel`, `parquet`, `json`, `jsonl`, `sqlite` |
| `--timeout` | `-t` | `30` | Request timeout in seconds |
| `--proxy` | `-x` | none | HTTP/HTTPS proxy URL |
| `--same-domain/--any-domain` | | `--same-domain` | Restrict crawling to seed domain |
| `--ignore-robots` | | `false` | Ignore robots.txt |
| `--cache` | | `false` | Enable response caching |
| `--cache-dir` | | `.ergane_cache` | Cache directory |
| `--cache-ttl` | | `3600` | Cache TTL in seconds |
| `--resume` | | | Resume from checkpoint |
| `--checkpoint-interval` | | `100` | Save checkpoint every N pages |
| `--log-level` | | `INFO` | `DEBUG`, `INFO`, `WARNING`, `ERROR` |
| `--log-file` | | none | Write logs to file |
| `--no-progress` | | | Disable progress bar |
| `--config` | `-C` | none | Config file path |
Run `ergane --help` for the full list.
### Advanced CLI Examples
```bash
# Crawl with a proxy
ergane -u https://example.com -o data.csv --proxy http://localhost:8080
# Resume an interrupted crawl (requires prior checkpoint)
ergane -u https://example.com -n 500 --resume
# Save checkpoints every 50 pages with debug logging
ergane -u https://example.com -n 500 --checkpoint-interval 50 \
--log-level DEBUG --log-file crawl.log
# Use a YAML config file and override concurrency from CLI
ergane -u https://example.com -C config.yaml -c 20
# Combine preset with custom URL and explicit format
ergane --preset hacker-news -u https://news.ycombinator.com/newest \
-f csv -o newest.csv -n 200
```
## Configuration
Ergane looks for a config file in these locations (first match wins):
1. Explicit path via `--config`/`-C`
2. `~/.ergane.yaml`
3. `./.ergane.yaml`
4. `./ergane.yaml`
```yaml
crawler:
max_pages: 100
max_depth: 3
concurrency: 10
rate_limit: 10.0
defaults:
output_format: "csv"
checkpoint_interval: 100
logging:
level: "INFO"
file: null
```
CLI flags override config file values.
## Troubleshooting
### Getting empty or partial output
- **Check `--max-depth`**: depth 0 means only the seed URL is crawled.
Increase with `-d 3` to follow links.
- **Same-domain filtering**: by default Ergane only follows links on the
same domain as the seed URL. Use `--any-domain` to crawl cross-domain.
- **Selector mismatch**: if using a custom schema, verify your CSS
selectors match the actual site HTML (sites change frequently).
### Blocked by robots.txt
If a target site disallows your user-agent in `robots.txt`, Ergane will
return 403 for those URLs. Options:
```bash
# Ignore robots.txt (use responsibly)
ergane -u https://example.com --ignore-robots -o data.csv
```
### Rate limiting or 429 responses
Lower the request rate and concurrency:
```bash
ergane -u https://example.com -r 2 -c 3 -o data.csv
```
The built-in per-domain token-bucket rate limiter (`-r`) controls requests
per second. Reducing concurrency (`-c`) also lowers overall load.
### Timeouts and connection errors
Increase the request timeout and enable retries (3 retries is the default):
```bash
ergane -u https://slow-site.com -t 60 -o data.csv
```
### Resuming after a crash
Ergane periodically saves checkpoints (default: every 100 pages). To
resume:
```bash
ergane -u https://example.com -n 1000 --resume
```
The checkpoint file is automatically deleted after a successful crawl.
## License
MIT
| text/markdown | pyamin1878 | null | null | null | MIT | async, crawler, httpx, selectolax, spider, web-scraper | [
"Development Status :: 4 - Beta",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
... | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1.0",
"fastexcel>=0.7.0",
"httpx[http2]>=0.27.0",
"polars>=1.0.0",
"pydantic>=2.0.0",
"pyyaml>=6.0.0",
"rich>=13.0.0",
"selectolax>=0.3.21",
"xlsxwriter>=3.1.0",
"beautifulsoup4>=4.12.0; extra == \"dev\"",
"lxml>=5.0.0; extra == \"dev\"",
"mcp[cli]>=1.0.0; extra == \"dev\"",
"mypy>... | [] | [] | [] | [
"Homepage, https://github.com/pyamin1878/ergane",
"Repository, https://github.com/pyamin1878/ergane",
"Issues, https://github.com/pyamin1878/ergane/issues"
] | uv/0.9.26 {"installer":{"name":"uv","version":"0.9.26","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Pop!_OS","version":"22.04","id":"jammy","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-18T10:36:05.969334 | ergane-0.7.0.tar.gz | 182,679 | 07/de/f9b7f5688e8c9c694cd0c9359952275b0113c125723dae8c786328c569ac/ergane-0.7.0.tar.gz | source | sdist | null | false | 80c0dcf6d5a8f13d9386acf617db4e3a | 426b63a91f3423735ea78a8fc953ccfbf6b3d363a64e7100dafdf94d7c5ba8b7 | 07def9b7f5688e8c9c694cd0c9359952275b0113c125723dae8c786328c569ac | null | [
"LICENSE"
] | 269 |
2.4 | nuiitivet | 0.3.0 | Intuitive desktop UI framework for Python | # Nuiitivet
Nuiitivet is an intuitive UI framework for Python.
## 1. Welcome to Nuiitivet
Hi there, thanks for stopping by.
I'd like to take a little of your time to introduce you to Nuiitivet. It should only take about 10 minutes to read, so I'd appreciate it if you could stick with me for a bit.
### 1.1 Declarative UI
Do you ever create small applications for work or as a hobby? With Python, you can start writing code immediately and build things easily, which is very convenient. But even for small tools, you often find yourself wanting a UI, don't you? That's where Nuiitivet comes in. You can build a UI quickly using a declarative UI style like Flutter or SwiftUI.
For example, a login form can be written like this:
```python
login_form = Column(
[
# Username and Password fields
OutlinedTextField(
value="",
label="Username",
width=300,
),
OutlinedTextField(
value="",
label="Password",
width=300,
),
# Login Button
FilledButton(
"Login",
on_click=lambda: print("Login clicked"),
width=300,
)
],
gap=20,
padding=20,
)
```

If you know Flutter or SwiftUI, you know how convenient declarative UIs are.
Even if you don't, I hope you can see how intuitive it is to write.
But if you do know Flutter or SwiftUI, you might be worried about "Widget nesting hell" or "Modifier chain hell".
Don't worry. We've balanced the roles of Widgets, parameters, and Modifiers perfectly to keep things simple.
For example, if you specify padding or size with Padding or SizedBox like in Flutter, the Widget nesting tends to get deep. But with Nuiitivet, you can specify them directly as parameters, so you can write it simply.
```python
# Writing in Flutter style often leads to deep nesting
Padding(
padding=EdgeInsets.all(12),
child=SizedBox(
width=200,
child=Text("Hello"),
),
)
```
```python
# With Nuiitivet, you can specify them directly
Text(
"Hello",
padding=12,
width=200,
)
```
Modifiers are positioned for intermediate users and above. For small applications, you probably won't need to use Modifiers.
We explain Widgets and parameters in [3.1 Layout](#31-layout), so check it out if you're interested.
Modifiers are explained in [3.2 Modifier](#32-modifier).
### 1.2 Data Binding
It's fine when the application is small, but as it grows, UI code and logic code tend to get mixed up, making maintenance difficult. This is a problem that has plagued me in many languages, not just Python.
So, leveraging my experience, Nuiitivet provides a mechanism to cleanly separate UI and logic. First, let me explain logic -> UI updates.
For logic -> UI updates, we adopted the Reactive concept.
In Nuiitivet, when you set a value to an Observable, the UI is automatically updated.
```python
class CounterApp(ComposableWidget):
def __init__(self):
super().__init__()
self.count = Observable(0)
def increment(self):
self.count.value += 1
def build(self):
return Column(
[
# Count display
Text(self.count),
# Increment button
FilledButton(
"Increment",
on_click=self.increment,
)
]
)
```

This might not fully convey the benefits of Reactive programming.
Let's look at an example where we increase counters and display the total.
```python
class MultiCounterApp(ComposableWidget):
def __init__(self):
super().__init__()
self.count_a = Observable(0)
self.count_b = Observable(0)
self.total = self.count_a.combine(self.count_b).compute(lambda a, b: a + b)
def increment_a(self):
self.count_a.value += 1
def increment_b(self):
self.count_b.value += 1
```
Take a look at the `self.total` line.
You can read from the code that `total` is defined as the sum of `count_a` and `count_b`. Of course, `total` is automatically recalculated when `count_a` or `count_b` is updated, and in the UI code, you just need to specify `total` as is.
```python
def build(self):
return Column(
[
# Counter A
Row(
[
Text(self.count_a.value),
FilledButton("+", on_click=self.increment_a),
],
),
# Counter B
Row(
[
Text(self.count_b.value),
FilledButton("+", on_click=self.increment_b),
],
),
# Just specify total!
Text(self.total),
],
)
```

In the UI code, you just specify `total` without worrying about the logic. I think it's cleanly separated. Moreover, the definition of `total` can also be written Reactively, making the intent easy to read from the code.
Detailed usage of Observable is summarized in [3.3 Observable](#33-observable), so check it out if you're interested.
### 1.3. Event Handlers
For UI -> logic, you just write the processing sequentially in event handlers.
Since logic -> UI is written declaratively with Reactive, shouldn't this be declarative too?
No, no, no. Ask yourself honestly. When a UI event occurs, don't you really want to write "what to do" sequentially?
```python
class CounterApp(ComposableWidget):
count = Observable(0)
# Write procedures in event handler
def handle_increment(self):
# 1. Output log
print(f"Current count: {self.count.value}")
# 2. Increment count
self.count.value += 1
# 3. Milestone check
if self.count.value % 10 == 0:
print("Milestone reached!")
def build(self):
return Column(
[
Text(f"count: {self.count.value}"),
FilledButton(
"Increment",
on_click=self.handle_increment, # Execute on click
)
]
)
```
Don't try to force it to be declarative; just write the procedures sequentially.
Another common case is displaying a dialog. You click a button, show a dialog, and branch processing based on OK/Cancel. You want to write this procedurally too, right?
### 1.4. Declarative vs Imperative
I've introduced Nuiitivet, but what do you think?
You might feel uneasy mixing declarative and imperative styles. But if you think about it, SQL retrieves data declaratively, but application code is written imperatively, right? So it's not strange at all for UI code to mix declarative and imperative styles. The important thing is that it can be written "intuitively".
"Intuitive" differs from person to person, so I don't know if Nuiitivet is intuitive for everyone. But I think it has become a framework that I can write intuitively. So please give it a try.
## 2. First Steps
### 2.1. Requirements
- Python 3.10 or higher
- macOS(tested) / Windows(not tested) / Linux(not tested)
Main internal libraries used (drawing/rendering):
- pyglet
- PyOpenGL
- skia-python
- material-color-utilities
See [LICENSES/](LICENSES/) for third-party licenses.
### 2.2. Installation
You can install it easily with pip.
```bash
pip install nuiitivet
```
### 2.3. Your First App
To create an application with Nuiitivet, follow these two steps:
- Inherit from `ComposableWidget` to create a UI component
- Pass the UI component to `MaterialApp` and start the application
```python
from nuiitivet.material.app import MaterialApp
from nuiitivet.material import Text, FilledButton
from nuiitivet.layout.column import Column
from nuiitivet.observable import Observable
from nuiitivet.widgeting.widget import ComposableWidget
class CounterApp(ComposableWidget):
def __init__(self):
super().__init__()
self.count = Observable(0)
def handle_increment(self):
# 1. Output log
print(f"Current count: {self.count.value}")
# 2. Increment count
self.count.value += 1
# 3. Milestone check
if self.count.value % 10 == 0:
print("Milestone reached!")
def build(self):
return Column(
[
Text(self.count),
FilledButton(
"Increment",
on_click=self.handle_increment,
)
],
gap=20,
padding=20,
)
def main():
# Create counter app
counter_app = CounterApp()
# Start with MaterialApp
app = MaterialApp(content=counter_app)
app.run()
if __name__ == "__main__":
main()
```
## 3. Nuiitivet Concepts
### 3.1. Layout
In Nuiitivet, you can build UIs using only Widgets and parameters.
You don't need unnecessary wrapper widgets.
```python
from nuiitivet.layout.column import Column
from nuiitivet.layout.row import Row
from nuiitivet.material import Text, FilledButton, TextButton
# Layout vertically with Column
Column(
children=[
Text("Title", padding=10),
Text("Subtitle", padding=10),
Text("Body", padding=10),
],
gap=16, # Space between children
padding=20, # Outer padding
cross_alignment="start", # Cross axis alignment (start/center/end)
)
# Layout horizontally with Row
Row(
children=[
FilledButton("OK"),
TextButton("Cancel"),
],
gap=12, # Space between children
main_alignment="end", # Main axis alignment (start/center/end/space-between)
cross_alignment="center", # Cross axis alignment
)
```

By providing appropriate parameters according to the Widget's role, you can keep Widget nesting shallow.
- **All Widgets**
- `padding`: Inner padding of the Widget
- `width` / `height`: Widget size specification (fixed value or automatic)
- Square widgets like Icons are specified only with `size`
- **Single Child Layout Widgets**
- `alignment`: Alignment of the single child (Container)
- **Multi-Child Layout Widgets**
- `gap`: Space between child elements (Column / Row)
- `main_alignment` / `cross_alignment`: Alignment of multiple children (Column / Row)
The following Layout Widgets are available:
- **Column**: Layout children vertically
- **Row**: Layout children horizontally
- **Stack**: Layout children overlapping each other
- **Flow**: Layout children with wrapping
- **Grid**: Layout children in a grid
- **Container**: Basic layout Widget containing a single child
- **Spacer**: Insert blank space
### 3.2. Modifier
Modifiers are a mechanism for adding functionality to Widgets.
Use them when you want to add decorations like background color or corner radius to a Widget.
You can add functionality to a Widget by passing a Modifier to the `modifier()` method that all Widgets have. If you want to attach multiple Modifiers, you can chain them with the `|` operator.
```python
from nuiitivet.material import Text
from nuiitivet.modifiers import background, corner_radius, border
# Add background color with Background
text1 = Text("Hello").modifier(background("#FF5722"))
# Add corner radius with CornerRadius
text2 = Text("Rounded Box").modifier(background("#2196F3") | corner_radius(8))
```

Currently, the Modifiers available in Nuiitivet are:
**Decoration:**
- **background**: Add background color
- **border**: Add border
- **corner_radius**: Add corner radius
- **clip**: Add clipping
- **shadow**: Add shadow
**Interaction:**
- **clickable**: Make clickable
- **hoverable**: Make hoverable
- **focusable**: Make focusable
**Others:**
- **scrollable**: Make scrollable
- **will_pop**: Handle back navigation
It's similar to Modifiers in SwiftUI / Jetpack Compose, but Nuiitivet does not provide layout-related functions in Modifiers. Layout should be handled by Widgets and parameters alone; allowing Modifiers to handle layout would make the code complex.
### 3.3. Observable
Observable is a mechanism that uses Reactive programming concepts to simplify UI updates. When a value changes, the UI is automatically updated.
Observables can be transformed and combined using methods like `.map()`, `.combine()`, and `Observable.compute()`.
```python
from nuiitivet.observable import Observable, combine
# 1-to-1 transformation with .map()
price = Observable(1000)
formatted_price = price.map(lambda p: f"${p:,}")
# Combine multiple Observables (two) with .combine()
price = Observable(1000)
quantity = Observable(2)
subtotal = price.combine(quantity).compute(lambda p, q: p * q)
# Combine 3 or more with combine() function
tax_rate = Observable(0.1)
total = combine(price, quantity, tax_rate).compute(
lambda p, q, t: int(p * q * (1 + t))
)
# Complex calculation and automatic dependency tracking with Observable.compute()
class CartViewModel:
def __init__(self):
self.price = Observable(1000)
self.quantity = Observable(2)
self.discount = Observable(0.1)
self.tax_rate = Observable(0.1)
# Automatically track dependent Observables
self.total = Observable.compute(
lambda: int(
self.price.value
* self.quantity.value
* (1 - self.discount.value)
* (1 + self.tax_rate.value)
)
)
```
Here are the APIs available in Observable and points on how to use them.
**Basic Operations:**
- **`.value`**: Get/set the current value of the Observable
- **`.subscribe(callback)`**: Observe value changes and execute a callback when changed
**Transformation / Combination:**
- **`.map(fn)`**: Transform a single Observable (e.g., number -> string)
- **`.combine(other)`**: Combine two Observables
- **`combine(a, b, ...)`**: Combine 3 or more Observables
- **`Observable.compute(fn)`**: When there is complex logic such as conditional branching, or when automatic dependency tracking is convenient
**Timing Control:**
- **`.debounce(seconds)`**: Notify only if the value has not changed for the specified number of seconds (search input, form validation, etc.)
- **`.throttle(seconds)`**: Notify the first value immediately, then notify at most once every specified number of seconds (mouse tracking, scroll position, etc.)
**Thread Control:**
- **`.dispatch_to_ui()`**: Dispatch value change notifications to the UI thread in a multi-threaded environment
## 4. License
Nuiitivet is licensed under the Apache License 2.0. See the LICENSE file for more info.
## Appendix: README Samples
All README examples are available as runnable modules under `src/samples/`.
| text/markdown | null | Yukinobu Imai <kotatu.kotatu@gmail.com> | null | null | null | ui, desktop, framework, graphics, opengl, skia, material design | [
"Intended Audience :: Developers",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Operating System :: Microsoft :: Windows",
"Topic :: Software ... | [] | null | null | >=3.10 | [] | [] | [] | [
"material-color-utilities<=0.2.6",
"pyglet>=2.1.11",
"pyopengl>=3.1.10",
"skia-python>=138.0"
] | [] | [] | [] | [
"Changelog, https://github.com/yuksblog/nuiitivet/releases",
"Documentation, https://yuksblog.github.io/nuiitivet/",
"Homepage, https://github.com/yuksblog/nuiitivet",
"Issues, https://github.com/yuksblog/nuiitivet/issues",
"Repository, https://github.com/yuksblog/nuiitivet"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-18T10:36:01.017143 | nuiitivet-0.3.0.tar.gz | 16,443,721 | 65/bf/83b85c3aa9e7fea5432c1f6f1b845e323c92a5519ed5aa43d798b7ad1bfb/nuiitivet-0.3.0.tar.gz | source | sdist | null | false | 9cc7f2834c22593b444d9a8d29f3aabf | f408349b05e3dc944ba8d1941a7fc615a01a94d61e6c5c792a4e32a2164de078 | 65bf83b85c3aa9e7fea5432c1f6f1b845e323c92a5519ed5aa43d798b7ad1bfb | Apache-2.0 | [
"LICENSE",
"LICENSES/material-color-utilities-LICENSE.txt",
"LICENSES/pyglet-LICENSE.txt",
"LICENSES/pyopengl-LICENSE.txt",
"LICENSES/skia-python-LICENSE.txt"
] | 249 |
2.4 | praisonaiagents | 1.5.15 | Praison AI agents for completing complex tasks with Self Reflection Agents | <p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="docs/logo/dark.png" />
<source media="(prefers-color-scheme: light)" srcset="docs/logo/light.png" />
<img alt="PraisonAI Logo" src="docs/logo/light.png" />
</picture>
</p>
<!-- mcp-name: io.github.MervinPraison/praisonai -->
<p align="center">
<a href="https://github.com/MervinPraison/PraisonAI"><img src="https://static.pepy.tech/badge/PraisonAI" alt="Total Downloads" /></a>
<a href="https://github.com/MervinPraison/PraisonAI"><img src="https://img.shields.io/github/v/release/MervinPraison/PraisonAI" alt="Latest Stable Version" /></a>
<a href="https://github.com/MervinPraison/PraisonAI"><img src="https://img.shields.io/badge/License-MIT-yellow.svg" alt="License" /></a>
<a href="https://registry.modelcontextprotocol.io/servers/io.github.MervinPraison/praisonai"><img src="https://img.shields.io/badge/MCP-Registry-blue" alt="MCP Registry" /></a>
</p>
<div align="center">
# Praison AI
<a href="https://trendshift.io/repositories/9130" target="_blank"><img src="https://trendshift.io/api/badge/repositories/9130" alt="MervinPraison%2FPraisonAI | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
</div>
PraisonAI is a production-ready Multi-AI Agents framework with self-reflection, designed to create AI Agents to automate and solve problems ranging from simple tasks to complex challenges. It provides a low-code solution to streamline the building and management of multi-agent LLM systems, emphasising simplicity, customisation, and effective human-agent collaboration.
<div align="center">
<a href="https://docs.praison.ai">
<p align="center">
<img src="https://img.shields.io/badge/📚_Documentation-Visit_docs.praison.ai-blue?style=for-the-badge&logo=bookstack&logoColor=white" alt="Documentation" />
</p>
</a>
</div>
---
> **Quick Paths:**
> - 🆕 **New here?** → [Quick Start](#-quick-start) *(1 minute to first agent)*
> - 📦 **Installing?** → [Installation](#-installation)
> - 🐍 **Python SDK?** → [Python Examples](#-using-python-code)
> - 🎯 **CLI user?** → [CLI Quick Reference](#cli-quick-reference)
> - 🔧 **Need config?** → [Configuration](#-configuration--integration)
> - 🤝 **Contributing?** → [Development](#-development)
---
## 📑 Table of Contents
<details open>
<summary><strong>Getting Started</strong></summary>
- [🚀 Quick Start](#-quick-start)
- [📦 Installation](#-installation)
- [⚡ Performance](#-performance)
</details>
<details>
<summary><strong>Python SDK</strong></summary>
- [📘 Python Examples](#-using-python-code)
- [1. Single Agent](#1-single-agent) | [2. Multi Agents](#2-multi-agents) | [3. Planning Mode](#3-agent-with-planning-mode)
- [4. Deep Research](#4-deep-research-agent) | [5. Query Rewriter](#5-query-rewriter-agent) | [6. Agent Memory](#6-agent-memory-zero-dependencies)
- [7. Rules & Instructions](#7-rules--instructions) | [8. Auto-Generated Memories](#8-auto-generated-memories) | [9. Agentic Workflows](#9-agentic-workflows)
- [10. Hooks](#10-hooks) | [11. Shadow Git Checkpoints](#11-shadow-git-checkpoints) | [12. Background Tasks](#12-background-tasks)
- [13. Policy Engine](#13-policy-engine) | [14. Thinking Budgets](#14-thinking-budgets) | [15. Output Styles](#15-output-styles)
- [16. Context Compaction](#16-context-compaction) | [17. Field Names Reference](#17-field-names-reference-a-i-g-s) | [18. Extended agents.yaml](#18-extended-agentsyaml-with-workflow-patterns)
- [19. MCP Protocol](#19-mcp-model-context-protocol) | [20. A2A Protocol](#20-a2a-agent2agent-protocol)
- [🛠️ Custom Tools](#️-custom-tools)
</details>
<details>
<summary><strong>JavaScript SDK</strong></summary>
- [💻 JavaScript Examples](#-using-javascript-code)
</details>
<details>
<summary><strong>CLI Reference</strong></summary>
- [🎯 CLI Overview](#-cli--no-code-interface) | [CLI Quick Reference](#cli-quick-reference)
- [Auto Mode](#auto-mode) | [Interactive Mode](#interactive-mode-cli) | [Deep Research CLI](#deep-research-cli) | [Planning Mode CLI](#planning-mode-cli)
- [Memory CLI](#memory-cli) | [Workflow CLI](#workflow-cli) | [Knowledge CLI](#knowledge-cli) | [Session CLI](#session-cli)
- [Tools CLI](#tools-cli) | [MCP Config CLI](#mcp-config-cli) | [External Agents CLI](#external-agents-cli) | [CLI Features Summary](#cli-features)
</details>
<details>
<summary><strong>Configuration & Features</strong></summary>
- [✨ Key Features](#-key-features) | [🌐 Supported Providers](#-supported-providers)
- [🔧 Configuration & Integration](#-configuration--integration) | [Ollama](#ollama-integration) | [Groq](#groq-integration) | [100+ Models](#100-models-support)
- [📋 Agents Playbook](#-agents-playbook)
- [🔬 Advanced Features](#-advanced-features)
</details>
<details>
<summary><strong>Architecture & Patterns</strong></summary>
- [📊 Process Types & Patterns](#-process-types--patterns)
- [Sequential](#sequential-process) | [Hierarchical](#hierarchical-process) | [Workflow](#workflow-process) | [Agentic Patterns](#agentic-patterns)
</details>
<details>
<summary><strong>Data & Persistence</strong></summary>
- [💾 Persistence (Databases)](#-persistence-databases)
- [📚 Knowledge & Retrieval (RAG)](#-knowledge--retrieval-rag)
- [🔧 Tools Table](#-tools-table)
</details>
<details>
<summary><strong>Learning & Community</strong></summary>
- [🎓 Video Tutorials](#-video-tutorials) | [⭐ Star History](#-star-history)
- [👥 Contributing](#-contributing) | [🔧 Development](#-development) | [❓ FAQ & Troubleshooting](#-faq--troubleshooting)
</details>
---
## ⚡ Performance
PraisonAI Agents is the **fastest AI agent framework** for agent instantiation.
| Framework | Avg Time (μs) | Relative |
|-----------|---------------|----------|
| **PraisonAI** | **3.77** | **1.00x (fastest)** |
| OpenAI Agents SDK | 5.26 | 1.39x |
| Agno | 5.64 | 1.49x |
| PraisonAI (LiteLLM) | 7.56 | 2.00x |
| PydanticAI | 226.94 | 60.16x |
| LangGraph | 4,558.71 | 1,209x |
<details>
<summary>Run benchmarks yourself</summary>
```bash
cd praisonai-agents
python benchmarks/simple_benchmark.py
```
</details>
---
## 🚀 Quick Start
Get started with PraisonAI in under 1 minute:
```bash
# Install
pip install praisonaiagents
# Set API key
export OPENAI_API_KEY=your_key_here
# Create a simple agent
python -c "from praisonaiagents import Agent; Agent(instructions='You are a helpful AI assistant').start('Write a haiku about AI')"
```
> **Next Steps:** [Single Agent Example](#1-single-agent) | [Multi Agents](#2-multi-agents) | [CLI Auto Mode](#auto-mode)
---
## 📦 Installation
### Python SDK
Lightweight package dedicated for coding:
```bash
pip install praisonaiagents
```
For the full framework with CLI support:
```bash
pip install praisonai
```
### JavaScript SDK
```bash
npm install praisonai
```
### Environment Variables
| Variable | Required | Description |
|----------|----------|-------------|
| `OPENAI_API_KEY` | Yes* | OpenAI API key |
| `ANTHROPIC_API_KEY` | No | Anthropic Claude API key |
| `GOOGLE_API_KEY` | No | Google Gemini API key |
| `GROQ_API_KEY` | No | Groq API key |
| `OPENAI_BASE_URL` | No | Custom API endpoint (for Ollama, Groq, etc.) |
> *At least one LLM provider API key is required.
```bash
# Set your API key
export OPENAI_API_KEY=your_key_here
# For Ollama (local models)
export OPENAI_BASE_URL=http://localhost:11434/v1
# For Groq
export OPENAI_API_KEY=your_groq_key
export OPENAI_BASE_URL=https://api.groq.com/openai/v1
```
---
## ✨ Key Features
<details open>
<summary><strong>🤖 Core Agents</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Single Agent | [Example](examples/python/agents/single-agent.py) | [📖](https://docs.praison.ai/agents/single) |
| Multi Agents | [Example](examples/python/general/mini_agents_example.py) | [📖](https://docs.praison.ai/concepts/agents) |
| Auto Agents | [Example](examples/python/general/auto_agents_example.py) | [📖](https://docs.praison.ai/features/autoagents) |
| Self Reflection AI Agents | [Example](examples/python/concepts/self-reflection-details.py) | [📖](https://docs.praison.ai/features/selfreflection) |
| Reasoning AI Agents | [Example](examples/python/concepts/reasoning-extraction.py) | [📖](https://docs.praison.ai/features/reasoning) |
| Multi Modal AI Agents | [Example](examples/python/general/multimodal.py) | [📖](https://docs.praison.ai/features/multimodal) |
</details>
<details>
<summary><strong>🔄 Workflows</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Simple Workflow | [Example](examples/python/workflows/simple_workflow.py) | [📖](https://docs.praison.ai/features/workflows) |
| Workflow with Agents | [Example](examples/python/workflows/workflow_with_agents.py) | [📖](https://docs.praison.ai/features/workflows) |
| Agentic Routing (`route()`) | [Example](examples/python/workflows/workflow_routing.py) | [📖](https://docs.praison.ai/features/routing) |
| Parallel Execution (`parallel()`) | [Example](examples/python/workflows/workflow_parallel.py) | [📖](https://docs.praison.ai/features/parallelisation) |
| Loop over List/CSV (`loop()`) | [Example](examples/python/workflows/workflow_loop_csv.py) | [📖](https://docs.praison.ai/features/repetitive) |
| Evaluator-Optimizer (`repeat()`) | [Example](examples/python/workflows/workflow_repeat.py) | [📖](https://docs.praison.ai/features/evaluator-optimiser) |
| Conditional Steps | [Example](examples/python/workflows/workflow_conditional.py) | [📖](https://docs.praison.ai/features/workflows) |
| Workflow Branching | [Example](examples/python/workflows/workflow_branching.py) | [📖](https://docs.praison.ai/features/workflows) |
| Workflow Early Stop | [Example](examples/python/workflows/workflow_early_stop.py) | [📖](https://docs.praison.ai/features/workflows) |
| Workflow Checkpoints | [Example](examples/python/workflows/workflow_checkpoints.py) | [📖](https://docs.praison.ai/features/workflows) |
</details>
<details>
<summary><strong>💻 Code & Development</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Code Interpreter Agents | [Example](examples/python/agents/code-agent.py) | [📖](https://docs.praison.ai/features/codeagent) |
| AI Code Editing Tools | [Example](examples/python/code/code_editing_example.py) | [📖](https://docs.praison.ai/code/editing) |
| External Agents (All) | [Example](examples/python/code/external_agents_example.py) | [📖](https://docs.praison.ai/code/external-agents) |
| Claude Code CLI | [Example](examples/python/code/claude_code_example.py) | [📖](https://docs.praison.ai/code/claude-code) |
| Gemini CLI | [Example](examples/python/code/gemini_cli_example.py) | [📖](https://docs.praison.ai/code/gemini-cli) |
| Codex CLI | [Example](examples/python/code/codex_cli_example.py) | [📖](https://docs.praison.ai/code/codex-cli) |
| Cursor CLI | [Example](examples/python/code/cursor_cli_example.py) | [📖](https://docs.praison.ai/code/cursor-cli) |
</details>
<details>
<summary><strong>🧠 Memory & Knowledge</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Memory (Short & Long Term) | [Example](examples/python/general/memory_example.py) | [📖](https://docs.praison.ai/concepts/memory) |
| File-Based Memory | [Example](examples/python/general/memory_example.py) | [📖](https://docs.praison.ai/concepts/memory) |
| Claude Memory Tool | [Example](#claude-memory-tool-cli) | [📖](https://docs.praison.ai/features/claude-memory-tool) |
| Add Custom Knowledge | [Example](examples/python/concepts/knowledge-agents.py) | [📖](https://docs.praison.ai/features/knowledge) |
| RAG Agents | [Example](examples/python/concepts/rag-agents.py) | [📖](https://docs.praison.ai/features/rag) |
| Chat with PDF Agents | [Example](examples/python/concepts/chat-with-pdf.py) | [📖](https://docs.praison.ai/features/chat-with-pdf) |
| Data Readers (PDF, DOCX, etc.) | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-readers-api) |
| Vector Store Selection | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-vector-store-api) |
| Retrieval Strategies | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-retrieval-api) |
| Rerankers | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-reranker-api) |
| Index Types (Vector/Keyword/Hybrid) | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-index-api) |
| Query Engines (Sub-Question, etc.) | [CLI](#knowledge-cli) | [📖](https://docs.praison.ai/api/praisonai/knowledge-query-engine-api) |
</details>
<details>
<summary><strong>🔬 Research & Intelligence</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Deep Research Agents | [Example](examples/python/agents/research-agent.py) | [📖](https://docs.praison.ai/agents/deep-research) |
| Query Rewriter Agent | [Example](#5-query-rewriter-agent) | [📖](https://docs.praison.ai/agents/query-rewriter) |
| Native Web Search | [Example](examples/python/agents/websearch-agent.py) | [📖](https://docs.praison.ai/agents/websearch) |
| Built-in Search Tools | [Example](examples/python/agents/websearch-agent.py) | [📖](https://docs.praison.ai/tools/tavily) |
| Unified Web Search | [Example](src/praisonai-agents/examples/web_search_example.py) | [📖](https://docs.praison.ai/tools/web-search) |
| Web Fetch (Anthropic) | [Example](#web-search-web-fetch--prompt-caching) | [📖](https://docs.praison.ai/features/model-capabilities) |
</details>
<details>
<summary><strong>📋 Planning & Execution</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Planning Mode | [Example](examples/python/agents/planning-agent.py) | [📖](https://docs.praison.ai/features/planning-mode) |
| Planning Tools | [Example](#3-agent-with-planning-mode) | [📖](https://docs.praison.ai/features/planning-mode) |
| Planning Reasoning | [Example](#3-agent-with-planning-mode) | [📖](https://docs.praison.ai/features/planning-mode) |
| Prompt Chaining | [Example](examples/python/general/prompt_chaining.py) | [📖](https://docs.praison.ai/features/promptchaining) |
| Evaluator Optimiser | [Example](examples/python/general/evaluator-optimiser.py) | [📖](https://docs.praison.ai/features/evaluator-optimiser) |
| Orchestrator Workers | [Example](examples/python/general/orchestrator-workers.py) | [📖](https://docs.praison.ai/features/orchestrator-worker) |
</details>
<details>
<summary><strong>👥 Specialized Agents</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Data Analyst Agent | [Example](examples/python/agents/data-analyst-agent.py) | [📖](https://docs.praison.ai/agents/data-analyst) |
| Finance Agent | [Example](examples/python/agents/finance-agent.py) | [📖](https://docs.praison.ai/agents/finance) |
| Shopping Agent | [Example](examples/python/agents/shopping-agent.py) | [📖](https://docs.praison.ai/agents/shopping) |
| Recommendation Agent | [Example](examples/python/agents/recommendation-agent.py) | [📖](https://docs.praison.ai/agents/recommendation) |
| Wikipedia Agent | [Example](examples/python/agents/wikipedia-agent.py) | [📖](https://docs.praison.ai/agents/wikipedia) |
| Programming Agent | [Example](examples/python/agents/programming-agent.py) | [📖](https://docs.praison.ai/agents/programming) |
| Math Agents | [Example](examples/python/agents/math-agent.py) | [📖](https://docs.praison.ai/features/mathagent) |
| Markdown Agent | [Example](examples/python/agents/markdown-agent.py) | [📖](https://docs.praison.ai/agents/markdown) |
| Prompt Expander Agent | [Example](#prompt-expansion) | [📖](https://docs.praison.ai/agents/prompt-expander) |
</details>
<details>
<summary><strong>🎨 Media & Multimodal</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Image Generation Agent | [Example](examples/python/image/image-agent.py) | [📖](https://docs.praison.ai/features/image-generation) |
| Image to Text Agent | [Example](examples/python/agents/image-to-text-agent.py) | [📖](https://docs.praison.ai/agents/image-to-text) |
| Video Agent | [Example](examples/python/agents/video-agent.py) | [📖](https://docs.praison.ai/agents/video) |
| Camera Integration | [Example](examples/python/camera/) | [📖](https://docs.praison.ai/features/camera-integration) |
</details>
<details>
<summary><strong>🔌 Protocols & Integration</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| MCP Transports | [Example](examples/python/mcp/mcp-transports-overview.py) | [📖](https://docs.praison.ai/mcp/transports) |
| WebSocket MCP | [Example](examples/python/mcp/websocket-mcp.py) | [📖](https://docs.praison.ai/mcp/sse-transport) |
| MCP Security | [Example](examples/python/mcp/mcp-security.py) | [📖](https://docs.praison.ai/mcp/transports) |
| MCP Resumability | [Example](examples/python/mcp/mcp-resumability.py) | [📖](https://docs.praison.ai/mcp/sse-transport) |
| MCP Config Management | [Example](#mcp-config-cli) | [📖](https://docs.praison.ai/docs/cli/mcp) |
| LangChain Integrated Agents | [Example](examples/python/general/langchain_example.py) | [📖](https://docs.praison.ai/features/langchain) |
</details>
<details>
<summary><strong>🛡️ Safety & Control</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Guardrails | [Example](examples/python/guardrails/comprehensive-guardrails-example.py) | [📖](https://docs.praison.ai/features/guardrails) |
| Human Approval | [Example](examples/python/general/human_approval_example.py) | [📖](https://docs.praison.ai/features/approval) |
| Rules & Instructions | [Example](#7-rules--instructions) | [📖](https://docs.praison.ai/features/rules) |
</details>
<details>
<summary><strong>⚙️ Advanced Features</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Async & Parallel Processing | [Example](examples/python/general/async_example.py) | [📖](https://docs.praison.ai/features/async) |
| Parallelisation | [Example](examples/python/general/parallelisation.py) | [📖](https://docs.praison.ai/features/parallelisation) |
| Repetitive Agents | [Example](examples/python/concepts/repetitive-agents.py) | [📖](https://docs.praison.ai/features/repetitive) |
| Agent Handoffs | [Example](examples/python/handoff/handoff_basic.py) | [📖](https://docs.praison.ai/features/handoffs) |
| Stateful Agents | [Example](examples/python/stateful/workflow-state-example.py) | [📖](https://docs.praison.ai/features/stateful-agents) |
| Autonomous Workflow | [Example](examples/python/general/autonomous-agent.py) | [📖](https://docs.praison.ai/features/autonomous-workflow) |
| Structured Output Agents | [Example](examples/python/general/structured_agents_example.py) | [📖](https://docs.praison.ai/features/structured) |
| Model Router | [Example](examples/python/agents/router-agent-cost-optimization.py) | [📖](https://docs.praison.ai/features/model-router) |
| Prompt Caching | [Example](#web-search-web-fetch--prompt-caching) | [📖](https://docs.praison.ai/features/model-capabilities) |
| Fast Context | [Example](examples/context/00_agent_fast_context_basic.py) | [📖](https://docs.praison.ai/features/fast-context) |
</details>
<details>
<summary><strong>🛠️ Tools & Configuration</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| 100+ Custom Tools | [Example](examples/python/general/tools_example.py) | [📖](https://docs.praison.ai/tools/tools) |
| YAML Configuration | [Example](examples/cookbooks/yaml/secondary_market_research_agents.yaml) | [📖](https://docs.praison.ai/developers/agents-playbook) |
| 100+ LLM Support | [Example](examples/python/providers/openai/openai_gpt4_example.py) | [📖](https://docs.praison.ai/models) |
| Callback Agents | [Example](examples/python/general/advanced-callback-systems.py) | [📖](https://docs.praison.ai/features/callbacks) |
| Hooks | [Example](#10-hooks) | [📖](https://docs.praison.ai/features/hooks) |
| Middleware System | [Example](examples/middleware/basic_middleware.py) | [📖](https://docs.praison.ai/features/middleware) |
| Configurable Model | [Example](examples/middleware/configurable_model.py) | [📖](https://docs.praison.ai/features/configurable-model) |
| Rate Limiter | [Example](examples/middleware/rate_limiter.py) | [📖](https://docs.praison.ai/features/rate-limiter) |
| Injected Tool State | [Example](examples/middleware/injected_state.py) | [📖](https://docs.praison.ai/features/injected-state) |
| Shadow Git Checkpoints | [Example](#11-shadow-git-checkpoints) | [📖](https://docs.praison.ai/features/checkpoints) |
| Background Tasks | [Example](examples/background/basic_background.py) | [📖](https://docs.praison.ai/features/background-tasks) |
| Policy Engine | [Example](examples/policy/basic_policy.py) | [📖](https://docs.praison.ai/features/policy-engine) |
| Thinking Budgets | [Example](examples/thinking/basic_thinking.py) | [📖](https://docs.praison.ai/features/thinking-budgets) |
| Output Styles | [Example](examples/output/basic_output.py) | [📖](https://docs.praison.ai/features/output-styles) |
| Context Compaction | [Example](examples/compaction/basic_compaction.py) | [📖](https://docs.praison.ai/features/context-compaction) |
</details>
<details>
<summary><strong>📊 Monitoring & Management</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Sessions Management | [Example](examples/python/sessions/comprehensive-session-management.py) | [📖](https://docs.praison.ai/features/sessions) |
| Auto-Save Sessions | [Example](#session-management-python) | [📖](https://docs.praison.ai/docs/cli/session) |
| History in Context | [Example](#session-management-python) | [📖](https://docs.praison.ai/docs/cli/session) |
| Telemetry | [Example](examples/python/telemetry/production-telemetry-example.py) | [📖](https://docs.praison.ai/features/telemetry) |
| Project Docs (.praison/docs/) | [Example](#docs-cli) | [📖](https://docs.praison.ai/docs/cli/docs) |
| AI Commit Messages | [Example](#ai-commit-cli) | [📖](https://docs.praison.ai/docs/cli/commit) |
| @Mentions in Prompts | [Example](#mentions-in-prompts) | [📖](https://docs.praison.ai/docs/cli/mentions) |
</details>
<details>
<summary><strong>🖥️ CLI Features</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Slash Commands | [Example](examples/python/cli/slash_commands_example.py) | [📖](https://docs.praison.ai/docs/cli/slash-commands) |
| Autonomy Modes | [Example](examples/python/cli/autonomy_modes_example.py) | [📖](https://docs.praison.ai/docs/cli/autonomy-modes) |
| Cost Tracking | [Example](examples/python/cli/cost_tracking_example.py) | [📖](https://docs.praison.ai/docs/cli/cost-tracking) |
| Repository Map | [Example](examples/python/cli/repo_map_example.py) | [📖](https://docs.praison.ai/docs/cli/repo-map) |
| Interactive TUI | [Example](examples/python/cli/interactive_tui_example.py) | [📖](https://docs.praison.ai/docs/cli/interactive-tui) |
| Git Integration | [Example](examples/python/cli/git_integration_example.py) | [📖](https://docs.praison.ai/docs/cli/git-integration) |
| Sandbox Execution | [Example](examples/python/cli/sandbox_execution_example.py) | [📖](https://docs.praison.ai/docs/cli/sandbox-execution) |
| CLI Compare | [Example](examples/compare/cli_compare_basic.py) | [📖](https://docs.praison.ai/docs/cli/compare) |
| Profile/Benchmark | [Example](#profile-benchmark) | [📖](https://docs.praison.ai/docs/cli/profile) |
| Auto Mode | [Example](#auto-mode) | [📖](https://docs.praison.ai/docs/cli/auto) |
| Init | [Example](#init) | [📖](https://docs.praison.ai/docs/cli/init) |
| File Input | [Example](#file-input) | [📖](https://docs.praison.ai/docs/cli/file-input) |
| Final Agent | [Example](#final-agent) | [📖](https://docs.praison.ai/docs/cli/final-agent) |
| Max Tokens | [Example](#max-tokens) | [📖](https://docs.praison.ai/docs/cli/max-tokens) |
</details>
<details>
<summary><strong>🧪 Evaluation</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Accuracy Evaluation | [Example](examples/eval/accuracy_example.py) | [📖](https://docs.praison.ai/docs/cli/eval) |
| Performance Evaluation | [Example](examples/eval/performance_example.py) | [📖](https://docs.praison.ai/docs/cli/eval) |
| Reliability Evaluation | [Example](examples/eval/reliability_example.py) | [📖](https://docs.praison.ai/docs/cli/eval) |
| Criteria Evaluation | [Example](examples/eval/criteria_example.py) | [📖](https://docs.praison.ai/docs/cli/eval) |
</details>
<details>
<summary><strong>🎯 Agent Skills</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Skills Management | [Example](examples/skills/basic_skill_usage.py) | [📖](https://docs.praison.ai/features/skills) |
| Custom Skills | [Example](examples/skills/custom_skill_example.py) | [📖](https://docs.praison.ai/features/skills) |
</details>
<details>
<summary><strong>⏰ 24/7 Scheduling</strong></summary>
| Feature | Code | Docs |
|---------|:----:|:----:|
| Agent Scheduler | [Example](examples/python/scheduled_agents/news_checker_live.py) | [📖](https://docs.praison.ai/docs/cli/scheduler) |
</details>
---
## 🌐 Supported Providers
PraisonAI supports 100+ LLM providers through seamless integration:
<details>
<summary><strong>View all 24 providers</strong></summary>
| Provider | Example |
|----------|:-------:|
| OpenAI | [Example](examples/python/providers/openai/openai_gpt4_example.py) |
| Anthropic | [Example](examples/python/providers/anthropic/anthropic_claude_example.py) |
| Google Gemini | [Example](examples/python/providers/google/google_gemini_example.py) |
| Ollama | [Example](examples/python/providers/ollama/ollama-agents.py) |
| Groq | [Example](examples/python/providers/groq/kimi_with_groq_example.py) |
| DeepSeek | [Example](examples/python/providers/deepseek/deepseek_example.py) |
| xAI Grok | [Example](examples/python/providers/xai/xai_grok_example.py) |
| Mistral | [Example](examples/python/providers/mistral/mistral_example.py) |
| Cohere | [Example](examples/python/providers/cohere/cohere_example.py) |
| Perplexity | [Example](examples/python/providers/perplexity/perplexity_example.py) |
| Fireworks | [Example](examples/python/providers/fireworks/fireworks_example.py) |
| Together AI | [Example](examples/python/providers/together/together_ai_example.py) |
| OpenRouter | [Example](examples/python/providers/openrouter/openrouter_example.py) |
| HuggingFace | [Example](examples/python/providers/huggingface/huggingface_example.py) |
| Azure OpenAI | [Example](examples/python/providers/azure/azure_openai_example.py) |
| AWS Bedrock | [Example](examples/python/providers/aws/aws_bedrock_example.py) |
| Google Vertex | [Example](examples/python/providers/vertex/vertex_example.py) |
| Databricks | [Example](examples/python/providers/databricks/databricks_example.py) |
| Cloudflare | [Example](examples/python/providers/cloudflare/cloudflare_example.py) |
| AI21 | [Example](examples/python/providers/ai21/ai21_example.py) |
| Replicate | [Example](examples/python/providers/replicate/replicate_example.py) |
| SageMaker | [Example](examples/python/providers/sagemaker/sagemaker_example.py) |
| Moonshot | [Example](examples/python/providers/moonshot/moonshot_example.py) |
| vLLM | [Example](examples/python/providers/vllm/vllm_example.py) |
</details>
---
## 📘 Using Python Code
### 1. Single Agent
Create app.py file and add the code below:
```python
from praisonaiagents import Agent
agent = Agent(instructions="Your are a helpful AI assistant")
agent.start("Write a movie script about a robot in Mars")
```
Run:
```bash
python app.py
```
### 2. Multi Agents
Create app.py file and add the code below:
```python
from praisonaiagents import Agent, Agents
research_agent = Agent(instructions="Research about AI")
summarise_agent = Agent(instructions="Summarise research agent's findings")
agents = Agents(agents=[research_agent, summarise_agent])
agents.start()
```
Run:
```bash
python app.py
```
### 3. Agent with Planning Mode
Enable planning for any agent - the agent creates a plan, then executes step by step:
```python
from praisonaiagents import Agent
def search_web(query: str) -> str:
return f"Search results for: {query}"
agent = Agent(
name="AI Assistant",
instructions="Research and write about topics",
planning=True, # Enable planning mode
planning_tools=[search_web], # Tools for planning research
planning_reasoning=True # Chain-of-thought reasoning
)
result = agent.start("Research AI trends in 2025 and write a summary")
```
**What happens:**
1. 📋 Agent creates a multi-step plan
2. 🚀 Executes each step sequentially
3. 📊 Shows progress with context passing
4. ✅ Returns final result
### 4. Deep Research Agent
Automated research with real-time streaming, web search, and citations using OpenAI or Gemini Deep Research APIs.
```python
from praisonaiagents import DeepResearchAgent
# OpenAI Deep Research
agent = DeepResearchAgent(
model="o4-mini-deep-research", # or "o3-deep-research"
verbose=True
)
result = agent.research("What are the latest AI trends in 2025?")
print(result.report)
print(f"Citations: {len(result.citations)}")
```
```python
# Gemini Deep Research
from praisonaiagents import DeepResearchAgent
agent = DeepResearchAgent(
model="deep-research-pro", # Auto-detected as Gemini
verbose=True
)
result = agent.research("Research quantum computing advances")
print(result.report)
```
**Features:**
- 🔍 Multi-provider support (OpenAI, Gemini, LiteLLM)
- 📡 Real-time streaming with reasoning summaries
- 📚 Structured citations with URLs
- 🛠️ Built-in tools: web search, code interpreter, MCP, file search
- 🔄 Automatic provider detection from model name
### 5. Query Rewriter Agent
Transform user queries to improve RAG retrieval quality using multiple strategies.
```python
from praisonaiagents import QueryRewriterAgent, RewriteStrategy
agent = QueryRewriterAgent(model="gpt-4o-mini")
# Basic - expands abbreviations, adds context
result = agent.rewrite("AI trends")
print(result.primary_query) # "What are the current trends in Artificial Intelligence?"
# HyDE - generates hypothetical document for semantic matching
result = agent.rewrite("What is quantum computing?", strategy=RewriteStrategy.HYDE)
# Step-back - generates broader context question
result = agent.rewrite("GPT-4 vs Claude 3?", strategy=RewriteStrategy.STEP_BACK)
# Sub-queries - decomposes complex questions
result = agent.rewrite("RAG setup and best embedding models?", strategy=RewriteStrategy.SUB_QUERIES)
# Contextual - resolves references using chat history
result = agent.rewrite("What about cost?", chat_history=[...])
```
**Strategies:**
- **BASIC**: Expand abbreviations, fix typos, add context
- **HYDE**: Generate hypothetical document for semantic matching
- **STEP_BACK**: Generate higher-level concept questions
- **SUB_QUERIES**: Decompose multi-part questions
- **MULTI_QUERY**: Generate multiple paraphrased versions
- **CONTEXTUAL**: Resolve references using conversation history
- **AUTO**: Automatically detect best strategy
### 6. Agent Memory (Zero Dependencies)
Enable persistent memory for agents - works out of the box without any extra packages.
```python
from praisonaiagents import Agent
from praisonaiagents.memory import FileMemory
# Enable memory with a single parameter
agent = Agent(
name="Personal Assistant",
instructions="You are a helpful assistant that remembers user preferences.",
memory=True, # Enables file-based memory (no extra deps!)
user_id="user123" # Isolate memory per user
)
# Memory is automatically injected into conversations
result = agent.start("My name is John and I prefer Python")
# Agent will remember this for future conversations
```
**Memory Types:**
- **Short-term**: Rolling buffer of recent context (auto-expires)
- **Long-term**: Persistent important facts (sorted by importance)
- **Entity**: People, places, organizations with attributes
- **Episodic**: Date-based interaction history
**Advanced Features:**
```python
from praisonaiagents.memory import FileMemory
memory = FileMemory(user_id="user123")
# Session Save/Resume
memory.save_session("project_session", conversation_history=[...])
memory.resume_session("project_session")
# Context Compression
memory.compress(llm_func=lambda p: agent.chat(p), max_items=10)
# Checkpointing
memory.create_checkpoint("before_refactor", include_files=["main.py"])
memory.restore_checkpoint("before_refactor", restore_files=True)
# Slash Commands
memory.handle_command("/memory show")
memory.handle_command("/memory save my_session")
```
**Storage Options:**
| Option | Dependencies | Description |
|--------|-------------|-------------|
| `memory=True` | None | File-based JSON storage (default) |
| `memory="file"` | None | Explicit file-based storage |
| `memory="sqlite"` | Built-in | SQLite with indexing |
| `memory="chromadb"` | chromadb | Vector/semantic search |
### 7. Rules & Instructions
PraisonAI auto-discovers instruction files from your project root and git root:
| File | Description | Priority |
|------|-------------|----------|
| `PRAISON.md` | PraisonAI native instructions | High |
| `PRAISON.local.md` | Local overrides (gitignored) | Higher |
| `CLAUDE.md` | Claude Code memory file | High |
| `CLAUDE.local.md` | Local overrides (gitignored) | Higher |
| `AGENTS.md` | OpenAI Codex CLI instructions | High |
| `GEMINI.md` | Gemini CLI memory file | High |
| `.cursorrules` | Cursor IDE rules | High |
| `.windsurfrules` | Windsurf IDE rules | High |
| `.claude/rules/*.md` | Claude Code modular rules | Medium |
| `.windsurf/rules/*.md` | Windsurf modular rules | Medium |
| `.cursor/rules/*.mdc` | Cursor modular rules | Medium |
| `.praison/rules/*.md` | Workspace rules | Medium |
| `~/.praison/rules/*.md` | Global rules | Low |
```python
from praisonaiagents import Agent
# Agent auto-discovers CLAUDE.md, AGENTS.md, GEMINI.md, etc.
agent = Agent(name="Assistant", instructions="You are helpful.")
# Rules are injected into system prompt automatically
```
**@Import Syntax:**
```markdown
# CLAUDE.md
See @README for project overview
See @docs/architecture.md for system design
@~/.praison/my-preferences.md
```
**Rule File Format (with YAML frontmatter):**
```markdown
---
description: Python coding guidelines
globs: ["**/*.py"]
activation: always # always, glob, manual, ai_decision
---
# Guidelines
- Use type hints
- Follow PEP 8
```
### 8. Auto-Generated Memories
```python
from praisonaiagents.memory import FileMemory, AutoMemory
memory = FileMemory(user_id="user123")
auto = AutoMemory(memory, enabled=True)
# Automatically extracts and stores memories from conversations
memories = auto.process_interaction(
"My name is John and I prefer Python for backend work"
)
# Extracts: name="John", preference="Python for backend"
```
### 9. Agentic Workflows
Create powerful multi-agent workflows with the `Workflow` class:
```python
from praisonaiagents import Agent, Workflow
# Create agents
researcher = Agent(
name="Researcher",
role="Research Analyst",
goal="Research topics thoroughly",
instructions="Provide concise, factual information."
)
writer = Agent(
name="Writer",
role="Content Writer",
goal="Write engaging content",
instructions="Write clear, engaging content based on research."
)
# Create workflow with agents as steps
workflow = Workflow(steps=[researcher, writer])
# Run workflow - agents process sequentially
result = workflow.start("What are the benefits of AI agents?")
print(result["output"])
```
**Key Features:**
- **Agent-first** - Pass `Agent` objects directly as workflow steps
- **Pattern helpers** - Use `route()`, `parallel()`, `loop()`, `repeat()`
- **Planning mode** - Enable with `planning=True`
- **Callbacks** - Monitor with `on_step_complete`, `on_workflow_complete`
- **Async execution** - Use `workflow.astart()` for async
### Workflow Patterns (route, parallel, loop, repeat)
```python
from praisonaiagents import Agent, Workflow
from praisonaiagents.workflows import route, parallel, loop, repeat
# 1. ROUTING - Classifier agent routes to specialized agents
classifier = Agent(name="Classifier", instructions="Respond with 'technical' or 'creative'")
tech_agent = Agent(name="TechExpert", role="Technical Expert")
creative_agent = Agent(name="Creative", role="Creative Writer")
workflow = Workflow(steps=[
classifier,
route({
"technical": [tech_agent],
"creative": [creative_agent]
})
])
# 2. PARALLEL - Multiple agents work concurrently
market_agent = Agent(name="Market", role="Market Researcher")
competitor_agent = Agent(name="Competitor", role="Competitor Analyst")
aggregator = Agent(name="Aggregator", role="Synthesizer")
workflow = Workflow(steps=[
parallel([market_agent, competitor_agent]),
aggregator
])
# 3. LOOP - Agent processes each item
processor = Agent(name="Processor", role="Item Processor")
summarizer = Agent(name="Summarizer", role="Summarizer")
workflow = Workflow(
steps=[loop(processor, over="items"), summarizer],
variables={"items": ["AI", "ML", "NLP"]}
)
# 4. REPEAT - Evaluator-Optimizer pattern
generator = Agent(name="Generator", role="Content Generator")
evaluator = Agent(name="Evaluator", instructions="Say 'APPROVED' if good")
workflow = Workflow(steps=[
generator,
repeat(evaluator, until=lambda ctx: "approved" in ctx.previous_result.lower(), max_iterations=3)
])
# 5. CALLBACKS
workflow = Workflow(
steps=[researcher, writer],
on_step_complete=lambda name, r: print(f"✅ {name} done")
)
# 6. WITH PLANNING & REASONING
workflow = Workflow(
steps=[researcher, writer],
planning=True,
reasoning=True
)
# 7. ASYNC EXECUTION
result = asyncio.run(workflow.astart("input"))
# 8. STATUS TRACKING
workflow.status # "not_started" | "running" | "completed"
workflow.step_statuses # {"step1": "completed", "step2": "skipped"}
```
### YAML Workflow Template
```yaml
# .praison/workflows/research.yaml
name: Research Workflow
description: Research and write content with all patterns
agents:
researcher:
role: Research Expert
goal: Find accurate information
tools: [tavily_search, web_scraper]
writer:
role: Content Writer
goal: Write engaging content
editor:
role: Editor
goal: Polish content
steps:
# Sequential
- agent: researcher
action: Research {{topic}}
output_variable: research_data
# Routing
- name: classifier
action: Classify content type
route:
technical: [tech_handler]
creative: [creative_handler]
default: [general_handler]
# Parallel
- name: parallel_research
parallel:
- agent: researcher
action: Research market
- agent: researcher
action: Research competitors
# Loop
- agent: writer
action: Write about {{item}}
loop_over: topics
loop_var: item
# Repeat (evaluator-optimizer)
- agent: editor
action: Review and improve
repeat:
until: "quality > 8"
max_iterations: 3
# Output to file
- agent: writer
action: Write final report
output_file: output/{{topic}}_report.md
variables:
topic: AI trends
topics: [ML, NLP, Vision]
workflow:
planning: true
planning_llm: gpt-4o
memory_config:
provider: chroma
persist: true
```
### Loading YAML Workflows
```python
from praisonaiagents.workflows import YAMLWorkflowParser, WorkflowManager
# Option 1: Parse YAML string
| text/markdown | Mervin Praison | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic>=2.10.0",
"rich",
"openai>=2.0.0",
"posthog>=3.0.0",
"aiohttp>=3.8.0",
"mcp>=1.20.0; extra == \"mcp\"",
"fastapi>=0.115.0; extra == \"mcp\"",
"uvicorn>=0.34.0; extra == \"mcp\"",
"websockets>=12.0; extra == \"mcp\"",
"chromadb>=1.0.0; extra == \"memory\"",
"litellm>=1.81.0; extra == \"... | [] | [] | [] | [] | uv/0.8.22 | 2026-02-18T10:35:21.989421 | praisonaiagents-1.5.15.tar.gz | 1,209,876 | d6/46/959510dcc4e73c50be214f956ea2e1df75232120da162b1a3fc68d32a840/praisonaiagents-1.5.15.tar.gz | source | sdist | null | false | a0e375a459412c60889f4556eaad56d9 | e710f3f4dfe91239dc7cd21b59bcc548f6a964ff31a5e7e70959748b2070c984 | d646959510dcc4e73c50be214f956ea2e1df75232120da162b1a3fc68d32a840 | null | [] | 780 |
2.4 | maxsciencelib | 0.1.17 | Biblioteca de funções compartilhadas do time de Data Science da Maxpar | # MaxScienceLib
Biblioteca com funções utilitárias para a rotina de **Ciência de Dados** na **Maxpar**, focada em **produtividade**, **padronização** e **alta performance**.
## 📚 Sumário
* [Instalação e uso](#-instalação-e-uso)
* [Módulos disponíveis](#-módulos-disponíveis)
* [`leitura`](#leitura)
* [`leitura_snowflake`](#leitura_snowflake)
* [`leitura_tableau`](#leitura_tableau)
* [`leitura_fipe`](#leitura_fipe)
* [`leitura_metabase`](#leitura_metabase)
* [`upload`](#upload)
* [`upload_sharepoint`](#upload_sharepoint)
* [`tratamento`](#tratamento)
* [`media_saneada`](#media_saneada)
* [`media_saneada_groupby`](#media_saneada_groupby)
* [`agrupar_produto`](#agrupar_produto)
* [`limpar_texto`](#limpar_texto)
* [`extrair_intervalo_ano_modelo`](#extrair_intervalo_ano_modelo)
* [`machine_learning`](#machine_learning)
* [`monitorar_degradacao`](#monitorar_degradacao)
* [`feature_engineering`](#feature_engineering)
* [`escolha_variaveis`](#escolha_variaveis)
* [`time_features`](#time_features)
* [`chassi_features`](#chassi_features)
* [`analise_exploratoria`](#analise_exploratoria)
* [`relatorio_modelo`](#relatorio_modelo)
* [`plot_lift_barplot`](#plot_lift_barplot)
* [`plot_ks_colunas`](#plot_ks_colunas)
* [`plot_correlacoes`](#plot_correlacoes)
* [Licença](#licença)
* [Autores](#autores)
## Instalação e uso
Instale a biblioteca via `pip`:
```bash
pip install maxsciencelib
```
Importe os módulos no seu código:
```python
from maxsciencelib import leitura_snowflake
```
---
## Módulos disponíveis
# leitura
Módulo Python para **leitura** de dados, de forma simples, segura e perfomática, resultando em Dataframes Polars
## 🔹 `leitura_snowflake`
Função Python para leitura de dados do **Snowflake** de forma simples, segura e performática, retornando os resultados diretamente como **DataFrame Polars**.
A função abstrai toda a complexidade de conexão, autenticação via `externalbrowser` e execução de queries, permitindo que o usuário execute consultas com apenas **uma função**.
### Funcionalidades
- Conexão automática com Snowflake via `externalbrowser`
- Execução de queries SQL
- Retorno direto em **Polars DataFrame**
- Uso nativo de **Apache Arrow** (alta performance)
- Silenciamento de logs e warnings internos
- Fechamento seguro de conexão e cursor
### Requisitos
- Python **3.11+** (recomendado)
- Acesso ao Snowflake configurado no navegador
### Uso básico
```python
from leitura_snowflake import leitura_snowflake
query = """
SELECT *
FROM MINHA_TABELA
LIMIT 1000
"""
df = leitura_snowflake(
email_corporativo="nome.sobrenome@empresa.com",
token_account="abc123.us-east-1",
query=query
)
df.head()
```
O retorno será um objeto:
```python
polars.DataFrame
```
| Parâmetro | Tipo | Descrição |
| ------------------- | ----- | ------------------------------------------------- |
| `email_corporativo` | `str` | Email corporativo utilizado no login do Snowflake |
| `token_account` | `str` | Identificador da conta Snowflake |
| `query` | `str` | Query SQL a ser executada |
---
## 🔹 `leitura_tableau`
Função Python para leitura de dados do **Tableau Server** de forma simples, segura e performática, retornando os resultados diretamente como **DataFrame Polars**.
A função abstrai toda a complexidade de autenticação via **Personal Access Token**, conexão com o Tableau Server (HTTP/HTTPS) e download da view, permitindo que o usuário consuma dados com apenas **uma função**.
### Funcionalidades
* Autenticação via **Personal Access Token (PAT)**
* Conexão automática com Tableau Server (fallback HTTP → HTTPS)
* Download de views diretamente do Tableau
* Retorno direto em **Polars DataFrame**
* Leitura eficiente de CSV em memória
* Silenciamento de warnings internos
* Encerramento seguro da sessão (`sign_out`)
### Requisitos
* Python **3.10+** (recomendado)
* Acesso ao Tableau Server
* Personal Access Token ativo no Tableau
### Uso básico
```python
from maxsciencelib import leitura_tableau
df = leitura_tableau(
nome_token="meu_token_tableau",
token_acesso="XXXXXXXXXXXXXXXXXXXXXXXX",
view_id="abcd1234-efgh-5678"
)
df.head()
```
### Retorno
O retorno da função será um objeto:
```python
polars.DataFrame
```
### Parâmetros
| Parâmetro | Tipo | Descrição |
| -------------- | ----- | --------------------------------------------------- |
| `nome_token` | `str` | Nome do Personal Access Token cadastrado no Tableau |
| `token_acesso` | `str` | Token de acesso pessoal do Tableau |
| `view_id` | `str` | Identificador da view no Tableau Server |
---
## 🔹 `leitura_fipe`
Função Python para **categorização de veículos com base na Tabela FIPE**, utilizando **quantis dinâmicos por tipo de veículo** e separação entre **veículos antigos e recentes**, retornando os resultados em **Polars DataFrame**.
A função abstrai toda a lógica estatística de cálculo de quantis, tratamento de dados e categorização, permitindo que o usuário obtenha a classificação do veículo com **apenas uma função**.
### Funcionalidades
* Leitura da Tabela FIPE diretamente de arquivo Excel
* Padronização automática de colunas
* Tratamento do ano (`ZERO KM` → ano vigente)
* Criação da chave `FIPE-ANO`
* Separação automática entre:
* Veículos **antigos** (`ano < 2015`)
* Veículos **recentes** (`ano ≥ 2015`)
* Categorização baseada em quantis por tipo de veículo:
* **Antigo Popular**
* **Antigo Premium**
* **Popular**
* **Intermediário**
* **Premium**
* Processamento totalmente vetorizado em **Polars**
* Alta performance para grandes volumes de dados
* Interface simples e pronta para uso analítico
### Requisitos
* Python **3.10+** (recomendado)
* Acesso ao arquivo da Tabela FIPE
* Estrutura de colunas compatível com a base FIPE padrão
### Dependências
```bash
pip install polars pyarrow fastexcel
```
> O pacote `fastexcel` é utilizado pelo Polars para leitura eficiente de arquivos Excel.
### Uso básico
```python
from maxsciencelib import leitura_fipe
df_fipe_categoria = leitura_fipe()
df_fipe_categoria.head()
```
### Retorno
A função retorna um objeto do tipo:
```python
polars.DataFrame
```
com as seguintes colunas:
| Coluna | Descrição |
| ----------- | -------------------------------------------- |
| `fipe_ano` | Código FIPE concatenado com o ano do veículo |
| `ano` | Ano do veículo |
| `marca` | Marca do veículo |
| `modelo` | Modelo do veículo |
| `categoria` | Categoria FIPE calculada |
### Lógica de categorização
A categorização é feita **por tipo de veículo**, seguindo as regras abaixo:
#### Veículos antigos (`ano < 2015`)
| Condição | Categoria |
| ------------- | -------------- |
| `valor ≤ P60` | Antigo Popular |
| `valor > P60` | Antigo Premium |
#### Veículos recentes (`ano ≥ 2015`)
| Condição | Categoria |
| ------------------- | ------------- |
| `valor ≤ P50` | Popular |
| `P50 < valor ≤ P70` | Intermediário |
| `valor > P70` | Premium |
> Os percentis são calculados **dinamicamente por `tipo_veiculo`**.
---
## 🔹 `leitura_metabase`
Função para **consumo direto de dados do Metabase** a partir do **id** da sua view, retornando os resultados como **Polars DataFrame** de forma simples e segura.
A função abstrai todo o processo de **autenticação via API do Metabase**, gerenciamento de **sessão**, tratamento de **expiração (HTTP 401)** e conversão automática do JSON retornado para **Polars**, sendo ideal para **pipelines analíticos e análise exploratória**.
### Funcionalidades
* Autenticação automática no **Metabase API**
* Reutilização de sessão durante a execução
* Retentativa automática em caso de **sessão expirada (401)**
* Download direto de **Id** via API
* Conversão automática para **Polars DataFrame**
* Controle de timeout e número de tentativas
* Logs opcionais para acompanhamento da execução
* Tratamento robusto de erros HTTP e de requisição
### Uso básico
```python
from maxsciencelib import leitura_metabase
df = leitura_metabase(
metabase_url="http://258.23.45.15:1233",
id=123,
username="usuario_metabase",
password="senha_metabase"
)
df.head()
```
### Retorno
A função retorna:
```python
polars.DataFrame | None
```
* `polars.DataFrame` → quando a consulta é bem-sucedida
* `None` → em caso de erro de autenticação, requisição ou resposta inválida
### Parâmetros
| Parâmetro | Tipo | Descrição |
| -------------- | ------------ | ------------------------------------------------------------- |
| `metabase_url` | `str` | URL base do Metabase (ex: `https://metabase.exemplo.com`) |
| `id` | `int \| str` | ID do Metabase |
| `username` | `str` | Usuário com acesso ao Card |
| `password` | `str` | Senha do usuário do Metabase |
| `max_retries` | `int` | Número máximo de retentativas em caso de erro 401 (default=2) |
| `timeout` | `int` | Timeout das requisições HTTP em segundos (default=30) |
| `verbose` | `bool` | Exibe logs no console se `True` (default=True) |
---
# upload
Módulo Python para **upload** de dados, com foco em realizar carga e output de dados.
## Instalação
```bash
pip install maxsciencelib[upload]
```
---
## 🔹 `upload_sharepoint`
Função Python para **upload automático de arquivos no SharePoint** utilizando automação via navegador (**Selenium + Microsoft Edge**).
A função abstrai toda a complexidade de interação com a interface web do SharePoint, permitindo realizar o upload de **todos os arquivos de um diretório local** com apenas **uma chamada de função**.
> Esta funcionalidade utiliza automação de UI e depende do layout do SharePoint. Recomendada para uso interno e controlado.
### Funcionalidades
- Upload automático de múltiplos arquivos para SharePoint
- Suporte a upload em massa a partir de um diretório local
- Automação via Microsoft Edge (Selenium)
- Detecção automática de sobrescrita (`Substituir tudo`)
- Controle de timeout e tempo de espera
- Fechamento seguro do navegador
### Requisitos
- Python **3.11+** (recomendado)
- Microsoft Edge instalado
- Edge WebDriver compatível
- Acesso ao SharePoint via navegador (login manual)
### Dependências
Caso esteja usando a biblioteca `maxsciencelib` recomenda-se instalar com:
```bash
pip install maxsciencelib[upload]
```
### Uso básico
```python
from maxsciencelib import upload_sharepoint
upload_sharepoint(
url_sharepoint="https://autoglass365.sharepoint.com/sites/XXXXXXXXX/Shared%20Documents/Forms/AllItems.aspx",
diretorio=r"C:\Users\usuario\Desktop\arquivos_para_upload"
)
```
### Comportamento da função
* Todos os arquivos presentes no diretório informado serão enviados
* Caso o arquivo já exista no SharePoint, a função tentará clicar em **“Substituir tudo”**
* O navegador será fechado automaticamente ao final do processo
* Em caso de erro, a função lança exceções claras (`FileNotFoundError`, `RuntimeError`)
### Parâmetros
| Parâmetro | Tipo | Descrição |
| ------------------ | ----- | ----------------------------------------------------------------------- |
| `url_sharepoint` | `str` | URL do diretório do SharePoint onde os arquivos serão carregados |
| `diretorio` | `str` | Caminho local contendo **apenas** os arquivos a serem enviados |
| `tempo_espera_fim` | `int` | Tempo (em segundos) de espera após o upload antes de fechar o navegador |
| `timeout` | `int` | Timeout máximo (em segundos) para espera de elementos na interface |
### Retorno
```python
None
```
A função não retorna valores.
Caso ocorra algum erro durante o processo, uma exceção será lançada.
---
# tratamento
Módulo Python para **tratamento** de dados, com métricas desenvolvidas pelo time, de modo a padronizar resultados.
## Instalação
```bash
pip install maxsciencelib[tratamento]
```
---
## 🔹 `agrupar_produto`
Função Python para **padronização e agrupamento de descrições de produtos automotivos**, abstraindo regras complexas de **marca**, **lado (LE/LD)** e **casos específicos por tipo de peça**, retornando o resultado diretamente no **DataFrame original** com uma nova coluna agrupada.
A função foi desenhada para que o usuário precise chamar **apenas uma função**, informando o **DataFrame**, a **coluna de origem** e o **nome da nova coluna**, mantendo a coluna original intacta.
### Funcionalidades
* Agrupamento automático por **tipo de produto**
* Vidro
* Retrovisor
* Farol / Lanterna
* Remoção padronizada de **marca**
* Remoção padronizada de **lado (LE / LD / E / D)**
* Tratamento de **casos específicos**
* Limpeza de sufixos como:
* `EXC`
* `AMT`
* `AMT CNT`
* `AMT AER`
* Preserva a coluna original
* Compatível com valores nulos (`NaN`)
* Interface simples, orientada a **DataFrame**
* Pronta para uso em pipelines analíticos e feature engineering
### Requisitos
* Python **3.9+**
* Pandas
### Dependências
```bash
pip install pandas
```
### Uso básico
```python
from maxsciencelib import agrupar_produto
df = agrupar_produto(
df,
coluna_origem="produto_descricao",
coluna_nova="produto_agrupado"
)
df.head()
```
### Uso com controle de regras
```python
df = agrupar_produto(
df,
coluna_origem="produto_descricao",
coluna_nova="produto_agrupado",
agrupar_marca=False,
agrupar_lado=True
)
```
### Retorno
A função retorna o próprio DataFrame com a nova coluna adicionada:
```python
pandas.DataFrame
```
### Parâmetros
| Parâmetro | Tipo | Descrição |
| --------------- | --------- | -------------------------------------------------------------- |
| `df` | DataFrame | DataFrame de entrada |
| `coluna_origem` | `str` | Nome da coluna que contém a descrição original do produto |
| `coluna_nova` | `str` | Nome da nova coluna com o produto agrupado |
| `agrupar_marca` | `bool` | Remove marcas do produto (`True` por padrão) |
| `agrupar_lado` | `bool` | Remove indicação de lado (LE / LD / E / D) (`True` por padrão) |
### Regras de agrupamento (interno)
A função identifica automaticamente o tipo de produto com base na descrição:
| Tipo identificado | Regra aplicada |
| ----------------- | --------------------------------- |
| `VID` | Agrupamento de vidros |
| `RETROV` | Agrupamento de retrovisores |
| `FAROL` / `LANT` | Agrupamento de faróis e lanternas |
| Outros | Mantém a descrição original |
---
## 🔹 `media_saneada`
Função para cálculo de **média saneada**, removendo outliers de forma iterativa com base no **coeficiente de variação (CV)**, garantindo maior robustez estatística e **alto desempenho computacional**.
A implementação foi projetada para **grandes volumes de dados**, utilizando:
* **NumPy puro no caminho crítico**
* **Paralelização real por grupo (multiprocessing)**
São disponibilizadas **duas funções públicas**:
* uma função **core**, para cálculo direto sobre vetores numéricos
* uma função **groupby**, para agregações eficientes em **DataFrames Pandas**, com paralelização automática
## Funcionalidades
* Cálculo de média robusta com saneamento iterativo
* Remoção automática de outliers com base em:
* média
* desvio padrão
* coeficiente de variação (CV)
* Fallback seguro para **mediana**
* Controle de:
* número mínimo de amostras
* CV máximo permitido
* Alta performance:
* NumPy puro no loop crítico
* Paralelização por múltiplos processos
* Compatível com:
* `list`
* `numpy.ndarray`
* `pandas.Series`
* Integração nativa com **Pandas `groupby`**
### Assinatura
```python
media_saneada(
valores,
min_amostras: int = 3,
cv_max: float = 0.25
) -> float
```
### Parâmetros
| Parâmetro | Tipo | Descrição |
| -------------- | ----------------------------------- | ---------------------------------------- |
| `valores` | `list` | `np.ndarray` | `pd.Series` | Conjunto de valores numéricos |
| `min_amostras` | `int` | Número mínimo de amostras permitidas |
| `cv_max` | `float` | Coeficiente de variação máximo aceitável |
### Retorno
```python
float
```
* Retorna a **média saneada** se o CV estiver dentro do limite
* Caso contrário, retorna a **mediana** dos últimos `min_amostras` valores
* Nunca lança erro para vetores pequenos (fallback seguro)
### Uso básico
```python
from maxsciencelib import media_saneada
media = media_saneada([100, 102, 98, 500, 101])
```
---
## 🔹 `media_saneada_groupby`
Aplica a média saneada por grupo em um **DataFrame Pandas**, utilizando **paralelização por múltiplos processos** para reduzir drasticamente o tempo de execução.
### Assinatura
```python
media_saneada_groupby(
df: pd.DataFrame,
group_cols: list[str],
value_col: str,
min_amostras: int = 3,
cv_max: float = 0.25,
n_jobs: int = -1,
output_col: str = "media_saneada"
) -> pd.DataFrame
```
### Parâmetros
| Parâmetro | Tipo | Descrição |
| -------------- | -------------- | ----------------------------------------------------- |
| `df` | `pd.DataFrame` | DataFrame de entrada |
| `group_cols` | `list[str]` | Colunas de agrupamento |
| `value_col` | `str` | Coluna numérica a ser agregada |
| `min_amostras` | `int` | Número mínimo de amostras por grupo |
| `cv_max` | `float` | Coeficiente de variação máximo aceitável |
| `n_jobs` | `int` | Número de processos paralelos (`-1` = todos os cores) |
| `output_col` | `str` | Nome da coluna de saída |
### Retorno
```python
pd.DataFrame
```
DataFrame agregado contendo uma linha por grupo e a média saneada calculada.
---
### Exemplo de uso
```python
import pandas as pd
from maxsciencelib import media_saneada_groupby
df = pd.DataFrame({
"grupo": ["A", "A", "A", "A", "B", "B", "B"],
"valor": [100, 102, 98, 500, 50, 52, 51]
})
resultado = media_saneada_groupby(
df,
group_cols=["grupo"],
value_col="valor"
)
```
---
## 🔹 `limpar_texto`
Função Python para **limpeza, normalização e padronização de textos**, suportando tanto **strings individuais** quanto **colunas do Polars (`Series` ou `Expr`)**, com alta performance e reutilização em pipelines de dados.
A função abstrai todo o tratamento comum de textos — remoção de acentos, pontuações, quebras de linha, normalização de espaços e padronização de case — permitindo aplicar o mesmo padrão de limpeza **tanto em valores isolados quanto diretamente em DataFrames Polars**.
### Funcionalidades
* Limpeza de **strings individuais**
* Suporte nativo a **Polars (`Series` e `Expr`)**
* Remoção de acentos (`unidecode`)
* Remoção de quebras de linha e tags `<br>`
* Normalização de espaços
* Remoção total de pontuação ou preservação de `.` e `,`
* Padronização de **lowercase** ou **uppercase**
* Regex pré-compilados para maior performance
* Retorno consistente (`None` para strings vazias ou inválidas)
### Requisitos
* Python **3.10+**
* Biblioteca **polars**
* Biblioteca **unidecode**
### Uso básico
#### 🔸 String simples
```python
from maxsciencelib import limpar_texto
texto = "Olá, Mundo! <br> Teste de TEXTO."
resultado = limpar_texto(
texto,
case="lower",
mantem_pontuacao=False
)
print(resultado)
```
**Saída:**
```text
ola mundo teste de texto
```
#### 🔸 Coluna Polars (`Series`)
```python
import polars as pl
from maxsciencelib import limpar_texto
df = pl.DataFrame({
"descricao": [
"Peça NOVA<br>",
"Motor 2.0, Turbo!",
None
]
})
df = df.with_columns(
limpar_texto(pl.col("descricao")).alias("descricao_limpa")
)
df
```
#### 🔸 Uso em expressões (`Expr`)
```python
df = df.with_columns(
limpar_texto(
pl.col("descricao"),
case="upper",
mantem_pontuacao=True
).alias("descricao_padronizada")
)
```
### Retorno
O retorno da função será um dos tipos abaixo, dependendo da entrada:
```python
str | polars.Series | polars.Expr
```
### Parâmetros
| Parâmetro | Tipo | Descrição |
| ------------------ | ----------------------------- | ----------------------------------------------- |
| `texto` | `str \| pl.Series \| pl.Expr` | Texto ou coluna Polars a ser tratada |
| `case` | `str` | Define o case do texto (`"lower"` ou `"upper"`) |
| `mantem_pontuacao` | `bool` | Se `True`, mantém apenas `.` e `,` no texto |
---
## 🔹 `extrair_intervalo_ano_modelo`
Função Python para **extração e normalização de intervalos de ano modelo** a partir de **colunas string em Polars**, retornando **expressões (`pl.Expr`) prontas para uso em `with_columns`**.
A função identifica padrões do tipo `YY/YY` ou `YY/` (ano inicial aberto), converte corretamente para anos com quatro dígitos (`YYYY`) e trata automaticamente a virada de século, além de preencher o ano final com o **ano atual** quando necessário.
### Funcionalidades
* Extração de intervalos no formato `YY/YY`
* Suporte a intervalos abertos (`YY/`)
* Conversão automática para anos com 4 dígitos
* `>= 50` → século XX (19xx)
* `< 50` → século XXI (20xx)
* Preenchimento automático do ano final com o **ano atual**
* Retorno como **expressões Polars (`pl.Expr`)**
* Personalização dos nomes das colunas de saída
* Tratamento seguro de valores inválidos (retorno `null`)
### Requisitos
* Python **3.10+**
* Biblioteca **polars**
### Uso básico
#### 🔸 Exemplo simples
```python
import polars as pl
from maxsciencelib import extrair_intervalo_ano_modelo
df = pl.DataFrame({
"ano_modelo": ["10/18", "98/04", "15/", "abc", None]
})
df = df.with_columns(
extrair_intervalo_ano_modelo(pl.col("ano_modelo"))
)
df
```
### Uso com nomes personalizados de colunas
```python
df = df.with_columns(
extrair_intervalo_ano_modelo(
pl.col("ano_modelo"),
nome_inicio="ano_ini",
nome_fim="ano_fim"
)
)
```
### Uso com ano atual customizado
```python
df = df.with_columns(
extrair_intervalo_ano_modelo(
pl.col("ano_modelo"),
ano_atual=2023
)
)
```
### Retorno
A função retorna uma lista contendo **duas expressões Polars**:
```python
list[polars.Expr]
```
Essas expressões representam:
1. Ano modelo inicial
2. Ano modelo final
### Parâmetros
| Parâmetro | Tipo | Descrição |
| ------------- | ------------- | --------------------------------------------------------------------- |
| `col` | `pl.Expr` | Coluna string contendo o intervalo de ano modelo |
| `ano_atual` | `int \| None` | Ano usado para intervalos abertos (`YY/`). Se `None`, usa o ano atual |
| `nome_inicio` | `str` | Nome da coluna de ano modelo inicial |
| `nome_fim` | `str` | Nome da coluna de ano modelo final |
### Padrões reconhecidos
| Valor original | Ano Inicial | Ano Final |
| -------------- | ----------- | --------- |
| `"10/18"` | 2010 | 2018 |
| `"98/04"` | 1998 | 2004 |
| `"15/"` | 2015 | Ano atual |
| `"abc"` | `null` | `null` |
| `None` | `null` | `null` |
---
# feature_engineering
Módulo Python para **feature engineering**, com funçções para seleção e geração de variáveis, com métricas desenvolvidas pelo time, de modo a padronizar resultados e metodologias.
---
## 🔹 `escolha_variaveis`
A função Python para **seleção automática de variáveis** para modelagem preditiva, combinando testes estatísticos, explicabilidade via SHAP, importância por permutação e análise incremental de desempenho.
### Requisitos
* Python **3.9+**
* polars
* scikit-learn>=1.3
* lightgbm>=4.0
* shap>=0.44
* optuna>=3.4
* imbalanced-learn>=0.11
* scipy>=1.10
* joblib>=1.3
* matplotlib>=3.7
* tqdm
### Dependências
```bash
pip install maxsciencelib[feature_engineering]
```
### Uso básico
```python
pip install maxsciencelib
pip install maxsciencelib[feature_engineering]
tabela_resultado, variaveis_selecionadas = escolha_variaveis(
data = pl.from_pandas(df),
nivel= 3, #default 3
random_state = 42, #default 42
coluna_data_ref = "DATA_REFERENCIA", # data de referência caso for utilizar o split temporal
max_periodo_treino = 202401,
features = features,
target = "Fraude_new",
split_aleatorio = True, #default True
p_valor = 0.1, #default 0.05 - quanto maior, menos rígido
parametro_nivel_0 = 0.1, #default 0.1 - quanto menor, menos rígido
parametro_nivel_1 = 0.8, #default 0.1 - quanto maior, menos rígido
parametro_nivel_2 = 0.01, #default 0.0005 - quanto menor, menos rígido
parametro_nivel_3 = 0.0001, #default 0.00001 - quanto menor, menos rígido
qui_quadrado = True #default False
)
```
## Parâmetros
A documentação completa do funcionamento da função, junto com os parâmetros estão disponíveis no arquivo hmtl no caminho **R:\\Célula de Dados e Implantação\\Ciencia\\Pastas_individuais\\Elias\\Função escolha de variáveis**
---
## 🔹 `time_features`
Função para **engenharia de atributos temporais** a partir de uma coluna de timestamp, voltada para **modelagem preditiva e análise exploratória**.
A função cria automaticamente **features de data e hora**, identifica **feriados nacionais do Brasil**, adiciona **indicadores de fim de semana**, gera **encoding cíclico** (seno e cosseno) e classifica o **período do dia**, retornando um **Polars DataFrame enriquecido**.
Para mais time_features, recomenda-se a biblioteca tsfresh.
### Funcionalidades
* Extração de atributos temporais básicos (mês, dia, hora, dia da semana)
* Identificação automática de **feriados nacionais brasileiros**
* Flag de **fim de semana**
* **Encoding cíclico** para:
* Mês do ano
* Dia da semana
* Classificação do **período do dia** (madrugada, manhã, tarde, noite)
* Implementação performática com **Polars**
### Uso básico
```python
from maxsciencelib import time_features
df_feat = time_features(
df=base_eventos,
ts_col="data_evento"
)
```
### Retorno
A função retorna:
```python
polars.DataFrame
```
Com novas colunas adicionadas à base original.
### Features geradas
| Coluna | Descrição |
| --------------- | -------------------------------------------- |
| `mes` | Mês do ano (1–12) |
| `dia` | Dia do mês (1–31) |
| `dia_semana` | Dia da semana (0=Seg, …,6=Dom) |
| `hora` | Hora do dia (0–23) |
| `feriado` | Indica se a data é feriado nacional (Brasil) |
| `fim_de_semana` | Indica sábado ou domingo |
| `mes_sin` | Seno do mês (encoding cíclico) |
| `mes_cos` | Cosseno do mês (encoding cíclico) |
| `dow_sin` | Seno do dia da semana |
| `dow_cos` | Cosseno do dia da semana |
| `periodo_dia` | Madrugada / Manhã / Tarde / Noite |
### Parâmetros
| Parâmetro | Tipo | Descrição |
| --------- | ------------------ | -------------------------------------------- |
| `df` | `polars.DataFrame` | Base de dados contendo a coluna de timestamp |
| `ts_col` | `str` | Nome da coluna de data/hora |
---
Segue a **documentação da função `chassi_features`**, no **mesmo padrão das anteriores**, pronta para uso em README ou documentação da sua biblioteca.
---
## 🔹 `chassi_features`
Função Python para **extração de features estruturadas a partir do número de chassi (VIN)**, retornando informações relevantes para **análise veicular, modelagem e feature engineering**.
A função valida o VIN conforme o padrão internacional (ISO 3779), normaliza o valor e extrai automaticamente **continente/país de origem**, **fabricante (WMI)** e **ano modelo**, considerando corretamente os **ciclos de 30 anos** do código de ano do VIN.
### Funcionalidades
* Validação do VIN (17 caracteres, padrão internacional)
* Normalização automática (upper + trim)
* Extração do **continente / país de origem**
* Extração do **fabricante (WMI – World Manufacturer Identifier)**
* Cálculo correto do **ano modelo** considerando ciclos de 30 anos
* Retorno direto em **DataFrame Pandas**
* Tratamento seguro de valores inválidos (retorno `None`)
---
### Requisitos
* Python **3.10+**
* **pandas**
### Uso básico
```python
from maxsciencelib.veiculos import chassi_features
df = pd.DataFrame({
"vin": [
"9BWZZZ377VT004251",
"1HGCM82633A004352",
"vin_invalido",
None
]
})
df = chassi_features(df, col_vin="vin")
df
```
### Retorno
A função retorna o **DataFrame original enriquecido** com três novas colunas:
| Coluna | Descrição |
| ------------ | ---------------------------------------------------------------- |
| `continente` | Continente ou país de origem do veículo |
| `fabricante` | Fabricante identificado pelo WMI (3 primeiros caracteres do VIN) |
| `ano_modelo` | Ano modelo estimado a partir do VIN |
### Parâmetros
| Parâmetro | Tipo | Descrição |
| --------- | -------------- | -------------------------------------------------- |
| `df` | `pd.DataFrame` | DataFrame contendo a coluna de VIN |
| `col_vin` | `str` | Nome da coluna que contém o número de chassi (VIN) |
### Validação do VIN
A função considera válido apenas VINs que:
* Possuem exatamente **17 caracteres**
* Contêm apenas caracteres alfanuméricos permitidos
* **Excluem** letras inválidas: `I`, `O`, `Q`
VINs inválidos ou ausentes retornam `None` para todas as features.
### Ano modelo — lógica aplicada
* O **10º caractere** do VIN define o código do ano
* O código segue a sequência:
```text
ABCDEFGHJKLMNPRSTVWXY123456789
```
* O cálculo considera ciclos de **30 anos**
* O ano retornado é o **mais recente possível**, sem ultrapassar o ano atual
Exemplo:
| Código | Ano base | Anos possíveis | Ano escolhido |
| ------ | -------- | -------------- | ------------- |
| `A` | 1980 | 1980, 2010 | 2010 |
| `Y` | 2000 | 2000, 2030* | 2000 |
* Anos futuros são descartados.
---
# machine_learning
Módulo Python para **Machine Learning**, com funções relacionadas a criação e monitoramento de modelos, com métricas desenvolvidas pelo time, de modo a padronizar resultados e metodologias.
---
## 🔹 `monitorar_degradacao`
Função Python para **monitoramento de degradação de variáveis ao longo do tempo**, calculando métricas clássicas de **estabilidade e poder discriminativo** — **KS (Kolmogorov-Smirnov)** e **PSI (Population Stability Index)**.
A função percorre automaticamente todas as **variáveis numéricas** do DataFrame, calcula as métricas por período e, opcionalmente, gera **gráficos interativos em Plotly** para acompanhamento visual das variáveis mais relevantes.
### Funcionalidades
* Cálculo de **KS** por variável e período
* Cálculo de **PSI** por variável e período
* Uso do **primeiro período como base de referência** para o PSI
* Suavização temporal via **média móvel**
* Seleção automática das **variáveis numéricas**
* Exclusão de colunas indesejadas
* Monitoramento visual das **Top N variáveis**
* Gráficos interativos com **eixo duplo (KS e PSI)**
* Retorno sempre em **DataFrame Pandas**
### Requisitos
* Python **3.10+**
* **pandas**
* **numpy**
* **scipy**
* **plotly**
### Uso básico
```python
from maxsciencelib import monitorar_degradacao
df_metricas = monitorar_degradacao(
df=df_modelo,
data_col="data_ref",
target_col="target"
)
df_metricas.head()
```
### Uso com exclusão de colunas
```python
df_metricas = monitorar_degradacao(
df=df_modelo,
data_col="data_ref",
target_col="target",
excluir=["id_cliente", "score_final"]
)
```
### Uso sem geração de gráficos
```python
df_metricas = monitorar_degradacao(
df=df_modelo,
data_col="data_ref",
target_col="target",
plotar=False
)
```
### Retorno
O retorno da função será um objeto:
```python
pandas.DataFrame
```
Com as colunas:
| Coluna | Descrição |
| ---------- | ------------------------------------- |
| `periodo` | Período de referência |
| `variavel` | Nome da variável numérica |
| `KS` | Estatística KS da variável no período |
| `PSI` | Population Stability Index no período |
## 🖼️ Exemplo visual
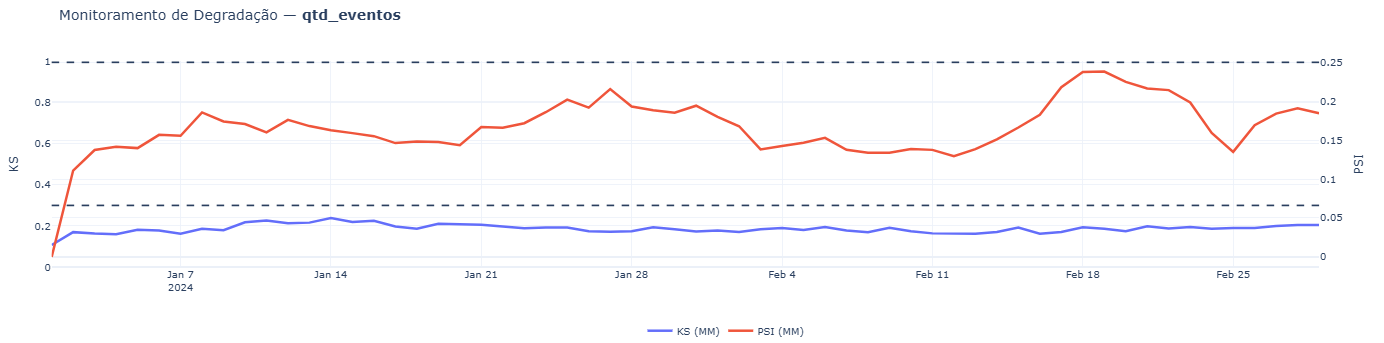
### Parâmetros
| Parâmetro | Tipo | Descrição |
| ------------ | ------------------- | ---------------------------------------------- |
| `df` | `pd.DataFrame` | DataFrame contendo os dados do modelo |
| `data_col` | `str` | Coluna de data ou período |
| `target_col` | `str` | Coluna binária do target (`0` / `1`) |
| `excluir` | `list[str] \| None` | Lista de colunas a serem excluídas da análise |
| `bins` | `int` | Número de bins usados no cálculo do PSI |
| `top_n` | `int` | Quantidade de variáveis exibidas nos gráficos |
| `window` | `int` | Janela da média móvel para suavização temporal |
| `ks_ref` | `float` | Linha de referência para KS no gráfico |
| `psi_ref` | `float` | Linha de referência para PSI no gráfico |
| `plotar` | `bool` | Se `True`, gera gráficos interativos |
### Interpretação das métricas (referência)
* **KS**
* `> 0.30` → bom poder discriminativo
* Queda consistente → possível degradação do modelo
* **PSI**
* `< 0.10` → população estável
* `0.10 – 0.25` → alerta
* `> 0.25` → mudança significativa de população
---
# analise-exploratoria
Módulo Python para **análise exploratória, avaliação e diagnóstico de modelos de classificação**, com foco em **métricas estatísticas, visualizações interpretáveis e relatórios prontos para tomada de decisão**.
O módulo abstrai cálculos comuns de avaliação de modelos (ROC, AUC, matriz de confusão, métricas clássicas, análise por decis e threshold), entregando **gráficos padronizados e relatório textual** a partir de **uma única função**.
## Instalação
```bash
pip install maxsciencelib[analise_exploratoria]
```
## Funcionalidades
Atualmente, o módulo contém:
### 🔹 `relatorio_modelo`
Função para **avaliação completa de modelos de classificação binária**, incluindo:
* Curva **ROC** e cálculo de **AUC**
* **Matriz de confusão**
* Métricas clássicas de classificação
* Distribuição de scores com **threshold configurável**
* **Precisão por decil** (análise de poder discriminatório)
* Comparação com a **taxa base**
* Relatório textual consolidado
* Visualização padronizada em um único painel (2x2)
Outras funções de análise exploratória poderão ser adicionadas ao módulo futuramente.
## 🖼️ Exemplo visual
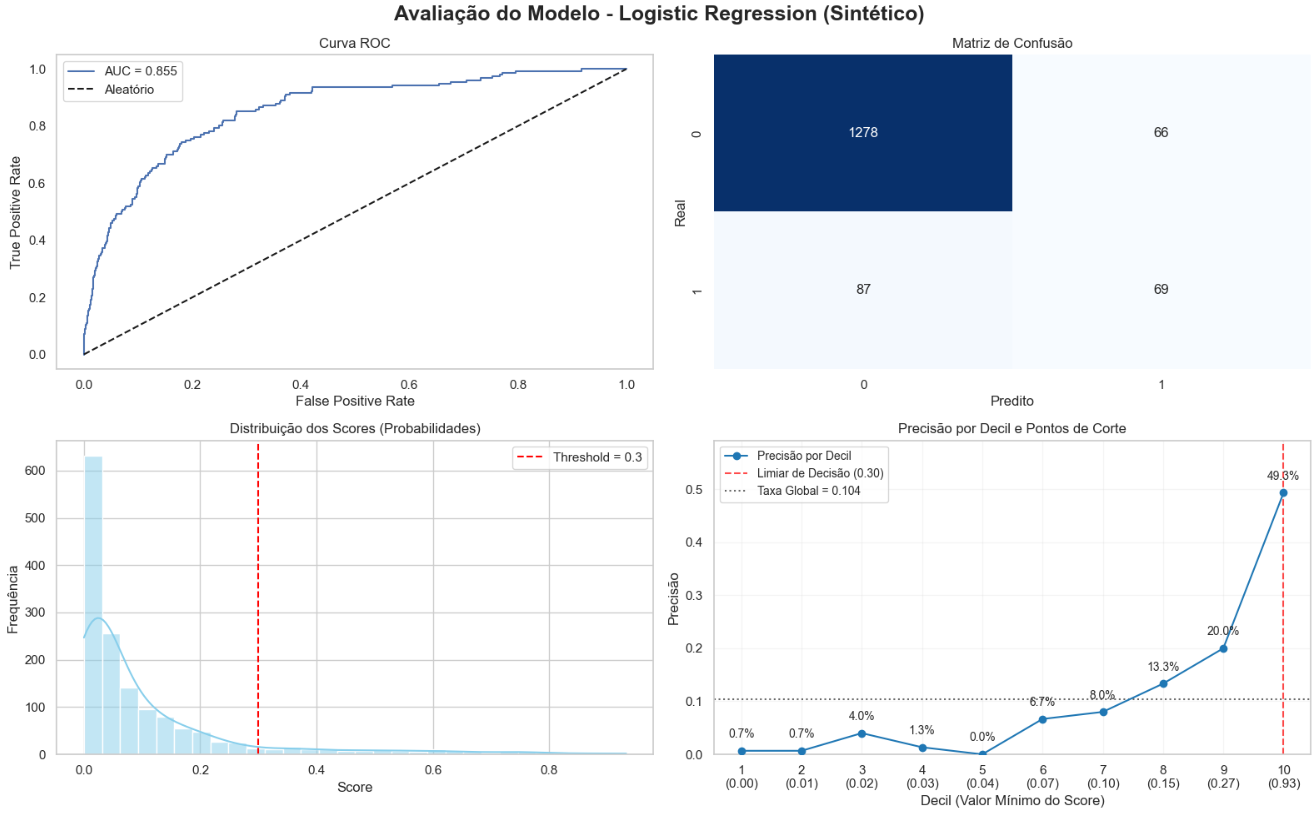
## Requisitos
* Python **3.9+** (recomendado 3.10+)
* Modelo de classificação com método `predict_proba`
Dependências principais:
* `numpy`
* `pandas`
* `matplotlib`
* `seaborn`
* `scikit-learn`
## Uso básico
```python
from maxsciencelib import relatorio_modelo
relatorio_modelo(
model=modelo_treinado,
X_test=X_test,
y_test=y_test,
nome_modelo="Modelo de Fraude",
threshold=0.3
)
```
## Retorno
A função **não retorna objetos**, mas produz:
* **Painel gráfico** com:
* Curva ROC
* Matriz de confusão
* Distribuição de scores
* Precisão por decil
* **Relatório textual** impresso no console com métricas consolidadas
---
## Parâmetros
| Parâmetro | Tipo | Descrição |
| ------------- | -------------- | ------------------------------------------------------------ |
| `model` | | text/markdown | null | Daniel Antunes <daniel.ant.cord@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"pandas>=1.5",
"numpy>=1.23",
"polars>=0.20.0",
"pyarrow>=14.0.0",
"snowflake-connector-python>=3.5.0",
"tableauserverclient>=0.25",
"fastexcel",
"selenium>=4.15; extra == \"upload\"",
"matplotlib>=3.7; extra == \"analise-exploratoria\"",
"seaborn>=0.12; extra == \"analise-exploratoria\"",
"scip... | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.11 | 2026-02-18T10:35:06.863257 | maxsciencelib-0.1.17.tar.gz | 77,258 | 44/38/d0fef4087fa0457e0f823235588997ef319df0298b654765fd2bdb4635b7/maxsciencelib-0.1.17.tar.gz | source | sdist | null | false | 2ba1e78c7a58058b8bac5e1279cf4702 | fa5b6492a843b2f91daf70e66624d153860c2fe2869c61d35f125a82444358db | 4438d0fef4087fa0457e0f823235588997ef319df0298b654765fd2bdb4635b7 | null | [
"LICENCE"
] | 251 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.