
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 48 51 | id int64 600M 4.46B | node_id stringlengths 18 24 | number int64 2 8.2k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC]date 2020-04-14 18:18:51 2026-05-16 13:28:01 | updated_at timestamp[ns, tz=UTC]date 2020-04-29 09:23:05 2026-05-21 16:18:22 | closed_at timestamp[ns, tz=UTC]date 2020-04-29 09:23:05 2026-05-20 10:46:58 ⌀ | assignee dict | author_association stringclasses 4
values | issue_field_values listlengths 0 0 | type float64 | active_lock_reason float64 | sub_issues_summary dict | issue_dependencies_summary dict | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 4
values | pinned_comment float64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/7517 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7517/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7517/comments | https://api.github.com/repos/huggingface/datasets/issues/7517/events | https://github.com/huggingface/datasets/issues/7517 | 2,996,106,077 | I_kwDODunzps6ylPNd | 7,517 | Image Feature in Datasets Library Fails to Handle bytearray Objects from Spark DataFrames | {
"avatar_url": "https://avatars.githubusercontent.com/u/73196164?v=4",
"events_url": "https://api.github.com/users/giraffacarp/events{/privacy}",
"followers_url": "https://api.github.com/users/giraffacarp/followers",
"following_url": "https://api.github.com/users/giraffacarp/following{/other_user}",
"gists_u... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/73196164?v=4",
"events_url": "https://api.github.com/users/giraffacarp/events{/privacy}",
"followers_url": "https://api.github.com/users/giraffacarp/followers",
"following_url": "https://api.github.com/users/giraffacarp/following{/other_user}"... | null | [
"Hi ! The `Image()` type accepts either\n- a `bytes` object containing the image bytes\n- a `str` object containing the image path\n- a `PIL.Image` object\n\nbut it doesn't support `bytearray`, maybe you can convert to `bytes` beforehand ?",
"Hi @lhoestq, \nconverting to bytes is certainly possible and would work... | 2025-04-15T11:29:17Z | 2025-05-07T14:17:30Z | 2025-05-07T14:17:30Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/73196164?v=4",
"events_url": "https://api.github.com/users/giraffacarp/events{/privacy}",
"followers_url": "https://api.github.com/users/giraffacarp/followers",
"following_url": "https://api.github.com/users/giraffacarp/following{/other_user}",
"gists_u... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When using `IterableDataset.from_spark()` with a Spark DataFrame containing image data, the `Image` feature class fails to properly process this data type, causing an `AttributeError: 'bytearray' object has no attribute 'get'`
### Steps to reproduce the bug
1. Create a Spark DataFrame with a col... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7517/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7517/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3928 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3928/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3928/comments | https://api.github.com/repos/huggingface/datasets/issues/3928/events | https://github.com/huggingface/datasets/issues/3928 | 1,170,017,132 | I_kwDODunzps5FvQts | 3,928 | Frugal score deprecations | {
"avatar_url": "https://avatars.githubusercontent.com/u/30974685?v=4",
"events_url": "https://api.github.com/users/ierezell/events{/privacy}",
"followers_url": "https://api.github.com/users/ierezell/followers",
"following_url": "https://api.github.com/users/ierezell/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @Ierezell, thanks for reporting.\r\n\r\nI'm making a PR to suppress those logs from the terminal. "
] | 2022-03-15T18:10:42Z | 2022-03-17T08:37:24Z | 2022-03-17T08:37:24Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
The frugal score returns a really verbose output with warnings that can be easily changed.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
from datasets.load import load_metric
frugal = load_metric("frugalscore")
frugal.compute(predictions=["Do you like spinach... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3928/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3928/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6051 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6051/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6051/comments | https://api.github.com/repos/huggingface/datasets/issues/6051/events | https://github.com/huggingface/datasets/issues/6051 | 1,811,549,650 | I_kwDODunzps5r-g3S | 6,051 | Skipping shard in the remote repo and resume upload | {
"avatar_url": "https://avatars.githubusercontent.com/u/9029817?v=4",
"events_url": "https://api.github.com/users/rs9000/events{/privacy}",
"followers_url": "https://api.github.com/users/rs9000/followers",
"following_url": "https://api.github.com/users/rs9000/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | [] | null | [
"Hi! `_select_contiguous` fetches a (zero-copy) slice of the dataset's Arrow table to build a shard, so I don't think this part is the problem. To me, the issue seems to be the step where we embed external image files' bytes (a lot of file reads). You can use `.map` with multiprocessing to perform this step before ... | 2023-07-19T09:25:26Z | 2023-07-20T18:16:01Z | 2023-07-20T18:16:00Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
For some reason when I try to resume the upload of my dataset, it is very slow to reach the index of the shard from which to resume the uploading.
From my understanding, the problem is in this part of the code:
arrow_dataset.py
```python
for index, shard in logging.tqdm(
enume... | {
"avatar_url": "https://avatars.githubusercontent.com/u/9029817?v=4",
"events_url": "https://api.github.com/users/rs9000/events{/privacy}",
"followers_url": "https://api.github.com/users/rs9000/followers",
"following_url": "https://api.github.com/users/rs9000/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6051/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6051/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6913 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6913/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6913/comments | https://api.github.com/repos/huggingface/datasets/issues/6913/events | https://github.com/huggingface/datasets/issues/6913 | 2,309,605,889 | I_kwDODunzps6JqcoB | 6,913 | Column order is nondeterministic when loading from JSON | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2024-05-22T05:30:14Z | 2024-05-29T13:12:24Z | 2024-05-29T13:12:24Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | As reported by @meg-huggingface, the order of the JSON object keys is not preserved while loading a dataset from a JSON file with a list of objects.
For example, when loading a JSON files with a list of objects, each with the following ordered keys:
- [ID, Language, Topic],
the resulting dataset may have column... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6913/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6913/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3637/comments | https://api.github.com/repos/huggingface/datasets/issues/3637/events | https://github.com/huggingface/datasets/issues/3637 | 1,115,526,438 | I_kwDODunzps5CfZUm | 3,637 | [TypeError: Couldn't cast array of type] Cannot load dataset in v1.18 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi @lewtun!\r\n \r\nThis one was tricky to debug. Initially, I tought there is a bug in the recently-added (by @lhoestq ) `cast_array_to_feature` function because `git bisect` points to the https://github.com/huggingface/datasets/commit/6ca96c707502e0689f9b58d94f46d871fa5a3c9c commit. Then, I noticed that the feat... | 2022-01-26T21:38:02Z | 2022-02-09T16:15:53Z | 2022-02-09T16:15:53Z | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
I am trying to load the [`GEM/RiSAWOZ` dataset](https://huggingface.co/datasets/GEM/RiSAWOZ) in `datasets` v1.18.1 and am running into a type error when casting the features. The strange thing is that I can load the dataset with v1.17.0. Note that the error is also present if I install from `master... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3637/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3637/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6079 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6079/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6079/comments | https://api.github.com/repos/huggingface/datasets/issues/6079/events | https://github.com/huggingface/datasets/issues/6079 | 1,822,597,471 | I_kwDODunzps5soqFf | 6,079 | Iterating over DataLoader based on HF datasets is stuck forever | {
"avatar_url": "https://avatars.githubusercontent.com/u/5454868?v=4",
"events_url": "https://api.github.com/users/arindamsarkar93/events{/privacy}",
"followers_url": "https://api.github.com/users/arindamsarkar93/followers",
"following_url": "https://api.github.com/users/arindamsarkar93/following{/other_user}",... | [] | closed | false | [] | null | [
"When the process starts to hang, can you interrupt it with CTRL + C and paste the error stack trace here? ",
"Thanks @mariosasko for your prompt response, here's the stack trace:\r\n\r\n```\r\nKeyboardInterrupt Traceback (most recent call last)\r\nCell In[12], line 4\r\n 2 t = time.t... | 2023-07-26T14:52:37Z | 2024-02-07T17:46:52Z | 2023-07-30T14:09:06Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I am using Amazon Sagemaker notebook (Amazon Linux 2) with python 3.10 based Conda environment.
I have a dataset in parquet format locally. When I try to iterate over it, the loader is stuck forever. Note that the same code is working for python 3.6 based conda environment seamlessly. What shou... | {
"avatar_url": "https://avatars.githubusercontent.com/u/5454868?v=4",
"events_url": "https://api.github.com/users/arindamsarkar93/events{/privacy}",
"followers_url": "https://api.github.com/users/arindamsarkar93/followers",
"following_url": "https://api.github.com/users/arindamsarkar93/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6079/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6079/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2741/comments | https://api.github.com/repos/huggingface/datasets/issues/2741/events | https://github.com/huggingface/datasets/issues/2741 | 957,979,559 | MDU6SXNzdWU5NTc5Nzk1NTk= | 2,741 | Add Hypersim dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",... | open | false | [] | null | [] | 2021-08-02T10:06:50Z | 2021-12-08T12:06:51Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Adding a Dataset
- **Name:** Hypersim
- **Description:** photorealistic synthetic dataset for holistic indoor scene understanding
- **Paper:** *link to the dataset paper if available*
- **Data:** https://github.com/apple/ml-hypersim
Instructions to add a new dataset can be found [here](https://github.com/hugg... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2741/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2741/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7378/comments | https://api.github.com/repos/huggingface/datasets/issues/7378/events | https://github.com/huggingface/datasets/issues/7378 | 2,802,957,388 | I_kwDODunzps6nEbxM | 7,378 | Allow pushing config version to hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/129072?v=4",
"events_url": "https://api.github.com/users/momeara/events{/privacy}",
"followers_url": "https://api.github.com/users/momeara/followers",
"following_url": "https://api.github.com/users/momeara/following{/other_user}",
"gists_url": "https://... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [
"Hi ! This sounds reasonable to me, feel free to open a PR :)"
] | 2025-01-21T22:35:07Z | 2025-01-30T13:56:56Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Currently, when datasets are created, they can be versioned by passing the `version` argument to `load_dataset(...)`. For example creating `outcomes.csv` on the command line
```
echo "id,value\n1,0\n2,0\n3,1\n4,1\n" > outcomes.csv
```
and creating it
```
import datasets
dataset = datasets.load_dat... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7378/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7378/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6202 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6202/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6202/comments | https://api.github.com/repos/huggingface/datasets/issues/6202/events | https://github.com/huggingface/datasets/issues/6202 | 1,876,630,351 | I_kwDODunzps5v2xtP | 6,202 | avoid downgrading jax version | {
"avatar_url": "https://avatars.githubusercontent.com/u/1332458?v=4",
"events_url": "https://api.github.com/users/chrisflesher/events{/privacy}",
"followers_url": "https://api.github.com/users/chrisflesher/followers",
"following_url": "https://api.github.com/users/chrisflesher/following{/other_user}",
"gists... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"https://github.com/huggingface/datasets/blob/main/setup.py#L236\r\nCurrently has the highest version at 0.3.25; Not sure if there is any reason for this, other than that was the tested version?"
] | 2023-09-01T02:57:57Z | 2023-10-12T16:28:59Z | 2023-10-12T16:28:59Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Whenever I `pip install datasets[jax]` it downgrades jax to version 0.3.25. I seem to be able to install this library first then upgrade jax back to version 0.4.13.
### Motivation
It would be nice to not overwrite currently installed version of jax if possible.
### Your contribution
I... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6202/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6202/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3490 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3490/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3490/comments | https://api.github.com/repos/huggingface/datasets/issues/3490/events | https://github.com/huggingface/datasets/issues/3490 | 1,089,730,181 | I_kwDODunzps5A8_aF | 3,490 | Does datasets support load text from HDFS? | {
"avatar_url": "https://avatars.githubusercontent.com/u/20511825?v=4",
"events_url": "https://api.github.com/users/dancingpipi/events{/privacy}",
"followers_url": "https://api.github.com/users/dancingpipi/followers",
"following_url": "https://api.github.com/users/dancingpipi/following{/other_user}",
"gists_u... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [
"Hi ! `datasets` currently supports reading local files or files over HTTP. We may add support for other filesystems (cloud storages, hdfs...) at one point though :)"
] | 2021-12-28T08:56:02Z | 2022-02-14T14:00:51Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | The raw text data is stored on HDFS due to the dataset's size is too large to store on my develop machine,
so I wander does datasets support read data from hdfs? | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3490/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3490/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6043 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6043/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6043/comments | https://api.github.com/repos/huggingface/datasets/issues/6043/events | https://github.com/huggingface/datasets/issues/6043 | 1,807,771,750 | I_kwDODunzps5rwGhm | 6,043 | Compression kwargs have no effect when saving datasets as csv | {
"avatar_url": "https://avatars.githubusercontent.com/u/128361578?v=4",
"events_url": "https://api.github.com/users/exs-avianello/events{/privacy}",
"followers_url": "https://api.github.com/users/exs-avianello/followers",
"following_url": "https://api.github.com/users/exs-avianello/following{/other_user}",
"... | [] | open | false | [] | null | [
"Hello @exs-avianello, I have reproduced the bug successfully and have understood the problem. But I am confused regarding this part of the statement, \"`pandas.DataFrame.to_csv` is always called with a buf-like `path_or_buf`\".\r\n\r\nCan you please elaborate on it?\r\n\r\nThanks!",
"Hi @aryanxk02 ! Sure, what I... | 2023-07-17T13:19:21Z | 2023-07-22T17:34:18Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Attempting to save a dataset as a compressed csv file, the compression kwargs provided to `.to_csv()` that get piped to panda's `pandas.DataFrame.to_csv` do not have any effect - resulting in the dataset not getting compressed.
A warning is raised if explicitly providing a `compression` kwarg, ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6043/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6043/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/1600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1600/comments | https://api.github.com/repos/huggingface/datasets/issues/1600/events | https://github.com/huggingface/datasets/issues/1600 | 770,582,960 | MDU6SXNzdWU3NzA1ODI5NjA= | 1,600 | AttributeError: 'DatasetDict' object has no attribute 'train_test_split' | {
"avatar_url": "https://avatars.githubusercontent.com/u/5028974?v=4",
"events_url": "https://api.github.com/users/david-waterworth/events{/privacy}",
"followers_url": "https://api.github.com/users/david-waterworth/followers",
"following_url": "https://api.github.com/users/david-waterworth/following{/other_user... | [
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | [] | null | [
"Hi @david-waterworth!\r\n\r\nAs indicated in the error message, `load_dataset(\"csv\")` returns a `DatasetDict` object, which is mapping of `str` to `Dataset` objects. I believe in this case the behavior is to return a `train` split with all the data.\r\n`train_test_split` is a method of the `Dataset` object, so y... | 2020-12-18T05:37:10Z | 2023-05-03T04:22:55Z | 2020-12-21T07:38:58Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | The following code fails with "'DatasetDict' object has no attribute 'train_test_split'" - am I doing something wrong?
```
from datasets import load_dataset
dataset = load_dataset('csv', data_files='data.txt')
dataset = dataset.train_test_split(test_size=0.1)
```
> AttributeError: 'DatasetDict' object has no at... | {
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1600/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1600/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/874 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/874/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/874/comments | https://api.github.com/repos/huggingface/datasets/issues/874/events | https://github.com/huggingface/datasets/issues/874 | 748,193,140 | MDU6SXNzdWU3NDgxOTMxNDA= | 874 | trec dataset unavailable | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | [] | null | [
"This was fixed in #740 \r\nCould you try to update `datasets` and try again ?",
"This has been fixed in datasets 1.1.3"
] | 2020-11-22T08:09:36Z | 2020-11-27T13:56:42Z | 2020-11-27T13:56:42Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi
when I try to load the trec dataset I am getting these errors, thanks for your help
`datasets.load_dataset("trec", split="train")
`
```
File "<stdin>", line 1, in <module>
File "/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/load.py", line 611, in load_dataset
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/874/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/874/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1644/comments | https://api.github.com/repos/huggingface/datasets/issues/1644/events | https://github.com/huggingface/datasets/issues/1644 | 775,375,880 | MDU6SXNzdWU3NzUzNzU4ODA= | 1,644 | HoVeR dataset fails to load | {
"avatar_url": "https://avatars.githubusercontent.com/u/1473778?v=4",
"events_url": "https://api.github.com/users/urikz/events{/privacy}",
"followers_url": "https://api.github.com/users/urikz/followers",
"following_url": "https://api.github.com/users/urikz/following{/other_user}",
"gists_url": "https://api.g... | [] | closed | false | [] | null | [
"Hover was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `hover` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"hover\")\r\n```"
] | 2020-12-28T12:27:07Z | 2022-10-05T12:40:34Z | 2022-10-05T12:40:34Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi! I'm getting an error when trying to load **HoVeR** dataset. Another one (**SQuAD**) does work for me. I'm using the latest (1.1.3) version of the library.
Steps to reproduce the error:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("hover")
Traceback (most recent call last):
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1644/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1644/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2901 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2901/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2901/comments | https://api.github.com/repos/huggingface/datasets/issues/2901/events | https://github.com/huggingface/datasets/issues/2901 | 995,232,844 | MDU6SXNzdWU5OTUyMzI4NDQ= | 2,901 | Incompatibility with pytest | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Sorry, my bad... When implementing `xpathopen`, I just considered the use case in the COUNTER dataset... I'm fixing it!"
] | 2021-09-13T19:12:17Z | 2021-09-14T08:40:47Z | 2021-09-14T08:40:47Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | COLLABORATOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
pytest complains about xpathopen / path.open("w")
## Steps to reproduce the bug
Create a test file, `test.py`:
```python
import datasets as ds
def load_dataset():
ds.load_dataset("counter", split="train", streaming=True)
```
And launch it with pytest:
```bash
python -m pyt... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2901/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2901/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4276 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4276/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4276/comments | https://api.github.com/repos/huggingface/datasets/issues/4276/events | https://github.com/huggingface/datasets/issues/4276 | 1,224,949,252 | I_kwDODunzps5JAz4E | 4,276 | OpenBookQA has missing and inconsistent field names | {
"avatar_url": "https://avatars.githubusercontent.com/u/458335?v=4",
"events_url": "https://api.github.com/users/vblagoje/events{/privacy}",
"followers_url": "https://api.github.com/users/vblagoje/followers",
"following_url": "https://api.github.com/users/vblagoje/following{/other_user}",
"gists_url": "https... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @vblagoje.\r\n\r\nIndeed, I noticed some of these issues while reviewing this PR:\r\n- #4259 \r\n\r\nThis is in my TODO list. ",
"Ok, awesome @albertvillanova How about #4275 ?",
"On the other hand, I am not sure if we should always preserve the original nested structure. I think we shoul... | 2022-05-04T05:51:52Z | 2022-10-11T17:11:53Z | 2022-10-05T13:50:03Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
OpenBookQA implementation is inconsistent with the original dataset.
We need to:
1. The dataset field [question][stem] is flattened into question_stem. Unflatten it to match the original format.
2. Add missing additional fields:
- 'fact1': row['fact1'],
- 'humanScore': row['humanSc... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4276/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4276/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6369/comments | https://api.github.com/repos/huggingface/datasets/issues/6369/events | https://github.com/huggingface/datasets/issues/6369 | 1,971,794,108 | I_kwDODunzps51hzC8 | 6,369 | Multi process map did not load cache file correctly | {
"avatar_url": "https://avatars.githubusercontent.com/u/14285786?v=4",
"events_url": "https://api.github.com/users/nursery42/events{/privacy}",
"followers_url": "https://api.github.com/users/nursery42/followers",
"following_url": "https://api.github.com/users/nursery42/following{/other_user}",
"gists_url": "... | [] | closed | false | [] | null | [
"The inconsistency may be caused by the usage of \"update_fingerprint\" and setting \"trust_remote_code\" to \"True.\"\r\nWhen the tokenizer employs \"trust_remote_code,\" the behavior of the map function varies with each code execution. Even if the remote code of the tokenizer remains the same, the result of \"ash... | 2023-11-01T06:36:54Z | 2023-11-30T16:04:46Z | 2023-11-30T16:04:45Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When I was training model on Multiple GPUs by DDP, the dataset is tokenized multiple times after main process.

"
] | 2025-07-03T11:24:15Z | 2025-07-03T12:27:16Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When parsing this image in the ImageNet1K dataset, the `datasets` crashs whole training process just because unable to parse an invalid EXIF tag.

### Steps to reproduce the bug
Use the `datasets.Image.decod... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7668/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7668/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6195 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6195/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6195/comments | https://api.github.com/repos/huggingface/datasets/issues/6195/events | https://github.com/huggingface/datasets/issues/6195 | 1,874,195,585 | I_kwDODunzps5vtfSB | 6,195 | Force to reuse cache at given path | {
"avatar_url": "https://avatars.githubusercontent.com/u/43507393?v=4",
"events_url": "https://api.github.com/users/Luosuu/events{/privacy}",
"followers_url": "https://api.github.com/users/Luosuu/followers",
"following_url": "https://api.github.com/users/Luosuu/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | [] | null | [
"realized that need to pass the path at `cache_file_name` like\r\n\r\n```python\r\ntokenized_datasets = raw_datasets[\"train\"].map(\r\n tokenize_function,\r\n batched=True,\r\n num_proc=data_args.preprocessing_num_workers,\r\n remove_columns=[text_column_... | 2023-08-30T18:44:54Z | 2023-11-03T10:14:21Z | 2023-08-30T19:00:45Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I have run the official example of MLM like:
```bash
python run_mlm.py \
--model_name_or_path roberta-base \
--dataset_name togethercomputer/RedPajama-Data-1T \
--dataset_config_name arxiv \
--per_device_train_batch_size 10 \
--preprocessing_num_workers 20 ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/43507393?v=4",
"events_url": "https://api.github.com/users/Luosuu/events{/privacy}",
"followers_url": "https://api.github.com/users/Luosuu/followers",
"following_url": "https://api.github.com/users/Luosuu/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6195/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6195/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7994 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7994/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7994/comments | https://api.github.com/repos/huggingface/datasets/issues/7994/events | https://github.com/huggingface/datasets/issues/7994 | 3,906,330,806 | I_kwDODunzps7o1eC2 | 7,994 | Bump fsspec upper bound constraint | {
"avatar_url": "https://avatars.githubusercontent.com/u/528003?v=4",
"events_url": "https://api.github.com/users/hadim/events{/privacy}",
"followers_url": "https://api.github.com/users/hadim/followers",
"following_url": "https://api.github.com/users/hadim/following{/other_user}",
"gists_url": "https://api.gi... | [] | closed | false | [] | null | [] | 2026-02-06T11:37:54Z | 2026-02-16T15:29:00Z | 2026-02-16T15:29:00Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Would it be possible to bump fsspec upper bound to the latest (2026.2.0)?
I saw you had some API compat issues in the past (https://github.com/huggingface/datasets/issues/7326) and I understand the need for an upper bound.
But I wonder if you think your CI and tests are a good proxy to catch fsspec API breakage? If t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7994/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7994/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3440/comments | https://api.github.com/repos/huggingface/datasets/issues/3440/events | https://github.com/huggingface/datasets/issues/3440 | 1,081,528,426 | I_kwDODunzps5AdtBq | 3,440 | datasets keeps reading from cached files, although I disabled it | {
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi ! What version of `datasets` are you using ? Can you also provide the logs you get before it raises the error ?"
] | 2021-12-15T21:26:22Z | 2022-02-24T09:12:22Z | 2022-02-24T09:12:22Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Hi,
I am trying to avoid dataset library using cached files, I get the following bug when this tried to read the cached files. I tried to do the followings:
```
from datasets import set_caching_enabled
set_caching_enabled(False)
```
also force redownlaod:
```
download_mode='force_redownloa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3440/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5696 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5696/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5696/comments | https://api.github.com/repos/huggingface/datasets/issues/5696/events | https://github.com/huggingface/datasets/issues/5696 | 1,651,707,008 | I_kwDODunzps5icwyA | 5,696 | Shuffle a sharded iterable dataset without seed can lead to duplicate data | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2023-04-03T09:40:03Z | 2023-04-04T14:58:18Z | 2023-04-04T14:58:18Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | As reported in https://github.com/huggingface/datasets/issues/5360
If `seed=None` in `.shuffle()`, shuffled datasets don't use the same shuffling seed across nodes.
Because of that, the lists of shards is not shuffled the same way across nodes, and therefore some shards may be assigned to multiple nodes instead o... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5696/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5696/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7248 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7248/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7248/comments | https://api.github.com/repos/huggingface/datasets/issues/7248/events | https://github.com/huggingface/datasets/issues/7248 | 2,609,926,089 | I_kwDODunzps6bkE_J | 7,248 | ModuleNotFoundError: No module named 'datasets.tasks' | {
"avatar_url": "https://avatars.githubusercontent.com/u/93593941?v=4",
"events_url": "https://api.github.com/users/shoowadoo/events{/privacy}",
"followers_url": "https://api.github.com/users/shoowadoo/followers",
"following_url": "https://api.github.com/users/shoowadoo/following{/other_user}",
"gists_url": "... | [] | open | false | [] | null | [
"tasks was removed in v3: #6999 \r\n\r\nI also don't see why TextClassification is imported, since it's not used after. So the fix is simple: delete this line.",
"I opened https://huggingface.co/datasets/knowledgator/events_classification_biotech/discussions/7 to remove the line, hopefully the dataset owner will ... | 2024-10-23T21:58:25Z | 2024-10-24T17:00:19Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
[<ipython-input-9-13b5f31bd391>](https://bcb6shpazyu-496ff2e9c6d22116-0-colab.googleusercontent.com/outputframe.html?vrz=colab_20241022-060119_R... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7248/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7248/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6562/comments | https://api.github.com/repos/huggingface/datasets/issues/6562/events | https://github.com/huggingface/datasets/issues/6562 | 2,067,904,504 | I_kwDODunzps57Qbf4 | 6,562 | datasets.DownloadMode.FORCE_REDOWNLOAD use cache to download dataset features with load_dataset function | {
"avatar_url": "https://avatars.githubusercontent.com/u/73234162?v=4",
"events_url": "https://api.github.com/users/LsTam91/events{/privacy}",
"followers_url": "https://api.github.com/users/LsTam91/followers",
"following_url": "https://api.github.com/users/LsTam91/following{/other_user}",
"gists_url": "https:... | [] | open | false | [] | null | [] | 2024-01-05T19:10:25Z | 2024-01-05T19:10:25Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I have updated my dataset by adding a new feature, and push it to the hub. When I want to download it on my machine which contain the old version by using `datasets.load_dataset("your_dataset_name", download_mode=datasets.DownloadMode.FORCE_REDOWNLOAD)` I get an error (paste bellow).
Seems that... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6562/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6562/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5362/comments | https://api.github.com/repos/huggingface/datasets/issues/5362/events | https://github.com/huggingface/datasets/issues/5362 | 1,497,643,744 | I_kwDODunzps5ZRDrg | 5,362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | {
"avatar_url": "https://avatars.githubusercontent.com/u/52023469?v=4",
"events_url": "https://api.github.com/users/shaoyuta/events{/privacy}",
"followers_url": "https://api.github.com/users/shaoyuta/followers",
"following_url": "https://api.github.com/users/shaoyuta/following{/other_user}",
"gists_url": "htt... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @shaoyuta.\r\n\r\nWe have checked and yes, apparently there is an issue with the server hosting the data of the \"enron_emails\" subset of \"the_pile\" dataset: http://eaidata.bmk.sh/data/enron_emails.jsonl.zst\r\nIt seems to be down: The connection has timed out.\r\n\r\nPlease note that at t... | 2022-12-15T01:23:03Z | 2022-12-15T07:45:54Z | 2022-12-15T07:45:53Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
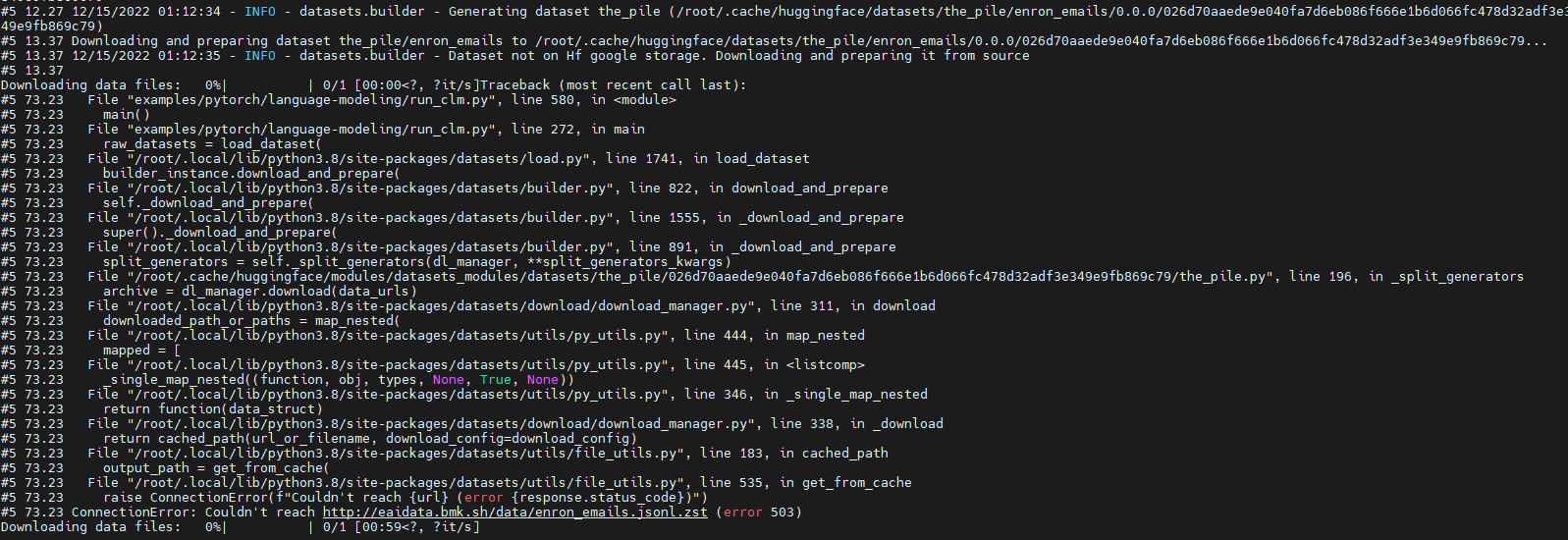
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5362/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7442 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7442/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7442/comments | https://api.github.com/repos/huggingface/datasets/issues/7442/events | https://github.com/huggingface/datasets/issues/7442 | 2,905,543,017 | I_kwDODunzps6tLxFp | 7,442 | Flexible Loader | {
"avatar_url": "https://avatars.githubusercontent.com/u/13894030?v=4",
"events_url": "https://api.github.com/users/dipta007/events{/privacy}",
"followers_url": "https://api.github.com/users/dipta007/followers",
"following_url": "https://api.github.com/users/dipta007/following{/other_user}",
"gists_url": "htt... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"Ideally `save_to_disk` should save in a format compatible with load_dataset, wdyt ?",
"> Ideally `save_to_disk` should save in a format compatible with load_dataset, wdyt ?\n\nThat would be perfect if not at least a flexible loader.",
"@lhoestq For now, you can use this small utility library: [nanoml](https://... | 2025-03-09T16:55:03Z | 2026-02-21T19:58:58Z | 2026-02-21T19:58:58Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Can we have a utility function that will use `load_from_disk` when given the local path and `load_dataset` if given an HF dataset?
It can be something as simple as this one:
```
def load_hf_dataset(path_or_name):
if os.path.exists(path_or_name):
return load_from_disk(path_or_name)
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/13894030?v=4",
"events_url": "https://api.github.com/users/dipta007/events{/privacy}",
"followers_url": "https://api.github.com/users/dipta007/followers",
"following_url": "https://api.github.com/users/dipta007/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7442/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7442/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6377/comments | https://api.github.com/repos/huggingface/datasets/issues/6377/events | https://github.com/huggingface/datasets/issues/6377 | 1,973,937,612 | I_kwDODunzps51p-XM | 6,377 | Support pyarrow 14.0.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-11-02T10:22:08Z | 2023-11-02T15:15:45Z | 2023-11-02T15:15:45Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Support pyarrow 14.0.0 by fixing the root cause of:
- #6374
and revert:
- #6375 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6377/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/726 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/726/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/726/comments | https://api.github.com/repos/huggingface/datasets/issues/726/events | https://github.com/huggingface/datasets/issues/726 | 719,313,754 | MDU6SXNzdWU3MTkzMTM3NTQ= | 726 | "Checksums didn't match for dataset source files" error while loading openwebtext dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/16469472?v=4",
"events_url": "https://api.github.com/users/SparkJiao/events{/privacy}",
"followers_url": "https://api.github.com/users/SparkJiao/followers",
"following_url": "https://api.github.com/users/SparkJiao/following{/other_user}",
"gists_url": "... | [] | closed | false | [] | null | [
"Hi try, to provide more information please.\r\n\r\nExample code in a colab to reproduce the error, details on what you are trying to do and what you were expected and details on your environment (OS, PyPi packages version).",
"> Hi try, to provide more information please.\r\n> \r\n> Example code in a colab to re... | 2020-10-12T11:45:10Z | 2022-02-17T17:53:54Z | 2022-02-15T10:38:57Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi,
I have encountered this problem during loading the openwebtext dataset:
```
>>> dataset = load_dataset('openwebtext')
Downloading and preparing dataset openwebtext/plain_text (download: 12.00 GiB, generated: 37.04 GiB, post-processed: Unknown size, total: 49.03 GiB) to /home/admin/.cache/huggingface/datasets/op... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/726/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/726/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/743/comments | https://api.github.com/repos/huggingface/datasets/issues/743/events | https://github.com/huggingface/datasets/issues/743 | 724,703,980 | MDU6SXNzdWU3MjQ3MDM5ODA= | 743 | load_dataset for CSV files not working | {
"avatar_url": "https://avatars.githubusercontent.com/u/2815308?v=4",
"events_url": "https://api.github.com/users/iliemihai/events{/privacy}",
"followers_url": "https://api.github.com/users/iliemihai/followers",
"following_url": "https://api.github.com/users/iliemihai/following{/other_user}",
"gists_url": "h... | [] | open | false | [] | null | [
"Thank you !\r\nCould you provide a csv file that reproduces the error ?\r\nIt doesn't have to be one of your dataset. As long as it reproduces the error\r\nThat would help a lot !",
"I think another good example is the following:\r\n`\r\nfrom datasets import load_dataset\r\n`\r\n`\r\ndataset = load_dataset(\"csv... | 2020-10-19T14:53:51Z | 2025-04-24T06:35:25Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Similar to #622, I've noticed there is a problem when trying to load a CSV file with datasets.
`
from datasets import load_dataset
`
`
dataset = load_dataset("csv", data_files=["./sample_data.csv"], delimiter="\t", column_names=["title", "text"], script_version="master")
`
Displayed error:
`
...
ArrowInva... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/743/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/743/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6274 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6274/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6274/comments | https://api.github.com/repos/huggingface/datasets/issues/6274/events | https://github.com/huggingface/datasets/issues/6274 | 1,921,036,328 | I_kwDODunzps5ygLAo | 6,274 | FileNotFoundError for dataset with multiple builder config | {
"avatar_url": "https://avatars.githubusercontent.com/u/97120485?v=4",
"events_url": "https://api.github.com/users/LouisChen15/events{/privacy}",
"followers_url": "https://api.github.com/users/LouisChen15/followers",
"following_url": "https://api.github.com/users/LouisChen15/following{/other_user}",
"gists_u... | [] | closed | false | [] | null | [
"Please tell me if the above info is not enough for solving the problem. I will then make my dataset public temporarily so that you can really reproduce the bug. ",
"Hi! \r\nCould you share how to solve this problem? \r\nI faced this same error. "
] | 2023-10-01T23:45:56Z | 2024-08-14T04:42:02Z | 2023-10-02T20:09:38Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When there is only one config and only the dataset name is entered when using datasets.load_dataset(), it works fine. But if I create a second builder_config for my dataset and enter the config name when using datasets.load_dataset(), the following error will happen.
FileNotFoundError: [Errno 2... | {
"avatar_url": "https://avatars.githubusercontent.com/u/97120485?v=4",
"events_url": "https://api.github.com/users/LouisChen15/events{/privacy}",
"followers_url": "https://api.github.com/users/LouisChen15/followers",
"following_url": "https://api.github.com/users/LouisChen15/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6274/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6274/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5371 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5371/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5371/comments | https://api.github.com/repos/huggingface/datasets/issues/5371/events | https://github.com/huggingface/datasets/issues/5371 | 1,501,369,036 | I_kwDODunzps5ZfRLM | 5,371 | Add a robustness benchmark dataset for vision | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
... | null | [
"Ccing @nazneenrajani @lvwerra @osanseviero "
] | 2022-12-17T12:35:13Z | 2022-12-20T06:21:41Z | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Name
ImageNet-C
### Paper
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
### Data
https://github.com/hendrycks/robustness
### Motivation
It's a known fact that vision models are brittle when they meet with slightly corrupted and perturbed data. This is also corre... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5371/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5371/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/817 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/817/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/817/comments | https://api.github.com/repos/huggingface/datasets/issues/817/events | https://github.com/huggingface/datasets/issues/817 | 739,145,369 | MDU6SXNzdWU3MzkxNDUzNjk= | 817 | Add MRQA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url"... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | [] | null | [
"Done! cf #1117 and #1022"
] | 2020-11-09T15:52:19Z | 2020-12-04T15:44:42Z | 2020-12-04T15:44:41Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Adding a Dataset
- **Name:** MRQA
- **Description:** Collection of different (subsets of) QA datasets all converted to the same format to evaluate out-of-domain generalization (the datasets come from different domains, distributions, etc.). Some datasets are used for training and others are used for evaluation. Th... | {
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/817/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/817/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7020 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7020/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7020/comments | https://api.github.com/repos/huggingface/datasets/issues/7020/events | https://github.com/huggingface/datasets/issues/7020 | 2,387,940,990 | I_kwDODunzps6OVRZ- | 7,020 | Casting list array to fixed size list raises error | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2024-07-03T07:54:49Z | 2024-07-03T08:41:56Z | 2024-07-03T08:41:56Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | When trying to cast a list array to fixed size list, an AttributeError is raised:
> AttributeError: 'pyarrow.lib.FixedSizeListType' object has no attribute 'length'
Steps to reproduce the bug:
```python
import pyarrow as pa
from datasets.table import array_cast
arr = pa.array([[0, 1]])
array_cast(arr, pa.lis... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7020/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7020/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3991 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3991/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3991/comments | https://api.github.com/repos/huggingface/datasets/issues/3991/events | https://github.com/huggingface/datasets/issues/3991 | 1,177,362,901 | I_kwDODunzps5GLSHV | 3,991 | Add Lung Image Database Consortium image collection (LIDC-IDRI) dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",... | open | false | [] | null | [] | 2022-03-22T22:16:05Z | 2022-03-23T12:57:16Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Adding a Dataset
- **Name:** *Lung Image Database Consortium image collection (LIDC-IDRI)*
- **Description:** *Consists of diagnostic and lung cancer screening thoracic computed tomography (CT) scans with marked-up annotated lesions. It is a web-accessible international resource for development, training, and ev... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3991/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3991/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6396/comments | https://api.github.com/repos/huggingface/datasets/issues/6396/events | https://github.com/huggingface/datasets/issues/6396 | 1,987,308,077 | I_kwDODunzps52c-ot | 6,396 | Issue with pyarrow 14.0.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | [] | null | [
"Looks like we should stop using `PyExtensionType` and use `ExtensionType` instead\r\n\r\nsee https://github.com/apache/arrow/commit/f14170976372436ec1d03a724d8d3f3925484ecf",
"https://github.com/huggingface/datasets-server/pull/2089#pullrequestreview-1724449532\r\n\r\n> Yes, I understand now: they have disabled ... | 2023-11-10T10:02:12Z | 2025-08-19T18:13:30Z | 2023-11-14T10:23:30Z | null | COLLABORATOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | See https://github.com/huggingface/datasets-server/pull/2089 for reference
```
from datasets import (Array2D, Dataset, Features)
feature_type = Array2D(shape=(2, 2), dtype="float32")
content = [[0.0, 0.0], [0.0, 0.0]]
features = Features({"col": feature_type})
dataset = Dataset.from_dict({"col": [content]}, fea... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6396/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6396/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6108 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6108/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6108/comments | https://api.github.com/repos/huggingface/datasets/issues/6108/events | https://github.com/huggingface/datasets/issues/6108 | 1,830,347,187 | I_kwDODunzps5tGOGz | 6,108 | Loading local datasets got strangely stuck | {
"avatar_url": "https://avatars.githubusercontent.com/u/48412571?v=4",
"events_url": "https://api.github.com/users/LoveCatc/events{/privacy}",
"followers_url": "https://api.github.com/users/LoveCatc/followers",
"following_url": "https://api.github.com/users/LoveCatc/following{/other_user}",
"gists_url": "htt... | [] | open | false | [] | null | [
"Yesterday I waited for more than 12 hours to make sure it was really **stuck** instead of proceeding too slow.",
"I've had similar weird issues with `load_dataset` as well. Not multiple files, but dataset is quite big, about 50G.",
"We use a generic multiprocessing code, so there is little we can do about this... | 2023-08-01T02:28:06Z | 2024-12-31T16:01:00Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I try to use `load_dataset()` to load several local `.jsonl` files as a dataset. Every line of these files is a json structure only containing one key `text` (yeah it is a dataset for NLP model). The code snippet is as:
```python
ds = load_dataset("json", data_files=LIST_OF_FILE_PATHS, num_proc=... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6108/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6108/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6793 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6793/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6793/comments | https://api.github.com/repos/huggingface/datasets/issues/6793/events | https://github.com/huggingface/datasets/issues/6793 | 2,231,400,200 | I_kwDODunzps6FAHcI | 6,793 | Loading just one particular split is not possible for imagenet-1k | {
"avatar_url": "https://avatars.githubusercontent.com/u/165930106?v=4",
"events_url": "https://api.github.com/users/PaulPSta/events{/privacy}",
"followers_url": "https://api.github.com/users/PaulPSta/followers",
"following_url": "https://api.github.com/users/PaulPSta/following{/other_user}",
"gists_url": "ht... | [] | open | false | [] | null | [
"+1",
"+1\n"
] | 2024-04-08T14:39:14Z | 2025-06-23T09:55:08Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I'd expect the following code to download just the validation split but instead I get all data on my disk (train, test and validation splits)
`
from datasets import load_dataset
dataset = load_dataset("imagenet-1k", split="validation", trust_remote_code=True)
`
Is it expected to work li... | null | {
"+1": 5,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6793/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6793/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7504 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7504/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7504/comments | https://api.github.com/repos/huggingface/datasets/issues/7504/events | https://github.com/huggingface/datasets/issues/7504 | 2,979,410,641 | I_kwDODunzps6xljLR | 7,504 | BuilderConfig ParquetConfig(...) doesn't have a 'use_auth_token' key. | {
"avatar_url": "https://avatars.githubusercontent.com/u/20015750?v=4",
"events_url": "https://api.github.com/users/tteguayco/events{/privacy}",
"followers_url": "https://api.github.com/users/tteguayco/followers",
"following_url": "https://api.github.com/users/tteguayco/following{/other_user}",
"gists_url": "... | [] | open | false | [] | null | [
"I encountered the same error, have you resolved it?",
"Hi ! `use_auth_token` has been deprecated and removed some time ago. You should use `token` instead in `load_dataset()`",
"Hi @lhoestq, I'd like to take this up.\n\nAs discussed in #7504, the issue arises when `use_auth_token` is passed to `load_dataset`, ... | 2025-04-08T10:55:03Z | 2025-06-28T09:18:09Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Trying to run the following fine-tuning script (based on this page [here](https://github.com/huggingface/instruction-tuned-sd)):
```
! accelerate launch /content/instruction-tuned-sd/finetune_instruct_pix2pix.py \
--pretrained_model_name_or_path=${MODEL_ID} \
--dataset_name=${DATASET_NAME... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7504/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7504/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6953 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6953/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6953/comments | https://api.github.com/repos/huggingface/datasets/issues/6953/events | https://github.com/huggingface/datasets/issues/6953 | 2,333,366,120 | I_kwDODunzps6LFFdo | 6,953 | Remove canonical datasets from docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | [] | null | [
"Canonical datasets are no longer mentioned in the docs."
] | 2024-06-04T12:09:03Z | 2024-07-01T11:31:25Z | 2024-07-01T11:31:25Z | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Remove canonical datasets from docs, now that we no longer have canonical datasets. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6953/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6953/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3497 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3497/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3497/comments | https://api.github.com/repos/huggingface/datasets/issues/3497/events | https://github.com/huggingface/datasets/issues/3497 | 1,090,050,148 | I_kwDODunzps5A-Nhk | 3,497 | Changing sampling rate in audio dataset and subsequently mapping with `num_proc > 1` leads to weird bug | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Same error occures when using max samples with https://github.com/huggingface/transformers/blob/master/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py",
"I'm seeing this too, when using preprocessing_num_workers with \r\nhttps://github.com/huggingface/transformers/blob/master/examples/pytor... | 2021-12-28T18:03:49Z | 2022-01-21T13:22:27Z | 2022-01-21T13:22:27Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Running:
```python
from datasets import load_dataset, DatasetDict
import datasets
from transformers import AutoFeatureExtractor
raw_datasets = DatasetDict()
raw_datasets["train"] = load_dataset("common_voice", "ab", split="train")
feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2ve... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3497/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3497/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/355 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/355/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/355/comments | https://api.github.com/repos/huggingface/datasets/issues/355/events | https://github.com/huggingface/datasets/issues/355 | 653,451,013 | MDU6SXNzdWU2NTM0NTEwMTM= | 355 | can't load SNLI dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"I just added the processed files of `snli` on our google storage, so that when you do `load_dataset` it can download the processed files from there :)\r\n\r\nWe are thinking about having available those processed files for more datasets in the future, because sometimes files aren't available (like for `snli`), or ... | 2020-07-08T16:54:14Z | 2020-07-18T05:15:57Z | 2020-07-15T07:59:01Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | `nlp` seems to load `snli` from some URL based on nlp.stanford.edu. This subdomain is frequently down -- including right now, when I'd like to load `snli` in a Colab notebook, but can't.
Is there a plan to move these datasets to huggingface servers for a more stable solution?
Btw, here's the stack trace:
```
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/355/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/355/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5046 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5046/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5046/comments | https://api.github.com/repos/huggingface/datasets/issues/5046/events | https://github.com/huggingface/datasets/issues/5046 | 1,391,372,519 | I_kwDODunzps5S7qjn | 5,046 | Audiofolder creates empty Dataset if files same level as metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/577139?v=4",
"events_url": "https://api.github.com/users/msis/events{/privacy}",
"followers_url": "https://api.github.com/users/msis/followers",
"following_url": "https://api.github.com/users/msis/following{/other_user}",
"gists_url": "https://api.githu... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"descript... | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_u... | null | [
"Hi! Unfortunately, I can't reproduce this behavior. Instead, I get `ValueError: audio at 2063_fe9936e7-62b2-4e62-a276-acbd344480ce_1.wav doesn't have metadata in /audio-data/metadata.csv`, which can be fixed by removing the `./` from the file name.\r\n\r\n(Link to a Colab that tries to reproduce this behavior: htt... | 2022-09-29T19:17:23Z | 2022-10-28T13:05:07Z | 2022-10-28T13:05:07Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gi... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
When audio files are at the same level as the metadata (`metadata.csv` or `metadata.jsonl` ), the `load_dataset` returns a `DatasetDict` with no rows but the correct columns.
https://github.com/huggingface/datasets/blob/1ea4d091b7a4b83a85b2eeb8df65115d39af3766/docs/source/audio_dataset.mdx?plain... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5046/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5046/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4673/comments | https://api.github.com/repos/huggingface/datasets/issues/4673/events | https://github.com/huggingface/datasets/issues/4673 | 1,301,010,331 | I_kwDODunzps5Ni9eb | 4,673 | load_datasets on csv returns everything as a string | {
"avatar_url": "https://avatars.githubusercontent.com/u/25102613?v=4",
"events_url": "https://api.github.com/users/courtneysprouse/events{/privacy}",
"followers_url": "https://api.github.com/users/courtneysprouse/followers",
"following_url": "https://api.github.com/users/courtneysprouse/following{/other_user}"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi @courtneysprouse, thanks for reporting.\r\n\r\nYes, you are right: by default the \"csv\" loader loads all columns as strings. \r\n\r\nYou could tweak this behavior by passing the `feature` argument to `load_dataset`, but it is also true that currently it is not possible to perform some kind of casts, due to la... | 2022-07-11T17:30:24Z | 2024-11-05T03:55:10Z | 2022-07-12T13:33:08Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
If you use:
`conll_dataset.to_csv("ner_conll.csv")`
It will create a csv file with all of your data as expected, however when you load it with:
`conll_dataset = load_dataset("csv", data_files="ner_conll.csv")`
everything is read in as a string. For example if I look at everything in 'n... | {
"avatar_url": "https://avatars.githubusercontent.com/u/25102613?v=4",
"events_url": "https://api.github.com/users/courtneysprouse/events{/privacy}",
"followers_url": "https://api.github.com/users/courtneysprouse/followers",
"following_url": "https://api.github.com/users/courtneysprouse/following{/other_user}"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4673/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4673/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5612/comments | https://api.github.com/repos/huggingface/datasets/issues/5612/events | https://github.com/huggingface/datasets/issues/5612 | 1,611,262,510 | I_kwDODunzps5gCeou | 5,612 | Arrow map type in parquet files unsupported | {
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_u... | [] | open | false | [] | null | [
"I'm attaching a minimal reproducible example:\r\n```python\r\nfrom datasets import load_dataset\r\nimport pyarrow as pa\r\nimport pyarrow.parquet as pq\r\n\r\ntable_with_map = pa.Table.from_pydict(\r\n {\"a\": [1, 2], \"b\": [[(\"a\", 2)], [(\"b\", 4)]]},\r\n schema=pa.schema({\"a\": pa.int32(), \"b\": pa.ma... | 2023-03-06T12:03:24Z | 2024-03-15T18:56:12Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When I try to load parquet files that were processed with Spark, I get the following issue:
`ValueError: Arrow type map<string, string ('warc_headers')> does not have a datasets dtype equivalent.`
Strangely, loading the dataset with `streaming=True` solves the issue.
### Steps to reproduce ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 5,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5612/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5612/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/252 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/252/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/252/comments | https://api.github.com/repos/huggingface/datasets/issues/252/events | https://github.com/huggingface/datasets/issues/252 | 634,563,239 | MDU6SXNzdWU2MzQ1NjMyMzk= | 252 | NonMatchingSplitsSizesError error when reading the IMDB dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/17463361?v=4",
"events_url": "https://api.github.com/users/antmarakis/events{/privacy}",
"followers_url": "https://api.github.com/users/antmarakis/followers",
"following_url": "https://api.github.com/users/antmarakis/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"I just tried on my side and I didn't encounter your problem.\r\nApparently the script doesn't generate all the examples on your side.\r\n\r\nCan you provide the version of `nlp` you're using ?\r\nCan you try to clear your cache and re-run the code ?",
"I updated it, that was it, thanks!",
"Hello, I am facing t... | 2020-06-08T12:26:24Z | 2021-08-27T15:20:58Z | 2020-06-08T14:01:26Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi!
I am trying to load the `imdb` dataset with this line:
`dataset = nlp.load_dataset('imdb', data_dir='/A/PATH', cache_dir='/A/PATH')`
but I am getting the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/mounts/Users/cisintern/antmarakis/anaconda3/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/17463361?v=4",
"events_url": "https://api.github.com/users/antmarakis/events{/privacy}",
"followers_url": "https://api.github.com/users/antmarakis/followers",
"following_url": "https://api.github.com/users/antmarakis/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/252/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/252/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4595/comments | https://api.github.com/repos/huggingface/datasets/issues/4595/events | https://github.com/huggingface/datasets/issues/4595 | 1,288,275,976 | I_kwDODunzps5MyYgI | 4,595 | Dataset Viewer issue with False positive PII redaction | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | [] | null | [
"The value is in the data, it's not an issue with the \"dataset-viewer\".\r\n\r\n<img width=\"1161\" alt=\"Capture d’écran 2022-06-29 à 10 25 51\" src=\"https://user-images.githubusercontent.com/1676121/176389325-4d2a9a7f-1583-45b8-aa7a-960ffaa6a36a.png\">\r\n\r\n Maybe open a PR: https://huggingface.co/datasets/... | 2022-06-29T07:15:57Z | 2022-06-29T08:29:41Z | 2022-06-29T08:27:49Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Link
https://huggingface.co/datasets/cakiki/rosetta-code
### Description
Hello, I just noticed an entry being redacted that shouldn't have been:
`RootMeanSquare@Range[10]` is being displayed as `[email protected][10]`
### Owner
_No response_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4595/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4595/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2971 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2971/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2971/comments | https://api.github.com/repos/huggingface/datasets/issues/2971/events | https://github.com/huggingface/datasets/issues/2971 | 1,007,696,522 | I_kwDODunzps48EDqK | 2,971 | masakhaner dataset load problem | {
"avatar_url": "https://avatars.githubusercontent.com/u/8900094?v=4",
"events_url": "https://api.github.com/users/huu4ontocord/events{/privacy}",
"followers_url": "https://api.github.com/users/huu4ontocord/followers",
"following_url": "https://api.github.com/users/huu4ontocord/following{/other_user}",
"gists... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @ontocord. We are fixing the wrong metadata."
] | 2021-09-27T04:59:07Z | 2021-09-27T12:59:59Z | 2021-09-27T12:59:59Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Masakhaner dataset is not loading
## Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset("masakhaner",'amh')
```
## Expected results
Expected the return of a dataset
## Actual results
```
NonMatchingSplitsSizesError Traceback (mo... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2971/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2971/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6980 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6980/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6980/comments | https://api.github.com/repos/huggingface/datasets/issues/6980/events | https://github.com/huggingface/datasets/issues/6980 | 2,360,909,930 | I_kwDODunzps6MuKBq | 6,980 | Support NumPy 2.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/730137?v=4",
"events_url": "https://api.github.com/users/NeilGirdhar/events{/privacy}",
"followers_url": "https://api.github.com/users/NeilGirdhar/followers",
"following_url": "https://api.github.com/users/NeilGirdhar/following{/other_user}",
"gists_url... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [] | 2024-06-18T23:30:22Z | 2024-07-12T12:04:54Z | 2024-07-12T12:04:53Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Support NumPy 2.0.
### Motivation
NumPy introduces the Array API, which bridges the gap between machine learning libraries. Many clients of HuggingFace are eager to start using the Array API.
Besides that, NumPy 2 provides a cleaner interface than NumPy 1.
### Tasks
NumPy 2.0 was ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6980/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6980/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6765 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6765/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6765/comments | https://api.github.com/repos/huggingface/datasets/issues/6765/events | https://github.com/huggingface/datasets/issues/6765 | 2,215,933,515 | I_kwDODunzps6EFHZL | 6,765 | Compatibility issue between s3fs, fsspec, and datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/33383515?v=4",
"events_url": "https://api.github.com/users/njbrake/events{/privacy}",
"followers_url": "https://api.github.com/users/njbrake/followers",
"following_url": "https://api.github.com/users/njbrake/following{/other_user}",
"gists_url": "https:... | [] | closed | false | [] | null | [
"Hi! Instead of running `pip install` separately for each package, you should pass all the packages to a single `pip install` call (in this case, `pip install datasets s3fs`) to let `pip` properly resolve their versions.",
"> Hi! Instead of running `pip install` separately for each package, you should pass all th... | 2024-03-29T19:57:24Z | 2024-11-12T14:50:48Z | 2024-04-03T14:33:12Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Here is the full error stack when installing:
```
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
datasets 2.18.0 requires fsspec[http]<=2024.2.0,>=2023.1.0, but you ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/33383515?v=4",
"events_url": "https://api.github.com/users/njbrake/events{/privacy}",
"followers_url": "https://api.github.com/users/njbrake/followers",
"following_url": "https://api.github.com/users/njbrake/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6765/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6765/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2538 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2538/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2538/comments | https://api.github.com/repos/huggingface/datasets/issues/2538/events | https://github.com/huggingface/datasets/issues/2538 | 927,940,691 | MDU6SXNzdWU5Mjc5NDA2OTE= | 2,538 | Loading partial dataset when debugging | {
"avatar_url": "https://avatars.githubusercontent.com/u/9061913?v=4",
"events_url": "https://api.github.com/users/reachtarunhere/events{/privacy}",
"followers_url": "https://api.github.com/users/reachtarunhere/followers",
"following_url": "https://api.github.com/users/reachtarunhere/following{/other_user}",
... | [] | open | false | [] | null | [
"Hi ! `load_dataset` downloads the full dataset once and caches it, so that subsequent calls to `load_dataset` just reloads the dataset from your disk.\r\nThen when you specify a `split` in `load_dataset`, it will just load the requested split from the disk. If your specified split is a sliced split (e.g. `\"train[... | 2021-06-23T07:19:52Z | 2023-04-19T11:05:38Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I am using PyTorch Lightning along with datasets (thanks for so many datasets already prepared and the great splits).
Every time I execute load_dataset for the imdb dataset it takes some time even if I specify a split involving very few samples. I guess this due to hashing as per the other issues.
Is there a wa... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2538/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2538/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5876 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5876/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5876/comments | https://api.github.com/repos/huggingface/datasets/issues/5876/events | https://github.com/huggingface/datasets/issues/5876 | 1,717,978,985 | I_kwDODunzps5mZkdp | 5,876 | Incompatibility with DataLab | {
"avatar_url": "https://avatars.githubusercontent.com/u/26192135?v=4",
"events_url": "https://api.github.com/users/helpmefindaname/events{/privacy}",
"followers_url": "https://api.github.com/users/helpmefindaname/followers",
"following_url": "https://api.github.com/users/helpmefindaname/following{/other_user}"... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | [] | null | [
"Indeed, `clobber=True` (with a warning if the existing protocol will be overwritten) should fix the issue, but maybe a better solution is to register our compression filesystem before the script is executed and unregister them afterward. WDYT @lhoestq @albertvillanova?",
"I think we should use clobber and show a... | 2023-05-20T01:39:11Z | 2023-05-25T06:42:34Z | 2023-05-25T06:42:34Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Hello,
I am currently working on a project where both [DataLab](https://github.com/ExpressAI/DataLab) and [datasets](https://github.com/huggingface/datasets) are subdependencies.
I noticed that I cannot import both libraries, as they both register FileSystems in `fsspec`, expecting the FileSyste... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5876/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5876/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6089 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6089/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6089/comments | https://api.github.com/repos/huggingface/datasets/issues/6089/events | https://github.com/huggingface/datasets/issues/6089 | 1,825,761,476 | I_kwDODunzps5s0ujE | 6,089 | AssertionError: daemonic processes are not allowed to have children | {
"avatar_url": "https://avatars.githubusercontent.com/u/138426806?v=4",
"events_url": "https://api.github.com/users/codingl2k1/events{/privacy}",
"followers_url": "https://api.github.com/users/codingl2k1/followers",
"following_url": "https://api.github.com/users/codingl2k1/following{/other_user}",
"gists_url... | [] | open | false | [] | null | [
"We could add a \"threads\" parallel backend to `datasets.parallel.parallel_backend` to support downloading with threads but note that `download_and_extract` also decompresses archives, and this is a CPU-intensive task, which is not ideal for (Python) threads (good for IO-intensive tasks).",
"> We could add a \"t... | 2023-07-28T06:04:00Z | 2023-07-31T02:34:02Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When I load_dataset with num_proc > 0 in a deamon process, I got an error:
```python
File "/Users/codingl2k1/Work/datasets/src/datasets/download/download_manager.py", line 564, in download_and_extract
return self.extract(self.download(url_or_urls))
^^^^^^^^^^^^^^^^^
File "/Users... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6089/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6089/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/524 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/524/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/524/comments | https://api.github.com/repos/huggingface/datasets/issues/524/events | https://github.com/huggingface/datasets/issues/524 | 683,686,359 | MDU6SXNzdWU2ODM2ODYzNTk= | 524 | Some docs are missing parameter names | {
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists... | [] | closed | false | [] | null | [
"Indeed, good catch!"
] | 2020-08-21T16:47:34Z | 2020-08-25T09:04:03Z | 2020-08-25T09:04:03Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | See https://huggingface.co/nlp/master/package_reference/main_classes.html#nlp.Dataset.map. I believe this is because the parameter names are enclosed in backticks in the docstrings, maybe it's an old docstring format that doesn't work with the current Sphinx version. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/524/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/524/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2552 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2552/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2552/comments | https://api.github.com/repos/huggingface/datasets/issues/2552/events | https://github.com/huggingface/datasets/issues/2552 | 931,354,687 | MDU6SXNzdWU5MzEzNTQ2ODc= | 2,552 | Keys should be unique error on code_search_net | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Two questions:\r\n- with `datasets-cli env` we don't have any information on the dataset script version used. Should we give access to this somehow? Either as a note in the Error message or as an argument with the name of the dataset to `datasets-cli env`?\r\n- I don't really understand why the id is duplicated in... | 2021-06-28T09:15:20Z | 2021-09-06T14:08:30Z | 2021-09-02T08:25:29Z | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Loading `code_search_net` seems not possible at the moment.
## Steps to reproduce the bug
```python
>>> load_dataset('code_search_net')
Downloading: 8.50kB [00:00, 3.09MB/s] ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2552/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2552/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5581/comments | https://api.github.com/repos/huggingface/datasets/issues/5581/events | https://github.com/huggingface/datasets/issues/5581 | 1,600,675,489 | I_kwDODunzps5faF6h | 5,581 | [DOC] Mistaken docs on set_format | {
"avatar_url": "https://avatars.githubusercontent.com/u/36224762?v=4",
"events_url": "https://api.github.com/users/NightMachinery/events{/privacy}",
"followers_url": "https://api.github.com/users/NightMachinery/followers",
"following_url": "https://api.github.com/users/NightMachinery/following{/other_user}",
... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | [] | null | [
"Thanks for reporting!"
] | 2023-02-27T08:03:09Z | 2023-02-28T19:19:17Z | 2023-02-28T19:19:17Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
https://huggingface.co/docs/datasets/v2.10.0/en/package_reference/main_classes#datasets.Dataset.set_format
<img width="700" alt="image" src="https://user-images.githubusercontent.com/36224762/221506973-ae2e3991-60a7-4d4e-99f8-965c6eb61e59.png">
While actually running it will result in:
<img w... | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5581/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5581/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/8006 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/8006/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/8006/comments | https://api.github.com/repos/huggingface/datasets/issues/8006/events | https://github.com/huggingface/datasets/issues/8006 | 3,944,394,074 | I_kwDODunzps7rGq1a | 8,006 | Regression: from_generator crashes if one generator call returns no results | {
"avatar_url": "https://avatars.githubusercontent.com/u/53510?v=4",
"events_url": "https://api.github.com/users/hartmans/events{/privacy}",
"followers_url": "https://api.github.com/users/hartmans/followers",
"following_url": "https://api.github.com/users/hartmans/following{/other_user}",
"gists_url": "https:... | [] | closed | false | [] | null | [] | 2026-02-15T16:16:48Z | 2026-02-24T13:58:12Z | 2026-02-24T13:58:12Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Dataset.from_generator splits any list kwarg to the generator and makes a separate call to the generator for each member of the list even in the num_proc=1 case.
I have a generator that processes a number of files, filtering them and producing examples. It used to be the case that things worked fi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/8006/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/8006/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/866 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/866/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/866/comments | https://api.github.com/repos/huggingface/datasets/issues/866/events | https://github.com/huggingface/datasets/issues/866 | 745,719,222 | MDU6SXNzdWU3NDU3MTkyMjI= | 866 | OSCAR from Inria group | {
"avatar_url": "https://avatars.githubusercontent.com/u/34098722?v=4",
"events_url": "https://api.github.com/users/jchwenger/events{/privacy}",
"followers_url": "https://api.github.com/users/jchwenger/followers",
"following_url": "https://api.github.com/users/jchwenger/following{/other_user}",
"gists_url": "... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | [] | null | [
"PR is already open here : #348 \r\nThe only thing remaining is to compute the metadata of each subdataset (one per language + shuffled/unshuffled).\r\nAs soon as #863 is merged we can start computing them. This will take a bit of time though",
"Grand, thanks for this!"
] | 2020-11-18T14:40:54Z | 2020-11-18T15:01:30Z | 2020-11-18T15:01:30Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Adding a Dataset
- **Name:** *OSCAR* (Open Super-large Crawled ALMAnaCH coRpus), multilingual parsing of Common Crawl (separate crawls for many different languages), [here](https://oscar-corpus.com/).
- **Description:** *OSCAR or Open Super-large Crawled ALMAnaCH coRpus is a huge multilingual corpus obtained by la... | {
"avatar_url": "https://avatars.githubusercontent.com/u/34098722?v=4",
"events_url": "https://api.github.com/users/jchwenger/events{/privacy}",
"followers_url": "https://api.github.com/users/jchwenger/followers",
"following_url": "https://api.github.com/users/jchwenger/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/866/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/866/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5160 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5160/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5160/comments | https://api.github.com/repos/huggingface/datasets/issues/5160/events | https://github.com/huggingface/datasets/issues/5160 | 1,422,193,938 | I_kwDODunzps5UxPUS | 5,160 | Automatically add filename for image/audio folder | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_use... | null | [
"Also cc @anton-l ",
"BTW the exact same holds true for the audio folder",
"I'm fine with adding a new column with the file name personally. Not sure how breaking this is though",
"@patrickvonplaten do you mean just filename or full relative path inside the repo?\r\nI think it shouldn't be breaking, at least ... | 2022-10-25T09:56:49Z | 2022-10-26T16:51:46Z | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
When creating a custom audio of image dataset, it would be great to automatically have access to the filename. It should be both:
a) Automatically displayed in the viewer
b) Automatically added as a column to the dataset when doing `load_dataset`
In `diffusers` our test rely quite heavily on i... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5160/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5160/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6328 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6328/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6328/comments | https://api.github.com/repos/huggingface/datasets/issues/6328/events | https://github.com/huggingface/datasets/issues/6328 | 1,955,857,904 | I_kwDODunzps50lAXw | 6,328 | شبکه های متن به گفتار ابتدا متن داده شده را به بازنمایی میانی | {
"avatar_url": "https://avatars.githubusercontent.com/u/147399213?v=4",
"events_url": "https://api.github.com/users/shabnam706/events{/privacy}",
"followers_url": "https://api.github.com/users/shabnam706/followers",
"following_url": "https://api.github.com/users/shabnam706/following{/other_user}",
"gists_url... | [] | closed | false | [] | null | [
"شبکه های متن به گفتار ابتدا متن داده شده را به بازنمایی میانی"
] | 2023-10-22T11:07:21Z | 2023-10-23T09:22:38Z | 2023-10-23T09:22:38Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6328/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6328/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5827 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5827/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5827/comments | https://api.github.com/repos/huggingface/datasets/issues/5827/events | https://github.com/huggingface/datasets/issues/5827 | 1,698,891,246 | I_kwDODunzps5lQwXu | 5,827 | load json dataset interrupt when dtype cast problem occured | {
"avatar_url": "https://avatars.githubusercontent.com/u/46060451?v=4",
"events_url": "https://api.github.com/users/1014661165/events{/privacy}",
"followers_url": "https://api.github.com/users/1014661165/followers",
"following_url": "https://api.github.com/users/1014661165/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"Indeed the JSON dataset builder raises an error when it encounters an unexpected type.\r\n\r\nThere's an old PR open to add away to ignore such elements though, if it can help: https://github.com/huggingface/datasets/pull/2838",
"Hi ! with #8027 you will be able to do \n```python\nfrom datasets import load_datas... | 2023-05-07T04:52:09Z | 2026-03-09T15:58:00Z | 2026-03-09T15:58:00Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
i have a json like this:
[
{"id": 1, "name": 1},
{"id": 2, "name": "Nan"},
{"id": 3, "name": 3},
....
]
,which have several problematic rows data like row 2, then i load it with datasets.load_dataset('json', data_files=['xx.json'], split='train'), it will report like this:
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5827/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5827/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3499 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3499/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3499/comments | https://api.github.com/repos/huggingface/datasets/issues/3499/events | https://github.com/huggingface/datasets/issues/3499 | 1,090,132,618 | I_kwDODunzps5A-hqK | 3,499 | Adjusting chunk size for streaming datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/3775944?v=4",
"events_url": "https://api.github.com/users/JoelNiklaus/events{/privacy}",
"followers_url": "https://api.github.com/users/JoelNiklaus/followers",
"following_url": "https://api.github.com/users/JoelNiklaus/following{/other_user}",
"gists_ur... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"Hi ! Data streaming uses `fsspec` to read the data files progressively. IIRC the block size for buffering is 5MiB by default. So every time you finish iterating over a block, it downloads the next one. You can still try to increase the `fsspec` block size for buffering if it can help. To do so you just need to inc... | 2021-12-28T21:17:53Z | 2022-05-06T16:29:05Z | 2022-05-06T16:29:05Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | **Is your feature request related to a problem? Please describe.**
I want to use mc4 which I cannot save locally, so I stream it. However, I want to process the entire dataset and filter some documents from it. With the current chunk size of around 1000 documents (right?) I hit a performance bottleneck because of the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3499/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3499/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5791 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5791/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5791/comments | https://api.github.com/repos/huggingface/datasets/issues/5791/events | https://github.com/huggingface/datasets/issues/5791 | 1,683,473,943 | I_kwDODunzps5kV8YX | 5,791 | TIFF/TIF support | {
"avatar_url": "https://avatars.githubusercontent.com/u/31293221?v=4",
"events_url": "https://api.github.com/users/sebasmos/events{/privacy}",
"followers_url": "https://api.github.com/users/sebasmos/followers",
"following_url": "https://api.github.com/users/sebasmos/following{/other_user}",
"gists_url": "htt... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"The issue with multichannel TIFF images has already been reported in Pillow (https://github.com/python-pillow/Pillow/issues/1888). We can't do much about it on our side.\r\n\r\nStill, to avoid the error, you can bypass the default Pillow decoding and define a custom one as follows:\r\n```python\r\nimport tifffile ... | 2023-04-25T16:14:18Z | 2024-01-15T16:40:33Z | 2024-01-15T16:40:16Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
I currently have a dataset (with tiff and json files) where I have to do this:
`wget path_to_data/images.zip && unzip images.zip`
`wget path_to_data/annotations.zip && unzip annotations.zip`
Would it make sense a contribution that supports these type of files?
### Motivation
instead o... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5791/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5791/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5641/comments | https://api.github.com/repos/huggingface/datasets/issues/5641/events | https://github.com/huggingface/datasets/issues/5641 | 1,625,942,730 | I_kwDODunzps5g6erK | 5,641 | Features cannot be named "self" | {
"avatar_url": "https://avatars.githubusercontent.com/u/14365168?v=4",
"events_url": "https://api.github.com/users/alialamiidrissi/events{/privacy}",
"followers_url": "https://api.github.com/users/alialamiidrissi/followers",
"following_url": "https://api.github.com/users/alialamiidrissi/following{/other_user}"... | [] | closed | false | [] | null | [] | 2023-03-15T17:16:40Z | 2023-03-16T17:14:51Z | 2023-03-16T17:14:51Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Hi,
I noticed that we cannot create a HuggingFace dataset from Pandas DataFrame with a column named `self`.
The error seems to be coming from arguments validation in the `Features.from_dict` function.
### Steps to reproduce the bug
```python
import datasets
dummy_pandas = pd.DataFrame([0... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5641/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5641/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1939 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1939/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1939/comments | https://api.github.com/repos/huggingface/datasets/issues/1939/events | https://github.com/huggingface/datasets/issues/1939 | 815,680,510 | MDU6SXNzdWU4MTU2ODA1MTA= | 1,939 | [firewalled env] OFFLINE mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Thanks for reporting and for all the details and suggestions.\r\n\r\nI'm totally in favor of having a HF_DATASETS_OFFLINE env variable to disable manually all the connection checks, remove retries etc.\r\n\r\nMoreover you may know that the use case that you are mentioning is already supported from `datasets` 1.3.0... | 2021-02-24T17:13:42Z | 2021-03-05T05:09:54Z | 2021-03-05T05:09:54Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | This issue comes from a need to be able to run `datasets` in a firewalled env, which currently makes the software hang until it times out, as it's unable to complete the network calls.
I propose the following approach to solving this problem, using the example of `run_seq2seq.py` as a sample program. There are 2 pos... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1939/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1939/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1776 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1776/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1776/comments | https://api.github.com/repos/huggingface/datasets/issues/1776/events | https://github.com/huggingface/datasets/issues/1776 | 792,755,249 | MDU6SXNzdWU3OTI3NTUyNDk= | 1,776 | [Question & Bug Report] Can we preprocess a dataset on the fly? | {
"avatar_url": "https://avatars.githubusercontent.com/u/14048129?v=4",
"events_url": "https://api.github.com/users/shuaihuaiyi/events{/privacy}",
"followers_url": "https://api.github.com/users/shuaihuaiyi/followers",
"following_url": "https://api.github.com/users/shuaihuaiyi/following{/other_user}",
"gists_u... | [] | closed | false | [] | null | [
"We are very actively working on this. How does your dataset look like in practice (number/size/type of files)?",
"It's a text file with many lines (about 1B) of Chinese sentences. I use it to train language model using https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm_wwm... | 2021-01-24T09:28:24Z | 2021-05-20T04:15:58Z | 2021-05-20T04:15:58Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I know we can use `Datasets.map` to preprocess a dataset, but I'm using it with very large corpus which generates huge cache file (several TB cache from a 400 GB text file). I have no disk large enough to save it. Can we preprocess a dataset on the fly without generating cache?
BTW, I tried raising `writer_batch_si... | {
"avatar_url": "https://avatars.githubusercontent.com/u/14048129?v=4",
"events_url": "https://api.github.com/users/shuaihuaiyi/events{/privacy}",
"followers_url": "https://api.github.com/users/shuaihuaiyi/followers",
"following_url": "https://api.github.com/users/shuaihuaiyi/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1776/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1776/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3143 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3143/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3143/comments | https://api.github.com/repos/huggingface/datasets/issues/3143/events | https://github.com/huggingface/datasets/issues/3143 | 1,033,569,655 | I_kwDODunzps49mwV3 | 3,143 | Provide a way to check if the features (in info) match with the data of a split | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "E5583E",
"default": fals... | open | false | [] | null | [
"Related: #3144 "
] | 2021-10-22T13:13:36Z | 2021-10-22T13:17:56Z | null | null | COLLABORATOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | **Is your feature request related to a problem? Please describe.**
I understand that currently the data loaded has not always the type described in the info features
**Describe the solution you'd like**
Provide a way to check if the rows have the type described by info features
**Describe alternatives you'v... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3143/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3143/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4581/comments | https://api.github.com/repos/huggingface/datasets/issues/4581/events | https://github.com/huggingface/datasets/issues/4581 | 1,286,362,907 | I_kwDODunzps5MrFcb | 4,581 | Dataset Viewer issue for pn_summary | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"linked to https://github.com/huggingface/datasets/issues/4580#issuecomment-1168373066?",
"Note that I refreshed twice this dataset, and I still have (another) error on one of the splits\r\n\r\n```\r\nStatus code: 400\r\nException: ClientResponseError\r\nMessage: 403, message='Forbidden', url=URL('htt... | 2022-06-27T20:56:12Z | 2022-06-28T14:42:03Z | 2022-06-28T14:42:03Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Link
https://huggingface.co/datasets/pn_summary/viewer/1.0.0/validation
### Description
Getting an index error on the `validation` and `test` splits:
```
Server error
Status code: 400
Exception: IndexError
Message: list index out of range
```
### Owner
No | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4581/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4581/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7113 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7113/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7113/comments | https://api.github.com/repos/huggingface/datasets/issues/7113/events | https://github.com/huggingface/datasets/issues/7113 | 2,475,029,640 | I_kwDODunzps6ThfSI | 7,113 | Stream dataset does not iterate if the batch size is larger than the dataset size (related to drop_last_batch) | {
"avatar_url": "https://avatars.githubusercontent.com/u/4197249?v=4",
"events_url": "https://api.github.com/users/memray/events{/privacy}",
"followers_url": "https://api.github.com/users/memray/followers",
"following_url": "https://api.github.com/users/memray/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | [] | null | [
"That's expected behavior, it's also the same in `torch`:\r\n\r\n```python\r\n>>> list(DataLoader(list(range(5)), batch_size=10, drop_last=True))\r\n[]\r\n```"
] | 2024-08-20T08:26:40Z | 2024-08-26T04:24:11Z | 2024-08-26T04:24:10Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Hi there,
I use streaming and interleaving to combine multiple datasets saved in jsonl files. The size of dataset can vary (from 100ish to 100k-ish). I use dataset.map() and a big batch size to reduce the IO cost. It was working fine with datasets-2.16.1 but this problem shows up after I upgr... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7113/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7113/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3099 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3099/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3099/comments | https://api.github.com/repos/huggingface/datasets/issues/3099/events | https://github.com/huggingface/datasets/issues/3099 | 1,028,338,078 | I_kwDODunzps49SzGe | 3,099 | AttributeError: module 'huggingface_hub.hf_api' has no attribute 'DatasetInfo' | {
"avatar_url": "https://avatars.githubusercontent.com/u/49268567?v=4",
"events_url": "https://api.github.com/users/JTWang2000/events{/privacy}",
"followers_url": "https://api.github.com/users/JTWang2000/followers",
"following_url": "https://api.github.com/users/JTWang2000/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @JTWang2000, thanks for reporting.\r\n\r\nHowever, I cannot reproduce your reported bug:\r\n```python\r\n>>> from datasets import load_dataset\r\n\r\n>>> dataset = load_dataset(\"sst\", \"default\")\r\n>>> dataset\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['sentence', 'label', 'tokens', 'tre... | 2021-10-17T14:17:47Z | 2021-11-09T16:42:29Z | 2021-11-09T16:42:28Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
When using `pip install datasets`
or use `conda install -c huggingface -c conda-forge datasets`
cannot install datasets
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("sst", "default")
```
## Actual results
---------------------------... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3099/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3099/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4697 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4697/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4697/comments | https://api.github.com/repos/huggingface/datasets/issues/4697/events | https://github.com/huggingface/datasets/issues/4697 | 1,307,332,253 | I_kwDODunzps5N7E6d | 4,697 | Trouble with streaming frgfm/imagenette vision dataset with TAR archive | {
"avatar_url": "https://avatars.githubusercontent.com/u/26927750?v=4",
"events_url": "https://api.github.com/users/frgfm/events{/privacy}",
"followers_url": "https://api.github.com/users/frgfm/followers",
"following_url": "https://api.github.com/users/frgfm/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @frgfm, thanks for reporting.\r\n\r\nAs the error message says, streaming mode is not supported out of the box when the dataset contains TAR archive files.\r\n\r\nTo make the dataset streamable, you have to use `dl_manager.iter_archive`.\r\n\r\nThere are several examples in other datasets, e.g. food101: https:/... | 2022-07-18T02:51:09Z | 2022-08-01T15:10:57Z | 2022-08-01T15:10:57Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Link
https://huggingface.co/datasets/frgfm/imagenette
### Description
Hello there :wave:
Thanks for the amazing work you've done with HF Datasets! I've just started playing with it, and managed to upload my first dataset. But for the second one, I'm having trouble with the preview since there is some archive... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4697/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4697/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2650/comments | https://api.github.com/repos/huggingface/datasets/issues/2650/events | https://github.com/huggingface/datasets/issues/2650 | 944,672,565 | MDU6SXNzdWU5NDQ2NzI1NjU= | 2,650 | [load_dataset] shard and parallelize the process | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}"... | null | [
"I need the same feature for distributed training",
"I think @TevenLeScao is exploring adding multiprocessing in `GeneratorBasedBuilder._prepare_split` - feel free to post updates here :)",
"Posted a PR to address the building side, still needs something to load sharded arrow files + tests",
"Closing as this ... | 2021-07-14T18:04:58Z | 2023-11-28T19:11:41Z | 2023-11-28T19:11:40Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_u... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | - Some huge datasets take forever to build the first time. (e.g. oscar/en) as it's done in a single cpu core.
- If the build crashes, everything done up to that point gets lost
Request: Shard the build over multiple arrow files, which would enable:
- much faster build by parallelizing the build process
- if the p... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 5,
"-1": 0,
"confused": 0,
"eyes": 3,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 10,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2650/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2650/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/829 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/829/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/829/comments | https://api.github.com/repos/huggingface/datasets/issues/829/events | https://github.com/huggingface/datasets/issues/829 | 740,061,699 | MDU6SXNzdWU3NDAwNjE2OTk= | 829 | [GEM] add Schema-Guided Dialogue | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | [] | null | [] | 2020-11-10T16:33:44Z | 2020-12-03T13:37:50Z | 2020-12-03T13:37:50Z | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Adding a Dataset
- **Name:** The Schema-Guided Dialogue Dataset
- **Description:** The Schema-Guided Dialogue (SGD) dataset consists of over 20k annotated multi-domain, task-oriented conversations between a human and a virtual assistant. These conversations involve interactions with services and APIs spanning 20 d... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/829/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/829/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2279 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2279/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2279/comments | https://api.github.com/repos/huggingface/datasets/issues/2279/events | https://github.com/huggingface/datasets/issues/2279 | 870,431,662 | MDU6SXNzdWU4NzA0MzE2NjI= | 2,279 | Compatibility with Ubuntu 18 and GLIBC 2.27? | {
"avatar_url": "https://avatars.githubusercontent.com/u/11379648?v=4",
"events_url": "https://api.github.com/users/tginart/events{/privacy}",
"followers_url": "https://api.github.com/users/tginart/followers",
"following_url": "https://api.github.com/users/tginart/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"From the trace this seems like an error in the tokenizer library instead.\r\n\r\nDo you mind opening an issue at https://github.com/huggingface/tokenizers instead?",
"Hi @tginart, thanks for reporting.\r\n\r\nI think this issue is already open at `tokenizers` library: https://github.com/huggingface/tokenizers/is... | 2021-04-28T22:08:07Z | 2021-04-29T07:42:42Z | 2021-04-29T07:42:42Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
For use on Ubuntu systems, it seems that datasets requires GLIBC 2.29. However, Ubuntu 18 runs with GLIBC 2.27 and it seems [non-trivial to upgrade GLIBC to 2.29 for Ubuntu 18 users](https://www.digitalocean.com/community/questions/how-install-glibc-2-29-or-higher-in-ubuntu-18-04).
I'm not sure... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2279/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2279/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7394/comments | https://api.github.com/repos/huggingface/datasets/issues/7394/events | https://github.com/huggingface/datasets/issues/7394 | 2,847,172,115 | I_kwDODunzps6ptGYT | 7,394 | Using load_dataset with data_files and split arguments yields an error | {
"avatar_url": "https://avatars.githubusercontent.com/u/61103399?v=4",
"events_url": "https://api.github.com/users/devon-research/events{/privacy}",
"followers_url": "https://api.github.com/users/devon-research/followers",
"following_url": "https://api.github.com/users/devon-research/following{/other_user}",
... | [] | open | false | [] | null | [
"Hi, \nI want to work on this issue involving adding a verification test for the **`HuggingFaceM4/InterleavedWebDocuments`** dataset. \nThis will be my first contribution to `datasets`, \nI plan to add a simple loading and basic structure verification test like other recent dataset tests. \nYou can expect a PR ... | 2025-02-12T04:50:11Z | 2025-11-21T14:05:23Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
It seems the list of valid splits recorded by the package becomes incorrectly overwritten when using the `data_files` argument.
If I run
```python
from datasets import load_dataset
load_dataset("allenai/super", split="all_examples", data_files="tasks/expert.jsonl")
```
then I get the error
```
Va... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7394/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7394/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6020 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6020/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6020/comments | https://api.github.com/repos/huggingface/datasets/issues/6020/events | https://github.com/huggingface/datasets/issues/6020 | 1,799,720,536 | I_kwDODunzps5rRY5Y | 6,020 | Inconsistent "The features can't be aligned" error when combining map, multiprocessing, and variable length outputs | {
"avatar_url": "https://avatars.githubusercontent.com/u/38166299?v=4",
"events_url": "https://api.github.com/users/kheyer/events{/privacy}",
"followers_url": "https://api.github.com/users/kheyer/followers",
"following_url": "https://api.github.com/users/kheyer/following{/other_user}",
"gists_url": "https://a... | [] | open | false | [] | null | [
"This scenario currently requires explicitly passing the target features (to avoid the error): \r\n```python\r\nimport datasets\r\n\r\n...\r\n\r\nfeatures = dataset.features\r\nfeatures[\"output\"] = = [{\"test\": datasets.Value(\"int64\")}]\r\ntest2 = dataset.map(lambda row, idx: test_func(row, idx), with_indices=... | 2023-07-11T20:40:38Z | 2024-10-27T06:30:13Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I'm using a dataset with map and multiprocessing to run a function that returned a variable length list of outputs. This output list may be empty. Normally this is handled fine, but there is an edge case that crops up when using multiprocessing. In some cases, an empty list result ends up in a dat... | null | {
"+1": 7,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 7,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6020/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6020/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5585/comments | https://api.github.com/repos/huggingface/datasets/issues/5585/events | https://github.com/huggingface/datasets/issues/5585 | 1,602,190,030 | I_kwDODunzps5ff3rO | 5,585 | Cache is not transportable | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | [] | closed | false | [] | null | [
"Hi ! No the cache is not transportable in general. It will work on a shared filesystem if you use the same python environment, but not across machines/os/environments.\r\n\r\nIn particular, reloading cached datasets does work, but reloading cached processed datasets (e.g. from `map`) may not work. This is because ... | 2023-02-28T00:53:06Z | 2023-02-28T21:26:52Z | 2023-02-28T21:26:52Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I would like to share cache between two machines (a Windows host machine and a WSL instance).
I run most my code in WSL. I have just run out of space in the virtual drive. Rather than expand the drive size, I plan to move to cache to the host Windows machine, thereby sharing the downloads.
I... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5585/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5585/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/993 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/993/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/993/comments | https://api.github.com/repos/huggingface/datasets/issues/993/events | https://github.com/huggingface/datasets/issues/993 | 755,135,768 | MDU6SXNzdWU3NTUxMzU3Njg= | 993 | Problem downloading amazon_reviews_multi | {
"avatar_url": "https://avatars.githubusercontent.com/u/29229602?v=4",
"events_url": "https://api.github.com/users/hfawaz/events{/privacy}",
"followers_url": "https://api.github.com/users/hfawaz/followers",
"following_url": "https://api.github.com/users/hfawaz/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | [] | null | [
"Hi @hfawaz ! This is working fine for me. Is it a repeated occurence? Have you tried from the latest verion?",
"Hi, it seems a connection problem. \r\nNow it says: \r\n`ConnectionError: Couldn't reach https://amazon-reviews-ml.s3-us-west-2.amazonaws.com/json/train/dataset_ja_train.json`"
] | 2020-12-02T10:15:57Z | 2022-10-05T12:21:34Z | 2022-10-05T12:21:34Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Thanks for adding the dataset.
After trying to load the dataset, I am getting the following error:
`ConnectionError: Couldn't reach https://amazon-reviews-ml.s3-us-west-2.amazonaws.com/json/train/dataset_fr_train.json
`
I used the following code to load the dataset:
`load_dataset(
dataset_name,
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/993/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/993/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7455 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7455/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7455/comments | https://api.github.com/repos/huggingface/datasets/issues/7455/events | https://github.com/huggingface/datasets/issues/7455 | 2,921,933,250 | I_kwDODunzps6uKSnC | 7,455 | Problems with local dataset after upgrade from 3.3.2 to 3.4.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/60151338?v=4",
"events_url": "https://api.github.com/users/andjoer/events{/privacy}",
"followers_url": "https://api.github.com/users/andjoer/followers",
"following_url": "https://api.github.com/users/andjoer/following{/other_user}",
"gists_url": "https:... | [] | open | false | [] | null | [
"Hi ! I just released 3.4.1 with a fix, let me know if it's working now !"
] | 2025-03-15T09:22:50Z | 2025-03-17T16:20:43Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I was not able to open a local saved dataset anymore that was created using an older datasets version after the upgrade yesterday from datasets 3.3.2 to 3.4.0
The traceback is
```
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/datasets/packaged_modules/arrow/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7455/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7455/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/8010 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/8010/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/8010/comments | https://api.github.com/repos/huggingface/datasets/issues/8010/events | https://github.com/huggingface/datasets/issues/8010 | 3,963,448,558 | I_kwDODunzps7sPWzu | 8,010 | audiofolder / folder-based loader rejects metadata.csv when file_name column is inferred as large_string | {
"avatar_url": "https://avatars.githubusercontent.com/u/119339573?v=4",
"events_url": "https://api.github.com/users/Koosh0610/events{/privacy}",
"followers_url": "https://api.github.com/users/Koosh0610/followers",
"following_url": "https://api.github.com/users/Koosh0610/following{/other_user}",
"gists_url": ... | [] | closed | false | [] | null | [
"Proposing a PR for this [here](https://github.com/huggingface/datasets/pull/8011)\n\nPS: I didn't find a contributing documentation. Please recommend any changes in issue or PR if any. Thank you!"
] | 2026-02-19T15:06:09Z | 2026-02-19T15:29:41Z | 2026-02-19T15:29:41Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When loading a dataset with load_dataset("audiofolder", data_dir=...) and a metadata.csv (with a file_name column), loading can fail with:
`ValueError: file_name or *_file_name must be present as dictionary key (with type string) in metadata files`
even when the CSV clearly has a file_name colum... | {
"avatar_url": "https://avatars.githubusercontent.com/u/119339573?v=4",
"events_url": "https://api.github.com/users/Koosh0610/events{/privacy}",
"followers_url": "https://api.github.com/users/Koosh0610/followers",
"following_url": "https://api.github.com/users/Koosh0610/following{/other_user}",
"gists_url": ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/8010/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/8010/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7741/comments | https://api.github.com/repos/huggingface/datasets/issues/7741/events | https://github.com/huggingface/datasets/issues/7741 | 3,334,848,656 | I_kwDODunzps7GxcCQ | 7,741 | Preserve tree structure when loading HDF5 | {
"avatar_url": "https://avatars.githubusercontent.com/u/17013474?v=4",
"events_url": "https://api.github.com/users/klamike/events{/privacy}",
"followers_url": "https://api.github.com/users/klamike/followers",
"following_url": "https://api.github.com/users/klamike/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [] | 2025-08-19T15:42:05Z | 2025-08-26T15:28:06Z | 2025-08-26T15:28:06Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
https://github.com/huggingface/datasets/pull/7740#discussion_r2285605374
### Motivation
`datasets` has the `Features` class for representing nested features. HDF5 files have groups of datasets which are nested, though in #7690 the keys are flattened. We should preserve that structure for the user... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7741/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7741/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5757 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5757/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5757/comments | https://api.github.com/repos/huggingface/datasets/issues/5757/events | https://github.com/huggingface/datasets/issues/5757 | 1,669,910,503 | I_kwDODunzps5jiM_n | 5,757 | Tilde (~) is not supported | {
"avatar_url": "https://avatars.githubusercontent.com/u/2437102?v=4",
"events_url": "https://api.github.com/users/eli-osherovich/events{/privacy}",
"followers_url": "https://api.github.com/users/eli-osherovich/followers",
"following_url": "https://api.github.com/users/eli-osherovich/following{/other_user}",
... | [] | closed | false | [] | null | [] | 2023-04-16T11:48:10Z | 2023-04-20T15:30:51Z | 2023-04-20T15:30:51Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
It seems that `~` is not recognized correctly in local paths. Whenever I try to use it I get an exception
### Steps to reproduce the bug
```python
load_dataset("imagefolder", data_dir="~/data/my_dataset")
```
Will generate the following error:
```
EmptyDatasetError: The directory at ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5757/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5757/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3190 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3190/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3190/comments | https://api.github.com/repos/huggingface/datasets/issues/3190/events | https://github.com/huggingface/datasets/issues/3190 | 1,041,153,631 | I_kwDODunzps4-Dr5f | 3,190 | combination of shuffle and filter results in a bug | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"I cannot reproduce this on master and pyarrow==4.0.1.\r\n",
"Hi ! There was a regression in `datasets` 1.12 that introduced this bug. It has been fixed in #3019 in 1.13\r\n\r\nCan you try to update `datasets` and try again ?",
"Thanks a lot, fixes with 1.13"
] | 2021-11-01T13:07:29Z | 2021-11-02T10:50:49Z | 2021-11-02T10:50:49Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Hi,
I would like to shuffle a dataset, then filter it based on each existing label. however, the combination of `filter`, `shuffle` seems to results in a bug. In the minimal example below, as you see in the filtered results, the filtered labels are not unique, meaning filter has not worked. Any su... | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3190/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3190/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2923 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2923/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2923/comments | https://api.github.com/repos/huggingface/datasets/issues/2923/events | https://github.com/huggingface/datasets/issues/2923 | 997,351,590 | I_kwDODunzps47cmCm | 2,923 | Loading an autonlp dataset raises in normal mode but not in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "E5583E",
"default": false,
"descrip... | closed | false | [] | null | [
"Closing since autonlp dataset are now supported"
] | 2021-09-15T17:44:38Z | 2022-04-12T10:09:40Z | 2022-04-12T10:09:39Z | null | COLLABORATOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
The same dataset (from autonlp) raises an error in normal mode, but does not raise in streaming mode
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("severo/autonlp-data-sentiment_detection-3c8bcd36", split="train", streaming=False)
## raises an err... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2923/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2923/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/727/comments | https://api.github.com/repos/huggingface/datasets/issues/727/events | https://github.com/huggingface/datasets/issues/727 | 719,386,366 | MDU6SXNzdWU3MTkzODYzNjY= | 727 | Parallel downloads progress bar flickers | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | open | false | [] | null | [
"Hi! Triaging older issues this week — I think this one has shipped and can be closed.\n\nThe exact fix suggested in the original report (assign `position=i` to each parallel tqdm bar so they don't share a line) is in place on current `main` (4.8.6.dev0):\n\n- `src/datasets/utils/py_utils.py:401` — the per-worker t... | 2020-10-12T13:36:05Z | 2020-10-12T13:36:05Z | null | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | When there are parallel downloads using the download manager, the tqdm progress bar flickers since all the progress bars are on the same line.
To fix that we could simply specify `position=i` for i=0 to n the number of files to download when instantiating the tqdm progress bar.
Another way would be to have one "... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/727/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3630/comments | https://api.github.com/repos/huggingface/datasets/issues/3630/events | https://github.com/huggingface/datasets/issues/3630 | 1,114,578,625 | I_kwDODunzps5Cbx7B | 3,630 | DuplicatedKeysError of NewsQA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/37647985?v=4",
"events_url": "https://api.github.com/users/StevenTang1998/events{/privacy}",
"followers_url": "https://api.github.com/users/StevenTang1998/followers",
"following_url": "https://api.github.com/users/StevenTang1998/following{/other_user}",
... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @StevenTang1998.\r\n\r\nI'm fixing it. "
] | 2022-01-26T03:05:49Z | 2022-02-14T08:37:19Z | 2022-02-14T08:37:19Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | After processing the dataset following official [NewsQA](https://github.com/Maluuba/newsqa), I used datasets to load it:
```
a = load_dataset('newsqa', data_dir='news')
```
and the following error occurred:
```
Using custom data configuration default-data_dir=news
Downloading and preparing dataset newsqa/defaul... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3630/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3630/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5404/comments | https://api.github.com/repos/huggingface/datasets/issues/5404/events | https://github.com/huggingface/datasets/issues/5404 | 1,517,566,331 | I_kwDODunzps5adDl7 | 5,404 | Better integration of BIG-bench | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [
"Hi, I made my version : https://huggingface.co/datasets/tasksource/bigbench"
] | 2023-01-03T15:37:57Z | 2023-02-09T20:30:26Z | null | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Ideally, it would be nice to have a maintained PyPI package for `bigbench`.
### Motivation
We'd like to allow anyone to access, explore and use any task.
### Your contribution
@lhoestq has opened an issue in their repo:
- https://github.com/google/BIG-bench/issues/906 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5404/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5404/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/2849 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2849/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2849/comments | https://api.github.com/repos/huggingface/datasets/issues/2849/events | https://github.com/huggingface/datasets/issues/2849 | 982,631,420 | MDU6SXNzdWU5ODI2MzE0MjA= | 2,849 | Add Open Catalyst Project Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | [] | null | [] | 2021-08-30T10:14:39Z | 2021-08-30T10:14:39Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Adding a Dataset
- **Name:** Open Catalyst 2020 (OC20) Dataset
- **Website:** https://opencatalystproject.org/
- **Data:** https://github.com/Open-Catalyst-Project/ocp/blob/master/DATASET.md
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATAS... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2849/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2849/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3918 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3918/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3918/comments | https://api.github.com/repos/huggingface/datasets/issues/3918/events | https://github.com/huggingface/datasets/issues/3918 | 1,169,366,117 | I_kwDODunzps5Fsxxl | 3,918 | datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files | {
"avatar_url": "https://avatars.githubusercontent.com/u/51409295?v=4",
"events_url": "https://api.github.com/users/willowdong/events{/privacy}",
"followers_url": "https://api.github.com/users/willowdong/followers",
"following_url": "https://api.github.com/users/willowdong/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "cfd3d7",
"default": true,
"descript... | closed | false | [] | null | [
"Hi @willowdong! These issues were fixed on master. We will have a new release of `datasets` later today. In the meantime, you can avoid these issues by installing `datasets` from master as follows:\r\n```bash\r\npip install git+https://github.com/huggingface/datasets.git\r\n```",
"You should force redownload:\r\... | 2022-03-15T08:53:45Z | 2022-03-16T15:36:58Z | 2022-03-15T14:01:25Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Can't load the dataset
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset('multi_news')
dataset_2=load_dataset("reddit_tifu", "long")
## Actual results
raise NonMatchingChecksumError(error_msg + s... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3918/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3918/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3984 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3984/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3984/comments | https://api.github.com/repos/huggingface/datasets/issues/3984/events | https://github.com/huggingface/datasets/issues/3984 | 1,175,822,117 | I_kwDODunzps5GFZ8l | 3,984 | Local and automatic tests fail | {
"avatar_url": "https://avatars.githubusercontent.com/u/20767068?v=4",
"events_url": "https://api.github.com/users/MarkusSagen/events{/privacy}",
"followers_url": "https://api.github.com/users/MarkusSagen/followers",
"following_url": "https://api.github.com/users/MarkusSagen/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi ! To be able to run the tests, you need to install all the test dependencies and additional ones with\r\n```\r\npip install -e .[tests]\r\npip install -r additional-tests-requirements.txt --no-deps\r\n```\r\n\r\nIn particular, you probably need to `sacrebleu`. It looks like it wasn't able to instantiate `sacreb... | 2022-03-21T19:07:37Z | 2023-07-25T15:18:40Z | 2023-07-25T15:18:40Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Running the tests from CircleCI on a PR or locally fails, even with no changes. Tests seem to fail on `test_metric_common.py`
## Steps to reproduce the bug
```shell
git clone https://huggingface/datasets.git
cd datasets
```
```python
python -m pip install -e .
pytest
```
## Expected... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3984/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3984/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3706 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3706/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3706/comments | https://api.github.com/repos/huggingface/datasets/issues/3706/events | https://github.com/huggingface/datasets/issues/3706 | 1,132,218,874 | I_kwDODunzps5DfEn6 | 3,706 | Unable to load dataset 'big_patent' | {
"avatar_url": "https://avatars.githubusercontent.com/u/26432753?v=4",
"events_url": "https://api.github.com/users/ankitk2109/events{/privacy}",
"followers_url": "https://api.github.com/users/ankitk2109/followers",
"following_url": "https://api.github.com/users/ankitk2109/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi @ankitk2109,\r\n\r\nHave you tried passing the split name with the keyword `split=`? See e.g. an example in our Quick Start docs: https://huggingface.co/docs/datasets/quickstart.html#load-the-dataset-and-model\r\n```python\r\n ds = load_dataset(\"big_patent\", \"d\", split=\"validation\")",
"Hi @albertvillano... | 2022-02-11T09:48:34Z | 2022-02-14T15:26:03Z | 2022-02-14T15:26:03Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\dat... | {
"avatar_url": "https://avatars.githubusercontent.com/u/26432753?v=4",
"events_url": "https://api.github.com/users/ankitk2109/events{/privacy}",
"followers_url": "https://api.github.com/users/ankitk2109/followers",
"following_url": "https://api.github.com/users/ankitk2109/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3706/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3706/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6124 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6124/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6124/comments | https://api.github.com/repos/huggingface/datasets/issues/6124/events | https://github.com/huggingface/datasets/issues/6124 | 1,837,868,112 | I_kwDODunzps5ti6RQ | 6,124 | Datasets crashing runs due to KeyError | {
"avatar_url": "https://avatars.githubusercontent.com/u/25208228?v=4",
"events_url": "https://api.github.com/users/conceptofmind/events{/privacy}",
"followers_url": "https://api.github.com/users/conceptofmind/followers",
"following_url": "https://api.github.com/users/conceptofmind/following{/other_user}",
"g... | [] | closed | false | [] | null | [
"i once had the same error and I could fix that by pushing a fake or a dummy commit on my hugging face dataset repo",
"Hi! We need a reproducer to fix this. Can you provide a link to the dataset (if it's public)?",
"> Hi! We need a reproducer to fix this. Can you provide a link to the dataset (if it's public)?\... | 2023-08-05T17:48:56Z | 2023-11-30T16:28:57Z | 2023-11-30T16:28:57Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Hi all,
I have been running into a pretty persistent issue recently when trying to load datasets.
```python
train_dataset = load_dataset(
'llama-2-7b-tokenized',
split = 'train'
)
```
I receive a KeyError which crashes the runs.
```
Traceback (most recent call... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6124/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6124/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5117 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5117/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5117/comments | https://api.github.com/repos/huggingface/datasets/issues/5117/events | https://github.com/huggingface/datasets/issues/5117 | 1,409,571,346 | I_kwDODunzps5UBFoS | 5,117 | Progress bars have color red and never completed to 100% | {
"avatar_url": "https://avatars.githubusercontent.com/u/63857529?v=4",
"events_url": "https://api.github.com/users/echatzikyriakidis/events{/privacy}",
"followers_url": "https://api.github.com/users/echatzikyriakidis/followers",
"following_url": "https://api.github.com/users/echatzikyriakidis/following{/other_... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/9879252?v=4",
"events_url": "https://api.github.com/users/david1542/events{/privacy}",
"followers_url": "https://api.github.com/users/david1542/followers",
"following_url": "https://api.github.com/users/david1542/following{/other_user}",
"... | null | [
"Hi @echatzikyriakidis, thanks for submitting the issue.\r\nWhich shell are you using exactly? I tried to run the command you sent, but I don't see colors at all 🧐\r\n\r\nI tried from bash and zsh as well.",
"Hi @david1542 ,\r\n\r\nI use Google Colab.\r\n",
"Got it. I [created a PR](https://github.com/huggingf... | 2022-10-14T16:12:30Z | 2024-06-19T19:03:42Z | 2022-10-23T12:58:41Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/9879252?v=4",
"events_url": "https://api.github.com/users/david1542/events{/privacy}",
"followers_url": "https://api.github.com/users/david1542/followers",
"following_url": "https://api.github.com/users/david1542/following{/other_user}",
"gists_url": "h... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Progress bars after transformative operations turn in red and never be completed to 100%
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset('rotten_tomatoes', split='test').filter(lambda o: True)
```
## Expected results
Progress bar should be 100% an... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5117/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5117/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5284 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5284/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5284/comments | https://api.github.com/repos/huggingface/datasets/issues/5284/events | https://github.com/huggingface/datasets/issues/5284 | 1,461,519,733 | I_kwDODunzps5XHQV1 | 5,284 | Features of IterableDataset set to None by remove column | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "fef2c0",
"default": false,
"descrip... | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}"... | null | [
"Related to https://github.com/huggingface/datasets/issues/5245",
"#self-assign",
"Thanks @lhoestq and @alvarobartt!\r\n\r\nThis would be extremely helpful to have working for the Whisper fine-tuning event - we're **only** training using streaming mode, so it'll be quite important to have this feature working t... | 2022-11-23T10:54:59Z | 2025-02-07T11:36:41Z | 2022-11-28T12:53:24Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
The `remove_column` method of the IterableDataset sets the dataset features to None.
### Steps to reproduce the bug
```python
from datasets import Audio, load_dataset
# load LS in streaming mode
dataset = load_dataset("librispeech_asr", "clean", split="validation", streaming=True)
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5284/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5284/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4642 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4642/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4642/comments | https://api.github.com/repos/huggingface/datasets/issues/4642/events | https://github.com/huggingface/datasets/issues/4642 | 1,295,748,083 | I_kwDODunzps5NO4vz | 4,642 | Streaming issue for ccdv/pubmed-summarization | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting @lewtun.\r\n\r\nI confirm there is an issue with streaming: it does not stream locally. ",
"Oh, after investigation, the source of the issue is in the Hub dataset loading script.\r\n\r\nI'm opening a PR on the Hub dataset.",
"I've opened a PR on their Hub dataset to support streaming: http... | 2022-07-06T12:13:07Z | 2022-07-06T14:17:34Z | 2022-07-06T14:17:34Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Link
https://huggingface.co/datasets/ccdv/pubmed-summarization
### Description
This was reported by a [user of AutoTrain Evaluate](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions/7). It seems like streaming doesn't work due to the way the dataset loading script is defined?
```
Status c... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4642/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4642/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1954/comments | https://api.github.com/repos/huggingface/datasets/issues/1954/events | https://github.com/huggingface/datasets/issues/1954 | 817,565,563 | MDU6SXNzdWU4MTc1NjU1NjM= | 1,954 | add a new column | {
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url"... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi\r\nnot sure how change the lable after creation, but this is an issue not dataset request. thanks ",
"Hi ! Currently you have to use `map` . You can see an example of how to do it in this comment: https://github.com/huggingface/datasets/issues/853#issuecomment-727872188\r\n\r\nIn the future we'll add support ... | 2021-02-26T18:17:27Z | 2021-04-29T14:50:43Z | 2021-04-29T14:50:43Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi
I'd need to add a new column to the dataset, I was wondering how this can be done? thanks
@lhoestq | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1954/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7909 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7909/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7909/comments | https://api.github.com/repos/huggingface/datasets/issues/7909/events | https://github.com/huggingface/datasets/issues/7909 | 3,749,885,131 | I_kwDODunzps7fgrTL | 7,909 | Support cast_kwargs in cast_columns | {
"avatar_url": "https://avatars.githubusercontent.com/u/49304833?v=4",
"events_url": "https://api.github.com/users/Moenupa/events{/privacy}",
"followers_url": "https://api.github.com/users/Moenupa/followers",
"following_url": "https://api.github.com/users/Moenupa/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [] | 2025-12-20T10:02:07Z | 2025-12-20T10:28:01Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
expose `cast(**cast_kwargs)` to `cast_column()`
https://github.com/huggingface/datasets/blob/0feb65dd8733191dd2d1e74215b422fc5939a56a/src/datasets/arrow_dataset.py#L2205
### Motivation
`cast_column()` wraps `cast()` function without exposing any `cast()` args. For large multi-modal datasets, e.g... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7909/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7909/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7990 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7990/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7990/comments | https://api.github.com/repos/huggingface/datasets/issues/7990/events | https://github.com/huggingface/datasets/issues/7990 | 3,895,870,826 | I_kwDODunzps7oNkVq | 7,990 | Dataset.map crashes when first examples return None and later examples return dict — writer not initialized | {
"avatar_url": "https://avatars.githubusercontent.com/u/30819640?v=4",
"events_url": "https://api.github.com/users/meta-program/events{/privacy}",
"followers_url": "https://api.github.com/users/meta-program/followers",
"following_url": "https://api.github.com/users/meta-program/following{/other_user}",
"gist... | [] | open | false | [] | null | [
"map() expects a function that always return dict or that always return none"
] | 2026-02-04T10:43:20Z | 2026-04-16T09:27:35Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I detected a serious [bug from datasets/arrow_dataset.py](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L3676)
---
**Description of the bug**
`Dataset.map` crashes with `writer is None` when the map function returns `None` for the first few examples and a diction... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7990/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7990/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7916/comments | https://api.github.com/repos/huggingface/datasets/issues/7916/events | https://github.com/huggingface/datasets/issues/7916 | 3,764,901,707 | I_kwDODunzps7gZ9dL | 7,916 | No description provided. | {
"avatar_url": "https://avatars.githubusercontent.com/u/61858900?v=4",
"events_url": "https://api.github.com/users/howitry/events{/privacy}",
"followers_url": "https://api.github.com/users/howitry/followers",
"following_url": "https://api.github.com/users/howitry/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [] | 2025-12-27T16:33:11Z | 2025-12-27T16:45:22Z | 2025-12-27T16:45:22Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/61858900?v=4",
"events_url": "https://api.github.com/users/howitry/events{/privacy}",
"followers_url": "https://api.github.com/users/howitry/followers",
"following_url": "https://api.github.com/users/howitry/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7916/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5699 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5699/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5699/comments | https://api.github.com/repos/huggingface/datasets/issues/5699/events | https://github.com/huggingface/datasets/issues/5699 | 1,652,437,419 | I_kwDODunzps5ifjGr | 5,699 | Issue when wanting to split in memory a cached dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47528215?v=4",
"events_url": "https://api.github.com/users/FrancoisNoyez/events{/privacy}",
"followers_url": "https://api.github.com/users/FrancoisNoyez/followers",
"following_url": "https://api.github.com/users/FrancoisNoyez/following{/other_user}",
"g... | [] | open | false | [] | null | [
"Hi ! Good catch, this is wrong indeed and thanks for opening a PR :)",
"Facing the same issue. Kindly fix this bug."
] | 2023-04-03T17:00:07Z | 2024-05-15T13:12:18Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
**In the 'train_test_split' method of the Dataset class** (defined datasets/arrow_dataset.py), **if 'self.cache_files' is not empty**, then, **regarding the input parameters 'train_indices_cache_file_name' and 'test_indices_cache_file_name', if they are None**, we modify them to make them not No... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5699/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5699/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5394/comments | https://api.github.com/repos/huggingface/datasets/issues/5394/events | https://github.com/huggingface/datasets/issues/5394 | 1,513,976,229 | I_kwDODunzps5aPXGl | 5,394 | CI error: TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers' | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"I still getting the same error :\r\n\r\n`python -m spacy download fr_core_news_lg\r\n`.\r\n`import spacy`",
"@MFatnassi, this issue and the corresponding fix only affect our Continuous Integration testing environment.\r\n\r\nNote that `datasets` does not depend on `spacy`."
] | 2022-12-29T18:58:44Z | 2022-12-30T10:40:51Z | 2022-12-29T21:00:27Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
While installing the dependencies, the CI raises a TypeError:
```
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 183, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/opt/hoste... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5394/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5394/timeline | null | completed | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.