
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 48 51 | id int64 600M 4.46B | node_id stringlengths 18 24 | number int64 2 8.2k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC]date 2020-04-14 18:18:51 2026-05-16 13:28:01 | updated_at timestamp[ns, tz=UTC]date 2020-04-29 09:23:05 2026-05-21 16:18:22 | closed_at timestamp[ns, tz=UTC]date 2020-04-29 09:23:05 2026-05-20 10:46:58 ⌀ | assignee dict | author_association stringclasses 4
values | issue_field_values listlengths 0 0 | type float64 | active_lock_reason float64 | sub_issues_summary dict | issue_dependencies_summary dict | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 4
values | pinned_comment float64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/720 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/720/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/720/comments | https://api.github.com/repos/huggingface/datasets/issues/720/events | https://github.com/huggingface/datasets/issues/720 | 716,581,266 | MDU6SXNzdWU3MTY1ODEyNjY= | 720 | OSError: Cannot find data file when not using the dummy dataset in RAG | {
"avatar_url": "https://avatars.githubusercontent.com/u/4112135?v=4",
"events_url": "https://api.github.com/users/josemlopez/events{/privacy}",
"followers_url": "https://api.github.com/users/josemlopez/followers",
"following_url": "https://api.github.com/users/josemlopez/following{/other_user}",
"gists_url":... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Same issue here. I will be digging further, but it looks like the [script](https://github.com/huggingface/datasets/blob/master/datasets/wiki_dpr/wiki_dpr.py#L132) is attempting to open a file that is not downloaded yet. \r\n\r\n```\r\n99dcbca09109e58502e6b9271d4d3f3791b43f61f3161a76b25d2775ab1a4498.lock\r\n```\r\n... | 2020-10-07T14:27:13Z | 2020-12-23T14:04:31Z | 2020-12-23T14:04:31Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Environment info
transformers version: 3.3.1
Platform: Linux-4.19
Python version: 3.7.7
PyTorch version (GPU?): 1.6.0
Tensorflow version (GPU?): No
Using GPU in script?: Yes
Using distributed or parallel set-up in script?: No
## To reproduce
Steps to reproduce the behaviour... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/720/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/720/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4676/comments | https://api.github.com/repos/huggingface/datasets/issues/4676/events | https://github.com/huggingface/datasets/issues/4676 | 1,302,202,028 | I_kwDODunzps5Nngas | 4,676 | Dataset.map gets stuck on _cast_to_python_objects | {
"avatar_url": "https://avatars.githubusercontent.com/u/662612?v=4",
"events_url": "https://api.github.com/users/srobertjames/events{/privacy}",
"followers_url": "https://api.github.com/users/srobertjames/followers",
"following_url": "https://api.github.com/users/srobertjames/following{/other_user}",
"gists_... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"descript... | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/5697926?v=4",
"events_url": "https://api.github.com/users/szmoro/events{/privacy}",
"followers_url": "https://api.github.com/users/szmoro/followers",
"following_url": "https://api.github.com/users/szmoro/following{/other_user}",
"gists_url... | null | [
"Are you able to reproduce this? My example is small enough that it should be easy to try.",
"Hi! Thanks for reporting and providing a reproducible example. Indeed, by default, `datasets` performs an expensive cast on the values returned by `map` to convert them to one of the types supported by PyArrow (the under... | 2022-07-12T15:09:58Z | 2022-10-03T13:01:04Z | 2022-10-03T13:01:03Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/5697926?v=4",
"events_url": "https://api.github.com/users/szmoro/events{/privacy}",
"followers_url": "https://api.github.com/users/szmoro/followers",
"following_url": "https://api.github.com/users/szmoro/following{/other_user}",
"gists_url": "https://ap... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
`Dataset.map`, when fed a Huggingface Tokenizer as its map func, can sometimes spend huge amounts of time doing casts. A minimal example follows.
Not all usages suffer from this. For example, I profiled the preprocessor at https://github.com/huggingface/notebooks/blob/main/examples/question_an... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4676/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4676/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7927 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7927/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7927/comments | https://api.github.com/repos/huggingface/datasets/issues/7927/events | https://github.com/huggingface/datasets/issues/7927 | 3,775,302,438 | I_kwDODunzps7hBosm | 7,927 | Using Stateful Dataloader with Split Dataset By Node and DCP for DDP | {
"avatar_url": "https://avatars.githubusercontent.com/u/25208228?v=4",
"events_url": "https://api.github.com/users/conceptofmind/events{/privacy}",
"followers_url": "https://api.github.com/users/conceptofmind/followers",
"following_url": "https://api.github.com/users/conceptofmind/following{/other_user}",
"g... | [] | open | false | [] | null | [
"Does it need to be pickled?\n\n```python\n def load_state_dict(self, state_dict):\n hf_state = pickle.loads(state_dict[\"data\"])\n self.train_dataset.load_state_dict(hf_state)\n\n def state_dict(self):\n return {\"data\": pickle.dumps(self.train_dataset.state_dict())}\n```",
"Pickling... | 2026-01-01T22:27:07Z | 2026-02-01T06:13:30Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I am trying to determine how to save and load the Stateful Dataloader State with DCP and Split Dataset by Node for DDP.
Currently, I am running into the issue where I am receiving a slow resume.
```
Neither dataset nor iter(dataset) defines state_dict/load_state_dict so we are naively fast-forwar... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7927/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7927/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/735 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/735/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/735/comments | https://api.github.com/repos/huggingface/datasets/issues/735/events | https://github.com/huggingface/datasets/issues/735 | 722,225,270 | MDU6SXNzdWU3MjIyMjUyNzA= | 735 | Throw error when an unexpected key is used in data_files | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url":... | [] | closed | false | [] | null | [
"Thanks for reporting !\r\nWe'll add support for other keys"
] | 2020-10-15T10:55:27Z | 2020-10-30T13:23:52Z | 2020-10-30T13:23:52Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I have found that only "train", "validation" and "test" are valid keys in the `data_files` argument. When you use any other ones, those attached files are silently ignored - leading to unexpected behaviour for the users.
So the following, unintuitively, returns only one key (namely `train`).
```python
datasets =... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/735/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/735/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7893 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7893/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7893/comments | https://api.github.com/repos/huggingface/datasets/issues/7893/events | https://github.com/huggingface/datasets/issues/7893 | 3,688,454,085 | I_kwDODunzps7b2VfF | 7,893 | push_to_hub OOM: _push_parquet_shards_to_hub accumulates all shard bytes in memory | {
"avatar_url": "https://avatars.githubusercontent.com/u/175985783?v=4",
"events_url": "https://api.github.com/users/The-Obstacle-Is-The-Way/events{/privacy}",
"followers_url": "https://api.github.com/users/The-Obstacle-Is-The-Way/followers",
"following_url": "https://api.github.com/users/The-Obstacle-Is-The-Wa... | [] | closed | false | [] | null | [
"`preupload_lfs_files` removes the parquet bytes in `shard_addition` since the default is `free_memory=True`: it doesn't accumulate in memory. Can you check this is indeed the case, i.e. that `shard_addition.path_or_fileobj` is indeed empty ?",
"@lhoestq Thank you for pushing back on this and helping me understan... | 2025-12-03T04:19:34Z | 2025-12-05T22:45:59Z | 2025-12-05T22:44:16Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Summary
Large dataset uploads crash or hang due to memory exhaustion. This appears to be the root cause of several long-standing issues.
### Related Issues
This is the root cause of:
- #5990 - Pushing a large dataset on the hub consistently hangs (46 comments, open since 2023)
- #7400 - 504 Gateway Timeout when u... | {
"avatar_url": "https://avatars.githubusercontent.com/u/175985783?v=4",
"events_url": "https://api.github.com/users/The-Obstacle-Is-The-Way/events{/privacy}",
"followers_url": "https://api.github.com/users/The-Obstacle-Is-The-Way/followers",
"following_url": "https://api.github.com/users/The-Obstacle-Is-The-Wa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7893/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7893/timeline | null | not_planned | null |
https://api.github.com/repos/huggingface/datasets/issues/4508 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4508/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4508/comments | https://api.github.com/repos/huggingface/datasets/issues/4508/events | https://github.com/huggingface/datasets/issues/4508 | 1,272,718,921 | I_kwDODunzps5L3CZJ | 4,508 | cast_storage method from datasets.features | {
"avatar_url": "https://avatars.githubusercontent.com/u/67968596?v=4",
"events_url": "https://api.github.com/users/romainremyb/events{/privacy}",
"followers_url": "https://api.github.com/users/romainremyb/followers",
"following_url": "https://api.github.com/users/romainremyb/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Hi! We've recently added a check to the `ClassLabel` type to ensure the values are in the valid label range `-1, 0, ..., num_classes-1` (-1 is used for missing values). The error in your case happens only if the `labels` column is of type `Sequence(ClassLabel(...))` before the `map` call and can be avoided by call... | 2022-06-15T20:47:22Z | 2022-06-16T13:54:07Z | 2022-06-16T13:54:07Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
A bug occurs when mapping a function to a dataset object. I ran the same code with the same data yesterday and it worked just fine. It works when i run locally on an old version of datasets.
## Steps to reproduce the bug
Steps are:
- load whatever datset
- write a preprocessing function such ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4508/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4508/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/233 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/233/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/233/comments | https://api.github.com/repos/huggingface/datasets/issues/233/events | https://github.com/huggingface/datasets/issues/233 | 630,432,132 | MDU6SXNzdWU2MzA0MzIxMzI= | 233 | Fail to download c4 english corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/16605764?v=4",
"events_url": "https://api.github.com/users/donggyukimc/events{/privacy}",
"followers_url": "https://api.github.com/users/donggyukimc/followers",
"following_url": "https://api.github.com/users/donggyukimc/following{/other_user}",
"gists_u... | [] | closed | false | [] | null | [
"Hello ! Thanks for noticing this bug, let me fix that.\r\n\r\nAlso for information, as specified in the changelog of the latest release, C4 currently needs to have a runtime for apache beam to work on. Apache beam is used to process this very big dataset and it can work on dataflow, spark, flink, apex, etc. You ca... | 2020-06-04T01:06:38Z | 2021-01-08T07:17:32Z | 2020-06-08T09:16:59Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | i run following code to download c4 English corpus.
```
dataset = nlp.load_dataset('c4', 'en', beam_runner='DirectRunner'
, data_dir='/mypath')
```
and i met failure as follows
```
Downloading and preparing dataset c4/en (download: Unknown size, generated: Unknown size, total: Unknown size) to /home/adam/.... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/233/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/233/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7934 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7934/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7934/comments | https://api.github.com/repos/huggingface/datasets/issues/7934/events | https://github.com/huggingface/datasets/issues/7934 | 3,792,642,445 | I_kwDODunzps7iDyGN | 7,934 | xPath cannot handle hdfs:///xxxx properly | {
"avatar_url": "https://avatars.githubusercontent.com/u/73142299?v=4",
"events_url": "https://api.github.com/users/li-yi-dong/events{/privacy}",
"followers_url": "https://api.github.com/users/li-yi-dong/followers",
"following_url": "https://api.github.com/users/li-yi-dong/following{/other_user}",
"gists_url"... | [] | open | false | [] | null | [] | 2026-01-08T12:14:11Z | 2026-01-08T12:14:11Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
_as_str('hdfs:///xxxx') would return hdfs://xxxx. Removing one / and making the path invalid.
For the use case like
```
ds = load_dataset(
"parquet",
data_files={
"train": "hdfs:///user/path/to/data/train*.parquet",
},
streaming=True,
storage_options={
"host": ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7934/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7934/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5468 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5468/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5468/comments | https://api.github.com/repos/huggingface/datasets/issues/5468/events | https://github.com/huggingface/datasets/issues/5468 | 1,558,066,625 | I_kwDODunzps5c3jXB | 5,468 | Allow opposite of remove_columns on Dataset and DatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/346853?v=4",
"events_url": "https://api.github.com/users/hollance/events{/privacy}",
"followers_url": "https://api.github.com/users/hollance/followers",
"following_url": "https://api.github.com/users/hollance/following{/other_user}",
"gists_url": "https... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | [] | null | [
"Hi! I agree it would be nice to have a method like that. Instead of `keep_columns`, we can name it `select_columns` to be more aligned with PyArrow's naming convention (`pa.Table.select`).",
"Hi, I am a newbie to open source and would like to contribute. @mariosasko can I take up this issue ?",
"Hey, I also wa... | 2023-01-26T12:28:09Z | 2023-02-13T09:59:38Z | 2023-02-13T09:59:38Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
In this blog post https://huggingface.co/blog/audio-datasets, I noticed the following code:
```python
COLUMNS_TO_KEEP = ["text", "audio"]
all_columns = gigaspeech["train"].column_names
columns_to_remove = set(all_columns) - set(COLUMNS_TO_KEEP)
gigaspeech = gigaspeech.remove_columns(column... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5468/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5468/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/832 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/832/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/832/comments | https://api.github.com/repos/huggingface/datasets/issues/832/events | https://github.com/huggingface/datasets/issues/832 | 740,077,228 | MDU6SXNzdWU3NDAwNzcyMjg= | 832 | [GEM] add WikiAuto text simplification dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | [] | null | [] | 2020-11-10T16:53:23Z | 2020-12-03T13:38:08Z | 2020-12-03T13:38:08Z | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Adding a Dataset
- **Name:** WikiAuto
- **Description:** Sentences in English Wikipedia and their corresponding sentences in Simple English Wikipedia that are written with simpler grammar and word choices. A lot of lexical and syntactic paraphrasing.
- **Paper:** https://www.aclweb.org/anthology/2020.acl-main.70... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/832/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/832/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6358/comments | https://api.github.com/repos/huggingface/datasets/issues/6358/events | https://github.com/huggingface/datasets/issues/6358 | 1,965,014,595 | I_kwDODunzps51H75D | 6,358 | Mounting datasets cache fails due to absolute paths. | {
"avatar_url": "https://avatars.githubusercontent.com/u/72921588?v=4",
"events_url": "https://api.github.com/users/charliebudd/events{/privacy}",
"followers_url": "https://api.github.com/users/charliebudd/followers",
"following_url": "https://api.github.com/users/charliebudd/following{/other_user}",
"gists_u... | [] | closed | false | [] | null | [
"You may be able to make it work by tweaking some environment variables, such as [`HF_HOME`](https://huggingface.co/docs/huggingface_hub/main/en/package_reference/environment_variables#hfhome) or [`HF_DATASETS_CACHE`](https://huggingface.co/docs/datasets/cache#cache-directory).",
"> You may be able to make it wor... | 2023-10-27T08:20:27Z | 2024-04-10T08:50:06Z | 2023-11-28T14:47:12Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Creating a datasets cache and mounting this into, for example, a docker container, renders the data unreadable due to absolute paths written into the cache.
### Steps to reproduce the bug
1. Create a datasets cache by downloading some data
2. Mount the dataset folder into a docker contain... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6358/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6358/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/302 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/302/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/302/comments | https://api.github.com/repos/huggingface/datasets/issues/302/events | https://github.com/huggingface/datasets/issues/302 | 643,910,418 | MDU6SXNzdWU2NDM5MTA0MTg= | 302 | Question - Sign Language Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/5757359?v=4",
"events_url": "https://api.github.com/users/AmitMY/events{/privacy}",
"followers_url": "https://api.github.com/users/AmitMY/followers",
"following_url": "https://api.github.com/users/AmitMY/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | closed | false | [] | null | [
"Even more complicating - \r\n\r\nAs I see it, datasets can have \"addons\".\r\nFor example, the WebNLG dataset is a dataset for data-to-text. However, a work of mine and other works enriched this dataset with text plans / underlying text structures. In that case, I see a need to load the dataset \"WebNLG\" with \"... | 2020-06-23T14:53:40Z | 2020-11-25T11:25:33Z | 2020-11-25T11:25:33Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | An emerging field in NLP is SLP - sign language processing.
I was wondering about adding datasets here, specifically because it's shaping up to be large and easily usable.
The metrics for sign language to text translation are the same.
So, what do you think about (me, or others) adding datasets here?
An exa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/5757359?v=4",
"events_url": "https://api.github.com/users/AmitMY/events{/privacy}",
"followers_url": "https://api.github.com/users/AmitMY/followers",
"following_url": "https://api.github.com/users/AmitMY/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/302/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/302/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7375/comments | https://api.github.com/repos/huggingface/datasets/issues/7375/events | https://github.com/huggingface/datasets/issues/7375 | 2,800,609,218 | I_kwDODunzps6m7efC | 7,375 | vllm批量推理报错 | {
"avatar_url": "https://avatars.githubusercontent.com/u/51228154?v=4",
"events_url": "https://api.github.com/users/YuShengzuishuai/events{/privacy}",
"followers_url": "https://api.github.com/users/YuShengzuishuai/followers",
"following_url": "https://api.github.com/users/YuShengzuishuai/following{/other_user}"... | [] | open | false | [] | null | [
"Make sure you have installed a recent version of `soundfile`"
] | 2025-01-21T03:22:23Z | 2025-01-30T14:02:40Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug

### Steps to reproduce the bug
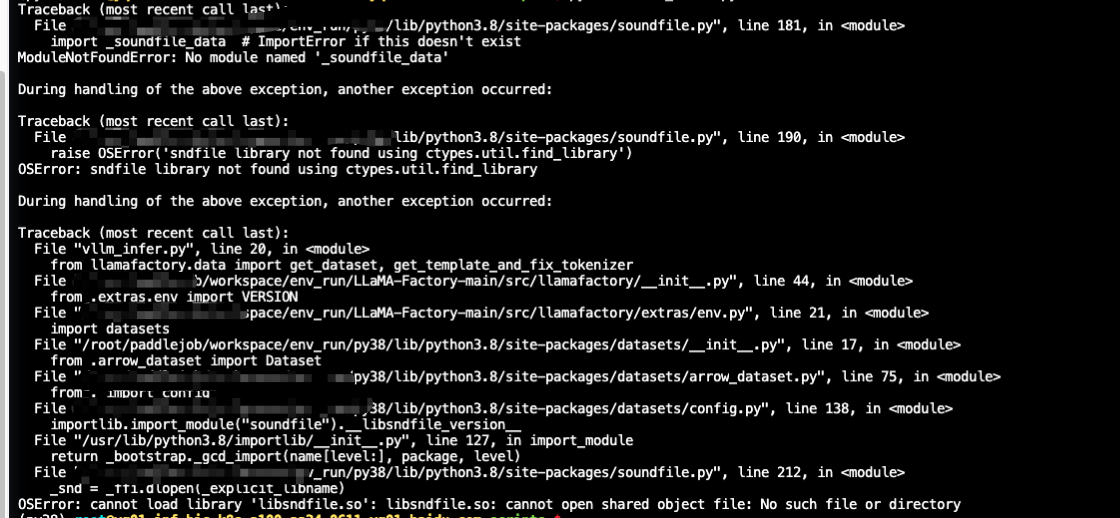
### Expected behavior
\r\n\r\nWe don't support `large_list` yet, though it should be added to `Sequence` IMO (maybe with a parameter `large=True` ?)"
] | 2024-06-19T11:38:48Z | 2024-08-12T14:43:46Z | 2024-08-12T14:43:46Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
This returns error.
```python
from datasets import Dataset
dsdf = Dataset.from_dict({"x": [[1, 2], [3, 4, 5]], "y": ["a", "b"]})
Dataset.from_polars(dsdf.to_polars())
```
ValueError: Arrow type large_list<item: int64> does not have a datasets dtype equivalent.
### Motivation
When datasets... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6984/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6984/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5785 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5785/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5785/comments | https://api.github.com/repos/huggingface/datasets/issues/5785/events | https://github.com/huggingface/datasets/issues/5785 | 1,680,956,964 | I_kwDODunzps5kMV4k | 5,785 | Unsupported data files raise TypeError: 'NoneType' object is not iterable | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-04-24T10:38:03Z | 2023-04-27T12:57:30Z | 2023-04-27T12:57:30Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Currently, we raise a TypeError for unsupported data files:
```
TypeError: 'NoneType' object is not iterable
```
See:
- https://github.com/huggingface/datasets-server/issues/1073
We should give a more informative error message. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5785/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5785/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4351 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4351/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4351/comments | https://api.github.com/repos/huggingface/datasets/issues/4351/events | https://github.com/huggingface/datasets/issues/4351 | 1,235,950,209 | I_kwDODunzps5JqxqB | 4,351 | Add optional progress bar for .save_to_disk(..) and .load_from_disk(..) when working with remote filesystems | {
"avatar_url": "https://avatars.githubusercontent.com/u/5154447?v=4",
"events_url": "https://api.github.com/users/Rexhaif/events{/privacy}",
"followers_url": "https://api.github.com/users/Rexhaif/followers",
"following_url": "https://api.github.com/users/Rexhaif/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"Hi! I like this idea. For consistency with `load_dataset`, we can use `fsspec`'s `TqdmCallback` in `.load_from_disk` to monitor the number of bytes downloaded, and in `.save_to_disk`, we can track the number of saved shards for consistency with `push_to_hub` (after we implement https://github.com/huggingface/data... | 2022-05-14T11:30:42Z | 2022-12-14T18:22:59Z | 2022-12-14T18:22:59Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | **Is your feature request related to a problem? Please describe.**
When working with large datasets stored on remote filesystems(such as s3), the process of uploading a dataset could take really long time. For instance: I was uploading a re-processed version of wmt17 en-ru to my s3 bucket and it took like 35 minutes(a... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4351/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4351/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3192 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3192/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3192/comments | https://api.github.com/repos/huggingface/datasets/issues/3192/events | https://github.com/huggingface/datasets/issues/3192 | 1,041,308,086 | I_kwDODunzps4-ERm2 | 3,192 | Multiprocessing filter/map (tests) not working on Windows | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url":... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | [] | null | [] | 2021-11-01T15:36:08Z | 2021-11-01T15:57:03Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | While running the tests, I found that the multiprocessing examples fail on Windows, or rather they do not complete: they cause a deadlock. I haven't dug deep into it, but they do not seem to work as-is. I currently have no time to tests this in detail but at least the tests seem not to run correctly (deadlocking).
#... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3192/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3192/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/620/comments | https://api.github.com/repos/huggingface/datasets/issues/620/events | https://github.com/huggingface/datasets/issues/620 | 699,815,135 | MDU6SXNzdWU2OTk4MTUxMzU= | 620 | map/filter multiprocessing raises errors and corrupts datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"It seems that I ran into the same problem\r\n```\r\ndef tokenize(cols, example):\r\n for in_col, out_col in cols.items():\r\n example[out_col] = hf_tokenizer.convert_tokens_to_ids(hf_tokenizer.tokenize(example[in_col]))\r\n return example\r\ncola = datasets.load_dataset('glue', 'cola')\r\ntokenized_cola = col... | 2020-09-11T22:30:06Z | 2020-10-08T16:31:47Z | 2020-10-08T16:31:46Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | {
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/620/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/620/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/297 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/297/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/297/comments | https://api.github.com/repos/huggingface/datasets/issues/297/events | https://github.com/huggingface/datasets/issues/297 | 643,444,625 | MDU6SXNzdWU2NDM0NDQ2MjU= | 297 | Error in Demo for Specific Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/60150701?v=4",
"events_url": "https://api.github.com/users/s-jse/events{/privacy}",
"followers_url": "https://api.github.com/users/s-jse/followers",
"following_url": "https://api.github.com/users/s-jse/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | [] | null | [
"Thanks for reporting these errors :)\r\n\r\nI can actually see two issues here.\r\n\r\nFirst, datasets like `natural_questions` require apache_beam to be processed. Right now the import is not at the right place so we have this error message. However, even the imports are fixed, the nlp viewer doesn't actually hav... | 2020-06-23T00:38:42Z | 2020-07-17T17:43:06Z | 2020-07-17T17:43:06Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Selecting `natural_questions` or `newsroom` dataset in the online demo results in an error similar to the following.

| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/297/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/297/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2335 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2335/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2335/comments | https://api.github.com/repos/huggingface/datasets/issues/2335/events | https://github.com/huggingface/datasets/issues/2335 | 881,291,887 | MDU6SXNzdWU4ODEyOTE4ODc= | 2,335 | Index error in Dataset.map | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [] | 2021-05-08T20:44:57Z | 2021-05-10T13:26:12Z | 2021-05-10T13:26:12Z | null | COLLABORATOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | The following code, if executed on master, raises an IndexError (due to overflow):
```python
>>> from datasets import *
>>> d = load_dataset("bookcorpus", split="train")
Reusing dataset bookcorpus (C:\Users\Mario\.cache\huggingface\datasets\bookcorpus\plain_text\1.0.0\44662c4a114441c35200992bea923b170e6f13f2f0beb7c... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2335/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2335/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1758 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1758/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1758/comments | https://api.github.com/repos/huggingface/datasets/issues/1758/events | https://github.com/huggingface/datasets/issues/1758 | 790,626,116 | MDU6SXNzdWU3OTA2MjYxMTY= | 1,758 | dataset.search() (elastic) cannot reliably retrieve search results | {
"avatar_url": "https://avatars.githubusercontent.com/u/49048309?v=4",
"events_url": "https://api.github.com/users/afogarty85/events{/privacy}",
"followers_url": "https://api.github.com/users/afogarty85/followers",
"following_url": "https://api.github.com/users/afogarty85/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"Hi !\r\nI tried your code on my side and I was able to workaround this issue by waiting a few seconds before querying the index.\r\nMaybe this is because the index is not updated yet on the ElasticSearch side ?",
"Thanks for the feedback! I added a 30 second \"sleep\" and that seemed to work well!"
] | 2021-01-21T02:26:37Z | 2021-01-22T00:25:50Z | 2021-01-22T00:25:50Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I am trying to use elastic search to retrieve the indices of items in the dataset in their precise order, given shuffled training indices.
The problem I have is that I cannot retrieve reliable results with my data on my first search. I have to run the search **twice** to get the right answer.
I am indexing data t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/49048309?v=4",
"events_url": "https://api.github.com/users/afogarty85/events{/privacy}",
"followers_url": "https://api.github.com/users/afogarty85/followers",
"following_url": "https://api.github.com/users/afogarty85/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1758/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1758/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7359/comments | https://api.github.com/repos/huggingface/datasets/issues/7359/events | https://github.com/huggingface/datasets/issues/7359 | 2,771,137,842 | I_kwDODunzps6lLDUy | 7,359 | There are multiple 'mteb/arguana' configurations in the cache: default, corpus, queries with HF_HUB_OFFLINE=1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/723146?v=4",
"events_url": "https://api.github.com/users/Bhavya6187/events{/privacy}",
"followers_url": "https://api.github.com/users/Bhavya6187/followers",
"following_url": "https://api.github.com/users/Bhavya6187/following{/other_user}",
"gists_url": ... | [] | open | false | [] | null | [
"Related to https://github.com/embeddings-benchmark/mteb/issues/1714"
] | 2025-01-06T17:42:49Z | 2025-01-06T17:43:31Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Hey folks,
I am trying to run this code -
```python
from datasets import load_dataset, get_dataset_config_names
ds = load_dataset("mteb/arguana")
```
with HF_HUB_OFFLINE=1
But I get the following error -
```python
Using the latest cached version of the dataset since mteb/arguana... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7359/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7359/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6271 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6271/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6271/comments | https://api.github.com/repos/huggingface/datasets/issues/6271/events | https://github.com/huggingface/datasets/issues/6271 | 1,920,420,295 | I_kwDODunzps5yd0nH | 6,271 | Overwriting Split overwrites data but not metadata, corrupting dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/13859249?v=4",
"events_url": "https://api.github.com/users/govindrai/events{/privacy}",
"followers_url": "https://api.github.com/users/govindrai/followers",
"following_url": "https://api.github.com/users/govindrai/following{/other_user}",
"gists_url": "... | [] | closed | false | [] | null | [] | 2023-09-30T22:37:31Z | 2023-10-16T13:30:50Z | 2023-10-16T13:30:50Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I want to be able to overwrite/update/delete splits in my dataset. Currently the only way to do is to manually go into the dataset and delete the split. If I try to overwrite programmatically I end up in an error state and (somewhat) corrupting the dataset. Read below.
**Current Behavior**
Whe... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6271/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6271/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4570 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4570/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4570/comments | https://api.github.com/repos/huggingface/datasets/issues/4570/events | https://github.com/huggingface/datasets/issues/4570 | 1,284,846,168 | I_kwDODunzps5MlTJY | 4,570 | Dataset sharding non-contiguous? | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"This was silly; I was sure I'd looked for a `contiguous` argument, and was certain there wasn't one the first time I looked :smile:\r\n\r\nSorry about that.",
"Hi! You can pass `contiguous=True` to `.shard()` get contiguous shards. More info on this and the default behavior can be found in the [docs](https://hug... | 2022-06-26T08:34:05Z | 2022-06-30T11:00:47Z | 2022-06-26T14:36:20Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
I'm not sure if this is a bug; more likely normal behavior but i wanted to double check.
Is it normal that `datasets.shard` does not produce chunks that, when concatenated produce the original ordering of the sharded dataset?
This might be related to this pull request (https://github.com/huggi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4570/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4570/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3051 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3051/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3051/comments | https://api.github.com/repos/huggingface/datasets/issues/3051/events | https://github.com/huggingface/datasets/issues/3051 | 1,021,852,234 | I_kwDODunzps486DpK | 3,051 | Non-Matching Checksum Error with crd3 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8942987?v=4",
"events_url": "https://api.github.com/users/RylanSchaeffer/events{/privacy}",
"followers_url": "https://api.github.com/users/RylanSchaeffer/followers",
"following_url": "https://api.github.com/users/RylanSchaeffer/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"I got the same error for another dataset (`multi_woz_v22`):\r\n\r\n```\r\ndatasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:\r\n['https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/dialog_acts.json', 'https://github.com/budzianowski/multiwoz/raw/... | 2021-10-10T01:32:43Z | 2022-03-15T15:54:26Z | 2022-03-15T15:54:26Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
When I try loading the crd3 dataset (https://huggingface.co/datasets/crd3), an error is thrown.
## Steps to reproduce the bug
```python
dataset = load_dataset('crd3', split='train')
```
## Expected results
I expect no error to be thrown.
## Actual results
A non-matching checksum err... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3051/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3051/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3304 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3304/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3304/comments | https://api.github.com/repos/huggingface/datasets/issues/3304/events | https://github.com/huggingface/datasets/issues/3304 | 1,059,130,494 | I_kwDODunzps4_IQx- | 3,304 | Dataset object has no attribute `to_tf_dataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/59993678?v=4",
"events_url": "https://api.github.com/users/RajkumarGalaxy/events{/privacy}",
"followers_url": "https://api.github.com/users/RajkumarGalaxy/followers",
"following_url": "https://api.github.com/users/RajkumarGalaxy/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"The issue is due to the older version of transformers and datasets. It has been resolved by upgrading their versions.\r\n\r\n```\r\n# upgrade transformers and datasets to latest versions\r\n!pip install --upgrade transformers\r\n!pip install --upgrade datasets\r\n```\r\n\r\nRegards!"
] | 2021-11-20T12:03:59Z | 2021-11-21T07:07:25Z | 2021-11-21T07:07:25Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I am following HuggingFace Course. I am at Fine-tuning a model.
Link: https://huggingface.co/course/chapter3/2?fw=tf
I use tokenize_function and `map` as mentioned in the course to process data.
`# define a tokenize function`
`def Tokenize_function(example):`
` return tokenizer(example['sentence'], truncat... | {
"avatar_url": "https://avatars.githubusercontent.com/u/59993678?v=4",
"events_url": "https://api.github.com/users/RajkumarGalaxy/events{/privacy}",
"followers_url": "https://api.github.com/users/RajkumarGalaxy/followers",
"following_url": "https://api.github.com/users/RajkumarGalaxy/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3304/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3304/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2256 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2256/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2256/comments | https://api.github.com/repos/huggingface/datasets/issues/2256/events | https://github.com/huggingface/datasets/issues/2256 | 866,708,609 | MDU6SXNzdWU4NjY3MDg2MDk= | 2,256 | Running `datase.map` with `num_proc > 1` uses a lot of memory | {
"avatar_url": "https://avatars.githubusercontent.com/u/8143425?v=4",
"events_url": "https://api.github.com/users/roskoN/events{/privacy}",
"followers_url": "https://api.github.com/users/roskoN/followers",
"following_url": "https://api.github.com/users/roskoN/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Thanks for reporting ! We are working on this and we'll do a patch release very soon.",
"We did a patch release to fix this issue.\r\nIt should be fixed in the new version 1.6.1\r\n\r\nThanks again for reporting and for the details :)"
] | 2021-04-24T09:56:20Z | 2021-04-26T17:12:15Z | 2021-04-26T17:12:15Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Running `datase.map` with `num_proc > 1` leads to a tremendous memory usage that requires swapping on disk and it becomes very slow.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dstc8_datset = load_dataset("roskoN/dstc8-reddit-corpus", keep_in_memory=False)
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2256/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2256/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5532 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5532/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5532/comments | https://api.github.com/repos/huggingface/datasets/issues/5532/events | https://github.com/huggingface/datasets/issues/5532 | 1,584,505,128 | I_kwDODunzps5ecaEo | 5,532 | train_test_split in arrow_dataset does not ensure to keep single classes in test set | {
"avatar_url": "https://avatars.githubusercontent.com/u/37191008?v=4",
"events_url": "https://api.github.com/users/Ulipenitz/events{/privacy}",
"followers_url": "https://api.github.com/users/Ulipenitz/followers",
"following_url": "https://api.github.com/users/Ulipenitz/following{/other_user}",
"gists_url": "... | [] | closed | false | [] | null | [
"Hi! You can get this behavior by specifying `stratify_by_column=\"label\"` in `train_test_split`.\r\n\r\nThis is the full example:\r\n```python\r\nimport numpy as np\r\nfrom datasets import Dataset, ClassLabel\r\n\r\ndata = [\r\n {'label': 0, 'text': \"example1\"},\r\n {'label': 1, 'text': \"example2\"},\r\n... | 2023-02-14T16:52:29Z | 2023-02-15T16:09:19Z | 2023-02-15T16:09:19Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When I have a dataset with very few (e.g. 1) examples per class and I call the train_test_split function on it, sometimes the single class will be in the test set. thus will never be considered for training.
### Steps to reproduce the bug
```
import numpy as np
from datasets import Dataset
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5532/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5532/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/119 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/119/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/119/comments | https://api.github.com/repos/huggingface/datasets/issues/119/events | https://github.com/huggingface/datasets/issues/119 | 618,652,145 | MDU6SXNzdWU2MTg2NTIxNDU= | 119 | 🐛 Colab : type object 'pyarrow.lib.RecordBatch' has no attribute 'from_struct_array' | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "htt... | [] | closed | false | [] | null | [
"It's strange, after installing `nlp` on Colab, the `pyarrow` version seems fine from `pip` but not from python :\r\n\r\n```python\r\nimport pyarrow\r\n\r\n!pip show pyarrow\r\nprint(\"version = {}\".format(pyarrow.__version__))\r\n```\r\n\r\n> Name: pyarrow\r\nVersion: 0.17.0\r\nSummary: Python library for Apache ... | 2020-05-15T02:27:26Z | 2020-05-15T05:11:22Z | 2020-05-15T02:45:28Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I'm trying to load CNN/DM dataset on Colab.
[Colab notebook](https://colab.research.google.com/drive/11Mf7iNhIyt6GpgA1dBEtg3cyMHmMhtZS?usp=sharing)
But I meet this error :
> AttributeError: type object 'pyarrow.lib.RecordBatch' has no attribute 'from_struct_array'
| {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/119/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/119/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/413/comments | https://api.github.com/repos/huggingface/datasets/issues/413/events | https://github.com/huggingface/datasets/issues/413 | 660,063,655 | MDU6SXNzdWU2NjAwNjM2NTU= | 413 | Is there a way to download only NQ dev? | {
"avatar_url": "https://avatars.githubusercontent.com/u/1563902?v=4",
"events_url": "https://api.github.com/users/tholor/events{/privacy}",
"followers_url": "https://api.github.com/users/tholor/followers",
"following_url": "https://api.github.com/users/tholor/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | [] | null | [
"Unfortunately it's not possible to download only the dev set of NQ.\r\n\r\nI think we could add a way to download only the test set by adding a custom configuration to the processing script though.",
"Ok, got it. I think this could be a valuable feature - especially for large datasets like NQ, but potentially al... | 2020-07-18T10:28:23Z | 2022-02-11T09:50:21Z | 2022-02-11T09:50:21Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Maybe I missed that in the docs, but is there a way to only download the dev set of natural questions (~1 GB)?
As we want to benchmark QA models on different datasets, I would like to avoid downloading the 41GB of training data.
I tried
```
dataset = nlp.load_dataset('natural_questions', split="validation", bea... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/413/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/413/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5454 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5454/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5454/comments | https://api.github.com/repos/huggingface/datasets/issues/5454/events | https://github.com/huggingface/datasets/issues/5454 | 1,552,890,419 | I_kwDODunzps5cjzoz | 5,454 | Save and resume the state of a DataLoader | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | open | false | [] | null | [
"Something that'd be nice to have is \"manual update of state\". One of the learning from training LLMs is the ability to skip some batches whenever we notice huge spike might be handy.",
"Your outline spec is very sound and clear, @lhoestq - thank you!\r\n\r\n@thomasw21, indeed that would be a wonderful extra fe... | 2023-01-23T10:58:54Z | 2024-11-27T01:19:21Z | null | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | It would be nice when using `datasets` with a PyTorch DataLoader to be able to resume a training from a DataLoader state (e.g. to resume a training that crashed)
What I have in mind (but lmk if you have other ideas or comments):
For map-style datasets, this requires to have a PyTorch Sampler state that can be sav... | null | {
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 8,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 12,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5454/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5454/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5878 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5878/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5878/comments | https://api.github.com/repos/huggingface/datasets/issues/5878/events | https://github.com/huggingface/datasets/issues/5878 | 1,718,203,843 | I_kwDODunzps5mabXD | 5,878 | Prefetching for IterableDataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/30946190?v=4",
"events_url": "https://api.github.com/users/vyeevani/events{/privacy}",
"followers_url": "https://api.github.com/users/vyeevani/followers",
"following_url": "https://api.github.com/users/vyeevani/following{/other_user}",
"gists_url": "htt... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [
"Very cool! Do you have a link to the code that you're using to eagerly fetch the data? Would also be interested in hacking around something here for pre-fetching iterable datasets",
"I ended up just switching back to the pytorch dataloader and using it's multiprocessing functionality to handle this :(. I'm just ... | 2023-05-20T15:25:40Z | 2025-09-01T20:57:32Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Add support for prefetching the next n batches through iterabledataset to reduce batch loading bottleneck in training loop.
### Motivation
The primary motivation behind this is to use hardware accelerators alongside a streaming dataset. This is required when you are in a low ram or low disk... | null | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5878/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5878/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6919 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6919/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6919/comments | https://api.github.com/repos/huggingface/datasets/issues/6919/events | https://github.com/huggingface/datasets/issues/6919 | 2,315,618,993 | I_kwDODunzps6KBYqx | 6,919 | Invalid YAML in README.md: unknown tag !<tag:yaml.org,2002:python/tuple> | {
"avatar_url": "https://avatars.githubusercontent.com/u/67964?v=4",
"events_url": "https://api.github.com/users/juanqui/events{/privacy}",
"followers_url": "https://api.github.com/users/juanqui/followers",
"following_url": "https://api.github.com/users/juanqui/following{/other_user}",
"gists_url": "https://a... | [] | open | false | [] | null | [] | 2024-05-24T14:59:45Z | 2024-05-24T14:59:45Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I wrote a notebook to load an existing dataset, process it, and upload as a private dataset using `dataset.push_to_hub(...)` at the end. The push to hub is failing with:
```
ValueError: Invalid metadata in README.md.
- Invalid YAML in README.md: unknown tag !<tag:yaml.org,2002:python[/tuple](... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6919/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6919/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/2648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2648/comments | https://api.github.com/repos/huggingface/datasets/issues/2648/events | https://github.com/huggingface/datasets/issues/2648 | 944,484,522 | MDU6SXNzdWU5NDQ0ODQ1MjI= | 2,648 | Add web_split dataset for Paraphase and Rephrase benchmark | {
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/... | null | [
"#take"
] | 2021-07-14T14:24:36Z | 2021-07-14T14:26:12Z | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}"... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe:
For getting simple sentences from complex sentence there are dataset and task like wiki_split that is available in hugging face datasets. This web_split is a very similar dataset. There some research paper which states that by combining these two datasets we if we train the model it will yield better resu... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2648/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2648/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6949 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6949/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6949/comments | https://api.github.com/repos/huggingface/datasets/issues/6949/events | https://github.com/huggingface/datasets/issues/6949 | 2,332,336,573 | I_kwDODunzps6LBKG9 | 6,949 | load_dataset error | {
"avatar_url": "https://avatars.githubusercontent.com/u/27952522?v=4",
"events_url": "https://api.github.com/users/frederichen01/events{/privacy}",
"followers_url": "https://api.github.com/users/frederichen01/followers",
"following_url": "https://api.github.com/users/frederichen01/following{/other_user}",
"g... | [] | closed | false | [] | null | [
"Hi, @lion-ops.\r\n\r\nIn our Continuous Integration we have many tests on loading JSON files and all of them work properly.\r\n\r\nCould you please share your \"train.json\" file, so that we can try to reproduce the issue you have? ",
"> Hi, @lion-ops.\r\n> \r\n> In our Continuous Integration we have many tests ... | 2024-06-04T01:24:45Z | 2024-07-01T11:33:46Z | 2024-07-01T11:33:46Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Why does the program get stuck when I use load_dataset method, and it still gets stuck after loading for several hours? In fact, my json file is only 21m, and I can load it in one go using open('', 'r').
### Steps to reproduce the bug
1. pip install datasets==2.19.2
2. from datasets import Data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6949/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6949/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/686/comments | https://api.github.com/repos/huggingface/datasets/issues/686/events | https://github.com/huggingface/datasets/issues/686 | 711,385,739 | MDU6SXNzdWU3MTEzODU3Mzk= | 686 | Dataset browser url is still https://huggingface.co/nlp/viewer/ | {
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists... | [] | closed | false | [] | null | [
"Yes! might do it with @srush one of these days. Hopefully it won't break too many links (we can always redirect from old url to new)",
"This was fixed but forgot to close the issue. cc @lhoestq @yjernite \r\n\r\nThanks @jarednielsen!"
] | 2020-09-29T19:21:52Z | 2021-01-08T18:29:26Z | 2021-01-08T18:29:26Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Might be worth updating to https://huggingface.co/datasets/viewer/ | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/686/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/686/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/175 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/175/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/175/comments | https://api.github.com/repos/huggingface/datasets/issues/175/events | https://github.com/huggingface/datasets/issues/175 | 621,929,428 | MDU6SXNzdWU2MjE5Mjk0Mjg= | 175 | [Manual data dir] Error message: nlp.load_dataset('xsum') -> TypeError | {
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "h... | [] | closed | false | [] | null | [] | 2020-05-20T17:00:32Z | 2020-05-20T18:18:50Z | 2020-05-20T18:18:50Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | v 0.1.0 from pip
```python
import nlp
xsum = nlp.load_dataset('xsum')
```
Issue is `dl_manager.manual_dir`is `None`
```python
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-42-8a32f06... | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/175/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/175/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5947 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5947/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5947/comments | https://api.github.com/repos/huggingface/datasets/issues/5947/events | https://github.com/huggingface/datasets/issues/5947 | 1,754,359,316 | I_kwDODunzps5okWYU | 5,947 | Return the audio filename when decoding fails due to corrupt files | {
"avatar_url": "https://avatars.githubusercontent.com/u/8949105?v=4",
"events_url": "https://api.github.com/users/wetdog/events{/privacy}",
"followers_url": "https://api.github.com/users/wetdog/followers",
"following_url": "https://api.github.com/users/wetdog/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [
"Hi ! The audio data don't always exist as files on disk - the blobs are often stored in the Arrow files. For now I'd suggest disabling decoding with `.cast_column(\"audio\", Audio(decode=False))` and apply your own decoding that handles corrupted files (maybe to filter them out ?)\r\n\r\ncc @sanchit-gandhi since i... | 2023-06-13T08:44:09Z | 2023-06-14T12:45:01Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Return the audio filename when the audio decoding fails. Although currently there are some checks for mp3 and opus formats with the library version there are still cases when the audio decoding could fail, eg. Corrupt file.
### Motivation
When you try to load an object file dataset and the... | null | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5947/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5947/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5546 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5546/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5546/comments | https://api.github.com/repos/huggingface/datasets/issues/5546/events | https://github.com/huggingface/datasets/issues/5546 | 1,590,346,349 | I_kwDODunzps5eysJt | 5,546 | Downloaded datasets do not cache at $HF_HOME | {
"avatar_url": "https://avatars.githubusercontent.com/u/79091831?v=4",
"events_url": "https://api.github.com/users/ErfanMoosaviMonazzah/events{/privacy}",
"followers_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followers",
"following_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followin... | [] | closed | false | [] | null | [
"Hi ! Can you make sure you set `HF_HOME` before importing `datasets` ?\r\n\r\nThen you can print\r\n```python\r\nprint(datasets.config.HF_CACHE_HOME)\r\nprint(datasets.config.HF_DATASETS_CACHE)\r\n```"
] | 2023-02-18T13:30:35Z | 2023-07-24T14:22:43Z | 2023-07-24T14:22:43Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
In the huggingface course (https://huggingface.co/course/chapter3/2?fw=pt) it said that if we set HF_HOME, downloaded datasets would be cached at specified address but it does not. downloaded models from checkpoint names are downloaded and cached at HF_HOME but this is not the case for datasets, t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5546/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5546/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5659/comments | https://api.github.com/repos/huggingface/datasets/issues/5659/events | https://github.com/huggingface/datasets/issues/5659 | 1,635,447,540 | I_kwDODunzps5hevL0 | 5,659 | [Audio] Soundfile/libsndfile requirements too stringent for decoding mp3 files | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | [] | closed | false | [] | null | [
"cc @polinaeterna @lhoestq ",
"@sanchit-gandhi can you please also post the logs of `pip install soundfile==0.12.1`? To check what wheel is being installed or if it's being built from source (I think it's the latter case). \r\nRequired `libsndfile` binary **should** be bundeled with `soundfile` wheel but I assume... | 2023-03-22T10:07:33Z | 2024-07-12T01:35:01Z | 2023-04-07T08:51:28Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I'm encountering several issues trying to load mp3 audio files using `datasets` on a TPU v4.
The PR https://github.com/huggingface/datasets/pull/5573 updated the audio loading logic to rely solely on the `soundfile`/`libsndfile` libraries for loading audio samples, regardless of their file t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5659/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5659/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6640/comments | https://api.github.com/repos/huggingface/datasets/issues/6640/events | https://github.com/huggingface/datasets/issues/6640 | 2,115,864,531 | I_kwDODunzps5-HYfT | 6,640 | Sign Language Support | {
"avatar_url": "https://avatars.githubusercontent.com/u/6684795?v=4",
"events_url": "https://api.github.com/users/Merterm/events{/privacy}",
"followers_url": "https://api.github.com/users/Merterm/followers",
"following_url": "https://api.github.com/users/Merterm/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [] | 2024-02-02T21:54:51Z | 2024-02-02T21:54:51Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Currently, there are only several Sign Language labels, I would like to propose adding all the Signed Languages as new labels which are described in this ISO standard: https://www.evertype.com/standards/iso639/sign-language.html
### Motivation
Datasets currently only have labels for several signe... | null | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6640/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6640/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3240 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3240/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3240/comments | https://api.github.com/repos/huggingface/datasets/issues/3240/events | https://github.com/huggingface/datasets/issues/3240 | 1,048,376,021 | I_kwDODunzps4-fPLV | 3,240 | Couldn't reach data file for disaster_response_messages | {
"avatar_url": "https://avatars.githubusercontent.com/u/81331791?v=4",
"events_url": "https://api.github.com/users/pandya6988/events{/privacy}",
"followers_url": "https://api.github.com/users/pandya6988/followers",
"following_url": "https://api.github.com/users/pandya6988/following{/other_user}",
"gists_url"... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | [] | null | [
"It looks like the dataset isn't available anymore on appen.com\r\n\r\nThe CSV files appear to still be available at https://www.kaggle.com/landlord/multilingual-disaster-response-messages though. It says that the data are under the CC0 license so I guess we can host the dataset elsewhere instead ?"
] | 2021-11-09T09:26:42Z | 2021-12-14T14:38:29Z | 2021-12-14T14:38:29Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Following command gives an ConnectionError.
## Steps to reproduce the bug
```python
disaster = load_dataset('disaster_response_messages')
```
## Error
```
ConnectionError: Couldn't reach https://datasets.appen.com/appen_datasets/disaster_response_data/disaster_response_messages_training.... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3240/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3240/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/822 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/822/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/822/comments | https://api.github.com/repos/huggingface/datasets/issues/822/events | https://github.com/huggingface/datasets/issues/822 | 739,579,314 | MDU6SXNzdWU3Mzk1NzkzMTQ= | 822 | datasets freezes | {
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/followin... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | [] | null | [
"Pytorch is unable to convert strings to tensors unfortunately.\r\nYou can use `set_format(type=\"torch\")` on columns that can be converted to tensors, such as token ids.\r\n\r\nThis makes me think that we should probably raise an error or at least a warning when one tries to create pytorch tensors out of text col... | 2020-11-10T05:10:19Z | 2023-07-20T16:08:14Z | 2023-07-20T16:08:13Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi, I want to load these two datasets and convert them to Dataset format in torch and the code freezes for me, could you have a look please? thanks
dataset1 = load_dataset("squad", split="train[:10]")
dataset1 = dataset1.set_format(type='torch', columns=['context', 'answers', 'question'])
dataset2 = load_datase... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/822/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/822/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1827 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1827/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1827/comments | https://api.github.com/repos/huggingface/datasets/issues/1827/events | https://github.com/huggingface/datasets/issues/1827 | 802,353,974 | MDU6SXNzdWU4MDIzNTM5NzQ= | 1,827 | Regarding On-the-fly Data Loading | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"Possible duplicate\r\n\r\n#1776 https://github.com/huggingface/datasets/issues/\r\n\r\nreally looking PR for this feature",
"Hi @acul3 \r\n\r\nIssue #1776 talks about doing on-the-fly data pre-processing, which I think is solved in the next release as mentioned in the issue #1825. I also look forward to using t... | 2021-02-05T17:43:48Z | 2021-02-18T13:55:16Z | 2021-02-18T13:55:16Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi,
I was wondering if it is possible to load images/texts as a batch during the training process, without loading the entire dataset on the RAM at any given point.
Thanks,
Gunjan | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1827/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1827/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4955 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4955/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4955/comments | https://api.github.com/repos/huggingface/datasets/issues/4955/events | https://github.com/huggingface/datasets/issues/4955 | 1,366,382,314 | I_kwDODunzps5RcVbq | 4,955 | Raise a more precise error when the URL is unreachable in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [] | 2022-09-08T13:52:37Z | 2022-09-08T13:53:36Z | null | null | COLLABORATOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | See for example:
- https://github.com/huggingface/datasets/issues/3191
- https://github.com/huggingface/datasets/issues/3186
It would help provide clearer information on the Hub and help the dataset maintainer solve the issue by themselves quicker. Currently:
- https://huggingface.co/datasets/compguesswhat
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4955/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4955/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7287 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7287/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7287/comments | https://api.github.com/repos/huggingface/datasets/issues/7287/events | https://github.com/huggingface/datasets/issues/7287 | 2,646,958,393 | I_kwDODunzps6dxWE5 | 7,287 | Support for identifier-based automated split construction | {
"avatar_url": "https://avatars.githubusercontent.com/u/5719745?v=4",
"events_url": "https://api.github.com/users/alex-hh/events{/privacy}",
"followers_url": "https://api.github.com/users/alex-hh/followers",
"following_url": "https://api.github.com/users/alex-hh/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [
"Hi ! You can already configure the README.md to have multiple sets of splits, e.g.\r\n\r\n```yaml\r\nconfigs:\r\n- config_name: my_first_set_of_split\r\n data_files:\r\n - split: train\r\n path: *.csv\r\n- config_name: my_second_set_of_split\r\n data_files:\r\n - split: train\r\n path: train-*.csv\r\n -... | 2024-11-10T07:45:19Z | 2024-11-19T14:37:02Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
As far as I understand, automated construction of splits for hub datasets is currently based on either file names or directory structure ([as described here](https://huggingface.co/docs/datasets/en/repository_structure))
It would seem to be pretty useful to also allow splits to be based on ide... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7287/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7287/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/2885 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2885/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2885/comments | https://api.github.com/repos/huggingface/datasets/issues/2885/events | https://github.com/huggingface/datasets/issues/2885 | 992,160,544 | MDU6SXNzdWU5OTIxNjA1NDQ= | 2,885 | Adding an Elastic Search index to a Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/36195371?v=4",
"events_url": "https://api.github.com/users/MotzWanted/events{/privacy}",
"followers_url": "https://api.github.com/users/MotzWanted/followers",
"following_url": "https://api.github.com/users/MotzWanted/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | [] | null | [
"Hi, is this bug deterministic in your poetry env ? I mean, does it always stop at 90% or is it random ?\r\n\r\nAlso, can you try using another version of Elasticsearch ? Maybe there's an issue with the one of you poetry env",
"I face similar issue with oscar dataset on remote ealsticsearch instance. It was mainl... | 2021-09-09T12:21:39Z | 2021-10-20T18:57:11Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
When trying to index documents from the squad dataset, the connection to ElasticSearch seems to break:
Reusing dataset squad (/Users/andreasmotz/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)
90%|████████████████████████████... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2885/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2885/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6951 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6951/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6951/comments | https://api.github.com/repos/huggingface/datasets/issues/6951/events | https://github.com/huggingface/datasets/issues/6951 | 2,333,231,042 | I_kwDODunzps6LEkfC | 6,951 | load_dataset() should load all subsets, if no specific subset is specified | {
"avatar_url": "https://avatars.githubusercontent.com/u/5577741?v=4",
"events_url": "https://api.github.com/users/windmaple/events{/privacy}",
"followers_url": "https://api.github.com/users/windmaple/followers",
"following_url": "https://api.github.com/users/windmaple/following{/other_user}",
"gists_url": "h... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"@xianbaoqian ",
"Feel free to open a PR in `m-a-p/COIG-CQIA` to define a default subset. Currently there is no default.\r\n\r\nYou can find some documentation at https://huggingface.co/docs/hub/datasets-manual-configuration#multiple-configurations",
"@lhoestq \r\n\r\nWhilst having a default subset readily avai... | 2024-06-04T11:02:33Z | 2024-11-26T08:32:18Z | 2024-07-01T11:33:10Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Currently load_dataset() is forcing users to specify a subset. Example
`from datasets import load_dataset
dataset = load_dataset("m-a-p/COIG-CQIA")`
```---------------------------------------------------------------------------
ValueError Traceback (most recen... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6951/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6951/timeline | null | not_planned | null |
https://api.github.com/repos/huggingface/datasets/issues/6285 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6285/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6285/comments | https://api.github.com/repos/huggingface/datasets/issues/6285/events | https://github.com/huggingface/datasets/issues/6285 | 1,932,306,325 | I_kwDODunzps5zLKeV | 6,285 | TypeError: expected str, bytes or os.PathLike object, not dict | {
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url"... | [] | open | false | [] | null | [
"You should be able to load the images by modifying the `load_dataset` call like this:\r\n```python\r\ndataset = load_dataset(\"imagefolder\", data_dir=\"/content/datasets/PotholeDetectionYOLOv8-1\")\r\n```\r\n\r\nThe `imagefolder` builder expects the image files to be in `path/label/image_file` (e.g. .`.../train/d... | 2023-10-09T04:56:26Z | 2023-10-10T13:17:33Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
my dataset is in form : train- image /n -labels
and tried the code:
```
from datasets import load_dataset
data_files = {
"train": "/content/datasets/PotholeDetectionYOLOv8-1/train/",
"validation": "/content/datasets/PotholeDetectionYOLOv8-1/valid/",
"test": "/content/dat... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6285/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6285/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/805 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/805/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/805/comments | https://api.github.com/repos/huggingface/datasets/issues/805/events | https://github.com/huggingface/datasets/issues/805 | 737,019,360 | MDU6SXNzdWU3MzcwMTkzNjA= | 805 | On loading a metric from datasets, I get the following error | {
"avatar_url": "https://avatars.githubusercontent.com/u/36405283?v=4",
"events_url": "https://api.github.com/users/laibamehnaz/events{/privacy}",
"followers_url": "https://api.github.com/users/laibamehnaz/followers",
"following_url": "https://api.github.com/users/laibamehnaz/following{/other_user}",
"gists_u... | [] | closed | false | [] | null | [
"Hi ! We support only pyarrow > 0.17.1 so that we have access to the `PyExtensionType` object.\r\nCould you update pyarrow and try again ?\r\n```\r\npip install --upgrade pyarrow\r\n```"
] | 2020-11-05T15:14:38Z | 2022-02-14T15:32:59Z | 2022-02-14T15:32:59Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | `from datasets import load_metric`
`metric = load_metric('bleurt')`
Traceback:
210 class _ArrayXDExtensionType(pa.PyExtensionType):
211
212 ndims: int = None
AttributeError: module 'pyarrow' has no attribute 'PyExtensionType'
Any help will be appreciated. Thank you. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/805/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/805/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1988 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1988/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1988/comments | https://api.github.com/repos/huggingface/datasets/issues/1988/events | https://github.com/huggingface/datasets/issues/1988 | 822,324,605 | MDU6SXNzdWU4MjIzMjQ2MDU= | 1,988 | Readme.md is misleading about kinds of datasets? | {
"avatar_url": "https://avatars.githubusercontent.com/u/878399?v=4",
"events_url": "https://api.github.com/users/surak/events{/privacy}",
"followers_url": "https://api.github.com/users/surak/followers",
"following_url": "https://api.github.com/users/surak/following{/other_user}",
"gists_url": "https://api.gi... | [] | closed | false | [] | null | [
"Hi ! Yes it's possible to use image data. There are already a few of them available (MNIST, CIFAR..)"
] | 2021-03-04T17:04:20Z | 2021-08-04T18:05:23Z | 2021-08-04T18:05:23Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi!
At the README.MD, you say: "efficient data pre-processing: simple, fast and reproducible data pre-processing for the above public datasets as well as your own local datasets in CSV/JSON/text. "
But here:
https://github.com/huggingface/datasets/blob/master/templates/new_dataset_script.py#L82-L117
You menti... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1988/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1988/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2189 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2189/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2189/comments | https://api.github.com/repos/huggingface/datasets/issues/2189/events | https://github.com/huggingface/datasets/issues/2189 | 853,052,891 | MDU6SXNzdWU4NTMwNTI4OTE= | 2,189 | save_to_disk doesn't work when we use concatenate_datasets function before creating the final dataset_object. | {
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "htt... | [] | closed | false | [] | null | [
"Hi ! We refactored save_to_disk in #2025 so this doesn't happen.\r\nFeel free to try it on master for now\r\nWe'll do a new release soon"
] | 2021-04-08T04:42:53Z | 2022-06-01T16:32:15Z | 2022-06-01T16:32:15Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | As you can see, it saves the entire dataset.
@lhoestq
You can check by going through the following example,
```
from datasets import load_from_disk,concatenate_datasets
loaded_data=load_from_disk('/home/gsir059/HNSW-ori/my_knowledge_dataset')
n=20
kb_list=[loaded_data.shard(n, i, contiguous=True) for i... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2189/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2189/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/324 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/324/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/324/comments | https://api.github.com/repos/huggingface/datasets/issues/324/events | https://github.com/huggingface/datasets/issues/324 | 647,525,725 | MDU6SXNzdWU2NDc1MjU3MjU= | 324 | Error when calculating glue score | {
"avatar_url": "https://avatars.githubusercontent.com/u/47185867?v=4",
"events_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/events{/privacy}",
"followers_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/followers",
"following_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/following{/other_... | [] | closed | false | [] | null | [
"The glue metric for cola is a metric for classification. It expects label ids as integers as inputs.",
"I want to evaluate a sentence pair whether they are semantically equivalent, so I used MRPC and it gives the same error, does that mean we have to encode the sentences and parse as input?\r\n\r\nusing BertToke... | 2020-06-29T16:53:48Z | 2020-07-09T09:13:34Z | 2020-07-09T09:13:34Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I was trying glue score along with other metrics here. But glue gives me this error;
```
import nlp
glue_metric = nlp.load_metric('glue',name="cola")
glue_score = glue_metric.compute(predictions, references)
```
```
---------------------------------------------------------------------------
--------------... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/324/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/324/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1781 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1781/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1781/comments | https://api.github.com/repos/huggingface/datasets/issues/1781/events | https://github.com/huggingface/datasets/issues/1781 | 793,914,556 | MDU6SXNzdWU3OTM5MTQ1NTY= | 1,781 | AttributeError: module 'pyarrow' has no attribute 'PyExtensionType' during import | {
"avatar_url": "https://avatars.githubusercontent.com/u/45964869?v=4",
"events_url": "https://api.github.com/users/PalaashAgrawal/events{/privacy}",
"followers_url": "https://api.github.com/users/PalaashAgrawal/followers",
"following_url": "https://api.github.com/users/PalaashAgrawal/following{/other_user}",
... | [] | closed | false | [] | null | [
"Hi ! I'm not able to reproduce the issue. Can you try restarting your runtime ?\r\n\r\nThe PyExtensionType is available in pyarrow starting 0.17.1 iirc. If restarting your runtime doesn't fix this, can you try updating pyarrow ?\r\n```\r\npip install pyarrow --upgrade\r\n```",
"We should bump up the version test... | 2021-01-26T04:18:35Z | 2024-07-07T17:55:12Z | 2022-10-05T12:37:06Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I'm using Colab. And suddenly this morning, there is this error. Have a look below!

| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1781/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1781/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1686/comments | https://api.github.com/repos/huggingface/datasets/issues/1686/events | https://github.com/huggingface/datasets/issues/1686 | 778,921,684 | MDU6SXNzdWU3Nzg5MjE2ODQ= | 1,686 | Dataset Error: DaNE contains empty samples at the end | {
"avatar_url": "https://avatars.githubusercontent.com/u/23721977?v=4",
"events_url": "https://api.github.com/users/KennethEnevoldsen/events{/privacy}",
"followers_url": "https://api.github.com/users/KennethEnevoldsen/followers",
"following_url": "https://api.github.com/users/KennethEnevoldsen/following{/other_... | [] | closed | false | [] | null | [
"Thanks for reporting, I opened a PR to fix that",
"One the PR is merged the fix will be available in the next release of `datasets`.\r\n\r\nIf you don't want to wait the next release you can still load the script from the master branch with\r\n\r\n```python\r\nload_dataset(\"dane\", script_version=\"master\")\r\... | 2021-01-05T11:54:26Z | 2021-01-05T14:01:09Z | 2021-01-05T14:00:13Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | The dataset DaNE, contains empty samples at the end. It is naturally easy to remove using a filter but should probably not be there, to begin with as it can cause errors.
```python
>>> import datasets
[...]
>>> dataset = datasets.load_dataset("dane")
[...]
>>> dataset["test"][-1]
{'dep_ids': [], 'dep_labels': ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1686/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1686/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3419 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3419/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3419/comments | https://api.github.com/repos/huggingface/datasets/issues/3419/events | https://github.com/huggingface/datasets/issues/3419 | 1,077,350,974 | I_kwDODunzps5ANxI- | 3,419 | `.to_json` is extremely slow after `.select` | {
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"events_url": "https://api.github.com/users/eladsegal/events{/privacy}",
"followers_url": "https://api.github.com/users/eladsegal/followers",
"following_url": "https://api.github.com/users/eladsegal/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | [] | null | [
"Hi ! It's slower indeed because a datasets on which `select`/`shard`/`train_test_split`/`shuffle` has been called has to do additional steps to retrieve the data of the dataset table in the right order.\r\n\r\nIndeed, if you call `dataset.select([0, 5, 10])`, the underlying table of the dataset is not altered to k... | 2021-12-11T01:36:31Z | 2021-12-21T15:49:07Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Saving a dataset to JSON with `to_json` is extremely slow after using `.select` on the original dataset.
## Steps to reproduce the bug
```python
from datasets import load_dataset
original = load_dataset("squad", split="train")
original.to_json("from_original.json") # Takes 0 seconds
se... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3419/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3419/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7744 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7744/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7744/comments | https://api.github.com/repos/huggingface/datasets/issues/7744/events | https://github.com/huggingface/datasets/issues/7744 | 3,343,510,686 | I_kwDODunzps7HSeye | 7,744 | dtype: ClassLabel is not parsed correctly in `features.py` | {
"avatar_url": "https://avatars.githubusercontent.com/u/43553003?v=4",
"events_url": "https://api.github.com/users/cmatKhan/events{/privacy}",
"followers_url": "https://api.github.com/users/cmatKhan/followers",
"following_url": "https://api.github.com/users/cmatKhan/following{/other_user}",
"gists_url": "htt... | [] | closed | false | [] | null | [
"I think it's \"class_label\"",
"> I think it's \"class_label\"\n\nI see -- thank you. This works\n\n```yaml\nlicense: mit\nlanguage:\n- en\ntags:\n- genomics\n- yeast\n- transcription\n- perturbation\n- response\n- overexpression\npretty_name: Hackett, 2020 Overexpression\nsize_categories:\n- 1M<n<10M\ndataset_i... | 2025-08-21T23:28:50Z | 2025-09-10T15:23:41Z | 2025-09-10T15:23:41Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | `dtype: ClassLabel` in the README.md yaml metadata is parsed incorrectly and causes the data viewer to fail.
This yaml in my metadata ([source](https://huggingface.co/datasets/BrentLab/yeast_genome_resources/blob/main/README.md), though i changed `ClassLabel` to `string` to using different dtype in order to avoid the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/43553003?v=4",
"events_url": "https://api.github.com/users/cmatKhan/events{/privacy}",
"followers_url": "https://api.github.com/users/cmatKhan/followers",
"following_url": "https://api.github.com/users/cmatKhan/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7744/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7744/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7169 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7169/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7169/comments | https://api.github.com/repos/huggingface/datasets/issues/7169/events | https://github.com/huggingface/datasets/issues/7169 | 2,546,894,076 | I_kwDODunzps6XzoT8 | 7,169 | JSON lines with missing columns raise CastError | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2024-09-25T04:43:28Z | 2024-09-26T06:42:08Z | 2024-09-26T06:42:08Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | JSON lines with missing columns raise CastError:
> CastError: Couldn't cast ... to ... because column names don't match
Related to:
- #7159
- #7161 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7169/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7169/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2837 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2837/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2837/comments | https://api.github.com/repos/huggingface/datasets/issues/2837/events | https://github.com/huggingface/datasets/issues/2837 | 979,298,297 | MDU6SXNzdWU5NzkyOTgyOTc= | 2,837 | prepare_module issue when loading from read-only fs | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hello, I opened #2887 to fix this."
] | 2021-08-25T15:21:26Z | 2021-10-05T17:58:22Z | 2021-10-05T17:58:22Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
When we use prepare_module from a readonly file system, we create a FileLock using the `local_path`.
This path is not necessarily writable.
`lock_path = local_path + ".lock"`
## Steps to reproduce the bug
Run `load_dataset` on a readonly python loader file.
```python
ds = load_datas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2837/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2837/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4578/comments | https://api.github.com/repos/huggingface/datasets/issues/4578/events | https://github.com/huggingface/datasets/issues/4578 | 1,286,086,400 | I_kwDODunzps5MqB8A | 4,578 | [Multi Configs] Use directories to differentiate between subsets/configurations | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [
"I want to be able to create folders in a model.",
"How to set new split names, instead of train/test/validation? For example, I have a local dataset, consists of several subsets, named \"A\", \"B\", and \"C\". How can I create a huggingface dataset, with splits A/B/C ?\r\n\r\nThe document in https://huggingface.... | 2022-06-27T16:55:11Z | 2023-06-14T15:43:05Z | null | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Currently to define several subsets/configurations of your dataset, you need to use a dataset script.
However it would be nice to have a no-code way to to this.
For example we could specify different configurations of a dataset (for example, if a dataset contains different languages) with one directory per confi... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 5,
"heart": 9,
"hooray": 0,
"laugh": 0,
"rocket": 5,
"total_count": 19,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4578/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/2818 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2818/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2818/comments | https://api.github.com/repos/huggingface/datasets/issues/2818/events | https://github.com/huggingface/datasets/issues/2818 | 974,552,009 | MDU6SXNzdWU5NzQ1NTIwMDk= | 2,818 | cannot load data from my loacal path | {
"avatar_url": "https://avatars.githubusercontent.com/u/46920280?v=4",
"events_url": "https://api.github.com/users/yang-collect/events{/privacy}",
"followers_url": "https://api.github.com/users/yang-collect/followers",
"following_url": "https://api.github.com/users/yang-collect/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi ! The `data_files` parameter must be a string, a list/tuple or a python dict.\r\n\r\nCan you check the type of your `config.train_path` please ? Or use `data_files=str(config.train_path)` ?"
] | 2021-08-19T11:13:30Z | 2023-07-25T17:42:15Z | 2023-07-25T17:42:15Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
I just want to directly load data from my local path,but find a bug.And I compare it with pandas to provide my local path is real.
here is my code
```python3
# print my local path
print(config.train_path)
# read data and print data length
tarin=pd.read_csv(config.train_path)
print(len(tari... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2818/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2818/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1102 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1102/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1102/comments | https://api.github.com/repos/huggingface/datasets/issues/1102/events | https://github.com/huggingface/datasets/issues/1102 | 757,016,515 | MDU6SXNzdWU3NTcwMTY1MTU= | 1,102 | Add retries to download manager | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
... | null | [] | 2020-12-04T11:08:11Z | 2020-12-22T15:34:06Z | 2020-12-22T15:34:06Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1102/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1102/timeline | null | completed | null | |
https://api.github.com/repos/huggingface/datasets/issues/3172 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3172/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3172/comments | https://api.github.com/repos/huggingface/datasets/issues/3172/events | https://github.com/huggingface/datasets/issues/3172 | 1,038,351,587 | I_kwDODunzps494_zj | 3,172 | `SystemError 15` thrown in `Dataset.__del__` when using `Dataset.map()` with `num_proc>1` | {
"avatar_url": "https://avatars.githubusercontent.com/u/9859840?v=4",
"events_url": "https://api.github.com/users/vlievin/events{/privacy}",
"followers_url": "https://api.github.com/users/vlievin/followers",
"following_url": "https://api.github.com/users/vlievin/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"NB: even if the error is raised, the dataset is successfully cached. So restarting the script after every `map()` allows to ultimately run the whole preprocessing. But this prevents to realistically run the code over multiple nodes.",
"Hi,\r\n\r\nIt's not easy to debug the problem without the script. I may be wr... | 2021-10-28T10:29:00Z | 2024-04-02T18:13:21Z | 2021-11-03T11:26:10Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
I use `datasets.map` to preprocess some data in my application. The error `SystemError 15` is thrown at the end of the execution of `Dataset.map()` (only with `num_proc>1`. Traceback included bellow.
The exception is raised only when the code runs within a specific context. Despite ~10h spent ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/9859840?v=4",
"events_url": "https://api.github.com/users/vlievin/events{/privacy}",
"followers_url": "https://api.github.com/users/vlievin/followers",
"following_url": "https://api.github.com/users/vlievin/following{/other_user}",
"gists_url": "https:/... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3172/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3172/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3308 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3308/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3308/comments | https://api.github.com/repos/huggingface/datasets/issues/3308/events | https://github.com/huggingface/datasets/issues/3308 | 1,059,255,705 | I_kwDODunzps4_IvWZ | 3,308 | "dataset_infos.json" missing for chr_en and mc4 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8587189?v=4",
"events_url": "https://api.github.com/users/amitness/events{/privacy}",
"followers_url": "https://api.github.com/users/amitness/followers",
"following_url": "https://api.github.com/users/amitness/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"descrip... | open | false | [] | null | [
"Hi ! Thanks for reporting :) \r\nWe can easily add the metadata for `chr_en` IMO, but for mC4 it will take more time, since it requires to count the number of examples in each language",
"No problem. I am trying to do some analysis on the metadata of all available datasets. Is reading `metadata_infos.json` for e... | 2021-11-21T00:07:22Z | 2022-01-19T13:55:32Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
In the repository, every dataset has its metadata in a file called`dataset_infos.json`. But, this file is missing for two datasets: `chr_en` and `mc4`.
## Steps to reproduce the bug
Check [chr_en](https://github.com/huggingface/datasets/tree/master/datasets/chr_en) and [mc4](https://github.com/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3308/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3308/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7904 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7904/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7904/comments | https://api.github.com/repos/huggingface/datasets/issues/7904/events | https://github.com/huggingface/datasets/issues/7904 | 3,727,978,498 | I_kwDODunzps7eNHAC | 7,904 | Request: Review pending neuroimaging PRs (#7886 BIDS loader, #7887 lazy loading) | {
"avatar_url": "https://avatars.githubusercontent.com/u/175985783?v=4",
"events_url": "https://api.github.com/users/The-Obstacle-Is-The-Way/events{/privacy}",
"followers_url": "https://api.github.com/users/The-Obstacle-Is-The-Way/followers",
"following_url": "https://api.github.com/users/The-Obstacle-Is-The-Wa... | [] | open | false | [] | null | [
"Hi ! sure I'll be happy to take a look, sorry for the delay :)"
] | 2025-12-14T20:34:31Z | 2025-12-15T11:25:29Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Summary
I'm building production neuroimaging pipelines that depend on `datasets` and would benefit greatly from two pending PRs being reviewed/merged.
## Pending PRs
| PR | Description | Status | Open Since |
|----|-------------|--------|------------|
| [#7886](https://github.com/huggingface/datasets/pull/7886) |... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7904/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7904/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5610/comments | https://api.github.com/repos/huggingface/datasets/issues/5610/events | https://github.com/huggingface/datasets/issues/5610 | 1,610,698,006 | I_kwDODunzps5gAU0W | 5,610 | use datasets streaming mode in trainer ddp mode cause memory leak | {
"avatar_url": "https://avatars.githubusercontent.com/u/15223544?v=4",
"events_url": "https://api.github.com/users/gromzhu/events{/privacy}",
"followers_url": "https://api.github.com/users/gromzhu/followers",
"following_url": "https://api.github.com/users/gromzhu/following{/other_user}",
"gists_url": "https:... | [] | open | false | [] | null | [
"Same problem, \r\ntransformers 4.28.1\r\ndatasets 2.12.0\r\n\r\nleak around 100Mb per 10 seconds when use dataloader_num_werker > 0 in training argumennts for transformer train, possile bug in transformers repo, but still not found solution :(\r\n",
"found an article described a problem, may be helpful for someb... | 2023-03-06T05:26:49Z | 2024-03-07T01:11:32Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
use datasets streaming mode in trainer ddp mode cause memory leak
### Steps to reproduce the bug
import os
import time
import datetime
import sys
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, Sequenti... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5610/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/8178 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/8178/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/8178/comments | https://api.github.com/repos/huggingface/datasets/issues/8178/events | https://github.com/huggingface/datasets/issues/8178 | 4,397,310,407 | I_kwDODunzps8AAAABBhmhxw | 8,178 | The full dataset viewer is not available (click to read why). Only showing a preview of the rows. Job manager crashed while running this job (missing heartbeats). Error code: JobManagerCrashedError | {
"avatar_url": "https://avatars.githubusercontent.com/u/73682340?v=4",
"events_url": "https://api.github.com/users/kakamond/events{/privacy}",
"followers_url": "https://api.github.com/users/kakamond/followers",
"following_url": "https://api.github.com/users/kakamond/following{/other_user}",
"gists_url": "htt... | [] | open | false | [] | null | [
"Oh yeah, we hit something pretty similar when running a dataset viewer on a large collection (~3M rows) a few months back. The JobManagerCrashedError with missing heartbeats usually showed up for us when the server process ran out of memory or couldn’t keep up with the load spikes during dataset streaming. Turns o... | 2026-05-07T08:33:48Z | 2026-05-12T04:57:48Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
The full dataset viewer is not available (click to read why). Only showing a preview of the rows.
Job manager crashed while running this job (missing heartbeats).
Error code: JobManagerCrashedError
see: https://huggingface.co/datasets/Genius-Society/tt100k/viewer
### Steps to reproduce the bug... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/8178/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/8178/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6846 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6846/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6846/comments | https://api.github.com/repos/huggingface/datasets/issues/6846/events | https://github.com/huggingface/datasets/issues/6846 | 2,267,352,120 | I_kwDODunzps6HJQw4 | 6,846 | Unimaginable super slow iteration | {
"avatar_url": "https://avatars.githubusercontent.com/u/88258534?v=4",
"events_url": "https://api.github.com/users/rangehow/events{/privacy}",
"followers_url": "https://api.github.com/users/rangehow/followers",
"following_url": "https://api.github.com/users/rangehow/following{/other_user}",
"gists_url": "htt... | [] | closed | false | [] | null | [
"In every iteration you load the full \"random_input\" column in memory, only then to access it's i-th element.\r\n\r\nYou can try using this instead\r\n\r\na,b=dataset[i]['random_input'],dataset[i]['random_output']"
] | 2024-04-28T05:24:14Z | 2024-05-06T08:30:03Z | 2024-05-06T08:30:03Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Assuming there is a dataset with 52000 sentences, each with a length of 500, it takes 20 seconds to extract a sentence from the dataset……?Is there something wrong with my iteration?
### Steps to reproduce the bug
```python
import datasets
import time
import random
num_rows = 52000
n... | {
"avatar_url": "https://avatars.githubusercontent.com/u/88258534?v=4",
"events_url": "https://api.github.com/users/rangehow/events{/privacy}",
"followers_url": "https://api.github.com/users/rangehow/followers",
"following_url": "https://api.github.com/users/rangehow/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6846/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6846/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7208 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7208/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7208/comments | https://api.github.com/repos/huggingface/datasets/issues/7208/events | https://github.com/huggingface/datasets/issues/7208 | 2,575,484,256 | I_kwDODunzps6ZgsVg | 7,208 | Iterable dataset.filter should not override features | {
"avatar_url": "https://avatars.githubusercontent.com/u/5719745?v=4",
"events_url": "https://api.github.com/users/alex-hh/events{/privacy}",
"followers_url": "https://api.github.com/users/alex-hh/followers",
"following_url": "https://api.github.com/users/alex-hh/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | [] | null | [
"closed by https://github.com/huggingface/datasets/pull/7209, thanks @alex-hh !"
] | 2024-10-09T10:23:45Z | 2024-10-09T16:08:46Z | 2024-10-09T16:08:45Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When calling filter on an iterable dataset, the features get set to None
### Steps to reproduce the bug
import numpy as np
import time
from datasets import Dataset, Features, Array3D
```python
features=Features(**{"array0": Array3D((None, 10, 10), dtype="float32"), "array1": Array3D((None,... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7208/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7208/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6152 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6152/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6152/comments | https://api.github.com/repos/huggingface/datasets/issues/6152/events | https://github.com/huggingface/datasets/issues/6152 | 1,852,494,646 | I_kwDODunzps5uatM2 | 6,152 | FolderBase Dataset automatically resolves under current directory when data_dir is not specified | {
"avatar_url": "https://avatars.githubusercontent.com/u/11533479?v=4",
"events_url": "https://api.github.com/users/npuichigo/events{/privacy}",
"followers_url": "https://api.github.com/users/npuichigo/followers",
"following_url": "https://api.github.com/users/npuichigo/following{/other_user}",
"gists_url": "... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/126772439?v=4",
"events_url": "https://api.github.com/users/debrupf2946/events{/privacy}",
"followers_url": "https://api.github.com/users/debrupf2946/followers",
"following_url": "https://api.github.com/users/debrupf2946/following{/other_user}... | null | [
"@lhoestq ",
"Makes sense, I guess this can be fixed in the load_dataset_builder method.\r\nIt concerns every packaged builder I think (see values in `_PACKAGED_DATASETS_MODULES`)",
"I think the behavior is related to these lines, which short circuited the error handling.\r\nhttps://github.com/huggingface/datas... | 2023-08-16T04:38:09Z | 2025-06-18T14:18:42Z | 2025-06-18T14:18:42Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/126772439?v=4",
"events_url": "https://api.github.com/users/debrupf2946/events{/privacy}",
"followers_url": "https://api.github.com/users/debrupf2946/followers",
"following_url": "https://api.github.com/users/debrupf2946/following{/other_user}",
"gists_... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
FolderBase Dataset automatically resolves under current directory when data_dir is not specified.
For example:
```
load_dataset("audiofolder")
```
takes long time to resolve and collect data_files from current directory. But I think it should reach out to this line for error handling https:... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6152/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6152/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2812 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2812/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2812/comments | https://api.github.com/repos/huggingface/datasets/issues/2812/events | https://github.com/huggingface/datasets/issues/2812 | 972,936,889 | MDU6SXNzdWU5NzI5MzY4ODk= | 2,812 | arXiv Dataset verification problem | {
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"events_url": "https://api.github.com/users/eladsegal/events{/privacy}",
"followers_url": "https://api.github.com/users/eladsegal/followers",
"following_url": "https://api.github.com/users/eladsegal/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"descrip... | open | false | [] | null | [] | 2021-08-17T18:01:48Z | 2022-01-19T14:15:35Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
`dataset_infos.json` for `arxiv_dataset` contains a fixed number of training examples, however the data (downloaded from an external source) is updated every week with additional examples.
Therefore, loading the dataset without `ignore_verifications=True` results in a verification error. | null | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2812/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2812/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/202 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/202/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/202/comments | https://api.github.com/repos/huggingface/datasets/issues/202/events | https://github.com/huggingface/datasets/issues/202 | 625,493,983 | MDU6SXNzdWU2MjU0OTM5ODM= | 202 | Mistaken `_KWARGS_DESCRIPTION` for XNLI metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/33572125?v=4",
"events_url": "https://api.github.com/users/phiyodr/events{/privacy}",
"followers_url": "https://api.github.com/users/phiyodr/followers",
"following_url": "https://api.github.com/users/phiyodr/following{/other_user}",
"gists_url": "https:... | [] | closed | false | [] | null | [
"Indeed, good catch ! thanks\r\nFixing it right now"
] | 2020-05-27T08:34:42Z | 2020-05-28T13:22:36Z | 2020-05-28T13:22:36Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi!
The [`_KWARGS_DESCRIPTION`](https://github.com/huggingface/nlp/blob/7d0fa58641f3f462fb2861dcdd6ce7f0da3f6a56/metrics/xnli/xnli.py#L45) for the XNLI metric uses `Args` and `Returns` text from [BLEU](https://github.com/huggingface/nlp/blob/7d0fa58641f3f462fb2861dcdd6ce7f0da3f6a56/metrics/bleu/bleu.py#L58) metric:
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/202/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/202/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2523 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2523/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2523/comments | https://api.github.com/repos/huggingface/datasets/issues/2523/events | https://github.com/huggingface/datasets/issues/2523 | 925,421,008 | MDU6SXNzdWU5MjU0MjEwMDg= | 2,523 | Fr | {
"avatar_url": "https://avatars.githubusercontent.com/u/71971234?v=4",
"events_url": "https://api.github.com/users/aDrIaNo34500/events{/privacy}",
"followers_url": "https://api.github.com/users/aDrIaNo34500/followers",
"following_url": "https://api.github.com/users/aDrIaNo34500/following{/other_user}",
"gist... | [] | closed | false | [] | null | [] | 2021-06-19T15:56:32Z | 2021-06-19T18:48:23Z | 2021-06-19T18:48:23Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | __Originally posted by @lewtun in https://github.com/huggingface/datasets/pull/2469__ | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2523/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2523/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4725/comments | https://api.github.com/repos/huggingface/datasets/issues/4725/events | https://github.com/huggingface/datasets/issues/4725 | 1,311,907,096 | I_kwDODunzps5OMh0Y | 4,725 | the_pile datasets URL broken. | {
"avatar_url": "https://avatars.githubusercontent.com/u/12433427?v=4",
"events_url": "https://api.github.com/users/TrentBrick/events{/privacy}",
"followers_url": "https://api.github.com/users/TrentBrick/followers",
"following_url": "https://api.github.com/users/TrentBrick/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @TrentBrick. We are addressing the change with their data host server.\r\n\r\nOn the meantime, if you would like to work with your fixed local copy of the_pile script, you should use:\r\n```python\r\nload_dataset(\"path/to/your/local/the_pile/the_pile.py\",...\r\n```\r\ninstead of just `load_... | 2022-07-20T20:57:30Z | 2022-07-22T06:09:46Z | 2022-07-21T07:38:19Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | https://github.com/huggingface/datasets/pull/3627 changed the Eleuther AI Pile dataset URL from https://the-eye.eu/ to https://mystic.the-eye.eu/ but the latter is now broken and the former works again.
Note that when I git clone the repo and use `pip install -e .` and then edit the URL back the codebase doesn't se... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4725/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4725/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6394/comments | https://api.github.com/repos/huggingface/datasets/issues/6394/events | https://github.com/huggingface/datasets/issues/6394 | 1,985,947,116 | I_kwDODunzps52XyXs | 6,394 | TorchFormatter images (H, W, C) instead of (C, H, W) format | {
"avatar_url": "https://avatars.githubusercontent.com/u/37351874?v=4",
"events_url": "https://api.github.com/users/Modexus/events{/privacy}",
"followers_url": "https://api.github.com/users/Modexus/followers",
"following_url": "https://api.github.com/users/Modexus/following{/other_user}",
"gists_url": "https:... | [] | closed | false | [] | null | [
"Here's a PR for that. https://github.com/huggingface/datasets/pull/6402\r\n\r\nIt's not backward compatible, unfortunately. ",
"Just ran into this working on data lib that's attempting to achieve common interfaces across hf datasets, webdataset, native torch style datasets. The defacto standards for image tensor... | 2023-11-09T16:02:15Z | 2024-04-11T12:40:16Z | 2024-04-11T12:40:16Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Using .set_format("torch") leads to images having shape (H, W, C), the same as in numpy.
However, pytorch normally uses (C, H, W) format.
Maybe I'm missing something but this makes the format a lot less useful as I then have to permute it anyways.
If not using the format it is possible to ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/37351874?v=4",
"events_url": "https://api.github.com/users/Modexus/events{/privacy}",
"followers_url": "https://api.github.com/users/Modexus/followers",
"following_url": "https://api.github.com/users/Modexus/following{/other_user}",
"gists_url": "https:... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6394/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6394/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7327 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7327/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7327/comments | https://api.github.com/repos/huggingface/datasets/issues/7327/events | https://github.com/huggingface/datasets/issues/7327 | 2,738,514,909 | I_kwDODunzps6jOmvd | 7,327 | .map() is not caching and ram goes OOM | {
"avatar_url": "https://avatars.githubusercontent.com/u/7136076?v=4",
"events_url": "https://api.github.com/users/simeneide/events{/privacy}",
"followers_url": "https://api.github.com/users/simeneide/followers",
"following_url": "https://api.github.com/users/simeneide/following{/other_user}",
"gists_url": "h... | [] | open | false | [] | null | [
"I have the same issue - any update on this?"
] | 2024-12-13T14:22:56Z | 2025-02-10T10:42:38Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Im trying to run a fairly simple map that is converting a dataset into numpy arrays. however, it just piles up on memory and doesnt write to disk. Ive tried multiple cache techniques such as specifying the cache dir, setting max mem, +++ but none seem to work. What am I missing here?
### Steps to... | null | {
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7327/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7327/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3269 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3269/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3269/comments | https://api.github.com/repos/huggingface/datasets/issues/3269/events | https://github.com/huggingface/datasets/issues/3269 | 1,053,218,769 | I_kwDODunzps4-xtfR | 3,269 | coqa NonMatchingChecksumError | {
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @ZhaofengWu, thanks for reporting.\r\n\r\nUnfortunately, I'm not able to reproduce your bug:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset(\"coqa\")\r\nDownloading: 3.82kB [00:00, 1.91MB/s]\r\nDownloading: 1.79kB [00:00, 1.79MB/s]\r\nUsing custom data configuration d... | 2021-11-15T05:04:07Z | 2022-01-19T13:58:19Z | 2022-01-19T13:58:19Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ```
>>> from datasets import load_dataset
>>> dataset = load_dataset("coqa")
Downloading: 3.82kB [00:00, 1.26MB/s] ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3269/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3269/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1670/comments | https://api.github.com/repos/huggingface/datasets/issues/1670/events | https://github.com/huggingface/datasets/issues/1670 | 776,608,579 | MDU6SXNzdWU3NzY2MDg1Nzk= | 1,670 | wiki_dpr pre-processing performance | {
"avatar_url": "https://avatars.githubusercontent.com/u/753898?v=4",
"events_url": "https://api.github.com/users/dbarnhart/events{/privacy}",
"followers_url": "https://api.github.com/users/dbarnhart/followers",
"following_url": "https://api.github.com/users/dbarnhart/following{/other_user}",
"gists_url": "ht... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "72f99f",
"default": fals... | open | false | [] | null | [
"Hi ! And thanks for the tips :) \r\n\r\nIndeed currently `wiki_dpr` takes some time to be processed.\r\nMultiprocessing for dataset generation is definitely going to speed up things.\r\n\r\nRegarding the index note that for the default configurations, the index is downloaded instead of being built, which avoid spe... | 2020-12-30T19:41:43Z | 2021-01-28T09:41:36Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I've been working with wiki_dpr and noticed that the dataset processing is seriously impaired in performance [1]. It takes about 12h to process the entire dataset. Most of this time is simply loading and processing the data, but the actual indexing is also quite slow (3h).
I won't repeat the concerns around multipro... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1670/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1670/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6745 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6745/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6745/comments | https://api.github.com/repos/huggingface/datasets/issues/6745/events | https://github.com/huggingface/datasets/issues/6745 | 2,198,541,732 | I_kwDODunzps6DCxWk | 6,745 | Scraping the whole of github including private repos is bad; kindly stop | {
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.git... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"It's not twitter here"
] | 2024-03-20T20:54:06Z | 2024-03-21T12:28:04Z | 2024-03-21T10:24:56Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
https://github.com/bigcode-project/opt-out-v2 - opt out is not consent. kindly quit this ridiculous nonsense.
### Motivation
[EDITED: insults not tolerated]
### Your contribution
[EDITED: insults not tolerated] | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6745/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6745/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3596/comments | https://api.github.com/repos/huggingface/datasets/issues/3596/events | https://github.com/huggingface/datasets/issues/3596 | 1,107,345,338 | I_kwDODunzps5CAL-6 | 3,596 | Loss of cast `Image` feature on certain dataset method | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_ur... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi! Thanks for reporting! The issue with `cast_column` should be fixed by #3575 and after we merge that PR I'll start working on the `push_to_hub` support for the `Image`/`Audio` feature.",
"> Hi! Thanks for reporting! The issue with `cast_column` should be fixed by #3575 and after we merge that PR I'll start wo... | 2022-01-18T20:44:01Z | 2022-01-21T18:07:28Z | 2022-01-21T18:07:28Z | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
When an a column is cast to an `Image` feature, the cast type appears to be lost during certain operations. I first noticed this when using the `push_to_hub` method on a dataset that contained urls pointing to images which had been cast to an `image`. This also happens when using select on a data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3596/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3596/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6409 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6409/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6409/comments | https://api.github.com/repos/huggingface/datasets/issues/6409/events | https://github.com/huggingface/datasets/issues/6409 | 1,991,960,865 | I_kwDODunzps52uukh | 6,409 | using DownloadManager to download from local filesystem and disable_progress_bar, there will be an exception | {
"avatar_url": "https://avatars.githubusercontent.com/u/16574677?v=4",
"events_url": "https://api.github.com/users/neiblegy/events{/privacy}",
"followers_url": "https://api.github.com/users/neiblegy/followers",
"following_url": "https://api.github.com/users/neiblegy/following{/other_user}",
"gists_url": "htt... | [] | closed | false | [] | null | [] | 2023-11-14T04:21:01Z | 2023-11-22T16:42:09Z | 2023-11-22T16:42:09Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
i'm using datasets.download.download_manager.DownloadManager to download files like "file:///a/b/c.txt", and i disable_progress_bar() to disable bar. there will be an exception as follows:
`AttributeError: 'function' object has no attribute 'close'
Exception ignored in: <function TqdmCallback.... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6409/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6409/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/172 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/172/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/172/comments | https://api.github.com/repos/huggingface/datasets/issues/172/events | https://github.com/huggingface/datasets/issues/172 | 621,377,386 | MDU6SXNzdWU2MjEzNzczODY= | 172 | Clone not working on Windows environment | {
"avatar_url": "https://avatars.githubusercontent.com/u/51091425?v=4",
"events_url": "https://api.github.com/users/codehunk628/events{/privacy}",
"followers_url": "https://api.github.com/users/codehunk628/followers",
"following_url": "https://api.github.com/users/codehunk628/following{/other_user}",
"gists_u... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Should be fixed on master now :)",
"Thanks @lhoestq 👍 Now I can uninstall WSL and get back to work with windows.🙂"
] | 2020-05-20T00:45:14Z | 2020-05-23T12:49:13Z | 2020-05-23T11:27:52Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Cloning in a windows environment is not working because of use of special character '?' in folder name ..
Please consider changing the folder name ....
Reference to folder -
nlp/datasets/cnn_dailymail/dummy/3.0.0/3.0.0/dummy_data-zip-extracted/dummy_data/uc?export=download&id=0BwmD_VLjROrfM1BxdkxVaTY2bWs/dailymail/s... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/172/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/172/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4007 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4007/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4007/comments | https://api.github.com/repos/huggingface/datasets/issues/4007/events | https://github.com/huggingface/datasets/issues/4007 | 1,179,381,021 | I_kwDODunzps5GS-0d | 4,007 | set_format does not work with multi dimension tensor | {
"avatar_url": "https://avatars.githubusercontent.com/u/5902432?v=4",
"events_url": "https://api.github.com/users/phihung/events{/privacy}",
"followers_url": "https://api.github.com/users/phihung/followers",
"following_url": "https://api.github.com/users/phihung/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi! Use the `ArrayXD` feature type (where X is the number of dimensions) to get correctly formated tensors. So in your case, define the dataset as follows :\r\n```python\r\nds = Dataset.from_dict({\"A\": [torch.rand((2, 2))]}, features=Features({\"A\": Array2D(shape=(2, 2), dtype=\"float32\")}))\r\n```\r\n",
"Hi... | 2022-03-24T11:27:43Z | 2022-03-30T07:28:57Z | 2022-03-24T14:39:29Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
set_format only transforms the last dimension of a multi-dimension list to tensor
## Steps to reproduce the bug
```python
import torch
from datasets import Dataset
ds = Dataset.from_dict({"A": [torch.rand((2, 2))]})
# ds = Dataset.from_dict({"A": [np.random.rand(2, 2)]}) # => same result... | {
"avatar_url": "https://avatars.githubusercontent.com/u/5902432?v=4",
"events_url": "https://api.github.com/users/phihung/events{/privacy}",
"followers_url": "https://api.github.com/users/phihung/followers",
"following_url": "https://api.github.com/users/phihung/following{/other_user}",
"gists_url": "https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4007/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4007/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6196 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6196/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6196/comments | https://api.github.com/repos/huggingface/datasets/issues/6196/events | https://github.com/huggingface/datasets/issues/6196 | 1,875,070,972 | I_kwDODunzps5vw0_8 | 6,196 | Split order is not preserved | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-08-31T08:47:16Z | 2023-08-31T13:48:43Z | 2023-08-31T13:48:43Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I have noticed that in some cases the split order is not preserved.
For example, consider a no-script dataset with configs:
```yaml
configs:
- config_name: default
data_files:
- split: train
path: train.csv
- split: test
path: test.csv
```
- Note the defined split order is [train, test]
On... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6196/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6196/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2643/comments | https://api.github.com/repos/huggingface/datasets/issues/2643/events | https://github.com/huggingface/datasets/issues/2643 | 944,220,273 | MDU6SXNzdWU5NDQyMjAyNzM= | 2,643 | Enum used in map functions will raise a RecursionError with dill. | {
"avatar_url": "https://avatars.githubusercontent.com/u/100702?v=4",
"events_url": "https://api.github.com/users/jorgeecardona/events{/privacy}",
"followers_url": "https://api.github.com/users/jorgeecardona/followers",
"following_url": "https://api.github.com/users/jorgeecardona/following{/other_user}",
"gis... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | [] | null | [
"I'm running into this as well. (Thank you so much for reporting @jorgeecardona — was staring at this massive stack trace and unsure what exactly was wrong!)",
"Hi ! Thanks for reporting :)\r\n\r\nUntil this is fixed on `dill`'s side, we could implement a custom saving in our Pickler indefined in utils.py_utils.p... | 2021-07-14T09:16:08Z | 2021-11-02T09:51:11Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Enums used in functions pass to `map` will fail at pickling with a maximum recursion exception as described here: https://github.com/uqfoundation/dill/issues/250#issuecomment-852566284
In my particular case, I use an enum to define an argument with fixed options using the `TraininigArguments` ... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2643/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2643/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7194 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7194/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7194/comments | https://api.github.com/repos/huggingface/datasets/issues/7194/events | https://github.com/huggingface/datasets/issues/7194 | 2,563,364,199 | I_kwDODunzps6YydVn | 7,194 | datasets.exceptions.DatasetNotFoundError for private dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/20212179?v=4",
"events_url": "https://api.github.com/users/kdutia/events{/privacy}",
"followers_url": "https://api.github.com/users/kdutia/followers",
"following_url": "https://api.github.com/users/kdutia/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | [] | null | [
"Actually there is no such dataset available, that is why you are getting that error.",
"Fixed with @kdutia in Slack chat. Generating a new token fixed this issue. "
] | 2024-10-03T07:49:36Z | 2024-10-03T10:09:28Z | 2024-10-03T10:09:28Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
The following Python code tries to download a private dataset and fails with the error `datasets.exceptions.DatasetNotFoundError: Dataset 'ClimatePolicyRadar/all-document-text-data-weekly' doesn't exist on the Hub or cannot be accessed.`. Downloading a public dataset doesn't work.
``` py
fro... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7194/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7194/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2646/comments | https://api.github.com/repos/huggingface/datasets/issues/2646/events | https://github.com/huggingface/datasets/issues/2646 | 944,379,954 | MDU6SXNzdWU5NDQzNzk5NTQ= | 2,646 | downloading of yahoo_answers_topics dataset failed | {
"avatar_url": "https://avatars.githubusercontent.com/u/66781249?v=4",
"events_url": "https://api.github.com/users/vikrant7k/events{/privacy}",
"followers_url": "https://api.github.com/users/vikrant7k/followers",
"following_url": "https://api.github.com/users/vikrant7k/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi ! I just tested and it worked fine today for me.\r\n\r\nI think this is because the dataset is stored on Google Drive which has a quota limit for the number of downloads per day, see this similar issue https://github.com/huggingface/datasets/issues/996 \r\n\r\nFeel free to try again today, now that the quota wa... | 2021-07-14T12:31:05Z | 2022-08-04T08:28:24Z | 2022-08-04T08:28:24Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
I get an error datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files when I try to download the yahoo_answers_topics dataset
## Steps to reproduce the bug
self.dataset = load_dataset(
'yahoo_answers_topics', cache_dir=self.config... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2646/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2646/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3154 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3154/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3154/comments | https://api.github.com/repos/huggingface/datasets/issues/3154/events | https://github.com/huggingface/datasets/issues/3154 | 1,034,361,806 | I_kwDODunzps49pxvO | 3,154 | Sacrebleu unexpected behaviour/requirement for data format | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url":... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi @BramVanroy!\r\n\r\nGood question. This project relies on PyArrow (tables) to store data too big to fit in RAM. In the case of metrics, this means that the number of predictions and references has to match to form a table.\r\n\r\nThat's why your example throws an error even though it matches the schema:\r\n```p... | 2021-10-24T08:55:33Z | 2021-10-31T09:08:32Z | 2021-10-31T09:08:31Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
When comparing with the original `sacrebleu` implementation, the `datasets` implementation does some strange things that I do not quite understand. This issue was triggered when I was trying to implement TER and found the datasets implementation of BLEU [here](https://github.com/huggingface/dataset... | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url":... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3154/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3154/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1632/comments | https://api.github.com/repos/huggingface/datasets/issues/1632/events | https://github.com/huggingface/datasets/issues/1632 | 774,388,625 | MDU6SXNzdWU3NzQzODg2MjU= | 1,632 | SICK dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | [] | null | [] | 2020-12-24T12:40:14Z | 2021-02-05T15:49:25Z | 2021-02-05T15:49:25Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi, this would be great to have this dataset included. I might be missing something, but I could not find it in the list of already included datasets. Thank you.
## Adding a Dataset
- **Name:** SICK
- **Description:** SICK consists of about 10,000 English sentence pairs that include many examples of the lexical,... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1632/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1632/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1611/comments | https://api.github.com/repos/huggingface/datasets/issues/1611/events | https://github.com/huggingface/datasets/issues/1611 | 771,486,456 | MDU6SXNzdWU3NzE0ODY0NTY= | 1,611 | shuffle with torch generator | {
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/followin... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"Is there a way one can convert the two generator? not sure overall what alternatives I could have to shuffle the datasets with a torch generator, thanks ",
"@lhoestq let me please expalin in more details, maybe you could help me suggesting an alternative to solve the issue for now, I have multiple large dataset... | 2020-12-20T00:57:14Z | 2022-06-01T15:30:13Z | 2022-06-01T15:30:13Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi
I need to shuffle mutliple large datasets with `generator = torch.Generator()` for a distributed sampler which needs to make sure datasets are consistent across different cores, for this, this is really necessary for me to use torch generator, based on documentation this generator is not supported with datasets, I... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1611/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1611/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7984 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7984/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7984/comments | https://api.github.com/repos/huggingface/datasets/issues/7984/events | https://github.com/huggingface/datasets/issues/7984 | 3,891,431,105 | I_kwDODunzps7n8obB | 7,984 | Data | {
"avatar_url": "https://avatars.githubusercontent.com/u/228845628?v=4",
"events_url": "https://api.github.com/users/iLenceJhay/events{/privacy}",
"followers_url": "https://api.github.com/users/iLenceJhay/followers",
"following_url": "https://api.github.com/users/iLenceJhay/following{/other_user}",
"gists_url... | [] | open | false | [] | null | [] | 2026-02-03T14:01:48Z | 2026-02-03T14:01:48Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7984/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7984/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6306 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6306/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6306/comments | https://api.github.com/repos/huggingface/datasets/issues/6306/events | https://github.com/huggingface/datasets/issues/6306 | 1,946,363,452 | I_kwDODunzps50AyY8 | 6,306 | pyinstaller : OSError: could not get source code | {
"avatar_url": "https://avatars.githubusercontent.com/u/57702070?v=4",
"events_url": "https://api.github.com/users/dusk877647949/events{/privacy}",
"followers_url": "https://api.github.com/users/dusk877647949/followers",
"following_url": "https://api.github.com/users/dusk877647949/following{/other_user}",
"g... | [] | closed | false | [] | null | [
"more information:\r\n``` \r\nFile \"text2vec\\__init__.py\", line 8, in <module>\r\nFile \"<frozen importlib._bootstrap>\", line 1027, in _find_and_load\r\nFile \"<frozen importlib._bootstrap>\", line 1006, in _find_and_load_unlocked\r\nFile \"<frozen importlib._bootstrap>\", line 688, in _load_unlocked\r\nFile \"... | 2023-10-17T01:41:51Z | 2023-11-02T07:24:51Z | 2023-10-18T14:03:42Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I ran a package with pyinstaller and got the following error:
### Steps to reproduce the bug
```
...
File "datasets\__init__.py", line 52, in <module>
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_an... | {
"avatar_url": "https://avatars.githubusercontent.com/u/57702070?v=4",
"events_url": "https://api.github.com/users/dusk877647949/events{/privacy}",
"followers_url": "https://api.github.com/users/dusk877647949/followers",
"following_url": "https://api.github.com/users/dusk877647949/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6306/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6306/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/809 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/809/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/809/comments | https://api.github.com/repos/huggingface/datasets/issues/809/events | https://github.com/huggingface/datasets/issues/809 | 737,832,701 | MDU6SXNzdWU3Mzc4MzI3MDE= | 809 | Add Google Taskmaster dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | [] | null | [
"Hey @yjernite. Was going to start working on this but found taskmaster 1,2 & 3 in the datasets library already so think this can be closed now?",
"You are absolutely right :) \r\n\r\nClosed by https://github.com/huggingface/datasets/pull/1193 https://github.com/huggingface/datasets/pull/1197 https://github.com/h... | 2020-11-06T15:10:41Z | 2021-04-20T13:09:26Z | 2021-04-20T13:09:26Z | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Adding a Dataset
- **Name:** Taskmaster
- **Description:** A large dataset of task-oriented dialogue with annotated goals (55K dialogues covering entertainment and travel reservations)
- **Paper:** https://arxiv.org/abs/1909.05358
- **Data:** https://github.com/google-research-datasets/Taskmaster
- **Motivation... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/809/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/809/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4122 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4122/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4122/comments | https://api.github.com/repos/huggingface/datasets/issues/4122/events | https://github.com/huggingface/datasets/issues/4122 | 1,196,095,072 | I_kwDODunzps5HSvZg | 4,122 | medical_dialog zh has very slow _generate_examples | {
"avatar_url": "https://avatars.githubusercontent.com/u/24982805?v=4",
"events_url": "https://api.github.com/users/nbroad1881/events{/privacy}",
"followers_url": "https://api.github.com/users/nbroad1881/followers",
"following_url": "https://api.github.com/users/nbroad1881/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @nbroad1881, thanks for reporting.\r\n\r\nLet me have a look to try to improve its performance. ",
"Thanks @nbroad1881 for reporting! I don't recall it taking so long. I will also have a look at this. \r\n@albertvillanova please let me know if I am doing something unnecessary or time consuming.",
"Hi @nbro... | 2022-04-07T14:00:51Z | 2022-04-08T16:20:51Z | 2022-04-08T16:20:51Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
After downloading the files from Google Drive, `load_dataset("medical_dialog", "zh", data_dir="./")` takes an unreasonable amount of time. Generating the train/test split for 33% of the dataset takes over 4.5 hours.
## Steps to reproduce the bug
The easiest way I've found to download files from... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4122/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4122/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5941/comments | https://api.github.com/repos/huggingface/datasets/issues/5941/events | https://github.com/huggingface/datasets/issues/5941 | 1,751,838,897 | I_kwDODunzps5oavCx | 5,941 | Load Data Sets Too Slow In Train Seq2seq Model | {
"avatar_url": "https://avatars.githubusercontent.com/u/19569322?v=4",
"events_url": "https://api.github.com/users/xyx361100238/events{/privacy}",
"followers_url": "https://api.github.com/users/xyx361100238/followers",
"following_url": "https://api.github.com/users/xyx361100238/following{/other_user}",
"gist... | [] | closed | false | [] | null | [
"Hi ! you can speed it up using multiprocessing by passing `num_proc=` to `load_dataset()`",
"already did,but not useful for step Generating train split,it works in step \"Resolving data files\" & \"Downloading data files\" ",
"@mariosasko some advice , thanks!",
"I met the same problem, terrible experience... | 2023-06-12T03:58:43Z | 2023-08-15T02:52:22Z | 2023-08-15T02:52:22Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
step 'Generating train split' in load_dataset is too slow:

### Steps to reproduce the bug
Data: own data,16K16B Mono wav
Oficial Script:[ run_speech_recognition_seq2seq.py](https://github... | {
"avatar_url": "https://avatars.githubusercontent.com/u/19569322?v=4",
"events_url": "https://api.github.com/users/xyx361100238/events{/privacy}",
"followers_url": "https://api.github.com/users/xyx361100238/followers",
"following_url": "https://api.github.com/users/xyx361100238/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5941/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5941/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4051 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4051/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4051/comments | https://api.github.com/repos/huggingface/datasets/issues/4051/events | https://github.com/huggingface/datasets/issues/4051 | 1,184,400,179 | I_kwDODunzps5GmIMz | 4,051 | ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/2.0.0/datasets/glue/glue.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/39409233?v=4",
"events_url": "https://api.github.com/users/klyuhang9/events{/privacy}",
"followers_url": "https://api.github.com/users/klyuhang9/followers",
"following_url": "https://api.github.com/users/klyuhang9/following{/other_user}",
"gists_url": "... | [] | closed | false | [] | null | [
"Hi @klyuhang9,\r\n\r\nI'm sorry but I can't reproduce your problem:\r\n```python\r\nIn [4]: ds = load_dataset(\"glue\", \"sst2\", download_mode=\"force_redownload\")\r\nDownloading builder script: 28.8kB [00:00, 9.15MB/s] ... | 2022-03-29T07:00:31Z | 2022-05-08T07:27:32Z | 2022-03-29T08:29:25Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi, I meet a problem.
When I run the code:
`dataset = load_dataset('glue','sst2')`
There is a issue raising:
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/2.0.0/datasets/glue/glue.py
I don't know why; it is ok when I use Google Chrome to view this url.
Thanks for your... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4051/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4051/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6077 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6077/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6077/comments | https://api.github.com/repos/huggingface/datasets/issues/6077/events | https://github.com/huggingface/datasets/issues/6077 | 1,822,486,810 | I_kwDODunzps5soPEa | 6,077 | Mapping gets stuck at 99% | {
"avatar_url": "https://avatars.githubusercontent.com/u/21087104?v=4",
"events_url": "https://api.github.com/users/Laurent2916/events{/privacy}",
"followers_url": "https://api.github.com/users/Laurent2916/followers",
"following_url": "https://api.github.com/users/Laurent2916/following{/other_user}",
"gists_u... | [] | open | false | [] | null | [
"The `MAX_MAP_BATCH_SIZE = 1_000_000_000` hack is bad as it loads the entire dataset into RAM when performing `.map`. Instead, it's best to use `.iter(batch_size)` to iterate over the data batches and compute `mean` for each column. (`stddev` can be computed in another pass).\r\n\r\nAlso, these arrays are big, so i... | 2023-07-26T14:00:40Z | 2024-07-22T12:28:06Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Hi !
I'm currently working with a large (~150GB) unnormalized dataset at work.
The dataset is available on a read-only filesystem internally, and I use a [loading script](https://huggingface.co/docs/datasets/dataset_script) to retreive it.
I want to normalize the features of the dataset, ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6077/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6077/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5823 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5823/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5823/comments | https://api.github.com/repos/huggingface/datasets/issues/5823/events | https://github.com/huggingface/datasets/issues/5823 | 1,697,024,789 | I_kwDODunzps5lJosV | 5,823 | [2.12.0] DatasetDict.save_to_disk not saving to S3 | {
"avatar_url": "https://avatars.githubusercontent.com/u/5233185?v=4",
"events_url": "https://api.github.com/users/thejamesmarq/events{/privacy}",
"followers_url": "https://api.github.com/users/thejamesmarq/followers",
"following_url": "https://api.github.com/users/thejamesmarq/following{/other_user}",
"gists... | [] | closed | false | [] | null | [
"Hi ! Can you try adding the `s3://` prefix ?\r\n```python\r\nf\"s3://{s3_bucket}/{s3_dir}/{dataset_name}\"\r\n```",
"Ugh, yeah that was it. Thank you!",
"Hi @thejamesmarq, by any chance, did you use multiprocessing `num_proc > 1` when saving your dataset on the s3 bucket ? I'm struggling making it work in a mu... | 2023-05-05T05:22:59Z | 2024-05-30T16:11:31Z | 2023-05-05T15:01:17Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When trying to save a `DatasetDict` to a private S3 bucket using `save_to_disk`, the artifacts are instead saved locally, and not in the S3 bucket.
I have tried using the deprecated `fs` as well as the `storage_options` arguments and I get the same results.
### Steps to reproduce the bug
1. C... | {
"avatar_url": "https://avatars.githubusercontent.com/u/5233185?v=4",
"events_url": "https://api.github.com/users/thejamesmarq/events{/privacy}",
"followers_url": "https://api.github.com/users/thejamesmarq/followers",
"following_url": "https://api.github.com/users/thejamesmarq/following{/other_user}",
"gists... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5823/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5823/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1756 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1756/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1756/comments | https://api.github.com/repos/huggingface/datasets/issues/1756/events | https://github.com/huggingface/datasets/issues/1756 | 790,380,028 | MDU6SXNzdWU3OTAzODAwMjg= | 1,756 | Ccaligned multilingual translation dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47894090?v=4",
"events_url": "https://api.github.com/users/flozi00/events{/privacy}",
"followers_url": "https://api.github.com/users/flozi00/followers",
"following_url": "https://api.github.com/users/flozi00/following{/other_user}",
"gists_url": "https:... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | [] | null | [] | 2021-01-20T22:18:44Z | 2021-03-01T10:36:21Z | 2021-03-01T10:36:21Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- CCAligned consists of parallel or comparable web-document pairs in 137 languages aligned with English. These web-document pairs were constructed by performing language ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1756/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1756/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3404/comments | https://api.github.com/repos/huggingface/datasets/issues/3404/events | https://github.com/huggingface/datasets/issues/3404 | 1,073,657,561 | I_kwDODunzps4__rbZ | 3,404 | Optimize ZIP format inference | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2021-12-07T18:44:49Z | 2021-12-14T17:08:41Z | 2021-12-14T17:08:41Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | **Is your feature request related to a problem? Please describe.**
When hundreds of ZIP files are present in a dataset, format inference takes too long.
See: https://github.com/bigscience-workshop/data_tooling/issues/232#issuecomment-986685497
**Describe the solution you'd like**
Iterate over a maximum number o... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3404/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3404/timeline | null | completed | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.