
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 48 51 | id int64 600M 4.46B | node_id stringlengths 18 24 | number int64 2 8.2k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC]date 2020-04-14 18:18:51 2026-05-16 13:28:01 | updated_at timestamp[ns, tz=UTC]date 2020-04-29 09:23:05 2026-05-21 16:18:22 | closed_at timestamp[ns, tz=UTC]date 2020-04-29 09:23:05 2026-05-20 10:46:58 ⌀ | assignee dict | author_association stringclasses 4
values | issue_field_values listlengths 0 0 | type float64 | active_lock_reason float64 | sub_issues_summary dict | issue_dependencies_summary dict | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 4
values | pinned_comment float64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3146 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3146/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3146/comments | https://api.github.com/repos/huggingface/datasets/issues/3146/events | https://github.com/huggingface/datasets/issues/3146 | 1,033,605,947 | I_kwDODunzps49m5M7 | 3,146 | CLI test command throws NonMatchingSplitsSizesError when saving infos | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2021-10-22T13:50:53Z | 2021-10-27T08:01:49Z | 2021-10-27T08:01:49Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | When trying to generate a datset JSON metadata, a `NonMatchingSplitsSizesError` is thrown:
```
$ datasets-cli test datasets/arabic_billion_words --save_infos --all_configs
Testing builder 'Alittihad' (1/10)
Downloading and preparing dataset arabic_billion_words/Alittihad (download: 332.13 MiB, generated: Unknown si... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3146/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3146/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5425/comments | https://api.github.com/repos/huggingface/datasets/issues/5425/events | https://github.com/huggingface/datasets/issues/5425 | 1,534,581,850 | I_kwDODunzps5bd9xa | 5,425 | Sort on multiple keys with datasets.Dataset.sort() | {
"avatar_url": "https://avatars.githubusercontent.com/u/101344863?v=4",
"events_url": "https://api.github.com/users/rocco-fortuna/events{/privacy}",
"followers_url": "https://api.github.com/users/rocco-fortuna/followers",
"following_url": "https://api.github.com/users/rocco-fortuna/following{/other_user}",
"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | [] | null | [
"Hi! \r\n\r\n`Dataset.sort` calls `df.sort_values` internally, and `df.sort_values` brings all the \"sort\" columns in memory, so sorting on multiple keys could be very expensive. This makes me think that maybe we can replace `df.sort_values` with `pyarrow.compute.sort_indices` - the latter can also sort on multipl... | 2023-01-16T09:22:26Z | 2023-02-24T16:15:11Z | 2023-02-24T16:15:11Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5425/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5425/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6112 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6112/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6112/comments | https://api.github.com/repos/huggingface/datasets/issues/6112/events | https://github.com/huggingface/datasets/issues/6112 | 1,833,693,299 | I_kwDODunzps5tS_Bz | 6,112 | yaml error using push_to_hub with generated README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/1643887?v=4",
"events_url": "https://api.github.com/users/kevintee/events{/privacy}",
"followers_url": "https://api.github.com/users/kevintee/followers",
"following_url": "https://api.github.com/users/kevintee/following{/other_user}",
"gists_url": "http... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Thanks for reporting! This is a bug in converting the `ArrayXD` types to YAML. It will be fixed soon."
] | 2023-08-02T18:21:21Z | 2023-12-12T15:00:44Z | 2023-12-12T15:00:44Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When I construct a dataset with the following features:
```
features = Features(
{
"pixel_values": Array3D(dtype="float64", shape=(3, 224, 224)),
"input_ids": Sequence(feature=Value(dtype="int64")),
"attention_mask": Sequence(Value(dtype="int64")),
"token... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6112/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6112/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7280 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7280/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7280/comments | https://api.github.com/repos/huggingface/datasets/issues/7280/events | https://github.com/huggingface/datasets/issues/7280 | 2,639,977,077 | I_kwDODunzps6dWtp1 | 7,280 | Add filename in error message when ReadError or similar occur | {
"avatar_url": "https://avatars.githubusercontent.com/u/37046039?v=4",
"events_url": "https://api.github.com/users/elisa-aleman/events{/privacy}",
"followers_url": "https://api.github.com/users/elisa-aleman/followers",
"following_url": "https://api.github.com/users/elisa-aleman/following{/other_user}",
"gist... | [] | open | false | [] | null | [
"Hi Elisa, please share the error traceback here, and if you manage to find the location in the `datasets` code where the error occurs, feel free to open a PR to add the necessary logging / improve the error message.",
"> please share the error traceback\n\nI don't have access to it but it should be during [this ... | 2024-11-07T06:00:53Z | 2024-11-20T13:23:12Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Please update error messages to include relevant information for debugging when loading datasets with `load_dataset()` that may have a few corrupted files.
Whenever downloading a full dataset, some files might be corrupted (either at the source or from downloading corruption).
However the errors often only let me k... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7280/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7280/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7155 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7155/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7155/comments | https://api.github.com/repos/huggingface/datasets/issues/7155/events | https://github.com/huggingface/datasets/issues/7155 | 2,533,641,870 | I_kwDODunzps6XBE6O | 7,155 | Dataset viewer not working! Failure due to more than 32 splits. | {
"avatar_url": "https://avatars.githubusercontent.com/u/81933585?v=4",
"events_url": "https://api.github.com/users/sleepingcat4/events{/privacy}",
"followers_url": "https://api.github.com/users/sleepingcat4/followers",
"following_url": "https://api.github.com/users/sleepingcat4/following{/other_user}",
"gist... | [] | closed | false | [] | null | [
"I have fixed it! But I would appreciate a new feature wheere I could iterate over and see what each file looks like. "
] | 2024-09-18T12:43:21Z | 2024-09-18T13:20:03Z | 2024-09-18T13:20:03Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hello guys,
I have a dataset and I didn't know I couldn't upload more than 32 splits. Now, my dataset viewer is not working. I don't have the dataset locally on my node anymore and recreating would take a week. And I have to publish the dataset coming Monday. I read about the practice, how I can resolve it and avoi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/81933585?v=4",
"events_url": "https://api.github.com/users/sleepingcat4/events{/privacy}",
"followers_url": "https://api.github.com/users/sleepingcat4/followers",
"following_url": "https://api.github.com/users/sleepingcat4/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7155/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7155/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/8038 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/8038/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/8038/comments | https://api.github.com/repos/huggingface/datasets/issues/8038/events | https://github.com/huggingface/datasets/issues/8038 | 4,020,184,168 | I_kwDODunzps7vnyRo | 8,038 | Typo in iterable_dataset.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/28946888?v=4",
"events_url": "https://api.github.com/users/sybaik1/events{/privacy}",
"followers_url": "https://api.github.com/users/sybaik1/followers",
"following_url": "https://api.github.com/users/sybaik1/following{/other_user}",
"gists_url": "https:... | [] | closed | false | [] | null | [] | 2026-03-04T05:37:15Z | 2026-03-09T17:12:54Z | 2026-03-09T17:12:54Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
`streaming=True**kwargs,` should be `streaming=True, **kwargs,`
https://github.com/huggingface/datasets/blob/81027be09d5cd9f06a6d64ef1a8a3e9ebd0f86fd/src/datasets/iterable_dataset.py#L2950
### Steps to reproduce the bug
```
from Datasets import Dataset
IterableDataset.from_csv("file.csv")
```
#... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/8038/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/8038/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3485 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3485/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3485/comments | https://api.github.com/repos/huggingface/datasets/issues/3485/events | https://github.com/huggingface/datasets/issues/3485 | 1,089,027,581 | I_kwDODunzps5A6T39 | 3,485 | skip columns which cannot set to specific format when set_format | {
"avatar_url": "https://avatars.githubusercontent.com/u/13161779?v=4",
"events_url": "https://api.github.com/users/tshu-w/events{/privacy}",
"followers_url": "https://api.github.com/users/tshu-w/followers",
"following_url": "https://api.github.com/users/tshu-w/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"You can add columns that you wish to set into `torch` format using `dataset.set_format(\"torch\", ['id', 'abc'])` so that input batch of the transform only contains those columns",
"Sorry, I miss `output_all_columns` args and thought after `dataset.set_format(\"torch\", columns=columns)` I can only get specific ... | 2021-12-27T07:19:55Z | 2021-12-27T09:07:07Z | 2021-12-27T09:07:07Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | **Is your feature request related to a problem? Please describe.**
When using `dataset.set_format("torch")`, I must make sure every columns in datasets can convert to `torch`, however, sometimes I want to keep some string columns.
**Describe the solution you'd like**
skip columns which cannot set to specific forma... | {
"avatar_url": "https://avatars.githubusercontent.com/u/13161779?v=4",
"events_url": "https://api.github.com/users/tshu-w/events{/privacy}",
"followers_url": "https://api.github.com/users/tshu-w/followers",
"following_url": "https://api.github.com/users/tshu-w/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3485/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3485/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6778 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6778/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6778/comments | https://api.github.com/repos/huggingface/datasets/issues/6778/events | https://github.com/huggingface/datasets/issues/6778 | 2,226,040,636 | I_kwDODunzps6Erq88 | 6,778 | Dataset.to_csv() missing commas in columns with lists | {
"avatar_url": "https://avatars.githubusercontent.com/u/100041276?v=4",
"events_url": "https://api.github.com/users/mpickard-dataprof/events{/privacy}",
"followers_url": "https://api.github.com/users/mpickard-dataprof/followers",
"following_url": "https://api.github.com/users/mpickard-dataprof/following{/other... | [] | open | false | [] | null | [
"Hello!\r\n\r\nThis is due to how pandas write numpy arrays to csv. [Source](https://stackoverflow.com/questions/54753179/to-csv-saves-np-array-as-string-instead-of-as-a-list)\r\nTo fix this, you can convert them to list yourselves.\r\n\r\n```python\r\ndf = ds.to_pandas()\r\ndf['int'] = df['int'].apply(lambda arr: ... | 2024-04-04T16:46:13Z | 2024-04-08T15:24:41Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
The `to_csv()` method does not output commas in lists. So when the Dataset is loaded back in the data structure of the column with a list is not correct.
Here's an example:
Obviously, it's not as trivial as inserting commas in the list, since its a comma-separated file. But hopefully there... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6778/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6778/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5773 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5773/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5773/comments | https://api.github.com/repos/huggingface/datasets/issues/5773/events | https://github.com/huggingface/datasets/issues/5773 | 1,675,984,633 | I_kwDODunzps5j5X75 | 5,773 | train_dataset does not implement __len__ | {
"avatar_url": "https://avatars.githubusercontent.com/u/38179632?v=4",
"events_url": "https://api.github.com/users/zyb8543d/events{/privacy}",
"followers_url": "https://api.github.com/users/zyb8543d/followers",
"following_url": "https://api.github.com/users/zyb8543d/following{/other_user}",
"gists_url": "htt... | [] | open | false | [] | null | [
"Thanks for reporting, @v-yunbin.\r\n\r\nCould you please give more details, the steps to reproduce the bug, the complete error back trace and the environment information (`datasets-cli env`)?",
"this is a detail error info from transformers:\r\n```\r\nTraceback (most recent call last):\r\n File \"finetune.py\",... | 2023-04-20T04:37:05Z | 2023-07-19T20:33:13Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | when train using data precessored by the datasets, I get follow warning and it leads to that I can not set epoch numbers:
`ValueError: The train_dataset does not implement __len__, max_steps has to be specified. The number of steps needs to be known in advance for the learning rate scheduler.` | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5773/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5773/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3155 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3155/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3155/comments | https://api.github.com/repos/huggingface/datasets/issues/3155/events | https://github.com/huggingface/datasets/issues/3155 | 1,034,468,757 | I_kwDODunzps49qL2V | 3,155 | Illegal instruction (core dumped) at datasets import | {
"avatar_url": "https://avatars.githubusercontent.com/u/91226467?v=4",
"events_url": "https://api.github.com/users/hacobe/events{/privacy}",
"followers_url": "https://api.github.com/users/hacobe/followers",
"following_url": "https://api.github.com/users/hacobe/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"It seems to be an issue with how conda-forge is building the binaries. It works on some machines, but not a machine with AMD Opteron 8384 processors."
] | 2021-10-24T17:21:36Z | 2021-11-18T19:07:04Z | 2021-11-18T19:07:03Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
I install datasets using conda and when I import datasets I get: "Illegal instruction (core dumped)"
## Steps to reproduce the bug
```
conda create --prefix path/to/env
conda activate path/to/env
conda install -c huggingface -c conda-forge datasets
# exits with output "Illegal instruction... | {
"avatar_url": "https://avatars.githubusercontent.com/u/91226467?v=4",
"events_url": "https://api.github.com/users/hacobe/events{/privacy}",
"followers_url": "https://api.github.com/users/hacobe/followers",
"following_url": "https://api.github.com/users/hacobe/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3155/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3155/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4121 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4121/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4121/comments | https://api.github.com/repos/huggingface/datasets/issues/4121/events | https://github.com/huggingface/datasets/issues/4121 | 1,196,000,018 | I_kwDODunzps5HSYMS | 4,121 | datasets.load_metric can not load a local metirc | {
"avatar_url": "https://avatars.githubusercontent.com/u/51749469?v=4",
"events_url": "https://api.github.com/users/SadGare/events{/privacy}",
"followers_url": "https://api.github.com/users/SadGare/followers",
"following_url": "https://api.github.com/users/SadGare/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hello, could you tell me how this issue can be fixed? I'm coming across the same issue."
] | 2022-04-07T12:48:56Z | 2023-01-18T14:30:46Z | 2022-04-07T13:53:27Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
No matter how I hard try to tell load_metric that I want to load a local metric file, it still continues to fetch things on the Internet. And unfortunately it says 'ConnectionError: Couldn't reach'. However I can download this file without connectionerror and tell load_metric its local directory. A... | {
"avatar_url": "https://avatars.githubusercontent.com/u/51749469?v=4",
"events_url": "https://api.github.com/users/SadGare/events{/privacy}",
"followers_url": "https://api.github.com/users/SadGare/followers",
"following_url": "https://api.github.com/users/SadGare/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4121/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4121/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6584/comments | https://api.github.com/repos/huggingface/datasets/issues/6584/events | https://github.com/huggingface/datasets/issues/6584 | 2,078,454,878 | I_kwDODunzps574rRe | 6,584 | np.fromfile not supported | {
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url"... | [] | open | false | [] | null | [
"@lhoestq\r\nCan you provide me with some ideas?",
"Hi ! What's the error ?",
"@lhoestq \r\n```\r\nTraceback (most recent call last):\r\n File \"/home/dongzf/miniconda3/envs/dataset_ai/lib/python3.11/runpy.py\", line 198, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n ^^... | 2024-01-12T09:46:17Z | 2024-01-15T05:20:50Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | How to do np.fromfile to use it like np.load
```python
def xnumpy_fromfile(filepath_or_buffer, *args, download_config: Optional[DownloadConfig] = None, **kwargs):
import numpy as np
if hasattr(filepath_or_buffer, "read"):
return np.fromfile(filepath_or_buffer, *args, **kwargs)
else:
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6584/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6584/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6552 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6552/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6552/comments | https://api.github.com/repos/huggingface/datasets/issues/6552/events | https://github.com/huggingface/datasets/issues/6552 | 2,063,157,187 | I_kwDODunzps56-UfD | 6,552 | Loading a dataset from Google Colab hangs at "Resolving data files". | {
"avatar_url": "https://avatars.githubusercontent.com/u/99779?v=4",
"events_url": "https://api.github.com/users/KelSolaar/events{/privacy}",
"followers_url": "https://api.github.com/users/KelSolaar/followers",
"following_url": "https://api.github.com/users/KelSolaar/following{/other_user}",
"gists_url": "htt... | [] | closed | false | [] | null | [
"This bug comes from the `huggingface_hub` library, see: https://github.com/huggingface/huggingface_hub/issues/1952\r\n\r\nA fix is provided at https://github.com/huggingface/huggingface_hub/pull/1953. Feel free to install `huggingface_hub` from this PR, or wait for it to be merged and the new version of `huggingfa... | 2024-01-03T02:18:17Z | 2024-01-08T10:09:04Z | 2024-01-08T10:09:04Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Hello,
I'm trying to load a dataset from Google Colab but the process hangs at `Resolving data files`:

It is happening when the `_get_origin_metadata` definition is invoked:
```python
d... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6552/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6552/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4555 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4555/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4555/comments | https://api.github.com/repos/huggingface/datasets/issues/4555/events | https://github.com/huggingface/datasets/issues/4555 | 1,283,451,651 | I_kwDODunzps5Mf-sD | 4,555 | Dataset Viewer issue for xtreme | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | null | [
"Fixed, thanks."
] | 2022-06-24T08:46:08Z | 2022-06-24T09:50:45Z | 2022-06-24T09:50:45Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Link
https://huggingface.co/datasets/xtreme/viewer/PAN-X.de/test
### Description
There seems to be a problem with the cache of this config / split:
```
Server error
Status code: 400
Exception: FileNotFoundError
Message: [Errno 2] No such file or directory: '/cache/modules/datasets_modules/data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4555/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4555/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7508 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7508/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7508/comments | https://api.github.com/repos/huggingface/datasets/issues/7508/events | https://github.com/huggingface/datasets/issues/7508 | 2,986,612,934 | I_kwDODunzps6yBBjG | 7,508 | Iterating over Image feature columns is extremely slow | {
"avatar_url": "https://avatars.githubusercontent.com/u/11831521?v=4",
"events_url": "https://api.github.com/users/sohamparikh/events{/privacy}",
"followers_url": "https://api.github.com/users/sohamparikh/followers",
"following_url": "https://api.github.com/users/sohamparikh/following{/other_user}",
"gists_u... | [] | open | false | [] | null | [
"Hi ! Could it be because the `Image()` type in dataset does `image = Image.open(image_path)` and also `image.load()` which actually loads the image data in memory ? This is needed to avoid too many open files issues, see https://github.com/huggingface/datasets/issues/3985",
"Yes, that seems to be it. For my pur... | 2025-04-10T19:00:54Z | 2025-04-15T17:57:08Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | We are trying to load datasets where the image column stores `PIL.PngImagePlugin.PngImageFile` images. However, iterating over these datasets is extremely slow.
What I have found:
1. It is the presence of the image column that causes the slowdown. Removing the column from the dataset results in blazingly fast (as expe... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7508/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7508/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4888 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4888/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4888/comments | https://api.github.com/repos/huggingface/datasets/issues/4888/events | https://github.com/huggingface/datasets/issues/4888 | 1,349,447,521 | I_kwDODunzps5Qbu9h | 4,888 | Dataset Viewer issue for subjqa | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | null | [
"It's a bug in the viewer, thanks for reporting it. We're hoping to update to a new version in the next few days which should fix it.",
"Fixed \r\n\r\nhttps://huggingface.co/datasets/subjqa\r\n\r\n<img width=\"1040\" alt=\"Capture d’écran 2022-09-08 à 10 23 26\" src=\"https://user-images.githubusercontent.com/1... | 2022-08-24T13:26:20Z | 2022-09-08T08:23:42Z | 2022-09-08T08:23:42Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Link
https://huggingface.co/datasets/subjqa
### Description
Getting the following error for this dataset:
```
Status code: 500
Exception: Status500Error
Message: 2 or more items returned, instead of 1
```
Not sure what's causing it though 🤔
### Owner
Yes | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4888/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4888/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7185 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7185/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7185/comments | https://api.github.com/repos/huggingface/datasets/issues/7185/events | https://github.com/huggingface/datasets/issues/7185 | 2,558,508,748 | I_kwDODunzps6Yf77M | 7,185 | CI benchmarks are broken | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | [] | null | [
"Fixed by #7205"
] | 2024-10-01T08:16:08Z | 2024-10-09T16:07:48Z | 2024-10-09T16:07:48Z | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Since Aug 30, 2024, CI benchmarks are broken: https://github.com/huggingface/datasets/actions/runs/11108421214/job/30861323975
```
{"level":"error","message":"Resource not accessible by integration","name":"HttpError","request":{"body":"{\"body\":\"<details>\\n<summary>Show benchmarks</summary>\\n\\nPyArrow==8.0.0\\n... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7185/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7185/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4635/comments | https://api.github.com/repos/huggingface/datasets/issues/4635/events | https://github.com/huggingface/datasets/issues/4635 | 1,294,475,931 | I_kwDODunzps5NKCKb | 4,635 | Dataset Viewer issue for vadis/sv-ident | {
"avatar_url": "https://avatars.githubusercontent.com/u/20404466?v=4",
"events_url": "https://api.github.com/users/e-tornike/events{/privacy}",
"followers_url": "https://api.github.com/users/e-tornike/followers",
"following_url": "https://api.github.com/users/e-tornike/following{/other_user}",
"gists_url": "... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @e-tornike \r\n\r\nSome context:\r\n- #4527 \r\n\r\nThe dataset loads locally in streaming mode:\r\n```python\r\nIn [2]: from datasets import load_dataset; ds = load_dataset(\"vadis/sv-ident\", split=\"validation\", streaming=True); item = next(iter(ds)); item\r\nUsing custom data configurati... | 2022-07-05T15:48:13Z | 2022-07-06T07:13:33Z | 2022-07-06T07:12:14Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Link
https://huggingface.co/datasets/vadis/sv-ident/viewer/default/validation
### Description
Error message when loading validation split in the viewer:
```
Status code: 400
Exception: Status400Error
Message: The split cache is empty.
```
### Owner
_No response_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4635/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4635/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1981 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1981/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1981/comments | https://api.github.com/repos/huggingface/datasets/issues/1981/events | https://github.com/huggingface/datasets/issues/1981 | 821,411,109 | MDU6SXNzdWU4MjE0MTExMDk= | 1,981 | wmt datasets fail to load | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"@stas00 Mea culpa... May I fix this tomorrow morning?",
"yes, of course, I reverted to the version before that and it works ;)\r\n\r\nbut since a new release was just made you will probably need to make a hotfix.\r\n\r\nand add the wmt to the tests?",
"Sure, I will implement a regression test!",
"@stas00 it ... | 2021-03-03T19:21:39Z | 2021-03-04T14:16:47Z | 2021-03-03T22:48:36Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | on master:
```
python -c 'from datasets import load_dataset; load_dataset("wmt14", "de-en")'
Downloading and preparing dataset wmt14/de-en (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/stas/.cache/huggingface/datasets/wmt14/de-en/1.0.0/43e717d978d226150... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1981/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1981/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7323 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7323/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7323/comments | https://api.github.com/repos/huggingface/datasets/issues/7323/events | https://github.com/huggingface/datasets/issues/7323 | 2,736,008,698 | I_kwDODunzps6jFC36 | 7,323 | Unexpected cache behaviour using load_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/74349080?v=4",
"events_url": "https://api.github.com/users/Moritz-Wirth/events{/privacy}",
"followers_url": "https://api.github.com/users/Moritz-Wirth/followers",
"following_url": "https://api.github.com/users/Moritz-Wirth/following{/other_user}",
"gist... | [] | closed | false | [] | null | [
"Hi ! Since `datasets` 3.x, the `datasets` specific files are in `cache_dir=` and the HF files are cached using `huggingface_hub` and you can set its cache directory using the `HF_HOME` environment variable.\r\n\r\nThey are independent, for example you can delete the Hub cache (containing downloaded files) but sti... | 2024-12-12T14:03:00Z | 2025-01-31T11:34:24Z | 2025-01-31T11:34:24Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Following the (Cache management)[https://huggingface.co/docs/datasets/en/cache] docu and previous behaviour from datasets version 2.18.0, one is able to change the cache directory. Previously, all downloaded/extracted/etc files were found in this folder. As i have recently update to the latest v... | {
"avatar_url": "https://avatars.githubusercontent.com/u/74349080?v=4",
"events_url": "https://api.github.com/users/Moritz-Wirth/events{/privacy}",
"followers_url": "https://api.github.com/users/Moritz-Wirth/followers",
"following_url": "https://api.github.com/users/Moritz-Wirth/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7323/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7323/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/483 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/483/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/483/comments | https://api.github.com/repos/huggingface/datasets/issues/483/events | https://github.com/huggingface/datasets/issues/483 | 675,080,694 | MDU6SXNzdWU2NzUwODA2OTQ= | 483 | rotten tomatoes movie review dataset taken down | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"found a mirror: https://storage.googleapis.com/seldon-datasets/sentence_polarity_v1/rt-polaritydata.tar.gz",
"fixed in #484 ",
"Closing this one. Thanks again @jxmorris12 for taking care of this :)"
] | 2020-08-07T15:12:01Z | 2020-09-08T09:36:34Z | 2020-09-08T09:36:33Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | In an interesting twist of events, the individual who created the movie review seems to have left Cornell, and their webpage has been removed, along with the movie review dataset (http://www.cs.cornell.edu/people/pabo/movie-review-data/rt-polaritydata.tar.gz). It's not downloadable anymore. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/483/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/483/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5797 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5797/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5797/comments | https://api.github.com/repos/huggingface/datasets/issues/5797/events | https://github.com/huggingface/datasets/issues/5797 | 1,685,501,199 | I_kwDODunzps5kdrUP | 5,797 | load_dataset is case sentitive? | {
"avatar_url": "https://avatars.githubusercontent.com/u/34729065?v=4",
"events_url": "https://api.github.com/users/haonan-li/events{/privacy}",
"followers_url": "https://api.github.com/users/haonan-li/followers",
"following_url": "https://api.github.com/users/haonan-li/following{/other_user}",
"gists_url": "... | [] | open | false | [] | null | [
"Hi @haonan-li , thank you for the report! It seems to be a bug on the [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) site, there is even no such dataset as `mbzuai/bactrian-x` on the Hub. I opened and [issue](https://github.com/huggingface/huggingface_hub/issues/1453) there.",
"I think `loa... | 2023-04-26T18:19:04Z | 2023-04-27T11:56:58Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
load_dataset() function is case sensitive?
### Steps to reproduce the bug
The following two code, get totally different behavior.
1. load_dataset('mbzuai/bactrian-x','en')
2. load_dataset('MBZUAI/Bactrian-X','en')
### Expected behavior
Compare 1 and 2.
1 will download all 52 subsets, sh... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5797/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5797/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3064 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3064/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3064/comments | https://api.github.com/repos/huggingface/datasets/issues/3064/events | https://github.com/huggingface/datasets/issues/3064 | 1,023,900,075 | I_kwDODunzps49B3mr | 3,064 | Make `interleave_datasets` more robust | {
"avatar_url": "https://avatars.githubusercontent.com/u/32699797?v=4",
"events_url": "https://api.github.com/users/sbmaruf/events{/privacy}",
"followers_url": "https://api.github.com/users/sbmaruf/followers",
"following_url": "https://api.github.com/users/sbmaruf/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [
"Hi @lhoestq Any response on this issue?",
"Hi ! Sorry for the late response\r\n\r\nI agree `interleave_datasets` would benefit a lot from having more flexibility. If I understand correctly it would be nice to be able to define stopping strategies like `stop=\"first_exhausted\"` (default) or `stop=\"all_exhauste... | 2021-10-12T14:34:53Z | 2022-07-30T08:47:26Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | **Is your feature request related to a problem? Please describe.**
Right now there are few hiccups using `interleave_datasets`. Interleaved dataset iterates until the smallest dataset completes it's iterator. In this way larger datasets may not complete full epoch of iteration.
It creates new problems in calculation... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3064/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3064/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6366/comments | https://api.github.com/repos/huggingface/datasets/issues/6366/events | https://github.com/huggingface/datasets/issues/6366 | 1,970,213,490 | I_kwDODunzps51bxJy | 6,366 | with_format() function returns bytes instead of PIL images even when image column is not part of "columns" | {
"avatar_url": "https://avatars.githubusercontent.com/u/17809020?v=4",
"events_url": "https://api.github.com/users/leot13/events{/privacy}",
"followers_url": "https://api.github.com/users/leot13/followers",
"following_url": "https://api.github.com/users/leot13/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | [] | null | [
"Thanks for reporting! I've opened a PR with a fix."
] | 2023-10-31T11:10:48Z | 2023-11-02T14:21:17Z | 2023-11-02T14:21:17Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When using the with_format() function on a dataset containing images, even if the image column is not part of the columns provided in the function, its type will be changed to bytes.
Here is a minimal reproduction of the bug:
https://colab.research.google.com/drive/1hyaOspgyhB41oiR1-tXE3k_gJCdJU... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6366/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6366/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2377/comments | https://api.github.com/repos/huggingface/datasets/issues/2377/events | https://github.com/huggingface/datasets/issues/2377 | 894,918,927 | MDU6SXNzdWU4OTQ5MTg5Mjc= | 2,377 | ArrowDataset.save_to_disk produces files that cannot be read using pyarrow.feather | {
"avatar_url": "https://avatars.githubusercontent.com/u/1829149?v=4",
"events_url": "https://api.github.com/users/Ark-kun/events{/privacy}",
"followers_url": "https://api.github.com/users/Ark-kun/followers",
"following_url": "https://api.github.com/users/Ark-kun/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | [] | null | [
"Hi ! This is because we are actually using the arrow streaming format. We plan to switch to the arrow IPC format.\r\nMore info at #1933 ",
"Not sure if this was resolved, but I am getting a similar error when trying to load a dataset.arrow file directly: `ArrowInvalid: Not an Arrow file`",
"Since we're using t... | 2021-05-19T02:04:37Z | 2024-01-18T08:06:15Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from pyarrow import feather
dataset = load_dataset('imdb', split='train')
dataset.save_to_disk('dataset_dir')
table = feather.read_table('dataset_dir/dataset.arro... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2377/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4721 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4721/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4721/comments | https://api.github.com/repos/huggingface/datasets/issues/4721/events | https://github.com/huggingface/datasets/issues/4721 | 1,310,253,552 | I_kwDODunzps5OGOHw | 4,721 | PyArrow Dataset error when calling `load_dataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/16828657?v=4",
"events_url": "https://api.github.com/users/piraka9011/events{/privacy}",
"followers_url": "https://api.github.com/users/piraka9011/followers",
"following_url": "https://api.github.com/users/piraka9011/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | [] | null | [
"Hi ! It looks like a bug in `pyarrow`. If you manage to end up with only one chunk per parquet file it should workaround this issue.\r\n\r\nTo achieve that you can try to lower the value of `max_shard_size` and also don't use `map` before `push_to_hub`.\r\n\r\nDo you have a minimum reproducible example that we can... | 2022-07-20T01:16:03Z | 2022-07-22T14:11:47Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
I am fine tuning a wav2vec2 model following the script here using my own dataset: https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
Loading my Audio dataset from the hub which was originally generated from disk results in th... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4721/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4721/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/290 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/290/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/290/comments | https://api.github.com/repos/huggingface/datasets/issues/290/events | https://github.com/huggingface/datasets/issues/290 | 641,978,286 | MDU6SXNzdWU2NDE5NzgyODY= | 290 | ConnectionError - Eli5 dataset download | {
"avatar_url": "https://avatars.githubusercontent.com/u/8490096?v=4",
"events_url": "https://api.github.com/users/JovanNj/events{/privacy}",
"followers_url": "https://api.github.com/users/JovanNj/followers",
"following_url": "https://api.github.com/users/JovanNj/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | [] | null | [
"It should ne fixed now, thanks for reporting this one :)\r\nIt was an issue on our google storage.\r\n\r\nLet me now if you're still facing this issue.",
"It works now, thanks for prompt help!"
] | 2020-06-19T13:40:33Z | 2020-06-20T13:22:24Z | 2020-06-20T13:22:24Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi, I have a problem with downloading Eli5 dataset. When typing `nlp.load_dataset('eli5')`, I get ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/eli5/LFQA_reddit/1.0.0/explain_like_im_five-train_eli5.arrow
I would appreciate if you could help me with this issue. | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/290/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/290/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7415/comments | https://api.github.com/repos/huggingface/datasets/issues/7415/events | https://github.com/huggingface/datasets/issues/7415 | 2,865,774,546 | I_kwDODunzps6q0D_S | 7,415 | Shard Dataset at specific indices | {
"avatar_url": "https://avatars.githubusercontent.com/u/11044035?v=4",
"events_url": "https://api.github.com/users/nikonikolov/events{/privacy}",
"followers_url": "https://api.github.com/users/nikonikolov/followers",
"following_url": "https://api.github.com/users/nikonikolov/following{/other_user}",
"gists_u... | [] | open | false | [] | null | [
"Hi ! if it's an option I'd suggest to have one sequence per row instead.\n\nOtherwise you'd have to make your own save/load mechanism",
"Saving one sequence per row is very difficult and heavy and makes all the optimizations pointless. How would a custom save/load mechanism look like?",
"You can use `pyarrow` ... | 2025-02-20T10:43:10Z | 2025-02-24T11:06:45Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I have a dataset of sequences, where each example in the sequence is a separate row in the dataset (similar to LeRobotDataset). When running `Dataset.save_to_disk` how can I provide indices where it's possible to shard the dataset such that no episode spans more than 1 shard. Consequently, when I run `Dataset.load_from... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7415/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7415/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7880 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7880/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7880/comments | https://api.github.com/repos/huggingface/datasets/issues/7880/events | https://github.com/huggingface/datasets/issues/7880 | 3,667,561,864 | I_kwDODunzps7amo2I | 7,880 | Spurious label column created when audiofolder/imagefolder directories match split names | {
"avatar_url": "https://avatars.githubusercontent.com/u/132138786?v=4",
"events_url": "https://api.github.com/users/neha222222/events{/privacy}",
"followers_url": "https://api.github.com/users/neha222222/followers",
"following_url": "https://api.github.com/users/neha222222/following{/other_user}",
"gists_url... | [] | open | false | [] | null | [] | 2025-11-26T13:36:24Z | 2025-11-26T13:36:24Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
When using `audiofolder` or `imagefolder` with directories for **splits** (train/test) rather than class labels, a spurious `label` column is incorrectly created.
**Example:** https://huggingface.co/datasets/datasets-examples/doc-audio-4
```
from datasets import load_dataset
ds = load_dataset("dat... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7880/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7880/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/156 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/156/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/156/comments | https://api.github.com/repos/huggingface/datasets/issues/156/events | https://github.com/huggingface/datasets/issues/156 | 620,263,687 | MDU6SXNzdWU2MjAyNjM2ODc= | 156 | SyntaxError with WMT datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/9419158?v=4",
"events_url": "https://api.github.com/users/tomhosking/events{/privacy}",
"followers_url": "https://api.github.com/users/tomhosking/followers",
"following_url": "https://api.github.com/users/tomhosking/following{/other_user}",
"gists_url":... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/followin... | null | [
"Jeez - don't know what happened there :D Should be fixed now! \r\n\r\nThanks a lot for reporting this @tomhosking !",
"Hi @patrickvonplaten!\r\n\r\nI'm now getting the below error:\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nTypeError ... | 2020-05-18T14:38:18Z | 2020-07-23T16:41:55Z | 2020-07-23T16:41:55Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | The following snippet produces a syntax error:
```
import nlp
dataset = nlp.load_dataset('wmt14')
print(dataset['train'][0])
```
```
Traceback (most recent call last):
File "/home/tom/.local/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 3326, in run_code
exec(code_obj, self.... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/156/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/156/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7676/comments | https://api.github.com/repos/huggingface/datasets/issues/7676/events | https://github.com/huggingface/datasets/issues/7676 | 3,216,857,559 | I_kwDODunzps6_vVnX | 7,676 | Many things broken since the new 4.0.0 release | {
"avatar_url": "https://avatars.githubusercontent.com/u/37179323?v=4",
"events_url": "https://api.github.com/users/mobicham/events{/privacy}",
"followers_url": "https://api.github.com/users/mobicham/followers",
"following_url": "https://api.github.com/users/mobicham/following{/other_user}",
"gists_url": "htt... | [] | open | false | [] | null | [
"Happy to take a look, do you have a list of impacted datasets ?",
"Thanks @lhoestq , related to lm-eval, at least `winogrande`, `mmlu` and `hellaswag`, based on my tests yesterday. But many others like <a href=\"https://huggingface.co/datasets/lukaemon/bbh\">bbh</a>, most probably others too. ",
"Hi @mobicham ... | 2025-07-09T18:59:50Z | 2026-02-17T17:18:19Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
The new changes in 4.0.0 are breaking many datasets, including those from lm-evaluation-harness.
I am trying to revert back to older versions, like 3.6.0 to make the eval work but I keep getting:
``` Python
File /venv/main/lib/python3.12/site-packages/datasets/features/features.py:1474, in genera... | null | {
"+1": 23,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 23,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7676/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7676/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/508 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/508/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/508/comments | https://api.github.com/repos/huggingface/datasets/issues/508/events | https://github.com/huggingface/datasets/issues/508 | 679,705,734 | MDU6SXNzdWU2Nzk3MDU3MzQ= | 508 | TypeError: Receiver() takes no arguments | {
"avatar_url": "https://avatars.githubusercontent.com/u/1225851?v=4",
"events_url": "https://api.github.com/users/sebastiantomac/events{/privacy}",
"followers_url": "https://api.github.com/users/sebastiantomac/followers",
"following_url": "https://api.github.com/users/sebastiantomac/following{/other_user}",
... | [] | closed | false | [] | null | [
"Which version of Apache Beam do you have (can you copy your full environment info here)?",
"apache-beam==2.23.0\r\nnlp==0.4.0\r\n\r\nFor me this was resolved by running the same python script on Linux (or really WSL). ",
"Do you manage to run a dummy beam pipeline with python on windows ? \r\nYou can test a du... | 2020-08-16T07:18:16Z | 2020-09-01T14:53:33Z | 2020-09-01T14:49:03Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I am trying to load a wikipedia data set
```
import nlp
from nlp import load_dataset
dataset = load_dataset("wikipedia", "20200501.en", split="train", cache_dir=data_path, beam_runner='DirectRunner')
#dataset = load_dataset('wikipedia', '20200501.sv', cache_dir=data_path, beam_runner='DirectRunner')
```
Th... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1225851?v=4",
"events_url": "https://api.github.com/users/sebastiantomac/events{/privacy}",
"followers_url": "https://api.github.com/users/sebastiantomac/followers",
"following_url": "https://api.github.com/users/sebastiantomac/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/508/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/508/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4522 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4522/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4522/comments | https://api.github.com/repos/huggingface/datasets/issues/4522/events | https://github.com/huggingface/datasets/issues/4522 | 1,274,929,328 | I_kwDODunzps5L_eCw | 4,522 | Try to reduce the number of datasets that require manual download | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [] | open | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [] | 2022-06-17T11:42:03Z | 2022-06-17T11:52:48Z | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | COLLABORATOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | > Currently, 41 canonical datasets require manual download. I checked their scripts and I'm pretty sure this number can be reduced to ≈ 30 by not relying on bash scripts to download data, hosting data directly on the Hub when the license permits, etc. Then, we will mostly be left with datasets with restricted access, w... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4522/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4522/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6203 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6203/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6203/comments | https://api.github.com/repos/huggingface/datasets/issues/6203/events | https://github.com/huggingface/datasets/issues/6203 | 1,877,491,602 | I_kwDODunzps5v6D-S | 6,203 | Support loading from a DVC remote repository | {
"avatar_url": "https://avatars.githubusercontent.com/u/16692099?v=4",
"events_url": "https://api.github.com/users/bilelomrani1/events{/privacy}",
"followers_url": "https://api.github.com/users/bilelomrani1/followers",
"following_url": "https://api.github.com/users/bilelomrani1/following{/other_user}",
"gist... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"(cross-posting from the linked DVC issue)\r\n\r\nI think this should already work out of the box with the current `datasets` and `dvc.api` releases by passing the correct `storage_options` into the datasets calls. `storage_options` is essentially just the kwargs dict that gets passed to the fsspec fs constructor.\... | 2023-09-01T14:04:52Z | 2023-09-15T15:11:27Z | 2023-09-15T15:11:27Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Adding support for loading a file from a DVC repository, tracked remotely on a SCM.
### Motivation
DVC is a popular version control system to version and manage datasets. The files are stored on a remote object storage platform, but they are tracked using Git. Integration with DVC is possible thr... | {
"avatar_url": "https://avatars.githubusercontent.com/u/16692099?v=4",
"events_url": "https://api.github.com/users/bilelomrani1/events{/privacy}",
"followers_url": "https://api.github.com/users/bilelomrani1/followers",
"following_url": "https://api.github.com/users/bilelomrani1/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6203/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6203/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5896 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5896/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5896/comments | https://api.github.com/repos/huggingface/datasets/issues/5896/events | https://github.com/huggingface/datasets/issues/5896 | 1,726,022,500 | I_kwDODunzps5m4QNk | 5,896 | HuggingFace does not cache downloaded files aggressively/early enough | {
"avatar_url": "https://avatars.githubusercontent.com/u/2124157?v=4",
"events_url": "https://api.github.com/users/jack-jjm/events{/privacy}",
"followers_url": "https://api.github.com/users/jack-jjm/followers",
"following_url": "https://api.github.com/users/jack-jjm/following{/other_user}",
"gists_url": "http... | [] | closed | false | [] | null | [
"I also faced this. Any update?",
"We've dropped the `apache-beam` dependency in https://huggingface.co/datasets/wikipedia/discussions/19, so you should no longer get this error."
] | 2023-05-25T15:14:36Z | 2024-03-15T15:36:07Z | 2024-03-15T15:36:07Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I wrote the following script:
```
import datasets
dataset = datasets.load.load_dataset("wikipedia", "20220301.en", split="train[:10000]")
```
I ran it and spent 90 minutes downloading a 20GB file. Then I saw:
```
Downloading: 100%|████████████████████████████████████████████████████... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5896/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5896/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3227 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3227/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3227/comments | https://api.github.com/repos/huggingface/datasets/issues/3227/events | https://github.com/huggingface/datasets/issues/3227 | 1,046,667,845 | I_kwDODunzps4-YuJF | 3,227 | Error in `Json(datasets.ArrowBasedBuilder)` class | {
"avatar_url": "https://avatars.githubusercontent.com/u/7796965?v=4",
"events_url": "https://api.github.com/users/JunShern/events{/privacy}",
"followers_url": "https://api.github.com/users/JunShern/followers",
"following_url": "https://api.github.com/users/JunShern/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"I have additionally identified the source of the error, being that [this condition](https://github.com/huggingface/datasets/blob/fc46bba66ba4f432cc10501c16a677112e13984c/src/datasets/packaged_modules/json/json.py#L124-L126) in the file\r\n`python3.8/site-packages/datasets/packaged_modules/json/json.py` is not bein... | 2021-11-07T05:50:32Z | 2021-11-09T19:09:15Z | 2021-11-09T19:09:15Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
When a json file contains a `text` field that is larger than the block_size, the JSON dataset builder fails.
## Steps to reproduce the bug
Create a folder that contains the following:
```
.
├── testdata
│ └── mydata.json
└── test.py
```
Please download [this file](https://github.com/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/7796965?v=4",
"events_url": "https://api.github.com/users/JunShern/events{/privacy}",
"followers_url": "https://api.github.com/users/JunShern/followers",
"following_url": "https://api.github.com/users/JunShern/following{/other_user}",
"gists_url": "http... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3227/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3227/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7425/comments | https://api.github.com/repos/huggingface/datasets/issues/7425/events | https://github.com/huggingface/datasets/issues/7425 | 2,883,684,686 | I_kwDODunzps6r4YlO | 7,425 | load_dataset("livecodebench/code_generation_lite", version_tag="release_v2") TypeError: 'NoneType' object is not callable | {
"avatar_url": "https://avatars.githubusercontent.com/u/42167236?v=4",
"events_url": "https://api.github.com/users/dshwei/events{/privacy}",
"followers_url": "https://api.github.com/users/dshwei/followers",
"following_url": "https://api.github.com/users/dshwei/following{/other_user}",
"gists_url": "https://a... | [] | open | false | [] | null | [
"> datasets\n\nHi, have you solved this bug? Today I also met the same problem about `livecodebench/code_generation_lite` when evaluating the `Open-R1` repo. I am looking forward to your reply!\n\n",
"Hey guys,\nI tried to re... | 2025-02-27T07:36:02Z | 2025-03-27T05:05:33Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
from datasets import load_dataset
lcb_codegen = load_dataset("livecodebench/code_generation_lite", version_tag="release_v2")
or
configs = get_dataset_config_names("livecodebench/code_generation_lite", trust_remote_code=True)
both error:
Traceback (most recent call last):
File "", line 1, in
File... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7425/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7425/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/2629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2629/comments | https://api.github.com/repos/huggingface/datasets/issues/2629/events | https://github.com/huggingface/datasets/issues/2629 | 941,819,205 | MDU6SXNzdWU5NDE4MTkyMDU= | 2,629 | Load datasets from the Hub without requiring a dataset script | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"This is so cool, let us know if we can help with anything on the hub side (@Pierrci @elishowk) 🎉 "
] | 2021-07-12T08:45:17Z | 2021-08-25T14:18:08Z | 2021-08-25T14:18:08Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | As a user I would like to be able to upload my csv/json/text/parquet/etc. files in a dataset repository on the Hugging Face Hub and be able to load this dataset with `load_dataset` without having to implement a dataset script.
Moreover I would like to be able to specify which file goes into which split using the `da... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 7,
"hooray": 2,
"laugh": 0,
"rocket": 2,
"total_count": 11,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2629/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2629/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4053 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4053/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4053/comments | https://api.github.com/repos/huggingface/datasets/issues/4053/events | https://github.com/huggingface/datasets/issues/4053 | 1,184,500,378 | I_kwDODunzps5Gmgqa | 4,053 | Modify datatype from `int32` to `float` for pearsonr, spearmanr. | {
"avatar_url": "https://avatars.githubusercontent.com/u/86637320?v=4",
"events_url": "https://api.github.com/users/woodywarhol9/events{/privacy}",
"followers_url": "https://api.github.com/users/woodywarhol9/followers",
"following_url": "https://api.github.com/users/woodywarhol9/following{/other_user}",
"gist... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"@Woodywarhol9 good catch, thanks for reporting.\r\n\r\nWe are fixing this."
] | 2022-03-29T08:27:41Z | 2022-03-29T14:02:20Z | 2022-03-29T14:02:20Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | **Is your feature request related to a problem? Please describe.**
- Now [Pearsonr](https://github.com/huggingface/datasets/blob/master/metrics/pearsonr/pearsonr.py) and [Spearmanr](https://github.com/huggingface/datasets/blob/master/metrics/spearmanr/spearmanr.py) both get input data as 'int32'.
**Describe the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4053/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4053/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5959 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5959/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5959/comments | https://api.github.com/repos/huggingface/datasets/issues/5959/events | https://github.com/huggingface/datasets/issues/5959 | 1,757,397,507 | I_kwDODunzps5ov8ID | 5,959 | read metric glue.py from local file | {
"avatar_url": "https://avatars.githubusercontent.com/u/31148397?v=4",
"events_url": "https://api.github.com/users/JiazhaoLi/events{/privacy}",
"followers_url": "https://api.github.com/users/JiazhaoLi/followers",
"following_url": "https://api.github.com/users/JiazhaoLi/following{/other_user}",
"gists_url": "... | [] | closed | false | [] | null | [
"Sorry, I solve this by call `evaluate.load('glue_metric.py','sst-2')`\r\n"
] | 2023-06-14T17:59:35Z | 2023-06-14T18:04:16Z | 2023-06-14T18:04:16Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Currently, The server is off-line. I am using the glue metric from the local file downloaded from the hub.
I download / cached datasets using `load_dataset('glue','sst2', cache_dir='/xxx')` to cache them and then in the off-line mode, I use `load_dataset('xxx/glue.py','sst2', cache_dir='/xxx'... | {
"avatar_url": "https://avatars.githubusercontent.com/u/31148397?v=4",
"events_url": "https://api.github.com/users/JiazhaoLi/events{/privacy}",
"followers_url": "https://api.github.com/users/JiazhaoLi/followers",
"following_url": "https://api.github.com/users/JiazhaoLi/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5959/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5959/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/373/comments | https://api.github.com/repos/huggingface/datasets/issues/373/events | https://github.com/huggingface/datasets/issues/373 | 654,845,133 | MDU6SXNzdWU2NTQ4NDUxMzM= | 373 | Segmentation fault when loading local JSON dataset as of #372 | {
"avatar_url": "https://avatars.githubusercontent.com/u/24683907?v=4",
"events_url": "https://api.github.com/users/vegarab/events{/privacy}",
"followers_url": "https://api.github.com/users/vegarab/followers",
"following_url": "https://api.github.com/users/vegarab/following{/other_user}",
"gists_url": "https:... | [] | closed | false | [] | null | [
"I've seen this sort of thing before -- it might help to delete the directory -- I've also noticed that there is an error with the json Dataloader for any data I've tried to load. I've replaced it with this, which skips over the data feature population step:\r\n\r\n\r\n```python\r\nimport os\r\n\r\nimport pyarrow.j... | 2020-07-10T15:04:25Z | 2022-10-04T18:05:47Z | 2022-10-04T18:05:47Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | The last issue was closed (#369) once the #372 update was merged. However, I'm still not able to load a SQuAD formatted JSON file. Instead of the previously recorded pyarrow error, I now get a segmentation fault.
```
dataset = nlp.load_dataset('json', data_files={nlp.Split.TRAIN: ["./datasets/train-v2.0.json"]}, f... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/373/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/373/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7497 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7497/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7497/comments | https://api.github.com/repos/huggingface/datasets/issues/7497/events | https://github.com/huggingface/datasets/issues/7497 | 2,968,553,693 | I_kwDODunzps6w8Ijd | 7,497 | How to convert videos to images? | {
"avatar_url": "https://avatars.githubusercontent.com/u/171649931?v=4",
"events_url": "https://api.github.com/users/Loki-Lu/events{/privacy}",
"followers_url": "https://api.github.com/users/Loki-Lu/followers",
"following_url": "https://api.github.com/users/Loki-Lu/following{/other_user}",
"gists_url": "https... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [
"Hi ! there is some documentation here on how to read video frames: https://huggingface.co/docs/datasets/video_load"
] | 2025-04-03T07:08:39Z | 2025-04-15T12:35:15Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Does someone know how to return the images from videos?
### Motivation
I am trying to use openpi(https://github.com/Physical-Intelligence/openpi) to finetune my Lerobot dataset(V2.0 and V2.1). I find that although the codedaset is v2.0, they are different. It seems like Lerobot V2.0 has two versi... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7497/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7497/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/1994 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1994/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1994/comments | https://api.github.com/repos/huggingface/datasets/issues/1994/events | https://github.com/huggingface/datasets/issues/1994 | 822,871,238 | MDU6SXNzdWU4MjI4NzEyMzg= | 1,994 | not being able to get wikipedia es language | {
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url"... | [] | open | false | [] | null | [
"@lhoestq I really appreciate if you could help me providiing processed datasets, I do not really have access to enough resources to run the apache-beam and need to run the codes on these datasets. Only en/de/fr currently works, but I need all the languages more or less. thanks ",
"Hi @dorost1234, I think I can ... | 2021-03-05T08:31:48Z | 2021-03-11T20:46:21Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi
I am trying to run a code with wikipedia of config 20200501.es, getting:
Traceback (most recent call last):
File "run_mlm_t5.py", line 608, in <module>
main()
File "run_mlm_t5.py", line 359, in main
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
File "/dara/libs... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1994/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1994/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7467 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7467/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7467/comments | https://api.github.com/repos/huggingface/datasets/issues/7467/events | https://github.com/huggingface/datasets/issues/7467 | 2,930,067,107 | I_kwDODunzps6upUaj | 7,467 | load_dataset with streaming hangs on parquet datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/10550252?v=4",
"events_url": "https://api.github.com/users/The0nix/events{/privacy}",
"followers_url": "https://api.github.com/users/The0nix/followers",
"following_url": "https://api.github.com/users/The0nix/following{/other_user}",
"gists_url": "https:... | [] | closed | false | [] | null | [
"Hi ! The issue comes from `pyarrow`, I reported it here: https://github.com/apache/arrow/issues/45214 (feel free to comment / thumb up).\n\nAlternatively we can try to find something else than `ParquetFileFragment.to_batches()` to iterate on Parquet data and keep the option the pass `filters=`...",
"I pushed a w... | 2025-03-18T23:33:54Z | 2026-05-06T16:07:14Z | 2026-05-06T16:06:09Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When I try to load a dataset with parquet files (e.g. "bigcode/the-stack") the dataset loads, but python interpreter can't exit and hangs
### Steps to reproduce the bug
```python3
import datasets
print('Start')
dataset = datasets.load_dataset("bigcode/the-stack", data_dir="data/yaml", streaming... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7467/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7467/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1728 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1728/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1728/comments | https://api.github.com/repos/huggingface/datasets/issues/1728/events | https://github.com/huggingface/datasets/issues/1728 | 784,458,342 | MDU6SXNzdWU3ODQ0NTgzNDI= | 1,728 | Add an entry to an arrow dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/18645407?v=4",
"events_url": "https://api.github.com/users/ameet-1997/events{/privacy}",
"followers_url": "https://api.github.com/users/ameet-1997/followers",
"following_url": "https://api.github.com/users/ameet-1997/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"Hi @ameet-1997,\r\nI think what you are looking for is the `concatenate_datasets` function: https://huggingface.co/docs/datasets/processing.html?highlight=concatenate#concatenate-several-datasets\r\n\r\nFor your use case, I would use the [`map` method](https://huggingface.co/docs/datasets/processing.html?highlight... | 2021-01-12T18:01:47Z | 2021-01-18T19:15:32Z | 2021-01-18T19:15:32Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Is it possible to add an entry to a dataset object?
**Motivation: I want to transform the sentences in the dataset and add them to the original dataset**
For example, say we have the following code:
``` python
from datasets import load_dataset
# Load a dataset and print the first examples in the training s... | {
"avatar_url": "https://avatars.githubusercontent.com/u/18645407?v=4",
"events_url": "https://api.github.com/users/ameet-1997/events{/privacy}",
"followers_url": "https://api.github.com/users/ameet-1997/followers",
"following_url": "https://api.github.com/users/ameet-1997/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1728/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1728/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2250 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2250/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2250/comments | https://api.github.com/repos/huggingface/datasets/issues/2250/events | https://github.com/huggingface/datasets/issues/2250 | 865,402,449 | MDU6SXNzdWU4NjU0MDI0NDk= | 2,250 | some issue in loading local txt file as Dataset for run_mlm.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/14968123?v=4",
"events_url": "https://api.github.com/users/alighofrani95/events{/privacy}",
"followers_url": "https://api.github.com/users/alighofrani95/followers",
"following_url": "https://api.github.com/users/alighofrani95/following{/other_user}",
"g... | [] | closed | false | [] | null | [
"Hi,\r\n\r\n1. try\r\n ```python\r\n dataset = load_dataset(\"text\", data_files={\"train\": [\"a1.txt\", \"b1.txt\"], \"test\": [\"c1.txt\"]})\r\n ```\r\n instead.\r\n\r\n Sadly, I can't reproduce the error on my machine. If the above code doesn't resolve the issue, try to update the library to the ... | 2021-04-22T19:39:13Z | 2022-03-30T08:29:47Z | 2022-03-30T08:29:47Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | 
first of all, I tried to load 3 .txt files as a dataset (sure that the directory and permission is OK.), I face with the below error.
> FileNotFoundError: [Errno 2] No such file or directory: 'c'
by ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2250/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2250/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6752 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6752/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6752/comments | https://api.github.com/repos/huggingface/datasets/issues/6752/events | https://github.com/huggingface/datasets/issues/6752 | 2,204,043,839 | I_kwDODunzps6DXwo_ | 6,752 | Precision being changed from float16 to float32 unexpectedly | {
"avatar_url": "https://avatars.githubusercontent.com/u/21228908?v=4",
"events_url": "https://api.github.com/users/gcervantes8/events{/privacy}",
"followers_url": "https://api.github.com/users/gcervantes8/followers",
"following_url": "https://api.github.com/users/gcervantes8/following{/other_user}",
"gists_u... | [] | open | false | [] | null | [
"This is because of the formatter (`torch` in this case).\r\nIt defaults to `float32`.\r\n\r\nYou can load it in `float16` using `dataset.set_format(\"torch\", dtype=torch.float16)`.",
"I am having a similar issue when _building_ a dataset given `float16`-valued data.\n\n```py\nfrom datasets import Features, Valu... | 2024-03-23T20:53:56Z | 2025-11-04T22:40:01Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I'm loading a HuggingFace Dataset for images.
I'm running a preprocessing (map operation) step that runs a few operations, one of them being conversion to float16. The Dataset features also say that the 'img' is of type float16. Whenever I take an image from that HuggingFace Dataset instance... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6752/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6752/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3186 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3186/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3186/comments | https://api.github.com/repos/huggingface/datasets/issues/3186/events | https://github.com/huggingface/datasets/issues/3186 | 1,040,369,397 | I_kwDODunzps4-Asb1 | 3,186 | Dataset viewer for nli_tr | {
"avatar_url": "https://avatars.githubusercontent.com/u/2246791?v=4",
"events_url": "https://api.github.com/users/e-budur/events{/privacy}",
"followers_url": "https://api.github.com/users/e-budur/followers",
"following_url": "https://api.github.com/users/e-budur/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"It's an issue with the streaming mode:\r\n\r\n```python\r\n>>> import datasets\r\n>>> dataset = datasets.load_dataset('nli_tr', name='snli_tr',split='test', streaming=True)\r\n>>> next(iter(dataset))\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/slesage/hf/datas... | 2021-10-31T03:56:33Z | 2022-09-12T09:15:34Z | 2022-09-12T08:43:09Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Dataset viewer issue for '*nli_tr*'
**Link:** https://huggingface.co/datasets/nli_tr
Hello,
Thank you for the new dataset preview feature that will help the users to view the datasets online.
We just noticed that the dataset viewer widget in the `nli_tr` dataset shows the error below. The error must be d... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3186/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3186/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5829 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5829/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5829/comments | https://api.github.com/repos/huggingface/datasets/issues/5829/events | https://github.com/huggingface/datasets/issues/5829 | 1,699,958,189 | I_kwDODunzps5lU02t | 5,829 | (mach-o file, but is an incompatible architecture (have 'arm64', need 'x86_64')) | {
"avatar_url": "https://avatars.githubusercontent.com/u/18206728?v=4",
"events_url": "https://api.github.com/users/elcolie/events{/privacy}",
"followers_url": "https://api.github.com/users/elcolie/followers",
"following_url": "https://api.github.com/users/elcolie/following{/other_user}",
"gists_url": "https:... | [] | closed | false | [] | null | [
"Can you paste the error stack trace?",
"That is weird. I can't reproduce it again after reboot.\r\n```python\r\nIn [2]: import platform\r\n\r\nIn [3]: platform.platform()\r\nOut[3]: 'macOS-13.2-arm64-arm-64bit'\r\n\r\nIn [4]: from datasets import load_dataset\r\n ...:\r\n ...: jazzy = load_dataset(\"nomic-ai... | 2023-05-08T10:07:14Z | 2023-06-30T11:39:14Z | 2023-05-09T00:46:42Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
M2 MBP can't run
```python
from datasets import load_dataset
jazzy = load_dataset("nomic-ai/gpt4all-j-prompt-generations", revision='v1.2-jazzy')
```
### Steps to reproduce the bug
1. Use M2 MBP
2. Python 3.10.10 from pyenv
3. Run
```
from datasets import load_dataset
jazzy = load_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/18206728?v=4",
"events_url": "https://api.github.com/users/elcolie/events{/privacy}",
"followers_url": "https://api.github.com/users/elcolie/followers",
"following_url": "https://api.github.com/users/elcolie/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5829/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5829/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2036 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2036/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2036/comments | https://api.github.com/repos/huggingface/datasets/issues/2036/events | https://github.com/huggingface/datasets/issues/2036 | 829,909,258 | MDU6SXNzdWU4Mjk5MDkyNTg= | 2,036 | Cannot load wikitext | {
"avatar_url": "https://avatars.githubusercontent.com/u/19349207?v=4",
"events_url": "https://api.github.com/users/Gpwner/events{/privacy}",
"followers_url": "https://api.github.com/users/Gpwner/followers",
"following_url": "https://api.github.com/users/Gpwner/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | [] | null | [
"Solved!"
] | 2021-03-12T09:09:39Z | 2021-03-15T08:45:02Z | 2021-03-15T08:44:44Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | when I execute these codes
```
>>> from datasets import load_dataset
>>> test_dataset = load_dataset("wikitext")
```
I got an error,any help?
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/xxx/anaconda3/envs/transformer/lib/python3.7/site-packages/datasets/load.p... | {
"avatar_url": "https://avatars.githubusercontent.com/u/19349207?v=4",
"events_url": "https://api.github.com/users/Gpwner/events{/privacy}",
"followers_url": "https://api.github.com/users/Gpwner/followers",
"following_url": "https://api.github.com/users/Gpwner/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2036/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2036/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7102 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7102/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7102/comments | https://api.github.com/repos/huggingface/datasets/issues/7102/events | https://github.com/huggingface/datasets/issues/7102 | 2,466,893,106 | I_kwDODunzps6TCc0y | 7,102 | Slow iteration speeds when using IterableDataset.shuffle with load_dataset(data_files=..., streaming=True) | {
"avatar_url": "https://avatars.githubusercontent.com/u/13192126?v=4",
"events_url": "https://api.github.com/users/lajd/events{/privacy}",
"followers_url": "https://api.github.com/users/lajd/followers",
"following_url": "https://api.github.com/users/lajd/following{/other_user}",
"gists_url": "https://api.git... | [] | open | false | [] | null | [
"Hi @lajd , I was skeptical about how we are saving the shards each as their own dataset (arrow file) in the script above, and so I updated the script to try out saving the shards in a few different file formats. From the experiments I ran, I saw binary format show significantly the best performance, with arrow a... | 2024-08-14T21:44:44Z | 2024-08-15T16:17:31Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When I load a dataset from a number of arrow files, as in:
```
random_dataset = load_dataset(
"arrow",
data_files={split: shard_filepaths},
streaming=True,
split=split,
)
```
I'm able to get fast iteration speeds when iterating over the dataset without shuffling.
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7102/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7102/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6086 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6086/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6086/comments | https://api.github.com/repos/huggingface/datasets/issues/6086/events | https://github.com/huggingface/datasets/issues/6086 | 1,825,009,268 | I_kwDODunzps5sx250 | 6,086 | Support `fsspec` in `Dataset.to_<format>` methods | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}"... | null | [
"Hi @mariosasko unless someone's already working on it, I guess I can tackle it!",
"Hi! Sure, feel free to tackle this.",
"#self-assign",
"I'm assuming this should just cover `to_csv`, `to_parquet`, and `to_json`, right? As `to_list` and `to_dict` just return Python objects, `to_pandas` returns a `pandas.Data... | 2023-07-27T19:08:37Z | 2024-03-07T07:22:43Z | 2024-03-07T07:22:42Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | COLLABORATOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Supporting this should be fairly easy.
Requested on the forum [here](https://discuss.huggingface.co/t/how-can-i-convert-a-loaded-dataset-in-to-a-parquet-file-and-save-it-to-the-s3/48353). | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6086/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6086/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3333 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3333/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3333/comments | https://api.github.com/repos/huggingface/datasets/issues/3333/events | https://github.com/huggingface/datasets/issues/3333 | 1,065,346,919 | I_kwDODunzps4_f-dn | 3,333 | load JSON files, get the errors | {
"avatar_url": "https://avatars.githubusercontent.com/u/38966558?v=4",
"events_url": "https://api.github.com/users/PatricYan/events{/privacy}",
"followers_url": "https://api.github.com/users/PatricYan/followers",
"following_url": "https://api.github.com/users/PatricYan/following{/other_user}",
"gists_url": "... | [] | closed | false | [] | null | [
"Hi ! The message you're getting is not an error. It simply says that your JSON dataset is being prepared to a location in `/root/.cache/huggingface/datasets`",
"> \r\n\r\nbut I want to load local JSON file by command\r\n`python3 run.py --do_train --task qa --dataset squad-retrain-data/train-v2.0.json --output_di... | 2021-11-28T14:29:58Z | 2021-12-01T09:34:31Z | 2021-12-01T03:57:48Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi, does this bug be fixed? when I load JSON files, I get the same errors by the command
`!python3 run.py --do_train --task qa --dataset squad-retrain-data/train-v2.0.json --output_dir ./re_trained_model/`
change the dateset to load json by refering to https://huggingface.co/docs/datasets/loading.html
`dataset = ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/38966558?v=4",
"events_url": "https://api.github.com/users/PatricYan/events{/privacy}",
"followers_url": "https://api.github.com/users/PatricYan/followers",
"following_url": "https://api.github.com/users/PatricYan/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3333/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3333/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3580/comments | https://api.github.com/repos/huggingface/datasets/issues/3580/events | https://github.com/huggingface/datasets/issues/3580 | 1,104,663,242 | I_kwDODunzps5B19LK | 3,580 | Bug in wiki bio load | {
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"events_url": "https://api.github.com/users/tuhinjubcse/events{/privacy}",
"followers_url": "https://api.github.com/users/tuhinjubcse/followers",
"following_url": "https://api.github.com/users/tuhinjubcse/following{/other_user}",
"gists_ur... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | [] | null | [
"+1, here's the error I got: \r\n\r\n```\r\n>>> from datasets import load_dataset\r\n>>>\r\n>>> load_dataset(\"wiki_bio\")\r\nDownloading: 7.58kB [00:00, 4.42MB/s]\r\nDownloading: 2.71kB [00:00, 1.30MB/s]\r\nUsing custom data configuration default\r\nDownloading and preparing dataset wiki_bio/default (download: 318... | 2022-01-15T10:04:33Z | 2022-01-31T08:38:09Z | 2022-01-31T08:38:09Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
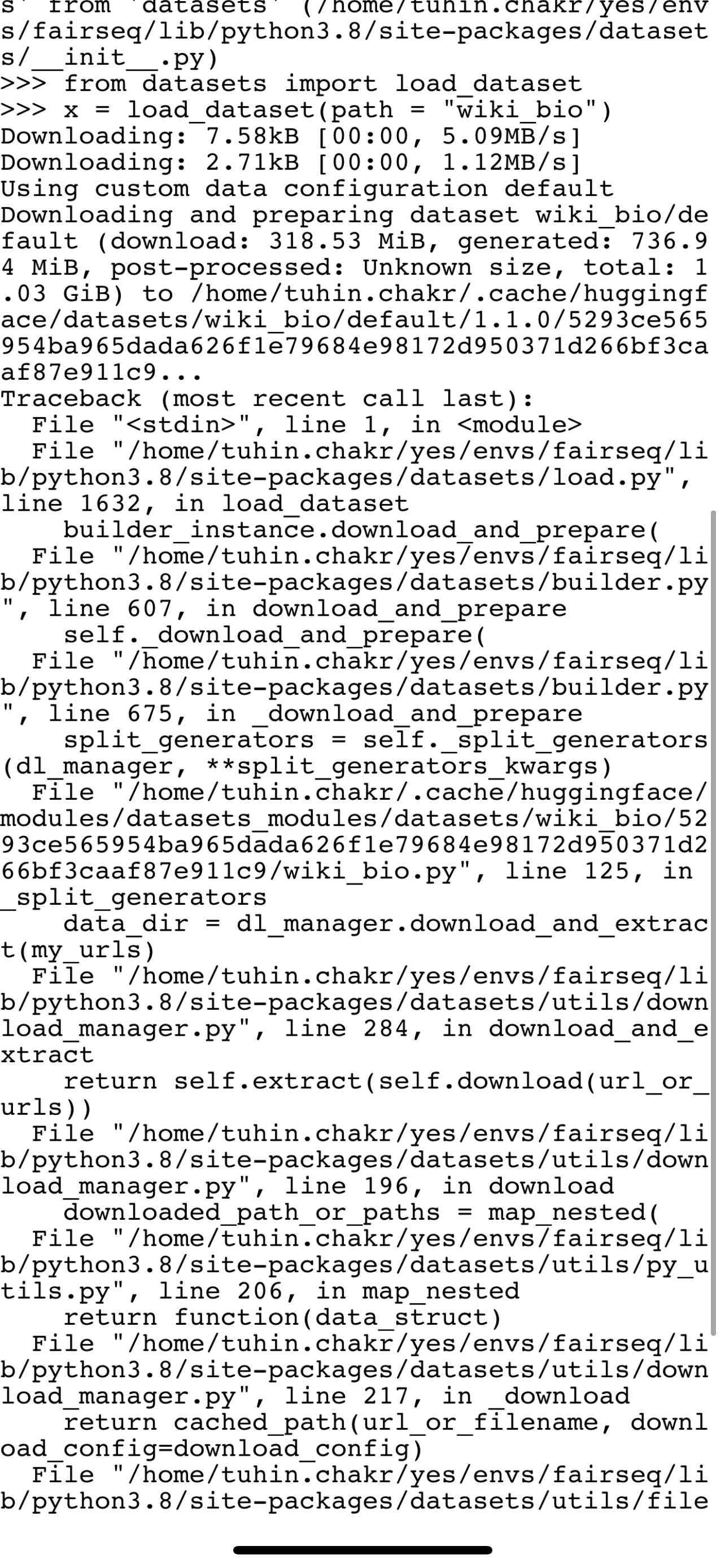
 does not support tsv | {
"avatar_url": "https://avatars.githubusercontent.com/u/26873178?v=4",
"events_url": "https://api.github.com/users/dipsivenkatesh/events{/privacy}",
"followers_url": "https://api.github.com/users/dipsivenkatesh/followers",
"following_url": "https://api.github.com/users/dipsivenkatesh/following{/other_user}",
... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/77767961?v=4",
"events_url": "https://api.github.com/users/harsh1504660/events{/privacy}",
"followers_url": "https://api.github.com/users/harsh1504660/followers",
"following_url": "https://api.github.com/users/harsh1504660/following{/other_use... | null | [
"#self-assign",
"Hi @dipsivenkatesh,\r\n\r\nPlease note that this functionality is already implemented. Our CSV builder uses `pandas.read_csv` under the hood, and you can pass the parameter `delimiter=\"\\t\"` to read TSV files.\r\n\r\nSee the list of CSV config parameters in our docs: https://huggingface.co/docs... | 2024-02-24T05:56:04Z | 2024-02-26T07:15:07Z | 2024-02-26T07:09:35Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/77767961?v=4",
"events_url": "https://api.github.com/users/harsh1504660/events{/privacy}",
"followers_url": "https://api.github.com/users/harsh1504660/followers",
"following_url": "https://api.github.com/users/harsh1504660/following{/other_user}",
"gist... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
the load_dataset() for local functions support file types like csv, json etc but not of type tsv (tab separated values).
### Motivation
cant easily load files of type tsv, have to convert them to another type like csv then load
### Your contribution
Can try by raising a PR with a little help, c... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6691/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6691/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7686/comments | https://api.github.com/repos/huggingface/datasets/issues/7686/events | https://github.com/huggingface/datasets/issues/7686 | 3,237,201,090 | I_kwDODunzps7A88TC | 7,686 | load_dataset does not check .no_exist files in the hub cache | {
"avatar_url": "https://avatars.githubusercontent.com/u/3627235?v=4",
"events_url": "https://api.github.com/users/jmaccarl/events{/privacy}",
"followers_url": "https://api.github.com/users/jmaccarl/followers",
"following_url": "https://api.github.com/users/jmaccarl/following{/other_user}",
"gists_url": "http... | [] | open | false | [] | null | [] | 2025-07-16T20:04:00Z | 2025-07-16T20:04:00Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I'm not entirely sure if this should be submitted as a bug in the `datasets` library or the `huggingface_hub` library, given it could be fixed at different levels of the stack.
The fundamental issue is that the `load_datasets` api doesn't use the `.no_exist` files in the hub cache unlike other wr... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7686/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7686/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7832 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7832/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7832/comments | https://api.github.com/repos/huggingface/datasets/issues/7832/events | https://github.com/huggingface/datasets/issues/7832 | 3,555,991,552 | I_kwDODunzps7T9CAA | 7,832 | [DOCS][minor] TIPS paragraph not compiled in docs/stream | {
"avatar_url": "https://avatars.githubusercontent.com/u/110672812?v=4",
"events_url": "https://api.github.com/users/art-test-stack/events{/privacy}",
"followers_url": "https://api.github.com/users/art-test-stack/followers",
"following_url": "https://api.github.com/users/art-test-stack/following{/other_user}",
... | [] | closed | false | [] | null | [] | 2025-10-27T10:03:22Z | 2025-10-27T10:10:54Z | 2025-10-27T10:10:54Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | In the client documentation, the markdown 'TIP' paragraph for paragraph in docs/stream#shuffle is not well executed — not as the other in the same page / while markdown is correctly considering it.
Documentation:
https://huggingface.co/docs/datasets/v4.3.0/en/stream#shuffle:~:text=%5B!TIP%5D%5BIterableDataset.shuffle(... | {
"avatar_url": "https://avatars.githubusercontent.com/u/110672812?v=4",
"events_url": "https://api.github.com/users/art-test-stack/events{/privacy}",
"followers_url": "https://api.github.com/users/art-test-stack/followers",
"following_url": "https://api.github.com/users/art-test-stack/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7832/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7832/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4052 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4052/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4052/comments | https://api.github.com/repos/huggingface/datasets/issues/4052/events | https://github.com/huggingface/datasets/issues/4052 | 1,184,447,977 | I_kwDODunzps5GmT3p | 4,052 | metric = metric_cls( TypeError: 'NoneType' object is not callable | {
"avatar_url": "https://avatars.githubusercontent.com/u/39409233?v=4",
"events_url": "https://api.github.com/users/klyuhang9/events{/privacy}",
"followers_url": "https://api.github.com/users/klyuhang9/followers",
"following_url": "https://api.github.com/users/klyuhang9/following{/other_user}",
"gists_url": "... | [] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @klyuhang9,\r\n\r\nI'm sorry but I can't reproduce your problem:\r\n```python\r\nIn [2]: metric = load_metric('glue', 'rte')\r\nDownloading builder script: 5.76kB [00:00, 2.40MB/s]\r\n```\r\n\r\nCould you please, retry to load the metric? Sometimes there are temporary connectivity issues.\r\n\r\nFeel free to re... | 2022-03-29T07:43:08Z | 2022-03-29T14:06:01Z | 2022-03-29T14:06:01Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi, friend. I meet a problem.
When I run the code:
`metric = load_metric('glue', 'rte')`
There is a problem raising:
`metric = metric_cls(
TypeError: 'NoneType' object is not callable `
I don't know why. Thanks for your help!
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4052/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4052/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6169 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6169/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6169/comments | https://api.github.com/repos/huggingface/datasets/issues/6169/events | https://github.com/huggingface/datasets/issues/6169 | 1,862,360,199 | I_kwDODunzps5vAVyH | 6,169 | Configurations in yaml not working | {
"avatar_url": "https://avatars.githubusercontent.com/u/45085098?v=4",
"events_url": "https://api.github.com/users/tsor13/events{/privacy}",
"followers_url": "https://api.github.com/users/tsor13/followers",
"following_url": "https://api.github.com/users/tsor13/following{/other_user}",
"gists_url": "https://a... | [] | open | false | [] | null | [
"Unfortunately, I cannot reproduce this behavior on my machine or Colab - the reproducer returns `['main_data', 'additional_data']` as expected.",
"Thank you for looking into this, Mario. Is this on [my repository](https://huggingface.co/datasets/tsor13/test), or on another one that you have reproduced? Would you... | 2023-08-23T00:13:22Z | 2023-08-23T15:35:31Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Dataset configurations cannot be created in YAML/README
Hello! I'm trying to follow the docs here in order to create structure in my dataset as added from here (#5331): https://github.com/huggingface/datasets/blob/8b8e6ee067eb74e7965ca2a6768f15f9398cb7c8/docs/source/repository_structure.mdx#L110-L118
I have t... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6169/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6169/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5717 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5717/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5717/comments | https://api.github.com/repos/huggingface/datasets/issues/5717/events | https://github.com/huggingface/datasets/issues/5717 | 1,658,729,866 | I_kwDODunzps5i3jWK | 5,717 | Errror when saving to disk a dataset of images | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.githu... | [] | open | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Looks like as long as the number of shards makes a batch lower than 1000 images it works. In my training set I have 40K images. If I use `num_shards=40` (batch of 1000 images) I get the error, but if I update it to `num_shards=50` (batch of 800 images) it works.\r\n\r\nI will be happy to share my dataset privately... | 2023-04-07T11:59:17Z | 2025-07-13T08:27:47Z | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
Hello!
I have an issue when I try to save on disk my dataset of images. The error I get is:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 1442, in save_... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5717/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5717/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6439 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6439/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6439/comments | https://api.github.com/repos/huggingface/datasets/issues/6439/events | https://github.com/huggingface/datasets/issues/6439 | 2,002,916,514 | I_kwDODunzps53YhSi | 6,439 | Download + preparation speed of datasets.load_dataset is 20x slower than huggingface hub snapshot and manual loding | {
"avatar_url": "https://avatars.githubusercontent.com/u/10792502?v=4",
"events_url": "https://api.github.com/users/AntreasAntoniou/events{/privacy}",
"followers_url": "https://api.github.com/users/AntreasAntoniou/followers",
"following_url": "https://api.github.com/users/AntreasAntoniou/following{/other_user}"... | [] | open | false | [] | null | [
"Hi Antreas, facing a similar type of bug, did you find any workaround?? "
] | 2023-11-20T20:07:23Z | 2025-12-17T09:49:21Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I am working with a dataset I am trying to publish.
The path is Antreas/TALI.
It's a fairly large dataset, and contains images, video, audio and text.
I have been having multiple problems when the dataset is being downloaded using the load_dataset function -- even with 64 workers takin... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6439/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6439/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3345 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3345/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3345/comments | https://api.github.com/repos/huggingface/datasets/issues/3345/events | https://github.com/huggingface/datasets/issues/3345 | 1,067,622,951 | I_kwDODunzps4_oqIn | 3,345 | Failed to download species_800 from Google Drive zip file | {
"avatar_url": "https://avatars.githubusercontent.com/u/4812544?v=4",
"events_url": "https://api.github.com/users/tianjianjiang/events{/privacy}",
"followers_url": "https://api.github.com/users/tianjianjiang/followers",
"following_url": "https://api.github.com/users/tianjianjiang/following{/other_user}",
"gi... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi,\r\n\r\nthe dataset is downloaded normally on my machine. Maybe the URL was down at the time of your download. Could you try again?",
"> Hi,\r\n> \r\n> the dataset is downloaded normally on my machine. Maybe the URL was down at the time of your download. Could you try again?\r\n\r\nI have tried that many time... | 2021-11-30T20:00:28Z | 2021-12-01T17:53:15Z | 2021-12-01T17:53:15Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
One can manually download the zip file on Google Drive, but `load_dataset()` cannot.
related: #3248
## Steps to reproduce the bug
```shell
> python
Python 3.7.12 (default, Sep 5 2021, 08:34:29)
[Clang 11.0.3 (clang-1103.0.32.62)] on darwin
Type "help", "copyright", "credits" or "license" ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4812544?v=4",
"events_url": "https://api.github.com/users/tianjianjiang/events{/privacy}",
"followers_url": "https://api.github.com/users/tianjianjiang/followers",
"following_url": "https://api.github.com/users/tianjianjiang/following{/other_user}",
"gi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3345/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3345/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6787 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6787/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6787/comments | https://api.github.com/repos/huggingface/datasets/issues/6787/events | https://github.com/huggingface/datasets/issues/6787 | 2,229,103,264 | I_kwDODunzps6E3Wqg | 6,787 | TimeoutError in map | {
"avatar_url": "https://avatars.githubusercontent.com/u/48146603?v=4",
"events_url": "https://api.github.com/users/Jiaxin-Wen/events{/privacy}",
"followers_url": "https://api.github.com/users/Jiaxin-Wen/followers",
"following_url": "https://api.github.com/users/Jiaxin-Wen/following{/other_user}",
"gists_url"... | [] | open | false | [] | null | [
"From my current understanding, this timeout is only used when we need to get the results.\r\n\r\nOne of:\r\n1. All tasks are done\r\n2. One worker died\r\n\r\nYour function should work fine and it's definitely a bug if it doesn't.",
"When one of the `map`'s worker processes crashes, the linked code re-raises an ... | 2024-04-06T06:25:39Z | 2024-08-14T02:09:57Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
```python
from datasets import Dataset
def worker(example):
while True:
continue
example['a'] = 100
return example
data = Dataset.from_list([{"a": 1}, {"a": 2}])
data = data.map(worker)
print(data[0])
```
I'm implementing a worker function whose runtime will de... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6787/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6787/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/2663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2663/comments | https://api.github.com/repos/huggingface/datasets/issues/2663/events | https://github.com/huggingface/datasets/issues/2663 | 946,552,273 | MDU6SXNzdWU5NDY1NTIyNzM= | 2,663 | [`to_json`] add multi-proc sharding support | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"Hi @stas00, \r\nI want to work on this issue and I was thinking why don't we use `imap` [in this loop](https://github.com/huggingface/datasets/blob/440b14d0dd428ae1b25881aa72ba7bbb8ad9ff84/src/datasets/io/json.py#L99)? This way, using offset (which is being used to slice the pyarrow table) we can convert pyarrow ... | 2021-07-16T19:41:50Z | 2021-09-13T13:56:37Z | 2021-09-13T13:56:37Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | As discussed on slack it appears that `to_json` is quite slow on huge datasets like OSCAR.
I implemented sharded saving, which is much much faster - but the tqdm bars all overwrite each other, so it's hard to make sense of the progress, so if possible ideally this multi-proc support could be implemented internally i... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2663/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2663/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4995 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4995/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4995/comments | https://api.github.com/repos/huggingface/datasets/issues/4995/events | https://github.com/huggingface/datasets/issues/4995 | 1,379,108,482 | I_kwDODunzps5SM4aC | 4,995 | Get a specific Exception when the dataset has no data | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "E5583E",
"default": fals... | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2022-09-20T09:31:59Z | 2022-09-21T12:21:25Z | 2022-09-21T12:21:25Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | COLLABORATOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | In the dataset viewer on the Hub (https://huggingface.co/datasets/glue/viewer), we would like (https://github.com/huggingface/moon-landing/issues/3882) to show a specific message when the repository lacks any data files.
In that case, instead of showing a complex traceback, we want to show a call to action to help t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4995/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4995/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1987 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1987/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1987/comments | https://api.github.com/repos/huggingface/datasets/issues/1987/events | https://github.com/huggingface/datasets/issues/1987 | 822,308,956 | MDU6SXNzdWU4MjIzMDg5NTY= | 1,987 | wmt15 is broken | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | [] | null | [
"It's reachable for the viewer and me, so I suppose it was down at that moment?"
] | 2021-03-04T16:46:25Z | 2022-10-05T13:12:26Z | 2022-10-05T13:12:26Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | While testing the hotfix, I tried a random other wmt release and found wmt15 to be broken:
```
python -c 'from datasets import load_dataset; load_dataset("wmt15", "de-en")'
Downloading: 2.91kB [00:00, 818kB/s]
Downloading: 3.02kB [00:00, 897kB/s]
Downloading: 41.1kB [00:00, 19.1MB/s]
Downloading and preparing da... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1987/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1987/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2645/comments | https://api.github.com/repos/huggingface/datasets/issues/2645/events | https://github.com/huggingface/datasets/issues/2645 | 944,374,284 | MDU6SXNzdWU5NDQzNzQyODQ= | 2,645 | load_dataset processing failed with OS error after downloading a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/40395156?v=4",
"events_url": "https://api.github.com/users/fake-warrior8/events{/privacy}",
"followers_url": "https://api.github.com/users/fake-warrior8/followers",
"following_url": "https://api.github.com/users/fake-warrior8/following{/other_user}",
"g... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi ! It looks like an issue with pytorch.\r\n\r\nCould you try to run `import torch` and see if it raises an error ?",
"> Hi ! It looks like an issue with pytorch.\r\n> \r\n> Could you try to run `import torch` and see if it raises an error ?\r\n\r\nIt works. Thank you!"
] | 2021-07-14T12:23:53Z | 2021-07-15T09:34:02Z | 2021-07-15T09:34:02Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
After downloading a dataset like opus100, there is a bug that
OSError: Cannot find data file.
Original error:
dlopen: cannot load any more object with static TLS
## Steps to reproduce the bug
```python
from datasets import load_dataset
this_dataset = load_dataset('opus100', 'af-en')
```
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/40395156?v=4",
"events_url": "https://api.github.com/users/fake-warrior8/events{/privacy}",
"followers_url": "https://api.github.com/users/fake-warrior8/followers",
"following_url": "https://api.github.com/users/fake-warrior8/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2645/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2645/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7739 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7739/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7739/comments | https://api.github.com/repos/huggingface/datasets/issues/7739/events | https://github.com/huggingface/datasets/issues/7739 | 3,331,537,762 | I_kwDODunzps7Gkzti | 7,739 | Replacement of "Sequence" feature with "List" breaks backward compatibility | {
"avatar_url": "https://avatars.githubusercontent.com/u/15764776?v=4",
"events_url": "https://api.github.com/users/evmaki/events{/privacy}",
"followers_url": "https://api.github.com/users/evmaki/followers",
"following_url": "https://api.github.com/users/evmaki/following{/other_user}",
"gists_url": "https://a... | [] | open | false | [] | null | [
"Backward compatibility here means 4.0.0 can load datasets saved with older versions.\n\nYou will need 4.0.0 to load datasets saved with 4.0.0"
] | 2025-08-18T17:28:38Z | 2025-09-10T14:17:50Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | PR #7634 replaced the Sequence feature with List in 4.0.0, so datasets saved with version 4.0.0 with that feature cannot be loaded by earlier versions. There is no clear option in 4.0.0 to use the legacy feature type to preserve backward compatibility.
Why is this a problem? I have a complex preprocessing and training... | null | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7739/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7739/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/2160 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2160/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2160/comments | https://api.github.com/repos/huggingface/datasets/issues/2160/events | https://github.com/huggingface/datasets/issues/2160 | 849,052,921 | MDU6SXNzdWU4NDkwNTI5MjE= | 2,160 | data_args.preprocessing_num_workers almost freezes | {
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"Hi.\r\nI cannot always reproduce this issue, and on later runs I did not see it so far. Sometimes also I set 8 processes but I see less being showed, is this normal, here only 5 are shown for 8 being set, thanks\r\n\r\n```\r\n#3: 11%|███████████████▊ ... | 2021-04-02T07:56:13Z | 2021-04-02T10:14:32Z | 2021-04-02T10:14:31Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi @lhoestq
I am running this code from huggingface transformers https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm.py
to speed up tokenization, since I am running on multiple datasets, I am using data_args.preprocessing_num_workers = 4 with opus100 corpus but this moves ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2160/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2160/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7058 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7058/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7058/comments | https://api.github.com/repos/huggingface/datasets/issues/7058/events | https://github.com/huggingface/datasets/issues/7058 | 2,422,560,355 | I_kwDODunzps6QZVZj | 7,058 | New feature type: Document | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [] | open | false | [] | null | [] | 2024-07-22T10:49:20Z | 2024-07-22T10:49:20Z | null | null | COLLABORATOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | It would be useful for PDF.
https://github.com/huggingface/dataset-viewer/issues/2991#issuecomment-2242656069 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7058/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7058/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5262 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5262/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5262/comments | https://api.github.com/repos/huggingface/datasets/issues/5262/events | https://github.com/huggingface/datasets/issues/5262 | 1,455,171,100 | I_kwDODunzps5WvCYc | 5,262 | AttributeError: 'Value' object has no attribute 'names' | {
"avatar_url": "https://avatars.githubusercontent.com/u/102913847?v=4",
"events_url": "https://api.github.com/users/emnaboughariou/events{/privacy}",
"followers_url": "https://api.github.com/users/emnaboughariou/followers",
"following_url": "https://api.github.com/users/emnaboughariou/following{/other_user}",
... | [] | closed | false | [] | null | [
"Hi ! It looks like your \"isDif\" column is a Sequence of Value(\"string\"), not a Sequence of ClassLabel.\r\n\r\nYou can convert your Value(\"string\") feature type to a ClassLabel feature type this way:\r\n```python\r\nfrom datasets import ClassLabel, Sequence\r\n\r\n# provide the label_names yourself\r\nlabel_n... | 2022-11-18T13:58:42Z | 2022-11-22T10:09:24Z | 2022-11-22T10:09:23Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hello
I'm trying to build a model for custom token classification
I already followed the token classification course on huggingface
while adapting the code to my work, this message occures :
'Value' object has no attribute 'names'
Here's my code:
`raw_datasets`
generates
DatasetDict({
train: Datas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/102913847?v=4",
"events_url": "https://api.github.com/users/emnaboughariou/events{/privacy}",
"followers_url": "https://api.github.com/users/emnaboughariou/followers",
"following_url": "https://api.github.com/users/emnaboughariou/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5262/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5262/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/1662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1662/comments | https://api.github.com/repos/huggingface/datasets/issues/1662/events | https://github.com/huggingface/datasets/issues/1662 | 775,890,154 | MDU6SXNzdWU3NzU4OTAxNTQ= | 1,662 | Arrow file is too large when saving vector data | {
"avatar_url": "https://avatars.githubusercontent.com/u/22360336?v=4",
"events_url": "https://api.github.com/users/weiwangorg/events{/privacy}",
"followers_url": "https://api.github.com/users/weiwangorg/followers",
"following_url": "https://api.github.com/users/weiwangorg/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"Hi !\r\nThe arrow file size is due to the embeddings. Indeed if they're stored as float32 then the total size of the embeddings is\r\n\r\n20 000 000 vectors * 768 dimensions * 4 bytes per dimension ~= 60GB\r\n\r\nIf you want to reduce the size you can consider using quantization for example, or maybe using dimensi... | 2020-12-29T13:23:12Z | 2021-01-21T14:12:39Z | 2021-01-21T14:12:39Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I computed the sentence embedding of each sentence of bookcorpus data using bert base and saved them to disk. I used 20M sentences and the obtained arrow file is about 59GB while the original text file is only about 1.3GB. Are there any ways to reduce the size of the arrow file? | {
"avatar_url": "https://avatars.githubusercontent.com/u/22360336?v=4",
"events_url": "https://api.github.com/users/weiwangorg/events{/privacy}",
"followers_url": "https://api.github.com/users/weiwangorg/followers",
"following_url": "https://api.github.com/users/weiwangorg/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1662/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1662/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/8169 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/8169/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/8169/comments | https://api.github.com/repos/huggingface/datasets/issues/8169/events | https://github.com/huggingface/datasets/issues/8169 | 4,366,520,018 | I_kwDODunzps8AAAABBEPO0g | 8,169 | Streaming dataset hangs consistently | {
"avatar_url": "https://avatars.githubusercontent.com/u/7244206?v=4",
"events_url": "https://api.github.com/users/michaelpginn/events{/privacy}",
"followers_url": "https://api.github.com/users/michaelpginn/followers",
"following_url": "https://api.github.com/users/michaelpginn/following{/other_user}",
"gists... | [] | closed | false | [] | null | [
"+1 also encountered",
"I pushed a workaround for the current version of PyArrow (24.0.0) and older versions at https://github.com/huggingface/datasets/pull/8176\n\nFor future versions it should be fixed directly in PyArrow"
] | 2026-05-01T20:27:58Z | 2026-05-06T16:07:04Z | 2026-05-06T16:06:08Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
When loading a dataset with `streaming=True`, some background process prevents the script from ever returning (or at least for a very long time).
This did not happen with `huggingface-hub < 1`.
### Steps to reproduce the bug
from datasets import load_dataset
ds = load_dataset("IRIIS-RESEARCH/N... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/8169/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/8169/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7289 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7289/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7289/comments | https://api.github.com/repos/huggingface/datasets/issues/7289/events | https://github.com/huggingface/datasets/issues/7289 | 2,648,019,507 | I_kwDODunzps6d1ZIz | 7,289 | Dataset viewer displays wrong statists | {
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"events_url": "https://api.github.com/users/speedcell4/events{/privacy}",
"followers_url": "https://api.github.com/users/speedcell4/followers",
"following_url": "https://api.github.com/users/speedcell4/following{/other_user}",
"gists_url":... | [] | closed | false | [] | null | [
"i think this issue is more for https://github.com/huggingface/dataset-viewer"
] | 2024-11-11T03:29:27Z | 2024-11-13T13:02:25Z | 2024-11-13T13:02:25Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
In [my dataset](https://huggingface.co/datasets/speedcell4/opus-unigram2), there is a column called `lang2`, and there are 94 different classes in total, but the viewer says there are 83 values only. This issue only arises in the `train` split. The total number of values is also 94 in the `test`... | {
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"events_url": "https://api.github.com/users/speedcell4/events{/privacy}",
"followers_url": "https://api.github.com/users/speedcell4/followers",
"following_url": "https://api.github.com/users/speedcell4/following{/other_user}",
"gists_url":... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7289/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7289/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3431/comments | https://api.github.com/repos/huggingface/datasets/issues/3431/events | https://github.com/huggingface/datasets/issues/3431 | 1,079,866,083 | I_kwDODunzps5AXXLj | 3,431 | Unable to resolve any data file after loading once | {
"avatar_url": "https://avatars.githubusercontent.com/u/84694183?v=4",
"events_url": "https://api.github.com/users/LzyFischer/events{/privacy}",
"followers_url": "https://api.github.com/users/LzyFischer/followers",
"following_url": "https://api.github.com/users/LzyFischer/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"Hi ! `load_dataset` accepts as input either a local dataset directory or a dataset name from the Hugging Face Hub.\r\n\r\nSo here you are getting this error the second time because it tries to load the local `wiki_dpr` directory, instead of `wiki_dpr` from the Hub. It doesn't work since it's a **cache** directory,... | 2021-12-14T15:02:15Z | 2022-12-11T10:53:04Z | 2022-02-24T09:13:52Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | when I rerun my program, it occurs this error
" Unable to resolve any data file that matches '['**train*']' at /data2/whr/lzy/open_domain_data/retrieval/wiki_dpr with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'zip']", so how could i deal with this problem?
thx.
And below is my code .
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3431/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3431/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4211 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4211/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4211/comments | https://api.github.com/repos/huggingface/datasets/issues/4211/events | https://github.com/huggingface/datasets/issues/4211 | 1,214,361,837 | I_kwDODunzps5IYbDt | 4,211 | DatasetDict containing Datasets with different features when pushed to hub gets remapped features | {
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Hi @pietrolesci, thanks for reporting.\r\n\r\nPlease note that this is a design purpose: a `DatasetDict` has the same features for all its datasets. Normally, a `DatasetDict` is composed of several sub-datasets each corresponding to a different **split**.\r\n\r\nTo handle sub-datasets with different features, we u... | 2022-04-25T11:22:54Z | 2023-04-06T19:25:50Z | 2022-05-20T15:15:30Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi there,
I am trying to load a dataset to the Hub. This dataset is a `DatasetDict` composed of various splits. Some splits have a different `Feature` mapping. Locally, the DatasetDict preserves the individual features but if I `push_to_hub` and then `load_dataset`, the features are all the same.
Dataset and code... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4211/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4211/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2737 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2737/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2737/comments | https://api.github.com/repos/huggingface/datasets/issues/2737/events | https://github.com/huggingface/datasets/issues/2737 | 957,124,881 | MDU6SXNzdWU5NTcxMjQ4ODE= | 2,737 | SacreBLEU update | {
"avatar_url": "https://avatars.githubusercontent.com/u/46989091?v=4",
"events_url": "https://api.github.com/users/devrimcavusoglu/events{/privacy}",
"followers_url": "https://api.github.com/users/devrimcavusoglu/followers",
"following_url": "https://api.github.com/users/devrimcavusoglu/following{/other_user}"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi @devrimcavusoglu, \r\nI tried your code with latest version of `datasets`and `sacrebleu==1.5.1` and it's running fine after changing one small thing:\r\n```\r\nsacrebleu = datasets.load_metric('sacrebleu')\r\npredictions = [\"It is a guide to action which ensures that the military always obeys the commands of t... | 2021-07-30T23:53:08Z | 2021-09-22T10:47:41Z | 2021-08-03T04:23:37Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | With the latest release of [sacrebleu](https://github.com/mjpost/sacrebleu), `datasets.metrics.sacrebleu` is broken, and getting error.
AttributeError: module 'sacrebleu' has no attribute 'DEFAULT_TOKENIZER'
this happens since in new version of sacrebleu there is no `DEFAULT_TOKENIZER`, but sacrebleu.py tries... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2737/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2737/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7691/comments | https://api.github.com/repos/huggingface/datasets/issues/7691/events | https://github.com/huggingface/datasets/issues/7691 | 3,245,547,170 | I_kwDODunzps7Bcx6i | 7,691 | Large WebDataset: pyarrow.lib.ArrowCapacityError on load() even with streaming | {
"avatar_url": "https://avatars.githubusercontent.com/u/122366389?v=4",
"events_url": "https://api.github.com/users/cleong110/events{/privacy}",
"followers_url": "https://api.github.com/users/cleong110/followers",
"following_url": "https://api.github.com/users/cleong110/following{/other_user}",
"gists_url": ... | [] | open | false | [] | null | [
"It seems the error occurs right here, as it tries to infer the Features: https://github.com/huggingface/datasets/blob/main/src/datasets/packaged_modules/webdataset/webdataset.py#L78-L90",
"It seems to me that if we have something that is so large that it cannot fit in pa.table, the fallback method should be to j... | 2025-07-19T18:40:27Z | 2025-07-25T08:51:10Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
I am creating a large WebDataset-format dataset for sign language processing research, and a number of the videos are over 2GB. The instant I hit one of the shards with one of those videos, I get a ArrowCapacityError, even with streaming.
I made a config for the dataset that specifically inclu... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7691/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7691/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5998 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5998/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5998/comments | https://api.github.com/repos/huggingface/datasets/issues/5998/events | https://github.com/huggingface/datasets/issues/5998 | 1,781,805,018 | I_kwDODunzps5qNC_a | 5,998 | The current implementation has a potential bug in the sort method | {
"avatar_url": "https://avatars.githubusercontent.com/u/22192665?v=4",
"events_url": "https://api.github.com/users/wangyuxinwhy/events{/privacy}",
"followers_url": "https://api.github.com/users/wangyuxinwhy/followers",
"following_url": "https://api.github.com/users/wangyuxinwhy/following{/other_user}",
"gist... | [] | closed | false | [] | null | [
"Thanks for reporting, @wangyuxinwhy. "
] | 2023-06-30T03:16:57Z | 2023-06-30T14:21:03Z | 2023-06-30T14:11:25Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Describe the bug
In the sort method,here's a piece of code
```python
# column_names: Union[str, Sequence_[str]]
# Check proper format of and for duplicates in column_names
if not isinstance(column_names, list):
column_names = [column_names]
```
I get an error when I pass in a tuple based on the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5998/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5998/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/6013 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6013/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6013/comments | https://api.github.com/repos/huggingface/datasets/issues/6013/events | https://github.com/huggingface/datasets/issues/6013 | 1,796,083,437 | I_kwDODunzps5rDg7t | 6,013 | [FR] `map` should reuse unchanged columns from the previous dataset to avoid disk usage | {
"avatar_url": "https://avatars.githubusercontent.com/u/36224762?v=4",
"events_url": "https://api.github.com/users/NightMachinery/events{/privacy}",
"followers_url": "https://api.github.com/users/NightMachinery/followers",
"following_url": "https://api.github.com/users/NightMachinery/following{/other_user}",
... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "BDE59C",
"default": fals... | open | false | [] | null | [
"You can use the `remove_columns` parameter in `map` to avoid duplicating the columns (and save disk space) and then concatenate the original dataset with the map result:\r\n```python\r\nfrom datasets import concatenate_datasets\r\n# dummy example\r\nds_new = ds.map(lambda x: {\"new_col\": x[\"col\"] + 2}, remove_c... | 2023-07-10T06:42:20Z | 2025-06-19T06:30:38Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
Currently adding a new column with `map` will cause all the data in the dataset to be duplicated and stored/cached on the disk again. It should reuse unchanged columns.
### Motivation
This allows having datasets with different columns but sharing some basic columns. Currently, these datasets wou... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6013/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6013/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4037 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4037/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4037/comments | https://api.github.com/repos/huggingface/datasets/issues/4037/events | https://github.com/huggingface/datasets/issues/4037 | 1,183,144,486 | I_kwDODunzps5GhVom | 4,037 | Error while building documentation | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"After some investigation, maybe the bug is in `doc-builder`.\r\n\r\nI've opened an issue there:\r\n- huggingface/doc-builder#160",
"Fixed by @lewtun (thank you):\r\n- huggingface/doc-builder@31fe6c8bc7225810e281c2f6c6cd32f38828c504"
] | 2022-03-28T09:22:44Z | 2022-03-28T10:01:52Z | 2022-03-28T10:00:48Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Documentation building is failing:
- https://github.com/huggingface/datasets/runs/5716300989?check_suite_focus=true
```
ValueError: There was an error when converting ../datasets/docs/source/package_reference/main_classes.mdx to the MDX format.
Unable to find datasets.filesystems.S3FileSystem... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4037/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4037/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2070 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2070/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2070/comments | https://api.github.com/repos/huggingface/datasets/issues/2070/events | https://github.com/huggingface/datasets/issues/2070 | 833,799,035 | MDU6SXNzdWU4MzM3OTkwMzU= | 2,070 | ArrowInvalid issue for squad v2 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/29818977?v=4",
"events_url": "https://api.github.com/users/MichaelYxWang/events{/privacy}",
"followers_url": "https://api.github.com/users/MichaelYxWang/followers",
"following_url": "https://api.github.com/users/MichaelYxWang/following{/other_user}",
"g... | [] | closed | false | [] | null | [
"Hi ! This error happens when you use `map` in batched mode and then your function doesn't return the same number of values per column.\r\n\r\nIndeed since you're using `map` in batched mode, `prepare_validation_features` must take a batch as input (i.e. a dictionary of multiple rows of the dataset), and return a b... | 2021-03-17T13:51:49Z | 2021-08-04T17:57:16Z | 2021-08-04T17:57:16Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hello, I am using the huggingface official question answering example notebook (https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/question_answering.ipynb).
In the prepare_validation_features function, I made some modifications to tokenize a new set of quesions with the original co... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2070/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2070/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/486 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/486/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/486/comments | https://api.github.com/repos/huggingface/datasets/issues/486/events | https://github.com/huggingface/datasets/issues/486 | 675,649,034 | MDU6SXNzdWU2NzU2NDkwMzQ= | 486 | Bookcorpus data contains pretokenized text | {
"avatar_url": "https://avatars.githubusercontent.com/u/99543?v=4",
"events_url": "https://api.github.com/users/orsharir/events{/privacy}",
"followers_url": "https://api.github.com/users/orsharir/followers",
"following_url": "https://api.github.com/users/orsharir/following{/other_user}",
"gists_url": "https:... | [] | closed | false | [] | null | [
"Yes indeed it looks like some `'` and spaces are missing (for example in `dont` or `didnt`).\r\nDo you know if there exist some copies without this issue ?\r\nHow would you fix this issue on the current data exactly ? I can see that the data is raw text (not tokenized) so I'm not sure I understand how you would do... | 2020-08-09T06:53:24Z | 2022-10-04T17:44:33Z | 2022-10-04T17:44:33Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | It seem that the bookcoprus data downloaded through the library was pretokenized with NLTK's Treebank tokenizer, which changes the text in incompatible ways to how, for instance, BERT's wordpiece tokenizer works. For example, "didn't" becomes "did" + "n't", and double quotes are changed to `` and '' for start and end q... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/486/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/486/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/7386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7386/comments | https://api.github.com/repos/huggingface/datasets/issues/7386/events | https://github.com/huggingface/datasets/issues/7386 | 2,840,032,524 | I_kwDODunzps6pR3UM | 7,386 | Add bookfolder Dataset Builder for Digital Book Formats | {
"avatar_url": "https://avatars.githubusercontent.com/u/22115108?v=4",
"events_url": "https://api.github.com/users/shikanime/events{/privacy}",
"followers_url": "https://api.github.com/users/shikanime/followers",
"following_url": "https://api.github.com/users/shikanime/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"On second thought, probably not a good idea."
] | 2025-02-08T14:27:55Z | 2025-02-08T14:30:10Z | 2025-02-08T14:30:09Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
This feature proposes adding a new dataset builder called bookfolder to the datasets library. This builder would allow users to easily load datasets consisting of various digital book formats, including: AZW, AZW3, CB7, CBR, CBT, CBZ, EPUB, MOBI, and PDF.
### Motivation
Currently, loading dataset... | {
"avatar_url": "https://avatars.githubusercontent.com/u/22115108?v=4",
"events_url": "https://api.github.com/users/shikanime/events{/privacy}",
"followers_url": "https://api.github.com/users/shikanime/followers",
"following_url": "https://api.github.com/users/shikanime/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7386/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7386/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2722/comments | https://api.github.com/repos/huggingface/datasets/issues/2722/events | https://github.com/huggingface/datasets/issues/2722 | 954,446,053 | MDU6SXNzdWU5NTQ0NDYwNTM= | 2,722 | Missing cache file | {
"avatar_url": "https://avatars.githubusercontent.com/u/33200481?v=4",
"events_url": "https://api.github.com/users/PosoSAgapo/events{/privacy}",
"followers_url": "https://api.github.com/users/PosoSAgapo/followers",
"following_url": "https://api.github.com/users/PosoSAgapo/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"This could be solved by going to the glue/ directory and delete sst2 directory, then load the dataset again will help you redownload the dataset.",
"Hi ! Not sure why this file was missing, but yes the way to fix this is to delete the sst2 directory and to reload the dataset"
] | 2021-07-28T03:52:07Z | 2022-03-21T08:27:51Z | 2022-03-21T08:27:51Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Strangely missing cache file after I restart my program again.
`glue_dataset = datasets.load_dataset('glue', 'sst2')`
`FileNotFoundError: [Errno 2] No such file or directory: /Users/chris/.cache/huggingface/datasets/glue/sst2/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96d6053ad/dataset_info.json... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2722/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2722/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/507 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/507/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/507/comments | https://api.github.com/repos/huggingface/datasets/issues/507/events | https://github.com/huggingface/datasets/issues/507 | 679,400,683 | MDU6SXNzdWU2Nzk0MDA2ODM= | 507 | Errors when I use | {
"avatar_url": "https://avatars.githubusercontent.com/u/30506151?v=4",
"events_url": "https://api.github.com/users/mchari/events{/privacy}",
"followers_url": "https://api.github.com/users/mchari/followers",
"following_url": "https://api.github.com/users/mchari/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | [] | null | [
"Looks like an issue with 3.0.2 transformers version. Works fine when I use \"master\" version of transformers."
] | 2020-08-14T21:03:57Z | 2020-08-14T21:39:10Z | 2020-08-14T21:39:10Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I tried the following example code from https://huggingface.co/deepset/roberta-base-squad2 and got errors
I am using **transformers 3.0.2** code .
from transformers.pipelines import pipeline
from transformers.modeling_auto import AutoModelForQuestionAnswering
from transformers.tokenization_auto import AutoToke... | {
"avatar_url": "https://avatars.githubusercontent.com/u/30506151?v=4",
"events_url": "https://api.github.com/users/mchari/events{/privacy}",
"followers_url": "https://api.github.com/users/mchari/followers",
"following_url": "https://api.github.com/users/mchari/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/507/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/507/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3795 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3795/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3795/comments | https://api.github.com/repos/huggingface/datasets/issues/3795/events | https://github.com/huggingface/datasets/issues/3795 | 1,153,261,281 | I_kwDODunzps5EvV7h | 3,795 | can not flatten natural_questions dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/38466901?v=4",
"events_url": "https://api.github.com/users/Hannibal046/events{/privacy}",
"followers_url": "https://api.github.com/users/Hannibal046/followers",
"following_url": "https://api.github.com/users/Hannibal046/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"same issue. downgrade it to a lower version.",
"Thanks for reporting, I'll take a look tomorrow :)"
] | 2022-02-27T13:57:40Z | 2022-03-21T14:36:12Z | 2022-03-21T14:36:12Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
after downloading the natural_questions dataset, can not flatten the dataset considering there are `long answer` and `short answer` in `annotations`.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset('natural_questions',cache_dir = 'data/datase... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3795/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3795/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2553/comments | https://api.github.com/repos/huggingface/datasets/issues/2553/events | https://github.com/huggingface/datasets/issues/2553 | 931,365,926 | MDU6SXNzdWU5MzEzNjU5MjY= | 2,553 | load_dataset("web_nlg") NonMatchingChecksumError | {
"avatar_url": "https://avatars.githubusercontent.com/u/33730312?v=4",
"events_url": "https://api.github.com/users/alxthm/events{/privacy}",
"followers_url": "https://api.github.com/users/alxthm/followers",
"following_url": "https://api.github.com/users/alxthm/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Hi ! Thanks for reporting. This is due to the WebNLG repository that got updated today.\r\nI just pushed a fix at #2558 - this shouldn't happen anymore in the future.",
"This is fixed on `master` now :)\r\nWe'll do a new release soon !"
] | 2021-06-28T09:26:46Z | 2021-06-28T17:23:39Z | 2021-06-28T17:23:16Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi! It seems the WebNLG dataset gives a NonMatchingChecksumError.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset('web_nlg', name="release_v3.0_en", split="dev")
```
Gives
```
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['h... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2553/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2553/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3950 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3950/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3950/comments | https://api.github.com/repos/huggingface/datasets/issues/3950/events | https://github.com/huggingface/datasets/issues/3950 | 1,171,560,585 | I_kwDODunzps5F1JiJ | 3,950 | Streaming Datasets don't work with Transformers Trainer when dataloader_num_workers>1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/9633?v=4",
"events_url": "https://api.github.com/users/dlwh/events{/privacy}",
"followers_url": "https://api.github.com/users/dlwh/followers",
"following_url": "https://api.github.com/users/dlwh/following{/other_user}",
"gists_url": "https://api.github.... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"descript... | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Hi, thanks for reporting. This could be related to https://github.com/huggingface/datasets/issues/3148 too\r\n\r\nWe should definitely make `TorchIterableDataset` picklable by moving it in the main code instead of inside a function. If you'd like to contribute, feel free to open a Pull Request :)\r\n\r\nI'm also t... | 2022-03-16T21:14:11Z | 2022-06-10T20:47:26Z | 2022-06-10T20:47:26Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Streaming Datasets can't be pickled, so any interaction between them and multiprocessing results in a crash.
## Steps to reproduce the bug
```python
import transformers
from transformers import Trainer, AutoModelForCausalLM, TrainingArguments
import datasets
ds = datasets.load_dataset('os... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3950/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3950/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/887 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/887/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/887/comments | https://api.github.com/repos/huggingface/datasets/issues/887/events | https://github.com/huggingface/datasets/issues/887 | 750,868,831 | MDU6SXNzdWU3NTA4Njg4MzE= | 887 | pyarrow.lib.ArrowNotImplementedError: MakeBuilder: cannot construct builder for type extension<arrow.py_extension_type> | {
"avatar_url": "https://avatars.githubusercontent.com/u/5757359?v=4",
"events_url": "https://api.github.com/users/AmitMY/events{/privacy}",
"followers_url": "https://api.github.com/users/AmitMY/followers",
"following_url": "https://api.github.com/users/AmitMY/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | [] | null | [
"Yes right now `ArrayXD` can only be used as a column feature type, not a subtype.\r\nWith the current Arrow limitations I don't think we'll be able to make it work as a subtype, however it should be possible to allow dimensions of dynamic sizes (`Array3D(shape=(None, 137, 2), dtype=\"float32\")` for example since ... | 2020-11-25T14:32:21Z | 2021-09-09T17:03:40Z | null | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | I set up a new dataset, with a sequence of arrays (really, I want to have an array of (None, 137, 2), and the first dimension is dynamic)
```python
def _info(self):
return datasets.DatasetInfo(
description=_DESCRIPTION,
# This defines the different columns of the dataset and ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/887/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/887/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3548/comments | https://api.github.com/repos/huggingface/datasets/issues/3548/events | https://github.com/huggingface/datasets/issues/3548 | 1,096,409,512 | I_kwDODunzps5BWeGo | 3,548 | Specify the feature types of a dataset on the Hub without needing a dataset script | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gis... | null | [
"After looking into this, discovered that this is already supported if the `dataset_infos.json` file is configured correctly! Here is a working example: https://huggingface.co/datasets/abidlabs/test-audio-13\r\n\r\nThis should be probably be documented, though. "
] | 2022-01-07T15:17:06Z | 2022-01-20T14:48:38Z | 2022-01-20T14:48:38Z | {
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "http... | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | **Is your feature request related to a problem? Please describe.**
Currently if I upload a CSV with paths to audio files, the column type is string instead of Audio.
**Describe the solution you'd like**
I'd like to be able to specify the types of the column, so that when loading the dataset I directly get the feat... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "http... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3548/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3548/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2026 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2026/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2026/comments | https://api.github.com/repos/huggingface/datasets/issues/2026/events | https://github.com/huggingface/datasets/issues/2026 | 828,194,467 | MDU6SXNzdWU4MjgxOTQ0Njc= | 2,026 | KeyError on using map after renaming a column | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url"... | [] | closed | false | [] | null | [
"Hi,\r\n\r\nActually, the error occurs due to these two lines:\r\n```python\r\nraw_dataset.set_format('torch',columns=['img','label'])\r\nraw_dataset = raw_dataset.rename_column('img','image')\r\n```\r\n`Dataset.rename_column` doesn't update the `_format_columns` attribute, previously defined by `Dataset.set_format... | 2021-03-10T18:54:17Z | 2021-03-11T14:39:34Z | 2021-03-11T14:38:40Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Hi,
I'm trying to use `cifar10` dataset. I want to rename the `img` feature to `image` in order to make it consistent with `mnist`, which I'm also planning to use. By doing this, I was trying to avoid modifying `prepare_train_features` function.
Here is what I try:
```python
transform = Compose([ToPILImage(),... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2026/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2026/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2108 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2108/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2108/comments | https://api.github.com/repos/huggingface/datasets/issues/2108/events | https://github.com/huggingface/datasets/issues/2108 | 840,181,055 | MDU6SXNzdWU4NDAxODEwNTU= | 2,108 | Is there a way to use a GPU only when training an Index in the process of add_faisis_index? | {
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | open | false | [] | null | [] | 2021-03-24T21:32:16Z | 2021-03-25T06:31:43Z | null | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | Motivation - Some FAISS indexes like IVF consist of the training step that clusters the dataset into a given number of indexes. It would be nice if we can use a GPU to do the training step and covert the index back to CPU as mention in [this faiss example](https://gist.github.com/mdouze/46d6bbbaabca0b9778fca37ed2bcccf6... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2108/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2108/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4382/comments | https://api.github.com/repos/huggingface/datasets/issues/4382/events | https://github.com/huggingface/datasets/issues/4382 | 1,243,839,783 | I_kwDODunzps5KI30n | 4,382 | First time trying | {
"avatar_url": "https://avatars.githubusercontent.com/u/87345839?v=4",
"events_url": "https://api.github.com/users/Aeckard45/events{/privacy}",
"followers_url": "https://api.github.com/users/Aeckard45/followers",
"following_url": "https://api.github.com/users/Aeckard45/following{/other_user}",
"gists_url": "... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | [] | null | [] | 2022-05-21T02:15:18Z | 2022-05-21T19:20:44Z | 2022-05-21T19:20:44Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4382/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4382/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2415/comments | https://api.github.com/repos/huggingface/datasets/issues/2415/events | https://github.com/huggingface/datasets/issues/2415 | 903,923,097 | MDU6SXNzdWU5MDM5MjMwOTc= | 2,415 | Cached dataset not loaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/715491?v=4",
"events_url": "https://api.github.com/users/borisdayma/events{/privacy}",
"followers_url": "https://api.github.com/users/borisdayma/followers",
"following_url": "https://api.github.com/users/borisdayma/following{/other_user}",
"gists_url": ... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"It actually seems to happen all the time in above configuration:\r\n* the function `filter_by_duration` correctly loads cached processed dataset\r\n* the function `prepare_dataset` is always reexecuted\r\n\r\nI end up solving the issue by saving to disk my dataset at the end but I'm still wondering if it's a bug o... | 2021-05-27T15:40:06Z | 2021-06-02T13:15:47Z | 2021-06-02T13:15:47Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
I have a large dataset (common_voice, english) where I use several map and filter functions.
Sometimes my cached datasets after specific functions are not loaded.
I always use the same arguments, same functions, no seed…
## Steps to reproduce the bug
```python
def filter_by_duration(batch):
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/715491?v=4",
"events_url": "https://api.github.com/users/borisdayma/events{/privacy}",
"followers_url": "https://api.github.com/users/borisdayma/followers",
"following_url": "https://api.github.com/users/borisdayma/following{/other_user}",
"gists_url": ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2415/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2415/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3329 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3329/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3329/comments | https://api.github.com/repos/huggingface/datasets/issues/3329/events | https://github.com/huggingface/datasets/issues/3329 | 1,065,096,971 | I_kwDODunzps4_fBcL | 3,329 | Map function: Type error on iter #999 | {
"avatar_url": "https://avatars.githubusercontent.com/u/52659318?v=4",
"events_url": "https://api.github.com/users/josephkready666/events{/privacy}",
"followers_url": "https://api.github.com/users/josephkready666/followers",
"following_url": "https://api.github.com/users/josephkready666/following{/other_user}"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Hi, thanks for reporting.\r\n\r\nIt would be really helpful if you could provide the actual code of the `text_numbers_to_int` function so we can reproduce the error.",
"```\r\ndef text_numbers_to_int(text, column=\"\"):\r\n \"\"\"\r\n Convert text numbers to int.\r\n\r\n :param text: text numbers\r\n ... | 2021-11-27T17:53:05Z | 2021-11-29T20:40:15Z | 2021-11-29T20:40:15Z | null | NONE | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
Using the map function, it throws a type error on iter #999
Here is the code I am calling:
```
dataset = datasets.load_dataset('squad')
dataset['validation'].map(text_numbers_to_int, input_columns=['context'], fn_kwargs={'column': 'context'})
```
text_numbers_to_int returns the input text ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/52659318?v=4",
"events_url": "https://api.github.com/users/josephkready666/events{/privacy}",
"followers_url": "https://api.github.com/users/josephkready666/followers",
"following_url": "https://api.github.com/users/josephkready666/following{/other_user}"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3329/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3329/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/4779 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4779/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4779/comments | https://api.github.com/repos/huggingface/datasets/issues/4779/events | https://github.com/huggingface/datasets/issues/4779 | 1,325,997,225 | I_kwDODunzps5PCRyp | 4,779 | Loading natural_questions requires apache_beam even with existing preprocessed data | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [] | 2022-08-02T15:06:57Z | 2022-08-02T16:03:18Z | 2022-08-02T16:03:18Z | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
When loading "natural_questions", the package "apache_beam" is required:
```
ImportError: To be able to use natural_questions, you need to install the following dependency: apache_beam.
Please install it using 'pip install apache_beam' for instance'
```
This requirement is unnecessary, once ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4779/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4779/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/3480 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3480/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3480/comments | https://api.github.com/repos/huggingface/datasets/issues/3480/events | https://github.com/huggingface/datasets/issues/3480 | 1,088,267,110 | I_kwDODunzps5A3aNm | 3,480 | the compression format requested when saving a dataset in json format is not respected | {
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"events_url": "https://api.github.com/users/SaulLu/events{/privacy}",
"followers_url": "https://api.github.com/users/SaulLu/followers",
"following_url": "https://api.github.com/users/SaulLu/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | [] | null | [
"Thanks for reporting @SaulLu.\r\n\r\nAt first sight I think the problem is caused because `pandas` only takes into account the `compression` parameter if called with a non-null file path or buffer. And in our implementation, we call pandas `to_json` with `None` `path_or_buf`.\r\n\r\nWe should fix this:\r\n- either... | 2021-12-24T09:23:51Z | 2022-01-05T13:03:35Z | 2022-01-05T13:03:35Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ## Describe the bug
In the documentation of the `to_json` method, it is stated in the parameters that
> **to_json_kwargs – Parameters to pass to pandas’s pandas.DataFrame.to_json.
however when we pass for example `compression="gzip"`, the saved file is not compressed.
Would you also have expected compression t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3480/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3480/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/5665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5665/comments | https://api.github.com/repos/huggingface/datasets/issues/5665/events | https://github.com/huggingface/datasets/issues/5665 | 1,637,193,648 | I_kwDODunzps5hlZew | 5,665 | Feature request: IterableDataset.push_to_hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | [] | null | [
"+1",
"+1",
"+1, should be possible now? :) https://huggingface.co/blog/xethub-joins-hf",
"Haha we're working hard to integrate Xet in the HF back-end, it will enable cool use cases :)\n\nAnyway about `IterableDataset.push_to_hub`, I'd be happy to to provide guidance and answer questions if anyone wants to st... | 2023-03-23T09:53:04Z | 2025-06-06T16:13:22Z | 2025-06-06T16:12:36Z | null | CONTRIBUTOR | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | ### Feature request
It'd be great to have a lazy push to hub, similar to the lazy loading we have with `IterableDataset`.
Suppose you'd like to filter [LAION](https://huggingface.co/datasets/laion/laion400m) based on certain conditions, but as LAION doesn't fit into your disk, you'd like to leverage streaming:
`... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 32,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 32,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5665/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5665/timeline | null | completed | null |
https://api.github.com/repos/huggingface/datasets/issues/2485 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2485/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2485/comments | https://api.github.com/repos/huggingface/datasets/issues/2485/events | https://github.com/huggingface/datasets/issues/2485 | 919,099,218 | MDU6SXNzdWU5MTkwOTkyMTg= | 2,485 | Implement layered building | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | [] | null | [] | 2021-06-11T18:54:25Z | 2021-06-11T18:54:25Z | null | null | MEMBER | [] | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | As discussed with @stas00 and @lhoestq (see also here https://github.com/huggingface/datasets/issues/2481#issuecomment-859712190):
> My suggestion for this would be to have this enabled by default.
>
> Plus I don't know if there should be a dedicated issue to that is another functionality. But I propose layered b... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2485/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2485/timeline | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.