
text stringlengths 7 318k | id stringlengths 14 166 | metadata dict | __index_level_0__ int64 0 439 |
|---|---|---|---|
# docstyle-ignore
INSTALL_CONTENT = """
# Datasets installation
! pip install datasets transformers
# To install from source instead of the last release, comment the command above and uncomment the following one.
# ! pip install git+https://github.com/huggingface/datasets.git
"""
notebook_first_cells = [{"type": "code... | datasets/docs/source/_config.py/0 | {
"file_path": "datasets/docs/source/_config.py",
"repo_id": "datasets",
"token_count": 118
} | 55 |
# Create a dataset
Sometimes, you may need to create a dataset if you're working with your own data. Creating a dataset with 🤗 Datasets confers all the advantages of the library to your dataset: fast loading and processing, [stream enormous datasets](stream), [memory-mapping](https://huggingface.co/course/chapter5/4?... | datasets/docs/source/create_dataset.mdx/0 | {
"file_path": "datasets/docs/source/create_dataset.mdx",
"repo_id": "datasets",
"token_count": 2167
} | 56 |
# Load a dataset from the Hub
Finding high-quality datasets that are reproducible and accessible can be difficult. One of 🤗 Datasets main goals is to provide a simple way to load a dataset of any format or type. The easiest way to get started is to discover an existing dataset on the [Hugging Face Hub](https://huggin... | datasets/docs/source/load_hub.mdx/0 | {
"file_path": "datasets/docs/source/load_hub.mdx",
"repo_id": "datasets",
"token_count": 1685
} | 57 |
# Share a dataset using the CLI
At Hugging Face, we are on a mission to democratize good Machine Learning and we believe in the value of open source. That's why we designed 🤗 Datasets so that anyone can share a dataset with the greater ML community. There are currently thousands of datasets in over 100 languages in t... | datasets/docs/source/share.mdx/0 | {
"file_path": "datasets/docs/source/share.mdx",
"repo_id": "datasets",
"token_count": 1511
} | 58 |
# Metric Card for BLEU
## Metric Description
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another. Quality is considered to be the correspondence between a machine's output and that of a human: "the closer a ma... | datasets/metrics/bleu/README.md/0 | {
"file_path": "datasets/metrics/bleu/README.md",
"repo_id": "datasets",
"token_count": 1990
} | 59 |
# Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | datasets/metrics/coval/coval.py/0 | {
"file_path": "datasets/metrics/coval/coval.py",
"repo_id": "datasets",
"token_count": 5730
} | 60 |
# Metric Card for MAE
## Metric Description
Mean Absolute Error (MAE) is the mean of the magnitude of difference between the predicted and actual numeric values:
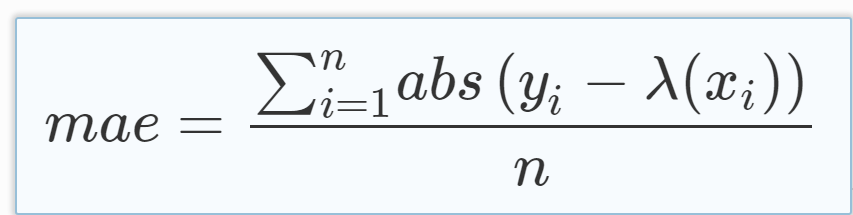
## How to Use
At minimum, this metric re... | datasets/metrics/mae/README.md/0 | {
"file_path": "datasets/metrics/mae/README.md",
"repo_id": "datasets",
"token_count": 1421
} | 61 |
# Metric Card for Perplexity
## Metric Description
Given a model and an input text sequence, perplexity measures how likely the model is to generate the input text sequence. This can be used in two main ways:
1. to evaluate how well the model has learned the distribution of the text it was trained on
- In this cas... | datasets/metrics/perplexity/README.md/0 | {
"file_path": "datasets/metrics/perplexity/README.md",
"repo_id": "datasets",
"token_count": 1345
} | 62 |
# Metric Card for Spearman Correlation Coefficient Metric (spearmanr)
## Metric Description
The Spearman rank-order correlation coefficient is a measure of the
relationship between two datasets. Like other correlation coefficients,
this one varies between -1 and +1 with 0 implying no correlation.
Positive correlation... | datasets/metrics/spearmanr/README.md/0 | {
"file_path": "datasets/metrics/spearmanr/README.md",
"repo_id": "datasets",
"token_count": 1585
} | 63 |
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | datasets/metrics/wiki_split/wiki_split.py/0 | {
"file_path": "datasets/metrics/wiki_split/wiki_split.py",
"repo_id": "datasets",
"token_count": 5827
} | 64 |
import os
import re
import shutil
from argparse import ArgumentParser, Namespace
from datasets.commands import BaseDatasetsCLICommand
from datasets.utils.logging import get_logger
HIGHLIGHT_MESSAGE_PRE = """<<<<<<< This should probably be modified because it mentions: """
HIGHLIGHT_MESSAGE_POST = """=======
>>>>>>>... | datasets/src/datasets/commands/convert.py/0 | {
"file_path": "datasets/src/datasets/commands/convert.py",
"repo_id": "datasets",
"token_count": 3822
} | 65 |
# ruff: noqa
__all__ = [
"Audio",
"Array2D",
"Array3D",
"Array4D",
"Array5D",
"ClassLabel",
"Features",
"Sequence",
"Value",
"Image",
"Translation",
"TranslationVariableLanguages",
]
from .audio import Audio
from .features import Array2D, Array3D, Array4D, Array5D, Class... | datasets/src/datasets/features/__init__.py/0 | {
"file_path": "datasets/src/datasets/features/__init__.py",
"repo_id": "datasets",
"token_count": 165
} | 66 |
# Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | datasets/src/datasets/inspect.py/0 | {
"file_path": "datasets/src/datasets/inspect.py",
"repo_id": "datasets",
"token_count": 9910
} | 67 |
# Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# U... | datasets/src/datasets/splits.py/0 | {
"file_path": "datasets/src/datasets/splits.py",
"repo_id": "datasets",
"token_count": 9636
} | 68 |
import os
from apache_beam.io.filesystems import FileSystems
from apache_beam.pipeline import Pipeline
from .logging import get_logger
CHUNK_SIZE = 2 << 20 # 2mb
logger = get_logger(__name__)
class BeamPipeline(Pipeline):
"""Wrapper over `apache_beam.pipeline.Pipeline` for convenience"""
def is_local(se... | datasets/src/datasets/utils/beam_utils.py/0 | {
"file_path": "datasets/src/datasets/utils/beam_utils.py",
"repo_id": "datasets",
"token_count": 847
} | 69 |
{
"language": [
"found",
"crowdsourced",
"expert-generated",
"machine-generated",
"other"
],
"annotations": [
"found",
"crowdsourced",
"expert-generated",
"machine-generated",
"no-annotation",
"other"
]
}
| datasets/src/datasets/utils/resources/creators.json/0 | {
"file_path": "datasets/src/datasets/utils/resources/creators.json",
"repo_id": "datasets",
"token_count": 119
} | 70 |
## Add Dummy data test
**Important** In order to pass the `load_dataset_<dataset_name>` test, dummy data is required for all possible config names.
First we distinguish between datasets scripts that
- A) have no config class and
- B) have a config class
For A) the dummy data folder structure, will always look as fol... | datasets/tests/README.md/0 | {
"file_path": "datasets/tests/README.md",
"repo_id": "datasets",
"token_count": 928
} | 71 |
import os
import random
import tempfile
import unittest
import numpy as np
import pandas as pd
import pyarrow as pa
import pytest
from absl.testing import parameterized
import datasets
from datasets.arrow_writer import ArrowWriter
from datasets.features import Array2D, Array3D, Array4D, Array5D, Value
from datasets.f... | datasets/tests/features/test_array_xd.py/0 | {
"file_path": "datasets/tests/features/test_array_xd.py",
"repo_id": "datasets",
"token_count": 9826
} | 72 |
import pytest
from datasets import Dataset, DatasetDict, Features, NamedSplit, Value
from datasets.io.text import TextDatasetReader
from ..utils import assert_arrow_memory_doesnt_increase, assert_arrow_memory_increases
def _check_text_dataset(dataset, expected_features):
assert isinstance(dataset, Dataset)
... | datasets/tests/io/test_text.py/0 | {
"file_path": "datasets/tests/io/test_text.py",
"repo_id": "datasets",
"token_count": 1833
} | 73 |
import copy
import os
from pathlib import Path
from typing import List
from unittest.mock import patch
import fsspec
import pytest
from fsspec.registry import _registry as _fsspec_registry
from fsspec.spec import AbstractFileSystem
from datasets.data_files import (
DataFilesDict,
DataFilesList,
DataFilesP... | datasets/tests/test_data_files.py/0 | {
"file_path": "datasets/tests/test_data_files.py",
"repo_id": "datasets",
"token_count": 12239
} | 74 |
import os
from pathlib import Path
import pytest
from datasets.inspect import (
get_dataset_config_info,
get_dataset_config_names,
get_dataset_default_config_name,
get_dataset_infos,
get_dataset_split_names,
inspect_dataset,
inspect_metric,
)
from datasets.packaged_modules.csv import csv
... | datasets/tests/test_inspect.py/0 | {
"file_path": "datasets/tests/test_inspect.py",
"repo_id": "datasets",
"token_count": 2081
} | 75 |
from copy import deepcopy
from unittest.case import TestCase
import pytest
from datasets.arrow_dataset import Dataset
from datasets.features import Audio, ClassLabel, Features, Image, Sequence, Value
from datasets.info import DatasetInfo
from datasets.tasks import (
AudioClassification,
AutomaticSpeechRecogni... | datasets/tests/test_tasks.py/0 | {
"file_path": "datasets/tests/test_tasks.py",
"repo_id": "datasets",
"token_count": 4249
} | 76 |
<jupyter_start><jupyter_text>Unit 3: Deep Q-Learning with Atari Games 👾 using RL Baselines3 ZooIn this notebook, **you'll train a Deep Q-Learning agent** playing Space Invaders using [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), a training framework based on [Stable-Baselines3](https://stable-basel... | deep-rl-class/notebooks/unit3/unit3.ipynb/0 | {
"file_path": "deep-rl-class/notebooks/unit3/unit3.ipynb",
"repo_id": "deep-rl-class",
"token_count": 3982
} | 77 |
# Conclusion [[conclusion]]
Congrats on finishing this unit! **That was the biggest one**, and there was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep RL agents and shared them with the community! 🥳
It's **normal if you still feel confused by some of these elements... | deep-rl-class/units/en/unit1/conclusion.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit1/conclusion.mdx",
"repo_id": "deep-rl-class",
"token_count": 349
} | 78 |
# Hands-on [[hands-on]]
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/notebooks/unit2/unit2.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord"... | deep-rl-class/units/en/unit2/hands-on.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit2/hands-on.mdx",
"repo_id": "deep-rl-class",
"token_count": 13932
} | 79 |
# Glossary
This is a community-created glossary. Contributions are welcomed!
- **Tabular Method:** Type of problem in which the state and action spaces are small enough to approximate value functions to be represented as arrays and tables.
**Q-learning** is an example of tabular method since a table is used to repr... | deep-rl-class/units/en/unit3/glossary.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit3/glossary.mdx",
"repo_id": "deep-rl-class",
"token_count": 721
} | 80 |
# (Optional) What is Curiosity in Deep Reinforcement Learning?
This is an (optional) introduction to Curiosity. If you want to learn more, you can read two additional articles where we dive into the mathematical details:
- [Curiosity-Driven Learning through Next State Prediction](https://medium.com/data-from-the-tren... | deep-rl-class/units/en/unit5/curiosity.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit5/curiosity.mdx",
"repo_id": "deep-rl-class",
"token_count": 1153
} | 81 |
# Hands-on
Now that you learned the basics of multi-agents, you're ready to train your first agents in a multi-agent system: **a 2vs2 soccer team that needs to beat the opponent team**.
And you’re going to participate in AI vs. AI challenges where your trained agent will compete against other classmates’ **agents eve... | deep-rl-class/units/en/unit7/hands-on.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit7/hands-on.mdx",
"repo_id": "deep-rl-class",
"token_count": 5036
} | 82 |
# Conclusion [[conclusion]]
Congrats on finishing this bonus unit!
You can now sit and enjoy playing with your Huggy 🐶. And don't **forget to spread the love by sharing Huggy with your friends 🤗**. And if you share about it on social media, **please tag us @huggingface and me @simoninithomas**
<img src="https://hu... | deep-rl-class/units/en/unitbonus1/conclusion.mdx/0 | {
"file_path": "deep-rl-class/units/en/unitbonus1/conclusion.mdx",
"repo_id": "deep-rl-class",
"token_count": 227
} | 83 |
# Model Based Reinforcement Learning (MBRL)
Model-based reinforcement learning only differs from its model-free counterpart in learning a *dynamics model*, but that has substantial downstream effects on how the decisions are made.
The dynamics model usually models the environment transition dynamics, \\( s_{t+1} = f_... | deep-rl-class/units/en/unitbonus3/model-based.mdx/0 | {
"file_path": "deep-rl-class/units/en/unitbonus3/model-based.mdx",
"repo_id": "deep-rl-class",
"token_count": 641
} | 84 |
<!---
Copyright 2022 - The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law o... | diffusers/README.md/0 | {
"file_path": "diffusers/README.md",
"repo_id": "diffusers",
"token_count": 5394
} | 85 |
FROM nvidia/cuda:12.1.0-runtime-ubuntu20.04
LABEL maintainer="Hugging Face"
LABEL repository="diffusers"
ENV DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y bash \
build-essential \
git \
git-lfs \
curl \
ca-certificates \
libsndfile1-dev \
libgl1 \
python3.9 \
... | diffusers/docker/diffusers-pytorch-compile-cuda/Dockerfile/0 | {
"file_path": "diffusers/docker/diffusers-pytorch-compile-cuda/Dockerfile",
"repo_id": "diffusers",
"token_count": 450
} | 86 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/api/loaders/single_file.md/0 | {
"file_path": "diffusers/docs/source/en/api/loaders/single_file.md",
"repo_id": "diffusers",
"token_count": 480
} | 87 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/api/pipelines/dance_diffusion.md/0 | {
"file_path": "diffusers/docs/source/en/api/pipelines/dance_diffusion.md",
"repo_id": "diffusers",
"token_count": 370
} | 88 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/api/pipelines/stable_diffusion/sdxl_turbo.md/0 | {
"file_path": "diffusers/docs/source/en/api/pipelines/stable_diffusion/sdxl_turbo.md",
"repo_id": "diffusers",
"token_count": 678
} | 89 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/optimization/coreml.md/0 | {
"file_path": "diffusers/docs/source/en/optimization/coreml.md",
"repo_id": "diffusers",
"token_count": 3089
} | 90 |
# Create a dataset for training
There are many datasets on the [Hub](https://huggingface.co/datasets?task_categories=task_categories:text-to-image&sort=downloads) to train a model on, but if you can't find one you're interested in or want to use your own, you can create a dataset with the 🤗 [Datasets](hf.co/docs/data... | diffusers/docs/source/en/training/create_dataset.md/0 | {
"file_path": "diffusers/docs/source/en/training/create_dataset.md",
"repo_id": "diffusers",
"token_count": 1301
} | 91 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/tutorials/autopipeline.md/0 | {
"file_path": "diffusers/docs/source/en/tutorials/autopipeline.md",
"repo_id": "diffusers",
"token_count": 2762
} | 92 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/using-diffusers/freeu.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/freeu.md",
"repo_id": "diffusers",
"token_count": 1634
} | 93 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/using-diffusers/sdxl.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/sdxl.md",
"repo_id": "diffusers",
"token_count": 7004
} | 94 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/quicktour.md/0 | {
"file_path": "diffusers/docs/source/ko/quicktour.md",
"repo_id": "diffusers",
"token_count": 11430
} | 95 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/using-diffusers/conditional_image_generation.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/conditional_image_generation.md",
"repo_id": "diffusers",
"token_count": 1552
} | 96 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/using-diffusers/stable_diffusion_jax_how_to.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/stable_diffusion_jax_how_to.md",
"repo_id": "diffusers",
"token_count": 8475
} | 97 |
"""
modeled after the textual_inversion.py / train_dreambooth.py and the work
of justinpinkney here: https://github.com/justinpinkney/stable-diffusion/blob/main/notebooks/imagic.ipynb
"""
import inspect
import warnings
from typing import List, Optional, Union
import numpy as np
import PIL.Image
import torch
im... | diffusers/examples/community/imagic_stable_diffusion.py/0 | {
"file_path": "diffusers/examples/community/imagic_stable_diffusion.py",
"repo_id": "diffusers",
"token_count": 10425
} | 98 |
import inspect
from copy import deepcopy
from enum import Enum
from typing import List, Optional, Tuple, Union
import torch
from tqdm.auto import tqdm
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffu... | diffusers/examples/community/mixture_tiling.py/0 | {
"file_path": "diffusers/examples/community/mixture_tiling.py",
"repo_id": "diffusers",
"token_count": 9148
} | 99 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/examples/community/rerender_a_video.py/0 | {
"file_path": "diffusers/examples/community/rerender_a_video.py",
"repo_id": "diffusers",
"token_count": 26689
} | 100 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/examples/community/stable_diffusion_repaint.py/0 | {
"file_path": "diffusers/examples/community/stable_diffusion_repaint.py",
"repo_id": "diffusers",
"token_count": 21148
} | 101 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LI... | diffusers/examples/consistency_distillation/train_lcm_distill_lora_sd_wds.py/0 | {
"file_path": "diffusers/examples/consistency_distillation/train_lcm_distill_lora_sd_wds.py",
"repo_id": "diffusers",
"token_count": 26782
} | 102 |
# Copyright 2023 Custom Diffusion authors. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by appl... | diffusers/examples/custom_diffusion/retrieve.py/0 | {
"file_path": "diffusers/examples/custom_diffusion/retrieve.py",
"repo_id": "diffusers",
"token_count": 1430
} | 103 |
import warnings
from diffusers import StableDiffusionInpaintPipeline as StableDiffusionInpaintPipeline # noqa F401
warnings.warn(
"The `inpainting.py` script is outdated. Please use directly `from diffusers import"
" StableDiffusionInpaintPipeline` instead."
)
| diffusers/examples/inference/inpainting.py/0 | {
"file_path": "diffusers/examples/inference/inpainting.py",
"repo_id": "diffusers",
"token_count": 89
} | 104 |
# [DreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth) by [colossalai](https://github.com/hpcaitech/ColossalAI.git)
[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
The `train_dre... | diffusers/examples/research_projects/colossalai/README.md/0 | {
"file_path": "diffusers/examples/research_projects/colossalai/README.md",
"repo_id": "diffusers",
"token_count": 1659
} | 105 |
import argparse
import math
import os
import torch
from neural_compressor.utils.pytorch import load
from PIL import Image
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, StableDiffusionPipeline, UNet2DConditionModel
def parse_args():
parser = argparse.ArgumentParser()
... | diffusers/examples/research_projects/intel_opts/textual_inversion_dfq/text2images.py/0 | {
"file_path": "diffusers/examples/research_projects/intel_opts/textual_inversion_dfq/text2images.py",
"repo_id": "diffusers",
"token_count": 1518
} | 106 |
# coding=utf-8
# Copyright 2023 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/examples/text_to_image/test_text_to_image.py/0 | {
"file_path": "diffusers/examples/text_to_image/test_text_to_image.py",
"repo_id": "diffusers",
"token_count": 7412
} | 107 |
## Training an unconditional diffusion model
Creating a training image set is [described in a different document](https://huggingface.co/docs/datasets/image_process#image-datasets).
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
T... | diffusers/examples/unconditional_image_generation/README.md/0 | {
"file_path": "diffusers/examples/unconditional_image_generation/README.md",
"repo_id": "diffusers",
"token_count": 1939
} | 108 |
import argparse
import torch
from diffusers import MotionAdapter
def convert_motion_module(original_state_dict):
converted_state_dict = {}
for k, v in original_state_dict.items():
if "pos_encoder" in k:
continue
else:
converted_state_dict[
k.replace("... | diffusers/scripts/convert_animatediff_motion_module_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_animatediff_motion_module_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 696
} | 109 |
#!/usr/bin/env python3
import argparse
import fnmatch
from safetensors.torch import load_file
from diffusers import Kandinsky3UNet
MAPPING = {
"to_time_embed.1": "time_embedding.linear_1",
"to_time_embed.3": "time_embedding.linear_2",
"in_layer": "conv_in",
"out_layer.0": "conv_norm_out",
"out_l... | diffusers/scripts/convert_kandinsky3_unet.py/0 | {
"file_path": "diffusers/scripts/convert_kandinsky3_unet.py",
"repo_id": "diffusers",
"token_count": 1403
} | 110 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/scripts/convert_stable_diffusion_checkpoint_to_onnx.py/0 | {
"file_path": "diffusers/scripts/convert_stable_diffusion_checkpoint_to_onnx.py",
"repo_id": "diffusers",
"token_count": 4385
} | 111 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/loaders/lora.py/0 | {
"file_path": "diffusers/src/diffusers/loaders/lora.py",
"repo_id": "diffusers",
"token_count": 34909
} | 112 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/autoencoders/autoencoder_asym_kl.py/0 | {
"file_path": "diffusers/src/diffusers/models/autoencoders/autoencoder_asym_kl.py",
"repo_id": "diffusers",
"token_count": 3209
} | 113 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/src/diffusers/models/modeling_pytorch_flax_utils.py/0 | {
"file_path": "diffusers/src/diffusers/models/modeling_pytorch_flax_utils.py",
"repo_id": "diffusers",
"token_count": 3051
} | 114 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/unet_1d_blocks.py/0 | {
"file_path": "diffusers/src/diffusers/models/unet_1d_blocks.py",
"repo_id": "diffusers",
"token_count": 3633
} | 115 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/unets/unet_motion_model.py/0 | {
"file_path": "diffusers/src/diffusers/models/unets/unet_motion_model.py",
"repo_id": "diffusers",
"token_count": 18687
} | 116 |
from dataclasses import dataclass
from typing import List, Union
import numpy as np
import PIL.Image
import torch
from ...utils import BaseOutput
@dataclass
class AnimateDiffPipelineOutput(BaseOutput):
r"""
Output class for AnimateDiff pipelines.
Args:
frames (`List[List[PIL.Image.Image]]` or `... | diffusers/src/diffusers/pipelines/animatediff/pipeline_output.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/animatediff/pipeline_output.py",
"repo_id": "diffusers",
"token_count": 226
} | 117 |
import html
import inspect
import re
import urllib.parse as ul
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from transformers import CLIPImageProcessor, T5EncoderModel, T5Tokenizer
from ...loaders import LoraLoaderMixin
from ...models import UNet2DCond... | diffusers/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img.py",
"repo_id": "diffusers",
"token_count": 18623
} | 118 |
from typing import TYPE_CHECKING
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
_import_structure = {
"mel": ["Mel"],
"pipeline_audio_diffusion": ["AudioDiffusionPipeline"],
}
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
from .mel import Mel
from .pipeline_audio_diffusion import AudioDiffusi... | diffusers/src/diffusers/pipelines/deprecated/audio_diffusion/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/audio_diffusion/__init__.py",
"repo_id": "diffusers",
"token_count": 212
} | 119 |
from typing import TYPE_CHECKING
from ....utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and i... | diffusers/src/diffusers/pipelines/deprecated/stable_diffusion_variants/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/stable_diffusion_variants/__init__.py",
"repo_id": "diffusers",
"token_count": 817
} | 120 |
# Copyright 2023 Microsoft and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless require... | diffusers/src/diffusers/pipelines/deprecated/vq_diffusion/pipeline_vq_diffusion.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/vq_diffusion/pipeline_vq_diffusion.py",
"repo_id": "diffusers",
"token_count": 6463
} | 121 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_controlnet_img2img.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_controlnet_img2img.py",
"repo_id": "diffusers",
"token_count": 7539
} | 122 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/musicldm/pipeline_musicldm.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/musicldm/pipeline_musicldm.py",
"repo_id": "diffusers",
"token_count": 13584
} | 123 |
# Copyright 2023 Open AI and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required ... | diffusers/src/diffusers/pipelines/shap_e/pipeline_shap_e.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/shap_e/pipeline_shap_e.py",
"repo_id": "diffusers",
"token_count": 5793
} | 124 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_depth2img.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_depth2img.py",
"repo_id": "diffusers",
"token_count": 19001
} | 125 |
from typing import TYPE_CHECKING
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and i... | diffusers/src/diffusers/pipelines/stable_diffusion_gligen/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion_gligen/__init__.py",
"repo_id": "diffusers",
"token_count": 613
} | 126 |
from typing import TYPE_CHECKING
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_flax_available,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_additional_imports = {}
_import_structure = {"pipel... | diffusers/src/diffusers/pipelines/stable_diffusion_xl/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion_xl/__init__.py",
"repo_id": "diffusers",
"token_count": 1202
} | 127 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth_img2img.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth_img2img.py",
"repo_id": "diffusers",
"token_count": 17537
} | 128 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen.py",
"repo_id": "diffusers",
"token_count": 9246
} | 129 |
import contextlib
import copy
import random
from typing import Any, Dict, Iterable, List, Optional, Union
import numpy as np
import torch
from .models import UNet2DConditionModel
from .utils import (
convert_state_dict_to_diffusers,
convert_state_dict_to_peft,
deprecate,
is_peft_available,
is_torc... | diffusers/src/diffusers/training_utils.py/0 | {
"file_path": "diffusers/src/diffusers/training_utils.py",
"repo_id": "diffusers",
"token_count": 7930
} | 130 |
# This file is autogenerated by the command `make fix-copies`, do not edit.
from ..utils import DummyObject, requires_backends
class AltDiffusionImg2ImgPipeline(metaclass=DummyObject):
_backends = ["torch", "transformers"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch", "transf... | diffusers/src/diffusers/utils/dummy_torch_and_transformers_objects.py/0 | {
"file_path": "diffusers/src/diffusers/utils/dummy_torch_and_transformers_objects.py",
"repo_id": "diffusers",
"token_count": 18600
} | 131 |
import inspect
from diffusers.utils import is_flax_available
from diffusers.utils.testing_utils import require_flax
if is_flax_available():
import jax
@require_flax
class FlaxModelTesterMixin:
def test_output(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
mo... | diffusers/tests/models/test_modeling_common_flax.py/0 | {
"file_path": "diffusers/tests/models/test_modeling_common_flax.py",
"repo_id": "diffusers",
"token_count": 1124
} | 132 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/tests/others/test_dependencies.py/0 | {
"file_path": "diffusers/tests/others/test_dependencies.py",
"repo_id": "diffusers",
"token_count": 776
} | 133 |
# coding=utf-8
# Copyright 2023 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/audioldm/test_audioldm.py/0 | {
"file_path": "diffusers/tests/pipelines/audioldm/test_audioldm.py",
"repo_id": "diffusers",
"token_count": 7499
} | 134 |
# coding=utf-8
# Copyright 2023 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/i2vgen_xl/test_i2vgenxl.py/0 | {
"file_path": "diffusers/tests/pipelines/i2vgen_xl/test_i2vgenxl.py",
"repo_id": "diffusers",
"token_count": 4207
} | 135 |
# coding=utf-8
# Copyright 2023 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/kandinsky2_2/test_kandinsky_prior_emb2emb.py/0 | {
"file_path": "diffusers/tests/pipelines/kandinsky2_2/test_kandinsky_prior_emb2emb.py",
"repo_id": "diffusers",
"token_count": 3479
} | 136 |
# These are canonical sets of parameters for different types of pipelines.
# They are set on subclasses of `PipelineTesterMixin` as `params` and
# `batch_params`.
#
# If a pipeline's set of arguments has minor changes from one of the common sets
# of arguments, do not make modifications to the existing common sets of a... | diffusers/tests/pipelines/pipeline_params.py/0 | {
"file_path": "diffusers/tests/pipelines/pipeline_params.py",
"repo_id": "diffusers",
"token_count": 1584
} | 137 |
# coding=utf-8
# Copyright 2023 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py",
"repo_id": "diffusers",
"token_count": 13114
} | 138 |
import contextlib
import gc
import inspect
import io
import json
import os
import re
import tempfile
import unittest
import uuid
from typing import Callable, Union
import numpy as np
import PIL.Image
import torch
from huggingface_hub import ModelCard, delete_repo
from huggingface_hub.utils import is_jinja_available
fr... | diffusers/tests/pipelines/test_pipelines_common.py/0 | {
"file_path": "diffusers/tests/pipelines/test_pipelines_common.py",
"repo_id": "diffusers",
"token_count": 24363
} | 139 |
# coding=utf-8
# Copyright 2023 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/wuerstchen/test_wuerstchen_prior.py/0 | {
"file_path": "diffusers/tests/pipelines/wuerstchen/test_wuerstchen_prior.py",
"repo_id": "diffusers",
"token_count": 4397
} | 140 |
import torch
from diffusers import HeunDiscreteScheduler
from diffusers.utils.testing_utils import torch_device
from .test_schedulers import SchedulerCommonTest
class HeunDiscreteSchedulerTest(SchedulerCommonTest):
scheduler_classes = (HeunDiscreteScheduler,)
num_inference_steps = 10
def get_scheduler_... | diffusers/tests/schedulers/test_scheduler_heun.py/0 | {
"file_path": "diffusers/tests/schedulers/test_scheduler_heun.py",
"repo_id": "diffusers",
"token_count": 3279
} | 141 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/utils/check_dummies.py/0 | {
"file_path": "diffusers/utils/check_dummies.py",
"repo_id": "diffusers",
"token_count": 2592
} | 142 |
# Keras Dreambooth event! 🤗
This document summarises all the relevant information required for the event 📋.
## Introduction
Dreambooth is a fine-tuning technique to teach new visual concepts to text-conditioned Diffusion models with just 3-5 images. With Dreambooth, you could generate funny and realistic images ... | diffusion-models-class/units/en/events/3.mdx/0 | {
"file_path": "diffusion-models-class/units/en/events/3.mdx",
"repo_id": "diffusion-models-class",
"token_count": 3063
} | 143 |
- title: Introduction au cours
sections:
- local: unit0/1
title: Introduction
- title: 1. Introduction aux modèles de diffusion
sections:
- local: unit1/1
title: Vue d'ensemble
- local: unit1/2
title: Introduction à 🤗 Diffusers
- local: unit1/3
title: Implémentation à partir de 0
- title:... | diffusion-models-class/units/fr/_toctree.yml/0 | {
"file_path": "diffusion-models-class/units/fr/_toctree.yml",
"repo_id": "diffusion-models-class",
"token_count": 494
} | 144 |
<jupyter_start><jupyter_text>Manipulation de plusieurs séquences (TensorFlow) Installez la bibliothèque 🤗 *Transformers* pour exécuter ce *notebook*.<jupyter_code>!pip install transformers[sentencepiece]
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
checkpoint = ... | notebooks/course/fr/chapter2/section5_tf.ipynb/0 | {
"file_path": "notebooks/course/fr/chapter2/section5_tf.ipynb",
"repo_id": "notebooks",
"token_count": 810
} | 145 |
<jupyter_start><jupyter_text>Données massives ? 🤗 Datasets à la rescousse ! Installez les bibliothèques 🤗 Transformers et 🤗 Datasets pour exécuter ce *notebook*.<jupyter_code>!pip install datasets evaluate transformers[sentencepiece]
!pip install zstandard
from datasets import load_dataset
# Cela prend quelques min... | notebooks/course/fr/chapter5/section4.ipynb/0 | {
"file_path": "notebooks/course/fr/chapter5/section4.ipynb",
"repo_id": "notebooks",
"token_count": 1168
} | 146 |
<jupyter_start><jupyter_text>Classification de token (TensorFlow) Installez les bibliothèques 🤗 *Datasets*, 🤗 *Transformers* et 🤗 *Accelerate* pour exécuter ce *notebook*.<jupyter_code>!pip install datasets transformers[sentencepiece]
!apt install git-lfs<jupyter_output><empty_output><jupyter_text>Vous aurez besoin... | notebooks/course/fr/chapter7/section2_tf.ipynb/0 | {
"file_path": "notebooks/course/fr/chapter7/section2_tf.ipynb",
"repo_id": "notebooks",
"token_count": 2616
} | 147 |
<jupyter_start><jupyter_text>You will need an authentication token with your Hugging Face credentials to use the `push_to_hub` method. Execute `huggingface-cli login` in your terminal or by uncommenting the following cell:<jupyter_code># !huggingface-cli login
import numpy as np
from datasets import load_dataset, load... | notebooks/course/videos/push_to_hub_new.ipynb/0 | {
"file_path": "notebooks/course/videos/push_to_hub_new.ipynb",
"repo_id": "notebooks",
"token_count": 1284
} | 148 |
<jupyter_start><jupyter_text>Image2Image Pipeline for Stable Diffusion using 🧨 Diffusers This notebook shows how to create a custom `diffusers` pipeline for text-guided image-to-image generation with Stable Diffusion model using 🤗 Hugging Face [🧨 Diffusers library](https://github.com/huggingface/diffusers). For a ... | notebooks/diffusers/image_2_image_using_diffusers.ipynb/0 | {
"file_path": "notebooks/diffusers/image_2_image_using_diffusers.ipynb",
"repo_id": "notebooks",
"token_count": 1520
} | 149 |
<jupyter_start><jupyter_text>Pre-Training a 🤗 Transformers model on TPU with **Flax/JAX**In this notebook, we will see how to pretrain one of the [🤗 Transformers](https://github.com/huggingface/transformers) models on TPU using [**Flax**](https://flax.readthedocs.io/en/latest/index.html). GPT2's causal language model... | notebooks/examples/causal_language_modeling_flax.ipynb/0 | {
"file_path": "notebooks/examples/causal_language_modeling_flax.ipynb",
"repo_id": "notebooks",
"token_count": 8784
} | 150 |
<jupyter_start><jupyter_text>Multivariate Probabilistic Time Series Forecasting with Informer IntroductionA few months ago we introduced the [Time Series Transformer](https://huggingface.co/blog/time-series-transformers), which is the vanilla Transformer ([Vaswani et al., 2017](https://arxiv.org/abs/1706.03762)) applie... | notebooks/examples/multivariate_informer.ipynb/0 | {
"file_path": "notebooks/examples/multivariate_informer.ipynb",
"repo_id": "notebooks",
"token_count": 15125
} | 151 |
<jupyter_start><jupyter_text>If you're opening this Notebook on colab, you will probably need to install 🤗 Transformers and 🤗 Datasets as well as other dependencies. Uncomment the following cell and run it. Note the `rouge-score` and `nltk` dependencies - even if you've used 🤗 Transformers before, you may not have t... | notebooks/examples/summarization-tf.ipynb/0 | {
"file_path": "notebooks/examples/summarization-tf.ipynb",
"repo_id": "notebooks",
"token_count": 8798
} | 152 |
<jupyter_start><jupyter_text>If you're opening this Notebook on colab, you will probably need to install 🤗 Transformers and 🤗 Datasets. Uncomment the following cell and run it.<jupyter_code>#! pip install datasets transformers[sentencepiece] sacrebleu<jupyter_output><empty_output><jupyter_text>If you're opening this ... | notebooks/examples/translation.ipynb/0 | {
"file_path": "notebooks/examples/translation.ipynb",
"repo_id": "notebooks",
"token_count": 5285
} | 153 |
<jupyter_start><jupyter_text>Huggingface Sagemaker-sdk - training with custom metrics Binary Classification with `Trainer` and `imdb` dataset In this demo, we extend the basic classification demo by adding **metrics definition** to capture and visualize training metrics.The documentation of the SageMaker metrics captur... | notebooks/sagemaker/06_sagemaker_metrics/sagemaker-notebook.ipynb/0 | {
"file_path": "notebooks/sagemaker/06_sagemaker_metrics/sagemaker-notebook.ipynb",
"repo_id": "notebooks",
"token_count": 3000
} | 154 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.