
organization string | repo_name string | base_commit string | iss_html_url string | iss_label string | title string | body string | code null | pr_html_url string | commit_html_url string | file_loc string | own_code_loc list | ass_file_loc list | other_rep_loc list | analysis dict | loctype dict | iss_has_pr int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
ansible | ansible | f8d20f970f16806aee1ef555f9f2db115cec7f34 | https://github.com/ansible/ansible/issues/36293 | cloud
aws
module
affects_2.4
support:core
bug | Add support for Timeout (--timeout-in-minutes) parameter in Cloudformation module | ##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
Cloudformation module
##### ANSIBLE VERSION
<!--- Paste verbatim output from "ansible --version" between quotes below -->
```
ansible 2.4.2.0
config file = /etc/ansible/ansible.cfg
configured module search path = [u'/home/ubuntu/.ansible/plugins/m... | null | https://github.com/ansible/ansible/pull/36445 | null | {'base_commit': 'f8d20f970f16806aee1ef555f9f2db115cec7f34', 'files': [{'path': 'lib/ansible/modules/cloud/amazon/cloudformation.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [32, 209]}, "(None, 'create_stack', 300)": {'add': [306], 'mod': [304, 305]}, "(None, 'main', 535)": {'add': [544]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"lib/ansible/modules/cloud/amazon/cloudformation.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
scikit-learn | scikit-learn | abb31d0a7ca769a1e6406553a58a7fb0bd3b259a | https://github.com/scikit-learn/scikit-learn/issues/4744 | Bug | Bug with using TreeClassifier with OOB score and sparse matrices | When using the ExtraTreesClassifier (and likely other classes that are derived from BaseTreeClassifier), there is a problem when using sparsematrices: `ValueError: X should be in csr_matrix format, got <class 'scipy.sparse.csc.csc_matrix'>`.
I tracked the issue down to the following lines:
On line 195 of forest.py th... | null | https://github.com/scikit-learn/scikit-learn/pull/4954 | null | {'base_commit': 'abb31d0a7ca769a1e6406553a58a7fb0bd3b259a', 'files': [{'path': 'doc/whats_new.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [114]}}}, {'path': 'sklearn/ensemble/forest.py', 'status': 'modified', 'Loc': {"('ForestClassifier', '_set_oob_score', 374)": {'add': [375]}, "('ForestRegressor... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"sklearn/ensemble/forest.py"
],
"doc": [
"doc/whats_new.rst"
],
"test": [
"sklearn/ensemble/tests/test_forest.py"
],
"config": [],
"asset": []
} | 1 |
fastapi | fastapi | 543ef7753aff639ad3aed7c153e42f719e361d38 | https://github.com/fastapi/fastapi/issues/737 | bug
answered
reviewed | dependency_overrides does not play well with scopes | **Describe the bug**
When working with `Security()` dependencies, the scopes disappear when `app.dependency_overrides` is executed. The callable dealing with the scopes gets an empty list instead of the scopes.
**To Reproduce**
```python
from fastapi import FastAPI, Header, Security, Depends
from fastapi.secur... | null | https://github.com/fastapi/fastapi/pull/1549 | null | {'base_commit': '543ef7753aff639ad3aed7c153e42f719e361d38', 'files': [{'path': 'fastapi/dependencies/utils.py', 'status': 'modified', 'Loc': {"(None, 'solve_dependencies', 432)": {'add': [480]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": null,
"info_type": null
} | {
"code": [
"fastapi/dependencies/utils.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
ultralytics | yolov5 | 1e95337f3aec4c12244802bb6e493b07b27aa795 | https://github.com/ultralytics/yolov5/issues/459 | bug | custom anchors get flushed when loading pretrain weights | Before submitting a bug report, please be aware that your issue **must be reproducible** with all of the following, otherwise it is non-actionable, and we can not help you:
- **Current repo**: run `git fetch && git status -uno` to check and `git pull` to update repo
- **Common dataset**: coco.yaml or coco128.yaml
... | null | https://github.com/ultralytics/yolov5/pull/462 | null | {'base_commit': '1e95337f3aec4c12244802bb6e493b07b27aa795', 'files': [{'path': 'train.py', 'status': 'modified', 'Loc': {"(None, 'train', 46)": {'add': [132, 135], 'mod': [134]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"train.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
AntonOsika | gpt-engineer | 65d7a9b9902ad85f27b17d759bd13b59c2afc474 | https://github.com/AntonOsika/gpt-engineer/issues/589 | "No API key provided" - altough it is provided in the .env file | ## Expected Behavior
If the OpenAI API key is provided in the .env file, it should be recognized and used.
## Current Behavior
Runtime error message: openai.error.AuthenticationError: No API key provided.
### Steps to Reproduce
1. Set the key in the .env file
2. Run the app with gpt-engineer projects/my... | null | https://github.com/AntonOsika/gpt-engineer/pull/592 | null | {'base_commit': '65d7a9b9902ad85f27b17d759bd13b59c2afc474', 'files': [{'path': 'gpt_engineer/main.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [5]}, "(None, 'load_env_if_needed', 19)": {'add': [21]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"gpt_engineer/main.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
scrapy | scrapy | 57dc58123b98e2026025cc87bdee474bf0656dcb | https://github.com/scrapy/scrapy/issues/4976 | bug
Windows | Fix and document asyncio reactor problems on Windows | As described in https://twistedmatrix.com/trac/ticket/9766 you cannot just enable AsyncioSelectorReactor on Windows with recent Python, you either need fixed Twisted (which is not released yet, the merged fix is https://github.com/twisted/twisted/pull/1338) or, supposedly, add some manual fix as documented [here](https... | null | https://github.com/scrapy/scrapy/pull/5315 | null | {'base_commit': '57dc58123b98e2026025cc87bdee474bf0656dcb', 'files': [{'path': '.github/workflows/tests-windows.yml', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [25]}}}, {'path': 'docs/topics/asyncio.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [38]}}}, {'path': 'scrapy/utils/react... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"scrapy/utils/reactor.py",
"tests/CrawlerProcess/asyncio_enabled_reactor.py"
],
"doc": [
"docs/topics/asyncio.rst"
],
"test": [
"tests/test_utils_asyncio.py",
"tests/test_crawler.py",
"tests/test_commands.py",
"tests/test_downloader_handlers.py"
],
"config": [
"... | 1 |
pandas-dev | pandas | 9b4dfa195e3f23d81389745c26bff8e0087e74b0 | https://github.com/pandas-dev/pandas/issues/22046 | Bug
Indexing | Replacing multiple columns (or just one) with iloc does not work | #### Code Sample, a copy-pastable example if possible
```python
import pandas
columns = pandas.DataFrame({'a2': [11, 12, 13], 'b2': [14, 15, 16]})
inputs = pandas.DataFrame({'a1': [1, 2, 3], 'b1': [4, 5, 6], 'c1': [7, 8, 9]})
inputs.iloc[:, [1]] = columns.iloc[:, [0]]
print(inputs)
```
#### Problem de... | null | https://github.com/pandas-dev/pandas/pull/37728 | null | {'base_commit': '9b4dfa195e3f23d81389745c26bff8e0087e74b0', 'files': [{'path': 'doc/source/whatsnew/v1.2.0.rst', 'status': 'modified', 'Loc': {'(None, None, 591)': {'add': [591]}}}, {'path': 'pandas/core/indexing.py', 'status': 'modified', 'Loc': {"('_LocationIndexer', '__setitem__', 675)": {'mod': [684]}, "('_iLocInde... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"pandas/core/indexing.py"
],
"doc": [
"doc/source/whatsnew/v1.2.0.rst"
],
"test": [
"pandas/tests/frame/indexing/test_setitem.py",
"pandas/tests/indexing/test_indexing.py",
"pandas/tests/indexing/test_iloc.py"
],
"config": [],
"asset": []
} | null |
geekan | MetaGPT | 5446c7e490e7203c61b2ff31181551b2c0f4a86b | https://github.com/geekan/MetaGPT/issues/1430 | DO NOT FORCE VALIDATE '{'Required Python packages'}' by default | **Bug description**
`metagpt\actions\action_node.py", line 432, in _aask_v1
instruct_content = output_class(**parsed_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "..........\Lib\site-packages\pydantic\main.py", line 171, in __init__
self.__pydantic_validator__.validate_python(data, self_... | null | https://github.com/FoundationAgents/MetaGPT/pull/1435 | null | {'base_commit': '5446c7e490e7203c61b2ff31181551b2c0f4a86b', 'files': [{'path': 'metagpt/actions/design_api_an.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [47], 'mod': [8, 50, 69]}}}, {'path': 'metagpt/actions/project_management_an.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [8,... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"metagpt/actions/design_api_an.py",
"metagpt/actions/project_management_an.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | null | |
CorentinJ | Real-Time-Voice-Cloning | 5425557efe30863267f805851f918124191e0be0 | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/447 | dependencies | Pytorch synthesizer | Splitting this off from #370, which will remain for tensorflow2 conversion. I would prefer this route if we can get it to work. Asking for help from the community on this one.
One example of a pytorch-based tacotron is: https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2
A... | null | https://github.com/CorentinJ/Real-Time-Voice-Cloning/pull/472 | null | {'base_commit': '5425557efe30863267f805851f918124191e0be0', 'files': [{'path': 'README.md', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [18, 23, 24, 65, 66, 68, 70]}}}, {'path': 'demo_cli.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [13, 43, 162], 'mod': [24, 25, 26, 30, 31, 32, 70, ... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"synthesizer/models/modules.py",
"synthesizer/models/tacotron.py",
"synthesizer/train.py",
"synthesizer/models/attention.py",
"synthesizer_train.py",
"demo_cli.py",
"toolbox/__init__.py",
"demo_toolbox.py",
"synthesizer/models/architecture_wrappers.py",
"synthesizer... | 1 |
OpenInterpreter | open-interpreter | 3c922603c0a7d1ad4113245a3d2bcd23bf4b1619 | https://github.com/OpenInterpreter/open-interpreter/issues/875 | Bug | NameError: name 'computer' is not defined | ### Describe the bug
When I run `interpreter --os`
And then attempt a command like:
`Play a boiler room set on youtube`
I get a `NameError`:
```
▌ OS Control enabled ... | null | https://github.com/OpenInterpreter/open-interpreter/pull/937 | null | {'base_commit': '3c922603c0a7d1ad4113245a3d2bcd23bf4b1619', 'files': [{'path': 'interpreter/core/computer/terminal/terminal.py', 'status': 'modified', 'Loc': {"('Terminal', 'run', 36)": {'mod': [40]}}}, {'path': 'interpreter/terminal_interface/start_terminal_interface.py', 'status': 'modified', 'Loc': {'(None, None, No... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"interpreter/core/computer/terminal/terminal.py",
"interpreter/terminal_interface/start_terminal_interface.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
oobabooga | text-generation-webui | ad14f0e49929d426560413c0b9de19986cbeac9e | https://github.com/oobabooga/text-generation-webui/issues/461 | bug | SileroTTS creates new audio file for each token | ### Describe the bug
I've just performed a fresh install to confirm this.
Unless i turn on no stream, SileroTTS will attempt to create an audio file for each word / token.
Silero should not attempt to create audio until the response is complete.
Silero extension output directory is being filled up with aud... | null | https://github.com/oobabooga/text-generation-webui/pull/192 | null | {'base_commit': 'ad14f0e49929d426560413c0b9de19986cbeac9e', 'files': [{'path': 'extensions/silero_tts/script.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [0, 5, 14, 35], 'mod': [10, 18]}, "(None, 'input_modifier', 36)": {'add': [41]}, "(None, 'output_modifier', 44)": {'add': [59, 65, 67], 'mod': [49... | [] | [] | [] | {
"iss_type": "3",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"extensions/silero_tts/script.py",
"modules/shared.py",
"modules/text_generation.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
pandas-dev | pandas | 896256ee02273bebf723428ee41cab31930a69f4 | https://github.com/pandas-dev/pandas/issues/41423 | Docs
good first issue | DOC: pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False) | No proper information on "copy" is present under [Documentation](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.html) | null | https://github.com/pandas-dev/pandas/pull/41514 | null | {'base_commit': '896256ee02273bebf723428ee41cab31930a69f4', 'files': [{'path': 'pandas/core/series.py', 'status': 'modified', 'Loc': {"('Series', None, 194)": {'add': [253], 'mod': [226]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"pandas/core/series.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
deepfakes | faceswap | 917acaa4524e0195c52a636fccf6a0de4eedd37b | https://github.com/deepfakes/faceswap/issues/1170 | docker | CUDA version incorrect in Dockerfile.gpu | The Dockerfile.gpu doesn't work for me. The built doesn't use GPU at all.
I found that tensorflow cannot find shared library file libXXXX.so.11.0 (If I remember correctly, it's libcudart.so.11.0). I realize that the tensorflow version installed needs CUDA 11.0. But the original Dockerfile.gpu installs the CUDA 10.1.... | null | https://github.com/deepfakes/faceswap/pull/1232 | null | {'base_commit': '917acaa4524e0195c52a636fccf6a0de4eedd37b', 'files': [{'path': 'Dockerfile.gpu', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [1, 22]}}}, {'path': 'INSTALL.md', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [39, 279, 285], 'mod': [237, 239, 240, 241, 242, 243, 244, 245, 246,... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [
"INSTALL.md"
],
"test": [],
"config": [
"Dockerfile.gpu"
],
"asset": []
} | 1 |
All-Hands-AI | OpenHands | 9908e1b28525fe96394446be95fcb00785d0ca0c | https://github.com/All-Hands-AI/OpenHands/issues/5365 | bug | [Bug]: Editing Error "No replacement was performed" is not informative enough | ### Is there an existing issue for the same bug?
- [X] I have checked the existing issues.
### Describe the bug and reproduction steps
The agent got this error:
```
ERROR:
No replacement was performed. Multiple occurrences of old_str ` output_path = Path.joinpath(self._output_dir, "recipe_state.pt")
... | null | https://github.com/All-Hands-AI/OpenHands/pull/5397 | null | {'base_commit': '9908e1b28525fe96394446be95fcb00785d0ca0c', 'files': [{'path': 'openhands/runtime/action_execution_server.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [11, 13]}, "('ActionExecutor', 'run_ipython', 178)": {'add': [201]}}}, {'path': 'poetry.lock', 'status': 'modified', 'Loc': {'(None, ... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"openhands/runtime/action_execution_server.py"
],
"doc": [],
"test": [
"tests/unit/test_agent_skill.py"
],
"config": [
"poetry.lock",
"pyproject.toml"
],
"asset": []
} | 1 |
pandas-dev | pandas | fa78ea801392f4f0d37ea7ddbbfe44e9c8c102bd | https://github.com/pandas-dev/pandas/issues/49647 | Code Style
good first issue | STYLE place standard library imports at top of file | Imports should typically be placed at the top of files. Sometimes, imports are placed inside functions to:
- avoid circular imports
- avoid `ImportError` if it's an optional dependency
Standard library imports should really always be at the top of files.
Noticed in https://github.com/pandas-dev/pandas/pull/4964... | null | https://github.com/pandas-dev/pandas/pull/50116 | null | {'base_commit': 'fa78ea801392f4f0d37ea7ddbbfe44e9c8c102bd', 'files': [{'path': 'pandas/tests/apply/test_series_apply.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [4]}, "(None, 'test_apply', 35)": {'mod': [40]}, "(None, 'test_map_decimal', 527)": {'mod': [528]}}}, {'path': 'pandas/tests/arrays/test_d... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [],
"test": [
"pandas/tests/arrays/test_datetimelike.py",
"pandas/tests/frame/methods/test_to_records.py",
"pandas/tests/indexes/test_common.py",
"pandas/tests/groupby/test_timegrouper.py",
"pandas/tests/reshape/test_get_dummies.py",
"pandas/tests/groupby/test_grouping... | 1 |
pallets | flask | 024f0d384cf5bb65c76ac59f8ddce464b2dc2ca1 | https://github.com/pallets/flask/issues/3555 | json | Remove simplejson | In modern Python it's unlikely to be significantly better than the built-in `json`. The module used by `JSONMixin` is overridable, so users can plug it in again if they want.
See pallets/itsdangerous#146 and pallets/werkzeug#1766. | null | https://github.com/pallets/flask/pull/3562 | null | {'base_commit': '024f0d384cf5bb65c76ac59f8ddce464b2dc2ca1', 'files': [{'path': 'CHANGES.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [8]}}}, {'path': 'docs/api.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [287, 288, 289, 290, 291, 293, 295, 296, 297, 298, 300, 302, 304, 305, 30... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"src/flask/json/__init__.py",
"src/flask/json/tag.py"
],
"doc": [
"docs/api.rst",
"docs/installation.rst",
"CHANGES.rst"
],
"test": [
"tests/test_helpers.py"
],
"config": [
"tox.ini"
],
"asset": []
} | 1 |
3b1b | manim | 384895b9a8da0fcdb3b92868fb5965c5e6de1ed5 | https://github.com/3b1b/manim/issues/293 | Outdated DockerFile dependencies | The DockerFile inside the manim-master still contains the python version 2.7.12. Considering that manim had no longer support the python 2. This could lead to a syntax error. Please fix this issue ASAP. | null | https://github.com/3b1b/manim/pull/301 | null | {'base_commit': '384895b9a8da0fcdb3b92868fb5965c5e6de1ed5', 'files': [{'path': 'Dockerfile', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [7, 13], 'mod': [1, 2, 3, 4, 6, 9, 10, 11, 12, 15, 16, 18, 19, 20, 22]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [],
"test": [],
"config": [
"Dockerfile"
],
"asset": []
} | 1 | |
yt-dlp | yt-dlp | 3699eeb67cad333272b14a42dd3843d93fda1a2e | https://github.com/yt-dlp/yt-dlp/issues/9567 | site-bug | [TikTok] New API fix adds non-playable video codec in available formats | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [X] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [X] I'm reporting that yt-dlp is broken on a **supported** site
- [X] I've verified that I have **updated yt-dlp to nightly or master** ([update instruc... | null | https://github.com/yt-dlp/yt-dlp/pull/9575 | null | {'base_commit': '3699eeb67cad333272b14a42dd3843d93fda1a2e', 'files': [{'path': 'yt_dlp/extractor/tiktok.py', 'status': 'modified', 'Loc': {"('TikTokBaseIE', 'extract_addr', 275)": {'add': [276, 288], 'mod': [290]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"yt_dlp/extractor/tiktok.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
xtekky | gpt4free | 0d8e4ffa2c0706b0381f53c3985d04255b7170f5 | https://github.com/xtekky/gpt4free/issues/2173 | bug
stale | Disable g4f logging completely | **Bug description**
In my script I have my customized logging, but whenever I use it it prints 2 times (one from my logger, one from g4f logger).
How can I turn off the logger inside the library? Already tried a bunch of stuff with no results.
P.S. Are you using the root logger maybe? If that is the case, please u... | null | https://github.com/xtekky/gpt4free/pull/2347 | null | {'base_commit': '0d8e4ffa2c0706b0381f53c3985d04255b7170f5', 'files': [{'path': 'g4f/Provider/Ai4Chat.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [11]}, "('Ai4Chat', 'create_async_generator', 37)": {'mod': [87]}}}, {'path': 'g4f/Provider/Mhystical.py', 'status': 'modified', 'Loc': {'(None, None, Non... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"g4f/Provider/Ai4Chat.py",
"g4f/Provider/Mhystical.py",
"g4f/Provider/you/har_file.py",
"setup.py",
"g4f/api/__init__.py",
"g4f/__init__.py",
"g4f/gui/server/api.py",
"g4f/api/_logging.py"
],
"doc": [],
"test": [],
"config": [
"requirements.txt"
],
"asset": ... | 1 |
pandas-dev | pandas | 324208eaa66a528f1e88f938c71c2d8efb8304f3 | https://github.com/pandas-dev/pandas/issues/5420 | Bug
Docs
Indexing | BUG: loc should not fallback for integer indexing for multi-index | https://groups.google.com/forum/m/#!topic/pydata/W0e3l0UvNwI
| null | https://github.com/pandas-dev/pandas/pull/7497 | null | {'base_commit': '324208eaa66a528f1e88f938c71c2d8efb8304f3', 'files': [{'path': 'doc/source/v0.14.1.txt', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [64]}}}, {'path': 'pandas/core/index.py', 'status': 'modified', 'Loc': {"('Index', '_convert_list_indexer_for_mixed', 607)": {'mod': [612]}}}, {'path': 'pa... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"pandas/core/index.py"
],
"doc": [
"doc/source/v0.14.1.txt"
],
"test": [
"pandas/tests/test_indexing.py"
],
"config": [],
"asset": []
} | 1 |
pandas-dev | pandas | 6d2c57fa010c12f21f700034b5651519670b9b9d | https://github.com/pandas-dev/pandas/issues/3561 | Bug
Indexing | DataFrame.ix losing row ordering when index has duplicates | ``` python
import pandas as pd
ind = ['A', 'A', 'B', 'C']i
df = pd.DataFrame({'test':range(len(ind))}, index=ind)
rows = ['C', 'B']
res = df.ix[rows]
assert rows == list(res.index) # fails
```
The problem is that the resulting DataFrame keeps the ordering of the `df.index` and not the `rows` key. You'll notice that ... | null | https://github.com/pandas-dev/pandas/pull/3563 | null | {'base_commit': '6d2c57fa010c12f21f700034b5651519670b9b9d', 'files': [{'path': 'RELEASE.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [93, 150]}}}, {'path': 'doc/source/indexing.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [1370]}}}, {'path': 'pandas/core/index.py', 'status': 'm... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"pandas/index.pyx",
"pandas/core/index.py",
"pandas/core/indexing.py",
"pandas/lib.pyx"
],
"doc": [
"doc/source/indexing.rst",
"RELEASE.rst"
],
"test": [
"pandas/tests/test_indexing.py",
"pandas/tests/test_frame.py"
],
"config": [],
"asset": []
} | 1 |
All-Hands-AI | OpenHands | ce8a11a62f8a126ed54dd0ede51cf2c196ed310d | https://github.com/All-Hands-AI/OpenHands/issues/2977 | good first issue
frontend
severity:low
small effort | Rename and/or properly document the two different `changeAgentState` functions | There are two `changeAgentState` functions that should probably be renamed and properly documented to avoid confusion for the future.
https://github.com/OpenDevin/OpenDevin/blob/01ce1e35b5b40e57d96b15a7fc9bee4eb8f6966d/frontend/src/state/agentSlice.tsx#L10-L12
https://github.com/OpenDevin/OpenDevin/blob/01ce1e35b... | null | https://github.com/All-Hands-AI/OpenHands/pull/3050 | null | {'base_commit': 'ce8a11a62f8a126ed54dd0ede51cf2c196ed310d', 'files': [{'path': 'frontend/src/services/observations.ts', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [1]}, "(None, 'handleObservationMessage', 10)": {'mod': [28]}}}, {'path': 'frontend/src/state/agentSlice.tsx', 'status': 'modified', 'Loc': ... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"frontend/src/state/agentSlice.tsx",
"frontend/src/services/observations.ts"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
deepfakes | faceswap | 9438672b1cf80602fc93536670d9601d655377f5 | https://github.com/deepfakes/faceswap/issues/224 | feature | Align rotation of input faces for GAN conversions | Currently, the extractor finds a rotation matrix for each face using umeyama so it can generate a faceset with all the faces mostly upright. Unfortunately this rotation matrix isn't stored in the alignments file, only the bbox (of the un-rotated face) and facial alignments. For the GAN model, when it comes time to conv... | null | https://github.com/deepfakes/faceswap/pull/217 | null | {'base_commit': '9438672b1cf80602fc93536670d9601d655377f5', 'files': [{'path': 'faceswap.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [8]}}}, {'path': 'lib/ModelAE.py', 'status': 'removed', 'Loc': {}}, {'path': 'lib/cli.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [2, 17]}}}, {'p... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"lib/training_data.py",
"plugins/Convert_Adjust.py",
"plugins/Convert_GAN.py",
"plugins/Extract_Align.py",
"plugins/Model_GAN/Model.py",
"plugins/Model_LowMem.py",
"scripts/train.py",
"faceswap.py",
"plugins/Model_Original.py",
"plugins/Convert_Masked.py",
"plug... | 1 |
scrapy | scrapy | 2bf09b8a2026b79b11d178d391327035dde9f948 | https://github.com/scrapy/scrapy/issues/710 | item_dropped signal should pass response arg as item_scraped does | I highly use request and response.meta in item_scraped signal handler.
Why item_dropped doesn't pass response argument as well as item_scraper does?
| null | https://github.com/scrapy/scrapy/pull/724 | null | {'base_commit': '2bf09b8a2026b79b11d178d391327035dde9f948', 'files': [{'path': 'docs/topics/signals.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [98], 'mod': [86]}}}, {'path': 'scrapy/core/scraper.py', 'status': 'modified', 'Loc': {"('Scraper', '_itemproc_finished', 198)": {'mod': [208]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"scrapy/core/scraper.py"
],
"doc": [
"docs/topics/signals.rst"
],
"test": [],
"config": [],
"asset": []
} | 1 | |
comfyanonymous | ComfyUI | f81dbe26e2e363c28ad043db67b59c11bb33f446 | https://github.com/comfyanonymous/ComfyUI/issues/2851 | Differential Diffusion: Giving Each Pixel Its Strength | Hello,
I would like to suggest implementing my paper: Differential Diffusion: Giving Each Pixel Its Strength.
The paper allows a user to edit a picture by a change map that describes how much each region should change.
The editing process is typically guided by textual instructions, although it can also be applied w... | null | https://github.com/comfyanonymous/ComfyUI/pull/2876 | null | {'base_commit': 'f81dbe26e2e363c28ad043db67b59c11bb33f446', 'files': [{'path': 'comfy/samplers.py', 'status': 'modified', 'Loc': {"('KSamplerX0Inpaint', 'forward', 277)": {'add': [278]}}}, {'path': 'nodes.py', 'status': 'modified', 'Loc': {"(None, 'init_custom_nodes', 1936)": {'add': [1963]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"nodes.py",
"comfy/samplers.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
pandas-dev | pandas | bcc5160b3a5b0fc9c531da194c6bb83619045434 | https://github.com/pandas-dev/pandas/issues/18734 | good first issue
Needs Tests | ddof for np.std in df.agg changes depending on how given & lambda expression does not work correctly in a list of functions | #### Code Sample, a copy-pastable example if possible
```python
In [31]: import numpy as np
In [32]: import pandas as pd
In [33]: df = pd.DataFrame(np.arange(6).reshape(3, 2), columns=['A', 'B'])
In [34]: df
Out[34]:
A B
0 0 1
1 2 3
2 4 5
In [35]: df.agg(np.std) # Behavior of ddof=0
Out... | null | https://github.com/pandas-dev/pandas/pull/52371 | null | {'base_commit': 'bcc5160b3a5b0fc9c531da194c6bb83619045434', 'files': [{'path': 'pandas/tests/apply/test_frame_apply.py', 'status': 'modified', 'Loc': {"(None, 'test_agg_list_like_func_with_args', 1648)": {'add': [1667]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [],
"test": [
"pandas/tests/apply/test_frame_apply.py"
],
"config": [],
"asset": []
} | 1 |
scikit-learn | scikit-learn | c13703c8dfb7324a05a82e8befe9b203a6590257 | https://github.com/scikit-learn/scikit-learn/issues/29742 | Bug
Sprint | spin docs --no-plot runs the examples | Seen at the EuroScipy sprint
Commands run by spin:
```
$ export SPHINXOPTS=-W -D plot_gallery=0 -j auto
$ cd doc
$ make html
```
Looks like our Makefile does not use SPHINXOPTS the same way as expected:
Probably we have a slightly different way of building the doc
```
❯ make html-noplot -n
sphinx-build... | null | https://github.com/scikit-learn/scikit-learn/pull/29744 | null | {'base_commit': 'c13703c8dfb7324a05a82e8befe9b203a6590257', 'files': [{'path': 'doc/Makefile', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [68], 'mod': [5]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [
"doc/Makefile"
],
"test": [],
"config": [],
"asset": []
} | 1 |
huggingface | transformers | 147c8166852db64de12b851b8307f44c9e8fe0dd | https://github.com/huggingface/transformers/issues/15640 | Add support for ONNX-TensorRT conversion for GPT-J6B (and possible bug in rotary embedding) | ### Who can help
@patil-suraj
## Information
Model I am using: GPT-J
The problem arises when using:
* [x] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
## Description
I opened this issue for two reasons:
1. This is not strictly a bug report, rat... | null | https://github.com/huggingface/transformers/pull/16492 | null | {'base_commit': '147c8166852db64de12b851b8307f44c9e8fe0dd', 'files': [{'path': 'src/transformers/models/gptj/modeling_gptj.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [64]}, "(None, 'apply_rotary_pos_emb', 65)": {'mod': [66]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"src/transformers/models/gptj/modeling_gptj.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
deepfakes | faceswap | 5007d8e996cbe6c23dcf2b5792775d8fde104128 | https://github.com/deepfakes/faceswap/issues/252 | added image sort tool to faceswap | I added image sort tool to faceswap, which very useful to extract one face from various faces
Example original aligned folder:

Sort it by similarity:
`python.exe faceswap\sorttool... | null | https://github.com/deepfakes/faceswap/pull/255 | null | {'base_commit': '5007d8e996cbe6c23dcf2b5792775d8fde104128', 'files': [{'path': 'plugins/PluginLoader.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [0]}, "('PluginLoader', '_import', 20)": {'add': [23]}}}, {'path': 'scripts/convert.py', 'status': 'modified', 'Loc': {"('ConvertImage', 'add_optional_arg... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "0",
"info_type": "Code"
} | {
"code": [
"scripts/train.py",
"scripts/convert.py",
"plugins/PluginLoader.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
xtekky | gpt4free | b615a95a417d8a857b1f822bd2d2f993737d532a | https://github.com/xtekky/gpt4free/issues/1347 | bug | Bing stopped working | **Bug description**
Yesterday, Bing still worked, but today brings up only:
```
Using Bing provider
0, message='Attempt to decode JSON with unexpected mimetype: text/html; charset=utf-8', url=URL('https://www.bing.com/turing/conversation/create?bundleVersion=1.1381.8')
127.0.0.1 - - [14/Dec/2023 20:22:32] "POST /b... | null | https://github.com/xtekky/gpt4free/pull/1356 | null | {'base_commit': 'b615a95a417d8a857b1f822bd2d2f993737d532a', 'files': [{'path': 'g4f/Provider/Bing.py', 'status': 'modified', 'Loc': {"(None, 'stream_generate', 432)": {'mod': [442, 443]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"g4f/Provider/Bing.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
psf | requests | 95161ed313db11296c3bd473336340dbb19bb347 | https://github.com/psf/requests/issues/1995 | Planned
Contributor Friendly | Create an Extra for Better SSL Support | So right now the SSL connections when you use pyOpenSSL, ndg-httspclient, and pyasn1 are more secure than if you just use the stdlib options. However it's hard to actually remember those three things. It would be cool if requests would add an extra to it's setup.py so that people can install requests with betterssl, so... | null | https://github.com/psf/requests/pull/2195 | null | {'base_commit': '95161ed313db11296c3bd473336340dbb19bb347', 'files': [{'path': 'setup.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [62]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"setup.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
AUTOMATIC1111 | stable-diffusion-webui | 458eda13211ac3498485f1e5154d90808fbcfb60 | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/12104 | bug | [Bug]: Generating using LoRA fails with Runtime Error with `Lora/Networks: use old method` enabled | ### Is there an existing issue for this?
- [x] I have searched the existing issues and checked the recent builds/commits
### What happened?
I'm on commit 68f336bd994bed5442ad95bad6b6ad5564a5409a, master HEAD at time of posting.
None of my LORAs seem to be working anymore. Normal prompting works fine, but as soon as... | null | https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/12466 | null | {'base_commit': '458eda13211ac3498485f1e5154d90808fbcfb60', 'files': [{'path': 'extensions-builtin/Lora/networks.py', 'status': 'modified', 'Loc': {"(None, 'network_forward', 338)": {'mod': [360]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"extensions-builtin/Lora/networks.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
scikit-learn | scikit-learn | 14d03f60ed366df942be09ee4bc394a69958e09c | https://github.com/scikit-learn/scikit-learn/issues/2185 | Bug
Moderate | MinibatchKMeans bad center reallocation causes duplicate centers | For instance have a look at:
http://scikit-learn.org/dev/auto_examples/cluster/plot_dict_face_patches.html
some of the centroids are duplicated, presumably because of a bug in the bad cluster reallocation heuristic.
| null | https://github.com/scikit-learn/scikit-learn/pull/3376 | null | {'base_commit': '14d03f60ed366df942be09ee4bc394a69958e09c', 'files': [{'path': 'sklearn/cluster/k_means_.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [28]}, "(None, '_labels_inertia_precompute_dense', 399)": {'add': [411], 'mod': [399, 402, 403, 409]}, "(None, '_labels_inertia', 416)": {'add': [433,... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"sklearn/utils/setup.py",
"sklearn/cluster/k_means_.py"
],
"doc": [],
"test": [
"sklearn/cluster/tests/test_k_means.py",
"sklearn/utils/tests/test_extmath.py"
],
"config": [],
"asset": []
} | 1 |
scrapy | scrapy | c8f3d07e86dd41074971b5423fb932c2eda6db1e | https://github.com/scrapy/scrapy/issues/3341 | Overriding the MailSender class | I'd like to use the built-in email notification service for when a scraper exceeds a certain memory limit (`MEMUSAGE_NOTIFY_MAIL` setting), but it looks like it's not possible to specify the MailSender class to use to send the email. I don't want to use SMTP, I'd like to use a third-party mail sender (e.g. sendgrid).
... | null | https://github.com/scrapy/scrapy/pull/3346 | null | {'base_commit': 'c8f3d07e86dd41074971b5423fb932c2eda6db1e', 'files': [{'path': 'docs/topics/email.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [70, 108], 'mod': [11, 12, 13, 14, 15, 17, 18, 20, 21, 23, 24, 26, 27, 29, 30, 32, 34, 36, 38, 39, 41, 42, 83, 114, 115]}}}, {'path': 'docs/topics/settings.... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"scrapy/extensions/statsmailer.py",
"scrapy/settings/default_settings.py",
"scrapy/extensions/memusage.py",
"scrapy/mail.py"
],
"doc": [
"docs/topics/settings.rst",
"docs/topics/email.rst"
],
"test": [
"tests/test_mail.py",
"scrapy/utils/test.py"
],
"config": []... | 1 | |
3b1b | manim | dbdd7996960ba46ed044a773290b02f17478c760 | https://github.com/3b1b/manim/issues/1059 | Impossible to open 'CC:/manim/manim_3_feb/media/videos/example_scenes/480p15/partial_movie_files/SquareToCircle/00000.mp4' | 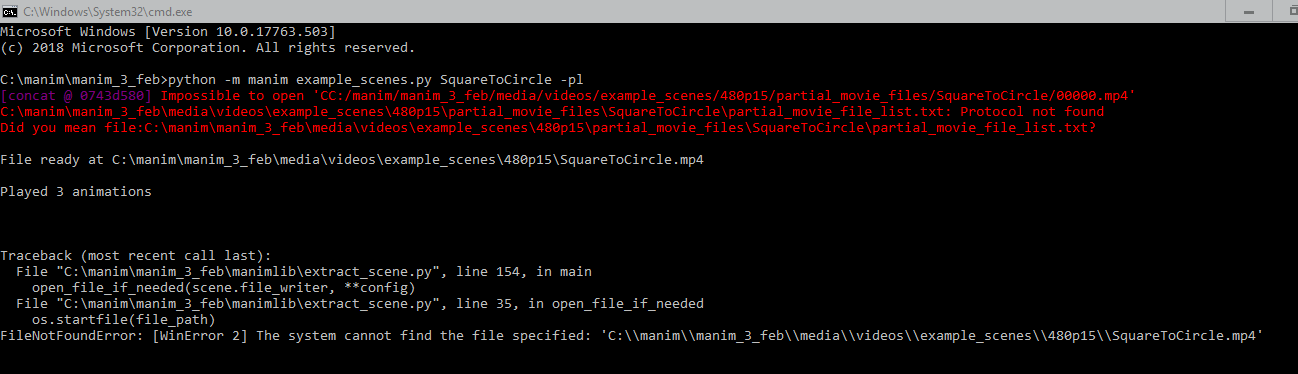
Help me solve this | null | https://github.com/3b1b/manim/pull/1057 | null | {'base_commit': 'dbdd7996960ba46ed044a773290b02f17478c760', 'files': [{'path': 'manimlib/scene/scene_file_writer.py', 'status': 'modified', 'Loc': {"('SceneFileWriter', 'combine_movie_files', 253)": {'mod': [289]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"manimlib/scene/scene_file_writer.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
python | cpython | ae00b810d1d3ad7f1f7e226b02ece37c986330e7 | https://github.com/python/cpython/issues/104803 | OS-windows | Allow detecting Dev Drive on Windows | Windows just announced a new [Dev Drive](https://learn.microsoft.com/en-us/windows/dev-drive/) feature, optimised for high I/O scenarios such as build and test. It also works as a very clear signal that the user is a developer and is doing developer-like tasks.
We should add a function to allow querying whether a sp... | null | https://github.com/python/cpython/pull/104805 | null | {'base_commit': 'ae00b810d1d3ad7f1f7e226b02ece37c986330e7', 'files': [{'path': 'Doc/library/os.path.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [306]}}}, {'path': 'Lib/ntpath.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [869]}}}, {'path': 'Lib/test/test_ntpath.py', 'status': 'm... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"Modules/clinic/posixmodule.c.h",
"Lib/ntpath.py",
"Modules/posixmodule.c"
],
"doc": [
"Doc/library/os.path.rst"
],
"test": [
"Lib/test/test_ntpath.py"
],
"config": [],
"asset": []
} | 1 |
scrapy | scrapy | 2814e0e1972fa38151b6800c881d49f50edf9c6b | https://github.com/scrapy/scrapy/issues/5226 | enhancement
good first issue
docs | Document Reppy Python version support | The optional dependency on reppy for one of the built-in robots.txt parsers is [preventing us from running the extra-dependencies CI job with Python 3.9+](https://github.com/seomoz/reppy/issues/122). https://github.com/seomoz/reppy has not have a commit for ~1.5 years.
So I think we should deprecate the component.
... | null | https://github.com/scrapy/scrapy/pull/5231 | null | {'base_commit': '2814e0e1972fa38151b6800c881d49f50edf9c6b', 'files': [{'path': 'docs/topics/downloader-middleware.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [1072]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [
"docs/topics/downloader-middleware.rst"
],
"test": [],
"config": [],
"asset": []
} | 1 |
psf | requests | 9968a10fcfad7268b552808c4f8946eecafc956a | https://github.com/psf/requests/issues/1650 | Requests doesn't catch requests.packages.urllib3.exceptions.ProxyError | Requests doesn't catch requests.packages.urllib3.exceptions.ProxyError and translate it into a requests module specific exception which derives from RequestException as it does for other errors originating from urllib3. This means if trying to catch any exception derived from RequestException so as to treat it speciall... | null | https://github.com/psf/requests/pull/1651 | null | {'base_commit': '9968a10fcfad7268b552808c4f8946eecafc956a', 'files': [{'path': 'requests/adapters.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [24], 'mod': [26]}, "('HTTPAdapter', 'send', 283)": {'add': [355]}}}, {'path': 'requests/exceptions.py', 'status': 'modified', 'Loc': {'(None, None, None)': ... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"requests/adapters.py",
"requests/exceptions.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
AUTOMATIC1111 | stable-diffusion-webui | 7f8ab1ee8f304031b3404e25761dd0f4c7be7df8 | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/873 | enhancement | Outpainting script does not save multiple images when using batch sliders | When using the batch-count slider and the batch-size slider, the outpainting script does not save multiple images, but just the first one.
Looking at the console window we can see the actual processing is happening for all the N images (batch-count * batch-size), but at the end of the process only the first one is s... | null | https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/3244 | null | {'base_commit': '7f8ab1ee8f304031b3404e25761dd0f4c7be7df8', 'files': [{'path': 'scripts/outpainting_mk_2.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [262]}, "('Script', 'run', 142)": {'mod': [175, 177, 179, 245, 247, 248, 249, 250, 251, 252, 253, 254, 256, 259, 261]}, "('Script', 'expand', 179)": {... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"scripts/outpainting_mk_2.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
AntonOsika | gpt-engineer | 803eb82362278b755127649e9bb5f385639a23ca | https://github.com/AntonOsika/gpt-engineer/issues/613 | good first issue
sweep | Add numpy doc strings | Add numpy style doc strings to all functions apart from the main.py file.
<details>
<summary>Checklist</summary>
- [X] `gpt_engineer/ai.py`
> • For each function in this file, add or replace the existing docstring with a numpy-style docstring. The docstring should include a brief description of the function, a l... | null | https://github.com/AntonOsika/gpt-engineer/pull/615 | null | {'base_commit': '803eb82362278b755127649e9bb5f385639a23ca', 'files': [{'path': 'gpt_engineer/ai.py', 'status': 'modified', 'Loc': {"('AI', None, 39)": {'add': [40, 52, 59, 62, 65, 97, 101, 127, 141, 144]}, "('AI', 'next', 68)": {'add': [77]}, "('AI', 'update_token_usage_log', 104)": {'add': [106]}, "(None, 'fallback_mo... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"gpt_engineer/learning.py",
"gpt_engineer/db.py",
"gpt_engineer/chat_to_files.py",
"gpt_engineer/ai.py",
"gpt_engineer/collect.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
abi | screenshot-to-code | b9522fede2835b3c3b4728e1d005541087ec2208 | https://github.com/abi/screenshot-to-code/issues/29 | Allow user to open the preview website in a new window | null | null | https://github.com/abi/screenshot-to-code/pull/99 | null | {'base_commit': 'b9522fede2835b3c3b4728e1d005541087ec2208', 'files': [{'path': 'frontend/src/App.tsx', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [99, 316], 'mod': [322, 323, 324, 325, 326, 327, 328]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"frontend/src/App.tsx"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
huggingface | transformers | eb3bd73ce35bfef56eeb722d697f2d39a06a8f8d | https://github.com/huggingface/transformers/issues/8171 | New model | Need suggestion on contributing TFDPR | # 🌟 New model addition
## Model description
Hi, I would love to try contributing TFDPR . This is the first time to me, so I need some suggestions.
I have followed @sshleifer 's [great PR on TFBart model](https://github.com/huggingface/transformers/commit/829842159efeb1f920cbbb1daf5ad67e0114d0b9) on 4 files :` __i... | null | https://github.com/huggingface/transformers/pull/8203 | null | {'base_commit': 'eb3bd73ce35bfef56eeb722d697f2d39a06a8f8d', 'files': [{'path': 'docs/source/model_doc/dpr.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [101]}}}, {'path': 'src/transformers/__init__.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [408, 715]}}}, {'path': 'src/transfor... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"src/transformers/utils/dummy_pt_objects.py",
"src/transformers/utils/dummy_tf_objects.py",
"src/transformers/__init__.py",
"src/transformers/modeling_tf_auto.py",
"utils/check_repo.py",
"src/transformers/convert_pytorch_checkpoint_to_tf2.py"
],
"doc": [
"docs/source/model_... | 1 |
huggingface | transformers | 9bee9ff5db6e68fb31065898d7e924d07c1eb9c1 | https://github.com/huggingface/transformers/issues/34390 | bug | [mask2former] torch.export error for Mask2Former | ### System Info
- `transformers` version: 4.46.0.dev0
- Platform: Linux-6.8.0-47-generic-x86_64-with-glibc2.35
- Python version: 3.11.9
- Huggingface_hub version: 0.25.2
- Safetensors version: 0.4.5
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.4.1+cu121 (True)... | null | https://github.com/huggingface/transformers/pull/34393 | null | {'base_commit': '9bee9ff5db6e68fb31065898d7e924d07c1eb9c1', 'files': [{'path': 'src/transformers/models/mask2former/modeling_mask2former.py', 'status': 'modified', 'Loc': {"('Mask2FormerPixelDecoder', 'forward', 1280)": {'add': [1333], 'mod': [1305, 1307, 1323, 1337, 1339, 1341, 1345]}, "('Mask2FormerPixelDecoderEncode... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"src/transformers/models/mask2former/modeling_mask2former.py"
],
"doc": [],
"test": [
"tests/models/mask2former/test_modeling_mask2former.py"
],
"config": [],
"asset": []
} | 1 |
scrapy | scrapy | 19d0942c74731d797a3590b1d8d46ece5a6d751f | https://github.com/scrapy/scrapy/issues/3077 | bug
upstream issue | scrapy selector fails when large lines are present response | Originally encoutered when scraping [Amazon restaurant](https://www.amazon.com/restaurants/zzzuszimbos0015gammaloc1name-new-york/d/B01HH7CS44?ref_=amzrst_pnr_cp_b_B01HH7CS44_438).
This page contains multiple script tag with lines greater then 64,000 character in one line.
The selector (xpath and css) does not sear... | null | https://github.com/scrapy/scrapy/pull/261 | null | {'base_commit': '19d0942c74731d797a3590b1d8d46ece5a6d751f', 'files': [{'path': 'docs/contributing.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [76]}}}, {'path': 'scrapy/tests/test_utils_url.py', 'status': 'modified', 'Loc': {"('UrlUtilsTest', None, 8)": {'add': [50]}, '(None, None, None)': {'mod': ... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"scrapy/utils/url.py"
],
"doc": [
"docs/contributing.rst"
],
"test": [
"scrapy/tests/test_utils_url.py"
],
"config": [],
"asset": []
} | 1 |
pandas-dev | pandas | 953757a3e37ffb80570a20a8eca52dae35fc27bb | https://github.com/pandas-dev/pandas/issues/22471 | Testing
Clean
good first issue | TST/CLN: remove TestData from frame-tests; replace with fixtures | Following review in #22236:
> ok, pls open a new issue that refs this, to remove use of `TestData` in favor of fixtures
Started the process in that PR by creating a `conftest.py` that translates all the current attributes of `TestData` to fixtures, with the following "translation guide":
* `frame` -> `float_fra... | null | https://github.com/pandas-dev/pandas/pull/29226 | null | {'base_commit': '953757a3e37ffb80570a20a8eca52dae35fc27bb', 'files': [{'path': 'pandas/tests/frame/common.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [1, 3, 5, 6, 8, 9, 11, 12, 13, 15, 17, 18, 21, 22, 23, 24, 26, 27, 28, 30, 31, 32, 33, 35, 36, 37, 39, 40, 41, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"pandas/tests/frame/common.py"
],
"doc": [],
"test": [
"pandas/tests/frame/test_indexing.py",
"pandas/tests/frame/test_query_eval.py"
],
"config": [],
"asset": []
} | null |
Significant-Gravitas | AutoGPT | 98efd264560983ed1d383222e3d5d22ed87169be | https://github.com/Significant-Gravitas/AutoGPT/issues/75 | API access | API Rate Limit Reached with new key | I just create a new key and it's failing to run:
```
Continue (y/n): y
Error: API Rate Limit Reached. Waiting 10 seconds...
Error: API Rate Limit Reached. Waiting 10 seconds...
Error: API Rate Limit Reached. Waiting 10 seconds...
Error: API Rate Limit Reached. Waiting 10 seconds...
Error: API Rate Limit Rea... | null | https://github.com/Significant-Gravitas/AutoGPT/pull/1304 | null | {'base_commit': '98efd264560983ed1d383222e3d5d22ed87169be', 'files': [{'path': 'README.md', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [147], 'mod': [108]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "3",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [
"README.md"
],
"test": [],
"config": [],
"asset": []
} | 1 |
oobabooga | text-generation-webui | 6a03ad082492268d60fa23ba5f3dcebd1630593e | https://github.com/oobabooga/text-generation-webui/issues/317 | enhancement | Support for ChatGLM | **Description**
[ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B)
A Chinese chat AI based on GLM was released by THU.
| null | https://github.com/oobabooga/text-generation-webui/pull/1256 | null | {'base_commit': '6a03ad082492268d60fa23ba5f3dcebd1630593e', 'files': [{'path': 'README.md', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [221]}}}, {'path': 'download-model.py', 'status': 'modified', 'Loc': {"(None, 'get_download_links_from_huggingface', 82)": {'mod': [111]}}}, {'path': 'models/config.yam... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"modules/shared.py",
"modules/chat.py",
"download-model.py",
"modules/models.py"
],
"doc": [
"README.md"
],
"test": [],
"config": [
"models/config.yaml"
],
"asset": []
} | 1 |
scikit-learn | scikit-learn | 130601e076ec5ca8298b95c3d02122ac5d8cf8eb | https://github.com/scikit-learn/scikit-learn/issues/2372 | Bug
Moderate | StratifiedKFold should do its best to preserve the dataset dependency structure | As highlighted in this [notebook](http://nbviewer.ipython.org/urls/raw.github.com/ogrisel/notebooks/master/Non%2520IID%2520cross-validation.ipynb) the current implementation of `StratifiedKFold` (which is used by default by `cross_val_score` and `GridSearchCV` for classification problems) breaks the dependency structur... | null | https://github.com/scikit-learn/scikit-learn/pull/2463 | null | {'base_commit': '130601e076ec5ca8298b95c3d02122ac5d8cf8eb', 'files': [{'path': 'doc/modules/cross_validation.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [108, 109, 115, 122, 123, 124, 125, 200, 201, 205, 206, 209, 210]}}}, {'path': 'doc/tutorial/statistical_inference/model_selection.rst', 'status'... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"sklearn/cross_validation.py"
],
"doc": [
"doc/modules/cross_validation.rst",
"doc/tutorial/statistical_inference/model_selection.rst",
"doc/whats_new.rst"
],
"test": [
"sklearn/tests/test_naive_bayes.py",
"sklearn/feature_selection/tests/test_rfe.py",
"sklearn/tests/te... | 1 |
Significant-Gravitas | AutoGPT | 6ff8478118935b72c35f3ec1b31e74f2a1aa2e90 | https://github.com/Significant-Gravitas/AutoGPT/issues/528 | enhancement
good first issue
potential plugin
Stale | Auto-GPT System Awareness | ### System Awareness
- [X] I have searched the existing issues
### Summary 💡
Before going out to look at the internet
It would be helpful if upon activation the AI took inventory of the system it was on and shared the available tools and capabilities
and if they were insufficient begin researching and deve... | null | https://github.com/Significant-Gravitas/AutoGPT/pull/4548 | null | {'base_commit': '6ff8478118935b72c35f3ec1b31e74f2a1aa2e90', 'files': [{'path': '.github/PULL_REQUEST_TEMPLATE.md', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [44]}}}, {'path': '.github/workflows/ci.yml', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [72]}}}, {'path': '.pre-commit-config.y... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"autogpt/plugins.py",
"scripts/install_plugin_deps.py"
],
"doc": [
".github/PULL_REQUEST_TEMPLATE.md"
],
"test": [
"tests/integration/test_web_selenium.py",
"tests/integration/test_plugins.py"
],
"config": [
".github/workflows/ci.yml",
".pre-commit-config.yaml"
],... | 1 |
All-Hands-AI | OpenHands | 707ab7b3f84fb5664ff63da0b52e7b0d2e4df545 | https://github.com/All-Hands-AI/OpenHands/issues/908 | bug | Agent stuck in the "starting task" step--Unsupported Protocol | <!-- You MUST fill out this template. We will close issues that don't include enough information to reproduce -->
#### Describe the bug
<!-- a short description of the problem -->
I asked the agent to build a calculator, but it didn't give me any response, just stuck in the starting step.
#### Setup and configura... | null | https://github.com/All-Hands-AI/OpenHands/pull/960 | null | {'base_commit': '707ab7b3f84fb5664ff63da0b52e7b0d2e4df545', 'files': [{'path': 'opendevin/config.py', 'status': 'modified', 'Loc': {"(None, 'get_all', 78)": {'mod': [78, 82]}}}, {'path': 'opendevin/server/agent/manager.py', 'status': 'modified', 'Loc': {"('AgentManager', 'create_controller', 93)": {'mod': [107, 108, 10... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "0",
"info_type": ""
} | {
"code": [
"opendevin/config.py",
"opendevin/server/agent/manager.py",
"opendevin/server/listen.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
ageitgey | face_recognition | 59f4d299b6ae3232a1d8fe5d5d9652bffa17a728 | https://github.com/ageitgey/face_recognition/issues/809 | facerec_from_webcam_multiprocessing.py run Global is not defined | * face_recognition version: 1.23
* Python version: 3.6.6
* Operating System: windows 10
### Description

### What I Did
```
facerec_from_webcam_multiprocessing.py run Global is not defined. pls fi... | null | https://github.com/ageitgey/face_recognition/pull/905 | null | {'base_commit': '59f4d299b6ae3232a1d8fe5d5d9652bffa17a728', 'files': [{'path': 'examples/facerec_from_webcam_multiprocessing.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [5, 113], 'mod': [3, 125, 130, 131, 154, 189]}, "(None, 'next_id', 17)": {'mod': [17]}, "(None, 'prev_id', 25)": {'mod': [25]}, "(... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"examples/facerec_from_webcam_multiprocessing.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | null | |
pandas-dev | pandas | dc86509b44b3fb0cd9a1a6d6ed564b082dc50848 | https://github.com/pandas-dev/pandas/issues/26139 | Docs
IO HDF5 | Doc for HDFStore compression unclear on what the default value of None does | The doc for the `HDFStore` class mentions:
```
complevel : int, 0-9, default None
Specifies a compression level for data.
A value of 0 disables compression.
```
That doesn't actually answer the question of what compression level is used when the default (None) is used, though. Is N... | null | https://github.com/pandas-dev/pandas/pull/26158 | null | {'base_commit': 'dc86509b44b3fb0cd9a1a6d6ed564b082dc50848', 'files': [{'path': 'pandas/io/pytables.py', 'status': 'modified', 'Loc': {"('HDFStore', None, 401)": {'mod': [425]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "0",
"info_type": ""
} | {
"code": [
"pandas/io/pytables.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
nvbn | thefuck | 0949d2e77022ad69cc07d4b25a858a7e023503ac | https://github.com/nvbn/thefuck/issues/1207 | git push upstream branch does not exist, wrong command recommended first | <!-- If you have any issue with The Fuck, sorry about that, but we will do what we
can to fix that. Actually, maybe we already have, so first thing to do is to
update The Fuck and see if the bug is still there. -->
<!-- If it is (sorry again), check if the problem has not already been reported and
if not, just op... | null | https://github.com/nvbn/thefuck/pull/1208 | null | {'base_commit': '0949d2e77022ad69cc07d4b25a858a7e023503ac', 'files': [{'path': 'thefuck/rules/git_hook_bypass.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [26]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"thefuck/rules/git_hook_bypass.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
scrapy | scrapy | b8a43011e75da4353b0d5ef314c96cb1276f12f0 | https://github.com/scrapy/scrapy/issues/3893 | [Bug] 1.7.1 not support 1.6.0 script | Hello All,
My spider is created by scrapy 1.6.0.
These days, the scrapy updated to 1.7.1, and we found that it cannot support the code build by 1.6.0.
Here is the error:
```
Traceback (most recent call last):
File "/usr/bin/scrapy", line 6, in <module>
from scrapy.cmdline import execute
File "/usr/l... | null | https://github.com/scrapy/scrapy/pull/3896 | null | {'base_commit': 'b8a43011e75da4353b0d5ef314c96cb1276f12f0', 'files': [{'path': 'scrapy/utils/conf.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [7], 'mod': [4]}, "(None, 'get_config', 94)": {'mod': [97]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "0",
"info_type": ""
} | {
"code": [
"scrapy/utils/conf.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
All-Hands-AI | OpenHands | 454e9613b0b4c7a9dbb2b8273aff0b36c4d8a2bb | https://github.com/All-Hands-AI/OpenHands/issues/1276 | bug | [Bug]: Browsing is not working | ### Is there an existing issue for the same bug?
- [X] I have checked the troubleshooting document at https://github.com/OpenDevin/OpenDevin/blob/main/docs/guides/Troubleshooting.md
- [X] I have checked the existing issues.
### Describe the bug
When I ask a question that requires browsing the web to get the a... | null | https://github.com/All-Hands-AI/OpenHands/pull/1184 | null | {'base_commit': '454e9613b0b4c7a9dbb2b8273aff0b36c4d8a2bb', 'files': [{'path': 'containers/app/Dockerfile', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [50]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [],
"test": [],
"config": [
"containers/app/Dockerfile"
],
"asset": []
} | 1 |
fastapi | fastapi | 92c825be6a7362099400c9c3fe8b01ea13add3dc | https://github.com/fastapi/fastapi/issues/8 | feature
answered
reviewed | Nesting FastAPI instances doesn't work very well | Do this:
main_app = FastAPI()
sub_api = FastAPI()
...
main_app.router.routes.append(Mount('/subapi', app=sub_api))
`sub_api` will correctly serve ever `/subapi` -- docs, methods, all that. However, the docs will still look for `/openapi.json` (absolute link) when trying to load the openapi sp... | null | https://github.com/fastapi/fastapi/pull/26 | null | {'base_commit': '92c825be6a7362099400c9c3fe8b01ea13add3dc', 'files': [{'path': 'fastapi/applications.py', 'status': 'modified', 'Loc': {"('FastAPI', '__init__', 20)": {'add': [27, 45]}, "('FastAPI', 'openapi', 61)": {'add': [68]}, "('FastAPI', 'setup', 72)": {'mod': [83, 91]}}}, {'path': 'fastapi/openapi/utils.py', 'st... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"fastapi/openapi/utils.py",
"fastapi/applications.py"
],
"doc": [
"mkdocs.yml"
],
"test": [],
"config": [],
"asset": []
} | 1 |
localstack | localstack | 9f1b9dbf60f406e8d6205402b8ac078195cd0c01 | https://github.com/localstack/localstack/issues/4517 | type: bug
status: triage needed
aws:cloudformation
aws:iam | bug: AWS::NoValue produces error when used in IAM policy template | ### Is there an existing issue for this?
- [x] I have searched the existing issues
### Current Behavior
When I try to create a role with S3 resource and I use `!Ref AWS::NoValue` for its resource, it fails with errors. It is supposed to be removed from array entry, but it looks like it evaluates as `__aws_no_v... | null | https://github.com/localstack/localstack/pull/6760 | null | {'base_commit': '9f1b9dbf60f406e8d6205402b8ac078195cd0c01', 'files': [{'path': 'localstack/services/cloudformation/models/cloudwatch.py', 'status': 'modified', 'Loc': {"('CloudWatchAlarm', None, 6)": {'add': [11]}}}, {'path': 'localstack/services/cloudformation/models/iam.py', 'status': 'modified', 'Loc': {"('IAMRole',... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"localstack/services/cloudformation/models/cloudwatch.py",
"tests/integration/cloudformation/test_cloudformation_iam.snapshot.json",
"localstack/services/cloudformation/models/iam.py"
],
"doc": [],
"test": [
"tests/integration/cloudformation/test_cloudformation_iam.py"
],
"config... | 1 |
AntonOsika | gpt-engineer | c4c1203fc07b2e23c3e5a5e9277266a711ab9466 | https://github.com/AntonOsika/gpt-engineer/issues/117 | bug | GPT Engineer will not save individual files when given specs that result in many files. | The generated code goes into the logfile however it would be more useful if the tool could make all those files automatically. | null | https://github.com/AntonOsika/gpt-engineer/pull/120 | null | {'base_commit': 'c4c1203fc07b2e23c3e5a5e9277266a711ab9466', 'files': [{'path': 'gpt_engineer/chat_to_files.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [4]}, "(None, 'parse_chat', 6)": {'add': [11], 'mod': [6, 7, 8, 10, 13, 14, 15, 16, 17, 18, 19]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"gpt_engineer/chat_to_files.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
scrapy | scrapy | 40e623b2768598e36c4f367bd166b36fffceb3f6 | https://github.com/scrapy/scrapy/issues/6177 | enhancement
docs | Switch to the latest sphinx | The docs fail to build with the current Sphinx (7.2.6):
```
reading sources... [ 48%] topics/downloader-middleware
Extension error (scrapydocs):
Handler <function collect_scrapy_settings_refs at 0x7f81fc663a60> for event 'doctree-read' threw an exception (exception: Next node is not a target)
```
So we should... | null | https://github.com/scrapy/scrapy/pull/6200 | null | {'base_commit': '40e623b2768598e36c4f367bd166b36fffceb3f6', 'files': [{'path': 'docs/requirements.txt', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [1, 2, 3, 4]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [
"docs/requirements.txt"
],
"test": [],
"config": [],
"asset": []
} | 1 |
geekan | MetaGPT | 0958cc333ee13d1ce5216ae0bdeaa53b5eacc6ea | https://github.com/geekan/MetaGPT/issues/1059 | bug | ReadTimeout when using local LLM | **Bug description**
When hosting the following model; https://huggingface.co/oobabooga/CodeBooga-34B-v0.1 locally using LMStudio 0.2.14 on Linux Mint 21.3 Cinnamon I am sometimes (usually after several iterations when the context gets large) confronted with a ReadTimeout.
MetaGPT main branch, commit id: adb42f4, it... | null | https://github.com/geekan/MetaGPT/pull/1060 | null | {'base_commit': '0958cc333ee13d1ce5216ae0bdeaa53b5eacc6ea', 'files': [{'path': 'config/config2.example.yaml', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [6]}}}, {'path': 'metagpt/actions/action_node.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [19]}, "('ActionNode', '_aask_v1', 411)... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"metagpt/configs/llm_config.py",
"metagpt/provider/zhipuai_api.py",
"metagpt/provider/ollama_api.py",
"metagpt/provider/spark_api.py",
"metagpt/provider/anthropic_api.py",
"metagpt/provider/qianfan_api.py",
"metagpt/actions/action_node.py",
"metagpt/provider/openai_api.py",... | 1 |
Textualize | rich | b5f0b743a7f50c72199eb792cd6e70730b60651f | https://github.com/Textualize/rich/issues/2047 | Needs triage | [BUG] printing -\n- in rich.progress context manager will kill the jupyter. | try this code in the jupyter notebook:
```python
from rich.progress import Progress
with Progress() as progress:
print("-\n-")
print("finished")
```
and it will show a popup message displaying that the kernel has died.
I have tested it on google colab and mint.
also, I have installed rich using
```
p... | null | https://github.com/Textualize/rich/pull/2209 | null | {'base_commit': 'b5f0b743a7f50c72199eb792cd6e70730b60651f', 'files': [{'path': 'CHANGELOG.md', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [18]}}}, {'path': 'rich/file_proxy.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [2]}, "('FileProxy', 'flush', 50)": {'mod': [51, 52, 53, 54]}}}, ... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"rich/file_proxy.py"
],
"doc": [
"CHANGELOG.md"
],
"test": [
"tests/test_file_proxy.py"
],
"config": [],
"asset": []
} | 1 |
scikit-learn | scikit-learn | 439c19596a248a31cd1aa8220f54a622a0322160 | https://github.com/scikit-learn/scikit-learn/issues/3689 | using sparse matrix in fit_params | When the value of a fit_params is sparse matrix, it will raise error from the following code.
sklearn/cross_validation.py
```
1224 if hasattr(v, '__len__') and len(v) == n_samples else v)
1225 for k, v in fit_params.items()])
```
It is because the `__len__` of sparse matrix... | null | https://github.com/scikit-learn/scikit-learn/pull/4049 | null | {'base_commit': '439c19596a248a31cd1aa8220f54a622a0322160', 'files': [{'path': 'sklearn/cross_validation.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [1073]}, "(None, '_fit_and_predict', 1150)": {'mod': [1186, 1188, 1189, 1190]}, "(None, '_fit_and_score', 1305)": {'mod': [1379, 1381, 1382, 1383, 138... | [] | [] | [] | {
"iss_type": "3",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"sklearn/cross_validation.py"
],
"doc": [],
"test": [
"sklearn/tests/test_cross_validation.py"
],
"config": [],
"asset": []
} | 1 | |
scikit-learn | scikit-learn | adc1e590d4dc1e230b49a4c10b4cd7b672bb3d69 | https://github.com/scikit-learn/scikit-learn/issues/9174 | Bug
help wanted | SVC and OneVsOneClassifier decision_function inconsistent on sub-sample | Hi,
I'm seeing inconsistent numerical results with SVC's decision_function.
When estimated over an entire batch of samples ( (n_samples, n_features) matrix ) compared to analyzing sample-by-sample, the results are not the same.
This is true for both the individual numerical values per sample and the overall distri... | null | https://github.com/scikit-learn/scikit-learn/pull/10440 | null | {'base_commit': 'adc1e590d4dc1e230b49a4c10b4cd7b672bb3d69', 'files': [{'path': 'doc/modules/multiclass.rst', 'status': 'modified', 'Loc': {'(None, None, 230)': {'mod': [230]}}}, {'path': 'doc/modules/svm.rst', 'status': 'modified', 'Loc': {'(None, None, 116)': {'mod': [116]}, '(None, None, 118)': {'mod': [118]}}}, {'pa... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"sklearn/utils/multiclass.py",
"sklearn/utils/estimator_checks.py",
"sklearn/svm/base.py"
],
"doc": [
"doc/whats_new/v0.21.rst",
"doc/modules/multiclass.rst",
"doc/modules/svm.rst"
],
"test": [
"sklearn/utils/tests/test_multiclass.py"
],
"config": [],
"asset": []
... | null |
scrapy | scrapy | da90449edfa13b5be1550b3acc212dbf3a8c6e69 | https://github.com/scrapy/scrapy/issues/1064 | allow spiders to return dicts instead of Items | In many cases the requirement to define and yield Items from a spider is an unnecessary complication.
An example from Scrapy tutorial:
```
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
class DmozSpider(scrapy.Spider):
name = "dmoz"
... | null | https://github.com/scrapy/scrapy/pull/1081 | null | {'base_commit': 'da90449edfa13b5be1550b3acc212dbf3a8c6e69', 'files': [{'path': 'docs/index.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [61, 86], 'mod': [59, 75, 76]}}}, {'path': 'docs/topics/architecture.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [105, 108]}}}, {'path': 'doc... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"scrapy/core/scraper.py",
"scrapy/commands/parse.py",
"scrapy/contracts/default.py",
"scrapy/contrib/exporter/__init__.py",
"tests/spiders.py",
"scrapy/contrib/pipeline/images.py",
"scrapy/contrib/pipeline/files.py"
],
"doc": [
"docs/topics/practices.rst",
"docs/top... | 1 | |
scikit-learn | scikit-learn | effd75dda5f4afa61f988035ff8fe4b3a447464e | https://github.com/scikit-learn/scikit-learn/issues/10059 | Duplicated input points silently create duplicated clusters in KMeans | #### Description
When there are duplicated input points to Kmeans resulting to number of unique points < number of requested clusters, there is no error thrown. Instead, clustering continues to (seemingly) produce the number of clusters requested, but some of them are exactly the same, so the cluster labels produced f... | null | https://github.com/scikit-learn/scikit-learn/pull/10099 | null | {'base_commit': 'effd75dda5f4afa61f988035ff8fe4b3a447464e', 'files': [{'path': 'doc/whats_new/v0.20.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [136]}}}, {'path': 'sklearn/cluster/k_means_.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [34]}, "(None, 'k_means', 167)": {'add': [37... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": "code"
} | {
"code": [
"sklearn/cluster/k_means_.py"
],
"doc": [
"doc/whats_new/v0.20.rst"
],
"test": [
"sklearn/cluster/tests/test_k_means.py"
],
"config": [],
"asset": []
} | 1 | |
scrapy | scrapy | 0dad0fce72266aa7b38b536f87bab26e7f233c74 | https://github.com/scrapy/scrapy/issues/4477 | bug | is_generator_with_return_value raises IndentationError with a flush left doc string | ### Description
Code that is accepted by the python interpreter raises when fed through `textwrap.dedent`
### Steps to Reproduce
1. Create `is_generator_bug.py` with the content below (which I simplified from [the `is_generator_with_return_value` method body](https://github.com/scrapy/scrapy/blob/2.0.1/scrapy/... | null | https://github.com/scrapy/scrapy/pull/4935 | null | {'base_commit': '0dad0fce72266aa7b38b536f87bab26e7f233c74', 'files': [{'path': 'scrapy/utils/misc.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [12]}, "(None, 'is_generator_with_return_value', 217)": {'mod': [230]}, "(None, 'warn_on_generator_with_return_value', 240)": {'mod': [245, 247, 248, 249, 25... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"scrapy/utils/misc.py"
],
"doc": [],
"test": [
"tests/test_utils_misc/test_return_with_argument_inside_generator.py"
],
"config": [],
"asset": []
} | 1 |
scikit-learn | scikit-learn | e217b68fd00bb7c54b81a492ee6f9db6498517fa | https://github.com/scikit-learn/scikit-learn/issues/18146 | Bug | Something goes wrong with KernelPCA with 32 bits input data | When given 32 bits input, KernelPCA succeed to transform the data into a 17-dimensional feature space while the original space was 3 features. I did not debug yet but this seems really unlikely.
```python
# %%
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
X, y = make_... | null | https://github.com/scikit-learn/scikit-learn/pull/18149 | null | {'base_commit': 'e217b68fd00bb7c54b81a492ee6f9db6498517fa', 'files': [{'path': 'doc/whats_new/v0.24.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [118], 'mod': [25, 26]}}}, {'path': 'sklearn/decomposition/tests/test_kernel_pca.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [12]}, "... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"sklearn/utils/validation.py"
],
"doc": [
"doc/whats_new/v0.24.rst"
],
"test": [
"sklearn/decomposition/tests/test_kernel_pca.py"
],
"config": [],
"asset": []
} | 1 |
localstack | localstack | 6c8f52d42563c1207a8cb3fbbfccb6d4af2a0670 | https://github.com/localstack/localstack/issues/544 | priority: high | S3 object metadata not saved when uploaded with presigned url | Use case:
I'm enabling users to directly upload to s3 using presigned url. S3 is configured to add event to SQS on Put. Queue consumer, reads the queue and makes HEAD requests with object keys to get the metadata and save information to database (generic image upload, so I know where to add file).
Test script in no... | null | https://github.com/localstack/localstack/pull/1745 | null | {'base_commit': '6c8f52d42563c1207a8cb3fbbfccb6d4af2a0670', 'files': [{'path': 'localstack/services/s3/s3_listener.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [44, 308]}, "('ProxyListenerS3', 'forward_request', 514)": {'add': [563]}, "('ProxyListenerS3', 'return_response', 595)": {'mod': [665]}}}, ... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"localstack/services/s3/s3_listener.py"
],
"doc": [],
"test": [
"tests/integration/test_s3.py"
],
"config": [],
"asset": []
} | 1 |
Significant-Gravitas | AutoGPT | a2723f16f2d5c748c382359c6ce5fdd1e53728d3 | https://github.com/Significant-Gravitas/AutoGPT/issues/1639 | function: process text | This model's maximum context length is 8191 tokens, however you requested 89686 tokens (89686 in your prompt) | ### Duplicates
- [X] I have searched the existing issues
### Steps to reproduce 🕹
The program is trying to process an absurd amount of information at once. It happens over and over again.
Adding chunk 17 / 20 to memory
SYSTEM: Command browse_website returned: Error: This model's maximum context length is 8191 ... | null | https://github.com/Significant-Gravitas/AutoGPT/pull/2542 | null | {'base_commit': 'a2723f16f2d5c748c382359c6ce5fdd1e53728d3', 'files': [{'path': '.env.template', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [154], 'mod': [10, 11]}}}, {'path': 'autogpt/config/config.py', 'status': 'modified', 'Loc': {"('Config', '__init__', 19)": {'mod': [34]}}}, {'path': 'autogpt/proce... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"autogpt/processing/text.py",
"autogpt/config/config.py"
],
"doc": [],
"test": [],
"config": [
"requirements.txt",
".env.template"
],
"asset": []
} | 1 |
ansible | ansible | 141d638e590897d4ec5371c4868f027dad95a38e | https://github.com/ansible/ansible/issues/36691 | module
affects_2.4
support:core
docs | stat documentation: mime_type vs mimetype, mime output vs descriptive output | <!---
Verify first that your issue/request is not already reported on GitHub.
Also test if the latest release, and devel branch are affected too.
-->
##### ISSUE TYPE
- Documentation Report
##### COMPONENT NAME
stat
##### ANSIBLE VERSION
<!--- Paste verbatim output from "ansible --version" between quote... | null | https://github.com/ansible/ansible/pull/36693 | null | {'base_commit': '141d638e590897d4ec5371c4868f027dad95a38e', 'files': [{'path': 'lib/ansible/modules/files/stat.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [318, 324]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"lib/ansible/modules/files/stat.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
huggingface | transformers | ba1b3db70907b975b5ca52b9957c5ed7a186a0fa | https://github.com/huggingface/transformers/issues/12990 | kindly adding some documentations on t5-v1_1-base"" | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script... | null | https://github.com/huggingface/transformers/pull/13240 | null | {'base_commit': 'ba1b3db70907b975b5ca52b9957c5ed7a186a0fa', 'files': [{'path': 'README.md', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [274]}}}, {'path': 'docs/source/index.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [610], 'mod': [285, 288, 291, 295, 298, 301, 303, 306, 310, 313]... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"src/transformers/models/t5/modeling_flax_t5.py",
"src/transformers/models/t5/modeling_t5.py",
"src/transformers/models/t5/modeling_tf_t5.py"
],
"doc": [
"docs/source/model_doc/t5.rst",
"docs/source/index.rst",
"docs/source/model_doc/mt5.rst",
"README.md",
"docs/source/... | 1 | |
nvbn | thefuck | 8fa10b1049ddf21f188b9605bcd5afbe33bf33db | https://github.com/nvbn/thefuck/issues/975 | enhancement
hacktoberfest | Correcting `app-install` to `apt-get install` rather than `install` | <!-- If you have any issue with The Fuck, sorry about that, but we will do what we
can to fix that. Actually, maybe we already have, so first thing to do is to
update The Fuck and see if the bug is still there. -->
<!-- If it is (sorry again), check if the problem has not already been reported and
if not, just op... | null | https://github.com/nvbn/thefuck/pull/977 | null | {'base_commit': '8fa10b1049ddf21f188b9605bcd5afbe33bf33db', 'files': [{'path': 'README.md', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [338]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [
"README.md"
],
"test": [],
"config": [],
"asset": []
} | 1 |
pandas-dev | pandas | ad24759871ea43131711cfce1e5fc69c06d82956 | https://github.com/pandas-dev/pandas/issues/16668 | Clean | CLN: private impl of OrderedDefaultDict can be removed | https://github.com/pandas-dev/pandas/blob/master/pandas/compat/__init__.py#L376
I think this was leftover from 2.6 compat. | null | https://github.com/pandas-dev/pandas/pull/16939 | null | {'base_commit': 'ad24759871ea43131711cfce1e5fc69c06d82956', 'files': [{'path': 'pandas/compat/__init__.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [24]}, "('OrderedDefaultdict', None, 376)": {'mod': [376, 378, 379, 380, 381, 382, 383, 384, 385, 386, 387, 389, 390, 391, 392, 393, 395, 396, 397]}}}, ... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"pandas/core/panel.py",
"pandas/compat/__init__.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
ansible | ansible | 3694711a7e975324d52c258ab73a8f5e766a3f1c | https://github.com/ansible/ansible/issues/54746 | module
support:community
bug
traceback
affects_2.7
crypto | acme_certificate - dest must include path info or fails | <!--- Verify first that your issue is not already reported on GitHub -->
<!--- Also test if the latest release and devel branch are affected too -->
<!--- Complete *all* sections as described, this form is processed automatically -->
##### SUMMARY
<!--- Explain the problem briefly below -->
Calling acme_certific... | null | https://github.com/ansible/ansible/pull/54754 | null | {'base_commit': '3694711a7e975324d52c258ab73a8f5e766a3f1c', 'files': [{'path': 'lib/ansible/module_utils/acme.py', 'status': 'modified', 'Loc': {"(None, 'write_file', 79)": {'mod': [122, 124]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"lib/ansible/module_utils/acme.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
huggingface | transformers | 41750a6cff55e401364568868d619747de3db037 | https://github.com/huggingface/transformers/issues/3785 | wontfix
Core: Encoder-Decoder | How to fine tune EncoderDecoder model for training a new corpus of data ? | is there any documentation available for the same? | null | https://github.com/huggingface/transformers/pull/3383 | null | {'base_commit': '41750a6cff55e401364568868d619747de3db037', 'files': [{'path': 'docs/source/index.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [91]}}}, {'path': 'src/transformers/__init__.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [43], 'mod': [270]}}}, {'path': 'src/transform... | [] | [] | [] | {
"iss_type": "3",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"src/transformers/configuration_auto.py",
"src/transformers/__init__.py",
"src/transformers/modeling_auto.py",
"src/transformers/utils_encoder_decoder.py",
"src/transformers/modeling_utils.py",
"src/transformers/modeling_bert.py",
"src/transformers/modeling_encoder_decoder.py"
... | 1 |
ansible | ansible | 2908a2c32a81fca78277a22f15fa8e3abe75e092 | https://github.com/ansible/ansible/issues/71517 | easyfix
python3
module
support:core
bug
has_pr
P3
system
affects_2.9 | Reboot module doesn't work with async | <!--- Verify first that your issue is not already reported on GitHub -->
<!--- Also test if the latest release and devel branch are affected too -->
<!--- Complete *all* sections as described, this form is processed automatically -->
##### SUMMARY
The `reboot` module does not work with `async`, `poll`, and `async... | null | https://github.com/ansible/ansible/pull/80017 | null | {'base_commit': '2908a2c32a81fca78277a22f15fa8e3abe75e092', 'files': [{'path': 'lib/ansible/plugins/action/reboot.py', 'status': 'modified', 'Loc': {"('ActionModule', 'run', 409)": {'mod': [411]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "0",
"info_type": "Code"
} | {
"code": [
"lib/ansible/plugins/action/reboot.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
pandas-dev | pandas | c482b5727e3bd98b6f9780e51615791e413d542d | https://github.com/pandas-dev/pandas/issues/29916 | Enhancement
IO HDF5 | HDF5: empty groups and keys | Hi,
With some of the hdf5 files I have, `pandas.HDFStore.groups()` returns an empty list. (as does `.keys()` which iterates over the groups). However, the data are accessible via `.get()` or `.get_node()`.
This is related to #21543 and #21372 where the `.groups()` logic was changed, in particular using `self._han... | null | https://github.com/pandas-dev/pandas/pull/32723 | null | {'base_commit': 'c482b5727e3bd98b6f9780e51615791e413d542d', 'files': [{'path': 'doc/source/whatsnew/v1.1.0.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [964]}}}, {'path': 'pandas/io/pytables.py', 'status': 'modified', 'Loc': {"('HDFStore', 'keys', 583)": {'add': [586, 590], 'mod': [592]}, "('HDFSto... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"pandas/io/pytables.py"
],
"doc": [
"doc/source/whatsnew/v1.1.0.rst"
],
"test": [
"pandas/tests/io/pytables/test_store.py"
],
"config": [],
"asset": []
} | 1 |
scrapy | scrapy | f3372a3753643fea601564c01fcf65cc25a2db62 | https://github.com/scrapy/scrapy/issues/4667 | bug | List of fields incorrectly accessed for dataclass items | ### Description
If I make a `dataclass` item and want to export to csv, I get this error:
```
...
File "/home/tadej/miniconda3/envs/main/lib/python3.7/site-packages/scrapy/exporters.py", line 251, in _write_headers_and_set_fields_to_export
self.fields_to_export = list(item.fields.keys())
AttributeError:... | null | https://github.com/scrapy/scrapy/pull/4668 | null | {'base_commit': 'f3372a3753643fea601564c01fcf65cc25a2db62', 'files': [{'path': 'scrapy/exporters.py', 'status': 'modified', 'Loc': {"('CsvItemExporter', '_write_headers_and_set_fields_to_export', 243)": {'mod': [246, 247, 248, 249, 250, 251]}}}, {'path': 'tests/test_exporters.py', 'status': 'modified', 'Loc': {'(None, ... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"scrapy/exporters.py"
],
"doc": [],
"test": [
"tests/test_exporters.py"
],
"config": [],
"asset": []
} | 1 |
AntonOsika | gpt-engineer | 2b8e056d5d4d14665b88a01c41356253c94b9259 | https://github.com/AntonOsika/gpt-engineer/issues/322 | enhancement
good first issue | Print and store how many tokens were used in memory/logs | In this way, we can also store this to benchmark results.
A huge increase in tokens will not be worth a minor improvement in benchmark resultss. | null | https://github.com/AntonOsika/gpt-engineer/pull/438 | null | {'base_commit': '2b8e056d5d4d14665b88a01c41356253c94b9259', 'files': [{'path': 'gpt_engineer/ai.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [4, 7, 11, 56]}, "('AI', 'next', 34)": {'add': [54]}, "('AI', None, 12)": {'mod': [17, 34]}, "('AI', 'start', 17)": {'mod': [23]}}}, {'path': 'gpt_engineer/mai... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": null,
"info_type": null
} | {
"code": [
"gpt_engineer/ai.py",
"gpt_engineer/main.py",
"gpt_engineer/steps.py"
],
"doc": [],
"test": [],
"config": [
"pyproject.toml"
],
"asset": []
} | 1 |
huggingface | transformers | 6dda14dc47d82f0e32df05fea8ba6444ba52b90a | https://github.com/huggingface/transformers/issues/20058 | Push to Hub fails with `model_name` | ### System Info
- `transformers` version: 4.25.0.dev0
- Platform: Linux-5.15.0-48-generic-x86_64-with-glibc2.31
- Python version: 3.9.13
- Huggingface_hub version: 0.10.1
- PyTorch version (GPU?): 1.13.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed... | null | https://github.com/huggingface/transformers/pull/20117 | null | {'base_commit': '6dda14dc47d82f0e32df05fea8ba6444ba52b90a', 'files': [{'path': 'src/transformers/models/clip/processing_clip.py', 'status': 'modified', 'Loc': {"('CLIPProcessor', 'decode', 102)": {'add': [107]}}}, {'path': 'src/transformers/models/flava/processing_flava.py', 'status': 'modified', 'Loc': {"('FlavaProces... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"src/transformers/models/clip/processing_clip.py",
"src/transformers/models/layoutlmv2/processing_layoutlmv2.py",
"src/transformers/models/vilt/processing_vilt.py",
"src/transformers/models/x_clip/processing_x_clip.py",
"src/transformers/models/markuplm/processing_markuplm.py",
"sr... | 1 | |
ansible | ansible | b8e8fb48a84b65e805aecd263ebb7cd303e671ee | https://github.com/ansible/ansible/issues/34896 | networking
module
affects_2.4
support:community
aci
feature
cisco | aci_epg module needs to support PreferredGroup |
##### ISSUE TYPE
- Feature Idea
##### COMPONENT NAME
aci_epg
##### ANSIBLE VERSION
```
[root@ansible-server ~]# ansible --version
ansible 2.4.0.0
config file = None
configured module search path = [u'/root/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module loc... | null | https://github.com/ansible/ansible/pull/35265 | null | {'base_commit': 'b8e8fb48a84b65e805aecd263ebb7cd303e671ee', 'files': [{'path': 'lib/ansible/modules/network/aci/aci_epg.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [66, 86]}, "(None, 'main', 161)": {'add': [171, 185, 191, 230], 'mod': [196]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"lib/ansible/modules/network/aci/aci_epg.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
All-Hands-AI | OpenHands | 4405b109e3abcd197666430708de2881e7cde8da | https://github.com/All-Hands-AI/OpenHands/issues/4280 | enhancement
good first issue
frontend
large effort | Update the frontend to use i18n keys | **What problem or use case are you trying to solve?**
The new UI hardcodes english text throughout the app. In order to support i18n, we should extend our i18n provider and replaced the hardcoded values with the new keys
**Describe the UX of the solution you'd like**
**Do you have thoughts on the technical imple... | null | https://github.com/All-Hands-AI/OpenHands/pull/4464 | null | {'base_commit': '4405b109e3abcd197666430708de2881e7cde8da', 'files': [{'path': 'frontend/src/components/form/custom-input.tsx', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [0, 15], 'mod': [21]}}}, {'path': 'frontend/src/components/form/settings-form.tsx', 'status': 'modified', 'Loc': {'(None, None, None... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "0",
"info_type": ""
} | {
"code": [
"frontend/src/components/modals/AccountSettingsModal.tsx",
"frontend/src/components/modals/security/Security.tsx",
"frontend/src/components/form/settings-form.tsx",
"frontend/src/components/modals/security/invariant/Invariant.tsx",
"frontend/src/components/modals/LoadingProject.tsx",
... | 1 |
scikit-learn | scikit-learn | e8a15d544490b3fe80ef77dd995d12de84194d00 | https://github.com/scikit-learn/scikit-learn/issues/7435 | [RFC?] Make cross_val_score output a dict/named tuple. | Two major things here -
- Often I see that only a partial output of `_fit_and_score` is taken for use. It is wasteful to generate and discard arrays. It would rather be much better to generate only the stuff that is required.
- Now that we have more options, like @jnothman says [here](https://github.com/scikit-learn/sc... | null | https://github.com/scikit-learn/scikit-learn/pull/7388 | null | {'base_commit': 'e8a15d544490b3fe80ef77dd995d12de84194d00', 'files': [{'path': 'doc/modules/classes.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [225]}}}, {'path': 'doc/modules/cross_validation.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [174], 'mod': [189]}}}, {'path': 'doc/m... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"sklearn/model_selection/_search.py",
"sklearn/metrics/scorer.py",
"sklearn/model_selection/_validation.py",
"sklearn/model_selection/__init__.py"
],
"doc": [
"doc/modules/classes.rst",
"doc/modules/model_evaluation.rst",
"doc/modules/cross_validation.rst",
"doc/whats_n... | 1 | |
huggingface | transformers | a73883ae9ec66cb35a8222f204a5f2fafc326d3f | https://github.com/huggingface/transformers/issues/24100 | [Trainer] Why not use `tqdm`'s `dynamic_ncols=True` option? | ### Feature request
# Problem
Tqdm progress bar is getting ugly when the width of the terminal is shrunk!

It progress bar makes the new line on every update! It is very ugly...
# Solution
Simply a... | null | https://github.com/huggingface/transformers/pull/24101 | null | {'base_commit': 'a73883ae9ec66cb35a8222f204a5f2fafc326d3f', 'files': [{'path': 'src/transformers/trainer_callback.py', 'status': 'modified', 'Loc': {"('ProgressCallback', 'on_train_begin', 474)": {'mod': [476]}, "('ProgressCallback', 'on_prediction_step', 484)": {'mod': [487]}}}]} | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"src/transformers/trainer_callback.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
nvbn | thefuck | f0f49c1865162fd1eef9199ab895811846516ada | https://github.com/nvbn/thefuck/issues/422 | obsolete | Shell alias clobbers some history lines | I was trying this out, and found that large swathes of my history were missing after running "fuck" a single time. This should _not_ modify history except to insert a command it executes..
| null | https://github.com/nvbn/thefuck/pull/432 | null | {'base_commit': 'f0f49c1865162fd1eef9199ab895811846516ada', 'files': [{'path': 'README.md', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [285, 309]}}}, {'path': 'thefuck/conf.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [19], 'mod': [27, 29]}, "('Settings', '_val_from_env', 120)": {'m... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"thefuck/types.py",
"thefuck/conf.py"
],
"doc": [
"README.md"
],
"test": [],
"config": [],
"asset": []
} | 1 |
scrapy | scrapy | bd8c293a97f7f08989cff1db0d9c32f5a2208b77 | https://github.com/scrapy/scrapy/issues/2518 | AttributeError: 'FeedExporter' object has no attribute 'slot' | I have this simple spider, when I call `scrapy crawl dataspider` it works fine and prints the item in the output :
import json
from scrapy.spiders import Spider
class dataspider(Spider):
name='dataspider'
start_urls=('https://www.google.com/finance/match?matchtype=matchall&ei=UVlP... | null | https://github.com/scrapy/scrapy/pull/2433 | null | {'base_commit': 'bd8c293a97f7f08989cff1db0d9c32f5a2208b77', 'files': [{'path': 'scrapy/spiderloader.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [2]}, "('SpiderLoader', '_load_all_spiders', 26)": {'mod': [28, 29]}}}, {'path': 'tests/test_spiderloader/__init__.py', 'status': 'modified', 'Loc': {'(Non... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"tests/test_spiderloader/__init__.py",
"scrapy/spiderloader.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
scikit-learn | scikit-learn | bb385394b87e382a34db829bc7ed60d347af73c9 | https://github.com/scikit-learn/scikit-learn/issues/11194 | Build / CI
Blocker | NumPy dev causes test errors due to use of np.matrix | We are getting many warnings like `PendingDeprecationWarning('the matrix subclass is not the recommended way to represent matrices or deal with linear algebra (see https://docs.scipy.org/doc/numpy/user/numpy-for-matlab-users.html). Please adjust your code to use regular ndarray.` using numpy master (see logs at https:/... | null | https://github.com/scikit-learn/scikit-learn/pull/11251 | null | {'base_commit': 'bb385394b87e382a34db829bc7ed60d347af73c9', 'files': [{'path': 'sklearn/ensemble/tests/test_iforest.py', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [8], 'mod': [18]}, "(None, 'test_iforest_error', 91)": {'mod': [108, 109]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [],
"test": [
"sklearn/ensemble/tests/test_iforest.py"
],
"config": [],
"asset": []
} | 1 |
yt-dlp | yt-dlp | 96da9525043f78aca4544d01761b13b2140e9ae6 | https://github.com/yt-dlp/yt-dlp/issues/9825 | good first issue
site-bug
patch-available | [cbc.ca] "unable to extract OpenGraph description" | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [X] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [X] I'm reporting that yt-dlp is broken on a **supported** site
- [X] I've verified that I have **updated yt-dlp to nightly or master** ([update instruc... | null | https://github.com/yt-dlp/yt-dlp/pull/9866 | null | {'base_commit': '96da9525043f78aca4544d01761b13b2140e9ae6', 'files': [{'path': 'yt_dlp/extractor/cbc.py', 'status': 'modified', 'Loc': {"('CBCPlayerIE', None, 152)": {'add': [279], 'mod': [154]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"yt_dlp/extractor/cbc.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 |
zylon-ai | private-gpt | 77447e50c0b8143edcf34896af80dd58925582f9 | https://github.com/zylon-ai/private-gpt/issues/2 | TypeError: generate() got an unexpected keyword argument 'new_text_callback' | /privateGPT/gpt4all_j.py", line 152, in _call
text = self.client.generate(
TypeError: generate() got an unexpected keyword argument 'new_text_callback' | null | https://github.com/zylon-ai/private-gpt/pull/3 | null | {'base_commit': '77447e50c0b8143edcf34896af80dd58925582f9', 'files': [{'path': 'requirements.txt', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [1]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [],
"test": [],
"config": [
"requirements.txt"
],
"asset": []
} | 1 | |
sherlock-project | sherlock | 9db8c213ffdad873380c9de41c142923ba0dc260 | https://github.com/sherlock-project/sherlock/issues/1366 | enhancement | Add xlsx Export | <!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Put x into all boxes (like this [x]) once you have... | null | https://github.com/sherlock-project/sherlock/pull/1367 | null | {'base_commit': '9db8c213ffdad873380c9de41c142923ba0dc260', 'files': [{'path': '.gitignore', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [24]}}}, {'path': 'requirements.txt', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [7]}}}, {'path': 'sherlock/sherlock.py', 'status': 'modified', 'Loc':... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"sherlock/sherlock.py"
],
"doc": [],
"test": [],
"config": [
".gitignore",
"requirements.txt"
],
"asset": []
} | 1 |
geekan | MetaGPT | 8b209d4e17ad7dfc1ad7a80505eac42f71228734 | https://github.com/geekan/MetaGPT/issues/1539 | ollama llm vision api call error: async for raw_chunk in stream_resp: TypeError: 'async for' requires an object with __aiter__ method, got bytes | **Bug description**
when running any vision llm call (like example/llm_vision.py)
there seems to be an issue with async def _achat_completion_stream(self, messages: list[dict], timeout: int = USE_CONFIG_TIMEOUT) -> str: method
**Bug solved method**
No solve yet
**Environment information**
system metal, llm ol... | null | https://github.com/geekan/MetaGPT/pull/1544 | null | {'base_commit': '8b209d4e17ad7dfc1ad7a80505eac42f71228734', 'files': [{'path': 'examples/llm_vision.py', 'status': 'modified', 'Loc': {"(None, 'main', 12)": {'mod': [18, 19]}}}, {'path': 'metagpt/configs/llm_config.py', 'status': 'modified', 'Loc': {"('LLMType', None, 18)": {'mod': [29]}, "('LLMConfig', 'check_llm_key'... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"examples/llm_vision.py",
"metagpt/configs/llm_config.py",
"metagpt/provider/general_api_requestor.py",
"metagpt/provider/ollama_api.py",
"metagpt/provider/general_api_base.py"
],
"doc": [],
"test": [
"tests/metagpt/provider/test_ollama_api.py"
],
"config": [],
"asset":... | 1 | |
3b1b | manim | dbdd7996960ba46ed044a773290b02f17478c760 | https://github.com/3b1b/manim/issues/1065 | Example_scenes.py run problem question | I was able to get the install success thanks to help. I ran the example_scenes.py file and have the results below. I am now also going through https://talkingphysics.wordpress.com/2019/01/08/getting-started-animating-with-manim-and-python-3-7/ and have similar errors when running the first run python -m manim pymani... | null | https://github.com/3b1b/manim/pull/1057 | null | {'base_commit': 'dbdd7996960ba46ed044a773290b02f17478c760', 'files': [{'path': 'manimlib/scene/scene_file_writer.py', 'status': 'modified', 'Loc': {"('SceneFileWriter', 'combine_movie_files', 253)": {'mod': [289]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"manimlib/scene/scene_file_writer.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
yt-dlp | yt-dlp | c84aeac6b5695e7e1ac629d17fc51eb68ab91bae | https://github.com/yt-dlp/yt-dlp/issues/502 | external issue | [youtube] YouTube serving erroneous DASH Manifest VP9 formats | <!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Carefully read and work through this check lis... | null | https://github.com/yt-dlp/yt-dlp/pull/536 | null | {'base_commit': 'c84aeac6b5695e7e1ac629d17fc51eb68ab91bae', 'files': [{'path': 'README.md', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [1340, 1341]}}}, {'path': 'yt_dlp/downloader/youtube_live_chat.py', 'status': 'modified', 'Loc': {"('YoutubeLiveChatFD', 'download_and_parse_fragment', 111)": {'mod': [... | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "3",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"yt_dlp/extractor/youtube.py",
"yt_dlp/downloader/youtube_live_chat.py"
],
"doc": [
"README.md"
],
"test": [],
"config": [],
"asset": []
} | 1 |
deepfakes | faceswap | 59ca996eb1b510cef7ae60a179c36ea7f353f71e | https://github.com/deepfakes/faceswap/issues/197 | Face on angles >180 degrees not recognized on extraction | Hi guys thanks for the amazing work here!
I have been following the landmark detection dialogue #187 and have tried both hog and cnn with both face-alignment and face_recognition. I got face-alignment with cnn working great, with pytorch on win10 now. However, I noticed that none of the above are able to reliably a... | null | https://github.com/deepfakes/faceswap/pull/253 | null | {'base_commit': '59ca996eb1b510cef7ae60a179c36ea7f353f71e', 'files': [{'path': 'lib/cli.py', 'status': 'modified', 'Loc': {"('DirectoryProcessor', 'get_faces_alignments', 140)": {'add': [144]}, '(None, None, None)': {'mod': [9]}, "('DirectoryProcessor', None, 29)": {'mod': [157]}, "('DirectoryProcessor', 'get_faces', 1... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"lib/utils.py",
"lib/faces_detect.py",
"lib/cli.py",
"scripts/convert.py",
"scripts/extract.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
deepfakes | faceswap | 9438672b1cf80602fc93536670d9601d655377f5 | https://github.com/deepfakes/faceswap/issues/239 | EOL Error when training | After pulling the latest commit today I am now getting the below error when trying to train.
**Command**
python faceswap.py train -A "D:\Fakes\Data\Dataset_A\Faces" -B "D:\Fakes\Data\Dataset_B\Faces" -m "D:\Fakes\Model" -p -s 100 -bs 80 -t LowMem
**Error**
Traceback (most recent call last):
File "faceswap.py... | null | null | https://github.com/deepfakes/faceswap/commit/9438672b1cf80602fc93536670d9601d655377f5 | {'base_commit': '9438672b1cf80602fc93536670d9601d655377f5', 'files': [{'path': 'scripts/convert.py', 'status': 'modified', 'Loc': {}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "commit",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"scripts/convert.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | null | |
huggingface | transformers | 5f7a07c0c867abedbb3ebf135915eeee56add24b | https://github.com/huggingface/transformers/issues/9326 | Issue with 'char_to_token()' function of DistilBertTokenizerFast | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.0.1
- Platform: Google Colab
- Python version: 3.8
- PyTorch version (GPU?):
- Tensorflow version (G... | null | https://github.com/huggingface/transformers/pull/9378 | null | {'base_commit': '5f7a07c0c867abedbb3ebf135915eeee56add24b', 'files': [{'path': 'docs/source/custom_datasets.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [564], 'mod': [561, 562, 566]}}}]} | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": null,
"info_type": null
} | {
"code": [],
"doc": [
"docs/source/custom_datasets.rst"
],
"test": [],
"config": [],
"asset": []
} | 1 | |
zylon-ai | private-gpt | 2940f987c0996fe083d1777bdc117fc28c576c08 | https://github.com/zylon-ai/private-gpt/issues/1007 | bug
primordial | running ingest throws attribute error module 'chromadb' has no attribute 'PersistentClient' | ```
(privategpt-py3.11) (base) ➜ privateGPT git:(main) ✗ python ingest.py
Traceback (most recent call last):
File "/Volumes/Projects/privateGPT/ingest.py", line 169, in <module>
main()
File "/Volumes/Projects/privateGPT/ingest.py", line 146, in main
chroma_client = chromadb.PersistentClient(settings=... | null | https://github.com/zylon-ai/private-gpt/pull/1015 | null | {'base_commit': '2940f987c0996fe083d1777bdc117fc28c576c08', 'files': [{'path': 'pyproject.toml', 'status': 'modified', 'Loc': {'(None, None, None)': {'mod': [11, 12, 13, 14, 15, 16, 18, 19, 23]}}}]} | [] | [] | [] | {
"iss_type": "1",
"iss_reason": "1",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [],
"doc": [],
"test": [],
"config": [
"pyproject.toml"
],
"asset": []
} | 1 |
geekan | MetaGPT | bbb9645f7c60c35177922d10ccc7ed4b90d261c3 | https://github.com/geekan/MetaGPT/issues/979 | `utils.text.reduce_message_length` Not reducing text length | **Bug description**
I come across this issue.
```python
File "/Users/azure/Documents/Workspace/Datasci/lib/python3.10/site-packages/metagpt/utils/text.py", line 31, in reduce_message_length
raise RuntimeError("fail to reduce message length")
RuntimeError: fail to reduce message length
```
**Bug solved me... | null | https://github.com/geekan/MetaGPT/pull/986 | null | {'base_commit': 'bbb9645f7c60c35177922d10ccc7ed4b90d261c3', 'files': [{'path': 'metagpt/actions/research.py', 'status': 'modified', 'Loc': {"('CollectLinks', 'run', 94)": {'mod': [137]}}}, {'path': 'metagpt/config2.py', 'status': 'modified', 'Loc': {"('Config', 'default', 88)": {'mod': [95]}}}, {'path': 'metagpt/utils/... | [] | [] | [] | {
"iss_type": "2",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"metagpt/actions/research.py",
"metagpt/config2.py",
"metagpt/utils/token_counter.py"
],
"doc": [],
"test": [],
"config": [],
"asset": []
} | 1 | |
scikit-learn | scikit-learn | c56bce482db698c7c7e7b583b8b2e08a211eb48b | https://github.com/scikit-learn/scikit-learn/issues/10463 | API | Toward a consistent API for NearestNeighbors & co | ### Estimators relying on `NearestNeighbors` (NN), and their related params:
`params = (algorithm, leaf_size, metric, p, metric_params, n_jobs)`
**sklearn.neighbors:**
- `NearestNeighbors(n_neighbors, radius, *params)`
- `KNeighborsClassifier(n_neighbors, *params)`
- `KNeighborsRegressor(n_neighbors, *params)`
... | null | https://github.com/scikit-learn/scikit-learn/pull/10482 | null | {'base_commit': 'c56bce482db698c7c7e7b583b8b2e08a211eb48b', 'files': [{'path': 'doc/glossary.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [699]}}}, {'path': 'doc/modules/classes.rst', 'status': 'modified', 'Loc': {'(None, None, None)': {'add': [1236, 1239]}}}, {'path': 'doc/modules/neighbors.rst', ... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"sklearn/neighbors/unsupervised.py",
"sklearn/neighbors/regression.py",
"sklearn/manifold/t_sne.py",
"sklearn/neighbors/__init__.py",
"sklearn/neighbors/base.py",
"sklearn/manifold/locally_linear.py",
"sklearn/manifold/_utils.pyx",
"sklearn/cluster/dbscan_.py",
"sklearn... | 1 |
python | cpython | 55d50d147c953fab37b273bca9ab010f40e067d3 | https://github.com/python/cpython/issues/102500 | type-feature
topic-typing
3.12 | Implement PEP 688: Making the buffer protocol accessible in Python | PEP-688 has just been accepted. I will use this issue to track its implementation in CPython.
<!-- gh-linked-prs -->
### Linked PRs
* gh-102521
* gh-102571
* gh-104174
* gh-104281
* gh-104288
* gh-104317
<!-- /gh-linked-prs -->
| null | https://github.com/python/cpython/pull/102521 | null | {'base_commit': '55d50d147c953fab37b273bca9ab010f40e067d3', 'files': [{'path': 'Include/internal/pycore_global_objects_fini_generated.h', 'status': 'modified', 'Loc': {"(None, '_PyStaticObjects_CheckRefcnt', 24)": {'add': [595, 694, 1124]}}}, {'path': 'Include/internal/pycore_global_strings.h', 'status': 'modified', 'L... | [] | [] | [] | {
"iss_type": "4",
"iss_reason": "2",
"loc_way": "pr",
"loc_scope": "",
"info_type": ""
} | {
"code": [
"Objects/typeobject.c",
"Lib/inspect.py",
"Tools/build/generate_global_objects.py",
"Include/internal/pycore_global_objects_fini_generated.h",
"Tools/c-analyzer/cpython/ignored.tsv",
"Objects/clinic/memoryobject.c.h",
"Lib/_collections_abc.py",
"Tools/c-analyzer/cpython/glo... | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.