
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,896,525 | Exploring Blockchain Technology Beyond Cryptocurrencies | Introduction Blockchain technology has made groundbreaking changes in the world of... | 0 | 2024-06-22T00:31:59 | https://dev.to/kartikmehta8/exploring-blockchain-technology-beyond-cryptocurrencies-2k48 | javascript, beginners, programming, tutorial | ## Introduction
Blockchain technology has made groundbreaking changes in the world of cryptocurrencies. However, its potential extends far beyond that. This revolutionary technology has the ability to transform various industries and bring significant benefits to businesses. In this article, we will explore the advant... | kartikmehta8 |
1,896,524 | How to create and connect to a Linux VM on Azure using a Public Key. | Table of content. Introduction Log In Step 1: Create VM Step 2: Add all Basic Parameters Step 3:... | 0 | 2024-06-22T00:22:48 | https://dev.to/phillip_ajifowobaje_68724/how-to-create-and-connect-to-a-linux-vm-on-azure-using-a-public-key-5fm1 | Table of content.
- Introduction
- Log In
- Step 1: Create VM
- Step 2: Add all Basic Parameters
- Step 3: Review + Create VM
- Step 4: Machine Validation Passed
- Step 5: Create for VM deployment
- Step 6: Connect Linux VM Via SSH
**INTRODUCTION**: Linux Virtual machines is a type of machine that is powered by the L... | phillip_ajifowobaje_68724 | |
1,896,523 | GIF to JPG: Transitioning Between Image Formats | What Are the Differences Between GIF and JPG? GIF (Graphics Interchange Format) and JPG... | 0 | 2024-06-22T00:19:23 | https://dev.to/msmith99994/gif-to-jpg-transitioning-between-image-formats-2e28 | ## What Are the Differences Between GIF and JPG?
GIF (Graphics Interchange Format) and JPG (or JPEG - Joint Photographic Experts Group) are two of the most widely used image formats, each serving different purposes and possessing distinct characteristics.
### GIF
**- Compression:** GIF uses lossless compression, whic... | msmith99994 | |
1,895,155 | Discover the Heart of Ethical Software Development: Principles, Practices, and Real-World Examples | As software developers, we hold the keys to powerful tools that shape our world. Whether it's a... | 27,798 | 2024-06-22T00:19:09 | https://dev.to/andresordazrs/discover-the-heart-of-ethical-software-development-principles-practices-and-real-world-examples-2eb | ethicaldevelopment, privacyandsecurity, softwareengineering, techethics | As software developers, we hold the keys to powerful tools that shape our world. Whether it's a mobile app simplifying daily tasks or a complex system managing vast amounts of data, the software we create impacts lives in significant ways. But with this power comes a great responsibility: to ensure that our creations a... | andresordazrs |
1,896,522 | How To Create And Connect To A Linux Virtual Machine Using A Public Key | To do this effectively, you must follow the below steps; 1. Sign up to Azure portal 2. Click on... | 0 | 2024-06-22T00:17:21 | https://dev.to/romanus_onyekwere/how-to-create-and-connect-to-a-linux-virtual-machine-using-a-public-key-53dc | virtual, microsoft, system, technology | To do this effectively, you must follow the below steps;
**1. Sign up to Azure portal**

**2. Click on Virtual Machine**
 and software design principles. Here is a comprehensive guide to help you prepare effectively:
### 1. Understand the Basics of OOD
- **Object-Oriented Principles**: Learn the four main principles o... | muhammad_salem | |
1,896,517 | Project Stage-3: Reflections and Final Thoughts on Implementing AFMV in GCC | As the summer project for SPO600 comes to a close, it’s time to reflect on the journey of... | 0 | 2024-06-21T23:50:08 | https://dev.to/yuktimulani/project-stage-3-reflections-and-final-thoughts-on-implementing-afmv-in-gcc-45gp | As the summer project for SPO600 comes to a close, it’s time to reflect on the journey of implementing Automatic Function Multi-Versioning (AFMV) for AArch64 systems in GCC. This final blog post summarizes the accomplishments, challenges, and learnings from this project, and provides insights into the future work that ... | yuktimulani | |
1,896,516 | Any opinions on this new AI powered mutation testing tool? | I read a Medium article about this software testing tool that uses AI. I’m curious to know if someone... | 0 | 2024-06-21T23:44:02 | https://dev.to/devlevy/any-opinions-on-this-new-ai-powered-mutation-testing-tool-lho | opensource, discuss, webdev, python | I read a [Medium](https://medium.com/codeintegrity-engineering/transforming-qa-mutahunter-and-the-power-of-llm-enhanced-mutation-testing-18c1ea19add8) article about this software testing [tool](https://github.com/codeintegrity-ai/mutahunter) that uses AI. I’m curious to know if someone with deep experience in software ... | devlevy |
1,896,515 | I just created a simple & stupid notepad (Looking for advice) | Salam (Peace) everyone! I've recently started learning C# coding. After mastering the basics and... | 0 | 2024-06-21T23:39:22 | https://dev.to/dzt/i-just-created-a-simple-stupid-notepad-looking-for-advice-2gnh | csharp, help, programming, beginners | Salam (Peace) everyone! I've recently started learning C# coding. After mastering the basics and console apps, I've moved on to GUI using WinForms to gain more experience and develop my skills in C#. I hope someone here can assist me in developing this notepad application. I'm facing several issues, particularly with t... | dzt |
1,896,514 | GIF to PNG: Transitioning Between Image Formats | What Are the Differences Between GIF and PNG? GIF (Graphics Interchange Format) and PNG... | 0 | 2024-06-21T23:33:15 | https://dev.to/msmith99994/gif-to-png-transitioning-between-image-formats-239 | ## What Are the Differences Between GIF and PNG?
GIF (Graphics Interchange Format) and PNG (Portable Network Graphics) are two widely-used image formats, each with unique characteristics that cater to different needs. Understanding these differences helps in deciding when and why to use each format, and how to convert ... | msmith99994 | |
1,896,513 | How to create a resource group in Azure Portal | What is a Resource group?: A resource is a logical container for housing our resources in... | 0 | 2024-06-21T23:32:45 | https://dev.to/realcloudprojects/how-to-create-a-resource-group-in-azure-portal-2h8j | webdev, beginners, tutorial, productivity | **What is a Resource group?**: A resource is a logical container for housing our resources in Azure.
**Here are the steps to create one in Azure**
Step1: Search for resource in the search resource, documents& services field and click enter
 for... | 0 | 2024-06-21T23:18:33 | https://dev.to/yuktimulani/project-stage-3leveraging-advanced-gcc-flags-5e2l | Hello there!!
As our journey towards implementing Automatic Function Multi-Versioning (AFMV) for AArch64 systems continues, I’ve encountered some intriguing challenges and solutions regarding the support of SVE2 (Scalable Vector Extension version 2) in GCC. This blog post explores how advanced GCC flags can be leverag... | yuktimulani | |
1,896,502 | form backend service fabform.io | FabForm.io is a service designed to handle form submissions for static sites and web applications... | 0 | 2024-06-21T23:18:04 | https://dev.to/irishgeoff22/form-backend-service-fabformio-45ip | FabForm.io is a service designed to handle form submissions for static sites and web applications without needing a custom backend. Here’s a step-by-step guide on how to use FabForm.io:
### 1. Sign Up and Set Up Your Account
1. **Sign Up**: Go to the FabForm.io website and create an account.
2. **Create a Project**: O... | irishgeoff22 | |
1,896,393 | How to Add Nodemon to your TS files | The dev package nodemon has been a great help providing server-side hot-reloading as we code in our... | 0 | 2024-06-21T23:13:03 | https://dev.to/finalgirl321/how-to-add-nodemon-to-your-ts-files-4736 | The dev package nodemon has been a great help providing server-side hot-reloading as we code in our JavaScript, json, and other files while developing the in the NodeJS environment. To include the benefits of nodemon in your TypeScript projects so that the _unbuilt_ ts file hot-reloads as you go takes a bit more config... | finalgirl321 | |
1,896,499 | Project Stage-3: Overcoming Compiler Attribute Challenges | Welcome back folks!! In our quest to implement Automatic Function Multi-Versioning (AFMV) for... | 0 | 2024-06-21T23:05:11 | https://dev.to/yuktimulani/project-stage-3-overcoming-compiler-attribute-challenges-3le3 | Welcome back folks!! In our quest to implement Automatic Function Multi-Versioning (AFMV) for AArch64, one of the critical challenges has been dealing with compiler attribute errors. The target("sve2") attribute error was a particular stumbling block. Here’s how I tackled it.
## Initial Error Message:
```
error: prag... | yuktimulani | |
1,894,509 | 4 useState Mistakes You Should Avoid in React🚫 | Introduction React.js has become a cornerstone of modern web development, with its unique... | 0 | 2024-06-21T23:00:00 | https://dev.to/safdarali/4-usestate-mistakes-you-should-avoid-in-react-1ol0 | technology, javascript, react, programming | ## Introduction
React.js has become a cornerstone of modern web development, with its unique approach to managing state within components. One common hook, useState, is fundamental but often misused. Understanding and avoiding these common mistakes is crucial for both beginners and experienced developers aiming to cre... | safdarali |
1,896,497 | Firebase Authentication: Are you truly secure? | INTRODUCTION Verizon’s 2023 Data Breach Investigations Report (DBIR) reported that 49% of... | 0 | 2024-06-21T22:53:28 | https://dev.to/oyegoke/firebase-authentication-are-you-truly-secure-1bo4 | webdev, javascript, beginners, react | ## **INTRODUCTION**
Verizon’s 2023 Data Breach Investigations Report (DBIR) reported that 49% of security breaches involved compromised credentials. This highlights the critical importance of implementing a robust website authentication system on the developer's part.
Firebase authentication is a comprehensive authent... | oyegoke |
1,896,498 | Crear un proyecto nuevo con Eslint, Stylelint, CommitLint y Husky | En este artículo vamos a ver cómo configurar tu proyecto utilizando herramientas de revisión de... | 0 | 2024-06-21T22:47:33 | https://dev.to/altaskur/crear-un-proyecto-nuevo-con-eslint-stylelint-commitlint-y-husky-k6j | webdev, programming, spanish, tutorial | En este artículo vamos a ver cómo configurar tu proyecto utilizando herramientas de revisión de código y vamos a modificar Git para que podamos ejecutar estas herramientas antes de subir nuestro código al repositorio, asegurándonos de mantener unas reglas, estructuras y configuraciones que homogenicen y limpien nuestro... | altaskur |
1,896,494 | Acessibilidade = Usabilidade | Um rant rápido considerando acessibilidade | 0 | 2024-06-21T22:43:53 | https://dev.to/andrewmat/acessibilidade-usabilidade-362c | braziliandevs, frontend, a11y | ---
title: Acessibilidade = Usabilidade
published: true
description: Um rant rápido considerando acessibilidade
tags: braziliandevs, frontend, a11y
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-21 22:10 +0000
---
Nós devs frontend não devemos pensar em... | andrewmat |
1,896,496 | Project Stage-3: Digging Deeper | Hi Peeps!! Welcome back. Without wasting any time lets continue from the last blog. The error... | 0 | 2024-06-21T22:43:26 | https://dev.to/yuktimulani/project-stage-3-digging-deeper-mcg | Hi Peeps!! Welcome back. Without wasting any time lets continue from the [last blog](https://dev.to/yuktimulani/project-stage-3-error-analysis-3lm4).
The error message related to the target("sve2") attribute has been a key focus in the latest phase of our AFMV implementation. The message was clear but presented a cha... | yuktimulani | |
1,896,490 | Los 6 lenguajes de programación de ciencia de datos que hay que aprender en 2024 | Hoy en día, el campo de la ciencia de datos está experimentando un gran crecimiento. Existe una... | 0 | 2024-06-21T22:43:01 | https://dev.to/pirisaurio32/los-6-lenguajes-de-programacion-de-ciencia-de-datos-que-hay-que-aprender-en-2024-1ln9 | Hoy en día, el campo de la ciencia de datos está experimentando un gran crecimiento. Existe una demanda de personas capaces de extraer información de los datos, sobre todo porque la cantidad de datos sigue aumentando a un ritmo exponencial. En el campo de la ciencia de datos, los profesionales utilizan lenguajes de pro... | pirisaurio32 | |
1,896,493 | [Game of Purpose] Day 34 | Today I made my drone drop a granade and explode on impact. A problem I currently face is that... | 27,434 | 2024-06-21T22:32:28 | https://dev.to/humberd/game-of-purpose-day-34-47j4 | gamedev | Today I made my drone drop a granade and explode on impact.
{% embed https://youtu.be/n-Vs0QikzeE %}
A problem I currently face is that when the granade is attached via a PhysicsConstraint it will contribute to a drone's mass and will slowly fall down, because there is not enough thrust. I tried to add granade's mass... | humberd |
1,896,492 | Networking and Sockets: Syn and Accept queue | In my previous article, we discussed endianness, its importance, and how to work with it.... | 27,728 | 2024-06-21T22:31:03 | https://www.kungfudev.com/blog/2024/06/14/network-sockets-syn-and-accept-queue | linux, rust, networking, socket |
In my previous [article](https://www.kungfudev.com/blog/2024/06/14/network-sockets-endianness), we discussed endianness, its importance, and how to work with it. Understanding endianness is crucial for dealing with data at the byte level, especially in network programming. We examined several examples that highlighte... | douglasmakey |
1,896,491 | Project Stage-3: Error Analysis | Hi folks!!! Welcome to my series of Summer Project blogs. As part of the SPO600 2024 Summer Project,... | 0 | 2024-06-21T22:29:50 | https://dev.to/yuktimulani/project-stage-3-error-analysis-3lm4 | Hi folks!!! Welcome to my series of Summer Project blogs. As part of the SPO600 2024 Summer Project, my objective in Stage 3 is to resolve Automatic Function Multi-Versioning (AFMV) error messages within the GNU Compiler Collection (GCC). AFMV is a cutting-edge feature designed to optimize function calls across differe... | yuktimulani | |
1,896,480 | Interceptors nestjs | How do I use Interceptors in nestjs? | 0 | 2024-06-21T21:56:19 | https://dev.to/azuli_jerson_86d70f94325d/interceptors-nestjs-2m7e | How do I use Interceptors in nestjs? | azuli_jerson_86d70f94325d | |
1,895,955 | Revolutionizing Resume Screening: How ATS-B-Gone Can Keep The Buzzwords Away | Revolutionizing Resume Screening: Beyond ATS Limitations With so much happening across... | 0 | 2024-06-21T22:27:32 | https://dev.to/brandonbaz/revolutionizing-resume-screening-how-ats-b-gone-can-keep-the-buzzwords-away-1pg2 | ### Revolutionizing Resume Screening: Beyond ATS Limitations
With so much happening across nearly all industries, I’ve noticed a trend: highly skilled professionals are being approached by managers or recruiters for positions they didn’t even know they’d applied for because their resumes got tossed by ATS systems. Key... | brandonbaz | |
1,896,477 | My First Scrimba Project | Technical writing has been my chosen profession for the last three years. My interest started seven... | 0 | 2024-06-21T22:13:29 | https://dev.to/eryn_bing_d82c364c570aff3/my-first-scrimba-project-1kn7 | Technical writing has been my chosen profession for the last three years. My interest started seven years ago when I was a senior in high school. After researching writing careers in the bls.gov, the only thing I knew about technical writing was that it included writing manuals. Despite my skint knowledge in the field,... | eryn_bing_d82c364c570aff3 | |
1,896,487 | Maiu Online - Browser MMORPG #indiegamedev #babylonjs Ep22 - Map editor | Hey Currently I’m working on collisions detection. For now I’m using SAT 2D and later in future maybe... | 0 | 2024-06-21T22:13:11 | https://dev.to/maiu/maiu-online-browser-mmorpg-indiegamedev-babylonjs-ep22-map-editor-3f3f | babylonjs, indiegamedev, mmorpg, devlog | Hey
Currently I’m working on collisions detection. For now I’m using SAT 2D and later in future maybe I’ll change it to something different (maybe navmesh, will se…). To make creation of map and collisions data a little bit more automatic I prepared very simple map editor. Which prints in the output whole map config wi... | maiu |
1,896,482 | Trouble in implementing pagination in django rest framework | https://stackoverflow.com/questions/78654425/trouble-in-implementing-pagination-in-django-rest-framew... | 0 | 2024-06-21T21:58:58 | https://dev.to/abhaylearns/trouble-in-implementing-pagination-in-django-rest-framework-46m | https://stackoverflow.com/questions/78654425/trouble-in-implementing-pagination-in-django-rest-framework | abhaylearns | |
1,896,481 | My Flow and Productivity has Improved with the Simplicity of Neovim | I don't think it's a surprise if you've been following along with me lately that I've pivoted my... | 0 | 2024-06-21T21:56:46 | https://www.binaryheap.com/productivity-and-flow-improved-with-neovim/ | programming, development | I don't think it's a surprise if you've been following along with me lately that I've pivoted my daily programming setup to Neovim. What might surprise you is that I started my career working on HP-UX and remoting into servers because the compilers and toolchains only existed on those servers I was building for. When... | benbpyle |
1,896,478 | 💾 Database Management Systems (DBMS) Explained | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-21T21:52:45 | https://dev.to/aviralgarg05/database-management-systems-dbms-explained-44ia | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
DBMS 💾 is software that manages and organizes data in databases 📚. It allows users to store, retrieve, update, and delete data efficiently 🗃️. With features like data security 🔒 an... | aviralgarg05 |
1,896,475 | How make Auth Nestjs | Could anyone help me with implementing Auth JWT in a nestjs application? | 0 | 2024-06-21T21:48:48 | https://dev.to/azuli_jerson_86d70f94325d/how-make-auth-nestjs-3d7f | Could anyone help me with implementing Auth JWT in a nestjs application? | azuli_jerson_86d70f94325d | |
1,896,474 | Day 976 : Manifest | liner notes: Professional : Not a bad day. Took some training. Applied for a Visa, again. haha... | 0 | 2024-06-21T21:44:11 | https://dev.to/dwane/day-976-manifest-llo | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Not a bad day. Took some training. Applied for a Visa, again. haha Responded to some community questions. Worked on refactoring a feature in an app to use a new SDK.
- Personal : Last night, I went through tracks and put together a playlist for the radio show. I set up the social media ... | dwane |
1,896,473 | MysterySkulls Crud Nestjs | I'm having difficulty creating a crud in nestjs and I need help, I bought a course and it turned out... | 0 | 2024-06-21T21:44:06 | https://dev.to/azuli_jerson_86d70f94325d/mysteryskulls-crud-nestjs-2km4 | nestjs, help | I'm having difficulty creating a crud in nestjs and I need help, I bought a course and it turned out that the guy was a crook and I was scammed so I would only like some help if it's not too problematic
I would like to receive a tip or assistance in creating a crud | azuli_jerson_86d70f94325d |
1,896,471 | What do a bug screen and a firewall have in common? | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-21T21:38:40 | https://dev.to/yowise/what-do-a-bug-screen-and-a-firewall-have-in-common-olg | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Firewall is like a bug screen, essential to defend our space against vermin intruders when we open the window. In order to save yourself from hosting the banquet of malware creepy-craw... | yowise |
1,896,470 | Preparing for AWS Cloud Practitioner CLF-C02: A Beginner’s Guide to Getting Started | Introduction The AWS Cloud Practitioner CLF-C02 exam is a foundational certification... | 0 | 2024-06-21T21:35:29 | https://dev.to/rahul_chandra/preparing-for-aws-cloud-practitioner-clf-c02-a-beginners-guide-to-getting-started-370o | aws, cloud, productivity, learning | ## **Introduction**
The AWS Cloud Practitioner CLF-C02 exam is a foundational certification offered by Amazon Web Services (AWS), designed for individuals who want to demonstrate a basic understanding of the AWS Cloud. As someone who has just embarked on this journey, I’m excited to share my initial steps, study plans,... | rahul_chandra |
1,896,469 | React Router | React Router DOM | What is React Router? Traditional multi-page web apps have multiple view files for... | 0 | 2024-06-21T21:33:00 | https://dev.to/geetika_bajpai_a654bfd1e0/react-router-react-router-dom-1blo | ## What is React Router?
Traditional multi-page web apps have multiple view files for rendering different views, while modern Single Page Applications (SPAs) use component-based views. This necessitates switching components based on the URL, which is handled via routing. Although not all development requirements in Re... | geetika_bajpai_a654bfd1e0 | |
1,896,468 | ZenCortex Reviews (Hearing Health Support) Is Zen Cortex Recommended By Experts? | ❤️👉 Click here to buy ZenCortex from official website and get a VIP discount👈 OFFER====>... | 0 | 2024-06-21T21:32:00 | https://dev.to/zencortenow/zencortex-reviews-hearing-health-support-is-zen-cortex-recommended-by-experts-1fof | zencortex | ❤️👉 Click here to buy ZenCortex from official website and get a VIP discount👈
OFFER====> https://mwebgraceful.com/9133/246/10/
ZenCortex is a progressive dietary enhancement carefully created to upgrade hearing wellbeing and mental capability normally. With north of 20 plant-based fixings, this exceptional equation ... | zencortenow |
1,896,467 | ZenCortex Reviews (Hearing Health Support) Is Zen Cortex Recommended By Experts? | ❤️👉 Click here to buy ZenCortex from official website and get a VIP discount👈 In a world loaded up... | 0 | 2024-06-21T21:29:14 | https://dev.to/zencortenow/zencortex-reviews-hearing-health-support-is-zen-cortex-recommended-by-experts-26c0 | zencortex | ❤️👉 Click here to buy ZenCortex from official website and get a VIP discount👈
In a world loaded up with commotion and interruptions, tracking down a characteristic answer for help sound hearing and smartness resembles finding an unlikely treasure. ZenCortex offers an exceptional equation intended to support your hear... | zencortenow |
1,896,465 | Average Churn Rate for Subscription Services in 2024 | This Blog was Originally Posted to Churnfree Blog The average churn rate for subscription services... | 0 | 2024-06-21T21:22:29 | https://churnfree.com/blog/average-churn-rate-for-subscription-services/ | churnrate, churnfree, churnreduction, saaschurn | This Blog was Originally Posted to [Churnfree Blog](https://churnfree.com/blog/average-churn-rate-for-subscription-services/)
The average churn rate for subscription services varies from industry to industry. Understanding the average churn rate for subscription services is essential for any business to grow in 2024.
... | churnfree |
1,896,394 | Security news weekly round-up - 21st June 2024 | Weekly review of top security news between June 14, 2024, and June 21, 2024 | 6,540 | 2024-06-21T21:16:14 | https://dev.to/ziizium/security-news-weekly-round-up-21st-june-2024-34j0 | security | ---
title: Security news weekly round-up - 21st June 2024
published: true
description: Weekly review of top security news between June 14, 2024, and June 21, 2024
tags: security
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/0jupjut8w3h9mjwm8m57.jpg
series: Security news weekly round-up
---
## __Introduction__... | ziizium |
1,883,868 | Tips for collaborating with a new project codebase | Working on a new project codebase can be both exciting and challenging. Whether you're an experienced... | 0 | 2024-06-21T21:08:18 | https://dev.to/wdp/tips-for-collaborating-with-a-new-project-codebase-4kpf | codereview, softwaredevelopment, programmingtips |
Working on a new project codebase can be both exciting and challenging. Whether you're an experienced developer or a newcomer, understanding how to navigate and contribute to an unfamiliar codebase is crucial for efficient and effective collaboration.
In this article, we provide tips to help you get started, what to... | marianacaldas |
1,893,279 | Basics of Web Dev + Hosting on Github Pages - Day 0/? | This would be a very rough draft or more like pointed-down stuff of whatever I will be learning. I... | 27,813 | 2024-06-21T21:07:03 | https://dev.to/theshakeabhi/re-learning-the-basics-of-web-day-0-1o6o | webdev, beginners, htmlcssjs | This would be a very rough draft or more like pointed-down stuff of whatever I will be learning. I have been a web developer for the last 3 years, but I still feel like I am lagging in some areas.
So the plan is to read the entire MDN [Guides Section](https://developer.mozilla.org/en-US/docs/Learn), blog every day wh... | theshakeabhi |
1,896,365 | Disable Effects of a Controller On its Pods in Kubernetes | A controller is the name for several different elements in Kubernetes. One of these elements... | 0 | 2024-06-21T20:57:34 | https://dev.to/umairk/disable-effects-of-a-controller-on-its-pods-in-kubernetes-64a | kubernetes, devops, tutorial, docker | A controller is the name for several different elements in Kubernetes. One of these elements designates the global name of any resource responsible, among other things, for the creation and lifecycle management of the pods.
A typical controller is a Deployment, which is used to deploy pods in several replicas but is a... | umairk |
1,889,031 | Swimming Like a Fish (Bite-size Article) | Introduction Many fish swim continuously throughout their lives. Especially, fish like... | 0 | 2024-06-21T20:56:35 | https://dev.to/koshirok096/swimming-like-a-fish-bite-size-article-29bm | life, mentalhealth | #Introduction
Many fish swim continuously throughout their lives. Especially, fish like sharks and tuna take in oxygen by swimming, maintaining the activities necessary for survival. These fish, which possess this habit, survive by always moving forward.
So, <u>do we need to keep swimming continuously in our lives lik... | koshirok096 |
1,896,392 | AWS Polling - What is it and why you should do it | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-21T20:56:14 | https://dev.to/onesoltechnologies/aws-polling-what-is-it-and-why-you-should-do-it-4cob | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
In [AWS](https://aws.amazon.com/) Lambda polling, we find the most optimal configuration for your AWS Lambda. These configurations refer to the memory size and its relation to runtime &... | onesoltechnologies |
1,896,389 | Crafting Effective UI Layouts: Day 4 of My UI/UX Design Journey | Day 4: Mastering Layout in UI Design 👋 Hello, Dev Community! I'm Prince Chouhan, a B.Tech CSE... | 0 | 2024-06-21T20:52:25 | https://dev.to/prince_chouhan/crafting-effective-ui-layouts-day-4-of-my-uiux-design-journey-4i87 | ui, uidesign, ux, uxdesign | Day 4: Mastering Layout in UI Design
👋 Hello, Dev Community!
I'm Prince Chouhan, a B.Tech CSE student with a passion for UI/UX design. Today, I'm excited to share my learnings on the principles of creating effective layouts in UI design.
---
🗓️ Day 4 Topic: Layout Principles in UI Design
---
📚 Today's Learning... | prince_chouhan |
1,891,804 | A practical summary of React State variables & Props! | There are so many videos and documentation out there to help you learn the concept and usage of State... | 0 | 2024-06-21T20:49:37 | https://dev.to/atenajoon/react-state-variables-vs-props-21o7 | reactjsdevelopment, state, props, react | There are so many videos and documentation out there to help you learn the concept and usage of _State_ and _Props_ with code examples. this article is not about teaching you these concepts from scratch or providing you with code examples. The main point of this blog is to briefly give you a practical summary of **what... | atenajoon |
1,896,388 | shadcn-ui/ui codebase analysis: How is “Blocks” page built — Part 5 | In this article, I discuss how Blocks page is built on ui.shadcn.com. Blocks page has a lot of... | 0 | 2024-06-21T20:44:22 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-how-is-blocks-page-built-part-5-54o3 | javascript, nextjs, opensource, shadcnui | In this article, I discuss how [Blocks page](https://ui.shadcn.com/blocks) is built on [ui.shadcn.com](http://ui.shadcn.com). [Blocks page](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/(app)/blocks/page.tsx) has a lot of utilities used, hence I broke down this Blocks page analysis into 5 parts.
1. [shadcn-u... | ramunarasinga |
1,896,387 | Integración Jenkins con MSBuild e IIS | Estos dias me he planteado realizar la implementacion de CI (Integración Continua) en mis proyectos.... | 0 | 2024-06-21T20:41:31 | https://dev.to/re-al-/integracion-jenkins-con-msbuild-e-iis-4212 | cicd, msbuild, iis, jenkins | Estos dias me he planteado realizar la implementacion de CI (Integración Continua) en mis proyectos. Para ello he acudido a Jenkins.
### Jenkins
[Jenkins](https://jenkins.io/) nos permite, de una manera facil e intuitiva, programar el despliegue de nuestras aplicaciones.
Verán que instalarlo es muy simple. [Aquí](ht... | re-al- |
1,896,386 | Blockchain in Banking: Revolutionizing the Financial Sector | Introduction Blockchain technology, originally devised for Bitcoin, has evolved into... | 27,673 | 2024-06-21T20:40:51 | https://dev.to/rapidinnovation/blockchain-in-banking-revolutionizing-the-financial-sector-54j6 | ## Introduction
Blockchain technology, originally devised for Bitcoin, has evolved into a
decentralized digital ledger that records transactions securely and
transparently. This technology is transforming data management across various
sectors, including banking.
## What is Blockchain?
Blockchain is a distributed le... | rapidinnovation | |
1,896,063 | What is a Ledger and Why Floating Points Are Not Recommended? | Portugue Version What is Ledger Series What is a Ledger and why you need to learn about... | 0 | 2024-06-21T20:37:29 | https://dev.to/woovi/what-is-a-ledger-and-why-floating-points-are-not-recommended-1f4l | webdev, javascript, programming, tutorial | [Portugue Version](https://daniloab.substack.com/p/o-que-e-um-ledger-e-por-que-pontos)
## What is Ledger Series
1. [What is a Ledger and why you need to learn about it?](https://dev.to/woovi/what-is-ledger-and-why-does-it-need-idempotence-18n9)
2. [What is Ledger and why does it need Idempotence?](https://dev.to/woovi... | daniloab |
1,896,385 | Documentar tu proyecto ASP.Net y mostrarlo como un formulario mas | Ahora mostraré como puedes hacer que tu proyecto WebForms ASP.Net genere cada vez su propia... | 0 | 2024-06-21T20:37:15 | https://dev.to/re-al-/documentar-tu-proyecto-aspnet-y-mostrarlo-como-un-formulario-mas-1na1 | csharp, aspnet, documentation | Ahora mostraré como puedes hacer que tu proyecto WebForms ASP.Net genere cada vez su propia documentación en base a los comentarios del código fuente y además se muestre como un formulario.
### Para empezar
Para ello utilizaremos dos recursos:
* [VsXMd](https://github.com/lijunle) de [lijunle](https://github.com/lij... | re-al- |
1,896,337 | HOW TO CREATE AND CONNECT TO A LINUX VM USING A PUBLIC KEY | In this blog, you will be taught how to create a Linux Virtual Machine running on Ubuntu image, how... | 0 | 2024-06-21T20:35:22 | https://dev.to/presh1/how-to-create-and-connect-to-a-linux-vm-using-a-public-key-2h1h | signintoazure, createavirtualmachine, connecttothevirtualmachine | In this blog, you will be taught how to create a Linux Virtual Machine running on Ubuntu image, how to connect to the virtual machine through a SSH protocol using a Public Key and go the extra mile of creating a web application, connect to it using the public key and lastly browse the web server.
**SIGN IN TO AZURE P... | presh1 |
1,895,799 | #TestInPublic: Charty App | Update These issues are in the process of being addressed where appropriate. See this... | 0 | 2024-06-21T20:34:15 | https://dev.to/ashleygraf_/testinpublic-charty-app-151a | testing, startup | 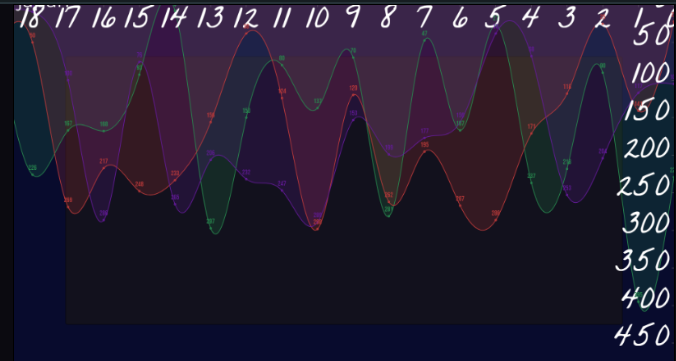
## Update
These issues are in the process of being addressed where appropriate.
See <a href="https://x.com/excentiodev/status/1804351579404878294">this Twitter post</a> for the first set.
## Introduction
Hi! I'm ... | ashleygraf_ |
1,896,384 | OpenLDAP con CSharp | En mi empresa hemos empezado a trabajar con OpenLDAP, y esto implica cambiar todos los metodos de... | 0 | 2024-06-21T20:33:45 | https://dev.to/re-al-/openldap-con-csharp-3h8n | csharp, openldap | En mi empresa hemos empezado a trabajar con OpenLDAP, y esto implica cambiar todos los metodos de autenticacion de los sistemas desarrollados, a éste protocolo.
Al principio parecia dificil, pero no fue asi. Todo se hizo mas facil con la ayuda de algunos articulos de stackoverflow.
Al final pude armar una clase **h... | re-al- |
1,896,383 | Aplicacion para descargar imagenes de una página web | Hace algun tiempo tuve la necesidad de descargar las imágenes de una página web. Esto sería tarea... | 0 | 2024-06-21T20:32:15 | https://dev.to/re-al-/aplicacion-para-descargar-imagenes-de-una-pagina-web-35k0 | csharp, projects | Hace algun tiempo tuve la necesidad de descargar las imágenes de una página web. Esto sería tarea sencilla de no ser porque existian mas de 50 imágenes en esa página. ASi que me propuse a realizar una aplicación de escritorio que se encargue de realizar ese trabajo por mi.
Pueden encontrar la aplicación y el codigo fu... | re-al- |
1,896,382 | Mostrar archivo PDF alojado en un servidor FTP con C# | Tenemos un repositorio FTP donde varias oficinas en distintos lugares van alojando archivos PDF que... | 0 | 2024-06-21T20:30:59 | https://dev.to/re-al-/mostrar-archivo-pdf-alojado-en-un-servidor-ftp-con-c-27f3 | csharp, ftp, pdf | Tenemos un repositorio FTP donde varias oficinas en distintos lugares van alojando archivos PDF que generan con información de su respectivo trabajo. Basicamente todos pueden acceder al FTP y consultar los documentos subidos.
Sin embargo, un nuevo requerimiento necesitaba revisar y calificar el documento. Para ello, s... | re-al- |
1,896,381 | ClosedXML y el uso de plantillas | Para facilitar la tarea de crear reportes o documentos en formato XLS o XLSX, se tiene el paquete... | 0 | 2024-06-21T20:29:26 | https://dev.to/re-al-/closedxml-y-el-uso-de-plantillas-m06 | netframework, corenet, closedxml, excel | Para facilitar la tarea de crear reportes o documentos en formato XLS o XLSX, se tiene el paquete ClosedXML. El mismo tiene soporte para el uso de templates.
Lo primero que tenemos que hacer es instalar el paquete Nuget en nuestro proyecto:
```
PM> Install-Package ClosedXML
```
Después, el bloque de codigo necesario... | re-al- |
1,896,380 | Generar colores hexadecimales aleatorios con Postgres | Hoy me he visto en la necesidad de obtener Varias fechas de una tabla en PostgreSql y mostrar cada... | 0 | 2024-06-21T20:25:18 | https://dev.to/re-al-/generar-colores-hexadecimales-aleatorios-con-postgres-1ihd | sql, postgres, hex | Hoy me he visto en la necesidad de obtener Varias fechas de una tabla en PostgreSql y mostrar cada una con un color diferente en un Sistema Web.
Mi primera alternativa era buscar una funcion en PHP que me permitiera generar colores hexadecimales aleatorios, pero como tengo más experiencia en PLPgSql, decidí empezar po... | re-al- |
1,896,378 | Modernizing Legacy Applications with Ballerina | https://www.meetup.com/austin-developer-community/events/301626607/?utm_medium=referral&utm_campa... | 0 | 2024-06-21T20:19:15 | https://dev.to/harsha_thirimanna_39edfd6/modernizing-legacy-applications-with-ballerina-1hei | https://www.meetup.com/austin-developer-community/events/301626607/?utm_medium=referral&utm_campaign=share-btn_savedevents_share_modal&utm_source=linkedin
 | harsha_thirimanna_39edfd6 | |
1,896,377 | Todo App in 3 hours | Creating a Todo app with Refine and Supabase This article will cover the technical aspects... | 0 | 2024-06-21T20:14:42 | https://dev.to/stefan_hodoroaba/todo-app-in-3-hours-4f33 | refine, react, supabase | ## Creating a Todo app with Refine and Supabase
This article will cover the technical aspects of how I made a Todo app in a few hours using Refine and Supabase. I tried to take a few detours from the official way of doing things to showcase a few possible ways one can achieve the same result.
All the code is available... | stefan_hodoroaba |
1,896,376 | 6 Captivating Linux Command Line Tutorials from LabEx 🐧 | The article is about a captivating collection of six Linux command line tutorials from the LabEx platform. It introduces readers to a wide range of topics, including mastering Linux processes, streamlining text manipulation with the `nl` command, conquering virtual battlefields through directory mastery, unveiling secr... | 27,674 | 2024-06-21T20:13:08 | https://dev.to/labex/6-captivating-linux-command-line-tutorials-from-labex-ec8 | linux, coding, programming, tutorial |
Welcome to an exciting journey through the realm of Linux command line mastery! LabEx, the premier platform for hands-on technical education, has curated a collection of six captivating tutorials that will empower you to navigate the Linux ecosystem with confidence and finesse.
## Unravel the Mysteries of Linux Proce... | labby |
1,896,375 | CVPR Edition: Voxel51 Filtered Views Newsletter - June 21, 2024 | This week's CVPR conference was AWESOME! Here's a quick spotlight on the papers we found insightful... | 0 | 2024-06-21T20:11:30 | https://voxel51.com/blog/voxel51-filtered-views-newsletter-june-21-2024/ | computervision, machinelearning, ai, datascience | This week's CVPR conference was AWESOME! Here's a quick spotlight on the papers we found insightful at this year's show.
## 📙 Good Reads by Jacob Marks
### 🔥 CVPR 2024 Paper Spotlight: CoDeF 🔥
Recent progress in video editing/translation has been driven by techniques like Tune-A-Video and FateZero, which utilize ... | jguerrero-voxel51 |
1,896,351 | 𝐓𝐞𝐦𝐩𝐥𝐚𝐭𝐞𝐌𝐨𝐧𝐬𝐭𝐞𝐫 𝐃𝐢𝐠𝐢𝐭𝐚𝐥 𝐌𝐚𝐫𝐤𝐞𝐭𝐩𝐥𝐚𝐜𝐞 𝐓𝐮𝐫𝐧𝐬 𝟐𝟐! | I think everybody knows I have joined the community of authors offering website designs and... | 0 | 2024-06-21T19:18:11 | https://dev.to/hasnaindev1/-1l10 | tmbday22, website, webdev, wordpress |

I think everybody knows I have joined the community of authors offering website designs and creations in the [𝐓𝐞𝐦𝐩𝐥𝐚𝐭𝐞𝐌𝐨𝐧𝐬𝐭𝐞𝐫 𝐝𝐢𝐠𝐢𝐭𝐚𝐥 𝐦𝐚𝐫𝐤𝐞𝐭𝐩𝐥𝐚𝐜𝐞](https://rebrand.ly/templates-marke... | hasnaindev1 |
1,896,372 | What is the difference between Library and Framework | While the terms "framework" and "library" are usually used interchangeably in software development,... | 0 | 2024-06-21T20:04:21 | https://dev.to/chintamani_pala/what-is-the-difference-between-library-and-framework-1b8g | webdev, react, angular, javascriptlibraries | While the terms "**framework**" and "**library**" are usually used interchangeably in software development, they relate to two concepts that serve different purposes, with distinctly different implications for their usage in a project. Here are the major differences:
 phenomenon strikes again!
We've all been there. Different operating systems, software versions, and local configurations can turn a seemingly perfect so... | ssadasivuni |
1,896,370 | Looking for a tech cofounder (golfer desired) | Hi guys, I am looking for a technical co-founder for my startup birdiefit.com. If you are or if you... | 0 | 2024-06-21T19:58:31 | https://dev.to/luka_karaula_daca8e314562/looking-for-a-techcofounder-golfer-desired-51h1 | partner, cofounder, startup | Hi guys, I am looking for a technical co-founder for my startup birdiefit.com. If you are or if you know a developer who is also a golfer, comment or DM me.
The app already has paying customers. The ideal person will take care of the technical side of things, making sure the code is neat, new features are implemented,... | luka_karaula_daca8e314562 |
1,896,366 | The MEVN Stack: A Modern Web Development Powerhouse | Hey Dev.to community! 🌟 Let's dive into one of the hottest tech stacks of 2024: the MEVN stack.... | 0 | 2024-06-21T19:47:09 | https://dev.to/matin_mollapur/the-mevn-stack-a-modern-web-development-powerhouse-34ji | webdev, javascript, beginners, programming | Hey Dev.to community! 🌟
Let's dive into one of the hottest tech stacks of 2024: the MEVN stack. Whether you're new to web development or looking to expand your skill set, this stack has got you covered with everything from front-end to back-end, all using the mighty JavaScript.
## What is the MEVN Stack?
The MEVN ... | matin_mollapur |
1,896,363 | 2024 and Beyond: The Evolving Role of Scriptless Test Automation in Agile Development | Test automation has become crucial to modern software development and testing lifecycles. With the... | 0 | 2024-06-21T19:42:44 | https://dev.to/sophie_wilson0412/2024-and-beyond-the-evolving-role-of-scriptless-test-automation-in-agile-development-2e6l | codeless, automation, selfhealing, scriptless | Test automation has become crucial to modern software development and testing lifecycles. With the rapidly evolving expectations for speed and scale from end users, it is not feasible for organizations to continue with their traditional software testing processes. Nearly most organizations have adopted Agile and DevOps... | sophie_wilson0412 |
1,896,362 | The RSA Algorithm | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-21T19:39:50 | https://dev.to/achilles_68b2e35472911b34/the-rsa-algorithm-23ed | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
The RSA algorithm encrypts with a public key and decrypts with a private key. The former is based on a product of two primes; these primes generate the latter. Large key size makes fac... | achilles_68b2e35472911b34 |
1,896,359 | The Ultimate Guide to Essential SEO Elements | Introduction Navigating the intricate world of SEO can be daunting, but mastering its... | 0 | 2024-06-21T19:32:52 | https://dev.to/gohil1401/the-ultimate-guide-to-essential-seo-elements-4gcn | webdev, beginners, tutorial, seo |
## Introduction
Navigating the intricate world of SEO can be daunting, but mastering its essential elements is key to enhancing your website's visibility and performance. This comprehensive guide explores critical SEO components, from Sitemap.XML and robots.txt to SSL certificates and structured data, providing action... | gohil1401 |
1,896,358 | Understanding JavaScript Promises | Introduction JavaScript Promises are a powerful way to handle asynchronous operations, allowing you... | 0 | 2024-06-21T19:26:37 | https://dev.to/just_ritik/understanding-javascript-promises-2eib | webdev, javascript, beginners, programming | **Introduction**
JavaScript Promises are a powerful way to handle asynchronous operations, allowing you to write cleaner and more manageable code. In this post, we'll dive deep into Promises and explore how they can improve your code.
**Understanding Promises**
A Promise in JavaScript represents the eventual complet... | just_ritik |
1,896,338 | How RAG with txtai works | txtai is an all-in-one embeddings database for semantic search, LLM orchestration and language... | 11,018 | 2024-06-21T18:42:49 | https://neuml.hashnode.dev/how-rag-with-txtai-works | ai, llm, rag, vectordatabase | [](https://colab.research.google.com/github/neuml/txtai/blob/master/examples/63_How_RAG_with_txtai_works.ipynb)
[txtai](https://github.com/neuml/txtai) is an all-in-one embeddings database for semantic search, LLM orchestration and language model workflows.
... | davidmezzetti |
1,896,357 | Crafting Clarity: A Journey into the World of Clean Code Code Needs Care!🤯 | Introduction ✍🏻 Do you spend countless hours fixing bugs in your code? Have you wondered why it takes... | 0 | 2024-06-21T19:26:18 | https://dev.to/rowan_ibrahim/crafting-clarity-a-journey-into-the-world-of-clean-codecode-needs-care-32mi | cleancode, cleancoding, writing, career | **Introduction ✍🏻**
Do you spend countless hours fixing bugs in your code? Have you wondered why it takes so long?
Everyone can write code that computers understand. But, not everyone can write code that humans can easily read.
As software developers, understanding how to write clean code is essential. Let’s dive in... | rowan_ibrahim |
1,896,356 | Comparing CI/CD Tools | This article was originally published on the Shipyard Blog Continuous integration (CI) pipelines,... | 0 | 2024-06-21T19:24:56 | https://shipyard.build/blog/cicd-tools/ | cicd, devops, githubactions, testing | *<a href="https://shipyard.build/blog/cicd-tools/" target="_blank">This article was originally published on the Shipyard Blog</a>*
---
<a href="https://www.redhat.com/en/topics/devops/what-is-ci-cd#continuous-integration" target="_blank">Continuous integration (CI) pipelines</a>, when used as intended, are something ... | shipyard |
1,896,355 | Unlock Creativity with MonsterONE! | Hey there! 👋 As a seasoned web developer, I'm excited to share my experience with MonsterONE - the... | 0 | 2024-06-21T19:22:09 | https://dev.to/hasnaindev1/unlock-creativity-with-monsterone-4ong | website, webcomponents, themes, webdev |
Hey there! 👋 As a seasoned web developer, I'm excited to share my experience with **MonsterONE** - the ultimate subscription service for all things web development! With **MonsterONE**, I've unlocked a treasure trove of digital assets, from **WordPress themes** to graphic designs and audio/video resources.
The varie... | hasnaindev1 |
1,896,353 | Regulatory Compliance Challenges for US Financial Institutions in the UAE and the Middle East | The Middle East is one of the fastest regions when it comes to economy and technology. The US... | 0 | 2024-06-21T19:20:11 | https://dev.to/muhammad_78f9e1864a36d0a4/regulatory-compliance-challenges-for-us-financial-institutions-in-the-uae-and-the-middle-east-2oip | regulatorycompliance, usa, uae, fis | > The Middle East is one of the fastest regions when it comes to economy and technology. The US companies and investors are curious to grab every opportunity in the hindsight. There is a huge market of real estate on the hand, the financial sector is booming at an accelerated pace on the other hand. However, alongside ... | muhammad_78f9e1864a36d0a4 |
1,896,352 | Smart Contracts Evolution: Enhancing Efficiency in DApp Development | In the ever-evolving landscape of blockchain engineering, smart contracts are a testament to the... | 0 | 2024-06-21T19:19:39 | https://dev.to/sophie_wilson0412/smart-contracts-evolution-enhancing-efficiency-in-dapp-development-a5a | blockchain, development, engineering, technology | In the ever-evolving landscape of blockchain engineering, smart contracts are a testament to the continuous pursuit of smart efficiency, security, and innovation in decentralized application (DApp) development. Smart contracts have gone through a remarkable journey, from their conceptualization by Nick Szabo to their r... | sophie_wilson0412 |
1,896,349 | Speed Up Your React App: A Guide to Lazy Loading 🚀 | Enhancing Performance with Asynchronous Component Loading 🔻 In the world of modern web... | 0 | 2024-06-21T19:13:07 | https://dev.to/alisamirali/speed-up-your-react-app-a-guide-to-lazy-loading-24pm | react, javascript, frontend, performance | ## Enhancing Performance with Asynchronous Component Loading 🔻
---
In the world of modern web development, optimizing the performance of web applications is a critical consideration.
One effective technique for improving React applications' load times and overall performance is lazy loading.
React Lazy Loading i... | alisamirali |
1,896,347 | Técnicas de Concorrência e Gerenciamento de Estado em Elixir com FSM | Introdução Elixir é uma linguagem funcional que roda na máquina virtual BEAM, a mesma do... | 0 | 2024-06-21T19:09:00 | https://dev.to/zoedsoupe/tecnicas-de-concorrencia-e-gerenciamento-de-estado-em-elixir-com-fsm-3f83 | architecture, elixir, programming | ## Introdução
Elixir é uma linguagem funcional que roda na máquina virtual BEAM, a mesma do Erlang, famosa por suas capacidades de concorrência e tolerância a falhas. Um dos padrões poderosos que podem ser implementados em Elixir é a Máquina de Estado Finito (FSM - Finite State Machine), combinada com processamento as... | zoedsoupe |
1,896,346 | Optimizing Web Performance: Lazy Loading Images and Components | Optimizing web performance is crucial for providing a superior user experience, improving SEO, and... | 0 | 2024-06-21T19:08:10 | https://dev.to/henriqueschroeder/optimizing-web-performance-lazy-loading-images-and-components-noe | webdev, javascript, react, nextjs |
Optimizing web performance is crucial for providing a superior user experience, improving SEO, and increasing conversion rates. For intermediate and experienced developers, lazy loading images and components is an advanced technique that can make a significant difference in web application performance. Let's explore t... | henriqueschroeder |
1,896,345 | 10 secret rules of Development every Programmer should know | Every profession has its quirks and unspoken rules, and development is no exception. From the... | 27,390 | 2024-06-21T19:07:16 | https://dev.to/buildwebcrumbs/10-secret-rules-of-development-every-programmer-should-know-2kj1 | jokes, watercooler | Every profession has its quirks and unspoken rules, and development is no exception.
From the inexplicable faith in turning it off and on again (hey, it often works!) to the mysterious art of centering a div (this doesn't work as often🥲), here are ten secrets that every programmer will nod knowingly about.
### 1. **... | pachicodes |
1,896,323 | Proxy Pattern: A Practical Guide to Smarter Object Handling | The Proxy Pattern is an object-oriented programming concept that acts as a “substitute” or... | 0 | 2024-06-21T18:17:36 | https://dev.to/robertoumbelino/proxy-pattern-a-practical-guide-to-smarter-object-handling-4mpl | The Proxy Pattern is an object-oriented programming concept that acts as a “substitute” or “representative” for another object. This pattern is very useful when we need to control access to an object or add extra functionalities without directly modifying its code. Basically, the Proxy acts as an intermediary between t... | robertoumbelino | |
1,896,343 | 🚀 Um Guia Prático para Configurar Zsh, Oh My Zsh, asdf e Spaceship Prompt com Zinit para Seu Ambiente de Desenvolvimento | Introdução 🌟 Melhore seu ambiente de desenvolvimento com este guia sobre como instalar e... | 0 | 2024-06-21T19:03:22 | https://dev.to/girordo/um-guia-pratico-para-configurar-zsh-oh-my-zsh-asdf-e-spaceship-prompt-com-zinit-para-seu-ambiente-de-desenvolvimento-13ld | shell, zsh, terminal, tutorial | ### **Introdução** 🌟
Melhore seu ambiente de desenvolvimento com este guia sobre como instalar e configurar o **Zsh**, **Oh My Zsh**, **asdf** e o tema **Spaceship Prompt**. Também utilizaremos o **Zinit** para gerenciamento adicional de plugins. Vamos começar!
### 🛠️ **Passo 1: Instalando o Zsh**
O **Zsh** é um s... | girordo |
1,896,342 | Recursion: Computer Science Challenge | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-21T19:03:05 | https://dev.to/karim_abdallah/recursion-computer-science-challenge-b6p | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
**Recursion**: A function that calls itself! Solves problems by breaking them into smaller, similar problems. Pow... | karim_abdallah |
1,896,461 | ReAPI Client: A Comprehensive Guide to My React API Request Builder | Introduction Welcome to my blog! I'm Dipankar Paul, a frontend developer with a passion... | 27,831 | 2024-06-23T18:04:33 | https://iamdipankarpaul.hashnode.dev/reapi-client-a-comprehensive-guide-to-my-react-api-request-builder | react, javascript, projects, api | ---
title: ReAPI Client: A Comprehensive Guide to My React API Request Builder
published: true
date: 2024-06-21 18:54:17 UTC
tags: React,JavaScript,projects,APIs
series: Projects
canonical_url: https://iamdipankarpaul.hashnode.dev/reapi-client-a-comprehensive-guide-to-my-react-api-request-builder
---
## Introduction
W... | dipankarpaul |
1,896,341 | My First Blog | Welcome to my first blog post! If you're here, you're probably pondering one of two questions:... | 0 | 2024-06-21T18:51:19 | https://dev.to/shrishti_srivastava_/my-first-blog-3e9k | webdev, javascript, beginners, programming | **Welcome to my first blog post!**
If you're here, you're probably pondering one of two questions: "Which domain should I go into?" or "How do I really delve into web development?" Today, I’ll tackle both!
Which Domain to Choose?
You chose B.Tech to land a job in the IT sector or maybe your dream company like MANG o... | shrishti_srivastava_ |
1,896,340 | Discover Exceptional Orthodontic Care in Austin | Are you searching for the perfect orthodontist in Austin to transform your smile? Look no further... | 0 | 2024-06-21T18:46:30 | https://dev.to/harry_feddrick_/discover-exceptional-orthodontic-care-in-austin-16k6 | healthydebate, dentist, austin, orthodontist | Are you searching for the perfect orthodontist in Austin to transform your smile? Look no further than the vibrant community of orthodontic specialists right here in our city. Austin is not only known for its music scene and vibrant culture but also for its commitment to top-notch dental care, including orthodontics.
... | harry_feddrick_ |
1,896,336 | Big O Notation | A mathematical notation describing the upper limit of an algorithm's runtime or space requirements in... | 0 | 2024-06-21T18:41:01 | https://dev.to/pirisaurio32/big-o-notation-40bb | devchallenge, cschallenge, computerscience, beginners | A mathematical notation describing the upper limit of an algorithm's runtime or space requirements in the worst-case scenario. It's crucial for comparing efficiency, helping developers optimize code and understand performance as input size grows. | pirisaurio32 |
1,896,283 | DAY3 -> Scaling Databases (Replication) | As in my previous blogs, We talked about vertical scaling. In this We will talk about Horizontal... | 0 | 2024-06-21T18:39:43 | https://dev.to/taniskannpurna/day3-scaling-databases-replication-30pd | systemdesign, system, softwaredevelopment, softwareengineering | - As in my previous blogs, We talked about vertical scaling. In this We will talk about Horizontal Scaling.
**HORIZONTAL SCALING**
- We know that for any db read & write ratio is 90:10;
- The very basic scaling that we can do is have separate db just for reading and separate db for writing.
- Through API we can send r... | taniskannpurna |
1,896,335 | DEV's Wanted! | Hey everyone. It's since a long time that I have this idea of a MIT Licensed app dedicated to home... | 0 | 2024-06-21T18:38:28 | https://dev.to/jsfreu/devs-wanted-138k | opensource, mit, development | Hey everyone. It's since a long time that I have this idea of a MIT Licensed app dedicated to home based business owners. Yesterday I have been generating a overview of all different integrations my ideal platform must need. Having small to none experience on php development but rather more on html and css for now. I w... | jsfreu |
1,896,334 | Are you burning your money? | Recently I've became very spending conscientious. Partially because there are more and more services... | 0 | 2024-06-21T18:33:41 | https://dev.to/sein_digital/are-you-burning-your-money-2m6f | productivity, discuss, community, startup | Recently I've became very spending conscientious. Partially because there are more and more services that adapt subscription based model, and partially because I became more and more aware how much every possible industry giants try to milk their customers as much as possible. I've became quite resentful towards those ... | sein_digital |
1,891,801 | O que é JSON (Javasript Object Notation) e como usamos ? | É bastante comum pra galera que ta começando na programação ficar um pouco perdido com muitos... | 0 | 2024-06-21T18:33:39 | https://dev.to/henriqueleme/o-que-e-json-javasript-object-notation-e-como-usamos--2b1d | beginners, braziliandevs, json, programming | É bastante comum pra galera que ta começando na programação ficar um pouco perdido com muitos **acronismos** nas primeiras semanas. Hoje, vamos dar uma passada sobre algo que é muito comum no dia a dia da nossa profissão e que é bem fácil de pegar as manhas, pode confiar!! Neste artigo, vamos explicar o que significa a... | henriqueleme |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.