
Id stringlengths 1 6 | PostTypeId stringclasses 7
values | AcceptedAnswerId stringlengths 1 6 ⌀ | ParentId stringlengths 1 6 ⌀ | Score stringlengths 1 4 | ViewCount stringlengths 1 7 ⌀ | Body stringlengths 0 38.7k | Title stringlengths 15 150 ⌀ | ContentLicense stringclasses 3
values | FavoriteCount stringclasses 3
values | CreationDate stringlengths 23 23 | LastActivityDate stringlengths 23 23 | LastEditDate stringlengths 23 23 ⌀ | LastEditorUserId stringlengths 1 6 ⌀ | OwnerUserId stringlengths 1 6 ⌀ | Tags list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
537 | 2 | null | 534 | 15 | null | Your example is that of a [controlled experiment](http://en.wikipedia.org/wiki/Controlled_experiment). The only other context that I know of where a correlation can imply causation is that of a [natural experiment](http://en.wikipedia.org/wiki/Natural_experiment).
Basically, a natural experiment takes advantage of an ... | null | CC BY-SA 2.5 | null | 2010-07-23T02:42:39.580 | 2010-07-23T02:42:39.580 | null | null | null | null |
538 | 2 | null | 534 | 46 | null | Correlation is not sufficient for causation. One can get around the Wikipedia example by imagining that those twins always cheated in their tests by having a device that gives them the answers. The twin that goes to the amusement park loses the device, hence the low grade.
A good way to get this stuff straight is to th... | null | CC BY-SA 3.0 | null | 2010-07-23T04:49:41.213 | 2013-12-24T23:44:38.263 | 2013-12-24T23:44:38.263 | 556 | 260 | null |
539 | 1 | 4183 | null | 64 | 56374 | In answering [this question on discrete and continuous data](https://stats.stackexchange.com/questions/206/discrete-and-continuous) I glibly asserted that it rarely makes sense to treat categorical data as continuous.
On the face of it that seems self-evident, but intuition is often a poor guide for statistics, or at l... | Does it ever make sense to treat categorical data as continuous? | CC BY-SA 2.5 | 1 | 2010-07-23T06:17:10.517 | 2022-12-14T06:46:23.663 | 2017-07-24T11:31:19.080 | 11887 | 174 | [
"categorical-data",
"data-transformation",
"ordinal-data",
"continuous-data"
] |
540 | 2 | null | 534 | 14 | null | In my opinion the APA Statistical Task force summarised it quite well
>
''Inferring causality from nonrandomized
designs is a risky enterprise.
Researchers using nonrandomized
designs have an extra obligation to
explain the logic behind covariates
included in their designs and to alert
the reader to plausi... | null | CC BY-SA 2.5 | null | 2010-07-23T06:17:56.740 | 2010-07-23T06:17:56.740 | null | null | 183 | null |
541 | 2 | null | 539 | 21 | null | If there are only two categories, then transforming them to (0,1) makes sense. In fact, this is commonly done where the resulting dummy variable is used in regression models.
If there are more than two categories, then I think it only makes sense if the data are ordinal, and then only in very specific circumstances. Fo... | null | CC BY-SA 2.5 | null | 2010-07-23T06:22:04.313 | 2010-07-23T06:22:04.313 | null | null | 159 | null |
542 | 2 | null | 499 | 7 | null | In the social science context where I come from, the issue is whether you are interested in (a) prediction or (b) testing a focused research question.
If the purpose is prediction then data driven approaches are appropriate.
If the purpose is to examine a focused research question then it is important to consider which... | null | CC BY-SA 2.5 | null | 2010-07-23T06:49:38.953 | 2010-07-23T06:49:38.953 | null | null | 183 | null |
543 | 2 | null | 10 | 10 | null | In addition to what has already been said above about summated scales, I'd also mention that the issue can change when analysing data at the group-level. For example, if you were examining
- life satisfaction of states or countries,
- job satisfaction of organisations or departments,
- student satisfaction in subjec... | null | CC BY-SA 2.5 | null | 2010-07-23T07:13:03.533 | 2010-07-23T07:13:03.533 | null | null | 183 | null |
544 | 2 | null | 539 | 18 | null | It is common practice to treat ordered categorical variables with many categories as continuous. Examples of this:
- Number of items correct on a 100 item test
- A summated psychological scale (e.g., that is the mean of 10 items each on a five point scale)
And by "treating as continuous" I mean including the variab... | null | CC BY-SA 3.0 | null | 2010-07-23T07:27:31.830 | 2013-08-13T03:53:08.900 | 2013-08-13T03:53:08.900 | 183 | 183 | null |
545 | 2 | null | 481 | 1 | null | The problem (dilemma) you face appears to be the one of selecting an optimal (or otherwise good) sampling interval for revising your forecasts. To start with, see [link text](http://books.google.com.au/books?id=XXFNW_QaJYgC&pg=PA42) of Brown's famous book, which would also qualify as a good reference. It all boils down... | null | CC BY-SA 2.5 | null | 2010-07-23T08:15:23.430 | 2010-07-23T08:15:23.430 | null | null | 273 | null |
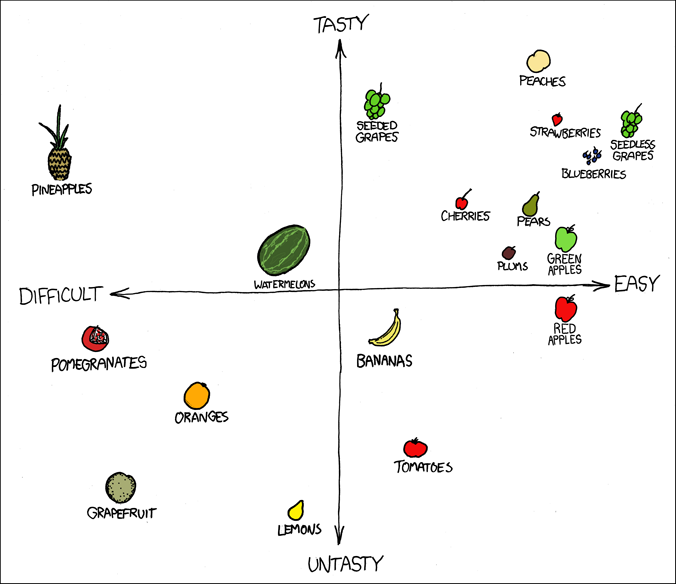
546 | 2 | null | 423 | 44 | null | Another one from [xkcd](http://xkcd.com/388/):
| null | CC BY-SA 2.5 | null | 2010-07-23T08:18:52.737 | 2010-08-11T09:20:21.947 | 2017-03-09T17:30:36.260 | -1 | 183 | null |
547 | 2 | null | 534 | 16 | null | There is also a problem with the opposite case, when lack of correlation is used as a proof for the lack of causation. This problem is nonlinearity; when looking at correlation people usually check Pearson, which is only a tip of an iceberg.
| null | CC BY-SA 2.5 | null | 2010-07-23T08:33:04.260 | 2010-07-23T08:33:04.260 | null | null | null | null |
548 | 1 | 559 | null | 9 | 3252 | In an answer to [this question about treating categorical data as continuous](https://stats.stackexchange.com/questions/539/does-it-ever-make-sense-to-treat-categorical-data-as-continuous), optimal scaling was mentioned. How does this method work and how is it applied?
| How can I use optimal scaling to scale an ordinal categorical variable? | CC BY-SA 2.5 | null | 2010-07-23T10:51:52.960 | 2010-07-23T16:30:41.750 | 2017-04-13T12:44:51.217 | -1 | 266 | [
"categorical-data",
"data-transformation",
"optimal-scaling"
] |
549 | 2 | null | 539 | 6 | null | In an analysis of ranking by frequency, as with a Pareto chart and associated values (eg how many categories make up the top 80% of product faults)
| null | CC BY-SA 2.5 | null | 2010-07-23T13:28:55.297 | 2010-07-23T13:28:55.297 | null | null | 270 | null |
550 | 2 | null | 155 | 12 | null | I have used the drunkard's walk before for random walk, and the drunk and her dog for cointegration; they're very helpful (partially because they're amusing).
One of my favorite common examples is the [Birthday Paradox](http://mathworld.wolfram.com/BirthdayProblem.html) ([wikipedia entry](http://en.wikipedia.org/wiki/B... | null | CC BY-SA 2.5 | null | 2010-07-23T13:58:07.597 | 2010-07-23T16:25:03.033 | 2010-07-23T16:25:03.033 | 5 | 5 | null |
551 | 2 | null | 298 | 97 | null | I always tell students there are three reasons to transform a variable by taking the natural logarithm. The reason for logging the variable will determine whether you want to log the independent variable(s), dependent or both. To be clear throughout I'm talking about taking the natural logarithm.
Firstly, to improve m... | null | CC BY-SA 3.0 | null | 2010-07-23T14:43:14.180 | 2016-03-10T09:17:17.420 | 2016-03-10T09:17:17.420 | 20921 | 215 | null |
552 | 2 | null | 486 | 29 | null | AIC = -2Ln(L)+ 2k
where L is the maximised value of Likelihood function for that model and k is the number of parameters in the model.
In your example -2Ln(L)+ 2k <0 means that the log-likelihood at the maximum was > 0
which means that the likelihood at the maximum was > 1.
There is no problem with a positive log-like... | null | CC BY-SA 2.5 | null | 2010-07-23T14:53:50.583 | 2010-07-23T14:53:50.583 | null | null | 215 | null |
553 | 2 | null | 276 | 11 | null | The trivial answer is that more data are always preferred to less data.
The problem of small sample size is clear. In linear regression (OLS) technically you can fit a model such as OLS where n = k+1 but you will get rubbish out of it i.e. very large standard errors. There is a great paper by Arthur Goldberger called ... | null | CC BY-SA 2.5 | null | 2010-07-23T15:02:40.983 | 2010-07-23T15:20:15.537 | 2010-07-23T15:20:15.537 | 215 | 215 | null |
554 | 2 | null | 155 | 12 | null | I like to demonstrate sampling variation and essentially the Central Limit Theorem through an "in-class" exercise. Everybody in the class of say 100 students writes their age on a piece of paper. All pieces of paper are the same size and folded in the same fashion after I've calculated the average. This is the populati... | null | CC BY-SA 2.5 | null | 2010-07-23T15:09:02.370 | 2010-07-23T15:09:02.370 | null | null | 215 | null |
555 | 1 | 557 | null | 103 | 15497 | ANOVA is equivalent to linear regression with the use of suitable dummy variables. The conclusions remain the same irrespective of whether you use ANOVA or linear regression.
In light of their equivalence, is there any reason why ANOVA is used instead of linear regression?
Note: I am particularly interested in hearing ... | Why is ANOVA taught / used as if it is a different research methodology compared to linear regression? | CC BY-SA 4.0 | null | 2010-07-23T15:17:56.770 | 2021-10-27T06:02:33.423 | 2021-10-27T06:02:33.423 | 44269 | null | [
"regression",
"anova"
] |
556 | 2 | null | 206 | -4 | null | Discrete data can take on only integer values whereas continuous data can take on any value. For instance the number of cancer patients treated by a hospital each year is discrete but your weight is continuous. Some data are continuous but measured in a discrete way e.g. your age. It is common to report your age as say... | null | CC BY-SA 2.5 | null | 2010-07-23T15:18:34.053 | 2010-07-23T15:18:34.053 | null | null | 215 | null |
557 | 2 | null | 555 | 61 | null | As an economist, the analysis of variance (ANOVA) is taught and usually understood in relation to linear regression (e.g. in Arthur Goldberger's A Course in Econometrics). Economists/Econometricians typically view ANOVA as uninteresting and prefer to move straight to regression models. From the perspective of linear (o... | null | CC BY-SA 3.0 | null | 2010-07-23T15:35:55.653 | 2013-09-30T15:35:44.163 | 2013-09-30T15:35:44.163 | 30872 | 215 | null |
558 | 1 | null | null | 17 | 1027 | I am trying to get a global perspective on some of the essential ideas in machine learning, and I was wondering if there is a comprehensive treatment of the different notions of loss (squared, log, hinge, proxy, etc.). I was thinking something along the lines of a more comprehensive, formal presentation of John Langfo... | Comprehensive overview of loss functions? | CC BY-SA 2.5 | null | 2010-07-23T16:15:33.137 | 2022-11-27T20:48:05.443 | 2017-08-29T15:23:29.323 | 53690 | 39 | [
"references",
"loss-functions"
] |
559 | 2 | null | 548 | 7 | null | The general idea is that you should scale the categorical variable in such way that the resulting continuous variables will be just the most useful. So, it is always coupled with some regression or learning procedure and so the fitting of the model is accompanied by optimization (or trying various possibilities) of ord... | null | CC BY-SA 2.5 | null | 2010-07-23T16:30:41.750 | 2010-07-23T16:30:41.750 | null | null | null | null |
560 | 2 | null | 507 | 22 | null | I use the Gelman-Rubin convergence diagnostic as well. A potential problem with Gelman-Rubin is that it may mis-diagnose convergence if the shrink factor happens to be close to 1 by chance, in which case you can use a Gelman-Rubin-Brooks plot. See the ["General Methods for Monitoring Convergence of Iterative Simulati... | null | CC BY-SA 3.0 | null | 2010-07-23T16:36:50.980 | 2015-03-20T07:04:21.643 | 2015-03-20T07:04:21.643 | 183 | 5 | null |
561 | 2 | null | 534 | 21 | null | At the heart of your question is the question "when is a relationship causal?" It doesn't just need to be correlation implying (or not) causation.
A good book on this topic is called Mostly Harmless Econometrics by Johua Angrist and Jorn-Steffen Pischke. They start from the experimental ideal where we are able to rando... | null | CC BY-SA 2.5 | null | 2010-07-23T16:49:47.407 | 2010-07-23T16:49:47.407 | null | null | 215 | null |
562 | 1 | 566 | null | 13 | 6132 | This is a fairly general question:
I have typically found that using multiple different models outperforms one model when trying to predict a time series out of sample. Are there any good papers that demonstrate that the combination of models will outperform a single model? Are there any best-practices around combini... | When to use multiple models for prediction? | CC BY-SA 2.5 | null | 2010-07-23T16:51:11.790 | 2012-03-24T02:28:14.880 | 2012-03-23T03:44:56.367 | 9007 | 5 | [
"time-series",
"modeling",
"model-comparison"
] |
563 | 1 | null | null | 44 | 14907 | Instrumental variables are becoming increasingly common in applied economics and statistics. For the uninitiated, can we have some non-technical answers to the following questions:
- What is an instrumental variable?
- When would one want to employ an instrumental variable?
- How does one find or choose an instrumen... | What is an instrumental variable? | CC BY-SA 2.5 | null | 2010-07-23T16:53:20.117 | 2018-01-24T21:54:03.920 | 2010-11-23T17:06:45.300 | 8 | 215 | [
"regression",
"econometrics",
"instrumental-variables"
] |
564 | 1 | null | null | 53 | 99562 | Difference in differences has long been popular as a non-experimental tool, especially in economics. Can somebody please provide a clear and non-technical answer to the following questions about difference-in-differences.
What is a difference-in-difference estimator?
Why is a difference-in-difference estimator any use?... | What is difference-in-differences? | CC BY-SA 3.0 | null | 2010-07-23T16:57:50.063 | 2019-08-05T09:47:24.193 | 2014-11-24T13:37:12.850 | 26338 | 215 | [
"regression",
"econometrics",
"difference-in-difference"
] |
565 | 2 | null | 562 | 2 | null | The most spectacular example is the [Netflix challenge](http://www.netflixprize.com/), which made really boosted blending popularity.
| null | CC BY-SA 2.5 | null | 2010-07-23T17:02:28.887 | 2010-07-23T17:02:28.887 | null | null | null | null |
566 | 2 | null | 562 | 8 | null | Sometimes this kind of models are called an ensemble. For example [this page](http://wapedia.mobi/en/Machine_learning_ensemble) gives a nice overview how it works. Also the references mentioned there are very useful.
| null | CC BY-SA 2.5 | null | 2010-07-23T17:05:52.033 | 2010-07-23T17:05:52.033 | null | null | 190 | null |
567 | 2 | null | 170 | 20 | null | I've often found the Engineering Statistics Handbook useful. It can be found [here](http://www.itl.nist.gov/div898/handbook/).
Although I've never read it myself, I hear [Introduction to Probability and Statistics Using R](https://rdrr.io/cran/IPSUR/f/inst/doc/IPSUR.pdf) is very good. It's a full ~400 page ebook (also ... | null | CC BY-SA 4.0 | null | 2010-07-23T17:11:35.127 | 2021-05-31T03:49:17.623 | 2021-05-31T03:49:17.623 | 287839 | 92 | null |
568 | 2 | null | 31 | 8 | null | In statistics you can never say something is absolutely certain, so statisticians use another approach to gauge whether a hypothesis is true or not. They try to reject all the other hypotheses that are not supported by the data.
To do this, statistical tests have a null hypothesis and an alternate hypothesis. The p-va... | null | CC BY-SA 2.5 | null | 2010-07-23T17:29:50.730 | 2010-07-23T17:29:50.730 | null | null | 92 | null |
569 | 2 | null | 562 | 4 | null | Following up on Peter's response on ensemble methods:
- This is covered in "The Elements of Statistical Learning" (see page 288, for example).
- Witten and Frank "Data Mining: Practical Machine Learning Tools and Techniques" covers this in section 7.5, including a discussion of Bagging, Randomization, Boosting, Addit... | null | CC BY-SA 2.5 | null | 2010-07-23T17:32:44.140 | 2010-07-23T17:32:44.140 | null | null | 5 | null |
570 | 1 | 3798 | null | 14 | 1152 | I'm curious if there are graphical techniques particular, or more applicable, to structural equation modeling. I guess this could fall into categories for exploratory tools for covariance analysis or graphical diagnostics for SEM model evaluation. (I'm not really thinking of path/graph diagrams here.)
| What graphical techniques are used in Structural Equation Modeling? | CC BY-SA 2.5 | null | 2010-07-23T17:59:27.367 | 2013-02-25T06:23:08.783 | 2010-07-27T00:49:21.897 | 251 | 251 | [
"structural-equation-modeling",
"data-visualization"
] |
571 | 2 | null | 534 | 8 | null | One useful sufficient condition for some definitions of causation:
Causation can be claimed when one of the correlated variables can be controlled (we can directly set its value) and correlation is still present.
| null | CC BY-SA 2.5 | null | 2010-07-23T18:29:41.240 | 2010-07-23T18:29:41.240 | null | null | 217 | null |
572 | 2 | null | 555 | 24 | null | I think Graham's second paragraph gets at the heart of the matter. I suspect it's not so much technical than historical, probably due to the influence of "[Statistical Methods for Research Workers](http://en.wikipedia.org/wiki/Ronald_Fisher)", and the ease of teaching/applying the tool for non-statisticans in experime... | null | CC BY-SA 2.5 | null | 2010-07-23T18:42:05.440 | 2010-07-23T18:54:03.763 | 2010-07-23T18:54:03.763 | 251 | 251 | null |
573 | 1 | null | null | 11 | 1784 | In "[Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations](http://dx.doi.org/10.1145/1553374.1553453)" by Lee et. al.([PDF](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.149.802&rep=rep1&type=pdf)) Convolutional DBN's are proposed. Also the method is evaluated... | How to understand a convolutional deep belief network for audio classification? | CC BY-SA 3.0 | null | 2010-07-23T19:45:45.270 | 2017-11-09T12:58:33.937 | 2017-11-09T12:58:33.937 | 128677 | 190 | [
"classification",
"unsupervised-learning",
"intuition",
"deep-belief-networks"
] |
574 | 2 | null | 212 | 0 | null | Assuming there is some training involved, you may use some kind of cross-validation, or bootstrap of a train set.
If not, stick to the Srikant solution. I would do it even simpler, just assuming that the number of error is Poisson distributed.
| null | CC BY-SA 2.5 | null | 2010-07-23T20:07:51.003 | 2010-07-23T20:07:51.003 | null | null | null | null |
575 | 1 | 762 | null | 20 | 24177 | What is the preferred method for for conducting post-hocs for within subjects tests? I've seen published work where Tukey's HSD is employed but a review of Keppel and Maxwell & Delaney suggests that the likely violation of sphericity in these designs makes the error term incorrect and this approach problematic. Maxwe... | Post-hocs for within subjects tests? | CC BY-SA 3.0 | null | 2010-07-23T20:14:05.327 | 2022-11-29T18:53:35.480 | 2013-07-16T15:46:47.513 | 17230 | 196 | [
"r",
"repeated-measures",
"multiple-comparisons",
"post-hoc",
"sphericity"
] |
576 | 2 | null | 564 | 6 | null | [Wikipedia has a decent entry on this subject](http://en.wikipedia.org/wiki/Difference_in_differences), but why not just use linear regression allowing for interactions between your independent variables of interest? This seems more interpretable to me. Then you might read up on [analysis of simple slopes (in the Cohen... | null | CC BY-SA 2.5 | null | 2010-07-23T20:42:43.260 | 2010-07-23T20:42:43.260 | null | null | 36 | null |
577 | 1 | 767 | null | 283 | 236285 | The AIC and BIC are both methods of assessing model fit penalized for the number of estimated parameters. As I understand it, BIC penalizes models more for free parameters than does AIC. Beyond a preference based on the stringency of the criteria, are there any other reasons to prefer AIC over BIC or vice versa?
| Is there any reason to prefer the AIC or BIC over the other? | CC BY-SA 2.5 | null | 2010-07-23T20:49:12.340 | 2022-11-29T18:45:04.257 | 2018-12-14T20:24:18.153 | 196 | 196 | [
"modeling",
"aic",
"cross-validation",
"bic",
"model-selection"
] |
578 | 2 | null | 527 | 2 | null | If you have no way of knowing the true concentration, the simplest approach would be a correlation. A step beyond that might be to conduct a simple regression predicting the outcome on method 2 using method 1 (or vice versa). If the methods are identical the intercept should be 0; if the intercept is greater or less t... | null | CC BY-SA 2.5 | null | 2010-07-23T21:18:52.370 | 2010-07-23T21:18:52.370 | null | null | 196 | null |
579 | 2 | null | 577 | 10 | null | Indeed the only difference is that BIC is AIC extended to take number of objects (samples) into account. I would say that while both are quite weak (in comparison to for instance cross-validation) it is better to use AIC, than more people will be familiar with the abbreviation -- indeed I have never seen a paper or a p... | null | CC BY-SA 3.0 | null | 2010-07-23T21:23:18.427 | 2014-04-11T11:31:10.767 | 2014-04-11T11:31:10.767 | 17230 | null | null |
581 | 1 | 588 | null | 21 | 27139 | I am currently using Viterbi training for an image segmentation problem. I wanted to know what the advantages/disadvantages are of using the Baum-Welch algorithm instead of Viterbi training.
| What are the differences between the Baum-Welch algorithm and Viterbi training? | CC BY-SA 4.0 | null | 2010-07-23T22:12:36.750 | 2018-10-03T16:53:01.837 | 2018-10-03T16:53:01.837 | null | 99 | [
"machine-learning",
"hidden-markov-model",
"image-processing",
"viterbi-algorithm",
"baum-welch"
] |
582 | 2 | null | 577 | 7 | null | As you mentioned, AIC and BIC are methods to penalize models for having more regressor variables. A penalty function is used in these methods, which is a function of the number of parameters in the model.
- When applying AIC, the penalty function is z(p) = 2 p.
- When applying BIC, the penalty function is z(p) = p l... | null | CC BY-SA 2.5 | null | 2010-07-23T23:38:20.190 | 2010-07-23T23:43:40.540 | 2010-07-23T23:43:40.540 | 108 | 108 | null |
583 | 2 | null | 577 | 103 | null | Though AIC and BIC are both [Maximum Likelihood estimate](http://en.wikipedia.org/wiki/Maximum_likelihood) driven and penalize free parameters in an effort to combat overfitting, they do so in ways that result in significantly different behavior. Lets look at one commonly presented version of the methods (which result... | null | CC BY-SA 4.0 | null | 2010-07-24T00:07:06.830 | 2022-06-07T21:34:59.793 | 2022-06-07T21:34:59.793 | 126931 | 39 | null |
584 | 2 | null | 581 | 1 | null | Forward-backward is used when you want to count 'invisible things'. For example, when using E-M to improve a model via unsupervised data. I think that Petrov's paper is an example. In the technique I'm thinking of, you first train a model with annotated data with fairly coarse annotations (e.g. a tag for 'Verb'). Then ... | null | CC BY-SA 2.5 | null | 2010-07-24T00:44:43.103 | 2010-07-24T00:44:43.103 | null | null | 240 | null |
585 | 2 | null | 526 | 5 | null | You can certainly get different results simply because you train on different examples. I very much doubt that there's an algorithm or problem domain where the results of the two would differ in some predictable way.
| null | CC BY-SA 2.5 | null | 2010-07-24T00:46:15.330 | 2010-07-24T00:46:15.330 | null | null | 240 | null |
586 | 2 | null | 558 | 8 | null | The [Tutorial on Energy-Based Learning](https://web.archive.org/web/20100701041534/http://yann.lecun.com/exdb/publis/) by LeCun et al. might get you a good part of the way there. They describe a number of loss functions and discuss what makes them "good or bad" for energy based models.
| null | CC BY-SA 4.0 | null | 2010-07-24T01:41:28.650 | 2022-11-23T11:32:12.237 | 2022-11-23T11:32:12.237 | 362671 | 251 | null |
587 | 2 | null | 577 | 88 | null | My quick explanation is
- AIC is best for prediction as it is asymptotically equivalent to cross-validation.
- BIC is best for explanation as it is allows consistent estimation of the underlying data generating process.
| null | CC BY-SA 2.5 | null | 2010-07-24T03:58:58.333 | 2010-07-24T03:58:58.333 | null | null | 159 | null |
588 | 2 | null | 581 | 28 | null | The Baum-Welch algorithm and the Viterbi algorithm calculate different things.
If you know the transition probabilities for the hidden part of your model, and the emission probabilities for the visible outputs of your model, then the Viterbi algorithm gives you the most likely complete sequence of hidden states conditi... | null | CC BY-SA 3.0 | null | 2010-07-24T04:22:01.467 | 2018-02-27T19:30:29.797 | 2018-02-27T19:30:29.797 | 132399 | 61 | null |
589 | 2 | null | 411 | 9 | null | Computational issues are the strongest argument I've heard one way or the other. The single biggest advantage of the Kolmogorov distance is that it's very easy to compute analytically for pretty much any CDF. Most other distance metrics don't have a closed-form expression except, sometimes, in the Gaussian case.
The ... | null | CC BY-SA 2.5 | null | 2010-07-24T04:54:53.943 | 2010-07-24T04:54:53.943 | null | null | 61 | null |
590 | 1 | 611 | null | 4 | 375 | In some papers, for example in ["The Geometric Density with Unknown Location Parameter"](http://www.jstor.org/stable/2239262) by Klotz, a Geometric Distribution is called a Geometric Density.
For me, this claim looks erroneous, however Klotz is a serious statistician and a professor in the field.
My question is, to wha... | To what extent can we call a Geometric Distribution a Geometric Density | CC BY-SA 2.5 | null | 2010-07-24T09:09:14.243 | 2010-08-03T19:39:42.083 | 2010-07-25T10:09:23.647 | 190 | 190 | [
"distributions",
"discrete-data"
] |
591 | 2 | null | 558 | 5 | null | The loss function is given by the problem. It could be anything. For example, you could also penalize the used CPU time and space.
In reinforcement learning, the loss function is an unknown non-deterministic function.
You cannot redefine it without changing the problem.
| null | CC BY-SA 2.5 | null | 2010-07-24T09:33:01.940 | 2010-07-24T09:33:01.940 | null | null | 200 | null |
592 | 2 | null | 421 | 5 | null | It is a bit old, but I have found Chris Chatfield's book,
[Statistics for Technology: A Course in Applied Technology](http://rads.stackoverflow.com/amzn/click/0412253402)
to be an excellent introduction.
It was how I first learned about statistics from a conceptual point of view.
| null | CC BY-SA 2.5 | null | 2010-07-24T09:52:52.377 | 2010-08-11T08:38:27.217 | 2010-08-11T08:38:27.217 | 509 | 57 | null |
593 | 2 | null | 575 | 5 | null | I recall some discussion on this in the past; I'm not aware of any implementation of Maxwell & Delaney's approach, although it shouldn't be too difficult to do. Have a look at "[Repeated Measures ANOVA using R](https://web.archive.org/web/20100124203354/http://gribblelab.org/2009/03/09/repeated-measures-anova-using-r/... | null | CC BY-SA 4.0 | null | 2010-07-24T12:09:08.743 | 2022-11-29T18:53:35.480 | 2022-11-29T18:53:35.480 | 362671 | 5 | null |
594 | 1 | 599 | null | 18 | 698 | The E-M procedure appears, to the uninitiated, as more or less black magic. Estimate parameters of an HMM (for example) using supervised data. Then decode untagged data, using forward-backward to 'count' events as if the data were tagged, more or less. Why does this make the model better? I do know something about the ... | E-M, is there an intuitive explanation? | CC BY-SA 2.5 | null | 2010-07-24T19:25:59.147 | 2015-10-05T23:56:07.353 | 2015-10-05T23:56:07.353 | 12359 | 240 | [
"expectation-maximization",
"intuition"
] |
595 | 2 | null | 492 | 7 | null | You could use the (fast :) ) discrete wavelet transform. The package wavethresh under R will do all the work.
Anyway, I like the solution of @James because it is simple and seems to go straigh to the point.
| null | CC BY-SA 2.5 | null | 2010-07-24T19:43:24.270 | 2010-08-03T19:40:40.863 | 2010-08-03T19:40:40.863 | 223 | 223 | null |
596 | 1 | 1722 | null | 4 | 996 | E-M provides a way to improve the estimation of a generative model with unannotated data. Is there anything out there that works the same way for discriminative models (e.g. perceptrons)?
For example, consider averaged perceptron tagger. It would be handy to be able to throw the entire Gigaword through some process of ... | Something like E-M for discriminative models? | CC BY-SA 4.0 | null | 2010-07-24T19:50:48.730 | 2022-11-24T03:18:28.493 | 2022-11-24T03:14:16.043 | 362671 | 240 | [
"machine-learning",
"expectation-maximization"
] |
597 | 2 | null | 558 | 6 | null | Well, there's [this](http://docs.google.com/viewer?a=v&q=cache%3acfjRh4vE38kJ%3abooks.nips.cc/papers/files/nips16/NIPS2003_LT21.pdf+passive-aggressive+machine+learning&hl=en&gl=us&pid=bl&srcid=ADGEEShVh5WierOOrVz8pTpfOPVUCm8HIqkUCm1rxCsUPm5UUapNONytwRMjMq63zcOye0L3djRjQCZW6YN_r12SvIEaWCtbx3b5La7EJ8nQuoWm2Jw8n8DuLEjS19K... | null | CC BY-SA 2.5 | null | 2010-07-24T19:55:30.013 | 2010-07-24T19:55:30.013 | null | null | 240 | null |
598 | 2 | null | 3 | 7 | null | Few more on top of already mentioned:
- KNIME together with R, Python and Weka integration extensions for data mining
- Mondrian for quick EDA
And from spatial perspective:
- GeoDa for spatial EDA and clustering of areal data
- SaTScan for clustering of point data
| null | CC BY-SA 4.0 | null | 2010-07-24T20:15:20.653 | 2022-11-27T23:25:03.597 | 2022-11-27T23:25:03.597 | 362671 | 22 | null |
599 | 2 | null | 594 | 12 | null | Just to save some typing, call the observed data $X$, the missing data $Z$ (e.g. the hidden states of the HMM), and the parameter vector we're trying to find $Q$ (e.g. transition/emission probabilities).
The intuitive explanation is that we basically cheat, pretend for a moment we know $Q$ so we can find a conditional ... | null | CC BY-SA 3.0 | null | 2010-07-24T20:23:06.997 | 2013-05-15T04:27:01.810 | 2013-05-15T04:27:01.810 | 805 | 61 | null |
600 | 2 | null | 411 | 12 | null | Mark,
the main reason of which I am aware for the use of K-S is because it arises naturally from Glivenko-Cantelli theorems in univariate empirical processes. The one reference I'd recommend is A.W.van der Vaart "Asymptotic Statistics", ch. 19. A more advanced monograph is "Weak Convergence and Empirical Processes" by ... | null | CC BY-SA 2.5 | null | 2010-07-24T20:36:13.223 | 2010-07-24T20:36:13.223 | null | null | 30 | null |
602 | 1 | 1733 | null | 4 | 361 | Do you know any good heuristics for finding optimal value of ν in case of ν-SVM classification? In this particular problem I have a radial basis kernel, if it helps.
| Heuristics for optimizing ν-SVM? | CC BY-SA 2.5 | null | 2010-07-24T22:29:40.557 | 2010-08-16T09:23:45.913 | null | null | null | [
"machine-learning",
"svm"
] |
603 | 2 | null | 526 | 3 | null | >
Usually of course the difference is
unnoticeable, and so goes my question
-- can you think of an example when the result of one type is
significantly different from another?
I am not sure at all the difference is unnoticeable, and that only in ad hoc example it will be noticeable. Both cross-validation and b... | null | CC BY-SA 2.5 | null | 2010-07-24T22:54:13.430 | 2010-07-24T22:54:13.430 | null | null | 30 | null |
604 | 1 | null | null | 7 | 776 | I am puzzled by something I found using Linear Discriminant Analysis. Here is the problem - I first ran the Discriminant analysis using 20 or so independent variables to predict 5 segments. Among the outputs, I asked for the Predicted Segments, which are the same as the original segments for around 80% of the cases. Th... | Why prediction of a predicted variable from a discriminant analysis is imperfect | CC BY-SA 3.0 | null | 2010-07-24T23:09:05.870 | 2011-05-03T09:00:53.737 | 2011-05-03T09:00:53.737 | 183 | 165 | [
"regression",
"discriminant-analysis"
] |
605 | 2 | null | 604 | 1 | null | This is quite normal in case of machine learning -- it does not need to be optimal, it must be general.
| null | CC BY-SA 2.5 | null | 2010-07-24T23:25:48.150 | 2010-07-24T23:25:48.150 | null | null | null | null |
606 | 2 | null | 490 | 20 | null | A very popular approach is penalized logistic regression, in which one maximizes the sum of the log-likelihood and a penalization term consisting of the L1-norm ("lasso"), L2-norm ("ridge"), a combination of the two ("elastic"), or a penalty associated to groups of variables ("group lasso"). This approach has several a... | null | CC BY-SA 2.5 | null | 2010-07-25T02:37:06.947 | 2010-07-25T02:37:06.947 | null | null | 30 | null |
607 | 2 | null | 6 | 227 | null | I think the answer to your first question is simply in the affirmative. Take any issue of Statistical Science, JASA, Annals of Statistics of the past 10 years and you'll find papers on boosting, SVM, and neural networks, although this area is less active now. Statisticians have appropriated the work of Valiant and Vapn... | null | CC BY-SA 3.0 | null | 2010-07-25T03:29:41.460 | 2017-11-06T11:17:18.020 | 2017-11-06T11:17:18.020 | 79114 | 30 | null |
608 | 1 | null | null | 28 | 1690 | In a [question](https://stats.stackexchange.com/questions/577/is-there-any-reason-to-prefer-the-aic-or-bic-over-the-other) elsewhere on this site, several answers mentioned that the AIC is equivalent to leave-one-out (LOO) cross-validation and that the BIC is equivalent to K-fold cross validation. Is there a way to e... | How can one empirically demonstrate in R which cross-validation methods the AIC and BIC are equivalent to? | CC BY-SA 2.5 | null | 2010-07-25T05:08:20.333 | 2010-08-03T22:58:09.447 | 2017-04-13T12:44:35.347 | -1 | 196 | [
"r",
"aic",
"cross-validation",
"bic"
] |
609 | 2 | null | 411 | 10 | null | As a summary, my answer is : if you have an explicit expression or can figure out some how what your distance is measuring (what "differences" it gives weigth to), then you can say what it is better for. An other complementary way to analyse and compare such test is the minimax theory.
At the end some test will be good... | null | CC BY-SA 4.0 | null | 2010-07-25T07:18:44.263 | 2022-08-03T22:46:15.427 | 2022-08-03T22:46:15.427 | 79696 | 223 | null |
610 | 2 | null | 492 | 9 | null | It sounds dodgy to me as the trend estimate will be biased near the point where you splice on the false data. An alternative approach is a nonparametric regression smoother such as loess or splines.
| null | CC BY-SA 2.5 | null | 2010-07-25T09:13:59.517 | 2010-07-25T09:13:59.517 | null | null | 159 | null |
611 | 2 | null | 590 | 6 | null | Heuristic answer: Without much mathematic you could say that a continuous variable has a density with respect to the Lebesgue measure, and a discrete random variable has a density with respect to the counting measure.
Developped answer: The concept of density is much wider than you may think. A density of a probability... | null | CC BY-SA 2.5 | null | 2010-07-25T12:36:23.680 | 2010-08-03T19:39:42.083 | 2010-08-03T19:39:42.083 | 223 | 223 | null |
612 | 1 | 136936 | null | 70 | 56577 | I have tried to reproduce some research (using PCA) from SPSS in R. In my experience, `principal()` [function](http://www.personality-project.org/r/html/principal.html) from package `psych` was the only function that came close (or if my memory serves me right, dead on) to match the output. To match the same results as... | Is PCA followed by a rotation (such as varimax) still PCA? | CC BY-SA 3.0 | null | 2010-07-25T14:31:31.773 | 2018-03-08T17:58:40.510 | 2015-12-15T20:37:16.417 | 12615 | 144 | [
"r",
"spss",
"pca",
"factor-analysis",
"factor-rotation"
] |
613 | 2 | null | 130 | 11 | null | I have been a heavy R user for the past 6-7 years. As a language, it has several design limitations. Yet, for work in econometrics and in data analysis, I still wholeheartedly recommend it. It has a large number of packages that would be relevant to you for econometrics, time series, consumer choice modeling etc. and o... | null | CC BY-SA 2.5 | null | 2010-07-25T14:33:25.313 | 2010-07-25T14:33:25.313 | null | null | 30 | null |
614 | 1 | null | null | 40 | 10561 | There have been a few questions about statistical [textbooks](https://stats.stackexchange.com/questions/tagged/textbook), such as the question [Free statistical textbooks](https://stats.stackexchange.com/questions/170/free-statistical-textbooks). However, I am looking for textbooks that are Open Source, for example, ha... | Open Source statistical textbooks? | CC BY-SA 2.5 | null | 2010-07-25T14:53:50.473 | 2016-10-06T19:43:59.697 | 2017-04-13T12:44:21.160 | -1 | 107 | [
"references",
"open-source"
] |
615 | 2 | null | 612 | 2 | null | Thanks to the chaos in definitions of both they are effectively a synonyms. Don't believe words and look deep into the docks to find the equations.
| null | CC BY-SA 2.5 | null | 2010-07-25T14:56:32.433 | 2010-07-25T14:56:32.433 | null | null | null | null |
616 | 2 | null | 614 | 7 | null | The ["Statistics"](http://en.wikibooks.org/wiki/Statistics) book on wikibooks
| null | CC BY-SA 2.5 | null | 2010-07-25T15:25:13.873 | 2010-07-25T15:32:14.903 | 2010-07-25T15:32:14.903 | 5 | 5 | null |
617 | 2 | null | 614 | 10 | null | [Multivariate statistics with R](http://www.opentextbook.org/2009/04/03/multivariate-statistics-with-r/)
| null | CC BY-SA 2.5 | null | 2010-07-25T15:32:59.290 | 2010-07-25T15:32:59.290 | null | null | 5 | null |
618 | 2 | null | 36 | 28 | null | I've always liked this one:
source: [http://pubs.acs.org/doi/abs/10.1021/ci700332k](http://pubs.acs.org/doi/abs/10.1021/ci700332k)
| null | CC BY-SA 2.5 | null | 2010-07-25T18:02:06.573 | 2010-07-25T18:10:35.387 | 2010-07-25T18:10:35.387 | 54 | 54 | null |
619 | 2 | null | 524 | 4 | null | I have a depressing and not-very-specific anecdote to share here. I spent some time as a co-worker of a statistical MT researcher. If you want to see a really big, complex, model, look no further.
He was putting me through NLP bootcamp for his own amusement. I am, in general, the sort of programmer who lives and dies b... | null | CC BY-SA 2.5 | null | 2010-07-25T20:08:35.907 | 2010-07-25T20:08:35.907 | null | null | 240 | null |
620 | 2 | null | 614 | 4 | null | [R programming wiki book](http://en.wikibooks.org/wiki/R_Programming)
| null | CC BY-SA 2.5 | null | 2010-07-25T22:04:16.257 | 2010-07-25T22:04:16.257 | null | null | 253 | null |
621 | 2 | null | 614 | 4 | null | Some googling found [Statistics & Probability on CollegeOpenTextbooks.org](http://collegeopentextbooks.org/textbook-listings/textbooks-by-subject/statisticsandprobability). Still, be aware that most of CC-ed material is share-aliked (so you must also publish your work on CC) or at least attributed (so you must add info... | null | CC BY-SA 3.0 | null | 2010-07-25T23:56:43.840 | 2016-10-06T19:43:59.697 | 2016-10-06T19:43:59.697 | 122650 | null | null |
622 | 1 | 628 | null | 67 | 29552 | I see these terms being used and I keep getting them mixed up. Is there a simple explanation of the differences between them?
| What is the difference between a partial likelihood, profile likelihood and marginal likelihood? | CC BY-SA 2.5 | null | 2010-07-26T09:12:21.093 | 2022-05-17T12:52:26.377 | 2022-05-17T12:52:26.377 | 11887 | 159 | [
"estimation",
"maximum-likelihood",
"likelihood",
"profile-likelihood"
] |
623 | 2 | null | 175 | 5 | null | Garbage in, garbage out....
Implicit in getting the full benefit of linear regression is that the noise follows a normal distribution. Ideally you have mostly data and a little noise.... not mostly noise and a little data. You can test for normality of residuals after the linear fit by looking at the residuals. You ... | null | CC BY-SA 4.0 | null | 2010-07-26T09:46:48.410 | 2020-09-18T08:21:19.847 | 2020-09-18T08:21:19.847 | 22047 | 87 | null |
624 | 1 | 625 | null | 3 | 460 | In engineering, we usually have Handbooks that pretty much dictate the state of the practice. These books are usually devoid of theory and focus on the applied methodology. Is there a forecasting Handbook out there? that solely focuses on the technique and not the background?
| Forecasting handbooks | CC BY-SA 2.5 | null | 2010-07-26T11:53:11.027 | 2010-09-30T21:25:14.480 | 2010-09-30T21:25:14.480 | 930 | 59 | [
"forecasting"
] |
625 | 2 | null | 624 | 4 | null | There are two that I know of:
- Handbook of economic forecasting. Relatively theoretical. Not for undergraduates. A narrow look at forecasting --- specifically about economic forecasting.
- Principles of forecasting. Simpler, broader. Widely used by forecasting practitioners. Often reflects the idiosyncratic opinions... | null | CC BY-SA 2.5 | null | 2010-07-26T12:01:58.983 | 2010-07-26T12:20:12.410 | 2010-07-26T12:20:12.410 | 159 | 159 | null |
626 | 2 | null | 125 | 16 | null | "[Bayesian Core: A Practical Approach to Computational Bayesian Statistics](http://amzn.to/2kxDAo2)" by Marin and Robert, Springer-Verlag (2007).
"Why?": the author explain the why of the bayesian choice and the how very well. It's a practical book, but written by one of the finest bayesian thinkers alive. It's not exh... | null | CC BY-SA 4.0 | null | 2010-07-26T12:38:40.610 | 2018-12-20T11:35:42.960 | 2018-12-20T11:35:42.960 | 7224 | 30 | null |
627 | 2 | null | 170 | 17 | null | I really like [The Little Handbook of Statistical Practice](https://web.archive.org/web/20100731030727/http://www.tufts.edu/%7Egdallal/LHSP.HTM) by Gerard E. Dallal
| null | CC BY-SA 4.0 | null | 2010-07-26T12:53:22.357 | 2023-06-02T11:54:01.243 | 2023-06-02T11:54:01.243 | 362671 | 236 | null |
628 | 2 | null | 622 | 67 | null | The likelihood function usually depends on many parameters. Depending on the application, we are usually interested in only a subset of these parameters. For example, in linear regression, interest typically lies in the slope coefficients and not on the error variance.
Denote the parameters we are interested in as $\b... | null | CC BY-SA 4.0 | null | 2010-07-26T14:40:27.763 | 2018-11-10T16:48:52.343 | 2018-11-10T16:48:52.343 | 165856 | null | null |
631 | 1 | 28567 | null | 56 | 42285 | What is an estimator of standard deviation of standard deviation if normality of data can be assumed?
| Standard deviation of standard deviation | CC BY-SA 2.5 | null | 2010-07-26T16:10:45.817 | 2017-12-14T19:07:13.493 | 2017-11-25T22:29:39.437 | 128677 | null | [
"estimation",
"standard-deviation",
"normality-assumption"
] |
632 | 2 | null | 631 | 5 | null | Assume you observe $X_1,\dots,X_n$ iid from a normal with mean zero and variance $\sigma^2$. The (empirical) standard deviation is the square root of the estimator $\hat{\sigma}^2$ of $\sigma^2$ (unbiased or not that is not the question). As an estimator (obtained with $X_1,\dots,X_n$), $\hat{\sigma}$ has a variance th... | null | CC BY-SA 3.0 | null | 2010-07-26T16:23:25.073 | 2012-06-08T12:25:22.157 | 2012-06-08T12:25:22.157 | 4856 | 223 | null |
633 | 1 | 634 | null | 6 | 5522 | I have a data set of about 3,000 field observations.
The data collected is divided into 20 variables (real numbers), 30 boolean variables, and 10 or so look up variables and one "answer" variable
We have about 20,000 objects in the field, and i'm trying to produce an "answer" for the 20,000 objects based on the 3,000 ... | Incorporating boolean data into analysis | CC BY-SA 2.5 | null | 2010-07-26T17:29:19.477 | 2010-11-02T18:47:07.033 | 2010-10-17T19:07:16.110 | 930 | 59 | [
"modeling",
"categorical-data",
"model-selection",
"binary-data"
] |
634 | 2 | null | 633 | 8 | null | You are decribing "[categorical variables](http://www.oswego.edu/~srp/stats/variable_types.htm)" (represented in R a factors). These can be incorporated into almost any statistical model by being assigned levels. You would need to give more detail about your particular problem in order to be advised on a particular me... | null | CC BY-SA 2.5 | null | 2010-07-26T17:46:45.127 | 2010-07-26T18:25:45.280 | 2010-07-26T18:25:45.280 | 5 | 5 | null |
635 | 2 | null | 480 | 17 | null | Implementations of RF differ slightly. I know that Salford Systems' [proprietary implementation](http://salford-systems.com/products/randomforests/overview.html) is supposed to be better than the [vanilla one](http://cran.r-project.org/web/packages/randomForest/) in R. A description of the algorithm is in [ESL by Fried... | null | CC BY-SA 3.0 | null | 2010-07-26T17:50:21.780 | 2011-08-21T20:53:14.543 | 2011-08-21T20:53:14.543 | 740 | 30 | null |
636 | 2 | null | 633 | 1 | null | Try Random Forest; from my experience it may perform well on such kind of data, and gives you a some additional interesting information, like variable importance and object similarity measure.
| null | CC BY-SA 2.5 | null | 2010-07-26T17:50:37.240 | 2010-07-26T18:21:26.337 | 2010-07-26T18:21:26.337 | null | null | null |
637 | 2 | null | 633 | 4 | null | It sounds like you are trying to predict your boolean response, yes?
This is called classification.
Logistic Regression is the obvious choice here, but there are other methods too. You can't do traditional regression, because the response is not a real number.
The lookup variables are called nominals, and can be dealt ... | null | CC BY-SA 2.5 | null | 2010-07-26T18:22:33.917 | 2010-07-26T18:22:33.917 | null | null | 74 | null |
638 | 1 | 644 | null | 10 | 2346 | Provided a sample size "N" that I plan on using to forecast data. What are some of the ways to subdivide the data so that I use some of it to establish a model, and the remainder data to validate the model?
I know there is no black and white answer to this, but it would be interesting to know some "rules of thumb" or ... | Calculating ratio of sample data used for model fitting/training and validation | CC BY-SA 3.0 | null | 2010-07-26T18:24:35.737 | 2016-08-03T22:15:51.213 | 2016-08-03T22:15:51.213 | 22468 | 59 | [
"machine-learning",
"modeling",
"sample",
"validation"
] |
641 | 1 | 646 | null | 5 | 7900 | Sites like eMarketer offer general survey results about internet usage.
Who else has a big set of survey results, or regularly releases them?
- Preferably marketing research focused.
Thanks!
| Where is a good place to find survey results? | CC BY-SA 2.5 | null | 2010-07-26T19:20:53.477 | 2015-12-04T16:03:27.630 | 2010-09-16T12:42:31.387 | null | 74 | [
"dataset",
"survey"
] |
642 | 2 | null | 641 | 2 | null | government websites usually .... I use the [RITA](http://www.rita.dot.gov/) a lot
| null | CC BY-SA 2.5 | null | 2010-07-26T19:23:19.133 | 2010-07-26T19:23:19.133 | null | null | 59 | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.