
code stringlengths 114 1.05M | path stringlengths 3 312 | quality_prob float64 0.5 0.99 | learning_prob float64 0.2 1 | filename stringlengths 3 168 | kind stringclasses 1
value |
|---|---|---|---|---|---|
import multiprocessing as mp
from collections import OrderedDict
from typing import Any, Callable, List, Optional, Sequence, Tuple, Type, Union
import gym
import numpy as np
from stable_baselines3.common.vec_env.base_vec_env import (
CloudpickleWrapper,
VecEnv,
VecEnvIndices,
VecEnvObs,
VecEnvStepReturn,
)
def _worker(
remote: mp.connection.Connection, parent_remote: mp.connection.Connection, env_fn_wrapper: CloudpickleWrapper
) -> None:
# Import here to avoid a circular import
from stable_baselines3.common.env_util import is_wrapped
parent_remote.close()
env = env_fn_wrapper.var()
while True:
try:
cmd, data = remote.recv()
if cmd == "step":
observation, reward, done, info = env.step(data)
if done:
# save final observation where user can get it, then reset
info["terminal_observation"] = observation
observation = env.reset()
remote.send((observation, reward, done, info))
elif cmd == "seed":
remote.send(env.seed(data))
elif cmd == "reset":
observation = env.reset()
remote.send(observation)
elif cmd == "render":
remote.send(env.render(data))
elif cmd == "close":
env.close()
remote.close()
break
elif cmd == "get_spaces":
remote.send((env.observation_space, env.action_space))
elif cmd == "env_method":
method = getattr(env, data[0])
remote.send(method(*data[1], **data[2]))
elif cmd == "get_attr":
remote.send(getattr(env, data))
elif cmd == "set_attr":
remote.send(setattr(env, data[0], data[1]))
elif cmd == "is_wrapped":
remote.send(is_wrapped(env, data))
else:
raise NotImplementedError(f"`{cmd}` is not implemented in the worker")
except EOFError:
break
class SubprocVecEnv(VecEnv):
"""
Creates a multiprocess vectorized wrapper for multiple environments, distributing each environment to its own
process, allowing significant speed up when the environment is computationally complex.
For performance reasons, if your environment is not IO bound, the number of environments should not exceed the
number of logical cores on your CPU.
.. warning::
Only 'forkserver' and 'spawn' start methods are thread-safe,
which is important when TensorFlow sessions or other non thread-safe
libraries are used in the parent (see issue #217). However, compared to
'fork' they incur a small start-up cost and have restrictions on
global variables. With those methods, users must wrap the code in an
``if __name__ == "__main__":`` block.
For more information, see the multiprocessing documentation.
:param env_fns: Environments to run in subprocesses
:param start_method: method used to start the subprocesses.
Must be one of the methods returned by multiprocessing.get_all_start_methods().
Defaults to 'forkserver' on available platforms, and 'spawn' otherwise.
"""
def __init__(self, env_fns: List[Callable[[], gym.Env]], start_method: Optional[str] = None):
self.waiting = False
self.closed = False
n_envs = len(env_fns)
if start_method is None:
# Fork is not a thread safe method (see issue #217)
# but is more user friendly (does not require to wrap the code in
# a `if __name__ == "__main__":`)
forkserver_available = "forkserver" in mp.get_all_start_methods()
start_method = "forkserver" if forkserver_available else "spawn"
ctx = mp.get_context(start_method)
self.remotes, self.work_remotes = zip(*[ctx.Pipe() for _ in range(n_envs)])
self.processes = []
for work_remote, remote, env_fn in zip(self.work_remotes, self.remotes, env_fns):
args = (work_remote, remote, CloudpickleWrapper(env_fn))
# daemon=True: if the main process crashes, we should not cause things to hang
process = ctx.Process(target=_worker, args=args, daemon=True) # pytype:disable=attribute-error
process.start()
self.processes.append(process)
work_remote.close()
self.remotes[0].send(("get_spaces", None))
observation_space, action_space = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions: np.ndarray) -> None:
for remote, action in zip(self.remotes, actions):
remote.send(("step", action))
self.waiting = True
def step_wait(self) -> VecEnvStepReturn:
results = [remote.recv() for remote in self.remotes]
self.waiting = False
obs, rews, dones, infos = zip(*results)
return _flatten_obs(obs, self.observation_space), np.stack(rews), np.stack(dones), infos
def seed(self, seed: Optional[int] = None) -> List[Union[None, int]]:
if seed is None:
seed = np.random.randint(0, 2**32 - 1)
for idx, remote in enumerate(self.remotes):
remote.send(("seed", seed + idx))
return [remote.recv() for remote in self.remotes]
def reset(self) -> VecEnvObs:
for remote in self.remotes:
remote.send(("reset", None))
obs = [remote.recv() for remote in self.remotes]
return _flatten_obs(obs, self.observation_space)
def close(self) -> None:
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(("close", None))
for process in self.processes:
process.join()
self.closed = True
def get_images(self) -> Sequence[np.ndarray]:
for pipe in self.remotes:
# gather images from subprocesses
# `mode` will be taken into account later
pipe.send(("render", "rgb_array"))
imgs = [pipe.recv() for pipe in self.remotes]
return imgs
def get_attr(self, attr_name: str, indices: VecEnvIndices = None) -> List[Any]:
"""Return attribute from vectorized environment (see base class)."""
target_remotes = self._get_target_remotes(indices)
for remote in target_remotes:
remote.send(("get_attr", attr_name))
return [remote.recv() for remote in target_remotes]
def set_attr(self, attr_name: str, value: Any, indices: VecEnvIndices = None) -> None:
"""Set attribute inside vectorized environments (see base class)."""
target_remotes = self._get_target_remotes(indices)
for remote in target_remotes:
remote.send(("set_attr", (attr_name, value)))
for remote in target_remotes:
remote.recv()
def env_method(self, method_name: str, *method_args, indices: VecEnvIndices = None, **method_kwargs) -> List[Any]:
"""Call instance methods of vectorized environments."""
target_remotes = self._get_target_remotes(indices)
for remote in target_remotes:
remote.send(("env_method", (method_name, method_args, method_kwargs)))
return [remote.recv() for remote in target_remotes]
def env_is_wrapped(self, wrapper_class: Type[gym.Wrapper], indices: VecEnvIndices = None) -> List[bool]:
"""Check if worker environments are wrapped with a given wrapper"""
target_remotes = self._get_target_remotes(indices)
for remote in target_remotes:
remote.send(("is_wrapped", wrapper_class))
return [remote.recv() for remote in target_remotes]
def _get_target_remotes(self, indices: VecEnvIndices) -> List[Any]:
"""
Get the connection object needed to communicate with the wanted
envs that are in subprocesses.
:param indices: refers to indices of envs.
:return: Connection object to communicate between processes.
"""
indices = self._get_indices(indices)
return [self.remotes[i] for i in indices]
def _flatten_obs(obs: Union[List[VecEnvObs], Tuple[VecEnvObs]], space: gym.spaces.Space) -> VecEnvObs:
"""
Flatten observations, depending on the observation space.
:param obs: observations.
A list or tuple of observations, one per environment.
Each environment observation may be a NumPy array, or a dict or tuple of NumPy arrays.
:return: flattened observations.
A flattened NumPy array or an OrderedDict or tuple of flattened numpy arrays.
Each NumPy array has the environment index as its first axis.
"""
assert isinstance(obs, (list, tuple)), "expected list or tuple of observations per environment"
assert len(obs) > 0, "need observations from at least one environment"
if isinstance(space, gym.spaces.Dict):
assert isinstance(space.spaces, OrderedDict), "Dict space must have ordered subspaces"
assert isinstance(obs[0], dict), "non-dict observation for environment with Dict observation space"
return OrderedDict([(k, np.stack([o[k] for o in obs])) for k in space.spaces.keys()])
elif isinstance(space, gym.spaces.Tuple):
assert isinstance(obs[0], tuple), "non-tuple observation for environment with Tuple observation space"
obs_len = len(space.spaces)
return tuple(np.stack([o[i] for o in obs]) for i in range(obs_len))
else:
return np.stack(obs) | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/subproc_vec_env.py | 0.877004 | 0.244504 | subproc_vec_env.py | pypi |
from collections import OrderedDict
from typing import Any, Dict, List, Tuple
import gym
import numpy as np
from stable_baselines3.common.preprocessing import check_for_nested_spaces
from stable_baselines3.common.vec_env.base_vec_env import VecEnvObs
def copy_obs_dict(obs: Dict[str, np.ndarray]) -> Dict[str, np.ndarray]:
"""
Deep-copy a dict of numpy arrays.
:param obs: a dict of numpy arrays.
:return: a dict of copied numpy arrays.
"""
assert isinstance(obs, OrderedDict), f"unexpected type for observations '{type(obs)}'"
return OrderedDict([(k, np.copy(v)) for k, v in obs.items()])
def dict_to_obs(obs_space: gym.spaces.Space, obs_dict: Dict[Any, np.ndarray]) -> VecEnvObs:
"""
Convert an internal representation raw_obs into the appropriate type
specified by space.
:param obs_space: an observation space.
:param obs_dict: a dict of numpy arrays.
:return: returns an observation of the same type as space.
If space is Dict, function is identity; if space is Tuple, converts dict to Tuple;
otherwise, space is unstructured and returns the value raw_obs[None].
"""
if isinstance(obs_space, gym.spaces.Dict):
return obs_dict
elif isinstance(obs_space, gym.spaces.Tuple):
assert len(obs_dict) == len(obs_space.spaces), "size of observation does not match size of observation space"
return tuple(obs_dict[i] for i in range(len(obs_space.spaces)))
else:
assert set(obs_dict.keys()) == {None}, "multiple observation keys for unstructured observation space"
return obs_dict[None]
def obs_space_info(obs_space: gym.spaces.Space) -> Tuple[List[str], Dict[Any, Tuple[int, ...]], Dict[Any, np.dtype]]:
"""
Get dict-structured information about a gym.Space.
Dict spaces are represented directly by their dict of subspaces.
Tuple spaces are converted into a dict with keys indexing into the tuple.
Unstructured spaces are represented by {None: obs_space}.
:param obs_space: an observation space
:return: A tuple (keys, shapes, dtypes):
keys: a list of dict keys.
shapes: a dict mapping keys to shapes.
dtypes: a dict mapping keys to dtypes.
"""
check_for_nested_spaces(obs_space)
if isinstance(obs_space, gym.spaces.Dict):
assert isinstance(obs_space.spaces, OrderedDict), "Dict space must have ordered subspaces"
subspaces = obs_space.spaces
elif isinstance(obs_space, gym.spaces.Tuple):
subspaces = {i: space for i, space in enumerate(obs_space.spaces)}
else:
assert not hasattr(obs_space, "spaces"), f"Unsupported structured space '{type(obs_space)}'"
subspaces = {None: obs_space}
keys = []
shapes = {}
dtypes = {}
for key, box in subspaces.items():
keys.append(key)
shapes[key] = box.shape
dtypes[key] = box.dtype
return keys, shapes, dtypes | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/util.py | 0.947878 | 0.763572 | util.py | pypi |
from copy import deepcopy
from typing import Dict, Union
import numpy as np
from gym import spaces
from stable_baselines3.common.preprocessing import is_image_space, is_image_space_channels_first
from stable_baselines3.common.vec_env.base_vec_env import VecEnv, VecEnvStepReturn, VecEnvWrapper
class VecTransposeImage(VecEnvWrapper):
"""
Re-order channels, from HxWxC to CxHxW.
It is required for PyTorch convolution layers.
:param venv:
:param skip: Skip this wrapper if needed as we rely on heuristic to apply it or not,
which may result in unwanted behavior, see GH issue #671.
"""
def __init__(self, venv: VecEnv, skip: bool = False):
assert is_image_space(venv.observation_space) or isinstance(
venv.observation_space, spaces.dict.Dict
), "The observation space must be an image or dictionary observation space"
self.skip = skip
# Do nothing
if skip:
super().__init__(venv)
return
if isinstance(venv.observation_space, spaces.dict.Dict):
self.image_space_keys = []
observation_space = deepcopy(venv.observation_space)
for key, space in observation_space.spaces.items():
if is_image_space(space):
# Keep track of which keys should be transposed later
self.image_space_keys.append(key)
observation_space.spaces[key] = self.transpose_space(space, key)
else:
observation_space = self.transpose_space(venv.observation_space)
super().__init__(venv, observation_space=observation_space)
@staticmethod
def transpose_space(observation_space: spaces.Box, key: str = "") -> spaces.Box:
"""
Transpose an observation space (re-order channels).
:param observation_space:
:param key: In case of dictionary space, the key of the observation space.
:return:
"""
# Sanity checks
assert is_image_space(observation_space), "The observation space must be an image"
assert not is_image_space_channels_first(
observation_space
), f"The observation space {key} must follow the channel last convention"
height, width, channels = observation_space.shape
new_shape = (channels, height, width)
return spaces.Box(low=0, high=255, shape=new_shape, dtype=observation_space.dtype)
@staticmethod
def transpose_image(image: np.ndarray) -> np.ndarray:
"""
Transpose an image or batch of images (re-order channels).
:param image:
:return:
"""
if len(image.shape) == 3:
return np.transpose(image, (2, 0, 1))
return np.transpose(image, (0, 3, 1, 2))
def transpose_observations(self, observations: Union[np.ndarray, Dict]) -> Union[np.ndarray, Dict]:
"""
Transpose (if needed) and return new observations.
:param observations:
:return: Transposed observations
"""
# Do nothing
if self.skip:
return observations
if isinstance(observations, dict):
# Avoid modifying the original object in place
observations = deepcopy(observations)
for k in self.image_space_keys:
observations[k] = self.transpose_image(observations[k])
else:
observations = self.transpose_image(observations)
return observations
def step_wait(self) -> VecEnvStepReturn:
observations, rewards, dones, infos = self.venv.step_wait()
# Transpose the terminal observations
for idx, done in enumerate(dones):
if not done:
continue
if "terminal_observation" in infos[idx]:
infos[idx]["terminal_observation"] = self.transpose_observations(infos[idx]["terminal_observation"])
return self.transpose_observations(observations), rewards, dones, infos
def reset(self) -> Union[np.ndarray, Dict]:
"""
Reset all environments
"""
return self.transpose_observations(self.venv.reset())
def close(self) -> None:
self.venv.close() | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/vec_transpose.py | 0.937868 | 0.659446 | vec_transpose.py | pypi |
import os
from typing import Callable
from gym.wrappers.monitoring import video_recorder
from stable_baselines3.common.vec_env.base_vec_env import VecEnv, VecEnvObs, VecEnvStepReturn, VecEnvWrapper
from stable_baselines3.common.vec_env.dummy_vec_env import DummyVecEnv
from stable_baselines3.common.vec_env.subproc_vec_env import SubprocVecEnv
class VecVideoRecorder(VecEnvWrapper):
"""
Wraps a VecEnv or VecEnvWrapper object to record rendered image as mp4 video.
It requires ffmpeg or avconv to be installed on the machine.
:param venv:
:param video_folder: Where to save videos
:param record_video_trigger: Function that defines when to start recording.
The function takes the current number of step,
and returns whether we should start recording or not.
:param video_length: Length of recorded videos
:param name_prefix: Prefix to the video name
"""
def __init__(
self,
venv: VecEnv,
video_folder: str,
record_video_trigger: Callable[[int], bool],
video_length: int = 200,
name_prefix: str = "rl-video",
):
VecEnvWrapper.__init__(self, venv)
self.env = venv
# Temp variable to retrieve metadata
temp_env = venv
# Unwrap to retrieve metadata dict
# that will be used by gym recorder
while isinstance(temp_env, VecEnvWrapper):
temp_env = temp_env.venv
if isinstance(temp_env, DummyVecEnv) or isinstance(temp_env, SubprocVecEnv):
metadata = temp_env.get_attr("metadata")[0]
else:
metadata = temp_env.metadata
self.env.metadata = metadata
self.record_video_trigger = record_video_trigger
self.video_recorder = None
self.video_folder = os.path.abspath(video_folder)
# Create output folder if needed
os.makedirs(self.video_folder, exist_ok=True)
self.name_prefix = name_prefix
self.step_id = 0
self.video_length = video_length
self.recording = False
self.recorded_frames = 0
def reset(self) -> VecEnvObs:
obs = self.venv.reset()
self.start_video_recorder()
return obs
def start_video_recorder(self) -> None:
self.close_video_recorder()
video_name = f"{self.name_prefix}-step-{self.step_id}-to-step-{self.step_id + self.video_length}"
base_path = os.path.join(self.video_folder, video_name)
self.video_recorder = video_recorder.VideoRecorder(
env=self.env, base_path=base_path, metadata={"step_id": self.step_id}
)
self.video_recorder.capture_frame()
self.recorded_frames = 1
self.recording = True
def _video_enabled(self) -> bool:
return self.record_video_trigger(self.step_id)
def step_wait(self) -> VecEnvStepReturn:
obs, rews, dones, infos = self.venv.step_wait()
self.step_id += 1
if self.recording:
self.video_recorder.capture_frame()
self.recorded_frames += 1
if self.recorded_frames > self.video_length:
print(f"Saving video to {self.video_recorder.path}")
self.close_video_recorder()
elif self._video_enabled():
self.start_video_recorder()
return obs, rews, dones, infos
def close_video_recorder(self) -> None:
if self.recording:
self.video_recorder.close()
self.recording = False
self.recorded_frames = 1
def close(self) -> None:
VecEnvWrapper.close(self)
self.close_video_recorder()
def __del__(self):
self.close() | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/vec_video_recorder.py | 0.769773 | 0.288995 | vec_video_recorder.py | pypi |
from collections import OrderedDict
from copy import deepcopy
from typing import Any, Callable, List, Optional, Sequence, Type, Union
import gym
import numpy as np
from stable_baselines3.common.vec_env.base_vec_env import VecEnv, VecEnvIndices, VecEnvObs, VecEnvStepReturn
from stable_baselines3.common.vec_env.util import copy_obs_dict, dict_to_obs, obs_space_info
class DummyVecEnv(VecEnv):
"""
Creates a simple vectorized wrapper for multiple environments, calling each environment in sequence on the current
Python process. This is useful for computationally simple environment such as ``cartpole-v1``,
as the overhead of multiprocess or multithread outweighs the environment computation time.
This can also be used for RL methods that
require a vectorized environment, but that you want a single environments to train with.
:param env_fns: a list of functions
that return environments to vectorize
"""
def __init__(self, env_fns: List[Callable[[], gym.Env]]):
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
obs_space = env.observation_space
self.keys, shapes, dtypes = obs_space_info(obs_space)
self.buf_obs = OrderedDict([(k, np.zeros((self.num_envs,) + tuple(shapes[k]), dtype=dtypes[k])) for k in self.keys])
self.buf_dones = np.zeros((self.num_envs,), dtype=bool)
self.buf_rews = np.zeros((self.num_envs,), dtype=np.float32)
self.buf_infos = [{} for _ in range(self.num_envs)]
self.actions = None
self.metadata = env.metadata
def step_async(self, actions: np.ndarray) -> None:
self.actions = actions
def step_wait(self) -> VecEnvStepReturn:
for env_idx in range(self.num_envs):
obs, self.buf_rews[env_idx], self.buf_dones[env_idx], self.buf_infos[env_idx] = self.envs[env_idx].step(
self.actions[env_idx]
)
if self.buf_dones[env_idx]:
# save final observation where user can get it, then reset
self.buf_infos[env_idx]["terminal_observation"] = obs
obs = self.envs[env_idx].reset()
self._save_obs(env_idx, obs)
return (self._obs_from_buf(), np.copy(self.buf_rews), np.copy(self.buf_dones), deepcopy(self.buf_infos))
def seed(self, seed: Optional[int] = None) -> List[Union[None, int]]:
if seed is None:
seed = np.random.randint(0, 2**32 - 1)
seeds = []
for idx, env in enumerate(self.envs):
seeds.append(env.seed(seed + idx))
return seeds
def reset(self) -> VecEnvObs:
for env_idx in range(self.num_envs):
obs = self.envs[env_idx].reset()
self._save_obs(env_idx, obs)
return self._obs_from_buf()
def close(self) -> None:
for env in self.envs:
env.close()
def get_images(self) -> Sequence[np.ndarray]:
return [env.render(mode="rgb_array") for env in self.envs]
def render(self, mode: str = "human") -> Optional[np.ndarray]:
"""
Gym environment rendering. If there are multiple environments then
they are tiled together in one image via ``BaseVecEnv.render()``.
Otherwise (if ``self.num_envs == 1``), we pass the render call directly to the
underlying environment.
Therefore, some arguments such as ``mode`` will have values that are valid
only when ``num_envs == 1``.
:param mode: The rendering type.
"""
if self.num_envs == 1:
return self.envs[0].render(mode=mode)
else:
return super().render(mode=mode)
def _save_obs(self, env_idx: int, obs: VecEnvObs) -> None:
for key in self.keys:
if key is None:
self.buf_obs[key][env_idx] = obs
else:
self.buf_obs[key][env_idx] = obs[key]
def _obs_from_buf(self) -> VecEnvObs:
return dict_to_obs(self.observation_space, copy_obs_dict(self.buf_obs))
def get_attr(self, attr_name: str, indices: VecEnvIndices = None) -> List[Any]:
"""Return attribute from vectorized environment (see base class)."""
target_envs = self._get_target_envs(indices)
return [getattr(env_i, attr_name) for env_i in target_envs]
def set_attr(self, attr_name: str, value: Any, indices: VecEnvIndices = None) -> None:
"""Set attribute inside vectorized environments (see base class)."""
target_envs = self._get_target_envs(indices)
for env_i in target_envs:
setattr(env_i, attr_name, value)
def env_method(self, method_name: str, *method_args, indices: VecEnvIndices = None, **method_kwargs) -> List[Any]:
"""Call instance methods of vectorized environments."""
target_envs = self._get_target_envs(indices)
return [getattr(env_i, method_name)(*method_args, **method_kwargs) for env_i in target_envs]
def env_is_wrapped(self, wrapper_class: Type[gym.Wrapper], indices: VecEnvIndices = None) -> List[bool]:
"""Check if worker environments are wrapped with a given wrapper"""
target_envs = self._get_target_envs(indices)
# Import here to avoid a circular import
from stable_baselines3.common import env_util
return [env_util.is_wrapped(env_i, wrapper_class) for env_i in target_envs]
def _get_target_envs(self, indices: VecEnvIndices) -> List[gym.Env]:
indices = self._get_indices(indices)
return [self.envs[i] for i in indices] | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/dummy_vec_env.py | 0.925819 | 0.491029 | dummy_vec_env.py | pypi |
from typing import Any, Dict, List, Optional, Tuple, Union
import numpy as np
from gym import spaces
from stable_baselines3.common.vec_env.base_vec_env import VecEnv, VecEnvWrapper
from stable_baselines3.common.vec_env.stacked_observations import StackedDictObservations, StackedObservations
class VecFrameStack(VecEnvWrapper):
"""
Frame stacking wrapper for vectorized environment. Designed for image observations.
Uses the StackedObservations class, or StackedDictObservations depending on the observations space
:param venv: the vectorized environment to wrap
:param n_stack: Number of frames to stack
:param channels_order: If "first", stack on first image dimension. If "last", stack on last dimension.
If None, automatically detect channel to stack over in case of image observation or default to "last" (default).
Alternatively channels_order can be a dictionary which can be used with environments with Dict observation spaces
"""
def __init__(self, venv: VecEnv, n_stack: int, channels_order: Optional[Union[str, Dict[str, str]]] = None):
self.venv = venv
self.n_stack = n_stack
wrapped_obs_space = venv.observation_space
if isinstance(wrapped_obs_space, spaces.Box):
assert not isinstance(
channels_order, dict
), f"Expected None or string for channels_order but received {channels_order}"
self.stackedobs = StackedObservations(venv.num_envs, n_stack, wrapped_obs_space, channels_order)
elif isinstance(wrapped_obs_space, spaces.Dict):
self.stackedobs = StackedDictObservations(venv.num_envs, n_stack, wrapped_obs_space, channels_order)
else:
raise Exception("VecFrameStack only works with gym.spaces.Box and gym.spaces.Dict observation spaces")
observation_space = self.stackedobs.stack_observation_space(wrapped_obs_space)
VecEnvWrapper.__init__(self, venv, observation_space=observation_space)
def step_wait(
self,
) -> Tuple[Union[np.ndarray, Dict[str, np.ndarray]], np.ndarray, np.ndarray, List[Dict[str, Any]],]:
observations, rewards, dones, infos = self.venv.step_wait()
observations, infos = self.stackedobs.update(observations, dones, infos)
return observations, rewards, dones, infos
def reset(self) -> Union[np.ndarray, Dict[str, np.ndarray]]:
"""
Reset all environments
"""
observation = self.venv.reset() # pytype:disable=annotation-type-mismatch
observation = self.stackedobs.reset(observation)
return observation
def close(self) -> None:
self.venv.close() | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/vec_frame_stack.py | 0.962462 | 0.644673 | vec_frame_stack.py | pypi |
import inspect
import warnings
from abc import ABC, abstractmethod
from typing import Any, Dict, Iterable, List, Optional, Sequence, Tuple, Type, Union
import cloudpickle
import gym
import numpy as np
# Define type aliases here to avoid circular import
# Used when we want to access one or more VecEnv
VecEnvIndices = Union[None, int, Iterable[int]]
# VecEnvObs is what is returned by the reset() method
# it contains the observation for each env
VecEnvObs = Union[np.ndarray, Dict[str, np.ndarray], Tuple[np.ndarray, ...]]
# VecEnvStepReturn is what is returned by the step() method
# it contains the observation, reward, done, info for each env
VecEnvStepReturn = Tuple[VecEnvObs, np.ndarray, np.ndarray, List[Dict]]
def tile_images(img_nhwc: Sequence[np.ndarray]) -> np.ndarray: # pragma: no cover
"""
Tile N images into one big PxQ image
(P,Q) are chosen to be as close as possible, and if N
is square, then P=Q.
:param img_nhwc: list or array of images, ndim=4 once turned into array. img nhwc
n = batch index, h = height, w = width, c = channel
:return: img_HWc, ndim=3
"""
img_nhwc = np.asarray(img_nhwc)
n_images, height, width, n_channels = img_nhwc.shape
# new_height was named H before
new_height = int(np.ceil(np.sqrt(n_images)))
# new_width was named W before
new_width = int(np.ceil(float(n_images) / new_height))
img_nhwc = np.array(list(img_nhwc) + [img_nhwc[0] * 0 for _ in range(n_images, new_height * new_width)])
# img_HWhwc
out_image = img_nhwc.reshape((new_height, new_width, height, width, n_channels))
# img_HhWwc
out_image = out_image.transpose(0, 2, 1, 3, 4)
# img_Hh_Ww_c
out_image = out_image.reshape((new_height * height, new_width * width, n_channels))
return out_image
class VecEnv(ABC):
"""
An abstract asynchronous, vectorized environment.
:param num_envs: the number of environments
:param observation_space: the observation space
:param action_space: the action space
"""
metadata = {"render.modes": ["human", "rgb_array"]}
def __init__(self, num_envs: int, observation_space: gym.spaces.Space, action_space: gym.spaces.Space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
@abstractmethod
def reset(self) -> VecEnvObs:
"""
Reset all the environments and return an array of
observations, or a tuple of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
:return: observation
"""
raise NotImplementedError()
@abstractmethod
def step_async(self, actions: np.ndarray) -> None:
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
raise NotImplementedError()
@abstractmethod
def step_wait(self) -> VecEnvStepReturn:
"""
Wait for the step taken with step_async().
:return: observation, reward, done, information
"""
raise NotImplementedError()
@abstractmethod
def close(self) -> None:
"""
Clean up the environment's resources.
"""
raise NotImplementedError()
@abstractmethod
def get_attr(self, attr_name: str, indices: VecEnvIndices = None) -> List[Any]:
"""
Return attribute from vectorized environment.
:param attr_name: The name of the attribute whose value to return
:param indices: Indices of envs to get attribute from
:return: List of values of 'attr_name' in all environments
"""
raise NotImplementedError()
@abstractmethod
def set_attr(self, attr_name: str, value: Any, indices: VecEnvIndices = None) -> None:
"""
Set attribute inside vectorized environments.
:param attr_name: The name of attribute to assign new value
:param value: Value to assign to `attr_name`
:param indices: Indices of envs to assign value
:return:
"""
raise NotImplementedError()
@abstractmethod
def env_method(self, method_name: str, *method_args, indices: VecEnvIndices = None, **method_kwargs) -> List[Any]:
"""
Call instance methods of vectorized environments.
:param method_name: The name of the environment method to invoke.
:param indices: Indices of envs whose method to call
:param method_args: Any positional arguments to provide in the call
:param method_kwargs: Any keyword arguments to provide in the call
:return: List of items returned by the environment's method call
"""
raise NotImplementedError()
@abstractmethod
def env_is_wrapped(self, wrapper_class: Type[gym.Wrapper], indices: VecEnvIndices = None) -> List[bool]:
"""
Check if environments are wrapped with a given wrapper.
:param method_name: The name of the environment method to invoke.
:param indices: Indices of envs whose method to call
:param method_args: Any positional arguments to provide in the call
:param method_kwargs: Any keyword arguments to provide in the call
:return: True if the env is wrapped, False otherwise, for each env queried.
"""
raise NotImplementedError()
def step(self, actions: np.ndarray) -> VecEnvStepReturn:
"""
Step the environments with the given action
:param actions: the action
:return: observation, reward, done, information
"""
self.step_async(actions)
return self.step_wait()
def get_images(self) -> Sequence[np.ndarray]:
"""
Return RGB images from each environment
"""
raise NotImplementedError
def render(self, mode: str = "human") -> Optional[np.ndarray]:
"""
Gym environment rendering
:param mode: the rendering type
"""
try:
imgs = self.get_images()
except NotImplementedError:
warnings.warn(f"Render not defined for {self}")
return
# Create a big image by tiling images from subprocesses
bigimg = tile_images(imgs)
if mode == "human":
import cv2 # pytype:disable=import-error
cv2.imshow("vecenv", bigimg[:, :, ::-1])
cv2.waitKey(1)
elif mode == "rgb_array":
return bigimg
else:
raise NotImplementedError(f"Render mode {mode} is not supported by VecEnvs")
@abstractmethod
def seed(self, seed: Optional[int] = None) -> List[Union[None, int]]:
"""
Sets the random seeds for all environments, based on a given seed.
Each individual environment will still get its own seed, by incrementing the given seed.
:param seed: The random seed. May be None for completely random seeding.
:return: Returns a list containing the seeds for each individual env.
Note that all list elements may be None, if the env does not return anything when being seeded.
"""
pass
@property
def unwrapped(self) -> "VecEnv":
if isinstance(self, VecEnvWrapper):
return self.venv.unwrapped
else:
return self
def getattr_depth_check(self, name: str, already_found: bool) -> Optional[str]:
"""Check if an attribute reference is being hidden in a recursive call to __getattr__
:param name: name of attribute to check for
:param already_found: whether this attribute has already been found in a wrapper
:return: name of module whose attribute is being shadowed, if any.
"""
if hasattr(self, name) and already_found:
return f"{type(self).__module__}.{type(self).__name__}"
else:
return None
def _get_indices(self, indices: VecEnvIndices) -> Iterable[int]:
"""
Convert a flexibly-typed reference to environment indices to an implied list of indices.
:param indices: refers to indices of envs.
:return: the implied list of indices.
"""
if indices is None:
indices = range(self.num_envs)
elif isinstance(indices, int):
indices = [indices]
return indices
class VecEnvWrapper(VecEnv):
"""
Vectorized environment base class
:param venv: the vectorized environment to wrap
:param observation_space: the observation space (can be None to load from venv)
:param action_space: the action space (can be None to load from venv)
"""
def __init__(
self,
venv: VecEnv,
observation_space: Optional[gym.spaces.Space] = None,
action_space: Optional[gym.spaces.Space] = None,
):
self.venv = venv
VecEnv.__init__(
self,
num_envs=venv.num_envs,
observation_space=observation_space or venv.observation_space,
action_space=action_space or venv.action_space,
)
self.class_attributes = dict(inspect.getmembers(self.__class__))
def step_async(self, actions: np.ndarray) -> None:
self.venv.step_async(actions)
@abstractmethod
def reset(self) -> VecEnvObs:
pass
@abstractmethod
def step_wait(self) -> VecEnvStepReturn:
pass
def seed(self, seed: Optional[int] = None) -> List[Union[None, int]]:
return self.venv.seed(seed)
def close(self) -> None:
return self.venv.close()
def render(self, mode: str = "human") -> Optional[np.ndarray]:
return self.venv.render(mode=mode)
def get_images(self) -> Sequence[np.ndarray]:
return self.venv.get_images()
def get_attr(self, attr_name: str, indices: VecEnvIndices = None) -> List[Any]:
return self.venv.get_attr(attr_name, indices)
def set_attr(self, attr_name: str, value: Any, indices: VecEnvIndices = None) -> None:
return self.venv.set_attr(attr_name, value, indices)
def env_method(self, method_name: str, *method_args, indices: VecEnvIndices = None, **method_kwargs) -> List[Any]:
return self.venv.env_method(method_name, *method_args, indices=indices, **method_kwargs)
def env_is_wrapped(self, wrapper_class: Type[gym.Wrapper], indices: VecEnvIndices = None) -> List[bool]:
return self.venv.env_is_wrapped(wrapper_class, indices=indices)
def __getattr__(self, name: str) -> Any:
"""Find attribute from wrapped venv(s) if this wrapper does not have it.
Useful for accessing attributes from venvs which are wrapped with multiple wrappers
which have unique attributes of interest.
"""
blocked_class = self.getattr_depth_check(name, already_found=False)
if blocked_class is not None:
own_class = f"{type(self).__module__}.{type(self).__name__}"
error_str = (
f"Error: Recursive attribute lookup for {name} from {own_class} is "
f"ambiguous and hides attribute from {blocked_class}"
)
raise AttributeError(error_str)
return self.getattr_recursive(name)
def _get_all_attributes(self) -> Dict[str, Any]:
"""Get all (inherited) instance and class attributes
:return: all_attributes
"""
all_attributes = self.__dict__.copy()
all_attributes.update(self.class_attributes)
return all_attributes
def getattr_recursive(self, name: str) -> Any:
"""Recursively check wrappers to find attribute.
:param name: name of attribute to look for
:return: attribute
"""
all_attributes = self._get_all_attributes()
if name in all_attributes: # attribute is present in this wrapper
attr = getattr(self, name)
elif hasattr(self.venv, "getattr_recursive"):
# Attribute not present, child is wrapper. Call getattr_recursive rather than getattr
# to avoid a duplicate call to getattr_depth_check.
attr = self.venv.getattr_recursive(name)
else: # attribute not present, child is an unwrapped VecEnv
attr = getattr(self.venv, name)
return attr
def getattr_depth_check(self, name: str, already_found: bool) -> str:
"""See base class.
:return: name of module whose attribute is being shadowed, if any.
"""
all_attributes = self._get_all_attributes()
if name in all_attributes and already_found:
# this venv's attribute is being hidden because of a higher venv.
shadowed_wrapper_class = f"{type(self).__module__}.{type(self).__name__}"
elif name in all_attributes and not already_found:
# we have found the first reference to the attribute. Now check for duplicates.
shadowed_wrapper_class = self.venv.getattr_depth_check(name, True)
else:
# this wrapper does not have the attribute. Keep searching.
shadowed_wrapper_class = self.venv.getattr_depth_check(name, already_found)
return shadowed_wrapper_class
class CloudpickleWrapper:
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
:param var: the variable you wish to wrap for pickling with cloudpickle
"""
def __init__(self, var: Any):
self.var = var
def __getstate__(self) -> Any:
return cloudpickle.dumps(self.var)
def __setstate__(self, var: Any) -> None:
self.var = cloudpickle.loads(var) | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/base_vec_env.py | 0.920007 | 0.475788 | base_vec_env.py | pypi |
import warnings
from typing import Any, Dict, List, Optional, Tuple, Union
import numpy as np
from gym import spaces
from stable_baselines3.common.preprocessing import is_image_space, is_image_space_channels_first
class StackedObservations:
"""
Frame stacking wrapper for data.
Dimension to stack over is either first (channels-first) or
last (channels-last), which is detected automatically using
``common.preprocessing.is_image_space_channels_first`` if
observation is an image space.
:param num_envs: number of environments
:param n_stack: Number of frames to stack
:param observation_space: Environment observation space.
:param channels_order: If "first", stack on first image dimension. If "last", stack on last dimension.
If None, automatically detect channel to stack over in case of image observation or default to "last" (default).
"""
def __init__(
self,
num_envs: int,
n_stack: int,
observation_space: spaces.Space,
channels_order: Optional[str] = None,
):
self.n_stack = n_stack
(
self.channels_first,
self.stack_dimension,
self.stackedobs,
self.repeat_axis,
) = self.compute_stacking(num_envs, n_stack, observation_space, channels_order)
super().__init__()
@staticmethod
def compute_stacking(
num_envs: int,
n_stack: int,
observation_space: spaces.Box,
channels_order: Optional[str] = None,
) -> Tuple[bool, int, np.ndarray, int]:
"""
Calculates the parameters in order to stack observations
:param num_envs: Number of environments in the stack
:param n_stack: The number of observations to stack
:param observation_space: The observation space
:param channels_order: The order of the channels
:return: tuple of channels_first, stack_dimension, stackedobs, repeat_axis
"""
channels_first = False
if channels_order is None:
# Detect channel location automatically for images
if is_image_space(observation_space):
channels_first = is_image_space_channels_first(observation_space)
else:
# Default behavior for non-image space, stack on the last axis
channels_first = False
else:
assert channels_order in {
"last",
"first",
}, "`channels_order` must be one of following: 'last', 'first'"
channels_first = channels_order == "first"
# This includes the vec-env dimension (first)
stack_dimension = 1 if channels_first else -1
repeat_axis = 0 if channels_first else -1
low = np.repeat(observation_space.low, n_stack, axis=repeat_axis)
stackedobs = np.zeros((num_envs,) + low.shape, low.dtype)
return channels_first, stack_dimension, stackedobs, repeat_axis
def stack_observation_space(self, observation_space: spaces.Box) -> spaces.Box:
"""
Given an observation space, returns a new observation space with stacked observations
:return: New observation space with stacked dimensions
"""
low = np.repeat(observation_space.low, self.n_stack, axis=self.repeat_axis)
high = np.repeat(observation_space.high, self.n_stack, axis=self.repeat_axis)
return spaces.Box(low=low, high=high, dtype=observation_space.dtype)
def reset(self, observation: np.ndarray) -> np.ndarray:
"""
Resets the stackedobs, adds the reset observation to the stack, and returns the stack
:param observation: Reset observation
:return: The stacked reset observation
"""
self.stackedobs[...] = 0
if self.channels_first:
self.stackedobs[:, -observation.shape[self.stack_dimension] :, ...] = observation
else:
self.stackedobs[..., -observation.shape[self.stack_dimension] :] = observation
return self.stackedobs
def update(
self,
observations: np.ndarray,
dones: np.ndarray,
infos: List[Dict[str, Any]],
) -> Tuple[np.ndarray, List[Dict[str, Any]]]:
"""
Adds the observations to the stack and uses the dones to update the infos.
:param observations: numpy array of observations
:param dones: numpy array of done info
:param infos: numpy array of info dicts
:return: tuple of the stacked observations and the updated infos
"""
stack_ax_size = observations.shape[self.stack_dimension]
self.stackedobs = np.roll(self.stackedobs, shift=-stack_ax_size, axis=self.stack_dimension)
for i, done in enumerate(dones):
if done:
if "terminal_observation" in infos[i]:
old_terminal = infos[i]["terminal_observation"]
if self.channels_first:
new_terminal = np.concatenate(
(self.stackedobs[i, :-stack_ax_size, ...], old_terminal),
axis=0, # self.stack_dimension - 1, as there is not batch dim
)
else:
new_terminal = np.concatenate(
(self.stackedobs[i, ..., :-stack_ax_size], old_terminal),
axis=self.stack_dimension,
)
infos[i]["terminal_observation"] = new_terminal
else:
warnings.warn("VecFrameStack wrapping a VecEnv without terminal_observation info")
self.stackedobs[i] = 0
if self.channels_first:
self.stackedobs[:, -observations.shape[self.stack_dimension] :, ...] = observations
else:
self.stackedobs[..., -observations.shape[self.stack_dimension] :] = observations
return self.stackedobs, infos
class StackedDictObservations(StackedObservations):
"""
Frame stacking wrapper for dictionary data.
Dimension to stack over is either first (channels-first) or
last (channels-last), which is detected automatically using
``common.preprocessing.is_image_space_channels_first`` if
observation is an image space.
:param num_envs: number of environments
:param n_stack: Number of frames to stack
:param channels_order: If "first", stack on first image dimension. If "last", stack on last dimension.
If None, automatically detect channel to stack over in case of image observation or default to "last" (default).
"""
def __init__(
self,
num_envs: int,
n_stack: int,
observation_space: spaces.Dict,
channels_order: Optional[Union[str, Dict[str, str]]] = None,
):
self.n_stack = n_stack
self.channels_first = {}
self.stack_dimension = {}
self.stackedobs = {}
self.repeat_axis = {}
for key, subspace in observation_space.spaces.items():
assert isinstance(subspace, spaces.Box), "StackedDictObservations only works with nested gym.spaces.Box"
if isinstance(channels_order, str) or channels_order is None:
subspace_channel_order = channels_order
else:
subspace_channel_order = channels_order[key]
(
self.channels_first[key],
self.stack_dimension[key],
self.stackedobs[key],
self.repeat_axis[key],
) = self.compute_stacking(num_envs, n_stack, subspace, subspace_channel_order)
def stack_observation_space(self, observation_space: spaces.Dict) -> spaces.Dict:
"""
Returns the stacked verson of a Dict observation space
:param observation_space: Dict observation space to stack
:return: stacked observation space
"""
spaces_dict = {}
for key, subspace in observation_space.spaces.items():
low = np.repeat(subspace.low, self.n_stack, axis=self.repeat_axis[key])
high = np.repeat(subspace.high, self.n_stack, axis=self.repeat_axis[key])
spaces_dict[key] = spaces.Box(low=low, high=high, dtype=subspace.dtype)
return spaces.Dict(spaces=spaces_dict)
def reset(self, observation: Dict[str, np.ndarray]) -> Dict[str, np.ndarray]:
"""
Resets the stacked observations, adds the reset observation to the stack, and returns the stack
:param observation: Reset observation
:return: Stacked reset observations
"""
for key, obs in observation.items():
self.stackedobs[key][...] = 0
if self.channels_first[key]:
self.stackedobs[key][:, -obs.shape[self.stack_dimension[key]] :, ...] = obs
else:
self.stackedobs[key][..., -obs.shape[self.stack_dimension[key]] :] = obs
return self.stackedobs
def update(
self,
observations: Dict[str, np.ndarray],
dones: np.ndarray,
infos: List[Dict[str, Any]],
) -> Tuple[Dict[str, np.ndarray], List[Dict[str, Any]]]:
"""
Adds the observations to the stack and uses the dones to update the infos.
:param observations: Dict of numpy arrays of observations
:param dones: numpy array of dones
:param infos: dict of infos
:return: tuple of the stacked observations and the updated infos
"""
for key in self.stackedobs.keys():
stack_ax_size = observations[key].shape[self.stack_dimension[key]]
self.stackedobs[key] = np.roll(
self.stackedobs[key],
shift=-stack_ax_size,
axis=self.stack_dimension[key],
)
for i, done in enumerate(dones):
if done:
if "terminal_observation" in infos[i]:
old_terminal = infos[i]["terminal_observation"][key]
if self.channels_first[key]:
new_terminal = np.vstack(
(
self.stackedobs[key][i, :-stack_ax_size, ...],
old_terminal,
)
)
else:
new_terminal = np.concatenate(
(
self.stackedobs[key][i, ..., :-stack_ax_size],
old_terminal,
),
axis=self.stack_dimension[key],
)
infos[i]["terminal_observation"][key] = new_terminal
else:
warnings.warn("VecFrameStack wrapping a VecEnv without terminal_observation info")
self.stackedobs[key][i] = 0
if self.channels_first[key]:
self.stackedobs[key][:, -stack_ax_size:, ...] = observations[key]
else:
self.stackedobs[key][..., -stack_ax_size:] = observations[key]
return self.stackedobs, infos | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/stacked_observations.py | 0.930134 | 0.694898 | stacked_observations.py | pypi |
import time
import warnings
from typing import Optional, Tuple
import numpy as np
from stable_baselines3.common.vec_env.base_vec_env import VecEnv, VecEnvObs, VecEnvStepReturn, VecEnvWrapper
class VecMonitor(VecEnvWrapper):
"""
A vectorized monitor wrapper for *vectorized* Gym environments,
it is used to record the episode reward, length, time and other data.
Some environments like `openai/procgen <https://github.com/openai/procgen>`_
or `gym3 <https://github.com/openai/gym3>`_ directly initialize the
vectorized environments, without giving us a chance to use the ``Monitor``
wrapper. So this class simply does the job of the ``Monitor`` wrapper on
a vectorized level.
:param venv: The vectorized environment
:param filename: the location to save a log file, can be None for no log
:param info_keywords: extra information to log, from the information return of env.step()
"""
def __init__(
self,
venv: VecEnv,
filename: Optional[str] = None,
info_keywords: Tuple[str, ...] = (),
):
# Avoid circular import
from stable_baselines3.common.monitor import Monitor, ResultsWriter
# This check is not valid for special `VecEnv`
# like the ones created by Procgen, that does follow completely
# the `VecEnv` interface
try:
is_wrapped_with_monitor = venv.env_is_wrapped(Monitor)[0]
except AttributeError:
is_wrapped_with_monitor = False
if is_wrapped_with_monitor:
warnings.warn(
"The environment is already wrapped with a `Monitor` wrapper"
"but you are wrapping it with a `VecMonitor` wrapper, the `Monitor` statistics will be"
"overwritten by the `VecMonitor` ones.",
UserWarning,
)
VecEnvWrapper.__init__(self, venv)
self.episode_returns = None
self.episode_lengths = None
self.episode_count = 0
self.t_start = time.time()
env_id = None
if hasattr(venv, "spec") and venv.spec is not None:
env_id = venv.spec.id
if filename:
self.results_writer = ResultsWriter(
filename, header={"t_start": self.t_start, "env_id": env_id}, extra_keys=info_keywords
)
else:
self.results_writer = None
self.info_keywords = info_keywords
def reset(self) -> VecEnvObs:
obs = self.venv.reset()
self.episode_returns = np.zeros(self.num_envs, dtype=np.float32)
self.episode_lengths = np.zeros(self.num_envs, dtype=np.int32)
return obs
def step_wait(self) -> VecEnvStepReturn:
obs, rewards, dones, infos = self.venv.step_wait()
self.episode_returns += rewards
self.episode_lengths += 1
new_infos = list(infos[:])
for i in range(len(dones)):
if dones[i]:
info = infos[i].copy()
episode_return = self.episode_returns[i]
episode_length = self.episode_lengths[i]
episode_info = {"r": episode_return, "l": episode_length, "t": round(time.time() - self.t_start, 6)}
for key in self.info_keywords:
episode_info[key] = info[key]
info["episode"] = episode_info
self.episode_count += 1
self.episode_returns[i] = 0
self.episode_lengths[i] = 0
if self.results_writer:
self.results_writer.write_row(episode_info)
new_infos[i] = info
return obs, rewards, dones, new_infos
def close(self) -> None:
if self.results_writer:
self.results_writer.close()
return self.venv.close() | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/vec_monitor.py | 0.811825 | 0.412648 | vec_monitor.py | pypi |
import typing
from copy import deepcopy
from typing import Optional, Type, Union
from stable_baselines3.common.vec_env.base_vec_env import CloudpickleWrapper, VecEnv, VecEnvWrapper
from stable_baselines3.common.vec_env.dummy_vec_env import DummyVecEnv
from stable_baselines3.common.vec_env.stacked_observations import StackedDictObservations, StackedObservations
from stable_baselines3.common.vec_env.subproc_vec_env import SubprocVecEnv
from stable_baselines3.common.vec_env.vec_check_nan import VecCheckNan
from stable_baselines3.common.vec_env.vec_extract_dict_obs import VecExtractDictObs
from stable_baselines3.common.vec_env.vec_frame_stack import VecFrameStack
from stable_baselines3.common.vec_env.vec_monitor import VecMonitor
from stable_baselines3.common.vec_env.vec_normalize import VecNormalize
from stable_baselines3.common.vec_env.vec_transpose import VecTransposeImage
from stable_baselines3.common.vec_env.vec_video_recorder import VecVideoRecorder
# Avoid circular import
if typing.TYPE_CHECKING:
from stable_baselines3.common.type_aliases import GymEnv
def unwrap_vec_wrapper(env: Union["GymEnv", VecEnv], vec_wrapper_class: Type[VecEnvWrapper]) -> Optional[VecEnvWrapper]:
"""
Retrieve a ``VecEnvWrapper`` object by recursively searching.
:param env:
:param vec_wrapper_class:
:return:
"""
env_tmp = env
while isinstance(env_tmp, VecEnvWrapper):
if isinstance(env_tmp, vec_wrapper_class):
return env_tmp
env_tmp = env_tmp.venv
return None
def unwrap_vec_normalize(env: Union["GymEnv", VecEnv]) -> Optional[VecNormalize]:
"""
:param env:
:return:
"""
return unwrap_vec_wrapper(env, VecNormalize) # pytype:disable=bad-return-type
def is_vecenv_wrapped(env: Union["GymEnv", VecEnv], vec_wrapper_class: Type[VecEnvWrapper]) -> bool:
"""
Check if an environment is already wrapped by a given ``VecEnvWrapper``.
:param env:
:param vec_wrapper_class:
:return:
"""
return unwrap_vec_wrapper(env, vec_wrapper_class) is not None
# Define here to avoid circular import
def sync_envs_normalization(env: "GymEnv", eval_env: "GymEnv") -> None:
"""
Sync eval env and train env when using VecNormalize
:param env:
:param eval_env:
"""
env_tmp, eval_env_tmp = env, eval_env
while isinstance(env_tmp, VecEnvWrapper):
if isinstance(env_tmp, VecNormalize):
# Only synchronize if observation normalization exists
if hasattr(env_tmp, "obs_rms"):
eval_env_tmp.obs_rms = deepcopy(env_tmp.obs_rms)
eval_env_tmp.ret_rms = deepcopy(env_tmp.ret_rms)
env_tmp = env_tmp.venv
eval_env_tmp = eval_env_tmp.venv | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/__init__.py | 0.783699 | 0.357932 | __init__.py | pypi |
import pickle
import warnings
from copy import deepcopy
from typing import Any, Dict, List, Optional, Union
import gym
import numpy as np
from stable_baselines3.common import utils
from stable_baselines3.common.running_mean_std import RunningMeanStd
from stable_baselines3.common.vec_env.base_vec_env import VecEnv, VecEnvStepReturn, VecEnvWrapper
class VecNormalize(VecEnvWrapper):
"""
A moving average, normalizing wrapper for vectorized environment.
has support for saving/loading moving average,
:param venv: the vectorized environment to wrap
:param training: Whether to update or not the moving average
:param norm_obs: Whether to normalize observation or not (default: True)
:param norm_reward: Whether to normalize rewards or not (default: True)
:param clip_obs: Max absolute value for observation
:param clip_reward: Max value absolute for discounted reward
:param gamma: discount factor
:param epsilon: To avoid division by zero
:param norm_obs_keys: Which keys from observation dict to normalize.
If not specified, all keys will be normalized.
"""
def __init__(
self,
venv: VecEnv,
training: bool = True,
norm_obs: bool = True,
norm_reward: bool = True,
clip_obs: float = 10.0,
clip_reward: float = 10.0,
gamma: float = 0.99,
epsilon: float = 1e-8,
norm_obs_keys: Optional[List[str]] = None,
):
VecEnvWrapper.__init__(self, venv)
self.norm_obs = norm_obs
self.norm_obs_keys = norm_obs_keys
# Check observation spaces
if self.norm_obs:
self._sanity_checks()
if isinstance(self.observation_space, gym.spaces.Dict):
self.obs_spaces = self.observation_space.spaces
self.obs_rms = {key: RunningMeanStd(shape=self.obs_spaces[key].shape) for key in self.norm_obs_keys}
else:
self.obs_spaces = None
self.obs_rms = RunningMeanStd(shape=self.observation_space.shape)
self.ret_rms = RunningMeanStd(shape=())
self.clip_obs = clip_obs
self.clip_reward = clip_reward
# Returns: discounted rewards
self.returns = np.zeros(self.num_envs)
self.gamma = gamma
self.epsilon = epsilon
self.training = training
self.norm_obs = norm_obs
self.norm_reward = norm_reward
self.old_obs = np.array([])
self.old_reward = np.array([])
def _sanity_checks(self) -> None:
"""
Check the observations that are going to be normalized are of the correct type (spaces.Box).
"""
if isinstance(self.observation_space, gym.spaces.Dict):
# By default, we normalize all keys
if self.norm_obs_keys is None:
self.norm_obs_keys = list(self.observation_space.spaces.keys())
# Check that all keys are of type Box
for obs_key in self.norm_obs_keys:
if not isinstance(self.observation_space.spaces[obs_key], gym.spaces.Box):
raise ValueError(
f"VecNormalize only supports `gym.spaces.Box` observation spaces but {obs_key} "
f"is of type {self.observation_space.spaces[obs_key]}. "
"You should probably explicitely pass the observation keys "
" that should be normalized via the `norm_obs_keys` parameter."
)
elif isinstance(self.observation_space, gym.spaces.Box):
if self.norm_obs_keys is not None:
raise ValueError("`norm_obs_keys` param is applicable only with `gym.spaces.Dict` observation spaces")
else:
raise ValueError(
"VecNormalize only supports `gym.spaces.Box` and `gym.spaces.Dict` observation spaces, "
f"not {self.observation_space}"
)
def __getstate__(self) -> Dict[str, Any]:
"""
Gets state for pickling.
Excludes self.venv, as in general VecEnv's may not be pickleable."""
state = self.__dict__.copy()
# these attributes are not pickleable
del state["venv"]
del state["class_attributes"]
# these attributes depend on the above and so we would prefer not to pickle
del state["returns"]
return state
def __setstate__(self, state: Dict[str, Any]) -> None:
"""
Restores pickled state.
User must call set_venv() after unpickling before using.
:param state:"""
# Backward compatibility
if "norm_obs_keys" not in state and isinstance(state["observation_space"], gym.spaces.Dict):
state["norm_obs_keys"] = list(state["observation_space"].spaces.keys())
self.__dict__.update(state)
assert "venv" not in state
self.venv = None
def set_venv(self, venv: VecEnv) -> None:
"""
Sets the vector environment to wrap to venv.
Also sets attributes derived from this such as `num_env`.
:param venv:
"""
if self.venv is not None:
raise ValueError("Trying to set venv of already initialized VecNormalize wrapper.")
VecEnvWrapper.__init__(self, venv)
# Check only that the observation_space match
utils.check_for_correct_spaces(venv, self.observation_space, venv.action_space)
self.returns = np.zeros(self.num_envs)
def step_wait(self) -> VecEnvStepReturn:
"""
Apply sequence of actions to sequence of environments
actions -> (observations, rewards, dones)
where ``dones`` is a boolean vector indicating whether each element is new.
"""
obs, rewards, dones, infos = self.venv.step_wait()
self.old_obs = obs
self.old_reward = rewards
if self.training and self.norm_obs:
if isinstance(obs, dict) and isinstance(self.obs_rms, dict):
for key in self.obs_rms.keys():
self.obs_rms[key].update(obs[key])
else:
self.obs_rms.update(obs)
obs = self.normalize_obs(obs)
if self.training:
self._update_reward(rewards)
rewards = self.normalize_reward(rewards)
# Normalize the terminal observations
for idx, done in enumerate(dones):
if not done:
continue
if "terminal_observation" in infos[idx]:
infos[idx]["terminal_observation"] = self.normalize_obs(infos[idx]["terminal_observation"])
self.returns[dones] = 0
return obs, rewards, dones, infos
def _update_reward(self, reward: np.ndarray) -> None:
"""Update reward normalization statistics."""
self.returns = self.returns * self.gamma + reward
self.ret_rms.update(self.returns)
def _normalize_obs(self, obs: np.ndarray, obs_rms: RunningMeanStd) -> np.ndarray:
"""
Helper to normalize observation.
:param obs:
:param obs_rms: associated statistics
:return: normalized observation
"""
return np.clip((obs - obs_rms.mean) / np.sqrt(obs_rms.var + self.epsilon), -self.clip_obs, self.clip_obs)
def _unnormalize_obs(self, obs: np.ndarray, obs_rms: RunningMeanStd) -> np.ndarray:
"""
Helper to unnormalize observation.
:param obs:
:param obs_rms: associated statistics
:return: unnormalized observation
"""
return (obs * np.sqrt(obs_rms.var + self.epsilon)) + obs_rms.mean
def normalize_obs(self, obs: Union[np.ndarray, Dict[str, np.ndarray]]) -> Union[np.ndarray, Dict[str, np.ndarray]]:
"""
Normalize observations using this VecNormalize's observations statistics.
Calling this method does not update statistics.
"""
# Avoid modifying by reference the original object
obs_ = deepcopy(obs)
if self.norm_obs:
if isinstance(obs, dict) and isinstance(self.obs_rms, dict):
# Only normalize the specified keys
for key in self.norm_obs_keys:
obs_[key] = self._normalize_obs(obs[key], self.obs_rms[key]).astype(np.float32)
else:
obs_ = self._normalize_obs(obs, self.obs_rms).astype(np.float32)
return obs_
def normalize_reward(self, reward: np.ndarray) -> np.ndarray:
"""
Normalize rewards using this VecNormalize's rewards statistics.
Calling this method does not update statistics.
"""
if self.norm_reward:
reward = np.clip(reward / np.sqrt(self.ret_rms.var + self.epsilon), -self.clip_reward, self.clip_reward)
return reward
def unnormalize_obs(self, obs: Union[np.ndarray, Dict[str, np.ndarray]]) -> Union[np.ndarray, Dict[str, np.ndarray]]:
# Avoid modifying by reference the original object
obs_ = deepcopy(obs)
if self.norm_obs:
if isinstance(obs, dict) and isinstance(self.obs_rms, dict):
for key in self.norm_obs_keys:
obs_[key] = self._unnormalize_obs(obs[key], self.obs_rms[key])
else:
obs_ = self._unnormalize_obs(obs, self.obs_rms)
return obs_
def unnormalize_reward(self, reward: np.ndarray) -> np.ndarray:
if self.norm_reward:
return reward * np.sqrt(self.ret_rms.var + self.epsilon)
return reward
def get_original_obs(self) -> Union[np.ndarray, Dict[str, np.ndarray]]:
"""
Returns an unnormalized version of the observations from the most recent
step or reset.
"""
return deepcopy(self.old_obs)
def get_original_reward(self) -> np.ndarray:
"""
Returns an unnormalized version of the rewards from the most recent step.
"""
return self.old_reward.copy()
def reset(self) -> Union[np.ndarray, Dict[str, np.ndarray]]:
"""
Reset all environments
:return: first observation of the episode
"""
obs = self.venv.reset()
self.old_obs = obs
self.returns = np.zeros(self.num_envs)
if self.training and self.norm_obs:
if isinstance(obs, dict) and isinstance(self.obs_rms, dict):
for key in self.obs_rms.keys():
self.obs_rms[key].update(obs[key])
else:
self.obs_rms.update(obs)
return self.normalize_obs(obs)
@staticmethod
def load(load_path: str, venv: VecEnv) -> "VecNormalize":
"""
Loads a saved VecNormalize object.
:param load_path: the path to load from.
:param venv: the VecEnv to wrap.
:return:
"""
with open(load_path, "rb") as file_handler:
vec_normalize = pickle.load(file_handler)
vec_normalize.set_venv(venv)
return vec_normalize
def save(self, save_path: str) -> None:
"""
Save current VecNormalize object with
all running statistics and settings (e.g. clip_obs)
:param save_path: The path to save to
"""
with open(save_path, "wb") as file_handler:
pickle.dump(self, file_handler)
@property
def ret(self) -> np.ndarray:
warnings.warn("`VecNormalize` `ret` attribute is deprecated. Please use `returns` instead.", DeprecationWarning)
return self.returns | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/vec_env/vec_normalize.py | 0.936735 | 0.486941 | vec_normalize.py | pypi |
from typing import Optional, Union
import numpy as np
from gym import Env, Space
from gym.spaces import Box, Discrete, MultiBinary, MultiDiscrete
from stable_baselines3.common.type_aliases import GymObs, GymStepReturn
class IdentityEnv(Env):
def __init__(self, dim: Optional[int] = None, space: Optional[Space] = None, ep_length: int = 100):
"""
Identity environment for testing purposes
:param dim: the size of the action and observation dimension you want
to learn. Provide at most one of ``dim`` and ``space``. If both are
None, then initialization proceeds with ``dim=1`` and ``space=None``.
:param space: the action and observation space. Provide at most one of
``dim`` and ``space``.
:param ep_length: the length of each episode in timesteps
"""
if space is None:
if dim is None:
dim = 1
space = Discrete(dim)
else:
assert dim is None, "arguments for both 'dim' and 'space' provided: at most one allowed"
self.action_space = self.observation_space = space
self.ep_length = ep_length
self.current_step = 0
self.num_resets = -1 # Becomes 0 after __init__ exits.
self.reset()
def reset(self) -> GymObs:
self.current_step = 0
self.num_resets += 1
self._choose_next_state()
return self.state
def step(self, action: Union[int, np.ndarray]) -> GymStepReturn:
reward = self._get_reward(action)
self._choose_next_state()
self.current_step += 1
done = self.current_step >= self.ep_length
return self.state, reward, done, {}
def _choose_next_state(self) -> None:
self.state = self.action_space.sample()
def _get_reward(self, action: Union[int, np.ndarray]) -> float:
return 1.0 if np.all(self.state == action) else 0.0
def render(self, mode: str = "human") -> None:
pass
class IdentityEnvBox(IdentityEnv):
def __init__(self, low: float = -1.0, high: float = 1.0, eps: float = 0.05, ep_length: int = 100):
"""
Identity environment for testing purposes
:param low: the lower bound of the box dim
:param high: the upper bound of the box dim
:param eps: the epsilon bound for correct value
:param ep_length: the length of each episode in timesteps
"""
space = Box(low=low, high=high, shape=(1,), dtype=np.float32)
super().__init__(ep_length=ep_length, space=space)
self.eps = eps
def step(self, action: np.ndarray) -> GymStepReturn:
reward = self._get_reward(action)
self._choose_next_state()
self.current_step += 1
done = self.current_step >= self.ep_length
return self.state, reward, done, {}
def _get_reward(self, action: np.ndarray) -> float:
return 1.0 if (self.state - self.eps) <= action <= (self.state + self.eps) else 0.0
class IdentityEnvMultiDiscrete(IdentityEnv):
def __init__(self, dim: int = 1, ep_length: int = 100):
"""
Identity environment for testing purposes
:param dim: the size of the dimensions you want to learn
:param ep_length: the length of each episode in timesteps
"""
space = MultiDiscrete([dim, dim])
super().__init__(ep_length=ep_length, space=space)
class IdentityEnvMultiBinary(IdentityEnv):
def __init__(self, dim: int = 1, ep_length: int = 100):
"""
Identity environment for testing purposes
:param dim: the size of the dimensions you want to learn
:param ep_length: the length of each episode in timesteps
"""
space = MultiBinary(dim)
super().__init__(ep_length=ep_length, space=space)
class FakeImageEnv(Env):
"""
Fake image environment for testing purposes, it mimics Atari games.
:param action_dim: Number of discrete actions
:param screen_height: Height of the image
:param screen_width: Width of the image
:param n_channels: Number of color channels
:param discrete: Create discrete action space instead of continuous
:param channel_first: Put channels on first axis instead of last
"""
def __init__(
self,
action_dim: int = 6,
screen_height: int = 84,
screen_width: int = 84,
n_channels: int = 1,
discrete: bool = True,
channel_first: bool = False,
):
self.observation_shape = (screen_height, screen_width, n_channels)
if channel_first:
self.observation_shape = (n_channels, screen_height, screen_width)
self.observation_space = Box(low=0, high=255, shape=self.observation_shape, dtype=np.uint8)
if discrete:
self.action_space = Discrete(action_dim)
else:
self.action_space = Box(low=-1, high=1, shape=(5,), dtype=np.float32)
self.ep_length = 10
self.current_step = 0
def reset(self) -> np.ndarray:
self.current_step = 0
return self.observation_space.sample()
def step(self, action: Union[np.ndarray, int]) -> GymStepReturn:
reward = 0.0
self.current_step += 1
done = self.current_step >= self.ep_length
return self.observation_space.sample(), reward, done, {}
def render(self, mode: str = "human") -> None:
pass | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/envs/identity_env.py | 0.956967 | 0.690976 | identity_env.py | pypi |
from typing import Dict, Union
import gym
import numpy as np
from stable_baselines3.common.type_aliases import GymStepReturn
class SimpleMultiObsEnv(gym.Env):
"""
Base class for GridWorld-based MultiObs Environments 4x4 grid world.
.. code-block:: text
____________
| 0 1 2 3|
| 4|¯5¯¯6¯| 7|
| 8|_9_10_|11|
|12 13 14 15|
¯¯¯¯¯¯¯¯¯¯¯¯¯¯
start is 0
states 5, 6, 9, and 10 are blocked
goal is 15
actions are = [left, down, right, up]
simple linear state env of 15 states but encoded with a vector and an image observation:
each column is represented by a random vector and each row is
represented by a random image, both sampled once at creation time.
:param num_col: Number of columns in the grid
:param num_row: Number of rows in the grid
:param random_start: If true, agent starts in random position
:param channel_last: If true, the image will be channel last, else it will be channel first
"""
def __init__(
self,
num_col: int = 4,
num_row: int = 4,
random_start: bool = True,
discrete_actions: bool = True,
channel_last: bool = True,
):
super().__init__()
self.vector_size = 5
if channel_last:
self.img_size = [64, 64, 1]
else:
self.img_size = [1, 64, 64]
self.random_start = random_start
self.discrete_actions = discrete_actions
if discrete_actions:
self.action_space = gym.spaces.Discrete(4)
else:
self.action_space = gym.spaces.Box(0, 1, (4,))
self.observation_space = gym.spaces.Dict(
spaces={
"vec": gym.spaces.Box(0, 1, (self.vector_size,), dtype=np.float64),
"img": gym.spaces.Box(0, 255, self.img_size, dtype=np.uint8),
}
)
self.count = 0
# Timeout
self.max_count = 100
self.log = ""
self.state = 0
self.action2str = ["left", "down", "right", "up"]
self.init_possible_transitions()
self.num_col = num_col
self.state_mapping = []
self.init_state_mapping(num_col, num_row)
self.max_state = len(self.state_mapping) - 1
def init_state_mapping(self, num_col: int, num_row: int) -> None:
"""
Initializes the state_mapping array which holds the observation values for each state
:param num_col: Number of columns.
:param num_row: Number of rows.
"""
# Each column is represented by a random vector
col_vecs = np.random.random((num_col, self.vector_size))
# Each row is represented by a random image
row_imgs = np.random.randint(0, 255, (num_row, 64, 64), dtype=np.uint8)
for i in range(num_col):
for j in range(num_row):
self.state_mapping.append({"vec": col_vecs[i], "img": row_imgs[j].reshape(self.img_size)})
def get_state_mapping(self) -> Dict[str, np.ndarray]:
"""
Uses the state to get the observation mapping.
:return: observation dict {'vec': ..., 'img': ...}
"""
return self.state_mapping[self.state]
def init_possible_transitions(self) -> None:
"""
Initializes the transitions of the environment
The environment exploits the cardinal directions of the grid by noting that
they correspond to simple addition and subtraction from the cell id within the grid
- up => means moving up a row => means subtracting the length of a column
- down => means moving down a row => means adding the length of a column
- left => means moving left by one => means subtracting 1
- right => means moving right by one => means adding 1
Thus one only needs to specify in which states each action is possible
in order to define the transitions of the environment
"""
self.left_possible = [1, 2, 3, 13, 14, 15]
self.down_possible = [0, 4, 8, 3, 7, 11]
self.right_possible = [0, 1, 2, 12, 13, 14]
self.up_possible = [4, 8, 12, 7, 11, 15]
def step(self, action: Union[int, float, np.ndarray]) -> GymStepReturn:
"""
Run one timestep of the environment's dynamics. When end of
episode is reached, you are responsible for calling `reset()`
to reset this environment's state.
Accepts an action and returns a tuple (observation, reward, done, info).
:param action:
:return: tuple (observation, reward, done, info).
"""
if not self.discrete_actions:
action = np.argmax(action)
else:
action = int(action)
self.count += 1
prev_state = self.state
reward = -0.1
# define state transition
if self.state in self.left_possible and action == 0: # left
self.state -= 1
elif self.state in self.down_possible and action == 1: # down
self.state += self.num_col
elif self.state in self.right_possible and action == 2: # right
self.state += 1
elif self.state in self.up_possible and action == 3: # up
self.state -= self.num_col
got_to_end = self.state == self.max_state
reward = 1 if got_to_end else reward
done = self.count > self.max_count or got_to_end
self.log = f"Went {self.action2str[action]} in state {prev_state}, got to state {self.state}"
return self.get_state_mapping(), reward, done, {"got_to_end": got_to_end}
def render(self, mode: str = "human") -> None:
"""
Prints the log of the environment.
:param mode:
"""
print(self.log)
def reset(self) -> Dict[str, np.ndarray]:
"""
Resets the environment state and step count and returns reset observation.
:return: observation dict {'vec': ..., 'img': ...}
"""
self.count = 0
if not self.random_start:
self.state = 0
else:
self.state = np.random.randint(0, self.max_state)
return self.state_mapping[self.state] | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/envs/multi_input_envs.py | 0.944957 | 0.697635 | multi_input_envs.py | pypi |
from collections import OrderedDict
from typing import Any, Dict, Optional, Union
import numpy as np
from gym import GoalEnv, spaces
from gym.envs.registration import EnvSpec
from stable_baselines3.common.type_aliases import GymStepReturn
class BitFlippingEnv(GoalEnv):
"""
Simple bit flipping env, useful to test HER.
The goal is to flip all the bits to get a vector of ones.
In the continuous variant, if the ith action component has a value > 0,
then the ith bit will be flipped.
:param n_bits: Number of bits to flip
:param continuous: Whether to use the continuous actions version or not,
by default, it uses the discrete one
:param max_steps: Max number of steps, by default, equal to n_bits
:param discrete_obs_space: Whether to use the discrete observation
version or not, by default, it uses the ``MultiBinary`` one
:param image_obs_space: Use image as input instead of the ``MultiBinary`` one.
:param channel_first: Whether to use channel-first or last image.
"""
spec = EnvSpec("BitFlippingEnv-v0")
def __init__(
self,
n_bits: int = 10,
continuous: bool = False,
max_steps: Optional[int] = None,
discrete_obs_space: bool = False,
image_obs_space: bool = False,
channel_first: bool = True,
):
super().__init__()
# Shape of the observation when using image space
self.image_shape = (1, 36, 36) if channel_first else (36, 36, 1)
# The achieved goal is determined by the current state
# here, it is a special where they are equal
if discrete_obs_space:
# In the discrete case, the agent act on the binary
# representation of the observation
self.observation_space = spaces.Dict(
{
"observation": spaces.Discrete(2**n_bits),
"achieved_goal": spaces.Discrete(2**n_bits),
"desired_goal": spaces.Discrete(2**n_bits),
}
)
elif image_obs_space:
# When using image as input,
# one image contains the bits 0 -> 0, 1 -> 255
# and the rest is filled with zeros
self.observation_space = spaces.Dict(
{
"observation": spaces.Box(
low=0,
high=255,
shape=self.image_shape,
dtype=np.uint8,
),
"achieved_goal": spaces.Box(
low=0,
high=255,
shape=self.image_shape,
dtype=np.uint8,
),
"desired_goal": spaces.Box(
low=0,
high=255,
shape=self.image_shape,
dtype=np.uint8,
),
}
)
else:
self.observation_space = spaces.Dict(
{
"observation": spaces.MultiBinary(n_bits),
"achieved_goal": spaces.MultiBinary(n_bits),
"desired_goal": spaces.MultiBinary(n_bits),
}
)
self.obs_space = spaces.MultiBinary(n_bits)
if continuous:
self.action_space = spaces.Box(-1, 1, shape=(n_bits,), dtype=np.float32)
else:
self.action_space = spaces.Discrete(n_bits)
self.continuous = continuous
self.discrete_obs_space = discrete_obs_space
self.image_obs_space = image_obs_space
self.state = None
self.desired_goal = np.ones((n_bits,))
if max_steps is None:
max_steps = n_bits
self.max_steps = max_steps
self.current_step = 0
def seed(self, seed: int) -> None:
self.obs_space.seed(seed)
def convert_if_needed(self, state: np.ndarray) -> Union[int, np.ndarray]:
"""
Convert to discrete space if needed.
:param state:
:return:
"""
if self.discrete_obs_space:
# The internal state is the binary representation of the
# observed one
return int(sum(state[i] * 2**i for i in range(len(state))))
if self.image_obs_space:
size = np.prod(self.image_shape)
image = np.concatenate((state * 255, np.zeros(size - len(state), dtype=np.uint8)))
return image.reshape(self.image_shape).astype(np.uint8)
return state
def convert_to_bit_vector(self, state: Union[int, np.ndarray], batch_size: int) -> np.ndarray:
"""
Convert to bit vector if needed.
:param state:
:param batch_size:
:return:
"""
# Convert back to bit vector
if isinstance(state, int):
state = np.array(state).reshape(batch_size, -1)
# Convert to binary representation
state = ((state[:, :] & (1 << np.arange(len(self.state)))) > 0).astype(int)
elif self.image_obs_space:
state = state.reshape(batch_size, -1)[:, : len(self.state)] / 255
else:
state = np.array(state).reshape(batch_size, -1)
return state
def _get_obs(self) -> Dict[str, Union[int, np.ndarray]]:
"""
Helper to create the observation.
:return: The current observation.
"""
return OrderedDict(
[
("observation", self.convert_if_needed(self.state.copy())),
("achieved_goal", self.convert_if_needed(self.state.copy())),
("desired_goal", self.convert_if_needed(self.desired_goal.copy())),
]
)
def reset(self) -> Dict[str, Union[int, np.ndarray]]:
self.current_step = 0
self.state = self.obs_space.sample()
return self._get_obs()
def step(self, action: Union[np.ndarray, int]) -> GymStepReturn:
if self.continuous:
self.state[action > 0] = 1 - self.state[action > 0]
else:
self.state[action] = 1 - self.state[action]
obs = self._get_obs()
reward = float(self.compute_reward(obs["achieved_goal"], obs["desired_goal"], None))
done = reward == 0
self.current_step += 1
# Episode terminate when we reached the goal or the max number of steps
info = {"is_success": done}
done = done or self.current_step >= self.max_steps
return obs, reward, done, info
def compute_reward(
self, achieved_goal: Union[int, np.ndarray], desired_goal: Union[int, np.ndarray], _info: Optional[Dict[str, Any]]
) -> np.float32:
# As we are using a vectorized version, we need to keep track of the `batch_size`
if isinstance(achieved_goal, int):
batch_size = 1
elif self.image_obs_space:
batch_size = achieved_goal.shape[0] if len(achieved_goal.shape) > 3 else 1
else:
batch_size = achieved_goal.shape[0] if len(achieved_goal.shape) > 1 else 1
desired_goal = self.convert_to_bit_vector(desired_goal, batch_size)
achieved_goal = self.convert_to_bit_vector(achieved_goal, batch_size)
# Deceptive reward: it is positive only when the goal is achieved
# Here we are using a vectorized version
distance = np.linalg.norm(achieved_goal - desired_goal, axis=-1)
return -(distance > 0).astype(np.float32)
def render(self, mode: str = "human") -> Optional[np.ndarray]:
if mode == "rgb_array":
return self.state.copy()
print(self.state)
def close(self) -> None:
pass | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/envs/bit_flipping_env.py | 0.941183 | 0.613266 | bit_flipping_env.py | pypi |
from typing import Any, Callable, Dict, Iterable, Optional
import torch
from torch.optim import Optimizer
class RMSpropTFLike(Optimizer):
r"""Implements RMSprop algorithm with closer match to Tensorflow version.
For reproducibility with original stable-baselines. Use this
version with e.g. A2C for stabler learning than with the PyTorch
RMSProp. Based on the PyTorch v1.5.0 implementation of RMSprop.
See a more throughout conversion in pytorch-image-models repository:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/optim/rmsprop_tf.py
Changes to the original RMSprop:
- Move epsilon inside square root
- Initialize squared gradient to ones rather than zeros
Proposed by G. Hinton in his
`course <http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf>`_.
The centered version first appears in `Generating Sequences
With Recurrent Neural Networks <https://arxiv.org/pdf/1308.0850v5.pdf>`_.
The implementation here takes the square root of the gradient average before
adding epsilon (note that TensorFlow interchanges these two operations). The effective
learning rate is thus :math:`\alpha/(\sqrt{v} + \epsilon)` where :math:`\alpha`
is the scheduled learning rate and :math:`v` is the weighted moving average
of the squared gradient.
:params: iterable of parameters to optimize or dicts defining
parameter groups
:param lr: learning rate (default: 1e-2)
:param momentum: momentum factor (default: 0)
:param alpha: smoothing constant (default: 0.99)
:param eps: term added to the denominator to improve
numerical stability (default: 1e-8)
:param centered: if ``True``, compute the centered RMSProp,
the gradient is normalized by an estimation of its variance
:param weight_decay: weight decay (L2 penalty) (default: 0)
"""
def __init__(
self,
params: Iterable[torch.nn.Parameter],
lr: float = 1e-2,
alpha: float = 0.99,
eps: float = 1e-8,
weight_decay: float = 0,
momentum: float = 0,
centered: bool = False,
):
if not 0.0 <= lr:
raise ValueError(f"Invalid learning rate: {lr}")
if not 0.0 <= eps:
raise ValueError(f"Invalid epsilon value: {eps}")
if not 0.0 <= momentum:
raise ValueError(f"Invalid momentum value: {momentum}")
if not 0.0 <= weight_decay:
raise ValueError(f"Invalid weight_decay value: {weight_decay}")
if not 0.0 <= alpha:
raise ValueError(f"Invalid alpha value: {alpha}")
defaults = dict(lr=lr, momentum=momentum, alpha=alpha, eps=eps, centered=centered, weight_decay=weight_decay)
super().__init__(params, defaults)
def __setstate__(self, state: Dict[str, Any]) -> None:
super().__setstate__(state)
for group in self.param_groups:
group.setdefault("momentum", 0)
group.setdefault("centered", False)
@torch.no_grad()
def step(self, closure: Optional[Callable[[], None]] = None) -> Optional[torch.Tensor]:
"""Performs a single optimization step.
:param closure: A closure that reevaluates the model
and returns the loss.
:return: loss
"""
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
for p in group["params"]:
if p.grad is None:
continue
grad = p.grad
if grad.is_sparse:
raise RuntimeError("RMSpropTF does not support sparse gradients")
state = self.state[p]
# State initialization
if len(state) == 0:
state["step"] = 0
# PyTorch initialized to zeros here
state["square_avg"] = torch.ones_like(p, memory_format=torch.preserve_format)
if group["momentum"] > 0:
state["momentum_buffer"] = torch.zeros_like(p, memory_format=torch.preserve_format)
if group["centered"]:
state["grad_avg"] = torch.zeros_like(p, memory_format=torch.preserve_format)
square_avg = state["square_avg"]
alpha = group["alpha"]
state["step"] += 1
if group["weight_decay"] != 0:
grad = grad.add(p, alpha=group["weight_decay"])
square_avg.mul_(alpha).addcmul_(grad, grad, value=1 - alpha)
if group["centered"]:
grad_avg = state["grad_avg"]
grad_avg.mul_(alpha).add_(grad, alpha=1 - alpha)
# PyTorch added epsilon after square root
# avg = square_avg.addcmul(grad_avg, grad_avg, value=-1).sqrt_().add_(group['eps'])
avg = square_avg.addcmul(grad_avg, grad_avg, value=-1).add_(group["eps"]).sqrt_()
else:
# PyTorch added epsilon after square root
# avg = square_avg.sqrt().add_(group['eps'])
avg = square_avg.add(group["eps"]).sqrt_()
if group["momentum"] > 0:
buf = state["momentum_buffer"]
buf.mul_(group["momentum"]).addcdiv_(grad, avg)
p.add_(buf, alpha=-group["lr"])
else:
p.addcdiv_(grad, avg, value=-group["lr"])
return loss | /rigged_sb3-0.0.1-py3-none-any.whl/stable_baselines3/common/sb2_compat/rmsprop_tf_like.py | 0.972244 | 0.770983 | rmsprop_tf_like.py | pypi |
Rigger
======
Introduction
------------
Rigger is an event handling framwork. It allows for an arbitrary number of plugins to be
setup to respond to events, with a namspacing system to allow data to be passed to and from
these plugins. It is extensible and customizable enough that it can be used for a variety of
purposes.
Plugins
-------
The main guts of Rigger is around the plugins. Before Rigger can do anything it must have
a configured plugin. This plugin is then configured to bind certain functions inside itself
to certain events. When Rigger is triggered to handle a certain event, it will tell the plugin
that that particular event has happened and the plugin will respond accordingly.
In addition to the plugins, Rigger can also run certain callback functions before and after
the hook function itself. These are call pre and post hook callbacks. Rigger allows multiple
pre and post hook callbacks to be defined per event, but does not guarantee the order that they
are executed in.
Let's take the example of using the unit testing suite py.test as an example for Rigger.
Suppose we have a number of tests that run as part of a test suite and we wish to store a text
file that holds the time the test was run and its result. This information is required to reside
in a folder that is relevant to the test itself. This type of job is what Rigger was designed
for.
To begin with, we need to create a plugin for Rigger. Consider the following piece of code::
from riggerlib import RiggerBasePlugin
import time
class Test(RiggerBasePlugin):
def plugin_initialize(self):
self.register_plugin_hook('start_test', self.start_test)
self.register_plugin_hook('finish_test', self.finish_test)
def start_test(self, test_name, test_location, artifact_path):
filename = artifact_path + "-" + self.ident + ".log"
with open(filename, "w") as f:
f.write(test_name + "\n")
f.write(str(time.time()) + "\n")
def finish_test(self, test_name, artifact_path, test_result):
filename = artifact_path + "-" + self.ident + ".log"
with open(filename, "w+") as f:
f.write(test_result)
This is a typical plugin in Rigger, it consists of 2 things. The first item is
the special function called ``plugin_initialize()``. This is important
and is equivilent to the ``__init__()`` that would usually be found in a class definition.
Rigger calls ``plugin_initialize()`` for each plugin as it loads it.
Inside this section we register the hook functions to their associated events. Each event
can only have a single function associated with it. Event names are able to be freely assigned
so you can customize plugins to work to specific events for your use case.
The ``register_plugin_hook()`` takes an event name as a string and a function to callback when
that event is experienced.
Next we have the hook functions themselves, ``start_test()`` and ``finish_test()``. These
have arguments in their prototypes and these arguments are supplied by Rigger and are
created either as arguments to the ``fire_hook()`` function, which is responsible for actually
telling Rigger that an even has occured, or they are created in the pre hook script.
Local and Global Namespaces
---------------------------
To allow data to be passed to and from hooks, Rigger has the idea of global and event local
namespaces. The global values persist in the Rigger instance for its lifetime, but the event local
values are destroyed at the end of each event.
Rigger uses the global and local values referenced earlier to store these argument values.
When a pre, post or hook callback finishes, it has the opportunity to supply updates to both
the global and local values dictionaries. In doing this, a pre-hook script can prepare data,
which will could be stored in the locals dictionary and then passed to the actual plugin hook
as a keyword argument. When a hook function is called, the local values override global values to
provide a single set of keyword arguments that are passed to the hook or callback.
In the example above would probably fire the hook with something like this::
rigger.fire_hook('start_test', test_name="my_test", test_location="var/test/")
Notice that we don't specify what the artifact_path value is. In the concept of testing, we may
want to store multiple artifacts and so we would not want each plugin to have to compute the
artifact path for itself. Rather, we would create this path during a pre-hook callback and update
the local namespace with the key. So the process of events would follow like so.
1. Local namespace has {test_name: "my_test", test_location: "var/test"}
2. Prehook callback fires with the arguments [test_name, test_location]
3. Prehook exits and updates the local namespace with artifact_path
4. Local namespace has {test_name: "my_test", test_location: "var/test", artifact_path: "var/test/my_test"}
5. Hook 'start_test' is called for the 'test' plugin with the arguments [test_name, test_location, artifact_path]
6. Hook exits with no updates
7. Posthook callback fires with the arguments [test_name, test_location, artifact_path]
8. Posthook exits
See how the prehook sets up a key value which is the made available to all the other plugin hooks.
TCP Server
----------
Rigger can use a TCP server which can be started up to allow either non-Python or remote machines
to still communicate with the Rigger process. Rigger has a client that can be imported to use within
Python projects, called RiggerClient. An instance of the RiggerClient is initialised with a server
address and port like so::
from riggerlib import RiggerClient
rig_client = RiggerClient('127.0.0.1', 21212)
Events can then be fired off in exactly the same way as before with the fire_hook method, which
emulates the same API as the in-object Rigger instance. Internally the data is converted to JSON
before being piped across the TCP connection. In this way data sent over the TCP link must be JSON
serializable. The format is as follows::
{'hook_name': 'start_session',
'data':
{'arg1': 'value1',
'arg2': 'value2'
}
}
Terminating
-----------
To terminate the rigger server, use the ``terminate`` method of the RiggerClient.
Queues and Backgrounding Instances
----------------------------------
Rigger has two queues that it uses to stack up hooks. In the first instance, all hooks are delivered
into the ``_global_queue``. This queue is continually polled in a separate thread and once an item
is discovered, it is processed. During processing, after the pre-hook callback, if it is discovered
that the plugin instance has the background flag set, then the hook is passed into the ``_background_queue``
to be processed as and when in a separate thread. In this way tasks like archiving can be dealt with
in the background without affecting the main thread.
Threading
---------
There are three main threads running in Rigger. The main thread, which will be part of the main loop
of the importing script, the background thread, and the global queue thread. During hook processing
an option is available to thread and parallelise the instance hooks. Since Rigger doesn't guarantee
the order of plugin instances processing anyway, this is not an issue. If order is a concern, then
please use a second event signal.
Configuration
-------------
Rigger takes few options to start, it, an example is shown below::
squash_exceptions: True
threaded: True
server_address: 127.0.0.1
server_port: 21212
server_enabled: True
plugins:
test:
enabled: True
plugin: test
* ``squash_exceptions`` option tells Rigger whether to ignore exceptions that happen inside
the ``fire_hook()`` call and just log them, or if it should raise them.
* ``threaded`` option tells Rigger to run the fire_hook plugins as threads or sequentially.
* ``server_address`` option tells Rigger which ip to bind the TCP server to.
* ``server_port`` option tells Rigger which port to bind the TCP server to.
* ``server_enabled`` option tells Rigger if it should run up the TCP server.
| /riggerlib-3.1.5.tar.gz/riggerlib-3.1.5/README.rst | 0.797754 | 0.731826 | README.rst | pypi |
import math
class RightTriangle:
"""Representation of a right-angled (or right) triangle.
A right triangle is a triangle in which one angle is a right angle
(90-degree angle) (angle C).
The side opposite the right angle is called the hypotenuse (side c).
The sides adjacent to the right angle are called legs (side a and side b).
Side a is the side adjacent to angle B and opposed to angle A.
Side b is the side adjacent to angle A and opposed to angle B.
Do not use the default constructor.
Use one of the factory methods instead (make, from_*).
"""
def __init__(
self,
side_a: float,
side_b: float,
side_c: float,
angle_a: float,
angle_b: float,
):
"""Do not use the default constructor.
Use one of the factory methods instead (make, from_*).
"""
self._side_a = side_a
self._side_b = side_b
self._side_c = side_c
self._angle_a = angle_a
self._angle_b = angle_b
@property
def side_a(self) -> float:
"""The length of side a."""
return self._side_a
@property
def side_b(self) -> float:
"""The length of side b."""
return self._side_b
@property
def side_c(self) -> float:
"""The length of side c (the hypotenuse)."""
return self._side_c
@property
def angle_a(self) -> float:
"""Angle A in degrees."""
return self._angle_a
@property
def angle_b(self) -> float:
"""Angle B in degrees."""
return self._angle_b
@property
def angle_c(self) -> float:
"""Angle C in degrees. It is the right angle, so it is always 90."""
return 90
@classmethod
def make(
cls,
side_a: float = None,
side_b: float = None,
side_c: float = None,
angle_a: float = None,
angle_b: float = None,
) -> "RightTriangle":
"""Universal constructor for ``RightTriangle``.
Provide the length of one side and any other attribute,
and it constructs the ``RightTriangle`` object.
"""
if side_a and side_b:
return cls.from_side_a_and_side_b(side_a, side_b)
elif side_a and side_c:
return cls.from_side_a_and_side_c(side_a, side_c)
elif side_b and side_c:
return cls.from_side_b_and_side_c(side_b, side_c)
elif side_a and angle_a:
return cls.from_side_a_and_angle_a(side_a, angle_a)
elif side_b and angle_a:
return cls.from_side_b_and_angle_a(side_b, angle_a)
elif side_c and angle_a:
return cls.from_side_c_and_angle_a(side_c, angle_a)
elif side_a and angle_b:
return cls.from_side_a_and_angle_b(side_a, angle_b)
elif side_b and angle_b:
return cls.from_side_b_and_angle_b(side_b, angle_b)
elif side_c and angle_b:
return cls.from_side_c_and_angle_b(side_c, angle_b)
else:
raise ValueError(
f"Insufficient parameters for a RightTriangle: "
f"{side_a=}, {side_b=}, {side_c=}, {angle_a=}, {angle_b=}"
)
@classmethod
def from_side_a_and_side_b(cls, side_a: float, side_b: float) -> "RightTriangle":
side_c = calculate_hypotenuse_from_legs(side_a, side_b)
angle_a, angle_b = calculate_acute_angles_from_legs(side_a, side_b)
return cls(side_a, side_b, side_c, angle_a, angle_b)
@classmethod
def from_side_a_and_side_c(cls, side_a: float, side_c: float) -> "RightTriangle":
side_b = calculate_leg_from_other_leg_and_hypotenuse(side_a, side_c)
angle_a, angle_b = calculate_acute_angles_from_legs(side_a, side_b)
return cls(side_a, side_b, side_c, angle_a, angle_b)
@classmethod
def from_side_b_and_side_c(cls, side_b: float, side_c: float) -> "RightTriangle":
side_a = calculate_leg_from_other_leg_and_hypotenuse(side_b, side_c)
angle_a, angle_b = calculate_acute_angles_from_legs(side_a, side_b)
return cls(side_a, side_b, side_c, angle_a, angle_b)
@classmethod
def from_side_a_and_angle_a(cls, side_a: float, angle_a: float) -> "RightTriangle":
side_b = calculate_leg_from_other_leg_and_adjacent_angle(side_a, angle_a)
side_c = calculate_hypotenuse_from_legs(side_a, side_b)
angle_b = calculate_acute_angle_from_other_acute_angle(angle_a)
return cls(side_a, side_b, side_c, angle_a, angle_b)
@classmethod
def from_side_b_and_angle_a(cls, side_b: float, angle_a: float) -> "RightTriangle":
side_a = calculate_leg_from_other_leg_and_opposed_angle(side_b, angle_a)
side_c = calculate_hypotenuse_from_legs(side_a, side_b)
angle_b = calculate_acute_angle_from_other_acute_angle(angle_a)
return cls(side_a, side_b, side_c, angle_a, angle_b)
@classmethod
def from_side_c_and_angle_a(cls, side_c: float, angle_a: float) -> "RightTriangle":
side_a = calculate_leg_from_hypotenuse_and_opposed_angle(side_c, angle_a)
side_b = calculate_leg_from_other_leg_and_hypotenuse(side_a, side_c)
angle_b = calculate_acute_angle_from_other_acute_angle(angle_a)
return cls(side_a, side_b, side_c, angle_a, angle_b)
@classmethod
def from_side_a_and_angle_b(cls, side_a: float, angle_b: float) -> "RightTriangle":
angle_a = calculate_acute_angle_from_other_acute_angle(angle_b)
side_b = calculate_leg_from_other_leg_and_adjacent_angle(side_a, angle_a)
side_c = calculate_hypotenuse_from_legs(side_a, side_b)
return cls(side_a, side_b, side_c, angle_a, angle_b)
@classmethod
def from_side_b_and_angle_b(cls, side_b: float, angle_b: float) -> "RightTriangle":
angle_a = calculate_acute_angle_from_other_acute_angle(angle_b)
side_a = calculate_leg_from_other_leg_and_opposed_angle(side_b, angle_a)
side_c = calculate_hypotenuse_from_legs(side_a, side_b)
return cls(side_a, side_b, side_c, angle_a, angle_b)
@classmethod
def from_side_c_and_angle_b(cls, side_c: float, angle_b: float) -> "RightTriangle":
angle_a = calculate_acute_angle_from_other_acute_angle(angle_b)
side_a = calculate_leg_from_hypotenuse_and_opposed_angle(side_c, angle_a)
side_b = calculate_leg_from_other_leg_and_hypotenuse(side_a, side_c)
return cls(side_a, side_b, side_c, angle_a, angle_b)
def __str__(self):
return (
"RightTriangle" + "\n"
"\t" + f"{self.side_a=}" + "\n"
"\t" + f"{self.side_b=}" + "\n"
"\t" + f"{self.side_c=}" + "\n"
"\t" + f"{self.angle_a=}" + "\n"
"\t" + f"{self.angle_b=}"
)
def calculate_acute_angles_from_legs(side_a: float, side_b: float):
side_c = calculate_hypotenuse_from_legs(side_a, side_b)
angle_a = math.degrees(math.asin(side_a / side_c))
angle_b = calculate_acute_angle_from_other_acute_angle(angle_a)
return angle_a, angle_b
def calculate_leg_from_hypotenuse_and_opposed_angle(
hypotenuse, opposed_angle):
leg = hypotenuse * math.sin(math.radians(opposed_angle))
return leg
def calculate_leg_from_other_leg_and_opposed_angle(
other_leg, opposed_angle):
leg = other_leg * math.tan(math.radians(opposed_angle))
return leg
def calculate_acute_angle_from_other_acute_angle(other_acute_angle):
angle = 90 - other_acute_angle
return angle
def calculate_leg_from_other_leg_and_adjacent_angle(
other_leg, adjacent_angle):
leg = other_leg / math.tan(math.radians(adjacent_angle))
return leg
def calculate_hypotenuse_from_legs(leg_a, leg_b):
hypotenuse = math.sqrt(leg_a ** 2 + leg_b ** 2)
return hypotenuse
def calculate_leg_from_other_leg_and_hypotenuse(other_leg, hypotenuse):
leg = math.sqrt(hypotenuse ** 2 - other_leg ** 2)
return leg | /right_triangle-0.2.0-py3-none-any.whl/right_triangle.py | 0.939157 | 0.9271 | right_triangle.py | pypi |
from __future__ import absolute_import
import binascii
import codecs
import os
from io import BytesIO
from .packages import six
from .packages.six import b
from .fields import RequestField
writer = codecs.lookup("utf-8")[3]
def choose_boundary():
"""
Our embarrassingly-simple replacement for mimetools.choose_boundary.
"""
boundary = binascii.hexlify(os.urandom(16))
if not six.PY2:
boundary = boundary.decode("ascii")
return boundary
def iter_field_objects(fields):
"""
Iterate over fields.
Supports list of (k, v) tuples and dicts, and lists of
:class:`~urllib3.fields.RequestField`.
"""
if isinstance(fields, dict):
i = six.iteritems(fields)
else:
i = iter(fields)
for field in i:
if isinstance(field, RequestField):
yield field
else:
yield RequestField.from_tuples(*field)
def iter_fields(fields):
"""
.. deprecated:: 1.6
Iterate over fields.
The addition of :class:`~urllib3.fields.RequestField` makes this function
obsolete. Instead, use :func:`iter_field_objects`, which returns
:class:`~urllib3.fields.RequestField` objects.
Supports list of (k, v) tuples and dicts.
"""
if isinstance(fields, dict):
return ((k, v) for k, v in six.iteritems(fields))
return ((k, v) for k, v in fields)
def encode_multipart_formdata(fields, boundary=None):
"""
Encode a dictionary of ``fields`` using the multipart/form-data MIME format.
:param fields:
Dictionary of fields or list of (key, :class:`~urllib3.fields.RequestField`).
:param boundary:
If not specified, then a random boundary will be generated using
:func:`urllib3.filepost.choose_boundary`.
"""
body = BytesIO()
if boundary is None:
boundary = choose_boundary()
for field in iter_field_objects(fields):
body.write(b("--%s\r\n" % (boundary)))
writer(body).write(field.render_headers())
data = field.data
if isinstance(data, int):
data = str(data) # Backwards compatibility
if isinstance(data, six.text_type):
writer(body).write(data)
else:
body.write(data)
body.write(b"\r\n")
body.write(b("--%s--\r\n" % (boundary)))
content_type = str("multipart/form-data; boundary=%s" % boundary)
return body.getvalue(), content_type | /rightfoot-1.3.2-py3-none-any.whl/pypi__urllib3/urllib3/filepost.py | 0.70202 | 0.150871 | filepost.py | pypi |
from __future__ import absolute_import
from .filepost import encode_multipart_formdata
from .packages.six.moves.urllib.parse import urlencode
__all__ = ["RequestMethods"]
class RequestMethods(object):
"""
Convenience mixin for classes who implement a :meth:`urlopen` method, such
as :class:`~urllib3.connectionpool.HTTPConnectionPool` and
:class:`~urllib3.poolmanager.PoolManager`.
Provides behavior for making common types of HTTP request methods and
decides which type of request field encoding to use.
Specifically,
:meth:`.request_encode_url` is for sending requests whose fields are
encoded in the URL (such as GET, HEAD, DELETE).
:meth:`.request_encode_body` is for sending requests whose fields are
encoded in the *body* of the request using multipart or www-form-urlencoded
(such as for POST, PUT, PATCH).
:meth:`.request` is for making any kind of request, it will look up the
appropriate encoding format and use one of the above two methods to make
the request.
Initializer parameters:
:param headers:
Headers to include with all requests, unless other headers are given
explicitly.
"""
_encode_url_methods = {"DELETE", "GET", "HEAD", "OPTIONS"}
def __init__(self, headers=None):
self.headers = headers or {}
def urlopen(
self,
method,
url,
body=None,
headers=None,
encode_multipart=True,
multipart_boundary=None,
**kw
): # Abstract
raise NotImplementedError(
"Classes extending RequestMethods must implement "
"their own ``urlopen`` method."
)
def request(self, method, url, fields=None, headers=None, **urlopen_kw):
"""
Make a request using :meth:`urlopen` with the appropriate encoding of
``fields`` based on the ``method`` used.
This is a convenience method that requires the least amount of manual
effort. It can be used in most situations, while still having the
option to drop down to more specific methods when necessary, such as
:meth:`request_encode_url`, :meth:`request_encode_body`,
or even the lowest level :meth:`urlopen`.
"""
method = method.upper()
urlopen_kw["request_url"] = url
if method in self._encode_url_methods:
return self.request_encode_url(
method, url, fields=fields, headers=headers, **urlopen_kw
)
else:
return self.request_encode_body(
method, url, fields=fields, headers=headers, **urlopen_kw
)
def request_encode_url(self, method, url, fields=None, headers=None, **urlopen_kw):
"""
Make a request using :meth:`urlopen` with the ``fields`` encoded in
the url. This is useful for request methods like GET, HEAD, DELETE, etc.
"""
if headers is None:
headers = self.headers
extra_kw = {"headers": headers}
extra_kw.update(urlopen_kw)
if fields:
url += "?" + urlencode(fields)
return self.urlopen(method, url, **extra_kw)
def request_encode_body(
self,
method,
url,
fields=None,
headers=None,
encode_multipart=True,
multipart_boundary=None,
**urlopen_kw
):
"""
Make a request using :meth:`urlopen` with the ``fields`` encoded in
the body. This is useful for request methods like POST, PUT, PATCH, etc.
When ``encode_multipart=True`` (default), then
:meth:`urllib3.filepost.encode_multipart_formdata` is used to encode
the payload with the appropriate content type. Otherwise
:meth:`urllib.urlencode` is used with the
'application/x-www-form-urlencoded' content type.
Multipart encoding must be used when posting files, and it's reasonably
safe to use it in other times too. However, it may break request
signing, such as with OAuth.
Supports an optional ``fields`` parameter of key/value strings AND
key/filetuple. A filetuple is a (filename, data, MIME type) tuple where
the MIME type is optional. For example::
fields = {
'foo': 'bar',
'fakefile': ('foofile.txt', 'contents of foofile'),
'realfile': ('barfile.txt', open('realfile').read()),
'typedfile': ('bazfile.bin', open('bazfile').read(),
'image/jpeg'),
'nonamefile': 'contents of nonamefile field',
}
When uploading a file, providing a filename (the first parameter of the
tuple) is optional but recommended to best mimic behavior of browsers.
Note that if ``headers`` are supplied, the 'Content-Type' header will
be overwritten because it depends on the dynamic random boundary string
which is used to compose the body of the request. The random boundary
string can be explicitly set with the ``multipart_boundary`` parameter.
"""
if headers is None:
headers = self.headers
extra_kw = {"headers": {}}
if fields:
if "body" in urlopen_kw:
raise TypeError(
"request got values for both 'fields' and 'body', can only specify one."
)
if encode_multipart:
body, content_type = encode_multipart_formdata(
fields, boundary=multipart_boundary
)
else:
body, content_type = (
urlencode(fields),
"application/x-www-form-urlencoded",
)
extra_kw["body"] = body
extra_kw["headers"] = {"Content-Type": content_type}
extra_kw["headers"].update(headers)
extra_kw.update(urlopen_kw)
return self.urlopen(method, url, **extra_kw) | /rightfoot-1.3.2-py3-none-any.whl/pypi__urllib3/urllib3/request.py | 0.849753 | 0.195729 | request.py | pypi |
from __future__ import absolute_import
import email.utils
import mimetypes
import re
from .packages import six
def guess_content_type(filename, default="application/octet-stream"):
"""
Guess the "Content-Type" of a file.
:param filename:
The filename to guess the "Content-Type" of using :mod:`mimetypes`.
:param default:
If no "Content-Type" can be guessed, default to `default`.
"""
if filename:
return mimetypes.guess_type(filename)[0] or default
return default
def format_header_param_rfc2231(name, value):
"""
Helper function to format and quote a single header parameter using the
strategy defined in RFC 2231.
Particularly useful for header parameters which might contain
non-ASCII values, like file names. This follows RFC 2388 Section 4.4.
:param name:
The name of the parameter, a string expected to be ASCII only.
:param value:
The value of the parameter, provided as ``bytes`` or `str``.
:ret:
An RFC-2231-formatted unicode string.
"""
if isinstance(value, six.binary_type):
value = value.decode("utf-8")
if not any(ch in value for ch in '"\\\r\n'):
result = u'%s="%s"' % (name, value)
try:
result.encode("ascii")
except (UnicodeEncodeError, UnicodeDecodeError):
pass
else:
return result
if six.PY2: # Python 2:
value = value.encode("utf-8")
# encode_rfc2231 accepts an encoded string and returns an ascii-encoded
# string in Python 2 but accepts and returns unicode strings in Python 3
value = email.utils.encode_rfc2231(value, "utf-8")
value = "%s*=%s" % (name, value)
if six.PY2: # Python 2:
value = value.decode("utf-8")
return value
_HTML5_REPLACEMENTS = {
u"\u0022": u"%22",
# Replace "\" with "\\".
u"\u005C": u"\u005C\u005C",
u"\u005C": u"\u005C\u005C",
}
# All control characters from 0x00 to 0x1F *except* 0x1B.
_HTML5_REPLACEMENTS.update(
{
six.unichr(cc): u"%{:02X}".format(cc)
for cc in range(0x00, 0x1F + 1)
if cc not in (0x1B,)
}
)
def _replace_multiple(value, needles_and_replacements):
def replacer(match):
return needles_and_replacements[match.group(0)]
pattern = re.compile(
r"|".join([re.escape(needle) for needle in needles_and_replacements.keys()])
)
result = pattern.sub(replacer, value)
return result
def format_header_param_html5(name, value):
"""
Helper function to format and quote a single header parameter using the
HTML5 strategy.
Particularly useful for header parameters which might contain
non-ASCII values, like file names. This follows the `HTML5 Working Draft
Section 4.10.22.7`_ and matches the behavior of curl and modern browsers.
.. _HTML5 Working Draft Section 4.10.22.7:
https://w3c.github.io/html/sec-forms.html#multipart-form-data
:param name:
The name of the parameter, a string expected to be ASCII only.
:param value:
The value of the parameter, provided as ``bytes`` or `str``.
:ret:
A unicode string, stripped of troublesome characters.
"""
if isinstance(value, six.binary_type):
value = value.decode("utf-8")
value = _replace_multiple(value, _HTML5_REPLACEMENTS)
return u'%s="%s"' % (name, value)
# For backwards-compatibility.
format_header_param = format_header_param_html5
class RequestField(object):
"""
A data container for request body parameters.
:param name:
The name of this request field. Must be unicode.
:param data:
The data/value body.
:param filename:
An optional filename of the request field. Must be unicode.
:param headers:
An optional dict-like object of headers to initially use for the field.
:param header_formatter:
An optional callable that is used to encode and format the headers. By
default, this is :func:`format_header_param_html5`.
"""
def __init__(
self,
name,
data,
filename=None,
headers=None,
header_formatter=format_header_param_html5,
):
self._name = name
self._filename = filename
self.data = data
self.headers = {}
if headers:
self.headers = dict(headers)
self.header_formatter = header_formatter
@classmethod
def from_tuples(cls, fieldname, value, header_formatter=format_header_param_html5):
"""
A :class:`~urllib3.fields.RequestField` factory from old-style tuple parameters.
Supports constructing :class:`~urllib3.fields.RequestField` from
parameter of key/value strings AND key/filetuple. A filetuple is a
(filename, data, MIME type) tuple where the MIME type is optional.
For example::
'foo': 'bar',
'fakefile': ('foofile.txt', 'contents of foofile'),
'realfile': ('barfile.txt', open('realfile').read()),
'typedfile': ('bazfile.bin', open('bazfile').read(), 'image/jpeg'),
'nonamefile': 'contents of nonamefile field',
Field names and filenames must be unicode.
"""
if isinstance(value, tuple):
if len(value) == 3:
filename, data, content_type = value
else:
filename, data = value
content_type = guess_content_type(filename)
else:
filename = None
content_type = None
data = value
request_param = cls(
fieldname, data, filename=filename, header_formatter=header_formatter
)
request_param.make_multipart(content_type=content_type)
return request_param
def _render_part(self, name, value):
"""
Overridable helper function to format a single header parameter. By
default, this calls ``self.header_formatter``.
:param name:
The name of the parameter, a string expected to be ASCII only.
:param value:
The value of the parameter, provided as a unicode string.
"""
return self.header_formatter(name, value)
def _render_parts(self, header_parts):
"""
Helper function to format and quote a single header.
Useful for single headers that are composed of multiple items. E.g.,
'Content-Disposition' fields.
:param header_parts:
A sequence of (k, v) tuples or a :class:`dict` of (k, v) to format
as `k1="v1"; k2="v2"; ...`.
"""
parts = []
iterable = header_parts
if isinstance(header_parts, dict):
iterable = header_parts.items()
for name, value in iterable:
if value is not None:
parts.append(self._render_part(name, value))
return u"; ".join(parts)
def render_headers(self):
"""
Renders the headers for this request field.
"""
lines = []
sort_keys = ["Content-Disposition", "Content-Type", "Content-Location"]
for sort_key in sort_keys:
if self.headers.get(sort_key, False):
lines.append(u"%s: %s" % (sort_key, self.headers[sort_key]))
for header_name, header_value in self.headers.items():
if header_name not in sort_keys:
if header_value:
lines.append(u"%s: %s" % (header_name, header_value))
lines.append(u"\r\n")
return u"\r\n".join(lines)
def make_multipart(
self, content_disposition=None, content_type=None, content_location=None
):
"""
Makes this request field into a multipart request field.
This method overrides "Content-Disposition", "Content-Type" and
"Content-Location" headers to the request parameter.
:param content_type:
The 'Content-Type' of the request body.
:param content_location:
The 'Content-Location' of the request body.
"""
self.headers["Content-Disposition"] = content_disposition or u"form-data"
self.headers["Content-Disposition"] += u"; ".join(
[
u"",
self._render_parts(
((u"name", self._name), (u"filename", self._filename))
),
]
)
self.headers["Content-Type"] = content_type
self.headers["Content-Location"] = content_location | /rightfoot-1.3.2-py3-none-any.whl/pypi__urllib3/urllib3/fields.py | 0.849535 | 0.387545 | fields.py | pypi |
from __future__ import absolute_import
from ..packages.six.moves import http_client as httplib
from ..exceptions import HeaderParsingError
def is_fp_closed(obj):
"""
Checks whether a given file-like object is closed.
:param obj:
The file-like object to check.
"""
try:
# Check `isclosed()` first, in case Python3 doesn't set `closed`.
# GH Issue #928
return obj.isclosed()
except AttributeError:
pass
try:
# Check via the official file-like-object way.
return obj.closed
except AttributeError:
pass
try:
# Check if the object is a container for another file-like object that
# gets released on exhaustion (e.g. HTTPResponse).
return obj.fp is None
except AttributeError:
pass
raise ValueError("Unable to determine whether fp is closed.")
def assert_header_parsing(headers):
"""
Asserts whether all headers have been successfully parsed.
Extracts encountered errors from the result of parsing headers.
Only works on Python 3.
:param headers: Headers to verify.
:type headers: `httplib.HTTPMessage`.
:raises urllib3.exceptions.HeaderParsingError:
If parsing errors are found.
"""
# This will fail silently if we pass in the wrong kind of parameter.
# To make debugging easier add an explicit check.
if not isinstance(headers, httplib.HTTPMessage):
raise TypeError("expected httplib.Message, got {0}.".format(type(headers)))
defects = getattr(headers, "defects", None)
get_payload = getattr(headers, "get_payload", None)
unparsed_data = None
if get_payload:
# get_payload is actually email.message.Message.get_payload;
# we're only interested in the result if it's not a multipart message
if not headers.is_multipart():
payload = get_payload()
if isinstance(payload, (bytes, str)):
unparsed_data = payload
if defects or unparsed_data:
raise HeaderParsingError(defects=defects, unparsed_data=unparsed_data)
def is_response_to_head(response):
"""
Checks whether the request of a response has been a HEAD-request.
Handles the quirks of AppEngine.
:param conn:
:type conn: :class:`httplib.HTTPResponse`
"""
# FIXME: Can we do this somehow without accessing private httplib _method?
method = response._method
if isinstance(method, int): # Platform-specific: Appengine
return method == 3
return method.upper() == "HEAD" | /rightfoot-1.3.2-py3-none-any.whl/pypi__urllib3/urllib3/util/response.py | 0.832339 | 0.244848 | response.py | pypi |
from __future__ import absolute_import
import time
import logging
from collections import namedtuple
from itertools import takewhile
import email
import re
from ..exceptions import (
ConnectTimeoutError,
MaxRetryError,
ProtocolError,
ReadTimeoutError,
ResponseError,
InvalidHeader,
ProxyError,
)
from ..packages import six
log = logging.getLogger(__name__)
# Data structure for representing the metadata of requests that result in a retry.
RequestHistory = namedtuple(
"RequestHistory", ["method", "url", "error", "status", "redirect_location"]
)
class Retry(object):
"""Retry configuration.
Each retry attempt will create a new Retry object with updated values, so
they can be safely reused.
Retries can be defined as a default for a pool::
retries = Retry(connect=5, read=2, redirect=5)
http = PoolManager(retries=retries)
response = http.request('GET', 'http://example.com/')
Or per-request (which overrides the default for the pool)::
response = http.request('GET', 'http://example.com/', retries=Retry(10))
Retries can be disabled by passing ``False``::
response = http.request('GET', 'http://example.com/', retries=False)
Errors will be wrapped in :class:`~urllib3.exceptions.MaxRetryError` unless
retries are disabled, in which case the causing exception will be raised.
:param int total:
Total number of retries to allow. Takes precedence over other counts.
Set to ``None`` to remove this constraint and fall back on other
counts. It's a good idea to set this to some sensibly-high value to
account for unexpected edge cases and avoid infinite retry loops.
Set to ``0`` to fail on the first retry.
Set to ``False`` to disable and imply ``raise_on_redirect=False``.
:param int connect:
How many connection-related errors to retry on.
These are errors raised before the request is sent to the remote server,
which we assume has not triggered the server to process the request.
Set to ``0`` to fail on the first retry of this type.
:param int read:
How many times to retry on read errors.
These errors are raised after the request was sent to the server, so the
request may have side-effects.
Set to ``0`` to fail on the first retry of this type.
:param int redirect:
How many redirects to perform. Limit this to avoid infinite redirect
loops.
A redirect is a HTTP response with a status code 301, 302, 303, 307 or
308.
Set to ``0`` to fail on the first retry of this type.
Set to ``False`` to disable and imply ``raise_on_redirect=False``.
:param int status:
How many times to retry on bad status codes.
These are retries made on responses, where status code matches
``status_forcelist``.
Set to ``0`` to fail on the first retry of this type.
:param iterable method_whitelist:
Set of uppercased HTTP method verbs that we should retry on.
By default, we only retry on methods which are considered to be
idempotent (multiple requests with the same parameters end with the
same state). See :attr:`Retry.DEFAULT_METHOD_WHITELIST`.
Set to a ``False`` value to retry on any verb.
:param iterable status_forcelist:
A set of integer HTTP status codes that we should force a retry on.
A retry is initiated if the request method is in ``method_whitelist``
and the response status code is in ``status_forcelist``.
By default, this is disabled with ``None``.
:param float backoff_factor:
A backoff factor to apply between attempts after the second try
(most errors are resolved immediately by a second try without a
delay). urllib3 will sleep for::
{backoff factor} * (2 ** ({number of total retries} - 1))
seconds. If the backoff_factor is 0.1, then :func:`.sleep` will sleep
for [0.0s, 0.2s, 0.4s, ...] between retries. It will never be longer
than :attr:`Retry.BACKOFF_MAX`.
By default, backoff is disabled (set to 0).
:param bool raise_on_redirect: Whether, if the number of redirects is
exhausted, to raise a MaxRetryError, or to return a response with a
response code in the 3xx range.
:param bool raise_on_status: Similar meaning to ``raise_on_redirect``:
whether we should raise an exception, or return a response,
if status falls in ``status_forcelist`` range and retries have
been exhausted.
:param tuple history: The history of the request encountered during
each call to :meth:`~Retry.increment`. The list is in the order
the requests occurred. Each list item is of class :class:`RequestHistory`.
:param bool respect_retry_after_header:
Whether to respect Retry-After header on status codes defined as
:attr:`Retry.RETRY_AFTER_STATUS_CODES` or not.
:param iterable remove_headers_on_redirect:
Sequence of headers to remove from the request when a response
indicating a redirect is returned before firing off the redirected
request.
"""
DEFAULT_METHOD_WHITELIST = frozenset(
["HEAD", "GET", "PUT", "DELETE", "OPTIONS", "TRACE"]
)
RETRY_AFTER_STATUS_CODES = frozenset([413, 429, 503])
DEFAULT_REDIRECT_HEADERS_BLACKLIST = frozenset(["Authorization"])
#: Maximum backoff time.
BACKOFF_MAX = 120
def __init__(
self,
total=10,
connect=None,
read=None,
redirect=None,
status=None,
method_whitelist=DEFAULT_METHOD_WHITELIST,
status_forcelist=None,
backoff_factor=0,
raise_on_redirect=True,
raise_on_status=True,
history=None,
respect_retry_after_header=True,
remove_headers_on_redirect=DEFAULT_REDIRECT_HEADERS_BLACKLIST,
):
self.total = total
self.connect = connect
self.read = read
self.status = status
if redirect is False or total is False:
redirect = 0
raise_on_redirect = False
self.redirect = redirect
self.status_forcelist = status_forcelist or set()
self.method_whitelist = method_whitelist
self.backoff_factor = backoff_factor
self.raise_on_redirect = raise_on_redirect
self.raise_on_status = raise_on_status
self.history = history or tuple()
self.respect_retry_after_header = respect_retry_after_header
self.remove_headers_on_redirect = frozenset(
[h.lower() for h in remove_headers_on_redirect]
)
def new(self, **kw):
params = dict(
total=self.total,
connect=self.connect,
read=self.read,
redirect=self.redirect,
status=self.status,
method_whitelist=self.method_whitelist,
status_forcelist=self.status_forcelist,
backoff_factor=self.backoff_factor,
raise_on_redirect=self.raise_on_redirect,
raise_on_status=self.raise_on_status,
history=self.history,
remove_headers_on_redirect=self.remove_headers_on_redirect,
respect_retry_after_header=self.respect_retry_after_header,
)
params.update(kw)
return type(self)(**params)
@classmethod
def from_int(cls, retries, redirect=True, default=None):
""" Backwards-compatibility for the old retries format."""
if retries is None:
retries = default if default is not None else cls.DEFAULT
if isinstance(retries, Retry):
return retries
redirect = bool(redirect) and None
new_retries = cls(retries, redirect=redirect)
log.debug("Converted retries value: %r -> %r", retries, new_retries)
return new_retries
def get_backoff_time(self):
"""Formula for computing the current backoff
:rtype: float
"""
# We want to consider only the last consecutive errors sequence (Ignore redirects).
consecutive_errors_len = len(
list(
takewhile(lambda x: x.redirect_location is None, reversed(self.history))
)
)
if consecutive_errors_len <= 1:
return 0
backoff_value = self.backoff_factor * (2 ** (consecutive_errors_len - 1))
return min(self.BACKOFF_MAX, backoff_value)
def parse_retry_after(self, retry_after):
# Whitespace: https://tools.ietf.org/html/rfc7230#section-3.2.4
if re.match(r"^\s*[0-9]+\s*$", retry_after):
seconds = int(retry_after)
else:
retry_date_tuple = email.utils.parsedate_tz(retry_after)
if retry_date_tuple is None:
raise InvalidHeader("Invalid Retry-After header: %s" % retry_after)
if retry_date_tuple[9] is None: # Python 2
# Assume UTC if no timezone was specified
# On Python2.7, parsedate_tz returns None for a timezone offset
# instead of 0 if no timezone is given, where mktime_tz treats
# a None timezone offset as local time.
retry_date_tuple = retry_date_tuple[:9] + (0,) + retry_date_tuple[10:]
retry_date = email.utils.mktime_tz(retry_date_tuple)
seconds = retry_date - time.time()
if seconds < 0:
seconds = 0
return seconds
def get_retry_after(self, response):
""" Get the value of Retry-After in seconds. """
retry_after = response.getheader("Retry-After")
if retry_after is None:
return None
return self.parse_retry_after(retry_after)
def sleep_for_retry(self, response=None):
retry_after = self.get_retry_after(response)
if retry_after:
time.sleep(retry_after)
return True
return False
def _sleep_backoff(self):
backoff = self.get_backoff_time()
if backoff <= 0:
return
time.sleep(backoff)
def sleep(self, response=None):
"""Sleep between retry attempts.
This method will respect a server's ``Retry-After`` response header
and sleep the duration of the time requested. If that is not present, it
will use an exponential backoff. By default, the backoff factor is 0 and
this method will return immediately.
"""
if self.respect_retry_after_header and response:
slept = self.sleep_for_retry(response)
if slept:
return
self._sleep_backoff()
def _is_connection_error(self, err):
"""Errors when we're fairly sure that the server did not receive the
request, so it should be safe to retry.
"""
if isinstance(err, ProxyError):
err = err.original_error
return isinstance(err, ConnectTimeoutError)
def _is_read_error(self, err):
"""Errors that occur after the request has been started, so we should
assume that the server began processing it.
"""
return isinstance(err, (ReadTimeoutError, ProtocolError))
def _is_method_retryable(self, method):
"""Checks if a given HTTP method should be retried upon, depending if
it is included on the method whitelist.
"""
if self.method_whitelist and method.upper() not in self.method_whitelist:
return False
return True
def is_retry(self, method, status_code, has_retry_after=False):
"""Is this method/status code retryable? (Based on whitelists and control
variables such as the number of total retries to allow, whether to
respect the Retry-After header, whether this header is present, and
whether the returned status code is on the list of status codes to
be retried upon on the presence of the aforementioned header)
"""
if not self._is_method_retryable(method):
return False
if self.status_forcelist and status_code in self.status_forcelist:
return True
return (
self.total
and self.respect_retry_after_header
and has_retry_after
and (status_code in self.RETRY_AFTER_STATUS_CODES)
)
def is_exhausted(self):
""" Are we out of retries? """
retry_counts = (self.total, self.connect, self.read, self.redirect, self.status)
retry_counts = list(filter(None, retry_counts))
if not retry_counts:
return False
return min(retry_counts) < 0
def increment(
self,
method=None,
url=None,
response=None,
error=None,
_pool=None,
_stacktrace=None,
):
"""Return a new Retry object with incremented retry counters.
:param response: A response object, or None, if the server did not
return a response.
:type response: :class:`~urllib3.response.HTTPResponse`
:param Exception error: An error encountered during the request, or
None if the response was received successfully.
:return: A new ``Retry`` object.
"""
if self.total is False and error:
# Disabled, indicate to re-raise the error.
raise six.reraise(type(error), error, _stacktrace)
total = self.total
if total is not None:
total -= 1
connect = self.connect
read = self.read
redirect = self.redirect
status_count = self.status
cause = "unknown"
status = None
redirect_location = None
if error and self._is_connection_error(error):
# Connect retry?
if connect is False:
raise six.reraise(type(error), error, _stacktrace)
elif connect is not None:
connect -= 1
elif error and self._is_read_error(error):
# Read retry?
if read is False or not self._is_method_retryable(method):
raise six.reraise(type(error), error, _stacktrace)
elif read is not None:
read -= 1
elif response and response.get_redirect_location():
# Redirect retry?
if redirect is not None:
redirect -= 1
cause = "too many redirects"
redirect_location = response.get_redirect_location()
status = response.status
else:
# Incrementing because of a server error like a 500 in
# status_forcelist and a the given method is in the whitelist
cause = ResponseError.GENERIC_ERROR
if response and response.status:
if status_count is not None:
status_count -= 1
cause = ResponseError.SPECIFIC_ERROR.format(status_code=response.status)
status = response.status
history = self.history + (
RequestHistory(method, url, error, status, redirect_location),
)
new_retry = self.new(
total=total,
connect=connect,
read=read,
redirect=redirect,
status=status_count,
history=history,
)
if new_retry.is_exhausted():
raise MaxRetryError(_pool, url, error or ResponseError(cause))
log.debug("Incremented Retry for (url='%s'): %r", url, new_retry)
return new_retry
def __repr__(self):
return (
"{cls.__name__}(total={self.total}, connect={self.connect}, "
"read={self.read}, redirect={self.redirect}, status={self.status})"
).format(cls=type(self), self=self)
# For backwards compatibility (equivalent to pre-v1.9):
Retry.DEFAULT = Retry(3) | /rightfoot-1.3.2-py3-none-any.whl/pypi__urllib3/urllib3/util/retry.py | 0.792344 | 0.306034 | retry.py | pypi |
r"""
The ``codes`` object defines a mapping from common names for HTTP statuses
to their numerical codes, accessible either as attributes or as dictionary
items.
>>> requests.codes['temporary_redirect']
307
>>> requests.codes.teapot
418
>>> requests.codes['\o/']
200
Some codes have multiple names, and both upper- and lower-case versions of
the names are allowed. For example, ``codes.ok``, ``codes.OK``, and
``codes.okay`` all correspond to the HTTP status code 200.
"""
from .structures import LookupDict
_codes = {
# Informational.
100: ('continue',),
101: ('switching_protocols',),
102: ('processing',),
103: ('checkpoint',),
122: ('uri_too_long', 'request_uri_too_long'),
200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'),
201: ('created',),
202: ('accepted',),
203: ('non_authoritative_info', 'non_authoritative_information'),
204: ('no_content',),
205: ('reset_content', 'reset'),
206: ('partial_content', 'partial'),
207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'),
208: ('already_reported',),
226: ('im_used',),
# Redirection.
300: ('multiple_choices',),
301: ('moved_permanently', 'moved', '\\o-'),
302: ('found',),
303: ('see_other', 'other'),
304: ('not_modified',),
305: ('use_proxy',),
306: ('switch_proxy',),
307: ('temporary_redirect', 'temporary_moved', 'temporary'),
308: ('permanent_redirect',
'resume_incomplete', 'resume',), # These 2 to be removed in 3.0
# Client Error.
400: ('bad_request', 'bad'),
401: ('unauthorized',),
402: ('payment_required', 'payment'),
403: ('forbidden',),
404: ('not_found', '-o-'),
405: ('method_not_allowed', 'not_allowed'),
406: ('not_acceptable',),
407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'),
408: ('request_timeout', 'timeout'),
409: ('conflict',),
410: ('gone',),
411: ('length_required',),
412: ('precondition_failed', 'precondition'),
413: ('request_entity_too_large',),
414: ('request_uri_too_large',),
415: ('unsupported_media_type', 'unsupported_media', 'media_type'),
416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'),
417: ('expectation_failed',),
418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'),
421: ('misdirected_request',),
422: ('unprocessable_entity', 'unprocessable'),
423: ('locked',),
424: ('failed_dependency', 'dependency'),
425: ('unordered_collection', 'unordered'),
426: ('upgrade_required', 'upgrade'),
428: ('precondition_required', 'precondition'),
429: ('too_many_requests', 'too_many'),
431: ('header_fields_too_large', 'fields_too_large'),
444: ('no_response', 'none'),
449: ('retry_with', 'retry'),
450: ('blocked_by_windows_parental_controls', 'parental_controls'),
451: ('unavailable_for_legal_reasons', 'legal_reasons'),
499: ('client_closed_request',),
# Server Error.
500: ('internal_server_error', 'server_error', '/o\\', '✗'),
501: ('not_implemented',),
502: ('bad_gateway',),
503: ('service_unavailable', 'unavailable'),
504: ('gateway_timeout',),
505: ('http_version_not_supported', 'http_version'),
506: ('variant_also_negotiates',),
507: ('insufficient_storage',),
509: ('bandwidth_limit_exceeded', 'bandwidth'),
510: ('not_extended',),
511: ('network_authentication_required', 'network_auth', 'network_authentication'),
}
codes = LookupDict(name='status_codes')
def _init():
for code, titles in _codes.items():
for title in titles:
setattr(codes, title, code)
if not title.startswith(('\\', '/')):
setattr(codes, title.upper(), code)
def doc(code):
names = ', '.join('``%s``' % n for n in _codes[code])
return '* %d: %s' % (code, names)
global __doc__
__doc__ = (__doc__ + '\n' +
'\n'.join(doc(code) for code in sorted(_codes))
if __doc__ is not None else None)
_init() | /rightfoot-1.3.2-py3-none-any.whl/pypi__requests/requests/status_codes.py | 0.842264 | 0.387864 | status_codes.py | pypi |
from . import sessions
def request(method, url, **kwargs):
"""Constructs and sends a :class:`Request <Request>`.
:param method: method for the new :class:`Request` object.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
:param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
:param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
:param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content-type'`` is a string
defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
to add for the file.
:param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
:param timeout: (optional) How many seconds to wait for the server to send data
before giving up, as a float, or a :ref:`(connect timeout, read
timeout) <timeouts>` tuple.
:type timeout: float or tuple
:param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
:type allow_redirects: bool
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
:param verify: (optional) Either a boolean, in which case it controls whether we verify
the server's TLS certificate, or a string, in which case it must be a path
to a CA bundle to use. Defaults to ``True``.
:param stream: (optional) if ``False``, the response content will be immediately downloaded.
:param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
:return: :class:`Response <Response>` object
:rtype: requests.Response
Usage::
>>> import requests
>>> req = requests.request('GET', 'https://httpbin.org/get')
<Response [200]>
"""
# By using the 'with' statement we are sure the session is closed, thus we
# avoid leaving sockets open which can trigger a ResourceWarning in some
# cases, and look like a memory leak in others.
with sessions.Session() as session:
return session.request(method=method, url=url, **kwargs)
def get(url, params=None, **kwargs):
r"""Sends a GET request.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
kwargs.setdefault('allow_redirects', True)
return request('get', url, params=params, **kwargs)
def options(url, **kwargs):
r"""Sends an OPTIONS request.
:param url: URL for the new :class:`Request` object.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
kwargs.setdefault('allow_redirects', True)
return request('options', url, **kwargs)
def head(url, **kwargs):
r"""Sends a HEAD request.
:param url: URL for the new :class:`Request` object.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
kwargs.setdefault('allow_redirects', False)
return request('head', url, **kwargs)
def post(url, data=None, json=None, **kwargs):
r"""Sends a POST request.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request('post', url, data=data, json=json, **kwargs)
def put(url, data=None, **kwargs):
r"""Sends a PUT request.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request('put', url, data=data, **kwargs)
def patch(url, data=None, **kwargs):
r"""Sends a PATCH request.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request('patch', url, data=data, **kwargs)
def delete(url, **kwargs):
r"""Sends a DELETE request.
:param url: URL for the new :class:`Request` object.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request('delete', url, **kwargs) | /rightfoot-1.3.2-py3-none-any.whl/pypi__requests/requests/api.py | 0.872007 | 0.417746 | api.py | pypi |
from .compat import OrderedDict, Mapping, MutableMapping
class CaseInsensitiveDict(MutableMapping):
"""A case-insensitive ``dict``-like object.
Implements all methods and operations of
``MutableMapping`` as well as dict's ``copy``. Also
provides ``lower_items``.
All keys are expected to be strings. The structure remembers the
case of the last key to be set, and ``iter(instance)``,
``keys()``, ``items()``, ``iterkeys()``, and ``iteritems()``
will contain case-sensitive keys. However, querying and contains
testing is case insensitive::
cid = CaseInsensitiveDict()
cid['Accept'] = 'application/json'
cid['aCCEPT'] == 'application/json' # True
list(cid) == ['Accept'] # True
For example, ``headers['content-encoding']`` will return the
value of a ``'Content-Encoding'`` response header, regardless
of how the header name was originally stored.
If the constructor, ``.update``, or equality comparison
operations are given keys that have equal ``.lower()``s, the
behavior is undefined.
"""
def __init__(self, data=None, **kwargs):
self._store = OrderedDict()
if data is None:
data = {}
self.update(data, **kwargs)
def __setitem__(self, key, value):
# Use the lowercased key for lookups, but store the actual
# key alongside the value.
self._store[key.lower()] = (key, value)
def __getitem__(self, key):
return self._store[key.lower()][1]
def __delitem__(self, key):
del self._store[key.lower()]
def __iter__(self):
return (casedkey for casedkey, mappedvalue in self._store.values())
def __len__(self):
return len(self._store)
def lower_items(self):
"""Like iteritems(), but with all lowercase keys."""
return (
(lowerkey, keyval[1])
for (lowerkey, keyval)
in self._store.items()
)
def __eq__(self, other):
if isinstance(other, Mapping):
other = CaseInsensitiveDict(other)
else:
return NotImplemented
# Compare insensitively
return dict(self.lower_items()) == dict(other.lower_items())
# Copy is required
def copy(self):
return CaseInsensitiveDict(self._store.values())
def __repr__(self):
return str(dict(self.items()))
class LookupDict(dict):
"""Dictionary lookup object."""
def __init__(self, name=None):
self.name = name
super(LookupDict, self).__init__()
def __repr__(self):
return '<lookup \'%s\'>' % (self.name)
def __getitem__(self, key):
# We allow fall-through here, so values default to None
return self.__dict__.get(key, None)
def get(self, key, default=None):
return self.__dict__.get(key, default) | /rightfoot-1.3.2-py3-none-any.whl/pypi__requests/requests/structures.py | 0.906736 | 0.436262 | structures.py | pypi |
# __
# /__) _ _ _ _ _/ _
# / ( (- (/ (/ (- _) / _)
# /
"""
Requests HTTP Library
~~~~~~~~~~~~~~~~~~~~~
Requests is an HTTP library, written in Python, for human beings. Basic GET
usage:
>>> import requests
>>> r = requests.get('https://www.python.org')
>>> r.status_code
200
>>> 'Python is a programming language' in r.content
True
... or POST:
>>> payload = dict(key1='value1', key2='value2')
>>> r = requests.post('https://httpbin.org/post', data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
The other HTTP methods are supported - see `requests.api`. Full documentation
is at <http://python-requests.org>.
:copyright: (c) 2017 by Kenneth Reitz.
:license: Apache 2.0, see LICENSE for more details.
"""
import urllib3
import chardet
import warnings
from .exceptions import RequestsDependencyWarning
def check_compatibility(urllib3_version, chardet_version):
urllib3_version = urllib3_version.split('.')
assert urllib3_version != ['dev'] # Verify urllib3 isn't installed from git.
# Sometimes, urllib3 only reports its version as 16.1.
if len(urllib3_version) == 2:
urllib3_version.append('0')
# Check urllib3 for compatibility.
major, minor, patch = urllib3_version # noqa: F811
major, minor, patch = int(major), int(minor), int(patch)
# urllib3 >= 1.21.1, <= 1.25
assert major == 1
assert minor >= 21
assert minor <= 25
# Check chardet for compatibility.
major, minor, patch = chardet_version.split('.')[:3]
major, minor, patch = int(major), int(minor), int(patch)
# chardet >= 3.0.2, < 3.1.0
assert major == 3
assert minor < 1
assert patch >= 2
def _check_cryptography(cryptography_version):
# cryptography < 1.3.4
try:
cryptography_version = list(map(int, cryptography_version.split('.')))
except ValueError:
return
if cryptography_version < [1, 3, 4]:
warning = 'Old version of cryptography ({}) may cause slowdown.'.format(cryptography_version)
warnings.warn(warning, RequestsDependencyWarning)
# Check imported dependencies for compatibility.
try:
check_compatibility(urllib3.__version__, chardet.__version__)
except (AssertionError, ValueError):
warnings.warn("urllib3 ({}) or chardet ({}) doesn't match a supported "
"version!".format(urllib3.__version__, chardet.__version__),
RequestsDependencyWarning)
# Attempt to enable urllib3's SNI support, if possible
try:
from urllib3.contrib import pyopenssl
pyopenssl.inject_into_urllib3()
# Check cryptography version
from cryptography import __version__ as cryptography_version
_check_cryptography(cryptography_version)
except ImportError:
pass
# urllib3's DependencyWarnings should be silenced.
from urllib3.exceptions import DependencyWarning
warnings.simplefilter('ignore', DependencyWarning)
from .__version__ import __title__, __description__, __url__, __version__
from .__version__ import __build__, __author__, __author_email__, __license__
from .__version__ import __copyright__, __cake__
from . import utils
from . import packages
from .models import Request, Response, PreparedRequest
from .api import request, get, head, post, patch, put, delete, options
from .sessions import session, Session
from .status_codes import codes
from .exceptions import (
RequestException, Timeout, URLRequired,
TooManyRedirects, HTTPError, ConnectionError,
FileModeWarning, ConnectTimeout, ReadTimeout
)
# Set default logging handler to avoid "No handler found" warnings.
import logging
from logging import NullHandler
logging.getLogger(__name__).addHandler(NullHandler())
# FileModeWarnings go off per the default.
warnings.simplefilter('default', FileModeWarning, append=True) | /rightfoot-1.3.2-py3-none-any.whl/pypi__requests/requests/__init__.py | 0.696371 | 0.258303 | __init__.py | pypi |
from .core import encode, decode, alabel, ulabel, IDNAError
import codecs
import re
_unicode_dots_re = re.compile(u'[\u002e\u3002\uff0e\uff61]')
class Codec(codecs.Codec):
def encode(self, data, errors='strict'):
if errors != 'strict':
raise IDNAError("Unsupported error handling \"{0}\"".format(errors))
if not data:
return "", 0
return encode(data), len(data)
def decode(self, data, errors='strict'):
if errors != 'strict':
raise IDNAError("Unsupported error handling \"{0}\"".format(errors))
if not data:
return u"", 0
return decode(data), len(data)
class IncrementalEncoder(codecs.BufferedIncrementalEncoder):
def _buffer_encode(self, data, errors, final):
if errors != 'strict':
raise IDNAError("Unsupported error handling \"{0}\"".format(errors))
if not data:
return ("", 0)
labels = _unicode_dots_re.split(data)
trailing_dot = u''
if labels:
if not labels[-1]:
trailing_dot = '.'
del labels[-1]
elif not final:
# Keep potentially unfinished label until the next call
del labels[-1]
if labels:
trailing_dot = '.'
result = []
size = 0
for label in labels:
result.append(alabel(label))
if size:
size += 1
size += len(label)
# Join with U+002E
result = ".".join(result) + trailing_dot
size += len(trailing_dot)
return (result, size)
class IncrementalDecoder(codecs.BufferedIncrementalDecoder):
def _buffer_decode(self, data, errors, final):
if errors != 'strict':
raise IDNAError("Unsupported error handling \"{0}\"".format(errors))
if not data:
return (u"", 0)
# IDNA allows decoding to operate on Unicode strings, too.
if isinstance(data, unicode):
labels = _unicode_dots_re.split(data)
else:
# Must be ASCII string
data = str(data)
unicode(data, "ascii")
labels = data.split(".")
trailing_dot = u''
if labels:
if not labels[-1]:
trailing_dot = u'.'
del labels[-1]
elif not final:
# Keep potentially unfinished label until the next call
del labels[-1]
if labels:
trailing_dot = u'.'
result = []
size = 0
for label in labels:
result.append(ulabel(label))
if size:
size += 1
size += len(label)
result = u".".join(result) + trailing_dot
size += len(trailing_dot)
return (result, size)
class StreamWriter(Codec, codecs.StreamWriter):
pass
class StreamReader(Codec, codecs.StreamReader):
pass
def getregentry():
return codecs.CodecInfo(
name='idna',
encode=Codec().encode,
decode=Codec().decode,
incrementalencoder=IncrementalEncoder,
incrementaldecoder=IncrementalDecoder,
streamwriter=StreamWriter,
streamreader=StreamReader,
) | /rightfoot-1.3.2-py3-none-any.whl/pypi__idna/idna/codec.py | 0.541651 | 0.271024 | codec.py | pypi |
__version__ = "11.0.0"
scripts = {
'Greek': (
0x37000000374,
0x37500000378,
0x37a0000037e,
0x37f00000380,
0x38400000385,
0x38600000387,
0x3880000038b,
0x38c0000038d,
0x38e000003a2,
0x3a3000003e2,
0x3f000000400,
0x1d2600001d2b,
0x1d5d00001d62,
0x1d6600001d6b,
0x1dbf00001dc0,
0x1f0000001f16,
0x1f1800001f1e,
0x1f2000001f46,
0x1f4800001f4e,
0x1f5000001f58,
0x1f5900001f5a,
0x1f5b00001f5c,
0x1f5d00001f5e,
0x1f5f00001f7e,
0x1f8000001fb5,
0x1fb600001fc5,
0x1fc600001fd4,
0x1fd600001fdc,
0x1fdd00001ff0,
0x1ff200001ff5,
0x1ff600001fff,
0x212600002127,
0xab650000ab66,
0x101400001018f,
0x101a0000101a1,
0x1d2000001d246,
),
'Han': (
0x2e8000002e9a,
0x2e9b00002ef4,
0x2f0000002fd6,
0x300500003006,
0x300700003008,
0x30210000302a,
0x30380000303c,
0x340000004db6,
0x4e0000009ff0,
0xf9000000fa6e,
0xfa700000fada,
0x200000002a6d7,
0x2a7000002b735,
0x2b7400002b81e,
0x2b8200002cea2,
0x2ceb00002ebe1,
0x2f8000002fa1e,
),
'Hebrew': (
0x591000005c8,
0x5d0000005eb,
0x5ef000005f5,
0xfb1d0000fb37,
0xfb380000fb3d,
0xfb3e0000fb3f,
0xfb400000fb42,
0xfb430000fb45,
0xfb460000fb50,
),
'Hiragana': (
0x304100003097,
0x309d000030a0,
0x1b0010001b11f,
0x1f2000001f201,
),
'Katakana': (
0x30a1000030fb,
0x30fd00003100,
0x31f000003200,
0x32d0000032ff,
0x330000003358,
0xff660000ff70,
0xff710000ff9e,
0x1b0000001b001,
),
}
joining_types = {
0x600: 85,
0x601: 85,
0x602: 85,
0x603: 85,
0x604: 85,
0x605: 85,
0x608: 85,
0x60b: 85,
0x620: 68,
0x621: 85,
0x622: 82,
0x623: 82,
0x624: 82,
0x625: 82,
0x626: 68,
0x627: 82,
0x628: 68,
0x629: 82,
0x62a: 68,
0x62b: 68,
0x62c: 68,
0x62d: 68,
0x62e: 68,
0x62f: 82,
0x630: 82,
0x631: 82,
0x632: 82,
0x633: 68,
0x634: 68,
0x635: 68,
0x636: 68,
0x637: 68,
0x638: 68,
0x639: 68,
0x63a: 68,
0x63b: 68,
0x63c: 68,
0x63d: 68,
0x63e: 68,
0x63f: 68,
0x640: 67,
0x641: 68,
0x642: 68,
0x643: 68,
0x644: 68,
0x645: 68,
0x646: 68,
0x647: 68,
0x648: 82,
0x649: 68,
0x64a: 68,
0x66e: 68,
0x66f: 68,
0x671: 82,
0x672: 82,
0x673: 82,
0x674: 85,
0x675: 82,
0x676: 82,
0x677: 82,
0x678: 68,
0x679: 68,
0x67a: 68,
0x67b: 68,
0x67c: 68,
0x67d: 68,
0x67e: 68,
0x67f: 68,
0x680: 68,
0x681: 68,
0x682: 68,
0x683: 68,
0x684: 68,
0x685: 68,
0x686: 68,
0x687: 68,
0x688: 82,
0x689: 82,
0x68a: 82,
0x68b: 82,
0x68c: 82,
0x68d: 82,
0x68e: 82,
0x68f: 82,
0x690: 82,
0x691: 82,
0x692: 82,
0x693: 82,
0x694: 82,
0x695: 82,
0x696: 82,
0x697: 82,
0x698: 82,
0x699: 82,
0x69a: 68,
0x69b: 68,
0x69c: 68,
0x69d: 68,
0x69e: 68,
0x69f: 68,
0x6a0: 68,
0x6a1: 68,
0x6a2: 68,
0x6a3: 68,
0x6a4: 68,
0x6a5: 68,
0x6a6: 68,
0x6a7: 68,
0x6a8: 68,
0x6a9: 68,
0x6aa: 68,
0x6ab: 68,
0x6ac: 68,
0x6ad: 68,
0x6ae: 68,
0x6af: 68,
0x6b0: 68,
0x6b1: 68,
0x6b2: 68,
0x6b3: 68,
0x6b4: 68,
0x6b5: 68,
0x6b6: 68,
0x6b7: 68,
0x6b8: 68,
0x6b9: 68,
0x6ba: 68,
0x6bb: 68,
0x6bc: 68,
0x6bd: 68,
0x6be: 68,
0x6bf: 68,
0x6c0: 82,
0x6c1: 68,
0x6c2: 68,
0x6c3: 82,
0x6c4: 82,
0x6c5: 82,
0x6c6: 82,
0x6c7: 82,
0x6c8: 82,
0x6c9: 82,
0x6ca: 82,
0x6cb: 82,
0x6cc: 68,
0x6cd: 82,
0x6ce: 68,
0x6cf: 82,
0x6d0: 68,
0x6d1: 68,
0x6d2: 82,
0x6d3: 82,
0x6d5: 82,
0x6dd: 85,
0x6ee: 82,
0x6ef: 82,
0x6fa: 68,
0x6fb: 68,
0x6fc: 68,
0x6ff: 68,
0x70f: 84,
0x710: 82,
0x712: 68,
0x713: 68,
0x714: 68,
0x715: 82,
0x716: 82,
0x717: 82,
0x718: 82,
0x719: 82,
0x71a: 68,
0x71b: 68,
0x71c: 68,
0x71d: 68,
0x71e: 82,
0x71f: 68,
0x720: 68,
0x721: 68,
0x722: 68,
0x723: 68,
0x724: 68,
0x725: 68,
0x726: 68,
0x727: 68,
0x728: 82,
0x729: 68,
0x72a: 82,
0x72b: 68,
0x72c: 82,
0x72d: 68,
0x72e: 68,
0x72f: 82,
0x74d: 82,
0x74e: 68,
0x74f: 68,
0x750: 68,
0x751: 68,
0x752: 68,
0x753: 68,
0x754: 68,
0x755: 68,
0x756: 68,
0x757: 68,
0x758: 68,
0x759: 82,
0x75a: 82,
0x75b: 82,
0x75c: 68,
0x75d: 68,
0x75e: 68,
0x75f: 68,
0x760: 68,
0x761: 68,
0x762: 68,
0x763: 68,
0x764: 68,
0x765: 68,
0x766: 68,
0x767: 68,
0x768: 68,
0x769: 68,
0x76a: 68,
0x76b: 82,
0x76c: 82,
0x76d: 68,
0x76e: 68,
0x76f: 68,
0x770: 68,
0x771: 82,
0x772: 68,
0x773: 82,
0x774: 82,
0x775: 68,
0x776: 68,
0x777: 68,
0x778: 82,
0x779: 82,
0x77a: 68,
0x77b: 68,
0x77c: 68,
0x77d: 68,
0x77e: 68,
0x77f: 68,
0x7ca: 68,
0x7cb: 68,
0x7cc: 68,
0x7cd: 68,
0x7ce: 68,
0x7cf: 68,
0x7d0: 68,
0x7d1: 68,
0x7d2: 68,
0x7d3: 68,
0x7d4: 68,
0x7d5: 68,
0x7d6: 68,
0x7d7: 68,
0x7d8: 68,
0x7d9: 68,
0x7da: 68,
0x7db: 68,
0x7dc: 68,
0x7dd: 68,
0x7de: 68,
0x7df: 68,
0x7e0: 68,
0x7e1: 68,
0x7e2: 68,
0x7e3: 68,
0x7e4: 68,
0x7e5: 68,
0x7e6: 68,
0x7e7: 68,
0x7e8: 68,
0x7e9: 68,
0x7ea: 68,
0x7fa: 67,
0x840: 82,
0x841: 68,
0x842: 68,
0x843: 68,
0x844: 68,
0x845: 68,
0x846: 82,
0x847: 82,
0x848: 68,
0x849: 82,
0x84a: 68,
0x84b: 68,
0x84c: 68,
0x84d: 68,
0x84e: 68,
0x84f: 68,
0x850: 68,
0x851: 68,
0x852: 68,
0x853: 68,
0x854: 82,
0x855: 68,
0x856: 85,
0x857: 85,
0x858: 85,
0x860: 68,
0x861: 85,
0x862: 68,
0x863: 68,
0x864: 68,
0x865: 68,
0x866: 85,
0x867: 82,
0x868: 68,
0x869: 82,
0x86a: 82,
0x8a0: 68,
0x8a1: 68,
0x8a2: 68,
0x8a3: 68,
0x8a4: 68,
0x8a5: 68,
0x8a6: 68,
0x8a7: 68,
0x8a8: 68,
0x8a9: 68,
0x8aa: 82,
0x8ab: 82,
0x8ac: 82,
0x8ad: 85,
0x8ae: 82,
0x8af: 68,
0x8b0: 68,
0x8b1: 82,
0x8b2: 82,
0x8b3: 68,
0x8b4: 68,
0x8b6: 68,
0x8b7: 68,
0x8b8: 68,
0x8b9: 82,
0x8ba: 68,
0x8bb: 68,
0x8bc: 68,
0x8bd: 68,
0x8e2: 85,
0x1806: 85,
0x1807: 68,
0x180a: 67,
0x180e: 85,
0x1820: 68,
0x1821: 68,
0x1822: 68,
0x1823: 68,
0x1824: 68,
0x1825: 68,
0x1826: 68,
0x1827: 68,
0x1828: 68,
0x1829: 68,
0x182a: 68,
0x182b: 68,
0x182c: 68,
0x182d: 68,
0x182e: 68,
0x182f: 68,
0x1830: 68,
0x1831: 68,
0x1832: 68,
0x1833: 68,
0x1834: 68,
0x1835: 68,
0x1836: 68,
0x1837: 68,
0x1838: 68,
0x1839: 68,
0x183a: 68,
0x183b: 68,
0x183c: 68,
0x183d: 68,
0x183e: 68,
0x183f: 68,
0x1840: 68,
0x1841: 68,
0x1842: 68,
0x1843: 68,
0x1844: 68,
0x1845: 68,
0x1846: 68,
0x1847: 68,
0x1848: 68,
0x1849: 68,
0x184a: 68,
0x184b: 68,
0x184c: 68,
0x184d: 68,
0x184e: 68,
0x184f: 68,
0x1850: 68,
0x1851: 68,
0x1852: 68,
0x1853: 68,
0x1854: 68,
0x1855: 68,
0x1856: 68,
0x1857: 68,
0x1858: 68,
0x1859: 68,
0x185a: 68,
0x185b: 68,
0x185c: 68,
0x185d: 68,
0x185e: 68,
0x185f: 68,
0x1860: 68,
0x1861: 68,
0x1862: 68,
0x1863: 68,
0x1864: 68,
0x1865: 68,
0x1866: 68,
0x1867: 68,
0x1868: 68,
0x1869: 68,
0x186a: 68,
0x186b: 68,
0x186c: 68,
0x186d: 68,
0x186e: 68,
0x186f: 68,
0x1870: 68,
0x1871: 68,
0x1872: 68,
0x1873: 68,
0x1874: 68,
0x1875: 68,
0x1876: 68,
0x1877: 68,
0x1878: 68,
0x1880: 85,
0x1881: 85,
0x1882: 85,
0x1883: 85,
0x1884: 85,
0x1885: 84,
0x1886: 84,
0x1887: 68,
0x1888: 68,
0x1889: 68,
0x188a: 68,
0x188b: 68,
0x188c: 68,
0x188d: 68,
0x188e: 68,
0x188f: 68,
0x1890: 68,
0x1891: 68,
0x1892: 68,
0x1893: 68,
0x1894: 68,
0x1895: 68,
0x1896: 68,
0x1897: 68,
0x1898: 68,
0x1899: 68,
0x189a: 68,
0x189b: 68,
0x189c: 68,
0x189d: 68,
0x189e: 68,
0x189f: 68,
0x18a0: 68,
0x18a1: 68,
0x18a2: 68,
0x18a3: 68,
0x18a4: 68,
0x18a5: 68,
0x18a6: 68,
0x18a7: 68,
0x18a8: 68,
0x18aa: 68,
0x200c: 85,
0x200d: 67,
0x202f: 85,
0x2066: 85,
0x2067: 85,
0x2068: 85,
0x2069: 85,
0xa840: 68,
0xa841: 68,
0xa842: 68,
0xa843: 68,
0xa844: 68,
0xa845: 68,
0xa846: 68,
0xa847: 68,
0xa848: 68,
0xa849: 68,
0xa84a: 68,
0xa84b: 68,
0xa84c: 68,
0xa84d: 68,
0xa84e: 68,
0xa84f: 68,
0xa850: 68,
0xa851: 68,
0xa852: 68,
0xa853: 68,
0xa854: 68,
0xa855: 68,
0xa856: 68,
0xa857: 68,
0xa858: 68,
0xa859: 68,
0xa85a: 68,
0xa85b: 68,
0xa85c: 68,
0xa85d: 68,
0xa85e: 68,
0xa85f: 68,
0xa860: 68,
0xa861: 68,
0xa862: 68,
0xa863: 68,
0xa864: 68,
0xa865: 68,
0xa866: 68,
0xa867: 68,
0xa868: 68,
0xa869: 68,
0xa86a: 68,
0xa86b: 68,
0xa86c: 68,
0xa86d: 68,
0xa86e: 68,
0xa86f: 68,
0xa870: 68,
0xa871: 68,
0xa872: 76,
0xa873: 85,
0x10ac0: 68,
0x10ac1: 68,
0x10ac2: 68,
0x10ac3: 68,
0x10ac4: 68,
0x10ac5: 82,
0x10ac6: 85,
0x10ac7: 82,
0x10ac8: 85,
0x10ac9: 82,
0x10aca: 82,
0x10acb: 85,
0x10acc: 85,
0x10acd: 76,
0x10ace: 82,
0x10acf: 82,
0x10ad0: 82,
0x10ad1: 82,
0x10ad2: 82,
0x10ad3: 68,
0x10ad4: 68,
0x10ad5: 68,
0x10ad6: 68,
0x10ad7: 76,
0x10ad8: 68,
0x10ad9: 68,
0x10ada: 68,
0x10adb: 68,
0x10adc: 68,
0x10add: 82,
0x10ade: 68,
0x10adf: 68,
0x10ae0: 68,
0x10ae1: 82,
0x10ae2: 85,
0x10ae3: 85,
0x10ae4: 82,
0x10aeb: 68,
0x10aec: 68,
0x10aed: 68,
0x10aee: 68,
0x10aef: 82,
0x10b80: 68,
0x10b81: 82,
0x10b82: 68,
0x10b83: 82,
0x10b84: 82,
0x10b85: 82,
0x10b86: 68,
0x10b87: 68,
0x10b88: 68,
0x10b89: 82,
0x10b8a: 68,
0x10b8b: 68,
0x10b8c: 82,
0x10b8d: 68,
0x10b8e: 82,
0x10b8f: 82,
0x10b90: 68,
0x10b91: 82,
0x10ba9: 82,
0x10baa: 82,
0x10bab: 82,
0x10bac: 82,
0x10bad: 68,
0x10bae: 68,
0x10baf: 85,
0x10d00: 76,
0x10d01: 68,
0x10d02: 68,
0x10d03: 68,
0x10d04: 68,
0x10d05: 68,
0x10d06: 68,
0x10d07: 68,
0x10d08: 68,
0x10d09: 68,
0x10d0a: 68,
0x10d0b: 68,
0x10d0c: 68,
0x10d0d: 68,
0x10d0e: 68,
0x10d0f: 68,
0x10d10: 68,
0x10d11: 68,
0x10d12: 68,
0x10d13: 68,
0x10d14: 68,
0x10d15: 68,
0x10d16: 68,
0x10d17: 68,
0x10d18: 68,
0x10d19: 68,
0x10d1a: 68,
0x10d1b: 68,
0x10d1c: 68,
0x10d1d: 68,
0x10d1e: 68,
0x10d1f: 68,
0x10d20: 68,
0x10d21: 68,
0x10d22: 82,
0x10d23: 68,
0x10f30: 68,
0x10f31: 68,
0x10f32: 68,
0x10f33: 82,
0x10f34: 68,
0x10f35: 68,
0x10f36: 68,
0x10f37: 68,
0x10f38: 68,
0x10f39: 68,
0x10f3a: 68,
0x10f3b: 68,
0x10f3c: 68,
0x10f3d: 68,
0x10f3e: 68,
0x10f3f: 68,
0x10f40: 68,
0x10f41: 68,
0x10f42: 68,
0x10f43: 68,
0x10f44: 68,
0x10f45: 85,
0x10f51: 68,
0x10f52: 68,
0x10f53: 68,
0x10f54: 82,
0x110bd: 85,
0x110cd: 85,
0x1e900: 68,
0x1e901: 68,
0x1e902: 68,
0x1e903: 68,
0x1e904: 68,
0x1e905: 68,
0x1e906: 68,
0x1e907: 68,
0x1e908: 68,
0x1e909: 68,
0x1e90a: 68,
0x1e90b: 68,
0x1e90c: 68,
0x1e90d: 68,
0x1e90e: 68,
0x1e90f: 68,
0x1e910: 68,
0x1e911: 68,
0x1e912: 68,
0x1e913: 68,
0x1e914: 68,
0x1e915: 68,
0x1e916: 68,
0x1e917: 68,
0x1e918: 68,
0x1e919: 68,
0x1e91a: 68,
0x1e91b: 68,
0x1e91c: 68,
0x1e91d: 68,
0x1e91e: 68,
0x1e91f: 68,
0x1e920: 68,
0x1e921: 68,
0x1e922: 68,
0x1e923: 68,
0x1e924: 68,
0x1e925: 68,
0x1e926: 68,
0x1e927: 68,
0x1e928: 68,
0x1e929: 68,
0x1e92a: 68,
0x1e92b: 68,
0x1e92c: 68,
0x1e92d: 68,
0x1e92e: 68,
0x1e92f: 68,
0x1e930: 68,
0x1e931: 68,
0x1e932: 68,
0x1e933: 68,
0x1e934: 68,
0x1e935: 68,
0x1e936: 68,
0x1e937: 68,
0x1e938: 68,
0x1e939: 68,
0x1e93a: 68,
0x1e93b: 68,
0x1e93c: 68,
0x1e93d: 68,
0x1e93e: 68,
0x1e93f: 68,
0x1e940: 68,
0x1e941: 68,
0x1e942: 68,
0x1e943: 68,
}
codepoint_classes = {
'PVALID': (
0x2d0000002e,
0x300000003a,
0x610000007b,
0xdf000000f7,
0xf800000100,
0x10100000102,
0x10300000104,
0x10500000106,
0x10700000108,
0x1090000010a,
0x10b0000010c,
0x10d0000010e,
0x10f00000110,
0x11100000112,
0x11300000114,
0x11500000116,
0x11700000118,
0x1190000011a,
0x11b0000011c,
0x11d0000011e,
0x11f00000120,
0x12100000122,
0x12300000124,
0x12500000126,
0x12700000128,
0x1290000012a,
0x12b0000012c,
0x12d0000012e,
0x12f00000130,
0x13100000132,
0x13500000136,
0x13700000139,
0x13a0000013b,
0x13c0000013d,
0x13e0000013f,
0x14200000143,
0x14400000145,
0x14600000147,
0x14800000149,
0x14b0000014c,
0x14d0000014e,
0x14f00000150,
0x15100000152,
0x15300000154,
0x15500000156,
0x15700000158,
0x1590000015a,
0x15b0000015c,
0x15d0000015e,
0x15f00000160,
0x16100000162,
0x16300000164,
0x16500000166,
0x16700000168,
0x1690000016a,
0x16b0000016c,
0x16d0000016e,
0x16f00000170,
0x17100000172,
0x17300000174,
0x17500000176,
0x17700000178,
0x17a0000017b,
0x17c0000017d,
0x17e0000017f,
0x18000000181,
0x18300000184,
0x18500000186,
0x18800000189,
0x18c0000018e,
0x19200000193,
0x19500000196,
0x1990000019c,
0x19e0000019f,
0x1a1000001a2,
0x1a3000001a4,
0x1a5000001a6,
0x1a8000001a9,
0x1aa000001ac,
0x1ad000001ae,
0x1b0000001b1,
0x1b4000001b5,
0x1b6000001b7,
0x1b9000001bc,
0x1bd000001c4,
0x1ce000001cf,
0x1d0000001d1,
0x1d2000001d3,
0x1d4000001d5,
0x1d6000001d7,
0x1d8000001d9,
0x1da000001db,
0x1dc000001de,
0x1df000001e0,
0x1e1000001e2,
0x1e3000001e4,
0x1e5000001e6,
0x1e7000001e8,
0x1e9000001ea,
0x1eb000001ec,
0x1ed000001ee,
0x1ef000001f1,
0x1f5000001f6,
0x1f9000001fa,
0x1fb000001fc,
0x1fd000001fe,
0x1ff00000200,
0x20100000202,
0x20300000204,
0x20500000206,
0x20700000208,
0x2090000020a,
0x20b0000020c,
0x20d0000020e,
0x20f00000210,
0x21100000212,
0x21300000214,
0x21500000216,
0x21700000218,
0x2190000021a,
0x21b0000021c,
0x21d0000021e,
0x21f00000220,
0x22100000222,
0x22300000224,
0x22500000226,
0x22700000228,
0x2290000022a,
0x22b0000022c,
0x22d0000022e,
0x22f00000230,
0x23100000232,
0x2330000023a,
0x23c0000023d,
0x23f00000241,
0x24200000243,
0x24700000248,
0x2490000024a,
0x24b0000024c,
0x24d0000024e,
0x24f000002b0,
0x2b9000002c2,
0x2c6000002d2,
0x2ec000002ed,
0x2ee000002ef,
0x30000000340,
0x34200000343,
0x3460000034f,
0x35000000370,
0x37100000372,
0x37300000374,
0x37700000378,
0x37b0000037e,
0x39000000391,
0x3ac000003cf,
0x3d7000003d8,
0x3d9000003da,
0x3db000003dc,
0x3dd000003de,
0x3df000003e0,
0x3e1000003e2,
0x3e3000003e4,
0x3e5000003e6,
0x3e7000003e8,
0x3e9000003ea,
0x3eb000003ec,
0x3ed000003ee,
0x3ef000003f0,
0x3f3000003f4,
0x3f8000003f9,
0x3fb000003fd,
0x43000000460,
0x46100000462,
0x46300000464,
0x46500000466,
0x46700000468,
0x4690000046a,
0x46b0000046c,
0x46d0000046e,
0x46f00000470,
0x47100000472,
0x47300000474,
0x47500000476,
0x47700000478,
0x4790000047a,
0x47b0000047c,
0x47d0000047e,
0x47f00000480,
0x48100000482,
0x48300000488,
0x48b0000048c,
0x48d0000048e,
0x48f00000490,
0x49100000492,
0x49300000494,
0x49500000496,
0x49700000498,
0x4990000049a,
0x49b0000049c,
0x49d0000049e,
0x49f000004a0,
0x4a1000004a2,
0x4a3000004a4,
0x4a5000004a6,
0x4a7000004a8,
0x4a9000004aa,
0x4ab000004ac,
0x4ad000004ae,
0x4af000004b0,
0x4b1000004b2,
0x4b3000004b4,
0x4b5000004b6,
0x4b7000004b8,
0x4b9000004ba,
0x4bb000004bc,
0x4bd000004be,
0x4bf000004c0,
0x4c2000004c3,
0x4c4000004c5,
0x4c6000004c7,
0x4c8000004c9,
0x4ca000004cb,
0x4cc000004cd,
0x4ce000004d0,
0x4d1000004d2,
0x4d3000004d4,
0x4d5000004d6,
0x4d7000004d8,
0x4d9000004da,
0x4db000004dc,
0x4dd000004de,
0x4df000004e0,
0x4e1000004e2,
0x4e3000004e4,
0x4e5000004e6,
0x4e7000004e8,
0x4e9000004ea,
0x4eb000004ec,
0x4ed000004ee,
0x4ef000004f0,
0x4f1000004f2,
0x4f3000004f4,
0x4f5000004f6,
0x4f7000004f8,
0x4f9000004fa,
0x4fb000004fc,
0x4fd000004fe,
0x4ff00000500,
0x50100000502,
0x50300000504,
0x50500000506,
0x50700000508,
0x5090000050a,
0x50b0000050c,
0x50d0000050e,
0x50f00000510,
0x51100000512,
0x51300000514,
0x51500000516,
0x51700000518,
0x5190000051a,
0x51b0000051c,
0x51d0000051e,
0x51f00000520,
0x52100000522,
0x52300000524,
0x52500000526,
0x52700000528,
0x5290000052a,
0x52b0000052c,
0x52d0000052e,
0x52f00000530,
0x5590000055a,
0x56000000587,
0x58800000589,
0x591000005be,
0x5bf000005c0,
0x5c1000005c3,
0x5c4000005c6,
0x5c7000005c8,
0x5d0000005eb,
0x5ef000005f3,
0x6100000061b,
0x62000000640,
0x64100000660,
0x66e00000675,
0x679000006d4,
0x6d5000006dd,
0x6df000006e9,
0x6ea000006f0,
0x6fa00000700,
0x7100000074b,
0x74d000007b2,
0x7c0000007f6,
0x7fd000007fe,
0x8000000082e,
0x8400000085c,
0x8600000086b,
0x8a0000008b5,
0x8b6000008be,
0x8d3000008e2,
0x8e300000958,
0x96000000964,
0x96600000970,
0x97100000984,
0x9850000098d,
0x98f00000991,
0x993000009a9,
0x9aa000009b1,
0x9b2000009b3,
0x9b6000009ba,
0x9bc000009c5,
0x9c7000009c9,
0x9cb000009cf,
0x9d7000009d8,
0x9e0000009e4,
0x9e6000009f2,
0x9fc000009fd,
0x9fe000009ff,
0xa0100000a04,
0xa0500000a0b,
0xa0f00000a11,
0xa1300000a29,
0xa2a00000a31,
0xa3200000a33,
0xa3500000a36,
0xa3800000a3a,
0xa3c00000a3d,
0xa3e00000a43,
0xa4700000a49,
0xa4b00000a4e,
0xa5100000a52,
0xa5c00000a5d,
0xa6600000a76,
0xa8100000a84,
0xa8500000a8e,
0xa8f00000a92,
0xa9300000aa9,
0xaaa00000ab1,
0xab200000ab4,
0xab500000aba,
0xabc00000ac6,
0xac700000aca,
0xacb00000ace,
0xad000000ad1,
0xae000000ae4,
0xae600000af0,
0xaf900000b00,
0xb0100000b04,
0xb0500000b0d,
0xb0f00000b11,
0xb1300000b29,
0xb2a00000b31,
0xb3200000b34,
0xb3500000b3a,
0xb3c00000b45,
0xb4700000b49,
0xb4b00000b4e,
0xb5600000b58,
0xb5f00000b64,
0xb6600000b70,
0xb7100000b72,
0xb8200000b84,
0xb8500000b8b,
0xb8e00000b91,
0xb9200000b96,
0xb9900000b9b,
0xb9c00000b9d,
0xb9e00000ba0,
0xba300000ba5,
0xba800000bab,
0xbae00000bba,
0xbbe00000bc3,
0xbc600000bc9,
0xbca00000bce,
0xbd000000bd1,
0xbd700000bd8,
0xbe600000bf0,
0xc0000000c0d,
0xc0e00000c11,
0xc1200000c29,
0xc2a00000c3a,
0xc3d00000c45,
0xc4600000c49,
0xc4a00000c4e,
0xc5500000c57,
0xc5800000c5b,
0xc6000000c64,
0xc6600000c70,
0xc8000000c84,
0xc8500000c8d,
0xc8e00000c91,
0xc9200000ca9,
0xcaa00000cb4,
0xcb500000cba,
0xcbc00000cc5,
0xcc600000cc9,
0xcca00000cce,
0xcd500000cd7,
0xcde00000cdf,
0xce000000ce4,
0xce600000cf0,
0xcf100000cf3,
0xd0000000d04,
0xd0500000d0d,
0xd0e00000d11,
0xd1200000d45,
0xd4600000d49,
0xd4a00000d4f,
0xd5400000d58,
0xd5f00000d64,
0xd6600000d70,
0xd7a00000d80,
0xd8200000d84,
0xd8500000d97,
0xd9a00000db2,
0xdb300000dbc,
0xdbd00000dbe,
0xdc000000dc7,
0xdca00000dcb,
0xdcf00000dd5,
0xdd600000dd7,
0xdd800000de0,
0xde600000df0,
0xdf200000df4,
0xe0100000e33,
0xe3400000e3b,
0xe4000000e4f,
0xe5000000e5a,
0xe8100000e83,
0xe8400000e85,
0xe8700000e89,
0xe8a00000e8b,
0xe8d00000e8e,
0xe9400000e98,
0xe9900000ea0,
0xea100000ea4,
0xea500000ea6,
0xea700000ea8,
0xeaa00000eac,
0xead00000eb3,
0xeb400000eba,
0xebb00000ebe,
0xec000000ec5,
0xec600000ec7,
0xec800000ece,
0xed000000eda,
0xede00000ee0,
0xf0000000f01,
0xf0b00000f0c,
0xf1800000f1a,
0xf2000000f2a,
0xf3500000f36,
0xf3700000f38,
0xf3900000f3a,
0xf3e00000f43,
0xf4400000f48,
0xf4900000f4d,
0xf4e00000f52,
0xf5300000f57,
0xf5800000f5c,
0xf5d00000f69,
0xf6a00000f6d,
0xf7100000f73,
0xf7400000f75,
0xf7a00000f81,
0xf8200000f85,
0xf8600000f93,
0xf9400000f98,
0xf9900000f9d,
0xf9e00000fa2,
0xfa300000fa7,
0xfa800000fac,
0xfad00000fb9,
0xfba00000fbd,
0xfc600000fc7,
0x10000000104a,
0x10500000109e,
0x10d0000010fb,
0x10fd00001100,
0x120000001249,
0x124a0000124e,
0x125000001257,
0x125800001259,
0x125a0000125e,
0x126000001289,
0x128a0000128e,
0x1290000012b1,
0x12b2000012b6,
0x12b8000012bf,
0x12c0000012c1,
0x12c2000012c6,
0x12c8000012d7,
0x12d800001311,
0x131200001316,
0x13180000135b,
0x135d00001360,
0x138000001390,
0x13a0000013f6,
0x14010000166d,
0x166f00001680,
0x16810000169b,
0x16a0000016eb,
0x16f1000016f9,
0x17000000170d,
0x170e00001715,
0x172000001735,
0x174000001754,
0x17600000176d,
0x176e00001771,
0x177200001774,
0x1780000017b4,
0x17b6000017d4,
0x17d7000017d8,
0x17dc000017de,
0x17e0000017ea,
0x18100000181a,
0x182000001879,
0x1880000018ab,
0x18b0000018f6,
0x19000000191f,
0x19200000192c,
0x19300000193c,
0x19460000196e,
0x197000001975,
0x1980000019ac,
0x19b0000019ca,
0x19d0000019da,
0x1a0000001a1c,
0x1a2000001a5f,
0x1a6000001a7d,
0x1a7f00001a8a,
0x1a9000001a9a,
0x1aa700001aa8,
0x1ab000001abe,
0x1b0000001b4c,
0x1b5000001b5a,
0x1b6b00001b74,
0x1b8000001bf4,
0x1c0000001c38,
0x1c4000001c4a,
0x1c4d00001c7e,
0x1cd000001cd3,
0x1cd400001cfa,
0x1d0000001d2c,
0x1d2f00001d30,
0x1d3b00001d3c,
0x1d4e00001d4f,
0x1d6b00001d78,
0x1d7900001d9b,
0x1dc000001dfa,
0x1dfb00001e00,
0x1e0100001e02,
0x1e0300001e04,
0x1e0500001e06,
0x1e0700001e08,
0x1e0900001e0a,
0x1e0b00001e0c,
0x1e0d00001e0e,
0x1e0f00001e10,
0x1e1100001e12,
0x1e1300001e14,
0x1e1500001e16,
0x1e1700001e18,
0x1e1900001e1a,
0x1e1b00001e1c,
0x1e1d00001e1e,
0x1e1f00001e20,
0x1e2100001e22,
0x1e2300001e24,
0x1e2500001e26,
0x1e2700001e28,
0x1e2900001e2a,
0x1e2b00001e2c,
0x1e2d00001e2e,
0x1e2f00001e30,
0x1e3100001e32,
0x1e3300001e34,
0x1e3500001e36,
0x1e3700001e38,
0x1e3900001e3a,
0x1e3b00001e3c,
0x1e3d00001e3e,
0x1e3f00001e40,
0x1e4100001e42,
0x1e4300001e44,
0x1e4500001e46,
0x1e4700001e48,
0x1e4900001e4a,
0x1e4b00001e4c,
0x1e4d00001e4e,
0x1e4f00001e50,
0x1e5100001e52,
0x1e5300001e54,
0x1e5500001e56,
0x1e5700001e58,
0x1e5900001e5a,
0x1e5b00001e5c,
0x1e5d00001e5e,
0x1e5f00001e60,
0x1e6100001e62,
0x1e6300001e64,
0x1e6500001e66,
0x1e6700001e68,
0x1e6900001e6a,
0x1e6b00001e6c,
0x1e6d00001e6e,
0x1e6f00001e70,
0x1e7100001e72,
0x1e7300001e74,
0x1e7500001e76,
0x1e7700001e78,
0x1e7900001e7a,
0x1e7b00001e7c,
0x1e7d00001e7e,
0x1e7f00001e80,
0x1e8100001e82,
0x1e8300001e84,
0x1e8500001e86,
0x1e8700001e88,
0x1e8900001e8a,
0x1e8b00001e8c,
0x1e8d00001e8e,
0x1e8f00001e90,
0x1e9100001e92,
0x1e9300001e94,
0x1e9500001e9a,
0x1e9c00001e9e,
0x1e9f00001ea0,
0x1ea100001ea2,
0x1ea300001ea4,
0x1ea500001ea6,
0x1ea700001ea8,
0x1ea900001eaa,
0x1eab00001eac,
0x1ead00001eae,
0x1eaf00001eb0,
0x1eb100001eb2,
0x1eb300001eb4,
0x1eb500001eb6,
0x1eb700001eb8,
0x1eb900001eba,
0x1ebb00001ebc,
0x1ebd00001ebe,
0x1ebf00001ec0,
0x1ec100001ec2,
0x1ec300001ec4,
0x1ec500001ec6,
0x1ec700001ec8,
0x1ec900001eca,
0x1ecb00001ecc,
0x1ecd00001ece,
0x1ecf00001ed0,
0x1ed100001ed2,
0x1ed300001ed4,
0x1ed500001ed6,
0x1ed700001ed8,
0x1ed900001eda,
0x1edb00001edc,
0x1edd00001ede,
0x1edf00001ee0,
0x1ee100001ee2,
0x1ee300001ee4,
0x1ee500001ee6,
0x1ee700001ee8,
0x1ee900001eea,
0x1eeb00001eec,
0x1eed00001eee,
0x1eef00001ef0,
0x1ef100001ef2,
0x1ef300001ef4,
0x1ef500001ef6,
0x1ef700001ef8,
0x1ef900001efa,
0x1efb00001efc,
0x1efd00001efe,
0x1eff00001f08,
0x1f1000001f16,
0x1f2000001f28,
0x1f3000001f38,
0x1f4000001f46,
0x1f5000001f58,
0x1f6000001f68,
0x1f7000001f71,
0x1f7200001f73,
0x1f7400001f75,
0x1f7600001f77,
0x1f7800001f79,
0x1f7a00001f7b,
0x1f7c00001f7d,
0x1fb000001fb2,
0x1fb600001fb7,
0x1fc600001fc7,
0x1fd000001fd3,
0x1fd600001fd8,
0x1fe000001fe3,
0x1fe400001fe8,
0x1ff600001ff7,
0x214e0000214f,
0x218400002185,
0x2c3000002c5f,
0x2c6100002c62,
0x2c6500002c67,
0x2c6800002c69,
0x2c6a00002c6b,
0x2c6c00002c6d,
0x2c7100002c72,
0x2c7300002c75,
0x2c7600002c7c,
0x2c8100002c82,
0x2c8300002c84,
0x2c8500002c86,
0x2c8700002c88,
0x2c8900002c8a,
0x2c8b00002c8c,
0x2c8d00002c8e,
0x2c8f00002c90,
0x2c9100002c92,
0x2c9300002c94,
0x2c9500002c96,
0x2c9700002c98,
0x2c9900002c9a,
0x2c9b00002c9c,
0x2c9d00002c9e,
0x2c9f00002ca0,
0x2ca100002ca2,
0x2ca300002ca4,
0x2ca500002ca6,
0x2ca700002ca8,
0x2ca900002caa,
0x2cab00002cac,
0x2cad00002cae,
0x2caf00002cb0,
0x2cb100002cb2,
0x2cb300002cb4,
0x2cb500002cb6,
0x2cb700002cb8,
0x2cb900002cba,
0x2cbb00002cbc,
0x2cbd00002cbe,
0x2cbf00002cc0,
0x2cc100002cc2,
0x2cc300002cc4,
0x2cc500002cc6,
0x2cc700002cc8,
0x2cc900002cca,
0x2ccb00002ccc,
0x2ccd00002cce,
0x2ccf00002cd0,
0x2cd100002cd2,
0x2cd300002cd4,
0x2cd500002cd6,
0x2cd700002cd8,
0x2cd900002cda,
0x2cdb00002cdc,
0x2cdd00002cde,
0x2cdf00002ce0,
0x2ce100002ce2,
0x2ce300002ce5,
0x2cec00002ced,
0x2cee00002cf2,
0x2cf300002cf4,
0x2d0000002d26,
0x2d2700002d28,
0x2d2d00002d2e,
0x2d3000002d68,
0x2d7f00002d97,
0x2da000002da7,
0x2da800002daf,
0x2db000002db7,
0x2db800002dbf,
0x2dc000002dc7,
0x2dc800002dcf,
0x2dd000002dd7,
0x2dd800002ddf,
0x2de000002e00,
0x2e2f00002e30,
0x300500003008,
0x302a0000302e,
0x303c0000303d,
0x304100003097,
0x30990000309b,
0x309d0000309f,
0x30a1000030fb,
0x30fc000030ff,
0x310500003130,
0x31a0000031bb,
0x31f000003200,
0x340000004db6,
0x4e0000009ff0,
0xa0000000a48d,
0xa4d00000a4fe,
0xa5000000a60d,
0xa6100000a62c,
0xa6410000a642,
0xa6430000a644,
0xa6450000a646,
0xa6470000a648,
0xa6490000a64a,
0xa64b0000a64c,
0xa64d0000a64e,
0xa64f0000a650,
0xa6510000a652,
0xa6530000a654,
0xa6550000a656,
0xa6570000a658,
0xa6590000a65a,
0xa65b0000a65c,
0xa65d0000a65e,
0xa65f0000a660,
0xa6610000a662,
0xa6630000a664,
0xa6650000a666,
0xa6670000a668,
0xa6690000a66a,
0xa66b0000a66c,
0xa66d0000a670,
0xa6740000a67e,
0xa67f0000a680,
0xa6810000a682,
0xa6830000a684,
0xa6850000a686,
0xa6870000a688,
0xa6890000a68a,
0xa68b0000a68c,
0xa68d0000a68e,
0xa68f0000a690,
0xa6910000a692,
0xa6930000a694,
0xa6950000a696,
0xa6970000a698,
0xa6990000a69a,
0xa69b0000a69c,
0xa69e0000a6e6,
0xa6f00000a6f2,
0xa7170000a720,
0xa7230000a724,
0xa7250000a726,
0xa7270000a728,
0xa7290000a72a,
0xa72b0000a72c,
0xa72d0000a72e,
0xa72f0000a732,
0xa7330000a734,
0xa7350000a736,
0xa7370000a738,
0xa7390000a73a,
0xa73b0000a73c,
0xa73d0000a73e,
0xa73f0000a740,
0xa7410000a742,
0xa7430000a744,
0xa7450000a746,
0xa7470000a748,
0xa7490000a74a,
0xa74b0000a74c,
0xa74d0000a74e,
0xa74f0000a750,
0xa7510000a752,
0xa7530000a754,
0xa7550000a756,
0xa7570000a758,
0xa7590000a75a,
0xa75b0000a75c,
0xa75d0000a75e,
0xa75f0000a760,
0xa7610000a762,
0xa7630000a764,
0xa7650000a766,
0xa7670000a768,
0xa7690000a76a,
0xa76b0000a76c,
0xa76d0000a76e,
0xa76f0000a770,
0xa7710000a779,
0xa77a0000a77b,
0xa77c0000a77d,
0xa77f0000a780,
0xa7810000a782,
0xa7830000a784,
0xa7850000a786,
0xa7870000a789,
0xa78c0000a78d,
0xa78e0000a790,
0xa7910000a792,
0xa7930000a796,
0xa7970000a798,
0xa7990000a79a,
0xa79b0000a79c,
0xa79d0000a79e,
0xa79f0000a7a0,
0xa7a10000a7a2,
0xa7a30000a7a4,
0xa7a50000a7a6,
0xa7a70000a7a8,
0xa7a90000a7aa,
0xa7af0000a7b0,
0xa7b50000a7b6,
0xa7b70000a7b8,
0xa7b90000a7ba,
0xa7f70000a7f8,
0xa7fa0000a828,
0xa8400000a874,
0xa8800000a8c6,
0xa8d00000a8da,
0xa8e00000a8f8,
0xa8fb0000a8fc,
0xa8fd0000a92e,
0xa9300000a954,
0xa9800000a9c1,
0xa9cf0000a9da,
0xa9e00000a9ff,
0xaa000000aa37,
0xaa400000aa4e,
0xaa500000aa5a,
0xaa600000aa77,
0xaa7a0000aac3,
0xaadb0000aade,
0xaae00000aaf0,
0xaaf20000aaf7,
0xab010000ab07,
0xab090000ab0f,
0xab110000ab17,
0xab200000ab27,
0xab280000ab2f,
0xab300000ab5b,
0xab600000ab66,
0xabc00000abeb,
0xabec0000abee,
0xabf00000abfa,
0xac000000d7a4,
0xfa0e0000fa10,
0xfa110000fa12,
0xfa130000fa15,
0xfa1f0000fa20,
0xfa210000fa22,
0xfa230000fa25,
0xfa270000fa2a,
0xfb1e0000fb1f,
0xfe200000fe30,
0xfe730000fe74,
0x100000001000c,
0x1000d00010027,
0x100280001003b,
0x1003c0001003e,
0x1003f0001004e,
0x100500001005e,
0x10080000100fb,
0x101fd000101fe,
0x102800001029d,
0x102a0000102d1,
0x102e0000102e1,
0x1030000010320,
0x1032d00010341,
0x103420001034a,
0x103500001037b,
0x103800001039e,
0x103a0000103c4,
0x103c8000103d0,
0x104280001049e,
0x104a0000104aa,
0x104d8000104fc,
0x1050000010528,
0x1053000010564,
0x1060000010737,
0x1074000010756,
0x1076000010768,
0x1080000010806,
0x1080800010809,
0x1080a00010836,
0x1083700010839,
0x1083c0001083d,
0x1083f00010856,
0x1086000010877,
0x108800001089f,
0x108e0000108f3,
0x108f4000108f6,
0x1090000010916,
0x109200001093a,
0x10980000109b8,
0x109be000109c0,
0x10a0000010a04,
0x10a0500010a07,
0x10a0c00010a14,
0x10a1500010a18,
0x10a1900010a36,
0x10a3800010a3b,
0x10a3f00010a40,
0x10a6000010a7d,
0x10a8000010a9d,
0x10ac000010ac8,
0x10ac900010ae7,
0x10b0000010b36,
0x10b4000010b56,
0x10b6000010b73,
0x10b8000010b92,
0x10c0000010c49,
0x10cc000010cf3,
0x10d0000010d28,
0x10d3000010d3a,
0x10f0000010f1d,
0x10f2700010f28,
0x10f3000010f51,
0x1100000011047,
0x1106600011070,
0x1107f000110bb,
0x110d0000110e9,
0x110f0000110fa,
0x1110000011135,
0x1113600011140,
0x1114400011147,
0x1115000011174,
0x1117600011177,
0x11180000111c5,
0x111c9000111cd,
0x111d0000111db,
0x111dc000111dd,
0x1120000011212,
0x1121300011238,
0x1123e0001123f,
0x1128000011287,
0x1128800011289,
0x1128a0001128e,
0x1128f0001129e,
0x1129f000112a9,
0x112b0000112eb,
0x112f0000112fa,
0x1130000011304,
0x113050001130d,
0x1130f00011311,
0x1131300011329,
0x1132a00011331,
0x1133200011334,
0x113350001133a,
0x1133b00011345,
0x1134700011349,
0x1134b0001134e,
0x1135000011351,
0x1135700011358,
0x1135d00011364,
0x113660001136d,
0x1137000011375,
0x114000001144b,
0x114500001145a,
0x1145e0001145f,
0x11480000114c6,
0x114c7000114c8,
0x114d0000114da,
0x11580000115b6,
0x115b8000115c1,
0x115d8000115de,
0x1160000011641,
0x1164400011645,
0x116500001165a,
0x11680000116b8,
0x116c0000116ca,
0x117000001171b,
0x1171d0001172c,
0x117300001173a,
0x118000001183b,
0x118c0000118ea,
0x118ff00011900,
0x11a0000011a3f,
0x11a4700011a48,
0x11a5000011a84,
0x11a8600011a9a,
0x11a9d00011a9e,
0x11ac000011af9,
0x11c0000011c09,
0x11c0a00011c37,
0x11c3800011c41,
0x11c5000011c5a,
0x11c7200011c90,
0x11c9200011ca8,
0x11ca900011cb7,
0x11d0000011d07,
0x11d0800011d0a,
0x11d0b00011d37,
0x11d3a00011d3b,
0x11d3c00011d3e,
0x11d3f00011d48,
0x11d5000011d5a,
0x11d6000011d66,
0x11d6700011d69,
0x11d6a00011d8f,
0x11d9000011d92,
0x11d9300011d99,
0x11da000011daa,
0x11ee000011ef7,
0x120000001239a,
0x1248000012544,
0x130000001342f,
0x1440000014647,
0x1680000016a39,
0x16a4000016a5f,
0x16a6000016a6a,
0x16ad000016aee,
0x16af000016af5,
0x16b0000016b37,
0x16b4000016b44,
0x16b5000016b5a,
0x16b6300016b78,
0x16b7d00016b90,
0x16e6000016e80,
0x16f0000016f45,
0x16f5000016f7f,
0x16f8f00016fa0,
0x16fe000016fe2,
0x17000000187f2,
0x1880000018af3,
0x1b0000001b11f,
0x1b1700001b2fc,
0x1bc000001bc6b,
0x1bc700001bc7d,
0x1bc800001bc89,
0x1bc900001bc9a,
0x1bc9d0001bc9f,
0x1da000001da37,
0x1da3b0001da6d,
0x1da750001da76,
0x1da840001da85,
0x1da9b0001daa0,
0x1daa10001dab0,
0x1e0000001e007,
0x1e0080001e019,
0x1e01b0001e022,
0x1e0230001e025,
0x1e0260001e02b,
0x1e8000001e8c5,
0x1e8d00001e8d7,
0x1e9220001e94b,
0x1e9500001e95a,
0x200000002a6d7,
0x2a7000002b735,
0x2b7400002b81e,
0x2b8200002cea2,
0x2ceb00002ebe1,
),
'CONTEXTJ': (
0x200c0000200e,
),
'CONTEXTO': (
0xb7000000b8,
0x37500000376,
0x5f3000005f5,
0x6600000066a,
0x6f0000006fa,
0x30fb000030fc,
),
} | /rightfoot-1.3.2-py3-none-any.whl/pypi__idna/idna/idnadata.py | 0.408985 | 0.313472 | idnadata.py | pypi |
from .mbcharsetprober import MultiByteCharSetProber
from .codingstatemachine import CodingStateMachine
from .chardistribution import SJISDistributionAnalysis
from .jpcntx import SJISContextAnalysis
from .mbcssm import SJIS_SM_MODEL
from .enums import ProbingState, MachineState
class SJISProber(MultiByteCharSetProber):
def __init__(self):
super(SJISProber, self).__init__()
self.coding_sm = CodingStateMachine(SJIS_SM_MODEL)
self.distribution_analyzer = SJISDistributionAnalysis()
self.context_analyzer = SJISContextAnalysis()
self.reset()
def reset(self):
super(SJISProber, self).reset()
self.context_analyzer.reset()
@property
def charset_name(self):
return self.context_analyzer.charset_name
@property
def language(self):
return "Japanese"
def feed(self, byte_str):
for i in range(len(byte_str)):
coding_state = self.coding_sm.next_state(byte_str[i])
if coding_state == MachineState.ERROR:
self.logger.debug('%s %s prober hit error at byte %s',
self.charset_name, self.language, i)
self._state = ProbingState.NOT_ME
break
elif coding_state == MachineState.ITS_ME:
self._state = ProbingState.FOUND_IT
break
elif coding_state == MachineState.START:
char_len = self.coding_sm.get_current_charlen()
if i == 0:
self._last_char[1] = byte_str[0]
self.context_analyzer.feed(self._last_char[2 - char_len:],
char_len)
self.distribution_analyzer.feed(self._last_char, char_len)
else:
self.context_analyzer.feed(byte_str[i + 1 - char_len:i + 3
- char_len], char_len)
self.distribution_analyzer.feed(byte_str[i - 1:i + 1],
char_len)
self._last_char[0] = byte_str[-1]
if self.state == ProbingState.DETECTING:
if (self.context_analyzer.got_enough_data() and
(self.get_confidence() > self.SHORTCUT_THRESHOLD)):
self._state = ProbingState.FOUND_IT
return self.state
def get_confidence(self):
context_conf = self.context_analyzer.get_confidence()
distrib_conf = self.distribution_analyzer.get_confidence()
return max(context_conf, distrib_conf) | /rightfoot-1.3.2-py3-none-any.whl/pypi__chardet/chardet/sjisprober.py | 0.575469 | 0.172102 | sjisprober.py | pypi |
from .charsetprober import CharSetProber
from .enums import ProbingState
FREQ_CAT_NUM = 4
UDF = 0 # undefined
OTH = 1 # other
ASC = 2 # ascii capital letter
ASS = 3 # ascii small letter
ACV = 4 # accent capital vowel
ACO = 5 # accent capital other
ASV = 6 # accent small vowel
ASO = 7 # accent small other
CLASS_NUM = 8 # total classes
Latin1_CharToClass = (
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # 00 - 07
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # 08 - 0F
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # 10 - 17
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # 18 - 1F
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # 20 - 27
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # 28 - 2F
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # 30 - 37
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # 38 - 3F
OTH, ASC, ASC, ASC, ASC, ASC, ASC, ASC, # 40 - 47
ASC, ASC, ASC, ASC, ASC, ASC, ASC, ASC, # 48 - 4F
ASC, ASC, ASC, ASC, ASC, ASC, ASC, ASC, # 50 - 57
ASC, ASC, ASC, OTH, OTH, OTH, OTH, OTH, # 58 - 5F
OTH, ASS, ASS, ASS, ASS, ASS, ASS, ASS, # 60 - 67
ASS, ASS, ASS, ASS, ASS, ASS, ASS, ASS, # 68 - 6F
ASS, ASS, ASS, ASS, ASS, ASS, ASS, ASS, # 70 - 77
ASS, ASS, ASS, OTH, OTH, OTH, OTH, OTH, # 78 - 7F
OTH, UDF, OTH, ASO, OTH, OTH, OTH, OTH, # 80 - 87
OTH, OTH, ACO, OTH, ACO, UDF, ACO, UDF, # 88 - 8F
UDF, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # 90 - 97
OTH, OTH, ASO, OTH, ASO, UDF, ASO, ACO, # 98 - 9F
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # A0 - A7
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # A8 - AF
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # B0 - B7
OTH, OTH, OTH, OTH, OTH, OTH, OTH, OTH, # B8 - BF
ACV, ACV, ACV, ACV, ACV, ACV, ACO, ACO, # C0 - C7
ACV, ACV, ACV, ACV, ACV, ACV, ACV, ACV, # C8 - CF
ACO, ACO, ACV, ACV, ACV, ACV, ACV, OTH, # D0 - D7
ACV, ACV, ACV, ACV, ACV, ACO, ACO, ACO, # D8 - DF
ASV, ASV, ASV, ASV, ASV, ASV, ASO, ASO, # E0 - E7
ASV, ASV, ASV, ASV, ASV, ASV, ASV, ASV, # E8 - EF
ASO, ASO, ASV, ASV, ASV, ASV, ASV, OTH, # F0 - F7
ASV, ASV, ASV, ASV, ASV, ASO, ASO, ASO, # F8 - FF
)
# 0 : illegal
# 1 : very unlikely
# 2 : normal
# 3 : very likely
Latin1ClassModel = (
# UDF OTH ASC ASS ACV ACO ASV ASO
0, 0, 0, 0, 0, 0, 0, 0, # UDF
0, 3, 3, 3, 3, 3, 3, 3, # OTH
0, 3, 3, 3, 3, 3, 3, 3, # ASC
0, 3, 3, 3, 1, 1, 3, 3, # ASS
0, 3, 3, 3, 1, 2, 1, 2, # ACV
0, 3, 3, 3, 3, 3, 3, 3, # ACO
0, 3, 1, 3, 1, 1, 1, 3, # ASV
0, 3, 1, 3, 1, 1, 3, 3, # ASO
)
class Latin1Prober(CharSetProber):
def __init__(self):
super(Latin1Prober, self).__init__()
self._last_char_class = None
self._freq_counter = None
self.reset()
def reset(self):
self._last_char_class = OTH
self._freq_counter = [0] * FREQ_CAT_NUM
CharSetProber.reset(self)
@property
def charset_name(self):
return "ISO-8859-1"
@property
def language(self):
return ""
def feed(self, byte_str):
byte_str = self.filter_with_english_letters(byte_str)
for c in byte_str:
char_class = Latin1_CharToClass[c]
freq = Latin1ClassModel[(self._last_char_class * CLASS_NUM)
+ char_class]
if freq == 0:
self._state = ProbingState.NOT_ME
break
self._freq_counter[freq] += 1
self._last_char_class = char_class
return self.state
def get_confidence(self):
if self.state == ProbingState.NOT_ME:
return 0.01
total = sum(self._freq_counter)
if total < 0.01:
confidence = 0.0
else:
confidence = ((self._freq_counter[3] - self._freq_counter[1] * 20.0)
/ total)
if confidence < 0.0:
confidence = 0.0
# lower the confidence of latin1 so that other more accurate
# detector can take priority.
confidence = confidence * 0.73
return confidence | /rightfoot-1.3.2-py3-none-any.whl/pypi__chardet/chardet/latin1prober.py | 0.41941 | 0.165931 | latin1prober.py | pypi |
from .charsetprober import CharSetProber
from .codingstatemachine import CodingStateMachine
from .enums import LanguageFilter, ProbingState, MachineState
from .escsm import (HZ_SM_MODEL, ISO2022CN_SM_MODEL, ISO2022JP_SM_MODEL,
ISO2022KR_SM_MODEL)
class EscCharSetProber(CharSetProber):
"""
This CharSetProber uses a "code scheme" approach for detecting encodings,
whereby easily recognizable escape or shift sequences are relied on to
identify these encodings.
"""
def __init__(self, lang_filter=None):
super(EscCharSetProber, self).__init__(lang_filter=lang_filter)
self.coding_sm = []
if self.lang_filter & LanguageFilter.CHINESE_SIMPLIFIED:
self.coding_sm.append(CodingStateMachine(HZ_SM_MODEL))
self.coding_sm.append(CodingStateMachine(ISO2022CN_SM_MODEL))
if self.lang_filter & LanguageFilter.JAPANESE:
self.coding_sm.append(CodingStateMachine(ISO2022JP_SM_MODEL))
if self.lang_filter & LanguageFilter.KOREAN:
self.coding_sm.append(CodingStateMachine(ISO2022KR_SM_MODEL))
self.active_sm_count = None
self._detected_charset = None
self._detected_language = None
self._state = None
self.reset()
def reset(self):
super(EscCharSetProber, self).reset()
for coding_sm in self.coding_sm:
if not coding_sm:
continue
coding_sm.active = True
coding_sm.reset()
self.active_sm_count = len(self.coding_sm)
self._detected_charset = None
self._detected_language = None
@property
def charset_name(self):
return self._detected_charset
@property
def language(self):
return self._detected_language
def get_confidence(self):
if self._detected_charset:
return 0.99
else:
return 0.00
def feed(self, byte_str):
for c in byte_str:
for coding_sm in self.coding_sm:
if not coding_sm or not coding_sm.active:
continue
coding_state = coding_sm.next_state(c)
if coding_state == MachineState.ERROR:
coding_sm.active = False
self.active_sm_count -= 1
if self.active_sm_count <= 0:
self._state = ProbingState.NOT_ME
return self.state
elif coding_state == MachineState.ITS_ME:
self._state = ProbingState.FOUND_IT
self._detected_charset = coding_sm.get_coding_state_machine()
self._detected_language = coding_sm.language
return self.state
return self.state | /rightfoot-1.3.2-py3-none-any.whl/pypi__chardet/chardet/escprober.py | 0.796965 | 0.172033 | escprober.py | pypi |
import logging
import re
from .enums import ProbingState
class CharSetProber(object):
SHORTCUT_THRESHOLD = 0.95
def __init__(self, lang_filter=None):
self._state = None
self.lang_filter = lang_filter
self.logger = logging.getLogger(__name__)
def reset(self):
self._state = ProbingState.DETECTING
@property
def charset_name(self):
return None
def feed(self, buf):
pass
@property
def state(self):
return self._state
def get_confidence(self):
return 0.0
@staticmethod
def filter_high_byte_only(buf):
buf = re.sub(b'([\x00-\x7F])+', b' ', buf)
return buf
@staticmethod
def filter_international_words(buf):
"""
We define three types of bytes:
alphabet: english alphabets [a-zA-Z]
international: international characters [\x80-\xFF]
marker: everything else [^a-zA-Z\x80-\xFF]
The input buffer can be thought to contain a series of words delimited
by markers. This function works to filter all words that contain at
least one international character. All contiguous sequences of markers
are replaced by a single space ascii character.
This filter applies to all scripts which do not use English characters.
"""
filtered = bytearray()
# This regex expression filters out only words that have at-least one
# international character. The word may include one marker character at
# the end.
words = re.findall(b'[a-zA-Z]*[\x80-\xFF]+[a-zA-Z]*[^a-zA-Z\x80-\xFF]?',
buf)
for word in words:
filtered.extend(word[:-1])
# If the last character in the word is a marker, replace it with a
# space as markers shouldn't affect our analysis (they are used
# similarly across all languages and may thus have similar
# frequencies).
last_char = word[-1:]
if not last_char.isalpha() and last_char < b'\x80':
last_char = b' '
filtered.extend(last_char)
return filtered
@staticmethod
def filter_with_english_letters(buf):
"""
Returns a copy of ``buf`` that retains only the sequences of English
alphabet and high byte characters that are not between <> characters.
Also retains English alphabet and high byte characters immediately
before occurrences of >.
This filter can be applied to all scripts which contain both English
characters and extended ASCII characters, but is currently only used by
``Latin1Prober``.
"""
filtered = bytearray()
in_tag = False
prev = 0
for curr in range(len(buf)):
# Slice here to get bytes instead of an int with Python 3
buf_char = buf[curr:curr + 1]
# Check if we're coming out of or entering an HTML tag
if buf_char == b'>':
in_tag = False
elif buf_char == b'<':
in_tag = True
# If current character is not extended-ASCII and not alphabetic...
if buf_char < b'\x80' and not buf_char.isalpha():
# ...and we're not in a tag
if curr > prev and not in_tag:
# Keep everything after last non-extended-ASCII,
# non-alphabetic character
filtered.extend(buf[prev:curr])
# Output a space to delimit stretch we kept
filtered.extend(b' ')
prev = curr + 1
# If we're not in a tag...
if not in_tag:
# Keep everything after last non-extended-ASCII, non-alphabetic
# character
filtered.extend(buf[prev:])
return filtered | /rightfoot-1.3.2-py3-none-any.whl/pypi__chardet/chardet/charsetprober.py | 0.78016 | 0.25081 | charsetprober.py | pypi |
from .charsetprober import CharSetProber
from .enums import CharacterCategory, ProbingState, SequenceLikelihood
class SingleByteCharSetProber(CharSetProber):
SAMPLE_SIZE = 64
SB_ENOUGH_REL_THRESHOLD = 1024 # 0.25 * SAMPLE_SIZE^2
POSITIVE_SHORTCUT_THRESHOLD = 0.95
NEGATIVE_SHORTCUT_THRESHOLD = 0.05
def __init__(self, model, reversed=False, name_prober=None):
super(SingleByteCharSetProber, self).__init__()
self._model = model
# TRUE if we need to reverse every pair in the model lookup
self._reversed = reversed
# Optional auxiliary prober for name decision
self._name_prober = name_prober
self._last_order = None
self._seq_counters = None
self._total_seqs = None
self._total_char = None
self._freq_char = None
self.reset()
def reset(self):
super(SingleByteCharSetProber, self).reset()
# char order of last character
self._last_order = 255
self._seq_counters = [0] * SequenceLikelihood.get_num_categories()
self._total_seqs = 0
self._total_char = 0
# characters that fall in our sampling range
self._freq_char = 0
@property
def charset_name(self):
if self._name_prober:
return self._name_prober.charset_name
else:
return self._model['charset_name']
@property
def language(self):
if self._name_prober:
return self._name_prober.language
else:
return self._model.get('language')
def feed(self, byte_str):
if not self._model['keep_english_letter']:
byte_str = self.filter_international_words(byte_str)
if not byte_str:
return self.state
char_to_order_map = self._model['char_to_order_map']
for i, c in enumerate(byte_str):
# XXX: Order is in range 1-64, so one would think we want 0-63 here,
# but that leads to 27 more test failures than before.
order = char_to_order_map[c]
# XXX: This was SYMBOL_CAT_ORDER before, with a value of 250, but
# CharacterCategory.SYMBOL is actually 253, so we use CONTROL
# to make it closer to the original intent. The only difference
# is whether or not we count digits and control characters for
# _total_char purposes.
if order < CharacterCategory.CONTROL:
self._total_char += 1
if order < self.SAMPLE_SIZE:
self._freq_char += 1
if self._last_order < self.SAMPLE_SIZE:
self._total_seqs += 1
if not self._reversed:
i = (self._last_order * self.SAMPLE_SIZE) + order
model = self._model['precedence_matrix'][i]
else: # reverse the order of the letters in the lookup
i = (order * self.SAMPLE_SIZE) + self._last_order
model = self._model['precedence_matrix'][i]
self._seq_counters[model] += 1
self._last_order = order
charset_name = self._model['charset_name']
if self.state == ProbingState.DETECTING:
if self._total_seqs > self.SB_ENOUGH_REL_THRESHOLD:
confidence = self.get_confidence()
if confidence > self.POSITIVE_SHORTCUT_THRESHOLD:
self.logger.debug('%s confidence = %s, we have a winner',
charset_name, confidence)
self._state = ProbingState.FOUND_IT
elif confidence < self.NEGATIVE_SHORTCUT_THRESHOLD:
self.logger.debug('%s confidence = %s, below negative '
'shortcut threshhold %s', charset_name,
confidence,
self.NEGATIVE_SHORTCUT_THRESHOLD)
self._state = ProbingState.NOT_ME
return self.state
def get_confidence(self):
r = 0.01
if self._total_seqs > 0:
r = ((1.0 * self._seq_counters[SequenceLikelihood.POSITIVE]) /
self._total_seqs / self._model['typical_positive_ratio'])
r = r * self._freq_char / self._total_char
if r >= 1.0:
r = 0.99
return r | /rightfoot-1.3.2-py3-none-any.whl/pypi__chardet/chardet/sbcharsetprober.py | 0.841142 | 0.195114 | sbcharsetprober.py | pypi |
from .charsetprober import CharSetProber
from .enums import ProbingState, MachineState
class MultiByteCharSetProber(CharSetProber):
"""
MultiByteCharSetProber
"""
def __init__(self, lang_filter=None):
super(MultiByteCharSetProber, self).__init__(lang_filter=lang_filter)
self.distribution_analyzer = None
self.coding_sm = None
self._last_char = [0, 0]
def reset(self):
super(MultiByteCharSetProber, self).reset()
if self.coding_sm:
self.coding_sm.reset()
if self.distribution_analyzer:
self.distribution_analyzer.reset()
self._last_char = [0, 0]
@property
def charset_name(self):
raise NotImplementedError
@property
def language(self):
raise NotImplementedError
def feed(self, byte_str):
for i in range(len(byte_str)):
coding_state = self.coding_sm.next_state(byte_str[i])
if coding_state == MachineState.ERROR:
self.logger.debug('%s %s prober hit error at byte %s',
self.charset_name, self.language, i)
self._state = ProbingState.NOT_ME
break
elif coding_state == MachineState.ITS_ME:
self._state = ProbingState.FOUND_IT
break
elif coding_state == MachineState.START:
char_len = self.coding_sm.get_current_charlen()
if i == 0:
self._last_char[1] = byte_str[0]
self.distribution_analyzer.feed(self._last_char, char_len)
else:
self.distribution_analyzer.feed(byte_str[i - 1:i + 1],
char_len)
self._last_char[0] = byte_str[-1]
if self.state == ProbingState.DETECTING:
if (self.distribution_analyzer.got_enough_data() and
(self.get_confidence() > self.SHORTCUT_THRESHOLD)):
self._state = ProbingState.FOUND_IT
return self.state
def get_confidence(self):
return self.distribution_analyzer.get_confidence() | /rightfoot-1.3.2-py3-none-any.whl/pypi__chardet/chardet/mbcharsetprober.py | 0.614163 | 0.189203 | mbcharsetprober.py | pypi |
from __future__ import absolute_import, print_function, unicode_literals
import argparse
import sys
from chardet import __version__
from chardet.compat import PY2
from chardet.universaldetector import UniversalDetector
def description_of(lines, name='stdin'):
"""
Return a string describing the probable encoding of a file or
list of strings.
:param lines: The lines to get the encoding of.
:type lines: Iterable of bytes
:param name: Name of file or collection of lines
:type name: str
"""
u = UniversalDetector()
for line in lines:
line = bytearray(line)
u.feed(line)
# shortcut out of the loop to save reading further - particularly useful if we read a BOM.
if u.done:
break
u.close()
result = u.result
if PY2:
name = name.decode(sys.getfilesystemencoding(), 'ignore')
if result['encoding']:
return '{0}: {1} with confidence {2}'.format(name, result['encoding'],
result['confidence'])
else:
return '{0}: no result'.format(name)
def main(argv=None):
"""
Handles command line arguments and gets things started.
:param argv: List of arguments, as if specified on the command-line.
If None, ``sys.argv[1:]`` is used instead.
:type argv: list of str
"""
# Get command line arguments
parser = argparse.ArgumentParser(
description="Takes one or more file paths and reports their detected \
encodings")
parser.add_argument('input',
help='File whose encoding we would like to determine. \
(default: stdin)',
type=argparse.FileType('rb'), nargs='*',
default=[sys.stdin if PY2 else sys.stdin.buffer])
parser.add_argument('--version', action='version',
version='%(prog)s {0}'.format(__version__))
args = parser.parse_args(argv)
for f in args.input:
if f.isatty():
print("You are running chardetect interactively. Press " +
"CTRL-D twice at the start of a blank line to signal the " +
"end of your input. If you want help, run chardetect " +
"--help\n", file=sys.stderr)
print(description_of(f, f.name))
if __name__ == '__main__':
main() | /rightfoot-1.3.2-py3-none-any.whl/pypi__chardet/chardet/cli/chardetect.py | 0.537041 | 0.18591 | chardetect.py | pypi |
# Dependencies
from lxml import html, etree
import requests
import numpy as np
import pandas as pd
import datetime as dt
class _GetDataFromURL(object):
"""This "private" class does all the heavy lifting of fetching data from the
URL provided, and then returns data to the main `rightmove_data` class
instance. The reason for this is so that all the validation and web-scraping
is done when an instance is created, and afterwards the data is accessible
quickly via methods on the `rightmove_data` instance."""
def __init__(self, url):
"""Initialize an instance of the scraper by passing a URL from the
results of a property search on www.rightmove.co.uk."""
self.url = url
self.first_page = self.make_request(self.url)
self.validate_url()
self.get_results = self.__get_results
def validate_url(self):
"""Basic validation that the URL at least starts in the right format and
returns status code 200."""
real_url = "{}://www.rightmove.co.uk/{}/find.html?"
protocols = ["http", "https"]
types = ["property-to-rent", "property-for-sale", "new-homes-for-sale"]
left_urls = [real_url.format(p, t) for p in protocols for t in types]
conditions = [self.url.startswith(u) for u in left_urls]
conditions.append(self.first_page[1] == 200)
if not any(conditions):
raise ValueError("Invalid rightmove URL:\n\n\t{}".format(self.url))
@property
def rent_or_sale(self):
"""Tag to determine if the search is for properties for rent or sale.
Required beacuse the Xpaths are different for the target elements."""
if "/property-for-sale/" in self.url \
or "/new-homes-for-sale/" in self.url:
return "sale"
elif "/property-to-rent/" in self.url:
return "rent"
else:
raise ValueError("Invalid rightmove URL:\n\n\t{}".format(self.url))
@property
def results_count(self):
"""Returns an integer of the total number of listings as displayed on
the first page of results. Note that not all listings are available to
scrape because rightmove limits the number of accessible pages."""
tree = html.fromstring(self.first_page[0])
xpath = """//span[@class="searchHeader-resultCount"]/text()"""
try:
return int(tree.xpath(xpath)[0].replace(",", ""))
except:
print('error extracting the result count header')
return 1050
@property
def page_count(self):
"""Returns the number of result pages returned by the search URL. There
are 24 results per page. Note that the website limits results to a
maximum of 42 accessible pages."""
page_count = self.results_count // 24
if self.results_count % 24 > 0: page_count += 1
# Rightmove will return a maximum of 42 results pages, hence:
if page_count > 42: page_count = 42
return page_count
@staticmethod
def make_request(url):
r = requests.get(url)
content = r.content
status_code = r.status_code
del r
# Minimise the amount returned to reduce overheads:
return content, status_code
def get_page(self, request_content):
"""Method to scrape data from a single page of search results. Used
iteratively by the `get_results` method to scrape data from every page
returned by the search."""
# Process the html:
tree = html.fromstring(request_content)
# Set xpath for price:
if self.rent_or_sale == "rent":
xp_prices = """//span[@class="propertyCard-priceValue"]/text()"""
elif self.rent_or_sale == "sale":
xp_prices = """//div[@class="propertyCard-priceValue"]/text()"""
# Set xpaths for listing title, property address, URL, and agent URL:
xp_titles = """//div[@class="propertyCard-details"]\
//a[@class="propertyCard-link"]\
//h2[@class="propertyCard-title"]/text()"""
xp_addresses = """//address[@class="propertyCard-address"]//span/text()"""
xp_weblinks = """//div[@class="propertyCard-details"]\
//a[@class="propertyCard-link"]/@href"""
xp_agent_urls = """//div[@class="propertyCard-contactsItem"]\
//div[@class="propertyCard-branchLogo"]\
//a[@class="propertyCard-branchLogo-link"]/@href"""
# Create data lists from xpaths:
price_pcm = tree.xpath(xp_prices)
titles = tree.xpath(xp_titles)
addresses = tree.xpath(xp_addresses)
base = "http://www.rightmove.co.uk"
weblinks = ["{}{}".format(base, tree.xpath(xp_weblinks)[w]) \
for w in range(len(tree.xpath(xp_weblinks)))]
agent_urls = ["{}{}".format(base, tree.xpath(xp_agent_urls)[a]) \
for a in range(len(tree.xpath(xp_agent_urls)))]
#get floorplan from property urls
floorplan_urls = []
for weblink in weblinks:
rc = self.make_request(weblink)
tree = html.fromstring(rc[0])
del rc
xp_floorplan_url = """//*[@id="floorplanTabs"]/div[2]/div[2]/img/@src"""
floorplan_url = tree.xpath(xp_floorplan_url)
if floorplan_url == []:
floorplan_urls.append(np.nan)
else:
floorplan_urls.append(floorplan_url[0])
# Store the data in a Pandas DataFrame:
data = [price_pcm, titles, addresses, weblinks, agent_urls, floorplan_urls]
temp_df = pd.DataFrame(data)
temp_df = temp_df.transpose()
temp_df.columns = ["price", "type", "address", "url", "agent_url", "floorplan_url"]
del price_pcm, titles, addresses, weblinks, agent_urls, floorplan_urls
# Drop empty rows which come from placeholders in the html:
temp_df = temp_df[temp_df["address"].notnull()]
return temp_df
@property
def __get_results(self):
"""Pandas DataFrame with all results returned by the search."""
# Create DataFrame of the first page (which has already been requested):
results = self.get_page(self.first_page[0])
# Iterate through the rest of the pages scraping results:
if self.page_count > 1:
for p in range(1, self.page_count + 1, 1):
# Create the URL of the specific results page:
p_url = "{}&index={}".format(str(self.url), str((p * 24)))
# Make the request:
rc = self.make_request(p_url)
# Requests to scrape lots of pages eventually get status 400, so:
if rc[1] != 200: break
# Create a temporary dataframe of page results:
temp_df = self.get_page(rc[0])
# Concatenate the temporary dataframe with the full dataframe:
frames = [results, temp_df]
results = pd.concat(frames)
del temp_df, rc, frames
# Reset the index:
results.reset_index(inplace=True, drop=True)
# Convert price column to numeric type:
results["price"].replace(regex=True, inplace=True, to_replace=r"\D", value=r"")
results["price"] = pd.to_numeric(results["price"])
# Extract postcodes to a separate column:
pat = r"\b([A-Za-z][A-Za-z]?[0-9][0-9]?[A-Za-z]?)\b"
results["postcode"] = results["address"].astype(str).str.extract(pat, expand=True)
# Extract number of bedrooms from "type" to a separate column:
pat = r"\b([\d][\d]?)\b"
results["number_bedrooms"] = results.type.astype(str).str.extract(pat, expand=True)
results.loc[results["type"].astype(str).str.contains("studio", case=False), "number_bedrooms"] = 0
# Clean up annoying white spaces and newlines in "type" column:
for row in range(len(results)):
type_str = results.loc[row, "type"]
clean_str = type_str.strip("\n").strip()
results.loc[row, "type"] = clean_str
# Add column with datetime when the search was run (i.e. now):
now = dt.datetime.today()
results["search_date"] = now
return results
class rightmove_data(object):
"""The `rightmove_data` web scraper collects structured data on properties
returned by a search performed on www.rightmove.co.uk
An instance of the class created with a rightmove URL provides attributes to
easily access data from the search results, the most useful being
`get_results`, which returns all results as a Pandas DataFrame object.
"""
def __init__(self, url):
"""Initialize the scraper with a URL from the results of a property
search performed on www.rightmove.co.uk"""
self.__request_object = _GetDataFromURL(url)
self.__url = url
@property
def url(self):
return self.__url
@property
def get_results(self):
"""Pandas DataFrame of all results returned by the search."""
return self.__request_object.get_results
@property
def results_count(self):
"""Total number of results returned by `get_results`. Note that the
rightmove website may state a much higher number of results; this is
because they artificially restrict the number of results pages that can
be accessed to 42."""
return len(self.get_results)
@property
def average_price(self):
"""Average price of all results returned by `get_results` (ignoring
results which don't list a price)."""
total = self.get_results["price"].dropna().sum()
return int(total / self.results_count)
def summary(self, by="number_bedrooms"):
"""Pandas DataFrame summarising the the results by mean price and count.
By default grouped by the `number_bedrooms` column but will accept any
column name from `get_results` as a grouper."""
df = self.get_results.dropna(axis=0, subset=["price"])
groupers = {"price":["count", "mean"]}
df = df.groupby(df[by]).agg(groupers).astype(int)
df.columns = df.columns.get_level_values(1)
df.reset_index(inplace=True)
if "number_bedrooms" in df.columns:
df["number_bedrooms"] = df["number_bedrooms"].astype(int)
df.sort_values(by=["number_bedrooms"], inplace=True)
else:
df.sort_values(by=["count"], inplace=True, ascending=False)
return df.reset_index(drop=True) | /rightmove_floorscraper-0.4-py3-none-any.whl/rightmove_floorscraper/__init__.py | 0.798854 | 0.338296 | __init__.py | pypi |
import datetime
from lxml import html
import numpy as np
import pandas as pd
import requests
class RightmoveData:
"""The `RightmoveData` webscraper collects structured data on properties
returned by a search performed on www.rightmove.co.uk
An instance of the class provides attributes to access data from the search
results, the most useful being `get_results`, which returns all results as a
Pandas DataFrame object.
The query to rightmove can be renewed by calling the `refresh_data` method.
"""
def __init__(self, url: str, get_floorplans: bool = False):
"""Initialize the scraper with a URL from the results of a property
search performed on www.rightmove.co.uk.
Args:
url (str): full HTML link to a page of rightmove search results.
get_floorplans (bool): optionally scrape links to the individual
floor plan images for each listing (be warned this drastically
increases runtime so is False by default).
"""
self._status_code, self._first_page = self._request(url)
self._url = url
self._validate_url()
self._results = self._get_results(get_floorplans=get_floorplans)
@staticmethod
def _request(url: str):
r = requests.get(url)
return r.status_code, r.content
def refresh_data(self, url: str = None, get_floorplans: bool = False):
"""Make a fresh GET request for the rightmove data.
Args:
url (str): optionally pass a new HTML link to a page of rightmove
search results (else defaults to the current `url` attribute).
get_floorplans (bool): optionally scrape links to the individual
flooplan images for each listing (this drastically increases
runtime so is False by default).
"""
url = self.url if not url else url
self._status_code, self._first_page = self._request(url)
self._url = url
self._validate_url()
self._results = self._get_results(get_floorplans=get_floorplans)
def _validate_url(self):
"""Basic validation that the URL at least starts in the right format and
returns status code 200."""
real_url = "{}://www.rightmove.co.uk/{}/find.html?"
protocols = ["http", "https"]
types = ["property-to-rent", "property-for-sale", "new-homes-for-sale"]
urls = [real_url.format(p, t) for p in protocols for t in types]
conditions = [self.url.startswith(u) for u in urls]
conditions.append(self._status_code == 200)
if not any(conditions):
raise ValueError(f"Invalid rightmove search URL:\n\n\t{self.url}")
@property
def url(self):
return self._url
@property
def get_results(self):
"""Pandas DataFrame of all results returned by the search."""
return self._results
@property
def results_count(self):
"""Total number of results returned by `get_results`. Note that the
rightmove website may state a much higher number of results; this is
because they artificially restrict the number of results pages that can
be accessed to 42."""
return len(self.get_results)
@property
def average_price(self):
"""Average price of all results returned by `get_results` (ignoring
results which don't list a price)."""
total = self.get_results["price"].dropna().sum()
return total / self.results_count
def summary(self, by: str = None):
"""DataFrame summarising results by mean price and count. Defaults to
grouping by `number_bedrooms` (residential) or `type` (commercial), but
accepts any column name from `get_results` as a grouper.
Args:
by (str): valid column name from `get_results` DataFrame attribute.
"""
if not by:
by = "type" if "commercial" in self.rent_or_sale else "number_bedrooms"
assert by in self.get_results.columns, f"Column not found in `get_results`: {by}"
df = self.get_results.dropna(axis=0, subset=["price"])
groupers = {"price": ["count", "mean"]}
df = df.groupby(df[by]).agg(groupers)
df.columns = df.columns.get_level_values(1)
df.reset_index(inplace=True)
if "number_bedrooms" in df.columns:
df["number_bedrooms"] = df["number_bedrooms"].astype(int)
df.sort_values(by=["number_bedrooms"], inplace=True)
else:
df.sort_values(by=["count"], inplace=True, ascending=False)
return df.reset_index(drop=True)
@property
def rent_or_sale(self):
"""String specifying if the search is for properties for rent or sale.
Required because Xpaths are different for the target elements."""
if "/property-for-sale/" in self.url or "/new-homes-for-sale/" in self.url:
return "sale"
elif "/property-to-rent/" in self.url:
return "rent"
elif "/commercial-property-for-sale/" in self.url:
return "sale-commercial"
elif "/commercial-property-to-let/" in self.url:
return "rent-commercial"
else:
raise ValueError(f"Invalid rightmove URL:\n\n\t{self.url}")
@property
def results_count_display(self):
"""Returns an integer of the total number of listings as displayed on
the first page of results. Note that not all listings are available to
scrape because rightmove limits the number of accessible pages."""
tree = html.fromstring(self._first_page)
xpath = """//span[@class="searchHeader-resultCount"]/text()"""
return int(tree.xpath(xpath)[0].replace(",", ""))
@property
def page_count(self):
"""Returns the number of result pages returned by the search URL. There
are 24 results per page. Note that the website limits results to a
maximum of 42 accessible pages."""
page_count = self.results_count_display // 24
if self.results_count_display % 24 > 0:
page_count += 1
# Rightmove will return a maximum of 42 results pages, hence:
if page_count > 42:
page_count = 42
return page_count
def _get_page(self, request_content: str, get_floorplans: bool = False):
"""Method to scrape data from a single page of search results. Used
iteratively by the `get_results` method to scrape data from every page
returned by the search."""
# Process the html:
tree = html.fromstring(request_content)
# Set xpath for price:
if "rent" in self.rent_or_sale:
xp_prices = """//span[@class="propertyCard-priceValue"]/text()"""
elif "sale" in self.rent_or_sale:
xp_prices = """//div[@class="propertyCard-priceValue"]/text()"""
else:
raise ValueError("Invalid URL format.")
# Set xpaths for listing title, property address, URL, and agent URL:
xp_titles = """//div[@class="propertyCard-details"]\
//a[@class="propertyCard-link"]\
//h2[@class="propertyCard-title"]/text()"""
xp_addresses = """//address[@class="propertyCard-address"]//span/text()"""
xp_weblinks = """//div[@class="propertyCard-details"]//a[@class="propertyCard-link"]/@href"""
xp_agent_urls = """//div[@class="propertyCard-contactsItem"]\
//div[@class="propertyCard-branchLogo"]\
//a[@class="propertyCard-branchLogo-link"]/@href"""
# Create data lists from xpaths:
price_pcm = tree.xpath(xp_prices)
titles = tree.xpath(xp_titles)
addresses = tree.xpath(xp_addresses)
base = "http://www.rightmove.co.uk"
weblinks = [f"{base}{tree.xpath(xp_weblinks)[w]}" for w in range(len(tree.xpath(xp_weblinks)))]
agent_urls = [f"{base}{tree.xpath(xp_agent_urls)[a]}" for a in range(len(tree.xpath(xp_agent_urls)))]
# Optionally get floorplan links from property urls (longer runtime):
floorplan_urls = list() if get_floorplans else np.nan
if get_floorplans:
for weblink in weblinks:
status_code, content = self._request(weblink)
if status_code != 200:
continue
tree = html.fromstring(content)
xp_floorplan_url = """//*[@id="floorplanTabs"]/div[2]/div[2]/img/@src"""
floorplan_url = tree.xpath(xp_floorplan_url)
if floorplan_url:
floorplan_urls.append(floorplan_url[0])
else:
floorplan_urls.append(np.nan)
# Store the data in a Pandas DataFrame:
data = [price_pcm, titles, addresses, weblinks, agent_urls]
data = data + [floorplan_urls] if get_floorplans else data
temp_df = pd.DataFrame(data)
temp_df = temp_df.transpose()
columns = ["price", "type", "address", "url", "agent_url"]
columns = columns + ["floorplan_url"] if get_floorplans else columns
temp_df.columns = columns
# Drop empty rows which come from placeholders in the html:
temp_df = temp_df[temp_df["address"].notnull()]
return temp_df
def _get_results(self, get_floorplans: bool = False):
"""Build a Pandas DataFrame with all results returned by the search."""
results = self._get_page(self._first_page, get_floorplans=get_floorplans)
# Iterate through all pages scraping results:
for p in range(1, self.page_count + 1, 1):
# Create the URL of the specific results page:
p_url = f"{str(self.url)}&index={p * 24}"
# Make the request:
status_code, content = self._request(p_url)
# Requests to scrape lots of pages eventually get status 400, so:
if status_code != 200:
break
# Create a temporary DataFrame of page results:
temp_df = self._get_page(content, get_floorplans=get_floorplans)
# Concatenate the temporary DataFrame with the full DataFrame:
frames = [results, temp_df]
results = pd.concat(frames)
return self._clean_results(results)
@staticmethod
def _clean_results(results: pd.DataFrame):
# Reset the index:
results.reset_index(inplace=True, drop=True)
# Convert price column to numeric type:
results["price"].replace(regex=True, inplace=True, to_replace=r"\D", value=r"")
results["price"] = pd.to_numeric(results["price"])
# Extract short postcode area to a separate column:
pat = r"\b([A-Za-z][A-Za-z]?[0-9][0-9]?[A-Za-z]?)\b"
results["postcode"] = results["address"].astype(str).str.extract(pat, expand=True)[0]
# Extract full postcode to a separate column:
pat = r"([A-Za-z][A-Za-z]?[0-9][0-9]?[A-Za-z]?[0-9]?\s[0-9]?[A-Za-z][A-Za-z])"
results["full_postcode"] = results["address"].astype(str).str.extract(pat, expand=True)[0]
# Extract number of bedrooms from `type` to a separate column:
pat = r"\b([\d][\d]?)\b"
results["number_bedrooms"] = results["type"].astype(str).str.extract(pat, expand=True)[0]
results.loc[results["type"].str.contains("studio", case=False), "number_bedrooms"] = 0
results["number_bedrooms"] = pd.to_numeric(results["number_bedrooms"])
# Clean up annoying white spaces and newlines in `type` column:
results["type"] = results["type"].str.strip("\n").str.strip()
# Add column with datetime when the search was run (i.e. now):
now = datetime.datetime.now()
results["search_date"] = now
return results | /rightmove_webscraper-1.1.2-py3-none-any.whl/rightmove_webscraper/scraper.py | 0.876026 | 0.441252 | scraper.py | pypi |
import numpy as np
# define a function to calculate the slope and y-intercept of the line
def linear_regression(x, y):
n = len(x)
x_mean = np.mean(x)
y_mean = np.mean(y)
numerator = 0
denominator = 0
for i in range(n):
numerator += (x[i] - x_mean) * (y[i] - y_mean)
denominator += (x[i] - x_mean) ** 2
slope = numerator / denominator
y_intercept = y_mean - slope * x_mean
return slope, y_intercept
# define a function to make predictions using the calculated slope and y-intercept
def predict_linear(x, slope, y_intercept):
y_pred = slope * x + y_intercept
return y_pred
#polynomial regression
import numpy as np
# define a function to create a polynomial feature matrix
def create_polynomial_features(x, degree):
x_poly = np.zeros((len(x), degree))
for i in range(degree):
x_poly[:, i] = x ** (i+1)
return x_poly
# define a function to perform polynomial regression
def polynomial_regression(x, y, degree):
x_poly = create_polynomial_features(x, degree)
model = np.linalg.lstsq(x_poly, y, rcond=None)[0]
return model
# define a function to make predictions using the polynomial model
def predict_polynomial(x, model):
y_pred = np.zeros_like(x)
for i in range(len(model)):
y_pred += model[i] * x ** (i+1)
return y_pred
#multiple linear regression
import numpy as np
# define a function to perform multiple linear regression
def multiple_linear_regression(x, y):
X = np.column_stack((np.ones(len(x)), x)) # add a column of ones for the intercept term
model = np.linalg.lstsq(X, y, rcond=None)[0]
return model
# define a function to make predictions using the multiple linear regression model
def predict_multiple(x, model):
X = np.column_stack((np.ones(len(x)), x))
y_pred = np.dot(X, model)
return y_pred
def mean_absolute_error(y_actual, y_pred):
return np.mean(np.abs(y_actual - y_pred))
import numpy as np
def root_mean_squared_error(y_actual, y_pred):
return np.sqrt(np.mean((y_actual - y_pred)**2))
import numpy as np
def r_squared(y_actual, y_pred):
ssr = np.sum((y_actual - y_pred)**2)
sst = np.sum((y_actual - np.mean(y_actual))**2)
return 1 - (ssr / sst) | /rigi-1.0-py3-none-any.whl/regi/regi.py | 0.53607 | 0.796055 | regi.py | pypi |
import numpy as np
from anytree import NodeMixin, RenderTree, Walker
from quaternion import as_float_array, as_quat_array, from_rotation_matrix
from rigid_body_motion.core import (
TransformMatcher,
_estimate_angular_velocity,
_estimate_linear_velocity,
_resolve_rf,
)
from rigid_body_motion.utils import qinv, rotate_vectors
_registry = {}
def _register(rf, update=False):
""" Register a reference frame. """
if rf.name is None:
raise ValueError("Reference frame name cannot be None.")
if rf.name in _registry:
if update:
# TODO keep children?
_registry[rf.name].parent = None
else:
raise ValueError(
f"Reference frame with name {rf.name} is already registered. "
f"Specify update=True to overwrite."
)
# TODO check if name is a cs transform?
_registry[rf.name] = rf
def _deregister(name):
""" Deregister a reference frame. """
if name not in _registry:
raise ValueError(
"Reference frame with name " + name + " not found in registry"
)
_registry.pop(name)
def render_tree(root):
""" Render a reference frame tree.
Parameters
----------
root: str or ReferenceFrame
The root of the rendered tree.
"""
for pre, _, node in RenderTree(_resolve_rf(root)):
print(f"{pre}{node.name}")
def register_frame(
name,
parent=None,
translation=None,
rotation=None,
timestamps=None,
inverse=False,
discrete=False,
update=False,
):
""" Register a new reference frame in the registry.
Parameters
----------
name: str
The name of the reference frame.
parent: str or ReferenceFrame, optional
The parent reference frame. If str, the frame will be looked up
in the registry under that name. If not specified, this frame
will be a root node of a new reference frame tree.
translation: array_like, optional
The translation of this frame wrt the parent frame. Not
applicable if there is no parent frame.
rotation: array_like, optional
The rotation of this frame wrt the parent frame. Not
applicable if there is no parent frame.
timestamps: array_like, optional
The timestamps for translation and rotation of this frame. Not
applicable if this is a static reference frame.
inverse: bool, default False
If True, invert the transform wrt the parent frame, i.e. the
translation and rotation are specified for the parent frame wrt this
frame.
discrete: bool, default False
If True, transformations with timestamps are assumed to be events.
Instead of interpolating between timestamps, transformations are
fixed between their timestamp and the next one.
update: bool, default False
If True, overwrite if there is a frame with the same name in the
registry.
"""
# TODO make this a class with __call__, from_dataset etc. methods?
rf = ReferenceFrame(
name,
parent=parent,
translation=translation,
rotation=rotation,
timestamps=timestamps,
inverse=inverse,
discrete=discrete,
)
_register(rf, update=update)
def deregister_frame(name):
""" Remove a reference frame from the registry.
Parameters
----------
name: str
The name of the reference frame.
"""
_deregister(name)
def clear_registry():
""" Clear the reference frame registry. """
_registry.clear()
class ReferenceFrame(NodeMixin):
""" A three-dimensional reference frame. """
def __init__(
self,
name=None,
parent=None,
translation=None,
rotation=None,
timestamps=None,
inverse=False,
discrete=False,
):
""" Constructor.
Parameters
----------
name: str, optional
The name of this reference frame.
parent: str or ReferenceFrame, optional
The parent reference frame. If str, the frame will be looked up
in the registry under that name. If not specified, this frame
will be a root node of a new reference frame tree.
translation: array_like, optional
The translation of this frame wrt the parent frame. Not
applicable if there is no parent frame.
rotation: array_like, optional
The rotation of this frame wrt the parent frame. Not
applicable if there is no parent frame.
timestamps: array_like, optional
The timestamps for translation and rotation of this frame. Not
applicable if this is a static reference frame.
inverse: bool, default False
If True, invert the transform wrt the parent frame, i.e. the
translation and rotation are specified for the parent frame wrt
this frame.
discrete: bool, default False
If True, transformations with timestamps are assumed to be events.
Instead of interpolating between timestamps, transformations are
fixed between their timestamp and the next one.
"""
super(ReferenceFrame, self).__init__()
# TODO check name requirement
self.name = name
if parent is not None:
self.parent = _resolve_rf(parent)
(
self.translation,
self.rotation,
self.timestamps,
) = self._init_arrays(translation, rotation, timestamps, inverse)
else:
self.parent = None
self._verify_root(translation, rotation, timestamps)
self.translation, self.rotation, self.timestamps = None, None, None
if discrete and self.timestamps is None:
raise ValueError("timestamps must be provided when discrete=True")
else:
self.discrete = discrete
def __del__(self):
""" Destructor. """
if self.name in _registry and _registry[self.name] is self:
_deregister(self.name)
def __str__(self):
""" String representation. """
return f"<ReferenceFrame '{self.name}'>"
def __repr__(self):
""" String representation. """
return self.__str__()
@staticmethod
def _init_arrays(translation, rotation, timestamps, inverse):
""" Initialize translation, rotation and timestamp arrays. """
if timestamps is not None:
timestamps = np.asarray(timestamps)
if timestamps.ndim != 1:
raise ValueError("timestamps must be one-dimensional.")
t_shape = (len(timestamps), 3)
r_shape = (len(timestamps), 4)
else:
t_shape = (3,)
r_shape = (4,)
if translation is not None:
translation = np.asarray(translation)
if translation.shape != t_shape:
raise ValueError(
f"Expected translation to be of shape {t_shape}, got "
f"{translation.shape}"
)
else:
translation = np.zeros(t_shape)
if rotation is not None:
rotation = np.asarray(rotation)
if rotation.shape != r_shape:
raise ValueError(
f"Expected rotation to be of shape {r_shape}, got "
f"{rotation.shape}"
)
else:
rotation = np.zeros(r_shape)
rotation[..., 0] = 1.0
if inverse:
rotation = qinv(rotation)
translation = -rotate_vectors(rotation, translation)
return translation, rotation, timestamps
@staticmethod
def _verify_root(translation, rotation, timestamps):
""" Verify arguments for root node. """
# TODO test
if translation is not None:
raise ValueError("translation specified without parent frame.")
if rotation is not None:
raise ValueError("rotation specified without parent frame.")
if timestamps is not None:
raise ValueError("timestamps specified without parent frame.")
@classmethod
def _validate_input(cls, arr, axis, n_axis, timestamps, time_axis):
""" Validate shape of array and timestamps. """
# TODO process DataArray (dim=str, timestamps=str)
arr = np.asarray(arr)
if arr.shape[axis] != n_axis:
raise ValueError(
f"Expected array to have length {n_axis} along axis {axis}, "
f"got {arr.shape[axis]}"
)
if timestamps is not None:
timestamps = np.asarray(timestamps)
if timestamps.ndim != 1:
raise ValueError("timestamps must be one-dimensional")
if arr.shape[time_axis] != len(timestamps):
raise ValueError(
f"Axis {time_axis} of the array must have the same length "
f"as the timestamps"
)
# TODO this should be done somewhere else
arr = np.swapaxes(arr, 0, time_axis)
return arr, timestamps
@classmethod
def _expand_singleton_axes(cls, t_or_r, ndim):
""" Expand singleton axes for correct broadcasting with array. """
if t_or_r.ndim > 1:
for _ in range(ndim - 2):
t_or_r = np.expand_dims(t_or_r, 1)
return t_or_r
@classmethod
def _match_arrays(cls, arrays, timestamps=None):
""" Match multiple arrays with timestamps. """
matcher = TransformMatcher()
for array in arrays:
matcher.add_array(*array)
return matcher.get_arrays(timestamps)
def _walk(self, to_rf):
""" Walk from this frame to a target frame along the tree. """
to_rf = _resolve_rf(to_rf)
walker = Walker()
up, _, down = walker.walk(self, to_rf)
return up, down
def _get_matcher(self, to_frame, arrays=None):
""" Get a TransformMatcher from this frame to another. """
up, down = self._walk(to_frame)
matcher = TransformMatcher()
for rf in up:
matcher.add_reference_frame(rf)
for rf in down:
matcher.add_reference_frame(rf, inverse=True)
if arrays is not None:
for array in arrays:
matcher.add_array(*array)
return matcher
@classmethod
def from_dataset(
cls,
ds,
translation,
rotation,
timestamps,
parent,
name=None,
inverse=False,
discrete=False,
):
""" Construct a reference frame from a Dataset.
Parameters
----------
ds: xarray Dataset
The dataset from which to construct the reference frame.
translation: str
The name of the variable representing the translation
wrt the parent frame.
rotation: str
The name of the variable representing the rotation
wrt the parent frame.
timestamps: str
The name of the variable or coordinate representing the
timestamps.
parent: str or ReferenceFrame
The parent reference frame. If str, the frame will be looked up
in the registry under that name.
name: str, default None
The name of the reference frame.
inverse: bool, default False
If True, invert the transform wrt the parent frame, i.e. the
translation and rotation are specified for the parent frame wrt
this frame.
discrete: bool, default False
If True, transformations with timestamps are assumed to be events.
Instead of interpolating between timestamps, transformations are
fixed between their timestamp and the next one.
Returns
-------
rf: ReferenceFrame
The constructed reference frame.
"""
# TODO raise errors here if dimensions etc. don't match
return cls(
name,
parent,
ds[translation].data,
ds[rotation].data,
ds[timestamps].data,
inverse=inverse,
discrete=discrete,
)
@classmethod
def from_translation_dataarray(
cls, da, timestamps, parent, name=None, inverse=False, discrete=False,
):
""" Construct a reference frame from a translation DataArray.
Parameters
----------
da: xarray DataArray
The array that describes the translation of this frame
wrt the parent frame.
timestamps: str
The name of the variable or coordinate representing the
timestamps.
parent: str or ReferenceFrame
The parent reference frame. If str, the frame will be looked up
in the registry under that name.
name: str, default None
The name of the reference frame.
inverse: bool, default False
If True, invert the transform wrt the parent frame, i.e. the
translation is specified for the parent frame wrt this frame.
discrete: bool, default False
If True, transformations with timestamps are assumed to be events.
Instead of interpolating between timestamps, transformations are
fixed between their timestamp and the next one.
Returns
-------
rf: ReferenceFrame
The constructed reference frame.
"""
# TODO raise errors here if dimensions etc. don't match
return cls(
name,
parent,
translation=da.data,
timestamps=da[timestamps].data,
inverse=inverse,
discrete=discrete,
)
@classmethod
def from_rotation_dataarray(
cls, da, timestamps, parent, name=None, inverse=False, discrete=False,
):
""" Construct a reference frame from a rotation DataArray.
Parameters
----------
da: xarray DataArray
The array that describes the rotation of this frame
wrt the parent frame.
timestamps: str
The name of the variable or coordinate representing the
timestamps.
parent: str or ReferenceFrame
The parent reference frame. If str, the frame will be looked up
in the registry under that name.
name: str, default None
The name of the reference frame.
inverse: bool, default False
If True, invert the transform wrt the parent frame, i.e. the
rotation is specified for the parent frame wrt this frame.
discrete: bool, default False
If True, transformations with timestamps are assumed to be events.
Instead of interpolating between timestamps, transformations are
fixed between their timestamp and the next one.
Returns
-------
rf: ReferenceFrame
The constructed reference frame.
"""
# TODO raise errors here if dimensions etc. don't match
return cls(
name,
parent,
rotation=da.data,
timestamps=da[timestamps].data,
inverse=inverse,
discrete=discrete,
)
@classmethod
def from_rotation_matrix(cls, mat, parent, name=None, inverse=False):
""" Construct a static reference frame from a rotation matrix.
Parameters
----------
mat: array_like, shape (3, 3)
The rotation matrix that describes the rotation of this frame
wrt the parent frame.
parent: str or ReferenceFrame
The parent reference frame. If str, the frame will be looked up
in the registry under that name.
name: str, default None
The name of the reference frame.
inverse: bool, default False
If True, invert the transform wrt the parent frame, i.e. the
rotation is specified for the parent frame wrt this frame.
Returns
-------
rf: ReferenceFrame
The constructed reference frame.
"""
# TODO support moving reference frame
if mat.shape != (3, 3):
raise ValueError(
f"Expected mat to have shape (3, 3), got {mat.shape}"
)
return cls(
name,
parent,
rotation=as_float_array(from_rotation_matrix(mat)),
inverse=inverse,
)
def get_transformation(self, to_frame):
""" Alias for lookup_transform.
See Also
--------
ReferenceFrame.lookup_transform
"""
import warnings
warnings.warn(
DeprecationWarning(
"get_transformation is deprecated, use lookup_transform "
"instead."
)
)
return self.lookup_transform(to_frame)
def lookup_transform(self, to_frame):
""" Look up the transformation from this frame to another.
Parameters
----------
to_frame: str or ReferenceFrame
The target reference frame. If str, the frame will be looked up
in the registry under that name.
Returns
-------
t: array_like, shape (3,) or (n_timestamps, 3)
The translation from this frame to the target frame.
r: array_like, shape (4,) or (n_timestamps, 4)
The rotation from this frame to the target frame.
ts: array_like, shape (n_timestamps,) or None
The timestamps for which the transformation is defined.
See Also
--------
lookup_transform
"""
matcher = self._get_matcher(to_frame)
return matcher.get_transformation()
def transform_vectors(
self,
arr,
to_frame,
axis=-1,
time_axis=0,
timestamps=None,
return_timestamps=False,
):
""" Transform array of vectors from this frame to another.
Parameters
----------
arr: array_like
The array to transform.
to_frame: str or ReferenceFrame
The target reference frame. If str, the frame will be looked up
in the registry under that name.
axis: int, default -1
The axis of the array representing the spatial coordinates of the
vectors.
time_axis: int, default 0
The axis of the array representing the timestamps of the vectors.
timestamps: array_like, optional
The timestamps of the vectors, corresponding to the `time_axis`
of the array. If not None, the axis defined by `time_axis` will be
re-sampled to the timestamps for which the transformation is
defined.
return_timestamps: bool, default False
If True, also return the timestamps after the transformation.
Returns
-------
arr_transformed: array_like
The transformed array.
ts: array_like, shape (n_timestamps,) or None
The timestamps after the transformation.
"""
arr, arr_ts = self._validate_input(arr, axis, 3, timestamps, time_axis)
matcher = self._get_matcher(to_frame, arrays=[(arr, arr_ts)])
t, r, ts = matcher.get_transformation()
arr, _ = matcher.get_arrays(ts)
r = self._expand_singleton_axes(r, arr.ndim)
arr = rotate_vectors(r, arr, axis=axis)
# undo time axis swap
if time_axis is not None:
arr = np.swapaxes(arr, 0, time_axis)
if not return_timestamps:
return arr
else:
return arr, ts
def transform_points(
self,
arr,
to_frame,
axis=-1,
time_axis=0,
timestamps=None,
return_timestamps=False,
):
""" Transform array of points from this frame to another.
Parameters
----------
arr: array_like
The array to transform.
to_frame: str or ReferenceFrame
The target reference frame. If str, the frame will be looked up
in the registry under that name.
axis: int, default -1
The axis of the array representing the spatial coordinates of the
points.
time_axis: int, default 0
The axis of the array representing the timestamps of the points.
timestamps: array_like, optional
The timestamps of the vectors, corresponding to the `time_axis`
of the array. If not None, the axis defined by `time_axis` will be
re-sampled to the timestamps for which the transformation is
defined.
return_timestamps: bool, default False
If True, also return the timestamps after the transformation.
Returns
-------
arr_transformed: array_like
The transformed array.
ts: array_like, shape (n_timestamps,) or None
The timestamps after the transformation.
"""
arr, arr_ts = self._validate_input(arr, axis, 3, timestamps, time_axis)
matcher = self._get_matcher(to_frame, arrays=[(arr, arr_ts)])
t, r, ts = matcher.get_transformation()
arr, _ = matcher.get_arrays(ts)
t = self._expand_singleton_axes(t, arr.ndim)
r = self._expand_singleton_axes(r, arr.ndim)
arr = rotate_vectors(r, arr, axis=axis)
arr = arr + np.array(t)
# undo time axis swap
if time_axis is not None:
arr = np.swapaxes(arr, 0, time_axis)
if not return_timestamps:
return arr
else:
return arr, ts
def transform_quaternions(
self,
arr,
to_frame,
axis=-1,
time_axis=0,
timestamps=None,
return_timestamps=False,
):
""" Transform array of quaternions from this frame to another.
Parameters
----------
arr: array_like
The array to transform.
to_frame: str or ReferenceFrame
The target reference frame. If str, the frame will be looked up
in the registry under that name.
axis: int, default -1
The axis of the array representing the spatial coordinates of the
quaternions.
time_axis: int, default 0
The axis of the array representing the timestamps of the
quaternions.
timestamps: array_like, optional
The timestamps of the quaternions, corresponding to the `time_axis`
of the array. If not None, the axis defined by `time_axis` will be
re-sampled to the timestamps for which the transformation is
defined.
return_timestamps: bool, default False
If True, also return the timestamps after the transformation.
Returns
-------
arr_transformed: array_like
The transformed array.
ts: array_like, shape (n_timestamps,) or None
The timestamps after the transformation.
"""
arr, arr_ts = self._validate_input(arr, axis, 4, timestamps, time_axis)
matcher = self._get_matcher(to_frame, arrays=[(arr, arr_ts)])
t, r, ts = matcher.get_transformation()
arr, _ = matcher.get_arrays(ts)
r = self._expand_singleton_axes(r, arr.ndim)
arr = np.swapaxes(arr, axis, -1)
arr = as_quat_array(r) * as_quat_array(arr)
arr = np.swapaxes(as_float_array(arr), -1, axis)
# undo time axis swap
if time_axis is not None:
arr = np.swapaxes(arr, 0, time_axis)
if not return_timestamps:
return arr
else:
return arr, ts
def transform_angular_velocity(
self,
arr,
to_frame,
what="reference_frame",
axis=-1,
time_axis=0,
timestamps=None,
return_timestamps=False,
cutoff=None,
):
""" Transform array of angular velocities from this frame to another.
Parameters
----------
arr: array_like
The array to transform.
to_frame: str or ReferenceFrame
The target reference frame. If str, the frame will be looked up
in the registry under that name.
what: str, default "reference_frame"
What frame of the velocity to transform. Can be "reference_frame",
"moving_frame" or "representation_frame".
axis: int, default -1
The axis of the array representing the spatial coordinates of the
velocities.
time_axis: int, default 0
The axis of the array representing the timestamps of the
velocities.
timestamps: array_like, optional
The timestamps of the velocities, corresponding to the `time_axis`
of the array. If not None, the axis defined by `time_axis` will be
re-sampled to the timestamps for which the transformation is
defined.
return_timestamps: bool, default False
If True, also return the timestamps after the transformation.
cutoff: float, optional
Frequency of a low-pass filter applied to linear and angular
velocity after the twist estimation as a fraction of the Nyquist
frequency.
Returns
-------
arr_transformed: array_like
The transformed array.
ts: array_like, shape (n_timestamps,) or None
The timestamps after the transformation.
See Also
--------
transform_angular_velocity
"""
if what == "reference_frame":
angular, angular_ts = self.lookup_angular_velocity(
to_frame,
to_frame,
cutoff=cutoff,
allow_static=True,
return_timestamps=True,
)
elif what == "moving_frame":
angular, angular_ts = _resolve_rf(
to_frame
).lookup_angular_velocity(
self,
to_frame,
cutoff=cutoff,
allow_static=True,
return_timestamps=True,
)
elif what == "representation_frame":
return self.transform_vectors(
arr,
to_frame,
axis=axis,
time_axis=time_axis,
timestamps=timestamps,
return_timestamps=return_timestamps,
)
else:
raise ValueError(
f"Expected 'what' to be 'reference_frame', 'moving_frame' or "
f"'representation_frame', got {what}"
)
arr, ts = self.transform_vectors(
arr,
to_frame,
axis=axis,
time_axis=time_axis,
timestamps=timestamps,
return_timestamps=True,
)
arr, angular, ts_out = self._match_arrays(
[(arr, ts), (angular, angular_ts)]
)
arr += angular
if return_timestamps:
return arr, ts_out
else:
return arr
def transform_linear_velocity(
self,
arr,
to_frame,
what="reference_frame",
moving_frame=None,
reference_frame=None,
axis=-1,
time_axis=0,
timestamps=None,
return_timestamps=False,
outlier_thresh=None,
cutoff=None,
):
""" Transform array of linear velocities from this frame to another.
Parameters
----------
arr: array_like
The array to transform.
to_frame: str or ReferenceFrame
The target reference frame. If str, the frame will be looked up
in the registry under that name.
what: str, default "reference_frame"
What frame of the velocity to transform. Can be "reference_frame",
"moving_frame" or "representation_frame".
moving_frame: str or ReferenceFrame, optional
The moving frame when transforming the reference frame of the
velocity.
reference_frame: str or ReferenceFrame, optional
The reference frame when transforming the moving frame of the
velocity.
axis: int, default -1
The axis of the array representing the spatial coordinates of the
velocities.
time_axis: int, default 0
The axis of the array representing the timestamps of the
velocities.
timestamps: array_like, optional
The timestamps of the velocities, corresponding to the `time_axis`
of the array. If not None, the axis defined by `time_axis` will be
re-sampled to the timestamps for which the transformation is
defined.
return_timestamps: bool, default False
If True, also return the timestamps after the transformation.
cutoff: float, optional
Frequency of a low-pass filter applied to linear and angular
velocity after the twist estimation as a fraction of the Nyquist
frequency.
outlier_thresh: float, optional
Suppress outliers by throwing out samples where the
norm of the second-order differences of the position is above
`outlier_thresh` and interpolating the missing values.
Returns
-------
arr_transformed: array_like
The transformed array.
ts: array_like, shape (n_timestamps,) or None
The timestamps after the transformation.
See Also
--------
transform_linear_velocity
"""
if what == "reference_frame":
linear, angular, linear_ts = self.lookup_twist(
to_frame,
to_frame,
cutoff=cutoff,
outlier_thresh=outlier_thresh,
allow_static=True,
return_timestamps=True,
)
angular_ts = linear_ts
translation, _, translation_ts = _resolve_rf(
moving_frame
).lookup_transform(self)
elif what == "moving_frame":
to_frame = _resolve_rf(to_frame)
linear, linear_ts = to_frame.lookup_linear_velocity(
self,
to_frame,
cutoff=cutoff,
outlier_thresh=outlier_thresh,
allow_static=True,
return_timestamps=True,
)
angular, angular_ts = self.lookup_angular_velocity(
reference_frame,
to_frame,
cutoff=cutoff,
allow_static=True,
return_timestamps=True,
)
translation, _, translation_ts = to_frame.lookup_transform(self)
elif what == "representation_frame":
return self.transform_vectors(
arr,
to_frame,
axis=axis,
time_axis=time_axis,
timestamps=timestamps,
return_timestamps=return_timestamps,
)
else:
raise ValueError(
f"Expected 'what' to be 'reference_frame', 'moving_frame' or "
f"'representation_frame', got {what}"
)
arr, ts = self.transform_vectors(
arr,
to_frame,
axis=axis,
time_axis=time_axis,
timestamps=timestamps,
return_timestamps=True,
)
translation, translation_ts = self.transform_vectors(
translation,
to_frame,
timestamps=translation_ts,
return_timestamps=True,
)
arr, linear, angular, translation, ts_out = self._match_arrays(
[
(arr, ts),
(linear, linear_ts),
(angular, angular_ts),
(translation, translation_ts),
]
)
arr = arr + linear + np.cross(angular, translation)
if return_timestamps:
return arr, ts_out
else:
return arr
def lookup_twist(
self,
reference=None,
represent_in=None,
outlier_thresh=None,
cutoff=None,
mode="quaternion",
allow_static=False,
return_timestamps=False,
):
""" Estimate linear and angular velocity of this frame wrt a reference.
Parameters
----------
reference: str or ReferenceFrame, optional
The reference frame wrt which the twist is estimated. Defaults to
the parent frame.
represent_in: str or ReferenceFrame, optional
The reference frame in which the twist is represented. Defaults
to the parent frame.
outlier_thresh: float, optional
Suppress outliers by throwing out samples where the
norm of the second-order differences of the position is above
`outlier_thresh` and interpolating the missing values.
cutoff: float, optional
Frequency of a low-pass filter applied to linear and angular
velocity after the estimation as a fraction of the Nyquist
frequency.
mode: str, default "quaternion"
If "quaternion", compute the angular velocity from the quaternion
derivative. If "rotation_vector", compute the angular velocity from
the gradient of the axis-angle representation of the rotations.
allow_static: bool, default False
If True, return a zero velocity vector and None for timestamps if
the transform between this frame and the reference frame is static.
Otherwise, a `ValueError` will be raised.
return_timestamps: bool, default False
If True, also return the timestamps of the lookup.
Returns
-------
linear: numpy.ndarray, shape (N, 3)
Linear velocity of moving frame wrt reference frame, represented
in representation frame.
angular: numpy.ndarray, shape (N, 3)
Angular velocity of moving frame wrt reference frame, represented
in representation frame.
timestamps: each numpy.ndarray
Timestamps of the twist.
"""
try:
reference = _resolve_rf(reference or self.parent)
represent_in = _resolve_rf(represent_in or self.parent)
except TypeError:
raise ValueError(f"Frame {self.name} has no parent frame")
translation, rotation, timestamps = self.lookup_transform(reference)
if timestamps is None:
if allow_static:
return np.zeros(3), np.zeros(3), None
else:
raise ValueError(
"Twist cannot be estimated for static transforms"
)
linear = _estimate_linear_velocity(
translation,
timestamps,
outlier_thresh=outlier_thresh,
cutoff=cutoff,
)
angular = _estimate_angular_velocity(
rotation, timestamps, cutoff=cutoff, mode=mode
)
# linear velocity is represented in reference frame after estimation
linear, linear_ts = reference.transform_vectors(
linear, represent_in, timestamps=timestamps, return_timestamps=True
)
# angular velocity is represented in moving frame after estimation
angular, angular_ts = self.transform_vectors(
angular,
represent_in,
timestamps=timestamps,
return_timestamps=True,
)
angular, linear, twist_ts = self._match_arrays(
[(angular, angular_ts), (linear, linear_ts)],
)
if return_timestamps:
return linear, angular, twist_ts
else:
return linear, angular
def lookup_linear_velocity(
self,
reference=None,
represent_in=None,
outlier_thresh=None,
cutoff=None,
allow_static=False,
return_timestamps=False,
):
""" Estimate linear velocity of this frame wrt a reference.
Parameters
----------
reference: str or ReferenceFrame, optional
The reference frame wrt which the twist is estimated. Defaults to
the parent frame.
represent_in: str or ReferenceFrame, optional
The reference frame in which the twist is represented. Defaults
to the parent frame.
outlier_thresh: float, optional
Suppress outliers by throwing out samples where the
norm of the second-order differences of the position is above
`outlier_thresh` and interpolating the missing values.
cutoff: float, optional
Frequency of a low-pass filter applied to linear and angular
velocity after the estimation as a fraction of the Nyquist
frequency.
allow_static: bool, default False
If True, return a zero velocity vector and None for timestamps if
the transform between this frame and the reference frame is static.
Otherwise, a `ValueError` will be raised.
return_timestamps: bool, default False
If True, also return the timestamps of the lookup.
Returns
-------
linear: numpy.ndarray, shape (N, 3)
Linear velocity of moving frame wrt reference frame, represented
in representation frame.
timestamps: each numpy.ndarray
Timestamps of the linear velocity.
"""
try:
reference = _resolve_rf(reference or self.parent)
represent_in = _resolve_rf(represent_in or self.parent)
except TypeError:
raise ValueError(f"Frame {self.name} has no parent frame")
translation, _, timestamps = self.lookup_transform(reference)
if timestamps is None:
if allow_static:
return np.zeros(3), None
else:
raise ValueError(
"Velocity cannot be estimated for static transforms"
)
linear = _estimate_linear_velocity(
translation,
timestamps,
outlier_thresh=outlier_thresh,
cutoff=cutoff,
)
# linear velocity is represented in reference frame after estimation
linear, linear_ts = reference.transform_vectors(
linear, represent_in, timestamps=timestamps, return_timestamps=True
)
if return_timestamps:
return linear, linear_ts
else:
return linear
def lookup_angular_velocity(
self,
reference=None,
represent_in=None,
outlier_thresh=None,
cutoff=None,
mode="quaternion",
allow_static=False,
return_timestamps=False,
):
""" Estimate angular velocity of this frame wrt a reference.
Parameters
----------
reference: str or ReferenceFrame, optional
The reference frame wrt which the twist is estimated. Defaults to
the parent frame.
represent_in: str or ReferenceFrame, optional
The reference frame in which the twist is represented. Defaults
to the parent frame.
outlier_thresh: float, optional
Suppress samples where the norm of the second-order differences of
the rotation is above `outlier_thresh` and interpolate the missing
values.
cutoff: float, optional
Frequency of a low-pass filter applied to linear and angular
velocity after the estimation as a fraction of the Nyquist
frequency.
mode: str, default "quaternion"
If "quaternion", compute the angular velocity from the quaternion
derivative. If "rotation_vector", compute the angular velocity from
the gradient of the axis-angle representation of the rotations.
allow_static: bool, default False
If True, return a zero velocity vector and None for timestamps if
the transform between this frame and the reference frame is static.
Otherwise, a `ValueError` will be raised.
return_timestamps: bool, default False
If True, also return the timestamps of the lookup.
Returns
-------
angular: numpy.ndarray, shape (N, 3)
Angular velocity of moving frame wrt reference frame, represented
in representation frame.
timestamps: each numpy.ndarray
Timestamps of the angular velocity.
"""
try:
reference = _resolve_rf(reference or self.parent)
represent_in = _resolve_rf(represent_in or self.parent)
except TypeError:
raise ValueError(f"Frame {self.name} has no parent frame")
_, rotation, timestamps = self.lookup_transform(reference)
if timestamps is None:
if allow_static:
return np.zeros(3), None
else:
raise ValueError(
"Velocity cannot be estimated for static transforms"
)
angular = _estimate_angular_velocity(
rotation,
timestamps,
cutoff=cutoff,
mode=mode,
outlier_thresh=outlier_thresh,
)
# angular velocity is represented in moving frame after estimation
angular, angular_ts = self.transform_vectors(
angular,
represent_in,
timestamps=timestamps,
return_timestamps=True,
)
if return_timestamps:
return angular, angular_ts
else:
return angular
def register(self, update=False):
""" Register this frame in the registry.
Parameters
----------
update: bool, default False
If True, overwrite if there is a frame with the same name in the
registry.
"""
_register(self, update=update)
def deregister(self):
""" Remove this frame from the registry. """
_deregister(self.name) | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/reference_frames.py | 0.617628 | 0.482917 | reference_frames.py | pypi |
import warnings
from collections import namedtuple
import numpy as np
from quaternion import (
as_float_array,
as_quat_array,
as_rotation_vector,
derivative,
quaternion,
squad,
)
from scipy.interpolate import interp1d
from scipy.signal import butter, filtfilt
Frame = namedtuple(
"Frame", ("translation", "rotation", "timestamps", "discrete", "inverse"),
)
Array = namedtuple("Array", ("data", "timestamps"))
class TransformMatcher:
""" Matcher for timestamps from reference frames and arrays. """
def __init__(self):
""" Constructor. """
self.frames = []
self.arrays = []
@classmethod
def _check_timestamps(cls, timestamps, arr_shape):
""" Make sure timestamps are monotonic. """
if timestamps is not None:
if np.any(np.diff(timestamps.astype(float)) < 0):
raise ValueError("Timestamps must be monotonic")
if len(timestamps) != arr_shape[0]:
raise ValueError(
"Number of timestamps must match length of first axis "
"of array"
)
@classmethod
def _transform_from_frame(cls, frame, timestamps):
""" Get the transform from a frame resampled to the timestamps. """
if timestamps is None and frame.timestamps is not None:
raise ValueError("Cannot convert timestamped to static transform")
if frame.timestamps is None:
if timestamps is None:
translation = frame.translation
rotation = frame.rotation
else:
translation = np.tile(frame.translation, (len(timestamps), 1))
rotation = np.tile(frame.rotation, (len(timestamps), 1))
elif frame.discrete:
translation = np.tile(frame.translation[0], (len(timestamps), 1))
for t, ts in zip(frame.translation, frame.timestamps):
translation[timestamps >= ts, :] = t
rotation = np.tile(frame.rotation[0], (len(timestamps), 1))
for r, ts in zip(frame.rotation, frame.timestamps):
rotation[timestamps >= ts, :] = r
else:
# TODO method + optional scipy dependency?
translation = interp1d(
frame.timestamps.astype(float), frame.translation, axis=0
)(timestamps.astype(float))
rotation = as_float_array(
squad(
as_quat_array(frame.rotation),
frame.timestamps.astype(float),
timestamps.astype(float),
)
)
return translation, rotation
@classmethod
def _resample_array(cls, array, timestamps):
""" Resample an array to the timestamps. """
if timestamps is None and array.timestamps is not None:
raise ValueError("Cannot convert timestamped to static array")
if array.timestamps is None:
if timestamps is None:
return array.data
else:
return np.tile(array.data, (len(timestamps), 1))
else:
# TODO better way to check if quaternion
if array.data.shape[-1] == 4:
return as_float_array(
squad(
as_quat_array(array.data),
array.timestamps.astype(float),
timestamps.astype(float),
)
)
else:
# TODO method + optional scipy dependency?
return interp1d(
array.timestamps.astype(float), array.data, axis=0
)(timestamps.astype(float))
def add_reference_frame(self, frame, inverse=False):
""" Add a reference frame to the matcher.
Parameters
----------
frame: ReferenceFrame
The frame to add.
inverse: bool, default False
If True, invert the transformation of the reference frame.
"""
self._check_timestamps(frame.timestamps, frame.translation.shape)
self.frames.append(
Frame(
frame.translation,
frame.rotation,
frame.timestamps,
frame.discrete,
inverse,
)
)
def add_array(self, array, timestamps=None):
""" Add an array to the matcher.
Parameters
----------
array: array_like
The array to add.
timestamps: array_like, optional
If provided, the timestamps of the array.
"""
self._check_timestamps(timestamps, array.shape)
self.arrays.append(Array(array, timestamps))
def get_range(self):
""" Get the range for which the transformation is defined.
Returns
-------
first: numeric or None
The first timestamp for which the transformation is defined.
last: numeric or None
The last timestamp for which the transformation is defined.
"""
first_stamps = []
for frame in self.frames:
if frame.timestamps is not None and not frame.discrete:
first_stamps.append(frame.timestamps[0])
for array in self.arrays:
if array.timestamps is not None:
first_stamps.append(array.timestamps[0])
last_stamps = []
for frame in self.frames:
if frame.timestamps is not None and not frame.discrete:
last_stamps.append(frame.timestamps[-1])
for array in self.arrays:
if array.timestamps is not None:
last_stamps.append(array.timestamps[-1])
first = np.max(first_stamps) if len(first_stamps) else None
last = np.min(last_stamps) if len(last_stamps) else None
return first, last
def get_timestamps(self, arrays_first=True):
""" Get the timestamps for which the transformation is defined.
Parameters
----------
arrays_first: bool, default True
If True, the first array in the list defines the sampling of the
timestamps. Otherwise, the first reference frame in the list
defines the sampling.
Returns
-------
timestamps: array_like
The timestamps for which the transformation is defined.
"""
# TODO specify rf name as priority?
ts_range = self.get_range()
# first and last timestamp can be None for only discrete transforms
if ts_range[0] is None:
ts_range = (-np.inf, ts_range[1])
elif ts_range[1] is None:
ts_range = (ts_range[0], np.inf)
arrays = [
array for array in self.arrays if array.timestamps is not None
]
discrete_frames = [
frame
for frame in self.frames
if frame.discrete and frame.timestamps is not None
]
continuous_frames = [
frame
for frame in self.frames
if not frame.discrete and frame.timestamps is not None
]
if arrays_first:
elements = arrays + continuous_frames
else:
elements = continuous_frames + arrays
if len(elements):
# The first element with timestamps determines the timestamps
# TODO check if this fails for datetime timestamps
timestamps = elements[0].timestamps
timestamps = timestamps[
(timestamps >= ts_range[0]) & (timestamps <= ts_range[-1])
]
elif len(discrete_frames):
# If there are no continuous frames or arrays with timestamps
# we merge together all discrete timestamps
timestamps = np.concatenate(
[d.timestamps for d in discrete_frames]
)
timestamps = np.unique(timestamps)
else:
timestamps = None
return timestamps
def get_transformation(self, timestamps=None, arrays_first=True):
""" Get the transformation across all reference frames.
Parameters
----------
timestamps: array_like, shape (n_timestamps,), optional
Timestamps to which the transformation should be matched. If not
provided the matcher will call `get_timestamps` for the target
timestamps.
arrays_first: bool, default True
If True and timestamps aren't provided, the first array in the
list defines the sampling of the timestamps. Otherwise, the first
reference frame in the list defines the sampling.
Returns
-------
translation: array_like, shape (3,) or (n_timestamps, 3)
The translation across all reference frames.
rotation: array_like, shape (4,) or (n_timestamps, 4)
The rotation across all reference frames.
timestamps: array_like, shape (n_timestamps,) or None
The timestamps for which the transformation is defined.
"""
from rigid_body_motion.utils import rotate_vectors
if timestamps is None:
timestamps = self.get_timestamps(arrays_first)
translation = np.zeros(3) if timestamps is None else np.zeros((1, 3))
rotation = quaternion(1.0, 0.0, 0.0, 0.0)
for frame in self.frames:
t, r = self._transform_from_frame(frame, timestamps)
if frame.inverse:
translation = rotate_vectors(
1 / as_quat_array(r), translation - np.array(t)
)
rotation = 1 / as_quat_array(r) * rotation
else:
translation = rotate_vectors(
as_quat_array(r), translation
) + np.array(t)
rotation = as_quat_array(r) * rotation
return translation, as_float_array(rotation), timestamps
def get_arrays(self, timestamps=None, arrays_first=True):
""" Get re-sampled arrays
Parameters
----------
timestamps: array_like, shape (n_timestamps,), optional
Timestamps to which the arrays should be matched. If not provided
the matcher will call `get_timestamps` for the target timestamps.
arrays_first: bool, default True
If True and timestamps aren't provided, the first array in the
list defines the sampling of the timestamps. Otherwise, the first
reference frame in the list defines the sampling.
Returns
-------
*arrays: one or more array_like
Input arrays, matched to the timestamps.
timestamps: array_like, shape (n_timestamps,) or None
The timestamps for which the transformation is defined.
"""
if timestamps is None:
timestamps = self.get_timestamps(arrays_first)
arrays = tuple(
self._resample_array(array, timestamps) for array in self.arrays
)
return (*arrays, timestamps)
def _resolve_axis(axis, ndim):
""" Convert axis argument into actual array axes. """
if isinstance(axis, int) and axis < 0:
axis = ndim + axis
elif isinstance(axis, tuple):
axis = tuple(ndim + a if a < 0 else a for a in axis)
elif axis is None:
axis = tuple(np.arange(ndim))
if isinstance(axis, tuple):
if any(a < 0 or a >= ndim for a in axis):
raise IndexError("Axis index out of range")
elif axis < 0 or axis >= ndim:
raise IndexError("Axis index out of range")
return axis
def _resolve_rf(rf):
""" Retrieve frame by name from registry, if applicable. """
# TODO test
# TODO raise error if not ReferenceFrame instance?
from rigid_body_motion.reference_frames import ReferenceFrame, _registry
if isinstance(rf, ReferenceFrame):
return rf
elif isinstance(rf, str):
try:
return _registry[rf]
except KeyError:
raise ValueError(f"Frame '{rf}' not found in registry.")
else:
raise TypeError(
f"Expected frame to be str or ReferenceFrame, "
f"got {type(rf).__name__}"
)
def _replace_dim(coords, dims, axis, into, dimensionality):
""" Replace the spatial dimension. """
# TODO can we improve this with assign_coords / swap_dims?
old_dim = dims[axis]
if dimensionality == 2:
if into == "cartesian":
new_dim = "cartesian_axis"
new_coord = ["x", "y"]
elif into == "polar":
new_dim = "polar_axis"
new_coord = ["r", "phi"]
elif dimensionality == 3:
if into == "cartesian":
new_dim = "cartesian_axis"
new_coord = ["x", "y", "z"]
elif into == "spherical":
new_dim = "spherical_axis"
new_coord = ["r", "theta", "phi"]
elif into == "quaternion":
new_dim = "quaternion_axis"
new_coord = ["w", "x", "y", "z"]
dims = tuple((d if d != old_dim else new_dim) for d in dims)
coords = {c: coords[c] for c in coords if old_dim not in coords[c].dims}
coords[new_dim] = new_coord
return coords, dims
def _maybe_unpack_dataarray(
arr, dim=None, axis=None, time_axis=None, timestamps=None
):
""" If input is DataArray, unpack into data, coords and dims. """
from rigid_body_motion.utils import is_dataarray
ndim = np.asanyarray(arr).ndim
if not is_dataarray(arr):
if dim is not None:
raise ValueError("dim argument specified without DataArray input")
axis = axis or -1
time_axis = time_axis or 0
time_dim = None
coords = None
dims = None
name = None
attrs = None
else:
if dim is not None and axis is not None:
raise ValueError(
"You can either specify the dim or the axis argument, not both"
)
elif dim is not None:
axis = arr.dims.index(dim)
else:
axis = axis or -1
dim = str(arr.dims[axis])
if isinstance(timestamps, str):
# TODO convert datetimeindex?
time_axis = arr.dims.index(timestamps)
time_dim = timestamps
timestamps = arr[timestamps].data
elif timestamps is None:
if arr.ndim > 1:
time_axis = time_axis or 0
time_dim = arr.dims[time_axis]
timestamps = arr.coords[time_dim]
else:
time_dim = None
elif timestamps is False:
timestamps = None
time_dim = None
else:
raise NotImplementedError(
"timestamps argument must be dimension name, None or False"
)
coords = dict(arr.coords)
dims = arr.dims
name = arr.name
attrs = arr.attrs.copy()
arr = arr.data
if timestamps is not None and axis % ndim == time_axis % ndim:
raise ValueError(
"Spatial and time dimension refer to the same array axis"
)
return (
arr,
axis,
dim,
time_axis,
time_dim,
timestamps,
coords,
dims,
name,
attrs,
)
def _make_dataarray(arr, coords, dims, name, attrs, time_dim, ts_out):
""" Make DataArray out of transformation results. """
import xarray as xr
if time_dim is None:
# no timestamps specified
if ts_out is not None:
coords["time"] = ts_out
dims = ("time",) + dims
elif isinstance(time_dim, str):
# timestamps specified as coord
# TODO transpose if time dim is not first?
if time_dim not in coords:
raise ValueError(
f"{time_dim} is not a coordinate of this DataArray"
)
assert ts_out is not None
if len(coords[time_dim]) != len(ts_out) or np.any(
coords[time_dim] != ts_out
):
# interpolate if timestamps after transform have changed
for c in coords:
if time_dim in coords[c].dims and c != time_dim:
if np.issubdtype(coords[c].dtype, np.number):
coords[c] = coords[c].interp({time_dim: ts_out})
else:
coords[c] = coords[c].sel(
{time_dim: ts_out}, method="nearest"
)
coords[time_dim] = ts_out
else:
# timestamps specified as array
# TODO time_dim argument
raise NotImplementedError(
"timestamps argument must be dimension name or None"
)
return xr.DataArray(arr, coords, dims, name, attrs)
def _transform(
method,
arr,
into,
outof,
dim,
axis,
timestamps,
time_axis,
what=None,
return_timestamps=False,
**kwargs,
):
""" Base transform method. """
(
arr,
axis,
dim,
time_axis,
time_dim,
ts_in,
coords,
dims,
name,
attrs,
) = _maybe_unpack_dataarray(
arr, dim=dim, axis=axis, time_axis=time_axis, timestamps=timestamps
)
if method is None:
method_lookup = {
"position": "transform_points",
"translation": "transform_points",
"orientation": "transform_quaternions",
"rotation": "transform_quaternions",
}
try:
# TODO warn if method doesn't match attrs["motion_type"]
method = method_lookup[attrs["motion_type"]]
except (KeyError, TypeError):
raise ValueError(
f"'method' must be specified unless you provide a DataArray "
f"whose ``attrs`` contain a 'motion_type' entry "
f"containing any of {method_lookup.keys()}"
)
if what is None:
if method == "transform_vectors":
what = "representation_frame"
else:
what = "reference_frame"
if outof is None:
if attrs is not None and what in attrs:
outof = _resolve_rf(attrs[what])
else:
raise ValueError(
f"'outof' must be specified unless you provide a DataArray "
f"whose ``attrs`` contain a '{what}' entry with "
f"the name of a registered frame"
)
else:
outof = _resolve_rf(outof)
if attrs is not None and what in attrs and attrs[what] != outof.name:
warnings.warn(
f"You are transforming the '{what}' of the array out of "
f"{outof.name}, but the current '{what}' the array is "
f"{attrs[what]}"
)
into = _resolve_rf(into)
if method in ("transform_angular_velocity", "transform_linear_velocity"):
kwargs["what"] = what
if attrs is not None:
attrs[what] = into.name
attrs["representation_frame"] = into.name
arr, ts_out = getattr(outof, method)(
arr,
into,
axis=axis,
timestamps=ts_in,
time_axis=time_axis,
return_timestamps=True,
**kwargs,
)
if coords is not None:
return _make_dataarray(
arr, coords, dims, name, attrs, time_dim, ts_out
)
elif return_timestamps or return_timestamps is None and ts_out is not None:
return arr, ts_out
else:
return arr
def _make_transform_or_pose_dataset(
translation, rotation, frame, timestamps, pose=False
):
""" Create Dataset with translation and rotation. """
import xarray as xr
if pose:
linear_name = "position"
angular_name = "orientation"
else:
linear_name = "translation"
angular_name = "rotation"
if timestamps is not None:
ds = xr.Dataset(
{
linear_name: (["time", "cartesian_axis"], translation),
angular_name: (["time", "quaternion_axis"], rotation),
},
{
"time": timestamps,
"cartesian_axis": ["x", "y", "z"],
"quaternion_axis": ["w", "x", "y", "z"],
},
)
else:
ds = xr.Dataset(
{
linear_name: ("cartesian_axis", translation),
angular_name: ("quaternion_axis", rotation),
},
{
"cartesian_axis": ["x", "y", "z"],
"quaternion_axis": ["w", "x", "y", "z"],
},
)
ds[linear_name].attrs.update(
{
"representation_frame": frame.name,
"reference_frame": frame.name,
"motion_type": linear_name,
"long_name": linear_name.capitalize(),
"units": "m",
}
)
ds[angular_name].attrs.update(
{
"representation_frame": frame.name,
"reference_frame": frame.name,
"motion_type": angular_name,
"long_name": angular_name.capitalize(),
}
)
return ds
def _make_twist_dataset(
angular, linear, moving_frame, reference, represent_in, timestamps
):
""" Create Dataset with linear and angular velocity. """
import xarray as xr
twist = xr.Dataset(
{
"angular_velocity": (["time", "cartesian_axis"], angular),
"linear_velocity": (["time", "cartesian_axis"], linear),
},
{"time": timestamps, "cartesian_axis": ["x", "y", "z"]},
)
twist.angular_velocity.attrs.update(
{
"representation_frame": represent_in.name,
"reference_frame": reference.name,
"moving_frame": moving_frame.name,
"motion_type": "angular_velocity",
"long_name": "Angular velocity",
"units": "rad/s",
}
)
twist.linear_velocity.attrs.update(
{
"representation_frame": represent_in.name,
"reference_frame": reference.name,
"moving_frame": moving_frame.name,
"motion_type": "linear_velocity",
"long_name": "Linear velocity",
"units": "m/s",
}
)
return twist
def _make_velocity_dataarray(
velocity, motion_type, moving_frame, reference, represent_in, timestamps
):
""" Create DataArray with linear or angular velocity. """
import xarray as xr
if motion_type not in ("linear", "angular"):
raise ValueError(
f"motion_type must be 'linear' or 'angular', got {motion_type}"
)
da = xr.DataArray(
velocity,
coords={"time": timestamps, "cartesian_axis": ["x", "y", "z"]},
dims=("time", "cartesian_axis"),
name=f"{motion_type}_velocity",
)
da.attrs.update(
{
"representation_frame": represent_in.name,
"reference_frame": reference.name,
"moving_frame": moving_frame.name,
"motion_type": f"{motion_type}_velocity",
"long_name": f"{motion_type.capitalize()} velocity",
"units": "rad/s" if motion_type == "angular" else "m/s",
}
)
return da
def _estimate_angular_velocity(
rotation,
timestamps,
axis=-1,
time_axis=0,
mode="quaternion",
outlier_thresh=None,
cutoff=None,
):
""" Estimate angular velocity of transform. """
if np.issubdtype(timestamps.dtype, np.datetime64):
timestamps = timestamps.astype(float) / 1e9
axis = axis % rotation.ndim
time_axis = time_axis % rotation.ndim
# fix time axis if it's the last axis of the array and will be swapped with
# axis when converting to quaternion dtype
if time_axis == rotation.ndim - 1:
time_axis = axis
r = np.swapaxes(rotation, axis, -1)
if mode == "quaternion":
# any NaNs need to be removed because derivative breaks otherwise
nan_idx = np.any(
np.isnan(r),
axis=tuple(a for a in range(r.ndim) if a != time_axis),
)
valid_idx = [slice(None)] * r.ndim
valid_idx[time_axis] = ~nan_idx
valid_idx = tuple(valid_idx)
dq = as_quat_array(
derivative(r[valid_idx], timestamps[~nan_idx], axis=time_axis)
)
q = as_quat_array(r[valid_idx])
angular = np.nan * np.ones_like(r[..., :-1])
angular[valid_idx] = as_float_array(2 * q.conjugate() * dq)[..., 1:]
elif mode == "rotation_vector":
rv = as_rotation_vector(as_quat_array(r))
angular = np.gradient(rv, timestamps, axis=time_axis)
else:
raise ValueError(
f"'mode' can be 'quaternion' or 'rotation_vector', got {mode}"
)
if outlier_thresh is not None:
dr = np.linalg.norm(
np.diff(as_rotation_vector(as_quat_array(r)), n=2, axis=time_axis),
axis=-1,
)
dr = np.hstack((dr, 0.0, 0.0)) + np.hstack((0.0, dr, 0.0))
angular = interp1d(
timestamps[dr <= outlier_thresh],
angular[dr <= outlier_thresh],
axis=time_axis,
bounds_error=False,
)(timestamps)
if cutoff is not None:
angular = filtfilt(*butter(7, cutoff), angular, axis=time_axis)
angular = np.swapaxes(angular, axis, -1)
# TODO transform representation frame to match linear velocity estimate
return angular
def _estimate_linear_velocity(
translation, timestamps, time_axis=0, outlier_thresh=None, cutoff=None
):
""" Estimate linear velocity of transform. """
if np.issubdtype(timestamps.dtype, np.datetime64):
timestamps = timestamps.astype(float) / 1e9
linear = np.gradient(translation, timestamps, axis=time_axis)
if outlier_thresh is not None:
dt = np.linalg.norm(np.diff(translation, n=2, axis=time_axis), axis=1)
dt = np.hstack((dt, 0.0, 0.0)) + np.hstack((0.0, dt, 0.0))
linear = interp1d(
timestamps[dt <= outlier_thresh],
linear[dt <= outlier_thresh],
axis=time_axis,
bounds_error=False,
)(timestamps)
if cutoff is not None:
linear = filtfilt(*butter(7, cutoff), linear, axis=time_axis)
return linear | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/core.py | 0.66628 | 0.604924 | core.py | pypi |
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.patches import FancyArrowPatch
from mpl_toolkits.mplot3d import proj3d
from rigid_body_motion.core import _resolve_rf
from rigid_body_motion.utils import rotate_vectors
class Arrow3D(FancyArrowPatch):
""" Colored arrows representing coordinate system. """
def __init__(self, xs, ys, zs, *args, **kwargs):
""" Constructor. """
FancyArrowPatch.__init__(self, (0, 0), (0, 0), *args, **kwargs)
self._verts3d = xs, ys, zs
def draw(self, renderer):
""" Draw to the given renderer. """
xs3d, ys3d, zs3d = self._verts3d
xs, ys, _ = proj3d.proj_transform(xs3d, ys3d, zs3d, renderer.M)
self.set_positions((xs[0], ys[0]), (xs[1], ys[1]))
FancyArrowPatch.draw(self, renderer)
def do_3d_projection(self, renderer=None):
""" Do 3d projection. """
xs3d, ys3d, zs3d = self._verts3d
xs, ys, zs = proj3d.proj_transform(xs3d, ys3d, zs3d, self.axes.M)
self.set_positions((xs[0], ys[0]), (xs[1], ys[1]))
return np.min(zs)
def _add_frame(ax, frame, world_frame=None, arrow_len=1.0):
""" Add coordinates representing a reference frame. """
from rigid_body_motion import transform_points
o = [0.0, 0.0, 0.0]
x = [arrow_len, 0.0, 0.0]
y = [0.0, arrow_len, 0.0]
z = [0.0, 0.0, arrow_len]
if world_frame is not None:
o = transform_points(o, outof=frame, into=world_frame)
x = transform_points(x, outof=frame, into=world_frame)
y = transform_points(y, outof=frame, into=world_frame)
z = transform_points(z, outof=frame, into=world_frame)
arrow_prop_dict = dict(
mutation_scale=20, arrowstyle="->", shrinkA=0, shrinkB=0
)
x_arrow = Arrow3D(
[o[0], x[0]], [o[1], x[1]], [o[2], x[2]], **arrow_prop_dict, color="r"
)
ax.add_artist(x_arrow)
y_arrow = Arrow3D(
[o[0], y[0]], [o[1], y[1]], [o[2], y[2]], **arrow_prop_dict, color="g"
)
ax.add_artist(y_arrow)
z_arrow = Arrow3D(
[o[0], z[0]], [o[1], z[1]], [o[2], z[2]], **arrow_prop_dict, color="b"
)
ax.add_artist(z_arrow)
# manually update axis limits
x_lim_old = ax.get_xlim3d()
y_lim_old = ax.get_ylim3d()
z_lim_old = ax.get_zlim3d()
x_lim_new = [
np.min((x_lim_old[0], o[0], x[0], y[0], z[0])),
np.max((x_lim_old[1], o[0], x[0], y[0], z[0])),
]
y_lim_new = [
np.min((y_lim_old[0], o[1], x[1], y[1], z[1])),
np.max((y_lim_old[1], o[1], x[1], y[1], z[1])),
]
z_lim_new = [
np.min((z_lim_old[0], o[2], x[2], y[2], z[2])),
np.max((z_lim_old[1], o[2], x[2], y[2], z[2])),
]
ax.set_xlim3d(x_lim_new)
ax.set_ylim3d(y_lim_new)
ax.set_ylim3d(z_lim_new)
return [x_arrow, y_arrow, z_arrow]
def _set_axes_equal(ax):
""" Make axes of 3D plot have equal scale.
from https://stackoverflow.com/a/31364297
"""
x_limits = ax.get_xlim3d()
y_limits = ax.get_ylim3d()
z_limits = ax.get_zlim3d()
x_range = abs(x_limits[1] - x_limits[0])
x_middle = np.mean(x_limits)
y_range = abs(y_limits[1] - y_limits[0])
y_middle = np.mean(y_limits)
z_range = abs(z_limits[1] - z_limits[0])
z_middle = np.mean(z_limits)
# The plot bounding box is a sphere in the sense of the infinity
# norm, hence I call half the max range the plot radius.
plot_radius = 0.5 * max([x_range, y_range, z_range])
ax.set_xlim3d([x_middle - plot_radius, x_middle + plot_radius])
ax.set_ylim3d([y_middle - plot_radius, y_middle + plot_radius])
ax.set_zlim3d([z_middle - plot_radius, z_middle + plot_radius])
def plot_reference_frame(
frame, world_frame=None, ax=None, figsize=(6, 6), arrow_len=1.0
):
""" Plot a 3D coordinate system representing a static reference frame.
Parameters
----------
frame: str or ReferenceFrame
The reference frame to plot. If str, the frame will be looked up
in the registry under that name.
world_frame: str or ReferenceFrame, optional
If specified, the world reference frame that defines the origin of the
plot. If str, the frame will be looked up in the registry under that
name.
ax: matplotlib.axes.Axes instance, optional
If provided, plot the points onto these axes.
figsize:
If `ax` is not provided, create a figure of this size.
arrow_len:
Length of the arrows of the coordinate system.
Returns
-------
arrows: list of Arrow3D
A list of three arrows representing the plotted coordinate system.
"""
if ax is None:
fig = plt.figure(figsize=figsize)
ax = fig.add_subplot(111, projection="3d")
frame = _resolve_rf(frame)
if frame.timestamps is not None:
raise NotImplementedError("Can only plot static reference frames")
arrows = _add_frame(ax, frame, world_frame, arrow_len=arrow_len)
_set_axes_equal(ax)
return arrows
def plot_points(arr, ax=None, figsize=(6, 6), fmt="", **kwargs):
""" Plot an array of 3D points.
Parameters
----------
arr: array_like, shape (3,) or (N, 3)
Array of 3D points to plot.
ax: matplotlib.axes.Axes instance, optional
If provided, plot the points onto these axes.
figsize:
If `ax` is not provided, create a figure of this size.
fmt: str, optional
A format string, e.g. 'ro' for red circles.
kwargs:
Additional keyword arguments passed to ax.plot().
Returns
-------
lines: list of Line3D
A list of lines representing the plotted data.
"""
if ax is None:
fig = plt.figure(figsize=figsize)
ax = fig.add_subplot(111, projection="3d")
arr = np.asarray(arr)
if arr.ndim == 1:
arr = arr[np.newaxis, :]
if arr.ndim > 2 or arr.shape[1] != 3:
raise ValueError("array must have shape (3,) or (N,3)")
lines = ax.plot(arr[:, 0], arr[:, 1], arr[:, 2], fmt, **kwargs)
_set_axes_equal(ax)
return lines
def plot_quaternions(arr, base=None, ax=None, figsize=(6, 6), **kwargs):
""" Plot an array of quaternions.
Parameters
----------
arr: array_like, shape (4,) or (N, 4)
Array of quaternions to plot.
base: array_like, shape (4,) or (N, 4), optional
If provided, base points of the quaternions.
ax: matplotlib.axes.Axes instance, optional
If provided, plot the points onto these axes.
figsize:
If `ax` is not provided, create a figure of this size.
kwargs:
Additional keyword arguments passed to ax.quiver().
Returns
-------
lines: list of Line3DCollection
A list of lines representing the plotted data.
"""
if ax is None:
fig = plt.figure(figsize=figsize)
ax = fig.add_subplot(111, projection="3d")
vx = rotate_vectors(arr, np.array((1, 0, 0)), one_to_one=False)
vy = rotate_vectors(arr, np.array((0, 1, 0)), one_to_one=False)
vz = rotate_vectors(arr, np.array((0, 0, 1)), one_to_one=False)
lines = [
plot_vectors(vx, base, ax, color="r", length=0.5, **kwargs),
plot_vectors(vy, base, ax, color="g", length=0.5, **kwargs),
plot_vectors(vz, base, ax, color="b", length=0.5, **kwargs),
]
return lines
def plot_vectors(arr, base=None, ax=None, figsize=(6, 6), **kwargs):
""" Plot an array of 3D vectors.
Parameters
----------
arr: array_like, shape (3,) or (N, 3)
Array of 3D points to plot.
base: array_like, shape (3,) or (N, 3), optional
If provided, base points of the vectors.
ax: matplotlib.axes.Axes instance, optional
If provided, plot the points onto these axes.
figsize:
If `ax` is not provided, create a figure of this size.
kwargs:
Additional keyword arguments passed to ax.quiver().
Returns
-------
lines: Line3DCollection
A collection of lines representing the plotted data.
"""
if ax is None:
fig = plt.figure(figsize=figsize)
ax = fig.add_subplot(111, projection="3d")
arr = np.asarray(arr)
if arr.ndim == 1:
arr = arr[np.newaxis, :]
if arr.ndim > 2 or arr.shape[1] != 3:
raise ValueError("array must have shape (3,) or (N,3)")
if base is not None:
base = np.asarray(base)
if base.ndim == 1:
base = base[np.newaxis, :]
if base.shape != arr.shape:
raise ValueError("base must have the same shape as array")
else:
base = np.zeros_like(arr)
lines = ax.quiver(
base[:, 0],
base[:, 1],
base[:, 2],
arr[:, 0],
arr[:, 1],
arr[:, 2],
**kwargs,
)
_set_axes_equal(ax)
return lines | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/plotting.py | 0.909987 | 0.568595 | plotting.py | pypi |
import operator
from functools import reduce
from pathlib import Path
import numpy as np
from quaternion import (
as_float_array,
as_quat_array,
from_rotation_vector,
quaternion,
)
from quaternion import rotate_vectors as quat_rv
from quaternion import squad
from rigid_body_motion.core import _resolve_axis
def qinv(q, qaxis=-1):
""" Quaternion inverse.
Parameters
----------
q: array_like
Array containing quaternions whose inverse is to be computed. Its dtype
can be quaternion, otherwise `qaxis` specifies the axis representing
the quaternions.
qaxis: int, default -1
If `q` is not quaternion dtype, axis of the quaternion array
representing the coordinates of the quaternions.
Returns
-------
qi: ndarray
A new array containing the inverse values.
"""
# TODO xarray support
if q.dtype != quaternion:
q = np.swapaxes(q, qaxis, -1)
qi = as_float_array(1 / as_quat_array(q))
return np.swapaxes(qi, -1, qaxis)
else:
return 1 / q
def qmul(*q, qaxis=-1):
""" Quaternion multiplication.
Parameters
----------
q: iterable of array_like
Arrays containing quaternions to multiply. Their dtype can be
quaternion, otherwise `qaxis` specifies the axis representing
the quaternions.
qaxis: int, default -1
If `q` are not quaternion dtype, axis of the quaternion arrays
representing the coordinates of the quaternions.
Returns
-------
qm: ndarray
A new array containing the multiplied quaternions.
"""
# TODO xarray support
if len(q) < 2:
raise ValueError("Please provide at least 2 quaternions to multiply")
if all(qq.dtype != quaternion for qq in q):
q = (as_quat_array(np.swapaxes(qq, qaxis, -1)) for qq in q)
qm = reduce(operator.mul, q, 1)
return np.swapaxes(as_float_array(qm), -1, qaxis)
elif all(qq.dtype == quaternion for qq in q):
return reduce(operator.mul, q, 1)
else:
raise ValueError(
"Either all or none of the provided quaternions must be "
"quaternion dtype"
)
def qmean(q, axis=None, qaxis=-1):
""" Quaternion mean.
Adapted from https://github.com/christophhagen/averaging-quaternions.
Parameters
----------
q: array_like
Array containing quaternions whose mean is to be computed. Its dtype
can be quaternion, otherwise `qaxis` specifies the axis representing
the quaternions.
axis: None or int or tuple of ints, optional
Axis or axes along which the means are computed. The default is to
compute the mean of the flattened array.
qaxis: int, default -1
If `q` is not quaternion dtype, axis of the quaternion array
representing the coordinates of the quaternions.
Returns
-------
qm: ndarray
A new array containing the mean values.
"""
# TODO xarray support
if q.dtype != quaternion:
q = np.swapaxes(q, qaxis, -1)
was_quaternion = False
else:
q = as_float_array(q)
was_quaternion = True
axis = _resolve_axis(axis, q.ndim - 1)
# compute outer product of quaternion elements
q = q[..., np.newaxis]
qt = np.swapaxes(q, -2, -1)
A = np.mean(q * qt, axis=axis)
# compute largest eigenvector of A
l, v = np.linalg.eig(A)
idx = np.unravel_index(l.argsort()[..., ::-1], l.shape) + (0,)
v = v[idx]
qm = np.real(v)
if was_quaternion:
return as_quat_array(qm)
else:
return np.swapaxes(qm, -1, qaxis)
def qinterp(q, t_in, t_out, axis=0, qaxis=-1):
""" Quaternion interpolation.
Parameters
----------
q: array_like
Array containing quaternions to interpolate. Its dtype
can be quaternion, otherwise `qaxis` specifies the axis representing
the quaternions.
t_in: array_like
Array of current sampling points of `q`.
t_out: array_like
Array of desired sampling points of `q`.
axis: int, default 0
Axis along which the quaternions are interpolated.
qaxis: int, default -1
If `q` is not quaternion dtype, axis of the quaternion array
representing the coordinates of the quaternions.
Returns
-------
qi: ndarray
A new array containing the interpolated values.
"""
# TODO xarray support
axis = axis % q.ndim
t_in = np.array(t_in).astype(float)
t_out = np.array(t_out).astype(float)
if q.dtype != quaternion:
qaxis = qaxis % q.ndim
# fix axis if it's the last axis of the array and will be swapped with
# axis when converting to quaternion dtype
if axis == q.ndim - 1:
axis = qaxis
q = as_quat_array(np.swapaxes(q, qaxis, -1))
was_quaternion = False
else:
was_quaternion = True
q = np.swapaxes(q, axis, 0)
try:
qi = squad(q, t_in, t_out)
except ValueError:
raise RuntimeError(
"Error using SQUAD with multi-dimensional array, please upgrade "
"the quaternion package to the latest version"
)
qi = np.swapaxes(qi, 0, axis)
if was_quaternion:
return qi
else:
return np.swapaxes(as_float_array(qi), -1, qaxis)
def rotate_vectors(q, v, axis=-1, qaxis=-1, one_to_one=True):
""" Rotate an array of vectors by an array of quaternions.
Parameters
----------
q: array_like
Array of quaternions. Its dtype can be quaternion, otherwise `q_axis`
specifies the axis representing the quaternions.
v: array_like
The array of vectors to be rotated.
axis: int, default -1
The axis of the `v` array representing the coordinates of the
vectors. Must have length 3.
qaxis: int, default -1
If `q` is not quaternion dtype, axis of the quaternion array
representing the coordinates of the quaternions.
one_to_one: bool, default True
If True, rotate each vector by a single quaternion. In this case,
non-singleton dimensions of `q` and `v` must match. Otherwise,
perform rotations for all combinations of `q` and `v`.
Returns
-------
vr: array_like
The array of rotated vectors. If `one_to_one=True` this array has
the shape of all non-singleton dimensions in `q` and `v`.
Otherwise, this array has shape `q.shape` + `v.shape`.
"""
# TODO proper broadcasting if v is DataArray
q = np.asarray(q)
v = np.asarray(v)
if q.dtype != quaternion:
q = as_quat_array(np.swapaxes(q, qaxis, -1))
if not one_to_one or q.ndim == 0:
return quat_rv(q, v, axis=axis)
if v.shape[axis] != 3:
raise ValueError(
f"Expected axis {axis} of v to have length 3, got {v.shape[axis]}"
)
# make sure that non-singleton axes match
v_shape = list(v.shape)
v_shape.pop(axis)
nonmatching_axes = (
qs != vs for qs, vs in zip(q.shape, v_shape) if qs != 1 and vs != 1
)
if q.ndim != v.ndim - 1 or any(nonmatching_axes):
raise ValueError(
f"Incompatible shapes for q and v: {q.shape} and {v.shape}."
)
# compute rotation
q = as_float_array(q)
r = q[..., 1:]
s = np.swapaxes(q[..., :1], -1, axis)
m = np.swapaxes(np.linalg.norm(q, axis=-1, keepdims=True), -1, axis)
rxv = np.cross(r, v, axisb=axis, axisc=axis)
vr = v + 2 * np.cross(r, s * v + rxv, axisb=axis, axisc=axis) / m
return vr
def from_euler_angles(
rpy=None,
roll=None,
pitch=None,
yaw=None,
axis=-1,
order="rpy",
return_quaternion=False,
):
""" Construct quaternions from Euler angles.
This method differs from the method found in the quaternion package in
that it is actually useful for converting commonly found Euler angle
representations to quaternions.
Parameters
----------
rpy: array-like, shape (..., 3, ...), optional
Array with roll, pitch and yaw values. Mutually exclusive with `roll`,
`pitch` and `yaw` arguments.
roll: array-like, optional
Array with roll values. Mutually exclusive with `rpy` argument.
pitch: array-like, optional
Array with pitch values. Mutually exclusive with `rpy` argument.
yaw: array-like, optional
Array with yaw values. Mutually exclusive with `rpy` argument.
axis: int, default -1
Array axis representing RPY values of `rpy` argument.
order: str, default "rpy"
Order of consecutively applied rotations. Defaults to
roll -> pitch -> yaw.
return_quaternion: bool, default False
If True, return result as quaternion dtype.
Returns
-------
q: array-like
Array with quaternions
"""
if rpy is not None:
if roll is not None or pitch is not None or yaw is not None:
raise ValueError(
"Cannot specify roll, pitch or yaw when rpy is provided"
)
rpy = np.swapaxes(np.asarray(rpy), axis, -1)
roll = rpy[..., 0]
pitch = rpy[..., 1]
yaw = rpy[..., 2]
shape = rpy.shape[:-1]
else:
shape = None
if roll is not None:
roll = np.asarray(roll)
shape = roll.shape
roll = from_rotation_vector(
np.stack((roll, np.zeros(shape), np.zeros(shape)), axis=-1)
)
if pitch is not None:
pitch = np.asarray(pitch)
if shape is None:
shape = np.shape(pitch)
elif shape != pitch.shape:
raise ValueError(
f"Inconsistent shape for pitch argument: expected {shape}, "
f"got {pitch.shape}"
)
pitch = from_rotation_vector(
np.stack((np.zeros(shape), pitch, np.zeros(shape)), axis=-1)
)
if yaw is not None:
yaw = np.asarray(yaw)
if shape is None:
shape = np.shape(yaw)
elif shape != yaw.shape:
raise ValueError(
f"Inconsistent shape for yaw argument: expected {shape}, "
f"got {yaw.shape}"
)
yaw = from_rotation_vector(
np.stack((np.zeros(shape), np.zeros(shape), yaw), axis=-1)
)
if shape is None:
raise ValueError(
"Must specify at least one of rpy, roll, pitch or yaw"
)
# rearrange rotors according to order
rotors = [None] * 3
try:
rotors[order.index("r")] = roll
rotors[order.index("p")] = pitch
rotors[order.index("y")] = yaw
except (ValueError, IndexError):
raise ValueError(
f"order must be a permutation of 'r', 'p' and 'y', got {order}"
)
# chain rotors
q = quaternion(1, 0, 0, 0)
for r in rotors:
if r is not None:
q = q * r
if return_quaternion:
return q
else:
return np.swapaxes(as_float_array(q), -1, axis)
def is_dataarray(obj, require_attrs=None):
""" Check whether an object is a DataArray.
Parameters
----------
obj: anything
The object to be checked.
require_attrs: list of str, optional
The attributes the object has to have in order to pass as a DataArray.
Returns
-------
bool
Whether the object is a DataArray or not.
"""
require_attrs = require_attrs or [
"values",
"coords",
"dims",
"name",
"attrs",
]
return all([hasattr(obj, name) for name in require_attrs])
def is_dataset(obj, require_attrs=None):
""" Check whether an object is a Dataset.
Parameters
----------
obj: anything
The object to be checked.
require_attrs: list of str, optional
The attributes the object has to have in order to pass as a Dataset.
Returns
-------
bool
Whether the object is a Dataset or not.
"""
require_attrs = require_attrs or [
"data_vars",
"coords",
"dims",
"to_array",
]
return all([hasattr(obj, name) for name in require_attrs])
class ExampleDataStore:
""" Storage interface for example data. """
base_url = "https://github.com/phausamann/rbm-data/raw/main/"
registry = {
"head": (
"head.nc",
"874eddaa51bf775c7311f0046613c6f969adef6e34fe4aea2e1248a75ed3fee3",
),
"left_eye": (
"left_eye.nc",
"56d5488fb8d3ff08450663ed0136ac659c1d51eb5340a7e3ed52f5ecf019139c",
),
"right_eye": (
"right_eye.nc",
"b038c4cb2f6932e4334f135cdf7e24ff9c3b5789977b2ae0206ba80acf54c647",
),
"rosbag": (
"example.bag",
"8d27f5e554f5a0e02e0bec59b60424e582f6104380f96c3f226b4d85c107f2bc",
),
}
def __getitem__(self, item):
try:
import pooch
except ImportError:
raise ModuleNotFoundError(
"pooch must be installed to load example data"
)
try:
dataset, known_hash = self.registry[item]
except KeyError:
raise KeyError(f"'{item}' is not a valid example dataset")
return Path(
pooch.retrieve(url=self.base_url + dataset, known_hash=known_hash)
) | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/utils.py | 0.857455 | 0.76745 | utils.py | pypi |
import numpy as np
import xarray as xr
from xarray.core.utils import either_dict_or_kwargs
from .utils import qinterp, qinv
@xr.register_dataarray_accessor("rbm")
class DataArrayAccessor:
""" Accessor for DataArrays. """
def __init__(self, obj):
""" Constructor. """
self._obj = obj
def qinterp(self, coords=None, qdim="quaternion_axis", **coords_kwargs):
""" Quaternion interpolation.
Parameters
----------
coords: dict, optional
Mapping from dimension names to the new coordinates.
New coordinate can be a scalar, array-like or DataArray.
qdim: str, default "quaternion_axis"
Name of the dimension representing the quaternions.
**coords_kwargs : {dim: coordinate, ...}, optional
The keyword arguments form of ``coords``.
One of coords or coords_kwargs must be provided.
Returns
-------
interpolated: xr.DataArray
New array on the new coordinates.
Examples
--------
>>> import xarray as xr
>>> import rigid_body_motion as rbm
>>> ds_head = xr.load_dataset(rbm.example_data["head"])
>>> ds_left_eye = xr.load_dataset(rbm.example_data["left_eye"])
>>> ds_head.orientation.rbm.qinterp(time=ds_left_eye.time) # doctest:+ELLIPSIS
<xarray.DataArray 'orientation' (time: 113373, quaternion_axis: 4)>
array(...)
Coordinates:
* time (time) datetime64[ns] ...
* quaternion_axis (quaternion_axis) object 'w' 'x' 'y' 'z'
Attributes:
long_name: Orientation
""" # noqa
coords = either_dict_or_kwargs(coords, coords_kwargs, "interp")
if len(coords) != 1:
raise NotImplementedError(
"qinterp only works along a single dimension so far"
)
interp_dim = next(iter(coords))
if interp_dim not in self._obj.dims:
raise ValueError(
f"{interp_dim} is not a dimension of this DataArray"
)
if np.asanyarray(coords[interp_dim]).ndim != 1:
raise NotImplementedError(
"qinterp only supports one-dimensional coords so far"
)
if qdim not in self._obj.dims:
raise ValueError(f"{qdim} is not a dimension of this DataArray")
# interpolate
arr = self._obj.values
t_in = self._obj.coords[interp_dim]
t_out = coords[interp_dim]
axis = self._obj.dims.index(interp_dim)
qaxis = self._obj.dims.index(qdim)
arr_out = qinterp(arr, t_in, t_out, axis, qaxis)
# update coords either by interpolating or selecting nearest for
# non-numerical coords
coords_out = dict(self._obj.coords)
for c in coords_out:
if c == interp_dim:
coords_out[c] = t_out
elif interp_dim in coords_out[c].dims:
if np.issubdtype(coords_out[c].dtype, np.number):
coords_out[c] = coords_out[c].interp(coords)
else:
coords_out[c] = coords_out[c].sel(coords, method="nearest")
interpolated = xr.DataArray(
arr_out,
coords_out,
self._obj.dims,
self._obj.name,
self._obj.attrs,
)
return interpolated
def qinv(self, qdim="quaternion_axis"):
""" Quaternion inverse.
Parameters
----------
qdim: str, default "quaternion_axis"
Name of the dimension representing the quaternions.
Returns
-------
inverse: xr.DataArray
New array with inverted quaternions.
Examples
--------
>>> import xarray as xr
>>> import rigid_body_motion as rbm
>>> ds_head = xr.load_dataset(rbm.example_data["head"])
>>> ds_head.orientation.rbm.qinv() # doctest:+ELLIPSIS
<xarray.DataArray 'orientation' (time: 66629, quaternion_axis: 4)>
array(...)
Coordinates:
* time (time) datetime64[ns] ...
* quaternion_axis (quaternion_axis) object 'w' 'x' 'y' 'z'
Attributes:
long_name: Orientation
"""
if qdim not in self._obj.dims:
raise ValueError(f"{qdim} is not a dimension of this DataArray")
qaxis = self._obj.dims.index(qdim)
inverse = self._obj.copy()
inverse.values = qinv(self._obj.values, qaxis)
return inverse | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/accessors.py | 0.916671 | 0.587085 | accessors.py | pypi |
__author__ = """Peter Hausamann"""
__email__ = "peter.hausamann@tum.de"
__version__ = "0.9.1"
# ROS module has to be imported first because of PyKDL
from . import ros # noqa
from . import io, plot # noqa
from .coordinate_systems import (
cartesian_to_polar,
cartesian_to_spherical,
polar_to_cartesian,
spherical_to_cartesian,
)
from .core import (
_make_dataarray,
_make_transform_or_pose_dataset,
_make_twist_dataset,
_make_velocity_dataarray,
_maybe_unpack_dataarray,
_replace_dim,
_resolve_rf,
_transform,
)
from .estimators import (
best_fit_rotation,
best_fit_transform,
estimate_angular_velocity,
estimate_linear_velocity,
iterative_closest_point,
shortest_arc_rotation,
)
from .reference_frames import ReferenceFrame
from .reference_frames import _registry as registry
from .reference_frames import (
clear_registry,
deregister_frame,
register_frame,
render_tree,
)
from .utils import (
ExampleDataStore,
from_euler_angles,
qinterp,
qinv,
qmean,
qmul,
rotate_vectors,
)
try:
import rigid_body_motion.accessors # noqa
except ImportError:
pass
__all__ = [
"transform_points",
"transform_quaternions",
"transform_vectors",
"transform_angular_velocity",
"transform_linear_velocity",
# coordinate system transforms
"cartesian_to_polar",
"polar_to_cartesian",
"cartesian_to_spherical",
"spherical_to_cartesian",
# reference frames
"registry",
"register_frame",
"deregister_frame",
"clear_registry",
"ReferenceFrame",
"render_tree",
# estimators
"estimate_linear_velocity",
"estimate_angular_velocity",
"shortest_arc_rotation",
"best_fit_rotation",
"best_fit_transform",
"iterative_closest_point",
"lookup_transform",
"lookup_pose",
"lookup_twist",
"lookup_linear_velocity",
"lookup_angular_velocity",
# utils
"from_euler_angles",
"example_data",
"qinterp",
"qinv",
"qmean",
"qmul",
"rotate_vectors",
]
_cs_funcs = {
"cartesian": {
"polar": cartesian_to_polar,
"spherical": cartesian_to_spherical,
},
"polar": {"cartesian": polar_to_cartesian},
"spherical": {"cartesian": spherical_to_cartesian},
}
example_data = ExampleDataStore()
def transform_vectors(
arr,
into,
outof=None,
dim=None,
axis=None,
timestamps=None,
time_axis=None,
return_timestamps=False,
):
""" Transform an array of vectors between reference frames.
Parameters
----------
arr: array_like
The array to transform.
into: str or ReferenceFrame
ReferenceFrame instance or name of a registered reference frame in
which the array will be represented after the transformation.
outof: str or ReferenceFrame, optional
ReferenceFrame instance or name of a registered reference frame in
which the array is currently represented. Can be omitted if the array
is a DataArray whose ``attrs`` contain a "representation_frame" entry
with the name of a registered frame.
dim: str, optional
If the array is a DataArray, the name of the dimension
representing the spatial coordinates of the vectors.
axis: int, optional
The axis of the array representing the spatial coordinates of the
vectors. Defaults to the last axis of the array.
timestamps: array_like or str, optional
The timestamps of the vectors, corresponding to the `time_axis`
of the array. If str and the array is a DataArray, the name of the
coordinate with the timestamps. The axis defined by `time_axis` will
be re-sampled to the timestamps for which the transformation is
defined.
time_axis: int, optional
The axis of the array representing the timestamps of the vectors.
Defaults to the first axis of the array.
return_timestamps: bool, default False
If True, also return the timestamps after the transformation.
Returns
-------
arr_transformed: array_like
The transformed array.
ts: array_like
The timestamps after the transformation.
See Also
--------
transform_quaternions, transform_points, ReferenceFrame
"""
return _transform(
"transform_vectors",
arr,
into,
outof,
dim,
axis,
timestamps,
time_axis,
return_timestamps=return_timestamps,
)
def transform_points(
arr,
into,
outof=None,
dim=None,
axis=None,
timestamps=None,
time_axis=None,
return_timestamps=False,
):
""" Transform an array of points between reference frames.
Parameters
----------
arr: array_like
The array to transform.
into: str or ReferenceFrame
ReferenceFrame instance or name of a registered reference frame in
which the array will be represented after the transformation.
outof: str or ReferenceFrame, optional
ReferenceFrame instance or name of a registered reference frame which
is the current reference frame of the array. Can be omitted if the
array is a DataArray whose ``attrs`` contain a "reference_frame" entry
with the name of a registered frame.
dim: str, optional
If the array is a DataArray, the name of the dimension
representing the spatial coordinates of the points.
axis: int, optional
The axis of the array representing the spatial coordinates of the
points. Defaults to the last axis of the array.
timestamps: array_like or str, optional
The timestamps of the points, corresponding to the `time_axis`
of the array. If str and the array is a DataArray, the name of the
coordinate with the timestamps. The axis defined by `time_axis` will
be re-sampled to the timestamps for which the transformation is
defined.
time_axis: int, optional
The axis of the array representing the timestamps of the points.
Defaults to the first axis of the array.
return_timestamps: bool, default False
If True, also return the timestamps after the transformation.
Returns
-------
arr_transformed: array_like
The transformed array.
ts: array_like
The timestamps after the transformation.
See Also
--------
transform_vectors, transform_quaternions, ReferenceFrame
"""
return _transform(
"transform_points",
arr,
into,
outof,
dim,
axis,
timestamps,
time_axis,
return_timestamps=return_timestamps,
)
def transform_quaternions(
arr,
into,
outof=None,
dim=None,
axis=None,
timestamps=None,
time_axis=None,
return_timestamps=False,
):
""" Transform an array of quaternions between reference frames.
Parameters
----------
arr: array_like
The array to transform.
into: str or ReferenceFrame
ReferenceFrame instance or name of a registered reference frame in
which the array will be represented after the transformation.
outof: str or ReferenceFrame, optional
ReferenceFrame instance or name of a registered reference frame which
is the current reference frame of the array. Can be omitted if the
array is a DataArray whose ``attrs`` contain a "reference_frame" entry
with the name of a registered frame.
dim: str, optional
If the array is a DataArray, the name of the dimension
representing the spatial coordinates of the quaternions.
axis: int, optional
The axis of the array representing the spatial coordinates of the
quaternions. Defaults to the last axis of the array.
timestamps: array_like or str, optional
The timestamps of the quaternions, corresponding to the `time_axis`
of the array. If str and the array is a DataArray, the name of the
coordinate with the timestamps. The axis defined by `time_axis` will
be re-sampled to the timestamps for which the transformation is
defined.
time_axis: int, optional
The axis of the array representing the timestamps of the quaternions.
Defaults to the first axis of the array.
return_timestamps: bool, default False
If True, also return the timestamps after the transformation.
Returns
-------
arr_transformed: array_like
The transformed array.
ts: array_like
The timestamps after the transformation.
See Also
--------
transform_vectors, transform_points, ReferenceFrame
"""
return _transform(
"transform_quaternions",
arr,
into,
outof,
dim,
axis,
timestamps,
time_axis,
return_timestamps=return_timestamps,
)
def transform_angular_velocity(
arr,
into,
outof=None,
what="reference_frame",
dim=None,
axis=None,
timestamps=None,
time_axis=None,
cutoff=None,
return_timestamps=False,
):
""" Transform an array of angular velocities between frames.
The array represents the velocity of a moving body or frame wrt a
reference frame, expressed in a representation frame.
The transformation changes either the reference frame, the moving
frame or the representation frame of the velocity from this frame to
another. In either case, it is assumed that the array is represented in
the frame that is being changed and will be represented in the new
frame after the transformation.
When transforming the reference frame R to a new frame R' while keeping
the moving frame M fixed, the transformed velocity is calculated
according to the formula:
.. math:: \omega_{M/R'} = \omega_{M/R} + \omega_{R/R'}
When transforming the moving frame M to a new frame M' while keeping
the reference frame R fixed, the transformed velocity is calculated
according to the formula:
.. math:: \omega_{M'/R} = \omega_{M/R} + \omega_{M'/M}
Parameters
----------
arr: array_like
The array to transform.
into: str or ReferenceFrame
The target reference frame.
outof: str or ReferenceFrame, optional
The source reference frame. Can be omitted if the array
is a DataArray whose ``attrs`` contain a "representation_frame",
"reference_frame" or "moving_frame" entry with the name of a
registered frame (depending on what you want to transform, see `what`).
what: str
What frame of the velocity to transform. Can be "reference_frame",
"moving_frame" or "representation_frame".
dim: str, optional
If the array is a DataArray, the name of the dimension
representing the spatial coordinates of the velocities.
axis: int, optional
The axis of the array representing the spatial coordinates of the
velocities. Defaults to the last axis of the array.
timestamps: array_like or str, optional
The timestamps of the velocities, corresponding to the `time_axis`
of the array. If str and the array is a DataArray, the name of the
coordinate with the timestamps. The axis defined by `time_axis` will
be re-sampled to the timestamps for which the transformation is
defined.
time_axis: int, optional
The axis of the array representing the timestamps of the velocities.
Defaults to the first axis of the array.
cutoff: float, optional
Frequency of a low-pass filter applied to linear and angular
velocity after the twist estimation as a fraction of the Nyquist
frequency.
return_timestamps: bool, default False
If True, also return the timestamps after the transformation.
Returns
-------
arr_transformed: array_like
The transformed array.
ts: array_like
The timestamps after the transformation.
See Also
--------
transform_linear_velocity, transform_vectors, transform_quaternions,
transform_points, ReferenceFrame
""" # noqa
return _transform(
"transform_angular_velocity",
arr,
into,
outof,
dim,
axis,
timestamps,
time_axis,
what=what,
cutoff=cutoff,
return_timestamps=return_timestamps,
)
def transform_linear_velocity(
arr,
into,
outof=None,
what="reference_frame",
moving_frame=None,
reference_frame=None,
dim=None,
axis=None,
timestamps=None,
time_axis=None,
cutoff=None,
outlier_thresh=None,
return_timestamps=False,
):
""" Transform an array of linear velocities between frames.
The array represents the velocity of a moving body or frame wrt a
reference frame, expressed in a representation frame.
The transformation changes either the reference frame, the moving
frame or the representation frame of the velocity from this frame to
another. In either case, it is assumed that the array is represented in
the frame that is being changed and will be represented in the new
frame after the transformation.
When transforming the reference frame R to a new frame R' while keeping
the moving frame M fixed, the transformed velocity is calculated
according to the formula:
.. math:: v_{M/R'} = v_{M/R} + v_{R/R'} + \omega_{R/R'} \\times t_{M/R}
When transforming the moving frame M to a new frame M' while keeping
the reference frame R fixed, the transformed velocity is calculated
according to the formula:
.. math:: v_{M'/R} = v_{M/R} + v_{M'/M} + \omega_{M/R} \\times t_{M'/M}
Parameters
----------
arr: array_like
The array to transform.
into: str or ReferenceFrame
The target reference frame.
outof: str or ReferenceFrame, optional
The source reference frame. Can be omitted if the array
is a DataArray whose ``attrs`` contain a "representation_frame",
"reference_frame" or "moving_frame" entry with the name of a
registered frame (depending on what you want to transform, see `what`).
what: str
What frame of the velocity to transform. Can be "reference_frame",
"moving_frame" or "representation_frame".
moving_frame: str or ReferenceFrame, optional
The moving frame when transforming the reference frame of the
velocity.
reference_frame: str or ReferenceFrame, optional
The reference frame when transforming the moving frame of the
velocity.
dim: str, optional
If the array is a DataArray, the name of the dimension
representing the spatial coordinates of the velocities.
axis: int, optional
The axis of the array representing the spatial coordinates of the
velocities. Defaults to the last axis of the array.
timestamps: array_like or str, optional
The timestamps of the velocities, corresponding to the `time_axis`
of the array. If str and the array is a DataArray, the name of the
coordinate with the timestamps. The axis defined by `time_axis` will
be re-sampled to the timestamps for which the transformation is
defined.
time_axis: int, optional
The axis of the array representing the timestamps of the velocities.
Defaults to the first axis of the array.
cutoff: float, optional
Frequency of a low-pass filter applied to linear and angular
velocity after the twist estimation as a fraction of the Nyquist
frequency.
outlier_thresh: float, optional
Some SLAM-based trackers introduce position corrections when a new
camera frame becomes available. This introduces outliers in the
linear velocity estimate. The estimation algorithm used here
can suppress these outliers by throwing out samples where the
norm of the second-order differences of the position is above
`outlier_thresh` and interpolating the missing values. For
measurements from the Intel RealSense T265 tracker, set this value
to 1e-3.
return_timestamps: bool, default False
If True, also return the timestamps after the transformation.
Returns
-------
arr_transformed: array_like
The transformed array.
ts: array_like
The timestamps after the transformation.
See Also
--------
transform_angular_velocity, transform_vectors, transform_quaternions,
transform_points, ReferenceFrame
""" # noqa
return _transform(
"transform_linear_velocity",
arr,
into,
outof,
dim,
axis,
timestamps,
time_axis,
what=what,
moving_frame=moving_frame,
reference_frame=reference_frame,
cutoff=cutoff,
outlier_thresh=outlier_thresh,
return_timestamps=return_timestamps,
)
def transform_coordinates(
arr, into, outof=None, dim=None, axis=None, replace_dim=True
):
""" Transform motion between coordinate systems.
Parameters
----------
arr: array_like
The array to transform.
into: str
The name of a coordinate system in which the array will be represented
after the transformation.
outof: str, optional
The name of a coordinate system in which the array is currently
represented. Can be omitted if the array is a DataArray whose ``attrs``
contain a "coordinate_system" entry with the name of a valid coordinate
system.
dim: str, optional
If the array is a DataArray, the name of the dimension representing
the coordinates of the motion.
axis: int, optional
The axis of the array representing the coordinates of the motion.
Defaults to the last axis of the array.
replace_dim: bool, default True
If True and the array is a DataArray, replace the dimension
representing the coordinates by a new dimension that describes the
new coordinate system and its axes (e.g.
``cartesian_axis: [x, y, z]``). All coordinates that contained the
original dimension will be dropped.
Returns
-------
arr_transformed: array_like
The transformed array.
See Also
--------
cartesian_to_polar, polar_to_cartesian, cartesian_to_spherical,
spherical_to_cartesian
"""
arr, axis, _, _, _, _, coords, dims, name, attrs = _maybe_unpack_dataarray(
arr, dim, axis, timestamps=False
)
if outof is None:
if attrs is not None and "coordinate_system" in attrs:
# TODO warn if outof(.name) != attrs["coordinate_system"]
outof = attrs["coordinate_system"]
else:
raise ValueError(
"'outof' must be specified unless you provide a DataArray "
"whose ``attrs`` contain a 'coordinate_system' entry with the "
"name of a valid coordinate system"
)
try:
transform_func = _cs_funcs[outof][into]
except KeyError:
raise ValueError(f"Unsupported transformation: {outof} to {into}.")
if attrs is not None and "coordinate_system" in attrs:
attrs.update({"coordinate_system": into})
arr = transform_func(arr, axis=axis)
if coords is not None:
if replace_dim:
# TODO accept (name, coord) tuple
coords, dims = _replace_dim(
coords, dims, axis, into, arr.shape[axis]
)
return _make_dataarray(arr, coords, dims, name, attrs, None, None)
else:
return arr
def lookup_transform(outof, into, as_dataset=False, return_timestamps=False):
""" Look up transformation from one frame to another.
The transformation is a rotation `r` followed by a translation `t` which,
when applied to a point expressed wrt the base frame `B`, yields that
point wrt the target frame `T`:
.. math:: p_T = rot(r, p_B) + t
Parameters
----------
outof: str or ReferenceFrame
Base frame of the transformation.
into: str or ReferenceFrame
Target frame of the transformation.
as_dataset: bool, default False
If True, return an xarray.Dataset. Otherwise, return a tuple of
translation and rotation.
return_timestamps: bool, default False
If True, and `as_dataset` is False, also return the timestamps of the
lookup.
Returns
-------
translation, rotation: each numpy.ndarray
Translation and rotation of transformation between the frames,
if `as_dataset` is False.
timestamps: numpy.ndarray
Corresponding timestamps of the lookup if `return_timestamps` is True.
ds: xarray.Dataset
The above arrays as an xarray.Dataset, if `as_dataset` is True.
"""
into = _resolve_rf(into)
outof = _resolve_rf(outof)
translation, rotation, timestamps = outof.lookup_transform(into)
if as_dataset:
return _make_transform_or_pose_dataset(
translation, rotation, outof, timestamps
)
elif return_timestamps:
return translation, rotation, timestamps
else:
return translation, rotation
def lookup_pose(frame, reference, as_dataset=False, return_timestamps=False):
""" Look up pose of one frame wrt a reference.
Parameters
----------
frame: str or ReferenceFrame
Frame for which to look up the pose.
reference: str or ReferenceFrame
Reference frame of the pose.
as_dataset: bool, default False
If True, return an xarray.Dataset. Otherwise, return a tuple of
position and orientation.
return_timestamps: bool, default False
If True, and `as_dataset` is False, also return the timestamps of the
lookup.
Returns
-------
position, orientation: each numpy.ndarray
Position and orientation of the pose between the frames,
if `as_dataset` is False.
timestamps: numpy.ndarray
Corresponding timestamps of the lookup if `return_timestamps` is True.
ds: xarray.Dataset
The above arrays as an xarray.Dataset, if `as_dataset` is True.
"""
reference = _resolve_rf(reference)
frame = _resolve_rf(frame)
position, orientation, timestamps = frame.lookup_transform(reference)
if as_dataset:
return _make_transform_or_pose_dataset(
position, orientation, reference, timestamps, pose=True
)
elif return_timestamps:
return position, orientation, timestamps
else:
return position, orientation
def lookup_twist(
frame,
reference=None,
represent_in=None,
outlier_thresh=None,
cutoff=None,
mode="quaternion",
as_dataset=False,
return_timestamps=False,
):
""" Estimate linear and angular velocity of a frame wrt a reference.
Parameters
----------
frame: str or ReferenceFrame
The reference frame whose twist is estimated.
reference: str or ReferenceFrame, optional
The reference frame wrt which the twist is estimated. Defaults to
the parent frame of the moving frame.
represent_in: str or ReferenceFrame, optional
The reference frame in which the twist is represented. Defaults
to the reference frame.
outlier_thresh: float, optional
Some SLAM-based trackers introduce position corrections when a new
camera frame becomes available. This introduces outliers in the
linear velocity estimate. The estimation algorithm used here
can suppress these outliers by throwing out samples where the
norm of the second-order differences of the position is above
`outlier_thresh` and interpolating the missing values. For
measurements from the Intel RealSense T265 tracker, set this value
to 1e-3.
cutoff: float, optional
Frequency of a low-pass filter applied to linear and angular
velocity after the estimation as a fraction of the Nyquist
frequency.
mode: str, default "quaternion"
If "quaternion", compute the angular velocity from the quaternion
derivative. If "rotation_vector", compute the angular velocity from
the gradient of the axis-angle representation of the rotations.
as_dataset: bool, default False
If True, return an xarray.Dataset. Otherwise, return a tuple of linear
and angular velocity.
return_timestamps: bool, default False
If True, and `as_dataset` is False, also return the timestamps of the
lookup.
Returns
-------
linear, angular: each numpy.ndarray
Linear and angular velocity of moving frame wrt reference frame,
represented in representation frame, if `as_dataset` is False.
timestamps: numpy.ndarray
Corresponding timestamps of the lookup if `return_timestamps` is True.
ds: xarray.Dataset
The above arrays as an xarray.Dataset, if `as_dataset` is True.
"""
frame = _resolve_rf(frame)
reference = _resolve_rf(reference or frame.parent)
represent_in = _resolve_rf(represent_in or reference)
linear, angular, timestamps = frame.lookup_twist(
reference,
represent_in,
outlier_thresh=outlier_thresh,
cutoff=cutoff,
mode=mode,
return_timestamps=True,
)
if as_dataset:
return _make_twist_dataset(
angular, linear, frame, reference, represent_in, timestamps
)
elif return_timestamps:
return linear, angular, timestamps
else:
return linear, angular
def lookup_linear_velocity(
frame,
reference=None,
represent_in=None,
outlier_thresh=None,
cutoff=None,
as_dataarray=False,
return_timestamps=False,
):
""" Estimate linear velocity of a frame wrt a reference.
Parameters
----------
frame: str or ReferenceFrame
The reference frame whose velocity is estimated.
reference: str or ReferenceFrame, optional
The reference frame wrt which the velocity is estimated. Defaults to
the parent frame of the moving frame.
represent_in: str or ReferenceFrame, optional
The reference frame in which the twist is represented. Defaults
to the reference frame.
outlier_thresh: float, optional
Some SLAM-based trackers introduce position corrections when a new
camera frame becomes available. This introduces outliers in the
linear velocity estimate. The estimation algorithm used here
can suppress these outliers by throwing out samples where the
norm of the second-order differences of the position is above
`outlier_thresh` and interpolating the missing values. For
measurements from the Intel RealSense T265 tracker, set this value
to 1e-3.
cutoff: float, optional
Frequency of a low-pass filter applied to linear and angular
velocity after the estimation as a fraction of the Nyquist
frequency.
as_dataarray: bool, default False
If True, return an xarray.DataArray.
return_timestamps: bool, default False
If True and `as_dataarray` is False, also return the timestamps of the
lookup.
Returns
-------
linear: numpy.ndarray or xarray.DataArray
Linear velocity of moving frame wrt reference frame, represented in
representation frame.
timestamps: numpy.ndarray
Corresponding timestamps of the lookup if `return_timestamps` is True.
"""
frame = _resolve_rf(frame)
reference = _resolve_rf(reference or frame.parent)
represent_in = _resolve_rf(represent_in or reference)
linear, timestamps = frame.lookup_linear_velocity(
reference,
represent_in,
outlier_thresh=outlier_thresh,
cutoff=cutoff,
return_timestamps=True,
)
if as_dataarray:
return _make_velocity_dataarray(
linear, "linear", frame, reference, represent_in, timestamps
)
elif return_timestamps:
return linear, timestamps
else:
return linear
def lookup_angular_velocity(
frame,
reference=None,
represent_in=None,
outlier_thresh=None,
cutoff=None,
mode="quaternion",
as_dataarray=False,
return_timestamps=False,
):
""" Estimate angular velocity of a frame wrt a reference.
Parameters
----------
frame: str or ReferenceFrame
The reference frame whose velocity is estimated.
reference: str or ReferenceFrame, optional
The reference frame wrt which the velocity is estimated. Defaults to
the parent frame of the moving frame.
represent_in: str or ReferenceFrame, optional
The reference frame in which the twist is represented. Defaults
to the reference frame.
outlier_thresh: float, optional
Suppress samples where the norm of the second-order differences of the
rotation is above `outlier_thresh` and interpolate the missing values.
cutoff: float, optional
Frequency of a low-pass filter applied to angular and angular
velocity after the estimation as a fraction of the Nyquist
frequency.
mode: str, default "quaternion"
If "quaternion", compute the angular velocity from the quaternion
derivative. If "rotation_vector", compute the angular velocity from
the gradient of the axis-angle representation of the rotations.
as_dataarray: bool, default False
If True, return an xarray.DataArray.
return_timestamps: bool, default False
If True and `as_dataarray` is False, also return the timestamps of the
lookup.
Returns
-------
angular: numpy.ndarray or xarray.DataArray
Angular velocity of moving frame wrt reference frame, represented in
representation frame.
timestamps: numpy.ndarray
Corresponding timestamps of the lookup if `return_timestamps` is True.
"""
frame = _resolve_rf(frame)
reference = _resolve_rf(reference or frame.parent)
represent_in = _resolve_rf(represent_in or reference)
angular, timestamps = frame.lookup_angular_velocity(
reference,
represent_in,
outlier_thresh=outlier_thresh,
cutoff=cutoff,
mode=mode,
return_timestamps=True,
)
if as_dataarray:
return _make_velocity_dataarray(
angular, "angular", frame, reference, represent_in, timestamps,
)
elif return_timestamps:
return angular, timestamps
else:
return angular | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/__init__.py | 0.888445 | 0.478407 | __init__.py | pypi |
import numpy as np
from quaternion import as_float_array, from_rotation_matrix
from scipy.spatial import cKDTree
from rigid_body_motion.core import (
_estimate_angular_velocity,
_estimate_linear_velocity,
_make_dataarray,
_maybe_unpack_dataarray,
_replace_dim,
)
from rigid_body_motion.utils import rotate_vectors
def _reshape_vectors(v1, v2, axis, dim, same_shape=True):
""" Reshape input vectors to two dimensions. """
# TODO v2 as DataArray with possibly different dimension order
v1, axis, _, _, _, _, coords, *_ = _maybe_unpack_dataarray(
v1, dim, axis, None, False
)
v2, *_ = _maybe_unpack_dataarray(v2, None, axis, None)
if v1.shape[axis] != 3 or v2.shape[axis] != 3:
raise ValueError(
f"Shape of v1 and v2 along axis {axis} must be 3, got "
f"{v1.shape[axis]} for v1 and {v2.shape[axis]} for v2"
)
if v1.ndim < 2:
raise ValueError("v1 must have at least two dimensions")
# flatten everything except spatial dimension
v1 = np.swapaxes(v1, axis, -1).reshape(-1, 3)
v2 = np.swapaxes(v2, axis, -1).reshape(-1, 3)
if same_shape and v1.shape != v2.shape:
raise ValueError("v1 and v2 must have the same shape")
return v1, v2, coords is not None
def _make_transform_dataarrays(translation, rotation):
""" Make translation and rotation DataArrays. """
import xarray as xr
translation = xr.DataArray(
translation,
{"cartesian_axis": ["x", "y", "z"]},
"cartesian_axis",
name="translation",
)
rotation = xr.DataArray(
rotation,
{"quaternion_axis": ["w", "x", "y", "z"]},
"quaternion_axis",
name="rotation",
)
return translation, rotation
def estimate_linear_velocity(
arr,
dim=None,
axis=None,
timestamps=None,
time_axis=None,
outlier_thresh=None,
cutoff=None,
):
""" Estimate linear velocity from a time series of translation.
Parameters
----------
arr: array_like
Array of translations.
dim: str, optional
If the array is a DataArray, the name of the dimension
representing the spatial coordinates of the points.
axis: int, optional
The axis of the array representing the spatial coordinates of the
points. Defaults to the last axis of the array.
timestamps: array_like or str, optional
The timestamps of the points, corresponding to the `time_axis`
of the array. If str and the array is a DataArray, the name of the
coordinate with the timestamps. The axis defined by `time_axis` will
be re-sampled to the timestamps for which the transformation is
defined.
time_axis: int, optional
The axis of the array representing the timestamps of the points.
Defaults to the first axis of the array.
cutoff: float, optional
Frequency of a low-pass filter applied to the linear velocity after
the estimation as a fraction of the Nyquist frequency.
outlier_thresh: float, optional
Some SLAM-based trackers introduce position corrections when a new
camera frame becomes available. This introduces outliers in the
linear velocity estimate. The estimation algorithm used here
can suppress these outliers by throwing out samples where the
norm of the second-order differences of the position is above
`outlier_thresh` and interpolating the missing values. For
measurements from the Intel RealSense T265 tracker, set this value
to 1e-3.
Returns
-------
linear: array_like
Array of linear velocities.
"""
(
arr,
axis,
dim,
time_axis,
time_dim,
timestamps,
coords,
dims,
name,
attrs,
) = _maybe_unpack_dataarray(
arr, dim=dim, axis=axis, time_axis=time_axis, timestamps=timestamps
)
linear = _estimate_linear_velocity(
arr,
timestamps,
time_axis=time_axis,
outlier_thresh=outlier_thresh,
cutoff=cutoff,
)
if coords is not None:
return _make_dataarray(
linear, coords, dims, name, attrs, time_dim, timestamps
)
else:
return linear
def estimate_angular_velocity(
arr,
dim=None,
axis=None,
timestamps=None,
time_axis=None,
mode="quaternion",
outlier_thresh=None,
cutoff=None,
):
""" Estimate angular velocity from a time series of rotations.
Parameters
----------
arr: array_like
Array of rotations, expressed in quaternions.
dim: str, optional
If the array is a DataArray, the name of the dimension
representing the spatial coordinates of the quaternions.
axis: int, optional
The axis of the array representing the spatial coordinates of the
quaternions. Defaults to the last axis of the array.
timestamps: array_like or str, optional
The timestamps of the quaternions, corresponding to the `time_axis`
of the array. If str and the array is a DataArray, the name of the
coordinate with the timestamps. The axis defined by `time_axis` will
be re-sampled to the timestamps for which the transformation is
defined.
time_axis: int, optional
The axis of the array representing the timestamps of the quaternions.
Defaults to the first axis of the array.
mode: str, default "quaternion"
If "quaternion", compute the angular velocity from the quaternion
derivative. If "rotation_vector", compute the angular velocity from
the gradient of the axis-angle representation of the rotations.
outlier_thresh: float, optional
Suppress samples where the norm of the second-order differences of the
rotation is above `outlier_thresh` and interpolate the missing values.
cutoff: float, optional
Frequency of a low-pass filter applied to the angular velocity after
the estimation as a fraction of the Nyquist frequency.
Returns
-------
angular: array_like
Array of angular velocities.
"""
(
arr,
axis,
dim,
time_axis,
time_dim,
timestamps,
coords,
dims,
name,
attrs,
) = _maybe_unpack_dataarray(
arr, dim=dim, axis=axis, time_axis=time_axis, timestamps=timestamps
)
angular = _estimate_angular_velocity(
arr,
timestamps,
axis=axis,
time_axis=time_axis,
mode=mode,
outlier_thresh=outlier_thresh,
cutoff=cutoff,
)
if coords is not None:
coords, dims = _replace_dim(coords, dims, axis, "cartesian", 3)
return _make_dataarray(
angular, coords, dims, name, attrs, time_dim, timestamps
)
else:
return angular
def shortest_arc_rotation(v1, v2, dim=None, axis=None):
""" Estimate the shortest-arc rotation between two arrays of vectors.
This method computes the rotation `r` that satisfies:
.. math:: v_2 / ||v_2|| = rot(r, v_1) / ||v_1||
Parameters
----------
v1: array_like, shape (..., 3, ...)
The first array of vectors.
v2: array_like, shape (..., 3, ...)
The second array of vectors.
dim: str, optional
If the first array is a DataArray, the name of the dimension
representing the spatial coordinates of the vectors.
axis: int, optional
The axis of the arrays representing the spatial coordinates of the
vectors. Defaults to the last axis of the arrays.
Returns
-------
rotation: array_like, shape (..., 4, ...)
The quaternion representation of the shortest-arc rotation.
"""
v1, axis, _, _, _, _, coords, dims, name, attrs = _maybe_unpack_dataarray(
v1, dim, axis, None
)
v1 = np.asarray(v1)
v2 = np.asarray(v2)
sn1 = np.sum(v1 ** 2, axis=axis, keepdims=True)
sn2 = np.sum(v2 ** 2, axis=axis, keepdims=True)
d12 = np.sum(v1 * v2, axis=axis, keepdims=True)
c12 = np.cross(v1, v2, axis=axis)
rotation = np.concatenate((np.sqrt(sn1 * sn2) + d12, c12), axis=axis)
rotation /= np.linalg.norm(rotation, axis=axis, keepdims=True)
if coords is not None:
coords, dims = _replace_dim(coords, dims, axis, "quaternion", 3)
return _make_dataarray(rotation, coords, dims, name, attrs, None, None)
else:
return rotation
def best_fit_rotation(v1, v2, dim=None, axis=None):
""" Least-squares best-fit rotation between two arrays of vectors.
Finds the rotation `r` that minimizes:
.. math:: || v_2 - rot(r, v_1) ||
Parameters
----------
v1: array_like, shape (..., 3, ...)
The first array of vectors.
v2: array_like, shape (..., 3, ...)
The second array of vectors.
dim: str, optional
If the first array is a DataArray, the name of the dimension
representing the spatial coordinates of the vectors.
axis: int, optional
The axis of the arrays representing the spatial coordinates of the
vectors. Defaults to the last axis of the arrays.
Returns
-------
rotation: array_like, shape (4,)
Rotation of transform.
References
----------
Adapted from https://github.com/ClayFlannigan/icp
See Also
--------
iterative_closest_point, best_fit_transform
"""
v1, v2, was_dataarray = _reshape_vectors(v1, v2, axis, dim)
# rotation matrix
H = np.dot(v1.T, v2)
U, S, Vt = np.linalg.svd(H)
R = np.dot(Vt.T, U.T)
# rotation as quaternion
rotation = as_float_array(from_rotation_matrix(R))
if was_dataarray:
import xarray as xr
rotation = xr.DataArray(
rotation,
{"quaternion_axis": ["w", "x", "y", "z"]},
"quaternion_axis",
name="rotation",
)
return rotation
def best_fit_transform(v1, v2, dim=None, axis=None):
""" Least-squares best-fit transform between two arrays of vectors.
Finds the rotation `r` and the translation `t` that minimize:
.. math:: || v_2 - (rot(r, v_1) + t) ||
Parameters
----------
v1: array_like, shape (..., 3, ...)
The first array of vectors.
v2: array_like, shape (..., 3, ...)
The second array of vectors.
dim: str, optional
If the first array is a DataArray, the name of the dimension
representing the spatial coordinates of the vectors.
axis: int, optional
The axis of the arrays representing the spatial coordinates of the
vectors. Defaults to the last axis of the arrays.
Returns
-------
translation: array_like, shape (3,)
Translation of transform.
rotation: array_like, shape (4,)
Rotation of transform.
References
----------
Adapted from https://github.com/ClayFlannigan/icp
See Also
--------
iterative_closest_point, best_fit_rotation
"""
v1, v2, was_dataarray = _reshape_vectors(v1, v2, axis, dim)
# translate points to their centroids
mean_v1 = np.mean(v1, axis=0)
mean_v2 = np.mean(v2, axis=0)
v1_centered = v1 - mean_v1
v2_centered = v2 - mean_v2
# rotation matrix
H = np.dot(v1_centered.T, v2_centered)
U, S, Vt = np.linalg.svd(H)
R = np.dot(Vt.T, U.T)
# special reflection case
if np.linalg.det(R) < 0:
Vt[2, :] *= -1
R = np.dot(Vt.T, U.T)
# rotation as quaternion
rotation = as_float_array(from_rotation_matrix(R))
# translation
translation = mean_v2.T - np.dot(R, mean_v1.T)
if was_dataarray:
translation, rotation = _make_transform_dataarrays(
translation, rotation
)
return translation, rotation
def _nearest_neighbor(v1, v2):
""" Find the nearest neighbor in v2 for each point in v1. """
kd_tree = cKDTree(v2)
distances, idx = kd_tree.query(v1, 1)
return idx.ravel(), distances.ravel()
def iterative_closest_point(
v1,
v2,
dim=None,
axis=None,
init_transform=None,
max_iterations=20,
tolerance=1e-3,
):
""" Iterative closest point algorithm matching two arrays of vectors.
Finds the rotation `r` and the translation `t` such that:
.. math:: v_2 \simeq rot(r, v_1) + t
Parameters
----------
v1: array_like, shape (..., 3, ...)
The first array of vectors.
v2: array_like, shape (..., 3, ...)
The second array of vectors.
dim: str, optional
If the first array is a DataArray, the name of the dimension
representing the spatial coordinates of the vectors.
axis: int, optional
The axis of the arrays representing the spatial coordinates of the
vectors. Defaults to the last axis of the arrays.
init_transform: tuple, optional
Initial guess as (translation, rotation) tuple.
max_iterations: int, default 20
Maximum number of iterations.
tolerance: float, default 1e-3
Abort if the mean distance error between the transformed arrays does
not improve by more than this threshold between iterations.
Returns
-------
translation: array_like, shape (3,)
Translation of transform.
rotation: array_like, shape (4,)
Rotation of transform.
References
----------
Adapted from https://github.com/ClayFlannigan/icp
Notes
-----
For points with known correspondences (e.g. timeseries of positions), it is
recommended to interpolate the points to a common sampling base and use the
`best_fit_transform` method.
See Also
--------
best_fit_transform, best_fit_rotation
""" # noqa
v1, v2, was_dataarray = _reshape_vectors(
v1, v2, axis, dim, same_shape=False
)
v1_new = np.copy(v1)
# apply the initial pose estimation
if init_transform is not None:
t, r = init_transform
v1_new = rotate_vectors(np.asarray(r), v1_new) + np.asarray(t)
prev_error = 0
for i in range(max_iterations):
# find the nearest neighbors between the current source and destination
# points
idx, distances = _nearest_neighbor(v1_new, v2)
# compute the transformation between the current source and nearest
# destination points
t, r = best_fit_transform(v1_new, v2[idx])
# update the current source
v1_new = rotate_vectors(r, v1_new) + t
# check error
mean_error = np.mean(distances)
if np.abs(prev_error - mean_error) < tolerance:
break
prev_error = mean_error
# calculate final transformation
translation, rotation = best_fit_transform(v1, v1_new)
if was_dataarray:
translation, rotation = _make_transform_dataarrays(
translation, rotation
)
return translation, rotation | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/estimators.py | 0.780412 | 0.676593 | estimators.py | pypi |
import numpy as np
def cartesian_to_polar(arr, axis=-1):
""" Transform cartesian to polar coordinates in two dimensions.
Parameters
----------
arr : array_like
Input array.
axis : int, default -1
Axis of input array representing x and y in cartesian coordinates.
Must be of length 2.
Returns
-------
arr_polar : array_like
Output array.
"""
if arr.shape[axis] != 2:
raise ValueError(
f"Expected length of axis {axis} to be 2, got {arr.shape[axis]} "
f"instead."
)
r = np.linalg.norm(arr, axis=axis)
phi = np.arctan2(np.take(arr, 1, axis=axis), np.take(arr, 0, axis=axis))
return np.stack((r, phi), axis=axis)
def polar_to_cartesian(arr, axis=-1):
""" Transform polar to cartesian coordinates in two dimensions.
Parameters
----------
arr : array_like
Input array.
axis : int, default -1
Axis of input array representing r and phi in polar coordinates.
Must be of length 2.
Returns
-------
arr_cartesian : array_like
Output array.
"""
if arr.shape[axis] != 2:
raise ValueError(
f"Expected length of axis {axis} to be 2, got {arr.shape[axis]} "
f"instead."
)
x = np.take(arr, 0, axis=axis) * np.cos(np.take(arr, 1, axis=axis))
y = np.take(arr, 0, axis=axis) * np.sin(np.take(arr, 1, axis=axis))
return np.stack((x, y), axis=axis)
def cartesian_to_spherical(arr, axis=-1):
""" Transform cartesian to spherical coordinates in three dimensions.
The spherical coordinate system is defined according to ISO 80000-2.
Parameters
----------
arr : array_like
Input array.
axis : int, default -1
Axis of input array representing x, y and z in cartesian coordinates.
Must be of length 3.
Returns
-------
arr_spherical : array_like
Output array.
"""
if arr.shape[axis] != 3:
raise ValueError(
f"Expected length of axis {axis} to be 3, got {arr.shape[axis]} "
f"instead."
)
r = np.linalg.norm(arr, axis=axis)
theta = np.arccos(np.take(arr, 2, axis=axis) / r)
phi = np.arctan2(np.take(arr, 1, axis=axis), np.take(arr, 0, axis=axis))
return np.stack((r, theta, phi), axis=axis)
def spherical_to_cartesian(arr, axis=-1):
""" Transform spherical to cartesian coordinates in three dimensions.
The spherical coordinate system is defined according to ISO 80000-2.
Parameters
----------
arr : array_like
Input array.
axis : int, default -1
Axis of input array representing r, theta and phi in spherical
coordinates. Must be of length 3.
Returns
-------
arr_cartesian : array_like
Output array.
"""
if arr.shape[axis] != 3:
raise ValueError(
f"Expected length of axis {axis} to be 3, got {arr.shape[axis]} "
f"instead."
)
x = (
np.take(arr, 0, axis=axis)
* np.sin(np.take(arr, 1, axis=axis))
* np.cos(np.take(arr, 2, axis=axis))
)
y = (
np.take(arr, 0, axis=axis)
* np.sin(np.take(arr, 1, axis=axis))
* np.sin(np.take(arr, 2, axis=axis))
)
z = np.take(arr, 0, axis=axis) * np.cos(np.take(arr, 1, axis=axis))
return np.stack((x, y, z), axis=axis) | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/coordinate_systems.py | 0.950319 | 0.903337 | coordinate_systems.py | pypi |
from threading import Thread
import numpy as np
from anytree import PreOrderIter
from rigid_body_motion.core import _resolve_rf
from rigid_body_motion.reference_frames import ReferenceFrame
class Transformer:
""" Wrapper class for tf2_ros.Buffer.
Can be constructed from a ReferenceFrame instance.
"""
def __init__(self, cache_time=None):
""" Constructor.
Parameters
----------
cache_time : float, optional
Cache time of the buffer in seconds.
"""
import rospy
import tf2_ros
if cache_time is not None:
self._buffer = tf2_ros.Buffer(
cache_time=rospy.Duration.from_sec(cache_time), debug=False
)
else:
self._buffer = tf2_ros.Buffer(debug=False)
@staticmethod
def from_reference_frame(reference_frame):
""" Construct Transformer instance from static reference frame tree.
Parameters
----------
reference_frame : ReferenceFrame
Reference frame instance from which to construct the transformer.
Returns
-------
Transformer
Transformer instance.
"""
root = reference_frame.root
# get the first and last timestamps for all moving reference frames
# TODO float timestamps
t_start_end = list(
zip(
*[
(
node.timestamps[0].astype(float) / 1e9,
node.timestamps[-1].astype(float) / 1e9,
)
for node in PreOrderIter(root)
if node.timestamps is not None
]
)
)
if len(t_start_end) == 0:
transformer = Transformer(cache_time=None)
else:
# cache time from earliest start to latest end
cache_time = np.max(t_start_end[1]) - np.min(t_start_end[0])
transformer = Transformer(cache_time=cache_time)
for node in PreOrderIter(root):
if isinstance(node, ReferenceFrame):
if node.parent is not None:
if node.timestamps is None:
transformer.set_transform_static(node)
else:
transformer.set_transforms(node)
else:
raise NotImplementedError()
return transformer
def set_transform_static(self, reference_frame):
""" Add static transform from reference frame to buffer.
Parameters
----------
reference_frame : ReferenceFrame
Static reference frame to add.
"""
from .msg import static_rf_to_transform_msg
self._buffer.set_transform_static(
static_rf_to_transform_msg(reference_frame), "default_authority"
)
def set_transforms(self, reference_frame):
""" Add transforms from moving reference frame to buffer.
Parameters
----------
reference_frame : ReferenceFrame
Static reference frame to add.
"""
from .msg import make_transform_msg
for translation, rotation, timestamp in zip(
reference_frame.translation,
reference_frame.rotation,
reference_frame.timestamps,
):
self._buffer.set_transform(
make_transform_msg(
translation,
rotation,
reference_frame.parent.name,
reference_frame.name,
timestamp.astype(float) / 1e9,
),
"default_authority",
)
def can_transform(self, target_frame, source_frame, time=0.0):
""" Check if transform from source to target frame is possible.
Parameters
----------
target_frame : str
Name of the frame to transform into.
source_frame : str
Name of the input frame.
time : float, default 0.0
Time at which to get the transform. (0 will get the latest)
Returns
-------
bool
True if the transform is possible, false otherwise.
"""
import rospy
return self._buffer.can_transform(
target_frame, source_frame, rospy.Time.from_sec(time)
)
def lookup_transform(self, target_frame, source_frame, time=0.0):
""" Get the transform from the source frame to the target frame.
Parameters
----------
target_frame : str
Name of the frame to transform into.
source_frame : str
Name of the input frame.
time : float, default 0.0
Time at which to get the transform. (0 will get the latest)
Returns
-------
t : tuple, len 3
The translation between the frames.
r : tuple, len 4
The rotation between the frames.
"""
import rospy
from .msg import unpack_transform_msg
transform = self._buffer.lookup_transform(
target_frame, source_frame, rospy.Time.from_sec(time)
)
return unpack_transform_msg(transform, stamped=True)
def transform_vector(self, v, target_frame, source_frame, time=0.0):
""" Transform a vector from the source frame to the target frame.
Parameters
----------
v : iterable, len 3
Input vector in source frame.
target_frame : str
Name of the frame to transform into.
source_frame : str
Name of the input frame.
time : float, default 0.0
Time at which to get the transform. (0 will get the latest)
Returns
-------
tuple, len 3
Transformed vector in target frame.
"""
import rospy
import tf2_geometry_msgs
from .msg import make_vector_msg, unpack_vector_msg
transform = self._buffer.lookup_transform(
target_frame, source_frame, rospy.Time.from_sec(time)
)
v_msg = make_vector_msg(v, source_frame, time)
vt_msg = tf2_geometry_msgs.do_transform_vector3(v_msg, transform)
return unpack_vector_msg(vt_msg, stamped=True)
def transform_point(self, p, target_frame, source_frame, time=0.0):
""" Transform a point from the source frame to the target frame.
Parameters
----------
p : iterable, len 3
Input point in source frame.
target_frame : str
Name of the frame to transform into.
source_frame : str
Name of the input frame.
time : float, default 0.0
Time at which to get the transform. (0 will get the latest)
Returns
-------
tuple, len 3
Transformed point in target frame.
"""
import rospy
import tf2_geometry_msgs
from .msg import make_point_msg, unpack_point_msg
transform = self._buffer.lookup_transform(
target_frame, source_frame, rospy.Time.from_sec(time)
)
p_msg = make_point_msg(p, source_frame, time)
pt_msg = tf2_geometry_msgs.do_transform_point(p_msg, transform)
return unpack_point_msg(pt_msg, stamped=True)
def transform_quaternion(self, q, target_frame, source_frame, time=0.0):
""" Transform a quaternion from the source frame to the target frame.
Parameters
----------
q : iterable, len 4
Input quaternion in source frame.
target_frame : str
Name of the frame to transform into.
source_frame : str
Name of the input frame.
time : float, default 0.0
Time at which to get the transform. (0 will get the latest)
Returns
-------
tuple, len 4
Transformed quaternion in target med quaternion in target frame.
"""
import rospy
import tf2_geometry_msgs
from .msg import make_pose_msg, unpack_pose_msg
transform = self._buffer.lookup_transform(
target_frame, source_frame, rospy.Time.from_sec(time)
)
p_msg = make_pose_msg((0.0, 0.0, 0.0), q, source_frame, time)
pt_msg = tf2_geometry_msgs.do_transform_pose(p_msg, transform)
return unpack_pose_msg(pt_msg, stamped=True)[1]
def transform_pose(self, p, o, target_frame, source_frame, time=0.0):
""" Transform a pose from the source frame to the target frame.
Parameters
----------
p : iterable, len 3
Input position in source frame.
o : iterable, len 3
Input orientation in source frame.
target_frame : str
Name of the frame to transform into.
source_frame : str
Name of the input frame.
time : float, default 0.0
Time at which to get the transform. (0 will get the latest)
Returns
-------
pt : tuple, len 3
Transformed position in target frame.
ot : tuple, len 4
Transformed orientation in target frame.
"""
import rospy
import tf2_geometry_msgs
from .msg import make_pose_msg, unpack_pose_msg
transform = self._buffer.lookup_transform(
target_frame, source_frame, rospy.Time.from_sec(time)
)
p_msg = make_pose_msg(p, o, source_frame, time)
pt_msg = tf2_geometry_msgs.do_transform_pose(p_msg, transform)
return unpack_pose_msg(pt_msg, stamped=True)
class ReferenceFrameTransformBroadcaster:
""" TF broadcaster for the transform of a reference frame wrt another. """
def __init__(
self,
frame,
base=None,
publish_pose=False,
publish_twist=False,
subscribe=False,
twist_cutoff=None,
twist_outlier_thresh=None,
):
""" Constructor.
Parameters
----------
frame : str or ReferenceFrame
Reference frame for which to publish the transform.
base : str or ReferenceFrame, optional
Base reference wrt to which the transform is published. Defaults
to the parent reference frame.
publish_pose : bool, default False
If True, also publish a PoseStamped message on the topic
"/<frame>/pose".
publish_twist : bool, default False
If True, also publish a TwistStamped message with the linear and
angular velocity of the frame wrt the base on the topic
"/<frame>/twist".
subscribe : bool or str, default False
If True, subscribe to the "/tf" topic and publish transforms
when messages are broadcast whose `child_frame_id` is the name of
the base frame. If the frame is a moving reference frame, the
transform whose timestamp is the closest to the broadcast timestamp
is published. `subscribe` can also be a string, in which case this
broadcaster will be listening for TF messages with this
`child_frame_id`.
"""
import pandas as pd
import rospy
import tf2_ros
from geometry_msgs.msg import PoseStamped, TwistStamped
from tf.msg import tfMessage
self.frame = _resolve_rf(frame)
self.base = _resolve_rf(base or self.frame.parent)
(
self.translation,
self.rotation,
self.timestamps,
) = self.frame.lookup_transform(self.base)
if self.timestamps is None:
self.broadcaster = tf2_ros.StaticTransformBroadcaster()
else:
self.timestamps = pd.Index(self.timestamps)
self.broadcaster = tf2_ros.TransformBroadcaster()
if publish_pose:
self.pose_publisher = rospy.Publisher(
f"/{self.frame.name}/pose",
PoseStamped,
queue_size=1,
latch=True,
)
else:
self.pose_publisher = None
if publish_twist:
self.linear, self.angular = self.frame.lookup_twist(
reference=base,
represent_in=self.frame,
cutoff=twist_cutoff,
outlier_thresh=twist_outlier_thresh,
)
self.twist_publisher = rospy.Publisher(
f"/{self.frame.name}/twist",
TwistStamped,
queue_size=1,
latch=True,
)
else:
self.twist_publisher = None
if subscribe:
self.subscriber = rospy.Subscriber(
"/tf", tfMessage, self.handle_incoming_msg
)
if isinstance(subscribe, str):
self.subscribe_to_frame = subscribe
else:
self.subscribe_to_frame = self.base.name
else:
self.subscriber = None
self.idx = 0
self.stopped = False
self._thread = None
def publish(self, idx=None):
""" Publish a transform message.
Parameters
----------
idx : int, optional
Index of the transform to publish for a moving reference frame.
Uses ``self.idx`` as default.
"""
from .msg import make_pose_msg, make_transform_msg, make_twist_msg
if self.timestamps is None:
transform = make_transform_msg(
self.translation,
self.rotation,
self.base.name,
self.frame.name,
)
if self.pose_publisher is not None:
pose = make_pose_msg(
self.translation, self.rotation, self.base.name,
)
else:
idx = idx or self.idx
ts = self.timestamps.values[idx].astype(float) / 1e9
transform = make_transform_msg(
self.translation[idx],
self.rotation[idx],
self.base.name,
self.frame.name,
ts,
)
if self.pose_publisher is not None:
pose = make_pose_msg(
self.translation[idx],
self.rotation[idx],
self.base.name,
ts,
)
self.broadcaster.sendTransform(transform)
if self.pose_publisher is not None:
self.pose_publisher.publish(pose)
if self.twist_publisher is not None:
self.twist_publisher.publish(
make_twist_msg(
self.linear[idx], self.angular[idx], self.frame.name
)
)
def handle_incoming_msg(self, msg):
""" Publish on incoming message. """
import pandas as pd
import rospy
for transform in msg.transforms:
if transform.child_frame_id == self.subscribe_to_frame:
if self.timestamps is not None:
ts = pd.to_datetime(
rospy.Time.to_sec(transform.header.stamp), unit="s"
)
idx = self.timestamps.get_loc(ts, method="nearest")
self.publish(idx)
else:
self.publish()
def _spin_blocking(self):
""" Continuously publish messages. """
import pandas as pd
import rospy
self.stopped = False
if self.subscriber is None and self.timestamps is not None:
while not rospy.is_shutdown() and not self.stopped:
self.publish()
self.idx = (self.idx + 1) % len(self.timestamps)
if isinstance(self.timestamps, pd.DatetimeIndex):
dt = (
self.timestamps.values[self.idx].astype(float) / 1e9
- self.timestamps.values[self.idx - 1].astype(float)
/ 1e9
if self.idx > 0
else 0.0
)
else:
dt = float(
self.timestamps.values[self.idx]
- self.timestamps.values[self.idx - 1]
if self.idx > 0
else 0.0
)
rospy.sleep(dt)
else:
rospy.spin()
self.stopped = True
def spin(self, block=False):
""" Continuously publish messages.
Parameters
----------
block: bool, default False
If True, this method will block until the publisher is stopped,
e.g. by calling stop(). Otherwise, the main loop is
dispatched to a separate thread which is returned by this
function.
Returns
-------
thread: threading.Thread
If `block=True`, the Thread instance that runs the loop.
"""
if self.timestamps is None:
self.publish()
elif block:
self._spin_blocking()
else:
self._thread = Thread(target=self._spin_blocking)
self._thread.start()
def stop(self):
""" Stop publishing. """
self.stopped = True | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/ros/transformer.py | 0.884239 | 0.42054 | transformer.py | pypi |
from io import BytesIO
from threading import Thread
from rigid_body_motion.core import _resolve_rf
def hex_to_rgba(h):
""" Convert hex color string to ColorRGBA message.
Parameters
----------
h : str
Hex color string in the format #RRGGBBAA.
Returns
-------
c : ColorRGBA
ColorRGBA message.
"""
from std_msgs.msg import ColorRGBA
h = h.lstrip("#")
return ColorRGBA(*(int(h[i : i + 2], 16) / 255 for i in (0, 2, 4, 6)))
def get_marker(
marker_type=None,
frame_id="world",
scale=1.0,
color="#ffffffff",
position=(0.0, 0.0, 0.0),
orientation=(0.0, 0.0, 0.0, 1.0),
):
""" Create a Marker visualization message.
Parameters
----------
marker_type : int, default Marker.LINE_STRIP
Type of the marker.
frame_id : str, default "world"
Name of the reference frame of the marker.
scale : float or iterable of float, len 3, default 1.0
Scale of the marker.
color : str, default "#ffffffff"
Color of the marker.
position : iterable, len 3, default (0.0, 0.0, 0.0)
Position of the marker wrt its reference frame.
orientation : iterable, len 4, default (0.0, 0.0, 0.0, 1.0)
Orientation of the marker wrt its reference frame.
Returns
-------
marker: Marker
Marker message.
"""
from geometry_msgs.msg import Point, Quaternion, Vector3
from visualization_msgs.msg import Marker
marker = Marker()
marker.type = marker_type or Marker.LINE_STRIP
marker.header.frame_id = frame_id
if isinstance(scale, float):
marker.scale = Vector3(scale, scale, scale)
else:
marker.scale = Vector3(*scale)
marker.color = hex_to_rgba(color)
marker.pose.orientation = Quaternion(*orientation)
marker.pose.position = Point(*position)
# TOD0: make configurable via vector
marker.points = []
return marker
class BaseMarkerPublisher:
""" Base class for Marker publishers. """
def __init__(self, marker, topic, publish_interval=0.0, verbose=False):
""" Constructor.
Parameters
----------
marker : Marker
Marker message to publish.
topic : str
Name of the topic on which to publish.
publish_interval : float, default 0.0
Time in seconds between publishing when calling ``spin``.
"""
import rospy
from visualization_msgs.msg import Marker
self.marker = marker
self.topic = topic
self.publish_interval = publish_interval
self.last_message = BytesIO()
self.publisher = rospy.Publisher(
self.topic, Marker, queue_size=1, latch=True
)
if verbose:
rospy.loginfo("Created marker publisher")
self.stopped = False
self._thread = None
def publish(self):
""" Publish a marker message. """
current_message = BytesIO()
self.marker.serialize(current_message)
if current_message.getvalue() != self.last_message.getvalue():
self.last_message = current_message
self.publisher.publish(self.marker)
def _spin_blocking(self):
""" Continuously publish messages. """
import rospy
self.stopped = False
while not rospy.is_shutdown() and not self.stopped:
self.publish()
rospy.sleep(self.publish_interval)
self.stopped = True
def spin(self, block=False):
""" Continuously publish messages.
Parameters
----------
block: bool, default False
If True, this method will block until the publisher is stopped,
e.g. by calling stop(). Otherwise, the main loop is
dispatched to a separate thread which is returned by this
function.
Returns
-------
thread: threading.Thread
If `block=True`, the Thread instance that runs the loop.
"""
if block:
self._spin_blocking()
else:
self._thread = Thread(target=self._spin_blocking)
self._thread.start()
def stop(self):
""" Stop publishing. """
self.stopped = True
class ReferenceFrameMarkerPublisher(BaseMarkerPublisher):
""" Publisher for the translation of a reference frame wrt another. """
def __init__(
self,
frame,
base=None,
topic=None,
max_points=1000,
publish_interval=0.0,
scale=0.1,
color="#ffffffff",
verbose=False,
):
""" Constructor.
Parameters
----------
frame : str or ReferenceFrame
Reference frame for which to publish the translation.
base : str or ReferenceFrame, optional
Base reference wrt to which the translation is published. Defaults
to the parent reference frame.
topic : str, optional
Name of the topic on which to publish. Defaults to "/<frame>/path".
max_points : int, default 1000
Maximum number of points to add to the marker. Actual translation
array will be sub-sampled to this number of points.
publish_interval : float, default 0.0
Time in seconds between publishing when calling ``spin``.
"""
from geometry_msgs.msg import Point
self.frame = _resolve_rf(frame)
self.base = _resolve_rf(base or self.frame.parent)
self.translation, _, _ = self.frame.lookup_transform(self.base)
marker = get_marker(
frame_id=self.base.name, scale=(scale, 0.0, 0.0), color=color
)
show_every = self.translation.shape[0] // max_points
marker.points = [Point(*row) for row in self.translation[::show_every]]
topic = topic or f"/{self.frame.name}/path"
super().__init__(
marker, topic, publish_interval=publish_interval, verbose=verbose
)
def get_ros3d_widget(self, ros=None, tf_client=None):
""" Get a ros3d.Marker widget to display in a ros3d.Viewer.
Parameters
----------
ros : jupyros.ros3d.ROSConnection, optional
ros3d ROS connection instance.
tf_client : jupyros.ros3d.TFClient, optional
ros3d TF client instance.
Returns
-------
jupyros.ros3d.Marker
ros3d marker widget.
"""
from jupyros import ros3d
ros = ros or ros3d.ROSConnection()
tf_client = tf_client or ros3d.TFClient(
ros=ros, fixed_frame=self.base.name
)
return ros3d.Marker(
ros=ros, tf_client=tf_client, topic=self.topic, path=""
) | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/ros/visualization.py | 0.935935 | 0.409811 | visualization.py | pypi |
import atexit
import warnings
import numpy as np
def init_node(name, start_master=False):
""" Register a client node with the master.
Parameters
----------
name: str
Name of the node.
start_master: bool, default False
If True, start a ROS master if one isn't already running.
Returns
-------
master: ROSLaunchParent or ROSMasterStub instance
If a ROS master was started by this method, returns a
``ROSLaunchParent`` instance that can be used to shut down the master
with its ``shutdown()`` method. Otherwise, a ``ROSMasterStub`` is
returned that shows a warning when its ``shutdown()`` method is called.
"""
import roslaunch
import rospy
class ROSMasterStub:
@staticmethod
def shutdown():
warnings.warn(
"ROS master was started somewhere else and cannot be shut "
"down."
)
try:
rospy.get_master().getPid()
except ConnectionRefusedError:
if start_master:
master = roslaunch.parent.ROSLaunchParent(
"master", [], is_core=True
)
master.start()
# make sure master is shut down on exit
atexit.register(master.shutdown)
else:
raise RuntimeError("ROS master is not running.")
else:
master = ROSMasterStub()
rospy.init_node(name)
return master
def play_publisher(publisher, step=1, speed=1.0, skip=None, timestamps=None):
""" Interactive widget for playing back messages from a publisher.
Parameters
----------
publisher: object
Any object with a ``publish`` method that accepts an ``idx`` parameter
and publishes a message corresponding to that index.
step: int, default 1
Difference in indexes between consecutive messages, e.g. if ``step=2``
every second message will be published.
speed: float, default 1.0
Playback speed.
skip: int, optional
Number of messages to skip with the forward and backward buttons.
timestamps: array_like, datetime64 dtype, optional
Timestamps of publisher messages that determine time difference between
messages and total number of messages. The time difference is
calculated as the mean difference between the timestamps, i.e. it
assumes that the timestamps are more or less regular. If not provided,
the publisher must have a ``timestamps`` attribute which will be used
instead.
"""
from IPython.core.display import display
from ipywidgets import widgets
if timestamps is None:
timestamps = np.asarray(publisher.timestamps)
interval = np.mean(np.diff(timestamps.astype(float) / 1e6)) / speed
# position bar
s_idx = widgets.IntSlider(
min=0, max=len(timestamps) - 1, value=0, description="Index"
)
# forward button
def button_plus(name):
s_idx.value += skip or step if s_idx.value < s_idx.max else 0
forward = widgets.Button(
description="►►", layout=widgets.Layout(width="50px")
)
forward.on_click(button_plus)
# backward button
def button_minus(name):
s_idx.value -= skip or step if s_idx.value < s_idx.max else 0
backward = widgets.Button(
description="◄◄", layout=widgets.Layout(width="50px")
)
backward.on_click(button_minus)
# play button
play = widgets.Play(
interval=int(interval * step),
value=0,
min=s_idx.min,
max=s_idx.max,
step=step,
description="Press play",
disabled=False,
)
widgets.jslink((play, "value"), (s_idx, "value"))
# layout
ui = widgets.HBox([s_idx, backward, play, forward])
out = widgets.interactive_output(publisher.publish, {"idx": s_idx})
display(ui, out) | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/ros/utils.py | 0.786705 | 0.401101 | utils.py | pypi |
import rospy
from geometry_msgs.msg import (
Point,
PointStamped,
PoseStamped,
Quaternion,
QuaternionStamped,
TransformStamped,
TwistStamped,
Vector3,
Vector3Stamped,
)
# TODO stamped=True/False parameter
# TODO default values
def make_transform_msg(t, r, frame_id, child_frame_id, time=0.0):
""" Create a TransformStamped message. """
msg = TransformStamped()
msg.header.stamp = rospy.Time.from_sec(time)
msg.header.frame_id = frame_id
msg.child_frame_id = child_frame_id
msg.transform.translation = Vector3(*t)
msg.transform.rotation = Quaternion(r[1], r[2], r[3], r[0])
return msg
def unpack_transform_msg(msg, stamped=False):
""" Get translation and rotation from a Transform(Stamped) message. """
if stamped:
t = msg.transform.translation
r = msg.transform.rotation
else:
t = msg.translation
r = msg.rotation
return (t.x, t.y, t.z), (r.w, r.x, r.y, r.z)
def make_pose_msg(p, o, frame_id, time=0.0):
""" Create a PoseStamped message. """
msg = PoseStamped()
msg.header.stamp = rospy.Time.from_sec(time)
msg.header.frame_id = frame_id
msg.pose.position = Point(*p)
msg.pose.orientation = Quaternion(o[1], o[2], o[3], o[0])
return msg
def unpack_pose_msg(msg, stamped=False):
""" Get position and orientation from a Pose(Stamped) message. """
if stamped:
p = msg.pose.position
o = msg.pose.orientation
else:
p = msg.position
o = msg.orientation
return (p.x, p.y, p.z), (o.w, o.x, o.y, o.z)
def make_twist_msg(v, w, frame_id, time=0.0):
""" Create a TwistStamped message. """
msg = TwistStamped()
msg.header.stamp = rospy.Time.from_sec(time)
msg.header.frame_id = frame_id
msg.twist.linear = Vector3(*v)
msg.twist.angular = Vector3(*w)
return msg
def unpack_twist_msg(msg, stamped=False):
""" Get linear and angular velocity from a Twist(Stamped) message. """
if stamped:
v = msg.twist.linear
w = msg.twist.angular
else:
v = msg.linear
w = msg.angular
return (v.x, v.y, v.z), (w.x, w.y, w.z)
def make_vector_msg(v, frame_id, time=0.0):
""" Create a Vector3Stamped message. """
msg = Vector3Stamped()
msg.header.stamp = rospy.Time.from_sec(time)
msg.header.frame_id = frame_id
msg.vector = Vector3(*v)
return msg
def unpack_vector_msg(msg, stamped=False):
""" Get coordinates from a Vector3(Stamped) message. """
if stamped:
v = msg.vector
else:
v = msg
return v.x, v.y, v.z
def make_point_msg(p, frame_id, time=0.0):
""" Create a PointStamped message. """
msg = PointStamped()
msg.header.stamp = rospy.Time.from_sec(time)
msg.header.frame_id = frame_id
msg.point = Point(*p)
return msg
def unpack_point_msg(msg, stamped=False):
""" Get coordinates from a Point(Stamped) message. """
if stamped:
p = msg.point
else:
p = msg
return p.x, p.y, p.z
def make_quaternion_msg(q, frame_id, time=0.0):
""" Create a QuaternionStamped message. """
msg = QuaternionStamped()
msg.header.stamp = rospy.Time.from_sec(time)
msg.header.frame_id = frame_id
msg.quaternion = Quaternion(q[1], q[2], q[3], q[0])
return msg
def unpack_quaternion_msg(msg, stamped=False):
""" Get coordinates from a Quaternion(Stamped) message. """
if stamped:
q = msg.quaternion
else:
q = msg
return q.w, q.x, q.y, q.z
def static_rf_to_transform_msg(rf, time=0.0):
""" Convert a static ReferenceFrame to a TransformStamped message.
Parameters
----------
rf : ReferenceFrame
Static reference frame.
time : float, default 0.0
The time of the message.
Returns
-------
msg : TransformStamped
TransformStamped message.
"""
return make_transform_msg(
rf.translation, rf.rotation, rf.parent.name, rf.name, time=time
) | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/ros/msg.py | 0.597843 | 0.374448 | msg.py | pypi |
from pathlib import Path
import numpy as np
class RosbagReader:
""" Reader for motion topics from rosbag files. """
def __init__(self, bag_file):
""" Constructor.
Parameters
----------
bag_file: str
Path to rosbag file.
"""
self.bag_file = Path(bag_file)
self._bag = None
def __enter__(self):
import rosbag
self._bag = rosbag.Bag(self.bag_file, "r")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self._bag.close()
self._bag = None
@staticmethod
def _get_msg_type(bag, topic):
""" Get type of message. """
return bag.get_type_and_topic_info(topic).topics[topic].msg_type
def _get_filename(self, output_file, extension):
""" Get export filename and create folder. """
if output_file is None:
folder, filename = self.bag_file.parent, self.bag_file.stem
filename = folder / f"{filename}.{extension}"
else:
folder = output_file.parent
filename = output_file
folder.mkdir(parents=True, exist_ok=True)
return filename
@staticmethod
def _write_netcdf(ds, filename, dtype="int32"):
""" Write dataset to netCDF file. """
comp = {
"zlib": True,
"dtype": dtype,
"scale_factor": 0.0001,
"_FillValue": np.iinfo(dtype).min,
}
encoding = {}
for v in ds.data_vars:
encoding[v] = comp
ds.to_netcdf(filename, encoding=encoding)
def get_topics_and_types(self):
""" Get topics and corresponding message types included in rosbag.
Returns
-------
topics: dict
Names of topics and corresponding message types included in the
rosbag.
"""
if self._bag is None:
raise RuntimeError(
"get_topics must be called from within the RosbagReader "
"context manager"
)
info = self._bag.get_type_and_topic_info()
return {k: v[0] for k, v in info[1].items()}
def load_messages(self, topic):
""" Load messages from topic as dict.
Only nav_msgs/Odometry and geometry_msgs/TransformStamped topics are
supported so far.
Parameters
----------
topic: str
Name of the topic to load.
Returns
-------
messages: dict
Dict containing arrays of timestamps and other message contents.
"""
from .msg import (
unpack_point_msg,
unpack_quaternion_msg,
unpack_vector_msg,
)
if self._bag is None:
raise RuntimeError(
"load_messages must be called from within the RosbagReader "
"context manager"
)
msg_type = self._get_msg_type(self._bag, topic)
if msg_type == "nav_msgs/Odometry":
arr = np.array(
[
(
(msg.header.stamp if msg._has_header else ts).to_sec(),
*unpack_point_msg(msg.pose.pose.position),
*unpack_quaternion_msg(msg.pose.pose.orientation),
*unpack_vector_msg(msg.twist.twist.linear),
*unpack_vector_msg(msg.twist.twist.angular),
)
for _, msg, ts in self._bag.read_messages(topics=topic)
]
)
return_vals = {
"timestamps": arr[:, 0],
"position": arr[:, 1:4],
"orientation": arr[:, 4:8],
"linear_velocity": arr[:, 8:11],
"angular_velocity": arr[:, 11:],
}
elif msg_type == "geometry_msgs/TransformStamped":
arr = np.array(
[
(
(msg.header.stamp if msg._has_header else ts).to_sec(),
*unpack_point_msg(msg.transform.translation),
*unpack_quaternion_msg(msg.transform.rotation),
)
for _, msg, ts in self._bag.read_messages(topics=topic)
]
)
return_vals = {
"timestamps": arr[:, 0],
"position": arr[:, 1:4],
"orientation": arr[:, 4:8],
}
else:
raise ValueError(f"Unsupported message type {msg_type}")
return return_vals
def load_dataset(self, topic, cache=False):
""" Load messages from topic as xarray.Dataset.
Only nav_msgs/Odometry and geometry_msgs/TransformStamped topics are
supported so far.
Parameters
----------
topic: str
Name of the topic to load.
cache: bool, default False
If True, cache the dataset in ``cache/<topic>.nc`` in the same
folder as the rosbag.
Returns
-------
ds: xarray.Dataset
Messages as dataset.
"""
# TODO attrs
import pandas as pd
import xarray as xr
if cache:
filepath = (
self.bag_file.parent
/ "cache"
/ f"{topic.replace('/', '_')}.nc"
)
if not filepath.exists():
self.export(topic, filepath)
return xr.open_dataset(filepath)
motion = self.load_messages(topic)
coords = {
"cartesian_axis": ["x", "y", "z"],
"quaternion_axis": ["w", "x", "y", "z"],
"time": pd.to_datetime(motion["timestamps"], unit="s"),
}
data_vars = {
"position": (["time", "cartesian_axis"], motion["position"]),
"orientation": (
["time", "quaternion_axis"],
motion["orientation"],
),
}
if "linear_velocity" in motion:
data_vars.update(
(
{
"linear_velocity": (
["time", "cartesian_axis"],
motion["linear_velocity"],
),
"angular_velocity": (
["time", "cartesian_axis"],
motion["angular_velocity"],
),
}
)
)
ds = xr.Dataset(data_vars, coords)
return ds
def export(self, topic, output_file=None):
""" Export messages from topic as netCDF4 file.
Parameters
----------
topic: str
Topic to read.
output_file: str, optional
Path to output file. By default, the path to the bag file, but with
a different extension depending on the export format.
"""
ds = self.load_dataset(topic, cache=False)
self._write_netcdf(ds, self._get_filename(output_file, "nc"))
class RosbagWriter:
""" Writer for motion topics to rosbag files. """
def __init__(self, bag_file):
""" Constructor.
Parameters
----------
bag_file: str
Path to rosbag file.
"""
self.bag_file = Path(bag_file)
self._bag = None
def __enter__(self):
import rosbag
self._bag = rosbag.Bag(self.bag_file, "w")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self._bag.close()
self._bag = None
def write_transform_stamped(
self, timestamps, translation, rotation, topic, frame, child_frame
):
""" Write multiple geometry_msgs/TransformStamped messages.
Parameters
----------
timestamps: array_like, shape (n_timestamps,)
Array of timestamps.
translation: array_like, shape (n_timestamps, 3)
Array of translations.
rotation: array_like, shape (n_timestamps, 4)
Array of rotations.
topic: str
Topic of the messages.
frame: str
Parent frame of the transform.
child_frame: str
Child frame of the transform.
"""
from .msg import make_transform_msg
# check timestamps
timestamps = np.asarray(timestamps)
if timestamps.ndim != 1:
raise ValueError("timestamps must be one-dimensional")
# check translation
translation = np.asarray(translation)
if translation.shape != (len(timestamps), 3):
raise ValueError(
f"Translation must have shape ({len(timestamps)}, 3), "
f"got {translation.shape}"
)
# check rotation
rotation = np.asarray(rotation)
if rotation.shape != (len(timestamps), 4):
raise ValueError(
f"Rotation must have shape ({len(timestamps)}, 4), "
f"got {rotation.shape}"
)
# write messages to bag
for ts, t, r in zip(timestamps, translation, rotation):
msg = make_transform_msg(t, r, frame, child_frame, ts)
self._bag.write(topic, msg)
def write_transform_stamped_dataset(
self,
ds,
topic,
frame,
child_frame,
timestamps="time",
translation="position",
rotation="orientation",
):
""" Write a dataset as geometry_msgs/TransformStamped messages.
Parameters
----------
ds: xarray.Dataset
Dataset containing timestamps, translation and rotation
topic: str
Topic of the messages.
frame: str
Parent frame of the transform.
child_frame: str
Child frame of the transform.
timestamps: str, default 'time'
Name of the dimension containing the timestamps.
translation: str, default 'position'
Name of the variable containing the translation.
rotation: str, default 'orientation'
Name of the variable containing the rotation.
"""
if np.issubdtype(ds[timestamps].dtype, np.datetime64):
timestamps = ds[timestamps].astype(float) / 1e9
else:
timestamps = ds[timestamps]
self.write_transform_stamped(
timestamps,
ds[translation],
ds[rotation],
topic,
frame,
child_frame,
) | /rigid-body-motion-0.9.1.tar.gz/rigid-body-motion-0.9.1/rigid_body_motion/ros/io.py | 0.833833 | 0.287455 | io.py | pypi |
import numpy as np
import unittest
import numbers
import operator
SMALL_NUMBER = 1e-10
skew_symmetric = lambda v: np.array([[ 0., -v[2], v[1]],
[ v[2], 0., -v[0]],
[-v[1], v[0], 0.]])
class Vector2(object):
'''Representing an object living in 2-dimensional Euclidean space.'''
def __init__(self, x=0., y=0.):
self._x = x
self._y = y
@staticmethod
def identity(self):
'''Return vector (0, 0) in 2-dimensional Euclidean space.'''
return Vector2()
@property
def x(self):
return self._x
@property
def y(self):
return self._y
def __iadd__(self, other):
assert isinstance(other, Vector2)
self._x += other.x
self._y += other.y
return self
def __add__(self, other):
if not isinstance(other, Vector2):
raise ValueError("{} is not a type of Vector2".format(other))
return Vector2(self.x + other.x, self.y + other.y)
def __radd__(self, other):
if not isinstance(other, Vector2):
raise ValueError("{} is not a type of Vector2".format(other))
return Vector2(self.x + other.x, self.y + other.y)
def __mul__(self, other):
if not isinstance(other, numbers.Number):
raise ValueError("{} is not a valid number.".format(other))
return Vector2(other * self.x, other * self.y)
def __rmul__(self, other):
if not isinstance(other, numbers.Number):
raise ValueError("{} is not a valid number.".format(other))
return Vector2(other * self.x, other * self.y)
def __eq__(self, other):
if isinstance(other, Vector2):
norm_difference = \
np.linalg.norm((self.x - other.x, self.y - other.y))
return norm_difference < SMALL_NUMBER
return False
def normalized(self):
'''Return normalized vector2.'''
return self * (1 / np.linalg.norm((self.x, self.y)))
def norm(self):
'''Return Euclidean distance of the vector2.'''
return np.linalg.norm([self.x, self.y])
def __repr__(self):
return "Vector2(xy: ({}, {}))".format(self.x, self.y)
class Vector3(object):
'''Representing an object living in 3-dimensional Euclidean space.'''
def __init__(self, x=0., y=0., z=0):
self._x = x
self._y = y
self._z = z
@staticmethod
def identity(self):
'''Return vector (0, 0, 0) in 3-dimensional Euclidean space.'''
return Vector3()
@property
def x(self):
return self._x
@property
def y(self):
return self._y
@property
def z(self):
return self._z
def __iadd__(self, other):
assert isinstance(other, Vector3)
self._x += other.x
self._y += other.y
self._z += other.z
return self
def __add__(self, other):
if not isinstance(other, Vector3):
raise ValueError("{} is not a type of Vector3".format(other))
return Vector3(
self.x + other.x, self.y + other.y, self.z + other.z
)
def __radd__(self, other):
if not isinstance(other, Vector3):
raise ValueError("{} is not a type of Vector3".format(other))
return Vector3(
self.x + other.x, self.y + other.y, self.z + other.z
)
def __mul__(self, other):
if not isinstance(other, numbers.Number):
raise ValueError("{} is not a valid number.".format(other))
return Vector3(other * self.x, other * self.y, other * self.z)
def __rmul__(self, other):
if not isinstance(other, numbers.Number):
raise ValueError("{} is not a valid number.".format(other))
return Vector3(other * self.x, other * self.y, other * self.z)
def __eq__(self, other):
if isinstance(other, Vector3):
norm_difference = np.linalg.norm(
(self.x - other.x, self.y - other.y, self.z - other.z)
)
return norm_difference < SMALL_NUMBER
return False
def normalized(self):
return self * (1 / np.linalg.norm((self.x, self.y, self.z)))
def norm(self):
return np.linalg.norm([self.x, self.y, self.z])
def __repr__(self):
return "Vector3(xyz: ({:.4f}, {:.4f}, {:.4f}))".format(self.x, self.y, self.z)
class AxisAngle(object):
"""Representing rotation in axis-angle."""
def __init__(self, angle, axis):
assert isinstance(axis, Vector3)
self._angle = angle
self._axis = axis
def ToQuaternion(self):
w = np.cos(self._angle * 0.5)
v = np.sin(self._angle * 0.5) * self._axis.normalized()
return Quaternion(w, v.x, v.y, v.z)
class Quaternion(object):
def __init__(self, w=1., x=0., y=0., z=0.):
self._scaler = w
self._vector = Vector3(x, y, z)
@staticmethod
def identity():
return Quaternion()
def scalar(self):
return self._scaler
def vector(self):
return np.array([self._vector.x, self._vector.y, self._vector.z])
def __mul__(self, other):
if isinstance(other, Quaternion):
scalar = self.scalar() * other.scalar() \
- np.dot(self.vector(), other.vector())
vector = self.scalar() * other.vector() \
+ other.scalar() * self.vector() \
+ np.cross(self.vector(), other.vector())
return Quaternion(scalar, *vector)
elif isinstance(other, numbers.Number):
return Quaternion(
self.w * other,
self.x * other,
self.y * other,
self.z * other
)
elif isinstance(other, Vector3):
conjugation = self \
* Quaternion(0, other.x, other.y, other.z) \
* self.conjugate()
return Vector3(*conjugation.vector())
else:
raise ValueError(
"Quaterion can not multiply a object of type {}"
.format(type(other))
)
def __rmul__(self, other):
if isinstance(other, numbers.Number):
return Quaternion(
self.w * other,
self.x * other,
self.y * other,
self.z * other
)
else:
raise ValueError(
"An object of type {} multiply a quaternion is Not Defined."
.format(type(other))
)
def __add__(self, other):
if isinstance(other, Quaternion):
return Quaternion(
self.w + other.w,
self.x + other.x,
self.y + other.y,
self.z + other.z
)
elif isinstance(other, numbers.Number):
return self + Quaternion(other, 0, 0, 0)
else:
raise ValueError(
"The operation of adding a value of type"
"{} to a quaternion is Not Defined."
.format(type(other))
)
def __eq__(self, other):
if isinstance(other, Quaternion):
norm_difference = np.linalg.norm(
(self.w - other.w,
self.x - other.x,
self.y - other.y,
self.z - other.z)
)
return norm_difference < SMALL_NUMBER
return False
def __repr__(self):
return "Quaternion(wxyz: ({:.4f}, {:.4f}, {:.4f}, {:.4f}))".format(
self.scalar(), *self.vector()
)
def inverse(self):
return self.conjugate() * (1 / np.square(self.norm()))
def matrix(self):
v = self.vector()
qv = np.reshape(v, (3, 1))
R = (self.w * self.w - np.dot(v, v)) * np.identity(3) \
+ 2 * qv * qv.T + 2 * self.w * skew_symmetric(self.vector())
return R
def conjugate(self):
return Quaternion(self.w, -self.x, -self.y, -self.z)
@property
def w(self):
return self._scaler
@property
def x(self):
return self._vector.x
@property
def y(self):
return self._vector.y
@property
def z(self):
return self._vector.z
def norm(self):
return np.linalg.norm((self.w, self.x, self.y, self.z))
def normalized(self):
scale = 1. / self.norm()
return Quaternion(
self._w * scale,
self._x * scale,
self._y * scale,
self._z * scale
)
def ToEuler(self):
"""The Euler angle representation of the corresponding rotation.
Return (roll, pitch, yaw)
"""
w, x, y, z = self.w, self.x, self.y, self.z
roll = np.arctan2(2 * (w * x + y * z), 1 - 2 * (x**2 + y**2))
sinp = np.arcsin(2 * (w * y - z * x))
pitch = np.copysign(np.pi / 2, sinp) \
if abs(sinp) >= 1 else np.arcsin(sinp)
yaw = np.arctan2(2 * (w * z + x * y), 1 - 2 * (y**2 + z**2))
return (roll, pitch, yaw)
class Translation(Vector3):
"""Representing Translation by Vector3"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def __add__(self, other):
vector3 = super().__add__(other)
if isinstance(other, Translation):
return Translation(vector3.x, vector3.y, vector3.z)
else:
return vector3
def __repr__(self):
return "Translation({})".format(super().__repr__())
class Rotation(Quaternion):
"""Representing Rotation by Quaternion."""
def __init__(self, *args, **kwargs):
if "yaw" in kwargs and "roll" in kwargs and "pitch" in kwargs:
quaternion = \
AxisAngle(kwargs["roll"], Vector3(1, 0, 0)).ToQuaternion() \
* AxisAngle(kwargs["pitch"], Vector3(0, 1, 0)).ToQuaternion() \
* AxisAngle(kwargs["yaw"], Vector3(0, 0, 1)).ToQuaternion()
super().__init__(
quaternion.w, quaternion.x, quaternion.y, quaternion.z
)
elif "angle" in kwargs and "axis" in kwargs:
quaternion = AxisAngle(
kwargs["angle"], kwargs["axis"]).ToQuaterion()
super().__init__(
quaternion.w, quaternion.x, quaternion.y, quaternion.z
)
else:
super().__init__(*args, **kwargs)
def __mul__(self, other):
if isinstance(other, Translation):
translation = super().__mul__(other)
return Translation(
translation.x, translation.y, translation.z
)
elif isinstance(other, Rotation):
quaternion = super().__mul__(other)
return Rotation(
quaternion.w, quaternion.x, quaternion.y, quaternion.z
)
else:
return super().__mul__(other)
def inverse(self):
quaternion = super().inverse()
return Rotation(
quaternion.w, quaternion.x, quaternion.y, quaternion.z
)
def __repr__(self):
return "Rotation({})".format(super().__repr__())
class Rigid(object):
"""Representing Rigid Transformation."""
def __init__(self, translation=Translation(), rotation=Rotation()):
self._translation = translation
self._rotation = rotation
def inverse(self):
return Rigid(
-1 * (self._rotation.inverse() * self._translation),
self._rotation.inverse()
)
def __mul__(self, other):
if isinstance(other, Vector3):
return self._rotation * other + self._translation
elif isinstance(other, Rigid):
return Rigid(
self._rotation * other.translation + self._translation,
self._rotation * other.rotation
)
else:
raise ValueError(
"A Rigid object can not multiply an object of type {}".format(
type(other))
)
def __rmul__(self, other):
if not isinstance(other, Rigid):
raise ValueError(
"A Rigid object can not multiply an object of type {}".format(
type(other))
)
def __eq__(self, other):
return self._rotation == other.rotation and \
self._translation == other.translation
@property
def rotation(self):
return self._rotation
@property
def translation(self):
return self._translation
def __repr__(self):
return "Rigid({}, {})".format(self.translation, self.rotation)
class Rigid3(Rigid):
"""Representing Rigid Transformation living in SE(3)."""
def __mul__(self, other):
rigid = super().__mul__(other)
if isinstance(other, Rigid3):
return Rigid3(rigid.translation, rigid.rotation)
else:
return rigid
def __repr__(self):
return "Rigid3({}, {})".format(self.translation, self.rotation)
class Rigid2(Rigid):
"""Representing Rigid Transformation living in SE(2)."""
def __init__(self, x=0, y=0, theta=0):
super().__init__(
Translation(x, y, 0.),
Rotation(roll=0.0, pitch=0.0, yaw=theta)
)
@property
def x(self):
return self._translation.x
@property
def y(self):
return self._translation.y
@property
def theta(self):
roll, pitch, yaw = self._rotation.ToEuler()
return yaw
def inverse(self):
_inverse = super().inverse()
x, y = _inverse.translation.x, _inverse.translation.y
roll, pitch, yaw = _inverse.rotation.ToEuler()
return Rigid2(x, y, yaw)
def __mul__(self, other):
if isinstance(other, Vector2):
rigid = super().__mul__(
Rigid(Translation(other.x, other.y, 0.), Rotation())
)
x, y = rigid.translation.x, rigid.translation.y
return Vector2(x, y)
elif isinstance(other, Rigid):
rigid = super().__mul__(
Rigid(Translation(other.x, other.y, 0.),
Rotation(roll=0., pitch=0., yaw=other.theta))
)
x, y = rigid.translation.x, rigid.translation.y
roll, pitch, yaw = rigid.rotation.ToEuler()
return Rigid2(x, y, yaw)
else:
raise ValueError(
"A Rigid2 can not be multiplied by an object of type {}".format(
type(other))
)
def __repr__(self):
return "Rigid2(x,y,theta: {:.4f}, {:.4f}, {:.4f})".format(self.x, self.y, self.theta)
class TestVector2(unittest.TestCase):
def test_vector_plus(self):
v1 = Vector2(1., 2.)
v2 = Vector2(3., 4.)
self.assertEqual(v1 + v2, Vector2(4., 6.))
def test_vector_multiple(self):
v = Vector2(2.0, 3.0)
self.assertEqual(v * 4, Vector2(8.0, 12.0))
def test_norm(self):
self.assertEqual(Vector2(3., 4.).norm(), 5.0)
class TestVector3(unittest.TestCase):
def test_vector_plus(self):
v1 = Vector3(1., 1., 1.)
v2 = Vector3(1., 2., 3.)
v1 += v2
self.assertEqual(v1 + v2, Vector3(3., 5., 7.))
self.assertRaises(ValueError, operator.add, 1.0, v1)
self.assertRaises(ValueError, operator.add, v1, 1.0)
def test_vector_multiple(self):
v = Vector3(1., 2., 3.)
self.assertEqual(v * 2, Vector3(2., 4., 6.))
self.assertEqual(3 * v, Vector3(3., 6., 9.))
def test_norm(self):
self.assertEqual(Vector3(2,3,6).norm(), 7)
class TestAngleAxis(unittest.TestCase):
def test_angleaxis(self):
axis_angle = AxisAngle(np.pi / 2, Vector3(0., 0., 2.))
self.assertEqual(
axis_angle.ToQuaternion(),
Quaternion(0.7071067811865477, 0., 0., 0.7071067811865476))
class TestRigid2(unittest.TestCase):
def setUp(self):
self.A = Rigid2(1., 0., np.pi / 2)
self.B = Rigid2(1., 0., 0.)
def test_inverse(self):
self.assertEqual(self.A * self.A.inverse(), Rigid())
def test_multiply(self):
self.assertEqual(self.A * self.B, Rigid2(1., 1., np.pi / 2.))
def test_multiply_vector(self):
rigid2 = Rigid2(2., 1., np.pi / 2)
vector = Vector2(1.0, 0.)
self.assertEqual(rigid2 * vector, Vector2(2.0, 2.0))
class TestRotation(unittest.TestCase):
def setUp(self):
self.rotation = Rotation(roll=0.0, pitch=0.0, yaw=0.575)
def test_rotation(self):
self.assertAlmostEqual(self.rotation.w, 0.9589558)
self.assertAlmostEqual(self.rotation.z, 0.2835557)
def test_inverse(self):
self.assertEqual(self.rotation.inverse() * self.rotation,
Quaternion.identity())
class TestRigid(unittest.TestCase):
def setUp(self):
self.A = Rigid(Translation(1., 0., 0.),
Rotation(roll=0., pitch=0., yaw=np.pi / 2))
self.B = Rigid(Translation(1., 0., 0.),
Rotation(1.0, 0., 0., 0.))
self.C = Rigid(Translation(0., 1., 0.),
Rotation(roll=0., pitch=0., yaw=np.pi / 4))
def test_multiply(self):
T_AB = self.A * self.B
self.assertEqual(T_AB.translation, Translation(1., 1., 0.))
self.assertEqual(
T_AB.rotation, Rotation(roll=0., pitch=0., yaw=np.pi / 2))
T_AC = self.A * self.C
self.assertEqual(T_AC.translation, Translation(0., 0., 0.))
self.assertEqual(
T_AC.rotation,
Rotation(roll=0., pitch=0., yaw=(np.pi / 2 + np.pi / 4)))
def test_multiply_vector(self):
T = Rigid(Translation(1., 1., 1.), Rotation(roll=0., pitch=0., yaw=np.pi / 2))
vector = Translation(1., 0., 1.)
self.assertEqual(T * vector, Translation(1., 2., 2.))
def test_inverse(self):
self.assertEqual(self.A.inverse() * self.A, Rigid())
def test_exception(self):
invalid_float_value = 1.0
self.assertRaises(ValueError, lambda: self.A * invalid_float_value)
self.assertRaises(ValueError, lambda: invalid_float_value * self.A)
class TestQuaternion(unittest.TestCase):
def setUp(self):
self.q45 = AxisAngle(np.pi / 4, Vector3(0., 0., 1.)).ToQuaternion()
self.q90 = AxisAngle(np.pi / 2, Vector3(0., 0., 1.)).ToQuaternion()
self.v = Vector3(1., 0., 0.)
self.q1234 = Quaternion(1, 2, 3, 4)
def test_initialization(self):
identity = Quaternion()
self.assertTupleEqual(
(identity.w, identity.x, identity.y, identity.z),
(1.0, 0.0, 0.0, 0.0)
)
def test_multiple(self):
self.assertEqual(self.q45 * self.q45, self.q90)
self.assertEqual(self.q90 * self.v, Vector3(0., 1., 0.))
self.assertEqual(2. * Quaternion(1., 2., 3., 4.),
Quaternion(2., 4., 6., 8.))
self.assertRaises(ValueError, lambda: self.q45 * "invalid type")
self.assertRaises(ValueError, lambda: [1., 0., 0.] * self.q90)
self.assertRaises(ValueError, lambda: self.v * self.q90)
def test_addition(self):
q = Quaternion(1, 0, 0, 0) + Quaternion(0, 0, 1, 0)
self.assertTupleEqual((q.w, q.x, q.y, q.z), (1, 0, 1, 0))
q_and_scaler = Quaternion(0, 0, 0, 0) + 1
self.assertTupleEqual(
(q_and_scaler.w, q_and_scaler.x, q_and_scaler.y, q_and_scaler.z),
(1, 0, 0, 0)
)
self.assertRaises(ValueError, lambda: q + "invalid type")
def test_conjugate(self):
qc = self.q1234.conjugate()
self.assertTupleEqual((qc.w, qc.x, qc.y, qc.z), (1, -2, -3, -4))
def test_norm(self):
self.assertAlmostEqual(self.q1234.norm(), 5.4772, 4)
def test_inverse(self):
q = self.q1234.inverse() * self.q1234
i = Quaternion.identity()
self.assertTupleEqual(
(q.w, q.x, q.y, q.z),
(i.w, i.x, i.y, i.z)
)
def test_matrix(self):
diff_norm = np.linalg.norm(
np.reshape(self.q90.matrix(), 9) - np.array([0., -1., 0.,
1., 0., 0.,
0., 0., 1.]))
self.assertAlmostEqual(diff_norm, 0.)
if __name__=="__main__":
unittest.main(exit=False) | /rigid_transform_py-0.1.1-py3-none-any.whl/rigid_transform/transform.py | 0.902455 | 0.476701 | transform.py | pypi |
import sys
from ._types import MYPY
if MYPY:
from typing import Optional
from typing import Tuple
from typing import Any
from typing import Type
PY2 = sys.version_info[0] == 2
if PY2:
import urlparse # noqa
text_type = unicode # noqa
import Queue as queue # noqa
string_types = (str, text_type)
number_types = (int, long, float) # noqa
int_types = (int, long) # noqa
iteritems = lambda x: x.iteritems() # noqa: B301, E731
def implements_str(cls):
cls.__unicode__ = cls.__str__
cls.__str__ = lambda x: unicode(x).encode("utf-8") # noqa
return cls
exec("def reraise(tp, value, tb=None):\n raise tp, value, tb")
else:
import urllib.parse as urlparse # noqa
import queue # noqa
text_type = str
string_types = (text_type,) # type: Tuple[type]
number_types = (int, float) # type: Tuple[type, type]
int_types = (int,) # noqa
iteritems = lambda x: x.items() # noqa: E731
def _identity(x):
return x
def implements_str(x):
return x
def reraise(tp, value, tb=None):
# type: (Optional[Type[BaseException]], Optional[BaseException], Optional[Any]) -> None # noqa: E501
assert value is not None
if value.__traceback__ is not tb:
raise value.with_traceback(tb)
raise value
def with_metaclass(meta, *bases):
class metaclass(type): # noqa: N801
def __new__(cls, name, this_bases, d):
return meta(name, bases, d)
return type.__new__(metaclass, "temporary_class", (), {})
def check_thread_support():
# type: () -> None
try:
from uwsgi import opt # type: ignore
except ImportError:
return
# When `threads` is passed in as a uwsgi option,
# `enable-threads` is implied on.
if "threads" in opt:
return
enable_threads = str(opt.get("enable-threads", "0")).lower()
if enable_threads in ("false", "off", "no", "0"):
from warnings import warn
warn(
Warning(
"We detected the use of uwsgi with disabled threads. "
"This will cause issues with the transport you are "
"trying to use. Please enable threading for uwsgi. "
'(Enable the "enable-threads" flag).'
)
) | /rigidanalytics_tracker-2.0.5.tar.gz/rigidanalytics_tracker-2.0.5/rigidanalytics_tracker/_compat.py | 0.517083 | 0.203134 | _compat.py | pypi |
import functools
import numpy as np
def pr(a):
"""
For vectors A, divide each element of A by the last.
For matrices, divide each row by its rightmost element.
For arrays of high dimension, project along the last dimension.
"""
a = np.asarray(a)
return a[..., :-1] / a[..., -1:]
def unpr(a):
"""
For vectors A, return A with 1 appended.
For matrices, append a column of ones.
For arrays of higher dimension, append along the last dimension.
"""
a = np.asarray(a)
col_shape = a.shape[:-1] + (1,)
return np.concatenate((a, np.ones(col_shape)), axis=-1)
def normalized(a):
"""
For vertors A, return a unit vector in the direction of A.
For matrices, return a matrix of the same size where each row has unit norm.
For arrays of higher dimension, normalize along the last axis.
"""
a = np.asarray(a)
return a / np.sqrt(np.sum(np.square(a), axis=-1))[..., None]
def unreduce(a, mask, fill=0.):
"""
Create a vector in which the positions set to True in the mask vector are set to sequential values from A.
"""
a = np.asarray(a)
mask = np.asarray(mask)
x = np.repeat(fill, len(mask)).astype(a.dtype)
x[mask] = a
return x
def unreduce_2d(a, mask, fill=0.):
"""
Create a matrix in which the rows and columns set to True in the mask vector are set to the entries from A.
"""
a = np.asarray(a)
x = np.ones((len(mask), len(mask))) * fill
x[np.ix_(mask, mask)] = a
return x
def sumsq(a, axis=None):
"""
Compute the sum of squares.
"""
return np.sum(np.square(a), axis=axis)
def skew(a):
"""
Compute the skew-symmetric matrix for a. The returned matrix M has the property
that for any 3-vector v, M * v = a x v where x denotes the cross product.
"""
a = np.asarray(a)
assert a.shape == (3,), 'shape was was %s' % str(a.shape)
return np.array([[0, -a[2], a[1]],
[a[2], 0, -a[0]],
[-a[1], a[0], 0.]])
def unit(i, n):
"""
Compute a unit vector along the i-th axis in N dimensions.
"""
return (np.arange(n) == i).astype(float)
def orthonormalize(a):
"""
Find the closest orthonormal matrix to R.
Note that the returned matrix may have determinant +1 or -1, so the result
may be either a rotation or a rotoinversion.
"""
u, _, v = np.linalg.svd(a)
return np.dot(u, v)
def minmedmax(a):
"""
Compute [min(x), median(a), max(a)]
"""
if len(a) == 0:
raise Exception('warning [utils.minmedmax]: empty list passed')
else:
return np.min(a), np.median(a), np.max(a)
def cis(th):
"""
Compute [cos(th), sin(th)].
"""
return np.array((np.cos(th), np.sin(th)))
def dots(*a):
"""
Multiply an arbitrary number of matrices with np.dot.
"""
return functools.reduce(np.dot, a) | /rigidbody-0.13.tar.gz/rigidbody-0.13/arithmetic.py | 0.814864 | 0.884539 | arithmetic.py | pypi |
import numpy as np
from . import rotation
class SO3(object):
"""
Represents a rotation in three dimensions.
"""
DoF = 3
class Atlas(object):
"""
Represents an atlas for rotations.
"""
@classmethod
def dof(cls, _):
return SO3.DoF
@classmethod
def perturb(cls, r, tangent):
"""
Evaluate the chart for the given rotation.
"""
assert len(tangent) == SO3.DoF
return SO3(rotation.perturb_left(r.matrix, tangent))
@classmethod
def displacement(cls, r1, r2):
"""
Get a vector v such that perturb(x1, v) = x2.
"""
return rotation.log(np.dot(SO3.asarray(r2), SO3.asarray(r1).T))
def __init__(self, r):
"""
Initialize from a rotation matrix.
"""
self._r = r
@classmethod
def identity(cls):
"""
Construct the identity rotation.
"""
return SO3(np.eye(3))
@classmethod
def from_tangent(cls, v):
"""
Construct a rotation for the tangent space at the identity element.
"""
assert len(v) == SO3.DoF
return SO3(rotation.exp(v))
@classmethod
def asarray(cls, x):
"""
Convert an SO3 to a matrix.
"""
if isinstance(x, SO3):
return x.matrix
else:
return np.asarray(x)
@property
def matrix(self):
"""
Get the matrix representation of this rotation.
"""
return self._r
def __mul__(self, rhs):
"""
Multiply this rotation with another.
"""
return self.transform(rhs)
def transform(self, rhs):
"""
Multiply this rotation with another.
"""
if isinstance(rhs, SO3):
return SO3(np.dot(self._r, rhs._r))
elif isinstance(rhs, np.ndarray):
return SO3(np.dot(self._r, rhs))
def inverse(self):
"""
Get the inverse of this rotation
"""
return SO3(self._r.T)
def log(self):
"""
Compute the axis angle representation of this rotation.
"""
return rotation.log(self._r)
def __str__(self):
"""
Get a string representation of this rotation.
"""
return 'SO3(%s)' % str(self._r).replace('\n', '\n ')
class SE3(object):
"""
Represents a rigid transform in three dimensions.
"""
DoF = 6
class Atlas(object):
"""
Represents an atlas for rigid transforms.
"""
@classmethod
def dof(cls, _):
return SE3.DoF
@classmethod
def perturb(cls, pose, tangent):
"""
Evaluate the chart for the given pose at tangent.
"""
assert len(tangent) == SE3.DoF
return SE3(rotation.perturb_left(pose.orientation, tangent[:3]), pose.position + tangent[3:])
@classmethod
def displacement(cls, x1, x2):
"""
Get a vector v such that perturb(x1, v) = x2.
"""
return np.hstack((rotation.log(np.dot(x2.orientation, x1.orientation.T)), x2.position - x1.position))
def __init__(self, orientation, position):
"""
Initialize a rigid body transform from a rotation matrix and position vector.
"""
self._orientation = np.asarray(orientation, float)
self._position = np.asarray(position, float)
@classmethod
def identity(cls):
"""
Get the identity transform.
"""
return SE3(np.eye(3), np.zeros(3))
@classmethod
def from_tangent(cls, v):
"""
Construct a rigid body transform from the tangent space at the identity element.
"""
assert len(v) == SE3.DoF
return SE3(rotation.exp(v[:3]), v[3:])
@classmethod
def from_matrix(cls, m):
"""
Construct a rigid body transform from a 3x4 or 4x4 matrix
"""
m = np.asarray(m)
assert m.shape in ((3, 4), (4, 4)), 'shape was %s' % str(m.shape)
r = m[:3, :3]
t = m[:3, 3]
return SE3(r, -np.dot(r.T, t))
@property
def orientation(self):
"""
Get the orientation component of this transform.
"""
return self._orientation
@orientation.setter
def orientation(self, v):
"""
Set the orientation component of this transform.
"""
self._orientation = v
@property
def position(self):
"""
Get the position component of this transform.
"""
return self._position
@position.setter
def position(self, v):
"""
Set the position component of this transform.
"""
self._position = v
@property
def matrix(self):
"""
Get the matrix representation of this transform.
"""
return np.r_[np.c_[self._orientation, -np.dot(self._orientation, self._position)],
np.c_[0., 0., 0., 1.]]
@property
def rp(self):
"""
Get the (rotation, position) pair for this transform.
"""
return self._orientation, self._position
@property
def rt(self):
"""
Get the (rotation, translation) pair for this transform.
"""
return self._orientation, -np.dot(self._orientation, self._position)
def __mul__(self, rhs):
"""
Multiply this transform with another.
"""
return self.transform(rhs)
def transform(self, rhs):
"""
Multiply this transform with another.
"""
if isinstance(rhs, SE3):
r1, r2 = self._orientation, rhs._orientation
return SE3(np.dot(r1, r2), rhs.position + np.dot(r2.T, self.position))
elif isinstance(rhs, np.ndarray):
if rhs.shape[-1] == 3:
return np.dot(self._orientation, rhs - self.position)
elif rhs.shape[-1] == 4:
return np.dot(self.matrix, rhs)
def inverse(self):
"""
Get the inverse of this transform.
"""
return SE3(self._orientation.T, -np.dot(self.orientation, self.position))
def log(self):
"""
Map this transform to the Lie algebra se3.
"""
return np.concatenate((rotation.log(self.orientation), self.position))
def __str__(self):
"""
Get a string representation of this transform.
"""
return 'SE3(position=%s, log_rotation=%s)' % (self._position, rotation.log(self._orientation)) | /rigidbody-0.13.tar.gz/rigidbody-0.13/transform.py | 0.946523 | 0.745676 | transform.py | pypi |
from io import BytesIO
from math import sqrt
from re import search
import matplotlib.image as mpimg # type: ignore
import matplotlib.pyplot as plt # type: ignore
import numpy as np
from pyvisa import ResourceManager
from pyvisa.errors import LibraryError, VisaIOError
def find_visas():
# Return all VISA addresses (and the backend) which map to a Rigol DS1000Z.
RIGOL_IDN_REGEX = "^RIGOL TECHNOLOGIES,DS1[01][057]4Z(-S)?( Plus)?,.+$"
visas = []
for visa_backend in ["@ivi", "@py"]:
try:
visa_manager = ResourceManager(visa_backend)
except LibraryError:
pass
for visa_name in visa_manager.list_resources():
try:
visa_resource = visa_manager.open_resource(visa_name)
match = search(RIGOL_IDN_REGEX, visa_resource.query("*IDN?"))
if match:
visas.append((visa_name, visa_backend))
except VisaIOError:
pass
finally:
visa_resource.close()
return visas
def process_display(display, show=False, filename=None):
"""
Convert the query of the display byte array into an image.
Args:
display: The namedtuple returned from ``Rigol_DS100Z().display()``.
show (bool): Draw the display image to a new matplotlib figure.
filename (str): Save the display image to a file (PNG recommended).
"""
byte_stream = BytesIO(bytearray(display.data))
with byte_stream:
img = mpimg.imread(byte_stream, format="jpeg")
if filename is not None:
plt.imsave(filename, img)
if show:
rigol_xpx, rigol_ypx = 800, 480
rigol_diagin = 17.8 * 0.393701
rigol_dpi = sqrt(rigol_xpx**2 + rigol_ypx**2) / rigol_diagin
figsize = rigol_xpx / rigol_dpi, rigol_ypx / rigol_dpi
fig = plt.figure(figsize=figsize, dpi=rigol_dpi)
ax = fig.add_axes([0, 0, 1, 1])
ax.axis("off")
ax.imshow(img)
plt.show()
def process_waveform(waveform, show=False, filename=None):
"""
Convert the query of the waveform data into properly scaled Numpy arrays.
Args:
waveform: The namedtuple returned from ``Rigol_DS100Z().waveform()``.
show (bool): Draw the waveform to a new matplotlib figure.
filename (str): Save the display image to a file (CSV recommended).
Returns:
A tuple of two Numpy arrays, (xdata, ydata).
"""
if waveform.format == "ASC":
ydata = np.array(waveform.data[11:].split(","), dtype=float)
if waveform.format in ("BYTE", "WORD"):
ydata = (
np.array(waveform.data) - waveform.yorigin - waveform.yreference
) * waveform.yincrement
xdata = np.array(range(0, len(ydata)))
xdata = xdata * waveform.xincrement + waveform.xorigin + waveform.xreference
if show:
xlim = (xdata[0], xdata[-1])
ylim = tuple((np.array([-100, 100]) - waveform.yorigin) * waveform.yincrement)
plt.plot(xdata, ydata)
plt.xlim(*xlim)
plt.xticks(np.linspace(*xlim, 13), rotation=30)
plt.ylim(*ylim)
plt.yticks(np.linspace(*ylim, 9))
plt.ticklabel_format(style="sci", scilimits=(-3, 2))
plt.grid()
plt.show()
if filename is not None:
np.savetxt(filename, np.transpose(np.vstack((xdata, ydata))), delimiter=",")
return xdata, ydata | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/utils.py | 0.838878 | 0.458894 | utils.py | pypi |
from functools import partial
from time import sleep
from typing import Optional
from pyvisa import ResourceManager
from rigol_ds1000z.src.channel import channel
from rigol_ds1000z.src.display import display
from rigol_ds1000z.src.ieee import ieee
from rigol_ds1000z.src.timebase import timebase
from rigol_ds1000z.src.trigger import trigger
from rigol_ds1000z.src.waveform import waveform
from rigol_ds1000z.utils import find_visas
class Rigol_DS1000Z:
"""
A class for communicating with a Rigol DS1000Z series oscilloscope.
This class is compatible with context managers. The functional interfaces
``ieee``, ``channel``, ``timebase``, ``display``, ``waveform``, and ``trigger``
are bound to this object as partial functions.
Args:
visa (str): The VISA resource address string.
"""
def __init__(self, visa: Optional[str] = None):
visas = find_visas()
if visa is None:
self.visa_name, self.visa_backend = visas[0]
else:
self.visa_name = visa
for visa, backend in visas:
if self.visa_name == visa:
self.visa_backend = backend
self.ieee = partial(ieee, self)
self.channel = partial(channel, self)
self.timebase = partial(timebase, self)
self.display = partial(display, self)
self.waveform = partial(waveform, self)
self.trigger = partial(trigger, self)
def __enter__(self):
return self.open()
def __exit__(self, exc_type, exc_value, exc_traceback):
return self.close()
def open(self):
"""Open the VISA resource to establish the communication channel."""
self.visa_rsrc = ResourceManager(self.visa_backend).open_resource(
self.visa_name
)
return self
def close(self):
"""Close the VISA resource to terminate the communication channel."""
self.visa_rsrc.close()
def write(self, cmd: str):
"""
Write a command over the VISA communication interface.
The command is automatically appended with a ``*WAI`` command.
Args:
cmd (str): The command string to be written.
"""
self.visa_rsrc.write(cmd + ";*WAI")
def read(self):
"""
Read back over the VISA communication interface.
Returns:
The received string.
"""
return self.visa_rsrc.read().strip()
def query(self, cmd: str, delay: Optional[float] = None):
"""
Execute a query over the VISA communication interface.
The command is automatically appended with a ``*WAI`` command.
Args:
cmd (str): The command string to be written.
delay (float): Time delay between write and read (optional).
Returns:
The received string.
"""
return self.visa_rsrc.query(cmd + ";*WAI", delay).strip()
def autoscale(self):
"""``:AUToscale`` Autoscale the oscilloscope, followed by a 10s delay."""
self.write(":AUT")
sleep(10)
def clear(self):
"""``:CLEar`` Clear the oscilloscope display, followed by a 1s delay."""
self.write(":CLE")
sleep(1)
def run(self):
"""``:RUN`` Run the oscilloscope, followed by a 1s delay."""
self.write(":RUN")
sleep(1)
def stop(self):
"""``:STOP`` Stop the oscilloscope, followed by a 1s delay."""
self.write(":STOP")
sleep(1)
def single(self):
"""``:SINGle`` Single trigger the oscilloscope, followed by a 1s delay."""
self.write(":SING")
sleep(1)
def tforce(self):
"""``:TFORce`` Force trigger the oscilloscope, followed by a 1s delay."""
self.write(":TFOR")
sleep(1) | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/src/oscope.py | 0.903212 | 0.246511 | oscope.py | pypi |
from collections import namedtuple
from typing import Optional
CHANNEL = namedtuple(
"CHANNEL",
"bwlimit coupling display invert offset range tcal scale probe units vernier",
)
def channel(
oscope,
n: int,
bwlimit: Optional[bool] = None,
coupling: Optional[str] = None,
display: Optional[bool] = None,
invert: Optional[bool] = None,
offset: Optional[float] = None,
range: Optional[float] = None,
tcal: Optional[float] = None,
scale: Optional[float] = None,
probe: Optional[float] = None,
units: Optional[str] = None,
vernier: Optional[bool] = None,
):
"""
Send commands to control an oscilloscope's vertical channel.
Other than the channel number, all arguments are optional.
``range``, ``scale``, and ``offset`` are potentially conflicting
commands if all three are simultaneously specified; they are issued in that order.
Args:
n (int): The channel to be controlled (1 through 4).
bwlimit (bool): ``:CHANnel<n>:BWLimit``
coupling (str): ``:CHANnel<n>:COUPling``
display (bool): ``:CHANnel<n>:DISPlay``
invert (bool): ``:CHANnel<n>:INVert``
offset (float): ``:CHANnel<n>:OFFSet``
range (float): ``:CHANnel<n>:RANGe``
tcal (float): ``:CHANnel<n>:TCAL``
scale (float): ``:CHANnel<n>:SCALe``
probe (float): ``:CHANnel<n>:PROBe``
units (str): ``:CHANnel<n>:UNITs``
vernier (bool): ``:CHANnel<n>:VERNier``
Returns:
A namedtuple with fields corresponding to the named arguments of this function.
All fields are queried regardless of which arguments were initially provided.
"""
root = ":CHAN{:d}:".format(n)
if bwlimit is not None:
cmd = "20M" if bwlimit else "OFF"
oscope.write(root + "BWL " + cmd)
if coupling is not None:
oscope.write(root + "COUP " + coupling)
if display is not None:
oscope.write(root + "DISP {:d}".format(display))
if invert is not None:
oscope.write(root + "INV {:d}".format(invert))
if vernier is not None:
oscope.write(root + "VERN {:d}".format(vernier))
if probe is not None:
oscope.write(root + "PROB {:0.2f}".format(probe))
if range is not None:
oscope.write(root + "RANG {:0.10f}".format(range))
if scale is not None:
oscope.write(root + "SCAL {:0.10f}".format(scale))
if offset is not None:
oscope.write(root + "OFFS {:0.10f}".format(offset))
if tcal is not None:
oscope.write(root + "TCAL {:0.10f}".format(tcal))
if units is not None:
oscope.write(root + "UNIT " + units)
return CHANNEL(
bwlimit=oscope.query(root + "BWL?") == "20M",
coupling=oscope.query(root + "COUP?"),
display=bool(int(oscope.query(root + "DISP?"))),
invert=bool(int(oscope.query(root + "INV?"))),
vernier=bool(int(oscope.query(root + "VERN?"))),
probe=float(oscope.query(root + "PROB?")),
offset=float(oscope.query(root + "OFFS?")),
range=float(oscope.query(root + "RANG?")),
scale=float(oscope.query(root + "SCAL?")),
tcal=float(oscope.query(root + "TCAL?")),
units=oscope.query(root + "UNIT?"),
) | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/src/channel.py | 0.93365 | 0.36063 | channel.py | pypi |
from collections import namedtuple
from typing import Optional, Union
WAVEFORM = namedtuple(
"WAVEFORM",
(
"source mode format data xincrement xorigin xreference "
"yincrement yorigin yreference start stop preamble"
),
)
def waveform(
oscope,
source: Union[int, str, None] = None,
mode: Optional[str] = None,
format: Optional[str] = None,
start: Optional[int] = None,
stop: Optional[int] = None,
):
"""
Send commands to control an oscilloscope's waveform data capturing.
All arguments are optional.
Args:
source (int, str): ``:WAVeform:SOURce``
mode (str): ``:WAVeform:MODE``
format (str): ``:WAVeform:FORMat``
start (int): ``:WAVeform:STARt``
stop (int): ``:WAVeform:STOP``
Returns:
A namedtuple with fields corresponding to the named arguments of this function.
All fields are queried regardless of which arguments were initially provided.
The ``data`` field is additionally provided as a result of the query ``:WAVeform:DATA?``.
There are several other fields provided as well which are required for post-processing.
"""
if source is not None:
if isinstance(source, str):
oscope.write(":WAV:SOUR " + source)
else:
oscope.write(":WAV:SOUR CHAN{:d}".format(source))
source_query = oscope.query(":WAV:SOUR?")
if not source_query == "MATH":
source_query = int(source_query[-1])
if mode is not None:
oscope.write(":WAV:MODE " + mode)
if format is not None:
oscope.write(":WAV:FORM " + format)
format_query = oscope.query(":WAV:FORM?")
if start is not None:
oscope.write(":WAV:STAR {:d}".format(start))
if stop is not None:
oscope.write(":WAV:STOP {:d}".format(stop))
if format_query == "ASC":
data_query = oscope.query(":WAV:DATA?")
elif format_query == "BYTE":
data_query = oscope.visa_rsrc.query_binary_values(":WAV:DATA?", "B")
elif format_query == "WORD":
data_query = oscope.visa_rsrc.query_binary_values(":WAV:DATA?", "H")
else:
data_query = None
return WAVEFORM(
source=source_query,
mode=oscope.query(":WAV:MODE?"),
format=format_query,
data=data_query,
xincrement=float(oscope.query(":WAV:XINC?")),
xorigin=float(oscope.query(":WAV:XOR?")),
xreference=int(oscope.query(":WAV:XREF?")),
yincrement=float(oscope.query(":WAV:YINC?")),
yorigin=int(oscope.query(":WAV:YOR?")),
yreference=int(oscope.query(":WAV:YREF?")),
start=int(oscope.query(":WAV:STAR?")),
stop=int(oscope.query(":WAV:STOP?")),
preamble=oscope.query(":WAV:PRE?"),
) | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/src/waveform.py | 0.905697 | 0.390389 | waveform.py | pypi |
from collections import namedtuple
from typing import Optional, Union
DISPLAY = namedtuple(
"DISPLAY", "data type grading_time wave_brightness grid grid_brightness"
)
def display(
oscope,
clear: bool = False,
type: Optional[str] = None,
grading_time: Union[str, float, None] = None,
wave_brightness: Optional[int] = None,
grid: Optional[str] = None,
grid_brightness: Optional[int] = None,
):
"""
Send commands to control an oscilloscope's display. All arguments are optional.
Args:
clear (bool): ``:DISPlay:CLEar``
type (str): ``:DISPlay:TYPE``
grading_time (str, float): ``:DISPlay:GRADing:TIME``
wave_brightness (int): ``:DISPlay:WBRightness``
grid (str): ``:DISPlay:GRID``
grid_brightness: ``:DISPlay:GBRightness``
Returns:
A namedtuple with fields corresponding to the named arguments of this function.
All fields are queried regardless of which arguments were initially provided.
The ``data`` field is additionally provided as a result of the query ``:DISPlay:DATA?``.
"""
if clear:
oscope.write(":DISP:CLE")
if type is not None:
oscope.write(":DISP:TYPE {:s}".format(type))
if grading_time is not None:
if isinstance(grading_time, str):
oscope.write(":DISP:GRAD:TIME {:s}".format(grading_time))
else:
oscope.write(":DISP:GRAD:TIME {:g}".format(grading_time))
if wave_brightness is not None:
oscope.write(":DISP:WBR {:d}".format(wave_brightness))
if grid is not None:
oscope.write(":DISP:GRID {:s}".format(grid))
if grid_brightness is not None:
oscope.write(":DISP:GBR {:d}".format(grid_brightness))
time = oscope.query(":DISP:GRAD:TIME?")
if time not in ("MIN", "INF"):
time = float(time)
return DISPLAY(
data=oscope.visa_rsrc.query_binary_values(":DISP:DATA?", "B"),
type=oscope.query(":DISP:TYPE?"),
grading_time=time,
wave_brightness=int(oscope.query(":DISP:WBR?")),
grid=oscope.query(":DISP:GRID?"),
grid_brightness=int(oscope.query(":DISP:GBR?")),
) | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/src/display.py | 0.944485 | 0.485295 | display.py | pypi |
from collections import namedtuple
from time import sleep
from typing import Optional, Union
TRIGGER = namedtuple(
"TRIGGER",
"status sweep noisereject mode holdoff coupling source slope level",
defaults=(None,) * 5, # (status, sweep, noisereject, mode) are required
)
def trigger(
oscope,
sweep: Optional[str] = None,
noisereject: Optional[bool] = None,
mode: Optional[str] = None,
holdoff: Optional[float] = None,
coupling: Optional[str] = None,
source: Union[int, str, None] = None,
slope: Optional[str] = None,
level: Optional[float] = None,
):
"""
Send commands to control an oscilloscope's triggering behavior.
This interface is only partially implemented so as to support edge-triggering.
All arguments are optional. Depending on the triggering mode, only
the applicable arguments are utilized by the relevant helper function.
Args:
sweep (str): ``:TRIGger:SWEep``
noisereject (bool): ``:TRIGger:NREJect``
mode (str): ``:TRIGger:MODE``
holdoff (float): See helper functions.
coupling (str): See helper functions.
source (int, str): See helper functions.
slope (str): See helper functions.
level (float): See helper functions.
Returns:
A namedtuple with fields corresponding to the named arguments of this function.
All fields are queried regardless of which arguments were initially provided.
The ``status`` field is additionally provided as a result of the query ``:TRIGger:STATus?``.
"""
if sweep is not None:
oscope.write(":TRIG:SWE {:s}".format(sweep))
sleep(1)
if noisereject is not None:
oscope.write(":TRIG:NREJ {:d}".format(noisereject))
if mode is not None:
oscope.write(":TRIG:MODE {:s}".format(mode))
trigger_query = TRIGGER(
status=oscope.query(":TRIG:STAT?"),
sweep=oscope.query(":TRIG:SWE?"),
noisereject=bool(int(oscope.query(":TRIG:NREJ?"))),
mode=oscope.query(":TRIG:MODE?"),
)
if trigger_query.mode == "EDGE":
return trigger_edge(
oscope, trigger_query, holdoff, coupling, source, slope, level
)
return trigger_query
def trigger_edge(oscope, trigger_query, holdoff, coupling, source, slope, level):
"""
Helper function to configure edge-triggering, ``:TRIGger:MODE EDGE``.
Args:
holdoff (float): ``:TRIGger:HOLDoff``
coupling (str): ``:TRIGger:COUPling``
source (int, str): ``:TRIGger:EDGe:SOURce``
slope (str): ``:TRIGger:EDGe:SLOPe``
level (float): ``:TRIGger:EDGe:LEVel``
"""
if holdoff is not None:
oscope.write(":TRIG:HOLD {:0.10f}".format(holdoff))
if coupling is not None:
oscope.write(":TRIG:COUP {:s}".format(coupling))
if source is not None:
if isinstance(source, str):
oscope.write(":TRIG:EDG:SOUR {:s}".format(source))
else:
oscope.write(":TRIG:EDG:SOUR CHAN{:d}".format(source))
if slope is not None:
oscope.write(":TRIG:EDG:SLOP {:s}".format(slope))
if level is not None:
oscope.write("TRIG:EDG:LEV {:0.10f}".format(level))
source_query = oscope.query(":TRIG:EDG:SOUR?")
if not source_query == "AC":
source_query = int(source_query[-1])
return trigger_query._replace(
holdoff=float(oscope.query(":TRIG:HOLD?")),
coupling=oscope.query(":TRIG:COUP?"),
source=source_query,
slope=oscope.query(":TRIG:EDG:SLOP?"),
level=float(oscope.query(":TRIG:EDG:LEV?")),
) | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/src/trigger.py | 0.937196 | 0.465084 | trigger.py | pypi |
from abc import ABC, abstractmethod
from typing import Optional
from rich.console import RenderableType
from rich.text import Text
from si_prefix import si_format
from textual import events
from textual.keys import Keys
from textual.reactive import Reactive
from textual.widget import Widget
from rigol_ds1000z import Rigol_DS1000Z
def _float2si(raw, sigfigs, unit):
si = si_format(raw, precision=sigfigs - 1).split()
si_mag = "{:#.{:d}g}".format(float(si[0]), sigfigs).strip(".")
si_unit = si[1] if len(si) == 2 else ""
return si_mag + si_unit + unit
class TableControl_TUI(Widget, ABC):
highlight_field: Reactive[RenderableType] = Reactive("")
editing_field: Reactive[RenderableType] = Reactive(None)
editing_text: Reactive[RenderableType] = Reactive("")
editing_formatter = None
def __init__(self, oscope: Rigol_DS1000Z) -> None:
super().__init__()
self.oscope = oscope
self.update_oscope()
async def on_mouse_move(self, event: events.MouseMove) -> None:
field = event.style.meta.get("field")
if self.highlight_field != field:
self.highlight_field = field
self._edit_field(None)
async def on_key(self, event: events.Key) -> None:
if self.editing_field is None:
return
if event.key == Keys.Escape:
self._edit_field(None)
elif event.key in (Keys.Backspace, Keys.ControlH):
self.editing_text = self.editing_text[:-1]
elif event.key in (Keys.Enter, Keys.Return, Keys.ControlM):
try:
kwargs = {self.editing_field: self.editing_formatter(self.editing_text)}
except ValueError:
self._edit_field(None)
else:
self.update_oscope(**kwargs)
self._edit_field(None)
elif event.key != Keys.ControlAt:
self.editing_text += event.key
def _create_field(self, field: str, callback: str) -> Text:
editing = self.editing_field == field
highlighted = editing or self.highlight_field == field
value = self.editing_text if editing else getattr(self, field)
style = "reverse" if highlighted else ""
text = Text(value.ljust(9), style).on(click=callback, meta={"field": field})
return text
def _edit_field(self, field: Optional[str], formatter=float) -> None:
self.editing_field = field
self.editing_text = ""
self.editing_formatter = formatter
self.app.editing = field is not None
@abstractmethod
def update_oscope(self, **kwargs) -> None:
pass | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/app/tablecontrol_tui.py | 0.80784 | 0.287968 | tablecontrol_tui.py | pypi |
from rich.console import RenderableType
from rich.text import Text
from textual import events
from textual.reactive import Reactive
from textual.widget import Widget
from rigol_ds1000z.app.channel_tui import CHANNEL_COLORS
class Shortcuts(Widget):
highlight_key: Reactive[RenderableType] = Reactive("")
async def on_mouse_move(self, event: events.MouseMove) -> None:
self.highlight_key = event.style.meta.get("key")
async def on_leave(self, event: events.Leave) -> None:
self.highlight_key = ""
def _simple_button(self, key, name) -> RenderableType:
return Text.assemble(
(
" {:s} ".format(key.upper()),
"reverse" if self.highlight_key == key else "default on default",
),
(" {:s} ".format(name), "white on dark_green"),
meta={"key": key, "@click": "app.press('{:s}')".format(key)},
)
def _status_button(self, key, name, style, status) -> RenderableType:
if status != (self.highlight_key == key):
style = "reverse {:s}".format(style)
return Text.assemble(
(" {:s} ".format(key.upper()), style),
(" {:s} ".format(name), "white on dark_green"),
meta={"key": key, "@click": "app.press('{:s}')".format(key)},
)
class Shortcuts_Header(Shortcuts):
runstop: Reactive[RenderableType] = Reactive(True)
singlestatus: Reactive[RenderableType] = Reactive(False)
def render(self) -> RenderableType:
runstop_style = (
"black on sea_green2"
if self.runstop != (self.highlight_key == "s")
else "black on red1"
)
runstop_text = Text.assemble(
(" S ", runstop_style),
(" Run/Stop ", "white on dark_green"),
meta={"key": "s", "@click": "app.press('s')"},
)
single_style = (
"black on sea_green2"
if self.singlestatus != (self.highlight_key == "i")
else "default on default"
)
single_text = Text.assemble(
(" I ", single_style),
(" Single ", "white on dark_green"),
meta={"key": "i", "@click": "app.press('i')"},
)
return (
self._simple_button("q", "Quit")
+ self._simple_button("r", "Refresh")
+ self._simple_button("d", "Display")
+ self._simple_button("w", "Waveform")
+ self._simple_button("c", "Clear")
+ self._simple_button("a", "Autoscale")
+ runstop_text
+ single_text
+ self._simple_button("f", "Force")
)
class Shortcuts_Footer(Shortcuts):
channel1: Reactive[RenderableType] = Reactive(False)
channel2: Reactive[RenderableType] = Reactive(False)
channel3: Reactive[RenderableType] = Reactive(False)
channel4: Reactive[RenderableType] = Reactive(False)
def render(self) -> RenderableType:
return (
self._status_button("1", "Ch1", CHANNEL_COLORS[1], self.channel1)
+ self._status_button("2", "Ch2", CHANNEL_COLORS[2], self.channel2)
+ self._status_button("3", "Ch3", CHANNEL_COLORS[3], self.channel3)
+ self._status_button("4", "Ch4", CHANNEL_COLORS[4], self.channel4)
) | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/app/shortcuts.py | 0.603698 | 0.196749 | shortcuts.py | pypi |
from rich.console import RenderableType
from rich.panel import Panel
from rich.table import Table
from textual.reactive import Reactive
from rigol_ds1000z.app.tablecontrol_tui import TableControl_TUI, _float2si
class Timebase_TUI(TableControl_TUI):
mode: Reactive[RenderableType] = Reactive("")
main_scale: Reactive[RenderableType] = Reactive("")
main_offset: Reactive[RenderableType] = Reactive("")
delay_enable: Reactive[RenderableType] = Reactive("")
delay_scale: Reactive[RenderableType] = Reactive("")
delay_offset: Reactive[RenderableType] = Reactive("")
def update_oscope(self, **kwargs):
timebase = self.oscope.timebase(**kwargs)
self.mode = "YT" if timebase.mode == "MAIN" else timebase.mode
self.main_scale = _float2si(timebase.main_scale, sigfigs=3, unit="s")
self.main_offset = _float2si(timebase.main_offset, sigfigs=3, unit="s")
self.delay_enable = "ON" if timebase.delay_enable else "OFF"
self.delay_scale = _float2si(timebase.delay_scale, sigfigs=3, unit="s")
self.delay_offset = _float2si(timebase.delay_offset, sigfigs=3, unit="s")
def render(self) -> RenderableType:
table = Table(box=None, show_header=False)
table.add_column(no_wrap=True)
table.add_column(no_wrap=True)
table.add_row("Time Base ", self._create_field(field="mode"))
table.add_row("Delayed", self._create_field(field="delay_enable"))
table.add_row("Scale", self._create_field(field="scale"))
table.add_row("Offset", self._create_field(field="offset"))
return Panel(table, title="Horizontal")
def _create_field(self, field):
if field in ("scale", "offset"):
prefix = "main_" if self.delay_enable == "OFF" else "delay_"
field = prefix + field
return super()._create_field(
field=field, callback="app.edit_timebase('{:s}')".format(field)
)
async def edit_mode(self):
MODE_OPTIONS = ["MAIN", "XY", "ROLL"]
MODE_NAMES = ["YT", "XY", "ROLL"]
idx = MODE_NAMES.index(self.mode) + 1
idx = 0 if idx == len(MODE_OPTIONS) else idx
self.update_oscope(mode=MODE_OPTIONS[idx])
async def edit_main_scale(self):
self._edit_field("main_scale")
async def edit_main_offset(self):
self._edit_field("main_offset")
async def edit_delay_enable(self):
self.update_oscope(delay_enable=self.delay_enable == "OFF")
async def edit_delay_scale(self):
self._edit_field("delay_scale")
async def edit_delay_offset(self):
self._edit_field("delay_offset") | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/app/timebase_tui.py | 0.548915 | 0.167287 | timebase_tui.py | pypi |
from rich.console import RenderableType
from rich.panel import Panel
from rich.table import Table
from textual.reactive import Reactive
from rigol_ds1000z import Rigol_DS1000Z
from rigol_ds1000z.app.tablecontrol_tui import TableControl_TUI, _float2si
CHANNEL_COLORS = {
1: "bright_yellow",
2: "bright_cyan",
3: "plum2",
4: "turquoise2",
}
class Channel_TUI(TableControl_TUI):
bwlimit: Reactive[RenderableType] = Reactive("")
coupling: Reactive[RenderableType] = Reactive("")
probe: Reactive[RenderableType] = Reactive("")
invert: Reactive[RenderableType] = Reactive("")
vernier: Reactive[RenderableType] = Reactive("")
units: Reactive[RenderableType] = Reactive("")
scale: Reactive[RenderableType] = Reactive("")
offset: Reactive[RenderableType] = Reactive("")
range: Reactive[RenderableType] = Reactive("")
tcal: Reactive[RenderableType] = Reactive("")
label: Reactive[RenderableType] = Reactive("")
def __init__(self, oscope: Rigol_DS1000Z, n: int) -> None:
self.n = n
super().__init__(oscope)
self.label = "CH{:d}".format(n)
def update_oscope(self, **kwargs):
channel = self.oscope.channel(self.n, **kwargs)
self.bwlimit = "20M" if channel.bwlimit else "OFF"
self.coupling = channel.coupling
self.probe = "{:.2f}X".format(channel.probe).replace(".00", "")
self.invert = "ON" if channel.invert else "OFF"
self.vernier = "Fine" if channel.vernier else "Coarse"
self.units = "[{:s}]".format(channel.units[0])
self.scale = _float2si(channel.scale, sigfigs=3, unit=channel.units[0])
self.offset = _float2si(channel.offset, sigfigs=4, unit=channel.units[0])
self.range = _float2si(channel.range, sigfigs=3, unit=channel.units[0])
self.tcal = _float2si(channel.tcal, sigfigs=3, unit="s")
def render(self) -> RenderableType:
table = Table(box=None, show_header=False)
table.add_column(no_wrap=True, style=CHANNEL_COLORS[self.n])
table.add_column(no_wrap=True, style=CHANNEL_COLORS[self.n])
table.add_row("Scale", self._create_field(field="scale"))
table.add_row("Offset", self._create_field(field="offset"))
table.add_row("Range", self._create_field(field="range"))
table.add_row("Delay", self._create_field(field="tcal"))
table.add_row("Coupling", self._create_field(field="coupling"))
table.add_row("BW Limit", self._create_field(field="bwlimit"))
table.add_row("Probe", self._create_field(field="probe"))
table.add_row("Invert", self._create_field(field="invert"))
table.add_row("Volts/Div ", self._create_field(field="vernier"))
table.add_row("Unit", self._create_field(field="units"))
table.add_row("Label", self._create_field(field="label"))
return Panel(
table,
title="Channel {:d}".format(self.n),
border_style=CHANNEL_COLORS[self.n],
)
def _create_field(self, field):
return super()._create_field(
field=field, callback="app.edit_channel({:d}, '{:s}')".format(self.n, field)
)
async def edit_scale(self):
self._edit_field("scale")
async def edit_offset(self):
self._edit_field("offset")
async def edit_range(self):
self._edit_field("range")
async def edit_tcal(self):
self._edit_field("tcal")
async def edit_probe(self):
self._edit_field("probe")
async def edit_coupling(self):
COUPLING_OPTIONS = ["AC", "DC", "GND"]
idx = COUPLING_OPTIONS.index(self.coupling) + 1
idx = 0 if idx == len(COUPLING_OPTIONS) else idx
self.update_oscope(coupling=COUPLING_OPTIONS[idx])
async def edit_bwlimit(self):
self.update_oscope(bwlimit=self.bwlimit == "OFF")
async def edit_invert(self):
self.update_oscope(invert=self.invert == "OFF")
async def edit_vernier(self):
self.update_oscope(vernier=self.vernier == "Coarse")
async def edit_units(self):
UNITS_OPTIONS = ["WATT", "AMP", "VOLT", "UNKN"]
UNITS_OPTIONS_FIRST = [opt[0] for opt in UNITS_OPTIONS]
idx = UNITS_OPTIONS_FIRST.index(self.units.strip("[]")) + 1
idx = 0 if idx == len(UNITS_OPTIONS) else idx
self.update_oscope(units=UNITS_OPTIONS[idx])
async def edit_label(self):
self._edit_field("label") | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/app/channel_tui.py | 0.600891 | 0.341665 | channel_tui.py | pypi |
from rich.console import RenderableType
from rich.panel import Panel
from rich.table import Table
from textual.reactive import Reactive
from rigol_ds1000z import Rigol_DS1000Z
from rigol_ds1000z.app.channel_tui import Channel_TUI
from rigol_ds1000z.app.tablecontrol_tui import TableControl_TUI, _float2si
TRIGGER_MODES = {
"EDGE": "Edge",
"PULS": "Pulse",
"RUNT": "Runt",
"WIND": "Window",
"NEDG": "Nth",
"SLOP": "Slope",
"VID": "Video",
"PATT": "Pattern",
"DEL": "Delay",
"TIM": "Timeout",
"DUR": "Duration",
"SHOL": "StpHold",
"RS232": "RS232",
"IIC": "I2C",
"SPI": "SPI",
}
class Trigger_TUI(TableControl_TUI):
status: Reactive[RenderableType] = Reactive("")
sweep: Reactive[RenderableType] = Reactive("")
noisereject: Reactive[RenderableType] = Reactive("")
mode: Reactive[RenderableType] = Reactive("")
holdoff: Reactive[RenderableType] = Reactive("")
coupling: Reactive[RenderableType] = Reactive("")
source: Reactive[RenderableType] = Reactive("")
slope: Reactive[RenderableType] = Reactive("")
level: Reactive[RenderableType] = Reactive("")
def __init__(self, oscope: Rigol_DS1000Z, channels) -> None:
self.channels = channels
super().__init__(oscope)
def update_oscope(self, **kwargs):
trigger = self.oscope.trigger(**kwargs)
self.status = trigger.status
self.sweep = trigger.sweep
self.noisereject = "ON" if trigger.noisereject else "OFF"
self.mode = TRIGGER_MODES[trigger.mode]
self.holdoff = (
_float2si(trigger.holdoff, sigfigs=3, unit="s")
if trigger.mode == "EDGE"
else None
)
self.coupling = trigger.coupling if trigger.mode == "EDGE" else None
self.slope = trigger.slope if trigger.mode == "EDGE" else None
self.level = (
_float2si(
trigger.level,
sigfigs=3,
unit=self.channels[trigger.source - 1].units[1],
)
if trigger.mode == "EDGE" and not trigger.source == "AC"
else None
)
if trigger.mode == "EDGE":
if isinstance(trigger.source, int):
self.source = "CHAN{:d}".format(trigger.source)
else:
self.source = trigger.source
else:
self.source = None
def render(self) -> RenderableType:
table = Table(box=None, show_header=False)
table.add_column(no_wrap=True)
table.add_column(no_wrap=True)
table.add_row("Status", self.status)
table.add_row("Mode", self._create_field(field="sweep"))
table.add_row("Type", self._create_field(field="mode"))
if self.mode == "Edge":
table.add_row("Source", self._create_field(field="source"))
if self.source == "AC":
table.add_row("Slope", self._create_field(field="slope"))
table.add_row("Coupling", self.coupling)
table.add_row("Holdoff", self._create_field(field="holdoff"))
table.add_row("NoiseReject", self.noisereject)
else:
table.add_row("Level", self._create_field(field="level"))
table.add_row("Slope", self._create_field(field="slope"))
table.add_row("Coupling", self._create_field(field="coupling"))
table.add_row("Holdoff", self._create_field(field="holdoff"))
table.add_row("NoiseReject", self._create_field(field="noisereject"))
else:
table.add_row("NoiseReject", self._create_field(field="noisereject"))
return Panel(table, title="Trigger")
def _create_field(self, field):
return super()._create_field(
field=field, callback="app.edit_trigger('{:s}')".format(field)
)
async def edit_sweep(self):
SWEEP_OPTIONS = ["AUTO", "NORM", "SING"]
idx = SWEEP_OPTIONS.index(self.sweep) + 1
idx = 0 if idx == len(SWEEP_OPTIONS) else idx
self.update_oscope(sweep=SWEEP_OPTIONS[idx])
async def edit_noisereject(self):
self.update_oscope(noisereject=self.noisereject == "OFF")
async def edit_mode(self):
MODE_OPTIONS, MODE_NAMES = zip(*list(TRIGGER_MODES.items()))
idx = MODE_NAMES.index(self.mode) + 1
idx = 0 if idx == len(MODE_OPTIONS) else idx
self.update_oscope(mode=MODE_OPTIONS[idx])
async def edit_source(self):
SOURCE_OPTIONS = ["CHAN1", "CHAN2", "CHAN3", "CHAN4", "AC"]
idx = SOURCE_OPTIONS.index(self.source) + 1
idx = 0 if idx == len(SOURCE_OPTIONS) else idx
self.update_oscope(source=SOURCE_OPTIONS[idx])
async def edit_coupling(self):
COUPLING_OPTIONS = ["AC", "DC", "LFR", "HFR"]
idx = COUPLING_OPTIONS.index(self.coupling) + 1
idx = 0 if idx == len(COUPLING_OPTIONS) else idx
self.update_oscope(coupling=COUPLING_OPTIONS[idx])
async def edit_slope(self):
SLOPE_OPTIONS = ["POS", "NEG", "RFAL"]
idx = SLOPE_OPTIONS.index(self.slope) + 1
idx = 0 if idx == len(SLOPE_OPTIONS) else idx
self.update_oscope(slope=SLOPE_OPTIONS[idx])
async def edit_level(self):
self._edit_field("level")
async def edit_holdoff(self):
self._edit_field("holdoff") | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/app/trigger_tui.py | 0.567817 | 0.2819 | trigger_tui.py | pypi |
from rich.console import RenderableType
from rich.panel import Panel
from rich.table import Table
from si_prefix import si_format
from textual.reactive import Reactive
from rigol_ds1000z.app.tablecontrol_tui import TableControl_TUI, _float2si
class Display_TUI(TableControl_TUI):
type: Reactive[RenderableType] = Reactive("")
grading_time: Reactive[RenderableType] = Reactive("")
wave_brightness: Reactive[RenderableType] = Reactive("")
grid: Reactive[RenderableType] = Reactive("")
grid_brightness: Reactive[RenderableType] = Reactive("")
def update_oscope(self, **kwargs):
display = self.oscope.display(**kwargs)
self.type = "Vector" if display.type == "VECT" else "Dots"
self.wave_brightness = "{:d}%".format(display.wave_brightness)
self.grid = display.grid
self.grid_brightness = "{:d}%".format(display.grid_brightness)
if isinstance(display.grading_time, str):
self.grading_time = "Min" if display.grading_time == "MIN" else "Infinite"
else:
si = si_format(display.grading_time, precision=0).split()
si_unit = si[1] if len(si) == 2 else ""
self.grading_time = si[0] + si_unit + "s"
def render(self) -> RenderableType:
table = Table(box=None, show_header=False)
table.add_column(no_wrap=True)
table.add_column(no_wrap=True)
table.add_row("Type", self._create_field(field="type"))
table.add_row("Persis Time", self._create_field(field="grading_time"))
table.add_row("Intensity", self._create_field(field="wave_brightness"))
table.add_row("Grid", self._create_field(field="grid"))
table.add_row("Brightness", self._create_field(field="grid_brightness"))
return Panel(table, title="Display")
def _create_field(self, field):
return super()._create_field(
field=field, callback="app.edit_display('{:s}')".format(field)
)
async def edit_type(self):
self.update_oscope(type="VECT" if self.type == "Dots" else "DOTS")
async def edit_grading_time(self):
def grading_time_formatter(time):
try:
ftime = float(time)
except ValueError:
return time
else:
return "INF" if ftime == float("inf") else ftime
self._edit_field("grading_time", formatter=grading_time_formatter)
async def edit_wave_brightness(self):
self._edit_field("wave_brightness", formatter=int)
async def edit_grid(self):
GRID_OPTIONS = ["FULL", "HALF", "NONE"]
idx = GRID_OPTIONS.index(self.grid) + 1
idx = 0 if idx == len(GRID_OPTIONS) else idx
self.update_oscope(grid=GRID_OPTIONS[idx])
async def edit_grid_brightness(self):
self._edit_field("grid_brightness", formatter=int) | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/app/display_tui.py | 0.552902 | 0.316647 | display_tui.py | pypi |
from rich.console import RenderableType
from rich.panel import Panel
from rich.table import Table
from textual.reactive import Reactive
from rigol_ds1000z.app.tablecontrol_tui import TableControl_TUI, _float2si
class Waveform_TUI(TableControl_TUI):
source: Reactive[RenderableType] = Reactive("")
mode: Reactive[RenderableType] = Reactive("")
format: Reactive[RenderableType] = Reactive("")
start: Reactive[RenderableType] = Reactive("")
stop: Reactive[RenderableType] = Reactive("")
def update_oscope(self, **kwargs):
waveform = self.oscope.waveform(**kwargs)
self.source = (
waveform.source
if waveform.source == "MATH"
else "CHAN" + str(waveform.source)
)
self.mode = waveform.mode
self.format = waveform.format
self.start = str(waveform.start)
self.stop = str(waveform.stop)
def render(self) -> RenderableType:
table = Table(box=None, show_header=False)
table.add_column(no_wrap=True)
table.add_column(no_wrap=True)
table.add_row("Source", self._create_field(field="source"))
table.add_row("Mode", self._create_field(field="mode"))
table.add_row("Format ", self._create_field(field="format"))
table.add_row("Start", self._create_field(field="start"))
table.add_row("Stop", self._create_field(field="stop"))
return Panel(table, title="Waveform")
def _create_field(self, field):
return super()._create_field(
field=field, callback="app.edit_waveform('{:s}')".format(field)
)
async def edit_source(self):
SOURCE_OPTIONS = ["CHAN1", "CHAN2", "CHAN3", "CHAN4", "MATH"]
idx = SOURCE_OPTIONS.index(self.source) + 1
idx = 0 if idx == len(SOURCE_OPTIONS) else idx
self.update_oscope(source=SOURCE_OPTIONS[idx])
async def edit_mode(self):
MODE_OPTIONS = ["NORM", "MAX", "RAW"]
idx = MODE_OPTIONS.index(self.mode) + 1
idx = 0 if idx == len(MODE_OPTIONS) else idx
self.update_oscope(mode=MODE_OPTIONS[idx])
async def edit_format(self):
FORMAT_OPTIONS = ["WORD", "BYTE", "ASC"]
idx = FORMAT_OPTIONS.index(self.format) + 1
idx = 0 if idx == len(FORMAT_OPTIONS) else idx
self.update_oscope(format=FORMAT_OPTIONS[idx])
async def edit_start(self):
self._edit_field("start", formatter=int)
async def edit_stop(self):
self._edit_field("stop", formatter=int) | /rigol-ds1000z-0.3.0.tar.gz/rigol-ds1000z-0.3.0/rigol_ds1000z/app/waveform_tui.py | 0.57081 | 0.19389 | waveform_tui.py | pypi |
`Rigor` is a Domain Specific Language (DSL) and Command Line Interface (CLI)
for making HTTP requests, extracting data, and validating responses. The main
intent of Rigor is to be an HTTP-based API (e.g. REST) Testing Framework for
automated functional or integration testing.
<a href='https://codecov.io/github/genomoncology/rigor/'><img src='https://codecov.io/github/genomoncology/rigor/branch/master/graph/badge.svg' align="right" /></a>
<a href='https://pypi.python.org/pypi/rigor'><img src='https://img.shields.io/pypi/v/rigor.svg' align="right" /></a>
<br/>
# Requirements
* Python 3.6
# Installation
Install using `pip3`...
pip3 install rigor
# Feature List
* Functional testing without the need to write glue code. (e.g. Cucumber)
* Runs in either synchronous ([requests]) or asynchronous ([aiohttp]) mode.
* YAML-based format for Test Case files for easy test creation and maintenance.
* Response transformation using [jmespath.py] to reduce test fragility.
* Pretty HTML test execution reports using [cucumber-sandwich].
* [Swagger] path coverage report to ensure API surface area coverage.
* Syntax highlighted console or JSON-based logging using [structlog].
* Profiles for switching between different environments and settings.
* Tags and CLI options for selectively executing subsets of the test suite.
* Scenario Outlines (i.e. Tables) for cases with numerous scenarios.
* Beautiful Soup parsing for extraction from HTML data.
* Proper error code ($?) on suite success (0) or failure (!0)
* Case-scenario unique identifier (__uuid__) for managing session and race conditions.
# Command Line Interface (CLI) Options
$ rigor --help
Usage: rigor [OPTIONS] [PATHS]...
Options:
--profile TEXT Profile name (e.g. test)
--host TEXT Host name (e.g. http://localhost:8000)
-i, --includes TEXT Include tag of cases. (e.g. smoke)
-e, --excludes TEXT Exclude tag of cases to run. (e.g. broken)
-p, --prefixes TEXT Filter cases by file prefix. (e.g. smoke_)
-e, --extensions TEXT Filter cases by file extension. (e.g. rigor)
-c, --concurrency INTEGER # of concurrent HTTP requests. (default: 5)
-o, --output TEXT Report output folder.
-q, --quiet Run in quiet mode. (warning/critical level only)
-v, --verbose Run in verbose mode. (debug level logging)
-j, --json JSON-style logging.
-h, --html Generate HTML report.
-g, --coverage Generate Coverage report.
-r, --retries INTEGER # of retries for GET calls only. (default: 0)
-s, --sleep INTEGER Retry sleep (seconds multiplied by retry).
(default: 60)
-f, --retry_failed Retries all failed scenarios at the end.
--version Logs current version and exits.
--help Show this message and exit.
# Simple Example
(rigor) /p/tmp> cat test.rigor
name: Simple case.
steps:
- description: Simple step.
request:
host: https://httpbin.org
path: get
(rigor) /p/tmp> rigor test.rigor --html
2018-02-08 13:18.06 [info ] no config file not found [rigor] paths=('test.rigor',)
2018-02-08 13:18.06 [info ] collecting tests [rigor] cwd=/private/tmp paths=['test.rigor']
2018-02-08 13:18.06 [info ] tests collected [rigor] queued=1 skipped=0
2018-02-08 13:18.06 [info ] execute suite complete [rigor] failed=0 passed=1 timer=0.119s
2018-02-08 13:18.07 [info ] launching browser [rigor] report_path=/var/folders/b_/2hlrn_7930x81r009mfzl50m0000gn/T/tmps_8d7nn_/html-2018-02-08-08-18-06/cucumber-html-reports/cucumber-html-reports/overview-features.html
![list]
![detail]
# Object Model
* suite: set of cases that gets built dynamically based on cli arguments.
* case: set of scenarios and steps in a .rigor file.
* scenario: namespace for 1 run of case steps.
* step: request with response extract, validate, etc.
* iterate: repeats an individual step by iterating through iterable.
* request: http call (get, post, etc.) to path with parameters, data, or uploads
* extract: extract nested data from a response into a variable available to following steps.
* validate: check an actual value against an expected value using a comparator.
* transform: using [jmespath] to shape a JSON response into a specific format.
![objects]
# Comparators
Comparators are used by the validation phase of each step to check whether
an actual value is returning as expected. See the [comparisons.rigor] example
for more details.
* equals
* not equals
* same
* not same
* greater than
* less than
* greater than or equals
* less than or equals
* type
* in
* not in
* regex
* subset
* not subset
* length
* superset
* not superset
* keyset
* not keyset
* contains
* not contains
# Related Projects
* [Tavern] is an extremely similar project that was released a little too late for us to use.
* [Pyresttest] was the first library we used before deciding to roll our own testing framework.
* [Click] is the library used to build out the command-line options.
* [Related] is the library used for parsing the YAML test suite into an Python object model.
# More Examples
More examples can be found by reviewing the [tests/httpbin/] folder of this project.
# License
The MIT License (MIT)
Copyright (c) 2017 [Ian Maurer], [Genomoncology LLC]
[Click]: http://click.pocoo.org/
[PyRestTest]: https://github.com/svanoort/pyresttest/
[Related]: https://github.com/genomoncology/related
[Swagger]: https://swagger.io/specification/
[Tavern]: https://taverntesting.github.io/
[aiohttp]: http://aiohttp.readthedocs.io/en/stable/
[cucumber-sandwich]: https://github.com/damianszczepanik/cucumber-sandwich
[jmespath.py]: https://github.com/jmespath/jmespath.py
[requests]: http://docs.python-requests.org/en/master/
[structlog]: http://www.structlog.org/en/stable/
[tests/httpbin/]: ./tests/httpbin
[comparisons.rigor]: ./tests/httpbin/comparisons.rigor
[list]: ./.images/list.png
[detail]: ./.images/detail.png
[objects]: ./.images/objects.png
[Genomoncology LLC]: http://genomoncology.com
[Ian Maurer]: https://github.com/imaurer
[jmespath]: jmespath.org | /rigor-0.7.5.tar.gz/rigor-0.7.5/README.md | 0.887717 | 0.675504 | README.md | pypi |
<img src="http://yusukematsui.me/project/rii/img/logotype97.png" width="300">

[](https://rii.readthedocs.io/en/latest/?badge=latest)
[](https://badge.fury.io/py/rii)
[](https://pepy.tech/project/rii)
Reconfigurable Inverted Index (Rii): IVFPQ-based fast and memory efficient approximate nearest neighbor search method
with a subset-search functionality.
Reference:
- [Y. Matsui](http://yusukematsui.me/), [R. Hinami](http://www.satoh-lab.nii.ac.jp/member/hinami/), and [S. Satoh](http://research.nii.ac.jp/~satoh/index.html), "**Reconfigurable Inverted Index**", ACM Multimedia 2018 (oral). [**[paper](https://dl.acm.org/ft_gateway.cfm?id=3240630)**] [**[project](http://yusukematsui.me/project/rii/rii.html)**]
## Summary of features
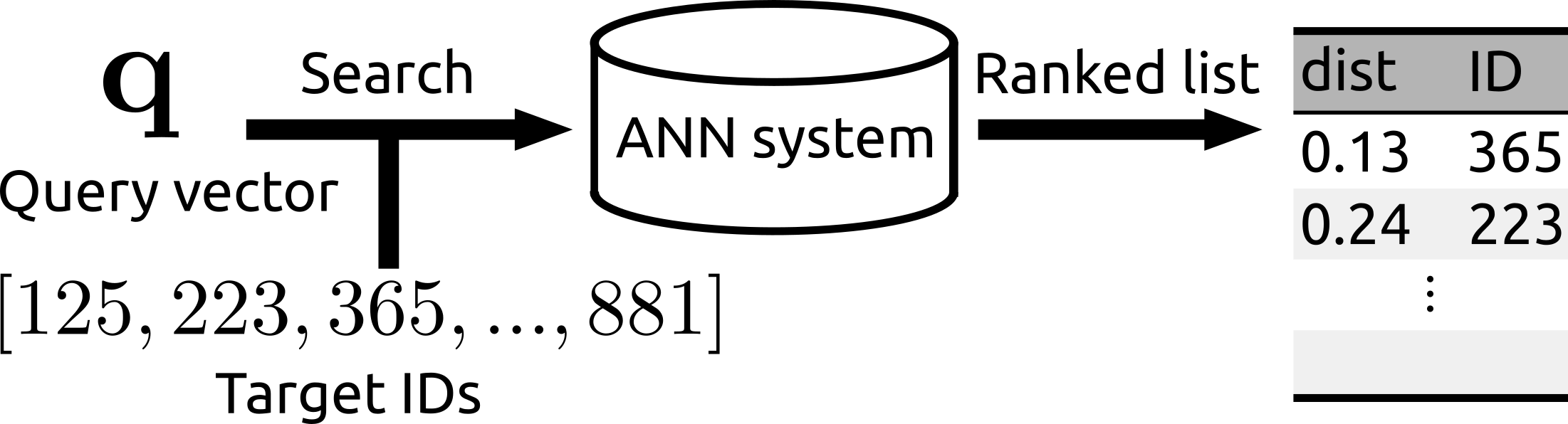 | 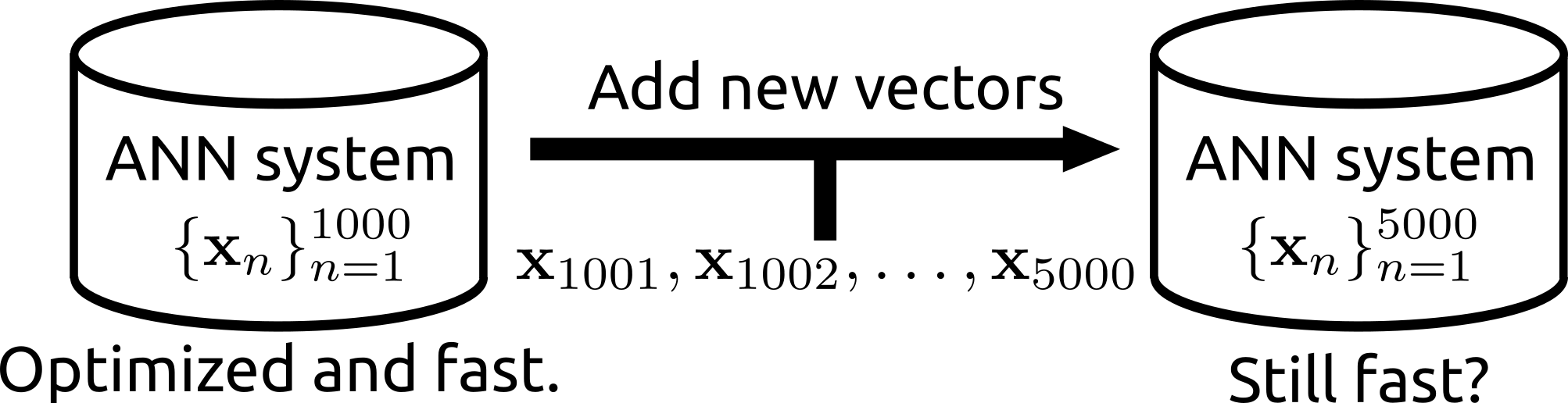
:---:|:---:
The search can be operated for a subset of a database. | Rii remains fast even after many new items are added.
- Fast and memory efficient ANN. Rii enables you to run billion-scale search in less than 10 ms.
- You can run the search over a **subset** of the whole database
- Rii Remains fast even after many vectors are newly added (i.e., the data structure can be **reconfigured**)
## Installing
You can install the package via pip. This library works with Python 3.6+ on linux/mac/wsl/Windows10
```
pip install rii
```
<details>
<summary>For windows (maintained by @ashleyabraham)</summary>
### Installing in Windows 10 via `pip install`
Requires MS Visual Studio Build tools C++ 14.0 or 14.1 toolset or above to compile and install via pip install
### Pre-compiled binary for Windows 10
Pre-compiled binaries doesn't require MS Visual Studio Build tools
```
#Python 3.8
pip install https://github.com/ashleyabraham/rii/releases/download/v0.2.8/rii-0.2.8-cp38-cp38-win_amd64.whl
```
```
#Python 3.7
pip install https://github.com/ashleyabraham/rii/releases/download/v0.2.8/rii-0.2.8-cp37-cp37m-win_amd64.whl
```
#### OpenMP
OpenMP requires libomp140_x86_64.dll to compile in windows, which is part of MS Visual Studio Build tools and it is not redistributable.
In order to use OpenMP 3.0 /openmp:llvm flag is used which causes warnings of multiple libs loading, use at your descretion when used with other parallel processing library loadings. To supress use
`SET KMP_DUPLICATE_LIB_OK=TRUE`
#### SIMD
The /arch:AVX2 flag is used in MSVC to set appropriate SIMD preprocessors and compiler intrinsics
</details>
## [Documentation](https://rii.readthedocs.io/en/latest/index.html)
- [Tutorial](https://rii.readthedocs.io/en/latest/source/tutorial.html)
- [Tips](https://rii.readthedocs.io/en/latest/source/tips.html)
- [API](https://rii.readthedocs.io/en/latest/source/api.html)
## Usage
### Basic ANN
```python
import rii
import nanopq
import numpy as np
N, Nt, D = 10000, 1000, 128
X = np.random.random((N, D)).astype(np.float32) # 10,000 128-dim vectors to be searched
Xt = np.random.random((Nt, D)).astype(np.float32) # 1,000 128-dim vectors for training
q = np.random.random((D,)).astype(np.float32) # a 128-dim vector
# Prepare a PQ/OPQ codec with M=32 sub spaces
codec = nanopq.PQ(M=32).fit(vecs=Xt) # Trained using Xt
# Instantiate a Rii class with the codec
e = rii.Rii(fine_quantizer=codec)
# Add vectors
e.add_configure(vecs=X)
# Search
ids, dists = e.query(q=q, topk=3)
print(ids, dists) # e.g., [7484 8173 1556] [15.06257439 15.38533878 16.16935158]
```
Note that you can construct a PQ codec and instantiate the Rii class at the same time if you want.
```python
e = rii.Rii(fine_quantizer=nanopq.PQ(M=32).fit(vecs=Xt))
e.add_configure(vecs=X)
```
Furthermore, you can even write them in one line by chaining a function.
```python
e = rii.Rii(fine_quantizer=nanopq.PQ(M=32).fit(vecs=Xt)).add_configure(vecs=X)
```
### Subset search
```python
# The search can be conducted over a subset of the database
target_ids = np.array([85, 132, 236, 551, 694, 728, 992, 1234]) # Specified by IDs
# For windows, you must specify dtype=np.int64 as follows.
# target_ids = np.array([85, 132, 236, 551, 694, 728, 992, 1234], dtype=np.int64)
ids, dists = e.query(q=q, topk=3, target_ids=target_ids)
print(ids, dists) # e.g., [728 85 132] [14.80522156 15.92787838 16.28690338]
```
### Data addition and reconfiguration
```python
# Add new vectors
X2 = np.random.random((1000, D)).astype(np.float32)
e.add(vecs=X2) # Now N is 11000
e.query(q=q) # Ok. (0.12 msec / query)
# However, if you add quite a lot of vectors, the search might become slower
# because the data structure has been optimized for the initial item size (N=10000)
X3 = np.random.random((1000000, D)).astype(np.float32)
e.add(vecs=X3) # A lot. Now N is 1011000
e.query(q=q) # Slower (0.96 msec/query)
# In such case, run the reconfigure function. That updates the data structure
e.reconfigure()
e.query(q=q) # Ok. (0.21 msec / query)
```
### I/O by pickling
```python
import pickle
with open('rii.pkl', 'wb') as f:
pickle.dump(e, f)
with open('rii.pkl', 'rb') as f:
e_dumped = pickle.load(f) # e_dumped is identical to e
```
### Util functions
```python
# Print the current parameters
e.print_params()
# Delete all PQ-codes and posting lists. fine_quantizer is kept.
e.clear()
# You can switch the verbose flag
e.verbose = False
# You can merge two Rii instances if they have the same fine_quantizer
e1 = rii.Rii(fine_quantizer=codec)
e2 = rii.Rii(fine_quantizer=codec)
e1.add_configure(vecs=X1)
e2.add_configure(vecs=X2)
e1.merge(e2) # Now e1 contains both X1 and X2
```
## [Examples](./examples)
- [Simple tag search](./examples/tag_search/simple_tag_search.ipynb)
- [Benchmark](./examples/benchmark/)
## Author
- [Yusuke Matsui](http://yusukematsui.me)
## Credits
- The logo is designed by [@richardbmx](https://github.com/richardbmx) ([#4](https://github.com/matsui528/rii/issues/4))
- The windows implementation is by [@ashleyabraham](https://github.com/ashleyabraham) ([#42](https://github.com/matsui528/rii/pull/42))
| /rii-0.2.9.tar.gz/rii-0.2.9/README.md | 0.720762 | 0.908171 | README.md | pypi |
from pygame.sprite import Group
from pygame import Rect
from riichiroyale.game import Tile
from riichiroyale.sprites import SMALL_TILE_SIZE, TILE_SIZE, TileRender
def render_hand(board_render, player_pov):
player = board_render.board.players[player_pov]
rect = Rect(board_render.surface.get_rect())
rect.y = rect.height - (TILE_SIZE[1] + 15)
tile_offset = 10
full_hand_width = len(player.hand) * (TILE_SIZE[0] + tile_offset) - tile_offset
xpos = (rect.width - full_hand_width) / 2
return _render_hand(board_render, TILE_SIZE, player, player.hand, player.melded_hand, rect, xpos, tile_offset)
def render_hidden_hand(board_render, pov, seat):
player = board_render.board.players[pov]
rect = Rect(board_render.surface.get_rect())
tile_offset = 5
full_hand_width = len(player.hand) * (SMALL_TILE_SIZE[0] + tile_offset) - tile_offset
TILE_POS = [
((rect.width - full_hand_width) / 2, (SMALL_TILE_SIZE[1] + 15)),
((SMALL_TILE_SIZE[1] + 15), (rect.height - full_hand_width) / 2),
((rect.width - full_hand_width) / 2, 10),
(10, (rect.height - full_hand_width) / 2)
]
xpos, ypos = TILE_POS[seat]
if seat == 0:
rect.bottom = ypos
elif seat == 1:
rect.x = rect.width - xpos
elif seat == 2:
rect.y = ypos
elif seat == 3:
rect.x = xpos
hand = [Tile.ERROR_PIECE] * len(player.hand)
if seat % 2 == 0:
return _render_hand(board_render, SMALL_TILE_SIZE, player, hand, player.melded_hand, rect, xpos, tile_offset=tile_offset, should_interact=False, small_tile=True)
return _render_vertical_hand(board_render, SMALL_TILE_SIZE, player, hand, player.melded_hand, rect, ypos, tile_offset=tile_offset, should_interact=False, rotation=1, small_tile=True)
def _render_hand(board_render, tile_dict, player, hand, melded_hand, rect, xpos, tile_offset=10, should_interact=True, small_tile=False):
group = Group()
tile_index = 0
number_of_melded_tiles = len(melded_hand) * 3
for tile in hand:
if tile_index + number_of_melded_tiles == 13:
xpos += 3 * tile_offset
tile_sprite = TileRender(board_render.small_dictionary if small_tile else board_render.dictionary, tile, (xpos, rect.y), owner=player, known_index=tile_index, interact=should_interact, small_tile=small_tile)
group.add(tile_sprite)
xpos += tile_dict[0] + tile_offset
tile_index += 1
return group
def _render_vertical_hand(board_render, tile_dict, player, hand, melded_hand, rect, ypos, tile_offset=10, rotation=0, should_interact=True, small_tile=False):
group = Group()
tile_index = 0
number_of_melded_tiles = len(melded_hand) * 3
for tile in hand:
if tile_index + number_of_melded_tiles == 13:
ypos += 3 * tile_offset
tile_sprite = TileRender(board_render.small_dictionary if small_tile else board_render.dictionary, tile, (rect.x, ypos), owner=player, known_index=tile_index, interact=should_interact, rotation=rotation, small_tile=small_tile)
group.add(tile_sprite)
ypos += tile_dict[0] + tile_offset
tile_index += 1
return group | /riichiroyale-cmiller548-0.0.6.tar.gz/riichiroyale-cmiller548-0.0.6/riichiroyale/sprites/elements/hand.py | 0.499512 | 0.596198 | hand.py | pypi |
from functools import reduce
from pygame.sprite import Group
from pygame import Rect
from riichiroyale.game import Tile, CallDirection
from riichiroyale.sprites import SMALL_TILE_SIZE, TileRender
def render_meld_hand(board_render, meld_hand, seat=0):
VERTICAL = seat % 2 != 0
group = Group()
calculated_meld_dimensions = list(map(lambda x: x.calculate_meld_sprite_dimensions(*SMALL_TILE_SIZE), meld_hand))
if len(calculated_meld_dimensions) > 2:
row_meld_dimensions = [calculated_meld_dimensions[:2], calculated_meld_dimensions[2:]]
else:
row_meld_dimensions = [calculated_meld_dimensions[:2], []]
max_meld_height = reduce(lambda acc, x: max(acc, reduce(lambda acc2, y: max(acc2, y[1]), x, 0)), row_meld_dimensions, 0)
max_row_width = reduce(lambda acc, x: max(acc, reduce(lambda acc2, y: acc2 + y[0], x, 0)), row_meld_dimensions, 0)
rect = Rect(board_render.surface.get_rect())
offset = 0
SEAT_POS = [
(rect.width - max_row_width - 65, rect.height - 25 - (max_meld_height * 2)),
(rect.width - 100 - (max_meld_height * 2), max_row_width),
(400 - max_row_width, 25),
(25 + (max_meld_height * 2), max_row_width),
]
xpos, ypos = SEAT_POS[seat]
i = 0
for meld in meld_hand:
if not VERTICAL:
group.add(render_meld(board_render, meld, xpos + offset, ypos, meld_rotation=seat))
else:
group.add(render_meld(board_render, meld, xpos, ypos + offset, meld_rotation=seat))
meld_width, meld_height = calculated_meld_dimensions[i]
max_meld_height = max(max_meld_height, meld_height)
offset += meld_width + 20
i += 1
if i == 2:
offset = 0
if VERTICAL:
xpos += max_meld_height + 10
else:
ypos += max_meld_height + 10
return group
def _get_tile_offset(offset, is_vertical, is_inverted):
VERT_INVERT_LUT = {
True: {
True: 0,
False: offset
},
False: {
True: 0,
False: 0
}
}
return VERT_INVERT_LUT[is_vertical][is_inverted]
def render_meld(board_render, meld, xpos, ypos, meld_rotation=0):
VERTICAL = meld_rotation % 2 != 0
INVERT_CALL_OFFSET = meld_rotation > 1
NONROTATED_MELD_PIECE = meld_rotation
ROTATED_MELD_PIECE = meld_rotation + 1
group = Group()
direction = meld.call_direction
i = 0
tile_length = len(meld.tiles)
while i < tile_length:
tile = meld.tiles[i]
rotation_i = 2 - i if meld_rotation in (1, 2) else i
rotation = ROTATED_MELD_PIECE if CallDirection.should_rotate_tile(rotation_i, meld) else NONROTATED_MELD_PIECE
offset = SMALL_TILE_SIZE[1] - SMALL_TILE_SIZE[0] if rotation == ROTATED_MELD_PIECE else NONROTATED_MELD_PIECE
tile_posx = xpos + _get_tile_offset(offset, VERTICAL, INVERT_CALL_OFFSET)
tile_posy = ypos + _get_tile_offset(offset, not VERTICAL, INVERT_CALL_OFFSET)
tile_pos = (tile_posx, tile_posy)
rendered_tile = Tile.ERROR_PIECE if direction == CallDirection.Concealed and i in (0, 3) else tile
sprite = TileRender(board_render.small_dictionary, rendered_tile, tile_pos, small_tile=True, rotation=rotation)
group.add(sprite)
if rotation == 1 and meld.converted_kan:
offset -= (5 + SMALL_TILE_SIZE[0])
tile_posx = xpos + (offset if VERTICAL else 0)
tile_posy = ypos + (offset if not VERTICAL else 0)
tile_pos = (tile_posx, tile_posy)
sprite = TileRender(board_render.small_dictionary, rendered_tile, tile_pos, small_tile=True, rotation=rotation)
group.add(sprite)
i += 1
next_tile_shift = SMALL_TILE_SIZE[1] if rotation == ROTATED_MELD_PIECE else SMALL_TILE_SIZE[0]
if VERTICAL:
ypos += next_tile_shift + 5
else:
xpos += next_tile_shift + 5
i += 1
return group | /riichiroyale-cmiller548-0.0.6.tar.gz/riichiroyale-cmiller548-0.0.6/riichiroyale/sprites/elements/meld.py | 0.403802 | 0.555616 | meld.py | pypi |
from pygame.sprite import Group
from pygame import Rect
from riichiroyale.sprites import TILE_SIZE, SMALL_TILE_SIZE, TileRender
def render_discard_pile(board_render, player_id):
group = Group()
board = board_render.board
player = board.players[0]
if player.discard_pile is None:
return group
rect = Rect(board_render.surface.get_rect())
rect.center = (0,0)
side_calculation = (SMALL_TILE_SIZE[1] + 10) * 3
if player_id == 0: rect.bottom = side_calculation + TILE_SIZE[1] + 20
if player_id == 2: rect.top = -side_calculation
tile_offset = 10
tiles_per_row = 12
i = 0
row = 0
row_offset = SMALL_TILE_SIZE[1] + tile_offset
full_width = tiles_per_row * (SMALL_TILE_SIZE[0] + tile_offset) - tile_offset
beginning_of_across_line = (rect.width - full_width) / 2
beginning_of_across_line += full_width if player_id == 2 else 0
across = beginning_of_across_line
for tile in player.discard_pile:
tile_pos = (across, -rect.y + (row * row_offset))
tile_sprite = TileRender(board_render.small_dictionary, tile, tile_pos, small_tile=True, rotation = player_id)
group.add(tile_sprite)
across += SMALL_TILE_SIZE[0] + tile_offset if player_id == 0 else -(SMALL_TILE_SIZE[0] + tile_offset)
i += 1
if i >= tiles_per_row:
i = 0
row += 1 if player_id == 0 else -1
across = beginning_of_across_line
return group
def render_vertical_discard_pile(board_render, player_id):
group = Group()
board = board_render.board
player = board.players[player_id]
if player.discard_pile is None:
return group
rect = Rect(board_render.surface.get_rect())
rect.center = (0,0)
side_calculation = (SMALL_TILE_SIZE[1] + 10) * 4
if player_id == 1: rect.right = side_calculation + 150
if player_id == 3: rect.left = -side_calculation - 150
tile_offset = 10
tiles_per_row = 12
i = 0
row = 0
row_offset = SMALL_TILE_SIZE[1] + tile_offset
full_width = tiles_per_row * (SMALL_TILE_SIZE[0] + tile_offset) - tile_offset
beginning_of_across_line = rect.height - ((rect.height - full_width) / 2)
beginning_of_across_line -= full_width if player_id == 3 else 0
across = beginning_of_across_line
for tile in player.discard_pile:
tile_pos = (-rect.x + (row * row_offset), across)
tile_sprite = TileRender(board_render.small_dictionary, tile, tile_pos, small_tile=True, rotation = player_id)
group.add(tile_sprite)
across -= SMALL_TILE_SIZE[0] + tile_offset if player_id == 1 else -(SMALL_TILE_SIZE[0] + tile_offset)
i += 1
if i >= tiles_per_row:
i = 0
row += 1 if player_id == 1 else -1
across = beginning_of_across_line
return group | /riichiroyale-cmiller548-0.0.6.tar.gz/riichiroyale-cmiller548-0.0.6/riichiroyale/sprites/elements/discard.py | 0.513425 | 0.477128 | discard.py | pypi |
from enum import IntEnum
class Tile(IntEnum):
TERMINAL_BIT = 1<<7
HONOR_SUIT = 0<<5
BAMBOO_SUIT = 1<<5
PIN_SUIT = 2<<5
CHARACTER_SUIT = 3<<5
RED_FIVE = 1<<4
ERROR_PIECE = 0
ONE_BAMBOO = BAMBOO_SUIT | 1 | TERMINAL_BIT
TWO_BAMBOO = BAMBOO_SUIT | 2
THREE_BAMBOO = BAMBOO_SUIT | 3
FOUR_BAMBOO = BAMBOO_SUIT | 4
FIVE_BAMBOO = BAMBOO_SUIT | 5
RED_FIVE_BAMBOO = BAMBOO_SUIT | 5 | RED_FIVE
SIX_BAMBOO = BAMBOO_SUIT | 6
SEVEN_BAMBOO = BAMBOO_SUIT | 7
EIGHT_BAMBOO = BAMBOO_SUIT | 8
NINE_BAMBOO = BAMBOO_SUIT | 9 | TERMINAL_BIT
ONE_PIN = PIN_SUIT | 1 | TERMINAL_BIT
TWO_PIN = PIN_SUIT | 2
THREE_PIN = PIN_SUIT | 3
FOUR_PIN = PIN_SUIT | 4
FIVE_PIN = PIN_SUIT | 5
RED_FIVE_PIN = PIN_SUIT | 5 | RED_FIVE
SIX_PIN = PIN_SUIT | 6
SEVEN_PIN = PIN_SUIT | 7
EIGHT_PIN = PIN_SUIT | 8
NINE_PIN = PIN_SUIT | 9 | TERMINAL_BIT
ONE_CHARACTER = CHARACTER_SUIT | 1 | TERMINAL_BIT
TWO_CHARACTER = CHARACTER_SUIT | 2
THREE_CHARACTER = CHARACTER_SUIT | 3
FOUR_CHARACTER = CHARACTER_SUIT | 4
FIVE_CHARACTER = CHARACTER_SUIT | 5
RED_FIVE_CHARACTER = CHARACTER_SUIT | 5 | RED_FIVE
SIX_CHARACTER = CHARACTER_SUIT | 6
SEVEN_CHARACTER = CHARACTER_SUIT | 7
EIGHT_CHARACTER = CHARACTER_SUIT | 8
NINE_CHARACTER = CHARACTER_SUIT | 9 | TERMINAL_BIT
EAST_WIND = HONOR_SUIT | 1
SOUTH_WIND = HONOR_SUIT | 2
WEST_WIND = HONOR_SUIT | 3
NORTH_WIND = HONOR_SUIT | 4
RED_DRAGON = HONOR_SUIT | 5
WHITE_DRAGON = HONOR_SUIT | 6
GREEN_DRAGON = HONOR_SUIT | 7
@staticmethod
def isHonor(piece):
return (piece.value & Tile.CHARACTER_SUIT) == Tile.ERROR_PIECE
@staticmethod
def isTerminal(piece):
return (piece.value & Tile.TERMINAL_BIT) != Tile.ERROR_PIECE
@staticmethod
def isBoardPiece(piece):
return piece & 0x0F != 0
@staticmethod
def getSuit(piece):
return Tile(piece.value & 3<<5)
@staticmethod
def isRedFive(piece):
return piece & Tile.RED_FIVE != Tile.ERROR_PIECE
@staticmethod
def getPieceNum(piece):
return piece.value & 15
def __lt__(self, other):
if (Tile.getSuit(self) != Tile.getSuit(other)):
return Tile.getSuit(self) > Tile.getSuit(other)
return Tile.getPieceNum(self) < Tile.getPieceNum(other)
def __add__(self, other):
if (Tile.isHonor(self)):
raise "Cannot add with Honor Tiles"
new_number = Tile.getPieceNum(self) + other
if new_number > 9:
raise "Integer overflow on tile addition"
suit = Tile.getSuit(self)
is_terminal = new_number in (1, 9)
if is_terminal:
return Tile(suit | new_number | Tile.TERMINAL_BIT)
return Tile(suit | new_number)
def __sub__(self, other):
if (Tile.isHonor(self)):
raise "Cannot subtract with Honor Tiles"
new_number = Tile.getPieceNum(self) - other
if new_number < 1:
raise "Integer underflow on tile subtraction"
suit = Tile.getSuit(self)
is_terminal = new_number in (1, 9)
if is_terminal:
return Tile(suit | new_number | Tile.TERMINAL_BIT)
return Tile(suit | new_number) | /riichiroyale-cmiller548-0.0.6.tar.gz/riichiroyale-cmiller548-0.0.6/riichiroyale/game/tile.py | 0.474631 | 0.151122 | tile.py | pypi |
# Material
```
Material(params: Dict, rid: RiiDataFrame)
```
This class provides the dielectric function for the material specified by given id. If the argument __bound_check__ is True, ValueError is raised when the wavelength exeeds the domain of experimental data.
__params__ can includes the following parameters,
* 'PEC' (bool): True if you want to create perfect electric conductor. Defaults to False.
* 'id' (int): ID number.
* 'book' (str): book value in catalog of RiiDataFrame.
* 'page' (str): page value in catalog of RiiDataFrame.
* 'RI' (complex): Constant refractive index.
* 'e' (complex): Constant permittivity.
* 'bound_check' (bool): True if bound check should be done. Defaults to True.
* 'im_factor' (floot): A magnification factor multiplied to the imaginary part of permittivity. Defaults to 1.0.
This class extends the functionality of refractiveindex.info database:
* It is possible to define dielectric materials that has constant permittivity.
* Imaginary part of dielectric function can be magnified using 'im_factor' parameter.
* Perfect Electric Conductor is defined as an artificial metal labeled "PEC", which has negative large permittivity (-1e8).
* Material is callable with a single value argument, angular frequency argument ω. The evaluation process is omitted if it is called with the same argument.
However, n, k and eps methos of this class are not numpy.ufunc. You can pass them only a single value.
```
import riip
rid = riip.RiiDataFrame()
water = riip.Material({'id': 428}, rid)
print(f"{water.catalog['book']} {water.catalog['page']}")
print(f"{water.catalog['wl_min']} <= λ <= {water.catalog['wl_max']}")
```
## Reflactive Index __n__
```
n(wl: ArrayLike) -> numpy.ndarray
```
## Extinction Coefficient __k__
```
k(wl: ArrayLike) -> numpy.ndarray
```
## Dielectric Function __eps__
```
eps(wl: ArrayLike) -> numpy.ndarray
```
Wavelengths __wl__ can be given as a single complex value or an array of complex values.
```
wl = 1.0
n = water.n(wl)
k = water.k(wl)
eps = water.eps(wl)
print(f"At λ={wl}μm:")
print(f" n={n}")
print(f" k={k}")
print(f" ε={eps}")
import numpy as np
wls = np.linspace(0.5, 1.6)
water.eps(wls)
```
## Bound_check
By default, __bound_check__ is set to __True__, so a ValueError is raised if the given range of wavelength exeeds the domain of experimental data.
```
wls = np.linspace(1.0, 2.0) # exeeds the domain of experimental data [wl_min, wl_max]
water = riip.Material({'id': 428}, rid)
try:
water.eps(wls)
except ValueError as e:
print("ValueError: ", e)
```
If the instance is created with _bound_check_=False, the dispersion formula is applied beyond the scope of experimental data.
```
water = rid.material({'id': 428, 'bound_check': False})
water.eps(wls)
```
## __plot__
```
plot(wls: Sequence | np.ndarray, comp: str = "n", fmt1: Optional[str] = "-", fmt2: Optional[str] = "--", **kwargs)
```
* wls (Sequence | np.ndarray): Wavelength coordinates to be plotted [μm].
* comp (str): 'n', 'k' or 'eps'
* fmt1 (Optional[str]): Plot format for n and Re(eps).
* fmt2 (Optional[str]): Plot format for k and Im(eps).
Plot refractive index (if set comp="n"), extinction coefficient (comp="k") or permittivity (comp="eps").
```
import matplotlib.pyplot as plt
water.plot(wls, "n")
plt.show()
water.plot(wls, "k")
plt.show()
water.plot(wls, "eps")
```
You can change plot style usint rcParams.
```
plt.style.use('seaborn-notebook')
plot_params = {
'figure.figsize': [6.0, 6.0],
'axes.labelsize': 'xx-large',
'xtick.labelsize': 'x-large',
'ytick.labelsize': 'x-large',
'legend.fontsize': 'x-large',
}
plt.rcParams.update(plot_params)
water.plot(wls, "n")
```
## Water with constant RI
```
import numpy as np
from riip import Material
water_const = Material({'RI': 1.333})
wl = [0.5, 1.0, 1.5]
n = water_const.n(wl)
k = water_const.k(wl)
eps = water_const.eps(wl)
print(f"At λ={wl}μm:")
print(f" n={n}")
print(f" k={k}")
print(f" ε={eps}")
```
## A definition of water in RIID
```
water = Material({"book": "H2O", "page": "Kedenburg"})
wl = [0.5, 1.0, 1.5]
n = water.n(wl)
k = water.k(wl)
eps = water.eps(wl)
print(f"At λ={wl} μm:")
print(f" n={n}")
print(f" k={k}")
print(f" ε={eps}")
```
## Plot them:
```
wls = np.linspace(0.6, 1.0)
water_const.plot(wls)
water.plot(wls)
```
## Material as a function
```
Material__call__(w: float | complex) -> complex
```
* w (float | complex): A float indicating the angular frequency
It returns the complex relative permittivity at given __angular frequency w__.
We use a unit system where the speed of light in vacuum c is 1 and the unit of length is μm.
So w is equal to the vacuum wavenumber ω/c [rad/μm]).
It is much faster than __eps__ method because the formula is accelerated using cython. In the case of same argument, it's even more faster.
```
gold = Material({'book': 'Au', 'page': 'Stewart-DLF'})
wls = [1.0, 1.5]
ws = [2 * np.pi / wl for wl in wls]
%%timeit
for i in range(1000):
gold.eps(wls[i % 2])
%%timeit
for i in range(1000):
gold.eps(wls[0])
%%timeit
for i in range(1000):
gold(ws[i % 2])
%%timeit
for i in range(1000):
gold(ws[0])
```
## However, Material is __not__ a numpy.ufunc
```
try:
gold(np.array(ws))
except ValueError as e:
print("ValueError: ", e)
```
## im_factor
```
gold_low_loss = Material({'book': 'Au', 'page': 'Stewart-DLF', 'im_factor': 0.1})
print("If im_factor=1.0: Im(ε)=", gold(6.28).imag)
print("If im_factor=0.1: Im(ε)=", gold_low_loss(6.28).imag)
print("Real parts are the same")
print(gold(6.28).real, gold_low_loss(6.28).real)
```
## PEC
```
pec = Material({"PEC": True})
print(pec.label, pec(1.0))
```
| /riip-0.6.16.tar.gz/riip-0.6.16/docs/notebooks/03_Material.ipynb | 0.52829 | 0.907599 | 03_Material.ipynb | pypi |
# RiiDataFrame
Here, a little bit more detail about RiiDataFrame class will be given.
```
import riip
ri = riip.RiiDataFrame()
```
RiiDataFrame has an attribute named __catalog__ that is a [Pandas](https://pandas.pydata.org/) DataFrame provinding the catalog of experimental data as shown below.
The columns _formula_ and _tabulated_ indicate the type of data. If n or k is included in the column __tamulated__, the experimentally observed refractive index _n_ or extinction coefficient _k_ is given in tabulated form, respectively. If __tabulated__ is f, only coefficients of formula are given.
On the other hand, the number written in the column __formula__ indicates the number of dispetsion formula that fits the experimental data. If the number is 0, only the tabulated data are given.
```
ri.catalog.head(3)
```
The experimental data are given by __raw_data__:
```
ri.raw_data.loc[3].head(5) # first 5 rows for the material whose id is 3
```
where n is the refractive index and k is the extinction coefficient at the vacuum wavelength wl_n (wl_k) in the unit of μm.
The column __c__ gives the coefficients for the dielectric function model.
In the above example, no coefficient is given because only the tabulated data are given (__formula__ number in __catalog__ is 0).
On the other hand, if __formula__ number is not 0, some coefficeints are given in the column __c__ as shown below.
In this case, __formula__ 21 means Drude-Lorentz model, which is explained in [Dispersion formulas](https://github.com/mnishida/RII_Pandas/blob/master/riip/data/my_database/doc/Dispersion%20formulas.pdf).
```
ri.catalog.tail(3)
ri.raw_data.loc[2911].head(5) # first 5 rows for the material whose id is 2912
```
Using the method _load_grid_data()_, you can get grid data calculated at 200 wavelength values in the range [__wl_min__, __wl_max__], which is the intersection between the domain of _n_ [__wl_n_min__, __wl_n_max__] and the domain of _k_ [__wl_k_min__, __wl_k_max__]. These values are shown in __catalog__.
```
grid_data = ri.load_grid_data(3)
grid_data
```
# Helper Methods
By using the functionality of Pandas, you may find what you want, easily. But, here some simple helper methods are implemented.
## __plot__
```
plot(id: int, comp: str = "n", fmt1: Optional[str] = "-", fmt2: Optional[str] = "--", **kwargs)
```
* id (int): ID number.
* comp (str): 'n', 'k' or 'eps'.
* fmt1 (Union[str, None]): Plot format for n and Re(eps).
* fmt2 (Union[str, None]): Plot format for k and Im(eps).
Plot refractive index (if set comp="n"), extinction coefficient (comp="k") or permittivity (comp="eps").
```
import matplotlib.pyplot as plt
ri.plot(3, "n")
plt.show()
ri.plot(3, "k")
plt.show()
ri.plot(3, "eps")
plt.show()
```
## __search__
```
search(name: str) -> DataFrame
```
This method searches data whose __book__ or __book_name__ contain given __name__ and return a simplified catalog for them.
```
ri.search("NaCl")
ri.search("sodium") # upper or lower case is not significant
```
## __select__
```
select(condition: str) -> DataFrame
```
This method make a query with the given __condition__ and return a simplified catalog. It will pick up materials whose experimental data contains some data that fulfill given __condition__.
```
ri.select("2.5 < n < 3 and 0.4 < wl < 0.8").head(10)
ri.plot(157)
```
## __show__
```
show(id: int | Sequence[int]) -> DataFrame
```
This method shows a simplified catalog for given __id__.
```
ri.show(1)
```
## __read__
```
read(id, as_dict=False)
```
This method returns the contants of a page associated with the id.
If you want the page contents as a python dict, give True for argument __as_dict__.
```
print(ri.read(0))
ri.read(0, as_dict=True)
```
## __references__
```
references(id: int)
```
This method returns the REFERENCES of a page associated with the id.
```
ri.references(20)
```
## __material__
```
material(params: dict) -> Material
```
Create __Material__-class instance for given parameter dict __params__.
__params__ can includes the following parameters,
* 'id': ID number. (int)
* 'book': book value in catalog of RiiDataFrame. (str)
* 'page': page value in catalog of RiiDataFrame. (str)
* 'RI': Constant refractive index. (complex)
* 'e': Constant permittivity. (complex)
* 'bound_check': True if bound check should be done. Defaults to True. (bool)
* 'im_factor': A magnification factor multiplied to the imaginary part of permittivity. Defaults to 1.0. (float)
```
water = ri.material({'id': 428})
water.catalog
```
| /riip-0.6.16.tar.gz/riip-0.6.16/docs/notebooks/02_RiiDataFrame.ipynb | 0.434941 | 0.978467 | 02_RiiDataFrame.ipynb | pypi |
# Tutorial
Let's start your survay of dielectric properties of various materials. The first thing you must do is to create a RiiDataFrame oject. The first trial will take a few minutes, because experimental data will be pulled down from Polyanskiy's [refractiveindex.info database](https://github.com/polyanskiy/refractiveindex.info-database) and equi-spaced grid data will be obtained by interpolating the experimental data.
```
import riip
ri = riip.RiiDataFrame()
```
You can use some helper methods for your survay.
## __search__
```
search(name: str) -> DataFrame
```
This method searches data that contain given __name__ of material and return a catalog for them.
```
ri.search("NaCl")
ri.search("sodium").head(5) # upper or lower case is not significant
```
## __select__
```
select(condition: str) -> DataFrame
```
This method make a query with the given __condition__ and return a catalog. For example, if you want to find a material whose refractive index n is in a range 2.5 < n < 3 somewhere in the wavelength range 0.4μm < wl < 0.8μm:
```
ri.select("2.5 < n < 3 and 0.4 < wl < 0.8").head(5)
```
## __show__
```
show(ids: int | Sequence[int]) -> DataFrame
```
This method shows the catalog for given __ids__.
```
ri.show([23, 118])
```
## __read__
```
read(id, as_dict=False)
```
This method returns the contants of a page associated with the id.
```
print(ri.read(23))
```
## __references__
```
references(id: int)
```
This method returns the REFERENCES of a page associated with the id.
```
ri.references(23)
```
## __plot__
```
plot(id: int, comp: str = "n", fmt1: str = "-", fmt2: str = "--", **kwargs)
```
* id: ID number
* comp: 'n', 'k' or 'eps'
* fmt1 (Union[str, None]): Plot format for n and Re(eps), such as "-", "--", ":", etc.
* fmt2 (Union[str, None]): Plot format for k and Im(eps).
This plot uses 200 data points only. If you want more fine plots, use __plot__ method of __RiiMaterial__ explained below.
```
ri.plot(23, "n")
ri.plot(23, "k")
ri.plot(23, "eps")
```
## __material__
```
material(params: dict) -> Material
```
This method returns __Material__-class instance for given parameter dict __params__.
__params__ can includes the following parameters,
* 'id': ID number. (int)
* 'book': book value in catalog of RiiDataFrame. (str)
* 'page': page value in catalog of RiiDataFrame. (str)
* 'RI': Constant refractive index. (complex)
* 'e': Constant permittivity. (complex)
* 'bound_check': True if bound check should be done. Defaults to True. (bool)
* 'im_factor': A magnification factor multiplied to the imaginary part of permittivity. Defaults to 1.0. (float)
```
Al = ri.material({'id': 23})
type(Al)
```
Using the created Material object, you can get refractive index n, extinction coefficient k, and dielectric function eps, and plot them.
### __Material.n__
```
n(wl: ArrayLike) -> ArrayLike
```
```
Al.n(1.0) # refractive index at wavelength = 1.0μm
```
### __Material.k__
```
k(wl: ArrayLikey) -> ArrayLike
```
```
Al.k(1.0) # extinction coeficient at wavelength = 1.0μm
```
### __Material.eps__
```
eps(wl: ArrayLike) -> ArrayLike
```
```
Al.eps(1.0) # permittivity at wavelength = 1.0μm
```
Wavelengths __wl__ can be a single complex value or an array of complex values.
```
import numpy as np
wls = np.linspace(0.5, 1.6)
Al.eps(wls)
```
### __Material.plot__
```
plot(wls: np.ndarray, comp: str = "n", fmt1: str = "-", fmt2: str = "--", **kwargs)
```
* wls: Wavelength [μm].
* comp: 'n', 'k' or 'eps'
* fmt1 (Union[str, None]): Plot format for n and Re(eps), such as "-", "--", ":", etc.
* fmt2 (Union[str, None]): Plot format for k and Im(eps).
```
import matplotlib.pyplot as plt
wls = np.linspace(0.5, 1.0)
Al.plot(wls, "n")
plt.show()
Al.plot(wls, "k")
plt.show()
Al.plot(wls, "eps")
plt.show()
```
| /riip-0.6.16.tar.gz/riip-0.6.16/docs/notebooks/01_tutorial.ipynb | 0.462716 | 0.981945 | 01_tutorial.ipynb | pypi |
from typing import Any
from urllib.parse import urlparse
import tensorflow_hub as tfhub
from rikai.internal.reflection import has_func
from rikai.logging import logger
from rikai.spark.sql.codegen.base import Registry
from rikai.spark.sql.model import ModelSpec
from rikai.spark.sql.model import is_fully_qualified_name
class TFHubModelSpec(ModelSpec):
def __init__(self, publisher, handle, raw_spec: "ModelSpec"):
spec = {
"version": "1.0",
"schema": raw_spec.get("schema", None),
"model": {
"flavor": raw_spec.get("flavor", None),
"uri": raw_spec["uri"],
"type": raw_spec.get("modelType", None),
},
}
# remove None value
if not spec["schema"]:
del spec["schema"]
# defaults to the `tensorflow` flavor
if not spec["model"]["flavor"]:
spec["model"]["flavor"] = "tensorflow"
model_type = spec["model"]["type"]
if model_type and not is_fully_qualified_name(model_type):
model_type = f"rikai.contrib.tfhub.{publisher}.{model_type}"
if has_func(model_type + ".MODEL_TYPE"):
logger.info(f"tfhub model_type: {model_type}")
spec["model"]["type"] = model_type
self.handle = handle
super().__init__(spec=spec, validate=True)
def load_model(self) -> Any:
"""Load the model artifact specified in this spec"""
return tfhub.load(self.handle)
class TFHubRegistry(Registry):
"""TFHub-based Model Registry"""
def __repr__(self):
return "TFHubRegistry"
def make_model_spec(self, raw_spec: dict):
uri = raw_spec["uri"]
parsed = urlparse(uri)
if parsed.netloc:
raise ValueError(
"URI with 2 forward slashes is not supported, "
"try URI with 1 slash instead"
)
if parsed.scheme != "tfhub":
raise ValueError(f"Expect schema: tfhub, but got {parsed.scheme}")
handle = f"https://tfhub.dev{parsed.path}"
publisher = parsed.path.lstrip("/").split("/")[0]
spec = TFHubModelSpec(publisher, handle, raw_spec)
return spec | /rikai_tfhub-0.1.0-py3-none-any.whl/rikai/experimental/tfhub/tfhub_registry.py | 0.854839 | 0.196094 | tfhub_registry.py | pypi |
from typing import Any
from urllib.parse import urlparse
import torch
from rikai.internal.reflection import find_func, has_func
from rikai.logging import logger
from rikai.spark.sql.codegen.base import Registry, udf_from_spec
from rikai.spark.sql.model import ModelSpec
class TorchHubModelSpec(ModelSpec):
def __init__(self, repo_or_dir: str, model: str, raw_spec: "ModelSpec"):
spec = {
"version": "1.0",
"schema": raw_spec.get("schema", None),
"model": {
"flavor": raw_spec.get("flavor", None),
"uri": raw_spec["uri"],
"type": raw_spec.get("modelType", None),
},
}
# remove None value
if not spec["schema"]:
del spec["schema"]
# defaults to the `pytorch` flavor
if not spec["model"]["flavor"]:
spec["model"]["flavor"] = "pytorch"
repo_proj = repo_or_dir.split(":")[0].replace("/", ".")
if not spec["model"]["type"]:
model_type = f"rikai.contrib.torchhub.{repo_proj}.{model}"
if has_func(model_type + ".MODEL_TYPE"):
spec["model"]["type"] = model_type
self.repo_or_dir = repo_or_dir
self.model = model
super().__init__(spec=spec, validate=True)
def load_model(self) -> Any:
"""Load the model artifact specified in this spec"""
return torch.hub.load(self.repo_or_dir, self.model)
class TorchHubRegistry(Registry):
"""TorchHub-based Model Registry"""
def __repr__(self):
return "TorchHubRegistry"
def make_model_spec(self, raw_spec: dict):
uri = raw_spec["uri"]
parsed = urlparse(uri)
if parsed.netloc:
raise ValueError(
"URI with 2 forward slashes is not supported, "
"try URI with 1 slash instead"
)
if parsed.scheme != "torchhub":
raise ValueError(
f"Expect schema: torchhub, but got {parsed.scheme}"
)
parts = parsed.path.strip("/").split("/")
if len(parts) != 3:
raise ValueError("Bad URI, expected torchhub:///<org>/<prj>/<mdl>")
repo_or_dir = "/".join(parts[:-1])
model = parts[-1]
return TorchHubModelSpec(repo_or_dir, model, raw_spec) | /rikai-torchhub-0.1.0.tar.gz/rikai-torchhub-0.1.0/rikai/experimental/torchhub/torchhub_registry.py | 0.834643 | 0.20456 | torchhub_registry.py | pypi |
riko FAQ
========
Index
-----
`What pipes are available`_ | `What file types are supported`_ | `What protocols are supported`_
What pipes are available?
-------------------------
Overview
^^^^^^^^
riko's available pipes are outlined below [#]_:
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| Pipe name | Pipe type | Pipe sub-type | Pipe description |
+======================+===========+===============+==============================================================================================+
| `count`_ | operator | aggregator | counts the number of items in a feed |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `csv`_ | processor | source | parses a csv file to yield items |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `currencyformat`_ | processor | transformer | formats a number to a given currency string |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `dateformat`_ | processor | transformer | formats a date |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `exchangerate`_ | processor | transformer | retrieves the current exchange rate for a given currency pair |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `feedautodiscovery`_ | processor | source | fetches and parses the first feed found on a site |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `fetch`_ | processor | source | fetches and parses a feed to return the entries |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `fetchdata`_ | processor | source | fetches and parses an XML or JSON file to return the feed entries |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `fetchpage`_ | processor | source | fetches the content of a given web site as a string |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `fetchsitefeed`_ | processor | source | fetches and parses the first feed found on a site |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `fetchtext`_ | processor | source | fetches and parses a text file |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `filter`_ | operator | composer | extracts items matching the given rules |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `hash`_ | processor | transformer | hashes the field of a feed item |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `input`_ | processor | source | prompts for text and parses it into a variety of different types, e.g., int, bool, date, etc |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `itembuilder`_ | processor | source | builds an item |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `join`_ | operator | aggregator | perform a SQL like join on two feeds |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `regex`_ | processor | transformer | replaces text in fields of a feed item using regexes |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `refind`_ | processor | transformer | finds text located before, after, or between substrings using regular expressions |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `rename`_ | processor | transformer | renames or copies fields in a feed item |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `reverse`_ | operator | composer | reverses the order of source items in a feed |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `rssitembuilder`_ | processor | source | builds an rss item |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `simplemath`_ | processor | transformer | performs basic arithmetic, such as addition and subtraction |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `slugify`_ | operator | transformer | slugifies text |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `sort`_ | operator | composer | sorts a feed according to a specified key |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `split`_ | operator | composer | splits a feed into identical copies |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `strconcat`_ | processor | transformer | concatenates strings |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `strfind`_ | processor | transformer | finds text located before, after, or between substrings |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `strreplace`_ | processor | transformer | replaces the text of a field of a feed item |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `strtransform`_ | processor | transformer | performs string transformations on the field of a feed item |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `subelement`_ | processor | transformer | extracts sub-elements for the item of a feed |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `substr`_ | processor | transformer | returns a substring of a field of a feed item |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `sum`_ | operator | aggregator | sums a field of items in a feed |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `tail`_ | operator | composer | truncates a feed to the last N items |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `timeout`_ | operator | composer | returns items from a stream until a certain amount of time has passed |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `tokenizer`_ | processor | transformer | splits a string by a delimiter |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `truncate`_ | operator | composer | returns a specified number of items from a feed |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `union`_ | operator | composer | merges multiple feeds together |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `uniq`_ | operator | composer | filters out non unique items according to a specified field |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `urlbuilder`_ | processor | transformer | builds a url |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `urlparse`_ | processor | transformer | parses a URL into its six components |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `xpathfetchpage`_ | processor | source | fetches the content of a given website as DOM nodes or a string |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
| `yql`_ | processor | source | fetches the result of a given YQL query |
+----------------------+-----------+---------------+----------------------------------------------------------------------------------------------+
Args
^^^^
riko ``pipes`` come in two flavors; ``operator`` and ``processor`` [#]_.
``operator``s operate on an entire ``stream`` at once. Example ``operator``s include ``pipecount``, ``pipefilter``,
and ``pipereverse``.
.. code-block:: python
>>> from riko.modules.reverse import pipe
>>>
>>> stream = [{'title': 'riko pt. 1'}, {'title': 'riko pt. 2'}]
>>> next(pipe(stream))
{'title': 'riko pt. 2'}
``processor``s process individual ``items``. Example ``processor``s include
``pipefetchsitefeed``, ``pipehash``, ``pipeitembuilder``, and ``piperegex``.
.. code-block:: python
>>> from riko.modules.hash import pipe
>>>
>>> item = {'title': 'riko pt. 1'}
>>> stream = pipe(item, field='title')
>>> next(stream)
{'title': 'riko pt. 1', 'hash': 2853617420L}
Kwargs
^^^^^^
The following table outlines the available kwargs.
========== ==== ================================================ =======
kwarg type description default
========== ==== ================================================ =======
conf dict The pipe configuration varies
extract str The key with which to get a value from `conf` None
listize bool Ensure that an `extract` value is list-like False
pdictize bool Convert `conf` / `extract` to a DotDict instance varies
objectify bool Convert `conf` to an Objectify instance varies
ptype str Used to convert `conf` items to a specific type. pass
dictize bool Convert the input `item` to a DotDict instance True
field str The key with which to get a value from the input None
ftype str Converts the input `item` to a specific type pass
count str The output count all
assign str Attribute used to assign output varies
emit bool Return the output as is (don't assign) varies
skip_if func Determines if processing should be skipped None
inputs dict Values to be used in place of prompting the user None
========== ==== ================================================ =======
Notes
^^^^^
.. [#] See `Design Principles`_ for explanation on `pipe` types and sub-types
.. [#] See `Alternate workflow creation`_ for pipe composition examples
What file types are supported?
------------------------------
File types that riko supports are outlined below:
==================== ======================= ===========================================
File type Recognized extension(s) Supported pipes
==================== ======================= ===========================================
HTML html feedautodiscovery, fetchpage, fetchsitefeed
XML xml fetch, fetchdata
JSON json fetchdata
Comma separated file csv, tsv csv
==================== ======================= ===========================================
What protocols are supported?
-----------------------------
Protocols that riko supports are outlined below:
======== =========================================
Protocol example
======== =========================================
http http://google.com
https https://github.com/reubano/feed
file file:///Users/reubano/Downloads/feed.xml
======== =========================================
.. _What pipes are available: #what-pipes-are-available
.. _What file types are supported: #what-file-types-are-supported
.. _What protocols are supported: #what-protocols-are-supported
.. _Design Principles: https://github.com/nerevu/riko/blob/master/README.rst#design-principles
.. _Alternate workflow creation: https://github.com/nerevu/riko/blob/master/docs/COOKBOOK.rst#synchronous-processing
.. _split: https://github.com/nerevu/riko/blob/master/riko/modules/split.py
.. _count: https://github.com/nerevu/riko/blob/master/riko/modules/count.py
.. _csv: https://github.com/nerevu/riko/blob/master/riko/modules/csv.py
.. _currencyformat: https://github.com/nerevu/riko/blob/master/riko/modules/currencyformat.py
.. _dateformat: https://github.com/nerevu/riko/blob/master/riko/modules/dateformat.py
.. _exchangerate: https://github.com/nerevu/riko/blob/master/riko/modules/exchangerate.py
.. _feedautodiscovery: https://github.com/nerevu/riko/blob/master/riko/modules/feedautodiscovery.py
.. _fetch: https://github.com/nerevu/riko/blob/master/riko/modules/fetch.py
.. _fetchdata: https://github.com/nerevu/riko/blob/master/riko/modules/fetchdata.py
.. _fetchpage: https://github.com/nerevu/riko/blob/master/riko/modules/fetchpage.py
.. _fetchsitefeed: https://github.com/nerevu/riko/blob/master/riko/modules/fetchsitefeed.py
.. _fetchtext: https://github.com/nerevu/riko/blob/master/riko/modules/fetchtext.py
.. _filter: https://github.com/nerevu/riko/blob/master/riko/modules/filter.py
.. _hash: https://github.com/nerevu/riko/blob/master/riko/modules/hash.py
.. _input: https://github.com/nerevu/riko/blob/master/riko/modules/input.py
.. _itembuilder: https://github.com/nerevu/riko/blob/master/riko/modules/itembuilder.py
.. _join: https://github.com/nerevu/riko/blob/master/riko/modules/join.py
.. _regex: https://github.com/nerevu/riko/blob/master/riko/modules/regex.py
.. _refind: https://github.com/nerevu/riko/blob/master/riko/modules/refind.py
.. _rename: https://github.com/nerevu/riko/blob/master/riko/modules/rename.py
.. _reverse: https://github.com/nerevu/riko/blob/master/riko/modules/reverse.py
.. _rssitembuilder: https://github.com/nerevu/riko/blob/master/riko/modules/rssitembuilder.py
.. _simplemath: https://github.com/nerevu/riko/blob/master/riko/modules/simplemath.py
.. _slugify: https://github.com/nerevu/riko/blob/master/riko/modules/slugify.py
.. _sort: https://github.com/nerevu/riko/blob/master/riko/modules/sort.py
.. _split: https://github.com/nerevu/riko/blob/master/riko/modules/split.py
.. _strconcat: https://github.com/nerevu/riko/blob/master/riko/modules/strconcat.py
.. _strfind: https://github.com/nerevu/riko/blob/master/riko/modules/strfind.py
.. _strreplace: https://github.com/nerevu/riko/blob/master/riko/modules/strreplace.py
.. _strtransform: https://github.com/nerevu/riko/blob/master/riko/modules/strtransform.py
.. _subelement: https://github.com/nerevu/riko/blob/master/riko/modules/subelement.py
.. _substr: https://github.com/nerevu/riko/blob/master/riko/modules/substr.py
.. _sum: https://github.com/nerevu/riko/blob/master/riko/modules/sum.py
.. _tail: https://github.com/nerevu/riko/blob/master/riko/modules/tail.py
.. _timeout: https://github.com/nerevu/riko/blob/master/riko/modules/timeout.py
.. _tokenizer: https://github.com/nerevu/riko/blob/master/riko/modules/tokenizer.py
.. _truncate: https://github.com/nerevu/riko/blob/master/riko/modules/truncate.py
.. _union: https://github.com/nerevu/riko/blob/master/riko/modules/union.py
.. _uniq: https://github.com/nerevu/riko/blob/master/riko/modules/uniq.py
.. _urlbuilder: https://github.com/nerevu/riko/blob/master/riko/modules/urlbuilder.py
.. _urlparse: https://github.com/nerevu/riko/blob/master/riko/modules/urlparse.py
.. _xpathfetchpage: https://github.com/nerevu/riko/blob/master/riko/modules/xpathfetchpage.py
.. _yql: https://github.com/nerevu/riko/blob/master/riko/modules/yql.py
| /riko-0.67.0.tar.gz/riko-0.67.0/docs/FAQ.rst | 0.926083 | 0.7153 | FAQ.rst | pypi |
from pprint import pprint
from functools import partial
from riko import get_path
from riko.bado import coroutine
from riko.collections import SyncPipe, AsyncPipe
BR = {"find": "<br>"}
DEF_CUR_CODE = "USD"
odesk_conf = {"url": get_path("odesk.json"), "path": "items"}
guru_conf = {"url": get_path("guru.json"), "path": "items"}
elance_conf = {"url": get_path("elance.json"), "path": "items"}
freelancer_conf = {"url": get_path("freelancer.json"), "path": "items"}
def make_regex(field, match, replace, default=None):
result = {"field": field, "match": match, "replace": replace, "default": default}
return result
def make_simplemath(other, op):
return {"other": {"subkey": other, "type": "number"}, "op": op}
def add_source(source):
subelement_conf = {"path": "k:source.content.1", "token_key": None}
sourced = source.urlparse(field="link", assign="k:source").subelement(
conf=subelement_conf, emit=False, assign="k:source"
)
return sourced
def add_id(source, rule, field="link"):
make_id_part = [{"subkey": "k:source"}, {"value": "-"}, {"subkey": "id"}]
ideed = source.strfind(conf={"rule": rule}, field=field, assign="id").strconcat(
conf={"part": make_id_part}, assign="id"
)
return ideed
def add_posted(source, rule="", field="summary"):
if rule:
conf = {"rule": rule}
source = source.strfind(conf=conf, field=field, assign="k:posted")
else:
rule = {"field": "updated", "newval": "k:posted"}
source = source.rename(conf={"rule": rule})
return source
def add_tags(source, rule, field="summary", assign="k:tags"):
tokenizer_conf = {"dedupe": True, "sort": True}
no_tags = {"field": assign}
tag_strreplace_rule = [
{"find": " ", "replace": ","},
{"find": ">", "replace": ","},
{"find": "&", "replace": "&"},
{"find": "Other -", "replace": ""},
# {'find': '-', 'replace': ''},
]
tagged = (
source.strfind(conf={"rule": rule}, field=field, assign=assign)
.strreplace(
conf={"rule": tag_strreplace_rule},
field=assign,
assign=assign,
skip_if=no_tags,
)
.strtransform(
conf={"rule": {"transform": "lower"}},
field=assign,
assign=assign,
skip_if=no_tags,
)
.tokenizer(conf=tokenizer_conf, field=assign, assign=assign, skip_if=no_tags)
)
return tagged
def add_budget(source, budget_text, fixed_text="", hourly_text="", double=True):
codes = "$£€₹"
no_raw_budget = {"field": "k:budget_raw"}
has_code = {"field": "k:cur_code", "include": True}
is_def_cur = {"field": "k:cur_code", "text": DEF_CUR_CODE}
not_def_cur = {"field": "k:cur_code", "text": DEF_CUR_CODE, "include": True}
isnt_fixed = {"field": "summary", "text": fixed_text, "include": True}
isnt_hourly = {"field": "summary", "text": hourly_text, "include": True}
no_symbol = {
"field": "k:budget_raw",
"text": codes,
"op": "intersection",
"include": True,
}
code_or_no_raw_budget = [has_code, no_raw_budget]
def_cur_or_no_raw_budget = [is_def_cur, no_raw_budget]
not_def_cur_or_no_raw_budget = [not_def_cur, no_raw_budget]
first_num_rule = {"find": r"\d+", "location": "at"}
last_num_rule = {"find": r"\d+", "location": "at", "param": "last"}
cur_rule = {"find": r"\b[A-Z]{3}\b", "location": "at"}
sym_rule = {"find": "[%s]" % codes, "location": "at"}
# make_regex('k:budget_raw', r'[(),.\s]', ''),
invalid_budgets = [
{"find": "Less than", "replace": "0-"},
{"find": "Under", "replace": "0-"},
{"find": "Upto", "replace": "0-"},
{"find": "or less", "replace": "-0"},
{"find": "k", "replace": "000"},
{"find": "Not Sure", "replace": ""},
{"find": "Not sure", "replace": ""},
{"find": "(", "replace": ""},
{"find": ")", "replace": ""},
{"find": ".", "replace": ""},
{"find": ",", "replace": ""},
{"find": " ", "replace": ""},
]
cur_strreplace_rule = [
{"find": "$", "replace": "USD"},
{"find": "£", "replace": "GBP"},
{"find": "€", "replace": "EUR"},
{"find": "₹", "replace": "INR"},
]
converted_budget_part = [
{"subkey": "k:budget_w_sym"},
{"value": " ("},
{"subkey": "k:budget_converted_w_sym"},
{"value": ")"},
]
def_full_budget_part = {"subkey": "k:budget_w_sym"}
hourly_budget_part = [{"subkey": "k:budget_full"}, {"value": " / hr"}]
exchangerate_conf = {"url": get_path("quote.json")}
native_currencyformat_conf = {"currency": {"subkey": "k:cur_code"}}
def_currencyformat_conf = {"currency": DEF_CUR_CODE}
ave_budget_conf = make_simplemath("k:budget_raw2_num", "mean")
convert_budget_conf = make_simplemath("k:rate", "multiply")
if fixed_text:
source = source.strconcat(
conf={"part": {"value": "fixed"}}, assign="k:job_type", skip_if=isnt_fixed
)
if hourly_text:
source = source.strconcat(
conf={"part": {"value": "hourly"}}, assign="k:job_type", skip_if=isnt_hourly
)
source = source.refind(
conf={"rule": cur_rule},
field="k:budget_raw",
assign="k:cur_code",
skip_if=no_raw_budget,
).strreplace(
conf={"rule": invalid_budgets},
field="k:budget_raw",
assign="k:budget_raw",
skip_if=no_raw_budget,
)
if double:
source = (
source.refind(
conf={"rule": first_num_rule},
field="k:budget_raw",
assign="k:budget_raw_num",
skip_if=no_raw_budget,
)
.refind(
conf={"rule": last_num_rule},
field="k:budget_raw",
assign="k:budget_raw2_num",
skip_if=no_raw_budget,
)
.simplemath(
conf=ave_budget_conf,
field="k:budget_raw_num",
assign="k:budget",
skip_if=no_raw_budget,
)
)
else:
source = source.refind(
conf={"rule": first_num_rule},
field="k:budget_raw",
assign="k:budget",
skip_if=no_raw_budget,
)
source = (
source.refind(
conf={"rule": sym_rule},
field="k:budget_raw",
assign="k:budget_raw_sym",
skip_if=no_symbol,
)
.strreplace(
conf={"rule": cur_strreplace_rule},
field="k:budget_raw_sym",
assign="k:cur_code",
skip_if=code_or_no_raw_budget,
)
.currencyformat(
conf=native_currencyformat_conf,
field="k:budget",
assign="k:budget_w_sym",
skip_if=no_raw_budget,
)
.exchangerate(
conf=exchangerate_conf,
field="k:cur_code",
assign="k:rate",
skip_if=def_cur_or_no_raw_budget,
)
.simplemath(
conf=convert_budget_conf,
field="k:budget",
assign="k:budget_converted",
skip_if=def_cur_or_no_raw_budget,
)
.currencyformat(
conf=def_currencyformat_conf,
field="k:budget_converted",
assign="k:budget_converted_w_sym",
skip_if=def_cur_or_no_raw_budget,
)
.strconcat(
conf={"part": converted_budget_part},
assign="k:budget_full",
skip_if=def_cur_or_no_raw_budget,
)
.strconcat(
conf={"part": def_full_budget_part},
assign="k:budget_full",
skip_if=not_def_cur_or_no_raw_budget,
)
)
if hourly_text:
source = source.strconcat(
conf={"part": hourly_budget_part},
assign="k:budget_full",
skip_if=isnt_hourly,
)
return source
def clean_locations(source):
no_client_loc = {"field": "k:client_location"}
no_work_loc = {"field": "k:work_location"}
rule = {"find": ", ", "replace": ""}
cleaned = source.strreplace(
conf={"rule": rule},
field="k:client_location",
assign="k:client_location",
skip_if=no_client_loc,
).strreplace(
conf={"rule": rule},
field="k:work_location",
assign="k:work_location",
skip_if=no_work_loc,
)
return cleaned
def remove_cruft(source):
remove_rule = [
{"field": "author"},
{"field": "content"},
{"field": "dc:creator"},
{"field": "links"},
{"field": "pubDate"},
{"field": "summary"},
{"field": "updated"},
{"field": "updated_parsed"},
{"field": "y:id"},
{"field": "y:title"},
{"field": "y:published"},
{"field": "k:budget_raw"},
{"field": "k:budget_raw2_num"},
{"field": "k:budget_raw_num"},
{"field": "k:budget_raw_sym"},
]
return source.rename(conf={"rule": remove_rule})
def parse_odesk(source, stream=True):
budget_text = "Budget</b>:"
no_budget = {"field": "summary", "text": budget_text, "include": True}
raw_budget_rule = [{"find": budget_text, "location": "after"}, BR]
title_rule = {"find": "- oDesk"}
find_id_rule = [{"find": "ID</b>:", "location": "after"}, BR]
categ_rule = [{"find": "Category</b>:", "location": "after"}, BR]
skills_rule = [{"find": "Skills</b>:", "location": "after"}, BR]
client_loc_rule = [{"find": "Country</b>:", "location": "after"}, BR]
posted_rule = [{"find": "Posted On</b>:", "location": "after"}, BR]
desc_rule = [{"find": "<p>", "location": "after"}, {"find": "<br><br><b>"}]
source = (
source.strfind(conf={"rule": title_rule}, field="title", assign="title")
.strfind(
conf={"rule": client_loc_rule}, field="summary", assign="k:client_location"
)
.strfind(conf={"rule": desc_rule}, field="summary", assign="description")
.strfind(
conf={"rule": raw_budget_rule},
field="summary",
assign="k:budget_raw",
skip_if=no_budget,
)
)
source = add_source(source)
source = add_posted(source, posted_rule)
source = add_id(source, find_id_rule, field="summary")
source = add_budget(source, budget_text, double=False)
source = add_tags(source, skills_rule)
source = add_tags(source, categ_rule, assign="k:categories")
source = clean_locations(source)
source = remove_cruft(source)
return source.output if stream else source
def parse_guru(source, stream=True):
budget_text = "budget:</b>"
fixed_text = "Fixed Price budget:</b>"
hourly_text = "Hourly budget:</b>"
no_budget = {"field": "summary", "text": budget_text, "include": True}
isnt_hourly = {"field": "summary", "text": hourly_text, "include": True}
raw_budget_rule = [{"find": budget_text, "location": "after"}, BR]
after_hourly = {"rule": {"find": "Rate:", "location": "after"}}
find_id_rule = {"find": "/", "location": "after", "param": "last"}
categ_rule = [{"find": "Category:</b>", "location": "after"}, BR]
skills_rule = [{"find": "Required skills:</b>", "location": "after"}, BR]
job_loc_conf = {
"rule": [{"find": "Freelancer Location:</b>", "location": "after"}, BR]
}
desc_conf = {"rule": [{"find": "Description:</b>", "location": "after"}, BR]}
source = (
source.strfind(conf=job_loc_conf, field="summary", assign="k:work_location")
.strfind(conf=desc_conf, field="summary", assign="description")
.strfind(
conf={"rule": raw_budget_rule},
field="summary",
assign="k:budget_raw",
skip_if=no_budget,
)
.strfind(
conf=after_hourly,
field="k:budget_raw",
assign="k:budget_raw",
skip_if=isnt_hourly,
)
)
kwargs = {"fixed_text": fixed_text, "hourly_text": hourly_text}
source = add_source(source)
source = add_posted(source)
source = add_id(source, find_id_rule)
source = add_budget(source, budget_text, **kwargs)
source = add_tags(source, skills_rule)
source = add_tags(source, categ_rule, assign="k:categories")
source = clean_locations(source)
source = remove_cruft(source)
return source.output if stream else source
def parse_elance(source, stream=True):
budget_text = "Budget:</b>"
fixed_text = "Budget:</b> Fixed Price"
hourly_text = "Budget:</b> Hourly"
no_job_loc = {"field": "summary", "text": "Preferred Job Location", "include": True}
no_client_loc = {"field": "summary", "text": "Client Location", "include": True}
no_budget = {"field": "summary", "text": budget_text, "include": True}
isnt_fixed = {"field": "summary", "text": fixed_text, "include": True}
isnt_hourly = {"field": "summary", "text": hourly_text, "include": True}
raw_budget_rule = [{"find": budget_text, "location": "after"}, BR]
after_hourly = {"rule": {"find": "Hourly", "location": "after"}}
after_fixed = {"rule": {"find": "Fixed Price", "location": "after"}}
title_conf = {"rule": {"find": "| Elance Job"}}
find_id_rule = [
{"find": "/", "param": "last"},
{"find": "/", "location": "after", "param": "last"},
]
categ_rule = [{"find": "Category:</b>", "location": "after"}, BR]
skills_rule = [{"find": "Desired Skills:</b>", "location": "after"}, BR]
job_loc_conf = {
"rule": [{"find": "Preferred Job Location:</b>", "location": "after"}, BR]
}
client_loc_conf = {
"rule": [{"find": "Client Location:</b>", "location": "after"}, BR]
}
desc_rule = [{"find": "<p>", "location": "after"}, {"find": "...\n <br>"}]
proposals_conf = {
"rule": [{"find": "Proposals:</b>", "location": "after"}, {"find": "("}]
}
jobs_posted_conf = {
"rule": [
{"find": "Client:</b> Client (", "location": "after"},
{"find": "jobs posted"},
]
}
jobs_awarded_conf = {
"rule": [{"find": "jobs posted,", "location": "after"}, {"find": "awarded"}]
}
purchased_conf = {
"rule": [
{"find": "total purchased"},
{"find": ",", "location": "after", "param": "last"},
]
}
ends_conf = {
"rule": [
{"find": "Time Left:</b>", "location": "after"},
{"find": ") <br>"},
{"find": "h (Ends", "location": "after"},
]
}
source = (
source.strfind(conf=title_conf, field="title", assign="title")
.strfind(conf=proposals_conf, field="summary", assign="k:submissions")
.strfind(conf=jobs_posted_conf, field="summary", assign="k:num_jobs")
.strfind(conf=jobs_awarded_conf, field="summary", assign="k:per_awarded")
.strfind(conf=purchased_conf, field="summary", assign="k:tot_purchased")
.strfind(conf=ends_conf, field="summary", assign="k:due")
.strfind(
conf=job_loc_conf,
field="summary",
assign="k:work_location",
skip_if=no_job_loc,
)
.strfind(
conf=client_loc_conf,
field="summary",
assign="k:client_location",
skip_if=no_client_loc,
)
.strfind(conf={"rule": desc_rule}, field="summary", assign="description")
.strfind(
conf={"rule": raw_budget_rule},
field="summary",
assign="k:budget_raw",
skip_if=no_budget,
)
.strfind(
conf=after_hourly,
field="k:budget_raw",
assign="k:budget_raw",
skip_if=isnt_hourly,
)
.strfind(
conf=after_fixed,
field="k:budget_raw",
assign="k:budget_raw",
skip_if=isnt_fixed,
)
)
kwargs = {"fixed_text": fixed_text, "hourly_text": hourly_text}
source = add_source(source)
source = add_posted(source)
source = add_id(source, find_id_rule)
source = add_budget(source, budget_text, **kwargs)
source = add_tags(source, skills_rule)
source = add_tags(source, categ_rule, assign="k:categories")
source = clean_locations(source)
source = remove_cruft(source)
return source.output if stream else source
def parse_freelancer(source, stream=True):
budget_text = "(Budget:"
no_budget = {"field": "summary", "text": budget_text, "include": True}
raw_budget_rule = [{"find": budget_text, "location": "after"}, {"find": ","}]
title_rule = {"find": " by "}
skills_rule = [{"find": ", Jobs:", "location": "after"}, {"find": ")</p>"}]
desc_rule = [{"find": "<p>", "location": "after"}, {"find": "(Budget:"}]
source = (
source.strfind(conf={"rule": title_rule}, field="title", assign="title")
.strfind(conf={"rule": desc_rule}, field="summary", assign="description")
.strfind(
conf={"rule": raw_budget_rule},
field="summary",
assign="k:budget_raw",
skip_if=no_budget,
)
)
source = add_source(source)
source = add_posted(source)
source = add_budget(source, budget_text)
source = add_tags(source, skills_rule)
source = clean_locations(source)
source = remove_cruft(source)
return source.output if stream else source
def pipe(test=False, parallel=False, threads=False):
kwargs = {"parallel": parallel, "threads": threads}
Pipe = partial(SyncPipe, "fetchdata", **kwargs)
odesk_source = Pipe(conf=odesk_conf)
guru_source = Pipe(conf=guru_conf)
freelancer_source = Pipe(conf=freelancer_conf)
elance_source = Pipe(conf=elance_conf)
# odesk_source = SyncPipe('fetchdata', conf=odesk_conf, **kwargs)
# guru_source = SyncPipe('fetchdata', conf=guru_conf, **kwargs)
# elance_source = SyncPipe('fetchdata', conf=elance_conf, **kwargs)
# freelancer_source = SyncPipe('fetchdata', conf=freelancer_conf, **kwargs)
odesk_pipe = parse_odesk(odesk_source, stream=False)
guru_stream = parse_guru(guru_source)
elance_stream = parse_elance(elance_source)
freelancer_stream = parse_freelancer(freelancer_source)
others = [guru_stream, freelancer_stream, elance_stream]
stream = odesk_pipe.union(others=others).list
pprint(stream[-1])
return stream
@coroutine
def async_pipe(reactor, test=None):
Pipe = partial(AsyncPipe, "fetchdata")
odesk_source = Pipe(conf=odesk_conf)
guru_source = Pipe(conf=guru_conf)
freelancer_source = Pipe(conf=freelancer_conf)
elance_source = Pipe(conf=elance_conf)
odesk_pipe = yield parse_odesk(odesk_source, stream=False)
guru_stream = yield parse_guru(guru_source)
elance_stream = yield parse_elance(elance_source)
freelancer_stream = yield parse_freelancer(freelancer_source)
others = [guru_stream, freelancer_stream, elance_stream]
stream = odesk_pipe.union(others=others).list
pprint(stream[-1]) | /riko-0.67.0.tar.gz/riko-0.67.0/examples/kazeeki.py | 0.404743 | 0.232033 | kazeeki.py | pypi |
from typing import List, Tuple
from uk_covid19 import Cov19API
def parse_csv_data(csv_filename: str) -> List[str]:
"""Returns a list of strings of the lines in the given csv file"""
with open(csv_filename, 'r', encoding='utf-8') as csv_file:
data = [line.strip() for line in csv_file]
return data
def process_covid_csv_data(row_list: List[str]) -> Tuple[int, int, int]:
"""Returns covid data based on a list of strings representing rows from a csv file"""
# Split each row in the list into a list of the values that were comma separated
data = list(map(lambda row: row.split(","), row_list))
# The first row contains the headers. The second row is empty and the third has incomplete data
data_from_last_7_days = data[3:10]
data_from_last_7_days = list(map(lambda column: column[6], data_from_last_7_days))
data_from_last_7_days = list(map(int, data_from_last_7_days))
cases_in_last_7_days = sum(data_from_last_7_days)
current_hospital_cases = int(data[1][5])
for row in data[1:]:
if row[4] != "":
total_deaths = int(row[4])
break
return (cases_in_last_7_days, current_hospital_cases, total_deaths)
def covid_api_request(location: str="Exeter", location_type: str="ltla") -> dict:
"""Proforms a covid api request.
Uses the given location parameters and returns the resulting data structure.
"""
api = Cov19API(
filters=[
"areaType=" + location_type,
"areaName=" + location
],
structure={
"date": "date",
"newCasesByPublishDate": "newCasesByPublishDate",
"cumCasesByPublishDate": "cumCasesByPublishDate",
"hospitalCases": "hospitalCases",
"newCasesBySpecimenDate": "newCasesBySpecimenDate",
"cumDeaths28DaysByDeathDate": "cumDeaths28DaysByDeathDate",
"newCasesByPublishDateRollingSum": "newCasesByPublishDateRollingSum"
}
)
# For some reason this returns a dict NOT json
data = api.get_json()
return data | /rillian_grant_university_project_covid19_dashboard-1.0.2-py3-none-any.whl/covid19_dashboard/covid_data_handler.py | 0.834643 | 0.527925 | covid_data_handler.py | pypi |
from typing import List, Tuple
from uk_covid19 import Cov19API
def parse_csv_data(csv_filename: str) -> List[str]:
"""Returns a list of strings of the lines in the given csv file"""
with open(csv_filename, 'r', encoding='utf-8') as csv_file:
data = [line.strip() for line in csv_file]
return data
def process_covid_csv_data(row_list: List[str]) -> Tuple[int, int, int]:
"""Returns covid data based on a list of strings representing rows from a csv file"""
# Split each row in the list into a list of the values that were comma separated
data = list(map(lambda row: row.split(","), row_list))
# The first row contains the headers. The second row is empty and the third has incomplete data
data_from_last_7_days = data[3:10]
data_from_last_7_days = list(map(lambda column: column[6], data_from_last_7_days))
data_from_last_7_days = list(map(int, data_from_last_7_days))
cases_in_last_7_days = sum(data_from_last_7_days)
current_hospital_cases = int(data[1][5])
for row in data[1:]:
if row[4] != "":
total_deaths = int(row[4])
break
return (cases_in_last_7_days, current_hospital_cases, total_deaths)
def covid_api_request(location: str="Exeter", location_type: str="ltla") -> dict:
"""Proforms a covid api request with the given location parameters and returns the resulting data structure"""
api = Cov19API(
filters=[
"areaType=" + location_type,
"areaName=" + location
],
structure={
"date": "date",
"newCasesByPublishDate": "newCasesByPublishDate",
"cumCasesByPublishDate": "cumCasesByPublishDate",
"hospitalCases": "hospitalCases",
"newCasesBySpecimenDate": "newCasesBySpecimenDate",
"cumDeaths28DaysByDeathDate": "cumDeaths28DaysByDeathDate",
"newCasesByPublishDateRollingSum": "newCasesByPublishDateRollingSum"
}
)
# For some reason this returns a dict NOT json
data = api.get_json()
return data | /rillian_grant_university_project_covid19_dashboard-1.0.2-py3-none-any.whl/dashboard/covid_data_handler.py | 0.83363 | 0.527195 | covid_data_handler.py | pypi |
import math
from random import Random
import time
from sklearn.base import BaseEstimator
from sympy import *
from .node import Node
from .rils_rols import RILSROLSRegressor, FitnessType
from joblib import Parallel, delayed
import warnings
from .solution import Solution
warnings.filterwarnings("ignore")
class RILSROLSEnsembleRegressor(BaseEstimator):
def __init__(self, max_fit_calls=100000, max_seconds=100, fitness_type=FitnessType.PENALTY, complexity_penalty=0.001, initial_sample_size=0.01, parallelism = 8, verbose=False, random_state=0):
self.max_seconds = max_seconds
self.max_fit_calls = max_fit_calls
self.complexity_penalty = complexity_penalty
self.random_state = random_state
self.parallelism = parallelism
self.verbose = verbose
self.fitness_type = fitness_type
self.initial_sample_size = initial_sample_size
rg = Random(random_state)
random_states = [rg.randint(10000, 99999) for i in range(self.parallelism)]
self.base_regressors = [RILSROLSRegressor(max_fit_calls=max_fit_calls, max_seconds=max_seconds, fitness_type=fitness_type,
complexity_penalty=complexity_penalty, initial_sample_size=initial_sample_size,
random_perturbations_order=True, verbose=verbose, random_state=random_states[i])
for i in range(len(random_states))]
def fit(self, X, y):
self.start = time.time()
# now run each base regressor (RILSROLSRegressor) as a separate process
results = Parallel(n_jobs=len(self.base_regressors))(delayed(reg.fit)(X, y) for reg in self.base_regressors)
print("All regressors have finished now")
best_model, best_model_simp = results[0]
best_fit = best_model.fitness(X, y, False)
for model, model_simp in results:
model_fit = model.fitness(X,y, False)
if self.base_regressors[0].compare_fitness(model_fit, best_fit)<0:
best_fit = model_fit
best_model = model
best_model_simp = model_simp
print('Model '+str(model)+'\t'+str(model_fit))
self.time_elapsed = time.time()-self.start
self.model = best_model
self.model_simp = best_model_simp
print('Best simplified model is '+str(self.model_simp) + ' with '+str(best_fit))
def predict(self, X):
Node.reset_node_value_cache()
return self.model.evaluate_all(X, False)
def size(self):
if self.model is not None:
return self.model.size()
return math.inf
def modelString(self):
if self.model_simp is not None:
return str(self.model_simp)
return ""
def fit_report_string(self, X, y):
if self.model==None:
raise Exception("Model is not build yet. First call fit().")
fitness = self.model.fitness(X,y, False)
return "maxTime={0}\tmaxFitCalls={1}\tseed={2}\tsizePenalty={3}\tR2={4:.7f}\tRMSE={5:.7f}\tsize={6}\tsec={7:.1f}\texpr={8}\texprSimp={9}\fitType={10}\tinitSampleSize={11}".format(
self.max_seconds,self.max_fit_calls,self.random_state,self.complexity_penalty, 1-fitness[0], fitness[1], self.complexity(), self.time_elapsed, self.model, self.model_simp, self.fitness_type, self.initial_sample_size)
def complexity(self):
c=0
for arg in preorder_traversal(self.model_simp):
c += 1
return c | /rils-rols-1.2.tar.gz/rils-rols-1.2/rils_rols/rils_rols_ensemble.py | 0.592313 | 0.218732 | rils_rols_ensemble.py | pypi |
import math
import matplotlib.pyplot as plt
from .Generaldistribution import Distribution
class Gaussian(Distribution):
""" Gaussian distribution class for calculating and
visualizing a Gaussian distribution.
Attributes:
mean (float) representing the mean value of the distribution
stdev (float) representing the standard deviation of the distribution
data_list (list of floats) a list of floats extracted from the data file
"""
def __init__(self, mu=0, sigma=1):
Distribution.__init__(self, mu, sigma)
def calculate_mean(self):
"""Function to calculate the mean of the data set.
Args:
None
Returns:
float: mean of the data set
"""
avg = 1.0 * sum(self.data) / len(self.data)
self.mean = avg
return self.mean
def calculate_stdev(self, sample=True):
"""Function to calculate the standard deviation of the data set.
Args:
sample (bool): whether the data represents a sample or population
Returns:
float: standard deviation of the data set
"""
if sample:
n = len(self.data) - 1
else:
n = len(self.data)
mean = self.calculate_mean()
sigma = 0
for d in self.data:
sigma += (d - mean) ** 2
sigma = math.sqrt(sigma / n)
self.stdev = sigma
return self.stdev
def plot_histogram(self):
"""Function to output a histogram of the instance variable data using
matplotlib pyplot library.
Args:
None
Returns:
None
"""
plt.hist(self.data)
plt.title('Histogram of Data')
plt.xlabel('data')
plt.ylabel('count')
def pdf(self, x):
"""Probability density function calculator for the gaussian distribution.
Args:
x (float): point for calculating the probability density function
Returns:
float: probability density function output
"""
return (1.0 / (self.stdev * math.sqrt(2*math.pi))) * math.exp(-0.5*((x - self.mean) / self.stdev) ** 2)
def plot_histogram_pdf(self, n_spaces = 50):
"""Function to plot the normalized histogram of the data and a plot of the
probability density function along the same range
Args:
n_spaces (int): number of data points
Returns:
list: x values for the pdf plot
list: y values for the pdf plot
"""
mu = self.mean
sigma = self.stdev
min_range = min(self.data)
max_range = max(self.data)
# calculates the interval between x values
interval = 1.0 * (max_range - min_range) / n_spaces
x = []
y = []
# calculate the x values to visualize
for i in range(n_spaces):
tmp = min_range + interval*i
x.append(tmp)
y.append(self.pdf(tmp))
# make the plots
fig, axes = plt.subplots(2,sharex=True)
fig.subplots_adjust(hspace=.5)
axes[0].hist(self.data, density=True)
axes[0].set_title('Normed Histogram of Data')
axes[0].set_ylabel('Density')
axes[1].plot(x, y)
axes[1].set_title('Normal Distribution for \n Sample Mean and Sample Standard Deviation')
axes[0].set_ylabel('Density')
plt.show()
return x, y
def __add__(self, other):
"""Function to add together two Gaussian distributions
Args:
other (Gaussian): Gaussian instance
Returns:
Gaussian: Gaussian distribution
"""
result = Gaussian()
result.mean = self.mean + other.mean
result.stdev = math.sqrt(self.stdev ** 2 + other.stdev ** 2)
return result
def __repr__(self):
"""Function to output the characteristics of the Gaussian instance
Args:
None
Returns:
string: characteristics of the Gaussian
"""
return "mean {}, standard deviation {}".format(self.mean, self.stdev) | /rim_prob_dist-0.1.tar.gz/rim_prob_dist-0.1/rim_prob_dist/Gaussiandistribution.py | 0.688364 | 0.853058 | Gaussiandistribution.py | pypi |
import warnings
class Decorators(object):
__warning_header = 'Decorator Warning: '
__warning_messages = {
'not_valid_column': 'Some columns names are not in the related '
'dataframe.',
'invalid_types': 'Not valid types.'
}
@classmethod
def __launch_warning(cls, warning_type):
warnings.warn(
cls.__warning_header +
cls.__warning_messages[warning_type]
)
@classmethod
def __validate_columns_list(cls, df, columns_list):
for c in columns_list:
if c not in df.columns.values:
return False
return True
@classmethod
def __get_param_from_arguments(cls, i, args, kwargs):
if i < len(args):
return args[i]
else:
kwargs_as_list = list(kwargs.items())
return kwargs_as_list[i-len(args)][1]
@classmethod
def validate_columns(cls, df_arg_pos, column_arg_pos):
def validate_column_generator(function_to_decorate):
def inner_function(*args, **kwargs):
df_to_validate = \
cls.__get_param_from_arguments(df_arg_pos, args, kwargs)
columns_to_validate = \
cls.__get_param_from_arguments(column_arg_pos, args, kwargs)
if isinstance(columns_to_validate, str):
if columns_to_validate in df_to_validate.columns.values:
return function_to_decorate(*args, **kwargs)
else:
cls.__launch_warning('not_valid_column')
return df_to_validate
elif isinstance(columns_to_validate, list):
if cls.__validate_columns_list(df_to_validate,
columns_to_validate):
return function_to_decorate(*args, **kwargs)
else:
cls.__launch_warning('not_valid_column')
return df_to_validate
else:
cls.__launch_warning('invalid_types')
return function_to_decorate(*args, **kwargs)
return inner_function
return validate_column_generator | /rimac-analytics-0.5.2.tar.gz/rimac-analytics-0.5.2/rimac_analytics/decorators/decorators.py | 0.493409 | 0.300002 | decorators.py | pypi |
from datetime import datetime
import pandas as pd
class FormatUtils(object):
__str_date_format = '%d/%m/%Y'
__dict_datetimes = {}
__dict_dateints = {}
@classmethod
def get_year(cls, period):
return period // 100
@classmethod
def get_month(cls, period):
return period % 100
@classmethod
def gap_in_months_for_periods(cls, period_1, period_2):
year_1 = cls.get_year(period_1)
year_2 = cls.get_year(period_2)
month_1 = cls.get_month(period_1)
month_2 = cls.get_month(period_2)
if year_1 == year_2:
basic_difference = abs(month_1 - month_2) - 1
if basic_difference < 0:
basic_difference = 0
return basic_difference
elif year_1 > year_2:
greater_year_dif = month_1
smaller_year_dif = 12 - month_2
basic_difference = greater_year_dif + smaller_year_dif
additional_months_difference = (year_1 - year_2 - 1) * 12
return basic_difference + additional_months_difference - 1
elif year_1 < year_2:
greater_year_dif = month_2
smaller_year_dif = 12 - month_1
basic_difference = greater_year_dif + smaller_year_dif
additional_months_difference = (year_2 - year_1 - 1) * 12
return basic_difference + additional_months_difference - 1
@classmethod
def get_difference_in_months(cls, datetime1, datetime2):
difference = datetime1 - datetime2
difference = abs(difference)
return difference.days//30
@classmethod
def format_date_into_integer(cls, raw_date):
if raw_date in cls.__dict_dateints:
return cls.__dict_dateints[raw_date]
else:
datetime_obj = datetime.strptime(raw_date, cls.__str_date_format)
if datetime_obj.month > 9:
current_month = datetime_obj.month
else:
current_month = '0'+str(datetime_obj.month)
formatted_date = '{year}{month}'.format(year=datetime_obj.year,
month=current_month)
integer_date = int(formatted_date)
cls.__dict_dateints[raw_date] = integer_date
return integer_date
@classmethod
def get_datetime(cls, raw_date):
if raw_date in cls.__dict_datetimes:
return cls.__dict_datetimes[raw_date]
else:
new_datetime = datetime.strptime(raw_date, cls.__str_date_format)
cls.__dict_datetimes[raw_date] = new_datetime
return new_datetime
@classmethod
def format_series_string_into_datetime(cls, string_series, format=None,
dayfirst=True):
"""
Return a datetime series or string formated by a pattern.
string_series: (str,series) Object to convert.
format: (str pattern) Format of the object.
dayfirst: Should the string_series have the day first ?
"""
if isinstance(string_series, str):
if len(string_series) == 6:
string_series = str(string_series) + '01'
return pd.to_datetime(string_series, format=format,
dayfirst=dayfirst)
else:
if len(string_series[0]) == 6:
string_series = string_series.map(lambda x: str(x) + '01')
dates = \
{date: pd.to_datetime(date, format=format, dayfirst=dayfirst)
for date in string_series.unique()}
return string_series.map(dates) | /rimac-analytics-0.5.2.tar.gz/rimac-analytics-0.5.2/rimac_analytics/utils/format_utils.py | 0.834677 | 0.353121 | format_utils.py | pypi |
import atexit
from pathlib import Path
from typing import List, Optional, Union
from urllib3.util import Retry
from rime_sdk.client import RETRY_HTTP_STATUS
from rime_sdk.internal.file_upload import GenerativeFirewallFileUploader
from rime_sdk.internal.rest_error_handler import RESTErrorHandler
from rime_sdk.swagger.swagger_client import (
ApiClient,
Configuration,
FirewallApi,
FirewallConfigurationApi,
GenerativefirewallFirewallRuleConfig,
GenerativefirewallValidateRequest,
ValidateRequestInput,
ValidateRequestOutput,
)
_DEFAULT_CHANNEL_TIMEOUT = 60.0
class GenerativeFirewall:
"""An interface to a Generative Firewall object.
To initialize the GenerativeFirewall, provide the address of your RIME instance.
Args:
domain: str
The base domain/address of the RIME service.
api_key: str
The API key used to authenticate to RIME services.
channel_timeout: float
The amount of time in seconds to wait for responses from the cluster.
Example:
.. code-block:: python
firewall = GenerativeFirewall("my_vpc.rime.com", "api-key")
"""
def __init__(
self,
domain: str,
api_key: str = "",
channel_timeout: float = _DEFAULT_CHANNEL_TIMEOUT,
):
"""Create a new Client connected to the services available at `domain`."""
configuration = Configuration()
configuration.api_key["X-Firewall-Api-Key"] = api_key
if domain.endswith("/"):
domain = domain[:-1]
if not domain.startswith("https://") and not domain.startswith("http://"):
domain = "https://" + domain
configuration.host = domain
self._api_client = ApiClient(configuration)
# Prevent race condition in pool.close() triggered by swagger generated code
atexit.register(self._api_client.pool.close)
# Sets the timeout and hardcoded retries parameter for the api client.
self._api_client.rest_client.pool_manager.connection_pool_kw[
"timeout"
] = channel_timeout
self._api_client.rest_client.pool_manager.connection_pool_kw["retries"] = Retry(
total=3, status_forcelist=RETRY_HTTP_STATUS
)
self._firewall_client = FirewallApi(self._api_client)
self._configuration_client = FirewallConfigurationApi(self._api_client)
def validate(
self, input: Optional[str] = None, output: Optional[str] = None
) -> List[dict]:
"""Validate model input and/or output text.
Args:
input: Optional[str]
The user input text to validate.
output: Optional[str]
The model output text to validate.
Returns:
List[dict]:
A list of validation results, each of which is a dictionary of rule
results for the input or output text.
Raises:
ValueError:
If neither input nor output text is provided or when there was an error
in the validation request to the RIME backend.
Example:
.. code-block:: python
results = firewall.validate(
input="Hello!", output="Hi, how can I help you?"
)
"""
if input is None and output is None:
raise ValueError("Must provide either input or output text to validate.")
body = GenerativefirewallValidateRequest(
input=ValidateRequestInput(user_input_text=input),
output=ValidateRequestOutput(output_text=output),
)
with RESTErrorHandler():
response = self._firewall_client.firewall_validate(body=body)
return [res.to_dict() for res in response.results]
def upload_file(self, file_path: Union[Path, str]) -> str:
"""Upload a file to make it accessible to the RIME cluster.
The uploaded file is stored in the RIME cluster in a blob store
using its file name.
Args:
file_path: Union[Path, str]
Path to the file to be uploaded to RIME's blob store.
Returns:
str:
A reference to the uploaded file's location in the blob store. This
reference can be used to refer to that object when writing RIME configs.
Please store this reference for future access to the file.
Raises:
FileNotFoundError
When the path ``file_path`` does not exist.
IOError
When ``file_path`` is not a file.
ValueError
When there was an error in obtaining a blobstore location from the
RIME backend or in uploading ``file_path`` to RIME's blob store.
When the file upload fails, the incomplete file is
NOT automatically deleted.
Example:
.. code-block:: python
uploaded_file_path = firewall.upload_file(file_path)
"""
if isinstance(file_path, str):
file_path = Path(file_path)
with RESTErrorHandler():
file_uploader = GenerativeFirewallFileUploader(self._api_client)
return file_uploader.upload_file(file_path)
def update_config(self, firewall_config: dict) -> dict:
"""Update the firewall configuration.
The update is performed via a PATCH request by merging the provided
`firewall_config` with the existing config, meaning that any fields not
explicitly provided in `firewall_config` will not be overwritten.
Args:
firewall_config: dict
A dictionary containing the firewall configuration components to update.
Returns:
dict:
The updated firewall configuration.
Raises:
ValueError:
If `firewall_config` is empty or contains unexpected keys, or when there
was an error in the update request to the RIME backend.
Example:
.. code-block:: python
updated_config = firewall.update_config(firewall_config)
"""
_config = firewall_config.copy()
body = GenerativefirewallFirewallRuleConfig(
fact_sheet_url=_config.pop("fact_sheet_url", None),
sensitive_terms_url=_config.pop("sensitive_terms_url", None),
allowed_topics=_config.pop("allowed_topics", None),
)
if _config:
raise ValueError(
"Found unexpected keys in firewall_config: " f"{list(_config.keys())}"
)
if all(val is None for val in body.to_dict().values()):
raise ValueError("Must provide a non-empty firewall_config to update.")
with RESTErrorHandler():
response = (
self._configuration_client.firewall_configuration_configure_firewall(
body
)
)
return response.config.to_dict() | /rime_sdk-2.3.0rc5.tar.gz/rime_sdk-2.3.0rc5/rime_sdk/generative_firewall.py | 0.874064 | 0.184841 | generative_firewall.py | pypi |
from datetime import datetime, timedelta
from typing import Any, Dict, List, Optional, TypeVar
from google.protobuf.json_format import MessageToDict
from google.protobuf.timestamp_pb2 import Timestamp
from rime_sdk.swagger.swagger_client import RimeUUID
def swagger_is_empty(swagger_val: Any) -> bool:
"""Check if a swagger object is empty."""
return not bool(swagger_val)
TYPE_KEY = "enum_type"
PROTO_FIELD_KEY = "proto_field"
PROTO_TYPE_KEY = "proto_type"
BASE_TYPES = ["str", "float", "int", "bool"]
T = TypeVar("T")
def parse_dict_to_swagger(obj_dict: Optional[Dict], new_obj: T) -> T:
"""Parse non-nested dicts into a new object."""
if obj_dict:
for key, value in obj_dict.items():
setattr(new_obj, key, value)
return new_obj
def parse_str_to_uuid(uuid_str: Optional[str]) -> Optional[RimeUUID]:
"""Parse a string into a RimeUUID."""
if uuid_str:
return RimeUUID(uuid_str)
return None
def serialize_datetime_to_proto_timestamp(date: datetime) -> Dict:
"""Convert datetime to swagger compatible grpc timestamp."""
timestamp = Timestamp()
timestamp.FromDatetime(date)
# Swagger serialize datetime to iso8601 format, convert to
# protobuf compatible serialization
return MessageToDict(timestamp)
def rest_to_timedelta(delta: str) -> timedelta:
"""Convert a REST API compatible string to a time delta."""
# REST API returns a string in seconds; e.g. one day is represented as "86400s"
return timedelta(seconds=int(delta[:-1]))
def timedelta_to_rest(delta: timedelta) -> str:
"""Convert a time delta to a REST API compatible string."""
return f"{int(delta.total_seconds())}s"
def select_oneof(oneof_map: Dict[str, Any], key_list: List[str]) -> Any:
"""Select one of the keys in the map.
Args:
oneof_map: The map to select from.
key_list: The list of keys to select from.
Returns:
The key that was selected.
Raises:
ValueError
When more than one of the keys are provided in the map.
"""
selected_key = None
for key in key_list:
if key in oneof_map:
if selected_key is not None:
raise ValueError(
f"More than one of the keys {key_list} were provided in the map."
)
selected_key = key
if selected_key is None:
raise ValueError(f"None of the keys {key_list} were provided in the map.")
return selected_key | /rime_sdk-2.3.0rc5.tar.gz/rime_sdk-2.3.0rc5/rime_sdk/internal/swagger_utils.py | 0.91463 | 0.234013 | swagger_utils.py | pypi |
from html import escape
from typing import Any, Dict, List, Optional, Sequence
from google.protobuf.field_mask_pb2 import FieldMask
from google.protobuf.json_format import MessageToDict
HEADER_TMPL = "<th>{0}</th>"
DATA_TMPL = "<td>{0}</td>"
ROW_TMPL = "<tr>{0}</tr>"
TABLE_TMPL = '<table style="width:100%">{0}</table>'
def make_link(link: str, link_text: Optional[str] = None) -> str:
"""Make the HTML link."""
if not link_text:
link_text = "Link"
return f'<a href="{link}" target="_blank" rel="noopener">{escape(link_text)}</a>'
def get_header_row_string(column_headers: Sequence[str]) -> str:
"""Return the table header row as a sring."""
headers = [HEADER_TMPL.format(header) for header in column_headers]
return ROW_TMPL.format("".join(headers))
def get_data_row_string(data_values: Sequence[str]) -> str:
"""Return a table data row as a string."""
data = [DATA_TMPL.format(datum) for datum in data_values]
return ROW_TMPL.format("".join(data))
def convert_dict_to_html(table_dict: Dict[str, str]) -> str:
"""Convert a dictionary to an HTML table."""
if len(table_dict) == 0:
return ""
all_rows = [
get_header_row_string(list(table_dict)),
get_data_row_string(list(table_dict.values())),
]
return TABLE_TMPL.format("".join(all_rows))
def assert_and_get_none_or_all_none(*args: Optional[Any]) -> bool:
"""Check that all arguments are None or all are not None.
Args:
*args: Arguments to check.
Returns:
True if all arguments are not None, False if all are None.
Raises:
ValueError
When some arguments are None and some are not.
"""
if all(arg is None for arg in args):
return False
elif all(arg is not None for arg in args):
return True
else:
raise ValueError(f"All arguments {args} must be None or all must be not None.")
def _get_field_mask_paths(v: Any, path_elements: List[str]) -> List[str]:
"""Get the field mask paths for a swagger object where the values are non-null."""
if v is None:
return []
if not isinstance(v, dict):
return [".".join(path_elements)]
mask_paths = []
for key, val in v.items():
mask_paths += _get_field_mask_paths(val, path_elements + [key])
return mask_paths
def get_swagger_field_mask(swagger_object: Any) -> dict:
"""Get a field mask for a swagger object that recursively masks non-null fields."""
mask_paths = _get_field_mask_paths(swagger_object.to_dict(), [])
mask = FieldMask(paths=mask_paths)
serialized_mask = MessageToDict(mask)
return serialized_mask | /rime_sdk-2.3.0rc5.tar.gz/rime_sdk-2.3.0rc5/rime_sdk/internal/utils.py | 0.900513 | 0.24987 | utils.py | pypi |
import re
from typing import Any, Dict, List, Union
import numpy as np
import pandas as pd
from rime_sdk.swagger.swagger_client.models import (
RimeCategoryTestResult,
TestrunresultTestBatchResult,
TestrunresultTestCase,
TestrunresultTestRunDetail,
)
from rime_sdk.swagger.swagger_client.models.detection_detection_event import (
DetectionDetectionEvent,
)
MODEL_PERF_REGEX = r"^metrics\.model_perf.*(ref_metric|eval_metric)$"
# Map of flattened field paths to their types in the Dataframe.
DEFAULT_TEST_RUN_COLUMN_INFO = {
# Metadata.
"test_run_id": "str",
"name": "str",
"project_id": "str",
"model_task": "str", # OPTIONAL
# The canonical JSON encoding converts enums to their string representations
# so we do not need to do manual conversions.
"testing_type": "str",
"upload_time": "str",
# Metrics.
"metrics.duration_millis": "Int64",
"metrics.num_inputs": "Int64",
"metrics.num_failing_inputs": "Int64",
"metrics.summary_counts.total": "Int64",
"metrics.summary_counts._pass": "Int64",
"metrics.summary_counts.warning": "Int64",
"metrics.summary_counts.fail": "Int64",
"metrics.summary_counts.skip": "Int64",
"metrics.severity_counts.num_none_severity": "Int64",
"metrics.severity_counts.num_low_severity": "Int64",
"metrics.severity_counts.num_high_severity": "Int64",
}
# List of all the columns to hide for a summary test DF.
SUMMARY_TEST_KEYS_TO_HIDE = [
"category_metrics",
"description",
"duration",
"suggestion",
]
# List of all the columns to hide for a test batch DF.
TEST_BATCH_KEYS_TO_HIDE = [
"show_in_test_comparisons",
"failing_rows_result",
"display",
]
# List of all the columns to hide for a Test Case DF.
TEST_CASE_KEYS_TO_HIDE = [
"display",
"url_safe_feature_id",
"test_case_id",
]
# TestBatchResult columns that need to be converted from string to int64
INT_TEST_BATCH_ATTRIBUTES = [
"duration_in_millis",
"summary_counts.total",
"summary_counts.warning",
"summary_counts._pass",
"summary_counts.fail",
"summary_counts.skip",
]
# Separator to use when flattening JSON into a dataframe.
# columns_to_keep definition relies on this separator.
DF_FLATTEN_SEPARATOR = "."
DATA_OPTIONS = [
"float_value",
"int_value",
"str_value",
"float_list",
"int_list",
"str_list",
]
EVENT_COLUMNS_TO_SHOW = [
"project_id",
"event_type",
"severity",
"event_object_name",
"event_object_id",
"risk_category_type",
"test_category",
"event_time_range.start_time",
"event_time_range.end_time",
"description",
"detail.metric_degradation.rca_result.description",
]
def _flatten_uuid_field_name(field_name: str) -> str:
"""Flatten a UUID field name."""
match = re.match(r"(.*)\.uuid$", field_name)
if match is None:
return field_name
return match.groups()[0]
def parse_test_run_metadata(test_run: TestrunresultTestRunDetail) -> pd.DataFrame:
"""Parse test run metadata Swagger message into a Pandas dataframe.
The columns are not guaranteed to be returned in sorted order.
Some values are optional and will appear as a NaN value in the dataframe.
"""
# Use the canonical JSON encoding for Protobuf messages.
test_run_dict = test_run.to_dict()
# Flatten out nested fields in the Protobuf message.
# The DF column name will be the field path joined by the `df_flatten_separator.`
normalized_df = pd.json_normalize(test_run_dict, sep=DF_FLATTEN_SEPARATOR)
normalized_df = normalized_df.rename(_flatten_uuid_field_name, axis="columns")
default_test_run_columns = list(DEFAULT_TEST_RUN_COLUMN_INFO.keys())
# Include the model perf columns with the set of DF columns.
# These are metrics like "Accuracy" over the reference and eval datasets.
model_perf_columns = [c for c in normalized_df if re.match(MODEL_PERF_REGEX, c)]
all_test_run_columns = default_test_run_columns + model_perf_columns
missing_columns = set(all_test_run_columns).difference(set(normalized_df.columns))
intersect_df = normalized_df[
normalized_df.columns.intersection(all_test_run_columns)
]
# Fill in the missing columns with None values.
kwargs: Dict[str, None] = {}
for column in missing_columns:
kwargs[column] = None
# Note that this step does not preserve column order.
full_df = intersect_df.assign(**kwargs)
# The canonical Protobuf<>JSON encoding converts int64 values to string,
# so we need to convert them back.
# https://developers.google.com/protocol-buffers/docs/proto3#json
# Note the type of all model perf metrics should be float64 so we do not have
# to do this conversion.
for key, value in DEFAULT_TEST_RUN_COLUMN_INFO.items():
if value == "Int64":
# Some nested fields such as `metrics.severity_counts.low` will be `None`
# because MessageToDict does not populate nested primitive fields with
# default values.
# Since some columns may be `None`, we must convert to `float` first.
# https://stackoverflow.com/questions/60024262/error-converting-object-string-to-int32-typeerror-object-cannot-be-converted
full_df[key] = full_df[key].astype("float").astype("Int64")
# Fix an order for the index of the df.
non_default_cols = list(
set(all_test_run_columns).difference(set(default_test_run_columns))
)
ordered_index = pd.Index(default_test_run_columns + sorted(non_default_cols))
return full_df.reindex(ordered_index, axis=1)
def parse_test_batch_result(
raw_result: TestrunresultTestBatchResult,
unpack_metrics: bool = False,
) -> pd.Series:
"""Parse test batch result into a series."""
result_dict = raw_result.to_dict()
del result_dict["metrics"]
if unpack_metrics:
_add_metric_cols(result_dict, raw_result)
# Note: some keys may be missing for nested singular messages, so we do
# a safe delete here.
for key in TEST_BATCH_KEYS_TO_HIDE:
result_dict.pop(key, None)
df = pd.json_normalize(result_dict, sep=DF_FLATTEN_SEPARATOR)
for key in INT_TEST_BATCH_ATTRIBUTES:
# Some nested fields such as `metrics.severity_counts.low` will be `None`
# because MessageToDict does not populate nested primitive fields with
# default values.
# Since some columns may be `None`, we must convert to `float` first.
# https://stackoverflow.com/questions/60024262/error-converting-object-string-to-int32-typeerror-object-cannot-be-converted
df[key] = df[key].astype("float").astype("Int64")
return df.squeeze(axis=0)
def parse_test_case_result(
raw_result: TestrunresultTestCase, unpack_metrics: bool = False
) -> dict:
"""Parse swagger Test Case result to pythonic form."""
result_dict = raw_result.to_dict()
del result_dict["metrics"]
if unpack_metrics:
_add_metric_cols(result_dict, raw_result)
# Drop the keys to hide if they are specified.
# Note: some keys may be missing for nested singular messages, so we do
# a safe delete here.
for key in TEST_CASE_KEYS_TO_HIDE:
result_dict.pop(key, None)
return result_dict
def _add_metric_cols(
result_dict: dict,
raw_result: Union[TestrunresultTestCase, TestrunresultTestBatchResult],
) -> None:
"""Unpack test metrics into separate fields."""
if raw_result.metrics:
for metric in raw_result.metrics:
category_string = metric.category
if category_string:
prefix = "TEST_METRIC_CATEGORY_"
category_string = category_string[len(prefix) :]
metric_value: Any = np.nan
if metric.empty:
pass
else:
for data_option in DATA_OPTIONS:
getter = getattr(metric, data_option)
if getter is not None:
metric_value = getter
break
result_dict[f"{category_string}:{metric.metric}"] = metric_value
def parse_summary_test_result(
raw_result: RimeCategoryTestResult,
unpack_metrics: bool = False,
) -> dict:
"""Parse swagger summary test result to pythonic form."""
raw_dict = raw_result.to_dict()
for key in SUMMARY_TEST_KEYS_TO_HIDE:
raw_dict.pop(key, None)
if unpack_metrics:
for metric in raw_result.category_metrics:
raw_dict[metric.name] = metric.value
severity_count_dict = raw_dict.pop("severity_counts")
for key in severity_count_dict:
raw_dict[key] = int(severity_count_dict[key])
return raw_dict
def parse_events_to_df(
events: List[DetectionDetectionEvent],
) -> pd.DataFrame:
"""Parse a list of Detection Events to a pandas DateFrame."""
event_dicts = [event.to_dict() for event in events]
df = pd.json_normalize(event_dicts, sep=DF_FLATTEN_SEPARATOR)
df = df.rename(_flatten_uuid_field_name, axis="columns")
intersect_df = df[df.columns.intersection(EVENT_COLUMNS_TO_SHOW)]
intersect_df = intersect_df.rename({"event_object_id": "monitor_id"}, axis=1)
return intersect_df | /rime_sdk-2.3.0rc5.tar.gz/rime_sdk-2.3.0rc5/rime_sdk/internal/swagger_parser.py | 0.867864 | 0.438364 | swagger_parser.py | pypi |
import logging
import time
logger = logging.getLogger(__name__)
class ThrottleQueue:
"""A throttle queue is used to regulate the rate of events.
The throttle queue queues a history of past events in order to
moderate the rate at which expensive events occur.
"""
def __init__(
self, desired_events_per_epoch: int, epoch_duration_sec: float
) -> None:
"""Create a new throttle queue for a given desired event rate.
Args:
desired_events_per_epoch: int
The number events that are desired for the given epoch.
epoch_duration_sec: float
The lenth of the epoch in seconds.
"""
# A circular queue of past event timestamps that is 3 times the size of
# the number of desired events.
self._timestamp_queue = [0.0] * (3 * desired_events_per_epoch)
self._timestamp_index = 0
self._desired_events_per_epoch = desired_events_per_epoch
self._epoch_duration_sec = epoch_duration_sec
self._desired_interval = (
self._epoch_duration_sec / self._desired_events_per_epoch
)
def throttle(self, throttling_msg: str) -> bool:
"""Register a new event and throttles it according to the past events.
Returns:
Whether or not this event was throttled.
"""
now = time.time()
# Compute the number of events in the current epoch above the desired number.
events_in_epoch = sum(
[now - x < self._epoch_duration_sec for x in self._timestamp_queue]
)
excess_events = events_in_epoch - self._desired_events_per_epoch
throttled = excess_events >= 0
if throttled:
logger.warning(f"Throttling: {throttling_msg}")
# Add an exponential sleep penalty to throttle the events toward the desired
# interval.
# Note: small amounts of throttling occur while excess_events < 0. The total
# contribution of this delay is
# T = DI * sum_{t=1}{N} 2^-t
# < DI * sum_{t=1}{inf} 2^-t
# = DI
# where DI is the desired interval and N is the desired events per epoch.
# Thus, there will be at most 1 unit of desired interval in delays before
# full throttling is applied.
time.sleep(self._desired_interval * 2.0**excess_events)
# Record the latest event in the circular queue.
self._timestamp_queue[self._timestamp_index] = time.time()
self._timestamp_index = (self._timestamp_index + 1) % len(self._timestamp_queue)
return throttled | /rime_sdk-2.3.0rc5.tar.gz/rime_sdk-2.3.0rc5/rime_sdk/internal/throttle_queue.py | 0.895088 | 0.459015 | throttle_queue.py | pypi |
from pathlib import Path
from typing import Any, Optional
import numpy as np
import pandas as pd
from rime_sdk.data_format_check.data_format_checker import DataFormatChecker
# Tabular Tasks
# TODO(RAT-1942): add Ranking
BINARY_CLASSIFICATION = "Binary Classification"
REGRESSION = "Regression"
MULTI_CLASS_CLASSIFICATION = "Multi-class Classification"
TABULAR_TASKS = {BINARY_CLASSIFICATION, REGRESSION, MULTI_CLASS_CLASSIFICATION}
# Accepted formats for the "timestamp" column
FORMAT_SECONDS = "%Y-%m-%d %H:%M:%S"
FORMAT_DAYS = "%Y-%m-%d"
WARNING_NO_PRED_COL = (
"WARNING: No prediction column is provided. Although you can still run RIME "
"without predictions, it will not be as powerful as if you run it WITH "
"predictions.\n"
)
WARNING_NO_LABEL_COL = (
"WARNING: No label column is provided. Although you can still run RIME without "
"labels, it will not be as powerful as if you run it WITH labels.\n"
)
ERROR_UNKNOWN_TASK = "Unrecognized Tabular task: '{task}'. Task must be one of {tasks}"
class TabularDataFormatChecker(DataFormatChecker):
"""Checker for ML tasks involving Tabular data."""
accepted_file_types = [".csv", ".parquet"]
def check(
self,
ref_path: Path,
eval_path: Path,
task: str,
label_col_name: Optional[str] = None,
pred_col_name: Optional[str] = None,
timestamp_col_name: Optional[str] = None,
**kwargs: Any,
) -> None:
"""Run all data checks."""
self.check_file_format(ref_path)
self.check_file_format(eval_path)
for file_path in [ref_path, eval_path]:
print(f"\nInspecting '{file_path}'")
self.check_data_file(file_path, task, label_col_name, pred_col_name)
print("Done!")
print("")
if pred_col_name is None:
print(WARNING_NO_PRED_COL)
if label_col_name is None:
print(WARNING_NO_LABEL_COL)
if timestamp_col_name is not None:
print(
f"Timestamp column provided: '{timestamp_col_name}'. Inspecting both "
f"datasets for format of timestamps ('{FORMAT_SECONDS}' or "
f"'{FORMAT_DAYS}')"
)
print("\n---\n")
print(self.success_msg)
def check_data_file(
self,
filename: Path,
task: str,
label_col_name: Optional[str],
pred_col_name: Optional[str],
timestamp_col_name: Optional[str] = None,
) -> None:
"""Perform multiple checks against the given file."""
if not filename.exists():
raise ValueError(f"File {filename} does not exist")
if filename.suffix == ".csv":
df = pd.read_csv(filename)
elif filename.suffix == ".parquet":
df = pd.read_parquet(filename)
else:
raise ValueError(
f"Invalid file type '{filename.suffix}'. File must be one of "
f"{self.accepted_file_types}"
)
if label_col_name is not None:
if label_col_name not in df:
raise ValueError(
f"Label column ({label_col_name}) not found in data "
f"({filename}). If a label column exists in one "
"dataset, it MUST exist in the other."
)
else:
self.check_labels(df[label_col_name], task)
if pred_col_name is not None:
if pred_col_name not in df:
raise ValueError(
f"Prediction column ({pred_col_name}) not found in data "
f"({filename}). If a prediction column exists in one dataset, "
f"it MUST exist in the other."
)
else:
self.check_predictions(df[pred_col_name], task)
if timestamp_col_name is not None:
self.check_timestamps(df[timestamp_col_name], timestamp_col_name)
def check_labels(self, ser: pd.Series, task: str) -> None:
"""Perform checks for the label data, based on the model type."""
if ser.isnull().any():
raise ValueError(
"Found nulls in label series, there should not be any nulls."
)
if task == REGRESSION:
if ser.dtype == object:
raise ValueError("Labels for regression should be numeric.")
elif task == BINARY_CLASSIFICATION:
if not ((ser == 1) | (ser == 0)).all():
raise ValueError(
"Labels for Binary Classification should be numeric, all 0s or 1s."
)
elif task == MULTI_CLASS_CLASSIFICATION:
if not (ser == ser.astype(int)).all():
raise ValueError(
"Labels for Multi-class Classification should be all integer "
"values."
)
else:
raise ValueError(ERROR_UNKNOWN_TASK.format(task=task, tasks=TABULAR_TASKS))
def check_predictions(self, ser: pd.Series, task: str) -> None:
"""Perform checks for the prediction data, based on the model type."""
if ser.isnull().any():
raise ValueError(
"Found nulls in prediction series, there should not be any nulls."
)
if task == REGRESSION:
if ser.dtype == object:
raise ValueError("Predictions for regression should be numeric.")
elif task == BINARY_CLASSIFICATION:
if not ((ser <= 1) & (ser >= 0)).all():
raise ValueError(
"Predictions for Binary Classification should be probabilities "
"between 0 and 1."
)
elif task == MULTI_CLASS_CLASSIFICATION:
raise ValueError(
"Prediction column for Multi-class Classification is not supported in"
" usual way, please contact Robust Intelligence for instructions."
)
else:
raise ValueError(ERROR_UNKNOWN_TASK.format(task=task, tasks=TABULAR_TASKS))
def check_timestamps(
self, timestamps: pd.Series, timestamp_col_name: Optional[str] = None
) -> None:
"""Validate format of timestamps."""
try:
timestamps = timestamps.astype(str)
# Note: providing a subset of values (e.g. just year and month) is valid
timestamps = pd.to_datetime(timestamps, format=FORMAT_SECONDS)
except ValueError as e:
# pd.to_datetime doesn't throw specific error type for this case,
# must parse manually
if "doesn't match format" in str(e):
try:
timestamps = pd.to_datetime(timestamps, format=FORMAT_DAYS)
except ValueError as new_error:
raise ValueError(
f"{timestamp_col_name} contains invalid formats."
f" Acceptable timestamp formats are {FORMAT_DAYS}"
f" and {FORMAT_SECONDS}.\n\n{new_error}"
)
else:
raise e
if pd.isnull(timestamps).any():
null_pos = np.where(pd.isnull(timestamps))[0]
null_idxs = timestamps.index[null_pos].tolist()
raise ValueError(
f"{timestamp_col_name} must not contain nulls."
f" Found null values at indexes: {null_idxs}"
)
if timestamps.nunique() < len(timestamps):
print(f"WARNING: {timestamp_col_name} contains duplicate values!") | /rime_sdk-2.3.0rc5.tar.gz/rime_sdk-2.3.0rc5/rime_sdk/data_format_check/tabular_checker.py | 0.628863 | 0.257791 | tabular_checker.py | pypi |
import gzip
import json
from pathlib import Path
from typing import IO, Any, Iterable, List, Optional
from schema import Schema, SchemaError
from tqdm import tqdm
from rime_sdk.data_format_check.data_format_checker import DataFormatChecker
# NLP Tasks
TEXT_CLASSIFICATION = "Text Classification"
NAMED_ENTITY_RECOGNITION = "Named Entity Recognition"
NLP_TASKS = {TEXT_CLASSIFICATION, NAMED_ENTITY_RECOGNITION}
# NLP JSON data schemas
# Text Classification
TC_SCHEMA_DEFAULT = Schema({"text": str}, ignore_extra_keys=True)
TC_SCHEMA_PREDS = Schema({"probabilities": [float]}, ignore_extra_keys=True)
TC_SCHEMA_MASTER = Schema(
{"text": str, "label": int, "probabilities": [float]}, ignore_extra_keys=True
)
# Named Entity Recognition Schemas
NER_SCHEMA_DEFAULT = Schema({"text": str}, ignore_extra_keys=True)
# NER has dicts, which need their own schemas
NER_SCHEMA_MENTION = Schema(
{"start_offset": int, "end_offset": int}, ignore_extra_keys=True
)
NER_SCHEMA_ENTITY = Schema(
{"mentions": [NER_SCHEMA_MENTION], "type": str}, ignore_extra_keys=True
)
NER_SCHEMA_PREDS = Schema(
{"predicted_entities": [NER_SCHEMA_ENTITY]}, ignore_extra_keys=True
)
NER_SCHEMA_MASTER = Schema(
{
"text": str,
"entities": [NER_SCHEMA_ENTITY],
"predicted_entities": [NER_SCHEMA_ENTITY],
},
ignore_extra_keys=True,
)
DEFAULT = "default"
PREDS = "preds"
MASTER = "master"
SCHEMA_BANK = {
TEXT_CLASSIFICATION: {
DEFAULT: TC_SCHEMA_DEFAULT,
PREDS: TC_SCHEMA_PREDS,
MASTER: TC_SCHEMA_MASTER,
},
NAMED_ENTITY_RECOGNITION: {
DEFAULT: NER_SCHEMA_DEFAULT,
PREDS: NER_SCHEMA_PREDS,
MASTER: NER_SCHEMA_MASTER,
},
}
# Validations can happen on these types of input
INPUT_PREDS_INCLUDED = "input_preds_included"
INPUT_PREDS_SEPARATE = "input_preds_separate"
PREDS = "preds"
INPUT_TYPES = set([INPUT_PREDS_INCLUDED, INPUT_PREDS_SEPARATE, PREDS])
ERROR_UNKNOWN_TASK = "Unrecognized NLP task: '{task}'. Task must be one of {tasks}"
ERROR_UNKNOWN_INPUT = (
"Unrecognized input type: '{input_type}'. Input type must be one of {accepted}"
)
# NLP Data loading methods
def _load_data_from_file_object(file_object: IO, file_name: str) -> Iterable[dict]:
path = Path(file_name)
try:
if path.suffix == ".json":
yield from json.load(file_object)
elif path.suffix == ".jsonl":
for line in file_object:
yield json.loads(line)
else:
raise ValueError(
f"Only .json and .jsonl files supported. Got {path.suffix}"
)
finally:
if not file_object.closed:
file_object.close()
def _load_data_multi_ext(base_path: Path) -> Iterable[dict]:
_gz_suffix = ".gz"
if base_path.suffix == _gz_suffix:
decompressed_name = str(base_path)[: -len(_gz_suffix)]
file_object = gzip.open(str(base_path), "rt", encoding="utf-8")
return _load_data_from_file_object(file_object, decompressed_name)
else:
file_object = base_path.open("r", encoding="utf-8")
return _load_data_from_file_object(file_object, str(base_path))
def _load_data(data_path: Path) -> List[dict]:
data = list(_load_data_multi_ext(data_path))
return data
def check_json_nlp_data(
file_path: Path,
schema: Schema = None,
task: str = "",
input_type: Optional[str] = None,
) -> None:
"""Validate that all objects in the loaded JSON data match the given Schema.
If no schema is provided, it will be inferred based on the task, first data point,
and input_type.
"""
if schema is None and (task is None or input_type is None):
raise ValueError(
"If schema is not provided, both task and input_type "
"must be provided to enable schema inference."
)
elif schema is None and (task is not None and input_type is not None):
if task not in NLP_TASKS:
raise ValueError(ERROR_UNKNOWN_TASK.format(task=task, tasks=NLP_TASKS))
if input_type not in INPUT_TYPES:
raise ValueError(
ERROR_UNKNOWN_INPUT.format(input_type=input_type, accepted=INPUT_TYPES)
)
list_data = _load_data(file_path)
if list_data is None or len(list_data) == 0:
raise ValueError(
f"No objects parsed from '{file_path}'. Please verify "
"presence and format of input data and retry."
)
schema = get_schema(schema, task, input_type, list_data)
print(f"\nInspecting '{file_path}':")
for i in tqdm(range(0, len(list_data))):
try:
# TODO(RAT-1940): add manual non-null/non-empty check
schema.validate(list_data[i])
except SchemaError as e:
schema_str_trimmed = str(schema).replace("Schema(", "").replace(")", "")
schema_msg = (
f"\n\n---\n\nInputs for task '{task}' must adhere to the "
f"following structure:\n\n{schema_str_trimmed}"
)
e.args = (
f"File '{file_path}', Index {i}:\n\n",
*e.args,
schema_msg,
)
raise
def get_schema(
schema: Optional[Schema],
task: str,
input_type: Optional[str],
list_data: List[dict],
) -> Schema:
"""Infer the schema to use if schema is not provided."""
if schema is not None:
return schema
# If schema is not provided, select or generate an appropriate one based
# on first data point and task/presence of predictions
if input_type == PREDS:
return SCHEMA_BANK[task][PREDS]
elif input_type == INPUT_PREDS_SEPARATE:
return infer_schema_from_datapoint(
task, list_data[0], set(SCHEMA_BANK[task][PREDS].schema.keys())
)
elif input_type == INPUT_PREDS_INCLUDED:
return infer_schema_from_datapoint(task, list_data[0])
else:
raise ValueError(
ERROR_UNKNOWN_INPUT.format(input_type=input_type, accepted=INPUT_TYPES)
)
def infer_schema_from_datapoint(
task: str, datapoint: dict, excluded_keys: Optional[Iterable] = None
) -> Schema:
"""Generate a custom schema using the given task and datapoint.
Start with the default schema (contains only required keys), and add keys as they
are observed in the datapoint.
Use only those keys that are present in the "master schema", unless they've been
explicitly excluded via excluded_keys.
"""
generated_schema = Schema(
schema=SCHEMA_BANK[task][DEFAULT].schema.copy(),
ignore_extra_keys=SCHEMA_BANK[task][DEFAULT].ignore_extra_keys,
)
master_schema = SCHEMA_BANK[task][MASTER]
datapoint_keys = list(datapoint.keys())
master_schema_keys = set(master_schema.schema.keys())
for key in datapoint_keys:
if excluded_keys is not None:
if key in master_schema_keys and key not in excluded_keys:
generated_schema.schema.update({key: master_schema.schema.get(key)})
elif key in master_schema_keys:
generated_schema.schema.update({key: master_schema.schema.get(key)})
return generated_schema
class NlpDataFormatChecker(DataFormatChecker):
"""Checker for NLP tasks."""
accepted_file_types = [".json", ".jsonl", ".json.gz", ".jsonl.gz"]
def check(
self,
ref_path: Path,
eval_path: Path,
task: str = "",
preds_ref_path: Optional[Path] = None,
preds_eval_path: Optional[Path] = None,
**kwargs: Any,
) -> None:
"""Execute NLP data checks based on provided inputs.
Uses rules defined in the global NLP data schemas.
"""
self.check_file_format(ref_path)
self.check_file_format(eval_path)
# Assume predictions are included unless observed otherwise
ref_input_type = INPUT_PREDS_INCLUDED
if preds_ref_path is not None:
self.check_file_format(preds_ref_path)
check_json_nlp_data(preds_ref_path, None, task, PREDS)
ref_input_type = INPUT_PREDS_SEPARATE
eval_input_type = INPUT_PREDS_INCLUDED
if preds_eval_path is not None:
self.check_file_format(preds_eval_path)
check_json_nlp_data(preds_eval_path, None, task, PREDS)
eval_input_type = INPUT_PREDS_SEPARATE
check_json_nlp_data(ref_path, None, task, ref_input_type)
check_json_nlp_data(eval_path, None, task, eval_input_type)
print("\n---\n")
print(self.success_msg) | /rime_sdk-2.3.0rc5.tar.gz/rime_sdk-2.3.0rc5/rime_sdk/data_format_check/nlp_checker.py | 0.574992 | 0.221067 | nlp_checker.py | pypi |
from argparse import ArgumentParser
from pathlib import Path
from typing import Union
from rime_sdk.data_format_check.nlp_checker import NLP_TASKS, NlpDataFormatChecker
from rime_sdk.data_format_check.tabular_checker import (
TABULAR_TASKS,
TabularDataFormatChecker,
)
def pprint_exception(e: Exception) -> None:
"""Neatly prints out contents of exception."""
args_joined = "".join([str(i) for i in e.args])
print(f"\n---\n\nError:\n\n{args_joined}\n")
def main() -> None:
"""Parse CLI inputs and executes appropriate methods."""
parser = ArgumentParser()
# Data type
group_types = parser.add_mutually_exclusive_group(required=True)
group_types.add_argument(
"-nlp", action="store_true", help="Whether this data is for NLP tasks"
)
group_types.add_argument(
"-tabular", action="store_true", help="Whether this data is tabular"
)
# Shared args
parser.add_argument(
"--ref-path", type=Path, required=True, help="Path to reference data file."
)
parser.add_argument(
"--eval-path", type=Path, required=True, help="Path to evaluation data file."
)
parser.add_argument(
"--task",
choices=list(TABULAR_TASKS) + list(NLP_TASKS),
required=True,
help="The desired ML task.",
)
# NLP args
parser.add_argument(
"--preds-ref-path",
type=Path,
required=False,
help="(Optional) The path to the reference predictions, if they are stored"
" in a separate file.",
)
parser.add_argument(
"--preds-eval-path",
type=Path,
required=False,
help="(Optional) The path to the evaluation predictions, if they are stored"
" in a separate file.",
)
# Tabular args
parser.add_argument(
"--label-col-name",
type=str,
required=False,
default=None,
help="Name of column in inputs that contains labels.",
)
parser.add_argument(
"--pred-col-name",
type=str,
required=False,
default=None,
help="Name of column in inputs that contains predictions.",
)
parser.add_argument(
"--timestamp-col-name",
type=str,
required=False,
default=None,
help="Name of column in inputs that contains timestamps. "
"Only applicable if using RIME Continuous Testing.",
)
argps = parser.parse_args()
if argps.nlp:
checker: Union[
TabularDataFormatChecker, NlpDataFormatChecker
] = NlpDataFormatChecker()
try:
checker.check(
argps.ref_path,
argps.eval_path,
argps.task,
preds_ref_path=argps.preds_ref_path,
preds_eval_path=argps.preds_eval_path,
)
except Exception as e:
pprint_exception(e)
elif argps.tabular:
checker = TabularDataFormatChecker()
try:
checker.check(
argps.ref_path,
argps.eval_path,
argps.task,
label_col_name=argps.label_col_name,
pred_col_name=argps.pred_col_name,
timestamp_col_name=argps.timestamp_col_name,
)
except Exception as e:
pprint_exception(e) | /rime_sdk-2.3.0rc5.tar.gz/rime_sdk-2.3.0rc5/rime_sdk/data_format_check/cli.py | 0.835685 | 0.250775 | cli.py | pypi |
import os.path
from rime.basic import consts
import rime.basic.targets.testset # NOQA
from rime.basic import test
from rime.core import codes as core_codes
from rime.core import targets
from rime.core import taskgraph
from rime.util import class_registry
class JudgeRunner(object):
def Run(self, infile, difffile, outfile, cwd, judgefile):
raise NotImplementedError()
class RimeJudgeRunner(JudgeRunner):
PREFIX = 'rime'
def Run(self, judge, infile, difffile, outfile, cwd, judgefile):
return judge.Run(
args=('--infile', infile,
'--difffile', difffile,
'--outfile', outfile),
cwd=cwd,
input=os.devnull,
output=judgefile,
timeout=None, precise=False,
redirect_error=True) # !redirect_error
class TestlibJudgeRunner(JudgeRunner):
PREFIX = 'testlib'
def Run(self, judge, infile, difffile, outfile, cwd, judgefile):
return judge.Run(
args=(infile, outfile, difffile),
cwd=cwd,
input=os.devnull,
output=judgefile,
timeout=None, precise=False,
redirect_error=True) # !redirect_error
judge_runner_registry = class_registry.ClassRegistry(JudgeRunner)
judge_runner_registry.Add(RimeJudgeRunner)
judge_runner_registry.Add(TestlibJudgeRunner)
class ReactiveRunner(object):
def Run(self, reactive, solution, args, cwd, input, output, timeout,
precise):
raise NotImplementedError()
class KUPCReactiveRunner(ReactiveRunner):
PREFIX = 'kupc'
def Run(self, reactive, args, cwd, input, output, timeout, precise):
return reactive.Run(
args=("'%s'" % ' '.join(args),),
cwd=cwd,
input=input,
output=output,
timeout=timeout,
precise=precise,
redirect_error=True) # !redirect_error
class TestlibReactiveRunner(ReactiveRunner):
PREFIX = 'testlib'
def Run(self, reactive, solution, args, cwd, input, output, timeout,
precise):
raise NotImplementedError()
class NEERCReactiveRunner(ReactiveRunner):
PREFIX = 'neerc'
def Run(self, reactive, solution, args, cwd, input, output, timeout,
precise):
raise NotImplementedError()
reactive_runner_registry = class_registry.ClassRegistry(ReactiveRunner)
reactive_runner_registry.Add(KUPCReactiveRunner)
# reactive_runner_registry.Add(TestlibReactiveRunner)
# reactive_runner_registry.Add(NEERCReactiveRunner)
class Testset(targets.registry.Testset):
def __init__(self, *args, **kwargs):
super(Testset, self).__init__(*args, **kwargs)
for judge_runner in judge_runner_registry.classes.values():
self.exports['{0}_judge_runner'.format(
judge_runner.PREFIX)] = judge_runner()
for reactive_runner in reactive_runner_registry.classes.values():
self.exports['{0}_reactive_runner'.format(
reactive_runner.PREFIX)] = reactive_runner()
@taskgraph.task_method
def _TestOneCaseNoCache(self, solution, testcase, ui):
"""Test a solution with one case.
Never cache results.
Returns TestCaseResult.
"""
outfile, judgefile = [
os.path.join(
solution.out_dir,
os.path.splitext(os.path.basename(testcase.infile))[0] + ext)
for ext in (consts.OUT_EXT, consts.JUDGE_EXT)]
precise = (ui.options.precise or ui.options.parallelism <= 1)
# reactive
if self.reactives:
if len(self.reactives) > 1:
ui.errors.Error(self, "Multiple reactive checkers registered.")
yield None
reactive = self.reactives[0]
if not reactive.variant:
reactive.variant = KUPCReactiveRunner()
res = yield reactive.variant.Run(
reactive=reactive,
args=solution.code.run_args, cwd=solution.out_dir,
input=testcase.infile,
output=outfile,
timeout=testcase.timeout, precise=precise)
else:
res = yield solution.Run(
args=(), cwd=solution.out_dir,
input=testcase.infile,
output=outfile,
timeout=testcase.timeout, precise=precise)
if res.status == core_codes.RunResult.TLE:
yield test.TestCaseResult(solution, testcase,
test.TestCaseResult.TLE,
time=None, cached=False)
if res.status != core_codes.RunResult.OK:
yield test.TestCaseResult(solution, testcase,
test.TestCaseResult.RE,
time=None, cached=False)
time = res.time
for judge in self.judges:
if not judge.variant:
judge.variant = RimeJudgeRunner()
res = yield judge.variant.Run(
judge=judge,
infile=testcase.infile,
difffile=testcase.difffile,
outfile=outfile,
cwd=self.out_dir,
judgefile=judgefile)
if res.status == core_codes.RunResult.NG:
yield test.TestCaseResult(solution, testcase,
test.TestCaseResult.WA,
time=None, cached=False)
elif res.status != core_codes.RunResult.OK:
yield test.TestCaseResult(
solution, testcase,
test.TestVerdict('Validator %s' % res.status),
time=None, cached=False)
yield test.TestCaseResult(solution, testcase, test.TestCaseResult.AC,
time=time, cached=False)
@taskgraph.task_method
def _RunReferenceSolutionOne(self, reference_solution, testcase, ui):
"""Run the reference solution against a single input file."""
if os.path.isfile(testcase.difffile):
yield True
# reactive
if self.reactives:
if len(self.reactives) > 1:
ui.errors.Error(self, "Multiple reactive checkers registered.")
yield None
reactive = self.reactives[0]
if not reactive.variant:
reactive.variant = KUPCReactiveRunner()
res = yield reactive.variant.Run(
reactive=reactive,
args=reference_solution.code.run_args,
cwd=reference_solution.out_dir,
input=testcase.infile,
output=testcase.difffile,
timeout=None, precise=False)
else:
res = yield reference_solution.Run(
args=(), cwd=reference_solution.out_dir,
input=testcase.infile,
output=testcase.difffile,
timeout=None, precise=False)
if res.status != core_codes.RunResult.OK:
ui.errors.Error(reference_solution, res.status)
raise taskgraph.Bailout([False])
ui.console.PrintAction('REFRUN', reference_solution,
'%s: DONE' % os.path.basename(testcase.infile),
progress=True)
yield True
@taskgraph.task_method
def _CompileJudges(self, ui):
res = (yield super(Testset, self)._CompileJudges(ui))
if not res:
yield False
results = yield taskgraph.TaskBranch([
self._CompileReactiveOne(reactive, ui)
for reactive in self.reactives])
yield all(results)
@taskgraph.task_method
def _CompileReactiveOne(self, reactive, ui):
"""Compile a single reative."""
if not reactive.QUIET_COMPILE:
ui.console.PrintAction('COMPILE', self, reactive.src_name)
res = yield reactive.Compile()
if res.status != core_codes.RunResult.OK:
ui.errors.Error(self, '%s: Compile Error (%s)'
% (reactive.src_name, res.status))
ui.console.PrintLog(reactive.ReadCompileLog())
yield False
yield True
targets.registry.Override('Testset', Testset) | /plugins/plus/flexible_judge.py | 0.55447 | 0.170197 | flexible_judge.py | pypi |
import fnmatch
import os.path
import re
from rime.basic import consts
import rime.basic.targets.solution # NOQA
import rime.basic.targets.testset # NOQA
from rime.basic import test
from rime.core import targets
from rime.core import taskgraph
from rime.util import files
class SubtaskTestCase(test.TestCase):
def __init__(self, testset, name, score, input_patterns):
super(SubtaskTestCase, self).__init__(
testset,
name, name)
self.name = name
self.score = score
self.input_patterns = input_patterns
@property
def timeout(self):
return None
class Testset(targets.registry.Testset):
def __init__(self, *args, **kwargs):
super(Testset, self).__init__(*args, **kwargs)
self.subtask_testcases = []
self.scoring_judge = False
def PreLoad(self, ui):
super(Testset, self).PreLoad(ui)
def subtask_testset(name, score=100, input_patterns=['*']):
self.subtask_testcases.append(SubtaskTestCase(
self, name, score, input_patterns))
self.exports['subtask_testset'] = subtask_testset
def scoring_judge():
self.scoring_judge = True
self.exports['scoring_judge'] = scoring_judge
@taskgraph.task_method
def _TestSolutionWithAllCases(self, solution, ui):
original_result = (
yield super(Testset, self)._TestSolutionWithAllCases(solution, ui))
if self.subtask_testcases:
max_score = 0
min_score = 0
for subtask in self.subtask_testcases:
subtask_results = [
r for (t, r) in original_result.results.items()
if any([fnmatch.fnmatch(os.path.basename(t.infile),
input_pattern)
for input_pattern in subtask.input_patterns])]
accepted = all([result.verdict == test.TestCaseResult.AC
for result in subtask_results
if result.verdict != test.TestCaseResult.NA])
unknown = any([result.verdict == test.TestCaseResult.NA
for result in subtask_results])
if accepted:
if not unknown:
min_score += subtask.score
max_score += subtask.score
if min_score == max_score:
detail = ('%s, score %s' % (original_result.detail, min_score))
else:
detail = ('%s, score %s <= x <= %s' %
(original_result.detail, min_score, max_score))
ui.errors.Warning(
self,
"If you want more precise score, set keep_going option.")
if solution.expected_score is not None:
expected_result = (min_score <= solution.expected_score and
solution.expected_score <= max_score)
if expected_result:
original_result.Finalize(
True, detail=detail, allow_override=True)
else:
original_result.Finalize(
False,
notable_testcase=test.TestCase(
self, 'unexpected_score.in'),
detail=detail, allow_override=True)
if min_score == max_score:
ui.errors.Error(self,
'expected score %s does not equal to '
'%s' %
(solution.expected_score, min_score))
else:
ui.errors.Error(
self,
'expected score x = %s does not satisfy'
'%s <= x <= %s' %
(solution.expected_score, min_score, max_score))
elif original_result.expected:
original_result.Finalize(
True, detail=detail, allow_override=True)
else:
original_result.Finalize(
False,
notable_testcase=original_result.notable_testcase,
detail=detail, allow_override=True)
elif original_result.IsAccepted() and self.scoring_judge:
score = 0
p = re.compile("IMOJUDGE<<<(\\d+)>>>")
for (testcase, result) in original_result.results.items():
judge_detail = files.ReadFile(
os.path.join(
solution.out_dir,
os.path.splitext(
os.path.basename(testcase.infile))[0] +
consts.JUDGE_EXT))
if judge_detail:
judge_detail = judge_detail.strip()
if judge_detail.isdigit():
score += int(judge_detail)
elif p.search(judge_detail):
score += int(p.search(judge_detail).group(1))
else:
ui.errors.Error(
self,
'the judge result does not indicate a score:'
'"%s"' % (judge_detail))
original_result.Finalize(
False,
notable_testcase=test.TestCase(
self, 'judge_error.in'),
detail=original_result.detail, allow_override=True)
yield original_result
else:
ui.errors.Error(self, 'the judge is silent.')
original_result.Finalize(
False,
notable_testcase=test.TestCase(self, 'judge_error.in'),
detail=original_result.detail, allow_override=True)
yield original_result
score /= float(len(original_result.results))
detail = ('%s, score %s' %
(original_result.detail, score))
expected_result = score == solution.expected_score
if expected_result or not solution.expected_score:
original_result.Finalize(
True, detail=detail, allow_override=True)
else:
original_result.Finalize(
False,
notable_testcase=test.TestCase(
self, 'unexpected_score.in'),
detail=detail, allow_override=True)
ui.errors.Error(self,
'expected score %d does not equal to %s' %
(solution.expected_score, score))
original_result.Finalize(True, detail=detail, allow_override=True)
yield original_result
class Solution(targets.registry.Solution):
def __init__(self, *args, **kwargs):
super(Solution, self).__init__(*args, **kwargs)
self.expected_score = None
def PreLoad(self, ui):
super(Solution, self).PreLoad(ui)
def expected_score(score):
self.expected_score = score
self.exports['expected_score'] = expected_score
targets.registry.Override('Solution', Solution)
targets.registry.Override('Testset', Testset) | /plugins/plus/subtask.py | 0.581422 | 0.292415 | subtask.py | pypi |
import getpass
import hashlib
import os
import socket
import sys
from enum import Enum
from itertools import groupby
from jinja2 import Environment
from jinja2 import FileSystemLoader
if sys.version_info[0] == 2:
import commands as builtin_commands # NOQA
else:
import subprocess as builtin_commands
from rime.basic import consts # NOQA
from rime.basic import codes as basic_codes # NOQA
from rime.basic import test # NOQA
class ItemState(Enum):
GOOD, NOTBAD, BAD, NA = range(4)
def SafeUnicode(s):
if sys.version_info.major == 2 and not isinstance(s, unicode): # NOQA
s = s.decode('utf-8')
return s
def GetFileSize(dir, filename):
filepath = os.path.join(dir, filename)
if os.path.exists(filepath):
return '%dB' % os.path.getsize(filepath)
else:
return '-'
def GetFileHash(dir, filename):
filepath = os.path.join(dir, filename)
if os.path.exists(filepath):
f = open(filepath)
r = f.read()
f.close()
return hashlib.md5(SafeUnicode(r).encode('utf-8')).hexdigest()
else:
return ''
def GetTestcaseComment(dir, filename):
filepath = os.path.join(dir, filename)
if os.path.exists(filepath):
f = open(filepath)
r = f.read().strip()
f.close()
return SafeUnicode(r)
else:
return ''
def GetTestCaseState(result):
"""Generate per testcase result for summary
Arguments:
result (rime.basic.test.TestCaseResult)
"""
if result.verdict is test.TestCaseResult.NA:
return {'status': ItemState.NA, 'detail': str(result.verdict)}
elif result.verdict is test.TestCaseResult.AC:
return {'status': ItemState.GOOD, 'detail': '%.2fs' % (result.time)}
else:
return {'status': ItemState.BAD, 'detail': str(result.verdict)}
def GenerateSummary(results, template_file, ui):
"""Generate a project summary.
Arguments:
results (array of rime.basic.test.TestCaseResult):
data used to generate a summary.
template_file (string): path to a jinja template file.
Returns:
Project summary as a string.
"""
(dirname, basename) = os.path.split(template_file)
jinja_env = Environment(loader=FileSystemLoader(dirname, encoding='utf8'))
template = jinja_env.get_template(basename)
template.globals['ItemState'] = ItemState
summ = GenerateProjectSummary(results, ui)
return template.render(**summ)
def GenerateProjectSummary(results, ui):
"""Generate an object for project summary.
Arguments:
results (array of rime.basic.test.TestsetResult):
data used to generate a summary.
"""
system = {
'rev': builtin_commands.getoutput(
'git show -s --oneline').replace('\n', ' ').replace('\r', ' '),
'username': getpass.getuser(),
'hostname': socket.gethostname(),
}
cc = os.getenv('CC', 'gcc')
cxx = os.getenv('CXX', 'g++')
java_home = os.getenv('JAVA_HOME')
if java_home is not None:
java = os.path.join(java_home, 'bin/java')
javac = os.path.join(java_home, 'bin/javac')
else:
java = 'java'
javac = 'javac'
environments = [
{
'type': 'gcc',
'detail': builtin_commands.getoutput(
'{0} --version'.format(cc)).strip(),
}, {
'type': 'g++',
'detail': builtin_commands.getoutput(
'{0} --version'.format(cxx)).strip(),
}, {
'type': 'javac',
'detail': builtin_commands.getoutput(
'{0} --version'.format(javac)).strip(),
}, {
'type': 'java',
'detail': builtin_commands.getoutput(
'{0} --version'.format(java)).strip(),
}]
# Generate content for each problem.
problems = [GenerateProblemSummary(k, g)
for k, g in groupby(results, lambda k: k.problem)]
return {
'system': system,
'environments': environments,
'problems': list(problems),
'errors': ui.errors.errors if ui.errors.HasError() else [],
'warnings': ui.errors.warnings if ui.errors.HasWarning() else []
}
def GenerateProblemSummary(problem, testset_results):
"""Generate an object for project summary for paticular problem.
Arguments:
problem (rime.basic.targets.problem.Problem):
A problem to summarize.
testset_results (array of rime.basic.test.TestsetResult):
An array of testset result of the specified problem.
"""
testset_results = list(
sorted(
testset_results,
key=lambda x: x.solution.name))
# Get test results from each testset (i.e. per solution)
solutions = []
testnames = set()
for testset in testset_results:
verdicts = {}
for (testcase, result) in testset.results.items():
testname = os.path.splitext(
os.path.basename(testcase.infile))[0]
testnames.add(testname)
verdicts[testname] = GetTestCaseState(result)
solutions.append({
'name': testset.solution.name,
'verdicts': verdicts,
})
# Populate missing results with NA.
empty_verdict = test.TestCaseResult(
None, None, test.TestCaseResult.NA, None, None)
for solution in solutions:
for testname in testnames:
if testname not in solution['verdicts']:
solution['verdicts'][testname] = empty_verdict
# Test case informations.
out_dir = problem.testset.out_dir
testcases = [{
'name': testname,
'insize': GetFileSize(out_dir, testname + consts.IN_EXT),
'outsize': GetFileSize(out_dir, testname + consts.DIFF_EXT),
'md5': GetFileHash(out_dir, testname + consts.IN_EXT)[:7],
'comment': GetTestcaseComment(out_dir, testname + '.comment'),
} for testname in sorted(testnames)]
# Get summary about the problem.
assignees = problem.assignees
if isinstance(assignees, list):
assignees = ','.join(assignees)
num_solutions = len(solutions)
num_tests = len(problem.testset.ListTestCases())
correct_solution_results = [result for result in testset_results
if result.solution.IsCorrect()]
num_corrects = len(correct_solution_results)
num_incorrects = num_solutions - num_corrects
num_agreed = len([result for result in correct_solution_results
if result.expected])
need_custom_judge = problem.need_custom_judge
# Solutions:
if num_corrects >= 2:
solutions_state = ItemState.GOOD
elif num_corrects >= 1:
solutions_state = ItemState.NOTBAD
else:
solutions_state = ItemState.BAD
# Input:
if num_tests >= 20:
inputs_state = ItemState.GOOD
else:
inputs_state = ItemState.BAD
# Output:
if num_corrects >= 2 and num_agreed == num_corrects:
outputs_state = ItemState.GOOD
elif num_agreed >= 2:
outputs_state = ItemState.NOTBAD
else:
outputs_state = ItemState.BAD
# Validator:
if problem.testset.validators:
validator_state = ItemState.GOOD
else:
validator_state = ItemState.BAD
# Judge:
if need_custom_judge:
custom_judges = [
judge for judge in problem.testset.judges
if judge.__class__ != basic_codes.InternalDiffCode]
if custom_judges:
judge_state = ItemState.GOOD
else:
judge_state = ItemState.BAD
else:
judge_state = ItemState.NA
# Done.
return {
'title': SafeUnicode(problem.title) or 'No Title',
'solutions': solutions,
'testcases': testcases,
'assignees': SafeUnicode(assignees),
'solution_state': {
'status': solutions_state,
'detail': '%d+%d' % (num_corrects, num_incorrects),
},
'input_state': {
'status': inputs_state,
'detail': str(num_tests),
},
'output_state': {
'status': outputs_state,
'detail': '%d/%d' % (num_agreed, num_corrects),
},
'validator': validator_state,
'judge': judge_state,
'wiki_name': SafeUnicode(problem.wiki_name) or 'No Wiki Name',
} | /plugins/summary/summary.py | 0.442637 | 0.178007 | summary.py | pypi |
"""Export profiles files from the platform to a given file."""
import argparse
import os
import sys
import riminder
from resume_exporter import api_utils
from resume_exporter import export_supervisor
from resume_exporter import printer
def parse_args():
"""Parse command line argument."""
argsParser = argparse.ArgumentParser(description='Send resume to the platform.')
argsParser.add_argument('--source_ids', nargs='*', default=None)
argsParser.add_argument('--api_key', default=None)
argsParser.add_argument('--target', default=None, required=True)
argsParser.add_argument('--verbose', action='store_const', const=True, default=False)
argsParser.add_argument('--silent', action='store_const', const=True, default=False)
argsParser.add_argument('--n-worker', default=3)
argsParser.add_argument('--logfile', default=None, required=False)
args = argsParser.parse_args()
return args
def get_all_source_ids(api):
"""Get all source id for a given key."""
res = []
resp, err = api_utils.exec_api_call(lambda: api.source.list())
if err is not None:
err = "Cannot get sources: {}".format(err)
return (None, err)
for source in resp:
res.append(source['source_id'])
return (res, None)
def get_from_stdin(message):
"""Prompt a message and wait for user input."""
print(message, end='', flush=True)
res = sys.stdin.readline()
res = res[:-1]
return res
def get_user_data(args):
"""Get command line missing datas."""
if args.api_key is None:
args.api_key = get_from_stdin('api secret key: ')
if args.source_ids is None:
api = riminder.Riminder(args.api_key)
source_ids, err = get_all_source_ids(api)
if err is not None:
return (args, err)
args.source_ids = source_ids
args.v_level = printer.VERBOSE_LEVEL_NORMAL
if args.silent:
args.v_level = printer.VERBOSE_LEVEL_SILENT
if args.verbose:
args.v_level = printer.VERBOSE_LEVEL_VERBOSE
return (args, None)
def main():
"""Well..."""
args = parse_args()
args, err = get_user_data(args)
if err is not None:
raise BaseException("Error during startup: {}".format(err))
if not os.path.isdir(args.target):
raise BaseException("'{}' is not a directory.".format(args.target))
if args.n_worker < 1:
raise BaseException("{} is not a valid n_worker, must be greater than 0".format(args.n_worker))
export_sup = export_supervisor.Export_supervisor(args)
export_sup.start()
if __name__ == '__main__':
main() | /riminder_resume_exporter-0.0.3-py3-none-any.whl/resume_exporter/resume_exporter.py | 0.49292 | 0.157979 | resume_exporter.py | pypi |
import os
import zlib
import json
import pickle
import hashlib
import logging
import threading
from pathlib import Path
from typing import MutableMapping, Callable, Tuple, Union, Any
_压缩 = {
'zlib': (
zlib.compress,
zlib.decompress,
)
}
try:
import lzma
_压缩['lzma'] = (
lzma.compress,
lzma.decompress,
)
except ModuleNotFoundError:
logging.warning('没有安装lzma!')
_序列化 = {
'pickle': (
pickle.dumps,
pickle.loads,
),
'json': (
lambda x: json.dumps(x, sort_keys=True, ensure_ascii=False, separators=(',', ':')).encode('utf8'),
json.loads,
),
}
_锁 = {hex(i)[2:].zfill(2): threading.Lock() for i in range(256)}
F = Union[str, Tuple[Callable, Callable], None]
def _cf(s: F, d: dict) -> Tuple[Callable, Callable]:
if s is None:
return lambda x: x, lambda x: x
elif isinstance(s, str):
return d[s]
else:
return s
class 好dict(MutableMapping[str, bytes]):
def __init__(self, path, compress: F = None):
self.path = Path(path)
if self.path.is_file():
raise Exception('你不对劲')
self.path.mkdir(parents=True, exist_ok=True)
self.dirs = set()
self.compress, self.decompress = _cf(compress, _压缩)
def __contains__(self, k: str):
return (self.path/k[:2]/(k[2:]+'_')).is_file()
def __getitem__(self, k: str):
if k not in self:
raise KeyError(k)
rk = hashlib.md5(k.encode('utf8')).hexdigest()[:2]
with _锁[rk]:
with open(self.path/k[:2]/(k[2:]+'_'), 'rb') as f:
t = f.read()
return self.decompress(t)
def __setitem__(self, k: str, v):
if k[:2] not in self.dirs:
(self.path/k[:2]).mkdir(exist_ok=True)
self.dirs.add(k[:2])
t = self.compress(v)
rk = hashlib.md5(k.encode('utf8')).hexdigest()[:2]
with _锁[rk]:
with open(self.path/k[:2]/(k[2:]+'_'), 'wb') as f:
f.write(t)
def __delitem__(self, k):
os.remove(self.path/k[:2]/(k[2:]+'_'))
def __len__(self):
return sum([len(os.listdir(self.path/a)) for a in os.listdir(self.path)])
def __iter__(self):
for a in os.listdir(self.path):
for b in os.listdir(self.path/a):
yield a+b[:-1]
# 它继承了MutableMapping[str, bytes],但是其实它是MutableMapping[str, Any],但是我也不知道怎么办
class 超dict(好dict):
def __init__(self, path, compress: F = None, serialize: F = 'json'):
super().__init__(path, compress)
self.serialize, self.deserialize = _cf(serialize, _序列化)
def __getitem__(self, k: str):
return self.deserialize(super().__getitem__(k))
def __setitem__(self, k: str, v: Any):
return super().__setitem__(k, self.serialize(v)) | /rimo_storage-1.3.2-py3-none-any.whl/rimo_storage/__init__.py | 0.473414 | 0.161023 | __init__.py | pypi |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.