
code stringlengths 114 1.05M | path stringlengths 3 312 | quality_prob float64 0.5 0.99 | learning_prob float64 0.2 1 | filename stringlengths 3 168 | kind stringclasses 1
value |
|---|---|---|---|---|---|
from dm_control import suite
from dm_control.rl.control import flatten_observation
from dm_control.rl.environment import StepType
import numpy as np
import pygame
from rllab.core import Serializable
from rllab.envs import Env
from rllab.envs import Step
from rllab.envs.dm_control_viewer import DmControlViewer
from rllab.spaces import Box
from rllab.spaces import Discrete
class DmControlEnv(Env, Serializable):
"""
Binding for [dm_control](https://arxiv.org/pdf/1801.00690.pdf)
"""
def __init__(
self,
domain_name,
task_name,
plot=False,
width=320,
height=240,
):
Serializable.quick_init(self, locals())
self._env = suite.load(domain_name=domain_name, task_name=task_name)
self._total_reward = 0
self._render_kwargs = {'width': width, 'height': height}
if plot:
self._viewer = DmControlViewer()
else:
self._viewer = None
def step(self, action):
time_step = self._env.step(action)
if time_step.reward:
self._total_reward += time_step.reward
return Step(flatten_observation(time_step.observation), \
time_step.reward, \
time_step.step_type == StepType.LAST, \
**time_step.observation)
def reset(self):
self._total_reward = 0
time_step = self._env.reset()
return flatten_observation(time_step.observation)
def render(self):
if self._viewer:
pixels_img = self._env.physics.render(**self._render_kwargs)
self._viewer.loop_once(pixels_img)
def terminate(self):
if self._viewer:
self._viewer.finish()
def _flat_shape(self, observation):
return np.sum(int(np.prod(v.shape)) for k, v in observation.items())
@property
def action_space(self):
action_spec = self._env.action_spec()
if (len(action_spec.shape) == 1) and (-np.inf in action_spec.minimum or
np.inf in action_spec.maximum):
return Discrete(np.prod(action_spec.shape))
else:
return Box(action_spec.minimum, action_spec.maximum)
@property
def observation_space(self):
flat_dim = self._flat_shape(self._env.observation_spec())
return Box(low=-np.inf, high=np.inf, shape=[flat_dim])
@property
def total_reward(self):
return self._total_reward | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/dm_control_env.py | 0.773644 | 0.257768 | dm_control_env.py | pypi |
import logging
import os
import os.path as osp
import traceback
import gym
import gym.envs
import gym.spaces
import gym.wrappers
try:
from gym import logger as monitor_logger
monitor_logger.setLevel(logging.WARNING)
except Exception as e:
traceback.print_exc()
from rllab.core import Serializable
from rllab.envs import Env
from rllab.envs import Step
from rllab.misc import logger
from rllab.spaces import Box
from rllab.spaces import Discrete
from rllab.spaces import Product
def convert_gym_space(space):
if isinstance(space, gym.spaces.Box):
return Box(low=space.low, high=space.high)
elif isinstance(space, gym.spaces.Discrete):
return Discrete(n=space.n)
elif isinstance(space, gym.spaces.Tuple):
return Product([convert_gym_space(x) for x in space.spaces])
else:
raise NotImplementedError
class CappedCubicVideoSchedule(object):
# Copied from gym, since this method is frequently moved around
def __call__(self, count):
if count < 1000:
return int(round(count**(1. / 3)))**3 == count
else:
return count % 1000 == 0
class FixedIntervalVideoSchedule(object):
def __init__(self, interval):
self.interval = interval
def __call__(self, count):
return count % self.interval == 0
class NoVideoSchedule(object):
def __call__(self, count):
return False
class GymEnv(Env, Serializable):
def __init__(self,
env_name,
record_video=True,
video_schedule=None,
log_dir=None,
record_log=True,
force_reset=False):
if log_dir is None:
if logger.get_snapshot_dir() is None:
logger.log(
"Warning: skipping Gym environment monitoring since "
"snapshot_dir not configured.")
else:
log_dir = os.path.join(logger.get_snapshot_dir(), "gym_log")
Serializable.quick_init(self, locals())
env = gym.envs.make(env_name)
self.env = env
self.env_id = env.spec.id
assert not (not record_log and record_video)
if log_dir is None or record_log is False:
self.monitoring = False
else:
if not record_video:
video_schedule = NoVideoSchedule()
else:
if video_schedule is None:
video_schedule = CappedCubicVideoSchedule()
self.env = gym.wrappers.Monitor(
self.env, log_dir, video_callable=video_schedule, force=True)
self.monitoring = True
self._observation_space = convert_gym_space(env.observation_space)
logger.log("observation space: {}".format(self._observation_space))
self._action_space = convert_gym_space(env.action_space)
logger.log("action space: {}".format(self._action_space))
self._horizon = env.spec.tags[
'wrapper_config.TimeLimit.max_episode_steps']
self._log_dir = log_dir
self._force_reset = force_reset
@property
def observation_space(self):
return self._observation_space
@property
def action_space(self):
return self._action_space
@property
def horizon(self):
return self._horizon
def reset(self):
if self._force_reset and self.monitoring:
from gym.wrappers.monitoring import Monitor
assert isinstance(self.env, Monitor)
recorder = self.env.stats_recorder
if recorder is not None:
recorder.done = True
return self.env.reset()
def step(self, action):
next_obs, reward, done, info = self.env.step(action)
return Step(next_obs, reward, done, **info)
def render(self):
self.env.render()
def terminate(self):
if self.monitoring:
self.env._close()
if self._log_dir is not None:
print("""
***************************
Training finished! You can upload results to OpenAI Gym by running the
following command:
python scripts/submit_gym.py %s
***************************
""" % self._log_dir) | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/gym_env.py | 0.698432 | 0.210523 | gym_env.py | pypi |
import numpy as np
from rllab.core import Serializable
from rllab.envs import Step
from rllab.envs.mujoco import MujocoEnv
from rllab.misc import autoargs
from rllab.misc import logger
from rllab.misc.overrides import overrides
class SimpleHumanoidEnv(MujocoEnv, Serializable):
FILE = 'simple_humanoid.xml'
@autoargs.arg(
'vel_deviation_cost_coeff',
type=float,
help='cost coefficient for velocity deviation')
@autoargs.arg(
'alive_bonus', type=float, help='bonus reward for being alive')
@autoargs.arg(
'ctrl_cost_coeff',
type=float,
help='cost coefficient for control inputs')
@autoargs.arg(
'impact_cost_coeff', type=float, help='cost coefficient for impact')
def __init__(self,
vel_deviation_cost_coeff=1e-2,
alive_bonus=0.2,
ctrl_cost_coeff=1e-3,
impact_cost_coeff=1e-5,
*args,
**kwargs):
self.vel_deviation_cost_coeff = vel_deviation_cost_coeff
self.alive_bonus = alive_bonus
self.ctrl_cost_coeff = ctrl_cost_coeff
self.impact_cost_coeff = impact_cost_coeff
super(SimpleHumanoidEnv, self).__init__(*args, **kwargs)
Serializable.quick_init(self, locals())
def get_current_obs(self):
data = self.sim.data
return np.concatenate([
data.qpos.flat,
data.qvel.flat,
np.clip(data.cfrc_ext, -1, 1).flat,
self.get_body_com("torso").flat,
])
def _get_com(self):
data = self.sim.data
mass = self.sim.body_mass
xpos = data.xipos
return (np.sum(mass * xpos, 0) / np.sum(mass))[0]
def step(self, action):
self.forward_dynamics(action)
next_obs = self.get_current_obs()
alive_bonus = self.alive_bonus
data = self.sim.data
comvel = self.get_body_comvel("torso")
lin_vel_reward = comvel[0]
lb, ub = self.action_bounds
scaling = (ub - lb) * 0.5
ctrl_cost = .5 * self.ctrl_cost_coeff * np.sum(
np.square(action / scaling))
impact_cost = .5 * self.impact_cost_coeff * np.sum(
np.square(np.clip(data.cfrc_ext, -1, 1)))
vel_deviation_cost = 0.5 * self.vel_deviation_cost_coeff * np.sum(
np.square(comvel[1:]))
reward = lin_vel_reward + alive_bonus - ctrl_cost - \
impact_cost - vel_deviation_cost
done = data.qpos[2] < 0.8 or data.qpos[2] > 2.0
return Step(next_obs, reward, done)
@overrides
def log_diagnostics(self, paths):
progs = [
path["observations"][-1][-3] - path["observations"][0][-3]
for path in paths
]
logger.record_tabular('AverageForwardProgress', np.mean(progs))
logger.record_tabular('MaxForwardProgress', np.max(progs))
logger.record_tabular('MinForwardProgress', np.min(progs))
logger.record_tabular('StdForwardProgress', np.std(progs)) | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/mujoco/simple_humanoid_env.py | 0.678753 | 0.317611 | simple_humanoid_env.py | pypi |
import numpy as np
from rllab.core import Serializable
from rllab.envs import Step
from rllab.envs.mujoco import MujocoEnv
from rllab.misc import autoargs
from rllab.misc import logger
from rllab.misc.overrides import overrides
class SwimmerEnv(MujocoEnv, Serializable):
FILE = 'swimmer.xml'
ORI_IND = 2
@autoargs.arg(
'ctrl_cost_coeff', type=float, help='cost coefficient for controls')
def __init__(self, ctrl_cost_coeff=1e-2, *args, **kwargs):
self.ctrl_cost_coeff = ctrl_cost_coeff
super(SwimmerEnv, self).__init__(*args, **kwargs)
Serializable.quick_init(self, locals())
def get_current_obs(self):
return np.concatenate([
self.sim.data.qpos.flat,
self.sim.data.qvel.flat,
self.get_body_com("torso").flat,
]).reshape(-1)
def get_ori(self):
return self.sim.data.qpos[self.__class__.ORI_IND]
def step(self, action):
self.forward_dynamics(action)
next_obs = self.get_current_obs()
lb, ub = self.action_bounds
scaling = (ub - lb) * 0.5
ctrl_cost = 0.5 * self.ctrl_cost_coeff * np.sum(
np.square(action / scaling))
forward_reward = self.get_body_comvel("torso")[0]
reward = forward_reward - ctrl_cost
done = False
return Step(next_obs, reward, done)
@overrides
def log_diagnostics(self, paths):
if len(paths) > 0:
progs = [
path["observations"][-1][-3] - path["observations"][0][-3]
for path in paths
]
logger.record_tabular('AverageForwardProgress', np.mean(progs))
logger.record_tabular('MaxForwardProgress', np.max(progs))
logger.record_tabular('MinForwardProgress', np.min(progs))
logger.record_tabular('StdForwardProgress', np.std(progs))
else:
logger.record_tabular('AverageForwardProgress', np.nan)
logger.record_tabular('MaxForwardProgress', np.nan)
logger.record_tabular('MinForwardProgress', np.nan)
logger.record_tabular('StdForwardProgress', np.nan) | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/mujoco/swimmer_env.py | 0.63273 | 0.211682 | swimmer_env.py | pypi |
import os
import os.path as osp
import tempfile
import warnings
from cached_property import cached_property
import mako.lookup
import mako.template
import mujoco_py
from mujoco_py import functions
from mujoco_py import load_model_from_path
from mujoco_py import MjSim
from mujoco_py import MjViewer
import numpy as np
import theano
from rllab import spaces
from rllab.envs import Env
from rllab.misc import autoargs
from rllab.misc import logger
from rllab.misc.overrides import overrides
warnings.simplefilter(action='ignore', category=FutureWarning)
MODEL_DIR = osp.abspath(
osp.join(osp.dirname(__file__), '../../../vendor/mujoco_models'))
BIG = 1e6
def q_inv(a):
return [a[0], -a[1], -a[2], -a[3]]
def q_mult(a, b): # multiply two quaternion
w = a[0] * b[0] - a[1] * b[1] - a[2] * b[2] - a[3] * b[3]
i = a[0] * b[1] + a[1] * b[0] + a[2] * b[3] - a[3] * b[2]
j = a[0] * b[2] - a[1] * b[3] + a[2] * b[0] + a[3] * b[1]
k = a[0] * b[3] + a[1] * b[2] - a[2] * b[1] + a[3] * b[0]
return [w, i, j, k]
class MujocoEnv(Env):
FILE = None
@autoargs.arg(
'action_noise',
type=float,
help='Noise added to the controls, which will be '
'proportional to the action bounds')
def __init__(self, action_noise=0.0, file_path=None, template_args=None):
# compile template
if file_path is None:
if self.__class__.FILE is None:
raise "Mujoco file not specified"
file_path = osp.join(MODEL_DIR, self.__class__.FILE)
if file_path.endswith(".mako"):
lookup = mako.lookup.TemplateLookup(directories=[MODEL_DIR])
with open(file_path) as template_file:
template = mako.template.Template(
template_file.read(), lookup=lookup)
content = template.render(
opts=template_args if template_args is not None else {}, )
tmp_f, file_path = tempfile.mkstemp(text=True)
with open(file_path, 'w') as f:
f.write(content)
self.model = load_model_from_path(file_path)
os.close(tmp_f)
else:
self.model = load_model_from_path(file_path)
self.sim = MjSim(self.model)
self.data = self.sim.data
self.viewer = None
self.init_qpos = self.sim.data.qpos
self.init_qvel = self.sim.data.qvel
self.init_qacc = self.sim.data.qacc
self.init_ctrl = self.sim.data.ctrl
self.qpos_dim = self.init_qpos.size
self.qvel_dim = self.init_qvel.size
self.ctrl_dim = self.init_ctrl.size
self.action_noise = action_noise
self.frame_skip = 1
self.dcom = None
self.current_com = None
self.reset()
super(MujocoEnv, self).__init__()
@cached_property
@overrides
def action_space(self):
bounds = self.model.actuator_ctrlrange
lb = bounds[:, 0]
ub = bounds[:, 1]
return spaces.Box(lb, ub)
@cached_property
@overrides
def observation_space(self):
shp = self.get_current_obs().shape
ub = BIG * np.ones(shp)
return spaces.Box(ub * -1, ub)
@property
def action_bounds(self):
return self.action_space.bounds
def reset_mujoco(self, init_state=None):
self.sim.reset()
if init_state is None:
self.sim.data.qpos[:] = self.init_qpos + np.random.normal(
size=self.init_qpos.shape) * 0.01
self.sim.data.qvel[:] = self.init_qvel + np.random.normal(
size=self.init_qvel.shape) * 0.1
self.sim.data.qacc[:] = self.init_qacc
self.sim.data.ctrl[:] = self.init_ctrl
else:
start = 0
for datum_name in ["qpos", "qvel", "qacc", "ctrl"]:
datum = getattr(self.sim.data, datum_name)
datum_dim = datum.shape[0]
datum = init_state[start:start + datum_dim]
setattr(self.sim.data, datum_name, datum)
start += datum_dim
@overrides
def reset(self, init_state=None):
self.reset_mujoco(init_state)
self.sim.forward()
self.current_com = self.sim.data.subtree_com[0]
self.dcom = np.zeros_like(self.current_com)
return self.get_current_obs()
def get_current_obs(self):
return self._get_full_obs()
def _get_full_obs(self):
data = self.sim.data
cdists = np.copy(self.sim.geom_margin).flat
for c in self.sim.data.contact:
cdists[c.geom2] = min(cdists[c.geom2], c.dist)
obs = np.concatenate([
data.qpos.flat,
data.qvel.flat,
data.cinert.flat,
data.cvel.flat,
data.qfrc_actuator.flat,
data.cfrc_ext.flat,
data.qfrc_constraint.flat,
cdists,
self.dcom.flat,
])
return obs
@property
def _state(self):
return np.concatenate(
[self.sim.data.qpos.flat, self.sim.data.qvel.flat])
@property
def _full_state(self):
return np.concatenate([
self.sim.data.qpos,
self.sim.data.qvel,
self.sim.data.qacc,
self.sim.data.ctrl,
]).ravel()
def inject_action_noise(self, action):
# generate action noise
noise = self.action_noise * \
np.random.normal(size=action.shape)
# rescale the noise to make it proportional to the action bounds
lb, ub = self.action_bounds
noise = 0.5 * (ub - lb) * noise
return action + noise
def forward_dynamics(self, action):
self.sim.data.ctrl[:] = self.inject_action_noise(action)
for _ in range(self.frame_skip):
self.sim.step()
self.sim.forward()
new_com = self.sim.data.subtree_com[0]
self.dcom = new_com - self.current_com
self.current_com = new_com
def get_viewer(self):
if self.viewer is None:
self.viewer = MjViewer(self.sim)
return self.viewer
def render(self, close=False, mode='human'):
if mode == 'human':
viewer = self.get_viewer()
viewer.render()
elif mode == 'rgb_array':
viewer = self.get_viewer()
viewer.render()
data, width, height = viewer.get_image()
return np.fromstring(
data, dtype='uint8').reshape(height, width, 3)[::-1, :, :]
if close:
self.stop_viewer()
def start_viewer(self):
viewer = self.get_viewer()
if not viewer.running:
viewer.start()
def stop_viewer(self):
if self.viewer:
self.viewer.finish()
def release(self):
# temporarily alleviate the issue (but still some leak)
functions.mj_deleteModel(self.sim._wrapped)
functions.mj_deleteData(self.data._wrapped)
def get_body_xmat(self, body_name):
return self.data.get_body_xmat(body_name).reshape((3, 3))
def get_body_com(self, body_name):
return self.data.get_body_xpos(body_name)
def get_body_comvel(self, body_name):
return self.data.get_body_xvelp(body_name)
def print_stats(self):
super(MujocoEnv, self).print_stats()
print("qpos dim:\t%d" % len(self.sim.data.qpos))
def action_from_key(self, key):
raise NotImplementedError | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/mujoco/mujoco_env.py | 0.579995 | 0.296616 | mujoco_env.py | pypi |
import math
import numpy as np
from rllab.core import Serializable
from rllab.envs import Step
from rllab.envs.mujoco import MujocoEnv
from rllab.envs.mujoco.mujoco_env import q_inv
from rllab.envs.mujoco.mujoco_env import q_mult
from rllab.misc import logger
from rllab.misc.overrides import overrides
class AntEnv(MujocoEnv, Serializable):
FILE = 'ant.xml'
ORI_IND = 3
def __init__(self, *args, **kwargs):
super(AntEnv, self).__init__(*args, **kwargs)
Serializable.__init__(self, *args, **kwargs)
def get_current_obs(self):
return np.concatenate([
self.sim.data.qpos.flat,
self.sim.data.qvel.flat,
np.clip(self.sim.data.cfrc_ext, -1, 1).flat,
self.get_body_xmat("torso").flat,
self.get_body_com("torso"),
]).reshape(-1)
def step(self, action):
self.forward_dynamics(action)
comvel = self.get_body_comvel("torso")
forward_reward = comvel[0]
lb, ub = self.action_bounds
scaling = (ub - lb) * 0.5
ctrl_cost = 0.5 * 1e-2 * np.sum(np.square(action / scaling))
contact_cost = 0.5 * 1e-3 * np.sum(
np.square(np.clip(self.sim.data.cfrc_ext, -1, 1))),
survive_reward = 0.05
reward = forward_reward - ctrl_cost - contact_cost + survive_reward
state = self._state
notdone = np.isfinite(state).all() \
and state[2] >= 0.2 and state[2] <= 1.0
done = not notdone
ob = self.get_current_obs()
return Step(ob, float(reward), done)
@overrides
def get_ori(self):
ori = [0, 1, 0, 0]
rot = self.sim.data.qpos[self.__class__.ORI_IND:self.__class__.ORI_IND
+ 4] # take the quaternion
ori = q_mult(q_mult(rot, ori),
q_inv(rot))[1:3] # project onto x-y plane
ori = math.atan2(ori[1], ori[0])
return ori
@overrides
def log_diagnostics(self, paths):
progs = [
path["observations"][-1][-3] - path["observations"][0][-3]
for path in paths
]
logger.record_tabular('AverageForwardProgress', np.mean(progs))
logger.record_tabular('MaxForwardProgress', np.max(progs))
logger.record_tabular('MinForwardProgress', np.min(progs))
logger.record_tabular('StdForwardProgress', np.std(progs)) | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/mujoco/ant_env.py | 0.621541 | 0.27881 | ant_env.py | pypi |
import numpy as np
from rllab.core import Serializable
from rllab.envs import Step
from rllab.envs.mujoco import MujocoEnv
from rllab.misc import autoargs
from rllab.misc import logger
from rllab.misc.overrides import overrides
# states: [
# 0: z-coord,
# 1: x-coord (forward distance),
# 2: forward pitch along y-axis,
# 6: z-vel (up = +),
# 7: xvel (forward = +)
class HopperEnv(MujocoEnv, Serializable):
FILE = 'hopper.xml'
@autoargs.arg(
'alive_coeff', type=float, help='reward coefficient for being alive')
@autoargs.arg(
'ctrl_cost_coeff', type=float, help='cost coefficient for controls')
def __init__(self, alive_coeff=1, ctrl_cost_coeff=0.01, *args, **kwargs):
self.alive_coeff = alive_coeff
self.ctrl_cost_coeff = ctrl_cost_coeff
super(HopperEnv, self).__init__(*args, **kwargs)
Serializable.quick_init(self, locals())
@overrides
def get_current_obs(self):
return np.concatenate([
self.sim.data.qpos[0:1].flat,
self.sim.data.qpos[2:].flat,
np.clip(self.sim.data.qvel, -10, 10).flat,
np.clip(self.sim.data.qfrc_constraint, -10, 10).flat,
self.get_body_com("torso").flat,
])
@overrides
def step(self, action):
self.forward_dynamics(action)
next_obs = self.get_current_obs()
lb, ub = self.action_bounds
scaling = (ub - lb) * 0.5
vel = self.get_body_comvel("torso")[0]
reward = vel + self.alive_coeff - \
0.5 * self.ctrl_cost_coeff * np.sum(np.square(action / scaling))
state = self._state
notdone = np.isfinite(state).all() and \
(np.abs(state[3:]) < 100).all() and (state[0] > .7) and \
(abs(state[2]) < .2)
done = not notdone
return Step(next_obs, reward, done)
@overrides
def log_diagnostics(self, paths):
progs = [
path["observations"][-1][-3] - path["observations"][0][-3]
for path in paths
]
logger.record_tabular('AverageForwardProgress', np.mean(progs))
logger.record_tabular('MaxForwardProgress', np.max(progs))
logger.record_tabular('MinForwardProgress', np.min(progs))
logger.record_tabular('StdForwardProgress', np.std(progs)) | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/mujoco/hopper_env.py | 0.665628 | 0.361672 | hopper_env.py | pypi |
import math
import os.path as osp
import tempfile
import xml.etree.ElementTree as ET
import numpy as np
from rllab import spaces
from rllab.core import Serializable
from rllab.envs import Step
from rllab.envs.mujoco.maze.maze_env_utils import construct_maze
from rllab.envs.mujoco.maze.maze_env_utils import point_distance
from rllab.envs.mujoco.maze.maze_env_utils import ray_segment_intersect
from rllab.envs.mujoco.mujoco_env import BIG
from rllab.envs.mujoco.mujoco_env import MODEL_DIR
from rllab.envs.proxy_env import ProxyEnv
from rllab.misc import logger
from rllab.misc.overrides import overrides
class MazeEnv(ProxyEnv, Serializable):
MODEL_CLASS = None
ORI_IND = None
MAZE_HEIGHT = None
MAZE_SIZE_SCALING = None
MAZE_MAKE_CONTACTS = False
MAZE_STRUCTURE = [
[1, 1, 1, 1, 1],
[1, 'r', 0, 0, 1],
[1, 1, 1, 0, 1],
[1, 'g', 0, 0, 1],
[1, 1, 1, 1, 1],
]
MANUAL_COLLISION = False
def __init__(
self,
n_bins=20,
sensor_range=10.,
sensor_span=math.pi,
maze_id=0,
length=1,
maze_height=0.5,
maze_size_scaling=2,
# a coef of 0 gives no reward to the maze from the wrapped env.
coef_inner_rew=0.,
goal_rew=1., # reward obtained when reaching the goal
*args,
**kwargs):
Serializable.quick_init(self, locals())
Serializable.quick_init(self, locals())
self._n_bins = n_bins
self._sensor_range = sensor_range
self._sensor_span = sensor_span
self._maze_id = maze_id
self.length = length
self.coef_inner_rew = coef_inner_rew
self.goal_rew = goal_rew
model_cls = self.__class__.MODEL_CLASS
if model_cls is None:
raise "MODEL_CLASS unspecified!"
xml_path = osp.join(MODEL_DIR, model_cls.FILE)
tree = ET.parse(xml_path)
worldbody = tree.find(".//worldbody")
self.MAZE_HEIGHT = height = maze_height
self.MAZE_SIZE_SCALING = size_scaling = maze_size_scaling
self.MAZE_STRUCTURE = structure = construct_maze(
maze_id=self._maze_id, length=self.length)
torso_x, torso_y = self._find_robot()
self._init_torso_x = torso_x
self._init_torso_y = torso_y
for i in range(len(structure)):
for j in range(len(structure[0])):
if str(structure[i][j]) == '1':
# offset all coordinates so that robot starts at the origin
ET.SubElement(
worldbody,
"geom",
name="block_%d_%d" % (i, j),
pos="%f %f %f" % (j * size_scaling - torso_x,
i * size_scaling - torso_y,
height / 2 * size_scaling),
size="%f %f %f" %
(0.5 * size_scaling, 0.5 * size_scaling,
height / 2 * size_scaling),
type="box",
material="",
contype="1",
conaffinity="1",
rgba="0.4 0.4 0.4 1")
torso = tree.find(".//body[@name='torso']")
geoms = torso.findall(".//geom")
for geom in geoms:
if 'name' not in geom.attrib:
raise Exception("Every geom of the torso must have a name "
"defined")
if self.__class__.MAZE_MAKE_CONTACTS:
contact = ET.SubElement(tree.find("."), "contact")
for i in range(len(structure)):
for j in range(len(structure[0])):
if str(structure[i][j]) == '1':
for geom in geoms:
ET.SubElement(
contact,
"pair",
geom1=geom.attrib["name"],
geom2="block_%d_%d" % (i, j))
_, file_path = tempfile.mkstemp(text=True)
tree.write(
file_path
) # here we write a temporal file with the robot specifications.
# Why not the original one??
self._goal_range = self._find_goal_range()
self._cached_segments = None
inner_env = model_cls(
*args, file_path=file_path,
**kwargs) # file to the robot specifications
ProxyEnv.__init__(
self, inner_env) # here is where the robot env will be initialized
def get_current_maze_obs(self):
# The observation would include both information about the robot itself
# as well as the sensors around its environment
robot_x, robot_y = self.wrapped_env.get_body_com("torso")[:2]
ori = self.get_ori()
structure = self.MAZE_STRUCTURE
size_scaling = self.MAZE_SIZE_SCALING
segments = []
# compute the distance of all segments
# Get all line segments of the goal and the obstacles
for i in range(len(structure)):
for j in range(len(structure[0])):
if structure[i][j] == 1 or structure[i][j] == 'g':
cx = j * size_scaling - self._init_torso_x
cy = i * size_scaling - self._init_torso_y
x1 = cx - 0.5 * size_scaling
x2 = cx + 0.5 * size_scaling
y1 = cy - 0.5 * size_scaling
y2 = cy + 0.5 * size_scaling
struct_segments = [
((x1, y1), (x2, y1)),
((x2, y1), (x2, y2)),
((x2, y2), (x1, y2)),
((x1, y2), (x1, y1)),
]
for seg in struct_segments:
segments.append(
dict(
segment=seg,
type=structure[i][j],
))
wall_readings = np.zeros(self._n_bins)
goal_readings = np.zeros(self._n_bins)
for ray_idx in range(self._n_bins):
ray_ori = ori - self._sensor_span * 0.5 + 1.0 * (
2 * ray_idx + 1) / (2 * self._n_bins) * self._sensor_span
ray_segments = []
for seg in segments:
p = ray_segment_intersect(
ray=((robot_x, robot_y), ray_ori), segment=seg["segment"])
if p is not None:
ray_segments.append(
dict(
segment=seg["segment"],
type=seg["type"],
ray_ori=ray_ori,
distance=point_distance(p, (robot_x, robot_y)),
))
if len(ray_segments) > 0:
first_seg = sorted(
ray_segments, key=lambda x: x["distance"])[0]
# print first_seg
if first_seg["type"] == 1:
# Wall -> add to wall readings
if first_seg["distance"] <= self._sensor_range:
wall_readings[ray_idx] = (
self._sensor_range -
first_seg["distance"]) / self._sensor_range
elif first_seg["type"] == 'g':
# Goal -> add to goal readings
if first_seg["distance"] <= self._sensor_range:
goal_readings[ray_idx] = (
self._sensor_range -
first_seg["distance"]) / self._sensor_range
else:
assert False
obs = np.concatenate([wall_readings, goal_readings])
return obs
def get_current_robot_obs(self):
return self.wrapped_env.get_current_obs()
def get_current_obs(self):
return np.concatenate(
[self.wrapped_env.get_current_obs(),
self.get_current_maze_obs()])
def get_ori(self):
"""
First it tries to use a get_ori from the wrapped env. If not
successfull, falls back to the default based on the ORI_IND specified in
Maze (not accurate for quaternions)
"""
obj = self.wrapped_env
while not hasattr(obj, 'get_ori') and hasattr(obj, 'wrapped_env'):
obj = obj.wrapped_env
try:
return obj.get_ori()
except (NotImplementedError, AttributeError) as e:
pass
return self.wrapped_env.sim.data.qpos[self.__class__.ORI_IND]
def reset(self):
self.wrapped_env.reset()
return self.get_current_obs()
@property
def viewer(self):
return self.wrapped_env.viewer
@property
@overrides
def observation_space(self):
shp = self.get_current_obs().shape
ub = BIG * np.ones(shp)
return spaces.Box(ub * -1, ub)
# space of only the robot observations (they go first in the get current
# obs) THIS COULD GO IN PROXYENV
@property
def robot_observation_space(self):
shp = self.get_current_robot_obs().shape
ub = BIG * np.ones(shp)
return spaces.Box(ub * -1, ub)
@property
def maze_observation_space(self):
shp = self.get_current_maze_obs().shape
ub = BIG * np.ones(shp)
return spaces.Box(ub * -1, ub)
def _find_robot(self):
structure = self.MAZE_STRUCTURE
size_scaling = self.MAZE_SIZE_SCALING
for i in range(len(structure)):
for j in range(len(structure[0])):
if structure[i][j] == 'r':
return j * size_scaling, i * size_scaling
assert False
def _find_goal_range(self): # this only finds one goal!
structure = self.MAZE_STRUCTURE
size_scaling = self.MAZE_SIZE_SCALING
for i in range(len(structure)):
for j in range(len(structure[0])):
if structure[i][j] == 'g':
minx = j * size_scaling - size_scaling \
* 0.5 - self._init_torso_x
maxx = j * size_scaling + size_scaling \
* 0.5 - self._init_torso_x
miny = i * size_scaling - size_scaling \
* 0.5 - self._init_torso_y
maxy = i * size_scaling + size_scaling \
* 0.5 - self._init_torso_y
return minx, maxx, miny, maxy
def _is_in_collision(self, pos):
x, y = pos
structure = self.MAZE_STRUCTURE
size_scaling = self.MAZE_SIZE_SCALING
for i in range(len(structure)):
for j in range(len(structure[0])):
if structure[i][j] == 1:
minx = j * size_scaling - size_scaling \
* 0.5 - self._init_torso_x
maxx = j * size_scaling + size_scaling \
* 0.5 - self._init_torso_x
miny = i * size_scaling - size_scaling \
* 0.5 - self._init_torso_y
maxy = i * size_scaling + size_scaling \
* 0.5 - self._init_torso_y
if minx <= x <= maxx and miny <= y <= maxy:
return True
return False
def step(self, action):
if self.MANUAL_COLLISION:
old_pos = self.wrapped_env.get_xy()
inner_next_obs, inner_rew, done, info = self.wrapped_env.step(
action)
new_pos = self.wrapped_env.get_xy()
if self._is_in_collision(new_pos):
self.wrapped_env.set_xy(old_pos)
done = False
else:
inner_next_obs, inner_rew, done, info = self.wrapped_env.step(
action)
next_obs = self.get_current_obs()
x, y = self.wrapped_env.get_body_com("torso")[:2]
# ref_x = x + self._init_torso_x
# ref_y = y + self._init_torso_y
info['outer_rew'] = 0
info['inner_rew'] = inner_rew
reward = self.coef_inner_rew * inner_rew
minx, maxx, miny, maxy = self._goal_range
if minx <= x <= maxx and miny <= y <= maxy:
done = True
reward += self.goal_rew
# we keep here the original one, so that theAvgReturn is directly
# the freq of success
info['rew_rew'] = 1
return Step(next_obs, reward, done, **info)
def action_from_key(self, key):
return self.wrapped_env.action_from_key(key)
@overrides
def log_diagnostics(self, paths, *args, **kwargs):
# we call here any logging related to the maze, strip the maze obs and
# call log_diag with the stripped paths we need to log the purely gather
# reward!!
with logger.tabular_prefix('Maze_'):
gather_undiscounted_returns = [
sum(path['env_infos']['outer_rew']) for path in paths
]
logger.record_tabular_misc_stat(
'Return', gather_undiscounted_returns, placement='front')
stripped_paths = []
for path in paths:
stripped_path = {}
for k, v in path.items():
stripped_path[k] = v
stripped_path['observations'] = stripped_path[
'observations'][:, :
self.wrapped_env.observation_space.flat_dim]
# this breaks if the obs of the robot are d>1 dimensional (not a
# vector)
stripped_paths.append(stripped_path)
with logger.tabular_prefix('wrapped_'):
wrapped_undiscounted_return = np.mean(
[np.sum(path['env_infos']['inner_rew']) for path in paths])
logger.record_tabular('AverageReturn', wrapped_undiscounted_return)
self.wrapped_env.log_diagnostics(stripped_paths, *args, **kwargs) | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/mujoco/maze/maze_env.py | 0.456652 | 0.255811 | maze_env.py | pypi |
from Box2D import b2ContactListener
from Box2D import b2DrawExtended
from Box2D import b2Vec2
import pygame
from pygame import KEYDOWN
from pygame import KEYUP
from pygame import MOUSEBUTTONDOWN
from pygame import MOUSEMOTION
from pygame import QUIT
class PygameDraw(b2DrawExtended):
"""
This debug draw class accepts callbacks from Box2D (which specifies what to
draw) and handles all of the rendering.
If you are writing your own game, you likely will not want to use debug
drawing. Debug drawing, as its name implies, is for debugging.
"""
surface = None
axisScale = 50.0
def __init__(self, test=None, **kwargs):
b2DrawExtended.__init__(self, **kwargs)
self.flipX = False
self.flipY = True
self.convertVertices = True
self.test = test
self.flags = dict(
drawShapes=True,
convertVertices=True,
)
def StartDraw(self):
self.zoom = self.test.viewZoom
self.center = self.test.viewCenter
self.offset = self.test.viewOffset
self.screenSize = self.test.screenSize
def EndDraw(self):
pass
def DrawPoint(self, p, size, color):
"""
Draw a single point at point p given a pixel size and color.
"""
self.DrawCircle(p, size / self.zoom, color, drawwidth=0)
def DrawAABB(self, aabb, color):
"""
Draw a wireframe around the AABB with the given color.
"""
points = [(aabb.lowerBound.x, aabb.lowerBound.y), (aabb.upperBound.x,
aabb.lowerBound.y),
(aabb.upperBound.x, aabb.upperBound.y), (aabb.lowerBound.x,
aabb.upperBound.y)]
pygame.draw.aalines(self.surface, color, True, points)
def DrawSegment(self, p1, p2, color):
"""
Draw the line segment from p1-p2 with the specified color.
"""
pygame.draw.aaline(self.surface, color.bytes, p1, p2)
def DrawTransform(self, xf):
"""
Draw the transform xf on the screen
"""
p1 = xf.position
p2 = self.to_screen(p1 + self.axisScale * xf.R.x_axis)
p3 = self.to_screen(p1 + self.axisScale * xf.R.y_axis)
p1 = self.to_screen(p1)
pygame.draw.aaline(self.surface, (255, 0, 0), p1, p2)
pygame.draw.aaline(self.surface, (0, 255, 0), p1, p3)
def DrawCircle(self, center, radius, color, drawwidth=1):
"""
Draw a wireframe circle given the center, radius, axis of orientation
and color.
"""
radius *= self.zoom
if radius < 1:
radius = 1
else:
radius = int(radius)
pygame.draw.circle(self.surface, color.bytes, center, radius,
drawwidth)
def DrawSolidCircle(self, center, radius, axis, color):
"""
Draw a solid circle given the center, radius, axis of orientation and
color.
"""
radius *= self.zoom
if radius < 1:
radius = 1
else:
radius = int(radius)
pygame.draw.circle(self.surface, (color / 2).bytes + [127], center,
radius, 0)
pygame.draw.circle(self.surface, color.bytes, center, radius, 1)
pygame.draw.aaline(
self.surface, (255, 0, 0), center,
(center[0] - radius * axis[0], center[1] + radius * axis[1]))
def DrawSolidCapsule(self, p1, p2, radius, color):
pass
def DrawPolygon(self, vertices, color):
"""
Draw a wireframe polygon given the screen vertices with the specified
color.
"""
if not vertices:
return
if len(vertices) == 2:
pygame.draw.aaline(self.surface, color.bytes, vertices[0],
vertices)
else:
pygame.draw.polygon(self.surface, color.bytes, vertices, 1)
def DrawSolidPolygon(self, vertices, color):
"""
Draw a filled polygon given the screen vertices with the specified
color.
"""
if not vertices:
return
if len(vertices) == 2:
pygame.draw.aaline(self.surface, color.bytes, vertices[0],
vertices[1])
else:
pygame.draw.polygon(self.surface, (color / 2).bytes + [127],
vertices, 0)
pygame.draw.polygon(self.surface, color.bytes, vertices, 1)
class Box2DViewer(b2ContactListener):
def __init__(self, world):
super(Box2DViewer, self).__init__()
self.world = world
self.world.contactListener = self
self._reset()
pygame.init()
caption = "Box2D Simulator"
pygame.display.set_caption(caption)
self.screen = pygame.display.set_mode((800, 600))
self.screenSize = b2Vec2(*self.screen.get_size())
self.renderer = PygameDraw(surface=self.screen, test=self)
self.world.renderer = self.renderer
# FIXME, commented to avoid Linux error due to font.
# try:
# self.font = pygame.font.Font(None, 15)
# except IOError:
# try:
# self.font = pygame.font.Font("freesansbold.ttf", 15)
# except IOError:
# print("Unable to load default font or 'freesansbold.ttf'")
# print("Disabling text drawing.")
# self.Print = lambda *args: 0
# self.DrawStringAt = lambda *args: 0
self.viewCenter = (0, 20.0)
self._viewZoom = 100
def _reset(self):
self._viewZoom = 10.0
self._viewCenter = None
self._viewOffset = None
self.screenSize = None
self.rMouseDown = False
self.textLine = 30
self.font = None
def setCenter(self, value):
"""
Updates the view offset based on the center of the screen.
Tells the debug draw to update its values also.
"""
self._viewCenter = b2Vec2(*value)
self._viewCenter *= self._viewZoom
self._viewOffset = self._viewCenter - self.screenSize / 2
def setZoom(self, zoom):
self._viewZoom = zoom
viewZoom = property(
lambda self: self._viewZoom,
setZoom,
doc='Zoom factor for the display')
viewCenter = property(
lambda self: self._viewCenter / self._viewZoom,
setCenter,
doc='Screen center in camera coordinates')
viewOffset = property(
lambda self: self._viewOffset,
doc='The offset of the top-left corner of the '
'screen')
def checkEvents(self):
"""
Check for pygame events (mainly keyboard/mouse events).
Passes the events onto the GUI also.
"""
for event in pygame.event.get():
if event.type == QUIT or (event.type == KEYDOWN
and event.key == pygame.K_ESCAPE):
return False
elif event.type == KEYDOWN:
self._Keyboard_Event(event.key, down=True)
elif event.type == KEYUP:
self._Keyboard_Event(event.key, down=False)
elif event.type == MOUSEBUTTONDOWN:
if event.button == 4:
self.viewZoom *= 1.1
elif event.button == 5:
self.viewZoom /= 1.1
elif event.type == MOUSEMOTION:
if self.rMouseDown:
self.viewCenter -= (event.rel[0] / 5.0,
-event.rel[1] / 5.0)
return True
def _Keyboard_Event(self, key, down=True):
"""
Internal keyboard event, don't override this.
Checks for the initial keydown of the basic testbed keys. Passes the
unused ones onto the test via the Keyboard() function.
"""
if down:
if key == pygame.K_z: # Zoom in
self.viewZoom = min(2 * self.viewZoom, 500.0)
elif key == pygame.K_x: # Zoom out
self.viewZoom = max(0.9 * self.viewZoom, 0.02)
def CheckKeys(self):
"""
Check the keys that are evaluated on every main loop iteration.
I.e., they aren't just evaluated when first pressed down
"""
pygame.event.pump()
self.keys = keys = pygame.key.get_pressed()
if keys[pygame.K_LEFT]:
self.viewCenter -= (0.5, 0)
elif keys[pygame.K_RIGHT]:
self.viewCenter += (0.5, 0)
if keys[pygame.K_UP]:
self.viewCenter += (0, 0.5)
elif keys[pygame.K_DOWN]:
self.viewCenter -= (0, 0.5)
if keys[pygame.K_HOME]:
self.viewZoom = 1.0
self.viewCenter = (0.0, 20.0)
def ConvertScreenToWorld(self, x, y):
return b2Vec2(
(x + self.viewOffset.x) / self.viewZoom,
((self.screenSize.y - y + self.viewOffset.y) / self.viewZoom))
def loop_once(self):
self.checkEvents()
# self.CheckKeys()
self.screen.fill((0, 0, 0))
if self.renderer is not None:
self.renderer.StartDraw()
self.world.DrawDebugData()
self.renderer.EndDraw()
pygame.display.flip()
def finish(self):
pygame.quit() | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/box2d/box2d_viewer.py | 0.713132 | 0.415314 | box2d_viewer.py | pypi |
import numpy as np
import pygame
from rllab.core import Serializable
from rllab.envs.box2d.box2d_env import Box2DEnv
from rllab.envs.box2d.parser import find_body
from rllab.misc import autoargs
from rllab.misc.overrides import overrides
# Tornio, Matti, and Tapani Raiko. "Variational Bayesian approach for
# nonlinear identification and control." Proc. of the IFAC Workshop on
# Nonlinear Model Predictive Control for Fast Systems, NMPC FS06. 2006.
class CartpoleSwingupEnv(Box2DEnv, Serializable):
@autoargs.inherit(Box2DEnv.__init__)
def __init__(self, *args, **kwargs):
super(CartpoleSwingupEnv, self).__init__(
self.model_path("cartpole.xml.mako"), *args, **kwargs)
self.max_cart_pos = 3
self.max_reward_cart_pos = 3
self.cart = find_body(self.world, "cart")
self.pole = find_body(self.world, "pole")
Serializable.__init__(self, *args, **kwargs)
@overrides
def reset(self):
self._set_state(self.initial_state)
self._invalidate_state_caches()
bounds = np.array([
[-1, -2, np.pi - 1, -3],
[1, 2, np.pi + 1, 3],
])
low, high = bounds
xpos, xvel, apos, avel = np.random.uniform(low, high)
self.cart.position = (xpos, self.cart.position[1])
self.cart.linearVelocity = (xvel, self.cart.linearVelocity[1])
self.pole.angle = apos
self.pole.angularVelocity = avel
return self.get_current_obs()
@overrides
def compute_reward(self, action):
yield
if self.is_current_done():
yield -100
else:
if abs(self.cart.position[0]) > self.max_reward_cart_pos:
yield -1
else:
yield np.cos(self.pole.angle)
@overrides
def is_current_done(self):
return abs(self.cart.position[0]) > self.max_cart_pos
@overrides
def action_from_keys(self, keys):
if keys[pygame.K_LEFT]:
return np.asarray([-10])
elif keys[pygame.K_RIGHT]:
return np.asarray([+10])
else:
return np.asarray([0]) | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/box2d/cartpole_swingup_env.py | 0.67104 | 0.33406 | cartpole_swingup_env.py | pypi |
import numpy as np
import pygame
from rllab.core import Serializable
from rllab.envs.box2d.box2d_env import Box2DEnv
from rllab.envs.box2d.parser import find_body
from rllab.envs.box2d.parser.xml_box2d import _get_name
from rllab.misc import autoargs
from rllab.misc.overrides import overrides
class CarParkingEnv(Box2DEnv, Serializable):
@autoargs.inherit(Box2DEnv.__init__)
@autoargs.arg(
"random_start",
type=bool,
help=
"Randomized starting position by uniforming sampling starting car angle"
"and position from a circle of radius 5")
@autoargs.arg(
"random_start_range",
type=float,
help="Defaulted to 1. which means possible angles are 1. * 2*pi")
def __init__(self, *args, **kwargs):
Serializable.__init__(self, *args, **kwargs)
self.random_start = kwargs.pop("random_start", True)
self.random_start_range = kwargs.pop("random_start_range", 1.)
super(CarParkingEnv, self).__init__(
self.model_path("car_parking.xml"), *args, **kwargs)
self.goal = find_body(self.world, "goal")
self.car = find_body(self.world, "car")
self.wheels = [
body for body in self.world.bodies if "wheel" in _get_name(body)
]
self.front_wheels = [
body for body in self.wheels if "front" in _get_name(body)
]
self.max_deg = 30.
self.goal_radius = 1.
self.vel_thres = 1e-1
self.start_radius = 5.
@overrides
def before_world_step(self, action):
desired_angle = self.car.angle + action[-1] / 180 * np.pi
for wheel in self.front_wheels:
wheel.angle = desired_angle
wheel.angularVelocity = 0 # kill angular velocity
# kill all wheels' lateral speed
for wheel in self.wheels:
ortho = wheel.GetWorldVector((1, 0))
lateral_speed = wheel.linearVelocity.dot(ortho) * ortho
impulse = wheel.mass * -lateral_speed
wheel.ApplyLinearImpulse(impulse, wheel.worldCenter, True)
# also apply a tiny bit of fraction
mag = wheel.linearVelocity.dot(wheel.linearVelocity)
if mag != 0:
wheel.ApplyLinearImpulse(
0.1 * wheel.mass * -wheel.linearVelocity / mag**0.5,
wheel.worldCenter, True)
@property
@overrides
def action_dim(self):
return super(CarParkingEnv, self).action_dim + 1
@property
@overrides
def action_bounds(self):
lb, ub = super(CarParkingEnv, self).action_bounds
return np.append(lb, -self.max_deg), np.append(ub, self.max_deg)
@overrides
def reset(self):
self._set_state(self.initial_state)
self._invalidate_state_caches()
if self.random_start:
pos_angle, car_angle = np.random.rand(
2) * np.pi * 2 * self.random_start_range
dis = (self.start_radius * np.cos(pos_angle),
self.start_radius * np.sin(pos_angle))
for body in [self.car] + self.wheels:
body.angle = car_angle
for wheel in self.wheels:
wheel.position = wheel.position - self.car.position + dis
self.car.position = dis
self.world.Step(self.extra_data.timeStep,
self.extra_data.velocityIterations,
self.extra_data.positionIterations)
return self.get_current_obs()
@overrides
def compute_reward(self, action):
yield
not_done = not self.is_current_done()
dist_to_goal = self.get_current_obs()[-3]
yield -1 * not_done - 2 * dist_to_goal
@overrides
def is_current_done(self):
pos_satified = np.linalg.norm(self.car.position) <= self.goal_radius
vel_satisfied = np.linalg.norm(
self.car.linearVelocity) <= self.vel_thres
return pos_satified and vel_satisfied
@overrides
def action_from_keys(self, keys):
go = np.zeros(self.action_dim)
if keys[pygame.K_LEFT]:
go[-1] = self.max_deg
if keys[pygame.K_RIGHT]:
go[-1] = -self.max_deg
if keys[pygame.K_UP]:
go[0] = 10
if keys[pygame.K_DOWN]:
go[0] = -10
return go | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/box2d/car_parking_env.py | 0.822225 | 0.363477 | car_parking_env.py | pypi |
import os.path as osp
import mako.lookup
import mako.template
import numpy as np
from rllab import spaces
from rllab.envs import Env
from rllab.envs import Step
from rllab.envs.box2d.box2d_viewer import Box2DViewer
from rllab.envs.box2d.parser.xml_box2d import find_body
from rllab.envs.box2d.parser.xml_box2d import find_joint
from rllab.envs.box2d.parser.xml_box2d import world_from_xml
from rllab.misc import autoargs
from rllab.misc.overrides import overrides
BIG = 1e6
class Box2DEnv(Env):
@autoargs.arg("frame_skip", type=int, help="Number of frames to skip")
@autoargs.arg(
'position_only',
type=bool,
help='Whether to only provide (generalized) position as the '
'observation (i.e. no velocities etc.)')
@autoargs.arg(
'obs_noise',
type=float,
help='Noise added to the observations (note: this makes the '
'problem non-Markovian!)')
@autoargs.arg(
'action_noise',
type=float,
help='Noise added to the controls, which will be '
'proportional to the action bounds')
def __init__(
self,
model_path,
frame_skip=1,
position_only=False,
obs_noise=0.0,
action_noise=0.0,
template_string=None,
template_args=None,
):
self.full_model_path = model_path
if template_string is None:
if model_path.endswith(".mako"):
with open(model_path) as template_file:
template = mako.template.Template(template_file.read())
template_string = template.render(
opts=template_args if template_args is not None else {}, )
else:
with open(model_path, "r") as f:
template_string = f.read()
world, extra_data = world_from_xml(template_string)
self.world = world
self.extra_data = extra_data
self.initial_state = self._state
self.viewer = None
self.frame_skip = frame_skip
self.timestep = self.extra_data.timeStep
self.position_only = position_only
self.obs_noise = obs_noise
self.action_noise = action_noise
self._action_bounds = None
# cache the computation of position mask
self._position_ids = None
self._cached_obs = None
self._cached_coms = {}
def model_path(self, file_name):
return osp.abspath(
osp.join(osp.dirname(__file__), 'models/%s' % file_name))
def _set_state(self, state):
splitted = np.array(state).reshape((-1, 6))
for body, body_state in zip(self.world.bodies, splitted):
xpos, ypos, apos, xvel, yvel, avel = body_state
body.position = (xpos, ypos)
body.angle = apos
body.linearVelocity = (xvel, yvel)
body.angularVelocity = avel
@overrides
def reset(self):
self._set_state(self.initial_state)
self._invalidate_state_caches()
return self.get_current_obs()
def _invalidate_state_caches(self):
self._cached_obs = None
self._cached_coms = {}
@property
def _state(self):
s = []
for body in self.world.bodies:
s.append(
np.concatenate([
list(body.position), [body.angle],
list(body.linearVelocity), [body.angularVelocity]
]))
return np.concatenate(s)
@property
@overrides
def action_space(self):
lb = np.array(
[control.ctrllimit[0] for control in self.extra_data.controls])
ub = np.array(
[control.ctrllimit[1] for control in self.extra_data.controls])
return spaces.Box(lb, ub)
@property
@overrides
def observation_space(self):
if self.position_only:
d = len(self._get_position_ids())
else:
d = len(self.extra_data.states)
ub = BIG * np.ones(d)
return spaces.Box(ub * -1, ub)
@property
def action_bounds(self):
return self.action_space.bounds
def forward_dynamics(self, action):
if len(action) != self.action_dim:
raise ValueError('incorrect action dimension: expected %d but got '
'%d' % (self.action_dim, len(action)))
lb, ub = self.action_bounds
action = np.clip(action, lb, ub)
for ctrl, act in zip(self.extra_data.controls, action):
if ctrl.typ == "force":
for name in ctrl.bodies:
body = find_body(self.world, name)
direction = np.array(ctrl.direction)
direction = direction / np.linalg.norm(direction)
world_force = body.GetWorldVector(direction * act)
world_point = body.GetWorldPoint(ctrl.anchor)
body.ApplyForce(world_force, world_point, wake=True)
elif ctrl.typ == "torque":
assert ctrl.joint
joint = find_joint(self.world, ctrl.joint)
joint.motorEnabled = True
# forces the maximum allowed torque to be taken
if act > 0:
joint.motorSpeed = 1e5
else:
joint.motorSpeed = -1e5
joint.maxMotorTorque = abs(act)
else:
raise NotImplementedError
self.before_world_step(action)
self.world.Step(self.extra_data.timeStep,
self.extra_data.velocityIterations,
self.extra_data.positionIterations)
def compute_reward(self, action):
"""
The implementation of this method should have two parts, structured
like the following:
<perform calculations before stepping the world>
yield
reward = <perform calculations after stepping the world>
yield reward
"""
raise NotImplementedError
@overrides
def step(self, action):
"""
Note: override this method with great care, as it post-processes the
observations, etc.
"""
reward_computer = self.compute_reward(action)
# forward the state
action = self._inject_action_noise(action)
for _ in range(self.frame_skip):
self.forward_dynamics(action)
# notifies that we have stepped the world
next(reward_computer)
# actually get the reward
reward = next(reward_computer)
self._invalidate_state_caches()
done = self.is_current_done()
next_obs = self.get_current_obs()
return Step(observation=next_obs, reward=reward, done=done)
def _filter_position(self, obs):
"""
Filter the observation to contain only position information.
"""
return obs[self._get_position_ids()]
def get_obs_noise_scale_factor(self, obs):
return np.ones_like(obs)
def _inject_obs_noise(self, obs):
"""
Inject entry-wise noise to the observation. This should not change
the dimension of the observation.
"""
noise = self.get_obs_noise_scale_factor(obs) * self.obs_noise * \
np.random.normal(size=obs.shape)
return obs + noise
def get_current_reward(self, state, xml_obs, action, next_state,
next_xml_obs):
raise NotImplementedError
def is_current_done(self):
raise NotImplementedError
def _inject_action_noise(self, action):
# generate action noise
noise = self.action_noise * \
np.random.normal(size=action.shape)
# rescale the noise to make it proportional to the action bounds
lb, ub = self.action_bounds
noise = 0.5 * (ub - lb) * noise
return action + noise
def get_current_obs(self):
"""
This method should not be overwritten.
"""
raw_obs = self.get_raw_obs()
noisy_obs = self._inject_obs_noise(raw_obs)
if self.position_only:
return self._filter_position(noisy_obs)
return noisy_obs
def _get_position_ids(self):
if self._position_ids is None:
self._position_ids = []
for idx, state in enumerate(self.extra_data.states):
if state.typ in ["xpos", "ypos", "apos", "dist", "angle"]:
self._position_ids.append(idx)
return self._position_ids
def get_raw_obs(self):
"""
Return the unfiltered & noiseless observation. By default, it computes
based on the declarations in the xml file.
"""
if self._cached_obs is not None:
return self._cached_obs
obs = []
for state in self.extra_data.states:
new_obs = None
if state.body:
body = find_body(self.world, state.body)
if state.local is not None:
l = state.local
position = body.GetWorldPoint(l)
linearVel = body.GetLinearVelocityFromLocalPoint(l)
# now I wish I could write angle = error "not supported"
else:
position = body.position
linearVel = body.linearVelocity
if state.to is not None:
to = find_body(self.world, state.to)
if state.typ == "xpos":
new_obs = position[0]
elif state.typ == "ypos":
new_obs = position[1]
elif state.typ == "xvel":
new_obs = linearVel[0]
elif state.typ == "yvel":
new_obs = linearVel[1]
elif state.typ == "apos":
new_obs = body.angle
elif state.typ == "avel":
new_obs = body.angularVelocity
elif state.typ == "dist":
new_obs = np.linalg.norm(position - to.position)
elif state.typ == "angle":
diff = to.position - position
abs_angle = np.arccos(
diff.dot((0, 1)) / np.linalg.norm(diff))
new_obs = body.angle + abs_angle
else:
raise NotImplementedError
elif state.joint:
joint = find_joint(self.world, state.joint)
if state.typ == "apos":
new_obs = joint.angle
elif state.typ == "avel":
new_obs = joint.speed
else:
raise NotImplementedError
elif state.com:
com_quant = self._compute_com_pos_vel(*state.com)
if state.typ == "xpos":
new_obs = com_quant[0]
elif state.typ == "ypos":
new_obs = com_quant[1]
elif state.typ == "xvel":
new_obs = com_quant[2]
elif state.typ == "yvel":
new_obs = com_quant[3]
else:
print(state.typ)
# orientation and angular velocity of the whole body is not
# supported
raise NotImplementedError
else:
raise NotImplementedError
if state.transform is not None:
if state.transform == "id":
pass
elif state.transform == "sin":
new_obs = np.sin(new_obs)
elif state.transform == "cos":
new_obs = np.cos(new_obs)
else:
raise NotImplementedError
obs.append(new_obs)
self._cached_obs = np.array(obs)
return self._cached_obs
def _compute_com_pos_vel(self, *com):
com_key = ",".join(sorted(com))
if com_key in self._cached_coms:
return self._cached_coms[com_key]
total_mass_quant = 0
total_mass = 0
for body_name in com:
body = find_body(self.world, body_name)
total_mass_quant += body.mass * np.array(
list(body.worldCenter) + list(body.linearVelocity))
total_mass += body.mass
com_quant = total_mass_quant / total_mass
self._cached_coms[com_key] = com_quant
return com_quant
def get_com_position(self, *com):
return self._compute_com_pos_vel(*com)[:2]
def get_com_velocity(self, *com):
return self._compute_com_pos_vel(*com)[2:]
@overrides
def render(self, states=None, actions=None, pause=False):
if not self.viewer:
self.viewer = Box2DViewer(self.world)
if states or actions or pause:
raise NotImplementedError
if not self.viewer:
self.start_viewer()
if self.viewer:
self.viewer.loop_once()
def before_world_step(self, action):
pass
def action_from_keys(self, keys):
raise NotImplementedError | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/box2d/box2d_env.py | 0.659405 | 0.397997 | box2d_env.py | pypi |
import numpy as np
from rllab.core import Serializable
from rllab.envs.box2d.box2d_env import Box2DEnv
from rllab.envs.box2d.parser import find_body
from rllab.misc import autoargs
from rllab.misc.overrides import overrides
# http://mlg.eng.cam.ac.uk/pilco/
class DoublePendulumEnv(Box2DEnv, Serializable):
@autoargs.inherit(Box2DEnv.__init__)
def __init__(self, *args, **kwargs):
# make sure mdp-level step is 100ms long
kwargs["frame_skip"] = kwargs.get("frame_skip", 2)
if kwargs.get("template_args", {}).get("noise", False):
self.link_len = (np.random.rand() - 0.5) + 1
else:
self.link_len = 1
kwargs["template_args"] = kwargs.get("template_args", {})
kwargs["template_args"]["link_len"] = self.link_len
super(DoublePendulumEnv, self).__init__(
self.model_path("double_pendulum.xml.mako"), *args, **kwargs)
self.link1 = find_body(self.world, "link1")
self.link2 = find_body(self.world, "link2")
Serializable.__init__(self, *args, **kwargs)
@overrides
def reset(self):
self._set_state(self.initial_state)
self._invalidate_state_caches()
stds = np.array([0.1, 0.1, 0.01, 0.01])
pos1, pos2, v1, v2 = np.random.randn(*stds.shape) * stds
self.link1.angle = pos1
self.link2.angle = pos2
self.link1.angularVelocity = v1
self.link2.angularVelocity = v2
return self.get_current_obs()
def get_tip_pos(self):
cur_center_pos = self.link2.position
cur_angle = self.link2.angle
cur_pos = (cur_center_pos[0] - self.link_len * np.sin(cur_angle),
cur_center_pos[1] - self.link_len * np.cos(cur_angle))
return cur_pos
@overrides
def compute_reward(self, action):
yield
tgt_pos = np.asarray([0, self.link_len * 2])
cur_pos = self.get_tip_pos()
dist = np.linalg.norm(cur_pos - tgt_pos)
yield -dist
def is_current_done(self):
return False | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/box2d/double_pendulum_env.py | 0.562417 | 0.24049 | double_pendulum_env.py | pypi |
import xml.etree.ElementTree as ET
import Box2D
import numpy as np
from rllab.envs.box2d.parser.xml_attr_types import Angle
from rllab.envs.box2d.parser.xml_attr_types import Bool
from rllab.envs.box2d.parser.xml_attr_types import Choice
from rllab.envs.box2d.parser.xml_attr_types import Either
from rllab.envs.box2d.parser.xml_attr_types import Float
from rllab.envs.box2d.parser.xml_attr_types import Hex
from rllab.envs.box2d.parser.xml_attr_types import Int
from rllab.envs.box2d.parser.xml_attr_types import List
from rllab.envs.box2d.parser.xml_attr_types import Point2D
from rllab.envs.box2d.parser.xml_attr_types import String
from rllab.envs.box2d.parser.xml_attr_types import Tuple
from rllab.envs.box2d.parser.xml_types import XmlAttr
from rllab.envs.box2d.parser.xml_types import XmlChild
from rllab.envs.box2d.parser.xml_types import XmlChildren
from rllab.envs.box2d.parser.xml_types import XmlElem
class XmlBox2D(XmlElem):
tag = "box2d"
class Meta:
world = XmlChild("world", lambda: XmlWorld, required=True)
def __init__(self):
self.world = None
def to_box2d(self, extra_data, world=None):
return self.world.to_box2d(extra_data, world=world)
class XmlWorld(XmlElem):
tag = "world"
class Meta:
bodies = XmlChildren("body", lambda: XmlBody)
gravity = XmlAttr("gravity", Point2D())
joints = XmlChildren("joint", lambda: XmlJoint)
states = XmlChildren("state", lambda: XmlState)
controls = XmlChildren("control", lambda: XmlControl)
warmStarting = XmlAttr("warmstart", Bool())
continuousPhysics = XmlAttr("continuous", Bool())
subStepping = XmlAttr("substepping", Bool())
velocityIterations = XmlAttr("velitr", Int())
positionIterations = XmlAttr("positr", Int())
timeStep = XmlAttr("timestep", Float())
def __init__(self):
self.bodies = []
self.gravity = None
self.joints = []
self.states = []
self.controls = []
self.warmStarting = True
self.continuousPhysics = True
self.subStepping = False
self.velocityIterations = 8
self.positionIterations = 3
self.timeStep = 0.02
def to_box2d(self, extra_data, world=None):
if world is None:
world = Box2D.b2World(allow_sleeping=False)
world.warmStarting = self.warmStarting
world.continuousPhysics = self.continuousPhysics
world.subStepping = self.subStepping
extra_data.velocityIterations = self.velocityIterations
extra_data.positionIterations = self.positionIterations
extra_data.timeStep = self.timeStep
if self.gravity:
world.gravity = self.gravity
for body in self.bodies:
body.to_box2d(world, self, extra_data)
for joint in self.joints:
joint.to_box2d(world, self, extra_data)
for state in self.states:
state.to_box2d(world, self, extra_data)
for control in self.controls:
control.to_box2d(world, self, extra_data)
return world
class XmlBody(XmlElem):
tag = "body"
TYPES = ["static", "kinematic", "dynamic"]
class Meta:
color = XmlAttr("color", List(Float()))
name = XmlAttr("name", String())
typ = XmlAttr(
"type", Choice("static", "kinematic", "dynamic"), required=True)
fixtures = XmlChildren("fixture", lambda: XmlFixture)
position = XmlAttr("position", Point2D())
def __init__(self):
self.color = None
self.name = None
self.typ = None
self.position = None
self.fixtures = []
def to_box2d(self, world, xml_world, extra_data):
body = world.CreateBody(type=self.TYPES.index(self.typ))
body.userData = dict(
name=self.name,
color=self.color,
)
if self.position:
body.position = self.position
for fixture in self.fixtures:
fixture.to_box2d(body, self, extra_data)
return body
class XmlFixture(XmlElem):
tag = "fixture"
class Meta:
shape = XmlAttr(
"shape",
Choice("polygon", "circle", "edge", "sine_chain"),
required=True)
vertices = XmlAttr("vertices", List(Point2D()))
box = XmlAttr(
"box",
Either(Point2D(), Tuple(Float(), Float(), Point2D(), Angle())))
radius = XmlAttr("radius", Float())
width = XmlAttr("width", Float())
height = XmlAttr("height", Float())
center = XmlAttr("center", Point2D())
angle = XmlAttr("angle", Angle())
position = XmlAttr("position", Point2D())
friction = XmlAttr("friction", Float())
density = XmlAttr("density", Float())
category_bits = XmlAttr("category_bits", Hex())
mask_bits = XmlAttr("mask_bits", Hex())
group = XmlAttr("group", Int())
def __init__(self):
self.shape = None
self.vertices = None
self.box = None
self.friction = None
self.density = None
self.category_bits = None
self.mask_bits = None
self.group = None
self.radius = None
self.width = None
self.height = None
self.center = None
self.angle = None
def to_box2d(self, body, xml_body, extra_data):
attrs = dict()
if self.friction:
attrs["friction"] = self.friction
if self.density:
attrs["density"] = self.density
if self.group:
attrs["groupIndex"] = self.group
if self.radius:
attrs["radius"] = self.radius
if self.shape == "polygon":
if self.box:
fixture = body.CreatePolygonFixture(box=self.box, **attrs)
else:
fixture = body.CreatePolygonFixture(
vertices=self.vertices, **attrs)
elif self.shape == "edge":
fixture = body.CreateEdgeFixture(vertices=self.vertices, **attrs)
elif self.shape == "circle":
if self.center:
attrs["pos"] = self.center
fixture = body.CreateCircleFixture(**attrs)
elif self.shape == "sine_chain":
if self.center:
attrs["pos"] = self.center
m = 100
vs = [(0.5 / m * i * self.width, self.height * np.sin(
(1. / m * i - 0.5) * np.pi)) for i in range(-m, m + 1)]
attrs["vertices_chain"] = vs
fixture = body.CreateChainFixture(**attrs)
else:
assert False
return fixture
def _get_name(x):
if isinstance(x.userData, dict):
return x.userData.get('name')
return None
def find_body(world, name):
return [body for body in world.bodies if _get_name(body) == name][0]
def find_joint(world, name):
return [joint for joint in world.joints if _get_name(joint) == name][0]
class XmlJoint(XmlElem):
tag = "joint"
JOINT_TYPES = {
"revolute": Box2D.b2RevoluteJoint,
"friction": Box2D.b2FrictionJoint,
"prismatic": Box2D.b2PrismaticJoint,
}
class Meta:
bodyA = XmlAttr("bodyA", String(), required=True)
bodyB = XmlAttr("bodyB", String(), required=True)
anchor = XmlAttr("anchor", Tuple(Float(), Float()))
localAnchorA = XmlAttr("localAnchorA", Tuple(Float(), Float()))
localAnchorB = XmlAttr("localAnchorB", Tuple(Float(), Float()))
axis = XmlAttr("axis", Tuple(Float(), Float()))
limit = XmlAttr("limit", Tuple(Angle(), Angle()))
ctrllimit = XmlAttr("ctrllimit", Tuple(Angle(), Angle()))
typ = XmlAttr(
"type", Choice("revolute", "friction", "prismatic"), required=True)
name = XmlAttr("name", String())
motor = XmlAttr("motor", Bool())
def __init__(self):
self.bodyA = None
self.bodyB = None
self.anchor = None
self.localAnchorA = None
self.localAnchorB = None
self.limit = None
self.ctrllimit = None
self.motor = False
self.typ = None
self.name = None
self.axis = None
def to_box2d(self, world, xml_world, extra_data):
bodyA = find_body(world, self.bodyA)
bodyB = find_body(world, self.bodyB)
args = dict()
if self.typ == "revolute":
if self.localAnchorA:
args["localAnchorA"] = self.localAnchorA
if self.localAnchorB:
args["localAnchorB"] = self.localAnchorB
if self.anchor:
args["anchor"] = self.anchor
if self.limit:
args["enableLimit"] = True
args["lowerAngle"] = self.limit[0]
args["upperAngle"] = self.limit[1]
elif self.typ == "friction":
if self.anchor:
args["anchor"] = self.anchor
elif self.typ == "prismatic":
if self.axis:
args["axis"] = self.axis
else:
raise NotImplementedError
userData = dict(
ctrllimit=self.ctrllimit, motor=self.motor, name=self.name)
joint = world.CreateJoint(
type=self.JOINT_TYPES[self.typ], bodyA=bodyA, bodyB=bodyB, **args)
joint.userData = userData
return joint
class XmlState(XmlElem):
tag = "state"
class Meta:
typ = XmlAttr(
"type",
Choice(
"xpos",
"ypos",
"xvel",
"yvel",
"apos",
"avel",
"dist",
"angle",
))
transform = XmlAttr("transform", Choice("id", "sin", "cos"))
body = XmlAttr("body", String())
to = XmlAttr("to", String())
joint = XmlAttr("joint", String())
local = XmlAttr("local", Point2D())
com = XmlAttr("com", List(String()))
def __init__(self):
self.typ = None
self.transform = None
self.body = None
self.joint = None
self.local = None
self.com = None
self.to = None
def to_box2d(self, world, xml_world, extra_data):
extra_data.states.append(self)
class XmlControl(XmlElem):
tag = "control"
class Meta:
typ = XmlAttr("type", Choice("force", "torque"), required=True)
body = XmlAttr(
"body", String(), help="name of the body to apply force on")
bodies = XmlAttr(
"bodies",
List(String()),
help="names of the bodies to apply force on")
joint = XmlAttr("joint", String(), help="name of the joint")
anchor = XmlAttr(
"anchor",
Point2D(),
help="location of the force in local coordinate frame")
direction = XmlAttr(
"direction",
Point2D(),
help="direction of the force in local coordinate frame")
ctrllimit = XmlAttr(
"ctrllimit",
Tuple(Float(), Float()),
help="limit of the control input in Newton")
def __init__(self):
self.typ = None
self.body = None
self.bodies = None
self.joint = None
self.anchor = None
self.direction = None
self.ctrllimit = None
def to_box2d(self, world, xml_world, extra_data):
if self.body != None:
assert self.bodies is None, ("Should not set body and bodies at "
"the same time")
self.bodies = [self.body]
extra_data.controls.append(self)
class ExtraData(object):
def __init__(self):
self.states = []
self.controls = []
self.velocityIterations = None
self.positionIterations = None
self.timeStep = None
def world_from_xml(s):
extra_data = ExtraData()
box2d = XmlBox2D.from_xml(ET.fromstring(s))
world = box2d.to_box2d(extra_data)
return world, extra_data | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/box2d/parser/xml_box2d.py | 0.620047 | 0.288995 | xml_box2d.py | pypi |
import numpy as np
class Type(object):
def __eq__(self, other):
return self.__class__ == other.__class__
def from_str(self, s):
raise NotImplementedError
class Float(Type):
def from_str(self, s):
return float(s)
class Int(Type):
def from_str(self, s):
return int(s)
class Hex(Type):
def from_str(self, s):
assert s.startswith("0x") or s.startswith("0X")
return int(s, 16)
class Choice(Type):
def __init__(self, *options):
self._options = options
def from_str(self, s):
if s in self._options:
return s
raise ValueError("Unexpected value %s: must be one of %s" %
(s, ", ".join(self._options)))
class List(Type):
def __init__(self, elem_type):
self.elem_type = elem_type
def __eq__(self, other):
return self.__class__ == other.__class__ \
and self.elem_type == other.elem_type
def from_str(self, s):
if ";" in s:
segments = s.split(";")
elif "," in s:
segments = s.split(",")
else:
segments = s.split(" ")
return list(map(self.elem_type.from_str, segments))
class Tuple(Type):
def __init__(self, *elem_types):
self.elem_types = elem_types
def __eq__(self, other):
return self.__class__ == other.__class__ \
and self.elem_types == other.elem_types
def from_str(self, s):
if ";" in s:
segments = s.split(";")
elif "," in s:
segments = s.split(",")
else:
segments = s.split(" ")
if len(segments) != len(self.elem_types):
raise ValueError(
"Length mismatch: expected a tuple of length %d; got %s instead"
% (len(self.elem_types), s))
return tuple(
[typ.from_str(seg) for typ, seg in zip(self.elem_types, segments)])
class Either(Type):
def __init__(self, *elem_types):
self.elem_types = elem_types
def from_str(self, s):
for typ in self.elem_types:
try:
return typ.from_str(s)
except ValueError:
pass
raise ValueError('No match found')
class String(Type):
def from_str(self, s):
return s
class Angle(Type):
def from_str(self, s):
if s.endswith("deg"):
return float(s[:-len("deg")]) * np.pi / 180.0
elif s.endswith("rad"):
return float(s[:-len("rad")])
return float(s) * np.pi / 180.0
class Bool(Type):
def from_str(self, s):
return s.lower() == "true" or s.lower() == "1"
Point2D = lambda: Tuple(Float(), Float()) | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/envs/box2d/parser/xml_attr_types.py | 0.681515 | 0.290156 | xml_attr_types.py | pypi |
from os.path import abspath
from os.path import dirname
import shutil
import google.protobuf.json_format as json_format
from jsonmerge import merge
import numpy as np
from tensorboard import summary as summary_lib
from tensorboard.backend.event_processing import plugin_event_multiplexer \
as event_multiplexer
from tensorboard.plugins.custom_scalar import layout_pb2
from tensorboard.plugins.custom_scalar import metadata
import tensorflow as tf
from rllab.misc.console import mkdir_p
import rllab.misc.logger
class TensorBoardOutput:
def __init__(self):
self._scalars = tf.Summary()
self._scope_tensor = {}
self._has_recorded_tensor = False
self._has_dumped_graph = False
self._histogram_ds = {}
self._histogram_summary_op = []
self._session = tf.Session()
self._histogram_distribute_list = [
'normal', 'gamma', 'poisson', 'uniform'
]
self._feed = {}
self._default_step = 0
self._writer = None
self._writer_dir = None
self._layout_writer = None
self._layout_writer_dir = None
def set_dir(self, dir_name):
if not dir_name:
if self._writer:
self._writer.close()
self._writer = None
else:
mkdir_p(dirname(dir_name))
self._writer_dir = dir_name
self._writer = tf.summary.FileWriter(dir_name)
self._layout_writer_dir = dirname(dirname(
abspath(dir_name))) + '/custom_scalar_config'
mkdir_p(self._layout_writer_dir)
self._default_step = 0
assert self._writer is not None
rllab.misc.logger.log("tensorboard data will be logged into:" +
dir_name)
def dump_tensorboard(self, step=None):
if not self._writer:
return
run_step = self._default_step
if step:
run_step = step
else:
self._default_step += 1
self._dump_graph()
self._dump_scalars(run_step)
self._dump_histogram(run_step)
self._dump_tensors()
def record_histogram(self, key, val):
if str(key) not in self._histogram_ds:
self._histogram_ds[str(key)] = tf.Variable(val)
self._histogram_summary_op.append(
tf.summary.histogram(str(key), self._histogram_ds[str(key)]))
self._histogram_summary_op_merge = tf.summary.merge(
self._histogram_summary_op)
self._feed[self._histogram_ds[str(key)]] = val
def record_histogram_by_type(self,
histogram_type,
key=None,
shape=[1000],
**kwargs):
'''
distribution type and args:
normal: mean, stddev
gamma: alpha
poisson: lam
uniform: maxval
'''
if histogram_type not in self._histogram_distribute_list:
raise Exception('histogram type error %s' % histogram_type,
'builtin type', self._histogram_distribute_list)
if str(key) not in self._histogram_ds:
self._histogram_ds[str(key)] = self._get_histogram_var_by_type(
histogram_type, shape, **kwargs)
self._histogram_summary_op.append(
tf.summary.histogram(
str(key), self._histogram_ds[str(key)][0]))
self._histogram_summary_op_merge = tf.summary.merge(
self._histogram_summary_op)
key_list = self._histogram_ds[str(key)][1]
val_list = self._get_histogram_val_by_type(histogram_type, **kwargs)
for key, val in zip(key_list, val_list):
self._feed[key] = val
def record_scalar(self, key, val):
self._scalars.value.add(tag=str(key), simple_value=float(val))
def record_tensor(self, key, val):
self._has_recorded_tensor = True
scope = str(key).split('/', 1)[0]
if scope not in self._scope_tensor:
self._scope_tensor[scope] = [key]
else:
if key not in self._scope_tensor[scope]:
self._scope_tensor[scope].append(key)
for idx, v in np.ndenumerate(np.array(val)):
self._scalars.value.add(
tag=key + '/' + str(idx).strip('()'), simple_value=float(v))
def _get_histogram_var_by_type(self, histogram_type, shape, **kwargs):
if histogram_type == "normal":
# Make a normal distribution, with a shifting mean
mean = tf.Variable(kwargs['mean'])
stddev = tf.Variable(kwargs['stddev'])
return tf.random_normal(
shape=shape, mean=mean, stddev=stddev), [mean, stddev]
elif histogram_type == "gamma":
# Add a gamma distribution
alpha = tf.Variable(kwargs['alpha'])
return tf.random_gamma(shape=shape, alpha=alpha), [alpha]
elif histogram_type == "poisson":
lam = tf.Variable(kwargs['lam'])
return tf.random_poisson(shape=shape, lam=lam), [lam]
elif histogram_type == "uniform":
# Add a uniform distribution
maxval = tf.Variable(kwargs['maxval'])
return tf.random_uniform(shape=shape, maxval=maxval), [maxval]
raise Exception('histogram type error %s' % histogram_type,
'builtin type', self._histogram_distribute_list)
def _get_histogram_val_by_type(self, histogram_type, **kwargs):
if histogram_type == "normal":
# Make a normal distribution, with a shifting mean
return [kwargs['mean'], kwargs['stddev']]
elif histogram_type == "gamma":
# Add a gamma distribution
self.alpha_v = kwargs['alpha']
return [kwargs['alpha']]
elif histogram_type == "poisson":
return [kwargs['lam']]
elif histogram_type == "uniform":
# Add a uniform distribution
return [kwargs['maxval']]
raise Exception('histogram type error %s' % histogram_type,
'builtin type', self._histogram_distribute_list)
def _dump_graph(self):
# We only need to write the graph event once (instead of per step).
if self._has_dumped_graph:
return
self._has_dumped_graph = True
self._writer.add_graph(tf.get_default_graph())
self._writer.flush()
def _dump_scalars(self, step):
self._writer.add_summary(self._scalars, int(step))
self._writer.flush()
del self._scalars.value[:]
def _dump_histogram(self, step):
if len(self._histogram_summary_op):
summary_str = self._session.run(
self._histogram_summary_op_merge, feed_dict=self._feed)
self._writer.add_summary(summary_str, global_step=step)
self._writer.flush()
def _dump_tensors(self):
if not self._has_recorded_tensor:
return
layout_categories = []
for scope in self._scope_tensor:
chart = []
for name in self._scope_tensor[scope]:
chart.append(
layout_pb2.Chart(
title=name,
multiline=layout_pb2.MultilineChartContent(
tag=[r'name(?!.*margin.*)'.replace('name', name)
])))
category = layout_pb2.Category(title=scope, chart=chart)
layout_categories.append(category)
if layout_categories:
layout_proto_to_write = layout_pb2.Layout(
category=layout_categories)
try:
# Load former layout_proto from self._layout_writer_dir.
multiplexer = event_multiplexer.EventMultiplexer()
multiplexer.AddRunsFromDirectory(self._layout_writer_dir)
multiplexer.Reload()
tensor_events = multiplexer.Tensors(
'.', metadata.CONFIG_SUMMARY_TAG)
shutil.rmtree(self._layout_writer_dir)
# Parse layout proto from disk.
string_array = tf.make_ndarray(tensor_events[0].tensor_proto)
content = np.asscalar(string_array)
layout_proto_from_disk = layout_pb2.Layout()
layout_proto_from_disk.ParseFromString(
tf.compat.as_bytes(content))
# Merge two layout proto.
merged_layout_json = merge(
json_format.MessageToJson(layout_proto_from_disk),
json_format.MessageToJson(layout_proto_to_write))
merged_layout_proto = layout_pb2.Layout()
json_format.Parse(str(merged_layout_json), merged_layout_proto)
self._layout_writer = tf.summary.FileWriter(
self._layout_writer_dir)
layout_summary = summary_lib.custom_scalar_pb(
merged_layout_proto)
self._layout_writer.add_summary(layout_summary)
self._layout_writer.close()
except KeyError:
# Write the current layout proto when there is no layout in the disk.
self._layout_writer = tf.summary.FileWriter(
self._layout_writer_dir)
layout_summary = summary_lib.custom_scalar_pb(
layout_proto_to_write)
self._layout_writer.add_summary(layout_summary)
self._layout_writer.close() | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/misc/tensorboard_output.py | 0.519278 | 0.278931 | tensorboard_output.py | pypi |
import numpy as np
import pygame
import pygame.gfxdraw
class Colors(object):
black = (0, 0, 0)
white = (255, 255, 255)
blue = (0, 0, 255)
red = (255, 0, 0)
green = (0, 255, 0)
class Viewer2D(object):
def __init__(self, size=(640, 480), xlim=None, ylim=None):
pygame.init()
screen = pygame.display.set_mode(size)
#surface = pygame.surface(size, pygame.SRCALPHA)
if xlim is None:
xlim = (0, size[0])
if ylim is None:
ylim = (0, size[1])
self._screen = screen
#self._surface = surface
#self.screen.blit(self.surface, (0, 0))
self._xlim = xlim
self._ylim = ylim
@property
def xlim(self):
return self._xlim
@xlim.setter
def xlim(self, value):
self._xlim = value
@property
def ylim(self):
return self._ylim
@ylim.setter
def ylim(self, value):
self._ylim = value
def reset(self):
self.fill(Colors.white)
def fill(self, color):
self.screen.fill(color)
def scale_x(self, world_x):
xmin, xmax = self.xlim
return int((world_x - xmin) * self.screen.get_width() / (xmax - xmin))
def scale_y(self, world_y):
ymin, ymax = self.ylim
return int(
(self.screen.get_height() -
(world_y - ymin) * self.screen.get_height() / (ymax - ymin)))
def scale_point(self, point):
x, y = point
return (self.scale_x(x), self.scale_y(y))
@property
def scale_factor(self):
xmin, xmax = self.xlim
ymin, ymax = self.ylim
return min(self.screen.get_width() / (xmax - xmin),
self.screen.get_height() / (ymax - ymin))
def scale_size(self, size):
if hasattr(size, '__len__'):
x, y = size
return (self.scale_x(x + self.xlim[0]),
self.screen.get_height() - self.scale_y(y + self.ylim[0]))
return size * self.scale_factor
def line(self, color, p1, p2, width=None):
if width is None:
width = 1
else:
width = int(width * self.scale_factor)
x1, y1 = self.scale_point(p1)
x2, y2 = self.scale_point(p2)
pygame.draw.line(self.screen, color, (x1, y1), (x2, y2), width)
def circle(self, color, p, radius):
pygame.draw.circle(self.screen, color, self.scale_point(p),
int(self.scale_size(radius)))
def rect(self, color, center, size):
cx, cy = self.scale_point(center)
w, h = self.scale_size(size)
if len(color) > 3:
s = pygame.Surface((w, h), pygame.SRCALPHA)
s.fill(color)
self.screen.blit(s, (cx - w / 2, cy - h / 2))
#pygame.draw.rect(self.surface, color, pygame.Rect(cx-w/2, cy-h/2, w, h))
else:
pygame.draw.rect(self.screen, color,
pygame.Rect(cx - w / 2, cy - h / 2, w, h))
def polygon(self, color, points):
if len(color) > 3:
s = pygame.Surface(
(self.screen.get_width(), self.screen.get_height()),
pygame.SRCALPHA)
s.fill((0, 0, 0, 0))
pygame.draw.polygon(s, color, list(map(self.scale_point, points)))
self.screen.blit(s, (0, 0))
else:
pygame.draw.polygon(self.screen, color,
list(map(self.scale_point, points)))
@property
def screen(self):
return self._screen
def loop_once(self):
pygame.display.flip()
# Draw a checker background
def checker(self,
colors=[Colors.white, Colors.black],
granularity=4,
offset=(0, 0)):
screen_height = self.screen.get_height()
screen_width = self.screen.get_width()
screen_size = min(screen_height, screen_width)
checker_size = int(screen_size / granularity)
offset_x = self.scale_x(offset[0] + self.xlim[0])
offset_y = self.scale_y(offset[1] + self.ylim[0])
start_idx = int(offset_x / checker_size) + int(offset_y / checker_size)
offset_x = ((offset_x % checker_size) + checker_size) % checker_size
offset_y = ((offset_y % checker_size) + checker_size) % checker_size
for row in range(-1,
int(np.ceil(screen_height * 1.0 / checker_size)) + 1):
for col in range(
-1,
int(np.ceil(screen_width * 1.0 / checker_size)) + 1):
the_square = (col * checker_size + offset_x,
row * checker_size + offset_y, checker_size,
checker_size)
self.screen.fill(colors[(start_idx + row + col) % 2],
the_square)
def pause(self):
print("press any key on the screen to continue...")
while True:
event = pygame.event.wait()
if event.type == pygame.KEYDOWN:
break
print("continuing") | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/misc/viewer2d.py | 0.649245 | 0.25406 | viewer2d.py | pypi |
import numpy as np
from rllab.misc import sliced_fun
EPS = np.finfo('float64').tiny
def cg(f_Ax, b, cg_iters=10, callback=None, verbose=False, residual_tol=1e-10):
"""
Demmel p 312
"""
p = b.copy()
r = b.copy()
x = np.zeros_like(b)
rdotr = r.dot(r)
fmtstr = "%10i %10.3g %10.3g"
titlestr = "%10s %10s %10s"
if verbose: print(titlestr % ("iter", "residual norm", "soln norm"))
for i in range(cg_iters):
if callback is not None:
callback(x)
if verbose: print(fmtstr % (i, rdotr, np.linalg.norm(x)))
z = f_Ax(p)
v = rdotr / p.dot(z)
x += v * p
r -= v * z
newrdotr = r.dot(r)
mu = newrdotr / rdotr
p = r + mu * p
rdotr = newrdotr
if rdotr < residual_tol:
break
if callback is not None:
callback(x)
if verbose:
print(fmtstr % (i + 1, rdotr, np.linalg.norm(x))) # pylint: disable=W0631
return x
def preconditioned_cg(f_Ax,
f_Minvx,
b,
cg_iters=10,
callback=None,
verbose=False,
residual_tol=1e-10):
"""
Demmel p 318
"""
x = np.zeros_like(b)
r = b.copy()
p = f_Minvx(b)
y = p
ydotr = y.dot(r)
fmtstr = "%10i %10.3g %10.3g"
titlestr = "%10s %10s %10s"
if verbose: print(titlestr % ("iter", "residual norm", "soln norm"))
for i in range(cg_iters):
if callback is not None:
callback(x, f_Ax)
if verbose: print(fmtstr % (i, ydotr, np.linalg.norm(x)))
z = f_Ax(p)
v = ydotr / p.dot(z)
x += v * p
r -= v * z
y = f_Minvx(r)
newydotr = y.dot(r)
mu = newydotr / ydotr
p = y + mu * p
ydotr = newydotr
if ydotr < residual_tol:
break
if verbose: print(fmtstr % (cg_iters, ydotr, np.linalg.norm(x)))
return x
def test_cg():
A = np.random.randn(5, 5)
A = A.T.dot(A)
b = np.random.randn(5)
x = cg(lambda x: A.dot(x), b, cg_iters=5, verbose=True) # pylint: disable=W0108
assert np.allclose(A.dot(x), b)
x = preconditioned_cg(
lambda x: A.dot(x),
lambda x: np.linalg.solve(A, x),
b,
cg_iters=5,
verbose=True) # pylint: disable=W0108
assert np.allclose(A.dot(x), b)
x = preconditioned_cg(
lambda x: A.dot(x),
lambda x: x / np.diag(A),
b,
cg_iters=5,
verbose=True) # pylint: disable=W0108
assert np.allclose(A.dot(x), b)
def lanczos(f_Ax, b, k):
"""
Runs Lanczos algorithm to generate a orthogonal basis for the Krylov subspace
b, Ab, A^2b, ...
as well as the upper hessenberg matrix T = Q^T A Q
from Demmel ch 6
"""
assert k > 1
alphas = []
betas = []
qs = []
q = b / np.linalg.norm(b)
beta = 0
qm = np.zeros_like(b)
for j in range(k):
qs.append(q)
z = f_Ax(q)
alpha = q.dot(z)
alphas.append(alpha)
z -= alpha * q + beta * qm
beta = np.linalg.norm(z)
betas.append(beta)
print("beta", beta)
if beta < 1e-9:
print("lanczos: early after %i/%i dimensions" % (j + 1, k))
break
else:
qm = q
q = z / beta
return np.array(qs, 'float64').T, np.array(alphas, 'float64'), np.array(
betas[:-1], 'float64')
def lanczos2(f_Ax, b, k, residual_thresh=1e-9):
"""
Runs Lanczos algorithm to generate a orthogonal basis for the Krylov subspace
b, Ab, A^2b, ...
as well as the upper hessenberg matrix T = Q^T A Q
from Demmel ch 6
"""
b = b.astype('float64')
assert k > 1
H = np.zeros((k, k))
qs = []
q = b / np.linalg.norm(b)
beta = 0
for j in range(k):
qs.append(q)
z = f_Ax(q.astype('float64')).astype('float64')
for (i, q) in enumerate(qs):
H[j, i] = H[i, j] = h = q.dot(z)
z -= h * q
beta = np.linalg.norm(z)
if beta < residual_thresh:
print(
"lanczos2: stopping early after %i/%i dimensions residual %f < %f"
% (j + 1, k, beta, residual_thresh))
break
else:
q = z / beta
return np.array(qs).T, H[:len(qs), :len(qs)]
def make_tridiagonal(alphas, betas):
assert len(alphas) == len(betas) + 1
N = alphas.size
out = np.zeros((N, N), 'float64')
out.flat[0:N**2:N + 1] = alphas
out.flat[1:N**2 - N:N + 1] = betas
out.flat[N:N**2 - 1:N + 1] = betas
return out
def tridiagonal_eigenvalues(alphas, betas):
T = make_tridiagonal(alphas, betas)
return np.linalg.eigvalsh(T)
def test_lanczos():
np.set_printoptions(precision=4)
A = np.random.randn(5, 5)
A = A.T.dot(A)
b = np.random.randn(5)
f_Ax = lambda x: A.dot(x) # pylint: disable=W0108
Q, alphas, betas = lanczos(f_Ax, b, 10)
H = make_tridiagonal(alphas, betas)
assert np.allclose(Q.T.dot(A).dot(Q), H)
assert np.allclose(Q.dot(H).dot(Q.T), A)
assert np.allclose(np.linalg.eigvalsh(H), np.linalg.eigvalsh(A))
Q, H1 = lanczos2(f_Ax, b, 10)
assert np.allclose(H, H1, atol=1e-6)
print("ritz eigvals:")
for i in range(1, 6):
Qi = Q[:, :i]
Hi = Qi.T.dot(A).dot(Qi)
print(np.linalg.eigvalsh(Hi)[::-1])
print("true eigvals:")
print(np.linalg.eigvalsh(A)[::-1])
print("lanczos on ill-conditioned problem")
A = np.diag(10**np.arange(5))
Q, H1 = lanczos2(f_Ax, b, 10)
print(np.linalg.eigvalsh(H1))
print("lanczos on ill-conditioned problem with noise")
def f_Ax_noisy(x):
return A.dot(x) + np.random.randn(x.size) * 1e-3
Q, H1 = lanczos2(f_Ax_noisy, b, 10)
print(np.linalg.eigvalsh(H1))
if __name__ == "__main__":
test_lanczos()
test_cg() | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/misc/krylov.py | 0.568416 | 0.316475 | krylov.py | pypi |
import numpy as np
import numpy.random as nr
from rllab.core import Serializable
from rllab.exploration_strategies import ExplorationStrategy
from rllab.misc import AttrDict
from rllab.misc.overrides import overrides
from rllab.spaces import Box
class OUStrategy(ExplorationStrategy, Serializable):
"""
This strategy implements the Ornstein-Uhlenbeck process, which adds
time-correlated noise to the actions taken by the deterministic policy.
The OU process satisfies the following stochastic differential equation:
dxt = theta*(mu - xt)*dt + sigma*dWt
where Wt denotes the Wiener process
"""
def __init__(self, env_spec, mu=0, theta=0.15, sigma=0.3, **kwargs):
assert isinstance(env_spec.action_space, Box)
assert len(env_spec.action_space.shape) == 1
Serializable.quick_init(self, locals())
self.mu = mu
self.theta = theta
self.sigma = sigma
self.action_space = env_spec.action_space
self.state = np.ones(self.action_space.flat_dim) * self.mu
self.reset()
def __getstate__(self):
d = Serializable.__getstate__(self)
d["state"] = self.state
return d
def __setstate__(self, d):
Serializable.__setstate__(self, d)
self.state = d["state"]
@overrides
def reset(self):
self.state = np.ones(self.action_space.flat_dim) * self.mu
def evolve_state(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * nr.randn(len(x))
self.state = x + dx
return self.state
@overrides
def get_action(self, t, observation, policy, **kwargs):
action, _ = policy.get_action(observation)
ou_state = self.evolve_state()
return np.clip(action + ou_state, self.action_space.low,
self.action_space.high)
if __name__ == "__main__":
ou = OUStrategy(
env_spec=AttrDict(action_space=Box(low=-1, high=1, shape=(1, ))),
mu=0,
theta=0.15,
sigma=0.3)
states = []
for i in range(1000):
states.append(ou.evolve_state()[0])
import matplotlib.pyplot as plt
plt.plot(states)
plt.show() | /rlgarage-0.1.0.tar.gz/rlgarage-0.1.0/rllab/exploration_strategies/ou_strategy.py | 0.822474 | 0.586641 | ou_strategy.py | pypi |
[](https://badge.fury.io/py/rlgraph)
[](https://www.python.org/downloads/release/python-356/)
[](https://github.com/rlgraph/rlgraph/blob/master/LICENSE)
[](https://rlgraph.readthedocs.io/en/latest/?badge=latest)
[](https://travis-ci.org/rlgraph/rlgraph)
# RLgraph
Modular computation graphs for deep reinforcement learning.
RLgraph is a framework to quickly prototype, define and execute reinforcement learning
algorithms both in research and practice. RLgraph is different from most other libraries as it can support
TensorFlow (or static graphs in general) or eager/define-by run execution (PyTorch) through
a single component interface. An introductory blogpost can also be found here: [link](https://rlgraph.github.io/rlgraph/2019/01/04/introducing-rlgraph.html).
RLgraph exposes a well defined API for using agents, and offers a novel component concept
for testing and assembly of machine learning models. By separating graph definition, compilation and execution,
multiple distributed backends and device execution strategies can be accessed without modifying
agent definitions. This means it is especially suited for a smooth transition from applied use case prototypes
to large scale distributed training.
The current state of RLgraph in version 0.4.0 is alpha. The core engine is substantially complete
and works for TensorFlow and PyTorch (1.0). Distributed execution on Ray is exemplified via Distributed
Prioritized Experience Replay (Ape-X), which also supports multi-gpu mode and solves e.g. Atari-Pong in ~1 hour
on a single-node. Algorithms like Ape-X or PPO can be used both with PyTorch and TensorFlow. Distributed TensorFlow can
be tested via the IMPALA agent. Please create an issue to discuss improvements or contributions.
RLgraph currently implements the following algorithms:
- DQN - ```dqn_agent``` - [paper](https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf)
- Double-DQN - ```dqn_agent``` - via ```double_dqn``` flag - [paper](https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/download/12389/11847)
- Dueling-DQN - ```dqn_agent``` - via ```dueling_dqn``` flag - [paper](https://arxiv.org/abs/1509.06461)
- Prioritized experience replay - via ```memory_spec``` option ```prioritized_replay``` - [paper](https://arxiv.org/abs/1511.05952)
- Deep-Q learning from demonstration ```dqfd_agent``` - [paper](https://arxiv.org/abs/1704.03732)
- Distributed prioritized experience replay (Ape-X) on Ray - via `apex_executor` - [paper](https://arxiv.org/abs/1803.00933)
- Importance-weighted actor-learner architecture (IMPALA) on distributed TF/Multi-threaded single-node - ```impala_agents``` - [paper](https://arxiv.org/abs/1802.01561)
- Proximal policy optimization with generalized advantage estimation - ```ppo_agent``` - [paper](https://arxiv.org/abs/1707.06347)
- Soft Actor-Critic / SAC ```sac_agent``` - [paper](https://arxiv.org/abs/1801.01290)
- Simple actor-critic for REINFORCE/A2C/A3C ```actor_critic_agent``` - [paper](https://arxiv.org/abs/1602.01783)
The ```SingleThreadedWorker``` implements high-performance environment vectorisation, and a ```RayWorker``` can execute
ray actor tasks in conjunction with a ```RayExecutor```. The ```examples``` folder contains simple scripts to
test these agents. There is also a very extensive test package including tests for virtually every component. Note
that we run tests on TensorFlow and have not reached full coverage/test compatibility with PyTorch.
For more detailed documentation on RLgraph and its API-reference, please visit
[our readthedocs page here](https://rlgraph.readthedocs.io).
Below we show some training results on gym tasks:
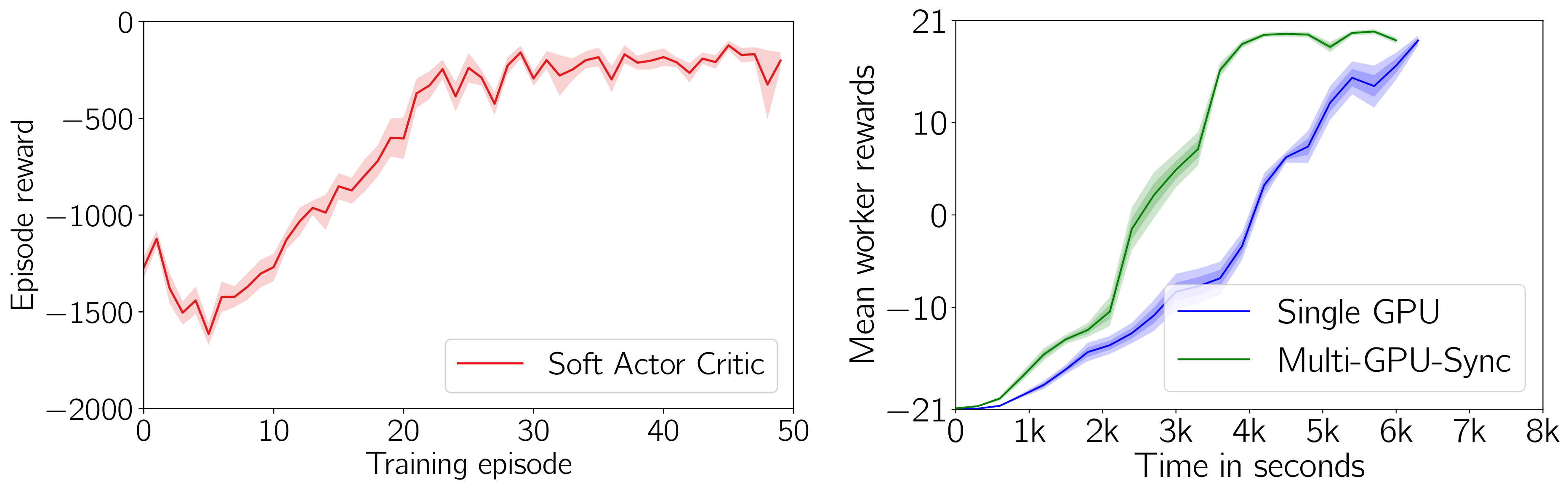
**Left:** Soft Actor Critic on Pendulum-v0 (10 seeds). **Right:** Multi-GPU Ape-X on Pong-v0 (10 seeds).
## Install
The simplest way to install RLgraph is from pip:
```pip install rlgraph```
Note that some backends (e.g. ray) need additional dependencies (see setup.py).
For example, to install dependencies for the distributed backend ray, enter:
```pip install rlgraph[ray]```
To successfully run tests, please also install OpenAI gym, e.g.
```pip install gym[all]```
Upon calling RLgraph, a config JSON is created under ~.rlgraph/rlgraph.json
which can be used to change backend settings. The current default stable
backend is TensorFlow ("tf"). The PyTorch backend ("pytorch") does not support
all utilities available in TF yet. Namely, device handling for PyTorch is incomplete,
and we will likely wait until a stable PyTorch 1.0 release in the coming weeks.
### Quickstart / example usage
We provide an example script for training the Ape-X algorithm on ALE using Ray in the [examples](examples) folder.
First, you'll have to ensure, that Ray is used as the distributed backend. RLgraph checks the file
`~/.rlgraph/rlgraph.json` for this configuration. You can use this command to
configure RLgraph to use TensorFlow as the backend and Ray as the distributed backend:
```bash
echo '{"BACKEND":"tf","DISTRIBUTED_BACKEND":"ray"}' > $HOME/.rlgraph/rlgraph.json
```
Then you can run our Ape-X example:
```bash
# Start ray on the head machine
ray start --head --redis-port 6379
# Optionally join to this cluster from other machines with ray start --redis-address=...
# Run script
python apex_pong.py
```
You can also train a simple DQN agent locally on OpenAI gym environments such as CartPole (this doesn't require Ray).
The following example script also contains a simple tf-summary switch for adding neural net variables to
your tensorboard reports (specify those Component by Perl-RegExp, whose variables you would like to see):
```bash
python dqn_cartpole_with_tf_summaries.py
```
## Import and use agents
Agents can be imported and used as follows:
```python
from rlgraph.agents import DQNAgent
from rlgraph.environments import OpenAIGymEnv
environment = OpenAIGymEnv('CartPole-v0')
# Create from .json file or dict, see agent API for all
# possible configuration parameters.
agent = DQNAgent.from_file(
"configs/dqn_cartpole.json",
state_space=environment.state_space,
action_space=environment.action_space
)
# Get an action, take a step, observe reward.
state = environment.reset()
action, preprocessed_state = agent.get_action(
states=state,
extra_returns="preprocessed_states"
)
# Execute step in environment.
next_state, reward, terminal, info = environment.step(action)
# Observe result.
agent.observe(
preprocessed_states=preprocessed_state,
actions=action,
internals=[],
next_states=next_state,
rewards=reward,
terminals=terminal
)
# Call update when desired:
loss = agent.update()
```
Full examples can be found in the examples folder.
## Cite
If you use RLgraph in your research, please cite the following paper: [link](https://arxiv.org/abs/1810.09028)
```
@InProceedings{Schaarschmidt2019,
author = {Schaarschmidt, Michael and Mika, Sven and Fricke, Kai and Yoneki, Eiko},
title = {{RLgraph: Modular Computation Graphs for Deep Reinforcement Learning}},
booktitle = {{Proceedings of the 2nd Conference on Systems and Machine Learning (SysML)}},
year = {2019},
month = apr,
}
``` | /rlgraph-0.5.5.tar.gz/rlgraph-0.5.5/README.md | 0.667581 | 0.99264 | README.md | pypi |
from typing import Any, List, Dict, Tuple, Generic, Optional
from .config import ActionParser, DoneCondition, ObsBuilder, RewardFunction, StateMutator, Renderer, TransitionEngine
from .typing import AgentID, ObsType, ActionType, EngineActionType, RewardType, StateType, SpaceType
class RLGym(Generic[AgentID, ObsType, ActionType, EngineActionType, RewardType, StateType, SpaceType]):
#TODO docs
def __init__(self,
state_mutator: StateMutator[StateType],
obs_builder: ObsBuilder[AgentID, ObsType, StateType, SpaceType],
action_parser: ActionParser[AgentID, ActionType, EngineActionType, StateType, SpaceType],
reward_fn: RewardFunction[AgentID, StateType, RewardType],
termination_cond: DoneCondition[AgentID, StateType],
truncation_cond: DoneCondition[AgentID, StateType],
transition_engine: TransitionEngine[AgentID, StateType, EngineActionType],
renderer: Optional[Renderer[StateType]]):
"""
TODO docs
:param state_mutator:
:param obs_builder:
:param action_parser:
:param reward_fn:
:param termination_cond:
:param truncation_cond:
:param transition_engine:
:param renderer:
"""
self.state_mutator = state_mutator
self.obs_builder = obs_builder
self.action_parser = action_parser
self.reward_fn = reward_fn
self.termination_cond = termination_cond
self.truncation_cond = truncation_cond
self.transition_engine = transition_engine
self.renderer = renderer
self.shared_info = {}
@property
def agents(self) -> List[AgentID]:
return self.transition_engine.agents
@property
def action_spaces(self) -> Dict[AgentID, SpaceType]:
spaces = {}
for agent in self.agents:
spaces[agent] = self.action_space(agent)
return spaces
@property
def observation_spaces(self) -> Dict[AgentID, SpaceType]:
spaces = {}
for agent in self.agents:
spaces[agent] = self.observation_space(agent)
return spaces
@property
def state(self) -> StateType:
return self.transition_engine.state
#TODO add snapshot property to all objects, save state and probably shared_info
def action_space(self, agent: AgentID) -> SpaceType:
return self.action_parser.get_action_space(agent)
def observation_space(self, agent: AgentID) -> SpaceType:
return self.obs_builder.get_obs_space(agent)
def set_state(self, desired_state: StateType) -> Dict[AgentID, ObsType]:
state = self.transition_engine.set_state(desired_state, self.shared_info)
return self.obs_builder.build_obs(self.agents, state, self.shared_info)
def reset(self) -> Dict[AgentID, ObsType]:
desired_state = self.transition_engine.create_base_state()
self.state_mutator.apply(desired_state, self.shared_info)
state = self.transition_engine.set_state(desired_state, self.shared_info)
self.obs_builder.reset(state, self.shared_info)
self.action_parser.reset(state, self.shared_info)
self.termination_cond.reset(state, self.shared_info)
self.truncation_cond.reset(state, self.shared_info)
self.reward_fn.reset(state, self.shared_info)
return self.obs_builder.build_obs(self.agents, state, self.shared_info)
def step(self, actions: Dict[AgentID, ActionType]) -> Tuple[Dict[AgentID, ObsType], Dict[AgentID, RewardType], Dict[AgentID, bool], Dict[AgentID, bool]]:
engine_actions = self.action_parser.parse_actions(actions, self.state, self.shared_info)
new_state = self.transition_engine.step(engine_actions, self.shared_info)
agents = self.agents
obs = self.obs_builder.build_obs(agents, new_state, self.shared_info)
is_terminated = self.termination_cond.is_done(agents, new_state, self.shared_info)
is_truncated = self.truncation_cond.is_done(agents, new_state, self.shared_info)
rewards = self.reward_fn.get_rewards(agents, new_state, is_terminated, is_truncated, self.shared_info)
return obs, rewards, is_terminated, is_truncated
def render(self) -> Any:
self.renderer.render(self.state, self.shared_info)
def close(self) -> None:
self.transition_engine.close()
if self.renderer is not None:
self.renderer.close() | /rlgym-api-2.0.0a1.tar.gz/rlgym-api-2.0.0a1/rlgym/api/rlgym.py | 0.669853 | 0.454593 | rlgym.py | pypi |
from abc import abstractmethod
from typing import Any, Dict, List, Generic
from ..typing import AgentID, ObsType, StateType, SpaceType
class ObsBuilder(Generic[AgentID, ObsType, StateType, SpaceType]):
@abstractmethod
def get_obs_space(self, agent: AgentID) -> SpaceType:
"""
Function that returns the observation space type. It will be called during the initialization of the environment.
:return: The type of the observation space
"""
raise NotImplementedError
@abstractmethod
def reset(self, initial_state: StateType, shared_info: Dict[str, Any]) -> None:
"""
Function to be called each time the environment is reset. Note that this does not need to return anything,
the environment will call `build_obs` automatically after reset, so the initial observation for a policy will be
constructed in the same way as every other observation.
:param initial_state: The initial game state of the reset environment.
:param shared_info: A dictionary with shared information across all config objects.
"""
raise NotImplementedError
@abstractmethod
def build_obs(self, agents: List[AgentID], state: StateType, shared_info: Dict[str, Any]) -> Dict[AgentID, ObsType]:
"""
Function to build observations for N agents. This is where observations will be constructed every step and
every reset. This function is given the current state, and it is expected that the observations returned by this
function will contain information from the perspective of each agent. This function is called only once per step.
:param agents: List of AgentIDs for which this ObsBuilder should return an Obs
:param state: The current state of the game.
:param shared_info: A dictionary with shared information across all config objects.
:return: An dictionary of observations, one for each AgentID in agents.
"""
raise NotImplementedError | /rlgym-api-2.0.0a1.tar.gz/rlgym-api-2.0.0a1/rlgym/api/config/obs_builder.py | 0.913334 | 0.590514 | obs_builder.py | pypi |
from abc import abstractmethod
from typing import Any, Dict, Generic
from ..typing import AgentID, ActionType, EngineActionType, StateType, SpaceType
class ActionParser(Generic[AgentID, ActionType, EngineActionType, StateType, SpaceType]):
@abstractmethod
def get_action_space(self, agent: AgentID) -> SpaceType:
"""
Function that returns the action space type. It will be called during the initialization of the environment.
:return: The type of the action space
"""
raise NotImplementedError
@abstractmethod
def reset(self, initial_state: StateType, shared_info: Dict[str, Any]) -> None:
"""
Function to be called each time the environment is reset.
:param initial_state: The initial state of the reset environment.
:param shared_info: A dictionary with shared information across all config objects.
"""
raise NotImplementedError
@abstractmethod
def parse_actions(self, actions: Dict[AgentID, ActionType], state: StateType, shared_info: Dict[str, Any]) -> Dict[AgentID, EngineActionType]:
#TODO update docs with new time dimension, array is now (ticks, actiondim=8)
"""
Function that parses actions from the action space into a format that rlgym understands.
The expected return value is a numpy float array of size (n, 8) where n is the number of agents.
The second dimension is indexed as follows: throttle, steer, yaw, pitch, roll, jump, boost, handbrake.
The first five values are expected to be in the range [-1, 1], while the last three values should be either 0 or 1.
:param actions: An dict of actions, as passed to the `env.step` function.
:param state: The GameState object of the current state that were used to generate the actions.
:param shared_info: A dictionary with shared information across all config objects.
:return: the parsed actions in the rlgym format.
"""
raise NotImplementedError | /rlgym-api-2.0.0a1.tar.gz/rlgym-api-2.0.0a1/rlgym/api/config/action_parser.py | 0.753829 | 0.57946 | action_parser.py | pypi |
import numpy as np
from typing import List
from rlbot.utils.structures.game_data_struct import GameTickPacket, FieldInfoPacket, PlayerInfo
from .physics_object import PhysicsObject
from .player_data import PlayerData
class GameState:
def __init__(self, game_info: FieldInfoPacket):
self.blue_score = 0
self.orange_score = 0
self.players: List[PlayerData] = []
self._on_ground_ticks = np.zeros(64)
self.ball: PhysicsObject = PhysicsObject()
self.inverted_ball: PhysicsObject = PhysicsObject()
# List of "booleans" (1 or 0)
self.boost_pads: np.ndarray = np.zeros(game_info.num_boosts, dtype=np.float32)
self.inverted_boost_pads: np.ndarray = np.zeros_like(self.boost_pads, dtype=np.float32)
def decode(self, packet: GameTickPacket, ticks_elapsed=1):
self.blue_score = packet.teams[0].score
self.orange_score = packet.teams[1].score
for i in range(packet.num_boost):
self.boost_pads[i] = packet.game_boosts[i].is_active
self.inverted_boost_pads[:] = self.boost_pads[::-1]
self.ball.decode_ball_data(packet.game_ball.physics)
self.inverted_ball.invert(self.ball)
self.players = []
for i in range(packet.num_cars):
player = self._decode_player(packet.game_cars[i], i, ticks_elapsed)
self.players.append(player)
if player.ball_touched:
self.last_touch = player.car_id
def _decode_player(self, player_info: PlayerInfo, index: int, ticks_elapsed: int) -> PlayerData:
player_data = PlayerData()
player_data.car_data.decode_car_data(player_info.physics)
player_data.inverted_car_data.invert(player_data.car_data)
if player_info.has_wheel_contact:
self._on_ground_ticks[index] = 0
else:
self._on_ground_ticks[index] += ticks_elapsed
player_data.car_id = index
player_data.team_num = player_info.team
player_data.is_demoed = player_info.is_demolished
player_data.on_ground = player_info.has_wheel_contact or self._on_ground_ticks[index] <= 6
player_data.ball_touched = False
player_data.has_jump = not player_info.jumped
player_data.has_flip = not player_info.double_jumped # RLGym does consider the timer/unlimited flip, but i'm to lazy to track that in rlbot
player_data.boost_amount = player_info.boost / 100
return player_data | /rlgym_compat-1.1.0.tar.gz/rlgym_compat-1.1.0/rlgym_compat/game_state.py | 0.637821 | 0.2328 | game_state.py | pypi |
import math
import numpy as np
from rlbot.utils.structures.game_data_struct import Physics, Vector3, Rotator
class PhysicsObject:
def __init__(self, position=None, euler_angles=None, linear_velocity=None, angular_velocity=None):
self.position: np.ndarray = position if position else np.zeros(3)
# ones by default to prevent mathematical errors when converting quat to rot matrix on empty physics state
self.quaternion: np.ndarray = np.ones(4)
self.linear_velocity: np.ndarray = linear_velocity if linear_velocity else np.zeros(3)
self.angular_velocity: np.ndarray = angular_velocity if angular_velocity else np.zeros(3)
self._euler_angles: np.ndarray = euler_angles if euler_angles else np.zeros(3)
self._rotation_mtx: np.ndarray = np.zeros((3,3))
self._has_computed_rot_mtx = False
self._invert_vec = np.asarray([-1, -1, 1])
self._invert_pyr = np.asarray([0, math.pi, 0])
def decode_car_data(self, car_data: Physics):
self.position = self._vector_to_numpy(car_data.location)
self._euler_angles = self._rotator_to_numpy(car_data.rotation)
self.linear_velocity = self._vector_to_numpy(car_data.velocity)
self.angular_velocity = self._vector_to_numpy(car_data.angular_velocity)
def decode_ball_data(self, ball_data: Physics):
self.position = self._vector_to_numpy(ball_data.location)
self.linear_velocity = self._vector_to_numpy(ball_data.velocity)
self.angular_velocity = self._vector_to_numpy(ball_data.angular_velocity)
def invert(self, other):
self.position = other.position * self._invert_vec
self._euler_angles = other.euler_angles() + self._invert_pyr
self.linear_velocity = other.linear_velocity * self._invert_vec
self.angular_velocity = other.angular_velocity * self._invert_vec
# pitch, yaw, roll
def euler_angles(self) -> np.ndarray:
return self._euler_angles
def pitch(self):
return self._euler_angles[0]
def yaw(self):
return self._euler_angles[1]
def roll(self):
return self._euler_angles[2]
def rotation_mtx(self) -> np.ndarray:
if not self._has_computed_rot_mtx:
self._rotation_mtx = self._euler_to_rotation(self._euler_angles)
self._has_computed_rot_mtx = True
return self._rotation_mtx
def forward(self) -> np.ndarray:
return self.rotation_mtx()[:, 0]
def right(self) -> np.ndarray:
return self.rotation_mtx()[:, 1] * -1 # These are inverted compared to rlgym because rlbot reasons
def left(self) -> np.ndarray:
return self.rotation_mtx()[:, 1]
def up(self) -> np.ndarray:
return self.rotation_mtx()[:, 2]
def _vector_to_numpy(self, vector: Vector3):
return np.asarray([vector.x, vector.y, vector.z])
def _rotator_to_numpy(self, rotator: Rotator):
return np.asarray([rotator.pitch, rotator.yaw, rotator.roll])
def _euler_to_rotation(self, pyr: np.ndarray):
CP = math.cos(pyr[0])
SP = math.sin(pyr[0])
CY = math.cos(pyr[1])
SY = math.sin(pyr[1])
CR = math.cos(pyr[2])
SR = math.sin(pyr[2])
theta = np.empty((3, 3))
# front direction
theta[0, 0] = CP * CY
theta[1, 0] = CP * SY
theta[2, 0] = SP
# left direction
theta[0, 1] = CY * SP * SR - CR * SY
theta[1, 1] = SY * SP * SR + CR * CY
theta[2, 1] = -CP * SR
# up direction
theta[0, 2] = -CR * CY * SP - SR * SY
theta[1, 2] = -CR * SY * SP + SR * CY
theta[2, 2] = CP * CR
return theta | /rlgym_compat-1.1.0.tar.gz/rlgym_compat-1.1.0/rlgym_compat/physics_object.py | 0.824603 | 0.662547 | physics_object.py | pypi |
import numpy as np
def get_dist(x, y):
return np.subtract(x, y)
def vector_projection(vec, dest_vec, mag_squared=None):
if mag_squared is None:
norm = vecmag(dest_vec)
if norm == 0:
return dest_vec
mag_squared = norm * norm
if mag_squared == 0:
return dest_vec
dot = np.dot(vec, dest_vec)
projection = np.multiply(np.divide(dot, mag_squared), dest_vec)
return projection
def scalar_projection(vec, dest_vec):
norm = vecmag(dest_vec)
if norm == 0:
return 0
dot = np.dot(vec, dest_vec) / norm
return dot
def squared_vecmag(vec):
x = np.linalg.norm(vec)
return x * x
def vecmag(vec):
norm = np.linalg.norm(vec)
return norm
def unitvec(vec):
return np.divide(vec, vecmag(vec))
def cosine_similarity(a, b):
return np.dot(a / np.linalg.norm(a), b / np.linalg.norm(b))
def quat_to_euler(quat):
w, x, y, z = quat
sinr_cosp = 2 * (w * x + y * z)
cosr_cosp = 1 - 2 * (x * x + y * y)
sinp = 2 * (w * y - z * x)
siny_cosp = 2 * (w * z + x * y)
cosy_cosp = 1 - 2 * (y * y + z * z)
roll = np.arctan2(sinr_cosp, cosr_cosp)
if abs(sinp) > 1:
pitch = np.pi / 2
else:
pitch = np.arcsin(sinp)
yaw = np.arctan2(siny_cosp, cosy_cosp)
return np.array([-pitch, yaw, -roll])
# From RLUtilities
def quat_to_rot_mtx(quat: np.ndarray) -> np.ndarray:
w = -quat[0]
x = -quat[1]
y = -quat[2]
z = -quat[3]
theta = np.zeros((3, 3))
norm = np.dot(quat, quat)
if norm != 0:
s = 1.0 / norm
# front direction
theta[0, 0] = 1.0 - 2.0 * s * (y * y + z * z)
theta[1, 0] = 2.0 * s * (x * y + z * w)
theta[2, 0] = 2.0 * s * (x * z - y * w)
# left direction
theta[0, 1] = 2.0 * s * (x * y - z * w)
theta[1, 1] = 1.0 - 2.0 * s * (x * x + z * z)
theta[2, 1] = 2.0 * s * (y * z + x * w)
# up direction
theta[0, 2] = 2.0 * s * (x * z + y * w)
theta[1, 2] = 2.0 * s * (y * z - x * w)
theta[2, 2] = 1.0 - 2.0 * s * (x * x + y * y)
return theta
def rotation_to_quaternion(m: np.ndarray) -> np.ndarray:
trace = np.trace(m)
q = np.zeros(4)
if trace > 0:
s = (trace + 1) ** 0.5
q[0] = s * 0.5
s = 0.5 / s
q[1] = (m[2, 1] - m[1, 2]) * s
q[2] = (m[0, 2] - m[2, 0]) * s
q[3] = (m[1, 0] - m[0, 1]) * s
else:
if m[0, 0] >= m[1, 1] and m[0, 0] >= m[2, 2]:
s = (1 + m[0, 0] - m[1, 1] - m[2, 2]) ** 0.5
inv_s = 0.5 / s
q[1] = 0.5 * s
q[2] = (m[1, 0] + m[0, 1]) * inv_s
q[3] = (m[2, 0] + m[0, 2]) * inv_s
q[0] = (m[2, 1] - m[1, 2]) * inv_s
elif m[1, 1] > m[2, 2]:
s = (1 + m[1, 1] - m[0, 0] - m[2, 2]) ** 0.5
inv_s = 0.5 / s
q[1] = (m[0, 1] + m[1, 0]) * inv_s
q[2] = 0.5 * s
q[3] = (m[1, 2] + m[2, 1]) * inv_s
q[0] = (m[0, 2] - m[2, 0]) * inv_s
else:
s = (1 + m[2, 2] - m[0, 0] - m[1, 1]) ** 0.5
inv_s = 0.5 / s
q[1] = (m[0, 2] + m[2, 0]) * inv_s
q[2] = (m[1, 2] + m[2, 1]) * inv_s
q[3] = 0.5 * s
q[0] = (m[1, 0] - m[0, 1]) * inv_s
# q[[0, 1, 2, 3]] = q[[3, 0, 1, 2]]
return -q
def euler_to_rotation(pyr):
cp, cy, cr = np.cos(pyr)
sp, sy, sr = np.sin(pyr)
theta = np.zeros((3, 3))
# front
theta[0, 0] = cp * cy
theta[1, 0] = cp * sy
theta[2, 0] = sp
# left
theta[0, 1] = cy * sp * sr - cr * sy
theta[1, 1] = sy * sp * sr + cr * cy
theta[2, 1] = -cp * sr
# up
theta[0, 2] = -cr * cy * sp - sr * sy
theta[1, 2] = -cr * sy * sp + sr * cy
theta[2, 2] = cp * cr
return theta
def rand_uvec3(rng: np.random.Generator = np.random):
vec = rng.random(3) - 0.5
return vec / np.linalg.norm(vec)
def rand_vec3(max_norm, rng: np.random.Generator = np.random):
return rand_uvec3(rng) * (rng.random() * max_norm) | /rlgym-rocket-league-2.0.0a2.tar.gz/rlgym-rocket-league-2.0.0a2/rlgym/rocket_league/math.py | 0.694095 | 0.630799 | math.py | pypi |
import numpy as np
from dataclasses import dataclass
from typing import TypeVar, Optional
from rlgym.rocket_league.engine.utils import create_default_init
from rlgym.rocket_league import math
T = TypeVar('T')
@dataclass(init=False)
class PhysicsObject:
INV_VEC = np.array([-1, -1, 1], dtype=np.float32)
INV_MTX = np.array([[-1, -1, -1], [-1, -1, -1], [1, 1, 1]], dtype=np.float32)
position: np.ndarray
linear_velocity: np.ndarray
angular_velocity: np.ndarray
_quaternion: Optional[np.ndarray]
_rotation_mtx: Optional[np.ndarray]
_euler_angles: Optional[np.ndarray]
__slots__ = tuple(__annotations__)
exec(create_default_init(__slots__))
def inverted(self: T) -> T:
inv = PhysicsObject()
inv.position = self.position * PhysicsObject.INV_VEC
inv.linear_velocity = self.linear_velocity * PhysicsObject.INV_VEC
inv.angular_velocity = self.angular_velocity * PhysicsObject.INV_VEC
if self._rotation_mtx is not None or self._quaternion is not None or self._euler_angles is not None:
inv.rotation_mtx = self.rotation_mtx * PhysicsObject.INV_MTX
return inv
@property
def quaternion(self) -> np.ndarray:
if self._quaternion is None:
if self._rotation_mtx is not None:
self._quaternion = math.rotation_to_quaternion(self._rotation_mtx)
elif self._euler_angles is not None:
#TODO support from euler for RLBot compat
raise NotImplementedError
else:
raise ValueError
return self._quaternion
@quaternion.setter
def quaternion(self, val: np.ndarray):
self._quaternion = val
self._rotation_mtx = None
self._euler_angles = None
@property
def rotation_mtx(self) -> np.ndarray:
if self._rotation_mtx is None:
if self._quaternion is not None:
self._rotation_mtx = math.quat_to_rot_mtx(self._quaternion)
elif self._euler_angles is not None:
self._rotation_mtx = math.euler_to_rotation(self._euler_angles)
else:
raise ValueError
return self._rotation_mtx
@rotation_mtx.setter
def rotation_mtx(self, val: np.ndarray):
self._rotation_mtx = val
self._quaternion = None
self._euler_angles = None
@property
def euler_angles(self) -> np.ndarray:
if self._euler_angles is None:
if self._quaternion is not None:
self._euler_angles = math.quat_to_euler(self._quaternion)
elif self._rotation_mtx is not None:
#TODO support from rot mtx
raise NotImplementedError
else:
raise ValueError
return self._euler_angles
@euler_angles.setter
def euler_angles(self, val: np.ndarray):
self._euler_angles = val
self._quaternion = None
self._rotation_mtx = None
@property
def forward(self) -> np.ndarray:
return self.rotation_mtx[:, 0]
@property
def right(self) -> np.ndarray:
return self.rotation_mtx[:, 1]
@property
def left(self) -> np.ndarray:
return self.rotation_mtx[:, 1] * -1
@property
def up(self) -> np.ndarray:
return self.rotation_mtx[:, 2]
@property
def pitch(self) -> float:
return self.euler_angles[0]
@property
def yaw(self) -> float:
return self.euler_angles[1]
@property
def roll(self) -> float:
return self.euler_angles[2] | /rlgym-rocket-league-2.0.0a2.tar.gz/rlgym-rocket-league-2.0.0a2/rlgym/rocket_league/engine/physics_object.py | 0.802672 | 0.398202 | physics_object.py | pypi |
import numpy as np
from dataclasses import dataclass
from typing import Optional, Generic
from rlgym.api.typing import AgentID
from rlgym.rocket_league.common_values import DOUBLEJUMP_MAX_DELAY, FLIP_TORQUE_TIME
from rlgym.rocket_league.engine.physics_object import PhysicsObject
from rlgym.rocket_league.engine.utils import create_default_init
@dataclass(init=False)
class Car(Generic[AgentID]):
# Misc Data
team_num: int #TODO switch to typed class?
hitbox_type: int # TODO should probably be typed too?
ball_touches: int # number of ball touches since last state was sent
bump_victim_id: Optional[AgentID]
# Actual State
demo_respawn_timer: float # 0 if alive
# TODO add num_wheels_contact when it's available in rsim
#num_wheels_contact: int # Needed for stuff like AutoRoll and some steering shenanigans
on_ground: bool # this is just numWheelsContact >=3 TODO make property when num_w_cts is available
supersonic_time: float # greater than 0 when supersonic, needed for state set since ssonic threshold changes with time
boost_amount: float
boost_active_time: float # you're forced to boost for at least 12 ticks
handbrake: float
# Jump Stuff
has_jumped: bool
is_holding_jump: bool # whether you pressed jump last tick or not
is_jumping: bool # changes to false after max jump time
jump_time: float # need jump time for state set, doesn't reset to 0 because of psyonix's landing jump cooldown
# Flip Stuff
has_flipped: bool
has_double_jumped: bool
air_time_since_jump: float
flip_time: float
flip_torque: np.ndarray
# AutoFlip Stuff - What helps you recover from turtling
is_autoflipping: bool
autoflip_timer: float
autoflip_direction: float # 1 or -1, determines roll direction
physics: PhysicsObject
_inverted_physics: PhysicsObject
__slots__ = tuple(__annotations__)
exec(create_default_init(__slots__))
@property
def can_flip(self) -> bool:
return not self.has_double_jumped and not self.has_flipped and self.air_time_since_jump < DOUBLEJUMP_MAX_DELAY
@property # TODO This one isn't in rsim python yet, emulate with prop
def is_flipping(self) -> bool:
return self.has_flipped and self.flip_time < FLIP_TORQUE_TIME
@is_flipping.setter
def is_flipping(self, value: bool):
if value:
self.has_flipped = True
if self.flip_time >= FLIP_TORQUE_TIME:
self.flip_time = 0
else:
self.flip_time = FLIP_TORQUE_TIME
@property
def inverted_physics(self) -> PhysicsObject:
if self._inverted_physics is None:
self._inverted_physics = self.physics.inverted()
return self._inverted_physics | /rlgym-rocket-league-2.0.0a2.tar.gz/rlgym-rocket-league-2.0.0a2/rlgym/rocket_league/engine/car.py | 0.504639 | 0.23524 | car.py | pypi |
import random
from typing import Dict, Any
import numpy as np
from rlgym.api.config.state_mutator import StateMutator
from rlgym.rocket_league.common_values import BLUE_TEAM, BALL_RADIUS
from rlgym.rocket_league.engine.game_state import GameState
class KickoffMutator(StateMutator[GameState]):
SPAWN_BLUE_POS = np.array([[-2048, -2560, 17], [2048, -2560, 17], [-256, -3840, 17], [256, -3840, 17], [0, -4608, 17]], dtype=np.float32)
SPAWN_BLUE_YAW = [0.25 * np.pi, 0.75 * np.pi, 0.5 * np.pi, 0.5 * np.pi, 0.5 * np.pi]
SPAWN_ORANGE_POS = np.array([[2048, 2560, 17], [-2048, 2560, 17], [256, 3840, 17], [-256, 3840, 17], [0, 4608, 17]], dtype=np.float32)
SPAWN_ORANGE_YAW = [-0.75 * np.pi, -0.25 * np.pi, -0.5 * np.pi, -0.5 * np.pi, -0.5 * np.pi]
def apply(self, state: GameState, shared_info: Dict[str, Any]) -> None:
# Put ball in center
state.ball.position = np.array([0, 0, BALL_RADIUS], dtype=np.float32)
state.ball.linear_velocity = np.zeros(3, dtype=np.float32)
state.ball.angular_velocity = np.zeros(3, dtype=np.float32)
# possible kickoff indices are shuffled
spawn_idx = [0, 1, 2, 3, 4]
random.shuffle(spawn_idx)
blue_count = 0
orange_count = 0
for car in state.cars.values():
if car.team_num == BLUE_TEAM:
# select a unique spawn state from pre-determined values
pos = self.SPAWN_BLUE_POS[spawn_idx[blue_count]]
yaw = self.SPAWN_BLUE_YAW[spawn_idx[blue_count]]
blue_count += 1
else:
# select a unique spawn state from pre-determined values
pos = self.SPAWN_ORANGE_POS[spawn_idx[orange_count]]
yaw = self.SPAWN_ORANGE_YAW[spawn_idx[orange_count]]
orange_count += 1
car.physics.position = pos
car.physics.linear_velocity = np.zeros(3, dtype=np.float32)
car.physics.angular_velocity = np.zeros(3, dtype=np.float32)
car.physics.euler_angles = np.array([0, yaw, 0], dtype=np.float32)
car.boost_amount = 0.33 | /rlgym-rocket-league-2.0.0a2.tar.gz/rlgym-rocket-league-2.0.0a2/rlgym/rocket_league/state_mutators/kickoff_mutator.py | 0.574753 | 0.291762 | kickoff_mutator.py | pypi |
from typing import Any
import RocketSim as rsim
import rlviser_py as rlviser
from rlgym.api.engine.renderer import Renderer
from rlgym.rocket_league.common_values import BOOST_LOCATIONS
from rlgym.rocket_league.engine.car import Car
from rlgym.rocket_league.engine.game_state import GameState
class RLViserRenderer(Renderer[GameState]):
def __init__(self, tick_rate=120/8):
rlviser.set_boost_pad_locations(BOOST_LOCATIONS)
self.tick_rate = tick_rate
self.packet_id = 0
def render(self, state: GameState) -> Any:
boost_pad_states = [bool(timer == 0) for timer in state.boost_pad_timers]
ball = rsim.BallState()
ball.pos = rsim.Vec(*state.ball.position)
ball.vel = rsim.Vec(*state.ball.linear_velocity)
ball.ang_vel = rsim.Vec(*state.ball.angular_velocity)
car_data = []
for idx, car in enumerate(state.cars.values()):
car_state = self._get_car_state(car)
car_data.append((idx, car.team_num, rsim.CarConfig(car.hitbox_type), car_state))
self.packet_id += 1
rlviser.render(tick_count=self.packet_id, tick_rate=self.tick_rate, boost_pad_states=boost_pad_states,
ball=ball, cars=car_data)
def close(self):
rlviser.quit()
# I stole this from RocketSimEngine
def _get_car_state(self, car: Car):
car_state = rsim.CarState()
car_state.pos = rsim.Vec(*car.physics.position)
car_state.vel = rsim.Vec(*car.physics.linear_velocity)
car_state.ang_vel = rsim.Vec(*car.physics.angular_velocity)
car_state.rot_mat = rsim.RotMat(*car.physics.rotation_mtx.transpose().flatten())
car_state.demo_respawn_timer = car.demo_respawn_timer
car_state.is_on_ground = car.on_ground
car_state.supersonic_time = car.supersonic_time
car_state.boost = car.boost_amount * 100
car_state.time_spent_boosting = car.boost_active_time
car_state.handbrake_val = car.handbrake
car_state.has_jumped = car.has_jumped
car_state.last_controls.jump = car.is_holding_jump
car_state.is_jumping = car.is_jumping
car_state.jump_time = car.jump_time
car_state.has_flipped = car.has_flipped
car_state.has_double_jumped = car.has_double_jumped
car_state.air_time_since_jump = car.air_time_since_jump
car_state.flip_time = car.flip_time
car_state.last_rel_dodge_torque = rsim.Vec(*car.flip_torque)
car_state.is_auto_flipping = car.is_autoflipping
car_state.auto_flip_timer = car.autoflip_timer
car_state.auto_flip_torque_scale = car.autoflip_direction
if car.bump_victim_id is not None:
car_state.car_contact_id = car.bump_victim_id
return car_state | /rlgym-rocket-league-2.0.0a2.tar.gz/rlgym-rocket-league-2.0.0a2/rlgym/rocket_league/sim/rlviser_renderer.py | 0.613584 | 0.295455 | rlviser_renderer.py | pypi |
import numpy as np
from typing import Dict, Any, List
from rlgym.api.engine.transition_engine import TransitionEngine
from rlgym.api.typing import AgentID
from rlgym.rocket_league.engine.game_state import GameState
class GameEngine(TransitionEngine[AgentID, GameState, np.ndarray]):
"""
WIP Don't use yet
"""
def __init__(self):
"""
:param game_speed: The speed the physics will run at, leave it at 100 unless your game can't run at over 240fps
:param launch_preference: Rocket League launch preference (rlgym.gamelaunch.LaunchPreference) or path to RocketLeague executable
:param use_injector: Whether to use RLGym's bakkesmod injector or not. Enable if launching multiple instances
:param force_paging: Enable forced paging of each spawned rocket league instance to reduce memory utilization
immediately, instead of allowing the OS to slowly page untouched allocations.
WARNING: This will require you to potentially expand your Windows Page File [1]
and it may substantially increase disk activity, leading to decreased disk lifetime.
Use at your own peril.
Default is off: OS dictates the behavior.
:param raise_on_crash: If enabled, raises an exception when Rocket League crashes instead of attempting to recover.
You can attempt a recovery manually by calling attempt_recovery()
:param auto_minimize: Automatically minimize the game window when launching Rocket League
[1]: https://www.tomshardware.com/news/how-to-manage-virtual-memory-pagefile-windows-10,36929.html
"""
pass
@property
def agents(self) -> List[AgentID]:
pass
@property
def max_num_agents(self) -> int:
pass
@property
def state(self) -> GameState:
pass
@property
def config(self) -> Dict[AgentID, Any]:
pass
def step(self, actions: Dict[AgentID, np.ndarray]) -> GameState:
pass
def create_base_state(self) -> GameState:
pass
def set_state(self, desired_state: GameState) -> GameState:
pass
def close(self) -> None:
pass | /rlgym-rocket-league-2.0.0a2.tar.gz/rlgym-rocket-league-2.0.0a2/rlgym/rocket_league/game/game_engine.py | 0.81772 | 0.28318 | game_engine.py | pypi |
import math
from typing import List, Dict, Any
import numpy as np
from rlgym.api.config.obs_builder import ObsBuilder
from rlgym.api.typing import AgentID
from rlgym.rocket_league.common_values import ORANGE_TEAM
from rlgym.rocket_league.engine.car import Car
from rlgym.rocket_league.engine.game_state import GameState
class DefaultObs(ObsBuilder[AgentID, np.ndarray, GameState, int]):
def __init__(self, zero_padding=3, pos_coef=1/2300, ang_coef=1/math.pi, lin_vel_coef=1/2300, ang_vel_coef=1/math.pi,
pad_timer_coef=1/10):
"""
:param zero_padding: Number of max cars per team, if not None the obs will be zero padded
:param pos_coef: Position normalization coefficient
:param ang_coef: Rotation angle normalization coefficient
:param lin_vel_coef: Linear velocity normalization coefficient
:param ang_vel_coef: Angular velocity normalization coefficient
:param pad_timer_coef: Boost pad timers normalization coefficient
"""
super().__init__()
self.POS_COEF = pos_coef
self.ANG_COEF = ang_coef
self.LIN_VEL_COEF = lin_vel_coef
self.ANG_VEL_COEF = ang_vel_coef
self.PAD_TIMER_COEF = pad_timer_coef
self.zero_padding = zero_padding
def get_obs_space(self, agent: AgentID) -> int:
if self.zero_padding is not None:
return 52 + 20 * self.zero_padding * 2
else:
return None # Without zero padding this depends on the initial state, but we don't want to crash for now
def reset(self, initial_state: GameState, shared_info: Dict[str, Any]) -> None:
pass
def build_obs(self, agents: List[AgentID], state: GameState, shared_info: Dict[str, Any]) -> Dict[AgentID, np.ndarray]:
obs = {}
for agent in agents:
obs[agent] = self._build_obs(agent, state, shared_info)
return obs
def _build_obs(self, agent: AgentID, state: GameState, shared_info: Dict[str, Any]) -> np.ndarray:
car = state.cars[agent]
if car.team_num == ORANGE_TEAM:
inverted = True
ball = state.inverted_ball
pads = state.inverted_boost_pad_timers
else:
inverted = False
ball = state.ball
pads = state.boost_pad_timers
obs = [ # Global stuff
ball.position * self.POS_COEF,
ball.linear_velocity * self.LIN_VEL_COEF,
ball.angular_velocity * self.ANG_VEL_COEF,
pads * self.PAD_TIMER_COEF,
[ # Partially observable variables
car.is_holding_jump,
car.handbrake,
car.has_jumped,
car.is_jumping,
car.has_flipped,
car.is_flipping,
car.has_double_jumped,
car.can_flip,
car.air_time_since_jump
]
]
car_obs = self._generate_car_obs(car, inverted)
obs.append(car_obs)
allies = []
enemies = []
for other, other_car in state.cars.items():
if other == agent:
continue
if other_car.team_num == car.team_num:
team_obs = allies
else:
team_obs = enemies
team_obs.append(self._generate_car_obs(other_car, inverted))
if self.zero_padding is not None:
# Padding for multi game mode
while len(allies) < self.zero_padding - 1:
allies.append(np.zeros_like(car_obs))
while len(enemies) < self.zero_padding:
enemies.append(np.zeros_like(car_obs))
obs.extend(allies)
obs.extend(enemies)
return np.concatenate(obs)
def _generate_car_obs(self, car: Car, inverted: bool) -> np.ndarray:
if inverted:
physics = car.inverted_physics
else:
physics = car.physics
return np.concatenate([
physics.position * self.POS_COEF,
physics.forward,
physics.up,
physics.linear_velocity * self.LIN_VEL_COEF,
physics.angular_velocity * self.ANG_VEL_COEF,
[car.boost_amount,
car.demo_respawn_timer,
int(car.on_ground),
int(car.boost_active_time > 0),
int(car.supersonic_time > 0)]
]) | /rlgym-rocket-league-2.0.0a2.tar.gz/rlgym-rocket-league-2.0.0a2/rlgym/rocket_league/obs_builders/default_obs.py | 0.761671 | 0.403038 | default_obs.py | pypi |
from typing import Dict, Any
import numpy as np
from rlgym.api.config.action_parser import ActionParser
from rlgym.api.typing import AgentID
from rlgym.rocket_league.engine.game_state import GameState
class LookupTableAction(ActionParser[AgentID, np.ndarray, np.ndarray, GameState, int]):
"""
World-famous discrete action parser which uses a lookup table to reduce the number of possible actions from 1944 to 90
"""
def __init__(self):
super().__init__()
self._lookup_table = self.make_lookup_table()
def get_action_space(self, agent: AgentID) -> int:
return len(self._lookup_table)
def reset(self, initial_state: GameState, shared_info: Dict[str, Any]) -> None:
pass
def parse_actions(self, actions: Dict[AgentID, np.ndarray], state: GameState, shared_info: Dict[str, Any]) -> Dict[AgentID, np.ndarray]:
parsed_actions = {}
for agent, action in actions.items():
# Action can have shape (Ticks, 1) or (Ticks)
assert len(action.shape) == 1 or (len(action.shape) == 2 and action.shape[1] == 1)
if len(action.shape) == 2:
action = action.squeeze(1)
parsed_actions[agent] = self._lookup_table[action]
return parsed_actions
@staticmethod
def make_lookup_table():
actions = []
# Ground
for throttle in (-1, 0, 1):
for steer in (-1, 0, 1):
for boost in (0, 1):
for handbrake in (0, 1):
if boost == 1 and throttle != 1:
continue
actions.append([throttle or boost, steer, 0, steer, 0, 0, boost, handbrake])
# Aerial
for pitch in (-1, 0, 1):
for yaw in (-1, 0, 1):
for roll in (-1, 0, 1):
for jump in (0, 1):
for boost in (0, 1):
if jump == 1 and yaw != 0: # Only need roll for sideflip
continue
if pitch == roll == jump == 0: # Duplicate with ground
continue
# Enable handbrake for potential wavedashes
handbrake = jump == 1 and (pitch != 0 or yaw != 0 or roll != 0)
actions.append([boost, yaw, pitch, yaw, roll, jump, boost, handbrake])
return np.array(actions) | /rlgym-rocket-league-2.0.0a2.tar.gz/rlgym-rocket-league-2.0.0a2/rlgym/rocket_league/action_parsers/lookup_table_action.py | 0.849472 | 0.404184 | lookup_table_action.py | pypi |
__version__ = '1.8.2'
release_notes = {
'1.8.2': """
- Fix no touch timer in GameCondition (Rolv)
- Update RLLib example (Aech)
""",
'1.8.1': """
- Refactor GameCondition (Rolv, Impossibum)
- Fix a small mistake in LookupAction (Rolv)
""",
'1.8.0': """
- Add lookup parser as used by Nexto/Tecko (Rolv)
- Add customizable odds to WallPracticeState (Soren)
- Add code for reducing SB3 model size for RLBot botpack, with example (DI3D)
- Update AdvancedPadder for RLGym 1.2 (Kaiyotech)
- Update example code for RLGym 1.2 (mstuettgen)
- Fix AdvancedStacker (Some Rando)
- Fix broken imports in SequentialRewards (Some Rando)
- Fix bad indent in JumpTouchReward (Some Rando)
""",
'1.7.0':
"""
- Add AdvancedObsPadder (Impossibum)
- Add JumpTouchReward (Impossibum)
- Fix NameError in KickoffReward (benjamincburns)
- Add generate_probabilities as a method to ReplaySetter (Rolv)
- Upgrade WallSetter (Soren) and fix bug when num_cars == 1 (Kaiyotech)
- Add max overtime to GameCondition (Rolv)
""",
'1.6.6':
"""
-WallStateSetter now has airdribble setups and harder wall plays
""",
'1.6.5':
"""
-GoalieStateSetter now better emulates incoming airdribbles
-fixed WallStateSetter bug and increased starting diversity
""",
'1.6.4':
"""
-Added wall play state setter (Soren)
""",
'1.6.3':
"""
- Fix hoops-like setter for multiple players (Carrot)
""",
'1.6.2':
"""
- Added hoops-like setter (Carrot)
- Fixed kickoff-like setter (Carrot)
- Fixed pitch in KBMAction (Rolv)
- Added include_frame option in replay converter (wrongu)
""",
'1.6.1':
"""
- Fixed angular velocities in replay augmenter
""",
'1.6.0':
"""
- Added GoaliePracticeState setter (Soren)
- Added ReplaySetter (Carrot)
- Added AugmentSetter (NeverCast)
- Fixed an error in replay converter
""",
'1.5.3':
"""
- Yet another fix for GameCondition
""",
'1.5.2':
"""
- Another fix for GameCondition
""",
'1.5.1':
"""
- Fix for GameCondition
""",
'1.5.0':
"""
- Add SB3CombinedLogReward (LuminousLamp)
- Add SB3InstantaneousFPSCallback (LuminousLamp)
- Add KickoffLikeSetter (Carrot)
- Add GameCondition (Rolv)
""",
'1.4.1':
"""
- Remove SB3MultiDiscreteWrapper
- Update SB3 examples to include action parsers
""",
'1.4.0':
"""
- Add KBM action parser
""",
'1.3.0':
"""
- Add KickoffReward (Impossibum)
- Add SequentialReward (Impossibum)
- Better individual reward logging for SB3 (LuminousLamp)
- Add launch_preference as parameter to SB3MultipleInstanceEnv
""",
'1.2.0':
"""
- Added multi-model support for SB3
- Added weighted sample setter
- Added general stacker
- Various bug fixes
""",
'1.1.4':
"""
- Bug fixes for AdvancedStacker
""",
'1.1.3':
"""
- Fix RLGym 1.0 incompatibility
""",
'1.1.2':
"""
- Fix version import (was absolute, now relative)
""",
'1.1.1':
"""
- Fixed an invalid Python 3.7 import
- AnnealRewards now has initial_count parameter
""",
'1.1.0':
"""
- Added functionality in SB3MultipleInstanceEnv to take multiple match objects (one for each instance).
- Added AnnealRewards for transitioning between reward functions.
- Added granularity option to SB3MultiDiscreteWrapper.
- Added negative slope parameter to DiffReward (negative values are multiplied by this).
""",
'1.0.0':
"""
- Added replay to rlgym GameState converter
- Moved SB3 environments from rlgym (now called SB3SingleInstanceEnv and SB3MultipleInstanceEnv) and fixed some bugs
- Added SB3MultiDiscreteWrapper, SB3DistributeRewardsWrapper and SB3LogReward
- Added extra reward functions (DiffReward, DistributeRewards and MultiplyRewards)
- Added RLLibEnv
- Added working example code for SB3 and RLlib
"""
}
def get_current_release_notes():
if __version__ in release_notes:
return release_notes[__version__]
return ''
def print_current_release_notes():
print(f"Version {__version__}")
print(get_current_release_notes())
print("") | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/version.py | 0.703244 | 0.377082 | version.py | pypi |
from typing import List
import numpy as np
from rlgym.utils.gamestates import GameState, PlayerData
from rlgym.utils.reward_functions import DefaultReward
class MultiModelReward(DefaultReward):
"""
Handles the distribution of rewards to specific models where each model uses a different reward function
"""
index_tracker = 0
def __init__(self, model_map: List[int], reward_funcs: List[DefaultReward]):
"""
Handles the distribution of rewards to specific models where each model uses a different reward function
:param model_map: A list containing the mapping of model index to player
:param reward_funcs: A list of reward functions for each model, in the same order as the list
of models used elsewhere
"""
if max(model_map) >= len(reward_funcs):
raise ValueError("model_map implies the existence of more models than reward funcs")
super().__init__()
self.model_map = model_map
self.reward_funcs = reward_funcs
# This will make sure the right instance index is passed
self.index = self.index_tracker
self.index_tracker += 1
def reset(self, initial_state: GameState):
for func in self.reward_funcs:
func.reset(initial_state)
def get_reward(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> float:
# look up which model it is
model_num = self.model_map[
self.index * len(state.players) + [bot.car_id for bot in state.players].index(player.car_id)]
return self.reward_funcs[model_num].get_reward(player, state, previous_action)
def get_final_reward(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> float:
# look up which model it is
model_num = self.model_map[
self.index * len(state.players) + [bot.car_id for bot in state.players].index(player.car_id)]
return self.reward_funcs[model_num].get_final_reward(player, state, previous_action) | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_rewards/multi_model_rewards.py | 0.92563 | 0.645371 | multi_model_rewards.py | pypi |
import numpy as np
from rlgym.utils import RewardFunction
from rlgym.utils.common_values import BLUE_TEAM
from rlgym.utils.gamestates import GameState, PlayerData
class DistributeRewards(RewardFunction):
"""
Inspired by OpenAI's Dota bot (OpenAI Five).
Modifies rewards using the formula (1-team_spirit) * own_reward + team_spirit * avg_team_reward - avg_opp_reward
For instance, in a 3v3 where scoring a goal gives 100 reward with team_spirit 0.3 / 0.6 / 0.9:
- Goal scorer gets 80 / 60 / 40
- Teammates get 10 / 20 / 30 each
- Opponents get -33.3 each
Note that this will bring mean reward close to zero, so tracking might be misleading.
If using one of the SB3 envs SB3DistributeRewardsWrapper can be used after logging.
"""
def __init__(self, reward_func: RewardFunction, team_spirit=0.3):
super().__init__()
self.reward_func = reward_func
self.team_spirit = team_spirit
self.last_state = None
self.base_rewards = {}
self.avg_blue = 0
self.avg_orange = 0
def _compute(self, state: GameState, final=False):
if state != self.last_state:
self.base_rewards = {}
sum_blue = 0
n_blue = 0
sum_orange = 0
n_orange = 0
for player in state.players:
if final:
rew = self.reward_func.get_final_reward(player, state, None)
else:
rew = self.reward_func.get_reward(player, state, None)
self.base_rewards[player.car_id] = rew
if player.team_num == BLUE_TEAM:
sum_blue += rew
n_blue += 1
else:
sum_orange += rew
n_orange += 1
self.avg_blue = sum_blue / (n_blue or 1)
self.avg_orange = sum_orange / (n_orange or 1)
self.last_state = state
def _get_individual_reward(self, player):
base_reward = self.base_rewards[player.car_id]
if player.team_num == BLUE_TEAM:
reward = self.team_spirit * self.avg_blue + (1 - self.team_spirit) * base_reward - self.avg_orange
else:
reward = self.team_spirit * self.avg_orange + (1 - self.team_spirit) * base_reward - self.avg_blue
return reward
def reset(self, initial_state: GameState):
self.reward_func.reset(initial_state)
def get_reward(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> float:
self._compute(state, final=False)
return self._get_individual_reward(player)
def get_final_reward(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> float:
self._compute(state, final=True)
return self._get_individual_reward(player) | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_rewards/distribute_rewards.py | 0.783947 | 0.360039 | distribute_rewards.py | pypi |
import math
from typing import Union
import numpy as np
from rlgym.utils import RewardFunction
from rlgym.utils.gamestates import PlayerData, GameState
from rlgym.utils.reward_functions.common_rewards import ConstantReward
class _DummyReward(RewardFunction):
def reset(self, initial_state: GameState): pass
def get_reward(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> float: return 0
class AnnealRewards(RewardFunction):
"""
Smoothly transitions between reward functions sequentially.
Example:
AnnealRewards(rew1, 10_000, rew2, 100_000, rew3)
will start by only rewarding rew1, then linearly transitions until 10_000 steps, where only rew2 is counted.
It then transitions between rew2 and rew3, and after 100_000 total steps and further, only rew3 is rewarded.
"""
STEP = 0
TOUCH = 1
GOAL = 2
def __init__(self, *alternating_rewards_steps: Union[RewardFunction, int],
mode: int = STEP, initial_count: int = 0):
"""
:param alternating_rewards_steps: an alternating sequence of (RewardFunction, int, RewardFunction, int, ...)
specifying reward functions, and the steps at which to transition.
:param mode: specifies whether to increment counter on steps, touches or goals.
:param initial_count: the count to start reward calculations at.
"""
self.rewards_steps = list(alternating_rewards_steps) + [float("inf"), _DummyReward()]
assert mode in (self.STEP, self.TOUCH, self.GOAL)
self.mode = mode
self.last_goals = 0
self.current_goals = 0
self.last_transition_step = 0
self.last_reward = self.rewards_steps.pop(0)
self.next_transition_step = self.rewards_steps.pop(0)
self.next_reward = self.rewards_steps.pop(0)
self.count = initial_count
self.last_state = None
def reset(self, initial_state: GameState):
self.last_reward.reset(initial_state)
self.next_reward.reset(initial_state)
self.last_state = None
while self.next_transition_step < self.count: # If initial_count is set, find the right rewards
self._transition(initial_state)
def _transition(self, state):
self.last_transition_step = self.next_transition_step
self.last_reward = self.next_reward
self.next_transition_step = self.rewards_steps.pop(0)
self.next_reward = self.rewards_steps.pop(0)
self.next_reward.reset(state) # Make sure initial values are set
def get_reward(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> float:
args = player, state, previous_action
if math.isinf(self.next_transition_step):
return self.last_reward.get_reward(*args)
if state != self.last_state:
if self.mode == self.STEP:
self.count += 1
elif self.mode == self.TOUCH and player.ball_touched:
self.count += 1
elif self.mode == self.GOAL:
self.last_goals = self.current_goals
self.current_goals = state.blue_score + state.orange_score
if self.current_goals > self.last_goals:
self.count += 1
self.last_state = state
frac = (self.count - self.last_transition_step) / (self.next_transition_step - self.last_transition_step)
rew = frac * self.next_reward.get_reward(*args) + (1 - frac) * self.last_reward.get_reward(*args)
if self.count >= self.next_transition_step:
self._transition(state)
return rew | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_rewards/anneal_rewards.py | 0.898463 | 0.595728 | anneal_rewards.py | pypi |
from rlgym.utils import TerminalCondition
from rlgym.utils.gamestates import GameState
class GameCondition(TerminalCondition): # Mimics a Rocket League game
def __init__(self, tick_skip=8, seconds_left=300, seconds_per_goal_forfeit=None,
max_overtime_seconds=float("inf"), max_no_touch_seconds=float("inf")):
# NOTE: Since game isn't reset to kickoff by default,
# you need to keep this outside the main loop as well,
# checking the done variable after each terminal
super().__init__()
self.tick_skip = tick_skip
self.seconds_left = seconds_left
self.timer = seconds_left
self.overtime = False
self.done = True
self.initial_state = None
self.seconds_per_goal_forfeit = seconds_per_goal_forfeit # SPG = Seconds Per Goal
self.max_overtime = max_overtime_seconds
self.max_no_touch = max_no_touch_seconds
self.last_touch = None
self.differential = None
def reset(self, initial_state: GameState):
if self.done: # New game
self.timer = self.seconds_left
self.initial_state = initial_state
self.overtime = False
self.done = False
self.last_touch = self.seconds_left
self.differential = 0
def is_terminal(self, current_state: GameState) -> bool:
reset = False
differential = ((current_state.blue_score - self.initial_state.blue_score)
- (current_state.orange_score - self.initial_state.orange_score))
if differential != self.differential: # Goal scored
reset = True
if self.overtime:
if differential != 0:
self.done = True
elif self.timer >= self.max_overtime:
self.done = True # Call it a draw
else:
self.timer += self.tick_skip / 120
self.done = False
else:
if self.timer <= 0 and current_state.ball.position[2] <= 110:
# Can't detect ball on ground directly, should be an alright approximation.
# Anything below z vel of ~690uu/s should be detected. 50% for 1380 etc.
if differential != 0:
self.done = True
else:
self.overtime = True
self.last_touch = self.timer # Just for convenience
self.done = False
reset = True
elif (self.seconds_per_goal_forfeit is not None
and abs(differential) >= 3
and self.timer / abs(differential) < self.seconds_per_goal_forfeit):
# Too few seconds per goal to realistically win
self.done = True
else:
self.timer -= self.tick_skip / 120
if abs(self.last_touch - self.timer) >= self.max_no_touch:
self.done = True
elif any(p.ball_touched for p in current_state.players):
self.last_touch = self.timer
self.differential = differential
return reset or self.done | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_terminals/game_condition.py | 0.666062 | 0.275824 | game_condition.py | pypi |
import numpy as np
from rlgym.envs import Match
from rlgym.utils.action_parsers import DiscreteAction
from stable_baselines3 import PPO
from stable_baselines3.common.callbacks import CheckpointCallback
from stable_baselines3.common.vec_env import VecMonitor, VecNormalize, VecCheckNan
from stable_baselines3.ppo import MlpPolicy
from rlgym.utils.obs_builders import AdvancedObs
from rlgym.utils.reward_functions.common_rewards import VelocityPlayerToBallReward
from rlgym.utils.state_setters import DefaultState
from rlgym.utils.terminal_conditions.common_conditions import TimeoutCondition, GoalScoredCondition
from rlgym_tools.sb3_utils import SB3MultipleInstanceEnv
if __name__ == '__main__': # Required for multiprocessing
frame_skip = 8 # Number of ticks to repeat an action
half_life_seconds = 5 # Easier to conceptualize, after this many seconds the reward discount is 0.5
fps = 120 / frame_skip
gamma = np.exp(np.log(0.5) / (fps * half_life_seconds)) # Quick mafs
print(f"fps={fps}, gamma={gamma})")
def get_match(): # Need to use a function so that each instance can call it and produce their own objects
return Match(
team_size=3, # 3v3 to get as many agents going as possible, will make results more noisy
tick_skip=frame_skip,
reward_function=VelocityPlayerToBallReward(), # Simple reward since example code
spawn_opponents=True,
terminal_conditions=[TimeoutCondition(round(fps * 30)), GoalScoredCondition()], # Some basic terminals
obs_builder=AdvancedObs(), # Not that advanced, good default
state_setter=DefaultState(), # Resets to kickoff position
action_parser=DiscreteAction() # Discrete > Continuous don't @ me
)
env = SB3MultipleInstanceEnv(get_match, 2) # Start 2 instances, waiting 60 seconds between each
env = VecCheckNan(env) # Optional
env = VecMonitor(env) # Recommended, logs mean reward and ep_len to Tensorboard
env = VecNormalize(env, norm_obs=False, gamma=gamma) # Highly recommended, normalizes rewards
# Hyperparameters presumably better than default; inspired by original PPO paper
model = PPO(
MlpPolicy,
env,
n_epochs=32, # PPO calls for multiple epochs
learning_rate=1e-5, # Around this is fairly common for PPO
ent_coef=0.01, # From PPO Atari
vf_coef=1., # From PPO Atari
gamma=gamma, # Gamma as calculated using half-life
verbose=3, # Print out all the info as we're going
batch_size=4096, # Batch size as high as possible within reason
n_steps=4096, # Number of steps to perform before optimizing network
tensorboard_log="out/logs", # `tensorboard --logdir out/logs` in terminal to see graphs
device="auto" # Uses GPU if available
)
# Save model every so often
# Divide by num_envs (number of agents) because callback only increments every time all agents have taken a step
# This saves to specified folder with a specified name
callback = CheckpointCallback(round(1_000_000 / env.num_envs), save_path="policy", name_prefix="rl_model")
model.learn(100_000_000, callback=callback)
# Now, if one wants to load a trained model from a checkpoint, use this function
# This will contain all the attributes of the original model
# Any attribute can be overwritten by using the custom_objects parameter,
# which includes n_envs (number of agents), which has to be overwritten to use a different amount
model = PPO.load(
"policy/rl_model_1000002_steps.zip",
env,
custom_objects=dict(n_envs=env.num_envs, _last_obs=None), # Need this to change number of agents
device="auto", # Need to set device again (if using a specific one)
force_reset=True # Make SB3 reset the env so it doesn't think we're continuing from last state
)
# Use reset_num_timesteps=False to keep going with same logger/checkpoints
model.learn(100_000_000, callback=callback, reset_num_timesteps=False) | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/examples/sb3_multi_example.py | 0.695131 | 0.385722 | sb3_multi_example.py | pypi |
import numpy as np
from rlgym.envs import Match
from rlgym.utils.action_parsers import DiscreteAction
from rlgym.utils.obs_builders import AdvancedObs
from rlgym.utils.reward_functions import DefaultReward
from rlgym.utils.reward_functions.common_rewards import VelocityPlayerToBallReward
from rlgym.utils.state_setters import DefaultState
from rlgym.utils.terminal_conditions.common_conditions import TimeoutCondition, GoalScoredCondition
from rlgym_tools.extra_rewards.multi_model_rewards import MultiModelReward
from rlgym_tools.sb3_utils import SB3MultipleInstanceEnv
from stable_baselines3 import PPO
from stable_baselines3.common.callbacks import CheckpointCallback
from rlgym_tools.sb3_utils.sb3_multi_agent_tools import multi_learn
if __name__ == '__main__':
frame_skip = 8
half_life_seconds = 5
fps = 120 / frame_skip
gamma = np.exp(np.log(0.5) / (fps * half_life_seconds)) # Quick mafs
print(f"fps={fps}, gamma={gamma}")
# models can only be created/loaded after the env, but the model_map and reward_funcs are used to create the env,
# so we create all of the lists except for the model list here
# map of players to model indexes, should be of length = n_envs * players_per_env
model_map = [0, 0, 1, 2, 3, 3, 2, 0]
# learning mask is the same size as the models list. True for the model to learn.
learning_mask = [True, False, True, True]
# some simple rewards for example purposes. reward_funcs should be in the same order as the list of models.
reward_funcs = [VelocityPlayerToBallReward(), DefaultReward(), VelocityPlayerToBallReward(), DefaultReward()]
def get_match():
return Match(
team_size=2, # 2v2 for this example because why not
tick_skip=frame_skip,
# use the MultiModelReward to handle the distribution of rewards to each model.
reward_function=MultiModelReward(model_map, reward_funcs),
spawn_opponents=True,
terminal_conditions=[TimeoutCondition(round(fps * 15)), GoalScoredCondition()], # Some basic terminals
obs_builder=AdvancedObs(), # Not that advanced, good default
state_setter=DefaultState(),
action_parser=DiscreteAction()
)
env = SB3MultipleInstanceEnv(get_match, 2) # Start 2 instances
# Hyperparameters presumably better than default; inspired by original PPO paper
models = [PPO('MlpPolicy', env) for _ in range(4)]
for _ in range(4):
model = PPO('MlpPolicy', env)
models.append(model)
# This saves to specified folder with a specified name
# callbacks is a list the same length as the list of models, in the same order.
callbacks = [CheckpointCallback(round(1_000_000 / env.num_envs), save_path="policy", name_prefix=f"multi_{n}") for n
in range(4)]
# It can be a good idea to call multi-learn multiple times in a loop, modifying model_map in-place (if it is not
# done in-place, the reward functions will desync) to get extra speed by limiting the number of models training at
# once. (more separate models training = more calculation time each step)
multi_learn(
models=models, # the list of models that will be used
total_timesteps=10_000_000, # total timestamps that will be trained for
env=env,
callbacks=callbacks, # list of callbacks, one for each model in the list of models
num_players=8, # team_size * num_instances * 2
model_map=model_map, # mapping of models to players.
learning_mask=learning_mask
) | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/examples/sb3_multiple_models_example.py | 0.501709 | 0.395251 | sb3_multiple_models_example.py | pypi |
from rlgym.utils.state_setters import StateSetter
from rlgym.utils.state_setters import StateWrapper
from rlgym.utils.common_values import BALL_RADIUS, CEILING_Z, BLUE_TEAM, ORANGE_TEAM
import numpy as np
from numpy import random as rand
X_MAX = 7000
Y_MAX = 9000
Z_MAX_CAR = 1900
GOAL_HEIGHT = 642.775
PITCH_MAX = np.pi / 2
ROLL_MAX = np.pi
BLUE_GOAL_POSITION = np.asarray([0, -5120, 0])
ORANGE_GOAL_POSITION = np.asarray([0, 5120, 0])
class HoopsLikeSetter(StateSetter):
def __init__(self, spawn_radius: float = 800):
"""
Hoops-like kickoff constructor
:param spawn_radius: Float determining how far away to spawn the cars from the ball.
"""
super().__init__()
self.spawn_radius = spawn_radius
self.yaw_vector = np.asarray([-1, 0, 0])
def reset(self, state_wrapper: StateWrapper):
"""
Modifies the StateWrapper to contain random values the ball and each car.
:param state_wrapper: StateWrapper object to be modified with desired state values.
"""
self._reset_ball_random(state_wrapper)
self._reset_cars_random(state_wrapper, self.spawn_radius)
def _reset_ball_random(self, state_wrapper: StateWrapper):
"""
Resets the ball according to a uniform distribution along y-axis and normal distribution along x-axis.
:param state_wrapper: StateWrapper object to be modified.
"""
new_x = rand.uniform(-4000, 4000)
new_y = rand.triangular(-5000, 0, 5000)
new_z = rand.uniform(GOAL_HEIGHT, CEILING_Z - 2 * BALL_RADIUS)
state_wrapper.ball.set_pos(new_x, new_y, new_z)
state_wrapper.ball.set_ang_vel(0, 0, 0)
state_wrapper.ball.set_lin_vel(0, 0, 0)
def _reset_cars_random(self, state_wrapper: StateWrapper, spawn_radius: float):
"""
Function to set all cars inbetween the ball and net roughly facing the ball. The other cars will be spawned
randomly.
:param state_wrapper: StateWrapper object to be modified.
:param spawn_radius: Float determining how far away to spawn the cars from the ball.
"""
orange_done = False
blue_done = False
for i, car in enumerate(state_wrapper.cars):
if car.team_num == BLUE_TEAM and not blue_done:
# just shorthands for ball_x and ball_y
bx = state_wrapper.ball.position[0]
by = state_wrapper.ball.position[1]
# add small variation to spawn radius
car_spawn_radius = rand.triangular(0.8, 1, 1.2) * spawn_radius
# calculate distance from ball to goal.
R = ((BLUE_GOAL_POSITION[0] - bx) ** 2 + (BLUE_GOAL_POSITION[1] - by) ** 2) ** 0.5
# use similarity of triangles to calculate offsets
x_offset = ((BLUE_GOAL_POSITION[0] - bx) / R) * car_spawn_radius
y_offset = ((BLUE_GOAL_POSITION[1] - by) / R) * car_spawn_radius
# offset the car's positions
car.set_pos(bx + x_offset, by + y_offset, 17)
# compute vector from ball to car
rel_ball_car_vector = car.position - state_wrapper.ball.position
# calculate the angle between the yaw vector and relative vector and use that as yaw.
yaw = np.arccos(np.dot(rel_ball_car_vector / np.linalg.norm(rel_ball_car_vector), self.yaw_vector))
# then sprinkle in more variation by offsetting by random angle up to pi/8 radians (this is arbitrary)
max_offset_angle = np.pi / 8
yaw += rand.random() * max_offset_angle * 2 - max_offset_angle
# random at least slightly above 0 boost amounts
car.boost = rand.uniform(0.2, 1)
# make car face the ball roughly
car.set_rot(pitch=0, roll=0, yaw=yaw)
# x angular velocity (affects pitch) set to 0
# y angular velocity (affects roll) set to 0
# z angular velocity (affects yaw) set to 0
car.set_ang_vel(x=0, y=0, z=0)
car.set_lin_vel(x=0, y=0, z=0)
blue_done = True
elif car.team_num == ORANGE_TEAM and not orange_done:
# just shorthands for ball_x and ball_y
bx = state_wrapper.ball.position[0]
by = state_wrapper.ball.position[1]
# add small variation to spawn radius
car_spawn_radius = rand.triangular(0.8, 1, 1.2) * spawn_radius
# calculate distance from ball to goal.
R = ((ORANGE_GOAL_POSITION[0] - bx) ** 2 + (ORANGE_GOAL_POSITION[1] - by) ** 2) ** 0.5
# use similarity of triangles to calculate offsets
x_offset = ((ORANGE_GOAL_POSITION[0] - bx) / R) * car_spawn_radius
y_offset = ((ORANGE_GOAL_POSITION[1] - by) / R) * car_spawn_radius
# offset the car's positions
car.set_pos(bx + x_offset, by + y_offset, 17)
# compute vector from ball to car
rel_ball_car_vector = car.position - state_wrapper.ball.position
# calculate the angle between the yaw vector and relative vector and use that as yaw.
yaw = np.arccos(np.dot(rel_ball_car_vector / np.linalg.norm(rel_ball_car_vector), self.yaw_vector))
# then sprinkle in more variation by offsetting by random angle up to pi/8 radians (this is arbitrary)
max_offset_angle = np.pi / 8
yaw += rand.random() * max_offset_angle * 2 - max_offset_angle
# random at least slightly above 0 boost amounts
car.boost = rand.uniform(0.2, 1)
# make car face the ball roughly
car.set_rot(pitch=0, roll=0, yaw=yaw - np.pi if yaw > 0 else yaw + np.pi)
# x angular velocity (affects pitch) set to 0
# y angular velocity (affects roll) set to 0
# z angular velocity (affects yaw) set to 0
car.set_ang_vel(x=0, y=0, z=0)
car.set_lin_vel(x=0, y=0, z=0)
orange_done = True
else:
car.set_pos(rand.uniform(-4096,4096)),rand.uniform(0,-1**(car.team_num-1)*5120,17)
car.boost = rand.uniform(0.2, 1)
# make car face the ball roughly
car.set_rot(pitch=0, roll=0, yaw=rand.uniform(-np.pi, np.pi))
# x angular velocity (affects pitch) set to 0
# y angular velocity (affects roll) set to 0
# z angular velocity (affects yaw) set to 0
car.set_ang_vel(x=0, y=0, z=0)
car.set_lin_vel(x=0, y=0, z=0) | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_state_setters/hoops_setter.py | 0.789599 | 0.412648 | hoops_setter.py | pypi |
import random
from typing import List, Union
import numpy as np
from rlgym.utils.state_setters import StateSetter
from rlgym.utils.state_setters import StateWrapper
class ReplaySetter(StateSetter):
def __init__(self, ndarray_or_file: Union[str, np.ndarray]):
"""
ReplayBasedSetter constructor
:param ndarray_or_file: A file string or a numpy ndarray of states for a single game mode.
"""
super().__init__()
if isinstance(ndarray_or_file, np.ndarray):
self.states = ndarray_or_file
elif isinstance(ndarray_or_file, str):
self.states = np.load(ndarray_or_file)
self.probabilities = self.generate_probabilities()
def generate_probabilities(self):
"""
Generates probabilities for each state.
:return: Numpy array of probabilities (summing to 1)
"""
return np.ones(len(self.states)) / len(self.states)
@classmethod
def construct_from_replays(cls, paths_to_replays: List[str], frame_skip: int = 150):
"""
Alternative constructor that constructs ReplayBasedSetter from replays given as paths.
:param paths_to_replays: Paths to all the reapls
:param frame_skip: Every frame_skip frame from the replay will be converted
:return: Numpy array of frames
"""
return cls(cls.convert_replays(paths_to_replays, frame_skip))
@staticmethod
def convert_replays(paths_to_each_replay: List[str], frame_skip: int = 150, verbose: int = 0, output_location=None):
from rlgym_tools.replay_converter import convert_replay
states = []
for replay in paths_to_each_replay:
replay_iterator = convert_replay(replay)
remainder = random.randint(0, frame_skip - 1) # Vary the delays slightly
for i, value in enumerate(replay_iterator):
if i % frame_skip == remainder:
game_state, _ = value
whole_state = []
ball = game_state.ball
ball_state = np.concatenate((ball.position, ball.linear_velocity, ball.angular_velocity))
whole_state.append(ball_state)
for player in game_state.players:
whole_state.append(np.concatenate((player.car_data.position,
player.car_data.euler_angles(),
player.car_data.linear_velocity,
player.car_data.angular_velocity,
np.asarray([player.boost_amount]))))
np_state = np.concatenate(whole_state)
states.append(np_state)
if verbose > 0:
print(replay, "done")
states = np.asarray(states)
if output_location is not None:
np.save(output_location, states)
return states
def reset(self, state_wrapper: StateWrapper):
"""
Modifies the StateWrapper to contain random values the ball and each car.
:param state_wrapper: StateWrapper object to be modified with desired state values.
"""
data = self.states[np.random.choice(len(self.states), p=self.probabilities)]
assert len(data) == len(state_wrapper.cars) * 13 + 9, "Data given does not match current game mode"
self._set_ball(state_wrapper, data)
self._set_cars(state_wrapper, data)
def _set_cars(self, state_wrapper: StateWrapper, data: np.ndarray):
"""
Sets the players according to the game state from replay
:param state_wrapper: StateWrapper object to be modified with desired state values.
:param data: Numpy array from the replay to get values from.
"""
data = np.split(data[9:], len(state_wrapper.cars))
for i, car in enumerate(state_wrapper.cars):
car.set_pos(*data[i][:3])
car.set_rot(*data[i][3:6])
car.set_lin_vel(*data[i][6:9])
car.set_ang_vel(*data[i][9:12])
car.boost = data[i][12]
def _set_ball(self, state_wrapper: StateWrapper, data: np.ndarray):
"""
Sets the ball according to the game state from replay
:param state_wrapper: StateWrapper object to be modified with desired state values.
:param data: Numpy array from the replay to get values from.
"""
state_wrapper.ball.set_pos(*data[:3])
state_wrapper.ball.set_lin_vel(*data[3:6])
state_wrapper.ball.set_ang_vel(*data[6:9]) | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_state_setters/replay_setter.py | 0.897382 | 0.623363 | replay_setter.py | pypi |
from rlgym.utils.state_setters import StateSetter
from rlgym.utils.state_setters import StateWrapper
from rlgym.utils.common_values import BALL_RADIUS, CEILING_Z, BLUE_TEAM
import numpy as np
from numpy import random as rand
X_MAX = 7000
Y_MAX = 9000
Z_MAX_CAR = 1900
PITCH_MAX = np.pi / 2
ROLL_MAX = np.pi
class KickoffLikeSetter(StateSetter):
def __init__(self, cars_on_ground: bool = True, ball_on_ground: bool = True):
"""
RandomState constructor.
:param cars_on_ground: Boolean indicating whether cars should only be placed on the ground.
:param ball_on_ground: Boolean indicating whether ball should only be placed on the ground.
"""
super().__init__()
self.cars_on_ground = cars_on_ground
self.ball_on_ground = ball_on_ground
self.yaw_vector = np.asarray([-1, 0, 0])
def reset(self, state_wrapper: StateWrapper):
"""
Modifies the StateWrapper to contain random values the ball and each car.
:param state_wrapper: StateWrapper object to be modified with desired state values.
"""
self._reset_ball_random(state_wrapper, self.ball_on_ground)
self._reset_cars_random(state_wrapper, self.cars_on_ground)
def _reset_ball_random(self, state_wrapper: StateWrapper, ball_grounded):
"""
Function to set the ball to a random position.
:param state_wrapper: StateWrapper object to be modified.
:param ball_grounded: Boolean indicating whether ball should only be placed on the ground.
"""
state_wrapper.ball.set_pos(rand.random() * X_MAX - X_MAX / 2, 0,
BALL_RADIUS if ball_grounded else rand.random() * (
CEILING_Z - 2 * BALL_RADIUS) + BALL_RADIUS)
def _reset_cars_random(self, state_wrapper: StateWrapper, on_ground: bool):
"""
Function to set all cars to a random position.
:param state_wrapper: StateWrapper object to be modified.
:param on_ground: Boolean indicating whether to place cars only on the ground.
"""
for i, car in enumerate(state_wrapper.cars):
# set random position and rotation for all cars based on pre-determined ranges
if car.team_num == BLUE_TEAM:
car.set_pos(rand.random() * X_MAX - X_MAX / 2, -abs(rand.random() * Y_MAX - Y_MAX / 2),
rand.random() * Z_MAX_CAR + 150)
# compute vector from ball to car
rel_ball_car_vector = car.position - state_wrapper.ball.position
# calculate the angle between the yaw vector and relative vector and use that as yaw.
yaw = np.arccos(np.dot(rel_ball_car_vector / np.linalg.norm(rel_ball_car_vector), self.yaw_vector))
# then sprinkle in more variation by offsetting by random angle up to pi/8 radians (this is arbitrary)
max_offset_angle = np.pi / 8
yaw += rand.random() * max_offset_angle * 2 - max_offset_angle
car.set_rot(rand.random() * PITCH_MAX - PITCH_MAX / 2, yaw, rand.random() * ROLL_MAX - ROLL_MAX / 2)
car.boost = np.random.uniform(0.2, 1)
# 100% of cars will be set on ground if on_ground == True
# otherwise, 50% of cars will be set on ground
if on_ground or rand.random() < 0.5:
# z position (up/down) is set to ground
car.set_pos(z=17)
# pitch (front of car up/down) set to 0
# roll (side of car up/down) set to 0
car.set_rot(pitch=0, roll=0, yaw=yaw)
# x angular velocity (affects pitch) set to 0
# y angular velocity (affects roll) set to 0
# z angular velocity (affects yaw) set to 0
car.set_ang_vel(x=0, y=0, z=0)
car.set_lin_vel(x=0, y=0, z=0)
else:
# the cars in state_wrapper.cars are in order, starting with blue so we can compute blue first and then
# just copy to orange cars, to assure symmetry
car_to_copy = state_wrapper.cars[i - len(state_wrapper.cars) // 2]
car.set_pos(car_to_copy.position[0], -car_to_copy.position[1], car_to_copy.position[2])
car.set_rot(car_to_copy.rotation[0], -car_to_copy.rotation[1], -car_to_copy.rotation[2])
car.boost = car_to_copy.boost
car.set_ang_vel(x=0, y=0, z=0)
car.set_lin_vel(x=0, y=0, z=0) | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_state_setters/symmetric_setter.py | 0.767167 | 0.39004 | symmetric_setter.py | pypi |
import math
from copy import deepcopy
from random import getrandbits, shuffle
from typing import List
import numpy as np
from rlgym.utils.state_setters.state_setter import StateSetter
from rlgym.utils.state_setters.wrappers import CarWrapper
from rlgym.utils.state_setters.wrappers import StateWrapper
PI = math.pi
class AugmentSetter(StateSetter):
MASK_SWAP_FRONT_BACK = 0b01
MASK_SWAP_LEFT_RIGHT = 0b10
def __init__(self, state_setter: StateSetter, shuffle_within_teams=True, swap_front_back=True,
swap_left_right=True):
super().__init__()
self.state_setter = state_setter
self.shuffle_within_teams = shuffle_within_teams
self.swap_front_back = swap_front_back
self.swap_left_right = swap_left_right
def reset(self, state_wrapper: StateWrapper):
self.state_setter.reset(state_wrapper)
# self._debug(state_wrapper)
bits = getrandbits(2)
if self.shuffle_within_teams:
self.shuffle_players(state_wrapper)
if self.swap_front_back and (bits & AugmentSetter.MASK_SWAP_FRONT_BACK):
self.mirror_front_back(state_wrapper)
if self.swap_left_right and (bits & AugmentSetter.MASK_SWAP_LEFT_RIGHT):
self.mirror_left_right(state_wrapper)
# self._debug(state_wrapper)
def _debug(self, state_wrapper: StateWrapper):
print("\n".join(f"Car {car.id}, team: {car.team_num}, pos: {car.position}" for car in state_wrapper.cars))
ball = state_wrapper.ball
print(f"Ball pos: {ball.position}")
@staticmethod
def _map_cars(cars0: List[CarWrapper], cars1: List[CarWrapper]):
# Transfer all the states from cars0 to cars1
for car0, car1 in zip(cars0, cars1):
if cars0 == car1: # By reference
continue
car0.position[:], car1.position[:] = \
car1.position[:].copy(), car0.position[:].copy()
car0.linear_velocity[:], car1.linear_velocity[:] = \
car1.linear_velocity[:].copy(), car0.linear_velocity[:].copy()
car0.rotation[:], car1.rotation[:] = \
car1.rotation[:].copy(), car0.rotation[:].copy()
car0.angular_velocity[:], car1.angular_velocity[:] = \
car1.angular_velocity[:].copy(), car0.angular_velocity[:].copy()
car0.boost, car1.boost = \
car1.boost, car0.boost
@staticmethod
def shuffle_players(state_wrapper: StateWrapper):
""" The cars within a team are randomly swapped with each other """
if len(state_wrapper.cars) <= 2:
return
blue_team = deepcopy(state_wrapper.blue_cars())
orange_team = deepcopy(state_wrapper.orange_cars())
shuffle(blue_team)
shuffle(orange_team)
AugmentSetter._map_cars(state_wrapper.blue_cars(), blue_team)
AugmentSetter._map_cars(state_wrapper.orange_cars(), orange_team)
@staticmethod
def switch_teams(state_wrapper):
""" Blue cars move to Orange positions, orange to blue """
AugmentSetter._map_cars(state_wrapper.orange_cars(), state_wrapper.blue_cars())
@staticmethod
def mirror_front_back(state_wrapper: StateWrapper):
AugmentSetter.switch_teams(state_wrapper)
mul = np.array([1, -1, 1])
for obj in [state_wrapper.ball] + state_wrapper.cars:
obj.set_pos(*(mul * obj.position))
obj.set_lin_vel(*(mul * obj.linear_velocity))
obj.set_ang_vel(*(-mul * obj.angular_velocity)) # Angular velocities are negated
if isinstance(obj, CarWrapper):
pitch, yaw, roll = obj.rotation
obj.set_rot(
pitch=pitch,
yaw=-yaw,
roll=-roll,
)
@staticmethod
def mirror_left_right(state_wrapper: StateWrapper):
mul = np.array([-1, 1, 1])
for obj in [state_wrapper.ball] + state_wrapper.cars:
obj.set_pos(*(mul * obj.position))
obj.set_lin_vel(*(mul * obj.linear_velocity))
obj.set_ang_vel(*(-mul * obj.angular_velocity)) # Angular velocities are negated
if isinstance(obj, CarWrapper):
pitch, yaw, roll = obj.rotation
obj.set_rot(
pitch=pitch,
yaw=PI - yaw,
roll=-roll,
) | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_state_setters/augment_setter.py | 0.775605 | 0.264133 | augment_setter.py | pypi |
from rlgym.utils.gamestates import PlayerData, GameState, PhysicsObject
from rlgym.utils.obs_builders import ObsBuilder
from typing import Any, List
from rlgym.utils import common_values
import numpy as np
import math
class AdvancedObsPadder(ObsBuilder):
"""adds 0 padding to accommodate differing numbers of agents"""
def __init__(self, team_size=3, expanding=False):
super().__init__()
self.team_size = team_size
self.POS_STD = 2300
self.ANG_STD = math.pi
self.expanding = expanding
def reset(self, initial_state: GameState):
pass
def build_obs(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> Any:
if player.team_num == common_values.ORANGE_TEAM:
inverted = True
ball = state.inverted_ball
pads = state.inverted_boost_pads
else:
inverted = False
ball = state.ball
pads = state.boost_pads
obs = [ball.position / self.POS_STD,
ball.linear_velocity / self.POS_STD,
ball.angular_velocity / self.ANG_STD,
previous_action,
pads]
player_car = self._add_player_to_obs(obs, player, ball, inverted)
allies = []
enemies = []
ally_count = 0
enemy_count = 0
for other in state.players:
if other.car_id == player.car_id:
continue
if other.team_num == player.team_num:
team_obs = allies
ally_count += 1
if ally_count > self.team_size-1:
continue
else:
team_obs = enemies
enemy_count += 1
if enemy_count > self.team_size:
continue
other_car = self._add_player_to_obs(team_obs, other, ball, inverted)
# Extra info
team_obs.extend([
(other_car.position - player_car.position) / self.POS_STD,
(other_car.linear_velocity - player_car.linear_velocity) / self.POS_STD
])
while ally_count < self.team_size-1:
self._add_dummy(allies)
ally_count += 1
while enemy_count < self.team_size:
self._add_dummy(enemies)
enemy_count += 1
obs.extend(allies)
obs.extend(enemies)
if self.expanding:
return np.expand_dims(np.concatenate(obs), 0)
return np.concatenate(obs)
def _add_dummy(self, obs: List):
obs.extend([
np.zeros(3),
np.zeros(3),
np.zeros(3),
np.zeros(3),
np.zeros(3),
np.zeros(3),
np.zeros(3),
[0, 0, 0, 0, 0]])
obs.extend([np.zeros(3), np.zeros(3)])
def _add_player_to_obs(self, obs: List, player: PlayerData, ball: PhysicsObject, inverted: bool):
if inverted:
player_car = player.inverted_car_data
else:
player_car = player.car_data
rel_pos = ball.position - player_car.position
rel_vel = ball.linear_velocity - player_car.linear_velocity
obs.extend([
rel_pos / self.POS_STD,
rel_vel / self.POS_STD,
player_car.position / self.POS_STD,
player_car.forward(),
player_car.up(),
player_car.linear_velocity / self.POS_STD,
player_car.angular_velocity / self.ANG_STD,
[player.boost_amount,
int(player.on_ground),
int(player.has_flip),
int(player.is_demoed),
int(player.has_jump)]])
return player_car
if __name__ == "__main__":
pass | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_obs/advanced_padder.py | 0.725551 | 0.288776 | advanced_padder.py | pypi |
import numpy as np
from typing import Any, List
from rlgym.utils import common_values
from rlgym.utils.gamestates import PlayerData, GameState, PhysicsObject
from rlgym.utils.obs_builders import ObsBuilder
class AdvancedStacker(ObsBuilder):
"""
Alternative observation to AdvancedObs. action_stacks past stack_size actions and appends them to AdvancedObs. If there were no previous actions, zeros are assumed as previous actions.
:param stack_size: number of frames to stack
"""
def __init__(self, stack_size: int = 15):
super().__init__()
self.POS_STD = 6000
self.VEL_STD = 3000
self.ANG_STD = 5.5
self.default_action = np.zeros(common_values.NUM_ACTIONS)
self.stack_size = stack_size
self.action_stacks = {}
self.action_size = self.default_action.shape[0]
def blank_stack(self, car_id: int) -> None:
def add_action_to_stack(self, new_action: np.ndarray, car_id: int):
stack = self.action_stacks[car_id]
stack[self.action_size:] = stack[:-self.action_size]
stack[:self.action_size] = new_action
def reset(self, initial_state: GameState):
self.action_stacks = {}
for p in initial_state.players:
self.action_stacks[p.car_id] = np.concatenate([default_action] * stack_size
def build_obs(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> Any:
self.add_action_to_stack(previous_action, player.car_id)
if player.team_num == common_values.ORANGE_TEAM:
inverted = True
ball = state.inverted_ball
pads = state.inverted_boost_pads
else:
inverted = False
ball = state.ball
pads = state.boost_pads
obs = [
ball.position / self.POS_STD,
ball.linear_velocity / self.VEL_STD,
ball.angular_velocity / self.ANG_STD,
previous_action,
pads,
]
obs.extend(list(self.action_stacks[player.car_id]))
player_car = self._add_player_to_obs(obs, player, ball, inverted)
allies = []
enemies = []
for other in state.players:
if other.car_id == player.car_id:
continue
if other.team_num == player.team_num:
team_obs = allies
else:
team_obs = enemies
other_car = self._add_player_to_obs(team_obs, other, ball, inverted)
# Extra info
team_obs.extend(
[
(other_car.position - player_car.position) / self.POS_STD,
(other_car.linear_velocity - player_car.linear_velocity)
/ self.VEL_STD,
]
)
obs.extend(allies)
obs.extend(enemies)
return np.concatenate(obs)
def _add_player_to_obs(self, obs: List, player: PlayerData, ball: PhysicsObject, inverted: bool):
if inverted:
player_car = player.inverted_car_data
else:
player_car = player.car_data
rel_pos = ball.position - player_car.position
rel_vel = ball.linear_velocity - player_car.linear_velocity
obs.extend(
[
rel_pos / self.POS_STD,
rel_vel / self.VEL_STD,
player_car.position / self.POS_STD,
player_car.forward(),
player_car.up(),
player_car.linear_velocity / self.VEL_STD,
player_car.angular_velocity / self.ANG_STD,
[
player.boost_amount,
int(player.on_ground),
int(player.has_flip),
int(player.is_demoed),
],
]
)
return player_car | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_obs/advanced_stacker.py | 0.786008 | 0.415432 | advanced_stacker.py | pypi |
import numpy as np
from pettingzoo import AECEnv
from rlgym.gym import Gym
class PettingZooEnv(AECEnv):
"""
Wrapper for using the RLGym env with PettingZoo,
"""
def __init__(self, env: Gym):
"""
:param env: the environment to wrap.
"""
super().__init__()
self.env = env
self.metadata = env.metadata
self.agents = list(range(self.env._match.agents))
self.possible_agents = self.agents.copy()
self.observation_spaces = {agent: self.env.observation_space for agent in self.agents}
self.action_spaces = {agent: self.env.action_space for agent in self.agents}
self._reset_values()
def _reset_values(self):
self.rewards = {agent: 0 for agent in self.agents}
self._cumulative_rewards = {agent: 0 for agent in self.agents}
self.dones = {agent: False for agent in self.agents}
self.infos = {agent: {} for agent in self.agents}
self.state = {agent: None for agent in self.agents}
self.observations = {agent: None for agent in self.agents}
self.actions = {} # For storing until we have enough actions to do an in-game step
# Somewhat redundant, but would support any type of agent
self._current_agent_index = 0
self.agent_selection = self.agents[0]
def reset(self):
self._reset_values()
observations = self.env.reset()
self.observations = dict(zip(self.agents, observations))
return self.observations
def step(self, action):
agent = self.agent_selection
self.actions[agent] = action
if self.agent_selection == self.agents[-1]: # Only apply once everyone has registered
action_array = np.stack([self.actions[agent] for agent in self.agents])
observations, rewards, done, info = self.env.step(action_array)
assert len(observations) == len(rewards) == self.num_agents
self.observations = dict(zip(self.agents, observations))
self.rewards = dict(zip(self.agents, rewards))
self.dones = {agent: done for agent in self.agents}
self.infos = {agent: info for agent in self.agents}
self._current_agent_index = (self.agent_selection + 1) % self.num_agents
self.agent_selection = self.agents[self._current_agent_index]
def observe(self, agent):
return self.observations[agent]
def render(self, mode='human'):
self.env.render(mode)
def state(self):
raise NotImplementedError
def seed(self, seed=None):
self.env.seed(seed)
def close(self):
self.env.close()
def parallel_pettingzoo_env(env: Gym):
# Preliminary solution for making a ParallelEnv
import supersuit as ss
return ss.to_parallel(PettingZooEnv(env)) | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/pettingzoo_utils/pettingzoo_env.py | 0.828488 | 0.506408 | pettingzoo_env.py | pypi |
from typing import Any
import gym
import numpy as np
from gym.spaces import Discrete
from rlgym.utils.action_parsers import ActionParser
from rlgym.utils.gamestates import GameState
class LookupAction(ActionParser):
def __init__(self, bins=None):
super().__init__()
if bins is None:
self.bins = [(-1, 0, 1)] * 5
elif isinstance(bins[0], (float, int)):
self.bins = [bins] * 5
else:
assert len(bins) == 5, "Need bins for throttle, steer, pitch, yaw and roll"
self.bins = bins
self._lookup_table = self.make_lookup_table(self.bins)
@staticmethod
def make_lookup_table(bins):
actions = []
# Ground
for throttle in bins[0]:
for steer in bins[1]:
for boost in (0, 1):
for handbrake in (0, 1):
if boost == 1 and throttle != 1:
continue
actions.append([throttle or boost, steer, 0, steer, 0, 0, boost, handbrake])
# Aerial
for pitch in bins[2]:
for yaw in bins[3]:
for roll in bins[4]:
for jump in (0, 1):
for boost in (0, 1):
if jump == 1 and yaw != 0: # Only need roll for sideflip
continue
if pitch == roll == jump == 0: # Duplicate with ground
continue
# Enable handbrake for potential wavedashes
handbrake = jump == 1 and (pitch != 0 or yaw != 0 or roll != 0)
actions.append([boost, yaw, pitch, yaw, roll, jump, boost, handbrake])
actions = np.array(actions)
return actions
def get_action_space(self) -> gym.spaces.Space:
return Discrete(len(self._lookup_table))
def parse_actions(self, actions: Any, state: GameState) -> np.ndarray:
return self._lookup_table[actions] | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/extra_action_parsers/lookup_act.py | 0.742048 | 0.435421 | lookup_act.py | pypi |
import time
from collections import deque
from typing import List
import gym
import numpy as np
import torch as th
from stable_baselines3 import PPO
from stable_baselines3.common import utils
from stable_baselines3.common.callbacks import BaseCallback
from stable_baselines3.common.type_aliases import GymEnv, MaybeCallback
from stable_baselines3.common.utils import obs_as_tensor, safe_mean
from stable_baselines3.common.vec_env import VecEnv
from typing import Dict, Optional, Union
# This is to allow sequential multi_learn calls
globs = {
"LAST_ALL_OBS" : None,
"LAST_MODEL_MAP" : None,
"OBS_SIZE" : None
} # type: Dict[str, Optional[Union[int, list]]]
# This function is heavily based off the collect_rollouts() method of the sb3 OnPolicyAlgorithm
def multi_collect_rollouts(
env: VecEnv, models: List[PPO], model_map: list, all_last_obs: list, n_rollout_steps: int,
obs_size: int, all_callbacks: List[BaseCallback], learning_mask: List[bool]):
n_steps = 0
all_last_episode_restarts = [models[model_map[num]]._last_episode_starts for num in range(len(model_map))]
for model in models:
model.rollout_buffer.reset()
for callback in all_callbacks: callback.on_rollout_start()
models_length = len(models)
map_length = len(model_map)
while n_steps < n_rollout_steps:
# create indexes to replace later
all_actions = [0 for _ in range(map_length)]
all_values = [0 for _ in range(map_length)]
all_log_probs = [0 for _ in range(map_length)]
all_clipped_actions = [0 for _ in range(map_length)]
# disgusting dict and list comprehension to put the same model obs together
per_model_obs = { model_index:
np.array([
all_last_obs[obs_index] for obs_index in range(map_length) if model_map[obs_index] == model_index
])
for model_index in range(models_length) if model_index in model_map
}
for model_index in range(models_length):
# get the actions from the policy
if model_index in model_map:
with th.no_grad():
obs_tensor = obs_as_tensor(per_model_obs[model_index], models[model_index].device)
actions, values, log_probs = models[model_index].policy.forward(obs_tensor)
actions = actions.cpu().numpy()
clipped_actions = actions #[0] # it is inside an extra layer for some reason, so take it out
if isinstance(models[model_index], gym.spaces.Box):
clipped_actions = np.clip(
actions,
models[model_index].action_space.low,
models[model_index].action_space.high
)
next_index_start = 0
# put everything back in terms of the model map
for i in range(model_map.count(model_index)):
next_index = model_map.index(model_index, next_index_start)
next_index_start = next_index + 1
all_clipped_actions[next_index] = clipped_actions[i]
all_actions[next_index] = actions[i]
all_values[next_index] = values[i]
all_log_probs[next_index] = log_probs[i]
# flatten the actions, then step the env
flat_clipped_actions = np.array(all_clipped_actions)
flat_new_obs, flat_rewards, flat_dones, flat_infos = env.step(flat_clipped_actions)
# split up the returns from the step
infos_length = len(flat_infos) // map_length
all_infos = [flat_infos[x*infos_length:(x+1)*infos_length] for x in range(map_length)]
all_rewards = [flat_rewards[x] for x in range(map_length)]
# increment num_timesteps
for obs_index in range(map_length):
models[model_map[obs_index]].num_timesteps += 1
# allow the callbacks to run
for callback in all_callbacks: callback.update_locals(locals())
if any(callback.on_step() is False for callback in all_callbacks):
return False, all_last_obs
# update the info buffer for each model
for model_index in range(models_length):
models[model_index]._update_info_buffer(
[all_infos[num][0] for num in range(map_length) if model_map[num] == model_index]
) # this should put the needed infos for each model in
n_steps += 1
# reshape for models with discrete action spaces
for obs_index in range(map_length):
if isinstance(models[model_map[obs_index]].action_space, gym.spaces.Discrete):
all_actions[obs_index] = all_actions[obs_index].reshape(-1,1)
# add data to the rollout buffers
for model_index in range(models_length):
if learning_mask[model_index] and model_index in model_map: # skip learing where not necessary
models[model_index].rollout_buffer.add( # disgusting list comprehension to send all the info to the buffer
np.asarray([all_last_obs[num][0] for num in range(len(model_map)) if model_map[num] == model_index]),
np.asarray([all_actions[num] for num in range(len(model_map)) if model_map[num] == model_index]),
np.asarray([all_rewards[num] for num in range(len(model_map)) if model_map[num] == model_index]),
np.asarray([all_last_episode_restarts[num] for num in range(len(model_map)) if model_map[num] == model_index]),
th.tensor([all_values[num] for num in range(len(model_map)) if model_map[num] == model_index]),
th.tensor([all_log_probs[num] for num in range(len(model_map)) if model_map[num] == model_index])
)
# shuffle variables for next iteration
new_obs_len = len(flat_new_obs) // map_length
all_last_obs = [flat_new_obs[obs_index * new_obs_len:(obs_index + 1) * new_obs_len] for obs_index in range(map_length)]
all_last_episode_restarts = flat_dones
all_last_values, all_last_dones = [], []
for obs_index in range(len(model_map)):
with th.no_grad():
# compute value for the last timestamp
# the og code uses new_obs where I have last_obs, so I hope this still works since they should hold the same value
obs_tensor = obs_as_tensor(all_last_obs[obs_index], models[model_map[obs_index]].device)
_, values, _ = models[model_map[obs_index]].policy.forward(obs_tensor)
all_last_values.append(values)
# compute the returns and advantage for each model
for model_index in range(len(models)):
if model_index in model_map:
models[model_index].rollout_buffer.compute_returns_and_advantage(
last_values=th.tensor([all_last_values[num] for num in range(len(model_map)) if model_map[num] == model_index]),
dones=np.asarray([all_last_episode_restarts[num] for num in range(len(model_map)) if model_map[num] == model_index])
)
for callback in all_callbacks: callback.on_rollout_end()
return True, all_last_obs
# This function is heavily based off the learn() method of the sb3 OnPolicyAlgorithm
def multi_learn(
models: List[PPO],
total_timesteps: int,
env,
num_players: int,
learning_mask: Optional[List[bool]] = None,
model_map: Optional[list] = None,
callbacks: List[MaybeCallback] = None,
log_interval: int = 1,
eval_env: Optional[GymEnv] = None,
eval_freq: int = -1,
n_eval_episodes: int = 5,
tb_log_name: str = "MultiPPO",
eval_log_path: Optional[str] = None,
reset_num_timesteps: bool = True,
):
model_map = model_map or [n % len(models) for n in range(num_players)]
learning_mask = learning_mask or [True for _ in range(len(models))]
# make sure everything lines up
if not len(models) == len(callbacks) == len(learning_mask):
raise ValueError("Length of models, callbacks, and learning_mask must all be equal.")
iteration = 0
# this for loop is essentially the setup method, done for each model
if globs['OBS_SIZE'] is None:
globs['OBS_SIZE'] = len(env.reset()) // len(model_map) # calculate the length of the each observation
all_total_timesteps = []
for model_index in range(len(models)):
models[model_index].start_time = time.time()
if models[model_index].ep_info_buffer is None or reset_num_timesteps:
models[model_index].ep_info_buffer = deque(maxlen=100)
models[model_index].ep_success_buffer = deque(maxlen=100)
if models[model_index].action_noise is not None:
models[model_index].action_noise.reset()
if reset_num_timesteps:
models[model_index].num_timesteps = 0
models[model_index]._episode_num = 0
all_total_timesteps.append(total_timesteps)
models[model_index]._total_timesteps = total_timesteps
else:
# make sure training timestamps are ahead of internal counter
all_total_timesteps.append(total_timesteps + models[model_index].num_timesteps)
models[model_index]._total_timesteps = total_timesteps + models[model_index].num_timesteps
# leaving out the environment reset that normally happens here, since that will be done for all at once
if eval_env is not None and models[model_index].seed is not None:
eval_env.seed(models[model_index].seed)
eval_env = models[model_index]._get_eval_env(eval_env)
# Configure logger's outputs if no logger was passed
if not models[model_index]._custom_logger:
models[model_index]._logger = utils.configure_logger(
models[model_index].verbose,
models[model_index].tensorboard_log,
tb_log_name + f'_model{model_index}',
reset_num_timesteps)
callbacks[model_index] = models[model_index]._init_callback(
callbacks[model_index], eval_env, eval_freq, n_eval_episodes, log_path=None)
for callback in callbacks: callback.on_training_start(locals(), globals())
if globs["LAST_ALL_OBS"] is None:
flat_last_obs = env.reset()
globs["LAST_ALL_OBS"] = [flat_last_obs[x*globs['OBS_SIZE']:(x+1)*globs['OBS_SIZE']] for x in range(num_players)]
# make sure the n_envs is correct for the models
for model_index in range(len(models)):
models[model_index].n_envs = model_map.count(model_index)
models[model_index].rollout_buffer.n_envs = model_map.count(model_index)
# I assume the correct thing here is to check each model separately for the while condition
while all([models[i].num_timesteps < all_total_timesteps[i] for i in range(len(models))]):
continue_training, globs["LAST_ALL_OBS"] = multi_collect_rollouts(
env, models, model_map, globs["LAST_ALL_OBS"], min(model.n_steps for model in models), globs["OBS_SIZE"], callbacks, learning_mask
)
if continue_training is False:
break
iteration += 1
for model_index in range(len(models)):
if model_index in model_map:
models[model_index]._update_current_progress_remaining(models[model_index].num_timesteps, total_timesteps)
# output to the logger
for model_index in range(len(models)):
if log_interval is not None and iteration % log_interval == 0 and learning_mask[model_index] and model_index in model_map:
fps = int(models[model_index].num_timesteps / (time.time() - models[model_index].start_time))
models[model_index].logger.record("time/iterations", iteration * model_map.count(model_index), exclude="tensorboard")
if len(models[model_index].ep_info_buffer) > 0 and len(models[model_index].ep_info_buffer[0]) > 0:
models[model_index].logger.record("rollout/ep_rew_mean", safe_mean([ep_info["r"] for ep_info in models[model_index].ep_info_buffer]))
models[model_index].logger.record("rollout/ep_len_mean", safe_mean([ep_info["l"] for ep_info in models[model_index].ep_info_buffer]))
models[model_index].logger.record("time/fps", fps)
models[model_index].logger.record("time/time_elapsed", int(time.time() - models[model_index].start_time), exclude="tensorboard")
models[model_index].logger.record("time/total_timesteps", models[model_index].num_timesteps, exclude="tensorboard")
models[model_index].logger.dump(step=models[model_index].num_timesteps)
for model_index in range(len(models)):
if learning_mask[model_index] and model_index in model_map: models[model_index].train()
for callback in callbacks: callback.on_training_end()
return models | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/sb3_utils/sb3_multi_agent_tools.py | 0.684159 | 0.431105 | sb3_multi_agent_tools.py | pypi |
import json
import os
from typing import Tuple, Optional, List
import numpy as np
from rlgym.utils import RewardFunction
from rlgym.utils.gamestates import PlayerData, GameState
from rlgym.utils.reward_functions import CombinedReward
from stable_baselines3.common.callbacks import BaseCallback
from stable_baselines3.common.logger import Logger
class SB3LogReward(RewardFunction):
"""
Simple reward function for logging individual rewards to a custom Logger.
"""
def __init__(self, logger: Logger, reward_function: RewardFunction):
super().__init__()
self.logger = logger
self.reward_function = reward_function
self.reward_sum = 0
self.episode_steps = 0
self.global_steps = 0
def reset(self, initial_state: GameState):
if self.episode_steps > 0:
rew_fn_type = type(self.reward_function)
mean_reward = self.reward_sum / self.episode_steps
if rew_fn_type.__str__ is not object.__str__:
self.logger.record(f"{self.reward_function}/ep_rew_mean", mean_reward)
else:
self.logger.record(f"{rew_fn_type.__name__}/ep_rew_mean", mean_reward)
self.logger.dump(self.global_steps)
self.reward_sum = 0
self.episode_steps = 0
self.global_steps += 1
self.reward_function.reset(initial_state)
def get_reward(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> float:
rew = self.reward_function.get_reward(player, state, previous_action)
self.reward_sum += rew
self.episode_steps += 1
return rew
def get_final_reward(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> float:
rew = self.reward_function.get_final_reward(player, state, previous_action)
self.reward_sum += rew
self.episode_steps += 1
return rew
class SB3CombinedLogReward(CombinedReward):
def __init__(
self,
reward_functions: Tuple[RewardFunction, ...],
reward_weights: Optional[Tuple[float, ...]] = None,
file_location: str = 'combinedlogfiles'
):
"""
Creates the combined reward using multiple rewards, and a potential set
of weights for each reward. Will also log the weighted rewards to
the model's logger if a SB3CombinedLogRewardCallback is provided to the
learner.
:param reward_functions: Each individual reward function.
:param reward_weights: The weights for each reward.
:param file_location: The path to the directory that will be used to
transfer reward info
"""
super().__init__(reward_functions, reward_weights)
# Make sure there is a folder to dump to
os.makedirs(file_location, exist_ok=True)
self.file_location = f'{file_location}/rewards.txt'
self.lockfile = f'{file_location}/reward_lock'
# Initiates the array that will store the episode totals
self.returns = np.zeros(len(self.reward_functions))
# Obtain the lock
while True:
try:
open(self.lockfile, 'x')
break
except FileExistsError:
pass
except PermissionError:
pass
except Exception as e:
print(f'Error obtaining lock in SB3CombinedLogReward.__init__:\n{e}')
# Empty the file by opening in w mode
with open(self.file_location, 'w') as f:
pass
# Release the lock
try:
os.remove(self.lockfile)
except FileNotFoundError:
print('No lock to release! ')
def reset(self, initial_state: GameState):
self.returns = np.zeros(len(self.reward_functions))
super().reset(initial_state)
def get_reward(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> float:
rewards = [
func.get_reward(player, state, previous_action)
for func in self.reward_functions
]
self.returns += [a * b for a, b in zip(rewards, self.reward_weights)] # store the rewards
return float(np.dot(self.reward_weights, rewards))
def get_final_reward(self, player: PlayerData, state: GameState, previous_action: np.ndarray) -> float:
rewards = [
func.get_final_reward(player, state, previous_action)
for func in self.reward_functions
]
# Add the rewards to the cumulative totals with numpy broadcasting
self.returns += [a * b for a, b in zip(rewards, self.reward_weights)]
# Obtain the lock
while True:
try:
open(self.lockfile, 'x')
break
except FileExistsError:
pass
except PermissionError:
pass
except Exception as e:
print(f'Error obtaining lock in SB3CombinedLogReward.get_final_reward:\n{e}')
# Write the rewards to file and reset
with open(self.file_location, 'a') as f:
f.write('\n' + json.dumps(self.returns.tolist()))
# reset the episode totals
self.returns = np.zeros(len(self.reward_functions))
# Release the lock
try:
os.remove(self.lockfile)
except FileNotFoundError:
print('No lock to release! ')
return float(np.dot(self.reward_weights, rewards))
class SB3CombinedLogRewardCallback(BaseCallback):
def __init__(self, reward_names: List[str], file_location: str = 'combinedlogfiles'):
"""
Callback to log the data from a SB3CombinedLogReward to the
same log as the model.
:param reward_names: List of names that the logger will use for
each reward.
:param file_location: The path to the directory that will be used to
transfer reward info
"""
super().__init__()
self.reward_names = reward_names
self.file_location = file_location + '/rewards.txt'
self.lockfile = file_location + '/reward_lock'
def _on_step(self) -> bool:
return True
def _on_rollout_end(self) -> None:
returns = []
# Obtain the lock
while True:
try:
open(self.lockfile, 'x')
break
except FileExistsError:
pass
except PermissionError:
pass
except Exception as e:
print(f'Error obtaining lock in SB3CombinedLogRewardCallback._on_rollout_end:\n{e}')
# Read the file into returns
with open(self.file_location, 'r') as f:
for line in f:
line = line.strip()
if line:
try:
line = json.loads(line)
returns.append(line)
except Exception as e:
print(f'Exception loading line {line}:\n\t{e}')
# Release the lock
try:
os.remove(self.lockfile)
except FileNotFoundError:
print('No lock to release! ')
# Make returns into a numpy array so we can make use of numpy features
returns = np.array(returns)
# Log each reward
for n in range(returns.shape[1]):
try:
name = self.reward_names[n]
except IndexError:
name = f'reward_{n}'
self.model.logger.record_mean('rewards/' + name, np.mean(returns[:, n])) | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/sb3_utils/sb3_log_reward.py | 0.837454 | 0.318442 | sb3_log_reward.py | pypi |
from typing import Optional, List, Union, Sequence, Type, Any
import gym
import numpy as np
from stable_baselines3.common.vec_env import VecEnv
from stable_baselines3.common.vec_env.base_vec_env import VecEnvIndices, VecEnvStepReturn, VecEnvObs
from rlgym.gym import Gym
class SB3SingleInstanceEnv(VecEnv):
"""
Class for wrapping a single rlgym env into a VecEnv (each car is treated as its own environment).
"""
def __init__(self, env: Gym):
"""
:param env: the environment to wrap.
"""
super().__init__(env._match.agents, env.observation_space, env.action_space)
self.env = env
self.step_result = None
def reset(self) -> VecEnvObs:
observations = self.env.reset()
if len(np.shape(observations)) == 1:
observations = [observations]
return np.asarray(observations)
def step_async(self, actions: np.ndarray) -> None:
self.step_result = self.env.step(actions)
def step_wait(self) -> VecEnvStepReturn:
observations, rewards, done, info = self.step_result
if type(rewards) not in (tuple, list, np.ndarray):
rewards = [rewards]
observations = [observations]
if done:
# Following what SubprocVecEnv does
infos = [info] * len(rewards)
for info, obs in zip(infos, observations):
info["terminal_observation"] = obs
observations = self.env.reset()
if len(np.shape(observations)) == 1:
observations = [observations]
else:
infos = [info] * len(rewards)
return np.asarray(observations), np.array(rewards), np.full(len(rewards), done), infos
def close(self) -> None:
self.env.close()
def seed(self, seed: Optional[int] = None) -> List[Union[None, int]]:
return [self.env.seed(seed)] * self.num_envs
# Now a bunch of functions that need to be overridden to work, might have to implement later
def get_attr(self, attr_name: str, indices: VecEnvIndices = None) -> List[Any]:
pass
def set_attr(self, attr_name: str, value: Any, indices: VecEnvIndices = None) -> None:
pass
def env_method(self, method_name: str, *method_args, indices: VecEnvIndices = None, **method_kwargs) -> List[Any]:
pass
def env_is_wrapped(self, wrapper_class: Type[gym.Wrapper], indices: VecEnvIndices = None) -> List[bool]:
return [False] * self.num_envs
def get_images(self) -> Sequence[np.ndarray]:
pass | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/sb3_utils/sb3_single_instance_env.py | 0.919769 | 0.51312 | sb3_single_instance_env.py | pypi |
import multiprocessing as mp
import os
import time
from typing import Optional, List, Union, Any, Callable, Sequence
import numpy as np
from stable_baselines3.common.vec_env import SubprocVecEnv, CloudpickleWrapper, VecEnv
from stable_baselines3.common.vec_env.base_vec_env import (
VecEnvObs,
VecEnvStepReturn,
VecEnvIndices,
)
from stable_baselines3.common.vec_env.subproc_vec_env import _worker
from rlgym.envs import Match
from rlgym.gym import Gym
from rlgym.gamelaunch import LaunchPreference
class SB3MultipleInstanceEnv(SubprocVecEnv):
"""
Class for launching several Rocket League instances into a single SubprocVecEnv for use with Stable Baselines.
"""
MEM_INSTANCE_LAUNCH = 3.5e9
MEM_INSTANCE_LIM = 4e6
@staticmethod
def estimate_supported_processes():
import psutil
vm = psutil.virtual_memory()
# Need 3.5GB to launch, reduces to 350MB after a while
est_proc_mem = round(
(vm.available - SB3MultipleInstanceEnv.MEM_INSTANCE_LAUNCH)
/ SB3MultipleInstanceEnv.MEM_INSTANCE_LAUNCH
)
est_proc_cpu = os.cpu_count()
est_proc = min(est_proc_mem, est_proc_cpu)
return est_proc
def __init__(
self,
match_func_or_matches: Union[Callable[[], Match], Sequence[Match]],
num_instances: Optional[int] = None,
launch_preference: Optional[Union[LaunchPreference, str]] = LaunchPreference.EPIC,
wait_time: float = 30,
force_paging: bool = False,
):
"""
:param match_func_or_matches: either a function which produces the a Match object, or a list of Match objects.
Needs to be a function so that each subprocess can call it and get their own objects.
:param num_instances: the number of Rocket League instances to start up,
or "auto" to estimate how many instances are supported (requires psutil).
:param wait_time: the time to wait between launching each instance. Default one minute.
:param force_paging: enable forced paging of each spawned rocket league instance to reduce memory utilization
immediately, instead of allowing the OS to slowly page untouched allocations.
WARNING: This will require you to potentially expand your Windows Page File, and it may
substantially increase disk activity, leading to decreased disk lifetime.
Use at your own peril.
https://www.tomshardware.com/news/how-to-manage-virtual-memory-pagefile-windows-10,36929.html
Default is off: OS dictates the behavior.
"""
if callable(match_func_or_matches):
assert num_instances is not None, (
"If using a function to generate Match objects, "
"num_instances must be specified"
)
if num_instances == "auto":
num_instances = SB3MultipleInstanceEnv.estimate_supported_processes()
match_func_or_matches = [
match_func_or_matches() for _ in range(num_instances)
]
def get_process_func(i):
def spawn_process():
match = match_func_or_matches[i]
env = Gym(
match,
pipe_id=os.getpid(),
launch_preference=launch_preference,
use_injector=True,
force_paging=force_paging,
)
return env
return spawn_process
# super().__init__([]) Super init intentionally left out since we need to launch processes with delay
env_fns = [get_process_func(i) for i in range(len(match_func_or_matches))]
# START - Code from SubprocVecEnv class
self.waiting = False
self.closed = False
n_envs = len(env_fns)
# Fork is not a thread safe method (see issue #217)
# but is more user friendly (does not require to wrap the code in
# a `if __name__ == "__main__":`)
forkserver_available = "forkserver" in mp.get_all_start_methods()
start_method = "forkserver" if forkserver_available else "spawn"
ctx = mp.get_context(start_method)
self.remotes, self.work_remotes = zip(*[ctx.Pipe() for _ in range(n_envs)])
self.processes = []
for work_remote, remote, env_fn in zip(
self.work_remotes, self.remotes, env_fns
):
args = (work_remote, remote, CloudpickleWrapper(env_fn))
# daemon=True: if the main process crashes, we should not cause things to hang
process = ctx.Process(
target=_worker, args=args, daemon=True
) # pytype:disable=attribute-error
process.start()
self.processes.append(process)
work_remote.close()
if len(self.processes) != len(env_fns):
time.sleep(wait_time) # ADDED - Waits between starting Rocket League instances
self.remotes[0].send(("get_spaces", None))
observation_space, action_space = self.remotes[0].recv()
# END - Code from SubprocVecEnv class
self.n_agents_per_env = [m.agents for m in match_func_or_matches]
self.num_envs = sum(self.n_agents_per_env)
VecEnv.__init__(self, self.num_envs, observation_space, action_space)
def reset(self) -> VecEnvObs:
for remote in self.remotes:
remote.send(("reset", None))
flat_obs = []
for remote, n_agents in zip(self.remotes, self.n_agents_per_env):
obs = remote.recv()
if n_agents <= 1:
flat_obs.append(obs)
else:
flat_obs += obs
return np.asarray(flat_obs)
def step_async(self, actions: np.ndarray) -> None:
i = 0
for remote, n_agents in zip(self.remotes, self.n_agents_per_env):
remote.send(("step", actions[i : i + n_agents]))
i += n_agents
self.waiting = True
def step_wait(self) -> VecEnvStepReturn:
flat_obs = []
flat_rews = []
flat_dones = []
flat_infos = []
for remote, n_agents in zip(self.remotes, self.n_agents_per_env):
obs, rew, done, info = remote.recv()
if n_agents <= 1:
flat_obs.append(obs)
flat_rews.append(rew)
flat_dones.append(done)
flat_infos.append(info)
else:
flat_obs += obs
flat_rews += rew
flat_dones += [done] * n_agents
flat_infos += [info] * n_agents
self.waiting = False
return (
np.asarray(flat_obs),
np.array(flat_rews),
np.array(flat_dones),
flat_infos,
)
def seed(self, seed: Optional[int] = None) -> List[Union[None, int]]:
res = super(SB3MultipleInstanceEnv, self).seed(seed)
return sum([r] * a for r, a in zip(res, self.n_agents_per_env))
def _get_target_remotes(self, indices: VecEnvIndices) -> List[Any]:
# Override to prevent out of bounds
indices = self._get_indices(indices)
remotes = []
for i in indices:
tot = 0
for remote, n_agents in zip(self.remotes, self.n_agents_per_env):
tot += n_agents
if i < tot:
remotes.append(remote)
break
return remotes | /rlgym_tools-1.8.2.tar.gz/rlgym_tools-1.8.2/rlgym_tools/sb3_utils/sb3_multiple_instance_env.py | 0.774541 | 0.34139 | sb3_multiple_instance_env.py | pypi |
from abc import ABC
from typing import List
from hive.agents.agent import Agent
from hive.envs.base import BaseEnv
from hive.runners.utils import Metrics
from hive.utils import schedule
from hive.utils.experiment import Experiment
from hive.utils.loggers import ScheduledLogger
class Runner(ABC):
"""Base Runner class used to implement a training loop.
Different types of training loops can be created by overriding the relevant
functions.
"""
def __init__(
self,
environment: BaseEnv,
agents: List[Agent],
logger: ScheduledLogger,
experiment_manager: Experiment,
train_steps: int = 1000000,
test_frequency: int = 10000,
test_episodes: int = 1,
max_steps_per_episode: int = 27000,
):
"""
Args:
environment (BaseEnv): Environment used in the training loop.
agents (list[Agent]): List of agents that interact with the environment.
logger (ScheduledLogger): Logger object used to log metrics.
experiment_manager (Experiment): Experiment object that saves the state of
the training.
train_steps (int): How many steps to train for. If this is -1, there is no
limit for the number of training steps.
test_frequency (int): After how many training steps to run testing episodes.
If this is -1, testing is not run.
test_episodes (int): How many episodes to run testing for.
"""
self._environment = environment
if isinstance(agents, list):
self._agents = agents
else:
self._agents = [agents]
self._logger = logger
self._experiment_manager = experiment_manager
if train_steps == -1:
self._train_schedule = schedule.ConstantSchedule(True)
else:
self._train_schedule = schedule.SwitchSchedule(True, False, train_steps)
if test_frequency == -1:
self._test_schedule = schedule.ConstantSchedule(False)
else:
self._test_schedule = schedule.PeriodicSchedule(False, True, test_frequency)
self._test_episodes = test_episodes
self._max_steps_per_episode = max_steps_per_episode
self._experiment_manager.experiment_state.update(
{
"train_schedule": self._train_schedule,
"test_schedule": self._test_schedule,
}
)
self._logger.register_timescale("train")
self._logger.register_timescale("test")
self._training = True
self._save_experiment = False
self._run_testing = False
def train_mode(self, training):
"""If training is true, sets all agents to training mode. If training is false,
sets all agents to eval mode.
Args:
training (bool): Whether to be in training mode.
"""
self._training = training
for agent in self._agents:
agent.train() if training else agent.eval()
def create_episode_metrics(self):
"""Create the metrics used during the loop."""
return Metrics(
self._agents,
[("reward", 0), ("episode_length", 0)],
[("full_episode_length", 0)],
)
def run_one_step(self, observation, turn, episode_metrics):
"""Run one step of the training loop.
Args:
observation: Current observation that the agent should create an action
for.
turn (int): Agent whose turn it is.
episode_metrics (Metrics): Keeps track of metrics for current episode.
"""
if self._training:
self._train_schedule.update()
self._logger.update_step("train")
self._run_testing = self._test_schedule.update() or self._run_testing
self._save_experiment = (
self._experiment_manager.update_step() or self._save_experiment
)
def run_end_step(self, episode_metrics, done):
"""Run the final step of an episode.
Args:
episode_metrics (Metrics): Keeps track of metrics for current episode.
done (bool): Whether this step was terminal.
"""
return NotImplementedError
def run_episode(self):
"""Run a single episode of the environment."""
return NotImplementedError
def run_training(self):
"""Run the training loop."""
self.train_mode(True)
while self._train_schedule.get_value():
# Run training episode
if not self._training:
self.train_mode(True)
episode_metrics = self.run_episode()
if self._logger.should_log("train"):
episode_metrics = episode_metrics.get_flat_dict()
self._logger.log_metrics(episode_metrics, "train")
# Run test episodes
if self._run_testing:
test_metrics = self.run_testing()
self._logger.update_step("test")
self._logger.log_metrics(test_metrics, "test")
self._run_testing = False
# Save experiment state
if self._save_experiment:
self._experiment_manager.save()
self._save_experiment = False
# Run a final test episode and save the experiment.
test_metrics = self.run_testing()
self._logger.update_step("test")
self._logger.log_metrics(test_metrics, "test")
self._experiment_manager.save()
def run_testing(self):
"""Run a testing phase."""
self.train_mode(False)
aggregated_episode_metrics = self.create_episode_metrics().get_flat_dict()
episodes = 0
while episodes <= self._test_episodes:
episode_metrics = self.run_episode()
episodes += 1
for metric, value in episode_metrics.get_flat_dict().items():
aggregated_episode_metrics[metric] += value / self._test_episodes
return aggregated_episode_metrics
def resume(self):
"""Resume a saved experiment."""
self._experiment_manager.resume()
self._train_schedule = self._experiment_manager.experiment_state[
"train_schedule"
]
self._test_schedule = self._experiment_manager.experiment_state["test_schedule"] | /rlhive-1.0.1-py3-none-any.whl/hive/runners/base.py | 0.939325 | 0.445831 | base.py | pypi |
import os
from collections import deque
import numpy as np
import torch
import yaml
from hive.utils.utils import PACKAGE_ROOT
def load_config(
config=None,
preset_config=None,
agent_config=None,
env_config=None,
logger_config=None,
):
"""Used to load config for experiments. Agents, environment, and loggers components
in main config file can be overrided based on other log files.
Args:
config (str): Path to configuration file. Either this or :obj:`preset_config`
must be passed.
preset_config (str): Path to a preset hive config. This path should be relative
to :obj:`hive/configs`. For example, the Atari DQN config would be
:obj:`atari/dqn.yml`.
agent_config (str): Path to agent configuration file. Overrides settings in
base config.
env_config (str): Path to environment configuration file. Overrides settings in
base config.
logger_config (str): Path to logger configuration file. Overrides settings in
base config.
"""
if config is not None:
with open(config) as f:
yaml_config = yaml.safe_load(f)
else:
with open(os.path.join(PACKAGE_ROOT, "configs", preset_config)) as f:
yaml_config = yaml.safe_load(f)
if agent_config is not None:
with open(agent_config) as f:
if "agents" in yaml_config:
yaml_config["agents"] = yaml.safe_load(f)
else:
yaml_config["agent"] = yaml.safe_load(f)
if env_config is not None:
with open(env_config) as f:
yaml_config["environment"] = yaml.safe_load(f)
if logger_config is not None:
with open(logger_config) as f:
yaml_config["loggers"] = yaml.safe_load(f)
return yaml_config
class Metrics:
"""Class used to keep track of separate metrics for each agent as well general
episode metrics.
"""
def __init__(self, agents, agent_metrics, episode_metrics):
"""
Args:
agents (list[Agent]): List of agents for which object will track metrics.
agent_metrics (list[(str, (callable | obj))]): List of metrics to track
for each agent. Should be a list of tuples (metric_name, metric_init)
where metric_init is either the initial value of the metric or a
callable that takes no arguments and creates the initial metric.
episode_metrics (list[(str, (callable | obj))]): List of non agent specific
metrics to keep track of. Should be a list of tuples
(metric_name, metric_init) where metric_init is either the initial
value of the metric or a callable with no arguments that creates the
initial metric.
"""
self._metrics = {}
self._agent_metrics = agent_metrics
self._episode_metrics = episode_metrics
self._agent_ids = [agent.id for agent in agents]
self.reset_metrics()
def reset_metrics(self):
"""Resets all metrics to their initial values."""
for agent_id in self._agent_ids:
self._metrics[agent_id] = {}
for metric_name, metric_value in self._agent_metrics:
self._metrics[agent_id][metric_name] = (
metric_value() if callable(metric_value) else metric_value
)
for metric_name, metric_value in self._episode_metrics:
self._metrics[metric_name] = (
metric_value() if callable(metric_value) else metric_value
)
def get_flat_dict(self):
"""Get a flat dictionary version of the metrics. Each agent metric will be
prefixed by the agent id.
"""
metrics = {}
for metric, _ in self._episode_metrics:
metrics[metric] = self._metrics[metric]
for agent_id in self._agent_ids:
for metric, _ in self._agent_metrics:
metrics[f"{agent_id}_{metric}"] = self._metrics[agent_id][metric]
return metrics
def __getitem__(self, key):
return self._metrics[key]
def __setitem__(self, key, value):
self._metrics[key] = value
def __repr__(self) -> str:
return str(self._metrics)
class TransitionInfo:
"""Used to keep track of the most recent transition for each agent.
Any info that the agent needs to remember for updating can be stored here. Should
be completely reset between episodes. After any info is extracted, it is
automatically removed from the object. Also keeps track of which agents have
started their episodes.
This object also handles padding and stacking observations for agents.
"""
def __init__(self, agents, stack_size):
"""
Args:
agents (list[Agent]): list of agents that will be kept track of.
stack_size (int): How many observations will be stacked.
"""
self._agent_ids = [agent.id for agent in agents]
self._num_agents = len(agents)
self._stack_size = stack_size
self.reset()
def reset(self):
"""Reset the object by clearing all info."""
self._transitions = {agent_id: {"reward": 0.0} for agent_id in self._agent_ids}
self._started = {agent_id: False for agent_id in self._agent_ids}
self._previous_observations = {
agent_id: deque(maxlen=self._stack_size - 1) for agent_id in self._agent_ids
}
def is_started(self, agent):
"""Check if agent has started its episode.
Args:
agent (Agent): Agent to check.
"""
return self._started[agent.id]
def start_agent(self, agent):
"""Set the agent's start flag to true.
Args:
agent (Agent): Agent to start.
"""
self._started[agent.id] = True
def record_info(self, agent, info):
"""Update some information for the agent.
Args:
agent (Agent): Agent to update.
info (dict): Info to add to the agent's state.
"""
self._transitions[agent.id].update(info)
if "observation" in info:
self._previous_observations[agent.id].append(info["observation"])
def update_reward(self, agent, reward):
"""Add a reward to the agent.
Args:
agent (Agent): Agent to update.
reward (float): Reward to add to agent.
"""
self._transitions[agent.id]["reward"] += reward
def update_all_rewards(self, rewards):
"""Update the rewards for all agents. If rewards is list, it updates the rewards
according to the order of agents provided in the initializer. If rewards is a
dict, the keys should be the agent ids for the agents and the values should be
the rewards for those agents. If rewards is a float or int, every agent is
updated with that reward.
Args:
rewards (float | list | np.ndarray | dict): Rewards to update agents with.
"""
if isinstance(rewards, list) or isinstance(rewards, np.ndarray):
for idx, agent_id in enumerate(self._agent_ids):
self._transitions[agent_id]["reward"] += rewards[idx]
elif isinstance(rewards, int) or isinstance(rewards, float):
for agent_id in self._agent_ids:
self._transitions[agent_id]["reward"] += rewards
else:
for agent_id in rewards:
self._transitions[agent_id]["reward"] += rewards[agent_id]
def get_info(self, agent, done=False):
"""Get all the info for the agent, and reset the info for that agent. Also adds
a done value to the info dictionary that is based on the done parameter to the
function.
Args:
agent (Agent): Agent to get transition update info for.
done (bool): Whether this transition is terminal.
"""
info = self._transitions[agent.id]
info["done"] = done
self._transitions[agent.id] = {"reward": 0.0}
return info
def get_stacked_state(self, agent, observation):
"""Create a stacked state for the agent. The previous observations recorded
by this agent are stacked with the current observation. If not enough
observations have been recorded, zero arrays are appended.
Args:
agent (Agent): Agent to get stacked state for.
observation: Current observation.
"""
if self._stack_size == 1:
return observation
while len(self._previous_observations[agent.id]) < self._stack_size - 1:
self._previous_observations[agent.id].append(zeros_like(observation))
stacked_observation = concatenate(
list(self._previous_observations[agent.id]) + [observation]
)
return stacked_observation
def __repr__(self):
return str(
{
"transtions": self._transitions,
"started": self._started,
"previous_observations": self._previous_observations,
}
)
def zeros_like(x):
"""Create a zero state like some state. This handles slightly more complex
objects such as lists and dictionaries of numpy arrays and torch Tensors.
Args:
x (np.ndarray | torch.Tensor | dict | list): State used to define
structure/state of zero state.
"""
if isinstance(x, np.ndarray):
return np.zeros_like(x)
elif isinstance(x, torch.Tensor):
return torch.zeros_like(x)
elif isinstance(x, dict):
return {k: zeros_like(v) for k, v in x.items()}
elif isinstance(x, list):
return [zeros_like(item) for item in x]
else:
return 0
def concatenate(xs):
"""Concatenates numpy arrays or dictionaries of numpy arrays.
Args:
xs (list): List of objects to concatenate.
"""
if len(xs) == 0:
return np.array([])
if isinstance(xs[0], dict):
return {k: np.concatenate([x[k] for x in xs], axis=0) for k in xs[0]}
else:
return np.concatenate(xs, axis=0) | /rlhive-1.0.1-py3-none-any.whl/hive/runners/utils.py | 0.82925 | 0.192141 | utils.py | pypi |
import argparse
import copy
from hive import agents as agent_lib
from hive import envs
from hive.runners.base import Runner
from hive.runners.utils import TransitionInfo, load_config
from hive.utils import experiment, loggers, schedule, utils
from hive.utils.registry import get_parsed_args
class SingleAgentRunner(Runner):
"""Runner class used to implement a sinle-agent training loop."""
def __init__(
self,
environment,
agent,
logger,
experiment_manager,
train_steps,
test_frequency,
test_episodes,
stack_size,
max_steps_per_episode=27000,
):
"""Initializes the Runner object.
Args:
environment (BaseEnv): Environment used in the training loop.
agent (Agent): Agent that will interact with the environment
logger (ScheduledLogger): Logger object used to log metrics.
experiment_manager (Experiment): Experiment object that saves the state of
the training.
train_steps (int): How many steps to train for. If this is -1, there is no
limit for the number of training steps.
test_frequency (int): After how many training steps to run testing
episodes. If this is -1, testing is not run.
test_episodes (int): How many episodes to run testing for duing each test
phase.
stack_size (int): The number of frames in an observation sent to an agent.
max_steps_per_episode (int): The maximum number of steps to run an episode
for.
"""
super().__init__(
environment,
agent,
logger,
experiment_manager,
train_steps,
test_frequency,
test_episodes,
max_steps_per_episode,
)
self._transition_info = TransitionInfo(self._agents, stack_size)
def run_one_step(self, observation, episode_metrics):
"""Run one step of the training loop.
Args:
observation: Current observation that the agent should create an action
for.
episode_metrics (Metrics): Keeps track of metrics for current episode.
"""
super().run_one_step(observation, 0, episode_metrics)
agent = self._agents[0]
stacked_observation = self._transition_info.get_stacked_state(
agent, observation
)
action = agent.act(stacked_observation)
next_observation, reward, done, _, other_info = self._environment.step(action)
info = {
"observation": observation,
"reward": reward,
"action": action,
"done": done,
"info": other_info,
}
if self._training:
agent.update(copy.deepcopy(info))
self._transition_info.record_info(agent, info)
episode_metrics[agent.id]["reward"] += info["reward"]
episode_metrics[agent.id]["episode_length"] += 1
episode_metrics["full_episode_length"] += 1
return done, next_observation
def run_episode(self):
"""Run a single episode of the environment."""
episode_metrics = self.create_episode_metrics()
done = False
observation, _ = self._environment.reset()
self._transition_info.reset()
self._transition_info.start_agent(self._agents[0])
steps = 0
# Run the loop until the episode ends or times out
while not done and steps < self._max_steps_per_episode:
done, observation = self.run_one_step(observation, episode_metrics)
steps += 1
return episode_metrics
def set_up_experiment(config):
"""Returns a :py:class:`SingleAgentRunner` object based on the config and any
command line arguments.
Args:
config: Configuration for experiment.
"""
args = get_parsed_args(
{
"seed": int,
"train_steps": int,
"test_frequency": int,
"test_episodes": int,
"max_steps_per_episode": int,
"stack_size": int,
"resume": bool,
"run_name": str,
"save_dir": str,
}
)
config.update(args)
full_config = utils.Chomp(copy.deepcopy(config))
if "seed" in config:
utils.seeder.set_global_seed(config["seed"])
environment, full_config["environment"] = envs.get_env(
config["environment"], "environment"
)
env_spec = environment.env_spec
# Set up loggers
logger_config = config.get("loggers", {"name": "NullLogger"})
if logger_config is None or len(logger_config) == 0:
logger_config = {"name": "NullLogger"}
if isinstance(logger_config, list):
logger_config = {
"name": "CompositeLogger",
"kwargs": {"logger_list": logger_config},
}
logger, full_config["loggers"] = loggers.get_logger(logger_config, "loggers")
# Set up agent
if config.get("stack_size", 1) > 1:
config["agent"]["kwargs"]["obs_dim"] = (
config["stack_size"] * env_spec.obs_dim[0][0],
*env_spec.obs_dim[0][1:],
)
else:
config["agent"]["kwargs"]["obs_dim"] = env_spec.obs_dim[0]
config["agent"]["kwargs"]["act_dim"] = env_spec.act_dim[0]
config["agent"]["kwargs"]["logger"] = logger
if "replay_buffer" in config["agent"]["kwargs"]:
replay_args = config["agent"]["kwargs"]["replay_buffer"]["kwargs"]
replay_args["observation_shape"] = env_spec.obs_dim[0]
agent, full_config["agent"] = agent_lib.get_agent(config["agent"], "agent")
# Set up experiment manager
saving_schedule, full_config["saving_schedule"] = schedule.get_schedule(
config["saving_schedule"], "saving_schedule"
)
experiment_manager = experiment.Experiment(
config["run_name"], config["save_dir"], saving_schedule
)
experiment_manager.register_experiment(
config=full_config,
logger=logger,
agents=agent,
)
# Set up runner
runner = SingleAgentRunner(
environment,
agent,
logger,
experiment_manager,
config.get("train_steps", -1),
config.get("test_frequency", -1),
config.get("test_episodes", 1),
config.get("stack_size", 1),
config.get("max_steps_per_episode", 1e9),
)
if config.get("resume", False):
runner.resume()
return runner
def main():
parser = argparse.ArgumentParser()
parser.add_argument("-c", "--config")
parser.add_argument("-p", "--preset-config")
parser.add_argument("-a", "--agent-config")
parser.add_argument("-e", "--env-config")
parser.add_argument("-l", "--logger-config")
args, _ = parser.parse_known_args()
if args.config is None and args.preset_config is None:
raise ValueError("Config needs to be provided")
config = load_config(
args.config,
args.preset_config,
args.agent_config,
args.env_config,
args.logger_config,
)
runner = set_up_experiment(config)
runner.run_training()
if __name__ == "__main__":
main() | /rlhive-1.0.1-py3-none-any.whl/hive/runners/single_agent_loop.py | 0.781997 | 0.403449 | single_agent_loop.py | pypi |
import argparse
import copy
from hive import agents as agent_lib
from hive import envs
from hive.runners.base import Runner
from hive.runners.utils import TransitionInfo, load_config
from hive.utils import experiment, loggers, schedule, utils
from hive.utils.registry import get_parsed_args
class MultiAgentRunner(Runner):
"""Runner class used to implement a multiagent training loop."""
def __init__(
self,
environment,
agents,
logger,
experiment_manager,
train_steps,
test_frequency,
test_episodes,
stack_size,
self_play,
max_steps_per_episode=27000,
):
"""Initializes the Runner object.
Args:
environment (BaseEnv): Environment used in the training loop.
agents (list[Agent]): List of agents that interact with the environment
logger (ScheduledLogger): Logger object used to log metrics.
experiment_manager (Experiment): Experiment object that saves the state of
the training.
train_steps (int): How many steps to train for. If this is -1, there is no
limit for the number of training steps.
test_frequency (int): After how many training steps to run testing
episodes. If this is -1, testing is not run.
test_episodes (int): How many episodes to run testing for.
stack_size (int): The number of frames in an observation sent to an agent.
max_steps_per_episode (int): The maximum number of steps to run an episode
for.
"""
super().__init__(
environment,
agents,
logger,
experiment_manager,
train_steps,
test_frequency,
test_episodes,
max_steps_per_episode,
)
self._transition_info = TransitionInfo(self._agents, stack_size)
self._self_play = self_play
def run_one_step(self, observation, turn, episode_metrics):
"""Run one step of the training loop.
If it is the agent's first turn during the episode, do not run an update step.
Otherwise, run an update step based on the previous action and accumulated
reward since then.
Args:
observation: Current observation that the agent should create an action
for.
turn (int): Agent whose turn it is.
episode_metrics (Metrics): Keeps track of metrics for current episode.
"""
super().run_one_step(observation, turn, episode_metrics)
agent = self._agents[turn]
if self._transition_info.is_started(agent):
info = self._transition_info.get_info(agent)
if self._training:
agent.update(copy.deepcopy(info))
episode_metrics[agent.id]["reward"] += info["reward"]
episode_metrics[agent.id]["episode_length"] += 1
episode_metrics["full_episode_length"] += 1
else:
self._transition_info.start_agent(agent)
stacked_observation = self._transition_info.get_stacked_state(
agent, observation
)
action = agent.act(stacked_observation)
next_observation, reward, done, turn, other_info = self._environment.step(
action
)
self._transition_info.record_info(
agent,
{
"observation": observation,
"action": action,
"info": other_info,
},
)
if self._self_play:
self._transition_info.record_info(
agent,
{
"agent_id": agent.id,
},
)
self._transition_info.update_all_rewards(reward)
return done, next_observation, turn
def run_end_step(self, episode_metrics, done=True):
"""Run the final step of an episode.
After an episode ends, iterate through agents and update then with the final
step in the episode.
Args:
episode_metrics (Metrics): Keeps track of metrics for current episode.
done (bool): Whether this step was terminal.
"""
for agent in self._agents:
if self._transition_info.is_started(agent):
info = self._transition_info.get_info(agent, done=done)
if self._training:
agent.update(info)
episode_metrics[agent.id]["episode_length"] += 1
episode_metrics["full_episode_length"] += 1
episode_metrics[agent.id]["reward"] += info["reward"]
def run_episode(self):
"""Run a single episode of the environment."""
episode_metrics = self.create_episode_metrics()
done = False
observation, turn = self._environment.reset()
self._transition_info.reset()
steps = 0
# Run the loop until the episode ends or times out
while not done and steps < self._max_steps_per_episode:
done, observation, turn = self.run_one_step(
observation, turn, episode_metrics
)
steps += 1
# Run the final update.
self.run_end_step(episode_metrics, done)
return episode_metrics
def set_up_experiment(config):
"""Returns a :py:class:`MultiAgentRunner` object based on the config and any
command line arguments.
Args:
config: Configuration for experiment.
"""
# Parses arguments from the command line.
args = get_parsed_args(
{
"seed": int,
"train_steps": int,
"test_frequency": int,
"test_episodes": int,
"max_steps_per_episode": int,
"stack_size": int,
"resume": bool,
"run_name": str,
"save_dir": str,
"self_play": bool,
"num_agents": int,
}
)
config.update(args)
full_config = utils.Chomp(copy.deepcopy(config))
if "seed" in config:
utils.seeder.set_global_seed(config["seed"])
# Set up environment
environment, full_config["environment"] = envs.get_env(
config["environment"], "environment"
)
env_spec = environment.env_spec
# Set up loggers
logger_config = config.get("loggers", {"name": "NullLogger"})
if logger_config is None or len(logger_config) == 0:
logger_config = {"name": "NullLogger"}
if isinstance(logger_config, list):
logger_config = {
"name": "CompositeLogger",
"kwargs": {"logger_list": logger_config},
}
logger, full_config["loggers"] = loggers.get_logger(logger_config, "loggers")
# Set up agents
agents = []
full_config["agents"] = []
num_agents = config["num_agents"] if config["self_play"] else len(config["agents"])
for idx in range(num_agents):
if not config["self_play"] or idx == 0:
agent_config = config["agents"][idx]
if config.get("stack_size", 1) > 1:
agent_config["kwargs"]["obs_dim"] = (
config["stack_size"] * env_spec.obs_dim[idx][0],
*env_spec.obs_dim[idx][1:],
)
else:
agent_config["kwargs"]["obs_dim"] = env_spec.obs_dim[idx]
agent_config["kwargs"]["act_dim"] = env_spec.act_dim[idx]
agent_config["kwargs"]["logger"] = logger
if "replay_buffer" in agent_config["kwargs"]:
replay_args = agent_config["kwargs"]["replay_buffer"]["kwargs"]
replay_args["observation_shape"] = env_spec.obs_dim[idx]
agent, full_agent_config = agent_lib.get_agent(
agent_config, f"agents.{idx}"
)
agents.append(agent)
full_config["agents"].append(full_agent_config)
else:
agents.append(copy.copy(agents[0]))
agents[-1]._id = idx
# Set up experiment manager
saving_schedule, full_config["saving_schedule"] = schedule.get_schedule(
config["saving_schedule"], "saving_schedule"
)
experiment_manager = experiment.Experiment(
config["run_name"], config["save_dir"], saving_schedule
)
experiment_manager.register_experiment(
config=full_config,
logger=logger,
agents=agents,
)
# Set up runner
runner = MultiAgentRunner(
environment,
agents,
logger,
experiment_manager,
config.get("train_steps", -1),
config.get("test_frequency", -1),
config.get("test_episodes", 1),
config.get("stack_size", 1),
config.get("self_play", False),
config.get("max_steps_per_episode", 1e9),
)
if config.get("resume", False):
runner.resume()
return runner
def main():
parser = argparse.ArgumentParser()
parser.add_argument("-c", "--config")
parser.add_argument("-p", "--preset-config")
parser.add_argument("-a", "--agent-config")
parser.add_argument("-e", "--env-config")
parser.add_argument("-l", "--logger-config")
args, _ = parser.parse_known_args()
if args.config is None and args.preset_config is None:
raise ValueError("Config needs to be provided")
config = load_config(
args.config,
args.preset_config,
args.agent_config,
args.env_config,
args.logger_config,
)
runner = set_up_experiment(config)
runner.run_training()
if __name__ == "__main__":
main() | /rlhive-1.0.1-py3-none-any.whl/hive/runners/multi_agent_loop.py | 0.811676 | 0.33546 | multi_agent_loop.py | pypi |
import logging
import os
import yaml
from hive.utils.utils import Chomp, create_folder
class Experiment(object):
"""Implementation of a simple experiment class."""
def __init__(self, name, dir_name, schedule):
"""Initializes an experiment object.
The experiment state is an exposed property of objects of this class. It can
be used to keep track of objects that need to be saved to keep track of the
experiment, but don't fit in one of the standard categories. One example of
this is the various schedules used in the Runner class.
Args:
name (str): Name of the experiment.
dir_name (str): Absolute path to the directory to save/load the experiment.
"""
self._name = name
self._dir_name = os.path.join(dir_name, name)
self._schedule = schedule
self._step = 0
create_folder(self._dir_name)
self._config = None
self._logger = None
self._agents = None
self._environment = None
self.experiment_state = Chomp()
self.experiment_state["saving_schedule"] = self._schedule
def register_experiment(
self,
config=None,
logger=None,
agents=None,
environment=None,
):
"""Registers all the components of an experiment.
Args:
config (Chomp): a config dictionary.
logger (Logger): a logger object.
agents (Agent | list[Agent]): either an agent object or a list of agents.
environment (BaseEnv): an environment object.
"""
self._config = config
self._logger = logger
self._logger.log_config(config)
if agents is not None and not isinstance(agents, list):
agents = [agents]
self._agents = agents
self._environment = environment
def update_step(self):
"""Updates the step of the saving schedule for the experiment."""
self._step += 1
return self._schedule.update()
def should_save(self):
"""Returns whether you should save the experiment at the current step."""
return self._schedule.get_value()
def save(self, tag="current"):
"""Saves the experiment.
Args:
tag (str): Tag to prefix the folder.
"""
save_dir = os.path.join(self._dir_name, tag)
create_folder(save_dir)
logging.info("Saving the experiment at {}".format(save_dir))
flag_file = os.path.join(save_dir, "flag.p")
if os.path.isfile(flag_file):
os.remove(flag_file)
if self._config is not None:
file_name = os.path.join(save_dir, "config.yml")
with open(file_name, "w") as f:
yaml.safe_dump(dict(self._config), f)
if self._logger is not None:
folder_name = os.path.join(save_dir, "logger")
create_folder(folder_name)
self._logger.save(folder_name)
if self._agents is not None:
for idx, agent in enumerate(self._agents):
agent_dir = os.path.join(save_dir, f"agent_{idx}")
create_folder(agent_dir)
agent.save(agent_dir)
if self._environment is not None:
file_name = os.path.join(save_dir, "environment.p")
self._environment.save(file_name)
file_name = os.path.join(save_dir, "experiment_state.p")
self.experiment_state.save(file_name)
file = open(flag_file, "w")
file.close()
def is_resumable(self, tag="current"):
"""Returns true if the experiment is resumable.
Args:
tag (str): Tag for the saved experiment.
"""
flag_file = os.path.join(self._dir_name, tag, "flag.p")
if os.path.isfile(flag_file):
return True
else:
return False
def resume(self, tag="current"):
"""Resumes the experiment from a checkpoint.
Args:
tag (str): Tag for the saved experiment.
"""
if self.is_resumable(tag):
save_dir = os.path.join(self._dir_name, tag)
logging.info("Loading the experiment from {}".format(save_dir))
if self._config is not None:
file_name = os.path.join(save_dir, "config.yml")
with open(file_name) as f:
self._config = Chomp(yaml.safe_load(f))
if self._logger is not None:
folder_name = os.path.join(save_dir, "logger")
self._logger.load(folder_name)
if self._agents is not None:
for idx, agent in enumerate(self._agents):
agent_dir = os.path.join(save_dir, f"agent_{idx}")
agent.load(agent_dir)
if self._environment is not None:
file_name = os.path.join(save_dir, "environment.p")
self._environment.load(file_name)
file_name = os.path.join(save_dir, "experiment_state.p")
self.experiment_state.load(file_name)
self._schedule = self.experiment_state["saving_schedule"] | /rlhive-1.0.1-py3-none-any.whl/hive/utils/experiment.py | 0.792825 | 0.238622 | experiment.py | pypi |
import abc
from hive.utils.registry import Registrable, registry
class Schedule(abc.ABC, Registrable):
@abc.abstractmethod
def get_value(self):
"""Returns the current value of the variable we are tracking"""
pass
@abc.abstractmethod
def update(self):
"""Update the value of the variable we are tracking and return the updated value.
The first call to update will return the initial value of the schedule."""
pass
@classmethod
def type_name(cls):
return "schedule"
class LinearSchedule(Schedule):
"""Defines a linear schedule between two values over some number of steps.
If updated more than the defined number of steps, the schedule stays at the
end value.
"""
def __init__(self, init_value, end_value, steps):
"""
Args:
init_value (int | float): Starting value for schedule.
end_value (int | float): End value for schedule.
steps (int): Number of steps for schedule. Should be positive.
"""
steps = max(int(steps), 1)
self._delta = (end_value - init_value) / steps
self._end_value = end_value
self._value = init_value - self._delta
def get_value(self):
return self._value
def update(self):
if self._value == self._end_value:
return self._value
self._value += self._delta
# Check if value is over the end_value
if ((self._value - self._end_value) > 0) == (self._delta > 0):
self._value = self._end_value
return self._value
def __repr__(self):
return (
f"<class {type(self).__name__}"
f" value={self.get_value()}"
f" delta={self._delta}"
f" end_value={self._end_value}>"
)
class ConstantSchedule(Schedule):
"""Returns a constant value over the course of the schedule"""
def __init__(self, value):
"""
Args:
value: The value to be returned.
"""
self._value = value
def get_value(self):
return self._value
def update(self):
return self._value
def __repr__(self):
return f"<class {type(self).__name__} value={self.get_value()}>"
class SwitchSchedule(Schedule):
"""Returns one value for the first part of the schedule. After the defined
number of steps is reached, switches to returning a second value.
"""
def __init__(self, off_value, on_value, steps):
"""
Args:
off_value: The value to be returned in the first part of the schedule.
on_value: The value to be returned in the second part of the schedule.
steps (int): The number of steps after which to switch from the off
value to the on value.
"""
self._steps = 0
self._flip_step = steps
self._off_value = off_value
self._on_value = on_value
def get_value(self):
if self._steps <= self._flip_step:
return self._off_value
else:
return self._on_value
def update(self):
self._steps += 1
value = self.get_value()
return value
def __repr__(self):
return (
f"<class {type(self).__name__}"
f" value={self.get_value()}"
f" steps={self._steps}"
f" off_value={self._off_value}"
f" on_value={self._on_value}"
f" flip_step={self._flip_step}>"
)
class DoublePeriodicSchedule(Schedule):
"""Returns off value for off period, then switches to returning on value for on
period. Alternates between the two.
"""
def __init__(self, off_value, on_value, off_period, on_period):
"""
Args:
on_value: The value to be returned for the on period.
off_value: The value to be returned for the off period.
on_period (int): the number of steps in the on period.
off_period (int): the number of steps in the off period.
"""
self._steps = -1
self._off_period = off_period
self._total_period = self._off_period + on_period
self._off_value = off_value
self._on_value = on_value
def get_value(self):
if (self._steps % self._total_period) < self._off_period:
return self._off_value
else:
return self._on_value
def update(self):
self._steps += 1
return self.get_value()
def __repr__(self):
return (
f"<class {type(self).__name__}"
f" value={self.get_value()}"
f" steps={self._steps}"
f" off_value={self._off_value}"
f" on_value={self._on_value}"
f" off_period={self._off_period}"
f" on_period={self._total_period - self._off_period}>"
)
class PeriodicSchedule(DoublePeriodicSchedule):
"""Returns one value on the first step of each period of a predefined number of
steps. Returns another value otherwise.
"""
def __init__(self, off_value, on_value, period):
"""
Args:
on_value: The value to be returned on the first step of each period.
off_value: The value to be returned for every other step in the period.
period (int): The number of steps in the period.
"""
super().__init__(off_value, on_value, period - 1, 1)
def __repr__(self):
return (
f"<class {type(self).__name__}"
f" value={self.get_value()}"
f" steps={self._steps}"
f" off_value={self._off_value}"
f" on_value={self._on_value}"
f" period={self._off_period + 1}>"
)
registry.register_all(
Schedule,
{
"LinearSchedule": LinearSchedule,
"ConstantSchedule": ConstantSchedule,
"SwitchSchedule": SwitchSchedule,
"PeriodicSchedule": PeriodicSchedule,
"DoublePeriodicSchedule": DoublePeriodicSchedule,
},
)
get_schedule = getattr(registry, f"get_{Schedule.type_name()}") | /rlhive-1.0.1-py3-none-any.whl/hive/utils/schedule.py | 0.913288 | 0.711346 | schedule.py | pypi |
import abc
import copy
import os
from typing import List
import torch
import wandb
from hive.utils.registry import Registrable, registry
from hive.utils.schedule import ConstantSchedule, Schedule, get_schedule
from hive.utils.utils import Chomp, create_folder
class Logger(abc.ABC, Registrable):
"""Abstract class for logging in hive."""
def __init__(self, timescales=None):
"""Constructor for base Logger class. Every Logger must call this constructor
in its own constructor
Args:
timescales (str | list(str)): The different timescales at which logger
needs to log. If only logging at one timescale, it is acceptable to
only pass a string.
"""
if timescales is None:
self._timescales = []
elif isinstance(timescales, str):
self._timescales = [timescales]
elif isinstance(timescales, list):
self._timescales = timescales
else:
raise ValueError("Need string or list of strings for timescales")
def register_timescale(self, timescale):
"""Register a new timescale with the logger.
Args:
timescale (str): Timescale to register.
"""
self._timescales.append(timescale)
@abc.abstractmethod
def log_config(self, config):
"""Log the config.
Args:
config (dict): Config parameters.
"""
pass
@abc.abstractmethod
def log_scalar(self, name, value, prefix):
"""Log a scalar variable.
Args:
name (str): Name of the metric to be logged.
value (float): Value to be logged.
prefix (str): Prefix to append to metric name.
"""
pass
@abc.abstractmethod
def log_metrics(self, metrics, prefix):
"""Log a dictionary of values.
Args:
metrics (dict): Dictionary of metrics to be logged.
prefix (str): Prefix to append to metric name.
"""
pass
@abc.abstractmethod
def save(self, dir_name):
"""Saves the current state of the log files.
Args:
dir_name (str): Name of the directory to save the log files.
"""
pass
@abc.abstractmethod
def load(self, dir_name):
"""Loads the log files from given directory.
Args:
dir_name (str): Name of the directory to load the log file from.
"""
pass
@classmethod
def type_name(cls):
return "logger"
class ScheduledLogger(Logger):
"""Abstract class that manages a schedule for logging.
The update_step method should be called for each step in the loop to update
the logger's schedule. The should_log method can be used to check whether
the logger should log anything.
This schedule is not strictly enforced! It is still possible to log something
even if should_log returns false. These functions are just for the purpose
of convenience.
"""
def __init__(self, timescales=None, logger_schedules=None):
"""
Any timescales not assigned schedule from logger_schedules will be assigned
a ConstantSchedule(True).
Args:
timescales (str|list[str]): The different timescales at which logger needs
to log. If only logging at one timescale, it is acceptable to only pass
a string.
logger_schedules (Schedule|list|dict): Schedules used to keep track of when
to log. If a single schedule, it is copied for each timescale. If a
list of schedules, the schedules are matched up in order with the list
of timescales provided. If a dictionary, the keys should be the
timescale and the values should be the schedule.
"""
super().__init__(timescales)
if logger_schedules is None:
logger_schedules = ConstantSchedule(True)
if isinstance(logger_schedules, dict):
self._logger_schedules = logger_schedules
elif isinstance(logger_schedules, list):
self._logger_schedules = {
self._timescales[idx]: logger_schedules[idx]
for idx in range(min(len(logger_schedules), len(self._timescales)))
}
elif isinstance(logger_schedules, Schedule):
self._logger_schedules = {
timescale: copy.deepcopy(logger_schedules)
for timescale in self._timescales
}
else:
raise ValueError(
"logger_schedule must be a dict, list of Schedules, or Schedule object"
)
for timescale, schedule in self._logger_schedules.items():
if isinstance(schedule, dict):
self._logger_schedules[timescale] = get_schedule(
schedule["name"], schedule["kwargs"]
)
for timescale in self._timescales:
if timescale not in self._logger_schedules:
self._logger_schedules[timescale] = ConstantSchedule(True)
self._steps = {timescale: 0 for timescale in self._timescales}
def register_timescale(self, timescale, schedule=None):
"""Register a new timescale.
Args:
timescale (str): Timescale to register.
schedule (Schedule): Schedule to use for this timescale.
"""
super().register_timescale(timescale)
if schedule is None:
schedule = ConstantSchedule(True)
self._logger_schedules[timescale] = schedule
self._steps[timescale] = 0
def update_step(self, timescale):
"""Update the step and schedule for a given timescale.
Args:
timescale (str): A registered timescale.
"""
self._steps[timescale] += 1
self._logger_schedules[timescale].update()
return self.should_log(timescale)
def should_log(self, timescale):
"""Check if you should log for a given timescale.
Args:
timescale (str): A registered timescale.
"""
return self._logger_schedules[timescale].get_value()
def save(self, dir_name):
logger_state = Chomp()
logger_state.timescales = self._timescales
logger_state.schedules = self._logger_schedules
logger_state.steps = self._steps
logger_state.save(os.path.join(dir_name, "logger_state.p"))
def load(self, dir_name):
logger_state = Chomp()
logger_state.load(os.path.join(dir_name, "logger_state.p"))
self._timescales = logger_state.timescales
self._logger_schedules = logger_state.schedules
self._steps = logger_state.steps
class NullLogger(ScheduledLogger):
"""A null logger that does not log anything.
Used if you don't want to log anything, but still want to use parts of the
framework that ask for a logger.
"""
def __init__(self, timescales=None, logger_schedules=None):
super().__init__(timescales, logger_schedules)
def log_config(self, config):
pass
def log_scalar(self, name, value, timescale):
pass
def log_metrics(self, metrics, timescale):
pass
def save(self, dir_name):
pass
def load(self, dir_name):
pass
class WandbLogger(ScheduledLogger):
"""A Wandb logger.
This logger can be used to log to wandb. It assumes that wandb is configured
locally on your system. Multiple timescales/loggers can be implemented by
instantiating multiple loggers with different logger_names. These should still
have the same project and run names.
Check the wandb documentation for more details on the parameters.
"""
def __init__(
self,
timescales=None,
logger_schedules=None,
project=None,
name=None,
dir=None,
mode=None,
id=None,
resume=None,
start_method=None,
**kwargs,
):
"""
Args:
timescales (str|list[str]): The different timescales at which logger needs
to log. If only logging at one timescale, it is acceptable to only pass
a string.
logger_schedules (Schedule|list|dict): Schedules used to keep track of when
to log. If a single schedule, it is copied for each timescale. If a
list of schedules, the schedules are matched up in order with the list
of timescales provided. If a dictionary, the keys should be the
timescale and the values should be the schedule.
project (str): Name of the project. Wandb's dash groups all runs with
the same project name together.
name (str): Name of the run. Used to identify the run on the wandb
dash.
dir (str): Local directory where wandb saves logs.
mode (str): The mode of logging. Can be "online", "offline" or "disabled".
In offline mode, writes all data to disk for later syncing to a server,
while in disabled mode, it makes all calls to wandb api's noop's, while
maintaining core functionality.
id (str, optional): A unique ID for this run, used for resuming.
It must be unique in the project, and if you delete a run you can't
reuse the ID.
resume (bool, str, optional): Sets the resuming behavior.
Options are the same as mentioned in Wandb's doc.
start_method (str): The start method to use for wandb's process. See
https://docs.wandb.ai/guides/track/launch#init-start-error.
**kwargs: You can pass any other arguments to wandb's init method as
keyword arguments. Note, these arguments can't be overriden from the
command line.
"""
super().__init__(timescales, logger_schedules)
settings = None
if start_method is not None:
settings = wandb.Settings(start_method=start_method)
wandb.init(
project=project,
name=name,
dir=dir,
mode=mode,
id=id,
resume=resume,
settings=settings,
**kwargs,
)
def log_config(self, config):
# Convert list parameters to nested dictionary
for k, v in config.items():
if isinstance(v, list):
config[k] = {}
for idx, param in enumerate(v):
config[k][idx] = param
wandb.config.update(config)
def log_scalar(self, name, value, prefix):
metrics = {f"{prefix}/{name}": value}
metrics.update(
{
f"{timescale}_step": self._steps[timescale]
for timescale in self._timescales
}
)
wandb.log(metrics)
def log_metrics(self, metrics, prefix):
metrics = {f"{prefix}/{name}": value for (name, value) in metrics.items()}
metrics.update(
{
f"{timescale}_step": self._steps[timescale]
for timescale in self._timescales
}
)
wandb.log(metrics)
class ChompLogger(ScheduledLogger):
"""This logger uses the Chomp data structure to store all logged values which are
then directly saved to disk.
"""
def __init__(self, timescales=None, logger_schedules=None):
super().__init__(timescales, logger_schedules)
self._log_data = Chomp()
def log_config(self, config):
self._log_data["config"] = config
def log_scalar(self, name, value, prefix):
metric_name = f"{prefix}/{name}"
if metric_name not in self._log_data:
self._log_data[metric_name] = [[], []]
if isinstance(value, torch.Tensor):
self._log_data[metric_name][0].append(value.item())
else:
self._log_data[metric_name][0].append(value)
self._log_data[metric_name][1].append(
{timescale: self._steps[timescale] for timescale in self._timescales}
)
def log_metrics(self, metrics, prefix):
for name in metrics:
metric_name = f"{prefix}/{name}"
if metric_name not in self._log_data:
self._log_data[metric_name] = [[], []]
if isinstance(metrics[name], torch.Tensor):
self._log_data[metric_name][0].append(metrics[name].item())
else:
self._log_data[metric_name][0].append(metrics[name])
self._log_data[metric_name][1].append(
{timescale: self._steps[timescale] for timescale in self._timescales}
)
def save(self, dir_name):
super().save(dir_name)
self._log_data.save(os.path.join(dir_name, "log_data.p"))
def load(self, dir_name):
super().load(dir_name)
self._log_data.load(os.path.join(dir_name, "log_data.p"))
class CompositeLogger(Logger):
"""This Logger aggregates multiple loggers together.
This logger is for convenience and allows for logging using multiple loggers without
having to keep track of several loggers. When timescales are updated, this logger
updates the timescale for each one of its component loggers. When logging, logs to
each of its component loggers as long as the logger is not a ScheduledLogger that
should not be logging for the timescale.
"""
def __init__(self, logger_list: List[Logger]):
super().__init__([])
self._logger_list = logger_list
def register_timescale(self, timescale, schedule=None):
for logger in self._logger_list:
if isinstance(logger, ScheduledLogger):
logger.register_timescale(timescale, schedule)
else:
logger.register_timescale(timescale)
def log_config(self, config):
for logger in self._logger_list:
logger.log_config(config)
def log_scalar(self, name, value, prefix):
for logger in self._logger_list:
logger.log_scalar(name, value, prefix)
def log_metrics(self, metrics, prefix):
for logger in self._logger_list:
logger.log_metrics(metrics, prefix=prefix)
def update_step(self, timescale):
"""Update the step and schedule for a given timescale for every
ScheduledLogger.
Args:
timescale (str): A registered timescale.
"""
for logger in self._logger_list:
if isinstance(logger, ScheduledLogger):
logger.update_step(timescale)
return self.should_log(timescale)
def should_log(self, timescale):
"""Check if you should log for a given timescale. If any logger in the list
is scheduled to log, returns True.
Args:
timescale (str): A registered timescale.
"""
for logger in self._logger_list:
if not isinstance(logger, ScheduledLogger) or logger.should_log(timescale):
return True
return False
def save(self, dir_name):
for idx, logger in enumerate(self._logger_list):
save_dir = os.path.join(dir_name, f"logger_{idx}")
create_folder(save_dir)
logger.save(save_dir)
def load(self, dir_name):
for idx, logger in enumerate(self._logger_list):
load_dir = os.path.join(dir_name, f"logger_{idx}")
logger.load(load_dir)
registry.register_all(
Logger,
{
"NullLogger": NullLogger,
"WandbLogger": WandbLogger,
"ChompLogger": ChompLogger,
"CompositeLogger": CompositeLogger,
},
)
get_logger = getattr(registry, f"get_{Logger.type_name()}") | /rlhive-1.0.1-py3-none-any.whl/hive/utils/loggers.py | 0.884894 | 0.458409 | loggers.py | pypi |
import argparse
import inspect
from copy import deepcopy
from functools import partial, update_wrapper
from typing import List, Mapping, Sequence, _GenericAlias
import yaml
class Registrable:
"""Class used to denote which types of objects can be registered in the RLHive
Registry. These objects can also be configured directly from the command line, and
recursively built from the config, assuming type annotations are present.
"""
@classmethod
def type_name(cls):
"""This should represent a string that denotes the which type of class you are
creating. For example, "logger", "agent", or "env".
"""
raise ValueError
class CallableType(Registrable):
"""A wrapper that allows any callable to be registered in the RLHive Registry.
Specifically, it maps the arguments and annotations of the wrapped function to the
resulting callable, allowing any argument names and type annotations of the
underlying function to be present for outer wrapper. When called with some
arguments, this object returns a partial function with those arguments assigned.
By default, the type_name is "callable", but if you want to create specific types
of callables, you can simply create a subclass and override the type_name method.
See :py:class:`hive.utils.utils.OptimizerFn`.
"""
def __init__(self, fn):
"""
Args:
fn: callable to be wrapped.
"""
self._fn = fn
update_wrapper(self, self._fn)
def __call__(self, *args, **kwargs):
return partial(self._fn, *args, **kwargs)
@classmethod
def type_name(cls):
return "callable"
def __repr__(self):
return f"<{type(self).__name__} {repr(self._fn)}>"
class Registry:
"""This is the Registry class for RLHive. It allows you to register different types
of :py:class:`Registrable` classes and objects and generates constructors for those
classes in the form of `get_{type_name}`.
These constructors allow you to construct objects from dictionary configs. These
configs should have two fields: `name`, which corresponds to the name used when
registering a class in the registry, and `kwargs`, which corresponds to the keyword
arguments that will be passed to the constructor of the object. These constructors
can also build objects recursively, i.e. if a config contains the config for
another `Registrable` object, this will be automatically created before being
passed to the constructor of the original object. These constructors also allow you
to directly specify/override arguments for object constructors directly from the
command line. These parameters are specified in dot notation. They also are able
to handle lists and dictionaries of Registrable objects.
For example, let's consider the following scenario:
Your agent class has an argument `arg1` which is annotated to be `List[Class1]`,
`Class1` is `Registrable`, and the `Class1` constructor takes an argument `arg2`.
In the passed yml config, there are two different Class1 object configs listed.
the constructor will check to see if both `--agent.arg1.0.arg2` and
`--agent.arg1.1.arg2` have been passed.
The parameters passed in the command line will be parsed according to the type
annotation of the corresponding low level constructor. If it is not one of
`int`, `float`, `str`, or `bool`, it simply loads the string into python using a
yaml loader.
Each constructor returns the object, as well a dictionary config with all the
parameters used to create the object and any Registrable objects created in the
process of creating this object.
"""
def __init__(self) -> None:
self._registry = {}
def register(self, name, constructor, type):
"""Register a Registrable class/object with RLHive.
Args:
name (str): Name of the class/object being registered.
constructor (callable): Callable that will be passed all kwargs from
configs and be analyzed to get type annotations.
type (type): Type of class/object being registered. Should be subclass of
Registrable.
"""
if not issubclass(type, Registrable):
raise ValueError(f"{type} is not Registrable")
if type.type_name() not in self._registry:
self._registry[type.type_name()] = {}
def getter(self, object_or_config, prefix=None):
if object_or_config is None:
return None, {}
elif isinstance(object_or_config, type):
return object_or_config, {}
name = object_or_config["name"]
kwargs = object_or_config.get("kwargs", {})
expanded_config = deepcopy(object_or_config)
if name in self._registry[type.type_name()]:
object_class = self._registry[type.type_name()][name]
parsed_args = get_callable_parsed_args(object_class, prefix=prefix)
kwargs.update(parsed_args)
kwargs, kwargs_config = construct_objects(
object_class, kwargs, prefix
)
expanded_config["kwargs"] = kwargs_config
return object_class(**kwargs), expanded_config
else:
raise ValueError(f"{name} class not found")
setattr(self.__class__, f"get_{type.type_name()}", getter)
self._registry[type.type_name()][name] = constructor
def register_all(self, base_class, class_dict):
"""Bulk register function.
Args:
base_class (type): Corresponds to the `type` of the register function
class_dict (dict[str, callable]): A dictionary mapping from name to
constructor.
"""
for cls in class_dict:
self.register(cls, class_dict[cls], base_class)
def __repr__(self):
return str(self._registry)
def construct_objects(object_constructor, config, prefix=None):
"""Helper function that constructs any objects specified in the config that
are registrable.
Returns the object, as well a dictionary config with all the parameters used to
create the object and any Registrable objects created in the process of creating
this object.
Args:
object_constructor (callable): constructor of object that corresponds to
config. The signature of this function will be analyzed to see if there
are any :py:class:`Registrable` objects that might be specified in the
config.
config (dict): The kwargs for the object being created. May contain configs for
other `Registrable` objects that need to be recursively created.
prefix (str): Prefix that is attached to the argument names when looking for
command line arguments.
"""
signature = inspect.signature(object_constructor)
prefix = "" if prefix is None else f"{prefix}."
expanded_config = deepcopy(config)
for argument in signature.parameters:
if argument not in config:
continue
expected_type = signature.parameters[argument].annotation
if isinstance(expected_type, type) and issubclass(expected_type, Registrable):
config[argument], expanded_config[argument] = registry.__getattribute__(
f"get_{expected_type.type_name()}"
)(config[argument], f"{prefix}{argument}")
if isinstance(expected_type, _GenericAlias):
origin = expected_type.__origin__
args = expected_type.__args__
if (
(origin == List or origin == list)
and len(args) == 1
and isinstance(args[0], type)
and issubclass(args[0], Registrable)
and isinstance(config[argument], Sequence)
):
objs = []
expanded_config[argument] = []
for idx, item in enumerate(config[argument]):
obj, obj_config = registry.__getattribute__(
f"get_{args[0].type_name()}"
)(item, f"{prefix}{argument}.{idx}")
objs.append(obj)
expanded_config[argument].append(obj_config)
config[argument] = objs
elif (
origin == dict
and len(args) == 2
and isinstance(args[1], type)
and issubclass(args[1], Registrable)
and isinstance(config[argument], Mapping)
):
objs = {}
expanded_config[argument] = {}
for key, val in config[argument].items():
obj, obj_config = registry.__getattribute__(
f"get_{args[1].type_name()}"
)(val, f"{prefix}{argument}.{key}")
objs[key] = obj
expanded_config[argument][key] = obj_config
config[argument] = objs
return config, expanded_config
def get_callable_parsed_args(callable, prefix=None):
"""Helper function that extracts the command line arguments for a given function.
Args:
callable (callable): function whose arguments will be inspected to extract
arguments from the command line.
prefix (str): Prefix that is attached to the argument names when looking for
command line arguments.
"""
signature = inspect.signature(callable)
arguments = {
argument: signature.parameters[argument]
for argument in signature.parameters
if argument != "self"
}
return get_parsed_args(arguments, prefix)
def get_parsed_args(arguments, prefix=None):
"""Helper function that takes a dictionary mapping argument names to types, and
extracts command line arguments for those arguments. If the dictionary contains
a key-value pair "bar": int, and the prefix passed is "foo", this function will
look for a command line argument "\-\-foo.bar". If present, it will cast it to an
int.
If the type for a given argument is not one of `int`, `float`, `str`, or `bool`,
it simply loads the string into python using a yaml loader.
Args:
arguments (dict[str, type]): dictionary mapping argument names to types
prefix (str): prefix that is attached to each argument name before searching
for command line arguments.
"""
prefix = "" if prefix is None else f"{prefix}."
parser = argparse.ArgumentParser()
for argument in arguments:
parser.add_argument(f"--{prefix}{argument}")
parsed_args, _ = parser.parse_known_args()
parsed_args = vars(parsed_args)
# Strip the prefix from the parsed arguments and remove arguments not present
parsed_args = {
(key[len(prefix) :] if key.startswith(prefix) else key): parsed_args[key]
for key in parsed_args
if parsed_args[key] is not None
}
for argument in parsed_args:
expected_type = arguments[argument]
if isinstance(expected_type, inspect.Parameter):
expected_type = expected_type.annotation
if expected_type in [int, str, float]:
parsed_args[argument] = expected_type(parsed_args[argument])
elif expected_type is bool:
value = str(parsed_args[argument]).lower()
parsed_args[argument] = not ("false".startswith(value) or value == "0")
else:
parsed_args[argument] = yaml.safe_load(parsed_args[argument])
return parsed_args
registry = Registry() | /rlhive-1.0.1-py3-none-any.whl/hive/utils/registry.py | 0.911975 | 0.467575 | registry.py | pypi |
import argparse
import json
import logging
import os
import pickle
from collections import defaultdict
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from matplotlib import cm
logging.basicConfig()
def find_single_run_data(run_folder):
"""Looks for a chomp logger data file in `run_folder` and it's subdirectories.
Once it finds one, it loads the file and returns the data.
Args:
run_folder (str): Which folder to search for the chomp logger data.
Returns:
The Chomp object containing the logger data.
"""
run_data_file = None
for path, _, filenames in os.walk(run_folder):
if "log_data.p" in filenames:
run_data_file = os.path.join(path, "log_data.p")
logging.info(f"Found run data at {run_data_file}")
break
if run_data_file is None:
logging.info(f"Run data not found for {run_folder}")
return
with open(run_data_file, "rb") as f:
run_data = pickle.load(f)
return run_data
def find_all_runs_data(runs_folder):
"""Iterates through each directory in runs_folder, finds one chomp logger
data file in each directory, and concatenates the data together under each
key present in the data.
Args:
runs_folder (str): Folder which contains subfolders, each of from which one
chomp logger data file is loaded.
Returns:
Dictionary with each key corresponding to a key in the chomp logger data files.
The values are the folder
"""
all_runs_data = defaultdict(lambda: [])
for run_folder in os.listdir(runs_folder):
full_run_folder = os.path.join(runs_folder, run_folder)
if os.path.isdir(full_run_folder):
run_data = find_single_run_data(full_run_folder)
for key in run_data:
all_runs_data[key].append(run_data[key])
return all_runs_data
def find_all_experiments_data(experiments_folder, runs_folders):
"""Finds and loads all log data in a folder.
Assuming the directory structure is as follows:
::
experiment
├── config_1_runs
| ├──seed0/
| ├──seed1/
| .
| .
| └──seedn/
├── config_2_runs
| ├──seed0/
| ├──seed1/
| .
| .
| └──seedn/
├── config_3_runs
| ├──seed0/
| ├──seed1/
| .
| .
| └──seedn/
Where there is some chomp logger data file under each seed directory, then
passing "experiment" and the list of config folders ("config_1_runs",
"config_2_runs", "config_3_runs"), will load all the data.
Args:
experiments_folder (str): Root folder with all experiments data.
runs_folders (list[str]): List of folders under root folder to load data
from.
"""
data = {}
for runs_folder in runs_folders:
full_runs_folderpath = os.path.join(experiments_folder, runs_folder)
data[runs_folder] = find_all_runs_data(full_runs_folderpath)
return data
def standardize_data(
experiment_data,
x_key,
y_key,
num_sampled_points=1000,
drop_last=True,
):
"""Extracts given keys from data, and standardizes the data across runs by sampling
equally spaced points along x data, and interpolating y data of each run.
Args:
experiment_data: Data object in the format of
:py:meth:`find_all_experiments_data`.
x_key (str): Key for x axis.
y_key (str): Key for y axis.
num_sampled_points (int): How many points to sample along x axis.
drop_last (bool): Whether to drop the last point in the data.
"""
if drop_last:
y_data = [data[0][:-1] for data in experiment_data[y_key]]
x_data = [
[x_datas[x_key] for x_datas in data[1][:-1]]
for data in experiment_data[y_key]
]
else:
y_data = [data[0] for data in experiment_data[y_key]]
x_data = [
[x_datas[x_key] for x_datas in data[1]] for data in experiment_data[y_key]
]
min_x = min([min(xs) for xs in x_data])
max_x = max([max(xs) for xs in x_data])
full_xs = np.linspace(min_x, max_x, num_sampled_points)
interpolated_ys = np.array(
[np.interp(full_xs, xs, ys) for (xs, ys) in zip(x_data, y_data)]
)
return full_xs, interpolated_ys
def find_and_standardize_data(
experiments_folder, runs_folders, x_key, y_key, num_sampled_points, drop_last
):
"""Finds and standardizes the data in `experiments_folder`.
Args:
experiments_folder (str): Root folder with all experiments data.
runs_folders (list[str]): List of folders under root folder to load data
from.
x_key (str): Key for x axis.
y_key (str): Key for y axis.
num_sampled_points (int): How many points to sample along x axis.
drop_last (bool): Whether to drop the last point in the data.
"""
if runs_folders is None:
runs_folders = os.listdir(experiments_folder)
data = find_all_experiments_data(experiments_folder, runs_folders)
aggregated_xs, aggregated_ys = list(
zip(
*[
standardize_data(
data[run_folder],
x_key,
y_key,
num_sampled_points=num_sampled_points,
drop_last=drop_last,
)
for run_folder in runs_folders
]
)
)
return runs_folders, aggregated_xs, aggregated_ys
def generate_lineplot(
x_datas,
y_datas,
smoothing_fn=None,
line_labels=None,
xlabel=None,
ylabel=None,
cmap_name=None,
output_file="output.png",
):
"""Aggregates data and generates lineplot."""
plt.figure()
if cmap_name is None:
cmap_name = "tab10" if len(x_datas) <= 10 else "tab20"
cmap = cm.get_cmap(cmap_name)
if line_labels is None:
line_labels = [None] * len(x_datas)
for idx, (x_data, y_data, line_label) in enumerate(
zip(x_datas, y_datas, line_labels)
):
mean_ys = np.mean(y_data, axis=0)
std_ys = np.std(y_data, axis=0)
if smoothing_fn is not None:
mean_ys = smoothing_fn(mean_ys)
std_ys = smoothing_fn(std_ys)
plt.plot(x_data, mean_ys, label=line_label, color=cmap(idx))
plt.fill_between(
x_data, mean_ys - std_ys, mean_ys + std_ys, color=cmap(idx), alpha=0.1
)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.legend()
plt.savefig(output_file)
plt.close()
def plot_results(
experiments_folder,
x_key,
y_key,
runs_folders=None,
drop_last=True,
run_names=None,
x_label=None,
y_label=None,
cmap_name=None,
smoothing_fn=None,
num_sampled_points=100,
output_file="output.png",
):
"""Plots results."""
runs_folders, aggregated_xs, aggregated_ys = find_and_standardize_data(
experiments_folder,
runs_folders,
x_key,
y_key,
num_sampled_points,
drop_last,
)
if run_names is None:
run_names = runs_folders
generate_lineplot(
aggregated_xs,
aggregated_ys,
smoothing_fn=smoothing_fn,
line_labels=run_names,
xlabel=x_label,
ylabel=y_label,
cmap_name=cmap_name,
output_file=output_file,
)
def create_exponential_smoothing_fn(smoothing=0.1):
def fn(values):
values = np.array(values)
return np.array(pd.DataFrame(values).ewm(alpha=1 - smoothing).mean()[0])
return fn
def create_moving_average_smoothing_fn(running_average=10):
def fn(values):
return np.convolve(values, np.ones(running_average), "valid") / running_average
return fn
def get_smoothing_fn(smoothing_fn, smoothing_fn_kwargs):
if smoothing_fn == "exponential":
return create_exponential_smoothing_fn(**smoothing_fn_kwargs)
elif smoothing_fn == "moving_average":
return create_moving_average_smoothing_fn(**smoothing_fn_kwargs)
else:
return None
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--experiments_folder", required=True)
parser.add_argument("--x_key", required=True)
parser.add_argument("--y_key", required=True)
parser.add_argument("--runs_folders", nargs="+")
parser.add_argument("--run_names", nargs="+")
parser.add_argument("--x_label")
parser.add_argument("--y_label")
parser.add_argument("--cmap_name")
parser.add_argument("--smoothing_fn", choices=["exponential", "moving_average"])
parser.add_argument("--smoothing_fn_kwargs")
parser.add_argument("--num_sampled_points", type=int, default=100)
parser.add_argument("--num_sampled_points", type=int, default=100)
parser.add_argument("--drop_last", action="store_true")
args = parser.parse_args()
if args.smoothing_fn is not None:
if args.smoothing_fn_kwargs is not None:
smoothing_fn_kwargs = json.loads(args.smoothing_fn_kwargs)
smoothing_fn = get_smoothing_fn(args.smoothing_fn, smoothing_fn_kwargs)
else:
smoothing_fn = None
plot_results(
experiments_folder=args.experiments_folder,
x_key=args.x_key,
y_key=args.y_key,
runs_folders=args.runs_folders,
drop_last=args.drop_last,
run_names=args.run_names,
x_label=args.x_label,
y_label=args.y_label,
cmap_name=args.cmap_name,
smoothing_fn=smoothing_fn,
num_sampled_points=args.num_sampled_points,
output_file=args.output_file,
) | /rlhive-1.0.1-py3-none-any.whl/hive/utils/visualization.py | 0.676834 | 0.479747 | visualization.py | pypi |
import os
import pickle
import random
import numpy as np
import torch
from hive.utils.registry import CallableType
PACKAGE_ROOT = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
def create_folder(folder):
"""Creates a folder.
Args:
folder (str): Folder to create.
"""
if not os.path.exists(folder):
os.makedirs(folder)
class Seeder:
"""Class used to manage seeding in RLHive. It sets the seed for all the frameworks
that RLHive currently uses. It also deterministically provides new seeds based on
the global seed, in case any other objects in RLHive (such as the agents) need
their own seed.
"""
def __init__(self):
self._seed = 0
self._current_seed = 0
def set_global_seed(self, seed):
"""This reduces some sources of randomness in experiments. To get reproducible
results, you must run on the same machine and set the environment variable
CUBLAS_WORKSPACE_CONFIG to ":4096:8" or ":16:8" before starting the experiment.
Args:
seed (int): Global seed.
"""
self._seed = seed
self._current_seed = seed
torch.manual_seed(self._seed)
random.seed(self._seed)
np.random.seed(self._seed)
torch.backends.cudnn.benchmark = False
torch.use_deterministic_algorithms(True)
def get_new_seed(self):
"""Each time it is called, it increments the current_seed and returns it."""
self._current_seed += 1
return self._current_seed
seeder = Seeder()
class Chomp(dict):
"""An extension of the dictionary class that allows for accessing through dot
notation and easy saving/loading.
"""
def __getattr__(self, k):
if k not in self:
raise AttributeError()
return self.__getitem__(k)
def __setattr__(self, k, v):
self.__setitem__(k, v)
def save(self, filename):
"""Saves the object using pickle.
Args:
filename (str): Filename to save object.
"""
pickle.dump(self, open(filename, "wb"))
def load(self, filename):
"""Loads the object.
Args:
filename (str): Where to load object from.
"""
self.clear()
self.update(pickle.load(open(filename, "rb")))
class OptimizerFn(CallableType):
"""A wrapper for callables that produce optimizer functions.
These wrapped callables can be partially initialized through configuration
files or command line arguments.
"""
@classmethod
def type_name(cls):
"""
Returns:
"optimizer_fn"
"""
return "optimizer_fn"
class LossFn(CallableType):
"""A wrapper for callables that produce loss functions.
These wrapped callables can be partially initialized through configuration
files or command line arguments.
"""
@classmethod
def type_name(cls):
"""
Returns:
"loss_fn"
"""
return "loss_fn" | /rlhive-1.0.1-py3-none-any.whl/hive/utils/utils.py | 0.754282 | 0.258025 | utils.py | pypi |
import numpy as np
import torch
from torch import optim
from hive.utils.registry import registry
from hive.utils.utils import LossFn, OptimizerFn
def numpify(t):
"""Convert object to a numpy array.
Args:
t (np.ndarray | torch.Tensor | obj): Converts object to :py:class:`np.ndarray`.
"""
if isinstance(t, np.ndarray):
return t
elif isinstance(t, torch.Tensor):
return t.detach().cpu().numpy()
else:
return np.array(t)
class RMSpropTF(optim.Optimizer):
"""
Direct cut-paste from rwhightman/pytorch-image-models.
https://github.com/rwightman/pytorch-image-models/blob/f7d210d759beb00a3d0834a3ce2d93f6e17f3d38/timm/optim/rmsprop_tf.py
Licensed under Apache 2.0, https://github.com/rwightman/pytorch-image-models/blob/master/LICENSE
Implements RMSprop algorithm (TensorFlow style epsilon)
NOTE: This is a direct cut-and-paste of PyTorch RMSprop with eps applied before sqrt
and a few other modifications to closer match Tensorflow for matching hyper-params.
Noteworthy changes include:
1. Epsilon applied inside square-root
2. square_avg initialized to ones
3. LR scaling of update accumulated in momentum buffer
Proposed by G. Hinton in his
`course <http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf>`_.
The centered version first appears in `Generating Sequences
With Recurrent Neural Networks <https://arxiv.org/pdf/1308.0850v5.pdf>`_.
Arguments:
params (iterable): iterable of parameters to optimize or dicts defining
parameter groups
lr (float, optional): learning rate (default: 1e-2)
momentum (float, optional): momentum factor (default: 0)
alpha (float, optional): smoothing (decay) constant (default: 0.9)
eps (float, optional): term added to the denominator to improve
numerical stability (default: 1e-10)
centered (bool, optional) : if ``True``, compute the centered RMSProp,
the gradient is normalized by an estimation of its variance
weight_decay (float, optional): weight decay (L2 penalty) (default: 0)
decoupled_decay (bool, optional): decoupled weight decay as per https://arxiv.org/abs/1711.05101
lr_in_momentum (bool, optional): learning rate scaling is included in the momentum buffer
update as per defaults in Tensorflow
"""
def __init__(
self,
params,
lr=1e-2,
alpha=0.9,
eps=1e-10,
weight_decay=0,
momentum=0.0,
centered=False,
decoupled_decay=False,
lr_in_momentum=True,
):
if not 0.0 <= lr:
raise ValueError("Invalid learning rate: {}".format(lr))
if not 0.0 <= eps:
raise ValueError("Invalid epsilon value: {}".format(eps))
if not 0.0 <= momentum:
raise ValueError("Invalid momentum value: {}".format(momentum))
if not 0.0 <= weight_decay:
raise ValueError("Invalid weight_decay value: {}".format(weight_decay))
if not 0.0 <= alpha:
raise ValueError("Invalid alpha value: {}".format(alpha))
defaults = dict(
lr=lr,
momentum=momentum,
alpha=alpha,
eps=eps,
centered=centered,
weight_decay=weight_decay,
decoupled_decay=decoupled_decay,
lr_in_momentum=lr_in_momentum,
)
super(RMSpropTF, self).__init__(params, defaults)
def __setstate__(self, state):
super(RMSpropTF, self).__setstate__(state)
for group in self.param_groups:
group.setdefault("momentum", 0)
group.setdefault("centered", False)
@torch.no_grad()
def step(self, closure=None):
"""Performs a single optimization step.
Arguments:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
for p in group["params"]:
if p.grad is None:
continue
grad = p.grad
if grad.is_sparse:
raise RuntimeError("RMSprop does not support sparse gradients")
state = self.state[p]
# State initialization
if len(state) == 0:
state["step"] = 0
state["square_avg"] = torch.ones_like(p) # PyTorch inits to zero
if group["momentum"] > 0:
state["momentum_buffer"] = torch.zeros_like(p)
if group["centered"]:
state["grad_avg"] = torch.zeros_like(p)
square_avg = state["square_avg"]
one_minus_alpha = 1.0 - group["alpha"]
state["step"] += 1
if group["weight_decay"] != 0:
if group["decoupled_decay"]:
p.mul_(1.0 - group["lr"] * group["weight_decay"])
else:
grad = grad.add(p, alpha=group["weight_decay"])
# Tensorflow order of ops for updating squared avg
square_avg.add_(grad.pow(2) - square_avg, alpha=one_minus_alpha)
# square_avg.mul_(alpha).addcmul_(grad, grad, value=1 - alpha) # PyTorch original
if group["centered"]:
grad_avg = state["grad_avg"]
grad_avg.add_(grad - grad_avg, alpha=one_minus_alpha)
avg = (
square_avg.addcmul(grad_avg, grad_avg, value=-1)
.add(group["eps"])
.sqrt_()
) # eps in sqrt
# grad_avg.mul_(alpha).add_(grad, alpha=1 - alpha) # PyTorch original
else:
avg = square_avg.add(group["eps"]).sqrt_() # eps moved in sqrt
if group["momentum"] > 0:
buf = state["momentum_buffer"]
# Tensorflow accumulates the LR scaling in the momentum buffer
if group["lr_in_momentum"]:
buf.mul_(group["momentum"]).addcdiv_(
grad, avg, value=group["lr"]
)
p.add_(-buf)
else:
# PyTorch scales the param update by LR
buf.mul_(group["momentum"]).addcdiv_(grad, avg)
p.add_(buf, alpha=-group["lr"])
else:
p.addcdiv_(grad, avg, value=-group["lr"])
return loss
registry.register_all(
OptimizerFn,
{
"Adadelta": OptimizerFn(optim.Adadelta),
"Adagrad": OptimizerFn(optim.Adagrad),
"Adam": OptimizerFn(optim.Adam),
"Adamax": OptimizerFn(optim.Adamax),
"AdamW": OptimizerFn(optim.AdamW),
"ASGD": OptimizerFn(optim.ASGD),
"LBFGS": OptimizerFn(optim.LBFGS),
"RMSprop": OptimizerFn(optim.RMSprop),
"RMSpropTF": OptimizerFn(RMSpropTF),
"Rprop": OptimizerFn(optim.Rprop),
"SGD": OptimizerFn(optim.SGD),
"SparseAdam": OptimizerFn(optim.SparseAdam),
},
)
registry.register_all(
LossFn,
{
"BCELoss": LossFn(torch.nn.BCELoss),
"BCEWithLogitsLoss": LossFn(torch.nn.BCEWithLogitsLoss),
"CosineEmbeddingLoss": LossFn(torch.nn.CosineEmbeddingLoss),
"CrossEntropyLoss": LossFn(torch.nn.CrossEntropyLoss),
"CTCLoss": LossFn(torch.nn.CTCLoss),
"HingeEmbeddingLoss": LossFn(torch.nn.HingeEmbeddingLoss),
"KLDivLoss": LossFn(torch.nn.KLDivLoss),
"L1Loss": LossFn(torch.nn.L1Loss),
"MarginRankingLoss": LossFn(torch.nn.MarginRankingLoss),
"MSELoss": LossFn(torch.nn.MSELoss),
"MultiLabelMarginLoss": LossFn(torch.nn.MultiLabelMarginLoss),
"MultiLabelSoftMarginLoss": LossFn(torch.nn.MultiLabelSoftMarginLoss),
"MultiMarginLoss": LossFn(torch.nn.MultiMarginLoss),
"NLLLoss": LossFn(torch.nn.NLLLoss),
"NLLLoss2d": LossFn(torch.nn.NLLLoss2d),
"PoissonNLLLoss": LossFn(torch.nn.PoissonNLLLoss),
"SmoothL1Loss": LossFn(torch.nn.SmoothL1Loss),
"SoftMarginLoss": LossFn(torch.nn.SoftMarginLoss),
"TripletMarginLoss": LossFn(torch.nn.TripletMarginLoss),
},
)
get_optimizer_fn = getattr(registry, f"get_{OptimizerFn.type_name()}")
get_loss_fn = getattr(registry, f"get_{LossFn.type_name()}") | /rlhive-1.0.1-py3-none-any.whl/hive/utils/torch_utils.py | 0.939796 | 0.598635 | torch_utils.py | pypi |
import os
from typing import Dict, Tuple
import numpy as np
from hive.replays.circular_replay import CircularReplayBuffer
from hive.utils.torch_utils import numpify
class PrioritizedReplayBuffer(CircularReplayBuffer):
"""Implements a replay with prioritized sampling. See
https://arxiv.org/abs/1511.05952
"""
def __init__(
self,
capacity: int,
beta: float = 0.5,
stack_size: int = 1,
n_step: int = 1,
gamma: float = 0.9,
observation_shape: Tuple = (),
observation_dtype: type = np.uint8,
action_shape: Tuple = (),
action_dtype: type = np.int8,
reward_shape: Tuple = (),
reward_dtype: type = np.float32,
extra_storage_types: Dict = None,
num_players_sharing_buffer=None,
):
"""
Args:
capacity (int): Total number of observations that can be stored in the
buffer. Note, this is not the same as the number of transitions that
can be stored in the buffer.
beta (float): Parameter controlling level of prioritization.
stack_size (int): The number of frames to stack to create an observation.
n_step (int): Horizon used to compute n-step return reward
gamma (float): Discounting factor used to compute n-step return reward
observation_shape: Shape of observations that will be stored in the buffer.
observation_dtype: Type of observations that will be stored in the buffer.
This can either be the type itself or string representation of the
type. The type can be either a native python type or a numpy type. If
a numpy type, a string of the form np.uint8 or numpy.uint8 is
acceptable.
action_shape: Shape of actions that will be stored in the buffer.
action_dtype: Type of actions that will be stored in the buffer. Format is
described in the description of observation_dtype.
action_shape: Shape of actions that will be stored in the buffer.
action_dtype: Type of actions that will be stored in the buffer. Format is
described in the description of observation_dtype.
reward_shape: Shape of rewards that will be stored in the buffer.
reward_dtype: Type of rewards that will be stored in the buffer. Format is
described in the description of observation_dtype.
extra_storage_types (dict): A dictionary describing extra items to store
in the buffer. The mapping should be from the name of the item to a
(type, shape) tuple.
num_players_sharing_buffer (int): Number of agents that share their
buffers. It is used for self-play.
"""
super().__init__(
capacity=capacity,
stack_size=stack_size,
n_step=n_step,
gamma=gamma,
observation_shape=observation_shape,
observation_dtype=observation_dtype,
action_shape=action_shape,
action_dtype=action_dtype,
reward_shape=reward_shape,
reward_dtype=reward_dtype,
extra_storage_types=extra_storage_types,
num_players_sharing_buffer=num_players_sharing_buffer,
)
self._sum_tree = SumTree(self._capacity)
self._beta = beta
def set_beta(self, beta):
self._beta = beta
def _add_transition(self, priority=None, **transition):
if priority is None:
priority = self._sum_tree.max_recorded_priority
self._sum_tree.set_priority(self._cursor, priority)
super()._add_transition(**transition)
def _pad_buffer(self, pad_length):
for _ in range(pad_length):
transition = {
key: np.zeros_like(self._storage[key][0]) for key in self._storage
}
transition["priority"] = 0
self._add_transition(**transition)
def _sample_indices(self, batch_size):
indices = self._sum_tree.stratified_sample(batch_size)
indices = self._filter_transitions(indices)
while len(indices) < batch_size:
new_indices = self._sum_tree.sample(batch_size - len(indices))
new_indices = self._filter_transitions(new_indices)
indices = np.concatenate([indices, new_indices])
return indices
def _filter_transitions(self, indices):
indices = super()._filter_transitions(indices - (self._stack_size - 1)) + (
self._stack_size - 1
)
if self._num_added < self._capacity:
indices = indices[indices < self._cursor - self._n_step]
indices = indices[indices >= self._stack_size - 1]
else:
low = (self._cursor - self._n_step) % self._capacity
high = (self._cursor + self._stack_size - 1) % self._capacity
if low < high:
indices = indices[np.logical_or(indices < low, indices > high)]
else:
indices = indices[~np.logical_or(indices >= low, indices <= high)]
return indices
def sample(self, batch_size):
batch = super().sample(batch_size)
indices = batch["indices"]
priorities = self._sum_tree.get_priorities(indices)
weights = (1.0 / (priorities + 1e-10)) ** self._beta
weights /= np.max(weights)
batch["weights"] = weights
return batch
def update_priorities(self, indices, priorities):
"""Update the priorities of the transitions at the specified indices.
Args:
indices: Which transitions to update priorities for. Can be numpy array
or torch tensor.
priorities: What the priorities should be updated to. Can be numpy array
or torch tensor.
"""
indices = numpify(indices)
priorities = numpify(priorities)
indices, unique_idxs = np.unique(indices, return_index=True)
priorities = priorities[unique_idxs]
self._sum_tree.set_priority(indices, priorities)
def save(self, dname):
super().save(dname)
self._sum_tree.save(dname)
def load(self, dname):
super().load(dname)
self._sum_tree.load(dname)
class SumTree:
"""Data structure used to implement prioritized sampling. It is implemented
as a tree where the value of each node is the sum of the values of the subtree
of the node.
"""
def __init__(self, capacity: int):
self._capacity = capacity
self._depth = int(np.ceil(np.log2(capacity))) + 1
self._tree = np.zeros(2 ** self._depth - 1)
self._last_level_start = 2 ** (self._depth - 1) - 1
self._priorities = self._tree[
self._last_level_start : self._last_level_start + self._capacity
]
self.max_recorded_priority = 1.0
def set_priority(self, indices, priorities):
"""Sets the priorities for the given indices.
Args:
indices (np.ndarray): Which transitions to update priorities for.
priorities (np.ndarray): What the priorities should be updated to.
"""
self.max_recorded_priority = max(self.max_recorded_priority, np.max(priorities))
indices = self._last_level_start + indices
diffs = priorities - self._tree[indices]
for _ in range(self._depth):
np.add.at(self._tree, indices, diffs)
indices = (indices - 1) // 2
def sample(self, batch_size):
"""Sample elements from the sum tree with probability proportional to their
priority.
Args:
batch_size (int): The number of elements to sample.
"""
indices = self.extract(np.random.rand(batch_size))
return indices
def stratified_sample(self, batch_size):
"""Performs stratified sampling using the sum tree.
Args:
batch_size (int): The number of elements to sample.
"""
query_values = (np.arange(batch_size) + np.random.rand(batch_size)) / batch_size
indices = self.extract(query_values)
return indices
def extract(self, queries):
"""Get the elements in the sum tree that correspond to the query.
For each query, the element that is selected is the one with the greatest
sum of "previous" elements in the tree, but also such that the sum is not
a greater proportion of the total sum of priorities than the query.
Args:
queries (np.ndarray): Queries to extract. Each element should be
between 0 and 1.
"""
queries *= self._tree[0]
indices = np.zeros(queries.shape[0], dtype=np.int64)
for i in range(self._depth - 1):
indices = indices * 2 + 1
left_child_values = self._tree[indices]
branch_right = (queries > left_child_values).nonzero()
indices[branch_right] += 1
queries[branch_right] -= left_child_values[branch_right]
return indices - self._last_level_start
def get_priorities(self, indices):
"""Get the priorities of the elements at indicies.
Args:
indices (np.ndarray): The indices to query.
"""
return self._priorities[indices]
def save(self, dname):
np.save(os.path.join(dname, "sumtree.npy"), self._tree)
def load(self, dname):
self._tree = np.load(os.path.join(dname, "sumtree.npy"))
self._priorities = self._tree[
self._last_level_start : self._last_level_start + self._capacity
] | /rlhive-1.0.1-py3-none-any.whl/hive/replays/prioritized_replay.py | 0.910394 | 0.588121 | prioritized_replay.py | pypi |
import os
import pickle
import numpy as np
from hive.replays.replay_buffer import BaseReplayBuffer
from hive.utils.utils import create_folder, seeder
class CircularReplayBuffer(BaseReplayBuffer):
"""An efficient version of a circular replay buffer that only stores each observation
once.
"""
def __init__(
self,
capacity: int = 10000,
stack_size: int = 1,
n_step: int = 1,
gamma: float = 0.99,
observation_shape=(),
observation_dtype=np.uint8,
action_shape=(),
action_dtype=np.int8,
reward_shape=(),
reward_dtype=np.float32,
extra_storage_types=None,
num_players_sharing_buffer: int = None,
):
"""Constructor for CircularReplayBuffer.
Args:
capacity (int): Total number of observations that can be stored in the
buffer. Note, this is not the same as the number of transitions that
can be stored in the buffer.
stack_size (int): The number of frames to stack to create an observation.
n_step (int): Horizon used to compute n-step return reward
gamma (float): Discounting factor used to compute n-step return reward
observation_shape: Shape of observations that will be stored in the buffer.
observation_dtype: Type of observations that will be stored in the buffer.
This can either be the type itself or string representation of the
type. The type can be either a native python type or a numpy type. If
a numpy type, a string of the form np.uint8 or numpy.uint8 is
acceptable.
action_shape: Shape of actions that will be stored in the buffer.
action_dtype: Type of actions that will be stored in the buffer. Format is
described in the description of observation_dtype.
action_shape: Shape of actions that will be stored in the buffer.
action_dtype: Type of actions that will be stored in the buffer. Format is
described in the description of observation_dtype.
reward_shape: Shape of rewards that will be stored in the buffer.
reward_dtype: Type of rewards that will be stored in the buffer. Format is
described in the description of observation_dtype.
extra_storage_types (dict): A dictionary describing extra items to store
in the buffer. The mapping should be from the name of the item to a
(type, shape) tuple.
num_players_sharing_buffer (int): Number of agents that share their
buffers. It is used for self-play.
"""
self._capacity = capacity
self._specs = {
"observation": (observation_dtype, observation_shape),
"done": (np.uint8, ()),
"action": (action_dtype, action_shape),
"reward": (reward_dtype, reward_shape),
}
if extra_storage_types is not None:
self._specs.update(extra_storage_types)
self._storage = self._create_storage(capacity, self._specs)
self._stack_size = stack_size
self._n_step = n_step
self._gamma = gamma
self._discount = np.asarray(
[self._gamma ** i for i in range(self._n_step)],
dtype=self._specs["reward"][0],
)
self._episode_start = True
self._cursor = 0
self._num_added = 0
self._rng = np.random.default_rng(seed=seeder.get_new_seed())
self._num_players_sharing_buffer = num_players_sharing_buffer
if num_players_sharing_buffer is not None:
self._episode_storage = [[] for _ in range(num_players_sharing_buffer)]
def size(self):
"""Returns the number of transitions stored in the buffer."""
return max(
min(self._num_added, self._capacity) - self._stack_size - self._n_step + 1,
0,
)
def _create_storage(self, capacity, specs):
"""Creates the storage buffer for each type of item in the buffer.
Args:
capacity: The capacity of the buffer.
specs: A dictionary mapping item name to a tuple (type, shape) describing
the items to be stored in the buffer.
"""
storage = {}
for key in specs:
dtype, shape = specs[key]
dtype = str_to_dtype(dtype)
specs[key] = dtype, shape
shape = (capacity,) + tuple(shape)
storage[key] = np.zeros(shape, dtype=dtype)
return storage
def _add_transition(self, **transition):
"""Internal method to add a transition to the buffer."""
for key in transition:
if key in self._storage:
self._storage[key][self._cursor] = transition[key]
self._num_added += 1
self._cursor = (self._cursor + 1) % self._capacity
def _pad_buffer(self, pad_length):
"""Adds padding to the buffer. Used when stack_size > 1, and padding needs to
be added to the beginning of the episode.
"""
for _ in range(pad_length):
transition = {
key: np.zeros_like(self._storage[key][0]) for key in self._storage
}
self._add_transition(**transition)
def add(self, observation, action, reward, done, **kwargs):
"""Adds a transition to the buffer.
The required components of a transition are given as positional arguments. The
user can pass additional components to store in the buffer as kwargs as long as
they were defined in the specification in the constructor.
"""
if self._episode_start:
self._pad_buffer(self._stack_size - 1)
self._episode_start = False
transition = {
"observation": observation,
"action": action,
"reward": reward,
"done": done,
}
transition.update(kwargs)
for key in self._specs:
obj_type = (
transition[key].dtype
if hasattr(transition[key], "dtype")
else type(transition[key])
)
if not np.can_cast(obj_type, self._specs[key][0], casting="same_kind"):
raise ValueError(
f"Key {key} has wrong dtype. Expected {self._specs[key][0]},"
f"received {type(transition[key])}."
)
if self._num_players_sharing_buffer is None:
self._add_transition(**transition)
else:
self._episode_storage[kwargs["agent_id"]].append(transition)
if done:
for transition in self._episode_storage[kwargs["agent_id"]]:
self._add_transition(**transition)
self._episode_storage[kwargs["agent_id"]] = []
if done:
self._episode_start = True
def _get_from_array(self, array, indices, num_to_access=1):
"""Retrieves consecutive elements in the array, wrapping around if necessary.
If more than 1 element is being accessed, the elements are concatenated along
the first dimension.
Args:
array: array to access from
indices: starts of ranges to access from
num_to_access: how many consecutive elements to access
"""
full_indices = np.indices((indices.shape[0], num_to_access))[1]
full_indices = (full_indices + np.expand_dims(indices, axis=1)) % (
self.size() + self._stack_size + self._n_step - 1
)
elements = array[full_indices]
elements = elements.reshape(indices.shape[0], -1, *elements.shape[3:])
return elements
def _get_from_storage(self, key, indices, num_to_access=1):
"""Gets values from storage.
Args:
key: The name of the component to retrieve.
indices: This can be a single int or a 1D numpyp array. The indices are
adjusted to fall within the current bounds of the buffer.
num_to_access: how many consecutive elements to access
"""
if not isinstance(indices, np.ndarray):
indices = np.array([indices])
if num_to_access == 0:
return np.array([])
elif num_to_access == 1:
return self._storage[key][
indices % (self.size() + self._stack_size + self._n_step - 1)
]
else:
return self._get_from_array(
self._storage[key], indices, num_to_access=num_to_access
)
def _sample_indices(self, batch_size):
"""Samples valid indices that can be used by the replay."""
indices = np.array([], dtype=np.int32)
while len(indices) < batch_size:
start_index = (
self._rng.integers(self.size(), size=batch_size - len(indices))
+ self._cursor
)
start_index = self._filter_transitions(start_index)
indices = np.concatenate([indices, start_index])
return indices + self._stack_size - 1
def _filter_transitions(self, indices):
"""Filters invalid indices."""
if self._stack_size == 1:
return indices
done = self._get_from_storage("done", indices, self._stack_size - 1)
done = done.astype(bool)
if self._stack_size == 2:
indices = indices[~done]
else:
indices = indices[~done.any(axis=1)]
return indices
def sample(self, batch_size):
"""Sample transitions from the buffer. For a given transition, if it's
done is True, the next_observation value should not be taken to have any
meaning.
Args:
batch_size (int): Number of transitions to sample.
"""
if self._num_added < self._stack_size + self._n_step:
raise ValueError("Not enough transitions added to the buffer to sample")
indices = self._sample_indices(batch_size)
batch = {}
batch["indices"] = indices
terminals = self._get_from_storage("done", indices, self._n_step)
if self._n_step == 1:
is_terminal = terminals
trajectory_lengths = np.ones(batch_size)
else:
is_terminal = terminals.any(axis=1).astype(int)
trajectory_lengths = (
np.argmax(terminals.astype(bool), axis=1) + 1
) * is_terminal + self._n_step * (1 - is_terminal)
trajectory_lengths = trajectory_lengths.astype(np.int64)
for key in self._specs:
if key == "observation":
batch[key] = self._get_from_storage(
"observation",
indices - self._stack_size + 1,
num_to_access=self._stack_size,
)
elif key == "done":
batch["done"] = is_terminal
elif key == "reward":
rewards = self._get_from_storage("reward", indices, self._n_step)
if self._n_step == 1:
rewards = np.expand_dims(rewards, 1)
rewards = rewards * np.expand_dims(self._discount, axis=0)
# Mask out rewards past trajectory length
mask = np.expand_dims(trajectory_lengths, 1) > np.arange(self._n_step)
rewards = np.sum(rewards * mask, axis=1)
batch["reward"] = rewards
else:
batch[key] = self._get_from_storage(key, indices)
batch["trajectory_lengths"] = trajectory_lengths
batch["next_observation"] = self._get_from_storage(
"observation",
indices + trajectory_lengths - self._stack_size + 1,
num_to_access=self._stack_size,
)
return batch
def save(self, dname):
"""Save the replay buffer.
Args:
dname (str): directory where to save buffer. Should already have been
created.
"""
storage_path = os.path.join(dname, "storage")
create_folder(storage_path)
for key in self._specs:
np.save(
os.path.join(storage_path, f"{key}"),
self._storage[key],
allow_pickle=False,
)
state = {
"episode_start": self._episode_start,
"cursor": self._cursor,
"num_added": self._num_added,
"rng": self._rng,
}
with open(os.path.join(dname, "replay.pkl"), "wb") as f:
pickle.dump(state, f)
def load(self, dname):
"""Load the replay buffer.
Args:
dname (str): directory where to load buffer from.
"""
storage_path = os.path.join(dname, "storage")
for key in self._specs:
self._storage[key] = np.load(
os.path.join(storage_path, f"{key}.npy"), allow_pickle=False
)
with open(os.path.join(dname, "replay.pkl"), "rb") as f:
state = pickle.load(f)
self._episode_start = state["episode_start"]
self._cursor = state["cursor"]
self._num_added = state["num_added"]
self._rng = state["rng"]
class SimpleReplayBuffer(BaseReplayBuffer):
"""A simple circular replay buffers.
Args:
capacity (int): repaly buffer capacity
compress (bool): if False, convert data to float32 otherwise keep it as
int8.
seed (int): Seed for a pseudo-random number generator.
"""
def __init__(self, capacity=1e5, compress=False, seed=42, **kwargs):
self._numpy_rng = np.random.default_rng(seed)
self._capacity = int(capacity)
self._compress = compress
self._dtype = {
"observation": "int8" if self._compress else "float32",
"action": "int8",
"reward": "int8" if self._compress else "float32",
"next_observation": "int8" if self._compress else "float32",
"done": "int8" if self._compress else "float32",
}
self._data = {}
for data_key in self._dtype:
self._data[data_key] = [None] * int(capacity)
self._write_index = -1
self._n = 0
self._previous_transition = None
def add(self, observation, action, reward, done, **kwargs):
"""
Adds transition to the buffer
Args:
observation: The current observation
action: The action taken on the current observation
reward: The reward from taking action at current observation
done: If current observation was the last observation in the episode
"""
if self._previous_transition is not None:
self._previous_transition["next_observation"] = observation
self._write_index = (self._write_index + 1) % self._capacity
self._n = int(min(self._capacity, self._n + 1))
for key in self._data:
self._data[key][self._write_index] = np.asarray(
self._previous_transition[key], dtype=self._dtype[key]
)
self._previous_transition = {
"observation": observation,
"action": action,
"reward": reward,
"done": done,
}
def sample(self, batch_size=32):
"""
sample a minibatch
Args:
batch_size (int): The number of examples to sample.
"""
if self.size() == 0:
raise ValueError("Buffer does not have any transitions yet." % batch_size)
indices = self._numpy_rng.integers(self._n, size=batch_size)
rval = {}
for key in self._data:
rval[key] = np.asarray(
[self._data[key][idx] for idx in indices], dtype="float32"
)
return rval
def size(self):
"""
returns the number of transitions stored in the replay buffer
"""
return self._n
def save(self, dname):
"""
Saves buffer checkpointing information to file for future loading.
Args:
dname (str): directory name where agent should save all relevant info.
"""
create_folder(dname)
sdict = {}
sdict["capacity"] = self._capacity
sdict["write_index"] = self._write_index
sdict["n"] = self._n
sdict["data"] = self._data
full_name = os.path.join(dname, "meta.ckpt")
with open(full_name, "wb") as f:
pickle.dump(sdict, f)
def load(self, dname):
"""
Loads buffer from file.
Args:
dname (str): directory name where buffer checkpoint info is stored.
Returns:
True if successfully loaded the buffer. False otherwise.
"""
full_name = os.path.join(dname, "meta.ckpt")
with open(full_name, "rb") as f:
sdict = pickle.load(f)
self._capacity = sdict["capacity"]
self._write_index = sdict["write_index"]
self._n = sdict["n"]
self._data = sdict["data"]
def str_to_dtype(dtype):
if isinstance(dtype, type):
return dtype
elif dtype.startswith("np.") or dtype.startswith("numpy."):
return np.typeDict[dtype.split(".")[1]]
else:
type_dict = {
"int": int,
"float": float,
"str": str,
"bool": bool,
}
return type_dict[dtype] | /rlhive-1.0.1-py3-none-any.whl/hive/replays/circular_replay.py | 0.867556 | 0.480783 | circular_replay.py | pypi |
import copy
from functools import partial
from typing import Tuple
import numpy as np
import torch
from hive.agents.dqn import DQNAgent
from hive.agents.qnets.base import FunctionApproximator
from hive.agents.qnets.noisy_linear import NoisyLinear
from hive.agents.qnets.qnet_heads import (
DistributionalNetwork,
DQNNetwork,
DuelingNetwork,
)
from hive.agents.qnets.utils import InitializationFn, calculate_output_dim
from hive.replays import PrioritizedReplayBuffer
from hive.replays.replay_buffer import BaseReplayBuffer
from hive.utils.loggers import Logger
from hive.utils.schedule import Schedule
from hive.utils.utils import LossFn, OptimizerFn, seeder
class RainbowDQNAgent(DQNAgent):
"""An agent implementing the Rainbow algorithm."""
def __init__(
self,
representation_net: FunctionApproximator,
obs_dim: Tuple,
act_dim: int,
optimizer_fn: OptimizerFn = None,
loss_fn: LossFn = None,
init_fn: InitializationFn = None,
id=0,
replay_buffer: BaseReplayBuffer = None,
discount_rate: float = 0.99,
n_step: int = 1,
grad_clip: float = None,
reward_clip: float = None,
update_period_schedule: Schedule = None,
target_net_soft_update: bool = False,
target_net_update_fraction: float = 0.05,
target_net_update_schedule: Schedule = None,
epsilon_schedule: Schedule = None,
test_epsilon: float = 0.001,
min_replay_history: int = 5000,
batch_size: int = 32,
device="cpu",
logger: Logger = None,
log_frequency: int = 100,
noisy: bool = True,
std_init: float = 0.5,
use_eps_greedy: bool = False,
double: bool = True,
dueling: bool = True,
distributional: bool = True,
v_min: float = 0,
v_max: float = 200,
atoms: int = 51,
):
"""
Args:
representation_net (FunctionApproximator): A network that outputs the
representations that will be used to compute Q-values (e.g.
everything except the final layer of the DQN).
obs_dim: The shape of the observations.
act_dim (int): The number of actions available to the agent.
id: Agent identifier.
optimizer_fn (OptimizerFn): A function that takes in a list of parameters
to optimize and returns the optimizer. If None, defaults to
:py:class:`~torch.optim.Adam`.
loss_fn (LossFn): Loss function used by the agent. If None, defaults to
:py:class:`~torch.nn.SmoothL1Loss`.
init_fn (InitializationFn): Initializes the weights of qnet using
create_init_weights_fn.
replay_buffer (BaseReplayBuffer): The replay buffer that the agent will
push observations to and sample from during learning. If None,
defaults to
:py:class:`~hive.replays.prioritized_replay.PrioritizedReplayBuffer`.
discount_rate (float): A number between 0 and 1 specifying how much
future rewards are discounted by the agent.
n_step (int): The horizon used in n-step returns to compute TD(n) targets.
grad_clip (float): Gradients will be clipped to between
[-grad_clip, grad_clip].
reward_clip (float): Rewards will be clipped to between
[-reward_clip, reward_clip].
update_period_schedule (Schedule): Schedule determining how frequently
the agent's Q-network is updated.
target_net_soft_update (bool): Whether the target net parameters are
replaced by the qnet parameters completely or using a weighted
average of the target net parameters and the qnet parameters.
target_net_update_fraction (float): The weight given to the target
net parameters in a soft update.
target_net_update_schedule (Schedule): Schedule determining how frequently
the target net is updated.
epsilon_schedule (Schedule): Schedule determining the value of epsilon
through the course of training.
test_epsilon (float): epsilon (probability of choosing a random action)
to be used during testing phase.
min_replay_history (int): How many observations to fill the replay buffer
with before starting to learn.
batch_size (int): The size of the batch sampled from the replay buffer
during learning.
device: Device on which all computations should be run.
logger (ScheduledLogger): Logger used to log agent's metrics.
log_frequency (int): How often to log the agent's metrics.
noisy (bool): Whether to use noisy linear layers for exploration.
std_init (float): The range for the initialization of the standard
deviation of the weights.
use_eps_greedy (bool): Whether to use epsilon greedy exploration.
double (bool): Whether to use double DQN.
dueling (bool): Whether to use a dueling network architecture.
distributional (bool): Whether to use the distributional RL.
vmin (float): The minimum of the support of the categorical value
distribution for distributional RL.
vmax (float): The maximum of the support of the categorical value
distribution for distributional RL.
atoms (int): Number of atoms discretizing the support range of the
categorical value distribution for distributional RL.
"""
self._noisy = noisy
self._std_init = std_init
self._double = double
self._dueling = dueling
self._distributional = distributional
self._atoms = atoms if self._distributional else 1
self._v_min = v_min
self._v_max = v_max
if loss_fn is None:
loss_fn = torch.nn.MSELoss
if replay_buffer is None:
replay_buffer = PrioritizedReplayBuffer(seed=seeder.get_new_seed())
super().__init__(
representation_net,
obs_dim,
act_dim,
optimizer_fn=optimizer_fn,
init_fn=init_fn,
loss_fn=loss_fn,
id=id,
replay_buffer=replay_buffer,
discount_rate=discount_rate,
n_step=n_step,
grad_clip=grad_clip,
reward_clip=reward_clip,
target_net_soft_update=target_net_soft_update,
target_net_update_fraction=target_net_update_fraction,
target_net_update_schedule=target_net_update_schedule,
update_period_schedule=update_period_schedule,
epsilon_schedule=epsilon_schedule,
test_epsilon=test_epsilon,
min_replay_history=min_replay_history,
batch_size=batch_size,
device=device,
logger=logger,
log_frequency=log_frequency,
)
self._supports = torch.linspace(
self._v_min, self._v_max, self._atoms, device=self._device
)
self._use_eps_greedy = use_eps_greedy
def create_q_networks(self, representation_net):
"""Creates the Q-network and target Q-network. Adds the appropriate heads
for DQN, Dueling DQN, Noisy Networks, and Distributional DQN.
Args:
representation_net: A network that outputs the representations that will
be used to compute Q-values (e.g. everything except the final layer
of the DQN).
"""
network = representation_net(self._obs_dim)
network_output_dim = np.prod(calculate_output_dim(network, self._obs_dim))
# Use NoisyLinear when creating output heads if noisy is true
linear_fn = (
partial(NoisyLinear, std_init=self._std_init)
if self._noisy
else torch.nn.Linear
)
# Set up Dueling heads
if self._dueling:
network = DuelingNetwork(
network, network_output_dim, self._act_dim, linear_fn, self._atoms
)
else:
network = DQNNetwork(
network, network_output_dim, self._act_dim * self._atoms, linear_fn
)
# Set up DistributionalNetwork wrapper if distributional is true
if self._distributional:
self._qnet = DistributionalNetwork(
network, self._act_dim, self._v_min, self._v_max, self._atoms
)
else:
self._qnet = network
self._qnet.to(device=self._device)
self._qnet.apply(self._init_fn)
self._target_qnet = copy.deepcopy(self._qnet).requires_grad_(False)
@torch.no_grad()
def act(self, observation):
if self._training:
if not self._learn_schedule.get_value():
epsilon = 1.0
elif not self._use_eps_greedy:
epsilon = 0.0
else:
epsilon = self._epsilon_schedule.update()
if self._logger.update_step(self._timescale):
self._logger.log_scalar("epsilon", epsilon, self._timescale)
else:
epsilon = self._test_epsilon
observation = torch.tensor(
np.expand_dims(observation, axis=0), device=self._device
).float()
qvals = self._qnet(observation)
if self._rng.random() < epsilon:
action = self._rng.integers(self._act_dim)
else:
action = torch.argmax(qvals).item()
if (
self._training
and self._logger.should_log(self._timescale)
and self._state["episode_start"]
):
self._logger.log_scalar("train_qval", torch.max(qvals), self._timescale)
self._state["episode_start"] = False
return action
def update(self, update_info):
"""
Updates the DQN agent.
Args:
update_info: dictionary containing all the necessary information to
update the agent. Should contain a full transition, with keys for
"observation", "action", "reward", "next_observation", and "done".
"""
if update_info["done"]:
self._state["episode_start"] = True
if not self._training:
return
# Add the most recent transition to the replay buffer.
self._replay_buffer.add(**self.preprocess_update_info(update_info))
# Update the q network based on a sample batch from the replay buffer.
# If the replay buffer doesn't have enough samples, catch the exception
# and move on.
if (
self._learn_schedule.update()
and self._replay_buffer.size() > 0
and self._update_period_schedule.update()
):
batch = self._replay_buffer.sample(batch_size=self._batch_size)
(
current_state_inputs,
next_state_inputs,
batch,
) = self.preprocess_update_batch(batch)
# Compute predicted Q values
self._optimizer.zero_grad()
pred_qvals = self._qnet(*current_state_inputs)
actions = batch["action"].long()
if self._double:
next_action = self._qnet(*next_state_inputs)
else:
next_action = self._target_qnet(*next_state_inputs)
next_action = next_action.argmax(1)
if self._distributional:
current_dist = self._qnet.dist(*current_state_inputs)
probs = current_dist[torch.arange(actions.size(0)), actions]
probs = torch.clamp(probs, 1e-6, 1) # NaN-guard
log_p = torch.log(probs)
with torch.no_grad():
target_prob = self.target_projection(
next_state_inputs, next_action, batch["reward"], batch["done"]
)
loss = -(target_prob * log_p).sum(-1)
else:
pred_qvals = pred_qvals[torch.arange(pred_qvals.size(0)), actions]
next_qvals = self._target_qnet(*next_state_inputs)
next_qvals = next_qvals[torch.arange(next_qvals.size(0)), next_action]
q_targets = batch["reward"] + self._discount_rate * next_qvals * (
1 - batch["done"]
)
loss = self._loss_fn(pred_qvals, q_targets)
if isinstance(self._replay_buffer, PrioritizedReplayBuffer):
td_errors = loss.sqrt().detach().cpu().numpy()
self._replay_buffer.update_priorities(batch["indices"], td_errors)
loss *= batch["weights"]
loss = loss.mean()
if self._logger.should_log(self._timescale):
self._logger.log_scalar(
"train_loss",
loss,
self._timescale,
)
loss.backward()
if self._grad_clip is not None:
torch.nn.utils.clip_grad_value_(
self._qnet.parameters(), self._grad_clip
)
self._optimizer.step()
# Update target network
if self._target_net_update_schedule.update():
self._update_target()
def target_projection(self, target_net_inputs, next_action, reward, done):
"""Project distribution of target Q-values.
Args:
target_net_inputs: Inputs to feed into the target net to compute the
projection of the target Q-values. Should be set from
:py:meth:`~hive.agents.dqn.DQNAgent.preprocess_update_batch`.
next_action (~torch.Tensor): Tensor containing next actions used to
compute target distribution.
reward (~torch.Tensor): Tensor containing rewards for the current batch.
done (~torch.Tensor): Tensor containing whether the states in the current
batch are terminal.
"""
reward = reward.reshape(-1, 1)
not_done = 1 - done.reshape(-1, 1)
batch_size = reward.size(0)
next_dist = self._target_qnet.dist(*target_net_inputs)
next_dist = next_dist[torch.arange(batch_size), next_action]
dist_supports = reward + not_done * self._discount_rate * self._supports
dist_supports = dist_supports.clamp(min=self._v_min, max=self._v_max)
dist_supports = dist_supports.unsqueeze(1)
dist_supports = dist_supports.tile([1, self._atoms, 1])
projected_supports = self._supports.tile([batch_size, 1]).unsqueeze(2)
delta = float(self._v_max - self._v_min) / (self._atoms - 1)
quotient = 1 - (torch.abs(dist_supports - projected_supports) / delta)
quotient = quotient.clamp(min=0, max=1)
projection = torch.sum(quotient * next_dist.unsqueeze(1), dim=2)
return projection | /rlhive-1.0.1-py3-none-any.whl/hive/agents/rainbow.py | 0.946794 | 0.411584 | rainbow.py | pypi |
import numpy as np
import torch
from hive.agents.rainbow import RainbowDQNAgent
class LegalMovesRainbowAgent(RainbowDQNAgent):
"""A Rainbow agent which supports games with legal actions."""
def create_q_networks(self, representation_net):
"""Creates the qnet and target qnet."""
super().create_q_networks(representation_net)
self._qnet = LegalMovesHead(self._qnet)
self._target_qnet = LegalMovesHead(self._target_qnet)
def preprocess_update_info(self, update_info):
preprocessed_update_info = {
"observation": update_info["observation"]["observation"],
"action": update_info["action"],
"reward": update_info["reward"],
"done": update_info["done"],
"action_mask": action_encoding(update_info["observation"]["action_mask"]),
}
if "agent_id" in update_info:
preprocessed_update_info["agent_id"] = int(update_info["agent_id"])
return preprocessed_update_info
def preprocess_update_batch(self, batch):
for key in batch:
batch[key] = torch.tensor(batch[key], device=self._device)
return (
(batch["observation"], batch["action_mask"]),
(batch["next_observation"], batch["next_action_mask"]),
batch,
)
@torch.no_grad()
def act(self, observation):
if self._training:
if not self._learn_schedule.get_value():
epsilon = 1.0
elif not self._use_eps_greedy:
epsilon = 0.0
else:
epsilon = self._epsilon_schedule.update()
if self._logger.update_step(self._timescale):
self._logger.log_scalar("epsilon", epsilon, self._timescale)
else:
epsilon = self._test_epsilon
vectorized_observation = torch.tensor(
np.expand_dims(observation["observation"], axis=0), device=self._device
).float()
legal_moves_as_int = [
i for i, x in enumerate(observation["action_mask"]) if x == 1
]
encoded_legal_moves = torch.tensor(
action_encoding(observation["action_mask"]), device=self._device
).float()
qvals = self._qnet(vectorized_observation, encoded_legal_moves).cpu()
if self._rng.random() < epsilon:
action = np.random.choice(legal_moves_as_int).item()
else:
action = torch.argmax(qvals).item()
if (
self._training
and self._logger.should_log(self._timescale)
and self._state["episode_start"]
):
self._logger.log_scalar("train_qval", torch.max(qvals), self._timescale)
self._state["episode_start"] = False
return action
class LegalMovesHead(torch.nn.Module):
def __init__(self, base_network):
super().__init__()
self.base_network = base_network
def forward(self, x, legal_moves):
x = self.base_network(x)
return x + legal_moves
def dist(self, x, legal_moves):
return self.base_network.dist(x)
def action_encoding(action_mask):
encoded_action_mask = np.zeros(action_mask.shape)
encoded_action_mask[action_mask == 0] = -np.inf
return encoded_action_mask | /rlhive-1.0.1-py3-none-any.whl/hive/agents/legal_moves_rainbow.py | 0.889924 | 0.403802 | legal_moves_rainbow.py | pypi |
import abc
from hive.utils.registry import Registrable
class Agent(abc.ABC, Registrable):
"""Base class for agents. Every implemented agent should be a subclass of
this class.
"""
def __init__(self, obs_dim, act_dim, id=0):
"""
Args:
obs_dim: Dimension of observations that agent will see.
act_dim: Number of actions that the agent needs to chose from.
id: Identifier for the agent.
"""
self._obs_dim = obs_dim
self._act_dim = act_dim
self._training = True
self._id = str(id)
@property
def id(self):
return self._id
@abc.abstractmethod
def act(self, observation):
"""Returns an action for the agent to perform based on the observation.
Args:
observation: Current observation that agent should act on.
Returns:
Action for the current timestep.
"""
pass
@abc.abstractmethod
def update(self, update_info):
"""
Updates the agent.
Args:
update_info (dict): Contains information agent needs to update
itself.
"""
pass
def train(self):
"""Changes the agent to training mode."""
self._training = True
def eval(self):
"""Changes the agent to evaluation mode"""
self._training = False
@abc.abstractmethod
def save(self, dname):
"""
Saves agent checkpointing information to file for future loading.
Args:
dname (str): directory where agent should save all relevant info.
"""
pass
@abc.abstractmethod
def load(self, dname):
"""
Loads agent information from file.
Args:
dname (str): directory where agent checkpoint info is stored.
"""
pass
@classmethod
def type_name(cls):
"""
Returns:
"agent"
"""
return "agent" | /rlhive-1.0.1-py3-none-any.whl/hive/agents/agent.py | 0.889108 | 0.49585 | agent.py | pypi |
import copy
import os
import numpy as np
import torch
from hive.agents.agent import Agent
from hive.agents.qnets.base import FunctionApproximator
from hive.agents.qnets.qnet_heads import DQNNetwork
from hive.agents.qnets.utils import (
InitializationFn,
calculate_output_dim,
create_init_weights_fn,
)
from hive.replays import BaseReplayBuffer, CircularReplayBuffer
from hive.utils.loggers import Logger, NullLogger
from hive.utils.schedule import (
LinearSchedule,
PeriodicSchedule,
Schedule,
SwitchSchedule,
)
from hive.utils.utils import LossFn, OptimizerFn, create_folder, seeder
class DQNAgent(Agent):
"""An agent implementing the DQN algorithm. Uses an epsilon greedy
exploration policy
"""
def __init__(
self,
representation_net: FunctionApproximator,
obs_dim,
act_dim: int,
id=0,
optimizer_fn: OptimizerFn = None,
loss_fn: LossFn = None,
init_fn: InitializationFn = None,
replay_buffer: BaseReplayBuffer = None,
discount_rate: float = 0.99,
n_step: int = 1,
grad_clip: float = None,
reward_clip: float = None,
update_period_schedule: Schedule = None,
target_net_soft_update: bool = False,
target_net_update_fraction: float = 0.05,
target_net_update_schedule: Schedule = None,
epsilon_schedule: Schedule = None,
test_epsilon: float = 0.001,
min_replay_history: int = 5000,
batch_size: int = 32,
device="cpu",
logger: Logger = None,
log_frequency: int = 100,
):
"""
Args:
representation_net (FunctionApproximator): A network that outputs the
representations that will be used to compute Q-values (e.g.
everything except the final layer of the DQN).
obs_dim: The shape of the observations.
act_dim (int): The number of actions available to the agent.
id: Agent identifier.
optimizer_fn (OptimizerFn): A function that takes in a list of parameters
to optimize and returns the optimizer. If None, defaults to
:py:class:`~torch.optim.Adam`.
loss_fn (LossFn): Loss function used by the agent. If None, defaults to
:py:class:`~torch.nn.SmoothL1Loss`.
init_fn (InitializationFn): Initializes the weights of qnet using
create_init_weights_fn.
replay_buffer (BaseReplayBuffer): The replay buffer that the agent will
push observations to and sample from during learning. If None,
defaults to
:py:class:`~hive.replays.circular_replay.CircularReplayBuffer`.
discount_rate (float): A number between 0 and 1 specifying how much
future rewards are discounted by the agent.
n_step (int): The horizon used in n-step returns to compute TD(n) targets.
grad_clip (float): Gradients will be clipped to between
[-grad_clip, grad_clip].
reward_clip (float): Rewards will be clipped to between
[-reward_clip, reward_clip].
update_period_schedule (Schedule): Schedule determining how frequently
the agent's Q-network is updated.
target_net_soft_update (bool): Whether the target net parameters are
replaced by the qnet parameters completely or using a weighted
average of the target net parameters and the qnet parameters.
target_net_update_fraction (float): The weight given to the target
net parameters in a soft update.
target_net_update_schedule (Schedule): Schedule determining how frequently
the target net is updated.
epsilon_schedule (Schedule): Schedule determining the value of epsilon
through the course of training.
test_epsilon (float): epsilon (probability of choosing a random action)
to be used during testing phase.
min_replay_history (int): How many observations to fill the replay buffer
with before starting to learn.
batch_size (int): The size of the batch sampled from the replay buffer
during learning.
device: Device on which all computations should be run.
logger (ScheduledLogger): Logger used to log agent's metrics.
log_frequency (int): How often to log the agent's metrics.
"""
super().__init__(obs_dim=obs_dim, act_dim=act_dim, id=id)
self._init_fn = create_init_weights_fn(init_fn)
self._device = torch.device("cpu" if not torch.cuda.is_available() else device)
self.create_q_networks(representation_net)
if optimizer_fn is None:
optimizer_fn = torch.optim.Adam
self._optimizer = optimizer_fn(self._qnet.parameters())
self._rng = np.random.default_rng(seed=seeder.get_new_seed())
self._replay_buffer = replay_buffer
if self._replay_buffer is None:
self._replay_buffer = CircularReplayBuffer()
self._discount_rate = discount_rate ** n_step
self._grad_clip = grad_clip
self._reward_clip = reward_clip
self._target_net_soft_update = target_net_soft_update
self._target_net_update_fraction = target_net_update_fraction
if loss_fn is None:
loss_fn = torch.nn.SmoothL1Loss
self._loss_fn = loss_fn(reduction="none")
self._batch_size = batch_size
self._logger = logger
if self._logger is None:
self._logger = NullLogger([])
self._timescale = self.id
self._logger.register_timescale(
self._timescale, PeriodicSchedule(False, True, log_frequency)
)
self._update_period_schedule = update_period_schedule
if self._update_period_schedule is None:
self._update_period_schedule = PeriodicSchedule(False, True, 1)
self._target_net_update_schedule = target_net_update_schedule
if self._target_net_update_schedule is None:
self._target_net_update_schedule = PeriodicSchedule(False, True, 10000)
self._epsilon_schedule = epsilon_schedule
if self._epsilon_schedule is None:
self._epsilon_schedule = LinearSchedule(1, 0.1, 100000)
self._test_epsilon = test_epsilon
self._learn_schedule = SwitchSchedule(False, True, min_replay_history)
self._state = {"episode_start": True}
self._training = False
def create_q_networks(self, representation_net):
"""Creates the Q-network and target Q-network.
Args:
representation_net: A network that outputs the representations that will
be used to compute Q-values (e.g. everything except the final layer
of the DQN).
"""
network = representation_net(self._obs_dim)
network_output_dim = np.prod(calculate_output_dim(network, self._obs_dim))
self._qnet = DQNNetwork(network, network_output_dim, self._act_dim).to(
self._device
)
self._qnet.apply(self._init_fn)
self._target_qnet = copy.deepcopy(self._qnet).requires_grad_(False)
def train(self):
"""Changes the agent to training mode."""
super().train()
self._qnet.train()
self._target_qnet.train()
def eval(self):
"""Changes the agent to evaluation mode."""
super().eval()
self._qnet.eval()
self._target_qnet.eval()
def preprocess_update_info(self, update_info):
"""Preprocesses the :obj:`update_info` before it goes into the replay buffer.
Clips the reward in update_info.
Args:
update_info: Contains the information from the current timestep that the
agent should use to update itself.
"""
if self._reward_clip is not None:
update_info["reward"] = np.clip(
update_info["reward"], -self._reward_clip, self._reward_clip
)
preprocessed_update_info = {
"observation": update_info["observation"],
"action": update_info["action"],
"reward": update_info["reward"],
"done": update_info["done"],
}
if "agent_id" in update_info:
preprocessed_update_info["agent_id"] = int(update_info["agent_id"])
return preprocessed_update_info
def preprocess_update_batch(self, batch):
"""Preprocess the batch sampled from the replay buffer.
Args:
batch: Batch sampled from the replay buffer for the current update.
Returns:
(tuple):
- (tuple) Inputs used to calculate current state values.
- (tuple) Inputs used to calculate next state values
- Preprocessed batch.
"""
for key in batch:
batch[key] = torch.tensor(batch[key], device=self._device)
return (batch["observation"],), (batch["next_observation"],), batch
@torch.no_grad()
def act(self, observation):
"""Returns the action for the agent. If in training mode, follows an epsilon
greedy policy. Otherwise, returns the action with the highest Q-value.
Args:
observation: The current observation.
"""
# Determine and log the value of epsilon
if self._training:
if not self._learn_schedule.get_value():
epsilon = 1.0
else:
epsilon = self._epsilon_schedule.update()
if self._logger.update_step(self._timescale):
self._logger.log_scalar("epsilon", epsilon, self._timescale)
else:
epsilon = self._test_epsilon
# Sample action. With epsilon probability choose random action,
# otherwise select the action with the highest q-value.
observation = torch.tensor(
np.expand_dims(observation, axis=0), device=self._device
).float()
qvals = self._qnet(observation)
if self._rng.random() < epsilon:
action = self._rng.integers(self._act_dim)
else:
# Note: not explicitly handling the ties
action = torch.argmax(qvals).item()
if (
self._training
and self._logger.should_log(self._timescale)
and self._state["episode_start"]
):
self._logger.log_scalar("train_qval", torch.max(qvals), self._timescale)
self._state["episode_start"] = False
return action
def update(self, update_info):
"""
Updates the DQN agent.
Args:
update_info: dictionary containing all the necessary information to
update the agent. Should contain a full transition, with keys for
"observation", "action", "reward", and "done".
"""
if update_info["done"]:
self._state["episode_start"] = True
if not self._training:
return
# Add the most recent transition to the replay buffer.
self._replay_buffer.add(**self.preprocess_update_info(update_info))
# Update the q network based on a sample batch from the replay buffer.
# If the replay buffer doesn't have enough samples, catch the exception
# and move on.
if (
self._learn_schedule.update()
and self._replay_buffer.size() > 0
and self._update_period_schedule.update()
):
batch = self._replay_buffer.sample(batch_size=self._batch_size)
(
current_state_inputs,
next_state_inputs,
batch,
) = self.preprocess_update_batch(batch)
# Compute predicted Q values
self._optimizer.zero_grad()
pred_qvals = self._qnet(*current_state_inputs)
actions = batch["action"].long()
pred_qvals = pred_qvals[torch.arange(pred_qvals.size(0)), actions]
# Compute 1-step Q targets
next_qvals = self._target_qnet(*next_state_inputs)
next_qvals, _ = torch.max(next_qvals, dim=1)
q_targets = batch["reward"] + self._discount_rate * next_qvals * (
1 - batch["done"]
)
loss = self._loss_fn(pred_qvals, q_targets).mean()
if self._logger.should_log(self._timescale):
self._logger.log_scalar("train_loss", loss, self._timescale)
loss.backward()
if self._grad_clip is not None:
torch.nn.utils.clip_grad_value_(
self._qnet.parameters(), self._grad_clip
)
self._optimizer.step()
# Update target network
if self._target_net_update_schedule.update():
self._update_target()
def _update_target(self):
"""Update the target network."""
if self._target_net_soft_update:
target_params = self._target_qnet.state_dict()
current_params = self._qnet.state_dict()
for key in list(target_params.keys()):
target_params[key] = (
1 - self._target_net_update_fraction
) * target_params[
key
] + self._target_net_update_fraction * current_params[
key
]
self._target_qnet.load_state_dict(target_params)
else:
self._target_qnet.load_state_dict(self._qnet.state_dict())
def save(self, dname):
torch.save(
{
"qnet": self._qnet.state_dict(),
"target_qnet": self._target_qnet.state_dict(),
"optimizer": self._optimizer.state_dict(),
"learn_schedule": self._learn_schedule,
"epsilon_schedule": self._epsilon_schedule,
"target_net_update_schedule": self._target_net_update_schedule,
"rng": self._rng,
},
os.path.join(dname, "agent.pt"),
)
replay_dir = os.path.join(dname, "replay")
create_folder(replay_dir)
self._replay_buffer.save(replay_dir)
def load(self, dname):
checkpoint = torch.load(os.path.join(dname, "agent.pt"))
self._qnet.load_state_dict(checkpoint["qnet"])
self._target_qnet.load_state_dict(checkpoint["target_qnet"])
self._optimizer.load_state_dict(checkpoint["optimizer"])
self._learn_schedule = checkpoint["learn_schedule"]
self._epsilon_schedule = checkpoint["epsilon_schedule"]
self._target_net_update_schedule = checkpoint["target_net_update_schedule"]
self._rng = checkpoint["rng"]
self._replay_buffer.load(os.path.join(dname, "replay")) | /rlhive-1.0.1-py3-none-any.whl/hive/agents/dqn.py | 0.849691 | 0.449816 | dqn.py | pypi |
import torch
from torch import nn
from hive.agents.qnets.mlp import MLPNetwork
from hive.agents.qnets.utils import calculate_output_dim
class ConvNetwork(nn.Module):
"""
Basic convolutional neural network architecture. Applies a number of
convolutional layers (each followed by a ReLU activation), and then
feeds the output into an :py:class:`hive.agents.qnets.mlp.MLPNetwork`.
Note, if :obj:`channels` is :const:`None`, the network created for the
convolution portion of the architecture is simply an
:py:class:`torch.nn.Identity` module. If :obj:`mlp_layers` is
:const:`None`, the mlp portion of the architecture is an
:py:class:`torch.nn.Identity` module.
"""
def __init__(
self,
in_dim,
channels=None,
mlp_layers=None,
kernel_sizes=1,
strides=1,
paddings=0,
normalization_factor=255,
noisy=False,
std_init=0.5,
):
"""
Args:
in_dim (tuple): The tuple of observations dimension (channels, width,
height).
channels (list): The size of output channel for each convolutional layer.
mlp_layers (list): The number of neurons for each mlp layer after the
convolutional layers.
kernel_sizes (list | int): The kernel size for each convolutional layer
strides (list | int): The stride used for each convolutional layer.
paddings (list | int): The size of the padding used for each convolutional
layer.
normalization_factor (float | int): What the input is divided by before
the forward pass of the network.
noisy (bool): Whether the MLP part of the network will use
:py:class:`~hive.agents.qnets.noisy_linear.NoisyLinear` layers or
:py:class:`torch.nn.Linear` layers.
std_init (float): The range for the initialization of the standard
deviation of the weights in
:py:class:`~hive.agents.qnets.noisy_linear.NoisyLinear`.
"""
super().__init__()
self._normalization_factor = normalization_factor
if channels is not None:
if isinstance(kernel_sizes, int):
kernel_sizes = [kernel_sizes] * len(channels)
if isinstance(strides, int):
strides = [strides] * len(channels)
if isinstance(paddings, int):
paddings = [paddings] * len(channels)
if not all(
len(x) == len(channels) for x in [kernel_sizes, strides, paddings]
):
raise ValueError("The lengths of the parameter lists must be the same")
# Convolutional Layers
channels.insert(0, in_dim[0])
conv_seq = []
for i in range(0, len(channels) - 1):
conv_seq.append(
torch.nn.Conv2d(
in_channels=channels[i],
out_channels=channels[i + 1],
kernel_size=kernel_sizes[i],
stride=strides[i],
padding=paddings[i],
)
)
conv_seq.append(torch.nn.ReLU())
self.conv = torch.nn.Sequential(*conv_seq)
else:
self.conv = torch.nn.Identity()
if mlp_layers is not None:
# MLP Layers
conv_output_size = calculate_output_dim(self.conv, in_dim)
self.mlp = MLPNetwork(
conv_output_size, mlp_layers, noisy=noisy, std_init=std_init
)
else:
self.mlp = torch.nn.Identity()
def forward(self, x):
if len(x.shape) == 3:
x = x.unsqueeze(0)
elif len(x.shape) == 5:
x = x.reshape(x.size(0), -1, x.size(-2), x.size(-1))
x = x.float()
x = x / self._normalization_factor
x = self.conv(x)
x = self.mlp(x)
return x | /rlhive-1.0.1-py3-none-any.whl/hive/agents/qnets/conv.py | 0.955173 | 0.777638 | conv.py | pypi |
import torch
import torch.nn.functional as F
from torch import nn
class DQNNetwork(nn.Module):
"""Implements the standard DQN value computation. Transforms output from
:obj:`base_network` with output dimension :obj:`hidden_dim` to dimension
:obj:`out_dim`, which should be equal to the number of actions.
"""
def __init__(
self,
base_network: nn.Module,
hidden_dim: int,
out_dim: int,
linear_fn: nn.Module = None,
):
"""
Args:
base_network (torch.nn.Module): Backbone network that computes the
representations that are used to compute action values.
hidden_dim (int): Dimension of the output of the :obj:`network`.
out_dim (int): Output dimension of the DQN. Should be equal to the
number of actions that you are computing values for.
linear_fn (torch.nn.Module): Function that will create the
:py:class:`torch.nn.Module` that will take the output of
:obj:`network` and produce the final action values. If
:obj:`None`, a :py:class:`torch.nn.Linear` layer will be used.
"""
super().__init__()
self.base_network = base_network
self._linear_fn = linear_fn if linear_fn is not None else nn.Linear
self.output_layer = self._linear_fn(hidden_dim, out_dim)
def forward(self, x):
x = self.base_network(x)
x = x.flatten(start_dim=1)
return self.output_layer(x)
class DuelingNetwork(nn.Module):
"""Computes action values using Dueling Networks (https://arxiv.org/abs/1511.06581).
In dueling, we have two heads---one for estimating advantage function and one for
estimating value function.
"""
def __init__(
self,
base_network: nn.Module,
hidden_dim: int,
out_dim: int,
linear_fn: nn.Module = None,
atoms: int = 1,
):
"""
Args:
base_network (torch.nn.Module): Backbone network that computes the
representations that are shared by the two estimators.
hidden_dim (int): Dimension of the output of the :obj:`base_network`.
out_dim (int): Output dimension of the Dueling DQN. Should be equal
to the number of actions that you are computing values for.
linear_fn (torch.nn.Module): Function that will create the
:py:class:`torch.nn.Module` that will take the output of
:obj:`network` and produce the final action values. If
:obj:`None`, a :py:class:`torch.nn.Linear` layer will be used.
atoms (int): Multiplier for the dimension of the output. For standard
dueling networks, this should be 1. Used by
:py:class:`~hive.agents.qnets.qnet_heads.DistributionalNetwork`.
"""
super().__init__()
self.base_network = base_network
self._hidden_dim = hidden_dim
self._out_dim = out_dim
self._atoms = atoms
self._linear_fn = linear_fn if linear_fn is not None else nn.Linear
self.init_networks()
def init_networks(self):
self.output_layer_adv = self._linear_fn(
self._hidden_dim, self._out_dim * self._atoms
)
self.output_layer_val = self._linear_fn(self._hidden_dim, 1 * self._atoms)
def forward(self, x):
x = self.base_network(x)
x = x.flatten(start_dim=1)
adv = self.output_layer_adv(x)
val = self.output_layer_val(x)
if adv.dim() == 1:
x = val + adv - adv.mean(0)
else:
adv = adv.reshape(adv.size(0), self._out_dim, self._atoms)
val = val.reshape(val.size(0), 1, self._atoms)
x = val + adv - adv.mean(dim=1, keepdim=True)
if self._atoms == 1:
x = x.squeeze(dim=2)
return x
class DistributionalNetwork(nn.Module):
"""Computes a categorical distribution over values for each action
(https://arxiv.org/abs/1707.06887)."""
def __init__(
self,
base_network: nn.Module,
out_dim: int,
vmin: float = 0,
vmax: float = 200,
atoms: int = 51,
):
"""
Args:
base_network (torch.nn.Module): Backbone network that computes the
representations that are used to compute the value distribution.
out_dim (int): Output dimension of the Distributional DQN. Should be
equal to the number of actions that you are computing values for.
vmin (float): The minimum of the support of the categorical value
distribution.
vmax (float): The maximum of the support of the categorical value
distribution.
atoms (int): Number of atoms discretizing the support range of the
categorical value distribution.
"""
super().__init__()
self.base_network = base_network
self._supports = torch.nn.Parameter(torch.linspace(vmin, vmax, atoms))
self._out_dim = out_dim
self._atoms = atoms
def forward(self, x):
x = self.dist(x)
x = torch.sum(x * self._supports, dim=2)
return x
def dist(self, x):
"""Computes a categorical distribution over values for each action."""
x = self.base_network(x)
x = x.view(-1, self._out_dim, self._atoms)
x = F.softmax(x, dim=-1)
return x | /rlhive-1.0.1-py3-none-any.whl/hive/agents/qnets/qnet_heads.py | 0.962108 | 0.746208 | qnet_heads.py | pypi |
import math
import torch
import torch.nn.functional as F
from torch import nn
class NoisyLinear(nn.Module):
"""NoisyLinear Layer. Implements the layer described in
https://arxiv.org/abs/1706.10295."""
def __init__(self, in_dim: int, out_dim: int, std_init: float = 0.5):
"""
Args:
in_dim (int): The dimension of the input.
out_dim (int): The desired dimension of the output.
std_init (float): The range for the initialization of the standard deviation of the
weights.
"""
super().__init__()
self.in_features = in_dim
self.out_features = out_dim
self.std_init = std_init
self.weight_mu = nn.Parameter(torch.empty(out_dim, in_dim))
self.weight_sigma = nn.Parameter(torch.empty(out_dim, in_dim))
self.register_buffer("weight_epsilon", torch.empty(out_dim, in_dim))
self.bias_mu = nn.Parameter(torch.empty(out_dim))
self.bias_sigma = nn.Parameter(torch.empty(out_dim))
self.register_buffer("bias_epsilon", torch.empty(out_dim))
self._reset_parameters()
self._sample_noise()
def _reset_parameters(self):
mu_range = 1.0 / math.sqrt(self.in_features)
self.weight_mu.data.uniform_(-mu_range, mu_range)
self.weight_sigma.data.fill_(self.std_init / math.sqrt(self.in_features))
self.bias_mu.data.uniform_(-mu_range, mu_range)
self.bias_sigma.data.fill_(self.std_init / math.sqrt(self.out_features))
def _scale_noise(self, size):
x = torch.randn(size)
return x.sign() * (x.abs().sqrt())
def _sample_noise(self):
epsilon_in = self._scale_noise(self.in_features)
epsilon_out = self._scale_noise(self.out_features)
weight_eps = epsilon_out.ger(epsilon_in)
bias_eps = epsilon_out
return weight_eps, bias_eps
def forward(self, inp):
if self.training:
weight_eps, bias_eps = self._sample_noise()
return F.linear(
inp,
self.weight_mu
+ self.weight_sigma * weight_eps.to(device=self.weight_sigma.device),
self.bias_mu
+ self.bias_sigma * bias_eps.to(device=self.bias_sigma.device),
)
else:
return F.linear(inp, self.weight_mu, self.bias_mu) | /rlhive-1.0.1-py3-none-any.whl/hive/agents/qnets/noisy_linear.py | 0.93441 | 0.586168 | noisy_linear.py | pypi |
import math
import torch
from hive.utils.registry import registry
from hive.utils.utils import CallableType
def calculate_output_dim(net, input_shape):
"""Calculates the resulting output shape for a given input shape and network.
Args:
net (torch.nn.Module): The network which you want to calculate the output
dimension for.
input_shape (int | tuple[int]): The shape of the input being fed into the
:obj:`net`. Batch dimension should not be included.
Returns:
The shape of the output of a network given an input shape.
Batch dimension is not included.
"""
if isinstance(input_shape, int):
input_shape = (input_shape,)
placeholder = torch.zeros((0,) + tuple(input_shape))
output = net(placeholder)
return output.size()[1:]
def create_init_weights_fn(initialization_fn):
"""Returns a function that wraps :func:`initialization_function` and applies
it to modules that have the :attr:`weight` attribute.
Args:
initialization_fn (callable): A function that takes in a tensor and
initializes it.
Returns:
Function that takes in PyTorch modules and initializes their weights.
Can be used as follows:
.. code-block:: python
init_fn = create_init_weights_fn(variance_scaling_)
network.apply(init_fn)
"""
if initialization_fn is not None:
def init_weights(m):
if hasattr(m, "weight"):
initialization_fn(m.weight)
return init_weights
else:
return lambda m: None
def calculate_correct_fan(tensor, mode):
"""Calculate fan of tensor.
Args:
tensor (torch.Tensor): Tensor to calculate fan of.
mode (str): Which type of fan to compute. Must be one of `"fan_in"`,
`"fan_out"`, and `"fan_avg"`.
Returns:
Fan of the tensor based on the mode.
"""
fan_in, fan_out = torch.nn.init._calculate_fan_in_and_fan_out(tensor)
if mode == "fan_in":
return fan_in
elif mode == "fan_out":
return fan_out
elif mode == "fan_avg":
return (fan_in + fan_out) / 2
else:
raise ValueError(f"Fan mode {mode} not supported")
def variance_scaling_(tensor, scale=1.0, mode="fan_in", distribution="uniform"):
"""Implements the :py:class:`tf.keras.initializers.VarianceScaling`
initializer in PyTorch.
Args:
tensor (torch.Tensor): Tensor to initialize.
scale (float): Scaling factor (must be positive).
mode (str): Must be one of `"fan_in"`, `"fan_out"`, and `"fan_avg"`.
distribution: Random distribution to use, must be one of
"truncated_normal", "untruncated_normal" and "uniform".
Returns:
Initialized tensor.
"""
fan = calculate_correct_fan(tensor, mode)
scale /= fan
if distribution == "truncated_normal":
# constant from scipy.stats.truncnorm.std(a=-2, b=2, loc=0., scale=1.)
stddev = math.sqrt(scale) / 0.87962566103423978
return torch.nn.init.trunc_normal_(tensor, 0.0, stddev, -2 * stddev, 2 * stddev)
elif distribution == "untruncated_normal":
stddev = math.sqrt(scale)
return torch.nn.init.normal_(tensor, 0.0, stddev)
elif distribution == "uniform":
limit = math.sqrt(3.0 * scale)
return torch.nn.init.uniform_(tensor, -limit, limit)
else:
raise ValueError(f"Distribution {distribution} not supported")
class InitializationFn(CallableType):
"""A wrapper for callables that produce initialization functions.
These wrapped callables can be partially initialized through configuration
files or command line arguments.
"""
@classmethod
def type_name(cls):
"""
Returns:
"init_fn"
"""
return "init_fn"
registry.register_all(
InitializationFn,
{
"uniform": InitializationFn(torch.nn.init.uniform_),
"normal": InitializationFn(torch.nn.init.normal_),
"constant": InitializationFn(torch.nn.init.constant_),
"ones": InitializationFn(torch.nn.init.ones_),
"zeros": InitializationFn(torch.nn.init.zeros_),
"eye": InitializationFn(torch.nn.init.eye_),
"dirac": InitializationFn(torch.nn.init.dirac_),
"xavier_uniform": InitializationFn(torch.nn.init.xavier_uniform_),
"xavier_normal": InitializationFn(torch.nn.init.xavier_normal_),
"kaiming_uniform": InitializationFn(torch.nn.init.kaiming_uniform_),
"kaiming_normal": InitializationFn(torch.nn.init.kaiming_normal_),
"orthogonal": InitializationFn(torch.nn.init.orthogonal_),
"sparse": InitializationFn(torch.nn.init.sparse_),
"variance_scaling": InitializationFn(variance_scaling_),
},
)
get_optimizer_fn = getattr(registry, f"get_{InitializationFn.type_name()}") | /rlhive-1.0.1-py3-none-any.whl/hive/agents/qnets/utils.py | 0.941949 | 0.721804 | utils.py | pypi |
from abc import ABC, abstractmethod
from hive.utils.registry import Registrable
class BaseEnv(ABC, Registrable):
"""
Base class for environments.
"""
def __init__(self, env_spec, num_players):
"""
Args:
env_spec (EnvSpec): An object containing information about the
environment.
num_players (int): The number of players in the environment.
"""
self._env_spec = env_spec
self._num_players = num_players
self._turn = 0
@abstractmethod
def reset(self):
"""
Resets the state of the environment.
Returns:
observation: The initial observation of the new episode.
turn (int): The index of the agent which should take turn.
"""
raise NotImplementedError
@abstractmethod
def step(self, action):
"""
Run one time-step of the environment using the input action.
Args:
action: An element of environment's action space.
Returns:
observation: Indicates the next state that is an element of environment's observation space.
reward: A reward achieved from the transition.
done (bool): Indicates whether the episode has ended.
turn (int): Indicates which agent should take turn.
info (dict): Additional custom information.
"""
raise NotImplementedError
def render(self, mode="rgb_array"):
"""
Displays a rendered frame from the environment.
"""
raise NotImplementedError
@abstractmethod
def seed(self, seed=None):
"""
Reseeds the environment.
Args:
seed (int): Seed to use for environment.
"""
raise NotImplementedError
def save(self, save_dir):
"""
Saves the environment.
Args:
save_dir (str): Location to save environment state.
"""
raise NotImplementedError
def load(self, load_dir):
"""
Loads the environment.
Args:
load_dir (str): Location to load environment state from.
"""
raise NotImplementedError
def close(self):
"""
Additional clean up operations
"""
raise NotImplementedError
@property
def env_spec(self):
return self._env_spec
@env_spec.setter
def env_spec(self, env_spec):
self._env_spec = env_spec
@classmethod
def type_name(cls):
"""
Returns: "env"
"""
return "env"
class ParallelEnv(BaseEnv):
"""Base class for environments that take make all agents step in parallel.
ParallelEnv takes an environment that expects an array of actions at each step
to execute in parallel, and allows you to instead pass it a single action at each
step.
This class makes use of Python's multiple inheritance pattern. Specifically,
when writing your parallel environment, it should extend both this class and
the class that implements the step method that takes in actions for all agents.
If environment class A has the logic for the step function that takes in the
array of actions, and environment class B is your parallel step version of that
environment, class B should be defined as:
.. code-block:: python
class B(ParallelEnv, A):
...
The order in which you list the classes is important. ParallelEnv **must** come
before A in the order.
"""
def __init__(self, env_name, num_players):
super().__init__(env_name, num_players)
self._actions = []
self._obs = None
self._info = None
self._done = False
def reset(self):
self._obs, _ = super().reset()
return self._obs[0], 0
def step(self, action):
self._actions.append(action)
if len(self._actions) == self._num_players:
observation, reward, done, _, info = super().step(self._actions)
self._actions = []
self._turn = 0
self._obs = observation
self._info = info
self._done = done
else:
self._turn = (self._turn + 1) % self._num_players
reward = 0
return (
self._obs[self._turn],
reward,
self._done and self._turn == 0,
self._turn,
self._info,
) | /rlhive-1.0.1-py3-none-any.whl/hive/envs/base.py | 0.924031 | 0.495911 | base.py | pypi |
import gym
from hive.envs.base import BaseEnv
from hive.envs.env_spec import EnvSpec
class GymEnv(BaseEnv):
"""
Class for loading gym environments.
"""
def __init__(self, env_name, num_players=1, **kwargs):
"""
Args:
env_name (str): Name of the environment (NOTE: make sure it is available
in gym.envs.registry.all())
num_players (int): Number of players for the environment.
kwargs: Any arguments you want to pass to :py:meth:`create_env` or
:py:meth:`create_env_spec` can be passed as keyword arguments to this
constructor.
"""
self.create_env(env_name, **kwargs)
super().__init__(self.create_env_spec(env_name, **kwargs), num_players)
def create_env(self, env_name, **kwargs):
"""Function used to create the environment. Subclasses can override this method
if they are using a gym style environment that needs special logic.
Args:
env_name (str): Name of the environment
"""
self._env = gym.make(env_name)
def create_env_spec(self, env_name, **kwargs):
"""Function used to create the specification. Subclasses can override this method
if they are using a gym style environment that needs special logic.
Args:
env_name (str): Name of the environment
"""
if isinstance(self._env.observation_space, gym.spaces.Tuple):
obs_spaces = self._env.observation_space.spaces
else:
obs_spaces = [self._env.observation_space]
if isinstance(self._env.action_space, gym.spaces.Tuple):
act_spaces = self._env.action_space.spaces
else:
act_spaces = [self._env.action_space]
return EnvSpec(
env_name=env_name,
obs_dim=[space.shape for space in obs_spaces],
act_dim=[space.n for space in act_spaces],
)
def reset(self):
observation = self._env.reset()
return observation, self._turn
def step(self, action):
observation, reward, done, info = self._env.step(action)
self._turn = (self._turn + 1) % self._num_players
return observation, reward, done, self._turn, info
def render(self, mode="rgb_array"):
return self._env.render(mode=mode)
def seed(self, seed=None):
self._env.seed(seed=seed)
def close(self):
self._env.close() | /rlhive-1.0.1-py3-none-any.whl/hive/envs/gym_env.py | 0.829803 | 0.364523 | gym_env.py | pypi |
import ale_py
import cv2
import numpy as np
from hive.envs.env_spec import EnvSpec
from hive.envs.gym_env import GymEnv
class AtariEnv(GymEnv):
"""
Class for loading Atari environments.
Adapted from the Dopamine's Atari preprocessing code:
https://github.com/google/dopamine/blob/6fbb58ad9bc1340f42897e8a551f85a01fb142ce/dopamine/discrete_domains/atari_lib.py
Licensed under Apache 2.0, https://github.com/google/dopamine/blob/master/LICENSE
"""
def __init__(
self,
env_name,
frame_skip=4,
screen_size=84,
sticky_actions=True,
):
"""
Args:
env_name (str): Name of the environment
sticky_actions (bool): Whether to use sticky_actions as per Machado et al.
frame_skip (int): Number of times the agent takes the same action in the environment
screen_size (int): Size of the resized frames from the environment
"""
env_version = "v0" if sticky_actions else "v4"
full_env_name = "{}NoFrameskip-{}".format(env_name, env_version)
if frame_skip <= 0:
raise ValueError(
"Frame skip should be strictly positive, got {}".format(frame_skip)
)
if screen_size <= 0:
raise ValueError(
"Target screen size should be strictly positive, got {}".format(
screen_size
)
)
self.frame_skip = frame_skip
self.screen_size = screen_size
super().__init__(full_env_name)
def create_env_spec(self, env_name, **kwargs):
obs_spaces = self._env.observation_space.shape
# Used for storing and pooling over two consecutive observations
self.screen_buffer = [
np.empty((obs_spaces[0], obs_spaces[1]), dtype=np.uint8),
np.empty((obs_spaces[0], obs_spaces[1]), dtype=np.uint8),
]
act_spaces = [self._env.action_space]
return EnvSpec(
env_name=env_name,
obs_dim=[(1, self.screen_size, self.screen_size)],
act_dim=[space.n for space in act_spaces],
)
def reset(self):
self._env.reset()
self._get_observation_screen(self.screen_buffer[1])
self.screen_buffer[0].fill(0)
return self._pool_and_resize(), self._turn
def step(self, action=None):
"""
Remarks:
* Executes the action for :attr:`self.frame_skips` steps in the the
environment.
* This may execute fewer than self.frame_skip steps in the environment, if
the done state is reached.
* In this case the returned observation should be ignored.
"""
assert action is not None
accumulated_reward = 0.0
done = False
info = {}
for time_step in range(self.frame_skip):
_, reward, done, info = self._env.step(action)
accumulated_reward += reward
if done:
break
elif time_step >= self.frame_skip - 2:
t = time_step - (self.frame_skip - 2)
self._get_observation_screen(self.screen_buffer[t])
observation = self._pool_and_resize()
return observation, accumulated_reward, done, self._turn, info
def _get_observation_screen(self, output):
"""Get the screen input of the current observation given empty numpy array in grayscale.
Args:
output (np.ndarray): screen buffer to hold the returned observation.
Returns:
observation (np.ndarray): the current observation in grayscale.
"""
self._env.ale.getScreenGrayscale(output)
return output
def _pool_and_resize(self):
"""Transforms two frames into a Nature DQN observation.
Returns:
transformed_screen (np.ndarray): pooled, resized screen.
"""
# Pool if there are enough screens to do so.
if self.frame_skip > 1:
np.maximum(
self.screen_buffer[0], self.screen_buffer[1], out=self.screen_buffer[1]
)
transformed_image = cv2.resize(
self.screen_buffer[1],
(self.screen_size, self.screen_size),
interpolation=cv2.INTER_AREA,
)
int_image = np.asarray(transformed_image, dtype=np.uint8)
return np.expand_dims(int_image, axis=0) | /rlhive-1.0.1-py3-none-any.whl/hive/envs/atari/atari.py | 0.911899 | 0.513546 | atari.py | pypi |
import gym
import numpy as np
from marlgrid.base import MultiGrid, MultiGridEnv, rotate_grid
from marlgrid.rendering import SimpleImageViewer
TILE_PIXELS = 32
class MultiGridEnvHive(MultiGridEnv):
def __init__(
self,
agents,
grid_size=None,
width=None,
height=None,
max_steps=100,
reward_decay=True,
seed=1337,
respawn=False,
ghost_mode=True,
full_obs=False,
agent_spawn_kwargs={},
):
self._full_obs = full_obs
super().__init__(
agents,
grid_size,
width,
height,
max_steps,
reward_decay,
seed,
respawn,
ghost_mode,
agent_spawn_kwargs,
)
def gen_obs_grid(self, agent):
# If the agent is inactive, return an empty grid and a visibility mask that hides everything.
if not agent.active:
# below, not sure orientation is correct but as of 6/27/2020 that doesn't matter because
# agent views are usually square and this grid won't be used for anything.
grid = MultiGrid(
(agent.view_size, agent.view_size), orientation=agent.dir + 1
)
vis_mask = np.zeros((agent.view_size, agent.view_size), dtype=np.bool)
return grid, vis_mask
if self._full_obs:
topX, topY, botX, botY = 0, 0, self.width, self.height
grid = self.grid.slice(topX, topY, self.width, self.height, rot_k=0)
vis_mask = np.ones((self.width, self.height), dtype=bool)
else:
topX, topY, botX, botY = agent.get_view_exts()
grid = self.grid.slice(
topX, topY, agent.view_size, agent.view_size, rot_k=agent.dir + 1
)
# Process occluders and visibility
# Note that this incurs some slight performance cost
vis_mask = agent.process_vis(grid.opacity)
# Warning about the rest of the function:
# Allows masking away objects that the agent isn't supposed to see.
# But breaks consistency between the states of the grid objects in the parial views
# and the grid objects overall.
if len(getattr(agent, "hide_item_types", [])) > 0:
for i in range(grid.width):
for j in range(grid.height):
item = grid.get(i, j)
if (
(item is not None)
and (item is not agent)
and (item.type in agent.hide_item_types)
):
if len(item.agents) > 0:
grid.set(i, j, item.agents[0])
else:
grid.set(i, j, None)
return grid, vis_mask
def render(
self,
mode="human",
close=False,
highlight=True,
tile_size=TILE_PIXELS,
show_agent_views=True,
max_agents_per_col=3,
agent_col_width_frac=0.3,
agent_col_padding_px=2,
pad_grey=100,
):
"""Render the whole-grid human view"""
if close:
if self.window:
self.window.close()
return
if mode == "human" and not self.window:
self.window = SimpleImageViewer(caption="Marlgrid")
# Compute which cells are visible to the agent
highlight_mask = np.full((self.width, self.height), False, dtype=np.bool)
for agent in self.agents:
if agent.active:
if self._full_obs:
xlow, ylow, xhigh, yhigh = 0, 0, self.width, self.height
else:
xlow, ylow, xhigh, yhigh = agent.get_view_exts()
dxlow, dylow = max(0, 0 - xlow), max(0, 0 - ylow)
dxhigh, dyhigh = max(0, xhigh - self.grid.width), max(
0, yhigh - self.grid.height
)
if agent.see_through_walls:
highlight_mask[
xlow + dxlow : xhigh - dxhigh, ylow + dylow : yhigh - dyhigh
] = True
else:
a, b = self.gen_obs_grid(agent)
highlight_mask[
xlow + dxlow : xhigh - dxhigh, ylow + dylow : yhigh - dyhigh
] |= rotate_grid(b, a.orientation)[
dxlow : (xhigh - xlow) - dxhigh, dylow : (yhigh - ylow) - dyhigh
]
# Render the whole grid
img = self.grid.render(
tile_size, highlight_mask=highlight_mask if highlight else None
)
rescale = lambda X, rescale_factor=2: np.kron(
X, np.ones((int(rescale_factor), int(rescale_factor), 1))
)
if show_agent_views:
target_partial_width = int(
img.shape[0] * agent_col_width_frac - 2 * agent_col_padding_px
)
target_partial_height = (
img.shape[1] - 2 * agent_col_padding_px
) // max_agents_per_col
agent_views = [self.gen_agent_obs(agent) for agent in self.agents]
agent_views = [
view["pov"] if isinstance(view, dict) else view for view in agent_views
]
agent_views = [
rescale(
view,
min(
target_partial_width / view.shape[0],
target_partial_height / view.shape[1],
),
)
for view in agent_views
]
agent_views = [
agent_views[pos : pos + max_agents_per_col]
for pos in range(0, len(agent_views), max_agents_per_col)
]
f_offset = (
lambda view: np.array(
[
target_partial_height - view.shape[1],
target_partial_width - view.shape[0],
]
)
// 2
)
cols = []
for col_views in agent_views:
col = np.full(
(img.shape[0], target_partial_width + 2 * agent_col_padding_px, 3),
pad_grey,
dtype=np.uint8,
)
for k, view in enumerate(col_views):
offset = f_offset(view) + agent_col_padding_px
offset[0] += k * target_partial_height
col[
offset[0] : offset[0] + view.shape[0],
offset[1] : offset[1] + view.shape[1],
:,
] = view
cols.append(col)
img = np.concatenate((img, *cols), axis=1)
if mode == "human":
if not self.window.isopen:
self.window.imshow(img)
self.window.window.set_caption("Marlgrid")
else:
self.window.imshow(img)
return img | /rlhive-1.0.1-py3-none-any.whl/hive/envs/marlgrid/ma_envs/base.py | 0.624866 | 0.288243 | base.py | pypi |
import operator
from functools import reduce
import gym
import numpy as np
class FlattenWrapper(gym.core.ObservationWrapper):
"""
Flatten the observation to one dimensional vector.
"""
def __init__(self, env):
super().__init__(env)
if isinstance(env.observation_space, gym.spaces.Tuple):
self.observation_space = gym.spaces.Tuple(
tuple(
gym.spaces.Box(
low=space.low.flatten(),
high=space.high.flatten(),
shape=(reduce(operator.mul, space.shape, 1),),
dtype=space.dtype,
)
for space in env.observation_space
)
)
self._is_tuple = True
else:
self.observation_space = gym.spaces.Box(
low=env.observation_space.low.flatten(),
high=env.observation_space.high.flatten(),
shape=(reduce(operator.mul, env.observation_space.shape, 1),),
dtype=env.observation_space.dtype,
)
self._is_tuple = False
def observation(self, obs):
if self._is_tuple:
return tuple(o.flatten() for o in obs)
else:
return obs.flatten()
class PermuteImageWrapper(gym.core.ObservationWrapper):
"""Changes the image format from HWC to CHW"""
def __init__(self, env):
super().__init__(env)
if isinstance(env.observation_space, gym.spaces.Tuple):
self.observation_space = gym.spaces.Tuple(
tuple(
gym.spaces.Box(
low=np.transpose(space.low, [2, 1, 0]),
high=np.transpose(space.high, [2, 1, 0]),
shape=(space.shape[-1],) + space.shape[:-1],
dtype=space.dtype,
)
for space in env.observation_space
)
)
self._is_tuple = True
else:
self.observation_space = gym.spaces.Box(
low=np.transpose(env.observation_space.low, [2, 1, 0]),
high=np.transpose(env.observation_space.high, [2, 1, 0]),
shape=(env.observation_space.shape[-1],)
+ env.observation_space.shape[:-1],
dtype=env.observation_space.dtype,
)
self._is_tuple = False
def observation(self, obs):
if self._is_tuple:
return tuple(np.transpose(o, [2, 1, 0]) for o in obs)
else:
return np.transpose(obs, [2, 1, 0]) | /rlhive-1.0.1-py3-none-any.whl/hive/envs/wrappers/gym_wrappers.py | 0.780955 | 0.46642 | gym_wrappers.py | pypi |
from importlib import import_module
import numpy as np
from hive.envs import BaseEnv
from hive.envs.env_spec import EnvSpec
class PettingZooEnv(BaseEnv):
"""
PettingZoo environment from https://github.com/PettingZoo-Team/PettingZoo
For now, we only support environments from PettingZoo with discrete actions.
"""
def __init__(
self,
env_name,
env_family,
num_players,
**kwargs,
):
"""
Args:
env_name (str): Name of the environment
env_family (str): Family of the environment such as "Atari",
"Classic", "SISL", "Butterfly", "MAgent", and "MPE".
num_players (int): Number of learning agents
"""
self._env_family = env_family
self.create_env(env_name, num_players, **kwargs)
self._env_spec = self.create_env_spec(env_name, **kwargs)
super().__init__(self.create_env_spec(env_name, **kwargs), num_players)
def create_env(self, env_name, num_players, **kwargs):
env_module = import_module("pettingzoo." + self._env_family + "." + env_name)
self._env = env_module.env(players=num_players)
def create_env_spec(self, env_name, **kwargs):
"""
Each family of environments have their own type of observations and actions.
You can add support for more families here by modifying obs_dim and act_dim.
"""
if self._env_family in ["classic"]:
obs_dim = [
space["observation"].shape
for space in self._env.observation_spaces.values()
]
elif self._env_family in ["sisl"]:
obs_dim = [space.shape for space in self._env.observation_spaces.values()]
else:
raise ValueError(
f"Hive does not support {self._env_family} environments from PettingZoo yet."
)
act_dim = [space.n for space in self._env.action_spaces.values()]
return EnvSpec(
env_name=env_name,
obs_dim=obs_dim,
act_dim=act_dim,
)
def reset(self):
self._env.reset()
observation, _, _, _ = self._env.last()
for key in observation.keys():
observation[key] = np.array(observation[key], dtype=np.uint8)
self._turn = self._env.agents.index(self._env.agent_selection)
return observation, self._turn
def step(self, action):
self._env.step(action)
observation, _, done, info = self._env.last()
self._turn = (self._turn + 1) % self._num_players
for key in observation.keys():
observation[key] = np.array(observation[key], dtype=np.uint8)
return (
observation,
[self._env.rewards[agent] for agent in self._env.agents],
done,
self._turn,
info,
)
def render(self, mode="rgb_array"):
return self._env.render(mode=mode)
def seed(self, seed=None):
self._env.seed(seed=seed)
def close(self):
self._env.close() | /rlhive-1.0.1-py3-none-any.whl/hive/envs/pettingzoo/pettingzoo.py | 0.754192 | 0.401864 | pettingzoo.py | pypi |
from importlib import import_module
import numpy as np
from hive.envs.base import BaseEnv
from hive.envs.env_spec import EnvSpec
class MinAtarEnv(BaseEnv):
"""
Class for loading MinAtar environments. See https://github.com/kenjyoung/MinAtar.
"""
def __init__(
self,
env_name,
sticky_action_prob=0.1,
difficulty_ramping=True,
):
"""
Args:
env_name (str): Name of the environment
sticky_actions (bool): Whether to use sticky_actions as per
Machado et al.
difficulty_ramping (bool): Whether to periodically increase difficulty.
"""
env_module = import_module("minatar.environments." + env_name)
self.env_name = env_name
self._env = env_module.Env(ramping=difficulty_ramping)
self.n_channels = self._env.state_shape()[2]
self.sticky_action_prob = sticky_action_prob
self.last_action = 0
self.visualized = False
self.closed = False
super().__init__(self.create_env_spec(env_name), num_players=1)
def create_env_spec(self, env_name):
obs_dim = tuple(self._env.state_shape())
new_positions = [2, 0, 1]
obs_dim = tuple(obs_dim[i] for i in new_positions)
return EnvSpec(
env_name=env_name,
obs_dim=[obs_dim],
act_dim=[6],
)
def reset(self):
self._env.reset()
return np.transpose(self._env.state(), [2, 1, 0]), 0
def seed(self, seed=None):
self._env.seed(seed=seed)
def step(self, action=None):
"""
Remarks:
* Execute self.frame_skips steps taking the action in the the environment.
* This may execute fewer than self.frame_skip steps in the environment,
if the done state is reached.
* Furthermore, in this case the returned observation should be ignored.
"""
assert action is not None
reward, done = self._env.act(action)
reward = float(reward)
info = {}
observation = np.transpose(self._env.state(), [2, 1, 0])
return observation, reward, done, None, info | /rlhive-1.0.1-py3-none-any.whl/hive/envs/minatar/minatar.py | 0.714528 | 0.311977 | minatar.py | pypi |
# [](https://colab.research.google.com/drive/1a0pSD-1tWhMmeJeeoyZM1A-HCW3yf1xR?usp=sharing) [](https://agarwl.github.io/rliable) [](https://ai.googleblog.com/2021/11/rliable-towards-reliable-evaluation.html)
`rliable` is an open-source Python library for reliable evaluation, even with a *handful
of runs*, on reinforcement learning and machine learnings benchmarks.
| **Desideratum** | **Current evaluation approach** | **Our Recommendation** |
| --------------------------------- | ----------- | --------- |
| Uncertainty in aggregate performance | **Point estimates**: <ul> <li> Ignore statistical uncertainty </li> <li> Hinder *results reproducibility* </li></ul> | Interval estimates using **stratified bootstrap confidence intervals** (CIs) |
|Performance variability across tasks and runs| **Tables with task mean scores**: <ul><li> Overwhelming beyond a few tasks </li> <li> Standard deviations frequently omitted </li> <li> Incomplete picture for multimodal and heavy-tailed distributions </li> </ul> | **Score distributions** (*performance profiles*): <ul> <li> Show tail distribution of scores on combined runs across tasks </li> <li> Allow qualitative comparisons </li> <li> Easily read any score percentile </li> </ul>|
|Aggregate metrics for summarizing benchmark performance | **Mean**: <ul><li> Often dominated by performance on outlier tasks </li></ul> **Median**: <ul> <li> Statistically inefficient (requires a large number of runs to claim improvements) </li> <li> Poor indicator of overall performance: 0 scores on nearly half the tasks doesn't change it </li> </ul>| **Interquartile Mean (IQM)** across all runs: <ul> <li> Performance on middle 50% of combined runs </li> <li> Robust to outlier scores but more statistically efficient than median </li> </ul> To show other aspects of performance gains, report *Probability of improvement* and *Optimality gap* |
`rliable` provides support for:
* Stratified Bootstrap Confidence Intervals (CIs)
* Performance Profiles (with plotting functions)
* Aggregate metrics
* Interquartile Mean (IQM) across all runs
* Optimality Gap
* Probability of Improvement
<div align="left">
<img src="https://raw.githubusercontent.com/google-research/rliable/master/images/aggregate_metric.png">
</div>
## Interactive colab
We provide a colab at [bit.ly/statistical_precipice_colab](https://colab.research.google.com/drive/1a0pSD-1tWhMmeJeeoyZM1A-HCW3yf1xR?usp=sharing),
which shows how to use the library with examples of published algorithms on
widely used benchmarks including Atari 100k, ALE, DM Control and Procgen.
### Paper
For more details, refer to the accompanying **NeurIPS 2021** paper (**Outstanding Paper** Award):
[Deep Reinforcement Learning at the Edge of the Statistical Precipice](https://arxiv.org/pdf/2108.13264.pdf).
### Installation
To install `rliable`, run:
```python
pip install -U rliable
```
To install latest version of `rliable` as a package, run:
```python
pip install git+https://github.com/google-research/rliable
```
To import `rliable`, we suggest:
```python
from rliable import library as rly
from rliable import metrics
from rliable import plot_utils
```
### Aggregate metrics with 95% Stratified Bootstrap CIs
##### IQM, Optimality Gap, Median, Mean
```python
algorithms = ['DQN (Nature)', 'DQN (Adam)', 'C51', 'REM', 'Rainbow',
'IQN', 'M-IQN', 'DreamerV2']
# Load ALE scores as a dictionary mapping algorithms to their human normalized
# score matrices, each of which is of size `(num_runs x num_games)`.
atari_200m_normalized_score_dict = ...
aggregate_func = lambda x: np.array([
metrics.aggregate_median(x),
metrics.aggregate_iqm(x),
metrics.aggregate_mean(x),
metrics.aggregate_optimality_gap(x)])
aggregate_scores, aggregate_score_cis = rly.get_interval_estimates(
atari_200m_normalized_score_dict, aggregate_func, reps=50000)
fig, axes = plot_utils.plot_interval_estimates(
aggregate_scores, aggregate_score_cis,
metric_names=['Median', 'IQM', 'Mean', 'Optimality Gap'],
algorithms=algorithms, xlabel='Human Normalized Score')
```
<div align="left">
<img src="https://raw.githubusercontent.com/google-research/rliable/master/images/ale_interval_estimates.png">
</div>
##### Probability of Improvement
```python
# Load ProcGen scores as a dictionary containing pairs of normalized score
# matrices for pairs of algorithms we want to compare
procgen_algorithm_pairs = {.. , 'x,y': (score_x, score_y), ..}
average_probabilities, average_prob_cis = rly.get_interval_estimates(
procgen_algorithm_pairs, metrics.probability_of_improvement, reps=2000)
plot_utils.plot_probability_of_improvement(average_probabilities, average_prob_cis)
```
<div align="center">
<img src="https://raw.githubusercontent.com/google-research/rliable/master/images/procgen_probability_of_improvement.png">
</div>
#### Sample Efficiency Curve
```python
algorithms = ['DQN (Nature)', 'DQN (Adam)', 'C51', 'REM', 'Rainbow',
'IQN', 'M-IQN', 'DreamerV2']
# Load ALE scores as a dictionary mapping algorithms to their human normalized
# score matrices across all 200 million frames, each of which is of size
# `(num_runs x num_games x 200)` where scores are recorded every million frame.
ale_all_frames_scores_dict = ...
frames = np.array([1, 10, 25, 50, 75, 100, 125, 150, 175, 200]) - 1
ale_frames_scores_dict = {algorithm: score[:, :, frames] for algorithm, score
in ale_all_frames_scores_dict.items()}
iqm = lambda scores: np.array([metrics.aggregate_iqm(scores[..., frame])
for frame in range(scores.shape[-1])])
iqm_scores, iqm_cis = rly.get_interval_estimates(
ale_frames_scores_dict, iqm, reps=50000)
plot_utils.plot_sample_efficiency_curve(
frames+1, iqm_scores, iqm_cis, algorithms=algorithms,
xlabel=r'Number of Frames (in millions)',
ylabel='IQM Human Normalized Score')
```
<div align="center">
<img src="https://raw.githubusercontent.com/google-research/rliable/master/images/ale_legend.png">
<img src="https://raw.githubusercontent.com/google-research/rliable/master/images/atari_sample_efficiency_iqm.png">
</div>
### Performance Profiles
```python
# Load ALE scores as a dictionary mapping algorithms to their human normalized
# score matrices, each of which is of size `(num_runs x num_games)`.
atari_200m_normalized_score_dict = ...
# Human normalized score thresholds
atari_200m_thresholds = np.linspace(0.0, 8.0, 81)
score_distributions, score_distributions_cis = rly.create_performance_profile(
atari_200m_normalized_score_dict, atari_200m_thresholds)
# Plot score distributions
fig, ax = plt.subplots(ncols=1, figsize=(7, 5))
plot_utils.plot_performance_profiles(
score_distributions, atari_200m_thresholds,
performance_profile_cis=score_distributions_cis,
colors=dict(zip(algorithms, sns.color_palette('colorblind'))),
xlabel=r'Human Normalized Score $(\tau)$',
ax=ax)
```
<div align="center">
<img src="https://raw.githubusercontent.com/google-research/rliable/master/images/ale_legend.png">
<img src="https://raw.githubusercontent.com/google-research/rliable/master/images/ale_score_distributions_new.png">
</div>
The above profile can also be plotted with non-linear scaling as follows:
```python
plot_utils.plot_performance_profiles(
perf_prof_atari_200m, atari_200m_tau,
performance_profile_cis=perf_prof_atari_200m_cis,
use_non_linear_scaling=True,
xticks = [0.0, 0.5, 1.0, 2.0, 4.0, 8.0]
colors=dict(zip(algorithms, sns.color_palette('colorblind'))),
xlabel=r'Human Normalized Score $(\tau)$',
ax=ax)
```
### Dependencies
The code was tested under `Python>=3.7` and uses these packages:
- arch == 5.0.1
- scipy >= 1.7.0
- numpy >= 0.9.0
- absl-py >= 1.16.4
- seaborn >= 0.11.2
Citing
------
If you find this open source release useful, please reference in your paper:
@article{agarwal2021deep,
title={Deep Reinforcement Learning at the Edge of the Statistical Precipice},
author={Agarwal, Rishabh and Schwarzer, Max and Castro, Pablo Samuel
and Courville, Aaron and Bellemare, Marc G},
journal={Advances in Neural Information Processing Systems},
year={2021}
}
Disclaimer: This is not an official Google product.
| /rliable-1.0.7.tar.gz/rliable-1.0.7/README.md | 0.925596 | 0.98631 | README.md | pypi |
import calendar as _calendar
import datetime as _datetime
import enum as _enum
import re as _re
__all__ = ['Period', 'Weekday', 'set_first_day_of_week', 'Time', 'Date', 'DateTime', 'timestamp']
class Period(_enum.Enum):
"""Enumeration of time periods."""
Day = 'd'
Week = 'w'
Month = 'm'
Year = 'y'
def __lt__(self, other):
"""Return True if *other* is shorter than self."""
order = {'d': 0, 'w': 1, 'm': 2, 'y': 3}
return isinstance(other, Period) and order[self.value] < order[other.value]
class Weekday(_enum.Enum):
"""Enumeration of week days."""
Monday = 0
Tuesday = 1
Wednesday = 2
Thursday = 3
Friday = 4
Saturday = 5
Sunday = 6
def __add__(self, n):
"""Return Weekday *n* days after self."""
return Weekday(self.value+(n % 7))
def __sub__(self, n):
"""Return Weekday *n* days before self.
Return difference in days between two week days if *n* is a Weekday.
"""
if isinstance(n, Weekday):
return self.value - n.value
else:
return Weekday(self.value+((7-n) % 7))
def __lt__(self, other):
"""Return True if *other* is before self."""
return isinstance(other, Weekday) and Weekday._order[self] < Weekday._order[other]
@classmethod
def first_day_of_week(cls):
"""Return Weekday with which the week begins."""
return cls.range()[0]
@classmethod
def last_day_of_week(cls):
"""Return Weekday with which the week ends."""
return cls.range()[-1]
@classmethod
def range(cls):
"""Return [Weekday] for one week."""
return list(cls._order.keys())
def set_first_day_of_week(weekday):
"""Set the Weekday wich which the week begins (defaults to Monday.)"""
Weekday._order = {Weekday(n % 7): p for p, n in enumerate(range(weekday.value, weekday.value+7))}
set_first_day_of_week(Weekday.Monday)
class Time:
"""Time representation with second precision."""
@classmethod
def now(cls):
"""Return Time object that represents 'now'."""
now = _datetime.datetime.now()
return cls(now.hour, now.minute, now.second)
@classmethod
def start_of_day(cls):
"""Return Time object that represents the start of the day (mid-night.)"""
return cls(0)
@classmethod
def end_of_day(cls):
"""Return Time object that represents the end of the day (one second to mid-night.)"""
return cls(23, 59, 59)
def _init(self, hour, minute, second):
"""Set and verify valid time.
Raise ValueError if *hour*, *minute*, or *second* is out of the valid range."""
self._hour = int(hour)
if self.hour < 0 or self.hour > 23:
raise ValueError(f'Invalid hour: {self.hour}')
self._minute = int(minute)
if self.minute < 0 or self.minute > 59:
raise ValueError(f'Invalid minute: {self.minute}')
self._second = int(second)
if self.second < 0 or self.second > 59:
raise ValueError(f'Invalid second: {self.second}')
def __init__(self, value, minute=0, second=0):
"""Create new Time object from integer arguments or a string of format 'hh:mm[:ss]'.
Raise ValueError if arguments are invalid or string cannot be parsed."""
if isinstance(value, int):
self._init(value, minute, second)
elif isinstance(value, str):
found = _re.match('^(\d{1,2}):(\d{1,2}):(\d{1,2})', value + ':00')
if not found:
raise ValueError(f'Invalid time: {value}')
self._init(found.group(1), found.group(2), found.group(3))
elif isinstance(value, Time):
self._init(value.hour, value.minute, value.second)
else:
raise ValueError(f'Invalid time: {value}')
@property
def hour(self):
return self._hour
@property
def minute(self):
return self._minute
@property
def second(self):
return self._second
def diff(self, other):
"""Return difference to *other* in seconds (positive if other is later.)"""
return (other.hour - self.hour) * 3600 + (other.minute - self.minute) * 60 + (other.second - self.second)
def __eq__(self, other):
return isinstance(other, Time) and self.hour == other.hour and self.minute == other.minute and self.second == other.second
def __lt__(self, other):
return self.diff(other) > 0
def __le__(self, other):
return self == other or self < other
def __str__(self):
return f'{self.hour:02}:{self.minute:02}:{self.second:02}'
def __repr__(self):
return self.__str__()
def __hash__(self):
return hash(self.__repr__())
class Date:
"""Date representation with utility methods."""
@classmethod
def today(cls):
"""Return Date object that represents 'today'."""
today = _datetime.date.today()
return cls(today.year, today.month, today.day)
@classmethod
def find_day(cls, year, month, weekday, n=1):
"""Return Date object which represents the *n*th *weekday* within a *month*, e.g. 3rd Monday.
Raise ValueError if *n* is not realistic e.g. 5th Monday."""
if n > 5:
raise ValueError('Cannot find day')
d = cls(year, month, 1)
while n > 0:
while d.weekday != weekday:
d = d.next()
n -= 1
if n > 0:
d = d.next()
if d.month != month:
raise ValueError('Cannot find day')
return d
_min_year = 1500
_max_year = 2500
def _init(self, year, month, day):
"""Set and verify valid date.
Raise ValueError if *year*, *month*, or *day* is out of the valid range."""
self._year = int(year)
if self.year < Date._min_year or self.year > Date._max_year:
raise ValueError(f'Invalid year ({Date._min_year}-{Date._max_year}): {self.year}')
self._month = int(month)
if self.month < 1 or self.month > 12:
raise ValueError(f'Invalid month: {self.month}')
self._day = int(day)
_, last_day_of_month = _calendar.monthrange(self.year, self.month)
if self.day < 1 or self.day > last_day_of_month:
raise ValueError(f'Invalid day (1-{last_day_of_month}): {self.day}')
def __init__(self, value, month=1, day=1):
"""Create new Date object from integer arguments or a string of format 'YYYY-MM-DD'.
Raise ValueError if arguments are invalid or string cannot be parsed."""
if isinstance(value, int):
self._init(value, month, day)
elif isinstance(value, str):
found = _re.match('^(\d{4})-(\d{1,2})-(\d{1,2})', value)
if not found:
raise ValueError(f'Invalid date: {value}')
self._init(found.group(1), found.group(2), found.group(3))
elif isinstance(value, Date):
self._init(value.year, value.month, value.day)
else:
raise ValueError(f'Invalid date: {value}')
@property
def year(self):
return self._year
@property
def month(self):
return self._month
@property
def day(self):
return self._day
@property
def weekday(self):
return Weekday(_calendar.weekday(self.year, self.month, self.day))
@property
def istoday(self):
"""True if self is today"""
return self == Date.today()
_weekend_days = {Weekday.Saturday, Weekday.Sunday}
@property
def isweekend(self):
"""True if self is Saturday or Sunday"""
return self.weekday in Date._weekend_days
@property
def isleap(self):
"""True if self is a Date within a leap year"""
return self.length(period=Period.Year) == 366
def move(self, n=0, period=Period.Day):
"""Return new Date *n* periods away from self. *n* can be negative or positive."""
if period is Period.Day:
moved_date = _datetime.date(self.year, self.month, self.day) + _datetime.timedelta(days=n)
return Date(moved_date.year, moved_date.month, moved_date.day)
if period is Period.Week:
return self.move(n*7, Period.Day)
if period is Period.Month:
if (self.month + n) < 1:
year = self.year + int((self.month + n - 12) / 12)
else:
year = self.year + int((self.month + n - 1) / 12)
month = (self.month + n) % 12
if month < 1:
month += 12
_, last_day_of_month = _calendar.monthrange(year, month)
return Date(year, month, min(self.day, last_day_of_month))
if period is Period.Year:
return Date(self.year + n, self.month, self.day)
def next(self, n=1, period=Period.Day):
"""Return new Date *n* periods after self."""
return self.move(+n, period)
def prev(self, n=1, period=Period.Day):
"""Return new Date *n* periods prior to self."""
return self.move(-n, period)
def envelope(self, period=Period.Week, to_date=None):
"""Return tuple of *period* that envelopes self. If *to_date* is not None, the envelope will
include both self and *to_date*."""
to_date = to_date or self
if period is Period.Day:
if to_date < self:
raise ValueError('to_date must be after this date')
return self, to_date
if period is Period.Week:
return self.move(-self.weekday.value), to_date.move(6-to_date.weekday.value)
if period is Period.Month:
_, last_day_of_month = _calendar.monthrange(to_date.year, to_date.month)
return Date(self.year, self.month, 1), Date(to_date.year, to_date.month, last_day_of_month)
if period is Period.Year:
return Date(self.year, 1, 1), Date(to_date.year, 12, 31)
def diff(self, other, period=Period.Day):
"""Return difference to *other* date in *period* (positive if other is later.)"""
if period is Period.Day:
return _datetime.date(other.year, other.month, other.day).toordinal() - _datetime.date(self.year, self.month, self.day).toordinal()
if period is Period.Week:
if self <= other:
first, last = self.envelope(period, other)
return int(first.diff(last) / 7)
first, last = other.envelope(period, self)
return -int(first.diff(last) / 7)
if period is Period.Month:
return (other.year - self.year) * 12 + (other.month - self.month)
if period is Period.Year:
return other.year - self.year
def length(self, period=Period.Month):
"""Return length in days of *period* that contains self (e.g. length of month or year.)"""
first, last = self.envelope(period)
return first.diff(last) + 1
def range(self, to_date=None, n=None):
"""Return list of dates between self and *to_date* or for *n* days starting with
self (backwards if *n* is negative or *to_date* is before self.)"""
if to_date is not None:
n = self.diff(to_date)
n = n + 1 if n >= 0 else n - 1
return [self.move(n=_) for _ in range(0, n, 1 if n >= 1 else -1)]
def __eq__(self, other):
return isinstance(other, Date) and self.year == other.year and self.month == other.month and self.day == other.day
def __lt__(self, other):
return self.year < other.year or \
(self.year == other.year and self.month < other.month) or \
(self.year == other.year and self.month == other.month and self.day < other.day)
def __le__(self, other):
return self == other or self < other
def __str__(self):
return 'f{self.year:04}-{self.month:02}-{self.day:02}'
def __repr__(self):
return self.__str__()
def __hash__(self):
return hash(self.__repr__())
# TODO Support other timezones.
class Timezone(_enum.Enum):
"""Supported time zones."""
EST5EDT = 'EST'
@classmethod
def default(cls):
"""Return module timezone."""
return cls.EST5EDT
@classmethod
def offset(cls, dt):
"""Return time offset for the date/time based on timezone and DST rules."""
assert dt.timezone == Timezone.EST5EDT
dst_start = Date.find_day(dt.date.year, 3, Weekday.Sunday, 2)
dst_end = Date.find_day(dt.date.year, 11, Weekday.Sunday, 1)
return 4 if dst_start <= dt.date <= dst_end else 5
class DateTime:
"""DateTime representation based on a tuple of Date and Time."""
@classmethod
def now(cls):
"""Return DateTime that represents 'now'."""
return cls((Date.today(), Time.now()))
def __init__(self, value):
"""Create new DateTime from a Date, a Date and Time tuple, an integer timestamp, or a string of format 'YYYY-MM-DD hh:mm[:ss]'.
Raise ValueError if arguments are invalid or string cannot be parsed."""
self._timezone = Timezone.default()
if isinstance(value, Date):
self._date = value
self._time = Time.start_of_day()
elif isinstance(value, tuple):
self._date, self._time = value
elif isinstance(value, str):
try:
found = _re.match('^([\d-]*)[ .,@:T]([\d:]*)', value)
self._date = Date(found.group(1))
self._time = Time(found.group(2))
except:
raise ValueError(f'Invalid date/time: {value}')
elif isinstance(value, int):
dt = _datetime.datetime.fromtimestamp(value)
self._date = Date(dt.year, dt.month, dt.day)
self._time = Time(dt.hour, dt.minute, dt.second)
elif isinstance(value, DateTime):
self._date = Date(value.date)
self._time = Time(value.time)
else:
raise ValueError(f'Invalid date/time: {value}')
@property
def date(self):
return self._date
@property
def time(self):
return self._time
@property
def timezone(self):
return self._timezone
@property
def offset(self):
"""Current time offset for the date based on timezone and DST rules"""
return Timezone.offset(self)
def diff(self, other):
"""Return difference to *other* in seconds (positive if other is later.)"""
assert other is None or self.timezone == other.timezone
delta = _datetime.datetime(other.date.year, other.date.month, other.date.day, other.time.hour, other.time.minute, other.time.second) - \
_datetime.datetime(self.date.year, self.date.month, self.date.day, self.time.hour, self.time.minute, self.time.second)
return int(delta.total_seconds())
def since(self):
"""Return seconds passed from self to now."""
return self.diff(DateTime.now())
def to(self, seconds):
"""Return new DateTime after *seconds* from self."""
dt = _datetime.datetime(self.date.year, self.date.month, self.date.day, self.time.hour, self.time.minute, self.time.second)
dt += _datetime.timedelta(seconds=seconds)
return DateTime((Date(dt.year, dt.month, dt.day), Time(dt.hour, dt.minute, dt.second)))
def __eq__(self, other):
assert other is None or self.timezone == other.timezone
return isinstance(other, DateTime) and self.date == other.date and self.time == other.time
def __lt__(self, other):
assert other is None or self.timezone == other.timezone
return self.date < other.date or (self.date == other.date and self.time < other.time)
def __le__(self, other):
return self == other or self < other
def isostr(self):
"""Return an ISO formatted string."""
return f'{self.date.year:04}-{self.date.month:02}-{self.date.day:02}T{self.time.hour:02}:{self.time.minute:02}:{self.time.second:02}.000000-{self.offset:02}:00'
def __str__(self):
return f'{self.date.year:04}-{self.date.month:02}-{self.date.day:02} {self.time.hour:02}:{self.time.minute:02}:{self.time.second:02} {self.timezone.value}'
def __repr__(self):
return self.__str__()
def __hash__(self):
return hash(self.__repr__())
def timestamp(value=None, prec=0.001):
"""Return POSIX timestamp as int for DateTime, Date, or Date and Time tuple in seconds.
Return current POSIX timestamp as int if value is None with given precision (defaults to 0.001 for milliseconds.)"""
if value is None:
return int(_datetime.datetime.now().timestamp()/prec)
if isinstance(value, DateTime):
date = value.date
time = value.time
elif isinstance(value, Date):
date = value
time = Time.start_of_day()
elif isinstance(value, tuple):
date, time = value
else:
raise ValueError(f'Invalid date/time: {value}')
return int(_datetime.datetime(year=date.year, month=date.month, day=date.day, hour=time.hour, minute=time.minute, second=time.second).timestamp()) | /rlib-date-0.1.tar.gz/rlib-date-0.1/rdate/__init__.py | 0.914032 | 0.430506 | __init__.py | pypi |
# @Author: Olivier Watté <user>
# @Date: 2018-04-22T06:05:58-04:00
# @Email: owatte@ipeos.com
# @Last modified by: user
# @Last modified time: 2018-12-18T14:47:24-04:00
# @License: GPLv3
# @Copyright: IPEOS I-Solutions
import argparse
import configparser
import json
import requests
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
class RliehSatLight(object):
"""This class manage PWM on RLIEH sat using the web API.
Attributes:
ini_file_path (str) : full path to the .ini file
light_phase (str): light phase
"""
def __init__(self, ini_file_path, light_phase):
"""Retrieve parames from .ini and build api request."""
self.ini_file_path = ini_file_path
self.light_phase = light_phase
# read config from .ini file
config = configparser.ConfigParser()
config.read(ini_file_path)
# pwm light values
limits = json.loads(config.get('light_thresholds', light_phase))
start = limits[0]
end = limits[1]
duration = config['light_duration'][light_phase]
# light IP
ip = config['hardware']['ip']
channel = config['hardware']['pwm_channel']
# api version (temp param waiting for API harmonization)
try:
version = config['hardware']['version']
except configparser.NoOptionError:
version = 0
except KeyError:
version = 0
if version == 0:
self.endpoint = 'http://{}/api/pwms/{}'.format(ip, channel)
else:
self.endpoint = 'http://{}/pwms/{}'.format(ip, channel)
# request payload
self.payload = {
'from': start,
'to': end,
'duration': duration
}
def requests_retry_session(self,
retries=3,
backoff_factor=0.3,
status_forcelist=(500, 502, 504),
session=None):
session = session or requests.Session()
retry = Retry(
total=retries,
read=retries,
connect=retries,
backoff_factor=backoff_factor,
status_forcelist=status_forcelist,
)
adapter = HTTPAdapter(max_retries=retry)
session.mount('http://', adapter)
session.mount('https://', adapter)
return session
def request(self):
"""performs API request."""
# r = requests.put(self.endpoint, data=self.payload)
r = self.requests_retry_session().put(self.endpoint, data=self.payload)
if r.status_code == 200:
return r.text
else:
raise ValueError('''could not manage light on {}.
Returned message was
{}'''.format(self.endpoint, self.light_phase))
def main():
parser = argparse.ArgumentParser(description='Manage light on RLIEH sat.')
parser.add_argument('-i', '--ini', help=".ini file path", required=True)
parser.add_argument('-p', '--phase', help="light phase", required=True)
parser.add_argument('-v', '--verbose', default=False, action='store_true')
args = parser.parse_args()
light = RliehSatLight(args.ini, args.phase)
r = light.request()
if args.verbose:
print(r)
if __name__ == "__main__":
main() | /rlieh_satlight-0.0.4.tar.gz/rlieh_satlight-0.0.4/rlieh_satlight/core.py | 0.706393 | 0.218576 | core.py | pypi |
# Install
`pip install rlim`
# What purpose does `rlim` serve?
When working with various APIs, I have found that in some cases the rate limits imposed on the user can be somewhat complex. For example, a single endpoint may have a limit of 3 calls per second *and* 5000 calls per hour (in a few rare instances, I have seen 3 limits for a single endpoint). The two other common rate limiting packages out there ([ratelimit](https://pypi.org/project/ratelimit/) and [ratelimiter](https://pypi.org/project/ratelimiter/)) only allow for a single rate limit to be set (e.g. 300 calls per 30 seconds). Although you could simply decorate a function multiple times, it can very quickly become wasteful in terms of memory and performance. Thus I decided to make a modern memory- and performance-efficient rate limiting module that allows for multiple limits to be imposed on a single rate limiter, as well as combining the best parts of the aforementioned packages.
# How to create and use the RateLimiter
The creation of a `RateLimiter` instance is rather simple, and there are numerous ways to implement it into your code. When creating a `RateLimiter` instance, you must provide one more more *criteria*. These are the rates/limits that the rate limiter will abide to. The `Rate` object is used for limiting constant-speed function calls (e.g. 2 calls per second), while the `Limit` object is used for limiting quotas (e.g. 3000 calls every 3600 seconds). Using these examples, you could create a `RateLimiter` like this:
```py
from rlim import RateLimiter, Rate, Limit
RateLimiter(Rate(2), Limit(3000, 3600))
```
When it comes to using this object, there are numerous ways in which to go about it:
## Decorators
A function can be decorated either with a `RateLimiter` instance or with the `placeholder` function decorator. When a function is decorated with either of these, it gains two attributes: `rate_limiter` and `rate_limiter_enabled`. If `rate_limiter` is not `None` and `rate_limiter_enabled` is `True`, the function will be rate limited; otherwise, the function will still run but without any rate limiting. **NOTE**: for all the below examples, the process is identical for async functions / methods.
### Decorating with a `RateLimiter` instance
Below is an example on how you might decorate a function with a new instance, as well as with an existing instance.
```py
from rlim import RateLimiter, Rate, Limit
@RateLimiter(Rate(3), Limit(1000, 3600))
def example():
...
rl = RateLimiter(Rate(3), Limit(1000, 3600))
@rl
def example():
...
```
### Decorating with `placeholder`
The purpose of `placeholder` is so that you can prepare a function to be rate limited (e.g. in a new class instance) and apply the `RateLimiter` instance afterward (e.g. in \_\_init\_\_). Setting the rate limiter can be done with the `set_rate_limiter` helper method, or by simply setting the function's `rate_limiter` attribute (via `.rate_limiter` or `.__dict__["rate_limiter"]`) to a `RateLimiter` instance.
```py
from rlim import RateLimiter, Rate, Limit, placeholder, set_rate_limiter
class Example:
def __init__(self, rl: RateLimiter):
set_rate_limiter(self.example_method, rl)
@placeholder
def example_method(self):
...
@placeholder
async def example():
...
rl = RateLimiter(Rate(3), Limit(1000, 3600))
eg = Example(rl)
example.rate_limiter = rl
```
## Using context managers
Another way to implement this into your code is to simply use a context manager.
```py
from rlim import RateLimiter, Rate, Limit
rl = RateLimiter(Rate(3), Limit(1000, 3600))
def example():
with rl:
...
async def example():
async with rl:
...
```
## Using `pause` and `apause`
In general, the decorator or context manager methods should be used, but if needed, there are also the `pause` and `apause` methods which can be used to simply pause within your code. This comes with the possiblity to exceed the rate limits of the API you are interacting with, as the next timestamp gets added directly after the pause, not after the encapsulated code has completed. So use this with caution.
```py
from rlim import RateLimiter, Rate, Limit
rl = RateLimiter(Rate(3), Limit(1000, 3600))
def example():
rl.pause()
...
async def example():
await rl.apause()
...
```
# List of functions and classes
- RateLimiter [*._ratelimit.RateLimiter*]
- The main class used to rate limit function calls.
- placeholder [*._ratelimit.placeholder*]
- Used to prepare a function for rate limiting when a rate limiter instance is not yet available.
- set_rate_limiter [*._ratelimit.set_rate_limiter*]
- Sets a function's rate limiter.
- set_rate_limiter_enabled [*._ratelimit.set_rate_limiter_enabled*]
- Enables or disables a function's rate limiter.
- get_rate_limiter [*._ratelimit.get_rate_limiter*]
- Get a function's rate limiter.
- get_rate_limiter_enabled [*._ratelimit.get_rate_limiter_enabled*]
- Get a function's rate limiter enabled status
- RateLimitExceeded [*.exceptions.RateLimitExceeded*]
- An exception raised if `raise_on_limit` is enabled in the `RateLimiter` instance.
- Rate [*.models.Rate*]
- A criteria for constant-rate limiting.
- Limit [*.models.Limit*]
- A criteria for quota limiting.
- *._ratelimit._maxrate*
- An internal method used for creating a new `Rate` instance if `autorate` is set to `True` upon instantiation of the `RateLimiter` instance.
- *._ratelimit._maxcalls*
- An internal method used for determining the size of the `RateLimiter` instance's `deque`.
- *._ratelimit._wrapper*
- An internal method used to create the base function wrapper.
| /rlim-0.0.3.tar.gz/rlim-0.0.3/README.md | 0.611382 | 0.994123 | README.md | pypi |
**WARNING: Rljax is currently in a beta version and being actively improved. Any contributions are welcome :)**
# Rljax
Rljax is a collection of RL algorithms written in JAX.
## Setup
You can install dependencies simply by executing the following. To use GPUs, CUDA (10.0, 10.1, 10.2 or 11.0) must be installed.
```bash
pip install https://storage.googleapis.com/jax-releases/`nvcc -V | sed -En "s/.* release ([0-9]*)\.([0-9]*),.*/cuda\1\2/p"`/jaxlib-0.1.55-`python3 -V | sed -En "s/Python ([0-9]*)\.([0-9]*).*/cp\1\2/p"`-none-manylinux2010_x86_64.whl jax==0.2.0
pip install -e .
```
If you don't have a GPU, please execute the following instead.
```bash
pip install jaxlib==0.1.55 jax==0.2.0
pip install -e .
```
If you want to use a [MuJoCo](http://mujoco.org/) physics engine, please install [mujoco-py](https://github.com/openai/mujoco-py).
```bash
pip install mujoco_py==2.0.2.11
```
## Algorithm
Currently, following algorithms have been implemented.
|**Algorithm**|**Action**|**Vector State**|**Pixel State**|**PER**[[11]](#reference)|**D2RL**[[15]](#reference)|
| :-- | :-- | :--: | :--: | :--: |:--: |
| PPO[[1]](#reference) | Continuous | :heavy_check_mark: | - | - | - |
| DDPG[[2]](#reference) | Continuous | :heavy_check_mark: | - | :heavy_check_mark: | :heavy_check_mark: |
| TD3[[3]](#reference) | Continuous | :heavy_check_mark: | - | :heavy_check_mark: | :heavy_check_mark: |
| SAC[[4,5]](#reference) | Continuous | :heavy_check_mark: | - | :heavy_check_mark: | :heavy_check_mark: |
| SAC+DisCor[[12]](#reference)| Continuous | :heavy_check_mark: | - | - | :heavy_check_mark: |
| TQC[[16]](#reference) | Continuous | :heavy_check_mark: | - | :heavy_check_mark: | :heavy_check_mark: |
| SAC+AE[[13]](#reference) | Continuous | - | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| SLAC[[14]](#reference) | Continuous | - | :heavy_check_mark: | - | :heavy_check_mark: |
| DQN[[6]](#reference) | Discrete | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - |
| QR-DQN[[7]](#reference) | Discrete | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - |
| IQN[[8]](#reference) | Discrete | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - |
| FQF[[9]](#reference) | Discrete | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - |
| SAC-Discrete[[10]](#reference)| Discrete | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - |
## Example
All algorithms can be trained in a few lines of code.
<details>
<summary>Getting started</summary>
Here is a quick example of how to train DQN on `CartPole-v0`.
```Python
import gym
from rljax.algorithm import DQN
from rljax.trainer import Trainer
NUM_AGENT_STEPS = 20000
SEED = 0
env = gym.make("CartPole-v0")
env_test = gym.make("CartPole-v0")
algo = DQN(
num_agent_steps=NUM_AGENT_STEPS,
state_space=env.observation_space,
action_space=env.action_space,
seed=SEED,
batch_size=256,
start_steps=1000,
update_interval=1,
update_interval_target=400,
eps_decay_steps=0,
loss_type="l2",
lr=1e-3,
)
trainer = Trainer(
env=env,
env_test=env_test,
algo=algo,
log_dir="/tmp/rljax/dqn",
num_agent_steps=NUM_AGENT_STEPS,
eval_interval=1000,
seed=SEED,
)
trainer.train()
```
</details>
<details>
<summary>MuJoCo(Gym)</summary>
I benchmarked my implementations in some environments from MuJoCo's `-v3` task suite, following [Spinning Up's benchmarks](https://spinningup.openai.com/en/latest/spinningup/bench.html) ([code](https://github.com/ku2482/rljax/blob/master/examples/mujoco)). In TQC, I set num_quantiles_to_drop to 0 for HalfCheetath-v3 and 2 for other environments. Note that I benchmarked with 3M agent steps, not 5M agent steps as in TQC's paper.
<img src="https://user-images.githubusercontent.com/37267851/97766058-2d89a700-1b58-11eb-9266-29c3605f7d6c.png" title="HalfCheetah-v3" width=400><img src="https://user-images.githubusercontent.com/37267851/97766061-2e223d80-1b58-11eb-94a0-44efb7e5d9b7.png" title="Walker2d-v3" width=400>
<img src="https://user-images.githubusercontent.com/37267851/97766056-2c587a00-1b58-11eb-9844-d704657857f8.png" title="Swimmer-v3" width=400><img src="https://user-images.githubusercontent.com/37267851/97766062-2ebad400-1b58-11eb-8cf1-6d3bd338c414.png" title="Ant-v3" width=400>
</details>
<details>
<summary>DeepMind Control Suite</summary>
I benchmarked SAC+AE and SLAC implementations in some environments from DeepMind Control Suite ([code](https://github.com/ku2482/rljax/blob/master/examples/dm_control)). Note that the horizontal axis represents the environment step, which is obtained by multiplying agent_step by action_repeat. I set action_repeat to 4 for cheetah-run and 2 for walker-walk.
<img src="https://user-images.githubusercontent.com/37267851/97359828-b7c7d600-18e0-11eb-8c79-852624dfa1e8.png" title="cheetah-run" width=400><img src="https://user-images.githubusercontent.com/37267851/97359825-b696a900-18e0-11eb-88e2-b532076de7e8.png" title="walker-walk" width=400>
</details>
<details>
<summary>Atari(Arcade Learning Environment)</summary>
I benchmarked SAC-Discrete implementation in `MsPacmanNoFrameskip-v4` from the Arcade Learning Environment(ALE) ([code](https://github.com/ku2482/rljax/blob/master/examples/atari)). Note that the horizontal axis represents the environment step, which is obtained by multiplying agent_step by 4.
<img src="https://user-images.githubusercontent.com/37267851/97410160-0e193100-1942-11eb-8056-df445eb6f5e9.png" title="MsPacmanNoFrameskip-v4" width=400>
</details>
## Reference
[[1]](https://arxiv.org/abs/1707.06347) Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
[[2]](https://arxiv.org/abs/1509.02971) Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015).
[[3]](https://arxiv.org/abs/1802.09477) Fujimoto, Scott, Herke Van Hoof, and David Meger. "Addressing function approximation error in actor-critic methods." arXiv preprint arXiv:1802.09477 (2018).
[[4]](https://arxiv.org/abs/1801.01290) Haarnoja, Tuomas, et al. "Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor." arXiv preprint arXiv:1801.01290 (2018).
[[5]](https://arxiv.org/abs/1812.05905) Haarnoja, Tuomas, et al. "Soft actor-critic algorithms and applications." arXiv preprint arXiv:1812.05905 (2018).
[[6]](https://www.nature.com/articles/nature14236?wm=book_wap_0005) Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." nature 518.7540 (2015): 529-533.
[[7]](https://arxiv.org/abs/1710.10044) Dabney, Will, et al. "Distributional reinforcement learning with quantile regression." Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[[8]](https://arxiv.org/abs/1806.06923) Dabney, Will, et al. "Implicit quantile networks for distributional reinforcement learning." arXiv preprint. 2018.
[[9]](https://arxiv.org/abs/1911.02140) Yang, Derek, et al. "Fully Parameterized Quantile Function for Distributional Reinforcement Learning." Advances in Neural Information Processing Systems. 2019.
[[10]](https://arxiv.org/abs/1910.07207) Christodoulou, Petros. "Soft Actor-Critic for Discrete Action Settings." arXiv preprint arXiv:1910.07207 (2019).
[[11]](https://arxiv.org/abs/1511.05952) Schaul, Tom, et al. "Prioritized experience replay." arXiv preprint arXiv:1511.05952 (2015).
[[12]](https://arxiv.org/abs/2003.07305) Kumar, Aviral, Abhishek Gupta, and Sergey Levine. "Discor: Corrective feedback in reinforcement learning via distribution correction." arXiv preprint arXiv:2003.07305 (2020).
[[13]](https://arxiv.org/abs/1910.01741) Yarats, Denis, et al. "Improving sample efficiency in model-free reinforcement learning from images." arXiv preprint arXiv:1910.01741 (2019).
[[14]](https://arxiv.org/abs/1907.00953) Lee, Alex X., et al. "Stochastic latent actor-critic: Deep reinforcement learning with a latent variable model." arXiv preprint arXiv:1907.00953 (2019).
[[15]](https://arxiv.org/abs/2010.09163) Sinha, Samarth, et al. "D2RL: Deep Dense Architectures in Reinforcement Learning." arXiv preprint arXiv:2010.09163 (2020).
[[16]](https://arxiv.org/abs/2005.04269) Kuznetsov, Arsenii, et al. "Controlling Overestimation Bias with Truncated Mixture of Continuous Distributional Quantile Critics." arXiv preprint arXiv:2005.04269 (2020). | /rljax-0.0.4.tar.gz/rljax-0.0.4/README.md | 0.738292 | 0.891811 | README.md | pypi |
import numpy as np
from scipy.stats import norm
from sklearn.preprocessing import OneHotEncoder
from gym import spaces
import gym
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore", category=UserWarning)
class JITAI_env(gym.Env):
def __init__(self, sigma, chosen_obs_names, seed=0, max_episode_length=50, n_version=0, n_context=2, n_actions=4,
δh=0.1, εh=0.05, δd=0.1, εd=0.4, µs=[0.1,0.1], ρ1=50., ρ2=200., ρ3=0., D_threshold=1,
b_add_time_inhomogeneous=True, b_display=True):
'''This is the class for JITAI environment. The possible obs names for chosen_obs_names are: 'C', 'P', 'L', 'H', 'D', 'T',
for example: chosen_obs_names=['C','H','D'] or ['P', 'T'], where C is for true contex, P is for probability of context=0,
L is for inferred context, H is for habituation, D is for disengagement and T is the binary indicator.'''
super(JITAI_env, self).__init__()
self.max_episode_length = max_episode_length
self.n_version = n_version
self.C = n_context
self.sigma = sigma
self.chosen_obs_names = chosen_obs_names
self.chosen_obs_names_str = '-'.join(chosen_obs_names)
self.seed = seed
self.rng = np.random.default_rng(self.seed)
self.b_add_time_inhomogeneous = b_add_time_inhomogeneous
self.δh = δh
self.εh = εh
self.δd = δd
self.εd = εd
self.µs = µs
self.ρ1 = ρ1
self.ρ2 = ρ2
self.ρ3 = ρ3
self.D_threshold = D_threshold
self.init_c_true = 0
self.init_probs = []
for i in range(self.C):
self.init_probs.append(1/self.C)
self.init_c_infer = 0
self.init_h = 0.1
self.init_d = 0.1
self.init_s = 0.1
self.current_state = self.reset()
min_obs, max_obs = self.extract_min_max(self.chosen_obs_names, b_add_time_inhomogeneous)
min_obs = np.array(min_obs)
max_obs = np.array(max_obs)
self.observation_space = spaces.Box(low=min_obs, high=max_obs, dtype = np.float32)
self.action_space = spaces.Discrete(n_actions,)
self.config = {'obs':self.chosen_obs_names_str, 'σ':sigma, 'δh':self.δh, 'εh':self.εh, 'δd':self.δd, 'εd':self.εd,
'µs':self.µs, 'ρ1':self.ρ1, 'ρ2':self.ρ2 , 'ρ3':self.ρ3, 'D_threshold':self.D_threshold}
if b_display:
str_config = ' '.join([k + '='+ str(v) for k,v in self.config.items()])
print('env config:', str_config)
assert(len(µs)==n_context), 'error: length of µs must match the number of contexts.'
def sample_context(self, chosen_rng, input_sigma, class_balance=.5):
'''This generates a context sample (with 2 contexts). The output is (c_true, p, c_infer), where:
c_true is the true context, p is the context probabilities, and c_infer is the inferred context.'''
mu = np.array([0,1])
sigma_values = np.array([input_sigma, input_sigma])
pc_true = np.array([class_balance, 1-class_balance])
c_true = chosen_rng.choice(2, p=pc_true)
x = mu[c_true] + sigma_values[c_true] * chosen_rng.standard_normal()
if input_sigma > 0.1:
p_num = norm.pdf((x-mu)/sigma_values) * pc_true
p = p_num/(np.sum(p_num))
else:
p = np.array([0,0])
if c_true == 0:
p[0] = 1
else:
p[1] = 1
c_infer = np.argmax(p)
return (c_true, p, c_infer)
def create_obs_array(self, input_c_true, input_probs, input_c_infer, input_h, input_d, input_s):
obs_array = [input_c_true]
for i in range(self.C):
obs_array.append(input_probs[i])
obs_array.append(input_c_infer)
obs_array.append(input_h)
obs_array.append(input_d)
obs_array.append(input_s)
return np.array(obs_array)
def unpack_obs_array(self,obs):
input_c_true = int(obs[0])
input_probs = obs[1:self.C+1]
input_c_infer = int(obs[self.C+1])
input_h = obs[self.C+2]
input_d = obs[self.C+3]
input_s = obs[self.C+4]
return({"c_true":input_c_true, "probs":input_probs, "c_infer":input_c_infer,"h":input_h, "d":input_d,"s":input_s})
def get_current_state(self):
return self.current_state
def get_C(self):
return self.unpack_obs_array(self.current_state)['c_true']
def get_H(self):
return self.unpack_obs_array(self.current_state)['h']
def get_P(self):
return self.unpack_obs_array(self.current_state)['probs'][0]
def get_L(self):
return self.unpack_obs_array(self.current_state)['c_infer']
def get_D(self):
return self.unpack_obs_array(self.current_state)['d']
def get_S(self):
return self.unpack_obs_array(self.current_state)['s']
def get_T(self):
indicator_value = 0 if ((self.current_t % 2) == 0) else 1
return indicator_value
def extract_obs(self, chosen_obs_names, b_add_time_inhomogeneous):
'''This extracts the obs in chosen_obs_names from the full state. If b_add_time_inhomogeneous is True,
then the full state is augmented with the time inhomogeneous (one hot vector).'''
obs_only = []
for check_obs in chosen_obs_names:
if check_obs == 'C':
obs_only.append(self.get_C())
elif check_obs == 'P':
obs_only.append(self.get_P())
elif check_obs == 'L':
obs_only.append(self.get_L())
elif check_obs == 'H':
obs_only.append(self.get_H())
elif check_obs == 'D':
obs_only.append(self.get_D())
elif check_obs == 'S':
obs_only.append(self.get_S())
elif check_obs == 'T':
obs_only.append(self.get_T())
else:
str_message = 'error in check_obs. obs name {} does not exist.'.format(check_obs)
print(str_message)
assert(1==2), str_message
if b_add_time_inhomogeneous:
enc = OneHotEncoder(handle_unknown='ignore')
X = np.arange(self.max_episode_length)
X = X.reshape(-1, 1)
enc.fit(X)
one_hot = list(enc.transform([[int(self.current_t)]]).toarray()[0])
obs_only = obs_only + one_hot
return obs_only
def extract_min_max(self, chosen_obs_names, b_add_time_inhomogeneous):
'''This extracts the min and max values for the obs in chosen_obs_names. If b_add_time_inhomogeneous is True,
then the results are augmented with the min and max values of the time inhomogeneous (one hot vector).'''
min_values = []; max_values = []
for check_obs in chosen_obs_names:
if check_obs == 'C':
min_values.append(0.)
max_values.append(1.)
elif check_obs == 'P':
min_values.append(0.)
max_values.append(1.)
elif check_obs == 'L':
min_values.append(0.)
max_values.append(1.)
elif check_obs == 'H':
min_values.append(0.)
max_values.append(1.)
elif check_obs == 'D':
min_values.append(0.)
max_values.append(1.)
elif check_obs == 'S':
min_values.append(0.)
max_values.append(300.)
elif check_obs == 'T':
min_values.append(0.)
max_values.append(1.)
else:
str_message = 'error in check_obs. obs name {} does not exist.'.format(check_obs)
print(str_message)
assert(1==2), str_message
if b_add_time_inhomogeneous:
min_values = min_values + list(np.zeros(self.max_episode_length))
max_values = max_values + list(np.ones(self.max_episode_length))
return min_values, max_values
def reset(self):
self.current_t = 0
self.current_state = self.create_obs_array(self.init_c_true, self.init_probs, self.init_c_infer, self.init_h, self.init_d, self.init_s)
self.obs = self.extract_obs(self.chosen_obs_names, self.b_add_time_inhomogeneous)
return self.obs
def step(self, agent_action: int):
a = int(agent_action)
ht = float(self.current_state[self.C+2])
dt = float(self.current_state[self.C+3])
st = float(self.current_state[self.C+4])
obs_dict = self.unpack_obs_array(self.current_state)
c_true = obs_dict["c_true"]
if a == 0:
h_next_mu = (1-self.δh) * ht
else:
h_next_mu = float(min(1, ht + self.εh))
x = 2 + c_true
if a == 0:
d_next_mu = dt
elif (a == 1) or (a == x):
d_next_mu = (1-self.δd) * dt
else:
d_next_mu = float(min(1, dt + self.εd))
if a == 0:
s_next_mu = self.µs[c_true]
elif a == 1:
s_next_mu = self.µs[c_true] + (1 - h_next_mu) * self.ρ1
elif a == x:
s_next_mu = self.µs[c_true] + (1 - h_next_mu) * self.ρ2
else:
s_next_mu = self.µs[c_true] + (1 - h_next_mu) * self.ρ3
c_true, probs_next_mu, c_infer_next_mu = self.sample_context(self.rng, self.sigma)
if self.n_version == 0:
probs_next = probs_next_mu
c_infer_next = c_infer_next_mu
h_next = h_next_mu
d_next = d_next_mu
s_next = s_next_mu
if self.n_version == 1:
probs_next = probs_next_mu
c_infer_next = c_infer_next_mu
h_next = float(self.rng.normal(h_next_mu,0.25,1))
d_next = float(self.rng.normal(d_next_mu,0.25,1))
s_next = float(self.rng.normal(s_next_mu,25,1))
c_infer_next = min(1,c_infer_next); c_infer_next = max(0,c_infer_next)
for i in range(self.C):
probs_next[i] = float(min(1,probs_next[i])); probs_next[i] = float(max(0,probs_next[i]))
h_next = float(min(1,h_next)); h_next = float(max(0,h_next))
d_next = float(min(1,d_next)); d_next = float(max(0,d_next))
step_reward = s_next
current_state = self.create_obs_array(c_true, probs_next, c_infer_next, h_next, d_next, s_next)
self.current_state = current_state
self.obs = self.extract_obs(self.chosen_obs_names, self.b_add_time_inhomogeneous)
self.current_t += 1
condition1 = (self.current_t >= self.max_episode_length)
condition2 = (d_next >= self.D_threshold)
if condition1 or condition2:
info = {}
if condition1:
info['done'] = 'found t={} (> max episode length)'.format(self.current_t)
if condition2:
info['done'] = 'found d={:.1f} (> disengage threshold)'.format(d_next, self.D_threshold)
done = True
return self.obs, step_reward, done, info
else:
done = False
return self.obs, step_reward, done, {}
def get_inferred_error(self, chosen_sigma, b_default=True, sample_seed=0, N_data=1000):
'''This computes the corresponding inferred error, given the uncertainty sigma.
If b_default is True then this uses some default values. If b_default is False then this computes the inferred error,
using N_data samples and sample_seed.'''
if b_default:
map_sigma_error = {'0':0., '0.4':0.096, '0.6':.175, '0.8':.273, '1':.311, '2':.414}
inferred_error = map_sigma_error[str(chosen_sigma)]
else:
c_true = np.zeros((N_data,),dtype=int)
c_infer = np.zeros((N_data,),dtype=int)
chosen_rng = np.random.default_rng(sample_seed)
for i in range(N_data):
c_true[i], _ ,c_infer[i] = self.sample_context(chosen_rng, chosen_sigma)
inferred_error = np.mean(c_true!=c_infer)
return inferred_error
def get_current_state_length(self):
return len(self.current_state)
def get_obs_length(self):
return len(self.obs)
def render(self):
pass | /rljitai-0.0.4.tar.gz/rljitai-0.0.4/rl_jitai_simulation/envs.py | 0.605799 | 0.379062 | envs.py | pypi |
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class PolicyNetwork(nn.Module):
def __init__(self, lr, input_dims, n_actions, fc1_dim, fc2_dim):
super(PolicyNetwork, self).__init__()
self.fc2_dim = fc2_dim
self.fc1 = nn.Linear(*input_dims, fc1_dim)
if self.fc2_dim is None:
self.a_logits = nn.Linear(fc1_dim, n_actions)
else:
self.fc2 = nn.Linear( fc1_dim, fc2_dim)
self.a_logits = nn.Linear(fc2_dim, n_actions)
self.optimizer = optim.Adam(self.parameters(), lr=lr)
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self.to(self.device)
def forward(self, state):
h = F.relu(self.fc1(state))
if self.fc2_dim is not None:
h = F.relu(self.fc2(h))
a_logits = self.a_logits(h)
return a_logits
class ReinforceAgent():
def __init__(self, lr, gamma, input_dims, fc1_dim, fc2_dim, n_actions=4):
self.fc1_dim = fc1_dim
self.gamma = gamma
self.lr = lr
self.reward_list = []
self.log_prob_action_list = []
self.policy = PolicyNetwork(self.lr, input_dims, n_actions, fc1_dim=fc1_dim, fc2_dim=fc2_dim)
if fc2_dim is None:
self.config = 'REINFORCE lr={} fc1={}'.format(lr, fc1_dim)
else:
self.config = 'REINFORCE lr={} fc1={} fc2={}'.format(lr, fc1_dim, fc2_dim)
def choose_action(self, observation, env_trajectory=None):
state = torch.tensor(observation, dtype=torch.float).to(self.policy.device)
action_probs = F.softmax(self.policy.forward(state), dim=0)
action_dist = torch.distributions.Categorical(action_probs)
action = action_dist.sample()
log_probs = action_dist.log_prob(action)
self.log_prob_action_list.append(log_probs)
chosen_action = action.item()
return chosen_action
def store_rewards(self, reward):
self.reward_list.append(reward)
def init_grad(self):
self.policy.optimizer.zero_grad()
self.loss = 0
def compute_grad(self):
G = np.zeros_like(self.reward_list, dtype=np.float64)
for t in range(len(self.reward_list)):
G_sum = 0
discount = 1
for k in range(t, len(self.reward_list)):
G_sum += self.reward_list[k] * discount
discount *= self.gamma
G[t] = G_sum
G = torch.tensor(G, dtype=torch.float).to(self.policy.device)
for g, logprob in zip(G, self.log_prob_action_list):
self.loss += -g * logprob
self.log_prob_action_list = []
self.reward_list = []
def take_step(self, chosen_M):
self.policy.optimizer.zero_grad()
self.loss = self.loss / chosen_M
self.loss.backward()
self.policy.optimizer.step()
class ReplayBuffer():
def __init__(self, max_size, input_shape, n_actions):
self.mem_size = max_size
self.mem_counter = 0
self.state_memory = np.zeros((self.mem_size, *input_shape), dtype=np.float32)
self.new_state_memory = np.zeros((self.mem_size, *input_shape), dtype=np.float32)
self.action_memory = np.zeros(self.mem_size, dtype=np.int64)
self.reward_memory = np.zeros(self.mem_size, dtype=np.float32)
self.done_memory = np.zeros(self.mem_size, dtype=bool)
def insert_buffer(self, state, action, reward, state_, done):
index = self.mem_counter % self.mem_size
self.state_memory[index] = state
self.new_state_memory[index] = state_
self.action_memory[index] = action
self.reward_memory[index] = reward
self.done_memory[index] = done
self.mem_counter += 1
def sample_buffer(self, batch_size):
max_mem = min(self.mem_counter, self.mem_size)
batch = np.random.choice(max_mem, batch_size, replace=False)
states = self.state_memory[batch]
actions = self.action_memory[batch]
rewards = self.reward_memory[batch]
states_ = self.new_state_memory[batch]
dones = self.done_memory[batch]
return states, actions, rewards, states_, dones
class DDQNetwork(nn.Module):
def __init__(self, lr, n_actions, input_dims, fc1_dim, fc2_dim):
super(DDQNetwork, self).__init__()
self.fc2_dim = fc2_dim
self.fc1 = nn.Linear(*input_dims, fc1_dim)
if self.fc2_dim is None:
self.V = nn.Linear(fc1_dim, 1)
self.A = nn.Linear(fc1_dim, n_actions)
else:
self.fc2 = nn.Linear(fc1_dim, fc2_dim)
self.V = nn.Linear(fc2_dim, 1)
self.A = nn.Linear(fc2_dim, n_actions)
self.optimizer = optim.Adam(self.parameters(), lr=lr)
self.loss = nn.MSELoss()
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self.to(self.device)
def forward(self, state):
l1 = F.relu(self.fc1(state))
if self.fc2_dim is None:
V = self.V(l1)
A = self.A(l1)
else:
l2 = F.relu(self.fc2(l1))
V = self.V(l2)
A = self.A(l2)
return V, A
class DQNAgent():
def __init__(self, gamma, batch_size, n_actions, input_dims, lr, fc1_dim, fc2_dim,
epsilon=1, eps_min=0.01, eps_dec=0.001, replace=1000, mem_size=1000000):
self.gamma = gamma
self.epsilon = epsilon
self.lr = lr
self.n_actions = n_actions
self.input_dims = input_dims
self.batch_size = batch_size
self.fc1_dim = fc1_dim
self.fc2_dim = fc2_dim
self.eps_min = eps_min
self.eps_dec = eps_dec
self.replace = replace
self.learn_step_counter = 0
self.action_space = [i for i in range(self.n_actions)]
self.buffer = ReplayBuffer(mem_size, input_dims, n_actions)
self.q_eval = DDQNetwork(self.lr, self.n_actions, self.input_dims, self.fc1_dim, self.fc2_dim)
self.q_next = DDQNetwork(self.lr, self.n_actions, self.input_dims, self.fc1_dim, self.fc2_dim)
self.q_next.load_state_dict(self.q_eval.state_dict())
self.config = 'DQN lr={} batch={} h={}-{} dec={} rep={}'.format(
self.lr, self.batch_size, self.fc1_dim, self.fc2_dim, self.eps_dec, self.replace)
def choose_action(self, observation):
if np.random.random() > self.epsilon:
state = torch.tensor(np.array([observation]),dtype=torch.float).to(self.q_eval.device)
_, advantage = self.q_eval.forward(state)
action = torch.argmax(advantage).item()
else:
action_choices = self.action_space
action = np.random.choice(action_choices)
return action
def observe(self, state, action, reward, state_, done):
self.buffer.insert_buffer(state, action, reward, state_, done)
def replace_target_network(self):
if self.learn_step_counter % self.replace == 0:
self.q_next.load_state_dict(self.q_eval.state_dict())
def decrement_epsilon(self):
self.epsilon = self.epsilon - self.eps_dec if self.epsilon > self.eps_min else self.eps_min
def update(self):
if self.buffer.mem_counter < self.batch_size:
return
self.q_eval.optimizer.zero_grad()
self.replace_target_network()
states, actions, rewards, states_, dones = self.buffer.sample_buffer(self.batch_size)
states = torch.tensor(states).to(self.q_eval.device)
rewards = torch.tensor(rewards).to(self.q_eval.device)
dones = torch.tensor(dones).to(self.q_eval.device)
actions = torch.tensor(actions).to(self.q_eval.device)
states_ = torch.tensor(states_).to(self.q_eval.device)
indices = np.arange(self.batch_size)
V_s, A_s = self.q_eval.forward(states)
V_s_, A_s_ = self.q_next.forward(states_)
q_pred = torch.add(V_s, (A_s - A_s.mean(dim=1, keepdim=True)))[indices, actions]
q_next = torch.add(V_s_, (A_s_ - A_s_.mean(dim=1, keepdim=True)))
q_target = rewards + self.gamma*torch.max(q_next, dim=1)[0].detach()
q_target[dones] = 0.0
loss = self.q_eval.loss(q_target, q_pred).to(self.q_eval.device)
loss.backward()
self.q_eval.optimizer.step()
self.learn_step_counter += 1
self.decrement_epsilon() | /rljitai-0.0.4.tar.gz/rljitai-0.0.4/rl_jitai_simulation/agents.py | 0.929919 | 0.361728 | agents.py | pypi |
import torch
import numpy as np
import torch.nn.functional as F
from .dqn import Qnet
class DoubleDQN:
"""Double DQN 算法"""
def __init__(self,
state_dim,
hidden_dim,
action_dim,
learning_rate,
gamma,
epsilon,
target_update,
device,
q_net=Qnet):
self.action_dim = action_dim
self.q_net = q_net(state_dim, hidden_dim, self.action_dim).to(device)
self.target_q_net = q_net(state_dim, hidden_dim,
self.action_dim).to(device)
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = gamma
self.epsilon = epsilon
self.target_update = target_update
self.count = 0
self.device = device
def take_action(self, state):
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax().item()
return action
def max_q_value(self, state):
"""在一堆Q值中寻找最大的Q"""
state = torch.tensor([state], dtype=torch.float).to(self.device)
return self.q_net(state).max().item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions) # q值的计算都是一样的
max_action = self.q_net(next_states).max(1)[1].view(-1, 1) # 动作选择有q-net负责
max_next_q_values = self.target_q_net(next_states).gather(1, max_action) # Q值计算由t-net负责
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones) # q_target的计算也是一样的
# 计算loss
loss = torch.mean(F.mse_loss(q_values, q_targets))
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(
self.q_net.state_dict()) # 更新目标网络
self.count += 1
class VAnet(torch.nn.Module):
"""只有一层隐藏层的A网络和V网络"""
def __init__(self, state_dim, hidden_dim, action_dim):
super(VAnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim) # 共享网络部分
self.fc_A = torch.nn.Linear(hidden_dim, action_dim)
self.fc_V = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
A = self.fc_A(F.relu(self.fc1(x)))
V = self.fc_V(F.relu(self.fc1(x)))
Q = V + A - A.mean(1).view(-1, 1) # Q值由V值和A值计算得到
return Q
class DuelingDQN:
"""Dueling DQN算法"""
def __init__(self,
state_dim,
hidden_dim,
action_dim,
learning_rate,
gamma,
epsilon,
target_update,
device):
self.action_dim = action_dim
self.q_net = VAnet(state_dim, hidden_dim,
self.action_dim).to(device)
self.target_q_net = VAnet(state_dim, hidden_dim,
self.action_dim).to(device)
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = gamma
self.epsilon = epsilon
self.target_update = target_update
self.count = 0
self.device = device
def take_action(self, state):
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax().item()
return action
def max_q_value(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
return self.q_net(state).max().item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions)
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1, 1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones)
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets))
self.optimizer.zero_grad()
dqn_loss.backward()
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(self.q_net.state_dict())
self.count += 1 | /rllife-1.0.3.tar.gz/rllife-1.0.3/life/dqn/dqn_improved.py | 0.839504 | 0.564038 | dqn_improved.py | pypi |
import torch
import torch.nn.functional as F
import numpy as np
class Qnet(torch.nn.Module):
''' 只有一层隐藏层的Q网络 '''
def __init__(self, state_dim, hidden_dim, action_dim):
super(Qnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x)) # 隐藏层使用ReLU激活函数
return self.fc2(x)
class DQN:
''' DQN算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,
epsilon, target_update, device, q_net=Qnet):
"""
:param state_dim:
:param hidden_dim:
:param action_dim:
:param learning_rate:
:param gamma:
:param epsilon:
:param target_update:
:param device:torch的device
:param q_net: 计算q值的网络,默认为2层的全连接神经网络,也可以自己定义网络
"""
self.action_dim = action_dim
self.q_net = q_net(state_dim, hidden_dim,
self.action_dim).to(device) # Q网络
# 目标网络
self.target_q_net = q_net(state_dim, hidden_dim,
self.action_dim).to(device)
# 使用Adam优化器
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略
self.target_update = target_update # 目标网络更新频率
self.count = 0 # 计数器,记录更新次数
self.device = device
def take_action(self, state): # epsilon-贪婪策略采取动作
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax().item()
return action
def max_q_value(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
return self.q_net(state).max().item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions) # Q值
# 下个状态的最大Q值
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(
-1, 1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones
) # TD误差目标
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets)) # 均方误差损失函数
self.optimizer.zero_grad() # PyTorch中默认梯度会累积,这里需要显式将梯度置为0
dqn_loss.backward() # 反向传播更新参数
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(
self.q_net.state_dict()) # 更新目标网络
self.count += 1 | /rllife-1.0.3.tar.gz/rllife-1.0.3/life/dqn/dqn.py | 0.806738 | 0.604282 | dqn.py | pypi |
import numpy as np
class Sarsa:
def __init__(self, n_state, epsilon, alpha, gamma, n_action=4):
"""Sarsa算法
Arguments:
ncol -- 环境列数
nrow -- 环境行数
epsilon -- 随机选择动作的概率
alpha -- 学习率
gamma -- 折扣因子
Keyword Arguments:
n_action -- 动作的个数 (default: {4})
"""
self.Q_table = np.zeros((n_state, n_action))
self.n_action = n_action
self.alpha = alpha
self.epsilon = epsilon
self.gamma = gamma
def take_action(self, state):
"""根据state选择下一步的操作,具体实现为epsilon-贪心"""
if np.random.rand() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def best_action(self, state):
"""用于打印策略"""
Q_max = np.max(self.Q_table[state])
a = [0 for _ in range(self.n_action)]
# 若两个动作的价值一样,都会被记录下来
for i in range(self.n_action):
if self.Q_table[state][i] == Q_max:
a[i] = 1
return a
def update(self, s0, a0, r, s1, a1):
""""更新Q表格"""
td_error = r + self.gamma * self.Q_table[s1, a1] - self.Q_table[s0, a0] # 时序差分误差
self.Q_table[s0, a0] += self.alpha * td_error
class MultiSarsa:
"""n步Sarsa算法"""
def __init__(self, n, n_state, epsilon, alpha, gamma, n_action=4):
self.Q_table = np.zeros((n_state, n_action))
self.n_action = n_action
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.n = n # 采用n步Sarsa算法
self.state_list = [] # 保存之前的状态
self.action_list = [] # 保存之前的动作
self.reward_list = [] # 保存之前的奖励
def take_action(self, state):
"""根据状态图选取一个动作"""
if np.random.rand() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def best_action(self, state):
"""用于输出state下的最优动作(训练完成后)"""
Q_max = np.max(self.Q_table[state])
a = [0 for _ in range(self.n_action)]
for i in range(self.n_action):
if self.Q_table[state, i] == Q_max:
a[i] = 1
return a
def update(self, s0, a0, r, s1, a1, done):
"""基于Sarsa算法,更新Q表格"""
self.state_list.append(s0)
self.action_list.append(a0)
self.reward_list.append(r)
if len(self.state_list) == self.n: # 若保存的数据可以进行n步更新
G = self.Q_table[s1, a1] # 得到Q(s_{t+n},a_{t+n})
for i in reversed(range(self.n)): # 不断向前计算每一步的回报,并折扣累加
G = self.gamma * G + self.reward_list[i]
if done and i > 0: # 虽然最后几步没有到达n步,但是到达了终止状态,也将其更新
s = self.state_list[i]
a = self.action_list[i]
self.Q_table[s, a] += self.alpha * (G - self.Q_table[s, a])
s = self.state_list.pop(0) # s_t
a = self.action_list.pop(0) # a_t
self.reward_list.pop(0) # r_t
# n步Sarsa的主要更新步骤
self.Q_table[s, a] += self.alpha * (G - self.Q_table[s, a])
if done:
# 到达终止状态,即将开始下一个序列,将列表清空
self.state_list.clear()
self.action_list.clear()
self.reward_list.clear() | /rllife-1.0.3.tar.gz/rllife-1.0.3/life/base/sarsa.py | 0.449513 | 0.530176 | sarsa.py | pypi |
import numpy as np
import random
class QLearning:
"""Q-Learning算法"""
def __init__(self, n_state, epsilon, alpha, gamma, n_action=4):
self.Q_table = np.zeros((n_state, n_action))
self.n_action = n_action
self.epsilon = epsilon
self.alpha = alpha
self.gamma = gamma
def take_action(self, state):
"""根据策略Q选取在state下的最有动作action"""
if np.random.rand() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def best_action(self, state):
"""训练完成后选择最优动作"""
Q_max = np.max(self.Q_table[state])
a = [0 for _ in range(self.n_action)]
for i in range(self.n_action):
if self.Q_table[state, i] == Q_max:
a[i] = 1
return a
def update(self, s0, a0, r, s1):
"""更新Q表格"""
td_error = r + self.gamma * self.Q_table[s1].max() - self.Q_table[s0, a0]
self.Q_table[s0, a0] += self.alpha * td_error
class DynaQ:
def __init__(self, n_state, epsilon, alpha, gamma, n_planning, n_action=4):
self.Q_table = np.zeros((n_state, n_action))
self.n_action = n_action
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.n_planning = n_planning # 每执行一次Q-learning,执行n_planning次Q-planning
self.model = dict() # 每次在真实环境中收集到新数据,就加入到字典中(如果之前不存在的话)
def take_action(self, state):
"""根据状态选取下一步的动作"""
if np.random.rand() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def q_learning(self, s0, a0, r, s1):
"""使用Q-learning的方法更新Q表格"""
td_error = r + self.gamma * self.Q_table[s1].max() - self.Q_table[s0, a0]
self.Q_table[s0, a0] += self.alpha * td_error
def update(self, s0, a0, r, s1):
"""Dyna-Q算法的主要部分,更新Q表格
使用Q-learning更新一次,在使用Q-planning从历史数据中更新n_planning次"""
self.q_learning(s0, a0, r, s1)
self.model[(s0, a0)] = r, s1 # 将新数据加入到model中
for _ in range(self.n_planning): # Q-planning循环
(s, a), (r, s_) = random.choice(list(self.model.items())) # 随机选择之前的数据
self.q_learning(s, a, r, s_) | /rllife-1.0.3.tar.gz/rllife-1.0.3/life/base/q_learning.py | 0.510985 | 0.491273 | q_learning.py | pypi |
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
class TwoLayerFC(nn.Module):
def __init__(self, num_in, num_out, hidden_dim, activation=F.relu, out_fn=lambda x: x) -> None:
super().__init__()
self.fc1 = nn.Linear(num_in, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, num_out)
self.activation = activation
self.out_fn = out_fn
def forward(self, x):
x = self.activation(self.fc1(x))
x = self.activation(self.fc2(x))
x = self.out_fn(self.fc3(x))
return x
class DDPG:
def __init__(self, num_in_actor, num_out_actor, num_in_critic, hidden_dim,
discrete, action_bound, sigma, actor_lr, critic_lr,
tau, gamma, device, common_net=TwoLayerFC):
"""
第一行是神经网络结构上的超参数
discrete:是否用于处理离散动作
action_bound:限制动作取值范围
sigma:用于添加高斯噪声的高斯分布参数
tau:软更新目标网络的参数
gamma:衰减因子
"""
out_fn = (lambda x: x) if discrete else (
lambda x: torch.tanh(x) * action_bound)
self.actor = common_net(num_in_actor, num_out_actor, hidden_dim,
activation=F.relu, out_fn=out_fn).to(device)
self.target_actor = common_net(num_in_actor, num_out_actor, hidden_dim,
activation=F.relu, out_fn=out_fn).to(device)
self.critic = common_net(num_in_critic, 1, hidden_dim).to(device)
self.target_critic = common_net(
num_in_critic, 1, hidden_dim).to(device)
# 设置目标价值网络并设置和价值网络相同的参数
self.target_critic.load_state_dict(self.critic.state_dict())
# 初始化目标策略网略并设置和策略相同的参数
self.target_actor.load_state_dict(self.actor.state_dict())
self.actor_optimizer = torch.optim.Adam(
self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(
self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
self.sigma = sigma # 高斯噪声的标准差,均值直接设为0
self.action_bound = action_bound
self.tau = tau # 目标网络软更新参数
self.action_dim = num_out_actor
self.device = device
def take_action(self, state):
"""输入状态,输出带有噪声的动作"""
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.actor(state).item()
# 给动作添加噪声,增加探索
action = action + self.gamma * np.random.randn(self.action_dim)
return action
def soft_update(self, net, target_net):
for param_target, param in zip(target_net.parameters(), net.parameters()):
param_target.data.copy_(
param_target.data * (1 - self.tau) + param.data * self.tau)
def update(self, transition_dict):
states = torch.tensor(
transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(
transition_dict['actions'], dtype=torch.float).view(-1, 1).to(self.device)
rewards = torch.tensor(
transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(
transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(
transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)
# 计算critic loss
next_q_values = self.target_critic(torch.cat([next_states,
self.target_actor(next_states)],
dim=1)) # Q_{w-}
q_targets = rewards + self.gamma * next_q_values * (1 - dones)
critic_loss = torch.mean(F.mse_loss(
self.critic(torch.cat([states, actions], dim=1)),
q_targets
))
# 优化
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 计算actor loss
actor_loss = - \
torch.mean(self.critic(
torch.cat([states, self.actor(states)], dim=1)))
# 优化
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 软更新两个两个目标网络
self.soft_update(self.critic, self.target_critic)
self.soft_update(self.actor, self.target_actor) | /rllife-1.0.3.tar.gz/rllife-1.0.3/life/policy/ddpg.py | 0.882877 | 0.529385 | ddpg.py | pypi |
import torch
from torch import nn
import torch.nn.functional as F
from torch.distributions import Normal
import numpy as np
class PolicyNetContinuous(nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim, action_bound):
super(PolicyNetContinuous, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, action_dim)
self.fc_std = nn.Linear(hidden_dim, action_dim)
self.action_bound = action_bound
def forward(self, x):
x = F.relu(self.fc1(x))
mu = self.fc_mu(x)
std = F.softplus(self.fc_std(x))
dist = Normal(mu, std)
normal_sample = dist.rsample() # 重参数化采样
log_prob = dist.log_prob(normal_sample) # log (pi)
action = torch.tanh(normal_sample)
log_prob = log_prob - torch.log(1 - torch.tanh(action).pow(2) + 1e-7)
action = action * self.action_bound
return action, log_prob
class QValueNetContinuous(nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim) -> None:
super().__init__()
self.fc1 = nn.Linear(state_dim + action_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, 1)
def forward(self, x, a):
"""state,action"""
cat = torch.cat([x, a], dim=1)
x = F.relu(self.fc1(cat))
x = F.relu(self.fc2(x))
return self.fc3(x)
class SACContinuous:
"""处理连续动作的SAC算法"""
def __init__(self, state_dim, hidden_dim, action_dim, action_bound,
actor_lr, critic_lr, alpha_lr,
target_entropy, tau, gamma, device,
actor_net=PolicyNetContinuous, critic_net=QValueNetContinuous):
# 5个网络
self.actor = actor_net(state_dim, hidden_dim, action_dim,
action_bound).to(device) # 策略网络
self.critic_1 = critic_net(state_dim, hidden_dim,
action_dim).to(device) # 第一个Q网络
self.critic_2 = critic_net(state_dim, hidden_dim,
action_dim).to(device) # 第二个Q网络
self.target_critic_1 = critic_net(state_dim,
hidden_dim, action_dim).to(
device) # 第一个目标Q网络
self.target_critic_2 = critic_net(state_dim,
hidden_dim, action_dim).to(
device) # 第二个目标Q网络
# 令目标价值网络的初始参数和价值网络一样
self.target_critic_1.load_state_dict(self.critic_1.state_dict())
self.target_critic_2.load_state_dict(self.critic_2.state_dict())
# 优化器
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),
lr=actor_lr)
self.critic_1_optimizer = torch.optim.Adam(self.critic_1.parameters(),
lr=critic_lr)
self.critic_2_optimizer = torch.optim.Adam(self.critic_2.parameters(),
lr=critic_lr)
# 使用alpha的Log值,可以使训练效果比较稳定
self.log_alpha = torch.tensor(np.log(0.01), dtype=torch.float)
self.log_alpha.requires_grad = True # 可以对alpha求梯度
self.log_alpha_optimizer = torch.optim.Adam(
[self.log_alpha], lr=alpha_lr)
self.target_entropy = target_entropy
self.gamma = gamma
self.tau = tau
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.actor(state)[0]
return [action.item()]
def calc_target(self, rewards, next_states, dones):
"""计算目标Q值"""
next_actions, log_prob = self.actor(next_states)
entropy = -log_prob
q1_value = self.target_critic_1(next_states, next_actions)
q2_value = self.target_critic_2(next_states, next_actions)
next_value = torch.min(q1_value, q2_value) + self.log_alpha.exp() * entropy
td_target = rewards + self.gamma * next_value * (1 - dones)
return td_target
def soft_update(self, net, target_net):
for param_target, param in zip(target_net.parameters(), net.parameters()):
param_target.data.copy_(
param_target.data * (1 - self.tau) + param.data * self.tau)
def update(self, transition_dict):
# 数据转换
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions'],
dtype=torch.float).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
# 和之前章节一样,对倒立摆环境的奖励进行重塑以便训练
rewards = (rewards + 8.0) / 8.0
# 更新两个Q网络
td_target = self.calc_target(rewards, next_states, dones)
critic_1_loss = torch.mean(F.mse_loss(self.critic_1(states, actions),
td_target.detach()))
critic_2_loss = torch.mean(F.mse_loss(self.critic_2(states, actions),
td_target.detach()))
# 优化
self.critic_1_optimizer.zero_grad()
critic_1_loss.backward()
self.critic_1_optimizer.step()
self.critic_2_optimizer.zero_grad()
critic_2_loss.backward()
self.critic_2_optimizer.step()
# 更新策略网络
new_actions, log_prob = self.actor(states)
entropy = -log_prob
q1_value = self.critic_1(states, new_actions)
q2_value = self.critic_2(states, new_actions)
actor_loss = torch.mean(-self.log_alpha.exp()
* entropy - torch.min(q1_value, q2_value))
# 优化
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 更新alpha的值
alpha_loss = torch.mean(
(entropy - self.target_entropy).detach() * self.log_alpha.exp())
self.log_alpha_optimizer.zero_grad()
alpha_loss.backward()
self.log_alpha_optimizer.step()
self.soft_update(self.critic_1, self.target_critic_1)
self.soft_update(self.critic_2, self.target_critic_2)
class PolicyNet(nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim) -> None:
super().__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)
class QValueNet(nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super().__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
class SACDiscrete:
"""处理离散动作的SAC"""
def __init__(self, state_dim, hidden_dim, action_dim,
actor_lr, critic_lr, alpha_lr,
target_entropy, tau, gamma, device,
actor_net=PolicyNet, critic_net=QValueNet):
# 策略网络
self.actor = actor_net(state_dim, hidden_dim, action_dim).to(device)
# 第一个Q网络
self.critic_1 = critic_net(state_dim, hidden_dim, action_dim).to(device)
# 第二个Q网络
self.critic_2 = critic_net(state_dim, hidden_dim, action_dim).to(device)
self.target_critic_1 = critic_net(state_dim, hidden_dim,
action_dim).to(device) # 第一个目标Q网络
self.target_critic_2 = critic_net(state_dim, hidden_dim,
action_dim).to(device) # 第二个目标Q网络
# 令目标Q网络的初始参数和Q网络一样
self.target_critic_1.load_state_dict(self.critic_1.state_dict())
self.target_critic_2.load_state_dict(self.critic_2.state_dict())
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),
lr=actor_lr)
self.critic_1_optimizer = torch.optim.Adam(self.critic_1.parameters(),
lr=critic_lr)
self.critic_2_optimizer = torch.optim.Adam(self.critic_2.parameters(),
lr=critic_lr)
# 使用alpha的log值,可以使训练结果比较稳定
self.log_alpha = torch.tensor(np.log(0.01), dtype=torch.float)
self.log_alpha.requires_grad = True # 可以对alpha求梯度
self.log_alpha_optimizer = torch.optim.Adam([self.log_alpha],
lr=alpha_lr)
self.target_entropy = target_entropy # 目标熵的大小
self.gamma = gamma
self.tau = tau
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
def calc_target(self, rewards, next_states, dones):
"""计算目标Q值,直接使用策略网络的输出概率进行计算"""
next_probs = self.actor(next_states)
next_log_probs = torch.log(next_probs + 1e-8)
entropy = -torch.sum(next_probs * next_log_probs, dim=1, keepdim=True) # 计算熵
q1_value = self.target_critic_1(next_states)
q2_value = self.target_critic_2(next_states)
q_value = torch.min(q1_value, q2_value) # q_value
min_value = torch.sum(next_probs * q_value, dim=1, keepdim=True)
next_value = min_value + self.log_alpha.exp() * entropy
td_target = rewards + self.gamma * next_value * (1 - dones)
return td_target
def soft_update(self, net, target_net):
"""软更新target_net"""
for param_target, param in zip(target_net.parameters(), net.parameters()):
param_target.data.copy_(param_target.data * (1 - self.tau) + param.data * self.tau)
def update(self, transition_dict):
# 数据类型转换
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device) # 动作不再是float类型
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
# 更新两个Q网络
td_target = self.calc_target(rewards, next_states, dones)
critic1_q_values = self.critic_1(states).gather(1, actions)
critic1_loss = torch.mean(F.mse_loss(critic1_q_values, td_target.detach()))
critic2_q_values = self.critic_2(states).gather(1, actions)
critic2_loss = torch.mean(F.mse_loss(critic2_q_values, td_target.detach()))
# 优化
self.critic_1_optimizer.zero_grad()
critic1_loss.backward()
self.critic_1_optimizer.step()
self.critic_2_optimizer.zero_grad()
critic2_loss.backward()
self.critic_2_optimizer.step()
# 更新策略网络
probs = self.actor(states)
log_probs = torch.log(probs + 1e-8)
# 直接根据概率计算熵
entropy = -torch.sum(probs * log_probs, dim=1, keepdim=True)
q1_value = self.critic_1(states)
q2_value = self.critic_2(states)
q_value = torch.min(q1_value, q2_value)
min_qvalue = torch.sum(probs * q_value, dim=1, keepdim=True)
# actor_loss
actor_loss = torch.mean(-self.log_alpha.exp() * entropy - min_qvalue)
# 优化
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 更新alpha的值
alpha_loss = torch.mean((entropy - target_entropy).detach() * self.log_alpha.exp())
self.log_alpha_optimizer.zero_grad()
alpha_loss.backward()
self.log_alpha_optimizer.step()
self.soft_update(self.critic_1, self.target_critic_1)
self.soft_update(self.critic_2, self.target_critic_2) | /rllife-1.0.3.tar.gz/rllife-1.0.3/life/policy/sac.py | 0.911098 | 0.560914 | sac.py | pypi |
import numpy as np
import random
class SumTree:
def __init__(self, capacity: int):
self.capacity = capacity # 叶子节点个数
self.data_pointer = 0
self.n_entries = 0
self.tree = np.zeros(2 * capacity - 1) # 树中总的节点个数
self.data = np.zeros(capacity, dtype=object)
def update(self, tree_idx, p):
"""Update the sampling weight
"""
change = p - self.tree[tree_idx]
self.tree[tree_idx] = p
while tree_idx != 0:
tree_idx = (tree_idx - 1) // 2
self.tree[tree_idx] += change
def add(self, p, data):
"""Adding new data to the sumTree
"""
tree_idx = self.data_pointer + self.capacity - 1
self.data[self.data_pointer] = data
# print ("tree_idx=", tree_idx)
# print ("nonzero = ", np.count_nonzero(self.tree))
self.update(tree_idx, p)
self.data_pointer += 1
if self.data_pointer >= self.capacity:
self.data_pointer = 0
if self.n_entries < self.capacity:
self.n_entries += 1
def get_leaf(self, v):
"""Sampling the data
"""
parent_idx = 0
while True:
cl_idx = 2 * parent_idx + 1
cr_idx = cl_idx + 1
if cl_idx >= len(self.tree):
leaf_idx = parent_idx
break
else:
if v <= self.tree[cl_idx]:
parent_idx = cl_idx
else:
v -= self.tree[cl_idx]
parent_idx = cr_idx
data_idx = leaf_idx - self.capacity + 1
return leaf_idx, self.tree[leaf_idx], self.data[data_idx]
def total(self):
return int(self.tree[0])
class ReplayTree:
"""ReplayTree for the per(Prioritized Experience Replay) DQN.
"""
def __init__(self, capacity):
self.capacity = capacity # the capacity for memory replay
self.tree = SumTree(capacity)
self.abs_err_upper = 1.
self.beta_increment_per_sampling = 0.001
self.alpha = 0.6
self.beta = 0.4
self.epsilon = 0.01
self.abs_err_upper = 1.
def __len__(self):
""" return the num of storage
"""
return self.tree.total()
def push(self, error, sample):
"""Push the sample into the replay according to the importance sampling weight
"""
p = (np.abs(error) + self.epsilon) ** self.alpha
self.tree.add(p, sample)
def sample(self, batch_size):
"""This is for sampling a batch data and the original code is from:
https://github.com/rlcode/per/blob/master/prioritized_memory.py
"""
pri_segment = self.tree.total() / batch_size
priorities = []
batch = []
idxs = []
self.beta = np.min([1., self.beta + self.beta_increment_per_sampling])
for i in range(batch_size):
a = pri_segment * i
b = pri_segment * (i + 1)
s = random.uniform(a, b)
idx, p, data = self.tree.get_leaf(s)
priorities.append(p)
batch.append(data)
idxs.append(idx)
sampling_probabilities = np.array(priorities) / self.tree.total()
is_weights = np.power(self.tree.n_entries * sampling_probabilities, -self.beta)
is_weights /= is_weights.max()
return zip(*batch), idxs, is_weights
def batch_update(self, tree_idx, abs_errors):
"""Update the importance sampling weight
"""
abs_errors += self.epsilon
clipped_errors = np.minimum(abs_errors, self.abs_err_upper)
ps = np.power(clipped_errors, self.alpha)
for ti, p in zip(tree_idx, ps):
self.tree.update(ti, p) | /rllife-1.0.3.tar.gz/rllife-1.0.3/life/utils/replay/per_replay_buffer.py | 0.605566 | 0.337913 | per_replay_buffer.py | pypi |
import torch
from torch import nn
import torch.nn.functional as F
class Discriminator(nn.Module):
"""判别器模型"""
def __init__(self, state_dim, hidden_dim, action_dim) -> None:
super().__init__()
self.fc1 = nn.Linear(state_dim + action_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
def forward(self, x, a):
cat = torch.cat([x, a], dim=1)
x = F.relu(self.fc1(cat))
return torch.sigmoid(self.fc2(x)) # 输出的是一个概率标量
class GAIL:
def __init__(self, agent, state_dim, action_dim, hidden_dim, lr_d, device, discriminator=Discriminator):
self.dicriminator = discriminator(state_dim, hidden_dim, action_dim).to(device)
self.dicriminator_optimizer = torch.optim.Adam(self.dicriminator.parameters(), lr=lr_d)
self.agent = agent
self.device = device
def learn(self, expert_s, expert_a, agent_s, agent_a, next_s, dones):
expert_states = torch.tensor(expert_s, dtype=torch.float).to(self.device)
expert_actions = torch.tensor(expert_a).to(self.device)
agent_states = torch.tensor(agent_s, dtype=torch.float).to(self.device)
agent_actions = torch.tensor(agent_a).to(self.device)
expert_actions = F.one_hot(expert_actions.to(torch.int64), num_classes=2).float() # 两个动作
agent_actions = F.one_hot(agent_actions.to(torch.int64), num_classes=2).float()
expert_prob = self.dicriminator(expert_states, expert_actions) # 前向传播,输出数据来自于专家的概率
agent_prob = self.dicriminator(agent_states, agent_actions)
# 计算判别器的损失
discriminator_loss = nn.BCELoss()(agent_prob, torch.ones_like(agent_prob)) + \
nn.BCELoss()(expert_prob, torch.zeros_like(expert_prob))
# 优化更新
self.dicriminator_optimizer.zero_grad()
discriminator_loss.backward()
self.dicriminator_optimizer.step()
# 将判别器的输出转换为策略的奖励信号
rewards = -torch.log(agent_prob).detach().cpu().numpy()
transition_dict = {
'states': agent_s,
'actions': agent_a,
'rewards': rewards, # 只有rewards改变了,换成了 概率(被判别器识破的概率)
'next_states': next_s,
'dones': dones
}
self.agent.update(transition_dict) | /rllife-1.0.3.tar.gz/rllife-1.0.3/life/imitation/gail.py | 0.897316 | 0.520679 | gail.py | pypi |
<div align=center>
<img src='./docs/assets/images/rllte-logo.png' style="width: 40%">
</div>
|<img src="https://img.shields.io/badge/License-MIT-%230677b8"> <img src="https://img.shields.io/badge/GPU-NVIDIA-%2377b900"> <img src="https://img.shields.io/badge/NPU-Ascend-%23c31d20"> <img src="https://img.shields.io/badge/Python-%3E%3D3.8-%2335709F"> <img src="https://img.shields.io/badge/Docs-Passing-%23009485"> <img src="https://img.shields.io/badge/Codestyle-Black-black"> <img src="https://img.shields.io/badge/PyPI%20Package-0.0.1-%23006DAD"> <img src="https://img.shields.io/badge/🤗Benchmark-HuggingFace-%23FFD21E"> <img src="https://img.shields.io/badge/Pytorch-%3E%3D2.0.0-%23EF5739"> <img src="https://img.shields.io/badge/Hydra-1.3.2-%23E88444"> <img src="https://img.shields.io/badge/Gymnasium-%3E%3D0.28.1-brightgreen"> <img src="https://img.shields.io/badge/DMC Suite-1.0.11-blue"> <img src="https://img.shields.io/badge/Procgen-0.10.7-blueviolet"> <img src="https://img.shields.io/badge/2.2.1-MiniGrid-%23c8c8c8"> <img src="https://img.shields.io/badge/PyBullet-3.2.5-%236A94D4"> <img src="https://img.shields.io/badge/Robosuite-1.4.0-%23b51800">|
|:-:|
**RLLTE: Long-Term Evolution Project of Reinforcement Learning** is inspired by the long-term evolution (LTE) standard project in telecommunications, which aims to track the latest research progress in reinforcement learning (RL) and provide stable and efficient baselines. In **rllte**, you can find everything you need in RL, such as training, evaluation, deployment, etc.
If you use **rllte** in your research, please cite this project like this:
``` tex
@software{rllte,
author = {Mingqi Yuan, Zequn Zhang, Yang Xu, Shihao Luo, Bo Li, Xin Jin, and Wenjun Zeng},
title = {RLLTE: Long-Term Evolution Project of Reinforcement Learning},
url = {https://github.com/RLE-Foundation/rllte},
year = {2023},
}
```
# Contents
- [Overview](#overview)
- [Quick Start](#quick-start)
- [Implemented Modules](#implemented-modules)
- [Benchmark](#benchmark)
- [API Documentation](#api-documentation)
- [How To Contribute](#how-to-contribute)
- [Acknowledgment](#acknowledgment)
# Overview
For the project tenet, please read [Evolution Tenet](https://docs.rllte.dev/tenet).
The highlight features of **rllte**:
- 👨✈️ Large language model-empowered copilot;
- ⏱️ Latest algorithms and tricks;
- 📕 Standard and sophisticated modules for redevelopment;
- 🧱 Highly modularized design for complete decoupling of RL algorithms;
- 🚀 Optimized workflow for full hardware acceleration;
- ⚙️ Support custom environments and modules;
- 🖥️ Support multiple computing devices like GPU and NPU;
- 🛠️ Support RL model engineering deployment (TensorRT, CANN, ...);
- 💾 Large number of reusable benchmarks (See [rllte-hub](https://hub.rllte.dev));
See the project structure below:
<div align=center>
<img src='./docs/assets/images/structure.svg' style="width: 100%">
</div>
- **[Common](https://docs.rllte.dev/common_index/)**: Base classes and auxiliary modules like logger and timer.
- **[Xploit](https://docs.rllte.dev/xploit_index/)**: Modules that focus on <font color="#B80000"><b>exploitation</b></font> in RL.
+ **Encoder**: *Neural nework-based encoders for processing observations.*
+ **Agent**: *Agents for interacting and learning.*
+ **Storage**: *Storages for storing collected experiences.*
- **[Xplore](https://docs.rllte.dev/xplore_index/)**: Modules that focus on <font color="#B80000"><b>exploration</b></font> in RL.
+ **Augmentation**: *PyTorch.nn-like modules for observation augmentation.*
+ **Distribution**: *Distributions for sampling actions.*
+ **Reward**: *Intrinsic reward modules for enhancing exploration.*
- **[Hub]()**: Reusable datasets and models.
- **[Env](https://docs.rllte.dev/env_index/)**: Packaged environments (e.g., Atari games) for fast invocation.
- **[Evaluation](https://docs.rllte.dev/evaluation_index/)**: Reasonable and reliable metrics for algorithm evaluation.
- **[Pre-training](https://docs.rllte.dev/pretraining_index/)**: Methods of <font color="#B80000"><b>pre-training</b></font> in RL.
- **[Deployment](https://docs.rllte.dev/deployment_index/)**: Methods of <font color="#B80000"><b>model deployment</b></font> in RL.
For more detiled descriptions of these modules, see [https://docs.rllte.dev/api](https://docs.rllte.dev/api)
# Quick Start
## Installation
- Prerequisites
Currently, we recommend `Python>=3.8`, and user can create an virtual environment by
``` sh
conda create -n rllte python=3.8
```
- with pip `recommended`
Open up a terminal and install **rllte** with `pip`:
``` shell
pip install rllte # basic installation
pip install rllte[envs] # for pre-defined environments
```
- with git
Open up a terminal and clone the repository from [GitHub](https://github.com/RLE-Foundation/rllte) with `git`:
``` sh
git clone https://github.com/RLE-Foundation/rllte.git
```
After that, run the following command to install package and dependencies:
``` sh
pip install -e . # basic installation
pip install -e .[envs] # for pre-defined environments
```
For more detailed installation instruction, see [https://docs.rllte.dev/getting_started](https://docs.rllte.dev/getting_started).
## Start Training
### On NVIDIA GPU
For example, we want to use [DrQ-v2](https://openreview.net/forum?id=_SJ-_yyes8) to solve a task of [DeepMind Control Suite](https://github.com/deepmind/dm_control), and it suffices to write a `train.py` like:
``` python
# import `env` and `agent` api
from rllte.env import make_dmc_env
from rllte.xploit.agent import DrQv2
if __name__ == "__main__":
device = "cuda:0"
# create env, `eval_env` is optional
env = make_dmc_env(env_id="cartpole_balance", device=device)
eval_env = make_dmc_env(env_id="cartpole_balance", device=device)
# create agent
agent = DrQv2(env=env,
eval_env=eval_env,
device='cuda',
tag="drqv2_dmc_pixel")
# start training
agent.train(num_train_steps=5000)
```
Run `train.py` and you will see the following output:
<div align=center>
<img src='./docs/assets/images/rl_training_gpu.png' style="filter: drop-shadow(0px 0px 7px #000);">
</div>
### On HUAWEI NPU
Similarly, if we want to train an agent on HUAWEI NPU, it suffices to replace `DrQv2` with `NpuDrQv2`:
``` python
# import `env` and `agent` api
from rllte.env import make_dmc_env
from rllte.xploit.agent import DrQv2
if __name__ == "__main__":
device = "npu:0"
# create env, `eval_env` is optional
env = make_dmc_env(env_id="cartpole_balance", device=device)
eval_env = make_dmc_env(env_id="cartpole_balance", device=device)
# create agent
agent = DrQv2(env=env,
eval_env=eval_env,
device='cuda',
tag="drqv2_dmc_pixel")
# start training
agent.train(num_train_steps=5000)
```
Then you will see the following output:
<div align=center>
<img src='./docs/assets/images/rl_training_npu.png' style="filter: drop-shadow(0px 0px 7px #000);">
</div>
> Please refer to [Implemented Modules](#implemented-modules) for the compatibility of NPU.
For more detailed tutorials, see [https://docs.rllte.dev/tutorials](https://docs.rllte.dev/tutorials).
# Implemented Modules
## RL Agents
<!-- |Module|Recurrent|Box|Discrete|MultiBinary|Multi Processing|NPU|Paper|Citations|
|:-|:-|:-|:-|:-|:-|:-|:-|:-|
|SAC|❌| ✔️ |❌|❌|❌|✔️ | [Link](http://proceedings.mlr.press/v80/haarnoja18b/haarnoja18b.pdf) |5077⭐|
|DrQ|❌| ✔️ |❌|❌|❌|✔️ | [Link](https://arxiv.org/pdf/2004.13649) |433⭐|
|DDPG|❌| ✔️ |❌|❌|❌|✔️ | [Link](https://arxiv.org/pdf/1509.02971.pdf?source=post_page---------------------------) |11819⭐|
|DrQ-v2|❌| ✔️ |❌|❌|❌|✔️ | [Link](https://arxiv.org/pdf/2107.09645.pdf?utm_source=morioh.com) |100⭐|
|PPO|❌| ✔️ |✔️|✔️|✔️|✔️ | [Link](https://arxiv.org/pdf/1707.06347) |11155⭐|
|DrAC|❌| ✔️ |✔️|✔️|✔️|✔️ | [Link](https://proceedings.neurips.cc/paper/2021/file/2b38c2df6a49b97f706ec9148ce48d86-Paper.pdf) |29⭐|
|DAAC|❌| ✔️ |✔️|✔️|✔️|✔️ | [Link](http://proceedings.mlr.press/v139/raileanu21a/raileanu21a.pdf) |56⭐|
|IMPALA|✔️| ✔️ |✔️|❌|✔️|🐌| [Link](http://proceedings.mlr.press/v80/espeholt18a/espeholt18a.pdf) |1219⭐| -->
<table>
<thead>
<tr>
<th>Type</th>
<th>Module</th>
<th>Recurrent</th>
<th>Box</th>
<th>Discrete</th>
<th>MultiBinary</th>
<th>Multi Processing</th>
<th>NPU</th>
<th>Paper</th>
<th>Citations</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="5">Original</td>
<td>SAC</td>
<td>❌</td>
<td>✔️</td>
<td>❌</td>
<td>❌</td>
<td>❌</td>
<td>✔️</td>
<td><a href="http://proceedings.mlr.press/v80/haarnoja18b/haarnoja18b.pdf" target="_blank" rel="noopener noreferrer">Link</a></td>
<td>5077⭐</td>
</tr>
<tr>
<td>DDPG</td>
<td>❌</td>
<td>✔️</td>
<td>❌</td>
<td>❌</td>
<td>❌</td>
<td>✔️</td>
<td><a href="https://arxiv.org/pdf/1509.02971.pdf?source=post_page---------------------------" target="_blank" rel="noopener noreferrer">Link</a></td>
<td>11819⭐</td>
</tr>
<tr>
<td>PPO</td>
<td>❌</td>
<td>✔️</td>
<td>✔️</td>
<td>✔️</td>
<td>✔️</td>
<td>✔️</td>
<td><a href="https://arxiv.org/pdf/1707.06347" target="_blank" rel="noopener noreferrer">Link</a></td>
<td>11155⭐</td>
</tr>
<tr>
<td>DAAC</td>
<td>❌</td>
<td>✔️</td>
<td>✔️</td>
<td>✔️</td>
<td>✔️</td>
<td>✔️</td>
<td><a href="http://proceedings.mlr.press/v139/raileanu21a/raileanu21a.pdf" target="_blank" rel="noopener noreferrer">Link</a></td>
<td>56⭐</td>
</tr>
<tr>
<td>IMPALA</td>
<td>✔️</td>
<td>✔️</td>
<td>✔️</td>
<td>❌</td>
<td>✔️</td>
<td>❌</td>
<td><a href="http://proceedings.mlr.press/v80/espeholt18a/espeholt18a.pdf" target="_blank" rel="noopener noreferrer">Link</a></td>
<td>1219⭐</td>
</tr>
<tr>
<td rowspan="3">Augmented</td>
<td>DrQ-v2</td>
<td>❌</td>
<td>✔️</td>
<td>❌</td>
<td>❌</td>
<td>❌</td>
<td>✔️</td>
<td><a href="https://arxiv.org/pdf/2107.09645.pdf?utm_source=morioh.com" target="_blank" rel="noopener noreferrer">Link</a></td>
<td>100⭐</td>
</tr>
<tr>
<td>DrQ</td>
<td>❌</td>
<td>✔️</td>
<td>❌</td>
<td>❌</td>
<td>❌</td>
<td>✔️</td>
<td><a href="https://arxiv.org/pdf/2004.13649" target="_blank" rel="noopener noreferrer">Link</a></td>
<td>433⭐</td>
</tr>
<tr>
<td>DrAC</td>
<td>❌</td>
<td>✔️</td>
<td>✔️</td>
<td>✔️</td>
<td>✔️</td>
<td>✔️</td>
<td><a href="https://proceedings.neurips.cc/paper/2021/file/2b38c2df6a49b97f706ec9148ce48d86-Paper.pdf" target="_blank" rel="noopener noreferrer">Link</a></td>
<td>29⭐</td>
</tr>
</tbody>
</table>
> - DrQ=SAC+Augmentation, DDPG=DrQ-v2-Augmentation, DrAC=PPO+Augmentation.
> - 🐌: Developing.
> - `NPU`: Support Neural-network processing unit.
> - `Recurrent`: Support recurrent neural network.
> - `Box`: A N-dimensional box that containes every point in the action space.
> - `Discrete`: A list of possible actions, where each timestep only one of the actions can be used.
> - `MultiBinary`: A list of possible actions, where each timestep any of the actions can be used in any combination.
## Intrinsic Reward Modules
| Module | Remark | Repr. | Visual | Reference |
|:-|:-|:-|:-|:-|
| PseudoCounts | Count-Based exploration |✔️|✔️|[Never Give Up: Learning Directed Exploration Strategies](https://arxiv.org/pdf/2002.06038) |
| ICM | Curiosity-driven exploration | ✔️|✔️| [Curiosity-Driven Exploration by Self-Supervised Prediction](http://proceedings.mlr.press/v70/pathak17a/pathak17a.pdf) |
| RND | Count-based exploration | ❌|✔️| [Exploration by Random Network Distillation](https://arxiv.org/pdf/1810.12894.pdf) |
| GIRM | Curiosity-driven exploration | ✔️ |✔️| [Intrinsic Reward Driven Imitation Learning via Generative Model](http://proceedings.mlr.press/v119/yu20d/yu20d.pdf)|
| NGU | Memory-based exploration | ✔️ |✔️| [Never Give Up: Learning Directed Exploration Strategies](https://arxiv.org/pdf/2002.06038) |
| RIDE| Procedurally-generated environment | ✔️ |✔️| [RIDE: Rewarding Impact-Driven Exploration for Procedurally-Generated Environments](https://arxiv.org/pdf/2002.12292)|
| RE3 | Entropy Maximization | ❌ |✔️| [State Entropy Maximization with Random Encoders for Efficient Exploration](http://proceedings.mlr.press/v139/seo21a/seo21a.pdf) |
| RISE | Entropy Maximization | ❌ |✔️| [Rényi State Entropy Maximization for Exploration Acceleration in Reinforcement Learning](https://ieeexplore.ieee.org/abstract/document/9802917/) |
| REVD | Divergence Maximization | ❌ |✔️| [Rewarding Episodic Visitation Discrepancy for Exploration in Reinforcement Learning](https://openreview.net/pdf?id=V2pw1VYMrDo)|
> - 🐌: Developing.
> - `Repr.`: The method involves representation learning.
> - `Visual`: The method works well in visual RL.
See [Tutorials: Use Intrinsic Reward and Observation Augmentation](https://docs.rllte.dev/tutorials/data_augmentation) for usage examples.
# Benchmark
**rllte** provides a large number of reusable bechmarks, see [https://hub.rllte.dev/](https://hub.rllte.dev/) and [https://docs.rllte.dev/benchmarks/](https://docs.rllte.dev/benchmarks/)
# API Documentation
View our well-designed documentation: [https://docs.rllte.dev/](https://docs.rllte.dev/)
# How To Contribute
Welcome to contribute to this project! Before you begin writing code, please read [CONTRIBUTING.md](https://github.com/RLE-Foundation/rllte/blob/main/CONTRIBUTING.md) for guide first.
# Acknowledgment
This project is supported by [The Hong Kong Polytechnic University](http://www.polyu.edu.hk/), [Eastern Institute for Advanced Study](http://www.eias.ac.cn/), and [FLW-Foundation](FLW-Foundation). [EIAS HPC](https://hpc.eias.ac.cn/) provides a GPU computing platform, and [Ascend Community](https://www.hiascend.com/) provides an NPU computing platform for our testing. Some code of this project is borrowed or inspired by several excellent projects, and we highly appreciate them. See [ACKNOWLEDGMENT.md](https://github.com/RLE-Foundation/rllte/blob/main/ACKNOWLEDGMENT.md).
| /rllte_core-0.0.1b1.tar.gz/rllte_core-0.0.1b1/README.md | 0.931103 | 0.957278 | README.md | pypi |
<div align=center>
<img src='/assets/images/structure.svg' style="width: 100%">
</div>
### <font color="#0053D6"><b>Common</b></font>: Auxiliary modules like trainer and logger.
- **Engine**: *Engine for building Hsuanwu application.*
- **Logger**: *Logger for managing output information.*
### <font color="#0053D6"><b>Xploit</b></font>: Modules that focus on <font color="#B80000"><b>exploitation</b></font> in RL.
+ **Agent**: *Agent for interacting and learning.*
| Module | Recurrent | Box | Discrete | MultiBinary | Multi Processing | NPU | Paper | Citations |
|---|---|---|---|---|---|---|---|---|
| SAC | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ | [Link](http://proceedings.mlr.press/v80/haarnoja18b/haarnoja18b.pdf) | 5077⭐ |
| DrQ | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ | [Link](https://arxiv.org/pdf/2004.13649) | 433⭐ |
| DDPG | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ | [Link](https://arxiv.org/pdf/1509.02971.pdf?source=post_page---------------------------) | 11819⭐ |
| DrQ-v2 | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ | [Link](https://arxiv.org/pdf/2107.09645.pdf?utm_source=morioh.com) | 100⭐ |
| DAAC | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | [Link](http://proceedings.mlr.press/v139/raileanu21a/raileanu21a.pdf) | 56⭐ |
| PPO | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | [Link](https://arxiv.org/pdf/1707.06347) | 11155⭐ |
| DrAC | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | [Link](https://proceedings.neurips.cc/paper/2021/file/2b38c2df6a49b97f706ec9148ce48d86-Paper.pdf) | 29⭐ |
| IMPALA | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ✔️ | [Link](http://proceedings.mlr.press/v80/espeholt18a/espeholt18a.pdf) | 1219⭐ |
!!! tip "Tips of Agent"
- 🐌: Developing.
- **NPU**: Support Neural-network processing unit.
- **Recurrent**: Support recurrent neural network.
- **Box**: A N-dimensional box that containes every point in the action space.
- **Discrete**: A list of possible actions, where each timestep only one of the actions can be used.
- **MultiBinary**: A list of possible actions, where each timestep any of the actions can be used in any combination.
+ **Encoder**: *Neural nework-based encoder for processing observations.*
|Module|Input|Reference|Target Task|
|:-|:-|:-|:-|
|EspeholtResidualEncoder|Images|[IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures](http://proceedings.mlr.press/v80/espeholt18a/espeholt18a.pdf)|Atari or Procgen games.|
|IdentityEncoder|States|N/A|DeepMind Control Suite: state|
|MnihCnnEncoder|Images|[Playing Atari with Deep Reinforcement Learning](https://arxiv.org/pdf/1312.5602.pdf?source=post_page---------------------------)|Atari games.|
|TassaCnnEncoder|Images|[DeepMind Control Suite](https://arxiv.org/pdf/1801.00690)|DeepMind Control Suite: pixel|
|PathakCnnEncoder|Images|[Curiosity-Driven Exploration by Self-Supervised Prediction](http://proceedings.mlr.press/v70/pathak17a/pathak17a.pdf)|Atari or MiniGrid games|
|VanillaMlpEncoder|States|N/A|DeepMind Control Suite: state|
!!! tip "Tips of Encoder"
- **Naming Rule**: 'Surname of the first author' + 'Backbone' + 'Encoder'
- **Input**: Input type.
- **Target Task**: The testing tasks in their paper or potential tasks.
+ **Storage**: *Storge for storing collected experiences.*
|Module|Remark|
|:-|:-|
|VanillaRolloutStorage|On-Policy RL|
|VanillaReplayStorage|Off-Policy RL|
|NStepReplayStorage|Off-Policy RL|
|PrioritizedReplayStorage|Off-Policy RL|
|DistributedStorage|Distributed RL|
### <font color="#0053D6"><b>Xplore</b></font>: Modules that focus on <font color="#B80000"><b>exploration</b></font> in RL.
+ **Augmentation**: *PyTorch.nn-like modules for observation augmentation.*
|Module|Input|Reference|
|:-|:-|:-|
|GaussianNoise|States| [Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
|RandomAmplitudeScaling|States|[Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
|GrayScale|Images|[Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
|RandomColorJitter|Images|[Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
|RandomConvolution|Images|[Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
|RandomCrop|Images|[Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
|RandomCutout|Images|[Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
|RandomCutoutColor|Images|[Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
|RandomFlip|Images|[Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
|RandomRotate|Images|[Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
|RandomShift|Images| [Mastering Visual Continuous Control: Improved Data-Augmented Reinforcement Learning](https://arxiv.org/pdf/2107.09645.pdf?utm_source=morioh.com)
|RandomTranslate|Images|[Reinforcement Learning with Augmented Data](https://proceedings.neurips.cc/paper/2020/file/e615c82aba461681ade82da2da38004a-Paper.pdf) |
+ **Distribution**: *Distributions for sampling actions.*
|Module|Type|Reference|
|:-|:-|:-|
|NormalNoise|Noise|[torch.distributions](https://pytorch.org/docs/stable/distributions.html)|
|OrnsteinUhlenbeckNoise|Noise|[Continuous Control with Deep Reinforcement Learning](https://arxiv.org/pdf/1509.02971.pdf?source=post_page---------------------------)|
|TruncatedNormalNoise|Noise|[Mastering Visual Continuous Control: Improved Data-Augmented Reinforcement Learning](https://arxiv.org/pdf/2107.09645.pdf?utm_source=morioh.com)|
|Bernoulli|Distribution|[torch.distributions](https://pytorch.org/docs/stable/distributions.html)|
|Categorical|Distribution|[torch.distributions](https://pytorch.org/docs/stable/distributions.html)|
|DiagonalGaussian|Distribution|[torch.distributions](https://pytorch.org/docs/stable/distributions.html)|
|SquashedNormal|Distribution|[torch.distributions](https://pytorch.org/docs/stable/distributions.html)|
!!! tip "Tips of Distribution"
- In Hsuanwu, the action noise is implemented via a `Distribution` manner to realize unification.
+ **Reward**: *Intrinsic reward modules for enhancing exploration.*
| Module | Remark | Repr. | Visual | Reference |
|:-|:-|:-|:-|:-|
| PseudoCounts | Count-Based exploration |✔️|✔️|[Never Give Up: Learning Directed Exploration Strategies](https://arxiv.org/pdf/2002.06038) |
| ICM | Curiosity-driven exploration | ✔️|✔️| [Curiosity-Driven Exploration by Self-Supervised Prediction](http://proceedings.mlr.press/v70/pathak17a/pathak17a.pdf) |
| RND | Count-based exploration | ❌|✔️| [Exploration by Random Network Distillation](https://arxiv.org/pdf/1810.12894.pdf) |
| GIRM | Curiosity-driven exploration | ✔️ |✔️| [Intrinsic Reward Driven Imitation Learning via Generative Model](http://proceedings.mlr.press/v119/yu20d/yu20d.pdf)|
| NGU | Memory-based exploration | ✔️ |✔️| [Never Give Up: Learning Directed Exploration Strategies](https://arxiv.org/pdf/2002.06038) |
| RIDE| Procedurally-generated environment | ✔️ |✔️| [RIDE: Rewarding Impact-Driven Exploration for Procedurally-Generated Environments](https://arxiv.org/pdf/2002.12292)|
| RE3 | Entropy Maximization | ❌ |✔️| [State Entropy Maximization with Random Encoders for Efficient Exploration](http://proceedings.mlr.press/v139/seo21a/seo21a.pdf) |
| RISE | Entropy Maximization | ❌ |✔️| [Rényi State Entropy Maximization for Exploration Acceleration in Reinforcement Learning](https://ieeexplore.ieee.org/abstract/document/9802917/) |
| REVD | Divergence Maximization | ❌ |✔️| [Rewarding Episodic Visitation Discrepancy for Exploration in Reinforcement Learning](https://openreview.net/pdf?id=V2pw1VYMrDo)|
!!! tip "Tips of Reward"
- **🐌**: Developing.
- **Repr.**: The method involves representation learning.
- **Visual**: The method works well in visual RL.
See [Tutorials: Use intrinsic reward and observation augmentation](./tutorials/data_augmentation.md) for usage examples.
### <font color="#0053D6"><b>Evaluation</b></font>: Reasonable and reliable metrics for algorithm <font color="#B80000"><b>evaluation</b></font>.
See [Tutorials: Evaluate your model](./tutorials/evaluation.md).
### <font color="#0053D6"><b>Env</b></font>: Packaged <font color="#B80000"><b>environments</b></font> (e.g., Atari games) for fast invocation.
|Module|Name|Remark|Reference|
|:-|:-|:-|:-|
|make_atari_env|Atari Games|Discrete control|[The Arcade Learning Environment: An Evaluation Platform for General Agents](https://www.jair.org/index.php/jair/article/download/10819/25823)|
|make_bullet_env|PyBullet Robotics Environments|Continuous control|[Pybullet: A Python Module for Physics Simulation for Games, Robotics and Machine Learning](https://docs.google.com/document/d/10sXEhzFRSnvFcl3XxNGhnD4N2SedqwdAvK3dsihxVUA)|
|make_dmc_env|DeepMind Control Suite|Continuous control|[DeepMind Control Suite](https://arxiv.org/pdf/1801.00690)|
|make_minigrid_env|MiniGrid Games|Discrete control|[Minimalistic Gridworld Environment for Gymnasium](https://github.com/Farama-Foundation/Minigrid)|
|make_procgen_env|Procgen Games|Discrete control|[Leveraging Procedural Generation to Benchmark Reinforcement Learning](http://proceedings.mlr.press/v119/cobbe20a/cobbe20a.pdf)|
|make_robosuite_env|Robosuite Robotics Environments|Continuous control|[Robosuite: A Modular Simulation Framework and Benchmark for Robot Learning](http://robosuite.ai/)|
### <font color="#0053D6"><b>Pre-training</b></font>: Methods of <font color="#B80000"><b>pre-training</b></font> in RL.
See [Tutorials: Pre-training in Hsuanwu](./tutorials/pre-training.md).
### <font color="#0053D6"><b>Deployment</b></font>: Methods of model <font color="#B80000"><b>deployment</b></font> in RL.
See [Tutorials: Deploy your model in inference devices](./tutorials/deployment.md). | /rllte_core-0.0.1b1.tar.gz/rllte_core-0.0.1b1/docs/api_old.md | 0.838051 | 0.761804 | api_old.md | pypi |
#
### plot_interval_estimates
[source](https://github.com/RLE-Foundation/rllte/blob/main/rllte/evaluation/visualization.py/#L141)
```python
.plot_interval_estimates(
metrics_dict: Dict[str, Dict], metric_names: List[str], algorithms: List[str],
colors: Optional[List[str]] = None, color_palette: str = 'colorblind',
max_ticks: float = 4, subfigure_width: float = 3.4, row_height: float = 0.37,
interval_height: float = 0.6, xlabel_y_coordinate: float = -0.16,
xlabel: str = 'NormalizedScore', **kwargs
)
```
---
Plots verious metrics of algorithms with stratified confidence intervals.
Based on: https://github.com/google-research/rliable/blob/master/rliable/plot_utils.py
See https://docs.rllte.dev/tutorials/evaluation/ for usage tutorials.
**Args**
* **metrics_dict** (Dict[str, Dict]) : The dictionary of various metrics of algorithms.
* **metric_names** (List[str]) : Names of the metrics corresponding to `metrics_dict`.
* **algorithms** (List[str]) : List of methods used for plotting.
* **colors** (Optional[List[str]]) : Maps each method to a color.
If None, then this mapping is created based on `color_palette`.
* **color_palette** (str) : `seaborn.color_palette` object for mapping each method to a color.
* **max_ticks** (float) : Find nice tick locations with no more than `max_ticks`. Passed to `plt.MaxNLocator`.
* **subfigure_width** (float) : Width of each subfigure.
* **row_height** (float) : Height of each row in a subfigure.
* **interval_height** (float) : Height of confidence intervals.
* **xlabel_y_coordinate** (float) : y-coordinate of the x-axis label.
* **xlabel** (str) : Label for the x-axis.
* **kwargs** : Arbitrary keyword arguments.
**Returns**
A matplotlib figure and an array of Axes.
----
### plot_performance_profile
[source](https://github.com/RLE-Foundation/rllte/blob/main/rllte/evaluation/visualization.py/#L331)
```python
.plot_performance_profile(
profile_dict: Dict[str, List], tau_list: np.ndarray,
use_non_linear_scaling: bool = False, figsize: Tuple[float, float] = (10.0, 5.0),
colors: Optional[List[str]] = None, color_palette: str = 'colorblind',
alpha: float = 0.15, xticks: Optional[Iterable] = None,
yticks: Optional[Iterable] = None,
xlabel: Optional[str] = 'NormalizedScore($\\tau$)',
ylabel: Optional[str] = 'Fractionofrunswithscore$>\\tau$',
linestyles: Optional[str] = None, **kwargs
)
```
---
Plots performance profiles with stratified confidence intervals.
Based on: https://github.com/google-research/rliable/blob/master/rliable/plot_utils.py
See https://docs.rllte.dev/tutorials/evaluation/ for usage tutorials.
**Args**
* **profile_dict** (Dict[str, List]) : A dictionary mapping a method to its performance.
* **tau_list** (np.ndarray) : 1D numpy array of threshold values on which the profile is evaluated.
* **use_non_linear_scaling** (bool) : Whether to scale the x-axis in proportion to the
number of runs within any specified range.
* **figsize** (Tuple[float]) : Size of the figure passed to `matplotlib.subplots`.
* **colors** (Optional[List[str]]) : Maps each method to a color. If None, then
this mapping is created based on `color_palette`.
* **color_palette** (str) : `seaborn.color_palette` object for mapping each method to a color.
* **alpha** (float) : Changes the transparency of the shaded regions corresponding to the confidence intervals.
* **xticks** (Optional[Iterable]) : The list of x-axis tick locations. Passing an empty list removes all xticks.
* **yticks** (Optional[Iterable]) : The list of y-axis tick locations between 0 and 1.
If None, defaults to `[0, 0.25, 0.5, 0.75, 1.0]`.
* **xlabel** (str) : Label for the x-axis.
* **ylabel** (str) : Label for the y-axis.
* **linestyles** (str) : Maps each method to a linestyle. If None, then the 'solid' linestyle is used for all methods.
* **kwargs** : Arbitrary keyword arguments for annotating and decorating the
figure. For valid arguments, refer to `_annotate_and_decorate_axis`.
**Returns**
A matplotlib figure and `axes.Axes` which contains the plot for performance profiles.
----
### plot_probability_improvement
[source](https://github.com/RLE-Foundation/rllte/blob/main/rllte/evaluation/visualization.py/#L221)
```python
.plot_probability_improvement(
poi_dict: Dict[str, List], pair_separator: str = '_', figsize: Tuple[float,
float] = (3.7, 2.1), colors: Optional[List[str]] = None,
color_palette: str = 'colorblind', alpha: float = 0.75, interval_height: float = 0.6,
xticks: Optional[Iterable] = [0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0],
xlabel: str = 'P(X>Y)', left_ylabel: str = 'AlgorithmX',
right_ylabel: str = 'AlgorithmY', **kwargs
)
```
---
Plots probability of improvement with stratified confidence intervals.
Based on: https://github.com/google-research/rliable/blob/master/rliable/plot_utils.py
See https://docs.rllte.dev/tutorials/evaluation/ for usage tutorials.
**Args**
* **poi_dict** (Dict[str, List]) : The dictionary of probability of improvements of different algorithms pairs.
* **pair_separator** (str) : Each algorithm pair name in dictionaries above is joined by a string separator.
For example, if the pairs are specified as 'X;Y', then the separator corresponds to ';'. Defaults to ','.
* **figsize** (Tuple[float]) : Size of the figure passed to `matplotlib.subplots`.
* **colors** (Optional[List[str]]) : Maps each method to a color. If None, then this mapping
is created based on `color_palette`.
* **color_palette** (str) : `seaborn.color_palette` object for mapping each method to a color.
* **interval_height** (float) : Height of confidence intervals.
* **alpha** (float) : Changes the transparency of the shaded regions corresponding to the confidence intervals.
* **xticks** (Optional[Iterable]) : The list of x-axis tick locations. Passing an empty list removes all xticks.
* **xlabel** (str) : Label for the x-axis.
* **left_ylabel** (str) : Label for the left y-axis. Defaults to 'Algorithm X'.
* **right_ylabel** (str) : Label for the left y-axis. Defaults to 'Algorithm Y'.
* **kwargs** : Arbitrary keyword arguments for annotating and decorating the
figure. For valid arguments, refer to `_annotate_and_decorate_axis`.
**Returns**
A matplotlib figure and `axes.Axes` which contains the plot for probability of improvement.
----
### plot_sample_efficiency_curve
[source](https://github.com/RLE-Foundation/rllte/blob/main/rllte/evaluation/visualization.py/#L409)
```python
.plot_sample_efficiency_curve(
sampling_dict: Dict[str, Dict], frames: np.ndarray, algorithms: List[str],
colors: Optional[List[str]] = None, color_palette: str = 'colorblind',
figsize: Tuple[float, float] = (3.7, 2.1),
xlabel: Optional[str] = 'NumberofFrames(inmillions)',
ylabel: Optional[str] = 'AggregateHumanNormalizedScore',
labelsize: str = 'xx-large', ticklabelsize: str = 'xx-large', **kwargs
)
```
---
Plots an aggregate metric with CIs as a function of environment frames.
Based on: https://github.com/google-research/rliable/blob/master/rliable/plot_utils.py
See https://docs.rllte.dev/tutorials/evaluation/ for usage tutorials.
**Args**
* **sampling_dict** (Dict[str, Dict]) : A dictionary of values with stratified confidence intervals in different frames.
* **frames** (np.ndarray) : Array containing environment frames to mark on the x-axis.
* **algorithms** (List[str]) : List of methods used for plotting.
* **colors** (Optional[List[str]]) : Maps each method to a color. If None, then this mapping
is created based on `color_palette`.
* **color_palette** (str) : `seaborn.color_palette` object for mapping each method to a color.
* **max_ticks** (float) : Find nice tick locations with no more than `max_ticks`. Passed to `plt.MaxNLocator`.
* **subfigure_width** (float) : Width of each subfigure.
* **row_height** (float) : Height of each row in a subfigure.
* **interval_height** (float) : Height of confidence intervals.
* **xlabel_y_coordinate** (float) : y-coordinate of the x-axis label.
* **xlabel** (str) : Label for the x-axis.
* **kwargs** : Arbitrary keyword arguments.
**Returns**
A matplotlib figure and an array of Axes.
| /rllte_core-0.0.1b1.tar.gz/rllte_core-0.0.1b1/docs/api_docs/evaluation/visualization.md | 0.939123 | 0.959913 | visualization.md | pypi |
# Model Evaluation
**rllte** provides evaluation methods based on:
> [Agarwal R, Schwarzer M, Castro P S, et al. Deep reinforcement learning at the edge of the statistical precipice[J]. Advances in neural information processing systems, 2021, 34: 29304-29320.](https://proceedings.neurips.cc/paper/2021/file/f514cec81cb148559cf475e7426eed5e-Paper.pdf)
We reconstruct and improve the code of the official repository [rliable](https://github.com/google-research/rliable), achieving higher convenience and efficiency.
## Download Data
- Suppose we want to evaluate algorithm performance on the [Procgen](https://github.com/openai/procgen) benchmark. First, download the data from
[rllte-hub](https://hub.rllte.dev/):
``` py title="example.py"
# load packages
from rllte.evaluation import Performance, Comparison, min_max_normalize
from rllte.evaluation import *
from rllte.hub.datasets import Procgen, Atari200M
import numpy as np
# load scores
procgen = Procgen()
procgen_scores = procgen.load_scores()
print(procgen_scores.keys())
# PPO-Normalized scores
ppo_norm_scores = dict()
MIN_SCORES = np.zeros_like(procgen_scores['PPO'])
MAX_SCORES = np.mean(procgen_scores['PPO'], axis=0)
for algo in procgen_scores.keys():
ppo_norm_scores[algo] = min_max_normalize(procgen_scores[algo],
min_scores=MIN_SCORES,
max_scores=MAX_SCORES)
# Output:
# dict_keys(['PPG', 'MixReg', 'PPO', 'IDAAC', 'PLR', 'UCB-DrAC'])
```
For each algorithm, this will return a `NdArray` of size (`10` x `16`) where scores[n][m] represent the score on run `n` of task `m`.
## Performance Evaluation
Import the performance evaluator:
``` py title="example.py"
perf = Performance(scores=ppo_norm_scores['PPO'],
get_ci=True # get confidence intervals
)
perf.aggregate_mean()
# Output:
# Computing confidence interval for aggregate MEAN...
# (1.0, array([[0.9737281 ], [1.02564405]]))
```
Available metrics:
|Metric|Remark|
|:-|:-|
|`.aggregate_mean`|Computes mean of sample mean scores per task.|
|`.aggregate_median`|Computes median of sample mean scores per task.|
|`.aggregate_og`|Computes optimality gap across all runs and tasks.|
|`.aggregate_iqm`|Computes the interquartile mean across runs and tasks.|
|`.create_performance_profile`|Computes the performance profilies.|
## Performance Comparison
`Comparison` module allows you to compare the performance between two algorithms:
``` py title="example.py"
comp = Comparison(scores_x=ppo_norm_scores['PPG'],
scores_y=ppo_norm_scores['PPO'],
get_ci=True)
comp.compute_poi()
# Output:
# Computing confidence interval for PoI...
# (0.8153125, array([[0.779375 ], [0.85000781]]))
```
This indicates the overall probability of imporvement of `PPG` over `PPO` is `0.8153125`.
Available metrics:
|Metric|Remark|
|:-|:-|
|`.compute_poi`|Compute the overall probability of imporvement of algorithm `X` over `Y`.|
## Visualization
### `.plot_interval_estimates`
`.plot_interval_estimates` can plot verious metrics of algorithms with stratified confidence intervals. Take [Procgen](https://github.com/openai/procgen) for example, we want to plot four reliable metrics computed by `Performance` evaluator:
```py title="example.py"
aggregate_performance_dict = {
"MEAN": {},
"MEDIAN": {},
"IQM": {},
"OG": {}
}
for algo in ppo_norm_scores.keys():
perf = Performance(scores=ppo_norm_scores[algo], get_ci=True)
aggregate_performance_dict['MEAN'][algo] = perf.aggregate_mean()
aggregate_performance_dict['MEDIAN'][algo] = perf.aggregate_median()
aggregate_performance_dict['IQM'][algo] = perf.aggregate_iqm()
aggregate_performance_dict['OG'][algo] = perf.aggregate_og()
fig, axes = plot_interval_estimates(aggregate_performance_dict,
metric_names=['MEAN', 'MEDIAN', 'IQM', 'OG'],
algorithms=['PPO', 'MixReg', 'UCB-DrAC', 'PLR', 'PPG', 'IDAAC'],
xlabel="PPO-Normalized Score")
fig.savefig('./plot_interval_estimates1.png', format='png', bbox_inches='tight')
fig, axes = plot_interval_estimates(aggregate_performance_dict,
metric_names=['MEAN', 'MEDIAN'],
algorithms=['PPO', 'MixReg', 'UCB-DrAC', 'PLR', 'PPG', 'IDAAC'],
xlabel="PPO-Normalized Score")
fig.savefig('./plot_interval_estimates2.png', format='png', bbox_inches='tight')
fig, axes = plot_interval_estimates(aggregate_performance_dict,
metric_names=['MEAN', 'MEDIAN'],
algorithms=['PPO', 'MixReg', 'UCB-DrAC', 'PLR', 'PPG', 'IDAAC'],
xlabel="PPO-Normalized Score")
fig.savefig('./plot_interval_estimates2.png', format='png', bbox_inches='tight')
```
The output figures are:
<div align=center>
<img src='../../assets/images/plot_interval_estimates1.png' style="filter: drop-shadow(0px 0px 7px #000);">
<img src='../../assets/images/plot_interval_estimates2.png' style="filter: drop-shadow(0px 0px 7px #000);">
<img src='../../assets/images/plot_interval_estimates3.png' style="filter: drop-shadow(0px 0px 7px #000);">
</div>
### `.plot_probability_improvement`
`.plot_probability_improvement` plots probability of improvement with stratified confidence intervals. An example is:
```py title="example.py"
pairs = [['IDAAC', 'PPG'], ['IDAAC', 'UCB-DrAC'], ['IDAAC', 'PPO'],
['PPG', 'PPO'], ['UCB-DrAC', 'PLR'],
['PLR', 'MixReg'], ['UCB-DrAC', 'MixReg'], ['MixReg', 'PPO']]
probability_of_improvement_dict = {}
for pair in pairs:
comp = Comparison(scores_x=ppo_norm_scores[pair[0]],
scores_y=ppo_norm_scores[pair[1]],
get_ci=True)
probability_of_improvement_dict['_'.join(pair)] = comp.compute_poi()
fig, ax = plot_probability_improvement(poi_dict=probability_of_improvement_dict)
fig.savefig('./plot_probability_improvement.png', format='png', bbox_inches='tight')
```
The output figure is:
<div align=center>
<img src='../../assets/images/plot_probability_improvement.png' style="filter: drop-shadow(0px 0px 7px #000);">
</div>
### `.plot_performance_profile`
`.plot_performance_profile` plots performance profiles with stratified confidence intervals. An example is:
```py title="example.py"
profile_dict = dict()
procgen_tau = np.linspace(0.5, 3.6, 101)
for algo in ppo_norm_scores.keys():
perf = Performance(scores=ppo_norm_scores[algo], get_ci=True, reps=2000)
profile_dict[algo] = perf.create_performance_profile(tau_list=procgen_tau)
fig, axes = plot_performance_profile(profile_dict,
procgen_tau,
figsize=(7, 5),
xlabel=r'PPO-Normalized Score $(\tau)$',
)
fig.savefig('./plot_performance_profile.png', format='png', bbox_inches='tight')
```
The output figure is:
<div align=center>
<img src='../../assets/images/plot_performance_profile.png' style="filter: drop-shadow(0px 0px 7px #000);">
</div>
### `.plot_sample_efficiency_curve`
`.plot_sample_efficiency_curve` plots an aggregate metric with CIs as a function of environment frames. An example is:
```py title="example.py"
ale_all_frames_scores_dict = Atari200M().load_curves()
frames = np.array([1, 10, 25, 50, 75, 100, 125, 150, 175, 200]) - 1
sampling_dict = dict()
for algo in ale_all_frames_scores_dict.keys():
sampling_dict[algo] = [[], [], []]
for frame in frames:
perf = Performance(ale_all_frames_scores_dict[algo][:, :, frame],
get_ci=True,
reps=2000)
value, CIs = perf.aggregate_iqm()
sampling_dict[algo][0].append(value)
sampling_dict[algo][1].append(CIs[0]) # lower bound
sampling_dict[algo][2].append(CIs[1]) # upper bound
sampling_dict[algo][0] = np.array(sampling_dict[algo][0]).reshape(-1)
sampling_dict[algo][1] = np.array(sampling_dict[algo][1]).reshape(-1)
sampling_dict[algo][2] = np.array(sampling_dict[algo][2]).reshape(-1)
algorithms = ['C51', 'DQN (Adam)', 'DQN (Nature)', 'Rainbow', 'IQN', 'REM', 'M-IQN', 'DreamerV2']
fig, axes = plot_sample_efficiency_curve(
sampling_dict,
frames+1,
figsize=(7, 4.5),
algorithms=algorithms,
xlabel=r'Number of Frames (in millions)',
ylabel='IQM Human Normalized Score')
fig.savefig('./plot_sample_efficiency_curve.png', format='png', bbox_inches='tight')
```
The output figure is:
<div align=center>
<img src='../../assets/images/plot_sample_efficiency_curve.png' style="filter: drop-shadow(0px 0px 7px #000);">
</div> | /rllte_core-0.0.1b1.tar.gz/rllte_core-0.0.1b1/docs/tutorials/evaluation.md | 0.946708 | 0.979629 | evaluation.md | pypi |
# Decoupling Algorithms by Module Replacement
## Decoupling Algorithms
The actual performance of an RL algorithm is affected by various factors (e.g., different network architectures and experience usage
strategies), which are difficult to quantify.
> Huang S, Dossa R F J, Raffin A, et al. The 37 Implementation Details of Proximal Policy Optimization[J]. The ICLR Blog Track 2023, 2022.
To address the problem, **rllte** has achieved complete decoupling of RL algorithms, and you can replace the following five parts using built-in or customized modules:
- **Encoder**: Moudles for processing observations and extracting features.
- **Storage**: Modules for storing and replaying collected experiences.
- **Distribution**: Modules for sampling actions.
- **Augmentation**: Modules for observations augmentation.
- **Reward**: Intrinsic reward modules for enhancing exploration.
!!! info
Despite **rllte** supports module replacement, it is not **mandatory** and will not affect the use of native algorithms.
## Module Replacement
For instance, we want to use [PPO](https://arxiv.org/pdf/1707.06347) agent to solve [Atari](https://www.jair.org/index.php/jair/article/download/10819/25823) games, it suffices to write `train.py` like:
``` py title="train.py"
from rllte.xploit.agent import PPO
from rllte.env import make_atari_env
if __name__ == "__main__":
# env setup
device = "cuda:0"
env = make_atari_env(device=device)
eval_env = make_atari_env(device=device)
# create agent
agent = PPO(env=env,
eval_env=eval_env,
device=device,
tag="ppo_atari")
# start training
agent.train(num_train_steps=5000)
```
Run `train.py` and you'll see the following output:
<div align=center>
<img src='../../assets/images/module_replacement1.png' style="filter: drop-shadow(0px 0px 7px #000);">
</div>
Suppose we want to use a `ResNet-based` encoder, it suffices to replace the encoder module using `.set` function:
``` py title="train.py"
from rllte.xploit.agent import PPO
from rllte.env import make_atari_env
from rllte.xploit.encoder import EspeholtResidualEncoder
if __name__ == "__main__":
# env setup
device = "cuda:0"
env = make_atari_env(device=device)
eval_env = make_atari_env(device=device)
# create agent
feature_dim = 512
agent = PPO(env=env,
eval_env=eval_env,
device=device,
tag="ppo_atari",
feature_dim=feature_dim)
# create a new encoder
encoder = EspeholtResidualEncoder(
observation_space=env.observation_space,
feature_dim=feature_dim)
# set the new encoder
agent.set(encoder=encoder)
# start training
agent.train(num_train_steps=5000)
```
Run `train.py` and you'll see the old `MnihCnnEncoder` has been replaced by `EspeholtResidualEncoder`:
<div align=center>
<img src='../../assets/images/module_replacement2.png' style="filter: drop-shadow(0px 0px 7px #000);">
</div>
For more replaceable modules, please refer to [https://docs.rllte.dev/api/](https://docs.rllte.dev/api/).
## Using Custom Modules
**rllte** is an open platform that supports custom modules. Just write a new module based on the `BaseClass`, then we can
insert it into an agent directly. Suppose we want to build a new encoder entitled `NewEncoder`. An example is
```py title="example.py"
from rllte.xploit.agent import PPO
from rllte.env import make_atari_env
from rllte.common.base_encoder import BaseEncoder
from gymnasium.spaces import Space
from torch import nn
import torch as th
class CustomEncoder(BaseEncoder):
"""Custom encoder.
Args:
observation_space (Space): The observation space of environment.
feature_dim (int): Number of features extracted.
Returns:
The new encoder instance.
"""
def __init__(self, observation_space: Space, feature_dim: int = 0) -> None:
super().__init__(observation_space, feature_dim)
obs_shape = observation_space.shape
assert len(obs_shape) == 3
self.trunk = nn.Sequential(
nn.Conv2d(obs_shape[0], 32, 3, stride=2), nn.ReLU(),
nn.Conv2d(32, 32, 3, stride=2), nn.ReLU(),
nn.Flatten(),
)
with th.no_grad():
sample = th.ones(size=tuple(obs_shape)).float()
n_flatten = self.trunk(sample.unsqueeze(0)).shape[1]
self.trunk.extend([nn.Linear(n_flatten, feature_dim), nn.ReLU()])
def forward(self, obs: th.Tensor) -> th.Tensor:
h = self.trunk(obs / 255.0)
return h.view(h.size()[0], -1)
if __name__ == "__main__":
# env setup
device = "cuda:0"
env = make_atari_env(device=device)
eval_env = make_atari_env(device=device)
# create agent
feature_dim = 512
agent = PPO(env=env,
eval_env=eval_env,
device=device,
tag="ppo_atari",
feature_dim=feature_dim)
# create a new encoder
encoder = CustomEncoder(observation_space=env.observation_space,
feature_dim=feature_dim)
# set the new encoder
agent.set(encoder=encoder)
# start training
agent.train(num_train_steps=5000)
```
Run `example.py` and you'll see the old `MnihCnnEncoder` has been replaced by `CustomEncoder`:
<div align=center>
<img src='../../assets/images/module_replacement3.png' style="filter: drop-shadow(0px 0px 7px #000);">
</div>
As for customizing modules like `Storage` and `Distribution`, etc., users should consider compatibility with specific algorithms. | /rllte_core-0.0.1b1.tar.gz/rllte_core-0.0.1b1/docs/tutorials/module_replacement.md | 0.790207 | 0.950365 | module_replacement.md | pypi |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.