
code stringlengths 114 1.05M | path stringlengths 3 312 | quality_prob float64 0.5 0.99 | learning_prob float64 0.2 1 | filename stringlengths 3 168 | kind stringclasses 1
value |
|---|---|---|---|---|---|
import multiprocessing
from rpyc_mem.client import RemoteModule, RpycMem
from rpyc_mem.connect import RpycMemConnect
from rpyc_mem.errors import RpycMemError
class RpycMemSession:
"""
``RpycMemSession`` brings ``RpycMemConnect``, ``RemoteModule`` and ``RpycMem`` under one
hood while enabling to create/manage remote objects efficiently. ``RpycMemSession`` will
repurpose the connection object for different operations. A similar raw RPyC connection
(underlying socket object is similar) when used in different processes may result in race
conditions (Refer https://github.com/tomerfiliba-org/rpyc/issues/482). ``RpycMemSession``
can deal with it by keeping track of processes. ``RpycMemSession`` has functionality for
creating ``RemoteModule`` object (singleton, accessible via ``rmod``) and ``RpycMem`` objects.
The underlying Rpyc Mem connection can be retrieved through ``rmem_conn`` property.
:param str hostname: RPyC memory service hostname
:param int port: RPyC memory service port
:param int max_retry: Number of times to retry upon connection failure (at session level).
:param int retry_delay: Retry delay in seconds between each re-connect attempt
:param bool ignore_version: Do not validate the server RPyC version with the client
:param bool process_safe: Create a new Rpyc Mem connection when the objects created by the
session are accessed by the process who is not the actual creator of the session.
"""
_DEFAULT = object()
def __init__(self, hostname, port, max_retry=4, retry_delay=3, ignore_version=False,
process_safe=True):
"""Initialize RpycMemSession"""
self.hostname = hostname
self.port = port
self.max_retry = max_retry
self.retry_delay = retry_delay
self.ignore_version = ignore_version
self.process_safe = process_safe
self._rmem_conn = None
self._process = multiprocessing.current_process().pid
self.rmod = RemoteModule(self._callable_rmem_conn)
@property
def rmem_conn(self):
"""
Return RpycMemConnection in a process-safe way (if set to True)
:return rpyc_mem.connect.RpycMemConnect:
"""
init_conn = False
# Check for process changes since the session creation
if self.process_safe:
curr_proc = multiprocessing.current_process().pid
if curr_proc != self._process:
self._process = curr_proc
init_conn = True
# Handle first time connection setup
if not self._rmem_conn:
init_conn = True
if init_conn:
self._rmem_conn = RpycMemConnect(
hostname=self.hostname, port=self.port, max_retry=self.max_retry,
retry_delay=self.retry_delay, ignore_version=self.ignore_version
)
return self._rmem_conn
def _callable_rmem_conn(self):
"""Callable wrapper around rmem_conn"""
return self.rmem_conn
def rmem(self, unique_key, robj=_DEFAULT, robj_gen=_DEFAULT):
"""
Create RpycMem object against the unique_key while using robj, robj_gen through
session's Rpyc memory connection
:param typing.Hashable unique_key: The unique-key for syncing the remote object with
Rpyc memory service.
:param typing.Any robj: The remote object to use for memoization (One among robj,
robj_gen should be passed).
:param typing.Callable robj_gen: The remote object generator to use for memoization
(One among robj, robj_gen should be passed).
:return:
"""
if not self._validate_obj_sources(robj, robj_gen):
raise RpycMemError('Either remote object or remote object generator should be passed')
if robj is not self._DEFAULT:
return RpycMem(
rmem_conn=self._callable_rmem_conn, unique_key=unique_key, robj=robj
)
else:
return RpycMem(
rmem_conn=self._callable_rmem_conn, unique_key=unique_key, robj_gen=robj_gen
)
@classmethod
def _validate_obj_sources(cls, robj, robj_gen):
"""
Validate object sources. Return False if both robj, robj_gen are set/not-set else True
:param typing.Any robj: Remote object
:param typing.Callable robj_gen: Remote object generator
:return:
"""
if (robj is cls._DEFAULT and robj_gen is cls._DEFAULT) or \
(robj is not cls._DEFAULT and robj_gen is not cls._DEFAULT):
return False
return True | /rpyc_mem-1.0.1-py3-none-any.whl/rpyc_mem/session/rpyc_mem_session.py | 0.800068 | 0.243806 | rpyc_mem_session.py | pypi |
import time
import rpyc
from rpyc_mem.errors import RpycMemConnError
class RpycMemConnect:
"""
Wrapper around ``rpyc.connect`` to connect with ``RpycMemService``. ``RpycMemConnect``
does some basic error recovery and validations on behalf of the user.
:param str hostname: RPyC memory service hostname
:param int port: RPyC memory service port
:param int max_retry: Number of times to retry upon connection failure.
:param int retry_delay: Retry delay in seconds between each re-connect attempt
:param bool ignore_version: Do not validate the server RPyC version with the client
.. automethod:: __getattr__
"""
_ROOT_ATTRS = [
'memoize', 'get', 'update', 'delete', 'is_memoized', 'remote_import',
'rpyc_version'
]
_RMEM_CONN_ERROR = RpycMemConnError('Unable to connect to RPyC memory service')
def __init__(self, hostname, port, max_retry=4, retry_delay=3, ignore_version=False):
"""Initialize RpycMemConnect object"""
self.hostname = hostname
self.port = port
self.max_retry = max_retry
self.retry_delay = retry_delay
self.ignore_version = ignore_version
# Setup connection with RPyC memory service
self.is_closed = False
self.rpyc_conn = None
self._retry = 0
self.wrapped_getattr = None
self.setup_rmem_conn()
# Verify client version with the server version
if not ignore_version:
srv_rpyc_ver = self.rpyc_version()
if srv_rpyc_ver != rpyc.__version__:
raise RpycMemConnError(
'Server RPyC version [%s] mismatches with the client version [%s]' %
(srv_rpyc_ver, rpyc.__version__)
)
def close(self):
"""
Close underlying RPyC connection. Exceptions are no more handled (until re-setup) after
this operation.
:return:
"""
try:
self.rpyc_conn.close()
except EOFError:
pass
self.is_closed = True
def rmem_except_handler(self, rmem_fn=None, on_reconnect=None):
"""
Function decorator for handling rpyc memory service related exceptions. Can be invoked as follows:
| + @rmem_except_handler -> sets on_reconnect to None
| + @rmem_except_handler(on_reconnect=reconnect_hook) -> sets on_reconnect to reconnect_hook
| + @rmem_except_handler() -> Same as @rmem_except_handler
| + @rmem_except_handler(func) -> Ambiguous case, breaks the code.
:param rmem_fn: Function to be wrapped
:param on_reconnect: Reconnect hook to be called when connection is re-established
:return: Wrapped function
"""
def fn_decorator(fn):
def wrapped_fn(*args, **kwargs):
# If connection is closed by calling close() dont handle any exceptions
if self.is_closed:
return fn(*args, **kwargs)
# Initiate rpyc memory connection setup if rpyc_conn is empty
just_now = False
if not self.rpyc_conn:
self.setup_rmem_conn()
just_now = True
try:
return fn(*args, **kwargs)
except EOFError:
if just_now:
raise self._RMEM_CONN_ERROR
# Retry for once after setting up connection freshly
self.setup_rmem_conn()
if on_reconnect:
# Call on_reconnect hook for special handling
on_reconnect()
try:
return fn(*args, **kwargs)
except EOFError:
raise self._RMEM_CONN_ERROR
return wrapped_fn
if rmem_fn:
return fn_decorator(rmem_fn)
else:
return fn_decorator
def setup_rmem_conn(self):
"""
Setup RPyC memory connection
:return:
"""
# Try closing stagnant connection
try:
self.rpyc_conn.close()
except: # noqa
pass
try:
self.rpyc_conn = rpyc.connect(self.hostname, self.port)
self.is_closed = False
self._retry = 0
except: # noqa
# Reset retry if exceeded max_retry (For this attempt of connection setup)
if self._retry > self.max_retry:
self._retry = 0
self._retry = self._retry + 1
if self._retry > self.max_retry:
raise self._RMEM_CONN_ERROR
# Retry connection setup after sleep
time.sleep(self.retry_delay)
self.setup_rmem_conn()
def __getattr__(self, name):
"""
Search an undefined attribute in underlying rpyc connection object (``rpyc_conn``).
The attributes of rpyc memory service are directly searched in ``rpyc_conn.root``.
Example: ``rmem_connect.get``, ``rmem_connect.root.get`` are similar
:param str name: The name of attribute to search in underlying rpyc memory connection.
:return:
"""
if not self.wrapped_getattr:
@self.rmem_except_handler
def fn(arg):
if arg in self._ROOT_ATTRS:
return getattr(self.rpyc_conn.root, arg)
return getattr(self.rpyc_conn, arg)
self.wrapped_getattr = fn
return self.wrapped_getattr(name) | /rpyc_mem-1.0.1-py3-none-any.whl/rpyc_mem/connect/rpyc_mem_connect.py | 0.713232 | 0.210949 | rpyc_mem_connect.py | pypi |
import threading
from importlib import import_module
import rpyc
from rpyc.utils.server import ThreadedServer
from rpyc_mem.errors import RpycMemSvcError
class RpycMemService(rpyc.Service):
"""
RPyC memory service provides functionality to create named and unnamed python objects on remote
hosts (one which runs this service). The remote objects are created using remote modules (see
``remote_import``). By default all objects created are unnamed, they can be mapped against
unique_key to make them named. named objects can be managed using unique_key. This service is
intended to be run with ``rpyc.utils.server.ThreadingServer`` or variants of it to maintain one
snapshot of the memory
:param str hostname: Hostname on which the service is run. Runs on ``0.0.0.0`` by default.
:param int port: Port on which the service is run. Picks a random by default. Can be queried
back with ``self.server_obj.port`` (this is available only when the service is ran).
:param args: Left for ``RPyC`` during ``Service`` initialization
:param kwargs: Left for ``RPyC`` during ``Service`` initialization
"""
_ALLOWED_GET_ATTRS = [
'memoize', 'get', 'update', 'delete', 'is_memoized', 'remote_import',
'rpyc_version'
]
_DEFAULT = object()
_shm_lock = threading.Lock()
_sharedmem = dict()
def __init__(self, hostname=None, port=None, *args, **kwargs):
"""Initialize Rpyc memory service"""
super().__init__(*args, **kwargs)
self.hostname = hostname
self.port = port
self.server_obj = None
def run(self, server=None, server_kwargs=None):
"""
Run the RPyC memory service. The ``host`` and ``port`` used are picked from the ``__init__``
configuration. By default ``ThreadingServer`` is used, however this can be altered by
passing different ``server`` and associated ``server_kwargs``.
:param server: The server to use for running the service.
:param server_kwargs: Update the default server arguments with these.
:return:
"""
if not server:
server = ThreadedServer
kwargs = {
'service': self.__class__,
'protocol_config': {
'allow_all_attrs': True,
'allow_setattr': True,
'allow_delattr': True
}
}
if self.hostname:
kwargs['hostname'] = self.hostname
if self.port:
kwargs['port'] = self.port
if server_kwargs:
kwargs.update(server_kwargs)
self.server_obj = server(**kwargs)
self.server_obj.start()
@classmethod
def memoize(cls, unique_key, robj=_DEFAULT, robj_gen=_DEFAULT):
"""
Memoize the mapping of remote object or remote object returned by the generator against
the unique_key
:param unique_key: The unique_key for creating/querying the mapping
:param typing.Any robj: The remote object for memoization (One among ``robj``, ``robj_gen``
should be passed)
:param typing.Callable robj_gen: The remote object generator for memoization (One among ``robj``,
``robj_gen`` should be passed)
:return: The memoized object
"""
if not cls._validate_obj_sources(robj, robj_gen):
raise RpycMemSvcError('Either object or object generator should be passed')
with cls._shm_lock:
if unique_key not in cls._sharedmem:
if robj is not cls._DEFAULT:
cls._sharedmem[unique_key] = robj
else:
cls._sharedmem[unique_key] = robj_gen() # noqa
return cls._sharedmem[unique_key]
@classmethod
def get(cls, unique_key):
"""
Get the remote object against the unique_key. Raise an exception if the mapping is not present
:param unique_key: The unique_key for querying the mapping
:return: The memoized object
"""
with cls._shm_lock:
if unique_key not in cls._sharedmem:
raise RpycMemSvcError('No remote object exists against the key')
return cls._sharedmem[unique_key]
@classmethod
def update(cls, unique_key, robj=_DEFAULT, robj_gen=_DEFAULT):
"""
Update the mapping with the remote object or remote object returned by the generator against
the unique_key (create new mapping if it doesnt exist)
:param unique_key: The unique_key for updating the mapping
:param typing.Any robj: The remote object for update (One among ``robj``, ``robj_gen`` should
be passed)
:param typing.Callable robj_gen: The remote object generator for update (One among ``robj``,
``robj_gen`` should be passed)
:return: The updated object
"""
if not cls._validate_obj_sources(robj, robj_gen):
raise RpycMemSvcError('Either object or object generator should be passed')
with cls._shm_lock:
if robj is not cls._DEFAULT:
cls._sharedmem[unique_key] = robj
else:
cls._sharedmem[unique_key] = robj_gen() # noqa
return cls._sharedmem[unique_key]
@classmethod
def delete(cls, unique_key):
"""
Delete the mapping against the unique_key. Raise an exception if the mapping is not present
:param unique_key: The unique_key for deleting the mapping
:return:
"""
with cls._shm_lock:
if unique_key not in cls._sharedmem:
raise RpycMemSvcError('No remote object exists against the key')
del cls._sharedmem[unique_key]
@classmethod
def is_memoized(cls, unique_key):
"""
Return ``True`` if a mapping exists against the unique_key
:param unique_key: The unique_key for querying the mapping
:return:
"""
with cls._shm_lock:
return unique_key in cls._sharedmem
@classmethod
def remote_import(cls, module, package=None):
"""
Make remote modules available to the clients, primarily for creating remote objects
:param str module: The module to import in absolute or relative terms (Ex: pkg.mod, ..mod)
:param str package: The package which acts as a base for resolving the module (should be set
when relative imports are used)
:return: Remote module
"""
return import_module(module, package)
@classmethod
def rpyc_version(cls):
"""
Return ``RPyC`` version of the server
:return:
"""
return rpyc.__version__
@classmethod
def _validate_obj_sources(cls, robj, robj_gen):
"""
Validate the object sources. Return False if both robj, robj_gen are set/not-set else True
:param robj: The remote object
:param robj_gen: The remote object generator
:return:
"""
if (robj is cls._DEFAULT and robj_gen is cls._DEFAULT) or \
(robj is not cls._DEFAULT and robj_gen is not cls._DEFAULT):
return False
return True
def _rpyc_getattr(self, name):
"""RPyC get attribute"""
if name in self._ALLOWED_GET_ATTRS:
return getattr(self, name)
raise AttributeError(
"'%s' object has no attribute '%s'" % (self.__class__.__name__, name)
)
def _rpyc_setattr(self, name, value):
"""RPyC set attribute"""
if name in self._ALLOWED_GET_ATTRS:
raise AttributeError('access denied')
raise AttributeError(
"'%s' object has no attribute '%s'" % (self.__class__.__name__, name)
)
def _rpyc_delattr(self, name):
"""RPyC delete attribute"""
if name in self._ALLOWED_GET_ATTRS:
raise AttributeError('access denied')
raise AttributeError(
"'%s' object has no attribute '%s'" % (self.__class__.__name__, name)
) | /rpyc_mem-1.0.1-py3-none-any.whl/rpyc_mem/service/rpyc_mem_service.py | 0.764012 | 0.238517 | rpyc_mem_service.py | pypi |
.. _theory:
Theory of Operation
===================
This is a short outline of the "Theory of Operation" of RPyC. It will introduce the main concepts
and terminology that's required in order to understand the library's internals.
Theory
------
The most fundamental concept of computer programming, which almost all operating systems
share, is the `process <http://en.wikipedia.org/wiki/Process_(computing)>`_.
A process is a unit of code and data, contained within an `address space
<http://en.wikipedia.org/wiki/address_space>`_ -- a region of (virtual) memory,
owned solely by that process. This ensures that all processes are isolated from one another,
so that they could run on the same hardware without interfering to each other.
While this isolation is essential to operating systems and the programming model we normally use,
it also has many downsides (most of which are out of the scope of this document).
Most importantly, from RPyC's perspective, processes impose artificial boundaries between
programs which forces programs to resort to monolithic structuring.
Several mechanism exist to overcome these boundaries, most notably
`remote procedure calls <http://en.wikipedia.org/wiki/Remote_procedure_call>`_.
Largely speaking, RPCs enable one process to execute code ("call procedures") that reside
outside of its address space (in another process) and be aware of their results.
Many such RPC frameworks exist, which all share some basic traits: they provide a way to
describe what functions are exposed, define a `serialization <http://en.wikipedia.org/wiki/serialization>`_
format, transport abstraction, and a client-side library/code-generator that allows clients
utilize these remote functions.
RPyC is *yet another RPC*. However, unlike most RPCs, RPyC is **transparent**. This may sound
like a rather weird virtue at first -- but this is the key to RPyC's power: you can "plug"
RPyC into existing code at (virtually) no cost. No need to write complicated definition files,
configure name servers, set up transport (HTTP) servers, or even use special invocation
syntax -- RPyC fits the python programming model like a glove. For instance, a function that
works on a local file object will work seamlessly on a remote file object -- it's
`duck-typing <http://en.wikipedia.org/wiki/Duck_typing>`_ to the extreme.
An interesting consequence of being transparent is **symmetry** -- there's no longer a
strict notion of what's a *server* as opposed to what's a *client* -- both the parties
may serve requests and dispatch replies; the server is simply the party that accepts incoming
connections -- but other than that, servers and clients are identical.
Being symmetrical opens the doors to lots of previously unheard-of features, like
`callback functions <http://en.wikipedia.org/wiki/Callback_(computer_science)>`_.
The result of these two properties is that local and remote objects are "equal in front of
the code": your program shouldn't even be aware of the "proximity" of object it is dealing with.
In other words, two processes connected by RPyC can be thought of as a **single process**.
I like to say that RPyC *unifies the address space* of both parties, although physically,
this address space may be split between several computers.
.. note::
The notion of address-space unification is mostly true for "classic RPyC";
with new-style RPyC, where services dominate, the analogy is of "unifying selected parts
of the address space".
In many situations, RPyC is employed in a master-slave relation, where the "client" takes
full control over the "server". This mainly allows the client to access remote resources
and perform operations on behalf of the server. However, RPyC can also be used as the basis
for `clustering <http://en.wikipedia.org/wiki/Cluster_(computing)>`_ and
`distributed computing <http://en.wikipedia.org/wiki/Distributed_computing>`_:
an array of RPyC servers on multiple machines can form a "huge computer" in terms of
computation power.
.. note::
This would require some sort of framework to distribute workload and guarantee
task completion. RPyC itself is just the mechanism.
Implementation
--------------
Boxing
^^^^^^
A major concept in the implementation of RPyC is *boxing*, which is a form of *serialization*
(encoding) that transfers objects between the two ends of the connection. Boxing relies on two
methods of serialization:
* `By Value <http://en.wikipedia.org/wiki/Evaluation_strategy#Call_by_value By>`_ -
simple, immutable python objects (like strings, integers, tuples, etc.) are passed
**by value**, meaning the value itself is passed to the other side. Since their value
cannot change, there is no restriction on duplicating them on both sides.
* `By Reference <http://en.wikipedia.org/wiki/Evaluation_strategy#Call_by_reference>`_ -
all other objects are passed **by reference**, meaning a "reference" to the object is
passed to the other side. This allows changes applied on the referencing (proxy) object
to be reflected on the actual object. Passing objects by reference also allows passing
of "location-aware" objects, like files or other operating system resources.
On the other side of the connection, the process of *unboxing* takes place: by-value data is
converted ("deserialized") to local objects, while by-reference data is converted
to *object proxies*.
Object Proxying
^^^^^^^^^^^^^^^
`Object proxying <http://en.wikipedia.org/wiki/Proxy_pattern>`_ is a technique of referencing
a remote object transparently: since the remote object cannot be transferred by-value,
a reference to it is passed. This reference is then wrapped by a special object,
called a *proxy* that "looks and behaves" just like the actual object (the *target*).
Any operation performed on the proxy is delivered transparently to the target, so that
code need not be aware of whether the object is local or not.
.. note::
RPyC uses the term ``netref`` (network reference) for a proxy object
Most of the operations performed on object proxies are *synchronous*, meaning the party that
issued the operation on the proxy waits for the operation to complete. However, sometimes
you want *asynchronous* mode of operation, especially when invoking remote functions which
might take a while to return their value. In this mode, you issue the operation and you
will later be notified of its completion, without having to block until it arrives.
RPyC supports both methods: proxy operations, are synchronous by default, but invocation
of remote functions can be made asynchronous by wrapping the proxy with an asynchronous
wrapper.
Services
^^^^^^^^
In older versions of RPyC, up to version 2.60 (now referred to as *classic RPyC*),
both parties had to "fully trust" each other and be "fully cooperative" -- there was no way
to limit the power of one party over the other. Either party could perform arbitrary
operations on the other, and there was no way to restrict it.
RPyC 3.0 introduced the concept of *services*. RPyC itself is only a "sophisticated
transport layer" -- it is a `mechanism <http://en.wikipedia.org/wiki/Separation_of_mechanism_and_policy>`_,
it does not set policies. RPyC allows each end of the connection to expose a (potentially
different) *service* that is responsible for the "policy", i.e., the set of supported operations.
For instance, *classic RPyC* is implemented by the ``SlaveService``, which grants arbitrary
access to all objects. Users of the library may define their own services, to meet their
requirements.
| /rpyc-op-3.2.1-openproximity.tar.gz/rpyc-op-3.2.1-openproximity/site/docs/theory.rst | 0.925179 | 0.863449 | theory.rst | pypi |
from rpyc.lib.compat import execute, is_py3k
class Service(object):
"""The service base-class. Derive from this class to implement custom RPyC
services:
* The name of the class implementing the ``Foo`` service should match the
pattern ``FooService`` (suffixed by the word 'Service') ::
class FooService(Service):
pass
FooService.get_service_name() # 'FOO'
FooService.get_service_aliases() # ['FOO']
* To supply a different name or aliases, use the ``ALIASES`` class attribute ::
class Foobar(Service):
ALIASES = ["foo", "bar", "lalaland"]
Foobar.get_service_name() # 'FOO'
Foobar.get_service_aliases() # ['FOO', 'BAR', 'LALALAND']
* Override :func:`on_connect` to perform custom initialization
* Override :func:`on_disconnect` to perform custom finalization
* To add exposed methods or attributes, simply define them normally,
but prefix their name by ``exposed_``, e.g. ::
class FooService(Service):
def exposed_add(self, x, y):
return x + y
* All other names (not prefixed by ``exposed_``) are local (not accessible
to the other party)
.. note::
You can override ``_rpyc_getattr``, ``_rpyc_setattr`` and ``_rpyc_delattr``
to change attribute lookup -- but beware of possible **security implications!**
"""
__slots__ = ["_conn"]
ALIASES = ()
def __init__(self, conn):
self._conn = conn
def on_connect(self):
"""called when the connection is established"""
pass
def on_disconnect(self):
"""called when the connection had already terminated for cleanup
(must not perform any IO on the connection)"""
pass
def _rpyc_getattr(self, name):
if name.startswith("exposed_"):
name = name
else:
name = "exposed_" + name
return getattr(self, name)
def _rpyc_delattr(self, name):
raise AttributeError("access denied")
def _rpyc_setattr(self, name, value):
raise AttributeError("access denied")
@classmethod
def get_service_aliases(cls):
"""returns a list of the aliases of this service"""
if cls.ALIASES:
return tuple(str(n).upper() for n in cls.ALIASES)
name = cls.__name__.upper()
if name.endswith("SERVICE"):
name = name[:-7]
return (name,)
@classmethod
def get_service_name(cls):
"""returns the canonical name of the service (which is its first
alias)"""
return cls.get_service_aliases()[0]
exposed_get_service_aliases = get_service_aliases
exposed_get_service_name = get_service_name
class VoidService(Service):
"""void service - an do-nothing service"""
__slots__ = ()
class ModuleNamespace(object):
"""used by the :class:`SlaveService` to implement the magical
'module namespace'"""
__slots__ = ["__getmodule", "__cache", "__weakref__"]
def __init__(self, getmodule):
self.__getmodule = getmodule
self.__cache = {}
def __getitem__(self, name):
if type(name) is tuple:
name = ".".join(name)
if name not in self.__cache:
self.__cache[name] = self.__getmodule(name)
return self.__cache[name]
def __getattr__(self, name):
return self[name]
class SlaveService(Service):
"""The SlaveService allows the other side to perform arbitrary imports and
execution arbitrary code on the server. This is provided for compatibility
with the classic RPyC (2.6) modus operandi.
This service is very useful in local, secure networks, but it exposes
a **major security risk** otherwise."""
__slots__ = ["exposed_namespace"]
def on_connect(self):
self.exposed_namespace = {}
self._conn._config.update(dict(
allow_all_attrs = True,
allow_pickle = True,
allow_getattr = True,
allow_setattr = True,
allow_delattr = True,
import_custom_exceptions = True,
instantiate_custom_exceptions = True,
instantiate_oldstyle_exceptions = True,
))
# shortcuts
self._conn.modules = ModuleNamespace(self._conn.root.getmodule)
self._conn.eval = self._conn.root.eval
self._conn.execute = self._conn.root.execute
self._conn.namespace = self._conn.root.namespace
if is_py3k:
self._conn.builtin = self._conn.modules.builtins
else:
self._conn.builtin = self._conn.modules.__builtin__
self._conn.builtins = self._conn.builtin
def exposed_execute(self, text):
"""execute arbitrary code (using ``exec``)"""
execute(text, self.exposed_namespace)
def exposed_eval(self, text):
"""evaluate arbitrary code (using ``eval``)"""
return eval(text, self.exposed_namespace)
def exposed_getmodule(self, name):
"""imports an arbitrary module"""
return __import__(name, None, None, "*")
def exposed_getconn(self):
"""returns the local connection instance to the other side"""
return self._conn | /rpyc-op-3.2.1-openproximity.tar.gz/rpyc-op-3.2.1-openproximity/rpyc/core/service.py | 0.818845 | 0.169063 | service.py | pypi |
from rpyc.lib import safe_import
from rpyc.lib.compat import Struct, BYTES_LITERAL
zlib = safe_import("zlib")
# * 64 bit length field?
# * separate \n into a FlushingChannel subclass?
# * add thread safety as a subclass?
class Channel(object):
"""Channel implementation.
Note: In order to avoid problems with all sorts of line-buffered transports,
we deliberately add ``\\n`` at the end of each frame.
"""
COMPRESSION_THRESHOLD = 3000
COMPRESSION_LEVEL = 1
FRAME_HEADER = Struct("!LB")
FLUSHER = BYTES_LITERAL("\n") # cause any line-buffered layers below us to flush
__slots__ = ["stream", "compress"]
def __init__(self, stream, compress = True):
self.stream = stream
if not zlib:
compress = False
self.compress = compress
def close(self):
"""closes the channel and underlying stream"""
self.stream.close()
@property
def closed(self):
"""indicates whether the underlying stream has been closed"""
return self.stream.closed
def fileno(self):
"""returns the file descriptor of the underlying stream"""
return self.stream.fileno()
def poll(self, timeout):
"""polls the underlying steam for data, waiting up to *timeout* seconds"""
return self.stream.poll(timeout)
def recv(self):
"""Receives the next packet (or *frame*) from the underlying stream.
This method will block until the packet has been read completely
:returns: string of data
"""
header = self.stream.read(self.FRAME_HEADER.size)
length, compressed = self.FRAME_HEADER.unpack(header)
data = self.stream.read(length + len(self.FLUSHER))[:-len(self.FLUSHER)]
if compressed:
data = zlib.decompress(data)
return data
def send(self, data):
"""Sends the given string of data as a packet over the underlying
stream. Blocks until the packet has been sent.
:param data: the byte string to send as a packet
"""
if self.compress and len(data) > self.COMPRESSION_THRESHOLD:
compressed = 1
data = zlib.compress(data, self.COMPRESSION_LEVEL)
else:
compressed = 0
header = self.FRAME_HEADER.pack(len(data), compressed)
buf = header + data + self.FLUSHER
self.stream.write(buf) | /rpyc-op-3.2.1-openproximity.tar.gz/rpyc-op-3.2.1-openproximity/rpyc/core/channel.py | 0.718792 | 0.197212 | channel.py | pypi |
import time
import threading
from rpyc.lib.colls import WeakValueDict
from rpyc.lib.compat import callable
from rpyc.core.consts import HANDLE_BUFFITER, HANDLE_CALL
from rpyc.core.netref import syncreq, asyncreq
def buffiter(obj, chunk = 10, max_chunk = 1000, factor = 2):
"""Buffered iterator - reads the remote iterator in chunks starting with
*chunk*, multiplying the chunk size by *factor* every time, as an
exponential-backoff, up to a chunk of *max_chunk* size.
``buffiter`` is very useful for tight loops, where you fetch an element
from the other side with every iterator. Instead of being limited by the
network's latency after every iteration, ``buffiter`` fetches a "chunk"
of elements every time, reducing the amount of network I/Os.
:param obj: An iterable object (supports ``iter()``)
:param chunk: the initial chunk size
:param max_chunk: the maximal chunk size
:param factor: the factor by which to multiply the chunk size after every
iterator (up to *max_chunk*). Must be >= 1.
:returns: an iterator
Example::
cursor = db.get_cursor()
for id, name, dob in buffiter(cursor.select("Id", "Name", "DoB")):
print id, name, dob
"""
if factor < 1:
raise ValueError("factor must be >= 1, got %r" % (factor,))
it = iter(obj)
count = chunk
while True:
items = syncreq(it, HANDLE_BUFFITER, count)
count = min(count * factor, max_chunk)
if not items:
break
for elem in items:
yield elem
def restricted(obj, attrs, wattrs = None):
"""Returns a 'restricted' version of an object, i.e., allowing access only to a subset of its
attributes. This is useful when returning a "broad" or "dangerous" object, where you don't
want the other party to have access to all of its attributes.
:param obj: any object
:param attrs: the set of attributes exposed for reading (``getattr``) or writing (``setattr``).
The same set will serve both for reading and writing, unless wattrs is explicitly
given.
:param wattrs: the set of attributes exposed for writing (``setattr``). If ``None``,
``wattrs`` will default to ``attrs``. To disable setting attributes completely,
set to an empty tuple ``()``.
:returns: a restricted view of the object
Example::
class MyService(rpyc.Service):
def exposed_open(self, filename):
f = open(filename, "r")
return rpyc.restricted(f, ["read", "close"]) # disallow access to `seek` or `write`
"""
if wattrs is None:
wattrs = attrs
class Restricted(object):
def _rpyc_getattr(self, name):
if name not in attrs:
raise AttributeError(name)
return getattr(obj, name)
__getattr__ = _rpyc_getattr
def _rpyc_setattr(self, name, value):
if name not in wattrs:
raise AttributeError(name)
setattr(obj, name, value)
__setattr__ = _rpyc_setattr
return Restricted()
class _Async(object):
"""Creates an async proxy wrapper over an existing proxy. Async proxies
are cached. Invoking an async proxy will return an AsyncResult instead of
blocking"""
__slots__ = ("proxy", "__weakref__")
def __init__(self, proxy):
self.proxy = proxy
def __call__(self, *args, **kwargs):
return asyncreq(self.proxy, HANDLE_CALL, args, tuple(kwargs.items()))
def __repr__(self):
return "async(%r)" % (self.proxy,)
_async_proxies_cache = WeakValueDict()
def async(proxy):
"""
Returns an asynchronous "version" of the given proxy. Invoking the returned
proxy will not block; instead it will return an
:class:`rpyc.core.async.AsyncResult` object that you can test for completion
:param proxy: any **callable** RPyC proxy
:returns: the proxy, wrapped by an asynchronous wrapper
Example::
async_sleep = rpyc.async(conn.modules.time.sleep)
res = async_sleep(5)
.. _async_note:
.. note::
In order to avoid overloading the GC, the returned asynchronous wrapper is
cached as a weak reference. Therefore, do not use::
rpyc.async(foo)(5)
Always store the returned asynchronous wrapper in a variable, e.g. ::
a_foo = rpyc.async(foo)
a_foo(5)
"""
pid = id(proxy)
if pid in _async_proxies_cache:
return _async_proxies_cache[pid]
if not hasattr(proxy, "____conn__") or not hasattr(proxy, "____oid__"):
raise TypeError("'proxy' must be a Netref: %r", (proxy,))
if not callable(proxy):
raise TypeError("'proxy' must be callable: %r" % (proxy,))
caller = _Async(proxy)
_async_proxies_cache[id(caller)] = _async_proxies_cache[pid] = caller
return caller
async.__doc__ = _Async.__doc__
class timed(object):
"""Creates a timed asynchronous proxy. Invoking the timed proxy will
run in the background and will raise an :class:`rpyc.core.async.AsyncResultTimeout`
exception if the computation does not terminate within the given time frame
:param proxy: any **callable** RPyC proxy
:param timeout: the maximal number of seconds to allow the operation to run
:returns: a ``timed`` wrapped proxy
Example::
t_sleep = rpyc.timed(conn.modules.time.sleep, 6) # allow up to 6 seconds
t_sleep(4) # okay
t_sleep(8) # will time out and raise AsyncResultTimeout
"""
__slots__ = ("__weakref__", "proxy", "timeout")
def __init__(self, proxy, timeout):
self.proxy = async(proxy)
self.timeout = timeout
def __call__(self, *args, **kwargs):
res = self.proxy(*args, **kwargs)
res.set_expiry(self.timeout)
return res
def __repr__(self):
return "timed(%r, %r)" % (self.proxy.proxy, self.timeout)
class BgServingThread(object):
"""Runs an RPyC server in the background to serve all requests and replies
that arrive on the given RPyC connection. The thread is started upon the
the instantiation of the ``BgServingThread`` object; you can use the
:meth:`stop` method to stop the server thread
Example::
conn = rpyc.connect(...)
bg_server = BgServingThread(conn)
...
bg_server.stop()
"""
# these numbers are magical...
SERVE_INTERVAL = 0.0
SLEEP_INTERVAL = 0.1
def __init__(self, conn):
self._conn = conn
self._thread = threading.Thread(target = self._bg_server)
self._thread.setDaemon(True)
self._active = True
self._thread.start()
def __del__(self):
if self._active:
self.stop()
def _bg_server(self):
try:
while self._active:
self._conn.serve(self.SERVE_INTERVAL)
time.sleep(self.SLEEP_INTERVAL) # to reduce contention
except Exception:
if self._active:
raise
def stop(self):
"""stop the server thread. once stopped, it cannot be resumed. you will
have to create a new BgServingThread object later."""
assert self._active
self._active = False
self._thread.join()
self._conn = None | /rpyc-op-3.2.1-openproximity.tar.gz/rpyc-op-3.2.1-openproximity/rpyc/utils/helpers.py | 0.778228 | 0.330687 | helpers.py | pypi |
import sys
from rpyc.lib import safe_import
ssl = safe_import("ssl")
class AuthenticationError(Exception):
"""raised to signal a failed authentication attempt"""
pass
class SSLAuthenticator(object):
"""An implementation of the authenticator protocol for ``SSL``. The given
socket is wrapped by ``ssl.wrap_socket`` and is validated based on
certificates
:param keyfile: the server's key file
:param certfile: the server's certificate file
:param ca_certs: the server's certificate authority file
:param cert_reqs: the certificate requirements. By default, if ``ca_cert`` is
specified, the requirement is set to ``CERT_REQUIRED``;
otherwise it is set to ``CERT_NONE``
:param ciphers: the list of ciphers to use, or ``None``, if you do not wish
to restrict the available ciphers. New in Python 2.7/3.2
:param ssl_version: the SSL version to use
Refer to `ssl.wrap_socket <http://docs.python.org/dev/library/ssl.html#ssl.wrap_socket>`_
for more info.
"""
def __init__(self, keyfile, certfile, ca_certs = None, cert_reqs = None,
ssl_version = None, ciphers = None):
self.keyfile = keyfile
self.certfile = certfile
self.ca_certs = ca_certs
self.ciphers = ciphers
if cert_reqs is None:
if ca_certs:
self.cert_reqs = ssl.CERT_REQUIRED
else:
self.cert_reqs = ssl.CERT_NONE
else:
self.cert_reqs = cert_reqs
if ssl_version is None:
self.ssl_version = ssl.PROTOCOL_TLSv1
else:
self.ssl_version = ssl_version
def __call__(self, sock):
kwargs = dict(keyfile = self.keyfile, certfile = self.certfile,
server_side = True, ca_certs = self.ca_certs, cert_reqs = self.cert_reqs,
ssl_version = self.ssl_version)
if self.ciphers is not None:
kwargs["ciphers"] = self.ciphers
try:
sock2 = ssl.wrap_socket(sock, **kwargs)
except ssl.SSLError:
ex = sys.exc_info()[1]
raise AuthenticationError(str(ex))
return sock2, sock2.getpeercert() | /rpyc-op-3.2.1-openproximity.tar.gz/rpyc-op-3.2.1-openproximity/rpyc/utils/authenticators.py | 0.430387 | 0.198724 | authenticators.py | pypi |
import socket
import threading
try:
from thread import interrupt_main
except ImportError:
from _thread import interrupt_main
from rpyc import Connection, Channel, SocketStream, TunneledSocketStream, PipeStream, VoidService
from rpyc.utils.registry import UDPRegistryClient
from rpyc.lib import safe_import
ssl = safe_import("ssl")
class DiscoveryError(Exception):
pass
#------------------------------------------------------------------------------
# API
#------------------------------------------------------------------------------
def connect_channel(channel, service = VoidService, config = {}):
"""creates a connection over a given channel
:param channel: the channel to use
:param service: the local service to expose (defaults to Void)
:param config: configuration dict
:returns: an RPyC connection
"""
return Connection(service, channel, config = config)
def connect_stream(stream, service = VoidService, config = {}):
"""creates a connection over a given stream
:param stream: the stream to use
:param service: the local service to expose (defaults to Void)
:param config: configuration dict
:returns: an RPyC connection
"""
return connect_channel(Channel(stream), service = service, config = config)
def connect_pipes(input, output, service = VoidService, config = {}):
"""
creates a connection over the given input/output pipes
:param input: the input pipe
:param output: the output pipe
:param service: the local service to expose (defaults to Void)
:param config: configuration dict
:returns: an RPyC connection
"""
return connect_stream(PipeStream(input, output), service = service, config = config)
def connect_stdpipes(service = VoidService, config = {}):
"""
creates a connection over the standard input/output pipes
:param service: the local service to expose (defaults to Void)
:param config: configuration dict
:returns: an RPyC connection
"""
return connect_stream(PipeStream.from_std(), service = service, config = config)
def connect(host, port, service = VoidService, config = {}, ipv6 = False):
"""
creates a socket-connection to the given host and port
:param host: the hostname to connect to
:param port: the TCP port to use
:param service: the local service to expose (defaults to Void)
:param config: configuration dict
:param ipv6: whether to use IPv6 or not
:returns: an RPyC connection
"""
s = SocketStream.connect(host, port, ipv6 = ipv6)
return connect_stream(s, service, config)
def ssl_connect(host, port, keyfile = None, certfile = None, ca_certs = None,
cert_reqs = None, ssl_version = None, ciphers = None,
service = VoidService, config = {}, ipv6 = False):
"""
creates an SSL-wrapped connection to the given host (encrypted and
authenticated).
:param host: the hostname to connect to
:param port: the TCP port to use
:param service: the local service to expose (defaults to Void)
:param config: configuration dict
:param ipv6: whether to create an IPv6 socket or an IPv4 one
The following arguments are passed directly to
`ssl.wrap_socket <http://docs.python.org/dev/library/ssl.html#ssl.wrap_socket>`_:
:param keyfile: see ``ssl.wrap_socket``. May be ``None``
:param certfile: see ``ssl.wrap_socket``. May be ``None``
:param ca_certs: see ``ssl.wrap_socket``. May be ``None``
:param cert_reqs: see ``ssl.wrap_socket``. By default, if ``ca_cert`` is specified,
the requirement is set to ``CERT_REQUIRED``; otherwise it is
set to ``CERT_NONE``
:param ssl_version: see ``ssl.wrap_socket``. The default is ``PROTOCOL_TLSv1``
:param ciphers: see ``ssl.wrap_socket``. May be ``None``. New in Python 2.7/3.2
:returns: an RPyC connection
"""
ssl_kwargs = {"server_side" : False}
if keyfile is not None:
ssl_kwargs["keyfile"] = keyfile
if certfile is not None:
ssl_kwargs["certfile"] = certfile
if ca_certs is not None:
ssl_kwargs["ca_certs"] = ca_certs
ssl_kwargs["cert_reqs"] = ssl.CERT_REQUIRED
if cert_reqs is not None:
ssl_kwargs["cert_reqs"] = cert_reqs
if ssl_version is None:
ssl_kwargs["ssl_version"] = ssl.PROTOCOL_TLSv1
else:
ssl_kwargs["ssl_version"] = ssl_version
if ciphers is not None:
ssl_kwargs["ciphers"] = ciphers
s = SocketStream.ssl_connect(host, port, ssl_kwargs, ipv6 = ipv6)
return connect_stream(s, service, config)
def _get_free_port():
"""attempts to find a free port"""
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(("localhost", 0))
_, port = s.getsockname()
s.close()
return port
def ssh_connect(sshctx, remote_port, service = VoidService, config = {}):
"""
Connects to an RPyC server over an SSH tunnel
:param sshctx: an :class:`rpyc.utils.ssh.SshContext` instance
:param remote_port: the port of the remote server
:param service: the local service to expose (defaults to Void)
:param config: configuration dict
:returns: an RPyC connection
"""
loc_port = _get_free_port()
tun = sshctx.tunnel(loc_port, remote_port)
stream = TunneledSocketStream.connect("localhost", loc_port)
stream.tun = tun
return Connection(service, Channel(stream), config = config)
def discover(service_name, host = None, registrar = None, timeout = 2):
"""
discovers hosts running the given service
:param service_name: the service to look for
:param host: limit the discovery to the given host only (None means any host)
:param registrar: use this registry client to discover services. if None,
use the default UDPRegistryClient with the default settings.
:param timeout: the number of seconds to wait for a reply from the registry
if no hosts are found, raises DiscoveryError
:raises: ``DiscoveryError`` if no server is found
:returns: a list of (ip, port) pairs
"""
if registrar is None:
registrar = UDPRegistryClient(timeout = timeout)
addrs = registrar.discover(service_name)
if not addrs:
raise DiscoveryError("no servers exposing %r were found" % (service_name,))
if host:
ips = socket.gethostbyname_ex(host)[2]
addrs = [(h, p) for h, p in addrs if h in ips]
if not addrs:
raise DiscoveryError("no servers exposing %r were found on %r" % (service_name, host))
return addrs
def connect_by_service(service_name, host = None, service = VoidService, config = {}):
"""create a connection to an arbitrary server that exposes the requested service
:param service_name: the service to discover
:param host: limit discovery to the given host only (None means any host)
:param service: the local service to expose (defaults to Void)
:param config: configuration dict
:raises: ``DiscoveryError`` if no server is found
:returns: an RPyC connection
"""
host, port = discover(service_name, host = host)[0]
return connect(host, port, service, config = config)
def connect_subproc(args, service = VoidService, config = {}):
"""runs an rpyc server on a child process that and connects to it over
the stdio pipes. uses the subprocess module.
:param args: the args to Popen, e.g., ["python", "-u", "myfile.py"]
:param service: the local service to expose (defaults to Void)
:param config: configuration dict
"""
from subprocess import Popen, PIPE
proc = Popen(args, stdin = PIPE, stdout = PIPE)
conn = connect_pipes(proc.stdout, proc.stdin, service = service, config = config)
conn.proc = proc # just so you can have control over the processs
return conn
def connect_thread(service = VoidService, config = {}, remote_service = VoidService, remote_config = {}):
"""starts an rpyc server on a new thread, bound to an arbitrary port,
and connects to it over a socket.
:param service: the local service to expose (defaults to Void)
:param config: configuration dict
:param server_service: the remote service to expose (of the server; defaults to Void)
:param server_config: remote configuration dict (of the server)
"""
listener = socket.socket()
listener.bind(("localhost", 0))
listener.listen(1)
def server(listener = listener):
client = listener.accept()[0]
listener.close()
conn = connect_stream(SocketStream(client), service = remote_service,
config = remote_config)
try:
conn.serve_all()
except KeyboardInterrupt:
interrupt_main()
t = threading.Thread(target = server)
t.setDaemon(True)
t.start()
host, port = listener.getsockname()
return connect(host, port, service = service, config = config) | /rpyc-op-3.2.1-openproximity.tar.gz/rpyc-op-3.2.1-openproximity/rpyc/utils/factory.py | 0.728265 | 0.209187 | factory.py | pypi |
import sys
import os
import inspect
import rpyc
from rpyc.lib.compat import pickle
from rpyc import SlaveService
from rpyc.utils import factory
SERVER_FILE = os.path.join(os.path.dirname(rpyc.__file__), "scripts", "rpyc_classic.py")
DEFAULT_SERVER_PORT = 18812
DEFAULT_SERVER_SSL_PORT = 18821
#===============================================================================
# connecting
#===============================================================================
def connect_channel(channel):
"""
Creates an RPyC connection over the given ``channel``
:param channel: the :class:`rpyc.core.channel.Channel` instance
:returns: an RPyC connection exposing ``SlaveService``
"""
return factory.connect_channel(channel, SlaveService)
def connect_stream(stream):
"""
Creates an RPyC connection over the given stream
:param channel: the :class:`rpyc.core.stream.Stream` instance
:returns: an RPyC connection exposing ``SlaveService``
"""
return factory.connect_stream(stream, SlaveService)
def connect_stdpipes():
"""
Creates an RPyC connection over the standard pipes (``stdin`` and ``stdout``)
:returns: an RPyC connection exposing ``SlaveService``
"""
return factory.connect_stdpipes(SlaveService)
def connect_pipes(input, output):
"""
Creates an RPyC connection over two pipes
:param input: the input pipe
:param output: the output pipe
:returns: an RPyC connection exposing ``SlaveService``
"""
return factory.connect_pipes(input, output, SlaveService)
def connect(host, port = DEFAULT_SERVER_PORT, ipv6 = False):
"""
Creates a socket connection to the given host and port.
:param host: the host to connect to
:param port: the TCP port
:param ipv6: whether to create an IPv6 socket or IPv4
:returns: an RPyC connection exposing ``SlaveService``
"""
return factory.connect(host, port, SlaveService, ipv6 = ipv6)
def ssl_connect(host, port = DEFAULT_SERVER_SSL_PORT, keyfile = None,
certfile = None, ca_certs = None, cert_reqs = None, ssl_version = None,
ciphers = None, ipv6 = False):
"""Creates a secure (``SSL``) socket connection to the given host and port,
authenticating with the given certfile and CA file.
:param host: the host to connect to
:param port: the TCP port to use
:param ipv6: whether to create an IPv6 socket or an IPv4 one
The following arguments are passed directly to
`ssl.wrap_socket <http://docs.python.org/dev/library/ssl.html#ssl.wrap_socket>`_:
:param keyfile: see ``ssl.wrap_socket``. May be ``None``
:param certfile: see ``ssl.wrap_socket``. May be ``None``
:param ca_certs: see ``ssl.wrap_socket``. May be ``None``
:param cert_reqs: see ``ssl.wrap_socket``. By default, if ``ca_cert`` is specified,
the requirement is set to ``CERT_REQUIRED``; otherwise it is
set to ``CERT_NONE``
:param ssl_version: see ``ssl.wrap_socket``. The default is ``PROTOCOL_TLSv1``
:param ciphers: see ``ssl.wrap_socket``. May be ``None``. New in Python 2.7/3.2
:returns: an RPyC connection exposing ``SlaveService``
.. _wrap_socket:
"""
return factory.ssl_connect(host, port, keyfile = keyfile, certfile = certfile,
ssl_version = ssl_version, ca_certs = ca_certs, service = SlaveService,
ipv6 = ipv6)
def ssh_connect(sshctx, remote_port):
"""Connects to the remote server over an SSH tunnel. See
:func:`rpyc.utils.factory.ssh_connect`.
:param sshctx: the :class:`rpyc.utils.ssh.SshContext` instance
:param remote_port: the remote TCP port
:returns: an RPyC connection exposing ``SlaveService``
"""
return factory.ssh_connect(sshctx, remote_port, SlaveService)
def connect_subproc():
"""Runs an RPyC classic server as a subprocess and return an RPyC
connection to it over stdio
:returns: an RPyC connection exposing ``SlaveService``
"""
return factory.connect_subproc([sys.executable, "-u", SERVER_FILE, "-q", "-m", "stdio"],
SlaveService)
def connect_thread():
"""
Starts a SlaveService on a thread and connects to it. Useful for testing
purposes. See :func:`rpyc.utils.factory.connect_thread`
:returns: an RPyC connection exposing ``SlaveService``
"""
return factory.connect_thread(SlaveService, remote_service = SlaveService)
#===============================================================================
# remoting utilities
#===============================================================================
def upload(conn, localpath, remotepath, filter = None, ignore_invalid = False, chunk_size = 16000):
"""uploads a file or a directory to the given remote path
:param localpath: the local file or directory
:param remotepath: the remote path
:param filter: a predicate that accepts the filename and determines whether
it should be uploaded; None means any file
:param chunk_size: the IO chunk size
"""
if os.path.isdir(localpath):
upload_dir(conn, localpath, remotepath, filter, chunk_size)
elif os.path.isfile(localpath):
upload_file(conn, localpath, remotepath, chunk_size)
else:
if not ignore_invalid:
raise ValueError("cannot upload %r" % (localpath,))
def upload_file(conn, localpath, remotepath, chunk_size = 16000):
lf = open(localpath, "rb")
rf = conn.builtin.open(remotepath, "wb")
while True:
buf = lf.read(chunk_size)
if not buf:
break
rf.write(buf)
lf.close()
rf.close()
def upload_dir(conn, localpath, remotepath, filter = None, chunk_size = 16000):
if not conn.modules.os.path.isdir(remotepath):
conn.modules.os.makedirs(remotepath)
for fn in os.listdir(localpath):
if not filter or filter(fn):
lfn = os.path.join(localpath, fn)
rfn = conn.modules.os.path.join(remotepath, fn)
upload(conn, lfn, rfn, filter = filter, ignore_invalid = True, chunk_size = chunk_size)
def download(conn, remotepath, localpath, filter = None, ignore_invalid = False, chunk_size = 16000):
"""
download a file or a directory to the given remote path
:param localpath: the local file or directory
:param remotepath: the remote path
:param filter: a predicate that accepts the filename and determines whether
it should be downloaded; None means any file
:param chunk_size: the IO chunk size
"""
if conn.modules.os.path.isdir(remotepath):
download_dir(conn, remotepath, localpath, filter)
elif conn.modules.os.path.isfile(remotepath):
download_file(conn, remotepath, localpath, chunk_size)
else:
if not ignore_invalid:
raise ValueError("cannot download %r" % (remotepath,))
def download_file(conn, remotepath, localpath, chunk_size = 16000):
rf = conn.builtin.open(remotepath, "rb")
lf = open(localpath, "wb")
while True:
buf = rf.read(chunk_size)
if not buf:
break
lf.write(buf)
lf.close()
rf.close()
def download_dir(conn, remotepath, localpath, filter = None, chunk_size = 16000):
if not os.path.isdir(localpath):
os.makedirs(localpath)
for fn in conn.modules.os.listdir(remotepath):
if not filter or filter(fn):
rfn = conn.modules.os.path.join(remotepath, fn)
lfn = os.path.join(localpath, fn)
download(conn, rfn, lfn, filter = filter, ignore_invalid = True)
def upload_package(conn, module, remotepath = None, chunk_size = 16000):
"""
uploads a module or a package to the remote party
:param conn: the RPyC connection to use
:param module: the local module/package object to upload
:param remotepath: the remote path (if ``None``, will default to the
remote system's python library (as reported by
``distutils``)
:param chunk_size: the IO chunk size
.. note:: ``upload_module`` is just an alias to ``upload_package``
example::
import foo.bar
...
rpyc.classic.upload_package(conn, foo.bar)
"""
if remotepath is None:
site = conn.modules["distutils.sysconfig"].get_python_lib()
remotepath = conn.modules.os.path.join(site, module.__name__)
localpath = os.path.dirname(inspect.getsourcefile(module))
upload(conn, localpath, remotepath, chunk_size = chunk_size)
upload_module = upload_package
def obtain(proxy):
"""obtains (copies) a remote object from a proxy object. the object is
``pickled`` on the remote side and ``unpickled`` locally, thus moved
**by value**. changes made to the local object will not reflect remotely.
:param proxy: an RPyC proxy object
.. note:: the remote object to must be ``pickle``-able
:returns: a copy of the remote object
"""
return pickle.loads(pickle.dumps(proxy))
def deliver(conn, localobj):
"""delivers (recreates) a local object on the other party. the object is
``pickled`` locally and ``unpickled`` on the remote side, thus moved
**by value**. changes made to the remote object will not reflect locally.
:param conn: the RPyC connection
:param localobj: the local object to deliver
.. note:: the object must be ``picklable``
:returns: a proxy to the remote object
"""
return conn.modules["rpyc.lib.compat"].pickle.loads(pickle.dumps(localobj))
class redirected_stdio(object):
"""
Redirects the other party's ``stdin``, ``stdout`` and ``stderr`` to
those of the local party, so remote IO will occur locally. It was
originally written as a ``contextmanager``, but was turned into a class
for compatibility with python 2.4
Here's the context-manager::
@contextmanager
def redirected_stdio(conn):
orig_stdin = conn.modules.sys.stdin
orig_stdout = conn.modules.sys.stdout
orig_stderr = conn.modules.sys.stderr
try:
conn.modules.sys.stdin = sys.stdin
conn.modules.sys.stdout = sys.stdout
conn.modules.sys.stderr = sys.stderr
yield
finally:
conn.modules.sys.stdin = orig_stdin
conn.modules.sys.stdout = orig_stdout
conn.modules.sys.stderr = orig_stderr
Example usage::
with redirected_stdio(conn):
# remote IO will occur locally
or ::
redir = redirected_stdio(conn)
try:
# remote IO will occur locally
finally:
redir.restore()
"""
def __init__(self, conn):
"""
:param conn: the RPyC connection whose stdio will be redirected
"""
self._restored = True
self.conn = conn
self.orig_stdin = self.conn.modules.sys.stdin
self.orig_stdout = self.conn.modules.sys.stdout
self.orig_stderr = self.conn.modules.sys.stderr
self.conn.modules.sys.stdin = sys.stdin
self.conn.modules.sys.stdout = sys.stdout
self.conn.modules.sys.stderr = sys.stderr
self._restored = False
def __del__(self):
self.restore()
def restore(self):
"""Restores the redirection"""
if self._restored:
return
self._restored = True
self.conn.modules.sys.stdin = self.orig_stdin
self.conn.modules.sys.stdout = self.orig_stdout
self.conn.modules.sys.stderr = self.orig_stderr
def __enter__(self):
return self
def __exit__(self, t, v, tb):
self.restore()
def pm(conn):
"""same as ``pdb.pm()`` but on a remote exception
:param conn: the RPyC connection
"""
#pdb.post_mortem(conn.root.getconn()._last_traceback)
redir = redirected_stdio(conn)
try:
conn.modules.pdb.post_mortem(conn.root.getconn()._last_traceback)
finally:
redir.restore()
def interact(conn, namespace = None):
"""remote interactive interpreter
:param conn: the RPyC connection
:param namespace: the namespace to use (a ``dict``)
"""
if namespace is None:
namespace = {}
namespace["conn"] = conn
redir = redirected_stdio(conn)
try:
conn.execute("""def _rinteract(ns):
import code
code.interact(local = dict(ns))""")
conn.namespace["_rinteract"](namespace)
finally:
redir.restore() | /rpyc-op-3.2.1-openproximity.tar.gz/rpyc-op-3.2.1-openproximity/rpyc/utils/classic.py | 0.65202 | 0.272109 | classic.py | pypi |
import argparse
import io
import logging
import os
import pickle
import pickletools
import re
import struct
import time
import zlib
from concurrent.futures import ThreadPoolExecutor
from hashlib import sha256
from typing import Callable
import plyvel
import requests
from ratelimit import limits, sleep_and_retry
import renpy.ast
import renpy.sl2.slast
import renpy.util
# A string at the start of each rpycv2 file.
RPYC2_HEADER = b"RENPY RPC2"
logger = logging.getLogger(__name__)
class GoogleTranslator:
"""
Google translate api wrapper
"""
session = requests.Session()
def __init__(self, src: str = "auto", dest: str = "zh-CN") -> None:
self.src_lang = src
self.dest_lang = dest
@sleep_and_retry
# limit calls per second
@limits(calls=5, period=1)
# google translate api is not free, so use cache
def translate(self, text: str) -> str:
"""
Translate text to dest language
"""
if text.strip() == "" or re.match(r"^[0-9\W]+$", text):
return text
forms = {
"client": "gtx",
"sl": self.src_lang,
"tl": self.dest_lang,
"dt": "t",
"q": text,
}
server = "https://translate.google.com"
resp = self.session.post(f"{server}/translate_a/single", data=forms)
if resp.status_code != 200:
raise ValueError(f"translate error: {resp.status_code}")
data = resp.json()
segments = ""
for sec in data[0]:
segments += sec[0]
return segments
class CachedTranslator:
"""
Translator wrapper with cache.
Use local disk cache to avoid translate same text again and again.
"""
cache = {}
_translate: Callable[[str], str]
def __init__(self, translator: Callable[[str], str], cache_dir=".cache") -> None:
self._translate = translator
self.cache = plyvel.DB(cache_dir, create_if_missing=True)
def translate(self, text: str) -> str:
"""
translate text and cache it
"""
start_time = time.time()
logger.debug(">>> [%s]", text)
cachekey = sha256(text.encode()).hexdigest().encode()
cached = self.cache.get(cachekey)
if cached:
decoded = cached.decode()
logger.debug("<-- [%s]", decoded)
return decoded
translated = self._translate(text)
self.cache.put(cachekey, translated.encode())
cost_time = time.time() - start_time
logger.debug("<<< [%s] [cost %f.2s]", translated, cost_time)
return translated
class CodeTranslator:
"""
Translate warpped for renpy code.
Parse text in renpy code(block, expr, text) and translate it.
"""
_translator: Callable[[str], str]
def __init__(self, translator: Callable[[str], str]) -> None:
"""
Parameters
----------
translator : Callable[[str], str]
translator function
"""
self.translator = translator
def _call_translate(self, line) -> str:
return self.translator(line)
def trans_placeholder(self, line) -> str:
"""
1. repalace placeholders with @
2. translate
3. replace back @ with placeholders
To avoid translate chars in placeholders
eg:
bad: {color=#ff0000}hello{/color} -> {颜色=#ff0000}你好{/颜色}
good: {color=#ff0000}hello{/color} -> @你好@ -> {color=#ff0000}你好{/color}
"""
ph_ch = "@" # placeholder char
phs = []
totranslate = ""
# {} []
braces, squares = [], []
for i, char in enumerate(line):
if i > 0 and line[i - 1] == "\\":
totranslate += char
continue
match char:
case "[":
squares.append(i)
case "]" if squares:
end = squares.pop()
if squares:
continue
phs.append(line[end : i + 1])
totranslate += ph_ch
case "{":
braces.append(i)
case "}" if braces:
end = braces.pop()
if braces:
continue
phs.append(line[end : i + 1])
totranslate += ph_ch
case _:
if not squares and not braces:
totranslate += char
translated = self._call_translate(totranslate) if totranslate else line
for placeholder in phs:
# translate in placeholder
# e.g. "{#r=hello}"
matched = re.search(r"{#\w=(.+?)}", placeholder)
if matched:
translated = self.trans_placeholder(matched.group(1))
placeholder = (
placeholder[: matched.start(1)]
+ translated
+ placeholder[matched.end(1) :]
)
translated = translated.replace(ph_ch, placeholder, 1)
return translated
def _on_text(self, text: str) -> str:
if text.strip() == "":
return text
if text[0] == '"' and text[-1] == '"':
return '"' + self._on_text(text[1:-1]) + '"'
if "%" in text: # format string
return text
result = self.trans_placeholder(text)
result = result.replace("%", "")
return result
def _on_expr(self, expr: str) -> str:
prev_end, dquoters = 0, []
result = ""
for i, char in enumerate(expr):
if i > 0 and expr[i - 1] == "\\":
continue
if char == '"':
if not dquoters:
result += expr[prev_end:i]
dquoters.append(i)
else:
result += self._on_text(expr[dquoters.pop() : i + 1])
prev_end = i + 1
result += expr[prev_end:]
return result
def _on_block(self, code: str) -> str:
"""
find strings in python expr and translate it
"""
results = []
for text in code.splitlines():
result = ""
prev_end = 0
# match _("hello") 's hello
for find in re.finditer(r'_\("(.+?)"\)', text):
start, group, end = find.start(1), find.group(1), find.end(1)
result += text[prev_end:start] + self._on_text(group)
prev_end = end
result += text[prev_end:]
results.append(result)
return "\n".join(results)
def translate(self, kind, text) -> str:
"""
translate text by kind
Parameters
----------
kind : str
text, expr, block
text : str
text to translate
"""
match kind:
case "text":
text = self._on_text(text)
case "expr":
text = self._on_expr(text)
case "block":
text = self._on_block(text)
case _:
text = self._on_text(text)
return text
def noop_translator(text: str) -> str:
"""
translate that do nothing but return text self
"""
return text
def walk_node(node, callback, **kwargs):
"""
callback: (kind, label, lang, old, new) -> translated
walk ast node and call callback on nodes that contains text/expr/block
"""
p_label, p_lang = kwargs.get("label"), kwargs.get("language")
if isinstance(node, renpy.ast.Translate):
pass
elif isinstance(node, renpy.ast.TranslateString):
node.new = callback(("text", p_label, node.language, node.old, node.new))
elif isinstance(node, renpy.ast.TranslateBlock):
pass
elif isinstance(node, renpy.ast.Say):
node.what = callback(("text", p_label, p_lang, node.what, None))
elif isinstance(node, renpy.sl2.slast.SLDisplayable):
if node.get_name() in ["text", "textbutton"]:
for i, val in enumerate(node.positional):
node.positional[i] = callback(("expr", p_lang, p_label, val, None))
elif isinstance(node, renpy.ast.Show):
pass
elif isinstance(node, renpy.ast.UserStatement):
pass
elif isinstance(node, renpy.ast.PyCode):
state = list(node.state)
state[1] = callback(("block", p_label, p_lang, state[1], None))
node.state = tuple(state)
elif isinstance(node, renpy.sl2.slast.SLBlock):
pass
elif isinstance(node, renpy.sl2.slast.SLUse):
if node.args:
for i, (name, val) in enumerate(node.args.arguments):
val = callback(("block", p_label, p_lang, val, None))
node.args.arguments[i] = (name, val)
elif isinstance(node, renpy.ast.Menu):
for i, item in enumerate(node.items):
_li = list(item)
_li[0] = callback(("text", p_label, p_lang, _li[0], None))
node.items[i] = tuple(_li)
def _do_consume(meta: tuple, cache: dict) -> str:
(_, label, _, old, new) = meta
key, val = label or old, new or old
return cache.get(key) or val
def _do_collect(meta: tuple, accept_lang: str, into: dict) -> str:
(kind, label, lang, old, new) = meta
key, val = label or old, new or old
if accept_lang and lang and lang != accept_lang:
return val
if lang or (not lang and key not in into):
into[key] = (kind, val)
return val
def _walk_callback(stmts, callback) -> str:
return renpy.util.get_code(
stmts,
modifier=lambda node, **kwargs: walk_node(node, callback, **kwargs),
)
def default_translator() -> Callable[[str], str]:
"""
default translator which use google translate api with CachedTranslator
"""
return CachedTranslator(GoogleTranslator().translate).translate
def translate_files(
base_dir: str,
files: list[str],
translator: Callable[[str], str],
include_tl_lang: str = "english",
concurent: int = 0,
) -> dict[str, str]:
"""
translate files and return a map of filename and code
"""
if not translator:
logger.info("using default translator")
translator = default_translator()
stmts_dict = {}
translations_dict = {}
# load translations
for filename in files:
logger.info("loading %s", filename)
stmts = load_file(os.path.join(base_dir, filename))
stmts_dict[filename] = stmts
_walk_callback(
stmts,
lambda meta: _do_collect(meta, include_tl_lang, translations_dict),
)
logger.info("loaded %d translations", len(translations_dict))
# translate
logger.info("translating")
results_dict = {}
code_translator = CodeTranslator(translator)
if concurent:
logger.info("translating with %d concurent", concurent)
with ThreadPoolExecutor(max_workers=concurent) as executor:
results = executor.map(
lambda item: (
item[0],
code_translator.translate(item[1][0], item[1][1]),
),
translations_dict.items(),
)
for label, result in results:
results_dict[label] = result
logger.info(
"translated %d/%d", len(results_dict), len(translations_dict)
)
else:
for label, (kind, text) in translations_dict.items():
results_dict[label] = code_translator.translate(kind, text)
logger.info("translated %d/%d", len(results_dict), len(translations_dict))
# generate code
code_files = {}
logger.info("generating code")
for filename, stmts in stmts_dict.items():
logger.info("gnerating code for %s", filename)
code_files[filename] = _walk_callback(
stmts, lambda meta: _do_consume(meta, results_dict)
)
return code_files
def translate(
input_path,
output_path=None,
translator: Callable[[str], str] = None,
include_tl_lang: str = "english",
concurent: int = 0,
):
"""
translate rpyc file or directory
"""
if os.path.isfile(input_path):
if not output_path:
output_path = input_path.removesuffix("c")
(_, code) = translate_files(
"",
[input_path],
translator=translator,
).popitem()
logger.info("writing %s", output_path)
write_file(output_path, code)
return
if not output_path:
output_path = input_path
matches = match_files(input_path, r".*\.rpym?c$")
file_codes = translate_files(
input_path,
matches,
translator=translator,
include_tl_lang=include_tl_lang,
concurent=concurent,
)
for filename, code in file_codes.items():
output_file = os.path.join(output_path, filename.removesuffix("c"))
logger.info("writing %s", output_file)
write_file(output_file, code)
def write_file(filename: str, data: str):
"""
write data to file
"""
if not os.path.exists(os.path.dirname(filename)):
os.makedirs(os.path.dirname(filename))
with open(filename, "w", encoding="utf-8") as file:
file.write(data)
def match_files(base_dir: str, pattern: str) -> list[str]:
"""
match files in dir with regex pattern
Parameters
----------
base_dir : str
directory to find in
pattern : str
regex pattern
Returns
-------
list[str]
matched filenames relative to base_dir
"""
if pattern == "":
pattern = ".*"
results = []
matched = re.compile(pattern)
for root, _, files in os.walk(base_dir):
for filename in files:
filename = os.path.relpath(os.path.join(root, filename), base_dir)
if matched.match(filename):
results.append(filename)
return results
def read_rpyc_data(file: io.FileIO, slot):
"""
Reads the binary data from `slot` in a .rpyc (v1 or v2) file. Returns
the data if the slot exists, or None if the slot does not exist.
"""
file.seek(0)
header_data = file.read(1024)
# Legacy path.
if header_data[: len(RPYC2_HEADER)] != RPYC2_HEADER:
if slot != 1:
return None
file.seek(0)
data = file.read()
return zlib.decompress(data)
# RPYC2 path.
pos = len(RPYC2_HEADER)
while True:
header_slot, start, length = struct.unpack("III", header_data[pos : pos + 12])
if slot == header_slot:
break
if header_slot == 0:
return None
pos += 12
file.seek(start)
data = file.read(length)
return zlib.decompress(data)
def load_file(filename, disasm: bool = False) -> renpy.ast.Node:
"""
load renpy code from rpyc file and return ast tree.
"""
ext = os.path.splitext(filename)[1]
if ext in [".rpy", ".rpym"]:
raise NotImplementedError(
"unsupport for pase rpy file or use renpy.parser.parse() in renpy's SDK"
)
if ext in [".rpyc", ".rpymc"]:
with open(filename, "rb") as file:
for slot in [1, 2]:
bindata = read_rpyc_data(file, slot)
if bindata:
if disasm:
disasm_file = filename + ".disasm"
with open(disasm_file, "w", encoding="utf-8") as disasm_f:
pickletools.dis(bindata, out=disasm_f)
_, stmts = pickle.loads(bindata)
return stmts
file.seek(0)
return None
def decompile_file(input_file, output_file=None):
"""
decompile rpyc file into rpy file and write to output.
"""
if not output_file:
output_file = input_file.removesuffix("c")
if not output_file.endswith(".rpy"):
output_file = os.path.join(
output_file, os.path.basename(input_file).removesuffix("c")
)
stmts = load_file(input_file)
code = renpy.util.get_code(stmts)
logger.info("writing %s", output_file)
write_file(output_file, code)
def decompile(input_path, output_path=None):
"""
decompile rpyc file or directory into rpy
Parameters
----------
input_path : str
path to rpyc file or directory contains rpyc files
output_path : str, optional
output path, by default it's same path of input_path.
"""
if not os.path.isdir(input_path):
decompile_file(input_path, output_path)
return
if not output_path:
output_path = input_path
for filename in match_files(input_path, r".*\.rpym?c$"):
decompile_file(
os.path.join(input_path, filename),
os.path.join(output_path, filename.removesuffix("c")),
)
def main():
"""
command line tool entry.
"""
logging.basicConfig(level=logging.INFO)
argparser = argparse.ArgumentParser()
argparser.add_argument(
"--concurent", "-n", type=int, default=0, help="concurent translate"
)
argparser.add_argument(
"--include-lang",
"-i",
default=None,
help="add items in tl/<lang> dir to translations",
)
argparser.add_argument(
"--verbose", "-v", action="store_true", help="verbose output"
)
argparser.add_argument(
"--translate", action="store_true", help="decompile and translate"
)
argparser.add_argument("src", nargs=1, help="rpyc file or directory")
argparser.add_argument("dest", nargs="?", help="output file or directory")
args = argparser.parse_args()
logging.basicConfig(level=logging.INFO)
if args.verbose:
logger.setLevel(logging.DEBUG)
if args.translate:
translate(
args.src[0],
args.dest,
concurent=args.concurent,
include_tl_lang=args.include_lang,
)
else:
decompile(args.src[0], args.dest)
if __name__ == "__main__":
main() | /rpycdec-0.1.1.tar.gz/rpycdec-0.1.1/rpycdec.py | 0.584864 | 0.162214 | rpycdec.py | pypi |
from . import ast
IDENT_CHAR = " "
def indent(code: str, level: int = 1) -> str:
return "".join(
map(
lambda x: f"{IDENT_CHAR * level}{x}",
filter(lambda x: x.strip(), code.splitlines(keepends=True)),
)
)
def get_code_properties(props: tuple | dict, newline: bool = False) -> str:
"""
:param keyword: tuple | dict
:param newline: bool
:return: str
>>> get_code_properties((("a", 1), ("b", 2)))
"a 1 b 2"
>>> get_code_properties((("a", 1), (None, b)), newline=True)
"a 1\\nb"
"""
list = []
if isinstance(props, dict):
props = props.items()
for k, v in props:
if v is None:
list.append(k)
else:
list.append(f"{k} {v}")
return ("\n" if newline else " ").join(list)
def __append_first_line(text, add) -> str:
lines = text.splitlines()
if lines:
v = lines[0]
i = len(v) - 1 if ":" in v else len(v)
lines[0] = v[:i] + add + v[i:]
return "\n".join(lines)
def get_code(node, **kwargs) -> str:
"""
Parameters
----------
node : ast.Node
kwargs : dict
indent : int
space indent level
modifier : Callable[[ast.Node], ast.Node]
modify node before get code
Returns
-------
str
generated code
Raises
------
NotImplementedError
if node type is not implemented or some attributes unable to handle.
"""
if isinstance(node, list):
rv = []
skip_next = 0
for idx, item in enumerate(node):
if skip_next > 0:
skip_next -= 1
continue
prev = node[idx - 1] if idx > 0 else None
next = node[idx + 1] if idx < len(node) - 1 else None
# TODO: it's a hack, fix it later
if (
isinstance(item, ast.Say)
and not item.interact
and isinstance(next, ast.Menu)
):
continue
if isinstance(item, ast.Label) and isinstance(next, ast.Menu):
if next.statement_start == item:
continue # skip label before menu
if isinstance(item, ast.With):
if item.paired:
continue
prevprev = node[idx - 2] if idx - 2 >= 0 else None
if isinstance(prevprev, ast.With) and prevprev.paired == item.expr:
rv[-1] = __append_first_line(rv[-1], f" with {item.expr}")
continue
if isinstance(item, ast.Label) and isinstance(prev, ast.Call):
rv[-1] = __append_first_line(rv[-1], f" from {item.name}")
if isinstance(next, ast.Pass):
# skip pass after call
skip_next += 1
continue
rv.append(get_code(item, **kwargs))
return "\n".join(rv)
# modify node before get code
modifier = kwargs.get("modifier")
if modifier:
modifier(node, **kwargs)
return node.get_code(**kwargs) | /rpycdec-0.1.1.tar.gz/rpycdec-0.1.1/renpy/util.py | 0.498535 | 0.294462 | util.py | pypi |
Introduction
============
`rq-dashboard` is a general purpose, lightweight,
[Flask](https://flask.palletsprojects.com/)-based web front-end to monitor your
[RQ](http://python-rq.org/) queues, jobs, and workers in realtime.
[](https://github.com/Parallels/rq-dashboard/actions/workflows/pr.yaml)
[](https://github.com/Parallels/rq-dashboard/actions/workflows/publish.yaml)
[](https://pypi.python.org/pypi/rq-dashboard)

Maturity notes
--------------
The RQ dashboard is currently being developed and is in beta stage.
How migrate to version 1.0 you can find [here](https://github.com/Parallels/rq-dashboard/wiki/How-to-migrate-to-1.0)
You can find help in the discussion page in [github]([http](https://github.com/Parallels/rq-dashboard)) or join our [discord server](https://discord.gg/reuhvMFT)
Installing with Docker
----------------------
You can also run the dashboard inside of docker:
* copy the ```docker-compose.yml``` file from the root of the repository to ```docker-compose.override.yml``` and change the environment variables to your liking.
* run the following command:
``` {.console}
$ docker-compose up
```
You can also find the official image on cjlapao/rq-dashboard:latest
Installing from PyPI
--------------------
``` {.console}
$ pip install rq-dashboard
```
Running the dashboard
---------------------
Run the dashboard standalone, like this:
``` {.console}
$ rq-dashboard
* Running on http://127.0.0.1:9181/
...
```
``` {.console}
$ rq-dashboard --help
Usage: rq-dashboard [OPTIONS]
Run the RQ Dashboard Flask server.
All configuration can be set on the command line or through environment
variables of the form RQ_DASHBOARD_*. For example RQ_DASHBOARD_USERNAME.
A subset of the configuration (the configuration parameters used by the
underlying flask blueprint) can also be provided in a Python module
referenced using --config, or with a .cfg file referenced by the
RQ_DASHBOARD_SETTINGS environment variable.
Options:
-b, --bind TEXT IP or hostname on which to bind HTTP server
-p, --port INTEGER Port on which to bind HTTP server
--url-prefix TEXT URL prefix e.g. for use behind a reverse
proxy
--username TEXT HTTP Basic Auth username (not used if not
set)
--password TEXT HTTP Basic Auth password
-c, --config TEXT Configuration file (Python module on search
path)
-u, --redis-url TEXT Redis URL. Can be specified multiple times.
Default: redis://127.0.0.1:6379
--poll-interval, --interval INTEGER
Refresh interval in ms
--extra-path TEXT Append specified directories to sys.path
--debug / --normal Enter DEBUG mode
-v, --verbose Enable verbose logging
--help Show this message and exit.
```
Integrating the dashboard in your Flask app
-------------------------------------------
The dashboard can be integrated in to your own [Flask](http://flask.pocoo.org/) app by accessing the blueprint directly in the normal way, e.g.:
``` {.python}
from flask import Flask
import rq_dashboard
app = Flask(__name__)
app.config.from_object(rq_dashboard.default_settings)
rq_dashboard.web.setup_rq_connection(app)
app.register_blueprint(rq_dashboard.blueprint, url_prefix="/rq")
@app.route("/")
def hello():
return "Hello World!"
if __name__ == "__main__":
app.run()
```
If you start the Flask app on the default port, you can access the
dashboard at <http://localhost:5000/rq>. The `cli.py:main` entry point
provides a simple working example.
Running on Heroku
-----------------
Consider using third-party project
[rq-dashboard-on-heroku](https://github.com/metabolize/rq-dashboard-on-heroku),
which installs rq-dashboard from PyPI and wraps in in
[Gunicorn](https://gunicorn.org) for deployment to Heroku.
rq-dashboard-on-heroku is maintained indepdently.
Running behind a Reverse Proxy
-------------------------------
You can run the dashboard as a `systemd` service in Linux or via a `suprevisor`
script and then use Apache or NGINX to direct traffic to the dashboard.
_This is for *non-production* functionality!_
Apache Reverse Proxy example:
```
ProxyPass /rq http://127.0.0.1:5001/rq
ProxyPassReverse /rq http://127.0.0.1:5001/rq
```
Systemd service example:
```
[Unit]
Description=Redis Queue Dashboard
[Install]
WantedBy=multi-user.target
[Service]
ExecStart=/bin/rq-dashboard -b 127.0.0.1 -p 5001 --url-prefix /rq -c rq_settings_dashboard --debug -v
StandardOutput=file:/var/log/redis/rq-dasbhoard.log
StandardError=file:/var/log/redis/rq-dashboard.log
User=redis-dash
Group=redis-dash
RemainAfterExit=yes
Type=simple
PermissionsStartOnly=false
PrivateTmp=no
```
* `--debug`,`-v` are optional -- they will write `stdout` to your specified files.
* `rq_settings_dashboard` is a Python file, with settings defined. You can use options that are available as environmental variables. (EX. `RQ_DASHBOARD_REDIS_PASSWORD = password`)
Developing
----------
Develop in a virtualenv and make sure you have all the necessary build
time (and run time) dependencies with
$ pip install -r requirements.txt
Develop in the normal way with
$ python setup.py develop
Stats
-----
- [PyPI stats](https://pypistats.org/packages/rq-dashboard)
- [Github stats](https://github.com/Parallels/rq-dashboard/graphs/traffic)
| /rq-dashboard-0.6.7.tar.gz/rq-dashboard-0.6.7/README.md | 0.703957 | 0.862988 | README.md | pypi |
# Python RQ Prometheus Exporter
[](https://pypi.org/project/rq-exporter/)
[](https://pypi.org/project/rq-exporter/)
[](https://libraries.io/pypi/rq-exporter)
[](https://hub.docker.com/r/mdawar/rq-exporter)
Prometheus metrics exporter for Python RQ (Redis Queue) job queue library.
[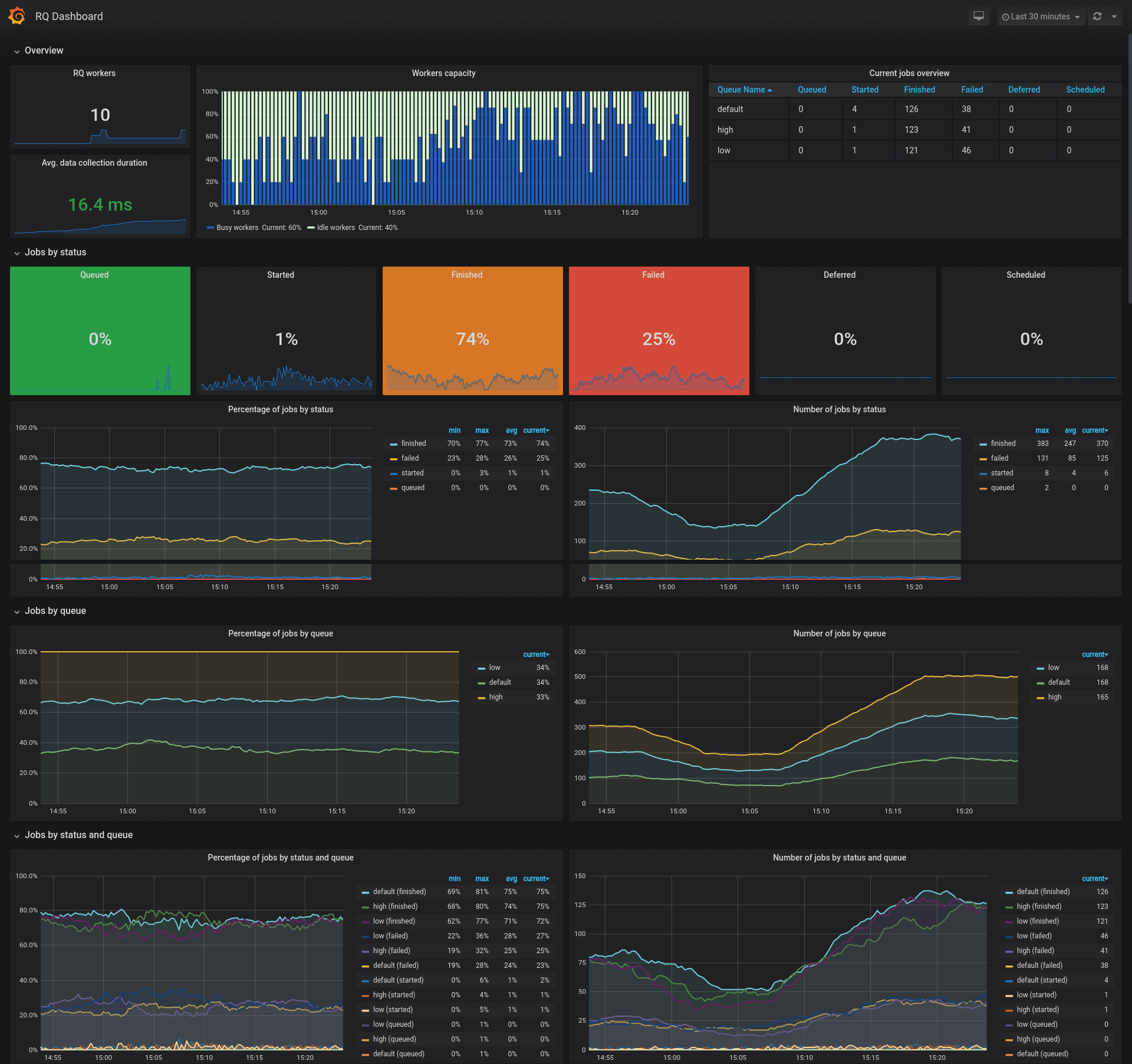](https://grafana.com/grafana/dashboards/12196)
## Installation
Install the Python package:
```sh
$ # Install the latest version
$ pip install rq-exporter
$ # Or install a specific version
$ pip install rq-exporter==2.1.0
```
Or download the [Docker image](https://hub.docker.com/r/mdawar/rq-exporter):
```sh
$ # Pull the latest image
$ docker pull mdawar/rq-exporter
$ # Or pull a specific version
$ docker pull mdawar/rq-exporter:v2.1.0
```
The releases are available as [Docker image tags](https://hub.docker.com/r/mdawar/rq-exporter/tags).
## Usage
**Python package**:
```sh
$ # Start the exporter on port 9726
$ rq-exporter
$ # Start the exporter on a specific port and host (Default: 0.0.0.0:9726)
$ rq-exporter --host localhost --port 8080
$ # By default the exporter will connect to Redis on `localhost` port `6379`
$ # You can specify a Redis URL
$ rq-exporter --redis-url redis://:123456@redis_host:6379/0
$ # Or specific Redis options (host, port, db, password)
$ rq-exporter --redis-host 192.168.1.10 --redis-port 6380 --redis-pass 123456 --redis-db 1
$ # You can also specify a password file path (eg: mounted Docker secret)
$ rq-exporter --redis-pass-file /run/secrets/redis_pass
```
**Docker image**:
```sh
$ # Run the exporter and publish the port 9726 on the host
$ docker run -it -p 9726:9726 rq-exporter
$ # Use the -d option to run the container in the background (detached)
$ docker run -d -p 9726:9726 rq-exporter
$ # All the command line arguments will be passed to rq-exporter
$ docker run -it -p 9726:9726 rq-exporter --redis-host redis --redis-pass 123456
$ # You can also configure the exporter using environment variables
$ docker run -it -p 9726:9726 -e RQ_REDIS_HOST=redis -e RQ_REDIS_PASS=123456 rq-exporter
```
## Grafana Dashboard
An example [**Grafana** dashboard](https://grafana.com/grafana/dashboards/12196) is available with the ID `12196` for showcasing this exporter's metrics.
You can also find the [JSON file of the dashboard](https://github.com/mdawar/rq-exporter/tree/master/grafana/rq-dashboard.json) in this repository.
**Note**:
- This is just an example dashboard, feel free to use it as a base for your custom dashboard
- You need to adjust the color thresholds to suit your needs for the job status percentage _singlestat_ panels
- Some panels might seem duplicated providing percentages and current values, these are just for showcasing the PromQL queries
## Exported Metrics
**RQ metrics:**
| Metric Name | Type | Labels | Description |
| ------------------------------- | ------- | ------------------------- | --------------------------------------- |
| `rq_workers` | Gauge | `name`, `queues`, `state` | RQ workers |
| `rq_jobs` | Gauge | `queue`, `status` | RQ jobs by queue and status |
| `rq_workers_success_total` | Counter | `name`, `queues` | Successful job count by worker |
| `rq_workers_failed_total` | Counter | `name`, `queues` | Failed job count by worker |
| `rq_workers_working_time_total` | Counter | `name`, `queues` | Total working time in seconds by worker |
**Request processing metrics:**
| Metric Name | Type | Description |
| --------------------------------------- | ------- | -------------------------------------------- |
| `rq_request_processing_seconds_count` | Summary | Number of times the RQ data were collected |
| `rq_request_processing_seconds_sum` | Summary | Total sum of time spent collecting RQ data |
| `rq_request_processing_seconds_created` | Gauge | Time created at (`time.time()` return value) |
Example:
```sh
# HELP rq_request_processing_seconds Time spent collecting RQ data
# TYPE rq_request_processing_seconds summary
rq_request_processing_seconds_count 1.0
rq_request_processing_seconds_sum 0.029244607000009637
# TYPE rq_request_processing_seconds_created gauge
rq_request_processing_seconds_created 1.5878023726039658e+09
# HELP rq_workers RQ workers
# TYPE rq_workers gauge
rq_workers{name="40d33ed9541644d79373765e661b7f38", queues="default", state="idle"} 1.0
rq_workers{name="fe9a433575e04685a53e4794b2eaeea9", queues="high,default,low", state="busy"} 1.0
# HELP rq_jobs RQ jobs by state
# TYPE rq_jobs gauge
rq_jobs{queue="default", status="queued"} 2.0
rq_jobs{queue="default", status="started"} 1.0
rq_jobs{queue="default", status="finished"} 5.0
rq_jobs{queue="default", status="failed"} 1.0
rq_jobs{queue="default", status="deferred"} 1.0
rq_jobs{queue="default", status="scheduled"} 2.0
```
## Configuration
You can configure the exporter using command line arguments or environment variables:
| CLI Argument | Env Variable | Default Value | Description |
| ------------------- | ------------------------- | ------------------------------------------------------- | ------------------------------------------------------------------------ |
| `--host` | `RQ_EXPORTER_HOST` | `0.0.0.0` | Serve the exporter on this host |
| `-p`, `--port` | `RQ_EXPORTER_PORT` | `9726` | Serve the exporter on this port |
| `--redis-url` | `RQ_REDIS_URL` | `None` | Redis URL in the form `redis://:[password]@[host]:[port]/[db]` |
| `--redis-host` | `RQ_REDIS_HOST` | `localhost` | Redis host name |
| `--redis-port` | `RQ_REDIS_PORT` | `6379` | Redis port number |
| `--redis-db` | `RQ_REDIS_DB` | `0` | Redis database number |
| `--sentinel-host` | `RQ_SENTINEL_HOST` | `None` | Redis Sentinel hosts separated by commas e.g `sentinel1,sentinel2:26380` |
| `--sentinel-port` | `RQ_SENTINEL_PORT` | `26379` | Redis Sentinel port, default port used when not set with the host |
| `--sentinel-master` | `RQ_SENTINEL_MASTER` | `master` | Redis Sentinel master name |
| `--redis-pass` | `RQ_REDIS_PASS` | `None` | Redis password |
| `--redis-pass-file` | `RQ_REDIS_PASS_FILE` | `None` | Redis password file path (e.g. Path of a mounted Docker secret) |
| `--worker-class` | `RQ_WORKER_CLASS` | `rq.Worker` | RQ worker class |
| `--queue-class` | `RQ_QUEUE_CLASS` | `rq.Queue` | RQ queue class |
| `--log-level` | `RQ_EXPORTER_LOG_LEVEL` | `INFO` | Logging level |
| `--log-format` | `RQ_EXPORTER_LOG_FORMAT` | `[%(asctime)s] [%(name)s] [%(levelname)s]: %(message)s` | Logging handler format string |
| `--log-datefmt` | `RQ_EXPORTER_LOG_DATEFMT` | `%Y-%m-%d %H:%M:%S` | Logging date/time format string |
**Notes**:
- When Redis URL is set using `--redis-url` or `RQ_REDIS_URL` the other Redis options will be ignored
- When the Redis password is set using `--redis-pass-file` or `RQ_REDIS_PASS_FILE`, then `--redis-pass` and `RQ_REDIS_PASS` will be ignored
- The Sentinel port will default to the value of `--sentinel-port` if not set for each host with `--sentinel-host` or `RQ_SENTINEL_HOST`
## Serving with Gunicorn
The WSGI application can be created using the `rq_exporter.create_app()` function:
```sh
$ gunicorn "rq_exporter:create_app()" -b 0.0.0.0:9726 --log-level info
```
Example [`Dockerfile`](https://github.com/mdawar/rq-exporter/blob/master/Dockerfile.gunicorn) to create a **Docker** image to serve the application with **Gunicorn**
```dockerfile
FROM mdawar/rq-exporter:latest
USER root
RUN pip install --no-cache-dir gunicorn
USER exporter
ENTRYPOINT ["gunicorn", "rq_exporter:create_app()"]
CMD ["-b", "0.0.0.0:9726", "--threads", "2", "--log-level", "info", "--keep-alive", "3"]
```
**Note about concurrency**:
The exporter is going to work without any problems with multiple workers but you will get different values for these metrics:
- `rq_request_processing_seconds_count`
- `rq_request_processing_seconds_sum`
- `rq_request_processing_seconds_created`
This is fine if you don't care about these metrics, these are only for measuring the count and time processing the RQ data, so the other RQ metrics are not going to be affected.
But you can still use multiple threads with 1 worker process to handle multiple concurrent requests:
```sh
$ gunicorn "rq_exporter:create_app()" -b 0.0.0.0:9726 --threads 2
```
## Building the Docker Image
```sh
$ # Build the docker image and tag it rq-exporter:latest
$ docker build -t rq-exporter .
$ # Or
$ make build
$ # M1 MacOS Build the docker image and tag it rq-exporter:latest
$ docker buildx build --platform linux/amd64 -t rq-exporter .
```
The image can also be built using `docker compose`:
```sh
$ docker compose build
```
Check the `docker-compose.yml` file for usage example.
## Development
To start a full development environment with **RQ** workers, **Prometheus** and **Grafana**:
```sh
$ docker compose up
$ # If you want to start multiple workers use the --compatibility flag
$ # which will make docker compose read the `deploy` section and start multiple replicas
$ docker compose --compatibility up
```
You can access the services on these ports on your local machine:
- **RQ exporter**: [`9726`](http://localhost:9726)
- **Redis**: [`6379`](http://localhost:6379)
- **RQ Dashboard**: [`9181`](http://localhost:9181)
- **Prometheus**: [`9090`](http://localhost:9090)
- **Grafana**: [`3000`](http://localhost:3000) (Login using `admin:admin`)
You can specify the services that you want to start by their name in the `docker-compose.yml` file:
```sh
$ # Example starting only the `rq_exporter` and `redis` services
$ docker compose up rq_exporter redis
```
To run more workers and enqueue more jobs you can scale the `worker` and `enqueue` services:
```sh
$ # Run 5 workers
$ docker compose up -d --scale worker=5
$ # Enqueue more jobs
$ # Scale the enqueue service and the workers
$ docker compose up -d --scale worker=5 --scale enqueue=2
```
To cleanup after development:
```sh
$ # Use -v to remove volumes
$ docker compose down -v
```
You can also start another `rq-exporter` instance that collects stats from a project using custom **RQ** `Worker` and `Queue` classes:
```sh
$ # Using -f to pass multiple docker-compose files
$ # docker-compose.custom.yml defines services using custom RQ classes
$ docker compose -f docker-compose.yml -f docker-compose.custom.yml up
$ # To cleanup you need to also pass the same files
$ docker compose -f docker-compose.yml -f docker-compose.custom.yml down
```
A new **RQ exporter** instance will be exposed on port `9727` on your local machine.
**Note**: If you don't have `docker compose` installed follow the [installation](https://docs.docker.com/compose/install/) instructions on the official website.
If you want to use the package manually:
```sh
$ # Clone the repository
$ git clone <REPO_URL>
$ # Change to the project directory
$ cd rq-exporter
$ # Create a new virtualenv
$ python -m venv /path/to/env
$ # Activate the environment
$ source /path/to/env/bin/activate
$ # Install the requirements
$ pip install -r requirements.txt
$ # Start the exporter on port 9726
$ python -m rq_exporter
$ # You can configure the exporter using command line arguments
$ python -m rq_exporter --port 8080
```
## Running the Tests
```sh
$ make test
$ # Or
$ python -m unittest
```
## Contributing
1. Fork the [repository](https://github.com/mdawar/rq-exporter)
2. Clone the forked repository `git clone <URL>`
3. Create a new feature branch `git checkout -b <BRANCH_NAME>`
4. Make changes and add tests if needed and commit your changes `git commit -am "Your commit message"`
5. Push the new branch to Github `git push origin <BRANCH_NAME>`
6. Create a pull request
| /rq-exporter-2.1.0.tar.gz/rq-exporter-2.1.0/README.md | 0.525369 | 0.9463 | README.md | pypi |
from redis import Redis
from redis.sentinel import Sentinel
from rq import Queue, Worker
from rq.job import JobStatus
def get_redis_connection(host='localhost', port='6379', db='0', sentinel=None,
sentinel_port='26379', sentinel_master=None,
password=None, password_file=None, url=None):
"""Get the Redis connection instance.
Note:
If the `url` is provided, all the other options are ignored.
If `password_file` is provided it will be used instead of `password.`
Args:
host (str): Redis hostname
port (str, int): Redis server port number
db (str, int): Redis database number
sentinel (str): Redis sentinel
sentinel_port (str, int): Redis sentinel port number
sentinel_master (str): Redis sentinel master name
password (str): Redis password
password_file (str): Redis password file path
url (str): Full Redis connection URL
Returns:
redis.Redis: Redis connection instance.
Raises:
IOError: On errors opening the password file.
"""
if url:
return Redis.from_url(url)
# Use password file if provided
if password_file:
with open(password_file, 'r') as f:
password = f.read().strip()
if sentinel:
addr_list = [
(
url.split(':')[0],
url.split(':')[1] if ':' in url else sentinel_port
)
for url in sentinel.split(",")
]
sentinel = Sentinel(addr_list, socket_timeout=1)
return sentinel.master_for(sentinel_master, socket_timeout=1, db=db)
return Redis(host=host, port=port, db=db, password=password)
def get_workers_stats(worker_class=None):
"""Get the RQ workers stats.
Args:
worker_class (type): RQ Worker class
Returns:
list: List of worker stats as a dict {name, queues, state}
Raises:
redis.exceptions.RedisError: On Redis connection errors
"""
worker_class = worker_class if worker_class is not None else Worker
workers = worker_class.all()
return [
{
'name': w.name,
'queues': w.queue_names(),
'state': w.get_state(),
'successful_job_count': w.successful_job_count,
'failed_job_count': w.failed_job_count,
'total_working_time': w.total_working_time
}
for w in workers
]
def get_queue_jobs(queue_name, queue_class=None):
"""Get the jobs by status of a Queue.
Args:
queue_name (str): The RQ Queue name
queue_class (type): RQ Queue class
Returns:
dict: Number of jobs by job status
Raises:
redis.exceptions.RedisError: On Redis connection errors
"""
queue_class = queue_class if queue_class is not None else Queue
queue = queue_class(queue_name)
return {
JobStatus.QUEUED: queue.count,
JobStatus.STARTED: queue.started_job_registry.count,
JobStatus.FINISHED: queue.finished_job_registry.count,
JobStatus.FAILED: queue.failed_job_registry.count,
JobStatus.DEFERRED: queue.deferred_job_registry.count,
JobStatus.SCHEDULED: queue.scheduled_job_registry.count
}
def get_jobs_by_queue(queue_class=None):
"""Get the current jobs by queue.
Args:
queue_class (type): RQ Queue class
Returns:
dict: Dictionary of job count by status for each queue
Raises:
redis.exceptions.RedisError: On Redis connection errors
"""
queue_class = queue_class if queue_class is not None else Queue
queues = queue_class.all()
return {
q.name: get_queue_jobs(q.name, queue_class) for q in queues
} | /rq-exporter-2.1.0.tar.gz/rq-exporter-2.1.0/rq_exporter/utils.py | 0.859015 | 0.247839 | utils.py | pypi |
import os
from datetime import datetime, timedelta
from rq.queue import Queue
from rq.worker import Worker
from .queue import DeadLetterQueue
try:
import rq_scheduler
except ImportError:
rq_scheduler = None
class RetryWorker(Worker):
"""Worker class that periodically retries jobs on the FailedQueue.
All Workers check for maintenance tasks after running each job. The
RetryWorker retries jobs on the failed queue as part of its maintenance
tasks. The RetryWorker also has a configurable interval for how often
maintenance is performed.
All parameters supported by Worker are supported by RetryWorker. In
addition the parameters below, which must be passed as keyword
arguments are accepted.
Each parameter below can also be set by an environment variable
with its name uppercased. Examples below.
Settings
--------
maint_interval : timedelta or float or str
How often to perform maintenance tasks, i.e., to check for failed
jobs, as a `timedelta` or as a `float` or `str` value in seconds.
*Environment variable*: `RQ_RETRY_MAINT_INTERVAL`
*Default*: time
max_tries : int or str
Maximum number of times a job will be attempted before being moved
to the dead letter queue. A value of 2 means retry a job one time if
it fails. A value of 1 or less means do not retry the job. To retry
a job indefinitely use a large value.
*Environment variable*: `RQ_RETRY_MAX_TRIES`
*Default*: 3
delays : list(float) or str
Delays to use before each retry attempt, in seconds.
The first retry of a job uses the first delay in the list,
the second retry uses the second delay, etc. If there are not
enough delays in the list the last value is repeated. So to set a
delay of 5 seconds for all retries use `[5]`. To set with environment
variable use a comma separated list of numbers, no spaces:
*Environment variable*: `RQ_RETRY_DELAYS`
*Default*: [5]
dead_letter_queue : str
Name of dead letter queue. The default of `dead_letter_queue`
does not normally need to be changed unless you have multiple
dead letter queues.
*Environment variable*: `RQ_RETRY_DEAD_LETTER_QUEUE`
*Default*: 'dead_letter_queue'
"""
def __init__(self, *args, **kwargs):
default_config = dict(
maint_interval=timedelta(seconds=30),
max_tries=3,
delays=[5],
dead_letter_queue='dead_letter_queue')
retry_config = kwargs.pop('retry_config', {})
self.apply_config(retry_config, default_config)
if not isinstance(self.maint_interval, timedelta):
self.maint_interval = timedelta(seconds=float(self.maint_interval))
if isinstance(self.max_tries, str):
self.max_tries = int(self.max_tries)
if isinstance(self.delays, str):
try:
self.delays = list(map(float, self.delays.split(',')))
except ValueError:
self.delays = []
super(RetryWorker, self).__init__(*args, **kwargs)
self._dead_letter_queue = DeadLetterQueue(self.dead_letter_queue,
connection=self.connection)
def apply_config(self, config, defaults):
for name, default_value in defaults.items():
value = config.get(name)
if value is None:
value = os.environ.get('RQ_RETRY_{}'.format(name.upper()))
if value is None:
value = default_value
setattr(self, name, value)
def register_birth(self):
for p in ['maint_interval',
'max_tries',
'delays',
'dead_letter_queue']:
self.log.info('{} = {}'.format(p, getattr(self, p)))
self.log.info('Use RQ Scheduler? {}'.format(self.use_scheduler))
super(RetryWorker, self).register_birth()
@property
def use_scheduler(self):
return rq_scheduler is not None and len(self.delays) > 0
@property
def should_run_maintenance_tasks(self):
return (
self.last_cleaned_at is None or
(datetime.utcnow() - self.last_cleaned_at) > self.maint_interval
)
def clean_registries(self):
super(RetryWorker, self).clean_registries()
self.retry_failed_jobs()
def retry_failed_jobs(self):
self.log.info('Checking for failed jobs')
for job in self.failed_queue.jobs:
self.retry_failed_job(job)
def retry_failed_job(self, job):
job.meta['tries'] = job.meta.get('tries', 1)
if job.meta['tries'] < self.max_tries:
self.log.info('Retrying {job}, tries={tries}'.format(
job=job,
tries=job.meta['tries'] - 1))
self.requeue_job(job)
else:
self.log.warning('Moving {job} to {name!r} queue'.format(
job=job,
name=self._dead_letter_queue.name))
self._dead_letter_queue.quarantine(job, self.failed_queue)
def requeue_job(self, job):
if self.use_scheduler:
tries = job.meta['tries']
try:
delay = self.delays[tries - 1]
except IndexError:
delay = self.delays[-1]
scheduler = rq_scheduler.Scheduler(connection=self.connection,
queue_name=job.origin)
self.failed_queue.remove(job)
job = scheduler.enqueue_in(timedelta(seconds=delay),
job.func,
*job.args,
**job.kwargs)
job.meta['tries'] = tries + 1
job.save()
self.log.info('scheduled to run in {} seconds'.format(delay))
else:
job.meta['tries'] += 1
job.save()
self.failed_queue.requeue(job.id)
self.log.info('requeued') | /rq-retry-0.3.0.tar.gz/rq-retry-0.3.0/rq_retry/worker.py | 0.669637 | 0.408926 | worker.py | pypi |
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import calendar
import datetime
import importlib
import logging
import numbers
import sys
from distutils.version import StrictVersion
from redis.exceptions import ResponseError
from .compat import as_text, is_python_version, string_types, Iterable
from .exceptions import TimeoutFormatError
class _Colorizer(object):
def __init__(self):
esc = "\x1b["
self.codes = {}
self.codes[""] = ""
self.codes["reset"] = esc + "39;49;00m"
self.codes["bold"] = esc + "01m"
self.codes["faint"] = esc + "02m"
self.codes["standout"] = esc + "03m"
self.codes["underline"] = esc + "04m"
self.codes["blink"] = esc + "05m"
self.codes["overline"] = esc + "06m"
dark_colors = ["black", "darkred", "darkgreen", "brown", "darkblue",
"purple", "teal", "lightgray"]
light_colors = ["darkgray", "red", "green", "yellow", "blue",
"fuchsia", "turquoise", "white"]
x = 30
for d, l in zip(dark_colors, light_colors):
self.codes[d] = esc + "%im" % x
self.codes[l] = esc + "%i;01m" % x
x += 1
del d, l, x
self.codes["darkteal"] = self.codes["turquoise"]
self.codes["darkyellow"] = self.codes["brown"]
self.codes["fuscia"] = self.codes["fuchsia"]
self.codes["white"] = self.codes["bold"]
if hasattr(sys.stdout, "isatty"):
self.notty = not sys.stdout.isatty()
else:
self.notty = True
def reset_color(self):
return self.codes["reset"]
def colorize(self, color_key, text):
if self.notty:
return text
else:
return self.codes[color_key] + text + self.codes["reset"]
colorizer = _Colorizer()
def make_colorizer(color):
"""Creates a function that colorizes text with the given color.
For example:
green = make_colorizer('darkgreen')
red = make_colorizer('red')
Then, you can use:
print "It's either " + green('OK') + ' or ' + red('Oops')
"""
def inner(text):
return colorizer.colorize(color, text)
return inner
class ColorizingStreamHandler(logging.StreamHandler):
levels = {
logging.WARNING: make_colorizer('darkyellow'),
logging.ERROR: make_colorizer('darkred'),
logging.CRITICAL: make_colorizer('darkred'),
}
def __init__(self, exclude=None, *args, **kwargs):
self.exclude = exclude
super(ColorizingStreamHandler, self).__init__(*args, **kwargs)
@property
def is_tty(self):
isatty = getattr(self.stream, 'isatty', None)
return isatty and isatty()
def format(self, record):
message = logging.StreamHandler.format(self, record)
if self.is_tty:
colorize = self.levels.get(record.levelno, lambda x: x)
# Don't colorize any traceback
parts = message.split('\n', 1)
parts[0] = " ".join([parts[0].split(" ", 1)[0], colorize(parts[0].split(" ", 1)[1])])
message = '\n'.join(parts)
return message
def import_attribute(name):
"""Return an attribute from a dotted path name (e.g. "path.to.func")."""
module_name, attribute = name.rsplit('.', 1)
module = importlib.import_module(module_name)
return getattr(module, attribute)
def utcnow():
return datetime.datetime.utcnow()
_TIMESTAMP_FORMAT = '%Y-%m-%dT%H:%M:%S.%fZ'
def utcformat(dt):
return dt.strftime(as_text(_TIMESTAMP_FORMAT))
def utcparse(string):
try:
return datetime.datetime.strptime(string, _TIMESTAMP_FORMAT)
except ValueError:
# This catches any jobs remain with old datetime format
return datetime.datetime.strptime(string, '%Y-%m-%dT%H:%M:%SZ')
def first(iterable, default=None, key=None):
"""
Return first element of `iterable` that evaluates true, else return None
(or an optional default value).
>>> first([0, False, None, [], (), 42])
42
>>> first([0, False, None, [], ()]) is None
True
>>> first([0, False, None, [], ()], default='ohai')
'ohai'
>>> import re
>>> m = first(re.match(regex, 'abc') for regex in ['b.*', 'a(.*)'])
>>> m.group(1)
'bc'
The optional `key` argument specifies a one-argument predicate function
like that used for `filter()`. The `key` argument, if supplied, must be
in keyword form. For example:
>>> first([1, 1, 3, 4, 5], key=lambda x: x % 2 == 0)
4
"""
if key is None:
for el in iterable:
if el:
return el
else:
for el in iterable:
if key(el):
return el
return default
def is_nonstring_iterable(obj):
"""Returns whether the obj is an iterable, but not a string"""
return isinstance(obj, Iterable) and not isinstance(obj, string_types)
def ensure_list(obj):
"""
When passed an iterable of objects, does nothing, otherwise, it returns
a list with just that object in it.
"""
return obj if is_nonstring_iterable(obj) else [obj]
def current_timestamp():
"""Returns current UTC timestamp"""
return calendar.timegm(datetime.datetime.utcnow().utctimetuple())
def enum(name, *sequential, **named):
values = dict(zip(sequential, range(len(sequential))), **named)
# NOTE: Yes, we *really* want to cast using str() here.
# On Python 2 type() requires a byte string (which is str() on Python 2).
# On Python 3 it does not matter, so we'll use str(), which acts as
# a no-op.
return type(str(name), (), values)
def backend_class(holder, default_name, override=None):
"""Get a backend class using its default attribute name or an override"""
if override is None:
return getattr(holder, default_name)
elif isinstance(override, string_types):
return import_attribute(override)
else:
return override
def str_to_date(date_str):
if not date_str:
return
else:
return utcparse(date_str.decode())
def parse_timeout(timeout):
"""Transfer all kinds of timeout format to an integer representing seconds"""
if not isinstance(timeout, numbers.Integral) and timeout is not None:
try:
timeout = int(timeout)
except ValueError:
digit, unit = timeout[:-1], (timeout[-1:]).lower()
unit_second = {'d': 86400, 'h': 3600, 'm': 60, 's': 1}
try:
timeout = int(digit) * unit_second[unit]
except (ValueError, KeyError):
raise TimeoutFormatError('Timeout must be an integer or a string representing an integer, or '
'a string with format: digits + unit, unit can be "d", "h", "m", "s", '
'such as "1h", "23m".')
return timeout
def get_version(connection):
"""
Returns StrictVersion of Redis server version.
This function also correctly handles 4 digit redis server versions.
"""
try:
version_string = connection.info("server")["redis_version"]
except ResponseError: # fakeredis doesn't implement Redis' INFO command
version_string = "5.0.9"
return StrictVersion('.'.join(version_string.split('.')[:3])) | /rq27-1.7.0.tar.gz/rq27-1.7.0/rq/utils.py | 0.584627 | 0.155655 | utils.py | pypi |
from __future__ import (absolute_import, division, print_function,
unicode_literals)
from contextlib import contextmanager
from redis import Redis
from .local import LocalStack, release_local
class NoRedisConnectionException(Exception):
pass
@contextmanager
def Connection(connection=None): # noqa
if connection is None:
connection = Redis()
push_connection(connection)
try:
yield
finally:
popped = pop_connection()
assert popped == connection, \
'Unexpected Redis connection was popped off the stack. ' \
'Check your Redis connection setup.'
def push_connection(redis):
"""Pushes the given connection on the stack."""
_connection_stack.push(redis)
def pop_connection():
"""Pops the topmost connection from the stack."""
return _connection_stack.pop()
def use_connection(redis=None):
"""Clears the stack and uses the given connection. Protects against mixed
use of use_connection() and stacked connection contexts.
"""
assert len(_connection_stack) <= 1, \
'You should not mix Connection contexts with use_connection()'
release_local(_connection_stack)
if redis is None:
redis = Redis()
push_connection(redis)
def get_current_connection():
"""Returns the current Redis connection (i.e. the topmost on the
connection stack).
"""
return _connection_stack.top
def resolve_connection(connection=None):
"""Convenience function to resolve the given or the current connection.
Raises an exception if it cannot resolve a connection now.
"""
if connection is not None:
return connection
connection = get_current_connection()
if connection is None:
raise NoRedisConnectionException('Could not resolve a Redis connection')
return connection
_connection_stack = LocalStack()
__all__ = ['Connection', 'get_current_connection', 'push_connection',
'pop_connection', 'use_connection'] | /rq27-1.7.0.tar.gz/rq27-1.7.0/rq/connections.py | 0.682997 | 0.245825 | connections.py | pypi |
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import signal
class BaseTimeoutException(Exception):
"""Base exception for timeouts."""
pass
class JobTimeoutException(BaseTimeoutException):
"""Raised when a job takes longer to complete than the allowed maximum
timeout value.
"""
pass
class HorseMonitorTimeoutException(BaseTimeoutException):
"""Raised when waiting for a horse exiting takes longer than the maximum
timeout value.
"""
pass
class BaseDeathPenalty(object):
"""Base class to setup job timeouts."""
def __init__(self, timeout, exception=JobTimeoutException, **kwargs):
self._timeout = timeout
self._exception = exception
def __enter__(self):
self.setup_death_penalty()
def __exit__(self, type, value, traceback):
# Always cancel immediately, since we're done
try:
self.cancel_death_penalty()
except BaseTimeoutException:
# Weird case: we're done with the with body, but now the alarm is
# fired. We may safely ignore this situation and consider the
# body done.
pass
# __exit__ may return True to supress further exception handling. We
# don't want to suppress any exceptions here, since all errors should
# just pass through, BaseTimeoutException being handled normally to the
# invoking context.
return False
def setup_death_penalty(self):
raise NotImplementedError()
def cancel_death_penalty(self):
raise NotImplementedError()
class UnixSignalDeathPenalty(BaseDeathPenalty):
def handle_death_penalty(self, signum, frame):
raise self._exception('Task exceeded maximum timeout value '
'({0} seconds)'.format(self._timeout))
def setup_death_penalty(self):
"""Sets up an alarm signal and a signal handler that raises
an exception after the timeout amount (expressed in seconds).
"""
signal.signal(signal.SIGALRM, self.handle_death_penalty)
signal.alarm(self._timeout)
def cancel_death_penalty(self):
"""Removes the death penalty alarm and puts back the system into
default signal handling.
"""
signal.alarm(0)
signal.signal(signal.SIGALRM, signal.SIG_DFL) | /rq27-1.7.0.tar.gz/rq27-1.7.0/rq/timeouts.py | 0.728072 | 0.1933 | timeouts.py | pypi |
import os
import datetime
import pandas as pd
from rqalpha.data.data_proxy import DataProxy
from rqalpha.utils.datetime_func import convert_int_to_datetime
from rqalpha_data.datetime_utils import to_date_object
from rqalpha_data.quant_utils import to_order_book_id
class DataSource(DataProxy):
"""
直接使用RQAlpha的全部数据
"""
def __init__(self, data_bundle_path=None):
default_bundle_path = os.path.abspath(os.path.expanduser('~/.rqalpha'))
if data_bundle_path is None:
data_bundle_path = default_bundle_path
else:
data_bundle_path = os.path.abspath(os.path.join(data_bundle_path, '.'))
data_bundle_path = data_bundle_path + '/bundle'
self._data_bundle_path = data_bundle_path
# basic_system_log.debug('rqalpha data bundle path: ' + data_bundle_path)
if not os.path.exists(data_bundle_path):
self.update(skip_last_date_check=True)
from rqalpha.data.base_data_source import BaseDataSource
data_source = BaseDataSource(data_bundle_path)
super(DataSource, self).__init__(data_source)
self._last_date_date = None
self.get_data_last_date()
# basic_system_log.debug('rqalpha data bundle date: ' + self._last_date_date.strftime('%Y-%m-%d'))
def get_data_last_date(self):
"""返回最新数据日期"""
if self._last_date_date is not None:
return self._last_date_date
d = self._data_source
instrument = self.instruments('000001.XSHG')
raw = d._all_day_bars_of(instrument)
df = pd.DataFrame.from_dict(raw)
df['datetime'] = df['datetime'].map(lambda x: pd.to_datetime(str(x)[:8]))
self._last_date_date = df['datetime'].max().date()
del df, raw, instrument, d
return self._last_date_date
def get_last_trading_day(self):
"""返回最后交易日期"""
date = datetime.date.today()
while not self.is_trading_date(date):
date = date + datetime.timedelta(days=-1)
return date
def update(self, skip_last_date_check=False):
"""
更新最新的远程数据到本地
"""
if not skip_last_date_check:
last_trading_day = self.get_last_trading_day()
data_bundle_path = self._data_bundle_path
if os.path.exists(data_bundle_path):
date = self.get_data_last_date()
if date == last_trading_day:
return date # 数据已经是最新无需下载
# basic_system_log.debug('need update data bundle to ' + date.strftime('%Y-%m-%d'))
data_bundle_path = self._data_bundle_path
data_bundle_path = data_bundle_path[:len(data_bundle_path) - len('/bundle')]
from rqalpha import main
main.update_bundle(data_bundle_path=data_bundle_path)
if not skip_last_date_check:
date = self.get_data_last_date()
return date
def get_bar(self, order_book_id, dt, frequency='1d'):
order_book_id = to_order_book_id(order_book_id)
dt = to_date_object(dt)
return super(DataSource, self).get_bar(order_book_id=order_book_id, dt=dt, frequency=frequency)
def history_bars(self,
order_book_id,
bar_count,
frequency,
field,
dt,
skip_suspended=True, include_now=False,
adjust_type='pre', adjust_orig=None):
order_book_id = to_order_book_id(order_book_id)
dt = to_date_object(dt)
bars = super(DataSource, self).history_bars(order_book_id=order_book_id,
bar_count=bar_count,
frequency=frequency,
field=field,
dt=dt,
skip_suspended=skip_suspended,
include_now=include_now,
adjust_type=adjust_type,
adjust_orig=adjust_orig)
return bars
def get_bars(self,
order_book_id,
dt,
bar_count=1,
frequency='1d',
fields=None,
skip_suspended=True,
include_now=False,
adjust_type='pre',
adjust_orig=None,
convert_to_dataframe=False):
order_book_id = to_order_book_id(order_book_id)
dt = to_date_object(dt)
if fields is None:
fields = ['datetime', 'open', 'high', 'low', 'close', 'volume', 'total_turnover']
bars = super(DataSource, self).history_bars(order_book_id=order_book_id,
bar_count=bar_count,
frequency=frequency,
field=fields,
dt=dt,
skip_suspended=skip_suspended,
include_now=include_now,
adjust_type=adjust_type,
adjust_orig=adjust_orig)
if convert_to_dataframe:
df = pd.DataFrame.from_dict(bars)
if 'datetime' in df.columns:
df['datetime'] = df['datetime'].map(lambda x: convert_int_to_datetime(x))
df.set_index('datetime', inplace=True)
df.index.name = ''
return df
return bars
datasource = DataSource()
def is_trading_date(date):
datasource.is_trading_date(date)
def get_bar(order_book_id, dt, frequency='1d'):
return datasource.get_bar(order_book_id=order_book_id, dt=dt, frequency=frequency)
def history_bars(
order_book_id,
bar_count,
frequency,
field,
dt,
skip_suspended=True,
include_now=False,
adjust_type='pre',
adjust_orig=None):
return datasource.history_bars(order_book_id=order_book_id,
bar_count=bar_count,
frequency=frequency,
field=field,
dt=dt,
skip_suspended=skip_suspended,
include_now=include_now,
adjust_type=adjust_type,
adjust_orig=adjust_orig)
def get_bars(order_book_id,
dt,
bar_count=1,
frequency='1d',
fields=None,
skip_suspended=True,
include_now=False,
adjust_type='pre',
adjust_orig=None,
convert_to_dataframe=False):
return datasource.get_bars(order_book_id=order_book_id,
bar_count=bar_count,
dt=dt,
frequency=frequency,
fields=fields,
skip_suspended=skip_suspended,
include_now=include_now,
adjust_type=adjust_type,
adjust_orig=adjust_orig,
convert_to_dataframe=convert_to_dataframe) | /rqalpha-data-0.0.7.tar.gz/rqalpha-data-0.0.7/rqalpha_data/datasource.py | 0.419648 | 0.237974 | datasource.py | pypi |
import numpy as np
from rqalpha.const import SIDE, POSITION_EFFECT, ORDER_STATUS, COMMISSION_TYPE, MARGIN_TYPE
from rqalpha.model.order import LimitOrder
from ..utils import make_order_book_id, make_underlying_symbol, is_future, bytes2str
from .pyctp import ApiStruct
SIDE_REVERSE = {
ApiStruct.D_Buy: SIDE.BUY,
ApiStruct.D_Sell: SIDE.SELL,
}
class DataDict(dict):
def __init__(self, d=None):
if d:
super(DataDict, self).__init__(d)
else:
super(DataDict, self).__init__()
def copy(self):
return DataDict(super(DataDict, self).copy())
def __getattr__(self, item):
return self.__getitem__(item)
def __setattr__(self, key, value):
self.__setitem__(key, value)
class TickDict(DataDict):
def __init__(self, data=None):
super(TickDict, self).__init__()
self.order_book_id = None
self.date = None
self.time = None
self.open = None
self.last = None
self.low = None
self.high = None
self.prev_close = None
self.volume = None
self.total_turnover = None
self.open_interest = None
self.prev_settlement = None
self.b1 = None
self.b2 = None
self.b3 = None
self.b4 = None
self.b5 = None
self.b1_v = None
self.b2_v = None
self.b3_v = None
self.b4_v = None
self.b5_v = None
self.a1 = None
self.a2 = None
self.a3 = None
self.a4 = None
self.a5 = None
self.a1_v = None
self.a2_v = None
self.a3_v = None
self.a4_v = None
self.a5_v = None
self.limit_down = None
self.limit_up = None
self.is_valid = False
if data:
self.update_data(data)
def update_data(self, data):
self.order_book_id = make_order_book_id(data.InstrumentID)
try:
self.date = int(data.TradingDay)
self.time = int((bytes2str(data.UpdateTime).replace(':', ''))) * 1000 + int(data.UpdateMillisec)
self.open = data.OpenPrice
self.last = data.LastPrice
self.low = data.LowestPrice
self.high = data.HighestPrice
self.prev_close = data.PreClosePrice
self.volume = data.Volume
self.total_turnover = data.Turnover
self.open_interest = data.OpenInterest
self.prev_settlement = data.SettlementPrice
self.b1 = data.BidPrice1
self.b2 = data.BidPrice2
self.b3 = data.BidPrice3
self.b4 = data.BidPrice4
self.b5 = data.BidPrice5
self.b1_v = data.BidVolume1
self.b2_v = data.BidVolume2
self.b3_v = data.BidVolume3
self.b4_v = data.BidVolume4
self.b5_v = data.BidVolume5
self.a1 = data.AskPrice1
self.a2 = data.AskPrice2
self.a3 = data.AskPrice3
self.a4 = data.AskPrice4
self.a5 = data.AskPrice5
self.a1_v = data.AskVolume1
self.a2_v = data.AskVolume2
self.a3_v = data.AskVolume3
self.a4_v = data.AskVolume4
self.a5_v = data.AskVolume5
self.limit_up = data.UpperLimitPrice
self.limit_down = data.LowerLimitPrice
self.is_valid = True
except ValueError:
self.is_valid = False
# 由持仓构建的伪 tick 类,用于在拿不到行情的时候提供 last_board 。
class FakeTickDict(TickDict):
def __init__(self, pos_dict):
super(FakeTickDict, self).__init__()
self.update_data(pos_dict)
def update_data(self, data):
self.last = data.prev_settle_price
self.limit_up = data.prev_settle_price * 1.1
self.limit_down = data.prev_settle_price * 0.9
class PositionDict(DataDict):
def __init__(self, data, ins_dict=None):
super(PositionDict, self).__init__()
self.order_book_id = make_order_book_id(data.InstrumentID)
self.buy_old_quantity = 0
self.buy_quantity = 0
self.buy_today_quantity = 0
self.buy_transaction_cost = 0.
self.buy_realized_pnl = 0.
self.buy_avg_open_price = 0.
self.sell_old_quantity = 0
self.sell_quantity = 0
self.sell_today_quantity = 0
self.sell_transaction_cost = 0.
self.sell_realized_pnl = 0.
self.sell_avg_open_price = 0.
self.prev_settle_price = 0.
self.buy_open_cost = 0.
self.sell_open_cost = 0.
self.contract_multiplier = ins_dict.contract_multiplier if ins_dict is not None else 1
self.is_valid = False
self.update_data(data)
def update_data(self, data):
if data.PosiDirection in [ApiStruct.PD_Net, ApiStruct.PD_Long]:
if data.YdPosition and not data.TodayPosition:
self.buy_old_quantity = data.Position
if data.YdPosition and data.TodayPosition:
self.buy_old_quantity = data.Position - data.TodayPosition
if data.TodayPosition:
self.buy_today_quantity = data.TodayPosition
self.buy_quantity += data.Position
self.buy_transaction_cost += data.Commission
self.buy_realized_pnl += data.CloseProfit
self.buy_open_cost += data.OpenCost
self.buy_avg_open_price = self.buy_open_cost / (self.buy_quantity * self.contract_multiplier) if self.buy_quantity > 0 else 0
elif data.PosiDirection == ApiStruct.PD_Short:
if data.YdPosition:
self.sell_old_quantity = data.Position
if data.TodayPosition:
self.sell_today_quantity = data.TodayPosition
self.sell_quantity += data.Position
self.sell_transaction_cost += data.Commission
self.sell_realized_pnl += data.CloseProfit
self.sell_open_cost += data.OpenCost
self.sell_avg_open_price = self.sell_open_cost / (self.sell_quantity * self.contract_multiplier) if self.sell_quantity > 0 else 0
if data.PreSettlementPrice:
self.prev_settle_price = data.PreSettlementPrice
self.is_valid = True
class AccountDict(DataDict):
def __init__(self, data):
super(AccountDict, self).__init__()
self.yesterday_portfolio_value = data.PreBalance
class InstrumentDict(DataDict):
def __init__(self, data):
super(InstrumentDict, self).__init__()
self.order_book_id = None
self.underlying_symbol = None
self.exchange_id = None
self.contract_multiplier = None
self.long_margin_ratio = None
self.short_margin_ratio = None
self.margin_type = None
self.instrument_id = None
self.is_valid = False
self.update_data(data)
def update_data(self, data):
if is_future(data.InstrumentID):
self.order_book_id = make_order_book_id(data.InstrumentID)
self.underlying_symbol = make_underlying_symbol(data.InstrumentID)
self.exchange_id = data.ExchangeID
self.contract_multiplier = data.VolumeMultiple
self.long_margin_ratio = data.LongMarginRatio
self.short_margin_ratio = data.ShortMarginRatio
self.margin_type = MARGIN_TYPE.BY_MONEY
self.instrument_id = bytes2str(data.InstrumentID)
self.is_valid = True
else:
self.is_valid = False
class CommissionDict(DataDict):
def __init__(self, data):
super(CommissionDict, self).__init__()
self.underlying_symbol = None
self.close_ratio = None
self.open_ratio = None
self.close_today_ratio = None
self.commission_type = None
self.is_valid = False
if data is not None:
self.update_data(data)
def update_data(self, data):
self.underlying_symbol = make_underlying_symbol(data.InstrumentID)
if data.OpenRatioByMoney == 0 and data.CloseRatioByMoney:
self.open_ratio = data.OpenRatioByVolume
self.close_ratio = data.CloseRatioByVolume
self.close_today_ratio = data.CloseTodayRatioByVolume
if data.OpenRatioByVolume != 0 or data.CloseRatioByVolume != 0:
self.commission_type = COMMISSION_TYPE.BY_VOLUME
else:
self.commission_type = None
else:
self.open_ratio = data.OpenRatioByMoney
self.close_ratio = data.CloseRatioByMoney
self.close_today_ratio = data.CloseTodayRatioByMoney
if data.OpenRatioByVolume == 0 and data.CloseRatioByVolume== 0:
self.commission_type = COMMISSION_TYPE.BY_MONEY
else:
self.commission_type = None
self.is_valid = True
class OrderDict(DataDict):
def __init__(self, data, rejected=False):
super(OrderDict, self).__init__()
self.order_id = None
self.order_book_id = None
self.front_id = None
self.session_id = None
self.exchange_id = None
self.quantity = None
self.filled_quantity = None
self.unfilled_quantity = None
self.side = None
self.price = None
self.position_effect = None
self.status = None
self.style = None
self.is_valid = False
self.update_data(data, rejected)
def update_data(self, data, rejected=False):
if not data.InstrumentID:
return
try:
self.order_id = int(data.OrderRef)
except ValueError:
self.order_id = np.nan
self.order_book_id = make_order_book_id(data.InstrumentID)
try:
self.front_id = data.FrontID
self.session_id = data.SessionID
except AttributeError:
pass
self.quantity = data.VolumeTotalOriginal
try:
self.filled_quantity = data.VolumeTraded
self.unfilled_quantity = self.quantity - self.filled_quantity
except AttributeError:
pass
self.side = SIDE_REVERSE.get(data.Direction, SIDE.BUY)
self.price = data.LimitPrice
try:
self.exchange_id = data.ExchangeID
except AttributeError:
pass
if self.exchange_id == 'SHFE':
if data.CombOffsetFlag == ApiStruct.OF_Open:
self.position_effect = POSITION_EFFECT.OPEN
elif data.CombOffsetFlag == ApiStruct.OF_CloseToday:
self.position_effect = POSITION_EFFECT.CLOSE_TODAY
else:
self.position_effect = POSITION_EFFECT.CLOSE
else:
if data.CombOffsetFlag == ApiStruct.OF_Open:
self.position_effect = POSITION_EFFECT.OPEN
else:
self.position_effect = POSITION_EFFECT.CLOSE
if rejected:
self.status = ORDER_STATUS.REJECTED
else:
try:
if data.OrderStatus in [ApiStruct.OST_PartTradedQueueing, ApiStruct.OST_NoTradeQueueing]:
self.status = ORDER_STATUS.ACTIVE
elif data.OrderStatus == ApiStruct.OST_AllTraded:
self.status = ORDER_STATUS.FILLED
elif data.OrderStatus == ApiStruct.OST_Canceled:
self.status = ORDER_STATUS.CANCELLED
else:
return
except AttributeError:
pass
self.style = LimitOrder(self.price)
self.is_valid = True
class TradeDict(DataDict):
def __init__(self, data):
super(TradeDict, self).__init__()
self.order_id = None
self.trade_id = None
self.order_book_id = None
self.side = None
self.exchange_id = None
self.position_effect = None
self.quantity = None
self.style = None
self.price = None
self.is_valid = False
self.update_data(data)
def update_data(self, data):
self.order_id = int(data.OrderRef)
self.trade_id = data.TradeID
self.order_book_id = make_order_book_id(data.InstrumentID)
self.side = SIDE_REVERSE.get(data.Direction, SIDE.BUY)
self.exchange_id = data.ExchangeID
if self.exchange_id == 'SHFE':
if data.OffsetFlag == ApiStruct.OF_Open:
self.position_effect = POSITION_EFFECT.OPEN
elif data.OffsetFlag == ApiStruct.OF_CloseToday:
self.position_effect = POSITION_EFFECT.CLOSE_TODAY
else:
self.position_effect = POSITION_EFFECT.CLOSE
else:
if data.OffsetFlag == ApiStruct.OF_Open:
self.position_effect = POSITION_EFFECT.OPEN
else:
self.position_effect = POSITION_EFFECT.CLOSE
self.quantity = data.Volume
self.price = data.Price
self.style = LimitOrder(self.price)
self.is_valid = True | /rqalpha-mod-ctp-0.2.0.tar.gz/rqalpha-mod-ctp-0.2.0/rqalpha_mod_ctp/ctp/data_dict.py | 0.411347 | 0.281758 | data_dict.py | pypi |
import six
from rqalpha.model.position import Positions
from rqalpha.model.position.future_position import FuturePosition
from rqalpha.model.account.future_account import FutureAccount, margin_of
from rqalpha.model.order import Order
from rqalpha.const import SIDE, POSITION_EFFECT, ORDER_STATUS
class DataCache(object):
def __init__(self):
self._ins_cache = {}
self._future_info_cache = {}
self._account_dict = None
self._pos_cache = {}
self._trade_cache = {}
self._qry_order_cache = {}
self._snapshot_cache = {}
self._order_cache = {}
def cache_ins(self, ins_cache):
self._ins_cache = ins_cache
self._future_info_cache = {ins_dict.underlying_symbol: {'speculation': {
'long_margin_ratio': ins_dict.long_margin_ratio,
'short_margin_ratio': ins_dict.short_margin_ratio,
'margin_type': ins_dict.margin_type,
}} for ins_dict in self._ins_cache.values()}
def cache_commission(self, underlying_symbol, commission_dict):
self._future_info_cache[underlying_symbol]['speculation'].update({
'open_commission_ratio': commission_dict.open_ratio,
'close_commission_ratio': commission_dict.close_ratio,
'close_commission_today_ratio': commission_dict.close_today_ratio,
'commission_type': commission_dict.commission_type,
})
def cache_position(self, pos_cache):
self._pos_cache = pos_cache
def cache_account(self, account_dict):
self._account_dict = account_dict
def cache_qry_order(self, order_cache):
self._qry_order_cache = order_cache
def cache_snapshot(self, tick_dict):
self._snapshot_cache[tick_dict.order_book_id] = tick_dict
def cache_trade(self, trade_dict):
if trade_dict.order_book_id not in self._trade_cache:
self._trade_cache[trade_dict.order_book_id] = []
self._trade_cache[trade_dict.order_book_id].append(trade_dict)
def get_cached_order(self, order_dict):
try:
order = self._order_cache[order_dict.order_id]
except KeyError:
order = Order.__from_create__(order_dict.order_book_id, order_dict.quantity, order_dict.side, order_dict.style, order_dict.position_effect)
self.cache_order(order)
return order
def cache_order(self, order):
self._order_cache[order.order_id] = order
@property
def ins(self):
return self._ins_cache
@property
def future_info(self):
return self._future_info_cache
@property
def positions(self):
ps = Positions(FuturePosition)
for order_book_id, pos_dict in six.iteritems(self._pos_cache):
position = FuturePosition(order_book_id)
position._buy_old_holding_list = [(pos_dict.prev_settle_price, pos_dict.buy_old_quantity)]
position._sell_old_holding_list = [(pos_dict.prev_settle_price, pos_dict.sell_old_quantity)]
position._buy_transaction_cost = pos_dict.buy_transaction_cost
position._sell_transaction_cost = pos_dict.sell_transaction_cost
position._buy_realized_pnl = pos_dict.buy_realized_pnl
position._sell_realized_pnl = pos_dict.sell_realized_pnl
position._buy_avg_open_price = pos_dict.buy_avg_open_price
position._sell_avg_open_price = pos_dict.sell_avg_open_price
if order_book_id in self._trade_cache:
trades = sorted(self._trade_cache[order_book_id], key=lambda t: t.trade_id, reverse=True)
buy_today_holding_list = []
sell_today_holding_list = []
for trade_dict in trades:
if trade_dict.side == SIDE.BUY and trade_dict.position_effect == POSITION_EFFECT.OPEN:
buy_today_holding_list.append((trade_dict.price, trade_dict.amount))
elif trade_dict.side == SIDE.SELL and trade_dict.position_effect == POSITION_EFFECT.OPEN:
sell_today_holding_list.append((trade_dict.price, trade_dict.amount))
self.process_today_holding_list(pos_dict.buy_today_quantity, buy_today_holding_list)
self.process_today_holding_list(pos_dict.sell_today_quantity, sell_today_holding_list)
position._buy_today_holding_list = buy_today_holding_list
position._sell_today_holding_list = sell_today_holding_list
ps[order_book_id] = position
return ps
def process_today_holding_list(self, today_quantity, holding_list):
print(today_quantity, holding_list)
# check if list is empty
if not holding_list:
return
cum_quantity = sum(quantity for price, quantity in holding_list)
left_quantity = cum_quantity - today_quantity
while left_quantity > 0:
oldest_price, oldest_quantity = holding_list.pop()
if oldest_quantity > left_quantity:
consumed_quantity = left_quantity
holding_list.append(oldest_price, oldest_quantity - left_quantity)
else:
consumed_quantity = oldest_quantity
left_quantity -= consumed_quantity
@property
def account(self):
static_value = self._account_dict.yesterday_portfolio_value
ps = self.positions
realized_pnl = sum(position.realized_pnl for position in six.itervalues(ps))
cost = sum(position.transaction_cost for position in six.itervalues(ps))
margin = sum(position.margin for position in six.itervalues(ps))
total_cash = static_value + realized_pnl - cost - margin
account = FutureAccount(total_cash, ps)
account._frozen_cash = sum(
[margin_of(order_dict.order_book_id, order_dict.unfilled_quantity, order_dict.price) for order_dict in
self._qry_order_cache.values() if order_dict.status == ORDER_STATUS.ACTIVE])
return account, static_value
@property
def snapshot(self):
return self._snapshot_cache
class RQObjectCache(object):
def __init__(self):
self.orders = {}
def cache_order(self, order):
self.orders[order.order_id] = order | /rqalpha-mod-vnpy-0.9.30.tar.gz/rqalpha-mod-vnpy-0.9.30/rqalpha_mod_vnpy/ctp/data_cache.py | 0.638723 | 0.153074 | data_cache.py | pypi |
# rqdb
This is an unofficial python client for [rqlite](https://github.com/rqlite/rqlite), a
lightweight distributed relational database based on SQLite.
This client supports SQLite syntax, true parameterized queries, and a
calling syntax reminiscent of DB API 2.0.
Furthermore, this client has convenient asynchronous methods which match
the underlying rqlite API.
## Installation
```py
pip install rqdb
```
## Usage
Synchronous queries:
```py
import rqdb
import secrets
conn = rqdb.connect(['127.0.0.1:4001'])
cursor = conn.cursor()
cursor.execute('CREATE TABLE persons (id INTEGER PRIMARY KEY, uid TEXT UNIQUE NOT NULL, name TEXT NOT NULL)')
cursor.execute('CREATE TABLE pets (id INTEGER PRIMARY KEY, name TEXT NOT NULL, owner_id INTEGER NOT NULL REFERENCES persons(id) ON DELETE CASCADE)')
# standard execute
cursor.execute('INSERT INTO persons (uid, name) VALUES (?, ?)', (secrets.token_hex(8), 'Jane Doe'))
assert cursor.rows_affected == 1
# The following is stored in a single Raft entry and executed within a transaction.
person_name = 'John Doe'
person_uid = secrets.token_urlsafe(16)
pet_name = 'Fido'
result = cursor.executemany3((
(
'INSERT INTO persons (uid, name) VALUES (?, ?)',
(person_uid, person_name)
),
(
'INSERT INTO pets (name, owner_id) '
'SELECT'
' ?, persons.id '
'FROM persons '
'WHERE uid = ?',
(pet_name, person_uid)
)
)).raise_on_error()
assert result[0].rows_affected == 1
assert result[1].rows_affected == 1
```
Asynchronous queries:
```py
import rqdb
import secrets
async def main():
async with rqdb.connect_async(['127.0.0.1:4001']) as conn:
cursor = conn.cursor()
result = await cursor.execute(
'INSERT INTO persons (uid, name) VALUES (?, ?)',
(secrets.token_hex(8), 'Jane Doe')
)
assert result.rows_affected == 1
```
## Additional Features
### Read Consistency
Selecting read consistency is done at the cursor level, either by passing
`read_consistency` to the cursor constructor (`conn.cursor()`) or by setting
the instance variable `read_consistency` directly. The available consistencies
are `strong`, `weak`, and `none`. You may also indicate the `freshness` value
at the cursor level.
See [CONSISTENCY.md](https://github.com/rqlite/rqlite/blob/master/DOC/CONSISTENCY.md) for
details.
The default consistency is `weak`.
### Foreign Keys
Foreign key support in rqlite is disabled by default, to match sqlite. This is a common source
of confusion. It cannot be configured by the client reliably. Foreign key support
is enabled as described in
[FOREIGN_KEY_CONSTRAINTS.md](https://github.com/rqlite/rqlite/blob/master/DOC/FOREIGN_KEY_CONSTRAINTS.md)
### Nulls
Substituting "NULL" in parametrized queries can be error-prone. In particular,
sqlite needs null sent in a very particular way, which the rqlite server has
historically not handled properly.
By default, if you attempt to use "None" as a parameter to a query, this package
will perform string substition with the value "NULL" in the correct spot. Be
careful however - you will still need to handle nulls properly in the query,
since "col = NULL" and "col IS NULL" are not the same. In particular, `NULL = NULL`
is `NULL`, which evaluates to false. One way this could be handled is
```py
name: Optional[str] = None
# never matches a row since name is None, even if the rows name is null
cursor.execute('SELECT * FROM persons WHERE name = ?', (name,))
# works as expected
cursor.execute('SELECT * FROM persons WHERE ((? IS NULL AND name IS NULL) OR name = ?)', (name, name))
```
### Backup
Backups can be initiated using `conn.backup(filepath: str, raw: bool = False)`.
The download will be streamed to the given filepath. Both the sql format and a
compressed sqlite format are supported.
### Logging
By default this will log using the standard `logging` module. This can be disabled
using `log=False` in the `connect` call. If logging is desired but just needs to be
configured slightly, it can be done as follows:
```py
import rqdb
import logging
conn = rqdb.connect(
['127.0.0.1:4001'],
log=rqdb.LogConfig(
# Started a SELECT query
read_start={
'enabled': True,
'level': logging.DEBUG, # alternatively, 'method': logging.debug
},
# Started a UPDATE/INSERT query
write_start={
'enabled': True,
'level': logging.DEBUG,
},
# Got the response from the database for a SELECT query
read_response={
'enabled': True,
'level': logging.DEBUG,,
'max_length': 1024, # limits how much of the response we log
},
# Got the response from the database for a UPDATE/INSERT query
write_response={
'enabled': True,
'level': logging.DEBUG,
},
# Failed to connect to one of the nodes.
connect_timeout={
'enabled': True,
'level': logging.WARNING,
},
# Failed to connect to any node for a query
hosts_exhausted={
'enabled': True,
'level': logging.CRITICAL,
},
# The node returned a status code other than 200-299 or
# a redirect when a redirect is allowed.
non_ok_response={
'enabled': True,
'level': logging.WARNING
}
)
)
```
## Limitations
### Slow Transactions
The primary limitations is that by the connectionless nature of rqlite, while
transactions are possible, the entire transaction must be specified upfront.
That is, you cannot open a transaction, perform a query, and then use the
result of that query to perform another query before closing the transaction.
This can also be seen as a blessing, as these types of transactions are the most
common source of performance issues in traditional applications. They require
long-held locks that can easily lead to N^2 performance. The same behavior can
almost always be achieved with uids, as shown in the example. The repeated UID
lookup causes a consistent overhead, which is highly preferable to the
unpredictable negative feedback loop nature of long transactions.
## Other Notes
It is often helpful to combine this library with a sql builder such
as [pypika](https://pypika.readthedocs.io/en/latest/) when manipulating
complex queries.
| /rqdb-1.0.10.tar.gz/rqdb-1.0.10/README.md | 0.531453 | 0.748076 | README.md | pypi |
# Funcat
[](https://pypi.python.org/pypi/funcat)
[](https://pypi.python.org/pypi/funcat)
[](https://pypi.python.org/pypi/funcat)
Funcat 将同花顺、通达信、文华财经等的公式移植到了 Python 中。
同花顺、通达信、文华财经麦语言等公式的表达十分简洁,适合做技术分析。
苦于 Python 缺乏这种领域特定语言的表达能力,所以用 Python 基于 numpy 实现了一套。
## 安装
```
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -U funcat
```
## notebooks 教程
- [quick-start](https://github.com/cedricporter/funcat/blob/master/notebooks/funcat-tutorial.ipynb)
## API
### 行情变量
- 开盘价:`OPEN` `O`
- 收盘价:`CLOSE` `C`
- 最高价:`HIGH` `H`
- 最低价:`LOW` `L`
- 成交量:`VOLUME` `V` `VOL`
### 工具函数
- n天前的数据:`REF`
``` python
REF(C, 10) # 10天前的收盘价
```
- 金叉判断:`CROSS`
``` python
CROSS(MA(C, 5), MA(C, 10)) # 5日均线上穿10日均线
```
- 两个序列取最小值:`MIN`
``` python
MIN(O, C) # K线实体的最低价
```
- 两个序列取最大值:`MAX`
``` python
MAX(O, C) # K线实体的最高价
```
- n天都满足条件:`EVERY`
``` python
EVERY(C > MA(C, 5), 10) # 最近10天收盘价都大于5日均线
```
- n天内满足条件的天数:`COUNT`
``` python
COUNT(C > O, 10) # 最近10天收阳线的天数
```
- n天内最大值:`HHV`
``` python
HHV(MAX(O, C), 60) # 最近60天K线实体的最高价
```
- n天内最小值:`LLV`
``` python
LLV(MIN(O, C), 60) # 最近60天K线实体的最低价
```
- 求和n日数据 `SUM`
``` python
SUM(C, 10) # 求和10天的收盘价
```
- 求绝对值 `ABS`
``` python
ABS(C - O)
```
- 条件 `IF`
``` python
IF(OPEN > CLOSE, OPEN, CLOSE)
```
### 条件「和」与「或」
因为语法的问题,我们需要使用 `&` 代替 `and` 「和」,用 `|` 代替 `or` 「或」。
``` python
# 收盘价在10日均线上 且 10日均线在20日均线上
(C > MA(C, 10)) & (MA(C, 10) > MA(C, 20))
# 收阳线 或 收盘价大于昨收
(C > O) | (C > REF(C, 1))
```
### 指标
- 均线:`MA`
``` python
MA(C, 60) # 60日均线
```
其他更多请见:[指标库](https://github.com/cedricporter/funcat/blob/master/funcat/indicators.py)
还有更多的技术指标还在实现中,欢迎提交pr一起实现。
## 自定义公式示例
[KDJ指标](http://wiki.mbalib.com/wiki/KDJ)。随机指标(KDJ)由 George C.Lane 创制。它综合了动量观念、强弱指标及移动平均线的优点,用来度量股价脱离价格正常范围的变异程度。
``` python
N, M1, M2 = 9, 3, 3
RSV = (CLOSE - LLV(LOW, N)) / (HHV(HIGH, N) - LLV(LOW, N)) * 100
K = EMA(RSV, (M1 * 2 - 1))
D = EMA(K, (M2 * 2 - 1))
J = K * 3 - D * 2
print(K, D, J)
```
[DMI指标](http://wiki.mbalib.com/wiki/DMI)。动向指数又叫移动方向指数或趋向指数。是属于趋势判断的技术性指标,其基本原理是通过分析股票价格在上升及下跌过程中供需关系的均衡点,即供需关系受价格变动之影响而发生由均衡到失衡的循环过程,从而提供对趋势判断的依据。
对于 DMI 这个指标,你会发现 TALib 算出来的结果,和同花顺等软件的结果不一样,我对比了下实现方式,发现,是因为同花顺的公式和 TALib 的计算公式不一样,对于这种情况,我们把同花顺的公式搬过来,就可以算出和同花顺一样的结果。
``` python
M1, M2 = 14, 6
TR = SUM(MAX(MAX(HIGH - LOW, ABS(HIGH - REF(CLOSE, 1))), ABS(LOW - REF(CLOSE, 1))), M1)
HD = HIGH - REF(HIGH, 1)
LD = REF(LOW, 1) - LOW
DMP = SUM(IF((HD > 0) & (HD > LD), HD, 0), M1)
DMM = SUM(IF((LD > 0) & (LD > HD), LD, 0), M1)
DI1 = DMP * 100 / TR
DI2 = DMM * 100 / TR
ADX = MA(ABS(DI2 - DI1) / (DI1 + DI2) * 100, M2)
ADXR = (ADX + REF(ADX, M2)) / 2
print(DI1, DI2, ADX, ADXR)
```
## 选股
``` python
from funcat import *
# 选出涨停股
select(
lambda : C / C[1] - 1 >= 0.0995,
start_date=20161231,
end_date=20170104,
)
'''
[20170104]
20170104 000017.XSHE 000017.XSHE[深中华A]
20170104 000026.XSHE 000026.XSHE[飞亚达A]
20170104 000045.XSHE 000045.XSHE[深纺织A]
20170104 000585.XSHE 000585.XSHE[东北电气]
20170104 000595.XSHE 000595.XSHE[宝塔实业]
20170104 000678.XSHE 000678.XSHE[襄阳轴承]
...
'''
# 选出最近30天K线实体最高价最低价差7%以内,最近100天K线实体最高价最低价差大于25%,
# 最近10天,收盘价大于60日均线的天数大于3天
select(
lambda : ((HHV(MAX(C, O), 30) / LLV(MIN(C, O), 30) - 1 < 0.07)
& (HHV(MAX(C, O), 100) / LLV(MIN(C, O), 100) - 1 > 0.25)
& (COUNT(C > MA(C, 60), 10) > 3)
),
start_date=20161220,
)
'''
[20170104]
20170104 600512.XSHG 600512.XSHG[腾达建设]
[20170103]
[20161230]
20161230 000513.XSHE 000513.XSHE[丽珠集团]
...
'''
# 选出最近3天每天的成交量小于20日成交量均线,最近3天最低价低于20日均线,最高价高于20日均线
# 自定义选股回调函数
def callback(date, order_book_id, symbol):
print("Cool, 在", date, "选出", order_book_id, symbol)
select(
lambda : (EVERY(V < MA(V, 20) / 2, 3) & EVERY(L < MA(C, 20), 3) & EVERY(H > MA(C, 20), 3)),
start_date=20161231,
callback=callback,
)
'''
[20170104]
Cool, 在 20170104 选出 002633.XSHE 002633.XSHE[申科股份]
Cool, 在 20170104 选出 600857.XSHG 600857.XSHG[宁波中百]
...
'''
```
## 单股票研究
``` python
from funcat import *
from funcat.data.tushare_backend import TushareDataBackend
set_data_backend(TushareDataBackend())
# 设置目前天数为2017年1月4日
T("20170104")
# 设置关注股票为上证指数
S("000001.XSHG")
# 打印 Open High Low Close
>>> print(O, H, L, C)
3133.79 3160.1 3130.11 3158.79
# 当天涨幅
>>> C / C[1] - 1
0.0072929156356
# 打印60日均线
>>> MA(C, 60)
3154.78333333
# 判断收盘价是否大于60日均线
>>> C > MA(C, 60)
True
# 30日最高价
>>> HHV(H, 30)
3301.21
# 最近30日,收盘价 Close 大于60日均线的天数
>>> COUNT(C > MA(C, 60), 30)
17
# 10日均线上穿
>>> CROSS(MA(C, 10), MA(C, 20))
False
```
## DataBackend
默认实现了一个从 tushare 上面实时拉数据选股的 Backend。
还有一个 [RQAlpha](https://github.com/ricequant/rqalpha) 的 Backend,使用它可以为我们提供本地的数据源,比从 tushare 拉数据速度更有优势。
``` bash
pip install rqalpha # 安装依赖库 RQAlpha
rqalpha update_bundle # 更新数据
```
替换 DataBackend 为 RQAlpha 的 DataProxy,这样可以从 RQAlpha 的 bundle 中获取数据。
``` python
from funcat.data.rqalpha_data_backend import RQAlphaDataBackend
from funcat import *
set_data_backend(RQAlphaDataBackend("~/.rqalpha/bundle"))
```
为了更高的性能,您也可以自定义Backend使用本地数据。这样可以极大地提高运行速度。
| /rqfuncat-0.3.4.tar.gz/rqfuncat-0.3.4/README.md | 0.525612 | 0.961606 | README.md | pypi |
from .api import (
OPEN, HIGH, LOW, CLOSE, VOLUME, VOL,
ABS, MAX, HHV, LLV,
REF, IF, SUM, STD,
MA, EMA, SMA,
AVEDEV,
COUNT,
MIN,
AMOUNT,
SQRT,
ADVANCE,
DECLINE,
CAPITAL,
DMA,
INDEXO,
INDEXH,
INDEXL,
INDEXC,
INDEXV,
)
def KDJ(N=9, M1=3, M2=3):
"""
KDJ 随机指标
"""
RSV = (CLOSE - LLV(LOW, N)) / (HHV(HIGH, N) - LLV(LOW, N)) * 100
K = EMA(RSV, (M1 * 2 - 1))
D = EMA(K, (M2 * 2 - 1))
J = K * 3 - D * 2
return K, D, J
def DMI(M1=14, M2=6):
"""
DMI 趋向指标
"""
TR = SUM(MAX(MAX(HIGH - LOW, ABS(HIGH - REF(CLOSE, 1))), ABS(LOW - REF(CLOSE, 1))), M1)
HD = HIGH - REF(HIGH, 1)
LD = REF(LOW, 1) - LOW
DMP = SUM(IF((HD > 0) & (HD > LD), HD, 0), M1)
DMM = SUM(IF((LD > 0) & (LD > HD), LD, 0), M1)
DI1 = DMP * 100 / TR
DI2 = DMM * 100 / TR
ADX = MA(ABS(DI2 - DI1) / (DI1 + DI2) * 100, M2)
ADXR = (ADX + REF(ADX, M2)) / 2
return DI1, DI2, ADX, ADXR
def MACD(SHORT=12, LONG=26, M=9):
"""
MACD 指数平滑移动平均线
"""
DIF = EMA(CLOSE, SHORT) - EMA(CLOSE, LONG)
DEA = EMA(DIF, M)
MACD = (DIF - DEA) * 2
return MACD
def RSI(N1=6, N2=12, N3=24):
"""
RSI 相对强弱指标
"""
LC = REF(CLOSE, 1)
RSI1 = SMA(MAX(CLOSE - LC, 0), N1, 1) / SMA(ABS(CLOSE - LC), N1, 1) * 100
RSI2 = SMA(MAX(CLOSE - LC, 0), N2, 1) / SMA(ABS(CLOSE - LC), N2, 1) * 100
RSI3 = SMA(MAX(CLOSE - LC, 0), N3, 1) / SMA(ABS(CLOSE - LC), N3, 1) * 100
return RSI1, RSI2, RSI3
def BOLL(N=20, P=2):
"""
BOLL 布林带
"""
MID = MA(CLOSE, N)
UPPER = MID + STD(CLOSE, N) * P
LOWER = MID - STD(CLOSE, N) * P
return UPPER, MID, LOWER
def WR(N=10, N1=6):
"""
W&R 威廉指标
"""
WR1 = (HHV(HIGH, N) - CLOSE) / (HHV(HIGH, N) - LLV(LOW, N)) * 100
WR2 = (HHV(HIGH, N1) - CLOSE) / (HHV(HIGH, N1) - LLV(LOW, N1)) * 100
return WR1, WR2
def BIAS(L1=5, L4=3, L5=10):
"""
BIAS 乖离率
"""
BIAS = (CLOSE - MA(CLOSE, L1)) / MA(CLOSE, L1) * 100
BIAS2 = (CLOSE - MA(CLOSE, L4)) / MA(CLOSE, L4) * 100
BIAS3 = (CLOSE - MA(CLOSE, L5)) / MA(CLOSE, L5) * 100
return BIAS, BIAS2, BIAS3
def ASI(M1=26, M2=10):
"""
ASI 震动升降指标
"""
LC = REF(CLOSE, 1)
AA = ABS(HIGH - LC)
BB = ABS(LOW - LC)
CC = ABS(HIGH - REF(LOW, 1))
DD = ABS(LC - REF(OPEN, 1))
R = IF((AA > BB) & (AA > CC), AA + BB / 2 + DD / 4, IF((BB > CC) & (BB > AA), BB + AA / 2 + DD / 4, CC + DD / 4))
X = (CLOSE - LC + (CLOSE - OPEN) / 2 + LC - REF(OPEN, 1))
SI = X * 16 / R * MAX(AA, BB)
ASI = SUM(SI, M1)
ASIT = MA(ASI, M2)
return ASI, ASIT
def VR(M1=26):
"""
VR容量比率
"""
LC = REF(CLOSE, 1)
VR = SUM(IF(CLOSE > LC, VOL, 0), M1) / SUM(IF(CLOSE <= LC, VOL, 0), M1) * 100
return VR
def BRAR(N=26):
"""
BRAR人气意愿指标
"""
BR = SUM(MAX(0, HIGH - REF(CLOSE, 1)), N) / SUM(MAX(0, REF(CLOSE, 1) - LOW), N) * 100
AR = SUM(HIGH - OPEN, N) / SUM(OPEN - LOW, N) * 100
return BR, AR
def DPO(M1=20, M2=10, M3=6):
DPO = CLOSE - REF(MA(CLOSE, M1), M2)
MADPO = MA(DPO, M3)
return DPO, MADPO
def TRIX(M1=12, M2=20):
TR = EMA(EMA(EMA(CLOSE, M1), M1), M1)
TRIX = (TR - REF(TR, 1)) / REF(TR, 1) * 100
TRMA = MA(TRIX, M2)
return TRIX, TRMA
def ATR(N=14):
MTR = MAX(MAX((HIGH - LOW), ABS(REF(CLOSE, 1) - HIGH)), ABS(REF(CLOSE, 1) - LOW))
ATR = MA(MTR, N)
return ATR
def CCI(N=14):
TYP = (HIGH + LOW + CLOSE) / 3
CCI = (TYP - MA(TYP, N)) / (0.015 * AVEDEV(TYP, N))
return CCI
def PSY(N=12, M=6):
PSY = COUNT(CLOSE > REF(CLOSE, 1), N) / N * 100
PSYMA = MA(PSY, M)
return PSYMA
def EXPMA(M1=12, M2=50):
EXP1 = EMA(CLOSE, M1)
EXP2 = EMA(CLOSE, M2)
return EXP1, EXP2
def XS(N=13):
VAR2 = CLOSE * VOL
VAR3 = EMA((EMA(VAR2, 3) / EMA(VOL, 3) + EMA(VAR2, 6) / EMA(VOL, 6) + EMA(VAR2, 12) / EMA(VOL, 12) + EMA(VAR2,24)
/ EMA(VOL, 24)) / 4, N)
SUP = 1.06 * VAR3
SDN = VAR3 * 0.94
VAR4 = EMA(CLOSE, 9)
LUP = EMA(VAR4 * 1.14, 5)
LDN = EMA(VAR4 * 0.86, 5)
return SUP, SDN, LUP, LDN
def CYR(M=5, N=13):
DIVE = 0.01 * EMA(AMOUNT, N) / EMA(VOL, N)
CYR = (DIVE / REF(DIVE, 1) - 1) * 100
MACYR = MA(CYR, M)
return MACYR
def CYW():
VAR1 = CLOSE - LOW
VAR2 = HIGH - LOW
VAR3 = CLOSE - HIGH
VAR4 = IF(HIGH > LOW, (VAR1 / VAR2 + VAR3 / VAR2) * VOL, 0)
CYW = SUM(VAR4, 10) / 10000
return CYW
def HISV(N=60):
HSIV = STD(CLOSE, N) * SQRT(250) * 100.0
return HSIV
def ARMS(N=21, INDEX='000300.XSHG'):
ARMS = EMA(ADVANCE / DECLINE, N)
return ARMS
def FSL():
"""
若数据源为tushare,则只能拿到2016-08-09之后的流通股数,在此之前的流通股为np.nan
:return:
"""
SWL = (EMA(CLOSE, 5) * 7 + EMA(CLOSE, 10) * 3) / 10
SWS = DMA(EMA(CLOSE, 12), MAX(1, 100 * (SUM(VOL, 5) / (3 * CAPITAL))))
return SWL, SWS
def HMA(M1=6, M2=12, M3=30, M4=72, M5=144):
HMA1 = MA(HIGH, M1)
HMA2 = MA(HIGH, M2)
HMA3 = MA(HIGH, M3)
HMA4 = MA(HIGH, M4)
HMA5 = MA(HIGH, M5)
return HMA1, HMA2, HMA3, HMA4, HMA5
def LMA(M1=6, M2=12, M3=30, M4=72, M5=144):
LMA1 = MA(LOW, M1)
LMA2 = MA(LOW, M2)
LMA3 = MA(LOW, M3)
LMA4 = MA(LOW, M4)
LMA5 = MA(LOW, M5)
return LMA1, LMA2, LMA3, LMA4, LMA5
def AMV(M1=5, M2=13, M3=34, M4=60):
AMOV = VOL * (OPEN + CLOSE) / 2
AMV1 = SUM(AMOV, M1) / SUM(VOL, M1)
AMV2 = SUM(AMOV, M2) / SUM(VOL, M2)
AMV3 = SUM(AMOV, M3) / SUM(VOL, M3)
AMV4 = SUM(AMOV, M4) / SUM(VOL, M4)
return AMV1, AMV2, AMV3, AMV4
def ABI(M=10):
ABI = 100 * ABS(ADVANCE - DECLINE) / (ADVANCE + DECLINE)
MAABI = EMA(ABI, M)
return ABI, MAABI
def MCL(N1=19, N2=39):
DIF = ADVANCE - DECLINE
EMA1 = EMA(DIF, N1)
EMA2 = EMA(DIF, N2)
MCL = EMA1 - EMA2
MAMCL1 = EMA1
MAMCL2 = EMA2
return MCL, MAMCL1, MAMCL2
def MIKE(N=10):
HLC = REF(MA((HIGH + LOW + CLOSE) / 3, N), 1)
HV = EMA(HHV(HIGH, N), 3)
LV = EMA(LLV(LOW, N), 3)
STOR = EMA(2 * HV - LV, 3)
MIDR = EMA(HLC + HV - LV, 3)
WEKR = EMA(HLC * 2 - LV, 3)
WEKS = EMA(HLC * 2 - HV, 3)
MIDS = EMA(HLC - HV + LV, 3)
STOS = EMA(2 * LV - HV, 3)
return STOR, MIDR, WEKR, WEKS, MIDS, STOS
def CR(N=26):
MID = REF(HIGH + LOW, 1) / 2
CR = SUM(MAX(0, HIGH - MID), N) / SUM(MAX(0, MID - LOW), N) * 100
return CR
def ROC(N=12, M=6):
ROC = 100 * (CLOSE - REF(CLOSE, N)) / REF(CLOSE, N)
MAROC = MA(ROC, M)
return ROC, MAROC
def ZLMM():
LC = REF(CLOSE, 1)
RSI2 = SMA(MAX(CLOSE - LC, 0), 12, 1) / SMA(ABS(CLOSE - LC), 12, 1) * 100
RSI3 = SMA(MAX(CLOSE - LC, 0), 18, 1) / SMA(ABS(CLOSE - LC), 18, 1) * 100
MMS = MA(3 * RSI2 - 2 * SMA(MAX(CLOSE - LC, 0), 16, 1) / SMA(ABS(CLOSE - LC), 16, 1) * 100, 3)
MMM = EMA(MMS, 8)
MML = MA(3 * RSI3 - 2 * SMA(MAX(CLOSE - LC, 0), 12, 1) / SMA(ABS(CLOSE - LC), 12, 1) * 100, 5)
return MMS, MMM, MML
def LB():
ZY2 = VOL / INDEXV * 1000
return ZY2
def XDT(M=5, N=10):
QR = CLOSE / INDEXC * 1000
MQR1 = MA(QR, M)
MQR2 = MA(QR, N)
return QR, MQR1, MQR2
def SMX(N=50):
ZY = CLOSE / INDEXC * 2000
ZY1 = EMA(ZY, 3)
ZY2 = EMA(ZY, 17)
ZY3 = EMA(ZY, 34)
return ZY1, ZY2, ZY3
def RAD(D=3, S=30, M=30):
SM = (OPEN + HIGH + CLOSE + LOW) / 4
SMID = MA(SM, D)
IM = (INDEXO + INDEXH + INDEXL + INDEXC) / 4
IMID = MA(IM, D)
SI1 = (SMID - REF(SMID, 1)) / SMID
II = (IMID - REF(IMID, 1)) / IMID
RADER1 = SUM((SI1 - II) * 2, S) * 1000
RADERMA = SMA(RADER1, M, 1)
return RADER1, RADERMA | /rqfuncat-0.3.4.tar.gz/rqfuncat-0.3.4/funcat/indicators.py | 0.47025 | 0.186576 | indicators.py | pypi |
from functools import reduce
import numpy as np
import talib
from .context import ExecutionContext
from .utils import FormulaException, rolling_window, handle_numpy_warning
from .time_series import (
MarketDataSeries,
NumericSeries,
BoolSeries,
fit_series,
get_series,
get_bars,
ensure_timeseries,
)
class OneArgumentSeries(NumericSeries):
@staticmethod
def func(*args, **kwargs):
return talib.MA(*args, **kwargs)
def __init__(self, series, arg):
if isinstance(series, NumericSeries):
series = series.series
try:
series[series == np.inf] = np.nan
series = self.func(series, arg)
except Exception as e:
raise FormulaException(e)
super(OneArgumentSeries, self).__init__(series)
self.extra_create_kwargs["arg"] = arg
class MovingAverageSeries(OneArgumentSeries):
"""http://www.tadoc.org/indicator/MA.htm"""
@staticmethod
def func(*args, **kwargs):
return talib.MA(*args, **kwargs)
class WeightedMovingAverageSeries(OneArgumentSeries):
"""http://www.tadoc.org/indicator/WMA.htm"""
@staticmethod
def func(*args, **kwargs):
return talib.WMA(*args, **kwargs)
class ExponentialMovingAverageSeries(OneArgumentSeries):
"""http://www.fmlabs.com/reference/default.htm?url=ExpMA.htm"""
@staticmethod
def func(*args, **kwargs):
return talib.EMA(*args, **kwargs)
class StdSeries(OneArgumentSeries):
@staticmethod
def func(*args, **kwargs):
return talib.STDDEV(*args, **kwargs)
class TwoArgumentSeries(NumericSeries):
func = talib.STDDEV
def __init__(self, series, arg1, arg2):
if isinstance(series, NumericSeries):
series = series.series
try:
series[series == np.inf] = np.nan
series = self.func(series, arg1, arg2)
except Exception as e:
raise FormulaException(e)
super(TwoArgumentSeries, self).__init__(series)
self.extra_create_kwargs["arg1"] = arg1
self.extra_create_kwargs["arg2"] = arg2
class SMASeries(TwoArgumentSeries):
"""同花顺专用SMA"""
def func(self, series, n, _):
results = np.nan_to_num(series).copy()
# FIXME this is very slow
for i in range(1, len(series)):
results[i] = ((n - 1) * results[i - 1] + results[i]) / n
return results
class SumSeries(NumericSeries):
"""求和"""
def __init__(self, series, period):
if isinstance(series, NumericSeries):
series = series.series
try:
series[series == np.inf] = 0
series[series == -np.inf] = 0
if period == 0:
series = np.cumsum(series)
else:
series = talib.SUM(series, period)
except Exception as e:
raise FormulaException(e)
super(SumSeries, self).__init__(series)
self.extra_create_kwargs["period"] = period
class AbsSeries(NumericSeries):
def __init__(self, series):
if isinstance(series, NumericSeries):
series = series.series
try:
series[series == np.inf] = 0
series[series == -np.inf] = 0
series = np.abs(series)
except Exception as e:
raise FormulaException(e)
super(AbsSeries, self).__init__(series)
class AveDevSeries(NumericSeries):
def __init__(self, series, period):
result_series = MovingAverageSeries(series, period).series # used to store the result
if isinstance(series, NumericSeries):
series = series.series
try:
series[series == np.inf] = 0
series[series == -np.inf] = 0
temp_len = len(series)
for i in np.arange(period - 1, temp_len):
temp_start = i - period + 1
temp_series = series[temp_start:(i + 1)]
temp_avg = np.mean(temp_series)
temp_dev = temp_series - temp_avg
result_series[i] = np.mean(np.abs(temp_dev))
except Exception as e:
raise FormulaException(e)
super(AveDevSeries, self).__init__(result_series)
self.extra_create_kwargs["period"] = period
class DmaSeries(NumericSeries):
def __init__(self, series, weights):
if isinstance(series, NumericSeries):
series = series.series
try:
series_mean = np.nanmean(series)
series[series == np.inf] = series_mean
series[series == -np.inf] = series_mean
series[np.isnan(series)] = series_mean
weights_mean = np.nanmean(weights._series)
weights._series[np.isnan(weights._series)] = weights_mean
except Exception as e:
raise FormulaException(e)
result_series = series # used to store the result
for i in range(1, len(series)):
result_series[i] = (1 - weights._series[i]) * result_series[i - 1] + weights._series[i] * result_series[i]
super(DmaSeries, self).__init__(result_series)
@handle_numpy_warning
def CrossOver(s1, s2):
"""s1金叉s2
:param s1:
:param s2:
:returns: bool序列
:rtype: BoolSeries
"""
s1, s2 = ensure_timeseries(s1), ensure_timeseries(s2)
series1, series2 = fit_series(s1.series, s2.series)
cond1 = series1 > series2
series1, series2 = fit_series(s1[1].series, s2[1].series)
cond2 = series1 <= series2 # s1[1].series <= s2[1].series
cond1, cond2 = fit_series(cond1, cond2)
s = cond1 & cond2
return BoolSeries(s)
def Ref(s1, n):
return s1[n]
@handle_numpy_warning
def minimum(s1, s2):
s1, s2 = ensure_timeseries(s1), ensure_timeseries(s2)
if len(s1) == 0 or len(s2) == 0:
raise FormulaException("minimum size == 0")
series1, series2 = fit_series(s1.series, s2.series)
s = np.minimum(series1, series2)
return NumericSeries(s)
@handle_numpy_warning
def maximum(s1, s2):
s1, s2 = ensure_timeseries(s1), ensure_timeseries(s2)
if len(s1) == 0 or len(s2) == 0:
raise FormulaException("maximum size == 0")
series1, series2 = fit_series(s1.series, s2.series)
s = np.maximum(series1, series2)
return NumericSeries(s)
@handle_numpy_warning
def count(cond, n):
# TODO lazy compute
series = cond.series
size = len(cond.series) - n
try:
result = np.full(size, 0, dtype=np.int)
except ValueError as e:
raise FormulaException(e)
for i in range(size - 1, 0, -1):
s = series[-n:]
result[i] = len(s[s == True])
series = series[:-1]
return NumericSeries(result)
@handle_numpy_warning
def every(cond, n):
return count(cond, n) == n
@handle_numpy_warning
def hhv(s, n):
# TODO lazy compute
series = s.series
size = len(s.series) - n
try:
result = np.full(size, 0, dtype=np.float64)
except ValueError as e:
raise FormulaException(e)
result = np.max(rolling_window(series, n), 1)
return NumericSeries(result)
@handle_numpy_warning
def llv(s, n):
# TODO lazy compute
series = s.series
size = len(s.series) - n
try:
result = np.full(size, 0, dtype=np.float64)
except ValueError as e:
raise FormulaException(e)
result = np.min(rolling_window(series, n), 1)
return NumericSeries(result)
@handle_numpy_warning
def iif(condition, true_statement, false_statement):
series1 = get_series(true_statement)
series2 = get_series(false_statement)
cond_series, series1, series2 = fit_series(condition.series, series1, series2)
series = series2.copy()
series[cond_series] = series1[cond_series]
return NumericSeries(series) | /rqfuncat-0.3.4.tar.gz/rqfuncat-0.3.4/funcat/func.py | 0.664105 | 0.435721 | func.py | pypi |
import numpy as np
from .time_series import MarketDataSeries, MarketSeries, FinancialDataSeries, IndexDataSeries
from .func import (
SumSeries,
AbsSeries,
StdSeries,
SMASeries,
MovingAverageSeries,
WeightedMovingAverageSeries,
ExponentialMovingAverageSeries,
CrossOver,
minimum,
maximum,
every,
count,
hhv,
llv,
Ref,
iif,
AveDevSeries,
DmaSeries,
)
from .context import (
symbol,
set_current_security,
set_current_date,
set_start_date,
set_data_backend,
set_current_freq,
)
from .helper import select
from numpy import sqrt
# create open high low close volume datetime total_turnover
for name in ["open", "high", "low", "close", "volume", "datetime", "total_turnover"]:
dtype = np.float64 if name != "datetime" else np.uint64
cls = type("{}Series".format(name.capitalize()), (MarketDataSeries, ), {"name": name, "dtype": dtype})
obj = cls(dynamic_update=True)
for var in [name[0], name[0].upper(), name.upper()]:
globals()[var] = obj
# define classes to reflect market condition
for name in ["advance", "decline"]:
dtype = np.float64
cls = type("{}Series".format(name.capitalize()), (MarketSeries, ), {"name": name, "dtype": dtype})
obj = cls(dynamic_update=True)
for var in [name[0], name[0].upper(), name.upper()]:
globals()[var] = obj
# define classes to get financial data
for name in ["capital"]:
dtype = np.float64
cls = type("{}Series".format(name.capitalize()), (FinancialDataSeries, ), {"name": name, "dtype": dtype})
obj = cls(dynamic_update=True)
for var in [name.upper()]:
globals()[var] = obj
# define classes to get index data
for name in ["indexo", "indexh", "indexl", "indexc", "indexv", "indexa"]:
dtype = np.float64
cls = type("{}Series".format(name.capitalize()), (IndexDataSeries, ), {"name": name, "dtype": dtype})
obj = cls(dynamic_update=True)
for var in [name[0], name[0].upper(), name.upper()]:
globals()[var] = obj
VOL = VOLUME
AMOUNT = TOTAL_TURNOVER
SQRT = sqrt
MA = MovingAverageSeries
WMA = WeightedMovingAverageSeries
EMA = ExponentialMovingAverageSeries
SMA = SMASeries
SUM = SumSeries
ABS = AbsSeries
STD = StdSeries
CROSS = CrossOver
REF = Ref
MIN = minimum
MAX = maximum
EVERY = every
COUNT = count
HHV = hhv
LLV = llv
IF = IIF = iif
S = set_current_security
T = set_current_date
AVEDEV = AveDevSeries
DMA = DmaSeries
__all__ = [
"OPEN", "O",
"HIGH", "H",
"LOW", "L",
"CLOSE", "C",
"VOLUME", "V", "VOL",
"DATETIME",
"ADVANCE",
"DECLINE",
"CAPITAL",
"INDEXO",
"INDEXH",
"INDEXL",
"INDEXC",
"INDEXA",
"SMA",
"MA",
"EMA",
"WMA",
"SUM",
"ABS",
"STD",
"CROSS",
"REF",
"MAX",
"MIN",
"EVERY",
"COUNT",
"HHV",
"LLV",
"IF", "IIF",
"S",
"T",
"select",
"symbol",
"set_current_security",
"set_current_date",
"set_start_date",
"set_data_backend",
"set_current_freq",
"AVEDEV",
"AMOUNT",
"SQRT",
"DMA"
] | /rqfuncat-0.3.4.tar.gz/rqfuncat-0.3.4/funcat/api.py | 0.641198 | 0.342462 | api.py | pypi |
from funcat.data.backend import DataBackend
from funcat.utils import get_str_date_from_int, get_int_date, FormulaException
from functools import lru_cache
class RQDataBackend(DataBackend):
def __init__(self):
import rqdatac
self.rqdatac = rqdatac
@staticmethod
def convert_date_to_int(dt):
t = dt.year * 10000 + dt.month * 100 + dt.day
t *= 1000000
return t
@staticmethod
def convert_dt_to_int(dt):
t = RQDataBackend.convert_date_to_int(dt)
t += dt.hour * 10000 + dt.minute * 100 + dt.second
return t
@lru_cache(4096)
def get_price(self, order_book_id, start, end, freq, **kwargs):
start = get_str_date_from_int(start)
end = get_str_date_from_int(end)
df = self.rqdatac.get_price(order_book_id, start_date=start, end_date=end, frequency=freq, **kwargs)
suspended_df = self.rqdatac.is_suspended(order_book_id, start_date=start, end_date=end)
if suspended_df is None:
raise FormulaException("missing data {}".format(order_book_id))
df["suspended"] = suspended_df[order_book_id]
df = df[df["suspended"] == False]
df = df.reset_index()
df["datetime"] = df["index"].apply(RQDataBackend.convert_dt_to_int)
del df["index"]
arr = df.to_records()
return arr
@lru_cache()
def get_order_book_id_list(self):
order_book_id_list = sorted(self.rqdatac.all_instruments("CS").order_book_id.tolist())
return order_book_id_list
@lru_cache()
def get_trading_dates(self, start, end):
start = max(start, 20050101)
start = get_str_date_from_int(start)
end = get_str_date_from_int(end)
dates = self.rqdatac.get_trading_dates(start, end)
trading_dates = [get_int_date(date) for date in dates]
return trading_dates
@lru_cache(4096)
def symbol(self, order_book_id):
return "{}[{}]".format(order_book_id, self.rqdatac.instruments(order_book_id).symbol)
@lru_cache()
def get_index_component(self, order_book_id):
"""
获取指数组成成分
:param order_book_id: 股票代码
:return: list of str
"""
return self.rqdatac.index_components(order_book_id) | /rqfuncat-0.3.4.tar.gz/rqfuncat-0.3.4/funcat/data/rqdata_data_backend.py | 0.631026 | 0.268631 | rqdata_data_backend.py | pypi |
.. -*- coding: utf-8 -*-
===================================================
Specification "Relations Query Language" (Hercules)
===================================================
Introduction
============
Goals RQL
---------
The goal is to have a language emphasizing the way of browsing
relations. As such, attributes will be regarded as cases of
special relations (in terms of implementation, the user
language not to see virtually no difference between an attribute and a
relation).
RQL is inspired by SQL but is the highest level. A knowledge of the
`CubicWeb` schema defining the application is necessary.
Comparison with existing languages
----------------------------------
SQL
```
RQL builds on the features of SQL but is at a higher level
(the current implementation of RQL generates SQL). For that it is limited
to the way of browsing relations and introduces variables.
The user does not need to know the model underlying SQL, but the `CubicWeb`
scheam defining the application.
Versa
`````
Should I look in more detail, but here is already some ideas for
the moment ... Versa_ is the language most similar to what we wanted
to do, but the model underlying data being RDF, there is some
number of things such as namespaces or handling of the RDF types which
does not interest us. On the functionality level, Versa_ is very comprehensive
including through many functions of conversion and basic types manipulation,
which may need to be guided at one time or another.
Finally, the syntax is a little esoteric.
See also
``````````
RDFQL_
The different types of queries
------------------------------
Search ( `Any`)
This type of query can extract entities and attributes of entities.
Inserting entities ( `INSERT`)
This type of query is used to insert new entities in the database. It
will also create direct relationships entities newly created.
Update entities, relations creation( `SET`)
This type of query updates existing entities in the database,
or create relations between existing entities.
Deletion of entities or relationship ( `DELETE`)
This type of query allows for the removal of entities and relations existing
in the database.
Examples
========
(see the tutorial: ref: `tutorielRQL` for more examples)
Search Query
------------
[ `DISTINCT`] <entity type> V1 (V2) \ *
[ `GROUPBY` V1 (V2) \*] [ `ORDERBY` <orderterms>]
[ `WHERE` <restriction>]
[ `LIMIT` <value>] [ `OFFSET` <value>]
:entity type:
Type of selected variables.
The special type `Any` is equivalent to not specify a type.
:restriction:
list of relations to go through whic follow the pattern
`V1 relation V2 | <static value>`
:orderterms:
Definition of the selection order: variable or column number followed by
sorting method ( `ASC`, `DESC`), ASC is the default.
:note for grouped queries:
For grouped queries (e.g., a clause `GROUPBY`), all
selected variables must be aggregated or grouped.
- *Search for the object of identifier 53*
::
Any WHERE X
X eid 53
- *Search material such as comics, owned by syt and available*
::
WHERE X Document
X occurence_of F, F class C, C name 'Comics'
X owned_by U, U login 'syt'
X available true
- *Looking for people working for eurocopter interested in training*
::
Person P WHERE
P work_for P, S name 'Eurocopter'
P interested_by T, T name 'training'
- *Search note less than 10 days old written by jphc or ocy*
::
Note N WHERE
N written_on D, D day> (today -10),
N written_by P, P name 'jphc' or P name 'ocy'
- *Looking for people interested in training or living in Paris*
::
Person P WHERE
(P interested_by T, T name 'training') or
(P city 'Paris')
- *The name and surname of all people*
::
Any N, P WHERE
X is Person, X name N, X first_name P
Note that the selection of several entities generally force
the use of "Any" because the type specification applies otherwise
to all the selected variables. We could write here
::
String N, P WHERE
X is Person, X name N, X first_name P
Insertion query
---------------
`INSERT` <entity type> V1 (, <entity type> V2) \ * `:` <assignments>
[ `WHERE` <restriction>]
: assignments:
list of relations to assign in the form `V1 relationship V2 | <static value>`
The restriction can define variables used in assignments.
Caution, if a restriction is specified, the insertion is done for
*each line results returned by the restriction*.
- *Insert a new person named 'foo'*
::
INSERT Person X: X name 'widget'
- *Insert a new person named 'foo', another called 'nice' and a 'friend' relation
between them*
::
INSERT Person X, Person Y: X name 'foo', Y name 'nice', X friend Y
- *Insert a new person named 'foo' and a 'friend' relation with an existing
person called 'nice'*
::
INSERT Person X: X name 'foo', X friend Y WHERE name 'nice'
Update and relation creation queries
------------------------------------
`SET` <assignements>
[ `WHERE` <restriction>]
Caution, if a restriction is specified, the update is done *for
each line results returned by the restriction*.
- *Renaming of the person named 'foo' to 'bar' with the first name changed*
::
SET X name 'bar', X first_name 'original' where X is Person X name 'foo'
- *Insert a relation of type 'know' between objects linked by
the relation of type 'friend'*
::
SET X know Y WHERE X friend Y
Deletion query
--------------
`DELETE` (<entity type> V) | (V1 relation v2 ),...
[ `WHERE` <restriction>]
Caution, if a restriction is specified, the deletion is made *for
each line results returned by the restriction*.
- *Deletion of the person named 'foo'*
::
DELETE Person X WHERE X name 'foo'
- *Removal of all relations of type 'friend' from the person named 'foo'*
::
DELETE X friend Y WHERE X is Person, X name 'foo'
Language definition
===================
Reserved keywords
-----------------
The keywords are not case sensitive.
::
DISTINCT, INSERT, SET, DELETE,
WHERE, AND, OR, NOT
IN, LIKE, ILIKE,
TRUE, FALSE, NULL, TODAY, NOW
GROUPBY, ORDERBY, ASC, DESC
Variables and Typing
--------------------
With RQL, we do not distinguish between entities and attributes. The
value of an attribute is considered an entity of a particular type (see
below), linked to one (real) entity by a relation called the name of
the attribute.
Entities and values to browse and/or select are represented in
the query by *variables* that must be written in capital letters.
There is a special type **Any**, referring to a non specific type.
We can restrict the possible types for a variable using the
special relation **is**.
The possible type(s) for each variable is derived from the schema
according to the constraints expressed above and thanks to the relations between
each variable.
Built-in types
``````````````
The base types supported are string (between double or single quotes),
integers or floats (the separator is the'.'), dates and
boolean. We expect to receive a schema in which types String,
Int, Float, Date and Boolean are defined.
* `String` (literal: between double or single quotes).
* `Int`, `Float` (separator being'.').
* `Date`, `Datetime`, `Time` (literal: string YYYY/MM/DD [hh:mm] or keywords
`TODAY` and `NOW`).
* `Boolean` (keywords `TRUE` and `FALSE`).
* `Keyword` NULL.
Operators
---------
Logical Operators
```````````````````
::
AND, OR, ','
',' is equivalent to 'AND' but with the smallest among the priority
of logical operators (see :ref:`PriorityOperators`).
Mathematical Operators
``````````````````````
::
+, -, *, /
Comparison operators
````````````````````
::
=, <, <=, >=, > = ~, IN, LIKE, ILIKE
* The operator `=` is the default operator.
* The operator `LIKE` equivalent to `~=` can be used with the
special character `%` in a string to indicate that the chain
must start or finish by a prefix/suffix:
::
Any X WHERE X name =~ 'Th%'
Any X WHERE X name LIKE '%lt'
* The operator `ILIKE` is a case-insensitive version of `LIKE`.
* The operator `IN` provides a list of possible values:
::
Any X WHERE X name IN ( 'chauvat', 'fayolle', 'di mascio', 'thenault')
XXX nico: A trick <> 'bar' would not it be more convenient than NOT A
trick 'bar'?
.. _PriorityOperators:
Operators priority
``````````````````
1. '*', '/'
2. '+', '-'
3. 'and'
4. 'or'
5. ','
Advanced Features
-----------------
Functions aggregates
````````````````````
::
COUNT, MIN, MAX, AVG, SUM
Functions on string
```````````````````
::
UPPER, LOWER
Optional relations
``````````````````
* They allow you to select entities related or not to another.
* You must use the `?` behind the variable to specify that the relation
toward it is optional:
- Anomalies of a project attached or not to a version ::
Any X, V WHERE X concerns P, P eid 42, X corrected_in V?
- All cards and the project they document if necessary ::
Any C, P WHERE C is Card, P? documented_by C
BNF grammar
-----------
The terminal elements are in capital letters, non-terminal in lowercase.
The value of the terminal elements (between quotes) is a Python regular
expression.
::
statement:: = (select | delete | insert | update) ';'
# select specific rules
select ::= 'DISTINCT'? E_TYPE selected_terms restriction? group? sort?
selected_terms ::= expression ( ',' expression)*
group ::= 'GROUPBY' VARIABLE ( ',' VARIABLE)*
sort ::= 'ORDERBY' sort_term ( ',' sort_term)*
sort_term ::= VARIABLE sort_method =?
sort_method ::= 'ASC' | 'DESC'
# delete specific rules
delete ::= 'DELETE' (variables_declaration | relations_declaration) restriction?
# insert specific rules
insert ::= 'INSERT' variables_declaration ( ':' relations_declaration)? restriction?
# update specific rules
update ::= 'SET' relations_declaration restriction
# common rules
variables_declaration ::= E_TYPE VARIABLE (',' E_TYPE VARIABLE)*
relations_declaration ::= simple_relation (',' simple_relation)*
simple_relation ::= VARIABLE R_TYPE expression
restriction ::= 'WHERE' relations
relations ::= relation (LOGIC_OP relation)*
| '(' relations')'
relation ::= 'NOT'? VARIABLE R_TYPE COMP_OP? expression
| 'NOT'? R_TYPE VARIABLE 'IN' '(' expression (',' expression)* ')'
expression ::= var_or_func_or_const (MATH_OP var_or_func_or_const) *
| '(' expression ')'
var_or_func_or_const ::= VARIABLE | function | constant
function ::= FUNCTION '(' expression ( ',' expression) * ')'
constant ::= KEYWORD | STRING | FLOAT | INT
# tokens
LOGIC_OP ::= ',' | 'GOLD' | 'AND'
MATH_OP ::= '+' | '-' | '/' | '*'
COMP_OP ::= '>' | '>=' | '=' | '<=' | '<' | '~=' | 'LIKE' | 'ILIKE'
FUNCTION ::= 'MIN' | 'MAX' | 'SUM' | 'AVG' | 'COUNT' | 'upper' | 'LOWER'
VARIABLE ::= '[A-Z][A-Z0-9]*'
E_TYPE ::= '[A-Z]\w*'
R_TYPE ::= '[a-z_]+'
KEYWORD ::= 'TRUE' | 'FALSE' | 'NULL' | 'TODAY' | 'NOW'
STRING ::= "'([^'\]|\\.)*'" |'"([^\"]|\\.)*\"'
FLOAT ::= '\d+\.\d*'
INT ::= '\d+'
Remarks
-------
Sorting and groups
``````````````````
- For grouped queries (e.g. with a GROUPBY clause), all
selected variables should be grouped.
- To group and/or sort by attributes, we can do: "X,L user U, U
login L GROUPBY L, X ORDERBY L"
- If the sorting method (SORT_METHOD) is not specified, then the sorting is
ascendant.
Negation
````````
* A query such as `Document X WHERE NOT X owned_by U` means "the
documents have no relation `owned_by`".
* But the query `Document X WHERE NOT X owned_by U, U login "syt"`
means "the documents have no relation `owned_by` with the user
syt". They may have a relation "owned_by" with another user.
Identity
````````
You can use the special relation `identity` in a query to
add an identity constraint between two variables. This is equivalent
to ``is`` in python::
Any A WHERE A comments B, A identity B
return all objects that comment themselves. The relation
`identity` is especially useful when defining the rules for securities
with `RQLExpressions`.
Implementation
==============
Internal representation (syntactic tree)
----------------------------------------
The tree research does not contain the selected variables
(e.g. there is only what follows "WHERE").
The insertion tree does not contain the variables inserted or relations
defined on these variables (e.g. there is only what follows "WHERE").
The removal tree does not contain the deleted variables and relations
(e.g. there is only what follows the "WHERE").
The update tree does not contain the variables and relations updated
(e.g. there is only what follows the "WHERE").
::
Select ((Relationship | And | Gold)?, Group?, Sort?)
Insert (Relations | And | Gold)?
Delete (Relationship | And | Gold)?
Update (Relations | And | Gold)?
And ((Relationship | And | Gold), (Relationship | And | Gold))
Or ((Relationship | And | Gold), (Relationship | And | Gold))
Relationship ((VariableRef, Comparison))
Comparison ((Function | MathExpression | Keyword | Constant | VariableRef) +)
Function (())
MathExpression ((MathExpression | Keyword | Constant | VariableRef), (MathExpression | Keyword | Constant | VariableRef))
Group (VariableRef +)
Sort (SortTerm +)
SortTerm (VariableRef +)
VariableRef ()
Variable ()
Keyword ()
Constant ()
Remarks
-------
- The current implementation does not support linking two relations of type
'is' with a OR. I do not think that the negation is supported on this type
of relation (XXX FIXME to be confirmed).
- Relations defining the variables must be left to those using them.
For example::
Point P where P abs X, P ord Y, P value X+Y
is valid, but::
Point P where P abs X, P value X+Y, P ord Y
is not.
Conclusion
==========
Limitations
-----------
It lacks at the moment:
- COALESCE
- restrictions on groups (HAVING)
and certainly other things ...
A disadvantage is that to use this language we must know the
format used (with real relation names and entities, not those viewing
in the user interface). On the other hand, we can not really bypass
that, and it is the job of a user interface to hide the RQL.
Topics
------
It would be convenient to express the schema matching
relations (non-recursive rules)::
Document class Type <-> Document occurence_of Fiche class Type
Sheet class Type <-> Form collection Collection class Type
Therefore 1. becomes::
Document X where
X class C, C name 'Cartoon'
X owned_by U, U login 'syt'
X available true
I'm not sure that we should handle this at RQL level ...
There should also be a special relation 'anonymous'.
.. _Versa: Http://uche.ogbuji.net/tech/rdf/versa/
.. _RDFQL: Http://www.w3.org/TandS/QL/QL98/pp/rdfquery.html
| /rql-0.40.1.tar.gz/rql-0.40.1/docs/specifications_en.rst | 0.791257 | 0.826397 | specifications_en.rst | pypi |
# RQLAlchemy
[](https://travis-ci.org/pjwerneck/rqlalchemy)
Resource Query Language extension for SQLAlchemy
## Overview
Resource Query Language (RQL) is a query language designed for use in URIs, with object-style data structures.
rqlalchemy is an RQL extension for SQLAlchemy. It easily allows exposing SQLAlchemy tables or models as an HTTP API endpoint and performing complex queries using only querystring parameters.
## Installing
```
pip install rqlalchemy
```
## Usage
RQL queries can be supported by an application using SQLAlchemy by adding the `rqlalchemy.RQLQueryMixIn` class as a mix-in class to your base `Query` class:
```python
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import Query as BaseQuery
from rqlalchemy import RQLQueryMixIn
# create the declarative base
Base = declarative_base()
# create the custom query class
class RQLQuery(BaseQuery, RQLQueryMixIn):
_rql_default_limit = 10
_rql_max_limit = 100
# assign the custom query class to the declarative base
Base.query_class = RQLQuery
```
With that in place, you can perform RQL queries by passing the querystring to the query `rql()` method. For example, if you have a Flask HTTP API with an users collection endpoint querying your `User` model:
```python
from urllib.parse import unquote
from flask import request
@app.route('/users')
def get_users_collection():
qs = unquote(request.query_string.decode(request.charset))
query = session.query(User).rql(qs)
users = query.rql_all()
return render_response(users)
```
### Aggregates
As with the base SQLAlchemy Query class, you can retrieve results with the `all()` method, or by iterating over the query, however, if you want to support RQL expressions with aggregate functions or querying functions that result in a subset of columns, you must retrieve the results with `rql_all()`.
### Pagination
RQLAlchemy offers limit/offset pagination with the `rql_paginate()` method, which returns the requested page, the RQL expressions for previous and next pages if available, and the total number of items.
```python
from urllib.parse import unquote
from flask import request
@app.route('/users')
def get_users_collection():
qs = unquote(request.query_string.decode(request.charset))
query = session.query(User).rql(qs)
page, previous_page, next_page, total = query.rql_paginate()
response = {"data": page,
"total": total,
}
if previous_page:
response["previous"] = '/users?' + previous_page
if next_page:
response["next"] = '/users?' + next_page
return render_response(response)
```
Keep in mind that pagination requires a limit, either a `_rql_default_limit` value, a querystring `limit(x)`, or the `limit` parameter to the `rql()` method. Calling `rql_paginate()` without a limit will raise `RQLQueryError`.
## Reference Table
| RQL | SQLAlchemy | Obs. |
|-------------------------|----------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------|
| QUERYING | | |
| select(a,b,c,...) | .query(Model.a, Model.b, Model.c,...) | |
| values(a) | [o.a for o in query.from_self(a)] | |
| limit(count,start?) | .limit(count).offset(start) | |
| sort(attr1) | .order_by(attr) | |
| sort(-attr1) | .order_by(attr.desc()) | |
| distinct() | .distinct() | |
| first() | .limit(1) | |
| one() | [query.one()] | |
| FILTERING | | |
| eq(attr,value) | .filter(Model.attr == value) | |
| ne(attr,value) | .filter(Model.attr != value) | |
| lt(attr,value) | .filter(Model.attr < value) | |
| le(attr,value) | .filter(Model.attr <= value) | |
| gt(attr,value) | .filter(Model.attr > value) | |
| ge(attr,value) | .filter(Model.attr >= value) | |
| in(attr,value) | .filter(Model.attr.in_(value) | |
| out(attr,value) | .filter(not_(Model.attr.in_(value))) | |
| contains(attr,value) | .filter(Model.contains(value)) | Produces a LIKE expression when filtering against a string, or an IN expression when filtering against an iterable relationship |
| excludes(attr,value) | .filter(not_(Model.contains(value))) | See above. |
| and(expr1,expr2,...) | .filter(and_(expr1, expr2, ...)) | |
| or(expr1,expr2,...) | .filter(or_(expr1, expr2, ...)) | |
| AGGREGATING | | All aggregation functions return scalar results. |
| aggregate(a,b\(c\),...) | .query(Model.a, func.b(Model.c)).group_by(Model.a) | |
| sum(attr) | .query(func.sum(Model.attr)) | |
| mean(attr) | .query(func.avg(Model.attr)) | |
| max(attr) | .query(func.max(Model.attr)) | |
| min(attr) | .query(func.min(Model.attr)) | |
| count() | .query(func.count()) | |
| /rqlalchemy-0.4.2.tar.gz/rqlalchemy-0.4.2/README.md | 0.650578 | 0.852935 | README.md | pypi |
<h1 align="center">
<br>
<a href="#"><img src="https://raw.githubusercontent.com/pranavgupta1234/rqmonitor/master/artifacts/rqmonitor.png" alt="RQ Monitor" height="300" width="300"></a>
<br>
</h1>
<h3 align="center">RQ Monitor is Flask based more actionable and dynamic web frontend for monitoring your RQ.</h3>
<p align="center">
<a href="https://opensource.org/licenses/Apache-2.0">
<img alt="GitHub" src="https://img.shields.io/github/license/pranavgupta1234/rqmonitor?style=for-the-badge">
</a>
<a href="https://pypi.org/project/rqmonitor/">
<img alt="PyPI" src="https://img.shields.io/pypi/v/rqmonitor?style=for-the-badge">
</a>
<a href="https://pypi.org/project/rqmonitor/">
<img alt="PyPI - Python Version" src="https://img.shields.io/pypi/pyversions/rqmonitor?style=for-the-badge">
</a>
<a href="https://github.com/pranavgupta1234/rqmonitor/issues">
<img alt="GitHub issues" src="https://img.shields.io/github/issues/pranavgupta1234/rqmonitor?style=for-the-badge">
</a>
<a href="https://github.com/pranavgupta1234/rqmonitor/pulls">
<img alt="GitHub pull requests" src="https://img.shields.io/github/issues-pr/pranavgupta1234/rqmonitor?style=for-the-badge">
</a>
<a href="#">
<img alt="Travis (.org)" src="https://img.shields.io/travis/pranavgupta1234/rqmonitor?style=for-the-badge">
</a>
<a href="#">
<img alt="Docker Image Size (latest by date)" src="https://img.shields.io/docker/image-size/pranavgupta1234/rqmonitor?logo=docker&style=for-the-badge">
</a>
</p>
<p align="center">
<a href="#key-features">Key Features</a> •
<a href="#install">Install</a> •
<a href="#docker">Docker</a> •
<a href="#usage">Usage</a> •
<a href="#credits">Credits</a> •
<a href="#contribute">Contribute</a> •
<a href="#similar-tool">Similar Tool</a> •
<a href="#license">License</a>
</p>

## Key Features
* Redis RQ Memory Monitoring - Implemented through Lua Scripting
- Possibly RQ is not the only work your redis is doing and you want to keep a close eye on memory consumption of RQ namespace. Be little careful while executing it on production environment with large data as script may block your redis for some time.
* Send Signals to remote workers
- Using rqmonitor you can suspend/resume/delete your workers for debugging purposes which can be located on same instance running rqmonitor or some other instance in your network.
- rqmonitor internally uses [fabric](https://github.com/fabric/fabric) for sending commands to remote workers.
- Make sure the instance running rqmonitor have proper access to other instances running rq workers which can be achieved by properly configuring ssh, so make sure appropriate entries are added inside ssh_config.
* All data population through DataTables:
- Queues and Workers dashboard are rendered by client side DataTables so you get additional functionality of sorting, searching, robust pagination.
- Jobs dashboard is rendered with server side option enabled of DataTables for easy loading of very large number of jobs.(Ajax Pipeling also planned in future)
* More Ajax Less Reloading
- Once after firing up the dashboard, little to no refresh is necessary, almost every refresh is done via ajax.
* Jobs Filtering Support
- You can choose to view a set of jobs from certain queue with certain status.
* Global Actions
- You can easily delete/empty multiple queues, jobs and suspend/resume workers.
* Last but not the least is beautiful UI
* More features coming!
## Install
1. Install [`rqmonitor`](https://pypi.org/project/rqmonitor/) with pip
+ `$ pip install rqmonitor`
2. For Docker check below.
## Docker
You love docker, don't you ?
Pull rqmonitor latest docker image from dockerhub
```
docker pull pranavgupta1234/rqmonitor
docker run -p 8899:8899 pranavgupta1234/rqmonitor
```
The above command will successfully run the flask app but your redis is probably on your docker host then
provide your docker host private IP for redis url via env, like:
```
docker run --env RQ_MONITOR_REDIS_URL=redis://<your-private-ip>:6379 -p 8899:8899 pranavgupta1234/rqmonitor
```
## Usage
CLI options are similar to that of rq-dashboard.
Download latest version of rqmonitor from pypi and fire up your command line and type `rqmonitor --help`.
```
Usage: rqmonitor [OPTIONS]
Run the RQ Monitor Flask server.
All configuration can be set on the command line or through environment
variables of the form RQ_MONITOR_*. For example RQ_MONITOR_USERNAME.
A subset of the configuration (the configuration parameters used by the
underlying flask blueprint) can also be provided in a Python module
referenced using --config, or with a .cfg file referenced by the
RQ_MONITOR_SETTINGS environment variable.
Options:
-b, --bind TEXT IP or hostname on which to bind HTTP server
-p, --port INTEGER Port on which to bind HTTP server
--url-prefix TEXT URL prefix e.g. for use behind a reverse
proxy
--username TEXT HTTP Basic Auth username (not used if not
set)
--password TEXT HTTP Basic Auth password
-c, --config TEXT Configuration file (Python module on search
path)
-u, --redis-url TEXT Redis URL. Can be specified multiple times.
Default: redis://127.0.0.1:6379
--refresh-interval, --interval INTEGER
Refresh interval in ms
--extra-path TEXT Append specified directories to sys.path
--debug / --normal Enter DEBUG mode
-v, --verbose Enable verbose logging
--help Show this message and exit.
```
## Credits
This software is majorly dependent on the following open source packages:
- [rq](https://github.com/rq/rq)
- [flask](https://github.com/pallets/flask)
- [DataTables](https://github.com/DataTables/DataTables)
- [Concept Admin Dashboard](https://github.com/puikinsh/concept)
## Contribute
---
1. Clone repo and create a new branch:
`$ git checkout https://github.com/pranavgupta1234/rqmonitor -b name_for_new_branch`.
2. Make changes and test
3. Submit Pull Request with comprehensive description of changes
## Similar Tool
Some snippets in rqmonitor have been used from rq-dashboard.
- [rq-dashboard](https://github.com/Parallels/rq-dashboard) - Yet another RQ Dashboard
## License
Apache 2.0
| /rqmonitor-1.0.6.tar.gz/rqmonitor-1.0.6/README.md | 0.46393 | 0.805709 | README.md | pypi |
# Rqmts
<p align="center">
<b>Rqmts - Generate requirements.txt file for any project by analysing package imports</b><br><br>
<img alt="Rqmts logo" src="https://i.imgur.com/czbQOUj.png" width="400"><br>
<b>Click <a href="https://youtube.com/">here</a> to see the demo.<br>
Click <a href="https://github.com/0x48piraj/rqmts/wiki">here</a> for documentation.<br><br></b>
</p>
## About the project
**Rqmts** is a fantastic stand-alone tool which generates `requirements.txt` file for any project by analysing package imports.
It does not requires any dependency (works out-of-the-box), not needs internet to work _(is completely offline, upto this moment)_, nor uses regular expressions in such a violent way as existing projects do. Instead, it uses simple heuristic techniques and parse conditional trees, which is a better method for extracting imported names from statements, functions, etc.
## Why this project
### Questions
- **Why not just use pip's freeze command** to generate a `requirements.txt` file for my project ?
- Why to **re-invent the wheel** when there are modules such as **pipreqs**, **pigar**, **poetry** already present ?
- Why not manually ?
### Answers
* **Why not just pip freeze?**
* ``pip freeze`` only saves the packages that are installed with ``pip install`` in your environment.
* ``pip freeze`` saves all packages in the environment including those that you don't use in your current project. _(if you don't have virtualenv)_
* Why **re-invent the wheel** ?
* **pipreqs** fails on many occasions _(see - [pipreqs/issues](https://github.com/bndr/pipreqs/issues))_
* I found this repository and thought, _"Hmm.. I think I can simply this problem while trying to match **pipreqs** results"_
* **pigar** queries pypi servers, big no-no. Ideally, it should be local. _(on fallback? then maybe ..)_
* Other than that, **pigar** recommends using Pipenv ([pipenv has serious issues](https://news.ycombinator.com/item?id=18612590))
* **poetry** quotes "Be aware, however, that it will also install poetry's dependencies which might cause conflicts."
* Sheer curiousity. _"can I create a project that has potential of collecting thosands of stars and most importantly, hundreds of contributors?"_
* Manually ?
* _Are you serious right now ?_
## Installation
**Rqmts** provides a custom script that will run a **rqmts instance** isolated from the rest of your system by using file-less/memory-based execution. This is the recommended way of running Rqmts.
```
curl -sSL https://raw.githubusercontent.com/0x48piraj/rqmts/master/Rqmts.py | python
```
Alternatively, you can download `Rqmts.py` from the root directory and execute it separately.
Using **pip** to install [rqmts](https://pypi.org/project/rqmts/) is also possible.
```
pip install --user rqmts (windows)
pip3 install rqmts (linux)
```
## Usage
#### Command-line Interface
```
C:\rqmts>py -m rqmts -h
usage: __main__.py [-h] [-p FILE]
.===================================================================.
|| rqmts - Generate pip requirements.txt for any project ||
|| ||
|| ||
|| ___ ||
|| .' '. requirements.txt ||
|| / rqmts \ oOoOo. ||
|| | | | ,==|||||o. ||
|| \ pip / _|| |||||o. pip ||
|| '.___.' _.-'^|| ||||| ||
|| __/_______.-' '==rqmts ||
|| _.-'` / """"" ||
|| .-' / oOoOo. ||
|| `-._ / ,==|||||o. ||
|| '-/._|| |||||o. python ||
|| / ^|| ||||| ||
|| / '==rqmts ||
|| /________""""" ||
|| `\ `\ ||
|| \ `\ ||
|| \ `\ ||
|| / / ||
|| / / ||
|| @0x48piraj /_____ /_____ ||
|| ||
'==================================================================='
Options:
-p FILE, --path FILE Path of the Python script (inside quotation marks)
--REDACTED--
C:\rqmts>py -m rqmts -p "C:\test_proj\run.py"
--REDATED--
[!] System package found : string
[!] System package found : time
[!] System package found : random
[!] System package found : os
[!] System package found : re
[+] Success: Parsed the dependencies correctly
[*] Saving generated requirements.txt
[+] Success: requirements.txt saved
[+] Path where it can be found: C:\test_proj\requirements.txt
```
#### Interactive mode
```
C:\rqmts>py -m rqmts
.===================================================================.
|| rqmts - Generate pip requirements.txt for any project ||
|| ||
|| ||
|| ___ ||
|| .' '. requirements.txt ||
|| / rqmts \ oOoOo. ||
|| | | | ,==|||||o. ||
|| \ pip / _|| |||||o. pip ||
|| '.___.' _.-'^|| ||||| ||
|| __/_______.-' '==rqmts ||
|| _.-'` / """"" ||
|| .-' / oOoOo. ||
|| `-._ / ,==|||||o. ||
|| '-/._|| |||||o. python ||
|| / ^|| ||||| ||
|| / '==rqmts ||
|| /________""""" ||
|| `\ `\ ||
|| \ `\ ||
|| \ `\ ||
|| / / ||
|| / / ||
|| @0x48piraj /_____ /_____ ||
|| ||
'==================================================================='
[*] Path not provided, invoking interactive mode ...
[*] Enter the path of Python script
----> C:\test_proj\run.py
[!] System package found : random
[!] System package found : os
[!] System package found : re
[!] System package found : time
[!] System package found : string
[+] Success: Parsed the dependencies correctly
[*] Saving generated requirements.txt
[+] Success: requirements.txt saved
[+] Path where it can be found: C:\test_proj\requirements.txt
```
## Contribute
The major challenge of this project is to extract the required metadata from modules which are first extracted from the input script.
#### Challenges
- **Version numbers in python can be in very different places depending on the case**
- **Package name in the package index is independent of the module name we import**
and these quirks make this project interesting. There's a funny comment in the source which reflects the diversity between us and it goes like :
```py
# module_name.__version__ sucks, because we suck (PEP 0396)
```
This project aims to combine the best existing strategies to cover the broadest possible set of cases _(if not all)_. The project was built keeping in mind the modular programming paradigms and so other than being readable it's easily extensible making it possible to add new strategies/algorithms quickly.
If you have any issues or suggestions, please do not hesitate to **[open an issue](https://github.com/0x48piraj/rqmts/issues/new)** or a **[pull request](https://github.com/0x48piraj/rqmts/pulls)**!
## License
This software is licensed under **BSD 3-Clause "New" or "Revised" License**. To view a copy of this license, visit **[BSD 3-Clause](LICENSE)**. | /rqmts-2.0.1.tar.gz/rqmts-2.0.1/README.md | 0.472197 | 0.841174 | README.md | pypi |
r"""
The ``codes`` object defines a mapping from common names for HTTP statuses
to their numerical codes, accessible either as attributes or as dictionary
items.
Example::
>>> import requests
>>> requests.codes['temporary_redirect']
307
>>> requests.codes.teapot
418
>>> requests.codes['\o/']
200
Some codes have multiple names, and both upper- and lower-case versions of
the names are allowed. For example, ``codes.ok``, ``codes.OK``, and
``codes.okay`` all correspond to the HTTP status code 200.
"""
from .structures import LookupDict
_codes = {
# Informational.
100: ("continue",),
101: ("switching_protocols",),
102: ("processing",),
103: ("checkpoint",),
122: ("uri_too_long", "request_uri_too_long"),
200: ("ok", "okay", "all_ok", "all_okay", "all_good", "\\o/", "✓"),
201: ("created",),
202: ("accepted",),
203: ("non_authoritative_info", "non_authoritative_information"),
204: ("no_content",),
205: ("reset_content", "reset"),
206: ("partial_content", "partial"),
207: ("multi_status", "multiple_status", "multi_stati", "multiple_stati"),
208: ("already_reported",),
226: ("im_used",),
# Redirection.
300: ("multiple_choices",),
301: ("moved_permanently", "moved", "\\o-"),
302: ("found",),
303: ("see_other", "other"),
304: ("not_modified",),
305: ("use_proxy",),
306: ("switch_proxy",),
307: ("temporary_redirect", "temporary_moved", "temporary"),
308: (
"permanent_redirect",
"resume_incomplete",
"resume",
), # "resume" and "resume_incomplete" to be removed in 3.0
# Client Error.
400: ("bad_request", "bad"),
401: ("unauthorized",),
402: ("payment_required", "payment"),
403: ("forbidden",),
404: ("not_found", "-o-"),
405: ("method_not_allowed", "not_allowed"),
406: ("not_acceptable",),
407: ("proxy_authentication_required", "proxy_auth", "proxy_authentication"),
408: ("request_timeout", "timeout"),
409: ("conflict",),
410: ("gone",),
411: ("length_required",),
412: ("precondition_failed", "precondition"),
413: ("request_entity_too_large",),
414: ("request_uri_too_large",),
415: ("unsupported_media_type", "unsupported_media", "media_type"),
416: (
"requested_range_not_satisfiable",
"requested_range",
"range_not_satisfiable",
),
417: ("expectation_failed",),
418: ("im_a_teapot", "teapot", "i_am_a_teapot"),
421: ("misdirected_request",),
422: ("unprocessable_entity", "unprocessable"),
423: ("locked",),
424: ("failed_dependency", "dependency"),
425: ("unordered_collection", "unordered"),
426: ("upgrade_required", "upgrade"),
428: ("precondition_required", "precondition"),
429: ("too_many_requests", "too_many"),
431: ("header_fields_too_large", "fields_too_large"),
444: ("no_response", "none"),
449: ("retry_with", "retry"),
450: ("blocked_by_windows_parental_controls", "parental_controls"),
451: ("unavailable_for_legal_reasons", "legal_reasons"),
499: ("client_closed_request",),
# Server Error.
500: ("internal_server_error", "server_error", "/o\\", "✗"),
501: ("not_implemented",),
502: ("bad_gateway",),
503: ("service_unavailable", "unavailable"),
504: ("gateway_timeout",),
505: ("http_version_not_supported", "http_version"),
506: ("variant_also_negotiates",),
507: ("insufficient_storage",),
509: ("bandwidth_limit_exceeded", "bandwidth"),
510: ("not_extended",),
511: ("network_authentication_required", "network_auth", "network_authentication"),
}
codes = LookupDict(name="status_codes")
def _init():
for code, titles in _codes.items():
for title in titles:
setattr(codes, title, code)
if not title.startswith(("\\", "/")):
setattr(codes, title.upper(), code)
def doc(code):
names = ", ".join(f"``{n}``" for n in _codes[code])
return "* %d: %s" % (code, names)
global __doc__
__doc__ = (
__doc__ + "\n" + "\n".join(doc(code) for code in sorted(_codes))
if __doc__ is not None
else None
)
_init() | /rquest-2.28.2.tar.gz/rquest-2.28.2/requests/status_codes.py | 0.846308 | 0.566258 | status_codes.py | pypi |
from . import sessions
def request(method, url, **kwargs):
"""Constructs and sends a :class:`Request <Request>`.
:param method: method for the new :class:`Request` object: ``GET``, ``OPTIONS``, ``HEAD``, ``POST``, ``PUT``, ``PATCH``, or ``DELETE``.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
:param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
:param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
:param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content-type'`` is a string
defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
to add for the file.
:param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
:param timeout: (optional) How many seconds to wait for the server to send data
before giving up, as a float, or a :ref:`(connect timeout, read
timeout) <timeouts>` tuple.
:type timeout: float or tuple
:param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
:type allow_redirects: bool
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
:param verify: (optional) Either a boolean, in which case it controls whether we verify
the server's TLS certificate, or a string, in which case it must be a path
to a CA bundle to use. Defaults to ``True``.
:param stream: (optional) if ``False``, the response content will be immediately downloaded.
:param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
:return: :class:`Response <Response>` object
:rtype: requests.Response
Usage::
>>> import requests
>>> req = requests.request('GET', 'https://httpbin.org/get')
>>> req
<Response [200]>
"""
# By using the 'with' statement we are sure the session is closed, thus we
# avoid leaving sockets open which can trigger a ResourceWarning in some
# cases, and look like a memory leak in others.
with sessions.Session() as session:
return session.request(method=method, url=url, **kwargs)
def get(url, params=None, **kwargs):
r"""Sends a GET request.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request("get", url, params=params, **kwargs)
def options(url, **kwargs):
r"""Sends an OPTIONS request.
:param url: URL for the new :class:`Request` object.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request("options", url, **kwargs)
def head(url, **kwargs):
r"""Sends a HEAD request.
:param url: URL for the new :class:`Request` object.
:param \*\*kwargs: Optional arguments that ``request`` takes. If
`allow_redirects` is not provided, it will be set to `False` (as
opposed to the default :meth:`request` behavior).
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
kwargs.setdefault("allow_redirects", False)
return request("head", url, **kwargs)
def post(url, data=None, json=None, **kwargs):
r"""Sends a POST request.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request("post", url, data=data, json=json, **kwargs)
def put(url, data=None, **kwargs):
r"""Sends a PUT request.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request("put", url, data=data, **kwargs)
def patch(url, data=None, **kwargs):
r"""Sends a PATCH request.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request("patch", url, data=data, **kwargs)
def delete(url, **kwargs):
r"""Sends a DELETE request.
:param url: URL for the new :class:`Request` object.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request("delete", url, **kwargs) | /rquest-2.28.2.tar.gz/rquest-2.28.2/requests/api.py | 0.853486 | 0.411466 | api.py | pypi |
from collections import OrderedDict
from .compat import Mapping, MutableMapping
class CaseInsensitiveDict(MutableMapping):
"""A case-insensitive ``dict``-like object.
Implements all methods and operations of
``MutableMapping`` as well as dict's ``copy``. Also
provides ``lower_items``.
All keys are expected to be strings. The structure remembers the
case of the last key to be set, and ``iter(instance)``,
``keys()``, ``items()``, ``iterkeys()``, and ``iteritems()``
will contain case-sensitive keys. However, querying and contains
testing is case insensitive::
cid = CaseInsensitiveDict()
cid['Accept'] = 'application/json'
cid['aCCEPT'] == 'application/json' # True
list(cid) == ['Accept'] # True
For example, ``headers['content-encoding']`` will return the
value of a ``'Content-Encoding'`` response header, regardless
of how the header name was originally stored.
If the constructor, ``.update``, or equality comparison
operations are given keys that have equal ``.lower()``s, the
behavior is undefined.
"""
def __init__(self, data=None, **kwargs):
self._store = OrderedDict()
if data is None:
data = {}
self.update(data, **kwargs)
def __setitem__(self, key, value):
# Use the lowercased key for lookups, but store the actual
# key alongside the value.
self._store[key.lower()] = (key, value)
def __getitem__(self, key):
return self._store[key.lower()][1]
def __delitem__(self, key):
del self._store[key.lower()]
def __iter__(self):
return (casedkey for casedkey, mappedvalue in self._store.values())
def __len__(self):
return len(self._store)
def lower_items(self):
"""Like iteritems(), but with all lowercase keys."""
return ((lowerkey, keyval[1]) for (lowerkey, keyval) in self._store.items())
def __eq__(self, other):
if isinstance(other, Mapping):
other = CaseInsensitiveDict(other)
else:
return NotImplemented
# Compare insensitively
return dict(self.lower_items()) == dict(other.lower_items())
# Copy is required
def copy(self):
return CaseInsensitiveDict(self._store.values())
def __repr__(self):
return str(dict(self.items()))
class LookupDict(dict):
"""Dictionary lookup object."""
def __init__(self, name=None):
self.name = name
super().__init__()
def __repr__(self):
return f"<lookup '{self.name}'>"
def __getitem__(self, key):
# We allow fall-through here, so values default to None
return self.__dict__.get(key, None)
def get(self, key, default=None):
return self.__dict__.get(key, default) | /rquest-2.28.2.tar.gz/rquest-2.28.2/requests/structures.py | 0.926893 | 0.4231 | structures.py | pypi |
RQUGE🤗: Reference-Free Metric for Evaluating Question Generation by Answering the Question
=================
[](#python)
[](https://arxiv.org/abs/2211.01482)
[](https://pypi.python.org/pypi/rquge/)[](https://opensource.org/licenses/MIT)
[](https://github.com/psf/black)
<p align="center">
<img src="meta.jpeg" width="500"/>
</p>
We propose RQUGE, a **R**eference-free **QU**estion **G**eneration **E**valuation metric that can compute the quality of the candidate question without requiring the access to the reference question. Given the corresponding context and answer span, our metric calculates the acceptability score by applying a general question-answering module, followed by a span scorer. You can find more detail in [the paper](https://arxiv.org/abs/2211.01482) (ACL2023).
<p align="center">
<img src="main_model.jpg" width="700"/>
</p>
Contents
---------------
- [Huggingface Evaluate🤗](#hf_evaluate)
- [Installation](#install)
- [Calculation](#calculation)
- [Citation](#citation)
<a name="hf_evaluate"/>
HuggingFace Evaluation 🤗
--------------
RQUGE score is available on [Huggingface Evaluate](https://huggingface.co/docs/evaluate/index). It can be used as:
```
from evaluate import load
rqugescore = load("alirezamsh/rquge")
generated_questions = ["how is the weather?"]
contexts = ["the weather is sunny"]
answers = ["sunny"]
results = rquge.compute(generated_questions=generated_questions, contexts=contexts, answers=answers)
print(results["mean_score"])
>>> [5.05]
```
The demo and further details are also available on [here](https://huggingface.co/spaces/alirezamsh/rquge).
<a name="install"/>
Installation
--------------
You should have the following packages:
- transformers
- pytorch
- sentencepiece
Install from pypi with pip by
```
pip install rquge
```
Install latest unstable version from the master branch on Github by:
```
pip install git+https://github.com/alirezamshi/RQUGE
```
Install it from the source by:
```
git clone https://github.com/alirezamshi/RQUGE
cd RQUGE
pip install .
```
Note: you need to download the pre-trained model for the span scorer module (available on [Huggingface](https://huggingface.co/alirezamsh/quip-512-mocha)🤗 ```alirezamsh/quip-512-mocha```):
```
wget https://storage.googleapis.com/sfr-qafacteval-research/quip-512-mocha.tar.gz
tar -xzvf quip-512-mocha.tar.gz
rm quip-512-mocha.tar.gz
```
<a name="calculation"/>
RQUGE Calculation
--------------
#### Python Function
The RQUGE class is provided in ```rquge_score/scorer.py```. We also provide a python function in ```rquge_score_cli/scorer_cli.py``` to use different features of RQUGE metric.
#### Command Line Interface (CLI)
We provide a command line interface (CLI) of RQUGE, you can use it as follows:
```
rquge --input_type #MODE --sp_scorer_path #PATH_TO_SPAN_SCORER --qa_model_path #PATH_TO_QA_MODEL --context #CONTEXT_FILE --question #QUESTION --answer #ANSWER --output_path #OUTPUT
#MODE: The type of input (sample or offline). In the sample mode, "--context", "--question", and "--answer" commands contain string, while in offline mode, they contain path to files including contexts, corresponding questions and answers
#PATH_TO_SPAN_SCORER: path to the local checkpoint of span scorer model or "alirezamsh/quip-512-mocha"
#PATH_TO_QA_MODEL: name of QA model on Huggingface or local path
#CONTEXT_FILE: a text file containing one context per line (directly in the input in "sample" mode)
#QUESTION_FILE: a text file containing one question per line (directly in the input in "sample" mode)
#ANSWER_FILE: a text file containing one answer per line (directly in the input in "sample" mode)
#OUTPUT: local path for saving RQUGE scores for each (context,question,answer) pair
```
Here is a sample score computation for the interactive mode
```
rquge --input_type sample --sp_scorer_path ckpt/quip-512-mocha --qa_model_path 'allenai/unifiedqa-v2-t5-large-1363200' --context "the weather is sunny" --question "how is the weather?" --answer sunny
```
**Note:** the rquge score is between 1 to 5.
<a name="citation"/>
Citation
-------------
<a name="citations"/>
If you use this code for your research, please cite the following work:
```
@misc{mohammadshahi2022rquge,
title={RQUGE: Reference-Free Metric for Evaluating Question Generation by Answering the Question},
author={Alireza Mohammadshahi and Thomas Scialom and Majid Yazdani and Pouya Yanki and Angela Fan and James Henderson and Marzieh Saeidi},
year={2022},
eprint={2211.01482},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
Have a question not listed here? Open [a GitHub Issue](https://github.com/alirezamshi/RQUGE/issues) or
send us an [email](alireza.mohammadshahi@idiap.ch).
| /rquge-0.3.tar.gz/rquge-0.3/README.md | 0.459319 | 0.974386 | README.md | pypi |
from transformers import AutoModelForSequenceClassification, AutoTokenizer, T5Tokenizer, T5ForConditionalGeneration
from typing import Dict, List, Set
import re
import string
class RQUGE(object):
def __init__(self, sp_scorer_path=None, qa_model_path=None, device='cpu'):
self.device = device
## initialize the QA module
if qa_model_path is None:
raise ValueError("Please Specify QA Model")
self.tokenizer_qa = T5Tokenizer.from_pretrained(qa_model_path)
self.model_qa = T5ForConditionalGeneration.from_pretrained(qa_model_path).to(self.device)
## initialize the span scorer module
if sp_scorer_path is None:
raise ValueError("Please Specify Span Scorer Model")
self.sp_scorer = AutoModelForSequenceClassification.from_pretrained(sp_scorer_path).to(self.device)
self.sp_scorer.eval()
self.tokenizer_sp = AutoTokenizer.from_pretrained(sp_scorer_path)
def normalize_answer(self, s):
"""Lower text and remove punctuation, articles and extra whitespace.
"""
def remove_articles(text):
return re.sub(r'\b(a|an|the)\b', ' ', text)
def white_space_fix(text):
return ' '.join(text.split())
def remove_punc(text):
exclude = set(string.punctuation)
return ''.join(ch for ch in text if ch not in exclude)
def lower(text):
return text.lower()
return white_space_fix(remove_articles(remove_punc(lower(s))))
def predict_sp_score(self, input_sp):
inputs = self.tokenizer_sp(input_sp, max_length=512, truncation=True, \
padding="max_length", return_tensors="pt")
outputs = self.sp_scorer(input_ids=inputs["input_ids"].to(self.device), \
attention_mask=inputs["attention_mask"].to(self.device))
outputs = [x[0] for x in outputs[0].cpu().tolist()]
#outputs = [{"pred_score": x} for x in outputs]
return outputs[0]
def scorer(self, context, pred_question, gold_answer, max_new_tokens=30):
## generate the answer for the predicted question
input_string = pred_question + " \\n " + context
input_ids = self.tokenizer_qa.encode(input_string, return_tensors="pt").to(self.device)
res = self.model_qa.generate(input_ids, max_new_tokens=max_new_tokens)
pred_answer = self.tokenizer_qa.batch_decode(res, skip_special_tokens=True)[0]
## compute the score for the predicted answer span
input_sp = f"{self.normalize_answer(pred_question)} <q> {self.normalize_answer(gold_answer)} <r>" \
f" {self.normalize_answer(pred_answer)} <c> {self.normalize_answer(context)}"
score = self.predict_sp_score(input_sp)
return score | /rquge-0.3.tar.gz/rquge-0.3/rquge_score/scorer.py | 0.739046 | 0.382949 | scorer.py | pypi |
import torch
from rquge_score import RQUGE
import argparse
import os
def main():
torch.multiprocessing.set_sharing_strategy("file_system")
parser = argparse.ArgumentParser("Calculate RQUGE score")
parser.add_argument(
"--sp_scorer_path",
type=str,
default=None,
help='path to the span scorer model',
)
parser.add_argument(
"--qa_model_path",
type=str,
default=None,
help='path to QA model (either local path or name of the model in huggingface hub',
)
parser.add_argument(
"--context",
type=str,
default=None,
help='The context of generated question',
)
parser.add_argument(
"--question",
type=str,
default=None,
help='The generated question',
)
parser.add_argument(
"--answer",
type=str,
default=None,
help='The gold answer span',
)
parser.add_argument(
"--output_path",
type=str,
default=None,
help='The output path for offline mode',
)
parser.add_argument(
"--input_type",
type=str,
choices=["sample","offline"],
default="sample",
help='The type of input (sample or offline). In the sample mode, "--context", "--question", and '
'"--answer" commands contain string, while in offline mode, they contain path to files including contexts,'
' corresponding questions and answers',
)
args = parser.parse_args()
if not (args.context is not None and args.question is not None and args.answer is not None):
raise ValueError('None of "--context","--question", and "--answer" commands should be None!')
device = 'cuda' if torch.cuda.is_available() else 'cpu'
rquge_model = RQUGE(sp_scorer_path=args.sp_scorer_path, qa_model_path=args.qa_model_path, device=device)
print("RQUGE model is created....\n"
"Computing the score....")
if args.input_type == "sample":
print("Sample Mode is initiated...")
print(f'RQUGE score: {rquge_model.scorer(args.context, args.question, args.answer)}')
else:
contexts = []
with open(args.context, 'r') as f:
for line in f:
contexts.append(line.strip())
questions = []
with open(args.question, 'r') as f:
for line in f:
questions.append(line.strip())
answers = []
with open(args.answer, 'r') as f:
for line in f:
answers.append(line.strip())
output = []
total = 0
for context, question, answer in zip(contexts, questions, answers):
score = rquge_model.scorer(context, question, answer)
total += score
output.append(score)
with open(args.output_path,'w') as f:
for num in output:
f.write(str(num))
f.write("\n")
print(f'Output saved in {args.output_path}')
print(f'Average RQUGE score: {total/len(output)*1.0}')
if __name__ == "__main__":
main() | /rquge-0.3.tar.gz/rquge-0.3/rquge_score_cli/scorer_cli.py | 0.488283 | 0.264435 | scorer_cli.py | pypi |
class General:
DATABASE = 'rankset'
DEFAULT_USER = 'root'
DEFAULT_PASSWORD = 'password'
HOST = 'host'
DEFAULT_HOST = '127.0.0.1'
class Keys:
COLUMNS = 'columns'
STATUS_CODE = 'status_code'
DATA_TYPE = 'data_type_name'
DATA = 'data'
INFO = 'info'
COUNTRIES = 'countries'
COMPETITIONS = 'competitions'
TEAMS = 'teams'
PLAYERS = 'players'
OVERVIEW = 'overview'
STATS = 'stats'
RANK = 'ranking'
PLAYER_RANK = 'player_rank'
POSITION = 'position'
COUNT_OF_GAMES = 'count_of_games'
BASE_DATA = 'base_data'
TM_DATA = 'tm_data'
FM_DATA = 'fm_data'
NAME = 'name'
CONTRACT_EXPIRES = 'contract_expires'
MARKET_VALUE = 'market_value'
MARKET_VALUE_TYPE = 'market_value_type'
AGE = 'age'
NATION = 'place_of_birth'
ACHIEVEMENTS = 'achievements'
TM_HISTORY = 'transfer_history'
TM_INJURY = 'injury_stats'
ATTRIBUTES = 'player_attributes'
TEAM_ID = 'team_id'
NOT_FOUND_DATA = 'Not found data'
ERROR = 'error'
SUCCESS = 'success'
class Routs:
ENTITIES = 'entities'
PLAYERS = 'players'
RANKING = 'ranking'
class FilterData:
DEFAULT_STATS = ['minutes on field', 'goal', 'xg shot', 'assist', 'pre assist', 'shot assist', 'interception',
'yellow cards', 'red cards']
DEF_CB_PERC = ["interception", "interception success", "recovery", "recovery success", "aerial duel",
"aerial duel success", "defensive duel", "defensive duel success", "tackle", "tackle success",
"clearance", "clearance success"]
ATTK_CB_PERC = ["pass", "pass success", "dribble", "dribble success", "progressive pass",
"progressive pass success", "short medium pass", "short medium pass success", "key pass",
"key pass success", "long pass", "long pass success"]
DEF_DB_PERC = ["defensive duel", "defensive duel success", "tackle", "tackle success", "interception",
"interception success", "pressing duel", "loss", "loss success"]
ATTK_DB_PERC = ["dribble", "dribble success", "cross", "cross success", "deep completed cross",
"deep completed cross success", "pass to final third", "pass to final third success",
"key pass", "key pass success", "offensive duel", "offensive duel success"]
DEF_MID_SIX_PERC = ["defensive duel", "defensive duel success", "interceptions", "interceptions success",
"pressing duel", "loose ball duel", "loose ball duel success", "recovery",
"recovery success", "aerial duel", "aerial duel success", "heading", "heading success"]
ATTK_MID_SIX_PERC = ["offensive duel", "offensive duel success", "key pass", "key pass success", "pass",
"pass success", "loss", "loss success", "smart pass", "smart pass success",
"short medium pass", "short medium pass success", "dribble", "dribble success"]
DEF_MID_EIGHT_PERC = ["tackle", "tackle success", "defensive duel", "defensive duel success", "loose ball duel",
"loose ball duel success", "offensive duel", "offensive duel success", "pressing duel",
"interception", "interception success", "recovery", "recovery success"]
ATTK_MID_EIGHT_PERC = ["dribble", "dribble success", "pass to final third", "pass to final third success",
"pass to penalty area", "pass to penalty area success", "progressive pass",
"progressive pass success", "shot", "shot success", "key pass", "key pass success",
"loss", "loss success"]
DEF_MID_TEN_PERC = ["offensive duel", "offensive duel success", "defensive duel", "defensive duel success",
"loss", "loss success", "pass", "pass success", "interception", "interception success"]
ATTACK_MID_TEN_PERC = ["dribble", "dribble success", "key pass", "key pass success", "shot", "shot success",
"progressive pass", "progressive pass success", "pass to penalty area",
"pass to penalty area success", "shot assist", "shot assist success", "touch in box",
"touch in box success", "xg shot", "xg assist"]
DEF_WNG_PERC = ["defensive duel", "defensive duel success", "progressive run", "progressive run success",
"loss", "loss success", "pressing duel", "loose ball duel", "loose ball duel success"]
ATTK_WNG_PERC = ["pass to penalty area", "pass to penalty area success", "assist", "shot assist",
"shot assist success", "shot", "shot success", "touch in box", "touch in box success", "dribble",
"dribble success", "cross", "cross success", "offside", "key pass", "key pass success"]
GEN_CF_PERC = ["aerial duel", "aerial duel success", "pressing duel", "loose ball duel", "loose ball duel success",
"loss", "loss success", "pass", "pass success"]
ATTK_CF_PERC = ["xg shot", "shot", "shot success", "shot on goal", "shot on goal success", "touch in box",
"touch in box success", "heading", "heading success", "dribble", "dribble success"] | /rr-api-beta-4.11.tar.gz/rr-api-beta-4.11/api_utils/constants.py | 0.54819 | 0.218649 | constants.py | pypi |
import re
class BaseEntities:
@staticmethod
def countries():
return "select rc.wyscout_id as id, rc.rankset_name as name from rankset.countries as rc " \
"where rc.wyscout_id != 0 order by name asc;"
@staticmethod
def competitions(country_id: int):
return f"select * from wyscout.competitions where country_id = {country_id};"
@staticmethod
def teams(competition_id: int):
return f"select yt.competition_id, rt.rankset_id as id, rt.rankset_name as name from rankset.teams as rt, wyscout.teams as yt " \
f"where rt.wyscout_id = yt.id and yt.competition_id = {competition_id};"
@staticmethod
def players(team_id: int):
return "select distinct rt.rankset_id, rp.wyscout_id, rp.rankset_name from rankset.players as rp, rankset.teams as rt, wyscout.teams as wt " \
f"where rt.rankset_id = rp.main_id and wt.id = rt.wyscout_id and rt.rankset_id = {team_id} and rp.wyscout_id != 0;"
class Players:
@staticmethod
def player_basic_info(object_id: int, seasons=None):
if seasons is None:
seasons = ['22/23', 2023]
return "select rpr.player_id, rpr.player_name, rpr.position, rpm.age, rpm.place_of_birth, rpm.contract_expires, " \
"cast(CASE WHEN rpm.mv_type = 'Th.' THEN rpm.mv * 1000 " \
"WHEN rpm.mv_type = 'm' THEN rpm.mv * 1000000 WHEN rpm.mv_type = 'bn' THEN rpm.mv * 1000000000 " \
"ELSE 0 END as decimal (10)) as mv," \
" cast((select AVG(rpr1.player_rank) from rankset.player_rank as rpr1 where rpr.player_id = rpr1.player_id and rpr1.season <= rpr.season) as decimal (10, 2)) as final_rank " \
"from rankset.player_rank as rpr, rankset.player_metadata as rpm where exists " \
f"(select * from rankset.players as rp where rp.rankset_id = {object_id} and" \
f" rp.rankset_id = rpr.player_id and rpr.season in ('{seasons[0]}', '{seasons[1]}')) " \
"and rpm.player_id = rpr.player_id order by rpr.season desc limit 1;"
@staticmethod
def rank_similar_players(object_id: int, position: str, player_rank, seasons=None):
if seasons is None:
seasons = ['22/23', 2023, '21/22', 2022]
if player_rank is not None and type(player_rank) is not float:
player_rank = float(player_rank)
# cast(rpr.final_rank as decimal (10,2)) AS total_rank,"
return "select rpr.player_id as rankset_id, rpr.player_name, rpm.age, " \
"cast((select AVG(rpr1.final_rank) from rankset.player_rank as rpr1 where rpr.player_id = rpr1.player_id and rpr1.season <= rpr.season) as decimal (10, 2)) as total_rank," \
" rpr.team_rank, rpr.tour_rank, rpr.minutes_played, rpm.place_of_birth, rpm.contract_expires, " \
"cast(CASE WHEN rpm.mv_type = 'Th.' THEN rpm.mv * 1000 " \
"WHEN rpm.mv_type = 'm' THEN rpm.mv * 1000000 " \
"WHEN rpm.mv_type = 'bn' THEN rpm.mv * 1000000000 " \
"ELSE 0 END as decimal (10)) as mv, rpr.tour_name, rpr.team_name " \
"from rankset.player_rank as rpr, rankset.player_metadata as rpm " \
f"where rpr.player_id != {object_id} and rpr.position = '{position}' " \
"and exists (select * from rankset.player_rank as rpr1 where rpr.player_id = rpr1.player_id " \
f"and (select AVG(rpr1.final_rank) from rankset.player_rank as rpr1 where rpr.player_id = rpr1.player_id and rpr1.season <= rpr.season) between {round(player_rank - 1, 2)} and {round(player_rank + 1.5, 2)}) " \
f"and rpm.player_id = rpr.player_id and rpr.season in ('{seasons[0]}', '{seasons[1]}', '{seasons[2]}', '{seasons[3]}') order by total_rank desc;"
@staticmethod
def players_filter(object_id: int, data_type: int, argument: list = None):
""" Returns all players by data type "
- **current player team id **: 1
- **country id **: 2
"""
match data_type:
case 1:
return "select distinct rp.wyscout_id as id, rp.rankset_name as name, rp.rankset_id from rankset.players as rp, rankset.teams as rt, wyscout.teams as wt " \
f"where rt.rankset_id = rp.main_id and wt.id = rt.wyscout_id and rt.rankset_id = {object_id} and rp.wyscout_id != 0;"
case 2:
return f"select rp.wyscout_id as id, rp.rankset_name as name, rp.rankset_id from rankset.players as rp, rankset.teams as rt, " \
"wyscout.teams as wt, wyscout.competitions as wc where rt.rankset_id = rp.main_id and wt.id = rt.wyscout_id " \
f"and wc.id = wt.competition_id and wc.country_id = {object_id} and rp.wyscout_id != 0 "
case 3 | 4:
return "select distinct rp.wyscout_id as id, rp.rankset_name as name, rp.rankset_id from rankset.players as rp " \
f"where exists {get_internal_query(num=data_type, obj_id=object_id)} " \
"and exists (select * from rankset.position_metadata rpm " \
f"where rpm.player_id = rp.wyscout_id and rpm.position != 'n' and rpm.position in {str(get_argument(argument))}) " \
"group by rp.wyscout_id, rp.rankset_name;"
case 5 | 6:
val = argument[0]
position = [argument[1]]
return "select distinct rp.wyscout_id as id, rp.rankset_name as name, rp.rankset_id " \
f"{get_internal_query(num=data_type, obj_id=object_id, dt=data_type)} " \
f"and exists (select * from rankset.player_metadata as rpm, rankset.position_metadata as rpm2 " \
"where rpm.player_id = rp.rankset_id " \
f"and rp.wyscout_id = rpm2.player_id and {get_metadata_field(val, data_type)} and rpm2.position in {str(get_argument(position))}) " \
"group by rp.wyscout_id, rp.rankset_name;"
case 8:
return f"select distinct similar_ids from rankset.similar_players as rsp where rsp.player_id = {object_id} limit 1;"
@staticmethod
def overview_base(player_id: int):
return f"select player_name, age, place_of_birth, mv, mv_type, contract_expires, overview, achievements, transfer_history, injury_history, player_attributes, team_id " \
f"from rankset.player_metadata as rpm " \
f"where exists (select * from rankset.players as rp where rp.wyscout_id = {player_id} " \
"and rpm.player_id = rp.rankset_id) limit 1;"
@staticmethod
def stats(player_id: int, required_stats: list, year: int = 2022):
required_stat = str(required_stats).replace('[', '(').replace(']', ')')
return "select distinct stat_name, " \
f"cast(sum(stat_value) / (select count(distinct event_id) from stats.player_stats_{year} " \
f"where player_id = {player_id}) as decimal(10,2)) as stat_value " \
f"from stats.player_stats_{year} where player_id = {player_id} " \
f"and stat_name in {required_stat} group by stat_name order by stat_name asc;"
@staticmethod
def count_of_games(player_id: int):
return f"select count(distinct event_id) from wyscout.player_stats where object_id = {player_id};"
@staticmethod
def position(player_id: int):
return f"select position from rankset.position_metadata where player_id = {player_id} limit 1;"
@staticmethod
def search(content: str):
return f"select distinct rp.wyscout_id as id, rp.rankset_name as name, rp.rankset_id from rankset.players as rp" \
f" where rp.rankset_name like '%{content}%' order by rp.rankset_name asc limit 100;"
@staticmethod
def search_players(position: str, age_min: int, age_max: int, mv_min: int, mv_max: int,
position_options: str = None, countries_filter: str = None, place_of_birth: str = None,
contract_expires_year: str = None, data_limit: int = 1000):
position_options_syntax = '' if position_options is None else f" AND EXISTS (select * from rankset.position_metadata as rpm where" \
f" rpm.player_id = rp.wyscout_id and rpm.position REGEXP '{position_options}' and rpm.count_of_games > 10) "
countries_filter_syntax = '' if not countries_filter else f' AND rc.wyscout_id in ({countries_filter}) '
place_of_birth_syntax = '' if not place_of_birth else f" AND rpm.place_of_birth REGEXP '{place_of_birth}' "
contract_expires_syntax = '' if contract_expires_year is None else f" AND rpm.contract_expires REGEXP '-|{contract_expires_year}' "
return "SELECT DISTINCT rp.rankset_id,rp.rankset_name AS player_name,rpr.team_name,rpr.position,rpr.tour_name,rpr.season,cast(rpr.player_rank AS decimal(10,2))AS player_rank," \
"cast(rpr.player_rank_with_stats AS decimal(10,2))AS stats_rank,cast((SELECT AVG(rpr1.final_rank)FROM rankset.player_rank AS rpr1 WHERE rpr.player_id=rpr1.player_id AND rpr1.season<=rpr.season ORDER BY rpr1.season DESC)AS decimal(10,2))AS total_rank,rpr.tour_rank,rpr.team_rank,rpr.minutes_played,rpr.minutes_played_new,rpm.age,rpm.place_of_birth,rpm.contract_expires,CASE WHEN rpm.mv_type='Th.' THEN rpm.mv*1000 WHEN rpm.mv_type='m' THEN rpm.mv*1000000 WHEN rpm.mv_type='bn' THEN rpm.mv*1000000000 ELSE 0 END AS pmv FROM rankset.players AS rp,rankset.countries AS rc,rankset.player_rank AS rpr,rankset.player_metadata AS rpm,rankset.tour_rank AS rtr WHERE rpr.player_id=rp.rankset_id AND rtr.country_id=rc.rankset_id AND rpr.tour_id=rtr.tour_id AND rpm.player_id=rpr.player_id AND rpr.season in(2022,'21/22','22/23')AND " \
f"rpr.position='{position}' AND rpm.age BETWEEN {age_min} and {age_max} {countries_filter_syntax} {place_of_birth_syntax} {contract_expires_syntax} {position_options_syntax} " \
"GROUP BY rp.rankset_id,rp.rankset_name,rpr.team_name,rpr.tour_name,rpr.position,rpr.player_rank,rpr.final_rank," \
"rpr.player_rank_with_stats,rpr.tour_rank,rpr.team_rank,rpr.minutes_played,rpr.minutes_played_new," \
f"rpm.age,rpr.season,rpm.place_of_birth,rpm.contract_expires,rpm.mv,rpm.mv_type HAVING pmv between {mv_min} and {mv_max} ORDER BY rpm.contract_expires ASC limit {data_limit};"
@staticmethod
def get_players_by_ids(players, one_object: bool = False):
if not one_object:
return f"select distinct rp.wyscout_id as id, rp.rankset_name as name, rp.rankset_id from rankset.players as rp" \
f" where rp.rankset_id in {tuple(players)} order by rp.rankset_name asc;"
return f"select distinct rp.wyscout_id as id, rp.rankset_name as name, rp.rankset_id from rankset.players as rp" \
f" where rp.rankset_id = {players} limit 1;"
class Ranking:
@staticmethod
def players():
return "select rp.rankset_id, rp.rankset_name from rankset.players as rp, rankset.player_rank as rpr " \
"where rpr.player_id = rp.rankset_id order by rp.rankset_id asc"
@staticmethod
def players_ranking(data_type: int, object_id: int = None):
main_query = "select distinct rp.rankset_id, rp.rankset_name as player_name, rpr.team_name, rpr.position, rpr.tour_name, cast(rpr.player_rank as decimal (10,2)) AS player_rank," \
"cast(rpr.player_rank_with_stats as decimal (10,2)) AS stats_rank," \
" cast((select AVG(rpr1.final_rank) from rankset.player_rank as rpr1 where rpr.player_id = rpr1.player_id and rpr1.season <= rpr.season order by rpr1.season desc) as decimal (10, 2)) as total_rank, " \
" rpr.tour_rank, rpr.team_rank," \
" rpr.minutes_played, rpr.minutes_played_new, rpr.season, rpm.age, rpm.place_of_birth, rpm.contract_expires," \
"CASE WHEN rpm.mv_type = 'Th.' THEN rpm.mv * 1000 WHEN rpm.mv_type = 'm' THEN rpm.mv * 1000000 WHEN rpm.mv_type = 'bn' THEN rpm.mv * 1000000000 ELSE 0 END as mv " \
"from rankset.players as rp, rankset.countries as rc, rankset.player_rank as rpr, rankset.player_metadata as rpm, rankset.tour_rank as rtr " \
"where rpr.player_id = rp.rankset_id AND rtr.country_id = rc.rankset_id AND rpr.tour_id = rtr.tour_id and rpm.player_id = rpr.player_id"
end_query = " group by rp.rankset_id, rp.rankset_name, rpr.team_name, rpr.tour_name, rpr.position, rpr.player_rank," \
" rpr.final_rank, rpr.player_rank_with_stats, rpr.tour_rank, rpr.team_rank, rpr.minutes_played, rpr.minutes_played_new," \
" rpr.season, rpm.age,rpm.place_of_birth, rpm.contract_expires, rpm.mv, rpm.mv_type order by total_rank desc;"
# end_query = " order by total_rank desc;"
match data_type:
case 1:
return f"{main_query}{end_query}"
case 2:
print(f"{main_query} and rc.wyscout_id = {object_id} {end_query}")
return f"{main_query} and rc.wyscout_id = {object_id} {end_query}"
@staticmethod
def player_rank(player_id: int):
return f"select distinct rp.rankset_id, rp.rankset_name, cast(rpr.final_rank as decimal (10, 2)) as avg_rank " \
f"from rankset.players as rp, rankset.player_rank as rpr where rpr.player_id = {player_id} " \
"and rpr.player_id = rp.rankset_id;"
@staticmethod
def player_rank_info(player_id: int):
return f"select * from rankset.players as rp, rankset.player_rank as rpr where rpr.player_id = {player_id} " \
"and rpr.player_id = rp.rankset_id order by rpr.season desc;"
def get_internal_query(num: int, obj_id: int, dt: int = None):
cal = num % 2
if cal != 0 and not dt:
return "(select * from rankset.teams as rt, wyscout.teams as wt where rt.rankset_id = rp.main_id " \
f"and wt.id = rt.wyscout_id and rt.rankset_id = {obj_id} and rp.wyscout_id != 0)"
elif dt == 5 or dt == 6:
return "from rankset.players as rp, rankset.teams as rt, wyscout.teams as wt, wyscout.competitions as wc " \
"where rt.rankset_id = rp.main_id and wt.id = rt.wyscout_id and wc.id = wt.competition_id " \
f"and wc.country_id = {obj_id} and rp.wyscout_id != 0"
else:
return "(select * from rankset.teams as rt, wyscout.teams as wt, wyscout.competitions as wc " \
"where rt.rankset_id = rp.main_id and wt.id = rt.wyscout_id and wc.id = wt.competition_id " \
f"and wc.country_id = {obj_id} and rp.wyscout_id != 0)"
def get_argument(arg):
if len(arg) == 1:
return f"('{arg[0]}')"
else:
return tuple(arg)
def get_metadata_field(val, dt: int):
if dt == 5:
val = int(val)
min_age = val - 1
max_age = val + 1
return f'rpm.age in ({min_age}, {val}, {max_age})'
elif dt == 6:
mv = int(re.findall(r'\d+', val)[0])
if 'Th.' in val:
if mv + 25 <= 1000:
values = val, f"{mv - 5}Th.", f"{mv - 10}Th.", f"{mv - 15}Th.", f"{mv - 20}Th.", f"{mv - 25}Th.", \
f"{mv + 5}Th.", f"{mv + 10}Th.", f"{mv + 15}Th.", f"{mv + 20}Th.", f"{mv + 25}Th."
return f"CONCAT(rpm.mv, '', rpm.mv_type) in {str(values)}"
else:
return f"CONCAT(rpm.mv, '', rpm.mv_type) in ('{val}')"
elif 'm' in val:
sec_part = val.replace(str(mv), '')
if mv <= 1:
return f"CONCAT(rpm.mv, '', rpm.mv_type) in ('{val}')"
else:
if mv < 20:
mv_range = 1
else:
mv_range = 2
values = val, f"{mv - mv_range}{sec_part}", f"{mv - int(mv_range * 1.5)}{sec_part}", f"{mv - int(mv_range * 2)}{sec_part}", \
f"{mv + mv_range}{sec_part}", f"{mv + int(mv_range * 1.5)}{sec_part}", f"{mv + int(mv_range * 2)}{sec_part}",
return f"CONCAT(rpm.mv, '', rpm.mv_type) in {str(values)}" | /rr-api-beta-4.11.tar.gz/rr-api-beta-4.11/api_utils/query.py | 0.44071 | 0.23762 | query.py | pypi |
from api_utils import Routs, Keys, base_model, FilterData, utils
from api_utils.query import Players
from fastapi import APIRouter
import ast
class PlayersModel(base_model.BaseModel):
"""
Initiate entities model
"""
pass
router_players = APIRouter(
prefix=f"/{Routs.PLAYERS}",
tags=[Routs.PLAYERS]
)
@router_players.get(path="/overview/{player_id}", summary="Returns player overview")
async def overview(player_id: int):
"""
Returns player overview by unique player_id
"""
data = PlayersModel.Meta.database.get_data(query=Players.overview_base(player_id=player_id),
return_data_frame=True)
response_data = {}
if len(data) == 1:
response_data.setdefault(Keys.OVERVIEW, ast.literal_eval(data.overview.values[0]))
response_data.setdefault(Keys.ACHIEVEMENTS, ast.literal_eval(data.achievements.values[0]))
response_data.setdefault(Keys.TM_HISTORY, ast.literal_eval(data.transfer_history.values[0]))
response_data.setdefault(Keys.TM_INJURY, ast.literal_eval(data.injury_history.values[0].replace('nan', 'None')))
response_data.setdefault(Keys.ATTRIBUTES, ast.literal_eval(data.player_attributes.values[0]))
mv_data = utils.get_mv_data(data=data)
return {Keys.DATA_TYPE: Keys.OVERVIEW,
Keys.BASE_DATA: [response_data],
Keys.AGE: mv_data.get(Keys.AGE),
Keys.NATION: mv_data.get(Keys.NATION),
Keys.MARKET_VALUE: mv_data.get(Keys.MARKET_VALUE),
Keys.CONTRACT_EXPIRES: mv_data.get(Keys.CONTRACT_EXPIRES),
Keys.TEAM_ID: int(data.team_id.values[0]),
Keys.NAME: data.player_name.values[0],
Keys.POSITION: utils.get_position(PlayersModel.Meta.database,
Players.position(player_id=player_id)),
Keys.STATUS_CODE: 200}
else:
return {Keys.ERROR: Keys.NOT_FOUND_DATA}
@router_players.post(path="/stats/{player_id}/{id_type}", summary="Returns player stats")
async def stats(player_id: int, id_type: int, required_stats: list = FilterData.DEFAULT_STATS):
"""
Returns player stays by unique player_id
"""
if id_type != 1:
player_id = \
PlayersModel.Meta.database.get_data(query=Players.get_players_by_ids(players=player_id, one_object=True),
return_data_frame=True).id.values[0]
return {Keys.DATA_TYPE: Keys.STATS,
Keys.DATA:
PlayersModel.Meta.database.get_data(query=Players.stats(player_id=player_id,
required_stats=required_stats))[0],
Keys.COUNT_OF_GAMES:
PlayersModel.Meta.database.get_data(query=Players.count_of_games(player_id=player_id))[0],
Keys.STATUS_CODE: 200}
@router_players.get(path="/filter/{data_type}/{object_id}", summary="Returns all players by team or country id")
async def get_players_by_id(object_id: int, data_type: int = 1):
"""
data_type:
- current player team id: 1
- country id: 2
object_id:
- the main id, need to be unique.
"""
return {Keys.DATA_TYPE: Keys.PLAYERS,
Keys.DATA:
PlayersModel.Meta.database.get_data(
query=Players.players_filter(object_id=object_id, data_type=data_type))[0],
Keys.STATUS_CODE: 200}
@router_players.get(path="/search/{content}", summary="Returns all players that contain the required content")
async def search(content: str):
"""
content:
- need to be string
"""
return {Keys.DATA_TYPE: Keys.PLAYERS,
Keys.DATA:
PlayersModel.Meta.database.get_data(query=Players.search(content=content))[0],
Keys.STATUS_CODE: 200}
@router_players.get(path="/search_players/{position}", summary="Returns players by specific filter")
async def search_players(position: str, position_options: str = None, countries: str = None, age_min: int = 18,
age_max: int = 35, mv_min: int = 0,
mv_max: int = 5000000, place_of_birth: str = None, contract_expires_year: str = None,
data_limit: int = 1000):
data = PlayersModel.Meta.database.get_data(
query=Players.search_players(position=position, age_min=age_min, age_max=age_max,
mv_min=mv_min, mv_max=mv_max, countries_filter=countries,
place_of_birth=place_of_birth, contract_expires_year=contract_expires_year,
position_options=position_options, data_limit=data_limit))
return {Keys.DATA_TYPE: Keys.PLAYERS, Keys.DATA: data[0], Keys.COLUMNS: data[1], Keys.STATUS_CODE: 200}
@router_players.get(path="/filter/{data_type}/{object_id}/{key}",
summary="Returns all players by data type and key argument")
async def get_players_by_argument_type(object_id: int, key: str, data_type: int = 1):
"""
data_type options:
- current player team id: 1
- country id: 2
- position and team id: 3
- position and country id: 4
- age, country id and position: 5
- mv, country id and position: 6
- mv and position - 7
object_id:
- the main id, need to be unique.
"""
keys = key.split(', ')
return {Keys.DATA_TYPE: Keys.PLAYERS,
Keys.DATA:
PlayersModel.Meta.database.get_data(
query=Players.players_filter(object_id=object_id, data_type=data_type, argument=keys))[0],
Keys.STATUS_CODE: 200}
@router_players.get(path="/similar/{object_id}",
summary="Returns all players similar players for object id")
async def get_similar_players(object_id: int):
"""
object_id:
- the main id, need to be unique.
"""
similar_players = None
player_info = PlayersModel.Meta.database.get_data(
query=Players.player_basic_info(object_id=object_id))[0]
if player_info:
similar_players = PlayersModel.Meta.database.get_data(
query=Players.rank_similar_players(object_id=object_id, position=player_info[0][2],
player_rank=player_info[0][7]))
return {Keys.DATA_TYPE: Keys.PLAYERS,
Keys.DATA: [] if not similar_players else list(similar_players[0]),
Keys.INFO: [] if not player_info else list(player_info[0]),
Keys.COLUMNS: [] if not similar_players else list(similar_players[1]),
Keys.STATUS_CODE: 200} | /rr-api-beta-4.11.tar.gz/rr-api-beta-4.11/router/players.py | 0.670177 | 0.157169 | players.py | pypi |
class BaseEntities:
@staticmethod
def countries():
return "select * from wyscout.countries;"
@staticmethod
def competitions(country_id: int):
return f"select * from wyscout.competitions where country_id = {country_id};"
@staticmethod
def teams(competition_id: int):
return f"select competition_id, id, name from wyscout.teams where competition_id = {competition_id};"
@staticmethod
def players(team_id: int):
return f"select distinct team_id, player_id, player_name from player_object where team_id = {team_id};"
class Players:
@staticmethod
def players_filter(object_id: int, data_type: int):
""" Returns all players by data type "
- **current player team id **: 1
- **country id **: 2
"""
if data_type == 1:
where_field = 'team_id'
elif data_type == 2:
where_field = 'country_id'
else:
return
return f"select distinct player_id, player_name from wyscout.player_object where {where_field} = {object_id};"
@staticmethod
def overview(player_id: int):
return f"select overview_object from wyscout.player_object where player_id = {player_id} limit 1;"
@staticmethod
def stats(player_id: int, required_stats: list):
required_stat = str(required_stats).replace('[', '(').replace(']', ')')
return "select distinct stat_name, " \
"cast(sum(stat_value) / (select count(distinct event_id) from player_statistics " \
f"where object_id = {player_id}) as decimal(10,2)) as stat_value " \
f"from wyscout.player_statistics where object_id = {player_id} " \
f"and stat_name in {required_stat} group by stat_name order by stat_name asc;"
@staticmethod
def count_of_games(player_id: int):
return f"select count(distinct event_id) from player_statistics where object_id = {player_id};"
@staticmethod
def position(player_id: int):
return f"select stat_value from player_statistics where object_id = {player_id} " \
"and stat_name = 'positions' order by date desc limit 1;" | /rr-api-1.0.tar.gz/rr-api-1.0/api_utils/query.py | 0.552781 | 0.286544 | query.py | pypi |
import api_utils as au
from fastapi import APIRouter
class EntitiesModel(au.base_model.BaseModel):
"""
Initiate entities model
"""
pass
router_entities = APIRouter(
prefix=f"/{au.constants.Routs.ENTITIES}",
tags=[au.constants.Routs.ENTITIES]
)
@router_entities.get(path=f"/countries", summary="Returns all countries")
async def countries():
"""
Returns all competitions by country id
"""
return {au.constants.Keys.DATA_TYPE: au.constants.Keys.COUNTRIES,
au.constants.Keys.DATA:
EntitiesModel.Meta.database.get_data(query=au.query.BaseEntities.countries())[0],
au.constants.Keys.STATUS_CODE: 200}
@router_entities.get(path="/competitions/{country_id}", summary="Returns all competitions by country id")
async def competitions(country_id: int):
"""
Returns all competitions by country id
- **country**: The country unique id.
"""
return {au.constants.Keys.DATA_TYPE: au.constants.Keys.COMPETITIONS,
au.constants.Keys.DATA:
EntitiesModel.Meta.database.get_data(
query=au.query.BaseEntities.competitions(country_id=country_id))[0],
au.constants.Keys.STATUS_CODE: 200}
@router_entities.get(path="/teams/{competition_id}", summary="Returns all teams by competition id")
async def teams(competition_id: int):
"""
Returns all teams by country and competition id"
- **competition**: The competition unique id.
"""
return {au.constants.Keys.DATA_TYPE: au.constants.Keys.TEAMS,
au.constants.Keys.DATA:
EntitiesModel.Meta.database.get_data(
query=au.query.BaseEntities.teams(competition_id=competition_id))[
0],
au.constants.Keys.STATUS_CODE: 200}
@router_entities.get(path="/players/{team_id}",
summary="Returns all players by team id")
async def players(team_id: int):
"""
Returns all players by country, competition and team id
- **team**: The team unique id.
"""
return {au.constants.Keys.DATA_TYPE: au.constants.Keys.PLAYERS,
au.constants.Keys.DATA:
EntitiesModel.Meta.database.get_data(query=au.query.BaseEntities.players(team_id=team_id))[
0], au.constants.Keys.STATUS_CODE: 200} | /rr-api-1.0.tar.gz/rr-api-1.0/router/entities.py | 0.625209 | 0.181626 | entities.py | pypi |
import api_utils as au
from fastapi import APIRouter
class PlayersModel(au.base_model.BaseModel):
"""
Initiate entities model
"""
pass
router_players = APIRouter(
prefix=f"/{au.constants.Routs.PLAYERS}",
tags=[au.constants.Routs.PLAYERS]
)
@router_players.get(path="/overview/{player_id}", summary="Returns player overview")
async def overview(player_id: int):
"""
Returns player overview by unique player_id
"""
return {au.constants.Keys.DATA_TYPE: au.constants.Keys.OVERVIEW,
au.constants.Keys.DATA:
PlayersModel.Meta.database.get_data(query=au.query.Players.overview(player_id=player_id))[0],
au.constants.Keys.STATUS_CODE: 200}
@router_players.post(path="/stats/{player_id}", summary="Returns player overview")
async def stats(player_id: int, required_stats: list = au.constants.FilterData.DEFAULT_STATS):
"""
Returns player stays by unique player_id
"""
return {au.constants.Keys.DATA_TYPE: au.constants.Keys.STATS,
au.constants.Keys.DATA:
PlayersModel.Meta.database.get_data(query=au.query.Players.stats(player_id=player_id,
required_stats=required_stats))[0],
au.constants.Keys.POSITION:
PlayersModel.Meta.database.get_data(query=au.query.Players.position(player_id=player_id))[0],
au.constants.Keys.COUNT_OF_GAMES:
PlayersModel.Meta.database.get_data(query=au.query.Players.count_of_games(player_id=player_id))[0],
au.constants.Keys.STATUS_CODE: 200}
@router_players.get(path="/filter/{data_type}/{object_id}", summary="Returns all players by data type")
async def compare_players(object_id: int, data_type: int = 1):
"""
data_type:
- current player team id: 1
- country id: 2
object_id:
- the main id, need to be unique.
"""
return {au.constants.Keys.DATA_TYPE: au.constants.Keys.PLAYERS,
au.constants.Keys.DATA:
PlayersModel.Meta.database.get_data(
query=au.query.Players.players_filter(object_id=object_id, data_type=data_type))[0],
au.constants.Keys.STATUS_CODE: 200} | /rr-api-1.0.tar.gz/rr-api-1.0/router/players.py | 0.617974 | 0.179567 | players.py | pypi |
class Get:
@staticmethod
def get_events(tour_id: int, season: str, main_table: str, team_id: int = None):
if not team_id:
return " SELECT a.event_id, a.tour_id, a.season, a.round, a.home_team_id, a.home_team_name, " \
" a.away_team_id, a.away_team_name, b.initial_favorite as favorite_by_line," \
" b.initial_option_1, b.initial_option_2, b.initial_option_3, b.initial_line_id, b.final_line_id, " \
f" a.winner_code, a.start_time FROM odds AS b, {main_table} AS a " \
f" WHERE a.tour_id = {tour_id} AND a.season = '{season}' and b.market_id = 1 " \
" AND a.event_id = b.event_id AND a.start_time = b.start_time " \
" ORDER BY a.start_time ASC;"
else:
return " SELECT a.event_id, a.tour_id, a.season, a.round, a.home_team_id, a.home_team_name, " \
" a.away_team_id, a.away_team_name, b.initial_favorite as favorite_by_line," \
" b.initial_option_1, b.initial_option_2, b.initial_option_3, b.initial_line_id, b.final_line_id, " \
f" a.winner_code, a.start_time FROM odds_data AS b, {main_table} AS a " \
f" WHERE a.tour_id = {tour_id} AND a.season = '{season}' and b.market_id = 1 " \
f" AND a.home_team_id = {team_id} AND a.event_id = b.event_id AND a.start_time = b.start_time " \
f" OR a.tour_id = {tour_id} AND a.season = '{season}' and b.market_id = 1 " \
f" AND a.away_team_id = {team_id} AND a.event_id = b.event_id " \
" AND a.start_time = b.start_time ORDER BY a.start_time ASC;"
@staticmethod
def get_original_rank(tour_id: int, season: str = '21/22'):
return "select distinct ts.team_id, ts.team_name, " \
"(CASE WHEN ts.total_games_avg_rank < 1.7 THEN 1 WHEN ts.total_games_avg_rank < 2.20 THEN 1.5 " \
"WHEN ts.total_games_avg_rank < 2.5 THEN 2 WHEN ts.total_games_avg_rank < 3 THEN 2.5 " \
"WHEN ts.total_games_avg_rank < 3.5 THEN 3 WHEN ts.total_games_avg_rank < 4 THEN 3.5 " \
"WHEN ts.total_games_avg_rank < 4.5 THEN 4 WHEN ts.total_games_avg_rank < 5 THEN 4.5 " \
"WHEN ts.total_games_avg_rank < 5.5 THEN 5 " \
"ELSE 5.5 END) as general_rank, " \
" cast((ts.sum_home_line + ts.sum_away_line) as decimal(10,2)) as sum_line " \
" from events_data as ed, team_stock as ts " \
f" where ed.tour_id = {tour_id} " \
f" and ed.season = '{season}' " \
" and ts.team_id = ed.home_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
f" or ed.tour_id = {tour_id} " \
f" and ed.season = '{season}' " \
" and ts.team_id = ed.away_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
" group by ts.team_id, ts.team_name, ts.sum_home_line, " \
" ts.sum_away_line, ts.home_success_rate_in_percent, " \
" ts.away_success_rate_in_percent, ts.total_games_avg_rank " \
" order by general_rank asc;"
@staticmethod
def get_momentum(tour_id: int, team_id: int, season: str):
return "select home_team_id, away_team_id, " \
f"(CASE WHEN home_team_id = {team_id} THEN 'H' ELSE 'A' END) as home_or_away, " \
f"(CASE WHEN home_team_id = {team_id} THEN away_team_rank ELSE home_team_rank END) as against_rank," \
f"(CASE WHEN home_team_id = {team_id} and favorite_by_rank = 1 and winner_code = 1 THEN 0 " \
f"WHEN away_team_id = {team_id} and favorite_by_rank = 2 and winner_code = 2 THEN 0 " \
f"WHEN home_team_id = {team_id} and favorite_by_rank = 1 and winner_code != 1 THEN 2 " \
f"WHEN away_team_id = {team_id} and favorite_by_rank = 2 and winner_code != 2 THEN 2 " \
f"WHEN home_team_id = {team_id} and favorite_by_rank = 2 and winner_code = 2 THEN 1 " \
f"WHEN away_team_id = {team_id} and favorite_by_rank = 1 and winner_code = 2 THEN 1 " \
f"WHEN home_team_id = {team_id} and favorite_by_rank = 3 and winner_code = 2 THEN 2 " \
f"WHEN away_team_id = {team_id} and favorite_by_rank = 3 and winner_code = 1 THEN 1 " \
"ELSE 0 END) as pressure_level_by_rank, " \
f"(CASE WHEN home_team_id = {team_id} and favorite_by_line = 1 and winner_code = 1 THEN 0 " \
f"WHEN away_team_id = {team_id} and favorite_by_line = 2 and winner_code = 2 THEN 0 " \
f"WHEN home_team_id = {team_id} and favorite_by_line = 1 and winner_code != 1 THEN 2 " \
f"WHEN away_team_id = {team_id} and favorite_by_line = 2 and winner_code != 2 THEN 2 " \
f"WHEN home_team_id = {team_id} and favorite_by_line = 2 and winner_code = 2 THEN 1 " \
f"WHEN away_team_id = {team_id} and favorite_by_line = 1 and winner_code = 2 THEN 1 " \
f"WHEN home_team_id = {team_id} and favorite_by_line = 3 and winner_code = 2 THEN 2 " \
f"WHEN away_team_id = {team_id} and favorite_by_line = 3 and winner_code = 1 THEN 1 " \
"ELSE 0 END) as pressure_level_by_line, " \
f"(CASE WHEN home_team_id = {team_id} and winner_code = 1 THEN 'W' " \
f"WHEN away_team_id = {team_id} and winner_code = 2 THEN 'W' " \
f"WHEN home_team_id = {team_id} and winner_code = 2 THEN 'L' " \
f"WHEN away_team_id = {team_id} and winner_code = 1 THEN 'L' " \
"ELSE 'D' END) as momentum, " \
" winner_code, season_level, round," \
f"(CASE WHEN home_team_id = {team_id} THEN home_line_points_by_season " \
"ELSE away_line_points_by_season END) as update_line_points," \
f"start_time, (CASE WHEN home_team_id = {team_id} THEN home_level_pressure ELSE away_level_pressure END)" \
f" as current_pressure from events_pressure " \
f"where tour_id = {tour_id} " \
f"and home_team_id = {team_id} " \
f"and season = '{season}' " \
f"or tour_id = {tour_id} " \
f"and away_team_id = {team_id} " \
f"and season = '{season}' " \
"order by start_time desc " \
"limit 2"
@staticmethod
def get_goals_data(tour_id: int, team_id: int):
return "select ed.start_time, ed.tour_id," \
f"CONCAT(ed.home_team_name,' vs ', ed.away_team_name) as team_name," \
f"(CASE WHEN ed.home_team_id != {team_id} THEN ed.home_team_name " \
"ELSE ed.away_team_name END) as rival_name," \
f"(CASE WHEN ed.home_team_id = {team_id} THEN CONVERT(SUBSTRING(ed.full_time, 1, 1), UNSIGNED INTEGER) " \
"ELSE CONVERT(SUBSTRING(ed.full_time, 3, 1), UNSIGNED INTEGER) END) as team_goals, " \
f"(CASE WHEN ed.home_team_id != {team_id} THEN CONVERT(SUBSTRING(ed.full_time, 1, 1), UNSIGNED INTEGER) " \
"ELSE CONVERT(SUBSTRING(ed.full_time, 3, 1), UNSIGNED INTEGER) END) as rival_goals, ed.winner_code " \
"from events_data as ed, events_pressure as ep " \
f"where ep.event_id = ed.event_id and ed.tour_id = {tour_id} and ed.home_team_id = {team_id} " \
"group by ed.start_time, ed.tour_id, ed.home_team_id," \
" ed.away_team_id, ed.home_team_name, ed.away_team_name, ed.full_time, ed.winner_code " \
"order by ed.start_time asc"
class Insert:
@staticmethod
def pressure_state_template():
return "INSERT INTO events_pressure (event_id, tour_id, season, round," \
"season_level, home_team_id, home_team_name," \
"home_team_rank, home_pressure_balance, home_total_psy_rating, home_h2h_rating," \
"home_level_pressure, home_level_pressure_in_percent, home_last_game_pressure," \
"home_rank_pressure, away_team_id, away_team_name," \
"away_team_rank, away_pressure_balance, away_total_psy_rating, away_h2h_rating," \
"away_level_pressure, away_level_pressure_in_percent," \
"away_last_game_pressure, away_rank_pressure, favorite_by_rank, favorite_by_line, initial_line_id," \
"final_line_id, winner_code, start_time," \
"home_line_points_by_season,home_line_points_achieved_by_season, away_line_points_by_season," \
"away_line_points_achieved_by_season, rank_vs_rank_description)" \
"VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s" \
",%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
@staticmethod
def pressure_patterns_template():
return "INSERT INTO event_pattern (event_id, tour_id, season," \
"home_team_id, away_team_id, winner_code, pattern_type, pattern_desc, final_pattern," \
" rank_vs_rank_description, home_psy, away_psy) " \
"VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
@staticmethod
def pressure_simulations_template():
return "INSERT INTO simulation (tour_id, tour_name, event_id, event_obj, start_time) " \
"VALUES (%s,%s,%s,%s,%s)" | /rr_batch_process-1.4-py3-none-any.whl/rr_batch/sql.py | 0.538255 | 0.373476 | sql.py | pypi |
import logging
import math
from abc import ABCMeta, abstractmethod
from time import sleep
from rr_bot.bell import Bell
from rr_bot.regression import calculate_regression
MAX_CHANGES_IN_DATASET = 3.0
WEIGHT_REJECTION_THRESHOLD = 0.001
def inverse_lerp(a, b, c):
"""
Inverse function to `lerp`. Calculates t such that lerp(a, b, t) = c.
(will divide by zero if a = b)
"""
return (c - a) / (b - a)
def lerp(a, b, t):
"""
Linearly interpolates (unclamped) between a and b with factor t.
Acts such that `lerp(a, b, 0.0)` returns `a`, and `lerp(a, b, 1.0)` returns `b`.
"""
return (1 - t) * a + t * b
class Rhythm(metaclass=ABCMeta):
"""
An abstract Rhythm class, used as an interface by the Bot class to interact with Rhythms.
"""
@abstractmethod
def wait_for_bell_time(self, current_time: float, bell: Bell, row_number: int, place: int,
user_controlled: bool, stroke: bool):
""" Sleeps the thread until a given Bell should have rung. """
pass
@abstractmethod
def expect_bell(self, expected_bell: Bell, row_number: int, place: int, expected_stroke: bool):
"""
Indicates that a given Bell is expected to be rung at a given row, place and stroke.
Used by the rhythm so that when that bell is rung later, it can tell where that bell
_should_ have been in the ringing, and so can use that knowledge to inform the speed of the
ringing.
"""
pass
@abstractmethod
def on_bell_ring(self, bell: Bell, stroke: bool, real_time: float):
"""
Called when a bell is rung at a given stroke. Used as a callback from the Tower class.
"""
pass
@abstractmethod
def initialise_line(self, stage: int, user_controls_treble: bool, start_time: float,
number_of_user_controlled_bells: int):
""" Allow the Rhythm object to initialise itself when 'Look to' is called. """
pass
class WaitForUserRhythm(Rhythm):
""" A decorator class that adds the ability to wait for user-controlled bells to ring. """
logger_name = "RHYTHM:WaitForUser"
def __init__(self, rhythm: Rhythm):
"""
Initialise a wrapper around another Rhythm class that will decorate that class with the
ability to wait for other people to ring.
"""
self._inner_rhythm = rhythm
self._expected_bells = set()
self.delay = 0
self.logger = logging.getLogger(self.logger_name)
def wait_for_bell_time(self, current_time, bell, row_number, place, user_controlled, stroke):
""" Sleeps the thread until a given Bell should have rung. """
self._inner_rhythm.wait_for_bell_time(current_time - self.delay, bell, row_number, place,
user_controlled, stroke)
if user_controlled:
delay_for_user = 0
while (bell, stroke) in self._expected_bells:
sleep(0.01)
delay_for_user += 0.01
self.logger.debug(f"Waiting for {bell}")
if delay_for_user:
self.logger.info(f"Delayed for {delay_for_user}")
self.delay += delay_for_user
def expect_bell(self, expected_bell, row_number, place, expected_stroke):
"""
Indicates that a given Bell is expected to be rung at a given row, place and stroke.
Used by the rhythm so that when that bell is rung later, it can tell where that bell
_should_ have been in the ringing, and so can use that knowledge to inform the speed of the
ringing.
"""
self._inner_rhythm.expect_bell(expected_bell, row_number, place, expected_stroke)
self._expected_bells.add((expected_bell, expected_stroke))
def on_bell_ring(self, bell, stroke, real_time):
"""
Called when a bell is rung at a given stroke. Used as a callback from the Tower class.
"""
self._inner_rhythm.on_bell_ring(bell, stroke, real_time - self.delay)
try:
self._expected_bells.remove((bell, stroke))
except KeyError:
pass
def initialise_line(self, stage, user_controls_treble, start_time,
number_of_user_controlled_bells):
""" Allow the Rhythm object to initialise itself when 'Look to' is called. """
self._inner_rhythm.initialise_line(stage, user_controls_treble, start_time - self.delay,
number_of_user_controlled_bells)
class RegressionRhythm(Rhythm):
"""
A class that will use regression to figure out the current ringing speed and ring accordingly.
"""
logger_name = "RHYTHM:Regression"
def __init__(self, inertia, handstroke_gap=1):
""" Initialises a new RegressionRhythm with a given handstroke gap. """
# An inertia-like coefficient designed to allow the regression finder to slowly adjust to
# a new rhythm
# 0.0 means that a new regression line will take effect instantly
# 1.0 means that no effect is made at all
self._preferred_inertia = inertia
self._handstroke_gap = handstroke_gap
self.stage = 0
self.logger = logging.getLogger(self.logger_name)
self._start_time = 0
self._blow_interval = 0
self._number_of_user_controlled_bells = 0
self._expected_bells = {}
self.data_set = []
def _add_data_point(self, row_number, place, real_time, weight):
blow_time = self.index_to_blow_time(row_number, place)
self.data_set.append((blow_time, real_time, weight))
for (b, r, w) in self.data_set:
self.logger.debug(f" {b}\t{r}\t{w}")
max_dataset_length = MAX_CHANGES_IN_DATASET * self._number_of_user_controlled_bells
# Only calculate the regression line if there are at least two datapoints, otherwise
# just store the datapoint
if len(self.data_set) >= 2:
(new_start_time, new_blow_interval) = calculate_regression(self.data_set)
# Lerp between the new times and the old times, according to the desired inertia
# The inertia is set to 0 for the first change, to make sure that there's a smooth
# pullof
regression_preferred_inertia = self._preferred_inertia if row_number > 0 else 0.0
self._start_time = lerp(new_start_time, self._start_time, regression_preferred_inertia)
self._blow_interval = lerp(new_blow_interval, self._blow_interval,
regression_preferred_inertia)
self.logger.debug(f"Bell interval: {self._blow_interval}")
# Filter out datapoints with extremely low weights
self.data_set = list(filter(lambda d: d[2] > WEIGHT_REJECTION_THRESHOLD, self.data_set))
# Eventually forget about datapoints
if len(self.data_set) >= max_dataset_length:
del self.data_set[0]
def wait_for_bell_time(self, current_time, bell, row_number, place, user_controlled, stroke):
""" Sleeps the thread until a given Bell should have rung. """
if user_controlled and self._start_time == float('inf'):
self.logger.debug(f"Waiting for pull off")
while self._start_time == float('inf'):
sleep(0.01)
self.logger.debug(f"Pulled off")
return
bell_time = self.index_to_real_time(row_number, place)
if bell_time == float('inf') or self._start_time == 0:
self.logger.error(f"Bell Time {bell_time}; Start Time {self._start_time}")
sleep(self._blow_interval or 0.2)
elif bell_time > current_time:
sleep(bell_time - current_time)
else:
# Slow the ticks slightly
sleep(0.01)
def expect_bell(self, expected_bell, row_number, place, expected_stroke):
"""
Indicates that a given Bell is expected to be rung at a given row, place and stroke.
Used by the rhythm so that when that bell is rung later, it can tell where that bell
_should_ have been in the ringing, and so can use that knowledge to inform the speed of the
ringing.
"""
self.logger.debug(f"Expected bell {expected_bell} at index {row_number}:{place} at stroke" \
+ f"{expected_stroke}")
self._expected_bells[(expected_bell, expected_stroke)] = (row_number, place)
def on_bell_ring(self, bell, stroke, real_time):
"""
Called when a bell is rung at a given stroke. Used as a callback from the Tower class.
"""
# If this bell was expected at this stroke (i.e. is being rung by someone else)
if (bell, stroke) in self._expected_bells:
# Figure out where the bell was expected in ringing space
(row_number, place) = self._expected_bells[(bell, stroke)]
expected_blow_time = self.index_to_blow_time(row_number, place)
diff = self.real_time_to_blow_time(real_time) - expected_blow_time
self.logger.info(f"{bell} off by {diff} places")
# If this was the first bell, then overwrite the start_time to update
# the regression line
if expected_blow_time == 0:
self._start_time = real_time
# Calculate the weight (which will be 1 if it is either of the first two bells to be
# rung to not skew the data from the start)
weight = math.exp(- diff ** 2)
if len(self.data_set) <= 1:
weight = 1
# Add the bell as a datapoint with the calculated weight
self._add_data_point(
row_number,
place,
real_time,
weight
)
del self._expected_bells[(bell, stroke)]
else:
# If this bell wasn't expected, then log that
self.logger.warning(f"Bell {bell} unexpectedly rang at stroke {'H' if stroke else 'B'}")
def initialise_line(self, stage, user_controls_treble, start_time,
number_of_user_controlled_bells):
""" Allow the Rhythm object to initialise itself when 'Look to' is called. """
self._number_of_user_controlled_bells = number_of_user_controlled_bells
# Remove any data that's left over in the dataset from the last touch
self.data_set = []
# Find the default blow interval for the given stage (used when the bot isn't ringing
# both trebles)
self.stage = stage
self._blow_interval = {
4: 0.4,
6: 0.3,
8: 0.3,
10: 0.2,
12: 0.2
}[self.stage]
if not user_controls_treble:
# If the bot is ringing the first bell, then add it as a datapoint anyway, so that after
# the 2nd bell is rung, a regression line can be made
self._add_data_point(0, 0, start_time, 1)
self._start_time = start_time
else:
# If the bot isn't ringing the first bell, then set the expected time of the first bell
# to infinity so that the bot will wait indefinitely for the first bell to ring, and
# then it will extrapolate from that time
self._start_time = float('inf')
# Linear conversions between different time measurements
def index_to_blow_time(self, row_number, place):
""" Convert a row number and place into a blow_time, taking hanstroke gaps into account. """
return row_number * self.stage + place + (row_number // 2) * self._handstroke_gap
def blow_time_to_real_time(self, blow_time):
""" Convert from blow_time into real_time using the regression line. """
return self._start_time + self._blow_interval * blow_time
def index_to_real_time(self, row_number, place):
"""
Convert straight from row number and place into the expected real time according to the
regression line.
"""
return self.blow_time_to_real_time(self.index_to_blow_time(row_number, place))
def real_time_to_blow_time(self, real_time):
""" Convert backwards from a real time to the corresponding blow time. """
return (real_time - self._start_time) / self._blow_interval | /rr_bot-0.1.1-py3-none-any.whl/rr_bot/rhythm.py | 0.799011 | 0.480722 | rhythm.py | pypi |
import logging
import argparse
from rr_bot.rhythm import RegressionRhythm, WaitForUserRhythm
from rr_bot.tower import RingingRoomTower
from rr_bot.bot import Bot
from rr_bot.page_parser import get_load_balancing_url
from rr_bot.row_generation import RowGenerator, ComplibCompositionGenerator
from rr_bot.row_generation import MethodPlaceNotationGenerator
def row_generator(args):
""" Generates a row generator according to the given CLI arguments. """
if "comp" in args and args.comp is not None:
row_gen = ComplibCompositionGenerator(args.comp)
elif "method" in args:
row_gen = MethodPlaceNotationGenerator(args.method)
else:
assert False, \
"This shouldn't be possible because one of --method and --comp should always be defined"
# row_gen = PlainHuntGenerator(8)
# row_gen = PlaceNotationGenerator(8, "x1", bob={1: "6"})
# row_gen = DixonoidsGenerator(6, DixonoidsGenerator.DixonsRules)
# row_gen = PlaceNotationGenerator.stedman(11)
return row_gen
def rhythm(args):
""" Generates a rhythm object according to the given CLI arguments. """
regression = RegressionRhythm(args.inertia)
if args.wait:
return WaitForUserRhythm(regression)
return regression
def configure_logging():
""" Sets up the logging for the bot. """
logging.basicConfig(level=logging.WARNING)
logging.getLogger(RingingRoomTower.logger_name).setLevel(logging.INFO)
logging.getLogger(RowGenerator.logger_name).setLevel(logging.INFO)
logging.getLogger(RegressionRhythm.logger_name).setLevel(logging.INFO)
logging.getLogger(WaitForUserRhythm.logger_name).setLevel(logging.INFO)
def main():
"""
The main function of the bot.
This parses the CLI arguments, creates the Rhythm, RowGenerator and Bot objects, then starts
the bot's mainloop.
"""
# Parse the arguments
parser = argparse.ArgumentParser(
description="A bot to fill in bells during ringingroom.com practices"
)
parser.add_argument(
"room_id",
type=int,
help="The numerical ID of the tower to join, represented as a row on 9 bells, \
e.g. 763451928."
)
parser.add_argument(
"--url",
default="https://ringingroom.com",
type=str,
help="The URL of the server to join (defaults to 'https://ringingroom.com')"
)
parser.add_argument(
"-u", "--use-up-down-in",
action="store_true",
help="If set, then the bot will automatically go into changes after two rounds have been \
rung."
)
parser.add_argument(
"-s", "--stop-at-rounds",
action="store_true",
help="If set, then the bot will stand its bells after rounds is reached."
)
parser.add_argument(
"-H", "--handbell-style",
action="store_true",
help="If set, then the bot will ring 'handbell style', i.e. ringing two strokes of \
rounds then straight into changes, and stopping at the first set of rounds. By \
default, it will ring 'towerbell style', i.e. only taking instructions from the \
ringing-room calls. This is equivalent to using the '-us' flags."
)
# Rhythm arguments
parser.add_argument(
"-w", "--wait",
action="store_true",
help="If set, the bot will wait for users to ring rather than pushing on with the rhythm."
)
parser.add_argument(
"-i", "--inertia",
type=float,
default=0.5,
help="Overrides the bot's 'inertia' - now much the bot will take other ringers' positions \
into account when deciding when to ring. 0.0 means it will cling as closely as \
possible to the current rhythm, 1.0 means that it will completely ignore the other \
ringers. By default, it will set a value depending on what proportion of the bells \
are user controlled."
)
# Row generator arguments
row_gen_group = parser.add_mutually_exclusive_group(required=True)
row_gen_group.add_argument(
"--comp",
type=int,
help="The ID of the complib composition you want to ring"
)
row_gen_group.add_argument(
"--method",
type=str,
help="The title of the method you want to ring"
)
args = parser.parse_args()
# Run the program
configure_logging()
tower = RingingRoomTower(args.room_id, get_load_balancing_url(args.room_id, args.url))
bot = Bot(tower, row_generator(args), args.use_up_down_in or args.handbell_style,
args.stop_at_rounds or args.handbell_style, rhythm=rhythm(args))
with tower:
tower.wait_loaded()
print("=== LOADED ===")
bot.main_loop()
if __name__ == "__main__":
main() | /rr_bot-0.1.1-py3-none-any.whl/rr_bot/main.py | 0.583797 | 0.495361 | main.py | pypi |
class Bell:
""" A class to encapsulate the idea of a bell. """
@classmethod
def from_str(cls, bell_str: str):
"""
Generates a Bell object from a string representing that bell's name.
This works according to the standard convention, so Bell.from_str('1') will represent
the treble, and Bell.from_str('T') will represent the twelfth.
"""
try:
index = Bell._lookup_name.index(bell_str)
except ValueError:
raise ValueError(f"'{bell_str}' is not known bell symbol")
return cls(index)
@classmethod
def from_number(cls, bell_num: int):
"""
Generates a Bell from a 1-indexed number, so Bell.from_number(1) will return a Bell
representing the treble.
"""
return cls(bell_num - 1)
@classmethod
def from_index(cls, bell_index: int):
"""
Generates a Bell from a 0-indexed number, so Bell.from_number(0) will return a Bell
represeting the treble.
"""
return cls(bell_index)
def __init__(self, index: int):
"""
Constructs a Bell from a given 0-indexed index. Should not be used outside this class -
see `Bell.from_index` and `Bell.from_number` instead.
"""
if index < 0 or index >= len(self._lookup_name):
raise ValueError(f"'{index}' is not known bell index")
self.index = index
@property
def number(self):
""" Gets the 1-indexed number representing this bell. """
return self.index + 1
_lookup_name = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "0", "E", "T"]
def __str__(self):
""" Converts this bell to a single-character string representing this bell. """
return self._lookup_name[self.index]
def __eq__(self, other):
""" Determines if two Bells are equal. """
return isinstance(other, Bell) and other.index == self.index
def __hash__(self):
""" Generates a has of a Bell. """
return self.index | /rr_bot-0.1.1-py3-none-any.whl/rr_bot/bell.py | 0.882428 | 0.810404 | bell.py | pypi |
import collections
import logging
from time import sleep
from typing import Optional, Callable, Dict, List, Any
import socketio
from rr_bot.bell import Bell
class RingingRoomTower:
""" A class representing a tower, which will handle a single ringing-room session. """
logger_name = "TOWER"
def __init__(self, tower_id: int, url: str):
""" Initilise a tower with a given room id and url. """
self.tower_id = tower_id
self.logger = logging.getLogger(self.logger_name)
self._bell_state = []
self._assigned_users = {}
self.invoke_on_call: Dict[str, List[Callable[[], Any]]] = collections.defaultdict(list)
self.invoke_on_reset: List[Callable[[], Any]] = []
self.invoke_on_bell_rung: List[Callable[[int, bool], Any]] = []
self._url = url
self._socket_io_client: Optional[socketio.Client] = None
def __enter__(self):
""" Called when entering a 'with' block. Opens the socket-io connection. """
self.logger.debug("ENTER")
if self._socket_io_client is not None:
raise Exception("Trying to connect twice")
self._create_client()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
"""
Called when finishing a 'with' block. Clears up the object and disconnects the session.
"""
self.logger.debug("EXIT")
if self._socket_io_client:
self.logger.info("Disconnect")
self._socket_io_client.disconnect()
self._socket_io_client = None
@property
def number_of_bells(self):
""" Returns the number of bells currently in the tower. """
return len(self._bell_state)
def ring_bell(self, bell: Bell, handstroke: bool):
""" Send a request to the the server if the bell can be rung on the given stroke. """
try:
stroke = self.get_stroke(bell)
if stroke != handstroke:
self.logger.error(f"Bell {bell} on opposite stroke")
return False
self._emit(
"c_bell_rung",
{"bell": bell.number, "stroke": stroke, "tower_id": self.tower_id},
""
)
return True
except Exception as e:
self.logger.error(e)
return False
def user_controlled(self, bell: Bell):
""" Returns true if a given bell is controlled by a user other than the bot. """
return self._assigned_users.get(bell, "") != ""
def get_stroke(self, bell: Bell):
""" Returns the stroke of a given bell. """
if bell.index >= len(self._bell_state) or bell.index < 0:
self.logger.error(f"Bell {bell} not in tower")
return None
return self._bell_state[bell.index]
def make_call(self, call: str):
""" Broadcasts a given call to the other users of the tower. """
self._emit("c_call", {"call": call, "tower_id": self.tower_id}, f"Call '{call}'")
def set_at_hand(self):
""" Sets all the bells at hand. """
self._emit("c_set_bells", {"tower_id": self.tower_id}, f"Set at hand")
def set_number_of_bells(self, number: int):
""" Set the number of bells in the tower. """
self._emit(
"c_size_change",
{"new_size": number, "tower_id": self.tower_id},
f"Set number of bells '{number}'"
)
def wait_loaded(self):
""" Pause the thread until the socket-io connection is open and stable. """
if self._socket_io_client is None:
raise Exception("Not Connected")
iteration = 0
while not self._bell_state:
iteration += 1
if iteration % 50 == 0:
self._join_tower()
self._request_global_state()
sleep(0.1)
def _create_client(self):
""" Generates the socket-io client and attaches callbacks. """
self._socket_io_client = socketio.Client()
self._socket_io_client.connect(self._url)
self.logger.info(f"Connected to {self._url}")
self._join_tower()
self._socket_io_client.on("s_bell_rung", self._on_bell_rung)
self._socket_io_client.on("s_global_state", self._on_global_bell_state)
self._socket_io_client.on("s_size_change", self._on_size_change)
self._socket_io_client.on("s_assign_user", self._on_assign_user)
self._socket_io_client.on("s_call", self._on_call)
self._request_global_state()
def _join_tower(self):
""" Joins the tower as an anonymous user. """
self._emit(
"c_join",
{"anonymous_user": True, "tower_id": self.tower_id},
f"Joining tower {self.tower_id}"
)
def _request_global_state(self):
""" Send a request to the server to get the current state of the tower. """
self._emit('c_request_global_state', {"tower_id": self.tower_id}, "Request state")
def _emit(self, event: str, data, message: str):
""" Emit a socket-io signal. """
if self._socket_io_client is None:
raise Exception("Not Connected")
self._socket_io_client.emit(event, data)
if message:
self.logger.info(f"EMIT: {message}")
def _on_bell_rung(self, data):
""" Callback called when the client recieves a signal that a bell has been rung. """
self._on_global_bell_state(data)
who_rang = Bell.from_number(data["who_rang"])
for bell_ring_callback in self.invoke_on_bell_rung:
bell_ring_callback(who_rang, self.get_stroke(who_rang))
def _on_global_bell_state(self, data):
"""
Callback called when recieving an update to the global tower state.
Cannot have further callbacks assigned to it.
"""
bell_state = data["global_bell_state"]
self._bell_state = bell_state
self.logger.debug(f"RECEIVED: Bells '{['H' if x else 'B' for x in bell_state]}'")
def _on_size_change(self, data):
""" Callback called when the number of bells in the room changes. """
new_size = data["size"]
if new_size != self.number_of_bells:
self._assigned_users = {}
self._bell_state = self._bells_set_at_hand(new_size)
self.logger.info(f"RECEIVED: New tower size '{new_size}'")
for invoke_callback in self.invoke_on_reset:
invoke_callback()
def _on_assign_user(self, data):
""" Callback called when a bell assignment is changed. """
bell = Bell.from_number(data["bell"])
user = data["user"]
self._assigned_users[bell] = user
self.logger.info(f"RECEIVED: Assigned bell '{bell}' to '{user or 'BOT'}'")
def _on_call(self, data):
""" Callback called when a call is made. """
call = data["call"]
self.logger.info(f"RECEIVED: Call '{call}'")
found_callback = False
for call_callback in self.invoke_on_call.get(call, []):
call_callback()
found_callback = True
if not found_callback:
self.logger.warning(f"No callback found for '{call}'")
@staticmethod
def _bells_set_at_hand(number: int):
""" Returns the representation of `number` bells, all set at handstroke. """
return [True for _ in range(number)] | /rr_bot-0.1.1-py3-none-any.whl/rr_bot/tower.py | 0.813313 | 0.206954 | tower.py | pypi |
import time
from rr_bot import calls
from rr_bot.row_generation import RowGenerator
from rr_bot.bell import Bell
from rr_bot.rhythm import Rhythm
from rr_bot.tower import RingingRoomTower
class Bot:
"""
A class to hold all the information that the bot will use to glue together the rhythm,
row_gen and socket-io parts together into a useful program.
"""
def __init__(self, tower: RingingRoomTower, row_generator: RowGenerator, do_up_down_in,
stop_at_rounds, rhythm: Rhythm):
""" Initialise a Bot with all the parts it needs to run. """
self._rhythm = rhythm
self._do_up_down_in = do_up_down_in
self._stop_at_rounds = stop_at_rounds
self.row_generator = row_generator
self._tower = tower
self._tower.invoke_on_call[calls.LOOK_TO].append(self._on_look_to)
self._tower.invoke_on_call[calls.GO].append(self._on_go)
self._tower.invoke_on_call[calls.BOB].append(self._on_bob)
self._tower.invoke_on_call[calls.SINGLE].append(self._on_single)
self._tower.invoke_on_call[calls.THATS_ALL].append(self._on_thats_all)
self._tower.invoke_on_call[calls.STAND].append(self._on_stand_next)
self._tower.invoke_on_bell_rung.append(self._on_bell_ring)
self._is_ringing = False
self._is_ringing_rounds = True
self._should_start_method = False
self._should_start_ringing_rounds = False
self._should_stand = False
self._row_number = 0
self._place = 0
self._row = None
# Convenient properties that are frequently used
@property
def is_handstroke(self):
"""
Returns true if the current row (determined by self._row_number) represents a handstroke.
"""
return self._row_number % 2 == 0
@property
def stage(self):
""" Convenient property to find the number of bells in the current tower. """
return self._tower.number_of_bells
# Callbacks
def _on_look_to(self):
""" Callback called when a user calls 'Look To'. """
treble = Bell.from_number(1)
# Count number of user controlled bells
number_of_user_controlled_bells = 0
for i in range(self.stage):
if self._tower.user_controlled(Bell.from_index(i)):
number_of_user_controlled_bells += 1
self._rhythm.initialise_line(self.stage, self._tower.user_controlled(treble),
time.time() + 3, number_of_user_controlled_bells)
# Clear all the flags
self._should_stand = False
self._should_start_method = False
self._should_start_ringing_rounds = False
# Reset the state, so that the bot starts by ringing rounds
self._is_ringing = True
self._is_ringing_rounds = True
# Start at the first place of the first row
self._row_number = 0
self._place = 0
self.start_next_row()
def _on_go(self):
""" Callback called when a user calls 'Go'. """
if self._is_ringing_rounds:
self._should_start_method = True
def _on_bob(self):
""" Callback called when a user calls 'Bob'. """
self.row_generator.set_bob()
def _on_single(self):
""" Callback called when a user calls 'Single'. """
self.row_generator.set_single()
def _on_thats_all(self):
""" Callback called when a user calls 'That`s All'. """
self._should_start_ringing_rounds = True
def _on_stand_next(self):
""" Callback called when a user calls 'Stand Next'. """
self._should_stand = True
def _on_bell_ring(self, bell, stroke):
""" Callback called when the Tower recieves a signal that a bell has been rung. """
if self._tower.user_controlled(bell):
# This will give us the stroke _after_ the bell rings, we have to invert it, because
# otherwise this will always expect the bells on the wrong stroke and no ringing will
# ever happen
self._rhythm.on_bell_ring(bell, not stroke, time.time())
# Mainloop and helper methods
def expect_bell(self, index, bell):
""" Called to let the rhythm expect a user-controlled bell at a certain time and stroke. """
if self._tower.user_controlled(bell):
self._rhythm.expect_bell(
bell,
self._row_number,
index,
self.is_handstroke
)
def start_next_row(self):
"""
Creates a new row from the row generator and tells the rhythm to expect the new bells.
"""
if self._is_ringing_rounds:
for index in range(self.stage):
self.expect_bell(index, Bell.from_index(index))
else:
self._row = self.row_generator.next_row(self.is_handstroke)
for (index, bell) in enumerate(self._row):
self.expect_bell(index, bell)
def start_method(self):
"""
Called when the ringing is about to go into changes.
Resets the row_generator and starts the next row.
"""
assert self.row_generator.number_of_bells == self._tower.number_of_bells, \
f"{self.row_generator.number_of_bells} != {self._tower.number_of_bells}"
self.row_generator.reset()
self.start_next_row()
def tick(self):
""" Called every time the main loop is executed when the bot is ringing. """
bell = Bell.from_index(self._place) if self._is_ringing_rounds else self._row[self._place]
user_controlled = self._tower.user_controlled(bell)
self._rhythm.wait_for_bell_time(time.time(), bell, self._row_number, self._place,
user_controlled, self.is_handstroke)
if not user_controlled:
self._tower.ring_bell(bell, self.is_handstroke)
self._place += 1
if self._place == self.stage:
# Determine if we're finishing a handstroke
has_just_rung_rounds = True
if self._row is None:
has_just_rung_rounds = False
else:
for i, bell in enumerate(self._row):
if bell.index != i:
has_just_rung_rounds = False
# Generate the next row and update row indices
self._row_number += 1
self._place = 0
self.start_next_row()
# Implement handbell-style 'up down in'
if self._do_up_down_in:
if self._is_ringing_rounds and self._row_number == 2:
self._should_start_method = True
# Implement handbell-style stopping at rounds
if self._stop_at_rounds:
if has_just_rung_rounds:
self._should_stand = False
self._is_ringing = False
# If we're starting a handstroke, we should convert all the flags into actions
if self._row_number % 2 == 0:
if self._should_stand:
self._should_stand = False
self._is_ringing = False
if self._should_start_method and self._is_ringing_rounds:
self._should_start_method = False
self._is_ringing_rounds = False
self.start_method()
if self._should_start_ringing_rounds and not self._is_ringing_rounds:
self._should_start_ringing_rounds = False
self._is_ringing_rounds = True
def main_loop(self):
"""
The main_loop of the bot.
The main thread will get stuck forever in this function whilst the bot rings.
"""
while True:
if self._is_ringing:
self.tick()
time.sleep(0.01) | /rr_bot-0.1.1-py3-none-any.whl/rr_bot/bot.py | 0.678114 | 0.320702 | bot.py | pypi |
from typing import Dict, List
from rr_bot.bell import Bell
from .helpers import convert_pn
from .row_generator import RowGenerator
class DixonoidsGenerator(RowGenerator):
""" A class to generate rows of dixonoids. """
DixonsRules = {
0: ["x", "1"],
1: ["x", "2"],
2: ["x", "4"],
4: ["x", "4"]
}
DefaultBob = {1: ["x", "4"]}
DefaultSingle = {1: ["x", "1234"]}
def __init__(self, stage: int, plain_rules: Dict[int, List[str]],
bob_rules: Dict[int, List[str]] = None, single_rules: Dict[int, List[str]] = None):
"""
Initialises a dixonoid generator.
:param plain_rules: Dictionary of leading bell: [handstroke pn, backstroke pn]
0: Matches any other bell
:param bob_rules: Dictionary of leading bell: [handstroke pn, backstroke pn]
Only include bells which lead when a bob is rung
:param single_rules: Dictionary of leading bell: [handstroke pn, backstroke pn]
Only include bells which lead when a single is rung
"""
super(DixonoidsGenerator, self).__init__(stage)
if bob_rules is None:
bob_rules = self.DefaultBob
if single_rules is None:
single_rules = self.DefaultSingle
self.plain_rules = self._convert_pn_dict(plain_rules)
self.bob_rules = self._convert_pn_dict(bob_rules)
self.single_rules = self._convert_pn_dict(single_rules)
def _gen_row(self, previous_row: List[Bell], is_handstroke: bool, index: int) -> List[Bell]:
leading_bell = previous_row[0].number
pn_index = 0 if is_handstroke else 1
if self._has_bob and self.bob_rules.get(leading_bell):
place_notation = self.bob_rules[leading_bell][pn_index]
if not is_handstroke:
self.reset_calls()
elif self._has_single and self.single_rules.get(leading_bell):
place_notation = self.single_rules[leading_bell][pn_index]
if not is_handstroke:
self.reset_calls()
elif self.plain_rules.get(leading_bell):
place_notation = self.plain_rules[leading_bell][pn_index]
else:
place_notation = self.plain_rules[0][pn_index]
row = self.permute(previous_row, place_notation)
return row
@staticmethod
def _convert_pn_dict(rules: Dict[int, List[str]]) -> Dict[int, List[List[int]]]:
return {key: [convert_pn(pn)[0] for pn in places] for key, places in rules.items()} | /rr_bot-0.1.1-py3-none-any.whl/rr_bot/row_generation/dixonoids_generator.py | 0.866331 | 0.398465 | dixonoids_generator.py | pypi |
import logging
from abc import ABCMeta, abstractmethod
from typing import List
from rr_bot.bell import Bell
class RowGenerator(metaclass=ABCMeta):
""" Abstract base class for behaviours common to all row generators. """
logger_name = "ROWGEN"
def __init__(self, stage: int):
self.stage = stage
self.logger = logging.getLogger(self.logger_name)
# Ensure there is a cover bell
self.number_of_bells = self.stage + 1 if self.stage % 2 else self.stage
self._has_bob = False
self._has_single = False
self._index = 0
self._row = self.rounds()
def reset(self):
""" Reset the row generator. """
self.logger.info("Reset")
self._has_bob = False
self._has_single = False
self._index = 0
self._row = self.rounds()
def reset_calls(self):
""" Clear the pending call flags. """
self.logger.info("Reset calls")
self._has_bob = False
self._has_single = False
def next_row(self, is_handstroke: bool) -> List[Bell]:
""" Generate the next row, and mutate state accordingly. """
self._row = self._gen_row(self._row, is_handstroke, self._index)
self._add_cover_if_required()
self._index += 1
message = " ".join([str(bell) for bell in self._row])
self.logger.info(message)
return self._row
def set_bob(self):
""" Set the flag that a bob has been made. """
self._has_bob = True
def set_single(self):
""" Set the flag that a single has been made. """
self._has_single = True
def rounds(self) -> List[Bell]:
""" Generate rounds of the stage given by this RowGenerator. """
return [Bell.from_number(i) for i in range(1, self.number_of_bells + 1)]
def _add_cover_if_required(self):
if len(self._row) == self.number_of_bells - 1:
self._row.append(Bell.from_number(self.number_of_bells))
@abstractmethod
def _gen_row(self, previous_row: List[Bell], is_handstroke: bool, index: int) -> List[Bell]:
pass
def permute(self, row: List[Bell], places: List[int]) -> List[Bell]:
""" Permute a row by a place notation given by `places`. """
new_row = list(row)
i = 1
if places and places[0] % 2 == 0:
# Skip 1 for implicit lead when lowest pn is even
i += 1
while i < self.stage:
if i in places:
i += 1
continue
else:
# If not in place, must swap, index is 1 less than place
new_row[i - 1], new_row[i] = new_row[i], new_row[i - 1]
i += 2
return new_row | /rr_bot-0.1.1-py3-none-any.whl/rr_bot/row_generation/row_generator.py | 0.849628 | 0.253517 | row_generator.py | pypi |
from typing import List, Dict
from rr_bot.bell import Bell
from .helpers import convert_pn, convert_to_bell_string
from .row_generator import RowGenerator
class PlaceNotationGenerator(RowGenerator):
""" A row generator to generate rows given a place notation. """
# Dict Lead Index: String PlaceNotation
# -1 for end of the lead
DefaultBob = {-1: '14'}
DefaultSingle = {-1: '1234'}
def __init__(self, stage: int, method: str, bob: Dict[int, str] = None,
single: Dict[int, str] = None):
super(PlaceNotationGenerator, self).__init__(stage)
if bob is None:
bob = PlaceNotationGenerator.DefaultBob
if single is None:
single = PlaceNotationGenerator.DefaultSingle
self.method_pn = convert_pn(method)
self.lead_len = len(self.method_pn)
self.bobs_pn = {i % self.lead_len: convert_pn(pn) for i, pn in bob.items()}
self.singles_pn = {i % self.lead_len: convert_pn(pn) for i, pn in single.items()}
self._generating_call_pn: List[List[int]] = []
def _gen_row(self, previous_row: List[Bell], is_handstroke: bool, index: int) -> List[Bell]:
lead_index = index % self.lead_len
assert lead_index % 2 != is_handstroke
if self._has_bob and self.bobs_pn.get(lead_index):
self._generating_call_pn = list(self.bobs_pn[lead_index])
self.logger.info(f"Bob at index {lead_index}")
self.reset_calls()
elif self._has_single and self.singles_pn.get(lead_index):
self._generating_call_pn = list(self.singles_pn[lead_index])
self.logger.info(f"Single at index {lead_index}")
self.reset_calls()
if self._generating_call_pn:
place_notation = self._generating_call_pn.pop(0)
else:
place_notation = self.method_pn[lead_index]
return self.permute(previous_row, place_notation)
@staticmethod
def grandsire(stage: int):
""" Generates Grandsire on a given stage (even bell Grandsire will cause an exception). """
assert stage % 2 == 1
stage_bell = convert_to_bell_string(stage)
main_body = [stage_bell if i % 2 else "1" for i in range(1, 2 * stage + 1)]
main_body[0] = "3"
notation = ".".join(main_body)
return PlaceNotationGenerator(stage, notation, bob={-2: "3"}, single={-2: "3.123"})
@staticmethod
def stedman(stage: int):
""" Generates Stedman on a given stage (even bell Stedman will cause an exception). """
assert stage % 2 == 1
if stage == 5:
return PlaceNotationGenerator.stedman_doubles()
stage_bell = convert_to_bell_string(stage)
stage_bell_1 = convert_to_bell_string(stage - 1)
stage_bell_2 = convert_to_bell_string(stage - 2)
notation = f"3.1.{stage_bell}.3.1.3.1.3.{stage_bell}.1.3.1"
return PlaceNotationGenerator(stage, notation, bob={2: stage_bell_2, 8: stage_bell_2},
single={2: f"{stage_bell_2}{stage_bell_1}{stage_bell}",
8: f"{stage_bell_2}{stage_bell_1}{stage_bell}"})
@staticmethod
def stedman_doubles():
""" Generates Stedman on a given stage (even bell Stedman will cause an exception). """
notation = "3.1.5.3.1.3.1.3.5.1.3.1"
return PlaceNotationGenerator(5, notation, bob={}, single={5: "345", 11: "145"}) | /rr_bot-0.1.1-py3-none-any.whl/rr_bot/row_generation/place_notation_generator.py | 0.900379 | 0.492066 | place_notation_generator.py | pypi |
class Channel(object):
""" Packs tracks into ptc tracks
>>> tracks = [
... (1, 3, 0),
... (1, 1, 1),
... (4, 5, 2),
... (4, 4, 3),
... (0, 10, 4),
... ]
>>> channel_model = Channel(tracks)
>>> channel_model.pack_tracks()
>>> for ptc, tree in enumerate(channel_model.trees):
... print('ptc={}'.format(ptc))
... for itr in tree:
... x, y, idx = tracks[itr[2]]
... assert idx == itr[2]
... print(' tracks[{}] = ({}, {})'.format(itr[2], x, y))
ptc=0
tracks[4] = (0, 10)
ptc=1
tracks[0] = (1, 3)
tracks[2] = (4, 5)
ptc=2
tracks[1] = (1, 1)
tracks[3] = (4, 4)
>>> for ptc, min_v, max_v in channel_model.fill_empty(0, 10):
... print('ptc={} ({}, {})'.format(ptc, min_v, max_v))
ptc=1 (0, 0)
ptc=1 (6, 10)
ptc=2 (0, 0)
ptc=2 (2, 3)
ptc=2 (5, 10)
"""
def __init__(self, tracks):
"""
Attributes
----------
tracks : list of tuples of (min, max, idx)
"""
self.trees = []
self.tracks = sorted(tracks, key=lambda x: x[1] - x[0])
def _start_track(self, track):
self.trees.append([track])
def _add_track_to_tree(self, track, idx=-1):
self.trees[idx].append(track)
def _verify_trees(self):
for tree in self.trees:
for a, b in zip(tree, tree[1:]):
assert a[1] <= b[0]
def pack_tracks(self):
"""pack all tracks
Algorithm:
1. Sort tracks by length, shortest tracks first. Popping from back
of python lists is O(1).
2. Create stack for each starting values, inserting in length order.
3. Starting with the lowest starting value, greedly pack tracks
Algorithm weaknesses:
- Linear scan for lowest starting value
- Linear scan for packing
Both weaknesses are O(Number grid dim * Number of tracks) in
pathological case, however grid dimensions tend to be fairly small,
(e.g. 50T is 150), so scans are practically fast.
If the grid dimension size grows large, revisit how to find the
lowest starting value and next bucket pack. Relevant operation is
given coordinate, find next largest non-empty bucket.
3a. Pop largest track from smallest starting value, creating a new
channel
3b. Pop largest track starting from end of previous track until no
tracks can follow.
3c. Repeat 3 until everything is packed.
"""
by_low = {}
def pop(low):
track = by_low[low].pop()
if len(by_low[low]) == 0:
del by_low[low]
return track
for low, high, key in self.tracks:
if low not in by_low:
by_low[low] = []
by_low[low].append((high, key))
if len(by_low) > 0:
high = max(by_low)
while len(by_low) > 0:
track_low = min(by_low)
track_high, key = pop(track_low)
self._start_track((track_low, track_high, key))
while track_high is not None:
start = track_high + 1
track_high = None
for track_low in range(start, high + 1):
if track_low in by_low:
track_high, key = pop(track_low)
self._add_track_to_tree((track_low, track_high, key))
break
self._verify_trees()
def fill_empty(self, min_value, max_value):
"""Generator that yields tracks for any gaps in the channels.
"""
for idx, tree in enumerate(self.trees):
tracks = sorted(tree, key=lambda x: x[0])
if min_value <= tracks[0][0] - 1:
yield (idx, min_value, tracks[0][0] - 1)
for cur_track, next_track in zip(tracks, tracks[1:]):
if cur_track[1] + 1 <= next_track[0] - 1:
yield (idx, cur_track[1] + 1, next_track[0] - 1)
if tracks[-1][1] + 1 <= max_value:
yield (idx, tracks[-1][1] + 1, max_value) | /rr-graph-0.0.1.post14.tar.gz/rr-graph-0.0.1.post14/rr_graph/channel2.py | 0.852445 | 0.509276 | channel2.py | pypi |
from collections import namedtuple
class static_property(object):
"""
Descriptor (non-data) for building an attribute on-demand on first use.
"""
def __init__(self, factory):
"""
<factory> is called such: factory(instance) to build the attribute.
"""
self._attr_name = factory.__name__
self._factory = factory
self.__doc__ = factory.__doc__
def __get__(self, instance, owner):
if instance is None:
return self
# Build the attribute.
attr = self._factory(instance)
# Cache the value; hide ourselves.
setattr(instance, self._attr_name, attr)
return attr
# FIXME: define operators
Position = namedtuple("P", ("x", "y"))
P = Position # Even shorter alias
_Size = namedtuple("Size", ("w", "h"))
class Size(_Size):
"""
>>> s = Size(2, 3)
>>> s
Size(w=2, h=3)
>>> p = Position(4, 5)
>>> s + p
P(x=6, y=8)
>>> s + s
Size(w=4, h=6)
>>> s + 1
Traceback (most recent call last):
...
TypeError: unsupported operand type(s) for +: 'Size' and 'int'
"""
def __new__(cls, w, h):
assert w >= 0
assert h >= 0
return _Size.__new__(cls, w, h)
@static_property
def width(self):
return self.w
@static_property
def height(self):
return self.h
@static_property
def x(self):
return self.w
@static_property
def y(self):
return self.h
def walk(self):
for x in range(0, self.x):
for y in range(0, self.y):
yield Position(x, y)
def __add__(self, o):
if isinstance(o, Position):
return o.__class__(o.x + self.x, o.y + self.y)
elif isinstance(o, Size):
return o.__class__(o.x + self.x, o.y + self.y)
return NotImplemented
def __radd__(self, o):
if isinstance(o, Position):
return o.__class__(o.x + self.x, o.y + self.y)
elif isinstance(o, Size):
return o.__class__(o.x + self.x, o.y + self.y)
return NotImplemented
def __sub__(self, o):
if isinstance(o, Position):
return o.__class__(self.x - o.x, self.y - o.y)
elif isinstance(o, Size):
return o.__class__(self.x - o.x, self.y - o.y)
return NotImplemented
def __rsub__(self, o):
if isinstance(o, Position):
return o.__class__(o.x - self.x, o.y - self.y)
elif isinstance(o, Size):
return o.__class__(o.x - self.x, o.y - self.y)
return NotImplemented
S = Size
class Offset(Size):
pass
O = Offset # noqa: E741
def single_element(parent, name):
'''Return given single XML child entry in parent'''
elements = list(parent.iterfind(name))
assert len(elements) == 1, elements
return elements[0]
def node_pos(node):
# node as node_xml
loc = single_element(node, 'loc')
pos_low = Position(int(loc.get('xlow')), int(loc.get('ylow')))
pos_high = Position(int(loc.get('xhigh')), int(loc.get('yhigh')))
return pos_low, pos_high | /rr-graph-0.0.1.post14.tar.gz/rr-graph-0.0.1.post14/rr_graph/__init__.py | 0.76366 | 0.355188 | __init__.py | pypi |
from __future__ import print_function
from collections import namedtuple
from enum import Enum
from .tracks import Track
from . import channel2
from .utils import progressbar_utils
class SwitchType(Enum):
"""Enumeration of allowed VPR switch type
See: https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-switches-switch
""" # noqa: E501
INVALID_SWITCH_TYPE = 0
MUX = 1
TRISTATE = 2
PASS_GATE = 3
SHORT = 4
BUFFER = 5
class NodeType(Enum):
"""VPR Node type. This is a superset of Type in channel.py
See: https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-nodes-node
""" # noqa: E501
INVALID_NODE_TYPE = 0
CHANX = 1
CHANY = 2
SOURCE = 3
SINK = 4
OPIN = 5
IPIN = 6
class NodeDirection(Enum):
"""VPR Node Direction. This is a superset of Direction in channel.py
See: https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-nodes-node
""" # noqa: E501
NO_DIR = 0
INC_DIR = 1
DEC_DIR = 2
BI_DIR = 3
class PinType(Enum):
"""Enum for PinClass type
See: https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-blocks-pin_class
""" # noqa: E501
NONE = 0
OPEN = 1
OUTPUT = 2
INPUT = 3
class ChannelList(namedtuple('ChannelList', 'index info')):
"""VPR `x_list` and `y_list` tags in the channels
"""
class Channels(namedtuple(
'Channels', 'chan_width_max x_min y_min x_max y_max x_list y_list')):
"""Encapsulation for VPR channels tag
See: https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-channel-channel
""" # noqa: E501
class SwitchTiming(namedtuple('SwitchTiming',
'r c_in c_out c_internal t_del')):
"""Encapsulation for timing attributes of a VPR switch
see: https://vtr-verilog-to-routing.readthedocs.io/en/latest/arch/reference.html#switches
"""
class SwitchSizing(namedtuple('SwitchSizing', 'mux_trans_size buf_size')):
"""Encapsulation for sizing attributes of a VPR switch
see: https://vtr-verilog-to-routing.readthedocs.io/en/latest/arch/reference.html#switches
"""
class Switch(namedtuple('Switch', 'id name type timing sizing')):
"""Encapsulate VPR switch tag. Contains SwitchTiming and SwitchSizing tuples.
see: https://vtr-verilog-to-routing.readthedocs.io/en/latest/arch/reference.html#switches
"""
class SegmentTiming(namedtuple('SegmentTiming', 'r_per_meter c_per_meter')):
"""Encapsulation for timing attributes of a VPR segment.
see: https://vtr-verilog-to-routing.readthedocs.io/en/latest/arch/reference.html#wire-segments
"""
class Segment(namedtuple('Segment', 'id name timing')):
"""Encapsulate VPR segment tag. Contains SegmentTiming to encapsulate the timing attributes
see: https://vtr-verilog-to-routing.readthedocs.io/en/latest/arch/reference.html#wire-segments
"""
class Pin(namedtuple('Pin', 'ptc name')):
"""Encapsulation for VPR Pin tag
See: https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-blocks-pin
""" # noqa: E501
class PinClass(namedtuple('PinClass', 'type pin')):
"""Encapsulation for VPR PinClass tag
See: https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-blocks-pin_class
""" # noqa: E501
class BlockType(namedtuple('BlockType', 'id name width height pin_class')):
"""Encapsulation for VPR BlockType tag
See: https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-blocks-block_type
""" # noqa: E501
class GridLoc(namedtuple('GridLoc',
'x y block_type_id width_offset height_offset')):
"""
"""
class NodeTiming(namedtuple('NodeTiming', 'r c')):
"""https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-nodes-timing
"""
class NodeLoc(namedtuple('NodeLoc', 'x_low y_low x_high y_high side ptc')):
"""https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-nodes-loc
"""
class NodeMetadata(namedtuple('NodeMetadata',
'name x_offset y_offset z_offset value')):
"""https://vtr-verilog-to-routing.readthedocs.io/en/latest/arch/reference.html#architecture-metadata
"""
class NodeSegment(namedtuple('NodeSegment', 'segment_id')):
"""https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-nodes-segment
"""
class Node(namedtuple(
'Node', 'id type direction capacity loc timing metadata segment')):
"""https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-nodes-node
"""
class Edge(namedtuple('Edge', 'src_node sink_node switch_id metadata')):
"""https://vtr-verilog-to-routing.readthedocs.io/en/latest/vpr/file_formats.html#tag-edges-edge
"""
class GraphInput(namedtuple('GraphInput',
'switches segments block_types grid')):
"""Top level encapsulation of input Graph
"""
def process_track(track):
channel_model = channel2.Channel(track)
channel_model.pack_tracks()
return channel_model
class Graph(object):
""" Simple object for working with VPR RR graph.
This class does not handle serialization. A format specific class handles
serdes takes.
"""
def __init__(
self,
switches,
segments,
block_types,
grid,
nodes,
edges=None,
build_pin_edges=True
):
self.switches = switches
self.next_switch_id = max(switch.id for switch in self.switches) + 1
self.switch_name_map = {}
self.delayless_switch = None
for idx, switch in enumerate(self.switches):
assert idx == switch.id
assert switch.name not in self.switch_name_map
self.switch_name_map[switch.name] = switch.id
assert '__vpr_delayless_switch__' in self.switch_name_map, self.switch_name_map.keys(
)
self.delayless_switch = self.switch_name_map['__vpr_delayless_switch__'
]
self.segments = segments
self.segment_name_map = {}
for idx, segment in enumerate(self.segments):
assert idx == segment.id
assert segment.name not in self.segment_name_map
self.segment_name_map[segment.name] = segment.id
self.block_types = block_types
self.grid = grid
self.tracks = []
self.nodes = nodes
self.nodes.sort(key=lambda node: node.id)
self.edges = edges if edges is not None else []
# Map of (x, y) to GridLoc definitions.
self.loc_map = {}
# Maps grid location and pin class index to node index
# (x, y, pin class idx) -> node_idx
self.loc_pin_class_map = {}
# Maps grid location and pin index to node index
# (x, y, pin idx) -> [(node_idx, side)]
self.loc_pin_map = {}
# Maps pin name to block type id and pin idx.
# pin name -> block type id, pin class idx, pin idx
self.pin_name_map = {}
self.pin_ptc_to_name_map = {}
# Create pin_name_map and sanity check block_types.
for idx, block_type in enumerate(self.block_types):
assert idx == block_type.id
for pin_class_idx, pin_class in enumerate(block_type.pin_class):
for pin in pin_class.pin:
assert pin.name not in self.pin_name_map
self.pin_name_map[
pin.name] = (block_type.id, pin_class_idx, pin.ptc)
self.pin_ptc_to_name_map[(block_type.id,
pin.ptc)] = pin.name
# Create mapping from grid locations and pins to nodes.
for idx, node in enumerate(self.nodes):
assert node.id == idx, (idx, node)
if node.type in (
NodeType.IPIN,
NodeType.OPIN,
):
key = (node.loc.x_low, node.loc.y_low, node.loc.ptc)
if key not in self.loc_pin_map:
self.loc_pin_map[key] = []
self.loc_pin_map[key].append((node.id, node.loc.side))
if node.type in (
NodeType.SOURCE,
NodeType.SINK,
):
key = (node.loc.x_low, node.loc.y_low, node.loc.ptc)
assert key not in self.loc_pin_class_map, (
node, self.loc_pin_class_map[key]
)
self.loc_pin_class_map[key] = node.id
# Rebuild initial edges of IPIN -> SINK and SOURCE -> OPIN.
for loc in grid:
assert loc.block_type_id >= 0 and loc.block_type_id <= len(
self.block_types
), loc.block_type_id
block_type = self.block_types[loc.block_type_id]
key = (loc.x, loc.y)
assert key not in self.loc_map
self.loc_map[key] = loc
# Skip building IPIN -> SINK and OPIN -> SOURCE graph if edges
# are not required.
if not build_pin_edges:
continue
for pin_class_idx, pin_class in enumerate(block_type.pin_class):
pin_class_node = self.loc_pin_class_map[
(loc.x, loc.y, pin_class_idx)]
for pin in pin_class.pin:
for pin_node, _ in self.loc_pin_map[(loc.x, loc.y,
pin.ptc)]:
if pin_class.type == PinType.OUTPUT:
self.add_edge(
src_node=pin_class_node,
sink_node=pin_node,
switch_id=self.delayless_switch
)
elif pin_class.type == PinType.INPUT:
self.add_edge(
src_node=pin_node,
sink_node=pin_class_node,
switch_id=self.delayless_switch,
)
else:
assert False, (loc, pin_class)
def _create_node(
self,
type,
direction,
loc,
segment,
timing,
capacity=1,
metadata=None,
):
if timing is None:
if type in (NodeType.CHANX, NodeType.CHANY):
timing = NodeTiming(r=1, c=1)
else:
timing = NodeTiming(r=0, c=0)
self.nodes.append(
Node(
id=len(self.nodes),
type=type,
direction=direction,
capacity=capacity,
loc=loc,
timing=timing,
metadata=metadata,
segment=segment,
)
)
return self.nodes[-1].id
def get_segment_id_from_name(self, segment_name):
return self.segment_name_map[segment_name]
def get_delayless_switch_id(self):
return self.delayless_switch
def add_track(
self,
track,
segment_id,
capacity=1,
timing=None,
name=None,
ptc=None,
direction=NodeDirection.BI_DIR,
):
"""Take a Track and add node to the graph with supplimental data"""
if track.direction == 'X':
node_type = NodeType.CHANX
elif track.direction == 'Y':
node_type = NodeType.CHANY
else:
assert False, track
if name is not None:
metadata = [
NodeMetadata(
name=name,
x_offset=0,
y_offset=0,
z_offset=0,
value='',
)
]
else:
metadata = None
self.tracks.append(
self._create_node(
type=node_type,
direction=direction,
capacity=capacity,
loc=NodeLoc(
x_low=track.x_low,
y_low=track.y_low,
x_high=track.x_high,
y_high=track.y_high,
side=None,
ptc=ptc,
),
timing=timing,
segment=NodeSegment(segment_id=segment_id),
metadata=metadata,
)
)
return self.tracks[-1]
def create_pin_name_from_tile_type_and_pin(
self, tile_type, port_name, pin_idx=0
):
return '{}.{}[{}]'.format(tile_type, port_name, pin_idx)
def get_nodes_for_pin(self, loc, pin_name):
block_type_id, pin_class_idx, pin_idx = self.pin_name_map[pin_name]
grid_loc = self.loc_map[loc]
assert grid_loc.block_type_id == block_type_id
return self.loc_pin_map[(loc[0], loc[1], pin_idx)]
def _create_edge(
self, src_node, sink_node, switch_id, name=None, value=''
):
assert src_node >= 0 and src_node < len(self.nodes), src_node
assert sink_node >= 0 and sink_node < len(self.nodes), sink_node
assert switch_id >= 0 and switch_id < len(self.switches), switch_id
if name is not None:
metadata = [
NodeMetadata(
name=name, x_offset=0, y_offset=0, z_offset=0, value=value
)
]
else:
metadata = None
return Edge(
src_node=src_node,
sink_node=sink_node,
switch_id=switch_id,
metadata=metadata
)
def add_edge(self, src_node, sink_node, switch_id, name=None, value=''):
"""Add Edge to the graph
Appends a new edge to the graph and retruns the index in the edges list
"""
self.edges.append(
self._create_edge(
src_node=src_node,
sink_node=sink_node,
switch_id=switch_id,
name=name,
value=value
)
)
return len(self.edges) - 1
def add_switch(self, switch):
""" Inner add_switch method. Do not invoke directly.
This method adds a switch into the graph model. This method should
not be invoked directly, instead invoke add_switch on the serialization
graph object (e.g. rr_graph_xml.graph2.add_switch, etc).
"""
switch_dict = switch._asdict()
switch_dict['id'] = self.next_switch_id
self.next_switch_id += 1
switch = Switch(**switch_dict)
assert switch.name not in self.switch_name_map
self.switch_name_map[switch.name] = switch.id
self.switches.append(switch)
return switch.id
def check_ptc(self):
for node in self.nodes:
assert node.loc.ptc is not None, node
def set_track_ptc(self, track, ptc):
node_d = self.nodes[track]._asdict()
loc_d = self.nodes[track].loc._asdict()
assert loc_d['ptc'] is None
loc_d['ptc'] = ptc
node_d['loc'] = NodeLoc(**loc_d)
self.nodes[track] = Node(**node_d)
def create_channels(self, pad_segment, pool=None):
""" Pack tracks into channels and return Channels definition for tracks."""
assert len(self.tracks) > 0
xs = []
ys = []
for track in self.tracks:
track_node = self.nodes[track]
xs.append(track_node.loc.x_low)
xs.append(track_node.loc.x_high)
ys.append(track_node.loc.y_low)
ys.append(track_node.loc.y_high)
x_tracks = {}
y_tracks = {}
for track in self.tracks:
track_node = self.nodes[track]
if track_node.type == NodeType.CHANX:
assert track_node.loc.y_low == track_node.loc.y_high
x1, x2 = sorted((track_node.loc.x_low, track_node.loc.x_high))
if track_node.loc.y_low not in x_tracks:
x_tracks[track_node.loc.y_low] = []
x_tracks[track_node.loc.y_low].append((x1, x2, track))
elif track_node.type == NodeType.CHANY:
assert track_node.loc.x_low == track_node.loc.x_high
y1, y2 = sorted((track_node.loc.y_low, track_node.loc.y_high))
if track_node.loc.x_low not in y_tracks:
y_tracks[track_node.loc.x_low] = []
y_tracks[track_node.loc.x_low].append((y1, y2, track))
else:
assert False, track_node
x_list = []
y_list = []
x_channel_models = {}
y_channel_models = {}
if pool is not None:
for y in x_tracks:
x_channel_models[y] = pool.apply_async(
process_track, (x_tracks[y], )
)
for x in y_tracks:
y_channel_models[x] = pool.apply_async(
process_track, (y_tracks[x], )
)
for y in progressbar_utils.progressbar(range(max(x_tracks) + 1)):
if y in x_tracks:
if pool is None:
x_channel_models[y] = process_track(x_tracks[y])
else:
x_channel_models[y] = x_channel_models[y].get()
x_list.append(len(x_channel_models[y].trees))
for idx, tree in enumerate(x_channel_models[y].trees):
for i in tree:
self.set_track_ptc(track=i[2], ptc=idx)
else:
x_list.append(0)
for x in progressbar_utils.progressbar(range(max(y_tracks) + 1)):
if x in y_tracks:
if pool is None:
y_channel_models[x] = process_track(y_tracks[x])
else:
y_channel_models[x] = y_channel_models[x].get()
y_list.append(len(y_channel_models[x].trees))
for idx, tree in enumerate(y_channel_models[x].trees):
for i in tree:
self.set_track_ptc(track=i[2], ptc=idx)
else:
y_list.append(0)
x_min = min(xs)
y_min = min(ys)
x_max = max(xs)
y_max = max(ys)
num_padding = 0
for chan, channel_model in x_channel_models.items():
for ptc, start, end in channel_model.fill_empty(max(x_min, 1),
x_max):
num_padding += 1
self.add_track(
track=Track(
direction='X',
x_low=start,
y_low=chan,
x_high=end,
y_high=chan,
),
segment_id=pad_segment,
capacity=0,
timing=None,
ptc=ptc
)
for chan, channel_model in y_channel_models.items():
for ptc, start, end in channel_model.fill_empty(max(y_min, 1),
y_max):
num_padding += 1
self.add_track(
track=Track(
direction='Y',
x_low=chan,
y_low=start,
x_high=chan,
y_high=end,
),
segment_id=pad_segment,
capacity=0,
timing=None,
ptc=ptc
)
print('Number padding nodes {}'.format(num_padding))
return Channels(
chan_width_max=max(max(x_list), max(y_list)),
x_min=x_min,
y_min=y_min,
x_max=x_max,
y_max=y_max,
x_list=[ChannelList(idx, info) for idx, info in enumerate(x_list)],
y_list=[ChannelList(idx, info) for idx, info in enumerate(y_list)],
)
def block_type_at_loc(self, loc):
return self.block_types[self.loc_map[loc].block_type_id].name
def get_switch_id(self, switch_name):
return self.switch_name_map[switch_name]
def sort_nodes(self):
self.nodes.sort(key=lambda node: node.id) | /rr-graph-0.0.1.post14.tar.gz/rr-graph-0.0.1.post14/rr_graph/graph2.py | 0.850717 | 0.262269 | graph2.py | pypi |
import os.path
import re
from rr_graph import graph2
from rr_graph import tracks
import gc
import capnp
import capnp.lib.capnp
capnp.remove_import_hook()
CAMEL_CASE_CAPITALS = re.compile('([A-Z]+)')
ENUM_CACHE = {}
def enum_from_string(enum_type, s):
if s == 'uxsdInvalid':
return None
s = str(s)
key = (id(enum_type), s)
if key not in ENUM_CACHE:
ENUM_CACHE[key] = enum_type[CAMEL_CASE_CAPITALS.sub(r'_\1', s).upper()]
return ENUM_CACHE[key]
CAPNP_ENUM_CACHE = {}
def to_capnp_enum(enum_type, e):
key = (id(enum_type), e)
if key not in CAPNP_ENUM_CACHE:
# Convert from snake_case to camelCase.
parts = []
for idx, part in enumerate(e.name.split('_')):
if idx == 0:
parts.append(part.lower())
else:
parts.append(part.capitalize())
camel_case_e = "".join(parts)
CAPNP_ENUM_CACHE[key] = enum_type.__dict__[camel_case_e]
return CAPNP_ENUM_CACHE[key]
def cleanup_capnp_leak(f):
""" Cleanup capnp leak resulting from _parent pointers. """
popped = set()
strays = {}
# Some strays hold a reference to the input file
strays.update(
(id(obj), obj)
for obj in gc.get_referrers(f)
if 'capnp' in str(type(obj))
)
# Some strays are "floating"
for obj in gc.get_objects():
type_str = str(type(obj))
if 'capnp.lib.capnp._DynamicStructReader' in type_str:
strays[id(obj)] = obj
if len(strays) > 0:
# First expand all strays and find other capnp objects that still hold
# a reference to them (via the _parent pointer).
for obj_id in set(strays.keys()) - popped:
popped.add(obj_id)
strays.update(
(id(obj), obj)
for obj in gc.get_referrers(strays[obj_id])
if 'capnp' in str(type(obj))
)
# Clear their _parent pointer
for obj in strays.values():
obj._parent = None
# Make sure none of the strays are still referred to by anything
for obj in strays.values():
capnp_refs = [
None for obj in gc.get_referrers(strays[obj_id])
if 'capnp' in str(type(obj))
]
assert len(capnp_refs) == 0
# Make sure the file is not referenced by any files.
capnp_refs = [
None for obj in gc.get_referrers(f) if 'capnp' in str(type(obj))
]
assert len(capnp_refs) == 0
def read_switch(sw):
timing = sw.timing
sizing = sw.sizing
return graph2.Switch(
id=sw.id,
name=str(sw.name),
type=enum_from_string(graph2.SwitchType, sw.type),
timing=graph2.SwitchTiming(
r=timing.r,
c_in=timing.cin,
c_out=timing.cout,
c_internal=timing.cinternal,
t_del=timing.tdel,
),
sizing=graph2.SwitchSizing(
buf_size=sizing.bufSize,
mux_trans_size=sizing.muxTransSize,
),
)
def read_segment(seg):
timing = seg.timing
return graph2.Segment(
id=seg.id,
name=str(seg.name),
timing=graph2.SegmentTiming(
r_per_meter=timing.rPerMeter,
c_per_meter=timing.cPerMeter,
)
)
def read_pin(pin):
return graph2.Pin(
ptc=pin.ptc,
name=str(pin.value),
)
def read_pin_class(pin_class):
return graph2.PinClass(
type=enum_from_string(graph2.PinType, pin_class.type),
pin=[read_pin(pin) for pin in pin_class.pins]
)
def read_block_type(block_type):
return graph2.BlockType(
id=block_type.id,
name=str(block_type.name),
width=block_type.width,
height=block_type.height,
pin_class=[
read_pin_class(pin_class) for pin_class in block_type.pinClasses
]
)
def read_grid_loc(grid_loc):
return graph2.GridLoc(
x=grid_loc.x,
y=grid_loc.y,
block_type_id=grid_loc.blockTypeId,
width_offset=grid_loc.widthOffset,
height_offset=grid_loc.heightOffset,
)
def read_metadata(metadata):
if len(metadata.metas) == 0:
return None
else:
return [(str(m.name), str(m.value)) for m in metadata.metas]
def read_node(node, new_node_id=None):
node_loc = node.loc
node_timing = node.timing
return graph2.Node(
id=new_node_id if new_node_id is not None else node.id,
type=enum_from_string(graph2.NodeType, node.type),
direction=enum_from_string(graph2.NodeDirection, node.direction),
capacity=node.capacity,
loc=graph2.NodeLoc(
x_low=node_loc.xlow,
y_low=node_loc.ylow,
x_high=node_loc.xhigh,
y_high=node_loc.yhigh,
ptc=node_loc.ptc,
side=enum_from_string(tracks.Direction, node_loc.side),
),
timing=graph2.NodeTiming(r=node_timing.r, c=node_timing.c),
metadata=None,
segment=graph2.NodeSegment(segment_id=node.segment.segmentId),
)
def read_edge(edge):
return graph2.Edge(
src_node=edge.srcNode,
sink_node=edge.sinkNode,
switch_id=edge.switchId,
metadata=read_metadata(edge.metadata),
)
def graph_from_capnp(
rr_graph_schema,
input_file_name,
progressbar=None,
filter_nodes=True,
load_nodes=True,
load_edges=False,
rebase_nodes=False,
):
"""
Loads relevant information about the routing resource graph from an capnp
file.
"""
if rebase_nodes:
assert load_nodes
assert not load_edges
if progressbar is None:
progressbar = lambda x: x # noqa: E731
with open(input_file_name, 'rb') as f:
graph = rr_graph_schema.RrGraph.read(
f, traversal_limit_in_words=2**63 - 1
)
root_attrib = {
'tool_comment': str(graph.toolComment),
'tool_name': str(graph.toolName),
'tool_version': str(graph.toolVersion),
}
switches = [read_switch(sw) for sw in graph.switches.switches]
segments = [read_segment(seg) for seg in graph.segments.segments]
block_types = [
read_block_type(block_type)
for block_type in graph.blockTypes.blockTypes
]
grid = [read_grid_loc(g) for g in graph.grid.gridLocs]
nodes = []
if load_nodes:
for n in progressbar(graph.rrNodes.nodes):
if filter_nodes and n.type not in ['source', 'sink', 'opin', 'ipin'
]:
continue
if rebase_nodes:
node = read_node(n, new_node_id=len(nodes))
else:
node = read_node(n)
nodes.append(node)
edges = []
if load_edges:
edges = [read_edge(e) for e in graph.rrEdges.edges]
# File back capnp objects cannot outlive their input file,
# so verify that no dangling references exist.
del graph
gc.collect()
# Cleanup leaked capnp objects due to _parent in Cython.
cleanup_capnp_leak(f)
return dict(
root_attrib=root_attrib,
switches=switches,
segments=segments,
block_types=block_types,
grid=grid,
nodes=nodes,
edges=edges
)
class Graph(object):
def __init__(
self,
rr_graph_schema_fname,
input_file_name,
output_file_name=None,
progressbar=None,
build_pin_edges=True,
rebase_nodes=True,
filter_nodes=True,
load_nodes=True,
):
if progressbar is None:
progressbar = lambda x: x # noqa: E731
self.input_file_name = input_file_name
self.progressbar = progressbar
self.output_file_name = output_file_name
self.rr_graph_schema = capnp.load(
rr_graph_schema_fname,
imports=[os.path.dirname(os.path.dirname(capnp.__file__))]
)
graph_input = graph_from_capnp(
rr_graph_schema=self.rr_graph_schema,
input_file_name=input_file_name,
progressbar=progressbar,
filter_nodes=filter_nodes,
rebase_nodes=rebase_nodes,
load_nodes=load_nodes,
)
graph_input['build_pin_edges'] = build_pin_edges
self.root_attrib = graph_input["root_attrib"]
del graph_input["root_attrib"]
self.graph = graph2.Graph(**graph_input)
def _write_channels(self, rr_graph, channels):
"""
Writes the RR graph channels.
"""
rr_graph.channels.channel.chanWidthMax = channels.chan_width_max
rr_graph.channels.channel.xMax = channels.x_max
rr_graph.channels.channel.xMin = channels.x_min
rr_graph.channels.channel.yMax = channels.y_max
rr_graph.channels.channel.yMin = channels.y_min
xLists = rr_graph.channels.init('xLists', len(channels.x_list))
for out_x_list, x_list in zip(xLists, channels.x_list):
out_x_list.index = x_list.index
out_x_list.info = x_list.info
yLists = rr_graph.channels.init('yLists', len(channels.y_list))
for out_y_list, y_list in zip(yLists, channels.y_list):
out_y_list.index = y_list.index
out_y_list.info = y_list.info
def _write_nodes(self, rr_graph, num_nodes, nodes, node_remap):
""" Serialize list of Node objects to capnp.
Note that this method is extremely hot, len(nodes) is order 1-10 million.
Almost any modification of this function has a significant effect on
performance, so any modification to this function should be tested for
performance and correctness before commiting.
"""
rr_nodes = rr_graph.rrNodes.init('nodes', num_nodes)
nodes_written = 0
node_iter = iter(nodes)
for out_node, node in zip(rr_nodes, node_iter):
nodes_written += 1
out_node.id = node_remap(node.id)
out_node.type = to_capnp_enum(
self.rr_graph_schema.NodeType, node.type
)
out_node.capacity = node.capacity
if node.direction is not None:
out_node.direction = to_capnp_enum(
self.rr_graph_schema.NodeDirection, node.direction
)
node_loc = out_node.loc
node_loc.ptc = node.loc.ptc
if node.loc.side is not None:
node_loc.side = to_capnp_enum(
self.rr_graph_schema.LocSide, node.loc.side
)
node_loc.xhigh = node.loc.x_high
node_loc.xlow = node.loc.x_low
node_loc.yhigh = node.loc.y_high
node_loc.ylow = node.loc.y_low
if node.timing is not None:
timing = out_node.timing
timing.c = node.timing.c
timing.r = node.timing.r
if node.segment is not None:
segment = out_node.segment
segment.segmentId = node.segment.segment_id
if node.metadata is not None and len(node.metadata) > 0:
metas = out_node.metadata.init('metas', len(node.metadata))
for out_meta, meta in zip(metas, node.metadata):
out_meta.name = meta.name
out_meta.value = meta.value
assert nodes_written == num_nodes, 'Unwritten nodes!'
try:
_ = next(node_iter)
assert False, 'Unwritten nodes!'
except StopIteration:
pass
def _write_edges(self, rr_graph, num_edges, edges, node_remap):
""" Serialize list of edge tuples objects to capnp.
edge tuples are (src_node(int), sink_node(int), switch_id(int), metadata(NodeMetadata)).
metadata may be None.
Note that this method is extremely hot, len(edges) is order 5-50 million.
Almost any modification of this function has a significant effect on
performance, so any modification to this function should be tested for
performance and correctness before commiting.
"""
out_edges = rr_graph.rrEdges.init('edges', num_edges)
edges_written = 0
edges_iter = iter(edges)
for out_edge, (src_node, sink_node, switch_id,
metadata) in zip(out_edges, edges_iter):
edges_written += 1
out_edge.srcNode = node_remap(src_node)
out_edge.sinkNode = node_remap(sink_node)
out_edge.switchId = switch_id
if metadata is not None and len(metadata) > 0:
metas = out_edge.metadata.init('metas', len(metadata))
for out_meta, (name, value) in zip(metas, metadata):
out_meta.name = name
out_meta.value = value
assert edges_written == num_edges, 'Unwritten edges!'
try:
_ = next(edges_iter)
assert False, 'Unwritten edges!'
except StopIteration:
pass
def _write_switches(self, rr_graph):
"""
Writes the RR graph switches.
"""
switches = rr_graph.switches.init('switches', len(self.graph.switches))
for out_switch, switch in zip(switches, self.graph.switches):
out_switch.id = switch.id
out_switch.name = switch.name
out_switch.type = to_capnp_enum(
self.rr_graph_schema.SwitchType, switch.type
)
if switch.timing:
timing = out_switch.timing
timing.cin = switch.timing.c_in
timing.cinternal = switch.timing.c_internal
timing.cout = switch.timing.c_out
timing.r = switch.timing.r
timing.tdel = switch.timing.t_del
if switch.sizing:
sizing = out_switch.sizing
sizing.bufSize = switch.sizing.buf_size
sizing.muxTransSize = switch.sizing.mux_trans_size
def _write_segments(self, rr_graph):
"""
Writes the RR graph segments.
"""
segments = rr_graph.segments.init('segments', len(self.graph.segments))
for out_segment, segment in zip(segments, self.graph.segments):
out_segment.id = segment.id
out_segment.name = segment.name
if segment.timing:
timing = out_segment.timing
timing.cPerMeter = segment.timing.c_per_meter
timing.rPerMeter = segment.timing.r_per_meter
def _write_block_types(self, rr_graph):
"""
Writes the RR graph block types.
"""
block_types = rr_graph.blockTypes.init(
'blockTypes', len(self.graph.block_types)
)
for out_blk, blk in zip(block_types, self.graph.block_types):
out_blk.id = blk.id
out_blk.name = blk.name
out_blk.width = blk.width
out_blk.height = blk.height
pin_classes = out_blk.init('pinClasses', len(blk.pin_class))
for out_pin_class, pin_class in zip(pin_classes, blk.pin_class):
out_pin_class.type = to_capnp_enum(
self.rr_graph_schema.PinType, pin_class.type
)
pins = out_pin_class.init('pins', len(pin_class.pin))
for out_pin, pin in zip(pins, pin_class.pin):
out_pin.ptc = pin.ptc
out_pin.value = pin.name
def _write_grid(self, rr_graph):
"""
Writes the RR graph grid.
"""
grid_locs = rr_graph.grid.init('gridLocs', len(self.graph.grid))
for out_grid_loc, grid_loc in zip(grid_locs, self.graph.grid):
out_grid_loc.x = grid_loc.x
out_grid_loc.y = grid_loc.y
out_grid_loc.blockTypeId = grid_loc.block_type_id
out_grid_loc.widthOffset = grid_loc.width_offset
out_grid_loc.heightOffset = grid_loc.height_offset
def serialize_to_capnp(
self,
channels_obj,
num_nodes,
nodes_obj,
num_edges,
edges_obj,
node_remap=lambda x: x
):
"""
Writes the routing graph to the capnp file.
"""
self.graph.check_ptc()
rr_graph = self.rr_graph_schema.RrGraph.new_message()
rr_graph.toolComment = self.root_attrib['tool_comment']
rr_graph.toolName = self.root_attrib['tool_name']
rr_graph.toolVersion = self.root_attrib['tool_version']
self._write_channels(rr_graph, channels_obj)
self._write_switches(rr_graph)
self._write_segments(rr_graph)
self._write_block_types(rr_graph)
self._write_grid(rr_graph)
self._write_nodes(rr_graph, num_nodes, nodes_obj, node_remap)
self._write_edges(rr_graph, num_edges, edges_obj, node_remap)
# Open the file
with open(self.output_file_name, "wb") as f:
rr_graph.write(f)
def add_switch(self, switch):
""" Add switch into graph model.
Typically switches are imported from the architecture definition,
however VPR will not save unused switches from the arch. In this
case, the switches must be added back during routing import.
Important note: any switch present in the rr graph must also be present
in the architecture definition.
"""
# Add to Graph2 data structure
switch_id = self.graph.add_switch(switch)
return switch_id | /rr-graph-0.0.1.post14.tar.gz/rr-graph-0.0.1.post14/rr_graph/capnp/graph2.py | 0.483892 | 0.216012 | graph2.py | pypi |
import enum
import io
import pprint
import sys
from types import MappingProxyType
def frozendict(*args, **kwargs):
"""Version of a dictionary which can't be changed."""
return MappingProxyType(dict(*args, **kwargs))
class MostlyReadOnly:
"""Object which is **mostly** read only. Can set if not already set.
>>> class MyRO(MostlyReadOnly):
... __slots__ = ["_str", "_list", "_set", "_dict"]
>>> a = MyRO()
>>> a
MyRO(str=None, list=None, set=None, dict=None)
>>> a._str = 't'
>>> a.str
't'
>>> a._list = [1,2,3]
>>> a.list
(1, 2, 3)
>>> a._set = {1, 2, 3}
>>> a.set
frozenset({1, 2, 3})
>>> a._dict = {'a': 1, 'b': 2, 'c': 3}
>>> b = a.dict
>>> b['d'] = 4
Traceback (most recent call last):
...
b['d'] = 4
TypeError: 'mappingproxy' object does not support item assignment
>>> sorted(b.items())
[('a', 1), ('b', 2), ('c', 3)]
>>> a._dict['d'] = 4
>>> sorted(a._dict.items())
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
>>> sorted(b.items())
[('a', 1), ('b', 2), ('c', 3)]
>>> a
MyRO(str='t', list=[1, 2, 3], set={1, 2, 3}, dict={'a': 1, 'b': 2, 'c': 3, 'd': 4})
>>> a.missing
Traceback (most recent call last):
...
AttributeError: 'MyRO' object has no attribute 'missing'
>>> a.missing = 1
Traceback (most recent call last):
...
AttributeError: missing not found on <class 'rr_graph.utils.collections_extra.MyRO'>
>>> a.missing
Traceback (most recent call last):
...
AttributeError: 'MyRO' object has no attribute 'missing'
"""
def __setattr__(self, key, new_value=None):
if key.startswith("_"):
current_value = getattr(self, key[1:])
if new_value == current_value:
return
elif current_value is not None:
raise AttributeError(
"{} is already set to {}, can't be changed".format(
key, current_value
)
)
return super().__setattr__(key, new_value)
if "_" + key not in self.__class__.__slots__:
raise AttributeError(
"{} not found on {}".format(key, self.__class__)
)
self.__setattr__("_" + key, new_value)
def __getattr__(self, key):
if "_" + key not in self.__class__.__slots__:
super().__getattribute__(key)
value = getattr(self, "_" + key, None)
if isinstance(value,
(tuple, int, bytes, str, type(None), MostlyReadOnly)):
return value
elif isinstance(value, list):
return tuple(value)
elif isinstance(value, set):
return frozenset(value)
elif isinstance(value, dict):
return frozendict(value)
elif isinstance(value, enum.Enum):
return value
else:
raise AttributeError(
"Unable to return {}, don't now how to make type {} (from {!r}) read only."
.format(key, type(value), value)
)
def __repr__(self):
attribs = []
for attr in self.__slots__:
value = getattr(self, attr, None)
if isinstance(value, MostlyReadOnly):
rvalue = "{}()".format(value.__class__.__name__)
elif isinstance(value, (dict, set)):
s = io.StringIO()
pprint.pprint(value, stream=s, width=sys.maxsize)
rvalue = s.getvalue().strip()
else:
rvalue = repr(value)
if attr.startswith("_"):
attr = attr[1:]
attribs.append("{}={!s}".format(attr, rvalue))
return "{}({})".format(self.__class__.__name__, ", ".join(attribs))
class OrderedEnum(enum.Enum):
def __ge__(self, other):
if self.__class__ is other.__class__:
return self.name >= other.name
if hasattr(other.__class__, "name"):
return self.name >= other.name
return NotImplemented
def __gt__(self, other):
if self.__class__ is other.__class__:
return self.name > other.name
if hasattr(other.__class__, "name"):
return self.name > other.name
return NotImplemented
def __le__(self, other):
if self.__class__ is other.__class__:
return self.name <= other.name
if hasattr(other.__class__, "name"):
return self.name <= other.name
return NotImplemented
def __lt__(self, other):
if self.__class__ is other.__class__:
return self.name < other.name
if hasattr(other.__class__, "name"):
return self.name < other.name
return NotImplemented
class CompassDir(OrderedEnum):
"""
>>> print(repr(CompassDir.NN))
<CompassDir.NN: 'North'>
>>> print(str(CompassDir.NN))
( 0, -1, NN)
>>> for d in CompassDir:
... print(OrderedEnum.__str__(d))
CompassDir.NW
CompassDir.NN
CompassDir.NE
CompassDir.EE
CompassDir.SE
CompassDir.SS
CompassDir.SW
CompassDir.WW
>>> for y in (-1, 0, 1):
... for x in (-1, 0, 1):
... print(
... "(%2i %2i)" % (x, y),
... str(CompassDir.from_coords(x, y)),
... str(CompassDir.from_coords((x, y))),
... )
(-1 -1) (-1, -1, NW) (-1, -1, NW)
( 0 -1) ( 0, -1, NN) ( 0, -1, NN)
( 1 -1) ( 1, -1, NE) ( 1, -1, NE)
(-1 0) (-1, 0, WW) (-1, 0, WW)
( 0 0) None None
( 1 0) ( 1, 0, EE) ( 1, 0, EE)
(-1 1) (-1, 1, SW) (-1, 1, SW)
( 0 1) ( 0, 1, SS) ( 0, 1, SS)
( 1 1) ( 1, 1, SE) ( 1, 1, SE)
>>> print(str(CompassDir.NN.flip()))
( 0, 1, SS)
>>> print(str(CompassDir.SE.flip()))
(-1, -1, NW)
"""
NW = 'North West'
NN = 'North'
NE = 'North East'
EE = 'East'
SE = 'South East'
SS = 'South'
SW = 'South West'
WW = 'West'
# Single letter aliases
N = NN
E = EE
S = SS
W = WW
@property
def distance(self):
return sum(a * a for a in self.coords)
def __init__(self, *args, **kw):
self.__cords = None
pass
@property
def coords(self):
if not self.__cords:
self.__cords = self.convert_to_coords[self]
return self.__cords
@property
def x(self):
return self.coords[0]
@property
def y(self):
return self.coords[-1]
def __iter__(self):
return iter(self.coords)
def __getitem__(self, k):
return self.coords[k]
@classmethod
def from_coords(cls, x, y=None):
if y is None:
return cls.from_coords(*x)
return cls.convert_from_coords[(x, y)]
def flip(self):
return self.from_coords(self.flip_coords[self.coords])
def __add__(self, o):
return o.__class__(o[0] + self.x, o[1] + self.y)
def __radd__(self, o):
return o.__class__(o[0] + self.x, o[1] + self.y)
def __str__(self):
return "(%2i, %2i, %s)" % (self.x, self.y, self.name)
CompassDir.convert_to_coords = {}
CompassDir.convert_from_coords = {}
CompassDir.flip_coords = {}
CompassDir.straight = []
CompassDir.angled = []
for d in list(CompassDir) + [None]:
if d is None:
x, y = 0, 0
else:
if d.name[0] == 'N':
y = -1
elif d.name[0] == 'S':
y = 1
else:
assert d.name[0] in ('E', 'W')
y = 0
if d.name[1] == 'E':
x = 1
elif d.name[1] == 'W':
x = -1
else:
assert d.name[1] in ('N', 'S')
x = 0
CompassDir.convert_to_coords[d] = (x, y)
CompassDir.convert_from_coords[(x, y)] = d
CompassDir.flip_coords[(x, y)] = (-1 * x, -1 * y)
length = x * x + y * y
if length == 1:
CompassDir.straight.append(d)
elif length == 2:
CompassDir.angled.append(d)
if __name__ == "__main__":
import doctest
failure_count, test_count = doctest.testmod()
assert test_count > 0
assert failure_count == 0, "Doctests failed!" | /rr-graph-0.0.1.post14.tar.gz/rr-graph-0.0.1.post14/rr_graph/utils/collections_extra.py | 0.5083 | 0.202148 | collections_extra.py | pypi |
# rr-ml-config
[](https://gitlab.com/reactivereality/public/rr-ml-config-public)

[](https://www.gnu.org/licenses/)
---
**DISCLAIMER: This repository is the public version of a repository that is the property of [Reactive Reality](https://www.reactivereality.com/). This repository IS NOT OFFICIAL and can not to be maintained in the future. Some minor changed * are applied from the [official repository (GitLab)](https://gitlab.com/reactivereality/public/rr-ml-config-public) (under lesser GNU license).**
*documentation and other PyPI related changes
This package is a Config System which allows easy manipulation of config files for safe, clear and
repeatable experiments. In a few words, it is:
- built for Machine Learning with its constraints in mind, but also usable out-of-the-box for other
kinds of projects;
- built with scalability in mind and can adapt just as easily to large projects investigating
hundreds of well-organized parameters across many experiments;
- designed to encourage good coding practices for research purposes, and if used rigorously will
ensure a number of highly desirable properties such that **maintenance-less forward-compatibility**
of old configs, **easy reproducibility** of any experiment, and **extreme clarity** of former
experiments for your future self or collaborators.
[LINK TO DOCUMENTATION](https://gitlab.com/reactivereality/public/rr-ml-config-public/-/wikis/home)
## Installation
The package can be installed from our registry using pip: `pip install rr-ml-config`
## Getting started
This package is adapted to a *project* where you need to run a number of experiments. In this setup,
it can be useful to gather all the parameters in the project to a common location, some "config files",
so you can access and modify them easily. This package is based on YAML, therefore your config files
should be YAML files. One such YAML file could be :
```yaml
gpu: true
data_path: "./data"
learning_rate: 0.01
```
Those will be the default values for those three parameters, so we will keep them in the file
`my_project/configs/default.yaml`. Then, we just need to subclass the Configuration class in this package
so your project-specific subclass knows where to find the default values for your project. A minimalistic
project-specific subclass looks like:
```python
from rr.ml.config import Configuration
class ProjectSpecific(Configuration):
@staticmethod
def get_default_config_path():
return "./configs/default.yaml"
def parameters_pre_processing(self):
return {}
```
That's all there is to it! Now if we use `config = ProjectSpecific.load_config()`, we can then call
`config.data_path` or `config.learning_rate` to get their values as defined in the default config. We
don't need to specify where to get the default config because a project should only ever have one default
config, which centralizes all the parameters in that project. Since the location of the default config is
a project constant, it is defined in your project-specific subclass and there is no need to clutter your
main code with it. Now, for example, your main.py could look like:
```python
from project_config import ProjectSpecific
if __name__ == "__main__":
config = ProjectSpecific.load_config()
config.merge_from_command_line()
print(config.details())
```
Then, calling `python main.py --learning_rate=0.001`, the call to `merge_from_command_line` would parse
the command line and find the pre-existing parameter learning_rate, then change its value to 0.001.
Thus, the printed result would yield:
```script
MAIN CONFIG :
Configuration hierarchy :
> ./configs/default.yaml
- gpu : true
- data_path : ./data
- learning_rate : 0.001
```
The Configuration hierarchy tells you about the creation history of the config, in this case only the
default config was used. Then, all parameters are displayed. There are of course many other features
in this package which you can use to organize your parameters, hierarchise your experiments etc. The
idea being that once the bare minimum presented above is set up, scaling up is just as simple.
You can learn more about all these features in our [DOCUMENTATION](https://gitlab.com/reactivereality/public/rr-ml-config-public/-/wikis/home).
## config_history
The Config History is a side-feature of the main Config System. It can be configured for any project
which uses the Config System and provides a flexible framework to easily build graphs representing
past experiments. In these graphs, each node represents an experiment, and vertices are drawn between
your experiments to visualize easily which parameters changed from one node to another.
The graph can be coloured to show your most successful experiments, or grouped by parameters to see how
well they have been explored in your experiment history. This makes it very useful to review your past
work, share it with colleagues or make unexpected correlations appear.
Please refer to our [DOCUMENTATION](https://gitlab.com/reactivereality/public/rr-ml-config-public/-/wikis/home) to learn more about its setup and usage.
Requirements (**will not** be installed automatically by pip to keep this lightweight):
- `python>=3.7`
- `pygraphviz==1.7`
- `scipy`
- `numpy`
- `sudo apt install graphviz`
| /rr-ml-config-1.11.1.tar.gz/rr-ml-config-1.11.1/README.md | 0.525369 | 0.899828 | README.md | pypi |
from rr_psychology.by.common.constants import Keys
class Get:
@staticmethod
def original_rank(main_data: dict, by_team_id: bool=False):
if by_team_id:
by_team_id = f" and ts.team_id = {main_data.get(Keys.TEAM_ID)}"
return "select distinct ts.team_id, ts.team_name, " \
"(CASE WHEN ts.total_games_avg_rank < 1.7 THEN 1 WHEN ts.total_games_avg_rank < 2.20 THEN 1.5 " \
"WHEN ts.total_games_avg_rank < 2.5 THEN 2 WHEN ts.total_games_avg_rank < 3 THEN 2.5 " \
"WHEN ts.total_games_avg_rank < 3.5 THEN 3 WHEN ts.total_games_avg_rank < 4 THEN 3.5 " \
"WHEN ts.total_games_avg_rank < 4.5 THEN 4 WHEN ts.total_games_avg_rank < 5 THEN 4.5 " \
"WHEN ts.total_games_avg_rank < 5.5 THEN 5 " \
"ELSE 5.5 END) as general_rank, " \
" cast((ts.sum_home_line + ts.sum_away_line) as decimal(10,2)) as sum_line " \
" from events_data as ed, team_stock as ts " \
f" where ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
" and ts.team_id = ed.home_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
f"{by_team_id}" \
f" or ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
f"{by_team_id}" \
" and ts.team_id = ed.away_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
" group rr_psychology ts.team_id, ts.team_name, ts.sum_home_line, " \
" ts.sum_away_line, ts.home_success_rate_in_percent, " \
" ts.away_success_rate_in_percent, ts.total_games_avg_rank " \
" order rr_psychology general_rank asc;"
@staticmethod
def basic_psychology(main_data: dict, query_table: str, home_games: bool = True):
if home_games:
db_field = "home_team_id"
else:
db_field = "away_team_id"
return " select ed.tour_id, ed.round, ed.home_team_id, ed.home_team_name," \
" ed.away_team_id, ed.away_team_name, " \
" ed.winner_code, ind.home, ind.away, ind.time_unit," \
"(CASE WHEN time_unit <= 20 THEN 100 " \
"WHEN time_unit > 20 and time_unit <= 35 THEN 101 " \
"WHEN time_unit > 35 and time_unit <= 60 THEN 102 " \
"WHEN time_unit > 60 and time_unit <= 75 THEN 103 " \
"WHEN time_unit > 75 THEN 104 " \
"ELSE 0 END) as time_unit_significance," \
" ind.significance_home, " \
" ind.significance_away, ind.object_id, ind.object_name," \
" ind.is_home, ed.season, ed.start_time, ed.event_id " \
f" from {query_table} as ed, indicates as ind " \
f" where ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
f" and ed.{db_field} = {main_data.get(Keys.TEAM_ID)} " \
f" and ed.event_id = ind.event_id " \
" and ed.event_id = ind.event_id order rr_psychology round desc "
@staticmethod
def team_games(main_data: dict, pressure_view: bool):
team_id = main_data.get(Keys.TEAM_ID)
tour_id = main_data.get(Keys.TOUR_ID)
season = main_data.get(Keys.SEASON)
if not pressure_view:
return "select ed.event_id, ed.tour_id, ed.round, ed.home_team_id, ed.home_team_name, ed.away_team_name," \
"ed.away_team_id, ed.winner_code, od.initial_favorite, od.final_favorite, od.initial_home, " \
"od.initial_drew, od.initial_away, od.initial_line_id, od.final_line_id, " \
" (CASE" \
f" WHEN ed.home_team_id = {team_id} THEN 1" \
" ELSE 2" \
" END) as home_away," \
" (CASE" \
f" WHEN ed.home_team_id = {team_id} and ed.winner_code = 1 THEN 3" \
f" WHEN ed.home_team_id = {team_id} and ed.winner_code = 3 THEN 1" \
f" WHEN ed.away_team_id = {team_id} and ed.winner_code = 2 THEN 3" \
f" WHEN ed.away_team_id = {team_id} and ed.winner_code = 3 THEN 1" \
" ELSE 0" \
" END) as points," \
" ed.start_time from events_data as ed, odds_data as od" \
f" where ed.tour_id = {tour_id} " \
f" and ed.season = '{season}' " \
f" and ed.home_team_id = {team_id}" \
" and ed.event_id = od.event_id" \
f" or ed.tour_id = {tour_id} " \
f" and ed.season = '{season}' " \
f" and ed.away_team_id = {team_id}" \
" and ed.event_id = od.event_id" \
" order rr_psychology ed.start_time asc;"
else:
return "select event_id, tour_id, season, round," \
"season_level, home_team_id, home_team_name," \
"home_team_rank, home_level_pressure, home_level_pressure_in_percent, home_last_game_pressure," \
" away_team_id, away_team_name, away_team_rank," \
"away_level_pressure, away_level_pressure_in_percent," \
"away_last_game_pressure, " \
"favorite_by_rank, favorite_by_line, initial_line_id," \
"final_line_id, winner_code, start_time," \
"home_line_points_by_season,home_line_points_achieved_by_season, away_line_points_by_season," \
"away_line_points_achieved_by_season," \
" (CASE" \
f" WHEN home_team_id = {team_id} and winner_code = 1 THEN 3" \
f" WHEN home_team_id = {team_id} and winner_code = 3 THEN 1" \
f" WHEN away_team_id = {team_id} and winner_code = 2 THEN 3" \
f" WHEN away_team_id = {team_id} and winner_code = 3 THEN 1" \
" ELSE 0" \
" END) as points from events_pressure" \
f" WHERE tour_id = {tour_id} AND season = '{season}' and home_team_id = {team_id}" \
f" OR tour_id = {tour_id} AND season = '{season}' and away_team_id = {team_id}" \
" ORDER BY start_time ASC;" | /rr_psychology-2.3-py3-none-any.whl/by/common/sql.py | 0.50952 | 0.311662 | sql.py | pypi |
from rr_psychology.by.common.constants import Keys
class Get:
@staticmethod
def original_rank(main_data: dict, by_team_id: bool = False):
if by_team_id:
by_team_id = f" and ts.team_id = {main_data.get(Keys.TEAM_ID)}"
return "select distinct ts.team_id, ts.team_name, " \
"(CASE WHEN ts.total_games_avg_rank < 1.7 THEN 1 WHEN ts.total_games_avg_rank < 2.20 THEN 1.5 " \
"WHEN ts.total_games_avg_rank < 2.5 THEN 2 WHEN ts.total_games_avg_rank < 3 THEN 2.5 " \
"WHEN ts.total_games_avg_rank < 3.5 THEN 3 WHEN ts.total_games_avg_rank < 4 THEN 3.5 " \
"WHEN ts.total_games_avg_rank < 4.5 THEN 4 WHEN ts.total_games_avg_rank < 5 THEN 4.5 " \
"WHEN ts.total_games_avg_rank < 5.5 THEN 5 " \
"ELSE 5.5 END) as general_rank, " \
" cast((ts.sum_home_line + ts.sum_away_line) as decimal(10,2)) as sum_line " \
" from events_data as ed, team_stock as ts " \
f" where ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
" and ts.team_id = ed.home_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
f"{by_team_id}" \
f" or ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
f"{by_team_id}" \
" and ts.team_id = ed.away_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
" group by ts.team_id, ts.team_name, ts.sum_home_line, " \
" ts.sum_away_line, ts.home_success_rate_in_percent, " \
" ts.away_success_rate_in_percent, ts.total_games_avg_rank " \
" order by general_rank asc;"
@staticmethod
def basic_psychology(main_data: dict, query_table: str, home_games: bool = True):
if home_games:
db_field = "home_team_id"
else:
db_field = "away_team_id"
return " select ed.tour_id, ed.round, ed.home_team_id, ed.home_team_name," \
" ed.away_team_id, ed.away_team_name, " \
" ed.winner_code, ind.home, ind.away, ind.time_unit," \
"(CASE WHEN time_unit <= 20 THEN 100 " \
"WHEN time_unit > 20 and time_unit <= 35 THEN 101 " \
"WHEN time_unit > 35 and time_unit <= 60 THEN 102 " \
"WHEN time_unit > 60 and time_unit <= 75 THEN 103 " \
"WHEN time_unit > 75 THEN 104 " \
"ELSE 0 END) as time_unit_significance," \
" ind.significance_home, " \
" ind.significance_away, ind.object_id, ind.object_name," \
" ind.is_home, ed.season, ed.start_time, ed.event_id " \
f" from {query_table} as ed, indicates as ind " \
f" where ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
f" and ed.{db_field} = {main_data.get(Keys.TEAM_ID)} " \
f" and ed.event_id = ind.event_id " \
" and ed.event_id = ind.event_id order by round desc "
@staticmethod
def team_games(main_data: dict):
team_id = main_data.get(Keys.TEAM_ID)
tour_id = main_data.get(Keys.TOUR_ID)
season = main_data.get(Keys.SEASON)
return "select event_id, tour_id, season, round," \
"season_level, home_team_id, home_team_name," \
"home_team_rank, home_level_pressure, home_level_pressure_in_percent, home_last_game_pressure," \
" away_team_id, away_team_name, away_team_rank," \
"away_level_pressure, away_level_pressure_in_percent," \
"away_last_game_pressure, " \
"favorite_by_rank, favorite_by_line, initial_line_id," \
"final_line_id, winner_code, start_time," \
"home_line_points_by_season,home_line_points_achieved_by_season, away_line_points_by_season," \
"away_line_points_achieved_by_season," \
" (CASE" \
f" WHEN home_team_id = {team_id} and winner_code = 1 THEN 3" \
f" WHEN home_team_id = {team_id} and winner_code = 3 THEN 1" \
f" WHEN away_team_id = {team_id} and winner_code = 2 THEN 3" \
f" WHEN away_team_id = {team_id} and winner_code = 3 THEN 1" \
" ELSE 0" \
" END) as points from events_pressure" \
f" WHERE tour_id = {tour_id} AND season = '{season}' and home_team_id = {team_id}" \
f" OR tour_id = {tour_id} AND season = '{season}' and away_team_id = {team_id}" \
" ORDER BY start_time ASC;" | /rr_psychology-2.3-py3-none-any.whl/rr/by/common/sql.py | 0.520496 | 0.347468 | sql.py | pypi |
from rr_psychology.by.common.constants import Keys
class Get:
@staticmethod
def original_rank(main_data: dict, by_team_id: bool = False):
if by_team_id:
by_team_id = f" and ts.team_id = {main_data.get(Keys.TEAM_ID)}"
return "select distinct ts.team_id, ts.team_name, " \
"(CASE WHEN ts.total_games_avg_rank < 1.7 THEN 1 WHEN ts.total_games_avg_rank < 2.20 THEN 1.5 " \
"WHEN ts.total_games_avg_rank < 2.5 THEN 2 WHEN ts.total_games_avg_rank < 3 THEN 2.5 " \
"WHEN ts.total_games_avg_rank < 3.5 THEN 3 WHEN ts.total_games_avg_rank < 4 THEN 3.5 " \
"WHEN ts.total_games_avg_rank < 4.5 THEN 4 WHEN ts.total_games_avg_rank < 5 THEN 4.5 " \
"WHEN ts.total_games_avg_rank < 5.5 THEN 5 " \
"ELSE 5.5 END) as general_rank, " \
" cast((ts.sum_home_line + ts.sum_away_line) as decimal(10,2)) as sum_line " \
" from events_data as ed, team_stock as ts " \
f" where ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
" and ts.team_id = ed.home_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
f"{by_team_id}" \
f" or ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
f"{by_team_id}" \
" and ts.team_id = ed.away_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
" group by ts.team_id, ts.team_name, ts.sum_home_line, " \
" ts.sum_away_line, ts.home_success_rate_in_percent, " \
" ts.away_success_rate_in_percent, ts.total_games_avg_rank " \
" order by general_rank asc;"
@staticmethod
def basic_psychology(main_data: dict, query_table: str, home_games: bool = True):
if home_games:
db_field = "home_team_id"
else:
db_field = "away_team_id"
return " select ed.tour_id, ed.round, ed.home_team_id, ed.home_team_name," \
" ed.away_team_id, ed.away_team_name, " \
" ed.winner_code, ind.home, ind.away, ind.time_unit," \
"(CASE WHEN time_unit <= 20 THEN 100 " \
"WHEN time_unit > 20 and time_unit <= 35 THEN 101 " \
"WHEN time_unit > 35 and time_unit <= 60 THEN 102 " \
"WHEN time_unit > 60 and time_unit <= 75 THEN 103 " \
"WHEN time_unit > 75 THEN 104 " \
"ELSE 0 END) as time_unit_significance," \
" ind.significance_home, " \
" ind.significance_away, ind.object_id, ind.object_name," \
" ind.is_home, ed.season, ed.start_time, ed.event_id " \
f" from {query_table} as ed, indicates as ind " \
f" where ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
f" and ed.{db_field} = {main_data.get(Keys.TEAM_ID)} " \
f" and ed.event_id = ind.event_id " \
" and ed.event_id = ind.event_id order by round desc "
@staticmethod
def team_games(main_data: dict):
team_id = main_data.get(Keys.TEAM_ID)
tour_id = main_data.get(Keys.TOUR_ID)
season = main_data.get(Keys.SEASON)
return "select event_id, tour_id, season, round," \
"season_level, home_team_id, home_team_name," \
"home_team_rank, home_level_pressure, home_level_pressure_in_percent, home_last_game_pressure," \
" away_team_id, away_team_name, away_team_rank," \
"away_level_pressure, away_level_pressure_in_percent," \
"away_last_game_pressure, " \
"favorite_by_rank, favorite_by_line, initial_line_id," \
"final_line_id, winner_code, start_time," \
"home_line_points_by_season,home_line_points_achieved_by_season, away_line_points_by_season," \
"away_line_points_achieved_by_season," \
" (CASE" \
f" WHEN home_team_id = {team_id} and winner_code = 1 THEN 3" \
f" WHEN home_team_id = {team_id} and winner_code = 3 THEN 1" \
f" WHEN away_team_id = {team_id} and winner_code = 2 THEN 3" \
f" WHEN away_team_id = {team_id} and winner_code = 3 THEN 1" \
" ELSE 0" \
" END) as points from events_pressure" \
f" WHERE tour_id = {tour_id} AND season = '{season}' and home_team_id = {team_id}" \
f" OR tour_id = {tour_id} AND season = '{season}' and away_team_id = {team_id}" \
" ORDER BY start_time ASC;" | /rr_psychology-2.3-py3-none-any.whl/rr/common/sql.py | 0.520496 | 0.347468 | sql.py | pypi |
import rr_psychology
import pandas as pd
from rr import my_sql
class Pressure(my_sql.MySqlConnection):
def __init__(self, main_data: dict, psy_games_df: pd.DataFrame = None):
# initiate db instance
super().__init__(database=rr_psychology.by.common.General.DATABASE)
# objects - part 1
self.__main_data = main_data
self.__psy_games_df = psy_games_df
self.__team_games = self.__get_team_games
self.__team_rank = self.__general_rank
self.__rival_rank = None
self.__total_points = 0
self.__period_situation = None
self.__pressure_flow = None
self.__psy_flow = None
self.__winner_code = None
self.__points = None
self.__expected_points = None
self.__home_game = None
self.__home_team_id = None
self.__away_team_id = None
self.__results = []
self.__balance = 0
self.__state_result = None
self.__favorite_data = [[rr_psychology.by.common.Keys.FAVORITE, 0, 0],
[rr_psychology.by.common.Keys.UNDERDOG, 0, 0],
[rr_psychology.by.common.Keys.EQUAL, 0, 0]]
@property
def __get_results_data(self):
state_percent = 0
if '0.00/0.00' not in self.__state_result:
state_split = self.__state_result.split('/')
first = float(state_split[0])
second = float(state_split[1])
if first > 0 and second > 0:
state_percent = (first / second) * 100
result = pd.DataFrame(data=self.__results, columns=rr_psychology.by.common.Columns.PRESSURE).set_index(
rr_psychology.by.common.Keys.RANK)
return {rr_psychology.by.common.Keys.ID: self.__main_data.get(rr_psychology.by.common.Keys.TEAM_ID),
rr_psychology.by.common.Keys.NAME: self.__main_data.get(rr_psychology.by.common.Keys.TEAM_NAME),
rr_psychology.by.common.Keys.RANK: self.__team_rank,
rr_psychology.by.common.Keys.TOUR: self.__main_data.get(rr_psychology.by.common.Keys.TOUR_ID),
rr_psychology.by.common.Keys.SEASON: self.__main_data.get(rr_psychology.by.common.Keys.SEASON),
rr_psychology.by.common.Keys.IN_PERCENT: rr_psychology.by.common.General.DECIMAL_FORMAT.format(
state_percent),
rr_psychology.by.common.Keys.PRESSURE_LEVEL: rr_psychology.by.common.utilities.get_pressure(
state_percent, self.__team_rank),
rr_psychology.by.common.Keys.STATE: self.__state_result,
rr_psychology.by.common.Keys.DATA: result.to_json() if type(result) is pd.DataFrame and len(
result) > 0 else '{}',
rr_psychology.by.common.Keys.BALANCE: result[
result[rr_psychology.by.common.Keys.AGAINST_TANK] == rr_psychology.by.common.Keys.TOTAL].values[0][
4]}
@property
def __get_team_games(self):
return self.get_data(
query=rr_psychology.by.common.sql.Get.team_games(main_data=self.__main_data),
return_data_frame=True)
@property
def __initiate_period_situation_list(self):
return [[0, 0, self.__expected_points[0], 1], [0, 0, self.__expected_points[1], 2],
[0, 0, self.__expected_points[2], 3],
[0, 0, self.__expected_points[3], 4], [0, 0, self.__expected_points[3], 5]]
@property
def __general_rank(self):
try:
return float(
self.get_data(
query=rr_psychology.by.common.sql.Get.original_rank(main_data=self.__main_data, by_team_id=True),
close_connection=True)[0][0][
2])
except Exception as e:
print(e, f"\nfor {self.__main_data}")
return 5
def __update_expected_points_by_rank(self):
rank = self.__team_rank
if rank < 1.7:
self.__expected_points = 50, 50, 75, 100, 100
elif rank < 2.5:
self.__expected_points = 25, 50, 75, 75, 75
elif rank < 3.5:
self.__expected_points = 0, 25, 70, 70, 70
else:
self.__expected_points = 0, 0, 60, 60, 60
def __update_rival_rank_target(self):
if self.__rival_rank < 1.7:
self.__rival_rank = 1
elif self.__rival_rank < 2.7:
self.__rival_rank = 2
elif self.__rival_rank < 3.3:
self.__rival_rank = 3
elif self.__rival_rank < 4.0:
self.__rival_rank = 4
else:
self.__rival_rank = 5
def __set_favorite_by_rank(self, success):
if self.__team_rank < self.__rival_rank:
self.__favorite_data[0][1] = (self.__favorite_data[0][1] + 1)
self.__favorite_data[0][2] = (self.__favorite_data[0][2] + success)
elif self.__team_rank > self.__rival_rank:
self.__favorite_data[1][1] = (self.__favorite_data[1][1] + 1)
self.__favorite_data[1][2] = (self.__favorite_data[1][2] + success)
else:
self.__favorite_data[2][1] = (self.__favorite_data[2][1] + 1)
self.__favorite_data[2][2] = (self.__favorite_data[2][2] + success)
def __update_data(self):
self.__update_rival_rank_target()
self.__period_situation[self.__rival_rank - 1][0] = (self.__period_situation[self.__rival_rank - 1][0] + 1)
if self.__points == 3:
self.__period_situation[self.__rival_rank - 1][1] = (
100 + self.__period_situation[self.__rival_rank - 1][1])
self.__set_favorite_by_rank(1)
elif self.__points == 1:
self.__period_situation[self.__rival_rank - 1][1] = (33 + self.__period_situation[self.__rival_rank - 1][1])
self.__set_favorite_by_rank(0.5)
else:
self.__set_favorite_by_rank(0)
@staticmethod
def __divide(num1, num2):
if num1 == 0 or num2 == 0:
return 0
else:
return float(rr_psychology.by.common.General.DECIMAL_FORMAT.format(num1 / num2))
def __read_results(self):
current = 0
possible = 0
count_of_games = 0
results = []
for r, res in enumerate(self.__period_situation):
count_of_games += res[0]
current_result = self.__divide(res[1], res[0])
current_points = float(
rr_psychology.by.common.General.DECIMAL_FORMAT.format(
(3 * res[0]) * (self.__divide(float(current_result), 100))))
possible_points = float(
rr_psychology.by.common.General.DECIMAL_FORMAT.format((3 * res[0]) * (self.__divide(res[2], 100))))
current += current_points
possible += possible_points
results.append(
(res[3], res[3], res[0], float(current_points), possible_points,
float(rr_psychology.by.common.General.DECIMAL_FORMAT.format(current_points - possible_points))))
self.__state_result = f"'{r + 1}': 'current result = {current_result}%, expected result = {res[2]}%," \
f" possible points {rr_psychology.by.common.General.DECIMAL_FORMAT.format(current_points)}/" \
f"{rr_psychology.by.common.General.DECIMAL_FORMAT.format(possible_points)} (from {res[0]} games)',"
self.__balance = float(rr_psychology.by.common.General.DECIMAL_FORMAT.format(current - possible))
results.append((rr_psychology.by.common.Keys.TOTAL, rr_psychology.by.common.Keys.TOTAL, count_of_games,
float(rr_psychology.by.common.General.DECIMAL_FORMAT.format(current)),
float(rr_psychology.by.common.General.DECIMAL_FORMAT.format(possible)), self.__balance))
self.__state_result = f"{rr_psychology.by.common.General.DECIMAL_FORMAT.format(current)}/{rr_psychology.by.common.General.DECIMAL_FORMAT.format(possible)}"
return results
def __set_rival_rank(self, game_obj):
try:
if self.__main_data.get(rr_psychology.by.common.Keys.TEAM_ID) == game_obj[
rr_psychology.by.common.Keys.HOME_TEAM_ID]:
self.__rival_rank = game_obj[rr_psychology.by.common.Keys.AWAY_TEAM_RANK]
elif self.__main_data.get(rr_psychology.by.common.Keys.TEAM_ID) == game_obj[
rr_psychology.by.common.Keys.AWAY_TEAM_ID]:
self.__rival_rank = game_obj[rr_psychology.by.common.Keys.HOME_TEAM_RANK]
else:
self.__rival_rank = 5
except Exception:
self.__rival_rank = 5
def __calculate_data(self, pressure_flow: bool):
cal = 0.0
for game_obj in self.__team_games.iterrows():
game_obj = game_obj[1]
current_round = game_obj[rr_psychology.by.common.Keys.ROUND]
self.__winner_code = game_obj[rr_psychology.by.common.Keys.WINNER_CODE]
self.__points = game_obj[rr_psychology.by.common.Keys.POINTS]
self.__home_team_id = game_obj[rr_psychology.by.common.Keys.HOME_TEAM_ID]
self.__away_team_id = game_obj[rr_psychology.by.common.Keys.AWAY_TEAM_ID]
self.__set_rival_rank(game_obj)
self.__update_data()
self.__total_points += self.__points
if pressure_flow:
self.__pressure_flow.setdefault(f"{current_round}", self.__read_results())
games = self.__psy_games_df[self.__psy_games_df[rr_psychology.by.common.Keys.ROUND] < current_round]
cal = rr_psychology.by.unconditional_situations.Calculate(main_data=self.__main_data,
games_df=games).calculate()
self.__psy_flow.setdefault(f"{current_round}", cal[0])
self.__psy_flow.setdefault(rr_psychology.by.common.Keys.UPDATE_RATING, cal[1] if len(cal) == 2 else 0)
def calculate_pressure(self, pressure_flow: bool = True):
if pressure_flow:
self.__pressure_flow = {}
self.__psy_flow = {}
self.__update_expected_points_by_rank()
self.__period_situation = self.__initiate_period_situation_list
self.__calculate_data(pressure_flow=pressure_flow)
self.__results = self.__read_results()
return {rr_psychology.by.common.Keys.RESULT: self.__get_results_data,
rr_psychology.by.common.Keys.FLOW: self.__pressure_flow,
rr_psychology.by.common.Keys.PSYCHOLOGY: self.__psy_flow} | /rr_psychology-2.3-py3-none-any.whl/rr_psychology/by/pressure.py | 0.498535 | 0.151372 | pressure.py | pypi |
from rr_psychology.by.common.constants import Keys
class Get:
@staticmethod
def original_rank(main_data: dict, by_team_id: bool = False):
if by_team_id:
by_team_id = f" and ts.team_id = {main_data.get(Keys.TEAM_ID)}"
return "select distinct ts.team_id, ts.team_name, " \
"(CASE WHEN ts.total_games_avg_rank < 1.7 THEN 1 WHEN ts.total_games_avg_rank < 2.20 THEN 1.5 " \
"WHEN ts.total_games_avg_rank < 2.5 THEN 2 WHEN ts.total_games_avg_rank < 3 THEN 2.5 " \
"WHEN ts.total_games_avg_rank < 3.5 THEN 3 WHEN ts.total_games_avg_rank < 4 THEN 3.5 " \
"WHEN ts.total_games_avg_rank < 4.5 THEN 4 WHEN ts.total_games_avg_rank < 5 THEN 4.5 " \
"WHEN ts.total_games_avg_rank < 5.5 THEN 5 " \
"ELSE 5.5 END) as general_rank, " \
" cast((ts.sum_home_line + ts.sum_away_line) as decimal(10,2)) as sum_line " \
" from events_data as ed, team_stock as ts " \
f" where ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
" and ts.team_id = ed.home_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
f"{by_team_id}" \
f" or ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
f"{by_team_id}" \
" and ts.team_id = ed.away_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
" group by ts.team_id, ts.team_name, ts.sum_home_line, " \
" ts.sum_away_line, ts.home_success_rate_in_percent, " \
" ts.away_success_rate_in_percent, ts.total_games_avg_rank " \
" order by general_rank asc;"
@staticmethod
def basic_psychology(main_data: dict, query_table: str, home_games: bool = True):
if home_games:
db_field = "home_team_id"
else:
db_field = "away_team_id"
return " select ed.tour_id, ed.round, ed.home_team_id, ed.home_team_name," \
" ed.away_team_id, ed.away_team_name, " \
" ed.winner_code, ind.home, ind.away, ind.time_unit," \
"(CASE WHEN time_unit <= 20 THEN 100 " \
"WHEN time_unit > 20 and time_unit <= 35 THEN 101 " \
"WHEN time_unit > 35 and time_unit <= 60 THEN 102 " \
"WHEN time_unit > 60 and time_unit <= 75 THEN 103 " \
"WHEN time_unit > 75 THEN 104 " \
"ELSE 0 END) as time_unit_significance," \
" ind.significance_home, " \
" ind.significance_away, ind.object_id, ind.object_name," \
" ind.is_home, ed.season, ed.start_time, ed.event_id " \
f" from {query_table} as ed, indicates as ind " \
f" where ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
f" and ed.{db_field} = {main_data.get(Keys.TEAM_ID)} " \
f" and ed.event_id = ind.event_id " \
" and ed.event_id = ind.event_id order by round desc "
@staticmethod
def team_games(main_data: dict):
team_id = main_data.get(Keys.TEAM_ID)
tour_id = main_data.get(Keys.TOUR_ID)
season = main_data.get(Keys.SEASON)
return "select event_id, tour_id, season, round," \
"season_level, home_team_id, home_team_name," \
"home_team_rank, home_level_pressure, home_level_pressure_in_percent, home_last_game_pressure," \
" away_team_id, away_team_name, away_team_rank," \
"away_level_pressure, away_level_pressure_in_percent," \
"away_last_game_pressure, " \
"favorite_by_rank, favorite_by_line, initial_line_id," \
"final_line_id, winner_code, start_time," \
"home_line_points_by_season,home_line_points_achieved_by_season, away_line_points_by_season," \
"away_line_points_achieved_by_season," \
" (CASE" \
f" WHEN home_team_id = {team_id} and winner_code = 1 THEN 3" \
f" WHEN home_team_id = {team_id} and winner_code = 3 THEN 1" \
f" WHEN away_team_id = {team_id} and winner_code = 2 THEN 3" \
f" WHEN away_team_id = {team_id} and winner_code = 3 THEN 1" \
" ELSE 0" \
" END) as points from events_pressure" \
f" WHERE tour_id = {tour_id} AND season = '{season}' and home_team_id = {team_id}" \
f" OR tour_id = {tour_id} AND season = '{season}' and away_team_id = {team_id}" \
" ORDER BY start_time ASC;" | /rr_psychology-2.3-py3-none-any.whl/rr_psychology/by/common/sql.py | 0.520496 | 0.347468 | sql.py | pypi |
from rr_psychology.by.common.constants import Keys
class Get:
@staticmethod
def original_rank(main_data: dict, by_team_id: bool=False):
if by_team_id:
by_team_id = f" and ts.team_id = {main_data.get(Keys.TEAM_ID)}"
return "select distinct ts.team_id, ts.team_name, " \
"(CASE WHEN ts.total_games_avg_rank < 1.7 THEN 1 WHEN ts.total_games_avg_rank < 2.20 THEN 1.5 " \
"WHEN ts.total_games_avg_rank < 2.5 THEN 2 WHEN ts.total_games_avg_rank < 3 THEN 2.5 " \
"WHEN ts.total_games_avg_rank < 3.5 THEN 3 WHEN ts.total_games_avg_rank < 4 THEN 3.5 " \
"WHEN ts.total_games_avg_rank < 4.5 THEN 4 WHEN ts.total_games_avg_rank < 5 THEN 4.5 " \
"WHEN ts.total_games_avg_rank < 5.5 THEN 5 " \
"ELSE 5.5 END) as general_rank, " \
" cast((ts.sum_home_line + ts.sum_away_line) as decimal(10,2)) as sum_line " \
" from events_data as ed, team_stock as ts " \
f" where ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
" and ts.team_id = ed.home_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
f"{by_team_id}" \
f" or ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
f"{by_team_id}" \
" and ts.team_id = ed.away_team_id " \
" and ts.tour_id = ed.tour_id " \
" and ts.season = ed.season " \
" group rr_psychology ts.team_id, ts.team_name, ts.sum_home_line, " \
" ts.sum_away_line, ts.home_success_rate_in_percent, " \
" ts.away_success_rate_in_percent, ts.total_games_avg_rank " \
" order rr_psychology general_rank asc;"
@staticmethod
def basic_psychology(main_data: dict, query_table: str, home_games: bool = True):
if home_games:
db_field = "home_team_id"
else:
db_field = "away_team_id"
return " select ed.tour_id, ed.round, ed.home_team_id, ed.home_team_name," \
" ed.away_team_id, ed.away_team_name, " \
" ed.winner_code, ind.home, ind.away, ind.time_unit," \
"(CASE WHEN time_unit <= 20 THEN 100 " \
"WHEN time_unit > 20 and time_unit <= 35 THEN 101 " \
"WHEN time_unit > 35 and time_unit <= 60 THEN 102 " \
"WHEN time_unit > 60 and time_unit <= 75 THEN 103 " \
"WHEN time_unit > 75 THEN 104 " \
"ELSE 0 END) as time_unit_significance," \
" ind.significance_home, " \
" ind.significance_away, ind.object_id, ind.object_name," \
" ind.is_home, ed.season, ed.start_time, ed.event_id " \
f" from {query_table} as ed, indicates as ind " \
f" where ed.tour_id = {main_data.get(Keys.TOUR_ID)} " \
f" and ed.season = '{main_data.get(Keys.SEASON)}' " \
f" and ed.{db_field} = {main_data.get(Keys.TEAM_ID)} " \
f" and ed.event_id = ind.event_id " \
" and ed.event_id = ind.event_id order rr_psychology round desc "
@staticmethod
def team_games(main_data: dict, pressure_view: bool):
team_id = main_data.get(Keys.TEAM_ID)
tour_id = main_data.get(Keys.TOUR_ID)
season = main_data.get(Keys.SEASON)
if not pressure_view:
return "select ed.event_id, ed.tour_id, ed.round, ed.home_team_id, ed.home_team_name, ed.away_team_name," \
"ed.away_team_id, ed.winner_code, od.initial_favorite, od.final_favorite, od.initial_home, " \
"od.initial_drew, od.initial_away, od.initial_line_id, od.final_line_id, " \
" (CASE" \
f" WHEN ed.home_team_id = {team_id} THEN 1" \
" ELSE 2" \
" END) as home_away," \
" (CASE" \
f" WHEN ed.home_team_id = {team_id} and ed.winner_code = 1 THEN 3" \
f" WHEN ed.home_team_id = {team_id} and ed.winner_code = 3 THEN 1" \
f" WHEN ed.away_team_id = {team_id} and ed.winner_code = 2 THEN 3" \
f" WHEN ed.away_team_id = {team_id} and ed.winner_code = 3 THEN 1" \
" ELSE 0" \
" END) as points," \
" ed.start_time from events_data as ed, odds_data as od" \
f" where ed.tour_id = {tour_id} " \
f" and ed.season = '{season}' " \
f" and ed.home_team_id = {team_id}" \
" and ed.event_id = od.event_id" \
f" or ed.tour_id = {tour_id} " \
f" and ed.season = '{season}' " \
f" and ed.away_team_id = {team_id}" \
" and ed.event_id = od.event_id" \
" order rr_psychology ed.start_time asc;"
else:
return "select event_id, tour_id, season, round," \
"season_level, home_team_id, home_team_name," \
"home_team_rank, home_level_pressure, home_level_pressure_in_percent, home_last_game_pressure," \
" away_team_id, away_team_name, away_team_rank," \
"away_level_pressure, away_level_pressure_in_percent," \
"away_last_game_pressure, " \
"favorite_by_rank, favorite_by_line, initial_line_id," \
"final_line_id, winner_code, start_time," \
"home_line_points_by_season,home_line_points_achieved_by_season, away_line_points_by_season," \
"away_line_points_achieved_by_season," \
" (CASE" \
f" WHEN home_team_id = {team_id} and winner_code = 1 THEN 3" \
f" WHEN home_team_id = {team_id} and winner_code = 3 THEN 1" \
f" WHEN away_team_id = {team_id} and winner_code = 2 THEN 3" \
f" WHEN away_team_id = {team_id} and winner_code = 3 THEN 1" \
" ELSE 0" \
" END) as points from events_pressure" \
f" WHERE tour_id = {tour_id} AND season = '{season}' and home_team_id = {team_id}" \
f" OR tour_id = {tour_id} AND season = '{season}' and away_team_id = {team_id}" \
" ORDER BY start_time ASC;" | /rr_psychology-2.3-py3-none-any.whl/common/sql.py | 0.50952 | 0.311662 | sql.py | pypi |
from __future__ import absolute_import
from itertools import izip_longest
from collections import Iterable
import pkgutil
# Module-level variables
__version__ = pkgutil.get_data(__name__, "VERSION").strip()
_rtol = 1e-9 # default relative tolerance
_atol = 1e-12 # default absolute tolerance
def tolerance(x, y):
"""Compute the final tolerance for the approximate comparison of x and y."""
global _atol, _rtol
x = float(x)
y = float(y)
return _atol + _rtol * max(abs(x), abs(y))
def equal(x, y):
"""
Approximate floating point comparison using absolute and relative epsilons. This function is
equivalent to
|x - y| <= atol + rtol * max(|x|, |y|)
This is very similar to what is done in numpy, but this function is symmetric, that is,
the order of the two numbers is irrelevant to the result. In numpy.isclose(), the relative
tolerance is multiplied by the absolute value of the second number, so calling the function
with reversed arguments can give different results, which makes no sense at all. They're even
aware of that, there's a note on their website, but they don't fix it for some reason...
"""
x = float(x)
y = float(y)
if x == y:
return True
global _atol, _rtol
z = abs(x - y) - _atol
return z <= 0.0 or z <= _rtol * max(abs(x), abs(y))
class Approx(float):
"""
A float subclass to mitigate (but does not eliminate!) floating point rounding errors by
comparing approximately. Comparison operators are redefined to use the absolute and relative
tolerances defined in this module.
"""
__slots__ = () # prevent creation of a dictionary per Approx instance
def __repr__(self):
return float.__repr__(self) + "~"
def __str__(self):
return float.__str__(self) + "~"
tolerance = tolerance
# --------------------------------------------------------------------------
# Rich comparison operators
__eq__ = equal
def __ne__(self, x):
return not self.__eq__(x)
def __le__(self, x):
return float(self) <= float(x) or self.__eq__(x)
def __lt__(self, x):
return float(self) < float(x) and not self.__eq__(x)
def __ge__(self, x):
return float(self) >= float(x) or self.__eq__(x)
def __gt__(self, x):
return float(self) > float(x) and not self.__eq__(x)
# --------------------------------------------------------------------------
# Arithmetic operators
def __neg__(self):
return type(self)(-float(self))
def __pos__(self):
return type(self)(+float(self))
def __abs__(self):
return type(self)(abs(float(self)))
def __add__(self, other):
return type(self)(float(self) + other)
def __sub__(self, other):
return type(self)(float(self) - other)
def __mul__(self, other):
return type(self)(float(self) * other)
def __div__(self, other):
return type(self)(float(self) / other)
__truediv__ = __div__
def __floordiv__(self, other):
return type(self)(float(self) // other)
def __mod__(self, other):
return type(self)(float(self) % other)
def __pow__(self, other, modulo=None):
return type(self)(pow(float(self), other, modulo))
__radd__ = __add__
def __rsub__(self, other):
return type(self)(other - float(self))
__rmul__ = __mul__
def __rdiv__(self, other):
return type(self)(other / float(self))
__rtruediv__ = __rdiv__
def __rfloordiv__(self, other):
return type(self)(other // float(self))
def __rmod__(self, other):
return type(self)(other % float(self))
def __rpow__(self, other):
return type(self)(other ** float(self))
# --------------------------------------------------------------------------
# Rich comparison operators for iterables
@classmethod
def _apply(cls, op, x, y):
"""This internal function allows the application of rich comparison operators between two
numbers, a number and a (possibly nested) sequence of numbers, or two (flat/nested)
sequences of numbers. When comparing two sequences, missing values are filled with NaN.
Returns a generator expression in case sequences are involved, or a plain old boolean if
two numbers are being compared.
"""
x_is_iterable = isinstance(x, Iterable)
y_is_iterable = isinstance(y, Iterable)
if x_is_iterable and y_is_iterable:
return (cls._apply(op, u, v) for u, v in izip_longest(x, y, fillvalue=float("NaN")))
elif x_is_iterable:
return (cls._apply(op, u, y) for u in x)
elif y_is_iterable:
return (cls._apply(op, x, v) for v in y)
else:
return op(cls(x), y)
@classmethod
def eq(cls, x, y):
return cls._apply(x, y, cls.__eq__)
@classmethod
def ne(cls, x, y):
return cls._apply(x, y, cls.__ne__)
@classmethod
def le(cls, x, y):
return cls._apply(x, y, cls.__le__)
@classmethod
def lt(cls, x, y):
return cls._apply(x, y, cls.__lt__)
@classmethod
def ge(cls, x, y):
return cls._apply(x, y, cls.__ge__)
@classmethod
def gt(cls, x, y):
return cls._apply(x, y, cls.__gt__)
class ApproxContext(object):
"""
A context manager which temporarily changes the relative and/or absolute tolerances for
numeric comparisons. Note that this context manager *can* be reused multiple times.
"""
def __init__(self, rtol=None, atol=None):
global _rtol, _atol
self.rtol = rtol if rtol is not None else _rtol
self.atol = atol if atol is not None else _atol
self.orig_rtol = None
self.orig_atol = None
def __repr__(self):
return "{}(rtol={}, atol={})".format(type(self).__name__, self.rtol, self.atol)
@property
def active(self):
"""A context is active if it has been applied (and it cannot be applied multiple times)."""
return self.orig_rtol is not None
def apply(self):
"""Set the current relative and/or absolute tolerance for approximate comparisons."""
if self.active:
raise ValueError("{} is already active".format(self))
global _rtol, _atol
self.orig_rtol = _rtol
self.orig_atol = _atol
_rtol = self.rtol
_atol = self.atol
def restore(self):
"""Restore the values of 'rtol' and 'atol' that were saved when the context was applied."""
if not self.active:
raise ValueError("{} is not active".format(self))
global _rtol, _atol
_rtol = self.orig_rtol
_atol = self.orig_atol
self.orig_rtol = None
self.orig_atol = None
def __enter__(self):
self.apply()
def __exit__(self, exc_type, exc_val, exc_tb):
self.restore()
# Provide the context class as an alias through Approx
Approx.Context = ApproxContext | /rr.approx-0.1.2.zip/rr.approx-0.1.2/rr/approx/__init__.py | 0.862714 | 0.478833 | __init__.py | pypi |
import asyncio
from asyncio import Queue
from datetime import datetime, timezone
from typing import Callable, Dict, List
from rraft import (
Config,
ConfState,
EntryRef,
EntryType,
LoggerRef,
Logger,
MemStorage,
MessageRef,
OverflowStrategy,
InMemoryRawNode,
)
channel: Queue = Queue()
def now() -> int:
return int(datetime.now(tz=timezone.utc).timestamp() * 1000)
async def send_propose(logger: Logger | LoggerRef) -> None:
# Wait some time and send the request to the Raft.
await asyncio.sleep(10)
logger.info("propose a request")
# Send a command to the Raft, wait for the Raft to apply it
# and get the result.
raft_chan: Queue = Queue()
await channel.put(
{
"msg_type": "PROPOSE",
"id": 1,
"cb": lambda: raft_chan.put(0),
}
)
n = await raft_chan.get()
assert n == 0
logger.info("receive the propose callback")
await channel.put({"msg_type": "DISCONNECTED"})
async def on_ready(
raft_group: InMemoryRawNode, cbs: Dict[str, Callable]
) -> None:
if not raft_group.has_ready():
return
store = raft_group.get_raft().get_raft_log().get_store()
# Get the `Ready` with `RawNode::ready` interface.
ready = raft_group.ready()
async def handle_messages(msgs: List[MessageRef]):
for _msg in msgs:
# Send messages to other peers.
continue
if msgs := ready.messages():
# Send out the messages come from the node.
await handle_messages(msgs)
if ready.snapshot():
# This is a snapshot, we need to apply the snapshot at first.
cloned_ready = raft_group.ready()
store.wl().apply_snapshot(cloned_ready.snapshot())
_last_apply_index = 0
async def handle_committed_entries(committed_entries: List[EntryRef]):
for entry in committed_entries:
# Mostly, you need to save the last apply index to resume applying
# after restart. Here we just ignore this because we use a Memory storage.
nonlocal _last_apply_index
_last_apply_index = entry.get_index()
entry_data = entry.get_data()
if not entry.get_data():
# Emtpy entry, when the peer becomes Leader it will send an empty entry.
continue
if entry.get_entry_type() == EntryType.EntryNormal:
await cbs[entry_data[0]]()
del cbs[entry_data[0]]
# TODO: handle EntryConfChange
await handle_committed_entries(ready.committed_entries())
if entries := ready.entries():
# Append entries to the Raft log.
store.wl().append(entries)
if hs := ready.hs():
# Raft HardState changed, and we need to persist it.
store.wl().set_hardstate(hs)
if msgs := ready.persisted_messages():
# Send out the persisted messages come from the node.
await handle_messages(msgs)
# Advance the Raft.
light_rd = raft_group.advance(ready.make_ref())
# Update commit index.
if commit := light_rd.commit_index():
store.wl().hard_state().set_commit(commit)
# Send out the messages.
await handle_messages(light_rd.messages())
# Apply all committed entries.
await handle_committed_entries(light_rd.committed_entries())
# Advance the apply index.
raft_group.advance_apply()
async def main():
# Create a storage for Raft, and here we just use a simple memory storage.
# You need to build your own persistent storage in your production.
# Please check the Storage trait in src/storage.rs to see how to implement one.
storage = MemStorage.new_with_conf_state(ConfState(voters=[1], learners=[]))
# Create the configuration for the Raft node.
cfg = Config(
# The unique ID for the Raft node.
id=1,
# Election tick is for how long the follower may campaign again after
# it doesn't receive any message from the leader.
election_tick=10,
# Heartbeat tick is for how long the leader needs to send
# a heartbeat to keep alive.
heartbeat_tick=3,
# The max size limits the max size of each appended message. Mostly, 1 MB is enough.
max_size_per_msg=1024 * 1024 * 1024,
# Max inflight msgs that the leader sends messages to follower without
# receiving ACKs.
max_inflight_msgs=256,
# The Raft applied index.
# You need to save your applied index when you apply the committed Raft logs.
applied=0,
)
logger = Logger(chan_size=4096, overflow_strategy=OverflowStrategy.Block)
# Create the Raft node.
raw_node = InMemoryRawNode(cfg, storage, logger)
# Use another task to propose a Raft request.
asyncio.create_task(send_propose(logger))
t = now()
timeout = 100
# Use a dict to hold the `propose` callbacks.
cbs: Dict[str, Callable] = {}
# Loop forever to drive the Raft.
while True:
try:
top = await asyncio.wait_for(channel.get(), timeout / 1000)
msg_type = top["msg_type"]
if msg_type == "PROPOSE":
id, cb = top["id"], top["cb"]
cbs[id] = cb
raw_node.propose(context=[], data=[id])
elif msg_type == "RAFT":
# Here we don't use Raft Message, so there is no "msg" sender in this example.
msg = top["msg"]
raw_node.step(msg)
elif msg_type == "DISCONNECTED":
break
except asyncio.exceptions.TimeoutError:
pass
finally:
d = now() - t
t = now()
if d >= timeout:
timeout = 100
# We drive Raft every 100ms.
raw_node.tick()
else:
timeout -= d
await on_ready(raw_node, cbs)
if __name__ == "__main__":
asyncio.run(main()) | /rraft_py-0.2.14.tar.gz/rraft_py-0.2.14/example/single_mem_node/use_coroutine.py | 0.61115 | 0.378861 | use_coroutine.py | pypi |
from datetime import datetime, timezone
from queue import Queue, Empty as QueueEmptyException
from threading import Thread
from time import sleep
from typing import Dict, List, Callable
from rraft import (
Config,
ConfState,
EntryRef,
EntryType,
LoggerRef,
Logger,
MemStorage,
MessageRef,
OverflowStrategy,
InMemoryRawNode,
)
channel: Queue = Queue()
def now() -> int:
return int(datetime.now(tz=timezone.utc).timestamp() * 1000)
def send_propose(logger: Logger | LoggerRef) -> None:
def _send_propose():
# Wait some time and send the request to the Raft.
sleep(10)
logger.info("propose a request")
raft_chan = Queue()
# Send a command to the Raft, wait for the Raft to apply it
# and get the result.
channel.put(
{
"msg_type": "PROPOSE",
"id": 1,
"cb": lambda: raft_chan.put(0, block=True),
},
block=True,
)
n = raft_chan.get(block=True)
assert n == 0
logger.info("receive the propose callback")
channel.put(
{
"msg_type": "DISCONNECTED",
},
block=True,
)
Thread(name="single_mem_node", target=_send_propose).start()
def on_ready(raft_group: InMemoryRawNode, cbs: Dict[str, Callable]) -> None:
if not raft_group.has_ready():
return
store = raft_group.get_raft().get_raft_log().get_store()
# Get the `Ready` with `RawNode::ready` interface.
ready = raft_group.ready()
def handle_messages(msg_refs: List[MessageRef]):
for _msg_ref in msg_refs:
# Send messages to other peers.
continue
if msgs := ready.messages():
# Send out the messages come from the node.
handle_messages(msgs)
if ready.snapshot():
# This is a snapshot, we need to apply the snapshot at first.
cloned_ready = raft_group.ready()
store.wl().apply_snapshot(cloned_ready.snapshot())
_last_apply_index = 0
def handle_committed_entries(committed_entries: List[EntryRef]):
for entry in committed_entries:
# Mostly, you need to save the last apply index to resume applying
# after restart. Here we just ignore this because we use a Memory storage.
nonlocal _last_apply_index
_last_apply_index = entry.get_index()
entry_data = entry.get_data()
if not entry.get_data():
# Emtpy entry, when the peer becomes Leader it will send an empty entry.
continue
if entry.get_entry_type() == EntryType.EntryNormal:
cbs[entry_data[0]]()
del cbs[entry_data[0]]
# TODO: handle EntryConfChange
handle_committed_entries(ready.committed_entries())
if entries := ready.entries():
# Append entries to the Raft log.
store.wl().append(entries)
if hs := ready.hs():
# Raft HardState changed, and we need to persist it.
store.wl().set_hardstate(hs)
if msgs := ready.persisted_messages():
# Send out the persisted messages come from the node.
handle_messages(msgs)
# Advance the Raft.
light_rd = raft_group.advance(ready.make_ref())
# Update commit index.
if commit := light_rd.commit_index():
store.wl().hard_state().set_commit(commit)
# Send out the messages.
handle_messages(light_rd.messages())
# Apply all committed entries.
handle_committed_entries(light_rd.committed_entries())
# Advance the apply index.
raft_group.advance_apply()
# A simple example about how to use the Raft library in Python.
if __name__ == "__main__":
# Create a storage for Raft, and here we just use a simple memory storage.
# You need to build your own persistent storage in your production.
# Please check the Storage trait in src/storage.rs to see how to implement one.
storage = MemStorage.new_with_conf_state(ConfState(voters=[1], learners=[]))
# Create the configuration for the Raft node.
cfg = Config(
# The unique ID for the Raft node.
id=1,
# Election tick is for how long the follower may campaign again after
# it doesn't receive any message from the leader.
election_tick=10,
# Heartbeat tick is for how long the leader needs to send
# a heartbeat to keep alive.
heartbeat_tick=3,
# The max size limits the max size of each appended message. Mostly, 1 MB is enough.
max_size_per_msg=1024 * 1024 * 1024,
# Max inflight msgs that the leader sends messages to follower without
# receiving ACKs.
max_inflight_msgs=256,
# The Raft applied index.
# You need to save your applied index when you apply the committed Raft logs.
applied=0,
)
logger = Logger(chan_size=4096, overflow_strategy=OverflowStrategy.Block)
# Create the Raft node.
raw_node = InMemoryRawNode(cfg, storage, logger)
# Use another thread to propose a Raft request.
send_propose(logger)
t = now()
timeout = 100
# Use a HashMap to hold the `propose` callbacks.
cbs = {}
# Loop forever to drive the Raft.
while True:
try:
top = channel.get(block=True, timeout=timeout / 1000)
msg_type = top["msg_type"]
if msg_type == "PROPOSE":
id, cb = top["id"], top["cb"]
cbs[id] = cb
raw_node.propose(context=[], data=[id])
elif msg_type == "RAFT":
# Here we don't use Raft Message, so there is no "msg" sender in this example.
msg = top["msg"]
raw_node.step(msg)
elif msg_type == "DISCONNECTED":
break
else:
assert False, "Invalid msg_type."
except QueueEmptyException:
pass
finally:
d = now() - t
t = now()
if d >= timeout:
timeout = 100
# We drive Raft every 100ms.
raw_node.tick()
else:
timeout -= d
on_ready(raw_node, cbs) | /rraft_py-0.2.14.tar.gz/rraft_py-0.2.14/example/single_mem_node/use_threading.py | 0.631935 | 0.316184 | use_threading.py | pypi |
import pytest
from rraft import (
ConfState,
Logger_Ref,
MemStorage,
Config,
InMemoryRaft,
default_logger,
)
def new_storage(voters: int, learners: int) -> MemStorage:
cc = ConfState.default()
for i in range(1, voters + 1):
cc.set_voters([*cc.get_voters(), i])
for i in range(1, learners + 1):
cc.set_learners([*cc.get_learners(), voters + i])
return MemStorage.new_with_conf_state(cc)
def quick_raft(storage: MemStorage, logger: Logger_Ref):
id = 1
config = Config(id)
return InMemoryRaft(config, storage, logger)
@pytest.mark.benchmark(group="raft-creation", warmup=True)
def test_raft_creation_0_0(benchmark):
logger = default_logger()
storage = new_storage(0, 0)
benchmark(quick_raft, storage, logger)
@pytest.mark.benchmark(group="raft-creation", warmup=True)
def test_raft_creation_3_1(benchmark):
logger = default_logger()
storage = new_storage(3, 1)
benchmark(quick_raft, storage, logger)
@pytest.mark.benchmark(group="raft-creation", warmup=True)
def test_raft_creation_5_2(benchmark):
logger = default_logger()
storage = new_storage(5, 2)
benchmark(quick_raft, storage, logger)
@pytest.mark.benchmark(group="raft-creation", warmup=True)
def test_raft_creation_7_3(benchmark):
logger = default_logger()
storage = new_storage(7, 3)
benchmark(quick_raft, storage, logger)
# ---
@pytest.mark.benchmark(group="raft-campaign", warmup=True)
def test_raft_campaign__3_1_CampaignPreElection(benchmark):
logger = default_logger()
storage = new_storage(3, 1)
def bench(storage, logger):
raft = quick_raft(storage, logger)
raft.campaign("CampaignPreElection")
benchmark(bench, storage, logger)
@pytest.mark.benchmark(group="raft-campaign", warmup=True)
def test_raft_campaign__3_1_CampaignElection(benchmark):
logger = default_logger()
storage = new_storage(3, 1)
def bench(storage, logger):
raft = quick_raft(storage, logger)
raft.campaign("CampaignElection")
benchmark(bench, storage, logger)
@pytest.mark.benchmark(group="raft-campaign", warmup=True)
def test_raft_campaign__3_1_CampaignTransfer(benchmark):
logger = default_logger()
storage = new_storage(3, 1)
def bench(storage, logger):
raft = quick_raft(storage, logger)
raft.campaign("CampaignTransfer")
benchmark(bench, storage, logger)
@pytest.mark.benchmark(group="raft-campaign", warmup=True)
def test_raft_campaign__5_2_CampaignPreElection(benchmark):
logger = default_logger()
storage = new_storage(5, 2)
def bench(storage, logger):
raft = quick_raft(storage, logger)
raft.campaign("CampaignPreElection")
benchmark(bench, storage, logger)
@pytest.mark.benchmark(group="raft-campaign", warmup=True)
def test_raft_campaign__5_2_CampaignElection(benchmark):
logger = default_logger()
storage = new_storage(5, 2)
def bench(storage, logger):
raft = quick_raft(storage, logger)
raft.campaign("CampaignElection")
benchmark(bench, storage, logger)
@pytest.mark.benchmark(group="raft-campaign", warmup=True)
def test_raft_campaign__5_2_CampaignTransfer(benchmark):
logger = default_logger()
storage = new_storage(5, 2)
def bench(storage, logger):
raft = quick_raft(storage, logger)
raft.campaign("CampaignTransfer")
benchmark(bench, storage, logger)
@pytest.mark.benchmark(group="raft-campaign", warmup=True)
def test_raft_campaign__7_3_CampaignPreElection(benchmark):
logger = default_logger()
storage = new_storage(7, 3)
def bench(storage, logger):
raft = quick_raft(storage, logger)
raft.campaign("CampaignPreElection")
benchmark(bench, storage, logger)
@pytest.mark.benchmark(group="raft-campaign", warmup=True)
def test_raft_campaign__7_3_CampaignElection(benchmark):
logger = default_logger()
storage = new_storage(7, 3)
def bench(storage, logger):
raft = quick_raft(storage, logger)
raft.campaign("CampaignElection")
benchmark(bench, storage, logger)
@pytest.mark.benchmark(group="raft-campaign", warmup=True)
def test_raft_campaign__7_3_CampaignTransfer(benchmark):
logger = default_logger()
storage = new_storage(7, 3)
def bench(storage, logger):
raft = quick_raft(storage, logger)
raft.campaign("CampaignTransfer")
benchmark(bench, storage, logger) | /rraft_py-0.2.14.tar.gz/rraft_py-0.2.14/benches/suites/raft.py | 0.438785 | 0.372791 | raft.py | pypi |
from typing import List, Optional
from rraft import (
ConfChange,
ConfChangeSingle,
ConfChangeSingleRef,
ConfChangeType,
ConfChangeV2,
ConfState,
Config,
Entry,
EntryRef,
HardState,
Logger,
LoggerRef,
MemStorage,
MemStorageRef,
Message,
MessageType,
InMemoryRaft,
InMemoryRaftLogRef,
Snapshot,
SoftState,
StateRole,
NO_LIMIT,
)
from harness.src.interface import Interface
def ltoa(raft_log: InMemoryRaftLogRef) -> str:
s = f"commited {raft_log.get_committed()}\n"
s += f"applied {raft_log.get_applied()}\n"
for i, e in enumerate(raft_log.all_entries()):
s += f"#{i}: {e}\n"
return s
def new_storage() -> MemStorage:
return MemStorage()
def new_test_config(id: int, election_tick: int, heartbeat_size: int) -> Config:
return Config(
id=id,
election_tick=election_tick,
heartbeat_tick=heartbeat_size,
max_size_per_msg=NO_LIMIT,
max_inflight_msgs=256,
)
def new_test_raft(
id: int,
peers: List[int],
election: int,
heartbeat: int,
storage: MemStorage | MemStorageRef,
logger: Logger | LoggerRef,
) -> Interface:
config = new_test_config(id, election, heartbeat)
initial_state = storage.initial_state()
assert not (
initial_state.initialized() and not peers
), "new_test_raft with empty peers on initialized store"
if peers and not initial_state.initialized():
cs = ConfState(peers, [])
storage.initialize_with_conf_state(cs)
return new_test_raft_with_config(config, storage, logger)
def new_test_raft_with_prevote(
id: int,
peers: List[int],
election: int,
heartbeat: int,
storage: MemStorage | MemStorageRef,
pre_vote: bool,
logger: Logger | LoggerRef,
) -> Interface:
config = new_test_config(id, election, heartbeat)
config.set_pre_vote(pre_vote)
initial_state = storage.initial_state()
assert not (
initial_state.initialized() and not peers
), "new_test_raft with empty peers on initialized store"
if peers and not initial_state.initialized():
cs = ConfState(peers, [])
storage.initialize_with_conf_state(cs)
return new_test_raft_with_config(config, storage, logger)
def new_test_raft_with_logs(
id: int,
peers: List[int],
election: int,
heartbeat: int,
storage: MemStorage | MemStorageRef,
logs: List[Entry] | List[EntryRef],
logger: Logger | LoggerRef,
) -> Interface:
config = new_test_config(id, election, heartbeat)
initial_state = storage.initial_state()
assert not (
initial_state.initialized() and not peers
), "new_test_raft with empty peers on initialized store"
if peers and not initial_state.initialized():
cs = ConfState(peers, [])
storage.initialize_with_conf_state(cs)
storage.wl().append(logs)
return new_test_raft_with_config(config, storage, logger)
def new_test_raft_with_config(
config: Config,
storage: MemStorage | MemStorageRef,
logger: Logger | LoggerRef,
) -> Interface:
return Interface(InMemoryRaft(config, storage, logger))
def hard_state(term: int, commit: int, vote: int) -> HardState:
hs = HardState.default()
hs.set_term(term)
hs.set_commit(commit)
hs.set_vote(vote)
return hs
def soft_state(leader_id: int, raft_state: StateRole) -> SoftState:
ss = SoftState.default()
ss.set_leader_id(leader_id)
ss.set_raft_state(raft_state)
return ss
SOME_DATA = "somedata"
def new_message_with_entries(
from_: int, to: int, t: MessageType, ents: List[Entry]
) -> Message:
m = Message()
m.set_from(from_)
m.set_to(to)
m.set_msg_type(t)
if ents:
m.set_entries(ents)
return m
def new_message(from_: int, to: int, t: MessageType, n: int) -> Message:
m = new_message_with_entries(from_, to, t, [])
if n > 0:
ents = []
for _ in range(0, n):
ents.append(new_entry(0, 0, SOME_DATA))
m.set_entries(ents)
return m
def new_entry(term: int, index: int, data: Optional[str]) -> Entry:
e = Entry.default()
e.set_index(index)
e.set_term(term)
if data:
e.set_data(data.encode("utf-8"))
return e
def empty_entry(term: int, index: int) -> Entry:
return new_entry(term, index, None)
def new_snapshot(index: int, term: int, voters: List[int]) -> Snapshot:
s = Snapshot.default()
s.get_metadata().set_index(index)
s.get_metadata().set_term(term)
s.get_metadata().get_conf_state().set_voters(voters)
return s
def conf_change(ty: ConfChangeType, node_id: int) -> ConfChange:
cc = ConfChange.default()
cc.set_change_type(ty)
cc.set_node_id(node_id)
return cc
def remove_node(node_id: int) -> ConfChangeV2:
cc = conf_change(ConfChangeType.RemoveNode, node_id)
return cc.into_v2()
def add_node(node_id: int) -> ConfChangeV2:
cc = conf_change(ConfChangeType.AddNode, node_id)
return cc.into_v2()
def add_learner(node_id: int) -> ConfChangeV2:
cc = conf_change(ConfChangeType.AddLearnerNode, node_id)
return cc.into_v2()
def conf_state(voters: List[int], learners: List[int]) -> ConfState:
cs = ConfState.default()
cs.set_voters(voters)
cs.set_learners(learners)
return cs
def conf_state_v2(
voters: List[int],
learners: List[int],
voters_outgoing: List[int],
learners_next: List[int],
auto_leave: bool,
) -> ConfState:
cs = conf_state(voters, learners)
cs.set_voters_outgoing(voters_outgoing)
cs.set_learners_next(learners_next)
cs.set_auto_leave(auto_leave)
return cs
def conf_change_v2(
steps: List[ConfChangeSingle] | List[ConfChangeSingleRef],
) -> ConfChangeV2:
cc = ConfChangeV2.default()
cc.set_changes(steps)
return cc | /rraft_py-0.2.14.tar.gz/rraft_py-0.2.14/harness/utils.py | 0.785144 | 0.394376 | utils.py | pypi |
import RPi.GPIO as GPIO
import time
class RRB3:
MOTOR_DELAY = 0.2
RIGHT_PWM_PIN = 14
RIGHT_1_PIN = 10
RIGHT_2_PIN = 25
LEFT_PWM_PIN = 24
LEFT_1_PIN = 17
LEFT_2_PIN = 4
SW1_PIN = 11
SW2_PIN = 9
LED1_PIN = 8
LED2_PIN = 7
OC1_PIN = 22
OC2_PIN = 27
OC2_PIN_R1 = 21
OC2_PIN_R2 = 27
TRIGGER_PIN = 18
ECHO_PIN = 23
left_pwm = 0
right_pwm = 0
pwm_scale = 0
old_left_dir = -1
old_right_dir = -1
def __init__(self, battery_voltage=9.0, motor_voltage=6.0, revision=2):
self.pwm_scale = float(motor_voltage) / float(battery_voltage)
if self.pwm_scale > 1:
print("WARNING: Motor voltage is higher than battery votage. Motor may run slow.")
GPIO.setmode(GPIO.BCM)
GPIO.setwarnings(False)
GPIO.setup(self.LEFT_PWM_PIN, GPIO.OUT)
self.left_pwm = GPIO.PWM(self.LEFT_PWM_PIN, 500)
self.left_pwm.start(0)
GPIO.setup(self.LEFT_1_PIN, GPIO.OUT)
GPIO.setup(self.LEFT_2_PIN, GPIO.OUT)
GPIO.setup(self.RIGHT_PWM_PIN, GPIO.OUT)
self.right_pwm = GPIO.PWM(self.RIGHT_PWM_PIN, 500)
self.right_pwm.start(0)
GPIO.setup(self.RIGHT_1_PIN, GPIO.OUT)
GPIO.setup(self.RIGHT_2_PIN, GPIO.OUT)
GPIO.setup(self.LED1_PIN, GPIO.OUT)
GPIO.setup(self.LED2_PIN, GPIO.OUT)
GPIO.setup(self.OC1_PIN, GPIO.OUT)
if revision == 1:
self.OC2_PIN = self.OC2_PIN_R1
else:
self.OC2_PIN = self.OC2_PIN_R2
GPIO.setup(self.OC2_PIN_R2, GPIO.OUT)
GPIO.setup(self.SW1_PIN, GPIO.IN)
GPIO.setup(self.SW2_PIN, GPIO.IN)
GPIO.setup(self.TRIGGER_PIN, GPIO.OUT)
GPIO.setup(self.ECHO_PIN, GPIO.IN)
def set_motors(self, left_pwm, left_dir, right_pwm, right_dir):
if self.old_left_dir != left_dir or self.old_right_dir != right_dir:
self.set_driver_pins(0, 0, 0, 0) # stop motors between sudden changes of direction
time.sleep(self.MOTOR_DELAY)
self.set_driver_pins(left_pwm, left_dir, right_pwm, right_dir)
self.old_left_dir = left_dir
self.old_right_dir = right_dir
def set_driver_pins(self, left_pwm, left_dir, right_pwm, right_dir):
self.left_pwm.ChangeDutyCycle(left_pwm * 100 * self.pwm_scale)
GPIO.output(self.LEFT_1_PIN, left_dir)
GPIO.output(self.LEFT_2_PIN, not left_dir)
self.right_pwm.ChangeDutyCycle(right_pwm * 100 * self.pwm_scale)
GPIO.output(self.RIGHT_1_PIN, right_dir)
GPIO.output(self.RIGHT_2_PIN, not right_dir)
def forward(self, seconds=0, speed=0.5):
self.set_motors(speed, 0, speed, 0)
if seconds > 0:
time.sleep(seconds)
self.stop()
def stop(self):
self.set_motors(0, 0, 0, 0)
def reverse(self, seconds=0, speed=0.5):
self.set_motors(speed, 1, speed, 1)
if seconds > 0:
time.sleep(seconds)
self.stop()
def left(self, seconds=0, speed=0.5):
self.set_motors(speed, 0, speed, 1)
if seconds > 0:
time.sleep(seconds)
self.stop()
def right(self, seconds=0, speed=0.5):
self.set_motors(speed, 1, speed, 0)
if seconds > 0:
time.sleep(seconds)
self.stop()
def step_forward(self, delay, num_steps):
for i in range(0, num_steps):
self.set_driver_pins(1, 1, 1, 0)
time.sleep(delay)
self.set_driver_pins(1, 1, 1, 1)
time.sleep(delay)
self.set_driver_pins(1, 0, 1, 1)
time.sleep(delay)
self.set_driver_pins(1, 0, 1, 0)
time.sleep(delay)
self.set_driver_pins(0, 0, 0, 0)
def step_reverse(self, delay, num_steps):
for i in range(0, num_steps):
self.set_driver_pins(1, 0, 1, 0)
time.sleep(delay)
self.set_driver_pins(1, 0, 1, 1)
time.sleep(delay)
self.set_driver_pins(1, 1, 1, 1)
time.sleep(delay)
self.set_driver_pins(1, 1, 1, 0)
time.sleep(delay)
self.set_driver_pins(0, 0, 0, 0)
def sw1_closed(self):
return not GPIO.input(self.SW1_PIN)
def sw2_closed(self):
return not GPIO.input(self.SW2_PIN)
def set_led1(self, state):
GPIO.output(self.LED1_PIN, state)
def set_led2(self, state):
GPIO.output(self.LED2_PIN, state)
def set_oc1(self, state):
GPIO.output(self.OC1_PIN, state)
def set_oc2(self, state):
GPIO.output(self.OC2_PIN, state)
def _send_trigger_pulse(self):
GPIO.output(self.TRIGGER_PIN, True)
time.sleep(0.0001)
GPIO.output(self.TRIGGER_PIN, False)
def _wait_for_echo(self, value, timeout):
count = timeout
while GPIO.input(self.ECHO_PIN) != value and count > 0:
count -= 1
def get_distance(self):
self._send_trigger_pulse()
self._wait_for_echo(True, 10000)
start = time.time()
self._wait_for_echo(False, 10000)
finish = time.time()
pulse_len = finish - start
distance_cm = pulse_len / 0.000058
return distance_cm
def cleanup(self):
GPIO.cleanup() | /rrb3-1.1.tar.gz/rrb3-1.1/rrb3.py | 0.461745 | 0.242699 | rrb3.py | pypi |
import pandas as pd
import numpy as np
import rrcf
from sklearn.preprocessing import StandardScaler
class Outlier_Detector:
def __init__(self, x: np.array, num_trees: int, num_samples_per_tree: int):
self.x = x
self.num_trees = num_trees
self.num_samples_per_tree = num_samples_per_tree
self.forest = self.create_forest()
def create_forest(self):
n = self.x.shape[0]
forest_size = n // self.num_samples_per_tree
if self.num_trees <= 1:
forest = rrcf.RCTree(self.x, index_labels=[i for i in range(n)])
else:
forest = []
while len(forest) < self.num_trees:
ixs = np.random.choice(n, size=(forest_size, self.num_samples_per_tree),
replace=False)
# Add sampled trees to forest
trees = [rrcf.RCTree(self.x[ix, :], index_labels=ix) for ix in ixs]
forest.extend(trees)
return forest
def rrcf_outlier_score(self):
n = self.x.shape[0]
if self.num_trees <= 1:
avg_codisp = [self.forest.codisp(i) for i in [i for i in range(n)]]
else:
# Compute average CoDisp
avg_codisp = pd.Series(0.0, index=np.arange(n))
index = np.zeros(n)
for tree in self.forest:
codisp = pd.Series({leaf: tree.codisp(leaf)
for leaf in tree.leaves})
avg_codisp[codisp.index] += codisp
np.add.at(index, codisp.index.values, 1)
avg_codisp /= index
return avg_codisp
def rrcf_outlier_detector(self):
n = self.x.shape[0]
if self.num_trees <= 1:
avg_codisp = [self.forest.codisp(i) for i in [i for i in range(n)]]
else:
# Compute average CoDisp
avg_codisp = pd.Series(0.0, index=np.arange(n))
index = np.zeros(n)
for tree in self.forest:
codisp = pd.Series({leaf: tree.codisp(leaf)
for leaf in tree.leaves})
avg_codisp[codisp.index] += codisp
np.add.at(index, codisp.index.values, 1)
avg_codisp /= index
avg_codisp_std = np.absolute(StandardScaler().fit_transform(np.array(avg_codisp).reshape((-1, 1))))
detected_outliers = self.x[(avg_codisp_std >= 3)[:,0],:]
return detected_outliers | /rrcf-outlier-detector-MA-0.1.0.tar.gz/rrcf-outlier-detector-MA-0.1.0/RRCF_Outlier_Detection/rrcf_outlier_detection.py | 0.726717 | 0.504761 | rrcf_outlier_detection.py | pypi |
# rrcf 🌲🌲🌲
[](https://travis-ci.org/kLabUM/rrcf) [](https://coveralls.io/github/kLabUM/rrcf?branch=master) [](https://www.python.org/downloads/release/python-360/)  [](http://joss.theoj.org/papers/f8c83c0b01a984d0dbf934939b53c96d)
Implementation of the *Robust Random Cut Forest Algorithm* for anomaly detection by [Guha et al. (2016)](http://proceedings.mlr.press/v48/guha16.pdf).
> S. Guha, N. Mishra, G. Roy, & O. Schrijvers, *Robust random cut forest based anomaly
> detection on streams*, in Proceedings of the 33rd International conference on machine
> learning, New York, NY, 2016 (pp. 2712-2721).
## About
The *Robust Random Cut Forest* (RRCF) algorithm is an ensemble method for detecting outliers in streaming data. RRCF offers a number of features that many competing anomaly detection algorithms lack. Specifically, RRCF:
- Is designed to handle streaming data.
- Performs well on high-dimensional data.
- Reduces the influence of irrelevant dimensions.
- Gracefully handles duplicates and near-duplicates that could otherwise mask the presence of outliers.
- Features an anomaly-scoring algorithm with a clear underlying statistical meaning.
This repository provides an open-source implementation of the RRCF algorithm and its core data structures for the purposes of facilitating experimentation and enabling future extensions of the RRCF algorithm.
## Documentation
Read the docs [here 📖](https://klabum.github.io/rrcf/).
## Installation
Use `pip` to install `rrcf` via pypi:
```shell
$ pip install rrcf
```
Currently, only Python 3 is supported.
### Dependencies
The following dependencies are *required* to install and use `rrcf`:
- [numpy](http://www.numpy.org/) (>= 1.15)
The following *optional* dependencies are required to run the examples shown in the documentation:
- [pandas](https://pandas.pydata.org/) (>= 0.23)
- [scipy](https://www.scipy.org/) (>= 1.2)
- [scikit-learn](https://scikit-learn.org/stable/) (>= 0.20)
- [matplotlib](https://matplotlib.org/) (>= 3.0)
Listed version numbers have been tested and are known to work (this does not necessarily preclude older versions).
## Robust random cut trees
A robust random cut tree (RRCT) is a binary search tree that can be used to detect outliers in a point set. A RRCT can be instantiated from a point set. Points can also be added and removed from an RRCT.
### Creating the tree
```python
import numpy as np
import rrcf
# A (robust) random cut tree can be instantiated from a point set (n x d)
X = np.random.randn(100, 2)
tree = rrcf.RCTree(X)
# A random cut tree can also be instantiated with no points
tree = rrcf.RCTree()
```
### Inserting points
```python
tree = rrcf.RCTree()
for i in range(6):
x = np.random.randn(2)
tree.insert_point(x, index=i)
```
```
─+
├───+
│ ├───+
│ │ ├──(0)
│ │ └───+
│ │ ├──(5)
│ │ └──(4)
│ └───+
│ ├──(2)
│ └──(3)
└──(1)
```
### Deleting points
```
tree.forget_point(2)
```
```
─+
├───+
│ ├───+
│ │ ├──(0)
│ │ └───+
│ │ ├──(5)
│ │ └──(4)
│ └──(3)
└──(1)
```
## Anomaly score
The likelihood that a point is an outlier is measured by its collusive displacement (CoDisp): if including a new point significantly changes the model complexity (i.e. bit depth), then that point is more likely to be an outlier.
```python
# Seed tree with zero-mean, normally distributed data
X = np.random.randn(100,2)
tree = rrcf.RCTree(X)
# Generate an inlier and outlier point
inlier = np.array([0, 0])
outlier = np.array([4, 4])
# Insert into tree
tree.insert_point(inlier, index='inlier')
tree.insert_point(outlier, index='outlier')
```
```python
tree.codisp('inlier')
>>> 1.75
```
```python
tree.codisp('outlier')
>>> 39.0
```
## Batch anomaly detection
This example shows how a robust random cut forest can be used to detect outliers in a batch setting. Outliers correspond to large CoDisp.
```python
import numpy as np
import pandas as pd
import rrcf
# Set parameters
np.random.seed(0)
n = 2010
d = 3
num_trees = 100
tree_size = 256
# Generate data
X = np.zeros((n, d))
X[:1000,0] = 5
X[1000:2000,0] = -5
X += 0.01*np.random.randn(*X.shape)
# Construct forest
forest = []
while len(forest) < num_trees:
# Select random subsets of points uniformly from point set
ixs = np.random.choice(n, size=(n // tree_size, tree_size),
replace=False)
# Add sampled trees to forest
trees = [rrcf.RCTree(X[ix], index_labels=ix) for ix in ixs]
forest.extend(trees)
# Compute average CoDisp
avg_codisp = pd.Series(0.0, index=np.arange(n))
index = np.zeros(n)
for tree in forest:
codisp = pd.Series({leaf : tree.codisp(leaf) for leaf in tree.leaves})
avg_codisp[codisp.index] += codisp
np.add.at(index, codisp.index.values, 1)
avg_codisp /= index
```

## Streaming anomaly detection
This example shows how the algorithm can be used to detect anomalies in streaming time series data.
```python
import numpy as np
import rrcf
# Generate data
n = 730
A = 50
center = 100
phi = 30
T = 2*np.pi/100
t = np.arange(n)
sin = A*np.sin(T*t-phi*T) + center
sin[235:255] = 80
# Set tree parameters
num_trees = 40
shingle_size = 4
tree_size = 256
# Create a forest of empty trees
forest = []
for _ in range(num_trees):
tree = rrcf.RCTree()
forest.append(tree)
# Use the "shingle" generator to create rolling window
points = rrcf.shingle(sin, size=shingle_size)
# Create a dict to store anomaly score of each point
avg_codisp = {}
# For each shingle...
for index, point in enumerate(points):
# For each tree in the forest...
for tree in forest:
# If tree is above permitted size, drop the oldest point (FIFO)
if len(tree.leaves) > tree_size:
tree.forget_point(index - tree_size)
# Insert the new point into the tree
tree.insert_point(point, index=index)
# Compute codisp on the new point and take the average among all trees
if not index in avg_codisp:
avg_codisp[index] = 0
avg_codisp[index] += tree.codisp(index) / num_trees
```

## Contributing
We welcome contributions to the `rrcf` repo. To contribute, submit a [pull request](https://help.github.com/en/articles/about-pull-requests) to the `dev` branch.
#### Types of contributions
Some suggested types of contributions include:
- Bug fixes
- Documentation improvements
- Performance enhancements
- Extensions to the algorithm
Check the issue tracker for any specific issues that need help. If you encounter a problem using `rrcf`, or have an idea for an extension, feel free to raise an issue.
#### Guidelines for contributors
Please consider the following guidelines when contributing to the codebase:
- Ensure that any new methods, functions or classes include docstrings. Docstrings should include a description of the code, as well as descriptions of the inputs (arguments) and outputs (returns). Providing an example use case is recommended (see existing methods for examples).
- Write unit tests for any new code and ensure that all tests are passing with no warnings. Please ensure that overall code coverage does not drop below 80%.
#### Running unit tests
To run unit tests, first ensure that `pytest` and `pytest-cov` are installed:
```
$ pip install pytest pytest-cov
```
To run the tests, navigate to the root directory of the repo and run:
```
$ pytest --cov=rrcf/
```
## Citing
If you have used this codebase in a publication and wish to cite it, please use the [`Journal of Open Source Software article`](https://joss.theoj.org/papers/10.21105/joss.01336).
> M. Bartos, A. Mullapudi, & S. Troutman, *rrcf: Implementation of the Robust
> Random Cut Forest algorithm for anomaly detection on streams*,
> in: Journal of Open Source Software, The Open Journal, Volume 4, Number 35.
> 2019
```bibtex
@article{bartos_2019_rrcf,
title={{rrcf: Implementation of the Robust Random Cut Forest algorithm for anomaly detection on streams}},
authors={Matthew Bartos and Abhiram Mullapudi and Sara Troutman},
journal={{The Journal of Open Source Software}},
volume={4},
number={35},
pages={1336},
year={2019}
}
```
| /rrcf-0.4.4.tar.gz/rrcf-0.4.4/README.md | 0.648021 | 0.968411 | README.md | pypi |
# rrgit
`rrgit` is a command line utility to aid in the process of editing RepRapFirmware / Duet controller configuration files over a network connection. It is designed to be as git-like as possible in order to provide a familiar interface. Of course, however, the RepRapFirmware interface is far less extensive compared to git, so `rrgit` handles just the basics. It will allow you to clone, pull, push, and diff between the controller and local copies of the files.
## Installation
The simplest way to install is:
`pip install rrgit`
Alternatively:
```
git clone https://github.com/adammhaile/rrgit.git
cd rrgit
python setup.py install
```
This will install the necessary packages and make available the `rrgit` and `rrg` (simply an alias) commands.
## Usage
The following base commands are available. With the exception of `clone` all commands must be called from the root of the `rrgit` cloned directory.
### Clone
`rrgit clone HOSTNAME [DIRECTORY]`
Clone the config from `HOSTNAME` to `DIRECTORY`
The intent is to use `rrgit` much like you would `git` by starting from an existing set of configuration files, already on a remote machine.
`HOSTNAME` can be an IP address or local network hostname and can include http/https but it is not required. The base network address is the important item here.
`DIRECTORY` is optional if you simply want to clone down to the current working directy. Note that this is only an option if the current directory is completely empty. Otherwise provide an absolute or relative directory path. That directory need not exist as it will be created.
One cloned, the directory specified will be populated with all non-ignored (see more below on `.rrgitignore`) files from the specified remote machine.
Note that RepRapFirmware has very specific directories (such as `sys`, `gcodes`, and `macros`) that it uses. Anything other than the official directory names (which are pulled from the remote system at connection time) will be ignored. Therefore you could add any other files or directories into your `rrgit` directory and they will be ignored by `rrgit`.
### Status
`rrgit status`
Query both the remote machine and the local directory to automatically discover and report on any differences between the two. Note that, unlike `git`, this is only able to detect if files have a different timestamp or are a different size. The report will be broken down into the following categories:
- Remote only: files that only exist on remote
- Remote newer: files that are newer on remote than local
- Local only: files that only exist on local
- Local newer: files that are newer on local than remote
- Different size: files that have the same timestamp but differ in size. This is extremely unlikely. Typically all change detection is timestamp based.
### Pull
`rrgit pull [--force/-f] [--yes/-y] [file_patterns ...]`
Pulls remote files to local. Must be run from the root of the `rrgit` clone directory. With no options specified, it will only pull remote files that differ from local. Note that since there is no concept of history or commits as with actual git, this acts a little different. If you have made changes on both remote and local and then choose to pull, it will overwrite local with remote. There is no automatic conflict resolution.
However, it will ask you to confirm the overwrite if the local files are newer than remote or if they only exist on local (in which case they would be deleted locally). You can use the `--yes` option to suppress this confirmation request.
Using the `--force` option is effectively like re-cloning the configuration files. It will pull down all remote files to local, regardless of local state. This includes deletions locally.
Finally, you can optionally provide any number of relative file paths or [git pathspec](https://git-scm.com/docs/gitglossary#Documentation/gitglossary.txt-aiddefpathspecapathspec) style file patterns. It will then only act upon files that match those patterns.
Be aware that on Linux or Mac systems bash will provide file path expansion on any wildcard file patterns provided. This is fine when acting upon local files but with pull, the pattern matching is purely for remote files. If you let bash do the path expansion for you it will *only* match files that are also local. To get around this, it is recommended to wrap all file patterns in single quotes like this:
`rrgit pull 'sys/*.g'`
Which would pull all `.g` files from the `sys` directory on the remote system.
There is no need to use the single quote wrapping on Windows systems as `rrgit` will always handle wildcard file patterns internally.
### Push
`rrgit push [--force/-f] [--yes/-y] [file_patterns ...]`
The `push` command functions identically to the `pull` command, just in the other direction, local to remote.
### Diff
`rrgit diff [file_patterns ...]`
Show a diff report of all files that do not match between remote and local, if called with no file patterns. It will, by default, diff any files that would be shown in the `status` command report.
If file patterns are provided (which follow the same rules as described in the `pull` command) it will only show diffs for those files specified.
It will always show the diff output in a format with remote as file A and local as file B.
### Watch
`rrgit watch`
**NOTE:** Currently the `watch` command is disabled under Windows. I cannot get the `watchdog` python package to work reliably for Windows at this time.
Watch the local `rrgit` directory tree and automatically push all changes to the remote machine. This is useful if you will be making many changes and runnings tests after each. Instead of running the `push` command each time the files will be pushed as soon as they are saved locally.
## `.rrgitignore` file
`rrgit` will automatically create a file called `.rrgitignore` in the root of the cloned directory which can be used to filter out what is pulled and pushed. The format is identical to the [`.gitignore` file format](https://git-scm.com/docs/gitignore).
By default this file includes the following lines:
```
/www/
/gcodes/
/scans/
/menu/
*.uf2
*.bin
```
- `www` is the location of the DuetWebControl files and are unlikely that you will ever need to pull/push changes to those files.
- `gcodes` is the location of uploaded job files. These files can be quite large.
- `scans` is used for depth probe scanning in RepRapFirmware which is infrequently used.
- `menu` provides configuration files for older-style monochrome LCD displays.
- `*.uf2` and `*.bin` files are the binary firmware files for your controller and are often large files which really don't need to be synced in most cases.
These are simply defaults which make the initial clone fast and likely to include everything most people will want. If you would like these files, simple edit the file to remove those lines and call `rrg pull` to pull down the files that were filtered out during the itial clone.
## Usage with git
The entire intent of `rrgit` is to use it as a companion to `git` itself to provide backups and history for your RepRapFirmware / Duet configs. You can do this in a couple ways:
- Create an empty remote git repo, clone it down locally, and then use `rrgit clone` to pull the configuration files into the local git repo directory.
- Use `rrgit clone` to create a local `rrgit` directory, then use `git init` and `git remote add` inside of that directory to associate it with a remote git repo.
Once one of those options is done, you will be able to use all your normal `add`, `commit`, `push`, etc. commands with `git` to backup your configuration files. You basically will always want to use the opposite pull/push command in `rrgit` that you used with `git`. If you pull from the git back, use `rrgit push` to send that update to the remote machine, and vice versa.
| /rrgit-1.0.1.tar.gz/rrgit-1.0.1/README.md | 0.478041 | 0.891102 | README.md | pypi |
class ActionDenso:
def __init__(self, robot_object, robot_handle):
self.robot_object = robot_object
self.robot_handle = robot_handle
def motor_on(self):
command = "Motor"
parameters = [1, 0]
self.robot_object.robot_execute(self.robot_handle, command, parameters)
def motor_off(self):
command = "Motor"
parameters = [0, 0]
self.robot_object.robot_execute(self.robot_handle, command, parameters)
def move_joints(self, j1, j2, j3, j4, j5, j6):
joints_value = [j1, j2, j3, j4, j5, j6]
pose = [joints_value, "J", "@E"]
comp = 1
self.robot_object.robot_move(self.robot_handle, comp, pose, "")
def get_joints(self):
raise NotImplementedError("get_joints() is not implemented yet")
def move_cartesian(self, x, y, z, rx, ry, rz, fig):
cartesian_value = [x, y, z, rx, ry, rz, fig]
pose = [cartesian_value, "P", "@E"]
comp = 1
self.robot_object.robot_move(self.robot_handle, comp, pose, "")
def get_cartesian(self):
raise NotImplementedError("get_cartesian() is not implemented yet")
def move_to_home(self):
self.move_to_zero()
def move_to_zero(self):
joints_value = [0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
pose = [joints_value, "J", "@E"]
comp = 1
self.robot_object.robot_move(self.robot_handle, comp, pose, "")
def open_gripper(self):
raise NotImplementedError("open_gripper() is not implemented yet")
def close_gripper(self):
raise NotImplementedError("close_gripper() is not implemented yet")
def set_velocity(self, speed=10, acceleration=10, deceleration=10):
command = "ExtSpeed"
parameters = [speed, acceleration, deceleration]
self.robot_object.robot_execute(self.robot_handle, command, parameters)
def calibrate(self):
raise NotImplementedError("calibrate() is not implemented yet")
def go_to_sleep(self):
raise NotImplementedError("go_to_sleep() is not implemented yet") | /rria_api_denso-0.1.1-py3-none-any.whl/rria_api_denso/action_denso.py | 0.761804 | 0.482002 | action_denso.py | pypi |
from utils.bcapclient import BCAPClient
class ConnectDenso:
def __init__(self, ip_address, port=5007, timeout=2000):
self.ip_address = ip_address
self.port = port
self.timeout = timeout
self.parameters = None
self.bcap_client = None
self.controller_handle = None
self.robot_handle = None
def set_parameters(self, name="", provider="CaoProv.DENSO.RC8", machine="", option="Server=192.168.160.226"):
"""
Args:
name: string,
provider: string,
machine: string,
option: string
Returns:
list: list of values from parameters
Examples:
>>> ConnectDenso.set_parameters(name="", provider="CaoProv.DENSO.RC8", machine="", option="Server=192.168.160.226")
['', 'CaoProv.DENSO.RC8', '', 'Server=192.168.160.226']
"""
self.parameters = [name, provider, machine, option]
def connect_robot(self):
"""
Return the bcap_client and robot_handle objects. The bcap_client object is used to send all commands to the
robot and the robot_handle is used in movements commands.
Returns:
self.bcap_client: object
self.robot_handle: object
"""
# Connection processing of tcp communication
self.bcap_client = BCAPClient(self.ip_address, self.port, self.timeout)
self.bcap_client.service_start("")
# Connect to RC8 (RC8 provider)
self.controller_handle = self.bcap_client.controller_connect(self.parameters[0], self.parameters[1],
self.parameters[2], self.parameters[3])
# Get Robot Object robot_handle
self.robot_handle = self.bcap_client.controller_getrobot(self.controller_handle, "Arm", "")
# TakeArm
self.bcap_client.robot_execute(self.robot_handle, "TakeArm", [0, 0])
return self.bcap_client, self.robot_handle
def disconnect_robot(self, command, param):
# Give Arm
self.bcap_client.robot_execute(self.robot_handle, command, param)
# Disconnect
if self.robot_handle != 0:
self.bcap_client.robot_release(self.robot_handle)
if self.controller_handle != 0:
self.bcap_client.controller_disconnect(self.controller_handle)
self.bcap_client.service_stop() | /rria_api_denso-0.1.1-py3-none-any.whl/rria_api_denso/connect_denso.py | 0.807726 | 0.173551 | connect_denso.py | pypi |
from time import sleep
from rria_api_denso.action_denso import ActionDenso
from rria_api_denso.connect_denso import ConnectDenso
class RobotObject:
def __init__(self, ip_address, robot_type):
self.ip_address = ip_address
self.robot_type = robot_type
# This attribute is used to store the general robot instance
self.robot_instance = None
self.robot_handle = None
# This attribute is used to store the general connection instance
self.connection_instance = None
# This attribute is used to store the general action instance
self.action_object = None
def connect_robot(self):
"""
Connect robot depends on the robot type
:rtype: bool
"""
if self.robot_type == 'denso':
try:
self.connection_instance = ConnectDenso(self.ip_address)
self.connection_instance.set_parameters(option="Server=" + self.ip_address)
self.robot_instance, self.robot_handle = self.connection_instance.connect_robot()
# Create action object
self.action_object = ActionDenso(self.robot_instance, self.robot_handle)
return True
except(Exception,):
print('The connection attempt failed. Check the physical connection to the robot and try again later.')
return False
if self.robot_type == 'test':
sleep(1)
return True
def disconnect_robot(self):
"""
Close connection with robot
:rtype: None
"""
if self.robot_type == 'denso':
self.connection_instance.disconnect_robot()
if self.robot_type == 'test':
sleep(1)
return True
def safe_disconnect(self):
"""
Move robot for home position and close connection with robot. Home position depends on robot type. For Gen3 is
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0] degrees and for Ned is [0.0, 0.3, -1.3, 0.0, 0.0, 0.0] radians.
:rtype: None
"""
if self.robot_type == 'denso':
self.action_object.move_to_zero()
self.connection_instance.disconnect_robot()
if self.robot_type == 'test':
sleep(1)
return True
# Motor methods
def motor_on(self):
"""
Turn motor on
:rtype: None
"""
if self.robot_type == 'denso':
self.action_object.motor_on()
if self.robot_type == 'test':
sleep(1)
print('Motor on Tac Tac Tac')
return True
def motor_off(self):
"""
Turn motor off
:rtype: None
"""
if self.robot_type == 'denso':
self.action_object.motor_off()
if self.robot_type == 'test':
sleep(1)
print('Motor off Tac')
return True
# Move Joints/Cartesian methods
def joints(self):
return self.get_joints()
def get_joints(self):
"""
Get joints value in radians
You can also use a getter ::
joints = robot.get_joints()
joints = robot.joints
:return: List of joints value
:rtype: list[float]
"""
if self.robot_type == 'denso':
return self.action_object.get_joints()
if self.robot_type == 'test':
sleep(0.5)
return ['J1', 'J2', 'J3', 'J4', 'J5', 'J6']
def move_joints(self, j1, j2, j3, j4, j5, j6):
"""
Move robot joints. Joints are expressed in degrees.
All lines of the next example realize the same operation: ::
robot.move_joints(0.2, 0.1, 0.3, 0.0, 0.5, 0.0)
:param j1: joint 1,
:type j1: float
:param j2: joint 2,
:type j2: float
:param j3: joint 3,
:type j3: float
:param j4: joint 4,
:type j4: float
:param j5: joint 5,
:type j5: float
:param j6: joint 6,
:type j6: float
:rtype: None
"""
if self.robot_type == 'denso':
self.action_object.move_joints(j1, j2, j3, j4, j5, j6)
if self.robot_type == 'test':
sleep(1)
return True
def cartesian(self):
return self.get_cartesian()
def get_cartesian(self):
"""
Get end effector link pose as [x, y, z, roll, pitch, yaw].
x, y & z are expressed in meters / roll, pitch & yaw are expressed in radians
You can also use a getter ::
pose = robot.get_pose()
pose = robot.pose
:rtype: PoseObject
"""
if self.robot_type == 'denso':
return self.action_object.get_cartesian()
if self.robot_type == 'test':
sleep(1)
return True
def move_cartesian(self, x, y, z, roll, pitch, yaw):
"""
Move robot end effector pose to a (x, y, z, roll, pitch, yaw, frame_name) pose
in a particular frame (frame_name) if defined.
x, y & z are expressed in meters / roll, pitch & yaw are expressed in radians
All lines of the next example realize the same operation: ::
robot.move_cartesian(0.2, 0.1, 0.3, 0.0, 0.5, 0.0)
:param x: coordinate x,
:type x: float
:param y: coordinate y,
:type y: float
:param z: coordinate z,
:type z: float
:param roll: rotation on x-axis,
:type roll: float
:param pitch: rotation on y-axis,
:type pitch: float
:param yaw: rotation on z-axis,
:type yaw: float
:rtype: None
"""
if self.robot_type == 'denso':
return self.action_object.move_cartesian([x, y, z, roll, pitch, yaw])
if self.robot_type == 'test':
sleep(1)
return True
def move_to_home(self):
"""
Move robot for home position. Home position depends on robot type. For Gen3 is [0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
degrees and for Ned is [0.0, 0.3, -1.3, 0.0, 0.0, 0.0] radians.
:rtype: None
"""
if self.robot_type == 'denso':
self.action_object.move_to_home()
if self.robot_type == 'test':
sleep(1)
return True
def move_to_zero(self):
"""
Move robot for zero position. Home position depends on robot type. For Gen3 is [0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
degrees and for Ned is [0.0, 0.0, 0.0, 0.0, 0.0, 0.0] radians.
:rtype: None
"""
if self.robot_type == 'denso':
self.action_object.move_to_zero()
if self.robot_type == 'test':
sleep(1)
return True
def open_gripper(self):
"""
Open gripper.
:rtype: None
"""
if self.robot_type == 'denso':
self.action_object.open_gripper()
if self.robot_type == 'test':
sleep(1)
return True
def close_gripper(self):
"""
Close gripper
:rtype: None
"""
if self.robot_type == 'denso':
self.action_object.close_gripper()
if self.robot_type == 'test':
sleep(1)
return True
def set_velocity(self, speed, acceleration=10, deceleration=10):
"""
Limit arm max velocity to a percentage of its maximum velocity. For niryo one, velocity is a percentage of 100.
For gen3, there are two types of velocities, an angular and a cartesian. The speed used in this method is
angular.
Args:
speed: Should be between 1 & 100
acceleration: Should be between 1 & 100, value default is 10.
deceleration: Should be between 1 & 100, value default is 10.
"""
if self.robot_type == 'denso':
self.action_object.set_velocity(speed, acceleration, deceleration)
if self.robot_type == 'test':
sleep(1)
return True
def calibrate(self):
"""
Start an automatic motors calibration if motors are not calibrated yet
*NOT IMPLEMENTED*
:rtype: None
"""
if self.robot_type == 'denso':
...
if self.robot_type == 'test':
sleep(1)
return True
def go_to_sleep(self):
"""
Go home pose and activate learning mode. The function is available only for Ned robot.
*NOT IMPLEMENTED*
:rtype: None
"""
if self.robot_type == 'denso':
...
if self.robot_type == 'test':
sleep(1)
return True | /rria_api_denso-0.1.1-py3-none-any.whl/rria_api_denso/robot_object.py | 0.819135 | 0.500122 | robot_object.py | pypi |
"""
Software License Agreement (MIT License)
@copyright Copyright (c) 2017 DENSO WAVE INCORPORATED
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
"""
# -*- coding:utf-8 -*-
import select
import socket
import struct
from ctypes import *
from datetime import datetime
from rria_api_denso.utils.orinexception import *
from threading import Lock
from rria_api_denso.utils.variant import VarType
class BCAPClient:
_BCAP_SOH = 0x1
_BCAP_EOT = 0x4
_TIME_DIFFERENCE = 25569.0
_SEC_ONEDAY = 24 * 60 * 60
@staticmethod
def datetime2vntdate(date):
return date.timestamp() / BCAPClient._SEC_ONEDAY + BCAPClient._TIME_DIFFERENCE
@staticmethod
def vntdate2datetime(date):
return datetime.fromtimestamp((date - BCAPClient._TIME_DIFFERENCE) * BCAPClient._SEC_ONEDAY)
_DICT_TYPE2VT = {
int: (VarType.VT_I4, "i", False),
float: (VarType.VT_R8, "d", False),
datetime: (VarType.VT_DATE, "d", False),
str: (VarType.VT_BSTR, "I%ds", False),
bool: (VarType.VT_BOOL, "h", False),
c_bool: (VarType.VT_BOOL, "h", True),
c_ubyte: (VarType.VT_UI1, "B", True),
c_short: (VarType.VT_I2, "h", True),
c_ushort: (VarType.VT_UI2, "H", True),
c_int: (VarType.VT_I4, "i", True),
c_uint: (VarType.VT_UI4, "I", True),
c_long: (VarType.VT_I4, "l", True),
c_ulong: (VarType.VT_UI4, "L", True),
c_longlong: (VarType.VT_I8, "q", True),
c_ulonglong: (VarType.VT_UI8, "Q", True),
c_float: (VarType.VT_R4, "f", True),
c_double: (VarType.VT_R8, "d", True),
c_wchar_p: (VarType.VT_BSTR, "I%ds", True),
}
_DICT_VT2TYPE = {
VarType.VT_I2: ("h", 2),
VarType.VT_I4: ("i", 4),
VarType.VT_R4: ("f", 4),
VarType.VT_R8: ("d", 8),
VarType.VT_CY: ("q", 8),
VarType.VT_DATE: ("d", 8),
VarType.VT_BSTR: ("%ds", -1),
VarType.VT_ERROR: ("i", 4),
VarType.VT_BOOL: ("h", 2),
VarType.VT_UI1: ("B", 1),
VarType.VT_UI2: ("H", 2),
VarType.VT_UI4: ("I", 4),
VarType.VT_I8: ("q", 8),
VarType.VT_UI8: ("Q", 8),
}
def __init__(self, host, port, timeout):
self._serial = 1
self._version = 0
self._timeout = timeout
self._sock = None
self._lock = Lock()
try:
self._sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self._sock.setblocking(False)
self._sock.settimeout(timeout)
self._sock.connect((host, port))
except OSError as e:
if not (self._sock is None):
self._sock.close()
self._sock = None
raise e
self._sock.setblocking(True)
def __del__(self):
if not (self._sock is None):
try:
self._sock.shutdown(socket.SHUT_RDWR)
finally:
self._sock.close()
self._sock = None
def settimeout(self, timeout):
self._timeout = timeout
def gettimeout(self):
return self._timeout
def service_start(self, option=""):
self._send_and_recv(1, [option])
def service_stop(self):
self._send_and_recv(2, [])
def controller_connect(self, name, provider, machine, option):
return self._send_and_recv(3, [name, provider, machine, option])[0]
def controller_disconnect(self, handle):
self._send_and_recv(4, [handle])
def controller_getextension(self, handle, name, option=""):
return self._send_and_recv(5, [handle, name, option])[0]
def controller_getfile(self, handle, name, option=""):
return self._send_and_recv(6, [handle, name, option])[0]
def controller_getrobot(self, handle, name, option=""):
return self._send_and_recv(7, [handle, name, option])[0]
def controller_gettask(self, handle, name, option=""):
return self._send_and_recv(8, [handle, name, option])[0]
def controller_getvariable(self, handle, name, option=""):
return self._send_and_recv(9, [handle, name, option])[0]
def controller_getcommand(self, handle, name, option=""):
return self._send_and_recv(10, [handle, name, option])[0]
def controller_getextensionnames(self, handle, option=""):
return self._send_and_recv(11, [handle, option])[0]
def controller_getfilenames(self, handle, option=""):
return self._send_and_recv(12, [handle, option])[0]
def controller_getrobotnames(self, handle, option=""):
return self._send_and_recv(13, [handle, option])[0]
def controller_gettasknames(self, handle, option=""):
return self._send_and_recv(14, [handle, option])[0]
def controller_getvariablenames(self, handle, option=""):
return self._send_and_recv(15, [handle, option])[0]
def controller_getcommandnames(self, handle, option=""):
return self._send_and_recv(16, [handle, option])[0]
def controller_execute(self, handle, command, param=None):
return self._send_and_recv(17, [handle, command, param])[0]
def controller_getmessage(self, handle):
return self._send_and_recv(18, [handle])[0]
def controller_getattribute(self, handle):
return self._send_and_recv(19, [handle])[0]
def controller_gethelp(self, handle):
return self._send_and_recv(20, [handle])[0]
def controller_getname(self, handle):
return self._send_and_recv(21, [handle])[0]
def controller_gettag(self, handle):
return self._send_and_recv(22, [handle])[0]
def controller_puttag(self, handle, newval):
self._send_and_recv(23, [handle, newval])
def controller_getid(self, handle):
return self._send_and_recv(24, [handle])[0]
def controller_putid(self, handle, newval):
self._send_and_recv(25, [handle, newval])
def extension_getvariable(self, handle, name, option=""):
return self._send_and_recv(26, [handle, name, option])[0]
def extension_getvariablenames(self, handle, option=""):
return self._send_and_recv(27, [handle, option])[0]
def extension_execute(self, handle, command, param=None):
return self._send_and_recv(28, [handle, command, param])[0]
def extension_getattribute(self, handle):
return self._send_and_recv(29, [handle])[0]
def extension_gethelp(self, handle):
return self._send_and_recv(30, [handle])[0]
def extension_getname(self, handle):
return self._send_and_recv(31, [handle])[0]
def extension_gettag(self, handle):
return self._send_and_recv(32, [handle])[0]
def extension_puttag(self, handle, newval):
self._send_and_recv(33, [handle, newval])
def extension_getid(self, handle):
return self._send_and_recv(34, [handle])[0]
def extension_putid(self, handle, newval):
self._send_and_recv(35, [handle, newval])
def extension_release(self, handle):
self._send_and_recv(36, [handle])
def file_getfile(self, handle, name, option=""):
return self._send_and_recv(37, [handle, name, option])[0]
def file_getvariable(self, handle, name, option=""):
return self._send_and_recv(38, [handle, name, option])[0]
def file_getfilenames(self, handle, option=""):
return self._send_and_recv(39, [handle, option])[0]
def file_getvariablenames(self, handle, option=""):
return self._send_and_recv(40, [handle, option])[0]
def file_execute(self, handle, command, param=None):
return self._send_and_recv(41, [handle, command, param])[0]
def file_copy(self, handle, name, option=""):
self._send_and_recv(42, [handle, name, option])
def file_delete(self, handle, option=""):
self._send_and_recv(43, [handle, option])
def file_move(self, handle, name, option=""):
self._send_and_recv(44, [handle, name, option])
def file_run(self, handle, option=""):
return self._send_and_recv(45, [handle, option])[0]
def file_getdatecreated(self, handle):
return self._send_and_recv(46, [handle])[0]
def file_getdatelastaccessed(self, handle):
return self._send_and_recv(47, [handle])[0]
def file_getdatelastmodified(self, handle):
return self._send_and_recv(48, [handle])[0]
def file_getpath(self, handle):
return self._send_and_recv(49, [handle])[0]
def file_getsize(self, handle):
return self._send_and_recv(50, [handle])[0]
def file_gettype(self, handle):
return self._send_and_recv(51, [handle])[0]
def file_getvalue(self, handle):
return self._send_and_recv(52, [handle])[0]
def file_putvalue(self, handle, newval):
self._send_and_recv(53, [handle, newval])
def file_getattribute(self, handle):
return self._send_and_recv(54, [handle])[0]
def file_gethelp(self, handle):
return self._send_and_recv(55, [handle])[0]
def file_getname(self, handle):
return self._send_and_recv(56, [handle])[0]
def file_gettag(self, handle):
return self._send_and_recv(57, [handle])[0]
def file_puttag(self, handle, newval):
self._send_and_recv(58, [handle, newval])
def file_getid(self, handle):
return self._send_and_recv(59, [handle])[0]
def file_putid(self, handle, newval):
self._send_and_recv(60, [handle, newval])
def file_release(self, handle):
self._send_and_recv(61, [handle])
def robot_getvariable(self, handle, name, option=""):
return self._send_and_recv(62, [handle, name, option])[0]
def robot_getvariablenames(self, handle, option=""):
return self._send_and_recv(63, [handle, option])[0]
def robot_execute(self, handle, command, param=None):
return self._send_and_recv(64, [handle, command, param])[0]
def robot_accelerate(self, handle, axis, accel, decel):
self._send_and_recv(65, [handle, axis, c_float(accel), c_float(decel)])
def robot_change(self, handle, name):
self._send_and_recv(66, [handle, name])
def robot_chuck(self, handle, option=""):
self._send_and_recv(67, [handle, option])
def robot_drive(self, handle, axis, mov, option=""):
self._send_and_recv(68, [handle, axis, c_float(mov), option])
def robot_gohome(self, handle):
self._send_and_recv(69, [handle])
def robot_halt(self, handle, option=""):
self._send_and_recv(70, [handle, option])
def robot_hold(self, handle, option=""):
self._send_and_recv(71, [handle, option])
def robot_move(self, handle, comp, pose, option=""):
self._send_and_recv(72, [handle, comp, pose, option])
def robot_rotate(self, handle, rotsuf, deg, pivot, option=""):
self._send_and_recv(73, [handle, rotsuf, c_float(deg), pivot, option])
def robot_speed(self, handle, axis, speed):
self._send_and_recv(74, [handle, axis, c_float(speed)])
def robot_unchuck(self, handle, option=""):
self._send_and_recv(75, [handle, option])
def robot_unhold(self, handle, option=""):
self._send_and_recv(76, [handle, option])
def robot_getattribute(self, handle):
return self._send_and_recv(77, [handle])[0]
def robot_gethelp(self, handle):
return self._send_and_recv(78, [handle])[0]
def robot_getname(self, handle):
return self._send_and_recv(79, [handle])[0]
def robot_gettag(self, handle):
return self._send_and_recv(80, [handle])[0]
def robot_puttag(self, handle, newval):
self._send_and_recv(81, [handle, newval])
def robot_getid(self, handle):
return self._send_and_recv(82, [handle])[0]
def robot_putid(self, handle, newval):
self._send_and_recv(83, [handle, newval])
def robot_release(self, handle):
self._send_and_recv(84, [handle])
def task_getvariable(self, handle, name, option=""):
return self._send_and_recv(85, [handle, name, option])[0]
def task_getvariablenames(self, handle, option=""):
return self._send_and_recv(86, [handle, option])[0]
def task_execute(self, handle, command, param=None):
return self._send_and_recv(87, [handle, command, param])[0]
def task_start(self, handle, mode, option=""):
self._send_and_recv(88, [handle, mode, option])
def task_stop(self, handle, mode, option=""):
self._send_and_recv(89, [handle, mode, option])
def task_delete(self, handle, option=""):
self._send_and_recv(90, [handle, option])
def task_getfilename(self, handle):
return self._send_and_recv(91, [handle])[0]
def task_getattribute(self, handle):
return self._send_and_recv(92, [handle])[0]
def task_gethelp(self, handle):
return self._send_and_recv(93, [handle])[0]
def task_getname(self, handle):
return self._send_and_recv(94, [handle])[0]
def task_gettag(self, handle):
return self._send_and_recv(95, [handle])[0]
def task_puttag(self, handle, newval):
self._send_and_recv(96, [handle, newval])
def task_getid(self, handle):
return self._send_and_recv(97, [handle])[0]
def task_putid(self, handle, newval):
self._send_and_recv(98, [handle, newval])
def task_release(self, handle):
self._send_and_recv(99, [handle])
def variable_getdatetime(self, handle):
return self._send_and_recv(100, [handle])[0]
def variable_getvalue(self, handle):
return self._send_and_recv(101, [handle])[0]
def variable_putvalue(self, handle, newval):
self._send_and_recv(102, [handle, newval])
def variable_getattribute(self, handle):
return self._send_and_recv(103, [handle])[0]
def variable_gethelp(self, handle):
return self._send_and_recv(104, [handle])[0]
def variable_getname(self, handle):
return self._send_and_recv(105, [handle])[0]
def variable_gettag(self, handle):
return self._send_and_recv(106, [handle])[0]
def variable_puttag(self, handle, newval):
self._send_and_recv(107, [handle, newval])
def variable_getid(self, handle):
return self._send_and_recv(108, [handle])[0]
def variable_putid(self, handle, newval):
self._send_and_recv(109, [handle, newval])
def variable_getmicrosecond(self, handle):
return self._send_and_recv(110, [handle])[0]
def variable_release(self, handle):
self._send_and_recv(111, [handle])
def command_execute(self, handle, mode):
self._send_and_recv(112, [handle, mode])
def command_cancel(self, handle):
self._send_and_recv(113, [handle])
def command_gettimeout(self, handle):
return self._send_and_recv(114, [handle])[0]
def command_puttimeout(self, handle, newval):
self._send_and_recv(115, [handle, newval])
def command_getstate(self, handle):
return self._send_and_recv(116, [handle])[0]
def command_getparameters(self, handle):
return self._send_and_recv(117, [handle])[0]
def command_putparameters(self, handle, newval):
self._send_and_recv(118, [handle, newval])
def command_getresult(self, handle):
return self._send_and_recv(119, [handle])[0]
def command_getattribute(self, handle):
return self._send_and_recv(120, [handle])[0]
def command_gethelp(self, handle):
return self._send_and_recv(121, [handle])[0]
def command_getname(self, handle):
return self._send_and_recv(122, [handle])[0]
def command_gettag(self, handle):
return self._send_and_recv(123, [handle])[0]
def command_puttag(self, handle, newval):
self._send_and_recv(124, [handle, newval])
def command_getid(self, handle):
return self._send_and_recv(125, [handle])[0]
def command_putid(self, handle, newval):
self._send_and_recv(126, [handle, newval])
def command_release(self, handle):
self._send_and_recv(127, [handle])
def message_reply(self, handle, data):
self._send_and_recv(128, [handle, data])
def message_clear(self, handle):
self._send_and_recv(129, [handle])
def message_getdatetime(self, handle):
return self._send_and_recv(130, [handle])[0]
def message_getdescription(self, handle):
return self._send_and_recv(131, [handle])[0]
def message_getdestination(self, handle):
return self._send_and_recv(132, [handle])[0]
def message_getnumber(self, handle):
return self._send_and_recv(133, [handle])[0]
def message_getserialnumber(self, handle):
return self._send_and_recv(134, [handle])[0]
def message_getsource(self, handle):
return self._send_and_recv(135, [handle])[0]
def message_getvalue(self, handle):
return self._send_and_recv(136, [handle])[0]
def message_release(self, handle):
self._send_and_recv(137, [handle])
def _send_and_recv(self, funcid, args):
with self._lock:
self._bcap_send(self._serial, self._version, funcid, args)
(serial, version, hresult, retvals) = self._bcap_recv()
if self._serial >= 0xFFFF:
self._serial = 1
else:
self._serial += 1
if HResult.failed(hresult):
raise ORiNException(hresult)
if len(retvals) == 0:
retvals.append(None)
return retvals
def _bcap_send(self, serial, version, funcid, args):
buf = self._serialize(serial, version, funcid, args)
flags = 0
if hasattr(socket, 'MSG_NOSIGNAL'):
flags |= socket.MSG_NOSIGNAL
self._sock.sendall(buf, flags)
def _serialize(self, serial, version, funcid, args):
formatt = "<bIHhiH"
packet_data = [BCAPClient._BCAP_SOH, 0, serial, version, funcid, len(args)]
packed_args = self._serialize_args(args, True)
formatt += "%ds" % len(packed_args)
packet_data.append(packed_args)
formatt += "b"
packet_data.append(BCAPClient._BCAP_EOT)
buf = struct.pack(formatt, *packet_data)
buf = buf.replace(b'\0\0\0\0', struct.pack("<I", len(buf)), 1)
return buf
def _serialize_args(self, args, first=False):
formatt = "<"
packet_data = []
offset = 0
for arg in args:
if first:
formatt += "I"
packet_data.append(0)
packed_arg = self._serialize_arg(arg)
len_arg = len(packed_arg)
formatt += "%ds" % len_arg
packet_data.append(packed_arg)
if first:
packet_data[2 * offset] = len_arg
offset += 1
if len(packet_data) > 0:
return struct.pack(formatt, *packet_data)
else:
return b''
def _serialize_arg(self, arg):
formatt = "<HI"
packet_data = []
if arg is None:
packet_data = [VarType.VT_EMPTY, 1]
elif isinstance(arg, (list, tuple)):
len_arg = len(arg)
if len_arg <= 0:
packet_data = [VarType.VT_EMPTY, 1]
else:
is_vntary = False
type_o0 = type(arg[0])
for o in arg:
if type_o0 != type(o):
is_vntary = True
break
if is_vntary:
packed_args = self._serialize_args(arg)
formatt += "%ds" % len(packed_args)
packet_data += [VarType.VT_VARIANT | VarType.VT_ARRAY, len_arg, packed_args]
else:
if type_o0 in BCAPClient._DICT_TYPE2VT:
(vt, fmt, is_ctype) = BCAPClient._DICT_TYPE2VT[type_o0]
if vt == VarType.VT_DATE:
formatt += fmt * len_arg
packet_data += [vt | VarType.VT_ARRAY, len_arg]
for o in arg:
packet_data.append(BCAPClient.datetime2vntdate(o))
elif vt == VarType.VT_BSTR:
packet_data += [vt | VarType.VT_ARRAY, len_arg]
for o in arg:
if is_ctype:
str_tmp = o.value.encode("utf-16le")
else:
str_tmp = o.encode("utf-16le")
len_str = len(str_tmp)
formatt += fmt % len_str
packet_data += [len_str, str_tmp]
elif vt == VarType.VT_BOOL:
formatt += fmt * len_arg
packet_data += [vt | VarType.VT_ARRAY, len_arg]
for o in arg:
if o:
packet_data.append(-1)
else:
packet_data.append(0)
else:
formatt += fmt * len_arg
packet_data += [vt | VarType.VT_ARRAY, len_arg]
if is_ctype:
for o in arg:
packet_data.append(o.value)
else:
packet_data += arg
else:
raise ORiNException(HResult.E_CAO_VARIANT_TYPE_NOSUPPORT)
elif isinstance(arg, (bytes, bytearray)):
len_arg = len(arg)
formatt += "%ds" % len_arg
packet_data += [VarType.VT_ARRAY | VarType.VT_UI1, len_arg, arg]
else:
type_arg = type(arg)
if type_arg in BCAPClient._DICT_TYPE2VT:
(vt, fmt, is_ctype) = BCAPClient._DICT_TYPE2VT[type_arg]
if vt == VarType.VT_DATE:
formatt += fmt
date_tmp = BCAPClient.datetime2vntdate(arg)
packet_data += [vt, 1, date_tmp]
elif vt == VarType.VT_BSTR:
if is_ctype:
str_tmp = arg.value.encode("utf-16le")
else:
str_tmp = arg.encode("utf-16le")
len_str = len(str_tmp)
formatt += fmt % len_str
packet_data += [vt, 1, len_str, str_tmp]
elif vt == VarType.VT_BOOL:
formatt += fmt
if arg:
packet_data += [vt, 1, -1]
else:
packet_data += [vt, 1, 0]
else:
formatt += fmt
if is_ctype:
packet_data += [vt, 1, arg.value]
else:
packet_data += [vt, 1, arg]
else:
raise ORiNException(HResult.E_CAO_VARIANT_TYPE_NOSUPPORT)
return struct.pack(formatt, *packet_data)
def _bcap_recv(self):
while True:
buf_all = b''
buf_tmp = self._recv_with_select(1)
buf_all = b''.join([buf_all, buf_tmp])
buf_tmp = self._recv_with_select(4)
len_recv = struct.unpack("<I", buf_tmp)
buf_all = b''.join([buf_all, buf_tmp])
buf_tmp = self._recv_with_select(len_recv[0] - 5)
buf_all = b''.join([buf_all, buf_tmp])
(serial, version, hresult, retvals) = self._deserialize(buf_all)
if (self._serial == serial) and (hresult != HResult.S_EXECUTING):
break
return serial, version, hresult, retvals
def _recv_with_select(self, len_recv):
buf_recv = b''
while True:
(reads, writes, errors) = select.select(
[self._sock], [], [], self._timeout)
if len(reads) == 0:
raise ORiNException(HResult.E_TIMEOUT)
buf_recv = b''.join([buf_recv,
self._sock.recv(len_recv)])
if len(buf_recv) >= len_recv:
break
return buf_recv
def _deserialize(self, buf):
formatt = "<bIHhiH%dsb" % (len(buf) - 16)
(soh, len_buf, serial, version, hresult, len_args, buf_args, eot) \
= struct.unpack(formatt, buf)
if (soh != BCAPClient._BCAP_SOH) or (eot != BCAPClient._BCAP_EOT):
raise ORiNException(HResult.E_INVALIDPACKET)
(retvals, buf_args) = self._deserialize_args(buf_args, len_args, True)
return serial, version, hresult, retvals
def _deserialize_args(self, buf, len_args, first=False):
retvals = []
for i in range(len_args):
if first:
buf = buf[4:]
(retval, buf) = self._deserialize_arg(buf)
retvals.append(retval)
return retvals, buf
def _deserialize_arg(self, buf):
retval = None
formatt = "<HI%ds" % (len(buf) - 6)
(vt, len_arg, buf) = struct.unpack(formatt, buf)
if (vt & VarType.VT_ARRAY) != 0:
vt = vt ^ VarType.VT_ARRAY
if vt == VarType.VT_VARIANT:
(retval, buf) = self._deserialize_args(buf, len_arg)
elif vt == VarType.VT_UI1:
formatt = "<%ds%ds" % (len_arg, len(buf) - len_arg)
(retval, buf) = struct.unpack(formatt, buf)
elif vt in BCAPClient._DICT_VT2TYPE:
(fmt, len_val) = BCAPClient._DICT_VT2TYPE[vt]
if vt == VarType.VT_BSTR:
retval = []
for i in range(len_arg):
formatt = "<I%ds" % (len(buf) - 4)
(len_str, buf) = struct.unpack(formatt, buf)
formatt = "<%ds%ds" % (len_str, len(buf) - len_str)
(ret_tmp, buf) = struct.unpack(formatt, buf)
retval.append(ret_tmp.decode("utf-16le"))
else:
formatt = "<%s%ds" % (fmt * len_arg, len(buf) - (len_val * len_arg))
unpacked_arg = struct.unpack(formatt, buf)
retval = list(unpacked_arg[:-1])
buf = unpacked_arg[-1]
if vt == VarType.VT_DATE:
for i in range(len(retval)):
retval[i] = BCAPClient.vntdate2datetime(retval[i])
elif vt == VarType.VT_BOOL:
for i in range(len(retval)):
retval[i] = (retval[i] != 0)
else:
raise ORiNException(HResult.E_CAO_VARIANT_TYPE_NOSUPPORT)
else:
if vt in [VarType.VT_EMPTY, VarType.VT_NULL]:
pass
elif vt in BCAPClient._DICT_VT2TYPE:
(fmt, len_val) = BCAPClient._DICT_VT2TYPE[vt]
if vt == VarType.VT_BSTR:
formatt = "<I%ds" % (len(buf) - 4)
(len_str, buf) = struct.unpack(formatt, buf)
formatt = "<%ds%ds" % (len_str, len(buf) - len_str)
(retval, buf) = struct.unpack(formatt, buf)
retval = retval.decode("utf-16le")
else:
formatt = "<%s%ds" % (fmt, (len(buf) - len_val))
(retval, buf) = struct.unpack(formatt, buf)
if vt == VarType.VT_DATE:
retval = BCAPClient.vntdate2datetime(retval)
elif vt == VarType.VT_BOOL:
retval = (retval != 0)
else:
raise ORiNException(HResult.E_CAO_VARIANT_TYPE_NOSUPPORT)
return retval, buf | /rria_api_denso-0.1.1-py3-none-any.whl/rria_api_denso/utils/bcapclient.py | 0.728845 | 0.179297 | bcapclient.py | pypi |
"""
Software License Agreement (MIT License)
@copyright Copyright (c) 2017 DENSO WAVE INCORPORATED
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
"""
# -*- coding:utf-8 -*-
class VarType:
VT_EMPTY = 0
VT_NULL = 1
VT_I2 = 2
VT_I4 = 3
VT_R4 = 4
VT_R8 = 5
VT_CY = 6
VT_DATE = 7
VT_BSTR = 8
VT_DISPATCH = 9
VT_ERROR = 10
VT_BOOL = 11
VT_VARIANT = 12
VT_UNKNOWN = 13
VT_DECIMAL = 14
VT_I1 = 16
VT_UI1 = 17
VT_UI2 = 18
VT_UI4 = 19
VT_I8 = 20
VT_UI8 = 21
VT_INT = 22
VT_UINT = 23
VT_VOID = 24
VT_HRESULT = 25
VT_PTR = 26
VT_SAFEARRAY = 27
VT_CARRAY = 28
VT_USERDEFINED = 29
VT_LPSTR = 30
VT_LPWSTR = 31
VT_RECORD = 36
VT_INT_PTR = 37
VT_UINT_PTR = 38
VT_FILETIME = 64
VT_BLOB = 65
VT_STREAM = 66
VT_STORAGE = 67
VT_STREAMED_OBJECT = 68
VT_STORED_OBJECT = 69
VT_BLOB_OBJECT = 70
VT_CF = 71
VT_CLSID = 72
VT_VERSIONED_STREAM = 73
VT_BSTR_BLOB = 0xfff
VT_VECTOR = 0x1000
VT_ARRAY = 0x2000
VT_BYREF = 0x4000
VT_RESERVED = 0x8000
VT_ILLEGAL = 0xffff
VT_ILLEGALMASKED = 0xfff
VT_TYPEMASK = 0xfff | /rria_api_denso-0.1.1-py3-none-any.whl/rria_api_denso/utils/variant.py | 0.608827 | 0.161684 | variant.py | pypi |
from rria_api.ned.connect_ned import ConnectNed
from rria_api.ned.action_ned import ActionNed
from rria_api.gen3.connect_gen3 import ConnectGen3
from rria_api.gen3.action_gen3 import ActionGen3
from rria_api.robot_enum import RobotEnum
from time import sleep
class RobotObject:
def __init__(self, ip_address, robot_type):
"""
This class is used to initialize and use the robot object.
:param ip_address: string with the ip address of the robot
:param robot_type: enum with the type of the robot
"""
self.ip_address = ip_address
self.robot_type = robot_type
# This atribute is used to store the general robot instance
self.robot_instance = None
# This atribute is used to store the general connection instance
self.connection_instance = None
def connect_robot(self) -> bool:
"""
Connect robot depends on the robot type
:rtype: bool
"""
if self.robot_type is RobotEnum.GEN3_LITE:
try:
self.connection_instance = ConnectGen3(self.ip_address, ["admin", "admin"])
self.robot_instance = self.connection_instance.connect_robot()
return True
except(Exception,):
print('The connection attempt failed. Check the physical connection to the robot and try again later.')
return False
if self.robot_type is RobotEnum.NED:
try:
self.connection_instance = ConnectNed()
self.robot_instance = self.connection_instance.connect_robot(self.ip_address)
return True
except(Exception,):
print('The connection attempt failed. Check the physical connection to the robot and try again later.')
return False
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
def disconnect_robot(self):
"""
Close connection with robot
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
self.connection_instance.disconnect_robot()
if self.robot_type is RobotEnum.NED:
self.connection_instance.disconnect_robot()
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
def safe_disconnect(self):
"""
Move robot for home position and close connection with robot. Home position dependes on robot type. For Gen3 is
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0] degrees and for Ned is [0.0, 0.3, -1.3, 0.0, 0.0, 0.0] radians.
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
ActionGen3(self.robot_instance).move_to_zero()
self.connection_instance.disconnect_robot()
if self.robot_type is RobotEnum.NED:
ActionNed(self.robot_instance).move_to_home()
self.connection_instance.disconnect_robot()
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
# Move Joints/Cartesian methods
@property
def joints(self) -> list:
return self.get_joints()
def get_joints(self) -> list:
"""
Get joints value in radians
You can also use a getter ::
joints = robot.get_joints()
joints = robot.joints
:return: List of joints value
:rtype: list[float]
"""
if self.robot_type is RobotEnum.GEN3_LITE:
return ActionGen3(self.robot_instance).get_joints()
if self.robot_type is RobotEnum.NED:
return ActionNed(self.robot_instance).get_joints()
if self.robot_type is RobotEnum.DUMMY:
sleep(0.5)
return ['J1', 'J2', 'J3', 'J4', 'J5', 'J6']
def move_joints(self, j1, j2, j3, j4, j5, j6):
"""
Move robot joints. Joints are expressed in degrees.
All lines of the next example realize the same operation: ::
robot.move_joints(0.2, 0.1, 0.3, 0.0, 0.5, 0.0)
:param j1: joint 1,
:type j1: float
:param j2: joint 2,
:type j2: float
:param j3: joint 3,
:type j3: float
:param j4: joint 4,
:type j4: float
:param j5: joint 5,
:type j5: float
:param j6: joint 6,
:type j6: float
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
ActionGen3(self.robot_instance).move_joints([j1, j2, j3, j4, j5, j6])
if self.robot_type is RobotEnum.NED:
ActionNed(self.robot_instance).move_joints(j1, j2, j3, j4, j5, j6)
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
@property
def cartesian(self) -> list:
"""
Get end effector link pose as [x, y, z, roll, pitch, yaw].
Call this method is equivalent to call get_cartesian() method.
:return: Robot pose list.
:rtype: list[float]
"""
return self.get_cartesian()
def get_cartesian(self) -> list:
"""
Get end effector link pose as [x, y, z, roll, pitch, yaw].
x, y & z are expressed in meters / roll, pitch & yaw are expressed in radians
You can also use a getter ::
joints = robot.get_cartesian()
joints = robot.cartesian
:return: Robot pose list.
:rtype: list[float]
"""
if self.robot_type is RobotEnum.GEN3_LITE:
return ActionGen3(self.robot_instance).get_cartesian()
if self.robot_type is RobotEnum.NED:
return ActionNed(self.robot_instance).get_cartesian()
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return ['x', 'y', 'z', 'roll', 'pitch', 'yaw']
def move_cartesian(self, x, y, z, roll, pitch, yaw):
"""
Move robot end effector pose to a (x, y, z, roll, pitch, yaw, frame_name) pose
in a particular frame (frame_name) if defined.
x, y & z are expressed in meters / roll, pitch & yaw are expressed in radians
All lines of the next example realize the same operation: ::
robot.move_cartesian(0.2, 0.1, 0.3, 0.0, 0.5, 0.0)
:param x: coordinate x,
:type x: float
:param y: coordinate y,
:type y: float
:param z: coordinate z,
:type z: float
:param roll: rotation on x-axis,
:type roll: float
:param pitch: rotation on y-axis,
:type pitch: float
:param yaw: rotation on z-axis,
:type yaw: float
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
return ActionGen3(self.robot_instance).move_cartesian([x, y, z, roll, pitch, yaw])
if self.robot_type is RobotEnum.NED:
return ActionNed(self.robot_instance).move_cartesian(x, y, z, roll, pitch, yaw)
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
# TODO: Pegar os valores de home do robot
def move_to_home(self):
"""
Move robot for home position. Home position dependes on robot type. For Gen3 is [0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
degrees and for Ned is [0.0, 0.3, -1.3, 0.0, 0.0, 0.0] radians.
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
ActionGen3(self.robot_instance).move_to_home()
if self.robot_type is RobotEnum.NED:
ActionNed(self.robot_instance).move_to_home()
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
def move_to_zero(self):
"""
Move robot for zero position. Home position dependes on robot type. For Gen3 is [0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
degrees and for Ned is [0.0, 0.0, 0.0, 0.0, 0.0, 0.0] radians.
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
ActionGen3(self.robot_instance).move_to_zero()
if self.robot_type is RobotEnum.NED:
ActionNed(self.robot_instance).move_to_zero()
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
def open_gripper(self):
"""
Open gripper.
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
ActionGen3(self.robot_instance).open_gripper()
if self.robot_type is RobotEnum.NED:
ActionNed(self.robot_instance).open_gripper()
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
def close_gripper(self):
"""
Close gripper
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
ActionGen3(self.robot_instance).close_gripper()
if self.robot_type is RobotEnum.NED:
ActionNed(self.robot_instance).close_gripper()
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
# TODO: Ver a função de aumento de velocidade para o Gen3
def set_velocity(self, velocity):
"""
Limit arm max velocity to a percentage of its maximum velocity. For Niryo one, velocity is a percentage of 100.
For gen3, there are two types of velocities, an angular and a cartesian. The speed used in this method is
angular.
:param velocity: Should be between 1 & 100 for niryo
:type velocity: int
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
ActionGen3(self.robot_instance).set_velocity(velocity)
if self.robot_type is RobotEnum.NED:
ActionNed(self.robot_instance).set_velocity(velocity)
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
def calibrate(self):
"""
Start an automatic motors calibration if motors are not calibrated yet
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
print('Gen3 NÃO necessita de calibração')
if self.robot_type is RobotEnum.NED:
ActionNed(self.robot_instance).calibrate()
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
def go_to_sleep(self):
"""
Go home pose and activate learning mode. The function is available only for Ned robot.
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
...
if self.robot_type is RobotEnum.NED:
ActionNed(self.robot_instance).go_to_sleep()
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True
def apply_emergency_stop(self):
"""
Apply emergency stop. The function is available only for Kinova Gen3.
:rtype: None
"""
if self.robot_type is RobotEnum.GEN3_LITE:
ActionGen3(self.robot_instance).apply_emergency_stop()
if self.robot_type is RobotEnum.NED:
...
if self.robot_type is RobotEnum.DUMMY:
sleep(1)
return True | /rria_api-1.0.9.tar.gz/rria_api-1.0.9/rria_api/robot_object.py | 0.841403 | 0.437793 | robot_object.py | pypi |
from kortex_api.autogen.messages import Base_pb2
import threading
import time
TIMEOUT_DURATION = 10
# Classe de movimentação adaptada dos exemplos disponibilizados pela API.
# Essa classe é a única (até agora) que tem contato direto com a base (CPU) do Gen3
class Gen3Api:
@staticmethod
def check_for_end_or_abort(error):
def check(notification, e=error):
if notification.action_event == Base_pb2.ACTION_END or notification.action_event == Base_pb2.ACTION_ABORT:
e.set()
return check
def move_to_home(self, base):
# Make sure the arm is in Single Level Servoing mode
base_servo_mode = Base_pb2.ServoingModeInformation()
base_servo_mode.servoing_mode = Base_pb2.SINGLE_LEVEL_SERVOING
base.SetServoingMode(base_servo_mode)
# Move arm to ready position
action_type = Base_pb2.RequestedActionType()
action_type.action_type = Base_pb2.REACH_JOINT_ANGLES
action_list = base.ReadAllActions(action_type)
action_handle = None
for action in action_list.action_list:
if action.name == "Home":
action_handle = action.handle
if action_handle is None:
print("Can't reach safe position. Exiting")
return False
e = threading.Event()
notification_handle = base.OnNotificationActionTopic(
self.check_for_end_or_abort(e),
Base_pb2.NotificationOptions()
)
base.ExecuteActionFromReference(action_handle)
finished = e.wait(TIMEOUT_DURATION)
base.Unsubscribe(notification_handle)
if finished:
print("Safe position reached")
else:
print("Timeout on action notification wait")
return finished
@staticmethod
def populate_angular_pose(joint_pose, duration_factor):
waypoint = Base_pb2.AngularWaypoint()
waypoint.angles.extend(joint_pose)
waypoint.duration = duration_factor * 5.0
return waypoint
# Método utilizado para mover o robô para waypoints definidos.
def move_trajectory(self, base, joints_list):
base_servo_mode = Base_pb2.ServoingModeInformation()
base_servo_mode.servoing_mode = Base_pb2.SINGLE_LEVEL_SERVOING
base.SetServoingMode(base_servo_mode)
joint_poses = joints_list
waypoints = Base_pb2.WaypointList()
waypoints.duration = 0.0
waypoints.use_optimal_blending = False
index = 0
for joint_pose in joint_poses:
waypoint = waypoints.waypoints.add()
waypoint.name = "waypoint_" + str(index)
duration_factor = 1
# Joints/motors 5 and 7 are slower and need more time
if index == 4 or index == 6:
duration_factor = 6 # Min 30 seconds
waypoint.angular_waypoint.CopyFrom(self.populate_angular_pose(joint_pose, duration_factor))
index = index + 1
# Verify validity of waypoints
result = base.ValidateWaypointList(waypoints)
if len(result.trajectory_error_report.trajectory_error_elements) == 0:
e = threading.Event()
notification_handle = base.OnNotificationActionTopic(
self.check_for_end_or_abort(e),
Base_pb2.NotificationOptions()
)
base.ExecuteWaypointTrajectory(waypoints)
finished = e.wait(TIMEOUT_DURATION)
base.Unsubscribe(notification_handle)
if finished:
pass
else:
print("Timeout on action notification wait")
return finished
else:
pass
# O método move_joints chama esse método para mover as juntas.
def angular_movement(self, base, joints_list):
# Starting angular action movement
action = Base_pb2.Action()
action.name = "Angular action movement"
action.application_data = ""
# Place arm straight up
joint_id = 1
for joint_value in joints_list:
joint_angle = action.reach_joint_angles.joint_angles.joint_angles.add()
joint_angle.joint_identifier = joint_id
joint_angle.value = joint_value
joint_id += 1
e = threading.Event()
notification_handle = base.OnNotificationActionTopic(
self.check_for_end_or_abort(e),
Base_pb2.NotificationOptions()
)
# Executing action
base.ExecuteAction(action)
# Waiting for movement to finish
finished = e.wait(TIMEOUT_DURATION)
base.Unsubscribe(notification_handle)
if finished:
pass
else:
print("Timeout on action notification wait")
return finished
def cartesian_movement(self, base, cartesian_list):
# Starting Cartesian action movement
action = Base_pb2.Action()
action.name = "Example Cartesian action movement"
action.application_data = ""
cartesian_pose = action.reach_pose.target_pose
cartesian_pose.x = cartesian_list[0] # (meters)
cartesian_pose.y = cartesian_list[1] # (meters)
cartesian_pose.z = cartesian_list[2] # (meters)
cartesian_pose.theta_x = cartesian_list[3] # (degrees)
cartesian_pose.theta_y = cartesian_list[4] # (degrees)
cartesian_pose.theta_z = cartesian_list[5] # (degrees)
e = threading.Event()
notification_handle = base.OnNotificationActionTopic(
self.check_for_end_or_abort(e),
Base_pb2.NotificationOptions()
)
# Executing action
base.ExecuteAction(action)
# Waiting for movement to finish
finished = e.wait(TIMEOUT_DURATION)
base.Unsubscribe(notification_handle)
if finished:
pass
else:
print("Timeout on action notification wait")
return finished
# Função para fechar a garra. Ver outra opção ao sleep.
@staticmethod
def close_gripper(base, close_time):
# Create the GripperCommand we will send
gripper_command = Base_pb2.GripperCommand()
finger = gripper_command.gripper.finger.add()
# Close the gripper with position increments
gripper_command.mode = Base_pb2.GRIPPER_POSITION
finger.finger_identifier = 1
finger.value = 1
base.SendGripperCommand(gripper_command)
time.sleep(close_time)
# Função para abrir a garra. Ver outra opção ao sleep.
@staticmethod
def open_gripper(base, open_time):
# Create the GripperCommand we will send
gripper_command = Base_pb2.GripperCommand()
finger = gripper_command.gripper.finger.add()
# Close the gripper with position increments
gripper_command.mode = Base_pb2.GRIPPER_POSITION
finger.finger_identifier = 1
finger.value = 0
base.SendGripperCommand(gripper_command)
time.sleep(open_time)
@staticmethod
def get_joints(base_cyclic):
feedback = base_cyclic.RefreshFeedback()
joints = [round(feedback.actuators[joint].position, 3) for joint in range(0, 6)]
return joints
@staticmethod
def get_cartesian(base_cyclic):
fb = base_cyclic.RefreshFeedback()
pose_meters = [round(fb.base.tool_pose_x, 3), round(fb.base.tool_pose_y, 3), round(fb.base.tool_pose_z, 3),
round(fb.base.tool_pose_theta_x, 3), round(fb.base.tool_pose_theta_y, 3),
round(fb.base.tool_pose_theta_z, 3)]
return pose_meters
@staticmethod
def set_velocity(base, velocity):
...
@staticmethod
def apply_emergency_stop(base):
base.ApplyEmergencyStop() | /rria_api-1.0.9.tar.gz/rria_api-1.0.9/rria_api/gen3/api_gen3/gen3_api.py | 0.657098 | 0.216446 | gen3_api.py | pypi |
import os
import datetime
import typing
from dataclasses import dataclass
from redis import Redis
@dataclass
class Tier:
name: str
per_minute: int
per_hour: int
per_day: int
@dataclass
class DailyUsage:
date: datetime.date
calls: int
class RateLimitExceeded(Exception):
pass
def _get_redis_connection() -> Redis:
host = os.environ.get("RRL_REDIS_HOST", "localhost")
port = int(os.environ.get("RRL_REDIS_PORT", 6379))
db = int(os.environ.get("RRL_REDIS_DB", 0))
return Redis(host=host, port=port, db=db)
class RateLimiter:
"""
<prefix>:<key>:<hour><minute> expires in 2 minutes
<prefix>:<key>:<hour> expires in 2 hours
<prefix>:<key>:<day> never expires
"""
def __init__(
self,
tiers: typing.List[Tier],
*,
prefix: str = "",
use_redis_time: bool = True,
track_daily_usage: bool = True,
):
self.redis = _get_redis_connection()
self.tiers = {tier.name: tier for tier in tiers}
self.prefix = prefix
self.use_redis_time = use_redis_time
self.track_daily_usage = track_daily_usage
def check_limit(self, key: str, tier_name: str) -> bool:
try:
tier = self.tiers[tier_name]
except KeyError:
raise ValueError(f"unknown tier: {tier_name}")
if self.use_redis_time:
timestamp = self.redis.time()[0]
now = datetime.datetime.fromtimestamp(timestamp)
else:
now = datetime.datetime.utcnow()
pipe = self.redis.pipeline()
if tier.per_minute:
minute_key = f"{self.prefix}:{key}:m{now.minute}"
pipe.incr(minute_key)
pipe.expire(minute_key, 60)
if tier.per_hour:
hour_key = f"{self.prefix}:{key}:h{now.hour}"
pipe.incr(hour_key)
pipe.expire(hour_key, 3600)
if tier.per_day or self.track_daily_usage:
day = now.strftime("%Y%m%d")
day_key = f"{self.prefix}:{key}:d{day}"
pipe.incr(day_key)
# keep data around for usage tracking
if not self.track_daily_usage:
pipe.expire(day_key, 86400)
result = pipe.execute()
# the result is pairs of results of incr and expire calls, so if all 3 limits are set
# it looks like [per_minute_calls, True, per_hour_calls, True, per_day_calls]
# we increment value_pos as we consume values so we know which location we're looking at
value_pos = 0
if tier.per_minute:
if result[value_pos] > tier.per_minute:
raise RateLimitExceeded(
f"exceeded limit of {tier.per_minute}/min: {result[value_pos]}"
)
value_pos += 2
if tier.per_hour:
if result[value_pos] > tier.per_hour:
raise RateLimitExceeded(
f"exceeded limit of {tier.per_hour}/hour: {result[value_pos]}"
)
value_pos += 2
if tier.per_day:
if result[value_pos] > tier.per_day:
raise RateLimitExceeded(
f"exceeded limit of {tier.per_day}/day: {result[value_pos]}"
)
return True
def get_usage_since(
self,
key: str,
start: datetime.date,
end: typing.Optional[datetime.date] = None,
) -> typing.List[DailyUsage]:
if not self.track_daily_usage:
raise RuntimeError("track_daily_usage is not enabled")
if not end:
end = datetime.date.today()
days = []
day = start
while day <= end:
days.append(day)
day += datetime.timedelta(days=1)
day_keys = [f"{self.prefix}:{key}:d{day.strftime('%Y%m%d')}" for day in days]
return [
DailyUsage(d, int(calls.decode()) if calls else 0)
for d, calls in zip(days, self.redis.mget(day_keys))
] | /rrl-0.3.1.tar.gz/rrl-0.3.1/rrl.py | 0.499268 | 0.238484 | rrl.py | pypi |
import numpy as np
def _matern32(x, y, sigmas, corr_len):
"""
Generates a Matern (nu=3/2) covariance matrix that assumes x/y has the same correlation length
C_ij = \sigma_i \sigma_j (1 + sqrt(3) r_ij / l) exp(-sqrt(3) r_ij / l)
Args:
x (np.array): 1-D array of x coordinates
y (np.array): 1-D array of y coordinates
sigmas (np.array): 1-D array of errors on each pixel
corr_len (float): correlation length of the Matern function
Returns:
cov (np.array): 2-D covariance matrix parameterized by the Matern function
"""
r = np.sqrt((x[:, None] - x[None, :])**2 + (y[:, None] - y[None, :])**2)
arg = np.sqrt(3) * r / corr_len
cov = sigmas[:, None] * sigmas[None, :] * (1+arg) * np.exp(-arg)
return cov
def matern32(x, y, sigmas, corr_len):
"""
Generates a Matern (nu=3/2) covariance matrix that assumes x/y has the same correlation length
C_ij = \sigma_i \sigma_j (1 + sqrt(3) r_ij / l) exp(-sqrt(3) r_ij / l)
Args:
x (np.array): 1-D array of x coordinates
y (np.array): 1-D array of y coordinates
sigmas (np.array): 1-D array of errors on each pixel
corr_len (float): correlation length of the Matern function
Returns:
cov (np.array): 2-D covariance matrix parameterized by the Matern function
"""
return _matern32(x, y, sigmas, corr_len)
def _sq_exp(x, y, sigmas, corr_len):
"""
Generates square exponential covariance matrix that assumes x/y has the same correlation length
C_ij = \sigma_i \sigma_j exp(-r_ij^2/[2 l^2])
Args:
x (np.array): 1-D array of x coordinates
y (np.array): 1-D array of y coordinates
sigmas (np.array): 1-D array of errors on each pixel
corr_len (float): correlation length (i.e. standard deviation of Gaussian)
Returns:
cov (np.array): 2-D covariance matrix parameterized by the Matern function
"""
r = np.sqrt((x[:, None] - x[None, :])**2 + (y[:, None] - y[None, :])**2)
arg = r**2 / (2 * corr_len**2)
cov = sigmas[:, None] * sigmas[None, :] * np.exp(-arg)
return cov
def sq_exp(x, y, sigmas, corr_len):
"""
Generates square exponential covariance matrix that assumes x/y has the same correlation length
C_ij = \sigma_i \sigma_j exp(-r_ij^2/[2 l^2])
Args:
x (np.array): 1-D array of x coordinates
y (np.array): 1-D array of y coordinates
sigmas (np.array): 1-D array of errors on each pixel
corr_len (float): correlation length (i.e. standard deviation of Gaussian)
mode (string): either "numpy", "cython", or None, specifying the implementation of the kernel.
Returns:
cov (np.array): 2-D covariance matrix parameterized by the Matern function
"""
return _sq_exp(x, y, sigmas, corr_len)
def delta(x, y, sigmas, *args):
"""
Generates a diagonal covariance matrix
C_ij = \sigma_i \sigma_j delta_{ij}
Args:
x (np.array): 1-D array of x coordinates
y (np.array): 1-D array of y coordinates
sigmas (np.array): 1-D array of errors on each pixel
"""
return np.diag(sigmas**2) | /rrlfe-0.0.12.tar.gz/rrlfe-0.0.12/modules/covars.py | 0.879419 | 0.906901 | covars.py | pypi |
# This makes plots showing the effective temperature retrievals based on synthetic spectra
# produced by R.W.
# Created from parent restacking_scraped_data.ipynb 2021 March 17 by E.S.
import pandas as pd
from astropy.io.fits import getdata
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import os.path
import csv
import git
from . import *
def line_fit_temp_range(x_data_pass, y_data_pass, t_min, t_max):
'''
Find line of best fit
INPUTS:
x_data_pass: abcissa
y_data_pass: ordinate
OUTPUTS:
m: slope
err_m: error in slope
b: y-intercept
err_b: error in y-intercept
'''
# remove the stuff outside of 6000-7250 K
#x_data_rrl = x_data_pass.where(np.logical_and(x_data_pass>=5900,x_data_pass<=7350))
#y_data_rrl = x_data_pass.where(np.logical_and(x_data_pass>=5900,x_data_pass<=7350))
x_data_rrl = x_data_pass[np.where(np.logical_and(y_data_pass>=t_min,y_data_pass<=t_max))]
y_data_rrl = y_data_pass[np.where(np.logical_and(y_data_pass>=t_min,y_data_pass<=t_max))]
coeff, cov = np.polyfit(x_data_rrl, y_data_rrl, 1, full=False, cov=True)
m = coeff[0]
b = coeff[1]
err_m = np.sqrt(np.diag(cov))[0]
err_b = np.sqrt(np.diag(cov))[1]
logging.info("Fitting a Teff vs. Balmer line trend. Temperature range "+\
"restricted to " + str(int(t_min)) + ", " + str(int(t_max)) +" K")
return m, err_m, b, err_b
def temp_vs_balmer(df_poststack_file_name_read = config_red["data_dirs"]["DIR_EW_PRODS"]+config_red["file_names"]["RESTACKED_EW_DATA_W_METADATA"],
df_poststack_file_name_write = config_red["data_dirs"]["DIR_EW_PRODS"] + config_red["file_names"]["RESTACKED_EW_DATA_GOOD_ONLY_TEFFFIT"],
plot_write = config_red["data_dirs"]["DIR_BIN"] + config_red["file_names"]["PLOT_TEFF_VS_BALMER"],
teff_data_write = config_red["data_dirs"]["DIR_BIN"] + config_red["file_names"]["TREND_TEFF_VS_BALMER"],
plot = True,
test_flag=False):
'''
Finds a linear Teff vs. Balmer EW relation. This is an ancillary step before
running the MCMC further downstream in the pipeline.
INPUTS:
df_poststack_file_name_read: name of file that contains all the data from the upstream
pipeline and will be read in for the fit; it should contain columns with 'teff'
and 'EW_Balmer', with which a simple linear fit is made
df_poststack_file_name_write: name of file to write; this file is the same as
the one read in, except that now it also includes the best-fit values of the Teff
teff_data_write: file name of txt file containing info on the lienar trend
plot_write: file name of Teff vs Balmer plot to write
teff_data_write: name of file to write Teff data to
plot: flag whether to write plot or not
test_flag: if testing, suppress prompts in terminal
OUTPUTS:
m: slope
err_m: error in slope
b: y-intercept
err_b: error in y-intercept
'''
# the min and max Teff of spectra that the linear fit will be made to
t_min = int(config_red["teff_linear"]["MIN_TEFF"])
t_max = int(config_red["teff_linear"]["MAX_TEFF"])
# read in data
df_poststack = pd.read_csv(df_poststack_file_name_read)
# find linear trend of net Balmer EW with Teff
teff = df_poststack["teff"].values.astype(float)
# fit a straight line: net Balmer
ews_Balmer = df_poststack["EW_Balmer"].values.astype(float)
m, err_m, b, err_b = line_fit_temp_range(x_data_pass=ews_Balmer,
y_data_pass=teff,
t_min=t_min,
t_max=t_max)
logging.info("Best-fit line for Teff=m*EW_Balmer + b is [m, err_m, b, err_b] = " +
"[" + str(m) + ", " + str(err_m) + ", " + str(b) + ", " + str(err_b) + "]")
# add the best-fit Teffs to dataframe
teffs_bestfit = np.add(np.multiply(m,ews_Balmer),b)
df_poststack["teff_bestfit"] = teffs_bestfit
# write all the data to file
df_poststack.to_csv(df_poststack_file_name_write,index=False)
logging.info("Wrote out data file including linear-best-fit Teffs to " + df_poststack_file_name_write)
# retrieve hash
repo = git.Repo(search_parent_directories=True)
sha = repo.head.object.hexsha
# arrange info into dictionary
linfit_info={
"Hash" : sha,
"Teff_min" : t_min,
"Teff_max" : t_max,
"m" : m,
"err_m" : err_m,
"b" : b,
"err_b" : err_b
}
# write the Teff trend parameters alone to a separate text file
# (note this overwrites any previous existing file)
if (os.path.exists(teff_data_write) and test_flag==False): # pragma: no cover
print(teff_data_write)
input("Text file containing Teff linear fit trend already exists! \n" + \
teff_data_write + "\n" + \
"Do what you want with that file and hit [ENTER] (will overwrite)")
with open(teff_data_write, 'w') as file1:
# header
file1.write("Linear fit to Teff vs Balmer EW\n")
# data
for key, value in linfit_info.items():
file1.write('%s:%s\n' % (key, value))
file1.close()
logging.info("Wrote out text file with linear-best-fit params to " + teff_data_write)
# save an FYI plot
if plot: # pragma: no cover
plt.clf()
plt.title("Teff from the Balmer EW\n[m, err_m, b, err_b] = \n" +
"[" + str(np.round(m,2)) + ", " + str(np.round(err_m,2)) + ", " + str(np.round(b,2)) + ", " + str(np.round(err_b,2)) + "]")
plt.axhline(y=t_max, color="k", alpha=0.4)
plt.axhline(y=t_min, color="k", alpha=0.4)
plt.plot(ews_Balmer, teffs_bestfit, linestyle='--')
plt.scatter(ews_Balmer, teff, color="k", s=3)
plt.ylabel("Teff (K)")
plt.xlabel("EW (Angstr)")
plt.tight_layout()
plt.savefig(plot_write)
plt.clf()
logging.info("Wrote out plot of Teffs vs. Balmer EW to " + plot_write)
return df_poststack | /rrlfe-0.0.12.tar.gz/rrlfe-0.0.12/modules/teff_retrieval.py | 0.659624 | 0.444505 | teff_retrieval.py | pypi |
import numpy as np
from rrlpy.rrl.constants import Ry, k_B, h, m_e, e, c
def fnnp_app(n, dn):
"""
Eq. (1) Menzel (1969)
Parameters
----------
n : int
Principal quantum number.
dn : int
Jump between principal quantum numbers.
Returns
-------
fnnp : float
fnnp
"""
return n * mdn(dn) * (1.0 + 1.5 * dn / n)
def mdn(dn):
"""
Gives the :math:`M(\\Delta n)` factor for a given :math:`\\Delta n`.
ref. Menzel (1968)
Parameters
----------
dn : int
:math:`\\Delta n`. Up to n==5.
Returns
-------
mdn : float
:math:`M(\\Delta n)`
:Example:
>>> mdn(1)
0.1908
>>> mdn(5)
0.001812
"""
if dn == 1:
mdn_ = 0.1908
if dn == 2:
mdn_ = 0.02633
if dn == 3:
mdn_ = 0.008106
if dn == 4:
mdn_ = 0.003492
if dn == 5:
mdn_ = 0.001812
return mdn_
def tau_constant():
"""
Constants that go into the RRL optical depth.
"""
return (
h**3 * e**2.0 * np.pi / (np.power(2.0 * np.pi * m_e * k_B, 3.0 / 2.0) * m_e * c)
).cgs
def tau_exact(n, ne, te, ni, pl, fnnp, nu, dn, z):
"""
Optical depth of a RRL.
Parameters
----------
n : int
Principal quantum number.
ne : float
Electron density.
te : float
Electron temperature.
ni : float
Collisional partner density.
pl : float
Path length along the line of sight.
fnnp : float
nu : float
Frequency of the transition.
dn : int
Jump between energy levels.
z : int
Net charge of the atom.
"""
cte = tau_constant()
xi_ = xi(n, te, z)
return (
cte
* n**2
* fnnp
* ne
* ni
* pl
* np.power(te, -3.0 / 2.0)
* np.exp(xi_)
* (1.0 - np.exp(-h * nu / (k_B * te)))
)
def xi(n, te, z):
"""
Argument of the exponential factor in the Saha-Boltzmann equation.
Parameters
----------
n : int
Principal quantum number.
te : float
Electron temperature in K.
z : float
Net charge of the ion.
Returns
-------
xi : float
:math:`z^2 Ry / (n^2 k_{B} te)`
"""
return (z**2.0 * Ry / (n**2.0 * k_B * te)).cgs | /rrl/core.py | 0.935398 | 0.689482 | core.py | pypi |
# RRnlp
This library provides (easy!) access to a suite of models for extracting key data from abstracts of randomized controlled trials (RCTs).
In particular, `rrnlp` features lightweight variants of the models defined in Trialstreamer (https://trialstreamer.robotreviewer.net/; https://academic.oup.com/jamia/article/27/12/1903/5907063). However, the models here — all save for the sample size extractor constructed as linear layers on top of `SciBERT` representations, with only minimal fine tuning of `SciBERT` layers — are still experimental, and may not be as performant as the models used in Trialstreamer (yet!). See below for example usage.
# Use
```python
import rrnlp
trial_reader = rrnlp.TrialReader()
ti_abs = {"ti": 'A Cluster-Randomized Trial of Hydroxychloroquine for Prevention of Covid-19',
"ab": '''Background: Current strategies for preventing severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) infection are limited to nonpharmacologic interventions. Hydroxychloroquine has been proposed as a postexposure therapy to prevent coronavirus disease 2019 (Covid-19), but definitive evidence is lacking.\n\nMethods: We conducted an open-label, cluster-randomized trial involving asymptomatic contacts of patients with polymerase-chain-reaction (PCR)-confirmed Covid-19 in Catalonia, Spain. We randomly assigned clusters of contacts to the hydroxychloroquine group (which received the drug at a dose of 800 mg once, followed by 400 mg daily for 6 days) or to the usual-care group (which received no specific therapy). The primary outcome was PCR-confirmed, symptomatic Covid-19 within 14 days. The secondary outcome was SARS-CoV-2 infection, defined by symptoms compatible with Covid-19 or a positive PCR test regardless of symptoms. Adverse events were assessed for up to 28 days.\n\nResults: The analysis included 2314 healthy contacts of 672 index case patients with Covid-19 who were identified between March 17 and April 28, 2020. A total of 1116 contacts were randomly assigned to receive hydroxychloroquine and 1198 to receive usual care. Results were similar in the hydroxychloroquine and usual-care groups with respect to the incidence of PCR-confirmed, symptomatic Covid-19 (5.7% and 6.2%, respectively; risk ratio, 0.86 [95% confidence interval, 0.52 to 1.42]). In addition, hydroxychloroquine was not associated with a lower incidence of SARS-CoV-2 transmission than usual care (18.7% and 17.8%, respectively). The incidence of adverse events was higher in the hydroxychloroquine group than in the usual-care group (56.1% vs. 5.9%), but no treatment-related serious adverse events were reported.\n\nConclusions: Postexposure therapy with hydroxychloroquine did not prevent SARS-CoV-2 infection or symptomatic Covid-19 in healthy persons exposed to a PCR-positive case patient. (Funded by the crowdfunding campaign YoMeCorono and others; BCN-PEP-CoV2 ClinicalTrials.gov number, NCT04304053.).'''}
preds = trial_reader.read_trial(ti_abs)
```
Should yield the following dictionary
```python
import pprint
pp = pprint.PrettyPrinter(width=200)
pp.pprint(preds)
{'bias_ab_bot': {'prob_low_rob': 0.14128409107623344},
'pico_span_bot': {'i': ['hydroxychloroquine', 'Hydroxychloroquine', 'usual care', 'drug', 'usual-care group (which received no specific therapy', 'hydroxychloroquine group'],
'i_mesh': [{'cui': 'C0020336', 'mesh_term': 'Hydroxychloroquine', 'mesh_ui': 'D006886'},
{'cui': 'C0013227', 'mesh_term': 'Pharmaceutical Preparations', 'mesh_ui': 'D004364'},
{'cui': 'C1257890', 'mesh_term': 'Population Groups', 'mesh_ui': 'D044382'},
{'cui': 'C0087111', 'mesh_term': 'Therapeutics', 'mesh_ui': 'D013812'}],
'o': ['PCR-confirmed, symptomatic Covid-19',
'SARS-CoV-2 infection',
'incidence of adverse events',
'symptomatic Covid-19',
'Adverse',
'serious adverse events',
'Covid-19 or a positive PCR test',
'SARS-CoV-2',
'incidence of PCR-confirmed, symptomatic Covid-19',
'incidence of SARS-CoV-2 transmission',
'symptoms'],
'o_mesh': [{'cui': 'C0032520', 'mesh_term': 'Polymerase Chain Reaction', 'mesh_ui': 'D016133'},
{'cui': 'TS-COV19', 'mesh_term': 'COVID-19', 'mesh_ui': 'C000657245'},
{'cui': 'C1175743', 'mesh_term': 'SARS Virus', 'mesh_ui': 'D045473'},
{'cui': 'C3714514', 'mesh_term': 'Infection', 'mesh_ui': 'D007239'},
{'cui': 'C0021149', 'mesh_term': 'Incidence', 'mesh_ui': 'D015994'},
{'cui': 'C0040722', 'mesh_term': 'transmission', 'mesh_ui': 'Q000635'},
{'cui': 'C0683368', 'mesh_term': 'symptoms', 'mesh_ui': 'Q000175'}],
'p': ['2314 healthy contacts of 672 index case patients with Covid-19 who were identified between March 17 and April 28, 2020',
'asymptomatic contacts of patients with polymerase-chain-reaction',
'healthy persons',
'Covid-19 in Catalonia, Spain',
'PCR-positive'],
'p_mesh': [{'cui': 'C0600653', 'mesh_term': 'Index', 'mesh_ui': 'D020481'},
{'cui': 'C0030705', 'mesh_term': 'Patient', 'mesh_ui': 'D010361'},
{'cui': 'TS-COV19', 'mesh_term': 'COVID-19', 'mesh_ui': 'C000657245'},
{'cui': 'C0032520', 'mesh_term': 'Polymerase Chain Reaction', 'mesh_ui': 'D016133'},
{'cui': 'C0027361', 'mesh_term': 'Person', 'mesh_ui': 'D009272'},
{'cui': 'C0037747', 'mesh_term': 'Spain', 'mesh_ui': 'D013030'}]},
'punchline_bot': {'effect': '— no diff',
'punchline_text': 'Results were similar in the hydroxychloroquine and usual-care groups with respect to the incidence of PCR-confirmed, symptomatic Covid-19 (5.7% and 6.2%, '
'respectively; risk ratio, 0.86 [95% confidence interval, 0.52 to 1.42]).'},
'rct_bot': {'is_rct': True, 'prob_rct': 0.6828127889603965, 'scores': {'is_rct_balanced': True, 'is_rct_precise': True, 'is_rct_sensitive': True}},
'sample_size_bot': {'num_randomized': '2314'}}
```
# Installing
*NOTE*: As of mid-October 2021, installing `rrnlp` via `pip` does not cooperate well with python 3.10; we suggest using 3.9.
The easiest way to install the latest version is via `pip`.
```bash
pip install rrnlp
```
(Model weights will then be downloaded as needed when you import `rrnlp`.) We suggest using a custom environment, so if you're using `conda` this might look something like
```bash
conda create --name rrnlp python=3.9
conda activate rrnlp
pip install rrnlp
```
Alternatively, if you want to use the bleeding-edge (for better or worse) you can try installing directly via `git`
```bash
pip install git+https://github.com/bwallace/RRnlp.git
```
(Or can `clone` and then `install .` locally.)
# Citation
This set of models is a compilation of several different lines of work. If you use this and find it useful for your work, please consider citing (some subset of) the following.
For the overall system:
```
Marshall, I.J., Nye, B., Kuiper, J., Noel-Storr, A., Marshall, R., Maclean, R., Soboczenski, F., Nenkova, A., Thomas, J. and Wallace, B.C., 2020. Trialstreamer: A living, automatically updated database of clinical trial reports. Journal of the American Medical Informatics Association, 27(12), pp.1903-1912.
Nye, B.E., Nenkova, A., Marshall, I.J. and Wallace, B.C., 2020, July. Trialstreamer: mapping and browsing medical evidence in real-time. In Proceedings of the conference. Association for Computational Linguistics. North American Chapter. Meeting (Vol. 2020, p. 63).
```
For the "inference" component specifically ("punchlines" and directionality):
```
Eric Lehman, Jay DeYoung, Regina Barzilay, and Byron C. Wallace. Inferring Which Medical Treatments Work from Reports of Clinical Trials. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pages 3705–3717, 2019.
Jay DeYoung, Eric Lehman, Benjamin Nye, Iain Marshall, and Byron C. Wallace. Evidence Inference 2.0: More Data, Better Models. In Proceedings of BioNLP; co-located with the Association for Computational Linguistics (ACL), 2020.
```
If you are using the PICO snippets
```
Benjamin Nye, Jessy Li, Roma Patel, Yinfei Yang, Iain Marshall, Ani Nenkova, and Byron C. Wallace. A Corpus with Multi-Level Annotations of Patients, Interventions and Outcomes to Support Language Processing for Medical Literature. In Proceedings of the Conference of the Association for Computational Linguistics (ACL), pages 197–207, 2018.
```
For the RCT classifier
```
Marshall, Iain J., Anna Noel‐Storr, Joël Kuiper, James Thomas, and Byron C. Wallace. "Machine learning for identifying randomized controlled trials: an evaluation and practitioner's guide." Research Synthesis Methods 9, no. 4 (2018): 602-614.
```
And for risk of bias
```
Iain J. Marshall, Joël Kuiper, and Byron C. Wallace. RobotReviewer: Evaluation of a System for Automatically Assessing Bias in Clinical Trials. Journal of the American Medical Informatics Association (JAMIA), 23(1):193–201, 2016.
```
# Support
This work has been supported by National Institutes of Health (NIH) under the National Library of Medicine (NLM), grant R01-LM012086 and by the National Science Foundation (NSF) under Grant 1750978: "CAREER: Structured Scientific Evidence Extraction: Models and Corpora". The work has also been partially supported by the UK Medical Research Council (MRC), through its Skills Development Fellowship program, fellowship MR/N015185/1.
| /rrnlp-1.0.3.tar.gz/rrnlp-1.0.3/README.md | 0.448426 | 0.926437 | README.md | pypi |
import math
import matplotlib.pyplot as plt
from .Generaldistribution import Distribution
class Gaussian(Distribution):
""" Gaussian distribution class for calculating and
visualizing a Gaussian distribution.
Attributes:
mean (float) representing the mean value of the distribution
stdev (float) representing the standard deviation of the distribution
data_list (list of floats) a list of floats extracted from the data file
"""
def __init__(self, mu=0, sigma=1):
Distribution.__init__(self, mu, sigma)
def calculate_mean(self):
"""Function to calculate the mean of the data set.
Args:
None
Returns:
float: mean of the data set
"""
avg = 1.0 * sum(self.data) / len(self.data)
self.mean = avg
return self.mean
def calculate_stdev(self, sample=True):
"""Function to calculate the standard deviation of the data set.
Args:
sample (bool): whether the data represents a sample or population
Returns:
float: standard deviation of the data set
"""
if sample:
n = len(self.data) - 1
else:
n = len(self.data)
mean = self.calculate_mean()
sigma = 0
for d in self.data:
sigma += (d - mean) ** 2
sigma = math.sqrt(sigma / n)
self.stdev = sigma
return self.stdev
def plot_histogram(self):
"""Function to output a histogram of the instance variable data using
matplotlib pyplot library.
Args:
None
Returns:
None
"""
plt.hist(self.data)
plt.title('Histogram of Data')
plt.xlabel('data')
plt.ylabel('count')
def pdf(self, x):
"""Probability density function calculator for the gaussian distribution.
Args:
x (float): point for calculating the probability density function
Returns:
float: probability density function output
"""
return (1.0 / (self.stdev * math.sqrt(2 * math.pi))) * math.exp(-0.5 * ((x - self.mean) / self.stdev) ** 2)
def plot_histogram_pdf(self, n_spaces=50):
"""Function to plot the normalized histogram of the data and a plot of the
probability density function along the same range
Args:
n_spaces (int): number of data points
Returns:
list: x values for the pdf plot
list: y values for the pdf plot
"""
mu = self.mean
sigma = self.stdev
min_range = min(self.data)
max_range = max(self.data)
# calculates the interval between x values
interval = 1.0 * (max_range - min_range) / n_spaces
x = []
y = []
# calculate the x values to visualize
for i in range(n_spaces):
tmp = min_range + interval * i
x.append(tmp)
y.append(self.pdf(tmp))
# make the plots
fig, axes = plt.subplots(2, sharex=True)
fig.subplots_adjust(hspace=.5)
axes[0].hist(self.data, density=True)
axes[0].set_title('Normed Histogram of Data')
axes[0].set_ylabel('Density')
axes[1].plot(x, y)
axes[1].set_title('Normal Distribution for \n Sample Mean and Sample Standard Deviation')
axes[0].set_ylabel('Density')
plt.show()
return x, y
def __add__(self, other):
"""Function to add together two Gaussian rrp_distributions
Args:
other (Gaussian): Gaussian instance
Returns:
Gaussian: Gaussian distribution
"""
result = Gaussian()
result.mean = self.mean + other.mean
result.stdev = math.sqrt(self.stdev ** 2 + other.stdev ** 2)
return result
def __repr__(self):
"""Function to output the characteristics of the Gaussian instance
Args:
None
Returns:
string: characteristics of the Gaussian
"""
return "mean {}, standard deviation {}".format(self.mean, self.stdev) | /rrp_distributions-0.2.tar.gz/rrp_distributions-0.2/rrp_distributions/Gaussiandistribution.py | 0.903086 | 0.903507 | Gaussiandistribution.py | pypi |
import math
import matplotlib.pyplot as plt
from .Generaldistribution import Distribution
class Binomial(Distribution):
""" Binomial distribution class for calculating and
visualizing a Binomial distribution.
Attributes:
mean (float) representing the mean value of the distribution
stdev (float) representing the standard deviation of the distribution
data_list (list of floats) a list of floats to be extracted from the data file
p (float) representing the probability of an event occurring
"""
def __init__(self, prob=0.5, size=100):
self.p = prob
self.n = size
Distribution.__init__(self, self.calculate_mean(), self.calculate_stdev())
def calculate_mean(self):
"""Function to calculate the mean from p and n
Args:
None
Returns:
float: mean of the data set
"""
self.mean = self.p * self.n
return self.mean
def calculate_stdev(self):
"""Function to calculate the standard deviation from p and n.
Args:
None
Returns:
float: standard deviation of the data set
"""
var = self.n * self.p * (1 - self.p)
self.stdev = math.sqrt(var)
return self.stdev
def replace_stats_with_data(self):
"""Function to calculate p and n from the data set. The function updates the p and n variables of the object.
Args:
None
Returns:
float: the p value
float: the n value
"""
self.n = len(self.data)
self.p = sum(self.data) / self.n
self.calculate_mean()
self.calculate_stdev()
return self.p, self.n
def plot_bar(self):
"""Function to output a histogram of the instance variable data using
matplotlib pyplot library.
Args:
None
Returns:
None
"""
plt.bar([0, 1], height=[(1 - self.p) * self.n, self.p * self.n])
plt.title('Bar Chart of Data')
plt.xlabel('Data')
plt.ylabel('Count')
def pdf(self, k):
"""Probability density function calculator for the binomial distribution.
Args:
k (float): point for calculating the probability density function
Returns:
float: probability density function output
"""
nCk = math.factorial(self.n) / (math.factorial(k) * math.factorial(self.n - k))
prob_df = nCk * math.pow(self.p, k) * math.pow((1 - self.p), (self.n - k))
return prob_df
def plot_bar_pdf(self):
"""Function to plot the pdf of the binomial distribution
Args:
None
Returns:
list: x values for the pdf plot
list: y values for the pdf plot
"""
x = []
y = []
for i in range(self.n + 1):
x.append(i)
y.append(self.pdf(i))
plt.bar(x, y)
plt.title('Distribution of outcomes')
plt.xlabel('Outcome')
plt.ylabel('Probability')
plt.show()
return x, y
def __add__(self, other):
"""Function to add together two Binomial rrp_distributions with equal p
Args:
other (Binomial): Binomial instance
Returns:
Binomial: Binomial distribution
"""
try:
assert self.p == other.p, 'p values are not equal'
except AssertionError as error:
raise
new_bin = Binomial()
new_bin.n = self.n + other.n
new_bin.p = self.p
new_bin.calculate_mean()
new_bin.calculate_stdev()
return new_bin
def __repr__(self):
"""Function to output the characteristics of the Binomial instance
Args:
None
Returns:
string: characteristics of the Binomial object
"""
return 'mean {}, standard deviation {}, p {}, n {}'.format(self.mean, self.stdev, self.p, self.n) | /rrp_distributions-0.2.tar.gz/rrp_distributions-0.2/rrp_distributions/Binomialdistribution.py | 0.907873 | 0.835584 | Binomialdistribution.py | pypi |
import pickle
from pathlib import Path
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from matplotlib.patches import Polygon
from matplotlib.collections import PatchCollection
from matplotlib.ticker import MaxNLocator
from rrt_ml.algorithms.sl import *
from rrt_ml.utilities.configs import *
def run_sl(cfg: MasterConfig):
sample_learner = SL(cfg)
# Train
if cfg.general.is_train:
sample_learner.train()
# Test
else:
sample_learner.test()
def compare_hypers(cfg, name1, name2):
"""
Compare two configs.
:param name1: config 1
:param name2: config 2
"""
# Matplotlib params
mpl.rcParams["font.size"] = 10
# Experiments path
base_path = Path(__file__).resolve().parents[2]
exp_path = base_path / "experiments" / "sl"
file_path = (
base_path.parents[0] / "latex" / "figs" / "results" / "hiper_compare.png"
)
# Initialize figure
fig, ax = plt.subplots(nrows=1, ncols=2, sharex="all", sharey="all")
ax = ax.flatten()
plt.tight_layout()
# Axes counter
ax_counter1 = 0
ax_counter2 = 0
ax_counter3 = 0
path1 = exp_path / name1
path2 = exp_path / name2
with open(path1 / "stats.pickle", "rb") as file:
stats1 = pickle.load(file)
with open(path2 / "stats.pickle", "rb") as file:
stats2 = pickle.load(file)
# Plot
for i, stats in enumerate([stats1, stats2]):
# Aliases
x1, y1, x2, y2 = stats["list_cond_obstacles_epoch"][49][0, :]
ww = cfg.wall_width
pw = cfg.passage_width
# Left rectangle
lower_left = Polygon(
[
(x1 - ww / 2, 0),
(x1 + ww / 2, 0),
(x1 + ww / 2, y1 - pw / 2),
(x1 - ww / 2, y1 - pw / 2),
]
)
upper_left = Polygon(
[
(x1 - ww / 2, y1 + pw / 2),
(x1 + ww / 2, y1 + pw / 2),
(x1 + ww / 2, 10),
(x1 - ww / 2, 10),
]
)
# Right rectangle
lower_right = Polygon(
[
(x2 - ww / 2, 0),
(x2 + ww / 2, 0),
(x2 + ww / 2, y2 - pw / 2),
(x2 - ww / 2, y2 - pw / 2),
]
)
upper_right = Polygon(
[
(x2 - ww / 2, y2 + pw / 2),
(x2 + ww / 2, y2 + pw / 2),
(x2 + ww / 2, 10),
(x2 - ww / 2, 10),
]
)
patches = [lower_left, lower_right, upper_left, upper_right]
ax[i].add_collection(
PatchCollection(patches, edgecolors="k", facecolors="k")
) # type: plt.Axes
# Add limits
ax[ax_counter1].set_xlim(0, 10)
ax[ax_counter1].set_ylim(0, 10)
# Adjust aspect ratio
ax[i].set_aspect("equal", adjustable="box")
# ax[i].axis('equal')
# Add initial and final states
x1, y1, dx1, dy1, x2, y2, dx2, dy2 = stats["list_cond_states_epoch"][49][0, :]
ax[ax_counter1].arrow(x1, y1, 0.3 * dx1, 0.3 * dy1, width=0.1, ec="g", fc="g")
ax[ax_counter1].arrow(x2, y2, 0.3 * dx2, 0.3 * dy2, width=0.1, ec="r", fc="r")
# Add generated states
for state in stats["list_gen_states_epoch"][49][0:30]:
norm = np.sqrt(state[2] ** 2 + state[3] ** 2)
ax[ax_counter1].arrow(
state[0],
state[1],
0.2 * state[2] / norm,
0.2 * state[3] / norm,
width=0.01,
head_width=0.1,
head_length=0.1,
fc="b",
ec="b",
)
# Set title
name = name1 if i == 0 else name2
ax[i].title.set_text(f"Hiperparâmetro {name}")
# Save figure
fig.savefig(file_path, dpi=600)
def hyperparameter_search_samples(cfg):
"""
Graph for the various hyperparameters.
:param cfg: experiment config.
"""
# Matplotlib params
mpl.rcParams["font.size"] = 14
# Experiments path
base_path = Path(__file__).resolve().parents[2]
exp_path = base_path / "experiments" / "sl"
file_path1 = base_path.parents[0] / "latex" / "figs" / "apdx" / "sl_hiper1.png"
file_path2 = base_path.parents[0] / "latex" / "figs" / "apdx" / "sl_hiper2.png"
file_path3 = base_path.parents[0] / "latex" / "figs" / "apdx" / "sl_hiper3.png"
# Initialize figure 1
fig1, axs1 = plt.subplots(nrows=4, ncols=2, sharex="all", sharey="all")
fig1.set_size_inches(16, 22)
axs1 = axs1.flatten()
plt.tight_layout()
# Initialize figure 2
fig2, axs2 = plt.subplots(nrows=4, ncols=2, sharex="all", sharey="all")
fig2.set_size_inches(16, 22)
axs2 = axs2.flatten()
plt.tight_layout()
# Initialize figure 3
fig3, axs3 = plt.subplots(nrows=4, ncols=2, sharex="all", sharey="all")
fig3.set_size_inches(16, 22)
axs3 = axs3.flatten()
plt.tight_layout()
# Axes counter
ax_counter1 = 0
ax_counter2 = 0
ax_counter3 = 0
# Go to experiment folder
for param1 in [1, 2]:
for param2 in [1, 2]:
for param3 in [1, 2]:
for param4 in [1, 2, 3]:
path = exp_path / (
"a" + str(param1) + str(param2) + str(param3) + str(param4)
)
# Load stats file
with open(path / "stats.pickle", "rb") as file:
stats = pickle.load(file)
# Aliases
x1, y1, x2, y2 = stats["list_cond_obstacles_epoch"][49][0, :]
ww = cfg.wall_width
pw = cfg.passage_width
# Left rectangle
lower_left = Polygon(
[
(x1 - ww / 2, 0),
(x1 + ww / 2, 0),
(x1 + ww / 2, y1 - pw / 2),
(x1 - ww / 2, y1 - pw / 2),
]
)
upper_left = Polygon(
[
(x1 - ww / 2, y1 + pw / 2),
(x1 + ww / 2, y1 + pw / 2),
(x1 + ww / 2, 10),
(x1 - ww / 2, 10),
]
)
# Right rectangle
lower_right = Polygon(
[
(x2 - ww / 2, 0),
(x2 + ww / 2, 0),
(x2 + ww / 2, y2 - pw / 2),
(x2 - ww / 2, y2 - pw / 2),
]
)
upper_right = Polygon(
[
(x2 - ww / 2, y2 + pw / 2),
(x2 + ww / 2, y2 + pw / 2),
(x2 + ww / 2, 10),
(x2 - ww / 2, 10),
]
)
patches = [lower_left, lower_right, upper_left, upper_right]
# Figure 1
if ax_counter1 < 8:
# Add patches
axs1[ax_counter1].add_collection(
PatchCollection(patches)
) # type: plt.Axes
# Add limits
axs1[ax_counter1].set_xlim(0, 10)
axs1[ax_counter1].set_ylim(0, 10)
# Adjust aspect ratio
# axs1[ax_counter1].set_aspect('equal', adjustable='box')
# axs1[ax_counter1].axis('equal')
# Add initial and final states
x1, y1, dx1, dy1, x2, y2, dx2, dy2 = stats[
"list_cond_states_epoch"
][49][0, :]
axs1[ax_counter1].arrow(
x1, y1, 0.3 * dx1, 0.3 * dy1, width=0.1, fc="g"
)
axs1[ax_counter1].arrow(
x2, y2, 0.3 * dx2, 0.3 * dy2, width=0.1, fc="r"
)
# Add generated states
for state in stats["list_gen_states_epoch"][49][0:30]:
norm = np.sqrt(state[2] ** 2 + state[3] ** 2)
axs1[ax_counter1].arrow(
state[0],
state[1],
0.2 * state[2] / norm,
0.2 * state[3] / norm,
width=0.01,
head_width=0.1,
head_length=0.1,
fc="k",
)
# Set title
axs1[ax_counter1].title.set_text(
f"Hiperparâmetro {param1}{param2}{param3}{param4}"
)
# Next subplot
ax_counter1 += 1
# Figure 2
else:
if ax_counter2 < 8:
# Add patches
axs2[ax_counter2].add_collection(
PatchCollection(patches)
) # type: plt.Axes
# Add limits
axs2[ax_counter2].set_xlim(0, 10)
axs2[ax_counter2].set_ylim(0, 10)
# Adjust aspect ratio
# axs2[ax_counter2].set_aspect('equal')
# axs2[ax_counter2].axis('equal')
# Add initial and final states
x1, y1, dx1, dy1, x2, y2, dx2, dy2 = stats[
"list_cond_states_epoch"
][49][0, :]
axs2[ax_counter2].arrow(
x1, y1, 0.3 * dx1, 0.3 * dy1, width=0.1, fc="g"
)
axs2[ax_counter2].arrow(
x2, y2, 0.3 * dx2, 0.3 * dy2, width=0.1, fc="r"
)
# Add generated states
for state in stats["list_gen_states_epoch"][49][0:30]:
norm = np.sqrt(state[2] ** 2 + state[3] ** 2)
axs2[ax_counter2].arrow(
state[0],
state[1],
0.2 * state[2] / norm,
0.2 * state[3] / norm,
width=0.01,
head_width=0.1,
head_length=0.1,
fc="k",
)
# Set title
axs2[ax_counter2].title.set_text(
f"Hiperparâmetro {param1}{param2}{param3}{param4}"
)
# Next subplot
ax_counter2 += 1
else:
# Add patches
axs3[ax_counter3].add_collection(
PatchCollection(patches)
) # type: plt.Axes
# Add limits
axs3[ax_counter3].set_xlim(0, 10)
axs3[ax_counter3].set_ylim(0, 10)
# Adjust aspect ratio
# axs2[ax_counter2].set_aspect('equal')
# axs2[ax_counter2].axis('equal')
# Add initial and final states
x1, y1, dx1, dy1, x2, y2, dx2, dy2 = stats[
"list_cond_states_epoch"
][49][0, :]
axs3[ax_counter3].arrow(
x1, y1, 0.3 * dx1, 0.3 * dy1, width=0.1, fc="g"
)
axs3[ax_counter3].arrow(
x2, y2, 0.3 * dx2, 0.3 * dy2, width=0.1, fc="r"
)
# Add generated states
for state in stats["list_gen_states_epoch"][49][0:30]:
norm = np.sqrt(state[2] ** 2 + state[3] ** 2)
axs3[ax_counter3].arrow(
state[0],
state[1],
0.2 * state[2] / norm,
0.2 * state[3] / norm,
width=0.01,
head_width=0.1,
head_length=0.1,
fc="k",
)
# Set title
axs3[ax_counter3].title.set_text(
f"Hiperparâmetro {param1}{param2}{param3}{param4}"
)
# Next subplot
ax_counter3 += 1
# Save figure
fig1.savefig(file_path1, dpi=600)
fig2.savefig(file_path2, dpi=600)
fig3.savefig(file_path3, dpi=600)
def hyperparameter_search_loss(cfg):
"""
experiment config.
:param cfg: experiment config.
"""
# Matplotlib params
mpl.rcParams["font.size"] = 14
# Experiments path
base_path = Path(__file__).resolve().parents[2]
exp_path = base_path / "experiments" / "sl"
file_path1 = base_path.parents[0] / "latex" / "figs" / "apdx" / "sl_hiper_loss1.png"
file_path2 = base_path.parents[0] / "latex" / "figs" / "apdx" / "sl_hiper_loss2.png"
file_path3 = base_path.parents[0] / "latex" / "figs" / "apdx" / "sl_hiper_loss3.png"
# Initialize figure 1
fig1, axs1 = plt.subplots(nrows=4, ncols=2, sharex="all")
fig1.set_size_inches(16, 22)
axs1 = axs1.flatten()
# plt.tight_layout()
# Initialize figure 2
fig2, axs2 = plt.subplots(nrows=4, ncols=2, sharex="all")
fig2.set_size_inches(16, 22)
axs2 = axs2.flatten()
# plt.tight_layout()
# Initialize figure 3
fig3, axs3 = plt.subplots(nrows=4, ncols=2, sharex="all")
fig3.set_size_inches(16, 22)
axs3 = axs3.flatten()
# plt.tight_layout()
# Axes counter
ax_counter1 = 0
ax_counter2 = 0
ax_counter3 = 0
# Go to experiment folder
for param1 in [1, 2]:
for param2 in [1, 2]:
for param3 in [1, 2]:
for param4 in [1, 2, 3]:
path = exp_path / (
"a" + str(param1) + str(param2) + str(param3) + str(param4)
)
# Load stats file
with open(path / "stats.pickle", "rb") as file:
stats = pickle.load(file)
# Figure 1
if ax_counter1 < 8:
# Plot loss with twin axes
axs1[ax_counter1].plot(
range(1, 51),
_smooth(stats["list_loss_recon_val_epoch"], 0.8),
color="b",
)
axs1[ax_counter1].tick_params(axis="y", labelcolor="b")
axs1[ax_counter1].yaxis.set_major_locator(
MaxNLocator(nbins=5, integer=True)
)
ax2 = axs1[ax_counter1].twinx()
ax2.plot(
range(1, 51),
_smooth(stats["list_loss_kl_val_epoch"], 0.8),
color="g",
)
ax2.tick_params(axis="y", labelcolor="g")
ax2.yaxis.set_major_locator(MaxNLocator(nbins=5, integer=True))
ax_counter1 += 1
# Figure 2
else:
if ax_counter2 < 8:
# Plot loss with twin axes
axs2[ax_counter2].plot(
range(1, 51),
_smooth(stats["list_loss_recon_val_epoch"], 0.8),
color="b",
)
axs2[ax_counter2].tick_params(axis="y", labelcolor="b")
axs2[ax_counter2].yaxis.set_major_locator(
MaxNLocator(nbins=5, integer=True)
)
ax2 = axs2[ax_counter2].twinx()
ax2.plot(
range(1, 51),
_smooth(stats["list_loss_kl_val_epoch"], 0.8),
color="g",
)
ax2.tick_params(axis="y", labelcolor="g")
ax2.yaxis.set_major_locator(
MaxNLocator(nbins=5, integer=True)
)
ax_counter2 += 1
else:
# Plot loss with twin axes
axs3[ax_counter3].plot(
range(1, 51),
_smooth(stats["list_loss_recon_val_epoch"], 0.8),
color="b",
)
axs3[ax_counter3].tick_params(axis="y", labelcolor="b")
axs3[ax_counter3].yaxis.set_major_locator(
MaxNLocator(nbins=5, integer=True)
)
ax2 = axs3[ax_counter3].twinx()
ax2.plot(
range(1, 51),
_smooth(stats["list_loss_kl_val_epoch"], 0.8),
color="g",
)
ax2.tick_params(axis="y", labelcolor="g")
ax2.yaxis.set_major_locator(
MaxNLocator(nbins=5, integer=True)
)
ax_counter3 += 1
fig1.savefig(file_path1, dpi=600)
fig2.savefig(file_path2, dpi=600)
fig3.savefig(file_path3, dpi=600)
def _smooth(series, weight):
last = series[0] # First value in the plot (first timestep)
smoothed = list()
for point in series:
smoothed_val = last * weight + (1 - weight) * point # Calculate smoothed value
smoothed.append(smoothed_val) # Save it
last = smoothed_val # Anchor the last smoothed value
return smoothed | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/runner/run_sl.py | 0.653238 | 0.491822 | run_sl.py | pypi |
import time
from ctypes import windll
import gym
import pybullet as p
import pybullet_data as pd
from PIL import Image
from numpy.random import Generator
from rrt_ml.utilities.configs import *
from rrt_ml.utilities.formulas import *
from rrt_ml.utilities.hints import *
from rrt_ml.utilities.maps import *
from rrt_ml.utilities.misc import *
from rrt_ml.utilities.paths import *
from rrt_ml.utilities.stats import *
class CarNavigationBulletEnv(gym.Env):
def __init__(self, cfg: MasterConfig):
"""
Initialize env.
"""
self.cfg = cfg # type: MasterConfig | None
self.reward_weights = None # type: Vector2 | None
self.action_repeat = None # type: int | None
self.car = None # type: Car | None
self.target = None # type: Target | None
self.obstacles = None # type: list[Obstacle, ...] | None
self.init_pose = None # type: Vector3 | None
self.final_pose = None # type: Vector3 | None
self.timestep = None # type: int | None
self.bullet_timestep = None # type: int | None
self.episode_num = None # type: int | None
self.l_ghost_ids = None # type: list[list[int, ...], ...] | None
self.save_state = None # type: int | None
self.stats = None # type: EnvStats | None
self.rng = None # type: Generator | None
self.img_crop = None # type: Vector4 | None
self.img_extent = None # type: Vector4 | None
self._setup()
def compute_reward(self, achieved_goal: np.ndarray, desired_goal: np.ndarray, info: dict = None):
"""
Common API for calculating rewards in goal conditioned tasks.
:param achieved_goal: goal achieved
:param desired_goal: behavioural goal
:param info: additional info
:return: calculated reward
"""
self._setup_ignore_static_warnings(info)
# Calculate p-norm reward (works for vectorized calculations)
abs_dif = np.abs(achieved_goal - desired_goal)
weighted_abs_dif = np.dot(abs_dif, self.reward_weights)
reward = -np.power(weighted_abs_dif, self.cfg.env.reward.p_val)
# Make reward sparse (0 or 1 only)
reward = self._get_reward_sparse(reward)
return reward
def render(self, mode="human") -> None:
"""
Common API.
"""
self._setup_ignore_static_warnings()
print(f'Create env with "GUI" set to "True". Mode: {mode}')
def reset(self, **kwargs):
"""
Reset env.
:param kwargs: k/v 'reset_seed'/bool to set the seed
:return: initial observation
"""
self._set_restore_state()
self._set_place()
self._set_reset_joints()
self._set_increment_episode_num()
self._set_zero_timesteps()
self._set_stats()
return self._get_observation()
def reset_master(self):
"""
Reset for eval env to track trajectories with deterministic resetting.
"""
self._set_zero_episode_num()
self._set_seed()
def step(self, action: Vector2) -> tuple[dict, float, bool, dict]:
"""
Step environment.
:param action: agent action
:return: tuple [next_obs, reward, done, info]
"""
# Get current observation to save
obs = self._get_observation()
# Scale action from [-1, 1] to [v/phi_min v/phi_max] and set motors refs
v_ref = scale_to_range(action[0], [-1, 1], [-self.cfg.env.car.v_max, +self.cfg.env.car.v_max])
phi_ref = scale_to_range(action[1], [-1, 1], [-self.cfg.env.car.phi_max, +self.cfg.env.car.phi_max])
self.car.set_motors_refs_ackermann(v_ref, phi_ref)
# Action according to frequency
for i in range(self.action_repeat):
# Record stats
if self.cfg.env.general.stats:
# Normal stats
self._set_bullet_stats()
self._set_bullet_timestep()
# Step bullet
p.stepSimulation(physicsClientId=self.client)
# Calculate reward
next_obs = self._get_observation()
reward = self.compute_reward(next_obs['achieved_goal'], next_obs['desired_goal'], {})
done, done_info = self._get_done_indicator(reward)
# Update if in eval mode
if self.cfg.env.general.stats:
# Update mdp stats
self._set_mdp_stats(Transition.new(obs, next_obs, action, reward, done))
# Get top view if done
# self._set_new_image_top_view()
# Update timestep
self._set_increment_mdp_timestep()
return next_obs, reward, done, {'stats': self.stats, 'done_info': done_info}
def seed(self, num):
"""
Do nothing.
"""
return
def _get_collision_indicator(self):
"""
Check if the car collided with any obstacle.
:return: boolean indicator of collision
"""
# Return true on the first contact
if self.obstacles is not None:
for obstacle in self.obstacles:
contact = (
len(
p.getContactPoints(
self.car.id, obstacle.id, physicsClientId=self.client
)
)
> 0
)
if contact:
return True
return False
def _get_done_indicator(self, reward: float) -> tuple[bool, dict[str, bool]]:
"""
Check if episode should end.
:return: boolean indicator and a dict with reasons to terminate (whether they eval as True or False)
"""
# Get all boolean indicators
collided = self._get_collision_indicator()
time_is_up = self._get_time_is_up_indicator()
goal_reached = self._get_goal_reached_indicator(reward)
# Get info
d = dict(collision=collided, time=time_is_up, success=goal_reached)
return collided or time_is_up or goal_reached, d
def _get_goal_reached_indicator(self, reward: float) -> bool:
"""
Check if goal is reached by checking if 'reward' > 'epsilon' (tolerance).
:param reward: reward at this time step
:return: boolean indicating if goal was reached
"""
return reward > self.cfg.env.reward.epsilon
def _get_image_current_top_view(self) -> Image:
"""
Get top view image from bullet renderer.
:return: PIL image
"""
try:
import win32gui
import win32ui
except ImportError:
return
# Get image
hwnd = win32gui.FindWindow('DeviceWin32', None)
left, top, right, bot = win32gui.GetClientRect(hwnd)
windll.user32.SetProcessDPIAware()
w = right - left
h = bot - top
hwnd_dc = win32gui.GetWindowDC(hwnd)
mfc_dc = win32ui.CreateDCFromHandle(hwnd_dc)
save_dc = mfc_dc.CreateCompatibleDC()
save_bit_map = win32ui.CreateBitmap()
save_bit_map.CreateCompatibleBitmap(mfc_dc, w, h)
save_dc.SelectObject(save_bit_map)
windll.user32.PrintWindow(hwnd, save_dc.GetSafeHdc(), 2)
bmp_info = save_bit_map.GetInfo()
bmp_str = save_bit_map.GetBitmapBits(True)
img = Image.frombuffer('RGB', (bmp_info['bmWidth'], bmp_info['bmHeight']), bmp_str, 'raw', 'BGRX', 0, 1)
# Cleanup
win32gui.DeleteObject(save_bit_map.GetHandle())
save_dc.DeleteDC()
mfc_dc.DeleteDC()
win32gui.ReleaseDC(hwnd, hwnd_dc)
# Adjust image
new_img = img.crop(self.img_crop)
new_img = new_img.transpose(Image.FLIP_TOP_BOTTOM)
return new_img
def _get_observation(self):
"""
Get env observation.
:return: dict observation
"""
# Get values
state = self.car.get_state()
achieved_goal = self.car.get_achieved_goal()
desired_goal = self.target.get_desired_goal()
mpc_state = self.car.get_state_mpc()
return dict(
observation=state, achieved_goal=achieved_goal, desired_goal=desired_goal, mpc_state=mpc_state
)
def _get_reward_sparse(self, reward: Vector):
"""
Make reward sparse (0 or -1 values only).
:param reward: single reward or array
:return: sparse reward
"""
# Vectorized calculation
if isinstance(reward, list | tuple | np.ndarray):
for i, r in enumerate(reward):
if r < self.cfg.env.reward.epsilon:
reward[i] = -1
else:
reward[i] = 0
# reward[i] = r
# Single reward
else:
if reward < self.cfg.env.reward.epsilon:
reward = -1
else:
reward = 0
# reward = reward
return reward
def _get_time_is_up_indicator(self):
"""
Check end of episode by number of timesteps.
:return: boolean indicating that maximum timesteps was reached
"""
return self.timestep >= (self.cfg.env.general.max_timestep - 1)
def _set_bullet_stats(self):
"""
Add bullet physics statistics after each bullet step call.
"""
# Alias
ep = self.episode_num
t = self.bullet_timestep
# Add basic info
self.stats.bullet.time[ep, t, ...] = t * 1 / 240
self.stats.bullet.car_poses[ep, t, ...] = self.car.get_pose()
self.stats.bullet.target_poses[ep, t, ...] = self.target.get_pose()
# Calculate reward and add 'done'
obs = self._get_observation()
reward = self.compute_reward(obs['achieved_goal'], obs['desired_goal'], {})
self.stats.bullet.rewards[ep, t, ...] = reward
self.stats.bullet.dones[ep, t, ...] = self._get_done_indicator(reward)
# Add steer positions
steer_pos1, _, _, _ = p.getJointState(self.car.id, 4, physicsClientId=self.client)
steer_pos2, _, _, _ = p.getJointState(self.car.id, 6, physicsClientId=self.client)
self.stats.bullet.car_steers[ep, t, ...] = [steer_pos1, steer_pos2]
# Check velocity magnitude and then signal
v, _ = p.getBaseVelocity(self.car.id, physicsClientId=self.client)
pos, vel, _, _ = p.getJointState(self.car.id, 2, physicsClientId=self.client)
sign = 1 if vel > 0 else -1
self.stats.bullet.car_velocities[ep, t, ...] = sign * np.linalg.norm(v[:2])
# Add wall time
self.stats.bullet.wall_time[ep, t, ...] = time.time()
def _set_bullet_timestep(self):
"""
Increment bullet timestep counter.
"""
self.bullet_timestep += 1
def _set_place_trajectory_ghosts(self, episode_num: int, stats: EnvStats | None = None):
"""
Place ghosts in trajectory to take screenshot.
:param episode_num: number of the eval episode
:param stats: current env stats or other stats object
"""
# Get the stats where poses come from
if stats is None:
stats = self.stats
# Indexes = [start, end + step, step]
interval = self.cfg.env.test.general.ghost_interval
n_timesteps = len(stats.bullet.car_poses[0, :, 0])
idxs = np.arange(0, n_timesteps, interval)
# Get poses and steering angles
poses = stats.bullet.car_poses[episode_num, idxs, ...]
steers = stats.bullet.car_steers[episode_num, idxs, ...]
# Remove zeros
poses = remove_trailing_zeros(poses).reshape(-1, 3)
steers = remove_trailing_zeros(steers).reshape(-1, 2)
self.l_ghost_ids = []
for pose, steer in zip(poses, steers):
self._set_place_ghost_car(pose, steer)
def _set_remove_ghosts(self):
"""
Remove trajectory ghosts from GUI.
"""
# Return if no ghosts on scene
if self.l_ghost_ids is None:
return
if isinstance(self.l_ghost_ids, list):
if len(self.l_ghost_ids) == 0:
return
# Remove bodies
for idd in self.l_ghost_ids:
p.removeBody(idd, physicsClientId=self.client)
def _set_increment_episode_num(self):
"""
Increment number of episodes.
"""
self.episode_num += 1
def _set_increment_mdp_timestep(self):
"""
Set simulation timestep value or increase current value by one.
"""
self.timestep += 1 if self.timestep is not None else 0
def _set_mdp_stats(self, transition: 'Transition'):
"""
Add current time step info if on test mode.
"""
# Alias
ep = self.episode_num
t = self.timestep
# Add
self.stats.mdp.states[ep, t, ...] = transition.state
self.stats.mdp.achieved_goals[ep, t, ...] = transition.achieved_goal
self.stats.mdp.desired_goals[ep, t, ...] = transition.desired_goal
self.stats.mdp.next_states[ep, t, ...] = transition.next_state
self.stats.mdp.next_achieved_goals[ep, t, ...] = transition.next_achieved_goal
self.stats.mdp.next_desired_goals[ep, t, ...] = transition.next_desired_goal
self.stats.mdp.actions[ep, t, ...] = transition.action
self.stats.mdp.rewards[ep, t, ...] = transition.reward
self.stats.mdp.dones[ep, t, ...] = transition.done
def _set_place(self):
"""
Place dynamic objects (car and target)
"""
# Place car
car_pose = self.rng.uniform(self.car_reset_low, self.car_reset_high)
self.car.set_pose(car_pose)
# Place target
target_pose = self.rng.uniform(self.target_reset_low, self.target_reset_high)
self.target.set_pose(target_pose)
def _set_place_ghost_car(self, pose: Vector3 | None = None, steers: Vector2 | None = None):
"""
Place transparent visual shape of the car, at its current pose, to log trajectory.
"""
# Call with argument to set at desired pose
if pose is not None:
pos = [pose[0], pose[1], 0.001]
orn = p.getQuaternionFromEuler([0, 0, pose[2]])
pos1, pos2 = steers
# Get car's pose and steering wheels angles
else:
pos, orn = p.getBasePositionAndOrientation(self.car.id, physicsClientId=self.client)
pos1, _, _, _ = p.getJointState(self.car.id, 4, physicsClientId=self.client)
pos2, _, _, _ = p.getJointState(self.car.id, 6, physicsClientId=self.client)
# Load URDF at car's current pose
idd = p.loadURDF('ghost.urdf', pos, orn, useFixedBase=1, physicsClientId=self.client)
# Change steering angles for the shape
p.resetJointState(idd, 4, pos1, physicsClientId=self.client)
p.resetJointState(idd, 6, pos2, physicsClientId=self.client)
# Initialize list of ghosts if not initialized
if self.l_ghost_ids is None:
self.l_ghost_ids = []
self.l_ghost_ids.append(idd)
self.l_ghost_ids.append(idd)
def _set_reset_joints(self):
"""
Reset car joints to make velocity and steering null.
"""
joints = [2, 3, 4, 5, 6, 7]
for joint in joints:
p.resetJointState(self.car.id, joint, 0, physicsClientId=self.client)
def _set_seed(self):
"""
Set seed to make resets deterministic.
"""
if self.cfg.env.general.seed is not None:
self.rng = np.random.default_rng(self.cfg.env.general.seed)
else:
self.rng = np.random.default_rng()
def _set_stats(self):
"""
Dictionary to hold statistics.
"""
# Reset stats if current episode number is 1
if self.episode_num == 0:
# noinspection PyTypeChecker
self.stats = EnvStats.new(self.cfg)
def _set_wait_objects_fall(self):
"""
Wait for placed objects to fall.
"""
for _ in range(20):
p.stepSimulation(physicsClientId=self.client)
def _set_zero_episode_num(self):
"""
Zero out (actually set it to '-1') episode counter. Call it after setting the seed.
"""
self.episode_num = -1
def _set_zero_timesteps(self):
"""
Reset MDP timesteps counter.
"""
self.timestep = 0
self.bullet_timestep = 0
def _setup(self) -> None:
"""
Several initializations and configurations.
"""
self._setup_seed()
self._setup_client()
self._setup_action_space()
self._setup_observation_space()
self._setup_action_repeat()
self._setup_reset_bounds()
self._setup_reward_weights()
self._setup_urdf_paths()
self._setup_ground_plane()
self._setup_gravity()
self._setup_car()
self._setup_target()
self._setup_obstacles()
self._setup_save_state()
self._setup_init_final_pose()
self._setup_camera()
self._setup_episode_num()
def _setup_action_repeat(self):
"""
Set constant for repeating actions according to frequency.
"""
self.action_repeat = int(1 / (self.cfg.env.car.f_val * (1 / 240)))
def _setup_action_space(self) -> None:
"""
Set up gym action space.
"""
self.action_space = gym.spaces.Box(low=-1.0, high=1.0, shape=(2,), dtype=np.float32)
def _setup_camera(self):
"""
Set up matrices for image creation.
"""
# Get camera distance
if self.cfg.maps.general.map_name is None:
self.img_crop = self.cfg.env.test.none.img_crop
self.img_extent = self.cfg.env.test.none.img_extent
cam_dist = self.cfg.env.test.none.cam_dist
cam_target = self.cfg.env.test.none.cam_target
elif self.cfg.maps.general.map_name == 'narrow':
self.img_crop = self.cfg.env.test.narrow.img_crop
self.img_extent = self.cfg.env.test.narrow.img_extent
cam_dist = self.cfg.env.test.narrow.cam_dist
cam_target = self.cfg.env.test.narrow.cam_target
else:
raise NotImplementedError
# Remove GUI elements and set top view camera config
p.configureDebugVisualizer(p.COV_ENABLE_GUI, 0, physicsClientId=self.client)
p.configureDebugVisualizer(p.COV_ENABLE_SHADOWS, 0, physicsClientId=self.client)
p.resetDebugVisualizerCamera(cam_dist, 0, -89.99, cam_target, physicsClientId=self.client)
def _setup_car(self) -> None:
"""
Initialize car.
"""
self.car = Car(self.cfg, self.client)
def _setup_client(self) -> None:
"""
Assign a client ID, necessary for vectorized environments.
"""
self.client = p.connect(p.GUI) if self.cfg.env.general.gui else p.connect(p.DIRECT)
def _setup_episode_num(self) -> None:
"""
Initialize episode number with '-1' because calling 'reset' should increment it by one.
"""
self.episode_num = -1
def _setup_gravity(self):
"""
Set the gravity.
"""
p.setGravity(0, 0, -9.81, physicsClientId=self.client)
def _setup_ground_plane(self) -> None:
"""
Load the ground plane.
"""
p.setAdditionalSearchPath(str(Paths().deps_models))
self.plane = p.loadURDF("meshes/plane.urdf", useFixedBase=1, physicsClientId=self.client)
def _setup_ignore_static_warnings(self, info=None):
"""
Stop linting 'method may be static' or unused parameter by putting this method inside another method.
"""
pass
def _setup_init_final_pose(self):
"""
Set attributes 'init/final_pose' as the initial achieved/desired goal.
"""
self.init_pose = self.car.get_pose()
self.final_pose = self.target.get_pose()
def _setup_observation_space(self) -> None:
"""
Set up the gym observation space. State is [x y sinOrn cosOrn v steer]. Goal is [x y sinOrn cosOrn].
"""
self.observation_space = gym.spaces.Dict(
dict(
observation=gym.spaces.Box(
low=-np.inf, high=+np.inf, shape=(6,)
),
desired_goal=gym.spaces.Box(
low=-np.inf, high=+np.inf, shape=(4,)
),
achieved_goal=gym.spaces.Box(
low=-np.inf, high=+np.inf, shape=(4,)
),
)
)
def _setup_obstacles(self) -> None:
"""
Load all obstacles.
"""
# Return if there is no obstacles to set up
if self.cfg.maps.general.map_name is None:
return
# Create map and add to obstacles descriptions lists
m = Map(self.cfg)
# Iterate over vertices and orientations creating 'Obstacles'
self.obstacles = []
for vertex, orn in zip(m.vertices, m.orientations):
self.obstacles.append(Obstacle(self.cfg, vertex, orn, self.client))
def _setup_reset_bounds(self) -> None:
"""
Set up reset bounds.
"""
# Aliases
cp = self.cfg.env.car.pose
tp = self.cfg.env.target.pose
# Set car pose
if isinstance(cp, float | int):
self.car_reset_low = [-cp, -cp, 0]
self.car_reset_high = [+cp, +cp, 2 * np.pi]
elif isinstance(cp, list | tuple | np.ndarray):
self.car_reset_low = [cp[0], cp[1], cp[2]]
self.car_reset_high = [cp[0], cp[1], cp[2]]
# Set target pose
if isinstance(tp, float | int):
self.target_reset_low = [-tp, -tp, 0]
self.target_reset_high = [+tp, +tp, 2 * np.pi]
elif isinstance(tp, list | tuple | np.ndarray):
self.target_reset_low = [tp[0], tp[1], tp[2]]
self.target_reset_high = [tp[0], tp[1], tp[2]]
def _set_restore_state(self):
"""
Restore state to maintain contact information.
"""
p.restoreState(self.save_state, physicsClientId=self.client)
def _setup_reward_weights(self) -> None:
"""
Set up the reward weights for each state component.
"""
self.reward_weights = 0.5 * np.array(
[
self.cfg.env.reward.weights[0],
self.cfg.env.reward.weights[0],
self.cfg.env.reward.weights[1],
self.cfg.env.reward.weights[1],
]
)
def _setup_save_state(self):
"""
Save all information to guarantee deterministic resetting.
"""
# Get contact information for car
self.car.set_pose([0, 0, 0])
self.target.set_pose([0, 0, 0])
for _ in range(10):
p.stepSimulation(physicsClientId=self.client)
# Save this state
self.save_state = p.saveState(physicsClientId=self.client)
def _setup_seed(self):
"""
Set up random seed for placing car and target. Deterministic only if setting the seed through other method.
"""
self.rng = np.random.default_rng()
def _setup_target(self) -> None:
"""
Initialize target.
"""
self.target = Target(self.cfg, client=self.client)
def _setup_urdf_paths(self) -> None:
"""
Set additional search paths for pybullet.
"""
p.setAdditionalSearchPath(pd.getDataPath(), physicsClientId=self.client)
class Car:
def __init__(self, cfg: MasterConfig, client: int = 0):
"""
Initialize car.
:param client: pybullet client id
:param cfg: config object
"""
self.client = client
self.cfg = cfg
self.id = None # type: None | int
self._setup()
def get_achieved_goal(self):
"""
Get car achieved goal.
:return: vector [x y sinOrn cosOrn]
"""
# Get x, y and theta
pose = self.get_pose()
state = pose3_to_state4(pose)
return state
def get_pose(self):
"""
Get car position and orientation.
:return: car pose
"""
# Get from PyBullet
pos, orn = p.getLinkState(self.id, 0, physicsClientId=self.client)[:2]
# Get orientation
theta = quaternion_to_theta(orn)
return np.array([pos[0], pos[1], theta])
def get_state(self):
"""
Get car state.
:return: vector [x y sinOrn cosOrn v phi]
"""
# Get x, y and theta
pose = self.get_pose()
state = pose3_to_state4(pose)
# Get base velocity
lin_vel = p.getBaseVelocity(self.id, physicsClientId=self.client)
v = np.linalg.norm([lin_vel[0], lin_vel[1]])
# Get steering angle
phi = p.getJointState(self.id, 4, physicsClientId=self.client)[0]
return np.array([*state, v, phi])
def get_state_mpc(self):
"""
Get state for MPC controller (velocity is signed).
:return: state as [x y theta v phi]
"""
# Get pose
pose = self.get_pose()
# Get velocity with sign
lin_vel = p.getBaseVelocity(self.id, physicsClientId=self.client)
vel = np.linalg.norm([lin_vel[0], lin_vel[1]])
joint_pos, joint_vel, _, _ = p.getJointState(self.id, 2, physicsClientId=self.client)
sign = 1 if joint_vel > 0 else -1
vel = sign * vel
# Get steering angle
a = self.cfg.env.car.axis_dist
b = self.cfg.env.car.wheel_dist
phir, _, _, _ = p.getJointState(self.id, 6)
phi = np.arctan((2 * a * np.tan(phir)) / (2 * a - b * np.tan(phir)))
return np.array([*pose, vel, phi])
def set_pose(self, pose: Vector3):
"""
Set the target to a certain pose.
:param pose: vector of 3 components: (x y angle[rad])
"""
# Use PyBullet API
x, y = pose[0], pose[1]
z = self.cfg.env.car.reset_z
orn_quaternion = p.getQuaternionFromEuler([0, 0, pose[2]])
p.resetBasePositionAndOrientation(self.id, [x, y, z], orn_quaternion, physicsClientId=self.client)
# Perform collision detection because we may place the car at different poses to check free regions
p.performCollisionDetection(physicsClientId=self.client)
def set_motors_refs_ackermann(self, v_ref: float, phi_ref: float) -> None:
"""
Move car according to the Ackermann's geometry.
:param v_ref: desired linear velocity
:param phi_ref: desired steering angle
"""
# Use formula to calculate velocities and steering angles
vrl, vrr, vfl, vfr, phil, phir = get_ackermann_v_rf_lr_phi_lr(v_ref, phi_ref, self.cfg)
# Set linear velocities
v_dot_max = self.cfg.env.car.v_dot_max
p.setJointMotorControl2(self.id, 7, p.VELOCITY_CONTROL, force=v_dot_max, targetVelocity=vfr,
physicsClientId=self.client)
p.setJointMotorControl2(self.id, 5, p.VELOCITY_CONTROL, force=v_dot_max, targetVelocity=vfl,
physicsClientId=self.client)
p.setJointMotorControl2(self.id, 3, p.VELOCITY_CONTROL, force=v_dot_max, targetVelocity=vrr,
physicsClientId=self.client)
p.setJointMotorControl2(self.id, 2, p.VELOCITY_CONTROL, force=v_dot_max, targetVelocity=vfl,
physicsClientId=self.client)
# Set steering angles
phi_dot_max = self.cfg.env.car.phi_dot_max
p.setJointMotorControl2(self.id, 6, p.POSITION_CONTROL, maxVelocity=phi_dot_max, targetPosition=phir,
physicsClientId=self.client)
p.setJointMotorControl2(self.id, 4, p.POSITION_CONTROL, maxVelocity=phi_dot_max, targetPosition=phil,
physicsClientId=self.client)
def _setup(self):
"""
Set up.
"""
self._setup_id()
def _setup_id(self):
"""
Set up urdf.
"""
p.setAdditionalSearchPath(str(Paths().deps_models), physicsClientId=self.client)
self.id = p.loadURDF("racecar.urdf", physicsClientId=self.client)
def _setup_ignore_static_warnings(self):
"""
Ignore PyCharm static method warnings.
"""
pass
class Target:
def __init__(self, cfg: MasterConfig, client: int):
"""
Initialize target as desired pose.
"""
self.cfg = cfg
self.client = client
self.id = None
self._setup()
def get_pose(self):
"""
Get target pose.
:return: vector [x y sinTheta cosTheta]
"""
# Get from PyBullet
pos, orn = p.getBasePositionAndOrientation(self.id, physicsClientId=self.client)
# Get orientation
theta = quaternion_to_theta(orn)
return np.array([pos[0], pos[1], theta])
def get_desired_goal(self):
"""
Get desired goal.
:return: vector [x y sinTheta cosTheta]
"""
# Get x, y and theta
pose = self.get_pose()
state = pose3_to_state4(pose)
return state
def set_pose(self, pose: Vector3):
"""
Set the target to a certain pose.
:param pose: vector of 3 components: (x y angle[rad])
"""
# Use PyBullet API
x, y = pose[0], pose[1]
z = self.cfg.env.target.reset_z
orn_quaternion = p.getQuaternionFromEuler([0, 0, pose[2]])
p.resetBasePositionAndOrientation(self.id, [x, y, z], orn_quaternion, physicsClientId=self.client)
def _setup(self):
"""
Set up.
"""
self._setup_id()
def _setup_id(self):
"""
Set up urdf.
"""
p.setAdditionalSearchPath(str(Paths().deps_models), physicsClientId=self.client)
self.id = p.loadURDF('target.urdf', useFixedBase=1, globalScaling=0.025, physicsClientId=self.client)
class Obstacle:
def __init__(self, cfg: MasterConfig, top_left_bottom_right: Vector4, orn: float, client: int):
"""
Initialize.
"""
self.cfg = cfg
self.top_left_bottom_right = top_left_bottom_right
self.orn = orn
self.client = client
self.id = None
self._setup()
def _setup(self):
"""
Set up.
"""
self._setup_id()
def _setup_id(self):
"""
Set up id.
"""
# We set up a collision and visual shape
ln = self.top_left_bottom_right[2] - self.top_left_bottom_right[0]
w = self.top_left_bottom_right[1] - self.top_left_bottom_right[3]
h = self.cfg.maps.obstacles.height
c = self.cfg.maps.obstacles.color
m = self.cfg.maps.obstacles.mass
z = self.cfg.maps.obstacles.reset_z
# Create collision and visual shapes
collision_shape = p.createCollisionShape(
shapeType=p.GEOM_BOX,
halfExtents=[ln / 2, w / 2, h],
physicsClientId=self.client,
)
visual_shape = p.createVisualShape(
shapeType=p.GEOM_BOX,
halfExtents=[ln / 2, w / 2, h],
rgbaColor=c,
physicsClientId=self.client,
)
# Create a heavy multi-body, so that it can't be moved by the car
x = self.top_left_bottom_right[0] + ln / 2
y = self.top_left_bottom_right[3] + w / 2
orn = p.getQuaternionFromEuler([0, 0, self.orn])
self.id = p.createMultiBody(
baseMass=m,
baseCollisionShapeIndex=collision_shape,
baseVisualShapeIndex=visual_shape,
basePosition=[x, y, z],
baseOrientation=orn,
physicsClientId=self.client,
)
class Transition(BaseStats):
action: Vector2 | None = None
reward: float | None = None
done: bool | None = None
desired_goal: np.ndarray | None = None
achieved_goal: np.ndarray | None = None
state: np.ndarray | None = None
next_desired_goal: np.ndarray | None = None
next_achieved_goal: np.ndarray | None = None
next_state: np.ndarray | None = None
@classmethod
def new(cls, obs, next_obs, action, reward, done):
t = Transition()
t.desired_goal = obs['desired_goal']
t.achieved_goal = obs['achieved_goal']
t.state = obs['observation']
t.next_desired_goal = next_obs['desired_goal']
t.next_achieved_goal = next_obs['achieved_goal']
t.next_state = next_obs['observation']
t.action = action
t.reward = reward
t.done = done
return t | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/environments/car_navigation_bullet_env.py | 0.781664 | 0.252378 | car_navigation_bullet_env.py | pypi |
import torch as t
from numpy.random import Generator
from rich.progress import track
from torch.optim import Adam
from torch.utils.data import DataLoader, Dataset
from rrt_ml.algorithms.base import *
from rrt_ml.utilities.datasets import *
from rrt_ml.utilities.formulas import *
from rrt_ml.utilities.infos import *
from rrt_ml.utilities.maps import *
from rrt_ml.utilities.models import *
from rrt_ml.utilities.stats import *
class SL(Algorithm):
"""
Algorithm to learn to sample states for motion planning.
"""
def __init__(self, cfg):
"""
Initialize.
"""
super(SL, self).__init__(cfg)
self.dataset_train = None # type: None | Dataset
self.dataset_val = None # type: None | Dataset
self.dataloader_train = None # type: None | DataLoader
self.dataloader_val = None # type: None | DataLoader
self._setup()
def train(self):
"""
Train CVAE.
"""
# Training loop
for epoch_n in track(range(self.epoch + 1, self.cfg.sl.train.n_epochs), "Training CVAE..."):
# Initialize list of stats
t_l, v_l = [], []
t_kl_l, v_kl_l = [], []
t_r_l, v_r_l = [], []
# Train
for batch_n, sample in enumerate(iter(self.dataloader_train)):
l, kl, r = self._set_train_on_batch(sample)
t_l.append(l)
t_kl_l.append(kl)
t_r_l.append(r)
# Validate
for batch_n, sample in enumerate(iter(self.dataloader_val)):
l, kl, r = self._set_validate_on_batch(sample)
v_l.append(l)
v_kl_l.append(kl)
v_r_l.append(r)
# Get all epoch info and set validation loss attributes
epoch_info = SLEpochInfo.new(epoch_n, t_l, v_l, t_kl_l, v_kl_l, t_r_l, v_r_l)
self._set_attrs_after_epoch(epoch_info)
# Save
self.save_stats(epoch_info)
self.save_checkpoint()
# Log
self.log_console(epoch_info)
self.log_tensorboard(epoch_info)
# Set training flag and save attrs
self.training_over = True
self._set_save_attributes()
def test(self):
"""
Test SL config.
"""
self._test_plot_losses()
self._test_plot_multiple_problems()
self._test_plot_progression()
pass
def save_checkpoint(self):
"""
Save checkpoint.
"""
# Save attributes
self._set_save_attributes()
# Check if validation loss improved
if self.model_curr_loss < self.model_best_loss:
# Log
self.console.print(f"\n[red bold underline]Validation loss decreased from "
f"{self.model_best_loss:.2e} to {self.model_curr_loss:.2e}... Saving model...[/]")
# Save model
self._set_save_model()
def save_stats(self, epoch_info: 'SLEpochInfo') -> None:
"""
Save train statistics.
:param epoch_info: current epoch info.
:return: None.
"""
# Get locals
ep = epoch_info.epoch_n
t_l = epoch_info.train_loss
v_l = epoch_info.val_loss
t_kl_l = epoch_info.train_kl_loss
v_kl_l = epoch_info.val_kl_loss
t_r_l = epoch_info.train_recon_loss
v_r_l = epoch_info.val_recon_loss
b = self.cfg.sl.train.batch_size
# Compute mean loss = mean(epoch_losses) / batch_size
mean_train_loss = np.array(t_l).mean() / b
mean_val_loss = np.array(v_l).mean() / b
mean_train_kl_loss = np.array(t_kl_l).mean() / b
mean_val_kl_loss = np.array(v_kl_l).mean() / b
mean_train_recon_loss = np.array(t_r_l).mean() / b
mean_val_recon_loss = np.array(v_r_l).mean() / b
# Save to object
self.stats.train_loss.append(mean_train_loss)
self.stats.val_loss.append(mean_val_loss)
self.stats.train_kl_loss.append(mean_train_kl_loss)
self.stats.val_kl_loss.append(mean_val_kl_loss)
self.stats.train_recon_loss.append(mean_train_recon_loss)
self.stats.val_recon_loss.append(mean_val_recon_loss)
# Generate states and save
for idx in range(self.cfg.sl.val.n_maps):
# Get sample
sample = self.dataset_val[idx]
y = sample['y']
# Generate samples
states = self.get_samples(y, self.cfg.sl.val.n_states, np.random.default_rng())
# Append
self.stats.arr_epoch_idx_state_dim[ep, idx, :] = states
# Save object in file
self.stats.save_to_file(self.path_stats)
def log_console(self, epoch_info: 'SLEpochInfo') -> None:
"""
Log to console
:param epoch_info: current epoch info.
:return: None.
"""
# Get locals
epoch_n = epoch_info.epoch_n
t_l = epoch_info.train_loss
v_l = epoch_info.val_loss
b = self.cfg.sl.train.batch_size
# Compute mean loss = mean(epoch_losses) / batch_size
mean_train_loss = np.array(t_l).mean() / b
mean_val_loss = np.array(v_l).mean() / b
self.console.print(
f"\n[blue bold underline]Epoch:[/blue bold underline] [blue]{epoch_n}[/blue]\t"
f"[cyan bold underline]Train loss:[/cyan bold underline] [cyan]{mean_train_loss:.2e}[/cyan]\t"
f"[green bold underline]Val loss:[/green bold underline] [green]{mean_val_loss:.2e}[/green]"
)
def log_tensorboard(self, epoch_info: 'SLEpochInfo') -> None:
"""
Log info to tensorboard.
:param epoch_info: current epoch info.
:return: None
"""
epoch_n = epoch_info.epoch_n
t_l = epoch_info.train_loss
v_l = epoch_info.val_loss
t_kl_l = epoch_info.train_kl_loss
v_kl_l = epoch_info.val_kl_loss
t_r_l = epoch_info.train_recon_loss
v_r_l = epoch_info.val_recon_loss
b = self.cfg.sl.train.batch_size
# Compute mean loss = mean(epoch_losses) / batch_size
mean_train_loss = np.array(t_l).mean() / b
mean_val_loss = np.array(v_l).mean() / b
mean_train_kl_loss = np.array(t_kl_l).mean() / b
mean_val_kl_loss = np.array(v_kl_l).mean() / b
mean_train_recon_loss = np.array(t_r_l).mean() / b
mean_val_recon_loss = np.array(v_r_l).mean() / b
# Write losses to tensorboard
loss = {'train': mean_train_loss, 'val': mean_val_loss}
self.tb.add_scalars("loss", loss, epoch_n)
kl_loss = {'train': mean_train_kl_loss, 'val': mean_val_kl_loss}
self.tb.add_scalars("kl_loss", kl_loss, epoch_n)
recon_loss = {'train': mean_train_recon_loss, 'val': mean_val_recon_loss}
self.tb.add_scalars("recon_loss", recon_loss, epoch_n)
# Check generation of states
self.tb.add_figure("generated_poses", self._get_tb_plot_predictions(), epoch_n)
def get_conditions(self, map_num: int) -> tuple[np.ndarray, np.ndarray, np.ndarray]:
"""
Get conditions from validation dataset (sample with index 'map_num').
:return: obstacles, initial state and final state
"""
# Maps are grouped with different samples
# idx = 20 * map_num
idx = map_num
# Get whole condition vector
y = self.dataset_val[idx]['y']
# Separate
obstacles = y[0:self.cfg.sl.dim.obstacle] # type: t.Tensor
state_i = y[self.cfg.sl.dim.obstacle:(self.cfg.sl.dim.obstacle + self.cfg.sl.dim.state)] # type: t.Tensor
state_f = y[-self.cfg.sl.dim.state:] # type: t.Tensor
# Convert to numpy array
obstacles = obstacles.cpu().numpy() # type: np.ndarray
state_i = state_i.cpu().numpy() # type: np.ndarray
state_f = state_f.cpu().numpy() # type: np.ndarray
return obstacles, state_i, state_f
def get_samples(self, y: np.ndarray | t.Tensor | int, n_samples: int | None, rng: Generator) -> np.ndarray:
"""
Generate states.
"""
# Case y is int we get sample from validation set
if isinstance(y, int):
y = self.dataset_val[y]['y']
# First replicate condition vector along the first axis and move to cuda
if isinstance(y, np.ndarray):
y = t.tensor(y).repeat((n_samples, 1)).cuda()
else:
y = y.repeat((n_samples, 1)).cuda()
# Turn on eval mode and stop gradient tracking
self.model.eval()
with t.no_grad():
# Sample 'n_samples' from latent vector and concatenate with condition vector
z = t.tensor(rng.normal(0, 1, (n_samples, self.cfg.sl.dim.latent))).cuda()
z_and_y = t.cat((z, y), dim=1).float()
# Decode
x = self.model.mlp_decoder(z_and_y)
# Move to cpu and get as numpy array
x = x.cpu().numpy()
return x
def _get_tb_plot_predictions(self):
"""
Get plot of generated predictions on current epoch
:return: matplotlib figure to add to tensorboard
"""
# Get constants (idx is the first validation sample)
ep = self.epoch
idx = 0
# Get states from saved stats
states = self.stats.arr_epoch_idx_state_dim[ep, idx, :]
# Initialize map and get plot axis, then get figure from axis
maps = Map(self.cfg)
maps.set_add_states(states[:50, :], 'sl')
fig, ax = maps.get_plot_lines()
return fig
def _set_train_on_batch(self, sample: dict) -> Vector3:
"""
Train model on a batch
:param sample: batch sample
:return: total loss, KL loss and reconstruction loss
"""
# Prepare
self.model.train()
self.model_optimizer.zero_grad()
# Forward
x, mu, sigma = self.model(sample['x'], sample['y'])
# Loss and optimize
loss, kl_loss, recon_loss = self.model.loss(x, sample['x'], mu, sigma)
loss.backward()
self.model_optimizer.step()
return loss.item(), kl_loss.item(), recon_loss.item()
def _set_validate_on_batch(self, sample: dict) -> Vector3:
"""
Validate model on a batch.
:param sample: batch sample.
:return: total loss, KL loss and reconstruction loss.
"""
# Prepare model
self.model.eval()
# Don't track gradients and get loss
with t.no_grad():
x, mu, sigma = self.model(sample['x'], sample['y'])
loss, kl_loss, recon_loss = self.model.loss(x, sample['x'], mu, sigma)
return loss.item(), kl_loss.item(), recon_loss.item()
def _set_attrs_after_epoch(self, epoch_info):
"""
Set attributes after epoch of training.
:param epoch_info: current epoch info.
"""
# Update iteration
self.epoch = epoch_info.epoch_n
# Update current loss
self.model_curr_loss = np.array(epoch_info.val_loss).mean() / self.cfg.sl.train.batch_size
# Check best loss so far
if len(self.stats.val_loss) > 1:
self.model_best_loss = min(self.stats.val_loss)
def _test_plot_losses(self):
"""
Plot model training and validation losses.
"""
# Return if figure exists
path = self.path_figs / 'sl_erros.png'
if path.exists():
return
# Get figure
fig, axs = plt.subplots(3, 1, sharex='all', squeeze=True, figsize=(12, 9.6))
fig.subplots_adjust(hspace=0.25)
# Plot recon loss
axs[0].plot(range(1, 50), self.stats.train_recon_loss, label="Treino")
axs[0].plot(range(1, 50), self.stats.val_recon_loss, label="Validação")
axs[0].set_title('Erro de Reconstrução')
axs[0].legend()
axs[0].grid(True)
axs[0].set_ylim(None, 0.005)
# Plot KL loss
axs[1].plot(range(1, 50), self.stats.train_kl_loss, label="Treino")
axs[1].plot(range(1, 50), self.stats.val_kl_loss, label="Validação")
axs[1].set_title('Erro de Divergência KL')
axs[1].legend()
axs[1].grid(True)
# Plot total loss
axs[2].plot(range(1, 50), self.stats.train_loss, label="Treino")
axs[2].plot(range(1, 50), self.stats.val_loss, label="Validação")
axs[2].set_title('Erro Total')
axs[2].legend()
axs[2].grid(True)
axs[2].set_ylim(None, 0.01)
axs[2].set_xlabel('Época')
# Save
fig.savefig(str(path), dpi=600, bbox_inches='tight')
def _test_plot_progression(self):
"""
Plot progression of sample generation.
"""
# Return if figure exists
path = self.path_figs / 'sl_progresso.png'
if path.exists():
return
# Constants
map_num = 23
# Get problem conditions and change config before creating the map
obstacles, state_i, state_f = self.get_conditions(map_num)
cfg = self.cfg.copy(deep=True)
cfg.maps.general.map_name = 'narrow'
cfg.maps.narrow.narrow1_pos = obstacles[:2]
cfg.maps.narrow.narrow2_pos = obstacles[2:]
cfg.env.car.pose = state4_to_pose3(state_i)
cfg.env.target.pose = state4_to_pose3(state_f)
# Initialize figure
fig, axs = plt.subplots(2, 3, sharex='col', sharey='row', figsize=(12, 9.6)) # type: plt.Figure
fig.subplots_adjust(hspace=-0.2)
axs = axs.flatten()
# Which epochs to plot
epochs = [1, 9, 19, 29, 39, 49]
# Plot
for i, epoch in enumerate(epochs):
# Get states
states = self.stats.arr_epoch_idx_state_dim[epoch, map_num, :15]
# Create map and add states
mapp = Map(cfg)
mapp.set_add_states(states, 'sl')
mapp.set_add_states(state_i, 'init')
mapp.set_add_states(state_f, 'final')
mapp.get_plot_lines(axs[i])
# Add title
axs[i].set_title(f'Época {epoch}')
# Axes labels
if i in [0, 3]:
axs[i].set_ylabel('y [m]')
if i in [3, 4, 5]:
axs[i].set_xlabel('x [m]')
# Save
fig.savefig(str(path), dpi=600, bbox_inches='tight')
def _test_plot_multiple_problems(self):
"""
Get CVAE solution on test problems.
"""
# Return if figure exists
path = self.path_figs / 'sl_diversos_problemas.png'
if path.exists():
return
# Initialize figure
fig, axs = plt.subplots(2, 3, sharex='col', sharey='row', figsize=(12, 9.6)) # type: plt.Figure
fig.subplots_adjust(hspace=-0.2)
axs = axs.flatten()
# Get problems
problems = [20, 40, 60, 80, 100, 120]
# Plot
for i, p in enumerate(problems):
# Get conditions
obstacles, state_i, state_f = self.get_conditions(p)
cfg = self.cfg.copy(deep=True)
cfg.maps.general.map_name = 'narrow'
cfg.maps.narrow.narrow1_pos = obstacles[:2]
cfg.maps.narrow.narrow2_pos = obstacles[2:]
# cfg.env.car.pose = state4_to_pose3(state_i)
# cfg.env.target.pose = state4_to_pose3(state_f)
cfg.env.car.pose = [state_i[0], state_i[1], np.arctan2(state_i[3], state_i[2])]
cfg.env.target.pose = [state_f[0], state_f[1], np.arctan2(state_f[3], state_f[2])]
# Get samples
condition = np.concatenate([obstacles, state_i, state_f])
states = self.get_samples(condition, 15, np.random.default_rng(0))
# States are in the form [x y cos sin] but map needs [x y sin cos]
states = state4_sl_to_state4_rl(states)
state_i = state4_sl_to_state4_rl(state_i)
state_f = state4_sl_to_state4_rl(state_f)
# Create map and add states
mapp = Map(cfg)
mapp.set_add_states(states, 'sl')
mapp.set_add_states(state_i, 'init')
mapp.set_add_states(state_f, 'final')
mapp.get_plot_lines(axs[i])
# Add title
axs[i].set_title(f'Problema {i+1}')
# Axes labels
if i in [0, 3]:
axs[i].set_ylabel('y [m]')
if i in [3, 4, 5]:
axs[i].set_xlabel('x [m]')
# Save
fig.savefig(path, dpi=600, bbox_inches='tight')
def _setup(self):
"""
Set up.
"""
# Set up base algorithm settings
self._setup_paths()
self._setup_folders()
self._setup_save_config_to_file()
self._setup_attrs_to_save()
self._setup_init_base_attrs()
self._setup_init_model()
self._setup_checkpoint()
self._setup_stats()
self._setup_console()
self._setup_tensorboard()
# Set up SL settings
self._setup_dataset()
self._setup_dataloader()
self._setup_cuda()
def _setup_checkpoint(self):
"""
Set up checkpoint.
"""
# Check if there is a checkpoint
self.load_checkpoint = self._get_checkpoint_exists_indicator()
# Load model and attributes if it does
if self.load_checkpoint:
self._set_load_attributes()
self._set_load_model()
def _setup_cuda(self):
"""
Set up cuda.
"""
self.model.to("cuda")
def _setup_init_model(self):
"""
Set up CVAE model and optimizer.
"""
self.model = CVAE(self.cfg)
self.model_optimizer = Adam(self.model.parameters(), lr=self.cfg.sl.train.lr)
def _setup_dataloader(self):
"""
Set up train and validation loaders.
"""
self.dataloader_train = DataLoader(
self.dataset_train, self.cfg.sl.train.batch_size, pin_memory=False
)
self.dataloader_val = DataLoader(
self.dataset_val, self.cfg.sl.train.batch_size, pin_memory=False
)
def _setup_dataset(self):
"""
Set up train and validation datasets.
"""
self.dataset_train = NarrowCVAEDataset(cfg=self.cfg, train=True)
self.dataset_val = NarrowCVAEDataset(cfg=self.cfg, train=False)
def _setup_stats(self):
"""
Set up stats object.
"""
if self.load_checkpoint:
self.stats = SLStats.load_from_file(self.path_stats)
else:
self.stats = SLStats.new(self.cfg)
self.stats.save_to_file(self.path_stats) | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/algorithms/sl.py | 0.855127 | 0.348756 | sl.py | pypi |
from abc import ABC
from pathlib import Path
import matplotlib
import numpy as np
import torch as t
import yaml
from joblib import load, dump
from rich.console import Console
from torch.nn import Module
from torch.optim import Adam
from torch.utils.tensorboard import SummaryWriter
from rrt_ml.utilities.configs import MasterConfig
from rrt_ml.utilities.paths import Paths
from rrt_ml.utilities.stats import BaseStats
class Algorithm(ABC):
"""
Abstract base class.
"""
def __init__(self, cfg: MasterConfig):
# Base
self.cfg = cfg
self.console = None # type: Console | None
self.epoch = None
self.load_checkpoint = None # type: bool | None
self.model = None # type: None | Module
self.model_best_loss = None # type: None | float
self.model_optimizer = None # type: None | Adam
self.model_curr_loss = None # type: None | float
self.path_attrs = None # type: Path | None
self.path_figs = None # type: Path | None
self.path_model = None # type: Path | None
self.path_model_optimizer = None # type: Path | None
self.path_stats = None # type: Path | None
self.path_tb = None # type: Path | None
self.save_attrs = None # type: list[str, ...] | None
self.stats = None # type: BaseStats | None
self.tb = None # type: SummaryWriter | None
self.training_over = None # type: bool | None
def train(self, *args, **kwargs):
"""
Train algorithm / model.
"""
raise NotImplementedError
def test(self, *args, **kwargs):
"""
Test algorithm / model.
"""
raise NotImplementedError
def save_checkpoint(self, *args, **kwargs):
"""
Save algorithm every iteration using this function.
"""
pass
def save_stats(self, *args, **kwargs):
"""
Save training stats using this function.
"""
pass
def log_console(self, *args, **kwargs):
"""
Log iterations on the console using this function.
"""
raise NotImplementedError
def log_tensorboard(self, *args, **kwargs):
"""
Log iterations on tensorboard using this function.
"""
raise NotImplementedError
def _setup(self, *args, **kwargs):
"""
General _setup.
"""
# Set paths, load checkpoint, stats, console and tensorboard
self._setup_paths()
self._setup_folders()
self._setup_save_config_to_file()
self._setup_attrs_to_save()
self._setup_init_base_attrs()
self._setup_init_model()
self._setup_checkpoint()
self._setup_stats()
self._setup_console()
self._setup_tensorboard()
def _get_checkpoint_exists_indicator(self):
"""
Check if checkpoint exists.
:return: boolean indicating whether checkpoint exists.
"""
return self.path_attrs.exists()
def _set_ignore_static_warnings(self):
"""
Ignore linting errors.
"""
pass
def _set_load_attributes(self):
"""
Load algorithm attributes.
"""
attrs_dict = load(self.path_attrs)
for k in attrs_dict.keys():
if k in self.save_attrs:
setattr(self, k, attrs_dict[k])
def _set_load_model(self):
"""
Load model if it exists.
"""
# Load model
self.model.load_state_dict(t.load(self.path_model))
# Load optimizer and move parameters to cuda
for state in self.model_optimizer.state.values():
for k, v in state.items():
if isinstance(v, t.Tensor):
state[k] = v.cuda() if t.cuda.is_available() else state[k]
def _set_save_attributes(self):
"""
Save attributes to file.
"""
# Save attributes
save_dict = {}
for k, v in self.__dict__.items():
if k in self.save_attrs:
save_dict[k] = v
dump(save_dict, str(self.path_attrs))
def _set_save_model(self):
"""
Save model.
"""
t.save(self.model.state_dict(), self.path_model)
t.save(self.model_optimizer.state_dict(), self.path_model_optimizer)
def _setup_attrs_to_save(self, *args, **kwargs):
"""
Set up list of attributes to save on checkpoint.
"""
self.save_attrs = ['epoch', 'model_best_loss', 'model_curr_loss', 'training_over']
def _setup_checkpoint(self, *args, **kwargs):
"""
Initialize or load checkpoint object.
"""
pass
def _setup_console(self):
"""
Initialize console logger and log initial information.
"""
# Aliases
alg = self.cfg.general.algorithm
name = self.cfg.general.config_name_or_prefix
# Create object
self.console = Console(width=150)
# Ruler
self.console.rule(), self.console.rule()
# Log config algorithm and name
self.console.print(f"[blue bold underline]Algorithm:[/][blue] {alg}[/]", justify='center')
self.console.print(f"[magenta bold underline]Running config:[/][magenta] {name}[/]", justify='center')
# Log loading checkpoint
if self.load_checkpoint:
self.console.print(f"[red bold underline]Loading checkpoint... [/]", justify='center')
# Ruler
self.console.rule(), self.console.rule()
def _setup_folders(self):
"""
Set up experiment folders.
"""
# Get aliases
alg = self.cfg.general.algorithm
name = self.cfg.general.config_name_or_prefix
try:
Paths().exp(alg, name).mkdir()
except FileExistsError:
pass
try:
Paths().exp_checkpoint(alg, name).mkdir()
except FileExistsError:
pass
try:
Paths().exp_stats(alg, name).mkdir()
except FileExistsError:
pass
try:
Paths().exp_tensorboard(alg, name).mkdir()
except FileExistsError:
pass
try:
Paths().exp_fig(alg, name).mkdir()
except FileExistsError:
pass
def _setup_init_base_attrs(self):
"""
Initialize base attributes (epoch, model losses, etc)
"""
self.epoch = 0
self.model_curr_loss = np.inf
self.model_best_loss = np.inf
self.training_over = False
def _setup_init_model(self):
"""
Initialize model.
"""
pass
def _setup_paths(self, *args, **kwargs):
"""
Setup paths for checkpoints, models, etc.
"""
# Aliases
alg = self.cfg.general.algorithm
name = self.cfg.general.config_name_or_prefix
# Attributes path
self.path_attrs = Paths().exp_checkpoint(alg, name) / "attrs"
# Stats path
self.path_stats = Paths().exp_stats(alg, name) / "stats"
# Figures path
self.path_figs = Paths().exp_fig(alg, name)
# Tensorboard path
self.path_tb = Paths().exp_tensorboard(alg, name)
# Model and optimizer paths
self.path_model = Paths().exp_checkpoint(alg, name) / "model.pt"
self.path_model_optimizer = Paths().exp_checkpoint(alg, name) / "model_optimizer.pt"
def _setup_save_config_to_file(self):
"""
Save config to file.
"""
# Aliases
alg = self.cfg.general.algorithm
name = self.cfg.general.config_name_or_prefix
# Save config at experiment base folder
path = Paths().exp(alg, name) / 'config.yaml'
if not path.exists():
with open(str(path), 'w') as f:
yaml.dump(self.cfg.dict(), f)
def _setup_stats(self, *args, **kwargs):
"""
Set up stats object.
"""
pass
def _setup_tensorboard(self, *args, **kwargs):
"""
Setup tensorboard logging.
"""
# Don't show figure window
# matplotlib.use('Agg')
if not self.training_over:
self.tb = SummaryWriter(log_dir=str(self.path_tb)) | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/algorithms/base.py | 0.78691 | 0.175397 | base.py | pypi |
import time
from multiprocessing import cpu_count
import matplotlib.ticker as ticker
import mrl
import pandas as pd
import pybullet as p
import seaborn as sns
from matplotlib import pyplot as plt
from mrl.algorithms.continuous_off_policy import ActorPolicy, DDPG
from mrl.configs.continuous_off_policy import protoge_config
from mrl.modules.action_noise import ContinuousActionNoise
from mrl.modules.curiosity import DensityAchievedGoalCuriosity
from mrl.modules.density import RawKernelDensity
from mrl.modules.env import EnvModule
from mrl.modules.eval import EpisodicEval
from mrl.modules.goal_reward import GoalEnvReward
from mrl.modules.logging import Logger
from mrl.modules.model import PytorchModel
from mrl.modules.normalizer import Normalizer, MeanStdNormalizer
from mrl.modules.train import StandardTrain
from mrl.replays.online_her_buffer import OnlineHERBuffer
from mrl.utils.misc import make_activ
from mrl.utils.networks import Actor, FCBody, Critic
from mrl.utils.random_process import GaussianProcess
from mrl.utils.schedule import ConstantSchedule
from rich.progress import track
from torch import nn
from rrt_ml.algorithms.base import *
from rrt_ml.environments.car_navigation_bullet_env import *
from rrt_ml.utilities.analytic import *
from rrt_ml.utilities.configs import *
from rrt_ml.utilities.formulas import *
from rrt_ml.utilities.hints import *
from rrt_ml.utilities.infos import *
from rrt_ml.utilities.paths import *
from rrt_ml.utilities.stats import *
class RL(Algorithm):
def __init__(self, cfg: MasterConfig):
"""
Initialize.
:param cfg: configuration
"""
super(RL, self).__init__(cfg)
self.agent = None # type: None | mrl.Agent
self.eval_env = None # type: None | CarNavigationBulletEnv
self.mrl_config = None
# Setup
self._setup()
def train(self):
"""
Train agent.
"""
# No need if already trained
if self.training_over:
return
# Get total num of epochs
epochs_total = int(self.cfg.rl.train.n_timesteps // self.cfg.rl.val.interval)
# Train loop
for epoch_n in track(range(self.epoch + 1, epochs_total), "Training RL agent..."):
# Train for a number of timesteps
self.agent.train(num_steps=self.cfg.rl.val.interval)
# Evaluate with MRL (random resets) and custom (deterministic reset)
rand_val_reward = np.mean(self.agent.eval(num_episodes=self.cfg.rl.val.n_episodes).rewards)
env_stats, det_val_reward = self._get_eval_stats()
train_timestep_num = epoch_n * self.cfg.rl.val.interval
# Get and save epoch info
epoch_info = RLEpochInfo.new(det_val_reward, rand_val_reward, env_stats, train_timestep_num)
self._set_attrs_after_epoch(epoch_info)
# Save
self.save_stats(epoch_info)
self.save_checkpoint(epoch_info)
# Log
self.log_console(epoch_info)
self.log_tensorboard(epoch_info)
# Set training flag and save attrs
self.training_over = True
self._set_save_attributes()
def test(self):
"""
Test RL.
"""
self._test_plot_entropy()
self._test_plot_rewards()
self._test_plot_progress()
self._test_plot_horizon_success_rate()
self._test_plot_multiple_problems()
self._test_plot_compare_mpcrs()
self._test_plot_compare_rs()
self._test_plot_compare_rs_mpcrs()
self._test_chasing()
def save_checkpoint(self, epoch_info: 'RLEpochInfo'):
"""
Save checkpoint. Equal to base method except for last line.
"""
# Save attributes
self._set_save_attributes()
# Save agent if improved deterministic and random evaluations
if self.model_curr_loss > self.model_best_loss:
# Log
self.console.print(f"\n[red bold underline]Total reward increased from "
f"{self.model_best_loss:.2f} to {self.model_curr_loss:.2f}... Saving model...[/]")
# Save agent
self.agent.save("checkpoint")
def save_stats(self, epoch_info: 'RLEpochInfo'):
"""
Set up stats to save.
"""
self.stats.env_stats.append(epoch_info.env_stats)
self.stats.det_val_rewards.append(epoch_info.det_val_reward)
self.stats.rand_val_rewards.append(epoch_info.rand_val_reward)
self.stats.total_val_rewards.append(epoch_info.det_val_reward + epoch_info.rand_val_reward)
self.stats.train_timestep_nums.append(epoch_info.train_timestep_num)
self.stats.save_to_file(self.path_stats)
def log_console(self, epoch_info: 'RLEpochInfo'):
"""
Log to console.
:param epoch_info: current epoch info
"""
tt = epoch_info.train_timestep_num
rr = epoch_info.rand_val_reward
dr = epoch_info.det_val_reward
self.console.print(
f"\n[blue bold underline]Train Timestep:[/blue bold underline] [blue]{tt}[/blue]\t"
f"[cyan bold underline]Current Rewards (rand/det):[/cyan bold underline] [cyan]{rr}/{dr}[/cyan]\t"
)
def log_tensorboard(self, epoch_info: 'RLEpochInfo'):
"""
For consistency only, handled by MRL.
"""
pass
def get_distance_data(self, num_episodes=100000):
"""
Get distance data for training supervised models.
"""
# Create files and folders
train_file_path, val_file_path, test_file_path = self._get_distance_data_files_paths()
# Set agent to eval mode
self.agent.eval_mode()
# Create env with modified config and reset master to get all stats
cfg = self._get_distance_env_cfg()
env = CarNavigationBulletEnv(cfg)
# Loop episodes
ep_counter = 0
for i in range(num_episodes):
# Get data
data = []
l_obs = []
self._get_episode_info_recursive(env, l_obs, data)
# Increment counter
ep_counter += len(data)
# Save to file
if ep_counter % 2 == 0:
# Save batch
self._set_save_distance_batch(data, train_file_path, val_file_path, test_file_path)
# Log
self.console.print(
f"\n[blue bold underline]Generating distance data...[/blue bold underline]\t"
f"[cyan bold underline]Number of episodes:[/cyan bold underline] [cyan]{ep_counter}[/cyan]\t"
)
def get_action(self, obs: dict[str, Vector]) -> Vector2:
"""
Get agent prediction.
:return: action
"""
self.agent.eval_mode()
return self.agent.policy(obs).flatten()
def _get_distance_data_files_paths(self):
"""
Create files and folders to hold data.
:returns: train and validation csv paths
"""
# Set paths
folder_path = Paths().data_rl_distance / self.cfg.general.config_name_or_prefix
train_file_path = folder_path / 'train.csv'
val_file_path = folder_path / 'val.csv'
test_file_path = folder_path / 'test.csv'
# Create files and folders
if not folder_path.exists():
folder_path.mkdir()
if not train_file_path.exists():
with open(str(train_file_path), "w") as _:
pass
with open(str(val_file_path), "w") as _:
pass
with open(str(test_file_path), "w") as _:
pass
return train_file_path, val_file_path, test_file_path
def _get_distance_env_cfg(self):
"""
Change env config to generate distance data.
:return: new master config
"""
# Change config
cfg = MasterConfig.load_from_experiment('rl', self.cfg.rrt.names.rl)
cfg.env.car.pose = 0
cfg.env.target.pose = 5
cfg.env.general.max_timestep = 100
cfg.env.general.seed = None
cfg.env.general.stats = True
cfg.env.general.gui = False
return cfg
def _get_eval_stats(self) -> tuple[EnvStats, float]:
"""
Eval agent on episodes with deterministic resetting and capture stats.
:return: stats and accumulated reward
"""
# Set agent to eval mode (don't use dropout, etc)
self.agent.eval_mode()
# Master reset to set the seed and reset deterministically
self.eval_env.reset_master()
# Episodes loops
sum_rewards = 0
for i in range(self.cfg.rl.val.n_episodes):
done = False
obs = self.eval_env.reset()
while not done:
obs, reward, done, _ = self.eval_env.step(self.agent.policy(obs).flatten())
sum_rewards += reward
# Get stats
return self.eval_env.stats, sum_rewards / self.cfg.rl.val.n_episodes
def _get_episode_info_recursive(self, env: CarNavigationBulletEnv, l_obs: list[dict, ...], data: list[np.ndarray, ...]):
"""
Get episode info recursively.
:param env:
:param l_obs:
:param data:
:return:
"""
# If there are no list of observations we need to get it
if len(l_obs) == 0:
# If there is data we need to return it
if len(data) > 0:
return data
# Place target at random pose
env.reset_master()
env.reset()
# Place car at origin
env.car.set_pose([0, 0, 0])
# Get target obs
obs = env._get_observation()
car_state = obs['achieved_goal']
target_state = obs['desired_goal']
# Play episode
done, done_info = env._get_done_indicator(env.compute_reward(car_state, target_state))
info = {'done_info': done_info}
while not done:
# Policy action
action = self.agent.policy(obs).flatten()
# Step
obs, reward, done, info = env.step(action)
# Add to list of obs
l_obs.append(obs)
# Add to database
success = info['done_info']['success']
data.append(np.concatenate((
target_state,
np.array([success]),
np.array([env.stats.get_time_to_reach(0)]),
np.array([env.timestep]),
np.array([env.stats.get_distance_traveled(0)]))
))
self._get_episode_info_recursive(env, l_obs, data)
else:
# Reset to get stats and zero joints
env.reset_master()
env.reset()
# Transform to origin
env.car.set_pose([0, 0, 0])
env.target.set_pose(transform_to_origin(l_obs.pop(0)))
# Get new target pose
obs = env._get_observation()
car_state = obs['achieved_goal']
target_state = obs['desired_goal']
# Play episode
done, done_info = env._get_done_indicator(env.compute_reward(car_state, target_state))
info = {'done_info': done_info}
while not done:
# Policy action
action = self.agent.policy(obs).flatten()
# Step
obs, reward, done, info = env.step(action)
# Add to database
success = info['done_info']['success']
data.append(np.concatenate((
target_state,
np.array([success]),
np.array([env.stats.get_time_to_reach(0)]),
np.array([env.timestep]),
np.array([env.stats.get_distance_traveled(0)]))
))
# Replay until there are no intermediate observations
self._get_episode_info_recursive(env, l_obs, data)
return data
def _set_attrs_after_epoch(self, epoch_info):
"""
Set basic attributes after an epoch o training.
:param epoch_info: current epoch info
"""
# Update iteration
self.epoch = int(100 * epoch_info.train_timestep_num / self.cfg.rl.train.n_timesteps)
# Update current loss
self.model_curr_loss = epoch_info.det_val_reward + epoch_info.rand_val_reward
# Check best loss so far
if len(self.stats.total_val_rewards) > 1:
self.model_best_loss = max(self.stats.total_val_rewards)
def _set_save_distance_batch(self, data: list, train_file_path: str, val_file_path: str, test_file_path: str):
"""
Save batch of distance data
:param data: list of rows with x and y pairs
:param train_file_path: path to train_file
:param val_file_path: path to val_file
"""
# Ignore warnings
self._set_ignore_static_warnings()
# Generate 10% of data as validation and 20% as test
rand = np.random.rand()
if rand < 0.1:
with open(str(val_file_path), "a") as file:
# noinspection PyTypeChecker
np.savetxt(file, np.array(data), delimiter=",")
elif rand < 0.25:
with open(str(test_file_path), "a") as file:
# noinspection PyTypeChecker
np.savetxt(file, np.array(data), delimiter=",")
else:
with open(str(train_file_path), "a") as file:
# noinspection PyTypeChecker
np.savetxt(file, np.array(data), delimiter=",")
def _test_chasing(self):
"""
Test chasing different poses.
"""
# Env
cfg = self.cfg.copy(deep=True)
cfg.env.general.gui = True
cfg.env.car.pose = [0, 0, 0]
cfg.env.target.pose = 1
cfg.env.reward.epsilon = -0.15
cfg.env.general.max_timestep = 10000
env = CarNavigationBulletEnv(cfg)
obs = env.reset()
# Loop all episodes
for _ in range(100):
# Loop
time.sleep(0.5)
done = False
pose = np.random.uniform([-1, -1, 0], [1, 1, 2*np.pi])
env.target.set_pose(pose)
while not done:
obs, reward, done, info = env.step(self.get_action(obs))
time.sleep(1/45)
def _test_plot_compare_mpcrs(self):
"""
Compare RL and MPC with Reed-Shepp paths.
"""
# Return if figure exists
path = self.path_figs / 'rl_comparacao_rsmpc.png'
if path.exists():
return
# Change config
cfg = self.cfg.copy(deep=True)
cfg.env.general.seed = 1
cfg.env.general.gui = True
cfg.env.general.stats = True
cfg.env.target.pose = 1.5
cfg.env.car.pose = [0, 0, 0]
# Initialize env and reset master
env = CarNavigationBulletEnv(cfg)
env.reset_master()
# Initialize figure
fig, axs = plt.subplots(nrows=2, ncols=3, sharex='col', sharey='row', figsize=(12, 9.6))
fig.subplots_adjust(hspace=-0.2)
# Episode loop for RL
for ep in range(3):
# Get episode info for RL
done, obs = False, env.reset()
while not done:
obs, reward, done, info = env.step(self.get_action(obs))
# Get car info to place ghosts and actions
car_poses = env.stats.bullet.car_poses[ep, ...]
car_steers = env.stats.bullet.car_steers[ep, ...]
# Remove all zeros rows
car_poses = car_poses[~np.all(car_poses == 0, axis=1)]
car_steers = car_steers[~np.all(car_steers == 0, axis=1)]
# Get indexes to place ghosts
interval = cfg.env.test.general.ghost_interval
n_timesteps = car_poses.shape[0]
idxs = np.arange(0, n_timesteps, interval)
# Place ghosts
for pose, steer in zip(car_poses[idxs, :], car_steers[idxs, :]):
env._set_place_ghost_car(pose, steer)
# Place car at final pose
env.car.set_pose(car_poses[-1, :])
# Take screenshot and clear ghosts
img = env._get_image_current_top_view()
env._set_remove_ghosts()
# Plot on axis
axs[0, ep].imshow(img, origin='lower', extent=cfg.env.test.none.img_extent)
# Get distance traveled and time
length = env.stats.get_distance_traveled(ep)
time = env.stats.get_time_to_reach(ep)
axs[0, ep].set_title(f'Agente: {time:.2f}s / {length:.2f}m')
# Set y axis
if ep == 0:
axs[0, ep].set_ylabel('y [m]')
# Now get results for RSMPC, change config and re-init env
cfg.env.car.f_val = 240
cfg.env.general.max_timestep = 2000
p.disconnect(physicsClientId=env.client)
del env
env = CarNavigationBulletEnv(cfg)
env.reset_master()
# Change config and initialize MPCRS
rsmpc = MPCRS(cfg)
# Episode loop for MPCRS
for ep in range(3):
# Get episode info for RL
done, obs = False, env.reset()
while not done:
action = rsmpc.get_action(obs)
obs, reward, done, info = env.step(action)
# Get car info to place ghosts and actions
car_poses = env.stats.bullet.car_poses[ep, ...]
car_steers = env.stats.bullet.car_steers[ep, ...]
# Remove all zeros rows
car_poses = car_poses[~np.all(car_poses == 0, axis=1)]
car_steers = car_steers[~np.all(car_steers == 0, axis=1)]
# Get indexes to place ghosts
interval = cfg.env.test.general.ghost_interval
n_timesteps = car_poses.shape[0]
idxs = np.arange(0, n_timesteps, interval)
# Place ghosts
for pose, steer in zip(car_poses[idxs, :], car_steers[idxs, :]):
env._set_place_ghost_car(pose, steer)
# Place car at final pose
env.car.set_pose(car_poses[-1, :])
# Take screenshot and clear ghosts
img = env._get_image_current_top_view()
env._set_remove_ghosts()
# Plot on axis
axs[1, ep].imshow(img, origin='lower', extent=cfg.env.test.none.img_extent)
# Get distance traveled and time
length = env.stats.get_distance_traveled(ep)
time = env.stats.get_time_to_reach(ep)
axs[1, ep].set_title(f'CPM: {time:.2f}s / {length:.2f}m')
# Set x axis
axs[1, ep].set_xlabel('x [m]')
# Set y axis
if ep == 0:
axs[1, ep].set_ylabel('y [m]')
# Delete env
p.disconnect(physicsClientId=env.client)
# Save figure
fig.savefig(str(path), dpi=600, bbox_inches='tight')
def _test_plot_compare_rs(self):
"""
Compare RL path with RS path.
"""
# Return if figure exists
path = self.path_figs / 'rl_comparacao_rs.png'
if path.exists():
return
# Change config
cfg = self.cfg.copy(deep=True)
cfg.env.general.seed = 1
cfg.env.general.gui = True
cfg.env.general.stats = True
cfg.env.target.pose = 1.5
cfg.env.car.pose = [0, 0, 0]
cfg.rrt.rs.curvature = 2.5
# Initialize env and reset master
env = CarNavigationBulletEnv(cfg)
env.reset_master()
# Initialize figure
fig, axs = plt.subplots(nrows=2, ncols=3, sharex='col', sharey='row', figsize=(12, 9.6))
fig.subplots_adjust(hspace=-0.2)
# Episode loop for RL
ep = 0
for i, _ in enumerate(axs):
for j, _ in enumerate(axs[i, :]):
# Reset env
done, obs = False, env.reset()
# Get RS path length before changing env
rs = MPCRS(cfg)
rs._set_rs_path(obs)
length_rs = rs.get_distance(Node(env.car.get_pose()), Node(env.target.get_pose()))
while not done:
obs, reward, done, info = env.step(self.get_action(obs))
# Get car info to place ghosts and actions
car_poses = env.stats.bullet.car_poses[ep, ...]
car_steers = env.stats.bullet.car_steers[ep, ...]
# Remove all zeros rows
car_poses = car_poses[~np.all(car_poses == 0, axis=1)]
car_steers = car_steers[~np.all(car_steers == 0, axis=1)]
# Get indexes to place ghosts
interval = cfg.env.test.general.ghost_interval
n_timesteps = car_poses.shape[0]
idxs = np.arange(0, n_timesteps, interval)
# Place ghosts
for pose, steer in zip(car_poses[idxs, :], car_steers[idxs, :]):
env._set_place_ghost_car(pose, steer)
# Place car at final pose
env.car.set_pose(car_poses[-1, :])
# Take screenshot and clear ghosts
img = env._get_image_current_top_view()
env._set_remove_ghosts()
# Plot on axis
axs[i, j].imshow(img, origin='lower', extent=cfg.env.test.none.img_extent)
# Plot RS path
axs[i, j].plot(rs.rs_xs, rs.rs_ys, color='yellow', lw=2)
# Get distance traveled
length_rl = env.stats.get_distance_traveled(ep)
# Set title as lengths
axs[i, j].set_title(f'Agente: {length_rl:.2f}m\nRS: {length_rs:.2f}m')
# Set x axis
if i == 1:
axs[i, j].set_xlabel('x [m]')
# Set y axis
if j in [0, 3]:
axs[i, j].set_ylabel('y [m]')
# Increment episode counter
ep += 1
# Delete env
p.disconnect(physicsClientId=env.client)
# Save figure
fig.savefig(path, dpi=600, bbox_inches='tight')
def _test_plot_compare_rs_mpcrs(self):
"""
Compare RL, RS and MPC path lengths.
"""
# Return if figure exists
path = self.path_figs / 'rl_comparacao_rs_rsmpc.png'
if path.exists():
return
# Constants
n_trials = 20
# Change config
cfg = self.cfg.copy(deep=True)
cfg.env.general.seed = 1
cfg.env.general.gui = True
cfg.env.general.stats = True
cfg.env.target.pose = 1.5
# Initialize dataframe
df = pd.DataFrame({
'Critério': [],
'Custo': [],
'Semente': [],
'Abordagem': []
})
# Prepare for MPC
cfg.env.car.f_val = 240
cfg.env.general.max_timestep = 2000
# Episode loop for MPC
env = CarNavigationBulletEnv(cfg)
env.reset_master()
mpcrs = MPCRS(cfg)
success_ep_nums = []
i = -1
while len(success_ep_nums) < n_trials:
# Increment
i += 1
# Get episode info for RL
done, obs, info = False, env.reset(), {}
while not done:
action = mpcrs.get_action(obs)
obs, reward, done, info = env.step(action)
if info['done_info']['success']:
success_ep_nums.append(i)
# Add to dataframe
df.loc[len(df)] = ['Distância', env.stats.get_distance_traveled(i), i, 'RS+CPM']
df.loc[len(df)] = ['Tempo', env.stats.get_time_to_reach(i), i, 'RS+CPM']
# Episode loop for RL
p.disconnect(physicsClientId=env.client)
del env
cfg = self.cfg.copy(deep=True)
cfg.env.general.seed = 1
cfg.env.general.gui = True
cfg.env.general.stats = True
cfg.env.target.pose = 1.5
env = CarNavigationBulletEnv(cfg)
env.reset_master()
i = -1
for j in range(success_ep_nums[-1]+1):
# Reset before maybe continuing
done, obs = False, env.reset()
# Increment
i += 1
# Continue if not success for MPC
if i not in success_ep_nums:
continue
# Get episode info for RL
while not done:
obs, reward, done, info = env.step(self.get_action(obs))
# Add to dataframe
if i in success_ep_nums:
df.loc[len(df)] = ['Distância', env.stats.get_distance_traveled(i), i, 'Agente']
df.loc[len(df)] = ['Tempo', env.stats.get_time_to_reach(i), i, 'Agente']
# Prepare for RS
cfg.rrt.rs.curvature = 2.5
cfg.rrt.rs.step_size = 1/240
p.disconnect(physicsClientId=env.client)
del env
env = CarNavigationBulletEnv(cfg)
# Change config and initialize RS
env.reset_master()
mpcrs = MPCRS(cfg)
# Episode loop for RS
i = -1
for j in range(success_ep_nums[-1] + 1):
# Reset before maybe continuing
done, obs = False, env.reset()
# Increment
i += 1
# Continue if not success for MPC
if i not in success_ep_nums:
continue
# Get episode info for RL
mpcrs._set_rs_path(obs)
node_from = Node(env.car.get_pose())
node_to = Node(env.target.get_pose())
if i in success_ep_nums:
df.loc[len(df)] = ['Distância', mpcrs.get_distance(node_from, node_to), i, 'RS']
df.loc[len(df)] = ['Tempo', (1/240)*len(mpcrs.rs_xs), i, 'RS']
# Delete env
p.disconnect(physicsClientId=env.client)
# Rename members
df2 = df.replace('Distância', 'Distância (m)')
df2 = df2.replace('Tempo', 'Tempo (s)')
# Save figure
sns.set(font_scale=1.2)
sns.set_style('whitegrid')
ax = sns.barplot(data=df2, x="Critério", y="Custo", hue='Abordagem')
l = ax.legend()
l.set_title('')
ax.get_figure().savefig(str(path), dpi=600, bbox_inches='tight')
def _test_plot_entropy(self):
"""
Get entropy plot.
"""
# Return if figure exists
path = self.path_figs / 'rl_entropia.png'
if path.exists():
return
# Get entropy csv path
csv_path = next(self.path_figs.parent.glob('*entropy*'))
# Read as dataframe
df = pd.read_csv(str(csv_path))
# Plot
fig, ax = plt.subplots()
ax.plot(df['step'][7:], df['Explore/ag_kde_entropy'][7:])
ax.grid(True)
ax.set_xlabel('Passos de tempo')
ax.set_ylabel('Entropia')
fig.savefig(str(path), dpi=600, bbox_inches='tight')
def _test_plot_horizon_success_rate(self):
"""
Plot success rate for different horizons.
"""
# Return if figure exists
path = self.path_figs / 'rl_horizonte_taxa_sucesso.png'
if path.exists():
return
# Env without gui to go faster and car pose is always [0, 0, 0]
cfg = self.cfg.copy(deep=True)
cfg.env.general.gui = False
cfg.env.car.pose = [0, 0, 0]
# Initialize distances
distances = [0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0,
5.5, 6.0, 6.5, 7.0, 7.5, 8.0, 8.5, 9.0, 9.5, 10.0]
# Loop through distances
successes = []
for d in distances:
# Change env config distance and initialize
cfg.env.target.pose = d
env = CarNavigationBulletEnv(cfg)
# Loop all episodes
success = 0
for _ in range(100):
# Episode loop
done, obs, info = False, env.reset(), {}
while not done:
obs, reward, done, info = env.step(self.get_action(obs))
# Check done reason
if info['done_info']['success']:
success += 1
# Delete env
del env
# Add to list
successes.append(success)
# Log
self.console.print(f"\n[red bold underline]Done testing distance {d}...[/]")
# Initialize figure and plot
fig, ax = plt.subplots() # type: plt.Figure, plt.Axes
ax.bar([str(d) for d in distances], successes, color='blue', edgecolor='blue')
# Rotate x-axis labels to fit better
for label in ax.get_xticklabels():
label.set_rotation(45)
# Change y-axis to percent formatting
ax.yaxis.set_major_formatter(ticker.PercentFormatter())
# Add grid, axis labels
ax.grid(True)
ax.set_xlabel('c [m]')
ax.set_ylabel('Taxa de sucesso')
# Save
fig.savefig(str(path), dpi=600, bbox_inches='tight')
def _test_plot_rewards(self):
"""
Plot test reward curves.
"""
# Return if figure exists
path = self.path_figs / 'rl_recompensa.png'
if path.exists():
return
# Get constants
timesteps = self.stats.train_timestep_nums
rewards = self.stats.total_val_rewards
# Plot
fig, ax = plt.subplots()
ax.plot(timesteps, rewards)
ax.grid(True)
ax.set_xlabel('Passos de tempo')
ax.set_ylabel('Recompensa')
fig.savefig(path, dpi=600, bbox_inches='tight')
def _test_plot_multiple_problems(self):
"""
Plot agent actions in an episode.
"""
# Return if figure exists
path = self.path_figs / 'rl_diversos_problemas.png'
if path.exists():
return
# Change config
cfg = self.cfg.copy(deep=True)
cfg.env.general.seed = 0
cfg.env.general.gui = True
cfg.env.general.stats = True
cfg.env.target.pose = 1.5
cfg.env.car.pose = [0, 0, 0]
# Initialize env and reset master
env = CarNavigationBulletEnv(cfg)
env.reset_master()
# Initialize figure
fig, axs = plt.subplots(nrows=2, ncols=3, sharex='col', sharey='row', figsize=(12, 9.6))
fig.subplots_adjust(hspace=-0.2)
axs = axs.flatten()
# Episode loop
for ep in range(6):
# Get episode info
done, obs = False, env.reset()
while not done:
obs, reward, done, info = env.step(self.get_action(obs))
# Get car info to place ghosts and actions
car_poses = env.stats.bullet.car_poses[ep, ...]
car_steers = env.stats.bullet.car_steers[ep, ...]
# Remove all zeros rows
car_poses = car_poses[~np.all(car_poses == 0, axis=1)]
car_steers = car_steers[~np.all(car_steers == 0, axis=1)]
# Get indexes to place ghosts
interval = cfg.env.test.general.ghost_interval
n_timesteps = car_poses.shape[0]
idxs = np.arange(0, n_timesteps, interval)
# Place ghosts
for pose, steer in zip(car_poses[idxs, :], car_steers[idxs, :]):
env._set_place_ghost_car(pose, steer)
# Place car at final pose
env.car.set_pose(car_poses[-1, :])
# Take screenshot and clear ghosts
img = env._get_image_current_top_view()
env._set_remove_ghosts()
# Plot on axis
axs[ep].imshow(img, origin='lower', extent=cfg.env.test.none.img_extent)
# Set titles
axs[ep].set_title(f'Cenário {ep + 1}')
# Set axis labels
if ep in [0, 3]:
axs[ep].set_ylabel('y [m]')
if ep in [3, 4, 5]:
axs[ep].set_xlabel('x [m]')
# Disconnect env
p.disconnect(physicsClientId=env.client)
# Save figure
fig.savefig(str(path), dpi=600, bbox_inches='tight')
def _test_plot_progress(self):
"""
Plot policy trajectories over training time.
"""
# Return if figure exists
path = self.path_figs / 'rl_progresso.png'
if path.exists():
return
# Constants
ep_idx = 0
train_timesteps_idx = [1, 2, 3, 4, 5, 90]
# Change config before creating env
cfg = self.cfg.copy(deep=True)
cfg.env.general.gui = True
# Initialize env to get screenshot
env = CarNavigationBulletEnv(cfg)
# Initialize figure
fig, axs = plt.subplots(2, 3, sharex='col', sharey='row', figsize=(12, 9.6))
fig.subplots_adjust(hspace=-0.2)
axs = axs.flatten()
# Loop to get subplots
for i, idx in enumerate(train_timesteps_idx):
# Get target pose
desired_goal = self.stats.env_stats[idx].mdp.desired_goals[ep_idx, 0, ...]
target_pose = state4_to_pose3(desired_goal)
# Place target at desired pose
env.target.set_pose(target_pose)
# Get car info to place ghosts
car_poses = self.stats.env_stats[idx].bullet.car_poses[ep_idx, ...]
car_steers = self.stats.env_stats[idx].bullet.car_steers[ep_idx, ...]
# Remove all zeros rows
car_poses = car_poses[~np.all(car_poses == 0, axis=1)]
car_steers = car_steers[~np.all(car_steers == 0, axis=1)]
# Get indexes to place ghosts
interval = cfg.env.test.general.ghost_interval
n_timesteps = car_poses.shape[0]
idxs = np.arange(0, n_timesteps, interval)
# Place ghosts
for pose, steer in zip(car_poses[idxs, :], car_steers[idxs, :]):
env._set_place_ghost_car(pose, steer)
# Place car at final pose
env.car.set_pose(car_poses[-1, :])
# Take screenshot
img = env._get_image_current_top_view()
# Plot on axis
axs[i].imshow(img, origin='lower', extent=cfg.env.test.none.img_extent)
# Set title
axs[i].set_title(f'Época {idx}')
# Set axis labels
if i in [0, 3]:
axs[i].set_ylabel('y [m]')
if i in [3, 4, 5]:
axs[i].set_xlabel('x [m]')
# Clear ghosts
env._set_remove_ghosts()
# Disconnect env
p.disconnect(physicsClientId=env.client)
# Save figure
fig.savefig(str(path), dpi=600, bbox_inches='tight')
def _setup(self):
"""
Setup.
"""
# Set up agent must be called before everything
self._setup_agent()
# Set up base settings
self._setup_paths()
self._setup_folders()
self._setup_save_config_to_file()
self._setup_attrs_to_save()
self._setup_init_base_attrs()
self._setup_init_model()
self._setup_checkpoint()
self._setup_stats()
self._setup_console()
self._setup_tensorboard()
# Set up RL settings
self._setup_eval_env()
self._setup_just_use_policy()
def _setup_agent(self):
"""
Setup mega default and merge with user configuration.
"""
# Load default mega config
config = protoge_config()
# Differences from protoge
config.action_l2_regularization = self.cfg.rl.actor.l2
config.action_noise = self.cfg.rl.exploration.noise
config.activ = self.cfg.rl.net.activ
config.batch_size = self.cfg.rl.train.batch_size
config.eexplore = self.cfg.rl.exploration.epsilon
config.grad_value_clipping = self.cfg.rl.net.grad_value_clipping
config.initial_explore = self.cfg.rl.exploration.initial
config.layers = self.cfg.rl.net.layers
config.replay_size = self.cfg.rl.train.replay_size
config.target_network_update_freq = self.cfg.rl.target.update_freq
config.warm_up = self.cfg.rl.exploration.warm_up
config.her = self.cfg.rl.general.her
config.optimize_every = self.cfg.rl.train.optimize_every
config.replay_size = self.cfg.rl.train.replay_size
config.target_network_update_freq = self.cfg.rl.target.update_freq
# Experiments folder
config.parent_folder = Paths().experiments_rl
# Agent name
config.agent_name = str(self.cfg.general.config_name_or_prefix)
# Parallel
if self.cfg.rl.train.n_envs is None:
config.num_envs = max(cpu_count() - 2, 1)
else:
config.num_envs = self.cfg.rl.train.n_envs
if self.cfg.rl.val.n_envs is None:
config.num_eval_envs = 1
else:
config.num_eval_envs = self.cfg.rl.val.n_envs
# No parallel if testing?
if not self.cfg.general.is_train:
config.num_envs = 1
config.num_eval_envs = 1
# Train
config.train_timestep = self.cfg.rl.train.n_timesteps
# Setup and add basic modules to the config
config.update(
dict(
trainer=StandardTrain(),
evaluation=EpisodicEval(),
policy=ActorPolicy(),
logger=Logger(),
state_normalizer=Normalizer(MeanStdNormalizer()),
replay=OnlineHERBuffer(),
)
)
# Discount factor
if config.gamma < 1.0:
config.clip_target_range = (np.round(-(1 / (1 - config.gamma)), 2), 0.0)
if config.gamma == 1:
config.clip_target_range = (np.round(-self.cfg.env.general.max_timestep - 5, 2), 0.0)
# Prioritized experience replay
config.prioritized_mode = "none"
# Curiosity - ag density estimation
config.ag_kde_tophat = RawKernelDensity(
"ag",
optimize_every=100,
samples=10000,
kernel="tophat",
bandwidth=0.2,
tag="_tophat",
)
config.ag_kde = RawKernelDensity(
"ag",
optimize_every=1,
samples=10000,
kernel="gaussian",
bandwidth=0.1,
log_entropy=True,
)
config.ag_curiosity = DensityAchievedGoalCuriosity(
max_steps=self.cfg.env.general.max_timestep,
num_sampled_ags=100,
use_qcutoff=True,
keep_dg_percent=-0.1,
)
# Actor noise?
config.action_noise = ContinuousActionNoise(
GaussianProcess, std=ConstantSchedule(config.action_noise)
)
# Off-policy model
config.algorithm = DDPG()
# Change target pose and gui (for train and val is always off)
cfg = self.cfg.deep_copy_change('env.target.pose', self.cfg.rl.val.target_pose)
cfg = cfg.deep_copy_change('env.general.gui', False)
# Set up train environment
def train_env_fn():
return CarNavigationBulletEnv(cfg)
# Set up train environment
def val_env_fn():
return CarNavigationBulletEnv(cfg)
config.train_env = EnvModule(
train_env_fn, num_envs=config.num_envs
)
config.eval_env = EnvModule(
val_env_fn,
num_envs=config.num_eval_envs,
name="eval_env",
)
# Setup env success & done
config.first_visit_succ = True
config.first_visit_done = False
# Setup algorithm
config.algorithm = DDPG()
# Setup layer normalization
layer_norm_or_not = nn.LayerNorm if self.cfg.rl.net.layer_norm else nn.Identity
# Setup and add the networks to the config
e = config.eval_env
config.actor = PytorchModel(
"actor",
lambda: Actor(
FCBody(
e.state_dim + e.goal_dim,
self.cfg.rl.net.layers,
layer_norm_or_not,
make_activ(config.activ),
),
e.action_dim,
e.max_action,
),
)
config.critic = PytorchModel(
"critic",
lambda: Critic(
FCBody(
e.state_dim + e.goal_dim + e.action_dim,
self.cfg.rl.net.layers,
layer_norm_or_not,
make_activ(config.activ),
),
1,
),
)
# Intrinsic reward
config.goal_reward = GoalEnvReward()
# Return agent and complete config
self.agent = mrl.config_to_agent(config)
self.mrl_config = config
def _setup_best_rewards(self):
"""
Set up best rewards.
"""
self.best_det_val_reward = -np.inf
self.best_rand_val_reward = -np.inf
def _setup_checkpoint(self):
"""
Set up checkpoint.
"""
# Check if there is a checkpoint
self.load_checkpoint = self._get_checkpoint_exists_indicator()
if self.load_checkpoint:
self._set_load_attributes()
def _setup_eval_env(self):
"""
Set up evaluation env with deterministic resetting.
"""
# Change config before creating env
cfg = self.cfg.deep_copy_change('env.general.gui', self.cfg.rl.val.gui)
cfg = cfg.deep_copy_change('env.general.stats', self.cfg.rl.val.stats)
self.eval_env = CarNavigationBulletEnv(cfg=cfg)
def _setup_init_base_attrs(self):
"""
Initialize base attributes.
"""
self.epoch = 0
self.model_best_loss = -np.inf
self.model_curr_loss = -np.inf
def _setup_just_use_policy(self):
"""
If loading algorithm just to use the policy we delete all envs.
"""
# Disconnect all envs used for training, validation and testing
if self.cfg.rl.general.just_use_policy:
# Disconnect from eval env
p.disconnect(self.eval_env.client)
# Disconnect from train env module
for env in self.agent.env.env.envs:
p.disconnect(env.env.client)
# Disconnect from eval env module
for env in self.agent.eval_env.env.envs:
p.disconnect(env.env.client)
def _setup_stats(self):
"""
Set up stats.
"""
if self.load_checkpoint:
try:
self.stats = RLStats.load_from_file(self.path_stats)
except EOFError:
self.stats = RLStats.new(self.cfg)
self.stats.save_to_file(self.path_stats)
else:
self.stats = RLStats.new(self.cfg)
self.stats.save_to_file(self.path_stats)
def _setup_tensorboard(self):
"""
For consistency only, handled by MRL.
"""
pass | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/algorithms/rl.py | 0.710628 | 0.209551 | rl.py | pypi |
import pickle
import matplotlib.pyplot as plt
import numpy as np
from gekko import GEKKO
from scipy import signal
from rrt_ml.environments.car_navigation_bullet_env import *
from rrt_ml.utilities.configs import *
from rrt_ml.utilities.misc import *
cfg = MasterConfig()
cfg.env.general.stats = True
cfg.env.general.gui = True
cfg.env.general.max_timestep = 2000
cfg.env.car.f_val = 240
cfg.env.car.pose = [0, 0, 0]
env = CarNavigationBulletEnv(cfg)
env.reset_master()
obs = env.reset()
done = False
u = []
while not done:
action = env.action_space.sample()
for _ in range(np.random.randint(20, 80, 1)[0]):
obs, reward, done, info = env.step(action)
if done:
break
# Get curves
u_v = remove_trailing_zeros(env.stats.mdp.actions[0, :, 0])
u_phi = remove_trailing_zeros(env.stats.mdp.actions[0, :, 1])
time = remove_trailing_zeros(env.stats.bullet.time[0, :, 0])
phi1 = remove_trailing_zeros(env.stats.bullet.car_steers[0, :, 0])
phi2 = remove_trailing_zeros(env.stats.bullet.car_steers[0, :, 1])
vs = remove_trailing_zeros(env.stats.bullet.car_velocities[0, :, 0])
m = GEKKO()
dt = 1/240
m.time = np.arange(0, 2000*dt-dt, dt)
# Parameters
v_meas = m.Param(value=vs)
uv_meas = m.Param(value=u_v)
v_pred = m.Var()
kvx = m.FV(value=1)
# kphix = m.FV(value=1)
kvu = m.FV(value=1)
# kphiu = m.FV(value=1)
# Available to optimize
kvx.STATUS = 1
# kphix.STATUS = 1
kvu.STATUS = 1
# kphiu.STATUS = 1
# ODE's
m.Equation(v_pred.dt() == kvx*v_pred + kvu*uv_meas)
# Objective
m.Minimize((v_pred-v_meas)**2)
# Application options
m.options.IMODE = 2 # Dynamic Simultaneous - estimation
# Solve
m.solve(disp=True)
# show final objective
print('Final SSE Objective: ' + str(m.options.objfcnval))
# Test
A = [kvx.value[0]]
B = [kvu.value[0]]
C = [1.0]
D = [0.0]
sys = signal.StateSpace(A, B, C, D)
t_model, y_model = signal.step(sys)
# Env
env.reset_master()
env.reset()
for _ in range(25):
obs, reward, done, info = env.step([1, 0])
vs = remove_trailing_zeros(env.stats.bullet.car_velocities[0, :, 0])
fig, ax = plt.subplots()
ax.plot(np.arange(0, (1/240)*25, (1/240)), vs)
ax.plot(t_model, y_model, '--')
plt.show() | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/experiments/others/kinematic_model_fit.py | 0.458591 | 0.301761 | kinematic_model_fit.py | pypi |
import math
import matplotlib.pyplot as plt
import numpy as np
show_animation = True
class Path:
"""
Path data container
"""
def __init__(self):
# course segment length (negative value is backward segment)
self.lengths = []
# course segment type char ("S": straight, "L": left, "R": right)
self.ctypes = []
self.L = 0.0 # Total lengths of the path
self.x = [] # x positions
self.y = [] # y positions
self.yaw = [] # orientations [rad]
self.directions = [] # directions (1:forward, -1:backward)
def plot_arrow(x, y, yaw, length=1.0, width=0.5, fc="r", ec="k"):
if isinstance(x, list):
for (ix, iy, iyaw) in zip(x, y, yaw):
plot_arrow(ix, iy, iyaw)
else:
plt.arrow(x, y, length * math.cos(yaw), length * math.sin(yaw), fc=fc,
ec=ec, head_width=width, head_length=width)
plt.plot(x, y)
def mod2pi(x):
# Be consistent with fmod in cplusplus here.
v = np.mod(x, np.copysign(2.0 * math.pi, x))
if v < -math.pi:
v += 2.0 * math.pi
else:
if v > math.pi:
v -= 2.0 * math.pi
return v
def straight_left_straight(x, y, phi):
phi = mod2pi(phi)
if y > 0.0 and 0.0 < phi < math.pi * 0.99:
xd = - y / math.tan(phi) + x
t = xd - math.tan(phi / 2.0)
u = phi
v = math.sqrt((x - xd) ** 2 + y ** 2) - math.tan(phi / 2.0)
return True, t, u, v
elif y < 0.0 < phi < math.pi * 0.99:
xd = - y / math.tan(phi) + x
t = xd - math.tan(phi / 2.0)
u = phi
v = -math.sqrt((x - xd) ** 2 + y ** 2) - math.tan(phi / 2.0)
return True, t, u, v
return False, 0.0, 0.0, 0.0
def set_path(paths, lengths, ctypes, step_size):
path = Path()
path.ctypes = ctypes
path.lengths = lengths
path.L = sum(np.abs(lengths))
# check same path exist
for i_path in paths:
type_is_same = (i_path.ctypes == path.ctypes)
length_is_close = (sum(np.abs(i_path.lengths)) - path.L) <= step_size
if type_is_same and length_is_close:
return paths # same path found, so do not insert path
# check path is long enough
if path.L <= step_size:
return paths # too short, so do not insert path
paths.append(path)
return paths
def straight_curve_straight(x, y, phi, paths, step_size):
flag, t, u, v = straight_left_straight(x, y, phi)
if flag:
paths = set_path(paths, [t, u, v], ["S", "L", "S"], step_size)
flag, t, u, v = straight_left_straight(x, -y, -phi)
if flag:
paths = set_path(paths, [t, u, v], ["S", "R", "S"], step_size)
return paths
def polar(x, y):
r = math.sqrt(x ** 2 + y ** 2)
theta = math.atan2(y, x)
return r, theta
def left_straight_left(x, y, phi):
u, t = polar(x - math.sin(phi), y - 1.0 + math.cos(phi))
if t >= 0.0:
v = mod2pi(phi - t)
if v >= 0.0:
return True, t, u, v
return False, 0.0, 0.0, 0.0
def left_right_left(x, y, phi):
u1, t1 = polar(x - math.sin(phi), y - 1.0 + math.cos(phi))
if u1 <= 4.0:
u = -2.0 * math.asin(0.25 * u1)
t = mod2pi(t1 + 0.5 * u + math.pi)
v = mod2pi(phi - t + u)
if t >= 0.0 >= u:
return True, t, u, v
return False, 0.0, 0.0, 0.0
def curve_curve_curve(x, y, phi, paths, step_size):
flag, t, u, v = left_right_left(x, y, phi)
if flag:
paths = set_path(paths, [t, u, v], ["L", "R", "L"], step_size)
flag, t, u, v = left_right_left(-x, y, -phi)
if flag:
paths = set_path(paths, [-t, -u, -v], ["L", "R", "L"], step_size)
flag, t, u, v = left_right_left(x, -y, -phi)
if flag:
paths = set_path(paths, [t, u, v], ["R", "L", "R"], step_size)
flag, t, u, v = left_right_left(-x, -y, phi)
if flag:
paths = set_path(paths, [-t, -u, -v], ["R", "L", "R"], step_size)
# backwards
xb = x * math.cos(phi) + y * math.sin(phi)
yb = x * math.sin(phi) - y * math.cos(phi)
flag, t, u, v = left_right_left(xb, yb, phi)
if flag:
paths = set_path(paths, [v, u, t], ["L", "R", "L"], step_size)
flag, t, u, v = left_right_left(-xb, yb, -phi)
if flag:
paths = set_path(paths, [-v, -u, -t], ["L", "R", "L"], step_size)
flag, t, u, v = left_right_left(xb, -yb, -phi)
if flag:
paths = set_path(paths, [v, u, t], ["R", "L", "R"], step_size)
flag, t, u, v = left_right_left(-xb, -yb, phi)
if flag:
paths = set_path(paths, [-v, -u, -t], ["R", "L", "R"], step_size)
return paths
def curve_straight_curve(x, y, phi, paths, step_size):
flag, t, u, v = left_straight_left(x, y, phi)
if flag:
paths = set_path(paths, [t, u, v], ["L", "S", "L"], step_size)
flag, t, u, v = left_straight_left(-x, y, -phi)
if flag:
paths = set_path(paths, [-t, -u, -v], ["L", "S", "L"], step_size)
flag, t, u, v = left_straight_left(x, -y, -phi)
if flag:
paths = set_path(paths, [t, u, v], ["R", "S", "R"], step_size)
flag, t, u, v = left_straight_left(-x, -y, phi)
if flag:
paths = set_path(paths, [-t, -u, -v], ["R", "S", "R"], step_size)
flag, t, u, v = left_straight_right(x, y, phi)
if flag:
paths = set_path(paths, [t, u, v], ["L", "S", "R"], step_size)
flag, t, u, v = left_straight_right(-x, y, -phi)
if flag:
paths = set_path(paths, [-t, -u, -v], ["L", "S", "R"], step_size)
flag, t, u, v = left_straight_right(x, -y, -phi)
if flag:
paths = set_path(paths, [t, u, v], ["R", "S", "L"], step_size)
flag, t, u, v = left_straight_right(-x, -y, phi)
if flag:
paths = set_path(paths, [-t, -u, -v], ["R", "S", "L"], step_size)
return paths
def left_straight_right(x, y, phi):
u1, t1 = polar(x + math.sin(phi), y - 1.0 - math.cos(phi))
u1 = u1 ** 2
if u1 >= 4.0:
u = math.sqrt(u1 - 4.0)
theta = math.atan2(2.0, u)
t = mod2pi(t1 + theta)
v = mod2pi(t - phi)
if t >= 0.0 and v >= 0.0:
return True, t, u, v
return False, 0.0, 0.0, 0.0
def generate_path(q0, q1, max_curvature, step_size):
dx = q1[0] - q0[0]
dy = q1[1] - q0[1]
dth = q1[2] - q0[2]
c = math.cos(q0[2])
s = math.sin(q0[2])
x = (c * dx + s * dy) * max_curvature
y = (-s * dx + c * dy) * max_curvature
paths = []
paths = straight_curve_straight(x, y, dth, paths, step_size)
paths = curve_straight_curve(x, y, dth, paths, step_size)
paths = curve_curve_curve(x, y, dth, paths, step_size)
return paths
def calc_interpolate_dists_list(lengths, step_size):
interpolate_dists_list = []
for length in lengths:
d_dist = step_size if length >= 0.0 else -step_size
interp_dists = np.arange(0.0, length, d_dist)
interp_dists = np.append(interp_dists, length)
interpolate_dists_list.append(interp_dists)
return interpolate_dists_list
def generate_local_course(lengths, modes, max_curvature, step_size):
interpolate_dists_list = calc_interpolate_dists_list(lengths, step_size)
origin_x, origin_y, origin_yaw = 0.0, 0.0, 0.0
xs, ys, yaws, directions = [], [], [], []
for (interp_dists, mode, length) in zip(interpolate_dists_list, modes,
lengths):
for dist in interp_dists:
x, y, yaw, direction = interpolate(dist, length, mode,
max_curvature, origin_x,
origin_y, origin_yaw)
xs.append(x)
ys.append(y)
yaws.append(yaw)
directions.append(direction)
origin_x = xs[-1]
origin_y = ys[-1]
origin_yaw = yaws[-1]
return xs, ys, yaws, directions
def interpolate(dist, length, mode, max_curvature, origin_x, origin_y,
origin_yaw):
if mode == "S":
x = origin_x + dist / max_curvature * math.cos(origin_yaw)
y = origin_y + dist / max_curvature * math.sin(origin_yaw)
yaw = origin_yaw
else: # curve
ldx = math.sin(dist) / max_curvature
ldy = 0.0
yaw = None
if mode == "L": # left turn
ldy = (1.0 - math.cos(dist)) / max_curvature
yaw = origin_yaw + dist
elif mode == "R": # right turn
ldy = (1.0 - math.cos(dist)) / -max_curvature
yaw = origin_yaw - dist
gdx = math.cos(-origin_yaw) * ldx + math.sin(-origin_yaw) * ldy
gdy = -math.sin(-origin_yaw) * ldx + math.cos(-origin_yaw) * ldy
x = origin_x + gdx
y = origin_y + gdy
return x, y, yaw, 1 if length > 0.0 else -1
def pi_2_pi(angle):
return (angle + math.pi) % (2 * math.pi) - math.pi
def calc_paths(sx, sy, syaw, gx, gy, gyaw, maxc, step_size):
q0 = [sx, sy, syaw]
q1 = [gx, gy, gyaw]
paths = generate_path(q0, q1, maxc, step_size)
# bug fix
for i, path in enumerate(paths):
for le in path.lengths:
if le > 1000 or le < -1000:
del paths[i]
for path in paths:
xs, ys, yaws, directions = generate_local_course(path.lengths,
path.ctypes, maxc,
step_size * maxc)
# convert global coordinate
path.x = [math.cos(-q0[2]) * ix + math.sin(-q0[2]) * iy + q0[0] for
(ix, iy) in zip(xs, ys)]
path.y = [-math.sin(-q0[2]) * ix + math.cos(-q0[2]) * iy + q0[1] for
(ix, iy) in zip(xs, ys)]
path.yaw = [pi_2_pi(yaw + q0[2]) for yaw in yaws]
path.directions = directions
path.lengths = [length / maxc for length in path.lengths]
path.L = path.L / maxc
return paths
def reeds_shepp_path_planning(sx, sy, syaw, gx, gy, gyaw, maxc, step_size=0.2):
paths = calc_paths(sx, sy, syaw, gx, gy, gyaw, maxc, step_size)
if not paths:
return None, None, None, None, None # could not generate any path
# search minimum cost path
best_path_index = paths.index(min(paths, key=lambda p: abs(p.L)))
b_path = paths[best_path_index]
return b_path.x, b_path.y, b_path.yaw, b_path.ctypes, b_path.lengths
def main():
print("Reeds Shepp path planner sample start!!")
start_x = -1.0 # [m]
start_y = -4.0 # [m]
start_yaw = np.deg2rad(-20.0) # [rad]
end_x = 5.0 # [m]
end_y = 5.0 # [m]
end_yaw = np.deg2rad(25.0) # [rad]
curvature = 0.1
step_size = 0.05
xs, ys, yaws, modes, lengths = reeds_shepp_path_planning(start_x, start_y,
start_yaw, end_x,
end_y, end_yaw,
curvature,
step_size)
if show_animation: # pragma: no cover
plt.cla()
plt.plot(xs, ys, label="final course " + str(modes))
print(f"{lengths=}")
# plotting
plot_arrow(start_x, start_y, start_yaw)
plot_arrow(end_x, end_y, end_yaw)
plt.legend()
plt.grid(True)
plt.axis("equal")
plt.show()
if not xs:
assert False, "No path"
if __name__ == '__main__':
main() | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/deps/libraries/python_robotics_reeds_shepp.py | 0.65202 | 0.486758 | python_robotics_reeds_shepp.py | pypi |
import mrl
from mrl.utils.misc import AttrDict
import numpy as np
from copy import deepcopy
import time
class StandardTrain(mrl.Module):
def __init__(self):
super().__init__('train', required_agent_modules = ['env', 'policy', 'optimize'], locals=locals())
def _setup(self):
assert hasattr(self.config, 'optimize_every')
self.optimize_every = self.config.optimize_every
self.env_steps = 0
self.reset_idxs = []
def __call__(self, num_steps : int, render=False, dont_optimize=False, dont_train=False):
"""
Runs num_steps steps in the environment, saves collected experiences,
and trains at every step
"""
if not dont_train:
self.agent.train_mode()
env = self.env
state = env.state
for _ in range(num_steps // env.num_envs):
action = self.policy(state)
next_state, reward, done, info = env.step(action)
if self.reset_idxs:
env.reset(self.reset_idxs)
for i in self.reset_idxs:
done[i] = True
if not 'done_observation' in info[i]:
if isinstance(next_state, np.ndarray):
info[i].done_observation = next_state[i]
else:
for key in next_state:
info[i].done_observation = {k: next_state[k][i] for k in next_state}
next_state = env.state
self.reset_idxs = []
state, experience = debug_vectorized_experience(state, action, next_state, reward, done, info)
self.process_experience(experience)
if render:
time.sleep(0.02)
env.render()
for _ in range(env.num_envs):
self.env_steps += 1
if self.env_steps % self.optimize_every == 0 and not dont_optimize:
self.optimize()
# If using MEP prioritized replay, fit the density model
if self.config.prioritized_mode == 'mep':
self.prioritized_replay.fit_density_model()
self.prioritized_replay.update_priority()
def reset_next(self, idxs):
"""Resets specified envs on next step"""
self.reset_idxs = idxs
def save(self, save_folder):
self._save_props(['env_steps'], save_folder)
def load(self, save_folder):
self._load_props(['env_steps'], save_folder)
def debug_vectorized_experience(state, action, next_state, reward, done, info):
"""Gym returns an ambiguous "done" signal. VecEnv doesn't
let you fix it until now. See ReturnAndObsWrapper in env.py for where
these info attributes are coming from."""
experience = AttrDict(
state = state,
action = action,
reward = reward,
info = info
)
next_copy = deepcopy(next_state) # deepcopy handles dict states
for idx in np.argwhere(done):
i = idx[0]
if isinstance(next_copy, np.ndarray):
next_copy[i] = info[i].done_observation
else:
assert isinstance(next_copy, dict)
for key in next_copy:
next_copy[key][i] = info[i].done_observation[key]
experience.next_state = next_copy
experience.trajectory_over = done
experience.done = np.array([info[i].terminal_state for i in range(len(done))], dtype=np.float32)
experience.reset_state = next_state
return next_state, experience | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/deps/libraries/mrl/modules/train.py | 0.463687 | 0.359983 | train.py | pypi |
import mrl
import numpy as np
# temporary fix for dumb tensorflow / tensorboard error. https://github.com/pytorch/pytorch/issues/30966
try:
import tensorflow as tf
import tensorboard as tb
tf.io.gfile = tb.compat.tensorflow_stub.io.gfile
except:
import tensorboard as tb
from torch.utils.tensorboard import SummaryWriter
from tabulate import tabulate
from collections import defaultdict
import json
import os
import time
import csv
class Logger(mrl.Module):
"""
Logger that processes vectorized experiences and
records results to the console.
"""
def __init__(self, average_every=100):
super().__init__('logger', required_agent_modules=['env'], locals=locals())
self.average_every = average_every
self.writer = None
def _setup(self):
# rewards and steps are always tracked
self.rewards_per_env = np.zeros((self.env.num_envs, ))
self.steps_per_env = np.zeros((self.env.num_envs, ))
self.episode_rewards = []
self.episode_steps = []
self.steps = 0
self.episodes = 0
self.tabular = defaultdict(list)
self.last_log_step = defaultdict(int)
self.log_every_n_steps = self.config.log_every
self.save_config()
def lazy_init_writer(self):
if self.writer is None:
self.writer = SummaryWriter(self.agent_folder)
def update_csv(self, tag, value, step):
fields = ['wall_time', 'step', tag]
path = os.path.join(self.agent_folder, self.agent_name + '__' + tag.replace('/', '__') + '.csv')
if not os.path.exists(path):
with open(path, 'w') as f:
writer = csv.writer(f, delimiter=',')
writer.writerow(fields)
with open(path, 'a') as f:
writer = csv.writer(f)
writer.writerow([time.time(), step, value])
def add_scalar(self, tag, value, log_every=1000, step=None):
"""Adds scalar to tensorboard"""
self.lazy_init_writer()
if step is None:
step = self.config.env_steps
if step - self.last_log_step[tag] >= log_every:
self.last_log_step[tag] = step
self.writer.add_scalar(tag, value, step)
self.update_csv(tag, value, step)
def add_histogram(self, tag, values, log_every=1000, step=None, **kwargs):
"""Adds histogram to tensorboard"""
self.lazy_init_writer()
if isinstance(values, list):
values = np.array(values, dtype=np.float32)
elif isinstance(values, np.ndarray):
values = values.astype(np.float32)
if step is None:
step = self.config.env_steps
if step - self.last_log_step[tag] >= log_every:
self.last_log_step[tag] = step
self.writer.add_histogram(tag, values, step, **kwargs)
def add_embedding(self, tag, values, log_every=1000, step=None, **kwargs):
"""Adds embedding data to tensorboard"""
self.lazy_init_writer()
if isinstance(values, list):
values = np.array(values, dtype=np.float32)
elif isinstance(values, np.ndarray):
values = values.astype(np.float32)
assert len(values.shape) == 2
if step is None:
step = self.config.env_steps
if step - self.last_log_step[tag] >= log_every:
self.last_log_step[tag] = step
self.writer.add_embedding(mat=values, tag=tag, global_step=step, **kwargs)
def add_tabular(self, tag, value):
"""Adds scalar to console logger"""
self.tabular[tag].append(value)
def log_color(self, tag, value='', color='cyan'):
print(colorize(tag, color=color, bold=True), value)
def save_config(self):
config_json = convert_json({**self.config, **record_attrs(self.module_dict.values())})
config_json['agent_name'] = self.agent_name
output = json.dumps(config_json, separators=(',', ':\t'), indent=4, sort_keys=True)
print(colorize('\nAgent folder:', color='magenta', bold=True))
print(self.agent_folder)
print(colorize('\nSaving config:', color='cyan', bold=True))
print(output)
with open(os.path.join(self.agent_folder, "config.json"), 'w') as out:
out.write(output)
def flush_console(self):
table = [('Environment steps', self.steps), ('Total episodes', self.episodes),
('Avg rewards (last {})'.format(self.average_every), np.mean(self.episode_rewards[-self.average_every:])),
('Avg episode len (last {})'.format(self.average_every), np.mean(self.episode_steps[-self.average_every:]))
]
for k, v in self.tabular.items():
table.append(('Avg ' + k + ' (last {})'.format(self.average_every), np.mean(v[-self.average_every:])))
table = tabulate(table, headers=['Tag', 'Value'], tablefmt="psql", floatfmt="8.1f")
print(table)
def _process_experience(self, experience):
rewards, dones = experience.reward, experience.trajectory_over
self.rewards_per_env += rewards
self.steps_per_env += 1
if np.any(dones):
self.episode_rewards += list(self.rewards_per_env[dones])
self.episode_steps += list(self.steps_per_env[dones])
self.rewards_per_env[dones] = 0
self.steps_per_env[dones] = 0
self.episodes += np.sum(dones)
self.steps += self.env.num_envs
if self.steps % self.log_every_n_steps < self.env.num_envs:
self.flush_console()
self.add_scalar('Train/Episode_rewards', np.mean(self.episode_rewards[-30:]))
self.add_scalar('Train/Episode_steps', np.mean(self.episode_steps[-30:]))
def save(self, save_folder):
self._save_props([
'episode_rewards', 'episode_steps',
'steps', 'episodes', 'tabular', 'last_log_step'
], save_folder)
def load(self, save_folder):
self._load_props([
'episode_rewards', 'episode_steps',
'steps', 'episodes', 'tabular', 'last_log_step'
], save_folder)
color2num = dict(gray=30, red=31, green=32, yellow=33, blue=34, magenta=35, cyan=36, white=37, crimson=38)
def colorize(string, color, bold=False, highlight=False):
"""
Colorize a string.
This function was originally written by John Schulman.
"""
attr = []
num = color2num[color]
if highlight: num += 10
attr.append(str(num))
if bold: attr.append('1')
return '\x1b[%sm%s\x1b[0m' % (';'.join(attr), string)
def convert_json(obj, dict_to_str=False):
""" Convert obj to a version which can be serialized with JSON. """
if is_json_serializable(obj):
return obj
else:
if isinstance(obj, dict) and not dict_to_str:
return {convert_json(k): convert_json(v) for k, v in obj.items()}
elif isinstance(obj, tuple):
return tuple([convert_json(x) for x in obj])
elif isinstance(obj, list):
return [convert_json(x) for x in obj]
elif hasattr(obj, '__name__') and not ('lambda' in obj.__name__):
return convert_json(obj.__name__)
elif hasattr(obj, '__dict__') and obj.__dict__:
obj_dict = {convert_json(k): convert_json(v) for k, v in obj.__dict__.items()}
return {str(obj): obj_dict}
return str(obj)
def is_json_serializable(v):
try:
json.dumps(v)
return True
except:
return False
def record_attrs(module_list):
res = {}
for module in module_list:
res['module_' + module.module_name] = convert_json(strip_config_spec(module.config_spec), dict_to_str=True)
return res
def strip_config_spec(config_spec):
if '__class__' in config_spec:
del config_spec['__class__']
return config_spec | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/deps/libraries/mrl/modules/logging.py | 0.654895 | 0.306397 | logging.py | pypi |
import mrl
import torch, torch.nn as nn, torch.nn.functional as F
import numpy as np
import os
from mrl.replays.online_her_buffer import OnlineHERBuffer
class GoalSuccessPredictor(mrl.Module):
"""Predicts success using a learned discriminator"""
def __init__(self, batch_size = 50, history_length = 200, optimize_every=250, log_every=5000):
super().__init__(
'success_predictor',
required_agent_modules=[
'env', 'replay_buffer', 'goal_discriminator'
],
locals=locals())
self.log_every = log_every
self.batch_size = batch_size
self.history_length = history_length
self.optimize_every = optimize_every
self.opt_steps = 0
def _setup(self):
super()._setup()
assert isinstance(self.replay_buffer, OnlineHERBuffer)
assert self.env.goal_env
self.n_envs = self.env.num_envs
self.optimizer = torch.optim.Adam(self.goal_discriminator.model.parameters())
def _optimize(self):
self.opt_steps += 1
if len(self.replay_buffer.buffer.trajectories) > self.batch_size and self.opt_steps % self.optimize_every == 0:
trajs = self.replay_buffer.buffer.sample_trajectories(self.batch_size, group_by_buffer=True, from_m_most_recent=self.history_length)
successes = np.array([np.any(np.isclose(traj, 0.), axis=0) for traj in trajs[2]])
start_states = np.array([t[0] for t in trajs[0]])
behav_goals = np.array([t[0] for t in trajs[7]])
states = np.concatenate((start_states, behav_goals), -1)
targets = self.torch(successes)
inputs = self.torch(states)
# outputs here have not been passed through sigmoid
outputs = self.goal_discriminator(inputs)
loss = F.binary_cross_entropy_with_logits(outputs, targets)
if hasattr(self, 'logger'):
self.logger.add_histogram('predictions', torch.sigmoid(outputs), self.log_every)
self.logger.add_histogram('targets', targets, self.log_every)
# optimize
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def __call__(self, *states_and_maybe_goals):
"""Input / output are numpy arrays"""
states = np.concatenate(states_and_maybe_goals, -1)
return self.numpy(torch.sigmoid(self.goal_discriminator(self.torch(states))))
def save(self, save_folder : str):
path = os.path.join(save_folder, self.module_name + '.pt')
torch.save({
'opt_state_dict': self.optimizer.state_dict()
}, path)
def load(self, save_folder : str):
path = os.path.join(save_folder, self.module_name + '.pt')
checkpoint = torch.load(path)
self.optimizer.load_state_dict(checkpoint['opt_state_dict']) | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/deps/libraries/mrl/modules/success_prediction.py | 0.887455 | 0.385924 | success_prediction.py | pypi |
import mrl
import numpy as np
import torch, torch.nn.functional as F
import os
class GoalEnvReward(mrl.Module):
def __init__(self):
"""Wraps environment's compute reward function"""
super().__init__(
'goal_reward', required_agent_modules=['env'], locals=locals())
def _setup(self):
assert self.env.goal_env, "Environment must be a goal environment!"
assert hasattr(self.env, 'compute_reward'), "Environment must have compute reward defined!"
def __call__(self, achieved_goals, goals, info):
return self.env.compute_reward(achieved_goals, goals, info)
class NeighborReward(mrl.Module):
def __init__(self, max_neighbor_distance = 1, optimize_every = 5, batch_size = 1000, temperature = 1.):
"""Wraps environment's compute reward function. Should probably only be used for first-visit achievment."""
super().__init__(
'goal_reward', required_agent_modules=['replay_buffer', 'neighbor_embedding_network'], locals=locals())
self.step = 0
self.optimize_every = optimize_every
self.batch_size = batch_size
self.temperature = temperature
if max_neighbor_distance != 1: # this is the number of steps from which to count two goals as neighbors.
raise NotImplementedError
def _setup(self):
assert self.env.goal_env, "Environment must be a goal environment!"
assert hasattr(self.env, 'compute_reward'), "Environment must have compute reward defined!"
self.optimizer = torch.optim.Adam(
self.neighbor_embedding_network.model.parameters(),
lr=self.config.critic_lr, # just using critic hparams for now
weight_decay=self.config.critic_weight_decay)
def _optimize(self):
pag_buffer = self.replay_buffer.buffer.BUFF.buffer_previous_ag
ag_buffer = self.replay_buffer.buffer.BUFF.buffer_ag
self.step +=1
if self.step % self.optimize_every == 0 and len(ag_buffer):
sample_idxs = np.random.randint(len(ag_buffer), size=self.batch_size)
ags = ag_buffer.get_batch(sample_idxs)
pos = pag_buffer.get_batch(sample_idxs)
# mix it up to keep it symmetric for now...
temp = ags[:len(ags) //2].copy()
ags[:len(ags) //2] = pos[:len(ags) //2]
pos[:len(ags) //2] = temp
# get random negative samples by a 1 index roll
neg = np.roll(pos, 1, axis=0)
# move to torch
ags = self.torch(ags)
pos = self.torch(pos)
neg = self.torch(neg)
# get embeddings
embs = self.neighbor_embedding_network(torch.cat((ags, pos, neg), dim=0))
ags, pos, neg = torch.chunk(embs, 3)
pos_logits = -self.temperature * torch.norm(ags - pos, dim = 1)
neg_logits = -self.temperature * torch.norm(ags - neg, dim = 1)
# use soft targets
loss = F.binary_cross_entropy_with_logits(torch.exp(pos_logits), torch.ones_like(pos_logits) * 0.99) +\
F.binary_cross_entropy_with_logits(torch.exp(neg_logits), torch.ones_like(pos_logits) * 0.01)
self.logger.add_tabular('intrinsic_reward_loss', self.numpy(loss))
# optimize
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def __call__(self, achieved_goals, goals, info):
"""Should return 0 for ags, gs that are predicted to be neighbors, -1 otherwise, as a numpy array"""
ags = achieved_goals.reshape(-1, achieved_goals.shape[-1])
dgs = goals.reshape(-1, achieved_goals.shape[-1])
ags = self.torch(ags)
dgs = self.torch(dgs)
# get embeddings
embs = self.neighbor_embedding_network(torch.cat((ags, dgs), dim=0))
ags, dgs = torch.chunk(embs, 2)
# predict whether ags and dgs are transition neighbors
preds = torch.exp(-self.temperature * torch.norm(ags - dgs, dim = 1))
return -self.numpy(preds < 0.5).astype(np.float32)
def save(self, save_folder : str):
path = os.path.join(save_folder, self.module_name + '.pt')
torch.save({
'opt_state_dict': self.optimizer.state_dict()
}, path)
def load(self, save_folder : str):
path = os.path.join(save_folder, self.module_name + '.pt')
checkpoint = torch.load(path)
self.optimizer.load_state_dict(checkpoint['opt_state_dict'])
def load(self, save_folder):
self._load_props(['random_process'], save_folder) | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/deps/libraries/mrl/modules/goal_reward.py | 0.847826 | 0.449876 | goal_reward.py | pypi |
import mrl
import pickle
import os
import numpy as np
import torch
class RunningMeanStd(object):
# https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#Parallel_algorithm
def __init__(self, epsilon=1e-4, shape=()):
self.mean = np.zeros(shape, 'float64')
self.var = np.ones(shape, 'float64')
self.count = epsilon
def update(self, x):
batch_mean = np.mean(x, axis=0, keepdims=True)
batch_var = np.var(x, axis=0, keepdims=True)
batch_count = x.shape[0]
self.update_from_moments(batch_mean, batch_var, batch_count)
def update_from_moments(self, batch_mean, batch_var, batch_count):
delta = batch_mean - self.mean
tot_count = self.count + batch_count
new_mean = self.mean + delta * batch_count / tot_count
m_a = self.var * (self.count)
m_b = batch_var * (batch_count)
M2 = m_a + m_b + np.square(delta) * self.count * batch_count / (tot_count)
new_var = M2 / (tot_count)
self.mean = new_mean
self.var = new_var
self.count = tot_count
class Normalizer(mrl.Module):
def __init__(self, normalizer):
super().__init__('state_normalizer', required_agent_modules=[], locals=locals())
self.normalizer = normalizer
self.lazy_load = None
def __call__(self, *args, **kwargs):
if self.training:
self.normalizer.read_only = False
else:
self.normalizer.read_only = True
if self.lazy_load is not None:
self.normalizer(*args, **kwargs)
self.load(self.lazy_load)
print("LOADED NORMALIZER")
self.lazy_load = None
return self.normalizer(*args, **kwargs)
def save(self, save_folder):
if self.normalizer.state_dict() is not None:
with open(os.path.join(save_folder, 'normalizer.pickle'), 'wb') as f:
pickle.dump(self.normalizer.state_dict(), f)
def load(self, save_folder):
if self.normalizer.state_dict() is not None:
save_path = os.path.join(save_folder, 'normalizer.pickle')
if os.path.exists(save_path):
with open(save_path, 'rb') as f:
self.normalizer.load_state_dict(pickle.load(f))
else:
print('WARNING: No saved normalizer state to load.')
else:
self.lazy_load = save_folder
# Below from https://github.com/ShangtongZhang/DeepRL/blob/master/deep_rl/utils/normalizer.py
class BaseNormalizer:
def __init__(self, read_only=False):
self.read_only = read_only
def set_read_only(self):
self.read_only = True
def unset_read_only(self):
self.read_only = False
def state_dict(self):
return None
def load_state_dict(self, _):
return
class MeanStdNormalizer(BaseNormalizer):
def __init__(self, read_only=False, clip_before=200.0, clip_after=5.0, epsilon=1e-8):
BaseNormalizer.__init__(self, read_only)
self.read_only = read_only
self.rms = None
self.clip_before = clip_before
self.clip_after = clip_after
self.epsilon = epsilon
def __call__(self, x, update=True):
x = np.clip(np.asarray(x), -self.clip_before, self.clip_before)
if self.rms is None:
self.rms = RunningMeanStd(shape=(1, ) + x.shape[1:])
if not self.read_only and update:
self.rms.update(x)
return np.clip((x - self.rms.mean) / np.sqrt(self.rms.var + self.epsilon), -self.clip_after, self.clip_after)
def state_dict(self):
if self.rms is not None:
return {'mean': self.rms.mean, 'var': self.rms.var, 'count': self.rms.count}
def load_state_dict(self, saved):
self.rms.mean = saved['mean']
self.rms.var = saved['var']
self.rms.count = saved['count']
class RescaleNormalizer(BaseNormalizer):
def __init__(self, coef=1.0):
BaseNormalizer.__init__(self)
self.coef = coef
def __call__(self, x, *unused_args):
if not isinstance(x, torch.Tensor):
x = np.asarray(x)
return self.coef * x
class ImageNormalizer(RescaleNormalizer):
def __init__(self):
RescaleNormalizer.__init__(self, 1.0 / 255)
class SignNormalizer(BaseNormalizer):
def __call__(self, x, *unused_args):
return np.sign(x) | /rrt_ml-0.0.8-py3-none-any.whl/rrt_ml/deps/libraries/mrl/modules/normalizer.py | 0.815453 | 0.173323 | normalizer.py | pypi |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.