
code stringlengths 2.5k 150k | kind stringclasses 1
value |
|---|---|
```
import time
start = time.perf_counter()
import tensorflow as tf
import pickle
import import_ipynb
import os
from model import Model
from utils import build_dict, build_dataset, batch_iter
embedding_size=300
num_hidden = 300
num_layers = 3
learning_rate = 0.001
beam_width = 10
keep_prob = 0.8
glove = True
batch_size... | github_jupyter |
```
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
df_ice = pd.read_csv('input/icecream.csv', skiprows=2,header=None)
df_ice.columns = ['year', 'month', 'expenditure_yen']
y = pd.Series(df_ice.expenditure_yen.values, index=pd.date_range('2003-1', periods=len(df_ice), freq='M'))
y.plot()
from sta... | github_jupyter |
# Python Bindings Demo
This is a very simple demo / playground / testing site for the Python Bindings for BART.
This is mainly used to show off Numpy interoperability and give a basic sense for how more complex tools will look in Python.
## Overview
Currently, Python users can interact with BART via a command-line ... | github_jupyter |
# Convolutional Neural Networks
In this notebook we are going to explore the [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) dataset (you don't need to download this dataset, we are going to use keras to download this dataset). This is a great dataset to train models for visual recognition and to start to bui... | github_jupyter |
```
import numpy as np
import plotly
import plotly.graph_objs as go
from collections import deque
import pandas as pd
import plotly.express as px
aa_df = pd.read_csv("/Users/anafink/OneDrive - bwedu/Bachelor MoBi/5. Fachsemester/Python Praktikum/advanced_python_2021-22_HD/data/amino_acid_properties.csv")
metrics = {}... | github_jupyter |
Notes:
- Using pandas.cut for binning. bin_min=-inf, bin_max=inf. Binning on normalized data only.* (Other option to explore: sklearn KBinsDiscretizer. Issue is that bins cant be predefined. We need same bins for each batch of y. advantage: inverse is easily available)
- Changing y to categorical only for training. no... | github_jupyter |
```
%matplotlib inline
from matplotlib import style
style.use('fivethirtyeight')
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import datetime as dt
```
# Reflect Tables into SQLAlchemy ORM
```
# Python SQL toolkit and Object Relational Mapper
import sqlalchemy
from sqlalchemy.ext.automap imp... | github_jupyter |
## Scrape Archived Mini Normals from Mafiascum.net
#### Scrapy Structure/Lingo:
**Spiders** extract data **items**, which Scrapy send one by one to a configured **item pipeline** (if there is possible) to do post-processing on the items.)
## Import relevant packages...
```
import scrapy
import math
import logging
im... | github_jupyter |
While going through our script we will gradually understand the use of this packages
```
import tensorflow as tf #no need to describe ;)
import numpy as np #allows array operation
import pandas as pd #we will use it to read and manipulate files and columns content
from nltk.corpus import stopwords #provides list of e... | github_jupyter |
# Autonomous driving - Car detection
Welcome to your week 3 programming assignment. You will learn about object detection using the very powerful YOLO model. Many of the ideas in this notebook are described in the two YOLO papers: Redmon et al., 2016 (https://arxiv.org/abs/1506.02640) and Redmon and Farhadi, 2016 (htt... | github_jupyter |
# Do Neural Networks overfit?
This brief post is exploring overfitting neural networks. It comes from reading the paper:
Towards Understanding Generalization of Deep Learning: Perspective of Loss Landscapes
https://arxiv.org/pdf/1706.10239.pdf
We show that fitting a hugely overparameterised model to some linear regr... | github_jupyter |
<a href="https://colab.research.google.com/github/falconlee236/handson-ml2/blob/master/chapter4.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
import numpy as np
import matplotlib.pyplot as plt
X = 2 * np.random.rand(100, 1);
y = 4 + 3 * X + n... | github_jupyter |
```
import os
import csv
import platform
import pandas as pd
import networkx as nx
from graph_partitioning import GraphPartitioning, utils
run_metrics = True
cols = ["WASTE", "CUT RATIO", "EDGES CUT", "TOTAL COMM VOLUME", "Qds", "CONDUCTANCE", "MAXPERM", "NMI", "FSCORE", "FSCORE RELABEL IMPROVEMENT", "LONELINESS"]
#c... | github_jupyter |
# Data Scientist Nanodegree
## Supervised Learning
## Project: Finding Donors for *CharityML*
Welcome to the first project of the Data Scientist Nanodegree! In this notebook, some template code has already been provided for you, and it will be your job to implement the additional functionality necessary to successfull... | github_jupyter |
# Class activation map evaluation
```
import cv2
import numpy as np
import matplotlib.pyplot as plt
import json
import os
import pandas as pd
from pocovidnet.evaluate_covid19 import Evaluator
from pocovidnet.grad_cam import GradCAM
from pocovidnet.cam import get_class_activation_map
from pocovidnet.model import get_mo... | github_jupyter |
# Le Machine Learning, c'est pour tout le monde
## Le Machine Learning, kézako ?
Le Machine Learning, ou apprentissage automatique en français, est une façon de programmer les ordinateurs de façon à ce qu'ils exécutent une tâche souhaité sans avoir programmé explicitement les instructions pour cette tâche.
En progra... | github_jupyter |
# MMA 831 DOS1
This assignment requires R but is good Python practice.
## Some more visualizations using Python + Seaborn
```
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
plt.set_cmap('Set2')
import seaborn as sns
colours = sns.color_palette('Set2')
plt.rcParams["... | github_jupyter |
# Collect Physicists Raw Data
The goal of this notebook is to collect demographic data on the list of [physicists notable for their achievements](../data/raw/physicists.txt). Wikipedia contains this semi-structured data in an *Infobox* on the top right side of the article for each physicist. However, similar data is a... | github_jupyter |
# 1-1. AIとは何か?簡単なAIを設計してみよう
AIブームに伴って、様々なメディアでAIや機械学習、深層学習といった言葉が使われています。本章ではAIと機械学習(ML)、深層学習の違いを理解しましょう。
## 人工知能(AI)とは?
そもそも人工知能(AI)とは何でしょうか?
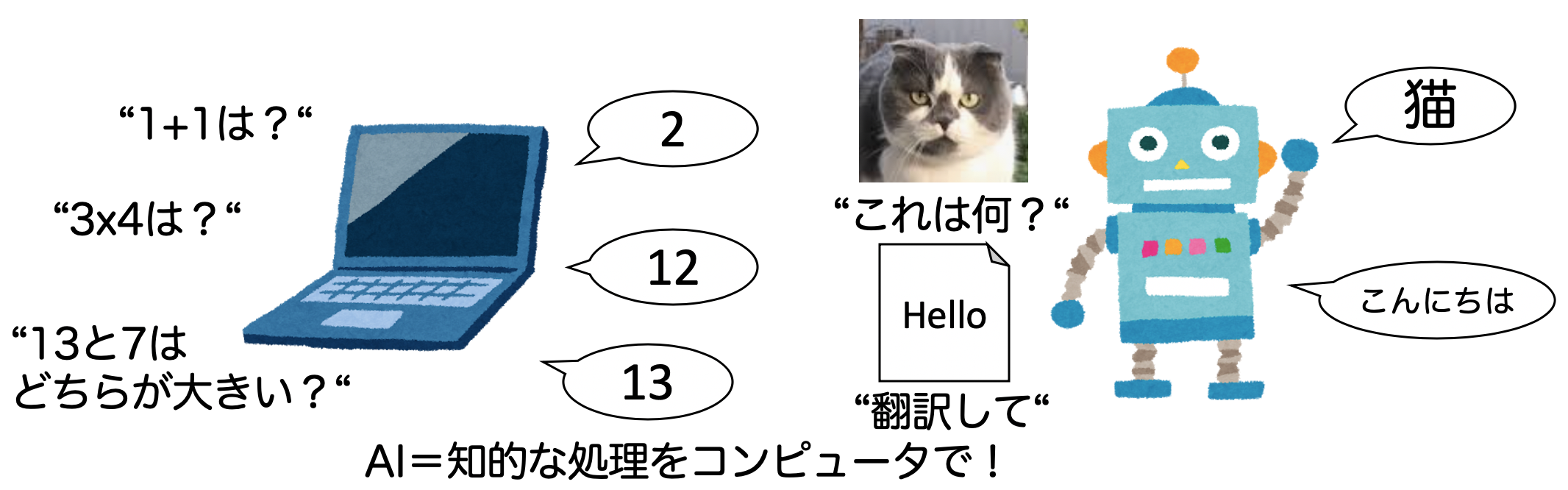
Wikipedia[1]によると、人工知能について以下のように書かれています。
人工知能(じんこうちのう、英: artificial intelligence、AI〈エーア... | github_jupyter |
# Pre-traitement
```
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName('Transform') \
.getOrCreate()
sc = spark.sparkContext
```
# CountVectorizer

`... | github_jupyter |
## UBC Intro to Machine Learning
### APIs
Instructor: Socorro Dominguez
February 05, 2022
## Exercise to try in your local machine
## Motivation
For our ML class, we want to do a Classifier that differentiates images from dogs and cats.
## Problem
We need a dataset to do this. Our friends don't have enough cats... | github_jupyter |
# contents from [sqlalchemy ORM tutorial](http://docs.sqlalchemy.org/en/latest/orm/tutorial.html)
---
# Version check
```
import sqlalchemy
sqlalchemy.__version__
```
# Connecting
+ create_engien() 함수 파라미터, database url 형식은 [여기](http://docs.sqlalchemy.org/en/latest/core/engines.html#database-urls)에서 확인
```
from sql... | github_jupyter |
```
#12/29/20
#runnign synthetic benchmark graphs for synthetic OR datasets generated
#making benchmark images
import keras
from keras.models import Sequential, Model, load_model
from keras.layers import Dense, Dropout, Activation, Flatten, Input, Lambda
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D... | github_jupyter |
# Signal Autoencoder
```
import numpy as np
import scipy as sp
import scipy.stats
import itertools
import logging
import matplotlib.pyplot as plt
import pandas as pd
import torch.utils.data as utils
import math
import time
import tqdm
import torch
import torch.optim as optim
import torch.nn.functional as F
from argpa... | github_jupyter |
Adapted from [https://github.com/PacktPublishing/Bioinformatics-with-Python-Cookbook-Second-Edition](https://github.com/PacktPublishing/Bioinformatics-with-Python-Cookbook-Second-Edition), Chapter 2.
```
conda config --add channels bioconda
conda install tabix pyvcf
```
You can also check the functions available in `s... | github_jupyter |
# Trabalhando com Arquivos
Tabela Modos de arquivo

# Métodos de uma lista usando biblioteca rich import inspect
```
from rich import inspect
a = open('arquivo1.txt', 'wt+')
inspect(a, methods=True)
```
# Criando Arquivo w(write) e x
# .close()
```
# cria a... | github_jupyter |
```
import autograd.numpy as np
import autograd.numpy.random as npr
npr.seed(0)
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set_style("white")
sns.set_context("talk")
color_names = ["windows blue",
"red",
"amber",
"faded green",
... | github_jupyter |
```
import numpy as np
import cv2
import matplotlib.pyplot as plt
from pathlib import Path
from seaborn import color_palette
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import models, transforms, utils
import copy
from utils import *
%matplo... | github_jupyter |
# Assignment 2: Implementation of Selection Sort
## Deliverables:
We will again generate random data for this assignment.
1) Please set up five data arrays of length 5,000, 10,000, 15,000, 20,000, and 25,000 of uniformly distributed random numbers (you may use either integers or floating point).
Ensu... | github_jupyter |
# Now You Code 4: Reddit News Sentiment Analysis
In this assignment you're tasked with performing a sentiment analysis on top Reddit news articles. (`https://www.reddit.com/r/news/top.json`)
You should perform the analysis on the titles only.
Start by getting the Reddit API to work, and extracting a list of titles ... | github_jupyter |
##### Copyright 2019 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | github_jupyter |
# Animalwatch validator
```
import glob
import os.path as op
import numpy as np
from io import open
from ruamel.yaml import YAML
yaml = YAML(typ="unsafe")
true_annotations_path = "E:\\data\\lynx_lynx\\zdo\\anotace"
annotations_path = "E:\\data\\lynx_lynx\\zdo\\anotace_test"
def evaluate_dir(true_annotations_path, ann... | github_jupyter |
# Demos: Lecture 17
## Demo 1: bit flip errors
```
import pennylane as qml
from pennylane import numpy as np
import matplotlib.pyplot as plt
from lecture17_helpers import *
from scipy.stats import unitary_group
dev = qml.device("default.mixed", wires=1)
@qml.qnode(dev)
def prepare_state(U, p):
qml.QubitUnitary(... | github_jupyter |
Imports
```
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision import models, datasets
from torch.autograd import Variable
import shutil
from torchsummary import summary
import os
import numpy a... | github_jupyter |
# Credit Risk Resampling Techniques
```
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
from pathlib import Path
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import... | github_jupyter |
# Overfitting y Regularización
El **overfitting** o sobreajuste es otro problema común al entrenar un modelo de aprendizaje automático. Consiste en entrenar modelos que aprenden a la perfección los datos de entrenamiento, perdiendo de esta forma generalidad. De modo, que si al modelo se le pasan datos nuevos que jamás... | github_jupyter |
# 概率潜在语义分析
概率潜在语义分析(probabilistic latent semantic analysis, PLSA),也称概率潜在语义索引(probabilistic latent semantic indexing, PLSI),是一种利用概率生成模型对文本集合进行话题分析的无监督学习方法。
模型最大特点是用隐变量表示话题,整个模型表示文本生成话题,话题生成单词,从而得到单词-文本共现数据的过程;假设每个文本由一个话题分布决定,每个话题由一个单词分布决定。
### **18.1.2 生成模型**
假设有单词集合 $W = $ {$w_{1}, w_{2}, ..., w_{M}$}, 其中M是单词个数;文本(... | github_jupyter |
## Training a differentially private LSTM model for name classification
In this tutorial we will build a differentially-private LSTM model to classify names to their source languages, which is the same task as in the tutorial **NLP From Scratch** (https://pytorch.org/tutorials/intermediate/char_rnn_classification_tuto... | github_jupyter |
##### Copyright 2019 The TensorFlow Authors.
Licensed under the Apache License, Version 2.0 (the "License");
```
#@title Licensed under the Apache License, Version 2.0 (the "License"); { display-mode: "form" }
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at... | github_jupyter |
```
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O... | github_jupyter |
# Creating a Sentiment Analysis Web App
## Using PyTorch and SageMaker
_Deep Learning Nanodegree Program | Deployment_
---
Now that we have a basic understanding of how SageMaker works we will try to use it to construct a complete project from end to end. Our goal will be to have a simple web page which a user can u... | github_jupyter |
# MNIST distributed training and batch transform
The SageMaker Python SDK helps you deploy your models for training and hosting in optimized, production-ready containers in SageMaker. The SageMaker Python SDK is easy to use, modular, extensible and compatible with TensorFlow and MXNet. This tutorial focuses on how to ... | github_jupyter |
##### Copyright 2018 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | github_jupyter |
Давайте решим следующую задачу.<br>
Необходимо написать робота, который будет скачивать новости с сайта Лента.Ру и фильтровать их в зависимости от интересов пользователя. От пользователя требуется отмечать интересующие его новости, по которым система будет выделять области его интересов.<br>
Для начала давайте разберем... | github_jupyter |
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import json
%matplotlib inline
```
### 1. Load the dataset into a data frame named loans
```
loans = pd.read_csv('../data/lending-club-data.csv')
loans.head(2)
# safe_loans = 1 => safe
# safe_loans = -1 => risky
loans['safe_loans'] = loans['b... | github_jupyter |
# Exercise 6 - Statistical Reasoning - ‘k’ Nearest Neighbour
### AIM:
To write a python program to implement the 'k' Nearest Neighbour algorithm.
### ALGORITHM :
```
Algorithm euclidian_dist(p1,p2)
Input : p1,p2 - points as Tuple()s
Output : euclidian distance between the two points
return sqrt(
... | github_jupyter |
# Find the comparables: extra_features.txt
The file `extra_features.txt` contains important property information like number and quality of pools, detached garages, outbuildings, canopies, and more. Let's load this file and grab a subset with the important columns to continue our study.
```
%load_ext autoreload
%auto... | github_jupyter |
# Python good practices
## Environment setup
```
!pip install papermill
import platform
print(f"Python version: {platform.python_version()}")
assert platform.python_version_tuple() >= ("3", "6")
import os
import papermill as pm
from IPython.display import YouTubeVideo
```
## Writing pythonic code
```
import this... | github_jupyter |
# Module
```
import numpy as np
import pandas as pd
import warnings
import gc
from tqdm import tqdm_notebook as tqdm
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import StratifiedKFold
from sklearn.... | github_jupyter |
This is the second day of the 5-Day Regression Challenge. You can find the first day's challenge [here](https://www.kaggle.com/rtatman/regression-challenge-day-1). Today, we’re going to learn how to fit a model to data and how to make sure we haven’t violated any of the underlying assumptions. First, though, you need a... | github_jupyter |
```
import torch
import torch.nn as nn
import torch.nn.functional as F
x = torch.ones((4,4))
x
```
Pytorch 입력의 형태
* input type: torch.Tensor
* input shape : `(batch_size, channel, height, width)`
```
x = x.view(-1, 1, 4, 4)
x
x.shape
```
## Conv2d
```
out = nn.Conv2d(1, 1, kernel_size = 3, stride = 1, padding = 1, ... | github_jupyter |
```
from IPython.display import display, Javascript
display(Javascript('IPython.notebook.execute_cells_below()'))
```
# Al Dhafra optimzation study
# inputs
-----
```
%%html
<script>
// AUTORUN ALL CELLS ON NOTEBOOK-LOAD!
require(
['base/js/namespace', 'jquery'],
function(jupyter, $) {
... | github_jupyter |
## Brute Force Attack Analysis - Standarized Vaults
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.path import Path
import matplotlib.patches as patches
from pylab import *
import itertools
from sklearn.metrics import confusion_matrix
from PlotUtils import *
import pathlib
i... | github_jupyter |
```
import os
import random
import torch
import torchvision.transforms as standard_transforms
import scipy.io as sio
import matplotlib
import pandas as pd
import misc.transforms as own_transforms
import warnings
from torch.autograd import Variable
from torch.utils.data import DataLoader
from PIL import Image, ImageOp... | github_jupyter |
### At least three questions related to business or real-world applications of how the data could be used.
## Preparing Data
```
#import necessary libraries
#import pandas package as pd
import pandas as pd
#import the numpy package as np
import numpy as np
#reading the csv file
stackoverflow=pd.read_csv('C:/Users/anu... | github_jupyter |
# Pandas and Scikit-learn
Pandas is a Python library that contains high-level data structures and manipulation tools designed for data analysis. Think of Pandas as a Python version of Excel. Scikit-learn, on the other hand, is an open-source machine learning library for Python.
While Scikit-learn does a lot of the he... | github_jupyter |
###### Content under Creative Commons Attribution license CC-BY 4.0, code under BSD 3-Clause License © 2017 L.A. Barba, N.C. Clementi
# Life expectancy and wealth
Welcome to **Lesson 4** of the second module in _Engineering Computations_. This module gives you hands-on data analysis experience with Python, using real... | github_jupyter |
```
%matplotlib inline
```
# Generating an input file
This examples shows how to generate an input file in HDF5-format, which can
then be processed by the `py-fmas` library code.
This is useful when the project-specific code is separate from the `py-fmas`
library code.
.. codeauthor:: Oliver Melchert <melchert@iqo... | github_jupyter |
# VacationPy
----
#### Note
* Instructions have been included for each segment. You do not have to follow them exactly, but they are included to help you think through the steps.
```
# Dependencies and Setup
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import requests
import gmaps
import os
... | github_jupyter |
# Train Telecom Customer Churn Prediction with XGBoost
This tutorial is based on [this](https://www.kaggle.com/pavanraj159/telecom-customer-churn-prediction/comments#6.-Model-Performances) Kaggle notebook and [this](https://github.com/gojek/feast/tree/master/examples/feast-xgboost-churn-prediction-tutorial) Feast note... | github_jupyter |
```
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="whitegrid")
import numpy as np
import scanpy.api as sc
from anndata import read_h5ad
from anndata import AnnData
import scipy as sp
import scipy.stats
from gprofiler import GProfiler
import pickle
# Other specific functions
fr... | github_jupyter |
# Using `bw2waterbalancer`
Notebook showing typical usage of `bw2waterbalancer`
## Generating the samples
`bw2waterbalancer` works with Brightway2. You only need set as current a project in which the database for which you want to balance water exchanges is imported.
```
import brightway2 as bw
import numpy as np
b... | github_jupyter |
# Brian Larsen - 28 April 2016 balarsen@lanl.gov
# Overview
This is meant to be a proof of concept example of the SWx to Mission instrument prediction planned for AFTAC funding.
## Abstract
There is currently no accepted method within SNDD for the time dependent quantification of environmental background in this missi... | github_jupyter |
```
import numpy as np
import pandas as pd
%matplotlib inline
import math
from xgboost.sklearn import XGBClassifier
from sklearn.cross_validation import cross_val_score
from sklearn import cross_validation
from sklearn.metrics import roc_auc_score
from matplotlib import pyplot
train = pd.read_csv("xtrain.csv")
target ... | github_jupyter |
# Insight into AirBNB Boston Data
A quick glance at [AirBnB Boston data](https://www.kaggle.com/airbnb/boston) arouse curiosity to see if following questions can be convincingly answered using data analysis.
- What are hot locations?
- What are peak seasons?
- Does number of properties in neighbourhood affect the occ... | github_jupyter |
<center>
<img src="https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DA0101EN-SkillsNetwork/labs/Module%203/images/IDSNlogo.png" width="300" alt="cognitiveclass.ai logo" />
</center>
# Data Analysis with Python
Estimated time needed: **30** minutes
## Objectives
After... | github_jupyter |
Thanks for:
https://www.kaggle.com/ttahara/osic-baseline-lgbm-with-custom-metric
https://www.kaggle.com/carlossouza/bayesian-experiments
## About
In this competition, participants are requiered to predict `FVC` and its **_`Confidence`_**.
Here, I trained Lightgbm to predict them at the same time by utilizing cust... | github_jupyter |
## Environment Initialization
This cell is used to initlialize necessary environments for pipcook to run, including Node.js 12.x.
```
!wget -P /tmp https://nodejs.org/dist/v12.19.0/node-v12.19.0-linux-x64.tar.xz
!rm -rf /usr/local/lib/nodejs
!mkdir -p /usr/local/lib/nodejs
!tar -xJf /tmp/node-v12.19.0-linux-x64.tar.xz... | github_jupyter |
# Travelling Salesman Problem (TSP)
If we have a list of city and distance between cities, travelling salesman problem is to find out the least sum of the distance visiting all the cities only once.
<img src="https://user-images.githubusercontent.com/5043340/45661145-2f8a7a80-bb37-11e8-99d1-42368906cfff.png" width="4... | github_jupyter |
# Mis on Jupyter / Jupyter Notebook?
* Interaktiivne Pythoni (ja teiste programeerimis keelte programeerimise keskkond).
* Põhirõhk on lihtsal eksperimenteerimisel ja katsetamisel. Samuti sellel et hiljem jääks katsetustest jälg.
* Lisaks Pythonile toetab ka muid programeerimiskeeli mida võiks vaja minna andmean... | github_jupyter |
# Spark on Tour
## Ejemplo de procesamiento de datos en streaming para generar un dashboard en NRT
En este notebook vamos a ver un ejemplo completo de como se podría utilizar la API de streaming estructurado de Spark para procesar un stream de eventos de puntuación en vivo, en el tiempo real, y generar como salida un ... | github_jupyter |
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-59152712-8"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-59152712-8');
</script>
# Enforce conformal 3-metric $\det{\bar{\gamma}_{ij}}=\det{... | github_jupyter |
```
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from typing import Callable
# Define some types
Func= Callable[..., np.float64]
```
# Monte Carlo Integration
$$
I(f) = \int_{\Omega} f(x) \, dx, \quad x\in\mathbb{R}^d
$$
## Numerical Integration
Any numerical integration method (includin... | github_jupyter |
## 1. KMeans vs GMM on a Generated Dataset
In the first example we'll look at, we'll generate a Gaussian dataset and attempt to cluster it and see if the clustering matches the original labels of the generated dataset.
We can use sklearn's [make_blobs](http://scikit-learn.org/stable/modules/generated/sklearn.datasets... | github_jupyter |
# Federated Tensorflow Mnist Tutorial
# Long-Living entities update
* We now may have director running on another machine.
* We use Federation API to communicate with Director.
* Federation object should hold a Director's client (for user service)
* Keeping in mind that several API instances may be connacted to one D... | github_jupyter |
# Responding to Events
```
import numpy as np
import holoviews as hv
from holoviews import opts
hv.extension('bokeh')
```
In the [Live Data](./07-Live_Data.ipynb) guide we saw how ``DynamicMap`` allows us to explore high dimensional data using the widgets in the same style as ``HoloMaps``. Although suitable for unbo... | github_jupyter |
```
# random data with a normal distribution curve thrown on top
from scipy.stats import norm
x = np.random.rand(1000)
fig, ax = plt.subplots()
ax = sns.distplot(x, fit=norm, kde=False)
# normal distribution vs. standard normal distribution
# 3 flavors of code using numpy/scipy to get simulated normal distribution
# s... | github_jupyter |
```
"""
You can run either this notebook locally (if you have all the dependencies and a GPU) or on Google Colab.
Instructions for setting up Colab are as follows:
1. Open a new Python 3 notebook.
2. Import this notebook from GitHub (File -> Upload Notebook -> "GITHUB" tab -> copy/paste GitHub URL)
3. Connect to an in... | github_jupyter |
# Building your Deep Neural Network: Step by Step
You will implement all the building blocks of a neural network and use these building blocks to build a neural network of any architecture you want. By completing this assignment you will:
- Develop an intuition of the over all structure of a neural network.
- Write ... | github_jupyter |
# Dissecting Nipype Workflows
<center>
Nipype team | contact: satra@mit.edu | nipy.org/nipype
<br>
(Hit Esc to get an overview)
</center>[Latest version][notebook] | [Latest slideshow][slideshow]
[notebook]: http://nbviewer.ipython.org/urls/raw.github.com/nipy/nipype/master/examples/nipype_tutorial.ipynb
[slideshow... | github_jupyter |
```
from google.colab import drive
drive.mount('/content/drive')
import os
print(os.getcwd())
os.chdir('/content/drive/My Drive/Colab Notebooks/summarization')
print(os.listdir())
import os
import numpy as np
import pandas as pd
import sys
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import tensorflow as tf
from... | github_jupyter |
## The goals / steps of this project are the following:
1) Compute the camera calibration matrix and distortion coefficients given a set of chessboard images.
2) Apply a distortion correction to raw images.
3) Use color transforms, gradients, etc., to create a thresholded binary image.
4) Apply a perspective transf... | github_jupyter |
<a href="https://colab.research.google.com/github/Tessellate-Imaging/monk_v1/blob/master/study_roadmaps/2_transfer_learning_roadmap/6_freeze_base_network/1.1)%20Understand%20the%20effect%20of%20freezing%20base%20model%20in%20transfer%20learning%20-%201%20-%20mxnet.ipynb" target="_parent"><img src="https://colab.researc... | github_jupyter |
```
#importing some useful packages
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import numpy as np
import cv2
# Import everything needed to edit/save/watch video clips
from moviepy.editor import VideoFileClip
from IPython.display import HTML
%matplotlib inline
```
### Import the image to be proces... | github_jupyter |
```
from nornir import InitNornir
nr = InitNornir(config_file="config.yaml")
```
# Executing tasks
Now that you know how to initialize nornir and work with the inventory let's see how we can leverage it to run tasks on groups of hosts.
Nornir ships a bunch of tasks you can use directly without having to code them yo... | github_jupyter |
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
```
## Some things I've learned about the data:
- there were fires in every state except Delaware in 2018.
- Fire names seem to be repeated, but it's hard for me to distinguish how to parse them
Could be cool to look at:
- States with the mos... | github_jupyter |
### Importing Libraries
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
```
### Import Dataset
```
dataset = pd.read_csv("Restaurant_Reviews.tsv", delimiter="\t",quoting=3)
```
### Cleaning the Texts
```
import re #simplify reviews
import nltk #for NLP,it allows us to download ensemb... | github_jupyter |
# 2040 le cap des 100% de voitures électriques
*Etude data - Projet 8 - @Nalron (août 2020)*\
*Traitement des données sur Jupyter Notebook (Distribution Anaconda)*\
*Etude réalisée en langage Python*
Visualisation des Tableaux de bord: [Tableau Public](https://public.tableau.com/profile/nalron#!/vizhome/ElectricCarsF... | github_jupyter |
# Alignment
The goal of this notebook is to align files using DTW, weakly-ordered Segmental DTW, or strictly-ordered Segmental DTW.
```
%matplotlib inline
%load_ext Cython
import numpy as np
import matplotlib.pyplot as plt
import librosa as lb
import os.path
from pathlib import Path
import pickle
import multiprocessi... | github_jupyter |
# Linear Regression
## Setup
First, let's set up some environmental dependencies. These just make the numerics easier and adjust some of the plotting defaults to make things more legible.
```
# Python 3 compatability
from __future__ import division, print_function
from six.moves import range
# system functions that... | github_jupyter |
<div class="alert alert-block alert-info">
<b><h1>ENGR 1330 Computational Thinking with Data Science </h1></b>
</div>
Copyright © 2021 Theodore G. Cleveland and Farhang Forghanparast
Last GitHub Commit Date:
# 11: Databases
- Fundamental Concepts
- Dataframes
- Read/Write to from files
---
## Objectives
... | github_jupyter |
```
from __future__ import division
from salishsea_tools import rivertools
from salishsea_tools import nc_tools
import numpy as np
import matplotlib.pyplot as plt
import netCDF4 as nc
import arrow
import numpy.ma as ma
import sys
sys.path.append('/ocean/klesouef/meopar/tools/I_ForcingFiles/Rivers')
%matplotlib inline
#... | github_jupyter |
# **Quora Question Pairs**
## **1. Business Problem**
### **1.1 Description**
Quora is a place to gain and share knowledge—about anything. It’s a platform to ask questions and connect with people who contribute unique insights and quality answers. This empowers people to learn from each other and to better understan... | github_jupyter |
# River Sediment Supply Modeling with HydroTrend
If you have never used the CSDMS Python Modeling Toolkit (PyMT), learn how to use it here.
We are using a theoretical river basin of ~1990 km2, with 1200m of relief and a river length of
~100 km. All parameters that are shown by default once the HydroTrend Model is loa... | github_jupyter |
```
%load_ext autoreload
%autoreload 2
%aiida
```
# Create structure using pymatgen
```
#!pip install pymatgen
import sys
sys.path.insert(0, '../src/')
from view import *
from functions import *
from pymatgen.core.structure import Structure, Lattice
from pymatgen.transformations.advanced_transformations import Cu... | github_jupyter |
# NetworKit User Guide
## About NetworKit
[NetworKit][networkit] is an open-source toolkit for high-performance
network analysis. Its aim is to provide tools for the analysis of large
networks in the size range from thousands to billions of edges. For this
purpose, it implements efficient graph algorithms, many of th... | github_jupyter |
# LASSO and Ridge Regression
This function shows how to use TensorFlow to solve lasso or ridge regression for $\boldsymbol{y} = \boldsymbol{Ax} + \boldsymbol{b}$
We will use the iris data, specifically: $\boldsymbol{y}$ = Sepal Length, $\boldsymbol{x}$ = Petal Width
```
# import required libraries
import matplotlib.... | github_jupyter |
## Use a Decision Optimization model deployed in Watson Machine Learning
This notebook shows you how to create and monitor jobs, and get solutions using the Watson Machine Learning Python Client.
This example only applies to Decision Optimization in Watson Machine Learning Local and Cloud Pak for Data/Watson Studio L... | github_jupyter |
## Preparation
Welcome to the Vectice tutorial notebook!
Through this notebook, we will be illustrating how to log the following information into Vectice using the Vectice Python library:
- Dataset versions
- Model versions
- Runs and lineage
For more information on the tutorial, please refer to the "Vectice Tutori... | github_jupyter |
## Loading of Stringer orientations data
includes some visualizations
```
#@title Data retrieval
import os, requests
fname = "stringer_orientations.npy"
url = "https://osf.io/ny4ut/download"
if not os.path.isfile(fname):
try:
r = requests.get(url)
except requests.ConnectionError:
print("!!! Failed to do... | github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.