
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
# Deep Q-Network (DQN)
---
In this notebook, you will implement a DQN agent with OpenAI Gym's LunarLander-v2 environment.
### 1. Import the Necessary Packages
```
import gym
import random
import torch
import numpy as np
from collections import deque
import matplotlib.pyplot as plt
%matplotlib inline
EXPERIMENT_NAME = "rainbow"
EXPERIMENT_DETAIL = "WiderVRangeEvenMoreAtoms"
```
### 2. Instantiate the Environment and Agent
Initialize the environment in the code cell below.
```
env = gym.make('LunarLander-v2')
env.seed(0)
print('State shape: ', env.observation_space.shape)
print('Number of actions: ', env.action_space.n)
```
Before running the next code cell, familiarize yourself with the code in **Step 2** and **Step 3** of this notebook, along with the code in `dqn_agent.py` and `model.py`. Once you have an understanding of how the different files work together,
- Define a neural network architecture in `model.py` that maps states to action values. This file is mostly empty - it's up to you to define your own deep Q-network!
- Finish the `learn` method in the `Agent` class in `dqn_agent.py`. The sampled batch of experience tuples is already provided for you; you need only use the local and target Q-networks to compute the loss, before taking a step towards minimizing the loss.
Once you have completed the code in `dqn_agent.py` and `model.py`, run the code cell below. (_If you end up needing to make multiple changes and get unexpected behavior, please restart the kernel and run the cells from the beginning of the notebook!_)
You can find the solution files, along with saved model weights for a trained agent, in the `solution/` folder. (_Note that there are many ways to solve this exercise, and the "solution" is just one way of approaching the problem, to yield a trained agent._)
```
# Hyperparameters
hyperparams = {
'seed': 101,
'buffer_size': int(1e5),
'batch_size': 32,
'start_since': 3200,
'gamma': 0.99,
'target_update_every': 4,
'tau': 1e-3,
'lr': 1e-4,
'weight_decay': 0,
'update_every': 4,
'priority_eps': 1e-5,
'a': 0.5,
'n_multisteps': 3,
'v_min': -500,
'v_max': 500,
'clip': None,
'n_atoms': 501,
'initial_sigma': 0.1,
'linear_type': 'noisy'
}
# Training Parameters
train_params = {
'n_episodes': 2000, 'max_t': 1000,
'eps_start': 0., 'eps_end': 0., 'eps_decay': 0.,
'beta_start': 0.4, 'beta_end': 1.0
}
from dqn_agent import Agent
agent = Agent(state_size=8, action_size=4, **hyperparams)
```
### 3. Train the Agent with DQN
Run the code cell below to train the agent from scratch. You are welcome to amend the supplied values of the parameters in the function, to try to see if you can get better performance!
```
def dqn(n_episodes=2000, max_t=1000,
eps_start=1.0, eps_end=0.01, eps_decay=0.995,
beta_start=0., beta_end=1.0,
continue_after_solved=True,
save_name="checkpoint_dueling_solved.pth"):
"""Deep Q-Learning.
Params
======
n_episodes (int): maximum number of training episodes
max_t (int): maximum number of timesteps per episode
eps_start (float): starting value of epsilon, for epsilon-greedy action selection
eps_end (float): minimum value of epsilon
eps_decay (float): multiplicative factor (per episode) for decreasing epsilon
"""
scores = [] # list containing scores from each episode
scores_window = deque(maxlen=100) # last 100 scores
eps = eps_start # initialize epsilon
prioritized = hasattr(agent, 'beta') # if using prioritized experience replay, initialize beta
if prioritized:
print("Priority Used")
agent.beta = beta_start
beta_increment = (beta_end - beta_start) / n_episodes
else:
print("Priority Not Used")
solved = False
epi_str_max_len = len(str(n_episodes))
for i_episode in range(1, n_episodes+1):
state = env.reset()
score = 0
for t in range(max_t):
action = agent.act(state, eps)
next_state, reward, done, _ = env.step(action)
agent.step(state, action, reward, next_state, done)
state = next_state
score += reward
if done:
break
else: # if not done (reached max_t)
agent.memory.reset_multisteps()
scores_window.append(score) # save most recent score
scores.append(score) # save most recent score
eps = max(eps_end, eps_decay*eps) # decrease epsilon
if prioritized:
agent.beta = min(beta_end, agent.beta + beta_increment)
print('\rEpisode {:>{epi_max_len}d} | Current Score: {:>7.2f} | Average Score: {:>7.2f} | Epsilon: {:>6.4f}'\
.format(i_episode, score, np.mean(scores_window), eps, epi_max_len=epi_str_max_len), end="")
if prioritized:
print(' | A: {:>6.4f} | Beta: {:>6.4f}'.format(agent.a, agent.beta), end='')
print(' ', end='')
if i_episode % 100 == 0:
print('\rEpisode {:>{epi_max_len}} | Current Score: {:>7.2f} | Average Score: {:>7.2f} | Epsilon: {:>6.4f}'\
.format(i_episode, score, np.mean(scores_window), eps, epi_max_len=epi_str_max_len), end='')
if prioritized:
print(' | A: {:>6.4f} | Beta: {:>6.4f}'.format(agent.a, agent.beta), end='')
print(' ')
if not solved and np.mean(scores_window)>=200.0:
print('\nEnvironment solved in {:d} episodes!\tAverage Score: {:.2f}'.format(i_episode-100, np.mean(scores_window)))
torch.save(agent.qnetwork_local.state_dict(), save_name)
solved = True
if not continue_after_solved:
break
return scores
scores = dqn(**train_params,
continue_after_solved=True,
save_name="experiment_{}_{}_solved.pth".format(EXPERIMENT_NAME, EXPERIMENT_DETAIL))
# plot the scores
plt.rcParams['figure.facecolor'] = 'w'
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(scores)), scores)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.show()
torch.save(agent.qnetwork_local.state_dict(), 'experiment_{}_{}_final.pth'.format(EXPERIMENT_NAME, EXPERIMENT_DETAIL))
agent.qnetwork_local.load_state_dict(torch.load('experiment_{}_{}_final.pth'.format(EXPERIMENT_NAME, EXPERIMENT_DETAIL)))
```
### 4. Watch a Smart Agent!
In the next code cell, you will load the trained weights from file to watch a smart agent!
```
agent.qnetwork_local.noise(False)
for i in range(10):
state = env.reset()
score = 0
for j in range(1000):
action = agent.act(state)
env.render()
state, reward, done, _ = env.step(action)
score += reward
if done:
break
print("Game {} Score: {} in {} steps".format(i, score, j + 1))
agent.qnetwork_local.noise(True)
env.close()
```
### 5. Explore
In this exercise, you have implemented a DQN agent and demonstrated how to use it to solve an OpenAI Gym environment. To continue your learning, you are encouraged to complete any (or all!) of the following tasks:
- Amend the various hyperparameters and network architecture to see if you can get your agent to solve the environment faster. Once you build intuition for the hyperparameters that work well with this environment, try solving a different OpenAI Gym task with discrete actions!
- You may like to implement some improvements such as prioritized experience replay, Double DQN, or Dueling DQN!
- Write a blog post explaining the intuition behind the DQN algorithm and demonstrating how to use it to solve an RL environment of your choosing.
```
def reset_env():
state = torch.from_numpy(env.reset()).unsqueeze(0).cuda()
with torch.no_grad():
p = agent.qnetwork_local(state).softmax(dim=-1)
action = np.argmax(agent.supports.mul(p).sum(dim=-1, keepdim=False).cpu().numpy())
env.render()
p = p.cpu().squeeze().numpy()
supports = agent.supports.cpu().numpy()
plt.rcParams['figure.facecolor'] = 'w'
fig, axes = plt.subplots(2, 2, figsize=(8, 8))
for ax in axes.reshape(-1):
ax.grid(True)
ax.set_ylabel("estimated probability")
ax.set_xlabel("supports")
axes[0, 0].set_title("do nothing")
axes[0, 1].set_title("left engine")
axes[1, 0].set_title("main engine")
axes[1, 1].set_title("right engine")
axes[0, 0].bar(x=supports, height=p[0], width=5)
axes[0, 1].bar(x=supports, height=p[1], width=5)
axes[1, 0].bar(x=supports, height=p[2], width=5)
axes[1, 1].bar(x=supports, height=p[3], width=5)
plt.tight_layout()
return action
def step(action, n_steps):
print(['nothing', 'left', 'main', 'right'][action])
score_gained = 0
for _ in range(n_steps):
state, reward, done, _ = env.step(action)
score_gained += reward
with torch.no_grad():
state = torch.from_numpy(state).unsqueeze(0).cuda()
p = agent.qnetwork_local(state).softmax(dim=-1)
action = np.argmax(agent.supports.mul(p).sum(dim=-1, keepdim=False).cpu().numpy())
env.render()
if done:
print(done)
break
print(score_gained)
p = p.cpu().squeeze().numpy()
supports = agent.supports.cpu().numpy()
plt.rcParams['figure.facecolor'] = 'w'
fig, axes = plt.subplots(2, 2, figsize=(8, 8))
for ax in axes.reshape(-1):
ax.grid(True)
ax.set_ylabel("estimated probability")
ax.set_xlabel("supports")
axes[0, 0].set_title("do nothing")
axes[0, 1].set_title("left engine")
axes[1, 0].set_title("main engine")
axes[1, 1].set_title("right engine")
axes[0, 0].bar(x=supports, height=p[0], width=5)
axes[0, 1].bar(x=supports, height=p[1], width=5)
axes[1, 0].bar(x=supports, height=p[2], width=5)
axes[1, 1].bar(x=supports, height=p[3], width=5)
plt.tight_layout()
return action
action = reset_env()
action = step(action, 50)
env.close()
agent.qnetwork_local(torch.from_numpy(state).unsqueeze(0).cuda()).softmax(dim=-1).mul(agent.supports).sum(dim=-1)
```
---
| github_jupyter |
## Compare PODNODE and DMD NIROM results using pre-computed solutions for the flow around a cylinder example
To run this notebook, download the precomputed PODNODE NIROM solution file ```cylinder_online_node_3850824_6.npz``` and ```cylinder_online_node_3851463_7.npz``` from
```
https://drive.google.com/drive/folders/19DEWdoS7Fkh-Cwe7Lbq6pdTdE290gYSS?usp=sharing
```
and place them in the ```../data/cylinder``` directory.
The DMD NIROM solutions can be generated by running the ```DMD_cylinder.ipynb``` notebook.
```
## Load modules
%matplotlib inline
import numpy as np
import scipy
import os
import gc
from scipy import interpolate
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import cm
from matplotlib.ticker import LinearLocator, ScalarFormatter, FormatStrFormatter
from matplotlib import animation
matplotlib.rc('animation', html='html5')
from IPython.display import display
import matplotlib.ticker as ticker
from matplotlib import rcParams
from matplotlib.offsetbox import AnchoredText
# Plot parameters
plt.rc('font', family='serif')
plt.rcParams.update({'font.size': 20,
'lines.linewidth': 2,
'axes.labelsize': 16, # fontsize for x and y labels (was 10)
'axes.titlesize': 20,
'xtick.labelsize': 16,
'ytick.labelsize': 16,
'legend.fontsize': 16,
'axes.linewidth': 2})
import itertools
colors = itertools.cycle(['tab:blue','tab:orange','tab:green','tab:purple',
'tab:brown','tab:olive','tab:cyan','tab:pink','tab:red'])
markers = itertools.cycle(['p','d','o','^','s','x','D','H','v']) #,'*'
base_dir = os.getcwd()
work_dir = os.path.join(base_dir,'../examples/')
data_dir = os.path.join(base_dir,'../data/')
nirom_data_dir = os.path.join(base_dir,'../data')
node_data_dir = os.path.join(base_dir,'../data/cylinder')
fig_dir = os.path.join(base_dir,'../figures/podnode')
import pynirom
from pynirom.pod import pod_utils as pod
from pynirom.utils import data_utils as du
from pynirom.node import main as nd
from pynirom.node import plotting as pu
from pynirom.node import node as node
### ------ Import Snapshot data -------------------
data = np.load(data_dir + 'cylinder_Re100.0_Nn14605_Nt3001.npz')
mesh = np.load(data_dir + 'OF_cylinder_mesh_Nn14605_Ne28624.npz')
print('HFM data has {0} snapshots of dimension {1} for p,u and v, spanning times [{2}, {3}]'.format(
data['time'].shape[0],data['p'].shape[0],
data['time'][0], data['time'][-1]))
## ------- Prepare training snapshots ----------------
print('\n-------Prepare training and testing data---------')
soln_names = ['p', 'v_x', 'v_y']
nodes = mesh['nodes']; node_ind = mesh['node_ind']
triangles = mesh['elems']; elem_ind = mesh['elem_ind']
Nn = nodes.shape[0]
snap_start = 1250
T_end = 5.0 ### 5 seconds
snap_incr = 4
snap_train, times_train = du.prepare_data(data, soln_names, start_skip=snap_start, T_end=T_end, incr=snap_incr)
print('Using {0} training snapshots for time interval [{1},{2}] seconds'.format(times_train.shape[0],
times_train[0], times_train[-1]))
## ------- Prepare testing snapshots ----------------
pred_incr = snap_incr -3
snap_pred_true, times_predict = du.prepare_data(data, soln_names, start_skip=snap_start, incr=pred_incr)
print('Using {0} testing snapshots for time interval [{1},{2}] seconds'.format(times_predict.shape[0],
times_predict[0], times_predict[-1]))
## ------- Save full HFM data without spinup time -----
snap_data, times_offline = du.prepare_data(data, soln_names, start_skip=snap_start,)
DT = (times_offline[1:] - times_offline[:-1]).mean()
Nt = times_offline.size
Nt_online = times_predict.size
## Normalize the time axis. Required for DMD fitting
tscale = DT*snap_incr ### Scaling for DMD ()
times_offline_dmd = times_offline/tscale ## Snapshots DT = 1
times_online_dmd = times_predict/tscale
del data
del mesh
gc.collect()
## Load best NODE models
best_models = [x for x in os.listdir(node_data_dir) if not os.path.isdir(os.path.join(node_data_dir, x))]
unode = {}
for nn,file in enumerate(best_models):
unode[nn] ={}
print('%d: '%(nn+1)+"Loading NODE model %s"%(file.split('node_')[1].split('.npz')[0]))
for key in soln_names:
unode[nn][key] = np.load(os.path.join(node_data_dir,file))[key]
print("Loaded %d NODE models"%(len(best_models)))
## Load best DMD models
DMD1 = np.load(os.path.join(nirom_data_dir,'cylinder_online_dmd_r20.npz'))
Xdmd1 = DMD1['dmd']; X_true = DMD1['true'];
DMD2 = np.load(os.path.join(nirom_data_dir,'cylinder_online_dmd_r8.npz'))
Xdmd2 = DMD2['dmd'];
interleaved_snapshots = DMD1['interleaved'] ## True if snapshots were interleaved while performing DMD
del DMD1
del DMD2
gc.collect()
## Compute the POD coefficients
# trunc_lvl = 0.9999995
trunc_lvl = 0.99
snap_normalized, snap_mean, U, D, W = pod.compute_pod_multicomponent(snap_train)
nw, U_r = pod.compute_trunc_basis(D, U, eng_cap = trunc_lvl)
Z_train = pod.project_onto_basis(snap_train, U_r, snap_mean)
### ------ Compute the POD coefficients for the truth snapshots on the prediction interval------------------
Z_pred_true = pod.project_onto_basis(snap_pred_true, U_r, snap_mean)
npod_total = np.sum(list(nw.values()))
true_pred_state_array = np.zeros((times_predict.size,npod_total));
ctr=0
for key in soln_names:
true_pred_state_array[:,ctr:ctr+nw[key]]=Z_pred_true[key].T
ctr+=nw[key]
tmp = {};znode ={}
for nn in range(len(best_models)):
tmp[nn] = pod.project_onto_basis(unode[nn],U_r,snap_mean)
znode[nn]=np.zeros((times_predict.size,npod_total))
ctr=0
for key in soln_names:
znode[nn][:,ctr:ctr+nw[key]]=tmp[nn][key].T
ctr+=nw[key]
def var_string(ky):
md = ky
return md
### --- Visualize POD coefficients of true solution and NODE predictions
mode1=0; mode2=2; mode3=4
x_inx = times_online_dmd*tscale
start_trunc = 10+0*np.searchsorted(times_predict,times_train[-1])//10
end_trunc = 10*np.searchsorted(times_predict,times_train[-1])//10
end_trunc = end_trunc + (Nt_online - end_trunc)//1
tr_mark = np.searchsorted(times_predict, times_train[-1])
time_ind = np.searchsorted(times_offline, times_predict)
ky1 = 'p'; ky2 = 'v_x'; ky3 = 'v_y'
md1 = var_string(ky1); md2 = var_string(ky2); md3 = var_string(ky3)
fig = plt.figure(figsize=(16,10))
ax1 = fig.add_subplot(2, 3, 1)
ax1.plot(x_inx[start_trunc:end_trunc], true_pred_state_array[start_trunc:end_trunc,mode1], color=next(colors),
marker=next(markers), markersize=8,label='True',lw=2,markevery=100)
for nn in range(len(best_models)):
ax1.plot(x_inx[start_trunc:end_trunc], znode[nn][start_trunc:end_trunc,mode1], color=next(colors),
marker=next(markers), markersize=8,label='NODE%d'%nn,lw=2,markevery=100)
# lg=plt.legend(ncol=1,fancybox=True,loc='best')
ax1.set_title('$\mathbf{%s}$: $%d$'%(md1,mode1+1))
ax2 = fig.add_subplot(2, 3, 2)
ax2.plot(x_inx[start_trunc:end_trunc], true_pred_state_array[start_trunc:end_trunc,mode2], color=next(colors),
marker=next(markers), markersize=8,label='True',lw=2,markevery=100)
for nn in range(len(best_models)):
ax2.plot(x_inx[start_trunc:end_trunc], znode[nn][start_trunc:end_trunc,mode2], color=next(colors),
marker=next(markers), markersize=8,label='NODE%d'%nn,lw=2,markevery=100)
# lg=plt.legend(ncol=1,fancybox=True,loc='best')
ax2.set_title('$\mathbf{%s}$: $%d$'%(md1,mode2+1))
ax3 = fig.add_subplot(2, 3, 3)
ax3.plot(x_inx[start_trunc:end_trunc], true_pred_state_array[start_trunc:end_trunc,mode3], color=next(colors),
marker=next(markers), markersize=8,label='True',lw=2,markevery=100)
for nn in range(len(best_models)):
ax3.plot(x_inx[start_trunc:end_trunc], znode[nn][start_trunc:end_trunc,mode3], color=next(colors),
marker=next(markers), markersize=8,label='NODE%d'%nn,lw=2,markevery=100)
# lg=plt.legend(ncol=1,fancybox=True,loc='best')
ax3.set_title('$\mathbf{%s}$: $%d$'%(md1,mode3+1))
ax4 = fig.add_subplot(2, 3, 4)
ax4.plot(x_inx[start_trunc:end_trunc], true_pred_state_array[start_trunc:end_trunc,nw['p']+mode1], color=next(colors),
marker=next(markers), markersize=8,label='True',lw=2,markevery=100)
for nn in range(len(best_models)):
ax4.plot(x_inx[start_trunc:end_trunc], znode[nn][start_trunc:end_trunc,nw['p']+mode1], color=next(colors),
marker=next(markers), markersize=8,label='NODE%d'%nn,lw=2,markevery=100)
# lg=plt.legend(ncol=1,fancybox=True,loc='best')
ax4.set_title('$\mathbf{%s}$: $%d$'%(md2,mode1+1))
ax4.set_xlabel('Time (seconds)')
ax5 = fig.add_subplot(2, 3, 5)
ax5.plot(x_inx[start_trunc:end_trunc], true_pred_state_array[start_trunc:end_trunc,nw['p']+mode2], color=next(colors),
marker=next(markers), markersize=8,label='True',lw=2,markevery=100)
for nn in range(len(best_models)):
ax5.plot(x_inx[start_trunc:end_trunc], znode[nn][start_trunc:end_trunc,nw['p']+mode2], color=next(colors),
marker=next(markers), markersize=8,label='NODE%d'%nn,lw=2,markevery=100)
# lg=plt.legend(ncol=1,fancybox=True,loc='best')
ax5.set_title('$\mathbf{%s}$: $%d$'%(md2,mode2+1))
ax5.set_xlabel('Time (seconds)')
ax6 = fig.add_subplot(2, 3, 6)
ax6.plot(x_inx[start_trunc:end_trunc], true_pred_state_array[start_trunc:end_trunc,nw['p']+mode3], color=next(colors),
marker=next(markers), markersize=8,label='True',lw=2,markevery=100)
for nn in range(len(best_models)):
ax6.plot(x_inx[start_trunc:end_trunc], znode[nn][start_trunc:end_trunc,nw['p']+mode3], color=next(colors),
marker=next(markers), markersize=8,label='NODE%d'%(nn+1),lw=2,markevery=100)
lg=plt.legend(ncol=5,fancybox=True,bbox_to_anchor=(0.65, -0.18)) #loc='best')
ax6.set_title('$\mathbf{%s}$: $%d$'%(md2,mode3+1))
ax6.set_xlabel('Time (seconds)')
# os.chdir(fig_dir)
# plt.savefig('OF_node_comp_proj_tskip%d_oskip%d.png'%(snap_incr,pred_incr),dpi=300,bbox_extra_artists=(lg,), bbox_inches='tight')
### Compute spatial RMS errors
fig = plt.figure(figsize=(16,4))
x_inx = times_online_dmd*tscale
start_trunc = 10+0*np.searchsorted(times_predict,times_train[-1])//10
end_trunc = 10*np.searchsorted(times_predict,times_train[-1])//10
end_trunc = end_trunc + (Nt_online - end_trunc)//1
tr_mark = np.searchsorted(times_predict, times_train[-1])
time_ind = np.searchsorted(times_offline, times_predict)
ky1 = 'p'; ky2 = 'v_x'; ky3 = 'v_y'
md1 = var_string(ky1); md2 = var_string(ky2); md3 = var_string(ky3)
Nc = len(soln_names)
dmd_err1 = {}; dmd_err2 = {}
node_err = {};
for nn in range(len(best_models)):
node_err[nn] = {}
for ivar,key in enumerate(soln_names):
node_err[nn][key] = np.linalg.norm(snap_data[key][:,time_ind]- unode[nn][key][:,:], axis=0)/np.sqrt(Nn) #\
for ivar,key in enumerate(soln_names):
dmd_err1[key] = np.linalg.norm(X_true[ivar::Nc,:] - Xdmd1[ivar::Nc,:], axis = 0)/np.sqrt(Nn)
dmd_err2[key] = np.linalg.norm(X_true[ivar::Nc,:] - Xdmd2[ivar::Nc,:], axis = 0)/np.sqrt(Nn)
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(x_inx[start_trunc:end_trunc], dmd_err1[ky1][start_trunc:end_trunc], color=next(colors),
marker=next(markers), markersize=8,label='DMD(20):$\mathbf{%s}$'%(md1),lw=2,markevery=100)
ax1.plot(x_inx[start_trunc:end_trunc], dmd_err2[ky1][start_trunc:end_trunc], color=next(colors),
marker=next(markers), markersize=8,label='DMD(8):$\mathbf{%s}$'%(md1),lw=2,markevery=100)
for nn in range(len(best_models)):
ax1.plot(x_inx[start_trunc:end_trunc], node_err[nn][ky1][start_trunc:end_trunc], color=next(colors),
markersize=8,marker = next(markers),label='NODE%d:$\mathbf{%s}$'%(nn+1,md1),lw=2,markevery=100)
ymax_ax1 = dmd_err2[ky1][start_trunc:end_trunc].max()
ax1.vlines(x_inx[tr_mark], 0, ymax_ax1, colors ='k', linestyles='dashdot')
ax1.set_xlabel('Time (seconds)');lg=plt.legend(ncol=2,fancybox=True,loc='best')
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(x_inx[start_trunc:end_trunc], dmd_err1[ky2][start_trunc:end_trunc], color=next(colors),
markersize=8,marker = next(markers),label='DMD(20):$\mathbf{%s}$'%(md2), lw=2,markevery=100)
ax2.plot(x_inx[start_trunc:end_trunc], dmd_err2[ky2][start_trunc:end_trunc], color=next(colors),
markersize=8,marker = next(markers),label='DMD(8):$\mathbf{%s}$'%(md2), lw=2,markevery=100)
for nn in range(len(best_models)):
ax2.plot(x_inx[start_trunc:end_trunc], node_err[nn][ky3][start_trunc:end_trunc],color=next(colors),
markersize=8,marker = next(markers),label='NODE%d:$\mathbf{%s}$'%(nn+1,md2), lw=2,markevery=100)
ymax_ax2 = np.maximum(dmd_err2[ky2][start_trunc:end_trunc].max(), dmd_err2[ky3][start_trunc:end_trunc].max())
ax2.vlines(x_inx[tr_mark],0,ymax_ax2, colors = 'k', linestyles ='dashdot')
ax2.set_xlabel('Time (seconds)');lg=plt.legend(ncol=2,fancybox=True,loc='best')
fig.suptitle('Spatial RMS errors of NIROM solutions', fontsize=18)
# os.chdir(fig_dir)
# plt.savefig('cyl_node_comp_rms_tskip%d_oskip%d.pdf'%(snap_incr,pred_incr), bbox_inches='tight')
def plot_nirom_soln(Xtrue, Xdmd, Xnode, Nc, Nt_plot, nodes, elems, times_online, comp_names, seed =100, flag = True):
np.random.seed(seed)
itime = np.searchsorted(times_online,2.90) #np.random.randint(0,Nt_plot)
ivar = 1 #np.random.randint(1,Nc)
ky = comp_names[ivar]
tn = times_online[itime]
if flag: ### for interleaved snapshots
tmp_dmd = Xdmd1[ivar::Nc,itime]
tmp_true = Xtrue[ivar::Nc,itime]
else:
tmp_dmd = Xdmd1[ivar*Nn:(ivar+1)*Nn,itime]
tmp_true = Xtrue[ivar*Nn:(ivar+1)*Nn,itime]
tmp_node = Xnode[ky][:,itime]
fig = plt.figure(figsize=(18,25));
ax1 = fig.add_subplot(5, 1, 1)
surf1 = ax1.tripcolor(nodes[:,0], nodes[:,1],elems, tmp_dmd, cmap=plt.cm.jet)
ax1.set_title('DMD solution: {0} at t={1:1.2f} seconds, {0} range = [{2:5.3g},{3:4.2g}]'.format(ky,tn,
tmp_dmd.min(),tmp_dmd.max()),fontsize=16)
plt.axis('off')
plt.colorbar(surf1, orientation='horizontal',shrink=0.6,aspect=40, pad = 0.03)
ax2 = fig.add_subplot(5, 1, 3)
surf2 = ax2.tripcolor(nodes[:,0], nodes[:,1],elems, tmp_true, cmap=plt.cm.jet)
ax2.set_title('HFM solution: {0} at t={1:1.2f} seconds, {0} range = [{2:5.3g},{3:4.2g}]'.format(ky,tn,
tmp_true.min(),tmp_true.max()),fontsize=16)
plt.axis('off')
plt.colorbar(surf2, orientation='horizontal',shrink=0.6,aspect=40, pad = 0.03)
err_dmd = tmp_dmd-tmp_true
ax3 = fig.add_subplot(5, 1, 4)
surf3 = ax3.tripcolor(nodes[:,0], nodes[:,1],elems, err_dmd, cmap=plt.cm.Spectral)
ax3.set_title('DMD error: {0} at t={1:1.2f} seconds, error range = [{2:5.3g},{3:4.2g}]'.format(ky,tn,
err_dmd.min(),err_dmd.max()),fontsize=16)
plt.axis('off')
plt.colorbar(surf3,orientation='horizontal',shrink=0.6,aspect=40, pad = 0.03)
ax4 = fig.add_subplot(5, 1, 2)
surf4 = ax4.tripcolor(nodes[:,0], nodes[:,1],elems, tmp_node, cmap=plt.cm.jet)
ax4.set_title('PODNODE solution: {0} at t={1:1.2f} seconds, {0} range = [{2:5.3g},{3:4.2g}]'.format(ky,tn,
tmp_node.min(),tmp_node.max()),fontsize=16)
plt.axis('off')
plt.colorbar(surf4, orientation='horizontal',shrink=0.6,aspect=40, pad = 0.03)
err_node = tmp_node-tmp_true
ax5 = fig.add_subplot(5, 1, 5)
surf5 = ax5.tripcolor(nodes[:,0], nodes[:,1],elems, err_node, cmap=plt.cm.Spectral)
ax5.set_title('PODNODE error: {0} at t={1:1.2f} seconds, error range = [{2:5.3g},{3:4.2g}]'.format(ky,tn,
err_node.min(),err_node.max()),fontsize=16)
plt.axis('off')
plt.colorbar(surf5,orientation='horizontal',shrink=0.6,aspect=40, pad = 0.03)
return tn
Nt_plot = np.searchsorted(times_predict, times_train[-1])
itime = plot_nirom_soln(X_true, Xdmd1, unode[0],Nc, Nt_plot, nodes, triangles, times_predict,
soln_names, seed=1990,flag = True)
# os.chdir(fig_dir)
# plt.savefig('cyl_nirom_t%.3f_tskip%d_oskip%d.pdf'%(itime,snap_incr,pred_incr), bbox_inches='tight')
```
| github_jupyter |
Python for Everyone!<br/>[Oregon Curriculum Network](http://4dsolutions.net/ocn/)
## VPython inside Jupyter Notebooks
### The Vector, Edge and Polyhedron types
The Vector class below is but a thin wrapper around VPython's built-in vector type. One might wonder, why bother? Why not just use vpython.vector and be done with it? Also, if wanting to reimplement, why not just subclass instead of wrap? All good questions.
A primary motivation is to keep the Vector and Edge types somewhat aloof from vpython's vector and more welded to vpython's cylinder instead. We want vectors and edges to materialize as cylinders quite easily.
So whether we subclass, or wrap, we want our vectors to have the ability to self-draw.
The three basis vectors must be negated to give all six spokes of the XYZ apparatus. Here's an opportunity to test our \_\_neg\_\_ operator then.
The overall plan is to have an XYZ "jack" floating in space, around which two tetrahedrons will be drawn, with a common center, as twins.
Their edges will intersect as at the respective face centers of the six-faced, twelve-edged hexahedron, our "duo-tet" cube (implied, but could be hard-wired as a next Polyhedron instance, just give it the six faces).
A lot of this wrapper code is about turning vpython.vectors into lists for feeding to Vector, which expects three separate arguments. A star in front of an iterable accomplishes the feat of exploding it into the separate arguments required.
Note that vector operations, including negation, always return fresh vectors. Even color has not been made a mutable property, but maybe could be.
```
from vpython import *
class Vector:
def __init__(self, x, y, z):
self.v = vector(x, y, z)
def __add__(self, other):
v_sum = self.v + other.v
return Vector(*v_sum.value)
def __neg__(self):
return Vector(*((-self.v).value))
def __sub__(self, other):
V = (self + (-other))
return Vector(*V.v.value)
def __mul__(self, scalar):
V = scalar * self.v
return Vector(*V.value)
def norm(self):
v = norm(self.v)
return Vector(*v.value)
def length(self):
return mag(self.v)
def draw(self):
self.the_cyl = cylinder(pos=vector(0,0,0), axis=self.v, radius=0.1)
self.the_cyl.color = color.cyan
XBASIS = Vector(1,0,0)
YBASIS = Vector(0,1,0)
ZBASIS = Vector(0,0,1)
XNEG = -XBASIS
YNEG = -YBASIS
ZNEG = -ZBASIS
XYZ = [XBASIS, XNEG, YBASIS, YNEG, ZBASIS, ZNEG]
sphere(pos=vector(0,0,0), color = color.orange, radius=0.2)
for radial in XYZ:
radial.draw()
```
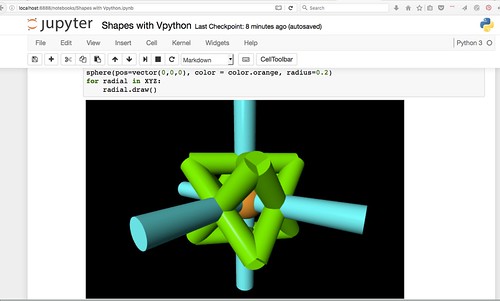
Even though the top code cell contains no instructions to draw, Vpython's way of integrating into Jupyter Notebook seems to be by adding a scene right after the first code cell. Look below for the code that made all of the above happen. Yes, that's a bit strange.
```
class Edge:
def __init__(self, v0, v1):
self.v0 = v0
self.v1 = v1
def draw(self):
"""cylinder wants a starting point, and a direction vector"""
pointer = (self.v1 - self.v0)
direction_v = norm(pointer) * pointer.length() # normalize then stretch
self.the_cyl = cylinder(pos = self.v0.v, axis=direction_v.v, radius=0.1)
self.the_cyl.color = color.green
class Polyhedron:
def __init__(self, faces, corners):
self.faces = faces
self.corners = corners
self.edges = self._get_edges()
def _get_edges(self):
"""
take a list of face-tuples and distill
all the unique edges,
e.g. ((1,2,3)) => ((1,2),(2,3),(1,3))
e.g. icosahedron has 20 faces and 30 unique edges
( = cubocta 24 + tetra's 6 edges to squares per
jitterbug)
"""
uniqueset = set()
for f in self.faces:
edgetries = zip(f, f[1:]+ (f[0],))
for e in edgetries:
e = tuple(sorted(e)) # keeps out dupes
uniqueset.add(e)
return tuple(uniqueset)
def draw(self):
for edge in self.edges:
the_edge = Edge(Vector(*self.corners[edge[0]]),
Vector(*self.corners[edge[1]]))
the_edge.draw()
the_verts = \
{ 'A': (0.35355339059327373, 0.35355339059327373, 0.35355339059327373),
'B': (-0.35355339059327373, -0.35355339059327373, 0.35355339059327373),
'C': (-0.35355339059327373, 0.35355339059327373, -0.35355339059327373),
'D': (0.35355339059327373, -0.35355339059327373, -0.35355339059327373),
'E': (-0.35355339059327373, -0.35355339059327373, -0.35355339059327373),
'F': (0.35355339059327373, 0.35355339059327373, -0.35355339059327373),
'G': (0.35355339059327373, -0.35355339059327373, 0.35355339059327373),
'H': (-0.35355339059327373, 0.35355339059327373, 0.35355339059327373)}
the_faces = (('A','B','C'),('A','C','D'),('A','D','B'),('B','C','D'))
other_faces = (('E','F','G'), ('E','G','H'),('E','H','F'),('F','G','H'))
tetrahedron = Polyhedron(the_faces, the_verts)
inv_tetrahedron = Polyhedron(other_faces, the_verts)
print(tetrahedron._get_edges())
print(inv_tetrahedron._get_edges())
tetrahedron.draw()
inv_tetrahedron.draw()
```
The code above shows how we might capture an Edge as the endpoints of two Vectors, setting the stage for a Polyhedron as a set of such edges. These edges are derived from faces, which are simply clockwise or counterclockwise circuits of named vertices.
Pass in a dict of vertices or corners you'll need, named by letter, along with the tuple of faces, and you're set. The Polyhedron will distill the edges for you, and render them as vpython.cylinder objects.
Remember to scroll up, to the scene right after the first code cell, to find the actual output of the preceding code cell.
At Oregon Curriculum Network (OCN) you will find material on Quadrays, oft used to generate 26 points of interest A-Z, the A-H above the beginning of the sequence. From the duo-tet cube we move to its dual, the octahedron, and then the 12 vertices of the cuboctahedron. 8 + 6 + 12 = 26.
When studying Synergetics (a namespace) you will encounter [canonical volume numbers](https://github.com/4dsolutions/Python5/blob/master/Computing%20Volumes.ipynb) for these as well: (Tetrahedron: 1, Cube: 3, Octahedron: 4, Rhombic Dodecahedron 6, Cuboctahedron 20).

<i>For Further Reading:</i>
[Polyhedrons 101](https://github.com/4dsolutions/Python5/blob/master/Polyhedrons%20101.ipynb)<br />
[STEM Mathematics](http://nbviewer.jupyter.org/github/4dsolutions/Python5/blob/master/STEM%20Mathematics.ipynb) -- with nbviewer
| github_jupyter |
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import shapiro, normaltest, bartlett, levene, f_oneway, ttest_ind, ranksums, kruskal, mannwhitneyu, spearmanr
from statsmodels.stats.multicomp import pairwise_tukeyhsd, MultiComparison
from statsmodels.graphics import gofplots
from scipy.stats import describe,anderson,t,ttest_rel
```
# Normality Tests



```
def normality_test(data, alpha=0.05):
# print col describe
print("Data describe","\n")
print(describe(data),"\n")
# drop nans and duplicates
# dist plot and qqplot
# plot col distplot
sns.distplot(data).set_title("DistPlot for data")
plt.show()
# qq plot
gofplots.qqplot(data, line='45', fit=True)
plt.title('Q-Q plot for data')
plt.show()
# Shapiro-Wilk test
print('Shapiro-Wilk Test')
stat, p = shapiro(data)
if p > alpha:
print('Accept Ho: Distribution is normal (alpha = {0})'.format(alpha))
else:
print('Reject Ho: Distribution is not normal (alpha = {0})'.format(alpha))
print('P_value: ', p,'\n')
# D’Agostino’s K^2 Test (tests Skewness and Kurtosis)
print('D’Agostino’s Test')
stat, p = normaltest(data)
if p > alpha:
print('Accept Ho: Distribution is normal (alpha = {0})'.format(alpha))
else:
print('Reject Ho: Distribution is not normal (alpha = {0})'.format(alpha))
print('P_value: ', p,'\n')
#Anderson DArling Tests
print('Anderson-Darling Test')
result = anderson(data)
print('Statistic: %.3f' % result.statistic)
p = 0
for i in range(len(result.critical_values)):
sl, cv = result.significance_level[i], result.critical_values[i]
if result.statistic < result.critical_values[i]:
print('%.3f: %.3f, Accept Ho: Distribution is normal' % (sl, cv))
else:
print('%.3f: %.3f, Reject Ho: Distribution is not normal (reject H0)' % (sl, cv))
print('======================================================================')
np.random.seed(45)
sample_size = 1000
normal_data = np.random.normal(0,1,size=sample_size)
uniform_data = np.random.uniform(0,10,sample_size)
normality_test(normal_data)
normality_test(uniform_data)
df = 6
t_dist_data = np.random.standard_t(df,size = sample_size)
normality_test(t_dist_data)
```
# HomogenetyTests(equal variances)
```
def homogeneity_test(data1,data2, alpha=0.05):
# Bartlett’s test (equal variances)
print("Homogenity tests","\n")
print("Data1 describe")
print(describe(data1),"\n")
print("Data1 describe")
print(describe(data2),"\n")
print('Bartlett’s test')
stat, p = bartlett(data1, data2)
if p > alpha:
print('Accept Ho: All input samples are from populations with equal variances (alpha = {0})'.format(alpha))
else:
print('Reject Ho: All input samples are not from populations with equal variances (alpha = {0})'.format(alpha))
print('\n')
# Levene test (equal variances)
print('Levene’s test')
stat, p = levene(data1, data2)
if p > alpha:
print('Accept Ho: All input samples are from populations with equal variances (alpha = 5%)')
else:
print('Reject Ho: All input samples are not from populations with equal variances (alpha = 5%)')
print('\n')
print('======================================================================')
np.random.seed(45)
data1 = np.random.normal(10,11,size = sample_size)
data2 = np.random.normal(20,20,size = sample_size)
homogeneity_test(data1,data2)
np.random.seed(45)
data1 = np.random.normal(10,11,size = sample_size)
data2 = np.random.normal(20,11.5,size = sample_size)
homogeneity_test(data1,data2)
```
# Parametric Tests

```
def ind_ttest(data1,data2,alpha=0.05):
print("Data1 describe")
print(describe(data1),"\n")
print("Data1 describe")
print(describe(data2),"\n")
X = np.concatenate((data1.reshape(-1,1),data2.reshape(-1,1)),axis=1)
sns.boxplot(data = X)
plt.show()
print('Inependent T-test')
stat, p = ttest_ind(data1, data2)
if p > alpha:
print('Accept Ho: Input samples are from populations with equal means (alpha = {0})'.format(alpha))
else:
print('Reject Ho: Input samples are not from populations with equal means (alpha = {0})'.format(alpha))
print('\n')
print('======================================================================')
np.random.seed(45)
sample_size = 100
data1 = np.random.normal(15,10,size = sample_size)
data2 = np.random.normal(10,10,size = sample_size)
ind_ttest(data1,data2,alpha = 0.05)
```
# Paired T-Test(not independent)
```
def rel_indtest(data1,data2,alpha=0.05):
print("Data1 describe")
print(describe(data1),"\n")
print("Data1 describe")
print(describe(data2),"\n")
X = np.concatenate((data1.reshape(-1,1),data2.reshape(-1,1)),axis=1)
sns.boxplot(data = X)
plt.show()
print('Inependent T-test')
stat, p = ttest_rel(data1, data2)
if p > alpha:
print('Accept Ho: Input samples are from populations with equal means (alpha = {0})'.format(alpha))
else:
print('Reject Ho: Input samples are not from populations with equal means (alpha = {0})'.format(alpha))
print('\n')
print('======================================================================')
data1 = 5 * np.random.randn(100) + 50
data2 = 5 * np.random.randn(100) + 51
rel_indtest(data1,data2)
```

```
def anova_test(data1,data2,data3,alpha=0.05):
# anova test (equal means)
print("Data1 describe")
print(describe(data1),"\n")
print("Data1 describe")
print(describe(data2),"\n")
X = np.concatenate((data1.reshape(-1,1),data2.reshape(-1,1),data3.reshape(-1,1)),axis=1)
sns.boxplot(data = X)
plt.show()
print("\n")
print('ANOVA test')
stat, p = f_oneway(data1, data2, data3)
if p > alpha:
print('Accept Ho: Input samples are from populations with equal means (alpha = {0})'.format(alpha))
else:
print('Reject Ho: Input samples are not from populations with equal means (alpha = {0})'.format(alpha))
print('\n')
print('======================================================================')
np.random.seed(45)
sample_size = 100
data1 = np.random.normal(15,10,size = sample_size)
data2 = np.random.normal(15,10,size = sample_size)
data3 = np.random.normal(10,10,size = sample_size)
anova_test(data1,data2,data3)
```
# Non-parametric tests

```
def mann_whitney(data1,data2,alpha=0.05):
# MannWhitney test for two independent samples (equal means)
print("Data1 describe")
print(describe(data1),"\n")
print("Data1 describe")
print(describe(data2),"\n")
sns.distplot(data1).set_title("data1")
plt.show()
sns.distplot(data2).set_title("data2")
plt.show()
print('Mann-Whitney test')
stat, p = mannwhitneyu(data1, data2)
if p > alpha:
print('Accept Ho: The distributions of both samples are equal. (alpha = {0})'.format(alpha))
else:
print('Reject Ho: the distributions of both samples are not equal. (alpha = {0})'.format(alpha))
print('\n')
data1 = 5 * np.random.randn(100) + 50
data2 = 5 * np.random.randn(100) + 50
mann_whitney(data1,data2)
data1 = 5 * np.random.randn(100) + 50
data2 = 5 * np.random.randn(100) + 51
mann_whitney(data1,data2)
```

```
def WilcoxonRankSum(data1,data2, alpha=0.05):
# Wilcoxon Rank-Sum test for two independent samples (equal means)
print("Data1 describe")
print(describe(data1),"\n")
print("Data1 describe")
print(describe(data2),"\n")
sns.distplot(data1).set_title("data1")
plt.show()
sns.distplot(data2).set_title("data2")
plt.show()
print('WilcoxonRankSum')
stat, p = ranksums(data1, data2)
if p > alpha:
print('Accept Ho: The distributions of both samples are equal. (alpha = {0})'.format(alpha))
else:
print('Reject Ho: the distributions of both samples are not equal. (alpha = {0})'.format(alpha))
print('\n')
data1 = 5 * np.random.randn(100) + 50
data2 = 5 * np.random.randn(100) + 50
WilcoxonRankSum(data1,data2)
data1 = 5 * np.random.randn(100) + 50
data2 = 5 * np.random.randn(100) + 55
WilcoxonRankSum(data1,data2)
```

```
def kruskal_wallis_h_test(data1,data2,data3, alpha=0.05):
# Kruskal-Wallis H-test for independent samples (non-parametric version of ANOVA)
print("Data1 describe")
print(describe(data1),"\n")
print("Data2 describe")
print(describe(data2),"\n")
print("Data3 describe")
print(describe(data3),"\n")
sns.distplot(data1).set_title("data1")
plt.show()
sns.distplot(data2).set_title("data2")
plt.show()
sns.distplot(data3).set_title("data2")
plt.show()
print('Kruskal-Wallis H-test')
stat, p = kruskal(data1, data2, data3)
if p > alpha:
print('Accept Ho: The distributions of both samples are equal. (alpha = {0})'.format(alpha))
else:
print('Reject Ho: the distributions of both samples are not equal. (alpha = {0})'.format(alpha))
print('\n')
data1 = 5 * np.random.randn(100) + 50
data2 = 5 * np.random.randn(100) + 53
data3 = 5 * np.random.randn(100) + 50
kruskal_wallis_h_test(data1,data2,data3)
```
| github_jupyter |
##### <small>
Copyright (c) 2017 Andrew Glassner
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
</small>
# Deep Learning From Basics to Practice
## by Andrew Glassner, https://dlbasics.com, http://glassner.com
------
## Chapter 24: Autoencoders
### Notebook 5: Denoising
This notebook is provided as a “behind-the-scenes” look at code used to make some of the figures in this chapter. It is still in the hacked-together form used to develop the figures, and is only lightly commented.
```
# some code adapted from https://blog.keras.io/building-autoencoders-in-keras.html
from keras.datasets import mnist
from keras.models import Sequential, Model
from keras.layers import Dense
from keras.layers.convolutional import Conv2D, UpSampling2D, MaxPooling2D, Conv2DTranspose
import h5py
import numpy as np
import matplotlib.pyplot as plt
#from pathlib import Path
from keras import backend as keras_backend
keras_backend.set_image_data_format('channels_last')
# Make a File_Helper for saving and loading files.
save_files = True
import os, sys, inspect
current_dir = os.path.dirname(os.path.abspath(inspect.getfile(inspect.currentframe())))
sys.path.insert(0, os.path.dirname(current_dir)) # path to parent dir
from DLBasics_Utilities import File_Helper
file_helper = File_Helper(save_files)
def get_mnist_samples():
random_seed = 42
np.random.seed(random_seed)
# Read MNIST data. We won't be using the y_train or y_test data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
pixels_per_image = np.prod(X_train.shape[1:])
# Cast values into the current floating-point type
X_train = keras_backend.cast_to_floatx(X_train)
X_test = keras_backend.cast_to_floatx(X_test)
X_train = np.reshape(X_train, (len(X_train), 28, 28, 1))
X_test = np.reshape(X_test, (len(X_test), 28, 28, 1))
# Normalize the range from [0,255] to [0,1]
X_train /= 255.
X_test /= 255.
return (X_train, X_test)
def add_noise_to_mnist(X_train, X_test, noise_factor=0.5): # add noise to the digita
X_train_noisy = X_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=X_train.shape)
X_test_noisy = X_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=X_test.shape)
X_train_noisy = np.clip(X_train_noisy, 0., 1.)
X_test_noisy = np.clip(X_test_noisy, 0., 1.)
return (X_train_noisy, X_test_noisy)
def build_autoencoder1():
# build the autoencoder.
model = Sequential()
model.add(Conv2D(32, (3,3), activation='relu', padding='same', input_shape=(28,28,1)))
model.add(MaxPooling2D((2,2,), padding='same'))
model.add(Conv2D(32, (3,3), activation='relu', padding='same'))
model.add(MaxPooling2D((2,2), padding='same'))
# down to 7, 7, 32 now go back up
model.add(Conv2D(32, (3,3), activation='relu', padding='same'))
model.add(UpSampling2D((2,2)))
model.add(Conv2D(32, (3,3), activation='relu', padding='same'))
model.add(UpSampling2D((2,2)))
model.add(Conv2D(1, (3,3), activation='sigmoid', padding='same'))
model.compile(optimizer='adadelta', loss='binary_crossentropy')
return model
def build_autoencoder2():
# build the autoencoder.
model = Sequential()
model.add(Conv2D(32, (3,3), activation='relu', padding='same', strides=2, input_shape=(28,28,1)))
model.add(Conv2D(32, (3,3), activation='relu', padding='same', strides=2))
# down to 7, 7, 32 now go back up
model.add(Conv2D(32, (3,3), activation='relu', padding='same'))
model.add(UpSampling2D((2,2)))
model.add(Conv2D(32, (3,3), activation='relu', padding='same'))
model.add(UpSampling2D((2,2)))
model.add(Conv2D(1, (3,3), activation='sigmoid', padding='same'))
model.compile(optimizer='adadelta', loss='binary_crossentropy')
return model
def build_autoencoder3():
# build the autoencoder.
model = Sequential()
model.add(Conv2D(32, (3,3), activation='relu', padding='same', strides=2, input_shape=(28,28,1)))
model.add(Conv2D(32, (3,3), activation='relu', padding='same', strides=2))
# down to 7, 7, 32 now go back up
model.add(Conv2DTranspose(32, (3,3), activation='relu', strides=2, padding='same'))
model.add(Conv2DTranspose(32, (3,3), activation='relu', strides=2, padding='same'))
model.add(Conv2D(1, (3,3), activation='sigmoid', padding='same'))
model.compile(optimizer='adadelta', loss='binary_crossentropy')
return model
def functional_api_build_autoencoder():
# build the autoencoder.
input_img = Input(shape=(28, 28, 1)) # using `channels_last` image data format
x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
# at this point the representation is (7, 7, 32)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
model = Model(input_img, decoded)
model.compile(optimizer='adadelta', loss='binary_crossentropy')
return model
(X_train, X_test) = get_mnist_samples()
(X_train_noisy, X_test_noisy) = add_noise_to_mnist(X_train, X_test, 0.5)
plt.figure(figsize=(10,3))
for i in range(8):
plt.subplot(2, 8, i+1)
plt.imshow(X_test[i].reshape(28, 28))
plt.gray()
plt.xticks([], [])
plt.yticks([], [])
plt.subplot(2, 8, i+1+8)
plt.imshow(X_test_noisy[i].reshape(28, 28))
plt.gray()
plt.xticks([], [])
plt.yticks([], [])
plt.tight_layout()
file_helper.save_figure("NB5-AE-noisy-mnist-input")
plt.show()
model1 = build_autoencoder1()
weights_filename = "NB5-Denoising-AE1"
np.random.seed(42)
if not file_helper.load_model_weights(model1, weights_filename):
history1 = model1.fit(X_train_noisy, X_train,
epochs=100,
batch_size=128,
shuffle=True,
validation_data=(X_test_noisy, X_test))
file_helper.save_model_weights(model1, weights_filename)
model2 = build_autoencoder2()
weights_filename = "NB5-Denoising-AE2"
np.random.seed(42)
if not file_helper.load_model_weights(model2, weights_filename):
history2 = model2.fit(X_train_noisy, X_train,
epochs=100,
batch_size=128,
shuffle=True,
validation_data=(X_test_noisy, X_test))
file_helper.save_model_weights(model2, weights_filename)
model3 = build_autoencoder3()
weights_filename = "NB5-Denoising-AE3"
np.random.seed(42)
if not file_helper.load_model_weights(model3, weights_filename):
history3 = model3.fit(X_train_noisy, X_train,
epochs=100,
batch_size=128,
shuffle=True,
validation_data=(X_test_noisy, X_test))
file_helper.save_model_weights(model3, weights_filename)
def draw_noisy_predictions_set(predictions, filename=None):
plt.figure(figsize=(8, 4))
for i in range(5):
plt.subplot(2, 5, i+1)
plt.imshow(X_test_noisy[i].reshape(28, 28), vmin=0, vmax=1, cmap="gray")
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.subplot(2, 5, i+6)
plt.imshow(predictions[i,:,:,0].reshape(28, 28), vmin=0, vmax=1, cmap="gray")
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.tight_layout()
file_helper.save_figure(filename+'-predictions')
plt.show()
predictions1 = model1.predict(X_test_noisy)
draw_noisy_predictions_set(predictions1, 'NB5-Noisy-Model1')
predictions2 = model2.predict(X_test_noisy)
draw_noisy_predictions_set(predictions2, 'NB5-Noisy-Model2')
predictions3 = model3.predict(X_test_noisy)
draw_noisy_predictions_set(predictions3, 'NB5-Noisy-Model3')
```
| github_jupyter |
##### Copyright 2019 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# Use XLA with tf.function
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://www.tensorflow.org/xla/tutorials/compile"><img src="https://www.tensorflow.org/images/tf_logo_32px.png" />View on TensorFlow.org</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/compiler/xla/g3doc/tutorials/jit_compile.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
</td>
<td>
<a href="https://storage.googleapis.com/tensorflow_docs/tensorflow/tensorflow/compiler/xla/g3doc/tutorials/jit_compile.ipynb"><img src="https://www.tensorflow.org/images/download_logo_32px.png" />Download notebook</a>
</td>
<td>
<a target="_blank" href="https://github.com/tensorflow/tensorflow/blob/master/tensorflow/compiler/xla/g3doc/tutorials/jit_compile.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />View source on GitHub</a>
</td>
</table>
This tutorial trains a TensorFlow model to classify the MNIST dataset, where the training function is compiled using XLA.
First, load TensorFlow and enable eager execution.
```
import tensorflow as tf
tf.compat.v1.enable_eager_execution()
```
Then define some necessary constants and prepare the MNIST dataset.
```
# Size of each input image, 28 x 28 pixels
IMAGE_SIZE = 28 * 28
# Number of distinct number labels, [0..9]
NUM_CLASSES = 10
# Number of examples in each training batch (step)
TRAIN_BATCH_SIZE = 100
# Number of training steps to run
TRAIN_STEPS = 1000
# Loads MNIST dataset.
train, test = tf.keras.datasets.mnist.load_data()
train_ds = tf.data.Dataset.from_tensor_slices(train).batch(TRAIN_BATCH_SIZE).repeat()
# Casting from raw data to the required datatypes.
def cast(images, labels):
images = tf.cast(
tf.reshape(images, [-1, IMAGE_SIZE]), tf.float32)
labels = tf.cast(labels, tf.int64)
return (images, labels)
```
Finally, define the model and the optimizer. The model uses a single dense layer.
```
layer = tf.keras.layers.Dense(NUM_CLASSES)
optimizer = tf.keras.optimizers.Adam()
```
# Define the training function
In the training function, you get the predicted labels using the layer defined above, and then minimize the gradient of the loss using the optimizer. In order to compile the computation using XLA, place it inside `tf.function` with `jit_compile=True`.
```
@tf.function(jit_compile=True)
def train_mnist(images, labels):
images, labels = cast(images, labels)
with tf.GradientTape() as tape:
predicted_labels = layer(images)
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=predicted_labels, labels=labels
))
layer_variables = layer.trainable_variables
grads = tape.gradient(loss, layer_variables)
optimizer.apply_gradients(zip(grads, layer_variables))
```
# Train and test the model
Once you have defined the training function, define the model.
```
for images, labels in train_ds:
if optimizer.iterations > TRAIN_STEPS:
break
train_mnist(images, labels)
```
And, finally, check the accuracy:
```
images, labels = cast(test[0], test[1])
predicted_labels = layer(images)
correct_prediction = tf.equal(tf.argmax(predicted_labels, 1), labels)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Prediction accuracy after training: %s" % accuracy)
```
Behind the scenes, the XLA compiler has compiled the entire TF function to HLO, which has enabled fusion optimizations. Using the introspection facilities, we can see the HLO code (other interesting possible values for "stage" are `optimized_hlo` for HLO after optimizations and `optimized_hlo_dot` for a Graphviz graph):
```
print(train_mnist.experimental_get_compiler_ir(images, labels)(stage='hlo'))
```
| github_jupyter |
```
import sys
sys.path.append("/home/ly/workspace/mmsa")
seed = 2245
import numpy as np
import torch
from torch import nn
from torch import optim
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
from models.mvsa_lymodel5 import *
from utils.train import *
from typing import *
from utils.load_mvsa import *
from utils.dataset import *
from utils.train import *
from utils.train import *
config
%%time
train_set, valid_set, test_set= load_glove_data(config)
batch_size = 64
workers = 4
train_loader, valid_loader, test_loader = get_loader(batch_size, workers, get_collate_fn(config), train_set, valid_set, test_set)
model = Model(config).cuda()
loss = nn.CrossEntropyLoss()
print(get_parameter_number(model), loss)
_interval = 5
lr = 1e-3
epoches = 50
stoping_step = 10
optimizer = get_regal_optimizer(model, optim.AdamW, lr)
viz = get_Visdom()
batch_loss_drawer = VisdomScalar(viz, f"batch_loss interval:{_interval}")
epoch_loss_drawer = VisdomScalar(viz, f"Train and valid loss", 2)
acc_drawer = VisdomScalar(viz, "Train and valid accuracy", 2)
text_writer = VisdomTextWriter(viz, "Training")
batch_loss = []
train_loss = []
valid_loss = []
train_acc = []
valid_acc = []
res, model = train_visdom_v2(model, optimizer, loss, viz, train_loader,
valid_loader, epoches, batch_loss, batch_loss_drawer,
train_loss, valid_loss, epoch_loss_drawer,
train_acc, valid_acc, acc_drawer, text_writer,
_interval=_interval, early_stop=stoping_step)
res
eval_model(model, test_loader, loss)
## 调参
config["embedding_dim"] = 50
config["text_hidden_size"] = 50
config
%%time
train_set, valid_set, test_set= load_glove_data(config)
batch_size = 64
workers = 4
train_loader, valid_loader, test_loader = get_loader(batch_size, workers, get_collate_fn(config), train_set, valid_set, test_set)
model = Model(config).cuda()
loss = nn.CrossEntropyLoss()
print(get_parameter_number(model), loss)
_interval = 5
lr = 1e-3
epoches = 50
stoping_step = 10
optimizer = get_regal_optimizer(model, optim.AdamW, lr)
viz = get_Visdom()
batch_loss_drawer = VisdomScalar(viz, f"batch_loss interval:{_interval}")
epoch_loss_drawer = VisdomScalar(viz, f"Train and valid loss", 2)
acc_drawer = VisdomScalar(viz, "Train and valid accuracy", 2)
text_writer = VisdomTextWriter(viz, "Training")
batch_loss = []
train_loss = []
valid_loss = []
train_acc = []
valid_acc = []
res, model = train_visdom_v2(model, optimizer, loss, viz, train_loader,
valid_loader, epoches, batch_loss, batch_loss_drawer,
train_loss, valid_loss, epoch_loss_drawer,
train_acc, valid_acc, acc_drawer, text_writer,
_interval=_interval, early_stop=stoping_step)
eval_model(model, test_loader, loss)
## 调参
config["embedding_dim"] = 25
config["text_hidden_size"] = 25
config["attention_nhead"] = 5
config["fusion_nheads"] = 5
config
%%time
train_set, valid_set, test_set= load_glove_data(config)
batch_size = 64
workers = 4
train_loader, valid_loader, test_loader = get_loader(batch_size, workers, get_collate_fn(config), train_set, valid_set, test_set)
model = Model(config).cuda()
loss = nn.CrossEntropyLoss()
print(get_parameter_number(model), loss)
_interval = 5
lr = 1e-3
epoches = 50
stoping_step = 10
optimizer = get_regal_optimizer(model, optim.AdamW, lr)
viz = get_Visdom()
batch_loss_drawer = VisdomScalar(viz, f"batch_loss interval:{_interval}")
epoch_loss_drawer = VisdomScalar(viz, f"Train and valid loss", 2)
acc_drawer = VisdomScalar(viz, "Train and valid accuracy", 2)
text_writer = VisdomTextWriter(viz, "Training")
batch_loss = []
train_loss = []
valid_loss = []
train_acc = []
valid_acc = []
res, model = train_visdom_v2(model, optimizer, loss, viz, train_loader,
valid_loader, epoches, batch_loss, batch_loss_drawer,
train_loss, valid_loss, epoch_loss_drawer,
train_acc, valid_acc, acc_drawer, text_writer,
_interval=_interval, early_stop=stoping_step)
eval_model(model, test_loader, loss)
## 调参
config["embedding_dim"] = 50
config
%%time
train_set, valid_set, test_set= load_glove_data(config)
batch_size = 64
workers = 4
train_loader, valid_loader, test_loader = get_loader(batch_size, workers, get_collate_fn(config), train_set, valid_set, test_set)
model = Model(config).cuda()
loss = nn.CrossEntropyLoss()
print(get_parameter_number(model), loss)
_interval = 5
lr = 1e-3
epoches = 50
stoping_step = 10
optimizer = get_regal_optimizer(model, optim.AdamW, lr)
viz = get_Visdom()
batch_loss_drawer = VisdomScalar(viz, f"batch_loss interval:{_interval}")
epoch_loss_drawer = VisdomScalar(viz, f"Train and valid loss", 2)
acc_drawer = VisdomScalar(viz, "Train and valid accuracy", 2)
text_writer = VisdomTextWriter(viz, "Training")
batch_loss = []
train_loss = []
valid_loss = []
train_acc = []
valid_acc = []
res, model = train_visdom_v2(model, optimizer, loss, viz, train_loader,
valid_loader, epoches, batch_loss, batch_loss_drawer,
train_loss, valid_loss, epoch_loss_drawer,
train_acc, valid_acc, acc_drawer, text_writer,
_interval=_interval, early_stop=stoping_step)
eval_model(model, test_loader, loss)
```
| github_jupyter |
# Basic data set generation
```
import numpy as np
import os
from scipy.misc import imread, imresize
import matplotlib.pyplot as plt
%matplotlib inline
print ("Package loaded")
cwd = os.getcwd()
print ("Current folder is %s" % (cwd) )
```
# SPECIFY THE FOLDER PATHS
## + RESHAPE SIZE + GRAYSCALE
```
# Training set folder
paths = {"../../img_dataset/celebs/Arnold_Schwarzenegger"
, "../../img_dataset/celebs/Junichiro_Koizumi"
, "../../img_dataset/celebs/Vladimir_Putin"
, "../../img_dataset/celebs/George_W_Bush"}
# The reshape size
imgsize = [64, 64]
# Grayscale
use_gray = 1
# Save name
data_name = "custom_data"
print ("Your images should be at")
for i, path in enumerate(paths):
print (" [%d/%d] %s/%s" % (i, len(paths), cwd, path))
print ("Data will be saved to %s"
% (cwd + '/data/' + data_name + '.npz'))
```
# RGB 2 GRAY FUNCTION
```
def rgb2gray(rgb):
if len(rgb.shape) is 3:
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
else:
# print ("Current Image if GRAY!")
return rgb
```
# LOAD IMAGES
```
nclass = len(paths)
valid_exts = [".jpg",".gif",".png",".tga", ".jpeg"]
imgcnt = 0
for i, relpath in zip(range(nclass), paths):
path = cwd + "/" + relpath
flist = os.listdir(path)
for f in flist:
if os.path.splitext(f)[1].lower() not in valid_exts:
continue
fullpath = os.path.join(path, f)
currimg = imread(fullpath)
# Convert to grayscale
if use_gray:
grayimg = rgb2gray(currimg)
else:
grayimg = currimg
# Reshape
graysmall = imresize(grayimg, [imgsize[0], imgsize[1]])/255.
grayvec = np.reshape(graysmall, (1, -1))
# Save
curr_label = np.eye(nclass, nclass)[i:i+1, :]
if imgcnt is 0:
totalimg = grayvec
totallabel = curr_label
else:
totalimg = np.concatenate((totalimg, grayvec), axis=0)
totallabel = np.concatenate((totallabel, curr_label), axis=0)
imgcnt = imgcnt + 1
print ("Total %d images loaded." % (imgcnt))
```
# DIVIDE TOTAL DATA INTO TRAINING AND TEST SET
```
def print_shape(string, x):
print ("Shape of '%s' is %s" % (string, x.shape,))
randidx = np.random.randint(imgcnt, size=imgcnt)
trainidx = randidx[0:int(3*imgcnt/5)]
testidx = randidx[int(3*imgcnt/5):imgcnt]
trainimg = totalimg[trainidx, :]
trainlabel = totallabel[trainidx, :]
testimg = totalimg[testidx, :]
testlabel = totallabel[testidx, :]
print_shape("trainimg", trainimg)
print_shape("trainlabel", trainlabel)
print_shape("testimg", testimg)
print_shape("testlabel", testlabel)
```
# SAVE TO NPZ
```
savepath = cwd + "/data/" + data_name + ".npz"
np.savez(savepath, trainimg=trainimg, trainlabel=trainlabel
, testimg=testimg, testlabel=testlabel, imgsize=imgsize, use_gray=use_gray)
print ("Saved to %s" % (savepath))
```
# LOAD TO CHECK!
```
# Load them!
cwd = os.getcwd()
loadpath = cwd + "/data/" + data_name + ".npz"
l = np.load(loadpath)
# See what's in here
l.files
# Parse data
trainimg_loaded = l['trainimg']
trainlabel_loaded = l['trainlabel']
testimg_loaded = l['testimg']
testlabel_loaded = l['testlabel']
print ("%d train images loaded" % (trainimg_loaded.shape[0]))
print ("%d test images loaded" % (testimg_loaded.shape[0]))
print ("Loaded from to %s" % (savepath))
```
# PLOT RANDOMLY SELECTED TRAIN IMAGES
```
ntrain_loaded = trainimg_loaded.shape[0]
batch_size = 10;
randidx = np.random.randint(ntrain_loaded, size=batch_size)
for i in randidx:
currimg = np.reshape(trainimg_loaded[i, :], (imgsize[0], -1))
currlabel_onehot = trainlabel_loaded[i, :]
currlabel = np.argmax(currlabel_onehot)
if use_gray:
currimg = np.reshape(trainimg[i, :], (imgsize[0], -1))
plt.matshow(currimg, cmap=plt.get_cmap('gray'))
plt.colorbar()
else:
currimg = np.reshape(trainimg[i, :], (imgsize[0], imgsize[1], 3))
plt.imshow(currimg)
title_string = "[%d] %d-class" % (i, currlabel)
plt.title(title_string)
plt.show()
```
# PLOT RANDOMLY SELECTED TEST IMAGES
```
# Do batch stuff using loaded data
ntest_loaded = testimg_loaded.shape[0]
batch_size = 3;
randidx = np.random.randint(ntest_loaded, size=batch_size)
for i in randidx:
currimg = np.reshape(testimg_loaded[i, :], (imgsize[0], -1))
currlabel_onehot = testlabel_loaded[i, :]
currlabel = np.argmax(currlabel_onehot)
if use_gray:
currimg = np.reshape(testimg[i, :], (imgsize[0], -1))
plt.matshow(currimg, cmap=plt.get_cmap('gray'))
plt.colorbar()
else:
currimg = np.reshape(testimg[i, :], (imgsize[0], imgsize[1], 3))
plt.imshow(currimg)
title_string = "[%d] %d-class" % (i, currlabel)
plt.title(title_string)
plt.show()
```
| github_jupyter |
# Tutorial about running analysis procedures
Standardized analysis procedures are provided as individual classes in the `locan.analysis` module.
Here we outline the principle use of any analysis class using a mock analysis procedure - the AnalysisExampleAlgorithm_1 class.
```
from pathlib import Path
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import locan as lc
from locan.analysis.analysis_example import AnalysisExampleAlgorithm_1, AnalysisExampleAlgorithm_2
lc.show_versions(system=False, dependencies=False, verbose=False)
```
## Some localization data
```
localization_dict = {
'Position_x': [0, 0, 1, 4, 5],
'Position_y': [0, 1, 3, 4, 1]
}
df = pd.DataFrame(localization_dict)
dat = lc.LocData.from_dataframe(dataframe=df)
dat.print_summary()
```
## Instantiating and using the Analysis class
### Instantiate the Analysis_example object
```
ae = AnalysisExampleAlgorithm_2()
```
Show the initialized parameters:
```
ae
ae.parameter
```
### Primary results of the analysis procedure
Some random data a and b is generated as primary result of the analysis procedure:
```
ae.compute(locdata=dat)
ae.results.head()
```
The class provides various methods for further dealing with the primary data.
```
methods = [x for x in dir(ae) if callable(getattr(ae, x)) and not x.startswith('_')]
methods
```
### Generating a plot of results
Typically the primary results are further analyzed and represented by visual representations. This can be a plot or a histogram. Secondary results may be generated e.g. by fitting the plot.
```
ae.plot()
ae.plot_2()
```
After a plot or histogram has been generated, secondary results may have been added as attributes.
```
attributes = [x for x in dir(ae) if not callable(getattr(ae, x)) and not x.startswith('_')]
attributes
print('Fit result:\n Center: {}\n Sigma: {}'.format(ae.attribute_center, ae.attribute_sigma))
```
### Generating a report
A report contains various plots, histograms and secondary results.
```
ae.report()
```
The report can be saved as pdf by providing a path:
```
# ae.report(path)
```
## Modifying plots for publication
### This is the original plot from the analysis class
```
ae.plot()
```
### Save the plot in various formats
```
from pathlib import Path
temp_directory = Path('.') / 'temp'
temp_directory.mkdir(parents=True, exist_ok=True)
path = temp_directory / 'filename.pdf'
path
ae.plot()
plt.savefig(fname=path, dpi=None, facecolor='w', edgecolor='w',
orientation='portrait', format=None,
transparent=False, bbox_inches=None, pad_inches=0.1)
```
Delete the file and empty directory
```
path.unlink()
temp_directory.rmdir()
```
### Make changes to this figure
```
ae.plot()
fig = plt.gcf()
ax = fig.axes
print('Number of axes: ', len(ax))
ax[0].set_title('This is some other title.', fontsize='large')
plt.show()
```
### Delete axis elements
```
# fig.delaxes()
```
## Comparing different datasets
### Instantiate the Analysis_example objects
```
ae_1 = AnalysisExampleAlgorithm_2().compute(locdata=dat)
ae_2 = AnalysisExampleAlgorithm_2().compute(locdata=dat)
```
### Combine all plots in one
```
fig, ax = plt.subplots(nrows=1, ncols=1)
ae_1.plot(ax=ax)
ae_2.plot(ax=ax)
legend_strings = list(ae_1.meta.identifier)*2 + list(ae_2.meta.identifier)*2
ax.legend(legend_strings, title='Identifier')
plt.show()
```
| github_jupyter |
```
from __future__ import division, print_function, absolute_import
import tflearn
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.normalization import local_response_normalization
from tflearn.layers.estimator import regression
import numpy as np
import matplotlib.pyplot as plt
import sklearn.utils
import tensorflow as tf
import h5py
from tflearn.data_preprocessing import ImagePreprocessing
from tflearn.data_augmentation import ImageAugmentation
%matplotlib inline
IMG_WIDTH = 32 # Side for each transformed Image
IMG_HEIGHT = 32
IMG_DEPTH = 1 # RGB files
MAX_DIGITS = 5
imgsAll = np.empty(shape = (0,IMG_HEIGHT, IMG_WIDTH), dtype=float)
labelsAll = np.empty(shape = (0,MAX_DIGITS), dtype=float)
numDigitsAll = np.empty(shape = (0), dtype=float)
for numDigits in range(1,MAX_DIGITS + 1):
h5FileName = 'svhn_' + str(numDigits) + '.h5'
data = h5py.File(h5FileName)
imgs = np.array(data['images']).astype(float)
labels = np.array(data['digits'])
# Buff up labels to MAX_DIGITS width
zerosToFill = np.zeros(shape = (labels.shape[0], MAX_DIGITS - numDigits ), dtype = float)
labels = np.concatenate ((labels, zerosToFill), axis = 1)
# Concat to full Dataset
imgsAll = np.concatenate((imgsAll, imgs), axis = 0)
labelsAll = np.concatenate((labelsAll, labels), axis = 0)
numDigitsAll = np.concatenate((numDigitsAll, np.full(labels.shape[0], numDigits, dtype= float))) # Add num of digits for this set of images
print (imgsAll.shape)
print (labelsAll.shape)
print (numDigitsAll.shape)
print (labelsAll[100000])
plt.imshow(imgsAll[100000], cmap='gray')
print (numDigitsAll[100000])
def dense_to_one_hot(labels_dense, num_classes=10):
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = np.arange(num_labels) * num_classes
labels_one_hot = np.zeros((num_labels, num_classes))
index_update = [int(x) for x in index_offset + labels_dense]
labels_one_hot.flat[index_update] = 1
return labels_one_hot
# Get the dataset
X = imgsAll.reshape([-1, IMG_HEIGHT, IMG_WIDTH, IMG_DEPTH])
Y = numDigitsAll
X, Y = sklearn.utils.shuffle(X, Y, random_state=0)
# Generate validation set
ratio = 0.9 # Train/Test set
randIdx = np.random.random(imgsAll.shape[0]) <= ratio
#print (sum(map(lambda x: int(x), randIdx)))
X_train = X[randIdx]
Y_train = Y[randIdx]
X_test = X[randIdx == False]
Y_test = Y[randIdx == False]
Y_train = dense_to_one_hot(Y_train, num_classes = MAX_DIGITS+1)
Y_test = dense_to_one_hot(Y_test, num_classes = MAX_DIGITS+1)
#del X, Y # release some space
print (X_train.shape)
print (Y_train.shape)
# Building convolutional network
with tf.Graph().as_default():
# Building convolutional network
# Real-time data preprocessing
img_prep = ImagePreprocessing()
img_prep.add_featurewise_zero_center()
img_prep.add_featurewise_stdnorm()
# Real-time data augmentation
img_aug = ImageAugmentation()
#img_aug.add_random_flip_leftright()
img_aug.add_random_rotation(max_angle=25.)
network = input_data(shape=[None, IMG_HEIGHT, IMG_WIDTH, IMG_DEPTH], name='input',
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='relu', regularizer="L2")
network = max_pool_2d(network, 2)
network = local_response_normalization(network)
network = conv_2d(network, 64, 3, activation='relu', regularizer="L2")
network = max_pool_2d(network, 2)
network = local_response_normalization(network)
fc_1 = fully_connected(network, 1024, activation='tanh')
softmax1 = fully_connected(fc_1, MAX_DIGITS + 1, activation='softmax')
network = regression(softmax1, optimizer='adam', learning_rate=0.001,
loss='categorical_crossentropy', name='target')
model = tflearn.DNN(network, tensorboard_verbose=3)
model.fit({'input': X_train}, Y_train,
validation_set= (X_test, Y_test), n_epoch=1, snapshot_step=100, show_metric=True, run_id='convnet_svhn_numDigits')
numImgEachAxis = 8
f,ax = plt.subplots(numImgEachAxis, numImgEachAxis, figsize=(10,10))
for i in range(numImgEachAxis):
for j in range(numImgEachAxis):
#res = np.array([np.argmax(x) for x in model.predict([X_train[i*numImgEachAxis + j]])])
#print (str(i) + ',' + str(j) + ' -> ' +str(res))
#ax[i][j].set_title(str([np.round(x,2) for x in res]))
ax[i][j].imshow(X_train[i*numImgEachAxis + j].reshape((IMG_HEIGHT,IMG_WIDTH)) ,cmap = 'gray')
plt.show() # or display.display(plt.gcf()) if you prefer
# print (model.evaluate(X_test,feedTestList))
```
| github_jupyter |
# *OPTIONAL* Astronomical widget libraries
The libraries demonstrated here are not as mature as the ones we've seen so far. Keep an eye on them for future developments!
## PyWWT - widget interface to the World Wide Telescope
### https://github.com/WorldWideTelescope/pywwt
World Wide Telescope (WWT) was developed by Microsoft for displaying images of the sky in a variety of projects and several layers; it is like `leaflet` for the sky. Now maintained by the American Astronomical Society (AAS), it now has a widget interface.
A javascript API has been available for WWT for a while. The PyWWT package includes javascript to call that API with front ends for both ipywidgets and qt.
### Installation
`pywwt` is on PyPI and on the `wwt` conda channel.
```
from pywwt.jupyter import WWTJupyterWidget
wwt = WWTJupyterWidget()
wwt
```
Several properties of the display can eclipsing binary changed from Python
```
wwt.constellation_figures = True
wwt.constellation_boundary_color = 'azure'
wwt.constellation_figure_color = '#D3BC8D'
wwt.constellation_selection_color = (1, 0, 1)
```
In addition to interacting with the display with mouse/keyboard, you can manipulate it programmatically.
```
from astropy import units as u
from astropy.coordinates import SkyCoord
orion_neb = SkyCoord.from_name('Orion Nebula')
wwt.center_on_coordinates(orion_neb, fov=10 * u.degree, instant=False)
```
A variety of markers can be added to the display, and one can construct tours of the sky.
```
wwt.load_tour('http://www.worldwidetelescope.org/docs/wtml/tourone.wtt')
wwt.pause_tour()
```
## ipyaladdin - interactive sky atlas backed by simbad/vizier databases
### https://github.com/cds-astro/ipyaladin
The [Simbad catlog]() and [VizieR database interface]() serve as respositories for most public astronomical data. The Aladin sky atlas, originally developed as a desktop application, then an in-browser javascipt app, now has an experimental widget interface.
### Installation
Installation instructions are at: https://github.com/cds-astro/ipyaladin#installation
```
import ipyaladin.aladin_widget as ipyal
aladin = ipyal.Aladin(target='Orion Nebula', fov=10, survey='P/allWISE/color')
aladin
```
### Add markers for items in a data table
```
from astroquery.simbad import Simbad
table = Simbad.query_region('Orion Nebula', radius=1 * u.degree)
import numpy as np
display_obj = np.random.choice(range(len(table)), size=100)
aladin.add_table(table[display_obj])
```
## Display a local image
One goal this week is to wrap the widget below (which displays images stored in a format called FITS that is widely used in astronomy) up in a easily installable widgets. The widget will be demoed during the tutorial but is not yet installable. Code will be in https://github.com/eteq/astrowidgets
| github_jupyter |
```
import numpy as np
import pandas as pd
pd.set_option('display.max_rows', 10)
pd.set_option('display.max_columns', 1000)
import datetime
import matplotlib.pylab as plt
%matplotlib inline
import seaborn as sns
sns.set_style('whitegrid')
import time
import os
import copy
```
#### 定义获取数据函数
```
def fix_data(path):
tmp = pd.read_csv(path, encoding="gbk", engine='python')
tmp.rename(columns={'Unnamed: 0':'trading_time'}, inplace=True)
tmp['trading_point'] = pd.to_datetime(tmp.trading_time)
del tmp['trading_time']
tmp.set_index(tmp.trading_point, inplace=True)
return tmp
def High_2_Low(tmp, freq):
"""处理从RiceQuant下载的分钟线数据,
从分钟线数据合成低频数据
2017-08-11
"""
# 分别处理bar数据
tmp_open = tmp['open'].resample(freq).ohlc()
tmp_open = tmp_open['open'].dropna()
tmp_high = tmp['high'].resample(freq).ohlc()
tmp_high = tmp_high['high'].dropna()
tmp_low = tmp['low'].resample(freq).ohlc()
tmp_low = tmp_low['low'].dropna()
tmp_close = tmp['close'].resample(freq).ohlc()
tmp_close = tmp_close['close'].dropna()
tmp_price = pd.concat([tmp_open, tmp_high, tmp_low, tmp_close], axis=1)
# 处理成交量
tmp_volume = tmp['volume'].resample(freq).sum()
tmp_volume.dropna(inplace=True)
return pd.concat([tmp_price, tmp_volume], axis=1)
```
#### 计算技术分析指标
```
import talib
def get_factors(index,
Open,
Close,
High,
Low,
Volume,
rolling = 26,
drop=False,
normalization=True):
tmp = pd.DataFrame()
tmp['tradeTime'] = index
#累积/派发线(Accumulation / Distribution Line,该指标将每日的成交量通过价格加权累计,
#用以计算成交量的动量。属于趋势型因子
tmp['AD'] = talib.AD(High, Low, Close, Volume)
# 佳庆指标(Chaikin Oscillator),该指标基于AD曲线的指数移动均线而计算得到。属于趋势型因子
tmp['ADOSC'] = talib.ADOSC(High, Low, Close, Volume, fastperiod=3, slowperiod=10)
# 平均动向指数,DMI因子的构成部分。属于趋势型因子
tmp['ADX'] = talib.ADX(High, Low, Close,timeperiod=14)
# 相对平均动向指数,DMI因子的构成部分。属于趋势型因子
tmp['ADXR'] = talib.ADXR(High, Low, Close,timeperiod=14)
# 绝对价格振荡指数
tmp['APO'] = talib.APO(Close, fastperiod=12, slowperiod=26)
# Aroon通过计算自价格达到近期最高值和最低值以来所经过的期间数,帮助投资者预测证券价格从趋势到区域区域或反转的变化,
#Aroon指标分为Aroon、AroonUp和AroonDown3个具体指标。属于趋势型因子
tmp['AROONDown'], tmp['AROONUp'] = talib.AROON(High, Low,timeperiod=14)
tmp['AROONOSC'] = talib.AROONOSC(High, Low,timeperiod=14)
# 均幅指标(Average TRUE Ranger),取一定时间周期内的股价波动幅度的移动平均值,
#是显示市场变化率的指标,主要用于研判买卖时机。属于超买超卖型因子。
tmp['ATR14']= talib.ATR(High, Low, Close, timeperiod=14)
tmp['ATR6']= talib.ATR(High, Low, Close, timeperiod=6)
# 布林带
tmp['Boll_Up'],tmp['Boll_Mid'],tmp['Boll_Down']= talib.BBANDS(Close, timeperiod=20, nbdevup=2, nbdevdn=2, matype=0)
# 均势指标
tmp['BOP'] = talib.BOP(Open, High, Low, Close)
#5日顺势指标(Commodity Channel Index),专门测量股价是否已超出常态分布范围。属于超买超卖型因子。
tmp['CCI5'] = talib.CCI(High, Low, Close, timeperiod=5)
tmp['CCI10'] = talib.CCI(High, Low, Close, timeperiod=10)
tmp['CCI20'] = talib.CCI(High, Low, Close, timeperiod=20)
tmp['CCI88'] = talib.CCI(High, Low, Close, timeperiod=88)
# 钱德动量摆动指标(Chande Momentum Osciliator),与其他动量指标摆动指标如相对强弱指标(RSI)和随机指标(KDJ)不同,
# 钱德动量指标在计算公式的分子中采用上涨日和下跌日的数据。属于超买超卖型因子
tmp['CMO_Close'] = talib.CMO(Close,timeperiod=14)
tmp['CMO_Open'] = talib.CMO(Close,timeperiod=14)
# DEMA双指数移动平均线
tmp['DEMA6'] = talib.DEMA(Close, timeperiod=6)
tmp['DEMA12'] = talib.DEMA(Close, timeperiod=12)
tmp['DEMA26'] = talib.DEMA(Close, timeperiod=26)
# DX 动向指数
tmp['DX'] = talib.DX(High, Low, Close,timeperiod=14)
# EMA 指数移动平均线
tmp['EMA6'] = talib.EMA(Close, timeperiod=6)
tmp['EMA12'] = talib.EMA(Close, timeperiod=12)
tmp['EMA26'] = talib.EMA(Close, timeperiod=26)
# KAMA 适应性移动平均线
tmp['KAMA'] = talib.KAMA(Close, timeperiod=30)
# MACD
tmp['MACD_DIF'],tmp['MACD_DEA'],tmp['MACD_bar'] = talib.MACD(Close, fastperiod=12, slowperiod=24, signalperiod=9)
# 中位数价格 不知道是什么意思
tmp['MEDPRICE'] = talib.MEDPRICE(High, Low)
# 负向指标 负向运动
tmp['MiNUS_DI'] = talib.MINUS_DI(High, Low, Close,timeperiod=14)
tmp['MiNUS_DM'] = talib.MINUS_DM(High, Low,timeperiod=14)
# 动量指标(Momentom Index),动量指数以分析股价波动的速度为目的,研究股价在波动过程中各种加速,
#减速,惯性作用以及股价由静到动或由动转静的现象。属于趋势型因子
tmp['MOM'] = talib.MOM(Close, timeperiod=10)
# 归一化平均值范围
tmp['NATR'] = talib.NATR(High, Low, Close,timeperiod=14)
# OBV 能量潮指标(On Balance Volume,OBV),以股市的成交量变化来衡量股市的推动力,
#从而研判股价的走势。属于成交量型因子
tmp['OBV'] = talib.OBV(Close, Volume)
# PLUS_DI 更向指示器
tmp['PLUS_DI'] = talib.PLUS_DI(High, Low, Close,timeperiod=14)
tmp['PLUS_DM'] = talib.PLUS_DM(High, Low, timeperiod=14)
# PPO 价格振荡百分比
tmp['PPO'] = talib.PPO(Close, fastperiod=6, slowperiod= 26, matype=0)
# ROC 6日变动速率(Price Rate of Change),以当日的收盘价和N天前的收盘价比较,
#通过计算股价某一段时间内收盘价变动的比例,应用价格的移动比较来测量价位动量。属于超买超卖型因子。
tmp['ROC6'] = talib.ROC(Close, timeperiod=6)
tmp['ROC20'] = talib.ROC(Close, timeperiod=20)
#12日量变动速率指标(Volume Rate of Change),以今天的成交量和N天前的成交量比较,
#通过计算某一段时间内成交量变动的幅度,应用成交量的移动比较来测量成交量运动趋向,
#达到事先探测成交量供需的强弱,进而分析成交量的发展趋势及其将来是否有转势的意愿,
#属于成交量的反趋向指标。属于成交量型因子
tmp['VROC6'] = talib.ROC(Volume, timeperiod=6)
tmp['VROC20'] = talib.ROC(Volume, timeperiod=20)
# ROC 6日变动速率(Price Rate of Change),以当日的收盘价和N天前的收盘价比较,
#通过计算股价某一段时间内收盘价变动的比例,应用价格的移动比较来测量价位动量。属于超买超卖型因子。
tmp['ROCP6'] = talib.ROCP(Close, timeperiod=6)
tmp['ROCP20'] = talib.ROCP(Close, timeperiod=20)
#12日量变动速率指标(Volume Rate of Change),以今天的成交量和N天前的成交量比较,
#通过计算某一段时间内成交量变动的幅度,应用成交量的移动比较来测量成交量运动趋向,
#达到事先探测成交量供需的强弱,进而分析成交量的发展趋势及其将来是否有转势的意愿,
#属于成交量的反趋向指标。属于成交量型因子
tmp['VROCP6'] = talib.ROCP(Volume, timeperiod=6)
tmp['VROCP20'] = talib.ROCP(Volume, timeperiod=20)
# RSI
tmp['RSI'] = talib.RSI(Close, timeperiod=14)
# SAR 抛物线转向
tmp['SAR'] = talib.SAR(High, Low, acceleration=0.02, maximum=0.2)
# TEMA
tmp['TEMA6'] = talib.TEMA(Close, timeperiod=6)
tmp['TEMA12'] = talib.TEMA(Close, timeperiod=12)
tmp['TEMA26'] = talib.TEMA(Close, timeperiod=26)
# TRANGE 真实范围
tmp['TRANGE'] = talib.TRANGE(High, Low, Close)
# TYPPRICE 典型价格
tmp['TYPPRICE'] = talib.TYPPRICE(High, Low, Close)
# TSF 时间序列预测
tmp['TSF'] = talib.TSF(Close, timeperiod=14)
# ULTOSC 极限振子
tmp['ULTOSC'] = talib.ULTOSC(High, Low, Close, timeperiod1=7, timeperiod2=14, timeperiod3=28)
# 威廉指标
tmp['WILLR'] = talib.WILLR(High, Low, Close, timeperiod=14)
# 标准化
if normalization:
factors_list = tmp.columns.tolist()[1:]
if rolling >= 26:
for i in factors_list:
tmp[i] = (tmp[i] - tmp[i].rolling(window=rolling, center=False).mean())\
/tmp[i].rolling(window=rolling, center=False).std()
elif rolling < 26 & rolling > 0:
print ('Recommended rolling range greater than 26')
elif rolling <=0:
for i in factors_list:
tmp[i] = (tmp[i] - tmp[i].mean())/tmp[i].std()
if drop:
tmp.dropna(inplace=True)
tmp.set_index('tradeTime', inplace=True)
return tmp
```
#### 处理数据
```
tmp = fix_data('期货测试数据/白银88.csv')
# targets 1d 数据合成
tmp_1d = High_2_Low(tmp, '1d')
rolling = 88
targets = tmp_1d
targets['returns'] = targets['close'].shift(-2) / targets['close'] - 1.0
targets['upper_boundary']= targets.returns.rolling(rolling).mean() + 0.5 * targets.returns.rolling(rolling).std()
targets['lower_boundary']= targets.returns.rolling(rolling).mean() - 0.5 * targets.returns.rolling(rolling).std()
targets.dropna(inplace=True)
targets['labels'] = 1
targets.loc[targets['returns']>=targets['upper_boundary'], 'labels'] = 2
targets.loc[targets['returns']<=targets['lower_boundary'], 'labels'] = 0
# factors 1d 数据合成
tmp_1d = High_2_Low(tmp, '1d')
Index = tmp_1d.index
High = tmp_1d.high.values
Low = tmp_1d.low.values
Close = tmp_1d.close.values
Open = tmp_1d.open.values
Volume = tmp_1d.volume.values
factors = get_factors(Index, Open, Close, High, Low, Volume, rolling = 26, drop=True)
factors = factors.loc[:targets.index[-1]]
tmp_factors_1 = factors.iloc[:12]
targets = targets.loc[tmp_factors_1.index[-1]:]
gather_list = np.arange(factors.shape[0])[11:]
```
#### 转换数据
```
inputs = np.array(factors).reshape(-1, 1, factors.shape[1])
def dense_to_one_hot(labels_dense):
"""标签 转换one hot 编码
输入labels_dense 必须为非负数
2016-11-21
"""
num_classes = len(np.unique(labels_dense)) # np.unique 去掉重复函数
raws_labels = labels_dense.shape[0]
index_offset = np.arange(raws_labels) * num_classes
labels_one_hot = np.zeros((raws_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
targets = dense_to_one_hot(targets['labels'])
targets = np.expand_dims(targets, axis=1)
```
#### 构建RNN模型
```
import tensorflow as tf
from FixPonderDNCore import DNCore_L3
from FixPonderDNCore import ResidualACTCore as ACTCore
class Classifier_PonderDNC_BasicLSTM_L3(object):
def __init__(self,
inputs,
targets,
gather_list=None,
mini_batch_size=1,
hidden_size=10,
memory_size=10,
threshold=0.99,
pondering_coefficient = 1e-2,
num_reads=3,
num_writes=1,
learning_rate = 1e-4,
optimizer_epsilon = 1e-10,
max_gard_norm = 50):
self._tmp_inputs = inputs
self._tmp_targets = targets
self._in_length = None
self._in_width = inputs.shape[2]
self._out_length = None
self._out_width = targets.shape[2]
self._mini_batch_size = mini_batch_size
self._batch_size = inputs.shape[1]
# 声明计算会话
self._sess = tf.InteractiveSession()
self._inputs = tf.placeholder(dtype=tf.float32,
shape=[self._in_length, self._batch_size, self._in_width],
name='inputs')
self._targets = tf.placeholder(dtype=tf.float32,
shape=[self._out_length, self._batch_size, self._out_width],
name='targets')
act_core = DNCore_L3( hidden_size=hidden_size,
memory_size=memory_size,
word_size=self._in_width,
num_read_heads=num_reads,
num_write_heads=num_writes)
self._InferenceCell = ACTCore(core=act_core,
output_size=self._out_width,
threshold=threshold,
get_state_for_halting=self._get_hidden_state)
self._initial_state = self._InferenceCell.initial_state(self._batch_size)
tmp, act_final_cumul_state = \
tf.nn.dynamic_rnn(cell=self._InferenceCell,
inputs=self._inputs,
initial_state=self._initial_state,
time_major=True)
act_output, (act_final_iteration, act_final_remainder) = tmp
# 测试
self._final_iteration = tf.reduce_mean(act_final_iteration)
self._act_output = act_output
if gather_list is not None:
out_sequences = tf.gather(act_output, gather_list)
else:
out_sequences = act_core
# 设置损失函数
pondering_cost = (act_final_iteration + act_final_remainder) * pondering_coefficient
rnn_cost = tf.nn.softmax_cross_entropy_with_logits(
labels=self._targets, logits=out_sequences)
self._pondering_cost = tf.reduce_mean(pondering_cost)
self._rnn_cost = tf.reduce_mean(rnn_cost)
self._cost = self._pondering_cost + self._rnn_cost
self._pred = tf.nn.softmax(out_sequences, dim=2)
correct_pred = tf.equal(tf.argmax(self._pred,2), tf.argmax(self._targets,2))
self._accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# 设置优化器
# Set up optimizer with global norm clipping.
trainable_variables = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(
tf.gradients(self._cost, trainable_variables), max_gard_norm)
global_step = tf.get_variable(
name="global_step",
shape=[],
dtype=tf.int64,
initializer=tf.zeros_initializer(),
trainable=False,
collections=[tf.GraphKeys.GLOBAL_VARIABLES, tf.GraphKeys.GLOBAL_STEP])
optimizer = tf.train.RMSPropOptimizer(
learning_rate=learning_rate, epsilon=optimizer_epsilon)
self._train_step = optimizer.apply_gradients(
zip(grads, trainable_variables), global_step=global_step)
# 待处理函数
def _get_hidden_state(self, state):
controller_state, access_state, read_vectors = state
layer_1, layer_2, layer_3 = controller_state
L1_next_state, L1_next_cell = layer_1
L2_next_state, L2_next_cell = layer_2
L3_next_state, L3_next_cell = layer_3
return tf.concat([L1_next_state, L2_next_state, L3_next_state], axis=-1)
def fit(self,
training_iters =1e2,
display_step = 5,
save_path = None,
restore_path = None):
self._sess.run(tf.global_variables_initializer())
# 保存和恢复
self._variables_saver = tf.train.Saver()
if restore_path is not None:
self._variables_saver.restore(self._sess, restore_path)
if self._batch_size == self._mini_batch_size:
for scope in range(np.int(training_iters)):
_, loss, acc, tp1, tp2, tp3 = \
self._sess.run([self._train_step,
self._cost,
self._accuracy,
self._pondering_cost,
self._rnn_cost,
self._final_iteration],
feed_dict = {self._inputs:self._tmp_inputs, self._targets:self._tmp_targets})
# 显示优化进程
if scope % display_step == 0:
print (scope,
' loss--', loss,
' acc--', acc,
' pondering_cost--',tp1,
' rnn_cost--', tp2,
' final_iteration', tp3)
# 保存模型可训练变量
if save_path is not None:
self._variables_saver.save(self._sess, save_path)
print ("Optimization Finished!")
else:
print ('未完待续')
def close(self):
self._sess.close()
print ('结束进程,清理tensorflow内存/显存占用')
def pred(self, inputs, gather_list=None, restore_path=None):
if restore_path is not None:
self._sess.run(tf.global_variables_initializer())
self._variables_saver = tf.train.Saver()
self._variables_saver.restore(self._sess, restore_path)
output_pred = self._act_output
if gather_list is not None:
output_pred = tf.gather(output_pred, gather_list)
probability = tf.nn.softmax(output_pred)
classification = tf.argmax(probability, axis=-1)
return self._sess.run([probability, classification],feed_dict = {self._inputs:inputs})
```
#### 训练模型
```
op1 = Classifier_PonderDNC_BasicLSTM_L3(
inputs= inputs,
targets= targets,
gather_list= gather_list,
hidden_size= 50,
memory_size= 50,
pondering_coefficient= 1e-2,
learning_rate= 1e-2)
op1.fit(training_iters = 100,
display_step = 10,
save_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_1.ckpt")
op1.close()
```
#### second
```
tf.reset_default_graph()
op2 = Classifier_PonderDNC_BasicLSTM_L3(
inputs= inputs,
targets= targets,
gather_list= gather_list,
hidden_size= 50,
memory_size= 50,
pondering_coefficient= 1e-2,
learning_rate= 1e-3)
op2.fit(training_iters = 100,
display_step = 10,
save_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_1.ckpt",
restore_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_1.ckpt")
```
#### third
```
tf.reset_default_graph()
op3 = Classifier_PonderDNC_BasicLSTM_L3(
inputs= inputs,
targets= targets,
gather_list= gather_list,
hidden_size= 50,
memory_size= 50,
pondering_coefficient= 1e-2,
learning_rate= 1e-3)
op3.fit(training_iters = 100,
display_step = 10,
save_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_1.ckpt",
restore_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_1.ckpt")
tf.reset_default_graph()
op4 = Classifier_PonderDNC_BasicLSTM_L3(
inputs= inputs,
targets= targets,
gather_list= gather_list,
hidden_size= 50,
memory_size= 50,
pondering_coefficient= 1e-2,
learning_rate= 1e-3)
op4.fit(training_iters = 50,
display_step = 10,
save_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_1.ckpt",
restore_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_1.ckpt")
op4.close()
tf.reset_default_graph()
op5 = Classifier_PonderDNC_BasicLSTM_L3(
inputs= inputs,
targets= targets,
gather_list= gather_list,
hidden_size= 50,
memory_size= 50,
pondering_coefficient= 1e-1,
learning_rate= 1e-3)
op5.fit(training_iters = 50,
display_step = 10,
save_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_2.ckpt",
restore_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_1.ckpt")
op5.close()
tf.reset_default_graph()
op6 = Classifier_PonderDNC_BasicLSTM_L3(
inputs= inputs,
targets= targets,
gather_list= gather_list,
hidden_size= 50,
memory_size= 50,
pondering_coefficient= 1e-1,
learning_rate= 1e-4)
op6.fit(training_iters = 100,
display_step = 10,
save_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_3.ckpt",
restore_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_2.ckpt")
tf.reset_default_graph()
op7 = Classifier_PonderDNC_BasicLSTM_L3(
inputs= inputs,
targets= targets,
gather_list= gather_list,
hidden_size= 50,
memory_size= 50,
pondering_coefficient= 1e-1,
learning_rate= 1e-4)
op7.fit(training_iters = 100,
display_step = 10,
save_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_4.ckpt",
restore_path = "/QuantPython/RqAlphaMod/Model_Saver/ResidualPonderDNC_3.ckpt")
model = op7
```
#### 设置回测框架
```
import rqalpha.api as rqa
from rqalpha import run_func
def init(context):
context.contract = 'AG88'
context.BarSpan = 200
context.TransactionRate = '1d'
context.DataFields = ['datetime', 'open', 'close','high', 'low', 'volume']
context.DefineQuantity = 5
context.func_get_factors = get_factors
context.model_classifier = model
def handle_bar(context, bar_dict):
# 合约池代码
contract = context.contract
#rqa.logger.info('------------------------------------')
#timepoint = rqa.history_bars(contract, 1, '1d', 'datetime')[0]
#timepoint = pd.to_datetime(str(timepoint))
#timepoint = rqa.get_next_trading_date(timepoint)
#rqa.logger.info (timepoint)
# 获取合约报价
Quotes = rqa.history_bars(
order_book_id= contract,
bar_count= context.BarSpan,
frequency= context.TransactionRate,
fields= context.DataFields)
Quotes = pd.DataFrame(Quotes)
# 计算技术分析指标
tmp_factors = context.func_get_factors(
index= pd.to_datetime(Quotes['datetime']),
Open= Quotes['open'].values,
Close= Quotes['close'].values,
High= Quotes['high'].values,
Low= Quotes['low'].values,
Volume=Quotes['volume'].values,
drop=True)
inputs = np.expand_dims(np.array(tmp_factors), axis=1)
# 模型预测
probability, classification = context.model_classifier.pred(inputs)
flag = classification[-1][0]
rqa.logger.info(str(flag))
#print (flag)
# 绘制估计概率
rqa.plot("估空概率", probability[-1][0][0])
rqa.plot("振荡概率", probability[-1][0][1])
rqa.plot("估多概率", probability[-1][0][2])
# 获取仓位
cur_position = context.portfolio.accounts['FUTURE'].positions
tmp_buy_quantity = 0
tmp_sell_quantity = 0
if cur_position:
tmp_buy_quantity = cur_position[contract].buy_quantity
tmp_sell_quantity = cur_position[contract].sell_quantity
# 沽空
if flag == 0:
rqa.logger.info ('沽空')
if tmp_buy_quantity > 0:
rqa.sell_close(contract, tmp_buy_quantity)
rqa.sell_open(contract, context.DefineQuantity)
rqa.logger.info ('平多单 开空单')
elif tmp_sell_quantity >0:
rqa.logger.info ('持有空头,不调仓')
else:
rqa.sell_open(contract, context.DefineQuantity)
rqa.logger.info ('开空单')
# 沽多
if flag == 2:
rqa.logger.info ('沽多')
if tmp_sell_quantity > 0:
rqa.buy_close(contract, tmp_sell_quantity)
rqa.buy_open(contract, context.DefineQuantity)
rqa.logger.info ('平空单 开多单')
elif tmp_buy_quantity > 0:
rqa.logger.info ('持有多头,不调仓')
pass
else:
rqa.logger.info ('开多单')
rqa.buy_open(contract, context.DefineQuantity)
if flag == 1:
rqa.logger.info ('振荡区间')
if tmp_sell_quantity > 0:
rqa.buy_close(contract, tmp_sell_quantity)
rqa.logger.info ('平空单')
if tmp_buy_quantity > 0:
rqa.sell_close(contract, tmp_buy_quantity)
rqa.logger.info ('平多单')
else:
rqa.logger.info ('空仓规避')
start_date = '2016-01-01'
end_date = '2017-01-01'
accounts = {'future':1e5}
config = {
'base':{'start_date':start_date, 'end_date':end_date, 'accounts':accounts},
'extra':{'log_level':'info'},
'mod':{'sys_analyser':{'enabled':True, 'plot':True}}
}
results = run_func(init=init, handle_bar=handle_bar, config=config)
start_date = '2017-01-01'
end_date = '2017-08-01'
accounts = {'future':1e5}
config = {
'base':{'start_date':start_date, 'end_date':end_date, 'accounts':accounts},
'extra':{'log_level':'info'},
'mod':{'sys_analyser':{'enabled':True, 'plot':True}}
}
results = run_func(init=init, handle_bar=handle_bar, config=config)
```
| github_jupyter |
```
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import time
mnist = input_data.read_data_sets('', one_hot = True)
def add_conv1d(x, n_filters, kernel_size, strides=1):
return tf.layers.conv1d(inputs = x,
filters = n_filters,
kernel_size = kernel_size,
strides = strides,
padding = 'valid',
use_bias = True,
activation = tf.nn.relu)
class Model:
def __init__(self, learning_rate = 1e-4,
top_k=5, n_filters=250):
self.n_filters = n_filters
self.kernels = [3, 4, 5]
self.top_k = top_k
self.X = tf.placeholder(tf.float32, [None, 28, 28])
self.Y = tf.placeholder(tf.float32, [None, 10])
parallels = []
for k in self.kernels:
p = add_conv1d(self.X, self.n_filters//len(self.kernels), kernel_size=k)
p = self.add_kmax_pooling(p)
parallels.append(p)
parallels = tf.concat(parallels, axis=-1)
parallels = tf.reshape(parallels, [-1, self.top_k * (len(self.kernels)*(self.n_filters//len(self.kernels)))])
feed = tf.nn.dropout(tf.layers.dense(parallels, self.n_filters, tf.nn.relu), 0.5)
self.logits = tf.layers.dense(parallels, 10)
self.cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = self.logits, labels = self.Y))
self.optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(self.cost)
self.correct_pred = tf.equal(tf.argmax(self.logits, 1), tf.argmax(self.Y, 1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_pred, tf.float32))
def add_kmax_pooling(self, x):
Y = tf.transpose(x, [0, 2, 1])
Y = tf.nn.top_k(Y, self.top_k, sorted=False).values
Y = tf.transpose(Y, [0, 2, 1])
return tf.reshape(Y, [-1, self.top_k, self.n_filters//len(self.kernels)])
sess = tf.InteractiveSession()
model = Model()
sess.run(tf.global_variables_initializer())
EPOCH = 10
BATCH_SIZE = 128
for i in range(EPOCH):
last = time.time()
TOTAL_LOSS, ACCURACY = 0, 0
for n in range(0, (mnist.train.images.shape[0] // BATCH_SIZE) * BATCH_SIZE, BATCH_SIZE):
batch_x = mnist.train.images[n: n + BATCH_SIZE, :].reshape((-1, 28, 28))
acc, cost, _ = sess.run([model.accuracy, model.cost, model.optimizer],
feed_dict = {model.X : batch_x,
model.Y : mnist.train.labels[n: n + BATCH_SIZE, :]})
ACCURACY += acc
TOTAL_LOSS += cost
TOTAL_LOSS /= (mnist.train.images.shape[0] // BATCH_SIZE)
ACCURACY /= (mnist.train.images.shape[0] // BATCH_SIZE)
print('epoch %d, avg loss %f, avg acc %f, time taken %f secs'%(i+1,TOTAL_LOSS,ACCURACY,time.time()-last))
```
| github_jupyter |
# BOM(Bill of materials)
1. 115 size drone (Estimated total: 250~350$)
~~~
Class / Name / Estimated Price($)
Body Frame-Carbon / AlfaRC AHX115 frame Kit / 12.5
4 in 1 ESC with FC / HGLRC FD445 Stack / 106
BLDC motor(1105 series) / iFlight 1105 6000KV Micro BLDC / 46
Propellers with spare / 2.5inch Propeller 4 sets(16 pcs) / 10.1
Lipo Battery-3s 1500mAh 100C XT60 / GOLDBAT 1500mAh 3s 11.1V 100C / 29
2.4GHz 16CH SBus Receiver / FlySky XM+ Micro D16 SBUS / 18
2.4GHz 10CH Controller / FlySky i6X FS-i6X 10CH / 56
~~~
2. FPV option for 115
~~~
Class / Name / Estimated Price($)
FPV receiver(smartphone) and Transmitter / ROTG02 with VTX02 / 35
~~~
3. Miscellanea (Estimated total: 50~$)
~~~
Class / Name / Estimated Price($)
Soldering iron / - / 10~30
Soldering lead / - / 0.1~2 per ft
Hex screw driver / - / 15~
XT60 premade / - / 3~
~~~
---
# Drone core parts suggestion(04/14/2021)
## I. A small drone based on 115 size
### 1. Frame: 115mm, BLDC, Racing (12.5$)
[banggood](https://www.banggood.com/AlfaRC-AHX115-115mm-Wheelbase-3mm-Arm-3K-Carbon-Fiber-Frame-Kit-for-RC-Drone-FPV-Racing-p-1429482.html?p=63061312105582015022&utm_source=Youtube&utm_medium=cussku&utm_content=tanghao&utm_campaign=Albert&cur_warehouse=CN)
### 2. FC with ESC(4 in 1) (105$)
[banggood](https://www.banggood.com/HGLRC-FD445-STACK-OMNIBUS-F4-V6-MINI-Flight-Controller-FD_45A-4-NI-1-BLHeli_32-2-6S-Brushless-ESC-20x20mm-p-1433718.html?p=CS101558118042016088&utm_campaign=mesh&utm_content=tanghao&cur_warehouse=CN)
or(62$)
[hglrc](https://www.hglrc.com/products/hglrc-fd445-stack-fd-f4-mini-flight-control-fd_45a_4ni1_mini-blheli_32-3-6s-esc)
or(only 4 esc, 45$)
[banggood](https://www.banggood.com/4X-HAKRC-BLHeli_32-Bit-35A-2-5S-ESC-Built-in-LED-Support-Dshot1200-Multishot-for-FPV-RC-Drone-p-1280430.html?p=CS101558118042016088&utm_campaign=mesh&utm_content=tanghao&cur_warehouse=CN)
### 3. Motor(1105 6000KV, pull 100~160g each)
[amazon](https://www.amazon.com/iFlight-6000KV-Brushless-Racing-Quadcopter/dp/B086QXCHT2/ref=sr_1_2_sspa?dchild=1&keywords=1105+motor&qid=1618337942&sr=8-2-spons&psc=1&spLa=ZW5jcnlwdGVkUXVhbGlmaWVyPUFPNVdHTkZHVDhJRVkmZW5jcnlwdGVkSWQ9QTAyNjIxNzhKNkNVUVJFQkxESlomZW5jcnlwdGVkQWRJZD1BMDAxOTk0NjRCMVRBRzAzOExTTyZ3aWRnZXROYW1lPXNwX2F0ZiZhY3Rpb249Y2xpY2tSZWRpcmVjdCZkb05vdExvZ0NsaWNrPXRydWU=)
### 4. 2.5inch propellers x4
[amazon](https://www.amazon.com/Anbee-Propellers-Minidrones-Airborne-Hydrofoil/dp/B019W2QDNO/ref=sr_1_4_sspa?dchild=1&keywords=2.5+inch+drone+propeller&qid=1618338304&sr=8-4-spons&psc=1&smid=A16KCHXWF4185R&spLa=ZW5jcnlwdGVkUXVhbGlmaWVyPUEzN0tJTkdITEgyQlFYJmVuY3J5cHRlZElkPUEwMjM0Mzg2MTMwTVYzWjc0WjgwViZlbmNyeXB0ZWRBZElkPUEwMjc2OTU4MUUxWEMzRkUxQlZDVCZ3aWRnZXROYW1lPXNwX2F0ZiZhY3Rpb249Y2xpY2tSZWRpcmVjdCZkb05vdExvZ0NsaWNrPXRydWU=)
### 5. Battery (11.1V 3s 1500mah 100C lipo)
[amazon](https://www.amazon.com/GOLDBAT-Softcase-m4-fpv250-Shredder-Helicopter/dp/B07ZFDJWR1/ref=sr_1_1_sspa?dchild=1&keywords=1500mah+3s+lipo&qid=1618338573&sr=8-1-spons&psc=1&spLa=ZW5jcnlwdGVkUXVhbGlmaWVyPUExQllLR05XUEU0RFpNJmVuY3J5cHRlZElkPUEwOTczOTE3MUQ3UzZXUjJHVkEzUiZlbmNyeXB0ZWRBZElkPUEwODMwNDIzM04zNEVZM1BPTDQ3NCZ3aWRnZXROYW1lPXNwX2F0ZiZhY3Rpb249Y2xpY2tSZWRpcmVjdCZkb05vdExvZ0NsaWNrPXRydWU=)
### 6. Controller/Receiver
[Banggood-Receiver](https://www.banggood.com/FrSky-XM+-Micro-D16-SBUS-Full-Range-Mini-RC-Receiver-Up-to-16CH-for-RC-FPV-Racing-Drone-p-1110020.html?cur_warehouse=CN&rmmds=search)
[Banggood-Controller](https://www.banggood.com/Flysky-i6X-FS-i6X-2_4GHz-10CH-AFHDS-2A-RC-Transmitter-With-X6B-or-IA6B-or-A8S-Receiver-for-FPV-RC-Drone-p-1090406.html?cur_warehouse=CN&ID=53081742482&rmmds=search)
### 7. necessary misc.
3-1. XT60 premade (Battery cable. refer videos below)
[bangood](https://www.banggood.com/search/xt60-premade.html?from=nav)
These are based on the following
[Video1](https://www.youtube.com/watch?v=pYDTvbwCxLQ&ab_channel=AlbertKim)
[Video2](https://www.youtube.com/watch?v=31ArBvYoG2Q&ab_channel=DroneMesh)
### 8. Small 5.8GHz FPV (Option)
- ROTG02 with VTX02
[banggood](https://www.banggood.com/Eachine-VTX02-+-ROTG02-FPV-Combo-5_8G-40CH-200mW-Diversity-Audio-Transmitter-Receiver-Set-Black-for-Android-Phone-Non-original-p-1731113.html?cur_warehouse=CN&rmmds=search)
Based on this [video](https://www.youtube.com/watch?v=MM0zBI7_rxE&ab_channel=AuthenTech-BenSchmanke)
or refer this [Walkthrough](https://www.youtube.com/watch?v=mYITNilUaHc&ab_channel=GalKremer)
----------------------------
# Background Knowledges
## 1. Core Parts
### 1-1. FC(Flight Controller)
This part consists of the main processor(Micro Processor Unit, or MPU), peripheral device control pins, and sensors
### 1-2. ESC(Electric Speed Controller)
This part helps FCs to control high-power motors. FCs don't have huge power. FC is the smartest but weakest part of a drone. We use ESC when we use BLDC motors, and the BLDC motor is dominant. If your drone has 6 motors(hexacopter), you need 6 ESCs.
### 1-3. PMU(Power Management Module) or Power supply module
Small drones normally use FCs with PMU or All-in-one ESC with PMU. Bigger drones sometimes need PMU.
### 1-4. Battery
Lipo(Lithium Polymer) battery technology lets drones fly. This type of battery has high capacity, high electric currents, and stability. Lithium cell batteries may explode, but Lipo won't explode. They just burn. :) Big drones should have high voltage batteries, so you should use 3s(Serial 3 cells) or higher batteries.
`3s lipo has 11.1V(3.7*3)`. 2s or higher batteries should charge using "Balance Charger" and discharge to storage voltage if you are going to store your battery for a long time. mAh or Wh means its capacity and C(coulomb) means its ability to discharge. If a 1000mAh battery has 100C, it can discharge a maximum of 100A. `(Maximum current = capacity*C)`
### 1-5. Motor
We usually use a BLDC motor rather than a DC motor. Some micro drones use coreless DC motor(small, strong, more expensive than DC), but BLDC is dominant. All motors must have a corresponding driver circuit. DC and coreless DC motor's driver is simple and small, but BLDC's is so much complicated. So they need ESC modules.
### 1-6. Radiofrequency PPM Receiver/transmitter
RF(Radio Frequency) is also an interesting area. PPM(Pulse Position Modulation) technology is now the dominant, reliable type of pulse modulation to control your drones safely.
### 1-7. Propellers
A quadcopter uses 2 CW(clock-wise) motors and 2 CCW(counter-clock-wise) motors. So, they need corresponding propellers.
## 2. Additional Parts (Read this if you are interested in challenging DIY projects.)
### 2-1. FPV: First Person View
This part consists of a camera, radio frequency transmitter, and MPU(Media Processing Unit). This allows you to control your drone from its perspective. You may use FPV goggles, such as a VR(Virtual Reality) headset.
### 2-2. MPU: Media Processing Unit
For advanced drones, often have various types of sensors. Such as stereo camera sensors(you can easily see under the many DJI drones). This technology is based on highly developed Sensor Fusion technology and Image/Signal Processing Technology. To implement this technology into drones, they must have this unit. This technology is not opened for everyone, but you can challenge using Raspberry Pi and odometry projects.
### 2-3. GPS: Global Positioning System
GPS is a useful technology for outdoor drone hovering and guided flight. It helps drones to fly without a driver's control signal.
### 2-4. Other actuators
Some FPV systems include gimbals which help a camera to take so much stable video without any post-processing. Gimbal helps drones using physical motors. Some FC support gimbal control. This technology and OIS technology in an expensive smartphone's camera have the same idea. On the other hand, you can add all kinds of actuators(especially motors), like a robot arm, but you may need an additional processor circuit because most FCs don't support custom actuators of your system.
### 2-5. More challenge
You can leave controlling your drone to your FC and think of something else. However, you can also try to control your drone without FC's help. If you use open-sourced FCs, you must study a lot but at least you may feel the depth of the control system theory. In online markets, there are old open source projects which became legacy these days.
## 3. Limitation of DIY
### 3-1. You need to understand the basic concepts of electric circuit theory.
At least you need to know that a red wire and a black wire should not join. If they were of a lithium battery, it will be on fire.
### 3-2. Drones will ask you if you are understanding basic flight theory.
Such as trimming, roll-pitch-yaw, hovering, etc.
### 3-3. Some parts will ask you a deep understanding of engineering skills.
### 3-4. You need to know how to calculate necessary physical quantities to search for proper parts in online markets.
### 3-5. Unfortunately, drones cannot fly on their own with just one sensor.
Basically, FCs have a gyro-accelerometer sensor. But they cannot measure its current position, like every modern sensor has its limit. To solve this problem, you can add another type of sensor, such as GPS, image flow sensor, etc. However, sensor fusion is based on extremely complicated mathematics. So, we should rely on FCs' help.
| github_jupyter |
# Teaching Numerical Analysis with Jupyter Notebook
<div style="text-align: center"><b> Xiaozhou Li (University of Electronic Science and Technology of China) </b></div>
<a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/80x15.png" /></a><br />This notebook by Xiaozhou Li is licensed under a <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Creative Commons Attribution 4.0 International License</a>.
All code examples are also licensed under the [MIT license](http://opensource.org/licenses/MIT).
## Teaching numerical analysis
A course in numerical methods normally includes two parts:
* the mathematical theory of numerical analysis
* the craft of implementing numerical algorithms.
## Why Jupyter notebook
The Jupyter notebook provides a single medium in which combines
* Mathematics (using LaTeX)
* Explanation texts (using Markdown)
* Executable code (in Python or other languages)
* Visualizations (figures and animations)
With the notebook, student can interact in order to learn both the theory and the craft of numerical methods.
That's much better than a printed textbook!
### Advantages of the notebook
* Python!
* Free
* Open source
* Text-based (the power of plain text)
- Can diff, merge, grep, search/replace, version control
- Can convert between formats
* nbviewer
## Uses of the notebook
* Homework exercises, perhaps with some code provided
* In-class computational demos
* In-class exercises
* Accessory/Replacement for the textbook
### In-class computational demos
* Solutions of time-dependent problems
* Iterative solvers
* ...
Some questions can be answered most effectively through the use of animation. Students learn more -- and have more fun -- when they can visualize the results of their work in this way.
## Challenges
* Installation
* Learning Python + the notebook
### Installation
#### Local installation
The simplest way to have a local installation of all the software on the computer is to install **Anaconda**. It is free and include Python, IPython, and all of the Python packages likely to be used in scientific computing course. More import, it can easily be installed on Linux, Mac, and Windows systems.
#### Cloud platforms
In order to avoid potential installation issues altogether, or as a secondary option, notebooks can be run using only cloud services.
* Sage Math Cloud
* Wakari
### Learning Python
| github_jupyter |
# Analytics
#### Date: 2020/02
#### SUMMARY:
- This notebook represents the project quality analysis of the date exposed right above.
### TEAM: SysArq
##### Semester: 2021/01
##### Professor: Hilmer Neri
##### Members:
- Member x
- Member y
### LIBRARIES
```
# Deal with data
import pandas as pd
import numpy as np
import json
# Deal with API request
import urllib3
from urllib3 import request
# Deal with visualization
import seaborn as sns
import matplotlib.pyplot as plt
```
### GRAPH SETTINGS
```
%config InlineBackend.figure_format ='retina'
sns.set(font_scale=1.5)
sns.set_style('darkgrid',
{'xtick.bottom' : True,
'ytick.left': True,
'grid.linestyle':'--',
'font.monospace': ['Computer Modern Typewriter'],
'axes.edgecolor' : 'white'})
```
### DATAFRAME SETTINGS
```
pd.set_option("display.max_rows", None, "display.max_columns", None)
```
### SonarCloud
#### KEYS
```
front_key = 'fga-eps-mds_2020.1-VC_Gestor-FrontEnd'
archives_key = 'fga-eps-mds_2020.1-VC_Gestor-BackEnd'
profile_key =
```
#### METRICS
```
metric_list = ['files',
'functions',
'complexity',
'comment_lines_density',
'duplicated_lines_density',
'security_rating',
'tests',
'test_success_density',
'test_execution_time',
'reliability_rating']
len(metric_list)
def generate_metric_string(metric_list):
metric_str = ''
for metric in metric_list:
metric_str += metric + ','
return metric_str
metric_str = generate_metric_string(metric_list)
```
#### URLS
```
front_url = f"https://sonarcloud.io/api/measures/component_tree?component={front_key}&metricKeys={metric_str}&ps=500"
back_url = f"https://sonarcloud.io/api/measures/component_tree?component={back_key}&metricKeys={metric_str}&ps=500"
```
#### API REQUEST
```
http = urllib3.PoolManager()
front_request = http.request('GET', front_url)
front_request.status
back_request = http.request('GET', back_url)
back_request.status
```
#### JSON DECODING
```
front_json = json.loads(front_request.data.decode('utf-8'))
back_json = json.loads(back_request.data.decode('utf-8'))
```
## DATA
### PROJECT
```
project_front_json = front_json['baseComponent']['measures']
project_back_json = back_json['baseComponent']['measures']
project_front_data = pd.DataFrame(project_front_json)
project_back_data = pd.DataFrame(project_back_json)
```
##### FRONT
```
project_front_data
```
##### BACK
```
project_back_data
```
### FILES
```
def metric_per_file(json):
file_json = []
for component in json['components']:
if component['qualifier'] == 'FIL':
file_json.append(component)
return file_json
front_file_json = metric_per_file(front_json)
back_file_json = metric_per_file(back_json)
def generate_file_dataframe(metric_list, json, language_extension):
df_columns = metric_list
df = pd.DataFrame(columns = df_columns)
for file in json:
try:
if file['language'] == language_extension:
for measure in file['measures']:
df.at[file['path'], measure['metric']] = measure['value']
except:
pass
df.reset_index(inplace = True)
df = df.rename({'index': 'path'}, axis=1).drop(['files'], axis=1)
return df
front_files_data = generate_file_dataframe(metric_list, front_file_json, language_extension = 'js')
back_files_data = generate_file_dataframe(metric_list, back_file_json, language_extension = 'js')
```
##### FRONT
```
front_files_data
```
##### BACK
```
back_files_data
```
# ANALYSIS
## MAINTAINABILITY
### CODE QUALITY
##### COMPLEXITY
```
def m1(df):
density_non_complex_files = round((len(df[(df['complexity'].astype(float)/df['functions'].astype(float)) < 10])/len(df))*100, 2)
return density_non_complex_files
```
##### COMMENTS
```
def m2(df):
density_comment_files = round((len(df[(df['comment_lines_density'].astype(float) > 10) & (df['comment_lines_density'].astype(float) < 30)])/len(df))*100, 2)
return density_comment_files
```
##### DUPLICATIONS
```
def m3(df):
duplication = round((len(df[(df['duplicated_lines_density'].astype(float) < 5)])/len(df))*100, 2)
return duplication
```
### BLOCKING CODE
#### NON-BLOCKING FILES
```
def m4(df):
non_blocking_files = round((len(df[(df['security_rating'].astype(float) >= 4)])/len(df))*100,2)
return non_blocking_files
```
## RELIABILITY
#### TEST SUCCESS
```
def m5(df):
test_success_file = df[['path', 'test_success_density']]
test_success_repository = df['test_success_density'].astype(float).mean()
print("Project test unit density: ", test_success_repository)
return test_success_file
```
#### FAST TESTS
```
def m6(df):
fast_test_df = df[(df['test_execution_time'].astype(float) < 300)]
fast_test_df['fast_test'] = fast_test_df['test_execution_time']/fast_test_df['tests']
fast_test_file = fast_test_df[['path', 'fast_test']]
fast_test_repository = fast_test_df['fast_test'].astype(float).mean()
print("Project test unit density: ", fast_test_repository)
return fast_test_file
```
## PRODUCTIVITY
### TIMEFRAME: PUT_YOUR_TIMEFRAME_HERE
```
NUMBER_OF_ISSUES_RESOLVED = 7
NUMBER_OF_ISSUES = 50
TAGS = {
"HOTFIX": 4,
"DOCS": 2,
"FEATURE": 3,
"ARQ": 2,
"DEVOPS": 5,
"ANALYTICS": 2,
"US": 4,
"EASY": 9,
"MEDIUM": 1,
"HARD": 2,
"EPS": 5,
"MDS": 7
}
```
#### RESOLVED ISSUES' THROUGHPUT
```
def m7(number_of_issues_resolved, number_of_issues):
resolved_issues_throughput = round((number_of_issues_resolved / number_of_issues) * 100, 2)
return resolved_issues_throughput
```
#### ISSUE TYPE IN A TIMEFRAME
```
def density(issue, number_of_issues):
issue_density = round((issue / number_of_issues) * 100, 2)
return issue_density
def m8(tag_dict, number_of_issues):
issue_densities = {
"hotfix": [density(tag_dict["HOTFIX"], number_of_issues)],
"docs": [density(tag_dict["DOCS"], number_of_issues)],
"feature": [density(tag_dict["FEATURE"], number_of_issues)],
"arq": [density(tag_dict["ARQ"], number_of_issues)],
"devops": [density(tag_dict["DEVOPS"], number_of_issues)],
"analytics": [density(tag_dict["ANALYTICS"], number_of_issues)],
"us": [density(tag_dict["US"], number_of_issues)],
"easy": [density(tag_dict["EASY"], number_of_issues)],
"medium": [density(tag_dict["MEDIUM"], number_of_issues)],
"hard": [density(tag_dict["HARD"], number_of_issues)],
"eps": [density(tag_dict["EPS"], number_of_issues)],
"mds": [density(tag_dict["MDS"], number_of_issues)]
}
issue_densities = pd.DataFrame.from_dict(issue_densities).T.reset_index()
issue_densities.columns = ['density' ,'percentage']
return issue_densities
```
#### BUGS RATIO
```
def m9(tag_dict, number_of_issues):
bugs_ratio = round(((tag_dict["DOCS"] + tag_dict["FEATURE"] + tag_dict["ARQ"] + tag_dict["DEVOPS"] + tag_dict["ANALYTICS"]) / number_of_issues) * 100, 2)
return bugs_ratio
```
### METRIC RESULTS
```
m1(back_files_data)
m2(back_files_data)
m3(back_files_data)
m4(back_files_data)
m5(back_files_data)
m6(back_files_data)
m7(NUMBER_OF_ISSUES_RESOLVED, NUMBER_OF_ISSUES)
m8(TAGS, NUMBER_OF_ISSUES)
m9(TAGS, NUMBER_OF_ISSUES)
```
| github_jupyter |
```
!pip install pyspark
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
from pyspark.sql.functions import mean,col,split, col, regexp_extract, when, lit, avg
from pyspark.ml.feature import StringIndexer
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.feature import QuantileDiscretizer
spark = SparkSession.builder.appName("PySparkTitanikJob").getOrCreate()
spark
titanic_df = spark.read.csv('train.csv', header = 'True', inferSchema='True')
display(titanic_df)
titanic_df.printSchema()
passengers_count = titanic_df.count()
titanic_df.show(5)
gropuBy_output = titanic_df.groupBy("Survived").count()
gropuBy_output.show()
avg_age = round(titanic_df.select(avg(col('Age'))).collect()[0][0],0)
avg_age
titanic_df = titanic_df.fillna({'Age': avg_age})
titanic_df.show()
titanic_df = titanic_df.fillna({"Embarked" : 'S'})
titanic_df = titanic_df.drop("Cabin")
titanic_df = titanic_df.withColumn("Family_Size",col('SibSp')+col('Parch'))
titanic_df = titanic_df.withColumn('Alone',lit(0))
titanic_df = titanic_df.withColumn("Alone",when(titanic_df["Family_Size"] == 0, 1).otherwise(titanic_df["Alone"]))
data_df = titanic_df
titanic_df.show(2)
indexers = [StringIndexer(inputCol=column, outputCol=column+"_index").fit(titanic_df) for column in ["Sex","Embarked"]]
pipeline = Pipeline(stages=indexers)
titanic_df = pipeline.fit(titanic_df).transform(titanic_df)
titanic_df = titanic_df.drop("PassengerId","Name","Ticket","Cabin","Embarked","Sex")
titanic_df.show()
feature = VectorAssembler(inputCols=titanic_df.columns[1:],outputCol="features")
feature_vector= feature.transform(titanic_df)
feature_vector.show()
(training_data, test_data) = feature_vector.randomSplit([0.8, 0.2],seed = 42)
training_data.show()
```
# ML models
# LogisticRegression
```
from pyspark.ml.classification import LogisticRegression
lr = LogisticRegression(labelCol="Survived", featuresCol="features")
#Training algo
lrModel = lr.fit(training_data)
lr_prediction = lrModel.transform(test_data)
lr_prediction.select("prediction", "Survived", "features").show(5)
evaluator = MulticlassClassificationEvaluator(labelCol="Survived", predictionCol="prediction", metricName="accuracy")
lr_accuracy = evaluator.evaluate(lr_prediction)
print("LogisticRegression [Accuracy] = %g"% (lr_accuracy))
print("LogisticRegression [Error] = %g " % (1.0 - lr_accuracy))
```
# DecisionTreeClassifier
```
from pyspark.ml.classification import DecisionTreeClassifier
dt = DecisionTreeClassifier(labelCol="Survived", featuresCol="features")
dt_model = dt.fit(training_data)
dt_prediction = dt_model.transform(test_data)
dt_prediction.select("prediction", "Survived", "features").show(5)
dt_accuracy = evaluator.evaluate(dt_prediction)
print("DecisionTreeClassifier [Accuracy] = %g"% (dt_accuracy))
print("DecisionTreeClassifier [Error] = %g " % (1.0 - dt_accuracy))
```
# RandomForestClassifier
```
from pyspark.ml.classification import RandomForestClassifier
rf = RandomForestClassifier(labelCol="Survived", featuresCol="features")
rf_model = rf.fit(training_data)
rf_prediction = rf_model.transform(test_data)
rf_prediction.select("prediction", "Survived", "features").show(5)
rf_accuracy = evaluator.evaluate(rf_prediction)
print("RandomForestClassifier [Accuracy] = %g"% (rf_accuracy))
print("RandomForestClassifier [Error] = %g" % (1.0 - rf_accuracy))
```
# Gradient-boosted tree classifier
```
from pyspark.ml.classification import GBTClassifier
gbt = GBTClassifier(labelCol="Survived", featuresCol="features",maxIter=10)
gbt_model = gbt.fit(training_data)
gbt_prediction = gbt_model.transform(test_data)
gbt_prediction.select("prediction", "Survived", "features").show(5)
gbt_accuracy = evaluator.evaluate(gbt_prediction)
print("Gradient-boosted [Accuracy] = %g"% (gbt_accuracy))
print("Gradient-boosted [Error] = %g"% (1.0 - gbt_accuracy))
```
# Save & Load Model
```
rf_model.save('rf_model')
from pyspark.ml.classification import RandomForestClassificationModel
type(RandomForestClassificationModel.load('rf_model'))
```
# Pipeline
```
from pyspark.ml.pipeline import PipelineModel
data_df = data_df.drop("PassengerId","Name","Ticket","Cabin")
train, validate = data_df.randomSplit([0.8, 0.2])
train.show(5)
indexer_sex = StringIndexer(inputCol="Sex", outputCol="Sex_index")
indexer_embarked = StringIndexer(inputCol="Embarked", outputCol="Embarked_index")
feature = VectorAssembler(
inputCols=["Pclass","Age","SibSp","Parch","Fare","Family_Size","Embarked_index","Sex_index"],
outputCol="features")
rf_classifier = RandomForestClassifier(labelCol="Survived", featuresCol="features")
pipeline = Pipeline(stages=[indexer_sex, indexer_embarked, feature, rf_classifier])
p_model = pipeline.fit(train)
type(p_model)
p_model.write().overwrite().save('p_model')
model = PipelineModel.load('p_model')
prediction = p_model.transform(validate)
validate.show(5)
prediction.select(["Pclass","Age","SibSp","Parch","Fare","Family_Size","Embarked_index","Sex_index"]).show(5)
prediction.printSchema()
evaluator = MulticlassClassificationEvaluator(labelCol="Survived", predictionCol="prediction", metricName="accuracy")
p_accuracy = evaluator.evaluate(prediction)
print("Pipeline model [Accuracy] = %g"% (p_accuracy))
print("Pipeline model [Error] = %g " % (1.0 - p_accuracy))
```
| github_jupyter |
# Using EMI-RNN on the HAR Dataset with custom Loss and Optimizer
This is a very simple example of how the existing EMI-RNN implementation can be used on the HAR dataset with a custom loss function and optimizer. We illustrate how to train a model that predicts on 48 step sequence in place of the 128 length baselines while attempting to predict early.
In the preprint of our work, we use the terms *bag* and *instance* to refer to the LSTM input sequence of original length and the shorter ones we want to learn to predict on, respectively. In the code though, *bag* is replaced with *instance* and *instance* is replaced with *sub-instance*. We will use the term *instance* and *sub-instance* interchangeably.
The network used here is a simple LSTM + Linear classifier network.
The UCI [Human Activity Recognition](https://archive.ics.uci.edu/ml/datasets/human+activity+recognition+using+smartphones) dataset.
```
from __future__ import print_function
import os
import sys
import tensorflow as tf
import numpy as np
# Making sure edgeml is part of python path
os.environ['CUDA_VISIBLE_DEVICES'] ='0'
np.random.seed(42)
tf.set_random_seed(42)
# MI-RNN and EMI-RNN imports
from edgeml_tf.graph.rnn import EMI_DataPipeline
from edgeml_tf.graph.rnn import EMI_BasicLSTM
from edgeml_tf.trainer.emirnnTrainer import EMI_Trainer, EMI_Driver
import edgeml_tf.utils
```
Let us set up some network parameters for the computation graph.
```
# Network parameters for our LSTM + FC Layer
NUM_HIDDEN = 32
NUM_TIMESTEPS = 48
ORIGINAL_NUM_TIMESTEPS = 128
NUM_FEATS = 9
FORGET_BIAS = 1.0
NUM_OUTPUT = 6
USE_DROPOUT = False
KEEP_PROB = 0.75
# For dataset API
PREFETCH_NUM = 5
BATCH_SIZE = 32
# Number of epochs in *one iteration*
NUM_EPOCHS = 2
# Number of iterations in *one round*. After each iteration,
# the model is dumped to disk. At the end of the current
# round, the best model among all the dumped models in the
# current round is picked up..
NUM_ITER = 4
# A round consists of multiple training iterations and a belief
# update step using the best model from all of these iterations
NUM_ROUNDS = 5
LEARNING_RATE=0.001
# Fraction of rounds to use with EMI loss function rather than
# MI loss function. It is usually better to let the model stabilize
# with the MI loss function before enforcing early prediciton
# requirement with EMI loss. Setting to 0 runs purely MI-RNN.
FRAC_EMI=0.5
# Beta term for Regularization
BETA = 0.01
# A staging direcory to store models
MODEL_PREFIX = '/tmp/model-lstm'
```
# Loading Data
Please make sure the data is preprocessed to a format that is compatible with EMI-RNN. `tf/examples/EMI-RNN/fetch_har.py` can be used to download and setup the HAR dataset.
```
# Loading the data
x_train, y_train = np.load('./HAR/48_16/x_train.npy'), np.load('./HAR/48_16/y_train.npy')
x_test, y_test = np.load('./HAR/48_16/x_test.npy'), np.load('./HAR/48_16/y_test.npy')
x_val, y_val = np.load('./HAR/48_16/x_val.npy'), np.load('./HAR/48_16/y_val.npy')
# BAG_TEST, BAG_TRAIN, BAG_VAL represent bag_level labels. These are used for the label update
# step of EMI/MI RNN
BAG_TEST = np.argmax(y_test[:, 0, :], axis=1)
BAG_TRAIN = np.argmax(y_train[:, 0, :], axis=1)
BAG_VAL = np.argmax(y_val[:, 0, :], axis=1)
NUM_SUBINSTANCE = x_train.shape[1]
print("x_train shape is:", x_train.shape)
print("y_train shape is:", y_train.shape)
print("x_test shape is:", x_val.shape)
print("y_test shape is:", y_val.shape)
```
# Computation Graph

The *EMI-RNN* computation graph is constructed out of the following three mutually disjoint parts:
1. `EMI_DataPipeline`: An efficient data input pipeline that using the Tensorflow Dataset API. This module ingests data compatible with EMI-RNN and provides two iterators for a batch of input data, $x$ and label $y$.
2. `EMI_RNN`: The 'abstract' `EMI-RNN` class defines the methods and attributes required for the forward computation graph. An implementation based on LSTM - `EMI_LSTM` is used in this document, though the user is free to implement his own computation graphs compatible with `EMI-RNN`. This module expects two Dataset API iterators for $x$-batch and $y$-batch as inputs and constructs the forward computation graph based on them. Every implementation of this class defines an `output` operation - the output of the forward computation graph.
3. `EMI_Trainer`: An instance of `EMI_Trainer` class which defines the loss functions and the training routine. This expects an `output` operator from an `EMI-RNN` implementation and attaches loss functions and training routines to it.
To build the computation graph, we create an instance of all the above and then connect them together.
Note that, the `EMI_BasicLSTM` class is an implementation that uses an LSTM cell and pushes the LSTM output at each step to a secondary classifier for classification. This secondary classifier is not implemented as part of `EMI_BasicLSTM` and is left to the user to define by overriding the `createExtendedGraph` method, and the `restoreExtendedgraph` method.
For the purpose of this example, we will be using a simple linear layer as a secondary classifier.
```
# Define the linear secondary classifier
def createExtendedGraph(self, baseOutput, *args, **kwargs):
W1 = tf.Variable(np.random.normal(size=[NUM_HIDDEN, NUM_OUTPUT]).astype('float32'), name='W1')
B1 = tf.Variable(np.random.normal(size=[NUM_OUTPUT]).astype('float32'), name='B1')
y_cap = tf.add(tf.tensordot(baseOutput, W1, axes=1), B1, name='y_cap_tata')
self.output = y_cap
self.graphCreated = True
def restoreExtendedGraph(self, graph, *args, **kwargs):
y_cap = graph.get_tensor_by_name('y_cap_tata:0')
self.output = y_cap
self.graphCreated = True
def feedDictFunc(self, keep_prob=None, inference=False, **kwargs):
if inference is False:
feedDict = {self._emiGraph.keep_prob: keep_prob}
else:
feedDict = {self._emiGraph.keep_prob: 1.0}
return feedDict
EMI_BasicLSTM._createExtendedGraph = createExtendedGraph
EMI_BasicLSTM._restoreExtendedGraph = restoreExtendedGraph
if USE_DROPOUT is True:
EMI_Driver.feedDictFunc = feedDictFunc
# Build the Computation Graph
inputPipeline = EMI_DataPipeline(NUM_SUBINSTANCE, NUM_TIMESTEPS, NUM_FEATS, NUM_OUTPUT)
emiLSTM = EMI_BasicLSTM(NUM_SUBINSTANCE, NUM_HIDDEN, NUM_TIMESTEPS, NUM_FEATS,
forgetBias=FORGET_BIAS, useDropout=USE_DROPOUT)
emiTrainer = EMI_Trainer(NUM_TIMESTEPS, NUM_OUTPUT,
stepSize=LEARNING_RATE, automode=False)
```
Note that, to use your custom loss and optimizer, overload `createLossOp` and `createTrainOp` function and return the newly created operators. Use `automode=False` while creating the EMI_Trainer call. For the purpose of this example, we will use Cross Entropy loss with L2 regularizer and Adagrad Optimizer.
```
# Define Custom Loss Function
def createLossOp(self, predicted, target):
with tf.name_scope(self.scope):
li = np.zeros([NUM_TIMESTEPS, NUM_OUTPUT])
li[-1, :] = 1
liTensor = tf.Variable(li.astype('float32'),
name='loss-indicator',
trainable=False)
name='loss-indicator-placeholder'
liPlaceholder = tf.placeholder(tf.float32,
name=name)
liAssignOp = tf.assign(liTensor, liPlaceholder,
name='loss-indicator-assign-op')
self.lossIndicatorTensor = liTensor
self.lossIndicatorPlaceholder = liPlaceholder
self.lossIndicatorAssignOp = liAssignOp
# predicted of dim [-1, numSubinstance, numTimeSteps, numOutput]
dims = [-1, NUM_TIMESTEPS, NUM_OUTPUT]
logits__ = tf.reshape(predicted, dims)
labels__ = tf.reshape(target, dims)
diff = (logits__ - labels__)
diff = tf.multiply(self.lossIndicatorTensor, diff)
# take loss only for the timesteps indicated by lossIndicator for softmax
logits__ = tf.multiply(self.lossIndicatorTensor, logits__)
labels__ = tf.multiply(self.lossIndicatorTensor, labels__)
logits__ = tf.reshape(logits__, [-1, self.numOutput])
labels__ = tf.reshape(labels__, [-1, self.numOutput])
softmax1 = tf.nn.softmax_cross_entropy_with_logits_v2(labels=labels__,
logits=logits__)
lossOp = tf.reduce_mean(softmax1)
regularizer = tf.nn.l2_loss(self.lossIndicatorTensor)
loss = tf.reduce_mean(lossOp + BETA * regularizer)
return loss
#Define Custom Optimizer
def createTrainOp(self):
with tf.name_scope(self.scope):
tst = tf.train.AdagradOptimizer(self.stepSize).minimize(self.lossOp)
return tst
# Add to Tensorflow Collections
def createOpCollections(self):
tf.add_to_collection('EMI-train-op', self.trainOp)
tf.add_to_collection('EMI-loss-op', self.lossOp)
# Override functions in EMI Trainer
EMI_Trainer.createLossOp = createLossOp
EMI_Trainer.createTrainOp = createTrainOp
EMI_Trainer.createOpCollections = createOpCollections
```
Now that we have all the elementary parts of the computation graph setup, we connect them together to form the forward graph.
```
tf.reset_default_graph()
g1 = tf.Graph()
with g1.as_default():
# Obtain the iterators to each batch of the data
x_batch, y_batch = inputPipeline()
# Create the forward computation graph based on the iterators
y_cap = emiLSTM(x_batch)
# Create loss graphs and training routines
emiTrainer(y_cap, y_batch)
```
# EMI Driver
The `EMI_Driver` implements the `EMI_RNN` algorithm. For more information on how the driver works, please refer to `tf/docs/EMI-RNN.md`.
Note that, during the training period, the accuracy printed is instance level accuracy with the current label information as target. Bag level accuracy, with which we are actually concerned, is calculated after the training ends.
```
with g1.as_default():
emiDriver = EMI_Driver(inputPipeline, emiLSTM, emiTrainer)
emiDriver.initializeSession(g1)
# y_updated,modelStats
y_updated, modelStats = emiDriver.run(numClasses=NUM_OUTPUT, x_train=x_train,
y_train=y_train, bag_train=BAG_TRAIN,
x_val=x_val, y_val=y_val, bag_val=BAG_VAL,
numIter=NUM_ITER, keep_prob=KEEP_PROB,
numRounds=NUM_ROUNDS, batchSize=BATCH_SIZE,
numEpochs=NUM_EPOCHS, modelPrefix=MODEL_PREFIX,
fracEMI=FRAC_EMI, updatePolicy='top-k', k=1)
```
# Evaluating the trained model

## Accuracy
Since the trained model predicts on a smaller 48-step input while our test data has labels for 128 step inputs (i.e. bag level labels), evaluating the accuracy of the trained model is not straight forward. We perform the evaluation as follows:
1. Divide the test data also into sub-instances; similar to what was done for the train data.
2. Obtain sub-instance level predictions for each bag in the test data.
3. Obtain bag level predictions from sub-instance level predictions. For this, we use our estimate of the length of the signature to estimate the expected number of sub-instances that would be non negative - $k$ illustrated in the figure. If a bag has $k$ consecutive sub-instances with the same label, that becomes the label of the bag. All other bags are labeled negative.
4. Compare the predicted bag level labels with the known bag level labels in test data.
## Early Savings
Early prediction is accomplished by defining an early prediction policy method. This method receives the prediction at each step of the learned LSTM for a sub-instance as input and is expected to return a predicted class and the 0-indexed step at which it made this prediction. This is illustrated below in code.
```
# Early Prediction Policy: We make an early prediction based on the predicted classes
# probability. If the predicted class probability > minProb at some step, we make
# a prediction at that step.
def earlyPolicy_minProb(instanceOut, minProb, **kwargs):
assert instanceOut.ndim == 2
classes = np.argmax(instanceOut, axis=1)
prob = np.max(instanceOut, axis=1)
index = np.where(prob >= minProb)[0]
if len(index) == 0:
assert (len(instanceOut) - 1) == (len(classes) - 1)
return classes[-1], len(instanceOut) - 1
index = index[0]
return classes[index], index
def getEarlySaving(predictionStep, numTimeSteps, returnTotal=False):
predictionStep = predictionStep + 1
predictionStep = np.reshape(predictionStep, -1)
totalSteps = np.sum(predictionStep)
maxSteps = len(predictionStep) * numTimeSteps
savings = 1.0 - (totalSteps / maxSteps)
if returnTotal:
return savings, totalSteps
return savings
k = 2
predictions, predictionStep = emiDriver.getInstancePredictions(x_test, y_test, earlyPolicy_minProb,
minProb=0.99, keep_prob=1.0)
bagPredictions = emiDriver.getBagPredictions(predictions, minSubsequenceLen=k, numClass=NUM_OUTPUT)
print('Accuracy at k = %d: %f' % (k, np.mean((bagPredictions == BAG_TEST).astype(int))))
mi_savings = (1 - NUM_TIMESTEPS / ORIGINAL_NUM_TIMESTEPS)
emi_savings = getEarlySaving(predictionStep, NUM_TIMESTEPS)
total_savings = mi_savings + (1 - mi_savings) * emi_savings
print('Savings due to MI-RNN : %f' % mi_savings)
print('Savings due to Early prediction: %f' % emi_savings)
print('Total Savings: %f' % (total_savings))
# A slightly more detailed analysis method is provided.
df = emiDriver.analyseModel(predictions, BAG_TEST, NUM_SUBINSTANCE, NUM_OUTPUT)
```
## Picking the best model
The `EMI_Driver.run()` method, upon finishing, returns a list containing information about the best models after each EMI-RNN round. This can be used to identify the best model (based on validation accuracy) at the end of each round - illustrated below.
```
devnull = open(os.devnull, 'r')
for val in modelStats:
round_, acc, modelPrefix, globalStep = val
emiDriver.loadSavedGraphToNewSession(modelPrefix, globalStep, redirFile=devnull)
predictions, predictionStep = emiDriver.getInstancePredictions(x_test, y_test, earlyPolicy_minProb,
minProb=0.99, keep_prob=1.0)
bagPredictions = emiDriver.getBagPredictions(predictions, minSubsequenceLen=k, numClass=NUM_OUTPUT)
print("Round: %2d, Validation accuracy: %.4f" % (round_, acc), end='')
print(', Test Accuracy (k = %d): %f, ' % (k, np.mean((bagPredictions == BAG_TEST).astype(int))), end='')
mi_savings = (1 - NUM_TIMESTEPS / ORIGINAL_NUM_TIMESTEPS)
emi_savings = getEarlySaving(predictionStep, NUM_TIMESTEPS)
total_savings = mi_savings + (1 - mi_savings) * emi_savings
print("Total Savings: %f" % total_savings)
```
| github_jupyter |
# Basic Spectrum Generation
The first and most simple way in which TARDIS calculates spectra is by calculating it directly from the Monte Carlo packets after the final [Monte Carlo Iteration](../montecarlo/index.rst). This simply requires knowledge of each packet's energy and frequency in the lab frame (see [Reference Frames](../montecarlo/propagation.rst#reference-frames)) at the end of the iteration. The only other quantity needed is the time duration of the simulation $\Delta t$, which is calculated based off of the luminosity of the supernova's photosphere (see [Energy Packet Initialization](../montecarlo/initialization.ipynb)).
<div class="alert alert-info">
Note
The only packets which are used for this calculation are the packets which escape the outer boundary of the
computational domain -- those reabsorbed into the photosphere are not included (see [Packet Propagation](../montecarlo/propagation.rst)).
</div>
The spectrum calculation is very straightforward. A packet of energy $E_\mathrm{packet}$ contributes a
luminosity
$$L_\mathrm{packet} = \frac{E_\mathrm{packet}}{\Delta t}$$
to the spectrum at its frequency.
In the code below, we will see an issue with merely relying on luminosity to give us a spectrum, which will allow us to develop the concept of luminosity *density*, and then correctly plot the TARDIS spectrum.
We start by importing the necessary packages, loading a configuration, and setting up a simulation object (see [Setting up the Simulation](../setup/index.rst)):
```
from tardis.io.config_reader import Configuration
from tardis.simulation import Simulation
from tardis.montecarlo import TARDISSpectrum
from tardis.io.atom_data.util import download_atom_data
from astropy import units as u
import numpy as np
import matplotlib.pyplot as plt
# We download the atomic data needed to run the simulation
download_atom_data('kurucz_cd23_chianti_H_He')
tardis_config = Configuration.from_yaml('tardis_example.yml')
sim = Simulation.from_config(tardis_config)
```
We now select a number of packets to run through the Monte Carlo simulation, and then run one Monte Carlo iteration (see [Monte Carlo Iteration](../montecarlo/index.rst)):
```
N_packets = 5000
# Using the commented out code below, we can also get the number of packets
# from the configuration -- try it out:
#N_packets = tardis_config.no_of_packets
sim.iterate(N_packets)
```
We call the arrays of each packet's frequency and how much energy the packet has:
```
nus = sim.runner.output_nu
nus
energies = sim.runner.output_energy
energies
```
Notice that some energies are negative. This means that the packet ended up being reabsorbed into the photosphere (we will separate out these packets later). Also note that the number of elements of our arrays of frequencies and energies is the same as the number of packets that we ran (as it should be):
```
len(nus), len(energies)
```
TARDIS will then calculate a list of the packet luminosities by dividing each element in the array of energies by the time of the simulation $\Delta t$:
```
luminosities = energies / sim.runner.time_of_simulation
luminosities
```
Now, as mentioned before, we only want to include the packets that make it through to the outer boundary. To do this, TARDIS creates an array of booleans (either True or False) called a mask that tells us if the packet should be counted in the spectrum. We then can use that mask to get an array of the frequencies and energies of only the packets which we are interested in:
```
emitted_mask = sim.runner.emitted_packet_mask
emitted_mask
emitted_nus = nus[emitted_mask]
emitted_nus
emitted_luminosities = luminosities[emitted_mask]
emitted_luminosities
```
The length of these lists is the number of packets that made it out of the supernova:
```
len(emitted_nus), len(emitted_luminosities)
```
Now, let's plot frequency versus luminosity. We will see a very strange graph, which will lead us into developing a new strategy for plotting the spectrum:
```
plt.scatter(emitted_nus, emitted_luminosities)
plt.xlabel('Frequency (Hz)')
plt.ylabel('Luminosity (erg/s)');
```
This is not the type of plot that we are looking for. We also cannot solve this problem by adding up the luminosities of all packets with the same frequency -- in fact, since frequency is a continuum, it would be extremely unlikely that any two packets have the same *exact* frequency. To solve this problem, we will need the concept of luminosity density.
## Luminosity Density
What we will have to do instead is plot a histogram where we bin up different frequencies that are close to each other into a certain number of bins. We then add up the luminosities of each packet in the bin and divide by the "width" of the bins. For example, if we are plotting between 0 Hz and 50 Hz in 5 bins, we would add up the luminosities of the packets between 0 Hz and 10 Hz, between 10 Hz and 20 Hz, between 20 Hz and 30 Hz, etc., and then divide each value by 10 Hz, which is the width of each bin (note that the bin widths need not be uniform). This will give us the luminosity density with respect to frequency, denoted by $L_\nu$, and measured in ergs per second per Hertz. This can be interpreted as the luminosity per unit Hertz, i.e. how much luminosity will be in an interval with a width of 1 Hz.
The division step here is crucial, as otherwise the values on the y-axis will, for example, approximately double if we double the widths of our bins (as we would be adding about double the luminosity contributions into that bin). We clearly want the values on the y-axis to be independent of the number of bins we break the luminosity into, thus making luminosity density the best way to plot a spectrum.
Note that we can also have luminosity density with respect to wavelength, $L_\lambda$, which we get by binning the packets by wavelength instead of frequency. Since the width of the bins would now have the dimensions of length, $L_\lambda$ will have units of ergs per second per Angstrom.
Now, to generate our spectrum, we select the bounds for our spectrum and the number of bins that we group the packets into. Feel free to change the number of bins to see how it affects the spectrum!
```
# The lowest frequency we plot
freq_start = 1.5e14 * u.Hz
# The highest frequency we plot
freq_stop = 3e15 * u.Hz
# The number of bins
N = 500
```
The above information can also be retrieved from the configuration using the commented-out code below. Note that the configuration has the bounds specified in terms of wavelengths. Therefore we must convert these to frequencies, noting that the frequency is the speed of light divided by the wavelength (Astropy has a built-in way to do this, which we shall use). Additionally, since wavelength and frequency are inversely related, the lower bound for the wavelengths is the upper bound for the frequencies and vice versa.
```
#freq_start = tardis_config.spectrum.stop.to('Hz', u.spectral())
#freq_stop = tardis_config.spectrum.start.to('Hz', u.spectral())
#N = tardis_config.spectrum.num
```
Next, TARDIS generates the list of frequency bins. The array shown contain the boundaries between successive bins as well as the lower and upper bounds of the spectrum:
```
spectrum_frequency = np.linspace(freq_start, freq_stop, N+1)
spectrum_frequency
```
Then, TARDIS creates a histogram where we add up the luminosity in each bin:
```
emitted_luminosity_hist = u.Quantity(np.histogram(emitted_nus,
weights=emitted_luminosities,
bins=spectrum_frequency.value,
)[0], "erg / s",)
emitted_luminosity_hist
```
Finally, we input this information into the TARDISSpectrum class, which will generate the luminosity density with respect to both wavelength and frequency and allow us to plot both of these.
```
spectrum = TARDISSpectrum(spectrum_frequency, emitted_luminosity_hist)
spectrum.plot(mode='frequency')
spectrum.plot(mode='wavelength')
```
<div class="alert alert-info">
Note
Most of this process is done internally by TARDIS. Given a simulation object `sim` that has been run, calling `sim.runner.spectrum` will give you a `TARDISSpectrum` object that can then be plotted using the `.plot()` method. See, for example, our [Quickstart Guide](../../quickstart.ipynb). This notebook just demonstrates how TARDIS generates this spectrum when `sim.runner.spectrum` is called.
</div>
You may notice that the bins are not uniformly spaced with respect to wavelength. This is because we use the same bins for both wavelength and frequency, and thus the bins which are uniformly spaced with respect to frequency are not uniformly spaced with respect to wavelength. This is okay though, since luminosity density allows us to alter the bins without significantly altering the graph!
Another thing you may notice in these graphs is the lack of a smooth curve. This is due to **noise**: the effects of the random nature of Monte Carlo simulations. This makes it very difficult to get a precise spectrum without drastically increasing the number of Monte Carlo packets. To solve this problem, TARDIS uses [virtual packets](virtualpackets.rst) and [the formal integral method](sourceintegration.rst) to generate a spectrum with less noise.
| github_jupyter |
```
import numpy as np
import matplotlib.pyplot as plt
from collections import defaultdict
%matplotlib inline
def bar_plot(ax, data, group_stretch=0.8, bar_stretch=0.95,
legend=True, x_labels=True, label_fontsize=8,
colors=None, barlabel_offset=1,
bar_labeler=lambda k, i, s: str(round(s, 3))):
"""
original version: https://stackoverflow.com/a/69170270/9388050
Draws a bar plot with multiple bars per data point.
:param dict data : The data we want to plot, wher keys are the
names of each bar group, and items is a list of bar
values for the corresponding group.
:param float group_stretch : 1 means groups occupy the most (largest groups
touch side to side if they have equal number of bars).
:param float bar_stretch : If 1, bars within a group will touch side to side.
:param bool x_labels : If true, x-axis will contain labels with the group
names given at data, centered at the bar group.
:param int label_fontsize : Font size for the label on top of each bar.
:param float barlabel_offset : Distance, in y-values, between the top of the
bar and its label.
:param function bar_labeler : If not None, must be a functor with signature
``f(group_name, i, scalar)->str``, where each scalar
is the entry found at data[group_name][i]. When given,
returns a label to put on the top of each bar.
Otherwise no labels on top of bars.
"""
for i in data.keys():
data[i] = sorted(data[i])
sorted_data = [(k, v) for k, v in data.items()]
sorted_data = sorted(sorted_data) ## sorting alphabetically
# Printing list of tuple
sorted_k, sorted_v = zip(*sorted_data)
max_n_bars = max(len(v) for v in data.values())
group_centers = np.cumsum([max_n_bars for _ in sorted_data]) - (max_n_bars / 2)
bar_offset = (1 - bar_stretch) / 2
bars = defaultdict(list)
#
if colors is None:
colors = {g_name: [f"C{i}" for _ in values]
for i, (g_name, values) in enumerate(data.items())}
#
for g_i, ((g_name, vals), g_center) in enumerate(zip(sorted_data,
group_centers)):
n_bars = len(vals)
group_beg = g_center - (n_bars / 2) + (bar_stretch / 2)
for val_i, val in enumerate(vals):
bar = ax.bar(group_beg + val_i + bar_offset,
height=val, width=bar_stretch,
color=colors[g_name][val_i])[0]
bars[g_name].append(bar)
if bar_labeler is not None:
x_pos = bar.get_x() + (bar.get_width() / 2.0)
y_pos = val + barlabel_offset
barlbl = bar_labeler(g_name, val_i, val)
ax.text(x_pos, y_pos, barlbl, ha="center", va="bottom",
fontsize=label_fontsize)
## Graph settings: Legend, axis, label
if legend:
ax.legend([bars[k][0] for k in sorted_k], sorted_k,
bbox_to_anchor=(1.05,0.65), loc="lower right", bbox_transform=fig.transFigure,
prop={'size': 15})
#
ax.set_xticks(group_centers)
if x_labels:
ax.set_xticklabels(sorted_k)
else:
ax.set_xticklabels()
##
ax.set_xlabel('Categories', rotation = 0, labelpad=10, fontsize = 20)
ax.set_ylabel('Values', rotation = 45, labelpad=40, fontsize = 17)
ax.tick_params(axis='x', labelsize= 20)
ax.tick_params(axis='y', labelsize= 17)
return bars, group_centers
fig, ax = plt.subplots(figsize=(12, 6), dpi=80)
data = {"Foo": [4, 2, 3, 1], "Zap": [0.5, 0.2], "Quack": [6], "Bar": [6.6, 2.2, 3.3, 4.4, 5.5]}
bar_plot(ax, data, group_stretch = 0.8, bar_stretch = 0.95, legend=True,
x_labels = True, label_fontsize = 10,
barlabel_offset = 0.05, bar_labeler = lambda k, i, s: str(round(s, 3)))
```
| github_jupyter |
<a href="https://colab.research.google.com/github/NicMaq/Reinforcement-Learning/blob/master/e_greedy_and_softmax_explained.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# ε-greedy and softmax policies
This Google Colab was published to support the post: XXX Best Practices for Reinforcement Learning. <br>
It also complements this [github](https://github.com/NicMaq/Reinforcement-Learning).
<br><br>
Here, I will detail the two policies ε-greedy and softmax.
<br><br>
The 𝜖-greedy policy is a special case of 𝜖-soft policies. It chooses the best action with a probability 1−𝜖 and a random action with probability 𝜖.
<br>
There are two problems with 𝜖-greedy. First, when it chooses the random actions, it chooses them uniformly, including the actions we know are bad. This limits the performance in training and this is bad for production environments. Therefore, when the network is used to evaluate performance or control a system, 𝜖 should be set to zero. On the flip side, setting 𝜖 to zero creates a second problem: we are now only exploiting our knowledge. We stopped exploring. If the dynamics of the system changes a little, our algorithm is unable to adapt.
<br>
A solution to this problem is to select random actions with probabilities proportional to their current values. This is what softmax policies do.
<br><br>
**The policies have two distinct roles.** They are used **to find the best action** and they are used **to calculate the TD update**.
<br>
First, in the following two cells, we import the required package and declare a few global constants.
<br>
I am running tensorflow 2.x.
```
%tensorflow_version 2.x
import tensorflow as tf
import numpy as np
# NUM_ACTIONS
ACTIONS = {
0: "NOOP",
1: "FIRE",
3: "RIGHT",
4: "LEFT",
#5: "RIGHTFIRE",
#6: "LEFTFIRE",
}
NUM_ACTIONS = len(ACTIONS)
# Tau = Softmax Policy
TAU = 0.001
# Epsilon = e-greedy Policy
epsilon = 0.5
# Gamma
GAMMA = 0.99
```
# e-greedy policy with tie management
```
# Create a fake value of Q(s,a) for a mini batch of three experiences:
qsa = [[-0.5, 0.7, 0.6, 0.8],[-0.6, 0.9, 0.7, 0.9],[-0.3, -0.9, -0.2, -0.4]]
qsa_tf = tf.convert_to_tensor(qsa)
print('qsa_tf is: ', qsa_tf)
batch_terminal = [[0],[0],[1]]
batch_reward = [[1],[2],[3]]
# Find the maximums of Q(s,a)
all_ones = tf.ones_like(qsa)
qsa_max = tf.math.reduce_max(qsa_tf, axis=1, keepdims=True)
print('qsa_max is: ', qsa_max)
qsa_max_mat = qsa_max * all_ones
print('qsa_max_mat is: ', qsa_max_mat)
losers = tf.zeros_like(qsa_tf)
qsa_maximums = tf.where(tf.equal(qsa_max_mat, qsa_tf), x =all_ones, y =losers)
print('qsa_maximums is: ', qsa_maximums)
qsa_maximums_ind = tf.where(tf.equal(qsa_max_mat, qsa_tf))
print('qsa_maximums_ind is: ', qsa_maximums_ind)
nb_maximums = tf.math.reduce_sum(qsa_maximums, axis=1, keepdims=True)
print('nb_maximums is: ', nb_maximums)
# Without tie management the best_action is:
best_action = tf.math.argmax(qsa, axis=1, output_type=tf.dtypes.int32)
print('best_action is: ', best_action)
# With tie management the best action is:
only_one_max = tf.ones_like(nb_maximums)
isMaxMany = nb_maximums > only_one_max
print('isMaxMany is: ', isMaxMany)
if tf.reduce_any(isMaxMany):
nbr_maximum_int = tf.reshape(nb_maximums,[-1])
nbr_maximum_int = tf.dtypes.cast(nbr_maximum_int, tf.int32)
for idx in tf.range(best_action.shape[0]):
print('idx is', idx)
if isMaxMany[idx]:
selected_idx = tf.random.uniform((), minval=0, maxval=nbr_maximum_int[idx], dtype=tf.int32)
rows_index = tf.slice(qsa_maximums_ind,[0,0],[-1,1])
all_actions = tf.slice(qsa_maximums_ind,[0,1],[-1,-1])
current_index = tf.ones_like(rows_index)
current_index = current_index * tf.cast(idx, dtype=tf.int64)
selected_rows = tf.where(tf.equal(rows_index,current_index))
select_action = tf.slice(selected_rows,[0,0],[-1,1])
select_action = tf.squeeze(select_action)
new_action = all_actions[select_action[selected_idx]]
new_action = tf.cast(new_action, dtype=tf.int32)
tf.print('***************************************************************************************** \n')
tf.print('egreedy tie management new_action is: ', new_action)
tf.print('***************************************************************************************** \n')
indice = tf.reshape(idx,(1,1))
tf.tensor_scatter_nd_update(best_action, indice, new_action)
print('best_action is: ', best_action)
# Calculate the TD update of the Bellman equation:
num_actions_float = tf.dtypes.cast(NUM_ACTIONS, tf.float32)
pi_s = tf.dtypes.cast(all_ones, tf.float32)
print('pi_s cast is: ', pi_s)
pi_s = pi_s * epsilon / num_actions_float
print('pi_s is: ', pi_s)
pi_max = (1 - epsilon)/nb_maximums
print('pi_max is: ', pi_max)
pi = qsa_maximums * pi_max + pi_s
print('pi is: ', pi)
pi_qsa = tf.multiply(pi, qsa)
print('pi_qsa is: ', pi_qsa)
sum_piq = tf.math.reduce_sum(pi_qsa, axis=1, keepdims=True)
print('sum_piq is: ', sum_piq)
# To understand tf.tensor_scatter_nd_update
indices = tf.constant([[4], [3], [1], [7]])
print('indices is: ', indices)
updates = tf.constant([9, 10, 11, 12])
print('updates is: ', updates)
tensor = tf.ones([8], dtype=tf.int32)
print(tf.tensor_scatter_nd_update(tensor, indices, updates))
```
# softmax policy
The Boltzmann "soft max" probability distribution is defined as follows for a state x:

The only change we will do is subtract from Q(s,a) a constant to prevent overflow. So we will implement:

```
# Calculate the preference
preferences = qsa_tf / TAU
# Calculate the max preference
max_preference = tf.math.reduce_max(qsa, axis=1, keepdims=True) / TAU
# Calcualte the difference
pref_minus_max = preferences - max_preference
# Then apply the boltzmann operator
exp_preferences = tf.math.exp(pref_minus_max)
sum_exp_preferences = tf.reduce_sum(exp_preferences, axis=1, keepdims=True)
action_probs = exp_preferences / sum_exp_preferences
print("Action probabilities are: ", action_probs)
# The selection of the best action will be achieve by:
best_action = np.random.choice(NUM_ACTIONS, p=action_probs[0])
print("Best action is: ", best_action)
# The TD update will be the following. I am using qsa for simplicity but keep in mind you should use the action-value of your next state:
expectation = tf.multiply(action_probs, qsa)
sum_expectation = tf.reduce_sum(expectation, axis=1, keepdims=True)
v_next_vect = batch_terminal * sum_expectation
target_vec = batch_reward + GAMMA * v_next_vect
print("The TD update is: ", target_vec )
```
| github_jupyter |
<table style="float:left; border:none">
<tr style="border:none">
<td style="border:none">
<a href="https://bokeh.org/">
<img
src="assets/bokeh-transparent.png"
style="width:50px"
>
</a>
</td>
<td style="border:none">
<h1>Bokeh Tutorial</h1>
</td>
</tr>
</table>
<div style="float:right;"><h2>05. Presentation and Layout</h2></div>
```
from bokeh.io import output_notebook, show
from bokeh.plotting import figure
output_notebook()
```
In the previous chapters we started to learn how to create single plots using differnet kinds of data. But we often want to plot more than one thing. Bokeh plots can be individually embedded in HTML documents, but it's often easier to
combine multiple plots in one of Bokeh's built-in layouts. We will learn how to do that in this chapter
The cell below defines a few data variables we will use in examples.
```
x = list(range(11))
y0, y1, y2 = x, [10-i for i in x], [abs(i-5) for i in x]
```
# Rows and Columns
The `bokeh.layouts` modules provides the ``row`` and ``column`` functions to arrange plot objects in vertical or horizontal layouts. Below is an example of three plots arranged in a row.
```
from bokeh.layouts import row
# create a new plot
s1 = figure(width=250, plot_height=250)
s1.circle(x, y0, size=10, color="navy", alpha=0.5)
# create another one
s2 = figure(width=250, height=250)
s2.triangle(x, y1, size=10, color="firebrick", alpha=0.5)
# create and another
s3 = figure(width=250, height=250)
s3.square(x, y2, size=10, color="olive", alpha=0.5)
# show the results in a row
show(row(s1, s2, s3))
# EXERCISE: use column to arrange a few plots vertically (don't forget to import column)
```
# Grid plots
Bokeh also provides a `gridplot` layout in `bokeh.layouts` for arranging plots in a grid, as show in the example below.
```
from bokeh.layouts import gridplot
# create a new plot
s1 = figure(width=250, plot_height=250)
s1.circle(x, y0, size=10, color="navy", alpha=0.5)
# create another one
s2 = figure(width=250, height=250)
s2.triangle(x, y1, size=10, color="firebrick", alpha=0.5)
# create and another
s3 = figure(width=250, height=250)
s3.square(x, y2, size=10, color="olive", alpha=0.5)
# put all the plots in a gridplot
p = gridplot([[s1, s2], [s3, None]], toolbar_location=None)
# show the results
show(p)
# EXERCISE: create a gridplot of your own
```
# Next Section
Click on this link to go to the next notebook: [06 - Linking and Interactions](06%20-%20Linking%20and%20Interactions.ipynb).
To go back to the overview, click [here](00%20-%20Introduction%20and%20Setup.ipynb).
| github_jupyter |
```
from __future__ import print_function
import os
from io import open
import requests
import shutil
import numpy as np
import json
from IPython.display import Image
from zipfile import ZipFile
import keras
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import LearningRateScheduler, ModelCheckpoint
from keras.layers import Dense, Activation, Conv2D, MaxPool2D, GlobalAvgPool2D, BatchNormalization, add, Input
from keras.models import Model
from tensorflow.python.keras.preprocessing import image
# Getting current directory
execution_path = os.getcwd()
DATASET_DIR = os.path.join(execution_path, "idenprof")
DATASET_TRAIN_DIR = os.path.join(DATASET_DIR, "train")
DATASET_TEST_DIR = os.path.join(DATASET_DIR, "test")
# Directory in which to create models
save_direc = os.path.join(os.getcwd(), 'idenprof_models')
# Name of model files
model_name = 'idenprof_weight_model.{epoch:03d}-{val_acc}.h5'
# Create Directory if it doesn't exist
if not os.path.isdir(save_direc):
os.makedirs(save_direc)
# Join the directory with the model file
modelpath = os.path.join(save_direc, model_name)
# Checkpoint to save best model
checkpoint = ModelCheckpoint(filepath = modelpath, monitor = 'val_acc', verbose = 1, save_best_only = True,
save_weights_only = True, period=1)
# Function for adjusting learning rate and saving dummy file
def lr_schedule(epoch):
"""
Learning Rate Schedule
"""
# Learning rate is scheduled to be reduced after 80, 120, 160, 180 epochs. Called automatically every
# epoch as part of callbacks during training.
lr = 1e-3
if epoch > 180:
lr *= 1e-4
elif epoch > 160:
lr *= 1e-3
elif epoch > 120:
lr *= 1e-2
elif epoch > 80:
lr *= 1e-1
print('Learning rate: ', lr)
return lr
lr_scheduler = LearningRateScheduler(lr_schedule)
def resnet_module(input, channel_depth, strided_pool=False):
residual_input = input
stride = 1
if (strided_pool):
stride = 2
residual_input = Conv2D(channel_depth, kernel_size=1, strides=stride, padding="same",
kernel_initializer="he_normal")(residual_input)
residual_input = BatchNormalization()(residual_input)
input = Conv2D(int(channel_depth / 4), kernel_size=1, strides=stride, padding="same",
kernel_initializer="he_normal")(input)
input = BatchNormalization()(input)
input = Activation("relu")(input)
input = Conv2D(int(channel_depth / 4), kernel_size=3, strides=1, padding="same", kernel_initializer="he_normal")(
input)
input = BatchNormalization()(input)
input = Activation("relu")(input)
input = Conv2D(channel_depth, kernel_size=1, strides=1, padding="same", kernel_initializer="he_normal")(input)
input = BatchNormalization()(input)
input = add([input, residual_input])
input = Activation("relu")(input)
return input
def resnet_first_block_first_module(input, channel_depth):
residual_input = input
stride = 1
residual_input = Conv2D(channel_depth, kernel_size=1, strides=1, padding="same", kernel_initializer="he_normal")(
residual_input)
residual_input = BatchNormalization()(residual_input)
input = Conv2D(int(channel_depth / 4), kernel_size=1, strides=stride, padding="same",
kernel_initializer="he_normal")(input)
input = BatchNormalization()(input)
input = Activation("relu")(input)
input = Conv2D(int(channel_depth / 4), kernel_size=3, strides=stride, padding="same",
kernel_initializer="he_normal")(input)
input = BatchNormalization()(input)
input = Activation("relu")(input)
input = Conv2D(channel_depth, kernel_size=1, strides=stride, padding="same", kernel_initializer="he_normal")(input)
input = BatchNormalization()(input)
input = add([input, residual_input])
input = Activation("relu")(input)
return input
def resnet_block(input, channel_depth, num_layers, strided_pool_first=False):
for i in range(num_layers):
pool = False
if (i == 0 and strided_pool_first):
pool = True
input = resnet_module(input, channel_depth, strided_pool=pool)
return input
def ResNet50(input_shape, num_classes=10):
input_object = Input(shape=input_shape)
layers = [3, 4, 6, 3]
channel_depths = [256, 512, 1024, 2048]
output = Conv2D(64, kernel_size=7, strides=2, padding="same", kernel_initializer="he_normal")(input_object)
output = BatchNormalization()(output)
output = Activation("relu")(output)
output = MaxPool2D(pool_size=(3, 3), strides=(2, 2))(output)
output = resnet_first_block_first_module(output, channel_depths[0])
for i in range(4):
channel_depth = channel_depths[i]
num_layers = layers[i]
strided_pool_first = True
if (i == 0):
strided_pool_first = False
num_layers = num_layers - 1
output = resnet_block(output, channel_depth=channel_depth, num_layers=num_layers,
strided_pool_first=strided_pool_first)
output = GlobalAvgPool2D()(output)
output = Dense(num_classes)(output)
output = Activation("softmax")(output)
model = Model(inputs=input_object, outputs=output)
return model
def train_network():
print(os.listdir(os.path.join(execution_path, "idenprof")))
optimizer = keras.optimizers.Adam(lr=0.01, decay=1e-4)
batch_size = 32
num_classes = 10
epochs = 200
model = ResNet50((224, 224, 3), num_classes=num_classes)
model.compile(loss="categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])
model.summary()
return model
print("Using real time Data Augmentation")
train_datagen = ImageDataGenerator(
rescale=1. / 255,
horizontal_flip=True)
test_datagen = ImageDataGenerator(
rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(DATASET_TRAIN_DIR, target_size=(224, 224),
batch_size=batch_size, class_mode="categorical")
test_generator = test_datagen.flow_from_directory(DATASET_TEST_DIR, target_size=(224, 224), batch_size=batch_size,
class_mode="categorical")
model.fit_generator(train_generator, steps_per_epoch=int(9000 / batch_size), epochs=epochs,
validation_data=test_generator,
validation_steps=int(2000 / batch_size), callbacks=[checkpoint, lr_scheduler])
# Train the network
model = train_network()
```
## Measuring the Accuracy
```
CLASS_INDEX = None
MODEL_PATH = os.path.join(execution_path, "idenprof_ResNet50_061-0.7933.h5")
JSON_PATH = os.path.join(execution_path, "idenprof_model_class.json")
model = ResNet50(input_shape=(224, 224, 3), num_classes=10)
model.load_weights(MODEL_PATH)
optimizer = keras.optimizers.Adam(lr=0.01, decay=1e-4)
model.compile(loss="categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])
test_datagen = ImageDataGenerator(rescale=1. / 255)
test_generator = test_datagen.flow_from_directory(DATASET_TEST_DIR, target_size=(224, 224), batch_size = 32,
class_mode="categorical")
model.evaluate_generator(test_generator,steps=int(2000 / 32))
```
## Predictions on real-world images
```
def preprocess_input(x):
x *= (1. / 255)
return x
def decode_predictions(preds, top=5, model_json=""):
global CLASS_INDEX
if CLASS_INDEX is None:
CLASS_INDEX = json.load(open(model_json))
results = []
for pred in preds:
top_indices = pred.argsort()[-top:][::-1]
for i in top_indices:
each_result = []
each_result.append(CLASS_INDEX[str(i)])
each_result.append(pred[i])
results.append(each_result)
return results
def run_inference(model,picture):
image_to_predict = image.load_img(picture, target_size=(224, 224))
image_to_predict = image.img_to_array(image_to_predict, data_format="channels_last")
image_to_predict = np.expand_dims(image_to_predict, axis=0)
image_to_predict = preprocess_input(image_to_predict)
prediction = model.predict(x=image_to_predict, steps=1)
predictiondata = decode_predictions(prediction, top=int(5), model_json=JSON_PATH)
for result in predictiondata:
print(str(result[0]), " : ", str(result[1] * 100))
picture = os.path.join(execution_path, "test-images/1.jpg")
display(Image(filename=picture))
run_inference(model,picture)
picture = os.path.join(execution_path, "test-images/2.jpg")
display(Image(filename=picture))
run_inference(model,picture)
picture = os.path.join(execution_path, "test-images/3.jpg")
display(Image(filename=picture))
run_inference(model,picture)
```
| github_jupyter |
# WQU Capstone project - Short-term trading strategy on G10 currencies
## Notebook one - Sampling technique
* Sergey Chigrinov - chigrinov.s.88@gmail.com
* Dhruv Agrawal - dhruva1@stanfordalumni.org
* Man Sing Ho - mshoalbert@gmail.com
### Jun-Aug-2020
This notebook is based on De Prado, "Advances in Financial Machine Learning" book. The idea is that the characteristics of financial time series sample data can be improved if we use sampling techniques other that time sampling. In this case we use "tick" sampliand and an approximation of "dollar" sampling. As an example we will use the data for AUD/USD pair for the last 4 years.
```
import sys
import os
#insert you own path or use relative path
path_to_project = os.path.realpath('..') # r'C:\WQU\Capstone\Working_files'
sys.path.append(path_to_project)
import pandas as pd
import numpy as np
import datetime as dt
import warnings
warnings.filterwarnings('ignore')
```
We packed the main part of the code into a library below for this project.
```
from WQUcapstoneCode.sampling import sampling
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.style.use('seaborn-talk')
plt.style.use('bmh')
save=True
ticker = 'AUD/USD'
input_path = os.path.join(path_to_project, 'input_data', ''.join(ticker.split('/')) + '.csv')
token = 'PLEASE CREATE YOUR TOKEN' # https://www.fxcm.com/fxcmpy
try:
import fxcmpy
con = fxcmpy.fxcmpy(access_token=token, log_level='error')
#cannot download everything in one go because FXCM api rerurns only a limited number of records so we split them in two time periods
start = dt.datetime(2015, 6, 1)
end = dt.datetime(2017, 6, 1)
pair = con.get_candles(ticker1, period='H2', start=start, end=end)
start = end
end = dt.datetime(2020, 6, 1)
pair = pair.append(con.get_candles(ticker, period='H2', start=start, end=end))
if save: pair.to_csv(os.path.join(input_path))
except:
print("Reading the data offline")
pair = pd.read_csv(input_path)
print(f'We have a total of {pair.shape[0]} records in the input data for {ticker}')
pd.concat([pair.head(3), pair.tail(3)]) # top and bottom 3
```
We will be working with the mid price and tick number. While we don't have volume and dollar volume per se, we can try to "model" the dollar volume by multiplying the mid price by the number of ticks. The disclaimer here is that we recognise that each tick may have different volume, it's just hard to get the volume data.
```
df = pd.DataFrame()
df['price'] = np.mean(pair[['bidclose','askclose']], axis = 1)
df['ticks'] = pair['tickqty']
df.index =[dt.datetime.strptime(date, '%Y-%m-%d %H:%M:%S') for date in pair.date]
#let's assume that price x ticks is an approximation for dollar volume
df['dv'] = df.price * df.ticks
sns.boxplot(df.price, )
```
As can be seen from the above, there are no large outliers so there's no need to clean this data.
Now when we have the data we may try to inprove it's characteristics by using a sampling technoque different from time sampling.
```
ticks_multiplier = 2. # for calculating average number of ticks/dollars exchanged in 4 hour intervals (2 hour interval is original data)
m_ticks = ticks_multiplier * df.ticks.sum()/df.shape[0] # average number of ticks in 4 hour interval
m_dollars = ticks_multiplier * df.dv.sum()/df.shape[0] # average number of dollars exchanged in 4 hour interval
#print(m_ticks,m_dollars)
tick_df = sampling.sampled_bar_df(df, 'ticks',m_ticks)
dollar_df = sampling.sampled_bar_df(df, 'dv',m_dollars)
print(f"""Number of variables in a sample
Time bar: {df.shape[0]:,}
Tick bar: {tick_df.shape[0]:,}
Dollar bar: {dollar_df.shape[0]:,}
""")
```
Now let's plot the last 255 intervals for time bars and the corresponding tick and dollar bars in that interval
```
#last 255 intervals for time bars and the corresponding tick bars in that interval
intervals_to_plot = 255
xdf, xtdf = sampling.select_sample_data(df, tick_df, 'price', start_date = df.index[-intervals_to_plot-1], end_date = df.index[-1])
#print(xdf.shape[0], xtdf.shape[0])
sampling.plot_sample_data(xdf, xtdf, 'tick bar', alpha=0.5, markersize=7)
#last 255 intervals for time bars and the corresponding dollar bars in that interval
xdf, xddf = sampling.select_sample_data(df, dollar_df, 'price', start_date = df.index[-intervals_to_plot-1], end_date = df.index[-1])
#print(xdf.shape[0], xddf.shape[0])
sampling.plot_sample_data(xdf, xddf, 'dollar bar', alpha=0.5, markersize=7)
bar_returns = sampling.returns(df.price), sampling.returns(tick_df.price), sampling.returns(dollar_df.price)
bar_types = ['time','tick', 'dollar']
```
Below are the tables autocorrelation and absolute autocorrelation statistics
```
autocorrs = sampling.get_test_stats(bar_types,bar_returns,pd.Series.autocorr)
display(autocorrs.sort_values('autocorr_stat'),
autocorrs.abs().sort_values('autocorr_stat'))
```
Autocorrelation drops with number of lags for both tick and dollar samples. However, looking at charts below, we can see that some lags actually have higher autocorrelation.
```
sampling.plot_autocorr(bar_types,bar_returns, ylim = [-0.1,0.1])
```
Now we can check if the distribution of the returns is closer to normal
```
sampling.plot_hist(bar_types,bar_returns)
```
Jarque-Bera Test (smaller - closer to normal):
```
sampling.get_test_stats(bar_types,bar_returns,sampling.jb)
```
Shapiro-Wilk Test (larger - closer to normal):
```
sampling.get_test_stats(bar_types,bar_returns,sampling.shapiro)
```
Both Jarque-Bera and Shapiro-Wilk Test have shown that tick and dollar sampling have have made the distribution of returns closer to normal
### Conclusion
The evidence above has shown that it is better to use tick and dollar sampling instead of time sampling.
The difference between tick and dollar sampling in our case is small. Since our dollar sampling does not take volumes into account in the most accurate manner and tick sampling has more favorable statistics, we will proceed with tick sampling.
| github_jupyter |
# Code-to-Code Comparison: IEA Task 26
### National Renewable Energy Laboratory
#### Rob Hammond
##### 27 May 2021
```
import os
import pickle
from copy import deepcopy
from time import perf_counter
from pprint import pprint
import numpy as np
import pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
from wombat.core import Simulation
from wombat.core.library import IEA_26, load_yaml
pd.set_option("display.max_rows", 1000)
pd.set_option("display.max_columns", 1000)
%matplotlib inline
tech_salary_annual = 100000
techs = 30
capacity = 400 * 1000 # 400MW -> kW
tech_salary_annual * techs / capacity
configs = [
"one_mobilization",
"one_mobilization_100pct_reduction",
"two_mobilizations",
"two_mobilizations_100pct_reduction",
"three_mobilizations",
"three_mobilizations_100pct_reduction",
]
columns = deepcopy(configs)
results = {
"availability - time based": [],
"availability - production based": [],
"capacity factor - net": [],
"capacity factor - gross": [],
"power production": [],
"task completion rate": [],
"total annual costs": [],
"technicians": [],
"materials": [],
"vessels": [],
"ctv cost": [],
"hlv cost": [],
"dsv cost": [],
"cab cost": [],
"manual reset": [],
"minor repair": [],
"major repair": [],
"major replacement": [],
"remote reset": [],
"annual service": [],
"bos": [], # substructure inspection + scour repair + substation inspection + small/large transformer repairs
"total downtime": [],
"ctv utilization": [],
"hlv utilization": [],
"dsv utilization": [],
"cab utilization": [],
}
for config in configs:
# Run the simulation
start = perf_counter()
config = load_yaml(os.path.join(str(IEA_26), "config"), f"{config}.yaml")
sim = Simulation.from_inputs(**config)
sim.run()
end = perf_counter()
print(f"{config['name'].rjust(45)} | {(end - start) / 60:.2f} m")
# Gather the results of interest
years = sim.metrics.events.year.unique().shape[0]
mil = 1000000
availability = sim.metrics.time_based_availability(frequency="project", by="windfarm")
availability_production = sim.metrics.production_based_availability(frequency="project", by="windfarm")
cf_net = sim.metrics.capacity_factor(which="net", frequency="project", by="windfarm")
cf_gross = sim.metrics.capacity_factor(which="gross", frequency="project", by="windfarm")
power_production = sim.metrics.power_production(frequency="project", by_turbine=False).values[0][0]
completion_rate = sim.metrics.task_completion_rate(which="both", frequency="project")
parts = sim.metrics.events[["materials_cost"]].sum().sum()
techs = sim.metrics.project_fixed_costs(frequency="project", resolution="medium").labor[0]
total = sim.metrics.events[["total_cost"]].sum().sum()
equipment = sim.metrics.equipment_costs(frequency="project", by_equipment=True)
equipment_sum = equipment.sum().sum()
ctv = equipment[[el for el in equipment.columns if "Crew Transfer Vessel" in el]].sum().sum()
hlv = equipment[[el for el in equipment.columns if "Jack-up Vessel" in el]].sum().sum()
dsv = equipment[[el for el in equipment.columns if "Diving Support Vessel" in el]].sum().sum()
cab = equipment[[el for el in equipment.columns if "Cable Laying Vessel" in el]].sum().sum()
times = sim.metrics.process_times()
times = times / years / 24 / 100 # events per turbine and year
utilization = sim.metrics.service_equipment_utilization(frequency="project")
ctv_ur = utilization[[el for el in utilization.columns if "Crew Transfer Vessel" in el]].mean().mean()
hlv_ur = utilization[[el for el in utilization.columns if "Jack-up Vessel" in el]].mean().mean()
dsv_ur = utilization[[el for el in utilization.columns if "Diving Support Vessel" in el]].mean().mean()
cab_ur = utilization[[el for el in utilization.columns if "Cable Laying Vessel" in el]].mean().mean()
# Log the results of interest
results["availability - time based"].append(availability)
results["availability - production based"].append(availability_production)
results["capacity factor - net"].append(cf_net)
results["capacity factor - gross"].append(cf_gross)
results["power production"].append(power_production)
results["task completion rate"].append(completion_rate)
results["total annual costs"].append((total + techs) / mil / years)
results["technicians"].append(techs / mil / years)
results["materials"].append(parts / mil / years)
results["vessels"].append(equipment_sum / mil / years)
results["ctv cost"].append(ctv / mil / years)
results["hlv cost"].append(hlv / mil / years)
results["dsv cost"].append(dsv / mil / years)
results["cab cost"].append(cab / mil / years)
results["manual reset"].append(times.loc[times.index.intersection(["manual reset"]), "downtime"].sum())
results["minor repair"].append(times.loc[times.index.intersection(["minor repair", ]), "downtime"].sum())
results["major repair"].append(times.loc[times.index.intersection(["major repair"]), "downtime"].sum())
results["major replacement"].append(times.loc[times.index.intersection(["major replacement"]), "downtime"].sum())
results["remote reset"].append(times.loc[times.index.intersection(["remote reset"]), "downtime"].sum())
results["annual service"].append(times.loc[times.index.intersection(["annual service"]), "downtime"].sum())
ix = [
"substructure inspection", "substation inspection",
"small foundation/scour repair", "cable replacement",
"small transformer repair", "large transformer repair"
]
results["bos"].append(times.loc[times.index.intersection(ix), "downtime"].sum())
results["total downtime"].append(times.loc[:, "downtime"].sum())
results["ctv utilization"].append(ctv_ur)
results["hlv utilization"].append(hlv_ur)
results["dsv utilization"].append(dsv_ur)
results["cab utilization"].append(cab_ur)
# Save the results
# pickled dictionary format
with open(os.path.join(str(IEA_26), "outputs", "results_dict.pkl"), "wb") as f:
pickle.dump(results, f)
# dataframe/csv format
results_df = pd.DataFrame(results.values(), columns=columns, index=results.keys()).fillna(0)
results_df.to_csv(os.path.join(str(IEA_26), "outputs", "results_data.csv"), index_label="result")
pd.options.display.float_format = '{:,.2f}'.format
results_df
```
| github_jupyter |
## Getting the GIS data
http://www.census.gov/geo/maps-data/data/tiger-data.html
# Setting up The database
Setting up the database for use with PostGIS
### Install PostGIS
```
sudo apt-get update
sudo apt-get install -y postgis postgresql-9.5-postgis-2.2
```
If you're on a mac,
ensure those are the latest versions
Install the postgis extensions in PostGres:
```
psql
```
```
CREATE EXTENSION postgis; CREATE EXTENSION postgis_topology;
```
Other extensions for additional geographic functionality available.
Databases should now support geographic datatypes and functions.
Sources:
http://www.saintsjd.com/2014/08/13/howto-install-postgis-on-ubuntu-trusty.html
http://postgis.net/install/
http://www.bostongis.com/PrinterFriendly.aspx?content_name=postgis_tut01
### Create and Load Geodatabase
http://www.bostongis.com/PrinterFriendly.aspx?content_name=postgis_tut01
Download your shapefiles.
You may need to prep them before loading some.
Figure out the SRID (spatial reference id) of the shapefiles
for GerryPy data it is going probably be 4269
This website is useful to find your srid: http://spatialreference.org/ref/epsg/4269/
Convert the Shapefiles to .sql:
Some tutorials talk about the commands being in a hard to get to directory. I had access to them right out of the box, and will proceed as though you have them too.
Run the following command from the directory that holds the shapefule (made up of .shp, .shx, .prj, .dbf, .xml, all with the same name).
```
shp2pgsql -s <srid> <shapefile_name> [optional table name] > <new_name for .sql file>.sql
```
You should now have a .sql file in that same directory. It contains the table and the geographic shapes. This is what we'll add to the database.
Load files to database:
```
psql -d <your_username> -h localhost -U <your_username> -f <your_new_.sql_file>
```
I sometimes have trouble with this last step. If you're getting errors about the table not existing. Try adding it to your username database. then use sql to copy it to a new database.
Check your DB! You should be ready to go.
## Finding the neighboring shapes with PostGIS
http://stackoverflow.com/questions/26866416/finding-neighbouring-polygons-postgis-query
The edges table is built by finding every set of bordering tracts. The PostGIS function ST_Touches is used to accomplish this. The code below is not for GerryPy, but is an example of a similar function.
```
Update gemstat_simple5 gem set spread=1, time=2
FROM (
SELECT (b."GEM_NR")
FROM gemstat_simple5 as a,
gemstat_simple5 as b
WHERE ST_Touches(a.the_geom, b.the_geom)
AND a."GEM_NR" != b."GEM_NR"
AND a.spread = 1
) as subquery
WHERE gem."GEM_NR" = subquery."GEM_NR"
```
## District View SQL
In your psql database run the following SQL to build a view that generates summary stats and shapes fomr your tract table "colorado_tracts".
```
CREATE VIEW vwDistrict
AS
SELECT t.districtid,
sum(t.tract_pop) as population,
sum(t.shape_area) as area,
cast(ST_MULTI(ST_UNION(t.geom)) as geometry(MultiPolygon,4269)) as geom
FROM colorado_tracts AS t
GROUP BY t.districtid;
```
## Getting PyQGIS working on your computer
We have to use python2 to work with QGIS (boo)
We dont yet know how to do tht accross the board, but we'll figure that out.
After installing QGIS, open up its desktop software. From the top toolbar: click Plugins > Python Console
In the console, type:
```
import qgis
print(qgis.__file__)
```
That should give you the location of the qgis scripts.
it should look something like :
"/usr/lib/python2.7/dist-packages/qgis/__init__.pyc"
go to your venv activate script and set a new environment variable for that path up until the qgis module.
```
export PYTHONPATH=/usr/lib/python2.7/dist-packages/
```
Now, in your module, you should be able to
```
import qgis
```
## Setting up PyQGIS
PyQGIS needs to be able to access its modules, which are buried somewhere on your computer. You probably wont be able to access them right away.
If you go to http://docs.qgis.org/testing/en/docs/pyqgis_developer_cookbook/intro.html#using-pyqgis-in-custom-applications
There's a solution, but it didnt work for me. My files are in a different directory.
Open up your QGIS Desktop app. Click on Plugins > Python Console. In console, type:
```
import qgis
print(qgis.__file__)
```
The retuen value should be something like. /usr/lib/python2.7/dist-packages/qgis/__init__.pyc
Copy the path up to 'qgis' and go to your bin/activate file in your venv.
Set a new environment variable for your PYTHONPATH that leads to that location, like so:
export PYTHONPATH=/usr/lib/python2.7/dist-packages/
Restart your venv and pyqgis modules should work. should...
##Working with Vectors
how to select by an attribute expression
http://gis.stackexchange.com/questions/131158/how-to-select-features-using-an-expression-with-pyqgis
| github_jupyter |
```
%pylab inline
import pandas as pd
import numpy as np
from pathlib import Path
import random
import shutil
from fast_progress import progress_bar
import PIL.Image
from functools import partial
IMGNET = Path('/DATA/kaggle/imgnetloc/')
IMAGES_TRAIN = Path('/DATA/kaggle/imgnetloc/ILSVRC/Data/CLS-LOC/train/')
IMAGES_VAL = Path('/DATA/kaggle/imgnetloc/ILSVRC/Data/CLS-LOC/val/')
TRAIN_SOLUTION_CSV = IMGNET/'LOC_train_solution.csv'
VALID_SOLUTION_CSV = IMGNET/'LOC_val_solution.csv'
ANNO_TRAIN = Path('/DATA/kaggle/imgnetloc/ILSVRC/Annotations/CLS-LOC/train/')
ANNO_VAL = Path('/DATA/kaggle/imgnetloc/ILSVRC/Annotations/CLS-LOC/val/')
# parse one line of class file, just going to grab first descriptions
def parse_class_line(l):
id = l.split(' ')[0]
classes = l[len(id):].strip().split(',')
return id, classes[0].strip()
# read in mapping of class id to text description
def read_classes(fn):
classes = dict(map(parse_class_line, open(fn,'r').readlines()))
return classes
classes = read_classes(IMGNET/'LOC_synset_mapping.txt')
def get_img_fns(img_train_path, class_id):
img_fns = []
for fn in (img_train_path/class_id).iterdir():
img_fns.append(fn)
return img_fns
def plot_samples(clsid):
img_fns = get_img_fns(IMAGES_TRAIN, clsid)
images = [PIL.Image.open(fn) for fn in np.random.choice(img_fns, 3)]
_,axes = plt.subplots(1,3, figsize=(12,3))
for i,ax in enumerate(axes.flat): ax.imshow(images[i])
pull_classes = [
'n01443537', 'n01669191', 'n01774750', 'n01641577', 'n01882714',
'n01983481', 'n02114367', 'n02115641', 'n02317335', 'n01806143',
'n01484850', 'n03063689', 'n03272010', 'n03124170', 'n02799071',
'n03400231', 'n03452741', 'n02802426', 'n02692877', 'n02787622',
'n03785016', 'n04252077', 'n02088466', 'n04254680', 'n02504458',
'n03345487', 'n03642806', 'n03063599'
]
for k in pull_classes:
plot_samples(k)
total_images = 0
for clsid in pull_classes:
img_fns = get_img_fns(IMAGES_TRAIN, clsid)
num_images = len(img_fns)
total_images += num_images
print(classes[clsid], num_images)
print('total images:', total_images)
valid_df = pd.read_csv(VALID_SOLUTION_CSV)
train_df = pd.read_csv(TRAIN_SOLUTION_CSV)
len(train_df), len(valid_df)
train_df['classid'] = train_df.ImageId.apply(lambda x: x.split('_')[0])
def parse_prediction_string(s):
ids = []
items = s.split(' ')
pred_count = len(items) // 5
for i in range(pred_count):
ids.append(items[i*5])
return ids[0]
valid_df['classid'] = valid_df.PredictionString.apply(parse_prediction_string)
small_train_df = train_df.loc[train_df.classid.isin(pull_classes)]
small_valid_df = valid_df.loc[valid_df.classid.isin(pull_classes)]
len(pull_classes), small_train_df.shape, small_valid_df.shape
IMGNET_SMALL = Path('/DATA/kaggle/imgnetloc_small/')
SMALL_DATA = IMGNET_SMALL/'ILSVRC/Data/CLS-LOC'
SMALL_ANNO = IMGNET_SMALL/'ILSVRC/Annotations/CLS-LOC'
SMALL_DATA.mkdir(parents=True, exist_ok=True)
SMALL_ANNO.mkdir(parents=True, exist_ok=True)
(SMALL_DATA/'train').mkdir(parents=True, exist_ok=True)
(SMALL_ANNO/'val').mkdir(parents=True, exist_ok=True)
# copy training directories
for k in progress_bar(pull_classes):
src_data_path = IMAGES_TRAIN/k
dest_data_path = SMALL_DATA/'train'/k
if dest_data_path.exists():
shutil.rmtree(dest_data_path)
shutil.copytree(src_data_path, dest_data_path)
src_data_path = ANNO_TRAIN/k
dest_data_path = SMALL_ANNO/'train'/k
if dest_data_path.exists():
shutil.rmtree(dest_data_path)
shutil.copytree(src_data_path, dest_data_path)
# copy validation directories
dest_val_data = SMALL_DATA/'val'
dest_val_anno = SMALL_ANNO/'val'
if dest_val_data.exists():
shutil.rmtree(dest_val_data)
if dest_val_anno.exists():
shutil.rmtree(dest_val_anno)
dest_val_data.mkdir(parents=True, exist_ok=True)
dest_val_anno.mkdir(parents=True, exist_ok=True)
for ix, row in progress_bar(list(small_valid_df.ImageId.items())):
src_file = IMAGES_VAL/f'{row}.JPEG'
dest_file = dest_val_data/f'{row}.JPEG'
shutil.copyfile(src_file, dest_file)
src_file = ANNO_VAL/f'{row}.xml'
dest_file = dest_val_anno/f'{row}.xml'
shutil.copyfile(src_file, dest_file)
# copy text files, filtering out classes we don't want
def copy_file_with_filter(src_file, dst_file, filter_func, has_header=True):
with open(src_file,'r') as rf:
src_lines = rf.readlines()
start_line = 1 if has_header else 0
with open(dst_file,'w') as wf:
if has_header: wf.write(src_lines[0])
for line in src_lines[start_line:]:
if filter_func(line):
wf.write(line)
def valid_is_desired_class(line, classes):
clsid = line.split(',')[1].split(' ')[0]
#print(clsid in classes)
return clsid in classes
def is_desired_class(line, classes):
clsid = line[0:9]
return clsid in classes
def copy_filtered_csv(src_path, dst_path, fn, classes, has_header, check_func):
copy_file_with_filter(src_path/fn, dst_path/fn, partial(check_func, classes=classes), has_header=has_header)
text_files = [
('LOC_val_solution.csv', True, valid_is_desired_class),
('LOC_train_solution.csv', True, is_desired_class),
('LOC_synset_mapping.txt', False, is_desired_class)
]
for fn,has_header,func in text_files: copy_filtered_csv(IMGNET, IMGNET_SMALL, fn, pull_classes, has_header, func)
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from matplotlib import pyplot as plt
%matplotlib inline
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=10, shuffle=True)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
foreground_classes = {'plane', 'car', 'bird'}
#foreground_classes = {'bird', 'cat', 'deer'}
background_classes = {'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'}
#background_classes = {'plane', 'car', 'dog', 'frog', 'horse','ship', 'truck'}
fg1,fg2,fg3 = 0,1,2
dataiter = iter(trainloader)
background_data=[]
background_label=[]
foreground_data=[]
foreground_label=[]
batch_size=10
for i in range(5000):
images, labels = dataiter.next()
for j in range(batch_size):
if(classes[labels[j]] in background_classes):
img = images[j].tolist()
background_data.append(img)
background_label.append(labels[j])
else:
img = images[j].tolist()
foreground_data.append(img)
foreground_label.append(labels[j])
foreground_data = torch.tensor(foreground_data)
foreground_label = torch.tensor(foreground_label)
background_data = torch.tensor(background_data)
background_label = torch.tensor(background_label)
def create_mosaic_img(bg_idx,fg_idx,fg):
"""
bg_idx : list of indexes of background_data[] to be used as background images in mosaic
fg_idx : index of image to be used as foreground image from foreground data
fg : at what position/index foreground image has to be stored out of 0-8
"""
image_list=[]
j=0
for i in range(9):
if i != fg:
image_list.append(background_data[bg_idx[j]])#.type("torch.DoubleTensor"))
j+=1
else:
image_list.append(foreground_data[fg_idx])#.type("torch.DoubleTensor"))
label = foreground_label[fg_idx]-fg1 # minus 7 because our fore ground classes are 7,8,9 but we have to store it as 0,1,2
#image_list = np.concatenate(image_list ,axis=0)
image_list = torch.stack(image_list)
return image_list,label
desired_num = 30000
mosaic_list_of_images =[] # list of mosaic images, each mosaic image is saved as list of 9 images
fore_idx =[] # list of indexes at which foreground image is present in a mosaic image i.e from 0 to 9
mosaic_label=[] # label of mosaic image = foreground class present in that mosaic
for i in range(desired_num):
np.random.seed(i)
bg_idx = np.random.randint(0,35000,8)
fg_idx = np.random.randint(0,15000)
fg = np.random.randint(0,9)
fore_idx.append(fg)
image_list,label = create_mosaic_img(bg_idx,fg_idx,fg)
mosaic_list_of_images.append(image_list)
mosaic_label.append(label)
class MosaicDataset(Dataset):
"""MosaicDataset dataset."""
def __init__(self, mosaic_list_of_images, mosaic_label, fore_idx):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.mosaic = mosaic_list_of_images
self.label = mosaic_label
self.fore_idx = fore_idx
def __len__(self):
return len(self.label)
def __getitem__(self, idx):
return self.mosaic[idx] , self.label[idx], self.fore_idx[idx]
batch = 250
msd = MosaicDataset(mosaic_list_of_images, mosaic_label , fore_idx)
train_loader = DataLoader( msd,batch_size= batch ,shuffle=False)
data,labels,fg_index = iter(train_loader).next()
ag = []
for i in range(120):
alphag = torch.ones((250,9))/9
ag.append( alphag.requires_grad_() )
class Module2(nn.Module):
def __init__(self):
super(Module2, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
self.fc4 = nn.Linear(10,3)
def forward(self,y): #z batch of list of 9 images
y1 = self.pool(F.relu(self.conv1(y)))
y1 = self.pool(F.relu(self.conv2(y1)))
y1 = y1.view(-1, 16 * 5 * 5)
y1 = F.relu(self.fc1(y1))
y1 = F.relu(self.fc2(y1))
y1 = F.relu(self.fc3(y1))
y1 = self.fc4(y1)
return y1
torch.manual_seed(1234)
what_net = Module2().double()
what_net = what_net.to("cuda")
def attn_avg(x,alpha):
y = torch.zeros([batch,3, 32,32], dtype=torch.float64)
y = y.to("cuda")
alpha = F.softmax(alpha,dim=1) # alphas
for i in range(9):
alpha1 = alpha[:,i]
y = y + torch.mul(alpha1[:,None,None,None],x[:,i])
return y,alpha
def calculate_attn_loss(dataloader,what,criter):
what.eval()
r_loss = 0
alphas = []
lbls = []
pred = []
fidices = []
correct = 0
tot = 0
with torch.no_grad():
for i, data in enumerate(dataloader, 0):
inputs, labels,fidx= data
lbls.append(labels)
fidices.append(fidx)
inputs = inputs.double()
alpha = ag[i] # alpha for ith batch
inputs, labels,alpha = inputs.to("cuda"),labels.to("cuda"),alpha.to("cuda")
avg,alpha = attn_avg(inputs,alpha)
alpha = alpha.to("cuda")
outputs = what(avg)
_, predicted = torch.max(outputs.data, 1)
correct += sum(predicted == labels)
tot += len(predicted)
pred.append(predicted.cpu().numpy())
alphas.append(alpha.cpu().numpy())
loss = criter(outputs, labels)
r_loss += loss.item()
alphas = np.concatenate(alphas,axis=0)
pred = np.concatenate(pred,axis=0)
lbls = np.concatenate(lbls,axis=0)
fidices = np.concatenate(fidices,axis=0)
#print(alphas.shape,pred.shape,lbls.shape,fidices.shape)
analysis = analyse_data(alphas,lbls,pred,fidices)
return r_loss/i,analysis,correct.item(),tot,correct.item()/tot
def analyse_data(alphas,lbls,predicted,f_idx):
'''
analysis data is created here
'''
batch = len(predicted)
amth,alth,ftpt,ffpt,ftpf,ffpf = 0,0,0,0,0,0
for j in range (batch):
focus = np.argmax(alphas[j])
if(alphas[j][focus] >= 0.5):
amth +=1
else:
alth +=1
if(focus == f_idx[j] and predicted[j] == lbls[j]):
ftpt += 1
elif(focus != f_idx[j] and predicted[j] == lbls[j]):
ffpt +=1
elif(focus == f_idx[j] and predicted[j] != lbls[j]):
ftpf +=1
elif(focus != f_idx[j] and predicted[j] != lbls[j]):
ffpf +=1
#print(sum(predicted==lbls),ftpt+ffpt)
return [ftpt,ffpt,ftpf,ffpf,amth,alth]
optim1 = []
for i in range(120):
optim1.append(optim.RMSprop([ag[i]], lr=0.1))
# instantiate optimizer
optimizer_what = optim.RMSprop(what_net.parameters(), lr=0.001)#, momentum=0.9)#,nesterov=True)
criterion = nn.CrossEntropyLoss()
acti = []
analysis_data_tr = []
analysis_data_tst = []
loss_curi_tr = []
loss_curi_tst = []
epochs = 200
# calculate zeroth epoch loss and FTPT values
running_loss,anlys_data,correct,total,accuracy = calculate_attn_loss(train_loader,what_net,criterion)
print('training epoch: [%d ] loss: %.3f correct: %.3f, total: %.3f, accuracy: %.3f' %(0,running_loss,correct,total,accuracy))
loss_curi_tr.append(running_loss)
analysis_data_tr.append(anlys_data)
# training starts
for epoch in range(epochs): # loop over the dataset multiple times
ep_lossi = []
running_loss = 0.0
what_net.train()
for i, data in enumerate(train_loader, 0):
# get the inputs
grads = []
inputs, labels,_ = data
inputs = inputs.double()
alpha = ag[i] # alpha for ith batch
inputs, labels,alpha = inputs.to("cuda"),labels.to("cuda"),alpha.to("cuda")
# zero the parameter gradients
optimizer_what.zero_grad()
optim1[i].zero_grad()
# forward + backward + optimize
avg,alpha = attn_avg(inputs,alpha)
outputs = what_net(avg)
loss = criterion(outputs, labels)
# print statistics
running_loss += loss.item()
alpha.retain_grad()
loss.backward(retain_graph=False)
optimizer_what.step()
optim1[i].step()
running_loss_tr,anls_data,correct,total,accuracy = calculate_attn_loss(train_loader,what_net,criterion)
analysis_data_tr.append(anls_data)
loss_curi_tr.append(running_loss_tr) #loss per epoch
print('training epoch: [%d ] loss: %.3f correct: %.3f, total: %.3f, accuracy: %.3f' %(epoch+1,running_loss_tr,correct,total,accuracy))
if running_loss_tr<=0.08:
break
print('Finished Training run ')
analysis_data_tr = np.array(analysis_data_tr)
columns = ["epochs", "argmax > 0.5" ,"argmax < 0.5", "focus_true_pred_true", "focus_false_pred_true", "focus_true_pred_false", "focus_false_pred_false" ]
df_train = pd.DataFrame()
df_test = pd.DataFrame()
df_train[columns[0]] = np.arange(0,epoch+2)
df_train[columns[1]] = analysis_data_tr[:,-2]
df_train[columns[2]] = analysis_data_tr[:,-1]
df_train[columns[3]] = analysis_data_tr[:,0]
df_train[columns[4]] = analysis_data_tr[:,1]
df_train[columns[5]] = analysis_data_tr[:,2]
df_train[columns[6]] = analysis_data_tr[:,3]
df_train
fig= plt.figure(figsize=(12,12))
plt.plot(df_train[columns[0]],df_train[columns[3]]/300, label ="focus_true_pred_true ")
plt.plot(df_train[columns[0]],df_train[columns[4]]/300, label ="focus_false_pred_true ")
plt.plot(df_train[columns[0]],df_train[columns[5]]/300, label ="focus_true_pred_false ")
plt.plot(df_train[columns[0]],df_train[columns[6]]/300, label ="focus_false_pred_false ")
plt.title("On Train set")
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("percentage of data")
#plt.vlines(vline_list,min(min(df_train[columns[3]]/300),min(df_train[columns[4]]/300),min(df_train[columns[5]]/300),min(df_train[columns[6]]/300)), max(max(df_train[columns[3]]/300),max(df_train[columns[4]]/300),max(df_train[columns[5]]/300),max(df_train[columns[6]]/300)),linestyles='dotted')
plt.show()
fig.savefig("train_analysis_every_20.pdf")
fig.savefig("train_analysis_every_20.png")
aph = []
for i in ag:
aph.append(F.softmax(i,dim=1).detach().numpy())
aph = np.concatenate(aph,axis=0)
torch.save({
'epoch': 500,
'model_state_dict': what_net.state_dict(),
'optimizer_state_dict': optimizer_what.state_dict(),
"optimizer_alpha":optim1,
"FTPT_analysis":analysis_data_tr,
"alpha":aph
}, "cifar_what_net_500.pt")
aph
running_loss_tr,anls_data,correct,total,accuracy = calculate_attn_loss(train_loader,what_net,criterion)
anls_data
```
| github_jupyter |
##### Copyright 2019 The TensorFlow Authors. [Licensed under the Apache License, Version 2.0](#scrollTo=Afd8bu4xJOgh).
```
// #@title Licensed under the Apache License, Version 2.0 (the "License"); { display-mode: "form" }
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// https://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
```
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://www.tensorflow.org/swift/tutorials/protocol_oriented_generics"><img src="https://www.tensorflow.org/images/tf_logo_32px.png" />View on TensorFlow.org</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/tensorflow/swift/blob/main/docs/site/tutorials/protocol_oriented_generics.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/tensorflow/swift/blob/main/docs/site/tutorials/protocol_oriented_generics.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />View source on GitHub</a>
</td>
</table>
# Protocol-oriented programming & generics
This tutorial will go over protocol-oriented programming, and different examples of how they can be used with generics in day-to-day examples.
## Protocols
Inheritance is a powerful way to organize code in programming languages that allows you to share code between multiple components of the program.
In Swift, there are different ways to express inheritance. You may already be familiar with one of those ways, from other languages: class inheritance. However, Swift has another way: protocols.
In this tutorial, we will explore protocols - an alternative to subclassing that allows you to achieve similar goals through different tradeoffs. In Swift, protocols contain multiple abstract members. Classes, structs and enums can conform to multiple protocols and the conformance relationship can be established retroactively. All that enables some designs that aren't easily expressible in Swift using subclassing. We will walk through the idioms that support the use of protocols (extensions and protocol constraints), as well as the limitations of protocols.
## Swift 💖's value types!
In addition to classes which have reference semantics, Swift supports enums and structs that are passed by value. Enums and structs support many features provided by classes. Let's take a look!
Firstly, let's look at how enums are similar to classes:
```
enum Color: String {
case red = "red"
case green = "green"
case blue = "blue"
// A computed property. Note that enums cannot contain stored properties.
var hint: String {
switch self {
case .red:
return "Roses are this color."
case .green:
return "Grass is this color."
case .blue:
return "The ocean is this color."
}
}
// An initializer like for classes.
init?(color: String) {
switch color {
case "red":
self = .red
case "green":
self = .green
case "blue":
self = .blue
default:
return nil
}
}
}
// Can extend the enum as well!
extension Color {
// A function.
func hintFunc() -> String {
return self.hint
}
}
let c = Color.red
print("Give me a hint for c: \(c.hintFunc())")
let invalidColor = Color(color: "orange")
print("is invalidColor nil: \(invalidColor == nil)")
```
Now, let's look at structs. Notice that we cannot inherit structs, but instead can use protocols:
```
struct FastCar {
// Can have variables and constants as stored properties.
var color: Color
let horsePower: Int
// Can have computed properties.
var watts: Float {
return Float(horsePower) * 745.7
}
// Can have lazy variables like in classes!
lazy var titleCaseColorString: String = {
let colorString = color.rawValue
return colorString.prefix(1).uppercased() +
colorString.lowercased().dropFirst()
}()
// A function.
func description() -> String {
return "This is a \(color) car with \(horsePower) horse power!"
}
// Can create a variety of initializers.
init(color: Color, horsePower: Int) {
self.color = color
self.horsePower = horsePower
}
// Can define extra initializers other than the default one.
init?(color: String, horsePower: Int) {
guard let enumColor = Color(color: color) else {
return nil
}
self.color = enumColor
self.horsePower = horsePower
}
}
var car = FastCar(color: .red, horsePower: 250)
print(car.description())
print("Horse power in watts: \(car.watts)")
print(car.titleCaseColorString)
```
Finally, let's see how they are pass by value types unlike classes:
```
// Notice we have no problem modifying a constant class with
// variable properties.
class A {
var a = "a"
}
func foo(_ a: A) {
a.a = "foo"
}
let a = A()
print(a.a)
foo(a)
print(a.a)
/*
Uncomment the following code to see how an error is thrown.
Structs are implicitly passed by value, so we cannot modify it.
> "error: cannot assign to property: 'car' is a 'let' constant"
*/
// func modify(car: FastCar, toColor color: Color) -> Void {
// car.color = color
// }
// car = FastCar(color: .red, horsePower: 250)
// print(car.description())
// modify(car: &car, toColor: .blue)
// print(car.description())
```
## Let's use protocols
Let's start by creating protocols for different cars:
```
protocol Car {
var color: Color { get set }
var price: Int { get }
func turnOn()
mutating func drive()
}
protocol Electric {
mutating func recharge()
// percentage of the battery level, 0-100%.
var batteryLevel: Int { get set }
}
protocol Gas {
mutating func refill()
// # of liters the car is holding, varies b/w models.
var gasLevelLiters: Int { get set }
}
```
In an object-oriented world (with no multiple inheritance), you may have made `Electric` and `Gas` abstract classes then used class inheritance to make both inherit from `Car`, and then have a specific car model be a base class. However, here both are completely separate protocols with **zero** coupling! This makes the entire system more flexible in how you design it.
Let's define a Tesla:
```
struct TeslaModelS: Car, Electric {
var color: Color // Needs to be a var since `Car` has a getter and setter.
let price: Int
var batteryLevel: Int
func turnOn() {
print("Starting all systems!")
}
mutating func drive() {
print("Self driving engaged!")
batteryLevel -= 8
}
mutating func recharge() {
print("Recharging the battery...")
batteryLevel = 100
}
}
var tesla = TeslaModelS(color: .red, price: 110000, batteryLevel: 100)
```
This specifies a new struct `TeslaModelS` that conforms to both protocols `Car` and `Electric`.
Now let’s define a gas powered car:
```
struct Mustang: Car, Gas{
var color: Color
let price: Int
var gasLevelLiters: Int
func turnOn() {
print("Starting all systems!")
}
mutating func drive() {
print("Time to drive!")
gasLevelLiters -= 1
}
mutating func refill() {
print("Filling the tank...")
gasLevelLiters = 25
}
}
var mustang = Mustang(color: .red, price: 30000, gasLevelLiters: 25)
```
### Extend protocols with default behaviors
What you can notice from the examples is that we have some redundancy. Every time we recharge an electric car, we need to set the battery percentage level to 100. Since all electric cars have a max capacity of 100%, but gas cars vary between gas tank capacity, we can default the level to 100 for electric cars.
This is where extensions in Swift can come in handy:
```
extension Electric {
mutating func recharge() {
print("Recharging the battery...")
batteryLevel = 100
}
}
```
So now, any new electric car we create will set the battery to 100 when we recharge it. Thus, we have just been able to decorate classes, structs, and enums with unique and default behavior.

Thanks to [Ray Wenderlich](https://www.raywenderlich.com/814-introducing-protocol-oriented-programming-in-swift-3) for the comic!
However, one thing to watch out for is the following. In our first implementation, we define `foo()` as a default implementation on `A`, but not make it required in the protocol. So when we call `a.foo()`, we get "`A default`" printed.
```
protocol Default {}
extension Default {
func foo() { print("A default")}
}
struct DefaultStruct: Default {
func foo() {
print("Inst")
}
}
let a: Default = DefaultStruct()
a.foo()
```
However, if we make `foo()` required on `A`, we get "`Inst`":
```
protocol Default {
func foo()
}
extension Default {
func foo() {
print("A default")
}
}
struct DefaultStruct: Default {
func foo() {
print("Inst")
}
}
let a: Default = DefaultStruct()
a.foo()
```
This occurs due to a difference between static dispatch in the first example and static dispatch in the second on protocols in Swift. For more info, refer to this [Medium post](https://medium.com/@PavloShadov/https-medium-com-pavloshadov-swift-protocols-magic-of-dynamic-static-methods-dispatches-dfe0e0c85509).
### Overriding default behavior
However, if we want to, we can still override the default behavior. One important thing to note is that this [doesn’t support dynamic dispatch](https://stackoverflow.com/questions/44703205/swift-protocol-extension-method-is-called-instead-of-method-implemented-in-subcl).
Let’s say we have an older version of an electric car, so the battery health has been reduced to 90%:
```
struct OldElectric: Car, Electric {
var color: Color // Needs to be a var since `Car` has a getter and setter.
let price: Int
var batteryLevel: Int
func turnOn() {
print("Starting all systems!")
}
mutating func drive() {
print("Self driving engaged!")
batteryLevel -= 8
}
mutating func reCharge() {
print("Recharging the battery...")
batteryLevel = 90
}
}
```
## Standard library uses of protocols
Now that we have an idea how protocols in Swift work, let's go through some typical examples of using the standard library protocols.
### Extend the standard library
Let's see how we can add additional functionality to types that exist in Swift already. Since types in Swift aren't built in, but are part of the standard library as structs, this is easy to do.
Let's try and do binary search on an array of elements, while also making sure to check that the array is sorted:
```
extension Collection where Element: Comparable {
// Verify that a `Collection` is sorted.
func isSorted(_ order: (Element, Element) -> Bool) -> Bool {
var i = index(startIndex, offsetBy: 1)
while i < endIndex {
// The longer way of calling a binary function like `<(_:_:)`,
// `<=(_:_:)`, `==(_:_:)`, etc.
guard order(self[index(i, offsetBy: -1)], self[i]) else {
return false
}
i = index(after: i)
}
return true
}
// Perform binary search on a `Collection`, verifying it is sorted.
func binarySearch(_ element: Element) -> Index? {
guard self.isSorted(<=) else {
return nil
}
var low = startIndex
var high = endIndex
while low <= high {
let mid = index(low, offsetBy: distance(from: low, to: high)/2)
if self[mid] == element {
return mid
} else if self[mid] < element {
low = index(after: mid)
} else {
high = index(mid, offsetBy: -1)
}
}
return nil
}
}
print([2, 2, 5, 7, 11, 13, 17].binarySearch(5)!)
print(["a", "b", "c", "d"].binarySearch("b")!)
print([1.1, 2.2, 3.3, 4.4, 5.5].binarySearch(3.3)!)
```
We do this by extending the [`Collection`](https://developer.apple.com/documentation/swift/collection) protocol which defines _"a sequence whose elements can be traversed multiple times, nondestructively, and accessed by an indexed subscript."_ Since arrays can be indexed using the square bracket notation, this is the protocol we want to extend.
Similarly, we only want to add this utility function to arrays whose elements can be compared. This is the reason why we have `where Element: Comparable`.
The `where` clause is a part of Swift's type system, which we will cover soon, but in short lets us add additional requirements to the extension we are writing, such as to require the type to implement a protocol, to require two types to be the same, or to require a class to have a particular superclass.
[`Element`](https://developer.apple.com/documentation/swift/sequence/2908099-element) is the associated type of the elements in a `Collection`-conforming type. `Element` is defined within the [`Sequence`](https://developer.apple.com/documentation/swift/sequence) protocol, but since `Collection` inherits from `Sequence`, it inherits the `Element` associated type.
[`Comparable`](https://developer.apple.com/documentation/swift/comparable) is a protocol that defines _"a type that can be compared using the relational operators `<`, `<=`, `>=`, and `>`."_. Since we are performing binary search on a sorted `Collection`, this of course has to be true or else we don't know whether to recurse/iterate left or right in the binary search.
As a side note about the implementation, for more info on the `index(_:offsetBy:)` function that was used, refer to the following [documentation](https://developer.apple.com/documentation/swift/string/1786175-index).
## Generics + protocols = 💥
Generics and protocols can be a powerful tool if used correctly to avoid duplicate code.
Firstly, look over another tutorial, [A Swift Tour](https://colab.research.google.com/github/tensorflow/swift/blob/main/docs/site/tutorials/a_swift_tour.ipynb), which briefly covers generics at the end of the Colab book.
Assuming you have a general idea about generics, let's quickly take a look at some advanced uses.
When a single type has multiple requirements such as a type conforming to several protocols, you have several options at your disposal:
```
typealias ComparableReal = Comparable & FloatingPoint
func foo1<T: ComparableReal>(a: T, b: T) -> Bool {
return a > b
}
func foo2<T: Comparable & FloatingPoint>(a: T, b: T) -> Bool {
return a > b
}
func foo3<T>(a: T, b: T) -> Bool where T: ComparableReal {
return a > b
}
func foo4<T>(a: T, b: T) -> Bool where T: Comparable & FloatingPoint {
return a > b
}
func foo5<T: FloatingPoint>(a: T, b: T) -> Bool where T: Comparable {
return a > b
}
print(foo1(a: 1, b: 2))
print(foo2(a: 1, b: 2))
print(foo3(a: 1, b: 2))
print(foo4(a: 1, b: 2))
print(foo5(a: 1, b: 2))
```
Notice the use of `typealias` at the top. This adds a named alias of an existing type into your program. After a type alias is declared, the aliased name can be used instead of the existing type everywhere in your program. Type aliases do not create new types; they simply allow a name to refer to an existing type.
Now, let's see how we can use protocols and generics together.
Let's imagine we are a computer store with the following requirements on any laptop we sell for determining how we organize them in the back of the store:
```
enum Box {
case small
case medium
case large
}
enum Mass {
case light
case medium
case heavy
}
// Note: `CustomStringConvertible` protocol lets us pretty-print a `Laptop`.
struct Laptop: CustomStringConvertible {
var name: String
var box: Box
var mass: Mass
var description: String {
return "(\(self.name) \(self.box) \(self.mass))"
}
}
```
However, we have a new requirement of grouping our `Laptop`s by mass since the shelves have weight restrictions.
```
func filtering(_ laptops: [Laptop], by mass: Mass) -> [Laptop] {
return laptops.filter { $0.mass == mass }
}
let laptops: [Laptop] = [
Laptop(name: "a", box: .small, mass: .light),
Laptop(name: "b", box: .large, mass: .medium),
Laptop(name: "c", box: .medium, mass: .heavy),
Laptop(name: "d", box: .large, mass: .light)
]
let filteredLaptops = filtering(laptops, by: .light)
print(filteredLaptops)
```
However, what if we wanted to filter by something other than `Mass`?
One option is to do the following:
```
// Define a protocol which will act as our comparator.
protocol DeviceFilterPredicate {
associatedtype Device
func shouldKeep(_ item: Device) -> Bool
}
// Define the structs we will use for passing into our filtering function.
struct BoxFilter: DeviceFilterPredicate {
typealias Device = Laptop
var box: Box
func shouldKeep(_ item: Laptop) -> Bool {
return item.box == box
}
}
struct MassFilter: DeviceFilterPredicate {
typealias Device = Laptop
var mass: Mass
func shouldKeep(_ item: Laptop) -> Bool {
return item.mass == mass
}
}
// Make sure our filter conforms to `DeviceFilterPredicate` and that we are
// filtering `Laptop`s.
func filtering<F: DeviceFilterPredicate>(
_ laptops: [Laptop],
by filter: F
) -> [Laptop] where Laptop == F.Device {
return laptops.filter { filter.shouldKeep($0) }
}
// Let's test the function out!
print(filtering(laptops, by: BoxFilter(box: .large)))
print(filtering(laptops, by: MassFilter(mass: .heavy)))
```
Awesome! Now we are able to filter based on any laptop constraint. However, we are only able to filter `Laptop`s.
What about being able to filter anything that is in a box and has mass? Maybe this warehouse of laptops will also be used for servers which have a different customer base:
```
// Define 2 new protocols so we can filter anything in a box and which has mass.
protocol Weighable {
var mass: Mass { get }
}
protocol Boxed {
var box: Box { get }
}
// Define the new Laptop and Server struct which have mass and a box.
struct Laptop: CustomStringConvertible, Boxed, Weighable {
var name: String
var box: Box
var mass: Mass
var description: String {
return "(\(self.name) \(self.box) \(self.mass))"
}
}
struct Server: CustomStringConvertible, Boxed, Weighable {
var isWorking: Bool
var name: String
let box: Box
let mass: Mass
var description: String {
if isWorking {
return "(working \(self.name) \(self.box) \(self.mass))"
} else {
return "(notWorking \(self.name) \(self.box) \(self.mass))"
}
}
}
// Define the structs we will use for passing into our filtering function.
struct BoxFilter<T: Boxed>: DeviceFilterPredicate {
var box: Box
func shouldKeep(_ item: T) -> Bool {
return item.box == box
}
}
struct MassFilter<T: Weighable>: DeviceFilterPredicate {
var mass: Mass
func shouldKeep(_ item: T) -> Bool {
return item.mass == mass
}
}
// Define the new filter function.
func filtering<F: DeviceFilterPredicate, T>(
_ elements: [T],
by filter: F
) -> [T] where T == F.Device {
return elements.filter { filter.shouldKeep($0) }
}
// Let's test the function out!
let servers = [
Server(isWorking: true, name: "serverA", box: .small, mass: .heavy),
Server(isWorking: false, name: "serverB", box: .medium, mass: .medium),
Server(isWorking: true, name: "serverC", box: .large, mass: .light),
Server(isWorking: false, name: "serverD", box: .medium, mass: .light),
Server(isWorking: true, name: "serverE", box: .small, mass: .heavy)
]
let products = [
Laptop(name: "a", box: .small, mass: .light),
Laptop(name: "b", box: .large, mass: .medium),
Laptop(name: "c", box: .medium, mass: .heavy),
Laptop(name: "d", box: .large, mass: .light)
]
print(filtering(servers, by: BoxFilter(box: .small)))
print(filtering(servers, by: MassFilter(mass: .medium)))
print(filtering(products, by: BoxFilter(box: .small)))
print(filtering(products, by: MassFilter(mass: .medium)))
```
We have now been able to filter an array by not only any property of a specific `struct`, but also be able to filter any struct which has that property!
# Tips for good API design
***This section was taken from the [WWDC 2019: Modern Swift API Design](https://developer.apple.com/videos/play/wwdc2019/415/) talk.***
Now that you understand how protocols behave, it's best to go over when you should use protocols. As powerful as protocols can be, it's not always the best idea to dive in and immediately start with protocols.
* Start with concrete use cases:
* First explore the use case with concrete types and understand what code it is you want to share and find is being repeated. Then, factor that shared code out with generics. It might mean to create new protocols. Discover a need for generic code.
* Consider composing new protocols from existing protocols defined in the standard library. Refer to the following [Apple documentation](https://developer.apple.com/documentation/swift/adopting_common_protocols) for a good example of this.
* Instead of a generic protocol, consider defining a generic type instead.
## Example: defining a custom vector type
Let's say we want to define a `GeometricVector` protocol on floating-point numbers to use in some geometry app we are making which defines 3 important vector operations:
```swift
protocol GeometricVector {
associatedtype Scalar: FloatingPoint
static func dot(_ a: Self, _ b: Self) -> Scalar
var length: Scalar { get }
func distance(to other: Self) -> Scalar
}
```
Let's say we want to store the dimensions of the vector, which the `SIMD` protocol can help us with, so we will make our new type refine the `SIMD` protocol. `SIMD` vectors can be thought of as fixed size vectors that are very fast when you use them to perform vector operations:
```swift
protocol GeometricVector: SIMD {
associatedtype Scalar: FloatingPoint
static func dot(_ a: Self, _ b: Self) -> Scalar
var length: Scalar { get }
func distance(to other: Self) -> Scalar
}
```
Now, let us define the default implementations of the operations above:
```swift
extension GeometricVector {
static func dot(_ a: Self, _ b: Self) -> Scalar {
(a * b).sum()
}
var length: Scalar {
Self.dot(self, self).squareRoot()
}
func distance(to other: Self) -> Scalar {
(self - other).length
}
}
```
And then we need to add a conformance to each of the types we want to add these abilities:
```swift
extension SIMD2: GeometricVector where Scalar: FloatingPoint { }
extension SIMD3: GeometricVector where Scalar: FloatingPoint { }
extension SIMD4: GeometricVector where Scalar: FloatingPoint { }
extension SIMD8: GeometricVector where Scalar: FloatingPoint { }
extension SIMD16: GeometricVector where Scalar: FloatingPoint { }
extension SIMD32: GeometricVector where Scalar: FloatingPoint { }
extension SIMD64: GeometricVector where Scalar: FloatingPoint { }
```
This three-step process of defining the protocol, giving it a default implementation, and then adding a conformance to multiple types is fairly repetitive.
## Was the protocol necessary?
The fact that none of the `SIMD` types have unique implementations is a warning sign. So in this case, the protocol isn't really giving us anything.
## Defining it in an extension of `SIMD`
If we write the 3 operators in an extension of the `SIMD` protocol, this can solve the problem more succinctly:
```swift
extension SIMD where Scalar: FloatingPoint {
static func dot(_ a: Self, _ b: Self) -> Scalar {
(a * b).sum()
}
var length: Scalar {
Self.dot(self, self).squareRoot()
}
func distance(to other: Self) -> Scalar {
(self - other).length
}
}
```
Using less lines of code, we added all the default implementations to all the types of `SIMD`.
Sometimes you may be tempted to create this hierarchy of types, but remember that it isn't always necessary. This also means the binary size of your compiled program will be smaller, and your code will be faster to compile.
However, this extension approach is great for when you have a few number of methods you want to add. However, it does hit a scalability issue when you are designing a larger API.
## Is-a? Has-a?
Earlier we said `GeometricVector` would refine `SIMD`. But is this a is-a relationship? The problem is that `SIMD` defines operations which lets us add a scalar 1 to a vector, but it doesn't make sense to define such an operation in the context of geometry.
So, maybe a has-a relationship would be better by wrapping `SIMD` in a new generic type that can handle any floating point number:
```swift
// NOTE: `Storage` is the underlying type that is storing the values,
// just like in a `SIMD` vector.
struct GeometricVector<Storage: SIMD> where Storage.Scalar: FloatingPoint {
typealias Scalar = Storage.Scalar
var value: Storage
init(_ value: Storage) { self.value = value }
}
```
We can then be careful and only define the operations that make sense only in the context of geometry:
```swift
extension GeometricVector {
static func + (a: Self, b: Self) -> Self {
Self(a.value + b.value)
}
static func - (a: Self, b: Self) -> Self {
Self(a.value - b.value)
}
static func * (a: Self, b: Scalar) -> Self {
Self(a.value * b)
}
}
```
And we can still use generic extensions to get the 3 previous operators we wanted to implement which look almost the exact same as before:
```swift
extension GeometricVector {
static func dot(_ a: Self, _ b: Self) -> Scalar {
(a.value * b.value).sum()
}
var length: Scalar {
Self.dot(self, self).squareRoot()
}
func distance(to other: Self) -> Scalar {
(self - other).length
}
}
```
Overall, we have been able to refine the behavior of our three operations to a type by simply using a struct. With protocols, we faced the issue of writing repetitive conformances to all the `SIMD` vectors, and also weren't able to prevent certain operators like `Scalar + Vector` from being available (which in this case we didn't want). As such, remember that protocols are not a be-all and end-all solution. But sometimes more traditional solutions can prove to be more powerful.
# More protocol-oriented programming resources
Here are additional resources on the topics discussed:
* [WWDC 2015: Protocol-Oriented Programming in Swift](https://developer.apple.com/videos/play/wwdc2015/408/): this was presented using Swift 2, so a lot has changed since then (e.g. name of the protocols they used in the presentation) but this is still a good resource for the theory and uses behind it.
* [Introducing Protocol-Oriented Programming in Swift 3](https://www.raywenderlich.com/814-introducing-protocol-oriented-programming-in-swift-3): this was written in Swift 3, so some of the code may need to be modified in order to have it compile successfully, but it is another great resource.
* [WWDC 2019: Modern Swift API Design](https://developer.apple.com/videos/play/wwdc2019/415/): goes over the differences between value and reference types, a use case of when protocols can prove to be the worse choice in API design (same as the "Tips for Good API Design" section above), key path member lookup, and property wrappers.
* [Generics](https://docs.swift.org/swift-book/LanguageGuide/Generics.html): Swift's own documentation for Swift 5 all about generics.
| github_jupyter |
## Check Member End Forces
This notebook reads files describing a structure, and the files output by Frame2D after an
analysis, and checks that the member end forces computed here from the displacements and
member loads agree with those computed by Frame2D.
It does this in the simplest way possible, using quite different logic than Frame2D, resulting
in a higher degree of confidence in the results. It would have been better had someone else
programmed it, but oh well ...
```
ds = 'KG82'
lcase = 'all'
#ds = 'l22x6'
#lcase = 'Case-2b'
def filename(basename,lc=None):
if lc is not None:
basename = lc + '/' + basename
return 'data/' + ds + '.d/' + basename + '.csv'
def Warn(msg):
print('!!!!! Warning: {}'.format(msg))
import pandas as pd
import math
class Node(object):
def __init__(self,id,x,y):
self.id = id
self.x = x
self.y = y
self.deltaX = 0.
self.deltaY = 0.
self.thetaZ = 0.
ntable = pd.read_csv(filename('nodes'))
NODES = {}
for i,n in ntable.iterrows():
if n.NODEID in NODES:
Warn("Node '{}' is multiply defined.".format(n.NODEID))
NODES[n.NODEID] = Node(n.NODEID,float(n.X),float(n.Y))
#ntable
dtable = pd.read_csv(filename('node_displacements',lcase))
for i,n in dtable.iterrows():
node = NODES[n.NODEID]
node.deltaX = float(n.DX)
node.deltaY = float(n.DY)
node.thetaZ = float(n.RZ)
dtable
pd.DataFrame([vars(v) for v in NODES.values()]).set_index('id')
class Member(object):
E = 200000.
def __init__(self,id,nodej,nodek):
self.id = id
self.nodej = nodej
self.nodek = nodek
dx = nodek.x - nodej.x
dy = nodek.y - nodej.y
self.L = L = math.sqrt(dx*dx + dy*dy)
self.cosx = dx/L
self.cosy = dy/L
self.Ix = 0.
self.A = 0.
self.loads = []
self.releases = set()
for a in 'FXJ FXK FYJ FYK MZJ MZK'.split():
setattr(self,a,0.)
table = pd.read_csv(filename('members'))
MEMBERS = {}
for i,m in table.iterrows():
if m.MEMBERID in MEMBERS:
Warn("Member '{}' is multiply defined.".format(m.MEMBERID))
MEMBERS[m.MEMBERID] = Member(m.MEMBERID,NODES[m.NODEJ],NODES[m.NODEK])
import sst
SST = sst.SST()
table = pd.read_csv(filename('properties'))
defIx = defA = None
for i,row in table.iterrows():
if not pd.isnull(row.SIZE):
defIx,defA = SST.section(row.SIZE,'Ix,A')
memb = MEMBERS[row.MEMBERID]
memb.Ix = float(defIx if pd.isnull(row.IX) else row.IX)
memb.A = float(defA if pd.isnull(row.A) else row.A)
if not pd.isnull(row.IX):
defIx = row.IX
if not pd.isnull(row.A):
defA = row.A
try:
lctable = pd.read_csv(filename('load_combinations'))
use_all = False
COMBO = {}
for i,row in lctable.iterrows():
if row.CASE == lcase:
COMBO[row.LOAD.lower()] = row.FACTOR
except OSError:
use_all = True
COMBO = None
COMBO
table = pd.read_csv(filename('member_loads'))
for i,row in table.iterrows():
memb = MEMBERS[row.MEMBERID]
typ = row.TYPE
f = 1.0 if use_all else COMBO.get(row.LOAD.lower(),0.)
if f != 0.:
w1 = None if pd.isnull(row.W1) else (float(row.W1)*f)
w2 = None if pd.isnull(row.W2) else (float(row.W2)*f)
a = None if pd.isnull(row.A) else float(row.A)
b = None if pd.isnull(row.B) else float(row.B)
c = None if pd.isnull(row.C) else float(row.C)
memb.loads.append((typ,w1,w2,a,b,c))
#MEMBERS['LC'].loads
table = pd.read_csv(filename('releases'))
for i,row in table.iterrows():
memb = MEMBERS[row.MEMBERID]
memb.releases.add(row.RELEASE.upper())
t = pd.DataFrame([vars(v) for v in MEMBERS.values()]).set_index('id')
del t['nodej']
del t['nodek']
del t['loads']
t
MEFS = pd.read_csv(filename('member_end_forces',lcase)).set_index('MEMBERID')
MEFS
cols = 'FXJ FXK FYJ FYK MZJ MZK'.split()
for m in MEMBERS.values():
for a in cols:
setattr(m,a,0.)
# difference in end displacements, global coords
dX = m.nodek.deltaX - m.nodej.deltaX
dY = m.nodek.deltaY - m.nodej.deltaY
# axial deformation / force:
ldX = dX*m.cosx + dY*m.cosy
T = m.E*m.A*ldX/m.L
m.FXK += T
m.FXJ += -T
#print(m.id,ldX,T)
# shear deformation / force:
vdY = dY*m.cosx - dX*m.cosy
M = -6.*m.E*m.Ix*vdY/(m.L*m.L)
V = 2.*M/m.L
m.MZJ += M
m.MZK += M
m.FYJ += V
m.FYK += -V
#print(m.id,vdY,M,V)
# end rotations / moments:
MJ = (m.E*m.Ix/m.L)*(4.*m.nodej.thetaZ + 2.*m.nodek.thetaZ)
MK = (m.E*m.Ix/m.L)*(2.*m.nodej.thetaZ + 4.*m.nodek.thetaZ)
VJ = (MJ+MK)/m.L
m.MZJ += MJ
m.MZK += MK
m.FYJ += VJ
m.FYK += -VJ
#print(m.id,m.nodej.thetaZ,m.nodek.thetaZ,MJ,MK,VJ)
# applied loads: fixed-end moments and shears:
for ltype,w1,w2,a,b,c in m.loads:
mj = mk = 0.
vj = vk = 0.
if ltype == 'PL':
b = m.L - a
P = w1
mj = -P*a*b*b/(m.L*m.L)
mk = P*b*a*a/(m.L*m.L)
vj = (-P*b + nj + mk)/m.L
vk = -P - vj
elif ltype == 'UDL':
mj = -w1*m.L**2/12.
mk = -mj
vj = -w1*m.L/2.
vk = vj
else:
Warn("Load type '{}' not implemented here ...".format(ltype))
continue
m.MZJ += mj
m.MZK += mk
m.FYJ += vj
m.FYK += vk
# member end moment releases:
relc = m.releases.copy()
if 'MZJ' in m.releases:
mj = -m.MZJ
mk = 0. if 'MZK' in m.releases else 0.5*mj
vj = (mj + mk)/m.L
##print(m.id,'MZJ',m.MZJ,m.MZK,mj,mk,rel)
m.MZJ += mj
m.MZK += mk
m.FYJ += vj
m.FYK += -vj
relc.remove('MZJ')
if 'MZK' in m.releases:
mk = -m.MZK
mj = 0. if 'MZJ' in m.releases else 0.5*mk
vj = (mj + mk)/m.L
##print(m.id,'MZK',m.MZJ,m.MZK,mj,mk,rel)
m.MZJ += mj
m.MZK += mk
m.FYJ += vj
m.FYK += -vj
relc.remove('MZK')
if relc:
Warn("Member end-releases not processed: {}".format(relc))
computed = pd.DataFrame([{k:getattr(m,k) for k in ['id']+cols}
for m in MEMBERS.values()]).set_index('id')
diff = (computed - MEFS[cols])
lim = 1E-12
for c in cols:
biggest = MEFS[c].abs().max()
diff[c][diff[c].abs() < biggest*lim] = 0
diff
diff.abs().max()
```
### Maximum relative differences
```
diff = (computed - MEFS[cols])
for c in cols:
biggest = MEFS[c].abs().max()
r = (diff[c]/biggest)
idr = r.abs().idxmax()
print(c,idr,r[idr])
```
| github_jupyter |
<a href="https://colab.research.google.com/github/rohinishimpatwar/The-NLP-News-Sentiment-Trading-Strategy/blob/master/Data/Part1_Data_Prepare_Label_Company_Industry.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
os.chdir('/Users/yangsu/Downloads/')
news = pd.read_csv('clean_news_dataset.csv')
news = news.iloc[-10000:,]
news = news.dropna()
news['text'] = news['text'].astype('str')
def word_count(s):
a = s.split(' ')
return len(a)
news['word_num'] = news['text'].apply(word_count)
news['word_num'].hist()
print(len(news))
comp_industry = pd.read_csv('sp500companies_industry.csv')
comp_ind = comp_industry[['Symbol', 'Security', 'GICS Sector']]
print(comp_ind.head())
tickers = np.array(comp_ind.Symbol)
names = np.array(comp_ind.Security)
sector = np.array(comp_ind['GICS Sector'])
# I use "|" as a seperater instead of "," because some company names contains ","
news['Company'] = ''
for comp in names:
news['Mask'] = news['text'].str.contains(comp)
news['Company'] = np.where( news['Mask'] == True, news['Company'].apply(lambda x: x + comp + '|' ),
news['Company'].apply(lambda x: x + '') )
# I don`t think it`s a good idea to search by ticker, because it`s too short, and sometimes they capitalize the text as well.
# I`ll leave this part of code here for now, in case we are short on observations.
# news['Ticker'] = ''
# for ticker in tickers:
# news['Mask'] = news['np.where( news['Mask'] == True, news['Ticker'].apply(lambda x: x + ' , ' + ticker),
# news['Ticker'].apply(lambda x: x + '') )
news = news.drop('Mask', axis = 1)
ind_news = news[news['Company'] != '']
def Convert(string):
li = list(string.split("|"))
return li
ind_news['Company'] = ind_news['Company'].apply(Convert)
ind_news
ind_news = pd.concat([ind_news, pd.DataFrame(ind_news.Company.values.tolist(), ind_news.index).add_prefix('company_')], axis = 1)
ind_news
# We have 1372 pieces of news that have company names, woo-hoo!
# Need to match industry to each company here
def get_industry(sector_list, company_list, company_name):
industry =[]
for name in company_name:
if name != '':
industry.append(sector_list[list(company_list).index(name)])
return industry
list_of_companies = list(ind_news['Company'])
industry_list = []
for company in ind_news['Company']:
industry_list.append(get_industry(sector, names, company))
ind_news['Industry'] = industry_list
ind_news = pd.concat([ind_news, pd.DataFrame(ind_news.Industry.values.tolist(), ind_news.index).add_prefix('industry_')], axis = 1)
ind_news
ind_news.to_csv('news_with_all_labels.csv')
```
| github_jupyter |
# Differential privacy: composition concepts
This notebook is a continuation of the notebook [Basic Concepts](./differential_privacy_basic_concepts.ipynb). Here, we explain more advanced Differential Privacy (DP) concepts, such as composition theorems and how to use them in the Sherpa.ai Federated Learning and Differential Privacy Framework. Before diving in, we recommend reading section 3.5 of [The Algorithmic Foundations of Differential Privacy](https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf) and everything related to Privacy Filters from the paper [Privacy Odometers and Filters: Pay-as-you-Go Composition](https://arxiv.org/pdf/1605.08294.pdf).
## Composition theorems
A great property of DP is that private mechanisms can be composed while preserving DP. The new values of $\epsilon$ and $\delta$ can be computed according to the composition theorems. Before the composition theorems are provided, we are going to state an experiment with an adversarial, which proposes a composition scenario for DP.
**Composition experiment $b \in \{ 0,1 \}$ for adversary $A$ with a given set, $M$, of DP mechanisms:**
For $i=1,\dots,k$:
1. $A$ generates two neighbouring databases $x_i^0$ and $x_i^1$ and selects a mechanism $\mathcal{M}_i$ from $M$.
2. $A$ receives the output $y_i \in \mathcal{M}_i(x_i^b)$, which is stored in $V^b$
Note that the adversary is stateful, that is, it stores the output in each iteration and selects the DP mechanism based on the observed outputs.
**Note on neighboring databases:**
It is important to know that when it comes to numeric databases, such as two arrays, $A=[1,2,3,4]$ and $B=[1,2,3,8]$ (which is the main use case for the Sherpa.ai Federated Learning and Differential Privacy Framework). They are neighboring databases if they differ in only one component, up to as much as 1 (the must have the same length), therefore A and B aren't neighboring databases but, $C=[1,28,91]$ and $D=[2,28,91]$ are.
```
from shfl.private.node import DataNode
from shfl.differential_privacy.dp_mechanism import LaplaceMechanism, GaussianMechanism
from math import log, exp
import numpy as np
def run_composition_experiment(M, db_storage, secret):
# Number of runs equals the number of mechanisms provided
k = len(M)
# Adversary's view in experiment 1
A_view1 = np.empty(shape=(k,))
# Adversary's view in experiment 2
A_view2 = np.empty(shape=(k,))
# Neighboring databases are created
db1 = "db1"
db2 = "db2"
db_storage.set_private_data(name=db1, data=secret)
db_storage.set_private_data(name=db2, data=secret+1)
# In the following loop, we reproduce both experiments for b=0 and for b=1
for i in range(k):
# The adversarial selects the dp-mechanism
db_storage.configure_data_access(db1, M[i])
db_storage.configure_data_access(db2, M[i])
# The outputs are stored in the adversary's view in each experiment
A_view1[i] = db_storage.query(db1)
A_view2[i] = db_storage.query(db2)
return A_view1, A_view2
```
As you can see in the following piece of code, privacy is preserved, as it is not possible to tell in which database the secret is stored. However, if this experiment is run enough times, the probability of telling the difference increases, so what is the privacy budget spent in these experiments? This is the fundamental question that composition theorems answer.
```
# Setup storage for all databases
db_storage = DataNode()
# List of DP-mechanisms
M = [LaplaceMechanism(1, epsilon=0.5),
LaplaceMechanism(1, epsilon=1),
GaussianMechanism(1, epsilon_delta=(0.5, 0.01))]
A_view1, A_view2 = run_composition_experiment(M, db_storage, 1)
print("Adversary's view from Experiment 1: {}, mean: {}".format(A_view1, np.mean(A_view1)))
print("Adversary's view from Experiment 2: {}, mean: {}".format(A_view2, np.mean(A_view2)))
```
As expected, if the experiment is carried on for enough rounds, we can determine in which database the secret is stored.
```
# Setup storage for all databases
db_storage = DataNode()
# List of DP-mechanisms
M = [LaplaceMechanism(1, epsilon=0.5),
LaplaceMechanism(1, epsilon=1),
GaussianMechanism(1, epsilon_delta=(0.5, 0.01))]*1000
A_view1, A_view2 = run_composition_experiment(M, db_storage, 1)
print("Adversary's view from Experiment 1 mean: {}".format(np.mean(A_view1)))
print("Adversary's view from Experiment 2 mean: {}".format(np.mean(A_view2)))
```
### Basic composition theorem
The first and most basic theorem that can be employed for composition is the Basic Composition Theorem.
The composition of a sequence $\{\mathcal{M}_k\}$ of ($\epsilon_i, \delta_i$)-differentially private mechanisms under the Composition experiment with $M=\{\mathcal{M}_k\}$, is ($\sum_{i=1}^{k} \epsilon_i, \sum_{i=1}^{k} \delta_i$)-differentially private.
In other words, it states that the resulting privacy budget is the sum of the privacy budget spent in each access.
Therefore, the budget expended in the previous experiment was:
```
epsilon_delta_access = [m.epsilon_delta for m in M]
epsilon_spent, delta_spent = map(sum, zip(*epsilon_delta_access))
print("{} epsilon was spent".format(epsilon_spent))
print("{} delta was spent".format(delta_spent))
```
The main disadvantage of this theorem is that it assumes a worst case scenario. A better bound can be stated using the Advanced Composition Theorem.
### Advanced composition theorem
For all $\epsilon, \delta, \delta' \geq 0$ the composition of a sequence $\{\mathcal{M}_k\}$ of ($\epsilon, \delta$)-differentially private mechanisms under the Composition experiment with $M=\{\mathcal{M}_k\}$, satisfies ($\epsilon', \delta''$)-DP with:
$$
\epsilon' = \sqrt{2k\ln(1/\delta')} + k \epsilon(e^{\epsilon}-1) \quad \text{and} \quad \delta'' = k\delta + \delta'
$$
In other words, for a small sacrifice $\delta$' in the global $\delta$ spent, we can achieve a better bound for the global $\epsilon$ spent. However, the theorem assumes that the same DP mechanism is used in each access:
```
from math import sqrt, log, exp
# Basic theorem computations
def basic_theorem_expense(epsilon, delta, k):
epsilon_spent = k*epsilon
delta_spent = k*delta
return epsilon_spent, delta_spent
# Advanced theorem computations
def advanced_theorem_expense(epsilon, delta, delta_sacrifice, k):
epsilon_spent = sqrt(2*k*log(1/delta_sacrifice)) + k * epsilon * (exp(epsilon) - 1)
delta_spent = k*delta + delta_sacrifice
return epsilon_spent, delta_spent
epsilon = 0.5
delta = 0
k = 3
delta_sacrifice = 0.1
basic = basic_theorem_expense(epsilon, delta, k)
advanced = advanced_theorem_expense(epsilon, delta, delta_sacrifice, k)
print("Epsilon: {} vs {} (basic theorem vs advanced theorem) ".format(basic[0], advanced[0]))
print("Delta: {} vs {} (basic theorem vs advanced theorem) ".format(basic[1], advanced[1]))
```
But wait, if the epsilon spent is worse with the new theorem, is it useless? Of course not, let's see what happens when we increase the number of iterations:
```
from math import sqrt, log, exp
epsilon = 0.5
delta = 0
k = 350
delta_sacrifice = 0.1
basic = basic_theorem_expense(epsilon, delta, k)
advanced = advanced_theorem_expense(epsilon, delta, delta_sacrifice, k)
print("Epsilon: {} vs {} (basic theorem vs advanced theorem) ".format(basic[0], advanced[0]))
print("Delta: {} vs {} (basic theorem vs advanced theorem) ".format(basic[1], advanced[1]))
```
So, we can conclude that the benefits of the advanced theorem are only noticeable when the number of mechanism accesses is huge. In particular, we can observe that for values of $k$ close to 150 (and $\delta=0.1$), the theorems are almost identical.
```
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(16,6))
k_values = np.arange(1, 300, 5)
ax.plot(k_values, [basic_theorem_expense(epsilon, delta, k)[0] for k in k_values], label = "Basic composition")
ax.plot(k_values, [advanced_theorem_expense(epsilon, delta, delta_sacrifice, k)[0] for k in k_values], label = "Advanced composition")
ax.set_xlabel('k')
ax.set_ylabel('$\epsilon$ expense')
plt.legend(title = "", loc="upper left")
plt.show()
```
While composition theorems are quite useful, they require some parameters to be defined upfront, such as the number of mechanisms to be composed. Therefore, no intermediate result can be observed and the privacy budget can be wasted. In such situations, a more fine grained composition technique, which allows to observe the result of each mechanism to be observed without compromising the privacy budget spent, is required. In order to remove some of the stated constraints, a more flexible experiment of composition can be introduced:
### Adaptive composition experiment $b \in \{ 0,1 \}$ for adversary $A$
For $i=1,\dots,k$:
1. $A$ generates two neighboring databases $x_i^0$ and $x_i^1$ and selects a mechanism $\mathcal{M}_i$ that is ($\epsilon_i, \delta_i$)-differentially private.
2. $A$ receives the output $y_i \in \mathcal{M}_i(x_i^b)$
Note that in these situations, the $\epsilon_i$ and $\delta_i$ of each mechanism is adaptively selected, based on the outputs of previous iterations.
Now we introduce the privacy filter, which can be used to guarantee with high probability in the Adaptive Composition experiments, the stated privacy budget $\epsilon_g$ is never exceeded. Privacy filters have similar composition theorems to those mentioned previously:
### Basic composition for privacy filters
For any $\epsilon_g, \delta_g \geq 0,\ $ $\texttt{COMP}_{\epsilon_g, \delta_g}$ is a valid Privacy Filter:
$$
\texttt{COMP}_{\epsilon_g,\delta_g}(\epsilon_1,\delta_1,...,\epsilon_{k},\delta_{k})= \begin{cases}
\texttt{HALT} & \text{if}\ \sum_{i=1}^{k} \delta_i > \delta_g \ \ \ \text{or} \ \ \ \sum_{i=1}^{k} \epsilon_i > \epsilon_g, \\
\texttt{CONT} & \text{otherwise}
\end{cases}
$$
### Advanced composition for privacy filters
We define $\mathcal{K}$ as follows:
$$
\mathcal{K} := \sum_{j=1}^{k} \epsilon_j \left( \frac{\exp{(\epsilon_j)}-1}{2} \right) +
\sqrt{\left( \sum_{i=1}^{k} \epsilon_i^2 + H \right) \left( 2 + \ln{\big( \frac{1}{H} \sum_{i=1}^{k} \epsilon_i^2 +1 \big)} \right) \ln{(2/\delta_g)}}
$$
with $$ H = \frac{\epsilon_g^2}{28.04 \ln(1/\delta_g)} $$
Then $\texttt{COMP}_{\epsilon_g, \delta_g}$ is a valid Privacy Filter for $\delta_g \in (0, 1/e)$ and $\epsilon_g > 0$, where:
$$
\texttt{COMP}_{\epsilon_g,\delta_g}(\epsilon_1,\delta_1,...,\epsilon_{k},\delta_{k})= \begin{cases}
\texttt{HALT} & \text{if}\ \sum_{i=1}^{k} \delta_i > \delta_g/2 \ \ \ \text{or} \ \ \ \mathcal{K} > \epsilon_g, \\
\texttt{CONT} & \text{otherwise}
\end{cases}
$$
The value of $\mathcal{K}$ might be strange at first sight, however, if we assume $\epsilon_j=\epsilon$ for all $j$, it remains:
$$
\mathcal{K} = \sqrt{ \left(k\epsilon^2 + H\right)\left(2+\ln{(\frac{k\epsilon^2}{H} + 1)}\right) \ln{(2/\delta)}} + k\epsilon^2 \left(\frac{\exp{(\epsilon)}-1}{2}\right)
$$
which is quite similar to the expression given in the Advanced Composition Theorem.
## Privacy filters in the Sherpa.ai Federated Learning and Differential Privacy Framework
This framework implements Privacy Filters and transparently applies both theorems stated before, so that there is no need to constantly check which theorem ensures a better ($\epsilon, \delta$) expense. When the fixed privacy budget is surpassed, an exception ExceededPrivacyBudgetError is raised. The following example shows two equivalent implementations of the Adaptive Composition experiment, stated before.
```
from shfl.private.node import DataNode
from shfl.differential_privacy.composition_dp import AdaptiveDifferentialPrivacy
from shfl.differential_privacy.composition_dp import ExceededPrivacyBudgetError
from shfl.differential_privacy.dp_mechanism import LaplaceMechanism
import numpy as np
import matplotlib.pyplot as plt
def run_adaptive_comp_experiment_v1(global_eps_delta, eps_delta_access):
# Define a place to store the data
node_single = DataNode()
# Store the private data
node_single.set_private_data(name="secret", data=np.array([1]))
# Choose your favorite differentially_private_mechanism
dpm = LaplaceMechanism(sensitivity=1, epsilon=eps_delta_access)
# Here we are specifying that we want to use composition theorems for Privacy Filters
# DP mechanis
default_data_access = AdaptiveDifferentialPrivacy(global_eps_delta, differentially_private_mechanism=dpm)
node_single.configure_data_access("secret", default_data_access)
result_query = []
while True:
try:
# Queries are performed using the Laplace mechanism
result_query.append(node_single.query(private_property="secret"))
except ExceededPrivacyBudgetError:
# At this point we have spent the entiry privacy budget
break
return result_query
def run_adaptive_comp_experiment_v2(global_eps_delta, eps_delta_access):
# Define a place to store the data
node_single = DataNode()
# Store the private data
node_single.set_private_data(name="secret", data=np.array([1]))
# Choose your favorite differentially_private_mechanism
dpm = LaplaceMechanism(sensitivity=1, epsilon=eps_delta_access)
# Here we are specifying that we want to use composition theorems for Privacy Filters
default_data_access = AdaptiveDifferentialPrivacy(global_eps_delta)
node_single.configure_data_access("secret", default_data_access)
result_query = []
while True:
try:
# DP mechanism is specified at time of query, in this case the Laplace mechanism
# if no mechanism is specified an exception is raised
result_query.append(node_single.query(private_property="secret", differentially_private_mechanism=dpm))
except ExceededPrivacyBudgetError:
# At this point we have spent the entire privacy budget
break
return result_query
```
In the following plot, we can see that the privacy budget is spent significantly faster, as $\epsilon$ moves away from 0.
```
global_epsilon_delta = (2e-1, 2e-30)
epsilon_values = np.arange(2e-3, 2e-1, 2e-3)
plt.style.use('fivethirtyeight')
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(16,6))
y_axis=[len(run_adaptive_comp_experiment_v1(global_epsilon_delta, e)) for e in epsilon_values]
ax.plot(epsilon_values, y_axis)
ax.set_xlabel('$\epsilon$')
ax.set_ylabel('Number of runs before the budget is spent')
plt.show()
```
**Note:**
These experiments are run with the same DP mechanism, for the sake of simplification. If you want to access your data with a different DP mechanism, we recommend using a schema similar to the one shown in the function *run_adaptive_comp_experiment_v2*.
| github_jupyter |
# Setting Up the Sample Specific Environment
In this section, we will be creating environmental variables specific to this sample.
## Get Global Variables
```
import sys
sys.path.append('../../../common')
from env_variables import *
```
## Set Environmental Variables Specific to This Sample
In the following sections, we will be creating a VM to act as our IoT Edge device. The following cell will set the type of VM that will be created.
Verify that the VM type is available in your region. You may view this page for a full list of [VMs by region](https://azure.microsoft.com/en-us/global-infrastructure/services/?regions=non-regional,us-east,us-east-2,us-central,us-north-central,us-south-central,us-west-central,us-west,us-west-2&products=virtual-machines).
For this sample, we will be using a Standard_DS3_v2 (CPU tier) VM.
```
vm_type = "Standard_DS3_v2" #CPU tier VM
tempVar = set_key(envPath, "VM_TYPE", vm_type)
```
The following cell will set a sample folder path absolute to the root folder of the repository.
```
lvaSamplePath = "utilities/video-analysis/notebooks/yolo/yolov4/yolov4-grpc-icpu-onnx"
tempVar = set_key(envPath, "LVA_SAMPLE_PATH", lvaSamplePath)
```
In later sections, we will be creating a Docker container image for our inference solution. The following cell will set the name of the Docker image to be used later.
```
containerImageName = "lvaextension:grpc.yolov4.v1"
tempVar = set_key(envPath, "CONTAINER_IMAGE_NAME", containerImageName)
```
The following cell will set the folder to which debug files will be outputted in the IoT Edge device. The default location for debug files is `/tmp` folder in your IoT Edge device. If you want debug files to be sent elsewhere, you can change the value of the `debugOutputFolder` variable below.
```
debugOutputFolder = "/tmp"
tempVar = set_key(envPath, "DEBUG_OUTPUT_FOLDER", debugOutputFolder)
```
The following cell will set the name of the media graph file to be used in this sample. We provide a variety of sample media graph files in the **live-video-analytics/MediaGraph** folder. To learn more about media graphs, [read our documentation here](https://docs.microsoft.com/en-us/azure/media-services/live-video-analytics-edge/media-graph-concept).
```
topologyFile = "grpcExtension/topology.json"
tempVar = set_key(envPath, "TOPOLOGY_FILE", topologyFile)
```
The following cell will extract the name of our sample media graph topology file.
```
import json
import os.path
with open(os.path.join("../../../../../../MediaGraph/topologies/", topologyFile)) as f:
data = json.load(f)
topologyName = data["name"]
tempVar = set_key(envPath, "TOPOLOGY_NAME", topologyName)
```
The following cell will set the name of the media graph instance that will be used in later sections. With LVA, you may set more than one topology instance, so be sure to give each instance a unique name.
```
graphInstanceName = "Sample-Graph-Instance"
tempVar = set_key(envPath, "GRAPH_INSTANCE_NAME", graphInstanceName)
```
The following cell will set the media graph parameters specific to this sample.
```
# Address of the RTSP camera stream source
rtspUrl = "rtsp://rtspsim:554/media/lots_284.mkv"
# Sensitivity of the motion detector low|medium|high
motionSensitivity = 'medium'
# gRPC connection endpoint URL of the lvaextension module
grpcExtensionAddress = "tcp://lvaextension:44000"
# Image file formats. Supported formats are jpeg, bmp and png
imageEncoding = "jpeg"
# Image Storage Quality. Values below 75 will result in significant decrease in image quality.
imageQuality = "90"
# preserveAspectRatio | pad: YOLOv3 model and its wrapper requires exact this scaling.
imageScaleMode = "pad"
# Be careful with dimensions. YOLOv3 model and its wrapper requires exact this size.
frameWidth = "416"
frameHeight = "416"
```
The following cell will create parameters in JSon format to be used while deploying the media graph.
```
mediaGraphTopologyParameters = {
"name": graphInstanceName,
"properties": {
"topologyName": topologyName,
"parameters": [
{
"name": "rtspUrl",
"value": rtspUrl
},
{
"name": "motionSensitivity",
"value": motionSensitivity
},
{
"name": "grpcExtensionAddress",
"value": grpcExtensionAddress
},
{
"name": "imageEncoding",
"value": imageEncoding
},
{
"name": "imageQuality",
"value": imageQuality
},
{
"name": "imageScaleMode",
"value": imageScaleMode
},
{
"name": "frameWidth",
"value": frameWidth
},
{
"name": "frameHeight",
"value": frameHeight
}
]
}
}
with open("../../../common/.media_graph_topology_parameters.json", "w") as f:
json.dump(mediaGraphTopologyParameters, f, indent=4)
```
| github_jupyter |
> This is one of the 100 recipes of the [IPython Cookbook](http://ipython-books.github.io/), the definitive guide to high-performance scientific computing and data science in Python.
# 5.6. Releasing the GIL to take advantage of multi-core processors with Cython and OpenMP
```
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import cython
%load_ext cythonmagic
```
This is Cython pushed to its limits: our code that was initially in pure Python is now in almost pure C, with very few Python API calls. Yet, we use the nice Python syntax. We explicitly release the GIL in all functions as they do not use Python, so that we can enable multithread computations on multicore processors with OpenMP.
```
%%cython --compile-args=/openmp --link-args=/openmp --force
from cython.parallel import prange
cimport cython
import numpy as np
cimport numpy as np
DBL = np.double
ctypedef np.double_t DBL_C
from libc.math cimport sqrt
cdef int w, h
cdef struct Vec3:
double x, y, z
cdef Vec3 vec3(double x, double y, double z) nogil:
cdef Vec3 v
v.x = x
v.y = y
v.z = z
return v
cdef double dot(Vec3 x, Vec3 y) nogil:
return x.x * y.x + x.y * y.y + x.z * y.z
cdef Vec3 normalize(Vec3 x) nogil:
cdef double n
n = sqrt(x.x * x.x + x.y * x.y + x.z * x.z)
return vec3(x.x / n, x.y / n, x.z / n)
cdef double max(double x, double y) nogil:
return x if x > y else y
cdef double min(double x, double y) nogil:
return x if x < y else y
cdef double clip_(double x, double m, double M) nogil:
return min(max(x, m), M)
cdef Vec3 clip(Vec3 x, double m, double M) nogil:
return vec3(clip_(x.x, m, M), clip_(x.y, m, M), clip_(x.z, m, M),)
cdef Vec3 add(Vec3 x, Vec3 y) nogil:
return vec3(x.x + y.x, x.y + y.y, x.z + y.z)
cdef Vec3 subtract(Vec3 x, Vec3 y) nogil:
return vec3(x.x - y.x, x.y - y.y, x.z - y.z)
cdef Vec3 minus(Vec3 x) nogil:
return vec3(-x.x, -x.y, -x.z)
cdef Vec3 multiply(Vec3 x, Vec3 y) nogil:
return vec3(x.x * y.x, x.y * y.y, x.z * y.z)
cdef Vec3 multiply_s(Vec3 x, double c) nogil:
return vec3(x.x * c, x.y * c, x.z * c)
cdef double intersect_sphere(Vec3 O,
Vec3 D,
Vec3 S,
double R) nogil:
# Return the distance from O to the intersection of the ray (O, D) with the
# sphere (S, R), or +inf if there is no intersection.
# O and S are 3D points, D (direction) is a normalized vector, R is a scalar.
cdef double a, b, c, disc, distSqrt, q, t0, t1
cdef Vec3 OS
a = dot(D, D)
OS = subtract(O, S)
b = 2 * dot(D, OS)
c = dot(OS, OS) - R * R
disc = b * b - 4 * a * c
if disc > 0:
distSqrt = sqrt(disc)
q = (-b - distSqrt) / 2.0 if b < 0 else (-b + distSqrt) / 2.0
t0 = q / a
t1 = c / q
t0, t1 = min(t0, t1), max(t0, t1)
if t1 >= 0:
return t1 if t0 < 0 else t0
return 1000000
cdef Vec3 trace_ray(Vec3 O, Vec3 D,) nogil:
cdef double t, radius, diffuse, specular_k, specular_c, DF, SP
cdef Vec3 M, N, L, toL, toO, col_ray, \
position, color, color_light, ambient
# Sphere properties.
position = vec3(0., 0., 1.)
radius = 1.
color = vec3(0., 0., 1.)
diffuse = 1.
specular_c = 1.
specular_k = 50.
# Light position and color.
L = vec3(5., 5., -10.)
color_light = vec3(1., 1., 1.)
ambient = vec3(.05, .05, .05)
# Find first point of intersection with the scene.
t = intersect_sphere(O, D, position, radius)
# Return None if the ray does not intersect any object.
if t == 1000000:
col_ray.x = 1000000
return col_ray
# Find the point of intersection on the object.
M = vec3(O.x + D.x * t, O.y + D.y * t, O.z + D.z * t)
N = normalize(subtract(M, position))
toL = normalize(subtract(L, M))
toO = normalize(subtract(O, M))
DF = diffuse * max(dot(N, toL), 0)
SP = specular_c * max(dot(N, normalize(add(toL, toO))), 0) ** specular_k
return add(ambient, add(multiply_s(color, DF), multiply_s(color_light, SP)))
@cython.boundscheck(False)
@cython.wraparound(False)
def run(int w, int h):
cdef DBL_C[:,:,:] img = np.zeros((h, w, 3))
cdef Vec3 img_
cdef int i, j
cdef double x, y
cdef Vec3 O, Q, D, col_ray
cdef double w_ = float(w)
cdef double h_ = float(h)
col_ray = vec3(0., 0., 0.)
# Camera.
O = vec3(0., 0., -1.) # Position.
# Loop through all pixels.
with nogil:
for i in prange(w):
Q = vec3(0., 0., 0.)
for j in range(h):
x = -1. + 2*(i)/w_
y = -1. + 2*(j)/h_
Q.x = x
Q.y = y
col_ray = trace_ray(O, normalize(subtract(Q, O)))
if col_ray.x == 1000000:
continue
img_ = clip(col_ray, 0., 1.)
img[h - j - 1, i, 0] = img_.x
img[h - j - 1, i, 1] = img_.y
img[h - j - 1, i, 2] = img_.z
return img
w, h = 200, 200
img = run(w, h)
plt.imshow(img);
plt.xticks([]); plt.yticks([]);
%timeit run(w, h)
```
> You'll find all the explanations, figures, references, and much more in the book (to be released later this summer).
> [IPython Cookbook](http://ipython-books.github.io/), by [Cyrille Rossant](http://cyrille.rossant.net), Packt Publishing, 2014 (500 pages).
| github_jupyter |
# Example: CanvasXpress radar Chart No. 5
This example page demonstrates how to, using the Python package, create a chart that matches the CanvasXpress online example located at:
https://www.canvasxpress.org/examples/radar-5.html
This example is generated using the reproducible JSON obtained from the above page and the `canvasxpress.util.generator.generate_canvasxpress_code_from_json_file()` function.
Everything required for the chart to render is included in the code below. Simply run the code block.
```
from canvasxpress.canvas import CanvasXpress
from canvasxpress.js.collection import CXEvents
from canvasxpress.render.jupyter import CXNoteBook
cx = CanvasXpress(
render_to="radar5",
data={
"z": {
"Annt1": [
"Desc:1",
"Desc:2",
"Desc:3",
"Desc:4"
],
"Annt2": [
"Desc:A",
"Desc:B",
"Desc:A",
"Desc:B"
],
"Annt3": [
"Desc:X",
"Desc:X",
"Desc:Y",
"Desc:Y"
],
"Annt4": [
5,
10,
15,
20
],
"Annt5": [
8,
16,
24,
32
],
"Annt6": [
10,
20,
30,
40
]
},
"x": {
"Factor1": [
"Lev:1",
"Lev:2",
"Lev:3",
"Lev:1",
"Lev:2",
"Lev:3"
],
"Factor2": [
"Lev:A",
"Lev:B",
"Lev:A",
"Lev:B",
"Lev:A",
"Lev:B"
],
"Factor3": [
"Lev:X",
"Lev:X",
"Lev:Y",
"Lev:Y",
"Lev:Z",
"Lev:Z"
],
"Factor4": [
5,
10,
15,
20,
25,
30
],
"Factor5": [
8,
16,
24,
32,
40,
48
],
"Factor6": [
10,
20,
30,
40,
50,
60
]
},
"y": {
"vars": [
"V1",
"V2",
"V3",
"V4"
],
"smps": [
"S1",
"S2",
"S3",
"S4",
"S5",
"S6"
],
"data": [
[
5,
10,
25,
40,
45,
50
],
[
95,
80,
75,
70,
55,
40
],
[
25,
30,
45,
60,
65,
70
],
[
55,
40,
35,
30,
15,
1
]
]
}
},
config={
"circularArc": 360,
"circularRotate": 0,
"circularType": "radar",
"colorScheme": "Bootstrap",
"graphType": "Circular",
"legendPosition": "top",
"ringGraphType": [
"stacked"
],
"showTransition": False,
"title": "Radar - Stacked",
"transitionStep": 50,
"transitionTime": 1500
},
width=613,
height=613,
events=CXEvents(),
after_render=[],
other_init_params={
"version": 35,
"events": False,
"info": False,
"afterRenderInit": False,
"noValidate": True
}
)
display = CXNoteBook(cx)
display.render(output_file="radar_5.html")
```
| github_jupyter |
# Estimate a linear trend for the Hawai'i climate data
Uses the data in `data/hawaii-TAVG-Trend.txt` to estimate a linear trend. Saves the trend to `results/hawaii-trend.csv` and the estimated coefficients to `manuscript/trend-results.tex` for inclusion in the manuscript text.
```
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
# Load out custom tool for loading and processing the data
from mypackage.io import load_berkeley_earth_data
from mypackage.processing import LinearTrend
```
## Load the data
Read in the data as a pandas.DataFrame and show the first few rows.
```
data = load_berkeley_earth_data('../../data/hawaii-TAVG-Trend.txt')
data.head()
```
Make a quick plot.
```
plt.figure()
plt.plot(data.year_decimal, data.monthly_temperature, '-')
plt.grid()
plt.xlabel('year')
plt.ylabel('monthly average temperature (C)')
plt.title('Monthly average temperature in Hawaii')
plt.tight_layout()
```
## Calculate the linear trend
Estimate a linear trend using the uncertainties as weights for the least-squares solution.
```
trend = LinearTrend().fit(data.year_decimal, data.monthly_temperature, data.monthly_error)
print(trend.linear_coef, trend.angular_coef)
```
Estimate the trend and plot it.
```
temperature_trend = trend.predict(data.year_decimal)
plt.figure()
plt.plot(data.year_decimal, data.monthly_temperature, '-')
plt.plot(data.year_decimal, temperature_trend, '-r')
plt.grid()
plt.xlabel('year')
plt.ylabel('monthly average temperature (C)')
plt.title('Temperature trend in Hawaii')
plt.tight_layout()
```
## Save the results
Save the estimate trend to a CSV file.
```
trend_data = pd.DataFrame({'year': data.year,
'month': data.month,
'year_decimal': data.year_decimal,
'temperature trend (C)': temperature_trend},
columns=['year', 'month', 'year_decimal', 'temperature trend (C)'])
trend_data.to_csv('../../results/hawaii-trend.csv')
```
Save the coefficients to a Latex file as new variables that can be used in the text.
```
# Need 3 {{{ because the first two become a single one for the Latex command.
# The third is used by the format method.
tex = r"""
% Generated by code/notebooks/estimate-hawaii-trend.ipynb
\newcommand{{\HawaiiLinearCoef}}{{{linear:.3f} C}}
\newcommand{{\HawaiiAngularCoef}}{{{angular:.3f} C/year}}
""".format(linear=trend.linear_coef, angular=trend.angular_coef)
with open('../../manuscript/hawaii_trend.tex', 'w') as f:
f.write(tex)
```
| github_jupyter |
# Performance of Inception-v3
```
% matplotlib inline
import os
import matplotlib.pyplot as plt
from scripts.utils import ExpResults
plotproperties = {'font.size': 13,
'axes.titlesize': 'xx-large',
'axes.labelsize': 'xx-large',
'xtick.labelsize': 'xx-large',
'xtick.major.size': 7,
'xtick.minor.size': 5,
'ytick.labelsize': 'xx-large',
'ytick.major.size': 7,
'ytick.minor.size': 5,
'legend.fontsize': 'xx-large',
'figure.figsize': (7, 6),
'savefig.dpi': 300,
'savefig.format': 'jpg'}
import matplotlib as mpl
mpl.rcParams.update(plotproperties)
```
## Parameters and definitions
```
log_dir = '/home/rbodo/.snntoolbox/data/imagenet/inceptionV3/keras/log'
runlabel_analog = '03'
path_analog = os.path.join(log_dir, 'gui', runlabel_analog)
clamp = 470 - 1
scale = 1e3 # Scale from Million to Billion operations
```
## Plot number of operations vs time
```
exp_analog = ExpResults(path_analog, 'SNN', '.', scale=scale)
experiments = [exp_analog]
for exp in experiments:
plt.plot(exp.time, exp.mean_computations_t, exp.marker, color=exp.color1, markersize=exp.markersize, label=exp.label)
plt.fill_between(exp.time, exp.mean_computations_t-exp.std_computations_t, exp.mean_computations_t+exp.std_computations_t, alpha=0.1, color=exp.color1)
plt.hlines(c_ANN, 0, experiments[0].time[-1], linewidth=1, label='ANN')
plt.vlines(clamp, 0, 12, linewidth=1, label='clamp lifted', colors='brown')
plt.ylabel('GOps')
plt.xlabel('Simulation time')
plt.legend()
plt.ylim(0, None)
plt.savefig(os.path.join(log_dir, 'ops_vs_t'), bbox_inches='tight')
```
## Plot error vs time
```
for exp in experiments:
plt.plot(exp.time, exp.e1_mean, exp.marker, color=exp.color1, markersize=exp.markersize, label=exp.label+' top-1')
plt.fill_between(exp.time, exp.e1_mean-exp.e1_confidence95, exp.e1_mean+exp.e1_confidence95, alpha=0.1, color=exp.color1)
plt.plot(exp.time, exp.e5_mean, exp.marker, color=exp.color5, markersize=exp.markersize, label=exp.label+' top-5')
plt.fill_between(exp.time, exp.e5_mean-exp.e5_confidence95, exp.e5_mean+exp.e5_confidence95, alpha=0.1, color=exp.color5)
plt.vlines(clamp, 0, 100, linewidth=1, label='clamp lifted')
plt.ylabel('Error [%]')
plt.xlabel('Simulation time')
plt.xlim(clamp-10, 550)
plt.ylim(0, 100)
plt.legend()
plt.savefig(os.path.join(log_dir, 'err_vs_t'), bbox_inches='tight')
```
## Plot error vs operations
```
show_numbers = False
exp = experiments[0]
plt.errorbar(exp.mean_computations_t[clamp:], exp.e1_mean[clamp:], xerr=exp.std_computations_t[clamp:],
yerr=exp.e1_confidence95[clamp:], fmt=exp.marker, label=exp.label+' top-1', capsize=0, elinewidth=0.1, color=exp.color1)
plt.errorbar(exp.mean_computations_t[clamp:], exp.e5_mean[clamp:], xerr=exp.std_computations_t[clamp:],
yerr=exp.e5_confidence95[clamp:], fmt=exp.marker, label=exp.label+' top-5', capsize=0, elinewidth=0.1, color=exp.color5)
plt.errorbar(exp.operations_ann, exp.e1_ann, marker='x', label='ANN top-1', color=exp.color1, markersize=15,
yerr=exp.e1_confidence95_ann, elinewidth=2, capthick=2, markeredgewidth=2, alpha=0.5)
plt.errorbar(exp.operations_ann, exp.e5_ann, marker='x', label='ANN top-5', color=exp.color5, markersize=15,
yerr=exp.e5_confidence95_ann, elinewidth=2, capthick=2, markeredgewidth=2, alpha=0.5)
if show_numbers:
plt.annotate('({:.2f}, {:.2f})'.format(exp.operations_ann, exp.e1_ann), xy=(exp.operations_ann - 0.15, exp.e1_ann + 10), color=exp.color1)
plt.annotate('({:.2f}, {:.2f})'.format(exp.operations_ann, exp.e5_ann), xy=(exp.operations_ann - 0.15, exp.e5_ann + 10), color=exp.color5)
plt.annotate('({:.2f}, {:.2f})'.format(exp.op1_optimal, exp.e1_optimal), xy=(exp.op1_optimal, exp.e1_optimal),
xytext=(exp.op1_optimal, exp.e1_optimal + 10),
arrowprops=dict(color=exp.color1, shrink=0.05, width=5, headwidth=10), color=exp.color1)
plt.annotate('({:.2f}, {:.2f})'.format(exp.op5_optimal, exp.e5_optimal), xy=(exp.op5_optimal, exp.e5_optimal),
xytext=(exp.op5_optimal, exp.e5_optimal + 10),
arrowprops=dict(color=exp.color5, shrink=0.05, width=5, headwidth=10), color=exp.color5)
plt.ylim(0, 105)
plt.xlim(0, None)
plt.ylabel('Error [%]')
plt.xlabel('GOps')
plt.legend(loc='upper right')
# plt.title('ANN vs SNN performance')
plt.savefig(os.path.join(log_dir, 'err_vs_ops'), bbox_inches='tight')
for exp in experiments:
print('ANN top-1: ({:.5f} GOps/frame, {:.2f} %)'.format(exp.operations_ann, exp.e1_ann))
print('SNN top-1 best error: ({:.5f} GOps/frame, {:.2f} %)'.format(exp.op1_0, exp.e1_0))
print('SNN top-1 converged: ({:.5f} GOps/frame, {:.2f} %)'.format(exp.op1_1, exp.e1_1))
print('SNN top-1 jointly optimal: ({:.5f} GOps/frame, {:.2f} %)'.format(exp.op1_optimal, exp.e1_optimal))
print('SNN top-1 same op: ({:.5f} GOps/frame, {:.2f} %)'.format(exp.op1_2, exp.e1_2))
print('ANN top-5: ({:.5f} GOps/frame, {:.2f} %)'.format(exp.operations_ann, exp.e5_ann))
print('SNN top-5 best error: ({:.5f} GOps/frame, {:.2f} %)'.format(exp.op5_0, exp.e5_0))
print('SNN top-5 converged: ({:.5f} GOps/frame, {:.2f} %)'.format(exp.op5_1, exp.e5_1))
print('SNN top-5 jointly optimal: ({:.5f} GOps/frame, {:.2f} %)'.format(exp.op5_optimal, exp.e5_optimal))
print('SNN top-5 same op: ({:.5f} GOps/frame, {:.2f} %)'.format(exp.op5_2, exp.e5_2))
```
| github_jupyter |
### 调用KNN函数来实现分类
数据采用的是经典的iris数据,是三分类问题
```
# 读取相应的库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# 读取数据 X, y
iris = datasets.load_iris()
X = iris.data
y = iris.target
print(X[:5])
print(y)
# 把数据分成训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2003)
# 构建KNN模型, K值为3、 并做训练
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(X_train, y_train)
# 计算准确率
from sklearn.metrics import accuracy_score
# correct = np.count_nonzero((clf.predict(X_test)==y_test)==True)
print("Accuracy is: %.3f" % accuracy_score(y_test, clf.predict(X_test)))
# print ("Accuracy is: %.3f" %(correct/len(X_test)))
```
### 从零开始自己写一个KNN算法
```
from sklearn import datasets
from collections import Counter # 为了做投票
from sklearn.model_selection import train_test_split
import numpy as np
# 导入iris数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2003)
def euc_dis(instance1, instance2):
"""
计算两个样本instance1和instance2之间的欧式距离
instance1: 第一个样本, array型
instance2: 第二个样本, array型
"""
# TODO
dist = np.sqrt(sum((instance1 - instance2)**2))
return dist
def knn_classify(X, y, testInstance, k):
"""
给定一个测试数据testInstance, 通过KNN算法来预测它的标签。
X: 训练数据的特征
y: 训练数据的标签
testInstance: 测试数据,这里假定一个测试数据 array型
k: 选择多少个neighbors?
"""
# TODO 返回testInstance的预测标签 = {0,1,2}
distances = [euc_dis(x, testInstance) for x in X]
kneighbors = np.argsort(distances)[:k]
count = Counter(y[kneighbors])
return count.most_common()[0][0]
# 预测结果。
predictions = [knn_classify(X_train, y_train, data, 3) for data in X_test]
correct = np.count_nonzero((predictions==y_test)==True)
#print("Accuracy is: %.3f" % accuracy_score(y_test, clf.predict(X_test)))
print ("Accuracy is: %.3f" %(correct/len(X_test)))
```
### KNN的决策边界
```
import matplotlib.pyplot as plt
import numpy as np
from itertools import product
from sklearn.neighbors import KNeighborsClassifier
# 生成一些随机样本
n_points = 100
X1 = np.random.multivariate_normal([1,50], [[1,0],[0,10]], n_points)
X2 = np.random.multivariate_normal([2,50], [[1,0],[0,10]], n_points)
X = np.concatenate([X1,X2])
y = np.array([0]*n_points + [1]*n_points)
print (X.shape, y.shape)
# KNN模型的训练过程
clfs = []
neighbors = [1,3,5,9,11,13,15,17,19]
for i in range(len(neighbors)):
clfs.append(KNeighborsClassifier(n_neighbors=neighbors[i]).fit(X,y))
# 可视化结果
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(3,3, sharex='col', sharey='row', figsize=(15, 12))
for idx, clf, tt in zip(product([0, 1, 2], [0, 1, 2]),
clfs,
['KNN (k=%d)'%k for k in neighbors]):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.4)
axarr[idx[0], idx[1]].scatter(X[:, 0], X[:, 1], c=y,
s=20, edgecolor='k')
axarr[idx[0], idx[1]].set_title(tt)
plt.show()
```
| github_jupyter |
# What a CNN sees - Visualize the `model_scratch`
In this notebook i will show you how you can visualize the layers of a CNN. This helps us to a better understanding what a CNN sees and how it learns.
For this demonstration I use the model from scratch constructed in dog_app.ipynb.
The demonstration is based on the following source: [Visualizing Convolution Neural Networks using Pytorch](https://towardsdatascience.com/visualizing-convolution-neural-networks-using-pytorch-3dfa8443e74e)
and the related Github-repo that you can find here: [Github - VisualizationCNN_Pytorch](https://github.com/Niranjankumar-c/DeepLearning-PadhAI/tree/master/DeepLearning_Materials/6_VisualizationCNN_Pytorch)
```
# import the necessary packages
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# check if CUDA is available
use_cuda = torch.cuda.is_available()
# Load the pretrained ResNeXt101-Model from pytorch
model_transfer = models.resnext101_32x8d(pretrained=True)
# Add a Dropout layer
model_transfer.add_module('drop', nn.Dropout(0.3))
# Add a fully-connected layer - This will be the last layer
model_transfer.add_module('fc1', nn.Linear(in_features=1000, out_features=133, bias=True))
# Freeze training for all parameters
for param in model_transfer.parameters():
param.requires_grad = False
# Replacing the last 3 layers for fine tuning
# Parameters of newly constructed modules have requires_grad=True by default
model_transfer.fc = nn.Linear(2048, 1000, bias=True)
model_transfer.drop = nn.Dropout(0.3)
model_transfer.fc1 = nn.Linear(in_features=1000, out_features=133, bias=True)
if use_cuda:
model_transfer = model_transfer.cuda()
model_transfer.load_state_dict(torch.load('model_transfer_resnext101.pt'))
# This helper-functions are imported from the related Github-repo
def plot_filters_single_channel_big(t):
#setting the rows and columns
nrows = t.shape[0]*t.shape[2]
ncols = t.shape[1]*t.shape[3]
npimg = np.array(t.numpy(), np.float32)
npimg = npimg.transpose((0, 2, 1, 3))
npimg = npimg.ravel().reshape(nrows, ncols)
npimg = npimg.T
#fig, ax = plt.subplots(figsize=(ncols/10, nrows/200))
fig, ax = plt.subplots(figsize=(20, 15))
imgplot = sns.heatmap(npimg, xticklabels=False, yticklabels=False, cmap='gray', ax=ax, cbar=False)
def plot_filters_single_channel(t):
#kernels depth * number of kernels
nplots = t.shape[0]*t.shape[1]
ncols = 12
nrows = 1 + nplots//ncols
#convert tensor to numpy image
npimg = np.array(t.numpy(), np.float32)
count = 0
fig = plt.figure(figsize=(ncols, nrows))
#looping through all the kernels in each channel
for i in range(t.shape[0]):
for j in range(t.shape[1]):
count += 1
ax1 = fig.add_subplot(nrows, ncols, count)
npimg = np.array(t[i, j].numpy(), np.float32)
npimg = (npimg - np.mean(npimg)) / np.std(npimg)
npimg = np.minimum(1, np.maximum(0, (npimg + 0.5)))
ax1.imshow(npimg)
ax1.set_title(str(i) + ',' + str(j))
ax1.axis('off')
ax1.set_xticklabels([])
ax1.set_yticklabels([])
plt.tight_layout()
plt.show()
def plot_filters_multi_channel(t):
#get the number of kernals
num_kernels = t.shape[0]
#define number of columns for subplots
num_cols = 12
#rows = num of kernels
num_rows = num_kernels
#set the figure size
fig = plt.figure(figsize=(num_cols,num_rows))
#looping through all the kernels
for i in range(t.shape[0]):
ax1 = fig.add_subplot(num_rows,num_cols,i+1)
#for each kernel, we convert the tensor to numpy
npimg = np.array(t[i].numpy(), np.float32)
#standardize the numpy image
npimg = (npimg - np.mean(npimg)) / np.std(npimg)
npimg = np.minimum(1, np.maximum(0, (npimg + 0.5)))
npimg = npimg.transpose((1, 2, 0))
ax1.imshow(npimg)
ax1.axis('off')
ax1.set_title(str(i))
ax1.set_xticklabels([])
ax1.set_yticklabels([])
#plt.savefig('myimage.png', dpi=100)
plt.tight_layout()
plt.show()
# Main function to plot the weights of the model
def plot_weights(model_layer, single_channel = True, collated = False):
'''
Plot the weights of a pretrained/saved model
Args:
model_layer: pretrained or saved model and layer
single_channel: Visualization mode
collated: Applicable for single-channel visualization only
Returns:
Index corresponding to VGG-16 model's prediction
'''
#extracting the model features at the particular layer number
layer = model_layer
#checking whether the layer is convolution layer or not
if isinstance(layer, nn.Conv2d):
#getting the weight tensor data
weight_tensor = layer.weight.data.clone()
weight_tensor = weight_tensor.cpu()
if single_channel:
if collated:
plot_filters_single_channel_big(weight_tensor)
else:
plot_filters_single_channel(weight_tensor)
else:
if weight_tensor.shape[1] == 3:
plot_filters_multi_channel(weight_tensor)
else:
print("Can only plot weights with three channels with single channel = False")
else:
print("Can only visualize layers which are convolutional")
#visualize weights for model_scratch - first conv layer
plot_weights(model_transfer.conv1, single_channel = False, collated=True)
```
| github_jupyter |
```
# Append 'src' directory to import modules from notebooks directory
#################################
import os,sys
src_dir = os.path.join(os.getcwd(), os.pardir)
sys.path.append(src_dir)
##################################
%load_ext autoreload
%autoreload 2
%pylab inline
import time
import os
import torchvision.models as models
import numpy as np
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
import torch.utils.model_zoo as model_zoo
import cv2
import torchvision
from torchvision import transforms
from torchvision.utils import make_grid
from collections import OrderedDict
from PIL import Image,ImageOps
import torch.optim as optim
from src.models import VGG19
from src import Utils
from src.PatchMatch import PatchMatchOrig
import scipy
def blend_features(feat_a, recon_feat_bb, alpha=0.8, tau=0.05, k=300.):
def sigmoid(x):
return 1. / (1. + np.exp(-x))
def clip_at_threshold(neuron_mag_a):
if True:
neuron_mag_a[neuron_mag_a < .01] = 0
return neuron_mag_a
norm_feat_a = feat_a**2
neuron_mag_a = (norm_feat_a - norm_feat_a.min(axis=(0,1,2),keepdims=True))/(norm_feat_a.max(axis=(0,1,2),keepdims=True)-norm_feat_a.min(axis=(0,1,2),keepdims=True))
neuron_mag_a = clip_at_threshold(neuron_mag_a)
neuron_mag_a = sigmoid(k*(neuron_mag_a - tau))
weight_a = alpha*neuron_mag_a
feat_aa = np.multiply(feat_a, weight_a) + np.multiply(recon_feat_bb, (1. - weight_a))
return feat_aa
def normalize_feat_map(feat_map):
"""
Normalize the feature map along the channels dimension
feat_map is a numpy array with channels along the 2nd dimension
"""
return feat_map/np.linalg.norm(feat_map,ord=2,axis=(2),keepdims=True)
def upsample_nnf(nnf,size):
temp = np.zeros((nnf.shape[0],nnf.shape[1],3))
for y in range(nnf.shape[0]):
for x in range(nnf.shape[1]):
temp[y][x] = [nnf[y][x][0],nnf[y][x][1],0]
img = np.zeros(shape=(size,size,2),dtype=np.int)
small_size = nnf.shape[0]
aw_ratio = ((size)//small_size)
ah_ratio = ((size)//small_size)
temp = cv2.resize(temp, None, fx=aw_ratio, fy=aw_ratio, interpolation= cv2.INTER_NEAREST)
for i in range(temp.shape[0]):
for j in range(temp.shape[1]):
pos = temp[i,j]
img[i,j] = pos[0]*aw_ratio , pos[1]*ah_ratio
return img
def reconstruct_avg(nnf,img,patch_size=5):
final = np.zeros_like(img)
print(final.shape)
for i in range(img.shape[0]):
for j in range(img.shape[1]):
dx0 = dy0 = patch_size // 2
dx1 = dy1 = patch_size // 2 + 1
dx0 = min(j, dx0)
dx1 = min(img.shape[0] - j, dx1)
dy0 = min(i, dy0)
dy1 = min(img.shape[1] - i, dy1)
patch = nnf[i - dy0:i + dy1, j - dx0:j + dx1]
lookups = np.zeros(shape=(patch.shape[0],patch.shape[1],3),dtype=np.float32)
for ay in range(patch.shape[0]):
for ax in range(patch.shape[1]):
x,y = patch[ay,ax]
lookups[ay,ax] = img[y,x]
if lookups.size > 0 :
value = np.average(lookups,axis=(0,1))
final[i,j] = value
return final
def main(imga_path,imgbb_path):
c_feat_ids = [29,20,11,6,1]
c_alphas = [.8,.7,.6,.1]
c_patch_sizes = [3,3,3,5,5]
c_patch_radii = [500,6,6,4,4]
c_iters = [700,700,700,700]
model = VGG19()
imga = Utils.load_image(img_path=imga_path,to_array=True,to_variable=True)
imgbb = Utils.load_image(img_path=imgbb_path,to_array=True,to_variable=True)
feata = model.get_features(img_tensor=imga)
featbb = model.get_features(img_tensor=imgbb)
###### Process L 5 ######
feat5a = feata[c_feat_ids[0]]
feat5bb = featbb[c_feat_ids[0]]
feat5a_norm = normalize_feat_map(feat5a)
feat5bb_norm = normalize_feat_map(feat5bb)
pm5ab = PatchMatchOrig(feat5a_norm,feat5a_norm,feat5bb_norm,feat5bb_norm, c_patch_sizes[0])
pm5ab.propagate(iters=5,rand_search_radius=c_patch_radii[0])
imga_raw = Utils.load_image(img_path=imga_path,to_array=False,to_variable=False).numpy().transpose(1,2,0)
imgbb_raw = Utils.load_image(img_path=imgbb_path,to_array=False,to_variable=False).numpy().transpose(1,2,0)
imga_raw.shape
recon = Utils.reconstruct_image(imgbb_raw,pm=pm5ab)
pm5ba = PatchMatchOrig(feat5bb_norm,feat5bb_norm,feat5a_norm,feat5a_norm,c_patch_sizes[0])
pm5ba.propagate(iters=5,rand_search_radius=c_patch_radii[0])
recon = Utils.reconstruct_image(imga_raw,pm=pm5ba)
warped_feat5bb = Utils.reconstruct_image(feat5bb,pm=pm5ab)
warped_feat5a = Utils.reconstruct_image(feat5a,pm=pm5ba)
###### Block L 5 Done ######
###### Process Block 4 ######
r4_bb = model.get_deconvoluted_feat(warped_feat5bb,5,iters=c_iters[0])
r4_a = model.get_deconvoluted_feat(warped_feat5a,5,iters=c_iters[0])
feat4a = feata[c_feat_ids[1]]
feat4bb = featbb[c_feat_ids[1]]
feat4aa = blend_features(feat4a,r4_bb,alpha=c_alphas[0])
feat4b = blend_features(feat4bb,r4_a,alpha=c_alphas[0])
feat4a_norm = normalize_feat_map(feat4a)
feat4bb_norm = normalize_feat_map(feat4bb)
feat4aa_norm = normalize_feat_map(feat4aa)
feat4b_norm = normalize_feat_map(feat4b)
pm4ab = PatchMatchOrig(feat4a_norm,feat4aa_norm,feat4b_norm,feat4bb_norm, c_patch_sizes[1])
pm4ab.nnf = upsample_nnf(nnf=pm5ba.nnf,size=28)
pm4ab.propagate(iters=5,rand_search_radius=c_patch_radii[1])
pm4ba = PatchMatchOrig(feat4bb_norm,feat4b_norm,feat4aa_norm,feat4a_norm, c_patch_sizes[1])
pm4ba.nnf = upsample_nnf(nnf=pm5ba.nnf,size=28)
pm4ba.propagate(iters=5,rand_search_radius=c_patch_radii[1])
warped_feat4bb = Utils.reconstruct_image(feat4bb,pm=pm4ab)
warped_feat4a = Utils.reconstruct_image(feat4a,pm=pm4ba)
###### Block 4 done ######
###### Process Block 3 ######
r3_bb = model.get_deconvoluted_feat(warped_feat4bb,4,iters=c_iters[1])
r3_a = model.get_deconvoluted_feat(warped_feat4a,4,iters=c_iters[1])
feat3a = feata[c_feat_ids[2]]
feat3bb = featbb[c_feat_ids[2]]
feat3aa = blend_features(feat3a,r3_bb,alpha=c_alphas[1])
feat3b = blend_features(feat3bb,r3_a,alpha=c_alphas[1])
feat3a_norm = normalize_feat_map(feat3a)
feat3bb_norm = normalize_feat_map(feat3bb)
feat3aa_norm = normalize_feat_map(feat3aa)
feat3b_norm = normalize_feat_map(feat3b)
pm3ab = PatchMatchOrig(feat3a_norm,feat3aa_norm,feat3b_norm,feat3bb_norm, c_patch_sizes[2])
pm3ab.nnf = upsample_nnf(nnf=pm4ab.nnf,size=56)
pm3ab.propagate(iters=5,rand_search_radius=c_patch_radii[2])
pm3ba = PatchMatchOrig(feat3bb_norm,feat3b_norm,feat3aa_norm,feat3a_norm, c_patch_sizes[2])
pm3ba.nnf = upsample_nnf(nnf=pm4ba.nnf,size=56)
pm3ba.propagate(iters=5,rand_search_radius=c_patch_radii[2])
warped_feat3bb = Utils.reconstruct_image(feat3bb,pm=pm3ab)
warped_feat3a = Utils.reconstruct_image(feat3a,pm=pm3ba)
###### Block 3 done ######
###### Process Block 2 ######
r2_bb = model.get_deconvoluted_feat(warped_feat3bb,3,iters=c_iters[2])
r2_a = model.get_deconvoluted_feat(warped_feat3a,3,iters=c_iters[2])
feat2a = feata[c_feat_ids[3]]
feat2bb = featbb[c_feat_ids[3]]
feat2aa = blend_features(feat2a,r2_bb,alpha=c_alphas[2])
feat2b = blend_features(feat2bb,r2_a,alpha=c_alphas[2])
feat2a_norm = normalize_feat_map(feat2a)
feat2bb_norm = normalize_feat_map(feat2bb)
feat2aa_norm = normalize_feat_map(feat2aa)
feat2b_norm = normalize_feat_map(feat2b)
pm2ab = PatchMatchOrig(feat2a_norm,feat2aa_norm,feat2b_norm,feat2bb_norm, c_patch_sizes[3])
pm2ab.nnf = upsample_nnf(nnf=pm3ab.nnf,size=112)
pm2ab.propagate(iters=5,rand_search_radius=c_patch_radii[3])
pm2ba = PatchMatchOrig(feat2bb_norm,feat2b_norm,feat2aa_norm,feat2a_norm, c_patch_sizes[3])
pm2ba.nnf = upsample_nnf(nnf=pm3ba.nnf,size=112)
pm2ba.propagate(iters=5,rand_search_radius=c_patch_radii[3])
warped_feat2bb = Utils.reconstruct_image(feat2bb,pm=pm2ab)
warped_feat2a = Utils.reconstruct_image(feat2a,pm=pm2ba)
###### Block 2 done ######
###### Process Block 1 ######
r1_bb = model.get_deconvoluted_feat(warped_feat2bb,2,iters=c_iters[3])
r1_a = model.get_deconvoluted_feat(warped_feat2a,2,iters=c_iters[3])
feat1a = feata[c_feat_ids[4]]
feat1bb = featbb[c_feat_ids[4]]
feat1aa = blend_features(feat1a,r1_bb,alpha=c_alphas[3])
feat1b = blend_features(feat1bb,r1_a,alpha=c_alphas[3])
feat1a_norm = normalize_feat_map(feat1a)
feat1bb_norm = normalize_feat_map(feat1bb)
feat1aa_norm = normalize_feat_map(feat1aa)
feat1b_norm = normalize_feat_map(feat1b)
pm1ab = PatchMatchOrig(feat1a_norm,feat1aa_norm,feat1b_norm,feat1bb_norm, c_patch_sizes[4])
pm1ab.nnf = upsample_nnf(nnf=pm2ab.nnf,size=224)
pm1ab.propagate(iters=5,rand_search_radius=c_patch_radii[4])
plt.axis('off')
plt.imshow(Utils.deprocess_image(Utils.reconstruct_image(img_a=imgbb_raw,pm=pm1ab)))
plt.show()
ups = upsample_nnf(nnf=pm1ab.nnf,size=224)
plt.axis('off')
resB = np.clip(Utils.deprocess_image(reconstruct_avg(pm1ab.nnf,imgbb_raw,patch_size=2)),0,1) # avg reconstruction
plt.imshow(resB)
plt.show()
%timeit -n 1 -r 1 main('../data/raw/mona.png','../data/raw/anime2.jpg')
```
| github_jupyter |
# Keras Functional API
## Recall: All models (layers) are callables
```python
from keras.layers import Input, Dense
from keras.models import Model
# this returns a tensor
inputs = Input(shape=(784,))
# a layer instance is callable on a tensor, and returns a tensor
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x)
# this creates a model that includes
# the Input layer and three Dense layers
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels) # starts training
```
# Multi-Input Networks
## Keras Merge Layer
Here's a good use case for the functional API: models with multiple inputs and outputs.
The functional API makes it easy to manipulate a large number of intertwined datastreams.
Let's consider the following model.
```python
from keras.layers import Dense, Input
from keras.models import Model
from keras.layers.merge import concatenate
left_input = Input(shape=(784, ), name='left_input')
left_branch = Dense(32, input_dim=784, name='left_branch')(left_input)
right_input = Input(shape=(784,), name='right_input')
right_branch = Dense(32, input_dim=784, name='right_branch')(right_input)
x = concatenate([left_branch, right_branch])
predictions = Dense(10, activation='softmax', name='main_output')(x)
model = Model(inputs=[left_input, right_input], outputs=predictions)
```
Such a two-branch model can then be trained via e.g.:
```python
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit([input_data_1, input_data_2], targets) # we pass one data array per model input
```
Keras supports different Merge strategies:
* `add`: element-wise sum
* `concatenate`: tensor concatenation. You can specify the concatenation axis via the argument concat_axis.
* `multiply`: element-wise multiplication
* `average`: tensor average
* `maximum`: element-wise maximum of the inputs.
* `dot`: dot product. You can specify which axes to reduce along via the argument dot_axes. You can also specify applying any normalisation. In that case, the output of the dot product is the cosine proximity between the two samples.
You can also pass a function as the mode argument, allowing for arbitrary transformations:
```python
merged = Merge([left_branch, right_branch], mode=lambda x: x[0] - x[1])
```
---
# Even more interesting
Here's a good use case for the functional API: models with multiple inputs and outputs.
The functional API makes it easy to manipulate a large number of intertwined datastreams.
Let's consider the following model (from: [https://keras.io/getting-started/functional-api-guide/](https://keras.io/getting-started/functional-api-guide/) )
## Problem and Data
We seek to predict how many retweets and likes a news headline will receive on Twitter.
The main input to the model will be the headline itself, as a sequence of words, but to spice things up, our model will also have an auxiliary input, receiving extra data such as the time of day when the headline was posted, etc.
The model will also be supervised via two loss functions.
Using the main loss function earlier in a model is a good regularization mechanism for deep models.
<img src="https://s3.amazonaws.com/keras.io/img/multi-input-multi-output-graph.png" width="40%" />
```
from keras.layers import Input, Embedding, LSTM, Dense, concatenate
from keras.models import Model
# Headline input: meant to receive sequences of 100 integers, between 1 and 10000.
# Note that we can name any layer by passing it a "name" argument.
main_input = Input(shape=(100,), dtype='int32', name='main_input')
# This embedding layer will encode the input sequence
# into a sequence of dense 512-dimensional vectors.
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# A LSTM will transform the vector sequence into a single vector,
# containing information about the entire sequence
lstm_out = LSTM(32)(x)
```
Here we insert the auxiliary loss, allowing the LSTM and Embedding layer to be trained smoothly even though the main loss will be much higher in the model.
```
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
```
At this point, we feed into the model our auxiliary input data by concatenating it with the LSTM output:
```
auxiliary_input = Input(shape=(5,), name='aux_input')
x = concatenate([lstm_out, auxiliary_input])
# We stack a deep densely-connected network on top
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# And finally we add the main logistic regression layer
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
```
### Model Definition
```
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
```
We compile the model and assign a weight of 0.2 to the auxiliary loss.
To specify different **loss_weights or loss** for each different output, you can use a list or a dictionary. Here we pass a single loss as the loss argument, so the same loss will be used on all outputs.
#### Note:
Since our inputs and outputs are named (we passed them a "name" argument),
We can compile&fit the model via:
```
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2})
```
```python
# And trained it via:
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': labels, 'aux_output': labels},
epochs=50, batch_size=32)
```
| github_jupyter |
```
# Copyright 2018 Esref Ozdemir
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# Train/Test Set Construction
In this document, we construct training and test sets from already computed feature sets. The sets are computed according to the following directory layout:
```
data
├── test
├── test_events
├── test_feature
├── test_hasball
├── train
├── train_events
├── train_feature
└── train_hasball
```
When ```dataset='test'```, events are read from test_events, features are read from test_feature, hasball data is read from test_hasball and the resulting test dataset is written to test. Same logic applies to ```dataset='train'```.
```
%matplotlib inline
from os import listdir
from os.path import join
import pickle
import numpy as np
import pandas as pd
import multiprocessing
from collections import Counter
from random import shuffle
from sklearn.metrics import f1_score, confusion_matrix
from utils import plot_hbar_nameval, plot_confusion_matrix
from sklearn.ensemble import RandomForestClassifier
pd.set_option('compute.use_bottleneck', True)
pd.set_option('compute.use_numexpr', True)
```
### Event IDs
```
event_names = {
0 : 'Null',
60 : 'Corner',
62 : 'Freekick',
80 : 'Goal',
93 : 'Penalty',
}
with open('../data/event_names.pkl', 'wb') as f:
pickle.dump(event_names, f)
```
**Null event(0)** represents all the event categories, apart from the ones we are interested in, **that occur when the game stops**. If events we want to predict are possession, corner, penalty, freekick, and goal, then other events may correspond to throw-in, out, goal-kick, etc.
### Complete Event List
```
event_names = pd.read_csv('../doc/event_definitions_en.csv')
print('Number of events: {}'.format(len(event_names)))
```
## Event Data
```
event_df = pd.read_csv('../data/train_events/20165_event.csv')
display(event_df.head())
event_ids = np.sort(event_df['eventId'].unique())
print('Event ids: {}'.format(event_ids))
print('Size: {}'.format(len(event_ids)))
event_df[event_df['eventId'] == 93]
```
## Dataset Construction
In this section, we construct a combined dataset containing event ids, coming from event data, and corresponding feature data, coming from feature data.
### Parameters
#### Intervals
When obtaining feature data for a given event, we get all the feature rows in a predefined time interval for that particular event type. The main rationale behind this is that events we try to predict spread over time.
* $+$: More efficient data usage.
* $-$: In the end, time intervals are yet another hyperparameter that needs to be optimized in order to obtain an optimal model.
* $-$: Arbitrary initial values may be totally different than reality.
* $-$: Too large intervals would lead to **greater label noise**.
Choose the dataset to construct
```
dataset = 'test'
import re
event_intervals = {
60 : ( 2, 0), # corner
61 : ( 1, 2), # out
62 : ( 2, 0), # freekick
63 : ( 2, 1), # indirect freekick
64 : ( 1, 0), # throw-in
65 : ( 2, 0), # offside
80 : ( 0, 15), # goal
93 : ( 0, 15), # penalty
98 : ( 0, 2), # injury
}
predict_event_ids = {60, 62, 80, 93}
other_event_ids = {61, 64, 65, 98}
# ratio of event_count/other_count
EVENT_TO_OTHER_RATIO = 8
# ratio of (other_count + event_count)/possession_count
EVENT_TO_POSSESSION_RATIO = 8
# file based constants
event_dir = '../data/{}_events'.format(dataset)
event_regex = re.compile(r'\d+_event.csv')
feature_dir = '../data/{}_feature'.format(dataset)
hasball_dir = '../data/{}_hasball'.format(dataset)
```
### Utility Functions
Generic utility functions used throughout the construction.
```
from utils import hms_to_sec, hms_to_sec_vec, separate_home_away
def get_event_seconds(feature_df, hasball_df, hms, span):
"""
Returns all frames from feature_df within time limits
[hms - span[0], hms + span[1]] at which the game is stopped.
Parameters
----------
feature_df: `pandas.DataFrame` containing the feature data.
hasball_df: `pandas.DataFrame` containing the hasball data.
hms: (half, minute, second) triple indicating when the event happened.
span: (past_limit, future_limit) pair.
"""
sec = hms_to_sec(hms)
begin_sec = sec - span[0]
end_sec = sec + span[1]
hms_vec = hms_to_sec_vec(feature_df[['half', 'minute', 'second']].values)
sec_mask = (hms_vec >= begin_sec) & (hms_vec <= end_sec)
result_df = feature_df[sec_mask]
for index, row in result_df.iterrows():
hasball_row = hasball_df[(hasball_df['half'] == row['half']) & (hasball_df['minute'] == row['minute']) & (hasball_df['second'] == row['second'])]
if hasball_row.empty or hasball_row.at[hasball_row.index[0], 'teamPoss'] != -1:
result_df = result_df.drop(index)
#gamestop_mask = hasball_df['teamPoss'] == -1
return result_df#[sec_mask & gamestop_mask]
```
### Construction Related Functions
These are functions that are heavily coupled with the construction code, and are mainly intended for local code reuse and code readability.
```
def collect_event_features(all_events_df, events,
feature_df, hasball_df, max_samples=None):
"""
Collects features for the given events for the duration
specified in event_intervals. Puts collected events to
all_events_df and corresponding second values to event_seconds.
If max_samples is specified, then collection stops as soon as
the number of collected samples is greater than max_samples.
"""
num_samples = 0
for eid, event_df in events.items():
span = event_intervals[eid]
for _, row in event_df.iterrows():
# get all the features from the time interval
features = get_event_seconds(
feature_df,
hasball_df,
row[['half', 'minute', 'second']],
span
)
num_samples += len(features)
features.insert(0, 'eventId', row['eventId'])
# accumulate data
all_events_df = all_events_df.append(
features.drop(['half', 'minute', 'second'], axis=1),
ignore_index=True
)
if max_samples is not None and num_samples >= max_samples:
return num_samples, all_events_df
return num_samples, all_events_df
```
### Construction
Here we construct the combined dataset from all match data we have in the given data directories.
```
def construct(event_file):
pd.options.mode.chained_assignment = None
all_events_df = pd.DataFrame()
# get event data
event_df = pd.read_csv(join(event_dir, event_file))
# get corresponding feature data
match_id = event_file.split('_')[0]
feature_file = match_id + '_feature.csv'
try:
with open(join(feature_dir, feature_file), 'r') as f:
feature_df = pd.read_csv(f)
feature_df = feature_df.drop(0).reset_index(drop=True)
except FileNotFoundError:
print('No feature data for {}'.format(match_id))
return
# get corresponding hasball data
hasball_file = match_id + '_hasball.csv'
try:
hasball_df = pd.read_csv(join(hasball_dir, hasball_file))
except FileNotFoundError:
print('No hasball data for {}'.format(match_id))
return
# get events we are interested in
predict_events = {eid: event_df[event_df['eventId'] == eid]
for eid in predict_event_ids}
# special treatment for events that need it
## start collecting goal frames 3 seconds after the event
predict_events[80].loc[:, 'second'] = predict_events[80]['second'] + 5
predict_events[93].loc[:, 'second'] = predict_events[93]['second'] + 10
## use multiple custom events for penalty to get as many frames as possible
custom_mask = (predict_events[80]['custom'] == 0)
predict_events[80] = predict_events[80][custom_mask]
custom_mask = (predict_events[93]['custom'] == 0) | (predict_events[93]['custom'] == 1)
predict_events[93] = predict_events[93][custom_mask]
# get "other" events
other_events = {eid: event_df[event_df['eventId'] == eid]
for eid in other_event_ids}
for eid in other_events.keys():
if not other_events[eid].empty:
other_events[eid] = other_events[eid].sample(frac=1)
# collect feature data corresponding to specified events
num_event_samples = 0
count, all_events_df = collect_event_features(
all_events_df,
predict_events,
feature_df,
hasball_df,
)
num_event_samples += count
# collect feature data corresponding to "other" events
count, all_events_df = collect_event_features(
all_events_df,
other_events,
feature_df,
hasball_df,
max_samples=int(num_event_samples//EVENT_TO_OTHER_RATIO)
)
num_event_samples += count
# first and second half begin and end seconds
home_mask = hasball_df['teamPoss'] == 1
away_mask = hasball_df['teamPoss'] == 0
# number of samples to collect for possession
num_possession_samples = int(num_event_samples//EVENT_TO_POSSESSION_RATIO)
num_home_samples = num_possession_samples//2
num_away_samples = num_possession_samples - num_home_samples
# collect possession samples for home team
try:
home_features = feature_df[home_mask].sample(frac=1)#n=num_home_samples)
home_features.insert(0, 'eventId', 0)
all_events_df = all_events_df.append(
home_features.drop(['half', 'minute', 'second'], axis=1),
ignore_index=True
)
except:
pass
# collect possession samples for away team
try:
away_features = feature_df[away_mask].sample(frac=1)#n=num_away_samples)
away_features.insert(0, 'eventId', 0)
all_events_df = all_events_df.append(
away_features.drop(['half', 'minute', 'second'], axis=1),
ignore_index=True
)
except:
pass
for i, row in all_events_df.iterrows():
if row['eventId'] in other_event_ids:
all_events_df.loc[i, 'eventId'] = 0
pd.options.mode.chained_assignment = 'warn'
return all_events_df
```
We speed up the computation by using all the CPU cores via multiprocessing module.
```
pool = multiprocessing.Pool()
event_csv_files = [f for f in listdir(event_dir) if event_regex.match(f)]
shuffle(event_csv_files)
print(len(event_csv_files))
df = pd.concat(pool.map(construct, event_csv_files))
df.sort_values('eventId', inplace=True)
df.reset_index(inplace=True, drop=True)
df.shape
Counter(df.values[:, 0])
display(df.head())
print('n_samples\t= {}\nn_features\t= {}'.format(*df.shape))
```
## Exporting
```
df.to_csv('../data/{dataset}/all_{dataset}.csv'.format(dataset=dataset), index=False)
```
| github_jupyter |
# 02 - Beginner Exercises
* Type Conversion
* Data Structure
## 🍑🍑
1.Ali's math score is ```19.5```. First we ask you to create a variable called the ```math_score``` and set it to ```19.5``` Then print the type of this variable using the ```type()``` function. Then, since in Ali's school, it is customary not to print grades in decimal in the report card, so you also define a variable called the ```final_score``` and convert the score into the integer and then print it.
```
# Write your own code in this cell
```
## 🍑
2.Sara analyzes a company's data.
This data contains a variable named ```employed``` For each person who has been looking for a job in this company.
If a person is employed, its value is equal to ```1```; otherwise, it is equal to ```0```.
Help Sara with converting her data to ```True``` or ```False```.
```
# Write your own code in this cell
# id = "x3q"
x3q_name = "Ebrahim Hamedi"
x3q_employed = 0
print()
# id = "b2w"
b2w_name = "Hassan Shamaizadeh"
b2w_employed = 1
print()
```
## 🍑
3.Sara later realizes that the company has a variable named ```desired_salary``` that is kept in a string of letters, making following calculation hard for her, so she decides to change it to the integer.
Kindly help Sara to do that and then by using the ```type()``` function print the final variable type.
```
# Write your own code in this cell
# id = "x3q"
x3q_desired_salary = "31000"
print()
# id = "b2w"
b2w_desired_salary = "15000"
print()
```
## 🍑🍑
4.Create an empty list, an empty dictionary, an empty set, and an empty tuple, then print their values and types.
```
# Write your own code in this cell
mystring = "!@#$%^&*_+~\\/"
print(mystring, type(mystring))
```
## 🍑
5.Create a list and add the first five terms of the Fibonacci sequence and print it, then add the sixth term and print it again.
```
# Write your own code in this cell
```
## 🍑
6.Create a set and add the first five terms of the Fibonacci sequence and print it, then add the sixth term and print it again.
- compare the results of these cell with the previous cell.
```
# Write your own code in this cell
```
## ✍️
7.Using the built-in ```tupel()``` function, try to create a tuple that contains only the sixth term of the Fibonacci sequence.
```
# Write your own code in this cell
```
## 🎃
8.Help Sara in creating a dictionary which key is equal to person's ID [*x3q, b2m*] and values are just another dictionary with the following keys: ```name``` , ```desired_salary```, ```employed```
and print this dictionary.
```
# Write your own code in this cell
```
| github_jupyter |
# Table of Contents
<div class="toc" style="margin-top: 1em;"><ul class="toc-item" id="toc-level0"><li><span><a href="http://localhost:8888/notebooks/ia898/master/tutorial_numpy_1_5a.ipynb#Introdução-ao-NumPy---Redução-de-eixo" data-toc-modified-id="Introdução-ao-NumPy---Redução-de-eixo-1"><span class="toc-item-num">1 </span>Introdução ao NumPy - Redução de eixo</a></span><ul class="toc-item"><li><span><a href="http://localhost:8888/notebooks/ia898/master/tutorial_numpy_1_5a.ipynb#Operação-combinando-todos-os-pixels" data-toc-modified-id="Operação-combinando-todos-os-pixels-1.1"><span class="toc-item-num">1.1 </span>Operação combinando todos os pixels</a></span></li><li><span><a href="http://localhost:8888/notebooks/ia898/master/tutorial_numpy_1_5a.ipynb#Operação-combinando-eixos-(redução-de-eixo)" data-toc-modified-id="Operação-combinando-eixos-(redução-de-eixo)-1.2"><span class="toc-item-num">1.2 </span>Operação combinando eixos (redução de eixo)</a></span></li><li><span><a href="http://localhost:8888/notebooks/ia898/master/tutorial_numpy_1_5a.ipynb#Outros-exemplos-numéricos" data-toc-modified-id="Outros-exemplos-numéricos-1.3"><span class="toc-item-num">1.3 </span>Outros exemplos numéricos</a></span></li><li><span><a href="http://localhost:8888/notebooks/ia898/master/tutorial_numpy_1_5a.ipynb#Cumsum---Soma-acumulativa-(não-é-redução-de-eixo)" data-toc-modified-id="Cumsum---Soma-acumulativa-(não-é-redução-de-eixo)-1.4"><span class="toc-item-num">1.4 </span>Cumsum - Soma acumulativa (não é redução de eixo)</a></span></li><li><span><a href="http://localhost:8888/notebooks/ia898/master/tutorial_numpy_1_5a.ipynb#Redução-no-eixo-com-aplicações-em-imagens" data-toc-modified-id="Redução-no-eixo-com-aplicações-em-imagens-1.5"><span class="toc-item-num">1.5 </span>Redução no eixo com aplicações em imagens</a></span></li></ul></li></ul></div>
# Introdução ao NumPy - Redução de eixo
## Operação combinando todos os pixels
Existem várias funções que calculam valores estatísticos da imagem, como valor máximo, valor médio,
soma, entre outras, que permitem sua aplicação em todos os pixels resultando num valor escalar único.
Vejam alguns exemplos de cálculo do máximo valor do array, valor médio e somatório de todos os valores:
```
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
a = mpimg.imread('../data/cameraman.tif')[:5*20:20,:4*20:20]
print("a = \n", a)
print('a.max()=', a.max())
print('a.mean()=', a.mean())
print('a.sum()=', a.sum())
```
A título de curiosidade, em processamento paralelo, fazer este tipo de operação, que acumula um
único valor a partir dos valores de cada pixel é uma das operações mais ineficientes, pois
existe o gargalo que todos os pixels precisam ser acumulados numa única variável. Este tipo
de operação, em processamento paralelo, é denominada ``redução``, pois você reduz todos os
elementos do ``ndarray`` a um único valor.
## Operação combinando eixos (redução de eixo)
É possível também fazer estas operações que combinam os pixels, apenas em alguns eixos, isto é
denominado redução de eixo. Para se conseguir isto, basta utilizar como parâmetro da função
usada para a combinação dos valores o eixo em que os valores serão calculados. Assim, se a
imagem for bidimensional, eixos 0 (linhas) e 1 (colunas), se quisermos combinar na direção
das linhas utilizamos 0 como parâmetro e se quisermos acumular na direção das colunas, utilizamos
um como parâmetro. Existem vários métodos que podem ser utilizados.
Vejamos os exemplos a seguir:
```
print('a =\n',a)
print('a.shape = ', a.shape)
print('a.max(axis=0) = ', a.max(0))
print('a.max(axis=0).shape = ', a.max(0).shape)
print('a.max(axis=1) = ', a.max(1))
print('a.max(axis=1).shape = ', a.max(1).shape)
```
Note que ``a.max(0)`` opera no eixo das linhas, resultando o valor máximo de cada coluna. O
resultado possui 4 elementos que é o número de colunas de ``a``. Note que o shape foi reduzido de (5,4) para (4,), pois a
operação se deu na dimensão 0.
Já o ``a.max(1)`` opera na direção do eixo nas colunas, resultando o máximo em cada linha.
O shape reduziu de (5,4) para (5,).
## Outros exemplos numéricos
A seguir outros exemplos reduzindo o eixo 0 (linhas). Em todos os exemplos a seguir, como a redução
se dá no eixo 0, o vetor resultante terá shape (4,), pois o eixo 0 do shape (5,4) de ``a``.
```
print('a =\n',a)
print('a.mean(axis=0) = ', a.mean(0))
print('a.min(axis=0) = ', a.min(0))
print('a.sum(axis=0) = ', a.sum(0))
```
## Cumsum - Soma acumulativa (não é redução de eixo)
```
import numpy as np
a = np.arange(10)
print(a)
print(np.cumsum(a))
a = np.arange(4*6).reshape(4,6)
print(a)
print('a.cumsum(axis=0) = \n', a.cumsum(axis=0))
```
## Redução no eixo com aplicações em imagens
No exemplo abaixo, calculamos o perfil médio das colunas numa imagem que
representa um recorte de uma parte de uma calculadora.
O perfil médio dos pixels é calculado com a operação de ``mean(0)`` para se fazer a redução
da dimensão 0 (linhas). Veja a interpretação da curva no gráfico. As teclas são escuras, porém as
letras são bem claras dando um valor médio
mais baixo que o fundo das teclas que possui um nível de cinza maior. Observe que ``mean(0)``
irá calcular a média de cada coluna, assim, o ``hmean[0]`` abaixo será a média de todos os pixels
da primeira coluna, o ``hmean[1]``, a média de todos os pixels da segunda coluna de ``f`` e
assim por diante. Veja que a operação sendo na direção das linhas (eixo 0), podemos interpretar
que o resultado é uma linha horizontal média da imagem ou é uma linha onde cada elemento é a
média dos pixels de cada coluna da imagem.
```
f = mpimg.imread('../data/keyb.tif')
plt.figure(0)
plt.imshow(f,cmap='gray'); plt.title('f: shape(%d,%d)' % (f.shape[0], f.shape[1]))
hmean = f.mean(axis=0)
plt.figure(1)
plt.plot(hmean,color='r')
plt.ylabel='intensidade'
plt.xlabel='coluna'
plt.title('f.mean(0), valor médio de cada coluna');
```
Veja o exemplo similar, mas agora calculando os valores mínimos de cada coluna.
```
f = mpimg.imread('../data/keyb.tif')
plt.figure(0)
plt.imshow(f,cmap='gray'); plt.title('f: shape(%d,%d)' % (f.shape[0], f.shape[1]))
hmin = f.min(axis=0)
plt.figure(1)
plt.plot(hmin,color='r')
plt.ylabel='intensidade'
plt.xlabel='coluna'
plt.title('f.mean(0), valor médio de cada coluna');
```
| github_jupyter |
----
<img src="../../../files/refinitiv.png" width="20%" style="vertical-align: top;">
# Data Library for Python
----
## Content layer - IPA - Swaption
This notebook demonstrates how to use Swaption pricing analytics.
#### Learn more
To learn more about the Refinitiv Data Library for Python please join the Refinitiv Developer Community. By [registering](https://developers.refinitiv.com/iam/register) and [logging](https://developers.refinitiv.com/content/devportal/en_us/initCookie.html) into the Refinitiv Developer Community portal you will have free access to a number of learning materials like
[Quick Start guides](https://developers.refinitiv.com/en/api-catalog/refinitiv-data-platform/refinitiv-data-library-for-python/quick-start),
[Tutorials](https://developers.refinitiv.com/en/api-catalog/refinitiv-data-platform/refinitiv-data-library-for-python/learning),
[Documentation](https://developers.refinitiv.com/en/api-catalog/refinitiv-data-platform/refinitiv-data-library-for-python/docs)
and much more.
#### Getting Help and Support
If you have any questions regarding using the API, please post them on
the [Refinitiv Data Q&A Forum](https://community.developers.refinitiv.com/spaces/321/index.html).
The Refinitiv Developer Community will be happy to help.
## Set the configuration file location
For a better ease of use, you have the option to set initialization parameters of the Refinitiv Data Library in the _refinitiv-data.config.json_ configuration file. This file must be located beside your notebook, in your user folder or in a folder defined by the _RD_LIB_CONFIG_PATH_ environment variable. The _RD_LIB_CONFIG_PATH_ environment variable is the option used by this series of examples. The following code sets this environment variable.
```
import os
os.environ["RD_LIB_CONFIG_PATH"] = "../../../Configuration"
```
## Some Imports to start with
```
import refinitiv.data as rd
from refinitiv.data.content.ipa.financial_contracts import swaption
from refinitiv.data.content.ipa.financial_contracts import swap
```
## Open the data session
The open_session() function creates and open sessions based on the information contained in the refinitiv-data.config.json configuration file. Please edit this file to set the session type and other parameters required for the session you want to open.
```
rd.open_session()
```
## Retrieve data
```
response = swaption.Definition(
instrument_tag="BermudanEURswaption",
settlement_type=swaption.SwaptionSettlementType.CASH,
tenor="7Y",
strike_percent=2.75,
buy_sell=swaption.BuySell.BUY,
call_put=swaption.CallPut.CALL,
exercise_style=swaption.ExerciseStyle.BERM,
bermudan_swaption_definition=swaption.BermudanSwaptionDefinition(
exercise_schedule_type=swaption.ExerciseScheduleType.FLOAT_LEG,
notification_days=0,
),
underlying_definition=swap.Definition(
tenor="2Y",
legs=[
swap.LegDefinition(
direction=swap.Direction.PAID,
notional_amount="10000000",
notional_ccy="EUR",
interest_type=swap.InterestType.FIXED,
interest_payment_frequency=swap.Frequency.QUARTERLY
),
swap.LegDefinition(
index_tenor="5Y",
cms_template="EUR_AB6E",
interest_type=swap.InterestType.FLOAT,
interest_payment_frequency=swap.Frequency.QUARTERLY,
direction=swap.Direction.RECEIVED,
notional_ccy="EUR",
),
],
pricing_parameters=swap.PricingParameters(discounting_tenor="ON"),
),
pricing_parameters=swaption.PricingParameters(
valuation_date="2020-04-24"
),
fields=[
"InstrumentTag",
"InstrumentDescription",
"ValuationDate",
"ExpiryDate",
"OptionType",
"ExerciseStyle",
"NotionalAmount",
"NotionalCcy",
"SettlementType",
"SettlementCcy",
"Tenor",
"UnderlyingTenor",
"StrikePercent",
"MarketValueInDealCcy",
"PremiumPercent",
"DeltaPercent",
"DeltaAmountInDealCcy",
"ThetaAmountInDealCcy",
"VegaAmountInDealCcy",
"GammaAmountInDealCcy",
],
).get_data()
response.data.df
```
## Close the session
```
rd.close_session()
```
| github_jupyter |
## CSCS530 Winter 2015
#### Complex Systems 530 - Computer Modeling of Complex Systems (Winter 2015)
* Course ID: CMPLXSYS 530
* Course Title: Computer Modeling of Complex Systems
* Term: Winter 2015
* Schedule: Wednesdays and Friday, 1:00-2:30PM ET
* Location: 120 West Hall (http://www.lsa.umich.edu/cscs/research/computerlab)
* Teachers: [Mike Bommarito](https://www.linkedin.com/in/bommarito) and [Sarah Cherng](https://www.linkedin.com/pub/sarah-cherng/35/1b7/316)
#### [View this repository on NBViewer](http://nbviewer.ipython.org/github/mjbommar/cscs-530-w2015/tree/master/)
## HIV Model Outline
### Goal
We will examine policy interventation strategies to address and control the spread of HIV in a sexual network.
### Justification
Given the heterogeneity of behavior and network effects of sexually-transmitted diseases, this problem requires ABM and network methodology. Differential equation compartment models will not allow for incomplete or scale-free graph structures or time-varying agent behavior, and so cannot be used.
### Outline
* Implement condom subsidy mechanics
* Implement gossip network to share status
* Vary condom subsidy and gossip network structure
* Observe how number of steps to 50% infected
* Observe the mean and standard deviation of sexual partner degree distribution
To formally describe our model, let's break it down into pieces:
### I. Space
In this model, our space will be a two-dimensional (2D) square grid. Each grid cell will contain zero or one people. Edges of the grid will wrap around.
### II. Actors
#### A. People
In this case, people are the carriers of HIV. We are modeling them as simply as possible, using only the following properties:
** Properties **
* _is_infected_: is the person infected with HIV?
* _condom_budget_: what is the person's budget for protection?
* _prob_hookup_: what is the probability that a person will want to hookup given contact?
For their step function, agents will perform the following:
* take a unit-distance step in a random direction
* evaluate neighboring cells for any potential people to hookup with
* for each pair, check against _prob_hookup_; if both people sample True, then hookup
* for a hookup, check against _max_budget_ and the global condom cost to see if either partner will purchase
#### B. Institution
A "public health" institution will manage the level of subsidy for condoms. For now, the subsidy level will be set at $t_0$ and constant over model run.
### III. Initial Conditions
#### A. People
* People will be randomly distributed throughout the grid by sampling from a uniform discrete distribution with replacement. In the event that an agent has already been placed at the sampled location, we continue drawing a new nandom position until it is unoccupied.
* People will have their ``prob_hookup`` randomly initialized to a value from a uniform continuous distribution.
* People will have their ``condom_budget`` randomly initialized to a value from a uniform continuous distribution.
* A single person will be selected at random at $t_0$ to have HIV.
#### B. Insitution
The public health institution will set a level of subsidy for condoms using a random uniform continuous distribution.
### IV. Model Parameters
Based on the description above, we need the following model parameters:
* ``grid_size``: size of the two-dimensional square grid, i.e., dimension length
* ``num_people``: number of persons to create; must be less than ${grid\_size}^2$
* ``min_subsidy``, ``max_subsidy``: the lower and upper bounds for the institution's subsidy
* ``min_condom_budget``, ``max_condom_budget``: the lower and upper bounds for initial conditions of people's ``condom_budget``
* ``condom_cost``: cost of a condom; fixed to $1.0$
* ``min_prob_hookup``, ``max_prob_hookup``: the lower and upper bounds for initial conditions of people's ``prob_hookup``
* ``prob_transmit``, ``prob_transmit_condom``: the probability of transmitting the disease without and with a condom
```
%matplotlib inline
# Standard imports
import copy
import itertools
# Scientific computing imports
import numpy
import matplotlib.pyplot as plt
import networkx
import pandas
import seaborn; seaborn.set()
# Import widget methods
from IPython.html.widgets import *
```
## Person Class
Below, we will define our person class. This can be broken up as follows:
* __constructor__: class constructor, which "initializes" or "creates" the person when we call ``Person()``. This is in the ``__init__`` method.
* ``decide_condom``: decide if the person will purchase a condom, i.e., by checking that $condom\_budget >= condom\_cost - subsidy$
* ``decide_hookup``: decide if the person will hookup, i.e., by sampling with $p=prob\_hookup$
```
class Person(object):
"""
Person class, which encapsulates the entire behavior of a person.
"""
def __init__(self, model, person_id, is_infected=False, condom_budget=1.0, prob_hookup=0.5):
"""
Constructor for Person class. By default,
* not infected
* will always buy condoms
* will hookup 50% of the time
Note that we must "link" the Person to their "parent" Model object.
"""
# Set model link and ID
self.model = model
self.person_id = person_id
# Set Person parameters.
self.is_infected = is_infected
self.condom_budget = condom_budget
self.prob_hookup = prob_hookup
def decide_condom(self):
"""
Decide if we will use a condom.
"""
if self.condom_budget >= (self.model.condom_cost - self.model.condom_subsidy):
return True
else:
return False
def decide_hookup(self):
"""
Decide if we want to hookup with a potential partner.
"""
if numpy.random.random() <= self.prob_hookup:
return True
else:
return False
def get_position(self):
"""
Return position, calling through model.
"""
return self.model.get_person_position(self.person_id)
def get_neighbors(self):
"""
Return neighbors, calling through model.
"""
return self.model.get_person_neighbors(self.person_id)
def __repr__(self):
'''
Return string representation.
'''
skip_none = True
repr_string = type(self).__name__ + " ["
except_list = "model"
elements = [e for e in dir(self) if str(e) not in except_list]
for e in elements:
# Make sure we only display "public" fields; skip anything private (_*), that is a method/function, or that is a module.
if not e.startswith("_") and eval('type(self.{0}).__name__'.format(e)) not in ['DataFrame', 'function', 'method', 'builtin_function_or_method', 'module', 'instancemethod']:
value = eval("self." + e)
if value != None and skip_none == True:
repr_string += "{0}={1}, ".format(e, value)
# Clean up trailing space and comma.
return repr_string.strip(" ").strip(",") + "]"
```
## Model Class
Below, we will define our model class. This can be broken up as follows:
* __constructor__: class constructor, which "initializes" or "creates" the model when we call ``Model()``. This is in the ``__init__`` method.
* __``setup_space``__: method to create our "space"
* __``setup_people``__: method to create our "people"
* __``setup_institution``__: method to create our "institution"
* __``get_neighbors``__: method to get neighboring agents based on position
* __``get_person_neighbors``__: method to get neighboring agents based on agent ID
* __``get_person_position``__: method to get position based on agent ID
* __``move_person``__: method to move an agent to a new position
* __``step_move``__: method to step through agent moves
* __``step_interact``__: method to step through agent interaction
* __``step``__: main step method to control each time step simulation
```
class Model(object):
"""
Model class, which encapsulates the entire behavior of a single "run" in our HIV ABM.
"""
def __init__(self, grid_size, num_people, min_subsidy=0.0, max_subsidy=1.0,
min_condom_budget=0.0, max_condom_budget=2.0,
condom_cost=1.0, min_prob_hookup=0.0, max_prob_hookup=1.0,
prob_transmit=0.9, prob_transmit_condom=0.1):
"""
Class constructor.
"""
# Set our model parameters; this is long but simple!
self.grid_size = grid_size
self.num_people = num_people
self.min_subsidy = min_subsidy
self.max_subsidy = max_subsidy
self.min_condom_budget = min_condom_budget
self.max_condom_budget = max_condom_budget
self.condom_cost = condom_cost
self.min_prob_hookup = min_prob_hookup
self.max_prob_hookup = max_prob_hookup
self.prob_transmit = prob_transmit
self.prob_transmit_condom = prob_transmit_condom
# Set our state variables
self.t = 0
self.space = numpy.array((0,0))
self.condom_subsidy = 0.0
self.people = []
self.num_interactions = 0
self.num_interactions_condoms = 0
self.num_infected = 0
# Setup our history variables.
self.history_space = []
self.history_space_infected = []
self.history_interactions = []
self.history_num_infected = []
self.history_num_interactions = []
self.history_num_interactions_condoms = []
# Call our setup methods to initialize space, people, and institution.
self.setup_space()
self.setup_people()
self.setup_institution()
def setup_space(self):
"""
Method to setup our space.
"""
# Initialize a space with a NaN's
self.space = numpy.full((self.grid_size, self.grid_size), numpy.nan)
def setup_people(self):
"""
Method to setup our space.
"""
# First, begin by creating all agents without placing them.
for i in xrange(self.num_people):
self.people.append(Person(model=self,
person_id=i,
is_infected=False,
condom_budget=numpy.random.uniform(self.min_condom_budget, self.max_condom_budget),
prob_hookup=numpy.random.uniform(self.min_prob_hookup, self.max_prob_hookup)))
# Second, once created, place them into the space.
for person in self.people:
# Loop until unique
is_occupied = True
while is_occupied:
# Sample location
random_x = numpy.random.randint(0, self.grid_size)
random_y = numpy.random.randint(0, self.grid_size)
# Check if unique
if numpy.isnan(self.space[random_x, random_y]):
is_occupied = False
else:
is_occupied = True
# Now place the person there by setting their ID.
self.space[random_x, random_y] = person.person_id
# Third, pick one person to be infected initially.
random_infected = numpy.random.choice(range(self.num_people))
self.people[random_infected].is_infected = True
self.num_infected += 1
def setup_institution(self):
"""
Method to setup our space.
"""
# Randomly sample a subsidy level
self.condom_subsidy = numpy.random.uniform(self.min_subsidy, self.max_subsidy)
def get_neighborhood(self, x, y, distance=1):
"""
Get a Moore neighborhood of distance from (x, y).
"""
neighbor_pos = [ ( x % self.grid_size, y % self.grid_size)
for x, y in itertools.product(xrange(x-distance, x+distance+1),
xrange(y-distance, y+distance+1))]
return neighbor_pos
def get_neighbors(self, x, y, distance=1):
"""
Get any neighboring persons within distance from (x, y).
"""
neighbor_pos = self.get_neighborhood(x, y, distance)
neighbor_list = []
for pos in neighbor_pos:
# Skip identity
if pos[0] == x and pos[1] == y:
continue
# Check if empty
if not numpy.isnan(self.space[pos[0], pos[1]]):
neighbor_list.append(int(self.space[pos[0], pos[1]]))
return neighbor_list
def get_person_position(self, person_id):
"""
Get the position of a person based on their ID.
"""
# Find the value that matches our ID in self.space, then reshape to a 2-element list.
return numpy.reshape(numpy.where(self.space == person_id), (1, 2))[0].tolist()
def get_person_neighbors(self, person_id, distance=1):
"""
Get the position of a person based on their ID.
"""
# Find the value that matches our ID in self.space, then reshape to a 2-element list.
x, y = self.get_person_position(person_id)
return self.get_neighbors(x, y, distance)
def move_person(self, person_id, x, y):
"""
Move a person to a new (x, y) location.
"""
# Get original
original_position = self.get_person_position(person_id)
# Check target location
if not numpy.isnan(self.space[x, y]):
raise ValueError("Unable to move person {0} to ({1}, {2}) since occupied.".format(person_id, x, y))
# Otherwise, move by emptying and setting.
self.space[original_position[0], original_position[1]] = numpy.nan
self.space[x, y] = person_id
def step_move(self):
"""
Model step move function, which handles moving agents randomly around.
"""
# Get a random order for the agents.
random_order = range(self.num_people)
numpy.random.shuffle(random_order)
# Iterate in random order.
for i in random_order:
# Get current position
x, y = self.get_person_position(i)
# Move our agent between -1, 0, +1 in each dimension
x_new = (x + numpy.random.randint(-1, 2)) % self.grid_size
y_new = (y + numpy.random.randint(-1, 2)) % self.grid_size
# Try to move them
try:
self.move_person(i, x_new, y_new)
except ValueError:
# Occupied, so fail.
pass
def step_interact(self):
"""
"Interact" the agents by seeing if they will hookup and spread.
"""
# Get a random order for the agents.
random_order = range(self.num_people)
numpy.random.shuffle(random_order)
# Track which pairs we've tested. Don't want to "interact" them twice w/in one step.
seen_pairs = []
# Iterate in random order.
for i in random_order:
# Get neighbors
neighbors = self.get_person_neighbors(i)
# Iterate over neighbors
for neighbor in neighbors:
# Check if we've already seen.
a = min(i, neighbor)
b = max(i, neighbor)
if (a, b) not in seen_pairs:
seen_pairs.append((a, b))
else:
continue
# Check if hookup if not seen.
hookup_a = self.people[a].decide_hookup()
hookup_b = self.people[b].decide_hookup()
if hookup_a and hookup_b:
# Hookup going to happen.
self.num_interactions += 1
# Check now for condoms and use resulting rate.
if self.people[a].decide_condom() or self.people[b].decide_condom():
# Using a condom.
self.num_interactions_condoms += 1
use_condom = True
if self.people[a].is_infected or self.people[b].is_infected:
is_transmission = numpy.random.random() <= self.prob_transmit_condom
else:
is_transmission = False
else:
# Not using a condom.
use_condom = False
if self.people[a].is_infected or self.people[b].is_infected:
is_transmission = numpy.random.random() <= self.prob_transmit
else:
is_transmission = False
# Now infect.
self.history_interactions.append((self.t, a, b, use_condom, is_transmission))
if is_transmission:
self.people[a].is_infected = True
self.people[b].is_infected = True
def get_num_infected(self):
"""
Get the number of infected persons.
"""
# Count
infected = 0
for person in self.people:
if person.is_infected:
infected += 1
return infected
def step(self):
"""
Model step function.
"""
# "Interact" agents.
self.step_interact()
# Move agents
self.step_move()
# Increment steps and track history.
self.t += 1
self.history_space.append(copy.deepcopy(self.space))
self.history_space_infected.append(self.get_space_infected())
self.num_infected = self.get_num_infected()
self.history_num_infected.append(self.num_infected)
self.history_num_interactions.append(self.num_interactions)
self.history_num_interactions_condoms.append(self.num_interactions_condoms)
def get_space_infected(self, t=None):
"""
Return a projection of the space that shows which cells have an infected person.
"""
if t == None:
# Initialize empty
infected_space = numpy.zeros_like(self.space)
# Iterate over persons and set.
for p in self.people:
x, y = self.get_person_position(p.person_id)
if p.is_infected:
infected_space[x, y] = +1
else:
infected_space[x, y] = -1
# Return
return infected_space
else:
# Return historical step
return self.history_space_infected[t]
def __repr__(self):
'''
Return string representation.
'''
skip_none = True
repr_string = type(self).__name__ + " ["
elements = dir(self)
for e in elements:
# Make sure we only display "public" fields; skip anything private (_*), that is a method/function, or that is a module.
e_type = eval('type(self.{0}).__name__'.format(e))
if not e.startswith("_") and e_type not in ['DataFrame', 'function', 'method', 'builtin_function_or_method', 'module', 'instancemethod']:
value = eval("self." + e)
if value != None and skip_none == True:
if e_type in ['list', 'set', 'tuple']:
repr_string += "\n\n\t{0}={1},\n\n".format(e, value)
elif e_type in ['ndarray']:
repr_string += "\n\n\t{0}=\t\n{1},\n\n".format(e, value)
else:
repr_string += "{0}={1}, ".format(e, value)
# Clean up trailing space and comma.
return repr_string.strip(" ").strip(",") + "]"
```
## Testing our model
In order to test our model, we can:
1. Initialize the model with some parameters. For example, below, we have set ``grid_size, num_people, min_prob_hookup,`` and ``max_prob_hookup``.
2. Iterate for some number of steps. Below, we take 1000 steps, outputting some information every 100 steps.
3. Plot some important statistics as time series plots and visualize interaction within the space. For example, below, we plot the time series of interactions with and without condoms and number of infected over time.
```
# Create model and output
m = Model(grid_size=20, num_people=25, min_prob_hookup=0.25, max_prob_hookup=0.5)
# Step over the model for a few steps
for i in xrange(1000):
# Step
m.step()
# Update every 100 steps
if i % 100 == 0:
print((m.t, m.get_num_infected(), m.num_interactions, m.num_interactions_condoms))
# Plot time series.
f = plt.figure()
plt.subplot(211)
plt.plot(m.history_num_infected)
plt.legend(("Number of infections"), loc="best")
plt.subplot(212)
plt.plot(numpy.array(m.history_num_interactions) - numpy.array(m.history_num_interactions_condoms))
plt.plot(m.history_num_interactions_condoms)
plt.legend(("Number of interactions without condoms",
"Number of interactions with condoms"),
loc="best")
```
## Visualizing space
In the code below, we use an IPython widget slider to visualize the movement in our space. The cells are color-coded so that:
* $-1$: agent without infection
* $0$: empty cell
* $+1$: agent with infection
```
# Get colormap
cmap = seaborn.cubehelix_palette(light=1, as_cmap=True)
def plot_space_infected(t=None):
"""
Return a projection of the space that shows which cells have an infected person.
"""
f = plt.figure()
plt.title("Infected space at t={0}".format(t))
plt.pcolor(m.get_space_infected(t), vmin=-1, vmax=1, cmap=cmap)
ax = f.gca()
ax.set_aspect(1./ax.get_data_ratio())
plt.colorbar()
interact(plot_space_infected,
t=IntSlider(min=1, max=m.t-1, step=1))
# Get the network of infections
edge_weight = {}
edge_color = {}
# Iterate over all interactions
for e in m.history_interactions:
# Check if we have recorded this pair before.
if (e[1], e[2]) not in edge_weight:
edge_weight[(e[1], e[2])] = 1
if e[-1] == True:
edge_color[(e[1], e[2])] = "red"
else:
edge_color[(e[1], e[2])] = "#dddddd"
else:
edge_weight[(e[1], e[2])] += 1
if e[-1] == True:
edge_color[(e[1], e[2])] = "red"
else:
edge_color[(e[1], e[2])] = "#dddddd"
# Create graph
g = networkx.Graph()
g.add_nodes_from(range(m.num_people))
g.add_edges_from(edge_weight.keys())
g_layout = networkx.spring_layout(g, iterations=100)
# Get node info
healthy_nodes = [i for i in range(m.num_people) if not m.people[i].is_infected]
infected_nodes = [i for i in range(m.num_people) if m.people[i].is_infected]
# Now we can visualize the infection network.
f = plt.figure(figsize=(16, 16))
ax = f.gca()
networkx.draw_networkx_nodes(g, g_layout,
nodelist=infected_nodes,
node_size=25,
node_color='#b92732')
networkx.draw_networkx_nodes(g, g_layout,
node_size=25,
nodelist=healthy_nodes,
node_color='#64a171')
networkx.draw_networkx_edges(g, g_layout,
width=1,
alpha=0.5,
edge_cmap=cmap,
edge_color=edge_weight.values())
ax.grid(False)
ax.set_axis_bgcolor("#333333")
```
| github_jupyter |
## Python Notes
```
price = '10.20'
print(price)
price = float(price)
print(price)
price = price *10
print(price)
favorite_num = 12.12
# Reassignment Real World Comparison
# Tab or running total (restaunt)
total = 0
total
ice_tea = 1.99
egg_roll = 4.99
noodle_bowl = 7.50
# Ordering ony an ice tea add to total
# the total is always defined in terms of itself (or its previous vaule)
total = total + ice_tea
total
total = total + ice_tea + egg_roll
total #ice tea + egg_roll +
# += is the dame as total = total + something (update)
total += noodle_bowl
total
# Boolean Values
# (True, False)
True
False
favorite_num <= 10
favorite_num
# All our compasion operators give us back a boolean value (True, False)
print(favorite_num == 2) #== compares values
print(favorite_num != 5) # != not equal to (Aint), you get true if the values are diffrent
print(favorite_num > 5) # only greater than five
print(favorite_num >= 5) # greater than or equal to five
```
### Math Operators
- Python takes care of Order of Operations
- Use parenthises when we need to create groupings or control the evaluation
```
x = 5
print(x + 10)
print(x - 11)
print(x * 12)
print(x / 5)
print(x ** 2)
# Use hold(option) to make curser cover whole code
# Floor Division or integer division w/ no remainder uses two forward slashes
3//2
3/2 # To get remainder
```
## Logical Operators Allow Us To Combine Statements
- we can combine values together w/ logical operators
- we can negate cvalues with logical operators
- And, Or, Not
- ANDs limit our possabilities
- ORs expand our possabilities
- A NOT operation flips the boolean value
```
not True
not False
right_here_now = True
doing_python = True
twenty_thousand_leagues_under_the_sea = False
# Ands only return True when all of their parts are true
twenty_thousand_leagues_under_the_sea and doing_python
# Truth Table for AND
print(True and True)
print(True and False)
print(False and True)
print(True and False)
# Ors add possability
# Ors return True if at least one True in the OR combination
twenty_thousand_leagues_under_the_sea or doing_python
good_with_pizza = True
good_with_bbq = False
good_with_seafood = False
good_with_bbq or good_with_seafood or good_with_pizza
# Truth Table for OR
print(True or True)
print(True or False)
print(False or True)
print(False or False)
```
## One weid trick to figure out truth tables in the real world
- Think of Ands in terms of allergies
- If youre allergic to A and B and C and...
- We're limiting the options
- Think of Ords in terms of food prefrence
- Are you good with A or B or C or...
- As long as youre good with one option you get True
```
right_here_now and (good_with_pizza or good_with_bbq)
twenty_thousand_leagues_under_the_sea and (good_with_pizza or good_with_bbq)
# Name boolean variable name with is or have for True and False output
is_first_of_the_month = True
report_has_been_sent = False
# should - tells part of the story
should_process_report = is_first_of_the_month and not report_has_been_sent
print(should_process_report)
```
## Strings and String Operations
- Strings are the data type for words/letters
```
favorite_color = 'Teal'
favorite_color
# Once you create a varibale in an abvoe cell, you can type the vaiable
# Then type the period hit TAB key, and then we get to see the avalible built-in methods
favorite_color.count("a")
favorite_color.isdecimal()
x = '5'
x.isdigit()
# We can put strings together with +
'con' + 'cat' + 'e' + 'nation'
# + sign concats stringsm adds numbers
'5'+'bannana'
# + sign can not 2 things at once, can not add digit with strings variables
# 5 + 'bannana'
# In operator is the Membership operator
'nana' in 'bannana'
'bob' in 'pineapple'
x = 'a'
x.lower()in list('a,e,i,o,u')
# If we want to combine/concat numbers and stringm recomend using format string
# whats a format string
favorite_num = 13
"My favorite number is " + str(favorite_num)
f"My favorite number is {favorite_num}!"
'ban ana'.split(', ')
# String methods return new copies and leave the original, if you need to reasign you can
x.upper()
fruit = "mango"
fruit [0] # square bracket sytax returns 0 indeced values
fruit [3:] # gives us the last two letters of mango
fruit [0:2] # gives use the first two letters of mango
fruit [-1] # gives us the last letter of mango
fruit [:-2] # gives us the first three letters of mango
```
## Let's Talk Lists!
- List hold values in numeric order
- Lists can hold any data type (including lists)
- Consider that a spreadsheet or db tableis a list of lists (b/c it has rows and columns)
- Lists of listis of listis >>> workbook or an entire db
```
beatles = ["John", "George", "Paul"]
beatles
beatles.append("Ringo")
beatles
beatles.reverse()
beatles
"John" in beatles
"Ringo" in beatles
beatles.remove("Paul")
beatles
"Paul" in beatles
beatles
x = [23, 2, 5, 6, 5, 7, 6]
sum(x) #Sigma
average = sum(x) / len(x)
average
x
# How to copy a list and change the copy but no the original.
y = x.copy()
y
sum(y)
y.append(2)
y
sum(y)
sum(x)
# List Comprehension is special syntax that produces new lists
# List Comprehension can contain conditional logic and even function calls inside
numbers = [1, 2, 3, 4, 5]
# Objective is to add one to every number and save as a new list called y
y = [n + 1 for n in numbers]
y
# Make a new list thayt contains the number of charecters in each string in a list
spice_girls = ["Posh", "Sporty", "Ginger", "Scary", "Baby"]
# list Comprehensions start with square brakets for the list'
[len(spice_girl) for spice_girl in spice_girls]
# Without the list comprehension, the code for above would look like: (Build up a list)
output = []
for spice_girl in spice_girls:
output.append(len(spice_girl))
output
# This x valriable here in NOT any x variable from other code
# The syntax of for x creates the variable and gives it a value
[x for x in range(1, 11) if x % 2 == 0] #Put if at end of function
```
### Recomendations
- Use plural for list varible names
- Then with the for loop sigular variable, use a singular version
- Use list comphernshions to make new lists w/ transformed outputs
```
x = [1,2,3]
type(x)
#Lists is a built-in function and a data type
list("bannana")
# What if we need a list that cant change, ever?
# A list that is a constent?
# Tuple
x = (1, 2, 3) # parentheses
x.count(2)
x[0] #Same square braket syntax as we had with lists and strings
# If you try to run this assignments or a tuple, youll get an error
#b/c tuples
# X[0] = 5
# if we need a list version of a tuples
y = list(x)
y
```
## Dictionaries
```
# Dictionaries == like a labled list!
# Dictionaries are created by curly brakets containing key:value pairs
fruit = {
"name": "apple",
"calories": 95,
"carbs": 20
}
fruit
type(fruit)
# With lists, we dont havbe any lable, only the numeric index
# ["apple", 95, 20]
# dictionary access syntax
fruit["carbs"]
fruit["carbs"] = 17 # Reassigning
fruit
another_fruit = {
"name": "mango",
"calroies": 100,
"carbs": 10
}
another_fruit
fruits = [fruit, another_fruit]
fruits
# How many carbs if we consume the apple and mango
total_carbs = fruit["carbs"] + another_fruit["carbs"]
total_carbs
student= dict()
student["name"] = "Jane Janway"
student["class_type"] = "Data Science"
student["grades"] = [95, 98, 90, 81]
student
# How to access this students name?
student["name"]
# How would we add a grade of 100 to the list of grades?
student["grades"].append(100)
student["grades"]
# how to get the students average grade
sum(student["grades"]) / len(student["grades"])
# With dictionaries we access by the key name.
student["class_type"]
student["class_type"] = "Web Development"
student["class_type"]
student["class_type"] = "Data Science"
student["class_type"]
```
| github_jupyter |
# Exercise - Working with Pandas and Seaborn
Now it's your turn to practice what we learned in the previous notebook.
Import the real estate dataset from the following Github path: `data/2017_StPaul_MN_Real_Estate.csv`
**Local Jupyter:** You can use the relative path `../data/2017_StPaul_MN_Real_Estate.csv` to import it.
**Colab:** You will need to upload this file into your Colab container first. Upload `2017_StPaul_MN_Real_Estate.csv` file to the content folder of Colab.
Call this DataFrame `houses`. Remember to import pandas first.
```
# Your code goes here
```
How many rows and columns are there in this dataset?
```
# Your code goes here
```
Use the `.format()` method on string to print a readable text based on this info. Here is an example:
```python
a = 10
print("The value of a is {} hence a * 3 becomes {}.".format(a, a*3))
```
> The value of a is 10 hence a * 3 becomes 30.
```
# Your code goes here
```
This dataset has too many columns to study. To start, let's create a new dataset with a smaller number of attributes. To do this, use the following list, `subset_columns`:
```
subset_columns = ['streetaddress','STREETNAME', 'PostalCode', 'StateOrProvince', 'City', 'SchoolDistrictNumber',
'SalesClosePrice', 'LISTDATE', 'offmarketdate', 'LISTPRICE', 'LISTTYPE',
'OriginalListPrice', 'PricePerTSFT', 'DAYSONMARKET', 'ROOF',
'SQFTABOVEGROUND', 'RoomArea1', 'YEARBUILT']
```
Using the list above create a new DataFrame called `df` that includes the columns specified. One can subset the columns by simply passing a list of the columns to the DataFrame, e.g., `DF[['col1', 'col2']]`. Have in mind that ['col1', 'col2'] was defined in the previous cell, so you can just use it:
```
# Your code goes here
```
Check the number of rows and columns on `df`:
```
# Your code goes here
```
Let's have a look at the first few rows of `df`:
```
# Your code goes here
```
Use `describe()` to get a high level summary of the data:
```
# Your code goes here
```
Using `.info()` extract more info regarding the missing values and columns types:
```
# Your code goes here
```
### How often are houses being sold above the listing price?
To answer this question let's first visually inspect the relationship of `LISTPRICE` vs. `SalesClosePrice`. Here is a step by step guide to do that:
First we want to tell `matplotlib` that we are running our code in a notebook mode:
```python
%matplotlib inline
```
```
# Your code goes here
```
Then import seaborn and use the alias `sns`:
```
# Your code goes here
```
Use seaborn's `lmplot()` function to make a scatterplot with a linear model on top. All you need to provide is `x`, `y`, and `data` arguments. If you are facing issues check out the help function `sns.lmplot?`.
```
# Your code goes here
```
From the plot it is evident that there is a linear relationship between the two variables as the list price is often times set with professionals. We have two many data points and it is hard to draw a conclusion from this chart. Let's take a different path: we will find the percentage difference between these two variables and plot its histogram. It should give us a better understanding of the relationship.
We can start with calculating this percentage difference, something like this:
```python
(df['SalesClosePrice'] - df['LISTPRICE'])/df['LISTPRICE'] * 100
```
Let's assign the result to a variable called `sales_vs_list`:
```
# Your code goes here
type(sales_vs_list)
```
From the type of this object it is clear that this resulted in a pandas Series object. [Series](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.html#pandas.Series) are one-dimensional ndarray with axis labels. Series is the datastructure for a single column of a DataFrame, not only conceptually, but literally, i.e. the data in a DataFrame is actually stored in memory as a collection of Series.
Now that we have our `sales_vs_list` ready let's try to answer our question.
First, use the `describe()` method on `sales_vs_list` to get the statistics summary (similar to DataFrame):
```
# Your code goes here
```
A positive `sales_vs_list` value means that the house was sold above the list price and a negative means the opposite. With a 0 median it looks like as many houses were sold above the list price as below. But let's look at the histogram to get a better picture.
Use seaborn's `distplot()` to plot a histogram. All you need to do is to pass our variable to it (remember this function is coming from seaborn so you will need to use `.` to access it from seaborn:
```
# Your code goes here
```
This is great, but let's make it even look nicer. You can set
```python
sns.set_style("ticks")
```
to give a little extra structure to the plot. Go back to the previous plot and add that line before your plot. Note that you only need to do it once in the notebook and the style will carry for the following cells.
Another "stylish" change you can make is to remove the top and right axes spines, which are not needed. The seaborn function `despine()` can be called to remove them. It has to be called the line after the plot:
```python
sns.despine()
```
To learn more about controlling figure aesthetics checkout [seaborn's documentation page](https://seaborn.pydata.org/tutorial/aesthetics.html).
Except some outliers it looks like the houses were sold within the 20% of the list price. We can checkout how many of these outliers are out there.
Filtering with Series is very similar to DataFrames; you can create a conditional such as `sales_vs_list > 20` and pass it to the original Series. Let's find all the instances where the house was sold more than 20% above the list price:
```
# Your code goes here
```
Okay, that long tail represent only 7 datapoints. Can you re-draw the histogram excluding the values above 20 and below -20?
This time use `kde=False` to ignore the gaussian kernel density estimate, use `bins=30` to include 30 bins, and specify `color="green"` for a change:
```
# Your code goes here
```
Can you find how many of the houses were sold within 1% of the list price?
```
# Your code goes here
```
What percentage of overall dataset does it translate to?
```
# Your code goes here
```
Now that we are a pro in plotting histograms let's go back to our `df` DataFrame and plot the histogram of `SalesClosePrice`.
Note that in the plot below I have used `.set_title("Distribution of Closing Price")` from `matplotlib` to assign a title. Just append that to the rest of your code. You will have to import the package: `import matplotlib.pyplot as plt`
```
# Your code goes here
```
Note: seaborn is built on top of matplotlib. This means that we can use matplotlib's functions along with it. For instance in the above plot I have used the followings to format my graph:
```python
plt.xticks(rotation=20)
plt.title("Distribution of Closing Price")
```
You still need to `import matplotlib.pyplot as plt`.
You can also use a violin plot to show the distribution. Violin plot is similar to a box plot, with the addition of a rotated kernel density plot on each side. We can simply use `sns.violinplot()` and pass `data` and `y` (or `x` depending on which direction you want the violin to be plotted).
Draw a violin plot using `SalesClosePrice`:
```
# Your code goes here
```
Repeat the previous plot with the difference of adding an `x` variable, `SchoolDistrictNumber` to create a violin plot per category:
```
# Your code goes here
```
Try this with `x="City"`:
```
# Your code goes here
```
## Handling Missing Vlaues
How many missing values are in `RoomArea1` column?
```
# Your code goes here
```
Create `df2` where all the records no `RoomArea1` entry are dropped. Check with `df2.info()` to confirm:
```
# Your code goes here
df2.info()
```
From the code below looks like **Asphalt Shingles** is the most commonly used roof in our dataset. Use that to replace the unknown roofs we have in our dataset.
WARNING: replacing NAs with another value is a common technique but has to be used with caution. For instance, the reason some of these properties don't have roofs could be because they are not buildings, in which case you might want to exclude them from your analysis, rather than keeping them and introducing values for their missing points.
```
df.groupby('ROOF')['ROOF'].count().sort_values(ascending=False)
# Your code goes here
df2.info()
```
| github_jupyter |
<h1><center>Multi-Agent Cooperation using Policy Gradients</center></h1>
## 1. Import Dependencies
```
#General Imports
import gym
import json
import math
import numpy as np
import pandas as pd
import pickle
import matplotlib as mpl
import matplotlib.pyplot as plt
import yfinance as yf
from Stock_Trade_Env import StockTradingEnv
import random
#Torch and Baseline Imports
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical
from torch.distributions import Normal
from torch.autograd import Variable
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import DummyVecEnv
checkpoint_name = './Checkpoint-Trade'
#Use GPU
use_cuda = torch.cuda.is_available()
device = torch.device('cuda' if use_cuda else 'cpu')
```
## 2. Replay Buffer
```
class ReplayBuffer:
def __init__(self,capacity):
self.capacity = capacity
self.buffer = []
self.position = 0
def push(self,state,action,reward,next_state,done):
if len(self.buffer)<self.capacity:
self.buffer.append(None)
self.buffer[self.position] = (state,action,reward,next_state,done)
self.position = (self.position+1)%self.capacity
def sample(self,batch_size):
batch = random.sample(self.buffer,batch_size)
state,action,reward,next_state,done = map(np.stack, zip(*batch))
return state,action,reward,next_state,done
def __len__(self):
return len(self.buffer)
```
## 3. Create Env and Pull Data
```
# ticker_list = ['AAPL','SPOT','FB','GOOGL','MSFT','SPY','NFLX','AMZN','TSLA','KRX','T']
# data = yf.download('SPY MSFT GOOGL FB SPOT AAPL', '2020-01-01', '2020-02-14', interval='2m')
ticker = 'AAPL'
data = yf.download(ticker, '2019-12-25', '2020-02-19', interval='2m')
print(data.shape)
data = data.to_csv('./data.csv')
data = pd.read_csv('./data.csv')
env = DummyVecEnv([lambda: StockTradingEnv(data)])
```
### 4.1 Manager Network
```
class ManagerNetwork(nn.Module):
def __init__(self, num_inputs, num_outputs, hidden_size, std=0.0):
super(ManagerNetwork, self).__init__()
self.critic = nn.Sequential(
nn.Linear(num_inputs, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, 1)
)
self.actor = nn.Sequential(
nn.Linear(num_inputs, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, num_outputs),
nn.Softmax(dim=1),
)
def forward(self, x):
value = self.critic(x)
probs = self.actor(x)
dist = Categorical(probs)
return dist, value
```
### 4.3 Order Network
```
class OrderNetwork(nn.Module):
def __init__(self, num_inputs, num_outputs, hidden_size, std=0.0):
super(OrderNetwork, self).__init__()
self.critic = nn.Sequential(
nn.Linear(num_inputs, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, 1)
)
self.actor = nn.Sequential(
nn.Linear(num_inputs, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, num_outputs),
nn.Softmax(dim=1),
)
def forward(self, x):
value = self.critic(x)
probs = self.actor(x)
dist = Categorical(probs)
return probs, dist, value
```
## 5. Update Rule
```
def compute_returns(next_value, rewards, masks, gamma=0.99):
R = next_value
returns = []
for step in reversed(range(len(rewards))):
R = rewards[step] + gamma * R * masks[step]
returns.insert(0, R)
return returns
```
## 6. Test Performance
```
print('Launching Environment...')
num_inputs = 6*6
num_outputs = 3
#Hyper params:
hidden_size = 2048
lr = 3e-4
num_steps = 1
manager_net = ManagerNetwork(num_inputs,num_outputs,hidden_size).to(device)
order_net = OrderNetwork(num_inputs,num_outputs,hidden_size).to(device)
optimizer_manager = optim.Adam(manager_net.parameters())
optimizer_order = optim.Adam(order_net.parameters())
load_model = False
if load_model==True:
#Load Actor Policy Net
manager_checkpoint = torch.load(checkpoint_name+'/manager_net.pth.tar')
manager_net.load_state_dict(manager_checkpoint['model_state_dict'])
optimizer_manager.load_state_dict(manager_checkpoint['optimizer_state_dict'])
#Load Order Policy Net
order_checkpoint = torch.load(checkpoint_name+'/order_net.pth.tar')
order_net.load_state_dict(order_checkpoint['model_state_dict'])
optimizer_order.load_state_dict(order_checkpoint['optimizer_state_dict'])
max_frames = 1
frame_idx = 0
test_rewards = []
state = env.reset()
state = np.expand_dims(state.ravel(),axis=0)
total_loss = []; manager_loss = []; order_loss = []
manager_act_loss = [];order_act_loss = [];manager_val_loss = [];order_val_loss = []
total_reward = [];profit = [];net_worth = [];total_sales = [];total_cost = [];shares_sold = [];shares_held = [];balance = [];
masks = []
print('Training Started...')
print('-'*100)
while frame_idx < max_frames:
log_probs_act = [];log_probs_order = []; rewards = [];
values_act = [];values_order = [];
entropy_act = 0; entropy_order = 0;
for i in range(num_steps):
#Sample action from Mnager Network
state = torch.FloatTensor(state).to(device)
dist_act, value_act = manager_net(state)
act = dist_act.sample()
#Sample amount from Order Network based on command from Manager
state = torch.cat((state,torch.FloatTensor([act for _ in range(1,num_inputs+1)]).unsqueeze(0)),0)
probs, dist_order, value_order = order_net(state)
order = max(probs[:,act])
#Execute action and observe next_state and reward
action = np.array([act.detach().cpu().numpy(), order.detach().cpu().numpy()])
action = action.T
print(action.shape)
next_state, reward, done, _ = env.step(action)
bal, s_held, s_sold, cost, sales, net, prof = env.render()
log_prob_act = dist_act.log_prob(act)
entropy_act += dist_act.entropy().mean()
log_probs_act.append(log_prob_act)
values_act.append(value_act)
log_prob_order = dist_order.log_prob(order)
entropy_order += dist_order.entropy().mean()
log_probs_order.append(log_prob_order)
values_order.append(value_order)
rewards.append(torch.FloatTensor(reward).unsqueeze(1).to(device))
masks.append(torch.FloatTensor(1 - done).unsqueeze(1).to(device))
next_state = np.expand_dims(next_state.ravel(),axis=0)
state = next_state
frame_idx += 1
total_reward.append(reward)
if frame_idx % 10 == 0 and i%1000 == 0:
test_rewards.append(np.mean([test_env() for _ in range(10)]))
print('Step-', str(frame_idx), '/', str(max_frames), '| Profit-', prof,'| Model Loss-', loss[-1])
torch.save({'model_state_dict': manager_net.state_dict(), 'optimizer_state_dict': optimizer_manager.state_dict()},checkpoint_name+'/manager_Net.pth.tar') #save PolicyNet
torch.save({'model_state_dict': order_net.state_dict(), 'optimizer_state_dict': optimizer_order.state_dict()},checkpoint_name+'/order_net.pth.tar') #save PolicyNet
#Sample next action from Manager Network
next_state = torch.FloatTensor(next_state).to(device)
next_dist_act, next_value_act = manager_net(next_state)
next_act = next_dist_act.sample()
#Update for Manager Network
returns_act = compute_returns(next_value_act, rewards, masks)
log_probs_act_temp = torch.cat(log_probs_act)
returns_act = torch.cat(returns_act).detach()
values_act = torch.cat(values_act)
advantage_act = returns_act - values_act
actor_loss = -(log_probs_act_temp * advantage_act.detach()).mean()
critic_loss = advantage_act.pow(2).mean()
loss = actor_loss + 0.5 * critic_loss - 0.001 * entropy_act
optimizer_manager.zero_grad()
loss.backward()
optimizer_manager.step()
manager_act_loss.append(actor_loss)
manager_val_loss.append(critic_loss)
manager_loss.append(loss)
#Sample next action from Order Network
next_state = torch.cat((next_state,torch.FloatTensor([next_act for _ in range(1,num_inputs+1)]).unsqueeze(0)),0)
probs,_,next_value_order = order_net(next_state)
#Update for Order Network
returns_order = compute_returns(next_value_order, rewards, masks)
log_probs_order_temp = torch.cat(log_probs_order)
returns_order = torch.cat(returns_order).detach()
values_order = torch.cat(values_order)
advantage_order = returns_order - values_order
actor_loss = -(log_probs_order_temp * advantage_order.detach()).mean()
critic_loss = advantage_order.pow(2).mean()
loss = actor_loss + 0.5 * critic_loss - 0.001 * entropy_order
optimizer_order.zero_grad()
loss.backward()
optimizer_order.step()
order_act_loss.append(actor_loss)
order_val_loss.append(critic_loss)
order_loss.append(loss)
#Log data
balance.append(bal),profit.append(prof),shares_held.append(s_held),shares_sold.append(s_sold),total_cost.append(cost)
total_sales.append(sales),net_worth.append(net)
total_loss.append(manager_loss[-1] + order_loss[-1])
```
## 8. Save Model and Data
```
data_save = {}
data_save['loss'] = total_loss
data_save['manager_loss'] = manager_loss
data_save['order_loss'] = order_loss
data_save['manager_act_loss'] = manager_act_loss
data_save['order_act_loss'] = order_act_loss
data_save['manager_val_loss'] = manager_val_loss
data_save['order_val_loss'] = order_val_loss
data_save['reward'] = total_reward
data_save['profit'] = profit
data_save['net_worth'] = net_worth
data_save['total_sales'] = total_sales
data_save['cost_basis'] = cost_basis
data_save['shares_sold'] = shares_sold
data_save['shares_held'] = shares_held
data_save['balance'] = balance
with open(checkpoint_name+'/data_save.pkl', 'wb') as f: #data+same as frame folder
pickle.dump(data_save, f)
```
## 9. Plot Results
```
#Plot reward and profit
plt.figure(figsize=(15,5))
plt.plot(reward)
plt.plot(profit)
plt.legend(['Reward','Profit'])
plt.show()
#Plot net worth and total sales value
plt.figure(figsize=(15,5))
plt.plot(net_worth)
plt.plot(total_sales_value)
plt.legend(['Net Worth','Total Sales Value'])
plt.show()
#Plot Shares
plt.figure(figsize=(15,5))
plt.plot(shares_held)
plt.plot(total_shares_sold)
plt.legend(['Shares Held','Shares Sold'])
plt.show()
#Plot cost-basis and balance
plt.figure(figsize=(15,5))
plt.plot(cost_basis)
plt.plot(balance)
plt.legend(['Cost Basis','Balance'])
plt.show()
```
| github_jupyter |
## Clustering Assignment: Web Scrape Yelp reviews for Korean, Scandinavian, Pakistani/Indian, and Brazilian restaurants in New York
Are cuisines that seem so dissimilar may actually be similar according to customers?
```
#First, import libraries as needed
import string
from lxml import html
import requests
# Grab unique url segments for each restaurant that we want to scrape as a list
CUISINES = ['woorijip-authentic-korean-food-new-york',
'barn-joo-35-new-york',
'her-name-is-han-new-york-3',
'jongro-bbq-new-york-3',
'tofu-tofu-new-york-5',
'aska-brooklyn-3',
'aquavit-new-york',
'nordic-preserves-fish-and-wildlife-company-new-york',
'agern-new-york',
'the-copenhagen-new-york',
'the-masalawala-new-york-2',
'bk-jani-bushwick',
'lahore-deli-new-york',
'lahori-chilli-brooklyn-2',
'kababish-jackson-heights',
'ipanema-restaurant-new-york',
'samba-kitchen-new-york-5',
'villa-brazil-cafe-grill-astoria',
'beco-brooklyn',
'berimbau-do-brasil-new-york']
#create a base url that will iterate later with the unique url segments we have in our CUISINES list
base_urls = [ 'http://www.yelp.com/biz/%s' % s for s in CUISINES]
reviews_per_page = 20 # Number of reviews we want for each page
order_sequence = range(0, (reviews_per_page+1), 40) #range to grab reviews from each page
import string
i=0
#start iteration of urls using the base_url and unique segments
for ur in base_urls:
for o in order_sequence:
page = requests.get(ur + ("?start=%s" % o))
tree = html.fromstring(page.text)
# this will make a list of all the reviews
reviews = tree.xpath('//p[@itemprop="description"]/text()')
review_list = []
for rev in reviews:
rev_listry = "".join(filter(lambda x: x in string.printable, rev))
rev_listry = rev_listry.replace(",",":")
rev_listry = rev_listry.replace("\'","")
review_list.append(rev_listry)
# this will make one text file for each restaurant with their reviews
with open(str(CUISINES[i])+".txt", 'w') as f:
f.write("\n".join(map(lambda x: str(x), review_list)))
i+=1
f.close()
#Open the file that we will iterate through and grab elements later
txtfile = open('restaurant_cuisine_names.txt', 'w')
for item in CUISINES:
txtfile.writelines("%s\n" % item)
txtfile.close()
#Start making a dendrogram that will show similarities of the restaurants
import numpy as np
import pandas as pd
import nltk
from bs4 import BeautifulSoup
import re
import os
import codecs
from sklearn import feature_extraction
import mpld3
#Start to grab the list of restaurants and reviews we saved from creating the text files
#Make two larger lists for both the files and the actual text of reviews
#List of text files
txt_files = []
#List of reviews in the text files
rev_txts = []
#Start the process
nyc_restaurants = open('restaurant_cuisine_names.txt').read().split('\n')
nyc_restaurants = nyc_restaurants[:20]
nyc_restaurant0 = open(nyc_restaurants[0]+'.txt','r').read()
rev_txts.append(nyc_restaurant0)
rev_txts[0] = rev_txts[0].replace("\n", " ")
nyc_restaurant1 = open(nyc_restaurants[1]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant1)
rev_txts[1] = rev_txts[1].replace("\n", " ")
nyc_restaurant2 = open(nyc_restaurants[2]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant2)
rev_txts[2] = rev_txts[2].replace("\n", " ")
nyc_restaurant3 = open(nyc_restaurants[3]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant3)
rev_txts[3] = rev_txts[3].replace("\n", " ")
nyc_restaurant4 = open(nyc_restaurants[4]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant4)
rev_txts[4] = rev_txts[4].replace("\n", " ")
nyc_restaurant5 = open(nyc_restaurants[5]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant5)
rev_txts[5] = rev_txts[5].replace("\n", " ")
nyc_restaurant6 = open(nyc_restaurants[6]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant6)
rev_txts[6] = rev_txts[6].replace("\n", " ")
nyc_restaurant7 = open(nyc_restaurants[7]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant7)
rev_txts[7] = rev_txts[7].replace("\n", " ")
nyc_restaurant8 = open(nyc_restaurants[8]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant8)
rev_txts[8] = rev_txts[8].replace("\n", " ")
nyc_restaurant9 = open(nyc_restaurants[9]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant9)
rev_txts[9] = rev_txts[9].replace("\n", " ")
nyc_restaurant10 = open(nyc_restaurants[10]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant10)
rev_txts[10] = rev_txts[10].replace("\n", " ")
nyc_restaurant11 = open(nyc_restaurants[11]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant11)
rev_txts[11] = rev_txts[11].replace("\n", " ")
nyc_restaurant12 = open(nyc_restaurants[12]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant12)
rev_txts[12] = rev_txts[12].replace("\n", " ")
nyc_restaurant13 = open(nyc_restaurants[13]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant13)
rev_txts[13] = rev_txts[13].replace("\n", " ")
nyc_restaurant14 = open(nyc_restaurants[14]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant14)
rev_txts[14] = rev_txts[14].replace("\n", " ")
nyc_restaurant15 = open(nyc_restaurants[15]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant15)
rev_txts[15] = rev_txts[15].replace("\n", " ")
nyc_restaurant16 = open(nyc_restaurants[16]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant16)
rev_txts[16] = rev_txts[16].replace("\n", " ")
nyc_restaurant17 = open(nyc_restaurants[17]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant17)
rev_txts[17] = rev_txts[17].replace("\n", " ")
nyc_restaurant18 = open(nyc_restaurants[18]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant18)
rev_txts[18] = rev_txts[18].replace("\n", " ")
nyc_restaurant19 = open(nyc_restaurants[19]+'.txt', 'r').read()
rev_txts.append(nyc_restaurant19)
rev_txts[19] = rev_txts[19].replace("\n", " ")
#print to double check we have all the restaurant names retrieved
print(nyc_restaurants)
cleaned_rev = []
for text in rev_txts:
text = BeautifulSoup(text, 'html.parser').getText()
#strips html formatting and converts to unicode
cleaned_rev.append(text)
# Check the result
stopwords = nltk.corpus.stopwords.words('english')
# I will stem the words to reduce the feature set
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer("english")
# Define a function that will tokenize and stem text
def tokenize_and_stem(text):
# first tokenize by sentence, then by word to ensure that punctuation is caught as it's own token
tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)]
filtered_tokens = []
# filter out any tokens not containing letters (e.g., numeric tokens, raw punctuation)
for token in tokens:
if re.search('[a-zA-Z]', token):
filtered_tokens.append(token)
stems = [stemmer.stem(t) for t in filtered_tokens]
return stems
totalvocab_stemmed = []
for s in cleaned_rev:
allwords_stemmed = tokenize_and_stem(s)
totalvocab_stemmed.extend(allwords_stemmed)
#define vectorizer parameters
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer(max_df=0.8, max_features=200000,
min_df=0.2, stop_words='english',
use_idf=True, tokenizer=tokenize_and_stem, ngram_range=(1,3))
%time tfidf_matrix = tfidf_vectorizer.fit_transform(cleaned_rev) #fit the vectorizer to clean reviews
print(tfidf_matrix.shape)
terms = tfidf_vectorizer.get_feature_names()
print("Total vocabulary: ", len(totalvocab_stemmed), "Terms used in the TF-IDF matrix: ", len(terms))
from sklearn.metrics.pairwise import cosine_similarity
dist = 1 - cosine_similarity(tfidf_matrix)
biznames = np.array(nyc_restaurants)
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import ward, dendrogram
linkage_matrix = ward(dist) #define the linkage_matrix using ward clustering pre-computed distances
fig, ax = plt.subplots(figsize=(15, 20)) # set size
ax = dendrogram(linkage_matrix, orientation="right", labels=biznames);
plt.tick_params(\
axis= 'x', # changes apply to the x-axis
which='both', # both major and minor ticks are affected
bottom='off', # ticks along the bottom edge are off
top='off', # ticks along the top edge are off
labelbottom='off')
plt.tight_layout() #show plot with tight layout
plt.show()
#uncomment below to save figure
plt.savefig('ward_clusters.png', dpi=200)
#save figure as ward_clusters
```
Build a dendrogram showing the similarities across the restaurants. Do restaurantas offering the same cuisine cluster together? (10pts.)
Based on our dendogram, it appears that restaurants offering the same cuisine for the most part cluster together. However, there is one exception. A dendogram looks at distances between data points on the y axis, which is based upon height and proximity. It first looks at one point closer to another, and then determines the distance between other seperate clusters. Here, we can scroll down to the pakastani/indian restaurants in green, and see that Nordic Preserves Fish and Wildlife Company cluster together in the same group, over being grouped with the other scandinavian restaurants. This is very interesting because these cuisines would probably be considered very different from each other. In addition, the clustering with the korean restaurants also appears to have some form of proximity/similarities, with the scandinavian restaurants. This is depicted in the bigger blue cluster connecting the two clusters together (macro-cluster). Overall, however, the sames cuisines cluster together.
| github_jupyter |
# Spectral Analysis of Deterministic Signals
*This jupyter notebook is part of a [collection of notebooks](../index.ipynb) on various topics of Digital Signal Processing.
## Introduction
The analysis of the spectral properties of a signal plays an important role in digital signal processing. Some application examples are the
* [Spectrum analyzer](https://en.wikipedia.org/wiki/Spectrum_analyzer)
* Detection of (harmonic) signals
* [Estimation of fundamental frequency and harmonics](https://en.wikipedia.org/wiki/Modal_analysis)
* Spectral suppression: acoustic echo suppression, noise reduction, ...
In the practical realization of spectral analysis techniques, the [discrete Fourier transform](https://en.wikipedia.org/wiki/Discrete_Fourier_transform) (DFT) is applied to discrete finite-length signals in order to gain insights into their spectral composition. A basic task in spectral analysis is to determine the amplitude (and phase) of dominant harmonic contributions in a signal mixture. The properties of the DFT with respect to the analysis of an harmonic exponential signal are discussed in the following.
## The Leakage Effect
[Spectral leakage](https://en.wikipedia.org/wiki/Spectral_leakage) is a fundamental effect of the DFT. It limits the ability to detect harmonic signals in signal mixtures and hence the performance of spectral analysis. In order to discuss this effect, the DFT of a discrete exponential signal is revisited starting from the Fourier transform of the continuous exponential signal. The connections between the Fourier transform, the [discrete-time Fourier transform](https://en.wikipedia.org/wiki/Discrete-time_Fourier_transform) (DTFT) and the DFT for a uniformly sampled signal are illustrated below.

Consequently, the leakage effect is discussed in the remainder of this section by considering the following four steps:
1. Fourier transform of an harmonic exponential signal,
2. discrete-time Fourier transform (DTFT) of a discrete harmonic exponential signal, and
3. DTFT of a finite-length discrete harmonic exponential signal
4. sampling of the DTFT.
### Fourier Transform of an Exponential Signal
The harmonic exponential signal is defined as
\begin{equation}
x(t) = \mathrm{e}^{\,\mathrm{j}\, \omega_0 \, t}
\end{equation}
where $\omega_0 = 2 \pi f$ denotes the angular frequency of the signal. The Fourier transform of the exponential signal is
\begin{equation}
X(\mathrm{j}\, \omega) = \int\limits_{-\infty}^{\infty} x(t) \,\mathrm{e}^{\,- \mathrm{j}\, \omega \,t} \mathrm{d}t = 2\pi \; \delta(\omega - \omega_0)
\end{equation}
The spectrum consists of a single shifted Dirac impulse located at the angular frequency $\omega_0$ of the exponential signal. Hence the spectrum $X(\mathrm{j}\, \omega)$ consists of a clearly isolated and distinguishable event. In practice, it is not possible to compute the Fourier transform of a continuous signal by means of digital signal processing.
### Discrete-Time Fourier Transform of a Discrete Exponential Signal
Now lets consider sampled signals. The discrete exponential signal $x[k]$ is derived from its continuous counterpart $x(t)$ above by equidistant sampling $x[k] := x(k T)$ with the sampling interval $T$
\begin{equation}
x[k] = \mathrm{e}^{\,\mathrm{j}\, \Omega_0 \,k}
\end{equation}
where $\Omega_0 = \omega_0 T$ denotes the normalized angular frequency. The DTFT is the Fourier transform of a sampled signal. For the exponential signal it is given as (see e.g. [reference card discrete signals and systems](../reference_cards/RC_discrete_signals_and_systems.pdf))
\begin{equation}
X(\mathrm{e}^{\,\mathrm{j}\, \Omega}) = \sum_{k = -\infty}^{\infty} x[k]\, \mathrm{e}^{\,-\mathrm{j}\, \Omega \,k} = 2\pi \sum_{n = -\infty}^{\infty} \delta((\Omega-\Omega_0) - 2\,\pi\,n)
\end{equation}
The spectrum of the DTFT is $2\pi$-periodic due to sampling. As a consequence, the transform of the discrete exponential signal consists of a series Dirac impulses. For the region of interest $-\pi < \Omega \leq \pi$ the spectrum consists of a clearly isolated and distinguishable event, as for the continuous case.
The DTFT cannot be realized in practice, since is requires the knowledge of the signal $x[k]$ for all time instants $k$. In general, a measured signal is only known within a finite time-interval. The DFT of a signal of finite length can be derived from the DTFT in two steps:
1. truncation (windowing) of the signal and
2. sampling of the DTFT spectrum of the windowed signal.
The consequences of these two steps are investigated in the following.
### Discrete-Time Fourier Transform of a Truncated Discrete Exponential Signal
In general, truncation of a signal $x[k]$ to a length of $N$ samples is modeled by multiplying the signal with a window function $w[k]$ of length $N$
\begin{equation}
x_N[k] = x[k] \cdot w[k]
\end{equation}
where $x_N[k]$ denotes the truncated signal and $w[k] = 0$ for $\{k: k < 0 \wedge k \geq N \}$. The spectrum $X_N(\mathrm{e}^{\,\mathrm{j}\, \Omega})$ can be derived from the multiplication theorem of the DTFT as
\begin{equation}
X_N(\mathrm{e}^{\,\mathrm{j}\, \Omega}) = \frac{1}{2 \pi} X(\mathrm{e}^{\,\mathrm{j}\, \Omega}) \circledast_N W(\mathrm{e}^{\,\mathrm{j}\, \Omega})
\end{equation}
where $\circledast_N$ denotes the cyclic/[circular convolution](https://en.wikipedia.org/wiki/Circular_convolution) of length $N$. A hard truncation of the signal to $N$ samples is modeled by the rectangular signal
\begin{equation}
w[k] = \text{rect}_N[k] = \begin{cases}
1 & \mathrm{for} \; 0\leq k<N \\
0 & \mathrm{otherwise}
\end{cases}
\end{equation}
Its spectrum is given as
\begin{equation}
W(\mathrm{e}^{\,\mathrm{j}\, \Omega}) = \mathrm{e}^{\,-\mathrm{j} \, \Omega \,\frac{N-1}{2}} \cdot \frac{\sin(\frac{N \,\Omega}{2})}{\sin(\frac{\Omega}{2})}
\end{equation}
The DTFT $X_N(\mathrm{e}^{\,\mathrm{j}\, \Omega})$ of the truncated exponential signal is derived by introducing the DTFT of the exponential signal and the window function into above cyclic convolution. Since, both the DTFT of the exponential signal and the window function are periodic with a period of $2 \pi$, the cyclic convolution with period $2 \pi$ is given by linear convolution of both spectra within $-\pi < \Omega \leq \pi$
\begin{equation}
X_N(\mathrm{e}^{\,\mathrm{j}\, \Omega}) = \delta(\Omega-\Omega_0) * \mathrm{e}^{\,-\mathrm{j} \, \Omega \,\frac{N-1}{2}} \cdot \frac{\sin(\frac{N \,\Omega}{2})}{\sin(\frac{\Omega}{2})} =
\mathrm{e}^{\,-\mathrm{j}\, (\Omega-\Omega_0) \, \frac{N-1}{2}} \cdot \frac{\sin(\frac{N\, (\Omega-\Omega_0)}{2})}{\sin(\frac{(\Omega-\Omega_0)}{2})}
\end{equation}
Note that $X_N(\mathrm{e}^{\,\mathrm{j}\, \Omega})$ is periodic with a period of $2 \pi$. Clearly the DTFT of the truncated harmonic exponential signal $x_N[k]$ is not given by a series of Dirac impulses. Above equation is evaluated numerically in order to illustrate the properties of $X_N(\mathrm{e}^{\,\mathrm{j}\, \Omega})$.
```
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
Om0 = 1 # frequency of exponential signal
N = 32 # length of signal
# DTFT of finite length exponential signal (analytic)
Om = np.linspace(-np.pi, np.pi, num=1024)
XN = np.exp(-1j * (Om-Om0) * (N-1) / 2) * (np.sin(N * (Om-Om0) / 2)) / (np.sin((Om-Om0) / 2))
# plot spectrum
plt.figure(figsize = (10, 8))
plt.plot(Om, abs(XN), 'r')
plt.title(r'Absolute value of the DTFT of a truncated exponential signal $e^{j \Omega_0 k}$ with $\Omega_0=$%2.2f' %Om0)
plt.xlabel(r'$\Omega$')
plt.ylabel(r'$|X_N(e^{j \Omega})|$')
plt.axis([-np.pi, np.pi, -0.5, N+5])
plt.grid()
```
**Exercise**
* Change the frequency `Om0` of the signal and rerun the example. How does the magnitude spectrum change?
* Change the length `N` of the signal and rerun the example. How does the magnitude spectrum change?
Solution: The maximum of the absolute value of the spectrum is located at the frequency $\Omega_0$. It should become clear that truncation of the exponential signal leads to a broadening of the spectrum. The shorter the signal, the wider the mainlobe becomes.
### The Leakage Effect of the Discrete Fourier Transform
The DFT is derived from the DTFT $X_N(\mathrm{e}^{\,\mathrm{j}\, \Omega})$ of the truncated signal $x_N[k]$ by sampling the DTFT equidistantly at $\Omega = \mu \frac{2 \pi}{N}$
\begin{equation}
X[\mu] = X_N(\mathrm{e}^{\,\mathrm{j}\, \Omega})\big\vert_{\Omega = \mu \frac{2 \pi}{N}}
\end{equation}
For the DFT of the exponential signal we finally get
\begin{equation}
X[\mu] = \mathrm{e}^{\,\mathrm{j}\, (\Omega_0 - \mu \frac{2 \pi}{N}) \frac{N-1}{2}} \cdot \frac{\sin(\frac{N \,(\Omega_0 - \mu \frac{2 \pi}{N})}{2})}{\sin(\frac{\Omega_0 - \mu \frac{2 \pi}{N}}{2})}
\end{equation}
The sampling of the DTFT is illustrated in the following example. Note that the normalized angular frequency $\Omega_0$ has been expressed in terms of the periodicity $P$ of the exponential signal $\Omega_0 = P \; \frac{2\pi}{N}$.
```
N = 32 # length of the signal
P = 10.33 # periodicity of the exponential signal
Om0 = P * (2*np.pi/N) # frequency of exponential signal
# truncated exponential signal
k = np.arange(N)
x = np.exp(1j*Om0*k)
# DTFT of finite length exponential signal (analytic)
Om = np.linspace(0, 2*np.pi, num=1024)
Xw = np.exp(-1j*(Om-Om0)*(N-1)/2)*(np.sin(N*(Om-Om0)/2))/(np.sin((Om-Om0)/2))
# DFT of the exponential signal by FFT
X = np.fft.fft(x)
mu = np.arange(N) * 2*np.pi/N
# plot spectra
plt.figure(figsize = (10, 8))
ax1 = plt.gca()
plt.plot(Om, abs(Xw), 'r', label=r'$|X_N(e^{j \Omega})|$')
plt.stem(mu, abs(X), label=r'$|X_N[\mu]|$', basefmt=' ')
plt.ylim([-0.5, N+5]);
plt.title(r'Absolute value of the DTFT/DFT of a truncated exponential signal $e^{j \Omega_0 k}$ with $\Omega_0=$%2.2f' %Om0, y=1.08)
plt.legend()
ax1.set_xlabel(r'$\Omega$')
ax1.set_xlim([Om[0], Om[-1]])
ax1.grid()
ax2 = ax1.twiny()
ax2.set_xlim([0, N])
ax2.set_xlabel(r'$\mu$', color='C0')
ax2.tick_params('x', colors='C0')
```
**Exercise**
* Change the periodicity `P` of the exponential signal and rerun the example. What happens if the periodicity is an integer? Why?
* Change the length `N` of the DFT? How does the spectrum change?
* What conclusions can be drawn for the analysis of a single exponential signal by the DFT?
Solution: You should have noticed that for an exponential signal whose periodicity is an integer $P \in \mathbb{N}$, the DFT consists of a discrete Dirac pulse $X[\mu] = N \cdot \delta[\mu - P]$. In this case, the sampling points coincide with the maximum of the main lobe or the zeros of the DTFT. For non-integer $P$, hence non-periodic exponential signals with respect to the signal length $N$, the DFT has additional contributions. The shorter the length $N$, the wider these contributions are spread in the spectrum. This smearing effect is known as *leakage effect* of the DFT. It limits the achievable frequency resolution of the DFT when analyzing signal mixtures consisting of more than one exponential signal or exponential signals under additive noise. This is illustrated by the following numerical examples.
### Analysis of Signal Mixtures by the Discrete Fourier Transform
In order to discuss the implications of the leakage effect when analyzing signal mixtures, the superposition of two exponential signals with different amplitudes and frequencies is considered
\begin{equation}
x_N[k] = A_1 \cdot e^{\mathrm{j} \Omega_1 k} + A_2 \cdot e^{\mathrm{j} \Omega_2 k}
\end{equation}
where $A_1, A_2 \in \mathbb{R}$. For convenience, a function is defined that calculates and plots the magnitude spectrum of $x_N[k]$.
```
def dft_signal_mixture(N, A1, P1, A2, P2):
# N: length of signal/DFT
# A1, P1, A2, P2: amplitude and periodicity of 1st/2nd complex exponential
# generate the signal mixture
Om0_1 = P1 * (2*np.pi/N) # frequency of 1st exponential signal
Om0_2 = P2 * (2*np.pi/N) # frequency of 2nd exponential signal
k = np.arange(N)
x = A1 * np.exp(1j*Om0_1*k) + A2 * np.exp(1j*Om0_2*k)
# DFT of the signal mixture
mu = np.arange(N)
X = np.fft.fft(x)
# plot spectrum
plt.figure(figsize = (10, 8))
plt.stem(mu, abs(X), basefmt=' ')
plt.title(r'Absolute value of the DFT of a signal mixture')
plt.xlabel(r'$\mu$')
plt.ylabel(r'$|X[\mu]|$')
plt.axis([0, N, -0.5, N+5]);
plt.grid()
```
Lets first consider the case that the frequencies of the two exponentials are rather far apart in terms of normalized angular frequency
```
dft_signal_mixture(32, 1, 10.3, 1, 15.2)
```
Investigating the magnitude spectrum one could conclude that the signal consists of two major contributions at the frequencies $\mu_1 = 10$ and $\mu_2 = 15$. Now lets take a look at a situation where the frequencies are closer together
```
dft_signal_mixture(32, 1, 10.3, 1, 10.9)
```
From visual inspection of the spectrum it is rather unclear if the mixture consists of one or two exponential signals. So far the levels of both signals where chosen equal.
Lets consider the case where the second signal has a much lower level that the first one. The frequencies have been chosen equal to the first example
```
dft_signal_mixture(32, 1, 10.3, 0.1, 15.2)
```
Now the contribution of the second exponential is almost hidden in the spread spectrum of the first exponential. From these examples it should have become clear that the leakage effect limits the spectral resolution of the DFT.
| github_jupyter |
# Data Loading
#Andrea Fassbender
#10/17/2019
```
%matplotlib inline
import xarray as xr
import matplotlib.pyplot as plt
import intake
import cartopy.crs as ccrs
import numpy as np
# util.py is in the local directory
# it contains code that is common across project notebooks
# or routines that are too extensive and might otherwise clutter
# the notebook design
import util
```
## Demonstrate how to use `intake-esm`
[Intake-esm](https://intake-esm.readthedocs.io) is a data cataloging utility that facilitates access to CMIP data. It's pretty awesome.
An `intake-esm` collection object establishes a link to a database that contains file locations and associated metadata (i.e. which experiement, model, etc. thet come from).
### Opening a collection
First step is to open a collection by pointing to the collection definition file, which is a JSON file that conforms to the [ESM Collection Specification](https://github.com/NCAR/esm-collection-spec).
The collection JSON files are stored locally in this repository for purposes of reproducibility---and because Cheyenne compute nodes don't have Internet access.
The primary source for these files is the [intake-esm-datastore](https://github.com/NCAR/intake-esm-datastore) repository. Any changes made to these files should be pulled from that repo. For instance, the Pangeo cloud collection is available [here](https://raw.githubusercontent.com/NCAR/intake-esm-datastore/master/catalogs/pangeo-cmip6.json).
```
if util.is_ncar_host():
col = intake.open_esm_datastore("../catalogs/glade-cmip6.json")
else:
col = intake.open_esm_datastore("../catalogs/pangeo-cmip6.json")
col
```
`intake-esm` is build on top of [pandas](https://pandas.pydata.org/pandas-docs/stable). It is possible to view the `pandas.DataFrame` as follows.
```
#col.df.head()
```
It is possible to interact with the `DataFrame`; for instance, we can see what the "attributes" of the datasets are by printing the columns.
```
#col.df.columns
#col.df.variable_id
```
### Search and discovery
#### Finding unique entries
Let's query the data to see what models ("source_id"), experiments ("experiment_id") and temporal frequencies ("table_id") are available.
```
import pprint
uni_dict = col.unique(['source_id', 'experiment_id', 'table_id'])
pprint.pprint(uni_dict, compact=True)
```
#### Searching for specific datasets
Let's find all the column integrated npp data at monthly frequency. A quick check of the avaialble data indicates that only historical data are available at present for this variable. https://docs.google.com/spreadsheets/d/1jn_FzGLw7GluO4sH_NHPIJ0R757b-LP-zV0ThSKvXDM/edit#gid=790478368
Use only 1st member of ensemble: r1i1p1f1
```
cat = col.search(experiment_id=['historical', 'ssp585'], table_id='Omon', variable_id='intpp', member_id='r1i1p1f1', grid_label='gn')
#cat.df
models = set(uni_dict['source_id']['values']) # all the models
for experiment_id in ['historical', 'ssp585']:
query = dict(experiment_id=experiment_id, table_id='Omon',
variable_id='intpp', grid_label='gn', member_id='r1i1p1f1')
cat = col.search(**query)
models = models.intersection({model for model in cat.df.source_id.unique().tolist()})
# for oxygen, ensure the CESM2 models are not included (oxygen was erroneously submitted to the archive)
# models = models - {'CESM2-WACCM', 'CESM2'}
models = list(models)
models
cat = col.search(experiment_id=['historical', 'ssp585'], table_id='Omon',
variable_id='intpp', grid_label='gn', member_id='r1i1p1f1', source_id=models)
cat.df
```
Now perform the same steps to get the gridcell area. [areacello] Grid-Cell Area for Ocean Variables
```
#list models with intpp
cat = col.search(experiment_id=['historical', 'ssp585'], table_id='Omon',
variable_id='intpp', member_id='r1i1p1f1', grid_label='gn',source_id='CESM2')
cat.df
#list models with ocean grid cell area
cat2 = col.search(experiment_id=['historical', 'ssp585'], table_id='Ofx',
variable_id='areacello', member_id='r1i1p1f1', grid_label='gn', source_id='CESM2')
cat2.df
```
### Loading data
`intake-esm` enables loading data directly into an [xarray.Dataset](http://xarray.pydata.org/en/stable/api.html#dataset).
Note that data on the cloud are in
[zarr](https://zarr.readthedocs.io/en/stable/) format and data on
[glade](https://www2.cisl.ucar.edu/resources/storage-and-file-systems/glade-file-spaces) are stored as
[netCDF](https://www.unidata.ucar.edu/software/netcdf/) files. This is opaque to the user.
`intake-esm` has rules for aggegating datasets; these rules are defined in the collection-specification file.
```
#intpp data
dset_dict = cat.to_dataset_dict(zarr_kwargs={'consolidated': True, 'decode_times': True},
cdf_kwargs={'chunks': {}, 'decode_times': True})
#ocean grid cell area data
dset_dict2 = cat2.to_dataset_dict(zarr_kwargs={'consolidated': True, 'decode_times': True},
cdf_kwargs={'chunks': {}, 'decode_times': True})
```
`dset_dict` is a dictionary of `xarray.Dataset`'s; its keys are constructed to refer to compatible groups.
```
#intpp keys
dset_dict.keys()
#ocean grid cell area keys
dset_dict2.keys()
```
We can access these datasets as follows.
```
ds_hist = dset_dict['CMIP.NCAR.CESM2.historical.Omon.gn']
ds_85 = dset_dict['ScenarioMIP.NCAR.CESM2.ssp585.Omon.gn']
ds_hist_oa = dset_dict2['CMIP.NCAR.CESM2.historical.Ofx.gn']
ds_85_oa = dset_dict2['ScenarioMIP.NCAR.CESM2.ssp585.Ofx.gn']
ds_lon = ds_85.lon
ds_lat = ds_85.lat
ds_lat
```
# Plot integrated npp at one location over time
```
def find_indices(xgrid, ygrid, xpoint, ypoint):
"""Returns the i, j index for a latitude/longitude point on a grid.
.. note::
Longitude and latitude points (``xpoint``/``ypoint``) should be in the same
range as the grid itself (e.g., if the longitude grid is 0-360, should be
200 instead of -160).
Args:
xgrid (array_like): Longitude meshgrid (shape M, N)
ygrid (array_like): Latitude meshgrid (shape M, N)
xpoint (int or double): Longitude of point searching for on grid.
ypoint (int or double): Latitude of point searching for on grid.
Returns:
i, j (int):
Keys for the inputted grid that lead to the lat/lon point the user is
seeking.
Examples:
>>> import esmtools as et
>>> import numpy as np
>>> x = np.linspace(0, 360, 37)
>>> y = np.linspace(-90, 90, 19)
>>> xx, yy = np.meshgrid(x, y)
>>> xp = 20
>>> yp = -20
>>> i, j = et.spatial.find_indices(xx, yy, xp, yp)
>>> print(xx[i, j])
20.0
>>> print(yy[i, j])
-20.0
"""
dx = xgrid - xpoint
dy = ygrid - ypoint
reduced_grid = abs(dx) + abs(dy)
min_ix = np.nanargmin(reduced_grid)
i, j = np.unravel_index(min_ix, reduced_grid.shape)
return i, j
[x,y]=find_indices(ds_lon, ds_lat, 360-145, 50)
ds_85_sub = ds_85.intpp.isel(nlon=x,nlat=y)
fig = plt.figure(figsize=(10,3))
ds_85_sub.plot()
# Make a map of intpp at the start and end of the time series
import numpy as np
levels = np.arange(0, 150, 5)
levels2 = np.arange(-25, 25, 2.5)
fig = plt.figure(figsize=(14, 3))
# Ask, out of a 1x1 grid, the first axes.
ax = fig.add_subplot(1, 3, 1)
(ds_85.intpp*(10**8)).isel(time=4).plot(levels=levels)
ax.set_ylabel('Latitude')
ax.set_xlabel('Longitude')
plt.title('May 2015 IntNPP')
ax2 = fig.add_subplot(1, 3, 2)
(ds_85.intpp*(10**8)).isel(time=1031-7).plot(levels=levels)
ax2.set_ylabel('Latitude')
ax2.set_xlabel('Longitude')
plt.title('May 2100 IntNPP')
ax3 = fig.add_subplot(1, 3, 3)
ds_diff = (ds_85.intpp*(10**8)).isel(time=1031-7) - (ds_85.intpp*(10**8)).isel(time=4)
ds_diff.plot(levels=levels2)
ax3.set_ylabel('Latitude')
ax3.set_xlabel('Longitude')
plt.title('May 2100 - May 2015 IntNPP')
ds_85_oa.areacello
# Make a map of ocean area as well as a meridional plot
fig = plt.figure(figsize=(12, 4))
ax = fig.add_subplot(1, 2, 1)
ds_85_oa.areacello.plot()
ax.set_ylabel('Latitude')
ax.set_xlabel('Longitude')
ax2 = fig.add_subplot(1, 2, 2)
ds_85_oa.areacello.isel(nlon=100).plot()
ax2.set_xlabel('Latitude')
```
# Save Data Frames
#this will allow for easy access in sucessive notebooks
```
# Check File type
type(ds_hist)
# Check file size for intpp
print('file size (GB):', ds_hist.nbytes / 1e9)
# Check file size for oa
print('file size (GB):', ds_hist_oa.nbytes / 1e9)
# Save files to my Cheyenne folder for easy access
ds_hist_mask = ds_hist['intpp'].where(ds_hist['intpp'] < 1e10)
ds_hist_mask.to_netcdf('Data/hist_intpp_mask.nc')
ds_85_mask = ds_85['intpp'].where(ds_85['intpp'] < 1e10)
ds_85_mask.to_netcdf('Data/ssp585_intpp_mask.nc')
ds_85_oa_mask = ds_85_oa['areacello'].where(ds_85_oa['areacello'] < 1e10)
ds_85_oa_mask.to_netcdf('Data/ssp585_oa_mask.nc')
ds_hist_oa_mask = ds_hist_oa['areacello'].where(ds_hist_oa['areacello'] < 1e10)
ds_hist_oa_mask.to_netcdf('Data/hist_oa_mask.nc')
ds_lon.to_netcdf('Data/ds_lon.nc')
ds_lat.to_netcdf('Data/ds_lat.nc')
```
| github_jupyter |
# Gradient Boost Regressor
***
### `class GradientBoostRegressor(data: [[String]], target: Int, till: Int, learningRate: Float, using: String)`
***
## Parameters:
#### `data` : [[String]]
Data with labels (see format below)
#### `target`: *Int*
column number of the labels
#### `till`: *Int*
Column number of the labels
#### `learningRate`: *Float, default: 0.1*
Column number of the labels
#### `using`: *String*
whether to use infoGain or giniImpurity
## Attributes:
#### `trees`: [DecisionTree]
Decision trees used in the regressor
***
## Methods
***
### `boost()` : Fits a Gradient Boost Regressor.
***
### `predict(this: [[String]])` : Predicts value for an example by getting all tree decisions.
### parameters:
#### `this`: [[String]]
String array with feature header to be classified.
### Returns:
Returns predicted classification as a string.
***
### `score(testData: [[String]])`: Scores the booster's accuracy on test data.
### parameters:
#### `testData`: [[String]]
test data as a 2D string array with feature header (see format below)
### Returns:
Returns accuracy of predictions as float
and predictions as string array
***
# Example
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://colab.research.google.com/github/param087/swiftML/blob/master/Notebooks/GradientRegressorTutorial.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/param087/swiftML/blob/master/Notebooks/GradientRegressorTutorial.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />View source on GitHub</a>
</td>
</table>
## Install the swiftML package from GitHub.
```
%install '.package(url: "https://github.com/param087/swiftML", from: "0.0.4")' swiftML
```
## Import Swift packages
```
import TensorFlow
import swiftML
```
## Load dataset & create booster
```
let patientDataTrain : [[String]] = [
["temperature", "nausea", "lumbar pain", "urine pushing", "micturition pains", "Burning of urethra, itch, swelling of urethra outlet", "Inflamtation of urinary bladder", "Nephritis of renal pelvis origin"],
["35.5", "no", "yes", "no", "no", "no", "no", "no"],
["35.9", "no", "no", "yes", "yes", "yes", "yes", "no"],
["36.0", "no", "no", "yes", "yes", "yes", "yes", "no"],
["36.0", "no", "yes", "no", "no", "no", "no", "no"],
["36.0", "no", "yes", "no", "no", "no", "no", "no"],
["36.2", "no", "no", "yes", "yes", "yes", "yes", "no"],
["36.2", "no", "yes", "no", "no", "no", "no", "no"],
["36.3", "no", "no", "yes", "yes", "yes", "yes", "no"],
["36.6", "no", "no", "yes", "yes", "yes", "yes", "no"],
["36.6", "no", "no", "yes", "yes", "yes", "yes", "no"],
["36.6", "no", "yes", "no", "no", "no", "no", "no"],
["36.6", "no", "yes", "no", "no", "no", "no", "no"],
["36.7", "no", "no", "yes", "yes", "yes", "yes", "no"],
["36.7", "no", "yes", "no", "no", "no", "no", "no"],
["36.7", "no", "yes", "no", "no", "no", "no", "no"],
["36.8", "no", "no", "yes", "yes", "yes", "yes", "no"],
["36.8", "no", "no", "yes", "yes", "yes", "yes", "no"],
["36.9", "no", "no", "yes", "yes", "yes", "yes", "no"],
["36.9", "no", "yes", "no", "no", "no", "no", "no"],
["37.0", "no", "no", "yes", "yes", "no", "yes", "no"],
["37.0", "no", "no", "yes", "yes", "no", "yes", "no"],
["37.0", "no", "yes", "no", "no", "no", "no", "no"],
["37.0", "no", "no", "yes", "yes", "yes", "yes", "no"],
["37.0", "no", "no", "yes", "yes", "yes", "yes", "no"],
["37.0", "no", "no", "yes", "yes", "yes", "yes", "no"],
["37.0", "no", "no", "yes", "no", "no", "yes", "no"],
["37.1", "no", "yes", "no", "no", "no", "no", "no"],
["37.1", "no", "no", "yes", "yes", "yes", "yes", "no"],
["37.1", "no", "no", "yes", "no", "no", "yes", "no"],
["37.2", "no", "no", "yes", "yes", "no", "yes", "no"],
["37.2", "no", "yes", "no", "no", "no", "no", "no"],
["37.2", "no", "no", "yes", "no", "no", "yes", "no"],
["37.3", "no", "yes", "no", "no", "no", "no", "no"],
["37.3", "no", "no", "yes", "yes", "yes", "yes", "no"],
["37.3", "no", "no", "yes", "no", "no", "yes", "no"],
["37.4", "no", "yes", "no", "no", "no", "no", "no"],
["37.4", "no", "no", "yes", "no", "no", "yes", "no"],
["37.5", "no", "no", "yes", "yes", "no", "yes", "no"],
["37.5", "no", "yes", "no", "no", "no", "no", "no"],
["37.5", "no", "yes", "no", "no", "no", "no", "no"],
["37.5", "no", "no", "yes", "yes", "yes", "yes", "no"],
["37.5", "no", "no", "yes", "no", "no", "yes", "no"],
["37.6", "no", "no", "yes", "yes", "no", "yes", "no"],
["37.6", "no", "no", "yes", "yes", "no", "yes", "no"],
["37.6", "no", "no", "yes", "yes", "yes", "yes", "no"],
["37.7", "no", "no", "yes", "yes", "no", "yes", "no"],
["37.7", "no", "yes", "no", "no", "no", "no", "no"],
["37.7", "no", "no", "yes", "no", "no", "yes", "no"],
["37.8", "no", "yes", "no", "no", "no", "no", "no"],
["37.8", "no", "no", "yes", "yes", "yes", "yes", "no"],
["37.8", "no", "no", "yes", "no", "no", "yes", "no"],
["37.9", "no", "no", "yes", "yes", "no", "yes", "no"],
["37.9", "no", "no", "yes", "yes", "no", "yes", "no"],
["37.9", "no", "yes", "no", "no", "no", "no", "no"],
["37.9", "no", "no", "yes", "yes", "yes", "yes", "no"],
["37.9", "no", "no", "yes", "no", "no", "yes", "no"],
["38.0", "no", "yes", "yes", "no", "yes", "no", "yes"],
["38.0", "no", "yes", "yes", "no", "yes", "no", "yes"],
["38.1", "no", "yes", "yes", "no", "yes", "no", "yes"],
["38.3", "no", "yes", "yes", "no", "yes", "no", "yes"],
["38.5", "no", "yes", "yes", "no", "yes", "no", "yes"],
["38.9", "no", "yes", "yes", "no", "yes", "no", "yes"],
["39.0", "no", "yes", "yes", "no", "yes", "no", "yes"],
["39.7", "no", "yes", "yes", "no", "yes", "no", "yes"],
["40.0", "yes", "yes", "yes", "yes", "yes", "yes", "yes"],
["40.0", "yes", "yes", "yes", "yes", "yes", "yes", "yes"],
["40.0", "yes", "yes", "yes", "yes", "no", "yes", "yes"],
["40.0", "no", "no", "no", "no", "no", "no", "no"],
["40.0", "no", "no", "no", "no", "no", "no", "no"],
["40.0", "yes", "yes", "no", "yes", "no", "no", "yes"],
["40.0", "no", "yes", "yes", "no", "yes", "no", "yes"],
["40.2", "yes", "yes", "yes", "yes", "yes", "yes", "yes"],
["40.2", "no", "no", "no", "no", "no", "no", "no"],
["40.2", "yes", "yes", "no", "yes", "no", "no", "yes"],
["40.3", "no", "yes", "yes", "no", "yes", "no", "yes"],
["40.4", "yes", "yes", "yes", "yes", "yes", "yes", "yes"],
["40.4", "yes", "yes", "yes", "yes", "no", "yes", "yes"],
["40.4", "yes", "yes", "yes", "yes", "no", "yes", "yes"],
["40.4", "no", "no", "no", "no", "no", "no", "no"],
["40.5", "yes", "yes", "yes", "yes", "no", "yes", "yes"],
["40.6", "yes", "yes", "yes", "yes", "yes", "yes", "yes"],
["40.6", "no", "no", "no", "no", "no", "no", "no"],
["40.6", "yes", "yes", "no", "yes", "no", "no", "yes"],
["40.7", "yes", "yes", "yes", "yes", "yes", "yes", "yes"],
["40.7", "yes", "yes", "yes", "yes", "no", "yes", "yes"],
["40.7", "yes", "yes", "no", "yes", "no", "no", "yes"],
["40.7", "no", "yes", "yes", "no", "yes", "no", "yes"],
["40.8", "no", "yes", "yes", "no", "yes", "no", "yes"],
["40.9", "no", "yes", "yes", "no", "yes", "no", "yes"],
["41.0", "yes", "yes", "yes", "yes", "yes", "yes", "yes"],
["41.0", "yes", "yes", "no", "yes", "no", "no", "yes"],
["41.0", "no", "yes", "yes", "no", "yes", "no", "yes"],
["41.1", "yes", "yes", "yes", "yes", "yes", "yes", "yes"],
["41.1", "yes", "yes", "yes", "yes", "no", "yes", "yes"],
["41.1", "no", "no", "no", "no", "no", "no", "no"],
["41.1", "no", "yes", "yes", "no", "yes", "no", "yes"],
["41.2", "yes", "yes", "yes", "yes", "yes", "yes", "yes"],
["41.2", "no", "no", "no", "no", "no", "no", "no"],
["41.2", "no", "yes", "yes", "no", "yes", "no", "yes"],
["41.3", "yes", "yes", "yes", "yes", "no", "yes", "yes"],
["41.4", "no", "yes", "yes", "no", "yes", "no", "yes"],
["41.5", "no", "no", "no", "no", "no", "no", "no"],
["41.5", "yes", "yes", "no", "yes", "no", "no", "yes"],
["41.5", "no", "yes", "yes", "no", "yes", "no", "yes"]
]
let patientDataTest : [[String]] = [
["temperature", "nausea", "lumbar pain", "urine pushing", "micturition pains", "Burning of urethra, itch, swelling of urethra outlet", "Inflamtation of urinary bladder", "Nephritis of renal pelvis origin"],
["41.5", "no", "yes", "yes", "no", "yes", "no", "yes"],
["41.2", "yes", "yes", "no", "yes", "no", "no", "yes"],
["41.1", "yes", "yes", "no", "yes", "no", "no", "yes"],
["41.0", "no", "no", "no", "no", "no", "no", "no"],
["40.9", "yes", "yes", "yes", "yes", "no", "yes", "yes"],
["40.9", "yes", "yes", "yes", "yes", "no", "yes", "yes"],
["40.7", "no", "no", "no", "no", "no", "no", "no"],
["40.4", "yes", "yes", "no", "yes", "no", "no", "yes"],
["40.1", "yes", "yes", "yes", "yes", "no", "yes", "yes"],
["40.0", "yes", "yes", "no", "yes", "no", "no", "yes"],
["39.4", "no", "yes", "yes", "no", "yes", "no", "yes"],
["38.7", "no", "yes", "yes", "no", "yes", "no", "yes"],
["37.7", "no", "no", "yes", "yes", "no", "yes", "no"],
["37.5", "no", "no", "yes", "no", "no", "yes", "no"],
["37.0", "no", "no", "yes", "yes", "yes", "yes", "no"],
["35.9", "no", "yes", "no", "no", "no", "no", "no"]
]
let booster = GradientBoostRegressor(data: patientDataTrain, target: 0, till: 200, learningRate: 0.1, using: "gini")
booster.boost()
```
## Fit a linear model
```
booster.boost()
```
### Classifying single example
```
let example = [
["temperature", "nausea", "lumbar pain", "urine pushing", "micturition pains", "Burning of urethra, itch, swelling of urethra outlet", "Inflamtation of urinary bladder", "Nephritis of renal pelvis origin"],
["?", "no", "yes", "no", "no", "no", "no", "no"]
]
booster.predict(this: example)
```
### Scoring model accuracy
```
let boosterOutput = booster.score(testData: patientDataTrain)
print(booster.trees.count)
print("accuracy: ", boosterOutput.0*100, "%")
print("predictions: ", boosterOutput.1)
```
| github_jupyter |
# Introduction to Modern, Web-based Methodologies
## Learning objectives
- What are modern, web-based image analysis methods?
- Why are web-based methods relevant for large images and reproducibility?
- How does open source software fit into the computational ecosystem?
## Modern, web-based image analysis and visualization
What is modern, web-based imaging analysis and visualization?
1. The user interface is **web browser**
2. Defacto communication on the internet with the **HTTPS** protocol
3. Computation can happen in the **cloud**
## Important Technologies
### Evergreen browsers

An **evergreen browser** releases frequently, striving for up-to-date and comprehensive support for *[web standards](https://en.wikipedia.org/wiki/Web_standards)*.
Modern evergreen browsers include:
- Google Chrome
- Mozilla Firefox
- Microsoft Edge
- Opera
- Apple Safari
Note that Chrome, Edge, and Opera are all based on the same open source Chromium foundation. Safari often lags behind or is limited in standard support. Internet Explorer is no longer supported by Microsoft as of August 17, 2021, but lacks support for many Modern Web standard features.
### Programming Languages
#### Client-side programming languages

Client-side programming languages are languages that run web browser page.
**JavaScript (JS)** is the *language of the web.* A working knowledge of JS is [a useful skill](https://www.youtube.com/watch?v=dFUlAQZB9Ng).

- JavaScript is the only language with ubiquitous support across modern web browsers.
- Modern JavaScript runtimes are highly engineered and very performant.
- JavaScript can also executed server side -- [*Node.js*](https://nodejs.org/en/) is the most popular server-side runtime.
- JavaScript has one of the largest software package ecosystems: the [Node package manager, NPM, the npm registry, and the npm CLI](https://www.npmjs.com/).
- The JavaScript language standard, [ECMAScript](https://en.wikipedia.org/wiki/ECMAScript), is a rapidly evolving, modern language. The most recent version is ES2020.
- Most client-side code deployed on websites, whether written in JS or another language, is transpiled down to ECMAScript version 5 with Node.js.
- The [Mozilla Developer Network (MDN)](https://developer.mozilla.org/en-US/docs/Web/JavaScript) is the best place to find JavaScript-related documentation.
**TypeScript (TS)** is a superset of JavaScript that adds optional static type definitions.

- Typescript is a popular alternative to JavaScript for writing client-side code.
- When Typescript is transpiled to JavaScript for deployment, static type checking occurs.
- In addition to compilation error checking, explicit types in interfaces and other typed language advantages are available, e.g. IDE features.
- Many language features that used to be unique to TypeScript, e.g. classes, have now been adopted into the JavaScript language standard.
Other languages can be compiled into **WebAssembly (Wasm)**, a portable compilation target enabling deployment on the web for client and server applications.

- WebAssembly is efficient and fast.
- Wasm can be transmitted in a binary format.
- Wasm supports hardware capabilities such as [atomics](https://courses.cs.washington.edu/courses/cse378/07au/lectures/L25-Atomic-Operations.pdf) and [SIMD](https://en.wikipedia.org/wiki/SIMD).
- Wasm focuses on secure, memory-safe sandboxed execution in the browser.
- Wasm runs on the same virtual machine as JavaScript, and it is debuggable in browsers.
- Wasm is part of the open web platform, supported by all major browsers.
- Wasm aims to be backwards compatible.
- A JavaScript API is provided ito interface with WebAssembly.
Performant image processing code can be written in the following languages, and compiled to Wasm:
- C/C++ via [Emscripten](https://emscripten.org/)
- Rust
- Java
Other browser **web standards** *important for scientific imaging* include:

- **[WebGL](https://www.khronos.org/webgl/)**: a *web standard for a low-level 3D graphics API based on OpenGL ES, exposed to ECMAScript via the HTML5 Canvas.*
- **[WebGPU](https://gpuweb.github.io/gpuweb/)**: *an API that exposes the capabilities of GPU hardware for the Web. The API is designed from the ground up to efficiently map to the Vulkan, Direct3D 12, and Metal native GPU APIs. WebGPU is not related to WebGL and does not explicitly target OpenGL ES.*
- **Web Worker's**: Runs JavaScript in background threads separate from a web page's main thread. Useful for parallelism.
- **ServiceWorker's**: another *worker* that acts as a proxy between the web browser page and the network. It can be used to *cache assets* to provide fast web apps with *offline* functionality.
Server-side programming languages for web-based imaging include:
- *Python*
- Java
- Rust
- JavaScript
- C++
### Web-based storage
Discussed in the [data storage](./04_Data_Storage.ipynb) tutorial.
### Cloud compute
Discussed in the [distributed image processing](./05_Distributed_Processing.ipynb) tutorial.
### Communication
Communication web standard for scientific imaging include:
- **REST**: *[Representational state transfer (REST)](https://en.wikipedia.org/wiki/Representational_state_transfer) is a software architectural style that defines a set of constraints to be used for creating Web services. HTTP-based RESTful APIs are defined with the following aspects: a base URI, such as http://api.example.com/, standard HTTP methods (e.g., GET, POST, PUT, and DELETE),
and, a media type that defines state transition data element.*
- **WebSockets** - a two-way communication channel that is more performant than HTTP requests. Used by Jupyter, Colab, etc.
- **[IPFS](https://en.wikipedia.org/wiki/InterPlanetary_File_System)** - *The InterPlanetary File System (IPFS) is a protocol and peer-to-peer network for storing and sharing data in a distributed file system.*
## Web-based methods, large images, and reproducibility
**Why are web-based methods uniquely appropriate for working with extremely large images?**
- Natural approach to remote storage
- Helpful when data needs to be stored near the microscope or in the *cloud*
- **Warning**: however, data-compute locality is often critical for performance!
- Partial image chunks can be fetched on demand for analysis or visualization
- Compression is a natural and commonplace component
**Why do web-based methods uniquely support open science and reproducibility?**
- Truely write once, run everywhere
- Backwards and forwards compatibility
- A standards-based ecosystem
- Distributed compute and storage resources, which improves sustainability
```
# A C++ image denoising method compiled to JavaScript over five years ago.
#
# No maintenance required, hosted on free resources, and executed by the client.
import IPython
url = 'https://insightsoftwareconsortium.github.io/ITKAnisotropicDiffusionLBR/'
width = 800
height = 1000
IPython.display.IFrame(url, width, height)
```
## Modern methods and traditional open source imaging software
**How to modern web-based methods extend and interface with traditional open source scientific imaging software?**
- **ImJoy**
- [ImJoy](https://imjoy.io/docs/#/) is a plugin-powered hybrid computing platform for deploying deep learning applications such as advanced image analysis tools.
- JavaScript or Python-based plugins.
- Take the dedicated [I2K ImJoy tutorial](https://www.janelia.org/sites/default/files/You%20%2B%20Janelia/Conferences/10.pdf).
- Read [the paper](https://rdcu.be/bYbGO).
- [ImageJ.js](https://ij.imjoy.io/) - ImageJ compiled to WebAssembly and exposed with ImJoy.
- [itk.js](https://insightsoftwareconsortium.github.io/itk-js/index.html): itk.js combines Emscripten and ITK to enable high-performance spatial analysis in a JavaScript runtime environment.
- [pyodide](https://github.com/iodide-project/pyodide/): CPython scientific Python libraries, e.g. scikit-image, compiled to WebAssembly.
- [Jupyter](https://jupyter.org/): browser-based literate programming, combining interactive code, equations, and visualizations
- [JupyterLab](https://jupyterlab.readthedocs.io/en/stable/): next generation browser interface, more JavaScript focus.
- [Colab](https://colab.research.google.com/notebooks/intro.ipynb#recent=true): alternative Jupyter notebook interface with GPGPU hardware backends for deep learning and Google integrations.
- [Voila](https://github.com/voila-dashboards/voila): quickly turn Jupyter notebooks into standalone web applications.
## Exercise: Learn about the web-browser development environment!
### Exercise 1: JavaScript Hello World!
```
%%javascript
console.log('Hello web world!')
```
After running the above cell, you just ran your first JavaScript *Hello World!* program -- congratulations!
However, where is the output? We can find out by exploring the amazing integrated development environment bundled with modern web browsers.
**To access Console in the brower's Developer Tools:**
From the Chrome browser: Menu -> More tools -> Developer Tools (or CTRL + Shift + I)
From the Firefox browser: Menu > Web Developer > Toggle Tools (or CTRL + Shift + I)
- *Find the Hello World output*
- *Use the console repl to:*
- *Print a new hello world message*
- *Create a [JavaScript Array](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array) with two elements, 3.0 and 8.0*
- *Create a [JavaScript Float32Array](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Float32Array) with two elements, 3.0 and 8.0*
### Exercise 2: The elements inspector
The elements inspector tab is to the left of the Console tab.
- *Use the elements inspector to select elements for inspection by:*
- *Clicking an element in the developers tools*
- *Click the "Select an element" button (to the left of the elements inspector tab) and clicking on an element in the page*
### Exercise 3: The debugger
Click on the *Sources* or *Debugger* tab to open up the debugger.
Click on the *01_Introduction.ipynb* file. Scroll down to a `<script>` element.
Click on a line number to set a breakpoint.
Refresh the page. Use the debugger tools to step through the JavaScript code, and inspect the call stack and variables.
### Bonus Exercise
Test the Network, Performance, and Memory developers tools.
| github_jupyter |
##### Copyright 2020 The Cirq Developers
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# Transforming circuits
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://quantumai.google/cirq/transform"><img src="https://quantumai.google/site-assets/images/buttons/quantumai_logo_1x.png" />View on QuantumAI</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/quantumlib/Cirq/blob/master/docs/transform.ipynb"><img src="https://quantumai.google/site-assets/images/buttons/colab_logo_1x.png" />Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/quantumlib/Cirq/blob/master/docs/transform.ipynb"><img src="https://quantumai.google/site-assets/images/buttons/github_logo_1x.png" />View source on GitHub</a>
</td>
<td>
<a href="https://storage.googleapis.com/tensorflow_docs/Cirq/docs/transform.ipynb"><img src="https://quantumai.google/site-assets/images/buttons/download_icon_1x.png" />Download notebook</a>
</td>
</table>
```
try:
import cirq
except ImportError:
print("installing cirq...")
!pip install --quiet cirq
print("installed cirq.")
```
## Circuit optimizers
Cirq comes with the concept of an optimizer. Optimizers will pass over a circuit and perform tasks that will modify the circuit in place. These can be used to transform a circuit in specific ways, such as combining single-qubit gates, commuting Z gates through the circuit, or readying the circuit for certain hardware or gate set configurations.
Optimizers will have a function `optimize_circuit()` that can be used to perform this optimization. Here is a simple example that removes empty moments:
```
import cirq
c=cirq.Circuit()
c.append(cirq.Moment([]))
c.append(cirq.Moment([cirq.X(cirq.GridQubit(1,1))]))
c.append(cirq.Moment([]))
print(f'Before optimization, Circuit has {len(c)} moments')
cirq.DropEmptyMoments().optimize_circuit(circuit=c)
print(f'After optimization, Circuit has {len(c)} moments')
```
Optimizers that come with cirq can be found in the `cirq.optimizers` package.
A few notable examples are:
* **ConvertToCzAndSingleGates**: Attempts to convert a circuit into CZ gates and single qubit gates. This uses gate's unitary and decompose methods to transform them into CZ + single qubit gates.
* **DropEmptyMoments** / **DropNegligible**: Removes moments that are empty or have very small effects, respectively.
* **EjectPhasedPaulis**: Pushes X, Y, and PhasedX gates towards the end of the circuit, potentially absorbing Z gates and modifying gates along the way.
* **EjectZ**: Pushes Z gates towards the end of the circuit, potentially adjusting phases of gates that they pass through.
* **ExpandComposite**: Uses `cirq.decompose` to expand composite gates.
* **MergeInteractions**: Combines series of adjacent one and two-qubit gates acting on a pair of qubits.
* **MergeSingleQubitGates**: Combines series of adjacent unitary 1-qubit operations
* **SynchronizeTerminalMeasurements**: Moves all measurements in a circuit to the final moment if possible.
### Create your own optimizers
You can create your own optimizers to transform and modify circuits to fit hardware, gate sets, or other requirements. Optimizers can also be used to generate noise. See [noise](noise.ipynb) for details.
You can do this by implementing the function `optimize_circuit`.
If your optimizer is a local optimizer and depends primarily on operator being examined, you can alternatively inherit `cirq.PointOptimizer` and implement the function `optimization_at(self, circuit, index, op)` that optimizes a single operation.
Below is an example of implementing a simple `PointOptimizer` that removes measurements.
```
class RemoveMeasurements(cirq.PointOptimizer):
def optimization_at(self, circuit: cirq.Circuit, index: int, op: cirq.Operation):
if isinstance(op.gate, cirq.MeasurementGate):
return cirq.PointOptimizationSummary(clear_span=1,
new_operations=[],
clear_qubits=op.qubits)
else:
return None
q=cirq.LineQubit(0)
c=cirq.Circuit(cirq.X(q), cirq.measure(q))
print('Before optimization')
print(c)
RemoveMeasurements().optimize_circuit(c)
print('After optimization')
print(c)
```
| github_jupyter |
```
import numpy as np
import imp
import sys
import os
import time
sys.path.append(os.path.expanduser('~/quantum-ml/nanowire_model'))
import copy
import potential_profile
import multiprocessing as mp
import markov
import physics
import thomas_fermi
import mask
import tunneling
import exceptions
imp.reload(tunneling)
imp.reload(markov)
imp.reload(physics)
imp.reload(thomas_fermi)
imp.reload(mask)
imp.reload(potential_profile)
imp.reload(exceptions)
physics_model = {}
# multiple of eV
physics_model['E_scale'] = 1
# multiple of nm
physics_model['dx_scale'] = 1
physics_model['kT'] = 1000e-6
b1 = [-200e-3,-0.3,0.1,1]
d = [200e-3,0.0,0.1,1]
b2 = [-200e-3,0.3,0.1,1]
physics_model['list_b'] = [b1,d,b2]
x = np.linspace(-1,1,100)
physics_model['x'] = x
physics_model['V'] = potential_profile.V_x_wire(x,[b1,d,b2])
physics_model['K_onsite'] = 5e-3
physics_model['sigma'] = x[1] - x[0]
physics_model['x_0'] = 0.1*(x[1] - x[0])
physics_model['mu_l'] = (100.0e-3,100.1e-3)
physics_model['battery_weight'] = 10
physics_model['short_circuit_current'] = 1
graph_model = (5,1)
tf_strategy = 'simple'
#timeit my_phys = physics.Physics(physics_model)
#%lprun -f physics.Physics.__init__ my_phys = physics.Physics(physics_model)
#timeit graph = markov.Markov(graph_model,physics_model,tf_strategy)
#%lprun -f thomas_fermi.ThomasFermi.tf_solver_fixed_mu graph = markov.Markov(graph_model,physics_model,tf_strategy)
st = time.time()
graph = markov.Markov(graph_model,physics_model,tf_strategy)
print(graph.find_n_dot_estimate())
print(graph.find_start_node())
print(graph.recalculate_graph)
graph.generate_graph()
print(graph.get_current())
print(graph.get_charge_state())
print("time",time.time()-st)
V_d_vec = np.linspace(200e-3,250e-3,1000)
I_vec = np.zeros(1000)
for i in range(len(V_d_vec)):
d[0] = V_d_vec[i]
physics_model['list_b'] = [b1,d,b2]
V = potential_profile.V_x_wire(x,physics_model['list_b'])
physics_model['V'] = potential_profile.V_x_wire(x,[b1,d,b2])
I_vec[i] = np.sum(calculate_current((graph,physics_model))['current'])
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(I_vec)
graph.tf.attempt_rate_scale/1e14
plt.plot(graph.tf.V)
def calculate_current(param):
graph = param[0]
physics_model = param[1]
try:
graph.physics = physics_model
graph.tf.__init__(physics_model)
graph.find_n_dot_estimate(fix_mask=False)
graph.find_start_node()
graph.generate_graph()
return graph.get_output()
except exceptions.NoBarrierState:
output = {}
output['current'] = graph.tf.short_circuit_current
output['charge_state'] = (0,)
output['prob_dist'] = (0,)
output['num_dot'] = 0
output['state'] = 'ShortCircuit'
return output
except exceptions.InvalidChargeState:
output = {}
output['current'] = 0
output['charge_state'] = (0,)
output['prob_dist'] = (0,)
output['num_dot'] = 0
output['state'] = 'NoDot'
return output
def calculate_curr_parr(physics_model):
graph_model = (10,1)
tf_strategy = 'simple_iter'
try:
graph = markov.Markov(graph_model,physics_model,tf_strategy)
graph.physics = physics_model
graph.tf.__init__(physics_model)
graph.find_n_dot_estimate(fix_mask=False)
graph.find_start_node()
graph.generate_graph()
I = graph.get_output()
del graph
return I
except exceptions.NoBarrierState:
return graph.tf.short_circuit_current
XX,YY = np.meshgrid(V_d_vec,V_d_vec)
plt.pcolor(XX,YY,np.array([x['current'] if x['current'] != None else 0.0 for x in output_vec]).reshape((N_v,N_v)),\
cmap='coolwarm',vmax=1e-3)
plt.xlabel(r'$V_{d1} (V)$',fontsize=16)
plt.ylabel(r'$V_{d2} (V)$',fontsize=16)
cbar = plt.colorbar()
cbar.set_label("Current (arb. units)",fontsize=16)
XX,YY = np.meshgrid(V_d_vec,V_d_vec)
def map_state_to_color(param):
(state,num_dot) = param
if state == 'QPC':
return 0
elif state == 'Dot' and num_dot == 1:
return 1
elif state == 'Dot' and num_dot == 2:
return 2
elif state == 'ShortCircuit':
return 3
else:
return 4
C = [map_state_to_color(x) for x in zip([y['state'] for y in output_vec],[y['num_dot'] for y in output_vec])]
import matplotlib as mpl
my_cmap = mpl.colors.ListedColormap([[0., .4, 1.], [0., .8, 1.],
[1., .8, 0.], [1., .4, 0.]])
C_new = [C[N_v*i : N_v*(i+1)] for i in range(N_v)]
plt.pcolor(XX,YY,C_new,cmap = my_cmap,alpha=0.9)
plt.xlabel(r'$V_{d1} (V)$',fontsize=16)
plt.ylabel(r'$V_{d2} (V)$',fontsize=16)
cbar = plt.colorbar(cmap=my_cmap,ticks=[0,1,2,3])
cbar.set_ticklabels(["QPC","SingleDot","DoubleDot","ShortCircuit"])
cbar.set_ticks([0.5,1.5,2.5,3.5])
plt.pcolor(XX,YY,np.array([np.sum(x['charge_state']) if x['charge_state'] != None else 0.0 for x in output_vec]).reshape((N_v,N_v)),alpha=0.9)
plt.xlabel(r'$V_{d1} (V)$',fontsize=16)
plt.ylabel(r'$V_{d2} (V)$',fontsize=16)
cbar = plt.colorbar()
cbar.set_label('Total Charge',fontsize=16)
```
| github_jupyter |
<div align="center">
<h1><img width="30" src="https://madewithml.com/static/images/rounded_logo.png"> <a href="https://madewithml.com/">Made With ML</a></h1>
Applied ML · MLOps · Production
<br>
Join 30K+ developers in learning how to responsibly <a href="https://madewithml.com/about/">deliver value</a> with ML.
<br>
</div>
<br>
<div align="center">
<a target="_blank" href="https://newsletter.madewithml.com"><img src="https://img.shields.io/badge/Subscribe-30K-brightgreen"></a>
<a target="_blank" href="https://github.com/GokuMohandas/MadeWithML"><img src="https://img.shields.io/github/stars/GokuMohandas/MadeWithML.svg?style=social&label=Star"></a>
<a target="_blank" href="https://www.linkedin.com/in/goku"><img src="https://img.shields.io/badge/style--5eba00.svg?label=LinkedIn&logo=linkedin&style=social"></a>
<a target="_blank" href="https://twitter.com/GokuMohandas"><img src="https://img.shields.io/twitter/follow/GokuMohandas.svg?label=Follow&style=social"></a>
<br>
🔥 Among the <a href="https://github.com/topics/deep-learning" target="_blank">top ML</a> repositories on GitHub
</div>
<br>
<hr>
# Transformers
In this lesson we will learn how to implement the Transformer architecture to extract contextual embeddings for our text classification task.
<div align="left">
<a target="_blank" href="https://madewithml.com/courses/foundations/transformers/"><img src="https://img.shields.io/badge/📖 Read-blog post-9cf"></a>
<a href="https://github.com/GokuMohandas/MadeWithML/blob/main/notebooks/15_Transformers.ipynb" role="button"><img src="https://img.shields.io/static/v1?label=&message=View%20On%20GitHub&color=586069&logo=github&labelColor=2f363d"></a>
<a href="https://colab.research.google.com/github/GokuMohandas/MadeWithML/blob/main/notebooks/15_Transformers.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
</div>
# Overview
Transformers are a very popular architecture that leverage and extend the concept of self-attention to create very useful representations of our input data for a downstream task.
- **advantages**:
- better representation for our input tokens via contextual embeddings where the token representation is based on the specific neighboring tokens using self-attention.
- sub-word tokens, as opposed to character tokens, since they can hold more meaningful representation for many of our keywords, prefixes, suffixes, etc.
- attend (in parallel) to all the tokens in our input, as opposed to being limited by filter spans (CNNs) or memory issues from sequential processing (RNNs).
- **disadvantages**:
- computationally intensive
- required large amounts of data (mitigated using pretrained models)
<div align="left">
<img src="https://raw.githubusercontent.com/GokuMohandas/MadeWithML/main/images/foundations/transformers/architecture.png" width="800">
</div>
<div align="left">
<small><a href="https://arxiv.org/abs/1706.03762" target="_blank">Attention Is All You Need</a></small>
</div>
# Set up
```
!pip install transformers==3.0.2 -q
import numpy as np
import pandas as pd
import random
import torch
import torch.nn as nn
SEED = 1234
def set_seeds(seed=1234):
"""Set seeds for reproducibility."""
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # multi-GPU# Set seeds for reproducibility
set_seeds(seed=SEED)
# Set seeds for reproducibility
set_seeds(seed=SEED)
# Set device
cuda = True
device = torch.device('cuda' if (
torch.cuda.is_available() and cuda) else 'cpu')
torch.set_default_tensor_type('torch.FloatTensor')
if device.type == 'cuda':
torch.set_default_tensor_type('torch.cuda.FloatTensor')
print (device)
```
## Load data
We will download the [AG News dataset](http://www.di.unipi.it/~gulli/AG_corpus_of_news_articles.html), which consists of 120K text samples from 4 unique classes (`Business`, `Sci/Tech`, `Sports`, `World`)
```
import numpy as np
import pandas as pd
import re
import urllib
# Load data
url = "https://raw.githubusercontent.com/GokuMohandas/MadeWithML/main/datasets/news.csv"
df = pd.read_csv(url, header=0) # load
df = df.sample(frac=1).reset_index(drop=True) # shuffle
df.head()
# Reduce data size (too large to fit in Colab's limited memory)
df = df[:10000]
print (len(df))
```
## Preprocessing
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
```
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
import re
nltk.download('stopwords')
STOPWORDS = stopwords.words('english')
print (STOPWORDS[:5])
porter = PorterStemmer()
def preprocess(text, stopwords=STOPWORDS):
"""Conditional preprocessing on our text unique to our task."""
# Lower
text = text.lower()
# Remove stopwords
pattern = re.compile(r'\b(' + r'|'.join(stopwords) + r')\b\s*')
text = pattern.sub('', text)
# Remove words in paranthesis
text = re.sub(r'\([^)]*\)', '', text)
# Spacing and filters
text = re.sub(r"([-;;.,!?<=>])", r" \1 ", text)
text = re.sub('[^A-Za-z0-9]+', ' ', text) # remove non alphanumeric chars
text = re.sub(' +', ' ', text) # remove multiple spaces
text = text.strip()
return text
# Sample
text = "Great week for the NYSE!"
preprocess(text=text)
# Apply to dataframe
preprocessed_df = df.copy()
preprocessed_df.title = preprocessed_df.title.apply(preprocess)
print (f"{df.title.values[0]}\n\n{preprocessed_df.title.values[0]}")
```
## Split data
```
import collections
from sklearn.model_selection import train_test_split
TRAIN_SIZE = 0.7
VAL_SIZE = 0.15
TEST_SIZE = 0.15
def train_val_test_split(X, y, train_size):
"""Split dataset into data splits."""
X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)
X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)
return X_train, X_val, X_test, y_train, y_val, y_test
# Data
X = preprocessed_df["title"].values
y = preprocessed_df["category"].values
# Create data splits
X_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(
X=X, y=y, train_size=TRAIN_SIZE)
print (f"X_train: {X_train.shape}, y_train: {y_train.shape}")
print (f"X_val: {X_val.shape}, y_val: {y_val.shape}")
print (f"X_test: {X_test.shape}, y_test: {y_test.shape}")
print (f"Sample point: {X_train[0]} → {y_train[0]}")
```
## Label encoder
```
class LabelEncoder(object):
"""Label encoder for tag labels."""
def __init__(self, class_to_index={}):
self.class_to_index = class_to_index
self.index_to_class = {v: k for k, v in self.class_to_index.items()}
self.classes = list(self.class_to_index.keys())
def __len__(self):
return len(self.class_to_index)
def __str__(self):
return f"<LabelEncoder(num_classes={len(self)})>"
def fit(self, y):
classes = np.unique(y)
for i, class_ in enumerate(classes):
self.class_to_index[class_] = i
self.index_to_class = {v: k for k, v in self.class_to_index.items()}
self.classes = list(self.class_to_index.keys())
return self
def encode(self, y):
y_one_hot = np.zeros((len(y), len(self.class_to_index)), dtype=int)
for i, item in enumerate(y):
y_one_hot[i][self.class_to_index[item]] = 1
return y_one_hot
def decode(self, y):
classes = []
for i, item in enumerate(y):
index = np.where(item == 1)[0][0]
classes.append(self.index_to_class[index])
return classes
def save(self, fp):
with open(fp, 'w') as fp:
contents = {'class_to_index': self.class_to_index}
json.dump(contents, fp, indent=4, sort_keys=False)
@classmethod
def load(cls, fp):
with open(fp, 'r') as fp:
kwargs = json.load(fp=fp)
return cls(**kwargs)
# Encode
label_encoder = LabelEncoder()
label_encoder.fit(y_train)
num_classes = len(label_encoder)
label_encoder.class_to_index
# Class weights
counts = np.bincount([label_encoder.class_to_index[class_] for class_ in y_train])
class_weights = {i: 1.0/count for i, count in enumerate(counts)}
print (f"counts: {counts}\nweights: {class_weights}")
# Convert labels to tokens
print (f"y_train[0]: {y_train[0]}")
y_train = label_encoder.encode(y_train)
y_val = label_encoder.encode(y_val)
y_test = label_encoder.encode(y_test)
print (f"y_train[0]: {y_train[0]}")
print (f"decode([y_train[0]]): {label_encoder.decode([y_train[0]])}")
```
## Tokenizer
We'll be using the [BertTokenizer](https://huggingface.co/transformers/model_doc/bert.html#berttokenizer) to tokenize our input text in to sub-word tokens.
```
from transformers import DistilBertTokenizer
from transformers import BertTokenizer
# Load tokenizer and model
# tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
tokenizer = BertTokenizer.from_pretrained("allenai/scibert_scivocab_uncased")
vocab_size = len(tokenizer)
print (vocab_size)
# Tokenize inputs
encoded_input = tokenizer(X_train.tolist(), return_tensors="pt", padding=True)
X_train_ids = encoded_input["input_ids"]
X_train_masks = encoded_input["attention_mask"]
print (X_train_ids.shape, X_train_masks.shape)
encoded_input = tokenizer(X_val.tolist(), return_tensors="pt", padding=True)
X_val_ids = encoded_input["input_ids"]
X_val_masks = encoded_input["attention_mask"]
print (X_val_ids.shape, X_val_masks.shape)
encoded_input = tokenizer(X_test.tolist(), return_tensors="pt", padding=True)
X_test_ids = encoded_input["input_ids"]
X_test_masks = encoded_input["attention_mask"]
print (X_test_ids.shape, X_test_masks.shape)
# Decode
print (f"{X_train_ids[0]}\n{tokenizer.decode(X_train_ids[0])}")
# Sub-word tokens
print (tokenizer.convert_ids_to_tokens(ids=X_train_ids[0]))
```
## Datasets
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
```
class TransformerTextDataset(torch.utils.data.Dataset):
def __init__(self, ids, masks, targets):
self.ids = ids
self.masks = masks
self.targets = targets
def __len__(self):
return len(self.targets)
def __str__(self):
return f"<Dataset(N={len(self)})>"
def __getitem__(self, index):
ids = torch.tensor(self.ids[index], dtype=torch.long)
masks = torch.tensor(self.masks[index], dtype=torch.long)
targets = torch.FloatTensor(self.targets[index])
return ids, masks, targets
def create_dataloader(self, batch_size, shuffle=False, drop_last=False):
return torch.utils.data.DataLoader(
dataset=self,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
pin_memory=False)
# Create datasets
train_dataset = TransformerTextDataset(ids=X_train_ids, masks=X_train_masks, targets=y_train)
val_dataset = TransformerTextDataset(ids=X_val_ids, masks=X_val_masks, targets=y_val)
test_dataset = TransformerTextDataset(ids=X_test_ids, masks=X_test_masks, targets=y_test)
print ("Data splits:\n"
f" Train dataset:{train_dataset.__str__()}\n"
f" Val dataset: {val_dataset.__str__()}\n"
f" Test dataset: {test_dataset.__str__()}\n"
"Sample point:\n"
f" ids: {train_dataset[0][0]}\n"
f" masks: {train_dataset[0][1]}\n"
f" targets: {train_dataset[0][2]}")
# Create dataloaders
batch_size = 128
train_dataloader = train_dataset.create_dataloader(
batch_size=batch_size)
val_dataloader = val_dataset.create_dataloader(
batch_size=batch_size)
test_dataloader = test_dataset.create_dataloader(
batch_size=batch_size)
batch = next(iter(train_dataloader))
print ("Sample batch:\n"
f" ids: {batch[0].size()}\n"
f" masks: {batch[1].size()}\n"
f" targets: {batch[2].size()}")
```
## Trainer
Let's create the `Trainer` class that we'll use to facilitate training for our experiments.
```
import torch.nn.functional as F
class Trainer(object):
def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):
# Set params
self.model = model
self.device = device
self.loss_fn = loss_fn
self.optimizer = optimizer
self.scheduler = scheduler
def train_step(self, dataloader):
"""Train step."""
# Set model to train mode
self.model.train()
loss = 0.0
# Iterate over train batches
for i, batch in enumerate(dataloader):
# Step
batch = [item.to(self.device) for item in batch] # Set device
inputs, targets = batch[:-1], batch[-1]
self.optimizer.zero_grad() # Reset gradients
z = self.model(inputs) # Forward pass
J = self.loss_fn(z, targets) # Define loss
J.backward() # Backward pass
self.optimizer.step() # Update weights
# Cumulative Metrics
loss += (J.detach().item() - loss) / (i + 1)
return loss
def eval_step(self, dataloader):
"""Validation or test step."""
# Set model to eval mode
self.model.eval()
loss = 0.0
y_trues, y_probs = [], []
# Iterate over val batches
with torch.inference_mode():
for i, batch in enumerate(dataloader):
# Step
batch = [item.to(self.device) for item in batch] # Set device
inputs, y_true = batch[:-1], batch[-1]
z = self.model(inputs) # Forward pass
J = self.loss_fn(z, y_true).item()
# Cumulative Metrics
loss += (J - loss) / (i + 1)
# Store outputs
y_prob = F.softmax(z).cpu().numpy()
y_probs.extend(y_prob)
y_trues.extend(y_true.cpu().numpy())
return loss, np.vstack(y_trues), np.vstack(y_probs)
def predict_step(self, dataloader):
"""Prediction step."""
# Set model to eval mode
self.model.eval()
y_probs = []
# Iterate over val batches
with torch.inference_mode():
for i, batch in enumerate(dataloader):
# Forward pass w/ inputs
inputs, targets = batch[:-1], batch[-1]
z = self.model(inputs)
# Store outputs
y_prob = F.softmax(z).cpu().numpy()
y_probs.extend(y_prob)
return np.vstack(y_probs)
def train(self, num_epochs, patience, train_dataloader, val_dataloader):
best_val_loss = np.inf
for epoch in range(num_epochs):
# Steps
train_loss = self.train_step(dataloader=train_dataloader)
val_loss, _, _ = self.eval_step(dataloader=val_dataloader)
self.scheduler.step(val_loss)
# Early stopping
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = self.model
_patience = patience # reset _patience
else:
_patience -= 1
if not _patience: # 0
print("Stopping early!")
break
# Logging
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.5f}, "
f"val_loss: {val_loss:.5f}, "
f"lr: {self.optimizer.param_groups[0]['lr']:.2E}, "
f"_patience: {_patience}"
)
return best_model
```
# Transformer
## Scaled dot-product attention
The most popular type of self-attention is scaled dot-product attention from the widely-cited [Attention is all you need](https://arxiv.org/abs/1706.03762) paper. This type of attention involves projecting our encoded input sequences onto three matrices, queries (Q), keys (K) and values (V), whose weights we learn.
$ inputs \in \mathbb{R}^{NXMXH} $ ($N$ = batch size, $M$ = sequence length, $H$ = hidden dim)
$ Q = XW_q $ where $ W_q \in \mathbb{R}^{HXd_q} $
$ K = XW_k $ where $ W_k \in \mathbb{R}^{HXd_k} $
$ V = XW_v $ where $ W_v \in \mathbb{R}^{HXd_v} $
$ attention (Q, K, V) = softmax( \frac{Q K^{T}}{\sqrt{d_k}} )V \in \mathbb{R}^{MXd_v} $
## Multi-head attention
Instead of applying self-attention only once across the entire encoded input, we can also separate the input and apply self-attention in parallel (heads) to each input section and concatenate them. This allows the different head to learn unique representations while maintaining the complexity since we split the input into smaller subspaces.
$ MultiHead(Q, K, V) = concat({head}_1, ..., {head}_{h})W_O $
* ${head}_i = attention(Q_i, K_i, V_i) $
* $h$ = # of self-attention heads
* $W_O \in \mathbb{R}^{hd_vXH} $
* $H$ = hidden dim. (or dimension of the model $d_{model}$)
## Positional encoding
With self-attention, we aren't able to account for the sequential position of our input tokens. To address this, we can use positional encoding to create a representation of the location of each token with respect to the entire sequence. This can either be learned (with weights) or we can use a fixed function that can better extend to create positional encoding for lengths during inference that were not observed during training.
$ PE_{(pos,2i)} = sin({pos}/{10000^{2i/H}}) $
$ PE_{(pos,2i+1)} = cos({pos}/{10000^{2i/H}}) $
where:
* $pos$ = position of the token $(1...M)$
* $i$ = hidden dim $(1..H)$
This effectively allows us to represent each token's relative position using a fixed function for very large sequences. And because we've constrained the positional encodings to have the same dimensions as our encoded inputs, we can simply concatenate them before feeding them into the multi-head attention heads.
## Architecture
And here's how it all fits together! It's an end-to-end architecture that creates these contextual representations and uses an encoder-decoder architecture to predict the outcomes (one-to-one, many-to-one, many-to-many, etc.) Due to the complexity of the architecture, they require massive amounts of data for training without overfitting, however, they can be leveraged as pretrained models to finetune with smaller datasets that are similar to the larger set it was initially trained on.
<div align="left">
<img src="https://raw.githubusercontent.com/GokuMohandas/MadeWithML/main/images/foundations/transformers/architecture.png" width="800">
</div>
<div align="left">
<small><a href="https://arxiv.org/abs/1706.03762" target="_blank">Attention Is All You Need</a></small>
</div>
> We're not going to the implement the Transformer [from scratch](https://nlp.seas.harvard.edu/2018/04/03/attention.html) but we will use the[ Hugging Face library](https://github.com/huggingface/transformers) to load a pretrained [BertModel](https://huggingface.co/transformers/model_doc/bert.html#bertmodel) , which we'll use as a feature extractor and fine-tune on our own dataset.
## Model
We're going to use a pretrained [BertModel](https://huggingface.co/transformers/model_doc/bert.html#bertmodel) to act as a feature extractor. We'll only use the encoder to receive sequential and pooled outputs (`is_decoder=False` is default).
```
from transformers import BertModel
# transformer = BertModel.from_pretrained("distilbert-base-uncased")
# embedding_dim = transformer.config.dim
transformer = BertModel.from_pretrained("allenai/scibert_scivocab_uncased")
embedding_dim = transformer.config.hidden_size
class Transformer(nn.Module):
def __init__(self, transformer, dropout_p, embedding_dim, num_classes):
super(Transformer, self).__init__()
self.transformer = transformer
self.dropout = torch.nn.Dropout(dropout_p)
self.fc1 = torch.nn.Linear(embedding_dim, num_classes)
def forward(self, inputs):
ids, masks = inputs
seq, pool = self.transformer(input_ids=ids, attention_mask=masks)
z = self.dropout(pool)
z = self.fc1(z)
return z
```
> We decided to work with the pooled output, but we could have just as easily worked with the sequential output (encoder representation for each sub-token) and applied a CNN (or other decoder options) on top of it.
```
# Initialize model
dropout_p = 0.5
model = Transformer(
transformer=transformer, dropout_p=dropout_p,
embedding_dim=embedding_dim, num_classes=num_classes)
model = model.to(device)
print (model.named_parameters)
```
## Training
```
# Arguments
lr = 1e-4
num_epochs = 100
patience = 10
# Define loss
class_weights_tensor = torch.Tensor(np.array(list(class_weights.values())))
loss_fn = nn.BCEWithLogitsLoss(weight=class_weights_tensor)
# Define optimizer & scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode="min", factor=0.1, patience=5)
# Trainer module
trainer = Trainer(
model=model, device=device, loss_fn=loss_fn,
optimizer=optimizer, scheduler=scheduler)
# Train
best_model = trainer.train(num_epochs, patience, train_dataloader, val_dataloader)
```
## Evaluation
```
import json
from sklearn.metrics import precision_recall_fscore_support
def get_performance(y_true, y_pred, classes):
"""Per-class performance metrics."""
# Performance
performance = {"overall": {}, "class": {}}
# Overall performance
metrics = precision_recall_fscore_support(y_true, y_pred, average="weighted")
performance["overall"]["precision"] = metrics[0]
performance["overall"]["recall"] = metrics[1]
performance["overall"]["f1"] = metrics[2]
performance["overall"]["num_samples"] = np.float64(len(y_true))
# Per-class performance
metrics = precision_recall_fscore_support(y_true, y_pred, average=None)
for i in range(len(classes)):
performance["class"][classes[i]] = {
"precision": metrics[0][i],
"recall": metrics[1][i],
"f1": metrics[2][i],
"num_samples": np.float64(metrics[3][i]),
}
return performance
# Get predictions
test_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)
y_pred = np.argmax(y_prob, axis=1)
# Determine performance
performance = get_performance(
y_true=np.argmax(y_true, axis=1), y_pred=y_pred, classes=label_encoder.classes)
print (json.dumps(performance['overall'], indent=2))
# Save artifacts
from pathlib import Path
dir = Path("transformers")
dir.mkdir(parents=True, exist_ok=True)
label_encoder.save(fp=Path(dir, "label_encoder.json"))
torch.save(best_model.state_dict(), Path(dir, "model.pt"))
with open(Path(dir, "performance.json"), "w") as fp:
json.dump(performance, indent=2, sort_keys=False, fp=fp)
```
## Inference
```
def get_probability_distribution(y_prob, classes):
"""Create a dict of class probabilities from an array."""
results = {}
for i, class_ in enumerate(classes):
results[class_] = np.float64(y_prob[i])
sorted_results = {k: v for k, v in sorted(
results.items(), key=lambda item: item[1], reverse=True)}
return sorted_results
# Load artifacts
device = torch.device("cpu")
tokenizer = BertTokenizer.from_pretrained("allenai/scibert_scivocab_uncased")
label_encoder = LabelEncoder.load(fp=Path(dir, "label_encoder.json"))
transformer = BertModel.from_pretrained("allenai/scibert_scivocab_uncased")
embedding_dim = transformer.config.hidden_size
model = Transformer(
transformer=transformer, dropout_p=dropout_p,
embedding_dim=embedding_dim, num_classes=num_classes)
model.load_state_dict(torch.load(Path(dir, "model.pt"), map_location=device))
model.to(device);
# Initialize trainer
trainer = Trainer(model=model, device=device)
# Create datasets
train_dataset = TransformerTextDataset(ids=X_train_ids, masks=X_train_masks, targets=y_train)
val_dataset = TransformerTextDataset(ids=X_val_ids, masks=X_val_masks, targets=y_val)
test_dataset = TransformerTextDataset(ids=X_test_ids, masks=X_test_masks, targets=y_test)
print ("Data splits:\n"
f" Train dataset:{train_dataset.__str__()}\n"
f" Val dataset: {val_dataset.__str__()}\n"
f" Test dataset: {test_dataset.__str__()}\n"
"Sample point:\n"
f" ids: {train_dataset[0][0]}\n"
f" masks: {train_dataset[0][1]}\n"
f" targets: {train_dataset[0][2]}")
# Dataloader
text = "The final tennis tournament starts next week."
X = preprocess(text)
encoded_input = tokenizer(X, return_tensors="pt", padding=True).to(torch.device("cpu"))
ids = encoded_input["input_ids"]
masks = encoded_input["attention_mask"]
y_filler = label_encoder.encode([label_encoder.classes[0]]*len(ids))
dataset = TransformerTextDataset(ids=ids, masks=masks, targets=y_filler)
dataloader = dataset.create_dataloader(batch_size=int(batch_size))
# Inference
y_prob = trainer.predict_step(dataloader)
y_pred = np.argmax(y_prob, axis=1)
label_encoder.index_to_class[y_pred[0]]
# Class distributions
prob_dist = get_probability_distribution(y_prob=y_prob[0], classes=label_encoder.classes)
print (json.dumps(prob_dist, indent=2))
```
## Interpretability
Let's visualize the self-attention weights from each of the attention heads in the encoder.
```
import sys
!rm -r bertviz_repo
!test -d bertviz_repo || git clone https://github.com/jessevig/bertviz bertviz_repo
if not "bertviz_repo" in sys.path:
sys.path += ["bertviz_repo"]
from bertviz import head_view
# Print input ids
print (ids)
print (tokenizer.batch_decode(ids))
# Get encoder attentions
seq, pool, attn = model.transformer(input_ids=ids, attention_mask=masks, output_attentions=True)
print (len(attn)) # 12 attention layers (heads)
print (attn[0].shape)
# HTML set up
def call_html():
import IPython
display(IPython.core.display.HTML('''
<script src="/static/components/requirejs/require.js"></script>
<script>
requirejs.config({
paths: {
base: '/static/base',
"d3": "https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.8/d3.min",
jquery: '//ajax.googleapis.com/ajax/libs/jquery/2.0.0/jquery.min',
},
});
</script>
'''))
# Visualize self-attention weights
call_html()
tokens = tokenizer.convert_ids_to_tokens(ids[0])
head_view(attention=attn, tokens=tokens)
```
> Now you're ready to start the [MLOps lessons](https://madewithml.com/#mlops) to learn how to apply all this foundational modeling knowledge to responsibly deliver value.
| github_jupyter |
<a href="https://colab.research.google.com/github/taishi-i/toiro/blob/develop/examples/01_getting_started_ja.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# <strong>1. はじめに</strong>
---
[Toiro](https://github.com/taishi-i/toiro) は、形態素解析器を比較する Python ライブラリです。
各解析器の比較を数行のコードで行えます。
* 処理速度の比較
* 単語分割の比較
* 後段タスク(テキスト分類)での精度比較
Google Colab では、下記のインストールにより7種類の解析器を比較することができます。
```
pip install toiro[all_tokenizers]
```
```
pip install toiro[all_tokenizers]
# 各ライブラリのインポート
import pprint
import warnings
import matplotlib.pyplot as plt
from toiro import tokenizers
from toiro import datadownloader
from toiro import classifiers
warnings.simplefilter('ignore')
```
# <strong>2. 解析器の一覧を表示する</strong>
---
Toiroでは、次の解析器(単語分割器、形態素解析器、サブワードトークナイザー)を比較することができます。
* mecab-python3
* janome
* nagisa
* spacy
* sudachipy
* ginza
* sentencepiece
* KyTea(本体のインストールが必要)
* Juman++(本体のインストールが必要)
また、Docker Hub からコンテナを利用することで、環境構築なしに9種類の解析器を比較することができます。
```
$ docker run --rm -it taishii/toiro /bin/bash
```
```
# 実行環境で利用可能な解析器を表示する
available_tokenizers = tokenizers.available_tokenizers()
pprint.pprint(available_tokenizers)
```
# <strong>3. コーパスをダウンロードする</strong>
---
Toiroでは、日本語コーパスのダウンローダーと前処理機能を標準で搭載しています。
現時点では、3種類の日本語コーパスを利用することができます。
* Livedoor news corpus
* Yahoo movie reviews
* Amazon reviews
コーパスのダウンロード後は、内部で前処理を行い、pandas.DataFrame として扱うことができます。
```
# ダウンロード可能なコーパスの一覧を表示する
corpora = datadownloader.available_corpus()
print(corpora)
# Livedoor News Corpus をダウンロードし、pandas.DataFrame として読み込む
corpus = corpora[0]
datadownloader.download_corpus(corpus)
train_df, dev_df, test_df = datadownloader.load_corpus(corpus)
texts = train_df[1]
train_df.head()
```
# <strong>4. 各解析器の処理速度を比較する</strong>
---
ダウンロードした Livedoor news corpus を利用して、各解析器の処理速度を比較します。
実行環境の情報、入力データの情報、各解析器の処理速度を辞書形式で出力します。
```
# tokenizers.compare では、リストを入力とする
report = tokenizers.compare(texts)
pprint.pprint(report)
```
# <strong>5. 各解析器の単語分割を比較する</strong>
---
入力テキストの単語分割結果を比較できます。
tokenizers.tokenize_*TOKENIZER_NAME* を利用することで、各解析器の単語分割の結果を取得できます。
```
# 各解析器の単語分割結果を出力する
text = "都庁所在地は新宿区。"
tokenizers.print_words(text, delimiter="|")
# sudachipy の単語分割結果を出力する
words = tokenizers.tokenize_sudachipy(text)
print(words)
# sentencepiece の単語分割結果を出力する
words = tokenizers.tokenize_sentencepiece(text)
print(words)
```
# <strong>6. 各解析器の結果を取得する</strong>
---
Toiroでは、各解析器の元の解析結果を取得できます。
tokenizers.original_*TOKENIZER_NAME* を利用することで、各解析器の解析結果を取得できます。
```
# mecab-python3 の解析結果を出力する
tokens = tokenizers.original_mecab(text)
print(tokens)
# GiNZA の解析結果を出力する
token = tokenizers.original_ginza(text)
for sent in token.sents:
for token in sent:
print(token.i, token.orth_, token.lemma_, token.pos_, token.tag_, token.dep_, token.head.i)
print('EOS')
```
# <strong>7. 後段タスク(テキスト分類)による精度比較</strong>
---
Toiroでは、SVM と BERT によるテキスト分類機能を搭載しています。
ここでは、SVM によるテキスト分類結果を比較することで、単語分割の性能を比較します。
BERT を利用する場合は、次のインストールを行ってください。
```
pip install toiro[all]
```
```
# Janome を単語分割に利用した SVM モデルの学習
model = classifiers.SVMClassificationModel(tokenizer='janome')
model.fit(train_df, dev_df)
# 分類精度の評価
result = model.eval(test_df)
print(result)
# 分類結果の予測
pred_y = model.predict(text)
print(pred_y)
# matplotlib のマーカを定義する
markers = [".", "X", "^", "<", ">", "p", "*", "h", "H", "+", "1"]
# 実行環境で利用できる解析器を取得する
avaiable_tokenizers = tokenizers.get_avaiable_tokenizers()
num_tokenizers = len(avaiable_tokenizers.items())
# 各解析器を利用した SVM モデル学習と評価を行う
for i, (k, v) in enumerate(avaiable_tokenizers.items(), 1):
model = classifiers.SVMClassificationModel(tokenizer=k)
model.fit(train_df, dev_df)
result = model.eval(test_df)
elapsed_time = result["elapsed_time"]
accuracy_score = result["accuracy_score"]
plt.scatter([elapsed_time ], [accuracy_score], label=k, marker=markers[i-1])
print(f"[{i}/{num_tokenizers}]: {k:<13}, {accuracy_score}, {elapsed_time}")
# 処理速度と分類精度の図を表示する
plt.title(f"{corpus}: Accuracy and elapsed time")
plt.ylabel("Accuracy score")
plt.xlabel("Elapsed time (s)")
plt.legend()
plt.show()
```
| github_jupyter |
# ***Introduction to Radar Using Python and MATLAB***
## Andy Harrison - Copyright (C) 2019 Artech House
<br/>
# Noncoherent Integration
***
Referring to Section 6.2.2, noncoherent integration shown in Figure6.8. Noncoherent processing does not make use of phase information. Pulse integration is performed after the signal amplitude of each pulse has been found (i.e., after the signal has passed through the envelope detector).
Noncoherent integration is less efficient than coherent integration and much work has been performed in this area to characterize the degradation in performance. While closed-form expressions generally do not exist, there are some empirical approximations. One approach is to write the degradation as a loss factor compared to coherent integration as (Equation 6.19)
$$
{SNR}_{{nci}} = \frac{{SNR}_{{ci}}}{L_{{nci}}},
$$
where ${SNR}_{{nci}}$ is the signal-to-noise ratio resulting from noncoherent integration and $L_{nci}}$ is the loss in integration as compared to coherent integration. One approximation for this loss factor is given as (Equation 6.20)
$$
L_{{nci}} = \frac{1 + {SNR}_0}{{SNR}_0},
$$
where ${SNR}_0$ is the required single pulse signal-to-noise ratio for noncoherent detection. An expression for finding the single pulse signal-to-noise ratio given the number of pulses and signal-to-noise required to produce a specific probability of detection and probability of false alarm is written as (Equation 6.21)
$$
{SNR}_0 = \frac{{SNR}_{{nci}}}{2 N} + \sqrt{\frac{{SNR}_{{nci}}^2}{4 N^2} + \frac{{SNR}_{{nci}}}{N}}.
$$
Another approach is to express the signal-to-noise ratio for noncoherent integration as a gain over the single pulse signal-to-noise ratio. Sometimes in literature this is referred to as the noncoherent integration improvement factor. In this case, the signal-to-noise ratio is (Equation 6.22)
$$
{SNR}_{{nci}} = G_{{nci}} + {SNR}_0 \hspace{0.5in}\text{(dB)},
$$
where $G_{{nci}}$ is the noncoherent integration gain, and ${SNR}_0$ is the single pulse signal-to-noise ratio. An approximation for $G_{{nci}}$ which has been shown to be accurate within $0.8$ dB is (Equation 6.23)
$$
G_{{nci}} = 6.79\, (1 + 0.235\, P_d) \left[1 + \frac{ \log_{10}(1/P_{fa})}{46.6} \right] \log_{10}(N) \times \big[1 - 0.14 \log_{10}(N) + 0.01831 \log_{10}^2(N) \big] \hspace{0.5in} \text{(dB)}.
$$
***
Begin by getting the library path
```
import lib_path
```
Set the signal to noise ration (dB), the probability of false alarm, and the number of pulses.
```
from numpy import linspace
snr_db = [-4.0, 20.0]
snr = 10.0 ** (linspace(snr_db[0], snr_db[1], 200) / 10.0)
pfa = 1e-9
number_of_pulses = 10
```
Set the target type (Swerling 0 - Swerling 4)
```
target_type = 'Swerling 1'
```
Calculate the probability of detection using the `probability_of_detection` routine
```
from Libs.detection.non_coherent_integration import probability_of_detection
pd = [probability_of_detection(s, pfa, number_of_pulses, target_type) for s in snr]
```
Display the probability of detection for coherent detection using the `matplotlib` routines
```
from matplotlib import pyplot as plt
from numpy import log10
# Set the figure size
plt.rcParams["figure.figsize"] = (15, 10)
# Display the results
plt.plot(10.0 * log10(snr), pd, '')
# Set the plot title and labels
plt.title('Nonoherent Integration', size=14)
plt.xlabel('Signal to Noise (dB)', size=12)
plt.ylabel('Probability of Detection', size=12)
# Set the tick label size
plt.tick_params(labelsize=12)
# Turn on the grid
plt.grid(linestyle=':', linewidth=0.5)
```
| github_jupyter |
```
import matplotlib.pyplot as plt
import sklearn.datasets as datasets
import torch
from torch import nn
from torch import optim
import numpy as np
from nflows.flows.base import Flow
from nflows.distributions.normal import StandardNormal
from nflows.transforms.base import CompositeTransform
from nflows.transforms.autoregressive import MaskedAffineAutoregressiveTransform
from nflows.transforms.permutations import ReversePermutation
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
mean = [6, 6]
cov = [[1, 0.5], [0.5, 1]] # diagonal covariance
mean1 = [10, 10]
cov1 = [[0.5, -0.2], [-0.2, 0.5]] # diagonal covariance
x_normal = np.random.multivariate_normal(mean, cov, 1000)
x_ab = np.random.multivariate_normal(mean1, cov1, 100)
plt.plot(x_normal[:,0], x_normal[:,1], '.')
plt.plot(x_ab[:,0], x_ab[:,1], '.')
# x, y = datasets.make_moons(1000, noise=.05)
# plt.scatter(x[:, 0], x[:, 1]);
num_layers = 5
base_dist = StandardNormal(shape=[2])
transforms = []
for _ in range(num_layers):
transforms.append(ReversePermutation(features=2))
transforms.append(MaskedAffineAutoregressiveTransform(features=2,
hidden_features=4))
transform = CompositeTransform(transforms)
flow = Flow(transform, base_dist)
flow.to(device)
optimizer = optim.Adam(flow.parameters(), lr = 1e-3)
num_iter = 1000
for i in range(num_iter):
# x, y = datasets.make_moons(1000, noise=.05)
x = torch.tensor(x_normal, dtype=torch.float32).to(device)
optimizer.zero_grad()
loss = -flow.log_prob(inputs=x).mean()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(i,loss)
# xline = torch.linspace(0, 12, 1000)
# # yline = torch.linspace(-.75, 1.25)
# # xgrid, ygrid = torch.meshgrid(xline, yline)
# # xyinput = torch.cat([xgrid.reshape(-1, 1), ygrid.reshape(-1, 1)], dim=1)
# with torch.no_grad():
# zgrid = flow.log_prob(xline).exp().reshape(100, 100)
# plt.contourf(xgrid.numpy(), ygrid.numpy(), zgrid.numpy())
# plt.title('iteration {}'.format(i + 1))
# plt.show()
# log probability of training data
log_p_normal = flow.log_prob(torch.Tensor(x_normal))
plt.figure()
plt.hist(log_p_normal.detach().numpy(), 50,density=True)
# print(log_p_normal.detach().sort())
log_p_ab = flow.log_prob(torch.Tensor(x_ab))
# plt.figure()
plt.hist(log_p_ab.detach().numpy(), 50,density=True)
samples0 = flow.sample(1000)
samples = samples0.detach().numpy()
plt.figure()
# plt.plot(samples[:,0], samples[:,1],'.')
log_p_new = flow.log_prob(samples0)
plt.figure()
plt.hist(log_p_new.detach().numpy(), 50,density=True)
```
| github_jupyter |
# Score Functions, Calibration, and Fairness
This chapter takes the perspective of {cite}`barocas-hardt-narayanan`, in less abstract language.
Decision making systems, and binary classification problems in particular, often involve developing an intermediate score function. A *score* function is a real-valued function that summarizes the data in a natural way for making a (yes/no) decision. Such a function becomes a classifier by *thresholding* the score.
A common score function is one that summarizes the data such that the output representing the probability that an event of interest occurs. A threshold for deciding such a decision is often set at 0.5.
**Score function: logistic regression**. Logistic regression considers a linear relationship between:
* predictor variables $X$,
* the log-odds of the event $Y = 1$ occurring.
This results in a score function that estimates the probability of $Y = 1$:
$$
p(x) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x)}}
$$
One can derive a classifier by thresholding this score at 0.5:
$$
C(x) = \left\{\begin{matrix}
0 {\rm\ if\ } p < 0.5 \\
1 {\rm\ if\ } p \geq 0.5 \\
\end{matrix}\right.
$$

**Conditional Expectation** Given historical data, the conditional expectation defines a natural scoring function: it's exactly the expectation of the outcome, given what's historically been observed. The formula for the score is:
$$
S(x) = E[Y | X = x]
$$
This function is essentially a 'look-up table' of joint empirical probabilities; given an occurrence $X$, look up the average outcome of similar occurrences.
Note: if $Y$ is binary, this is interpretable as a 'best guess' probability.
## From Scores to Classifiers
Given a score function $S$ define a classifier $C_t$ by thresholding at $t$:
$$
C_t(x) = \left\{\begin{matrix}
0 {\rm\ if\ } S(x) < t \\
1 {\rm\ if\ } S(x) \geq t \\
\end{matrix}\right.
$$
How do you choose $t$?
If $S$ represents a probability, then $t$ represents how confident for $C_t$ to make a certain decision. This generally depends on the utility of the context. How expensive is the cost for accepting a negative (FP)? for rejecting a positive (FP)? Choosing such a threshold is called choosing an "operating point".
The ROC Curve ("Receiver Operating Characteristic") captures the trade-off between choice of threshold $t$ for $S$ and the resulting TPR/FPR for $C_t$. It is a curve parameterized by $t$: every choice of threshold results in a classifier with a possibly different TPR/FPR, which is a point on the ROC curve.
For example, choosing
* the threshold $t = max_x{S(x)}$, results in a classifier $C_t$ that always predicts 0. The TPR is therefore 0 and the FPR 0. This is the point at the origin.
* the threshold $t = min_x{S(x)}$, results in a classifier $C_t$ that always predicts 1. The TPR is therefore 1 and the FPR 1. This is the point at $(1,1)$.
* Intermediate thresholds yield classifiers with $(TPR, FPR)$ in the unit square.
The more of the curve near (0,1), the better classifiers $C_t$ the score function $S$ creates, as seen in the graph below.

The *Area Under the Curve* (AUC) represents how predictive the score function is along all possible thresholds.
How does a data scientist choose the best threshold? Typically, one chooses a threshold from a score function by
* Measuring the utility of FN/FP and choosing a classifier that realizes the desired balance between them.
* Choosing the classifier of highest accuracy (if FP and FN are similar cost).
## Fairness of a Score Function
One can ask whether a score function satisfies similar notions to the parity conditions from previous lectures. We take two approaches:
1. Can construct a classifier from the score function that satisfies given parity conditions?
2. Does the distribution of scores themselves satisfy parity, in some sense?
These approaches are useful, as they point to ways of building a fair classifier from one that's unfair via post-processing (changing a threshold doesn't require knowing anything about the model).
We will approach this post-processing by using *derived classfiers* $Y = F(S, A)$ that result from applying a function to the score function $S$. For example:
* $F$ may choose different thresholds $t$ for individuals in different groups $a,b\in A$.
* $F$ may apply some randomization procedure for deciding which prediction to use from an underlying set of thresholds.
### Equalized Odds
Given a score function $S$, how can we choose a threshold $t$ so $C_t$ satisfies equalized odds? Recall that Equalized Odds requires parity of FNR/FPR across groups. If one considers the score function $S$ restricted to the two groups separately $S|a$, $S|b$, then we can plot the ROC curve for each score function:

(Figure from {cite}`barocas-hardt-narayanan`)
The point of intersection of the two ROC curves represents classifiers for the two groups that satisfies Equality of Odds (since FNR = 1 - TPR). However, these classifiers may have different thresholds. A single classifier satisfying Equality of Odds is obtained via a two-threshold derived classifier:
$$
F(x, c) = \left\{\begin{matrix}
0 {\rm\ if\ } (S|_a(x) < t_a) {\rm\ and\ } c = a \\
0 {\rm\ if\ } (S|_b(x) < t_b) {\rm\ and\ } c = b \\
1 {\rm\ if\ } (S|_a(x) \geq t_a {\rm\ and\ } c = a\\
1 {\rm\ if\ } (S|_b(x) \geq t_b) {\rm\ and\ } c = b \\
\end{matrix}\right.
$$
Where $t_a, t_b$ are the thresholds where the two curves intersect.
What if the two ROC curves don't intersect? Or if you have specific requirements for FPR and TPR from the model? You can choose a model from any point *under* both of the ROC curves.
If two classifiers $C_a, C_b$ are chosen from the ROC curves of groups $a,b$ respectively, then all classifiers on the line joining $C_a$ and $C_b$ are realized by:
$$
C(x) = \left\{\begin{matrix}
C_a(x) {\rm\ choose\ with\ probability\ } p \\
C_b(x) {\rm\ choose\ with\ probability\ } (1 - p) \\
\end{matrix}\right.
$$
Where $0 \leq p \leq 1$. Note that a classifier *under* the ROC curve will sacrifice utility: the TPR/FPR are lower than optimal.
### Calibration
Recall that Predictive Value Parity states, for all $a,b$ in $A$:
$$
P(Y = 1|C = 1, A = a) = P(Y = 1| C = 1, B = b) \\
P(Y = 1|C = 0, A = a) = P(Y = 1| C = 0, B = b)
$$
This is a special case, for binary classifiers of the condition "the true outcome $Y$ is independent of $A$, conditional on the prediction $C$. This notion is related to a concept called *calibration*.
A score function $S$ is *calibrated* if for all scores $s$,
$$
P(Y = 1|S = s) = s
$$
When $S$ is interpretable as a probability, this means that the positive proportion of all individuals given score $s$ should itself be $s$. For example, if the COMPAS score is calibrated, then among the defendants receiving the (lowest) risk score of 0.1, those that re-offended make up only 10% of that group. Similarly, those among the (highest) risk score 0.9 should consist mostly (90%) of those that actually did re-offend.
*Note:* An arbitrary score function can be calibrated via applying a scaling procedure called Platt scaling.
### Calibration within Groups
One notion of fairness for a score function is *calibrations within groups*:
$$
P(Y = 1| S = s, A = a) = s, \quad {\rm for\ all\ } s\in\mathbb{R}, a\in A
$$
Calibration requires similar scores to be meaningful. Calibration within groups requires similar scores be meaningful across groups as well. Calibration within groups for a score function implies that all induced classifiers satisfy predictive value parity.
### Balance for the Postive/Negative Class
Another notion of fairness for a score function is *balance for the positive (or negative) class*. This requires the average score of those who belong to the positive (negative) class be the same across groups:
$$
E[S|Y=1, A=a] = E[S|Y = 1, A = b]
$$
The condition is analogous for the negative class.
Balance for the positive/negative class is a continuous version of Equalized Odds. Indeed, it requires similar predictions for those with similar *true* behavior, across groups.
## Trade-Offs for Score Functions
An analogous version for score functions of the trade-offs theorem is found in {cite}`kleinberg2016inherent`.
Suppose a score function S satisfies the following three conditions:
* Calibration from within groups
* Balance for the positive class
* Balance for the negative class.
Then
* the score function must define a perfect predictor, or
* the groups have equal base-rates
This theorem is stronger than the trade-offs theorem for classifiers. One the one hand, score functions define many potential classifiers; this theorem makes a statement about all of these at once. On the other hand, the theorem also has an *approximate* version:
* The further the base-rates are from equal, the more severe the failure of at least one of the conditions.
* The further the classifier is from perfect, the more severe the failure of at least one of the conditions.
For proofs of these observations, see {cite}`kleinberg2016inherent`.
| github_jupyter |
---
#### 5. Load and preprocess somatic mutations from [TCGA in BigQuery]
(https://bigquery.cloud.google.com/table/isb-cgc:TCGA_hg38_data_v0.Somatic_Mutation?pli=1)
<a id="tcga"></a>
- Subset query has already been completed in BQ and saved to Google Cloud Storage
```
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import pandas as pd
import matplotlib.pyplot as plt
import os; os.chdir("..")
from tools.config import TCGA_MUT,GENE2VEC,FIGURES
tcga_raw = pd.read_csv(TCGA_MUT)
tcga_raw.head()
fig = plt.figure(figsize=(12,8)); title = 'Distribution of Mutation Indices by Occurrence'
ax = tcga_raw['Start_Position'].value_counts().plot(kind='hist', log=True,bins=20)
ax.set_title(title); ax.set_xlabel('Mutation Index Co-occurrence')
fig.savefig(FIGURES / title.lower().replace(' ','_'), dpi=fig.dpi, bbox_inches='tight', pad_inches=0.5)
def visualise_distributions(df, title, savefig=True):
"""
Plot distribution and frequency of features of interest for raw and processed TCGA df.
"""
import matplotlib.pyplot as plt
fig, axes = plt.subplots(nrows=2, ncols=2, figsize = (20,10))
fig.suptitle(title)
plt.subplots_adjust(hspace=0.6)
df.groupby('case_barcode').head(1)['project_short_name'].value_counts() \
.plot(kind='bar', title='Cases per Cancer type', ax=axes[0,0])
df['Variant_Classification'] \
.value_counts().plot(kind='bar', title='Variants per variant type', ax=axes[1,0], logy=True)
df['case_barcode'].value_counts() \
.plot(title='Log Variants per case, {0:d} cases'
.format(df['case_barcode'].value_counts().shape[0]),
ax=axes[0, 1], logy=True)
df['Hugo_Symbol'].value_counts() \
.plot(title='Log Variants per gene, {0:d} genes'
.format(df['Hugo_Symbol'].value_counts().shape[0]),
ax=axes[1, 1], logy=True)
if savefig:
fig.savefig(FIGURES/title.lower().replace(' ','_'), dpi=fig.dpi, bbox_inches='tight', pad_inches=0.5)
visualise_distributions(tcga_raw, 'Raw TCGA Data')
```
In absence of MutSigCV results use list of 459 driver genes from [Intogen](https://www.intogen.org/search)
```
def drop_low_mut_count(df, feature, cutoff=100):
"""
Drop rows which contain features which occur less than cutoff times in the dataset.
"""
subsample = df[feature].value_counts()[(df[feature].value_counts() > cutoff)].index.tolist()
return df[df[feature].isin(subsample)]
def merge_label(df, label1, label2, merged_label):
"""
Merge label1 and label2 into merged label within dataframe.
"""
df.loc[(df['project_short_name'] == label1) |
(df['project_short_name'] == label2), 'project_short_name'] = merged_label
return df
def process_labels(df):
"""
Merge cancers that are established clinically to be the same.
"""
# Colon and Rectal cancers are now considered the same cancer
# COAD, READ -> COADREAD
df = merge_label(df, 'TCGA-COAD', 'TCGA-READ', 'MERGE-COADREAD')
# GBM and LGG are both forms of brain Glioma
# GBM, LGG -> GBMLGG
df = merge_label(df, 'TCGA-GBM', 'TCGA-LGG', 'MERGE-GBMLGG')
# Stomach and Esophegal cancers are also considered the same
# ESCA, STAD -> STES
df = merge_label(df, 'TCGA-ESCA', 'TCGA-STAD', 'MERGE-STES')
return df
def filter_intogen_drivers(df):
"""
Filter only genes that intersect with listed drivers from Intogen.
"""
intogen_drivers = pd.read_csv(INTOGEN, sep='\t')
driver_genes = intogen_drivers['SYMBOL'].tolist()
return df[df['Hugo_Symbol'].isin(driver_genes)]
def filter_variants(df):
"""
Filter out variants according to a list provided by Dr Nic Waddel (QIMR).
"""
waddell_list = ['missense_variant',
'stop_gained',
'frameshift_variant',
'splice_acceptor_variant',
'splice_donor_variant',
'start_lost',
'inframe_deletion',
'inframe_insertion',
'stop_lost']
return df[df['One_Consequence'].isin(waddell_list)]
```
---
```
df_test = (tcga_raw.pipe(process_labels)
.pipe(filter_variants))
X_test = (df_test.pipe(dedup_and_get_variant_count)
.pipe(reshape_pivot))
y_test = (df_test.pipe(get_label_df, X_test))
X_test.shape, y_test.values.flatten().shape
# sklearn
import sklearn.ensemble as ske
from sklearn import datasets, model_selection, tree, preprocessing, metrics, linear_model
from sklearn.svm import LinearSVC
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.calibration import CalibratedClassifierCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LinearRegression, LogisticRegression, Ridge, Lasso, SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix
from sklearn.utils.multiclass import unique_labels
import matplotlib.pyplot as plt; import numpy as np
def plot_confusion_matrix(y_true, y_pred, classes,
name=None,
cmap='viridis',
savefig=True):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
title = 'Confusion Matrices'
# Compute confusion matrices
cm = confusion_matrix(y_true, y_pred, labels=classes)
cm_norm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
# Initialise plot
fig, axes = plt.subplots(ncols=2, figsize = (20,11))
fig.suptitle(title)
plt.subplots_adjust(hspace=0.6)
for i, ax in enumerate(axes):
if i == 1:
normalise = True
data = cm_norm
title = 'Normalised'
else:
normalise = False
data = cm
title = 'Non-Normalised'
ax.imshow(data, interpolation='nearest')
# ax.figure.colorbar()
# We want to show all ticks...
ax.set(xticks=np.arange(data.shape[1]),
yticks=np.arange(data.shape[0]),
# ... and label them with the respective list entries
xticklabels=classes, yticklabels=classes,
title=title,
ylabel='True label',
xlabel='Predicted label')
# Rotate the tick labels and set their alignment.
plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor")
# Loop over data dimensions and create text annotations.
fmt = '.1f' if normalise else 'd'
thresh = data.max() / 2.
for i in range(data.shape[0]):
for j in range(data.shape[1]):
ax.text(j, i, format(data[i, j], fmt),
ha="center", va="center",
color="white" if data[i, j] < thresh else "black")
fig.tight_layout()
plt.show()
def run_model(X_train, y_train, model, model_name, data_name, cv=10):
start_time = time.time()
train_pred, acc_cv, cv_proba = fit_ml_algo(model,
X_train,
y_train,
cv)
gbt_time = (time.time() - start_time)
print("Model: %s, DataFrame: %s" % (model_name, data_name))
print("Accuracy CV 10-Fold: %s" % acc_cv)
print("Running Time: %s" % datetime.timedelta(seconds=gbt_time))
print(metrics.classification_report(y_train, train_pred))
return train_pred, acc_cv, cv_proba
# Function that runs the requested algorithm and returns the accuracy metrics
def fit_ml_algo(algo, X_train, y_train, cv):
# CV
train_pred = model_selection.cross_val_predict(algo,
X_train,
y_train,
cv=cv,
n_jobs = -1)
cv_proba = model_selection.cross_val_predict(algo,
X_train,
y_train,
cv=cv,
method='predict_proba',
n_jobs=-1)
acc_cv = round(metrics.accuracy_score(y_train, train_pred) * 100, 2)
return train_pred, acc_cv, cv_proba
import time; import datetime
model = {
'model' : RandomForestClassifier(n_estimators=200,
min_samples_leaf=2,
min_samples_split=17,
criterion='gini',
max_features=40)
}
model['train_pred'], model['acc_cv'], model['cv_proba'] = run_model(X_test, y_test.values.flatten(), model['model'], 'rf', 'df_1')
plot_confusion_matrix(y_test,
model['train_pred'],
classes=y_test['project_short_name'].value_counts().index.values,
name='rf')
```
---
```
# empirical dim reduction
df_proc1 = (tcga_raw.pipe(process_labels)
.pipe(filter_variants)
.pipe(filter_intogen_drivers))
# statistical dim reductions
df_proc2 = (tcga_raw.pipe(process_labels)
.pipe(filter_variants)
.pipe(drop_low_mut_count, 'Hugo_Symbol', 200)) # naïvely remove very genes with few mutations as noise
visualise_distributions(df_proc1, 'Empirical Dim Reduction')
visualise_distributions(df_proc2, 'Statistical Dim Reduction')
def dedup_and_get_variant_count(df_in):
"""
Deduplicate gene sample combinations with >1 mutations and aggregate
with additional feature of variant count for gene sample combination.
"""
df = df_in.copy()
counts = df.groupby('case_barcode')['Hugo_Symbol'].value_counts()
df = df.drop_duplicates(subset=['case_barcode', 'Hugo_Symbol'])
df = df.set_index(['case_barcode', 'Hugo_Symbol'])
df['mutation_count'] = counts
df = df.reset_index()
return df
def reshape_pivot(df_in):
"""
Reduce df to crucial subset then pivot on cases and genes.
"""
df = (df_in[['case_barcode', 'Hugo_Symbol', 'mutation_count']]
.copy()
.pivot(index='case_barcode', columns='Hugo_Symbol', values='mutation_count')
.fillna(0)
.astype(int))
return df
def get_label_df(df_in, df_X):
"""
Get label df from flat processed df.
"""
df_y = (df_in.loc[df_in['case_barcode'].isin(df_X.index)]
.groupby('case_barcode')
.head(1)
.set_index('case_barcode')[['project_short_name']]
.sort_index())
return df_y
# Get processed dataframes ready for training
df_X1 = (df_proc1.pipe(dedup_and_get_variant_count)
.pipe(reshape_pivot))
df_X2 = (df_proc2.pipe(dedup_and_get_variant_count)
.pipe(reshape_pivot))
df_y1 = (df_proc1.pipe(get_label_df, df_X1))
df_y2 = (df_proc2.pipe(get_label_df, df_X2))
df_X1.head()
df_X2.head()
df_y1.head()
df_y2.head()
df_X1.shape
df_y1.shape
```
| github_jupyter |
# A Padantic Introduction to the Quaternion Gravity Proposal
The quaternion gravity proposal is the imaginary twin of special relativity. Two observers record the difference between two events. When the difference written as quaternion is squared, if the real interval is identical and thus the imaginary parts hereby called space-times-time must have differences, this is the domain of special relativity. Special relativity is viewed as an equivalence class for the real part which uses a Lorentz transformation to go between the two. The space-times-time can be used to determine exactly the relative motion of the two observers.
If the space-times-time values are identical, the real interval is different. This is what happens seemingly by chance in general relativity for the Schwarzschild solution in Schwarzschild coordinates outside a static, uncharged, non-rotating spherically-symmetric gravitational source mass. In the quaternion gravity proposal, observers that agree on the three space-times-time values is the equivalence class for gravity. Since this is an equivalence class, there is a transformation that can be constructed between the two.
In this iPython notebook, I will go through some detail to demonstrate these two equivalence classes.
## Calculation Tools
In the past, I used Mathematica to confirm my algebra was correct (it has caught errors in the past). The software at the time was crazy expensive (~\$2k), but has come down in price (\$300). Still, I would prefer to use an open source project. This motivated me to look into the iPython Notebook. Since I am a fan of the Python language, I took a closer look. I am quite impressed at the current state of affairs. It looked easy to mix and match real python code with text and images. But how to get iPython Notebook up and running? Anaconda.org is a commercial company that provides a free python environment. They are trying to get by through paid support and cloud services for companies. I liked that after installing anaconda, running "jupyter notebook" just worked. Jupyter is the notebook that then attaches to a variety of math tools of your choosing. This blog is being drafted as an iPython Notebook.
I decided to create my own tools for quaternions from scratch. Why? This is the opening few paragraphs of my "Q_tool_devo" notebook:
In this notebook, tools for working with quaternions for physics issues are developed.
The class QH treat quaternions as Hamilton would have done: as a 4-vector over the real numbers.
In physics, group theory plays a central role in the fundamental forces of Nature via
the standard model. The gauge symmetry U(1) a unit circle in the complex plane leads
to electric charge conservation. The unit quaternions SU(2) is the symmetry needed for
the weak force which leads to beta decay. The group SU(3) is the symmetry of the strong
force that keeps a nucleus together.
The class Q8 was written in the hope that group theory would be written in first, not
added as needed later. I call these "space-time numbers". The problem with such an
approach is that one does not use the mathematical field of real numbers. Instead one
relies on the set of positive reals. In some ways, this is like reverse engineering some
basic computer science. Libraries written in C have a notion of a signed versus unsigned
integer. The signed integer behaves like the familiar integers. The unsigned integer is
like the positive integers. The difference between the two is whether there is a
placeholder for the sign or not. All floats are signed. The modulo operations that work
for unsigned integers does not work for floats.
Test driven development was used. The same tests for class QH were used for Q8. Either
class can be used to study quaternions in physics.
Here is a list of the functions that were written for the Q8 classes:
abs_of_q, abs_of_vector, add, all_products, anti_commuting_products, boost,
commuting_products, conj, dif, divide_by, g_shift, invert, norm, norm_of_vector,
product, q4, q_one, q_zero, reduce, rotate, square, and triple_product.
Like all long list, this makes for dull prose. I had a little fun breaking up the multiplication product into the commuting and anti-commuting parts.
The most unusual method is "reduce". The Q8 class uses 8 positive numbers to represent a quaternion. Any number can be represented an infinite number of ways, so long as the difference between the positive and negative number remains the same. There is however only one reduced form for a number. That will have either the positive or its additive inverse set to zero (both can be zero also). It is mildly amusing to see a complicated calculation that fills up all eight slots that after the reduce step ends up with precisely the same result as appears from the QH or Hamilton quaternion class that uses real numbers. It feels uncomfortable to me to see these eight numbers since it is not my experience with calculations. Numbers in Nature do deeply odd things (think of the great boson/fermion divide in how states should be filled).
I program using a method called Test Driven Development. This means that all methods get a test so one knows each piece is working. That is critical with programs since one typo will means a tool does not work as expected. The same tests were applied to the Hamilton Q8 class as the Quaternion Group Q<sub>8</sub> class QH. The reduced form of all Q8 calculations are the same as the QH class.
If you have any interest it playing with the iPython notebook, feel free to clone it:
> git clone https://github.com/dougsweetser/ipq
## Equivalence classes
An equivalence class is part of set theory. Take a big set, carve it up into subsets, and a subset is an equivalence class. One uses an equivalence relation to determine if something is in a subset. As usual, you can [read more about that on wikipedia](https://en.wikipedia.org/wiki/Equivalence_class).
Start simple with the future equivalence class $[f]$. To be a member, all that an event needs is a positive measure of time.
$$[f] = \{ q \in Q \,|\, f \sim q \;\rm{if} \; \rm{Re}(q) > 0 \}$$
One can define an exact future class $[f_e]$ where two points are in the future the exact same amount:
$$[f_e] = \{ q \in Q \,|\, f_e \sim q \;\rm{if} \; \rm{Re}(q) > 0 \; \rm{and} \; \rm{Re}(q) = \rm{Re}(f_e)\}$$
One question can be asked of a pair of quaternions: are they both in the future equivalence class, and if so, are they exactly equal to one another? This type of question was particularly easy to ask of with the Q8 class in the reduced form. They would both be positive in the future if they had a non-zero time value. In the case that both were in the future, then one could ask further if the values were the same, up to a defined rounding error. The computer code felt like it was doing basic set theory: a pair of numbers was in or out. No inequalities were needed.
The two classes are easy enough to graph:

Figuring out if a pair of events are both in the past works the same. This time one looks to see if they both have non-zero values in the additive inverse $I^2$ (aka negative) time slot of the Q8 class. The same function was used, but telling the function to look at the additive inverses.
One can also see if both numbers are neither positive or negative. That only happens if the value of time is zero, or now. If so, the pair events gets marked as now exact.
Plucking events at random, the most common situation is that a pair of events would be disjoint: one in the future, the other in the past. This was the default case that resulted after all the other situations were investigated.
The 6 questions - are you both positive, if so, exact, negative, if so exact, both zeros or disjoint - can be asked for the three spatial dimensions: left versus right, up versus down, and near versus far. All use the same function to figure out which is the winning equivalence class (although disjoint is not an equivalence class).

The equivalence class EQ is fed 2 quaternions. It reduces these two to deal with the future/past, left/right, up/down, and near/far equivalence classes. All events in space-time map into four equivalence classes as one might expect for events in space-time.
There are two more general classes, one exceptionally narrow, the other the most common of all. The narrow class is when both are zero, the *now* class for time, and the *here* class for space.


Observers have all four of these exact matches since they are *here-now*. Being at here-now is the operational definition of an observer.
The most common situation for a pair of events is that they are disjoint. As usual, there are four ways to be disjoint:


Physics is an observational science. Every pair of events ever belongs in four of these equivalence classes or the disjoint classes. Every combination of these classes is out there in the event library of the Universe. This is the raw data of events. A problem with the raw data is that no observer can ever stay at one here-now. How do we deal with transient numbers?
## Ever Changing Events, Fixed Differences
It is simple enough for an observer to declare that a particular moment and location was the origin for all subsequent measurements. The problem is that even the observer herself cannot go back to the origin. This is in stark contrast to origins we are familiar with in analytic geometry. Go back years later, and where $z=0$ crosses $y=0$ remains the origin. How can one manage the transience of events? The difference between two events will be the same no matter how far in the future it is analyzed. A difference effectively removes
## Special Relativity as the Square of a Delta Quaternion
My proposal for special relativity works with the square of a quaternion. This must be done because the Lorentz invariant interval for inertial observers is time squared minus space squared. The expression mathematical is nearly identical to telling the past from the future:
$$[df] = \{ dq \in Q \,|\, df \sim dq \;\rm{if} \; \rm{Re}(dq^2) > 0 \}$$
The only difference is the square and the use of fixed difference quaternions.

Of course it might be the case that the events were both space-like separated because the first term of the square was negative:

The two exact equivalence classes, time-like exact or space-like exact, mean that the two observers are traveling at a constant velocity to each other. A Lorentz transformation can be used to go from one to the other along the hyperbola. Although there have been claims that one cannot represent the Lorentz group using real-valued quaternions, that is not the case. Wherever there is an exact equivalence class, there is a paired transformation.
| github_jupyter |
```
%matplotlib inline
from pyvista import set_plot_theme
set_plot_theme('document')
```
Multi-Window Plot
=================
Subplotting: having multiple scenes in a single window
```
import pyvista as pv
from pyvista import examples
```
This example shows how to create a multi-window plotter by specifying
the `shape` parameter. The window generated is a two by two window by
setting `shape=(2, 2)`. Use the
`pyvista.BasePlotter.subplot`{.interpreted-text role="func"} function to
select the subplot you wish to be the active subplot.
```
plotter = pv.Plotter(shape=(2, 2))
plotter.subplot(0, 0)
plotter.add_text("Render Window 0", font_size=30)
plotter.add_mesh(examples.load_globe())
plotter.subplot(0, 1)
plotter.add_text("Render Window 1", font_size=30)
plotter.add_mesh(pv.Cube(), show_edges=True, color="tan")
plotter.subplot(1, 0)
plotter.add_text("Render Window 2", font_size=30)
sphere = pv.Sphere()
plotter.add_mesh(sphere, scalars=sphere.points[:, 2])
plotter.add_scalar_bar("Z")
# plotter.add_axes()
plotter.add_axes(interactive=True)
plotter.subplot(1, 1)
plotter.add_text("Render Window 3", font_size=30)
plotter.add_mesh(pv.Cone(), color="g", show_edges=True)
plotter.show_bounds(all_edges=True)
# Display the window
plotter.show()
plotter = pv.Plotter(shape=(1, 2))
# Note that the (0, 0) location is active by default
# load and plot an airplane on the left half of the screen
plotter.add_text("Airplane Example\n", font_size=30)
plotter.add_mesh(examples.load_airplane(), show_edges=False)
# load and plot the uniform data example on the right-hand side
plotter.subplot(0, 1)
plotter.add_text("Uniform Data Example\n", font_size=30)
plotter.add_mesh(examples.load_uniform(), show_edges=True)
# Display the window
plotter.show()
```
Split the rendering window in half and subdivide it in a nr. of vertical
or horizontal subplots.
```
# This defines the position of the vertical/horizontal splitting, in this
# case 40% of the vertical/horizontal dimension of the window
pv.global_theme.multi_rendering_splitting_position = 0.40
# shape="3|1" means 3 plots on the left and 1 on the right,
# shape="4/2" means 4 plots on top of 2 at bottom.
plotter = pv.Plotter(shape='3|1', window_size=(1000, 1200))
plotter.subplot(0)
plotter.add_text("Airplane Example")
plotter.add_mesh(examples.load_airplane(), show_edges=False)
# load and plot the uniform data example on the right-hand side
plotter.subplot(1)
plotter.add_text("Uniform Data Example")
plotter.add_mesh(examples.load_uniform(), show_edges=True)
plotter.subplot(2)
plotter.add_text("A Sphere")
plotter.add_mesh(pv.Sphere(), show_edges=True)
plotter.subplot(3)
plotter.add_text("A Cone")
plotter.add_mesh(pv.Cone(), show_edges=True)
# Display the window
plotter.show()
```
To get full flexibility over the layout grid, you can define the
relative weighting of rows and columns and register groups that can span
over multiple rows and columns. A group is defined through a tuple
`(rows,cols)` of row and column indices or slices. The group always
spans from the smallest to the largest (row or column) id that is passed
through the list or slice.
```
# numpy is imported for a more convenient slice notation through np.s_
import numpy as np
shape = (5, 4) # 5 by 4 grid
row_weights = [0.5,1,1,2,1] # First row is half the size and fourth row is double the size of the other rows
col_weights = [1,1,0.5,2] # Third column is half the size and fourth column is double size of the other columns
groups = [
(0,np.s_[:]), # First group spans over all columns of the first row (0)
([1,3],0), # Second group spans over row 1-3 of the first column (0)
(np.s_[2:],[1,2]), # Third group spans over rows 2-4 and columns 1-2
(slice(1,-1),3) # Fourth group spans over rows 1-3 of the last column (3)
]
plotter = pv.Plotter(shape=shape,row_weights=row_weights,col_weights=col_weights,groups=groups)
# A grouped subplot can be activated through any of its composing cells using
# the :func:`pyvista.BasePlotter.subplot` function.
# Access all subplots and groups and plot something:
plotter.subplot(0,0)
plotter.add_text("Group 1")
plotter.add_mesh(pv.Cylinder(direction=[0,1,0],height=20))
plotter.view_yz()
plotter.camera.Zoom(10)
plotter.camera_set = True
plotter.subplot(2,0)
plotter.add_text("Group 2")
plotter.add_mesh(pv.ParametricCatalanMinimal(), show_edges=False, color="tan")
plotter.view_isometric()
plotter.camera.Zoom(2)
plotter.camera_set = True
plotter.subplot(2,1)
plotter.add_text("Group 3")
plotter.add_mesh(examples.load_uniform(), show_edges=True)
plotter.subplot(1,3)
plotter.add_text("Group 4")
plotter.add_mesh(examples.load_globe())
plotter.subplot(1,1)
plotter.add_text("Cell (1,1)")
sphere = pv.Sphere()
plotter.add_mesh(sphere, scalars=sphere.points[:, 2])
plotter.add_scalar_bar("Z")
plotter.add_axes(interactive=True)
plotter.subplot(1,2)
plotter.add_text("Cell (1,2)")
plotter.add_mesh(pv.Cone(), show_edges=True)
plotter.subplot(4,0)
plotter.add_text("Cell (4,0)")
plotter.add_mesh(examples.load_airplane(), show_edges=False)
plotter.subplot(4,3)
plotter.add_text("Cell (4,3)")
plotter.add_mesh(pv.Cube(), show_edges=True, color="tan")
# Display the window
plotter.show()
```
| github_jupyter |
# [Module 1] Train a Keras Sequential Model (TensorFlow 2.0)
### [Note] 본 주피터 노트북은 TensorFlow 2.0에서 핸즈온을 수행합니다. Amazon SageMaker는 2020년 1월부터 빌트인 딥러닝 컨테이너 형태로 TensorFlow 2.0을 지원하고 있습니다.
본 노트북(notebook)은 SageMaker 상에서 Keras Sequential model을 학습하는 방법을 단계별로 설명합니다. 본 노트북에서 사용한 모델은 간단한 deep CNN(Convolutional Neural Network) 모델로 [the Keras examples](https://github.com/keras-team/keras/blob/master/examples/cifar10_cnn.py)에 소개된 모델과 동일합니다.
- 참고로, 본 모델은 25 epoch 학습 후에 검증셋의 정확도(accuracy)가 약 75%이고 50 epoch 학습 후에 검증셋의 정확도가 약 79% 입니다.
- 본 워크샵 과정에서는 시간 관계상 5 epoch까지만 학습합니다. (단, Horovod 기반 분산 학습은 10 epoch까지 학습합니다.)
## The dataset
[CIFAR-10 dataset](https://www.cs.toronto.edu/~kriz/cifar.html)은 머신 러닝에서 가장 유명한 데이터셋 중 하나입니다.
이 데이터셋은 10개의 다른 클래스로 구성된(클래스당 6,000장) 60,000장의 32x32 픽셀 이미지들로 구성되어 있습니다.
아래 그림은 클래스당 10장의 이미지들을 랜덤으로 추출한 결과입니다.

본 실습에서 여러분들은 deep CNN을 학습하여 영상 분류(image classification) 작업을 수행합니다. 다음 노트북들에서
여러분들은 File Mode, Pipe Mode와 Horovod 기반 분산 학습(distributed training) 결과를 비교할 것입니다.
## Getting the data
아래 AWS CLI(Command Line Interface) 커맨드를 사용하여 S3(Amazon Simple Storage Service)에 저장된 TFRecord 데이터셋을 여러분의 로컬 노트북 인스턴스로 복사합니다.
S3 경로는 `s3://floor28/data/cifar10` 입니다.
### TFRecord는 무엇인가요?
- Google에서 Tensorflow backend로 모델링 시에 공식적으로 권장하는 binary 포맷입니다.
- Tensorflow의 protocol buffer 파일로 직렬화된 입력 데이터가 담겨 있습니다.
- 대용량 데이터를 멀티스레딩으로 빠르게 스트리밍할 때 유용합니다. (모든 데이터는 메모리의 하나의 블록에 저장되므로, 입력 파일이 개별로 저장된 경우보다 데이터 로딩에 필요한 시간이 대폭 단축됩니다.)
- Example 객체로 구성된 배열의 집합체입니다. (an array of Examples)
- 아래 그림은 $m$차원 feautre가 $n$개의 샘플로 구성된 TFRecord 예시입니다.

```
!pip install tensorflow==2.0.0
import tensorflow as tf
import numpy as np
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
!aws s3 cp --recursive s3://floor28/data/cifar10 ./data
```
## Run the training locally
본 스크립트는 모델 학습에 필요한 인자값(arguments)들을 사용합니다. 모델 학습에 필요한 인자값들은 아래와 같습니다.
1. `model_dir` - 로그와 체크 포인트를 저장하는 경로
2. `train, validation, eval` - TFRecord 데이터셋을 저장하는 경로
3. `epochs` - epoch 횟수
아래 명령어로 **<font color='red'>SageMaker 관련 API 호출 없이</font>** 로컬 노트북 인스턴스 환경에서 1 epoch만 학습해 봅니다. 참고로, MacBook Pro(15-inch, 2018) 2.6GHz Core i7 16GB 사양에서 2분 20초~2분 40초 소요됩니다.
```
%%time
!mkdir -p logs
!python training_script/cifar10_keras_tf2.py --model_dir ./logs \
--train data/train \
--validation data/validation \
--eval data/eval \
--epochs 1
!rm -rf logs
```
**<font color='blue'>본 스크립트는 SageMaker상의 notebook에서 구동하고 있지만, 여러분의 로컬 컴퓨터에서도 python과 jupyter notebook이 정상적으로 인스톨되어 있다면 동일하게 수행 가능합니다.</font>**
## Use TensorFlow Script Mode
TensorFlow 버전 1.11 이상에서 Amazon SageMaker Python SDK는 **스크립트 모드(Script mode)**를 지원합니다. 스크립트 모드는 종래 레거시 모드(Legacy mode) 대비 아래 장점들이 있습니다.
* 스크립트 모드의 학습 스크립트는 일반적으로 TensorFlow 용으로 작성하는 학습 스크립트와 더 유사하므로 TensorFlow 학습 스크립트를 최소한의 변경으로 실행할 수 있습니다. 따라서, 기존 레거시 모드보다 TensorFlow 학습 스크립트를 수정하는 것이 더 쉽습니다.
- 레거시 모드는 Tensorflow Estimator API를 기반으로 한 아래의 함수들을 반드시 포함해야 합니다.
- 아래 함수들에서 하나의 함수를 만드시 포함해야 합니다.
- `model_fn`: 학습할 모델을 정의합니다,
- `keras_model_fn`: 학습할 tf.keras 모델을 정의합니다.
- `estimator_fn`: 학습할 tf.estimator.Estimator를 정의합니다.
- `train_input_fn`: 학습 데이터 로딩과 전처리를 수행합니다.
- `eval_input_fn`: 검증 데이터의 로딩과 전처리를 수행합니다.
- (Optional) `serving_input_fn`: 예측(prediction) 중에 모델에 전달할 feautre를 정의합니다. 이 함수는 학습시에만 사용되지만, SageMaker 엔드포인트에서 모델을 배포할 때 필요합니다.
- `if __name__ == “__main__”:` 블록을 정의할 수 없어 디버깅이 쉽지 않습니다.
* 스크립트 모드는 Python 2.7-와 Python 3.6-을 지원합니다.
* 스크립트 모드는 **Hovorod 기반 분산 학습(distributed training)도 지원**합니다.
TensorFlow 스크립트 모드에서 학습 스크립트를 작성하는 방법 및 Tensorflow 스크립트 모드의 estimator와 model 사용법에 대한 자세한 내용은
https://sagemaker.readthedocs.io/en/stable/using_tf.html 을 참조하세요.
### Preparing your script for training in SageMaker
SageMaker 스크립트 모드의 학습 스크립트는 SageMaker 외부에서 실행할 수 있는 학습 스크립트와 매우 유사합니다.
SageMaker는 하나의 인자값(argument), model_dir와 로그 및 모델 아티팩트(model artifacts)에 사용되는 S3 경로로 학습 스크립트를 실행합니다.
SageMaker 학습 인스턴스에서는 학습의 컨테이너에 S3에 저장된 데이터를 다운로드하여 학습에 활용합니다. 그 때, S3 버킷의 데이터 경로와 컨테이너의 데이터 경로를 컨테이너 환경 변수를 통해 연결합니다.
여러분은 다양한 환경 변수를 통해 학습 환경에 대한 유용한 속성들(properties)에 액세스할 수 있습니다.
이 스크립트의 경우 `Train, Validation, Eval`이라는 3 개의 데이터 채널을 스크립트로 보냅니다.
**`training_script/cifar10_keras_tf2.py`에서 스크립트 사본을 생성 후, `training_script/cifar10_keras_sm_tf2.py`로 저장하세요.**
스크립트 사본을 생성하였다면 단계별로 아래의 작업들을 직접 시도합니다.
----
### TODO 1.
`cifar10_keras_sm_tf2.py`파일에서 SageMaker API 환경 변수 SM_CHANNEL_TRAIN, SM_CHANNEL_VALIDATION, SM_CHANNEL_EVAL에서 디폴트 값을 가져오기 위해 train, validation, eval 인수를 수정해 주세요.
`cifar10_keras_sm_tf2.py`의 `if __name__ == '__main__':` 블록 내에 아래 인자값을 수정해 주세요.
```python
parser.add_argument(
'--train',
type=str,
required=False,
default=os.environ.get('SM_CHANNEL_TRAIN'), # <-- 수정 부분
help='The directory where the CIFAR-10 input data is stored.')
parser.add_argument(
'--validation',
type=str,
required=False,
default=os.environ.get('SM_CHANNEL_VALIDATION'), # <-- 수정 부분
help='The directory where the CIFAR-10 input data is stored.')
parser.add_argument(
'--eval',
type=str,
required=False,
default=os.environ.get('SM_CHANNEL_EVAL'), # <-- 수정 부분
help='The directory where the CIFAR-10 input data is stored.')
```
환경 변수에 따른 S3 경로와 컨테이너 경로는 아래 표와 같습니다.
| S3 경로 | 환경 변수 | 컨테이너 경로 |
| :---- | :---- | :----|
| s3://bucket_name/prefix/train | `SM_CHANNEL_TRAIN` | `/opt/ml/input/data/train` |
| s3://bucket_name/prefix/validation | `SM_CHANNEL_VALIDATION` | `/opt/ml/input/data/validation` |
| s3://bucket_name/prefix/eval | `SM_CHANNEL_EVAL` | `/opt/ml/input/data/eval` |
| s3://bucket_name/prefix/model.tar.gz | `SM_MODEL_DIR` | `/opt/ml/model` |
| s3://bucket_name/prefix/output.tar.gz | `SM_OUTPUT_DATA_DIR` | `/opt/ml/output/data` |
얘를 들어, `/opt/ml/input/data/train`은 학습 데이터가 다운로드되는 컨테이너 내부의 디렉토리입니다.
자세한 내용은 아래의 SageMaker Python SDK 문서를 확인하시기 바랍니다.<br>
(https://sagemaker.readthedocs.io/en/stable/using_tf.html#preparing-a-script-mode-training-script)
SageMaker는 train, validation, eval 경로들을 직접 인자로 보내지 않고, 대신 스크립트에서 환경 변수를 사용하여 해당 인자를 필요하지 않은 것으로 표시합니다.
SageMaker는 유용한 환경 변수를 여러분이 작성한 학습 스크립트로 보냅니다. 예시들은 아래와 같습니다.
* `SM_MODEL_DIR`: 학습 작업이 모델 아티팩트(model artifacts)를 저장할 수 있는 로컬 경로를 나타내는 문자열입니다. 학습 완료 후, 해당 경로 내 모델 아티팩트는 모델 호스팅을 위해 S3에 업로드됩니다. 이는 S3 위치인 학습 스크립트에 전달 된 model_dir 인수와 다르다는 점을 주의해 주세요. SM_MODEL_DIR은 항상 `/opt/ml/model`로 설정됩니다.
* `SM_NUM_GPUS`: 호스트(Host)에서 사용 가능한 GPU 수를 나타내는 정수(integer)입니다.
* `SM_OUTPUT_DATA_DIR`: 출력 아티팩트를 저장할 디렉토리의 경로를 나타내는 문자열입니다. 출력 아티팩트에는 체크포인트, 그래프 및 다른 저장용 파일들이 포함될 수 있지만 모델 아티팩트는 포함되지 않습니다. 이 출력 아티팩트들은 압축되어 모델 아티팩트와 동일한 접두사가 있는 S3 버킷으로 S3에 업로드됩니다.
이 샘플 코드는 네트워크 지연을 줄이기 위해 모델의 체크포인트(checkpoints)를 로컬 환경에 저장합니다. 이들은 학습 종료 후 S3에 업로드할 수 있습니다.
----
### TODO 2.
`cifar10_keras_sm_tf2.py`의 `if __name__ == '__main__':` 블록 내에 아래 인자값을 추가해 주세요.
```python
parser.add_argument(
'--model_output_dir',
type=str,
default=os.environ.get('SM_MODEL_DIR'))
```
----
### TODO 3.
`ModelCheckpoint` 함수의 저장 경로를 새 경로로 아래와 같이 수정해 주세요.
From:
```python
callbacks.append(ModelCheckpoint(args.model_dir + '/checkpoint-{epoch}.h5'))
```
To:
```python
callbacks.append(ModelCheckpoint(args.model_output_dir + '/checkpoint-{epoch}.h5'))
```
----
### TODO 4.
`save_model` 함수의 인자값을 아래와 같이 수정해 주세요.
From:
```python
return save_model(model, args.model_dir)
```
To:
```python
return save_model(model, args.model_output_dir)
```
<font color='blue'>**본 노트북 실습에 어려움이 있다면 솔루션 파일 `training_script/cifar10_keras_sm_tf2_solution.py`을 참조하시면 됩니다.**</font>
### Test your script locally (just like on your laptop)
테스트를 위해 위와 동일한 명령(command)으로 새 스크립트를 실행하고, 예상대로 실행되는지 확인합니다. <br>
SageMaker TensorFlow API 호출 시에 환경 변수들은 자동으로 넘겨기지만, 로컬 주피터 노트북에서 테스트 시에는 수동으로 환경 변수들을 지정해야 합니다. (아래 예제 코드를 참조해 주세요.)
```python
%env SM_MODEL_DIR=./logs
```
```
%%time
!mkdir -p logs
# Number of GPUs on this machine
%env SM_NUM_GPUS=1
# Where to save the model
%env SM_MODEL_DIR=./logs
# Where the training data is
%env SM_CHANNEL_TRAIN=data/train
# Where the validation data is
%env SM_CHANNEL_VALIDATION=data/validation
# Where the evaluation data is
%env SM_CHANNEL_EVAL=data/eval
!python training_script/cifar10_keras_sm_tf2.py --model_dir ./logs --epochs 1
!rm -rf logs
```
### Use SageMaker local for local testing
본격적으로 학습을 시작하기 전에 로컬 모드를 사용하여 디버깅을 먼저 수행합니다. 로컬 모드는 학습 인스턴스를 생성하는 과정이 없이 로컬 인스턴스로 컨테이너를 가져온 후 곧바로 학습을 수행하기 때문에 코드를 보다 신속히 검증할 수 있습니다.
Amazon SageMaker Python SDK의 로컬 모드는 TensorFlow 또는 MXNet estimator서 단일 인자값을 변경하여 CPU (단일 및 다중 인스턴스) 및 GPU (단일 인스턴스) SageMaker 학습 작업을 에뮬레이션(enumlate)할 수 있습니다.
로컬 모드 학습을 위해서는 docker-compose 또는 nvidia-docker-compose (GPU 인스턴스인 경우)의 설치가 필요합니다. 아래 코드 셀을 통해 본 노트북 환경에 docker-compose 또는 nvidia-docker-compose를 설치하고 구성합니다.
로컬 모드의 학습을 통해 여러분의 코드가 현재 사용 중인 하드웨어를 적절히 활용하고 있는지 확인하기 위한 GPU 점유와 같은 지표(metric)를 쉽게 모니터링할 수 있습니다.
```
!wget -q https://raw.githubusercontent.com/aws-samples/amazon-sagemaker-script-mode/master/local_mode_setup.sh
!wget -q https://raw.githubusercontent.com/aws-samples/amazon-sagemaker-script-mode/master/daemon.json
!/bin/bash ./local_mode_setup.sh
import os
import sagemaker
from sagemaker import get_execution_role
sagemaker_session = sagemaker.Session()
role = get_execution_role()
```
학습 작업을 시작하기 위해 `estimator.fit() ` 호출 시, Amazon ECS에서 Amazon SageMaker TensorFlow 컨테이너를 로컬 노트북 인스턴스로 다운로드합니다.
`sagemaker.tensorflow` 클래스를 사용하여 SageMaker Python SDK의 Tensorflow Estimator 인스턴스를 생성합니다.
인자값으로 하이퍼파라메터와 다양한 설정들을 변경할 수 있습니다.
자세한 내용은 [documentation](https://sagemaker.readthedocs.io/en/stable/using_tf.html#training-with-tensorflow-estimator)을 확인하시기 바랍니다.
```
from sagemaker.tensorflow import TensorFlow
estimator = TensorFlow(base_job_name='cifar10',
entry_point='cifar10_keras_sm_tf2.py',
source_dir='training_script',
role=role,
framework_version='2.0.0',
py_version='py3',
script_mode=True,
hyperparameters={'epochs' : 1},
train_instance_count=1,
train_instance_type='local')
```
학습을 수행할 3개의 채널과 데이터의 경로를 지정합니다. **로컬 모드로 수행하기 때문에 S3 경로 대신 노트북 인스턴스의 경로를 지정하시면 됩니다.**
```
%%time
estimator.fit({'train': 'file://data/train',
'validation': 'file://data/validation',
'eval': 'file://data/eval'})
```
Estimator가 처음 실행될 때 Amazon ECR 리포지토리(repository)에서 컨테이너 이미지를 다운로드해야 하지만 학습을 즉시 시작할 수 있습니다. 즉, 별도의 학습 클러스터가 프로비저닝 될 때까지 기다릴 필요가 없습니다. 또한 반복 및 테스트시 필요할 수 있는 후속 실행에서 MXNet 또는 TensorFlow 스크립트에 대한 수정 사항이 즉시 실행되기 시작합니다.
### Using SageMaker for faster training time
이번에는 로컬 모드를 사용하지 않고 SageMaker 학습에 GPU 학습 인스턴스를 생성하여 학습 시간을 단축해 봅니다.<br>
로컬 모드와 다른 점들은 (1) `train_instance_type`이 로컬 모드의 ‘local’ 대신 여러분이 원하는 특정 인스턴스 유형으로 설정해야 하고, (2) 학습 데이터를 Amazon S3에 업로드 후 학습 경로를 S3 경로로 설정해야 합니다.
SageMaker SDK는 S3 업로드를 위한 간단한 함수(`Session.upload_data()`)를 제공합니다. 이 함수를 통해 리턴되는 값은 데이터가 저장된 S3 경로입니다.
좀 더 자세한 설정이 필요하다면 SageMaker SDK 대신 boto3를 사용하시면 됩니다.
*[Note]: 고성능 워크로드를 위해 Amazon EFS와 Amazon FSx for Lustre도 지원하고 있습니다. 자세한 정보는 아래의 AWS 블로그를 참조해 주세요.<br>
https://aws.amazon.com/blogs/machine-learning/speed-up-training-on-amazon-sagemaker-using-amazon-efs-or-amazon-fsx-for-lustre-file-systems/*
```
dataset_location = sagemaker_session.upload_data(path='data', key_prefix='data/DEMO-cifar10')
display(dataset_location)
```
S3에 데이터 업로드를 완료했다면, Estimator를 새로 생성합니다. <br>
아래 코드를 그대로 복사 후에 `train_instance_type='local'`을 `train_instance_type='ml.p2.xlarge'`로 수정하고
`hyperparameters={'epochs': 1}`를 `hyperparameters={'epochs': 5}`로 수정합니다.
```python
from sagemaker.tensorflow import TensorFlow
estimator = TensorFlow(base_job_name='cifar10',
entry_point='cifar10_keras_sm_tf2.py',
source_dir='training_script',
role=role,
framework_version='2.0.0',
py_version='py3',
script_mode=True,
hyperparameters={'epochs': 1},
train_instance_count=1,
train_instance_type='local')
```
*[Note]
2019년 8월부터 SageMaker에서도 학습 인스턴스에 EC2 spot instance를 사용하여 비용을 크게 절감할 수 있습니다. 자세한 정보는 아래의 AWS 블로그를 참조해 주세요.<br>
https://aws.amazon.com/ko/blogs/korea/managed-spot-training-save-up-to-90-on-your-amazon-sagemaker-training-jobs/*
만약 Managed Spot Instance로 학습하려면 다음 코드를 Estimator의 train_instance_type의 다음 행에 추가해 주세요.
```python
train_max_run = 3600,
train_use_spot_instances = 'True',
train_max_wait = 3600,
```
```
from sagemaker.tensorflow import TensorFlow
estimator = TensorFlow(base_job_name='cifar10',
entry_point='cifar10_keras_sm_tf2.py',
source_dir='training_script',
role=role,
framework_version='2.0.0',
py_version='py3',
script_mode=True,
hyperparameters={'epochs': 5},
train_instance_count=1,
train_instance_type='ml.p2.xlarge')
```
학습을 수행합니다. 이번에는 각각의 채널(`train, validation, eval`)에 S3의 데이터 저장 위치를 지정합니다.<br>
학습 완료 후 Billable seconds도 확인해 보세요. Billable seconds는 실제로 학습 수행 시 과금되는 시간입니다.
```
Billable seconds: <time>
```
참고로, `ml.p2.xlarge` 인스턴스로 5 epoch 학습 시 전체 6분-7분이 소요되고, 실제 학습에 소요되는 시간은 3분-4분이 소요됩니다.
```
%%time
estimator.fit({'train':'{}/train'.format(dataset_location),
'validation':'{}/validation'.format(dataset_location),
'eval':'{}/eval'.format(dataset_location)})
```
## Start a new SageMaker experiment
Amazon SageMaker Experiments는 데이타 과학자들이 머신 러닝 실험을 구성하고, 추적하고, 비교하고, 평가할 수 있게 합니다.
머신 러닝은 반복적인 과정 입니다. 데이타 과학자들은 증분적인 모델 정확도의 변화를 관찰하면서, 데이타, 알고리즘, 파라미터의 조합들을 가지고 실험을 할 필요가 있습니다. 이러한 반복적인 과정은 수 많은 모델 훈련 및 모델의 버전들을 가지게 됩니다. 이것은 성능이 좋은 모델들 및 입력 설정의 구성들을 추적하기가 어렵게 됩니다. 이것은 더욱 더 증분적인 향상을 위한 기회를 찾기 위해서, 현재의 실험들과 과거에 수행한 실험들의 비교를 더욱 더 어렵게 합니다.
**Amazon SageMaker Experiments는 반복적인 과정(시험, Trial)으로서의 입력 값들, 파라미터들, 구성 설정 값들 및 결과들을 자동으로 추적 할 수 있게 합니다.<br>
데이타 과학자들은 시험들(Trials)을 실험(Experiment) 안으로 할당하고, 그룹핑하고, 구성할 수 있습니다.**
Amazon SageMaker Experiments는 현재 및 과거의 실험들을 시각적으로 조회할 수 있게 하는 Amazon SageMaker Studio와 통합이 되어 있습니다. Amazon SageMaker Studio는 또한 주요 평가 지표를 가지고 시험들을 비교할 수 있으며, 가장 우수한 모델들을 확인할 수 있게 합니다.
`sagemaker-experiments` 패키지를 먼저 설치합니다.
```
!pip install sagemaker-experiments
```
이제 실험(Experiment)을 만듭니다.
```
from smexperiments.experiment import Experiment
from smexperiments.trial import Trial
import time
# Create an aexperiment
cifar10_experiment = Experiment.create(
experiment_name="TensorFlow-cifar10-experiment",
description="Classification of cifar10 images")
```
다음은 시험(Trial)을 생성 합니다. 이 시험은 GPU Instance 위에서 Epoch 5를 가지고 실행하게 됩니다.
```
# Create a trial
trial_name = f"cifar10-training-job-{int(time.time())}"
trial = Trial.create(
trial_name=trial_name,
experiment_name=cifar10_experiment.experiment_name
)
```
새로운 estimator를 생성 합니다.
```
from sagemaker.tensorflow import TensorFlow
estimator = TensorFlow(base_job_name='cifar10',
entry_point='cifar10_keras_sm_tf2.py',
source_dir='training_script',
role=role,
framework_version='2.0.0',
py_version='py3',
hyperparameters={'epochs' : 5},
train_instance_count=1,
train_instance_type='ml.p2.xlarge')
```
다음은 각각 입력 데이타의 채널에 대한 S3 data location을 사용합니다.
```python
dataset_location + '/train'
dataset_location + '/validation'
dataset_location + '/eval'
```
위에서 설정한 experiment config를 fit 함수의 파라미터로 추가합니다. 또한 시험은 훈련 Job과 연결이 됩니다.
<br>TrialComponent는 시험(Trail)의 한 요소를 의미합니다. 여기서는 "Training"의 훈련 요소를 지칭합니다.
```python
experiment_config={
"ExperimentName": cifar10_experiment.experiment_name,
"TrialName": trial.trial_name,
"TrialComponentDisplayName": "Training"}
```
```
estimator.fit({'train' : dataset_location + '/train',
'validation' : dataset_location + '/validation',
'eval' : dataset_location + '/eval'
},
experiment_config={
"ExperimentName": cifar10_experiment.experiment_name,
"TrialName": trial.trial_name,
"TrialComponentDisplayName": "Training"
}
)
```
## Analyze the experiments
여기서는 DisplayName 이 "Training"과 같은 시험 요소(Trial Component)만 찾는 필터를 생성합니다. <br>
위에서 설정한 TrialComponentDisplayName": "Training" 을 찾게 됩니다.
```
search_expression = {
"Filters":[
{
"Name": "DisplayName",
"Operator": "Equals",
"Value": "Training",
}
],
}
```
ExperimentAnalytics 함수에 experiment 이름과 위에서 생성한 필터를 파라미터로 제공합니다.
```
import pandas as pd
pd.options.display.max_columns = 500
from sagemaker.analytics import ExperimentAnalytics
trial_component_analytics = ExperimentAnalytics(
sagemaker_session=sagemaker_session,
experiment_name=cifar10_experiment.experiment_name,
search_expression=search_expression
)
table = trial_component_analytics.dataframe(force_refresh=True)
display(table)
```
### Clean up the Experiment
experiment 이름은 계정과 리젼에 유니크한 이름이기에, 사용을 하지 않는다면 지워주는 것이 좋습니다.<br>
위에서 생성한 cifar10_experiment 오브젝트를 아래 cleanup 함수에 파라미터로 주어서 지워주게 됩니다.
이 작업은 관련된 Trial Component, Trial 을 지우고, 마지막으로 experiment를 삭제합니다.
```
import boto3
sess = boto3.Session()
sm = sess.client('sagemaker')
from smexperiments.trial_component import TrialComponent
def cleanup(experiment):
for trial_summary in experiment.list_trials():
trial = Trial.load(sagemaker_boto_client=sm, trial_name=trial_summary.trial_name)
for trial_component_summary in trial.list_trial_components():
tc = TrialComponent.load(
sagemaker_boto_client=sm,
trial_component_name=trial_component_summary.trial_component_name)
trial.remove_trial_component(tc)
try:
# comment out to keep trial components
tc.delete()
except:
# tc is associated with another trial
continue
# to prevent throttling
time.sleep(.5)
trial.delete()
experiment.delete()
print("The experiemnt is deleted")
cleanup(cifar10_experiment)
```
**잘 하셨습니다.**
SageMaker에서 GPU 인스턴스를 사용해 5 epoch를 정상적으로 학습할 수 있었습니다.<br>
다음 노트북으로 계속 진행하기 전에 SageMaker 콘솔의 Training jobs 섹션을 살펴보고 여러분이 수행한 job을 찾아 configuration을 확인하세요.
스크립트 모드 학습에 대한 자세한 내용은 아래의 AWS 블로그를 참조해 주세요.<br>
[Using TensorFlow eager execution with Amazon SageMaker script mode](https://aws.amazon.com/ko/blogs/machine-learning/using-tensorflow-eager-execution-with-amazon-sagemaker-script-mode/)
| github_jupyter |
# <div align="center">Latent Dirichlet Allocation(LDA): Topic Modeling</div>
---------------------------------------------------------------------
Levon Khachatryan:
<img src="pics/LDA.jpg" />
<a id="top"></a> <br>
## Notebook Content
1. [LDA Algorithm](#1)
2. [Problem Definition](#2)
3. [Import Packages](#3)
4. [Load Data](#4)
5. [Used functions for Data Preprocessing](#5)
6. [Data Preprocessing](#6)
7. [Model Deployment](#7)
8. [Save Model to Disk](#8)
9. [Load Model From Disk](#9)
10. [Detailed Information of Topics](#10)
11. [Word Cloud](#11)
12. [Message Analysis by Country](#12)
<a id="1"></a> <br>
# <div align="center">1. LDA Algorithm</div>
---------------------------------------------------------------------
### Background
Topic modeling is the process of identifying topics in a set of documents. This can be useful for search engines, customer service automation, and any other instance where knowing the topics of documents is important. There are multiple methods of going about doing this, but here I will explain one: Latent Dirichlet Allocation (LDA).
### The Algorithm
LDA is a form of unsupervised learning that views documents as bags of words (**ie order does not matter**). LDA works by first making a key assumption: the way a document was generated was by picking a set of topics and then for each topic picking a set of words. Now you may be asking “ok so how does it find topics?” Well the answer is simple: it reverse engineers this process. To do this it does the following for each document m:
1. Assume there are k topics across all of the documents
2. Distribute these k topics across document m (this distribution is known as **α** and can be symmetric or asymmetric, more on this later) by assigning each word a topic.
3. For each word w in document m, assume its topic is wrong but every other word is assigned the correct topic.
4. Probabilistically assign word w a topic based on two things:
1. what topics are in document m
2. how many times word w has been assigned a particular topic across all of the documents (this distribution is called β, more on this later)
5. Repeat this process a number of times for each document and you’re done!
### The Model
<img src="pics/model.png" />
Smoothed LDA from https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
Above is what is known as a plate diagram of an LDA model where:
α is the per-document topic distributions,
β is the per-topic word distribution,
θ is the topic distribution for document m,
φ is the word distribution for topic k,
z is the topic for the n-th word in document m, and
w is the specific word
### Tweaking the Model
In the plate model diagram above, you can see that w is grayed out. This is because it is the only observable variable in the system while the others are latent. Because of this, to tweak the model there are a few things you can mess with and below I focus on two.
α is a matrix where each row is a document and each column represents a topic. A value in row i and column j represents how likely document i contains topic j. A symmetric distribution would mean that each topic is evenly distributed throughout the document while an asymmetric distribution favors certain topics over others. This affects the starting point of the model and can be used when you have a rough idea of how the topics are distributed to improve results.
β is a matrix where each row represents a topic and each column represents a word. A value in row i and column j represents how likely that topic i contains word j. Usually each word is distributed evenly throughout the topic such that no topic is biased towards certain words. This can be exploited though in order to bias certain topics to favor certain words. For example if you know you have a topic about Apple products it can be helpful to bias words like “iphone” and “ipad” for one of the topics in order to push the model towards finding that particular topic.
### Conclusion
This part is not meant to be a full-blown LDA tutorial, but rather to give an overview of how LDA models work and how to use them. There are many implementations out there such as Gensim that are easy to use and very effective.
<a id="2"></a> <br>
# <div align="center">2. Problem Definition</div>
---------------------------------------------------------------------
[go to top](#top)
So here we have a text data (from messenger) and our aim is to find some topics from data (do topic modeling). Topic modeling is a type of statistical modeling for discovering the abstract “topics” that occur in a collection of documents. Latent Dirichlet Allocation (LDA) is an example of topic model and is used to classify text in a document to a particular topic. It builds a topic per document model and words per topic model, modeled as Dirichlet distributions.
<a id="3"></a> <br>
# <div align="center">3. Import Packages</div>
---------------------------------------------------------------------
[go to top](#top)
```
'''
Loading numpy and pandas libraries
'''
import numpy as np
import pandas as pd
'''
Loading Gensim and nltk libraries
'''
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from nltk.stem import WordNetLemmatizer, SnowballStemmer
# from nltk.stem.porter import *
# from nltk.stem.porter import PorterStemmer
'''
Load english wards from nltk , and english stemmers
'''
import nltk
nltk.download('wordnet')
nltk.download('words')
words = set(nltk.corpus.words.words())
stemmer = SnowballStemmer("english")
'''
Load Regular expressions
'''
import re
'''
Load operator package, this will be used in dictionary sort
'''
import operator
'''
fix random state
'''
np.random.seed(42)
'''
Suppress warnings
'''
import warnings
warnings.filterwarnings("ignore")
'''
Load punctuation for data preprocesing
'''
from string import punctuation
'''
Word cloud implementation
'''
from PIL import Image
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from matplotlib import pyplot as plt
```
<a id="4"></a> <br>
# <div align="center">4. Load Data</div>
---------------------------------------------------------------------
[go to top](#top)
```
'''
Load data from csv file, which is in the same folder
'''
data = pd.read_csv('***.csv')
'''
Delete messages created by ***
'''
data = data[data.u_id != 1]
'''
Correct the Date column format
'''
data.date = data.date.str.slice(0, 10)
data['date'] = pd.to_datetime(data['date'], format='%Y-%m-%d')
'''
Choose only same part from data, in this example I Chose the messages created on last month
'''
data = data.loc[data.date >= '20190407']
'''
Delete messages containing no more than 3 characters
'''
data = data[data.text.str.len() > 3]
'''
Remaining conversations
'''
print('After delete unused messages the Remaining count of conversation is: {}'.format(data.c_id.nunique()))
'''
Group messages to appropriate conversations which we will consider as documents
'''
conversation = data.groupby('c_id')['text'].apply(lambda x: "%s" % ', '.join(x))
documents = conversation.to_frame(name=None)
```
<a id="5"></a> <br>
# <div align="center">5. Used Functions for Data Preprocessing</div>
---------------------------------------------------------------------
[go to top](#top)
```
def preprocess_word(word):
"""
Word preprocessing
This function will preprocess particular word
Parameters:
word: string
Returns:
string: will return initial string input but preprocessed ,
so from input string will delete all punctuation and repeated symbols.
"""
# Remove punctuation
word = ''.join(c for c in word if c not in punctuation)
# Convert more than 2 letter repetitions to 2 letter
# funnnnny --> funny
word = re.sub(r'(.)\1+', r'\1\1', word)
return word
# preprocess_word('aaa|sd''f,gh!jg&')
def is_valid_word(word):
"""
Word checking
This function will check if word starts with alphabet
Parameters:
word: string
Returns:
Boolean: Is valid or not , True means that word is valid
"""
# Check if word begins with an alphabet
return (re.search(r'^[a-zA-Z][a-z0-9A-Z\._]*$', word) is not None)
# is_valid_word('1dgh')
def handle_emojis(document):
"""
Emoji classifier
This function will replace emojis with EMO_POS or EMO_NEG , depending on its meaning
Parameters:
document: string
Returns:
string: initial string input replaced emojis by their meaning,
for example :) will replaced with EMO_POS but ): will replaced with EMO_NEG
"""
# Smile -- :), : ), :-), (:, ( :, (-:, :')
document = re.sub(r'(:\s?\)|:-\)|\(\s?:|\(-:|:\'\))', ' EMO_POS ', document)
# Laugh -- :D, : D, :-D, xD, x-D, XD, X-D
document = re.sub(r'(:\s?D|:-D|x-?D|X-?D)', ' EMO_POS ', document)
# Love -- <3, :*
document = re.sub(r'(<3|:\*)', ' EMO_POS ', document)
# Wink -- ;-), ;), ;-D, ;D, (;, (-;
document = re.sub(r'(;-?\)|;-?D|\(-?;)', ' EMO_POS ', document)
# Sad -- :-(, : (, :(, ):, )-:
document = re.sub(r'(:\s?\(|:-\(|\)\s?:|\)-:)', ' EMO_NEG ', document)
# Cry -- :,(, :'(, :"(
document = re.sub(r'(:,\(|:\'\(|:"\()', ' EMO_NEG ', document)
return document
# handle_emojis('dsf):ghj')
def preprocess_document(document, use_stemmer = False):
"""
Text preprocessing
This function will preprocess the input text
Parameters:
document: string (we can put the entire string row , for instance in our case I will pass conversation)
use_stemmer: Boolean (If True I will use stemmer as well as all other processes)
Returns:
string: processed input string
"""
def lemmatize_stemming(text):
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))
processed_document = []
# Convert to lower case
document = document.lower()
# Replaces URLs with the word URL
document = re.sub(r'((www\.[\S]+)|(https?://[\S]+))', ' URL ', document)
# Replace @handle with the word USER_MENTION
document = re.sub(r'@[\S]+', 'USER_MENTION', document)
# Replaces #hashtag with hashtag
document = re.sub(r'#(\S+)', r' \1 ', document)
# Replace 2+ dots with space
document = re.sub(r'\.{2,}', ' ', document)
# Strip space, " and ' from document
document = document.strip(' "\'')
# Replace emojis with either EMO_POS or EMO_NEG
document = handle_emojis(document)
# Replace multiple spaces with a single space
document = re.sub(r'\s+', ' ', document)
words = document.split()
for word in words:
word = preprocess_word(word)
if is_valid_word(word):
if use_stemmer:
word = lemmatize_stemming(word)
if word not in gensim.parsing.preprocessing.STOPWORDS and len(word) > 3:
processed_document.append(word)
processed_internal_state = ' '.join(processed_document)
processed_internal_state = re.sub(r'\b\w{1,3}\b', '', processed_internal_state)
processed_internal_state = ' '.join(processed_internal_state.split())
return processed_internal_state
def preprocess(preprocessed_document):
"""
tokenize and combine already preprocessed document
This function will tokenize document and will combine document such a way ,
that we can containing the number of times a word appears in the training set
using gensim.corpora.Dictionary
Parameters:
preprocessed_document: string (particular document obtained from preprocess_document function)
Returns:
list: tokenized documents in approprite form
"""
result=[]
for token in gensim.utils.simple_preprocess(preprocessed_document) :
result.append(token)
return result
```
<a id="6"></a> <br>
# <div align="center">6. Data Preprocessing</div>
---------------------------------------------------------------------
[go to top](#top)
```
'''
Create a list from 'documents' DataFrame and call it 'processed_docs'
'''
processed_docs = []
for doc in documents.values:
processed_docs.append(preprocess(preprocess_document(doc[0])))
'''
Create a dictionary from 'processed_docs' containing the number of times a word appears
in the data set using gensim.corpora.Dictionary and call it 'dictionary'
'''
dictionary = gensim.corpora.Dictionary(processed_docs)
# '''
# Checking dictionary created
# '''
# count = 0
# for k, v in dictionary.iteritems():
# print(k, v)
# count += 1
# if count > 10:
# break
'''
OPTIONAL STEP
Remove very rare and very common words:
- words appearing less than 15 times
- words appearing in more than 10% of all documents
'''
dictionary.filter_extremes(no_below=15, no_above=0.1, keep_n= 100000)
'''
Create the Bag-of-words model for each document i.e for each document we create a dictionary reporting how many
words and how many times those words appear. Save this to 'bow_corpus'
'''
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
# '''
# Preview BOW for our sample preprocessed document
# '''
# document_num = 50
# bow_doc_x = bow_corpus[document_num]
# for i in range(len(bow_doc_x)):
# print("Word {} (\"{}\") appears {} time.".format(bow_doc_x[i][0],
# dictionary[bow_doc_x[i][0]],
# bow_doc_x[i][1]))
```
<a id="7"></a> <br>
# <div align="center">7. Model Deployment</div>
---------------------------------------------------------------------
[go to top](#top)
Online Latent Dirichlet Allocation (LDA) in Python, using all CPU cores to parallelize and speed up model training.
The parallelization uses multiprocessing; in case this doesn’t work for you for some reason, try the gensim.models.ldamodel.LdaModel class which is an equivalent, but more straightforward and single-core implementation.
The training algorithm:
1. is streamed: training documents may come in sequentially, no random access required,
2. runs in constant memory w.r.t. the number of documents: size of the training corpus does not affect memory footprint, can process corpora larger than RAM
This module allows both LDA model estimation from a training corpus and inference of topic distribution on new, unseen documents. The model can also be updated with new documents for online training.
class **gensim.models.ldamulticore.LdaMulticore**(corpus=None, num_topics=100, id2word=None, workers=None, chunksize=2000, passes=1, batch=False, alpha='symmetric', eta=None, decay=0.5, offset=1.0, eval_every=10, iterations=50, gamma_threshold=0.001, random_state=None, minimum_probability=0.01, minimum_phi_value=0.01, per_word_topics=False, dtype=<type 'numpy.float32'>)
Bases: gensim.models.ldamodel.LdaModel
An optimized implementation of the LDA algorithm, able to harness the power of multicore CPUs. Follows the similar API as the parent class LdaModel.
**Parameters:**
1. corpus ({iterable of list of (int, float), scipy.sparse.csc}, optional) – Stream of document vectors or sparse matrix of shape (num_terms, num_documents). If not given, the model is left untrained (presumably because you want to call update() manually).
2. num_topics (int, optional) – The number of requested latent topics to be extracted from the training corpus.
3. id2word ({dict of (int, str), gensim.corpora.dictionary.Dictionary}) – Mapping from word IDs to words. It is used to determine the vocabulary size, as well as for debugging and topic printing.
4. workers (int, optional) – Number of workers processes to be used for parallelization. If None all available cores (as estimated by workers=cpu_count()-1 will be used. Note however that for hyper-threaded CPUs, this estimation returns a too high number – set workers directly to the number of your real cores (not hyperthreads) minus one, for optimal performance.
5. chunksize (int, optional) – Number of documents to be used in each training chunk.
6. passes (int, optional) – Number of passes through the corpus during training.
7. alpha ({np.ndarray, str}, optional) – Can be set to an 1D array of length equal to the number of expected topics that expresses our a-priori belief for the each topics’ probability. Alternatively default prior selecting strategies can be employed by supplying a string: ’asymmetric’: Uses a fixed normalized asymmetric prior of 1.0 / topicno.
8. gamma_threshold (float, optional) – Minimum change in the value of the gamma parameters to continue iterating.
9. minimum_probability (float, optional) – Topics with a probability lower than this threshold will be filtered out.
10. per_word_topics (bool) – If True, the model also computes a list of topics, sorted in descending order of most likely topics for each word, along with their phi values multiplied by the feature length (i.e. word count).
11. minimum_phi_value (float, optional) – if per_word_topics is True, this represents a lower bound on the term probabilities.
**Methods and functions**
There are varous methods for lda model which we can find in the lda documentation: https://radimrehurek.com/gensim/models/ldamulticore.html
```
# LDA mono-core -- fallback code in case LdaMulticore throws an error on your machine
# lda_model = gensim.models.LdaModel(bow_corpus,
# num_topics = 10,
# id2word = dictionary,
# passes = 50)
# LDA multicore
'''
Train your lda model using gensim.models.LdaMulticore and save it to 'lda_model'
'''
number_of_topics = 7
lda_model = gensim.models.LdaMulticore(bow_corpus,
num_topics = number_of_topics,
id2word = dictionary,
passes = 10,
workers = 2)
'''
For each topic, we will explore the words occuring in that topic and its relative weight
'''
for idx, topic in lda_model.print_topics(-1):
print("Topic: {} \nWords: {}".format(idx, topic ))
print("\n")
```
<a id="8"></a> <br>
# <div align="center">8. Save Model to Disk</div>
---------------------------------------------------------------------
[go to top](#top)
```
'''
Save model to disk.
'''
directory_to_save = 'C:\\_Files\\MyProjects\\***_TopicExtraction\\model\\model'
lda_model.save(directory_to_save)
```
<a id="9"></a> <br>
# <div align="center">9. Load Model From Disk</div>
---------------------------------------------------------------------
[go to top](#top)
```
'''
Load a potentially pretrained model from disk.
'''
lda_model = gensim.models.LdaMulticore.load(directory_to_save)
```
<a id="10"></a> <br>
# <div align="center">10. Detailed Information of Topics</div>
---------------------------------------------------------------------
[go to top](#top)
```
'''
Create (num_of_conv x num_of_topic) matrix with all 0 values and call it conversation_topic
'''
conversation_topic = np.zeros(shape=(len(bow_corpus), number_of_topics), dtype=float)
print(conversation_topic.shape)
print(conversation_topic)
'''
Fill appropriate probability of conversation i to belong topic j to conversation_topic matrix
'''
for i in range(len(bow_corpus)):
prob = lda_model.get_document_topics(bow_corpus[i], per_word_topics = False)
for k in range(len(prob)):
conversation_topic[i, prob[k][0]] = prob[k][1]
'''
Calculate summed probabilities of each topic and call it prob_dict
'''
prob_dict = dict()
for i in range(number_of_topics):
prob_dict[i] = round(conversation_topic.sum(axis = 0)[i] / len(bow_corpus), 2)
'''
Sort prob_dict dictionary t find the most probable topic over all conversation dataset
'''
sorted_prob = sorted(prob_dict.items(), key=operator.itemgetter(1))
print(sorted_prob)
'''
For each topic, we will explore the words occuring in that topic and its relative weight
'''
for idx, topic in lda_model.print_topics(-1):
print("Topic: {} \nWords: {}".format(idx, topic ))
print("\n")
```
<a id="11"></a> <br>
# <div align="center">11. Word Cloud</div>
---------------------------------------------------------------------
[go to top](#top)
```
'''
Combine all preprocessed conversations to one string and call it word_cloud_messenger
'''
word_cloud_messenger = []
for doc in processed_docs:
s = " "
word_cloud_messenger.append(s.join( doc ))
s = " "
word_cloud_messenger = s.join( word_cloud_messenger )
'''
Save generated word cloud to disk
'''
np.save('word_cloud_messenger.npy', word_cloud_messenger)
'''
Read generated word cloud from disk
'''
word_cloud_messenger = np.load('word_cloud_messenger.npy')
word_cloud_messenger = str(word_cloud_messenger)
'''
Generate Picture of words, so called word cloud
'''
# Create stopword list:
stopwords = set()
stopwords.update(["doritos", "doritosdoritos", "chirp", "chirpchirp", "mexico"])
# Generate a word cloud image
wordcloud = WordCloud(stopwords=stopwords,
background_color="white",
width = 800,
height = 800,
min_font_size = 10).generate(word_cloud_messenger)
# Save the image in the img folder:
wordcloud.to_file("first_review.png")
# Display the generated image:
# the matplotlib way:
plt.figure(figsize=(18, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show();
'''
Generate Picture of words following a color pattern (with mask).
'''
# Create stopword list:
stopwords = set()
stopwords.update(["doritos", "doritosdoritos", "chirp", "chirpchirp", "mexico"])
# Generate a word cloud image
mask = np.array(Image.open("Icon.jpg"))
wordcloud_ddxk_learn = WordCloud(stopwords=stopwords,
background_color="white",
mode="RGBA",
max_words=1000,
# width = 800,
# height = 800,
# min_font_size = 10,
mask=mask).generate(word_cloud_messenger)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=(18, 10))
plt.imshow(wordcloud_ddxk_learn.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("second_review.png", format="png")
plt.show();
```
<a id="12"></a> <br>
# <div align="center">12. Message Analysis by Country</div>
---------------------------------------------------------------------
[go to top](#top)
| github_jupyter |
```
"""A deep MNIST classifier using convolutional layers.
See extensive documentation at
https://www.tensorflow.org/get_started/mnist/pros
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import sys
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
FLAGS = None
def deepnn(x):
"""deepnn builds the graph for a deep net for classifying digits.
Args:
x: an input tensor with the dimensions (N_examples, 784), where 784 is the
number of pixels in a standard MNIST image.
Returns:
A tuple (y, keep_prob). y is a tensor of shape (N_examples, 10), with values
equal to the logits of classifying the digit into one of 10 classes (the
digits 0-9). keep_prob is a scalar placeholder for the probability of
dropout.
"""
# Reshape to use within a convolutional neural net.
# Last dimension is for "features" - there is only one here, since images are
# grayscale -- it would be 3 for an RGB image, 4 for RGBA, etc.
x_image = tf.reshape(x, [-1, 28, 28, 1])
# First convolutional layer - maps one grayscale image to 32 feature maps.
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# Pooling layer - downsamples by 2X.
h_pool1 = max_pool_2x2(h_conv1)
# Second convolutional layer -- maps 32 feature maps to 64.
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# Second pooling layer.
h_pool2 = max_pool_2x2(h_conv2)
# Fully connected layer 1 -- after 2 round of downsampling, our 28x28 image
# is down to 7x7x64 feature maps -- maps this to 1024 features.
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# Dropout - controls the complexity of the model, prevents co-adaptation of
# features.
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# Map the 1024 features to 10 classes, one for each digit
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
return y_conv, keep_prob
def conv2d(x, W):
"""conv2d returns a 2d convolution layer with full stride."""
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
"""max_pool_2x2 downsamples a feature map by 2X."""
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
def weight_variable(shape):
"""weight_variable generates a weight variable of a given shape."""
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
"""bias_variable generates a bias variable of a given shape."""
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def doit():
# Import data
mnist = input_data.read_data_sets(r'/tmp/tensorflow/mnist/input_data', one_hot=True)
# Create the model
x = tf.placeholder(tf.float32, [None, 784])
# Define loss and optimizer
y_ = tf.placeholder(tf.float32, [None, 10])
# Build the graph for the deep net
y_conv, keep_prob = deepnn(x)
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(5000):
batch = mnist.train.next_batch(50)
if i % 1000 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print('test accuracy %g' % accuracy.eval(session=sess, feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
%timeit -r1 -n1 doit()
#36s elapsed on GTX1060 6GB, at an average 70% saturation.
```
| github_jupyter |
# Convolutional Neural Networks
## Project: Write an Algorithm for a Dog Identification App
---
In this notebook, some template code has already been provided for you, and you will need to implement additional functionality to successfully complete this project. You will not need to modify the included code beyond what is requested. Sections that begin with **'(IMPLEMENTATION)'** in the header indicate that the following block of code will require additional functionality which you must provide. Instructions will be provided for each section, and the specifics of the implementation are marked in the code block with a 'TODO' statement. Please be sure to read the instructions carefully!
> **Note**: Once you have completed all of the code implementations, you need to finalize your work by exporting the Jupyter Notebook as an HTML document. Before exporting the notebook to html, all of the code cells need to have been run so that reviewers can see the final implementation and output. You can then export the notebook by using the menu above and navigating to **File -> Download as -> HTML (.html)**. Include the finished document along with this notebook as your submission.
In addition to implementing code, there will be questions that you must answer which relate to the project and your implementation. Each section where you will answer a question is preceded by a **'Question X'** header. Carefully read each question and provide thorough answers in the following text boxes that begin with **'Answer:'**. Your project submission will be evaluated based on your answers to each of the questions and the implementation you provide.
>**Note:** Code and Markdown cells can be executed using the **Shift + Enter** keyboard shortcut. Markdown cells can be edited by double-clicking the cell to enter edit mode.
The rubric contains _optional_ "Stand Out Suggestions" for enhancing the project beyond the minimum requirements. If you decide to pursue the "Stand Out Suggestions", you should include the code in this Jupyter notebook.
---
### Why We're Here
In this notebook, you will make the first steps towards developing an algorithm that could be used as part of a mobile or web app. At the end of this project, your code will accept any user-supplied image as input. If a dog is detected in the image, it will provide an estimate of the dog's breed. If a human is detected, it will provide an estimate of the dog breed that is most resembling. The image below displays potential sample output of your finished project (... but we expect that each student's algorithm will behave differently!).

In this real-world setting, you will need to piece together a series of models to perform different tasks; for instance, the algorithm that detects humans in an image will be different from the CNN that infers dog breed. There are many points of possible failure, and no perfect algorithm exists. Your imperfect solution will nonetheless create a fun user experience!
### The Road Ahead
We break the notebook into separate steps. Feel free to use the links below to navigate the notebook.
* [Step 0](#step0): Import Datasets
* [Step 1](#step1): Detect Humans
* [Step 2](#step2): Detect Dogs
* [Step 3](#step3): Create a CNN to Classify Dog Breeds (from Scratch)
* [Step 4](#step4): Create a CNN to Classify Dog Breeds (using Transfer Learning)
* [Step 5](#step5): Write your Algorithm
* [Step 6](#step6): Test Your Algorithm
---
<a id='step0'></a>
## Step 0: Import Datasets
Make sure that you've downloaded the required human and dog datasets:
**Note: if you are using the Udacity workspace, you *DO NOT* need to re-download these - they can be found in the `/data` folder as noted in the cell below.**
* Download the [dog dataset](https://s3-us-west-1.amazonaws.com/udacity-aind/dog-project/dogImages.zip). Unzip the folder and place it in this project's home directory, at the location `/dog_images`.
* Download the [human dataset](https://s3-us-west-1.amazonaws.com/udacity-aind/dog-project/lfw.zip). Unzip the folder and place it in the home directory, at location `/lfw`.
*Note: If you are using a Windows machine, you are encouraged to use [7zip](http://www.7-zip.org/) to extract the folder.*
In the code cell below, we save the file paths for both the human (LFW) dataset and dog dataset in the numpy arrays `human_files` and `dog_files`.
```
import numpy as np
from glob import glob
# load filenames for human and dog images
human_files = np.array(glob("/data/lfw/*/*"))
dog_files = np.array(glob("/data/dog_images/*/*/*"))
# print number of images in each dataset
print('There are %d total human images.' % len(human_files))
print('There are %d total dog images.' % len(dog_files))
```
<a id='step1'></a>
## Step 1: Detect Humans
In this section, we use OpenCV's implementation of [Haar feature-based cascade classifiers](http://docs.opencv.org/trunk/d7/d8b/tutorial_py_face_detection.html) to detect human faces in images.
OpenCV provides many pre-trained face detectors, stored as XML files on [github](https://github.com/opencv/opencv/tree/master/data/haarcascades). We have downloaded one of these detectors and stored it in the `haarcascades` directory. In the next code cell, we demonstrate how to use this detector to find human faces in a sample image.
```
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
# extract pre-trained face detector
face_cascade = cv2.CascadeClassifier('haarcascades/haarcascade_frontalface_alt.xml')
# load color (BGR) image
img = cv2.imread(human_files[0])
# convert BGR image to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# find faces in image
faces = face_cascade.detectMultiScale(gray)
# print number of faces detected in the image
print('Number of faces detected:', len(faces))
# get bounding box for each detected face
for (x,y,w,h) in faces:
# add bounding box to color image
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
# convert BGR image to RGB for plotting
cv_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# display the image, along with bounding box
plt.imshow(cv_rgb)
plt.show()
```
Before using any of the face detectors, it is standard procedure to convert the images to grayscale. The `detectMultiScale` function executes the classifier stored in `face_cascade` and takes the grayscale image as a parameter.
In the above code, `faces` is a numpy array of detected faces, where each row corresponds to a detected face. Each detected face is a 1D array with four entries that specifies the bounding box of the detected face. The first two entries in the array (extracted in the above code as `x` and `y`) specify the horizontal and vertical positions of the top left corner of the bounding box. The last two entries in the array (extracted here as `w` and `h`) specify the width and height of the box.
### Write a Human Face Detector
We can use this procedure to write a function that returns `True` if a human face is detected in an image and `False` otherwise. This function, aptly named `face_detector`, takes a string-valued file path to an image as input and appears in the code block below.
```
# returns "True" if face is detected in image stored at img_path
def face_detector(img_path):
img = cv2.imread(img_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray)
return len(faces) > 0
```
### (IMPLEMENTATION) Assess the Human Face Detector
__Question 1:__ Use the code cell below to test the performance of the `face_detector` function.
- What percentage of the first 100 images in `human_files` have a detected human face?
- What percentage of the first 100 images in `dog_files` have a detected human face?
Ideally, we would like 100% of human images with a detected face and 0% of dog images with a detected face. You will see that our algorithm falls short of this goal, but still gives acceptable performance. We extract the file paths for the first 100 images from each of the datasets and store them in the numpy arrays `human_files_short` and `dog_files_short`.
__Answer:__
* human_files have 98% detected human face
* dog_files have 17% detected human face
```
from tqdm import tqdm
human_files_short = human_files[:100]
dog_files_short = dog_files[:100]
#-#-# Do NOT modify the code above this line. #-#-#
## TODO: Test the performance of the face_detector algorithm
## on the images in human_files_short and dog_files_short.
deteced_human_face_human_files = 0
for human in human_files_short:
if face_detector(human) == True:
deteced_human_face_human_files += 1
print ("human_files have {}% detected human face".format(deteced_human_face_human_files))
deteced_human_face_dog_files = 0
for dog in dog_files_short:
if face_detector(dog) == True:
deteced_human_face_dog_files += 1
print ("dog_files have {}% detected human face".format(deteced_human_face_dog_files))
```
We suggest the face detector from OpenCV as a potential way to detect human images in your algorithm, but you are free to explore other approaches, especially approaches that make use of deep learning :). Please use the code cell below to design and test your own face detection algorithm. If you decide to pursue this _optional_ task, report performance on `human_files_short` and `dog_files_short`.
```
### (Optional)
### TODO: Test performance of anotherface detection algorithm.
### Feel free to use as many code cells as needed.
```
---
<a id='step2'></a>
## Step 2: Detect Dogs
In this section, we use a [pre-trained model](http://pytorch.org/docs/master/torchvision/models.html) to detect dogs in images.
### Obtain Pre-trained VGG-16 Model
The code cell below downloads the VGG-16 model, along with weights that have been trained on [ImageNet](http://www.image-net.org/), a very large, very popular dataset used for image classification and other vision tasks. ImageNet contains over 10 million URLs, each linking to an image containing an object from one of [1000 categories](https://gist.github.com/yrevar/942d3a0ac09ec9e5eb3a).
```
import torch
import torchvision.models as models
# define VGG16 model
VGG16 = models.vgg16(pretrained=True)
# check if CUDA is available
use_cuda = torch.cuda.is_available()
# move model to GPU if CUDA is available
if use_cuda:
VGG16 = VGG16.cuda()
```
Given an image, this pre-trained VGG-16 model returns a prediction (derived from the 1000 possible categories in ImageNet) for the object that is contained in the image.
### (IMPLEMENTATION) Making Predictions with a Pre-trained Model
In the next code cell, you will write a function that accepts a path to an image (such as `'dogImages/train/001.Affenpinscher/Affenpinscher_00001.jpg'`) as input and returns the index corresponding to the ImageNet class that is predicted by the pre-trained VGG-16 model. The output should always be an integer between 0 and 999, inclusive.
Before writing the function, make sure that you take the time to learn how to appropriately pre-process tensors for pre-trained models in the [PyTorch documentation](http://pytorch.org/docs/stable/torchvision/models.html).
```
from PIL import Image
import torchvision.transforms as transforms
def path_to_tensor(img_path):
img = Image.open(img_path)
normalize = transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
preprocess = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize])
return preprocess(img)[:3,:,:].unsqueeze(0)
def VGG16_predict(img_path):
'''
Use pre-trained VGG-16 model to obtain index corresponding to
predicted ImageNet class for image at specified path
Args:
img_path: path to an image
Returns:
Index corresponding to VGG-16 model's prediction
'''
## TODO: Complete the function.
## Load and pre-process an image from the given img_path
## Return the *index* of the predicted class for that image
# load image
img = path_to_tensor(img_path)
# use GPU if available
if use_cuda:
img = img.cuda()
ret = VGG16(img)
return torch.max(ret,1)[1].item() # predicted class index
```
### (IMPLEMENTATION) Write a Dog Detector
While looking at the [dictionary](https://gist.github.com/yrevar/942d3a0ac09ec9e5eb3a), you will notice that the categories corresponding to dogs appear in an uninterrupted sequence and correspond to dictionary keys 151-268, inclusive, to include all categories from `'Chihuahua'` to `'Mexican hairless'`. Thus, in order to check to see if an image is predicted to contain a dog by the pre-trained VGG-16 model, we need only check if the pre-trained model predicts an index between 151 and 268 (inclusive).
Use these ideas to complete the `dog_detector` function below, which returns `True` if a dog is detected in an image (and `False` if not).
```
### returns "True" if a dog is detected in the image stored at img_path
def dog_detector(img_path):
## TODO: Complete the function.
idx = VGG16_predict(img_path)
return idx >= 151 and idx <= 268 # true/false
```
### (IMPLEMENTATION) Assess the Dog Detector
__Question 2:__ Use the code cell below to test the performance of your `dog_detector` function.
- What percentage of the images in `human_files_short` have a detected dog?
- What percentage of the images in `dog_files_short` have a detected dog?
__Answer:__
* human_files have 0% detected dog
* dog_files have 100% detected dog
```
### TODO: Test the performance of the dog_detector function
### on the images in human_files_short and dog_files_short.
deteced_dog_human_files = 0
for human in human_files_short:
if dog_detector(human) == True:
deteced_dog_human_files += 1
print ("human_files have {}% detected dog".format(deteced_dog_human_files))
deteced_dog_dog_files = 0
for dog in dog_files_short:
if dog_detector(dog) == True:
deteced_dog_dog_files += 1
print ("dog_files have {}% detected dog".format(deteced_dog_dog_files))
```
We suggest VGG-16 as a potential network to detect dog images in your algorithm, but you are free to explore other pre-trained networks (such as [Inception-v3](http://pytorch.org/docs/master/torchvision/models.html#inception-v3), [ResNet-50](http://pytorch.org/docs/master/torchvision/models.html#id3), etc). Please use the code cell below to test other pre-trained PyTorch models. If you decide to pursue this _optional_ task, report performance on `human_files_short` and `dog_files_short`.
```
### (Optional)
### TODO: Report the performance of another pre-trained network.
### Feel free to use as many code cells as needed.
```
---
<a id='step3'></a>
## Step 3: Create a CNN to Classify Dog Breeds (from Scratch)
Now that we have functions for detecting humans and dogs in images, we need a way to predict breed from images. In this step, you will create a CNN that classifies dog breeds. You must create your CNN _from scratch_ (so, you can't use transfer learning _yet_!), and you must attain a test accuracy of at least 10%. In Step 4 of this notebook, you will have the opportunity to use transfer learning to create a CNN that attains greatly improved accuracy.
We mention that the task of assigning breed to dogs from images is considered exceptionally challenging. To see why, consider that *even a human* would have trouble distinguishing between a Brittany and a Welsh Springer Spaniel.
Brittany | Welsh Springer Spaniel
- | -
<img src="images/Brittany_02625.jpg" width="100"> | <img src="images/Welsh_springer_spaniel_08203.jpg" width="200">
It is not difficult to find other dog breed pairs with minimal inter-class variation (for instance, Curly-Coated Retrievers and American Water Spaniels).
Curly-Coated Retriever | American Water Spaniel
- | -
<img src="images/Curly-coated_retriever_03896.jpg" width="200"> | <img src="images/American_water_spaniel_00648.jpg" width="200">
Likewise, recall that labradors come in yellow, chocolate, and black. Your vision-based algorithm will have to conquer this high intra-class variation to determine how to classify all of these different shades as the same breed.
Yellow Labrador | Chocolate Labrador | Black Labrador
- | -
<img src="images/Labrador_retriever_06457.jpg" width="150"> | <img src="images/Labrador_retriever_06455.jpg" width="240"> | <img src="images/Labrador_retriever_06449.jpg" width="220">
We also mention that random chance presents an exceptionally low bar: setting aside the fact that the classes are slightly imabalanced, a random guess will provide a correct answer roughly 1 in 133 times, which corresponds to an accuracy of less than 1%.
Remember that the practice is far ahead of the theory in deep learning. Experiment with many different architectures, and trust your intuition. And, of course, have fun!
### (IMPLEMENTATION) Specify Data Loaders for the Dog Dataset
Use the code cell below to write three separate [data loaders](http://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) for the training, validation, and test datasets of dog images (located at `dog_images/train`, `dog_images/valid`, and `dog_images/test`, respectively). You may find [this documentation on custom datasets](http://pytorch.org/docs/stable/torchvision/datasets.html) to be a useful resource. If you are interested in augmenting your training and/or validation data, check out the wide variety of [transforms](http://pytorch.org/docs/stable/torchvision/transforms.html?highlight=transform)!
```
import os
from torchvision import datasets
### TODO: Write data loaders for training, validation, and test sets
## Specify appropriate transforms, and batch_sizes
# based on code discussed in lectures
import numpy as np
import torch
from torchvision import models, transforms
from torch.utils.data.sampler import SubsetRandomSampler
import matplotlib.pyplot as plt
# define dataloader parameters
batch_size = 20
num_workers = 0
# define training and test data directories
data_dir = '/data/dog_images/'
train_dir = os.path.join(data_dir, 'train')
valid_dir = os.path.join(data_dir, 'valid')
test_dir = os.path.join(data_dir, 'test')
# load and transform data using ImageFolder
data_transform = transforms.Compose([transforms.Resize(224),
transforms.CenterCrop(224),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_data = datasets.ImageFolder(train_dir, transform=data_transform)
valid_data = datasets.ImageFolder(valid_dir, transform=data_transform)
test_data = datasets.ImageFolder(test_dir, transform=data_transform)
## print out some data stats
print('Num training images: ', len(train_data))
print('Num validation images: ', len(valid_data))
print('Num test images: ', len(test_data))
# prepare data loaders
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_workers)
valid_loader = torch.utils.data.DataLoader(valid_data, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size, shuffle=True, num_workers=num_workers)
loaders_scratch = {'train': train_loader, 'valid': valid_loader, 'test': test_loader}
```
**Question 3:** Describe your chosen procedure for preprocessing the data.
- How does your code resize the images (by cropping, stretching, etc)? What size did you pick for the input tensor, and why?
- Did you decide to augment the dataset? If so, how (through translations, flips, rotations, etc)? If not, why not?
**Answer**:
I actually just resized and cropped them to 224 pixles and rotatet them randomly.
I also normalized the images, this has to be considered for printing the images and the later tests.
### (IMPLEMENTATION) Model Architecture
Create a CNN to classify dog breed. Use the template in the code cell below.
```
import torch.nn as nn
import torch.nn.functional as F
# define the CNN architecture
class Net(nn.Module):
### TODO: choose an architecture, and complete the class
def __init__(self):
super(Net, self).__init__()
## Define layers of a CNN
self.conv1 = nn.Conv2d(3, 32, 3, stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3,stride=2, padding=1)
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(128*7*7, 512)
self.fc2 = nn.Linear(512, 133)
self.dropout = nn.Dropout(0.3)
def forward(self, x):
## Define forward behavior
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 128 * 7 * 7)
x = self.dropout(x)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
#-#-# You so NOT have to modify the code below this line. #-#-#
# instantiate the CNN
model_scratch = Net()
# move tensors to GPU if CUDA is available
if use_cuda:
model_scratch.cuda()
```
__Question 4:__ Outline the steps you took to get to your final CNN architecture and your reasoning at each step.
__Answer:__
As a starting point I decided to use the network from the lectures and it turned out good enough.
To better understand the network I followed the provided guide: https://cs231n.github.io/convolutional-networks/#layers
The most common form of a ConvNet is:
* INPUT -> [[CONV -> RELU] N -> POOL?] M -> [FC -> RELU] * K -> FC
For the one used the paramters are the following:
* N=1 (N>=0 and N <=3)
* M=3 (M>= 0)
* K=1 (K>=0 and K<3)
So the final Network looks like this:
* INPUT -> [[CONV -> RELU] 1 -> POOL] 3 -> [FC -> RELU] * 1 -> FC
Additionally a dropout layer is used to prevent overfitting.
Of course the output of the final layer matches the classes, while the input matches the image size and color channels.
### (IMPLEMENTATION) Specify Loss Function and Optimizer
Use the next code cell to specify a [loss function](http://pytorch.org/docs/stable/nn.html#loss-functions) and [optimizer](http://pytorch.org/docs/stable/optim.html). Save the chosen loss function as `criterion_scratch`, and the optimizer as `optimizer_scratch` below.
```
import torch.optim as optim
### TODO: select loss function
criterion_scratch = nn.CrossEntropyLoss()
### TODO: select optimizer
optimizer_scratch = optim.SGD(model_scratch.parameters(), lr=0.05)
```
### (IMPLEMENTATION) Train and Validate the Model
Train and validate your model in the code cell below. [Save the final model parameters](http://pytorch.org/docs/master/notes/serialization.html) at filepath `'model_scratch.pt'`.
```
# workaround "OSError: image file is truncated"
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
def train(n_epochs, loaders, model, optimizer, criterion, use_cuda, save_path):
"""returns trained model"""
# initialize tracker for minimum validation loss
valid_loss_min = np.Inf
for epoch in range(1, n_epochs+1):
# initialize variables to monitor training and validation loss
train_loss = 0.0
valid_loss = 0.0
###################
# train the model #
###################
model.train()
for batch_idx, (data, target) in enumerate(loaders['train']):
# move to GPU
if use_cuda:
data, target = data.cuda(), target.cuda()
## find the loss and update the model parameters accordingly
## record the average training loss, using something like
## train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.data - train_loss))
# based on code discussed in lectures
optimizer.zero_grad() # clear the gradients of all optimized variables
output = model(data) # forward pass: compute predicted outputs by passing inputs to the model
loss = criterion(output, target) # calculate the batch loss
loss.backward() # backward pass: compute gradient of the loss with respect to model parameters
optimizer.step() # perform a single optimization step (parameter update)
train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.data - train_loss)) # update training loss
######################
# validate the model #
######################
model.eval()
for batch_idx, (data, target) in enumerate(loaders['valid']):
# move to GPU
if use_cuda:
data, target = data.cuda(), target.cuda()
## update the average validation loss
# based on code discussed in lectures
output = model(data) # forward pass: compute predicted outputs by passing inputs to the model
loss = criterion(output, target) # calculate the batch loss
valid_loss = valid_loss + ((1 / (batch_idx + 1)) * (loss.data - valid_loss)) # update average validation loss
# print training/validation statistics
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
epoch,
train_loss,
valid_loss
))
## TODO: save the model if validation loss has decreased
# based on code discussed in lectures
# save model if validation loss has decreased
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
valid_loss))
torch.save(model.state_dict(), save_path)
valid_loss_min = valid_loss
# return trained model
return model
# train the model
model_scratch = train(20, loaders_scratch, model_scratch, optimizer_scratch,
criterion_scratch, use_cuda, 'model_scratch.pt')
# load the model that got the best validation accuracy
model_scratch.load_state_dict(torch.load('model_scratch.pt'))
```
### (IMPLEMENTATION) Test the Model
Try out your model on the test dataset of dog images. Use the code cell below to calculate and print the test loss and accuracy. Ensure that your test accuracy is greater than 10%.
```
def test(loaders, model, criterion, use_cuda):
# monitor test loss and accuracy
test_loss = 0.
correct = 0.
total = 0.
model.eval()
for batch_idx, (data, target) in enumerate(loaders['test']):
# move to GPU
if use_cuda:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the loss
loss = criterion(output, target)
# update average test loss
test_loss = test_loss + ((1 / (batch_idx + 1)) * (loss.data - test_loss))
# convert output probabilities to predicted class
pred = output.data.max(1, keepdim=True)[1]
# compare predictions to true label
correct += np.sum(np.squeeze(pred.eq(target.data.view_as(pred))).cpu().numpy())
total += data.size(0)
print('Test Loss: {:.6f}\n'.format(test_loss))
print('\nTest Accuracy: %2d%% (%2d/%2d)' % (
100. * correct / total, correct, total))
# call test function
test(loaders_scratch, model_scratch, criterion_scratch, use_cuda)
```
---
<a id='step4'></a>
## Step 4: Create a CNN to Classify Dog Breeds (using Transfer Learning)
You will now use transfer learning to create a CNN that can identify dog breed from images. Your CNN must attain at least 60% accuracy on the test set.
### (IMPLEMENTATION) Specify Data Loaders for the Dog Dataset
Use the code cell below to write three separate [data loaders](http://pytorch.org/docs/master/data.html#torch.utils.data.DataLoader) for the training, validation, and test datasets of dog images (located at `dogImages/train`, `dogImages/valid`, and `dogImages/test`, respectively).
If you like, **you are welcome to use the same data loaders from the previous step**, when you created a CNN from scratch.
```
## TODO: Specify data loaders
loaders_transfer = loaders_scratch.copy()
```
### (IMPLEMENTATION) Model Architecture
Use transfer learning to create a CNN to classify dog breed. Use the code cell below, and save your initialized model as the variable `model_transfer`.
```
import torchvision.models as models
import torch.nn as nn
## TODO: Specify model architecture
model_transfer = models.resnet50(pretrained=True)
# freeze training for all "features" layers
for param in model_transfer.parameters():
param.requires_grad = False
# modify last layer to match it our classes
model_transfer.fc = nn.Linear(2048, 133, bias=True)
fc_parameters = model_transfer.fc.parameters()
for param in fc_parameters:
param.requires_grad = True
if use_cuda:
model_transfer = model_transfer.cuda()
```
__Question 5:__ Outline the steps you took to get to your final CNN architecture and your reasoning at each step. Describe why you think the architecture is suitable for the current problem.
__Answer:__
I decided to use the pretrained resnet5ß network as shown in the lectures.
In a first step I froze the features paramters as we dont want to change the net itself. We only want to optimice the classifier to match our classes. This is important for the optimizer too.
The last layer of the network is modified. We want to keep the number of inputs, but want the output to match our classes
Again to better understand the network I followed the provided guide: https://cs231n.github.io/convolutional-networks/#layers
### (IMPLEMENTATION) Specify Loss Function and Optimizer
Use the next code cell to specify a [loss function](http://pytorch.org/docs/master/nn.html#loss-functions) and [optimizer](http://pytorch.org/docs/master/optim.html). Save the chosen loss function as `criterion_transfer`, and the optimizer as `optimizer_transfer` below.
```
criterion_transfer = nn.CrossEntropyLoss()
optimizer_transfer = optim.Adam(model_transfer.fc.parameters(), lr=0.01)
```
### (IMPLEMENTATION) Train and Validate the Model
Train and validate your model in the code cell below. [Save the final model parameters](http://pytorch.org/docs/master/notes/serialization.html) at filepath `'model_transfer.pt'`.
```
# train the model
model_transfer = train(5, loaders_transfer, model_transfer, optimizer_transfer, criterion_transfer, use_cuda, 'model_transfer.pt')
# load the model that got the best validation accuracy (uncomment the line below)
model_transfer.load_state_dict(torch.load('model_transfer.pt'))
```
### (IMPLEMENTATION) Test the Model
Try out your model on the test dataset of dog images. Use the code cell below to calculate and print the test loss and accuracy. Ensure that your test accuracy is greater than 60%.
```
test(loaders_transfer, model_transfer, criterion_transfer, use_cuda)
```
### (IMPLEMENTATION) Predict Dog Breed with the Model
Write a function that takes an image path as input and returns the dog breed (`Affenpinscher`, `Afghan hound`, etc) that is predicted by your model.
```
### TODO: Write a function that takes a path to an image as input
### and returns the dog breed that is predicted by the model.
# list of class names by index, i.e. a name can be accessed like class_names[0]
class_names = [item[4:].replace("_", " ").title() for item in train_data.classes]
#dog_names = [item[35:-1] for item in sorted(glob("../../../data/dog_images/train/*/"))]
def predict_breed_transfer(img_path):
# extract bottleneck features
image_tensor = path_to_tensor(img_path)
if use_cuda:
image_tensor = image_tensor.cuda()
# obtain predicted vector
prediction = model_transfer(image_tensor)
# return dog breed that is predicted by the model
prediction = prediction.cpu()
prediction = prediction.data.numpy().argmax()
return class_names[prediction]
```
---
<a id='step5'></a>
## Step 5: Write your Algorithm
Write an algorithm that accepts a file path to an image and first determines whether the image contains a human, dog, or neither. Then,
- if a __dog__ is detected in the image, return the predicted breed.
- if a __human__ is detected in the image, return the resembling dog breed.
- if __neither__ is detected in the image, provide output that indicates an error.
You are welcome to write your own functions for detecting humans and dogs in images, but feel free to use the `face_detector` and `human_detector` functions developed above. You are __required__ to use your CNN from Step 4 to predict dog breed.
Some sample output for our algorithm is provided below, but feel free to design your own user experience!

### (IMPLEMENTATION) Write your Algorithm
```
### TODO: Write your algorithm.
### Feel free to use as many code cells as needed.
def run_app(img_path):
## handle cases for a human face, dog, and neither
img = Image.open(img_path)
plt.imshow(img)
plt.axis('off')
plt.show()
if dog_detector(img_path) > 0:
prediction = predict_breed_transfer(img_path)
print("This is a {0}".format(prediction))
elif face_detector(img_path) > 0:
prediction = predict_breed_transfer(img_path)
print("This photo looks like a {0}".format(prediction))
else:
print("Error")
```
---
<a id='step6'></a>
## Step 6: Test Your Algorithm
In this section, you will take your new algorithm for a spin! What kind of dog does the algorithm think that _you_ look like? If you have a dog, does it predict your dog's breed accurately? If you have a cat, does it mistakenly think that your cat is a dog?
### (IMPLEMENTATION) Test Your Algorithm on Sample Images!
Test your algorithm at least six images on your computer. Feel free to use any images you like. Use at least two human and two dog images.
__Question 6:__ Is the output better than you expected :) ? Or worse :( ? Provide at least three possible points of improvement for your algorithm.
__Answer:__
I am really impressed by the result!
Possible steps for improvement I can think of:
* More Training, maybe even with different optimizer
* Using more Images for training
* Resizing and only using fractions of the original images
```
## TODO: Execute your algorithm from Step 6 on
## at least 6 images on your computer.
## Feel free to use as many code cells as needed.
import os
for filename in os.listdir('samples'):
if filename.endswith('.jpg'):
run_app(os.path.join("samples", filename))
```
| github_jupyter |
# Simulate the Tree
This notebook simulates a phylogenetic tree under the dual-birth model [(Moshiri & Mirarab, 2017)](https://doi.org/10.1093/sysbio/syx088) and performs some basic analyses of the tree.
---
**Rule 2: Document Process, Not Just Results.** Here we describe the steps how to produce the dataset.
**Rule 3: Build a Pipeline.** This notebook describes the entire workflow, and its modularity makes it easy to change models or model parameters.
**Rule 7: Share and Explain Your Data.** To enable reproducibility we provide a `/intermediate_data` directory with files produced by the workflow.
---
## Define Tree Simulation Parameters
The dual-birth model is parameterized by two rates: the "birth rate" $\left(\lambda_b\right)$ and the "activation rate" $\left(\lambda_a\right)$, where $\lambda_a\le\lambda_b$. We will start by choosing our desired values for these two rates. For our purposes, we will choose the rate estimates for *Alu* elements as found in the original manuscript [(Moshiri & Mirarab, 2017)](https://doi.org/10.1093/sysbio/syx088).
Our tree simulations also require an end criterion: either a tree height or a number of leaves. We will specify that we want trees with *n* = 100 leaves.
We will also include import statements here to keep the notebook clean and organized.
```
OUTPUT_TREE_FILE = "./intermediate_data/dualbirth.tre"
BIRTH_RATE = 122.03
ACTIVATION_RATE = 0.73
NUM_LEAVES = 100
import matplotlib.pyplot as plt
from seaborn import distplot
from treesap import dualbirth_tree
```
## Simulate the Tree
We can now use [TreeSAP](https://github.com/niemasd/TreeSAP) to simulate the tree, which will return a [TreeSwift](https://github.com/niemasd/TreeSwift) `Tree` object.
```
tree = dualbirth_tree(Lb=BIRTH_RATE, La=ACTIVATION_RATE, end_num_leaves=NUM_LEAVES)
```
## Explore the Tree
Now that we've simulated our tree, we can begin to explore its properties and statistics. For example, consider the following questions:
* How many lineages exist at any given "time" (where "time" is measured in unit of "expected number of per-site mutations")?
* What is the branch length distribution? What about just internal branches? What about just terminal branches?
* What is the height? Diameter?
* What is the average branch length? Internal branch length? Terminal branch length?
* What is the Colless balance index? Sackin balance index? Gamma statistic? Treeness?
```
tree.ltt(); plt.show()
branch_lengths = dict()
branch_lengths['all'] = list(tree.branch_lengths())
branch_lengths['internal'] = list(tree.branch_lengths(terminal=False))
branch_lengths['terminal'] = list(tree.branch_lengths(internal=False))
colors = {'all':'blue', 'internal':'red', 'terminal':'green'}
for k in sorted(branch_lengths.keys()):
distplot(branch_lengths[k], kde=True, hist=False, color=colors[k], label=k.capitalize());
plt.title("Branch Length Distributions");
plt.xlabel("Branch Length");
plt.ylabel("Kernel Density Estimate");
print("Average Branch Length: %f" % tree.avg_branch_length())
print("Average Internal Branch Length: %f" % tree.avg_branch_length(terminal=False))
print("Average Termianl Branch Length: %f" % tree.avg_branch_length(internal=False))
print("Height: %f" % tree.height())
print("Diameter: %f" % tree.diameter())
print("Colless Balance Index: %f" % tree.colless())
print("Sackin Balance Index: %f" % tree.sackin())
print("Gamma Statistic: %f" % tree.gamma_statistic())
print("Treeness: %f" % tree.treeness())
```
## Save Dataset
Now that we have finished exploring our tree, we can save it in the Newick format. The tool that we wish to use next doesn't support the "rooted" prefix of the Newick format (`[&R]`), so we need to specify to TreeSwift that we wish to omit the "rooted" prefix.
```
tree.write_tree_newick(OUTPUT_TREE_FILE, hide_rooted_prefix=True)
```
## Next step
After you saved the dataset here, run the next step in the workflow [2-SimulateSequences.ipynb](./2-SimulateSequences.ipynb) or go back to [0-Workflow.ipynb](./0-Workflow.ipynb).
---
**Author:** [Niema Moshiri](https://niema.net/), UC San Diego, October 2, 2018
---
| github_jupyter |
# In Class Project
### Question 1
```
#Reading the data set
import pandas as pd
train=pd.read_csv('Tweets-train.csv')
#Selecting only sentiment and tweet column from the entire data set
train=train[['airline_sentiment','text']]
```
### Question 2
```
#See some positive sentiments
for each in train[train['airline_sentiment']=="positive"].sample(10,random_state=10)['text']:
print each
print
#See some negative sentiments
for each in train[train['airline_sentiment']=="negative"].sample(10,random_state=10)['text']:
print each
print
#See some neutral sentiments
for each in train[train['airline_sentiment']=="neutral"].sample(10,random_state=10)['text']:
print each
print
```
## What are the observations ?
#### 1. Data contains words starting with '@'
#### 2. Data contains words having '#'
#### 3. Data contains links 'https:...."
#### 4. Data contains emoticons and punctuations such as ' , . ; ❤️✨ ! etc etc
```
#@ mentions
import re
print train.text[5]
print
print re.sub(r'@+','',train.text[5])
#Links
print train.text[10]
print
print re.sub('http?://[A-Za-z0-9./]+','',train.text[10])
# selects only aplhabets numbers so that punctuations and emoticons are removed.
print train.text[22]
print
print re.sub("[^a-zA-Z0-9]", " ",train.text[22])
print
print
print train.text[5977]
print
print re.sub("[^a-zA-Z0-9]", " ",train.text[5977])
```
### Question 3
```
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
def tweet_cleaner(text):
text=re.sub(r'@+','',text)
text=re.sub('http?://[A-Za-z0-9./]+','',text)
text=re.sub("[^a-zA-Z]", " ",text)
lower_case = text.lower()
words = tokenizer.tokenize(lower_case)
return (" ".join(words)).strip()
train['Cleaned-Text']=map(lambda x:tweet_cleaner(x),train['text'])
train.head(4)
```
### Question 4
```
#See some words in All sentiments
from collections import Counter
for group_name,subset in train.groupby('airline_sentiment'):
sentimentData=subset['Cleaned-Text']
words=[]
for each in sentimentData:
words.extend(each.split(" "))
print group_name
print Counter(words).most_common(15)
print
```
### Question 5
```
from PreProcess import RemoveStopWords #created in previous exercises
train['Clean-Text-StopWords-Removed']=map(lambda x:RemoveStopWords(x),train['Cleaned-Text'])
#Again let's see the counts of most common words after removing stopwords.
from collections import Counter
for group_name,subset in train.groupby('airline_sentiment'):
sentimentData=subset['Clean-Text-StopWords-Removed']
words=[]
for each in sentimentData:
words.extend(each.split(" "))
print group_name
print Counter(words).most_common(15)
print
```
### Question 6
```
def RemoveExplicitlyMentionedWords(string,listofWordsToRemove):
listOfAllWords=string.split(" ")
listOfWords= [x for x in listOfAllWords if x not in listofWordsToRemove]
return (" ".join(listOfWords)).strip()
list_of_words_to_remove=['americanair','united','delta','southwestair','jetblue','virginamerica','usairways','flight','plane']
train['Final-Wrangled-Text']=map(lambda x:RemoveExplicitlyMentionedWords(x,list_of_words_to_remove),train['Clean-Text-StopWords-Removed'])
#Count Again words in All sentiments
from collections import Counter
for group_name,subset in train.groupby('airline_sentiment'):
sentimentData=subset['Final-Wrangled-Text']
words=[]
for each in sentimentData:
words.extend(each.split(" "))
print group_name
print Counter(words).most_common(15)
print
```
### Question 7
```
from sklearn.preprocessing import LabelEncoder
l=LabelEncoder()
train['SentimentLabel']=l.fit_transform(train['airline_sentiment'])
train.head(4)
```
### Question 8
```
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
x_train=vectorizer.fit_transform(train['Final-Wrangled-Text'])
```
### Question 9
```
y_train=train['SentimentLabel']
```
Preparing Model Using Naive Bayes classifier
```
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
nb = MultinomialNB()
nb.fit(x_train,y_train)
```
### Question 10
```
test=pd.read_csv('Tweets-test.csv')
test=test[['airline_sentiment','text']]
test['Cleaned-Text']=map(lambda x:tweet_cleaner(x),test['text'])
test['Clean-Text-StopWords-Removed']=map(lambda x:RemoveStopWords(x),test['Cleaned-Text'])
test['Final-Wrangled-Text']=map(lambda x:RemoveExplicitlyMentionedWords(x,list_of_words_to_remove),test['Clean-Text-StopWords-Removed'])
x_test=vectorizer.transform(test['Final-Wrangled-Text'])
#Encoding label for test data as well
test['SentimentLabel']=l.transform(test['airline_sentiment'])
y_test=test['SentimentLabel']
```
### Question 11
```
y_pred=nb.predict(x_test)
def GetOrignalSentiment(val):
if val==0:
return 'negative'
elif val==1:
return 'neutral'
else:
return 'positive'
Result=test[['text','airline_sentiment']]
Result['Predicted_sentiment']=map(lambda x:GetOrignalSentiment(x),y_pred)
Result.head(3)
```
### Question 12
```
print "Confusion Matrix:\n\n",metrics.confusion_matrix(Result['airline_sentiment'],Result['Predicted_sentiment'],labels=['negative','neutral','positive'])
#Explaning Confusion Matrix Elements
for i,x in Result.groupby(['airline_sentiment','Predicted_sentiment']):
print "Actual "+ i[0]+ " Predicted "+i[1]+ ":", len(x)
```
### Question 13
```
#Accuracy :
ActualNegativePrdictedNegative=2396
ActualNeutralPrdictedNeutral=333
ActualPositivePrdictedPositive=365
TotalCorrect=ActualNegativePrdictedNegative+ActualNeutralPrdictedNeutral+ActualPositivePrdictedPositive
print "Accuracy=",TotalCorrect*100.0/len(test) ,"%"
```
| github_jupyter |
# `Reaqtor.IoT`
Notebook equivalent of the Playground console application.
## Reference the library
We'll just import the entire console application to get the transitive closure of referenced assemblies.
```
#r "bin/Debug/net50/Reaqtor.IoT.dll"
```
## (Optional) Attach a debugger
If you'd like to step through the source code of the library while running samples, run the following cell, and follow instructions to start a debugger (e.g. Visual Studio). Navigate to the source code of the library to set breakpoints.
```
System.Diagnostics.Debugger.Launch();
```
## Import some namespaces
```
using System;
using System.Linq;
using System.Linq.CompilerServices.TypeSystem;
using System.Linq.Expressions;
using System.Threading;
using System.Threading.Tasks;
using Nuqleon.DataModel;
using Reaqtive;
using Reaqtive.Scheduler;
using Reaqtor;
using Reaqtor.IoT;
```
## Configure environment
**Query engines** host reactive artifacts, e.g. subscriptions, which can be stateful.
Query engines are a failover unit. State for all artifacts is persisted via checkpointing.
Query engines depend on services from the environment:
* A **scheduler** to process events on:
* There's one physical scheduler per host. Think of it as a thread pool.
* Each engine has a logical scheduler. Think of it as a collection of tasks. The engine suspends/resumes all work for checkpoint/recovery.
* A **key/value store** for state persistence, including:
* A transaction log of create/delete operations for reactive artifacts.
* Periodic checkpoint state, which includes:
* State of reactive artifacts (e.g. sum and count for an Average operator).
* Watermarks for ingress streams, enabling replay of events upon failover.
This sample also parameterizes query engines on an ingress/egress manager to receive/send events across the engine/environment boundary.
To run query engines in the notebook, we write a simple `WithEngine` helper. This part takes care of setting up the engine and creating the environment. The general lifecycle of an engine is as follows.
* Instantiate the object, passing the environment services.
* Recover the engine's state from the key/value store.
* Use the engine (through the `action` callback in the helper).
* Checkpoint the engine's state. This is typically done periodically, e.g. once per minute. The interval is a tradeoff between:
* I/O frequency versus I/O size, e.g. due to state growth as events get processed.
* Replay capacity for ingress events and duration of replay, e.g. having to replay up to 1 minute worth of events from a source.
* Unloading the engine. This is optional but useful for graceful shutdown. In the Reactor service this is used when a primary moves to another node in the cluster. It allows reactive artifacts to unload resources (e.g. connections).
```
var store = new InMemoryKeyValueStore();
var iemgr = new IngressEgressManager();
async Task WithEngine(Func<MiniQueryEngine, Task> action)
{
using var ps = PhysicalScheduler.Create();
using var scheduler = new LogicalScheduler(ps);
using var engine = new MiniQueryEngine(new Uri("iot://reactor/1"), scheduler, store, iemgr);
using (var reader = store.GetReader())
await engine.RecoverAsync(reader);
await action(engine);
using (var writer = store.GetWriter())
await engine.CheckpointAsync(writer);
await engine.UnloadAsync();
}
```
## Define artifacts
Illustrates populating the registry of defined artifacts in the engine. This is a one-time step for the environment creating a new engine.
* Artifact types that are defined include:
* Observables, e.g. sources of events, or query operators.
* Observers, e.g. sinks for events, or event handlers.
* Stream factories, not shown here. Useful for creation of "subjects" local to the engine.
* Subscription factories, not shown here. Useful for "templates" to create subscriptions with parameters.
* All Reactor artifacts use URIs for naming purposes.
The key take-away is that Reactor engines are empty by default and have no built-in artifacts whatsoever. The environment controls the registry, which includes standard query operators, specialized query operators, etc.
> **Note:** There's an alternative approach to having artifacts defined in and persisted by individual engine instances. The engine can also be parameterized on a queryable external catalog. This is useful for homogeneous environments.
```
await WithEngine(async engine =>
{
var ctx = new ReactorContext(engine);
await ctx.DefineObserverAsync(new Uri("iot://reactor/observers/cout"), ctx.Provider.CreateQbserver<T>(Expression.New(typeof(ConsoleObserver<T>))), null, CancellationToken.None);
await ctx.DefineObservableAsync<TimeSpan, DateTimeOffset>(new Uri("iot://reactor/observables/timer"), t => new TimerObservable(t).AsAsyncQbservable(), null, CancellationToken.None);
});
```
## Define query operators
Illustration of defining query operators, similar to defining other artifacts higher up. A few remarks:
- No operators are built-in. Below, we define essential operators like `Where`, `Select`, and `Take`. The URI for these is not even prescribed; the environment picks those.
- Implementations of the operators are provided in `Reaqtive`, similar to `System.Reactive` for classic Rx. The difference is mainly due to support for state persistence, which classic Rx lacks.
- Custom operators are as first-class as "standard query operators". That is, the query engine does not have an opinion about the operator surface provided.
Some ugly technicalities show up below, but those are entirely irrelevant to the user experience. The code below is part of the one-time setup provided by the environment. In particular:
- Define operations are done through `IReactiveProxy`, but could also be done straight on the engine (though it brings some additional complexity when doing so).
- There's some conversion friction to build expressions that fit through a "queryable" expression-tree based API but eventually bind to types in Reaqtive. That's all the As* stuff below.
```
await WithEngine(async engine =>
{
var ctx = new ReactorContext(engine);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, Func<T, bool>, T>(new Uri("iot://reactor/observables/filter"), (source, predicate) => source.AsSubscribable().Where(predicate).AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, Func<T, int, bool>, T>(new Uri("iot://reactor/observables/filter/indexed"), (source, predicate) => source.AsSubscribable().Where(predicate).AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, Func<T, R>, R>(new Uri("iot://reactor/observables/map"), (source, selector) => source.AsSubscribable().Select(selector).AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, Func<T, int, R>, R>(new Uri("iot://reactor/observables/map/indexed"), (source, selector) => source.AsSubscribable().Select(selector).AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, int, T>(new Uri("iot://reactor/observables/take"), (source, count) => source.AsSubscribable().Take(count).AsAsyncQbservable(), null, CancellationToken.None);
});
```
## Ingress and egress
Illustration of defining ingress/egress proxies as observable/observer artifacts.
Also see the implementation of `IngressObservable<T>` and `EgressObserver<T>`, which use the ingress/egress manager to connect to the outside world. The essence is this:
- To the query running inside the engine, these look like ordinary Rx artifacts implemented using interfaces base classes provided by Reactor:
- `ISubscribable<T>` rather than `IObservable<T>`, to support the richer lifecycle of artifacts in Reactor compared to Rx.
- `Load`/`Save` state operations for checkpointing.
- The external world communicates with the engine using a variant of the observable/observer interfaces, namely `IReliable*<T>`:
- Events received and produced have sequence numbers.
- Subscription handles to receive events from the outside world have additional operations:
- `Start(long)` to replay events from the given sequence number.
- `AcknowledgeRange(long)` to allow the external service to (optionally) prune events that are no longer needed by the engine.
- Proxies in the engine use the sequence number to provide reliability:
- `Save` persists the latest received sequence number. `Load` gets it back.
- Upon restart of an ingress proxy, the restored sequence number is used to ask for replay of events.
- Upon a successful checkpoint, the latest received sequence number is acknowledged to the source (allowing pruning).
The Reactor service implements such ingress/egress mechanisms using services like EventHub.
```
await WithEngine(async engine =>
{
var ctx = new ReactorContext(engine);
await ctx.DefineObserverAsync<string, T>(new Uri("iot://reactor/observers/egress"), stream => new EgressObserver<T>(stream).AsAsyncQbserver(), null, CancellationToken.None);
await ctx.DefineObservableAsync<string, T>(new Uri("iot://reactor/observables/ingress"), stream => new IngressObservable<T>(stream).AsAsyncQbservable(), null, CancellationToken.None);
});
```
## Define more query operators
Illustrates the definition of higher-order operators such as SelectMany and GroupBy which operate on sequences of sequences (IObservable<IObservable<T>>) which is one of the most powerful aspects of Rx.
```
await WithEngine(async engine =>
{
var ctx = new ReactorContext(engine);
// Average
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<int>, double>(new Uri("iot://reactor/observables/average/int32"), source => source.AsSubscribable().Average().AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<long>, double>(new Uri("iot://reactor/observables/average/int64"), source => source.AsSubscribable().Average().AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<double>, double>(new Uri("iot://reactor/observables/average/double"), source => source.AsSubscribable().Average().AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, Func<T, int>, double>(new Uri("iot://reactor/observables/average/selector/int32"), (source, selector) => source.AsSubscribable().Average(selector).AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, Func<T, long>, double>(new Uri("iot://reactor/observables/average/selector/int64"), (source, selector) => source.AsSubscribable().Average(selector).AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, Func<T, double>, double>(new Uri("iot://reactor/observables/average/selector/double"), (source, selector) => source.AsSubscribable().Average(selector).AsAsyncQbservable(), null, CancellationToken.None);
// DistinctUntilChanged
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, T>(new Uri("iot://reactor/observables/distinct"), source => source.AsSubscribable().DistinctUntilChanged().AsAsyncQbservable(), null, CancellationToken.None);
// SelectMany
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, Func<T, ISubscribable<R>>, R>(new Uri("iot://reactor/observables/bind"), (source, selector) => source.AsSubscribable().SelectMany(selector).AsAsyncQbservable(), null, CancellationToken.None);
// Window
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, TimeSpan, ISubscribable<T>>(new Uri("iot://reactor/observables/window/hopping/time"), (source, duration) => source.AsSubscribable().Window(duration).AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, int, ISubscribable<T>>(new Uri("iot://reactor/observables/window/hopping/count"), (source, count) => source.AsSubscribable().Window(count).AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, TimeSpan, TimeSpan, ISubscribable<T>>(new Uri("iot://reactor/observables/window/sliding/time"), (source, duration, shift) => source.AsSubscribable().Window(duration, shift).AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, int, int, ISubscribable<T>>(new Uri("iot://reactor/observables/window/sliding/count"), (source, count, skip) => source.AsSubscribable().Window(count, skip).AsAsyncQbservable(), null, CancellationToken.None);
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, TimeSpan, int, ISubscribable<T>>(new Uri("iot://reactor/observables/window/ferry"), (source, duration, count) => source.AsSubscribable().Window(duration, count).AsAsyncQbservable(), null, CancellationToken.None);
// GroupBy
await ctx.DefineObservableAsync<IAsyncReactiveQbservable<T>, Func<T, R>, IGroupedSubscribable<R, T>>(new Uri("iot://reactor/observables/group"), (source, selector) => source.AsSubscribable().GroupBy(selector).AsAsyncQbservable(), null, CancellationToken.None);
});
```
## Entity types
Reactor Core is built to be flexible with regards to data models, but the default data model that's well-supported originates from a graph database effort in Bing that predates Reactor. The `[Mapping]` attributes below are the means to annotate properties. These property names are used to normalize entity types in the serialized expression representation, so the query is not dependent on a concrete type in an assembly, thus allowing the structure of data types (here to represent events) to be serialized across machine boundaries without deployment of binaries.
```
public class SensorReading
{
[Mapping("iot://sensor/reading/room")]
public string Room { get; set; }
[Mapping("iot://sensor/reading/temperature")]
public double Temperature { get; set; }
}
```
## A temperature simulator
Add other streams to connect to the environment, simulating a temperature sensor reading and a feedback channel to control an A/C unit.
```
var readings = iemgr.CreateSubject<SensorReading>("bart://sensors/home/livingroom/temperature/readings");
var settings = iemgr.CreateSubject<double?>("bart://sensors/home/livingroom/temperature/settings");
```
Next, we define a few constants for the simulation.
```
var rand = new Random();
//
// Speed and granularity of simulation.
//
var timeStep = TimeSpan.FromMinutes(15);
var simulationDelay = TimeSpan.FromMilliseconds(250);
//
// Absolute value of temperature gain/loss per unit time of the house adjusting to the outside temperature.
//
var insulationTemperatureIncrement = 0.1;
//
// Absolute value of temperature gain/loss per unit time due to the A/C unit cooling down or heating up.
//
var acTemperatureIncrement = 0.2;
//
// Temperature sensitivity of the thermostat to trigger turning off the A/C unit, i.e. within this range from target.
//
var thermostatSensitivity = 0.5;
//
// Configuration of simulation: minimum and maximum temperature outside, and coldest time of day.
//
var outsideMin = 55;
var outsideMax = 85;
var coldestTime = new TimeSpan(5, 0, 0); // 5AM
//
// Scale for the temperature range, to multiply [0..1] by to obtain a temperature value that can be added to the minimum.
//
var scale = outsideMax - outsideMin;
//
// Offset to the midpoint of the temperature range. Outside temperature will vary as a sine wave around this value.
//
var offset = outsideMin + scale / 2;
#pragma warning disable CA5394 // Do not use insecure randomness. (Okay for simulation purposes.)
//
// Random initial value inside, within the range of temperatures.
//
var inside = outsideMin + rand.NextDouble() * scale;
#pragma warning restore CA5394
//
// null if A/C unit is off; otherwise, target temperature.
//
var target = default(double?);
//
// Clock driven by the simulation.
//
var time = DateTime.Today;
interactive.registerCommandHandler({commandType: 'SmartHomeCommand', handle: c => {
let visualisation = window.frames.visualisation;
if (visualisation)
{
visualisation.postMessage(c.command, '*');
}
}});
using Microsoft.DotNet.Interactive;
using Microsoft.DotNet.Interactive.Commands;
public class SmartHomeCommand : KernelCommand
{
public SmartHomeCommand(): base("javascript") {}
public DateTime? Timestamp {get; set; }
public Thermostat Thermostat {get; set; }
public Temperature Temperature {get; set; }
public ReaqtorStatus Reaqtor {get; set; }
}
public class Temperature
{
public double Inside {get; set; }
public double Outside {get; set; }
}
public class Thermostat
{
public string State {get; set; }
public string Mode {get; set; }
}
public class ReaqtorStatus
{
public ReaqtorState State {get; set; } = ReaqtorState.Off;
}
public enum ReaqtorState
{
Off = 0,
Starting = 1,
Crashing = 2,
FailingOver = 3,
Recovered = 4,
ShuttingDownGracefully = 5,
CreatingSubscription = 6,
DisposingSubscription = 7,
Running = 8,
}
var jsKernel = Kernel.Root.FindKernel("javascript");
jsKernel.RegisterCommandType<SmartHomeCommand>();
```
Now we can write a simulator routine that will generate `reading`, and set up a subscription to the `settings` stream to show the results emitted by the Reaqtor query we'll construct later.
```
IDisposable SubscribeToSettingsStream()
{
//
// Print commands arriving at thermostat.
//
return settings.Subscribe(Observer.Create<(long sequenceId, double? item)>(s =>
{
target = s.item;
Console.WriteLine($"STSS: {time} thermostat> {(target == null ? "OFF" : "ON " + (target > inside ? "heating" : "cooling") + " to " + target)}");
var task = jsKernel.SendAsync(
new SmartHomeCommand
{
Timestamp = time,
Thermostat = new Thermostat
{
State = (target == null ? "OFF" : "ON"),
Mode = (target > inside ? "heating" : "cooling")
}
});
}));
}
Task RunReadingsGenerator(CancellationToken token)
{
//
// Run simulation which adjusts both inside and outside temperature.
//
return Task.Run(async () =>
{
while (!token.IsCancellationRequested)
{
var now = (time.TimeOfDay - coldestTime - TimeSpan.FromHours(6)).TotalSeconds;
var secondsPerDay = TimeSpan.FromHours(24).TotalSeconds;
var outside = scale * Math.Sin(2 * Math.PI * now / secondsPerDay) / 2 + offset;
var environmentEffect = outside < inside ? -insulationTemperatureIncrement : insulationTemperatureIncrement;
var acUnitEffect = target != null ? (target < inside ? -acTemperatureIncrement : acTemperatureIncrement) : 0.0;
inside += environmentEffect + acUnitEffect;
if (target != null && Math.Abs(target.Value - inside) < thermostatSensitivity)
{
target = null;
}
await jsKernel.SendAsync(
new SmartHomeCommand
{
Timestamp = time,
Temperature = new Temperature
{
Inside = inside,
Outside = outside
}
});
// Console.WriteLine($"RRG: {time} temperature> inside = {inside} outside = {outside} target = {target}");
readings.OnNext((Environment.TickCount, new SensorReading { Room = "Hallway", Temperature = inside }));
await Task.Delay(simulationDelay);
time += timeStep;
}
});
}
<!DOCTYPE html>
<html>
<head>
<title></title>
<meta charset="utf-8" />
</head>
<body>
<iframe name="visualisation" src="https://reaqtor-house.netlify.app/?auto=false" width="100%" height="500"></iframe>
</body>
</html>
```
In the next cell, we'll write a higher-order query using `Window` and `SelectMany`, and run the simulator and logger while the query is running.
```
var stopEventProducer = new CancellationTokenSource();
Console.WriteLine("Starting simulator for temperature sensor readings...");
var logger = SubscribeToSettingsStream();
var producer = RunReadingsGenerator(stopEventProducer.Token);
var subUri = new Uri("iot://reactor/subscription/BD/livingroom/comfy");
Console.WriteLine("Setting up query engine...");
await jsKernel.SendAsync(new SmartHomeCommand { Reaqtor = new ReaqtorStatus { State = ReaqtorState.Starting }});
await WithEngine(async engine =>
{
var ctx = new ReactorContext(engine);
var input = ctx.GetObservable<string, SensorReading>(new Uri("iot://reactor/observables/ingress"));
var output = ctx.GetObserver<string, double?>(new Uri("iot://reactor/observers/egress"));
var readings = input("bart://sensors/home/livingroom/temperature/readings");
var settings = output("bart://sensors/home/livingroom/temperature/settings");
Console.WriteLine("Creating subscription...");
await jsKernel.SendAsync(new SmartHomeCommand { Reaqtor = new ReaqtorStatus { State = ReaqtorState.CreatingSubscription }});
await readings.Window(4).SelectMany(w => w.Average(r => r.Temperature)).Select(t => t < 70 || t > 80 ? 75 : default(double?)).DistinctUntilChanged().SubscribeAsync(settings, subUri, null, CancellationToken.None);
await jsKernel.SendAsync(new SmartHomeCommand { Reaqtor = new ReaqtorStatus { State = ReaqtorState.Running }});
// Run for a bit.
await Task.Delay(TimeSpan.FromSeconds(30));
await jsKernel.SendAsync(new SmartHomeCommand { Reaqtor = new ReaqtorStatus { State = ReaqtorState.FailingOver }});
Console.WriteLine("Engine failing over... Note we'll continue to see the producer's `temperature>` traces, but no `thermostat>` outputs.");
});
await Task.Delay(TimeSpan.FromSeconds(2));
await WithEngine(async engine =>
{
await jsKernel.SendAsync(new SmartHomeCommand { Reaqtor = new ReaqtorStatus { State = ReaqtorState.Recovered }});
Console.WriteLine("Engine recovered!");
var ctx = new ReactorContext(engine);
await jsKernel.SendAsync(new SmartHomeCommand { Reaqtor = new ReaqtorStatus { State = ReaqtorState.Running }});
// Run for a bit more.
await Task.Delay(TimeSpan.FromSeconds(30));
await jsKernel.SendAsync(new SmartHomeCommand { Reaqtor = new ReaqtorStatus { State = ReaqtorState.DisposingSubscription }});
Console.WriteLine("Disposing subscription...");
await ctx.GetSubscription(subUri).DisposeAsync();
});
await jsKernel.SendAsync(new SmartHomeCommand { Reaqtor = new ReaqtorStatus { State = ReaqtorState.ShuttingDownGracefully }});
Console.WriteLine("Stopping simulator...");
stopEventProducer.Cancel();
producer.Wait();
logger.Dispose();
await jsKernel.SendAsync(new SmartHomeCommand { Reaqtor = new ReaqtorStatus { State = ReaqtorState.Off }});
Console.WriteLine("Done!");
```
| github_jupyter |
# Simple ElasticNet
**This Code template is for Regression tasks using a ElasticNet based on the Regression linear model Technique.**
### Required Packages
```
import warnings as wr
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
from sklearn.metrics import mean_squared_error, r2_score,mean_absolute_error
wr.filterwarnings('ignore')
```
### Initialization
Filepath of CSV file
```
#filepath
file_path= ""
```
List of features which are required for model training .
```
#x_values
features=[]
```
Target feature for prediction.
```
#y_value
target=''
```
### Data Fetching
Pandas is an open-source, BSD-licensed library providing high-performance, easy-to-use data manipulation and data analysis tools.
We will use panda's library to read the CSV file using its storage path.And we use the head function to display the initial row or entry.
```
df=pd.read_csv(file_path) #reading file
df.head()#displaying initial entries
print('Number of rows are :',df.shape[0], ',and number of columns are :',df.shape[1])
df.columns.tolist()
```
### Data Preprocessing
Since the majority of the machine learning models in the Sklearn library doesn't handle string category data and Null value, we have to explicitly remove or replace null values. The below snippet have functions, which removes the null value if any exists. And convert the string classes data in the datasets by encoding them to integer classes.
```
def NullClearner(df):
if(isinstance(df, pd.Series) and (df.dtype in ["float64","int64"])):
df.fillna(df.mean(),inplace=True)
return df
elif(isinstance(df, pd.Series)):
df.fillna(df.mode()[0],inplace=True)
return df
else:return df
def EncodeX(df):
return pd.get_dummies(df)
```
#### Correlation Map
In order to check the correlation between the features, we will plot a correlation matrix. It is effective in summarizing a large amount of data where the goal is to see patterns.
```
plt.figure(figsize = (15, 10))
corr = df.corr()
mask = np.triu(np.ones_like(corr, dtype = bool))
sns.heatmap(corr, mask = mask, linewidths = 1, annot = True, fmt = ".2f")
plt.show()
correlation = df[df.columns[1:]].corr()[target][:]
correlation
```
### Feature Selections
It is the process of reducing the number of input variables when developing a predictive model. Used to reduce the number of input variables to both reduce the computational cost of modelling and, in some cases, to improve the performance of the model.
We will assign all the required input features to X and target/outcome to Y.
```
#Elminiating features that are irrlevant
df.drop([feature],axis=1,inplace = True)
#spliting data into X(features) and Y(Target)
X=df[features]
Y=df[target]
```
Calling preprocessing functions on the feature and target set.
```
x=X.columns.to_list()
for i in x:
X[i]=NullClearner(X[i])
X=EncodeX(X)
Y=NullClearner(Y)
X.head()
```
### Data Splitting
The train-test split is a procedure for evaluating the performance of an algorithm. The procedure involves taking a dataset and dividing it into two subsets. The first subset is utilized to fit/train the model. The second subset is used for prediction. The main motive is to estimate the performance of the model on new data.
```
#we can choose randomstate and test_size as over requerment
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2, random_state = 12) #performing datasplitting
```
## Model
### ElasticNet
Elastic Net first emerged as a result of critique on Lasso, whose variable selection can be too dependent on data and thus unstable. The solution is to combine the penalties of Ridge regression and Lasso to get the best of both worlds.
**Features of ElasticNet Regression-**
* It combines the L1 and L2 approaches.
* It performs a more efficient regularization process.
* It has two parameters to be set, λ and α.
#### Model Tuning Parameters
alpha=1.0, copy_X=True, fit_intercept=True, l1_ratio=0.5,
max_iter=1000, normalize=False, positive=False, precompute=False,
random_state=50, selection='cyclic', tol=0.0001, warm_start=False
1 alpha : float, default=1.0
1. alpha : float, default=1.0
> Constant that multiplies the penalty terms. Defaults to 1.0. See the notes for the exact mathematical meaning of this parameter. alpha = 0 is equivalent to an ordinary least square, solved by the LinearRegression object. For numerical reasons, using alpha = 0 with the Lasso object is not advised. Given this, you should use the LinearRegression object.
2. l1_ratio : float, default=0.5
> The ElasticNet mixing parameter, with 0 <= l1_ratio <= 1. For l1_ratio = 0 the penalty is an L2 penalty. For l1_ratio = 1 it is an L1 penalty. For 0 < l1_ratio < 1, the penalty is a combination of L1 and L2.
3. normalize : bool, default=False
>This parameter is ignored when fit_intercept is set to False. If True, the regressors X will be normalized before regression by subtracting the mean and dividing by the l2-norm. If you wish to standardize, please use StandardScaler before calling fit on an estimator with normalize=False.
4. precompute : bool or array-like of shape (n_features, n_features), default=False
>Whether to use a precomputed Gram matrix to speed up calculations. The Gram matrix can also be passed as argument. For sparse input this option is always False to preserve sparsity.
5. max_iter : int, default=1000
>The maximum number of iterations.
6. copy_X : bool, default=True
>If True, X will be copied; else, it may be overwritten.
7. tol : float, default=1e-4
>The tolerance for the optimization: if the updates are smaller than tol, the optimization code checks the dual gap for optimality and continues until it is smaller than tol.
8. warm_start : bool, default=False
>When set to True, reuse the solution of the previous call to fit as initialization, otherwise, just erase the previous solution. See the Glossary.
9. positive : bool, default=False
>When set to True, forces the coefficients to be positive.
10. random_state : int, RandomState instance, default=None
>The seed of the pseudo random number generator that selects a random feature to update. Used when selection == ‘random’. Pass an int for reproducible output across multiple function calls. See Glossary.
11. selection : {‘cyclic’, ‘random’}, default=’cyclic’
>If set to ‘random’, a random coefficient is updated every iteration rather than looping over features sequentially by default. This (setting to ‘random’) often leads to significantly faster convergence especially when tol is higher than 1e-4.
```
#training the GradientBoostingClassifier
model = ElasticNet(random_state = 50)
model.fit(X_train, y_train)
```
#### Model Accuracy
score() method return the mean accuracy on the given test data and labels.
In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted.
```
print("Accuracy score {:.2f} %\n".format(model.score(X_test,y_test)*100))
#prediction on testing set
prediction=model.predict(X_test)
```
### Model evolution
**r2_score:** The r2_score function computes the percentage variablility explained by our model, either the fraction or the count of correct predictions.
**MAE:** The mean abosolute error function calculates the amount of total error(absolute average distance between the real data and the predicted data) by our model.
**MSE:** The mean squared error function squares the error(penalizes the model for large errors) by our model.
```
print('Mean Absolute Error:', mean_absolute_error(y_test, prediction))
print('Mean Squared Error:', mean_squared_error(y_test, prediction))
print('Root Mean Squared Error:', np.sqrt(mean_squared_error(y_test, prediction)))
print("R-squared score : ",r2_score(y_test,prediction))
#ploting actual and predicted
red = plt.scatter(np.arange(0,80,5),prediction[0:80:5],color = "red")
green = plt.scatter(np.arange(0,80,5),y_test[0:80:5],color = "green")
plt.title("Comparison of Regression Algorithms")
plt.xlabel("Index of Candidate")
plt.ylabel("target")
plt.legend((red,green),('ElasticNet', 'REAL'))
plt.show()
```
#### Creator: Vipin Kumar , Github: [Profile](https://github.com/devVipin01)
| github_jupyter |
```
from sklearn.metrics import confusion_matrix, f1_score
from sklearn.utils.multiclass import unique_labels
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
import seaborn as sns
import numpy as np
from sklearn.metrics import ConfusionMatrixDisplay
import json
import re
import pandas as pd
import sys
sys.path.append("../src/")
from rule_based_triple_extraction import (
rule_based_triple_extraction,
_set_index,
_collapse_multiindex,
is_compound_series_ner,
known_compounds_foodb,
known_foods_foodb,
is_entity_series,
)
from column_srl_utils import initial_featurize_series, featurize_chardist_single, standardize_table_df
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.dummy import DummyClassifier
from sklearn.svm import SVC
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_validate
from sklearn.neural_network import MLPClassifier
from sklearn.naive_bayes import GaussianNB
def split_and_train(X, y, filter_features=False, heldout_test=False):
if heldout_test:
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=42, test_size=0.3
)
else:
X_train = X
y_train = y
if filter_features:
correlation = X_train.corrwith(pd.Series(y_train))
good_features = correlation.sort_values(ascending=False).head(1000).index
X_train = X_train[good_features]
X_test = X_test[good_features]
rfc = RandomForestClassifier(max_depth=20)
mlp = MLPClassifier(
hidden_layer_sizes=(
300,
150,
50,
),
max_iter=2000,
early_stopping=False,
n_iter_no_change=500,
)
dummy = DummyClassifier(strategy="most_frequent")
models = [dummy, rfc, mlp]
model_scores = {}
confusion_matrices = {}
for model in models:
scores = cross_validate(
model,
X_train,
y_train,
scoring=['accuracy','precision_macro','recall_macro','f1_macro'],
cv=StratifiedKFold(5),
return_train_score=True,
)
y_pred = cross_val_predict(model, X_train, y_train, cv=StratifiedKFold(5))
cm = confusion_matrix(y_train, y_pred)
confusion_matrices[model.__class__.__name__] = cm
model_scores[model.__class__.__name__] = scores
return model_scores, confusion_matrices
annotations = json.load(open('../data/labeling_output/column_srl/project-3-at-2021-04-16-19-46-1b007d8d.json'))
def _get_col_idx(col_xpath):
col_idxs = re.search(r'td\[([0-9]+)\]',col_xpath)
if col_idxs is not None:
col_idx = col_idxs.group(1)
else:
col_idxs = re.search(r'th\[([0-9]+)\]',col_xpath)
if col_idxs is not None:
col_idx = col_idxs.group(1)
else:
col_idx = None
return col_idx
columns = []
for annotation in annotations:
df = pd.read_html(annotation['data']['table_html'])[0]
df = standardize_table_df(df)
col_classes = {}
for col_annotation in annotation['annotations'][0]['result']:
col_xpath = col_annotation['value']['start']
print(col_xpath)
col_idx = _get_col_idx(col_xpath)
if col_idx is not None:
col_idx = int(col_idx) - 1
col_idx, col_name, col_series, col_values = initial_featurize_series(df, col_idx)
col_class = col_annotation['value']['htmllabels'][0]
columns.append([col_idx, col_name, col_series, ' '.join(list(col_values)), col_class])
else:
print(col_xpath)
data = pd.DataFrame(columns,columns=['col_idx','col_name','col_series', 'col_values','class_label'])
data = data.drop_duplicates(subset=['col_idx','col_name','col_values',])
data.loc[data.class_label == 'Food Origin', 'class_label'] = 'Food Varietal'
data.loc[data.class_label == 'Food Preparation', 'class_label'] = 'Food Varietal'
data.loc[data.class_label == 'Food Sample', 'class_label'] = 'Food Varietal'
data.loc[data.class_label == 'Composition Measurement (Variance)', 'class_label'] = 'Composition Measurement'
data.class_label.value_counts()
def featurize_columns_tfidf(data: pd.DataFrame):
vec = TfidfVectorizer(ngram_range=(1,6),analyzer='char')
features = vec.fit_transform(data['col_values'])
X = features
y = data['class_label']
return X, y
X, y = featurize_columns_tfidf(data)
model_scores, confusion_matrices = split_and_train(X, y)
results_df = []
for model, scores in model_scores.items():
x = pd.DataFrame(scores).mean()
results_df.append(x)
results_df = pd.DataFrame(results_df,index=model_scores.keys())
results_df[[col for col in results_df if 'test' in col]]
ConfusionMatrixDisplay(confusion_matrices['RandomForestClassifier'],display_labels=np.unique(data['class_label'])).plot()
def predict_rulebased(data):
labels = []
for s in data['col_series']:
if is_compound_series_ner(s,threshold=.5):
label = 'Food Constituent'
elif is_entity_series(s,known_foods_foodb,use_edit_distance=False):
label = 'Food'
else:
label = 'Other'
labels.append(label)
return labels
y_pred_rulebased = predict_rulebased(data)
print(list(zip(f1_score(data['class_label'], y_pred_rulebased, average=None),unique_labels(data['class_label']))))
confmat = confusion_matrix(data['class_label'],y_pred_rulebased)
ConfusionMatrixDisplay(confmat,display_labels=np.unique(data['class_label'])).plot()
```
# Scispacy featurization
```
import spacy
nlp = spacy.load('en_core_sci_lg')
def featurize_scispacy(data: pd.DataFrame):
col_values_vectors = np.array([nlp(x).vector for x in data.col_values])
col_names_vectors = np.array([nlp(x).vector for x in data.col_name])
features = np.concatenate([col_values_vectors],axis=1)
X = features
y = data['class_label']
return X, y
X, y = featurize_scispacy(data)
model_scores, confusion_matrices = split_and_train(X, y)
results_df = []
for model, scores in model_scores.items():
x = pd.DataFrame(scores).mean()
results_df.append(x)
results_df = pd.DataFrame(results_df,index=model_scores.keys())
results_df[[col for col in results_df if 'test' in col]]
ConfusionMatrixDisplay(confusion_matrices['RandomForestClassifier'],display_labels=np.unique(data['class_label'])).plot()
```
MLP does a bit better here at not predicting the majority class, + several points on macro recall and macro f1, just above 50% accuracy
```
ConfusionMatrixDisplay(confusion_matrices['MLPClassifier'],display_labels=np.unique(data['class_label'])).plot()
```
- scispacy vectorization does a little bit better at food varietal, a little worse on other, a little worse overall compared to tf-idf
- removing column name does a little bit better compared to tf-idf on the long-tail items
- maybe try balancing the dataset and see
# Character distribution featurization
```
from collections import Counter
def featurize_chardist(data):
values_chardist = pd.DataFrame([Counter(list(x)) for x in data['col_values']])
names_chardist = pd.DataFrame([Counter(list(x)) for x in data['col_name']])
chardist_features = pd.concat([values_chardist,names_chardist],axis=1)
X = chardist_features.fillna(0).values
y = data['class_label']
return X, y
X_chardist, y = featurize_chardist(data)
X_chardist = np.concatenate([X_chardist,data['col_idx'].values.reshape(-1,1)],axis=1)
model_scores, confusion_matrices = split_and_train(X_chardist, y)
results_df = []
for model, scores in model_scores.items():
x = pd.DataFrame(scores).mean()
results_df.append(x)
results_df = pd.DataFrame(results_df,index=model_scores.keys())
results_df[[col for col in results_df if 'test' in col]]
ConfusionMatrixDisplay(confusion_matrices['MLPClassifier'],display_labels=np.unique(data['class_label'])).plot()
X_chardist, y = featurize_chardist(data)
X_scispacy, y = featurize_scispacy(data)
X = np.concatenate([X_chardist,X_scispacy,data['col_idx'].values.reshape(-1,1)],axis=1)
model_scores, confusion_matrices = split_and_train(X, y)
ConfusionMatrixDisplay(confusion_matrices['MLPClassifier'],display_labels=np.unique(data['class_label'])).plot()
results_df = []
for model, scores in model_scores.items():
x = pd.DataFrame(scores).mean()
results_df.append(x)
results_df = pd.DataFrame(results_df,index=model_scores.keys())
results_df[[col for col in results_df if 'test' in col]]
```
Dataset balancing techniques
```
# from imblearn.under_sampling import RandomUnderSampler
# from imblearn.over_sampling import SMOTE
# sampling_strategy = data.class_label.value_counts().to_dict()
# # sampling_strategy['Other'] = 30
# sampling_strategy = {k: 86 for k,v in sampling_strategy.items()}
# # rus = RandomUnderSampler(sampling_strategy=sampling_strategy)
# smote = SMOTE(sampling_strategy=sampling_strategy)
# X, y = featurize_scispacy(data)
# # X_res, y_res = rus.fit_resample(X, y)
# X_res, y_res = smote.fit_resample(X, y)
# model_scores, confusion_matrices = split_and_train(X, y)
# results_df = []
# for model, scores in model_scores.items():
# x = pd.DataFrame(scores).mean()
# results_df.append(x)
# results_df = pd.DataFrame(results_df,index=model_scores.keys())
# results_df[[col for col in results_df if 'test' in col]]
# ConfusionMatrixDisplay(confusion_matrices['MLPClassifier'],display_labels=np.unique(data['class_label'])).plot()
# ConfusionMatrixDisplay(confusion_matrices['RandomForestClassifier'],display_labels=np.unique(data['class_label'])).plot()
from sklearn.utils.estimator_checks import check_estimator
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted
from sklearn.utils.multiclass import unique_labels
from sklearn.metrics import euclidean_distances
class TemplateClassifier(BaseEstimator, ClassifierMixin):
def __init__(self):
def fit(self, X, y):
# Check that X and y have correct shape
X, y = check_X_y(X, y)
# Store the classes seen during fit
self.classes_ = unique_labels(y)
self.X_ = X
self.y_ = y
# Return the classifier
return self
def predict(self, X):
# Check is fit had been called
check_is_fitted(self)
# Input validation
X = check_array(X)
closest = np.argmin(euclidean_distances(X, self.X_), axis=1)
return self.y_[closest]
from string import printable
list(printable)
```
| github_jupyter |
```
upos_maps={'a':'ADJ', 'p':'ADP', 'd':'ADV',
'u':'AUX', 'c':'CCONJ', 'h':'DET',
'e':'INTJ', 'n':'NOUN', 'm':'NUM',
'z':'PART', 'r':'PRON', 'nh':'PROPN',
'wp':'PUNCT', 'ws':'SYM',
'v':'VERB', 'x':'X'
}
upos_rev_maps={'SCONJ':['c'], 'NOUN':['ni', 'nl', 'ns', 'nt', 'nz', 'n', 'nd', 'nh']}
class WordUnit(object):
def __init__(self, i, text, dependency_relation, governor, head_text, pos, netag):
self.i=i
self.text=text
self.lemma=text
self.dependency_relation=dependency_relation
self.governor=governor
self.head_text=head_text
self.pos=pos
self.upos='X'
if pos in upos_maps:
self.upos=upos_maps[pos]
else:
for k,v in upos_rev_maps.items():
if pos in v:
self.upos=k
self.netag=netag
from sagas.nlu.uni_intf import WordIntf, SentenceIntf
from sagas.nlu.corenlp_parser import get_chunks
import sagas
from sagas.tool.misc import print_stem_chunks
from sagas.nlu.uni_viz import EnhancedViz
class RootWordImpl(WordIntf):
def setup(self, token):
features = {'index':0, 'text':'ROOT', 'lemma':'root', 'upos':'', 'xpos':'',
'feats':[], 'governor':0, 'dependency_relation':''}
return features
class LtpWordImpl(WordIntf):
def setup(self, token):
if token.dependency_relation=='HED':
governor=0
else:
governor=token.governor
idx=token.i+1 # start from 1
features = {'index':idx, 'text':token.text, 'lemma':token.lemma,
'upos':token.upos, 'xpos':token.pos,
'feats':[], 'governor':governor, 'dependency_relation':token.dependency_relation.lower(),
'entity':[token.netag]
}
return features
class LtpSentImpl(SentenceIntf):
def setup(self, sent):
words = []
for word in sent:
words.append(LtpWordImpl(word))
deps = []
return words, deps
def build_dependencies(self):
for word in self.words:
if word.governor == 0:
# make a word for the ROOT
governor = RootWordImpl(None)
else:
# id is index in words list + 1
governor = self.words[word.governor-1]
self.dependencies.append((governor, word.dependency_relation, word))
class LtpParserImpl(object):
def __init__(self, lang='zh-CN'):
self.lang = lang
def __call__(self, sentence):
from sagas.zh.ltp_procs import LtpProcs, ltp
# doc = spacy_doc(sents, self.lang)
words = ltp.segmentor.segment(sentence)
postags = ltp.postagger.postag(words)
arcs = ltp.parser.parse(words, postags)
roles = ltp.labeller.label(words, postags, arcs)
netags = ltp.recognizer.recognize(words, postags)
doc=[]
for i in range(len(words)):
a = words[int(arcs[i].head) - 1]
print("%s --> %s|%s|%s|%s" % (a, words[i], \
arcs[i].relation, postags[i], netags[i]))
unit=WordUnit(i=i, text=words[i],
dependency_relation=arcs[i].relation.lower(),
governor=arcs[i].head,
head_text=a, pos=postags[i], netag=netags[i])
rel=unit.dependency_relation
doc.append(unit)
return LtpSentImpl(doc)
p=LtpParserImpl()
doc=p('我送她一束花')
# print(doc.words)
doc.build_dependencies()
# print(doc.dependencies)
rs = get_chunks(doc)
# print(rs)
for r in rs:
df = sagas.to_df(r['domains'], ['rel', 'index', 'text', 'lemma', 'children', 'features'])
print('%s(%s)' % (r['type'], r['lemma']))
# sagas.print_df(df)
display(df)
print_stem_chunks(r)
cv = EnhancedViz(shape='egg', size='8,5', fontsize=20)
cv.analyse_doc(doc, None)
```
| github_jupyter |
```
# Load packages
import tensorflow as tf
from tensorflow import keras
import numpy as np
import pandas as pd
import os
import pickle
import time
import scipy as scp
import scipy.stats as scps
from scipy.optimize import differential_evolution
from scipy.optimize import minimize
from datetime import datetime
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# Load my own functions
#import dnnregressor_train_eval_keras as dnnk
#import make_data_wfpt as mdw
from kde_training_utilities import kde_load_data
import ddm_data_simulation as ddm_sim
import boundary_functions as bf
import yaml
with open('/media/data_cifs/afengler/git_repos/nn_likelihoods/kde_mle_parallel.yaml', 'r') as stream:
data_loaded = yaml.unsafe_load(stream)
#yaml.safe_load('/media/data_cifs/afengler/tmp/my_yaml_test.yaml')
data_loaded['param_bounds']
import os
os.getcwd()
# Handle some cuda business
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" # see issue #152
os.environ["CUDA_VISIBLE_DEVICES"]="1"
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
# Load Model
model_path = '/media/data_cifs/afengler/data/kde/linear_collapse/keras_models/dnnregressor_ddm_linear_collapse_06_22_19_23_27_28/model_0'
ckpt_path = '/media/data_cifs/afengler/data/kde/linear_collapse/keras_models/dnnregressor_ddm_linear_collapse_06_22_19_23_27_28/ckpt_0_130'
model = keras.models.load_model(model_path)
model.load_weights(ckpt_path)
model.predict()
# Initializations -----
n_runs = 100
n_samples = 2500
feature_file_path = '/media/data_cifs/afengler/data/kde/linear_collapse/train_test_data/test_features.pickle'
mle_out_path = '/media/data_cifs/afengler/data/kde/linear_collapse/mle_runs'
# NOTE PARAMETERS: WEIBULL: [v, a, w, node, shape, scale]
param_bounds = [(-1, 1), (0.3, 2), (0.3, 0.7), (0.01, 0.01), (0, np.pi / 2.2)]
my_optim_columns = ['v_sim', 'a_sim', 'w_sim', 'node_sim', 'theta_sim',
'v_mle', 'a_mle', 'w_mle', 'node_mle', 'theta_mle', 'n_samples']
# Get parameter names in correct ordering:
dat = pickle.load(open(feature_file_path,
'rb'))
parameter_names = list(dat.keys())[:-2] # :-1 to get rid of 'rt' and 'choice' here
# Make columns for optimizer result table
p_sim = []
p_mle = []
for parameter_name in parameter_names:
p_sim.append(parameter_name + '_sim')
p_mle.append(parameter_name + '_mle')
my_optim_columns = p_sim + p_mle + ['n_samples']
# Initialize the data frame in which to store optimizer results
optim_results = pd.DataFrame(np.zeros((n_runs, len(my_optim_columns))), columns = my_optim_columns)
optim_results.iloc[:, 2 * len(parameter_names)] = n_samples
# define boundary
boundary = bf.linear_collapse
boundary_multiplicative = False
# Define the likelihood function
def log_p(params = [0, 1, 0.9], model = [], data = [], parameter_names = []):
# Make feature array
feature_array = np.zeros((data[0].shape[0], len(parameter_names) + 2))
# Store parameters
cnt = 0
for i in range(0, len(parameter_names), 1):
feature_array[:, i] = params[i]
cnt += 1
# Store rts and choices
feature_array[:, cnt] = data[0].ravel() # rts
feature_array[:, cnt + 1] = data[1].ravel() # choices
# Get model predictions
prediction = model.predict(feature_array)
# Some post-processing of predictions
prediction[prediction < 1e-29] = 1e-29
return(- np.sum(np.log(prediction)))
def make_params(param_bounds = []):
params = np.zeros(len(param_bounds))
for i in range(len(params)):
params[i] = np.random.uniform(low = param_bounds[i][0], high = param_bounds[i][1])
return params
# ---------------------
# Main loop ----------- TD: Parallelize
for i in range(0, n_runs, 1):
# Get start time
start_time = time.time()
# # Sample parameters
# v_sim = np.random.uniform(high = v_range[1], low = v_range[0])
# a_sim = np.random.uniform(high = a_range[1], low = a_range[0])
# w_sim = np.random.uniform(high = w_range[1], low = w_range[0])
# #c1_sim = np.random.uniform(high = c1_range[1], low = c1_range[0])
# #c2_sim = np.random.uniform(high = c2_range[1], low = c2_range[0])
# node_sim = np.random.uniform(high = node_range[1], low = node_range[0])
# shape_sim = np.random.uniform(high = shape_range[1], low = shape_range[0])
# scale_sim = np.random.uniform(high = scale_range[1], low = scale_range[0])
tmp_params = make_params(param_bounds = param_bounds)
# Store in output file
optim_results.iloc[i, :len(parameter_names)] = tmp_params
# Print some info on run
print('Parameters for run ' + str(i) + ': ')
print(tmp_params)
# Define boundary params
boundary_params = {'node': tmp_params[3],
'theta': tmp_params[4]}
# Run model simulations
ddm_dat_tmp = ddm_sim.ddm_flexbound_simulate(v = tmp_params[0],
a = tmp_params[1],
w = tmp_params[2],
s = 1,
delta_t = 0.001,
max_t = 20,
n_samples = n_samples,
boundary_fun = boundary, # function of t (and potentially other parameters) that takes in (t, *args)
boundary_multiplicative = boundary_multiplicative, # CAREFUL: CHECK IF BOUND
boundary_params = boundary_params)
# Print some info on run
print('Mean rt for current run: ')
print(np.mean(ddm_dat_tmp[0]))
# Run optimizer
out = differential_evolution(log_p,
bounds = param_bounds,
args = (model, ddm_dat_tmp, parameter_names),
popsize = 30,
disp = True)
# Print some info
print('Solution vector of current run: ')
print(out.x)
print('The run took: ')
elapsed_time = time.time() - start_time
print(time.strftime("%H:%M:%S", time.gmtime(elapsed_time)))
# Store result in output file
optim_results.iloc[i, len(parameter_names):(2*len(parameter_names))] = out.x
# -----------------------
# Save optimization results to file
optim_results.to_csv(mle_out_path + '/mle_results_1.csv')
# Read in results
optim_results = pd.read_csv(os.getcwd() + '/experiments/ddm_flexbound_kde_mle_fix_v_0_c1_0_w_unbiased_arange_2_3/optim_results.csv')
plt.scatter(optim_results['v_sim'], optim_results['v_mle'], c = optim_results['c2_mle'])
# Regression for v
reg = LinearRegression().fit(np.expand_dims(optim_results['v_mle'], 1), np.expand_dims(optim_results['v_sim'], 1))
reg.score(np.expand_dims(optim_results['v_mle'], 1), np.expand_dims(optim_results['v_sim'], 1))
plt.scatter(optim_results['a_sim'], optim_results['a_mle'], c = optim_results['c2_mle'])
# Regression for a
reg = LinearRegression().fit(np.expand_dims(optim_results['a_mle'], 1), np.expand_dims(optim_results['a_sim'], 1))
reg.score(np.expand_dims(optim_results['a_mle'], 1), np.expand_dims(optim_results['a_sim'], 1))
plt.scatter(optim_results['w_sim'], optim_results['w_mle'])
# Regression for w
reg = LinearRegression().fit(np.expand_dims(optim_results['w_mle'], 1), np.expand_dims(optim_results['w_sim'], 1))
reg.score(np.expand_dims(optim_results['w_mle'], 1), np.expand_dims(optim_results['w_sim'], 1))
plt.scatter(optim_results['c1_sim'], optim_results['c1_mle'])
# Regression for c1
reg = LinearRegression().fit(np.expand_dims(optim_results['c1_mle'], 1), np.expand_dims(optim_results['c1_sim'], 1))
reg.score(np.expand_dims(optim_results['c1_mle'], 1), np.expand_dims(optim_results['c1_sim'], 1))
plt.scatter(optim_results['c2_sim'], optim_results['c2_mle'], c = optim_results['a_mle'])
# Regression for w
reg = LinearRegression().fit(np.expand_dims(optim_results['c2_mle'], 1), np.expand_dims(optim_results['c2_sim'], 1))
reg.score(np.expand_dims(optim_results['c2_mle'], 1), np.expand_dims(optim_results['c2_sim'], 1))
```
| github_jupyter |
# Algo - graphes aléatoires
Comment générer un graphe aléatoire... Générer une séquence de nombres aléatoires indépendants est un problème connu et plutôt bien résolu. Générer une structure aléatoire comme une graphe est aussi facile. En revanche, générer un graphe aléatoire vérifiant une propriété - la distribution des degrés - n'est pas aussi simple qu'anticipé.
```
from jyquickhelper import add_notebook_menu
add_notebook_menu()
%matplotlib inline
```
## Graphe aléatoire - matrice d'adjacence aléatoire
L'existence de chaque arc est défini par une variable binomiale de paramètre $p$.
```
import numpy
mat = numpy.random.random((15, 15))
mat = mat + mat.T
adja = (mat >= 1.4).astype(int)
for i in range(adja.shape[0]):
adja[i ,i] = 0
adja
```
En le visualisant...
```
import networkx
import matplotlib.pyplot as plt
fix, ax = plt.subplots(1, 1,figsize=(4,4))
G = networkx.from_numpy_matrix(adja)
networkx.draw(G, with_labels=True, ax=ax)
degres = adja.sum(axis=1)
degres
distrib = {}
for d in degres:
if d in distrib:
distrib[d] += 1
else:
distrib[d] = 1
distrib
```
## Vocabulaire lié aux graphes
* **arc (ou edge en anglais)** : lien liant deux noeuds, il peut être **orienté** ou non, s'il est orienté, les deux extrémités ne jouent pas le même rôle, l'arc ne peut être "parcouru" que de la première extrémité vers la seconde.
* **noeud (vertex en anglais)** : élément du graphe
* **graphe** : un graphe est défini par un ensemble de noeuds et un ensemble d'arcs
* **matrice d'adjacence** : matrice binaire de dimension $N \times N$, $A=(a_{ij})_{ij}$ et $a_{ij} = 1$ s'il existe un arc reliant le noeud *i* à *j*, 0 sinon.
* **chemin** : séquence de noeuds et d'arcs appartenant au graphe
* **prédécesseur et successeur** : si un arc orienté relie les noeuds *i* à *j*, *i* est le prédecesseur de *j*, *j* est le successeur de *i*. Par extension, si *i* apparaît toujours avec *j* dans tous les chemins possibles du graphes, *i* est un prédecesseur de *j*.
* **arbre** : cas particulier des graphes orientés, il existe un unique prédecesseur à tous les noeuds nommés la racine, un noeud sans successeur est appelé **feuille (ou leaf en anglais)**. Dans un arbre binaire, chaque noeud n'a que deux successeurs directs.
* **degré d'un noeud** : nombre d'arcs connectés à un noeud, on peut distinguer pour les graphes orientés le fait que les arcs partent ou arrivent à un noeud
* **Composante connexe** : au sein d'une composante connexe, il existe toujours un chemin reliant n'importe quelle paire de noeuds.
Quelques propriétés de la matrice d'adjacence :
* Pour un graphe non orienté, la matrice d'adjacence est symétrique.
* La somme sur la ligne *i* est égale au degré du noeud *i*.
* La matrice d'adjacence est triangulaire supérieue dans le cas d'un arbre dont les noeuds sont numérotés en largeur d'abord (un noeud a toujours un numéro supérieur à tous des niveaux moins profonds).
## Aparté : matrice d'adjacence à la puissance n
Si $A$ est une matrice d'adjacence, $a^2_{ik}$ et un coefficient de cette matrice. $a^2_{ik} \sum_j a_{ij} a_{jk}$. Comme $a_{pq} \in \{0, 1\}$, $a^2_{ik} > 0$ s'il existe un $j$ tel que $ a_{ij} = a_{jk} = 1$. Autrement dit, les noeuds $i j, k$ sont reliés. Si $a^2_{ik} > 0$, alors il existe un chemin de longueur 2 entre les noeuds $i, k$. Par récurrent, $A^3_{pq}$ est positif s'il existe un chemin de longueur 3 reliant les noeuds $p, q$.
On calcule $\sum{A}=A + A^2 + A^3 + ... + A^n$ où n est la dimension de la matrice.
```
adjan = adja.copy()
conne = numpy.zeros(adja.shape)
for i in range(1, adja.shape[0]):
conne += adjan
adjan = adjan @ adja
(conne > 0).astype(int)
```
D'après les remarques précédentes, $\sum A_{pq} > 0$ s'il existe un chemin reliant les noeuds $p, q$, donc s'il font partie de la même composante connexe. Et 0 si les deux noeuds font partie de deux composantes connexes distinctes.
## Trouver le nombre de composantes connexes
On s'inspire d'un algorithme de coloriage. Au début, chaque noeud appartient à sa propre composante connexe noté $c_i$. Pour chaque arc reliant deux noeuds *i* et *j*, on associe aux deux noeuds à la composante $\min(c_i, c_j)$. On continue tant qu'un noeud change de composante connexe.
```
mat = numpy.random.random((15, 15))
mat = mat + mat.T
adja = (mat >= 1.45).astype(int)
for i in range(adja.shape[0]):
adja[i ,i] = 0
fix, ax = plt.subplots(1, 1, figsize=(4, 4))
G = networkx.from_numpy_matrix(adja)
networkx.draw(G, with_labels=True, ax=ax)
C = numpy.arange(adja.shape[0])
maj = 1
while maj > 0:
maj = 0
for i in range(adja.shape[0]):
for j in range(i + 1, adja.shape[1]):
if adja[i, j] > 0 and C[i] != C[j]:
maj += 1
C[i] = C[j] = min(C[i], C[j])
C
set(C)
print("Il y a %r composantes connexes." % len(set(C)))
```
## Génération d'un graphe aléatoire
Les graphes issues de réseaux sociaux ont souvent des propriétés statistiques particulières. La distribution des degrés des noeuds suit souvent une loi à queue épaisse. C'est dans cette catégorie qu'on range les lois qui admettent une espérance mais pas de variance.
Donc on ne veut pas générer n'importe quel graphe aléatoire, on veut générer un graphe aléatoire dont la distribution des degrés des noeuds est connue.
On s'inspire de [algorithme graphe aléatoire](http://www.proba.jussieu.fr/pageperso/rebafka/BookGraphes/graphes-scale-free.html).
**Etape 1 :** transformer une distribution des degrés des noeuds en une liste de degré souhaité pour chaque noeud.
```
def distribution_to_degree_list(hist):
N = int(hist.sum())
deg = numpy.zeros(N, dtype=numpy.int32)
p = 0
for i, nh in enumerate(hist):
for n in range(nh):
deg[p] = i
p += 1
return deg
dist = numpy.array(numpy.array([0, 4, 3, 2]))
distribution_to_degree_list(dist)
```
**Etape 2 :** on part d'un tableau de même dimension qui représente les degrés du graphe en cours de construction. Il est nul au départ. On tire des noeuds de façon aléatoire tant que ce degré est inférieur au degré souhaité. On l'incrémente à chaque fois qu'un arc est créé.
### Version 1
```
import warnings
from tqdm import tqdm # pour visualiser la progression de l'algorithme
def random_graph(distribution_degree):
degrees = distribution_to_degree_list(distribution_degree)
current = numpy.zeros(degrees.shape[0], dtype=numpy.int32)
expected = degrees.sum()
adja = numpy.zeros((degrees.shape[0], degrees.shape[0]), dtype=numpy.int32)
nb = 0
# tqdm: une boucle qui affiche l'avancement dans un notebook
# on évite la boucle infinie en limitant le nombre d'itération
loop = tqdm(range(expected * 5))
for n_iter in loop:
loop.set_description("sum=%r expected=%r" % (nb, expected))
nodes = [i for i, (c, d) in enumerate(zip(current, degrees))
if c < d]
if len(nodes) == 1:
i, j = 0, 0
elif len(nodes) == 2:
di, dj = 0, 0
i, j = nodes[di], nodes[dj]
else:
di, dj = numpy.random.randint(0, len(nodes), 2)
i, j = nodes[di], nodes[dj]
if i == j or adja[i, j] == 1:
# arc déjà créé ou impossible
continue
current[i] += 1
current[j] += 1
adja[i, j] = 1
adja[j, i] = 1
nb += 2
if nb >= expected:
# Tous les noeuds ont le degré souhaité.
loop.set_description("sum=%r expected=%r" % (nb, expected))
break
if nb < expected:
warnings.warn("Graphe incomplet\ndegrees=%r\ncurrent=%r" % (degrees, current))
return adja
adja = random_graph(numpy.array([0, 5, 3, 2]))
adja
```
On remarque que la somme des degrés ne peut être impaire car chaque arc est connecté à deux noeuds.
```
adja = random_graph(numpy.array([0, 4, 3, 2]))
adja
```
On regarde la distribution des degrés :
```
adja.sum(axis=1)
from collections import Counter
Counter(adja.sum(axis=1))
```
L'algorithme ne semble pas aboutir à un graphe qui répond au critère souhaité. Il existe deux cas pour lesquels l'algorithme reste bloqué. On note $A_t$ l'ensemble des noeuds à l'itération *t* dont les degrés sont inférieurs au degré souhaité.
* Tous les noeuds dans l'ensemble $A_t$ sont déjà reliés entre eux.
* La seule option possible est de créer un arc entre un noeud et lui-même.
Pour éviter cela, on choisit après 5 tirages ne donnant lieu à aucune création d'arc d'en supprimer quelques-uns. L'algorithme qui suit n'est pas le plus efficace mais voyons déjà s'il marche avant de nous pencher sur un autre.
### Version 2
```
def random_graph_remove(distribution_degree):
degrees = distribution_to_degree_list(distribution_degree)
current = numpy.zeros(degrees.shape[0], dtype=numpy.int32)
expected = degrees.sum()
adja = numpy.zeros((degrees.shape[0], degrees.shape[0]), dtype=numpy.int32)
nb = 0
loop = tqdm(range(expected * 5))
last_added = 0
n_removed = 0
edges = {i: [] for i in range(current.shape[0])}
for n_iter in loop:
loop.set_description("sum=%r expected=%r n_removed=%r" % (nb, expected, n_removed))
nodes = [i for i, (c, d) in enumerate(zip(current, degrees))
if c < d]
if len(nodes) > 1:
di, dj = numpy.random.randint(0, len(nodes), 2)
i, j = nodes[di], nodes[dj]
else:
i = j = 0
if i == j or adja[i, j] == 1:
if last_added + 5 < n_iter:
# on supprime un arc
nodes = [i for i, c in enumerate(current) if c > 0]
di = (0 if len(nodes) <= 1 else
numpy.random.randint(0, len(nodes)))
i = nodes[di]
dh = (0 if len(edges[i]) <= 1 else
numpy.random.randint(0, len(edges[i])))
j = edges[i][dh]
adja[i, j] = 0
adja[j, i] = 0
edges[i].remove(j)
edges[j].remove(i)
current[i] -= 1
current[j] -= 1
nb -= 2
n_removed += 2
continue
current[i] += 1
current[j] += 1
adja[i, j] = 1
adja[j, i] = 1
nb += 2
last_added = n_iter
edges[i].append(j)
edges[j].append(i)
if nb >= expected:
# Tous les noeuds ont le degré souhaité.
loop.set_description("sum=%r expected=%r n_removed=%r" % (nb, expected, n_removed))
break
if nb < expected:
warnings.warn("Graphe incomplet\ndegrees=%r\ncurrent=%r" % (degrees, current))
return adja
adja = random_graph_remove(numpy.array([0, 4, 3, 2]))
adja
Counter(adja.sum(axis=1))
```
Il est possible que cet algorithme aboutisse au résultat souhaité même avec beaucoup de temps. Est-ce la stratégie ou le fait que la distribution des noeuds ne soit pas [réalisable](http://www.proba.jussieu.fr/pageperso/rebafka/BookGraphes/graphes-scale-free.html#suite-de-degr%C3%A9s-r%C3%A9alisable).
```
def distribution_degree_realisable(distribution):
degrees = -numpy.array(sorted(-distribution_to_degree_list(distribution)))
if degrees.sum() % 2 != 0:
return False
sumdi = 0
for i in range(degrees.shape[0] - 1):
sumdi += degrees[i]
mindi = numpy.minimum(degrees[i+1:], i + 1).sum()
if sumdi >= i * (i + 1) + mindi:
return False
return True
distribution_degree_realisable(numpy.array([0, 2, 0, 0, 0, 0, 0, 0, 0, 1]))
distribution_degree_realisable(numpy.array([0, 4, 3, 2]))
fix, ax = plt.subplots(1, 1, figsize=(4, 4))
G = networkx.from_numpy_matrix(adja)
networkx.draw(G, with_labels=True, ax=ax)
```
Pour ce type de structure, la génération aléatoire est d'autant plus rapide qu'il y a peu de tirages rejetés.
| github_jupyter |
STAT 453: Deep Learning (Spring 2021)
Instructor: Sebastian Raschka (sraschka@wisc.edu)
Course website: http://pages.stat.wisc.edu/~sraschka/teaching/stat453-ss2021/
GitHub repository: https://github.com/rasbt/stat453-deep-learning-ss21
---
```
%load_ext watermark
%watermark -a 'Sebastian Raschka' -v -p torch
```
# VGG-16 on Cifar-10
## Imports
```
import torch
import torchvision
import numpy as np
import matplotlib.pyplot as plt
# From local helper files
from helper_evaluation import set_all_seeds, set_deterministic, compute_confusion_matrix
from helper_train import train_model
from helper_plotting import plot_training_loss, plot_accuracy, show_examples, plot_confusion_matrix
from helper_dataset import get_dataloaders_cifar10, UnNormalize
```
## Settings and Dataset
```
##########################
### SETTINGS
##########################
RANDOM_SEED = 123
BATCH_SIZE = 256
NUM_EPOCHS = 50
DEVICE = torch.device('cuda:1' if torch.cuda.is_available() else 'cpu')
set_all_seeds(RANDOM_SEED)
#set_deterministic()
##########################
### CIFAR-10 DATASET
##########################
### Note: Network trains about 2-3x faster if you don't
# resize (keeping the orig. 32x32 res.)
# Test acc. I got via the 32x32 was lower though; ~77%
train_transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize((70, 70)),
torchvision.transforms.RandomCrop((64, 64)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
test_transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize((70, 70)),
torchvision.transforms.CenterCrop((64, 64)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_loader, valid_loader, test_loader = get_dataloaders_cifar10(
batch_size=BATCH_SIZE,
validation_fraction=0.1,
train_transforms=train_transforms,
test_transforms=test_transforms,
num_workers=2)
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
print('Class labels of 10 examples:', labels[:10])
break
```
## Model
```
##########################
### MODEL
##########################
class VGG16(torch.nn.Module):
def __init__(self, num_classes):
super().__init__()
self.block_1 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=3,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=64,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_2 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=64,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=128,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_3 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=128,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_4 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=256,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_5 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
height, width = 3, 3 ## you may want to change that depending on the input image size
self.classifier = torch.nn.Sequential(
torch.nn.Linear(512*height*width, 4096),
torch.nn.ReLU(True),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 4096),
torch.nn.ReLU(True),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, num_classes),
)
for m in self.modules():
if isinstance(m, torch.torch.nn.Conv2d) or isinstance(m, torch.torch.nn.Linear):
torch.nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')
if m.bias is not None:
m.bias.detach().zero_()
self.avgpool = torch.nn.AdaptiveAvgPool2d((height, width))
def forward(self, x):
x = self.block_1(x)
x = self.block_2(x)
x = self.block_3(x)
x = self.block_4(x)
x = self.block_5(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1) # flatten
logits = self.classifier(x)
#probas = F.softmax(logits, dim=1)
return logits
model = VGG16(num_classes=10)
model = model.to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), momentum=0.9, lr=0.01)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,
factor=0.1,
mode='max',
verbose=True)
minibatch_loss_list, train_acc_list, valid_acc_list = train_model(
model=model,
num_epochs=NUM_EPOCHS,
train_loader=train_loader,
valid_loader=valid_loader,
test_loader=test_loader,
optimizer=optimizer,
device=DEVICE,
scheduler=scheduler,
scheduler_on='valid_acc',
logging_interval=100)
plot_training_loss(minibatch_loss_list=minibatch_loss_list,
num_epochs=NUM_EPOCHS,
iter_per_epoch=len(train_loader),
results_dir=None,
averaging_iterations=200)
plt.show()
plot_accuracy(train_acc_list=train_acc_list,
valid_acc_list=valid_acc_list,
results_dir=None)
plt.ylim([60, 100])
plt.show()
model.cpu()
unnormalizer = UnNormalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
class_dict = {0: 'airplane',
1: 'automobile',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck'}
show_examples(model=model, data_loader=test_loader, unnormalizer=unnormalizer, class_dict=class_dict)
mat = compute_confusion_matrix(model=model, data_loader=test_loader, device=torch.device('cpu'))
plot_confusion_matrix(mat, class_names=class_dict.values())
plt.show()
```
| github_jupyter |
<a href="https://colab.research.google.com/github/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_07_5_gan_research.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# T81-558: Applications of Deep Neural Networks
**Module 7: Generative Adversarial Networks**
* Instructor: [Jeff Heaton](https://sites.wustl.edu/jeffheaton/), McKelvey School of Engineering, [Washington University in St. Louis](https://engineering.wustl.edu/Programs/Pages/default.aspx)
* For more information visit the [class website](https://sites.wustl.edu/jeffheaton/t81-558/).
# Module 7 Material
* Part 7.1: Introduction to GANS for Image and Data Generation [[Video]](https://www.youtube.com/watch?v=0QnCH6tlZgc&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_07_1_gan_intro.ipynb)
* Part 7.2: Implementing a GAN in Keras [[Video]](https://www.youtube.com/watch?v=T-MCludVNn4&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_07_2_Keras_gan.ipynb)
* Part 7.3: Face Generation with StyleGAN and Python [[Video]](https://www.youtube.com/watch?v=s1UQPK2KoBY&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_07_3_style_gan.ipynb)
* Part 7.4: GANS for Semi-Supervised Learning in Keras [[Video]](https://www.youtube.com/watch?v=ZPewmEu7644&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_07_4_gan_semi_supervised.ipynb)
* **Part 7.5: An Overview of GAN Research** [[Video]](https://www.youtube.com/watch?v=cvCvZKvlvq4&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_07_5_gan_research.ipynb)
# Part 7.5: An Overview of GAN Research
* [Keras Implementations of Generative Adversarial Networks](https://github.com/eriklindernoren/Keras-GAN)
* [Curated List of Awesome GAN Applications and Demo](https://github.com/nashory/gans-awesome-applications)
### Select Projects
* [Few-Shot Adversarial Learning of Realistic Neural Talking Head Models](https://arxiv.org/abs/1905.08233v1), [YouTube of Talking Heads](https://www.youtube.com/watch?v=p1b5aiTrGzY)
* [Pose Guided Person Image Generation](https://papers.nips.cc/paper/6644-pose-guided-person-image-generation.pdf)
* [Deep Fake](https://www.youtube.com/watch?v=cQ54GDm1eL0)
| github_jupyter |
**Initialization**
The next few steps(or code snippets) initialize the colab environment for running the fast.ai course. Each line of code that added are in place to avoid any error, please do not change the position of any snippet if you do not know what they do.
Be sure to change your runtime to GPU.
Note:- You will get an error saying that the code is closing in the memory limit of 12GB. You can click 'terminate other runtimes'.
This error is popping up because the dataset is taking up most of the space, so don't worry
```
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
!pip install -q fastai
# https://opencv.org/
# pre installation
!apt-get -qq install -y libsm6 libxext6 && pip install -q -U opencv-python
import cv2
# http://pytorch.org/
# pre installation
from os import path
from wheel.pep425tags import get_abbr_impl, get_impl_ver, get_abi_tag
platform = '{}{}-{}'.format(get_abbr_impl(), get_impl_ver(), get_abi_tag())
accelerator = 'cu80' if path.exists('/opt/bin/nvidia-smi') else 'cpu'
!pip install -q http://download.pytorch.org/whl/{accelerator}/torch-0.3.0.post4-{platform}-linux_x86_64.whl torchvision
import torch
!pip install Pillow==4.0.0
!pip install PIL --allow-external PIL --allow-unverified PIL
!pip install image
```
****Dataset****
First make an account on the kaggle website and accept the rules of the competition(Register for the competition). Then run the following commands. The competion name is the last string in the URL.
```
!pip install -q kaggle-cli
!kg download -u <username> -p <password> -c <competition>
!unzip train.zip -d data/
!unzip test_stg1.zip -d data/
!unzip test_stg2.zip -d data/
```
# Fisheries competition
In this notebook we're going to investigate a range of different techniques for the [Kaggle fisheries competition](https://www.kaggle.com/c/the-nature-conservancy-fisheries-monitoring). In this competition, The Nature Conservancy asks you to help them detect which species of fish appears on a fishing boat, based on images captured from boat cameras of various angles. Your goal is to predict the likelihood of fish species in each picture. Eight target categories are available in this dataset: Albacore tuna, Bigeye tuna, Yellowfin tuna, Mahi Mahi, Opah, Sharks, Other
You can use [this](https://github.com/floydwch/kaggle-cli) api to download the data from Kaggle.
```
# Put these at the top of every notebook, to get automatic reloading and inline plotting
# %reload_ext autoreload
# %autoreload 2
%matplotlib inline
# This file contains all the main external libs we'll use
from fastai.imports import *
from fastai.plots import *
from fastai.io import get_data
PATH = "data/fish/"
```
## First look at fish pictures
```
!ls {PATH}
!ls {PATH}train
files = !ls {PATH}train/ALB | head
files
img = plt.imread(f'{PATH}train/ALB/{files[0]}')
plt.imshow(img);
```
## Data pre-processing
Here we are changing the structure of the training data to make it more convinient. We will have all images in a common directory `images` and will have a file `train.csv` with all labels.
```
from os import listdir
from os.path import join
train_path = f'{PATH}/train'
dirs = [d for d in listdir(train_path) if os.path.isdir(join(train_path,d))]
print(dirs)
train_dict = {d: listdir(join(train_path, d)) for d in dirs}
train_dict["LAG"][:10]
sum(len(v) for v in train_dict.values())
with open(f"{PATH}train.csv", "w") as csv:
csv.write("img,label\n")
for d in dirs:
for f in train_dict[d]: csv.write(f'{f},{d}\n')
img_path = f'{PATH}images'
os.makedirs(img_path, exist_ok=True)
!cp {PATH}train/*/*.jpg {PATH}images/
```
## Our first model with Center Cropping
Here we import the libraries we need. We'll learn about what each does during the course.
```
from fastai.transforms import *
from fastai.conv_learner import *
from fastai.model import *
from fastai.dataset import *
from fastai.sgdr import *
sz=350
bs=64
csv_fname = os.path.join(PATH, "train.csv")
train_labels = list(open(csv_fname))
n = len(list(open(csv_fname)))-1
val_idxs = get_cv_idxs(n)
tfms = tfms_from_model(resnet34, sz)
data = ImageClassifierData.from_csv(PATH, "images", csv_fname, bs, tfms, val_idxs)
learn = ConvLearner.pretrained(resnet34, data, precompute=True, opt_fn=optim.Adam, ps=0.5)
lrf=learn.lr_find()
learn.sched.plot()
learn.fit(0.01, 4, cycle_len=1, cycle_mult=2)
lrs=np.array([1e-4,1e-3,1e-2])
learn.precompute=False
learn.freeze_to(6)
lrf=learn.lr_find(lrs/1e3)
learn.sched.plot()
```
## Same model with No cropping
NOTE: Before running this remove the temp file under data/fish.
```
sz = 350
tfms = tfms_from_model(resnet34, sz, crop_type=CropType.NO)
data = ImageClassifierData.from_csv(PATH, "images", csv_fname, bs, tfms, val_idxs)
learn = ConvLearner.pretrained(resnet34, data, precompute=True, opt_fn=optim.Adam, ps=0.5)
lrf=learn.lr_find()
learn.sched.plot()
learn.fit(0.01, 4, cycle_len=1, cycle_mult=2)
lrs=np.array([1e-4,1e-3,1e-2])
learn.precompute=False
learn.unfreeze()
lrf=learn.lr_find(lrs/1e3)
learn.sched.plot()
lrs=np.array([1e-5,1e-4,1e-3])
learn.fit(lrs, 5, cycle_len=1, cycle_mult=2)
```
## Predicting bounding boxes
### Getting bounding boxes data
This part needs to run just the first time to get the file `trn_bb_labels`
```
import json
anno_classes = ['alb', 'bet', 'dol', 'lag', 'other', 'shark', 'yft']
def get_annotations():
annot_urls = [
'5458/bet_labels.json', '5459/shark_labels.json', '5460/dol_labels.json',
'5461/yft_labels.json', '5462/alb_labels.json', '5463/lag_labels.json'
]
cache_subdir = os.path.abspath(os.path.join(PATH, 'annos'))
url_prefix = 'https://kaggle2.blob.core.windows.net/forum-message-attachments/147157/'
os.makedirs(cache_subdir, exist_ok=True)
for url_suffix in annot_urls:
fname = url_suffix.rsplit('/', 1)[-1]
get_data(url_prefix + url_suffix, f'{cache_subdir}/{fname}')
# run this code to get annotation files
get_annotations()
# creates a dictionary of all annotations per file
bb_json = {}
for c in anno_classes:
if c == 'other': continue # no annotation file for "other" class
j = json.load(open(f'{PATH}annos/{c}_labels.json', 'r'))
for l in j:
if 'annotations' in l.keys() and len(l['annotations'])>0:
bb_json[l['filename'].split('/')[-1]] = sorted(
l['annotations'], key=lambda x: x['height']*x['width'])[-1]
bb_json['img_04908.jpg']
raw_filenames = pd.read_csv(csv_fname)["img"].values
file2idx = {o:i for i,o in enumerate(raw_filenames)}
empty_bbox = {'height': 0., 'width': 0., 'x': 0., 'y': 0.}
for f in raw_filenames:
if not f in bb_json.keys(): bb_json[f] = empty_bbox
bb_params = ['height', 'width', 'x', 'y']
def convert_bb(bb):
bb = [bb[p] for p in bb_params]
bb[2] = max(bb[2], 0)
bb[3] = max(bb[3], 0)
return bb
trn_bbox = np.stack([convert_bb(bb_json[f]) for f in raw_filenames]).astype(np.float32)
trn_bb_labels = [f + ',' + ' '.join(map(str,o))+'\n' for f,o in zip(raw_filenames,trn_bbox)]
open(f'{PATH}trn_bb_labels', 'w').writelines(trn_bb_labels)
fnames,csv_labels,_,_ = parse_csv_labels(f'{PATH}trn_bb_labels', skip_header=False)
def bb_corners(bb):
bb = np.array(bb, dtype=np.float32)
row1 = bb[3]
col1 = bb[2]
row2 = row1 + bb[0]
col2 = col1 + bb[1]
return [row1, col1, row2, col2]
f = 'img_02642.jpg'
bb = csv_labels[f]
print(bb)
bb_corners(bb)
new_labels = [f + "," + " ".join(map(str, bb_corners(csv_labels[f]))) + "\n" for f in raw_filenames]
open(f'{PATH}trn_bb_corners_labels', 'w').writelines(new_labels)
```
### Looking at bounding boxes
```
# reading bb file
bbox = {}
bb_data = pd.read_csv(f'{PATH}trn_bb_labels', header=None)
fnames,csv_labels,_,_ = parse_csv_labels(f'{PATH}trn_bb_labels', skip_header=False)
fnames,corner_labels,_,_ = parse_csv_labels(f'{PATH}trn_bb_corners_labels', skip_header=False)
corner_labels["img_06297.jpg"]
csv_labels["img_06297.jpg"]
def create_rect(bb, color='red'):
return plt.Rectangle((bb[2], bb[3]), bb[1], bb[0], color=color, fill=False, lw=3)
def show_bb(path, f='img_04908.jpg'):
file_path = f'{path}images/{f}'
bb = csv_labels[f]
plots_from_files([file_path])
plt.gca().add_patch(create_rect(bb))
def create_corner_rect(bb, color='red'):
bb = np.array(bb, dtype=np.float32)
return plt.Rectangle((bb[1], bb[0]), bb[3]-bb[1], bb[2]-bb[0], color=color, fill=False, lw=3)
def show_corner_bb(path, f='img_04908.jpg'):
file_path = f'{path}images/{f}'
bb = corner_labels[f]
plots_from_files([file_path])
plt.gca().add_patch(create_corner_rect(bb))
show_corner_bb(PATH, f = 'img_02642.jpg')
```
### Model predicting bounding boxes
```
sz=299
bs=64
label_csv=f'{PATH}trn_bb_corners_labels'
n = len(list(open(label_csv)))-1
val_idxs = get_cv_idxs(n)
tfms = tfms_from_model(resnet34, sz, crop_type=CropType.NO, tfm_y=TfmType.COORD)
data = ImageClassifierData.from_csv(PATH, 'images', label_csv, tfms=tfms, val_idxs=val_idxs,
continuous=True, skip_header=False)
trn_ds = data.trn_dl.dataset
x, y = trn_ds[0]
print(x.shape, y)
learn = ConvLearner.pretrained(resnet34, data, precompute=True, opt_fn=optim.Adam, ps=0.5)
lrf=learn.lr_find()
learn.sched.plot()
learn.fit(0.01, 5, cycle_len=1, cycle_mult=2)
lrs=np.array([1e-4,1e-3,1e-2])
learn.precompute=False
learn.unfreeze()
lrf=learn.lr_find(lrs/1e3)
learn.sched.plot()
lrs=np.array([1e-5,1e-4,1e-3])
learn.fit(lrs, 5, cycle_len=1, cycle_mult=2)
```
## Looking into size of images
```
f="img_06297.jpg"
PIL.Image.open(PATH+"images/" + f).size
sizes = [PIL.Image.open(PATH+f).size for f in data.trn_ds.fnames]
raw_val_sizes = [PIL.Image.open(PATH+f).size for f in data.val_ds.fnames]
```
| github_jupyter |
```
import numpy.random as random
import jax.numpy as np
from tqdm import tqdm
from jax import vmap, grad, jit
import matplotlib.pyplot as plt
from cycler import cycler
import cvxpy as cp
plt.rcParams.update({
"text.usetex": True,
"font.family": "sans-serif",
"font.sans-serif": ["Helvetica Neue"],
"font.size": 28,
# "contour.negative_linestyle": 'solid',
})
plt.rc('axes', prop_cycle=cycler('linestyle', ['-', '--', ':', '-.']))
# Define problem
random.seed(0)
m, n = 500, 100
A = random.randn(m, n)
b = random.randn(m)
def f(x):
return np.linalg.norm(np.dot(A, x) - b, 1)
def f_prime(x):
return np.dot(A.T, np.sign(np.dot(A, x) - b))
# JIT functions for speed
f = jit(f)
f_prime = jit(f_prime)
k_vec = np.arange(6000)
# Solve with cvxpy
x_cp = cp.Variable(n)
f_star = cp.Problem(
cp.Minimize(cp.norm(A @ x_cp - b, 1))
).solve(solver=cp.ECOS)
# Solve fixed step size
x0 = random.randn(n)
x_hist = {}
subopt_hist = {}
step_sizes = [0.001, 0.0005, 0.0001, 0.00005]
for t in tqdm(step_sizes):
x_hist[t] = [x0]
f_best = f(x0)
subopt_hist[t] = [(f_best - f_star)/f_star]
for k in k_vec:
x_next = x_hist[t][-1] - t * f_prime(x_hist[t][-1])
x_hist[t].append(x_next)
f_next = f(x_next)
if f_next < f_best:
f_best = f_next
subopt_hist[t].append((f_best - f_star)/f_star)
# Solve with fixed-rule step size
step_size_rules = [lambda k: 0.01/np.sqrt(k+1),
lambda k: 0.001/np.sqrt(k+1),
lambda k: 0.01/(k + 1),
]
step_size_rules_str = [r"$0.01/\sqrt{k+1}$",
r"$0.001/\sqrt{k+1}$",
r"$0.01/(k+1)$",
]
x_hist_adapt = {}
subopt_hist_adapt = {}
for i, t in enumerate(tqdm(step_size_rules)):
x_hist_adapt[i] = [x0]
f_best = f(x0)
subopt_hist_adapt[i] = [(f_best - f_star)/f_star]
for k in k_vec:
x_next = x_hist_adapt[i][-1] - t(k) * f_prime(x_hist_adapt[i][-1])
x_hist_adapt[i].append(x_next)
f_next = f(x_next)
if f_next < f_best:
f_best = f_next
subopt_hist_adapt[i].append((f_best - f_star)/f_star)
# Solve with polyak step size
x_hist_polyak = [x0]
f_best = f(x0)
f_next = f(x0)
subopt_hist_polyak = [(f_best - f_star)/f_star]
for k in k_vec:
f_current = f_next
g = f_prime(x_hist_polyak[-1])
t = (f_current - f_star) / np.linalg.norm(g)**2
x_next = x_hist_polyak[-1] - t * g
x_hist_polyak.append(x_next)
f_next = f(x_next)
if f_next < f_best:
f_best = f_next
subopt_hist_polyak.append((f_best - f_star)/f_star)
# Plot
fig, ax = plt.subplots(1, 2, figsize=(20, 9))
# Fixed step size
for t in step_sizes:
ax[0].plot(k_vec, subopt_hist[t][:-1], color="k", label=r"$t = %.4f$" % t)
ax[0].set_yscale('log')
ax[0].set_ylabel(r"$(f_{\rm best}^{k} - f^\star)/f^\star$")
ax[0].set_xlabel(r"$k$")
ax[0].set_xlim([0, 6000])
ax[0].set_ylim([1e-05, 1e01])
ax[0].set_title(r"$\mbox{Fixed step size}$", y=1.05)
ax[0].legend()
for i, _ in enumerate(step_size_rules):
ax[1].plot(k_vec, subopt_hist_adapt[i][:-1], color="k",
label=step_size_rules_str[i])
ax[1].plot(k_vec, subopt_hist_polyak[:-1], color="k",
label=r"$\mbox{Polyak}$")
ax[1].set_yscale('log')
# ax[1].set_ylabel(r"$(f_{\rm best}^{k} - f^\star)/f^\star$")
ax[1].set_xlabel(r"$k$")
ax[1].set_xlim([0, 6000])
ax[1].set_ylim([1e-05, 1e01])
ax[1].set_title(r"$\mbox{Diminishing step size}$", y=1.05)
ax[1].legend()
plt.tight_layout()
plt.savefig("subgradient_method_1norm.pdf")
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import pandas_datareader.data as web
import matplotlib.pyplot as plt
from collections import OrderedDict
# Industry Stocks Under Consideration
# Food Stocks
food = ['KO','MNST','PEP','FIZZ','KHC','SBUX','DGE','MCD','UN','CPB','BGS','BN.PA']
food.sort()
# Energy Stocks
energy =['XOM','CVX','FP.PA','BP','PTR','BHP','GE','IMO','ENB']
energy.sort()
# Agriculture Stocks
agriculture = ['CVGW','AGCO','BG','FDP','MOS','SMG','CF','ADM','CAT','DE']
agriculture.sort()
# Mining Stocks
mining = ['AA','KALU','ARLP','WME.F','SCCO','BHP','GG','MT.AS']
miningFactors = []
# Mixed Stocks
mixed = []
mixed.append(food)
mixed.append(energy)
mixed.append(agriculture)
mixed.append(mining)
mixed.sort()
finalMixed = []
for x in mixed :
for y in x:
finalMixed.append(y)
list(OrderedDict.fromkeys(finalMixed))
stocksArray = []
stocksArray.append(food)
stocksArray.append(energy)
stocksArray.append(agriculture)
stocksArray.append(mining)
# stocksArray.append(finalMixed)
print(stocksArray)
for stocks in stocksArray:
# Stock Prices
stateDate ='01/01/2015'
stockDataReader = 'yahoo'
stockResults = web.DataReader(stocks,stockDataReader,startDate)['Adj Close']
stockResults.sort_index(inplace=True)
# Returns, Mean Daily Returns and Covariance
dailyReturns = stockResults.pct_change()
meanDailyReturns = dailyReturns.mean()
covarianceStocks = dailyReturns.cov()
# Number of Simulations
num_portfolios = 100000
initialisation = (4+len(stocks)-1,num_portfolios)
simulations = np.zeros(initialisation)
for i in xrange(num_portfolios):
# Weights Set
weights = np.array(np.random.random(len(stocks)))
# Normalise The Weights
weights /= np.sum(weights)
# Find Returns and Volatility Of Portfolio
CONSTANT = 252
finalReturn = np.sum(meanDailyReturns * weights) * CONSTANT
finalVolatility = np.sqrt(np.dot(weights.T,np.dot(covarianceStocks, weights))) * np.sqrt(CONSTANT)
# Save Results
simulations[0,i],simulations[1,i] = finalReturn,finalVolatility
# Save Sharpe Ratio (minus the risk free element)
sharpeRatio = simulations[0,i] / simulations[1,i]
simulations[2,i] = sharpeRatio
for j in range(len(weights)):
simulations[j+3,i] = weights[j]
# Add Results To DataFrame Object
if len(stocks) == 12:
finalResults = pd.DataFrame(simulations.T,columns=['ret','stdev','sharpe',stocks[0],stocks[1],stocks[2],stocks[3],stocks[4],stocks[5],stocks[6],stocks[7],stocks[8],stocks[9],stocks[10],stocks[11]])
elif len(stocks) == 9:
finalResults = pd.DataFrame(simulations.T,columns=['ret','stdev','sharpe',stocks[0],stocks[1],stocks[2],stocks[3],stocks[4],stocks[5],stocks[6],stocks[7],stocks[8]])
elif len(stocks) == 10:
finalResults = pd.DataFrame(simulations.T,columns=['ret','stdev','sharpe',stocks[0],stocks[1],stocks[2],stocks[3],stocks[4],stocks[5],stocks[6],stocks[7],stocks[8],stocks[9]])
elif len(stocks) == 8:
finalResults = pd.DataFrame(simulations.T,columns=['ret','stdev','sharpe',stocks[0],stocks[1],stocks[2],stocks[3],stocks[4],stocks[5],stocks[6],stocks[7]])
# else :
# finalResults = pd.DataFrame(simulations.T,columns=['ret','stdev','sharpe',stocks[0],stocks[1],stocks[2],stocks[3],stocks[4],stocks[5],stocks[6],stocks[7],stocks[8],stocks[9],stocks[10],stocks[11],stocks[12],stocks[13],stocks[14],stocks[15],stocks[16],stocks[17],stocks[18],stocks[19],stocks[20],stocks[21],stocks[22],stocks[23],stocks[24],stocks[25],stocks[26],stocks[27],stocks[28],stocks[29],stocks[30],stocks[31],stocks[32],stocks[33],stocks[34],stocks[35],stocks[36],stocks[37],stocks[38]])
# Portfolios With Best Sharp-Ratio and Lowest Volatility
bestSharpeRatio,lowestVolatility = finalResults.iloc[finalResults['sharpe'].idxmax()],finalResults.iloc[finalResults['stdev'].idxmin()]
if len(stocks) == 12:
# Plot Graphs
plt.figure()
plt.title('Food Industry Portfolio Distributon')
plt.scatter(finalResults.stdev,finalResults.ret,c=finalResults.sharpe,cmap='RdYlBu')
plt.xlabel('Volatility')
plt.ylabel('Returns')
plt.colorbar()
plt.scatter(bestSharpeRatio[1],bestSharpeRatio[0],marker=(5,1,0),color='r',s=100)
plt.scatter(lowestVolatility[1],lowestVolatility[0],marker=(5,1,0),color='g',s=100)
print(bestSharpeRatio)
print(lowestVolatility)
elif len(stocks) == 9:
plt.figure()
plt.title('Energy Industry Portfolio Distributon')
plt.scatter(finalResults.stdev,finalResults.ret,c=finalResults.sharpe,cmap='RdYlBu')
plt.xlabel('Volatility')
plt.ylabel('Returns')
plt.colorbar()
plt.scatter(bestSharpeRatio[1],bestSharpeRatio[0],marker=(5,1,0),color='r',s=100)
plt.scatter(lowestVolatility[1],lowestVolatility[0],marker=(5,1,0),color='g',s=100)
print(bestSharpeRatio)
print(lowestVolatility)
elif len(stocks) == 10:
plt.figure()
plt.title('Agriculture Industry Portfolio Distributon')
plt.scatter(finalResults.stdev,finalResults.ret,c=finalResults.sharpe,cmap='RdYlBu')
plt.xlabel('Volatility')
plt.ylabel('Returns')
plt.colorbar()
plt.scatter(bestSharpeRatio[1],bestSharpeRatio[0],marker=(5,1,0),color='r',s=100)
plt.scatter(lowestVolatility[1],lowestVolatility[0],marker=(5,1,0),color='g',s=100)
print(bestSharpeRatio)
print(lowestVolatility)
elif len(stocks) == 8:
plt.figure()
plt.title('Mining Industry Portfolio Distributon')
plt.scatter(finalResults.stdev,finalResults.ret,c=finalResults.sharpe,cmap='RdYlBu')
plt.xlabel('Volatility')
plt.ylabel('Returns')
plt.colorbar()
plt.scatter(bestSharpeRatio[1],bestSharpeRatio[0],marker=(5,1,0),color='r',s=100)
plt.scatter(lowestVolatility[1],lowestVolatility[0],marker=(5,1,0),color='g',s=100)
print(bestSharpeRatio)
print(lowestVolatility)
else :
plt.figure()
plt.title('Mixed Industry Portfolio Distributon')
plt.scatter(finalResults.stdev,finalResults.ret,c=finalResults.sharpe,cmap='RdYlBu')
plt.xlabel('Volatility')
plt.ylabel('Returns')
plt.colorbar()
plt.scatter(bestSharpeRatio[1],bestSharpeRatio[0],marker=(5,1,0),color='r',s=100)
plt.scatter(lowestVolatility[1],lowestVolatility[0],marker=(5,1,0),color='g',s=100)
print(bestSharpeRatio)
print(lowestVolatility)
import numpy as np
import pandas as pd
import pandas_datareader.data as web
import matplotlib.pyplot as plt
# Industry Stocks Under Consideration
# Food Stocks
food = ['KO','MNST','PEP','FIZZ','KHC','SBUX','DGE','MCD','UN','CPB','BGS','BN.PA']
food.sort()
foodFactors = [0.9,0.85,0.85,0.85,0.75,0.65,0.85,0.75,0.85,0.9,0.9,0.9]
# Energy Stocks
energy =['XOM','CVX','FP.PA','BP','PTR','BHP','GE','IMO','ENB']
energy.sort()
energyFactors = [0.7,0.7,0.8,0.6,0.7,0.8,0.7,0.65,0.7]
# Agriculture Stocks
agriculture = ['CVGW','AGCO','BG','FDP','MOS','SMG','CF','ADM','CAT','DE']
agriculture.sort()
agricultureFactors = [0.9,0.8,0.7,0.7,0.65,0.65,0.85,0.8,0.8,0.8]
# Mining Stocks
mining = ['AA','KALU','ARLP','WME.F','SCCO','BHP','GG','MT.AS']
miningFactors = []
miningFactors = [0.95,0.95,0.95,0.95,0.95,0.9,0.9,0.85]
finalMixed = []
for x in mixed :
for y in x:
finalMixed.append(y)
mixedFactors = []
mixedFactors.append(foodFactors)
mixedFactors.append(energyFactors)
mixedFactors.append(agricultureFactors)
mixedFactors.append(miningFactors)
finalMixedFactors = []
for x in mixed :
for y in x:
finalMixedFactors.append(y)
stocksArray = []
stocksArray.append(food)
stocksArray.append(energy)
stocksArray.append(agriculture)
stocksArray.append(mining)
print(stocksArray)
for stocks in stocksArray:
# Stock Prices
stateDate ='01/01/2015'
stockDataReader = 'yahoo'
stockResults = web.DataReader(stocks,stockDataReader,startDate)['Adj Close']
stockResults.sort_index(inplace=True)
# Returns, Mean Daily Returns and Covariance
dailyReturns = stockResults.pct_change()
meanDailyReturns = dailyReturns.mean()
covarianceStocks = dailyReturns.cov()
if len(stocks) == 12:
meanDailyReturns=[x*y for x, y in zip(foodFactors, meanDailyReturns)]
elif len(stocks) == 9:
meanDailyReturns=[x*y for x, y in zip(energyFactors, meanDailyReturns)]
elif len(stocks) == 10:
meanDailyReturns=[x*y for x, y in zip(agricultureFactors, meanDailyReturns)]
elif len(stocks) == 8:
meanDailyReturns=[x*y for x, y in zip(miningFactors, meanDailyReturns)]
else :
meanDailyReturns=[x*y for x, y in zip(mixedFactors, meanDailyReturns)]
# Number of Simulations
num_portfolios = 100000
initialisation = (4+len(stocks)-1,num_portfolios)
simulations = np.zeros(initialisation)
for i in xrange(num_portfolios):
# Weights Set
weights = np.array(np.random.random(len(stocks)))
# Normalise The Weights
weights /= np.sum(weights)
# Find Returns and Volatility Of Portfolio
CONSTANT = 252
finalReturn = np.sum(meanDailyReturns * weights) * CONSTANT
finalVolatility = np.sqrt(np.dot(weights.T,np.dot(covarianceStocks, weights))) * np.sqrt(CONSTANT)
# Save Results
simulations[0,i],simulations[1,i] = finalReturn,finalVolatility
# Save Sharpe Ratio (minus the risk free element)
sharpeRatio = simulations[0,i] / simulations[1,i]
simulations[2,i] = sharpeRatio
for j in range(len(weights)):
simulations[j+3,i] = weights[j]
# Add Results To DataFrame Object
if len(stocks) == 12:
finalResults = pd.DataFrame(simulations.T,columns=['ret','stdev','sharpe',stocks[0],stocks[1],stocks[2],stocks[3],stocks[4],stocks[5],stocks[6],stocks[7],stocks[8],stocks[9],stocks[10],stocks[11]])
elif len(stocks) == 9:
finalResults = pd.DataFrame(simulations.T,columns=['ret','stdev','sharpe',stocks[0],stocks[1],stocks[2],stocks[3],stocks[4],stocks[5],stocks[6],stocks[7],stocks[8]])
elif len(stocks) == 10:
finalResults = pd.DataFrame(simulations.T,columns=['ret','stdev','sharpe',stocks[0],stocks[1],stocks[2],stocks[3],stocks[4],stocks[5],stocks[6],stocks[7],stocks[8],stocks[9]])
elif len(stocks) == 8:
finalResults = pd.DataFrame(simulations.T,columns=['ret','stdev','sharpe',stocks[0],stocks[1],stocks[2],stocks[3],stocks[4],stocks[5],stocks[6],stocks[7]])
# else :
# finalResults = pd.DataFrame(simulations.T,columns=['ret','stdev','sharpe',stocks[0],stocks[1],stocks[2],stocks[3],stocks[4],stocks[5],stocks[6],stocks[7],stocks[8],stocks[9],stocks[10],stocks[11],stocks[12],stocks[13],stocks[14],stocks[15],stocks[16],stocks[17],stocks[18],stocks[19],stocks[20],stocks[21],stocks[22],stocks[23],stocks[24],stocks[25],stocks[26],stocks[27],stocks[28],stocks[29],stocks[30],stocks[31],stocks[32],stocks[33],stocks[34],stocks[35],stocks[36],stocks[37],stocks[38]])
# Portfolios With Best Sharp-Ratio and Lowest Volatility
bestSharpeRatio,lowestVolatility = finalResults.iloc[finalResults['sharpe'].idxmax()],finalResults.iloc[finalResults['stdev'].idxmin()]
if len(stocks) == 12:
# Plot Graphs
plt.figure()
plt.title('Food Industry Portfolio Distributon')
plt.scatter(finalResults.stdev,finalResults.ret,c=finalResults.sharpe,cmap='RdYlBu')
plt.xlabel('Volatility')
plt.ylabel('Returns')
plt.colorbar()
plt.scatter(bestSharpeRatio[1],bestSharpeRatio[0],marker=(5,1,0),color='r',s=100)
plt.scatter(lowestVolatility[1],lowestVolatility[0],marker=(5,1,0),color='g',s=100)
print(bestSharpeRatio)
print(lowestVolatility)
elif len(stocks) == 9:
plt.figure()
plt.title('Energy Industry Portfolio Distributon')
plt.scatter(finalResults.stdev,finalResults.ret,c=finalResults.sharpe,cmap='RdYlBu')
plt.xlabel('Volatility')
plt.ylabel('Returns')
plt.colorbar()
plt.scatter(bestSharpeRatio[1],bestSharpeRatio[0],marker=(5,1,0),color='r',s=100)
plt.scatter(lowestVolatility[1],lowestVolatility[0],marker=(5,1,0),color='g',s=100)
print(bestSharpeRatio)
print(lowestVolatility)
elif len(stocks) == 10:
plt.figure()
plt.title('Agriculture Industry Portfolio Distributon')
plt.scatter(finalResults.stdev,finalResults.ret,c=finalResults.sharpe,cmap='RdYlBu')
plt.xlabel('Volatility')
plt.ylabel('Returns')
plt.colorbar()
plt.scatter(bestSharpeRatio[1],bestSharpeRatio[0],marker=(5,1,0),color='r',s=100)
plt.scatter(lowestVolatility[1],lowestVolatility[0],marker=(5,1,0),color='g',s=100)
print(bestSharpeRatio)
print(lowestVolatility)
elif len(stocks) == 8:
plt.figure()
plt.title('Mining Industry Portfolio Distributon')
plt.scatter(finalResults.stdev,finalResults.ret,c=finalResults.sharpe,cmap='RdYlBu')
plt.xlabel('Volatility')
plt.ylabel('Returns')
plt.colorbar()
plt.scatter(bestSharpeRatio[1],bestSharpeRatio[0],marker=(5,1,0),color='r',s=100)
plt.scatter(lowestVolatility[1],lowestVolatility[0],marker=(5,1,0),color='g',s=100)
print(bestSharpeRatio)
print(lowestVolatility)
else :
plt.figure()
plt.title('Mixed Industry Portfolio Distributon')
plt.scatter(finalResults.stdev,finalResults.ret,c=finalResults.sharpe,cmap='RdYlBu')
plt.xlabel('Volatility')
plt.ylabel('Returns')
plt.colorbar()
plt.scatter(bestSharpeRatio[1],bestSharpeRatio[0],marker=(5,1,0),color='r',s=100)
plt.scatter(lowestVolatility[1],lowestVolatility[0],marker=(5,1,0),color='g',s=100)
print(bestSharpeRatio)
print(lowestVolatility)
```
| github_jupyter |
```
#Modules to install via pip pandas,ipynb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import json
from pprint import pprint
import os
import import_ipynb
import sys
import kmeans
sys.path.append('../')
from functions import *
from trace_analysis import *
from plots import *
from trace_analysis_cooja2 import *
from node import *
from plots_analysis import *
from pandas.plotting import scatter_matrix
import cmath as math
from mpl_toolkits.mplot3d import Axes3D
from sklearn import cluster
from sklearn.metrics import confusion_matrix
from sklearn.metrics.cluster import normalized_mutual_info_score
from sklearn.metrics.cluster import adjusted_rand_score
from sklearn.cluster import KMeans
# scipy
from scipy.cluster.vq import kmeans,vq,whiten
import sklearn.metrics as sm
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
%matplotlib inline
import random
random.seed(6666)
#directory=os.getcwd()+"/cooja3-9nodes/"
directory="../cooja3-9nodes/"
plots = [
#2 BH3
(directory+"traces/1bh-3", 'grid9_1bh-3_2019-02-13_16:28_',"BH"),
(directory+"traces/1bh-3", 'grid9_1bh-3_2019-02-13_22:05_',"BH"),
#2 BH5
(directory+"traces/1bh-5", 'grid9_1bh-5_2019-02-13_15:31_',"BH"),
(directory+"traces/1bh-5", 'grid9_1bh-5_2019-02-13_21:44_',"BH"),
#2 BH 6
(directory+"traces/1bh-6", 'grid9_1bh-6_2019-02-13_12:59_',"BH"),
(directory+"traces/1bh-6", 'grid9_1bh-6_2019-02-13_19:15_',"BH"),
#2 BH 7
(directory+"traces/1bh-7", 'grid9_1bh-7_2019-02-13_15:08_',"BH"),
(directory+"traces/1bh-7", 'grid9_1bh-7_2019-02-13_20:02_',"BH"),
#2 bh 9
(directory+"traces/1bh-9", 'grid9_1bh-9_2019-02-13_15:57_',"BH"),
(directory+"traces/1bh-9", 'grid9_1bh-9_2019-02-13_19:35_',"BH"),
#3 normal
(directory+"traces/normal", 'grid9_normal_2019-02-13_17:05_',"normal"),
(directory+"traces/normal", "grid9_normal_2019-02-13_18:51_","normal"),
(directory+"traces/normal", "grid9_normal_2019-02-13_22:23_","normal"),
]
analyze_network(directory,plots,200,12)
directory="../cooja3-9nodes/"
plots = [
#2 BH3
( "traces/1bh-3", 'grid9_1bh-3_2019-02-13_16:28_',"BH"),
( "traces/1bh-3", 'grid9_1bh-3_2019-02-13_22:05_',"BH"),
#2 BH5
( "traces/1bh-5", 'grid9_1bh-5_2019-02-13_15:31_',"BH"),
( "traces/1bh-5", 'grid9_1bh-5_2019-02-13_21:44_',"BH"),
#2 BH 6
( "traces/1bh-6", 'grid9_1bh-6_2019-02-13_12:59_',"BH"),
( "traces/1bh-6", 'grid9_1bh-6_2019-02-13_19:15_',"BH"),
#2 BH 7
( "traces/1bh-7", 'grid9_1bh-7_2019-02-13_15:08_',"BH"),
( "traces/1bh-7", 'grid9_1bh-7_2019-02-13_20:02_',"BH"),
#2 bh 9
( "traces/1bh-9", 'grid9_1bh-9_2019-02-13_15:57_',"BH"),
( "traces/1bh-9", 'grid9_1bh-9_2019-02-13_19:35_',"BH"),
#3 normal
( "traces/normal", 'grid9_normal_2019-02-13_17:05_',"normal"),
( "traces/normal", "grid9_normal_2019-02-13_18:51_","normal"),
( "traces/normal", "grid9_normal_2019-02-13_22:23_","normal"),
]
d= {
"directory":[],
"case":[],
"case_accuracy":[]
}
# for i in plots:
# d["directory"].append(i[0])
# d["case"].append(i[1])
# d["case_accuracy"].append(i[2])
# df=pd.DataFrame(d)
# df.to_csv("traces.csv", sep='', encoding='utf-8')
directory='../cooja3-9nodes/traces/traces.csv'
df=pd.read_csv(directory, sep=',', encoding='utf-8')
col=df["case"].values
print(col)
#for i in range(len(df)):
#print(i)
#print(df)
#col=df["cases"]
df
def import_nodes_Cooja_2(directory,tracemask,node_defaults):
#print(directory)
#print(tracemask)
files = []
# load all files and extract IPs of nodes
for file in os.listdir(directory):
try:
if file.startswith(tracemask) and file.index("routes"):
continue
except:
files.append(file)
nodes = pd.DataFrame(columns=['node_id', 'rank'])
packets_node = {}
# Load the ICMP traces
for file in files:
packets = pd.read_csv(directory + '/' + file,
sep=' |icmp_seq=|ttl=|time=',
na_filter=True,
header=None,
skiprows=1,
skipfooter=4,
usecols=[3, 5, 7, 9],
names=['node_id', 'seq', 'hop', 'rtt'],
engine='python').dropna().drop_duplicates()
if len(packets) < 1:
# Nodes affected by a black hole did not receive any packet
node_id = file[-24:-4]
packets = pd.DataFrame(columns=['node_id', 'seq', 'hop', 'rtt'],
data=[[node_id, 1, node_defaults[node_id], 1]])
nodes.loc[len(nodes)] = [file[-24:-4], node_defaults[node_id]]
packets_node[file[-24:-4]] = packets
else:
#print("qui")
packets['node_id'] = packets.apply(lambda row: row['node_id'][:-1], axis=1)
#print(packets["hop"].head())
#print(nodes)
#nodes.loc[len(nodes)-1] = [packets['node_id'][0], 64-packets['hop'][0]]
#print("ciao"+ str(64-packets['hop'][0]))
#print(nodes.loc[7])
packets = packets.sort_values(by=['node_id', 'seq'], ascending=True, na_position='first')
packets = packets[packets['rtt'] > 1]
packets["hop"]= 64-packets['hop']
packets_node[packets['node_id'][0]] = packets
nodes=nodes.sort_values(by=['rank', 'node_id'])
#tranformation in node
nodeList=[]
for n in packets_node.keys():
#print((packets_node[n]).head())
pkts=packets_node[n].drop(["node_id","hop"],axis=1)
#print(pkts)
hop=int(packets_node[n]["hop"][0])
ip=packets_node[n]["node_id"][0]
#print(hop)
n=node(ip,hop,pkts)
nodeList.append(n)
return nodeList
def import_Cooja2(df):
data=[]
node_defaults = {
"aaaa::212:7403:3:303": 1,
"aaaa::212:7402:2:202": 2,
"aaaa::212:7404:4:404": 2,
"aaaa::212:7406:6:606": 2,
"aaaa::212:7405:5:505": 3,
"aaaa::212:7407:7:707": 3,
"aaaa::212:7409:9:909": 3,
"aaaa::212:7408:8:808": 4,
"aaaa::212:740a:a:a0a": 4}
#for row in plots:
#print("Importing ./"+row[0]+"/"+row[1])
print(directory+df["directory"].values)
for i in range(len(df["directory"].values)):
nodeList=import_nodes_Cooja_2(directory+df["directory"].values[i],df["case"].values[i],node_defaults)
data.append(nodeList)
print(len(data))
print(len(data[0]))
return data
def analyze_network(directory,df,pings,window):
cases=[]
casesAccuracy=df["case_accuracy"].values
# for row in plots:
# cases.append(row[1])
# casesAccuracy.append(row[2])
# data=import_Cooja2(plots)
cases=df["case"].values
folder=df["directory"].values+directory
data=import_Cooja2(df)
#pings=getPings(data)
#All data collection is in variable node that is a list of list of nodes
#3 nets input x 9 nodes by net
print("Processing...")
d={ "label":[],
"type":[],
"count":[],
"std": [],
"mean": [],
"var": [],
"hop":[],
"packet loss":[],
"outliers":[],
"node":[]
}
#count=[]
labels=[]
var=[]
#window=100
#stats=pd.DataFrame(columns=columns)
n=pings
for i in range(len(data)):
#window=pings[i]
for j in range(len(data[i])):
#n=pings[i]
#print(n)
for z in range(0,n,int(window)):
#if(z+window>n):break
#print(z,z+window)
#df1 = df1.assign(e=p.Series(np.random.randn(sLength)).values)
node=data[i][j].pkts
name=str(j)+" "+cases[i]
nodeWindow=node[(node["seq"]<z+window) & (node["seq"]>=z)]
nodeWindowP=nodeWindow["rtt"]
d["count"].append(nodeWindowP.count())
#Case without outliers
#Case with outliers
std=0
if (nodeWindowP.std()>10):
std=1
std=nodeWindowP.std()
d["std"].append(std)
mean=nodeWindowP.mean()
#if(mean<1):print(mean)
d["mean"].append(mean)
var=0
if (nodeWindowP.var()>var): var=nodeWindowP.var()
d["var"].append(var)
d["label"].append(cases[i])
d["hop"].append(data[i][j].hop)
d["type"].append(casesAccuracy[i])
d["outliers"].append(getOutliers(nodeWindow)["rtt"].count())
missing=window-nodeWindow.count()
d["node"].append(data[i][j].ip)
mP=getPercentageMissingPackets(nodeWindow,window)
PL=0
if(mP>30):
PL=1
PL=mP
d["packet loss"].append(mP)
stats=pd.DataFrame(d)
dataK=stats.drop([
"label",
"mean",
"var",
"std",
#"packet loss",
"outliers",
"hop",
"count",
"node",
#"type"
],axis=1)
dataK=dataK.fillna(0)
#print(dataK)
correction=[]
correction_alt=[]
col=np.array(dataK["type"])
dataK=dataK.drop(["type"],axis=1)
#Creating simple array to correct unsupervised learning
#NB as it is unsupervised could happen that the correction are inverted
for i in range(len(col)):
el=d["type"][i]
if el=="normal":
correction.append(1)
correction_alt.append(0)
else:
correction.append(0)
correction_alt.append(1)
dataC=stats["label"]
kmeans = KMeans(n_clusters=2)
kmeans.fit(dataK)
labels = kmeans.predict(dataK)
centroids = kmeans.cluster_centers_
labels=accuracy_score_corrected(correction,labels)
predicted=[]
for i in range(len(labels)):
if(labels[i]==1):
predicted.append("normal")
else: predicted.append("BH")
#print(len(predicted))
stats["predicted"]=pd.Series(np.array(predicted))
stats["predicted number"]=pd.Series(np.array(labels))
stats["correction number"]=pd.Series(np.array(correction))
stats_csv=stats[[
"label",
"type",
"predicted",
"packet loss",
"outliers",
"std",
"hop",
"node",
"mean"
]]
stats_csv.to_csv("results_kmeans.csv", sep='\t', encoding='utf-8')
stats.head()
net_results={
"case":[],
"predicted":[],
"real":[]
}
#print(stats["predicted number"])
for case in range(len(cases)):
subset=stats[stats["label"]==cases[case]]
mean_predicted=str(subset["predicted number"].mean()*100)+"% normal"
net_results["case"].append(cases[case])
net_results["predicted"].append(mean_predicted)
net_results["real"].append(casesAccuracy[case])
results=pd.DataFrame(net_results)
results.to_csv("results_network_kmeans.csv", sep='\t', encoding='utf-8')
print(results)
path='../cooja3-9nodes/traces/'
#df=pd.read_csv(directory+"/traces/traces.csv", sep=',', encoding='utf-8')
#print(directory+df["directory"].values)
#print(directory)
#analyze_network(directory,df,200,50)
dirs=os.listdir(path)
print(dirs)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/pykeen/pykeen/blob/master/notebooks/hello_world/hello_world.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Hello, World!
This notebook is about your first steps with knowledge graph embedding models in PyKEEN.
You'll get to do the following:
1. train a model
2. evaluate how good it learned
3. turn it around and start making predictions.
```
# Install packages if they're not already found
! python -c "import pykeen" || pip install git+https://github.com/pykeen/pykeen.git
! python -c "import word_cloud" || pip install git+https://github.com/kavgan/word_cloud.git
import os
import matplotlib.pyplot as plt
import torch
import pykeen
from pykeen.datasets import Nations
from pykeen.pipeline import pipeline
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
pykeen.env()
```
## Train a Model
More tutorials on training your first model can be found [here](https://pykeen.readthedocs.io/en/latest/first_steps.html).
You can try switching out the model, add a `loss`, a `regularizer`, or switch the training assumption from `sLCWA` to `LCWA`. Each also has their own hyper-parameters, though PyKEEN tries to have reasonable defaults for you. The most useful one to change is the `num_epochs` in the `training_kwargs`, which is already below.
```
result = pipeline(
dataset='Nations',
model='PairRE',
# Training configuration
training_kwargs=dict(
num_epochs=200,
use_tqdm_batch=False,
),
# Runtime configuration
random_seed=1235,
device='cpu',
)
```
Save the trained model (which contains the triples and all of the learned parameters), the results from training, and all of the experimental metadata.
```
save_location = 'results' # this directory
result.save_to_directory(save_location)
os.listdir(save_location)
# How to look at the model
model = result.model
model
# How to look at the triples
tf = result.training
tf
tf.num_entities, tf.num_relations, tf.num_triples
```
## Evaluating the Results
Check that the loss is going down (and not oscillating) by plotting in the notebook.
```
result.plot_losses()
plt.show()
```
Look at the result. These are pretty tricky to interpret, so remember:
- adjusted mean rank is between [0, 2]. Closer to 0 is better!
- mean rank is a positive integer, with a bound based on the number of entities. Closer to 0 is better!
- hits@k is reported between [0, 1] and interpreted as a percentage. Closer to 1 is better!
```
result.metric_results.to_df()
```
## Turn it around: make predictions
It's very difficult to interpret KGEMs statistically, so it's best to sort order the predictions by their scores. All interaction functions in PyKEEN have been implemented such that the higher the score (or less negative the score), the more likely a triple is to be true.
Before making any predictions, we're goign to show some word clouds of the entities and relations in the Nations dataset, with size corresponding to frequency of appearance in triples.
```
tf.entity_word_cloud()
tf.relation_word_cloud()
testing_mapped_triples = Nations().testing.mapped_triples.to(model.device)
# Who do we predict brazil participates in inter-governmental organizations with?
model.get_tail_prediction_df('brazil', 'intergovorgs', triples_factory=tf, testing=testing_mapped_triples)
# Automatically filter out non-novel predictions (e.g. in training or in testing is True)
model.get_tail_prediction_df('brazil', 'intergovorgs', triples_factory=tf, testing=testing_mapped_triples, remove_known=True)
# Who do we predict to have a conference with brazil?
model.get_head_prediction_df('conferences', 'brazil', triples_factory=tf, testing=testing_mapped_triples)
# Score all triples
model.get_all_prediction_df(triples_factory=tf, testing=testing_mapped_triples)
```
| github_jupyter |
```
import numpy as np
import scipy
from scipy import stats, signal
import matplotlib.pyplot as plt
import matplotlib
import random as r
r.seed(12345)
plt.rcParams["figure.figsize"] = (15,10)
#Boris Chkodrov
```
#### Problem 1: Which is more probable when rolling 2 six-sided dice: rolling snake eyes or rolling sevens? What is the ratio of the probabilities?
I predict that rolling sevens is more common, as there is only a single way for two dice to roll snake eyes, whereas there are multiple ways for them to roll seven. I expect that rolling a seven will be about 6 times as likely as rolling snake eyes.
```
snakeeyes = 0
seven = 0
for roll in range(1,100000):
roll1 = r.randrange(1,7)
roll2 = r.randrange(1,7)
if(roll1 == 1 and roll2 == 2):
snakeeyes += 1
if(roll1+roll2 == 7):
seven += 1
print("Snake Eyes Count: " , snakeeyes)
print("Sevens Count: ", seven)
print("Ratio P(seven)/P(Snake Eyes): ", seven/snakeeyes)
```
As we can see, the numerical ratio of sevens to snake eyes is indeed near six.
#### Problem 2: Following what we did in class show how to use the convolution operator to determine the probability of the sum of 2 six sided dice. Do both analytically (math & counting) and numerically (computer program). Beware the implicit definition of the values (x-axis on histogram).
Analytical solution
$$P_{A+B}(x) = \sum_z P_A(z)P_B(x-z)$$
$P_{A+B}(7)=\sum_z{f(z)g(7-z)}$ where $1\leq z \leq 6$
$P_{A+B}(7)=f(1)g(6)+f(2)g(5)+...+f(6)g(1)$
As there are 6 total combinations of two dice which add up to 7, and any result on a single die is equally probable, we can say:
$P_{A+B}(7)=6*(\frac{1}{6}*\frac{1}{6}) = \frac{1}{6}$
Or, more generally: $P(x)=\frac{n}{6}$ Where x is any integer between 2 and 12, and n is the number of combinations of two dice which add up to x.
Numerical Solution:
```
d6 = [1/6, 1/6, 1/6, 1/6, 1/6, 1/6]
prob = scipy.signal.convolve(d6, d6)
x = np.arange(2,len(prob)+2)
plt.bar(x,prob)
plt.title('Convolution Probabilities For Two Six Sided Dice')
plt.show()
```
#### Problem 3: Calculate the mean and variance of the distribution in problem 2:
We choose to not use the sample variance formula, as we are looking at a distribution with fixed values and not a sample of a distribution.
```
mean = sum(prob*x)
variance = sum(prob*np.square(x)) - mean**2
print("Distribution Mean: " , np.round(mean, 3))
print("Distribution Variance: " , np.round(variance,3))
```
#### Problem 4: Repeat 2, and graph the average of 10 dice. Is this a Gaussian distribution? explain in depth.
```
x = np.arange(1,6.1,0.1).tolist()
p4 = d6
for i in range(1,10):
p4 = scipy.signal.convolve(p4,d6)
fig, (ax1,log1) = plt.subplots(1,2)
ax1.title.set_text("PMF of 10 die sum")
ax1.bar(x, p4)
log1.title.set_text("Log PMF of 10 die sum")
log1.bar(x, p4, log=True)
x = np.linspace(0,6)
plt.show()
```
Suppose we assume that our sample comes from a normal distribution. In that case, we would expect that when we perform the normal test, it should return a p-value greater than 0.05. If the normal test returns a smaller p-value, we can reject the null hypothesis and state that our sample did not come from a normal distribution - and therefore, the distribution we created through convolving the averages of 10 six sided dice is not gaussian.
In order to further make sure that our p-value is not a fluke, we will perform the normal test multiple times with new samples taken from both our distribution and the normal distribution, and then investigate the mean of those p-values.
```
#Take sample from the distribution we just made
s_sum = 0
n_sum = 0
for trial in range (1,101):
s = stats.rv_discrete(values=(x,p1)).rvs(size=50000)
n = stats.norm.rvs(size=50000)
s_sum += stats.normaltest(s).pvalue
n_sum += stats.normaltest(n).pvalue
s_mean = s_sum/100
n_mean = n_sum/100
#Compare sample to a random sample from a normal distribution
print("Average p-value of 100 samples taken from convolution distribution: " , np.round(s_mean,3))
print("Average p-value of 100 samples taken from normal distribution" , np.round(n_mean,3))
```
As we can see, the average probability that our sample comes from a normal distribution is greater than 0.05. Therefore we cannot the null hypothesis and it is possible that our distribution is gaussian. That said, when we compare the average p-value of our distribution to the average p-value of a sample taken from a normal distribution, we do see a marked difference. Therefore I expect (but cannot prove) that our convolution distribution approaches a gaussian distribution as we increae the number of dice we use.
#### Problem 5: Show that the sum and average of an initially Gaussian distribution is also a Gaussian. How does the standard deviation of the resulting sum or average Gaussian change? Explore what this means for integrating a signal over time.
```
x_init = np.linspace(-5,5,100)
d_init = stats.norm.pdf(x_init, loc=0,scale=2) #d_init is a gaussian function with mean=0 and standard deviation = 2
#Now we will convolve it:
p = d_init
n = 10
for i in range(n-1):
p = scipy.signal.convolve(p,d_init)
x = np.linspace(-5,5, len(p))
# fig, ((ax1,log1),(ax2,log2)) = plt.subplots(2,2)
fig, (ax1,ax2) = plt.subplots(1,2)
ax1.title.set_text("Original Gaussian Distribution, mean=0, sd = 2")
ax1.plot(x_init, d_init)
# log1.title.set_text("Log of Original Distribution")
# log1.bar(x_init, d_init, log=True)
ax2.title.set_text("10x Convolved Distribution")
ax2.plot(x, p, 'r')
# log2.title.set_text("Log of 10x Convolved Distribution")
# log2.bar(x, p, log=True)
plt.rcParams["figure.figsize"] = (15,5)
```
The left graph is the original Gaussian distribution, which has a standard deviation of two. The red graph on the right has been averaged ten times via convolution. Both graphs are clearly Gaussian distributions, however, the right graph is much more narrow and thus has a smaller standard deviation. We can also see that both distributions share the same mean.
Therefore, for integrating a signal over time, this shows that by averaging and processing data, we can narrow our distribution without changing the mean.
| github_jupyter |
<a href="https://qworld.net" target="_blank" align="left"><img src="../qworld/images/header.jpg" align="left"></a>
$ \newcommand{\bra}[1]{\langle #1|} $
$ \newcommand{\ket}[1]{|#1\rangle} $
$ \newcommand{\braket}[2]{\langle #1|#2\rangle} $
$ \newcommand{\dot}[2]{ #1 \cdot #2} $
$ \newcommand{\biginner}[2]{\left\langle #1,#2\right\rangle} $
$ \newcommand{\mymatrix}[2]{\left( \begin{array}{#1} #2\end{array} \right)} $
$ \newcommand{\myvector}[1]{\mymatrix{c}{#1}} $
$ \newcommand{\myrvector}[1]{\mymatrix{r}{#1}} $
$ \newcommand{\mypar}[1]{\left( #1 \right)} $
$ \newcommand{\mybigpar}[1]{ \Big( #1 \Big)} $
$ \newcommand{\sqrttwo}{\frac{1}{\sqrt{2}}} $
$ \newcommand{\dsqrttwo}{\dfrac{1}{\sqrt{2}}} $
$ \newcommand{\onehalf}{\frac{1}{2}} $
$ \newcommand{\donehalf}{\dfrac{1}{2}} $
$ \newcommand{\hadamard}{ \mymatrix{rr}{ \sqrttwo & \sqrttwo \\ \sqrttwo & -\sqrttwo }} $
$ \newcommand{\vzero}{\myvector{1\\0}} $
$ \newcommand{\vone}{\myvector{0\\1}} $
$ \newcommand{\stateplus}{\myvector{ \sqrttwo \\ \sqrttwo } } $
$ \newcommand{\stateminus}{ \myrvector{ \sqrttwo \\ -\sqrttwo } } $
$ \newcommand{\myarray}[2]{ \begin{array}{#1}#2\end{array}} $
$ \newcommand{\X}{ \mymatrix{cc}{0 & 1 \\ 1 & 0} } $
$ \newcommand{\I}{ \mymatrix{rr}{1 & 0 \\ 0 & 1} } $
$ \newcommand{\Z}{ \mymatrix{rr}{1 & 0 \\ 0 & -1} } $
$ \newcommand{\Htwo}{ \mymatrix{rrrr}{ \frac{1}{2} & \frac{1}{2} & \frac{1}{2} & \frac{1}{2} \\ \frac{1}{2} & -\frac{1}{2} & \frac{1}{2} & -\frac{1}{2} \\ \frac{1}{2} & \frac{1}{2} & -\frac{1}{2} & -\frac{1}{2} \\ \frac{1}{2} & -\frac{1}{2} & -\frac{1}{2} & \frac{1}{2} } } $
$ \newcommand{\CNOT}{ \mymatrix{cccc}{1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0} } $
$ \newcommand{\norm}[1]{ \left\lVert #1 \right\rVert } $
$ \newcommand{\pstate}[1]{ \lceil \mspace{-1mu} #1 \mspace{-1.5mu} \rfloor } $
$ \newcommand{\greenbit}[1] {\mathbf{{\color{green}#1}}} $
$ \newcommand{\bluebit}[1] {\mathbf{{\color{blue}#1}}} $
$ \newcommand{\redbit}[1] {\mathbf{{\color{red}#1}}} $
$ \newcommand{\brownbit}[1] {\mathbf{{\color{brown}#1}}} $
$ \newcommand{\blackbit}[1] {\mathbf{{\color{black}#1}}} $
<font style="font-size:28px;" align="left"><b> Qiskit installation and test </b></font>
<br>
_prepared by Abuzer Yakaryilmaz_
<br><br>
- [Check your system](#check)
- [Install qiskit](#install)
- [Tips](#tips)
- [Execute an example quantum program](#test)
<hr id="check">
### Check your system
Check your system, if Qiskit has already been installed:
```
import qiskit
versions = qiskit.__qiskit_version__
print("The version of Qiskit is",versions['qiskit'])
print()
print("The version of each component:")
for key in versions:
print(key,"->",versions[key])
```
**You should be able to see the version number of any library that is already installed in your system.**
<hr id="install">
### Install qiskit
(If you are an experienced user, visit this link: https://qiskit.org/documentation/install.html)
You can install Qiskit by executing the following cell:
```
!pip install "qiskit[visualization]" --user
```
__*Restart the kernel*__ (check "Kernel" menu) to apply the changes to the current notebook.
<hr id="tips">
### Tips
_Any terminal/shell command can be executed in the notebook cells by putting exclamation mark (!) to the beginning of the command._
_$\rightarrow$ For updating Qiskit version, execute the following command on a code cell_
!pip install -U qiskit --user
_$\rightarrow$ For uninstall Qiskit, execute the following command on a code cell_
!pip uninstall qiskit
```
#!pip install -U qiskit --user
#!pip uninstall qiskit
```
<hr id="test">
### Execute an example quantum program
1) Create a quantum circuit
```
# import the objects from qiskit
from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer
from random import randrange
# create a quantum circuit and its register objects
qreg = QuantumRegister(2) # quantum register with two quantum bits
creg = ClassicalRegister(2) # classical register with two classical bit
circuit = QuantumCircuit(qreg,creg) # quantum circuit composed by a quantum register and a classical register
# apply a Hadamard gate to the first qubit
circuit.h(qreg[0])
# set the second qubit to state |1>
circuit.x(qreg[1])
# apply CNOT(first_qubit,second_qubit)
circuit.cx(qreg[0],qreg[1])
# measure the both qubits
circuit.measure(qreg,creg)
print("The execution of the cell was completed, and the circuit was created :)")
```
2) Draw the circuit
_Run the cell once more if the figure is not shown_
```
# draw circuit
circuit.draw(output='mpl')
# the output will be a "matplotlib.Figure" object
```
3) Execute the circuit 1024 times in the local simulator and print the observed the outcomes
```
## execute the circuit 1024 times
job = execute(circuit,Aer.get_backend('qasm_simulator'),shots=1024)
# get the result
counts = job.result().get_counts(circuit)
print(counts)
```
| github_jupyter |
# Disease Outbreak Response Decision-making Under Uncertainty: A retrospective analysis of measles in Sao Paulo
```
%matplotlib inline
import pandas as pd
import numpy as np
import numpy.ma as ma
from datetime import datetime
import matplotlib.pyplot as plt
import pdb
from IPython.core.display import HTML
def css_styling():
styles = open("styles/custom.css", "r").read()
return HTML(styles)
css_styling()
data_dir = "data/"
```
Import outbreak data
```
measles_data = pd.read_csv(data_dir+"measles.csv", index_col=0)
measles_data.NOTIFICATION = pd.to_datetime(measles_data.NOTIFICATION)
measles_data.BIRTH = pd.to_datetime(measles_data.BIRTH)
measles_data.ONSET = pd.to_datetime(measles_data.ONSET)
measles_data = measles_data.replace({'DISTRICT': {'BRASILANDIA':'BRAZILANDIA'}})
```
Sao Paulo population by district
```
sp_pop = pd.read_csv(data_dir+'sp_pop.csv', index_col=0)
_names = sp_pop.index.values
_names[_names=='BRASILANDIA'] = 'BRAZILANDIA'
sp_pop.set_index(_names, inplace = True)
sp_pop.head()
```
Plot of cumulative cases by district
```
measles_onset_dist = measles_data.groupby(['DISTRICT','ONSET']).size().unstack(level=0).fillna(0)
measles_onset_dist.cumsum().plot(legend=False, grid=False)
total_district_cases = measles_onset_dist.sum()
```
Top 5 districts by number of cases
```
totals = measles_onset_dist.sum()
totals.sort(ascending=False)
totals[:5]
```
Age distribution of cases, by confirmation status
```
by_conclusion = measles_data.groupby(["YEAR_AGE", "CONCLUSION"])
counts_by_cause = by_conclusion.size().unstack().fillna(0)
ax = counts_by_cause.plot(kind='bar', stacked=True, xlim=(0,50), figsize=(15,5))
```
## Vaccination data
```
vaccination_data = pd.read_csv('data/BrazilVaxRecords.csv', index_col=0)
vaccination_data.head()
vaccination_data.VAX[:18]
vax_97 = np.r_[[0]*(1979-1921+1), vaccination_data.VAX[:17]]
n = len(vax_97)
FOI_mat = np.resize((1 - vax_97*0.9), (n,n)).T
# Mean age of infection for those born prior to vaccination coverage, assuming R0=16
A = 4.37
(1 - vax_97*0.9)[:-1]
np.tril(FOI_mat).sum(0)
natural_susc = np.exp((-1/A) * np.tril(FOI_mat).sum(0))[::-1]
vacc_susc = (1 - vax_97*0.9)[::-1]
vacc_susc[0] = 0.5
vacc_susc
sia_susc = np.ones(len(vax_97))
birth_year = np.arange(1922, 1998)[::-1]
by_mask = (birth_year > 1983) & (birth_year < 1992)
sia_susc[by_mask] *= 0.2
```
## Stochastic Disease Transmission Model
As a baseline for comparison, we can fit a model to all the clinically-confirmed cases, regardless of lab confirmation status. For this, we will use a simple SIR disease model, which will be fit using MCMC.
This model fits the series of 2-week infection totals in each district $i$ as a set of Poisson models:
\\[Pr(I(t)_{i} | \lambda(t)_i) = \text{Poisson}(\lambda(t)_i) \\]
Where the outbreak intensity is modeled as:
\\[\lambda(t)_i = \beta [I^{(w)}(t-1)_i]^{\alpha} S(t-1)_i\\]
\\[\alpha \sim \text{Exp}(1)\\]
We will assume here that the transmission rate is constant over time (and across districts):
\\[\beta \sim \text{Gamma}(1, 0.1)\\]
To account for the influence of infected individuals from neighboring districts on new infections, the outbreak intensity was modeled using a spatial-weighted average of infecteds across districts, where populations were weighted as an exponential function of the distance between district centroids:
\\[w_{d} = \text{exp}(-\theta d)\\]
\\[\theta \sim \text{Exp}(1)\\]
### Confirmation Sub-model
Rather than assume all clinical cases are true cases, we can adjust the model to account for lab confirmation probability. This is done by including a sub-model that estimates age group-specific probabilities of confirmation, and using these probabilities to estimate the number of lab-confirmed cases. These estimates are then plugged into the model in place of the clinically-confirmed cases.
We specified a structured confirmation model to retrospectively determine the age group-specific probabilities of lab confirmation for measles, conditional on clinical diagnosis. Individual lab confirmation events $c_i$ were modeled as Bernoulli random variables, with the probability of confirmation being allowed to vary by age group:
$$c_i \sim \text{Bernoulli}(p_{a(i)})$$
where $a(i)$ denotes the appropriate age group for the individual indexed by i. There were 16 age groups, the first 15 of which were 5-year age intervals $[0,5), [5, 10), \ldots , [70, 75)$, with the 16th interval including all individuals 75 years and older.
Since the age interval choices were arbitrary, and the confirmation probabilities of adjacent groups likely correlated, we modeled the correlation structure directly, using a multivariate logit-normal model. Specifically, we allowed first-order autocorrelation among the age groups, whereby the variance-covariance matrix retained a tridiagonal structure.
$$\begin{aligned}
\Sigma = \left[{
\begin{array}{c}
{\sigma^2} & {\sigma^2 \rho} & 0& \ldots & {0} & {0} \\
{\sigma^2 \rho} & {\sigma^2} & \sigma^2 \rho & \ldots & {0} & {0} \\
{0} & \sigma^2 \rho & {\sigma^2} & \ldots & {0} & {0} \\
\vdots & \vdots & \vdots & & \vdots & \vdots\\
{0} & {0} & 0 & \ldots & {\sigma^2} & \sigma^2 \rho \\
{0} & {0} & 0 & \ldots & \sigma^2 \rho & {\sigma^2}
\end{array}
}\right]
\end{aligned}$$
From this, the confirmation probabilities were specified as multivariate normal on the inverse-logit scale.
$$ \text{logit}(p_a) = \{a\} \sim N(\mu, \Sigma)$$
Priors for the confirmation sub-model were specified by:
$$\begin{aligned}
\mu_i &\sim N(0, 100) \\
\sigma &\sim \text{HalfCauchy}(25) \\
\rho &\sim U(-1, 1)
\end{aligned}$$
Age classes are defined in 5-year intervals.
```
age_classes = [0,5,10,15,20,25,30,35,40,100]
measles_data.dropna(subset=['YEAR_AGE'], inplace=True)
measles_data['YEAR_AGE'] = measles_data.YEAR_AGE.astype(int)
measles_data['AGE_GROUP'] = pd.cut(measles_data.AGE, age_classes, right=False)
```
Lab-checked observations are extracted for use in estimating lab confirmation probability.
```
CONFIRMED = measles_data.CONCLUSION == 'CONFIRMED'
CLINICAL = measles_data.CONCLUSION == 'CLINICAL'
DISCARDED = measles_data.CONCLUSION == 'DISCARDED'
```
Extract confirmed and clinical subset, with no missing county information.
```
lab_subset = measles_data[(CONFIRMED | CLINICAL) & measles_data.COUNTY.notnull()].copy()
age = lab_subset.YEAR_AGE.values
ages = lab_subset.YEAR_AGE.unique()
counties = lab_subset.COUNTY.unique()
y = (lab_subset.CONCLUSION=='CONFIRMED').values
_lab_subset = lab_subset.replace({"CONCLUSION": {"CLINICAL": "UNCONFIRMED"}})
by_conclusion = _lab_subset.groupby(["YEAR_AGE", "CONCLUSION"])
counts_by_cause = by_conclusion.size().unstack().fillna(0)
ax = counts_by_cause.plot(kind='bar', stacked=True, xlim=(0,50), figsize=(15,5), grid=False)
lab_subset[(lab_subset.CONCLUSION=='CONFIRMED') & (lab_subset.AGE>15) & (lab_subset.AGE<35)].shape
y.sum()
```
Proportion of lab-confirmed cases older than 20 years
```
(measles_data[CONFIRMED].YEAR_AGE>20).mean()
age_classes
#Extract cases by age and time.
age_group = pd.cut(age, age_classes, right=False)
age_index = np.array([age_group.categories.tolist().index(i) for i in age_group])
age_groups = age_group.categories
age_groups
age_slice_endpoints = [g[1:-1].split(',') for g in age_groups]
age_slices = [slice(int(i[0]), int(i[1])) for i in age_slice_endpoints]
# Get index from full crosstabulation to use as index for each district
dates_index = measles_data.groupby(
['ONSET', 'AGE_GROUP']).size().unstack().index
unique_districts = measles_data.DISTRICT.dropna().unique()
excludes = ['BOM RETIRO']
N = sp_pop.drop(excludes).ix[unique_districts].sum().drop('Total')
N
N_age = N.iloc[:8]
N_age.index = age_groups[:-1]
N_age[age_groups[-1]] = N.iloc[8:].sum()
N_age
```
Compile bi-weekly confirmed and unconfirmed data by Sao Paulo district
```
sp_counts_2w = lab_subset.groupby(
['ONSET', 'AGE_GROUP']).size().unstack().reindex(dates_index).fillna(0).resample('2W', how='sum')
# All confirmed cases, by district
confirmed_data = lab_subset[lab_subset.CONCLUSION=='CONFIRMED']
confirmed_counts = confirmed_data.groupby(
['ONSET', 'AGE_GROUP']).size().unstack().reindex(dates_index).fillna(0).sum()
all_confirmed_cases = confirmed_counts.reindex_axis(measles_data['AGE_GROUP'].unique()).fillna(0)
# Ensure the age groups are ordered
I_obs = sp_counts_2w.reindex_axis(measles_data['AGE_GROUP'].unique(),
axis=1).fillna(0).values.astype(int)
```
Check shape of data frame
- 28 bi-monthly intervals, 9 age groups
```
assert I_obs.shape == (28, len(age_groups))
```
Prior distribution on susceptible proportion:
$$p_s \sim \text{Beta}(2, 100)$$
```
I_obs
obs_date = '1997-12-01' #'1997-06-15'
obs_index = sp_counts_2w.index <= obs_date
I_obs_t = I_obs[obs_index]
np.sum(I_obs_t, (0)) / float(I_obs_t.sum())
from pymc import rgamma
plt.hist(rgamma(16,1,size=10000))
75./age.mean()
foo = np.random.normal(25, 5, size=10000)
foo
foo_group = pd.cut(foo, age_classes, right=False)
foo_group.value_counts().values
from pymc import MCMC, Matplot, AdaptiveMetropolis, Slicer, MAP
from pymc import (Uniform, DiscreteUniform, Beta, Binomial, Normal, CompletedDirichlet,
Poisson, NegativeBinomial, negative_binomial_like, poisson_like,
Lognormal, Exponential, binomial_like,
TruncatedNormal, Binomial, Gamma, HalfCauchy, normal_like,
MvNormalCov, Bernoulli, Uninformative,
Multinomial, rmultinomial, rbinomial,
Dirichlet, multinomial_like)
from pymc import (Lambda, observed, invlogit, deterministic, potential, stochastic,)
def measles_model(obs_date, confirmation=True, spatial_weighting=False, all_traces=True):
n_periods, n_age_groups = I_obs.shape
### Confirmation sub-model
if confirmation:
# Specify priors on age-specific means
age_classes = np.unique(age_index)
mu = Normal("mu", mu=0, tau=0.0001, value=[0]*len(age_classes))
sig = HalfCauchy('sig', 0, 25, value=1)
var = sig**2
cor = Uniform('cor', -1, 1, value=0)
# Build variance-covariance matrix with first-order correlation
# among age classes
@deterministic
def Sigma(var=var, cor=cor):
I = np.eye(len(age_classes))*var
E = np.diag(np.ones(len(age_classes)-1), k=-1)*var*cor
return I + E + E.T
# Age-specific probabilities of confirmation as multivariate normal
# random variables
beta_age = MvNormalCov("beta_age", mu=mu, C=Sigma,
value=[1]*len(age_classes))
p_age = Lambda('p_age', lambda t=beta_age: invlogit(t))
@deterministic(trace=False)
def p_confirm(beta=beta_age):
return invlogit(beta[age_index])
# Confirmation likelihood
lab_confirmed = Bernoulli('lab_confirmed', p=p_confirm, value=y,
observed=True)
'''
Truncate data at observation period
'''
obs_index = sp_counts_2w.index <= obs_date
I_obs_t = I_obs[obs_index]
# Index for observation date, used to index out values of interest
# from the model.
t_obs = obs_index.sum() - 1
if confirmation:
@stochastic(trace=all_traces, dtype=int)
def I(value=(I_obs_t*0.5).astype(int), n=I_obs_t, p=p_age):
# Binomial confirmation process
return np.sum([binomial_like(xi, ni, p) for xi,ni in zip(value,n)])
else:
I = I_obs_t
assert I.shape == (t_obs +1, n_age_groups)
# Transmission parameter
beta = HalfCauchy('beta', 0, 25, value=[8]*n_age_groups)
decay = Beta('decay', 1, 5, value=0.9)
@deterministic
def B(b=beta, d=decay):
B = b*np.eye(n_age_groups)
for i in range(1, n_age_groups):
B += np.diag(np.ones(n_age_groups-i)*b[i:]*d**i, k=-i)
B += np.diag(np.ones(n_age_groups-i)*b[:-i]*d**i, k=i)
return B
# Downsample annual series to observed age groups
downsample = lambda x: np.array([x[s].mean() for s in age_slices])
@deterministic
def R0(B=B):
evs = np.linalg.eigvals(B)
return max(evs[np.isreal(evs)])
A = Lambda('A', lambda R0=R0: 75./(R0 - 1))
lt_sum = downsample(np.tril(FOI_mat).sum(0)[::-1])
natural_susc = Lambda('natural_susc', lambda A=A: np.exp((-1/A) * lt_sum))
# natural_susc = Beta('natural_susc', 1, 1, value=[0.02]*n_age_groups)
@deterministic
def p_susceptible(natural_susc=natural_susc):
return downsample(sia_susc) * downsample(vacc_susc) * natural_susc
# Estimated total initial susceptibles
S_0 = Binomial('S_0', n=N_age.astype(int), p=p_susceptible)
# Data augmentation for migrant susceptibles
N_migrant = DiscreteUniform('N_migrant', 0, 15000, value=10000)
mu_age = Uniform('mu_age', 15, 35, value=25)
sd_age = Uniform('sd_age', 1, 10, value=5)
M_age = Normal('M_age', mu_age, sd_age**-2, size=15000)
@deterministic
def M_0(M=M_age, N=N_migrant):
# Take first N augmented susceptibles
M_real = M[:N]
# Drop into age groups
M_group = pd.cut(M_real,
[0, 5, 10, 15, 20, 25, 30, 35, 40, 100],
right=False)
return M_group.value_counts().values
p_migrant = Lambda('p_migrant', lambda M_0=M_0, S_0=S_0: M_0/(M_0 + S_0))
I_migrant = [Binomial('I_migrant_%i' % i, I[i], p_migrant) for i in range(t_obs + 1)]
I_local = Lambda('I_local',
lambda I=I, I_m=I_migrant: np.array([Ii - Imi for Ii,Imi in zip(I,I_m)]))
S = Lambda('S', lambda I=I, S_0=S_0, M_0=M_0: S_0 + M_0 - I.cumsum(0))
S_local = Lambda('S_local', lambda I=I_local, S_0=S_0: S_0 - I.cumsum(0))
# Check shape
assert S.value.shape == (t_obs+1., n_age_groups)
S_t = Lambda('S_t', lambda S=S: S[-1])
@deterministic
def R(B=B, S=S):
return (S.dot(B) / N_age.values).T
@deterministic
def R_local(B=B, S=S_local):
return (S.dot(B) / N_age.values).T
# Force of infection
@deterministic
def lam(B=B, I=I, S=S_local):
return (I.sum(1) * (S.dot(B) / N_age.values).T).T
# Check shape
assert lam.value.shape == (t_obs+1, n_age_groups)
# Poisson likelihood for observed cases
@potential
def new_cases(I=I, lam=lam):
return poisson_like(I[1:], lam[:-1])
return locals()
n_age_groups = 8
beta = np.arange(2, n_age_groups+2)
B = beta*np.eye(n_age_groups)
d = 0.9
for i in range(1, n_age_groups):
B += np.diag(np.ones(n_age_groups-i)*beta[i:]*d**i, k=-i)
B += np.diag(np.ones(n_age_groups-i)*beta[:-i]*d**i, k=i)
B.round(2)
np.linalg.eigvals(B)
iterations = 100000
burn = 90000
chains = 2
M = MCMC(measles_model('1997-06-15', confirmation=True))
M.use_step_method(AdaptiveMetropolis, M.beta)
for i in range(chains):
print('\nchain', i+1)
M.sample(iterations, burn)
chain = None
```
Proportion susceptible
```
Matplot.summary_plot(M.p_susceptible, chain=chain, custom_labels=age_groups)
```
Natural susceptibility
```
Matplot.summary_plot(M.natural_susc, chain=chain, custom_labels=age_groups)
Matplot.summary_plot(M.beta, chain=chain, custom_labels=age_groups)
```
Transmission decay parameter (for modeling decay in beta to other age groups)
```
Matplot.summary_plot(M.R)
Matplot.plot(M.decay)
Matplot.plot(M.R0)
```
Confirmation probabilities
```
Matplot.summary_plot(M.p_age, chain=chain, custom_labels=age_groups)
```
| github_jupyter |
# Faces recognition using TSNE and SVMs
The dataset used in this example is a preprocessed excerpt of the
"Labeled Faces in the Wild", aka LFW_:
http://vis-www.cs.umass.edu/lfw/lfw-funneled.tgz (233MB)
LFW: http://vis-www.cs.umass.edu/lfw/
```
%matplotlib inline
from time import time
import logging
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import fetch_lfw_people
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from sklearn import manifold
print(__doc__)
# Display progress logs on stdout
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
# introspect the images arrays to find the shapes (for plotting)
n_samples, h, w = lfw_people.images.shape
# for machine learning we use the 2 data directly (as relative pixel
# positions info is ignored by this model)
X = lfw_people.data
n_features = X.shape[1]
# the label to predict is the id of the person
y = lfw_people.target
target_names = lfw_people.target_names
n_classes = target_names.shape[0]
print("Total dataset size:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
print("n_classes: %d" % n_classes)
# split into a training and testing set
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42)
accuracies = []
components = []
# for nn in xrange(2,11,1):
nn = 2
n_components = nn
tsne = manifold.TSNE(n_components=n_components, init='pca', random_state=0)
X_train_changed = tsne.fit_transform(X_train)
X_test_changed = tsne.fit_transform(X_test)
param_grid = {'C': [1,1e1,1e2,5e2,1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)
clf = clf.fit(X_train_changed, y_train)
y_pred = clf.predict(X_test_changed)
accuracies.append(float(np.sum(y_test==y_pred))/len(y_pred))
components.append(n_components)
print('For '+str(n_components)+' components, accuracy is '+str(float(np.sum(y_test==y_pred))/len(y_pred))+' confusion matrix is: ')
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
print(classification_report(y_test, y_pred, target_names=target_names))
colors = ['b','g','r','c','m','y','k']
labels = ['Tony Blair','Hugo Chavez','Gerhard Schroeder','George W Bush','Donald Rumsfeld','Colin Powell','Ariel Sharon']
for i in xrange(len(labels)):
plt.scatter(X_train_changed[np.where(y_train==i)][:,0],X_train_changed[np.where(y_train==i)][:,1],color=colors[y_train[i]],label=labels[i])
plt.title('Scatter Plot for TSNE')
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.legend(prop={'size':6})
plt.show()
```
Plot for TSNE to 2 dimensional mapping
```
accuracies = []
components = []
# for nn in xrange(2,11,1):
nn = 3
n_components = nn
tsne = manifold.TSNE(n_components=n_components, init='pca', random_state=0)
X_train_changed = tsne.fit_transform(X_train)
X_test_changed = tsne.fit_transform(X_test)
param_grid = {'C': [1,1e1,1e2,5e2,1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)
clf = clf.fit(X_train_changed, y_train)
y_pred = clf.predict(X_test_changed)
accuracies.append(float(np.sum(y_test==y_pred))/len(y_pred))
components.append(n_components)
print('For '+str(n_components)+' components, accuracy is '+str(float(np.sum(y_test==y_pred))/len(y_pred))+' confusion matrix is: ')
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
print(classification_report(y_test, y_pred, target_names=target_names))
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
colors = ['b','g','r','c','m','y','k']
labels = ['Tony Blair','Hugo Chavez','Gerhard Schroeder','George W Bush','Donald Rumsfeld','Colin Powell','Ariel Sharon']
for i in xrange(len(labels)):
ax.scatter(X_train_changed[np.where(y_train==i)][:,0],X_train_changed[np.where(y_train==i)][:,1],X_train_changed[np.where(y_train==i)][:,2],color=colors[y_train[i]],label=labels[i])
plt.legend(prop={'size':6})
plt.title('Scatter Plot for TSNE')
ax.set_xlabel('Dimension 1')
ax.set_ylabel('Dimension 2')
ax.set_zlabel('Dimension 3')
plt.show()
```
| github_jupyter |
# Install necessary packages
- !pip install gensim
- !pip install wikipedia2vec
- !pip install pyemd # Necessary for one of Gensim's functions
**Update**: these are installed via Poetry, so if you set up your environment per the root readme and are correctly using that environment as your Jupyter Notebook kernel, the packages will be available to you.
# Experimenting with Gensim and Word2Vec
Following complete API documentation here:
https://radimrehurek.com/gensim/models/keyedvectors.html
```
#Import test texts and Word2Vec pre-loaded model
from gensim.test.utils import common_texts
from gensim.models import Word2Vec
# Instantiate Word2Vec
# See parameter explanations here:
# https://github.com/kavgan/nlp-in-practice/blob/master/word2vec/Word2Vec.ipynb
model = Word2Vec(common_texts, size=100, window=5, min_count=1, workers=4)
word_vectors = model.wv
# # Save word_vectors to disk
# from gensim.test.utils import get_tmpfile
# from gensim.models import KeyedVectors
# fname = get_tmpfile('vectors.kv')
# word_vectors.save(fname)
# word_vectors = KeyedVectors.load(fname, mmap='r')
# # Load word_vectors from disk
# # Possible for Wikipedia2Vec
# from gensim.test.utils import datapath
# wv_from_bin = KeyedVectors.load_word2vec_format(datapath("euclidean_vectors.bin", binary=True))
# Use API to download Glove wiki word embeddings
import gensim.downloader as api
word_vectors = api.load("glove-wiki-gigaword-100")
# Find the most similar word with positive and negative inputs
result = word_vectors.most_similar(positive=["woman", "king"], negative=["man"])
result
# Finds most similar word using "multiplicative combination objective"
# Less susceptible to one large distance dominating calculation
result = word_vectors.most_similar_cosmul(positive=['woman', 'king'], negative=['man'])
result
# Returns least non-matching word of input words
# Caution: If you input "breakfast lunch dinner", it will say "lunch"
# is least similar so no ability to say "All similar"
print(word_vectors.doesnt_match("breakfast cereal dinner lunch".split()))
# Calculates word similarity score
similarity = word_vectors.similarity('woman', 'man')
similarity
# Returns most similar words
result = word_vectors.similar_by_word("cat")
result
# Computes "Word Mover's Distance" between two documents
sentence_obama = 'Obama speaks to the media in Illinois'.lower().split()
sentence_president = 'The president greets the press in Chicago'.lower().split()
similarity = word_vectors.wmdistance(sentence_obama, sentence_president)
similarity
# Computes cosine distance between two words
distance = word_vectors.distance('media', 'media')
distance
distance = word_vectors.distance('media', 'press')
distance
distance = word_vectors.distance('media', 'mob')
distance
# Computes cosine similarity between two sets of words
sim = word_vectors.n_similarity(['sushi', 'shop'], ['japanese', 'restaurant'])
sim
# Each word has 100 length numbers as representation
print(word_vectors['computer'].shape)
print("First 10")
print(word_vectors['computer'][:10])
```
# Experimenting with Wikipedia2Vec
Following API usage here:
https://wikipedia2vec.github.io/wikipedia2vec/usage/
### Download word embeddings
You must first download the word embeddings binary file (3.3GB)
https://wikipedia2vec.github.io/wikipedia2vec/pretrained/
Use *enwiki_20180420* - 100d(bin)
```
from wikipedia2vec import Wikipedia2Vec
# Load unzipped pkl file
wiki2vec = Wikipedia2Vec.load("../../embeddings/enwiki_20180420_100d.pkl")
# Retrieve word vector
wv = wiki2vec.get_word_vector("royalty")
print(len(wv))
print(wv)
# Retrieve entity vector
wv = wiki2vec.get_entity_vector("Queen Elizabeth II")
print(len(wv))
print(wv)
# Retrieve a word
print(wiki2vec.get_word('royalty'))
print(type(wiki2vec.get_word('royalty')))
# Retrieve an entity
print(wiki2vec.get_entity('Metropolitan Museum'))
print(type(wiki2vec.get_entity('Metropolitan Museum')))
# Retrieve an entity
print(wiki2vec.get_entity('Harvard University'))
print(type(wiki2vec.get_entity('Metropolitan Museum')))
%%time
# Get most similar word
similar_yoda = wiki2vec.most_similar(wiki2vec.get_word('yoda'), 100)
similar_yoda
%%time
# Get most similar entity
similar_harvard = wiki2vec.most_similar(wiki2vec.get_entity('Harvard University'), 10)
similar_harvard
from wikipedia2vec.dictionary import Entity
# Retrieve only entities from word
yoda_entities = []
for i in similar_yoda:
# print(type(i[0]))
if isinstance(i[0], Entity):
yoda_entities.append(i)
if len(yoda_entities) == 3:
break
yoda_entities
```
# Using Gensim & Wikipedia2Vec Together
You can use gensim's `load_word2vec_format` to work with wikipedia2vec directly. However, you have to use the `(txt)` file from wikipedia2vec to do this, not the `(bin)` file. Given the greater number of modules provided by gensim, this is likely the preferred path.
```
# Import models type
from gensim.models import KeyedVectors
%%time
# Use model type to load txt file
w2v = KeyedVectors.load_word2vec_format("../../embeddings/enwiki_20180420_100d.txt")
```
In recent gensim versions you can load a subset starting from the front of the file using the optional limit parameter to load_word2vec_format(). So use limit=500000 to get the most-frequent 500,000 words' vectors.
```
result = w2v.most_similar("save")
result
result = w2v.most_similar(positive=['woman', 'king'], negative=['man'])
result
# Calculates word similarity score
similarity = w2v.similarity('woman', 'man')
similarity
# Calculate word distance
distance = w2v.distance('media', 'press')
distance
```
| github_jupyter |
# Dependencies
```
import os
import random
import warnings
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import class_weight
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, cohen_kappa_score
from keras import backend as K
from keras.models import Model
from keras import optimizers, applications
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import EarlyStopping, ReduceLROnPlateau, Callback, LearningRateScheduler
from keras.layers import Dense, Dropout, GlobalAveragePooling2D, Input
# Set seeds to make the experiment more reproducible.
from tensorflow import set_random_seed
def seed_everything(seed=0):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
set_random_seed(0)
seed_everything()
%matplotlib inline
sns.set(style="whitegrid")
warnings.filterwarnings("ignore")
```
# Load data
```
train = pd.read_csv('../input/aptos2019-blindness-detection/train.csv')
test = pd.read_csv('../input/aptos2019-blindness-detection/test.csv')
print('Number of train samples: ', train.shape[0])
print('Number of test samples: ', test.shape[0])
# Preprocecss data
train["id_code"] = train["id_code"].apply(lambda x: x + ".png")
test["id_code"] = test["id_code"].apply(lambda x: x + ".png")
train['diagnosis'] = train['diagnosis'].astype('str')
display(train.head())
```
# Model parameters
```
# Model parameters
BATCH_SIZE = 8
EPOCHS = 30
WARMUP_EPOCHS = 1
LEARNING_RATE = 1e-4
WARMUP_LEARNING_RATE = 1e-3
HEIGHT = 256
WIDTH = 256
CANAL = 3
N_CLASSES = train['diagnosis'].nunique()
ES_PATIENCE = 5
RLROP_PATIENCE = 3
DECAY_DROP = 0.5
def kappa(y_true, y_pred, n_classes=5):
y_trues = K.cast(K.argmax(y_true), K.floatx())
y_preds = K.cast(K.argmax(y_pred), K.floatx())
n_samples = K.cast(K.shape(y_true)[0], K.floatx())
distance = K.sum(K.abs(y_trues - y_preds))
max_distance = n_classes - 1
kappa_score = 1 - ((distance**2) / (n_samples * (max_distance**2)))
return kappa_score
def step_decay(epoch):
lrate = 30e-5
if epoch > 3:
lrate = 15e-5
if epoch > 7:
lrate = 7.5e-5
if epoch > 11:
lrate = 3e-5
if epoch > 15:
lrate = 1e-5
return lrate
def get_1cycle_schedule(lr_max=1e-3, n_data_points=8000, epochs=200, batch_size=40, verbose=0):
"""
Creates a look-up table of learning rates for 1cycle schedule with cosine annealing
See @sgugger's & @jeremyhoward's code in fastai library: https://github.com/fastai/fastai/blob/master/fastai/train.py
Wrote this to use with my Keras and (non-fastai-)PyTorch codes.
Note that in Keras, the LearningRateScheduler callback (https://keras.io/callbacks/#learningratescheduler) only operates once per epoch, not per batch
So see below for Keras callback
Keyword arguments:
lr_max chosen by user after lr_finder
n_data_points data points per epoch (e.g. size of training set)
epochs number of epochs
batch_size batch size
Output:
lrs look-up table of LR's, with length equal to total # of iterations
Then you can use this in your PyTorch code by counting iteration number and setting
optimizer.param_groups[0]['lr'] = lrs[iter_count]
"""
if verbose > 0:
print("Setting up 1Cycle LR schedule...")
pct_start, div_factor = 0.3, 25. # @sgugger's parameters in fastai code
lr_start = lr_max/div_factor
lr_end = lr_start/1e4
n_iter = (n_data_points * epochs // batch_size) + 1 # number of iterations
a1 = int(n_iter * pct_start)
a2 = n_iter - a1
# make look-up table
lrs_first = np.linspace(lr_start, lr_max, a1) # linear growth
lrs_second = (lr_max-lr_end)*(1+np.cos(np.linspace(0,np.pi,a2)))/2 + lr_end # cosine annealing
lrs = np.concatenate((lrs_first, lrs_second))
return lrs
class OneCycleScheduler(Callback):
"""My modification of Keras' Learning rate scheduler to do 1Cycle learning
which increments per BATCH, not per epoch
Keyword arguments
**kwargs: keyword arguments to pass to get_1cycle_schedule()
Also, verbose: int. 0: quiet, 1: update messages.
Sample usage (from my train.py):
lrsched = OneCycleScheduler(lr_max=1e-4, n_data_points=X_train.shape[0],
epochs=epochs, batch_size=batch_size, verbose=1)
"""
def __init__(self, **kwargs):
super(OneCycleScheduler, self).__init__()
self.verbose = kwargs.get('verbose', 0)
self.lrs = get_1cycle_schedule(**kwargs)
self.iteration = 0
def on_batch_begin(self, batch, logs=None):
lr = self.lrs[self.iteration]
K.set_value(self.model.optimizer.lr, lr) # here's where the assignment takes place
if self.verbose > 0:
print('\nIteration %06d: OneCycleScheduler setting learning '
'rate to %s.' % (self.iteration, lr))
self.iteration += 1
def on_epoch_end(self, epoch, logs=None): # this is unchanged from Keras LearningRateScheduler
logs = logs or {}
logs['lr'] = K.get_value(self.model.optimizer.lr)
self.iteration = 0
```
# Train test split
```
X_train, X_val = train_test_split(train, test_size=0.25, random_state=0)
```
# Data generator
```
train_datagen=ImageDataGenerator(rescale=1./255,
rotation_range=360,
brightness_range=[0.5, 1.5],
zoom_range=[1, 1.2],
zca_whitening=True,
horizontal_flip=True,
vertical_flip=True,
fill_mode='reflect',
cval=0.)
test_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator=train_datagen.flow_from_dataframe(
dataframe=X_train,
directory="../input/aptos2019-blindness-detection/train_images/",
x_col="id_code",
y_col="diagnosis",
class_mode="categorical",
batch_size=BATCH_SIZE,
target_size=(HEIGHT, WIDTH))
valid_generator=validation_datagen.flow_from_dataframe(
dataframe=X_val,
directory="../input/aptos2019-blindness-detection/train_images/",
x_col="id_code",
y_col="diagnosis",
class_mode="categorical",
batch_size=BATCH_SIZE,
target_size=(HEIGHT, WIDTH))
test_generator = test_datagen.flow_from_dataframe(
dataframe=test,
directory = "../input/aptos2019-blindness-detection/test_images/",
x_col="id_code",
batch_size=1,
class_mode=None,
shuffle=False,
target_size=(HEIGHT, WIDTH))
```
# Model
```
def create_model(input_shape, n_out):
input_tensor = Input(shape=input_shape)
base_model = applications.ResNet50(weights=None,
include_top=False,
input_tensor=input_tensor)
base_model.load_weights('../input/resnet50/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5')
x = GlobalAveragePooling2D()(base_model.output)
x = Dropout(0.5)(x)
x = Dense(2048, activation='relu')(x)
x = Dropout(0.5)(x)
final_output = Dense(n_out, activation='softmax', name='final_output')(x)
model = Model(input_tensor, final_output)
return model
```
# Train top layers
```
model = create_model(input_shape=(HEIGHT, WIDTH, CANAL), n_out=N_CLASSES)
for layer in model.layers:
layer.trainable = False
for i in range(-5, 0):
model.layers[i].trainable = True
class_weights = class_weight.compute_class_weight('balanced', np.unique(train['diagnosis'].astype('int').values), train['diagnosis'].astype('int').values)
metric_list = ["accuracy", kappa]
optimizer = optimizers.Adam(lr=WARMUP_LEARNING_RATE)
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=metric_list)
model.summary()
STEP_SIZE_TRAIN = train_generator.n//train_generator.batch_size
STEP_SIZE_VALID = valid_generator.n//valid_generator.batch_size
history_warmup = model.fit_generator(generator=train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
validation_data=valid_generator,
validation_steps=STEP_SIZE_VALID,
epochs=WARMUP_EPOCHS,
class_weight=class_weights,
verbose=1).history
```
# Fine-tune the complete model
```
for layer in model.layers:
layer.trainable = True
# lrstep = LearningRateScheduler(step_decay)
# lrcycle = OneCycleScheduler(lr_max=LEARNING_RATE, n_data_points=(train_generator.n + valid_generator.n), epochs=EPOCHS, batch_size=BATCH_SIZE, verbose=1)
es = EarlyStopping(monitor='val_loss', mode='min', patience=ES_PATIENCE, restore_best_weights=True, verbose=1)
rlrop = ReduceLROnPlateau(monitor='val_loss', mode='min', patience=RLROP_PATIENCE, factor=DECAY_DROP, min_lr=1e-6, verbose=1)
callback_list = [es, rlrop]
optimizer = optimizers.Adam(lr=LEARNING_RATE)
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=metric_list)
model.summary()
history_finetunning = model.fit_generator(generator=train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
validation_data=valid_generator,
validation_steps=STEP_SIZE_VALID,
epochs=EPOCHS,
callbacks=callback_list,
class_weight=class_weights,
verbose=1).history
```
# Model loss graph
```
history = {'loss': history_warmup['loss'] + history_finetunning['loss'],
'val_loss': history_warmup['val_loss'] + history_finetunning['val_loss'],
'acc': history_warmup['acc'] + history_finetunning['acc'],
'val_acc': history_warmup['val_acc'] + history_finetunning['val_acc'],
'kappa': history_warmup['kappa'] + history_finetunning['kappa'],
'val_kappa': history_warmup['val_kappa'] + history_finetunning['val_kappa']}
sns.set_style("whitegrid")
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, sharex='col', figsize=(20, 18))
ax1.plot(history['loss'], label='Train loss')
ax1.plot(history['val_loss'], label='Validation loss')
ax1.legend(loc='best')
ax1.set_title('Loss')
ax2.plot(history['acc'], label='Train accuracy')
ax2.plot(history['val_acc'], label='Validation accuracy')
ax2.legend(loc='best')
ax2.set_title('Accuracy')
ax3.plot(history['kappa'], label='Train kappa')
ax3.plot(history['val_kappa'], label='Validation kappa')
ax3.legend(loc='best')
ax3.set_title('Kappa')
plt.xlabel('Epochs')
sns.despine()
plt.show()
# Create empty arays to keep the predictions and labels
lastFullTrainPred = np.empty((0, N_CLASSES))
lastFullTrainLabels = np.empty((0, N_CLASSES))
lastFullValPred = np.empty((0, N_CLASSES))
lastFullValLabels = np.empty((0, N_CLASSES))
# Add train predictions and labels
for i in range(STEP_SIZE_TRAIN+1):
im, lbl = next(train_generator)
scores = model.predict(im, batch_size=train_generator.batch_size)
lastFullTrainPred = np.append(lastFullTrainPred, scores, axis=0)
lastFullTrainLabels = np.append(lastFullTrainLabels, lbl, axis=0)
# Add validation predictions and labels
for i in range(STEP_SIZE_VALID+1):
im, lbl = next(valid_generator)
scores = model.predict(im, batch_size=valid_generator.batch_size)
lastFullValPred = np.append(lastFullValPred, scores, axis=0)
lastFullValLabels = np.append(lastFullValLabels, lbl, axis=0)
lastFullComPred = np.concatenate((lastFullTrainPred, lastFullValPred))
lastFullComLabels = np.concatenate((lastFullTrainLabels, lastFullValLabels))
train_preds = [np.argmax(pred) for pred in lastFullTrainPred]
train_labels = [np.argmax(label) for label in lastFullTrainLabels]
validation_preds = [np.argmax(pred) for pred in lastFullValPred]
validation_labels = [np.argmax(label) for label in lastFullValLabels]
complete_labels = [np.argmax(label) for label in lastFullComLabels]
```
# Threshold optimization
```
def find_best_fixed_threshold(preds, targs, do_plot=True):
best_thr_list = [0 for i in range(preds.shape[1])]
for index in reversed(range(1, preds.shape[1])):
score = []
thrs = np.arange(0, 1, 0.01)
for thr in thrs:
preds_thr = [index if x[index] > thr else np.argmax(x) for x in preds]
score.append(cohen_kappa_score(targs, preds_thr))
score = np.array(score)
pm = score.argmax()
best_thr, best_score = thrs[pm], score[pm].item()
best_thr_list[index] = best_thr
print(f'thr={best_thr:.3f}', f'F2={best_score:.3f}')
if do_plot:
plt.plot(thrs, score)
plt.vlines(x=best_thr, ymin=score.min(), ymax=score.max())
plt.text(best_thr+0.03, best_score-0.01, ('Kappa[%s]=%.3f'%(index, best_score)), fontsize=14);
plt.show()
return best_thr_list
threshold_list = find_best_fixed_threshold(lastFullValPred, validation_labels, do_plot=True)
threshold_list[0] = 0 # In last instance assign label 0
# Apply optimized thresholds to the train predictions
train_preds_opt = [0 for i in range(lastFullTrainPred.shape[0])]
for idx, thr in enumerate(threshold_list):
for idx2, pred in enumerate(lastFullTrainPred):
if pred[idx] > thr:
train_preds_opt[idx2] = idx
# Apply optimized thresholds to the validation predictions
validation_preds_opt = [0 for i in range(lastFullValPred.shape[0])]
for idx, thr in enumerate(threshold_list):
for idx2, pred in enumerate(lastFullValPred):
if pred[idx] > thr:
validation_preds_opt[idx2] = idx
```
# Model Evaluation
## Confusion Matrix
```
# Original thresholds
fig, (ax1, ax2) = plt.subplots(1, 2, sharex='col', figsize=(24, 7))
labels = ['0 - No DR', '1 - Mild', '2 - Moderate', '3 - Severe', '4 - Proliferative DR']
train_cnf_matrix = confusion_matrix(train_labels, train_preds)
validation_cnf_matrix = confusion_matrix(validation_labels, validation_preds)
train_cnf_matrix_norm = train_cnf_matrix.astype('float') / train_cnf_matrix.sum(axis=1)[:, np.newaxis]
validation_cnf_matrix_norm = validation_cnf_matrix.astype('float') / validation_cnf_matrix.sum(axis=1)[:, np.newaxis]
train_df_cm = pd.DataFrame(train_cnf_matrix_norm, index=labels, columns=labels)
validation_df_cm = pd.DataFrame(validation_cnf_matrix_norm, index=labels, columns=labels)
sns.heatmap(train_df_cm, annot=True, fmt='.2f', cmap="Blues",ax=ax1).set_title('Train')
sns.heatmap(validation_df_cm, annot=True, fmt='.2f', cmap="Blues",ax=ax2).set_title('Validation')
plt.show()
# Optimized thresholds
fig, (ax1, ax2) = plt.subplots(1, 2, sharex='col', figsize=(24, 7))
train_cnf_matrix = confusion_matrix(train_labels, train_preds_opt)
validation_cnf_matrix = confusion_matrix(validation_labels, validation_preds_opt)
train_cnf_matrix_norm = train_cnf_matrix.astype('float') / train_cnf_matrix.sum(axis=1)[:, np.newaxis]
validation_cnf_matrix_norm = validation_cnf_matrix.astype('float') / validation_cnf_matrix.sum(axis=1)[:, np.newaxis]
train_df_cm = pd.DataFrame(train_cnf_matrix_norm, index=labels, columns=labels)
validation_df_cm = pd.DataFrame(validation_cnf_matrix_norm, index=labels, columns=labels)
sns.heatmap(train_df_cm, annot=True, fmt='.2f', cmap="Blues",ax=ax1).set_title('Train optimized')
sns.heatmap(validation_df_cm, annot=True, fmt='.2f', cmap="Blues",ax=ax2).set_title('Validation optimized')
plt.show()
```
## Quadratic Weighted Kappa
```
print(" --- Original thresholds --- ")
print("Train Cohen Kappa score: %.3f" % cohen_kappa_score(train_preds, train_labels, weights='quadratic'))
print("Validation Cohen Kappa score: %.3f" % cohen_kappa_score(validation_preds, validation_labels, weights='quadratic'))
print("Complete set Cohen Kappa score: %.3f" % cohen_kappa_score(train_preds+validation_preds, train_labels+validation_labels, weights='quadratic'))
print(" --- Optimized thresholds --- ")
print("Train Cohen Kappa score: %.3f" % cohen_kappa_score(train_preds_opt, train_labels, weights='quadratic'))
print("Validation Cohen Kappa score: %.3f" % cohen_kappa_score(validation_preds_opt, validation_labels, weights='quadratic'))
print("Complete set Cohen Kappa score: %.3f" % cohen_kappa_score(train_preds_opt+validation_preds_opt, train_labels+validation_labels, weights='quadratic'))
```
## Apply model to test set and output predictions
```
test_generator.reset()
STEP_SIZE_TEST = test_generator.n//test_generator.batch_size
preds = model.predict_generator(test_generator, steps=STEP_SIZE_TEST)
predictions = [np.argmax(pred) for pred in preds]
predictions_opt = [0 for i in range(preds.shape[0])]
for idx, thr in enumerate(threshold_list):
for idx2, pred in enumerate(preds):
if pred[idx] > thr:
predictions_opt[idx2] = idx
filenames = test_generator.filenames
results = pd.DataFrame({'id_code':filenames, 'diagnosis':predictions})
results['id_code'] = results['id_code'].map(lambda x: str(x)[:-4])
results_opt = pd.DataFrame({'id_code':filenames, 'diagnosis':predictions_opt})
results_opt['id_code'] = results_opt['id_code'].map(lambda x: str(x)[:-4])
```
# Predictions class distribution
```
fig, (ax1, ax2) = plt.subplots(1, 2, sharex='col', figsize=(24, 8.7))
sns.countplot(x="diagnosis", data=results, palette="GnBu_d", ax=ax1).set_title('Test')
sns.countplot(x="diagnosis", data=results_opt, palette="GnBu_d", ax=ax2).set_title('Test optimized')
sns.despine()
plt.show()
val_kappa = cohen_kappa_score(validation_preds, validation_labels, weights='quadratic')
val_opt_kappa = cohen_kappa_score(validation_preds_opt, validation_labels, weights='quadratic')
if val_kappa > val_opt_kappa:
results_name = 'submission.csv'
results_opt_name = 'submission_opt.csv'
else:
results_name = 'submission_norm.csv'
results_opt_name = 'submission.csv'
results.to_csv(results_name, index=False)
results.head(10)
results_opt.to_csv(results_opt_name, index=False)
results_opt.head(10)
```
| github_jupyter |
> Texto fornecido sob a Creative Commons Attribution license, CC-BY. Todo o código está disponível sob a FSF-approved BSD-3 license.<br>
> (c) Original por Lorena A. Barba, Gilbert F. Forsyth em 2017, traduzido por Felipe N. Schuch em 2020.<br>
> [@LorenaABarba](https://twitter.com/LorenaABarba) - [@fschuch](https://twitter.com/fschuch)
12 passos para Navier-Stokes
======
***
Você chegou até aqui? Este é o último passo! Quanto tempo você levou para escrever a sua própria solucão para Navier – Stokes em Python seguindo este módulo interativo? Conte para nós!
Passo 12: Escoamento em Canal com Navier–Stokes
----
***
A única diferença entre esta etapa final e a Etapa 11 é que vamos adicionar um termo de fonte à equação de momento na direção $u$, para imitar o efeito de um escoamento em canal acionado por pressão. Aqui estão nossas equações de Navier–Stokes modificadas:
$$\frac{\partial u}{\partial t}+u\frac{\partial u}{\partial x}+v\frac{\partial u}{\partial y}=-\frac{1}{\rho}\frac{\partial p}{\partial x}+\nu\left(\frac{\partial^2 u}{\partial x^2}+\frac{\partial^2 u}{\partial y^2}\right)+F$$
$$\frac{\partial v}{\partial t}+u\frac{\partial v}{\partial x}+v\frac{\partial v}{\partial y}=-\frac{1}{\rho}\frac{\partial p}{\partial y}+\nu\left(\frac{\partial^2 v}{\partial x^2}+\frac{\partial^2 v}{\partial y^2}\right)$$
$$\frac{\partial^2 p}{\partial x^2}+\frac{\partial^2 p}{\partial y^2}=-\rho\left(\frac{\partial u}{\partial x}\frac{\partial u}{\partial x}+2\frac{\partial u}{\partial y}\frac{\partial v}{\partial x}+\frac{\partial v}{\partial y}\frac{\partial v}{\partial y}\right)
$$
### Equações discretas
Com paciência e cuidado, escrevemos a forma discreta das equações. É altamente recomendável que você as escreva com suas próprias mãos, seguindo mentalmente cada termo enquanto o escreve.
Equação do momento para $u$:
$$
\begin{split}
& \frac{u_{i,j}^{n+1}-u_{i,j}^{n}}{\Delta t}+u_{i,j}^{n}\frac{u_{i,j}^{n}-u_{i-1,j}^{n}}{\Delta x}+v_{i,j}^{n}\frac{u_{i,j}^{n}-u_{i,j-1}^{n}}{\Delta y} = \\
& \qquad -\frac{1}{\rho}\frac{p_{i+1,j}^{n}-p_{i-1,j}^{n}}{2\Delta x} \\
& \qquad +\nu\left(\frac{u_{i+1,j}^{n}-2u_{i,j}^{n}+u_{i-1,j}^{n}}{\Delta x^2}+\frac{u_{i,j+1}^{n}-2u_{i,j}^{n}+u_{i,j-1}^{n}}{\Delta y^2}\right)+F_{i,j}
\end{split}
$$
Equação do momento para $v$:
$$
\begin{split}
& \frac{v_{i,j}^{n+1}-v_{i,j}^{n}}{\Delta t}+u_{i,j}^{n}\frac{v_{i,j}^{n}-v_{i-1,j}^{n}}{\Delta x}+v_{i,j}^{n}\frac{v_{i,j}^{n}-v_{i,j-1}^{n}}{\Delta y} = \\
& \qquad -\frac{1}{\rho}\frac{p_{i,j+1}^{n}-p_{i,j-1}^{n}}{2\Delta y} \\
& \qquad +\nu\left(\frac{v_{i+1,j}^{n}-2v_{i,j}^{n}+v_{i-1,j}^{n}}{\Delta x^2}+\frac{v_{i,j+1}^{n}-2v_{i,j}^{n}+v_{i,j-1}^{n}}{\Delta y^2}\right)
\end{split}
$$
E a equação da pressão:
$$
\begin{split}
& \frac{p_{i+1,j}^{n}-2p_{i,j}^{n}+p_{i-1,j}^{n}}{\Delta x^2} + \frac{p_{i,j+1}^{n}-2p_{i,j}^{n}+p_{i,j-1}^{n}}{\Delta y^2} = \\
& \qquad \rho\left[\frac{1}{\Delta t}\left(\frac{u_{i+1,j}-u_{i-1,j}}{2\Delta x}+\frac{v_{i,j+1}-v_{i,j-1}}{2\Delta y}\right) - \frac{u_{i+1,j}-u_{i-1,j}}{2\Delta x}\frac{u_{i+1,j}-u_{i-1,j}}{2\Delta x} - 2\frac{u_{i,j+1}-u_{i,j-1}}{2\Delta y}\frac{v_{i+1,j}-v_{i-1,j}}{2\Delta x} - \frac{v_{i,j+1}-v_{i,j-1}}{2\Delta y}\frac{v_{i,j+1}-v_{i,j-1}}{2\Delta y}\right]
\end{split}
$$
Como sempre, temos que reorganizar essas equações da forma que precisamos no código para proceder com as iterações.
Para as equações de momento nas direções de $u$ e $v$, isolamos a velocidade no passo de tempo `n + 1`:
$$
\begin{split}
u_{i,j}^{n+1} = u_{i,j}^{n} & - u_{i,j}^{n} \frac{\Delta t}{\Delta x} \left(u_{i,j}^{n}-u_{i-1,j}^{n}\right) - v_{i,j}^{n} \frac{\Delta t}{\Delta y} \left(u_{i,j}^{n}-u_{i,j-1}^{n}\right) \\
& - \frac{\Delta t}{\rho 2\Delta x} \left(p_{i+1,j}^{n}-p_{i-1,j}^{n}\right) \\
& + \nu\left[\frac{\Delta t}{\Delta x^2} \left(u_{i+1,j}^{n}-2u_{i,j}^{n}+u_{i-1,j}^{n}\right) + \frac{\Delta t}{\Delta y^2} \left(u_{i,j+1}^{n}-2u_{i,j}^{n}+u_{i,j-1}^{n}\right)\right] \\
& + \Delta t F
\end{split}
$$
$$
\begin{split}
v_{i,j}^{n+1} = v_{i,j}^{n} & - u_{i,j}^{n} \frac{\Delta t}{\Delta x} \left(v_{i,j}^{n}-v_{i-1,j}^{n}\right) - v_{i,j}^{n} \frac{\Delta t}{\Delta y} \left(v_{i,j}^{n}-v_{i,j-1}^{n}\right) \\
& - \frac{\Delta t}{\rho 2\Delta y} \left(p_{i,j+1}^{n}-p_{i,j-1}^{n}\right) \\
& + \nu\left[\frac{\Delta t}{\Delta x^2} \left(v_{i+1,j}^{n}-2v_{i,j}^{n}+v_{i-1,j}^{n}\right) + \frac{\Delta t}{\Delta y^2} \left(v_{i,j+1}^{n}-2v_{i,j}^{n}+v_{i,j-1}^{n}\right)\right]
\end{split}
$$
E para a equação da pressão, isolamos o termo $p_{i, j}^n $ para iterar no pseudo-tempo:
$$
\begin{split}
p_{i,j}^{n} = & \frac{\left(p_{i+1,j}^{n}+p_{i-1,j}^{n}\right) \Delta y^2 + \left(p_{i,j+1}^{n}+p_{i,j-1}^{n}\right) \Delta x^2}{2(\Delta x^2+\Delta y^2)} \\
& -\frac{\rho\Delta x^2\Delta y^2}{2\left(\Delta x^2+\Delta y^2\right)} \\
& \times \left[\frac{1}{\Delta t} \left(\frac{u_{i+1,j}-u_{i-1,j}}{2\Delta x} + \frac{v_{i,j+1}-v_{i,j-1}}{2\Delta y}\right) - \frac{u_{i+1,j}-u_{i-1,j}}{2\Delta x}\frac{u_{i+1,j}-u_{i-1,j}}{2\Delta x} - 2\frac{u_{i,j+1}-u_{i,j-1}}{2\Delta y}\frac{v_{i+1,j}-v_{i-1,j}}{2\Delta x} - \frac{v_{i,j+1}-v_{i,j-1}}{2\Delta y}\frac{v_{i,j+1}-v_{i,j-1}}{2\Delta y}\right]
\end{split}
$$
A condição inicial é $u, v, p = 0 $ em todos os lugares, e as condições de contorno são:
$u, v, p$ são periódicos em $x=0$ e $x=2$
$u, v =0$ em $y=0$ e $y=2$
$\frac{\partial p}{\partial y}=0$ em $y=0$ e $y=2$
$F=1$ em todo o domínio.
Vamos começar importando nossa série usual de bibliotecas:
```
import numpy
from matplotlib import pyplot, cm
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
```
Na etapa 11, isolamos uma parte de nossa equação discreta para facilitar a análise e vamos fazer a mesma coisa aqui. Uma coisa a notar é que temos condições de contorno periódicas em $x$, portanto, precisamos calcular explicitamente os valores na extremidade inicial e final do nosso vetor `u`.
```
def build_up_b(rho, dt, dx, dy, u, v):
b = numpy.zeros_like(u)
b[1:-1, 1:-1] = (rho * (1 / dt * ((u[2:,1:-1] - u[0:-2,1:-1]) / (2 * dx) +
(v[1:-1,2:] - v[1:-1,0:-2]) / (2 * dy)) -
((u[2:,1:-1] - u[0:-2,1:-1]) / (2 * dx))**2 -
2 * ((u[1:-1,2:] - u[1:-1,0:-2]) / (2 * dy) *
(v[2:,1:-1] - v[0:-2,1:-1]) / (2 * dx))-
((v[1:-1,2:] - v[1:-1,0:-2]) / (2 * dy))**2))
# CC pressão periódica @ x = 2
b[-1,1:-1] = (rho * (1 / dt * ((u[0,1:-1] - u[-2,1:-1]) / (2 * dx) +
(v[-1,2:] - v[-1,0:-2]) / (2 * dy)) -
((u[0,1:-1] - u[-2,1:-1]) / (2 * dx))**2 -
2 * ((u[-1,2:] - u[-1,0:-2]) / (2 * dy) *
(v[0,1:-1] - v[-2,1:-1]) / (2 * dx)) -
((v[-1,2:] - v[-1,0:-2]) / (2 * dy))**2))
# CC pressão periódica @ x = 0
b[0,1:-1] = (rho * (1 / dt * ((u[1,1:-1] - u[-1,1:-1]) / (2 * dx) +
(v[0,2:] - v[0,0:-2]) / (2 * dy)) -
((u[1,1:-1] - u[-1,1:-1]) / (2 * dx))**2 -
2 * ((u[0,2:] - u[0,0:-2]) / (2 * dy) *
(v[1,1:-1] - v[-1,1:-1]) / (2 * dx))-
((v[0,2:] - v[0,0:-2]) / (2 * dy))**2))
return b
```
Também definiremos uma função iterativa de Poisson para a pressão, novamente como fizemos na Etapa 11. Mais uma vez, observe que precisamos incluir as condições de contorno periódicas na borda inicial e final. Também temos que especificar as condições de contorno na parte superior e inferior da nossa malha.
```
def pressure_poisson_periodic(p, dx, dy):
pn = numpy.empty_like(p)
for q in range(nit):
pn = p.copy()
p[1:-1, 1:-1] = (((pn[2:,1:-1] + pn[0:-2,1:-1]) * dy**2 +
(pn[1:-1,2:] + pn[1:-1,0:-2]) * dx**2) /
(2 * (dx**2 + dy**2)) -
dx**2 * dy**2 / (2 * (dx**2 + dy**2)) * b[1:-1, 1:-1])
# CC pressão periódica @ x = 2
p[-1,1:-1] = (((pn[0,1:-1] + pn[-2,1:-1])* dy**2 +
(pn[-1,2:] + pn[-1,0:-2]) * dx**2) /
(2 * (dx**2 + dy**2)) -
dx**2 * dy**2 / (2 * (dx**2 + dy**2)) * b[-1,1:-1])
# CC pressão periódica @ x = 0
p[0,1:-1] = (((pn[1,1:-1] + pn[-1,1:-1])* dy**2 +
(pn[0,2:] + pn[0,0:-2]) * dx**2) /
(2 * (dx**2 + dy**2)) -
dx**2 * dy**2 / (2 * (dx**2 + dy**2)) * b[0,1:-1])
# Condição de contorno para pressure na parede
p[:,-1] =p[:,-2] # dp/dy = 0 at y = 2
p[:,0] = p[:,1] # dp/dy = 0 at y = 0
return p
```
Agora, temos nossa lista familiar de variáveis e condições iniciais a declarar antes de começar.
```
#Declaração das variáveis
x = numpy.linspace(0, 2, num=41)
y = numpy.linspace(0, 2, num=41)
nt = 10
nit = 50
c = 1
##Veriáveis físicas
rho = 1
nu = .1
F = 1
dt = .01
#Parâmetros da malha
nx = x.size
ny = y.size
dx = (x[-1] - x[0]) / (nx - 1)
dy = (y[-1] - y[0]) / (ny - 1)
X, Y = numpy.meshgrid(x, y)
#Condições Iniciais
u = numpy.zeros((nx, ny))
un = numpy.zeros((nx, ny))
v = numpy.zeros((nx, ny))
vn = numpy.zeros((nx, ny))
p = numpy.ones((nx, ny))
pn = numpy.ones((nx, ny))
b = numpy.zeros((nx, ny))
```
Para a cerne do nosso cálculo, vamos voltar a um truque que usamos no Passo 9 para a Equação de Laplace. Estamos interessados em como será nosso domínio quando chegarmos a um estado quase estável. Podemos especificar um número de intervalos de tempo `nt` e incrementá-lo até ficarmos satisfeitos com os resultados, ou podemos dizer ao nosso código para executar até que a diferença entre duas iterações consecutivas seja muito pequena.
Também temos que gerenciar **8** condições de contorno separadas para cada iteração. O código abaixo grava cada um deles explicitamente. Se você estiver interessado em um desafio, tente escrever uma função que possa lidar com algumas ou todas essas condições de contorno. Se você estiver interessado em resolver isso, provavelmente deve ler os [dicionários](http://docs.python.org/2/tutorial/datastructures.html#dictionaries) em Python.
```
udiff = 1
stepcount = 0
while udiff > .001:
un = u.copy()
vn = v.copy()
b = build_up_b(rho, dt, dx, dy, u, v)
p = pressure_poisson_periodic(p, dx, dy)
u[1:-1, 1:-1] = (un[1:-1, 1:-1] -
un[1:-1, 1:-1] * dt / dx *
(un[1:-1, 1:-1] - un[0:-2,1:-1]) -
vn[1:-1, 1:-1] * dt / dy *
(un[1:-1, 1:-1] - un[1:-1,0:-2]) -
dt / (2 * rho * dx) *
(p[2:,1:-1] - p[0:-2,1:-1]) +
nu * (dt / dx**2 *
(un[2:,1:-1] - 2 * un[1:-1,1:-1] + un[0:-2,1:-1]) +
dt / dy**2 *
(un[1:-1,2:] - 2 * un[1:-1, 1:-1] + un[1:-1,0:-2])) +
F * dt)
v[1:-1, 1:-1] = (vn[1:-1, 1:-1] -
un[1:-1, 1:-1] * dt / dx *
(vn[1:-1, 1:-1] - vn[0:-2,1:-1]) -
vn[1:-1, 1:-1] * dt / dy *
(vn[1:-1, 1:-1] - vn[1:-1,0:-2]) -
dt / (2 * rho * dy) *
(p[1:-1,2:] - p[1:-1,0:-2]) +
nu * (dt / dx**2 *
(vn[2:,1:-1] - 2 * vn[1:-1, 1:-1] + vn[0:-2,1:-1]) +
dt / dy**2 *
(vn[1:-1,2:] - 2 * vn[1:-1, 1:-1] + vn[1:-1,0:-2])))
# CC periódica para u @ x = 2
u[-1,1:-1] = (un[-1,1:-1] - un[-1,1:-1] * dt / dx *
(un[-1,1:-1] - un[-2,1:-1]) -
vn[-1,1:-1] * dt / dy *
(un[-1,1:-1] - un[-1,0:-2]) -
dt / (2 * rho * dx) *
(p[0,1:-1] - p[-2,1:-1]) +
nu * (dt / dx**2 *
(un[0,1:-1] - 2 * un[-1,1:-1] + un[-2,1:-1]) +
dt / dy**2 *
(un[-1,2:] - 2 * un[-1,1:-1] + un[-1,0:-2])) + F * dt)
# CC periódica para u @ x = 0
u[0,1:-1] = (un[0,1:-1] - un[0,1:-1] * dt / dx *
(un[0,1:-1] - un[-1,1:-1]) -
vn[0,1:-1] * dt / dy *
(un[0,1:-1] - un[0,0:-2]) -
dt / (2 * rho * dx) *
(p[1,1:-1] - p[-1,1:-1]) +
nu * (dt / dx**2 *
(un[1,1:-1] - 2 * un[0,1:-1] + un[-1,1:-1]) +
dt / dy**2 *
(un[0,2:] - 2 * un[0,1:-1] + un[0,0:-2])) + F * dt)
# CC periódica para v @ x = 2
v[-1,1:-1] = (vn[-1,1:-1] - un[-1,1:-1] * dt / dx *
(vn[-1,1:-1] - vn[-2,1:-1]) -
vn[-1,1:-1] * dt / dy *
(vn[-1,1:-1] - vn[-1,0:-2]) -
dt / (2 * rho * dy) *
(p[-1,2:] - p[-1,0:-2]) +
nu * (dt / dx**2 *
(vn[0,1:-1] - 2 * vn[-1,1:-1] + vn[-2,1:-1]) +
dt / dy**2 *
(vn[-1,2:] - 2 * vn[-1,1:-1] + vn[-1,0:-2])))
# CC periódica para v @ x = 0
v[0,1:-1] = (vn[0,1:-1] - un[0,1:-1] * dt / dx *
(vn[0,1:-1] - vn[-1,1:-1]) -
vn[0,1:-1] * dt / dy *
(vn[0,1:-1] - vn[0,0:-2]) -
dt / (2 * rho * dy) *
(p[0,2:] - p[0,0:-2]) +
nu * (dt / dx**2 *
(vn[1,1:-1] - 2 * vn[0,1:-1] + vn[-1,1:-1]) +
dt / dy**2 *
(vn[0,2:] - 2 * vn[0,1:-1] + vn[0,0:-2])))
# Condição de contorno na parede: u,v = 0 @ y = 0,2
u[:,0] = 0
u[:,-1] = 0
v[:,0] = 0
v[:,-1]=0
udiff = (numpy.sum(u) - numpy.sum(un)) / numpy.sum(u)
stepcount += 1
```
Você pode ver que também incluímos uma variável `stepcount` para ver quantas iterações nosso laço passou antes de nossa condição de parada ser atendida.
```
print(stepcount)
```
Se você quiser ver como o número de iterações aumenta à medida que nossa condição `udiff` se torna cada vez menor, tente definir uma função para executar o loop` while` escrito acima, que recebe uma entrada `udiff` e gera o número de iterações que o função é executada.
Por enquanto, vejamos nossos resultados. Usamos a função `quiver` para observar os resultados do escoamento em cavidade e ela também funciona bem para o escoamento em canal.
```
fig = pyplot.figure(figsize = (11,7), dpi=100)
pyplot.quiver(X[::3, ::3], Y[::3, ::3], u[::3, ::3].T, v[::3, ::3].T);
```
As estruturas no comando `quiver` que se parecem com `[::3,::3]` são úteis ao lidar com grandes quantidades de dados que você deseja visualizar. O que usadom acima diz ao `matplotlib` para plotar apenas cada terceiro dos ponto que temos. Se deixarmos de fora, você pode ver que os resultados podem parecer um pouco abarrotados.
```
fig = pyplot.figure(figsize = (11,7), dpi=100)
pyplot.quiver(X, Y, u.T, v.T);
```
Material Complementar
-----
***
##### Mas qual é o significado do termo $F$?
O passo 12 é um exercício que demonstra o problema do escoamento em um canal ou tubo. Se você se lembra da sua aula de mecânica de fluidos, um gradiente de pressão especificado é o que impulsiona o escoamento de Poisseulle.
Lembre-se da equação do momento em $x$:
$$\frac{\partial u}{\partial t}+u \cdot \nabla u = -\frac{\partial p}{\partial x}+\nu \nabla^2 u$$
O que realmente fazemos no Passo 12 é dividir a pressão em componentes de média e flutuação $p = P + p'$. O gradiente de pressão médio aplicado é a constante $-\frac{\partial P}{\partial x}=F$ (interpretado como um termo fonte), e o componente de flutuação é $\frac{\partial p'}{\partial x}$. Portanto, a pressão que resolvemos na Etapa 12 é na verdade $p'$, que para um escoamento constante é de fato igual a zero em todo o domínio.
<b>Por que fizemos isso?</b>
Observe que usamos condições de contorno periódicas para esse escoamento. Para um escoamento com um gradiente de pressão constante, o valor da pressão na borda esquerda do domínio deve ser diferente da pressão na borda direita. Portanto, não podemos aplicar condições periódicas de contorno diretamente à pressão. É mais fácil fixar o gradiente e depois resolver as perturbações na pressão.
<b> Então não devemos sempre esperar um $p'$ uniforme/constante? </b>
Isso é verdade apenas no caso de escoamentos laminares constantes. Em números altos de Reynolds, os escoamentos em canais podem se tornar turbulentos e veremos flutuações instáveis na pressão, o que resultará em valores diferentes de zero para $p'$.
Na etapa 12, observe que o próprio campo de pressão não é constante, mas é o campo de perturbação da pressão. O campo de pressão varia linearmente ao longo do canal com inclinação igual ao gradiente de pressão. Além disso, para fluxos incompressíveis, o valor absoluto da pressão é inconsequente.
##### E explore mais materiais on-line sobre CFD
O módulo interativo **12 Passos para Navier – Stokes** é um dos vários componentes da aula de Dinâmica dos Fluidos Computacional ministrada pela Prof. Lorena A. Barba na Universidade de Boston entre 2009 e 2013.
Para uma amostra de quais são os outros componentes desta disciplina, você pode explorar a seção **Resources** da versão da Primavera 2013 do [the course's Piazza site](https://piazza.com/bu/spring2013/me702/resources).
***
```
from IPython.core.display import HTML
def css_styling():
styles = open("../styles/custom.css", "r").read()
return HTML(styles)
css_styling()
```
> A célula acima executa o estilo para esse notebook. Nós modificamos o estilo encontrado no GitHub de [CamDavidsonPilon](https://github.com/CamDavidsonPilon), [@Cmrn_DP](https://twitter.com/cmrn_dp).
| github_jupyter |
# Convolutional Autoencoder
Sticking with the MNIST dataset, let's improve our autoencoder's performance using convolutional layers. Again, loading modules and the data.
```
%matplotlib inline
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', validation_size=0)
img = mnist.train.images[2]
plt.imshow(img.reshape((28, 28)), cmap='Greys_r')
```
## Network Architecture
The encoder part of the network will be a typical convolutional pyramid. Each convolutional layer will be followed by a max-pooling layer to reduce the dimensions of the layers. The decoder though might be something new to you. The decoder needs to convert from a narrow representation to a wide reconstructed image. For example, the representation could be a 4x4x8 max-pool layer. This is the output of the encoder, but also the input to the decoder. We want to get a 28x28x1 image out from the decoder so we need to work our way back up from the narrow decoder input layer. A schematic of the network is shown below.
<img src='assets/convolutional_autoencoder.png' width=500px>
Here our final encoder layer has size 4x4x8 = 128. The original images have size 28x28 = 784, so the encoded vector is roughly 16% the size of the original image. These are just suggested sizes for each of the layers. Feel free to change the depths and sizes, but remember our goal here is to find a small representation of the input data.
### What's going on with the decoder
Okay, so the decoder has these "Upsample" layers that you might not have seen before. First off, I'll discuss a bit what these layers *aren't*. Usually, you'll see **transposed convolution** layers used to increase the width and height of the layers. They work almost exactly the same as convolutional layers, but in reverse. A stride in the input layer results in a larger stride in the transposed convolution layer. For example, if you have a 3x3 kernel, a 3x3 patch in the input layer will be reduced to one unit in a convolutional layer. Comparatively, one unit in the input layer will be expanded to a 3x3 path in a transposed convolution layer. The TensorFlow API provides us with an easy way to create the layers, [`tf.nn.conv2d_transpose`](https://www.tensorflow.org/api_docs/python/tf/nn/conv2d_transpose).
However, transposed convolution layers can lead to artifacts in the final images, such as checkerboard patterns. This is due to overlap in the kernels which can be avoided by setting the stride and kernel size equal. In [this Distill article](http://distill.pub/2016/deconv-checkerboard/) from Augustus Odena, *et al*, the authors show that these checkerboard artifacts can be avoided by resizing the layers using nearest neighbor or bilinear interpolation (upsampling) followed by a convolutional layer. In TensorFlow, this is easily done with [`tf.image.resize_images`](https://www.tensorflow.org/versions/r1.1/api_docs/python/tf/image/resize_images), followed by a convolution. Be sure to read the Distill article to get a better understanding of deconvolutional layers and why we're using upsampling.
> **Exercise:** Build the network shown above. Remember that a convolutional layer with strides of 1 and 'same' padding won't reduce the height and width. That is, if the input is 28x28 and the convolution layer has stride = 1 and 'same' padding, the convolutional layer will also be 28x28. The max-pool layers are used the reduce the width and height. A stride of 2 will reduce the size by a factor of 2. Odena *et al* claim that nearest neighbor interpolation works best for the upsampling, so make sure to include that as a parameter in `tf.image.resize_images` or use [`tf.image.resize_nearest_neighbor`]( `https://www.tensorflow.org/api_docs/python/tf/image/resize_nearest_neighbor). For convolutional layers, use [`tf.layers.conv2d`](https://www.tensorflow.org/api_docs/python/tf/layers/conv2d). For example, you would write `conv1 = tf.layers.conv2d(inputs, 32, (5,5), padding='same', activation=tf.nn.relu)` for a layer with a depth of 32, a 5x5 kernel, stride of (1,1), padding is 'same', and a ReLU activation. Similarly, for the max-pool layers, use [`tf.layers.max_pooling2d`](https://www.tensorflow.org/api_docs/python/tf/layers/max_pooling2d).
```
mnist.train.images.shape[1]
learning_rate = 0.001
image_size = mnist.train.images.shape[1]
# Input and target placeholders
inputs_ = tf.placeholder(dtype = tf.float32,shape=(None,28,28,1),name='inputs')
targets_ = tf.placeholder(dtype = tf.float32,shape = (None,28,28,1), name='targets' )
### Encoder
conv1 = tf.layers.conv2d(inputs = inputs_, filters = 16, kernel_size=(3,3), strides=(1,1), padding='same', activation=tf.nn.relu)
# Now 28x28x16
maxpool1 = tf.layers.max_pooling2d(inputs =conv1, pool_size=2, strides = 2, padding='same')
# Now 14x14x16
conv2 = tf.layers.conv2d(inputs = maxpool1, filters=8, kernel_size=(3,3), strides=1, padding='same', activation=tf.nn.relu)
# Now 14x14x8
maxpool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=2, strides=2, padding='same')
# Now 7x7x8
conv3 = tf.layers.conv2d(inputs = maxpool2,filters = 8, kernel_size=3, strides = 1, padding='same', activation = tf.nn.relu)
# Now 7x7x8
# encoded = tf.layers.dense(inputs = conv3,units = 8,activation = None )
encoded = tf.layers.max_pooling2d(inputs = conv3, pool_size=2, strides=2, padding='same')
print('encoded shape = ',encoded.shape)
# Now 4x4x8, smaller than input of 28x28x1 (~16% of original )
### Decoder
# upsample1 = tf.image.resize_nearest_neighbor(images=encoded, size=7)
upsample1 = tf.image.resize_nearest_neighbor(encoded, (7,7))
print('upsample1 shape = ',upsample1.shape)
# Now 7x7x8
conv4 = tf.layers.conv2d(inputs = upsample1, filters = 8, kernel_size = 2, strides = 1, padding = 'same', activation = tf.nn.relu)
print('conv4 shape = ', conv4.shape)
# Now 7x7x8
upsample2 = tf.image.resize_nearest_neighbor(images = conv4, size = (14,14))
print('upsample2 shape = ', upsample2.shape)
# Now 14x14x8
conv5 = tf.layers.conv2d(inputs = upsample2, filters = 8, kernel_size = 3, strides = 1, padding='same', activation = tf.nn.relu)
print('conv5 shape = ', conv5.shape)
# Now 14x14x8
upsample3 = tf.image.resize_nearest_neighbor(images = conv5, size = (28,28))
print('upsample3 shape = ',upsample3.shape)
# Now 28x28x8
conv6 = tf.layers.conv2d(inputs = upsample3, filters = 16, kernel_size = 3, strides = 1, padding = 'same', activation = tf.nn.relu)
print('conv6 shape = ',conv6.shape)
# Now 28x28x16
logits = tf.layers.conv2d(inputs = conv6, filters =1, kernel_size = 3, padding='same',activation = None)
print('logits shape = ',logits.shape)
#Now 28x28x1
# Pass logits through sigmoid to get reconstructed image
decoded = tf.nn.sigmoid(logits, name = 'decoded')
# Pass logits through sigmoid and calculate the cross-entropy loss
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits = logits, labels = targets_)
# Get cost and define the optimizer
cost = tf.reduce_mean(loss)
opt = tf.train.AdamOptimizer(learning_rate).minimize(cost)
```
## Training
As before, here we'll train the network. Instead of flattening the images though, we can pass them in as 28x28x1 arrays.
```
sess = tf.Session()
epochs = 20
batch_size = 200
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for ii in range(mnist.train.num_examples//batch_size):
batch = mnist.train.next_batch(batch_size)
imgs = batch[0].reshape((-1, 28, 28, 1))
batch_cost, _ = sess.run([cost, opt], feed_dict={inputs_: imgs,
targets_: imgs})
print("Epoch: {}/{}...".format(e+1, epochs),
"Training loss: {:.4f}".format(batch_cost))
fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(20,4))
in_imgs = mnist.test.images[:10]
reconstructed = sess.run(decoded, feed_dict={inputs_: in_imgs.reshape((10, 28, 28, 1))})
for images, row in zip([in_imgs, reconstructed], axes):
for img, ax in zip(images, row):
ax.imshow(img.reshape((28, 28)), cmap='Greys_r')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
fig.tight_layout(pad=0.1)
sess.close()
```
## Denoising
As I've mentioned before, autoencoders like the ones you've built so far aren't too useful in practice. However, they can be used to denoise images quite successfully just by training the network on noisy images. We can create the noisy images ourselves by adding Gaussian noise to the training images, then clipping the values to be between 0 and 1. We'll use noisy images as input and the original, clean images as targets. Here's an example of the noisy images I generated and the denoised images.

Since this is a harder problem for the network, we'll want to use deeper convolutional layers here, more feature maps. I suggest something like 32-32-16 for the depths of the convolutional layers in the encoder, and the same depths going backward through the decoder. Otherwise the architecture is the same as before.
> **Exercise:** Build the network for the denoising autoencoder. It's the same as before, but with deeper layers. I suggest 32-32-16 for the depths, but you can play with these numbers, or add more layers.
```
learning_rate = 0.001
inputs_ = tf.placeholder(tf.float32, (None, 28, 28, 1), name='inputs')#not flattening images, so input is size of images
targets_ = tf.placeholder(tf.float32, (None, 28, 28, 1), name='targets')
### Encoder
conv1 = tf.layers.conv2d(inputs= inputs_,filters = 32, kernel_size =2 ,strides = 1, padding='same', activation=tf.nn.relu)
# Now 28x28x32
maxpool1 = tf.layers.max_pooling2d(inputs = conv1,pool_size = 2, padding='same',strides = 2)
# Now 14x14x32
conv2 = tf.layers.conv2d(inputs = maxpool1, filters = 32, kernel_size = 2, strides = 1, padding = 'same', activation = tf.nn.relu)
# Now 14x14x32
maxpool2 = tf.layers.max_pooling2d(inputs = conv2, pool_size = 3, padding = 'same', strides = 2)
# Now 7x7x32
conv3 = tf.layers.conv2d(inputs = maxpool2, filters = 16, kernel_size = 3, strides = 1, padding = 'same', activation = tf.nn.relu)
print('conv3 shape = ',conv3.shape)
# Now 7x7x16
encoded = tf.layers.max_pooling2d(inputs = conv3, pool_size = 3, padding = 'same', strides = 2)
print('encoded shape = ', encoded.shape)
# Now 4x4x16
### Decoder
upsample1 = tf.image.resize_nearest_neighbor(images = encoded, size = (7,7))
# Now 7x7x16
conv4 = tf.layers.conv2d(inputs = upsample1, filters = 16, kernel_size = 3, strides = 1, padding = 'same', activation = tf.nn.relu)
# Now 7x7x16
upsample2 = tf.image.resize_nearest_neighbor(images=conv4, size =(14,14))
# Now 14x14x16
conv5 = tf.layers.conv2d(inputs = upsample2, filters = 32, kernel_size = 3, strides = 1, padding = 'same', activation = tf.nn.relu)
# Now 14x14x32
upsample3 = tf.image.resize_nearest_neighbor(images = conv5, size = (28,28))
# Now 28x28x32
conv6 = tf.layers.conv2d(inputs = upsample3, filters = 32, kernel_size = 3, strides = 1, padding = 'same', activation = tf.nn.relu)
# Now 28x28x32
logits = tf.layers.conv2d(inputs = conv6, filters = 1, kernel_size = 3, strides = 1, padding = 'same', activation = None)
print('logits shape', logits.shape)
#Now 28x28x1
# Pass logits through sigmoid to get reconstructed image
decoded =tf.nn.sigmoid(logits)
# Pass logits through sigmoid and calculate the cross-entropy loss
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits = logits, labels = targets_)
# Get cost and define the optimizer
cost = tf.reduce_mean(loss)
opt = tf.train.AdamOptimizer(learning_rate).minimize(cost)
sess = tf.Session()
epochs = 100
batch_size = 200
# Set's how much noise we're adding to the MNIST images
noise_factor = 0.5
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for ii in range(mnist.train.num_examples//batch_size):
batch = mnist.train.next_batch(batch_size)
# Get images from the batch
imgs = batch[0].reshape((-1, 28, 28, 1))
# Add random noise to the input images
noisy_imgs = imgs + noise_factor * np.random.randn(*imgs.shape)
# Clip the images to be between 0 and 1
noisy_imgs = np.clip(noisy_imgs, 0., 1.)
# Noisy images as inputs, original images as targets
batch_cost, _ = sess.run([cost, opt], feed_dict={inputs_: noisy_imgs,
targets_: imgs})
print("Epoch: {}/{}...".format(e+1, epochs),
"Training loss: {:.4f}".format(batch_cost))
```
## Checking out the performance
Here I'm adding noise to the test images and passing them through the autoencoder. It does a suprisingly great job of removing the noise, even though it's sometimes difficult to tell what the original number is.
```
fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(20,4))
in_imgs = mnist.test.images[:10]
noisy_imgs = in_imgs + noise_factor * np.random.randn(*in_imgs.shape)
noisy_imgs = np.clip(noisy_imgs, 0., 1.)
reconstructed = sess.run(decoded, feed_dict={inputs_: noisy_imgs.reshape((10, 28, 28, 1))})
for images, row in zip([noisy_imgs, reconstructed], axes):
for img, ax in zip(images, row):
ax.imshow(img.reshape((28, 28)), cmap='Greys_r')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
fig.tight_layout(pad=0.1)
```
| github_jupyter |
# The Red Line Problem
Think Bayes, Second Edition
Copyright 2020 Allen B. Downey
License: [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/)
```
# If we're running on Colab, install empiricaldist
# https://pypi.org/project/empiricaldist/
import sys
IN_COLAB = 'google.colab' in sys.modules
if IN_COLAB:
!pip install empiricaldist
# Get utils.py
from os.path import basename, exists
def download(url):
filename = basename(url)
if not exists(filename):
from urllib.request import urlretrieve
local, _ = urlretrieve(url, filename)
print('Downloaded ' + local)
download('https://github.com/AllenDowney/ThinkBayes2/raw/master/soln/utils.py')
from utils import set_pyplot_params
set_pyplot_params()
```
The Red Line is a subway that connects Cambridge and Boston, Massachusetts. When I was working in Cambridge I took the Red Line from Kendall Square to South Station and caught the commuter rail to Needham. During rush hour Red Line trains run every 7–8 minutes, on average.
When I arrived at the subway stop, I could estimate the time until the next train based on the number of passengers on the platform. If there were only a few people, I inferred that I just missed a train and expected to wait about 7 minutes. If there were more passengers, I expected the train to arrive sooner. But if there were a large number of passengers, I suspected that trains were not running on schedule, so I would leave the subway stop and get a taxi.
While I was waiting for trains, I thought about how Bayesian estimation could help predict my wait time and decide when I should give up and take a taxi. This chapter presents the analysis I came up with.
This example is based on a project by Brendan Ritter and Kai Austin, who took a class with me at Olin College.
[Click here to run this notebook on Colab](https://colab.research.google.com/github/AllenDowney/ThinkBayes2/blob/master/notebooks/redline.ipynb)
Before we get to the analysis, we have to make some modeling decisions. First, I will treat passenger arrivals as a Poisson process, which means I assume that passengers are equally likely to arrive at any time, and that they arrive at a rate, λ, measured in passengers per minute. Since I observe passengers during a short period of time, and at the same time every day, I assume that λ is constant.
On the other hand, the arrival process for trains is not Poisson. Trains to Boston are supposed to leave from the end of the line (Alewife station) every 7–8 minutes during peak times, but by the time they get to Kendall Square, the time between trains varies between 3 and 12 minutes.
To gather data on the time between trains, I wrote a script that downloads real-time data from the [MBTA](http://www.mbta.com/rider_tools/developers/), selects south-bound trains arriving at Kendall square, and records their arrival times in a database. I ran the script from 4 pm to 6 pm every weekday for 5 days, and recorded about 15 arrivals per day. Then I computed the time between consecutive arrivals.
Here are the gap times I recorded, in seconds.
```
observed_gap_times = [
428.0, 705.0, 407.0, 465.0, 433.0, 425.0, 204.0, 506.0, 143.0, 351.0,
450.0, 598.0, 464.0, 749.0, 341.0, 586.0, 754.0, 256.0, 378.0, 435.0,
176.0, 405.0, 360.0, 519.0, 648.0, 374.0, 483.0, 537.0, 578.0, 534.0,
577.0, 619.0, 538.0, 331.0, 186.0, 629.0, 193.0, 360.0, 660.0, 484.0,
512.0, 315.0, 457.0, 404.0, 740.0, 388.0, 357.0, 485.0, 567.0, 160.0,
428.0, 387.0, 901.0, 187.0, 622.0, 616.0, 585.0, 474.0, 442.0, 499.0,
437.0, 620.0, 351.0, 286.0, 373.0, 232.0, 393.0, 745.0, 636.0, 758.0,
]
```
I'll convert them to minutes and use `kde_from_sample` to estimate the distribution.
```
import numpy as np
zs = np.array(observed_gap_times) / 60
from utils import kde_from_sample
qs = np.linspace(0, 20, 101)
pmf_z = kde_from_sample(zs, qs)
```
Here's what it looks like.
```
from utils import decorate
pmf_z.plot()
decorate(xlabel='Time (min)',
ylabel='PDF',
title='Distribution of time between trains')
```
## The Update
At this point we have an estimate for the distribution of time between trains.
Now let's suppose I arrive at the station and see 10 passengers on the platform.
What distribution of wait times should I expect?
We'll answer this question in two steps.
* First, we'll derive the distribution of gap times as observed by a random arrival (me).
* Then we'll derive the distribution of wait times, conditioned on the number of passengers.
When I arrive at the station, I am more likely to arrive during a long gap than a short one.
In fact, the probability that I arrive during any interval is proportional to its duration.
If we think of `pmf_z` as the prior distribution of gap time, we can do a Bayesian update to compute the posterior.
The likelihood of my arrival during each gap is the duration of the gap:
```
likelihood = pmf_z.qs
```
So here's the first update.
```
posterior_z = pmf_z * pmf_z.qs
posterior_z.normalize()
```
Here's what the posterior distribution looks like.
```
pmf_z.plot(label='prior', color='C5')
posterior_z.plot(label='posterior', color='C4')
decorate(xlabel='Time (min)',
ylabel='PDF',
title='Distribution of time between trains')
```
Because I am more likely to arrive during a longer gap, the distribution is shifted to the right.
The prior mean is about 7.8 minutes; the posterior mean is about 8.9 minutes.
```
pmf_z.mean(), posterior_z.mean()
```
This shift is an example of the "inspection paradox", which [I wrote an article about](https://towardsdatascience.com/the-inspection-paradox-is-everywhere-2ef1c2e9d709).
As an aside, the Red Line schedule reports that trains run every 9 minutes during peak times. This is close to the posterior mean, but higher than the prior mean. I exchanged email with a representative of the MBTA, who confirmed that the reported time between trains is deliberately conservative in order to account for variability.
## Elapsed time
Elapsed time, which I call `x`, is the time between the arrival of the previous train and the arrival of a passenger.
Wait time, which I call `y`, is the time between the arrival of a passenger and the next arrival of a train.
I chose this notation so that
```
z = x + y.
```
Given the distribution of `z`, we can compute the distribution of `x`. I’ll start with a simple case and then generalize. Suppose the gap between trains is either 5 or 10 minutes with equal probability.
If we arrive at a random time, we arrive during a 5 minute gap with probability 1/3, or a 10 minute gap with probability 2/3.
If we arrive during a 5 minute gap, `x` is uniform from 0 to 5 minutes. If we arrive during a 10 minute gap, `x` is uniform from 0 to 10.
So the distribution of wait times is a weighted mixture of two uniform distributions.
More generally, if we have the posterior distribution of `z`, we can compute the distribution of `x` by making a mixture of uniform distributions.
We'll use the following function to make the uniform distributions.
```
from empiricaldist import Pmf
def make_elapsed_dist(gap, qs):
qs = qs[qs <= gap]
n = len(qs)
return Pmf(1/n, qs)
```
`make_elapsed_dist` takes a hypothetical gap and an array of possible times.
It selects the elapsed times less than or equal to `gap` and puts them into a `Pmf` that represents a uniform distribution.
I'll use this function to make a sequence of `Pmf` objects, one for each gap in `posterior_z`.
```
qs = posterior_z.qs
pmf_seq = [make_elapsed_dist(gap, qs) for gap in qs]
```
Here's an example that represents a uniform distribution from 0 to 0.6 minutes.
```
pmf_seq[3]
```
The last element of the sequence is uniform from 0 to 20 minutes.
```
pmf_seq[-1].plot()
decorate(xlabel='Time (min)',
ylabel='PDF',
title='Distribution of wait time in 20 min gap')
```
Now we can use `make_mixture` to make a weighted mixture of uniform distributions, where the weights are the probabilities from `posterior_z`.
```
from utils import make_mixture
pmf_x = make_mixture(posterior_z, pmf_seq)
pmf_z.plot(label='prior gap', color='C5')
posterior_z.plot(label='posterior gap', color='C4')
pmf_x.plot(label='elapsed time', color='C1')
decorate(xlabel='Time (min)',
ylabel='PDF',
title='Distribution of gap and elapsed times')
posterior_z.mean(), pmf_x.mean()
```
The mean elapsed time is 4.4 minutes, half the posterior mean of `z`.
And that makes sense, since we expect to arrive in the middle of the gap, on average.
## Counting passengers
Now let's take into account the number of passengers waiting on the platform.
Let's assume that passengers are equally likely to arrive at any time, and that they arrive at a rate, `λ`, that is known to be 2 passengers per minute.
Under those assumptions, the number of passengers who arrive in `x` minutes follows a Poisson distribution with parameter `λ x`
So we can use the SciPy function `poisson` to compute the likelihood of 10 passengers for each possible value of `x`.
```
from scipy.stats import poisson
lam = 2
num_passengers = 10
likelihood = poisson(lam * pmf_x.qs).pmf(num_passengers)
```
With this likelihood, we can compute the posterior distribution of `x`.
```
posterior_x = pmf_x * likelihood
posterior_x.normalize()
```
Here's what it looks like:
```
pmf_x.plot(label='prior', color='C1')
posterior_x.plot(label='posterior', color='C2')
decorate(xlabel='Time (min)',
ylabel='PDF',
title='Distribution of time since last train')
```
Based on the number of passengers, we think it has been about 5 minutes since the last train.
```
pmf_x.mean(), posterior_x.mean()
```
## Wait time
Now how long do we think it will be until the next train?
Based on what we know so far, the distribution of `z` is `posterior_z`, and the distribution of `x` is `posterior_x`.
Remember that we defined
```
z = x + y
```
If we know `x` and `z`, we can compute
```
y = z - x
```
So we can use `sub_dist` to compute the distribution of `y`.
```
posterior_y = Pmf.sub_dist(posterior_z, posterior_x)
```
Well, almost. That distribution contains some negative values, which are impossible.
But we can remove them and renormalize, like this:
```
nonneg = (posterior_y.qs >= 0)
posterior_y = Pmf(posterior_y[nonneg])
posterior_y.normalize()
```
Based on the information so far, here are the distributions for `x`, `y`, and `z`, shown as CDFs.
```
posterior_x.make_cdf().plot(label='posterior of x', color='C2')
posterior_y.make_cdf().plot(label='posterior of y', color='C3')
posterior_z.make_cdf().plot(label='posterior of z', color='C4')
decorate(xlabel='Time (min)',
ylabel='PDF',
title='Distribution of elapsed time, wait time, gap')
```
Because of rounding errors, `posterior_y` contains quantities that are not in `posterior_x` and `posterior_z`; that's why I plotted it as a CDF, and why it appears jaggy.
## Decision analysis
At this point we can use the number of passengers on the platform to predict the distribution of wait times. Now let’s get to the second part of the question: when should I stop waiting for the train and go catch a taxi?
Remember that in the original scenario, I am trying to get to South Station to catch the commuter rail. Suppose I leave the office with enough time that I can wait 15 minutes and still make my connection at South Station.
In that case I would like to know the probability that `y` exceeds 15 minutes as a function of `num_passengers`.
To answer that question, we can run the analysis from the previous section with range of `num_passengers`.
But there’s a problem. The analysis is sensitive to the frequency of long delays, and because long delays are rare, it is hard to estimate their frequency.
I only have data from one week, and the longest delay I observed was 15 minutes. So I can’t estimate the frequency of longer delays accurately.
However, I can use previous observations to make at least a coarse estimate. When I commuted by Red Line for a year, I saw three long delays caused by a signaling problem, a power outage, and “police activity” at another stop. So I estimate that there are about 3 major delays per year.
But remember that my observations are biased. I am more likely to observe long delays because they affect a large number of passengers. So we should treat my observations as a sample of `posterior_z` rather than `pmf_z`.
Here's how we can augment the observed distribution of gap times with some assumptions about long delays.
From `posterior_z`, I'll draw a sample of 260 values (roughly the number of work days in a year).
Then I'll add in delays of 30, 40, and 50 minutes (the number of long delays I observed in a year).
```
sample = posterior_z.sample(260)
delays = [30, 40, 50]
augmented_sample = np.append(sample, delays)
```
I'll use this augmented sample to make a new estimate for the posterior distribution of `z`.
```
qs = np.linspace(0, 60, 101)
augmented_posterior_z = kde_from_sample(augmented_sample, qs)
```
Here's what it looks like.
```
augmented_posterior_z.plot(label='augmented posterior of z', color='C4')
decorate(xlabel='Time (min)',
ylabel='PDF',
title='Distribution of time between trains')
```
Now let's take the analysis from the previous sections and wrap it in a function.
```
qs = augmented_posterior_z.qs
pmf_seq = [make_elapsed_dist(gap, qs) for gap in qs]
pmf_x = make_mixture(augmented_posterior_z, pmf_seq)
lam = 2
num_passengers = 10
def compute_posterior_y(num_passengers):
"""Distribution of wait time based on `num_passengers`."""
likelihood = poisson(lam * qs).pmf(num_passengers)
posterior_x = pmf_x * likelihood
posterior_x.normalize()
posterior_y = Pmf.sub_dist(augmented_posterior_z, posterior_x)
nonneg = (posterior_y.qs >= 0)
posterior_y = Pmf(posterior_y[nonneg])
posterior_y.normalize()
return posterior_y
```
Given the number of passengers when we arrive at the station, it computes the posterior distribution of `y`.
As an example, here's the distribution of wait time if we see 10 passengers.
```
posterior_y = compute_posterior_y(10)
```
We can use it to compute the mean wait time and the probability of waiting more than 15 minutes.
```
posterior_y.mean()
1 - posterior_y.make_cdf()(15)
```
If we see 10 passengers, we expect to wait a little less than 5 minutes, and the chance of waiting more than 15 minutes is about 1%.
Let's see what happens if we sweep through a range of values for `num_passengers`.
```
nums = np.arange(0, 37, 3)
posteriors = [compute_posterior_y(num) for num in nums]
```
Here's the mean wait as a function of the number of passengers.
```
mean_wait = [posterior_y.mean()
for posterior_y in posteriors]
import matplotlib.pyplot as plt
plt.plot(nums, mean_wait)
decorate(xlabel='Number of passengers',
ylabel='Expected time until next train',
title='Expected wait time based on number of passengers')
```
If there are no passengers on the platform when I arrive, I infer that I just missed a train; in that case, the expected wait time is the mean of `augmented_posterior_z`.
The more passengers I see, the longer I think it has been since the last train, and the more likely a train arrives soon.
But only up to a point. If there are more than 30 passengers on the platform, that suggests that there is a long delay, and the expected wait time starts to increase.
Now here's the probability that wait time exceeds 15 minutes.
```
prob_late = [1 - posterior_y.make_cdf()(15)
for posterior_y in posteriors]
plt.plot(nums, prob_late)
decorate(xlabel='Number of passengers',
ylabel='Probability of being late',
title='Probability of being late based on number of passengers')
```
When the number of passengers is less than 20, we infer that the system is operating normally, so the probability of a long delay is small. If there are 30 passengers, we suspect that something is wrong and expect longer delays.
If we are willing to accept a 5% chance of missing the connection at South Station, we should stay and wait as long as there are fewer than 30 passengers, and take a taxi if there are more.
Or, to take this analysis one step further, we could quantify the cost of missing the connection and the cost of taking a taxi, then choose the threshold that minimizes expected cost.
This analysis is based on the assumption that the arrival rate, `lam`, is known.
If it is not known precisely, but is estimated from data, we could represent our uncertainty about `lam` with a distribution, compute the distribution of `y` for each value of `lam`, and make a mixture to represent the distribution of `y`.
I did that in the version of this problem in the first edition of *Think Bayes*; I left it out here because it is not the focus of the problem.
| github_jupyter |
```
import unicodedata
import string
import re
import time
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
import pickle
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import torch.utils.data as Data
from torch.optim import lr_scheduler
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
```
## 导入数据
- 导入数据
- 并将数据保存为pkl的格式
```
def convert_to_pickle(item, directory):
"""导出数据
"""
pickle.dump(item, open(directory,"wb"))
def load_from_pickle(directory):
"""导入数据
"""
return pickle.load(open(directory,"rb"))
```
## 数据的预处理
数据预处理大致分为下面几个部分.
1. 将所有字母转为Ascii
2. 将大写都转换为小写; 同时, 只保留常用的标点符号
3. 新建完成, word2idx, idx2word, word2count(每个单词出现的次数), n_word(总的单词个数)
4. 将句子转换为Tensor, 每个word使用index来进行代替
5. 对句子进行填充, 使每句句子的长度相同, 这样可以使用batch进行训练
6. 将label转换为one-hot的格式, 方便最后的训练(Pytorch中只需要转换为标号即可)
### 创建word2index和index2word
```
# 第一步数据预处理
def unicodeToAscii(s):
"""转换为Ascii
"""
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# 第二步数据预处理
def normalizeString(s):
"""转换为小写, 同时去掉奇怪的符号
"""
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
# 第三步数据预处理
class Lang():
def __init__(self):
self.word2index = {}
self.word2count = {}
# 初始的时候SOS表示句子开头(0还在padding的时候会进行填充), EOS表示句子结尾(或是表示没有加入index中的新的单词, 即不常用的单词)
self.index2word = {0:"SOS",1:"EOS"}
self.n_words = 2
def addSentence(self, sentence):
"""把句子中的每个单词加入字典中
"""
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words # 新单词的标号
self.word2count[word] = 1 # 新单词的个数
self.index2word[self.n_words] = word
self.n_words = self.n_words + 1
else:
self.word2count[word] = self.word2count[word] + 1
lang = Lang()
with open('./medium_text.txt', 'r', encoding="utf-8") as file:
for line in file:
# 每次读取文件的一行
text = file.readline()
# 接着将这一行的单词生成word2index
sentence_data = normalizeString(text)
lang.addSentence(sentence_data)
# 显示一些统计数据
print("Count word:{}".format(lang.n_words))
# 打印一下单词个数的分布
data_count = np.array(list(lang.word2count.values()))
# 有大量单词只出现了很少的次数
np.median(data_count), np.mean(data_count), np.max(data_count)
# 计算<n的单词, 单词的个数和总的单词个数
less_count = 0
total_count = 0
for _,count in lang.word2count.items():
if count < 2:
less_count = less_count + 1
total_count = total_count + 1
print("小于N的单词出现次数 : ",less_count,
"\n总的单词出现次数 : ",total_count,
"\n小于N的单词占总的单词个数比例 : ",less_count/total_count*100)
# 计算<n的单词, 出现次数占总的出现次数的比例
less_count = 0
total_count = 0
for _,count in lang.word2count.items():
if count < 2:
less_count = less_count + count
total_count = total_count + count
print("小于N的单词出现次数 : ",less_count,
"\n总的单词出现次数 : ",total_count,
"\n小于N的单词占单词个数比例 : ",less_count/total_count*100)
# 我们设置单词至少出现2次(我们还是保留这些单词吧)
lang_process = Lang()
for word,count in lang.word2count.items():
if count >= 1:
lang_process.word2index[word] = lang_process.n_words # 新单词的标号
lang_process.word2count[word] = count # 新单词的个数
lang_process.index2word[lang_process.n_words] = word
lang_process.n_words = lang_process.n_words + 1
# 显示一些统计数据
print("Count word:{}".format(lang_process.n_words))
# 简单查看一下lang_process留下的单词
lang_process.word2count
convert_to_pickle(lang_process, './data/lang_process.pkl')
```
## 构建数据集
- 构建数据集样式 ([ word_i-1, word_i_1 ], word_i(target word))
- 将word转为tensor
- 将数据集构建为batch的样式
```
# 对每句话构建数据集
train_data = []
target_data = []
with open('./medium_text.txt', 'r', encoding="utf-8") as file:
for line in file:
# 每次读取文件的一行
text = file.readline()
# 接着将这一行的单词生成word2index
sentence_datas = normalizeString(text)
# 将每一行数据做处理
sentence_datas_list = sentence_datas.split(' ')
# sentence_datas_list = [i for i in sentence_datas_list if i not in ['the','it','.', 'of', 'a']]
for i in range(1, len(sentence_datas_list)-1):
b = np.array([sentence_datas_list[i-1], sentence_datas_list[i+1]])
target_data.append(b)
train_data.append(sentence_datas_list[i])
# train_data = np.vstack((train_data, b))
# target_data = np.concatenate((target_data, [sentence_datas_list[i]]))
train_data = np.array(train_data)
target_data = np.array(target_data)
# 将word转为tensor
# 转换为tensor
train_tensor = torch.tensor([lang_process.word2index[w] for w in train_data], dtype=torch.long)
target_tensor = torch.zeros(target_data.shape, dtype=torch.long)
for num ,t_d in enumerate(target_data):
add_num = torch.tensor([lang_process.word2index[ws] for ws in t_d], dtype=torch.long)
target_tensor[num : num+1] = add_num
train_data[25:30]
train_tensor[25:30]
lang_process.index2word[4],lang.index2word[23],lang.index2word[24],lang.index2word[25]
target_data[25:30]
target_tensor[25:30]
```
## 构建Word2Vector网络-使用Skip-gram算法
- 构建model
```
class SkipGram(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super(SkipGram, self).__init__()
self.vocab_size = vocab_size
self.context_size = context_size
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear1 = nn.Linear(embedding_dim, 128)
self.linear2 = nn.Linear(128, vocab_size*context_size)
def forward(self, x):
# x的大小为, (batch_size, context_size=1, word_index)
# embedding(x)的大小为, (batch_size, context_size=1, embedding_dim)
# embeds的大小为, (batch_size, context_size*embedding_dim)
batch_size = x.size(0)
embeds = self.embeddings(x).squeeze(1)
output = F.relu(self.linear1(embeds)) # batch_size*128
output = F.log_softmax(self.linear2(output),dim=1).view(batch_size, self.vocab_size, self.context_size) # batch * vocab_size*context_size
output = output.permute(0,2,1)# batch * context_size * vocab_size
return output
# 网络的测试
skipgram = SkipGram(lang_process.n_words, embedding_dim=30, context_size=2)
# 网络的输入
output = skipgram(train_tensor[:3].view(-1,1))
# batch_size*vocab_size*context_size
output.shape
```
## Data Loader
- 数据集的划分, 训练集和测试集
- 数据集的加载, 使用DataLoader来加载数据集
```
# 加载dataloader
train_dataset = Data.TensorDataset(train_tensor.view(-1,1), target_tensor) # 训练样本
MINIBATCH_SIZE = 64
train_loader = Data.DataLoader(
dataset=train_dataset,
batch_size=MINIBATCH_SIZE,
shuffle=True,
num_workers=1 # set multi-work num read data
)
for num, (i,j) in enumerate(train_loader):
print(num, i.shape, j.shape)
break
```
到这里,就创建好了dataload, 后面就可以开始构建网络,可以开始训练了
## 训练模型
- 定义损失函数
- 定义优化器
- 开始训练
```
# 模型超参数
NUM_EPOCH = 100
losses = []
loss_function = nn.NLLLoss()
model = SkipGram(lang_process.n_words, embedding_dim=30, context_size=2)
optimizer = optim.Adam(model.parameters(), lr=0.05)
exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
# 模型开始训练
for epoch in range(NUM_EPOCH):
total_loss = 0
exp_lr_scheduler.step()
for num, (trainData, targetData) in enumerate(train_loader):
# 正向传播
log_probs = model(trainData)
# 两次loss分开加
loss = loss_function(log_probs[:,0,:], targetData[:,0])
loss = loss + loss_function(log_probs[:,1,:], targetData[:,1])
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Get the Python number from a 1-element Tensor by calling tensor.item()
total_loss += loss.item()
losses.append(total_loss)
if (epoch+1) % 5 == 0:
print('Epoch : {:0>3d}, Loss : {:<6.4f}, Lr : {:<6.7f}'.format(epoch, total_loss, optimizer.param_groups[0]['lr']))
# 打印出loss的变化情况
fig = plt.figure(figsize=(7,5))
ax = fig.add_subplot(1,1,1)
ax.plot(losses)
# 保存模型
torch.save(model, 'Word2Vec.pkl')
train_tensor[:3].view(-1,1).shape
train_data[1:14]
target_data[1:14]
# 查看一下使用模型预测的准确率
test_output = model(train_tensor[1:14].view(-1,1))
before_word = test_output[:,0,:]
after_word = test_output[:,1,:]
print(torch.max(before_word,1)[1])
print('=========')
print(torch.max(after_word,1)[1])
target_tensor[1:14]
lang_process.index2word[11]
```
## 使用t-SNE降维, 进行可视化
- 获取word2vector的值, 即nn.Embedding的weight
- 使用t-SNE进行降维, 降到2维, 方便之后的可视化(t-SNE是可以在没有label的情况下进行计算)
- 画出可视化的结果
```
model.embeddings(torch.tensor([1]))
model.embeddings.weight.data[1]
EMBEDDINGS = model.embeddings.weight.data
# 一共1110个单词, 每个单词使用长度为30的向量进行表示
print('EMBEDDINGS.shape: ', EMBEDDINGS.shape)
from sklearn.manifold import TSNE
print('running TSNE...')
tsne = TSNE(n_components = 2).fit_transform(EMBEDDINGS)
print('tsne.shape: ', tsne.shape) #(1110, 2)
# 保存每个词汇的横轴坐标
x, y = [], []
annotations = []
for idx, coord in enumerate(tsne):
# print(coord)
annotations.append(lang_process.index2word[idx])
x.append(coord[0])
y.append(coord[1])
# 随便画20个点, 看一下哪些点是接近的
plt.figure(figsize = (12, 12))
for i in range(50):
vocab_idx = random.randint(1,1110)
word = annotations[vocab_idx]
plt.scatter(x[vocab_idx], y[vocab_idx])
plt.annotate(word, xy = (x[vocab_idx], y[vocab_idx]), ha='right',va='bottom')
plt.show()
```
| github_jupyter |
# Multi-Label Text classification problem with Keras
Building a model with Multiple-Outputs and Multiple-Losses in Keras
### Importing Libraries
```
import pandas as pd
import re
from sqlalchemy import create_engine
import nltk
from nltk.corpus import stopwords
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.tokenize import word_tokenize
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.multioutput import MultiOutputClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score, f1_score
import matplotlib.pyplot as plt
import numpy as np
from sklearn.utils.class_weight import compute_class_weight
from sklearn.model_selection import GridSearchCV
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.models import Model
from keras.layers import Dense, Flatten, LSTM, Conv1D, MaxPooling1D, Dropout, Activation, Input
from keras.layers.embeddings import Embedding
```
### Loading data from database.
The dataset consists of real messages that are classified into 36 different classes.
The problem conists of a multi-label classfication problem, where one message can be
classified into more than 1 class.
```
# load data from database
engine = create_engine('sqlite:///data/DisasterResponse.db')
df = pd.read_sql_table('messages', engine) # Table Message
```
#### Output Columns Distributions
```
output_columns_all = ['related', 'request', 'offer', 'aid_related',
'medical_help', 'medical_products', 'search_and_rescue', 'security',
'military', 'child_alone', 'water', 'food', 'shelter', 'clothing',
'money', 'missing_people', 'refugees', 'death', 'other_aid',
'infrastructure_related', 'transport', 'buildings', 'electricity',
'tools', 'hospitals', 'shops', 'aid_centers', 'other_infrastructure',
'weather_related', 'floods', 'storm', 'fire', 'earthquake', 'cold',
'other_weather', 'direct_report']
```
As we can observe from the graphs below, the dataset is highly imbalanced. Some classes are more balanced than others.
```
df[output_columns_all].hist(figsize=(20,20));
```
#### Inputs
```
list(df['message'].head())
```
### Data Preparation
```
stop_words = stopwords.words("english")
lemmatizer = WordNetLemmatizer()
def clean_text(text):
text = text.lower()
# '@' mention. Even tough @ adds some information to the message,
# this information doesn't add value build the classifcation model
text = re.sub(r'@[A-Za-z0-9_]+','', text)
# Dealing with URL links
url_regex = 'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+'
text = re.sub(url_regex,'urlplaceholder', text)
# A lot of url are write as follows: http bit.ly. Apply Regex for these cases
utl_regex_2 = 'http [a-zA-Z]+\.[a-zA-Z]+'
text = re.sub(utl_regex_2,'urlplaceholder', text)
# Other formats: http : //t.co/ihW64e8Z
utl_regex_3 = 'http \: //[a-zA-Z]\.(co|com|pt|ly)/[A-Za-z0-9_]+'
text = re.sub(utl_regex_3,'urlplaceholder', text)
# Hashtags can provide useful informations. Removing only ``#``
text = re.sub('#',' ', text)
# Contractions
text = re.sub(r"what's", 'what is ', text)
text = re.sub(r"can't", 'cannot', text)
text = re.sub(r"\'s",' ', text)
text = re.sub(r"\'ve", ' have ', text)
text = re.sub(r"n't", ' not ', text)
text = re.sub(r"im", 'i am ', text)
text = re.sub(r"i'm", 'i am ', text)
text = re.sub(r"\'re", ' are ', text)
text = re.sub(r"\'d", ' would ', text)
text = re.sub(r"\'ll", ' will ', text)
# Operations and special words
text = re.sub(r",", " ", text)
text = re.sub(r"\.", " ", text)
text = re.sub(r"!", " ! ", text)
text = re.sub(r"\/", " ", text)
text = re.sub(r"\^", " ^ ", text)
text = re.sub(r"\+", " + ", text)
text = re.sub(r"\-", " - ", text)
text = re.sub(r"\=", " = ", text)
text = re.sub('foof', 'food', text)
text = re.sub('msg', 'message', text)
text = re.sub(' u ', 'you', text)
# Ponctuation Removal
text = re.sub(r'[^a-zA-Z0-9]', ' ', text)
text = text.split()
stop_words = stopwords.words("english")
text = [tok for tok in text if tok not in stop_words]
lemmatizer = WordNetLemmatizer()
text = [lemmatizer.lemmatize(w) for w in text]
return ' '.join(text)
```
### Tokenize and Create Sentence
```
# Cleaning Text
df['message'] = df['message'].map(lambda x: clean_text(x))
```
#### Chossing size of vocabulary
```
vocabulary_size = 20000
tokenizer = Tokenizer(num_words=vocabulary_size)
tokenizer.fit_on_texts(df['message'])
sequences = tokenizer.texts_to_sequences(df['message'])
```
#### Pads sequences to the same length: MAXLEN
```
MAXLEN = 50
X = pad_sequences(sequences, maxlen=MAXLEN)
y = df[output_columns_all]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state = 42)
```
### Creating RNN
The majority of the classes are binary, but one of them has 3 different classes. Because of that,
the model will be divided into two different types of outputs:
- binary
- sparse category: The output has integer targets, and differently from catergorical crossentropy,
the target doens't need to be one-hot encoded
Since the dataset is highly imblanced, I applied a class weight in order to try to balance the model prediction.
Keras contains the class_weight paramater, but as related into this [issue](https://github.com/keras-team/keras/issues/8011) on Keras, I came into the same bug. When you apply the class_weight paramter for a Multi Label Classification problem, keras throws the following error:
560 if sample_weight_mode is None:
ValueError: `class_weight` must contain all classes in the data. The classes {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 23, 30, 31, 32, 33, 34, 35, 36} exist in the data but not in `class_weight`.
The solution that I came up with was to create multiple outputs, one for every binary class, and another
for the sparse category class.
```
output_columns_binary = ['request', 'offer', 'aid_related',
'medical_help', 'medical_products', 'search_and_rescue', 'security',
'military', 'child_alone', 'water', 'food', 'shelter', 'clothing',
'money', 'missing_people', 'refugees', 'death', 'other_aid',
'infrastructure_related', 'transport', 'buildings', 'electricity',
'tools', 'hospitals', 'shops', 'aid_centers', 'other_infrastructure',
'weather_related', 'floods', 'storm', 'fire', 'earthquake', 'cold',
'other_weather', 'direct_report']
output_columns_categorical = ['related']
```
For building this model we'll use the Keras functional API and not the common used Sequential() model. This comes from the fact that with his API it's possible to build more complex models, such as multi-output and multi-inputs problems.
#### Model
```
main_input = Input(shape=(MAXLEN,), dtype='int32', name='main_input')
x = Embedding(vocabulary_size, 50, input_length=MAXLEN)(main_input)
x = Dropout(0.3)(x)
x = Conv1D(64, 5, activation='relu')(x)
x = MaxPooling1D(pool_size=4)(x)
x = LSTM(100)(x)
x = Dropout(0.3)(x)
```
##### Model output
A Dense layer will be create for each of ouput. The corresponding metrics and losses for each output will also be stored into dictionaries.
For the binary classes the metric used will be the `binary_accuracy` with the corresponding `binary_crossentropy`.
Since there is only two possible class for each output (0 or 1), the `sigmoid` function will be used as the activation function.
For the categorical classes the metric used will be the `sparse_categorical_accuracy` with the corresponding `sparse_categorical_crossentropy`. For this output there are 3 possibles outputs: 0, 1 and 2, this way the `softmax` activation function will be used.
```
output_array = []
metrics_array = {}
loss_array = {}
for i, dense_layer in enumerate(output_columns_binary):
name = f'binary_output_{i}'
binary_output = Dense(1, activation='sigmoid', name=name)(x)
output_array.append(binary_output)
metrics_array[name] = 'binary_accuracy'
loss_array[name] = 'binary_crossentropy'
```
The above code iterates through each of the output binary columns and creates a dense layer, saving
the corresponding metric and loss into a dictionary
The code below applies the same process to the multi class output column.
```
categorical_output = Dense(3, activation='softmax', name='categorical_output')(x)
output_array.append(categorical_output)
metrics_array['categorical_output'] = 'sparse_categorical_accuracy'
loss_array['categorical_output'] = 'sparse_categorical_crossentropy'
# model = Model(main_input, outputs=[binary_output, categorical_ouput])
model = Model(inputs=main_input, outputs=output_array)
model.compile(optimizer='adadelta',
loss=loss_array,
metrics = metrics_array)
y_train_output = []
for col in output_columns_binary:
y_train_output.append(y_train[col])
for col in output_columns_categorical:
y_train_output.append(y_train[col])
weight_binary = {0: 0.5, 1: 7}
weight_categorical = {0: 1.4, 1: 0.43, 2: 7}
classes_weights = {}
for i, dense_layer in enumerate(output_columns_binary):
name = f'binary_output_{i}'
classes_weights[name] = weight_binary
for i, dense_layer in enumerate(output_columns_categorical):
name = 'categorical_output'
classes_weights[name] = weight_categorical
model.fit(X_train, y_train_output,
epochs=40, batch_size=512,
class_weight=classes_weights, verbose=0);
model.summary()
```
### Model Evaluation
Since the dataset is quite imbalanced, we'll use the F1 score to evaluate the model performance, since this metric takes into account both precision and recall.
The precision explains how accurate our model is: for those predicted positive, how many of them are actual positive. The recall calculates how many of the actual positives our model capture through labeling it as positive, an important metric for an imbalanced dataset.
Considering the huge amount of outputs, comparing different results can be quite a challenge, you'd be dealing
with a total of 36 metrics to compare between different models. Therefore, in order to better evaluate the model result, a metric combining all the 36 outputs was created:
- Model Metric: sum of all the F1-score of each output
### Test
```
y_pred = model.predict(X_test)
THRESHOLD = 0.5 # threshold between classes
f1_score_results = []
# Binary Outputs
for col_idx, col in enumerate(output_columns_binary):
print(f'{col} accuracy \n')
# Transform array of probabilities to class: 0 or 1
y_pred[col_idx][y_pred[col_idx]>=THRESHOLD] = 1
y_pred[col_idx][y_pred[col_idx]<THRESHOLD] = 0
f1_score_results.append(f1_score(y_test[col], y_pred[col_idx], average='macro'))
print(classification_report(y_test[col], y_pred[col_idx]))
# Multi Class Output
for col_idx, col in enumerate(output_columns_categorical):
print(f'{col} accuracy \n')
# Select class with higher probability from the softmax output: 0, 1 or 2
y_pred_2 = np.argmax(y_pred[-1], axis=-1)
f1_score_results.append(f1_score(y_test[col], y_pred_2, average='macro'))
print(classification_report(y_test[col], y_pred_2))
print('Total :',np.sum(f1_score_results))
```
### Train
In order to check for overfitting, the model was also evaluated in the training set
```
y_pred_train = model.predict(X_train)
f1_score_results = []
# Binary Outputs
for col_idx, col in enumerate(output_columns_binary):
print(f'{col} accuracy \n')
# Transform array of probabilities to class: 0 or 1
y_pred_train[col_idx][y_pred_train[col_idx]>=THRESHOLD] = 1
y_pred_train[col_idx][y_pred_train[col_idx]<THRESHOLD] = 0
f1_score_results.append(f1_score(y_train[col], y_pred_train[col_idx], average='macro'))
print(classification_report(y_train[col], y_pred_train[col_idx]))
# Multi Class Output
for col_idx, col in enumerate(output_columns_categorical):
print(f'{col} accuracy \n')
# Select class with higher probability from the softmax output: 0, 1 or 2
y_pred_2 = np.argmax(y_pred_train[-1], axis=-1)
f1_score_results.append(f1_score(y_train[col], y_pred_2, average='macro'))
print(classification_report(y_train[col], y_pred_2))
print('Total :',np.sum(f1_score_results))
```
# Word Embeddings from the Glove
Instead of training the word embedding from scratch, the same model used before will be retrained using the Word Embedding from [Glove](https://nlp.stanford.edu/projects/glove/), an unsupervised learning algorithm for obtaining vector representations for words
The embedding size will be the same as before: MAXLEN=50
To download the model Glove go to: https://nlp.stanford.edu/projects/glove/
```
embeddings_index = dict()
f = open('glove/glove.6B.50d.txt')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
embedding_matrix = np.zeros((vocabulary_size, MAXLEN))
for word, index in tokenizer.word_index.items():
if index > vocabulary_size - 1:
break
else:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[index] = embedding_vector
main_input = Input(shape=(MAXLEN,), dtype='int32', name='main_input')
x = Embedding(vocabulary_size, 50, weights=[embedding_matrix], input_length=MAXLEN, trainable=False)(main_input)
x = Dropout(0.3)(x)
x = Conv1D(64, 5, activation='relu')(x)
x = MaxPooling1D(pool_size=4)(x)
x = LSTM(100)(x)
x = Dropout(0.3)(x)
output_array = []
metrics_array = {}
loss_array = {}
for i, dense_layer in enumerate(output_columns_binary):
name = f'binary_output_{i}'
binary_output = Dense(1, activation='sigmoid', name=name)(x)
output_array.append(binary_output)
metrics_array[name] = 'binary_accuracy'
loss_array[name] = 'binary_crossentropy'
categorical_output = Dense(3, activation='softmax', name='categorical_output')(x)
output_array.append(categorical_output)
metrics_array['categorical_output'] = 'sparse_categorical_accuracy'
loss_array['categorical_output'] = 'sparse_categorical_crossentropy'
# model = Model(main_input, outputs=[binary_output, categorical_ouput])
model = Model(inputs=main_input, outputs=output_array)
model.compile(optimizer='adadelta',
loss=loss_array,
metrics=metrics_array)
y_train_output = []
for col in output_columns_binary:
y_train_output.append(y_train[col])
for col in output_columns_categorical:
y_train_output.append(y_train[col])
weight_binary = {0: 0.5, 1: 7}
weight_categorical = {0: 1.4, 1: 0.43, 2: 7}
classes_weights = {}
for i, dense_layer in enumerate(output_columns_binary):
name = f'binary_output_{i}'
classes_weights[name] = weight_binary
for i, dense_layer in enumerate(output_columns_categorical):
name = 'categorical_output'
classes_weights[name] = weight_categorical
model.fit(X_train, y_train_output,
epochs=40, batch_size=512,
class_weight=classes_weights,
verbose=0);
```
### Model Evaluation
### Test
```
y_pred = model.predict(X_test)
THRESHOLD = 0.5 # threshold between classes
f1_score_results = []
# Binary Outputs
for col_idx, col in enumerate(output_columns_binary):
print(f'{col} accuracy \n')
# Transform array of probabilities to class: 0 or 1
y_pred[col_idx][y_pred[col_idx]>=THRESHOLD] = 1
y_pred[col_idx][y_pred[col_idx]<THRESHOLD] = 0
f1_score_results.append(f1_score(y_test[col], y_pred[col_idx], average='macro'))
print(classification_report(y_test[col], y_pred[col_idx]))
# Multi Class Output
for col_idx, col in enumerate(output_columns_categorical):
print(f'{col} accuracy \n')
# Select class with higher probability from the softmax output: 0, 1 or 2
y_pred_2 = np.argmax(y_pred[-1], axis=-1)
f1_score_results.append(f1_score(y_test[col], y_pred_2, average='macro'))
print(classification_report(y_test[col], y_pred_2))
print('Total :',np.sum(f1_score_results))
```
| github_jupyter |
```
#export
import tempfile
from fastai.basics import *
from fastai.learner import Callback
#hide
from nbdev.showdoc import *
#default_exp callback.neptune
```
# Neptune.ai
> Integration with [neptune.ai](https://www.neptune.ai).
> [Track fastai experiments](https://ui.neptune.ai/o/neptune-ai/org/fastai-integration) like in this example project.
## Registration
1. Create **free** account: [neptune.ai/register](https://neptune.ai/register).
2. Export API token to the environment variable (more help [here](https://docs.neptune.ai/python-api/tutorials/get-started.html#copy-api-token)). In your terminal run:
```
export NEPTUNE_API_TOKEN='YOUR_LONG_API_TOKEN'
```
or append the command above to your `~/.bashrc` or `~/.bash_profile` files (**recommended**). More help is [here](https://docs.neptune.ai/python-api/tutorials/get-started.html#copy-api-token).
## Installation
1. You need to install neptune-client. In your terminal run:
```
pip install neptune-client
```
or (alternative installation using conda). In your terminal run:
```
conda install neptune-client -c conda-forge
```
2. Install [psutil](https://psutil.readthedocs.io/en/latest/) to see hardware monitoring charts:
```
pip install psutil
```
## How to use?
Key is to call `neptune.init()` before you create `Learner()` and call `neptune_create_experiment()`, before you fit the model.
Use `NeptuneCallback` in your `Learner`, like this:
```
from fastai.callback.neptune import NeptuneCallback
neptune.init('USERNAME/PROJECT_NAME') # specify project
learn = Learner(dls, model,
cbs=NeptuneCallback()
)
neptune.create_experiment() # start experiment
learn.fit_one_cycle(1)
```
```
#export
import neptune
#export
class NeptuneCallback(Callback):
"Log losses, metrics, model weights, model architecture summary to neptune"
def __init__(self, log_model_weights=True, keep_experiment_running=False):
self.log_model_weights = log_model_weights
self.keep_experiment_running = keep_experiment_running
self.experiment = None
if neptune.project is None:
raise ValueError('You did not initialize project in neptune.\n',
'Please invoke `neptune.init("USERNAME/PROJECT_NAME")` before this callback.')
def before_fit(self):
try:
self.experiment = neptune.get_experiment()
except ValueError:
print('No active experiment. Please invoke `neptune.create_experiment()` before this callback.')
try:
self.experiment.set_property('n_epoch', str(self.learn.n_epoch))
self.experiment.set_property('model_class', str(type(self.learn.model)))
except:
print(f'Did not log all properties. Check properties in the {neptune.get_experiment()}.')
try:
with tempfile.NamedTemporaryFile(mode='w') as f:
with open(f.name, 'w') as g:
g.write(repr(self.learn.model))
self.experiment.log_artifact(f.name, 'model_summary.txt')
except:
print('Did not log model summary. Check if your model is PyTorch model.')
if self.log_model_weights and not hasattr(self.learn, 'save_model'):
print('Unable to log model to Neptune.\n',
'Use "SaveModelCallback" to save model checkpoints that will be logged to Neptune.')
def after_batch(self):
# log loss and opt.hypers
if self.learn.training:
self.experiment.log_metric('batch__smooth_loss', self.learn.smooth_loss)
self.experiment.log_metric('batch__loss', self.learn.loss)
self.experiment.log_metric('batch__train_iter', self.learn.train_iter)
for i, h in enumerate(self.learn.opt.hypers):
for k, v in h.items():
self.experiment.log_metric(f'batch__opt.hypers.{k}', v)
def after_epoch(self):
# log metrics
for n, v in zip(self.learn.recorder.metric_names, self.learn.recorder.log):
if n not in ['epoch', 'time']:
self.experiment.log_metric(f'epoch__{n}', v)
if n == 'time':
self.experiment.log_text(f'epoch__{n}', str(v))
# log model weights
if self.log_model_weights and hasattr(self.learn, 'save_model'):
if self.learn.save_model.every_epoch:
_file = join_path_file(f'{self.learn.save_model.fname}_{self.learn.save_model.epoch}',
self.learn.path / self.learn.model_dir,
ext='.pth')
else:
_file = join_path_file(self.learn.save_model.fname,
self.learn.path / self.learn.model_dir,
ext='.pth')
self.experiment.log_artifact(_file)
def after_fit(self):
if not self.keep_experiment_running:
try:
self.experiment.stop()
except:
print('No neptune experiment to stop.')
else:
print(f'Your experiment (id: {self.experiment.id}, name: {self.experiment.name}) is left in the running state.\n',
'You can log more data to it, like this: `neptune.log_metric()`')
```
| github_jupyter |
<a href="https://colab.research.google.com/github/NeuromatchAcademy/course-content/blob/master/tutorials/W1D4_MachineLearning/student/W1D4_Tutorial1.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Neuromatch Academy: Week 1, Day 4, Tutorial 1
# Machine Learning: GLMs
In this tutorial you will learn about Generalized Linear Models (GLMs), which are a fundamental framework for supervised learning.
The objective is to model retinal ganglion cell spike trains. First with a Linear-Gaussian GLM (also known as ordinary least-squares regression model) and then with a Poisson GLM (aka "Linear-Nonlinear-Poisson" model).
This tutorial is designed to run with retinal ganglion cell spike train data from [Uzzell & Chichilnisky 2004](https://journals.physiology.org/doi/full/10.1152/jn.01171.2003?url_ver=Z39.88-2003&rfr_id=ori:rid:crossref.org&rfr_dat=cr_pub%20%200pubmed).
*Acknowledgements:*
- We thank EJ Chichilnisky for providing the dataset. Please note that it is provided for tutorial purposes only, and should not be distributed or used for publication without express permission from the author (ej@stanford.edu).
- We thank Jonathan Pillow, much of this tutorial is inspired by exercises asigned in his 'Statistical Modeling and Analysis of Neural Data' class.
# Setup
Run these cells to get the tutorial started
```
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat
from scipy.optimize import minimize
#@title Plot setup
fig_w, fig_h = 8, 6
plt.rcParams.update({'figure.figsize': (fig_w, fig_h)})
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
#@title Helper functions
def plot_stim_and_spikes(stim, spikes, dt, nt=120):
"""Show time series of stim intensity and spike counts.
Args:
stim (1D array): vector of stimulus intensities
spikes (1D array): vector of spike counts
dt (number): duration of each time step
nt (number): number of time steps to plot
"""
timepoints = np.arange(120)
time = timepoints * dt_stim
f, (ax_stim, ax_spikes) = plt.subplots(
nrows=2, sharex=True, figsize=(8, 5),
)
ax_stim.plot(time, stim[timepoints])
ax_stim.set_ylabel('Stimulus intensity')
ax_spikes.plot(time, spikes[timepoints])
ax_spikes.set_xlabel('Time (s)')
ax_spikes.set_ylabel('Number of spikes')
f.tight_layout()
def plot_glm_matrices(X, y, nt=50):
"""Show X and Y as heatmaps.
Args:
X (2D array): Design matrix.
y (1D or 2D array): Target vector.
"""
Y = np.c_[y] # Ensure Y is 2D and skinny
f, (ax_y, ax_x) = plt.subplots(
ncols=2,
figsize=(4, 6),
sharey=True,
gridspec_kw=dict(width_ratios=(1, 6)),
)
ax_y.pcolormesh(Y[:nt], cmap="magma")
ax_x.pcolormesh(X[:nt], cmap="coolwarm")
ax_y.set(
title="Y (Spikes)",
ylabel="Time point",
)
ax_x.set(
title="X (Lagged stimulus)",
xlabel="Time lag",
xticks=[],
)
ax_y.invert_yaxis()
f.tight_layout()
def plot_spike_filter(theta, dt, **kws):
"""Plot estimated weights based on time lag model.
Args:
theta (1D array): Filter weights, not including DC term.
dt (number): Duration of each time bin.
kws: Pass additional keyword arguments to plot()
"""
d = len(theta)
t = np.arange(-d + 1, 1) * dt
ax = plt.gca()
ax.plot(t, theta, marker="o", **kws)
ax.axhline(0, color=".2", linestyle="--", zorder=1)
ax.set(
xlabel="Time before spike (s)",
ylabel="Filter weight",
)
def plot_spikes_with_prediction(
spikes, predicted_spikes, dt, nt=50, t0=120, **kws):
"""Plot actual and predicted spike counts.
Args:
spikes (1D array): Vector of actual spike counts
predicted_spikes (1D array): Vector of predicted spike counts
dt (number): Duration of each time bin.
nt (number): Number of time bins to plot
t0 (number): Index of first time bin to plot.
kws: Pass additional keyword arguments to plot()
"""
t = np.arange(t0, t0 + nt) * dt
f, ax = plt.subplots()
lines = ax.stem(t, spikes[:nt], use_line_collection=True)
plt.setp(lines, color=".5")
lines[-1].set_zorder(1)
kws.setdefault("linewidth", 3)
yhat, = ax.plot(t, predicted_spikes[:nt], **kws)
ax.set(
xlabel="Time (s)",
ylabel="Spikes",
)
ax.yaxis.set_major_locator(plt.MaxNLocator(integer=True))
ax.legend([lines[0], yhat], ["Spikes", "Predicted"])
#@title Data retrieval
import os
data_filename = 'RGCdata.mat'
if data_filename not in os.listdir():
!wget -qO $data_filename https://osf.io/mzujs/download
```
-----
## Linear-Gaussian GLM
```
#@title Video: General linear model
from IPython.display import YouTubeVideo
video = YouTubeVideo(id="oOHqjvDyrE8", width=854, height=480, fs=1)
print("Video available at https://youtube.com/watch?v=" + video.id)
video
```
### Load retinal ganglion cell activity data
In this exercise we will use data from an experiment studying retinal ganglion cell (RGC) responses to a "full-field flicker" binary white noise stimulus. In this experiment, a screen randomly alternated between two luminance values while spikes were recorded from 4 RGCs. The dataset includes the luminance of the screen on each refresh (~120Hz) and the number of spikes each neuron emitted in that time bin.
The file `RGCdata.mat` contains three variablies:
- `Stim`, the stimulus intensity at each time point. It is an array with shape $T \times 1$, where $T=144051$.
- `SpCounts`, the binned spike counts for 2 ON cells, and 2 OFF cells. It is a $144051 \times 4$ array, and each column has counts for a different cell.
- `dtStim`, the size of a single time bin (in seconds), which is needed for computing model output in units of spikes / s. The stimulus frame rate is given by `1 / dtStim`.
Because these data were saved in MATLAB, where everything is a matrix, we will also process the variables to more Pythonic representations (1D arrays or scalars, where appropriate) as we load the data.
```
data = loadmat('RGCdata.mat') # loadmat is a function in scipy.io
dt_stim = data['dtStim'].item() # .item extracts a scalar value
# Extract the stimulus intensity
stim = data['Stim'].squeeze() # .squeeze removes dimensions with 1 element
# Extract the spike counts for one cell
cellnum = 2
spikes = data['SpCounts'][:, cellnum]
# Don't use all of the timepoints in the dataset, for speed
keep_timepoints = 20000
stim = stim[:keep_timepoints]
spikes = spikes[:keep_timepoints]
```
Use the `plot_stim_and_spikes` helper function to visualize the changes in stimulus intensities and spike counts over time.
```
plot_stim_and_spikes(stim, spikes, dt_stim)
```
### Exercise: Create design matrix
Our goal is to predict the cell's activity from the stimulus intensities preceding it. That will help us understand how RGCs process information over time. To do so, we first need to create the *design matrix* for this model, which organizes the stimulus intensities in matrix form such that the $i$th row has the stimulus frames preceding timepoint $i$.
In this exercise, we will create the design matrix $X$ using $d=25$ time lags. That is, $X$ should be a $T \times d$ matrix. $d = 25$ (about 200 ms) is a choice we're making based on our prior knowledge of the temporal window that influences RGC responses. In practice, you might not know the right duration to use.
The last entry in row `t` should correspond to the stimulus that was shown at time `t`, the entry to the left of it should contain the value that was show one time bin earlier, etc. Specifically, $X_{ij}$ will be the stimulus intensity at time $i + d - 1 - j$.
Assume values of `stim` are 0 for the time lags prior to the first timepoint in the dataset. (This is known as "zero-padding", so that the design matrix has the same number of rows as the response vectors in `spikes`.)
Your tasks are to
- make a zero-padded version of the stimulus
- initialize an empty design matrix with the correct shape
- fill in each row of the design matrix, using the stimulus information
To visualize your design matrix (and the corresponding vector of spike counts), we will plot a "heatmap", which encodes the numerical value in each position of the matrix as a color. The helper functions include some code to do this.
```
def make_design_matrix(stim, d=25):
"""Create time-lag design matrix from stimulus intensity vector.
Args:
stim (1D array): Stimulus intensity at each time point.
d (number): Number of time lags to use.
Returns
X (2D array): GLM design matrix with shape T, d
"""
#####################################################################
# Fill in missing code (...) and then remove
raise NotImplementedError("Complete the make_design_matrix function")
#####################################################################
# Create version of stimulus vector with zeros before onset
padded_stim = ...
# Construct a matrix where each row has the d frames of
# the stimulus proceeding and including timepoint t
T = ... # Total number of timepoints
X = ...
for t in range(T):
X[t] = ...
return X
# Uncomment and run after completing `make_design_matrix`
# X = make_design_matrix(stim)
# plot_glm_matrices(X, spikes, nt=50)
```
[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W1D4_MachineLearning/solutions/W1D4_Tutorial1_Solution_7c705e30.py)
*Example output:*
<img alt='Solution hint' align='left' width=280 height=416 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W1D4_MachineLearning/static/W1D4_Tutorial1_Solution_7c705e30_0.png>
### Fit Linear-Gaussian regression model
First, we will use the design matrix to compute the maximum likelihood estimate for a linear-Gaussian GLM (aka "general linear model"). The maximum likelihood estimate of $\theta$ in this model can be solved analytically using the equation you learned about on Day 3:
$$\hat \theta = (X^TX)^{-1}X^Ty$$
Before we can apply this equation, we need to augment the design matrix to account for the mean of $y$, because the spike counts are all $\geq 0$. We do this by adding a constant column of 1's to the design matrix, which will allow the model to learn an additive offset weight. We will refer to this additional weight as $b$ (for bias), although it is alternatively known as a "DC term" or "intercept".
```
# Build the full design matrix
y = spikes
constant = np.ones_like(y)
X = np.column_stack([constant, make_design_matrix(stim)])
# Get the MLE weights for the LG model
all_theta = np.linalg.inv(X.T @ X) @ X.T @ y
theta_lg = all_theta[1:]
```
Plot the resulting maximum likelihood filter estimate (just the 25-element weight vector $\theta$ on the stimulus elements, not the DC term $b$).
```
plot_spike_filter(theta_lg, dt_stim)
```
---
### Exercise: Predict spike counts with Linear-Gaussian model
Now we are going to put these pieces together and write a function that outputs a predicted spike count for each timepoint using the stimulus information.
Your steps should be:
- Create the complete design matrix
- Obtain the MLE weights ($\hat \theta$)
- Compute $\hat y = X\hat \theta$
```
def predict_spike_counts_lg(stim, spikes, d=25):
"""Compute a vector of predicted spike counts given the stimulus.
Args:
stim (1D array): Stimulus values at each timepoint
spikes (1D array): Spike counts measured at each timepoint
d (number): Number of time lags to use.
Returns:
yhat (1D array): Predicted spikes at each timepoint.
"""
#####################################################################
# Fill in missing code (...) and then remove
raise NotImplementedError(
"Complete the predict_spike_counts_lg function"
)
#####################################################################
# Create the design matrix
...
# Get the MLE weights for the LG model
...
# Compute predicted spike counts
yhat = ...
return yhat
# Uncomment and run after completing the function to plot the prediction
# predicted_counts = predict_spike_counts_lg(stim, spikes)
# plot_spikes_with_prediction(spikes, predicted_counts, dt_stim)
```
[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W1D4_MachineLearning/solutions/W1D4_Tutorial1_Solution_6cbc5a73.py)
*Example output:*
<img alt='Solution hint' align='left' width=393 height=278 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W1D4_MachineLearning/static/W1D4_Tutorial1_Solution_6cbc5a73_0.png>
Is this a good model? The prediction line more-or-less follows the bumps in the spikes, but it never predicts as many spikes as are actually observed. And, more troublingly, it's predicting *negative* spikes for some time points.
The Poisson GLM will help to address these failures.
### Bonus challenge
The "spike-triggered average" falls out as a subcase of the linear Gaussian GLM: $\mathrm{STA} = X^T y \,/\, \textrm{sum}(y)$, where $y$ is the vector of spike counts of the neuron. In the LG GLM, the term $(X^TX)^{-1}$ corrects for potential correlation between the regressors. Because the experiment that produced these data used a white note stimulus, there are no such correlations. Therefore the two methods are equivalent. (How would you check the statement about no correlations?)
## Linear-Nonlinear-Poisson GLM
```
#@title Video: Generalized linear model
from IPython.display import YouTubeVideo
video = YouTubeVideo(id="eAd2ILUrPyE", width=854, height=480, fs=1)
print("Video available at https://youtube.com/watch?v=" + video.id)
video
```
### Nonlinear optimization with `scipy.optimize`
When we used the Linear-Gaussian model, we were able to obtain the maximum likelihood estimate for the parameter vector in a single line of code, because there is an analytical solution for that model. In the more general case, we don't have an analytical solution. Instead, we need to apply a nonlinear optimization algorithm to find the parameter values that minimize some *objective function*.
Note: when using this approach to perform maximum likelihood estimation, the objective function should return the *negative* log likelihood, because optimization algorithms are written with the convention that minimization is your goal.
The `scipy.optimize` module has a powerful function called [`minimize`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html) that provides a generic interface to a large number of optimization algorithms. The way it works is that you pass an objective function object and an "initial guess" for the parameter values. It then returns an dictionary that includes the minimum function value, the parameters that give this minimum, and other information.
Let's see how this works with a simple example.
```
f = np.square
res = minimize(f, x0=2) # Imported from scipy.optimize in a hidden cell
print(
f"Minimum value: {res['fun']:.4g}",
f"at x = {res['x']}",
)
```
When minimizing a $f(x) = x^2$, we get a minimum value of $f(x) \approx 0$ when $x \approx 0$. The algorithm doesn't return exactly $0$, because it stops when it gets "close enough" to a minimum. You can change the `tol` parameter to control how it defines "close enough".
A point about the code bears emphasis. The first argument to `minimize` is not just a number or a string but a *function*. Here, we used `np.square`. Take a moment to make sure you understand what's going on here, because it's a bit unusual, and it will be important for the exercise you're going to do in a moment.
In this example, we started at $x_0 = 2$. Let's try different values for the starting point:
```
f = np.square
start_points = -1, 1.5
xx = np.linspace(-2, 2, 100)
plt.plot(xx, f(xx), color=".2")
plt.xlabel("$x$")
plt.ylabel("$f(x)$")
for i, x0 in enumerate(start_points):
res = minimize(f, x0)
plt.plot(x0, f(x0), "o", color=f"C{i}", ms=10, label=f"Start {i}")
plt.plot(res["x"].item(), res["fun"], "x", c=f"C{i}", ms=10, mew=2, label=f"End {i}")
plt.legend()
```
The three runs started at different points (the dots), but they each ended up at roughly the same place (the cross): $f(x_\textrm{final}) \approx 0$. Let's see what happens if we use a different function:
```
g = lambda x: x / 5 + np.cos(x)
start_points = -.5, 1.5
xx = np.linspace(-4, 4, 100)
plt.plot(xx, g(xx), color=".2")
plt.xlabel("$x$")
plt.ylabel("$f(x)$")
for i, x0 in enumerate(start_points):
res = minimize(g, x0)
plt.plot(x0, g(x0), "o", color=f"C{i}", ms=10, label=f"Start {i}")
plt.plot(res["x"].item(), res["fun"], "x", color=f"C{i}", ms=10, mew=2, label=f"End {i}")
plt.legend()
```
Unlike $f(x) = x^2$, $g(x) = \frac{x}{5} + \cos(x)$ is not *convex*. That means that the final position of the minimization algorithm depends on the starting point. In practice, one way to deal with this would be to try a number of different starting points and then use the parameters that give the minimum value value across all runs. But we won't worry about that for now.
### Exercise: Fitting the Poisson GLM and prediction spikes
In this exercise, we will use [`scipy.optimize.minimize`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html) to compute maximum likelihood estimates for the filter weights in the Poissson GLM model with an exponential nonlinearity (LNP: Linear-Nonlinear-Poisson).
In practice, this will involve filling out two functions.
- The first should be an *objective function* that takes a design matrix, a spike count vector, and a vector of parameters. It should return a negative log likelihood.
- The second function should take `stim` and `spikes`, build the design matrix and then use `minimize` internally, and return the MLE parameters.
What should the objective function look like? We want it to return
$$-\log \mathcal{L} = -\log P(y \mid X, \theta).$$
In the Poisson GLM,
$$
\log P(y \mid X, \theta) = \sum_t \log P(y_t \mid \mathbf{x_t},\theta)
$$
and
$$
P(y_t \mid \mathbf{x_t}, \theta) \
= \frac{\lambda^{y_t}\exp(-\lambda)}{y_t!}
$$
with $$\lambda = \exp(\theta^T \mathbf{x_t}).$$
So we can get the log likelihood for all the data with
$$
\log \mathcal{L} = \sum_t y_t \log(\theta^T \mathbf{x_t}) - \theta^T \mathbf{x_t}
$$.
*Tip: Starting with a loop is the most obvious way to implement this equation, but it will be also be slow. Can you get the log likelihood for all trials using matrix operations?*
```
def neg_log_lik_lnp(theta, X, y):
"""Return -loglike for the Poisson GLM model.
Args:
theta (1D array): Parameter vector.
X (2D array): Full design matrix.
y (1D array): Data values.
Returns:
number: Negative log likelihood.
"""
#####################################################################
# Fill in missing code (...) and then remove
raise NotImplementedError("Complete the neg_log_lik_lnp function")
#####################################################################
# Compute the Poisson log likeliood
log_lik = ...
return ...
def fit_lnp(X, y, d=25):
"""Obtain MLE parameters for the Poisson GLM.
Args:
X (2D array): Full design matrix.
y (1D array): Data values.
d (number): Number of time lags to use.
Returns:
1D array: MLE parameters
"""
#####################################################################
# Fill in missing code (...) and then remove
raise NotImplementedError("Complete the fit_lnp function")
#####################################################################
# Build the design matrix
y = spikes
constant = np.ones_like(y)
X = np.column_stack([constant, make_design_matrix(stim)])
# Use a random vector of weights to start (mean 0, sd .2)
x0 = np.random.normal(0, .2, d + 1)
# Find parameters that minmize the negative log likelihood function
res = minimize(..., args=(X, y))
return ...
# Uncomment and run when the functions are ready
# theta_lnp = fit_lnp(X, spikes)
# plot_spike_filter(theta_lg[1:], dt_stim, color=".5", label="LG")
# plot_spike_filter(theta_lnp[1:], dt_stim, label="LNP")
# plt.legend(loc="upper left");
```
[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W1D4_MachineLearning/solutions/W1D4_Tutorial1_Solution_e834c7b4.py)
*Example output:*
<img alt='Solution hint' align='left' width=411 height=278 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W1D4_MachineLearning/static/W1D4_Tutorial1_Solution_e834c7b4_0.png>
Plotting the LG and LNP weights together, we see that they are broadly similar, but the LNP weights are generally larger. What does that mean for the model's ability to *predict* spikes? To see that, let's finish the exercise by filling out the `predict_spike_counts_lnp` function:
```
def predict_spike_counts_lnp(stim, spikes, theta=None, d=25):
"""Compute a vector of predicted spike counts given the stimulus.
Args:
stim (1D array): Stimulus values at each timepoint
spikes (1D array): Spike counts measured at each timepoint
theta (1D array): Filter weights; estimated if not provided.
d (number): Number of time lags to use.
Returns:
yhat (1D array): Predicted spikes at each timepoint.
"""
###########################################################################
# Fill in missing code (...) and then remove
raise NotImplementedError("Complete the predict_spike_counts_lnp function")
###########################################################################
y = spikes
constant = np.ones_like(spikes)
X = np.column_stack([constant, make_design_matrix(stim)])
if theta is None: # Allow pre-cached weights, as fitting is slow
theta = fit_lnp(X, y, d)
yhat = ...
return yhat
# Uncomment and run when predict_spike_counts_lnp is complete
# yhat = predict_spike_counts_lnp(stim, spikes, theta_lnp)
# plot_spikes_with_prediction(spikes, yhat, dt_stim)
```
[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/master//tutorials/W1D4_MachineLearning/solutions/W1D4_Tutorial1_Solution_1f9e3c70.py)
*Example output:*
<img alt='Solution hint' align='left' width=388 height=278 src=https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/tutorials/W1D4_MachineLearning/static/W1D4_Tutorial1_Solution_1f9e3c70_0.png>
We see that the LNP model does a better job of fitting the actual spiking data. Importantly, it never predicts negative spikes!
*Bonus:* Our statement that the LNP model "does a better job" is qualitative and based mostly on the visual appearance of the plot. But how would you make this a quantitative statement?
## Summary
In this first tutorial, we used two different models to learn something about how retinal ganglion cells respond to a flickering white noise stimulus. We learned how to construct a design matrix that we could pass to different GLMs, and we found that the Linear-Nonlinear-Poisson (LNP) model allowed us to predict spike rates better than a simple Linear-Gaussian (LG) model.
In the next tutorial, we'll extend these ideas further. We'll meet yet another GLM — logistic regression — and we'll learn how to ensure good model performance with large, high-dimensional datasets.
| github_jupyter |
Let's explore how convolutions work by creating a basic convolution on a 2D Grey Scale image. First we can load the image by taking the 'ascent' image from scipy. It's a nice, built-in picture with lots of angles and lines.
```
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
```
Next, we can use the pyplot library to draw the image so we know what it looks like.
```
import matplotlib.pyplot as plt
plt.gray()
plt.figure(figsize=(15,7))
plt.imshow(i)
```
The image is stored as a numpy array, so we can create the transformed image by just copying that array. Let's also get the dimensions of the image so we can loop over it later.
```
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
```
Now we can create a filter as a 3x3 array.
```
# This filter detects edges nicely
# It creates a convolution that only passes through sharp edges and straight
# lines.
#Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
#filter = [ [-3, 0, 2], [-1, 0, 3], [-2, 0, 3]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
#filter = [ [1, 0, 0], [0, 1, 0], [0, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
```
Now let's create a convolution. We will iterate over the image, leaving a 1 pixel margin, and multiply out each of the neighbors of the current pixel by the value defined in the filter.
i.e. the current pixel's neighbor above it and to the left will be multiplied by the top left item in the filter etc. etc. We'll then multiply the result by the weight, and then ensure the result is in the range 0-255
Finally we'll load the new value into the transformed image.
```
for x in range(1,size_x-1):
for y in range(1,size_y-1):
convolution = 0.0
convolution = convolution + (i[x - 1, y-1] * filter[0][0])
convolution = convolution + (i[x, y-1] * filter[0][1])
convolution = convolution + (i[x + 1, y-1] * filter[0][2])
convolution = convolution + (i[x-1, y] * filter[1][0])
convolution = convolution + (i[x, y] * filter[1][1])
convolution = convolution + (i[x+1, y] * filter[1][2])
convolution = convolution + (i[x-1, y+1] * filter[2][0])
convolution = convolution + (i[x, y+1] * filter[2][1])
convolution = convolution + (i[x+1, y+1] * filter[2][2])
convolution = convolution * weight
if(convolution<0):
convolution=0
if(convolution>255):
convolution=255
i_transformed[x, y] = convolution
```
Now we can plot the image to see the effect of the convolution!
```
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.figure(figsize=(15,7))
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()
```
This code will show a (2, 2) pooling. The idea here is to iterate over the image, and look at the pixel and it's immediate neighbors to the right, beneath, and right-beneath. Take the largest of them and load it into the new image. Thus the new image will be 1/4 the size of the old -- with the dimensions on X and Y being halved by this process. You'll see that the features get maintained despite this compression!
```
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
newImage[int(x/2),int(y/2)] = max(pixels)
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.figure(figsize=(15,7))
plt.imshow(newImage)
#plt.axis('off')
plt.show()
```
| github_jupyter |
# First Bayes
In the [problem for the education minister](havana_math) we had a sample of
fast-track-marked exams from 2019, and we found that the mean mark was about
58.74. We wondered what we could say about the eventual mean when we have the
marks for all 8000 or so students.
For example, we might wonder how likely it is that the eventual mean will be
near 65.25, as it was in 2018. Or we might wonder whether we could be say that
the eventual mean for all the papers will around the sample mean — 58.74 — plus
or minus a bit. If so, what value should we give to "a bit"?
This kind of problem can be called a problem of *reverse probability*.
We start with simple probabilities, where we ask questions like this: what is
the probability of seeing a mean around 58.74 if the population mean is
actually 65.25? Then we go in *reverse* to ask questions like: what is the
probability that the population mean is around 65.25 given the sample mean of
58.74?
## A reverse probability game
Imagine I offer you one of two boxes.
One box has four red balls and one green ball. Call this *BOX4*.
The other box has two red balls and three green balls. Call this *BOX2*.
I haven't told you which box I gave you, but I do tell you that there is a 30%
chance that I gave you BOX4, and a 70% chance I gave you BOX2.
Now let's say that you shake the box I gave you, to shuffle the balls, then
close your eyes, and take out one ball. You open your eyes to find you have a
red ball.
What is the chance that I gave you BOX4?
This is an example of a *reverse probability* problem. You are working *back*
from what you see (the red ball) to what I gave you (the box).
In our exam mark problem, we are working back from what we saw (the sample mean
of 54.51) to the eventual mean for all the exams.
How are we going to start on our solution to the BOX4, BOX2 reverse probability
problem? Simulation!
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('fivethirtyeight')
# Make a box with 4 red balls and 1 green ball
box4 = np.repeat(['red', 'green'], [4, 1])
box4
# Make a box with 2 red balls and 3 green balls
box2 = np.repeat(['red', 'green'], [2, 3])
box2
```
Now we make 10000 trials, where we:
* Choose BOX4 or BOX2, with a 30% chance of BOX4.
* Choose a ball at random from the resulting box.
```
n_iters = 10000
# The box for this trial.
box_nos = np.repeat([1], n_iters)
# The color of the ball we chose.
ball_colors = np.repeat(['green'], n_iters)
for i in np.arange(n_iters):
# Choose a box number with a 30% chance of BOX4
box_no = np.random.choice([4, 2], p=[0.3, 0.7])
# Choose a ball at random from the box.
if box_no == 4:
# Choose a ball at random from BOX4.
ball_color = np.random.choice(box4)
else: # box 4
# Choose a ball at random from BOX2.
ball_color = np.random.choice(box2)
# Store the results.
box_nos[i] = box_no
ball_colors[i] = ball_color
```
Last we put the results into a data frame for convenience:
```
# Make these into a data frame.
trial_results = pd.DataFrame()
trial_results['box no'] = box_nos
trial_results['ball color'] = ball_colors
trial_results.head()
```
Now we can see the proportion of trials on which we drew a red ball, where the
box we got was BOX4.
```
# Of the trials giving a red ball, what proportion came from box 4?
red_ball_trials = trial_results[trial_results['ball color'] == 'red']
p_box4 = np.count_nonzero(red_ball_trials['box no'] == 4) / len(red_ball_trials)
p_box4
```
Of the trials giving a red ball about 46% came from BOX4. If we see a red
ball, there is a 46% chance we have sampled from BOX4.
You have just solved your first problem in reverse probability. The problem
will soon reveal a simple calculation in probability called [Bayes
theorem](https://en.wikipedia.org/wiki/Bayes'_theorem).
This is a fundamental building block, so let's go back over the simulation, to think about why we got this number.
We can think of all these trials as coming about from a branching tree.
At the first branching point, we split into two branches, one for BOX4 and one
for BOX2. The BOX4 branch is width 0.3 and the BOX2 branch is width 0.7,
because the probability of BOX4 is 0.3 (30%).
The simulation is very unlikely to give these numbers exactly, because it took
a random sample. So, the simulation proportions will be close to the
probabilities we calculated above, but not exactly the same.
```
box4_trials = trial_results[trial_results['box no'] == 4]
box2_trials = trial_results[trial_results['box no'] == 2]
n_trials = len(trial_results)
print('Box4 proportion', len(box4_trials) / n_trials)
print('Box2 proportion', len(box2_trials) / n_trials)
```
At the second branching point, each branch splits into two.
* The BOX4 branch splits into a "red" branch, which carries 4/5 (0.8, 80%) of
the BOX4 trials, and a "green" branch, that carries 1/5 (0.2, 20%) of the
BOX4 trials, because the probability of getting a red ball from BOX4 is 4 in
5.
* The BOX2 branch splits into a "red" branch, which carries 2/5 (0.4, 40%) of
the BOX2 trials, and a "green" branch, which carries 3/5 (0.6, 60%) of the
BOX2 trials, because the probability of getting a red ball from BOX2 is 2 in
5.
Thus the proportion of trials that are *both* from BOX4 *and* give a red ball
is 0.3 (the width of the BOX4 branch) * 0.8 (the proportion of BOX4 trials
that give red) = 0.24.
```
box4_and_red = box4_trials[box4_trials['ball color'] == 'red']
prop_box4_and_red = len(box4_and_red) / n_trials
print('Box4 and red proportion', prop_box4_and_red)
```
The proportion of trials that are *both* from BOX2 *and* give a red ball
is 0.7 (the width of the BOX2 branch) * 0.4 (the proportion of BOX2 trials
that give red) = 0.28.
```
box2_and_red = box2_trials[box2_trials['ball color'] == 'red']
prop_box2_and_red = len(box2_and_red) / n_trials
print('Box2 and red proportion', prop_box2_and_red)
```
We get the overall proportion of red by adding the proportion that is BOX4
*and* red to the proportion that is BOX2 *and* red, because these are all the
red trials. This is 0.24 + 0.28 = 0.52.
```
n_red = len(box4_and_red) + len(box2_and_red)
prop_red = n_red / n_trials
print('Overall proportion of red', prop_red)
```
We've already discovered about that 0.24 (24%) of all trials are BOX4 *and*
red. So the proportion of *all* red trials, that are BOX4 *and* red, is 0.24 /
0.52 = 0.4615385.
```
print('Proportion of all red trials that are box4', (prop_box4_and_red / prop_red))
```
To go over the logic again:
* We want the proportion of "red" trials that came from BOX4.
* To do this, we calculate the proportion of trials that are *both* BOX4 and
red, and divide by the overall proportion of red trials.
* The proportion of red trials that are *both* BOX4 *and* red is (the
proportion of BOX4 trials) multiplied by (the proportion of BOX4 trials that
are red).
We have just [discovered Bayes theorem](bayes_theorem).
| github_jupyter |
# Python Chart Gallery
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
```
## Data
source: http://insideairbnb.com/get-the-data.html
Here I'm using the Airbnb London listings summary data
```
df = pd.read_csv('data/listings.csv',index_col=False)
df.head(3)
```
## Bar Charts
with all the chart attributes you need to show
### Standard Bars
#### How many listings for each room type?
```
ax = df['room_type'].value_counts().plot.bar(color='darkblue',figsize=(6,6),fontsize=14)
plt.title('Number of Listings per Room Type',fontsize=15,fontweight='bold')
plt.ylabel('Number of Listings',fontsize=13)
# customize ticks for clean looks
ax.set_yticks([0,15000,30000,45000])
ax.set_yticklabels(['0','15k','30k','45k'], fontsize=12)
ax.set_xticklabels(df['room_type'].unique(),fontsize=12)
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
# make data labels
labels = df['room_type'].value_counts()
rects = ax.patches
for rect, label in zip(rects, labels):
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width()/2, height + 0.005, label,
ha='center', va='bottom',fontsize=13)
```
#### What's the average price of each room type?
```
# same charts but with horizontal bar
ax = df.groupby(['room_type'])['price'].mean().sort_values(ascending=True).plot.barh(color='darkblue',
figsize=(8,6),fontsize=14,
width=0.7)
plt.title('Average Price by Room Type',fontsize=15,fontweight='bold')
plt.xlabel('Average Price',fontsize=13)
plt.ylabel('Room Type')
# customize ticks for clean looks
ax.set_xticks([0,50,100,150,200])
#ax.set_xticklabels(['0','15k','30k','45k'], fontsize=12)
# make data labels
labels = df.groupby(['room_type'])['price'].mean().round(decimals=2).sort_values(ascending=True)
rects = ax.patches
for i, v in enumerate(labels):
ax.text(v - 20, i-0.05 , str(v), color='white', fontweight='bold',fontsize=14)
```
### Stacked
Now say we want to know the distribution of room types in neighbourhoods with highest number of listings. We will visualize only the top 5.
```
top_neighbourhoods = df.neighbourhood.value_counts().sort_values(ascending=False)[:5]
top_neighbourhoods
```
Next we make the charts
```
sns.set(style='whitegrid')
# pick color
cmap=plt.cm.get_cmap('tab20c')
colors = [cmap(0),cmap(1),cmap(2)]
#draw chart
df[df.neighbourhood.isin(top_neighbourhoods.index)].groupby(['neighbourhood','room_type'])['id'].count().unstack('room_type').plot.barh(stacked=True
,color = colors
,figsize=(8,6))
plt.title('Listings per Room Type in Top 5 Neighbourhoods',fontsize=14,fontweight='bold')
plt.legend(['Entire home/apt','Private room','Shared room'],fontsize=13)
plt.xlabel('Number of Listings')
```
### 100% Stacked
This is a modification of https://python-graph-gallery.com/13-percent-stacked-barplot/
```
ax.patches[::-1]
# Data
sns.set(style='white')
r = range(1,6)
data = df[df.neighbourhood.isin(top_neighbourhoods.index)].groupby(['neighbourhood','room_type'])['id'].count().unstack('room_type')
# From raw value to percentage
totals = [i+j+k for i,j,k in zip(data['Entire home/apt'], data['Private room'], data['Shared room'])]
bar1 = [i / j * 100 for i,j in zip(data['Entire home/apt'], totals)]
bar2 = [i / j * 100 for i,j in zip(data['Private room'], totals)]
bar3 = [i / j * 100 for i,j in zip(data['Shared room'], totals)]
# plot
plt.figure(figsize=(10,10))
ax = plt.subplot(111)
cmap=plt.cm.get_cmap('Blues')
colors = [cmap(0.1),cmap(0.3),cmap(0.5)]
barWidth = 0.7
names = (top_neighbourhoods.index)
# Create green Bars
plt.bar(r, bar1, color=colors[0], edgecolor='white', width=barWidth)
# Create orange Bars
plt.bar(r, bar2, bottom=greenBars, color=colors[1], edgecolor='white', width=barWidth)
# Create blue Bars
plt.bar(r, bar3, bottom=[i+j for i,j in zip(bar1, bar2)], color=colors[2], edgecolor='white', width=barWidth)
# Custom axis label
plt.xticks(r, names)
plt.xlabel("NEIGHBOURHOOD",fontsize=13)
plt.ylabel('PERCENTAGE',fontsize=13)
plt.rc('ytick', labelsize=13)
plt.setp(plt.gca().get_xticklabels(),fontsize=12,weight='bold')
plt.setp(plt.gca().get_yticklabels(),fontsize=12,weight='bold')
plt.title('Distribution of Listings per Room Type in Top 5 Neighbourhoods',fontweight='bold',fontsize=16)
'''
# Shrink current axis to make space for legend (if you want axis to be outside the plot)
box = ax.get_position()
ax.set_position([box.x0, box.y0, box.width * 0.8, box.height])
'''
plt.legend(['Entire home/apt','Private room','Shared room'],loc=4, fontsize=14)
for p in ax.patches[::-1]:
if p.get_height()<50:
h = (100-p.get_height())
else:
h = p.get_height()/2
x = p.get_x()+p.get_width()/2
if h != 0:
ax.annotate("%.2f %%" % p.get_height(), xy=(x,h), xytext=(0,4), rotation=0,
textcoords="offset points", ha="center", va="bottom",weight='bold',
fontsize=13)
plt.show()
```
## Doughnut Pie Chart
Suppose someone is planning a budget for a trip, and he's considering to stay in Camden. He considers price per night of <=50 is cheap, 50-100 is okay, and >100 is expensive. Now he wants to figure out, based on his price classification, is Camden generally expensive?
```
def get_price_category(x):
if x<=50:
return 'cheap'
elif x>100:
return 'expensive'
else:
return 'okay'
df['his_price_category'] = df.price.apply(get_price_category)
# check result
df[['price','his_price_category']].head()
fig, ax = plt.subplots(figsize=(8,8), subplot_kw=dict(aspect="equal"))
my_circle=plt.Circle( (0,0), 0.7, color='white')
# pick colors
cmap=plt.cm.get_cmap('RdYlGn')
colors = [cmap(1.3),cmap(0.1),cmap(0.3)]
def func(pct, allvals):
# calculate percentage for data labels
absolute = int(pct/100.*np.sum(allvals))
return "{:.1f}%\n({:d})".format(pct, absolute)
data = df[df.neighbourhood=='Camden'].groupby('his_price_category')['id'].count().values
# plot and texts
wedges, texts, autotexts = plt.pie(df[df.neighbourhood=='Camden'].groupby('his_price_category')['id'].count(),
colors=colors,
autopct=lambda pct: func(pct, data),
textprops=dict(color="b"),pctdistance=0.8)
plt.setp(autotexts, size=14,weight='bold',color='white')
# adding attributes
ax.set_title("Percentage of Listings in Camden Based on Price Classification",fontsize=15,weight='bold')
labels = df[df.neighbourhood=='Camden'].groupby('his_price_category')['id'].count().index
plt.legend(labels,fontsize=14,loc='center')
# add circle
my_circle=plt.Circle( (0,0), 0.6, color='white')
p=plt.gcf()
p.gca().add_artist(my_circle)
plt.show()
```
## Comparing Two Values
#### Is Hackney Cheaper than Camden?
Now say we want to compare the price in Camden and Hackney based on the room type
```
# transform the data
grouped = df[df.neighbourhood.isin(['Camden','Hackney'])].groupby(['neighbourhood','room_type'])
chart_df= grouped.agg({'price': pd.Series.mean})
chart_df = chart_df.unstack('neighbourhood').reset_index()
chart_df
# put axis setting in the dataset
chart_df['yaxis_pos'] = range(1,len(chart_df)+1)
# reverse y position
chart_df['yaxis_pos'] = len(chart_df)+1-chart_df['yaxis_pos']
chart_df.head()
# make the chart
# https://python-graph-gallery.com/184-lollipop-plot-with-2-groups/
sns.set_style('darkgrid')
fig, ax = plt.subplots(figsize=(8,4))
data1 = chart_df.price.Camden
data2 = chart_df.price.Hackney
my_range=chart_df.yaxis_pos
labels = ['Camden','Hackney'] # labels for legend
plt.hlines(y=my_range, xmin=data1, xmax=data2, color='grey', alpha=0.6)
plt.scatter(data1, my_range, color='darkblue', alpha=0.8, label=labels[0],marker="^", s=100)
plt.scatter(data2, my_range, color='green', alpha=0.8 , label=labels[1],s=100)
plt.legend(fontsize=14, loc=4)
#axis labeling
plt.yticks(my_range, chart_df.room_type,fontsize='large')
plt.yticks(my_range, chart_df.room_type,fontsize='large')
plt.title('Comparison of Price in Camden and Hackney by Room Type', loc='center', fontsize=16,fontweight='bold')
plt.xlabel('Average Price', fontsize=12)
plt.ylabel('Category', fontsize=12)
plt.xticks([0,50,100,150,200])
ax.set_xticklabels([0,50,100,150,200],fontsize=12,weight='bold')
ax.set_yticklabels(ax.get_yticklabels(),fontsize=12,weight='bold')
```
## Line Charts
### Single Line
### Multilines
## Bar & Line Chart Combination
```
sns.set(style='white')
plt.figure(figsize=(8,6))
# plot line
lx = df.groupby(['room_type'])['price'].median().plot(marker='o',color='orange')
# plot bar
ax = df.groupby(['room_type'])['price'].mean().plot.bar(color=['#2068db','#2068db','#2068db'])
# put details
plt.title('Comparison of average and median price for room types', weight='bold',fontsize=14)
plt.ylabel('Average Price',fontsize=13)
plt.xlabel('Room Type')
plt.setp(plt.gca().get_xticklabels(), rotation=0, horizontalalignment='center',weight='bold')
labels = df.groupby(['room_type'])['price'].mean().round(decimals=2).sort_values(ascending=False)
rects = ax.patches
for rect, label in zip(rects, labels):
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width()/2, height + 0.005, label,
ha='center', va='bottom',fontsize=13)
```
| github_jupyter |
Example 1: Making a GTC/triangle plot with pygtc
==========================
This example is built from a jupyter notebook hosted on the [pyGTC GitHub repository](https://github.com/SebastianBocquet/pygtc/blob/master/demo.ipynb).
Import dependencies
------------------
```
%matplotlib inline
%config InlineBackend.figure_format = 'retina' # For mac users with Retina display
from matplotlib import pyplot as plt
import numpy as np
import pygtc
```
Generate fake data
-----------------
Let's create two sets of fake sample points with 8 dimensions each. Note that chains are allowed to have different lengths.
```
# Create Npoints samples from random multivariate, nDim-dimensional Gaussian
def create_random_samples(nDim, Npoints):
means = np.random.rand(nDim)
cov = .5 - np.random.rand(nDim**2).reshape((nDim,nDim))
cov = np.triu(cov)
cov += cov.T - np.diag(cov.diagonal())
cov = np.dot(cov,cov)
samples = np.random.multivariate_normal(means, cov, Npoints)
return samples
# Create two sets of fake data with 8 parameters
np.random.seed(0) # To be able to create the same fake data over and over again
samples1 = create_random_samples(8, 50000)
samples2 = 1+create_random_samples(8, 70000)
```
Omit one parameter for one chain
------------------------------
Let's assume the samples1 does not include the second to last parameter. In the figure, we only want to show this parameter for samples2. pygtc will omit parameters that only contain nan.
```
samples1[:,6] = None
```
Minimal example
--------------
Note that numpy throws a `RuntimeWarning` because we set one of the axes of `samples1` to `None` just above. As we understand the warning, let's move on!
```
GTC = pygtc.plotGTC(chains=[samples1,samples2])
```
Complete the figure
------------------
Now let's add:
* axis and data labels
* lines marking some important points in parameter space
* Gaussian distributions on the 1d histograms that could indicate Gaussian priors we assumed
Note that all these must match number of parameters!
```
# List of parameter names, supports latex
# NOTE: For capital greek letters in latex mode, use \mathsf{}
names = ['param name',
'$B_\mathrm{\lambda}$',
'$E$', '$\\lambda$',
'C',
'D',
'$\mathsf{\Omega}$',
'$\\gamma$']
# Labels for the different chains
chainLabels = ["data1 $\lambda$",
"data 2"]
# List of Gaussian curves to plot
#(to represent priors): mean, width
# Empty () or None if no prior to plot
priors = ((2, 1),
(-1, 2),
(),
(0, .4),
None,
(1,1),
None,
None)
# List of truth values, to mark best-fit or input values
# NOT a python array because of different lengths
# Here we choose two sets of truth values
truths = ((4, .5, None, .1, 0, None, None, 0),
(None, None, .3, 1, None, None, None, None))
# Labels for the different truths
truthLabels = ( 'the truth',
'also true')
# Do the magic
GTC = pygtc.plotGTC(chains=[samples1,samples2],
paramNames=names,
chainLabels=chainLabels,
truths=truths,
truthLabels=truthLabels,
priors=priors)
```
Make figure publication ready
---------------------------
* See how the prior for $B_{\lambda}$ is cut off on the left? Let's display $B_\lambda$ in the range (-5,4). Also, we could show a narrower range for $\lambda$ like (-3,3).
* Given that we're showing two sets of truth lines, let's show the line styles in the legend (``legendMarker=True``).
* Finally, let's make the figure size publication ready for MNRAS. Given that we're showing eight parameters, we'll want to choose ``figureSize='MNRAS_page'`` and show a full page-width figure.
* Save the figure as `fullGTC.pdf` and paste it into your publication!
```
# List of parameter ranges to show,
# empty () or None to let pyGTC decide
paramRanges = (None,
(-5,4),
(),
(-3,3),
None,
None,
None,
None)
# Do the magic
GTC = pygtc.plotGTC(chains=[samples1,samples2],
paramNames=names,
chainLabels=chainLabels,
truths=truths,
truthLabels=truthLabels,
priors=priors,
paramRanges=paramRanges,
figureSize='MNRAS_page',
plotName='fullGTC.pdf')
```
Single 2d panel
--------------
See how the covariance between C and D is a ground-breaking result? Let's look in more detail!
Here, we'll want single-column figures.
```
# Redefine priors and truths
priors2d = (None,(1,1))
truths2d = (0,None)
# The 2d panel and the 1d histograms
GTC = pygtc.plotGTC(chains=[samples1[:,4:6], samples2[:,4:6]],
paramNames=names[4:6],
chainLabels=chainLabels,
truths=truths2d,
truthLabels=truthLabels[0],
priors=priors2d,
figureSize='MNRAS_column')
# Only the 2d panel
Range2d = ((-3,5),(-3,7)) # To make sure there's enough space for the legend
GTC = pygtc.plotGTC(chains=[samples1[:,4:6],samples2[:,4:6]],
paramNames=names[4:6],
chainLabels=chainLabels,
truths=truths2d,
truthLabels=truthLabels[0],
priors=priors2d,
paramRanges=Range2d,
figureSize='MNRAS_column',
do1dPlots=False)
```
Single 1d panel
--------------
Finally, let's just plot the posterior on C
```
# Bit tricky, but remember each data set needs shape of (Npoints, nDim)
inputarr = [np.array([samples1[:,4]]).T,
np.array([samples2[:,4]]).T]
truth1d = [0.]
GTC = pygtc.plotGTC(chains=inputarr,
paramNames=names[4],
chainLabels=chainLabels,
truths=truth1d,
truthLabels=truthLabels[0],
figureSize='MNRAS_column',
doOnly1dPlot=True)
```
| github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.