
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
# Introduction to functional programming in Python
Why functional programming? Some people get happy just seeing another implementation of a Fibonacci sequence function. Other people just want to get the job done.
Functional programming vs. Object oriented:
* encapsulation through functions
* What are pure function... | github_jupyter |
```
import pandas as pd
import os, sys
sys.path.append(os.path.abspath('../../main/python'))
import thalesians.tsa.tsa as tsa
df = pd.DataFrame({
'col1': [10., 20., 30., 40., 50., 60., 70., 80., 90., 100., 110., 120., 130., 140., 150., 160., 170., 180., 190., 200.],
'col2': [100., 200., 300., 400., 500., 600.,... | github_jupyter |
# Hierarchical Partial Pooling
Suppose you are tasked with estimating baseball batting skills for several players. One such performance metric is batting average. Since players play a different number of games and bat in different positions in the order, each player has a different number of at-bats. However, you want... | github_jupyter |
# Update data
This notebook downlads recent GitHub activity for a number of organizations.
It will extract all issues, PRs, and comments that were updated within a
window of interest. It will then save them to disk as CSV files.
```
from update_mod import GitHubGraphQlQuery, extract_comments
import requests
import p... | github_jupyter |
```
import pickle, os
import numpy as np
import math
snapshot_dir = os.path.realpath('../generative_playground/molecules/train/genetic/data')
root_name = 'AA2scan8_v2_lr0.1_ew0.1.pkl'
root_name = 'AAscan8_v2_lr_0.1_ew_0.1.pkl'
root_name = 'Ascan8_v2_lr0.03_ew0.1.pkl'
with open(snapshot_dir + '/' + root_name,'rb') as... | github_jupyter |
### Training a Graph Convolution Model
Now that we have the data appropriately formatted, we can use this data to train a Graph Convolution model. First we need to import the necessary libraries.
```
import deepchem as dc
from deepchem.models import GraphConvModel
import numpy as np
import sys
import pandas as pd
imp... | github_jupyter |
<img style="float: left" src="images/ucl_logo.png">
# Classification using ENVI 5.2
## Aims
After completing this practical, you should be able to analyse one or more image datasets using classification methods. This includes learning to identify land cover classes in a dataset and consider class separability (using... | github_jupyter |
```
%matplotlib inline
%reload_ext autoreload
%autoreload 2
```
## Style transfer net
```
from fastai.conv_learner import *
from pathlib import Path
torch.cuda.set_device(0)
torch.backends.cudnn.benchmark=True
PATH = Path('data/imagenet')
PATH_TRN = PATH/'train'
fnames_full,label_arr_full,all_labels = folder_source(... | github_jupyter |
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.

# Use MLflow with ... | github_jupyter |
# GitHub repositories and users recommendations by embeddings
## Problem Statement
Currently, GitHub has two possibilities to explore users and repositories:
1. Direct search by search term leveraging names and tags.
2. Recommender system under 'Explore' tab which gives suggestions to a user based on his usage of ser... | github_jupyter |
# Interpreting numeric split points in H2O POJO tree based models
This notebook explains how to correctly interpret split points that you might see in POJOs of H2O tree based models.
*Motivation*: we had seen there are users who are parsing H2O POJO and translating the Java code into another representation (SQL statem... | github_jupyter |
# SP via class imbalance
Example [test scores](https://www.brookings.edu/blog/social-mobility-memos/2015/07/29/when-average-isnt-good-enough-simpsons-paradox-in-education-and-earnings/)
SImpson's paradox can also occur due to a class imbalance, where for example, over time the value of several differnt subgroups all ... | github_jupyter |
# Functions
*Prerequisites: assigning variables, mathematical operators, commenting, simple lists, simple for-loops
- A function is like a machine. This machine can take in some input (can be 0,1,2,..etc number of input) and return some output (output can be 0 or several items as well).
- The process of designing/bu... | github_jupyter |
```
import numpy as np
import pandas as pd
from sklearn import model_selection
from sklearn.model_selection import cross_validate
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accura... | github_jupyter |
# Implementing a new model with Jack
In this tutorial, we focus on the minimal steps required to implement a new model from scratch using Jack.
We will implement a simple Bi-LSTM baseline for extractive question answering.
The architecture is as follows:
- Words of question and support are embedded using random embed... | github_jupyter |
```
%matplotlib inline
import numpy as np
import pandas as pd
from pathlib import Path
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Model
from keras.layers import Input, Flatten, Dense, Dropout
from keras.callbacks import Callback, ModelCheckpoint
from keras.applications.vgg16 impor... | github_jupyter |
# Building a matrix for numerical methods using a Landlab grid
(Greg Tucker, University of Colorado Boulder, July 2020)
*This notebook explains how to use the matrix-building functions to construct a matrix for a finite-volume or finite-difference solution on a Landlab grid.*
## Introduction
Numerical solutions to ... | github_jupyter |
```
import math
import numpy as np
import os
import nemo
from nemo.utils.lr_policies import WarmupAnnealing
import nemo.collections.nlp as nemo_nlp
from nemo.collections.nlp import NemoBertTokenizer, TokenClassifier, TokenClassificationLoss
from nemo.collections.nlp.data.datasets import utils
from nemo.collections.nl... | github_jupyter |
```
import conllu
from conllu import parse,parse_incr
import pandas as pd
import numpy as np
from nltk.util import ngrams
from math import floor
import wget
def list_flat(alist):
flat_list = []
for sublist in alist:
for item in sublist:
flat_list.append(item)
return flat_list
### Convert... | github_jupyter |
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#import lightgbm as lgb
from sklearn.model_selection import KFold
import warnings
import gc
import time
import sys
import datetime
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import mean_squ... | github_jupyter |
## Lab for Linear Regression
### Linear Algebra in Python/Numpy
In this lab we will use:
- the `numpy` linear algebra package for computations
- the `bokeh` plotting package for graphics
The next cell loads these libraries.
```
import numpy as np
from bokeh.plotting import figure
from bokeh.io import show, output_n... | github_jupyter |
# KorniaのData AugmentationとTorchvisionの比較
GitHub
https://github.com/kornia/kornia
論文
https://arxiv.org/abs/2011.09832v1
最新Korniaドキュメント
https://kornia.readthedocs.io/en/latest
実装参考
https://colab.research.google.com/github/kornia/kornia/blob/master/examples/augmentation/kornia_augmentation.ipynb
<a href=... | github_jupyter |
# Index
- *Class & Objet*
- `__init__`
- *Inheritence*
- *Magic Method*
- `__call__`
- `__setitem__` , `__getitem__`
# Class & Object
```
class Computer:
pass
c = Computer()
print(c)
class Computer:
def __init__(self, computer_type, color):
self.computer_type = computer_type
self.colo... | github_jupyter |
# Using `keras`
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import h5py
warnings.resetwarnings()
warnings.simplefilter(action='ignore', category=ImportWarning)
warnings.simplefilter(action='ignore', category=R... | github_jupyter |
```
%reload_ext autoreload
%autoreload 2
%matplotlib inline
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID";
os.environ["CUDA_VISIBLE_DEVICES"]="0";
```
# Text Classification with Hugging Face Transformers in *ktrain*
As of v0.8.x, *ktrain* now includes an easy-to-use, thin wrapper to the Hugging Face transfor... | github_jupyter |
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.

# Logging
_**This notebook showcases various ways to use the ... | github_jupyter |
## 1. Obtain and review raw data
<p>One day, my old running friend and I were chatting about our running styles, training habits, and achievements, when I suddenly realized that I could take an in-depth analytical look at my training. I have been using a popular GPS fitness tracker called <a href="https://runkeeper.com... | github_jupyter |
```
%matplotlib inline
import pickle
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns ; sns.set_context('notebook')
import pystan
import stan_utility
import arviz as az
import patsy
import os
import warnings
warnings.simplefilter('ignore')#removes deprecation warnings
plt.s... | github_jupyter |
# Inferential statistics
**Add the `src` directory as one where we can import modules**
```
import os
import sys
# add the 'src' directory as one where we can import modules
src_dir = os.path.abspath(os.path.join(os.getcwd(), os.pardir, 'src'))
sys.path.append(src_dir)
print(src_dir)
import helper_funcs as hf
```
*... | github_jupyter |
#### Basic Tree-Plot in Plotly with [igraph](http://igraph.org/python/)
```
import sys, os
sys.path.insert(1, os.path.join(sys.path[0], '..'))
import config as at_cfg
import cairo
print(cairo.__file__)
from igraph import *
g = Graph()#Graph.Tree(9,3) #Create tree graph with 127 vertices each with 2 children
N_OPTIMIZE... | github_jupyter |
## Section Contents
* [plot(): analyze distributions](plot.ipynb)
* [plot_correlation(): analyze correlations](plot_correlation.ipynb)
* [plot_missing(): analyze missing values](plot_missing.ipynb)
* [plot_diff(): analyze difference between DataFrames](plot_diff.ipynb)
* [create_report(): create a profile report]... | github_jupyter |
```
"""Supervised data compression via linear
discriminant analysis"""
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
```
Manually Principal Component Analysis
```
# Reading wine data
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/wine... | github_jupyter |
```
import sys
sys.path.append('..')
%load_ext autoreload
%autoreload 2
from pprint import pprint
import torch
import transformers
from tqdm.auto import tqdm
from new_semantic_parsing import utils
from new_semantic_parsing import EncoderDecoderWPointerModel, Seq2SeqTrainer
from new_semantic_parsing.schema_tokenizer... | github_jupyter |
# Regularização em Machine Learning
<br>
<img src="img\regularizacao.png" style="height:350px">
<br>
Um dos principais aspectos do treinamento do seu modelo de aprendizado de máquina é evitar o overfitting, pois neste caso o modelo terá uma baixa precisão. Isso acontece porque o seu modelo dificilmente irá conseguir ... | github_jupyter |
# Using a Global Call Graph
Consider a (mutli-directed) Graph where every single node represents a single function and an edge represents a function call. Abstracting these ideas away into a Graph allows us to treat updating names of functions and classes as a Graph Identification problem, identifying node labels.
In... | github_jupyter |
```
'''
Source: http://mindmech.net
'''
import csv
import numpy as np
def process_msg(message, vocab):
'''
message: the message string to classify.
vocab: a dict of unique integers assigned to unique words.
Insert your preprocessing here. For now we'll just lowercase,
skip punctua... | github_jupyter |
This lab gives an overview of the Nvidia Nsight Tool and steps to profile an application with Nsight Systems command line interface with NVTX API. You will learn how to integrate NVTX markers in your application to trace CPU events when profiling using Nsight tools.
Let's execute the cell below to display information... | github_jupyter |
```
import specdist as pi
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from scipy.interpolate import interp1d
from matplotlib.pyplot import cm
import matplotlib.ticker as ticker
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
from matplotlib.collections import LineCollection
from ma... | github_jupyter |
<a href="https://colab.research.google.com/github/Emersonmiady/imagem-corporal-estat/blob/main/imagem_corporal.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# **Imagem corporal na adolescência: uma análise com a Estatística**
---
## **Contextual... | github_jupyter |
# ULMFiT + Siamese Network for Sentence Vectors
## Part Two: Pretraining
This notebook will build a language model from lesson 10 of the Fast ai course and retrain it on the SNLI dataset.
```
from fastai.text import *
import html
import json
import html
import re
import pickle
from collections import Counter
import r... | github_jupyter |
```
%%markdown
# References
* https://github.com/normandipalo/faceID_beta/blob/master/faceid_beta.ipynb
!ls -laFh /data/blogs/keras-faceid-recognition/
%%markdown
FaceID recreation using face embeddings and RGBD images.
Made by [Norman Di Palo](https://medium.com/@normandipalo), March 2018.
Let''s start by downloading... | github_jupyter |
<table width="100%"><tr style="background-color:white;">
<td style="text-align:left;padding:0px;width:142px'">
<a href="https://qworld.net" target="_blank">
<img src="../qworld/images/QWorld.png"></a></td>
<td width="*"> </td>
<!-- #####################... | github_jupyter |
<center>
<img src="https://gitlab.com/ibm/skills-network/courses/placeholder101/-/raw/master/labs/module%201/images/IDSNlogo.png" width="300" alt="cognitiveclass.ai logo" />
</center>
<h1> Geometric Operations and Other Mathematical Tools with Pillow</h1>
Estimated time needed: **40** minutes
<h2> Spatial Opera... | github_jupyter |
## Neural Network Overview
<img src="http://cs231n.github.io/assets/nn1/neural_net2.jpeg" alt="nn" style="width: 400px;"/>
## MNIST Dataset Overview
This example is using MNIST handwritten digits. The dataset contains 60,000 examples for training and 10,000 examples for testing. The digits have been size-normalized ... | github_jupyter |
<a href="https://www.bigdatauniversity.com"><img src = "https://ibm.box.com/shared/static/cw2c7r3o20w9zn8gkecaeyjhgw3xdgbj.png" width = 400, align = "center"></a>
<h1 align=center><font size = 5>CONTENT-BASED FILTERING</font></h1>
Recommendation systems are a collection of algorithms used to recommend items to users ... | github_jupyter |
# Demo for D-Wave on Braket: Factoring
In this tutorial we show how to solve a [constraint satisfaction problem](https://docs.ocean.dwavesys.com/en/stable/concepts/csp.html)(CSP) on a quantum computer with the example of factoring, which is realized by running a multiplication circuit in reverse using the D-Wave devic... | github_jupyter |
```
import os, time, datetime
import numpy as np
import pandas as pd
from tqdm import tqdm
import random
import logging
tqdm.pandas()
import seaborn as sns
from sklearn.model_selection import train_test_split
#NN Packages
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, random_split,DataL... | github_jupyter |
#KNN PCA
```
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
from operator import itemgetter
from tabulate import tabulate
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsClassifier
from sk... | github_jupyter |
```
# Imports
import numpy as np
import matplotlib.pyplot as plt
import time
import datetime
import tensorflow as tf
from tensorflow import keras
import pandas as pd
from pandas import read_csv
from sklearn.decomposition import PCA
import umap
import datetime
# Make numpy values easier to read.
np.set_printoptions(... | github_jupyter |
##### Copyright 2019 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | github_jupyter |
# Clustering Challenge
Clustering is an *unsupervised* machine learning technique in which you train a model to group similar entities into clusters based on their features.
In this exercise, you must separate a dataset consisting of three numeric features (**A**, **B**, and **C**) into clusters. Run the cell below t... | github_jupyter |
# Search and Load CMIP6 Data via ESGF / OPeNDAP
This notebooks shows how to search and load data via [Earth System Grid Federation](https://esgf.llnl.gov/) infrastructure. This infrastructure works great and is the foundation of the CMIP6 distribution system.
The main technologies used here are the [ESGF search API](... | github_jupyter |
<a href="https://colab.research.google.com/github/google/neural-tangents/blob/main/notebooks/weight_space_linearization.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
##### Copyright 2019 Google LLC.
Licensed under the Apache License, Version 2.0 ... | github_jupyter |
##### Copyright 2019 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | github_jupyter |
```
from inception_v4 import inception_v4
from keras.models import Model, model_from_json
from keras.layers import Dense, GlobalAveragePooling2D, Dropout, Flatten, AveragePooling2D
from keras.callbacks import ModelCheckpoint
from keras.optimizers import Adam
import numpy as np
import pandas as pd
import cv2
import math... | github_jupyter |
<a href="https://colab.research.google.com/github/Agnesing/UE/blob/main/Dotacje_UE_2014_2020.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Umowy o dotacje z funduszy UE w Polsce w latach 2014-2020
Notebook przestawia wizualizację danych dotyczą... | github_jupyter |
```
try:
from openmdao.utils.notebook_utils import notebook_mode
except ImportError:
!python -m pip install openmdao[notebooks]
```
# Advanced Recording Example
Below we demonstrate a more advanced example of case recording including the four different objects
that a recorder can be attached to. We will then ... | github_jupyter |
```
import os
import sys
sys.path.insert(0, os.path.abspath('..'))
import xarray as xr
import glob
import matplotlib.pyplot as plt
import numpy as np
import collections
from scipy.stats import linregress
import pandas as pd
# import utils as les_utils
from uwtrajectory import les_utils
import matplotlib as mpl
from uwt... | github_jupyter |
# Ensemble Methods
The goal of ensemble methods is to combine the predictions of several base estimators built with a given learning algorithm in order to improve generalizability / robustness over a single estimator.
Two families of ensemble methods are usually distinguished:
* In averaging methods, the driving prin... | github_jupyter |
<a href="https://colab.research.google.com/github/yukinaga/object_detection/blob/main/section_1/01_pytorch_cnn.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# CNNの実装
PyTorchを使って、畳み込みニューラルネットワーク(CNN)を実装します。
CNN自体はCNNの層を追加するのみで実装可能なのですが、今回はデータ拡張とド... | github_jupyter |
# Writing out a USGSCSM ISD from a PDS3 Dawn Framing Camera image
```
import os
import json
import ale
from ale.drivers.dawn_drivers import DawnFcPds3NaifSpiceDriver
from ale.formatters.usgscsm_formatter import to_usgscsm
```
## Instantiating an ALE driver
ALE drivers are objects that define how to acquire common I... | github_jupyter |
this notebook contains the pipeline run of the analysis in cardea version 0.0.2
```
import numpy as np
import pandas as pd
from cardea import Cardea
from cardea.modeling.modeler import Modeler
from cardea.featurization import Featurization
from cardea.data_loader.load_mimic import load_mimic_data
from featuretools.s... | github_jupyter |
```
!pip install pytorch-nlp
import numpy as np # to handle matrix and data operation
import pandas as pd # to read csv and handle dataframe
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data
from torch.autograd import Variable
from sklearn.metrics import roc_auc_score, f1_scor... | github_jupyter |
# Imports
```
%%time
#Imports requisite packages
import os
import time
import numpy
import pickle
import cProfile
import itertools
import matplotlib
from sklearn.svm import *
from sklearn.metrics import *
from sklearn.preprocessing import *
from matplotlib import pyplot as plt
from sklearn.cross_validation import *
fr... | github_jupyter |
| [**Overview**](./00_overview.ipynb) | [Getting Started](./01_jupyter_python.ipynb) | **Examples:** | [Access](./02_accessing_indexing.ipynb) | [Transform](./03_transform.ipynb) | [Plotting](./04_simple_vis.ipynb) | [Norm-Spiders](./05_norm_spiders.ipynb) | [Minerals](./06_minerals.ipynb) | [lambdas](./07_lambdas.ipyn... | github_jupyter |
```
from os import listdir
from os.path import isfile, join
import numpy as np
import cv2
import matplotlib.pyplot as plt
from segmentation_models import PSPNet
from segmentation_models import FPN
from segmentation_models import Unet
from segmentation_models.segmentation_models.backbones import get_preprocessing
fro... | github_jupyter |
# Setup
This section is for setup, imports, loading data, etc., that is needed prior to modeling. Please do not grade it :)
#### Model Controls
```
RUN_GRID_SEARCH_CV = True
```
#### Base Library Imports
```
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.ticker import ... | github_jupyter |
```
from pflow.particle_filter import BootstrapFilter, ObservationBase, FilterState, LikelihoodMethodBase, ProposalMethodBase
from pflow.base import BaseReweight
from pflow.optimal_transport.transportation_plan import Transport
from pflow.resampling.systematic import SystematicResampling
from pflow.optimal_transport.re... | github_jupyter |
# Developing an AI application
Going forward, AI algorithms will be incorporated into more and more everyday applications. For example, you might want to include an image classifier in a smart phone app. To do this, you'd use a deep learning model trained on hundreds of thousands of images as part of the overall appli... | github_jupyter |
# Huggingface Sagemaker - Vision Transformer
### Image Classification with the `google/vit` on `cifar10`
1. [Introduction](#Introduction)
2. [Development Environment and Permissions](#Development-Environment-and-Permissions)
1. [Installation](#Installation)
3. [Permissions](#Permissions)
3. [Processing](... | github_jupyter |
<a href="https://colab.research.google.com/github/DJCordhose/ml-workshop/blob/master/notebooks/intro/nn-01-regression.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Practical Introduction to Neural Networks: Regression using TensorFlow 2
# Hands... | github_jupyter |
CVR strings can be converted to the following formats via the `output_format` parameter:
* `compact`: only number strings without any seperators or whitespace, like "13585628"
* `standard`: CVR strings with proper whitespace in the proper places. Note that in the case of CVR, the compact format is the same as the stan... | github_jupyter |
# Object Following - Live Demo (对象跟踪-实时演示)
在这本笔记本中,我们将展示如何使用JetBot跟踪对象!我们将使用预先训练好的神经网络
这是在[COCO数据集](http://COCO dataset.org)上训练的,用来检测90个不同的公共对象。其中包括
*人(索引 0)、杯(索引 47)*
以及许多其他(您可以查看 [此文件](https://github.com/tensorflow/models/blob/master/research/object_detection/data/mscoo_complete_label_map.pbtxt) 以获取类索引的完整列表)。该模型来源... | github_jupyter |
# Visualizaing the predicate shifts
In the paper, we visualize all the predicate shifts that we learn. This notebook takes you through the process of creating such shifts.
```
from utils.visualization_utils import get_att_map, objdict, get_dict
from scipy.stats import multivariate_normal
import keras.backend as K
im... | github_jupyter |
# Jupyter Notebooks
In this chapter, we'll cover Jupyter Notebooks, including how to write and execute code and how to write text in the **Markdown** format. We'll also discuss what the kernel is, so that you understand generally how Jupyter Notebooks work.
<div class="alert alert-success">
Jupyter notebooks are a wa... | github_jupyter |
```
from sklearn.metrics import roc_auc_score, precision_recall_curve
from sklearn.metrics import auc as calculate_auc
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from scipy.stats.stats import pearsonr
import os
import subprocess
import pandas as pd
import numpy as np
rand... | github_jupyter |
## Explore the Squad Dataset 2.0
```
#@title specify file_path for Squad Dataset
from google.colab import drive
import json
import os
drive.mount('/content/drive')
squad_train_path = '' # path to train-v1.1.json on gdrive
squad_dev_path = '' # path to dev-v1.1.json on gdrive
with open(squad_train_path) as file_d:
... | github_jupyter |
```
import os
import csv
import platform
import pandas as pd
import networkx as nx
from graph_partitioning import GraphPartitioning, utils
run_metrics = True
cols = ["WASTE", "CUT RATIO", "EDGES CUT", "TOTAL COMM VOLUME", "Qds", "CONDUCTANCE", "MAXPERM", "NMI", "FSCORE", "FSCORE RELABEL IMPROVEMENT", "LONELINESS"]
#c... | github_jupyter |
### This tutorial provides you the basics of the Quantum Gates.
A quauntum gate
- acts on qubits i.e. 0 or 1.
- transforms the state of a qubit into other states.
If we denote a quantum gate using $U$, then acting on qubits can be represented as
$$
U \mid 0 \rangle \\
U \mid 1 \rangle.
$$
After applying $U$ on 0,... | github_jupyter |
# Vežbe 10: Runner
Runner nije deo kompajlera, već je to [interpreter](https://en.wikipedia.org/wiki/Interpreter_(computing)) koji prolaskom kroz AST indirektno izvršava izvorni kod.
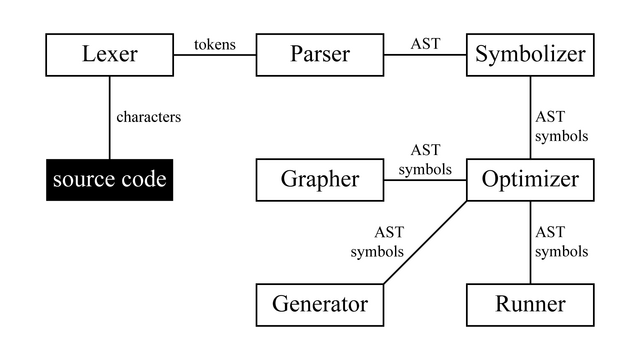
Autor: Lazar Jelić
Repozitorijum: https://github.com/jelic98/raf_pp_materials
Impo... | github_jupyter |
This notebook outlines some basic analysis of the terms used in the [DEDuCT](https://cb.imsc.res.in/deduct/) database. Some terms have been used that represent directed relationships with biomarkers, clinical endpoints, abundances of biological entities, activities of biological entities, ratios of biological entities,... | github_jupyter |
# Particle segmentation App
### If you have not already uploaded data, click on the link below data and use the Upload button:
### [Adding data](https://fl-7-206.zhdk.cloud.switch.ch)
```
import os, glob, copy
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ipywidgets as widgets
import n... | github_jupyter |
<h1 align=center><font size = 5>Introduction to Folium Maps</font></h1>
What is nice about **Folium** is that it was developed for the sole purpose of visualizing geospatial data. While other libraries are available to visualize geospatial data, such as **plotly**, they might have a cap on how many API calls you c... | github_jupyter |
```
import pandas as pd
import numpy as np
import re
%pwd
# !pip install soynlp
!pip show soynlp
data= pd.read_csv("song_data_fixed.csv")
song = pd.DataFrame(data)
song.head(3)
song.columns
song['artist'].value_counts()
song[song['artist'] == '키스'].head() # 키스는 누구인가? => 미국가수, 삭제예정
# 유니크한 가수의 수
len(song['artist'].uniq... | github_jupyter |
# MLE 모수 추정
## 베르누이 분포의 모수 추정
* 각각의 시도 $x_i$에 대한 확률은 베르누이 분포
$$ P(x ; \theta ) = \text{Bern}(x ; \theta ) = \theta^x (1 - \theta)^{1-x}$$
* $N$개의 독립 샘플 $x_{1:N}$ 이 있는 경우,
$$ L(\theta ; x_{1:N}) = P(x_{1:N};\theta) = \prod_{i=1}^N \theta^{x_i} (1 - \theta)^{1-x_i} $$
* Log-Likelihood
$$
\begin{eqnarray*}
\log... | github_jupyter |
# Weighted Least Squares
```
%matplotlib inline
from __future__ import print_function
import numpy as np
from scipy import stats
import statsmodels.api as sm
import matplotlib.pyplot as plt
from statsmodels.sandbox.regression.predstd import wls_prediction_std
from statsmodels.iolib.table import (SimpleTable, default_... | github_jupyter |
```
# header files needed
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torch.utils.tensorboard import SummaryWriter
from google.colab import drive
drive.mount('/content/drive')
np.random.seed(1234)
torch.manual_seed(1234)
torch.cuda.manual_seed(1234)
# define transforms
train_transforms... | github_jupyter |
```
import pandas as pd
import plotly.express as px
import plotly.graph_objs as go
import csv
my_df = pd.read_csv("totalDigitalTracking.csv", encoding = "latin-1")
#with open("totalDigitalTracking.csv") as f:
# reader = csv.reader(f)
# for row in reader:
# print(" ".join(row))
def read_cell(x, y):
w... | github_jupyter |
```
%matplotlib inline
```
Pytorch를 사용해 신경망 정의하기
====================================
딥러닝은 인공신경망(models)을 사용하며 이것은 상호연결된 집단의 많은 계층으로 구성된 계산 시스템입니다.
데이터가 이 상호연결된 집단을 통과하면서, 신경망은 입력을 출력으로 바꾸기 위해 요구된 계산 방법에 어떻게 근접하는 지를 배울 수 있습니다.
PyTorch에서, 신경망은 ``torch.nn`` 패키지를 사용해 구성할 수 있습니다.
소개
-----
PyTorch는 ``torch.nn`` 을 포함하여 신경... | github_jupyter |
<a href="https://colab.research.google.com/github/Raihan-J/Data-Compression-And-Encryption/blob/master/Exp-6%20Image%20Compression/Image%20Compression%20(JPEG).ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
*Sample Image*
```
!rm ferrari.*
!wget "... | github_jupyter |
```
import sys
import collections
import subprocess
from lxml import etree
import laf
from laf.fabric import LafFabric
from etcbc.preprocess import prepare
from etcbc.mql import MQL
fabric = LafFabric()
API = fabric.load('etcbc4', '--', 'mql', {
"xmlids": {"node": False, "edge": False},
"features": ('''
... | github_jupyter |
# Python - Introduction
In the following Notebooks, the key concepts of computer programs are discussed.
# Python-programs consist of statements, which are executed one by one
What is a Python-program? More generally, what is a (computer) program? All Python programs consist of a series of
statements or instructions.... | github_jupyter |
# Introduction to Python
- **Aggregate Types**
- lists (sequence of items)
- dictionaries (key-value pairs)
- **Flow Control**
- if.. elif.. else.. (Conditionals)
- for i in seq (For Loop)
- while i > 0 (While Loop)
- **Functions**
- def myfunc(a, b, c=0)
## **Variables**
Variables are contai... | github_jupyter |
# Data gathering
## Imports
```
#%matplotlib inline
%matplotlib notebook
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import pylab as pl
from matplotlib.ticker import FormatStrFormatter
params = {'axes.labelsize': 'large',
'axes.titlesize':'xx-large',
... | github_jupyter |
## Interpretability - Explanation Dashboard
In this example, similar to the "Interpretability - Tabular SHAP explainer" notebook, we use Kernel SHAP to explain a tabular classification model built from the Adults Census dataset and then visualize the explanation in the ExplanationDashboard from https://github.com/micr... | github_jupyter |

[](https://colab.research.google.com/github/JohnSnowLabs/nlu/blob/master/examples/colab/Training/multi_label_text_classification/NLU_traing_multi_label_classifier_E2e.ipynb)
... | github_jupyter |
# 11장. 레이블되지 않은 데이터 다루기 : 군집 분석
**아래 링크를 통해 이 노트북을 주피터 노트북 뷰어(nbviewer.jupyter.org)로 보거나 구글 코랩(colab.research.google.com)에서 실행할 수 있습니다.**
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://nbviewer.jupyter.org/github/rickiepark/python-machine-learning-book-2nd-edition/blob/m... | github_jupyter |
```
# Copyright 2021 NVIDIA Corporation. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applica... | github_jupyter |
```
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '2'
import tensorflow as tf
import malaya_speech
import malaya_speech.train
from malaya_speech.train.model import resnext as unet
from malaya_speech.utils import tf_featurization
import malaya_speech.augmentation.waveform as augmentation
import IPython.display as ipd
... | github_jupyter |
# Lambda School Data Science - Artificial General Intelligence and The Future

# Lecture
## Defining Intelligence
A straightforward definition of Artificial Intelligence would simply be "inte... | github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.