
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
```
# Copyright 2021 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writi... | github_jupyter |
```
import numpy as np
import tensorflow as tf
from sklearn.utils import shuffle
import re
import time
import collections
import os
def build_dataset(words, n_words, atleast=1):
count = [['PAD', 0], ['GO', 1], ['EOS', 2], ['UNK', 3]]
counter = collections.Counter(words).most_common(n_words)
counter = [i for... | github_jupyter |
```
from __future__ import print_function
import keras
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, Batch... | github_jupyter |
```
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import tqdm
from scipy import sparse
```
# Generate some indices
Even the sparse matrices won't fit in memory. So we will have to loop through them when making predictions or sampling random items.
```
#count number of items:
indptr = [0]
for... | github_jupyter |
```
# Major version: the feature setup
# Minor version: model hypertunning
VERSION = 'v1.1'
major_VERSION = VERSION.split('.')[0]+'.0'
```
# Model Details
## Features:
- One hot encoded **day of week** and **month** (not year)
- Weather feature (OHE):
- Icons (cloudy, partial cloudy, ...)
- Precipitates Type (... | github_jupyter |
# Vector Space Models
Representation text units (characters, phonemes, words, phrases, sentences, paragraphs, and documents) with vector of numbers.
## Basic Vectorization Approaches
One-Hot Encoding, cons:
1. The size of one-hot vector is directly proportional to size of the vocabulary, and most real-world corpora h... | github_jupyter |
# Dataset
```
from hana_ml import dataframe
import json
import time
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from data_load_utils import DataSets, Settings
import plotting_utils
url, port, user, pwd = Settings.load_config("../../config/e2edata.ini")
conn = dataframe.ConnectionContext(url,... | github_jupyter |
# COMP 562 – Lecture 12
$$
\newcommand{\xx}{\mathbf{x}}
\newcommand{\yy}{\mathbf{y}}
\newcommand{\zz}{\mathbf{z}}
\newcommand{\vv}{\mathbf{v}}
\newcommand{\bbeta}{\boldsymbol{\mathbf{\beta}}}
\newcommand{\mmu}{\boldsymbol{\mathbf{\mu}}}
\newcommand{\ssigma}{\boldsymbol{\mathbf{\sigma}}}
\newcommand{\reals}{\mathbb{R}}... | github_jupyter |
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.

# Train and expl... | github_jupyter |
```
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from pyGDM2 import (structures, materials, core,
linear, fields, propagators,
tools)
def get_spectrum(geometry, step):
""" Obtain a simulated absorption spectra for a hexagonal nanorod mesh
L --... | github_jupyter |
```
import glob
import sys
from mhc_parser import models, methods, utilities, pairwise_comp, net_mhc_func
import importlib
importlib.reload(models)
project_location = '/Users/carlomazzaferro/Desktop/Mali_2_prots_human_alleles/'
fasta_file = '/Users/carlomazzaferro/Desktop/Mali_2_prots_human_alleles/fasta_2_prots.fasta'... | github_jupyter |
```
import models
import numpy as np
import pandas as pd
from numpy import sqrt, exp, pi, power, tanh, vectorize
from scipy.integrate import odeint
from scipy.interpolate import make_interp_spline, interp1d
import matplotlib.pyplot as plt
folder = '/Users/clotilde/OneDrive/Professional/2019-2021_EuroTech/1.Project/2.St... | github_jupyter |
# Assessing the number of transition options
Here we calculate the number of transition options for the 1627 occupations presented in the Mapping Career Causeways report.
# 0. Import dependencies and inputs
```
%run ../notebook_preamble_Transitions.ipy
import os
data = load_data.Data()
```
## 0.1 Generate 'filteri... | github_jupyter |
```
#tag::start-ray-local[]
import ray
ray.init(num_cpus=20) # In theory auto sensed, in practice... eh
#end::start-ray-local[]
#tag::sleepy_task_hello_world[]
import timeit
def slow_task(x):
import time
time.sleep(2) # Do something sciency/business
return x
@ray.remote
def remote_task(x):
return slow... | github_jupyter |
```
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sw = pd.read_csv('../input/Steven Wilson.csv') # Steven Wilson
pt = pd.read_csv('../input/Porcupine Tree.csv', nrows=len(sw)) # Porcupine Tree
# remove useless columns
ignore = ['analysis_url', 'id', 'track_href', 'uri', 'type', 'album', ... | github_jupyter |
##### Set up the environment
```
import matplotlib.pyplot as plt
import numpy as np
import random
import math
from collections import namedtuple
%matplotlib inline
# Optimization for mathplotlib
import matplotlib as mpl
import matplotlib.style as mplstyle
mpl.rcParams['path.simplify'] = True
mpl.rcParams['path.simplif... | github_jupyter |
# Simulation Archive
<h1>Contents<span class="tocSkip"></span></h1>
<div class="toc"><ul class="toc-item"><li><span><a href="#Introduction" data-toc-modified-id="Introduction-1"><span class="toc-item-num">1 </span>Introduction</a></span></li><li><span><a href="#Note" data-toc-modified-id="Note-2"><span clas... | github_jupyter |
# Anchor explanations for fashion MNIST
```
import matplotlib
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, Dense, Dropout, Flatten, MaxPooling2D, Input
from tensorflow.keras.models import Model
from tensorflow.keras.utils impo... | github_jupyter |
# Inspecting training data <img align="right" src="../../Supplementary_data/dea_logo.jpg">
* [**Sign up to the DEA Sandbox**](https://docs.dea.ga.gov.au/setup/sandbox.html) to run this notebook interactively from a browser
* **Compatibility:** Notebook currently compatible with the `DEA Sandbox` environment
## Backg... | github_jupyter |
```
#Ref : https://musicinformationretrieval.com/novelty_functions.html
import os
import sys
from os import listdir
from os.path import isfile, join
import numpy as np
import scipy as sp
import matplotlib as mpl
import matplotlib.pyplot as plt
from PIL import Image
import librosa
import librosa.display
import IPython.... | github_jupyter |
## Gather
```
import pandas as pd
patients = pd.read_csv('patients.csv')
treatments = pd.read_csv('treatments.csv')
adverse_reactions = pd.read_csv('adverse_reactions.csv')
```
## Assess
```
patients
treatments
adverse_reactions
patients.info()
treatments.info()
adverse_reactions.info()
all_columns = pd.Series(list(... | github_jupyter |
(handling_errors)=
# Handling errors
When an _error_ occurs in Python, an _exception_ is _raised_.
(error_types)=
## Error types
The full list of built-in exceptions is available in the [documentation](https://docs.python.org/3/library/exceptions.html#concrete-exceptions).
For example, when we create a tuple with on... | github_jupyter |
SOP012 - Install unixodbc for Mac
=================================
Description
-----------
`azdata` may fail to install on Mac with the following error.
> ERROR:
> dlopen(/Users/user/.local/lib/python3.6/site-packages/pyodbc.cpython-36m-darwin.so,
> 2): Library not loaded: /usr/local/opt/unixodbc/lib/libodbc.2.dyli... | github_jupyter |
##### Copyright 2021 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | github_jupyter |
## Coding Basics for Researchers - Day 1
*Notebook by [Pedro V Hernandez Serrano](https://github.com/pedrohserrano)*
---
# 3. Python and Automation
* [3.1. Creating basic functions](#3.1)
* [3.2. Sharing is caring](#3.2)
---
## 3.1. Creating basic functions
<a id="3.1">
A function is a block of organized, reusable... | github_jupyter |
# NUMPY - Multidimensional Data Arrays
It is a package that provide high-performance vector, matrix and higher-dimensional data structures for Python. NumPy brings the computational power of languages like C and Fortran to Python, a language much easier to learn and use.
### Import Numpy Library
```
import numpy as ... | github_jupyter |
```
import os
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chromedriver_path = "C:\\Users\\Araf\\Desktop\\Script\\chromedriver_win32"
os.environ['PATH'] += chromedriver_path
driver = webdriver.Chrome()
driver.implicitly_wait(40)
driver.get("https://atcoder.jp")
# do login ma... | github_jupyter |
# Control Flow: If, For, and While Loops
When building programs, you may want to find ways to repeating certain sets of actions or choosing between sets of actions based on some condition. **Control flow** is the order that different statements or pieces of your code run in. In Python the three basic ways we can contr... | github_jupyter |
# Hyperparameter tuning
**Learning Objectives**
1. Learn how to use `cloudml-hypertune` to report the results for Cloud hyperparameter tuning trial runs
2. Learn how to configure the `.yaml` file for submitting a Cloud hyperparameter tuning job
3. Submit a hyperparameter tuning job to Cloud AI Platform
## Introductio... | github_jupyter |
### Authors:
Gabriele Bani 11640758
Andrii Skliar 11636785
# Lab 2: Inference in Graphical Models
### Machine Learning 2 (2017/2018)
* The lab exercises should be made in groups of two people.
* The deadline is Thursday, 29.04, 23:59.
* Assignment should be submitted through BlackBoard! Make sure to include your an... | github_jupyter |
# 3.3 Lexical Texts and their Relation to Literary Vocabulary
In section [3.2](./3_2_Lit_Lex.ipynb) we asked whether we can see differences between Old Babylonian literary compositions in their usage of vocabulary (lemmas and MWEs) attested in the lexical corpus. In this notebook we will change perspective and ask: ar... | github_jupyter |
# Univariate time series classification with sktime
In this notebook, we will use sktime for univariate time series classification. Here, we have a single time series variable and an associated label for multiple instances. The goal is to find a classifier that can learn the relationship between time series and label ... | github_jupyter |
# License Plate Detection with OpenCV
In this project we demonstrate how to use OpenCV only, with traditional computer vision approaches, to perform License Plate Detection (LPD).
We follow two approaches:
1- __Morphology based approach__: where only morphological transforms are used, along with some rules to detec... | github_jupyter |
## Initial Analysis and Plots
This section looks at the data and draws simple conclusions from it as used in the submitted paper
```
import pandas as pd
pd.set_option('display.max_columns', 50)
df = pd.read_csv("data.csv")
df.shape
df.head()
df.events.unique()
df['events'].value_counts()/sum(df['events'].value_counts(... | github_jupyter |
```
if 0 :
%matplotlib inline
else :
%matplotlib notebook
```
# Import libraries
```
import sys
import os
module_path = os.path.abspath('.') +"\\_scripts"
print(module_path)
if module_path not in sys.path:
sys.path.append(module_path)
from _00_Import_packages_git3 import *
from numpy import array
impor... | github_jupyter |
<center><h1><strong>tau-data Indonesia</strong></h1></center>
<center><h2><strong><font color="blue">Pendahuluan SQL dasar untuk Data Science - 01</font></strong></h2></center>
<img alt="" src="images/cover.jpg" />
<b><center>(C) Taufik Sutanto</center>
<center><h3><font color="blue">https://tau-data.id/dfds-01/</... | github_jupyter |
```
%matplotlib inline
import numpy as np
import pandas as pd
import os,sys
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
basepath = os.path.expanduser('~/Desktop/src/AllState_Claims_Severity/')
sys.path.append(os.path.join(basepath, 'src'))
np.random.seed(... | github_jupyter |
## Analytic Solutions Convergence Tests
This notebook runs series of simulations across different resolutions to extract error convergence information. Analytic Stokes flow solutions are used as a basis for error estimation.
```
from collections import OrderedDict as OD
regress_solns = [
# ("name", {soln_params}, ... | github_jupyter |
<a href="https://colab.research.google.com/github/probml/pyprobml/blob/master/book1/dimred/pca.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
# Standard Python libraries
from __future__ import absolute_import, division, print_function, unicode_... | github_jupyter |
```
import json
import numpy as np
import os
import pandas as pd
import sklearn
import sys
import tensorflow as tf
print(sys.version)
print(np.__version__)
print(sklearn.__version__)
print(tf.__version__)
```
## Deep Bayesian Bandits Reproducibility
This notebook explores the reproducibility around the [Deep Bayesia... | github_jupyter |
```
%load_ext lab_black
import csv
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import matplotlib.ticker as ticker
import matplotlib.axis as ax
from pywaffle import Waffle
import datetime
%matplotlib inline
path1 = "./"
path2 = "./"
filename1 = "All_Data_Original_magazine.csv"
filename2 = "Al... | github_jupyter |
```
%matplotlib inline
```
# Time-related feature engineering
This notebook introduces different strategies to leverage time-related features
for a bike sharing demand regression task that is highly dependent on business
cycles (days, weeks, months) and yearly season cycles.
In the process, we introduce how to perf... | github_jupyter |
```
# !wget https://huseinhouse-storage.s3-ap-southeast-1.amazonaws.com/bert-bahasa/quora.zip
# !unzip quora.zip
# !wget http://s3-ap-southeast-1.amazonaws.com/huseinhouse-storage/bert-bahasa/bert-bahasa-small.tar.gz
# !tar -zxf bert-bahasa-small.tar.gz
# !pip3 install bert-tensorflow sentencepiece
import bert
from ber... | github_jupyter |
```
import os
import time
import numpy as np
import pandas as pd
from sklearn.metrics import f1_score, roc_curve, auc, roc_auc_score, precision_recall_curve, recall_score, precision_score, confusion_matrix, average_precision_score
import matplotlib.pyplot as plt
%matplotlib inline
#data_features consists of lumisection... | github_jupyter |
```
test_index = 0
from load_data import *
# load_data()
from load_data import *
X_train,X_test,y_train,y_test = load_data()
len(X_train),len(y_train)
len(X_test),len(y_test)
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class Test_Model(nn.Module):
def __init__(self... | github_jupyter |
***
[http://schoolofweb.net/blog/posts/파이썬-제너레이터-generator/](http://schoolofweb.net/blog/posts/파이썬-제너레이터-generator/) 를 보고 정리하였습니다.
***
제너레이터란, 반복자(iterator)와 같은 루프의 작용을 컨트롤하기 위해 쓰여지는 특별한 함수 또는 루틴을 말합니다.
제너레이터는 배열이나 리스트를 리턴하는 함수와 비슷하지만 차이점은 한번에 모든 값을 만들어서 배열이나 리스트에 담은 다음 리턴하는 것이 아니라, yield구문을 이용해 한번 호출될 때마다 하나의 값만을 리턴... | github_jupyter |
# Estimating Workplace Location
This notebook illustrates how to re-estimate ActivitySim's auto ownership model. The steps in the process are:
- Run ActivitySim in estimation mode to read household travel survey files, run the ActivitySim submodels to write estimation data bundles (EDB) that contains the model util... | github_jupyter |
## Develop your model
```
import os
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.examples.tutorials.mnist import mnist
INPUT_DATA_DIR = '/tmp/tensorflow/mnist/input_data/'
MAX_STEPS = 1000
BATCH_S... | github_jupyter |
<a href="https://colab.research.google.com/github/kalz2q/mycolabnotebooks/blob/master/learnlatex.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# メモ
colab で latex を勉強するためのノートブックです。
colab で開いてください。
https://colab.research.google.com/github/kalz2q/m... | github_jupyter |
# Reef Check - abalone size/frequency data
Abalone size surveys are conducted north of the Golden Gate. Any red abalone encountered during usual Reef Check surveys are sized using calipers. In addition, independent abalone surveys are conducted where a diver swims over the reef and measures every red abalone encounter... | github_jupyter |
### Master Telefónica Big Data & Analytics
# **Prueba de Evaluación del Tema 4:**
## **Topic Modelling.**
Date: 2016/04/10
Para realizar esta prueba es necesario tener actualizada la máquina virtual con la versión más reciente de MLlib.
Para la actualización, debe seguir los pasos que se indican a continuación:
##... | github_jupyter |
```
# default_exp losses
# all_slow
```
# Loss functions
> Various loss functions in PyTorch
```
# hide
%load_ext autoreload
%autoreload 2
%matplotlib inline
# export
import torch
import torch.nn as nn
import torch.nn.functional as F
from fastai.torch_core import TensorBase
from fastai.losses import *
fr... | github_jupyter |
```
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import cv2
import glob
from skimage.feature import hog
from skimage import color, exposure
%matplotlib inline
# images are divided up into vehicles and non-vehicles
car_images_udacity = glob.glob(r'C:\Users\mohar\Desktop\Vinod\vehi... | github_jupyter |
We want to make sure not just the code we open-sourced, but also goes to dataset, so everyone can validate.
You can check in [Malaya-Dataset](https://github.com/huseinzol05/Malaya-Dataset) for our open dataset.
## [Article](https://github.com/huseinzol05/Malaya-Dataset/blob/master/articles)
Total size: 3.1 MB
1. Fi... | github_jupyter |
```
import errno
import json
import os
import cv2
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scipy.misc
from scipy.ndimage import rotate
from scipy.stats import bernoulli
%matplotlib inline
# Some useful constants
DRIVING_LOG_FILE = os.getcwd() + os.sep + os.pardir + '/datasets/data... | github_jupyter |
<a href="https://colab.research.google.com/github/livjab/DS-Unit-2-Sprint-3-Classification-Validation/blob/master/module2-baselines-validation/LS_DS_232_Baselines_Validation.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
_Lambda School Data Science... | github_jupyter |
```
import os
import sys
sys.path.append('../')
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import src.io as sio
import src.preprocessing as spp
import src.fitting as sft
import ipympl
DATA_FOLDER = "20210816_RTStageTesting_MW_MembraneSample"
DATA_FOLDERPATH = sio.get_qudiamond_folderpath(D... | github_jupyter |
# COCO Image Viewer
This notebook will allow you to view details about a COCO dataset and preview segmentations on annotated images.
Learn more about it at: http://cocodataset.org/
```
import IPython
import os
import json
import random
import numpy as np
import requests
from io import BytesIO
from math import trunc
fr... | github_jupyter |
<a href="http://landlab.github.io"><img style="float: left" src="../../landlab_header.png"></a>
# Introduction to the FlowAccumulator
Landlab directs flow and accumulates it using two types of components:
**FlowDirectors** use the topography to determine how flow moves between adjacent nodes. For every node in the g... | github_jupyter |
```
import numpy as np
import pandas as pd
import seaborn as sns
import scipy
import tables as tb
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
%matplotlib inline
```
# Load Datasets
```
test_data = pd.read_csv("testing_data_transform.csv.gz", compression="gzip")
test_data.head()
training_d... | github_jupyter |
## Superstore data analysis project using two types of Dataframes:
1. Pandas Dataframes.
2. Koalas Dataframes.
```
from pyspark.sql import SparkSession
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from databricks import koalas as ks
spark = SparkSession.builder.a... | github_jupyter |
# External catolog queries:
This notbook will demonstrate how to query catalogs using the CatalogQuery class. Each instance of this class
has to be connected to (and search in) a specific catalog and collection. Once the instance is created it provides methods to query for:
- all the sources with a certain distan... | github_jupyter |
## Linear Regression as a model of Emotional Appraisal
The first example we discuss involves building a simple linear regression model in Pyro. We consider a case that is relevant to affective computing --- how should we build a model to reason about someone's emotions? There are lots of emotion theories that one can ... | github_jupyter |
# Prestack seismic
**[Smaller single gather file on S3/agilegeo (3.8GB)](https://s3.amazonaws.com/agilegeo/3D_gathers_pstm_nmo_X1001.sgy)**
**[Larger gathers files on Open Seismic Repository (ca. 10GB)](https://opendtect.org/osr/pmwiki.php/Main/PENOBSCOT3DSABLEISLAND)**
For now we'll satisfy ourselves with reading s... | github_jupyter |
# D1 - 03 - Mini Projects
## Content
- Scalar product of two lists/tuples
- Arithmetic mean of a sequence
- Linear regression
- Numerical differentiation
- Taylor series expansion
## Remember jupyter notebooks
- To run the currently highlighted cell, hold <kbd>⇧ Shift</kbd> and press <kbd>⏎ Enter</kbd>.... | github_jupyter |
# Poster popularity by country
This notebook loads data of poster viewership at the SfN 2016 annual meeting, organized by the countries that were affiliated with each poster.
We find that the poster popularity across countries is not significant compare to what is expected by chance.
### Import libraries and load da... | github_jupyter |
이제 딥러닝 기술은 무서운 속도로 각 분야에 퍼져가고 있습니다. 그에 따라 활용 사례도 늘어나고 있고, 실전 적용에 막히는 여러가지 문제도 해결하고자 많은 연구가 활발히 이루어지고 있습니다. 딥러닝을 공부하시는 분이라면 딥러닝 코어 및 알고리즘은 물론 타 분야의 활용사례, 최근에 유행하고 있는 GAN과 강화학습까지 관심을 가지고 계실겁니다. 다양한 주제로 즐겁게 소통하고자 첫번째 '함께하는 딥러닝 컨퍼런스'를 대전에서 개최합니다. 대전은 정부출연연구원 및 정부청사, 우수한 대학교, 최첨단 기술 중심의 벤처회사들이 밀집된 지역인 만큼 다른 지역과는 또 다른 느낌의 소통... | github_jupyter |
```
import matplotlib.pyplot as plt
labels = 'Frogs', 'Hogs', 'Dogs', 'Logs'
sizes = [15, 30, 45, 10]
explode = (0, 0.1, 0, 0)
#这个explode是指将饼状图的部分与其他分割的大小,这里之分割出hogs,度数为0.1,这个数字表示和主图分割的距离
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
... | github_jupyter |
<a href="https://colab.research.google.com/github/sampath11/DS-Unit-1-Sprint-3-Statistical-Tests-and-Experiments/blob/master/Sam_Kumar_LS_DS_132_Sampling_Confidence_Intervals_and_Hypothesis_Testing_Assignment.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"... | github_jupyter |
<a href="https://colab.research.google.com/github/WittmannF/rnn-tutorial-rnnlm/blob/master/RNNLM.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Recurrent Neural Networks Tutorial, Part 2 – Implementing a Language Model RNN with Python, Numpy and ... | github_jupyter |
Source: https://realpython.com/python-pep8/
How to Write Beautiful Python Code With PEP 8
by Jasmine Finer
# Why We Need PEP 8
> “Readability counts.”
>
> — The Zen of Python
> “Code is read much more often than it is written.”
>
> — Guido van Rossum
> “Any fool can write code that a computer can understand,
>
> ... | github_jupyter |
# Load and process molecules with `rdkit`
This notebook does the following:
- Molecules downloaded in the [previous notebook](./ 1_Get_Molecular_libraries.ipynb) are processed using `rdkit`.
The output of this notebook is a the file `rdKit_db_molecules.obj`, which is a pandas data frame containing the rdkit object of... | github_jupyter |
# Enumerating BiCliques to Find Frequent Patterns
#### KDD 2019 Workshop
#### Authors
- Tom Drabas (Microsoft)
- Brad Rees (NVIDIA)
- Juan-Arturo Herrera-Ortiz (Microsoft)
#### Problem overview
From time to time PCs running Microsoft Windows fail: a program might crash or hang, or you experience a kernel crash leadi... | github_jupyter |
# Predicting Product Success When Review Data Is Available
_**Using XGBoost to Predict Whether Sales will Exceed the "Hit" Threshold**_
---
---
## Contents
1. [Background](#Background)
1. [Setup](#Setup)
1. [Data](#Data)
1. [Train](#Train)
1. [Host](#Host)
1. [Evaluation](#Evaluation)
1. [Extensions](#Extensions)
... | github_jupyter |
<!--NOTEBOOK_HEADER-->
*This notebook contains material from [PyRosetta](https://RosettaCommons.github.io/PyRosetta.notebooks);
content is available [on Github](https://github.com/RosettaCommons/PyRosetta.notebooks.git).*
<!--NAVIGATION-->
< [Working with Pose residues](http://nbviewer.jupyter.org/github/RosettaCommon... | github_jupyter |
```
#
# Code to generate sharp-LIME explanations on Camelyon images (without nuclei contours)
#
!pip uninstall lime -y
!pip install git+https://github.com/palatos/lime@ColorExperiments
import numpy as np
from matplotlib import pyplot as plt
import h5py
import tensorflow as tf
from tensorflow import keras
from tensorflo... | github_jupyter |
### Set up
#### 1. Set up accounts and role
```
import sagemaker
import boto3
from datetime import datetime
sagemaker_session = sagemaker.Session()
account_id = boto3.client('sts').get_caller_identity().get('Account')
region = boto3.session.Session().region_name
#role = sagemaker.get_execution_role()
role="arn:... | github_jupyter |
# Perceptron with Scale & QuantileTransformer
This Code template is for the Classification task using simple Perceptron with feature scaling using Scale and feature transformation using QuantileTransformer.
### Required Packages
```
!pip install imblearn -q
import warnings
import numpy as np
import pandas as pd
imp... | github_jupyter |
# Summary Statistics of SDSS Quiescent galaxies
There's been some issues dealing with simulated galaxies with instantaneous SFR=0 (see Issues [#31](https://github.com/IQcollaboratory/galpopFM/issues/31). These galaxies **in principle** because they don't have gas should not have dust. However, they have a sharp feature... | github_jupyter |
# Traffic sign recognition following German staddard
In this project, I used the dataset of [German Traffic Sign Recognition Benchmark on Kaggle](https://www.kaggle.com/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign), which consists of 40 classes and more than 50,000 images in total.
### Visualizing the data
```
# L... | github_jupyter |
# Tweets Disaster Classification: LSTM, Attention and Transformers <br>
Author: TeYang, Lau<br>
Created: 18/2/2020<br>
Last update: 6/1/2021<br>
<img src = 'https://bn1301files.storage.live.com/y4m-toxx6sX6SL9zvwtvAbEi9xPKLkgI6kdJ0PJ0uWjzQIR5GouWmvWfMBEuppVlUoFh3eZkKSrveb0QWnLNHPfHVwlBx55CtJMcmqurAYyBv-a2d1rSAmBUxU9CY... | github_jupyter |
**Srayan Gangopadhyay**
*1st June 2020*
# Adding masked array
## Fix for periodic boundary conditions
```
"""
Adding masked array (fix jumps)
Srayan Gangopadhyay
2020-05-27
"""
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from celluloid import Camera # easy animation m... | github_jupyter |
### Preprocessing
```
# import relevant statistical packages
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# import relevant data visualisation packages
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
```
### 11.a. Generating a response $Y$ with two ... | github_jupyter |
# 使用兼容 NetworkX 的 API 进行图操作
GraphScope 支持使用兼容 NetworkX 的 API 进行图操作。
本次教程参考了 [tutorial in NetworkX](https://networkx.org/documentation/stable/tutorial.html) 的组织方式来介绍这些 API。
```
# Install graphscope package if you are NOT in the Playground
!pip3 install graphscope
# Import the graphscope and graphscope networkx module... | github_jupyter |
# Module 1 - Python Fundamentals
## Sequence: String
- **Accessing String Characters with index**
- Accessing sub-strings with index slicing
- Iterating through Characters of a String
- More String Methods
-----
><font size="5" color="#00A0B2" face="verdana"> <B>Student will be able to</B></font>
- **Work with St... | github_jupyter |
### Google Earth Engine meets Geopandas
**Author:** René Kopeinig<br>
**Description:** Extracting Landsat 8 TOA and CHIRPS precipitation data from Google Earth Engine and use Geopandas capabilities to create time series analysis. Furthermore, data will be visualized through a time series viewer and also a heat map.
``... | github_jupyter |
# TALENT Course 11
## Learning from Data: Bayesian Methods and Machine Learning
### York, UK, June 10-28, 2019
### Christian Forssén, Chalmers University of Technology, Sweden
## Bayesian Optimization
Selected references
* Paper: [Bayesian optimization in ab initio nuclear physics](https://iopscience.iop.org/article/... | github_jupyter |
# Celcius to Farenheit equation
$$ f = c \times 1.8 + 32 $$
# Import TensorFlow 2.x.
```
try:
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
import tensorflow.keras.layers as layers
import tensorflow.keras.models as models
import numpy as np
np.random.seed(7)
import matplotlib.pyplot a... | github_jupyter |
```
import pandas as pd
import numpy as np
%matplotlib inline
```
# Reading CSV and splitting into training and test data
```
dtype_dict = {'bathrooms':float, 'waterfront':int, 'sqft_above':int, 'sqft_living15':float, 'grade':int, 'yr_renovated':int, 'price':float, 'bedrooms':float, 'zipcode':str, 'long':float, 'sqft... | github_jupyter |
# **Overview**
This notebook benchmarks the MONAI's implementation of global mutual information ANTsPyx's implementation.
# **Global Mutual Information**
Mutual information is an entropy-based measure of image alignment derived from probabilistic measures of image intensity
values. Because a large number of image samp... | github_jupyter |
## Investigating star formation in the W5 region
### About this notebook
This notebook demonstrates how to use the glue-jupyter package to explore Astronomical data for W5, which is a region in space where stars are currently forming. However, much of the functionality shown here would be applicable to other image an... | github_jupyter |
[source](../../api/alibi_detect.cd.mmd.rst)
# Maximum Mean Discrepancy
## Overview
The [Maximum Mean Discrepancy (MMD)](http://jmlr.csail.mit.edu/papers/v13/gretton12a.html) detector is a kernel-based method for multivariate 2 sample testing. The MMD is a distance-based measure between 2 distributions *p* and *q* ba... | github_jupyter |
# Build a DNN using the Keras Functional API
## Learning objectives
1. Review how to read in CSV file data using tf.data.
2. Specify input, hidden, and output layers in the DNN architecture.
3. Review and visualize the final DNN shape.
4. Train the model locally and visualize the loss curves.
5. Deploy and predict... | github_jupyter |
```
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
```
### Array operations with NumPy
Let's assume the next equation:
$$
u'_i = u_i - u_{i-1}
$$
If $u = [0,1,2,3,4,5]$, there are two different ways of computing the value of t... | github_jupyter |
# Lab 05 : Final code -- demo
```
# For Google Colaboratory
import sys, os
if 'google.colab' in sys.modules:
from google.colab import drive
drive.mount('/content/gdrive')
file_name = 'final_demo.ipynb'
import subprocess
path_to_file = subprocess.check_output('find . -type f -name ' + str(file_name)... | github_jupyter |
```
proverb = 'Хорошо написанная программа - это программа, написанная 2 раза'
while True:
index = proverb.find('программа')
if index == -1:
break
secret = proverb[:index].split()[-1]
proverb = proverb[index+9:]
proverb = 'Хорошо написанная программа - это программа, написанная 2 раза'
index = ... | github_jupyter |
```
%%html
<style>
.h1_cell, .just_text {
box-sizing: border-box;
padding-top:5px;
padding-bottom:5px;
font-family: "Times New Roman", Georgia, Serif;
font-size: 125%;
line-height: 22px; /* 5px +12px + 5px */
text-indent: 25px;
background-color: #fbfbea;
padding: 10px;
}
hr {
d... | github_jupyter |
# Prioritised Replay Noisy Duelling Double Deep Q Learning - A simple ambulance dispatch point allocation model
Double Deep Q Learning - A simple ambulance dispatch point allocation model
## Reinforcement learning introduction
### RL involves:
* Trial and error search
* Receiving and maximising reward (often delayed)... | github_jupyter |
```
# default_exp data.validation
```
# Spliting data
> Functions required to perform cross-validation and transform unique time series sequence into multiple samples ready to be used by a time series model.
```
#export
from imblearn.over_sampling import RandomOverSampler
from matplotlib.patches import Patch
from ma... | github_jupyter |
# Introduction to Data Science
## What is Data Science?
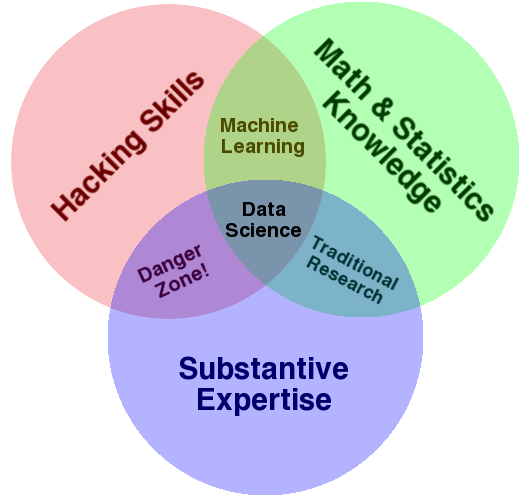
Source: http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram
## [What is a Data Scientist?](https://www.q... | github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.