
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
This notebook wants to make use of the evaluation techniques previously developed to select the best algorithms for this problem.
```
import pandas as pd
import numpy as np
import tubesml as tml
from sklearn.model_selection import KFold
from sklearn.pipeline import Pipeline
from sklearn.linear_model import Lasso, ... | github_jupyter |
```
%matplotlib inline
```
분류기(Classifier) 학습하기
============================
지금까지 어떻게 신경망을 정의하고, 손실을 계산하며 또 가중치를 갱신하는지에
대해서 배웠습니다.
이제 아마도 이런 생각을 하고 계실텐데요,
데이터는 어떻게 하나요?
------------------------
일반적으로 이미지나 텍스트, 오디오나 비디오 데이터를 다룰 때는 표준 Python 패키지를
이용하여 NumPy 배열로 불러오면 됩니다. 그 후 그 배열을 ``torch.*Tensor`` 로 변환합니다.
- 이미지... | github_jupyter |
## TODO:
<ul>
<li>Usar o libreoffice e encontrar 2000 palavras erradas (80h)</li>
<li>Classificar as palavras por tipo (80h)</li>
</ul>
## <b>Italian Pipeline</b>
```
# load hunspell
import urllib
import json
import numpy as np
import pandas as pd
import itertools
from matplotlib import pyplot as plt
import r... | github_jupyter |
# Anna KaRNNa
In this notebook, I'll build a character-wise RNN trained on Anna Karenina, one of my all-time favorite books. It'll be able to generate new text based on the text from the book.
This network is based off of Andrej Karpathy's [post on RNNs](http://karpathy.github.io/2015/05/21/rnn-effectiveness/) and [i... | github_jupyter |
# Bayesian Estimation Supersedes the T-Test
```
%matplotlib inline
import numpy as np
import pymc3 as pm
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('seaborn-darkgrid')
print('Running on PyMC3 v{}'.format(pm.__version__))
```
This model replicates the example used in:
Kruschke, John. (2012) **Ba... | github_jupyter |
# TensorFlow实战Titanic解析
## 一、数据读入及预处理
### 1. 使用pandas读入csv文件,读入为pands.DataFrame对象
```
import os
import numpy as np
import pandas as pd
import tensorflow as tf
# read data from file
data = pd.read_csv('data/train.csv')
print(data.info())
```
### 2. 预处理
1. 剔除空数据
2. 将'Sex'字段转换为int类型
3. 选取数值类型的字段,抛弃字符串类型字段
```
# fil... | github_jupyter |
# The Stanford Sentiment Treebank
The Stanford Sentiment Treebank consists of sentences from movie reviews and human annotations of their sentiment. The task is to predict the sentiment of a given sentence. We use the two-way (positive/negative) class split, and use only sentence-level labels.
```
from IPython.displa... | github_jupyter |
# データサイエンス100本ノック(構造化データ加工編) - Python
## はじめに
- 初めに以下のセルを実行してください
- 必要なライブラリのインポートとデータベース(PostgreSQL)からのデータ読み込みを行います
- pandas等、利用が想定されるライブラリは以下セルでインポートしています
- その他利用したいライブラリがあれば適宜インストールしてください("!pip install ライブラリ名"でインストールも可能)
- 処理は複数回に分けても構いません
- 名前、住所等はダミーデータであり、実在するものではありません
```
import os
import pandas as pd
import n... | github_jupyter |
# Setup the ABSA Demo
### Step 1 - Install aditional pip packages on your Compute instance
```
!pip install git+https://github.com/hnky/nlp-architect.git@absa
!pip install spacy==2.1.8
```
### Step 2 - Download Notebooks, Training Data, Training / Inference scripts
```
import azureml
from azureml.core import Worksp... | github_jupyter |
```
# default_exp pds.utils
# default_cls_lvl 3
```
# PDS Utils
> Utilities used by the `pds` sub-package.
```
# hide
from nbverbose.showdoc import show_doc # noqa
# export
from typing import Union
from fastcore.utils import Path
import pandas as pd
import pvl
from planetarypy import utils
# export
class IndexLabe... | github_jupyter |
# **Built in Functions**
# **bool()**
Valores vazios ou zeros são considerado False, do contrário são considerados True (Truth Value Testing).
"Truth Value Testing". Isto é, decidir quando um valor é considerado True ou False
```
print(bool(0))
print(bool(""))
print(bool(None))
print(bool(1))
print(bool(-100)... | github_jupyter |
<h1>Table of Contents<span class="tocSkip"></span></h1>
<div class="toc" style="margin-top: 1em;"><ul class="toc-item"><li><ul class="toc-item"><li><span><a href="#(a)" data-toc-modified-id="(a)-0.1"><span class="toc-item-num">0.1 </span>(a)</a></span></li><li><span><a href="#(b)" data-toc-modified-id="(b)-0... | github_jupyter |
```
import torch
from torch.autograd import Variable
from torch import nn
import matplotlib.pyplot as plt
%matplotlib inline
torch.manual_seed(3)
```
# make data
```
x_train = torch.Tensor([[1],[2],[3]])
y_train = torch.Tensor([[1],[2],[3]])
x, y = Variable(x_train), Variable(y_train)
plt.scatter(x.data.numpy(), ... | github_jupyter |
# Import Dependencies
```
from config import api_key
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import requests
import datetime
import json
```
# Use API to get .json
```
endpoint = 'breweries'
page = 1
url = f"https://sandbox-api.brewerydb.com/v2/{endpoint}/?key={api_key}&p={page}&withLo... | github_jupyter |
# Image features exercise
*Complete and hand in this completed worksheet (including its outputs and any supporting code outside of the worksheet) with your assignment submission. For more details see the [assignments page](http://vision.stanford.edu/teaching/cs231n/assignments.html) on the course website.*
We have see... | github_jupyter |
# Automate Retraining of Models using SageMaker Pipelines and Lambda
# Learning Objectives
1. Construct a [SageMaker Pipeline](https://aws.amazon.com/sagemaker/pipelines/) that consists of a data preprocessing step and a model training step.
2. Execute a SageMaker Pipeline manually
3. Build infrastructure, using [Clou... | github_jupyter |
## Simple regression
```
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
# Import relevant modules
import pymc
import numpy as np
def generateData(size, true_intercept, true_slope, order, noiseSigma):
x = np.linspace(0, 1, size)
# y = a + b*x
true_y = true_intercept + true_slope * (... | github_jupyter |
# Module 5: Hierarchical Generators
This module covers writing layout/schematic generators that instantiate other generators. We will write a two-stage amplifier generator, which instatiates the common-source amplifier followed by the source-follower amplifier.
## AmpChain Layout Example
First, we will write a layout... | github_jupyter |
# MNIST Convolutional Neural Network - Ensemble Learning
Gaetano Bonofiglio, Veronica Iovinella
In this notebook we will verify if our single-column architecture can get any advantage from using **ensemble learning**, so a multi-column architecture.
We will train multiple networks identical to the best one defined i... | github_jupyter |
# PyCaret Fugue Integration
[Fugue](https://github.com/fugue-project/fugue) is a low-code unified interface for different computing frameworks such as Spark, Dask and Pandas. PyCaret is using Fugue to support distributed computing scenarios.
## Hello World
### Classification
Let's start with the most standard examp... | github_jupyter |
We use Embeddings to represent text into a numerical form. Either into a one-hot encoding format called sparse vector or a fixed Dense representation called Dense Vector.
Every Word gets it meaning from the words it is surrounded by, So when we train our embeddings we want word with similar meaning or words used in si... | github_jupyter |
# Document Embedding with Amazon SageMaker Object2Vec
1. [Introduction](#Introduction)
2. [Background](#Background)
1. [Embedding documents using Object2Vec](#Embedding-documents-using-Object2Vec)
3. [Download and preprocess Wikipedia data](#Download-and-preprocess-Wikipedia-data)
1. [Install and load dependencies... | github_jupyter |
# Working with HEALPix data
[HEALPix](https://healpix.jpl.nasa.gov/) (Hierarchical Equal Area isoLatitude Pixelisation) is an algorithm that is often used to store data from all-sky surveys.
There are several tools in the Astropy ecosystem for working with HEALPix data, depending on what you need to do:
* The [astro... | github_jupyter |
# Datasets for the book
Here we provide links to the datasets used in the book.
Important Notes:
1. Note that these datasets are provided on external servers by third parties
2. Due to security issues with github you will have to cut and paste FTP links (they are not provided as clickable URLs)
# Python and the Sur... | github_jupyter |
# Table of Contents
<p><div class="lev1 toc-item"><a href="#Python-Basics-with-Numpy-(optional-assignment)" data-toc-modified-id="Python-Basics-with-Numpy-(optional-assignment)-1"><span class="toc-item-num">1 </span>Python Basics with Numpy (optional assignment)</a></div><div class="lev2 toc-item"><a href="... | github_jupyter |
```
import tensorflow as tf
from matplotlib import pylab
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
# Required for Data downaload and preparation
import struct
import gzip
import os
from six.moves.urllib.request import urlretrieve
```
## Defining Hyperparameters
Here we define the ... | github_jupyter |
```
import numpy as np
import random
import sys
from scipy.special import expit as sigmoid
training_data_path = sys.argv[1]
testing_data_path = sys.argv[2]
output_path = sys.argv[3]
batch_size = int(sys.argv[4])
n0 = float(sys.argv[5])
activation = sys.argv[6]
hidden_layers_sizes = []
for i in range(7,len(sys.argv)):
... | github_jupyter |
```
from pyesasky import ESASkyWidget
from pyesasky import Catalogue
from pyesasky import CatalogueDescriptor
from pyesasky import MetadataDescriptor
from pyesasky import MetadataType
from pyesasky import CooFrame
# instantiating pyESASky instance
esasky = ESASkyWidget()
# loading pyESASky instance
esasky
# Go to the C... | github_jupyter |
```
%pylab
%matplotlib inline
%run pdev notebook
```
# Radiosonde SONDE
```
ident = "SONDE"
plt.rcParams['figure.figsize'] = [12.0, 6.0]
plt.rcParams['lines.linewidth'] = 2
plt.rcParams['font.size'] = 15
yplevs = np.array([10,100,200,300,400,500,700,925])*100
save = True
!mkdir -p figures
rt.load_config()
rt.config
i... | github_jupyter |
<a href="https://colab.research.google.com/github/mancunian1792/causal_scene_generation/blob/master/causal_model/game_characters/GameCharacter_ImageClassification.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
from google.colab import drive
dr... | github_jupyter |
```
%reload_ext autoreload
%autoreload 2
from fastai.tabular import *
```
# Rossmann
## Data preparation
To create the feature-engineered train_clean and test_clean from the Kaggle competition data, run `rossman_data_clean.ipynb`. One important step that deals with time series is this:
```python
add_datepart(train,... | github_jupyter |
Code testing for https://github.com/pymc-devs/pymc3/pull/2986
```
import numpy as np
import pymc3 as pm
import pymc3.distributions.transforms as tr
import theano.tensor as tt
from theano.scan_module import until
import theano
import matplotlib.pylab as plt
import seaborn as sns
%matplotlib inline
```
# Polar transfo... | github_jupyter |
```
import pandas as pd
import os
import hashlib
import requests
from bs4 import BeautifulSoup
from bs4.element import Comment
import urllib.parse
from tqdm.notebook import tqdm
import random
from multiprocessing import Pool
import spacy
import numpy as np
industries = pd.read_csv("industry_categories.csv")
industries.... | github_jupyter |
## Dependencies
```
import json, warnings, shutil, glob
from jigsaw_utility_scripts import *
from scripts_step_lr_schedulers import *
from transformers import TFXLMRobertaModel, XLMRobertaConfig
from tensorflow.keras.models import Model
from tensorflow.keras import optimizers, metrics, losses, layers
SEED = 0
seed_ev... | github_jupyter |
# Plagiarism Detection Model
Now that you've created training and test data, you are ready to define and train a model. Your goal in this notebook, will be to train a binary classification model that learns to label an answer file as either plagiarized or not, based on the features you provide the model.
This task wi... | github_jupyter |
# Batch Processing!
#### A notebook to show some of the capilities available through the pCunch package
This is certainly not an exhaustive look at everything that the pCrunch module can do, but should hopefully provide some insight.
...or, maybe I'm just procrastinating doing more useful work.
```
# Python Modules ... | github_jupyter |
# Deep learning for computer vision
This notebook will teach you to build and train convolutional networks for image recognition. Brace yourselves.
# CIFAR dataset
This week, we shall focus on the image recognition problem on cifar10 dataset
* 60k images of shape 3x32x32
* 10 different classes: planes, dogs, cats, t... | github_jupyter |
# Load MXNet model
In this tutorial, you learn how to load an existing MXNet model and use it to run a prediction task.
## Preparation
This tutorial requires the installation of Java Kernel. For more information on installing the Java Kernel, see the [README](https://github.com/awslabs/djl/blob/master/jupyter/READM... | github_jupyter |
# Modeling and Simulation in Python
Chapter 18
Copyright 2017 Allen Downey
License: [Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0)
```
# Configure Jupyter so figures appear in the notebook
%matplotlib inline
# Configure Jupyter to display the assigned value after an a... | github_jupyter |
```
%load_ext autoreload
%autoreload 2
import ambry
l = ambry.get_library()
b = l.bundle('d04w001') # Geoschemas
sumlevels_p = l.partition('census.gov-acs_geofile-schemas-2009e-sumlevels')
sumlevels = {}
for row in sumlevels_p.stream(as_dict=True):
sumlevels[row['sumlevel']] = row['description']
from collections im... | github_jupyter |
```
import sys
from pathlib import Path
sys.path.append(str(Path.cwd().parent.parent))
import numpy as np
from kymatio.scattering2d.core.scattering2d import scattering2d
import matplotlib.pyplot as plt
import torch
import torchvision
from kymatio import Scattering2D
from PIL import Image
from IPython.display import di... | github_jupyter |
# Todoist Data Analysis
This notebook processed the downloaded history of your todoist tasks. See [todoist_downloader.ipynb](https://github.com/markwk/qs_ledger/blob/master/todoist/todoist_downloader.ipynb) to export and download your task history from Todoist.
---
```
from datetime import date, datetime as dt, time... | github_jupyter |
```
import scanpy as sc
import pandas as pd
import numpy as np
import scipy as sp
from statsmodels.stats.multitest import multipletests
import matplotlib.pyplot as plt
import seaborn as sns
import os
from os.path import join
import time
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['ps.fonttype'] = 42
# scTRS tools
... | github_jupyter |
# Properties of drugs
Find various properties of the individual drugs
1.) ATC
2.) GO Annotations
3.) Disease
4.) KeGG Pathways
5.) SIDER (known effects)
6.) Offside (known off sides)
7.) TwoSides
8.) Drug Properties (physico-chemical properties)
9.) Enzymes, Transporters and Carriers
10.) Chemic... | github_jupyter |
# Graded Programming Assignment
In this assignment, you will implement re-use the unsupervised anomaly detection algorithm but turn it into a simpler feed forward neural network for supervised classification.
You are training the neural network from healthy and broken samples and at later stage hook it up to a messag... | github_jupyter |
# Reproduce Allen smFISH results with Starfish
This notebook walks through a work flow that reproduces the smFISH result for one field of view using the starfish package.
```
from copy import deepcopy
from glob import glob
import json
import os
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
im... | github_jupyter |
```
# default_exp helpers
```
# helpers
> this didn't fit anywhere else
```
#export
import numpy as np
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.pyplot as plt
#ToDo: Propagate them through the methods
iters = 10
l2 = 1
n_std = 4
from pygments import highlight
from pygments.lexers impor... | github_jupyter |
<a href="https://colab.research.google.com/github/findingfoot/ML_practice-codes/blob/master/principal_component_analysis_.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as... | github_jupyter |
What you should know about C
----
- Write, compile and run a simple program in C
- Static types
- Control flow especially `for` loop
- Using functions
- Using structs
- Pointers and arrays
- Function pointers
- Dynamic memory allocation
- Separate compilation and `make`
### Structs
**Exercise 1**
Write and use a `s... | github_jupyter |
## Training Network
In supervised training, the network processes inputs and compares its resulting outputs against the desired outputs.
Errors are propagated back through the system, causing the system to adjust the weights which control the network. This is done using the Backpropagation algorithm, also called bac... | github_jupyter |
# Basic Motion
Welcome to JetBot's browser based programming interface! This document is
called a *Jupyter Notebook*, which combines text, code, and graphic
display all in one! Prett neat, huh? If you're unfamiliar with *Jupyter* we suggest clicking the
``Help`` drop down menu in the top toolbar. This has useful r... | github_jupyter |
# 머신 러닝 교과서 3판
# 14장 - 텐서플로의 구조 자세히 알아보기 (2/3)
**아래 링크를 통해 이 노트북을 주피터 노트북 뷰어(nbviewer.jupyter.org)로 보거나 구글 코랩(colab.research.google.com)에서 실행할 수 있습니다.**
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://nbviewer.jupyter.org/github/rickiepark/python-machine-learning-book-3r... | github_jupyter |
<h1 align="center">Welcome to SimpleITK Jupyter Notebooks</h1>
## Newcomers to Jupyter Notebooks:
1. We use two types of cells, code and markdown.
2. To run a code cell, select it (mouse or arrow key so that it is highlighted) and then press shift+enter which also moves focus to the next cell or ctrl+enter which does... | github_jupyter |
[View in Colaboratory](https://colab.research.google.com/github/PranY/FastAI_projects/blob/master/TSG.ipynb)
```
!pip install fastai
!pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu92/torch_nightly.html
! pip install kaggle
! pip install tqdm
from google.colab import drive
drive.mount('/conten... | github_jupyter |
# Measuring Monotonic Relationships
By Evgenia "Jenny" Nitishinskaya and Delaney Granizo-Mackenzie with example algorithms by David Edwards
Reference: DeFusco, Richard A. "Tests Concerning Correlation: The Spearman Rank Correlation Coefficient." Quantitative Investment Analysis. Hoboken, NJ: Wiley, 2007
Part of the ... | github_jupyter |
# In this notebook an estimator for the Volume will be trained. No hyperparameters will be searched for, and the ones from the 'Close' values estimator will be used instead.
```
# Basic imports
import os
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import datetime as dt
import scipy.optimize ... | github_jupyter |
## Dependencies
```
import json, glob
from tweet_utility_scripts import *
from tweet_utility_preprocess_roberta_scripts_aux import *
from transformers import TFRobertaModel, RobertaConfig
from tokenizers import ByteLevelBPETokenizer
from tensorflow.keras import layers
from tensorflow.keras.models import Model
```
# L... | github_jupyter |
[View in Colaboratory](https://colab.research.google.com/github/thonic92/chal_TM/blob/master/model_tweets.ipynb)
```
import json
import numpy as np
import pandas as pd
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LS... | github_jupyter |
<div align="center">
<h1>Homework 7</h1>
<p>
<div align="center">
<h2>Yutong Dai yutongd3@illinois.edu</h2>
</div>
</p>
</div>
## 6.33
The dual problem is
$$
\begin{align}
& \min \quad 3 w_1 + 6 w_2\\
& s.t \quad w_1 + 2w_2 \geq 2\\
& \qquad w_1 + 3w_2 \geq -3\\
& \qquad w_1\leq 0,... | github_jupyter |
# Assignment: Global average budgets in the CESM pre-industrial control simulation
## Learning goals
Students completing this assignment will gain the following skills and concepts:
- Continued practice working with the Jupyter notebook
- Familiarity with atmospheric output from the CESM simulation
- More complete c... | github_jupyter |
# SentencePiece and BPE
## Introduction to Tokenization
In order to process text in neural network models it is first required to **encode** text as numbers with ids, since the tensor operations act on numbers. Finally, if the output of the network is to be words, it is required to **decode** the predicted tokens ids... | github_jupyter |
### *IPCC SR15 scenario assessment*
<img style="float: right; height: 80px; padding-left: 20px;" src="../_static/IIASA_logo.png">
<img style="float: right; height: 80px;" src="../_static/IAMC_logo.jpg">
# Characteristics of four illustrative model pathways
## Figure 3b of the *Summary for Policymakers*
This notebook... | github_jupyter |
# MaterialsCoord benchmarking – sensitivity to perturbation analysis
This notebook demonstrates how to use MaterialsCoord to benchmark the sensitivity of bonding algorithms to structural perturbations. Perturbations are introduced according the Einstein crystal test rig, in which site is perturbed so that the distribu... | github_jupyter |
<a href="https://colab.research.google.com/github/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_12_02_qlearningreinforcement.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# T81-558: Applications of Deep Neural Networks
**Module 12: Re... | github_jupyter |
```
"""
Update Parameters Here
"""
COLLECTION_NAME = "Quaks"
CONTRACT = "0x07bbdaf30e89ea3ecf6cadc80d6e7c4b0843c729"
BEFORE_TIME = "2021-09-02T00:00:00" # One day after the last mint (e.g. https://etherscan.io/tx/0x206c846d0d1739faa9835e16ff419d15708a558357a9413619e65dacf095ac7a)
# these should usually stay the same
... | github_jupyter |
## INTRODUCTION
- It’s a Python based scientific computing package targeted at two sets of audiences:
- A replacement for NumPy to use the power of GPUs
- Deep learning research platform that provides maximum flexibility and speed
- pros:
- Iinteractively debugging PyTorch. Many users who have used both fr... | github_jupyter |
# TTV Retrieval for Kepler-36 (a well-studied, dynamically-interacting system)
In this notebook, we will perform a dynamical retrieval for Kepler-36 = KOI-277. With two neighboring planets of drastically different densities (the inner planet is rocky and the outer planet is gaseous; see [Carter et al. 2012](https://ui... | github_jupyter |
<a href="https://colab.research.google.com/github/AmberLJC/FedScale/blob/master/dataset/Femnist_stats.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# **[Jupyter notebook] Understand the heterogeneous FL data.**
# Download the Femnist dataset and ... | github_jupyter |
## Code for policy section
```
# Load libraries
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mlp
# Ensure type 1 fonts are used
mlp.rcParams['ps.useafm'] = True
mlp.rcParams['pdf.use14corefonts'] = True
mlp.rcParams['text.usetex'] = True
import seaborn as sns
import pandas as pd
import pic... | github_jupyter |
```
%load_ext autoreload
%autoreload 2
```
# Sampling from a Bayesian network: an open problem
A Bayesian network encodes a probability distribution. It is often desirable to be able to sample from a Bayesian network. The most common way to do this is via forward sampling (also called prior sampling). It's a really d... | github_jupyter |
```
import time
start = time.perf_counter()
import tensorflow as tf
import pickle
import import_ipynb
import os
from model import Model
from utils import build_dict, build_dataset, batch_iter
embedding_size=300
num_hidden = 300
num_layers = 3
learning_rate = 0.001
beam_width = 10
keep_prob = 0.8
glove = True
batch_size... | github_jupyter |
# Python Bindings Demo
This is a very simple demo / playground / testing site for the Python Bindings for BART.
This is mainly used to show off Numpy interoperability and give a basic sense for how more complex tools will look in Python.
## Overview
Currently, Python users can interact with BART via a command-line ... | github_jupyter |
## Scrape Archived Mini Normals from Mafiascum.net
#### Scrapy Structure/Lingo:
**Spiders** extract data **items**, which Scrapy send one by one to a configured **item pipeline** (if there is possible) to do post-processing on the items.)
## Import relevant packages...
```
import scrapy
import math
import logging
im... | github_jupyter |
While going through our script we will gradually understand the use of this packages
```
import tensorflow as tf #no need to describe ;)
import numpy as np #allows array operation
import pandas as pd #we will use it to read and manipulate files and columns content
from nltk.corpus import stopwords #provides list of e... | github_jupyter |
# Autonomous driving - Car detection
Welcome to your week 3 programming assignment. You will learn about object detection using the very powerful YOLO model. Many of the ideas in this notebook are described in the two YOLO papers: Redmon et al., 2016 (https://arxiv.org/abs/1506.02640) and Redmon and Farhadi, 2016 (htt... | github_jupyter |
```
import os
import csv
import platform
import pandas as pd
import networkx as nx
from graph_partitioning import GraphPartitioning, utils
run_metrics = True
cols = ["WASTE", "CUT RATIO", "EDGES CUT", "TOTAL COMM VOLUME", "Qds", "CONDUCTANCE", "MAXPERM", "NMI", "FSCORE", "FSCORE RELABEL IMPROVEMENT", "LONELINESS"]
#c... | github_jupyter |
# Class activation map evaluation
```
import cv2
import numpy as np
import matplotlib.pyplot as plt
import json
import os
import pandas as pd
from pocovidnet.evaluate_covid19 import Evaluator
from pocovidnet.grad_cam import GradCAM
from pocovidnet.cam import get_class_activation_map
from pocovidnet.model import get_mo... | github_jupyter |
# Collect Physicists Raw Data
The goal of this notebook is to collect demographic data on the list of [physicists notable for their achievements](../data/raw/physicists.txt). Wikipedia contains this semi-structured data in an *Infobox* on the top right side of the article for each physicist. However, similar data is a... | github_jupyter |
# 1-1. AIとは何か?簡単なAIを設計してみよう
AIブームに伴って、様々なメディアでAIや機械学習、深層学習といった言葉が使われています。本章ではAIと機械学習(ML)、深層学習の違いを理解しましょう。
## 人工知能(AI)とは?
そもそも人工知能(AI)とは何でしょうか?
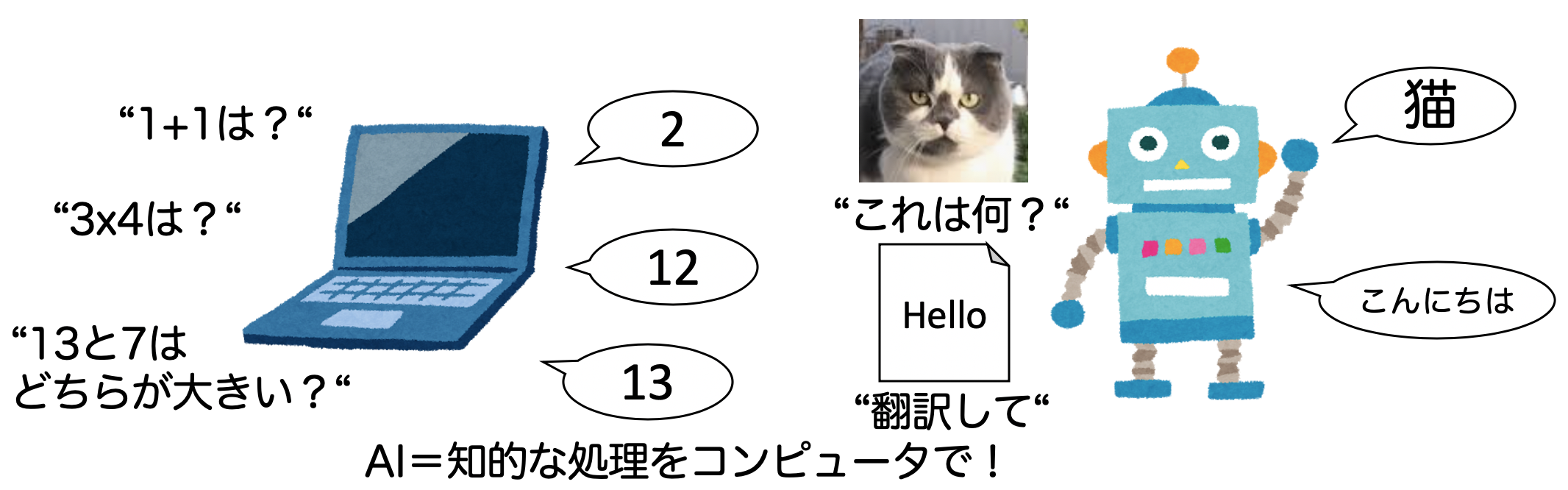
Wikipedia[1]によると、人工知能について以下のように書かれています。
人工知能(じんこうちのう、英: artificial intelligence、AI〈エーア... | github_jupyter |
## UBC Intro to Machine Learning
### APIs
Instructor: Socorro Dominguez
February 05, 2022
## Exercise to try in your local machine
## Motivation
For our ML class, we want to do a Classifier that differentiates images from dogs and cats.
## Problem
We need a dataset to do this. Our friends don't have enough cats... | github_jupyter |
```
#12/29/20
#runnign synthetic benchmark graphs for synthetic OR datasets generated
#making benchmark images
import keras
from keras.models import Sequential, Model, load_model
from keras.layers import Dense, Dropout, Activation, Flatten, Input, Lambda
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D... | github_jupyter |
# Signal Autoencoder
```
import numpy as np
import scipy as sp
import scipy.stats
import itertools
import logging
import matplotlib.pyplot as plt
import pandas as pd
import torch.utils.data as utils
import math
import time
import tqdm
import torch
import torch.optim as optim
import torch.nn.functional as F
from argpa... | github_jupyter |
# Trabalhando com Arquivos
Tabela Modos de arquivo

# Métodos de uma lista usando biblioteca rich import inspect
```
from rich import inspect
a = open('arquivo1.txt', 'wt+')
inspect(a, methods=True)
```
# Criando Arquivo w(write) e x
# .close()
```
# cria a... | github_jupyter |
```
import autograd.numpy as np
import autograd.numpy.random as npr
npr.seed(0)
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set_style("white")
sns.set_context("talk")
color_names = ["windows blue",
"red",
"amber",
"faded green",
... | github_jupyter |
# Assignment 2: Implementation of Selection Sort
## Deliverables:
We will again generate random data for this assignment.
1) Please set up five data arrays of length 5,000, 10,000, 15,000, 20,000, and 25,000 of uniformly distributed random numbers (you may use either integers or floating point).
Ensu... | github_jupyter |
# Demos: Lecture 17
## Demo 1: bit flip errors
```
import pennylane as qml
from pennylane import numpy as np
import matplotlib.pyplot as plt
from lecture17_helpers import *
from scipy.stats import unitary_group
dev = qml.device("default.mixed", wires=1)
@qml.qnode(dev)
def prepare_state(U, p):
qml.QubitUnitary(... | github_jupyter |
# Overfitting y Regularización
El **overfitting** o sobreajuste es otro problema común al entrenar un modelo de aprendizaje automático. Consiste en entrenar modelos que aprenden a la perfección los datos de entrenamiento, perdiendo de esta forma generalidad. De modo, que si al modelo se le pasan datos nuevos que jamás... | github_jupyter |
# 概率潜在语义分析
概率潜在语义分析(probabilistic latent semantic analysis, PLSA),也称概率潜在语义索引(probabilistic latent semantic indexing, PLSI),是一种利用概率生成模型对文本集合进行话题分析的无监督学习方法。
模型最大特点是用隐变量表示话题,整个模型表示文本生成话题,话题生成单词,从而得到单词-文本共现数据的过程;假设每个文本由一个话题分布决定,每个话题由一个单词分布决定。
### **18.1.2 生成模型**
假设有单词集合 $W = $ {$w_{1}, w_{2}, ..., w_{M}$}, 其中M是单词个数;文本(... | github_jupyter |
## Training a differentially private LSTM model for name classification
In this tutorial we will build a differentially-private LSTM model to classify names to their source languages, which is the same task as in the tutorial **NLP From Scratch** (https://pytorch.org/tutorials/intermediate/char_rnn_classification_tuto... | github_jupyter |
##### Copyright 2019 The TensorFlow Authors.
Licensed under the Apache License, Version 2.0 (the "License");
```
#@title Licensed under the Apache License, Version 2.0 (the "License"); { display-mode: "form" }
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at... | github_jupyter |
# MNIST distributed training and batch transform
The SageMaker Python SDK helps you deploy your models for training and hosting in optimized, production-ready containers in SageMaker. The SageMaker Python SDK is easy to use, modular, extensible and compatible with TensorFlow and MXNet. This tutorial focuses on how to ... | github_jupyter |
##### Copyright 2018 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | github_jupyter |
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import json
%matplotlib inline
```
### 1. Load the dataset into a data frame named loans
```
loans = pd.read_csv('../data/lending-club-data.csv')
loans.head(2)
# safe_loans = 1 => safe
# safe_loans = -1 => risky
loans['safe_loans'] = loans['b... | github_jupyter |
# Find the comparables: extra_features.txt
The file `extra_features.txt` contains important property information like number and quality of pools, detached garages, outbuildings, canopies, and more. Let's load this file and grab a subset with the important columns to continue our study.
```
%load_ext autoreload
%auto... | github_jupyter |
# Python good practices
## Environment setup
```
!pip install papermill
import platform
print(f"Python version: {platform.python_version()}")
assert platform.python_version_tuple() >= ("3", "6")
import os
import papermill as pm
from IPython.display import YouTubeVideo
```
## Writing pythonic code
```
import this... | github_jupyter |
# Module
```
import numpy as np
import pandas as pd
import warnings
import gc
from tqdm import tqdm_notebook as tqdm
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import StratifiedKFold
from sklearn.... | github_jupyter |
```
import os
import random
import torch
import torchvision.transforms as standard_transforms
import scipy.io as sio
import matplotlib
import pandas as pd
import misc.transforms as own_transforms
import warnings
from torch.autograd import Variable
from torch.utils.data import DataLoader
from PIL import Image, ImageOp... | github_jupyter |
```
%matplotlib inline
```
# Generating an input file
This examples shows how to generate an input file in HDF5-format, which can
then be processed by the `py-fmas` library code.
This is useful when the project-specific code is separate from the `py-fmas`
library code.
.. codeauthor:: Oliver Melchert <melchert@iqo... | github_jupyter |
# Using `bw2waterbalancer`
Notebook showing typical usage of `bw2waterbalancer`
## Generating the samples
`bw2waterbalancer` works with Brightway2. You only need set as current a project in which the database for which you want to balance water exchanges is imported.
```
import brightway2 as bw
import numpy as np
b... | github_jupyter |
```
import numpy as np
import pandas as pd
%matplotlib inline
import math
from xgboost.sklearn import XGBClassifier
from sklearn.cross_validation import cross_val_score
from sklearn import cross_validation
from sklearn.metrics import roc_auc_score
from matplotlib import pyplot
train = pd.read_csv("xtrain.csv")
target ... | github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.