
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
A1 de Linguagens de Programação – 28/09/2017
--
Professor: Renato Rocha Souza
--
Nome do Aluno(a):
```
meu_nome = input('Entre com o seu nome completo: ')
print('Olá, {}!'.format(meu_nome))
print('Bom trabalho!')
# Somente estes módulos podem ser importados para a realização das questões
import numpy as np
import m... | github_jupyter |
```
import csv
import argparse
import json
from collections import defaultdict, Counter
import re
from operator import itemgetter
MAX_WORDS=40
def process_repeat_dict(d):
if d["loop"] == "ntimes":
repeat_dict = {"repeat_key": "FOR"}
processed_d = process_dict(with_prefix(d, "loop.ntimes."))
... | github_jupyter |
# Convert a PaddlePaddle Model to ONNX and OpenVINO IR
This notebook shows how to convert a MobileNetV3 model from [PaddleHub](https://github.com/PaddlePaddle/PaddleHub), pretrained on the [ImageNet](https://www.image-net.org) dataset, to OpenVINO IR. It also shows how to perform classification inference on a sample i... | github_jupyter |
```
import sys, os
sys.path.insert(0, os.path.join("..", ".."))
```
# Project to graph
A key step in (current) network algorithms is to move each input "event" to the closest point on the network.
In this notebook, we explore efficient ways to do this.
```
%matplotlib inline
import matplotlib.pyplot as plt
import ... | github_jupyter |
<a href="https://colab.research.google.com/github/A4Git/Hyper-Island-AI-BC/blob/main/HyperIsland_python_pandas_data_analysis.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
```
# Analyzing Tabular Data using Python and Pandas

star_wars = star_wars[pd.notnull(star_wars["RespondentID"])]
star_wars.head()
```
## 2: Cleaning And Mapping Yes/No Columns
```
star_wars.columns
yes_no = {"Yes": True, "No": ... | github_jupyter |
# T1055 - Process Injection
Adversaries may inject code into processes in order to evade process-based defenses as well as possibly elevate privileges. Process injection is a method of executing arbitrary code in the address space of a separate live process. Running code in the context of another process may allow acce... | github_jupyter |
# High-Level RL Libraries
* [**PTAN**](https://github.com/Shmuma/ptan) - based on PyTorch, described below
* [Keras-RL](https://github.com/keras-rl/keras-rl) - based on Keras, includes basic RL methods
* [TF-Agents](https://www.tensorflow.org/agents) - based on TensorFlow, made by Google in 2018
* [Dopamine](https://gi... | github_jupyter |
# NLP Preprocessing
```
from fastai.gen_doc.nbdoc import *
from fastai.text import *
```
`text.tranform` contains the functions that deal behind the scenes with the two main tasks when preparing texts for modelling: *tokenization* and *numericalization*.
*Tokenization* splits the raw texts into tokens (wich can be w... | github_jupyter |
# Burning forests
* topics: Ecology, forest fires and arson, GDP per capita, sets in Python, Venn diagrams, interception of sets, pandas module, quantiles.
## Task
* Imagine you are the UN ambassador for climate change.
* It is pretty hard position since you cannot really do anything about the climate change.
* Which... | github_jupyter |
# 3 - Neural Machine Translation by Jointly Learning to Align and Translate
In this third notebook on sequence-to-sequence models using PyTorch and TorchText, we'll be implementing the model from [Neural Machine Translation by Jointly Learning to Align and Translate](https://arxiv.org/abs/1409.0473). This model achive... | github_jupyter |
<a href="https://colab.research.google.com/github/mengwangk/dl-projects/blob/master/04_06_auto_ml_3.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Automated ML - Tuning
```
COLAB = True
DATASET_NAME = '4D.zip'
FEATURE_DATASET_PREFIX = 'feature... | github_jupyter |
## Training a Convolutional Neural Network Model with Keras in Tensorflow
In this exercise, we will implement a convolutional neural network used for image classification with four hidden layers, using stochastic gradient descent. We will once again work with the MNIST data set, a famous collection of images used for ... | github_jupyter |
# 5장. 범주형 데이터 다루기
이 노트북을 주피터 노트북 뷰어(nbviewer.jupyter.org)로 보거나 구글 코랩(colab.research.google.com)에서 실행할 수 있습니다.
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://nbviewer.jupyter.org/github/rickiepark/machine-learning-with-python-cookbook/blob/master/05.ipynb"><img src="https... | github_jupyter |
```
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/bbc-text.csv \
-O /tmp/bbc-text.csv
import csv
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
#Stopwords list from https://github... | github_jupyter |
# Optimal Power Flow via PandaModels
### PandaModels.jl: Interfacing PowerModels with pandapower
This tutorial describes how to run the Optimal Power Flow via [PandaModels.jl](https://e2niee.github.io/PandaModels.jl/dev/) calling [PowerModels.jl](https://lanl-ansi.github.io/PowerModels.jl/stable/) package.
### Let's ... | github_jupyter |
```
import nltk
from nltk.util import ngrams
from nltk.stem import WordNetLemmatizer
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
import re
import pandas as pd
import numpy as np
file="D:\\My Personal Documents\\Learnings\\Data Science\\... | github_jupyter |
# Part 3 - Modeling
In this notebook we will be focusing on our full modeling process. I will be doing some preprocessing, hyperperameter tuning, and fiting our data into a variety of models in order to determine which model seems to perform best.
**Model Results**
|Model|AUC Score|
|---|---|
|Baseline - Logistic ... | github_jupyter |
**Grupo Bimbo Inventory Demand**
*Maio, 2019*
## **1. Descrição geral do problema**
---

O [Grupo Bimbo](https://www.grupobimbo.com), se esforça para atender a demanda diária dos consumidores por produtos frescos ... | github_jupyter |
```
import numpy as np
import math
import matplotlib.pyplot as plt
# operações basicas
#teste baseado em fact , introdução de um numero complexo
def dec():
real = float(input(" numero real "))
com = float(input(" numero complexo"))
#real = 4
#com = 4*pow(3,0.5)
num = complex(real,... | github_jupyter |
# An example of using multi-imbalance
Now we will demonstrate how to solve a multi-class imbalanced task by using our library.
We choose well-known glass data coming from the UCI ML repository.
It contains information about the purpose of glass, e.g. for windows or headlights in cars with are
categorized in several cla... | github_jupyter |
# Model My Watershed (MMW) API Demo
[Emilio Mayorga](https://github.com/emiliom/), University of Washington, Seattle. 2018-5-10. Demo put together using as a starting point instructions from Azavea from October 2017.
## Introduction
The [Model My Watershed API](https://modelmywatershed.org/api/docs/) allows you to d... | github_jupyter |
```
#ETL module, where we take in dirty json formated data, clean it, and put it into dataframe
#setting up dependencies
import json
import pandas as pd
import numpy as np
import re
from sqlalchemy import create_engine
from config import db_password
import time
# syntax for connect "postgres://[user]:[password]@[loca... | github_jupyter |
<a href="https://colab.research.google.com/github/kalz2q/mycolabnotebooks/blob/master/learnjavascript.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# はじめに、というか
Colab でJavaScript のを使うには 3 通りのやり方がある、と思う。
1. %%javascript セルマジックを使う。
1. %%script node ... | github_jupyter |
```
# Importing the Keras libraries and packages
import os
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Flatten
from keras.layers import Dense
dress_pat... | github_jupyter |
## Experiments using regular ensembles
We start by building the model and showing the basic inference procedure and calculation of the performance on the MNIST classification and the outlier detection task. Then perform multiple runs of the model with different number of samples in the ensemble to calculate performanc... | github_jupyter |
# Databases and ORM
## Relational Database
A key in the same table that is a primary key, if we reference this key on another table, then that is a foreign key.
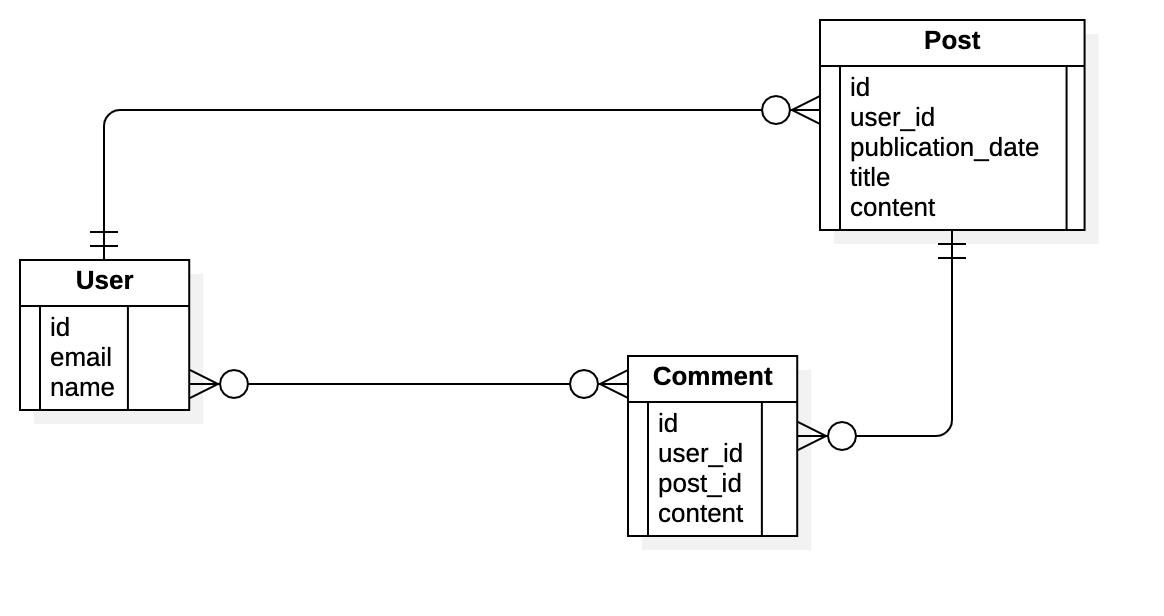
### NoSQL databases
- key-value : Redis
- graph : Neo4j
- document o... | github_jupyter |
```
import scanpy as sc
import numpy as np
import scipy as sp
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
from matplotlib import colors
import seaborn as sb
import logging
import warnings
warnings.filterwarnings('ignore')
import os
os.environ['PYTHONHASHSEED'] = '0'... | github_jupyter |
# **Real Estate Price Prediction**
- For Real Estate Price Prediction, we'll be using following algorithms:
1. Linear Regression
2. Decision Tree Regressor
3. Random Forest Regressor
- Following steps are followed:
1. **Data preprocessing and exploration** to understand what kind of data will we working on.
2. **... | github_jupyter |
<a href="https://colab.research.google.com/github/AlexandreBrown/AerialSemanticSegmentation/blob/main/SemanticSegmentation.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Semantic Segmentation
```
!pip3 install torch==1.10.0 matplotlib
!conda ins... | github_jupyter |
```
%matplotlib notebook
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.tri as tri
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
import skfuzzy as fuzz
from sklearn.datasets import make_blobs
from deepART import dataset
np.random.seed(0)
cluster_1 = np.random.uniform(low=0, hi... | github_jupyter |
# Analyzing the ASOT Top 1000
> Celebrating 1,000 episodes of A State of Trance.
- toc: true
- badges: true
- comments: false
- categories: [asot, bpm, artist, year]
- image: images/most-played-artists.png
```
#hide
%pip install spotipy pyyaml altair
#hide
import os
import yaml
import spotipy
import json
import alta... | github_jupyter |
<a href="https://colab.research.google.com/github/GhostBug-007/Cricket_Commentary_Classifier/blob/master/CricketCommentary_Classifier.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
---
**Connect the Google Drive to retrieve the data**
```
from goo... | github_jupyter |
# Use ssh agent to hold your keys
## Overview:
- **Teaching:** 20 min
- **Exercises:** 0 min
**Questions**
- Can I manage the deetails of my remotes to store details of credentials on different systems?
- Can I work more conveniently with keys so I don't have to use my passphrase everytime I access a resource?
**Obj... | github_jupyter |
```
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(
num_words=20000)
train_data[0].index(2)
# print("///////////////////////")
# print("the review label is : ",train_labels[0])
max([max(x) for x in train_data])
min([min(x) for x in train_data])
[max(x) for x in tr... | github_jupyter |
```
# import the important libraries
import pandas as pd
pd.set_option('display.max_columns', 500)
pd.set_option('display.max_rows', 1000)
# Check what's in this file
# The file is from NOAA for year 1950
df = pd.read_csv("StormEvents_details-ftp_v1.0_d1950_c20170120.csv")
ls
# the first 5 rows of the file
df.head()
... | github_jupyter |
```
import numpy as np
import pandas as pd
import scipy
import tables as tb
import matplotlib.pyplot as plt
%matplotlib inline
```
# Load Datasets
```
test_data = pd.read_csv("testing_data_transform.csv.gz", compression="gzip")
test_data.head()
training_data = pd.read_csv("training_data_transform.csv.gz", compressio... | github_jupyter |
```
import lightgbm as lgb
from lightgbm import LGBMClassifier
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
import pickle
from pathlib import Path
from tqdm.notebook import trange, tqdm
### USE FOR LOCAL JUPYTER NOTEBOOKS ###
DOWNLOAD_DIR = Path('../download')
DATA_DIR =... | github_jupyter |
<table class="ee-notebook-buttons" align="left">
<td><a target="_blank" href="https://github.com/giswqs/earthengine-py-notebooks/tree/master/Image/reclassify.ipynb"><img width=32px src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" /> View source on GitHub</a></td>
<td><a target="_blank" href="https... | github_jupyter |
<a href="https://colab.research.google.com/github/DeepInsider/playground-data/blob/master/docs/articles/tf2_keras_regression.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
##### Copyright 2020 Digital Advantage - Deep Insider.
```
#@title Licensed... | github_jupyter |
<table class="ee-notebook-buttons" align="left">
<td><a target="_blank" href="https://github.com/giswqs/earthengine-py-notebooks/tree/master/Image/pixel_lon_lat.ipynb"><img width=32px src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" /> View source on GitHub</a></td>
<td><a target="_blank" href="ht... | github_jupyter |
# Hours worked in G7countries
<hr>
According to OECD, the average number of annual hours worked corresponds to the total number of hours worked divided by the average number of people in employment, for a given annual period.
What is the evolution of the average number of hours worked per week per employee in G7 co... | github_jupyter |
# Quantum Teleportation
This notebook demonstrates quantum teleportation. We first use Qiskit's built-in aer simulator to test our quantum circuit, and then try it out on a real quantum computer.
## Contents
1. [Overview](#overview)
2. [The Quantum Teleportation Protocol](#how)
3. [Simulating the Teleport... | github_jupyter |
```
DATA_OFFSET = 0
IMG_IN_FOLDER = False
PATH_OUT = "./output"
PATH_CSV = "articles.csv"
PATH_DATA = "./images/"
import numpy as np
import pandas as pd
from pathlib import Path
import json
from urllib import request
import time
import cv2
# mount Google Drive when you run on Google Colab
# from google.colab import dri... | github_jupyter |
# Chapter1: Modeling Sequential Decision Process
**Modeling Definition**: <br> Can be viewed as building a bridge from a messy, poorly defined real-world problem to something with the clarity and a computer can understand.
## Five-Step Process for modeling Pocess:
### Step 1: The narrative - English disccussion
It ... | github_jupyter |
```
import tensorflow as tf
import tensorflow_probability as tfp #TFP needs TF>= 2.3
import scipy.optimize
import scipy.io
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import time
from pyDOE import lhs #Latin... | github_jupyter |
<img align="left" src="https://ithaka-labs.s3.amazonaws.com/static-files/images/tdm/tdmdocs/CC_BY.png"><br />
Created by [Nathan Kelber](http://nkelber.com) and Ted Lawless for [JSTOR Labs](https://labs.jstor.org/) under [Creative Commons CC BY License](https://creativecommons.org/licenses/by/4.0/)<br />
For questions... | github_jupyter |
>Note: This notebook works with IPython 4.2.0, matplotlib 1.5.1, and ipywidgets 5.1.3
```
%matplotlib notebook
import matplotlib.pyplot as plt
import numpy as np
import polo
import demo
```
Let's generate some demonstration data from a set of PyClaw runs:
```
data = demo.generate_data()
print data.head()
```
Here `... | github_jupyter |
# Amazon SageMaker Autopilot Data Exploration
This report provides insights about the dataset you provided as input to the AutoML job.
It was automatically generated by the AutoML training job: **predict-loan-default**.
As part of the AutoML job, the input dataset was randomly split into two pieces, one for **trainin... | github_jupyter |
# Introduction
```
import pprint
import operator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.datasets import load_iris, load_breast_cancer
from sklearn.metrics import accuracy_score
from sklearn.neighbors im... | github_jupyter |
<a href="https://colab.research.google.com/github/mnslarcher/cs224w-slides-to-code/blob/main/notebooks/02-traditional-methods-for-ml-on-graphs.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Traditional Methods for ML on Graphs
```
try:
# Che... | github_jupyter |
Lambda School Data Science
*Unit 2, Sprint 2, Module 2*
---
# Random Forests
## Assignment
- [ ] Read [“Adopting a Hypothesis-Driven Workflow”](https://outline.com/5S5tsB), a blog post by a Lambda DS student about the Tanzania Waterpumps challenge.
- [ ] Continue to participate in our Kaggle challenge.
- [ ] Define... | github_jupyter |
##### Copyright 2019 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | github_jupyter |
Analyze state of the union addresses.
Data source: https://en.wikisource.org/wiki/Portal:State_of_the_Union_Speeches_by_United_States_Presidents
scrape the text of all speeches and then maybe try to find patterns of speech of each president?
https://nlp.stanford.edu/IR-book/html/htmledition/sublinear-tf-scaling-1.htm... | github_jupyter |
<a href="https://colab.research.google.com/github/bxck75/piss-ant-pix2pix/blob/master/modeltransferv4_final.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
#@title Helpers Loader { vertical-output: true, output-height: 10 }
# remove defaults
im... | github_jupyter |
### 웹 크롤링
- 크롤링 절차
- 1. 웹서비스 확인 : URL을 가져옴
- 2. URL을 이용 -> request, response : json 포맷의 데이터를 가져옴 (str)
- 3. json(str) -> dict(parsing) : DataFrame을 얻어냄
- naver stock data
- kospi, kosdaq, usd(need login)
- 크롤링할 때 모바일 페이지가 있는지 먼저 확인해보는게 좋음
- referer : 요청하기 전 페이지
- user-agent : -> fake user-agen... | github_jupyter |
# ML-Agents Q-Learning with GridWorld
<img src="https://github.com/Unity-Technologies/ml-agents/blob/release_19_docs/docs/images/gridworld.png?raw=true" align="middle" width="435"/>
## Setup
```
#@title Install Rendering Dependencies { display-mode: "form" }
#@markdown (You only need to run this code when using Colab... | github_jupyter |
## Exercise 5.02: Choropleth plot with geojson data
In this exercise, we not only want work with geojson data, but also see how we can create a choropleth visualization.
They are espacially useful to display statistical variables in shaded areas. In our case the areas will be the outlines of the states of the USA.
... | github_jupyter |
# "Lessons learned and future directions"
> "What I think is worthy to work on in wide baseline stereo"
- toc: false
- image: images/yoy_cat.jpg
- branch: master
- badges: true
- comments: true
- hide: false
- search_exclude: false
I would like to share some lessons I have learned about wide baseline stereo and propos... | github_jupyter |
<a href="https://colab.research.google.com/github/tarun-jethwani/character_level_language_model/blob/master/generating_names_using_RNN_from_scratch.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
Building Character level language with RNN
This tuto... | github_jupyter |
# Mining the Social Web
## Mining LinkedIn
This Jupyter Notebook provides an interactive way to follow along with and explore the examples from the video series. The intent behind this notebook is to reinforce the concepts in a fun, convenient, and effective way.
# LinkedIn API Access
LinkedIn implements OAuth 2.0 ... | github_jupyter |
```
import os
os.environ['CUDA_VISIBLE_DEVICES']='2'
import time
import numpy as np
import tensorflow as tf
import os
import time
import numpy as np
import tensorflow as tf
class VGG16_GAP:
def __init__(self, scope_name="VGG16"):
"""
load pre-trained weights from path
:param vgg16_npy_path:... | github_jupyter |
# MACID tutorial
```
# helpful extensions
%load_ext autoreload
%autoreload 2
%matplotlib inline
%autosave 60
#importing necessary libraries
try:
import pycid
except ModuleNotFoundError:
import sys
!{sys.executable} -m pip install pycid # or !{sys.executable} -m pip install git+https://github.com/causalin... | github_jupyter |
```
from flask import Flask, render_template
from bs4 import BeautifulSoup as bs
import requests
```
## NASA Mars News
Scrape the NASA Mars News Site and collect the latest News Title and Paragraph Text. Assign the texts to variables that can be referenced later
```
# Send a GET request, convert the HTML to plain te... | github_jupyter |
##### Copyright 2019 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | github_jupyter |
# Text generation with miniature GPT
**Author:** [Apoorv Nandan](https://twitter.com/NandanApoorv)<br>
**Date created:** 2020/05/29<br>
**Last modified:** 2020/05/29<br>
**Description:** Implement a miniature version of GPT and train it to generate text.
## Introduction
This example demonstrates how to implement an ... | github_jupyter |
# Padding and Stride
:label:`sec_padding`
In the previous example, our input had both a height and width of $3$
and our convolution kernel had both a height and width of $2$,
yielding an output representation with dimension $2\times2$.
In general, assuming the input shape is $n_h\times n_w$
and the convolution kerne... | github_jupyter |
<div style="color:#777777;background-color:#ffffff;font-size:12px;text-align:right;">
prepared by Abuzer Yakaryilmaz (QuSoft@Riga) | November 07, 2018
</div>
<table><tr><td><i> I have some macros here. If there is a problem with displaying mathematical formulas, please run me to load these macros.</i></td></td></table... | github_jupyter |
```
import cv2
import numpy as np
import pandas as pd
import pickle as cPickle
import time
from matplotlib import pyplot as plt
from sklearn.cluster import MiniBatchKMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminan... | github_jupyter |
```
import spacy
import numpy as np
import pandas as pd
from stopwords import ENGLISH_STOP_WORDS
# from __future__ import unicode_literals
# import numba
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
en_nlp = spacy.load('en')
def spacy_get_vec(sentence):
vec = np.zeros(96)
doc ... | github_jupyter |
# Match the French dataset with Hebrew dataset
```
import re
import csv
import json
from pathlib import Path
from tf.fabric import Fabric
from Levenshtein import distance as levdist
FRENCH_FILE = "../../_private_/French/all verbs NBS11.CSV"
BHSA2FRENCH = "../../_private_/French/bhsa2french.json"
BHSA_DATA = "/Users/c... | github_jupyter |
# Python for Data Analysis
In this notebook, we are going to continue with our exposition of scientific computing with Python, particularly looking at data analysis tools in the Scipy stack. We are going to have a brief introduction to two libraries: pandas and scikit-learn.
## Pandas
Pandas - derived from 'panel data... | github_jupyter |
```
class Solution:
def pacificAtlantic(self, mat):
# 矩阵的斜对角上的两个值天然满足条件:
# 1、左下角坐标:(rows-1, 0), 右上角坐标:(0, cols-1)
# 2、如果在矩阵的四条边上,
# row = 0: 右、下条件之一
# col = 0:右、下条件之一
# row = rows - 1:左、上 条件之一
# col = cols - 1:左、上 条件之一
# 3、如果在矩阵的中间:需要满足(上,右... | github_jupyter |
<a href="https://colab.research.google.com/github/chriswmann/keras-google-colab-tpu/blob/master/keras_tpu.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Running Keras on Google Colab with TPU Acceleration
## Introduction
The purpose of this not... | github_jupyter |
```
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from tqdm import tqdm
import time
```
## **Loading dataset**
```
from torchvision import datasets, transforms
use_cuda = True
device = torch.device("cuda" if use_cuda else "cpu")
train_batch_size=64
test_batch_siz... | github_jupyter |
# TensorFlow Tutorial #17
# Estimator API
by [Magnus Erik Hvass Pedersen](http://www.hvass-labs.org/)
/ [GitHub](https://github.com/Hvass-Labs/TensorFlow-Tutorials) / [Videos on YouTube](https://www.youtube.com/playlist?list=PL9Hr9sNUjfsmEu1ZniY0XpHSzl5uihcXZ)
## Introduction
High-level API's are extremely important... | github_jupyter |
# Image recognition using convolutional neural networks
With acknowelagements to Maxim Borisyak
Just some imports
```
import tensorflow as tf
gpu_options = tf.GPUOptions(allow_growth=True,per_process_gpu_memory_fraction=0.333)
s = tf.InteractiveSession(config=tf.ConfigProto(gpu_options=gpu_options))
%matplotlib inli... | github_jupyter |
## Emailing Plotly Graphs
In the [Plotly Webapp](https://plot.ly/plot) you can share your graphs over email to your colleagues who are also Plotly members. If your making graphs periodically or automatically, e.g. [in Python with a cron job](http://moderndata.plot.ly/update-plotly-charts-with-cron-jobs-and-python/), i... | github_jupyter |
To get the peak performance and to make your model deployable, use `tf.function` to make graphs out of your programs. There are some tips for using `TF.function`:
* Don't rely on Python object attributes like mutation, list appending, etc.
* The `TF.function` works better with Tensorflow Ops, rather than Numpy Ops or P... | github_jupyter |
# NetworKit Randomization Tutorial
The randomization module implements algorithms to perturb existing graphs. This is commonly used to obtain a null-model for hypothesis testing in network analysis (see below for an example). Intuitively one tests whether an observation in original also appears in *similar* graphs. By... | github_jupyter |
# eICU Collaborative Research Database
# Notebook 1: Exploring the `patient` table
The aim of this notebook is to introduce the `patient` table, a key table in the eICU Collaborative Research Database.
The `patient` table contains patient demographics and admission and discharge details for hospital and ICU stays. ... | github_jupyter |
# MNIST Veri Seti ile Rakam Tanıma
https://www.kaggle.com/c/digit-recognizer/
MNIST veri seti $28\times 28$ pikselden oluşan elle yazılmış rakamlar içeren bir veri seti. Veri seti 32000 eğitim ve 10000 test rakamı içeriyor.
Normalde çok sınıflı bir sınıflandırma problemi olan rakam tanıma problemini güdümsüz öğrenme... | github_jupyter |
# Babyweight Estimation with Transformed Data
### Set global flags
```
PROJECT = 'ksalama-gcp-playground' # change to your project_Id
BUCKET = 'ksalama-gcs-cloudml' # change to your bucket name
REGION = 'europe-west1' # change to your region
ROOT_DIR = 'babyweight_tft' # directory where the output is stored locally o... | github_jupyter |
# Statistics: PMF, PDF and CDF in Statistics #6398
The probability density function(PDF) is the probability of the value of a continuous random variable falling within a range or an interval. In case of discrete random variables probability mass function(PMF) can be used. The meaning of Cumulate is to gather or sum up... | github_jupyter |
##### Copyright 2018 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | github_jupyter |
# GEE python
GEE 也有python接口,可以和command shell,web application和jupyter交互。和JS相比,python API可以在脚本间分享代码,允许序列调用GEE,有很多绘图选项,比如matplotlib,seaborn,plotly,bokeh,pygal,ggplot和altair等,可以常用python库一起使用。最直接的调用GEE的方式可以查看GEE原文档 [Python installation](https://developers.google.com/earth-engine/python_install),这里主要参考[GEEMAP](https://githu... | github_jupyter |
```
# Generate CI Data with the Python Faker library
# These are the CSV Rows:
# "CustomerId",
# "Address",
# "State",
# "StateProvince",
# "PreferredStore",
# "RewardsPoints",
# "StreetAddress",
# "NameCombined",
# "CountryCombined",
# "CityCombined",
# "PostalCodeCombined",
# "RetailDemoData_RetailSystem_RetailCusto... | github_jupyter |
```
import numpy as np;
a = np.arange(12)
a = np.aran
a
np.mean(a)
np.mean(a[a>5])
a = a/2
a
for e,i in enumerate(a, start=4):
print(e, i)
file_list = ['r1.tif', 'r2.tif', 'r3.tif']
[print(f, other) for f,other in zip(file_list, [0,1,2,3])]
import os
os.getcwd()
import rasterio
import glob
def write_image(input, ou... | github_jupyter |
```
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
import pandas_datareader as web
import datetime
import matplotlib.pyplot as plt
%matplotlib inline
#import arch.unitroot as at
import statsmodels.api as sm
import statistics
from collections import defaultdict
from pandas_data... | github_jupyter |
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import pandas_profiling as pp
%matplotlib inline
```
# Load The Data from UCI Machine Learning Repository in CSV
The UCI Machine Learning Repository is a collection of databases, domain theories, and data generators that ... | github_jupyter |
```
# https://stockcharts.com/school/doku.php?id=chart_school:technical_indicators:average_directional_index_adx
import pandas as pd
import sys
sys.path.append("..") # Adds higher directory to python modules path.
from ta import *
high_data =[30.19830,
30.27760,
30.44580,
29.34780,
29.34770,
29.28860,
28.83340,
28.734... | github_jupyter |
<a href="https://colab.research.google.com/github/jpdeleon/chronos/blob/master/notebooks/examples-lightcurves-tess-pathos.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
#!pip install git+https://github.com/jpdeleon/chronos.git@master
%matplotli... | github_jupyter |
# Convolutional Neural Network
### Imports
```
import time
import torch
import numpy as np
from torch import nn
import torch.nn.functional as F
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
```
### Settings and Dataset
```
device = torch.device("cuda" if... | github_jupyter |
# I. Introduction

As illustrated in the lectures, simulated annealing is a probablistic technique used for finding an approximate solution to an optimization problem--one of the simplest "gradient-free" optimization techniques. In this exercise you will check your understanding... | github_jupyter |
```
import os
from google.colab import drive
drive.mount('/content/drive')
path = "/content/drive/My Drive/segnet/"
os.chdir(path)
os.listdir(path)
import os
print (os.getcwd()) #获取当前工作目录路径
```
# 0. parameters
```
import torch.utils.data as data
import torch
import numpy as np
import h5py
import matplotlib.pyplot as... | github_jupyter |
# Live Streaming of Wikipedia Extraction
**The big picture**
[WikiRecentPhase0](imgAna_0.jupyter-py36.ipynb) illustrated accessing continious streams events from a notebook in Python as a way to explore the nature of the data and to understand how to develop it into useful insights. In that exploration data is collect... | github_jupyter |
```
# OK, now make a function to process images, collapse to a pointcloud and dump to an h5py file
%matplotlib qt
%load_ext autoreload
%autoreload 2
import time
from pathlib import Path
import numpy as np
import matplotlib.pyplot as plt
import torch
import sys, os, pickle
import cv2
from colour import Color
import ... | github_jupyter |
# Exploration of the crash severity information in CAS data
In this notebook, we will explore the severity of crashes, as it will be the
target of our predictive models.
```
from pathlib import Path
import numpy as np
import pandas as pd
import scipy.stats as st
import matplotlib.pyplot as plt
import seaborn as sb
fr... | github_jupyter |
### Make two folders: images, masks
```
data_processedv0/
images/
masks/
```
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors
import os
import skimage.draw
import numpy as np
from tqdm import tqdm
import cv2
from glob import glob
impor... | github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.