
code stringlengths 38 801k | repo_path stringlengths 6 263 |
|---|---|
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + active=""
# Text provided under a Creative Commons Attribution license, CC-BY. Code under MIT license. (c)2014 <NAME>, <NAME>. Thanks: NSF for support via CAREER award #1149784.
# -
# # Source Distribution on an Airfoil
# In [Lesson 3](03_Lesson03_doublet.ipynb) of *AeroPython*, you learned that it is possible to represent potential flow around a circular cylinder using the superposition of a doublet singularity and a free stream. But potential flow is even more powerful: you can represent the flow around *any* shape. How is it possible, you might ask?
#
# For non-lifting bodies, you can use a source distribution on the body surface, superposed with a free stream. In this assignment, you will build the flow around a NACA0012 airfoil, using a set of sources.
#
# Before you start, take a moment to think: in flow around a symmetric airfoil at $0^{\circ}$ angle of attack,
#
# * Where is the point of maximum pressure?
# * What do we call that point?
# * Will the airfoil generate any lift?
#
# At the end of this assignment, come back to these questions, and see if it all makes sense.
# ## Problem Setup
# You will read data files containing information about the location and the strength of a set of sources located on the surface of a NACA0012 airfoil.
#
# There are three data files: NACA0012_x.txt, NACA0012_y.txt, and NACA0012_sigma.txt. To load each file into a NumPy array, you need the function [`numpy.loadtxt`](http://docs.scipy.org/doc/numpy/reference/generated/numpy.loadtxt.html). The files should be found in the `resources` folder of the `lessons`.
# Using 51 mesh points in each direction, and a domain $[-1, 2]\times[-0.5, 0.5]$, compute the velocity due to the set of sources plus a free stream in the $x$-direction with $U_{\infty}=1$. Also compute the coefficient of pressure on your grid points.
# ## Questions:
# 1. What is the value of maximum pressure coefficient, $C_p$?
# 2. What are the array indices for the maximum value of $C_p$?
#
# Make the following plots to visualize and inspect the resulting flow pattern:
#
# * Stream lines in the domain and the profile of our NACA0012 airfoil, in one plot
# * Distribution of the pressure coefficient and a single marker on the location of the maximum pressure
# **Hint**: You might use the following NumPy functions: [`numpy.unravel_index`](http://docs.scipy.org/doc/numpy/reference/generated/numpy.unravel_index.html) and [`numpy.argmax`](http://docs.scipy.org/doc/numpy/reference/generated/numpy.argmax.html)
# ##### Think
# 1. Do the stream lines look like you expected?
# 2. What does the distribution of pressure tell you about lift generated by the airfoil?
# 3. Does the location of the point of maximum pressure seem right to you?
from IPython.core.display import HTML
def css_styling():
styles = open('../styles/custom.css', 'r').read()
return HTML(styles)
css_styling()
| lessons/03_Lesson03_Assignment.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Ozone Hole Data Journey
# <hr/>
# Data idea from - https://tthrowbackthurs.github.io/ , Posted by <NAME> on January 2, 2020
#
#
#
# # Content:
# - [Questions](#Questions:)
# - [History](#History:)
# - [Green Houses Gases](#Green-Houses-Gases)
# - [What is Natural gas](#What-is-Natural-gas)
# - [Data sources](#Data-sources)
# # Questions:
# <hr/>
#
# #### Why do I find this information intersting?
# - Can I see three other perspectives of why this information is intersting that is the oppisite of my own.
# <br>
#
#
# #### What can I learn from this information (how is this information teaching me)?
# - straight line anwer
# - inverse answer
#
# - mirror reflected around ____ computer vision term obstructed ___ object anser
# - mirror reflection answer
# - cause & effect
# - what not to do
# - (light and vision / geometry to conceptualize relationship of learning by teaching)
#
# <br>
#
# #### How can this learned information(lessons) be applyed? (information - lessions )
# - actons (phyiscal good, work done)
# - phyilosphy (public good)
# <br>
#
# #### How can these lessions help other people? (people vs human being vs human)
# - Direct
# - indirect
# <br>
#
# #### Confidence Matix of Life
# - What are the desired outcomes of these actions & phyilosphy
# - Who does it benifit ***TP***
# - Who does it hinder ***TN***
# - What are undesired outcomes of these actions & phyilosphy
# - Who does it benifit ***FP***
# - Who does it hinder ***FN***
#
#
# # History:
# <hr/>
# > The Ozone Hols is a seasonal depletion of the Ozone Layer - a protective layer of the atmosphere that is vital in protecting the Earth from the bulk of the Sun's ultraviolet radiation. The hole forms in the Southern Hemisphere, over Antarctica, during the Southern Hemisphere Spring. Chemical reactions driven by Bromine and Chlorine (coming from CFC's) cause the rapid degredation of the Ozone layer, with the hole peaking in late September or early October.
# > - <NAME>
#
#
# # Green Houses Gases
# <hr/>
#
# #### Major Long-Lived Greenhouse Gases and Their Characteristics
# | Greenhouse gas | How it's produced | Average lifetime in the atmosphere | 100-year global warming potential |
# | :------------- | :----------: | :----------: |-----------: |
# | Carbon dioxide |Emitted primarily through the burning of fossil fuels (oil, natural gas, and coal), solid waste, and trees and wood products. Changes in land use also play a role. Deforestation and soil degradation add carbon dioxide to the atmosphere, while forest regrowth takes it out of the atmosphere.| see below* | 1 |
# | Methane | Emitted during the production and transport of oil and natural gas as well as coal. Methane emissions also result from livestock and agricultural practices and from the anaerobic decay of organic waste in municipal solid waste landfills. |12.4 years** | 28–36|
# | Nitrous oxide| Emitted during agricultural and industrial activities, as well as during combustion of fossil fuels and solid waste. |121 years** | 265–298|
# | Fluorinated gases| A group of gases that contain fluorine, including hydrofluorocarbons, perfluorocarbons, and sulfur hexafluoride, among other chemicals. These gases are emitted from a variety of industrial processes and commercial and household uses and do not occur naturally. Sometimes used as substitutes for ozone-depleting substances such as chlorofluorocarbons (CFCs). | A few weeks to thousands of years| Varies (the highest is sulfur hexfluoride at 23,500|
#
# ** Carbon dioxides lifetime cannot be represented with a single value because the gas is not destroyed over time, but instead moves among different parts of the ocean–atmosphere–land system. Some of the excess carbon dioxide is absorbed quickly (for example, by the ocean surface), but some will remain in the atmosphere for thousands of years, due in part to the very slow process by which carbon is transferred to ocean sediments. $*
#
# *** The lifetimes shown for methane and nitrous oxide are perturbation lifetimes, which have been used to calculate the global warming potentials shown here. $*
#
#
# from https://www.epa.gov/climate-indicators/greenhouse-gases
# ### What is Natural gas
# <hr/>
#
# <img src='./img/natural_gas.png'>
# https://www.croftsystems.net/oil-gas-blog/natural-gas-composition/
# ### Natural gas
#
# Natural Gas = (
# methane : CH_4, 60 - 90
# ethane : C2H6, 0 - 20
# propane : C3H8, 0 - 20
# butane : C4H10, 0 - 20
# carbon dioxide : CO2, 0 - 8
# oxygen : 02, 0 - 0.2
# nitrogen : N2, 0 - 5
# hydrogen sulfide : H2S, 0 - 5
# rare gases : A, He, 0
# )
#
#
# # Data sources
# <hr/>
#
# Global Temp & Parcipitation changes
# https://climatedataguide.ucar.edu/climate-data/global-temperature-data-sets-overview-comparison-table
#
# Data source
# https://ozonewatch.gsfc.nasa.gov
#
# climate . GOV
# https://www.climate.gov/news-features/understanding-climate/climate-change-global-temperature
# NCAR Climate Data Guide
# https://climatedataguide.ucar.edu/climate-data/global-surface-temperatures-best-berkeley-earth-surface-temperatures
# Berkely Earth
# http://berkeleyearth.org/data/
# Climate Change Indicator
# https://www.epa.gov/climate-indicators/greenhouse-gases
# Annual carbon dioxide by openEI
# https://openei.org/datasets/dataset/annual-carbon-dioxide-emissions-2005-2009
#
#
# # Notes
# <hr/>
# # ? what would the holes look like
# # ? what is the chemical reation that happens between Bromine and Chlorine
# # ? when does the chemical reation happen
# # ? what is ozone, $O_3$
# # ? What does ozone look like, how does that attribute to its properties?
# # ? what is a Dobson Units
create visual awareness, PoSiTiVe
teaching tool to understand the earth
carbon tax - positive spin
- world tax on industry to same standards]
# +
data to add is CFC production levels?
dates of govermental polcy and time to effect curve
add
ocean temp
land temp
city temp London, NY, _, _, _,
production from
# -
| Ozone_Hole/.ipynb_checkpoints/README-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernel_info:
# name: python3
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + outputHidden=false inputHidden=false
# %load_ext autoreload
# %autoreload 2
# + outputHidden=false inputHidden=false
import json
import requests
import pandas as pd
from tqdm import tqdm
import matplotlib.pyplot as plt
from descartes import PolygonPatch
from shapely.affinity import scale, translate
import gzbuilder_analysis.parsing as pg
import gzbuilder_analysis.aggregation as ag
import lib.galaxy_utilities as gu
from asinh_cmap import asinh_cmap, asinh_cmap_r
import lib.make_cutouts as mkct
# + outputHidden=false inputHidden=false
subject_ids = [20902011, 20902022, 20902026, 20902027, 20902040]
# + outputHidden=false inputHidden=false
fitting_metadata = pd.read_pickle('lib/fitting_metadata.pkl')
# + outputHidden=false inputHidden=false
zoo_models = {}
scaled_models = {}
for s in subject_ids:
data = fitting_metadata.loc[s].galaxy_data
psf = fitting_metadata.loc[s].psf
sigma_image = fitting_metadata.loc[s].sigma_image
pic_array = np.array(gu.get_image(s))
cls_for_subjects = gu.classifications.query(
f'subject_ids == {s}'
)
zoo_models[s] = cls_for_subjects.apply(
pg.parse_classification,
axis=1,
image_size=np.array(pic_array.shape),
size_diff=fitting_metadata['size_diff'],
ignore_scale=True # ignore scale slider when aggregating
)
scaled_models[s] = zoo_models[s].apply(
pg.scale_model,
args=(fitting_metadata.loc[s]['size_diff'],),
)
# + outputHidden=false inputHidden=false
rot_matrix = lambda t: np.array(((np.cos(t), np.sin(t)), (-np.sin(t), np.cos(t))))
def plot_thing(s, model):
img = np.array(gu.download_image(s))
subject_data = json.loads(requests.get(json.loads(gu.subjects.loc[s].locations)['0']).text)
zoo_mask = np.array(subject_data['mask'])
zoo_gal = np.ma.masked_array(subject_data['imageData'], zoo_mask)
montaged_cutout = mkct.get_montaged_cutout(s).data
montaged_mask = gu.get_diff_data(s)['mask']
rotated_model = pg.rotate_model_about_centre(model, zoo_gal.data.shape, fitting_metadata.loc[s].rotation_correction)
reprojected_model = pg.reproject_model(
rotated_model,
fitting_metadata.loc[s]['montage_wcs'],
fitting_metadata.loc[s]['original_wcs'],
)
f, ax = plt.subplots(ncols=3, figsize=(12, 4), dpi=100)
ax[0].imshow(zoo_gal, cmap=asinh_cmap)
for i, (k, g) in enumerate(
ag.get_geoms(model).items()
):
if g is not None:
ax[0].add_patch(PolygonPatch(scale(g, 3, 3), fc='none', ec=f'C{i}'))
for points, params in model['spiral']:
ax[0].plot(*points.T, 'r')
ax[0].set_title('Zooniverse data')
l = montaged_cutout[
int(montaged_cutout.shape[0]/2) - 20: int(montaged_cutout.shape[0]/2) + 20,
int(montaged_cutout.shape[1]/2) - 20: int(montaged_cutout.shape[1]/2) + 20,
].max()
ax[1].imshow(np.ma.masked_array(montaged_cutout, montaged_mask), vmax=l, cmap=asinh_cmap)
for i, (k, g) in enumerate(
ag.get_geoms(rotated_model).items()
):
if g is not None:
ax[1].add_patch(PolygonPatch(scale(g, 3, 3), fc='none', ec=f'C{i}'))
for points, params in rotated_model['spiral']:
ax[1].plot(*points.T, 'r')
ax[1].set_title('Montaged cutout')
ax[2].imshow(fitting_metadata.loc[s].galaxy_data, cmap=asinh_cmap)
for i, (k, g) in enumerate(
ag.get_geoms(reprojected_model).items()
):
if g is not None:
ax[2].add_patch(PolygonPatch(scale(g, 3, 3), fc='none', ec=f'C{i}'))
for points, params in reprojected_model['spiral']:
ax[2].plot(*points.T, 'r')
ax[2].set_title('Fitting data')
return f, ax
# + outputHidden=false inputHidden=false
f, ax = plot_thing(subject_ids[0], scaled_models[subject_ids[0]].iloc[4])
# + outputHidden=false inputHidden=false
f, ax = plot_thing(subject_ids[1], scaled_models[subject_ids[1]].iloc[3])
# + outputHidden=false inputHidden=false
f, ax = plot_thing(subject_ids[2], scaled_models[subject_ids[2]].iloc[14])
# + outputHidden=false inputHidden=false
f, ax = plot_thing(subject_ids[3], scaled_models[subject_ids[3]].iloc[18])
# + outputHidden=false inputHidden=false
f, ax = plot_thing(subject_ids[4], scaled_models[subject_ids[4]].iloc[11])
# + outputHidden=false inputHidden=false
| wcs_test.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.8.10 64-bit
# language: python
# name: python3
# ---
import numpy as np
import torch
arr = np.array([1,2,3])
arr.dtype
tens = torch.FloatTensor(arr)
tens
tens.dtype
# ---------------------------------
torch.empty(2,2) # a placeholder tensor
torch.zeros(5, dtype=torch.int8)
torch.ones(2,4)
torch.arange(0, 18, 3).reshape(3, 2)
torch.linspace(0, 33, 6)
# ------------------------
tens = torch.tensor([1, 2, 3])
tens.dtype
tens.type(torch.int8)
# ----------------------------------
torch.rand(4, 3)
torch.randn(10)
torch.randint(12, 32, (4, 4))
x = torch.zeros(2, 5)
x
torch.rand_like(x)
# SEED FOR TORCH RANDOMS
torch.manual_seed(42)
| Courses/PyTorch for Deep Learning with Python/05 PyTorch Basics/02_Tensor_basics2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="WNYCBfpJ-sfV" colab_type="code" colab={}
from IPython.display import clear_output
board=['0','1','2','3','4','5','6','7','8']
empty = [0,1,2,3,4,5,6,7,8]
def display_board():
clear_output()
print(' | | ')
print(board[0]+' | '+board[1]+' | '+board[2])
print(' | | ')
print('---------')
print(' | | ')
print(board[3]+' | '+board[4]+' | '+board[5])
print(' | | ')
print('---------')
print(' | | ')
print(board[6]+' | '+board[7]+' | '+board[8])
print(' | | ')
def player_input(player):
player_symbol = ['X','O']
correct_input = True
#print('player {playerNo} chance! Choose field to fill {symbol}'.format(playerNo = player, symbol = player_symbol[player]))
position = int(input('player {playerNo} chance! Choose field to fill {symbol} '.format(playerNo = player +1, symbol = player_symbol[player])))
#print(type(position))
"""for eligible in empty:
if position == eligible:
correct_input = True"""
if board[position] == 'X' or board[position] == 'O':
correct_input = False
if not correct_input:
print("Position already equipped")
player_input(player)
else:
empty.remove(position)
board[position] = player_symbol[player]
return 1
def check_win():
player_symbol = ['X','O']
winning_positions =[[0,1,2],[3,4,5],[6,7,8],[0,3,6],[1,4,7],[2,5,8],[0,4,8],[2,4,6]]
for check in winning_positions:
first_symbol = board[check[0]]
if first_symbol != ' ':
won = True
for point in check:
if board[point] != first_symbol:
won = False
break
if won:
if first_symbol == player_symbol[0]:
print('player 1 won')
else:
print('player 2 won')
break
else:
won = False
if won:
return 0
else:
return 1
def play():
player = 0
while empty and check_win():
display_board()
player_input(player)
player = int(not player)
if not empty:
print("NO WINNER!")
# + id="_g797m85-wUv" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 238} outputId="ec323be3-565b-4749-b000-21e07a004ce2" executionInfo={"status": "ok", "timestamp": 1582041009703, "user_tz": 180, "elapsed": 3244, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDKNhUNvB3SoOs5mhC19euuvKokuJcdTSI_f-KgZig=s64", "userId": "12640118664655043159"}}
play()
| TicTacToe/TicTacToe.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# 该notebook为指导在树算法中实现一些额外的参数。
import os
os.sys.path.append(os.path.dirname(os.path.abspath('.')))
# ## max_depth
# ```max_depth```参数是控制树生成的最重要的参数之一。在递归生成树时没想到什么好办法可以直接获取当前树的深度,不过可以通过增加一个叶子节点数的全局变量来获取当前树的深度,原理在于深度为$d$的树,他的最小叶子节点数与最大叶子节点数是可以通过公式算出来的。以下代码全部引自之前的notebook,不再赘述。
# +
# import numpy as np
# from datasets.dataset import load_breast_cancer
# data=load_breast_cancer()
# X,Y=data.data,data.target
# del data
# from model_selection.train_test_split import train_test_split
# X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.2)
# training_data=np.c_[X_train,Y_train]
# testing_data=np.c_[X_test,Y_test]
# def Gini(data, y_idx=-1):
# K = np.unique(data[:, y_idx])
# n_sample = len(data)
# gini_idx = 1 - \
# np.sum([np.square(len(data[data[:, y_idx] == k])/n_sample) for k in K])
# return gini_idx
# def BinSplitData(data,f_idx,f_val):
# data_left=data[data[:,f_idx]<=f_val]
# data_right=data[data[:,f_idx]>f_val]
# return data_left,data_right
# from scipy import stats
# def Test(data, criteria='gini', min_samples_split=5, min_samples_leaf=5, min_impurity_decrease=0.0):
# n_sample, n_feature = data.shape
# if n_sample < min_samples_split or len(np.unique(data[:,-1]))==1:
# return None, stats.mode(data[:, -1])[0][0]
# Gini_before = Gini(data)
# best_gain = 0
# best_f_idx = None
# best_f_val = stats.mode(data[:, -1])[0][0]
# for f_idx in range(n_feature-1):
# for f_val in np.unique(data[:, f_idx]):
# data_left, data_right = BinSplitData(data, f_idx, f_val)
# if len(data_left) < min_samples_leaf or len(data_right) < min_samples_leaf:
# continue
# Gini_after = len(data_left)/n_sample*Gini(data_left) + \
# len(data_right)/n_sample*Gini(data_right)
# gain = Gini_before-Gini_after
# if gain < min_impurity_decrease or gain < best_gain:
# continue
# else:
# best_gain = gain
# best_f_idx, best_f_val = f_idx, f_val
# return best_f_idx, best_f_val
# -
# 在递归生成树的函数之前增加一个全局变量:```nodes```,用于实时监控CART树的叶节点数。
# +
# nodes=0
# max_depth=1
# def CART(data,criteria='gini',min_samples_split=5,min_samples_leaf=5,min_impurity_decrease=0.0):
# best_f_idx,best_f_val=Test(data,criteria,min_samples_split,min_samples_leaf,min_impurity_decrease)
# tree={}
# tree['cut_f']=best_f_idx
# tree['cut_val']=best_f_val
# nonlocal nodes
# nodes+=1
# if best_f_idx==None:
# return best_f_val
# # 节点数超过最大深度的限制,也要返回叶节点,叶节点的值为当前数据中的目标值众数
# if nodes>=2**max_depth:
# return stats.mode(data[:, -1])[0][0]
# data_left,data_right=BinSplitData(data,best_f_idx,best_f_val)
# tree['left']=CART(data_left,criteria,min_samples_split,min_samples_leaf,min_impurity_decrease)
# tree['right']=CART(data_right,criteria,min_samples_split,min_samples_leaf,min_impurity_decrease)
# return tree
# tree=CART(training_data)
# # CART树存储为字典形式,将其字符串化后,每一个'left'代表左叉树枝,每一个'right'代表右叉树枝
# # 节点数之和等于树枝数+1
# tree_str=str(tree)
# edge=tree_str.count('left')+tree_str.count('right')
# assert edge+1==nodes
# print(tree,nodes)
# -
# ## sample_weight
# 该参数用于控制样本在树的分裂时所占的权重,实质就是不同样本对于纯净度的贡献。因为sklearn中该参数是位于```fit```方法中,所以实现该参数需要结合```.py```工程文件来分析。
#
# ```DecisionTreeClassifier.py```中的```fit```方法只有两步:
# 1. 将```X_train```与```Y_train```拼接起来便于共同操作
# 2. 递归调用```CART```方法
#
# 而```CART```方法中又调用了```Test```方法与```BinSplitData```方法,所以需要修改的部分就是这四个方法。
#
# 思路:
# - 在```fit```方法中接受一个```sample_weight```参数,同样与```X_train```以及```Y_train```拼到一起
# - Gini指数的计算方式需要改变,因为样本权重改变了$p_{k}$值,同时还要更改做test时加权Gini指数的计算方式
# - 做test时注意不要扫描```weight```列与```Y```列
#
# 下面依次展示各方法中更改的代码部分:
def fit(self, X_train, Y_train,sample_weight=None):
# ...
sample_weight=sample_weight if sample_weight else np.array([1/len(X_train)]*len(X_train))
data = np.c_[X_train,sample_weight, Y_train] # 权重为倒数第二列,目标值为最后一列
# ...
def __Gini(self, data, y_idx=-1):
# ...
gini_idx = 1 - np.sum([np.square(np.sum(data[data[:, y_idx] == k][:,-2]) / np.sum(data[:,-2])) for k in K])
# ...
def __Test(self, data):
# ...
n_sample, n_feature = data.shape
n_feature-=-2 # 除去第一列与最后一列
# ...
# 加权Gini的计算方式需要更改,改成数据子集的权重和
Gini_after = np.sum(data_left[:,-2])/np.sum(data[:,-2]) * self.__Gini(data_left) + \
np.sum(data_right[:,-2])/np.sum(data[:,-2]) * self.__Gini(data_right)
# ...
| tree/add_param.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .r
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# ---
# + [markdown] colab_type="text" id="6dHNH184MplP"
# Authored by: <NAME>
#
# http://xcorr.net/
#
# Our aim is to fit a maximum entropy model for strings. We could use this to:
#
# - Model spelling / create a spell-checker
# - Generate fake words / RhymeMaster 3000
# - Do computational linguistics
#
# Maximum entropy models are generative models of exponential form:
#
# $p(x|\theta) = \frac {1}{Z(\theta)} \exp(\phi(x)^T \theta )$
#
# Where $Z(\theta)$ is a normalization constant:
#
# $Z(\theta) = \int \exp( \phi(x)^T \theta ) dx$
#
# The gradient of the log-likelihood will be:
#
# $\nabla L \equiv \frac{\partial \log p(x|\theta)}{\partial \theta} = \phi(x)^T \theta - \frac{ \partial \log(Z(\theta)) } { \partial \theta}$
#
# Taking the partial derivative in the second expression, we find:
#
# $\nabla L = \phi(x)^T \theta - \mathbb{E} (\phi(x))$
#
# The expected value on the right hand side is tricky to evaluate. The idea behind contrastive divergence and variants is to compute the expectation in this expression via several independent Markov chains. *Persistent* constrastive divergence means that we won't reset our Markov chains between gradient descent iterations -- although the distribution we need to sample from changes between GD iterations, it changes very slowly. One can prove mathematically that sampling this way converges to the correct ML estimate.
#
# For illustrative purposes, we'll limit our attention to sampling from fixed length strings -- sampling from non-fixed length strings is more annoying, but not necessarily more informative.
# + [markdown] colab_type="text" id="p83zKdZHg0KP"
# # Sampling from fixed-length strings
#
# Let's start by creating a sampler over fixed-length strings. We will use a Metropolis-Hastings (MH) proposal within a Gibbs sampler. What this means:
#
# - Gibbs: resample one character at a time at each iteration
# - MH: sample a tokeb from a proposal distribution and adjust based on the density function
# - Important life lesson: code the MH sampler on a log scale otherwise numerical problems ensue.
#
# Let's do this a dummy density function and verify that we're sampling from the right distribution -- it's very easy to mess up and sample from the wrong distro. Don't do it!
# + cellView="both" colab={"autoexec": {"startup": false, "wait_interval": 0}, "output_extras": []} colab_type="code" executionInfo={"elapsed": 843, "status": "ok", "timestamp": 1457681318876, "user": {"color": "#1FA15D", "displayName": "<NAME>", "isAnonymous": false, "isMe": true, "permissionId": "00759584880725894106", "photoUrl": "//lh3.googleusercontent.com/-CdPTZM1TPbU/AAAAAAAAAAI/AAAAAAAAABQ/MOmbIGKtlQA/s50-c-k-no/photo.jpg", "sessionId": "ab1f0339c96f28e", "userId": "103444865736961301998"}, "user_tz": 480} id="7LLOV3ngxxFu" outputId="9c98dd8c-7f6c-4f8e-8f6d-ca9b0e3cbd56"
import itertools
import numpy as np
import collections
class FixedLengthGMHMC:
"""Fixed-length string Gibbs-sampling Metropolis-Hastings Markov chain.
This class samples from a distribution over string variables of length str_len.
It only works on ASCII (or ISO-8859-1).
It does that by Gibbs sampling, one character at a time. It uses Metropolis
Hastings to sample from the marginal distribution of the next character using
a proposal distribution log_proposal_dist. The Q function is density_fun.
"""
def __init__(self,
str_len,
proposal_dist, # For individual letter
log_density_fun):
self.proposal_dist = proposal_dist
self.log_density_fun = log_density_fun
self.str_len = str_len
self.num_accepted = 0
self.num_tried = 0
def take_first_sample(self):
# Take a sample from the proposal distribution to start with
chars = []
for i in range(self.str_len):
chars.append(chr(
np.where(np.random.multinomial(1, self.proposal_dist))[0]))
chars = ''.join(chars)
self.last_sample = chars
self.last_sample_log_density = self.log_density_fun(chars)
def sample(self):
# Take a sample from the conditional distribution of the
# str_pos character via MH
# Pick which character to resample at random
str_pos = np.int(np.random.rand()*self.str_len)
# Sample a char from the proposal distribution
new_char = chr(np.where(np.random.multinomial(1, self.proposal_dist))[0])
# Splice it in
new_sample = (self.last_sample[:str_pos] +
new_char +
self.last_sample[str_pos+1:])
new_sample_log_density = self.log_density_fun(new_sample)
# We're doing everything on the log scale for numerical stability
alpha1 = np.exp(new_sample_log_density - self.last_sample_log_density)
# Q(x | x') / Q(x' | x)
old_char = self.last_sample[str_pos]
alpha2 = (self.proposal_dist[ord(old_char)] /
self.proposal_dist[ord(new_char)])
# Acceptance ratio
alpha = min(alpha1*alpha2, 1.0)
# Draw a binomial sample to decide whether to accept
accept = np.random.rand() < alpha
if accept:
self.last_sample = new_sample
self.last_sample_log_density = new_sample_log_density
self.num_accepted += 1
self.num_tried += 1
# + cellView="both" colab={"autoexec": {"startup": false, "wait_interval": 0}, "output_extras": [{"item_id": 1}]} colab_type="code" executionInfo={"elapsed": 1014, "status": "ok", "timestamp": 1457681363139, "user": {"color": "#1FA15D", "displayName": "<NAME>", "isAnonymous": false, "isMe": true, "permissionId": "00759584880725894106", "photoUrl": "//lh3.googleusercontent.com/-CdPTZM1TPbU/AAAAAAAAAAI/AAAAAAAAABQ/MOmbIGKtlQA/s50-c-k-no/photo.jpg", "sessionId": "ab1f0339c96f28e", "userId": "103444865736961301998"}, "user_tz": 480} id="lqZnawsf1HjY" outputId="e837aeea-d2e5-43b7-f105-f3085d606332"
# Test out the sampler on an example density on the letters
# ABab
def sample_log_density(arr):
# Is the initial letter an uppercase letter?
phi0 = (arr[0] == 'A' or
arr[0] == 'B')
# Does the second letter follow the first letter? e.g. 'ab'
phi1 = ord(arr[1]) - ord(arr[0]) == 1
return phi0 * 1.0 + phi1 * 1.5
# Compute the probability of every length 2 string containing the characters
# abAB
charset = 'abAB'
str_len = 2
ps = {}
for the_str in itertools.product(charset, repeat=str_len):
the_str = the_str[0] + the_str[1]
ps[the_str] = np.exp(sample_log_density(the_str))
# Create a non-uniform proposal distribution, because subtle bugs can lurk
# in the way we've coded up Q(x|x') / Q(x'|x)
proposal_distro = [(chr(x) in charset) / (1.0 + float(x)) for x in range(128)]
proposal_distro = [x / sum(proposal_distro) for x in proposal_distro]
sampler = FixedLengthGMHMC(str_len, proposal_distro, sample_log_density)
sampler.take_first_sample()
samples = []
# Take some samples
for i in range(10000):
sampler.sample()
samples.append(sampler.last_sample)
# Look at empirical distribution of samples
cnt = collections.Counter(samples)
# Concatenate the results
distros = np.array([[y, cnt[x]] for x, y in ps.iteritems()])
# Normalize
distros = distros / distros.sum(0).reshape((1,-1))
print 'String | Exact p(x)*1000 | Sample p(x)*1000'
print '\n'.join(['%s % 8d % 8d' % (x, y[0], y[1]) for x, y in
zip(ps.keys(), np.round(distros*1000))])
max_rel_disc = max(abs(.5 * (distros[:,0] - distros[:,1]) /
(distros[:,0] + distros[:,1])))
print 'Max relative discrepancy: %.3f' % max_rel_disc
# relative discrepancy should not be much higher than 6%
assert( max_rel_disc < .06)
print ('Acceptance probability: %.3f' % (sampler.num_accepted /
float(sampler.num_tried)))
# That looks good.
# + [markdown] colab_type="text" id="Ypf_jz8s15Rx"
# #Persistent contrastive divergence to estimate parameter values
#
# PCD is an algorithm for maximum likelihood estimation of MaxEnt models. It's essentially gradient descent with a twist: the gradient of a MaxEnt model includes a term corresponding to an expected value wrt. the distribution to be fitted. This value is approximated via parallel Markov chains. The Marjov chains are not reset every gradient descent iteration, hence the *persistence*.
# + cellView="both" colab={"autoexec": {"startup": false, "wait_interval": 0}, "output_extras": []} colab_type="code" executionInfo={"elapsed": 678, "status": "ok", "timestamp": 1457678926649, "user": {"color": "#1FA15D", "displayName": "<NAME>", "isAnonymous": false, "isMe": true, "permissionId": "00759584880725894106", "photoUrl": "//lh3.googleusercontent.com/-CdPTZM1TPbU/AAAAAAAAAAI/AAAAAAAAABQ/MOmbIGKtlQA/s50-c-k-no/photo.jpg", "sessionId": "ab1f0339c96f28e", "userId": "103444865736961301998"}, "user_tz": 480} id="341Wc9X4e4hv" outputId="c46706a2-8ea8-476e-db70-cbff8d75c21e"
# %matplotlib inline
import matplotlib.pyplot as plt
# + cellView="both" colab={"autoexec": {"startup": false, "wait_interval": 0}} colab_type="code" id="fHG5Ls_30x--"
class FixedLengthPCD:
"""Stores a run of persistent contrastive divergence. Some features of this
version of PCD:
- Uses a sequence of etas to gradient descent for better convergence.
- Uses RMSProp update rule
"""
def __init__(self,
words,
feature_fun,
S_chains = 10):
"""Initializes PCD on a given vocabulary.
Args:
words: a list of strings, all of the same size
feature_fun: a function which takes a string and returns an array of
features
S_chains: the number of parallel chains to use for PCD
"""
self.words = words
self.feature_fun = feature_fun
self.S_chains = S_chains
self.init_measurements()
self.init_params()
self.init_chains()
def init_measurements(self):
"""Make some measurements on the vocabulary"""
max_str_len = max(len(w) for w in self.words)
min_str_len = min(len(w) for w in self.words)
if min_str_len != max_str_len:
raise Error('This class only works for fixed-length strings')
# Compute the empirical distribution of tokens
all_chars = ''.join(self.words)
proposal_dist,_ = np.histogram(np.array([ord(x) for x in all_chars]),
bins=range(128))
proposal_dist = proposal_dist / np.float(proposal_dist.sum())
# Moment matching
X = np.array([self.feature_fun(w) for w in self.words])
phi_c = X.mean(0)
self.proposal_dist = proposal_dist
self.str_len = min_str_len
self.phi_c = phi_c
self.n_features = phi_c.size
def log_density_fun(self, word):
"""Returns the log density of a word, i.e. the inner product of the features
and the parameters"""
phi = self.feature_fun(word)
return phi.dot(self.theta)
def get_new_sampler(self):
"""Create a sampler from current set of parameters"""
s = FixedLengthGMHMC(self.str_len,
self.proposal_dist,
self.log_density_fun)
s.take_first_sample()
return s
def init_chains(self):
# Initialize MCMC chains
chains = []
for i in range(self.S_chains):
s = self.get_new_sampler()
chains.append(s)
self.chains = chains
def init_params(self):
# Initialize parameters
sd = .1
# Alternatively, we could use a crude estimate as an initializer
self.theta = sd * (np.random.randn(self.n_features) /
np.sqrt(self.n_features))
def run(self,
etas = [0.1],
k_steps_per = 5,
T = 100,
rms_prop_alpha = .9,
display_every = 1):
"""Run a number of persistent contrastive divergence iterations.
Args:
etas: a list of learning rates to use
k_steps_per: the number of MCMC steps to take per gradient descent
iteration
T: the number of gradient descent iterations
rms_prop_alpha: the decay rate of RMSProp being used
Returns:
(thetas, gnorm, likelihoods): sequences of (parameters,
norm of the gradient, likelihoods)
"""
# Fudge factor for RMSProp
ff = 0.001
thetas = np.zeros((T, self.n_features))
gnorms = np.zeros((T))
gnorms_adjusted = np.zeros((T))
likes = np.zeros((T))
running_g = np.ones((self.n_features))
for t in range(T):
which_eta = (t * len(etas)) / T
eta = etas[which_eta]
# Sample for a few steps
for s in self.chains:
for m in range(k_steps_per):
s.sample()
X_ = np.array([self.feature_fun(s.last_sample) for s in self.chains])
phi_t = X_.mean(0)
# Gradient
g = self.phi_c - phi_t
# Gradient ascent
# Use an RMSGrad update for more consistent convergence
gg = eta* (g / (ff + np.sqrt(running_g)))
self.theta = self.theta + gg
thetas[t,:] = self.theta
running_g = running_g*rms_prop_alpha + g**2
# Monitor convergence
gnorms[t] = np.sqrt((g**2).sum())
gnorms_adjusted[t] = np.sqrt((gg**2).sum())
# Evaluate model likelihood
like = sum(np.exp(np.array(
[self.log_density_fun(w) for w in self.words]))) / float(len(self.words))
likes[t] = like
if t % display_every == 0:
print "Iteration %04d, log likelihood = %.8f" % (t, like)
return thetas, gnorms, gnorms_adjusted, likes
# + cellView="both" colab={"autoexec": {"startup": false, "wait_interval": 0}} colab_type="code" id="TgSrXTSCnaQt"
def sample_feature_fun(arr):
# Is the initial letter an uppercase letter?
phi0 = (arr[0] == 'A' or
arr[0] == 'B')
# Does the second letter follow the first letter? e.g. 'ab'
phi1 = ord(arr[1]) - ord(arr[0]) == 1
return np.array([phi0*1.0, phi1*1.0])
# Draw some words
nsamples = 1000
keys = np.random.multinomial(nsamples, distros[:,0])
words = ps.keys()
vocab = list(itertools.chain(*[[words[i]]*k for i, k in enumerate(keys)]))
pcd = FixedLengthPCD(vocab,
sample_feature_fun,
S_chains = 100)
convergence = pcd.run(T = 600,
etas = [.1, 0.03, .01],
k_steps_per = 1,
rms_prop_alpha = 0.9,
display_every = 100)
# Plot some indices of convergence
plt.subplot(411)
plt.plot(convergence[0])
plt.title('theta')
plt.subplot(412)
plt.plot(convergence[1])
plt.xlabel('Iteration')
plt.title('||g||')
plt.subplot(413)
plt.plot(convergence[2])
plt.xlabel('Iteration')
plt.title('||g_a||')
plt.subplot(414)
plt.plot(convergence[3])
plt.title('likelihood')
print "Actual parameters"
print np.array([1.0, 1.5])
print "Estimated parameters"
print pcd.theta
samples = []
sampler = pcd.get_new_sampler()
sampler.proposal_dist = proposal_distro
for i in range(10000):
sampler.sample()
samples.append(sampler.last_sample)
# Look at empirical distribution of samples
cnt = collections.Counter(samples)
# Concatenate the results
distros_ = np.array([[y, cnt[x]] for x, y in ps.iteritems()])
# Normalize
distros_ = distros_ / distros_.sum(0).reshape((1,-1))
print 'String | Exact p(x)*1000 | Sample p(x)*1000'
print '\n'.join(['%s % 8d % 8d' % (x, y[0], y[1]) for x, y in
zip(ps.keys(), np.round(distros_*1000))])
max_rel_disc = max(abs(.5 * (distros_[:,0] - distros_[:,1]) /
(distros_[:,0] + distros_[:,1])))
print 'Max relative discrepancy: %.3f' % max_rel_disc
# + [markdown] colab_type="text" id="Q0J83HaPnhkc"
# # Run on real data
#
# Let's fit a toy spelling model with features like the number of each letter, whether a vowel is followed by a consonant, etc. for all the 7-letter words in the Wikipedia article on machine learning. We'll add a global feature that determines whether the word is "machine".
# + cellView="both" colab={"autoexec": {"startup": false, "wait_interval": 0}, "output_extras": []} colab_type="code" executionInfo={"elapsed": 613, "status": "ok", "timestamp": 1457682301818, "user": {"color": "#1FA15D", "displayName": "<NAME>", "isAnonymous": false, "isMe": true, "permissionId": "00759584880725894106", "photoUrl": "//lh3.googleusercontent.com/-CdPTZM1TPbU/AAAAAAAAAAI/AAAAAAAAABQ/MOmbIGKtlQA/s50-c-k-no/photo.jpg", "sessionId": "ab1f0339c96f28e", "userId": "103444865736961301998"}, "user_tz": 480} id="IhaHvfDgngvr" outputId="6e382b17-e015-4429-a074-36e9c2670a1f"
words = ['Machine', 'evolved', 'pattern', 'defined', 'machine', 'ability', 'without', 'Machine', 'operate', 'example', 'program', 'Machine', 'closely', 'related', 'focuses', 'through', 'domains', 'Machine', 'Example', 'include', 'optical', 'engines', 'vision.', 'Machine', 'focuses', 'quoted,', 'program', 'respect', 'measure', 'notable', 'machine', 'think?"', 'do?"[9]', 'Machine', 'system.', 'are[10]', 'example', 'desired', 'general', 'leaving', 'towards', 'program', 'dynamic', 'perform', 'certain', 'driving', 'without', 'teacher', 'telling', 'whether', 'Another', 'example', 'playing', 'against', 'Between', 'teacher', 'signal:', 'outputs', 'special', 'problem', 'targets', 'support', 'machine', 'divides', 'learned', 'machine', 'acquire', 'through', 'Another', 'machine', 'desired', 'divided', 'learner', 'produce', 'assigns', 'tackled', 'example', 'classes', 'outputs', 'divided', 'groups.', 'Density', 'mapping', 'related', 'program', 'similar', 'topics.', 'History', 'machine', 'Already', 'problem', 'various', '"neural', 'medical', 'between', 'machine', 'systems', 'plagued', 'systems', 'leading', 'outside', 'proper,', 'pattern', 'science', 'outside', 'Hinton.', 'success', 'Machine', 'started', 'changed', 'nature.', 'shifted', 'methods', 'Machine', 'methods', 'overlap', 'roughly', 'Machine', 'focuses', 'learned', 'focuses', 'unknown', 'overlap', 'machine', 'machine', 'employs', 'methods', 'improve', 'learner', 'between', 'machine', 'usually', 'respect', 'ability', 'unknown', 'respect', 'typical', 'methods', 'Machine', 'express', 'between', 'trained', 'problem', 'trained', 'predict', 'between', 'machine', 'Machine', 'closely', 'related', 'fields.', 'Michael', 'Jordan,', 'machine', 'science', 'overall', 'Breiman', 'wherein', 'machine', 'forest.', 'adopted', 'methods', 'machine', 'leading', 'learner', 'context', 'ability', 'machine', 'perform', 'unknown', 'learner', 'general', 'enables', 'produce', 'machine', 'science', 'theory.', 'Because', 'usually', 'common.', 'trained', 'unknown', 'complex', 'complex', 'minimum', 'bounds,', 'theory,', 'results', 'certain', 'learned', 'results', 'certain', 'classes', 'learned', 'between', 'machine', 'machine', 'between', 'network', 'network', 'usually', '"neural', 'aspects', 'usually', 'complex', 'between', 'capture', 'unknown', 'between', 'uniform', 'logical', 'program', 'entails', 'related', 'Support', 'Support', 'Support', 'related', 'methods', 'whether', 'example', 'Cluster', 'Cluster', 'subsets', '(called', 'cluster', 'similar', 'defined', 'example', 'between', 'members', 'between', 'methods', 'density', 'network', 'network', 'acyclic', 'acyclic', 'network', 'between', 'network', 'compute', 'various', 'perform', 'actions', 'reward.', 'attempt', 'actions', 'states.', 'differs', 'problem', 'correct', 'actions', 'Several', 'include', 'cluster', 'attempt', 'useful,', 'unknown', 'attempt', 'learned', 'attempt', 'learned', 'zeros).', 'without', 'defined', 'machine', 'factors', 'explain', 'machine', 'similar', 'similar', 'predict', 'objects', 'method,', 'assumed', 'sparse.', 'matrix,', 'solving', 'sparse.', 'assumed', 'freedom', 'NP-hard', 'popular', 'applied', 'several', 'problem', 'classes', 'belongs', 'Suppose', 'already', 'applied', 'Genetic', 'Genetic', 'genetic', 'process', 'natural', 'methods', 'finding', 'machine', 'genetic', 'machine', 'improve', 'genetic', 'machine', 'finance', 'vision,', 'Machine', 'Medical', 'Natural', 'systems', 'engines', 'opinion', 'mining)', 'pattern', 'Finance', 'company', 'Netflix', 'program', 'predict', 'improve', 'Shortly', 'Netflix', 'ratings', 'viewing', 'changed', 'Journal', 'machine', 'predict', 'article', 'machine', 'applied', 'History', 'between']
# + cellView="both" colab={"autoexec": {"startup": false, "wait_interval": 0}, "output_extras": [{"item_id": 11}, {"item_id": 12}]} colab_type="code" executionInfo={"elapsed": 65860, "status": "ok", "timestamp": 1457683062754, "user": {"color": "#1FA15D", "displayName": "<NAME>", "isAnonymous": false, "isMe": true, "permissionId": "00759584880725894106", "photoUrl": <KEY>", "sessionId": "ab1f0339c96f28e", "userId": "103444865736961301998"}, "user_tz": 480} id="MhZd2CNuoM2Y" outputId="b07e7071-4f46-4f99-ee06-243c833b911e"
def compute_features(word):
phis = []
# Check whether the first letter is uppercase
phis.append(1*(word[0] >= 'A' and word[0] <= 'Z'))
# Check whether the other letters are uppercase
phis.append(sum(l >= ord('A') and l <= ord('Z') for l in word[1:]))
# Check whether vowels are followed by consonants
vowels = 'aeiou'
letters = ('abcdefghijklmnopqrstuvwxyz'
'ABCDEFGHIJKLMNOPQRSTUVWXYZ')
phis.append(sum(x in letters and x not in vowels and y in vowels for x,y in
zip(word[:-1], word[1:])))
# Check the number of symbols
phis.append(sum(x not in letters for x in word))
# The number of each letter
phis += [sum(x == y for x in word) for y in letters]
# And whether the word is machine (to add a global feature)
phis.append(word == 'machine' or word == 'Machine')
return np.array(phis)
# Draw some words
pcd = FixedLengthPCD(words,
compute_features,
S_chains = 100)
convergence = pcd.run(T = 1000,
etas = [.1, 0.03, .01],
k_steps_per = 1,
rms_prop_alpha = 0.9,
display_every = 100)
# Plot some indices of convergence
plt.subplot(411)
plt.plot(convergence[0])
plt.title('theta')
plt.subplot(412)
plt.plot(convergence[1])
plt.xlabel('Iteration')
plt.title('||g||')
plt.subplot(413)
plt.plot(convergence[2])
plt.xlabel('Iteration')
plt.title('||g_a||')
plt.subplot(414)
plt.plot(convergence[3])
plt.title('likelihood')
print "Estimated parameters"
print pcd.theta
# + cellView="both" colab={"autoexec": {"startup": false, "wait_interval": 0}, "output_extras": [{"item_id": 1}, {"item_id": 2}]} colab_type="code" executionInfo={"elapsed": 2245, "status": "ok", "timestamp": 1457683148314, "user": {"color": "#1FA15D", "displayName": "<NAME>", "isAnonymous": false, "isMe": true, "permissionId": "00759584880725894106", "photoUrl": "//lh3.googleusercontent.com/-CdPTZM1TPbU/AAAAAAAAAAI/AAAAAAAAABQ/MOmbIGKtlQA/s50-c-k-no/photo.jpg", "sessionId": "ab1f0339c96f28e", "userId": "103444865736961301998"}, "user_tz": 480} id="mCQCiqgcq6RC" outputId="78717327-bc04-4597-c2a7-27b4ef3812e4"
samples = []
sampler = pcd.get_new_sampler()
for i in range(10000):
sampler.sample()
samples.append(sampler.last_sample)
print "Some samples:"
samples[::100]
# + cellView="both" colab={"autoexec": {"startup": false, "wait_interval": 0}, "output_extras": [{"item_id": 1}]} colab_type="code" executionInfo={"elapsed": 628, "status": "ok", "timestamp": 1457683466941, "user": {"color": "#1FA15D", "displayName": "<NAME>", "isAnonymous": false, "isMe": true, "permissionId": "00759584880725894106", "photoUrl": "//lh3.googleusercontent.com/-CdPTZM1TPbU/AAAAAAAAAAI/AAAAAAAAABQ/MOmbIGKtlQA/s50-c-k-no/photo.jpg", "sessionId": "ab1f0339c96f28e", "userId": "103444865736961301998"}, "user_tz": 480} id="Lb4NjJ7Er5Yq" outputId="5d45a1ae-a58e-446b-ae3c-c9681c7cf310"
print 'Most likely word'
print max([(sampler.log_density_fun(x),x) for x in words])
print 'log-likelihod of machine versus machina:'
print (sampler.log_density_fun('machine'),
sampler.log_density_fun('machina'))
print 'Number of machine samples out of 10000:'
print(sum(x == 'machine' for x in samples))
print "Weight for word 'machine'"
print pcd.theta[-1]
# + [markdown] colab_type="text" id="343ONLiisUZl"
# What's interesting is that the model has learned that machine is by far the most likely word -- it's given a huge weight of 14 to the corresponding feature -- but the sampler didn't find it once in 10k samples! If the chain ever stumbled onto the word machine, it would have a 1 in exp(14) chance of getting unstuck! The weight for the word machine is much too large, and this is because the chains don't mix well enough to find such a global feature. We have to be careful about blindly implementing global features then!
| python/demos/maxEntPersistentContrastiveDivergence.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
import sys
module_path = os.path.abspath(os.path.join('..'))
if module_path not in sys.path:
sys.path.append(module_path)
from fast_multipole_method import operation as op
import numpy as np
x = np.array([0.12, 0.13, 0.115])
p = 1
y1 = np.array([0.125, 0.125, 0.125])
r_y1_op = op.cartesian_to_spherical(y1-x)
Olm_y1_op = op.O_expansion(p, r_y1_op)
Olm_y1_op.Vp
Olm_y1_op.Vn
# O expansion on vectors with the oppsite direction are different by:
# if l is odd, flip the sign of real part
# if l is even, flip the sign of image part
y1 = np.array([0.125, 0.125, 0.125])
r_y1 = op.cartesian_to_spherical(x - y1)
Olm_y1 = op.O_expansion(p, r_y1)
Olm_y1.Vp
y2 = np.array([0.25, 0.25, 0.25])
r_y2 = op.cartesian_to_spherical(x-y2)
Olm_y2 = op.O_expansion(p, r_y2)
y21 = y1 - y2
y12 = y2 - y1
Olm_y1_t = op.O_to_O(Olm_y2, y12)
Olm_y1_t.Vp
Olm_y1_t.Vn
op.Olm_X12_to_X21(Olm_y1)
Olm_y1.Vn
Olm_t = op.O_expansion(p, op.cartesian_to_spherical(Y12))
Olm_t.Vp
Olm_t.Vn
y2 = np.array([0.25, 0.25, 0.25])
r_y2 = op.cartesian_to_spherical(x-y2)
Olm_y2 = op.O_expansion(p, r_y2)
Olm_y2.Vp
Olm_y2.Vn
p=0
y3 = np.array([0.75, 0.75, 0.75])
r_y3 = op.cartesian_to_spherical(y3-y3)
Mlm_y3 = op.M_expansion(p, r_y3)
Mlm_y3.V_matrix
Mlm_y3.Vn
Y31 = y1 - y3
Mlm_y3_t = op.O_to_M(Olm_y1, Y31)
Mlm_y3_t.Vp
y4 = np.array([0.875, 0.875, 0.875])
r_y4 = op.cartesian_to_spherical(x-y4)
Mlm_y4 = op.M_expansion(p, r_y4)
Mlm_y4.Vp
Y34 = y4 - y3
Mlm_y4_t = op.M_to_M(Mlm_y3, Y34)
Mlm_y4_t.Vp
Mlm_y4.Vp
x = np.array([0.1, 0.1, 0.1])
op.cartesian_to_spherical(x)
x = [0.1, 0.1, 0.1]
op.cartesian_to_spherical(x)
r_power = np.power(r[])
| CFMM_for_DFT/tests/test_operation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## [4.3 并行计算](http://www-inst.eecs.berkeley.edu/~cs61a/sp12/book/communication.html#parallel-computing)
#
# 计算机每一年都会变得越来越快。在 1965 年,英特尔联合创始人戈登·摩尔预测了计算机将如何随时间而变得越来越快。仅仅基于五个数据点,他推测,一个芯片中的晶体管数量每两年将翻一倍。近50年后,他的预测仍惊人地准确,现在称为摩尔定律。
#
# 尽管速度在爆炸式增长,计算机还是无法跟上可用数据的规模。根据一些估计,基因测序技术的进步将使可用的基因序列数据比处理器变得更快的速度还要快。换句话说,对于遗传数据,计算机变得越来越不能处理每年需要处理的问题规模,即使计算机本身变得越来越快。
#
# 为了规避对单个处理器速度的物理和机械约束,制造商正在转向另一种解决方案:多处理器。如果两个,或三个,或更多的处理器是可用的,那么许多程序可以更快地执行。当一个处理器在做一些计算的一个切面时,其他的可以在另一个切面工作。所有处理器都可以共享相同的数据,但工作并行执行。
#
#
# 为了能够合作,多个处理器需要能够彼此共享信息。这通过使用共享内存环境来完成。该环境中的变量、对象和数据结构对所有的进程可见。处理器在计算中的作用是执行编程语言的求值和执行规则。在一个共享内存模型中,不同的进程可能执行不同的语句,但任何语句都会影响共享环境。
#
# ### 4.3.1 共享状态的问题
#
# 多个进程之间的共享状态具有单一进程环境没有的问题。要理解其原因,让我们看看下面的简单计算:
x = 5
x = square(x)
x = x + 1
# `x`的值是随时间变化的。起初它是 5,一段时间后它是 25,最后它是 26。在单一处理器的环境中,没有时间依赖性的问题。`x`的值在结束时总是 26。但是如果存在多个进程,就不能这样说了。假设我们并行执行了上面代码的最后两行:一个处理器执行`x = square(x)`而另一个执行`x = x + 1`。每一个这些赋值语句都包含查找当前绑定到`x`的值,然后使用新值更新绑定。让我们假设`x`是共享的,同一时间只有一个进程读取或写入。即使如此,读和写的顺序可能会有所不同。例如,下面的例子显示了两个进程的每个进程的一系列步骤,`P1`和`P2`。每一步都是简要描述的求值过程的一部分,随时间从上到下执行:
# ```
# P1 P2
# read x: 5
# read x: 5
# calculate 5*5: 25 calculate 5+1: 6
# write 25 -> x
# write x-> 6
# ```
# 在这个顺序中,`x`的最终值为 6。如果我们不协调这两个过程,我们可以得到另一个顺序的不同结果:
# ```
# P1 P2
# read x: 5
# read x: 5 calculate 5+1: 6
# calculate 5*5: 25 write x->6
# write 25 -> x
# ```
# 在这个顺序中,`x`将是 25。事实上存在多种可能性,这取决于进程执行代码行的顺序。`x`的最终值可能最终为 5,25,或预期值 26。
#
# 前面的例子是无价值的。`square(x)`和`x = x + 1`是简单快速的计算。我们强迫一条语句跑在另一条的后面,并不会失去太多的时间。但是什么样的情况下,并行化是必不可少的?这种情况的一个例子是银行业。在任何给定的时间,可能有成千上万的人想用他们的银行账户进行交易:他们可能想在商店刷卡,存入支票,转帐,或支付账单。即使一个帐户在同一时间也可能有活跃的多个交易。
#
# 让我们看看第二章的`make_withdraw`函数,下面是修改过的版本,在更新余额之后打印而不是返回它。我们感兴趣的是这个函数将如何并发执行。
def make_withdraw(balance):
def withdraw(amount):
nonlocal balance
if amount > balance:
print('Insufficient funds')
else:
balance = balance - amount
print(balance)
return withdraw
# 现在想象一下,我们以 10 美元创建一个帐户,让我们想想,如果我们从帐户中提取太多的钱会发生什么。如果我们顺序执行这些交易,我们会收到资金不足的消息。
w = make_withdraw(10)
w(8)
w(7)
# 但是,在并行中可以有许多不同的结果。下面展示了一种可能性:
# ```
# P1: w(8) P2: w(7)
# read balance: 10
# read amount: 8 read balance: 10
# 8 > 10: False read amount: 7
# if False 7 > 10: False
# 10 - 8: 2 if False
# write balance -> 2 10 - 7: 3
# read balance: 2 write balance -> 3
# print 2 read balance: 3
# print 3
# ```
# 这个特殊的例子给出了一个不正确结果 3。就好像`w(8)`交易从来没有发生过。其他可能的结果是 2,和`'Insufficient funds'`。这个问题的根源是:如果`P2` 在`P1`写入值前读取余额,`P2`的状态是不一致的(反之亦然)。`P2`所读取的余额值是过时的,因为`P1`打算改变它。`P2`不知道,并且会用不一致的值覆盖它。
#
# 这个例子表明,并行化的代码不像把代码行分给多个处理器来执行那样容易。变量读写的顺序相当重要。
#
# 一个保证执行正确性的有吸引力的方式是,两个修改共享数据的程序不能同时执行。不幸的是,对于银行业这将意味着,一次只可以进行一个交易,因为所有的交易都修改共享数据。直观地说,我们明白,让 2 个不同的人同时进行完全独立的帐户交易应该没有问题。不知何故,这两个操作不互相干扰,但在同一帐户上的相同方式的同时操作就相互干扰。此外,当进程不读取或写入时,让它们同时运行就没有问题。
#
# ### 4.3.2 并行计算的正确性
#
# 并行计算环境中的正确性有两个标准。第一个是,结果应该总是相同。第二个是,结果应该和串行执行的结果一致。
#
# 第一个条件表明,我们必须避免在前面的章节中所示的变化,其中在不同的方式下的交叉读写会产生不同的结果。例子中,我们从 10 美元的帐户取出了`w(8)`和`w(7)`。这个条件表明,我们必须始终返回相同的答案,独立于`P1`和`P2`的指令执行顺序。无论如何,我们必须以这样一种方式来编写我们的程序,无论他们如何相互交叉,他们应该总是产生同样的结果。
#
# 第二个条件揭示了许多可能的结果中哪个是正确的。例子中,我们从 10 美元的帐户取出了`w(8)`和`w(7)`,这个条件表明结果必须总是余额不足,而不是 2 或者 3。
#
# 当一个进程在程序的临界区影响另一个进程时,并行计算中就会出现问题。这些都是需要执行的代码部分,它们看似是单一的指令,但实际上由较小的语句组成。一个程序会以一系列原子硬件指令执行,由于处理器的设计,这些是不能被打断或分割为更小单元的指令。为了在并行的情况下表现正确,程序代码的临界区需要具有原子性,保证他们不会被任何其他代码中断。
#
# 为了强制程序临界区在并发下的原子性,需要能够在重要的时刻将进程序列化或彼此同步。序列化意味着同一时间只运行一个进程 -- 这一瞬间就好像串行执行一样。同步有两种形式。首先是互斥,进程轮流访问一个变量。其次是条件同步,在满足条件(例如其他进程完成了它们的任务)之前进程一直等待,之后继续执行。这样,当一个程序即将进入临界区时,其他进程可以一直等待到它完成,然后安全地执行。
#
# ### 4.3.3 保护共享状态:锁和信号量
#
# 在本节中讨论的所有同步和序列化方法都使用相同的基本思想。它们在共享状态中将变量用作信号,所有过程都会理解并遵守它。这是一个相同的理念,允许分布式系统中的计算机协同工作 -- 它们通过传递消息相互协调,根据每一个参与者都理解和遵守的一个协议。
#
# 这些机制不是为了保护共享状态而出现的物理障碍。相反,他们是建立相互理解的基础上。和出现在十字路口的各种方向的车辆能够安全通行一样,是同一种相互理解。这里没有物理的墙壁阻止汽车相撞,只有遵守规则,红色意味着“停止”,绿色意味着“通行”。同样,没有什么可以保护这些共享变量,除非当一个特定的信号表明轮到某个进程了,进程才会访问它们。
#
# **锁。**锁,也被称为互斥体(`mutex`),是共享对象,常用于发射共享状态被读取或修改的信号。不同的编程语言实现锁的方式不同,但是在 Python 中,一个进程可以调用`acquire()`方法来尝试获得锁的“所有权”,然后在使用完共享变量的时候调用`release()`释放它。当进程获得了一把锁,任何试图执行`acquire()`操作的其他进程都会自动等待到锁被释放。这样,同一时间只有一个进程可以获得一把锁。
#
# 对于一把保护一组特定的变量的锁,所有的进程都需要编程来遵循一个规则:一个进程不拥有特定的锁就不能访问相应的变量。实际上,所有进程都需要在锁的`acquire()`和`release()`语句之间“包装”自己对共享变量的操作。
#
# 我们可以把这个概念用于银行余额的例子中。该示例的临界区是从余额读取到写入的一组操作。我们看到,如果一个以上的进程同时执行这个区域,问题就会发生。为了保护临界区,我们需要使用一把锁。我们把这把锁称为`balance_lock`(虽然我们可以命名为任何我们喜欢的名字)。为了锁定实际保护的部分,我们必须确保试图进入这部分时调用`acquire()`获取锁,以及之后调用`release()`释放锁,这样可以轮到别人。
from threading import Lock
def make_withdraw(balance):
balance_lock = Lock()
def withdraw(amount):
nonlocal balance
# try to acquire the lock
balance_lock.acquire()
# once successful, enter the critical section
if amount > balance:
print("Insufficient funds")
else:
balance = balance - amount
print(balance)
# upon exiting the critical section, release the lock
balance_lock.release()
# 如果我们建立和之前一样的情形:
# ```py
# w = make_withdraw(10)
# ```
# 现在就可以并行执行`w(8)`和`w(7)`了:
# ```
# P1 P2
# acquire balance_lock: ok
# read balance: 10 acquire balance_lock: wait
# read amount: 8 wait
# 8 > 10: False wait
# if False wait
# 10 - 8: 2 wait
# write balance -> 2 wait
# read balance: 2 wait
# print 2 wait
# release balance_lock wait
# acquire balance_lock:ok
# read balance: 2
# read amount: 7
# 7 > 2: True
# if True
# print 'Insufficient funds'
# release balance_lock
# ```
# 我们看到了,两个进程同时进入临界区是可能的。某个进程实例获取到了`balance_lock`,另一个就得等待,直到那个进程退出了临界区,它才能开始执行。
#
# 要注意程序不会自己终止,除非`P1`释放了`balance_lock`。如果它没有释放`balance_lock`,`P2`永远不可能获取它,而是一直会等待。忘记释放获得的锁是并行编程中的一个常见错误。
#
# **信号量。**信号量是用于维持有限资源访问的信号。它们和锁类似,除了它们可以允许某个限制下的多个访问。它就像电梯一样只能够容纳几个人。一旦达到了限制,想要使用资源的进程就必须等待。其它进程释放了信号量之后,它才可以获得。
#
# 例如,假设有许多进程需要读取中心数据库服务器的数据。如果过多的进程同时访问它,它就会崩溃,所以限制连接数量就是个好主意。如果数据库只能同时支持`N=2`的连接,我们就可以以初始值`N=2`来创建信号量。
from threading import Semaphore
db_semaphore = Semaphore(2) # set up the semaphore
database = []
def insert(data):
db_semaphore.acquire() # try to acquire the semaphore
database.append(data) # if successful, proceed
db_semaphore.release() # release the semaphore
insert(7)
insert(8)
insert(9)
# 信号量的工作机制是,所有进程只在获取了信号量之后才可以访问数据库。只有`N=2`个进程可以获取信号量,其它的进程都需要等到其中一个进程释放了信号量,之后在访问数据库之前尝试获取它。
# ```
# P1 P2 P3
# acquire db_semaphore: ok acquire db_semaphore: wait acquire db_semaphore: ok
# read data: 7 wait read data: 9
# append 7 to database wait append 9 to database
# release db_semaphore: ok acquire db_semaphore: ok release db_semaphore: ok
# read data: 8
# append 8 to database
# release db_semaphore: ok
# ```
# 值为 1 的信号量的行为和锁一样。
#
# ### 4.3.4 保持同步:条件变量
#
# 条件变量在并行计算由一系列步骤组成时非常有用。进程可以使用条件变量,来用信号告知它完成了特定的步骤。之后,等待信号的其它进程就会开始它们的任务。一个需要逐步计算的例子就是大规模向量序列的计算。在计算生物学,Web 范围的计算,和图像处理及图形学中,常常需要处理非常大型(百万级元素)的向量和矩阵。想象下面的计算:
#
# 
#
# 我们可以通过将矩阵和向量按行拆分,并把每一行分配到单独的线程上,来并行处理每一步。作为上面的计算的一个实例,想象下面的简单值:
#
# 
#
# 我们将前一半(这里是第一行)分配给一个线程,后一半(第二行)分配给另一个线程:
#
# 
#
# 在伪代码中,计算是这样的:
# +
def do_step_1(index):
A[index] = B[index] + C[index]
def do_step_2(index):
V[index] = M[index] . A
# -
# 进程 1 执行了:
do_step_1(1)
do_step_2(1)
# 进程 2 执行了:
do_step_1(2)
do_step_2(2)
# 如果允许不带同步处理,就造成下面的不一致性:
# ```py
# P1 P2
# read B1: 2
# read C1: 0
# calculate 2+0: 2
# write 2 -> A1 read B2: 0
# read M1: (1 2) read C2: 5
# read A: (2 0) calculate 5+0: 5
# calculate (1 2).(2 0): 2 write 5 -> A2
# write 2 -> V1 read M2: (1 2)
# read A: (2 5)
# calculate (1 2).(2 5):12
# write 12 -> V2
# ```
# 问题就是`V`直到所有元素计算出来时才会计算出来。但是,`P1`在`A`的所有元素计算出来之前,完成`A = B+C`并且移到`V = MA`。所以它与`M`相乘时使用了`A`的不一致的值。
#
# 我们可以使用条件变量来解决这个问题。
#
# **条件变量**是表现为信号的对象,信号表示某个条件被满足。它们通常被用于协调进程,这些进程需要在继续执行之前等待一些事情的发生。需要满足一定条件的进程可以等待一个条件变量,直到其它进程修改了条件变量来告诉它们继续执行。
#
# Python 中,任何数量的进程都可以使用`condition.wait()`方法,用信号告知它们正在等待某个条件。在调用该方法之后,它们会自动等待到其它进程调用了`condition.notify()`或`condition.notifyAll()`函数。`notify()`方法值唤醒一个进程,其它进程仍旧等待。`notifyAll()`方法唤醒所有等待中的进程。每个方法在不同情形中都很实用。
#
# 由于条件变量通常和决定条件是否为真的共享变量相联系,它们也提供了`acquire()`和`release()`方法。这些方法应该在修改可能改变条件状态的变量时使用。任何想要用信号告知条件已经改变的进程,必须首先使用`acquire()`来访问它。
#
# 在我们的例子中,在执行第二步之前必须满足的条件是,两个进程都必须完成了第一步。我们可以跟踪已经完成第一步的进程数量,以及条件是否被满足,通过引入下面两个变量:
step1_finished = 0
start_step2 = Condition()
# 我们在`do_step_2`的开头插入`start_step_2().wait()`。每个进程都会在完成步骤 1 之后自增`step1_finished`,但是我们只会在`step_1_finished = 2`时发送信号。下面的伪代码展示了它:
# +
step1_finished = 0
start_step2 = Condition()
def do_step_1(index):
A[index] = B[index] + C[index]
# access the shared state that determines the condition status
start_step2.acquire()
step1_finished += 1
if(step1_finished == 2): # if the condition is met
start_step2.notifyAll() # send the signal
#release access to shared state
start_step2.release()
def do_step_2(index):
# wait for the condition
start_step2.wait()
V[index] = M[index] . A
# -
# 在引入条件变量之后,两个进程会一起进入步骤 2,像下面这样:
# ```
# P1 P2
# read B1: 2
# read C1: 0
# calculate 2+0: 2
# write 2 -> A1 read B2: 0
# acquire start_step2: ok read C2: 5
# write 1 -> step1_finished calculate 5+0: 5
# step1_finished == 2: false write 5-> A2
# release start_step2: ok acquire start_step2: ok
# start_step2: wait write 2-> step1_finished
# wait step1_finished == 2: true
# wait notifyAll start_step_2: ok
# start_step2: ok start_step2:ok
# read M1: (1 2) read M2: (1 2)
# read A:(2 5)
# calculate (1 2). (2 5): 12 read A:(2 5)
# write 12->V1 calculate (1 2). (2 5): 12
# write 12->V2
# ```
# 在进入`do_step_2`的时候,`P1`需要在`start_step_2`之前等待,直到`P2`自增了`step1_finished`,发现了它等于 2,之后向条件发送信号。
#
# ### 4.3.5 死锁
#
# 虽然同步方法对保护共享状态十分有效,但它们也带来了麻烦。因为它们会导致一个进程等待另一个进程,这些进程就有**死锁**的风险。死锁是一种情形,其中两个或多个进程被卡住,互相等待对方完成。我们已经提到了忘记释放某个锁如何导致进程无限卡住。但是即使`acquire()`和`release()`调用的数量正确,程序仍然会构成死锁。
#
# 死锁的来源是**循环等待**,像下面展示的这样。没有进程能够继续执行,因为它们正在等待其它进程,而其它进程也在等待它完成。
#
# 
#
# 作为一个例子,我们会建立两个进程的死锁。假设有两把锁,`x_lock`和`y_lock`,并且它们像这样使用:
x_lock = Lock()
y_lock = Lock()
x = 1
y = 0
def compute():
x_lock.acquire()
y_lock.acquire()
y = x + y
x = x * x
y_lock.release()
x_lock.release()
def anti_compute():
y_lock.acquire()
x_lock.acquire()
y = y - x
x = sqrt(x)
x_lock.release()
y_lock.release()
# 如果`compute()`和`anti_compute()`并行执行,并且恰好像下面这样互相交错:
# ```
# P1 P2
# acquire x_lock: ok acquire y_lock: ok
# acquire y_lock: wait acquire x_lock: wait
# wait wait
# wait wait
# wait wait
# ... ...
# ```
# 所产生的情形就是死锁。`P1`和`P2`每个都持有一把锁,但是它们需要两把锁来执行。`P1`正在等待`P2`释放`y_lock`,而`P2`正在等待`P1`释放`x_lock`。所以,没有进程能够继续执行。
| Chapter 4/Section 4.3.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.8.1 32-bit
# name: python3
# ---
# ## Pumpkin Varieties and Color
#
# Load up required libraries and dataset. Convert the data to a dataframe containing a subset of the data:
#
# Let's look at the relationship between color and variety
# +
import pandas as pd
import numpy as np
pumpkins = pd.read_csv('../data/US-pumpkins.csv')
pumpkins.head()
# +
from sklearn.preprocessing import LabelEncoder
new_columns = ['Color','Origin','Item Size','Variety','City Name','Package']
new_pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1)
new_pumpkins.dropna(inplace=True)
new_pumpkins = new_pumpkins.apply(LabelEncoder().fit_transform)
new_pumpkins.info
# +
import seaborn as sns
g = sns.PairGrid(new_pumpkins)
g.map(sns.scatterplot)
| 2-Regression/4-Logistic/notebook.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# # Machine Learning Engineer Nanodegree
# ## Introduction and Foundations
# ## Project: Titanic Survival Exploration
#
# In 1912, the ship RMS Titanic struck an iceberg on its maiden voyage and sank, resulting in the deaths of most of its passengers and crew. In this introductory project, we will explore a subset of the RMS Titanic passenger manifest to determine which features best predict whether someone survived or did not survive. To complete this project, you will need to implement several conditional predictions and answer the questions below. Your project submission will be evaluated based on the completion of the code and your responses to the questions.
# > **Tip:** Quoted sections like this will provide helpful instructions on how to navigate and use an iPython notebook.
# # Getting Started
# To begin working with the RMS Titanic passenger data, we'll first need to `import` the functionality we need, and load our data into a `pandas` DataFrame.
# Run the code cell below to load our data and display the first few entries (passengers) for examination using the `.head()` function.
# > **Tip:** You can run a code cell by clicking on the cell and using the keyboard shortcut **Shift + Enter** or **Shift + Return**. Alternatively, a code cell can be executed using the **Play** button in the hotbar after selecting it. Markdown cells (text cells like this one) can be edited by double-clicking, and saved using these same shortcuts. [Markdown](http://daringfireball.net/projects/markdown/syntax) allows you to write easy-to-read plain text that can be converted to HTML.
# +
# Import libraries necessary for this project
import numpy as np
import pandas as pd
from IPython.display import display # Allows the use of display() for DataFrames
# Import supplementary visualizations code visuals.py
import visuals as vs
# Pretty display for notebooks
# %matplotlib inline
# Load the dataset
in_file = 'titanic_data.csv'
full_data = pd.read_csv(in_file)
# Print the first few entries of the RMS Titanic data
display(full_data.head())
# -
# From a sample of the RMS Titanic data, we can see the various features present for each passenger on the ship:
# - **Survived**: Outcome of survival (0 = No; 1 = Yes)
# - **Pclass**: Socio-economic class (1 = Upper class; 2 = Middle class; 3 = Lower class)
# - **Name**: Name of passenger
# - **Sex**: Sex of the passenger
# - **Age**: Age of the passenger (Some entries contain `NaN`)
# - **SibSp**: Number of siblings and spouses of the passenger aboard
# - **Parch**: Number of parents and children of the passenger aboard
# - **Ticket**: Ticket number of the passenger
# - **Fare**: Fare paid by the passenger
# - **Cabin** Cabin number of the passenger (Some entries contain `NaN`)
# - **Embarked**: Port of embarkation of the passenger (C = Cherbourg; Q = Queenstown; S = Southampton)
#
# Since we're interested in the outcome of survival for each passenger or crew member, we can remove the **Survived** feature from this dataset and store it as its own separate variable `outcomes`. We will use these outcomes as our prediction targets.
# Run the code cell below to remove **Survived** as a feature of the dataset and store it in `outcomes`.
# +
# Store the 'Survived' feature in a new variable and remove it from the dataset
outcomes = full_data['Survived']
data = full_data.drop('Survived', axis = 1)
# Show the new dataset with 'Survived' removed
display(data.head())
# -
# The very same sample of the RMS Titanic data now shows the **Survived** feature removed from the DataFrame. Note that `data` (the passenger data) and `outcomes` (the outcomes of survival) are now *paired*. That means for any passenger `data.loc[i]`, they have the survival outcome `outcomes[i]`.
#
# To measure the performance of our predictions, we need a metric to score our predictions against the true outcomes of survival. Since we are interested in how *accurate* our predictions are, we will calculate the proportion of passengers where our prediction of their survival is correct. Run the code cell below to create our `accuracy_score` function and test a prediction on the first five passengers.
#
# **Think:** *Out of the first five passengers, if we predict that all of them survived, what would you expect the accuracy of our predictions to be?*
# +
def accuracy_score(truth, pred):
""" Returns accuracy score for input truth and predictions. """
# Ensure that the number of predictions matches number of outcomes
if len(truth) == len(pred):
# Calculate and return the accuracy as a percent
return "Predictions have an accuracy of {:.2f}%.".format((truth == pred).mean()*100)
else:
return "Number of predictions does not match number of outcomes!"
# Test the 'accuracy_score' function
predictions = pd.Series(np.ones(5, dtype = int))
print accuracy_score(outcomes[:5], predictions)
# -
# > **Tip:** If you save an iPython Notebook, the output from running code blocks will also be saved. However, the state of your workspace will be reset once a new session is started. Make sure that you run all of the code blocks from your previous session to reestablish variables and functions before picking up where you last left off.
#
# # Making Predictions
#
# If we were asked to make a prediction about any passenger aboard the RMS Titanic whom we knew nothing about, then the best prediction we could make would be that they did not survive. This is because we can assume that a majority of the passengers (more than 50%) did not survive the ship sinking.
# The `predictions_0` function below will always predict that a passenger did not survive.
# +
def predictions_0(data):
""" Model with no features. Always predicts a passenger did not survive. """
predictions = []
for _, passenger in data.iterrows():
# Predict the survival of 'passenger'
predictions.append(0)
# Return our predictions
return pd.Series(predictions)
# Make the predictions
predictions = predictions_0(data)
# -
# ### Question 1
# *Using the RMS Titanic data, how accurate would a prediction be that none of the passengers survived?*
# **Hint:** Run the code cell below to see the accuracy of this prediction.
print accuracy_score(outcomes, predictions)
# **Answer:** It'd be 61.62%
# ***
# Let's take a look at whether the feature **Sex** has any indication of survival rates among passengers using the `survival_stats` function. This function is defined in the `titanic_visualizations.py` Python script included with this project. The first two parameters passed to the function are the RMS Titanic data and passenger survival outcomes, respectively. The third parameter indicates which feature we want to plot survival statistics across.
# Run the code cell below to plot the survival outcomes of passengers based on their sex.
vs.survival_stats(data, outcomes, 'Sex')
# Examining the survival statistics, a large majority of males did not survive the ship sinking. However, a majority of females *did* survive the ship sinking. Let's build on our previous prediction: If a passenger was female, then we will predict that they survived. Otherwise, we will predict the passenger did not survive.
# Fill in the missing code below so that the function will make this prediction.
# **Hint:** You can access the values of each feature for a passenger like a dictionary. For example, `passenger['Sex']` is the sex of the passenger.
# +
def predictions_1(data):
""" Model with one feature:
- Predict a passenger survived if they are female. """
predictions = []
for _, passenger in data.iterrows():
if passenger['Sex'] == "female":
predictions.append(1)
else:
predictions.append(0)
# Return our predictions
return pd.Series(predictions)
# Make the predictions
predictions = predictions_1(data)
# -
# ### Question 2
# *How accurate would a prediction be that all female passengers survived and the remaining passengers did not survive?*
# **Hint:** Run the code cell below to see the accuracy of this prediction.
print accuracy_score(outcomes, predictions)
# **Answer**: It'd be 78.68%
# ***
# Using just the **Sex** feature for each passenger, we are able to increase the accuracy of our predictions by a significant margin. Now, let's consider using an additional feature to see if we can further improve our predictions. For example, consider all of the male passengers aboard the RMS Titanic: Can we find a subset of those passengers that had a higher rate of survival? Let's start by looking at the **Age** of each male, by again using the `survival_stats` function. This time, we'll use a fourth parameter to filter out the data so that only passengers with the **Sex** 'male' will be included.
# Run the code cell below to plot the survival outcomes of male passengers based on their age.
vs.survival_stats(data, outcomes, 'Age', ["Sex == 'male'"])
# Examining the survival statistics, the majority of males younger than 10 survived the ship sinking, whereas most males age 10 or older *did not survive* the ship sinking. Let's continue to build on our previous prediction: If a passenger was female, then we will predict they survive. If a passenger was male and younger than 10, then we will also predict they survive. Otherwise, we will predict they do not survive.
# Fill in the missing code below so that the function will make this prediction.
# **Hint:** You can start your implementation of this function using the prediction code you wrote earlier from `predictions_1`.
# +
def predictions_2(data):
""" Model with two features:
- Predict a passenger survived if they are female.
- Predict a passenger survived if they are male and younger than 10. """
predictions = []
for _, passenger in data.iterrows():
if passenger['Sex'] == "female" or passenger['Age'] < 10:
predictions.append(1)
else:
predictions.append(0)
# Return our predictions
return pd.Series(predictions)
# Make the predictions
predictions = predictions_2(data)
# -
# ### Question 3
# *How accurate would a prediction be that all female passengers and all male passengers younger than 10 survived?*
# **Hint:** Run the code cell below to see the accuracy of this prediction.
print accuracy_score(outcomes, predictions)
# **Answer**: It'd be 79.35%
# ***
# Adding the feature **Age** as a condition in conjunction with **Sex** improves the accuracy by a small margin more than with simply using the feature **Sex** alone. Now it's your turn: Find a series of features and conditions to split the data on to obtain an outcome prediction accuracy of at least 80%. This may require multiple features and multiple levels of conditional statements to succeed. You can use the same feature multiple times with different conditions.
# **Pclass**, **Sex**, **Age**, **SibSp**, and **Parch** are some suggested features to try.
#
# Use the `survival_stats` function below to to examine various survival statistics.
# **Hint:** To use mulitple filter conditions, put each condition in the list passed as the last argument. Example: `["Sex == 'male'", "Age < 18"]`
# After exploring the survival statistics visualization, fill in the missing code below so that the function will make your prediction.
# Make sure to keep track of the various features and conditions you tried before arriving at your final prediction model.
# **Hint:** You can start your implementation of this function using the prediction code you wrote earlier from `predictions_2`.
vs.survival_stats(data, outcomes, 'Parch', ["Sex == 'male'", "Age < 40"])
# +
def predictFemale(passenger):
if passenger['Sex'] != "female":
raise Exception("Invalid passenger sex to predict.")
if passenger['Pclass'] <=2:
return 1
if passenger['SibSp'] == 0:
return 1
if passenger['Parch'] == 0:
return 1
if passenger['Fare'] >= 70:
return 1
return 0
def predictMale(passenger):
if passenger['Sex'] != "male":
raise Exception("Invalid passenger sex to predict.")
if passenger['Age'] < 10:
return 1
if passenger['Pclass'] == 1 and passenger['Age'] < 18:
return 1
if passenger['SibSp'] == 1 and passenger['Age'] < 15:
return 1
if passenger['Fare'] >= 80 and passenger['Age'] < 18:
return 1
return 0
def predictions_3(data):
""" Model with multiple features. Makes a prediction with an accuracy of at least 80%. """
predictions = []
for _, passenger in data.iterrows():
if passenger['Sex'] == "female":
predictions.append(predictFemale(passenger))
else:
predictions.append(predictMale(passenger))
# Return our predictions
return pd.Series(predictions)
# Make the predictions
predictions = predictions_3(data)
# -
# ### Question 4
# *Describe the steps you took to implement the final prediction model so that it got an accuracy of at least 80%. What features did you look at? Were certain features more informative than others? Which conditions did you use to split the survival outcomes in the data? How accurate are your predictions?*
# **Hint:** Run the code cell below to see the accuracy of your predictions.
print accuracy_score(outcomes, predictions)
# **Answer**: First, I tried to improve the survivors males prediction. To do that I've split the age to be between 0 and 20, and have found that almost all older than 20 did not survive. Also, I've found that most males from upper class younger than 18 survived and youngers than 15 that don't have siblings had also survived. The fare gave me some information too but not so much compared to the age of males. After doing this, I did the same with females. almost all females survived but to increase the accuracy, I had to find who didn't survived. First I took a look at the Class, SibSp and Parch to find patterns. Most females from lower class didn't survived, most of females who survived were alone, without siblings and parents or childrens. This analysis increased the prediction accuracy at 81.48%.
# # Conclusion
#
# After several iterations of exploring and conditioning on the data, you have built a useful algorithm for predicting the survival of each passenger aboard the RMS Titanic. The technique applied in this project is a manual implementation of a simple machine learning model, the *decision tree*. A decision tree splits a set of data into smaller and smaller groups (called *nodes*), by one feature at a time. Each time a subset of the data is split, our predictions become more accurate if each of the resulting subgroups are more homogeneous (contain similar labels) than before. The advantage of having a computer do things for us is that it will be more exhaustive and more precise than our manual exploration above. [This link](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/) provides another introduction into machine learning using a decision tree.
#
# A decision tree is just one of many models that come from *supervised learning*. In supervised learning, we attempt to use features of the data to predict or model things with objective outcome labels. That is to say, each of our data points has a known outcome value, such as a categorical, discrete label like `'Survived'`, or a numerical, continuous value like predicting the price of a house.
#
# ### Question 5
# *Think of a real-world scenario where supervised learning could be applied. What would be the outcome variable that you are trying to predict? Name two features about the data used in this scenario that might be helpful for making the predictions.*
# **Answer**: I'm thinking in a software to predict product demand of an e-commerce. The outcome variable would be the product's number of sales and the features would be the product brand and the product price. Other features like costumer location could also be applied to increase the accuracy.
# > **Note**: Once you have completed all of the code implementations and successfully answered each question above, you may finalize your work by exporting the iPython Notebook as an HTML document. You can do this by using the menu above and navigating to
# **File -> Download as -> HTML (.html)**. Include the finished document along with this notebook as your submission.
| Titanic-Survival-Exploration/src/titanic_survival_exploration.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## RDF
# The radial distribution function (RDF) denoted in equations by g(r) defines the probability of finding a particle at a distance r from another tagged particle. The RDF is strongly dependent on the type of matter so will vary greatly for solids, gases and liquids.
# <img src="../images/rdf.png" width="60%" height="60%">
# As you might have observed the code complexity of the algorithm in $N^{2}$ . Let us get into details of the sequential code. **Understand and analyze** the code present at:
#
# [RDF Serial Code](../../source_code/serial/rdf.f90)
#
# [Makefile](../../source_code/serial/Makefile)
#
# Open the downloaded file for inspection.
# !cd ../../source_code/serial && make clean && make
# We plan to follow the typical optimization cycle that every code needs to go through
# <img src="../images/workflow.png" width="70%" height="70%">
#
# In order analyze the application we we will make use of profiler "nsys" and add "nvtx" marking into the code to get more information out of the serial code. Before running the below cells, let's first start by divining into the profiler lab to learn more about the tools. Using Profiler gives us the hotspots and helps to understand which function is important to be made parallel.
#
# -----
#
# # <div style="text-align: center ;border:3px; border-style:solid; border-color:#FF0000 ; padding: 1em">[Profiling lab](../../../../../profiler/English/jupyter_notebook/profiling.ipynb)</div>
#
# -----
#
# Now, that we are familiar with the Nsight Profiler and know how to [NVTX](../../../../../profiler/English/jupyter_notebook/profiling.ipynb#nvtx), let's profile the serial code and checkout the output.
# !cd ../../source_code/serial&& nsys profile -t nvtx --stats=true --force-overwrite true -o rdf_serial ./rdf
# Once you run the above cell, you should see the following in the terminal.
#
# <img src="../images/serial.jpg" width="70%" height="70%">
#
# To view the profiler report, you would need to [Download the profiler output](../../source_code/serial/rdf_serial.qdrep) and open it via the GUI. For more information on how to open the report via the GUI, please checkout the section on [How to view the report](../../../../../profiler/English/jupyter_notebook/profiling-c.ipynb#gui-report).
#
# From the timeline view, right click on the nvtx row and click the "show in events view". Now you can see the nvtx statistic at the bottom of the window which shows the duration of each range. In the following labs, we will look in to the profiler report in more detail.
#
# <img src="../images/nvtx_serial.jpg" width="100%" height="100%">
#
# The obvious next step is to make **Pair Calculation** algorithm parallel using different approaches to GPU Programming. Please follow the below link and choose one of the approaches to parallelise th serial code.
#
# -----
#
# # <div style="text-align: center ;border:3px; border-style:solid; border-color:#FF0000 ; padding: 1em">[HOME](../../../nways_MD_start.ipynb)</div>
# -----
#
#
# # Links and Resources
# <!--[OpenACC API guide](https://www.openacc.org/sites/default/files/inline-files/OpenACC%20API%202.6%20Reference%20Guide.pdf)-->
#
# [NVIDIA Nsight System](https://docs.nvidia.com/nsight-systems/)
#
# <!--[NVIDIA Nsight Compute](https://developer.nvidia.com/nsight-compute)-->
#
# <!--[CUDA Toolkit Download](https://developer.nvidia.com/cuda-downloads)-->
#
# [Profiling timelines with NVTX](https://devblogs.nvidia.com/cuda-pro-tip-generate-custom-application-profile-timelines-nvtx/)
#
# **NOTE**: To be able to see the Nsight System profiler output, please download Nsight System latest version from [here](https://developer.nvidia.com/nsight-systems).
#
# Don't forget to check out additional [OpenACC Resources](https://www.openacc.org/resources) and join our [OpenACC Slack Channel](https://www.openacc.org/community#slack) to share your experience and get more help from the community.
#
# ---
#
# ## Licensing
#
# This material is released by NVIDIA Corporation under the Creative Commons Attribution 4.0 International (CC BY 4.0).
| hpc/nways/nways_labs/nways_MD/English/Fortran/jupyter_notebook/serial/rdf_overview.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Introduction to Photometry
# ### <NAME>, University of Hawaii Institute for Astronomy
# Aim: Demonstrate photometry on a series of bias and flat field corrected images of a Near Earth Asteroid.
# ## 0. Prerequisites
import numpy as np
import matplotlib.pyplot as plt
import astropy.io.fits as fits
## make matplotlib appear in the notebook rather than in a new window
# %matplotlib inline
# ### 0.1 Directory Set up
datadir = ''
objname = '2016HO3'
# ### 0.2 Display images
def plotfits(imno):
img = fits.open(datadir+objname+'_{0:02d}.fits'.format(numb))[0].data
f = plt.figure(figsize=(10,12))
#im = plt.imshow(img, cmap='hot')
im = plt.imshow(img[480:580, 460:600], cmap='hot')
plt.clim(1800, 2800)
plt.colorbar(im, fraction=0.034, pad=0.04)
plt.savefig("figure{0}.png".format(imno))
plt.show()
numb = 1
plotfits(numb)
numb = 2
plotfits(numb)
# ## 1. Photometry set up
# Select part of the image for ease of display.
partimg = fits.open(datadir+objname+'_01.fits'.format(numb))[0].data[480:580, 460:600]
# Define starting values. Fill in values here:
targcen = np.array([##,##]) ## target center
compcen = np.array([##,##]) ## comparison center
# Aperture photometry set up. Play around with adjusting the aperture radii sizes and see the resulting image under 'Tests'
# +
searchr = 6 ## search box size
ap_r = 2 ## aperture radius
sky_inner = 3
sky_outer = 5
# -
# ### 1.1 Centroiding: Center of Mass
# Calculate Center of Mass (CoM) defined as: $\bar{x} = \frac{\sum A_i x_i}{\sum A_i }$, $\bar{y} = \frac{\sum A_i y_i}{\sum A_i }$.
# +
def cent_weight(n):
"""
Assigns centroid weights
"""
wghts=np.zeros((n),np.float)
for i in range(n):
wghts[i]=float(i-n/2)+0.5
return wghts
def calc_CoM(psf, weights):
"""
Finds Center of Mass of image
"""
cent=np.zeros((2),np.float)
### Write Equations for finding Center of Mass here ###
return cent
# -
# Use centroiding algorithm to find the actual centers of the targe and comparison.
## Cut a box between search limits, centered around targcen
targbox = partimg[targcen[0]-searchr : targcen[0]+searchr, targcen[1]-searchr : targcen[1]+searchr]
weights = cent_weight(len(targbox))
tcenoffset = calc_CoM(targbox, weights)
print(tcenoffset)
tcenter = targcen + tcenoffset
# Inspect PSF to see whether shift makes sense
plt.plot(sum(targbox))
plt.show()
compbox = partimg[compcen[0]-searchr : compcen[0]+searchr, compcen[1]-searchr : compcen[1]+searchr]
compw = cent_weight(len(compbox))
ccenoffset = calc_CoM(compbox,compw)
ccenter = compcen + ccenoffset
print(tcenter)
compw
# ### 1.2 Aperture Photometry
# #### Science Aperture
def circle(npix, r1):
"""
Builds a circle
"""
pup=np.zeros((npix,npix),np.int)
for i in range(npix):
for j in range(npix):
r=np.sqrt((float(i-npix/2)+0.5)**2+(float(j-npix/2)+0.5)**2)
if r<=r1:
pup[i,j]=1
return pup
# #### Sky annulus
def annulus(npix, r_inner,r_outer=-1.):
"""
Builds an annulus
"""
pup=np.zeros((npix,npix),np.int)
for i in range(npix):
for j in range(npix):
#### Fill in annulus form here ####
if ((r<=r_outer)&(r>=r_inner)):
pup[i,j]=1
return pup
# #### Extract values from regions
# Create mask
circmask = circle(searchr*2, ap_r)
annmask = annulus(searchr*2, sky_inner, sky_outer)
# Define new regions where the target and comparison are centered.
newtarg = partimg[int(round(tcenter[0]))-searchr : int(round(tcenter[0]))+searchr, int(round(tcenter[1]))-searchr : int(round(tcenter[1]))+searchr]
newcomp = partimg[int(round(ccenter[0]))-searchr : int(round(ccenter[0]))+searchr, int(round(ccenter[1]))-searchr : int(round(ccenter[1]))+searchr]
# Place mask on region
targaper = newtarg * circmask
compaper = newcomp * circmask
# Place mask on sky annulus slice.
targann = newtarg * annmask
compann = newcomp * annmask
# ### 1.3 Tests
# a. Display image with target and comparison centers before and after centroiding
im = plt.imshow(partimg, cmap='hot')
plt.clim(1800, 2800)
plt.scatter(targcen[1], targcen[0], c='g', marker='x')
plt.scatter(compcen[1], compcen[0], c='g', marker='x')
plt.scatter(tcenter[1], tcenter[0], c='b', marker='x')
plt.scatter(ccenter[1], ccenter[0], c='b', marker='x')
plt.show()
# b. Disply image with aperture mask and sky annulus
im = plt.imshow(targaper, cmap='hot')
plt.clim(1800, 2800)
plt.show()
im = plt.imshow(targann, cmap='hot')
plt.clim(1800, 2800)
plt.show()
# ## 2. Photometry
# ### 2.1 Calculate SNR
# Calculate Signal-to-Noise Ratio. CCD noise = sqrt(signal + background + dark current + read noise). Ignore dark current and read noise here.
def calcsnr(target, bg):
signal = target - bg
noise = np.sqrt(signal + bg)
snr = signal / noise
return snr, noise
# Sum all flux inside target and comparison apertures and divide by number of pixels to get average count per pixel.
targc = np.sum(targaper) / np.sum(circmask)
targbg= np.sum(targann) / np.sum(annmask)
compc = np.sum(compaper) / np.sum(circmask)
compbg= np.sum(compann) / np.sum(annmask)
snr, noise = calcsnr(targc, targbg)
print(snr)
snr, noise = calcsnr(compc, compbg)
print(snr)
# ### 2.2 Optimize photometry aperture
# +
## Write code here that tries a range of photometry apertures and finds the best SNR ##
# -
print(bestaper)
print(snr)
# ### 2.3 Calculate the target's magnitude and uncertainty
#
# Given the comparison is of known magnitude of 19.4
# +
targc = circle(searchr*2, ap_r)*newtarg
targskyc = annulus(searchr*2, sky_inner, sky_outer)*newtarg
compc = circle(searchr*2, ap_r)*newcomp
compskyc = annulus(searchr*2, sky_inner, sky_outer)*newcomp
ratio = np.sum(compc)/np.sum(targc)
### complete here ###
### complete here ###
### complete here ###
refmag = 19.4
### complete here ###
print("Measured Magnitude = {:0.3f} ± {:0.3f}".format(mag, sigmamag))
# -
# # Further Exercises
#
# a. Perform photometry on all 10 images of the asteroid and find its period of rotation.
#
# b. Perform photometry using Gaussian PSF fitting.
| Sessions/Session05/Day2/Introduction to Photometry.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] colab_type="text" id="y6O1k7uixj1M"
# # Testing a Change in the Auto Owernship Model
#
# Create two auto ownership examples to illustrate running two scenarios and analyzing results. This notebook assumes users are familiar with the [Getting Started](getting_started.ipynb) notebook.
# -
# # Create two examples
# + colab={"base_uri": "https://localhost:8080/", "height": 51} colab_type="code" id="BnJ1oQKAxs2M" outputId="a84b6577-0a71-4378-a393-36a701a41f5e"
# !activitysim create -e example_mtc -d example_base_auto_own
# !activitysim create -e example_mtc -d example_base_auto_own_alternative
# -
# # Run base example
# +
# %cd example_base_auto_own
# !activitysim run -c configs -d data -o output
#return to root folder
# %cd ..
# -
# # Run alternative example with no input differences
# +
# %cd example_base_auto_own_alternative
# !activitysim run -c configs -d data -o output
#return to root folder
# %cd ..
# -
# # Confirm identical results before making changes to the alternative scenario
# +
import pandas as pd
hh_base = pd.read_csv("example_base_auto_own/output/final_households.csv")
hh_alt = pd.read_csv("example_base_auto_own_alternative/output/final_households.csv")
same_results = (hh_base.auto_ownership == hh_alt.auto_ownership).all()
print("Identical household auto ownership results base versus alternative scenario: " + str(same_results))
# -
# # Modify the alternative scenario
#
# Reduce young adult car ownership coefficient to simulate the idea of less car ownership among young adults
# + colab={"base_uri": "https://localhost:8080/", "height": 34} colab_type="code" id="CkPhwK-W8Jwm" outputId="975a49d9-44dc-4676-ad57-dbc0d91f06ed"
adjustment_factor = -2
coefficient_of_interest = "coef_cars1_persons_25_34"
alt_expressions = pd.read_csv("example_base_auto_own/configs/auto_ownership_coeffs.csv")
row_selector = (alt_expressions["coefficient_name"] == "coef_cars1_persons_25_34")
print(alt_expressions.loc[row_selector])
alt_expressions.loc[row_selector,"value"] = alt_expressions.loc[row_selector,"value"] + adjustment_factor
alt_expressions.to_csv("example_base_auto_own_alternative/configs/auto_ownership_coeffs.csv")
print(alt_expressions.loc[row_selector])
# -
# # Re-run alternative example
# +
# %cd example_base_auto_own_alternative
# !activitysim run -c configs -d data -o output
#return to root folder
# %cd ..
# + [markdown] colab_type="text" id="AkBFMdixzmbd"
# # Compare Results
#
# Plot the difference in household auto ownership. For additional summaries for downstream models, see the [Summarizing Results](summarizing_results.ipynb) notebook.
# + colab={"base_uri": "https://localhost:8080/", "height": 626} colab_type="code" id="4VQjhEAwzmrU" outputId="8614e33e-3311-42ed-c196-3098bb8f39af"
import matplotlib.pyplot as plt
#read and summarize data
hh_base = pd.read_csv("example_base_auto_own/output/final_households.csv")
hh_alt = pd.read_csv("example_base_auto_own_alternative/output/final_households.csv")
autos_base = hh_base["auto_ownership"].value_counts()
autos_alt = hh_alt["auto_ownership"].value_counts()
#create plot
# %matplotlib inline
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = (15,10)
plt.bar(x=autos_base.index - 0.15, height=autos_base.values, width=0.25, label="base", color="lightseagreen")
plt.bar(x=autos_alt.index + 0.15, height=autos_alt.values, width=0.25, label="alt", color="dodgerblue")
plt.title('Auto Ownership By Household')
plt.ylabel('Number of Households')
plt.legend()
plt.xticks(autos_base.index.values, autos_alt.index.values)
_ = plt.xlabel('Number of Vehicles')
# -
| activitysim/examples/example_mtc/notebooks/change_in_auto_ownership.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# `models.explainers` binary classification example (adult dataset)
# -----
#
# ### Load packages
# +
from transparentai.models import explainers
from transparentai.datasets import load_adult
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# -
# ### Load & prepare data
data = load_adult()
X, Y = data.drop(columns='income'), data['income']
X = X.select_dtypes('number')
Y = Y.replace({'>50K':1, '<=50K':0})
# Split train test
X_train, X_valid, Y_train, Y_valid = train_test_split(X, Y, test_size=0.33, random_state=42)
# ### Train classifier
clf = RandomForestClassifier()
clf.fit(X_train,Y_train)
# ### Use `models.explainers.ModelExplainer`
explainer = explainers.ModelExplainer(clf, X_train, model_type='tree')
explainer.explain_global_influence(X_train, nsamples=1000)
explainer.plot_global_explain()
explainer.explain_local_influence(X_valid.iloc[0])
explainer.plot_local_explain(X_valid.iloc[0])
explainer.plot_local_explain_interact(X_valid.iloc[0])
visible_features = ['age','hours-per-week']
explainer.plot_local_explain_interact(X_valid.iloc[0], visible_feat=visible_features)
| examples/models.explainers_binary_classification_example_adult_dataset.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
# +
projectDir = '/home/manojmenpadi/Documents/Soft Computing/Extraction of Skills/'
cleanResumeDir = projectDir + 'data/clean_resume/'
os.chdir(cleanResumeDir)
tokenized_resumes = []
for clean_resume in os.listdir(cleanResumeDir):
file = open(str(clean_resume), 'r')
resume = file.read()
tokenized_resumes.append(resume.split())
# -
print(tokenized_resumes[:3])
import gensim
from gensim.models import Word2Vec, KeyedVectors
import multiprocessing
# +
modelDir = projectDir + 'models/'
os.chdir(modelDir)
model = gensim.models.Word2Vec(tokenized_resumes, size=300, window=12, min_count=5, negative=15,
iter=15, workers=multiprocessing.cpu_count())
model.intersect_word2vec_format('GoogleNews-vectors-negative300.bin.gz', lockf=1.0, binary=True)
model.train(sentences = tokenized_resumes, total_examples=model.corpus_count, epochs = 10)
# +
word_vectors = model.wv
result = word_vectors.similar_by_word("math")
print("Most Similar to 'math' : \n", result[:5])
result = word_vectors.similar_by_word("account")
print("Most Similar to 'account' : \n", result[:5])
result = word_vectors.similar_by_word("data")
print("Most Similar to 'data' : \n", result[:5])
result = word_vectors.similar_by_word("algorithm")
print("Most Similar to 'algorithm' : \n", result[:5])
result = word_vectors.similar_by_word("engineer")
print("Most Similar to 'engineer' : \n", result[:5])
result = word_vectors.similar_by_word("supervised")
print("Most Similar to 'supervised' : \n", result[:5])
# -
print(model['supervision'])
modelDir = projectDir + 'models/'
os.chdir(modelDir)
model.init_sims(replace=True)
#SAVE THE MODEL
model_name = "model_skill_extraction"
model.save(model_name)
Z = model.wv.syn0
print(Z[0].shape)
Z[0]
| jupyter-notebooks/.ipynb_checkpoints/Word2Vec model-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + colab={"base_uri": "https://localhost:8080/", "height": 204} colab_type="code" id="IBQ_eVTu8OnB" outputId="a0117324-8e60-4944-c431-14ed244b4f6e"
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
# + colab={"base_uri": "https://localhost:8080/", "height": 170} colab_type="code" id="LP5lidXD8ViI" outputId="2ff8199e-96f9-40cd-dd5b-e85cb49178c2"
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0,1,2,3"
# + colab={"base_uri": "https://localhost:8080/", "height": 34} colab_type="code" id="rYOoAdFk8ma3" outputId="4e860915-8468-45db-fbcf-be0d20e5c2df"
# cd /media/datastorage/Phong/cifar100_png/
# + colab={"base_uri": "https://localhost:8080/", "height": 170} colab_type="code" id="mDdxdcwj8ozr" outputId="68605cb6-d5ad-42dd-ce42-3e58e2b7b5db"
# ls -l
# + colab={"base_uri": "https://localhost:8080/", "height": 51} colab_type="code" id="313ttIKg8riI" outputId="32ea2f07-35d7-4504-ce4c-2d7aa40c84bb"
#Images/n02105855-Shetland_sheepdog/n02105855_9415.jpg
import glob
import os
import numpy as np
from matplotlib.image import imread
# %matplotlib inline
import matplotlib.pyplot as plt
# get image parts
def get_image_parts(image_path):
"""Given a full path to an image, return its parts."""
parts = image_path.split(os.path.sep)
#print(parts)
filename = parts[2]
filename_no_ext = filename.split('.')[0]
classname = parts[1]
train_or_test = parts[0]
return train_or_test, classname, filename_no_ext, filename
sample_images = list(glob.glob(os.path.join('train/', '*/*'), recursive=True))
np.random.seed(42)
rand_imgs = np.random.choice(sample_images, size=5*5)
fig, axarr = plt.subplots(5, 5, figsize=(20, 20))
for i, rand_img in enumerate(rand_imgs):
train_or_test, classname, filename_no_ext, filename = get_image_parts(rand_img)
j = i // 5
k = i % 5
axarr[j][k].imshow(imread(rand_img))
axarr[j][k].title.set_text(classname)
axarr[j][k].grid(False)
# + colab={"base_uri": "https://localhost:8080/", "height": 170} colab_type="code" id="UOyt3E-j8tJo" outputId="969c4599-bc6b-46f0-f648-d2cfca0450b0"
## fix for multi_gpu_model prediction time longer
from keras.layers import Lambda, concatenate
from keras import Model
import tensorflow as tf
def multi_gpu_model(model, gpus):
if isinstance(gpus, (list, tuple)):
num_gpus = len(gpus)
target_gpu_ids = gpus
else:
num_gpus = gpus
target_gpu_ids = range(num_gpus)
def get_slice(data, i, parts):
shape = tf.shape(data)
batch_size = shape[:1]
input_shape = shape[1:]
step = batch_size // parts
if i == num_gpus - 1:
size = batch_size - step * i
else:
size = step
size = tf.concat([size, input_shape], axis=0)
stride = tf.concat([step, input_shape * 0], axis=0)
start = stride * i
return tf.slice(data, start, size)
all_outputs = []
for i in range(len(model.outputs)):
all_outputs.append([])
# Place a copy of the model on each GPU,
# each getting a slice of the inputs.
for i, gpu_id in enumerate(target_gpu_ids):
with tf.device('/gpu:%d' % gpu_id):
with tf.name_scope('replica_%d' % gpu_id):
inputs = []
# Retrieve a slice of the input.
for x in model.inputs:
input_shape = tuple(x.get_shape().as_list())[1:]
slice_i = Lambda(get_slice,
output_shape=input_shape,
arguments={'i': i,
'parts': num_gpus})(x)
inputs.append(slice_i)
# Apply model on slice
# (creating a model replica on the target device).
outputs = model(inputs)
if not isinstance(outputs, list):
outputs = [outputs]
# Save the outputs for merging back together later.
for o in range(len(outputs)):
all_outputs[o].append(outputs[o])
# Merge outputs on CPU.
with tf.device('/cpu:0'):
merged = []
for name, outputs in zip(model.output_names, all_outputs):
merged.append(concatenate(outputs,
axis=0, name=name))
return Model(model.inputs, merged)
# +
from keras.callbacks import Callback
import pickle
import sys
#Stop training on val_acc
class EarlyStoppingByAccVal(Callback):
def __init__(self, monitor='val_acc', value=0.00001, verbose=0):
super(Callback, self).__init__()
self.monitor = monitor
self.value = value
self.verbose = verbose
def on_epoch_end(self, epoch, logs={}):
current = logs.get(self.monitor)
if current is None:
warnings.warn("Early stopping requires %s available!" % self.monitor, RuntimeWarning)
if current >= self.value:
if self.verbose > 0:
print("Epoch %05d: early stopping" % epoch)
self.model.stop_training = True
#Save large model using pickle formate instead of h5
class SaveCheckPoint(Callback):
def __init__(self, model, dest_folder):
super(Callback, self).__init__()
self.model = model
self.dest_folder = dest_folder
#initiate
self.best_val_acc = 0
self.best_val_loss = sys.maxsize #get max value
def on_epoch_end(self, epoch, logs={}):
val_acc = logs['val_acc']
val_loss = logs['val_loss']
if val_acc > self.best_val_acc:
self.best_val_acc = val_acc
# Save weights in pickle format instead of h5
print('\nSaving val_acc %f at %s' %(self.best_val_acc, self.dest_folder))
weigh= self.model.get_weights()
#now, use pickle to save your model weights, instead of .h5
#for heavy model architectures, .h5 file is unsupported.
fpkl= open(self.dest_folder, 'wb') #Python 3
pickle.dump(weigh, fpkl, protocol= pickle.HIGHEST_PROTOCOL)
fpkl.close()
# model.save('tmp.h5')
elif val_acc == self.best_val_acc:
if val_loss < self.best_val_loss:
self.best_val_loss=val_loss
# Save weights in pickle format instead of h5
print('\nSaving val_acc %f at %s' %(self.best_val_acc, self.dest_folder))
weigh= self.model.get_weights()
#now, use pickle to save your model weights, instead of .h5
#for heavy model architectures, .h5 file is unsupported.
fpkl= open(self.dest_folder, 'wb') #Python 3
pickle.dump(weigh, fpkl, protocol= pickle.HIGHEST_PROTOCOL)
fpkl.close()
# -
# +
# # !pip3 install -U git+https://github.com/qubvel/efficientnet
# +
#MUL 1 - Inception - ST
# from keras.applications import InceptionV3
# from keras.applications import Xception
# from keras.applications.inception_resnet_v2 import InceptionResNetV2
from keras.models import Model
from keras.layers import concatenate
from keras.layers import Dense, GlobalAveragePooling2D, Input, Embedding, LSTM, Flatten, GRU, Reshape
# from keras.applications.inception_v3 import preprocess_input
from efficientnet.keras import preprocess_input
from keras.layers import GaussianNoise
import efficientnet.keras as efn
f1_base = efn.EfficientNetB2(include_top=False, weights='imagenet',
input_shape=(299, 299, 3),
pooling='avg')
# f1_base = Xception(weights='imagenet', include_top=False, input_shape=(450,450,3))
# f1_base = EfficientNetB4((224,224,3), classes=1000, include_top=False, weights='imagenet')
f1_x = f1_base.output
# f1_x = GlobalAveragePooling2D()(f1_x)
# f1_x = Flatten()(f1_x)
# f1_x = Reshape([1,1792])(f1_x)
# f1_x = GRU(2048,
# return_sequences=False,
# # dropout=0.8
# input_shape=[1,1792])(f1_x)
#Regularization with noise
f1_x = GaussianNoise(0.1)(f1_x)
f1_x = Dense(1024, activation='relu')(f1_x)
f1_x = Dense(100, activation='softmax')(f1_x)
model_1 = Model(inputs=[f1_base.input],outputs=[f1_x])
model_1.summary()
# + colab={} colab_type="code" id="p1E7n8ds9Mmh"
# + colab={"base_uri": "https://localhost:8080/", "height": 34} colab_type="code" id="FXZBAIXAElcd" outputId="0d8aaee3-0db2-4b08-c426-d26e581d2c10"
# cd ..
# + colab={"base_uri": "https://localhost:8080/", "height": 85} colab_type="code" id="19V0B0rIEgso" outputId="78573b3b-934c-45ae-9c10-ccb28e635e0e"
# ls -l
# + colab={"base_uri": "https://localhost:8080/", "height": 119} colab_type="code" id="1JMB1lsREbAE" outputId="1cad26f1-9c6f-4801-bb78-84f43a11e0c7"
# + colab={"base_uri": "https://localhost:8080/", "height": 153} colab_type="code" id="2suPqhuJDOLn" outputId="d0b80840-ba14-4470-cb33-c850af69491d"
# ls -l
# + colab={"base_uri": "https://localhost:8080/", "height": 122} colab_type="code" id="6SqCtLbgSoQ-" outputId="2a7c1ac8-a9b2-44c2-c368-91125b14a983"
from google.colab import drive
drive.mount('/content/gdrive', force_remount=True)
# + colab={} colab_type="code" id="dUUPvXA2S7ev"
# %cp gdrive/My\ Drive/cifar_train.zip cifar_train.zip
# %cp gdrive/My\ Drive/cifar_test.zip cifar_test.zip
# + colab={"base_uri": "https://localhost:8080/", "height": 1000} colab_type="code" id="UsII2atxTYdG" outputId="a1c0b166-9ed8-4005-faa8-d2932fa8de5a"
# !unzip cifar_train.zip
# !unzip cifar_test.zip
# + colab={"base_uri": "https://localhost:8080/", "height": 1000} colab_type="code" id="BL0e6CLIFwxN" outputId="960af38c-994c-41b2-9f00-a95d1d56ce6c"
# #Images/n02105855-Shetland_sheepdog/n02105855_9415.jpg
# import glob
# import os
# import numpy as np
# from matplotlib.image import imread
# # %matplotlib inline
# import matplotlib.pyplot as plt
# # get image parts
# def get_image_parts(image_path):
# """Given a full path to an image, return its parts."""
# parts = image_path.split(os.path.sep)
# #print(parts)
# filename = parts[2]
# filename_no_ext = filename.split('.')[0]
# classname = parts[1]
# train_or_test = parts[0]
# return train_or_test, classname, filename_no_ext, filename
# sample_images = list(glob.glob(os.path.join('train/', '*/*'), recursive=True))
# np.random.seed(42)
# rand_imgs = np.random.choice(sample_images, size=5*5)
# fig, axarr = plt.subplots(5, 5, figsize=(20, 20))
# for i, rand_img in enumerate(rand_imgs):
# train_or_test, classname, filename_no_ext, filename = get_image_parts(rand_img)
# j = i // 5
# k = i % 5
# axarr[j][k].imshow(imread(rand_img))
# axarr[j][k].title.set_text(classname)
# axarr[j][k].grid(False)
# + colab={} colab_type="code" id="CA1wZ0ODjKlX"
# ls -l
# + colab={} colab_type="code" id="u7tCxvDxjNU9"
# from PIL import Image
# import numpy
# def img_square(im_pth='', desired_size=224):
# im = Image.open(im_pth)
# old_size = im.size # (width, height) format
# ratio = float(desired_size)/max(old_size)
# new_size = tuple([int(x*ratio) for x in old_size])
# new_im = im.resize(new_size, Image.ANTIALIAS)
# return new_im
# path = 'train/0/twinjet_s_001442.png'
# orig_arr = img_square(path, 399)
# #convert to RGB and Save
# orig_arr = orig_arr.convert('RGB')
# orig_arr.save('test.jpg')
# from IPython.display import Image
# Image(filename='test.jpg')
# + colab={} colab_type="code" id="jgOQh92Ar10r"
from PIL import Image
import numpy
def convert_img_square(im_pth='', dest_path='', desired_size=224):
# print(im_pth)
im = Image.open(im_pth)
old_size = im.size # (width, height) format
ratio = float(desired_size)/max(old_size)
new_size = tuple([int(x*ratio) for x in old_size])
# new_im = im.resize(new_size, Image.ANTIALIAS)
new_im = im.resize(new_size)
new_im = new_im.convert('RGB')
new_im.save(dest_path)
return True
# path = 'train/0/twinjet_s_001442.png'
# dest_path = 't1/test4.jpg'
# orig_arr = convert_img_square(path, dest_path, 499)
# #convert to RGB and Save
# # orig_arr = orig_arr.convert('RGB')
# # orig_arr.save('t1/test2.jpg')
# from IPython.display import Image
# Image(filename='t1/test4.jpg')
# + colab={} colab_type="code" id="-Dj-itflssqh"
# ls -l
# + colab={} colab_type="code" id="IwbSVOPnorCq"
# %rm -r train_resized
# %mkdir train_resized
# + colab={"base_uri": "https://localhost:8080/", "height": 374} colab_type="code" id="cyl_Xjunolpe" outputId="0ca332e8-f4f4-4903-c7f3-68c5e41ff860"
# ####=======================
# import glob
# import os
# import shutil
# import random
# #move class folder from classname_# to classname/#
# def get_image_parts(image_path):
# """Given a full path to an image, return its parts."""
# parts = image_path.split(os.path.sep)
# #print(parts)
# filename = parts[2]
# filename_no_ext = filename.split('.')[0]
# classname = parts[1]
# train_or_test = parts[0]
# return train_or_test, classname, filename_no_ext, filename
# move_folders = ['train']
# dest_folder = 'train_resized_345'
# data_file = []
# # look for all images in sub-folders
# for folder in move_folders:
# class_folders = glob.glob(os.path.join(folder, '*'))
# print('folder %s' %class_folders)
# # for sub_folder in class_folders:
# # sub_class_folders = glob.glob(os.path.join(sub_folder, '*'))
# # print('sub folder %s' %sub_class_folders)
# for iid_class in class_folders:
# print(iid_class)
# class_files = glob.glob(os.path.join(iid_class, '*.png'))
# # #Determize Set# (No Suffle)
# set = len(class_files)
# inner = range(0*set, 1*set) #all
# print('moving %d files' %(len(inner)))
# # random_list = random.sample(range(len(class_files)), int(len(class_files)/5)) #1/5 dataset
# # for idx in range(len(random_list)):
# for idx in range(len(inner)):
# src = class_files[inner[idx]]
# train_or_test, classname, filename_no_ext, filename = get_image_parts(src)
# dst = os.path.join(dest_folder, classname, filename)
# # image directory
# img_directory = os.path.join(dest_folder, classname)
# # create folder if not existed
# if not os.path.exists(img_directory):
# os.makedirs(img_directory)
# # convert image
# convert_img_square(src, dst, 345)
# # #moving file
# # shutil.move(src, dst)
# # # shutil.copy(src, dst)
# + colab={"base_uri": "https://localhost:8080/", "height": 374} colab_type="code" id="zPyjRcTfytFG" outputId="2de3a5b1-a9f6-4103-fb2b-631c9e505281"
# ####=======================
# import glob
# import os
# import shutil
# import random
# #move class folder from classname_# to classname/#
# def get_image_parts(image_path):
# """Given a full path to an image, return its parts."""
# parts = image_path.split(os.path.sep)
# #print(parts)
# filename = parts[2]
# filename_no_ext = filename.split('.')[0]
# classname = parts[1]
# train_or_test = parts[0]
# return train_or_test, classname, filename_no_ext, filename
# move_folders = ['test']
# dest_folder = 'test_resized_345'
# data_file = []
# # look for all images in sub-folders
# for folder in move_folders:
# class_folders = glob.glob(os.path.join(folder, '*'))
# print('folder %s' %class_folders)
# # for sub_folder in class_folders:
# # sub_class_folders = glob.glob(os.path.join(sub_folder, '*'))
# # print('sub folder %s' %sub_class_folders)
# for iid_class in class_folders:
# print(iid_class)
# class_files = glob.glob(os.path.join(iid_class, '*.png'))
# # #Determize Set# (No Suffle)
# set = len(class_files)
# inner = range(0*set, 1*set) #all
# print('moving %d files' %(len(inner)))
# # random_list = random.sample(range(len(class_files)), int(len(class_files)/5)) #1/5 dataset
# # for idx in range(len(random_list)):
# for idx in range(len(inner)):
# src = class_files[inner[idx]]
# train_or_test, classname, filename_no_ext, filename = get_image_parts(src)
# dst = os.path.join(dest_folder, classname, filename)
# # image directory
# img_directory = os.path.join(dest_folder, classname)
# # create folder if not existed
# if not os.path.exists(img_directory):
# os.makedirs(img_directory)
# # convert image
# convert_img_square(src, dst, 345)
# # #moving file
# # shutil.move(src, dst)
# # # shutil.copy(src, dst)
# + colab={} colab_type="code" id="emlc7dUpq9C1"
path = 'train_resized/0/twinjet_s_001442.png'
# dest_path = 't1/test4.jpg'
# orig_arr = convert_img_square(path, dest_path, 499)
# #convert to RGB and Save
# # orig_arr = orig_arr.convert('RGB')
# # orig_arr.save('t1/test2.jpg')
from IPython.display import Image
Image(filename=path)
# + colab={} colab_type="code" id="N_sKj8LQqr-g"
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from time import sleep
# %matplotlib inline
image = mpimg.imread(path)
plt.imshow(image)
plt.show()
# + colab={} colab_type="code" id="zgL7cGRAqy7p"
# ls -l
# + colab={} colab_type="code" id="LtFSHddZq16W"
# !zip -r train_resized_299.zip train_resized
# !zip -r test_resized_299.zip test_resized
# + colab={} colab_type="code" id="WGOfqcePBqpH"
# %cp train_resized_299.zip gdrive/My\ Drive/cifar_train_resized_299.zip
# %cp test_resized_299.zip gdrive/My\ Drive/cifar_test_resized_299.zip
# + colab={} colab_type="code" id="5SjTDA8VC5Ah"
# cd gdrive/My\ Drive
# + colab={} colab_type="code" id="ILRxLOABDF7u"
# ls -l
# + colab={"base_uri": "https://localhost:8080/", "height": 275} colab_type="code" id="8pDocSJKCtV7" outputId="a56f8b2d-8684-4f05-e17f-16a84fdd6b3b"
# # !pip install keras_efficientnets
# + colab={"base_uri": "https://localhost:8080/", "height": 1000} colab_type="code" id="WJiLtHmPZ2Ts" outputId="2e15b430-2dfa-42b8-bc91-6418e714bf62"
# + colab={"base_uri": "https://localhost:8080/", "height": 221} colab_type="code" id="cdFkG0pEacF1" outputId="6682d252-6c53-4324-a2bf-83d285c6ff27"
# ls -l
# + colab={} colab_type="code" id="41MCKnMGanT1"
# mkdir checkpoints
# + colab={} colab_type="code" id="oVSEeQWrbWvn"
# mkdir cifar100_output
# + colab={} colab_type="code" id="RM7cE3Skbpw9"
# mkdir cifar100_output/logs
# + colab={"base_uri": "https://localhost:8080/", "height": 119} colab_type="code" id="P1hxliT6aR_a" outputId="a359bc33-6afa-4da1-a5fe-13aab3996ef7"
#Non-Groups
#Split training and validation
#Using Expert Data
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping, CSVLogger, ReduceLROnPlateau
from keras.optimizers import Adam
# from keras.utils import multi_gpu_model
import time, os
from math import ceil
import multiprocessing
train_datagen = ImageDataGenerator(
# rescale = 1./255,
rotation_range=30,
width_shift_range=0.3,
height_shift_range=0.3,
shear_range=0.3,
zoom_range=0.3,
horizontal_flip=True,
vertical_flip=True,##
# brightness_range=[0.5, 1.5],##
channel_shift_range=10,##
fill_mode='nearest',
preprocessing_function=preprocess_input,
)
test_datagen = ImageDataGenerator(
# rescale = 1./255
preprocessing_function=preprocess_input
)
NUM_GPU = 4
batch_size = 128
train_set = train_datagen.flow_from_directory('train_resized_299',
target_size = (299, 299),
batch_size = batch_size,
class_mode = 'categorical',
shuffle=True,
seed=7,
# subset="training"
)
valid_set = test_datagen.flow_from_directory('test_resized_299',
target_size = (299, 299),
batch_size = batch_size,
class_mode = 'categorical',
shuffle=False,
seed=7,
# subset="validation"
)
model_txt = 'st'
# Helper: Save the model.
savedfilename = os.path.join('checkpoints','Cifar100_Eff_B2_299_STD.hdf5')
checkpointer = ModelCheckpoint(savedfilename,
monitor='val_acc', verbose=1,
save_best_only=True, mode='max',save_weights_only=True)########
# Helper: TensorBoard
tb = TensorBoard(log_dir=os.path.join('cifar100_output', 'logs', model_txt))
# Helper: Save results.
timestamp = time.time()
csv_logger = CSVLogger(os.path.join('cifar100_output', 'logs', model_txt + '-' + 'training-' + \
str(timestamp) + '.log'))
earlystopping = EarlyStoppingByAccVal(monitor='val_acc', value=0.9900, verbose=1)
#Using multiple models if more than 1 GPU
if NUM_GPU != 1:
model_mul = multi_gpu_model(model_1, gpus=NUM_GPU)
else:
model_mul = model_1
epochs = 40##!!!
lr = 1e-4
decay = lr/epochs
optimizer = Adam(lr=lr, decay=decay)
model_mul.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])
step_size_train=ceil(train_set.n/train_set.batch_size)
step_size_valid=ceil(valid_set.n/valid_set.batch_size)
# step_size_test=ceil(testing_set.n//testing_set.batch_size)
result = model_mul.fit_generator(
generator = train_set,
steps_per_epoch = step_size_train,
validation_data = valid_set,
validation_steps = step_size_valid,
shuffle=True,
epochs=epochs,
callbacks=[earlystopping, checkpointer, csv_logger],
# callbacks=[tb, csv_logger, checkpointer, earlystopping],
verbose=1)
# -
model_mul.load_weights(os.path.join('checkpoints', 'Cifar100_Eff_B2_299_STD.hdf5'))
# +
#Non-Groups
#Split training and validation
#Using Expert Data
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping, CSVLogger, ReduceLROnPlateau
from keras.optimizers import Adam
# from keras.utils import multi_gpu_model
import time, os
from math import ceil
import multiprocessing
train_datagen = ImageDataGenerator(
# rescale = 1./255,
rotation_range=30,
width_shift_range=0.3,
height_shift_range=0.3,
shear_range=0.3,
zoom_range=0.3,
horizontal_flip=True,
vertical_flip=True,##
# brightness_range=[0.5, 1.5],##
channel_shift_range=10,##
fill_mode='nearest',
preprocessing_function=preprocess_input,
)
test_datagen = ImageDataGenerator(
# rescale = 1./255
preprocessing_function=preprocess_input
)
NUM_GPU = 4
batch_size = 96
train_set = train_datagen.flow_from_directory('train_resized_299',
target_size = (299, 299),
batch_size = batch_size,
class_mode = 'categorical',
shuffle=True,
seed=7,
# subset="training"
)
valid_set = test_datagen.flow_from_directory('test_resized_299',
target_size = (299, 299),
batch_size = batch_size,
class_mode = 'categorical',
shuffle=False,
seed=7,
# subset="validation"
)
model_txt = 'st'
# Helper: Save the model.
savedfilename = os.path.join('checkpoints','tmp_Cifar100_Eff_B3_299_STD.hdf5')
checkpointer = ModelCheckpoint(savedfilename,
monitor='val_acc', verbose=1,
save_best_only=True, mode='max',save_weights_only=True)########
# Helper: TensorBoard
tb = TensorBoard(log_dir=os.path.join('cifar100_output', 'logs', model_txt))
# Helper: Save results.
timestamp = time.time()
csv_logger = CSVLogger(os.path.join('cifar100_output', 'logs', model_txt + '-' + 'training-' + \
str(timestamp) + '.log'))
earlystopping = EarlyStoppingByAccVal(monitor='val_acc', value=0.9900, verbose=1)
#Using multiple models if more than 1 GPU
if NUM_GPU != 1:
model_mul = multi_gpu_model(model_1, gpus=NUM_GPU)
else:
model_mul = model_1
epochs = 40##!!!
lr = 1e-4
decay = lr/epochs
optimizer = Adam(lr=lr, decay=decay)
model_mul.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])
step_size_train=ceil(train_set.n/train_set.batch_size)
step_size_valid=ceil(valid_set.n/valid_set.batch_size)
# step_size_test=ceil(testing_set.n//testing_set.batch_size)
result = model_mul.fit_generator(
generator = train_set,
steps_per_epoch = step_size_train,
validation_data = valid_set,
validation_steps = step_size_valid,
shuffle=True,
epochs=epochs,
callbacks=[earlystopping, checkpointer, csv_logger],
# callbacks=[tb, csv_logger, checkpointer, earlystopping],
verbose=1)
# + colab={"base_uri": "https://localhost:8080/", "height": 853} colab_type="code" id="9it_mwRMLe-e" outputId="793a2e4b-544c-485f-b030-a2460c523a9b"
#Non-Groups
#Split training and validation
#Using Expert Data
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping, CSVLogger, ReduceLROnPlateau
from keras.optimizers import Adam
# from keras.utils import multi_gpu_model
import time, os
from math import ceil
import multiprocessing
savedfilename = os.path.join('checkpoints', 'Cifar100_Eff_B2_299_STD_L2.hdf5')
checkpointer = ModelCheckpoint(savedfilename,
monitor='val_acc', verbose=1,
save_best_only=True, mode='max',save_weights_only=True)########
epochs = 15##!!!
lr = 1e-5
decay = lr/epochs
optimizer = Adam(lr=lr, decay=decay)
model_mul.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])
result = model_mul.fit_generator(
generator = train_set,
steps_per_epoch = step_size_train,
validation_data = valid_set,
validation_steps = step_size_valid,
shuffle=True,
epochs=epochs,
callbacks=[earlystopping, checkpointer],
# callbacks=[tb, csv_logger, checkpointer, earlystopping],
verbose=1)
# + colab={} colab_type="code" id="7ZBm5kY_TxMv"
# #Using multiple models if more than 1 GPU
# NUM_GPU = 4
# if NUM_GPU != 1:
# model_mul = multi_gpu_model(model_1, gpus=NUM_GPU)
model_mul.load_weights(os.path.join('checkpoints', 'Cifar100_Eff_B2_299_STD_L2.hdf5'))
# +
#Non-Groups
#Split training and validation
#Using Expert Data
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping, CSVLogger, ReduceLROnPlateau
from keras.optimizers import Adam
# from keras.utils import multi_gpu_model
import time, os
from math import ceil
import multiprocessing
savedfilename = os.path.join('checkpoints', 'Cifar100_Eff_B2_299_STD_L3.hdf5')
checkpointer = ModelCheckpoint(savedfilename,
monitor='val_acc', verbose=1,
save_best_only=True, mode='max',save_weights_only=True)########
epochs = 15##!!!
lr = 1e-6
decay = lr/epochs
optimizer = Adam(lr=lr, decay=decay)
model_mul.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])
result = model_mul.fit_generator(
generator = train_set,
steps_per_epoch = step_size_train,
validation_data = valid_set,
validation_steps = step_size_valid,
shuffle=True,
epochs=epochs,
callbacks=[earlystopping, checkpointer],
# callbacks=[tb, csv_logger, checkpointer, earlystopping],
verbose=1)
# -
model_mul.load_weights(os.path.join('checkpoints', 'Cifar100_Eff_B2_299_STD_L3.hdf5'))
# +
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
import time, os
from math import ceil
# PREDICT ON OFFICIAL TEST
train_datagen = ImageDataGenerator(
# rescale = 1./255,
rotation_range=30,
width_shift_range=0.3,
height_shift_range=0.3,
shear_range=0.3,
zoom_range=0.3,
horizontal_flip=True,
vertical_flip=True,##
# brightness_range=[0.5, 1.5],##
channel_shift_range=10,##
fill_mode='nearest',
preprocessing_function=preprocess_input,
)
test_datagen1 = ImageDataGenerator(
# rescale = 1./255,
preprocessing_function=preprocess_input
)
batch_size = 36
train_set = train_datagen.flow_from_directory('train_resized_299',
target_size = (299, 299),
batch_size = batch_size,
class_mode = 'categorical',
shuffle=True,
seed=7,
# subset="training"
)
test_set1 = test_datagen1.flow_from_directory('test_resized_299',
target_size = (299, 299),
batch_size = batch_size,
class_mode = 'categorical',
shuffle=False,
seed=7,
# subset="validation"
)
if NUM_GPU != 1:
predict1=model_mul.predict_generator(test_set1, steps = ceil(test_set1.n/test_set1.batch_size),verbose=1)
# else:
# predict1=model.predict_generator(test_set1, steps = ceil(test_set1.n/test_set1.batch_size),verbose=1)
predicted_class_indices=np.argmax(predict1,axis=1)
labels = (train_set.class_indices)
labels = dict((v,k) for k,v in labels.items())
predictions1 = [labels[k] for k in predicted_class_indices]
import pandas as pd
filenames=test_set1.filenames
results=pd.DataFrame({"file_name":filenames,
"predicted1":predictions1,
})
results.to_csv('Cifar100_Eff_B2_299_0309_v1.csv')
results.head()
# -
# cp Cifar10_Eff_B5_345_1511_v1.csv /home/bribeiro/Phong/Nat19/Cifar10_Eff_B5_345_1511_v1.csv
np.save(os.path.join('pred_npy','Cifar100_Eff_B2_299_L3.npy'), predict1)
# +
from keras.preprocessing.image import ImageDataGenerator
from math import ceil
import numpy as np
batch_size = 72
#Crop-Official Test
def random_crop(img, random_crop_size):
# Note: image_data_format is 'channel_last'
assert img.shape[2] == 3
height, width = img.shape[0], img.shape[1]
dy, dx = random_crop_size
x = np.random.randint(0, width - dx + 1)
y = np.random.randint(0, height - dy + 1)
return img[y:(y+dy), x:(x+dx), :]
def crop_generator(batches, crop_length):
"""Generate random crops from the image batches"""
while True:
batch_x, batch_y = next(batches)
batch_crops = np.zeros((batch_x.shape[0], crop_length, crop_length, 3))
for i in range(batch_x.shape[0]):
batch_crops[i] = random_crop(batch_x[i], (crop_length, crop_length))
yield (batch_crops, batch_y)
test_datagen_crop = ImageDataGenerator(
# rescale = 1./255,
preprocessing_function=preprocess_input
)
testing_set_crop = test_datagen_crop.flow_from_directory('test_resized_345',
target_size = (370, 370),
batch_size = batch_size,
class_mode = 'categorical',
shuffle=False,
seed=7,
# subset="training"
)
#customized generator
test_crops = crop_generator(testing_set_crop, 345)
step_size_test_crop = ceil(testing_set_crop.n/testing_set_crop.batch_size)
tta_steps = 4
# predictions = []
# import tensorflow as tf
# with tf.device('/gpu:0'):
for i in range(tta_steps):
print(i)
testing_set_crop.reset()
if NUM_GPU != 1:
preds=model_mul.predict_generator(test_crops,
steps = step_size_test_crop,
# max_queue_size=16,
# use_multiprocessing=True,
# workers=1,
verbose=1)
# else:
# preds=model.predict_generator(test_crops,
# steps = step_size_test_crop,
# max_queue_size=16,
# # use_multiprocessing=True,
# workers=1,
# verbose=1)
# preds=model_2.predict_generator(test_crops,steps = step_size_test_crop,verbose=1)
predictions.append(preds)
mean_pred = np.mean(predictions, axis=0)
predicted_class_indices_mean=np.argmax(mean_pred,axis=1)
labels = (train_set.class_indices)
labels = dict((v,k) for k,v in labels.items())
finalpre = [labels[k] for k in predicted_class_indices_mean]
import pandas as pd
filenames=testing_set_crop.filenames
results=pd.DataFrame({"id":filenames,
"predicted":finalpre,
})
results.to_csv('Cifar10_Eff_B5_345_STD_tta_7.csv')
results.head(10)
# -
# cp Cifar10_Eff_B5_345_STD_tta_7.csv /home/bribeiro/Phong/Nat19/Cifar10_Eff_B5_345_STD_tta_7.csv
np.save(os.path.join('pred_npy','Cifar10_Eff_B5_345_L2_TTA3.npy'), mean_pred)
# +
#Non-Groups
#Split training and validation
#Using Expert Data
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping, CSVLogger, ReduceLROnPlateau
from keras.optimizers import Adam
# from keras.utils import multi_gpu_model
import time, os
from math import ceil
import multiprocessing
savedfilename = os.path.join('checkpoints', 'Cifar100_Eff_B7_299_STD_L3.hdf5')
checkpointer = ModelCheckpoint(savedfilename,
monitor='val_acc', verbose=1,
save_best_only=True, mode='max',save_weights_only=True)########
epochs = 15##!!!
lr = 1e-6
decay = lr/epochs
optimizer = Adam(lr=lr, decay=decay)
model_mul.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])
result = model_mul.fit_generator(
generator = train_set,
steps_per_epoch = step_size_train,
validation_data = valid_set,
validation_steps = step_size_valid,
shuffle=True,
epochs=epochs,
callbacks=[earlystopping, checkpointer],
# callbacks=[tb, csv_logger, checkpointer, earlystopping],
verbose=1)
# +
# #Using multiple models if more than 1 GPU
# NUM_GPU = 4
# if NUM_GPU != 1:
# model_mul = multi_gpu_model(model_1, gpus=NUM_GPU)
model_mul.load_weights(os.path.join('checkpoints', 'Cifar100_Eff_B7_299_STD_L3.hdf5'))
# +
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
import time, os
from math import ceil
# PREDICT ON OFFICIAL TEST
train_datagen = ImageDataGenerator(
# rescale = 1./255,
rotation_range=30,
width_shift_range=0.3,
height_shift_range=0.3,
shear_range=0.3,
zoom_range=0.3,
horizontal_flip=True,
vertical_flip=True,##
# brightness_range=[0.5, 1.5],##
channel_shift_range=10,##
fill_mode='nearest',
preprocessing_function=preprocess_input,
)
test_datagen1 = ImageDataGenerator(
# rescale = 1./255,
preprocessing_function=preprocess_input
)
batch_size = 36
train_set = train_datagen.flow_from_directory('train_resized_299',
target_size = (299, 299),
batch_size = batch_size,
class_mode = 'categorical',
shuffle=True,
seed=7,
# subset="training"
)
test_set1 = test_datagen1.flow_from_directory('test_resized_299',
target_size = (299, 299),
batch_size = batch_size,
class_mode = 'categorical',
shuffle=False,
seed=7,
# subset="validation"
)
if NUM_GPU != 1:
predict1=model_mul.predict_generator(test_set1, steps = ceil(test_set1.n/test_set1.batch_size),verbose=1)
# else:
# predict1=model.predict_generator(test_set1, steps = ceil(test_set1.n/test_set1.batch_size),verbose=1)
predicted_class_indices=np.argmax(predict1,axis=1)
labels = (train_set.class_indices)
labels = dict((v,k) for k,v in labels.items())
predictions1 = [labels[k] for k in predicted_class_indices]
import pandas as pd
filenames=test_set1.filenames
results=pd.DataFrame({"file_name":filenames,
"predicted1":predictions1,
})
results.to_csv('Cifar100_Eff_B7_299_2208_v1.csv')
results.head()
# -
np.save(os.path.join('pred_npy','Cifar100_Eff_B7_299_STD_L3_v2.npy'), predict1)
| Cifar100/sourcecode/Cifar100_Efficientnet_B2_299_STD.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # Exercise 02: Vortex dynamics
#
# We want to simulate vortex dynamics in a two-dimensional disk sample with $d=100 \,\text{nm}$ diameter and $5\,\text{nm}$ thickness with:
#
# - magnetisation saturation $M_\text{s} = 8 \times 10^{5} \,\text{A}\,\text{m}^{-1}$,
# - exchange energy constant $A = 13 \,\text{pJ}\,\text{m}^{-1}$,
# - gyrotropic ratio $\gamma = 2.211 \times 10^{5} \,\text{m}\,\text{A}^{-1}\,\text{s}^{-1}$, and
# - Gilbert damping $\alpha=0.2$.
#
# Please carry out the following steps:
#
# 1. Initialise the system so that $(m_{x}, m_{y}, m_{z}) = (-Ay, Ax, 10)$, where $A = 10^{9}\,\text{m}^{-1}$.
# 2. Minimise the system's energy. What state did you obtain?
# 3. Apply an external magnetic field of $H = 10^{4} \,\text{A}\,\text{m}^{-1}$ in the positive $x$ direction and relax the system. Did the vortex core move in the positive $y$ direction?
# 4. Turn off an external magnetic field and simulate the vortex dynamics for $t = 5 \,\text{ns}$ and save magnetisation in $n = 500$ steps. Plot all three components of magnetisation as a function of time.
#
# ## Solution
# +
# NBVAL_IGNORE_OUTPUT
import discretisedfield as df
import micromagneticmodel as mm
import oommfc as oc
# Geometry
d = 100e-9 # disk diameter (m)
thickness = dx = dy = dz = 5e-9 #discretisation cell (nm)
# Material (permalloy) parameters
Ms = 8e5 # saturation magnetisation (A/m)
A = 13e-12 # exchange energy constant (J/m)
# Dynamics (LLG equation) parameters
gamma0 = 2.211e5 # gyromagnetic ratio (m/As)
alpha = 0.2 # Gilbert damping
region = df.Region(p1=(-d/2, -d/2, 0), p2=(d/2, d/2, thickness))
mesh = df.Mesh(region=region, cell=(dx, dy, dz))
def Ms_fun(pos):
x, y, z = pos
if (x**2 + y**2)**0.5 < d/2:
return Ms
else:
return 0
def m_init(pos):
x, y, z = pos
A = 1e9 # (1/m)
return -A*y, A*x, 10
system = mm.System(name='vortex_dynamics')
system.energy = mm.Exchange(A=A) + mm.Demag()
system.dynamics = mm.Precession(gamma0=gamma0) + mm.Damping(alpha=alpha)
system.m = df.Field(mesh, dim=3, value=m_init, norm=Ms_fun)
md = oc.MinDriver()
md.drive(system)
system.m.k3d.vector(color_field=system.m.z, head_size=10)
# +
# NBVAL_IGNORE_OUTPUT
H = (1e4, 0, 0)
system.energy += mm.Zeeman(H=H)
md.drive(system)
system.m.k3d.vector(color_field=system.m.z, head_size=10)
# +
# NBVAL_IGNORE_OUTPUT
system.energy.zeeman.H = (0, 0, 0)
td = oc.TimeDriver()
td.drive(system, t=5e-9, n=500)
system.table.data.plot('t', ['mx', 'my', 'mz'])
| docs/06-getting-started-exercise-vortex-dynamics.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Rapids Nightly [py37]
# language: python
# name: rapids-nightly
# ---
# +
import cudf
import pandas as pd
df = cudf.DataFrame({'a': 1, 'b': 'cat'}, index=[pd.datetime(2019, 9, 1)])
# -
print(df)
df.head().to_pandas().T
| RAPIDS/notebooks/cudf_transpose_bug.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernel_info:
# name: python3-azureml
# kernelspec:
# display_name: Python 3.6 - AzureML
# language: python
# name: python3-azureml
# ---
# # Monitoring Data Drift
#
# Over time, models can become less effective at predicting accurately due to changing trends in feature data. This phenomenon is known as *data drift*, and it's important to monitor your machine learning solution to detect it so you can retrain your models if necessary.
#
# In this lab, you'll configure data drift monitoring for datasets.
# ## Before you start
#
# In addition to the latest version of the **azureml-sdk** and **azureml-widgets** packages, you'll need the **azureml-datadrift** package to run the code in this notebook. Run the cell below to verify that it is installed.
# !pip show azureml-datadrift
# ## Connect to your workspace
#
# With the required SDK packages installed, now you're ready to connect to your workspace.
#
# > **Note**: If you haven't already established an authenticated session with your Azure subscription, you'll be prompted to authenticate by clicking a link, entering an authentication code, and signing into Azure.
# + gather={"logged": 1634056457225}
from azureml.core import Workspace
# Load the workspace from the saved config file
ws = Workspace.from_config()
print('Ready to work with', ws.name)
# -
# ## Create a *baseline* dataset
#
# To monitor a dataset for data drift, you must register a *baseline* dataset (usually the dataset used to train your model) to use as a point of comparison with data collected in the future.
# + gather={"logged": 1634056511276}
from azureml.core import Datastore, Dataset
# Upload the baseline data
default_ds = ws.get_default_datastore()
default_ds.upload_files(files=['./data/diabetes.csv', './data/diabetes2.csv'],
target_path='diabetes-baseline',
overwrite=True,
show_progress=True)
# Create and register the baseline dataset
print('Registering baseline dataset...')
baseline_data_set = Dataset.Tabular.from_delimited_files(path=(default_ds, 'diabetes-baseline/*.csv'))
baseline_data_set = baseline_data_set.register(workspace=ws,
name='diabetes baseline',
description='diabetes baseline data',
tags = {'format':'CSV'},
create_new_version=True)
print('Baseline dataset registered!')
# -
# ## Create a *target* dataset
#
# Over time, you can collect new data with the same features as your baseline training data. To compare this new data to the baseline data, you must define a target dataset that includes the features you want to analyze for data drift as well as a timestamp field that indicates the point in time when the new data was current -this enables you to measure data drift over temporal intervals. The timestamp can either be a field in the dataset itself, or derived from the folder and filename pattern used to store the data. For example, you might store new data in a folder hierarchy that consists of a folder for the year, containing a folder for the month, which in turn contains a folder for the day; or you might just encode the year, month, and day in the file name like this: *data_2020-01-29.csv*; which is the approach taken in the following code:
# + gather={"logged": 1634056536274}
import datetime as dt
import pandas as pd
print('Generating simulated data...')
# Load the smaller of the two data files
data = pd.read_csv('data/diabetes2.csv')
# We'll generate data for the past 6 weeks
weeknos = reversed(range(6))
file_paths = []
for weekno in weeknos:
# Get the date X weeks ago
data_date = dt.date.today() - dt.timedelta(weeks=weekno)
# Modify data to ceate some drift
data['Pregnancies'] = data['Pregnancies'] + 1
data['Age'] = round(data['Age'] * 1.2).astype(int)
data['BMI'] = data['BMI'] * 1.1
# Save the file with the date encoded in the filename
file_path = 'data/diabetes_{}.csv'.format(data_date.strftime("%Y-%m-%d"))
data.to_csv(file_path)
file_paths.append(file_path)
# Upload the files
path_on_datastore = 'diabetes-target'
default_ds.upload_files(files=file_paths,
target_path=path_on_datastore,
overwrite=True,
show_progress=True)
# Use the folder partition format to define a dataset with a 'date' timestamp column
partition_format = path_on_datastore + '/diabetes_{date:yyyy-MM-dd}.csv'
target_data_set = Dataset.Tabular.from_delimited_files(path=(default_ds, path_on_datastore + '/*.csv'),
partition_format=partition_format)
# Register the target dataset
print('Registering target dataset...')
target_data_set = target_data_set.with_timestamp_columns('date').register(workspace=ws,
name='diabetes target',
description='diabetes target data',
tags = {'format':'CSV'},
create_new_version=True)
print('Target dataset registered!')
# -
# ## Create a data drift monitor
#
# Now you're ready to create a data drift monitor for the diabetes data. The data drift monitor will run periodicaly or on-demand to compare the baseline dataset with the target dataset, to which new data will be added over time.
#
# ### Create a compute target
#
# To run the data drift monitor, you'll need a compute target. Run the following cell to specify a compute cluster (if it doesn't exist, it will be created).
#
# > **Important**: Change *your-compute-cluster* to the name of your compute cluster in the code below before running it! Cluster names must be globally unique names between 2 to 16 characters in length. Valid characters are letters, digits, and the - character.
# + gather={"logged": 1634063584430}
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
cluster_name = "CT-915-02-JMDL"
try:
# Check for existing compute target
training_cluster = ComputeTarget(workspace=ws, name=cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
# If it doesn't already exist, create it
try:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_DS11_V2', max_nodes=2)
training_cluster = ComputeTarget.create(ws, cluster_name, compute_config)
training_cluster.wait_for_completion(show_output=True)
except Exception as ex:
print(ex)
# -
# > **Note**: Compute instances and clusters are based on standard Azure virtual machine images. For this exercise, the *Standard_DS11_v2* image is recommended to achieve the optimal balance of cost and performance. If your subscription has a quota that does not include this image, choose an alternative image; but bear in mind that a larger image may incur higher cost and a smaller image may not be sufficient to complete the tasks. Alternatively, ask your Azure administrator to extend your quota.
#
# ### Define the data drift monitor
#
# Now you're ready to use a **DataDriftDetector** class to define the data drift monitor for your data. You can specify the features you want to monitor for data drift, the name of the compute target to be used to run the monitoring process, the frequency at which the data should be compared, the data drift threshold above which an alert should be triggered, and the latency (in hours) to allow for data collection.
# + gather={"logged": 1634063666358}
from azureml.datadrift import DataDriftDetector
# set up feature list
features = ['Pregnancies', 'Age', 'BMI']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'mslearn-diabates-drift',
baseline_data_set,
target_data_set,
compute_target=cluster_name,
frequency='Week',
feature_list=features,
drift_threshold=.3,
latency=24)
monitor
# -
# ## Backfill the data drift monitor
#
# You have a baseline dataset and a target dataset that includes simulated weekly data collection for six weeks. You can use this to backfill the monitor so that it can analyze data drift between the original baseline and the target data.
#
# > **Note** This may take some time to run, as the compute target must be started to run the backfill analysis. The widget may not always update to show the status, so click the link to observe the experiment status in Azure Machine Learning studio!
# + gather={"logged": 1634064896329}
from azureml.widgets import RunDetails
backfill = monitor.backfill(dt.datetime.now() - dt.timedelta(weeks=6), dt.datetime.now())
RunDetails(backfill).show()
backfill.wait_for_completion()
# -
# ## Analyze data drift
#
# You can use the following code to examine data drift for the points in time collected in the backfill run.
# + gather={"logged": 1634065629538}
drift_metrics = backfill.get_metrics()
for metric in drift_metrics:
print(metric, drift_metrics[metric])
# -
# You can also visualize the data drift metrics in [Azure Machine Learning studio](https://ml.azure.com) by following these steps:
#
# 1. On the **Datasets** page, view the **Dataset monitors** tab.
# 2. Click the data drift monitor you want to view.
# 3. Select the date range over which you want to view data drift metrics (if the column chart does not show multiple weeks of data, wait a minute or so and click **Refresh**).
# 4. Examine the charts in the **Drift overview** section at the top, which show overall drift magnitude and the drift contribution per feature.
# 5. Explore the charts in the **Feature detail** section at the bottom, which enable you to see various measures of drift for individual features.
#
# > **Note**: For help understanding the data drift metrics, see the [How to monitor datasets](https://docs.microsoft.com/azure/machine-learning/how-to-monitor-datasets#understanding-data-drift-results) in the Azure Machine Learning documentation.
#
# ## Explore further
#
# This lab is designed to introduce you to the concepts and principles of data drift monitoring. To learn more about monitoring data drift using datasets, see the [Detect data drift on datasets](https://docs.microsoft.com/azure/machine-learning/how-to-monitor-datasets) in the Azure machine Learning documentation.
#
# You can also collect data from published services and use it as a target dataset for datadrift monitoring. See [Collect data from models in production](https://docs.microsoft.com/azure/machine-learning/how-to-enable-data-collection) for details.
#
| 17 - Monitor Data Drift.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="oxKYH6wCQ9Hf" colab_type="text"
# <table class="tfo-notebook-buttons" align="left">
# <td>
# <a target="_blank" href="https://colab.research.google.com/github/mlai-demo/TextExplore/blob/master/RePlutarch_TFembPub.ipynb">
# <img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
# </td><td>
# <a target="_blank" href="https://github.com/mlai-demo/TextExplore/blob/master/RePlutarch_TFembPub.ipynb"><img width=32px src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />View source on GitHub</a></td></table>
# + colab_type="code" id="PcIZDgAuNh7F" colab={}
from __future__ import absolute_import, division, print_function, unicode_literals
# Install TensorFlow - works on Colab only
try:
# # %tensorflow_version only exists in Colab.
# %tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
# + colab_type="code" id="o_hemWWxNh9E" outputId="b315abea-b2fd-415a-fc88-3334c30db5bb" colab={"base_uri": "https://localhost:8080/", "height": 34}
print(tf.__version__)
# + colab_type="code" id="BJGnfegTNh9e" colab={}
import os
fpath = os.getcwd(); fpath
# + colab_type="code" id="JkKkAhJaNh-s" colab={}
# if using Google Colab
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
# Click Files tab - the updloaded file(s) will be there
# + colab_type="code" id="P5NS5q_SNh_1" colab={}
import re
corpus = open(fpath + '/Plutarch.txt', 'rb').read().lower().decode(encoding='utf-8')
corpus = re.sub('\n', ' ', corpus) #remove new line
corpus = re.sub('\r', ' ', corpus) #remove "return"
# + colab_type="code" id="3c5UXe-nCfvS" colab={}
import nltk
from nltk.tokenize import sent_tokenize
nltk.download('punkt') #need in Colab upon resetting the runtime
# tokenize at sentence level
sentences = nltk.sent_tokenize(corpus)
#print("\n---\n".join(sentences))
print("The number of sentences is {}".format(len(sentences)))
# + colab_type="code" id="hOLDD9YoNh__" colab={}
from nltk.tokenize import word_tokenize
word_count = lambda sentence: len(word_tokenize(sentence))
#print(min(sentences, key=word_count))
#print('\n')
#print(max(sentences, key=word_count))
longest_sentence = max(sentences, key=word_count)
length_longest_sentence = len(word_tokenize(longest_sentence))
print("The longest sentence has {} words".format(length_longest_sentence))
# + colab_type="code" id="a12Qzu6VNiAH" colab={}
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
sent_numeric = tokenizer.texts_to_sequences(sentences)
# + colab_type="code" id="XnObx0kTHK9P" colab={}
len(tokenizer.word_index.items())
# + colab_type="code" id="dPTXdBmmKdQe" colab={}
word_index = {k:v for k,v in tokenizer.word_index.items()}
word_index["<PAD>"] = 0
vocab_size = len(word_index)
vocab_size
# + colab_type="code" id="hus87becUVy3" colab={}
for word in ['considering', 'therefore', 'great', 'oppose']:
print('{}: {}'.format(word, word_index[word]))
# + colab_type="code" id="y5C0OsHaUn4q" colab={}
sent_numeric[2:4]
# + colab_type="code" id="sPH5YlhTUoIc" colab={}
sentences[2:4]
# + colab_type="code" id="OeIR9L1OQSca" colab={}
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_data(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
#print(reverse_word_index)
# + colab_type="code" id="kjFQR80p-GuT" colab={}
decode_data(sent_numeric[3])
# + colab_type="code" id="S5yC-2YiKmn_" colab={}
sent_numeric[3]
# + colab_type="code" id="sfQeOGw_-Guc" colab={}
maxLen = length_longest_sentence
data = tf.keras.preprocessing.sequence.pad_sequences(sent_numeric,
value=word_index["<PAD>"],
padding='post',
maxlen=maxLen)
# + colab_type="code" id="kiKhvw28-Guk" colab={}
data[0]
# + colab_type="code" id="t4Bfi5wg-Gun" colab={}
decode_data(data[0])
# + id="EAC8TaROGI8P" colab_type="code" colab={}
# embedding layer by itself
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding
embedding_dim = 100
model_justembed = Sequential()
model_justembed.add(Embedding(vocab_size, embedding_dim, input_length=maxLen))
model_justembed.compile('adam', 'mse')
model_justembed.summary()
# + id="dSQJamyxGI8T" colab_type="code" colab={}
output_array = model_justembed.predict(data)
#output_array
# + colab_type="code" id="GJyKJf-bWhX2" colab={}
from tensorflow.keras import layers
from tensorflow.keras.layers import Dense
# + colab_type="code" id="JoLyHsHU-Gus" colab={}
embedding_dim=100
model = tf.keras.Sequential([
layers.Embedding(vocab_size, embedding_dim, input_length=maxLen, mask_zero=True),
layers.GlobalAveragePooling1D(),
#layers.Dense(100, activation='relu'), #uncomment to compare the versions
layers.Dense(1, activation='sigmoid')
])
model.summary()
# + colab_type="code" id="3ATFCAqBNiA0" colab={}
import numpy as np
adam = tf.keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, decay=0.0, amsgrad=False)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
batch_size = 16989
data_labels = np.zeros([batch_size, 1])
history = model.fit(
data,
data_labels,
epochs=200,
batch_size=batch_size,
verbose = 0)
# + colab_type="code" id="DOZgpRKO-Gux" colab={}
import matplotlib.pyplot as plt
history_dict = history.history
loss = history_dict['loss']
epochs = range(1, len(loss) + 1)
plt.figure(figsize=(12,9))
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.title('Training loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# + colab_type="code" id="OfdrSJiI-Guz" colab={}
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape)
# + colab_type="code" id="A5QCXG_B-Gu2" colab={}
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(vocab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()
# + [markdown] id="spnu2WTyGI82" colab_type="text"
# Go to projector.tensorflow.org and upload the two files
# + colab_type="code" id="IbBiOm-xNiBA" colab={}
f = open('vectors.tsv' ,'w')
f.write('{} {}\n'.format(vocab_size-1, embedding_dim))
# + colab_type="code" id="H3HJ95slNiBH" colab={}
vectors = model.get_weights()[0]
for words, i in tokenizer.word_index.items():
str_vec = ' '.join(map(str, list(vectors[i, :])))
f.write('{} {}\n'.format(words, str_vec))
f.close()
# + colab_type="code" id="shtizRH6-Gu8" colab={}
# if running in Colab, this will download files to the local machine (if double-click does not work)
try:
from google.colab import files
except ImportError:
pass
else:
files.download('vecs.tsv')
files.download('meta.tsv')
files.download('vectors.tsv')
# + colab_type="code" id="_uW6PvjhNiBU" colab={}
import gensim
# + colab_type="code" id="gEEwoTeZNiBe" colab={}
w2v = gensim.models.KeyedVectors.load_word2vec_format('./vectors.tsv', binary=False)
# + colab_type="code" id="q6uywFKRNiBt" colab={}
w2v.most_similar('rome')
# + colab_type="code" id="qOuk0pgn-GvE" colab={}
round(w2v.similarity('rome', 'caesar'),4)
# + colab_type="code" id="Tv8dcTkdEJ-U" colab={}
round(w2v.similarity('pompey', 'caesar'),4)
# + colab_type="code" id="81X0a0c8UuAq" colab={}
embedding_dim = 100
model2 = tf.keras.Sequential([
layers.Embedding(vocab_size, embedding_dim, mask_zero=True),
#layers.Bidirectional(layers.LSTM(64, return_sequences=True)), #another LSTM layer - uncomment to compare
layers.Bidirectional(layers.LSTM(64)),
layers.Dense(64, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model2.summary()
# + colab_type="code" id="TKN3G3aLNiCo" colab={}
import numpy as np
adam = tf.keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, decay=0.0, amsgrad=False)
model2.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
batch_size = 16989
data_labels = np.zeros([batch_size, 1])
history = model2.fit(
data,
data_labels,
epochs=20,
verbose = 0)
# + colab_type="code" id="mCAPKf53fJEK" outputId="2fae9c45-5392-4598-d0d5-bd851aed1100" colab={"base_uri": "https://localhost:8080/", "height": 34}
e2 = model2.layers[0]
weights2 = e2.get_weights()[0]
print(weights2.shape)
# + colab_type="code" id="41VQmJjrNiCy" colab={}
import io
out_v = io.open('vecs2.tsv', 'w', encoding='utf-8')
out_m = io.open('meta2.tsv', 'w', encoding='utf-8')
for word_num in range(vocab_size):
word = reverse_word_index[word_num]
embeddings = weights2[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()
# + [markdown] id="zxRxo3VCGI9s" colab_type="text"
# Go to projector.tensorflow.org and upload the two files
# + colab_type="code" id="Sn7jaLxVNiC1" colab={}
f = open('vectors2.tsv' ,'w')
f.write('{} {}\n'.format(vocab_size-1, 100))
# + colab_type="code" id="xng7X-BGNiC3" colab={}
vectors2 = model2.get_weights()[0]
for words, i in tokenizer.word_index.items():
str_vec = ' '.join(map(str, list(vectors2[i, :])))
f.write('{} {}\n'.format(words, str_vec))
f.close()
# + colab_type="code" id="JELEufg2NiC9" colab={}
w2v2 = gensim.models.KeyedVectors.load_word2vec_format('./vectors2.tsv', binary=False)
# + colab_type="code" id="wPsdrLFXNiDB" colab={}
w2v2.most_similar('rome')
# + colab_type="code" id="ne-vB8bGlh0I" colab={}
w2v2.most_similar('caesar')
# + colab_type="code" id="r69Ny8pPj6GX" colab={}
round(w2v2.similarity('pompey', 'caesar'),4)
# + colab_type="code" id="gCGpYepqj5rm" colab={}
round(w2v2.similarity('rome', 'caesar'),4)
# + colab_type="code" id="00P51yYpNiEW" colab={}
| RePlutarch_TFembPub.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Revisão Cálculo 1
# ## Limites e continuidade
# ### Propriedades
# ### Calculo de limites
# ### Continuidade
#
# 1. Em um número a:
# * $\lim\limits_{x\rightarrow a} f(x) = f(a)$
# 2. Em um intervalo aberto (a, b):
# * Se a função for contínua em todo intervalo aberto
# 3. Em um intervalo fechado [a, b]:
# * Se a função for contínua em todo intervalo aberto e:
# * $\lim\limits_{x\rightarrow a^+} f(x) = f(a)$
# * $\lim\limits_{x\rightarrow b^-} f(x) = f(b)$
#
# Funções contínuas em seus domínios:
# * polinônios
# * funções racionais
# * funções raízes
# * funções trigonométricas
# * funções trigonométricas inversas
# * funções exponenciais
# * funções logarítmicas
# ## Derivadas
# ### Funções diferenciáveis (deriváveis)
#
# Num intervalo aberto ou num ponto. Se $f$ for diferenciável em $a$, então $f$ é contínua em $a$.
# ### Regras de derivação
#
# * Regra da constante
# * Regra da multiplicação da constante
# * Regra da soma
# * Regra da diferença
# * Regra do produto
# * Regra do quociente
# * Regra da cadeia
# * Derivadas especiais
#
# http://tutorial.math.lamar.edu/pdf/Calculus_Cheat_Sheet_All.pdf
#
# http://tutorial.math.lamar.edu/Classes/CalcI/CalcI.aspx
#
# https://www.utdallas.edu/studentsuccess/mathlab/PatricksPDFs/math_reviews_jan132013/review%20of%202417%20for%202419%20solutions.pdf
#
# http://www.stat.wisc.edu/~ifischer/calculus.pdf
#
# https://www.math.washington.edu/~aloveles/Math324Fall2013/Calc1Review.pdf
# Derivação implícita
# Derivação logarítimica
# Análise marginal
# ## Integração
| Calculo1_revisao.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Classification problem
# + _cell_guid="79c7e3d0-c299-4dcb-8224-4455121ee9b0" _uuid="d629ff2d2480ee46fbb7e2d37f6b5fab8052498a"
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pandas_profiling import ProfileReport
# %matplotlib inline
# -
# Data scurce: Kaggle
df = pd.read_csv('Placement_Data_Full_Class.csv')
df.head(2)
# I'm going to drop few columns for better prediction
# +
# Label column: admission score: Placed / Not placed in status column
# -
# # Exploratory Data Analysis
df['salary'].isnull().sum()
# # Replace missing data
# Replace Nan values with median value. Mean is sensitive to the outliers
df1=df.fillna(df.median())
#df1=df.fillna(df.mean())
df1['salary'].isnull().sum()
#for col in df.columns:
# print(col, ' :', len(df[col].unique()), 'labels' )
# # Visualize data with pandas ProfileReport
profile= ProfileReport(df, title='Pandas Profile Report', explorative=True)
profile.to_widgets()
# # Save profile report to html file
profile.to_file('Campus_placement_profile.html')
# +
#df['hsc_s'].unique()
# -
df['hsc_s'].value_counts()
df.set_index('sl_no',inplace=True)
# # Encoding
def hot_encoding(df,col, prefix):
hot= pd.get_dummies(df[col], prefix=prefix, drop_first=True)
df=pd.concat([hot,df], axis=1)
df.drop(col, axis=1, inplace=True)
return df
def hot_encodingr(df,col, prefix):
hot= pd.get_dummies(df[col], prefix=prefix, drop_first=True)
df=pd.concat([df,hot], axis=1)
df.drop(col, axis=1, inplace=True)
return df
# # These categorical columns are encoded
# Features' columns (categorical)
cat_cols=('gender', 'ssc_b', 'hsc_b', 'hsc_s', 'degree_t', 'workex', 'specialisation' )
# Encoding the output column
df1=hot_encodingr(df1, 'status', 'status')
df1.head(2)
means1 = df1.groupby('degree_t')['status_Placed'].mean().to_dict()
means2 = df1.groupby('specialisation')['status_Placed'].mean().to_dict()
means3 = df1.groupby('degree_t')['status_Placed'].mean().to_dict()
means3
# +
#means1
# -
df1.head(2)
# Encoding features columns
for col in cat_cols:
df1=hot_encoding(df1, col, col)
# After encoding
df1.head(2)
# # Scaling the numerical values
from scipy.stats import zscore
from sklearn.preprocessing import MinMaxScaler
zscore_cols=['ssc_p', 'hsc_p', 'degree_p', 'mba_p']
# +
#df1['ssc_p']=zscore(df1['ssc_p'])
# +
#df1.head(2)
# -
for col in zscore_cols:
df1[col]=zscore(df1[col])
df1.head(2)
scaler = MinMaxScaler()
df1[['etest_p', 'salary']] = scaler.fit_transform(df1[['etest_p', 'salary']])
df1.head(3)
# +
# Set features and output matrices
# -
X=df1.iloc[:, 0:15].values
y=df1.iloc[:, -1].values
df1.shape
X.shape
y.shape
# # Training
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=20)
from sklearn.linear_model import LogisticRegression
# # Logistic regression
lr = LogisticRegression()
lr.fit(X_train,y_train)
lr.score(X_test,y_test)
# # Random Forest
from sklearn.ensemble import RandomForestClassifier
#random_forest = RandomForestRegressor(n_estimators = 1000, random_state = 42)
rfc = RandomForestClassifier(n_estimators=200, random_state=3)
rfc.fit(X_train,y_train)
rfc.score(X_test,y_test)
# # Xgboost classifier
from xgboost import XGBClassifier
xgb=XGBClassifier(random_state=1,learning_rate=0.01)
xgb.fit(X_train, y_train)
xgb.score(X_test,y_test)
from sklearn.metrics import precision_score
y_pred=xgb.predict(X_test)
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
# #dfcm= pd.DataFrame(
# confusion_matrix(y_test, y_pred, labels=['yes', 'no']),
# index=['true:yes', 'true:no'],
# columns=['pred:yes', 'pred:no']
# )
cm = confusion_matrix(y_test, y_pred)
# +
#dfc=pd.DataFrame(cm, index=['Not Placed', 'Placed'], index=['Not Placed', 'Placed'])
# -
dfc=pd.crosstab(y_test, y_pred, rownames=['Actual'], colnames=['Predicted'], margins=True) .transpose()
dfc
report=classification_report(y_test,y_pred, output_dict=True )
dfr = pd.DataFrame(report).transpose()
dfr
# # Hyper parameter tuning
# # Logistic regression
param_grid_lr=[
{'penalty': ['l1', 'l2', 'elasticnet', 'none'] ,
'C': np.logspace(-4,4, 20),
'solver': ['lbfgs', 'newtog-cg', 'liblinear', 'sag', 'saga'],
'max_iter': [1, 10, 100, 1000, 2000]
}
]
lreg = LogisticRegression()
from sklearn.model_selection import GridSearchCV
cvlrge= GridSearchCV(lreg, param_grid=param_grid_lr, cv=5, verbose=True, n_jobs=-1)
# +
#param_grid_lr
# -
best_lreg=cvlrge.fit(X,y)
best_lreg.best_estimator_
best_lreg.score(X,y)
best_lreg.best_score_
# # Random forest
rfc= RandomForestClassifier()
# +
n_estimators = [100, 300, 500, 800, 1200]
max_depth = [5, 8, 15, 25, 30]
min_samples_split = [2, 5, 10, 15, 100]
min_samples_leaf = [1, 2, 5, 10]
param_rfc = dict(n_estimators = n_estimators, max_depth = max_depth,
min_samples_split = min_samples_split,
min_samples_leaf = min_samples_leaf)
# -
cv_rfc = GridSearchCV(rfc, param_rfc, cv = 5, verbose = 1, n_jobs = -1) # multi-threaded
best_rfc= cv_rfc.fit(X,y)
best_rfc.best_estimator_
best_rfc.score(X,y)
best_rfc.best_score_
# # xgboost
xgb = XGBClassifier(objective = 'binary:logistic')
# +
param_xgb={
"learning_rate" : [0.05, 0.10, 0.15, 0.20, 0.25, 0.30 ] ,
"max_depth" : [ 3, 4, 5, 6, 8, 10, 12, 15],
"min_child_weight" : [ 1, 3, 5, 7 ],
"gamma" : [ 0.0, 0.1, 0.2 , 0.3, 0.4 ],
"colsample_bytree" : [ 0.3, 0.4, 0.5 , 0.7 ]
}
# -
cv_xgb = GridSearchCV(xgb, param_xgb, cv = 5, verbose = 1, n_jobs = -1)
best_xgb= cv_xgb.fit(X,y)
best_xgb.best_estimator_
best_xgb.score(X,y)
best_xgb.best_score_
| Compus_placement.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/ddsmit/teach_and_learn/blob/master/jupyter_training_data.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="YqoNlBIinc8j" colab_type="text"
# # Jupyter Training for Data
# ## Welcome!
# I'm writing this notebook for people who are new to Python and Jupyter, but have some background in programming. I will quickly go over some of the basics of Python (types, conditionals, and loops), and then I will get into some of the Python specific packages that make data analysis much easier. But first, an introduction into Jupyter.
# + [markdown] id="ir7OJ-kZnc8q" colab_type="text"
# ## What is Jupyter
# Jupyter is an app based on web technologies that allows for incremental processing and data exploration. Jupyter is made up of cells, which can come in a variety of formats. The cells I use most often are Markdown and Code cells. Markdown cells use the markdown format to create nicely formatted text, lists, images, etc for documenting the study and explaining the analysis process in the notebook (this cell and the previous cell is Markdown). Code cells take code as an input, and can show an output depending on the contents of the cell. The code cells we will be working with will be written in Python, but there are a variety of languages that can be used in the cells (R, Julia, Javascript, etc).
# + [markdown] id="SvEcj8ILnc8s" colab_type="text"
# ## Starting With Jupyter
# ### Basics
#
# Below are a couple important things to know to get started with Jupyter:
#
# - To execute a code cell or show the output of the markdown cell, you can click the "Run" button or use shift + ENTER
# - A new cell is created below the bottom cell when you run the cell.
# - To create a new cell without running a cell or to insert a cell, click the "insert cell below" (+) button
# - You can click the "up" and "down" buttons to shift cells around the notebook.
# ### The Kernel
#
# One thing that makes Jupyter great for analyzing large data sets (and also tricky to troubleshoot) is if data is assigned to a variable, it stays in memory as long as the kernel stays alive. This means that you don't have to load that massive data set or run that expensive query over and over again. It also means that it can be easy to accidently introduce bugs because you accidently used a variable twice, and the newer data persists when you try to run older cells.
# The "Kernel" menu has a variety of options for managing the kernel:
#
# - Interupt: This stops the processing, but does not kill the kernel.
# - Restart: Restarts the kernel, clearing the memory
# - Restart and Clear Output: Restarts the kernel and clears the output form the cells
# - Restart and Run All: Restarts the kernel and Reruns all Cells in the Notebook
# I have not used the last 2 options extensively, so I don't want to mispeak about their purpose. If you're curious, you can do some research yourself!
#
# Now, lets get started with a simple example to show how the kernel retains data. Run the cell below (#cell 1).
# + id="EDa3hN5nnc8v" colab_type="code" outputId="c0df9ff8-c923-4e67-817f-6ee34c037cb8" colab={"base_uri": "https://localhost:8080/", "height": 34}
#cell 1
#assign a value to a variable
x = 1
x
# + [markdown] id="p2RgneXMnc86" colab_type="text"
# Notice how the value of "X" was output. This is because Jupyter will show the output if something valid is on the bottom of the cell. Now run #cell 2 and #cell 3 below:
# + id="lSPPIP6unc88" colab_type="code" colab={}
#cell 2
x = 2
# + id="CU2PksOGnc9E" colab_type="code" outputId="915d1c9b-0546-4a0f-cc9b-78dcf72d03b6" colab={"base_uri": "https://localhost:8080/", "height": 34}
#cell 3
x
# + [markdown] id="S058QKmxnc9N" colab_type="text"
# As you would expect, the output was "2" because the value of 2 was assigned to "x". Now run #cell 1 and #cell 3 OMITTING #cell 2. What was the output?
# This behavior is part of the reason you need to be carefull with execution order in Jupyter to make sure you're not accidently changing your results.
# + [markdown] id="aPOrQ1Wmnc9Q" colab_type="text"
# # Python: Built in Types
# As with any programming languages, it is important to understand the basic/most common ways that data is stored in the language. There are many types built into the Python standard library, but we will focus on some of the types I've used most often in my data analysis.
# One feature of Python that makes it so powerful for quick interation is that it is a dynamically typed language. This means that you do not need to declare the type of a variable ahead of time. Also, you can assign a value of a different type to a variable without an issue
# + [markdown] id="LIp5Xihpnc9U" colab_type="text"
# ## String
# Python has a single type that covers all character/string data. This type has may built in functions that can be very helpful. First, we will start by assigning a string to a variable. To let python know a value is a string, you can use single quotes '', double quotes "", or triple quotes """""". Triple quotes allow for multi line text, and are typically reserved for such cases.
# + id="6sZ3JbO4nc9Z" colab_type="code" colab={}
first_name = 'David' #single quotes
last_name = "Smit" #double quotes
life_story = """
My life story is very short,
but it doesn't mean it only takes 1 line.
"""
# + [markdown] id="tgNrzu-Gnc9n" colab_type="text"
# What if you want to know how long a string is? Use the len() function.
# + id="AAk1Qy4Knc9r" colab_type="code" outputId="e30790bd-0af1-4aa8-db9b-3a074835d04e" colab={"base_uri": "https://localhost:8080/", "height": 34}
len(first_name)
# + [markdown] id="EANuDJZync92" colab_type="text"
# If you want to lower all of the letters, capitilize all of the letters, or capitlize the first letter, there are functions for that too!
# + id="Jsy6rjoKnc96" colab_type="code" outputId="97afad05-bfe2-4912-be8a-4c981fd70cc7" colab={"base_uri": "https://localhost:8080/", "height": 34}
last_name.lower()
# + id="OwM7cMcLnc-I" colab_type="code" outputId="3954a932-ce70-4a99-92a9-fbec831fabe4" colab={"base_uri": "https://localhost:8080/", "height": 34}
last_name.upper()
# + id="vXC-tfLtnc-T" colab_type="code" outputId="29f902a0-c60a-4441-ae1d-fa70cd152d65" colab={"base_uri": "https://localhost:8080/", "height": 34}
last_name.capitalize()
# + [markdown] id="NkBsyXsAnc-e" colab_type="text"
# You may have noticed how the syntax was different between the len and lower/upper/capitalize. This is because len is a function, and lower/upper/captilize are methods. We will get into that a little bit more in the intermediate notebook.
#
# If you only have (1) value in square brackets [] after the variable, it will return the value at that index (starting at 0). So if you use 0 in the brackets, you'd get:
# + id="wpx_Utptnc-h" colab_type="code" outputId="61c0502f-d655-4e2e-db85-3e656b5fa161" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[0]
# + [markdown] id="5JzXGKrmnc-o" colab_type="text"
# If you use 1 in the brackets, you get:
# + id="JcZoyE9Inc-q" colab_type="code" outputId="d931e755-460c-47eb-9635-fb06cad5e04d" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[1]
# + [markdown] id="5zmkL8UKnc-w" colab_type="text"
# Now, we will try slicing with strings. Slicing can be used on many datatypes to pull out sections of the data quickly and easily. In the case of text, you can pull out a specific section of the text.
# Slicing is done by putting square brackets [] behind a variable like finding the index, but you also include multiple values seperated by ":"
#
# [start index:end_index:step]
#
# If you ommit the value for step, it will default to 1. So to pull out indexes 0 to 2, you would do the following:
# + id="ft3236oinc-x" colab_type="code" outputId="9fe3dbc6-565f-4469-eb59-e68552396042" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[0:2]
# + [markdown] id="bE2974H0nc-4" colab_type="text"
# Notice how the output wasn't 'Dav', this is because the slice gets the values up to, but not including the index in the 2nd spot. You can also omit a value, which means it will default to the first or last index depending on which value is omitted.
# + id="JHm9_Fmwnc-6" colab_type="code" outputId="965ccb12-e0b0-4300-ddd7-d7ea85c0242f" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[:2] #Begining up to index 2
# + id="TtVK915cnc_B" colab_type="code" outputId="3cb57ea7-9383-493a-eb8e-cd71f9f07cb8" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[:3] #Begining up to index 3
# + id="2dRcYUs7nc_G" colab_type="code" outputId="88c4d8eb-be36-4f96-d73b-56839a8aa56a" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[1:] #From index 1 to end
# + id="3VdQW05Anc_J" colab_type="code" outputId="d28aafac-4521-4ca2-e4e9-c273598c49af" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[2:] #From index 2 to end
# + [markdown] id="phTjZMSGnc_N" colab_type="text"
# You can also use a negative value. In the first position, this will index from the end for the starting point (2 indexes from the end). This can be very helpful.
# + id="-fudHmhXnc_P" colab_type="code" outputId="9bc70abf-c6cc-4eae-aaf0-8709700c62bb" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[-2:]
# + id="dt-zptJcnc_T" colab_type="code" outputId="6763931a-dd2a-4726-f2c7-c415eeefe785" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[:-2]
# + [markdown] id="afi48l60nc_W" colab_type="text"
# The third value (step) can be used to index at a different increment other than 1. For example, if you use 2 in for the 3rd value, you will index through every other letter.
# + id="1D2Cxo5znc_X" colab_type="code" outputId="0b5afd8c-64dc-4d7e-fd9e-3bd684c90a46" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[::2]
# + [markdown] id="LbiJ9yGHnc_a" colab_type="text"
# You can also use a negative value to reverse the string.
# + id="nZKCa3a_nc_b" colab_type="code" outputId="54f49629-b577-4458-8325-98d03a010472" colab={"base_uri": "https://localhost:8080/", "height": 34}
first_name[::-1]
# + [markdown] id="uqhjU95HSSiC" colab_type="text"
# THe illustration below is a good reference to use for understanding how indexing works (the example is the string 'probe').
# .
#
# The original source of this image is https://www.programiz.com/python-programming/list, check out the article for more information on lists!
# + [markdown] id="RZXmJEMHnc_e" colab_type="text"
# ## List
# Another very helpful type in Python is the list. The list is a collection that is mutable and ordered. What does this mean? It means the contents can be changed, and the order is maintained. Lists can contain anything, including other collection types (like lists), and a list does not need to contain all of the same types. A list can be created by putting items in square brackets seperated by a comma. You can also create an empty list by using empty square brackets.
# Below is an example of a list being assigned to a variable.
# + id="7RM6obH7nc_f" colab_type="code" colab={}
people = ['David','Yolanda','Cydney','Mathilda','Kent']
# + [markdown] id="GPDsmf5znc_i" colab_type="text"
# Lists can be sliced in the same exact way as a string.
#
# + id="WsCF8Us8nc_j" colab_type="code" outputId="fab67919-4719-4a1c-cd62-4e50cbeca4d0" colab={"base_uri": "https://localhost:8080/", "height": 34}
people[0]
# + id="CD07etMZnc_n" colab_type="code" outputId="ae4d5780-570b-4a41-9375-e60c8dc2a7e9" colab={"base_uri": "https://localhost:8080/", "height": 34}
people[0:2]
# + id="eKNvpYThnc_q" colab_type="code" outputId="f298c772-1ffc-413d-e4d2-a9e84731fa80" colab={"base_uri": "https://localhost:8080/", "height": 34}
people[-1:]
# + id="Yrl7SisQnc_u" colab_type="code" outputId="8078e1f1-03bb-4898-9828-148d75b00857" colab={"base_uri": "https://localhost:8080/", "height": 34}
people[:-2]
# + id="gn3-xWqznc_y" colab_type="code" outputId="ea8f6cb1-4676-4114-b3f0-df29a4810389" colab={"base_uri": "https://localhost:8080/", "height": 34}
people[::-1]
# + id="WyLwGiHMnc_2" colab_type="code" outputId="e8da9a65-1a62-4fec-bdae-900ee4d7738f" colab={"base_uri": "https://localhost:8080/", "height": 34}
people[1:3]
# + [markdown] id="Bi6Httidnc_5" colab_type="text"
# You can use methods such as append, pop, and remove to update the list.
# Append will add an item to the end of the list.
# + id="_QSVHK-Mnc_6" colab_type="code" outputId="68275ffd-1c58-475a-8a1b-b3b230d9b9af" colab={"base_uri": "https://localhost:8080/", "height": 34}
people.append('Ina')
people
# + [markdown] id="s4LeLJc7ohwt" colab_type="text"
# Pop will remove the last item in the list, and return the value of the last item. Below, we are assigned the returned value to the variable "last_person" and then displaying both the last_person variable and the people list.
# + id="1vum_Q-cnc_9" colab_type="code" outputId="c5a9d631-34cc-40a2-fc17-782bc9c238f0" colab={"base_uri": "https://localhost:8080/", "height": 51}
last_person = people.pop()
print(last_person)
people
# + [markdown] id="BH1mmzOwo0bk" colab_type="text"
# Wait, what is "print"? This is a function that will either print out a value to standard out or in the output poriton of the cell.
# + [markdown] id="Gj3iLS4gUQxw" colab_type="text"
# ## Sets
# Sets are a mutable, unordered collection type. Only 1 of any value can exist in a set. I will covert a collection to a set as an easy was to eliminate duplicate values.
# You can create a set by using curly braces {} and seperating the values with a comma:
# + id="Do1j5spuUjGd" colab_type="code" outputId="9bba289e-62f0-4fdf-c4c1-bb27d20f9f08" colab={"base_uri": "https://localhost:8080/", "height": 34}
example_set = {'id1','id2','id3','id3','id4'}
example_set
# + [markdown] id="vIaCuuVqVG-W" colab_type="text"
# Notice how there was only 1 instance of id3, this is due to the behavior described above (only 1 instance of each value). To create an empty set (or to convert another collection to a set), you use the set function:
# + id="inOFYof8VWup" colab_type="code" outputId="a717c299-5a98-4f47-d8f4-13776a7644e0" colab={"base_uri": "https://localhost:8080/", "height": 34}
example_list2 = [1,2,3,3,3,2,5,4,2,4,6,7,8,6,5,4,3,3,]
example_set2 = set(example_list2)
example_set2
# + [markdown] id="UjTxUhvZV-cC" colab_type="text"
# ## Tuples
# Tuples are an imutable collection (cannot be changed). I most often use them as keys in a dictionary when I want multiple pieces of data to define a key (I wil explain more later on in dictionaries). Slicing in a tuple works just like a list, but many of the other functions for a list will not work with a tuple because it cannot change. A tuple can contain multiple data types including a mixture of types.
# Tuples can be created by seperating items with a comma in parenthesis ().
# + id="1rGPdTk1WhRm" colab_type="code" colab={}
example_tuple1 =
# + [markdown] id="sKr8Sa3LI54s" colab_type="text"
# ## Dictionaries
# A dictionary is a datatype that includes a key and a value. The key much be unique and m
# + id="b00NR9mlUi_s" colab_type="code" colab={}
# + id="1o11sDnnUi5C" colab_type="code" colab={}
# + id="wT3hry2dUiyF" colab_type="code" colab={}
# + id="wPeSWFq3UirT" colab_type="code" colab={}
# + id="OSMJOtjNUikt" colab_type="code" colab={}
# + id="qBOkGCbDUidX" colab_type="code" colab={}
# + id="GO7s11IUUiU2" colab_type="code" colab={}
# + id="mR8WzOzSUiND" colab_type="code" colab={}
# + id="h7SgWFzmUiEQ" colab_type="code" colab={}
# + id="afHu7jOrUh4Q" colab_type="code" colab={}
| Teaching/jupyter_training_data.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="4WSXmzOVBn-X"
# ##### Copyright 2021 Google LLC.
# + cellView="form" id="gkJ16-cKBuAK"
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# + [markdown] id="hGbNmaA5_si_"
# # Inverse Rendering
# <table class="tfo-notebook-buttons" align="left">
# <td>
# <a target="_blank" href="https://colab.research.google.com/github/tensorflow/graphics/blob/master/tensorflow_graphics/notebooks/inverse_rendering.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
# </td>
# <td>
# <a target="_blank" href="https://github.com/tensorflow/graphics/blob/master/tensorflow_graphics/notebooks/inverse_rendering.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />View source on GitHub</a>
# </td>
# </table>
# + [markdown] id="VvLMHI88DBVs"
# This notebook demonstrates an optimization that approximates an image of a 3D shape under unknown camera and lighting using differentiable rendering functions. The variables of optimization include: **camera rotation**, **position**, and **field-of-view**, **lighting direction**, and **background color**.
#
# Because the TFG rendering does not include global illumination effects such as shadows, the output rendering will not perfectly match the input shape. To overcome this issue, we use a robust loss based on the [structured similarity metric](https://www.tensorflow.org/api_docs/python/tf/image/ssim).
#
# As demonstrated here, accurate derivatives at occlusion boundaries are critical for the optimization to succeed. TensorFlow Graphics implements the **rasterize-then-splat** algorithm [Cole, et al., 2021] to produce derivatives at occlusions. Rasterization with no special treatment of occlusions is provided for comparison; without handling occlusion boundaries, the optimization diverges.
# + [markdown] id="ppRKISWUQIeB"
# ## Setup Notebook
# + id="pZs6dzmQsdY6" cellView="form"
# %%capture
#@title Install TensorFlow Graphics
# %pip install tensorflow_graphics
# + id="__t3mrMftAA2"
#@title Fetch the model and target image
# !wget -N https://www.cs.cmu.edu/~kmcrane/Projects/ModelRepository/spot.zip
# !unzip -o spot.zip
# !wget -N https://www.cs.cmu.edu/~kmcrane/Projects/ModelRepository/spot.png
# + cellView="form" id="3H__1-brS0ms"
#@title Import modules
import math
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from PIL import Image as PilImage
import tempfile
import tensorflow_graphics.geometry.transformation.quaternion as quat
import tensorflow_graphics.geometry.transformation.euler as euler
import tensorflow_graphics.geometry.transformation.look_at as look_at
import tensorflow_graphics.geometry.transformation.rotation_matrix_3d as rotation_matrix_3d
from tensorflow_graphics.rendering.camera import perspective
from tensorflow_graphics.rendering import triangle_rasterizer
from tensorflow_graphics.rendering import splat
from tensorflow_graphics.rendering.texture import texture_map
from tensorflow_graphics.geometry.representation.mesh import normals as normals_module
# + [markdown] id="2TebacgwQKeG"
# ## Load the Spot model
# + cellView="form" id="U98pmFE_OWtn"
#@title Load the mesh and texture
def load_and_flatten_obj(obj_path):
"""Loads an .obj and flattens the vertex lists into a single array.
.obj files may contain separate lists of positions, texture coordinates, and
normals. In this case, a triangle vertex will have three values: indices into
each of the position, texture, and normal lists. This function flattens those
lists into a single vertex array by looking for unique combinations of
position, texture, and normal, adding those to list, and then reindexing the
triangles.
This function processes only 'v', 'vt', 'vn', and 'f' .obj lines.
Args:
obj_path: the path to the Wavefront .obj file.
Returns:
a numpy array of vertices and a Mx3 numpy array of triangle indices.
The vertex array will have shape Nx3, Nx5, Nx6, or Nx8, depending on whether
position, position + texture, position + normals, or
position + texture + normals are present.
Unlike .obj, the triangle vertex indices are 0-based.
"""
VERTEX_TYPES = ['v', 'vt', 'vn']
vertex_lists = {n: [] for n in VERTEX_TYPES}
flat_vertices_list = []
flat_vertices_indices = {}
flat_triangles = []
# Keep track of encountered vertex types.
has_type = {t: False for t in VERTEX_TYPES}
with open(obj_path) as obj_file:
for line in iter(obj_file):
tokens = line.split()
if not tokens:
continue
line_type = tokens[0]
# We skip lines not starting with v, vt, vn, or f.
if line_type in VERTEX_TYPES:
vertex_lists[line_type].append([float(x) for x in tokens[1:]])
elif line_type == 'f':
triangle = []
for i in range(3):
# The vertex name is one of the form: 'v', 'v/vt', 'v//vn', or
# 'v/vt/vn'.
vertex_name = tokens[i + 1]
if vertex_name in flat_vertices_indices:
triangle.append(flat_vertices_indices[vertex_name])
continue
# Extract all vertex type indices ('' for unspecified).
vertex_indices = vertex_name.split('/')
while len(vertex_indices) < 3:
vertex_indices.append('')
flat_vertex = []
for vertex_type, index in zip(VERTEX_TYPES, vertex_indices):
if index:
# obj triangle indices are 1 indexed, so subtract 1 here.
flat_vertex += vertex_lists[vertex_type][int(index) - 1]
has_type[vertex_type] = True
else:
# Append zeros for missing attributes.
flat_vertex += [0, 0] if vertex_type == 'vt' else [0, 0, 0]
flat_vertex_index = len(flat_vertices_list)
flat_vertices_list.append(flat_vertex)
flat_vertices_indices[vertex_name] = flat_vertex_index
triangle.append(flat_vertex_index)
flat_triangles.append(triangle)
# Keep only vertex types that are used in at least one vertex.
flat_vertices_array = np.float32(flat_vertices_list)
flat_vertices = flat_vertices_array[:, :3]
if has_type['vt']:
flat_vertices = np.concatenate((flat_vertices, flat_vertices_array[:, 3:5]),
axis=-1)
if has_type['vn']:
flat_vertices = np.concatenate((flat_vertices, flat_vertices_array[:, -3:]),
axis=-1)
return flat_vertices, np.int32(flat_triangles)
def load_texture(texture_filename):
"""Returns a texture image loaded from a file (float32 in [0,1] range)."""
with open(texture_filename, 'rb') as f:
return np.asarray(PilImage.open(f)).astype(np.float32) / 255.0
spot_texture_map = load_texture('spot/spot_texture.png')
vertices, triangles = load_and_flatten_obj('spot/spot_triangulated.obj')
vertices, uv_coords = tf.split(vertices, (3,2), axis=-1)
normals = normals_module.vertex_normals(vertices, triangles)
print(vertices.shape, uv_coords.shape, normals.shape, triangles.shape)
# + cellView="form" id="WHDaIoh7RPSA"
#@title Load and display target image
from PIL import Image as PilImage
import matplotlib.pyplot as plt
def show_image(image, show=True):
plt.imshow(image, origin='lower')
plt.axis('off')
if show:
plt.show()
with open('spot.png', 'rb') as target_file:
target_image = PilImage.open(target_file)
target_image.thumbnail([200,200])
target_image = np.array(target_image).astype(np.float32) / 255.0
target_image = np.flipud(target_image)
image_width = target_image.shape[1]
image_height = target_image.shape[0]
show_image(target_image)
# + [markdown] id="FrVYSAlpQoM1"
# ## Set up rendering functions and variables
# + id="TDDSf5YQSXVV" cellView="form"
#@title Initial variables
import math
def make_initial_variables():
camera_translation = tf.Variable([[0.0, 0.0, -4]])
fov = tf.Variable([40.0 * math.pi / 180.0])
quaternion = tf.Variable(tf.expand_dims(
quat.from_euler((0.0, 0.0, 0.0)), axis=0))
background_color = tf.Variable([1.0, 1.0, 1.0, 1.0])
light_direction = tf.Variable([0.5, 0.5, 1.0])
return {
'quaternion': quaternion,
'translation': camera_translation,
'fov': fov,
'background_color': background_color,
'light_direction': light_direction
}
# + id="JEAeBBhvTAez" cellView="form"
#@title Rendering functions
def shade(rasterized, light_direction, ka=0.5, kd=0.5):
"""Shades the input rasterized buffer using a basic illumination model.
Args:
rasterized: a dictionary of interpolated attribute buffers.
light_direction: a vector defining the direction of a single light.
ka: ambient lighting coefficient.
kd: diffuse lighting coefficient.
Returns:
an RGBA buffer of shaded pixels.
"""
textured = texture_map.map_texture(rasterized['uv'][tf.newaxis, ...],
spot_texture_map)[0, ...]
light_direction = tf.reshape(light_direction, [1, 1, 3])
light_direction = tf.math.l2_normalize(light_direction, axis=-1)
n_dot_l = tf.clip_by_value(
tf.reduce_sum(
rasterized['normals'] * light_direction, axis=2, keepdims=True), 0.0,
1.0)
ambient = textured * ka
diffuse = textured * kd * n_dot_l
lit = ambient + diffuse
lit_rgba = tf.concat((lit, rasterized['mask']), -1)
return lit_rgba
def rasterize_without_splatting(projection, image_width, image_height,
light_direction):
rasterized = triangle_rasterizer.rasterize(vertices, triangles, {
'uv': uv_coords,
'normals': normals
}, projection, (image_height, image_width))
lit = shade(rasterized, light_direction)
return lit
def rasterize_then_splat(projection, image_width, image_height,
light_direction):
return splat.rasterize_then_splat(vertices, triangles, {
'uv': uv_coords,
'normals': normals
}, projection, (image_height, image_width),
lambda d: shade(d, light_direction))
def render_forward(variables, rasterization_func):
camera_translation = variables['translation']
eye = camera_translation
# Place the "center" of the scene along the Z axis from the camera.
center = tf.constant([[0.0, 0.0, 1.0]]) + camera_translation
world_up = tf.constant([[0.0, 1.0, 0.0]])
normalized_quaternion = variables['quaternion'] / tf.norm(
variables['quaternion'], axis=1, keepdims=True)
model_rotation_3x3 = rotation_matrix_3d.from_quaternion(normalized_quaternion)
model_rotation_4x4 = tf.pad(model_rotation_3x3 - tf.eye(3),
((0, 0), (0, 1), (0, 1))) + tf.eye(4)
look_at_4x4 = look_at.right_handed(eye, center, world_up)
perspective_4x4 = perspective.right_handed(variables['fov'],
(image_width / image_height,),
(0.01,), (10.0,))
projection = tf.matmul(perspective_4x4,
tf.matmul(look_at_4x4, model_rotation_4x4))
rendered = rasterization_func(projection, image_width, image_height,
variables['light_direction'])
background_rgba = variables['background_color']
background_rgba = tf.tile(
tf.reshape(background_rgba, [1, 1, 4]), [image_height, image_width, 1])
composited = rendered + background_rgba * (1.0 - rendered[..., 3:4])
return composited
# + cellView="form" id="9UU1JD7HPKLv"
#@title Loss function
def ssim_loss(target, rendered):
target_yuv = tf.compat.v2.image.rgb_to_yuv(target[..., :3])
rendered_yuv = tf.compat.v2.image.rgb_to_yuv(rendered[..., :3])
ssim = tf.compat.v2.image.ssim(target_yuv, rendered_yuv, max_val=1.0)
return 1.0 - ssim
# + cellView="form" id="0yYdpz-hPOLL"
#@title Backwards pass
@tf.function
def render_grad(target, variables, rasterization_func):
with tf.GradientTape() as g:
rendered = render_forward(variables, rasterization_func)
loss_value = ssim_loss(target, rendered)
grads = g.gradient(loss_value, variables)
return rendered, grads, loss_value
# + [markdown] id="lB9Xq96vO3us"
# ## Run optimization
# + cellView="form" id="vdcE4k8ZhaOT"
#@title Run gradient descent
variables = make_initial_variables()
# Change this to rasterize to test without RtS
rasterization_mode = 'rasterize then splat' #@param [ "rasterize then splat", "rasterize without splatting"]
rasterization_func = (
rasterize_then_splat
if rasterization_mode == 'rasterize then splat' else rasterize_without_splatting)
learning_rate = 0.02 #@param {type: "slider", min: 0.002, max: 0.05, step: 0.002}
start = render_forward(variables, rasterization_func)
optimizer = tf.keras.optimizers.Adam(learning_rate)
animation_images = [start.numpy()]
num_steps = 300 #@param { type: "slider", min: 100, max: 2000, step: 100}
for i in range(num_steps):
current, grads, loss = render_grad(target_image, variables, rasterization_func)
to_apply = [(grads[k], variables[k]) for k in variables.keys()]
optimizer.apply_gradients(to_apply)
if i > 0 and i % 10 == 0:
animation_images.append(current.numpy())
if i % 100 == 0:
print('Loss at step {:03d}: {:.3f}'.format(i, loss.numpy()))
pass
print('Final loss {:03d}: {:.3f}'.format(i, loss.numpy()))
# + cellView="form" id="dkThT6Oshf-9"
#@title Display results
plt.figure(figsize=[18,6])
plt.subplot(1,4,1)
plt.title('Initialization')
show_image(np.clip(start, 0.0, 1.0), show=False)
plt.subplot(1,4,2)
plt.title('After Optimization')
show_image(np.clip(current, 0.0, 1.0), show=False)
plt.subplot(1,4,3)
plt.title('Target')
show_image(target_image, show=False)
plt.subplot(1,4,4)
plt.title('Difference')
show_image(current[...,0] - target_image[...,0])
# + cellView="form" id="aQwoCByjhh44"
# %%capture
#@title Display animation
import matplotlib.animation as animation
def save_animation(images):
fig = plt.figure(figsize=(8, 8))
plt.axis('off')
ims = [[plt.imshow(np.flipud(np.clip(i, 0.0, 1.0)))] for i in images]
return animation.ArtistAnimation(fig, ims, interval=50, blit=True)
anim = save_animation(animation_images)
# + id="LTG19FACaTTK"
from IPython.display import HTML
HTML(anim.to_jshtml())
# + cellView="form" id="r2ibcdm1hkiC"
#@title Display initial and optimized camera parameters
def print_camera_params(v):
print(f"FoV (degrees): {v['fov'].numpy() * 180.0 / math.pi}")
print(f"Position: {v['translation'].numpy()}")
print(f"Orientation (xyz angles): {euler.from_quaternion(v['quaternion']).numpy()}")
print("INITIAL CAMERA:")
print_camera_params(make_initial_variables())
print("\nOPTIMIZED CAMERA:")
print_camera_params(variables)
| tensorflow_graphics/notebooks/inverse_rendering.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from utils import *
scale_all_images_in_folder('../data/lettuce_home/set3/original/', '../data/lettuce_home/set3/', 0.4)
sample_img = load_image('img1.jpg', '../data/calibration/set2/')
get_chessboard_points(cv2.cvtColor(sample_img, cv2.COLOR_BGR2GRAY))
| code/camera_calibration.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="aBVDc_NOqwqQ"
# # Inspecting TESS light curves for a project
# ---
#
#
# + id="zMKOnzykBILN"
# Provide the name of the project and the tess cycle it was observed in: 1 or 2; 3 is not yet set up (probably)
# This project must be set up with TESS_Prep.ipynb, but it doesn't have to be a Cantat-Gaudin cluster catalog.
project_name = 'Praesepe_tails'
# + [markdown] id="7fm8RcgOr83X"
# **Import Python modules**
# Python comes with only some basic functions pre-loaded. All other computer programs are included in "modules," which must be imported.
# + id="YJm5je2kr3AP"
# Plotting program
import matplotlib.pyplot as plt
# Plots are shown in the notebook
# %matplotlib inline
# Searches for files
from glob import glob
# Good for reading/writing data tables
import pandas as pd
from astropy.table import Table
# Better math, numbers, and array functions
import numpy as np
# How long does something take?
import time
# I forget what this does.
import warnings
warnings.filterwarnings('ignore')
# + [markdown] id="0_kowjcTBOK7"
# **Set up directories**
# + id="8CLU0d6uBQrb"
# The main directory in Google Drive:
dir_drive = "/content/gdrive/Shareddrives/DouglasGroup/"
dir_main = dir_drive # i have a bad habit of using dir_main and dir_drive interchangeably so i'll define both here.
# The various clusters we will analyze are organized in the "Projects" folder according to the name of the cluster.
# The "project_name" is set at the top of this notebook
dir_project = dir_drive + "tess_check/" + project_name + "/"
# + [markdown] id="gDnFzhXRsEJs"
# **Authorize access to our Drive**
# + colab={"base_uri": "https://localhost:8080/"} id="HfzSK3VqsCzB" executionInfo={"elapsed": 1110, "status": "ok", "timestamp": 1624907825588, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "17503869240391001005"}, "user_tz": 240} outputId="ae15e8ed-5505-4e32-f66b-fbc4fde2a22a"
# We need to give this notebook access to the data stored in our Google Drive.
from google.colab import drive
drive.mount('/content/gdrive/', force_remount=True)
# Google Colab has access to many of the Python modules we will need, and are available for import
# Others are not pre-installed, but are accessible online and can be downloaded and installed via pip (e.g., astroquery)
# However, our code is stored in our Drive. We have to tell the computer where it is located so that it will be available for import:
import sys
# First, we need to tell the system where it can locate the Python modules. This is done by adding the directories to the "path.""
# After that, we can import our modules just like we did previously for those already installed on the Google servers.
#### I have my own Python codes saved in folders located in /content/gdrive/My Drive/PythonCode/. I've modified this for Mark.
sys.path.append(dir_main)
# If/when you move these programs, you will need to edit myDir.py and then update its path name in the imports in tess_tools.py and tesscheck.py
from tess_check import myDir as myDir
#from tess_check import tess_tools as tess_tools
from tess_check import tesscheck as tesscheck
# Test to make sure myDir is working properly
dir_project_function = myDir.project_dir(project_name)
if dir_project_function != dir_project:
print('There is a problem with the "myDir" program. It is loading the incorrect path for the project')
# + id="zw0GfndrmsnW"
# from importlib import reload
#reload(tesscheck)
# + [markdown] id="6bswBEuWvEgV"
# **Check the status of this project**
#
# Each project includes a status file (status.txt), which includes some basic information on what has been done already.
# + colab={"base_uri": "https://localhost:8080/"} id="hlOdW27GrF7T" executionInfo={"elapsed": 171, "status": "ok", "timestamp": 1624907828019, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "17503869240391001005"}, "user_tz": 240} outputId="b33cbbd4-36aa-49ad-dcbd-d2bb97736b3e"
status_exist = glob(dir_project+'Status.txt')
if np.size(status_exist) == 0:
tesscheck.make_status(project_name,reset=True)
exist = 0
while exist == 0:
status_exist = glob(dir_project+'Status.txt')
if len(status_exist)>0:
print("status.txt has been created")
exist = 1
status = tesscheck.read_status(project_name)
else:
status = tesscheck.read_status(project_name)
status
# the first time this is run takes awhile becuase Drive is slow to recognize new files.
# + [markdown] id="YZdKSuM2vXPQ"
# **Auto-inspect all TESS data** **SKIP**
#
# Before a user inspects the TESS data, they must be analyzed automatically and indpendently by the computer.
# + colab={"base_uri": "https://localhost:8080/"} id="xel7m4IxALRF" executionInfo={"elapsed": 235, "status": "ok", "timestamp": 1624907831184, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "17503869240391001005"}, "user_tz": 240} outputId="823048aa-3467-4c81-f0e7-e12a1aefcad0"
# Check if it has been run...
# check if Status.txt exists
# read Status.txt
status = tesscheck.read_status(project_name)
if status['Auto'] == 'No':
# if auto hasnt been run yet, then do it.
# tesscheck_auto(project_name)
tesscheck.tesscheck_auto(project_name, tess_cycle=1, redo=False)
# update Status.txt
tesscheck.make_status(project_name,change_auto='Yes')
else:
print('Auto-inspect completed.')
# + id="Cl9V0UWCfO0q"
# + colab={"base_uri": "https://localhost:8080/", "height": 592} id="BUiEarsp4kve" executionInfo={"elapsed": 965, "status": "ok", "timestamp": 1624907835849, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "17503869240391001005"}, "user_tz": 240} outputId="df36c172-82b1-4703-aeb9-60923748e736"
tesscheck.prot_auto_show(project_name, clusters=False, pcut=0.1, av=0)
# + [markdown] id="BHuueIXZso-9"
# **Identify the user**
# The user must log in. If you are a new user (your name is not listed), select "other," then enter your name when prompted. This will add your profile to the results spreadsheet (ComaBer), and update the users listed in the status.txt file.
# + colab={"base_uri": "https://localhost:8080/"} id="zWaWjx7asRpq" executionInfo={"elapsed": 3537, "status": "ok", "timestamp": 1624907842249, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "17503869240391001005"}, "user_tz": 240} outputId="c87cd244-9449-47ec-d662-a0ffc8ad95b3"
# It takes ~4 seconds to verify an existing user, and ~10 seconds to add a new user.
user = tesscheck.tess_user(project_name)
# + [markdown] id="59tSXcAhstcc"
# **Load our project table (the Googele Sheet "ComaBer")**
#
# This also determines how many stars you still have to analyze.
# + colab={"base_uri": "https://localhost:8080/"} id="8gdXd9fnsnSU" executionInfo={"elapsed": 1400, "status": "ok", "timestamp": 1624907846049, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "17503869240391001005"}, "user_tz": 240} outputId="2abe71e7-c76d-4537-b7c2-15886ddd236c"
target_table = tesscheck.get_prot_table('Auto',project_name)
target_data_val = target_table.get_all_values()
target_data = pd.DataFrame.from_records(target_data_val[1:],columns=target_data_val[0])
dr2_list = target_data['DR2Name'].to_numpy()
gbr = target_data['BP_RP'].to_numpy()
prot_table = tesscheck.get_prot_table(user,project_name)
prot_data_val = prot_table.get_all_values()
prot_data = pd.DataFrame.from_records(prot_data_val[1:],columns=prot_data_val[0])
star_list = tesscheck.stars_todo(prot_data)
#star_list = stars_todo_split(prot_data,user)
number_stars = len(star_list)
print(str(number_stars)+' stars to analyze')
# + [markdown] id="LLijR6G0TUYn"
# **Set up interface (widgets)**
# + colab={"base_uri": "https://localhost:8080/"} id="SWx-z-SjuQeA" executionInfo={"elapsed": 386, "status": "ok", "timestamp": 1624907850431, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "17503869240391001005"}, "user_tz": 240} outputId="e04fbf7c-f65a-4b7c-c47d-8b461878a623"
# set up the widgets
axis_fontsize = 16
import matplotlib.pylab as pylab
params = {'axes.labelsize': 16,'axes.titlesize': 16,'xtick.labelsize': 14,'ytick.labelsize': 14}
pylab.rcParams.update(params)
import ipywidgets as widgets
from ipywidgets import HBox, VBox
import numpy as np
import matplotlib.pyplot as plt
from IPython.display import display
# %matplotlib inline
from IPython.core.display import clear_output
'''
sector_widget = widgets.ToggleButtons(
# options=['All','15', '16'],
options=['All'],
description='Sectors:',
disabled=False,
button_style=''
)
'''
lc_widget = widgets.ToggleButtons(
options=['CPM','SAP'],
description='Light Curve:',
disabled=False,
button_style=''
)
button_widget = widgets.ToggleButtons(
options=['Under Review','Publish','Good','Follow up','Flat', 'Garbage'],
description='Save/Reject:',
disabled=False,
button_style=''
)
sector_widget = widgets.SelectMultiple(
options=['ready','to','rumble'],
value=['ready','to','rumble'],
rows=3,
description='Sectors',
disabled=False
)
save_widget = widgets.ToggleButtons(
options=['Continue'],
description='Save',
disabled=False,
button_style=''
)
yra_widget = widgets.Text(
value='0.0',
placeholder='0.0',
description='Y-range:',
disabled=False
)
xra_widget = widgets.Text(
value='0',
placeholder='0',
description='X-range: xmin, xmax',
disabled=False
)
pmin_widget = widgets.Text(
value='0.09',
placeholder='0.09',
description='Min Period:',
disabled=False
)
pmax_widget = widgets.Text(
value='30.0',
placeholder='30.0',
description='Max Period:',
disabled=False
)
notes_widget = widgets.Text(
value='',
placeholder='',
description='Add note:',
disabled=False
)
sap_widget = widgets.Checkbox(False, description='Fit line to SAP?')
xlog_widget = widgets.Checkbox(False, description='X-log?')
double_widget = widgets.Checkbox(False, description='Double the period?')
multi_widget = widgets.Checkbox(False, description='Multi-periodic?')
flare_widget = widgets.Checkbox(False, description='Are there flares?')
print('widgets loaded')
# + colab={"background_save": true} id="M_ddHeQ56ZAA"
def meancolor(color):
spts = ['F3V', 'F4V', 'F5V', 'F6V', 'F7V', 'F8V', 'F9V', 'F9.5V', 'G0V',
'G1V', 'G2V', 'G3V', 'G4V', 'G5V', 'G6V', 'G7V', 'G8V', 'G9V',
'K0V', 'K1V', 'K2V', 'K3V', 'K4V', 'K5V', 'K6V', 'K7V', 'K8V',
'K9V', 'M0V', 'M0.5V', 'M1V', 'M1.5V', 'M2V', 'M2.5V', 'M3V',
'M3.5V', 'M4V', 'M4.5V', 'M5V', 'M5.5V', 'M6V', 'M6.5V', 'M7V',
'M7.5V', 'M8V', 'M8.5V', 'M9V', 'M9.5V']
color_means = np.array([0.518, 0.546, 0.587, 0.64 , 0.67 , 0.694, 0.719, 0.767, 0.784,
0.803, 0.823, 0.832, 0.841, 0.85 , 0.869, 0.88 , 0.9 , 0.95 ,
0.983, 1.01 , 1.1 , 1.21 , 1.34 , 1.43 , 1.53 , 1.7 , 1.73 ,
1.79 , 1.84 , 1.97 , 2.09 , 2.13 , 2.23 , 2.39 , 2.5 , 2.78 ,
2.94 , 3.16 , 3.35 , 3.71 , 4.16 , 4.5 , 4.65 , 4.72 , 4.86 ,
5.1 , 4.78 , 4.86 ])
diferences = np.abs(color_means - color)
spt = spts[np.argmin(diferences)]
return(spt)
# + colab={"base_uri": "https://localhost:8080/"} id="CKW5P7qiDCyX" executionInfo={"elapsed": 4120782, "status": "ok", "timestamp": 1624907731470, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "17503869240391001005"}, "user_tz": 240} outputId="a0968a55-b1f1-4d26-8dc7-02a8d58a1b8c"
#Do you want to look at specific objects?
specific = input('y to look at specific objects, n to continue your spreadsheet')
if specific == 'y':
print('Please provide Gaia DR2 names, comma seperated with no spaces!')
star_list = input('Which object(s)?=')
star_list = star_list.split(',')
number_stars = len(star_list)
print(str(number_stars)+' stars to analyze')
else:
target_table = tesscheck.get_prot_table('Auto',project_name)
target_data_val = target_table.get_all_values()
target_data = pd.DataFrame.from_records(target_data_val[1:],columns=target_data_val[0])
dr2_list = target_data['DR2Name'].to_numpy()
gbr = target_data['BP_RP'].to_numpy()
prot_table = tesscheck.get_prot_table(user,project_name)
prot_data_val = prot_table.get_all_values()
prot_data = pd.DataFrame.from_records(prot_data_val[1:],columns=prot_data_val[0])
star_list = tesscheck.stars_todo(prot_data)
#star_list = stars_todo_split(prot_data,user)
number_stars = len(star_list)
print(str(number_stars)+' stars to analyze')
do_now = {'i':0,'status':'first', 'step':'a','start_time':0.0}
global tstar #, times, flux
tstar = tesscheck.initiate_star(0,project_name,user=user,blank=True)
# + colab={"base_uri": "https://localhost:8080/", "height": 1000, "referenced_widgets": ["f1e22c8b18bf402f914c686fbdfcda79"]} id="PTUhaq3FgC0V" executionInfo={"elapsed": 418, "status": "ok", "timestamp": 1624907735911, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "17503869240391001005"}, "user_tz": 240} outputId="650b755d-538d-4f4c-b741-1c65727f223b"
<EMAIL>(sector_select=sector_widget, lc_select=lc_widget, sap_line = sap_widget, yra=yra_widget, pmin=pmin_widget, pmax=pmax_widget, xlog=xlog_widget, multi=multi_widget, double=double_widget, notes=notes_widget, button=button_widget)
#def plot(sector_select=sector_widget, lc_select=lc_widget, sap_line = sap_widget, yra=yra_widget, pmin=pmin_widget, pmax=pmax_widget, xlog=xlog_widget,multi=multi_widget, double=double_widget, notes=notes_widget, button=button_widget):
@widgets.interact_manual(lc_select=lc_widget, sector_selection = sector_widget, sap_line = sap_widget, xra=xra_widget, yra=yra_widget, pmin=pmin_widget, pmax=pmax_widget, xlog=xlog_widget, multi=multi_widget, flares=flare_widget, double=double_widget, notes=notes_widget, button=button_widget)
def plot(lc_select=lc_widget, sector_selection = sector_widget, sap_line = sap_widget, xra=xra_widget, yra=yra_widget, pmin=pmin_widget, pmax=pmax_widget, xlog=xlog_widget,multi=multi_widget, flares=flare_widget, double=double_widget, notes=notes_widget, button=button_widget):
# how many observations?
n_obs = len(star_list)
print(n_obs)
print('On star #'+str(do_now['i'])+' of '+str(n_obs))
# Some setup
global tstar #, times, flux
# Load the observation
if (do_now['i']<n_obs):
lead = 'Next star: '
if do_now['i'] ==0:
lead = 'First star: '
print(lead+star_list[do_now['i']],' Status= ',do_now['status'])
if len(tstar['Source']) == 0:
do_now['start_time'] = time.time()
star = tesscheck.make_star(target_data, star_list[do_now['i']])
tstar = tesscheck.initiate_star(star,project_name,user=user)
print('Gmag is '+str(tstar['Gmag'])+' and SpT estimate is '+meancolor(float(tstar['gbr'])))
tstar['which_sectors'] = tstar['sector_list']
# add in save now?
save_now = True
if do_now['status'] == 'first':
# time_1 = time.time()
tstar = tesscheck.display_tess_lite_v2(tstar, save = False, noplot = False)
#mark trying to make sector selector widget do just what we want
sector_widget.options = tstar['sector_list']
sector_widget.value = tstar['sector_list']
# print('Calculation 1: '+str(time.time()-time_1))
print('Sectors available: '+str(tstar['sector_list']))
if len(tstar['which_sectors']) > len(tstar['sector_list']):
sectors_to_use = []
for i_include_sector in range(len(tstar['sector_list'])):
id_include_sector = np.where(tstar['sector_list'][i_include_sector] == np.array(tstar['which_sectors']))
if len(id_include_sector[0]) == 1:
sectors_to_use.append(tstar['sector_list'][i_include_sector])
tstar['which_sectors'] = sectors_to_use
print('Sectors displayed: '+str(tstar['which_sectors']))
#print('Prot='+str(tstar['Prot_LS'])[0:7])
# Update settings based on widget changes
# Sector(s) to analyze
# sector_select = 'All'
tstar['which_sectors'] = sector_selection
# Which light curve to analyze
tstar['which_LC'] = lc_select
# Which light curve to analyze
tstar['SAP_line'] = sap_line
# Lomb-Scargle settings
tstar['pmin'] = float(pmin)
tstar['pmax'] = float(pmax)
if xlog == True:
tstar['pxlog'] = 1
else:
tstar['pxlog'] = 0
# Y-range for light curve plots
if float(yra)>0:
tstar['y_min'] = -float(yra)
tstar['y_max'] = float(yra)
# Y-range for light curve plots
if xra != '0':
xra_arr = xra.split(',')
tstar['x_min'] = float(xra_arr[0])
tstar['x_max'] = float(xra_arr[1])
# Analyze: are there multiple periods?
if multi == True:
tstar['Multi'] = 1
else:
tstar['Multi'] = 0
# Insepct if there are signs of flaring?
if flares == True:
tstar['Flares'] = 1
else:
tstar['Flares'] = 0
# Did the Lomb-Scargle peiodogram find the half-period harmonic?
if double == True:
tstar['is_it_double'] = 1
else:
tstar['is_it_double'] = 0
# Add a note?
if len(notes)>0:
tstar['Notes'] = notes
# Actions:
# Accept the Prot as validated
if button == 'Publish':
print('accept')
tstar['LC_Quality'] = 1
if button == 'Good':
print('accept')
tstar['LC_Quality'] = 1
# The Prot is unclear
if button == 'Follow up':
print('requires follow up')
tstar['LC_Quality'] = 1
tstar['Prot_final'] = -1
# There is no periodicity and/or the light curve is flat
if button == 'Flat':
print('flat')
tstar['LC_Quality'] = 0
tstar['Prot_final'] = -1
# The light curve is garbage, or suffers from strong systematics
if button == 'Garbage':
print('garbage')
tstar['LC_Quality'] = -1
tstar['Prot_final'] = -1
# Save the action
tstar['LC_Action'] = button
#do_now['status'] = button
if (tstar['LC_Action'] == 'Under Review') & (do_now['status'] != 'first'):
tstar = tesscheck.display_tess_lite_v2(tstar, save = False, noplot = False)
print('Prot='+str(tstar['Prot_LS'])[0:7])
if do_now['status'] == 'first':
do_now['status'] = 'in progress'
# Reset widgets, iterate, clear tstar
if button != 'Under Review':
tstar = tesscheck.display_tess_lite_v2(tstar, save = True, noplot = False)
print('Prot='+str(tstar['Prot_LS'])[0:7])
# update the table
tesscheck.update_prot_table(prot_table, tstar)
# modify panel filename
tesscheck.update_panelname(tstar)
# iterate the index to the next star
do_now['i'] += 1
# Reset the widgets
# sector_widget.value = 'All'
lc_widget.value = 'CPM'
sap_widget.value = False
xra_widget.value = '0'
yra_widget.value = '0.0'
pmin_widget.value = '0.09'
pmax_widget.value = '30.0'
multi_widget.value = False
flare_widget.value = False
double_widget.value = False
xlog_widget.value = False
notes_widget.value = ''
button_widget.value = 'Under Review'
#removing so doesn't rely on cycle_sectors
#sector_widget.options = cycle_sectors
#sector_widget.value = cycle_sectors
# Reset the tstar object
tstar = tesscheck.initiate_star(0,project_name,user=user,blank=True)
do_now['status'] = 'first'
elapsed_time = time.time() - do_now['start_time']
# print('Task completed in '+str(elapsed_time)+' sec')
print('Next star ready. Click "Run Interact" to continue."')
#star = make_star(target_data, star_list[do_now['i']])
#tstar = initiate_star(star,'NGC_7092',user=user)
save_now = False
#tstar = display_tess_lite_v2(tstar, save = save_now, noplot = False)
#print('...Next star:')
#print(star_list[do_now['i']])
# we are done.
if do_now['i'] == n_obs:
print('')
print('')
print('ALL DONE')
# extra buttons
# Prot=B - might be the right period, but lower confidence
# Prot Fail - not necessarily flat, but failed for some reason.
# + id="HD78LmLpth61"
def beat_check (period1,period2):
freq1 = 1.0/period1
freq2 = 1.0/period2
beat_freq = np.abs(freq2-freq1)
return (1/beat_freq)
# + colab={"base_uri": "https://localhost:8080/"} id="4xoKqtRdiyjW" executionInfo={"elapsed": 5, "status": "ok", "timestamp": 1623694682625, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="555e2c61-e042-4cff-9253-82190e69645a"
beat_check(0.200,0.400)
# + colab={"base_uri": "https://localhost:8080/", "height": 592} id="fWtLUpm5CAKq" executionInfo={"elapsed": 2245, "status": "ok", "timestamp": 1623947756245, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a/default-user=s64", "userId": "13543206571187779765"}, "user_tz": 240} outputId="de1bad2c-9593-4472-c196-ab1d218c9de7"
def prot_show(project_name, user, gbr, clusters=False, pcut=0.0, av=0.0):
# gbr = target_data['BP_RP'].to_numpy(dtype=float)
fig1, ax1 = plt.subplots(figsize=(15,9))
ax1.tick_params(axis='both', which='major', labelsize=15)
aw = 1.5
ax1.spines['top'].set_linewidth(aw)
ax1.spines['left'].set_linewidth(aw)
ax1.spines['right'].set_linewidth(aw)
ax1.spines['bottom'].set_linewidth(aw)
prot_table_now = tesscheck.get_prot_table(user,project_name)
prot_data_val_now = prot_table_now.get_all_values()
prot_data_now = pd.DataFrame.from_records(prot_data_val_now[1:],columns=prot_data_val_now[0])
pnow = prot_data_now['Prot_Final'].to_numpy()
qnow = prot_data_now['Quality'].to_numpy()
uu = np.where((pnow != '') & (pnow != '-1') & (gbr != 'nan') & (qnow != '-1'))
# uu = np.where((pnow != '') & (pnow != '-1') & (gbr != 'nan'))
prot_now = np.array(pnow[uu[0]],dtype=float)
color = gbr[uu[0]].astype(float) - 0.415*av
power_now = prot_data_now['Power_LS'].to_numpy()
vv = np.where((power_now[uu[0]].astype(float)>pcut) & (prot_now > 0) & (prot_now < 99))
ax1.set_xlim(0.4,3.5)
ax1.set_xlabel('$(BP - RP)_0$ (mag)',fontsize=20)
ax1.set_ylim(0,25)
ax1.set_ylabel('Rotation Period (days)',fontsize=20)
if clusters == True:
file = glob(dir_main+'tess_check/Curtis2020-ClustersTable.txt')
clus = Table.read(file[0], format="ascii.cds")
indices_Pleiades = np.where((clus["Cluster"] == "Pleiades"))
indices_Praesepe = np.where((clus["Cluster"] == "Praesepe"))
indices_NGC6811 = np.where((clus["Cluster"] == "NGC 6811"))
# pleiades = clus.iloc[indicesPl]
# praesepe = clus.iloc[indicesPr]
# NGC6811 = clus.iloc[indicesNGC]
ax1.plot(clus["(BP-RP)0"][indices_Pleiades[0]], clus["Prot"][indices_Pleiades[0]], markerfacecolor = 'blue', markeredgecolor='black', label = '120 Myr Pleiades',markersize=10,alpha=0.7,linestyle='',marker='.')
ax1.plot(clus["(BP-RP)0"][indices_Praesepe[0]], clus["Prot"][indices_Praesepe[0]], markerfacecolor = 'cyan', markeredgecolor='black', label = '670 Myr Praesepe',markersize=10,alpha=0.7,linestyle='',marker='.')
ax1.plot(clus["(BP-RP)0"][indices_NGC6811[0]], clus["Prot"][indices_NGC6811[0]], markerfacecolor = 'orange', markeredgecolor='black', label = '1 Gyr NGC 6811',markersize=10,alpha=0.7,linestyle='',marker='.')
ax1.plot(color[vv[0]], prot_now[vv[0]],markerfacecolor='lightgreen',markeredgecolor='black',marker='*',markersize=20,linestyle='',label=project_name)
# ax1.scatter(1.758118-0.415*av,13.2,c='red',s=200)
plt.legend(loc='upper left')
print("Number of rotators: "+str(len(vv[0])))
# ax1.plot([1.2375,1.2375],[0,20],c='green')
# ax1.plot([0.5,2.5],[11.677,11.677],c='green')
plt.show()
prot_show(project_name, user, gbr, clusters=True, pcut=0.0, av=0.0)
# + colab={"base_uri": "https://localhost:8080/"} id="vGUjqlEa3-oI" executionInfo={"elapsed": 104, "status": "ok", "timestamp": 1622063789817, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="58f88f86-15f8-43ba-f71d-4cda4f123e12"
1/(1/.265)+(1/.303)
# + id="HGLTiPEK1PU4"
1) get a list of stars with 'Prot_LS' == 0
we just import the whole target_table, check for prot == 0, then output the list of stars
2) we use check_cpm on that list of stars
if
# + id="at3mw92U1U6h"
# + id="kh8BgIbl1Xcm"
star = tesscheck.make_star(target_data, '2983526215016630912')
# + id="SnoMPk4DcIfe"
tstar= tesscheck.initiate_star(star, project_name, user=user)
# + colab={"base_uri": "https://localhost:8080/"} id="UOmloyYIOlFS" executionInfo={"elapsed": 8554, "status": "ok", "timestamp": 1623779217505, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="5821cac7-3f69-4ffc-96b2-309ba4420f24"
from astropy.coordinates import SkyCoord, Angle
import astropy.units as u
# !pip install astroquery
from astroquery.vizier import Vizier
from astropy.time import Time
from astropy.io import fits
# + id="Mk6JcpLdSF5W"
"""Make the Gaia Figure Elements"""
# Get the positions of the Gaia sources
c1 = SkyCoord(tstar['RA'], tstar['Dec'], frame="icrs", unit="deg")
# Use pixel scale for query size
pix_scale = 21.0 # arcseconds / pixel for TESS, default
magnitude_limit = 19.0
# + colab={"base_uri": "https://localhost:8080/"} id="W05ZicjiSLRY" executionInfo={"elapsed": 107, "status": "ok", "timestamp": 1623785305163, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="1c7689b6-5a06-4be9-a94f-991f6a24b447"
ffi_image = tesscheck.load_ffi_fromfile(tstar['file_ffi'][0])
tesscheck.ffi_test(ffi_image)
# + id="39ka1kGTUs1t"
#we want the header for the wcs coordinate system I think
ffi_data = fits.open(tstar['file_ffi'][0])
# + colab={"base_uri": "https://localhost:8080/", "height": 378} id="nwWDhDLkTb2l" executionInfo={"elapsed": 315, "status": "ok", "timestamp": 1623785311678, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="f2727146-376f-4cd7-f912-0bc4aab7a0a0"
panel = plt.figure(figsize=(5,5))
ffimage = panel.add_subplot()
ffimage.set_title('TESS Cutout Image')
color_map = plt.cm.get_cmap('gray')
reversed_color_map = color_map.reversed()
ffi_mod = np.clip(ffi_image-np.min(ffi_image),0,1000)
ffimage.imshow(ffi_mod,origin = 'lower',cmap=reversed_color_map)
ffimage.plot([15,17],[20,20],color='red')
ffimage.plot([23,25],[20,20],color='red')
ffimage.plot([20,20],[15,17],color='red')
ffimage.plot([20,20],[23,25],color='red')
ffimage.set_xlabel('Pixels')
ffimage.set_ylabel('Pixels')
# + colab={"base_uri": "https://localhost:8080/", "height": 86} id="InP6kH28cOaC" executionInfo={"elapsed": 157, "status": "ok", "timestamp": 1623785320291, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="08f43415-fed7-4554-a7a5-244bc8e540e1"
Vizier.ROW_LIMIT = -1
result = Vizier.query_region(
c1,
catalog=["I/345/gaia2"],
radius=Angle(19 * pix_scale, "arcsec"), #changed to 15 just to make it fit
)
no_targets_found_message = ValueError(
"Either no sources were found in the query region " "or Vizier is unavailable"
)
too_few_found_message = ValueError(
"No sources found brighter than {:0.1f}".format(magnitude_limit)
)
if result is None:
raise no_targets_found_message
elif len(result) == 0:
raise too_few_found_message
result = result["I/345/gaia2"].to_pandas()
result = result[result.Gmag < magnitude_limit]
if len(result) == 0:
raise no_targets_found_message
#This corrects for proper motion. Requires the time of the image. Going to see if we can avoid for now
'''
ra_corrected, dec_corrected, _ = _correct_with_proper_motion(
np.nan_to_num(np.asarray(result.RA_ICRS)) * u.deg, np.nan_to_num(np.asarray(result.DE_ICRS)) * u.deg,
np.nan_to_num(np.asarray(result.pmRA)) * u.milliarcsecond / u.year,
np.nan_to_num(np.asarray(result.pmDE)) * u.milliarcsecond / u.year,
Time(2457206.375, format="jd", scale="tdb"),
tpf.time[0])
result.RA_ICRS = ra_corrected.to(u.deg).value
result.DE_ICRS = dec_corrected.to(u.deg).value'''
# + id="iDQlnF73cmS_"
def _correct_with_proper_motion(ra, dec, pm_ra, pm_dec, equinox, new_time):
"""Return proper-motion corrected RA / Dec.
It also return whether proper motion correction is applied or not."""
# all parameters have units
if ra is None or dec is None or \
pm_ra is None or pm_dec is None or (np.all(pm_ra == 0) and np.all(pm_dec == 0)) or \
equinox is None:
return ra, dec, False
# To be more accurate, we should have supplied distance to SkyCoord
# in theory, for Gaia DR2 data, we can infer the distance from the parallax provided.
# It is not done for 2 reasons:
# 1. Gaia DR2 data has negative parallax values occasionally. Correctly handling them could be tricky. See:
# https://www.cosmos.esa.int/documents/29201/1773953/Gaia+DR2+primer+version+1.3.pdf/a4459741-6732-7a98-1406-a1bea243df79
# 2. For our purpose (ploting in various interact usage) here, the added distance does not making
# noticeable significant difference. E.g., applying it to Proxima Cen, a target with large parallax
# and huge proper motion, does not change the result in any noticeable way.
#
c = SkyCoord(ra, dec, pm_ra_cosdec=pm_ra, pm_dec=pm_dec,
frame='icrs', obstime=equinox)
# Suppress ErfaWarning temporarily as a workaround for:
# https://github.com/astropy/astropy/issues/11747
with warnings.catch_warnings():
# the same warning appears both as an ErfaWarning and a astropy warning
# so we filter by the message instead
warnings.filterwarnings("ignore", message="ERFA function")
new_c = c.apply_space_motion(new_obstime=new_time)
return new_c.ra, new_c.dec, True
# + colab={"base_uri": "https://localhost:8080/"} id="zAjHOr4xUOex" executionInfo={"elapsed": 183, "status": "ok", "timestamp": 1623785321699, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="5d1baeca-bf0f-4fd4-d679-a29ebf62e076"
ffi_image.shape[1:]
# + id="WTisUknyWamW"
from astropy import wcs
# + id="LFIZRc5iVKhH"
radecs = np.vstack([result["RA_ICRS"], result["DE_ICRS"]]).T
# + id="QEsTOdNhWeO6"
w = wcs.WCS(ffi_data[2].header)
# + colab={"base_uri": "https://localhost:8080/"} id="G5n1tz0VY50_" executionInfo={"elapsed": 128, "status": "ok", "timestamp": 1623785323788, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="03e8ca79-4d9a-4dcf-fefd-d47618dfab68"
w
# + colab={"base_uri": "https://localhost:8080/", "height": 164} id="pEBt0JRYdGcX" executionInfo={"elapsed": 115, "status": "error", "timestamp": 1623785324629, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="599543f4-2f15-415c-d5d0-46e3148de204"
print(sky)
# + id="_uiSgP34dH82"
coords = w.all_world2pix(radecs, 0)
# + id="LYTTvGcQfXzk"
sizes = 6400.0 / (16 ** (result["Gmag"] / 8.0))
# + colab={"base_uri": "https://localhost:8080/", "height": 378} id="NkKE6hDVd1F5" executionInfo={"elapsed": 724, "status": "ok", "timestamp": 1623785327295, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="4c8222ad-3113-48d0-eba0-149bb71aedc2"
panel = plt.figure(figsize=(5,5))
ffimage = panel.add_subplot()
ffimage.set_title('TESS Cutout Image')
color_map = plt.cm.get_cmap('gray')
reversed_color_map = color_map.reversed()
ffi_mod = np.clip(ffi_image-np.min(ffi_image),0,1000)
ffimage.imshow(ffi_mod,origin = 'lower',cmap=reversed_color_map)
ffimage.plot([15,17],[20,20],color='red')
ffimage.plot([23,25],[20,20],color='red')
ffimage.plot([20,20],[15,17],color='red')
ffimage.plot([20,20],[23,25],color='red')
for row,size in zip(coords,sizes.values):
ffimage.scatter((row[0]),row[1],marker='.',s=size,color='orange')
ffimage.set_xlabel('Pixels')
ffimage.set_ylabel('Pixels')
# + colab={"base_uri": "https://localhost:8080/"} id="E4JdmDKGd6Ms" executionInfo={"elapsed": 124, "status": "ok", "timestamp": 1623785271272, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="a4b306dd-b244-42e5-c247-b4bcc09b3010"
sizes
# + id="1ri8fQVNhMb6"
from astroquery.mast import Observations, Catalogs
# + id="Xcly9TcnyOKb"
gaia_ids = np.array(['2983526215016630912'])
# Query the TIC first
result = Catalogs.query_criteria(catalog="Tic", GAIA=gaia_ids)
# + colab={"base_uri": "https://localhost:8080/", "height": 153} id="a7xcMJTFyXKD" executionInfo={"elapsed": 15, "status": "ok", "timestamp": 1623779688142, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13543206571187779765"}, "user_tz": 240} outputId="8f5d8018-cf6b-4aaf-b74f-07571b8e3b5a"
result
# + id="bhhnluFCykD-"
| Run_tesscheck.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# Importing Libraries
import pandas as pd
import numpy as np
import math
import requests
# Request financial data from API (S&P 500 ETF, daily return, time_series = from 1999-11-01 onwards)
# +
API = "https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=SPY&outputsize=full&apikey=<KEY>"
req = requests.get(API)
data = req.json()
for i in data:
adjusted = data[i]
closing_prices = []
for i in adjusted:
a= adjusted[i]
closing_prices.append(float(a["4. close"]))
dates = []
for i in data:
for f in data[i]:
dates.append(f)
# -
df = pd.DataFrame(closing_prices,index = dates[5:],columns=["Closing Price"])
# Compute Moving Average
# +
window_size = 15
numbers_series = pd.Series(closing_prices)
windows = numbers_series.rolling(window_size)
moving_averages = windows.mean()
moving_averages_list = moving_averages.tolist()
df["MA"]= pd.Series(moving_averages_list)
# -
# Compute Moving Standard Deviation
# +
window_size = 15
numbers_series = pd.Series(closing_prices)
windows = numbers_series.rolling(window_size)
moving_standard_deviation = windows.std()
moving_standard_deviation_list = moving_averages.tolist()
df["Moving Standard Deviation"]= pd.Series(moving_standard_deviation_list)
# -
df
# %load_ext watermark
# %watermark -v -p wget,pandas,numpy,geopy,altair,vega,vega_datasets,watermark
pip install watermark
| Programming Final Project.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### Interpreting Results of Logistic Regression
#
# In this notebook (and quizzes), you will be getting some practice with interpreting the coefficients in logistic regression. Using what you saw in the previous video should be helpful in assisting with this notebook.
#
# The dataset contains four variables: `admit`, `gre`, `gpa`, and `prestige`:
#
# * `admit` is a binary variable. It indicates whether or not a candidate was admitted into UCLA (admit = 1) our not (admit = 0).
# * `gre` is the GRE score. GRE stands for Graduate Record Examination.
# * `gpa` stands for Grade Point Average.
# * `prestige` is the prestige of an applicant alta mater (the school attended before applying), with 1 being the highest (highest prestige) and 4 as the lowest (not prestigious).
#
# To start, let's read in the necessary libraries and data.
# +
import numpy as np
import pandas as pd
import statsmodels.api as sm
df = pd.read_csv("./admissions.csv")
df.head()
# -
# There are a few different ways you might choose to work with the `prestige` column in this dataset. For this dataset, we will want to allow for the change from prestige 1 to prestige 2 to allow a different acceptance rate than changing from prestige 3 to prestige 4.
#
# 1. With the above idea in place, create the dummy variables needed to change prestige to a categorical variable, rather than quantitative, then answer quiz 1 below.
df = df.join(pd.get_dummies(df.prestige))
df.head()
df['prestige'].value_counts()
# `2.` Now, fit a logistic regression model to predict if an individual is admitted using `gre`, `gpa`, and `prestige` with a baseline of the prestige value of `1`. Use the results to answer quiz 2 and 3 below. Don't forget an intercept.
df.head(1)
df['intercept'] = 1
model = sm.Logit(df.admit, df[['intercept', 'gpa', 'gre', 2, 3, 4]])
result = model.fit()
# +
from scipy import stats
stats.chisqprob = lambda chisq, df: stats.chi2.sf(chisq, df)
result.summary()
# -
np.exp(0.7793)
1/np.exp(-0.6801), 1/np.exp(-1.3387), 1/np.exp(-1.5534)
# Notice that in order to compare the lower prestigious values to the most prestigious (the baseline), we took one over the exponential of the coefficients. However, for a 1 unit increase, we could use the exponential directly.
| Practical Statistics/Regression/Logistic Regression/Interpret Results.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # VQE on Aer simulator with noise
#
# This notebook demonstrates using the [Qiskit Aer](https://qiskit.org/documentation/the_elements.html#aer) `aer_simulator` to run a simulation with noise, based on a given noise model. This can be useful to investigate behavior under different noise conditions. Aer not only allows you to define your own custom noise model, but also allows a noise model to be easily created based on the properties of a real quantum device. The latter is what this notebook will demonstrate since the goal is to show VQE with noise and not the more complex task of how to build custom noise models.
#
# [Qiskit Ignis](https://qiskit.org/documentation/apidoc/ignis.html) provides a solution to mitigate the measurement error when running on a noisy simulation or a real quantum device. This solution is leveraged by the `QuantumInstance` module which allows any algorithm using it to automatically have measurement noise mitigation applied.
#
# Further information on Qiskit Aer noise model can be found in the online [Qiskit Aer documentation](https://qiskit.org/documentation/apidoc/aer_noise.html), also there is tutorial for [building noise models](../simulators/3_building_noise_models.ipynb).
#
# Further information on measurement error mitigation in Qiskit Ignis can be found in the tutorial for [measurement error mitigation](https://qiskit.org/documentation/tutorials/noise/3_measurement_error_mitigation.html).
# +
import numpy as np
import pylab
from qiskit import Aer
from qiskit.utils import QuantumInstance, algorithm_globals
from qiskit.algorithms import VQE, NumPyMinimumEigensolver
from qiskit.algorithms.optimizers import SPSA
from qiskit.circuit.library import TwoLocal
from qiskit.opflow import I, X, Z
# -
# Noisy simulation will be demonstrated here with VQE, finding the minimum (ground state) energy of an Hamiltonian, but the technique applies to any quantum algorithm from Qiskit.
#
# So for VQE we need a qubit operator as input. Here, once again, we will take a set of paulis that were originally computed by Qiskit Nature, for an H2 molecule, so we can quickly create an Operator.
# +
H2_op = (-1.052373245772859 * I ^ I) + \
(0.39793742484318045 * I ^ Z) + \
(-0.39793742484318045 * Z ^ I) + \
(-0.01128010425623538 * Z ^ Z) + \
(0.18093119978423156 * X ^ X)
print(f'Number of qubits: {H2_op.num_qubits}')
# -
# As the above problem is still easily tractable classically we can use NumPyMinimumEigensolver to compute a reference value so we can compare later the results.
npme = NumPyMinimumEigensolver()
result = npme.compute_minimum_eigenvalue(operator=H2_op)
ref_value = result.eigenvalue.real
print(f'Reference value: {ref_value:.5f}')
# ## Performance *without* noise
#
# First we will run on the simulator without adding noise to see the result. I have created the backend and QuantumInstance, which holds the backend as well as various other run time configuration, which are defaulted here, so it easy to compare when we get to the next section where noise is added. There is no attempt to mitigate noise or anything in this notebook so the latter setup and running of VQE is identical.
# +
seed = 170
iterations = 125
algorithm_globals.random_seed = seed
backend = Aer.get_backend('aer_simulator')
qi = QuantumInstance(backend=backend, seed_simulator=seed, seed_transpiler=seed)
counts = []
values = []
def store_intermediate_result(eval_count, parameters, mean, std):
counts.append(eval_count)
values.append(mean)
ansatz = TwoLocal(rotation_blocks='ry', entanglement_blocks='cz')
spsa = SPSA(maxiter=iterations)
vqe = VQE(ansatz, optimizer=spsa, callback=store_intermediate_result, quantum_instance=qi)
result = vqe.compute_minimum_eigenvalue(operator=H2_op)
print(f'VQE on Aer qasm simulator (no noise): {result.eigenvalue.real:.5f}')
print(f'Delta from reference energy value is {(result.eigenvalue.real - ref_value):.5f}')
# -
# We captured the energy values above during the convergence so we can see what went on in the graph below.
pylab.rcParams['figure.figsize'] = (12, 4)
pylab.plot(counts, values)
pylab.xlabel('Eval count')
pylab.ylabel('Energy')
pylab.title('Convergence with no noise')
# ## Performance *with* noise
#
# Now we will add noise. Here we will create a noise model for Aer from an actual device. You can create custom noise models with Aer but that goes beyond the scope of this notebook. Links to further information on Aer noise model, for those that may be interested in doing this, were given above.
#
# First we need to get an actual device backend and from its `configuration` and `properties` we can setup a coupling map and a noise model to match the device. While we could leave the simulator with the default all to all map, this shows how to set the coupling map too. Note: We can also use this coupling map as the entanglement map for the variational form if we choose.
#
# Note: simulation with noise will take longer than without noise.
#
# Terra Mock Backends:
#
# We will use real noise data for an IBM Quantum device using the date stored in Qiskit Terra. Specifically, in this tutorial, the device is ibmq_vigo.
# +
import os
from qiskit.providers.aer import QasmSimulator
from qiskit.providers.aer.noise import NoiseModel
from qiskit.test.mock import FakeVigo
device_backend = FakeVigo()
backend = Aer.get_backend('aer_simulator')
counts1 = []
values1 = []
noise_model = None
device = QasmSimulator.from_backend(device_backend)
coupling_map = device.configuration().coupling_map
noise_model = NoiseModel.from_backend(device)
basis_gates = noise_model.basis_gates
print(noise_model)
print()
algorithm_globals.random_seed = seed
qi = QuantumInstance(backend=backend, seed_simulator=seed, seed_transpiler=seed,
coupling_map=coupling_map, noise_model=noise_model,)
def store_intermediate_result1(eval_count, parameters, mean, std):
counts1.append(eval_count)
values1.append(mean)
var_form = TwoLocal(rotation_blocks='ry', entanglement_blocks='cz')
spsa = SPSA(maxiter=iterations)
vqe = VQE(ansatz, optimizer=spsa, callback=store_intermediate_result1, quantum_instance=qi)
result1 = vqe.compute_minimum_eigenvalue(operator=H2_op)
print(f'VQE on Aer qasm simulator (with noise): {result1.eigenvalue.real:.5f}')
print(f'Delta from reference energy value is {(result1.eigenvalue.real - ref_value):.5f}')
# -
if counts1 or values1:
pylab.rcParams['figure.figsize'] = (12, 4)
pylab.plot(counts1, values1)
pylab.xlabel('Eval count')
pylab.ylabel('Energy')
pylab.title('Convergence with noise')
# ## Performance *with* noise and measurement error mitigation
#
# Now we will add method for measurement error mitigation, which increases the fidelity of measurement. Here we choose `CompleteMeasFitter` to mitigate the measurement error. The calibration matrix will be auto-refresh every 30 minute (default value).
#
# Note: simulation with noise will take longer than without noise.
# +
from qiskit.ignis.mitigation.measurement import CompleteMeasFitter
counts2 = []
values2 = []
if noise_model is not None:
algorithm_globals.random_seed = seed
qi = QuantumInstance(backend=backend, seed_simulator=seed, seed_transpiler=seed,
coupling_map=coupling_map, noise_model=noise_model,
measurement_error_mitigation_cls=CompleteMeasFitter,
cals_matrix_refresh_period=30)
def store_intermediate_result2(eval_count, parameters, mean, std):
counts2.append(eval_count)
values2.append(mean)
ansatz = TwoLocal(rotation_blocks='ry', entanglement_blocks='cz')
spsa = SPSA(maxiter=iterations)
vqe = VQE(ansatz, optimizer=spsa, callback=store_intermediate_result2, quantum_instance=qi)
result2 = vqe.compute_minimum_eigenvalue(operator=H2_op)
print(f'VQE on Aer qasm simulator (with noise and measurement error mitigation): {result2.eigenvalue.real:.5f}')
print(f'Delta from reference energy value is {(result2.eigenvalue.real - ref_value):.5f}')
# -
if counts2 or values2:
pylab.rcParams['figure.figsize'] = (12, 4)
pylab.plot(counts2, values2)
pylab.xlabel('Eval count')
pylab.ylabel('Energy')
pylab.title('Convergence with noise, measurement error mitigation enabled')
# Lets bring the results together here for a summary.
#
# We produced a reference value using a classical algorithm and then proceeded to run VQE on a qasm simulator. While the simulation is ideal (no noise) there is so called shot-noise due to sampling - increasing the number of shots reduces this as more and more samples are taken, but shots was left at the default of 1024 and we see a small effect in the outcome.
#
# Then we added noise using a model taken off a real device and can see the result is affected. Finally we added measurement noise mitigation which adjusts the results in an attempt to alleviate the affect of noise in the classical equipment measuring the qubits.
print(f'Reference value: {ref_value:.5f}')
print(f'VQE on Aer qasm simulator (no noise): {result.eigenvalue.real:.5f}')
print(f'VQE on Aer qasm simulator (with noise): {result1.eigenvalue.real:.5f}')
print(f'VQE on Aer qasm simulator (with noise and measurement error mitigation): {result2.eigenvalue.real:.5f}')
import qiskit.tools.jupyter
# %qiskit_version_table
# %qiskit_copyright
| tutorials/algorithms/03_vqe_simulation_with_noise.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="iIYqMbmAYNGc"
# # Installation
# + id="v-Od28y07Z2j" executionInfo={"status": "ok", "timestamp": 1602233207036, "user_tz": -120, "elapsed": 3305, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13803378101712423079"}} outputId="c1d002a3-bcf6-44b2-9816-998e8f70008b" colab={"base_uri": "https://localhost:8080/", "height": 148}
# !pip install sofasonix
# Mount Google Drive!
# + [markdown] id="nTJhQwkvYrs0"
# # Import Libraries
# + id="6m4piXnC7joV" executionInfo={"status": "ok", "timestamp": 1602233207038, "user_tz": -120, "elapsed": 3289, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13803378101712423079"}}
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from SOFASonix import SOFAFile
import scipy
import scipy.io.wavfile as wav
from scipy import signal
from scipy.stats import norm
import torch
import torch.utils.data as data_utils
import torch.nn as nn
import torch.nn.functional as F
import sys
sys.path.insert(0,'/content/drive/My Drive/binaural_localization/LRP/') # needed to import innvestigator.py file
from innvestigator import InnvestigateModel
# + [markdown] id="bSl0P5DyY0Ie"
# # Neural network class definition
# + id="aWn7EAVxrrPi" executionInfo={"status": "ok", "timestamp": 1602233207039, "user_tz": -120, "elapsed": 3282, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13803378101712423079"}}
class NN_3_layer(nn.Module):
def __init__(self, input_size, out_size_1, out_size_2, out_size_3, out_size_pred):
# call to the super class constructor
super().__init__()
self.fc1 = nn.Linear(in_features=input_size, out_features=out_size_1)
self.fc2 = nn.Linear(in_features=out_size_1, out_features=out_size_2)
self.fc3 = nn.Linear(in_features=out_size_2, out_features=out_size_3)
self.out = nn.Linear(in_features=out_size_3, out_features=out_size_pred)
def forward(self, t):
# (1) input layer
t = t
# (2) hidden linear layer
t = self.fc1(t)
t = F.relu(t)
# (3) hidden linear layer
t = self.fc2(t)
t = F.relu(t)
# (4) hidden linear layer
t = self.fc3(t)
t = F.relu(t)
# (5) output layer
t = self.out(t)
return t
# + [markdown] id="99El1Wnbhwg-"
# # Evaluation class definition
# + id="E6J3uywRXK8D" executionInfo={"status": "ok", "timestamp": 1602233208184, "user_tz": -120, "elapsed": 4420, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13803378101712423079"}}
class Evaluation():
'''
The class is used to load a model and its dataset and to apply error evaluation as well as layer-wise relevance propagation (LRP)
'''
def __init__(self, model_name, signal_name, front):
'''
Load the model and the dataset for evaluation
INPUT:
model_name: string; name of the model saved as .pt
signal_name: string; selection of the accustic signal used for direction of arrival (DOA) estimation
two options implemented, i.e. 'noise' and 'speech' (addidional cases can be added easily)
front: binary; if True only front directions are considered, if False all directions in the database are used
'''
PATH = '/content/drive/My Drive/binaural_localization/models/'
self.model = torch.load(PATH+model_name)
#self.model = torch.load('/content/drive/My Drive/binaural_localization/models/model (100, 40, 10) front=True epoch=20 batch_size=142578 lr=0.001.pt')
loadsofa = SOFAFile.load("/content/drive/My Drive/binaural_localization/HRIR_FULL2DEG.sofa")
data = loadsofa.data_ir
sr = int(loadsofa.Data_SamplingRate[0]) # sampling_rate in Hz
direction = loadsofa.SourcePosition
direction = direction[:,0:2]
if front == True:
# only the front -> no front back confusion
# directions from the front have azimuth angels in the range [0...90] and [270...360]
front_mask = np.logical_or(direction[:,0] < 90, direction[:,0] > 270)
direction = direction[front_mask]
data = data[front_mask]
# 90 degree left, 0 degree front, -90 degree right (positive angles increase counter clockwise)
func = np.vectorize(lambda d: d - 360 if d > 270 else d)
direction[:,0] = func(direction[:,0])
direction = direction*np.pi/180 # in rad
if signal_name == 'noise':
## create noise signal##
duration = 0.55 #seconds
sample_n = int(duration*sr)
noise = np.random.uniform(-1,1,sample_n)
signal = noise
if signal_name == 'speech':
## create speech signal
load_speech = wav.read('/content/drive/My Drive/binaural_localization/hallo_speech.wav')
speech = load_speech[1]
sampling_rate = load_speech[0]
if sampling_rate != sr:
print('Warning: sampling_rate != sr')
signal = speech
def get_spec(time_signal):
'''
Calculate the short time Fourier transformation (STFT)
INPUT:
time_signal: 1D numpy array being the accoustic signal in time domain
OUTPUT:
spec.T: STFT spectrogram transposed to have frequency bins on the x-axis
'''
win_length = int(sr*0.025) # 0.025s
hop_t = 0.01 # in s
nfft= win_length + 0 # zero padding
f, t, spec = scipy.signal.spectrogram(time_signal,
fs= sr,
window='hann', #'hann': cosine window; ('tukey', 0.25) creates a constant plateau in between
nperseg= win_length,
noverlap= int(sr*(0.025-hop_t)), #10ms hop_length => 25ms-10ms overlap
nfft= nfft,
detrend= False, #if 'constant': for every time frame substract its mean;
return_onesided= True, # return a one-sided spectrum for real data
scaling= 'density', # units of V**2/Hz, here no influence, since mode = ‘complex’
axis= -1,
mode= 'complex' )
f_mask = np.logical_and(f >= 20, f <= 20000)
spec = spec[f_mask]
return spec.T # dimension: n_time_frames x n_freq_samples => every time frame is a new data sample
def get_direction_data(signal, i_d):
'''
Calculate interaural level difference (ILD) for the direction with index i_d
INPUT:
signal: 1D numpy array being the accoustic signal in time domain
i_d: index of the direction in the HRIR database
OUPUT:
ILD: 2D numpy ndarray; ILD for the direction with index i_d
target_direction: 2D numpy ndarray of dimension n_time_frames x 2; direction in database with index i_d
'''
hrir_l, hrir_r = data[i_d][0], data[i_d][1]
spec_l = get_spec(np.convolve(signal, hrir_l, mode='valid'))
spec_r = get_spec(np.convolve(signal, hrir_r, mode='valid'))
ILD = 20*np.log10(np.abs(spec_l)) - 20*np.log10(np.abs(spec_r))
# duplicate the direction for every time_frame of the spectrogram, (NN will predict direction for every time_frame)
target_direction = np.vstack([direction[i_d]]*np.shape(ILD)[0])
# rows are ILD of one time_frame + direction for this time_frame
return ILD, target_direction
def get_all_directions(signal):
'''
Calculate interaural level difference (ILD) for the direction in data (which is set according to front = True/False)
INPUT:
signal: 1D numpy array being the accoustic signal in time domain
OUPUT:
features: 2D numpy ndarray; ILDs for all directions; every row is the Fourier transform of a time frame
targets: 2D numpy ndarray of dimension n_time_frames*n_directions x 2; direction of the ILD with the same row index
'''
test_feature, test_target = get_direction_data(signal, 0)
n_directions = np.shape(direction)[0]
n_t_frames = np.shape(test_feature)[0]
features = np.zeros( (n_directions * n_t_frames, np.shape(test_feature)[1]) )
targets = np.zeros( (n_directions * n_t_frames, 2) )
for i_d in range(n_directions):
features[i_d*n_t_frames: (i_d+1)*n_t_frames], targets[i_d*n_t_frames: (i_d+1)*n_t_frames] = get_direction_data(signal, i_d)
features = torch.tensor(features).float() # the tensor has to be casted to float for the propagation process
targets = torch.tensor(targets).float()
return features, targets
## get data, feed model and save prediction
self.features_tensor, self.targets_tensor = get_all_directions(signal) # create torch data
self.features, self.targets = self.features_tensor.numpy(), self.targets_tensor.numpy() # numpy data
self.targets_grad = self.targets*180/np.pi # in grad
self.model.eval()
with torch.no_grad():
self.preds_tensor = self.model(self.features_tensor) # calculate predictions with the NN model
self.preds = self.preds_tensor.numpy()
self.preds_grad = self.preds*180/np.pi # in grad
self.az = self.targets_grad[:,0]
self.el = self.targets_grad[:,1]
# make some variables accessable for other methods
self.direction = direction
self.signal = signal
self.data = data
self.signal_name = signal_name
########### Error evaluation methods ###########
def print_mse(self):
'''
Print the mean squared error (MSE) as it is used during training (containing azimuth and elevation)
'''
criterion = nn.MSELoss()
loss_mse = criterion(self.preds_tensor, self.targets_tensor)
print('MSE Loss in rad: ', np.round(loss_mse.item(), 2))
print('MSE Loss in grad: ', np.round(loss_mse.item()*180/np.pi, 2))
print('RMSE Loss in grad: ', np.round(np.sqrt(loss_mse.item())*180/np.pi, 2))
def print_mean_az_el_dist(self):
'''
Print MSE for azimuth and elevation seperately
'''
az_dist = np.abs(self.preds_grad[:,0]-self.az)
el_dist = np.abs(self.preds_grad[:,1]-self.el)
print('mean_az_dist in grad', np.round(np.mean(az_dist).item(), 2))
print('mean_el_dist in grad', np.round(np.mean(el_dist).item(), 2))
def plot_az_el_hist_fit(self):
'''
Plot the (discrete) probability density function (PDF) of angle differences for azimuth and elevation as histogram with a normal distributino fit.
The hight of each histogram bar is defined by the number of predictions which have a distance between predicted and true angle which falls into the corrosponding bin.
Histogram bars are normalized so that surface area over all bars is one. Hence, the hight can be interpreted as probability.
'''
plt.style.use('ggplot')
az_diff = self.preds_grad[:,0]-self.az
el_diff = self.preds_grad[:,1]-self.el
fig, ax = plt.subplots(nrows=2, ncols=1, figsize=(6.5,5))
fig.patch.set_facecolor('white')
fig.suptitle('Probability density function (PDF) of angle differences', fontsize=14)
# Azimuth
n,bins,patches=ax[0].hist(az_diff, density=True, bins=300, facecolor='gray')
(mu,sigma) = norm.fit(az_diff) # Gaussian normal distribution fit
r_mu, r_sigma = np.round(mu.item(),2), np.round(sigma.item(),2)
print(f'Normal distribution fit for az_diff: mu={r_mu}, sigma={r_sigma}')
bin_centers = 0.5*(bins[1:] + bins[:-1])
pdf = norm.pdf(x=bin_centers, loc=mu, scale=sigma) # probability density function
ax[0].plot(bin_centers, pdf, label=f"normal distribution fit:\n$\sigma={r_sigma}$, $\mu={r_mu}$ ", color='black') #Plot PDF
ax[0].legend()
ax[0].set(title='Azimuth', xlabel='(predicted azimuth - true azimuth) in degree ', ylabel='Probability')
fig.tight_layout()
# Elevation
n,bins,patches=ax[1].hist(el_diff, density=True, bins=300, facecolor='gray')
mu,sigma = norm.fit(el_diff) # Gaussian normal distribution fit
r_mu, r_sigma = np.round(mu.item(),2), np.round(sigma.item(),2)
print(f'Normal distribution fit for el_diff: mu={r_mu}, sigma={r_sigma}')
bin_centers = 0.5*(bins[1:] + bins[:-1])
pdf = norm.pdf(x=bin_centers, loc=mu, scale=sigma) # probability density function
ax[1].plot(bin_centers, pdf, label=f"normal distribution fit:\n$\sigma={r_sigma}$, $\mu={r_mu}$ ", color='black') #Plot PDF
ax[1].legend()
ax[1].set(title='Elevation', xlabel='(predicted elevation - true elevation) in degree ', ylabel='Probability')
fig.tight_layout()
fig.subplots_adjust(top=0.85)
fig.savefig(f'/content/drive/My Drive/binaural_localization/pictures/PDF of angle difference for {signal_name} front.png')
plt.style.use('default')
def distance_with_angular_mean(self):
'''
Plot azimuth and elevation angle distance as heatmap over directions. Azimuth and elevation are circular quantities and the difference between 359° and 1° azimuth should be -2° and not 359°-1°=358°.
Using the angle difference, 359°-1°=358° is projected on the unit circle and the angle of this projection is -2°. This es especially important when taking the absolute angle distance for full azimuth range.
https://en.wikipedia.org/wiki/Mean_of_circular_quantities
'''
print('distance_with_angular_mean')
az_ang_dist = np.abs(torch.atan2(torch.sin(self.preds_tensor[:,0] - self.targets_tensor[:,0]), torch.cos(self.preds_tensor[:,0] - self.targets_tensor[:,0]))*180/np.pi)
el_ang_dist = np.abs(torch.atan2(torch.sin(self.preds_tensor[:,1] - self.targets_tensor[:,1]), torch.cos(self.preds_tensor[:,1] - self.targets_tensor[:,1]))*180/np.pi)
print('az_ang_dist in grad: ', np.round(torch.mean(az_ang_dist).item(), 2))
print('el_ang_dist in grad: ', np.round(torch.mean(el_ang_dist).item(), 2))
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(7,3))
fig.patch.set_facecolor('white')
# Azimuth
map = ax[0].hexbin(self.az, self.el, C=az_ang_dist.numpy(), gridsize=60, cmap=matplotlib.cm.jet, bins=None)
cb = plt.colorbar(map, ax=ax[0])
cb.set_label('Azimuth distance in degree')
ax[0].set(title = 'Azimuth distance over direction', xlabel='Azimuth in degree', ylabel='Elevation in degree')
fig.tight_layout()
# Elevation
map = ax[1].hexbin(self.az, self.el, C=el_ang_dist.numpy(), gridsize=60, cmap=matplotlib.cm.jet, bins=None)
cb = plt.colorbar(map, ax=ax[1])
cb.set_label('Elevation distance in degree')
ax[1].set(title = 'Elevation distance over direction', xlabel='Azimuth in degree', ylabel='Elevation in degree')
fig.tight_layout()
fig.savefig(f'/content/drive/My Drive/binaural_localization/pictures/az el dist for {signal_name} front.png')
def get_i_d(self, az_wish, el_wish):
'''
Find the row index of the direction pair which is the closest do the desirec direction (az_wish, el_wish).
'''
m_altered = np.abs(self.direction[:,0]- az_wish) + np.abs(self.direction[:,1]- el_wish)
m_min = np.amin(m_altered, axis=0)
i_row = np.argwhere(m_altered == m_min)[0][0]
return i_row
def around_the_head_error(self, el_wish=0):
'''
Plot the angular distance of azimuth and elevation for a fixed elevation over azimuth.
INPUT:
el_wish: Elevation at which anular distances are evaluted
'''
n_az = 400 # set emperically; there are repetitions, but not too many
az = np.zeros(n_az)
el = np.zeros(n_az)
az_error = np.zeros(n_az)
el_error = np.zeros(n_az)
if front == True:
az_range = np.linspace(-np.pi/2,np.pi/2, n_az)
else:
az_range = np.linspace(0,2*np.pi, n_az)
for i, az_i in enumerate(az_range):
i_d = self.get_i_d(az_wish = az_i, el_wish=el_wish)
az_error[i] = np.abs(torch.atan2(torch.sin(self.preds_tensor[i_d,0] - self.targets_tensor[i_d,0]), torch.cos(self.preds_tensor[i_d,0] - self.targets_tensor[i_d,0])))
el_error[i] = np.abs(torch.atan2(torch.sin(self.preds_tensor[i_d,1] - self.targets_tensor[i_d,1]), torch.cos(self.preds_tensor[i_d,1] - self.targets_tensor[i_d,1])))
az[i] = self.direction[i_d, 0]
el[i] = self.direction[i_d, 1]
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(6,2.5))
fig.patch.set_facecolor('white')
ax.plot(az*180/np.pi, az_error*180/np.pi, label='azimuth angle distance')
ax.plot(az*180/np.pi, el_error*180/np.pi, label='elevation angle distance')
ax.legend()
ax.set(title = f'Azimuth and elevation distance over azimuth for {el_wish}° elevation', xlabel='Azimuth in degree', ylabel='Angle distance in degree')
fig.tight_layout()
fig.savefig(f'/content/drive/My Drive/binaural_localization/pictures/Spherical angle distance over azimuth for {el_wish} elevation for {signal_name} front.png')
def eval(self):
'''
Apply a set of error evaluation methods at once.
'''
self.print_mse()
self.print_mean_az_el_dist()
self.plot_az_el_hist_fit()
self.distance_with_angular_mean()
self.around_the_head_error(el_wish=0)
########### Layer-wise relevance propagation (LRP) methods ###########
def get_spec_full(self, convolved_signal):
'''
Calculate the short time Fourier transformation (STFT) and reurn also the frequency vector f and the time vector t
INPUT:
time_signal: 1D numpy array being the accoustic signal in time domain
OUTPUT:
complex_spec: 2D numpy array of dimension (len(f) x len(t)); STFT spectrogram
f: 1D array of frequency bins
t: 1D array of time frame bins
'''
sr = 48000 # Hz
win_length = int(sr*0.025) # 0.025s
hop_length = 0.01 # in s
nfft= win_length + 0 # zero padding
f, t, complex_spec = scipy.signal.spectrogram(convolved_signal,
fs= sr,
window='hann', #'hann': cosine window; ('tukey', 0.25) creates a constant plateau in between
nperseg= win_length,
noverlap= int(sr*(0.025-hop_length)), #10ms hop_length => 25ms-10ms overlap
nfft= nfft,
detrend= False, #if 'constant': for every time frame substract its mean;
return_onesided= True, # return a one-sided spectrum for real data
scaling= 'density', # units of V**2/Hz, but should have no influence, since mode = ‘complex’
axis= -1,
mode= 'complex' )
f_mask = np.logical_and(f >= 20, f <= 20000)
complex_spec = complex_spec[f_mask]
f = f[f_mask]
return f, t, complex_spec
def get_inn_model(self, model):
'''
Helper method to create a innvestigation model according to the defined LRP settings. This model can be used to create relevance heatmaps for specific input vectors.
'''
inn_model = InnvestigateModel(model, lrp_exponent=2,
method="e-rule",
beta=0) # Only relevant for method 'b-rule'
return inn_model
def relevance_heatmap_over_az(self, el_wish):
'''
Plot the ILD frequency bin relevance as heatmap over azimuth angles for a given elevation.
INPUT:
el_wish: Elevation at which relevance is plotted over azimuth
'''
n_az = 400 # set emperically; there are repetitions, but not too many
az = np.zeros(n_az)
inn_model = self.get_inn_model(self.model)
if front == True:
az_range = np.linspace(-np.pi/2,np.pi/2, n_az)
else:
az_range = np.linspace(0,2*np.pi, n_az)
for i, az_i in enumerate(az_range):
i_d = self.get_i_d(az_wish=az_i, el_wish=el_wish)
model_prediction, heatmap_i = inn_model.innvestigate(in_tensor=self.features_tensor[i_d])
if i == 0:
hrir_l = self.data[i_d][0]
f_l, t_l, complex_spec_l = self.get_spec_full(np.convolve(self.signal, hrir_l, mode='valid'))
f = f_l
m = np.zeros((len(heatmap_i),n_az))
m[:,i] = heatmap_i
az[i] = self.direction[i_d, 0]
relevance_heatmap = np.abs(m)
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(7,4))
fig.patch.set_facecolor('white')
spec = ax.pcolormesh(az*180/np.pi, f/1000, relevance_heatmap )
cb = plt.colorbar(spec, ax=ax)
cb.set_label('Relevance')
ax.set(title = f'Relevance heatmap over azimuth with elevation {el_wish}°', xlabel='Azimuth in degree', ylabel='Frequency in kHz')
fig.tight_layout()
fig.subplots_adjust(top=0.85)
fig.savefig(f'/content/drive/My Drive/binaural_localization/pictures/LWRP over azimuth for {el_wish} elevation for {signal_name} front abs.png')
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(7,4))
fig.patch.set_facecolor('white')
spec = ax.pcolormesh(az*180/np.pi, f/1000, 10*np.log10(relevance_heatmap) )
cb = plt.colorbar(spec, ax=ax)
cb.set_label('Relevance in dB')
ax.set(title = f'Relevance heatmap over azimuth with elevation {el_wish}°', xlabel='Azimuth in degree', ylabel='Frequency in kHz')
fig.tight_layout()
fig.subplots_adjust(top=0.85)
fig.savefig(f'/content/drive/My Drive/binaural_localization/pictures/LWRP over azimuth for {el_wish} elevation for {signal_name} front abs dB.png')
# + [markdown] id="Jiil4HfLaAnO"
# # Conduct Analysis of different networks and setups by creating 'Evaluation' instances
# + id="nL_cMeRMFecm" executionInfo={"status": "ok", "timestamp": 1602233291683, "user_tz": -120, "elapsed": 87911, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "13803378101712423079"}} outputId="9e9229c2-455a-4c3c-85c2-16a96e34aed6" colab={"base_uri": "https://localhost:8080/", "height": 1000}
model_name = 'model (100, 40, 10) front=True epoch=20 batch_size=142578 lr=0.001.pt'
signal_name ='speech'
front = True
test = Evaluation(model_name, signal_name, front)
test.eval()
test.relevance_heatmap_over_az(el_wish=0)
| 3_evaluation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# -
# ## One Neuron RNN
class SingleRNN(nn.Module):
def __init__(self, n_inputs, n_neurons):
super().__init__()
self.Wx = torch.randn(n_inputs, n_neurons) ## Wx : input state at T
self.Wy = torch.randn(n_neurons, n_neurons) ## Wy : previous state
self.b = torch.zeros(1, n_neurons)
def forward(self, X0, X1):
self.Y0 = torch.tanh(torch.mm(X0, self.Wx) + self.b)
self.Y1 = torch.tanh(torch.mm(self.Y0, self.Wy) + torch.mm(X1, self.Wx) + self.b)
return self.Y0, self.Y1
# +
N_INPUT = 4
N_NEURONS = 1
X0_batch = torch.tensor([[0,1,2,0], [3,4,5,0],
[6,7,8,0], [9,0,1,0]], dtype = torch.float) ## at time t=0
X1_batch = torch.tensor([[9,8,7,0], [0,0,0,0],
[6,5,4,0], [3,2,1,0]], dtype = torch.float) ## at time t=1
model = SingleRNN(N_INPUT, N_NEURONS)
Y0_val, Y1_val = model(X0_batch, X1_batch)
print(Y0_val)
print(Y1_val)
# -
# ## N-Neuron RNN
class BasicRNN(nn.Module):
def __init__(self, n_inputs, n_neurons):
super().__init__()
self.Wx = torch.randn(n_inputs, n_neurons) ## Wx : input state at T
self.Wy = torch.randn(n_neurons, n_neurons) ## Wy : previous state
self.b = torch.zeros(1, n_neurons)
def forward(self, X0, X1):
self.Y0 = torch.tanh(torch.mm(X0, self.Wx) + self.b)
self.Y1 = torch.tanh(torch.mm(self.Y0, self.Wy) + torch.mm(X1, self.Wx) + self.b)
return self.Y0, self.Y1
# +
N_INPUT = 3
N_NEURONS = 5
X0_batch = torch.tensor([[0,1,2], [3,4,5],
[6,7,8], [9,0,1]],
dtype = torch.float) #t=0 => 4 X 3
X1_batch = torch.tensor([[9,8,7], [0,0,0],
[6,5,4], [3,2,1]],
dtype = torch.float) #t=1 => 4 X 3
model = SingleRNN(N_INPUT, N_NEURONS)
Y0_val, Y1_val = model(X0_batch, X1_batch)
print(Y0_val)
print(Y1_val)
# -
# out is of dim 4x5 (input size x total neurons)
# ## Pytorch built in RNN cell
# +
rnn = nn.RNNCell(3,5) ## input x dim
X_batch = torch.tensor([[[0,1,2], [3,4,5],
[6,7,8], [9,0,1]],
[[9,8,7], [0,0,0],
[6,5,4], [3,2,1]]], dtype = torch.float) # X0 and X1
hx = torch.randn(4,5)
output = []
for i in range(2):
hx = rnn(X_batch[i], hx)
output.append(hx)
print(output[0])
print(output[1])
# -
# ## Classic Basic RNN
class ClassicRNN(nn.Module):
def __init__(self, batch_size, n_input, n_neurons):
super().__init__()
self.rnn = nn.RNNCell(n_input, n_neurons)
self.hx = torch.randn(batch_size, n_neurons) ## initialize the hidden
def forward(self, X):
output = []
for i in range(2):
self.hx = self.rnn(X[i], self.hx)
output.append(self.hx)
return output, self.hx
# +
FIXED_BATCH_SIZE = 4 # our batch size is fixed for now
N_INPUT = 3
N_NEURONS = 5
X_batch = torch.tensor([[[0,1,2], [3,4,5],
[6,7,8], [9,0,1]],
[[9,8,7], [0,0,0],
[6,5,4], [3,2,1]]
], dtype = torch.float) # X0 and X1
model = ClassicRNN(FIXED_BATCH_SIZE, N_INPUT, N_NEURONS)
output_val, states_val = model(X_batch)
print(output_val) # contains all output for all timesteps
print()
print(states_val) # contains values for final state or final timestep, i.e., t=1
# -
| nlp/7. RNN in Torch - Basic RNN.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [default]
# language: python
# name: python2
# ---
# # Workshop 4 - Performance Metrics
#
# In this workshop we study 2 performance metrics(Spread and Inter-Generational Distance) on GA optimizing the POM3 model.
# +
# %matplotlib inline
# All the imports
from __future__ import print_function, division
import pom3_ga, sys
import pickle
# TODO 1: Enter your unity ID here
__author__ = "pwang13"
# -
# To compute most measures, data(i.e objectives) is normalized. Normalization is scaling the data between 0 and 1. Why do we normalize?
#
# TODO2 : Answer the above question
#
# Answer: make it easier to compare when everything is in the same range.
def normalize(problem, points):
"""
Normalize all the objectives
in each point and return them
"""
meta = problem.objectives
all_objs = []
for point in points:
objs = []
for i, o in enumerate(problem.evaluate(point)):
low, high = meta[i].low, meta[i].high
# TODO 3: Normalize 'o' between 'low' and 'high'; Then add the normalized value to 'objs'
if high == low:
objs.append(0)
continue
objs.append((o - low) / (high - low))
all_objs.append(objs)
return all_objs
# #### Data Format
# For our experiments we store the data in the following format.
# ```
# data = {
# "expt1":[repeat1, repeat2, ...],
# "expt2":[repeat1, repeat2, ...],
# .
# .
# .
# }
# repeatx = [objs1, objs2, ....] // All of the final population
# objs1 = [norm_obj1, norm_obj2, ...] // Normalized objectives of each member of the final population.
# ```
# +
"""
Performing experiments for [5, 10, 50] generations.
"""
problem = pom3_ga.POM3()
pop_size = 10
repeats = 10
test_gens = [5, 10, 50]
def save_data(file_name, data):
"""
Save 'data' to 'file_name.pkl'
"""
with open(file_name + ".pkl", 'wb') as f:
pickle.dump(data, f, pickle.HIGHEST_PROTOCOL)
def load_data(file_name):
"""
Retrieve data from 'file_name.pkl'
"""
with open(file_name + ".pkl", 'rb') as f:
return pickle.load(f)
def build(problem, pop_size, repeats, test_gens):
"""
Repeat the experiment for 'repeats' number of repeats for each value in 'test_gens'
"""
tests = {t: [] for t in test_gens}
tests[0] = [] # For Initial Population
for _ in range(repeats):
init_population = pom3_ga.populate(problem, pop_size)
pom3_ga.say(".")
for gens in test_gens:
tests[gens].append(normalize(problem, pom3_ga.ga(problem, init_population, retain_size=pop_size, gens=gens)[1]))
tests[0].append(normalize(problem, init_population))
print("\nCompleted")
return tests
"""
Repeat Experiments
"""
# tests = build(problem, pop_size, repeats, test_gens)
"""
Save Experiment Data into a file
"""
# save_data("dump", tests)
"""
Load the experimented data from dump.
"""
tests = load_data("dump")
print(tests.keys())
# -
# #### Reference Set
# Almost all the traditional measures you consider need a reference set for its computation. A theoritical reference set would be the ideal pareto frontier. This is fine for
# a) Mathematical Models: Where we can solve the problem to obtain the set.
# b) Low Runtime Models: Where we can do a one time exaustive run to obtain the model.
#
# But most real world problems are neither mathematical nor have a low runtime. So what do we do?. **Compute an approximate reference set**
#
# One possible way of constructing it is:
# 1. Take the final generation of all the treatments.
# 2. Select the best set of solutions from all the final generations
# +
def make_reference(problem, *fronts):
"""
Make a reference set comparing all the fronts.
Here the comparison we use is bdom. It can
be altered to use cdom as well
"""
retain_size = len(fronts[0])
reference = []
for front in fronts:
reference+=front
def bdom(one, two):
"""
Return True if 'one' dominates 'two'
else return False
:param one - [pt1_obj1, pt1_obj2, pt1_obj3, pt1_obj4]
:param two - [pt2_obj1, pt2_obj2, pt2_obj3, pt2_obj4]
"""
dominates = False
for i, obj in enumerate(problem.objectives):
gt, lt = pom3_ga.gt, pom3_ga.lt
better = lt if obj.do_minimize else gt
# TODO 3: Use the varaibles declared above to check if one dominates two
if (better(one[i], two[i])):
dominates = True
elif one[i] != two[i]:
return False
return dominates
def fitness(one, dom):
return len([1 for another in reference if dom(one, another)])
fitnesses = []
for point in reference:
fitnesses.append((fitness(point, bdom), point))
reference = [tup[1] for tup in sorted(fitnesses, reverse=True)]
return reference[:retain_size]
assert len(make_reference(problem, tests[5][0], tests[10][0], tests[50][0])) == len(tests[5][0])
# -
# ### Spread
#
# Calculating spread:
#
# <img width=300 src="http://mechanicaldesign.asmedigitalcollection.asme.org/data/Journals/JMDEDB/27927/022006jmd3.jpeg">
#
# - Consider the population of final gen(P) and the Pareto Frontier(R).
# - Find the distances between the first point of P and first point of R(_d<sub>f</sub>_) and last point of P and last point of R(_d<sub>l</sub>_)
# - Find the distance between all points and their nearest neighbor _d<sub>i</sub>_ and
# their nearest neighbor
# - Then:
#
# <img width=300 src="https://raw.githubusercontent.com/txt/ase16/master/img/spreadcalc.png">
#
# - If all data is maximally spread, then all distances _d<sub>i</sub>_ are near mean d
# which would make _Δ=0_ ish.
#
# Note that _less_ the spread of each point to its neighbor, the _better_
# since this means the optimiser is offering options across more of the frontier.
# +
def eucledian(one, two):
"""
Compute Eucledian Distance between
2 vectors. We assume the input vectors
are normalized.
:param one: Vector 1
:param two: Vector 2
:return:
"""
# TODO 4: Code up the eucledian distance. https://en.wikipedia.org/wiki/Euclidean_distance
return (sum([(o - t) ** 2 for o, t in zip(one, two)]) / len(one)) ** 0.5
def sort_solutions(solutions):
"""
Sort a list of list before computing spread
"""
def sorter(lst):
m = len(lst)
weights = reversed([10 ** i for i in xrange(m)])
return sum([element * weight for element, weight in zip(lst, weights)])
return sorted(solutions, key=sorter)
def closest(one, many):
min_dist = sys.maxint
closest_point = None
for this in many:
dist = eucledian(this, one)
if dist < min_dist:
min_dist = dist
closest_point = this
return min_dist, closest_point
def spread(obtained, ideals):
"""
Calculate the spread (a.k.a diversity)
for a set of solutions
"""
s_obtained = sort_solutions(obtained)
s_ideals = sort_solutions(ideals)
d_f = closest(s_ideals[0], s_obtained)[0]
d_l = closest(s_ideals[-1], s_obtained)[0]
n = len(s_ideals)
distances = []
for i in range(len(s_obtained)-1):
distances.append(eucledian(s_obtained[i], s_obtained[i+1]))
d_bar = sum(distances) / len(distances)
# TODO 5: Compute the value of spread using the definition defined in the previous cell.
d_sum = sum([abs(d_i - d_bar) for d_i in distances])
delta = (d_f + d_l + d_sum) / (d_f + d_l + (n - 1)*d_bar)
return delta
ref = make_reference(problem, tests[5][0], tests[10][0], tests[50][0])
print(spread(tests[5][0], ref))
print(spread(tests[10][0], ref))
print(spread(tests[50][0], ref))
# -
# IGD = inter-generational distance; i.e. how good are you compared to the _best known_?
#
# - Find a _reference set_ (the best possible solutions)
# - For each optimizer
# - For each item in its final Pareto frontier
# - Find the nearest item in the reference set and compute the distance to it.
# - Take the mean of all the distances. This is IGD for the optimizer
#
# Note that the _less_ the mean IGD, the _better_ the optimizer since
# this means its solutions are closest to the best of the best.
# +
def igd(obtained, ideals):
"""
Compute the IGD for a
set of solutions
:param obtained: Obtained pareto front
:param ideals: Ideal pareto front
:return:
"""
# TODO 6: Compute the value of IGD using the definition defined in the previous cell.
igd_val = sum([closest(ideal, obtained)[0] for ideal in ideals]) / len(ideals)
# igd_val = 0
return igd_val
ref = make_reference(problem, tests[5][0], tests[10][0], tests[50][0])
print(igd(tests[5][0], ref))
print(igd(tests[10][0], ref))
print(igd(tests[50][0], ref))
# +
import sk
sk = reload(sk)
def format_for_sk(problem, data, measure):
"""
Convert the experiment data into the format
required for sk.py and computet the desired
'measure' for all the data.
"""
gens = data.keys()
reps = len(data[gens[0]])
measured = {gen:["gens_%d"%gen] for gen in gens}
for i in range(reps):
ref_args = [data[gen][i] for gen in gens]
ref = make_reference(problem, *ref_args)
for gen in gens:
measured[gen].append(measure(data[gen][i], ref))
return measured
def report(problem, tests, measure):
measured = format_for_sk(problem, tests, measure).values()
sk.rdivDemo(measured)
print("*** IGD ***")
report(problem, tests, igd)
print("\n*** Spread ***")
report(problem, tests, spread)
# -
| code/7/pwang13_performance.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="-K0TVsmwJmun"
# # 1. Text Cleaning
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 18954, "status": "ok", "timestamp": 1607041477004, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="f6l_sl2Owehh" outputId="fd737323-11e3-4d27-b6e5-5c6d4573f7f8"
import pandas as pd
import numpy as np
import os
base_dir = "YOUR_PATH/net2020-main"
os.chdir(base_dir)
import statsmodels
import statsmodels.api as sm
import scipy.stats as stats
import matplotlib.pyplot as plt
# import the csv file with all the comments and post togheter
comDB = pd.read_csv(r"database/com_liwc.csv", sep='\t', engine='python')
# import the csv file with JUST the politicians post
postDB = pd.read_csv(r"database/postDB.csv", engine='python')
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 18946, "status": "ok", "timestamp": 1607041477005, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="VWxYC4ocL-RS" outputId="aff17263-80a5-420f-d158-00bf9ada5dbf"
# general info ON COMMENT db
print('## Each row in the db is a comment, the information about the post that generate that comment are in the columns')
print('Number of colums in comDB : ', len(comDB.columns))
print('Number of rows in comDB : ', len(comDB.index))
print('')
# general info ON POST ONLY db
print('## Each row is a posts/tweets made by the politicians, this DB do not contain comments')
print('Number of colums in postDB : ', len(postDB.columns))
print('Number of rows in postDB : ', len(postDB.index))
# + colab={"base_uri": "https://localhost:8080/", "height": 651} executionInfo={"elapsed": 18938, "status": "ok", "timestamp": 1607041477007, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="5LyFYbpMMJjX" outputId="1ef44cb5-9917-435d-85ec-0a3237559b49"
# create the Data Frame
df = pd.DataFrame(data=comDB)
df_post = pd.DataFrame(data=postDB)
df
# add a new colum with sequence numbers
df['Count']=1
df_post['Count']=1
# print all the DF
pd.set_option('display.max_columns', None)
pd.set_option('display.max_row', 5)
df.head()
# + [markdown] id="O0YzWUSw4Oya"
# # Data Analysis
# + [markdown] id="Sl1UHq6F9hyJ"
# ## NaN values
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 19565, "status": "ok", "timestamp": 1607041477673, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="pfUiM6Du9lF9" outputId="bf5370b2-183e-46da-8ffa-8f970ec0dade"
print('Columns with Nan in df:\n', [(col, df[col].isna().sum()) for col in df.columns if df[col].isna().sum()>0], '\n')
print('Columns with Nan in df_post:\n', [(col, df_post[col].isna().sum()) for col in df_post.columns if df_post[col].isna().sum()>0])
# + [markdown] id="heENbub--lic"
# For the moment we are concerned about the NaN in the columns related to posts and comments text.
# + [markdown] id="DWr3GVGPDIV2"
# ### NaN in comments dataframe
# + colab={"base_uri": "https://localhost:8080/", "height": 0} executionInfo={"elapsed": 19559, "status": "ok", "timestamp": 1607041477674, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="o0dhq8de_Xd-" outputId="a2fd4976-91d0-40fb-abf3-120e86c37aa4"
# Identify rows with NaN in post text in df (comments dataframe)
df[df['p_text'].isna()][['Origin_file_order']]
# + colab={"base_uri": "https://localhost:8080/", "height": 0} executionInfo={"elapsed": 19553, "status": "ok", "timestamp": 1607041477675, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="saM7NH-p_6TP" outputId="4900d4e1-b972-4da4-8592-bbe4d554e210"
# Identify rows with NaN in comment text in df (comments dataframe)
df[df['c_text'].isna()][['Origin_file_order']]
# + [markdown] id="RgsdMJFLACJf"
# Row 45804 in comments dataframe can be removed since we have neither the text of the post nor the text of the comment associated with it.
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 19547, "status": "ok", "timestamp": 1607041477676, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="Teou5YsZE5cw" outputId="8c071e2a-cd7f-4b34-d55c-27a4e21be354"
print('df shape before dropping row: \t', df.shape)
df = df[df['c_text'].notna()]
print('df shape after dropping row: \t', df.shape)
print('Number of Nan in comments text: ', df['c_text'].isna().sum())
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 19542, "status": "ok", "timestamp": 1607041477677, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="QDtr2m-ZFZz6" outputId="0cec14a9-964b-4aac-8d93-395c122f7694"
df.shape
# + [markdown] id="Du_FS0UyDOlW"
# ### NaN in posts dataframe
# + colab={"base_uri": "https://localhost:8080/", "height": 0} executionInfo={"elapsed": 19535, "status": "ok", "timestamp": 1607041477677, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="1Ep9V-AWB7hh" outputId="b003da56-ab0e-41cc-f70b-cbdc93c3e2e9"
# Identify rows with NaN in post text in df_post (posts dataframe)
df_post[df_post['p_text'].isna()][['Origin_file_order']]
# + [markdown] id="-_PCClP-MkXx"
# # Comments Text Preprocessing
# + [markdown] id="cC4q2Sp3H7eO"
# Let us create a dataframe containing only the comments' text
# + executionInfo={"elapsed": 19528, "status": "ok", "timestamp": 1607041477678, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="zG39YHfdvvKf"
# comments = df[['c_text']].sample(n=1000, random_state=1).copy() # work with a sample
comments = df[['c_text']].copy()
comments.rename(columns={'c_text':'text'}, inplace=True)
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 19521, "status": "ok", "timestamp": 1607041477678, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="HKyvGTxjIKLI" outputId="acf02a29-2322-47e6-e360-17cc10228f2d"
import random
for i in list(np.random.choice(list(comments.index), 5)):
print(f'Comment {i}')
print(comments.loc[i]['text'], '\n')
# + [markdown] id="NCzIR5gs0dH5"
# ## Word cloud with raw data
# + [markdown] id="9fuXQsjtJ5r2"
# What if we generate a word cloud with no-preprocessed text?
# + executionInfo={"elapsed": 695, "status": "ok", "timestamp": 1607044406606, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="83g71J8pKYjC"
from PIL import Image
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
% matplotlib inline
# + colab={"base_uri": "https://localhost:8080/", "height": 198} executionInfo={"elapsed": 27525, "status": "ok", "timestamp": 1607035076496, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="uGpJRJh4KdlH" outputId="d583ec1c-764a-4465-8f29-09134a4dff4c"
full_text = " ".join(comm for comm in comments['text'])
wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(full_text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# + [markdown] id="LUsSEXK5Kyqr"
# The word cloud we get is full of so-called stop words, the only significant words we can recognize are names of parties or politicians. A bit of text pre-processing is therefore mandatory.
#
#
# + [markdown] id="8V7UUObN1xVx"
# ## Text pre-processing
# + [markdown] id="YmvoR7G13q3F"
# There are differnt types of text preprocessing steps which can be applied and the choice of these steps depends on the tasks to be performed.
#
#
# For this initial step, our goal is to identify the most used words in the comments and the main topics of discussion.
# + [markdown] id="5ogs-gPr2osT"
# ### Removal of patterns
# + id="cuR_nf-5Kle6"
import re
from collections import Counter
def remove_patterns(text, patterns):
for pattern in patterns:
r = re.findall(pattern, text)
for i in r:
text = re.sub(re.escape(i), '', text)
return text
def pattern_freq(docs, pattern):
p_freq = Counter()
for text in docs:
p_found= re.findall(pattern, text)
for p in p_found:
p_freq[p] += 1
return p_freq
# + id="JZ_1-IXF2znf"
PATTERNS = {'urls': re.compile(r'https?://\S+|www\.\S+'),
'users': re.compile(r'@[\w]*'),
#'hashtags': re.compile(r'#[\w]*'),
'digits': re.compile(r'(?<!\w)\d+|\d+(?!\w)'),
'emojis': re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U00002702-\U000027B0"
u"\U000024C2-\U0001F251"
"]+", flags=re.UNICODE)
}
# + [markdown] id="76c2iPpd9XIA"
# Before removing patterns we can answer dollowing questions:
# * Which are the most used hashtags?
# * Which are most tagged users?
# * Are there frequent URLs?
# * Which are most frequent emojis/emoticons?
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 27503, "status": "ok", "timestamp": 1607035076511, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="au91pHLa9bVj" outputId="85e9c632-4d93-41a6-cf0c-02b521972a05"
hashtags_patt = re.compile(r'#[\w]*')
hashtags_freq = pattern_freq(comments['text'].values, hashtags_patt)
hashtags_freq.most_common(10)
# + colab={"base_uri": "https://localhost:8080/", "height": 198} executionInfo={"elapsed": 27493, "status": "ok", "timestamp": 1607035076517, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="nF04TBt__V-Q" outputId="b738b5f4-e475-4a95-ff21-f2d866209e98"
wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate_from_frequencies(hashtags_freq)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 27480, "status": "ok", "timestamp": 1607035076520, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="9Q3owLSg-l7d" outputId="de065f9b-bda9-48dc-f1e0-b0e07f3ae08a"
users_freq = pattern_freq(comments['text'].values, PATTERNS['users'])
users_freq.most_common(10)
# + colab={"base_uri": "https://localhost:8080/", "height": 198} executionInfo={"elapsed": 28382, "status": "ok", "timestamp": 1607035077440, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="E9LnE_oY_OZs" outputId="7c051208-a663-4573-dc37-3484f483d95a"
wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate_from_frequencies(users_freq)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 28371, "status": "ok", "timestamp": 1607035077445, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="w7q7e5ig_8m1" outputId="39392563-9307-4758-99db-5a09d4baee95"
urls_freq = pattern_freq(comments['text'].values, PATTERNS['urls'])
urls_freq.most_common(10)
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 28902, "status": "ok", "timestamp": 1607035077996, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="zzul-s57DZZg" outputId="3c4a35d3-75e2-42e6-b33c-9b4237cec7a0"
emojis_freq = pattern_freq(comments['text'].values, PATTERNS['emojis'])
emojis_freq.most_common(10)
# + [markdown] id="Q7jubCuCx5Eq"
# ### Removal of redundant spaces
# + id="esNakwWkx39L"
def remove_spaces(text):
return ' '.join(text.split())
# + id="CKyzB6CKJRTa"
text_clean = comments["text"].apply(lambda text: remove_patterns(text, PATTERNS.values()))
text_clean = text_clean.apply(lambda text: remove_spaces(text))
comments["text_clean"] = text_clean
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 30879, "status": "ok", "timestamp": 1607035080042, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="_k3Pm4M4JIyE" outputId="ed5426b5-ef43-4eec-ce19-8196a44d5397"
import random
for i in list(np.random.choice(list(comments.index), 5)):
print(f'Comment {i}')
print(comments.loc[i]['text'])
print(comments.loc[i]['text_clean'], '\n')
print()
# + [markdown] id="aBw6RmERIAPv"
# ### NLP with Spacy
# + id="fhZVgNGdILr3"
# !python -m spacy download it_core_news_sm
import it_core_news_sm
nlp = it_core_news_sm.load()
# + id="BsOtGqjAI5f_"
text_nlp = comments["text_clean"].apply(lambda text: nlp(text))
comments['text_nlp'] = text_nlp
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 1265977, "status": "ok", "timestamp": 1607036315173, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="B6xeK-7FRbMg" outputId="8201375e-75fa-46ca-d1cb-13689c4afd85"
print(f"{'Token':<20}\t{'Lemma':<20}\t{'is-stop':<8}\t{'is-punct':<8}")
for token in comments['text_nlp'].iloc[0]:
print(f"{token.text:<20}\t{token.lemma_:<20}\t{token.is_stop:^8}\t{token.is_punct:^8}")
# + [markdown] id="iVjzFxlQUwyB"
# ## Removal of Stop-Words and Punctuation
# + id="CiS14tPYcBdQ"
# Import list of stopwords from it_stop_words.py
import sys
sys.path.append(os.path.join(base_dir, "common_start/text_preprocessing"))
from it_stop_words import get_italian_stop_words
my_it_stop_words = get_italian_stop_words()
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 1101, "status": "ok", "timestamp": 1607036452940, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="Bx_XthYzb1yL" outputId="df4e7a61-a388-4fee-d725-6a591b64d5be"
from spacy.lang.it.stop_words import STOP_WORDS as it_spacy_stopwords
import nltk
nltk.download('stopwords')
it_nltk_stopwords = nltk.corpus.stopwords.words('italian')
it_stopwords = set(it_spacy_stopwords) | set(it_nltk_stopwords) | my_it_stop_words
for stopword in it_stopwords:
nlp_vocab = nlp.vocab[stopword]
nlp_vocab.is_stop = True
# + id="hbBofJosEo1v"
def remove_stop_punct(tokens):
return(' '.join([token.text for token in tokens if not (token.is_stop or token.is_punct)]))
# + id="tItmKmuyWpmW"
text_wo_stop_punct = comments["text_nlp"].apply(lambda tokens: remove_stop_punct(tokens))
comments['text_clean'] = text_wo_stop_punct
# + [markdown] id="qezRUmhYgD-Z"
# ## Further removal of punctuation
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 2584, "status": "ok", "timestamp": 1607036454458, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="Q19qaN6ggD-Z" outputId="13f1ce61-bbed-4845-8797-bdb764cb6bec"
import string
print(f"Punctuation symbols: {string.punctuation}")
# + id="WtS5TmcPgD-a"
def remove_punctuation(text):
return(''.join([t for t in text if not t in string.punctuation]))
# + id="mRxrsOy5gbsG"
text_wo_stop_punct = comments['text_clean'].apply(lambda text: remove_punctuation(text))
comments['text_clean'] = text_wo_stop_punct
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 3236, "status": "ok", "timestamp": 1607036455150, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="UPLN7aAjg7Vy" outputId="1a2da94b-048c-4767-954e-e1effef59404"
import random
for i in list(np.random.choice(list(comments.index), 5)):
print(f'Comment {i}')
print(comments.loc[i]['text'])
print(comments.loc[i]['text_clean'])
print()
# + [markdown] id="u9oOhcY-xgQU"
# ## Lower casing
# + id="zrCofL-wykL-"
def lower_casing(text):
return(text.lower())
# + id="N7TyH936yttY"
comments['text_clean'] = comments['text_clean'].apply(lambda text: lower_casing(text)).apply(lambda text: remove_spaces(text))
# + [markdown] id="OAZUfFBvzFof"
# ## Resulting word-cloud
# + colab={"base_uri": "https://localhost:8080/", "height": 198} executionInfo={"elapsed": 8604, "status": "ok", "timestamp": 1607036460558, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="KLp72eEJhJgK" outputId="035f238f-ecc7-4015-9343-2987eaeae910"
full_cleaned_text = ' '.join([doc for doc in comments['text_clean']])
wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(full_cleaned_text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# + [markdown] id="Esfs7EuiUa5S"
# # Text Cleaning from function
# -
# See text_preprocessing folder
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 1389698, "status": "ok", "timestamp": 1607042870085, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="p_3_dt3--ubm" outputId="def7d643-7740-447c-c880-812828f02062"
# Import list of stopwords from it_stop_words.py
import sys
sys.path.append(os.path.join(base_dir, "Semantic_Group/text_preprocessing"))
from text_cleaning import *
cleaned_text = clean_content(comments['text'])
# + colab={"base_uri": "https://localhost:8080/", "height": 198} executionInfo={"elapsed": 6247, "status": "ok", "timestamp": 1607044423026, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GheSVYdvU2B31nj9GhqIfcCfGlzpMjnaq-mGz-Tgg=s64", "userId": "10385968581783702251"}, "user_tz": -60} id="LOHX3Hfx_dlP" outputId="1a8dde27-4a14-4e1d-90e8-48ea9de842a7"
full_cleaned_text = ' '.join(cleaned_text)
wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(full_cleaned_text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# + id="HbJLiqHFTudx"
| Semantic_Group/text_cleaning.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # 7章 線形回帰
# 必要ライブラリの宣言
# %matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
# PDF出力用
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('png', 'pdf')
# +
from sklearn.datasets import load_boston
# 学習用データ準備
boston = load_boston()
x_org, yt = boston.data, boston.target
feature_names = boston.feature_names
print('元データ', x_org.shape, yt.shape)
print('項目名: ', feature_names)
# データ絞り込み (項目 RMのみ)
x_data = x_org[:,feature_names == 'RM']
print('絞り込み後', x_data.shape)
# ダミー変数を追加
x = np.insert(x_data, 0, 1.0, axis=1)
print('ダミー変数追加後', x.shape)
# -
# 入力データxの表示 (ダミー変数を含む)
print(x.shape)
print(x[:5,:])
# 正解データ yの表示
print(yt[:5])
# 散布図の表示
plt.scatter(x[:,1], yt, s=10, c='b')
plt.xlabel('ROOM', fontsize=14)
plt.ylabel('PRICE', fontsize=14)
plt.show()
# 予測関数 (1, x)の値から予測値ypを計算する
def pred(x, w):
return(x @ w)
# +
# 初期化処理
# データ系列総数
M = x.shape[0]
# 入力データ次元数(ダミー変数を含む)
D = x.shape[1]
# 繰り返し回数
iters = 50000
# 学習率
alpha = 0.01
# 重みベクトルの初期値 (すべての値を1にする)
w = np.ones(D)
# 評価結果記録用 (損失関数値のみ記録)
history = np.zeros((0,2))
# -
# 繰り返しループ
for k in range(iters):
# 予測値の計算 (7.8.1)
yp = pred(x, w)
# 誤差の計算 (7.8.2)
yd = yp - yt
# 勾配降下法の実装 (7.8.4)
w = w - alpha * (x.T @ yd) / M
# 学習曲線描画用データの計算、保存
if ( k % 100 == 0):
# 損失関数値の計算 (7.6.1)
loss = np.mean(yd ** 2) / 2
# 計算結果の記録
history = np.vstack((history, np.array([k, loss])))
# 画面表示
print( "iter = %d loss = %f" % (k, loss))
# 最終的な損失関数初期値、最終値
print('損失関数初期値: %f' % history[0,1])
print('損失関数最終値: %f' % history[-1,1])
# 下記直線描画用の座標値計算
xall = x[:,1].ravel()
xl = np.array([[1, xall.min()],[1, xall.max()]])
yl = pred(xl, w)
# 散布図と回帰直線の描画
plt.figure(figsize=(6,6))
plt.scatter(x[:,1], yt, s=10, c='b')
plt.xlabel('ROOM', fontsize=14)
plt.ylabel('PRICE', fontsize=14)
plt.plot(xl[:,1], yl, c='k')
plt.show()
# 学習曲線の表示 (最初の1個分を除く)
plt.plot(history[1:,0], history[1:,1])
plt.show()
# ## 7.10 重回帰モデルへの拡張
# 列(LSTAT: 低所得者率)の追加
x_add = x_org[:,feature_names == 'LSTAT']
x2 = np.hstack((x, x_add))
print(x2.shape)
# 入力データxの表示 (ダミーデータを含む)
print(x2[:5,:])
# +
# 初期化処理
# データ系列総数
M = x2.shape[0]
# 入力データ次元数(ダミー変数を含む)
D = x2.shape[1]
# 繰り返し回数
iters = 50000
# 学習率
alpha = 0.01
# 重みベクトルの初期値 (すべての値を1にする)
w = np.ones(D)
# 評価結果記録用 (損失関数値のみ記録)
history = np.zeros((0,2))
# -
# 繰り返しループ
for k in range(iters):
# 予測値の計算 (7.8.1)
yp = pred(x2, w)
# 誤差の計算 (7.8.2)
yd = yp - yt
# 勾配降下法の実装 (7.8.4)
w = w - alpha * (x2.T @ yd) / M
# 学習曲線描画用データの計算、保存
if ( k % 100 == 0):
# 損失関数値の計算 (7.6.1)
loss = np.mean(yd ** 2) / 2
# 計算結果の記録
history = np.vstack((history, np.array([k, loss])))
# 画面表示
print( "iter = %d loss = %f" % (k, loss))
# +
# 初期化処理 (パラメータを適切な値に変更)
# データ系列総数
M = x2.shape[0]
# 入力データ次元数(ダミー変数を含む)
D = x2.shape[1]
# 繰り返し回数
#iters = 50000
iters = 2000
# 学習率
#alpha = 0.01
alpha = 0.001
# 重みベクトルの初期値 (すべての値を1にする)
w = np.ones(D)
# 評価結果記録用 (損失関数値のみ記録)
history = np.zeros((0,2))
# -
# 繰り返しループ
for k in range(iters):
# 予測値の計算 (7.8.1)
yp = pred(x2, w)
# 誤差の計算 (7.8.2)
yd = yp - yt
# 勾配降下法の実装 (7.8.4)
w = w - alpha * (x2.T @ yd) / M
# 学習曲線描画用データの計算、保存
if ( k % 100 == 0):
# 損失関数値の計算 (7.6.1)
loss = np.mean(yd ** 2) / 2
# 計算結果の記録
history = np.vstack((history, np.array([k, loss])))
# 画面表示
print( "iter = %d loss = %f" % (k, loss))
# 最終的な損失関数初期値、最終値
print('損失関数初期値: %f' % history[0,1])
print('損失関数最終値: %f' % history[-1,1])
# 学習曲線の表示 (最初の10個分を除く)
plt.plot(history[:,0], history[:,1])
plt.show()
| notebooks/ch07-regression.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from datetime import datetime as dt
import os
def getNow():
now = dt.now().strftime('%Y-%m-%d--%H-%M-%S')
nowFolder = os.path.join('./logFolder', now)
return nowFolder
# -
tf.reset_default_graph()
X = np.random.rand(100, 2)
y = 2*X[:, 0] + 3*X[:, 1] + 4
y = y.reshape((-1, 1))
# +
inp = tf.placeholder(dtype=tf.float32, shape=(None, 2), name='inp')
out = tf.placeholder(dtype=tf.float32, shape=(None, 1), name='out')
W = tf.Variable(initial_value=np.random.rand(2, 1), name='W', dtype=tf.float32)
b = tf.Variable(initial_value=0, name='b', dtype=tf.float32)
yHat = tf.matmul(inp, W )+ b
err = tf.reduce_mean((out - yHat)**2, name='err')
opt = tf.train.AdamOptimizer(learning_rate=0.01).minimize(err)
init = tf.global_variables_initializer()
# +
folder = getNow()
with tf.Session() as sess:
writer = tf.summary.FileWriter(folder, sess.graph)
sess.run(init)
errVal = sess.run( err, feed_dict={
inp : X,
out : y
})
writer.close()
print(errVal)
print('tensorboard --logdir={}'.format( folder ))
# -
# ## Variables persist between sessions
# +
folder = getNow()
with tf.Session() as sess:
writer = tf.summary.FileWriter(folder, sess.graph)
sess.run(init)
for i in range(5001):
_, errVal, WVal, bVal = sess.run( [opt, err, W, b], feed_dict={
inp : X,
out : y
})
if (i % 100) == 0:
print(errVal)
writer.close()
print(errVal)
print(WVal)
print(bVal)
print('tensorboard --logdir={}'.format( folder ))
# -
| notebooks/Tutorial 003.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="Ipoq5dkUZEI1" colab_type="text"
# # Singular Value Decomposition, SVD
# ## 奇异值分解
# + [markdown] id="149N2eYfZLed" colab_type="text"
# 任意一个$m$ x $n$ 矩阵,都可以表示为三个矩阵的乘积(因子分解)形式,分别是$m$阶**正交矩阵**,由**降序**排列的**非负**的对角线元素组成的$m$ x $n$ 矩形对角矩阵,和$n$阶**正交矩阵**,称为该矩阵的奇异值分解。矩阵的奇异值分解一定存在,但不唯一。
#
# 奇异值分解可以看作是矩阵数据压缩的一种方法,即用因子分解的方式近似地表示原始矩阵,这种近似是在平方损失意义下的最优近似。
# + [markdown] id="1i4xNylpaWVA" colab_type="text"
# 矩阵的奇异值分解是指,将一个非零的$m$ x $n$ **实矩阵**$A, A\in R^{m\times n}$表示为一下三个实矩阵乘积形式的运算:
# $A = U\Sigma V^{T}$,
# 其中 $U$ 是 $m$ 阶正交矩阵, $V$ 是 $n$ 阶正交矩阵,$\Sigma$ 是由降序排列的非负的对角线元素组成的$m$ x $n$矩形对角矩阵。称为$A$ 的奇异值分解。 $U$的列向量称为左奇异向量, $V$的列向量称为右奇异向量。
#
# 奇异值分解不要求矩阵$A$ 是方阵,事实上矩阵的奇异值分解可以看作方阵的对角化的推广。
#
# **紧奇奇异值分解**是与原始矩阵等秩的奇异值分解, **截断奇异值分解**是比原始矩阵低秩的奇异值分解。
# + [markdown] id="uAEFyqLD1Rbp" colab_type="text"
# ---------------------------------------------------------------------------------------------------------------------------------
# + id="RaH0xqPcZB94" colab_type="code" colab={}
# 实现奇异值分解, 输入一个numpy矩阵,输出 U, sigma, V
# https://zhuanlan.zhihu.com/p/54693391
import numpy as np
#基于矩阵分解的结果,复原矩阵
def rebuildMatrix(U, sigma, V):
a = np.dot(U, sigma)
a = np.dot(a, np.transpose(V))
return a
#基于特征值的大小,对特征值以及特征向量进行排序。倒序排列
def sortByEigenValue(Eigenvalues, EigenVectors):
index = np.argsort(-1*Eigenvalues)
Eigenvalues = Eigenvalues[index]
EigenVectors = EigenVectors[:,index]
return Eigenvalues, EigenVectors
#对一个矩阵进行奇异值分解
def SVD(matrixA, NumOfLeft=None):
#NumOfLeft是要保留的奇异值的个数,也就是中间那个方阵的宽度
#首先求transpose(A)*A
matrixAT_matrixA = np.dot(np.transpose(matrixA), matrixA)
#然后求右奇异向量
lambda_V, X_V = np.linalg.eig(matrixAT_matrixA)
lambda_V, X_V = sortByEigenValue(lambda_V, X_V)
#求奇异值
sigmas = lambda_V
sigmas = list(map(lambda x: np.sqrt(x) if x>0 else 0, sigmas))#python里很小的数有时候是负数
sigmas = np.array(sigmas)
sigmasMatrix = np.diag(sigmas)
if NumOfLeft==None:
rankOfSigmasMatrix = len(list(filter(lambda x: x>0, sigmas)))#大于0的特征值的个数
else:
rankOfSigmasMatrix =NumOfLeft
sigmasMatrix = sigmasMatrix[0:rankOfSigmasMatrix, :]#特征值为0的奇异值就不要了
#计算右奇异向量
X_U = np.zeros((matrixA.shape[0], rankOfSigmasMatrix))#初始化一个右奇异向量矩阵,这里直接进行裁剪
for i in range(rankOfSigmasMatrix):
X_U[:,i] = np.transpose(np.dot(matrixA,X_V[:, i])/sigmas[i])
#对右奇异向量和奇异值矩阵进行裁剪
X_V = X_V[:,0:NumOfLeft]
sigmasMatrix = sigmasMatrix[0:rankOfSigmasMatrix, 0:rankOfSigmasMatrix]
#print(rebuildMatrix(X_U, sigmasMatrix, X_V))
return X_U, sigmasMatrix, X_V
# + id="Hf9KqmH110KX" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 143} outputId="56ed2cdc-3f83-45eb-8c16-63881afee5a9"
A = np.array([[0, 0, 0, 2, 2], [0, 0, 0, 3, 3], [0, 0, 0, 1, 1], [1, 1, 1, 0, 0],
[2, 2, 2, 0, 0], [5, 5, 5, 0, 0], [1, 1, 1, 0, 0]])
A
# + id="Tmecvggl15Gn" colab_type="code" colab={}
X_U, sigmasMatrix, X_V = SVD(A, NumOfLeft=3)
# + id="r9TbEba32HcQ" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 143} outputId="abfa62a2-3ea8-419b-eb08-209afaa5cea1"
X_U
# + id="IoVH0RA32MxA" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 71} outputId="4b1ca501-7ce9-4cff-b929-150084bcd2fa"
sigmasMatrix
# + id="42ag3hPE2OBa" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 107} outputId="8fa214d1-3ec3-456e-8698-72c7e5ea5d8c"
X_V
# + id="1RHUFh0w2O0K" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 143} outputId="e6947501-4932-4c53-dee3-25dd38f542de"
# rebuild from U, sigma, V
rebuildMatrix(X_U, sigmasMatrix, X_V)
# + [markdown] id="c7FtRwkh2WlI" colab_type="text"
# same as A.
# + id="r_5WIyV33P1H" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 321} outputId="ee629ad1-caca-4f8b-8b8b-4ddb7df88824"
from PIL import Image
import requests
from io import BytesIO
url = 'https://images.mulberry.com/i/mulberrygroup/RL5792_000N651_L/small-hampstead-deep-amber-small-classic-grain-ayers/small-hampstead-deep-amber-small-classic-grain-ayers?v=3&w=304'
response = requests.get(url)
img = Image.open(BytesIO(response.content));img
| 第15章 奇异值分解/SVD.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] papermill={"duration": 0.016799, "end_time": "2020-11-27T13:39:00.495166", "exception": false, "start_time": "2020-11-27T13:39:00.478367", "status": "completed"} tags=[]
# # Augmented DNN
#
# This is a fork of my other notebook : [Can a simple DNN yield valuable results ?](https://www.kaggle.com/yzgast/minimal-dnn-keras)
#
# This is an attempt to see how much a simple deep neural network is able to perform. I also intend to use this kernel as the primay basic block and improve its future performances.
#
# + _cell_guid="b1076dfc-b9ad-4769-8c92-a6c4dae69d19" _uuid="8f2839f25d086af736a60e9eeb907d3b93b6e0e5" papermill={"duration": 7.023814, "end_time": "2020-11-27T13:39:07.532928", "exception": false, "start_time": "2020-11-27T13:39:00.509114", "status": "completed"} tags=[]
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.model_selection import KFold
from sklearn.preprocessing import MinMaxScaler
from tensorflow import random
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.callbacks import ReduceLROnPlateau, EarlyStopping
import matplotlib.pyplot as plt
random.set_seed(5577)
# + [markdown] papermill={"duration": 0.01367, "end_time": "2020-11-27T13:39:07.560651", "exception": false, "start_time": "2020-11-27T13:39:07.546981", "status": "completed"} tags=[]
# ## **Data Preparation**
# + _cell_guid="79c7e3d0-c299-4dcb-8224-4455121ee9b0" _uuid="d629ff2d2480ee46fbb7e2d37f6b5fab8052498a" papermill={"duration": 6.364664, "end_time": "2020-11-27T13:39:13.939094", "exception": false, "start_time": "2020-11-27T13:39:07.574430", "status": "completed"} tags=[]
trainFeatures = pd.read_csv('/kaggle/input/lish-moa/train_features.csv')
trainTargetScored = pd.read_csv('/kaggle/input/lish-moa/train_targets_scored.csv')
testFeatures = pd.read_csv('/kaggle/input/lish-moa/test_features.csv')
sampleSubmission = pd.read_csv('/kaggle/input/lish-moa/sample_submission.csv')
# + papermill={"duration": 0.169569, "end_time": "2020-11-27T13:39:14.122762", "exception": false, "start_time": "2020-11-27T13:39:13.953193", "status": "completed"} tags=[]
trainFeatures['cp_type'] = trainFeatures['cp_type'].map({'trt_cp':0, 'ctl_vehicle':1})
trainFeatures['cp_dose'] = trainFeatures['cp_dose'].map({'D1':0, 'D2':1})
trainFeatures = trainFeatures.drop(columns="sig_id")
trainTargetScored = trainTargetScored.drop(columns="sig_id")
testFeatures['cp_type'] = testFeatures['cp_type'].map({'trt_cp':0, 'ctl_vehicle':1})
testFeatures['cp_dose'] = testFeatures['cp_dose'].map({'D1':0, 'D2':1})
testFeatures = testFeatures.drop(columns="sig_id")
featuresCount = trainFeatures.shape[1]
print("Features count = %d" % featuresCount)
targetsCols = trainTargetScored.columns
targetsCount = len(targetsCols)
print("Targets count = %d" % targetsCount)
# + papermill={"duration": 4.256895, "end_time": "2020-11-27T13:39:18.394300", "exception": false, "start_time": "2020-11-27T13:39:14.137405", "status": "completed"} tags=[]
scaler = MinMaxScaler()
scaledTrain = scaler.fit_transform(trainFeatures)
scaledTest = scaler.transform(testFeatures)
pca = PCA(n_components=0.9)
pca.fit(scaledTrain)
sTrainFeatures = pca.transform(scaledTrain)
sTestFeatures = pca.transform(scaledTest)
print(sTrainFeatures.shape)
print(sTestFeatures.shape)
featuresCount = sTrainFeatures.shape[1]
# + [markdown] papermill={"duration": 0.015306, "end_time": "2020-11-27T13:39:18.427327", "exception": false, "start_time": "2020-11-27T13:39:18.412021", "status": "completed"} tags=[]
# ## **Model Creation**
# + papermill={"duration": 0.029298, "end_time": "2020-11-27T13:39:18.471712", "exception": false, "start_time": "2020-11-27T13:39:18.442414", "status": "completed"} tags=[]
def getModel(hiddenLayerSize=1024, dropOut=0.25):
model = Sequential()
model.add(Dense(hiddenLayerSize, input_dim=featuresCount, activation='relu'))
model.add(Dropout(dropOut))
model.add(Dense(hiddenLayerSize,activation='relu'))
model.add(Dropout(dropOut))
model.add(Dense(hiddenLayerSize,activation='relu'))
model.add(Dropout(dropOut))
model.add(Dense(targetsCount, activation="sigmoid"))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[])
return model
# + papermill={"duration": 0.02441, "end_time": "2020-11-27T13:39:18.511229", "exception": false, "start_time": "2020-11-27T13:39:18.486819", "status": "completed"} tags=[]
reduce_lr = ReduceLROnPlateau(monitor='val_loss', patience=3, verbose=0)
early_stop = EarlyStopping(monitor='val_loss', patience=6, restore_best_weights=True, verbose=0)
# + [markdown] papermill={"duration": 0.014914, "end_time": "2020-11-27T13:39:18.543481", "exception": false, "start_time": "2020-11-27T13:39:18.528567", "status": "completed"} tags=[]
# ## **Hyperparameters**
# Hyperparameters were set by few trial and error testing.
#
# + papermill={"duration": 0.024062, "end_time": "2020-11-27T13:39:18.582954", "exception": false, "start_time": "2020-11-27T13:39:18.558892", "status": "completed"} tags=[]
nSplits = 13
batchSize = 1000
epochCount = 64
hiddenLayerSize = 1024
dropOut = 0.3
# + [markdown] papermill={"duration": 0.015342, "end_time": "2020-11-27T13:39:18.613555", "exception": false, "start_time": "2020-11-27T13:39:18.598213", "status": "completed"} tags=[]
# ## **Fitting the model**
#
# + papermill={"duration": 1999.856174, "end_time": "2020-11-27T14:12:38.484805", "exception": false, "start_time": "2020-11-27T13:39:18.628631", "status": "completed"} tags=[]
models = []
losses = []
history = {}
verbosity = 0
kfold = KFold(n_splits=nSplits, shuffle=True)
for j, (train_idx, val_idx) in enumerate(kfold.split(sTrainFeatures)):
model = getModel(hiddenLayerSize, dropOut)
history[j] = model.fit(sTrainFeatures[train_idx], trainTargetScored.values[train_idx], validation_data=(sTrainFeatures[val_idx], trainTargetScored.values[val_idx]), callbacks=[reduce_lr, early_stop], batch_size=batchSize, epochs=epochCount, verbose=verbosity)
scores = model.evaluate(sTrainFeatures[val_idx], trainTargetScored.values[val_idx], verbose=verbosity)
print('Fold %d: %s of %.6f' % (j,model.metrics_names[0],scores))
losses.append(history[j].history["val_loss"][-1])
models.append(model)
print(losses)
# + [markdown] papermill={"duration": 0.027093, "end_time": "2020-11-27T14:12:38.536827", "exception": false, "start_time": "2020-11-27T14:12:38.509734", "status": "completed"} tags=[]
# ## **Plotting the loss & validation loss**
# + papermill={"duration": 0.451838, "end_time": "2020-11-27T14:12:39.009931", "exception": false, "start_time": "2020-11-27T14:12:38.558093", "status": "completed"} tags=[]
plt.figure(figsize=(15,7))
for k,v in history.items():
plt.plot(v.history["loss"], color='#bc3c1c', label="Loss Fold "+str(k))
plt.plot(v.history["val_loss"], color='#578e1f', label="ValLoss Fold "+str(k))
plt.xlabel('Epochs')
plt.ylabel('Error')
plt.title('Folds Error Compound')
plt.legend()
plt.show()
# + [markdown] papermill={"duration": 0.022202, "end_time": "2020-11-27T14:12:39.054546", "exception": false, "start_time": "2020-11-27T14:12:39.032344", "status": "completed"} tags=[]
# ## **Making the prediction & submitting results**
# + papermill={"duration": 10.710937, "end_time": "2020-11-27T14:12:49.788416", "exception": false, "start_time": "2020-11-27T14:12:39.077479", "status": "completed"} tags=[]
predictions = sampleSubmission.copy()
predictions[targetsCols] = 0
for model in models:
predictions.loc[:,targetsCols] += model.predict(sTestFeatures)
predictions.loc[:,targetsCols] /= len(models)
predictions.to_csv('submission.csv', index=False)
| kaggle/notebooks/moa-pca-dnn-callbacks-keras.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# **[SQL Home Page](https://www.kaggle.com/learn/intro-to-sql)**
#
# ---
#
# # Introduction
#
# [Stack Overflow](https://stackoverflow.com/) is a widely beloved question and answer site for technical questions. You'll probably use it yourself as you keep using SQL (or any programming language).
#
# Their data is publicly available. What cool things do you think it would be useful for?
#
# Here's one idea:
# You could set up a service that identifies the Stack Overflow users who have demonstrated expertise with a specific technology by answering related questions about it, so someone could hire those experts for in-depth help.
#
# In this exercise, you'll write the SQL queries that might serve as the foundation for this type of service.
#
# As usual, run the following cell to set up our feedback system before moving on.
# Set up feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.sql.ex6 import *
print("Setup Complete")
# Run the next cell to fetch the `stackoverflow` dataset.
# +
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "stackoverflow" dataset
dataset_ref = client.dataset("stackoverflow", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# -
# # Exercises
#
# ### 1) Explore the data
#
# Before writing queries or **JOIN** clauses, you'll want to see what tables are available.
#
# *Hint*: Tab completion is helpful whenever you can't remember a command. Type `client.` and then hit the tab key. Don't forget the period before hitting tab.
# +
# Get a list of available tables
tables = list(client.list_tables(dataset))
list_of_tables = [table.table_id for table in tables] # Your code here
# Print your answer
print(list_of_tables)
# Check your answer
q_1.check()
# -
# ### 2) Review relevant tables
#
# If you are interested in people who answer questions on a given topic, the `posts_answers` table is a natural place to look. Run the following cell, and look at the output.
# +
# Construct a reference to the "posts_answers" table
answers_table_ref = dataset_ref.table("posts_answers")
# API request - fetch the table
answers_table = client.get_table(answers_table_ref)
# Preview the first five lines of the "posts_answers" table
client.list_rows(answers_table, max_results=5).to_dataframe()
# -
# It isn't clear yet how to find users who answered questions on any given topic. But `posts_answers` has a `parent_id` column. If you are familiar with the Stack Overflow site, you might figure out that the `parent_id` is the question each post is answering.
#
# Look at `posts_questions` using the cell below.
# +
# Construct a reference to the "posts_questions" table
questions_table_ref = dataset_ref.table("posts_questions")
# API request - fetch the table
questions_table = client.get_table(questions_table_ref)
# Preview the first five lines of the "posts_questions" table
client.list_rows(questions_table, max_results=5).to_dataframe()
# -
# ### 3) Selecting the right questions
#
# A lot of this data is text.
#
# We'll explore one last technique in this course which you can apply to this text.
#
# A **WHERE** clause can limit your results to rows with certain text using the **LIKE** feature. For example, to select just the third row of the `pets` table from the tutorial, we could use the query in the picture below.
#
# 
#
# You can also use `%` as a "wildcard" for any number of characters. So you can also get the third row with:
#
# ```
# query = """
# SELECT *
# FROM `bigquery-public-data.pet_records.pets`
# WHERE Name LIKE '%ipl%'
# """
# ```
#
# Try this yourself. Write a query that selects the `id`, `title` and `owner_user_id` columns from the `posts_questions` table.
# - Restrict the results to rows that contain the word "bigquery" in the `tags` column.
# - Include rows where there is other text in addition to the word "bigquery" (e.g., if a row has a tag "bigquery-sql", your results should include that too).
# +
# Your code here
questions_query = """
SELECT id, title, owner_user_id
FROM `bigquery-public-data.stackoverflow.posts_questions`
WHERE tags LIKE '%bigquery%'
"""
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 1 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
questions_query_job = client.query(questions_query, job_config=safe_config) # Your code goes here
# API request - run the query, and return a pandas DataFrame
questions_results = questions_query_job.to_dataframe()# Your code goes here
# Preview results
print(questions_results.head())
# Check your answer
q_3.check()
# -
# ### 4) Your first join
# Now that you have a query to select questions on any given topic (in this case, you chose "bigquery"), you can find the answers to those questions with a **JOIN**.
#
# Write a query that returns the `id`, `body` and `owner_user_id` columns from the `posts_answers` table for answers to "bigquery"-related questions.
# - You should have one row in your results for each answer to a question that has "bigquery" in the tags.
# - Remember you can get the tags for a question from the `tags` column in the `posts_questions` table.
#
# Here's a reminder of what a **JOIN** looked like in the tutorial:
# ```
# query = """
# SELECT p.Name AS Pet_Name, o.Name AS Owner_Name
# FROM `bigquery-public-data.pet_records.pets` as p
# INNER JOIN `bigquery-public-data.pet_records.owners` as o
# ON p.ID = o.Pet_ID
# """
# ```
#
# It may be useful to scroll up and review the first several rows of the `posts_answers` and `posts_questions` tables.
# +
answers_query = """
SELECT a.id, a.body, a.owner_user_id
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
INNER JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON q.id = a.parent_id
WHERE q.tags LIKE '%bigquery%'
"""
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 1 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
answers_query_job = client.query(answers_query, job_config=safe_config)
# API request - run the query, and return a pandas DataFrame
answers_results = answers_query_job.to_dataframe()
# Preview results
print(answers_results.head())
# Check your answer
q_4.check()
# -
# ### 5) Answer the question
# You have the merge you need. But you want a list of users who have answered many questions... which requires more work beyond your previous result.
#
# Write a new query that has a single row for each user who answered at least one question with a tag that includes the string "bigquery". Your results should have two columns:
# - `user_id` - contains the `owner_user_id` column from the `posts_answers` table
# - `number_of_answers` - contains the number of answers the user has written to "bigquery"-related questions
# +
bigquery_experts_query = """
SELECT a.owner_user_id AS user_id, COUNT(1) AS number_of_answers
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
INNER JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON q.id = a.parent_Id
WHERE q.tags LIKE '%bigquery%'
GROUP BY a.owner_user_id
"""
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 1 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
bigquery_experts_query_job = client.query(bigquery_experts_query, job_config=safe_config)
# API request - run the query, and return a pandas DataFrame
bigquery_experts_results = bigquery_experts_query_job.to_dataframe()
# Preview results
print(bigquery_experts_results.head())
# Check your answer
q_5.check()
# -
# ### 6) Building a more generally useful service
#
# How could you convert what you've done to a general function a website could call on the backend to get experts on any topic?
#
def expert_finder(topic, client):
'''
Returns a DataFrame with the user IDs who have written Stack Overflow answers on a topic.
Inputs:
topic: A string with the topic of interest
client: A Client object that specifies the connection to the Stack Overflow dataset
Outputs:
results: A DataFrame with columns for user_id and number_of_answers. Follows similar logic to bigquery_experts_results shown above.
'''
my_query = """
SELECT a.owner_user_id AS user_id, COUNT(1) AS number_of_answers
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
INNER JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON q.id = a.parent_Id
WHERE q.tags like '%' + tag + '%'
GROUP BY a.owner_user_id
"""
# Set up the query (a real service would have good error handling for
# queries that scan too much data)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
my_query_job = client.query(my_query, job_config=safe_config)
# API request - run the query, and return a pandas DataFrame
results = my_query_job.to_dataframe()
return results
# ---
# **[SQL Home Page](https://www.kaggle.com/learn/intro-to-sql)**
#
#
#
#
#
# *Have questions or comments? Visit the [Learn Discussion forum](https://www.kaggle.com/learn-forum) to chat with other Learners.*
| Exercise_ Joining Data.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
print ("HOLA, EAE")
from IPython.display import HTML, SVG, YouTubeVideo
# **HTML**
HTML('''
<table style="border: 2px solid black;">
''' +
''.join(['<tr>' +
''.join([f'<td>{row},{col}</td>'
for col in range(5)]) +
'</tr>' for row in range(5)]) +
'''
</table>
''')
# **IMAGEN**
SVG('''<svg width="600" height="80">''' +
''.join([f'''<circle
cx="{(30 + 3*i) * (10 - i)}"
cy="30"
r="{3. * float(i)}"
fill="red"
stroke-width="2"
stroke="black">
</circle>''' for i in range(10)]) +
'''</svg>''')
# **VIDEO**
YouTubeVideo('tPgf_btTFlc')
# # Palabras reservadas
# Como todo programa, se usan comandos, para hacer cualquier cosa, y esos comandos NO los debemos usar en nuestros programas.
# Es algo así como marear al programa llamando a dos cosas con el mismo nombre.
# ## Lineas o sentencias
x = 2 #--> Sentencia con asignación de un valor
x = x + 2 #--> Sentencia con asignación de un valox y una expresión (númerica)
print(x) #---> Sentencia print para imprimer en pantalla
print(123) #--> Número
o = 123
print(98.6) #--> Entero
y = 98.6
print('Hello world') #--> String, carácter
x='Hello world'
type(o), type(y), type(x)
print(x)
x='125'
print(x)
type(x)
print(x)
print(x)
x=1200000000
print(x)
# - x = 2 --> Hemos creado una **VARIABLE** con el valor 2
# - x = x + 2 --> El signo + es un **OPERADOR**
# - 2 --> Es una **CONSTANTE**
# - Print --> es una **FUNCIÓN** al que le entra un input (X) y sale un output Imprimir en pantalla X
# 
# Una variable puede ser usada en su declaración
x = 3.9 * x * ( 1 - x )
print(x)
# ## Nombrar variables
# Sigue unas reglas
# - Bien:
# - spam
# - eggs
# - spam23
# - _speed
# - Mal:
# - 23spam
# - #sign
# - var.12
# - Son diferntes:
# - spam
# - Spam
# - SPAM
# ### Horror
#
x1q3z9ocd = 35.0
x1q3z9afd = 12.50
x1q3p9afd = x1q3z9ocd * x1q3z9afd
print(x1q3p9afd)
# ### Mejor
a = 35.0
b = 12.50
c = a * b
print(c)
horas = 35.0
ratio = 12.50
pagar = horas * ratio
print(pagar)
# ## Primeros condicionales
# 
x = 29 # Cambiar el número
if x < 10:
print('Pequeño')
if x > 20:
print('Grande')
print('Fin')
# ## Repertir pasos
# 
n = 5
while n > 0 :
print(n)
n = n-1
print('¡Para!')
# ## Expresiones numéricas
# 
xx = 2
xx = xx + 2 #-->suma
print(xx)
yy = 440 * 12 #--> multiplicación
print(yy)
zz = yy / 1000 #--> división
print(zz)
hh = 2**2
print (hh)
jj = 23
ll= jj/5
print(ll)
kk = jj % 5
print(kk)
print(4 ** 3)
# ## Precedencia en las operaciones
x = 1 + 2 * 3 - 4 / 5 ** 6
print(x)
# - Primero: Parentesís
# - Segundo: Potencia
# - Tercero: Multiplicación
# - Cuarto: Suma
# - Quinto: Izquierda a derecha
#
x = 1 + 2 ** 3 / 4 * 5
print(x)
# 
# ## Concatenar: el único operador que se usa con texto
ddd = 1 + 4
print(ddd)
eee = 'hola ' + 'EAE'
print(eee)
print(eee+1) #--> da error
eee = 'hola ' + 'EAE'
type(eee), type(1)
temp = 98.6
type(temp)
# ## Conversiones entre tipos de datos
# +
print(float(99) + 100)
i = 42
f = float(i)
type(i), type(f)
# -
print(10 / 2)
print(9 / 2)
print(99 / 100)
print(10.0 / 2.0)
print(99.0 / 100.0)
# #### Cómo pedir datos:
nam = input('¿Cómo te llamas, piltafrilla? ')
print('Bienvenido', nam)
# #### Como jugar con la entrada de datos
inp = input('¿Cuántos donuts te has comido?')
usf = int(inp) + 3
print('Realmente te has comido', usf)
| notebooks/1_Comenzar con Python.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: hypeScanKernel
# language: python
# name: hypescancentral
# ---
# + pycharm={"name": "#%% DESCRIPTION\n"}
"""
This notebook reconstructs full storytelling time series for each subject
from the parseEPI outputted listener and speaker time series.
It saves these out as nifti files with condition labels in the file
name (independent, joint) -- 2 files per subject.
These nifti files can be used by make_hyperalignment_datasets.py to
make pymvpa datasets. Note that these can later be sliced, for
example, into just listening or just reading intervals within the
dataset format to try things like hyperaligning on the listening
task and testing on the concatenated storytelling listening data, etc...
"""
# + pycharm={"name": "#%% import modules\n"}
import pickle
import numpy as np
import pandas as pd
import scipy.io as sio
from scipy import stats
from nilearn import image as nImage
from nilearn import input_data
# from nilearn import datasets
# from nilearn import surface
# from nilearn import plotting
# + pycharm={"name": "#%%\n"}
saveFolder = '/dartfs-hpc/rc/lab/W/WheatleyT/f00589z/hyperscanning/preprocessing/hyperalignment/input_nifti_files/'
# + pycharm={"name": "#%% load pairMap\n"}
loadFolder = '/dartfs-hpc/rc/lab/W/WheatleyT/f00589z/hyperscanning/storytelling/misc/'
with open(loadFolder + 'pairMap_all_DBIC_CBS_pairs.pkl', 'rb') as f:
pairMap = pickle.load(f)
# + pycharm={"name": "#%% get turn TRs\n"}
# kind of hacky but predefining the total number of TRs that will be in each concatenated time series
totTRs = 615
# number of TRs per turn
TRsPerTurn = 41
# number of speech turns per participant per condition
numTurns = round(totTRs / TRsPerTurn)
numPairs = 8
# get speaker/listener TR indices
turnTRs = [[]] * numTurns * 2
for TURN in range(int(numTurns * 2)):
if TURN == 0:
inds = np.array(list(range(TRsPerTurn)))
else:
inds = inds + TRsPerTurn
turnTRs[TURN] = inds
# + pycharm={"name": "#%%\n"}
pairMap
# + pycharm={"name": "#%% get condition indices\n"}
condInds = [[]] * 2
for COND in [0,1]:
condInds[COND] = np.where(pairMap['condition'] == COND)[0]
# + pycharm={"name": "#%% reformat pairMap\n"}
# preallocate data frame
fileList = pd.DataFrame(index=np.arange(int(pairMap.shape[0]*2)), columns=['subID','site','condition','speaker','file'])
site = ['DBIC','CBS']
siteID = ['dbicID','cbsID']
fileType = ['lFile','sFile']
# + pycharm={"name": "#%%\n"}
# fill in fileList
fROW = 0
for SITE in [0,1]: # dbic, cbs
for pROW in range(pairMap.shape[0]): # for each row of pairMap...
fileList['subID'][fROW] = pairMap[siteID[SITE]][pROW]
fileList['site'][fROW] = site[SITE]
fileList['condition'][fROW] = pairMap['condition'][pROW]
if SITE == pairMap['dbicSpeaker'][pROW]:
fileList['speaker'][fROW] = 0
else:
fileList['speaker'][fROW] = 1
fileList['file'][fROW] = pairMap[fileType[fileList['speaker'][fROW] == 1]][pROW]
# increment fileList row counter
fROW += 1
# + pycharm={"name": "#%% set path to mask\n"}
resampledMaskFile = '/dartfs-hpc/rc/lab/W/WheatleyT/f00589z/hyperscanning/misc/mni_icbm152_nlin_asym_09c/mni_icbm152_t1_tal_nlin_asym_09c_mask_RESAMPLED.nii'
# + pycharm={"name": "#%% rename the files in fileList so that youre loading .mat files generated with the updated mask\n"}
for ROW in range(fileList.shape[0]):
fileList['file'][ROW] = fileList['file'][ROW].replace('2021','newMask')
fileList
# + pycharm={"name": "#%%\n", "is_executing": true}
# get number of subjects
numSubs = len(np.unique(fileList['subID']))
# preallocate
data = [[]] * numSubs
# condition labels
condLabs = ['ind','joint']
ROW = 0
for SUB in range(numSubs):
data[SUB] = [[]] * 2
for COND in [0,1]:
# get .mat file names
if fileList['speaker'][ROW]: # if the first row is a speaker file...
sFile = fileList['file'][ROW]
lFile = fileList['file'][ROW+1]
else:
lFile = fileList['file'][ROW]
sFile = fileList['file'][ROW+1]
# get corresponding nifti file name (arbitrarily use speaker file as reference)
niiFile = sFile[0:sFile.find('nuisRegr')] + 'nuisRegr_newMask.nii.gz'
niiFile = niiFile.replace('parseEPI_output_files','nuisRegr_output_files')
# preallocate separated speaker/listener data
sepData = [[]] * 2 # 0=speaker, 1=listener
# load speaker data
print('loading ' + sFile + '...')
dummyFile = sio.loadmat(sFile)
if fileList['site'][ROW] == 'DBIC': # dbic
order = [0,1] # listener, speaker
sepData[0] = dummyFile['dbicSpeaker']
else: # cbs
order = [1,0] # speaker, listener
sepData[0] = dummyFile['cbsSpeaker']
del dummyFile
# load listener data
print('loading ' + lFile + '...')
dummyFile = sio.loadmat(lFile)
if fileList['site'][ROW] == 'DBIC': # dbic
sepData[1] = dummyFile['dbicListener']
else: # cbs
sepData[1] = dummyFile['cbsListener']
del dummyFile
# preallocate
data[SUB][COND] = np.empty([int(totTRs*2),sepData[0].shape[1]])
# initialize row indices
rowInds = np.copy(turnTRs[0])
# for each pair of speaker-listener turns
for TURN in range(numTurns):
for SPEAKER in order:
# get data
data[SUB][COND][rowInds,:] = sepData[SPEAKER][turnTRs[TURN],:]
rowInds += TRsPerTurn
# standardize the time series
data[SUB][COND] = stats.zscore(data[SUB][COND],axis=0)
#%% load whole brain mask
maskImg = nImage.load_img(resampledMaskFile)
# initialize masker object from whole brain mask and nuisRegr output .nii file
masker = input_data.NiftiMasker(maskImg)
masker.fit_transform(niiFile)
#%% make new nifti with parsedEPI time series
outputFile = niiFile.replace(niiFile[0:niiFile.find('sub-')],'')
outputFile = outputFile.replace(niiFile[-7:],'_interp_uncut_' + condLabs[COND] + '.nii.gz')
outputFile = saveFolder + outputFile
print('saving file ' + str(SUB*2+COND+1) + ' of ' + str(int(fileList.shape[0] / 2)) + ' to: ')
print(outputFile)
cleaned_img = masker.inverse_transform(data[SUB][COND])
cleaned_img.to_filename(outputFile)
# increment row indices
ROW += 2
# + pycharm={"name": "#%%\n"}
| current_code/resort_storytelling_time_series.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# Here we give a list of short and useful tips.
# #### “Automatic” Reshaping
# To change the dimensions of an array, you can omit one of the sizes which will then be deduced automatically:
import numpy as np
a = np.arange(30)
print(a,"Arange funcation")
a.shape = 2,-1,3 # -1 means "whatever is needed"
a
a.ndim
a.shape = 2,5,3
a
a.shape
a.ndim
# #### Vector Stacking
# How do we construct a 2D array from a list of equally-sized row vectors? In MATLAB this is quite easy: if x and y are two vectors of the same length you only need do m=[x;y]. In NumPy this works via the functions column_stack, dstack, hstack and vstack, depending on the dimension in which the stacking is to be done. For example:
x = np.arange(0,10,2) # x=([0,2,4,6,8])
y = np.arange(5) # y=([0,1,2,3,4])
m = np.vstack([x,y]) # m=([[0,2,4,6,8],
# [0,1,2,3,4]])
xy = np.hstack([x,y]) # xy =([0,2,4,6,8,0,1,2,3,4])
print(x,"\n",y,"\n",m,"\n",xy)
# The logic behind those functions in more than two dimensions can be strange.
# ### Histograms
# The NumPy histogram function applied to an array returns a pair of vectors: the histogram of the array and the vector of bins. Beware: matplotlib also has a function to build histograms (called hist, as in Matlab) that differs from the one in NumPy. The main difference is that pylab.hist plots the histogram automatically, while numpy.histogram only generates the data.
# +
import numpy as np
import matplotlib.pyplot as plt
# Build a vector of 10000 normal deviates with variance 0.5^2 and mean 2
mu, sigma = 2, 0.5
v = np.random.normal(mu,sigma,10000)
# Plot a normalized histogram with 50 bins
plt.hist(v, bins=1000, density=2) # matplotlib version (plot)
plt.show()
# -
# Compute the histogram with numpy and then plot it
(n, bins) = np.histogram(v, bins=50, density=True) # NumPy version (no plot)
plt.plot(.5*(bins[1:]+bins[:-1]), n)
plt.show()
| 12. Tricks and Tips.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
s = pd.Series(['pizza', 42])
s
s = pd.Series(['pizza', 42], index=['food', 'number'])
s
s.loc['food']
s.iloc[0]
scientists = pd.DataFrame({
'name': ['Franklin', 'Gosset'],
'job': ['chem', 'stats']
})
scientists
scientists = pd.read_csv('../data/scientists.csv')
scientists
scientists['Age'].describe()
scientists['Age'] * scientists['Age']
scientists['Age'] * 2
scientists['age_doubled'] = scientists['Age'] * 2
scientists
| notebooks/02-data.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.9.5 64-bit (''enterprise'': conda)'
# name: python3
# ---
# +
from sample_psrs import load_psrs, fake_model_2a
from fast_model import FastLogLikelihood, power_law, fourier_matrix
import numpy as np
import scipy.linalg as sl
# %load_ext autoreload
# %autoreload 2
# -
psrs = load_psrs(1e-15, 1000)
pta = fake_model_2a([psrs[0]])
# +
gamma = np.array([2.0, 3.0])
log10_A = np.array([-15.0, -16.0])
params = np.array([gamma, log10_A])
# -
F, freqs = fourier_matrix(psrs[0].toas)
power_law(params, freqs)
# +
gamma_rn = np.array([2.0, 3.0])
log10_A_rn = np.array([-15.0, -16.0])
gamma_gw = np.repeat(4.33, 2)
log10_A_gw = np.array([-15., -16.])
params_rn = np.array([gamma_rn, log10_A_rn])
params_gw = np.array([gamma_gw, log10_A_gw])
# -
like = FastLogLikelihood(psrs[0])
like([gamma_rn[0], log10_A_rn[0], log10_A_gw[0]])
# +
gamma_rn = np.array([2.0, 3.0])
log10_A_rn = np.array([-15.0, -16.0])
gamma_gw = np.repeat(4.33, 2)
log10_A_gw = np.array([-15., -16.])
params_rn = np.array([gamma_rn, log10_A_rn])
params_gw = np.array([gamma_gw, log10_A_gw])
# -
def generate_params(num=10):
gamma_rn = np.random.uniform(0, 7, num)
log10_A_rn = np.random.uniform(-20, -11, num)
gamma_gw = np.repeat(4.33, num)
log10_A_gw = np.random.uniform(-20, -12, num)
params_rn = np.array([gamma_rn, log10_A_rn])
params_gw = np.array([gamma_gw, log10_A_gw])
return params_gw, params_rn
like = FastLogLikelihood(psrs[0])
like(params_gw, params_rn)
params_gw, params_rn = generate_params(1000)
print(params_gw.shape)
# %%timeit
like(params_gw, params_rn)
123 / 1000
468 - 337
12.2 / 100
| single_pulsar_model/test.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/ddeMoivre/blog/blob/master/_notebooks/2022_02_09_Time_series_analysis.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="BHlDTKsuqnE7"
# # Time Series Analysis of the US Treasury 10- Year Yield
#
# - toc: true
# - badges: true
# - comments: true
# - categories: [jupyter]
# - image: images/Ohlc_chart.png
# + [markdown] id="gE_0K1WLqnE9"
# ### AR(p) Models
# + [markdown] id="g-V_-KVFqnE_"
# A time series model for the observed data $\{x_t\}$ is a specification of the joint distribution (or possibly only the means and covariances) of a sequence of random variables $\{X_t\}$ of which $\{x_t\}$ is postulated to be a realization.
#
# The causal autoregressive $AR(p)$ process is defined by
# $$
# X_t-\phi_1 X_{t-1} - ...-\phi_p X_{t-p}=c + Z_t, \ \ {Z_t} \sim WN(0,\sigma^2).
# $$
#
# A time series $\{X_t\}$ is (covariance) **stationnary** if the mean function $\mu_X(t):= E(X_t)$ is independent of $t$, and the autocovariance function (ACVF) of $\{X_t\}$ at lag $h$
#
# $$
# \gamma_X(t+h,t) := Cov(X_{t+h},X_t) = \mathbb{E}[(X_{t+h}-\mu_X(t+h))(X_{t}-\mu_X(t))]
# $$
#
# is independent of $t$ for each $h$.
#
# To assess the degree of dependence in the data and to select a model for the data that reflects this, one of the important tools we use is the sample autocorrelation function (sample ACF) of the data. Let $\{X_t\}$ be a stationary time series. The **autocorrelation function** of $\{X_t\}$ at lag $h$ is
#
# $$
# \rho_X(h):=\frac{\gamma_X(h)}{\gamma_X(0)} = Cor(X_{t+h},X_{t}).
# $$
#
# Let $x_1,...,x_n$ be observations of a time series. The **sample autocorrelation function** is
#
# $$
# \hat\rho(h) = \frac{\hat\gamma(h)}{\hat\gamma(0)},
# $$
#
# where $\hat\gamma(h)$ is the sample autocovariance function i.e., $\hat\gamma(h): = n^{-1}\sum_{t=1}^{n-|h|}(x_{n-|h|}-\bar{x})(x_t-\bar{x})$, for $\ -n<h<n$ and $\bar{x}:=n^{-1}\sum^n_{t=1} x_t$.
#
# We define sample PACF in an analogous way. If we believe that the data are realized values of a stationary time series $\{X_t\}$, then the sample ACF will provide us with an estimate of the ACF of $\{X_t\}$. This estimate may suggest which of the many possible stationary time series models is a suitable candidate for representing the dependence in the data. For example, a sample ACF that is close to zero for all nonzero lags suggests that an appropriate model for the data might be iid noise.
#
# A **partial autocorrelation function (PACF)** of an ARMA process $\{X_t\}$ is the function $\alpha(\cdot)$ defined by the equations
#
# $$
# \alpha(0) = 1 \ \ \text{and} \ \ \alpha(h) = \phi_{hh}, \ \ h \geq 1,
# $$
#
# where $\phi_{hh}$ is the last component of $\Phi_h = \Gamma^{-1}_{h}\gamma_h$, $\Gamma_h$ is $h$-dimensional the covariance matrix and $\gamma_h = [\gamma(1),\gamma(2),...,\gamma(h)]'$.
#
# The partial autocorrelation function is a tool that exploits the fact that, whereas an $AR(p)$ process has an autocorrelation function that is infinite in extent, the partial autocorrelations are zero beyond lag $p$. We define sample PACF for observed data in an analogous way.
#
# #### Reference
# * <NAME>, <NAME>, *Introduction to time series and forecasting*, third edition
# + [markdown] id="9LsFzbsuqnFB"
# ### Load python libraries and Federal Reserve data
# + [markdown] id="XVO9X_IOqnFC"
# The following commands re-load the data and evaluates the presence and nature of missing values.
# + colab={"base_uri": "https://localhost:8080/"} id="IA3u2Dijsc2B" outputId="bc34d21e-f292-4625-bcb2-3f554cbdf2d2"
#hide
from google.colab import drive
drive.mount('/content/drive')
# + colab={"base_uri": "https://localhost:8080/"} id="1yfkiFaKseYb" outputId="8be4abb6-92a0-44f4-c4e3-a8140b84e525"
#hide
# %cd /content/drive/MyDrive/"Time Series Analysis"
# + colab={"base_uri": "https://localhost:8080/"} id="KeruuSpByKoH" outputId="5658c686-70ac-4751-efcd-b06e6a93462e"
#hide
# !pip install statsmodels==0.11.1
# + id="UfGVxMFlqnFC"
# %matplotlib inline
import warnings
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
from statsmodels.tsa.ar_model import AutoReg
from pylab import mpl, plt
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
plt.style.use('seaborn')
mpl.rcParams['font.family'] = 'serif'
# + id="bkrLP74IqnFE"
fred_data = pd.read_csv("fred_data.csv", index_col="DATE")
# + colab={"base_uri": "https://localhost:8080/", "height": 238} id="a8_fGtJjqnFE" outputId="57ed7ccf-b0d0-4b7d-dada-049456b30579"
fred_data.head()
# + id="UxE3Qb8mqnFF"
#fred_data.plot(figsize=(10,5));
# + colab={"base_uri": "https://localhost:8080/", "height": 542} id="9KtusdvmqnFG" outputId="6c10d047-272e-468d-c052-52959318df79"
# Visualise U.S. Treasury Securities at 10-Year Constant Maturity
fig = px.line(fred_data, y='DGS10')
fig.show();
# + colab={"base_uri": "https://localhost:8080/"} id="zcMz5_g-qnFI" outputId="5b52f10a-8436-46f3-e963-9bd807f8a1ac"
# There are dates with missing values (NAs)
# Print out the counts of missing values
fred_data.isna().sum()
# + colab={"base_uri": "https://localhost:8080/"} id="YHA7OUtnqnFI" outputId="4a0fdc90-4bb8-4e8a-c8d1-b622be76c0d1"
# Identify rows for which DGS10 data is missing
fred_data[fred_data.isna()["DGS10"]==True].index
# + id="bdOE9OaPqnFI"
# Note that the FRED data is missing when there are holidays or market-closes
# in the bond market of the US.
# Define fred_data0 as sub matrix with nonmissing data for DGS10
fred_data0 = fred_data[fred_data.isna()["DGS10"]==False]
# + colab={"base_uri": "https://localhost:8080/"} id="W5Xy9AVeqnFJ" outputId="f848e979-9fa0-4aaa-e851-0c816bf5a73c"
fred_data0.isna().sum()
# + id="GggyZZpBqnFJ"
# Our focus is on DGS10, the yield of constant-maturity 10 Year US bond.
DGS10_daily = fred_data0[["DGS10"]]
# + colab={"base_uri": "https://localhost:8080/"} id="rs3nJHlBqnFK" outputId="e36a1f4b-6751-4937-9221-1ce85017bd05"
len(DGS10_daily)
# + colab={"base_uri": "https://localhost:8080/", "height": 238} id="lDbIP362qnFK" outputId="0b91c836-ab14-439e-9148-89eab5126e02"
DGS10_daily.head()
# + [markdown] id="WPIbU3G7qnFL"
# ### Create weekly and monthly time series
# + id="Kl3isZksqnFM"
# The function resample_plot() converts a time series data object
# to an Open/High/Low/Close series on a periodicity lower than the input data object.
# Plot OHLC chart which shows the open, high, low, and close price for a given period.
warnings.filterwarnings("ignore")
DGS10_daily['Date'] = pd.to_datetime(DGS10_daily.index, format='%Y/%m/%d')
DGS10_daily = DGS10_daily.set_index(['Date'])
DGS10_daily.columns = ['DGS10_daily']
def resample_plot(data, how):
df = pd.DataFrame(columns=['open', 'high', 'low', 'close'])
ohlc = {'open': lambda x: x[0],
'high': max,
'low': min,
'close': lambda x: x[-1]}
for key in ohlc.keys():
df[key] = data.resample(how).apply(ohlc[key])
fig = go.Figure(data=[go.Candlestick(x=df.index,
open=df.loc[:,'open'], high=df.loc[:,'high'],
low=df.loc[:,'low'], close=df.loc[:,'close'])
])
f = lambda x: 'week' if x=='W' else 'month'
fig.update_layout(title='OHLC chart for {}'.format(f(how)),
yaxis_title='DGS10',
xaxis_rangeslider_visible=False)
fig.show()
return df
# + colab={"base_uri": "https://localhost:8080/", "height": 542} id="pylIn-lgqnFM" outputId="ca94624e-9981-4d2b-c86f-7bae5b8cc6a1"
# OHLC Chart for week
OHLC_weekly = resample_plot(DGS10_daily,'W')
# + colab={"base_uri": "https://localhost:8080/", "height": 542} id="7gODtaERqnFM" outputId="eaf82216-3c70-4f4e-96c0-81d769dacfa2"
# OHLC Chart for month
OHLC_monthly = resample_plot(DGS10_daily,'M')
# + id="RJR2T4PMqnFN"
# Define the two vector time series of weekly close values and of monthly close values
DGS10_weekly = OHLC_weekly[['close']]
DGS10_weekly.columns = ['DGS10_weekly']
DGS10_monthly = OHLC_monthly[['close']]
DGS10_monthly.columns = ['DGS10_monthly']
# + colab={"base_uri": "https://localhost:8080/"} id="pG6kg9O0qnFN" outputId="06dfa298-9a17-43a1-855a-1c9d0c63d654"
# Note the dimensions when daily data reduced to weekly and to monthly periods
len(DGS10_weekly)
# + colab={"base_uri": "https://localhost:8080/"} id="PAsurrl_qnFN" outputId="01f104cd-e7fd-4e96-f0d2-2a11d0b6a7f5"
len(DGS10_monthly)
# + [markdown] id="iokX_KRfqnFO"
# ### The ACF and PACF for daily, weekly, monthly series
# + [markdown] id="2xpXdk6HqnFO"
# Plot the ACF (auto-correlation function) and PACF (partial auto-correlation function) for each periodicity.
# + id="ohaXoHjUqnFO"
def acf_pacf_plot(daily,weekly,monthly):
fig, ax = plt.subplots(2,3, figsize=(16,10))
sm.graphics.tsa.plot_acf(daily.values.squeeze(),
title = list(daily.columns)[0], ax=ax[0,0])
ax[0,0].set_ylabel('ACF')
sm.graphics.tsa.plot_acf(weekly.values.squeeze(),
title = list(weekly.columns)[0], ax=ax[0,1])
ax[0,1].set_ylabel('ACF')
sm.graphics.tsa.plot_acf(monthly.values.squeeze(),
title = list(monthly.columns)[0], ax=ax[0,2])
ax[0,2].set_ylabel('ACF')
sm.graphics.tsa.plot_pacf(daily.values.squeeze(),
title = list(daily.columns)[0], ax=ax[1,0])
ax[1,0].set_ylabel('Partial ACF')
sm.graphics.tsa.plot_pacf(weekly.values.squeeze(),
title = list(weekly.columns)[0], ax=ax[1,1])
ax[1,1].set_ylabel('Partial ACF')
sm.graphics.tsa.plot_pacf(monthly.values.squeeze(),
title = list(monthly.columns)[0], ax=ax[1,2])
ax[1,2].set_ylabel('Partial ACF');
# + colab={"base_uri": "https://localhost:8080/", "height": 606} id="j18PgeU_qnFP" outputId="3514ab41-1e26-4ec1-e1da-9899093991f0"
acf_pacf_plot(DGS10_daily, DGS10_weekly, DGS10_monthly)
# + [markdown] id="t8QEwasoqnFP"
# The high first-order auto-correlation suggests that the time series has a unit root on every periodicity (daily, weekly and monthly).
# + [markdown] id="GG4gRCDeqnFP"
# ### Conduct Augmented Dickey-Fuller Test for Unit Roots
# + [markdown] id="ch8wat0yqnFP"
# It is essential to determine whether the time series is "stationary". Informally, stationarity is when the auto-covariance is independent of time. Failure to establish stationarity will almost certainly lead to misinterpretation of model identification and diagnostics tests.
#
# We perform an Augmented Dickey-Fuller test to establish stationarity under the assumption that the time series has a constant bias but does not exhibit a time trend. In other words, we assume that the time series is already de-trended.
#
# If the stationarity test fails, even after first de-trending the time series, then one potential recourse is to simply take differences of time series and predict $\Delta y_t$.
# + [markdown] id="tNxsTL56qnFQ"
# For each periodicity, apply the function adfuller() twice:
# - to the un-differenced series (null hypothesis: input series has a unit root)
# - to the first-differenced series (same null hypothesis about differenced series)
# + [markdown] id="3y8VCkJYqnFQ"
# Results for the un-differenced series:
# + colab={"base_uri": "https://localhost:8080/", "height": 455} id="3mKSUgYFomg9" outputId="289206b7-5b69-4cce-e5d2-069bf7cb78b7"
DGS10_weekly
# + colab={"base_uri": "https://localhost:8080/"} id="i8cD4jZ0oQjg" outputId="3b4ab34b-45a5-4d5e-bcdf-a3f9c6367768"
print(sm.tsa.adfuller(DGS10_daily['DGS10_daily'])[1])
# + colab={"base_uri": "https://localhost:8080/"} id="M3j8JGEkqnFR" outputId="f2132831-6ce3-40d8-e34f-6205711a55ae"
print(sm.tsa.adfuller(DGS10_weekly['DGS10_weekly'])[1])
# + colab={"base_uri": "https://localhost:8080/"} id="QuhKXbvxqnFR" outputId="6e0c0af2-e35e-4e50-a7df-47d820f9e99b"
print(sm.tsa.adfuller(DGS10_monthly['DGS10_monthly'])[1])
# + [markdown] id="GKmcegYeqnFR"
# For each periodicity, the null hypothesis of a unit root for the time series DGS10 is not rejected at the 0.05 level. The p-value for each test does not fall below standard critical values of 0.05 or 0.01.
# The p-value is the probability (assuming the null hypothesis is true) of realizing a test statistic as extreme as that computed for the input series. Smaller values (i.e., lower probabilities) provide stronger evidence against the null hyptohesis.
# The p-value decreases as the periodicity of the data shortens. This suggests that the time-series structure in the series DGS10 may be stronger at higher frequencies.
# + [markdown] id="IaITBxNhqnFR"
# Results for the first-differenced series:
# + colab={"base_uri": "https://localhost:8080/"} id="zfjdP34prcLO" outputId="f0b52868-0341-4419-d8b3-e5743196983b"
print(sm.tsa.adfuller((DGS10_daily.shift(1)-DGS10_daily).dropna()['DGS10_daily'])[1])
# + colab={"base_uri": "https://localhost:8080/"} id="HPXy0RrstpEZ" outputId="f40ecf31-27f0-4b7f-f7f2-5d3c3182cc60"
print(sm.tsa.adfuller((DGS10_weekly.shift(1)-DGS10_weekly).dropna()['DGS10_weekly'])[1])
# + colab={"base_uri": "https://localhost:8080/"} id="vzNWdc5XtxkO" outputId="0ba46d80-0eba-4454-f38f-ced4e3eec1e7"
print(sm.tsa.adfuller((DGS10_monthly.shift(1)-DGS10_monthly).dropna()['DGS10_monthly'])[1])
# + [markdown] id="kMunMYyCqnFS"
# For each of the three time periodicities, the ADF test rejects the null hypothesis that a unit root is present for the first-differenced series.
# + [markdown] id="JNzHLbkzqnFS"
# ### The ACF and PACF for the differenced series of each periodicity
# + [markdown] id="zseYGTxyqnFT"
# One application of the operator $(1 − B)$ produces a new series $\{Y_t\}$ with no obvious deviations from stationarity.
# + id="WBNDMtVMqnFT"
diff_DGS10_daily = (DGS10_daily.shift(1)-DGS10_daily).dropna()
diff_DGS10_daily.columns = ['diff_DGS10_daily']
diff_DGS10_weekly = (DGS10_weekly.shift(1)-DGS10_weekly).dropna()
diff_DGS10_weekly.columns = ['diff_DGS10_weekly']
diff_DGS10_monthly = (DGS10_monthly.shift(1)-DGS10_monthly).dropna()
diff_DGS10_monthly.columns = ['diff_DGS10_monthly']
# + colab={"base_uri": "https://localhost:8080/", "height": 606} id="rTHm9mymqnFT" outputId="d1b1211f-79bc-49d7-ba8c-ed227673d1de"
acf_pacf_plot(diff_DGS10_daily, diff_DGS10_weekly, diff_DGS10_monthly)
# + [markdown] id="S7QcS_F6qnFT"
# The apparent time series structure of DGS10 varies with the periodicity:
#
# Daily:
#
# strong negative order-7 autocorrelation and partial autocorrelation
# strong positive order-30 autocorrelation and partial autocorrelation
#
# Weekly:
#
# strong negative order-1 autocorrelation and partial autocorrelation
# strong positive order-26 autocorrelation and partial autocorrelation
#
# Monthly:
#
# strong negative order-19 autocorrelation and partial autocorrelation.
# + colab={"base_uri": "https://localhost:8080/", "height": 717} id="lT80awQwqnFU" outputId="2907bd60-dd43-45f9-f730-7b61be7fa2b5"
fig0 = px.line(DGS10_monthly, y='DGS10_monthly', height=400)
fig0.show();
fig1 = px.line(diff_DGS10_monthly, y='diff_DGS10_monthly', height=300)
fig1.show();
# + [markdown] id="CzIfROUGqnFU"
# The differenced series diff_DGS10_monthly crosses the level 0.0 many times over the historical period. There does not appear to be a tendency for the differenced series to stay below (or above) the zero level. The series appears consistent with covariance-stationary time series structure but whether the structure is other than white noise can be evaluated by evaluating AR(p) models for p = 0, 1, 2, ... and determining whether an AR(p) model for p > 0 is identified as better than an AR(0), i.e., white noise.
# + [markdown] id="abALm7JDqnFU"
# ### The best AR(p) model for monthly data using the AIC criterion
# + colab={"base_uri": "https://localhost:8080/"} id="il7dVjHgqnFV" outputId="214ea037-9322-4f50-ff12-f7e68340806a"
warnings.filterwarnings("ignore")
# Define the d and q parameters to take any value between 0 and 1
p = range(0, 25)
AIC = []
AR_model = []
for param in p:
try:
model = AutoReg(diff_DGS10_monthly.values, param)
results = model.fit()
print('AR({}) - AIC:{}'.format(param, results.aic), end='\r')
AIC.append(results.aic)
AR_model.append([param])
except:
continue
# + id="NDWi90yR11tA"
# + colab={"base_uri": "https://localhost:8080/"} id="vWQgb_-YqnFV" outputId="129a9dba-a64c-44a1-9f28-3e3eb2fd7159"
print('The smallest AIC is {} for model AR({})'.format(min(AIC),
AR_model[AIC.index(min(AIC))][0]))
# + id="wN7UKU4EqnFV"
# Let's fit this model
model = AutoReg(diff_DGS10_monthly.values, 0)
results = model.fit()
# + colab={"base_uri": "https://localhost:8080/"} id="wrA6UDSdqnFW" outputId="a9a4f18f-2b55-4f2a-b3ce-5386ab952d54"
print(results.summary())
# + colab={"base_uri": "https://localhost:8080/", "height": 566} id="Lrh3ENoxqnFW" outputId="09cbfe9b-f771-47ab-c16e-c4329011070f"
results.plot_diagnostics(lags=40, figsize=(16, 9))
plt.show()
# + [markdown] id="px3JffyvqnFW"
# In the plots above, we can observe that the residuals are uncorrelated (bottom right plot) and do not exhibit any obvious seasonality (the top left plot). Also, the residuals and roughly normally distributed with zero mean (top right plot). The qq-plot on the bottom left shows that the ordered distribution of residuals (blue dots) roghly follows the linear trend of samples taken from a standard normal distribution with $N(0, 1)$. Again, this is a strong indication that the residuals are normally distributed.
# + [markdown] id="jHMGXyZvqnFW"
# We conclud that the best model for differenced data is AR(0), i.e., white noise. Thus for the original data the model is $X_t = 0.0048 + X_{t-1}+Z_t$, where $Z_t \sim WN(0,\sigma^2)$. The parameter $\sigma^2$ may be estimated by equating the sample ACVF with the model ACVF at lag 0.
# + colab={"base_uri": "https://localhost:8080/"} id="dF7teZi6qnFX" outputId="842122aa-0028-49ff-ee0b-00c6ee0f7f3f"
sm.tsa.stattools.acovf(diff_DGS10_monthly.values, nlag=0)
# + [markdown] id="CKiP_FeyqnFX"
# Using the approximate solution $\sigma^2 = 0.04$, we obtain the following model
#
# $$
# X_t = 0.0048 + X_{t-1}+Z_t, \ \ Z_t \sim WN(0,0.04).
# $$
# + [markdown] id="6pji30YHqnFX"
# ### The best AR(p) model for weekly data
# + colab={"base_uri": "https://localhost:8080/"} id="XxjsfNk9qnFY" outputId="e1183162-c276-4331-f85e-b6d2e9b0d6cc"
warnings.filterwarnings("ignore")
# Define the p parameter to take any value between 0 and 25
p = range(0, 25)
AIC = []
AR_model = []
for param in p:
try:
model = AutoReg(diff_DGS10_weekly.values, param)
results = model.fit()
print('AR({}) - AIC:{}'.format(param, results.aic), end='\r')
AIC.append(results.aic)
AR_model.append([param])
except:
continue
# + colab={"base_uri": "https://localhost:8080/"} id="MkXfpwDaqnFY" outputId="6a48153d-7dbc-4ac1-a3c8-81fcb9f92ef7"
print('The smallest AIC is {} for model AR({})'
.format(min(AIC), AR_model[AIC.index(min(AIC))][0]))
# + id="2ZJIHAsyqnFY"
# Let's fit this model
model = AutoReg(diff_DGS10_weekly.values, 2)
results = model.fit()
# + colab={"base_uri": "https://localhost:8080/"} id="MhgeD39WqnFY" outputId="915c9d7f-779e-4c54-9198-9fb0bafba18d"
print(results.summary())
# + colab={"base_uri": "https://localhost:8080/", "height": 566} id="OBfG9y1FqnFZ" outputId="a2e1a4f8-36df-45ef-c566-2540f56b1f78"
results.plot_diagnostics(lags=40, figsize=(16, 9));
# + [markdown] id="RsQAqsyTqnFZ"
# The residuals are consistent with their expected behavior under the model.
# + [markdown] id="DZsYGzywqnFZ"
# ### Evaluating the stationarity and cyclicality of the fitted AR(2) model to weekly data
# + [markdown] id="-IwJm5-OqnFa"
# To show the stationarity we have to show that all roots of characteristic polynomial lie outside the unit circle
#
# $$
# \phi(z) = 1-\phi_1 z-\phi_2 z^2 \neq 0 \ \ \text{for all} \ |z|=1.
# $$
#
# From summarize of the Auto Regression model results we have estimates $\hat\phi_1 = -0.1$ and $\hat\phi_2 = 0.04$.
# + id="BjXtd-RjqnFa"
phi_1 = -0.1
phi_2 = 0.04
# + colab={"base_uri": "https://localhost:8080/"} id="04R6jAviqnFa" outputId="5ea0b04e-31cf-4ba2-d9e1-0a8342811680"
# np.polyroots() method is used to compute the roots of a polynomial
np.polynomial.polynomial.polyroots((1, phi_1, phi_2))
# + [markdown] id="A2mL9shOqnFa"
# Both roots are complex located outside the unit circle, we conclud that the fitted model is stationary.
# + colab={"base_uri": "https://localhost:8080/"} id="6Gc9ktn_qnFa" outputId="1893af07-2b5f-4307-9cd8-f65ac4d71c9b"
# With complex roots, there is evidence of cyclicality in the series
# The following computation computes the period as it is determined by the
# coefficients of the characteristic polynomial.
twopif=np.arccos( abs(results.params[1])/(2*np.sqrt(results.params[2])))
f=twopif/(8*np.arctan(1))
period=-1/f
print(period)
# + id="M5hkUXjuqnFb"
# The data are consistent with cycle of period just over 5 weeks.
# + [markdown] id="ijfqY1cKqnFb"
# Yule–Walker estimator for $\sigma^2$:
# $$
# \hat\sigma^2 = \hat\gamma(0)-\hat\phi_1\hat\gamma(1)-\hat\phi_2\hat\gamma(2)
# $$
# + id="ZCF5xUK2qnFb"
sigma = sm.tsa.stattools.acovf(diff_DGS10_weekly.values, nlag=2)[0] - \
phi_1*sm.tsa.stattools.acovf(diff_DGS10_weekly.values, nlag=2)[1] - \
phi_2*sm.tsa.stattools.acovf(diff_DGS10_weekly.values, nlag=2)[2]
# + colab={"base_uri": "https://localhost:8080/"} id="dRKeafQLqnFb" outputId="7a6bf7e9-a49f-4de4-94b6-de8425095806"
print('sigma^2=', sigma)
# + [markdown] id="aYa9LyV6qnFc"
# Finally we conclude for differenced weekly times series
#
# $$
# Y_t =0.001 -0.1Y_{t-1}+0.04Y_{t-2} + Z_t, \ \ \ Z_t \sim WN(0,0.01)
# $$
#
# and for weekly time series
#
# $$
# (1+0.1B-0.04B^2)(1-B)X_t =0.001 + Z_{t}, \ \ \ Z_t \sim WN(0,0.01).
# $$
# + id="qwN80JlvqnFc"
| _notebooks/2022_02_09_Time_series_analysis.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: conda_python3
# language: python
# name: conda_python3
# ---
# <h2>Simple Regression Dataset - Linear Regression vs XGBoost</h2>
#
# Model is trained with XGBoost installed in notebook instance
#
# In the later examples, we will train using SageMaker's XGBoost algorithm.
#
# Training on SageMaker takes several minutes (even for simple dataset).
#
# If algorithm is supported on Python, we will try them locally on notebook instance
#
# This allows us to quickly learn an algorithm, understand tuning options and then finally train on SageMaker Cloud
#
# In this exercise, let's compare XGBoost and Linear Regression for simple regression dataset
# Install xgboost in notebook instance.
#### Command to install xgboost
# !conda install -y -c conda-forge xgboost
# +
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error, mean_absolute_error
# XGBoost
import xgboost as xgb
# Linear Regression
from sklearn.linear_model import LinearRegression
# -
# All data
df = pd.read_csv('linear_all.csv')
df.head()
plt.plot(df.x,df.y,label='Target')
plt.grid(True)
plt.xlabel('Input Feature')
plt.ylabel('Target')
plt.legend()
plt.title('Simple Regression Dataset')
plt.show()
# +
# Let's load Training and Validation Datasets
train_file = 'linear_train.csv'
validation_file = 'linear_validation.csv'
# Specify the column names as the file does not have column header
df_train = pd.read_csv(train_file,names=['y','x'])
df_validation = pd.read_csv(validation_file,names=['y','x'])
# -
df_train.head()
df_validation.head()
plt.scatter(df_train.x,df_train.y,label='Training',marker='.')
plt.scatter(df_validation.x,df_validation.y,label='Validation',marker='.')
plt.grid(True)
plt.xlabel('Input Feature')
plt.ylabel('Target')
plt.title('Simple Regression Dataset')
plt.legend()
plt.show()
# +
X_train = df_train.iloc[:,1:] # Features: 1st column onwards
y_train = df_train.iloc[:,0].ravel() # Target: 0th column
X_validation = df_validation.iloc[:,1:]
y_validation = df_validation.iloc[:,0].ravel()
# -
# Create an instance of XGBoost Regressor
# XGBoost Training Parameter Reference:
# https://github.com/dmlc/xgboost/blob/master/doc/parameter.md
regressor = xgb.XGBRegressor()
# Default Options
regressor
# Train the model
# Provide Training Dataset and Validation Dataset
# XGBoost reports training and validation error
regressor.fit(X_train,y_train, eval_set = [(X_train, y_train), (X_validation, y_validation)])
# Get the Training RMSE and Evaluation RMSE
eval_result = regressor.evals_result()
eval_result
training_rounds = range(len(eval_result['validation_0']['rmse']))
print(training_rounds)
plt.scatter(x=training_rounds,y=eval_result['validation_0']['rmse'],label='Training Error')
plt.scatter(x=training_rounds,y=eval_result['validation_1']['rmse'],label='Validation Error')
plt.grid(True)
plt.xlabel('Iterations')
plt.ylabel('RMSE')
plt.title('XGBoost Training Vs Validation Error')
plt.legend()
plt.show()
xgb.plot_importance(regressor)
plt.show()
# ## Validation Dataset Compare Actual and Predicted
result = regressor.predict(X_validation)
result[:5]
plt.title('XGBoost - Validation Dataset')
plt.scatter(df_validation.x,df_validation.y,label='actual',marker='.')
plt.scatter(df_validation.x,result,label='predicted',marker='.')
plt.grid(True)
plt.legend()
plt.show()
# RMSE Metrics
print('XGBoost Algorithm Metrics')
mse = mean_squared_error(df_validation.y,result)
print(" Mean Squared Error: {0:.2f}".format(mse))
print(" Root Mean Square Error: {0:.2f}".format(mse**.5))
# Residual
# Over prediction and Under Prediction needs to be balanced
# Training Data Residuals
residuals = df_validation.y - result
plt.hist(residuals)
plt.grid(True)
plt.xlabel('Actual - Predicted')
plt.ylabel('Count')
plt.title('XGBoost Residual')
plt.axvline(color='r')
plt.show()
# +
# Count number of values greater than zero and less than zero
value_counts = (residuals > 0).value_counts(sort=False)
print(' Under Estimation: {0}'.format(value_counts[True]))
print(' Over Estimation: {0}'.format(value_counts[False]))
# -
# Plot for entire dataset
plt.plot(df.x,df.y,label='Target')
plt.plot(df.x,regressor.predict(df[['x']]) ,label='Predicted')
plt.grid(True)
plt.xlabel('Input Feature')
plt.ylabel('Target')
plt.legend()
plt.title('XGBoost')
plt.show()
# ## Linear Regression Algorithm
lin_regressor = LinearRegression()
lin_regressor.fit(X_train,y_train)
# Compare Weights assigned by Linear Regression.
#
# Original Function: 5*x + 8 + some noise
#
lin_regressor.coef_
lin_regressor.intercept_
result = lin_regressor.predict(df_validation[['x']])
plt.title('LinearRegression - Validation Dataset')
plt.scatter(df_validation.x,df_validation.y,label='actual',marker='.')
plt.scatter(df_validation.x,result,label='predicted',marker='.')
plt.grid(True)
plt.legend()
plt.show()
# RMSE Metrics
print('Linear Regression Metrics')
mse = mean_squared_error(df_validation.y,result)
print(" Mean Squared Error: {0:.2f}".format(mse))
print(" Root Mean Square Error: {0:.2f}".format(mse**.5))
# Residual
# Over prediction and Under Prediction needs to be balanced
# Training Data Residuals
residuals = df_validation.y - result
plt.hist(residuals)
plt.grid(True)
plt.xlabel('Actual - Predicted')
plt.ylabel('Count')
plt.title('Linear Regression Residual')
plt.axvline(color='r')
plt.show()
# +
# Count number of values greater than zero and less than zero
value_counts = (residuals > 0).value_counts(sort=False)
print(' Under Estimation: {0}'.format(value_counts[True]))
print(' Over Estimation: {0}'.format(value_counts[False]))
# -
# Plot for entire dataset
plt.plot(df.x,df.y,label='Target')
plt.plot(df.x,lin_regressor.predict(df[['x']]) ,label='Predicted')
plt.grid(True)
plt.xlabel('Input Feature')
plt.ylabel('Target')
plt.legend()
plt.title('LinearRegression')
plt.show()
# <h2>Input Features - Outside range used for training</h2>
#
# XGBoost Prediction has an upper and lower bound (applies to tree based algorithms)
#
# Linear Regression extrapolates
# True Function
def straight_line(x):
return 5*x + 8
# +
# X is outside range of training samples
X = np.array([-100,-5,160,1000,5000])
y = straight_line(X)
df_tmp = pd.DataFrame({'x':X,'y':y})
df_tmp['xgboost']=regressor.predict(df_tmp[['x']])
df_tmp['linear']=lin_regressor.predict(df_tmp[['x']])
# -
df_tmp
# XGBoost Predictions have an upper bound and lower bound
# Linear Regression Extrapolates
plt.scatter(df_tmp.x,df_tmp.y,label='Actual',color='r')
plt.plot(df_tmp.x,df_tmp.linear,label='LinearRegression')
plt.plot(df_tmp.x,df_tmp.xgboost,label='XGBoost')
plt.legend()
plt.xlabel('X')
plt.ylabel('y')
plt.title('Input Outside Range')
plt.show()
# +
# X is inside range of training samples
X = np.array([0,1,3,5,7,9,11,15,18,125])
y = straight_line(X)
df_tmp = pd.DataFrame({'x':X,'y':y})
df_tmp['xgboost']=regressor.predict(df_tmp[['x']])
df_tmp['linear']=lin_regressor.predict(df_tmp[['x']])
# -
df_tmp
# XGBoost Predictions have an upper bound and lower bound
# Linear Regression Extrapolates
plt.scatter(df_tmp.x,df_tmp.y,label='Actual',color='r')
plt.plot(df_tmp.x,df_tmp.linear,label='LinearRegression')
plt.plot(df_tmp.x,df_tmp.xgboost,label='XGBoost')
plt.legend()
plt.xlabel('X')
plt.ylabel('y')
plt.title('Input within range')
plt.show()
# <h2>Summary</h2>
# 1. Use sagemaker notebook as your own server on the cloud
# 2. Install python packages
# 3. Train directly on SageMaker Notebook (for small datasets, it takes few seconds).
# 4. Once happy with algorithm and performance, you can train on sagemaker cloud (takes several minutes even for small datasets)
# 5. Not all algorithms are available for installation (for example: AWS algorithms like DeepAR are available only in SageMaker)
# 6. In this exercise, we installed XGBoost and compared performance of XGBoost model and Linear Regression
| xgboost/LinearAndQuadraticFunctionRegression/linear_xgboost_localmode.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # PMOD Grove OLED
# ----
# ## Aim/s
# * Write a Python Driver for the Grove OLED.
#
# ## References
# * [PYNQ Docs](https://pynq.readthedocs.io/en/latest/index.html)
# * [Grove OLED Display](https://www.seeedstudio.com/Grove-OLED-Display-0-96.html)
# * [Adafruit Python](https://github.com/adafruit/Adafruit_Python_GPIO/blob/master/Adafruit_GPIO/I2C.py)
# * [Arduino C++ OLED](https://github.com/Seeed-Studio/OLED_Display_128X64/archive/master.zip)
# * [Xilinx IIC Driver](https://github.com/analogdevicesinc/no-OS/blob/0629c39fac9aad8e236b648b28acccc3abb178dc/fmcomms1/Common/i2c_axi.c)
# * [Xilinx IIC Driver docs](http://www.xilinx.com/support/documentation/ip_documentation/axi_iic_ds756.pdf)
#
# ## Last revised
#
# * Feb 18, 2021, initial revision
#
# ----
# This notebook demonstrates writing two different grove OLED device drivers:
# 1. driver written completely in Python
# 2. driver using a Microblaze processor
#
# We will show how they perform in this notebook.
#
# # Preparation
# We need to load the overlay.
from pynq.overlays.base import BaseOverlay
base = BaseOverlay("base.bit")
# ----
# ## Python Grove OLED class
#
# This class is a demonstration of extending the PMODIIC class for fast development.
#
# For better performance, users should use the Microblaze C-based drivers (e.g. `grove_oled.bin`).
# +
from pynq.lib.pmod import PMOD_GROVE_G3
from pynq.lib.pmod import PMOD_GROVE_G4
from pynq.lib import Pmod_IIC
basic_font = \
[[0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00],
[0x00,0x00,0x5F,0x00,0x00,0x00,0x00,0x00],
[0x00,0x00,0x07,0x00,0x07,0x00,0x00,0x00],
[0x00,0x14,0x7F,0x14,0x7F,0x14,0x00,0x00],
[0x00,0x24,0x2A,0x7F,0x2A,0x12,0x00,0x00],
[0x00,0x23,0x13,0x08,0x64,0x62,0x00,0x00],
[0x00,0x36,0x49,0x55,0x22,0x50,0x00,0x00],
[0x00,0x00,0x05,0x03,0x00,0x00,0x00,0x00],
[0x00,0x1C,0x22,0x41,0x00,0x00,0x00,0x00],
[0x00,0x41,0x22,0x1C,0x00,0x00,0x00,0x00],
[0x00,0x08,0x2A,0x1C,0x2A,0x08,0x00,0x00],
[0x00,0x08,0x08,0x3E,0x08,0x08,0x00,0x00],
[0x00,0xA0,0x60,0x00,0x00,0x00,0x00,0x00],
[0x00,0x08,0x08,0x08,0x08,0x08,0x00,0x00],
[0x00,0x60,0x60,0x00,0x00,0x00,0x00,0x00],
[0x00,0x20,0x10,0x08,0x04,0x02,0x00,0x00],
[0x00,0x3E,0x51,0x49,0x45,0x3E,0x00,0x00],
[0x00,0x00,0x42,0x7F,0x40,0x00,0x00,0x00],
[0x00,0x62,0x51,0x49,0x49,0x46,0x00,0x00],
[0x00,0x22,0x41,0x49,0x49,0x36,0x00,0x00],
[0x00,0x18,0x14,0x12,0x7F,0x10,0x00,0x00],
[0x00,0x27,0x45,0x45,0x45,0x39,0x00,0x00],
[0x00,0x3C,0x4A,0x49,0x49,0x30,0x00,0x00],
[0x00,0x01,0x71,0x09,0x05,0x03,0x00,0x00],
[0x00,0x36,0x49,0x49,0x49,0x36,0x00,0x00],
[0x00,0x06,0x49,0x49,0x29,0x1E,0x00,0x00],
[0x00,0x00,0x36,0x36,0x00,0x00,0x00,0x00],
[0x00,0x00,0xAC,0x6C,0x00,0x00,0x00,0x00],
[0x00,0x08,0x14,0x22,0x41,0x00,0x00,0x00],
[0x00,0x14,0x14,0x14,0x14,0x14,0x00,0x00],
[0x00,0x41,0x22,0x14,0x08,0x00,0x00,0x00],
[0x00,0x02,0x01,0x51,0x09,0x06,0x00,0x00],
[0x00,0x32,0x49,0x79,0x41,0x3E,0x00,0x00],
[0x00,0x7E,0x09,0x09,0x09,0x7E,0x00,0x00],
[0x00,0x7F,0x49,0x49,0x49,0x36,0x00,0x00],
[0x00,0x3E,0x41,0x41,0x41,0x22,0x00,0x00],
[0x00,0x7F,0x41,0x41,0x22,0x1C,0x00,0x00],
[0x00,0x7F,0x49,0x49,0x49,0x41,0x00,0x00],
[0x00,0x7F,0x09,0x09,0x09,0x01,0x00,0x00],
[0x00,0x3E,0x41,0x41,0x51,0x72,0x00,0x00],
[0x00,0x7F,0x08,0x08,0x08,0x7F,0x00,0x00],
[0x00,0x41,0x7F,0x41,0x00,0x00,0x00,0x00],
[0x00,0x20,0x40,0x41,0x3F,0x01,0x00,0x00],
[0x00,0x7F,0x08,0x14,0x22,0x41,0x00,0x00],
[0x00,0x7F,0x40,0x40,0x40,0x40,0x00,0x00],
[0x00,0x7F,0x02,0x0C,0x02,0x7F,0x00,0x00],
[0x00,0x7F,0x04,0x08,0x10,0x7F,0x00,0x00],
[0x00,0x3E,0x41,0x41,0x41,0x3E,0x00,0x00],
[0x00,0x7F,0x09,0x09,0x09,0x06,0x00,0x00],
[0x00,0x3E,0x41,0x51,0x21,0x5E,0x00,0x00],
[0x00,0x7F,0x09,0x19,0x29,0x46,0x00,0x00],
[0x00,0x26,0x49,0x49,0x49,0x32,0x00,0x00],
[0x00,0x01,0x01,0x7F,0x01,0x01,0x00,0x00],
[0x00,0x3F,0x40,0x40,0x40,0x3F,0x00,0x00],
[0x00,0x1F,0x20,0x40,0x20,0x1F,0x00,0x00],
[0x00,0x3F,0x40,0x38,0x40,0x3F,0x00,0x00],
[0x00,0x63,0x14,0x08,0x14,0x63,0x00,0x00],
[0x00,0x03,0x04,0x78,0x04,0x03,0x00,0x00],
[0x00,0x61,0x51,0x49,0x45,0x43,0x00,0x00],
[0x00,0x7F,0x41,0x41,0x00,0x00,0x00,0x00],
[0x00,0x02,0x04,0x08,0x10,0x20,0x00,0x00],
[0x00,0x41,0x41,0x7F,0x00,0x00,0x00,0x00],
[0x00,0x04,0x02,0x01,0x02,0x04,0x00,0x00],
[0x00,0x80,0x80,0x80,0x80,0x80,0x00,0x00],
[0x00,0x01,0x02,0x04,0x00,0x00,0x00,0x00],
[0x00,0x20,0x54,0x54,0x54,0x78,0x00,0x00],
[0x00,0x7F,0x48,0x44,0x44,0x38,0x00,0x00],
[0x00,0x38,0x44,0x44,0x28,0x00,0x00,0x00],
[0x00,0x38,0x44,0x44,0x48,0x7F,0x00,0x00],
[0x00,0x38,0x54,0x54,0x54,0x18,0x00,0x00],
[0x00,0x08,0x7E,0x09,0x02,0x00,0x00,0x00],
[0x00,0x18,0xA4,0xA4,0xA4,0x7C,0x00,0x00],
[0x00,0x7F,0x08,0x04,0x04,0x78,0x00,0x00],
[0x00,0x00,0x7D,0x00,0x00,0x00,0x00,0x00],
[0x00,0x80,0x84,0x7D,0x00,0x00,0x00,0x00],
[0x00,0x7F,0x10,0x28,0x44,0x00,0x00,0x00],
[0x00,0x41,0x7F,0x40,0x00,0x00,0x00,0x00],
[0x00,0x7C,0x04,0x18,0x04,0x78,0x00,0x00],
[0x00,0x7C,0x08,0x04,0x7C,0x00,0x00,0x00],
[0x00,0x38,0x44,0x44,0x38,0x00,0x00,0x00],
[0x00,0xFC,0x24,0x24,0x18,0x00,0x00,0x00],
[0x00,0x18,0x24,0x24,0xFC,0x00,0x00,0x00],
[0x00,0x00,0x7C,0x08,0x04,0x00,0x00,0x00],
[0x00,0x48,0x54,0x54,0x24,0x00,0x00,0x00],
[0x00,0x04,0x7F,0x44,0x00,0x00,0x00,0x00],
[0x00,0x3C,0x40,0x40,0x7C,0x00,0x00,0x00],
[0x00,0x1C,0x20,0x40,0x20,0x1C,0x00,0x00],
[0x00,0x3C,0x40,0x30,0x40,0x3C,0x00,0x00],
[0x00,0x44,0x28,0x10,0x28,0x44,0x00,0x00],
[0x00,0x1C,0xA0,0xA0,0x7C,0x00,0x00,0x00],
[0x00,0x44,0x64,0x54,0x4C,0x44,0x00,0x00],
[0x00,0x08,0x36,0x41,0x00,0x00,0x00,0x00],
[0x00,0x00,0x7F,0x00,0x00,0x00,0x00,0x00],
[0x00,0x41,0x36,0x08,0x00,0x00,0x00,0x00],
[0x00,0x02,0x01,0x01,0x02,0x01,0x00,0x00],
[0x00,0x02,0x05,0x05,0x02,0x00,0x00,0x00]]
class Python_Grove_OLED(Pmod_IIC):
"""This class controls the Grove OLED.
This class inherits from the PMODIIC class.
Attributes
----------
iop : _IOP
The _IOP object returned from the DevMode.
scl_pin : int
The SCL pin number.
sda_pin : int
The SDA pin number.
iic_addr : int
The IIC device address.
"""
def __init__(self, pmod_id, gr_pins):
"""Return a new instance of a grove OLED object.
Note
----
Parameters
----------
pmod_id : int
The PMOD ID (1, 2) corresponding to (PMODA, PMODB).
gr_pins: list
Adapter pins selected.
"""
if gr_pins in [PMOD_GROVE_G3,PMOD_GROVE_G4]:
[scl_pin,sda_pin] = gr_pins
else:
raise ValueError("Valid Grove Pins are on G3 or G4.")
super().__init__(pmod_id, scl_pin, sda_pin, 0x3C)
# Unlock OLED driver IC MCU interface
self._send_cmd(0xFD)
self._send_cmd(0x12)
# Set display off
self._send_cmd(0xAE)
# Switch on display
self._send_cmd(0xAF)
self._send_cmd(0xA4)
def _send_cmd(self, word):
"""Send a command to the IIC driver.
This method relies on the send() in the parent class.
Parameters
----------
word : int
A 32-bit command word to be written to the driver.
Returns
-------
None
"""
self.send([0x80,word])
def _send_data(self, word):
"""Send a command to the IIC driver.
This method relies on the send() in the parent class.
Parameters
----------
word : int
A 32-bit data word to be written to the driver.
Returns
-------
None
"""
self.send([0x40,word])
def set_normal_mode(self):
"""Set the display mode to 'normal'.
Parameters
----------
None
Returns
-------
None
"""
self._send_cmd(0xA4)
def set_inverse_mode(self):
"""Set the display mode to 'inverse'.
This mode has white background and black characters.
Parameters
----------
None
Returns
-------
None
"""
self._send_cmd(0xA7)
def _put_char(self, chr):
"""Print a single character on the OLED screen.
Note
----
This method is only for internal use of this class. To print strings
or characters, users should use the write() method.
Parameters
----------
chr : str
A string of length 1 to be put onto the screen.
Returns
-------
None
"""
global basic_font
c_add=ord(chr)
if c_add<32 or c_add>127:
# Ignore non-printable ASCII characters
chr = ' '
c_add=ord(chr)
for j in range(8):
self._send_data(basic_font[c_add-32][j])
def set_XY(self, row, column):
"""Set the location where to start printing.
Parameters
----------
row : int
The row number indicating where to start.
column : int
The column number indicating where to start.
Returns
-------
None
"""
self._send_cmd(0xB0 + row)
self._send_cmd(0x00 + (8*column & 0x0F))
self._send_cmd(0x10 + ((8*column>>4)&0x0F))
def write(self, text):
"""Write the strings to the OLED screen.
This is the method to be used when writing strings.
Parameters
----------
text : str
A string to be put onto the screen.
Returns
-------
None
"""
for i in range(len(text)):
self._put_char(text[i])
def clear(self):
"""Clear the OLED screen.
Parameters
----------
None
Returns
-------
None
"""
for i in range(8):
self.set_XY(i,0)
for j in range(16):
self._put_char(' ')
self.set_XY(0,0)
# -
# ----
# ## Test of the PMOD Grove OLED - using above Python Class
#
# You may notice the screen is updated line by line slowly.
# +
from pynq import PL
from pynq.lib.pmod import PMOD_GROVE_G3
PL.reset()
oled = Python_Grove_OLED(base.PMODB,PMOD_GROVE_G3)
oled.clear()
oled.write('Hi from Python.')
# -
# ----
# ## Test of the PMOD Grove OLED - using existing Microblaze Driver
#
# Notice how much faster the text is driven to the OLED screen.
# +
from pynq.lib.pmod import Grove_OLED
from pynq.lib.pmod import PMOD_GROVE_G3
PL.reset()
oled = Grove_OLED(base.PMODB,PMOD_GROVE_G3)
oled.clear()
oled.write('Hello from Microblaze.')
# -
# ----
# Copyright (C) 2021 Xilinx, Inc
#
# SPDX-License-Identifier: BSD-3-Clause
# ----
#
# ----
| board/RFSoC2x2/base/notebooks/pmod/pmod_grove_oled.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Text als Sprache
# Als *Natural Language Processing* bezeichnet man die computergestützte Verarbeitung von natürlichen Sprachen, also von von Menschen gesprochenen Sprachen im Gegensatz zu Programmiersprachen. Computer sind gut darin, Programmiersprachen mit ihren starren Regeln zu verstehen, aber menschliche Sprachen mit ihren Unregelmäßigkeiten stellen immer noch eine Herausforderung dar. Die Wissenschaft, die sich mit diesen Problemen beschäftigt, ist die Computerlinguistik.
#
# Methoden der Computerlinguistik sind mittlerweile für eine Vielzahl von Anwendungsbereichen zentral. So sind etwa Suchmaschinen darauf trainiert, nicht nur den exakten Text einer Suchanfrage zu finden, sondern auch andere Flexionsformen. Eine Google-Suche nach „Parties in Hamburg“ findet so z.B. auch die Seite [Nachtleben & Party – hamburg.de](http://www.hamburg.de/nachtleben-party/). Dazu muss die Suchmaschine wissen, dass »Party« der Singular von »Parties« ist, und dass »in« als Präposition für den gesuchten Inhalt nicht zwingend relevant ist.
#
# Für die Analyse von Texten sind insbesondere zwei Verfahren interessant: *Generalisierung* und *Selektion*.
#
# **Generalisierung**
#
# Mit Generalisierung ist die Abbildung von verschiedenen Varianten auf eine gemeinsame, abstraktere Form gemeint. Im obigen Beispiel als die Abbildung der beiden unterschiedlichen Wortformen »Party« und »Parties« auf eine gemeinsame Grundform »Party«. Ziel der Generalisierung in der Textverarbeitung ist es, semantisch gleiche (oder zumindest sehr ähnliche) Einheiten auch dann zu identifizieren, wenn sie in unterschiedlichen Formen auftauchen.
#
# Dies kann nicht nur Wortformen betreffen, sondern z.B. auch die Bezeichnungen von Personen. In einem Text kann etwa wechselnd von »<NAME>«, »<NAME>«, »<NAME>« oder auch nur »die Bundeskanzlerin« die Rede sein.
#
# **Selektion**
#
# Mit Selektion ist gemeint, für die Analyse relevante Informationen aus der Gesamtmenge an Informationen zu extrahieren. Im obigen Beispiel wäre dies, »in« für die Suche zu ignorieren. Je nach Analsestrategie kann es sehr unterschiedlich sein, welche Informationen relevant sind und welche nicht.
# Der Ausgangspunkt für NLP ist dabei fast immer der reine Text, ohne Formatierung oder ähnliches. Als Beispiel soll der Anfang einer Rede der deutschen Bundeskanzlerin <NAME> dienen.
# +
import os
filepath = os.path.join('..', 'Daten', 'Rede_Jugend_forscht.txt')
with open(filepath) as infile:
rede = infile.read()
print(rede[0:200])
# -
# Wenn wir mit Texten arbeiten, sind wir meist aber nicht am Text als Ganzem interessiert, sondern an den Wörtern, aus denen er besteht. Wörter sind in den europäischen Sprachen meist durch Leerzeichen getrennt. So sehen die ersten Wörter nach der Anrede aus aus, wenn man den Text entsprechend aufspaltet:
# +
sample = rede[148:254]
print(' -- '.join(sample.split()))
# -
# Hier sieht man schon einige Probleme. Insbesondere werden hier die Satzzeichen noch beibehalten. Die verfälschen aber das Ergebnis, denn das Wort heißt ja nicht „willkommen**.**“, sondern einfach „willkommen“. Schon bei so einfachen Aufgaben wie dem Aufspalten kann es also nützlich sein, etwas ausgefeiltere Werkzeuge heranzuziehen. Einen einfachen Einstieg bietet dabei das Modul `TextBlob`, für das es auch eine auf die deutsche Sprache ausgelegte Version gibt:
from textblob_de import TextBlobDE as TextBlob
blob = TextBlob(sample)
print(' -- '.join(blob.words))
# Hier wird der Text mit einem geeigneteren Algorithmus, der auch Satzzeichen berücksichtigt, in Wörter aufgespalten.
#
# `TextBlob` stellt noch eine Reihe weiterer Methoden aus der Sprachverarbeitung bereit. So kann man etwa Worte auf ihre Grundformen zurückführen. Gerade bei stark flektierenden Sprachen wie dem Deutschen ist das oft nützlich. Diesen Schritt nennt man in der Computerlinguistik Lemmatisierung.
# +
base_forms = blob.words.lemmatize()
print(' -- '.join(base_forms))
# -
# Man kann sehen, dass der Schritt vergleichsweise fehleranfällig ist. Relevant für die Analyse, wie häufig ein bestimmtes Wort (und nicht eine bestimmte, flektierte Wortform) auftaucht, ist aber, dass eine gemeinsame Form gefunden wird, etwa »all« für »alle, alles, allen …« oder »sein« für »ist, sind, waren, …«.
#
# Insgesamt ist der Lemmatisierungsalgorithmus von `TextBlob` im vergleich zu anderen Werkzeugen eher schwach. Zur Demonstration und aufgrund der einfachen Handhabbarkeit reicht er hier aus. In Anwendungsfällen, in denen eine hohe Qualität der Verarbeitung wichtig ist, muss man aber ggf. nach besseren Werkzeugen suchen.
#
# Für weitere Analysen kann man auch die Grammatik eines Texts analysieren. Ein grundlegender Schritt ist dabei die Bestimming der Wortart (Substantiv, Verb, etc.), englisch »Part of Speech«. Hierfür werden in der Linguistik meist bestimmte Kürzel verwendet, die von `TextBlob` sind auf [dieser Seite](http://www.clips.ua.ac.be/pages/mbsp-tags) aufgelistet.
print(' -- '.join(['{}/{}'.format(word, tag) for word, tag in blob.pos_tags]))
# Dies kann etwa dazu verwendet werden, für bestimmte Anwendungen nur bestimmte Wortarten zu berücksichtigen. Falls etwa nur die Substantive interessieren, lassen sie sich aufgrund der PoS-Information herausfiltern.
#
# Um Informationen wie Lemma und Wortart nicht einzeln erzeugen zu müssen, kann man diese mit der `parse()`-Funktion auch in einem Durchlauf erzeugen. Da der Standard-Parser keine Lemmata erzeugt, müssen diese zunächst explizit aktiviert werden.
from textblob_de import PatternParser
lemma_parser = PatternParser(lemmata=True)
blob = TextBlob(sample, parser=lemma_parser)
parse = blob.parse()
parse
# Diese Form ist auf Anhieb nicht sehr gut lesbar. Es gibt auch eine tabellarische Darstellung, die mit dem Parameter `pprint` aktiviert werden kann:
blob2 = TextBlob(sample, parser=PatternParser(lemmata=True, pprint=True))
blob2.parse()
# Für die Weiterverarbeitung ist es hilfreich, für jedes Wort auf Informationen wie Wortart, Lemma etc. zugreifen zu können. Dafür kann die erste Form relativ leicht zerlegt werden. Dort werden alle Informationen zu einem Wort durch Schrägstriche getrennt angegeben. Dies ist eine übliche Konvention in der Linguistik. Die Bedeutung der einzelnen Elemente kann man sich anzeigen lassen:
parse.tags
# Um die Informationen für jedes Wort (*token*) leicht zugänglich zu machen, kann man in Python die Klasse `namedtuple()` nutzen, mit der man einzelne Felder in einer Liste (nichts anderes ist ein sogenanntes „tuple“ im Grunde) benennen kann. Die Idee ist hierbei, statt `token[4]` für das fünfte Tag zu einem Wort einfach `token.lemma` schreiben zu können.
#
# Da die Namen von Eigenschaften in Python kein '-' enthalten dürfen, wird es zunächst durch einen Unterstrich ersetzt. Auf der Grundlage können wir eine neue Datenstruktur (Klasse) erzeugen, die einen einfachen Zugriff auf die einzelnen Informationen erlaubt.
# +
from collections import namedtuple
fieldnames = ['word', 'part_of_speech', 'chunk', 'preposition', 'lemma']
Token = namedtuple('Token', fieldnames)
# Beispiel: „vor“
Token('vor', 'IN', 'B-PP', 'B-PNP', 'vor')
# -
# Ein kleiner Python-Exkurs: Der Klasse `Token` müssen die Informationen als einzelne Argumente übergeben werden. Das ist dann ein Problem, wenn die Informationen als Liste in einer einzelnen Variable vorliegen.
fields = ['vor', 'IN', 'B-PP', 'B-PNP', 'vor']
Token(fields)
# Die Klasse hätte fünf Argumente erwartet, hat aber nur eines, nämlich die Liste mit fünf Elementen, erhalten. (Ein Argument wird immer intern verwendet, daher spricht die Fehlermeldung von 6 und 2 statt von 5 und 1.) Mit `*` lassen sich aber Listen statt einzelner Argumente übergeben.
Token(*fields)
# Dies kann man sich nun zunutze machen, um aus dem »Parse« des Textes eine besser zu verarbeitende Datenstruktur zu gewinnen. Da einzelne Worte durch Leerzeichen und die einzelnen Informationen pro Wort durch Schrägstriche getrennt sind, muss der Parse nur zweimal aufgespalten werden. Die dadurch gewonnenen Einzelinformationen pro Wort werden in der Token-Klasse gespeichert.
tokens = parse.split(' ')
tokens[0:5]
# Im zweiten Schritt werden die Einzelinformationen der Tokens erneut aufgespalten.
#
# Damit immer genau die 5 Informationsfelder aufgespalten werden, aber nicht versehentlich mehr, wird der Parameter `maxsplit` übergeben. Dies ist nur in Randfällen, wie z.B. »2012/13« relevant.
tokens = [Token(*token.split('/', maxsplit=4)) for token in tokens]
tokens[0:5]
# Relevant wird diese Informationen nun, wenn man sie für die weitere Verarbeitung nutzt. Aufgrund dieser Information kann man die oben angesprochenen Verfahren *Generalisierung* und *Selektion* umsetzen: Als Generalisierung dient hier die Lemmatisierung, die Selektion erfolgt auf Basis der Wortarten.
#
# Eine Funktion kann so einen Text nehmen, in Wörter zerlegen, diese auf ihre Grundform zurückführen, und dann nach Wortart filtern.
def lemmatize_and_filter(text, tags):
"""
Tokenisierung, lemmatisiert und filtert einen Text.
Der erste Parameter `text` ist dabei ein unverarbeiteter *string*.
Der zweite Paramter `tags` ist eine Liste von Part-of-Speech-Tags, die in der Ausgabe
berücksichtigt werden sollen. Beispiel: ['NN', 'VB', 'JJ']
"""
# Tokenisierung
blob = TextBlob(text, parser=lemma_parser)
parse = blob.parse()
tokens = [Token(*token.split('/', maxsplit=4)) for token in parse.split(' ')]
# Generalisierung und Selektion
result = []
for token in tokens:
pos = token.part_of_speech[0:2]
# Filtern
if pos in tags:
if pos == 'NN':
# Substantive immer groß schreiben
result.append(token.lemma.title())
else:
restult.append(token.lemma)
return result
print(' -- '.join(lemmatize_and_filter(rede, ['NN'])[0:20]))
# Das Verfahren funktioniert in weiten Teilen, aber alle Methoden der Computerlinguistik sind mit einer gewissen Fehlerrate behaftet. Gute Verfahren haben dabei eine Genauigkeit von über 90% – was in der Gesamtschau immer noch eine Menge Fehler sind. In diesem Fall sieht man, dass der Wortfinde-Algorithmus nicht mit Gedankenstrichen umgehen kann. Hier würde eine entsprechende Vorbereitung des Textes helfen.
#
# Ein anderer Ansatz kann sein, nicht über die Wortarten, sondern über eine vorgegebene Liste an Wörtern zu filtern. Je nach Anwendungszweck kann eine solche Stoppwortliste länger oder kürzer sein. Ihr Ziel ist es, nicht bedeutungstragende Wörter herauszufiltern. Dies können neben Partikeln auch Hilfsverben und unspezifische Adjektive und Adverben (z.B. „sehr“) sein.
# +
path = os.path.join('..', 'Daten', 'stopwords.txt')
with open(path) as stopwordfile:
stopwords_de = stopwordfile.read().splitlines()
from string import punctuation # !"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~
punctuation += '»«›‹„“”‚‘’–' # additional quotation marks
def lemmatize_and_filter2(text, stopwords):
blob = TextBlob(text, parser=lemma_parser)
parse = blob.parse()
tokens = [Token(*token.split('/', maxsplit=4)) for token in parse.split(' ')]
result = []
for token in tokens:
pos = token.part_of_speech[0:2]
word = token.word
if not word.lower() in stopwords and not word.isdigit() and not word in punctuation:
if pos == 'NN':
result.append(token.lemma.title())
else:
result.append(token.lemma)
return result
print(' -- '.join(lemmatize_and_filter2(rede, stopwords_de)[0:20]))
| 03_Sprache/Text als Sprache.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import numpy as np
import matplotlib.pyplot as plt
# %matplotlib inline
from scipy.optimize import curve_fit
from scipy.interpolate import interp1d
import os
from glob import glob
from dl import queryClient as qc
from astropy.table import Table
import utils
from collections import Counter
import pdb
pltdir = 'results/plots'
if not os.path.exists(pltdir):
os.makedirs(pltdir)
os.getcwd()
gldrrl = np.loadtxt(r'samples/golden_RRab.txt',delimiter=',',dtype=str)
gldall = np.loadtxt(r'samples/all_gold_sample.txt',dtype=str)
gldelse = np.array(list(set(gldall) - set(gldrrl)))
varlist = Table.read(r'samples/nsc_dr2_variables.fits.gz')['id']
import tmpfit
tmps = Table.read('templates/layden_templates.fits',format='fits')['PH','RRA1','RRA2','RRA3','RRB1','RRB2','RRB3','RRC']
tmpfitter = tmpfit.tmpfitter(tmps,['u','g','r','i','z','Y','VR'])
# +
nm = gldrrl[590]
nm = gldrrl[0]
crvdat = tmpfit.get_data(nm)
pix = int(int(nm.split('_')[0])/1000)
ptbl = Table.read('../Psearch_res/periods/{}/{}.fits'.format(pix,nm))
pars,p,err,tmpind,minx2 = tmpfitter.tmpfit(crvdat['mjd'],crvdat['mag'],crvdat['err'],crvdat['fltr'],ptbl['periods'])
# -
minx2
crvdat['ph'] = (crvdat['mjd'] - pars[0])/p % 1
plt.scatter(crvdat['ph'],crvdat['mag'],c=crvdat['fltr'])
for i in set(crvdat['fltr']):
plt.plot(tmps['PH'],tmps['RRB3']*pars[1+i]+pars[8+i])
pars[1:-7]/pars[3]
len(gldrrl)
print('514 templates fit in 7h36m00s')
print('{:0.2f} sec/obj'.format((7*3600+36*60)/514))
usel = tblres['N u'] > 10
gsel = tblres['N g'] > 10
rsel = tblres['N r'] > 10
isel = tblres['N i'] > 10
zsel = tblres['N z'] > 10
Ysel = tblres['N Y'] > 10
VRsel = tblres['N VR'] > 10
print('u: ',sum(usel),'\ng:',sum(gsel),'\nr:',sum(rsel),'\ni:',
sum(isel),'\nz:',sum(zsel),'\nY:',sum(Ysel),'\nVR:',sum(VRsel))
plt.hist(tblres[usel*rsel]['u amp'])
def
i=55
nm = gldrrab[i]
nm = '136330_168078'
pix = int(int(nm.split('_')[0])/1000)
crvdat = RRLfit.get_data(nm)
display(Counter(crvdat['filter']))
ptbl = Table.read(r'D:\msu\RRLProject\Psearch_res\pdata\{}\{}.fits'.format(pix,nm))
# +
# plist, psi, inds = RRLfit.get_periods(crvdat['mjd'],crvdat['mag'],crvdat['err'],
# crvdat['fltr'],objname=nm,verbose=True)
# plt.plot(plist,psi)
# plt.scatter(plist[inds],psi[inds],c='r')
# plt.xscale('log')
# -
rrlfitter.ampratio = np.array([1.8148,1.4660,1.0,0.7833,0.7467,0.7187,1.0507])
RRLfit.fit_plot(rrlfitter,nm,plist=ptbl['periods'][:5],verbose=True)
# - - -
def
[u'#1f77b4', u'#ff7f0e', u'#2ca02c', u'#d62728', u'#9467bd', u'#8c564b', u'#e377c2', u'#7f7f7f', u'#bcbd22', u'#17becf']
# +
import selftemplate
starid = '93142_19513'
cat = selftemplate.get_data(starid)
period = 0.60527109
bands,pars2,template,chisq = selftemplate.selftemplate(cat,period,verbose=True)
nbands = len(bands)
t0 = pars2[1]
amp = pars2[2:2+nbands]
mnmag = pars2[-nbands:]
ph = (cat['mjd'] - pars2[1]) / period %1
sclmag = np.zeros(len(cat),float)
for i,b in enumerate(bands):
ind, = np.where(cat['fltr']==b)
sclmag[ind] = (cat['mag'][ind]-mnmag[i])/amp[i]
# -
normags = selftemplate.scaledmags(cat,template,pars2)
plt.scatter(ph,sclmag,c=cat['fltr'],s=10)
plt.plot(template['phase'],template['flux'],c='r')
# ----
plt.plot(template['phase'],template['flux'],c='green')
plt.plot(tmps['PH'],tmps['RRB1'],c='orange')
| .ipynb_checkpoints/Tmp Fitter-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + _uuid="8f2839f25d086af736a60e9eeb907d3b93b6e0e5" _cell_guid="b1076dfc-b9ad-4769-8c92-a6c4dae69d19"
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# + _uuid="d629ff2d2480ee46fbb7e2d37f6b5fab8052498a" _cell_guid="79c7e3d0-c299-4dcb-8224-4455121ee9b0"
# Major Libraries
import scipy
import bottleneck
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Data Mining / Data Preprocessing
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.feature_selection import VarianceThreshold
from sklearn.model_selection import train_test_split, cross_val_score, cross_val_predict
from sklearn.metrics import accuracy_score
# Supervised Learning
import xgboost as XGB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier,BaggingClassifier,GradientBoostingClassifier,AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
import yellowbrick as yb
from yellowbrick.classifier import ClassificationReport
from matplotlib import rcParams
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
# %matplotlib inline
# -
cardio = pd.read_csv('../input/cardiovascular-disease-dataset/cardio_train.csv',sep = ';')
type(cardio)
cardio.sample(5)
cardio.info()
cardio.describe()
cardio.shape
cardio.columns
cardio.dtypes
cardio.drop('id',axis=1, inplace=True)
# +
# cardio['age'] = cardio['age'].map(lambda x : x // 365)
# -
cardio.isnull().sum()
cardio.shape
cardio.head()
print(cardio['cardio'].value_counts())
# Exploratory Analysis
cardio.cardio.value_counts()
sns.countplot(x = 'cardio', data = cardio, palette = 'hls')
plt.show()
cardio.corr()
corr_matrix = cardio.corr()
corr_matrix["cardio"].sort_values(ascending=False)
# Multivariate Analysis
# Correation Matrix:
def plot_corr(df, size=12):
corr = cardio.corr()
fig, ax = plt.subplots(figsize=(size, size))
ax.matshow(corr)
plt.xticks(range(len(corr.columns)), corr.columns)
plt.yticks(range(len(corr.columns)), corr.columns)
plot_corr(cardio)
# Drawing the Heatmap
sns.heatmap(cardio.corr(),annot=True,cmap='RdYlGn')
fig=plt.gcf()
fig.set_size_inches(10,8)
plt.show
years = (cardio['age'] / 365).round().astype('int')
pd.crosstab(years, cardio.cardio).plot(kind='bar', figsize=(12,8))
plt.title('Cardiovascular Disease By Age')
plt.legend(['Not Having Cardiovascular Disease', 'Having Cardiovascular Disease'])
plt.show()
plt.figure(figsize=(8,6))
sns.distplot(cardio['weight'])
col=['cholesterol','gluc', 'smoke', 'alco', 'active']
data_value=pd.melt(cardio,id_vars="cardio",value_vars=cardio[col])
sns.catplot(x="variable",hue="value",col="cardio",data=data_value,kind="count")
# Predictive Analysis
X = cardio.drop('cardio',axis=1)
y = cardio['cardio']
X
y
# Feature Scaling
scaler = StandardScaler()
# Scaling the X data
scaler.fit_transform(X)
# Train Test Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("X_train: ",X_train.shape)
print("X_test: ",X_test.shape)
print("y_train: ",y_train.shape)
print("y_test: ",y_test.shape)
# Predictive Models
Classifiers = list()
# Classification Using XGBoost
XGBC = XGB.XGBClassifier()
XGBC.fit(X_train,y_train)
y_pred_XGB = XGBC.predict(X_test)
Classifiers.append(y_pred_XGB)
# Classification Using Random Forest
RFC = RandomForestClassifier(n_estimators=500,random_state=82)
RFC.fit(X_train,y_train)
y_pred_RF = RFC.predict(X_test)
Classifiers.append(y_pred_RF)
# Classification Using Decision Tree
DTC = DecisionTreeClassifier(max_depth=3, random_state=12, criterion='entropy')
DTC.fit(X_train,y_train)
y_pred_DT = DTC.predict(X_test)
Classifiers.append(y_pred_DT)
# Classification Using Ada Boost
ABC = AdaBoostClassifier(random_state = 741, n_estimators=70)
ABC.fit(X_train,y_train)
y_pred_AB = ABC.predict(X_test)
Classifiers.append(y_pred_AB)
# Classification Using Gradient Boosting
GB = GradientBoostingClassifier(random_state = 15)
GB.fit(X_train, y_train)
y_pred_GB = GB.predict(X_test)
Classifiers.append(y_pred_GB)
# Classification Using Bagging Classifier
BC = BaggingClassifier(random_state = 222, n_estimators=140)
BC.fit(X_train,y_train)
y_pred_BC = BC.predict(X_test)
Classifiers.append(y_pred_BC)
# Classification Using KNeighbors
KNN = KNeighborsClassifier(n_neighbors = 5, algorithm='brute')
KNN.fit(X_train,y_train)
y_pred_KN = KNN.predict(X_test)
Classifiers.append(y_pred_KN)
# Classification Using Logistic Regression
LR = LogisticRegression(solver='lbfgs')
LR.fit(X_train,y_train)
y_pred_LR = LR.predict(X_test)
Classifiers.append(y_pred_LR)
# +
Class = ['XGBoost', 'Random Forest', 'DecisionTree', 'AdaBoost', 'Gradient Boosting', 'Bagging Classifier', 'K Nearest Neighbors', 'Logistic Regression']
score=list()
a=0
index=0
from sklearn.metrics import accuracy_score
for pred in range(len(Classifiers)):
if a < accuracy_score(y_test,Classifiers[pred]):
a = accuracy_score(y_test,Classifiers[pred])
index=pred
print("Accuracy of {} Classifier is {:.2f}%".format(Class[pred],accuracy_score(y_test,Classifiers[pred])*100))
print("\nBest Classifier is {} and The Accuracy is {:.2f}%".format(Class[index],a*100))
# +
# Classification Report of Best Classifier
print(classification_report(y_test, y_pred_XGB))
print('\n')
print(" Accuracy: ",metrics.accuracy_score(y_test, y_pred_XGB))
print(" Precision: ",metrics.precision_score(y_test, y_pred_XGB))
print(" Recall: ",metrics.recall_score(y_test, y_pred_XGB))
print(" F1 Score: ",metrics.f1_score(y_test, y_pred_XGB))
# -
# Confusion Matrix of Best Classifier
print(confusion_matrix(y_test, y_pred_XGB))
# Visualization of Classification Report of Best Classifier
visualizer = ClassificationReport(XGBC)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
| CardioDataAnalysis.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# Import the necessary libraries
import numpy as np
import pandas as pd
import os
import time
import warnings
import gc
gc.collect()
import os
from six.moves import urllib
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
warnings.filterwarnings('ignore')
# %matplotlib inline
plt.style.use('seaborn')
from scipy import stats
from scipy.stats import norm, skew
from sklearn.preprocessing import StandardScaler
# +
#Add All the Models Libraries
# preprocessing
from sklearn.preprocessing import LabelEncoder
label_enc = LabelEncoder()
# Scalers
from sklearn.utils import shuffle
from sklearn.pipeline import Pipeline
from sklearn.pipeline import FeatureUnion
# Models
from sklearn.linear_model import Lasso
from sklearn.metrics import mean_squared_log_error,mean_squared_error, r2_score,mean_absolute_error
from sklearn.model_selection import train_test_split #training and testing data split
from sklearn import metrics #accuracy measure
from sklearn.metrics import confusion_matrix #for confusion matrix
from scipy.stats import reciprocal, uniform
from sklearn.model_selection import StratifiedKFold, RepeatedKFold
# Cross-validation
from sklearn.model_selection import KFold #for K-fold cross validation
from sklearn.model_selection import cross_val_score #score evaluation
from sklearn.model_selection import cross_val_predict #prediction
from sklearn.model_selection import cross_validate
# GridSearchCV
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
#Common data processors
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn import feature_selection
from sklearn import model_selection
from sklearn import metrics
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.utils import check_array
from scipy import sparse
# -
# to make this notebook's output stable across runs
np.random.seed(123)
gc.collect()
# To plot pretty figures
# %matplotlib inline
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
#Reduce the memory usage - by <NAME>
def reduce_mem_usage(df, verbose=True):
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose: print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (start_mem - end_mem) / start_mem))
return df
train = reduce_mem_usage(pd.read_csv('train.csv',parse_dates=["first_active_month"]))
test = reduce_mem_usage(pd.read_csv('test.csv', parse_dates=["first_active_month"]))
test.first_active_month = test.first_active_month.fillna(pd.to_datetime('2017-09-01'))
test.isnull().sum()
# +
# Now extract the month, year, day, weekday
train["month"] = train["first_active_month"].dt.month
train["year"] = train["first_active_month"].dt.year
train['week'] = train["first_active_month"].dt.weekofyear
train['dayofweek'] = train['first_active_month'].dt.dayofweek
train['days'] = (datetime.date(2018, 2, 1) - train['first_active_month'].dt.date).dt.days
train['quarter'] = train['first_active_month'].dt.quarter
test["month"] = test["first_active_month"].dt.month
test["year"] = test["first_active_month"].dt.year
test['week'] = test["first_active_month"].dt.weekofyear
test['dayofweek'] = test['first_active_month'].dt.dayofweek
test['days'] = (datetime.date(2018, 2, 1) - test['first_active_month'].dt.date).dt.days
test['quarter'] = test['first_active_month'].dt.quarter
# -
# Taking Reference from Other Kernels
def aggregate_transaction_hist(trans, prefix):
agg_func = {
'purchase_date' : ['max','min'],
'month_diff' : ['mean', 'min', 'max', 'var'],
'month_diff_lag' : ['mean', 'min', 'max', 'var'],
'weekend' : ['sum', 'mean'],
'authorized_flag': ['sum', 'mean'],
'category_1': ['sum','mean', 'max','min'],
'purchase_amount': ['sum', 'mean', 'max', 'min', 'std'],
'installments': ['sum', 'mean', 'max', 'min', 'std'],
'month_lag': ['max','min','mean','var'],
'card_id' : ['size'],
'month': ['nunique'],
'hour': ['nunique'],
'weekofyear': ['nunique'],
'dayofweek': ['nunique'],
'year': ['nunique'],
'subsector_id': ['nunique'],
'merchant_category_id' : ['nunique'],
'merchant_id' : ['nunique', lambda x:stats.mode(x)[0]],
'state_id' : ['nunique', lambda x:stats.mode(x)[0]],
}
agg_trans = trans.groupby(['card_id']).agg(agg_func)
agg_trans.columns = [prefix + '_'.join(col).strip() for col in agg_trans.columns.values]
agg_trans.reset_index(inplace=True)
df = (trans.groupby('card_id').size().reset_index(name='{}transactions_count'.format(prefix)))
agg_trans = pd.merge(df, agg_trans, on='card_id', how='left')
return agg_trans
transactions = reduce_mem_usage(pd.read_csv('historical_transactions_clean_outlier.csv'))
transactions = transactions.loc[transactions.purchase_amount < 50,]
transactions['authorized_flag'] = transactions['authorized_flag'].map({'Y': 1, 'N': 0})
transactions['category_1'] = transactions['category_1'].map({'Y': 0, 'N': 1})
# +
#Feature Engineering - Adding new features
transactions['purchase_date'] = pd.to_datetime(transactions['purchase_date'])
transactions['year'] = transactions['purchase_date'].dt.year
transactions['weekofyear'] = transactions['purchase_date'].dt.weekofyear
transactions['month'] = transactions['purchase_date'].dt.month
transactions['dayofweek'] = transactions['purchase_date'].dt.dayofweek
transactions['weekend'] = (transactions.purchase_date.dt.weekday >=5).astype(int)
transactions['hour'] = transactions['purchase_date'].dt.hour
transactions['quarter'] = transactions['purchase_date'].dt.quarter
transactions['month_diff'] = ((pd.to_datetime('01/03/2018') - transactions['purchase_date']).dt.days)//30
transactions['month_diff_lag'] = transactions['month_diff'] + transactions['month_lag']
gc.collect()
# +
def aggregate_bymonth(trans, prefix):
agg_func = {
'purchase_amount': ['sum', 'mean'],
'card_id' : ['size']
# 'merchant_category_id' : ['nunique', lambda x:stats.mode(x)[0]],
# 'merchant_id' : ['nunique', lambda x:stats.mode(x)[0]],
# 'state_id' : ['nunique', lambda x:stats.mode(x)[0]],
}
agg_trans = trans.groupby(['card_id','month','year']).agg(agg_func)
agg_trans.columns = [prefix + '_'.join(col).strip() for col in agg_trans.columns.values]
agg_trans.reset_index(inplace=True)
df = (trans.groupby('card_id').size().reset_index(name='{}transactions_count'.format(prefix)))
agg_trans = pd.merge(df, agg_trans, on='card_id', how='left')
return agg_trans
merge = aggregate_bymonth(transactions, prefix='hist_')
merge = merge.drop(['hist_transactions_count'], axis = 1)
# +
merge['Date'] = pd.to_datetime(merge[['year', 'month']].assign(Day=1))
merge1 = merge.loc[merge.groupby('card_id').Date.idxmax(),:][[ 'card_id','hist_card_id_size',
'hist_purchase_amount_sum','hist_purchase_amount_mean']]
new_names = [(i,i+'_last') for i in merge1.iloc[:, 1:].columns.values]
merge1.rename(columns = dict(new_names), inplace=True)
merge2 = merge.loc[merge.groupby('card_id').Date.idxmin(),:][['card_id','hist_card_id_size',
'hist_purchase_amount_sum','hist_purchase_amount_mean']]
new_names = [(i,i+'_first') for i in merge2.iloc[:, 1:].columns.values]
merge2.rename(columns = dict(new_names), inplace=True)
comb = pd.merge(merge1, merge2, on='card_id',how='left')
train = pd.merge(train, comb, on='card_id',how='left')
test = pd.merge(test, comb, on='card_id',how='left')
# +
## Same merchant purchase
df = (transactions.groupby(['card_id','merchant_id','purchase_amount']).size().reset_index(name='count_hist'))
df['purchase_amount_hist'] = df.groupby(['card_id','merchant_id'])['purchase_amount'].transform('sum')
df['count_hist'] = df.groupby(['card_id','merchant_id'])['count_hist'].transform('sum')
df = df.drop_duplicates()
df = df.loc[df['count_hist'] >= 2]
agg_func = {
'count_hist' : ['count'],
'purchase_amount_hist':['sum','mean'],
}
df = df.groupby(['card_id']).agg(agg_func)
df.columns = [''.join(col).strip() for col in df.columns.values]
train = pd.merge(train, df, on='card_id',how='left')
test = pd.merge(test, df, on='card_id',how='left')
# +
# Same category purchase
df = (transactions.groupby(['card_id','merchant_category_id','purchase_amount']).size().reset_index(name='hist_count'))
df['hist_purchase_amount'] = df.groupby(['card_id','merchant_category_id'])['purchase_amount'].transform('sum')
df['hist_count'] = df.groupby(['card_id','merchant_category_id'])['hist_count'].transform('sum')
df = df.drop_duplicates()
df = df.loc[df['hist_count'] >= 2]
df['hist_count_4'] = 0
df.loc[df['hist_count'] >= 4, 'hist_count_4'] = 1
df['hist_mean4'] = 0
df.loc[df['hist_count'] >= 4, 'hist_mean4'] = df['hist_purchase_amount']/df['hist_count']
agg_fun = {
'hist_count' : ['count'],
'hist_count_4' : ['sum'],
'hist_purchase_amount':['sum','mean'],
'hist_mean4' : ['sum','mean']
}
df = df.groupby(['card_id']).agg(agg_fun)
df.columns = [''.join(col).strip() for col in df.columns.values]
train = pd.merge(train, df, on='card_id',how='left')
test = pd.merge(test, df, on='card_id',how='left')
# +
# agg_func = {'mean': ['mean'],}
# for col in ['category_2','category_3']:
# transactions[col+'_mean'] = transactions['purchase_amount'].groupby(transactions[col]).agg('mean')
# transactions[col+'_max'] = transactions['purchase_amount'].groupby(transactions[col]).agg('max')
# transactions[col+'_min'] = transactions['purchase_amount'].groupby(transactions[col]).agg('min')
# transactions[col+'_var'] = transactions['purchase_amount'].groupby(transactions[col]).agg('var')
# agg_func[col+'_mean'] = ['mean']
# gc.collect()
# -
merchants = reduce_mem_usage(pd.read_csv('merchants_clean.csv'))
merchants = merchants.drop(['Unnamed: 0', 'merchant_group_id', 'merchant_category_id',
'subsector_id', 'numerical_1', 'numerical_2',
'active_months_lag3','active_months_lag6',
'city_id', 'state_id'
], axis = 1)
d = dict(zip(merchants.columns[1:], ['histchant_{}'.format(x) for x in (merchants.columns[1:])]))
d.update({"merchant_id": "hist_merchant_id_<lambda>"})
merchants = merchants.rename(index=str, columns= d)
## convert the month in business to categorical
merchants.histchant_active_months_lag12 = pd.cut(merchants.histchant_active_months_lag12, 4)
merge_trans = aggregate_transaction_hist(transactions, prefix='hist_')
merge_trans = merge_trans.merge(merchants, on = 'hist_merchant_id_<lambda>', how = 'left')
## hist transaction frequency
merge_trans['hist_freq'] = merge_trans.hist_transactions_count/(((merge_trans.hist_purchase_date_max -
merge_trans.hist_purchase_date_min).dt.total_seconds())/86400)
merge_trans['hist_freq_amount'] = merge_trans['hist_freq'] * merge_trans['hist_purchase_amount_mean']
merge_trans['hist_freq_install'] = merge_trans['hist_freq'] * merge_trans['hist_installments_mean']
cols = ['histchant_avg_sales_lag3','histchant_avg_purchases_lag3',
'histchant_avg_sales_lag6','histchant_avg_purchases_lag6',
'histchant_avg_sales_lag12','histchant_avg_purchases_lag12','hist_freq']
for col in cols:
merge_trans[col] = pd.qcut(merge_trans[col], 4)
for col in cols:
merge_trans[col].fillna(merge_trans[col].mode()[0], inplace=True)
label_enc.fit(list(merge_trans[col].values))
merge_trans[col] = label_enc.transform(list(merge_trans[col].values))
for col in ['histchant_category_1','histchant_most_recent_sales_range','histchant_most_recent_purchases_range',
'histchant_active_months_lag12','histchant_category_4','histchant_category_2']:
merge_trans[col].fillna(merge_trans[col].mode()[0], inplace=True)
label_enc.fit(list(merge_trans['hist_merchant_id_<lambda>'].values))
merge_trans['hist_merchant_id_<lambda>'] = label_enc.transform(list(merge_trans['hist_merchant_id_<lambda>'].values))
label_enc.fit(list(merge_trans['histchant_active_months_lag12'].values))
merge_trans['histchant_active_months_lag12'] = label_enc.transform(list(merge_trans['histchant_active_months_lag12'].values))
#del transactions
gc.collect()
train = pd.merge(train, merge_trans, on='card_id',how='left')
test = pd.merge(test, merge_trans, on='card_id',how='left')
#del merge_trans
gc.collect()
#Feature Engineering - Adding new features
train['hist_purchase_date_max'] = pd.to_datetime(train['hist_purchase_date_max'])
train['hist_purchase_date_min'] = pd.to_datetime(train['hist_purchase_date_min'])
train['hist_purchase_date_diff'] = (train['hist_purchase_date_max'] - train['hist_purchase_date_min']).dt.days
train['hist_purchase_date_average'] = train['hist_purchase_date_diff']/train['hist_card_id_size']
train['hist_purchase_date_uptonow'] = (pd.to_datetime('01/03/2018') - train['hist_purchase_date_max']).dt.days
train['hist_purchase_date_uptomin'] = (pd.to_datetime('01/03/2018') - train['hist_purchase_date_min']).dt.days
train['hist_first_buy'] = (train['hist_purchase_date_min'] - train['first_active_month']).dt.days
for feature in ['hist_purchase_date_max','hist_purchase_date_min']:
train[feature] = train[feature].astype(np.int64) * 1e-9
gc.collect()
# +
#Feature Engineering - Adding new features
test['hist_purchase_date_max'] = pd.to_datetime(test['hist_purchase_date_max'])
test['hist_purchase_date_min'] = pd.to_datetime(test['hist_purchase_date_min'])
test['hist_purchase_date_diff'] = (test['hist_purchase_date_max'] - test['hist_purchase_date_min']).dt.days
test['hist_purchase_date_average'] = test['hist_purchase_date_diff']/test['hist_card_id_size']
test['hist_purchase_date_uptonow'] = (pd.to_datetime('01/03/2018') - test['hist_purchase_date_max']).dt.days
test['hist_purchase_date_uptomin'] = (pd.to_datetime('01/03/2018') - test['hist_purchase_date_min']).dt.days
test['hist_first_buy'] = (test['hist_purchase_date_min'] - test['first_active_month']).dt.days
for feature in ['hist_purchase_date_max','hist_purchase_date_min']:
test[feature] = test[feature].astype(np.int64) * 1e-9
gc.collect()
# -
# Taking Reference from Other Kernels
def aggregate_transaction_new(trans, prefix):
agg_func = {
'purchase_date' : ['max','min'],
'month_diff' : ['mean', 'min', 'max'],
'month_diff_lag' : ['mean', 'min', 'max'],
'weekend' : ['sum', 'mean'],
'authorized_flag': ['sum'],
'category_1': ['sum','mean', 'max','min'],
'purchase_amount': ['sum', 'mean', 'max', 'min'],
'installments': ['sum', 'mean', 'max', 'min'],
'month_lag': ['max','min','mean'],
'card_id' : ['size'],
'month': ['nunique'],
'hour': ['nunique'],
'weekofyear': ['nunique'],
'dayofweek': ['nunique'],
'year': ['nunique'],
'subsector_id': ['nunique'],
'merchant_category_id' : ['nunique'],
'merchant_id' : ['nunique', lambda x:stats.mode(x)[0]],
'state_id' : ['nunique', lambda x:stats.mode(x)[0]],
}
agg_trans = trans.groupby(['card_id']).agg(agg_func)
agg_trans.columns = [prefix + '_'.join(col).strip() for col in agg_trans.columns.values]
agg_trans.reset_index(inplace=True)
df = (trans.groupby('card_id').size().reset_index(name='{}transactions_count'.format(prefix)))
agg_trans = pd.merge(df, agg_trans, on='card_id', how='left')
return agg_trans
# Now extract the data from the new transactions
new_transactions = reduce_mem_usage(pd.read_csv('new_merchant_transactions_clean_outlier.csv'))
new_transactions = new_transactions.loc[new_transactions.purchase_amount < 50,]
new_transactions['authorized_flag'] = new_transactions['authorized_flag'].map({'Y': 1, 'N': 0})
new_transactions['category_1'] = new_transactions['category_1'].map({'Y': 0, 'N': 1})
# +
#Feature Engineering - Adding new features inspired by Chau's first kernel
new_transactions['purchase_date'] = pd.to_datetime(new_transactions['purchase_date'])
new_transactions['year'] = new_transactions['purchase_date'].dt.year
new_transactions['weekofyear'] = new_transactions['purchase_date'].dt.weekofyear
new_transactions['month'] = new_transactions['purchase_date'].dt.month
new_transactions['dayofweek'] = new_transactions['purchase_date'].dt.dayofweek
new_transactions['weekend'] = (new_transactions.purchase_date.dt.weekday >=5).astype(int)
new_transactions['hour'] = new_transactions['purchase_date'].dt.hour
new_transactions['quarter'] = new_transactions['purchase_date'].dt.quarter
new_transactions['is_month_start'] = new_transactions['purchase_date'].dt.is_month_start
new_transactions['month_diff'] = ((pd.to_datetime('01/03/2018') - new_transactions['purchase_date']).dt.days)//30
new_transactions['month_diff_lag'] = new_transactions['month_diff'] + new_transactions['month_lag']
gc.collect()
# new_transactions['Christmas_Day_2017'] = (pd.to_datetime('2017-12-25') -
# new_transactions['purchase_date']).dt.days.apply(lambda x: x if x > 0 and x <= 15 else 0)
# new_transactions['Valentine_Day_2017'] = (pd.to_datetime('2017-06-13') -
# new_transactions['purchase_date']).dt.days.apply(lambda x: x if x > 0 and x <= 7 else 0)
# #Black Friday : 24th November 2017
# new_transactions['Black_Friday_2017'] = (pd.to_datetime('2017-11-27') -
# new_transactions['purchase_date']).dt.days.apply(lambda x: x if x > 0 and x <= 7 else 0)
# aggs = {'mean': ['mean'],}
# for col in ['category_2','category_3']:
# new_transactions[col+'_mean'] = new_transactions['purchase_amount'].groupby(new_transactions[col]).agg('mean')
# new_transactions[col+'_max'] = new_transactions['purchase_amount'].groupby(new_transactions[col]).agg('max')
# new_transactions[col+'_min'] = new_transactions['purchase_amount'].groupby(new_transactions[col]).agg('min')
# new_transactions[col+'_var'] = new_transactions['purchase_amount'].groupby(new_transactions[col]).agg('var')
# aggs[col+'_mean'] = ['mean']
# +
## Same merchant purchase
df = (new_transactions.groupby(['card_id','merchant_id','purchase_amount']).size().reset_index(name='count_new'))
df['purchase_amount_new'] = df.groupby(['card_id','merchant_id'])['purchase_amount'].transform('sum')
df['count_new'] = df.groupby(['card_id','merchant_id'])['count_new'].transform('sum')
df = df.drop_duplicates()
df = df.loc[df['count_new'] >= 2]
agg_func = {
'count_new' : ['count'],
'purchase_amount_new':['sum','mean'],
}
df = df.groupby(['card_id']).agg(agg_func)
df.columns = [''.join(col).strip() for col in df.columns.values]
train = pd.merge(train, df, on='card_id',how='left')
test = pd.merge(test, df, on='card_id',how='left')
# +
df = (new_transactions.groupby(['card_id','merchant_category_id']).size().reset_index(name='new_count'))
df['new_count'] = df.groupby(['card_id','merchant_category_id'])['new_count'].transform('sum')
df = df.drop_duplicates()
df = df.loc[df['new_count'] >= 2]
df['new_count_4'] = 0
df.loc[df['new_count'] >= 4, 'new_count_4'] = 1
agg_fun = {
'new_count' : ['count'],
'new_count_4' : ['sum'],
}
df = df.groupby(['card_id']).agg(agg_fun)
df.columns = [''.join(col).strip() for col in df.columns.values]
train = pd.merge(train, df, on='card_id',how='left')
test = pd.merge(test, df, on='card_id',how='left')
# -
merchants = reduce_mem_usage(pd.read_csv('merchants_clean.csv'))
merchants = merchants.drop(['Unnamed: 0', 'merchant_group_id', 'merchant_category_id',
'subsector_id', 'numerical_1', 'numerical_2',
'active_months_lag3','active_months_lag6',
'city_id', 'state_id',
], axis = 1)
d = dict(zip(merchants.columns[1:], ['newchant_{}'.format(x) for x in (merchants.columns[1:])]))
d.update({"merchant_id": "new_merchant_id_<lambda>"})
merchants = merchants.rename(index=str, columns= d)
## convert the month in business to categorical
merchants.newchant_active_months_lag12 = pd.cut(merchants.newchant_active_months_lag12, 4)
merge_new = aggregate_transaction_new(new_transactions, prefix='new_')
merge_new = merge_new.merge(merchants, on = 'new_merchant_id_<lambda>', how = 'left')
## new transaction frequency
merge_new['new_freq'] = merge_new.new_transactions_count/(((merge_new.new_purchase_date_max -
merge_new.new_purchase_date_min).dt.total_seconds())/86400)
merge_new['new_freq_amount'] = merge_new['new_freq'] * merge_new['new_purchase_amount_mean']
merge_new['new_freq_install'] = merge_new['new_freq'] * merge_new['new_installments_mean']
cols = ['newchant_avg_sales_lag3','newchant_avg_purchases_lag3',
'newchant_avg_sales_lag6','newchant_avg_purchases_lag6',
'newchant_avg_sales_lag12','newchant_avg_purchases_lag12','new_freq']
for col in cols:
merge_new[col] = pd.qcut(merge_new[col], 4)
for col in cols:
merge_new[col].fillna(merge_new[col].mode()[0], inplace=True)
label_enc.fit(list(merge_new[col].values))
merge_new[col] = label_enc.transform(list(merge_new[col].values))
for col in ['newchant_category_1','newchant_most_recent_sales_range','newchant_most_recent_purchases_range',
'newchant_active_months_lag12','newchant_category_4','newchant_category_2']:
merge_new[col].fillna(merge_new[col].mode()[0], inplace=True)
label_enc.fit(list(merge_new['new_merchant_id_<lambda>'].values))
merge_new['new_merchant_id_<lambda>'] = label_enc.transform(list(merge_new['new_merchant_id_<lambda>'].values))
label_enc.fit(list(merge_new['newchant_active_months_lag12'].values))
merge_new['newchant_active_months_lag12'] = label_enc.transform(list(merge_new['newchant_active_months_lag12'].values))
# +
#del new_transactions
gc.collect()
train = pd.merge(train, merge_new, on='card_id',how='left')
test = pd.merge(test, merge_new, on='card_id',how='left')
#del merge_new
gc.collect()
# -
train_na = train.isnull().sum()
train_na = train_na.drop(train_na[train_na == 0].index).sort_values(ascending=False)
missing_data = pd.DataFrame({'Missing Value' :train_na})
missing_data.head(5)
# +
for col in ['new_freq','new_purchase_amount_min','new_purchase_amount_max','newchant_category_4','new_weekend_mean',''
'new_purchase_amount_mean','newchant_active_months_lag12','new_weekend_sum','newchant_avg_purchases_lag12',
'newchant_avg_sales_lag12','newchant_avg_purchases_lag6','newchant_avg_sales_lag6','new_category_1_sum',
'newchant_avg_purchases_lag3','newchant_avg_sales_lag3','new_category_1_mean','new_category_1_max',
'new_category_1_min','newchant_most_recent_purchases_range','newchant_most_recent_sales_range',
'newchant_category_1'] : # -1
train[col] = train[col].fillna(-1.0)
test[col] = test[col].fillna(-1.0)
for col in ['new_installments_min','new_installments_max','new_installments_mean','new_installments_sum',
'new_purchase_amount_sum','new_state_id_<lambda>' ]: # -2
train[col] = train[col].fillna(-2.0)
test[col] = test[col].fillna(-2.0)
for col in ['newchant_category_2','new_authorized_flag_sum','new_month_lag_min','new_month_lag_max','new_card_id_size',
'new_month_lag_mean','new_weekofyear_nunique','new_year_nunique','new_state_id_nunique',
'new_merchant_id_<lambda>','new_merchant_id_nunique','new_merchant_category_id_nunique',
'new_subsector_id_nunique','new_dayofweek_nunique','new_hour_nunique','new_month_nunique',
'new_transactions_count','new_count_4sum','new_countcount','hist_count_4sum','hist_countcount',
'hist_purchase_amountmean','hist_purchase_amountsum','purchase_amount_newmean','purchase_amount_newsum',
'count_newcount','purchase_amount_histmean','purchase_amount_histsum','count_histcount','hist_mean4mean',
'hist_mean4sum']: # 0
train[col] = train[col].fillna(0.0)
test[col] = test[col].fillna(0.0)
train.new_month_diff_mean = train.new_month_diff_mean.fillna(23)
train.new_month_diff_min = train.new_month_diff_min.fillna(23)
train.new_month_diff_max = train.new_month_diff_max.fillna(24)
train.new_month_diff_lag_mean = train.new_month_diff_lag_mean.fillna(24)
train.new_month_diff_lag_min = train.new_month_diff_lag_min.fillna(24)
train.new_month_diff_lag_max = train.new_month_diff_lag_max.fillna(24)
test.new_month_diff_mean = test.new_month_diff_mean.fillna(23)
test.new_month_diff_min = test.new_month_diff_min.fillna(23)
test.new_month_diff_max = test.new_month_diff_max.fillna(24)
test.new_month_diff_lag_mean = test.new_month_diff_lag_mean.fillna(24)
test.new_month_diff_lag_min = test.new_month_diff_lag_min.fillna(24)
test.new_month_diff_lag_max = test.new_month_diff_lag_max.fillna(24)
# -
for col in ['new_purchase_date_min','new_purchase_date_max']:
train[col] = train[col].fillna(pd.to_datetime(1/9/2017))
test[col] = test[col].fillna(pd.to_datetime(1/9/2017))
# +
#Feature Engineering - Adding new features inspired by Chau's first kernel
train['total_count_merid'] = train['count_newcount'] + train['count_histcount']
train['total_count'] = train['new_countcount'] + train['hist_countcount']
train['new_purchase_date_max'] = pd.to_datetime(train['new_purchase_date_max'])
train['new_purchase_date_min'] = pd.to_datetime(train['new_purchase_date_min'])
train['new_purchase_date_diff'] = (train['new_purchase_date_max'] - train['new_purchase_date_min']).dt.days
train['new_purchase_date_average'] = train['new_purchase_date_diff']/train['new_card_id_size']
train['new_purchase_date_uptonow'] = (pd.to_datetime('01/03/2018') - train['new_purchase_date_max']).dt.days
train['new_purchase_date_uptomin'] = (pd.to_datetime('01/03/2018') - train['new_purchase_date_min']).dt.days
train['new_first_buy'] = (train['new_purchase_date_min'] - train['first_active_month']).dt.days
for feature in ['new_purchase_date_max','new_purchase_date_min']:
train[feature] = train[feature].astype(np.int64) * 1e-9
#Feature Engineering - Adding new features inspired by Chau's first kernel
test['total_count_merid'] = test['count_newcount'] + test['count_histcount']
test['total_count'] = test['new_countcount'] + test['hist_countcount']
test['new_purchase_date_max'] = pd.to_datetime(test['new_purchase_date_max'])
test['new_purchase_date_min'] = pd.to_datetime(test['new_purchase_date_min'])
test['new_purchase_date_diff'] = (test['new_purchase_date_max'] - test['new_purchase_date_min']).dt.days
test['new_purchase_date_average'] = test['new_purchase_date_diff']/test['new_card_id_size']
test['new_purchase_date_uptonow'] = (pd.to_datetime('01/03/2018') - test['new_purchase_date_max']).dt.days
test['new_purchase_date_uptomin'] = (pd.to_datetime('01/03/2018') - test['new_purchase_date_min']).dt.days
test['new_first_buy'] = (test['new_purchase_date_min'] - test['first_active_month']).dt.days
for feature in ['new_purchase_date_max','new_purchase_date_min']:
test[feature] = test[feature].astype(np.int64) * 1e-9
#added new feature - Interactive
train['card_id_total'] = train['new_card_id_size'] + train['hist_card_id_size']
train['purchase_amount_total'] = train['new_purchase_amount_sum'] + train['hist_purchase_amount_sum']
test['card_id_total'] = test['new_card_id_size'] + test['hist_card_id_size']
test['purchase_amount_total'] = test['new_purchase_amount_sum'] + test['hist_purchase_amount_sum']
gc.collect()
# +
train['amountmean_ratiolast'] = train.hist_purchase_amount_mean_last/train.hist_purchase_amount_mean
train['amountsum_ratiolast'] = train.hist_purchase_amount_sum_last/train.hist_purchase_amount_sum
train['transcount_ratiolast'] = train.hist_card_id_size_last/(train.hist_transactions_count/(train.hist_purchase_date_diff//30))
test['amountmean_ratiolast'] = test.hist_purchase_amount_mean_last/test.hist_purchase_amount_mean
test['amountsum_ratiolast'] = test.hist_purchase_amount_sum_last/test.hist_purchase_amount_sum
test['transcount_ratiolast'] = test.hist_card_id_size_last/(test.hist_transactions_count/(test.hist_purchase_date_diff//30))
# +
# train['amountmean_ratiofirst'] = train.hist_purchase_amount_mean_first/train.hist_purchase_amount_mean
# train['amountsum_ratiofirst'] = train.hist_purchase_amount_sum_first/train.hist_purchase_amount_sum
# train['transcount_ratiofirst'] = train.hist_card_id_size_first/(train.hist_transactions_count/(train.hist_purchase_date_diff//30))
# test['amountmean_ratiofirst'] = test.hist_purchase_amount_mean_first/test.hist_purchase_amount_mean
# test['amountsum_ratiofirst'] = test.hist_purchase_amount_sum_first/test.hist_purchase_amount_sum
# test['transcount_ratiofirst'] = test.hist_card_id_size_first/(test.hist_transactions_count/(test.hist_purchase_date_diff//30))
# +
# train['amountmean_lastfirst'] = train.hist_purchase_amount_mean_last/train.hist_purchase_amount_mean_first
# train['amountsum_lastfirst'] = train.hist_purchase_amount_sum_last/train.hist_purchase_amount_sum_first
# train['transcount_lastfirst'] = train.hist_card_id_size_last/train.hist_card_id_size_first
# test['amountmean_lastfirst'] = test.hist_purchase_amount_mean_last/test.hist_purchase_amount_mean_first
# test['amountsum_lastfirst'] = test.hist_purchase_amount_sum_last/test.hist_purchase_amount_sum_first
# test['transcount_lastfirst'] = test.hist_card_id_size_last/test.hist_card_id_size_first
# train = train.drop(['hist_card_id_size','new_card_id_size','card_id', 'first_active_month'], axis = 1)
# test = test.drop(['hist_card_id_size','new_card_id_size','card_id', 'first_active_month'], axis = 1)
# -
train.new_purchase_date_average = train.new_purchase_date_average.fillna(-1.0)
test.new_purchase_date_average = test.new_purchase_date_average.fillna(-1.0)
# +
cols = ['new_freq_amount',]
for col in cols:
train[col] = train[col].fillna(0)
train[col] = pd.qcut(train[col], 5)
label_enc.fit(list(train[col].values))
train[col] = label_enc.transform(list(train[col].values))
test[col] = test[col].fillna(0)
test[col] = pd.qcut(test[col], 5)
label_enc.fit(list(test[col].values))
test[col] = label_enc.transform(list(test[col].values))
train = train.drop(['new_freq_install'], axis = 1)
test = test.drop(['new_freq_install'], axis = 1)
# -
train = train.drop(['hist_card_id_size','new_card_id_size','card_id', 'first_active_month'], axis = 1)
test = test.drop(['hist_card_id_size','new_card_id_size','card_id', 'first_active_month'], axis = 1)
train.shape
# Remove the Outliers if any
train['outliers'] = 0
train.loc[train['target'] < -30, 'outliers'] = 1
train['outliers'].value_counts()
for features in ['feature_1','feature_2','feature_3']:
order_label = train.groupby([features])['outliers'].mean()
train[features] = train[features].map(order_label)
test[features] = test[features].map(order_label)
# Get the X and Y
df_train_columns = [c for c in train.columns if c not in ['target','outliers']]
cat_features = [c for c in df_train_columns if 'feature_' in c]
#df_train_columns
target = train['target']
del train['target']
# +
import lightgbm as lgb
param = {'num_leaves': 31,
'min_data_in_leaf': 30,
'objective':'regression',
'max_depth': -1,
'learning_rate': 0.01,
"min_child_samples": 20,
"boosting": "gbdt",
"feature_fraction": 0.9,
"bagging_freq": 1,
"bagging_fraction": 0.9 ,
"bagging_seed": 11,
"metric": 'rmse',
"lambda_l1": 0.1,
"verbosity": -1,
"nthread": 4,
"random_state": 4590}
folds = StratifiedKFold(n_splits=6, shuffle=True, random_state=4590)
oof = np.zeros(len(train))
predictions = np.zeros(len(test))
feature_importance_df = pd.DataFrame()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train,train['outliers'].values)):
print("fold {}".format(fold_))
trn_data = lgb.Dataset(train.iloc[trn_idx][df_train_columns], label=target.iloc[trn_idx])
val_data = lgb.Dataset(train.iloc[val_idx][df_train_columns], label=target.iloc[val_idx])
num_round = 10000
clf = lgb.train(param, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=-1, early_stopping_rounds = 200)
oof[val_idx] = clf.predict(train.iloc[val_idx][df_train_columns], num_iteration=clf.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = df_train_columns
fold_importance_df["importance"] = clf.feature_importance()
fold_importance_df["fold"] = fold_ + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
predictions += clf.predict(test[df_train_columns], num_iteration=clf.best_iteration) / folds.n_splits
np.sqrt(mean_squared_error(oof, target))
# +
cols = (feature_importance_df[["Feature", "importance"]]
.groupby("Feature")
.mean()
.sort_values(by="importance", ascending=False)[:1000].index)
best_features = feature_importance_df.loc[feature_importance_df.Feature.isin(cols)]
plt.figure(figsize=(14,25))
sns.barplot(x="importance",
y="Feature",
data=best_features.sort_values(by="importance",
ascending=False))
plt.title('LightGBM Features (avg over folds)')
plt.tight_layout()
plt.savefig('lgbm_importances.png')
# -
features = [c for c in train.columns if c not in ['card_id', 'first_active_month','target','outliers']]
cat_features = [c for c in features if 'feature_' in c]
# +
param = {'num_leaves': 31,
'min_data_in_leaf': 30,
'objective':'regression',
'max_depth': -1,
'learning_rate': 0.01,
"min_child_samples": 20,
"boosting": "gbdt",
"feature_fraction": 0.9,
"bagging_freq": 1,
"bagging_fraction": 0.9 ,
"bagging_seed": 11,
"metric": 'rmse',
"lambda_l1": 0.1,
"verbosity": -1,
"nthread": 4,
"random_state": 4590}
folds = RepeatedKFold(n_splits=6, n_repeats=2, random_state=4590)
oof_2 = np.zeros(len(train))
predictions_2 = np.zeros(len(test))
feature_importance_df_2 = pd.DataFrame()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train.values, target.values)):
print("fold {}".format(fold_))
trn_data = lgb.Dataset(train.iloc[trn_idx][features], label=target.iloc[trn_idx], categorical_feature=cat_features)
val_data = lgb.Dataset(train.iloc[val_idx][features], label=target.iloc[val_idx], categorical_feature=cat_features)
num_round = 10000
clf_r = lgb.train(param, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=-1, early_stopping_rounds = 200)
oof_2[val_idx] = clf_r.predict(train.iloc[val_idx][features], num_iteration=clf_r.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = features
fold_importance_df["importance"] = clf_r.feature_importance()
fold_importance_df["fold"] = fold_ + 1
feature_importance_df_2 = pd.concat([feature_importance_df_2, fold_importance_df], axis=0)
predictions_2 += clf_r.predict(test[features], num_iteration=clf_r.best_iteration) / (5 * 2)
print("CV score: {:<8.5f}".format(mean_squared_error(oof_2, target)**0.5))
# +
cols = (feature_importance_df_2[["Feature", "importance"]]
.groupby("Feature")
.mean()
.sort_values(by="importance", ascending=False)[:1000].index)
best_features = feature_importance_df_2.loc[feature_importance_df_2.Feature.isin(cols)]
plt.figure(figsize=(14,25))
sns.barplot(x="importance",
y="Feature",
data=best_features.sort_values(by="importance",
ascending=False))
plt.title('LightGBM Features (avg over folds)')
plt.tight_layout()
plt.savefig('lgbm_importances.png')
# +
from sklearn.linear_model import BayesianRidge
train_stack = np.vstack([oof,oof_2]).transpose()
test_stack = np.vstack([predictions, predictions_2]).transpose()
folds_stack = RepeatedKFold(n_splits=6, n_repeats=1, random_state=4590)
oof_stack = np.zeros(train_stack.shape[0])
predictions_3 = np.zeros(test_stack.shape[0])
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack,target)):
print("fold {}".format(fold_))
trn_data, trn_y = train_stack[trn_idx], target.iloc[trn_idx].values
val_data, val_y = train_stack[val_idx], target.iloc[val_idx].values
clf_3 = BayesianRidge()
clf_3.fit(trn_data, trn_y)
oof_stack[val_idx] = clf_3.predict(val_data)
predictions_3 += clf_3.predict(test_stack) / 6
np.sqrt(mean_squared_error(target.values, oof_stack))
# -
sample_submission = pd.read_csv('sample_submission.csv')
sample_submission['target'] = predictions_3
# combine = pd.read_csv('combining_submission.csv')
# sample_submission['target'] = predictions_3*0.7 + combine['target']*0.3
# q = sample_submission['target'].quantile(0.002)
# sample_submission['target'] = sample_submission['target'].apply(lambda x: x if x > q else x*1.12)
# sample_submission.loc[sample_submission.target < -18, 'target'] = -33.218750
sample_submission.to_csv('submission.csv', index=False)
((sample_submission.target <= -30) & (sample_submission.target > -35)).sum()
((target > -35) & (target < -30)).sum()
q
sample_submission.loc[sample_submission.target < -20]
sample_submission.head(5)
my = pd.read_csv('submission (1).csv')
my['target'][91179] = -33.218750
my.to_csv('submission91179.csv', index=False)
| Elo merchant/Elo_simplestack682.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:PythonData] *
# language: python
# name: conda-env-PythonData-py
# ---
# # VacationPy
# ----
#
# #### Note
# * Keep an eye on your API usage. Use https://developers.google.com/maps/reporting/gmp-reporting as reference for how to monitor your usage and billing.
#
# * Instructions have been included for each segment. You do not have to follow them exactly, but they are included to help you think through the steps.
# +
# Dependencies and Setup
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import requests
import gmaps
import os
# Import API key
from api_keys import g_key
# -
# ### Store Part I results into DataFrame
# * Load the csv exported in Part I to a DataFrame
# +
# Create a reference the CSV file desired
csv_path = "output_data_cities.csv"
# Read the CSV into a Pandas DataFrame
cities_df = pd.read_csv(csv_path)
cities_df
del cities_df["Unnamed: 0"]
cities_df
# -
# ### Humidity Heatmap
# * Configure gmaps.
# * Use the Lat and Lng as locations and Humidity as the weight.
# * Add Heatmap layer to map.
# +
# Store latitude and longitude in locations
locations = cities_df[["Latitude", "Longitude"]]
# Convert Humidity to float
humid = cities_df["Humidity"].astype(float)
# +
# Plot Heatmap
fig = gmaps.figure()
# Create heat layer
heat_layer = gmaps.heatmap_layer(locations, weights=humid,
dissipating=False, max_intensity=10,
point_radius=1)
# Add layer
fig.add_layer(heat_layer)
# Display figure
fig
# -
# ### Create new DataFrame fitting weather criteria
# * Narrow down the cities to fit weather conditions.
# * Drop any rows will null values.
# +
#run using loc function based on conditions
# -
#Remove Cities that are too hot
not_too_hot_df=cities_df.loc[cities_df["Max Temp"]<26.6667]
not_too_hot_df
#Remove Cities that are too cold
not_too_cold_df=not_too_hot_df[not_too_hot_df["Max Temp"]>21.1111]
not_too_cold_df
#Remove Cities that are too windy
not_too_windy_df=not_too_cold_df[not_too_cold_df["Wind Speed"]<10]
not_too_windy_df
#Remove Cities that are too cloudy
perfect_cities_df=not_too_windy_df[not_too_windy_df["Cloudiness"]==0]
perfect_cities_df
# ### Hotel Map
# * Store into variable named `hotel_df`.
# * Add a "Hotel Name" column to the DataFrame.
# * Set parameters to search for hotels with 5000 meters.
# * Hit the Google Places API for each city's coordinates.
# * Store the first Hotel result into the DataFrame.
# * Plot markers on top of the heatmap.
perfect_cities_df["Hotel"]=" "
perfect_cities_df.head()
# +
# create a params dict that will be updated with new city each iteration
params = {"key": g_key, "radius": 5000, "type": "lodging"}
x=1
# Loop through the cities_pd and run a lat/long search for each city
for index, row in perfect_cities_df.iterrows():
base_url = "https://maps.googleapis.com/maps/api/place/nearbysearch/json"
lat = row['Latitude']
lon = row['Longitude']
# update address key value
params['location'] = f"{lat},{lon}"
try:
# make request
hotel_cities_lat_lng = requests.get(base_url, params=params)
print(hotel_cities_lat_lng)
# print the cities_lat_lng url, avoid doing for public github repos in order to avoid exposing key
# print(cities_lat_lng.url)
# convert to json
hotel_cities_json = hotel_cities_lat_lng.json()
print(hotel_cities_json)
perfect_cities_df.loc[index, "Hotel"] = hotel_cities_json["results"][0]["name"]
# Handle exceptions for a character that is not available in the Star Wars API
except:
# Append null values
print("INVALID REQUEST")
pass
# -
# Visualize to confirm lat lng appear
perfect_cities_df.head()
# +
info_box_template ="""
<dl>
<dt>Name</dt><dd>{Hotel}</dd>
<dt>City</dt><dd>{City}</dd>
<dt>Country</dt><dd>{Country}</dd>
</dl>"""
# Store the DataFrame Row
hotel_info = [info_box_template.format(**row) for index, row in perfect_cities_df.iterrows()]
locations = perfect_cities_df[["Latitude", "Longitude"]]
hotel_info
# -
marker_layer = gmaps.marker_layer(locations, info_box_content=hotel_info)
fig.add_layer(marker_layer)
fig
| starter_code/VactionPy-Rick_Kassing.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import matplotlib
matplotlib.use('module://ipympl.backend_nbagg')
from matplotlib import pyplot as plt
plt.ion()
import math
import numpy as np
import pickle
import sys
sys.path.append('..')
import unzipping_simulation as uzsi
from unzipping_simulation import kB
sys.path.append('../../../cn_plot_style/')
import cn_plot_style as cnps
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:90% !important; }</style>"))
np.set_printoptions(precision=3)
# +
# Set the parameters of the DNA unzipping construct
with open('phage_lambda.fasta') as f:
sequence = ''.join([line.rstrip() for line in f if not line.startswith('>')])
bases = sequence[39302:40041]
# complementary linker sequence, primer, bases, primer, hairpin (polyT left out)
bases = 'GATACGTTCTTACCCATACTCCACCGTTGC' + 'TGTGCCAACA' + 'CATTGC' + bases + 'GCAATG' + 'CAAGCTACTG' + 'CCGGTCGTAT'
nbs = 10 # 2 * 5pT
nbs_loop = 10 # hairpin with 10 pT loop
seg_a = 42588 - 42168 + 1 + 2*(8 + 10)
seg_b = 43761 - 42854 + 1 + (6 + 10) + (8 + 10)
nbp = seg_a + seg_b # (1399)
# Set the parameters of the optical tweezers setup/assay
radius = 410e-9
r = radius
# distance between surface of the bead and the glass
h0 = 320e-9
z0 = h0
# 3D positioning
y0 = 0e-9
# A0 = attachment_point(x0, y0=y0, h0=h0, radius=radius)
# Stiffness
kappa = np.array([0.67058388e-3, 0.59549569e-3, 0.20775878e-3])
# Rotation
angles_r0 = np.array([100/180*math.pi, 45/180*math.pi])
r0_sph = np.array([radius, *angles_r0])
# lower values of k_rot decrease forces at the beginning of the unzipping
k_rot = np.array([0.1e-12*180/math.pi, 0.02e-12*180/math.pi])
#k_rot[0] = 0
#k_rot[1] = 0
T = 302.2
# Set stage displacement to be simulated
x0_min = 100e-9
x0_max = 1550e-9
resolution = 5e-9
# Set the boltzmann factor for selection of the probable states
# used to determine the simulated forces/unzipped basepairs
boltzmann_factor = 1e-5
# Set the parameters for the ssDNA model
# Elastic modulus S, literature values are
# in the range of 0.53 ≤ K ≤ 2.2 nN
S = 840e-12
# Persistence length 0.75 ≤ L_p ≤ 3.1 nm
L_p_ssDNA = 0.797e-9
# Contour length per base 0.43 ≤ L_0 ≤ 0.66 nm/base
# higher values stretch the unzipping curve in x
# The influence of z increases for higher numbers of unzipped basepairs
# (-> longer ssDNA -> more influence on curve)
z = 0.568e-9
# Set the parameters for the dsDNA model
pitch = 0.338e-9
L_p_dsDNA = 50e-9
# Use Nearest neighbour base-pairs for calculation of the unpairing energies?
NNBP = True
# Set the concentration of monovalent cations
c = 50e-3
# -
d_angles = np.array([math.pi, math.pi])
k_rot = np.array([0, 0.03])
uzsi.F_rot(d_angles, k_rot)
# +
angles = np.linspace(-90, 90, 181)
force = uzsi.F_rot(angles*math.pi/180, 0.1e-12*180/math.pi)
energy = uzsi.E_rot(angles*math.pi/180, 0.1e-12*180/math.pi, 410e-9)
energy_pedaci = uzsi.E_rot(angles*math.pi/180, 0.1e-12*180/math.pi, 410e-9, shifted=False)
with cnps.cn_plot(context='notebook', dark=False, usetex=False) as cnp:
fig, ax = plt.subplots()
ax2 = cnps.second_ax(fig=fig, link_ax=ax)
ax2.xaxis.set_visible(False)
ax.plot(angles, force*1e12, 'c', label='Force')
ax2.plot(angles, energy/(kB*T), 'm', label='Energy')
#plt.legend()
#fig.suptitle(r'Sphere rotated out of its equilibrium by angle $\Delta\theta$')
#ax.set_title('Force and energy of a ')
ax.set_xlabel(r'Angle $\Delta\theta$ (°)')
ax.set_ylabel('Force (pN)')
ax2.set_ylabel('Energy (kB*T)')
#fig.savefig('Force_and_energy_orig.png')
# +
# Calculate rotational force based on difference of r0 and r
# and plot it as tangent at the end of r
r0_theta = 180*math.pi/180
r0_phi = 0*math.pi/180
r_theta = 135*math.pi/180
r_phi = 0*math.pi/180
_k_rot = np.array([0.1e-12*180/math.pi, 0.1e-12*180/math.pi])
d_theta = r0_theta - r_theta
d_phi = r0_phi - r_phi
d_angles = np.array([d_theta, d_phi])
r0 = uzsi.sph2cart(radius*1e9, r0_theta, r0_phi)
r = uzsi.sph2cart(radius*1e9, r_theta, r_phi)
f_bead_rot_mag = uzsi.F_rot(d_angles, _k_rot)
f_bead_rot_cmp = np.r_[0, f_bead_rot_mag*1e14]
f_bead_rot = uzsi.coord_sph2cart(r_theta, r_phi, f_bead_rot_cmp, 0)
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.patches import FancyArrowPatch
from mpl_toolkits.mplot3d import proj3d
class Arrow3D(FancyArrowPatch):
def __init__(self, xs, ys, zs, *args, **kwargs):
FancyArrowPatch.__init__(self, (0,0), (0,0), *args, **kwargs)
self._verts3d = xs, ys, zs
def draw(self, renderer):
xs3d, ys3d, zs3d = self._verts3d
xs, ys, zs = proj3d.proj_transform(xs3d, ys3d, zs3d, renderer.M)
self.set_positions((xs[0],ys[0]),(xs[1],ys[1]))
FancyArrowPatch.draw(self, renderer)
fig = plt.figure()
ax = plt.subplot(111, projection='3d')
r0_arrow = np.c_[np.array([0,0,0]), r0]
r_arrow = np.c_[np.array([0,0,0]), r]
f_bead_rot_arrow = np.c_[r_arrow[:,1], r_arrow[:,1] + f_bead_rot]
f_bead_rot_arrow_neg = np.c_[r_arrow[:,1], r_arrow[:,1] - f_bead_rot]
# Plot scatter of points
ax.plot(*r0_arrow, lw=0)
ax.plot(*r_arrow, lw=0)
ax.plot(*f_bead_rot_arrow, lw=0)
ax.plot(*f_bead_rot_arrow_neg, lw=0)
_r0 = Arrow3D(*r0_arrow, mutation_scale=50,
lw=5, arrowstyle="-|>", color="k")
_r = Arrow3D(*r_arrow, mutation_scale=50,
lw=5, arrowstyle="-|>", color="b")
_f_bead = Arrow3D(*f_bead_rot_arrow, mutation_scale=50,
lw=5, arrowstyle="-|>", color="r")
_f_bead_rot = Arrow3D(*f_bead_rot_arrow_neg, mutation_scale=50,
lw=5, arrowstyle="-|>", color="c")
ax.add_artist(_r0)
ax.add_artist(_r)
ax.add_artist(_f_bead)
ax.add_artist(_f_bead_rot)
# +
plt.close('all')
fig, ax = plt.subplots()
theta = np.linspace(-math.pi / 2, math.pi / 2, 1000)
phi = np.linspace(-math.pi / 2, math.pi / 2, 1000)
b = np.array(uzsi.sph2cart(1, - math.pi/2, math.pi / 4))
# theta
angle_vectors = np.array([uzsi.angle(np.array(uzsi.sph2cart(1, t, 0)), b) for t in theta])**2
ax.plot(theta*180/math.pi, angle_vectors*180/math.pi)
# phi
angle_vectors = np.array([uzsi.angle(np.array(uzsi.sph2cart(1, -math.pi/2, p)), b) for p in phi])**2
ax.plot(phi*180/math.pi, angle_vectors*180/math.pi)
ax.set_xlabel('Angle theta of vector a')
ax.set_ylabel('Angle between vectors')
# +
#x0 = -745.369e-9
x0 = 530e-9
A0 = uzsi.attachment_point(x0=x0, y0=y0, h0=h0, radius=radius)
f_dna = 10e-12
x_ss = uzsi.ext_ssDNA(f_dna, nbs=nbs, S=S, L_p=L_p_ssDNA, z=z, T=T)
x_ds = uzsi.ext_dsDNA_wlc(f_dna, nbp=nbp, pitch=pitch, L_p=L_p_dsDNA, T=T)
f, d, d_angles, ext_app = uzsi.F_construct_3D(A0, x_ss=x_ss, x_ds=x_ds, f_dna=f_dna,
r0_sph=r0_sph, kappa=kappa, k_rot=k_rot,
verbose=True, deep_verbose=False, print_result=True)
print('DNA force: {:.3f} pN, displacement: {} nm'.format(f*1e12, d*1e9))
# +
x0 = 0e-9
f_dna = 10e-12
x_ss = uzsi.ext_ssDNA(f_dna, nbs=nbs, S=S, L_p=L_p_ssDNA, z=z, T=T)
x_ds = uzsi.ext_dsDNA_wlc(f_dna, nbp=nbp, pitch=pitch, L_p=L_p_dsDNA, T=T)
ANGLES_C = []
ANGLES_R = []
F_BEAD = []
F_DNA = []
D_BEAD = []
X0 = np.linspace(-800e-9, 800e-9, 101)
for x0 in X0:
A0 = uzsi.attachment_point(x0=x0, y0=y0, h0=h0, radius=radius)
f_dna_total, f_bead, d, angles_c, angles_r = uzsi.F_construct_3D(A0, x_ss=x_ss, x_ds=x_ds, f_dna=f_dna,
r0_sph=r0_sph, kappa=kappa, k_rot=k_rot,
verbose=False, return_plus=True)
ANGLES_C.append(angles_c)
ANGLES_R.append(angles_r)
F_BEAD.append(f_bead)
F_DNA.append(f_dna_total)
D_BEAD.append(d)
#print('e: {} nm, l: {:.2f} nm\nr: {} nm, r: {:.2f} nm \nd: {} nm \nf_bead: {} pN, f: {:.2f} pN'.format(e*1e9, np.linalg.norm(e)*1e9,
# R*1e9, np.linalg.norm(R)*1e9,
# d*1e9,
# f_bead*1e12, np.linalg.norm(f_bead)*1e12))
theta_c = np.array([angle[0] for angle in ANGLES_C])
phi_c = np.array([angle[1] for angle in ANGLES_C])
theta_r = np.array([angle[0] for angle in ANGLES_R])
phi_r = np.array([angle[1] for angle in ANGLES_R])
#INIT_R = np.c_[theta_r, phi_r]
#theta_r_min = np.array([min(init_r[0], r0_sph[1]) for init_r in INIT_R])
#theta_r_max = np.array([max(init_r[0], r0_sph[1]) for init_r in INIT_R])
#phi_r_min = np.array([min(init_r[1], r0_sph[2]) for init_r in INIT_R])
#phi_r_max = np.array([max(init_r[1], r0_sph[2]) for init_r in INIT_R])
f_bead = np.array([np.linalg.norm(f) for f in F_BEAD])
f_dna = np.array([np.linalg.norm(f) for f in F_DNA])
f = np.array([np.linalg.norm(f) for f in F_BEAD])
d_bead = np.array([d for d in D_BEAD])
plt.close('all')
fig, ax = plt.subplots()
ax.set_ylabel('Force (pN)')
#ax.plot(X0*1e9, f_bead*1e12, '*')
ax.plot(X0*1e9, f_bead*1e12, 'm')
ax.plot(X0*1e9, f_dna*1e12, 'c')
ax2 = plt.twinx(ax)
ax2.set_ylabel('Angle (°)')
ax2.plot(X0*1e9, theta_c*180/math.pi)
ax2.plot(X0*1e9, theta_r*180/math.pi, 'o')
ax2.plot(X0*1e9, phi_c*180/math.pi)
ax2.plot(X0*1e9, phi_r*180/math.pi, 'o')
#ax2.plot(X0*1e9, d_bead*1e9)
#ax.plot(X0*1e9, theta_r_min*180/math.pi, 'b,')
#ax.plot(X0*1e9, theta_r_max*180/math.pi, 'b,')
#ax.plot(X0*1e9, phi_r_min*180/math.pi, '.')
#ax.plot(X0*1e9, phi_r_max*180/math.pi, '.')
# +
x0 = -806e-9
A0 = uzsi.attachment_point(x0, y0=y0, h0=h0, radius=radius)
nuz = uzsi.approx_eq_nuz_rot(A0, bases=bases, nbs=nbs, nbp=nbp,
r0_sph=r0_sph, kappa=kappa, k_rot=k_rot,
S=S, L_p_ssDNA=L_p_ssDNA, z=z,
pitch=pitch, L_p_dsDNA=L_p_dsDNA,
NNBP=NNBP, c=c, T=T)
f, d, d_angles, ext_app = uzsi.F_0_3D(A0, nbs=nbs+nuz*2, S=S, L_p_ssDNA=L_p_ssDNA, z=z, T=T,
nbp=nbp, pitch=pitch, L_p_dsDNA=L_p_dsDNA,
r0_sph=r0_sph, kappa=kappa, k_rot=k_rot)
print('DNA force: {:.3f} pN, displacement: {} nm, rotation: {} °'.format(f*1e12, d*1e9, d_angles*180/math.pi))
#uzsi.equilibrium_xfe0_rot(A0, bases=bases, nuz=nuz, nbs=nbs, nbp=nbp, nbs_loop=nbs_loop,
# r0_sph=r0_sph, kappa=kappa, k_rot=k_rot,
# S=S, L_p_ssDNA=L_p_ssDNA, z=z,
# pitch=pitch, L_p_dsDNA=L_p_dsDNA,
# NNBP=NNBP, c=c, T=T)
r_2d = uzsi.xfe0_fast_nuz(abs(x0), bases=bases, nbs=nbs, nbp=nbp, nbs_loop=nbs_loop,
r=radius, z0=h0, kappa=kappa[[0,2]],
S=S, L_p_ssDNA=L_p_ssDNA, z=z,
pitch=pitch, L_p_dsDNA=L_p_dsDNA,
NNBP=NNBP, c=c, T=T)
r = uzsi.xfe0_fast_nuz_rot(A0, bases=bases, nbs=nbs, nbp=nbp, nbs_loop=nbs_loop,
r0_sph=r0_sph, kappa=kappa, k_rot=None,
S=S, L_p_ssDNA=L_p_ssDNA, z=z,
pitch=pitch, L_p_dsDNA=L_p_dsDNA,
NNBP=NNBP, c=c, T=T)
r_rot = uzsi.xfe0_fast_nuz_rot(A0, bases=bases, nbs=nbs, nbp=nbp, nbs_loop=nbs_loop,
r0_sph=r0_sph, kappa=kappa, k_rot=k_rot,
S=S, L_p_ssDNA=L_p_ssDNA, z=z,
pitch=pitch, L_p_dsDNA=L_p_dsDNA,
NNBP=NNBP, c=c, T=T)
print(' r r_rot r_2d')
print('nuz: {:6.0f} {:9.0f} {:9.0f}\nf_dna: {:.3f} pN {:.3f} pN {:.3f} pN\nf_lev: {:.3f} pN {:.3f} pN {:.3f} pN'.format(
round(float(r['NUZ0_avg'])), round(float(r_rot['NUZ0_avg'])), round(float(r_2d['NUZ0_avg'])),
float(r['F0_avg']*1e12), float(r_rot['F0_avg']*1e12), float(r_2d['F0_avg']*1e12),
float(np.sqrt(np.sum((r['D0_avg']*kappa)**2))*1e12), float(np.sqrt(np.sum((r_rot['D0_avg']*kappa)**2))*1e12), float(np.sqrt(np.sum((r_2d['D0_avg']*kappa[[0,2]])**2))*1e12),
))
# +
#plt.close('all')
# Plot energy landscape
x0 = 400e-9 + radius*0.817 - h0*0.17 - 57e-9
with cnps.cn_plot(context='notebook'):
fig, ax, ax2 = uzsi.plot_unzip_energy_rot(x0, y0=y0, h0=h0, bases=bases, nbs=nbs, nbp=nbp, nbs_loop=nbs_loop,
radius=radius, angles_r0=angles_r0, kappa=kappa, k_rot=k_rot,
S=S, L_p_ssDNA=L_p_ssDNA, z=z,
pitch=pitch, L_p_dsDNA=L_p_dsDNA,
NNBP=NNBP, c=c, T=T,
boltzmann_factor=boltzmann_factor)
#fig.savefig('Energy_number_unzipped_basepairs.png')
| notebooks/Test of functions.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: pymedphys-master
# language: python
# name: pymedphys-master
# ---
# +
import re
import sys
import pathlib
import functools
import traceback
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import imageio
import img2pdf
import IPython.display
import pydicom
# -
# Makes it so any changes in pymedphys is automatically
# propagated into the notebook without needing a kernel reset.
from IPython.lib.deepreload import reload
# %load_ext autoreload
# %autoreload 2
import pymedphys
from prototyping import *
# +
percent_deviation = 2
mm_dist_threshold = 0.5
logfile_directory = pathlib.Path(r'D:\LinacLogFiles')
monaco_directory = pathlib.Path(r'\\monacoda\FocalData\RCCC\1~Clinical')
output_directory = pathlib.Path(r'S:\Physics\Patient Specific Logfile Fluence')
pdf_directory = pathlib.Path(r'P:\Scanned Documents\RT\PhysChecks\Logfile PDFs')
# -
extra_patient_ids_to_check = []
with pymedphys.mosaiq.connect('msqsql') as cursor:
qcls = get_incomplete_qcls(cursor, 'Physics_Check')
qcls
patient_ids = extra_patient_ids_to_check + list(qcls['patient_id'])
patient_ids
# +
logfile_paths = {}
for patient_id in patient_ids:
paths = list(logfile_directory.joinpath('indexed').glob(f'*/{patient_id}_*/*/*/*/*.trf'))
if paths:
logfile_paths[patient_id] = paths
# -
logfile_paths
patiend_ids_with_logfiles = list(logfile_paths.keys())
patient_id = patiend_ids_with_logfiles[0]
# +
monaco_approval_comments = {}
for patient_id in patiend_ids_with_logfiles:
paths = list(monaco_directory.glob(f'*~{patient_id}/plan/*/*plan_comment'))
if paths:
monaco_approval_comments[patient_id] = paths
# -
monaco_approval_comments
patient_ids_with_approved_plans = list(monaco_approval_comments.keys())
# +
tel_files = {}
for patient_id in patient_ids_with_approved_plans:
paths = list(monaco_directory.glob(f'*~{patient_id}/plan/*/tel.1'))
if paths:
tel_files[patient_id] = paths
# -
tel_files
patient_ids_to_check = list(tel_files.keys())
# +
def run_for_a_patient_id(patient_id):
markdown_print(f"# {patient_id}")
for tel_file in tel_files[patient_id]:
markdown_print(f"## `{tel_file}`")
try:
mudensity_tel = get_mu_density_from_file(tel_file)
for trf_file in logfile_paths[patient_id]:
markdown_print(f"### `{trf_file}`")
mudensity_trf = get_mu_density_from_file(trf_file)
gamma = calc_gamma(to_tuple(mudensity_tel), to_tuple(mudensity_trf))
results_dir = output_directory.joinpath(patient_id, tel_file.parent.name, trf_file.stem)
results_dir.mkdir(exist_ok=True, parents=True)
header_text = (
f"Patient ID: {patient_id}\n"
f"Plan Name: {tel_file.parent.name}\n"
)
footer_text = (
f"tel.1 file path: {str(tel_file)}\n"
f"trf file path: {str(trf_file)}\n"
f"results path: {str(results_dir)}"
)
png_filepath = str(results_dir.joinpath("result.png").resolve())
pdf_filepath = str(pdf_directory.joinpath(f"{patient_id}.pdf").resolve())
fig = plot_and_save_results(
mudensity_tel, mudensity_trf,
gamma, png_filepath, pdf_filepath,
header_text=header_text, footer_text=footer_text
)
fig.tight_layout()
plt.savefig(png_filepath, dpi=300)
plt.show()
# !magick convert "{png_filepath}" "{pdf_filepath}"
except Exception as e:
traceback.print_exc()
for patient_id in patient_ids_to_check:
run_for_a_patient_id(patient_id)
| examples/site-specific/cancer-care-associates/production/Logfiles/MU Density/QCL Based Logfile to Monaco Comparison.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
import os
import sys
import tensorflow as tf
import numpy as np
import tensorflow_hub as hub
import wandb
from wandb.keras import WandbCallback
nb_dir = os.path.split(os.getcwd())[0]
if nb_dir not in sys.path:
sys.path.append(nb_dir)
feature_names = ["product", "sub_product", "issue", "sub_issue", "state", "zip_code", "company", "company_response", "timely_response", "consumer_disputed", "consumer_complaint_narrative"]
one_hot_features = ['product', 'sub_product', 'company_response', 'state', 'issue']
numeric_features = ['zip_code']
text_features = ['consumer_complaint_narrative']
df = pd.read_csv('../data/consumer_complaints_with_narrative.csv', usecols=feature_names)
df.head()
for col in one_hot_features:
print(col)
print(df[col].nunique())
df['consumer_disputed'] = df['consumer_disputed'].map({'Yes':1, 'No':0})
for feature in one_hot_features:
df[feature] = df[feature].astype("category").cat.codes
one_hot_x = [pd.np.asarray(tf.keras.utils.to_categorical(df[feature_name].values)) for feature_name in one_hot_features]
embedding_x = [pd.np.asarray(df[feature_name].values).reshape(-1) for feature_name in text_features]
df['zip_code'] = df['zip_code'].str.replace('X', '0', regex=True)
df['zip_code'] = df['zip_code'].str.replace(r'\[|\*|\+|\-|`|\.|\ |\$|\/|!|\(', '0', regex=True)
df['zip_code'] = df['zip_code'].fillna(0)
df['zip_code'] = df['zip_code'].astype('int32')
df['zip_code'] = df['zip_code'].apply(lambda x: x//10000)
numeric_x = [df['zip_code'].values]
X = one_hot_x + numeric_x + embedding_x
y = np.asarray(df["consumer_disputed"], dtype=np.uint8).reshape(-1)
def get_model(show_summary=True):
"""
Function defines a Keras model and returns the model as Keras object
"""
wandb.init(project="consumer-complaints")
config = wandb.config
config.name='final_features_wide'
config.hidden_layer_size = 256
config.optimizer = 'adam'
config.learning_rate = 0.001
config.data_version = 'cc_imbalanced_narrative'
config.one_hot_features = one_hot_features
config.numeric_features = numeric_features
config.text_features = text_features
# one-hot categorical features
num_products = 11
num_sub_products = 45
num_company_responses = 5
num_states = 60
num_issues = 90
input_product = tf.keras.Input(shape=(num_products,), name="product_xf")
input_sub_product = tf.keras.Input(shape=(num_sub_products,), name="sub_product_xf")
input_company_response = tf.keras.Input(shape=(num_company_responses,), name="company_response_xf")
input_state = tf.keras.Input(shape=(num_states,), name="state_xf")
input_issue = tf.keras.Input(shape=(num_issues,), name="issue_xf")
# numeric features
input_zip_code = tf.keras.Input(shape=(1,), name="zip_code_xf")
# text features
input_narrative = tf.keras.Input(shape=(1,), name="narrative_xf", dtype=tf.string)
# embed text features
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
embed = hub.KerasLayer(module_url)
reshaped_narrative = tf.reshape(input_narrative, [-1])
embed_narrative = embed(reshaped_narrative)
deep_ff = tf.keras.layers.Reshape((512, ), input_shape=(1, 512))(embed_narrative)
deep = tf.keras.layers.Dense(256, activation='relu')(deep_ff)
deep = tf.keras.layers.Dense(64, activation='relu')(deep)
deep = tf.keras.layers.Dense(16, activation='relu')(deep)
wide_ff = tf.keras.layers.concatenate(
[input_product, input_sub_product, input_company_response,
input_state, input_issue, input_zip_code])
wide = tf.keras.layers.Dense(16, activation='relu')(wide_ff)
both = tf.keras.layers.concatenate([deep, wide])
output = tf.keras.layers.Dense(1, activation='sigmoid')(both)
_inputs = [input_product, input_sub_product, input_company_response,
input_state, input_issue, input_zip_code, input_narrative]
keras_model = tf.keras.models.Model(_inputs, output)
keras_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=[
tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.TruePositives()
])
if show_summary:
keras_model.summary()
return keras_model
model = get_model(show_summary=False)
model.fit(x=X,
y=y,
batch_size=32,
validation_split=0.2,
epochs=5,
callbacks=[WandbCallback()]
)
# +
#from IPython.display import Image
file_name = 'model.png'
tf.keras.utils.plot_model(model, to_file=file_name)
#Image(filename=file_name)
# -
def get_model(show_summary=True):
"""
Function defines a Keras model and returns the model as Keras object
"""
# one-hot categorical features
num_products = 11
num_sub_products = 45
num_company_responses = 5
num_states = 60
num_issues = 90
input_product = tf.keras.Input(shape=(num_products,), name="product_xf")
input_sub_product = tf.keras.Input(shape=(num_sub_products,), name="sub_product_xf")
input_company_response = tf.keras.Input(shape=(num_company_responses,), name="company_response_xf")
input_state = tf.keras.Input(shape=(num_states,), name="state_xf")
input_issue = tf.keras.Input(shape=(num_issues,), name="issue_xf")
# numeric features
input_zip_code = tf.keras.Input(shape=(1,), name="zip_code_xf")
# text features
input_narrative = tf.keras.Input(shape=(1,), name="narrative_xf", dtype=tf.string)
# embed text features
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
embed = hub.KerasLayer(module_url)
reshaped_narrative = tf.reshape(input_narrative, [-1])
embed_narrative = embed(reshaped_narrative)
deep_ff = tf.keras.layers.Reshape((512, ), input_shape=(1, 512))(embed_narrative)
deep = tf.keras.layers.Dense(256, activation='relu')(deep_ff)
deep = tf.keras.layers.Dense(64, activation='relu')(deep)
deep = tf.keras.layers.Dense(16, activation='relu')(deep)
wide_ff = tf.keras.layers.concatenate(
[input_product, input_sub_product, input_company_response,
input_state, input_issue, input_zip_code])
wide = tf.keras.layers.Dense(16, activation='relu')(wide_ff)
both = tf.keras.layers.concatenate([deep, wide])
output = tf.keras.layers.Dense(1, activation='sigmoid')(both)
_inputs = [input_product, input_sub_product, input_company_response,
input_state, input_issue, input_zip_code, input_narrative]
keras_model = tf.keras.models.Model(_inputs, output)
keras_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=[
tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.TruePositives()
])
if show_summary:
keras_model.summary()
return keras_model
| pre-experiment-pipeline/experiment_6Mar.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + deletable=true editable=true
import csv
import datetime
import h5py
from sklearn.externals import joblib
import numpy as np
import os
import pandas as pd
import pickle
import sklearn.preprocessing
import sklearn.svm
import skm
import sys
import time
sys.path.append("../src")
import localmodule
# Define constants.
data_dir = localmodule.get_data_dir()
dataset_name = localmodule.get_dataset_name()
patch_width = 32
n_patches_per_clip = 1
aug_str = "original"
instanced_aug_str = aug_str
# Parse arguments.
args = ["unit05", "6"]
test_unit_str = args[0]
trial_id = int(args[1])
# Print header.
start_time = int(time.time())
print(str(datetime.datetime.now()) + " Start.")
print("Training probabilistic SVM for " + dataset_name + " clips.")
print("Test unit: " + test_unit_str + ".")
print("Trial ID: " + str(trial_id) + ".")
print("")
print("h5py version: {:s}".format(h5py.__version__))
print("numpy version: {:s}".format(np.__version__))
print("pandas version: {:s}".format(pd.__version__))
print("scikit-learn version: {:s}".format(sklearn.__version__))
print("skm version: {:s}".format(skm.__version__))
print("")
# Retrieve fold such that test_unit_str is in the test set.
folds = localmodule.fold_units()
fold = [f for f in folds if test_unit_str in f[0]][0]
test_units = fold[0]
training_units = fold[1]
validation_units = fold[2]
# Define input folder.
logmelspec_name = "_".join([dataset_name, "skm-logmelspec"])
logmelspec_dir = os.path.join(data_dir, logmelspec_name)
aug_dir = os.path.join(logmelspec_dir, aug_str)
# Initialize matrix of training data.
X_train = []
y_train = []
# Loop over training units.
for train_unit_str in training_units:
# Load HDF5 container of logmelspecs.
hdf5_name = "_".join([dataset_name, instanced_aug_str, train_unit_str])
in_path = os.path.join(aug_dir, hdf5_name + ".hdf5")
in_file = h5py.File(in_path)
# List clips.
clip_names = list(in_file["logmelspec"].keys())
# Loop over clips.
for clip_name in clip_names:
# Read label.
y_clip = int(clip_name.split("_")[3])
# Load logmelspec.
logmelspec = in_file["logmelspec"][clip_name].value
# Load time-frequency patches.
logmelspec_width = logmelspec.shape[1]
logmelspec_mid = np.round(logmelspec_width * 0.5).astype('int')
logmelspec_start = logmelspec_mid -\
np.round(patch_width * n_patches_per_clip * 0.5).astype('int')
# Extract patch.
patch_start = logmelspec_start
patch_stop = patch_start + patch_width
patch = logmelspec[:, patch_start:patch_stop]
# Ravel patch.
X_train.append(np.ravel(patch))
# Append label.
y_train.append(y_clip)
# Concatenate raveled patches as rows.
X_train = np.stack(X_train)
# Load SKM model.
models_dir = localmodule.get_models_dir()
model_name = "skm-cv"
model_dir = os.path.join(models_dir, model_name)
unit_dir = os.path.join(model_dir, test_unit_str)
trial_str = "trial-" + str(trial_id)
trial_dir = os.path.join(unit_dir, trial_str)
model_name = "_".join([
dataset_name, model_name, test_unit_str, trial_str, "model.pkl"
])
model_path = os.path.join(trial_dir, model_name)
skm_model = skm.SKM(k=256)
skm_model = skm_model.load(model_path)
# Transform training set with SKM.
X_train = skm_model.transform(X_train.T).T
# Load standardizer.
scaler_name = "_".join([
dataset_name,
"skm-cv",
test_unit_str,
trial_str,
"scaler.pkl"
])
scaler_path = os.path.join(trial_dir, scaler_name)
scaler = joblib.load(scaler_path)
# Standardize training set.
X_train = scaler.transform(X_train)
# Define CSV file for validation metrics.
val_metrics_name = "_".join([
dataset_name,
"skm-cv",
test_unit_str,
trial_str,
"svm-model",
"val-metrics.csv"
])
csv_header = [
"Dataset",
"Test unit",
"Trial ID",
"log2(C)",
"Validation accuracy (%)"
]
val_metrics_path = os.path.join(
trial_dir, val_metrics_name)
# Open CSV file as Pandas DataFrame.
val_metrics_df = pd.read_csv(val_metrics_path, header=None, names=csv_header)
# Find C maximizing validation accuracy.
max_val_acc = np.max(val_metrics_df["Validation accuracy (%)"])
best_log2C = val_metrics_df["log2(C)"][np.argmax(val_metrics_df["Validation accuracy (%)"])]
# Define SVM model.
svc = sklearn.svm.SVC(
C=2.0**best_log2C,
kernel='rbf',
degree=3,
gamma='auto',
coef0=0.0,
shrinking=True,
probability=True,
tol=0.001,
cache_size=200,
class_weight=None,
verbose=False,
max_iter=-1,
random_state=None)
# Train SVM model.
svc.fit(X_train, y_train)
# Save SVM model.
if np.sign(best_log2C) >= 0:
best_log2C_str = "+" + str(abs(best_log2C)).zfill(2)
else:
best_log2C_str = "-" + str(abs(best_log2C)).zfill(2)
svm_name = "_".join([
dataset_name,
"skm-cv",
test_unit_str,
trial_str,
"svm-proba-model",
"log2C-(" + best_log2C_str + ").pkl"
])
svm_path = os.path.join(trial_dir, svm_name)
joblib.dump(svc, svm_path)
# Initialize matrix of test data.
X_test = []
y_test_true = []
# Load HDF5 container of logmelspecs.
hdf5_name = "_".join([dataset_name, instanced_aug_str, test_unit_str])
in_path = os.path.join(aug_dir, hdf5_name + ".hdf5")
in_file = h5py.File(in_path)
# List clips.
clip_names = list(in_file["logmelspec"].keys())
# Loop over clips.
for clip_name in clip_names:
# Read label.
y_clip = int(clip_name.split("_")[3])
# Load logmelspec.
logmelspec = in_file["logmelspec"][clip_name].value
# Load time-frequency patches.
logmelspec_width = logmelspec.shape[1]
logmelspec_mid = np.round(logmelspec_width * 0.5).astype('int')
logmelspec_start = logmelspec_mid -\
np.round(patch_width * n_patches_per_clip * 0.5).astype('int')
# Extract patch.
patch_start = logmelspec_start
patch_stop = patch_start + patch_width
patch = logmelspec[:, patch_start:patch_stop]
# Ravel patch.
X_test.append(np.ravel(patch))
# Append label.
y_test_true.append(y_clip)
# Concatenate raveled patches as rows.
X_test = np.stack(X_test)
# Transform test set with SKM.
X_test = skm_model.transform(X_test.T).T
# Standardize test set.
X_test = scaler.transform(X_test)
# Predict.
y_test_pred = svc.predict(X_test)
# Create CSV file.
model_name = "skm-proba"
predict_unit_str = test_unit_str
prediction_name = "_".join([dataset_name, model_name,
"test-" + test_unit_str, trial_str, "predict-" + predict_unit_str,
"clip-predictions"])
prediction_path = os.path.join(trial_dir, prediction_name + ".csv")
csv_file = open(prediction_path, 'w')
csv_writer = csv.writer(csv_file, delimiter=',')
# Create CSV header.
csv_header = ["Dataset", "Test unit", "Prediction unit", "Timestamp",
"Key", "Predicted probability"]
csv_writer.writerow(csv_header)
# Loop over keys.
for clip_id, key in enumerate(clip_names[:1000]):
# Store prediction as DataFrame row.
key_split = key.split("_")
timestamp_str = key_split[1]
freq_str = key_split[2]
ground_truth_str = key_split[3]
aug_str = key_split[4]
predicted_probability = y_test_pred[clip_id]
predicted_probability_str = "{:.16f}".format(predicted_probability)
row = [dataset_name, test_unit_str, predict_unit_str, timestamp_str,
freq_str, aug_str, key, ground_truth_str, predicted_probability_str]
csv_writer.writerow(row)
# Close CSV file.
csv_file.close()
# Print score.
print("Accuracy = {:5.2f}".format(
100 * sklearn.metrics.accuracy_score(y_test_pred, y_test_true)))
print("")
# Print elapsed time.
print(str(datetime.datetime.now()) + " Finish.")
elapsed_time = time.time() - int(start_time)
elapsed_hours = int(elapsed_time / (60 * 60))
elapsed_minutes = int((elapsed_time % (60 * 60)) / 60)
elapsed_seconds = elapsed_time % 60.
elapsed_str = "{:>02}:{:>02}:{:>05.2f}".format(elapsed_hours,
elapsed_minutes,
elapsed_seconds)
print("Total elapsed time: " + elapsed_str + ".")
# -
| notebooks/024_train-probabilistic-svm.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Master_File_Housing_Data_LogisticReg2.csv')
df= dataset.dropna(how='any', subset=['CONSTRUCTIONTYPE'])
df['BELOWGROUNDAREA'].fillna(0,inplace=True)
X = df.iloc[:,2:-2].values
y = df.iloc[:,14].values
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values=np.nan, strategy='mean')
imputer.fit(X[:,[1,3,5,6,7,8,10]])
X[:,[1,3,5,6,7,8,10]]= imputer.transform(X[:,[1,3,5,6,7,8,10]])
#print(X[0])
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder = LabelEncoder()
X[:, 0] = labelencoder.fit_transform(X[:, 0])
X[:, 9] = labelencoder.fit_transform(X[:, 9])
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [0,9])
data = onehotencoder.fit_transform(X).toarray()
#print(data[0])
X2 = data[:,[0,1,2,3,4,5,6,8,9,10,11,12,14,15,16,17,18,19,20,21,22,23,24,25]]
NewData=X2
X_sig = NewData[:,[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,17,19,21,22,23]]
print(X_sig[0])
import statsmodels.api as sm
#Splitting the data into Training Set and Test Set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_sig,y,test_size=0.3,random_state=0)
# -
# PCA with 2 Components
# +
#Normalizing the features
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
#Applying PCA
from sklearn.decomposition import PCA
pcaObj = PCA(n_components=2)
X_train = pcaObj.fit_transform(X_train)
X_test = pcaObj.transform(X_test)
components_variance = pcaObj.explained_variance_ratio_
#Fitting Logistic Regression to Training Set
from sklearn.linear_model import LogisticRegression
classifierObj = LogisticRegression(random_state=0)
classifierObj.fit(X_train, y_train)
#Making predictions on the Test Set
y_pred = classifierObj.predict(X_test)
#Evaluating the predictions using a Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
# Visualising the Training set results
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifierObj.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'blue'))(i), label = j)
plt.title('Logistic Regression (Training set)')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show()
# Visualising the Test set results
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifierObj.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'blue'))(i), label = j)
plt.title('Logistic Regression (Test set)')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show()
# -
cm
#Model Accuracy
print("Model Accuracy PCA 2 Components=", classifierObj.score(X_test,y_test))
# +
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Master_File_Housing_Data_LogisticReg2.csv')
df= dataset.dropna(how='any', subset=['CONSTRUCTIONTYPE'])
df['BELOWGROUNDAREA'].fillna(0,inplace=True)
X = df.iloc[:,2:-2].values
y = df.iloc[:,14].values
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values=np.nan, strategy='mean')
imputer.fit(X[:,[1,3,5,6,7,8,10]])
X[:,[1,3,5,6,7,8,10]]= imputer.transform(X[:,[1,3,5,6,7,8,10]])
#print(X[0])
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder = LabelEncoder()
X[:, 0] = labelencoder.fit_transform(X[:, 0])
X[:, 9] = labelencoder.fit_transform(X[:, 9])
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [0,9])
data = onehotencoder.fit_transform(X).toarray()
#print(data[0])
X2 = data[:,[0,1,2,3,4,5,6,8,9,10,11,12,14,15,16,17,18,19,20,21,22,23,24,25]]
NewData=X2
X_sig = NewData[:,[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,17,19,21,22,23]]
print(X_sig[0])
import statsmodels.api as sm
#Splitting the data into Training Set and Test Set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_sig,y,test_size=0.3,random_state=0)
# +
#Normalizing the features
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
#Applying PCA
from sklearn.decomposition import PCA
pcaObj = PCA(n_components=1)
X_train = pcaObj.fit_transform(X_train)
X_test = pcaObj.transform(X_test)
components_variance = pcaObj.explained_variance_ratio_
#Fitting Logistic Regression to Training Set
from sklearn.linear_model import LogisticRegression
classifierObj = LogisticRegression(random_state=0)
classifierObj.fit(X_train, y_train)
#Making predictions on the Test Set
y_pred = classifierObj.predict(X_test)
#Evaluating the predictions using a Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
plt.scatter(X_test,y_test*0, c=y_pred, cmap = ListedColormap(('red', 'blue')))
plt.title('Logistic Regression (Test set)')
plt.xlabel('PCA')
plt.show()
# +
#Evaluating the predictions using a Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
y_pred = classifierObj.predict(X_test)
print('Model Accuracy:', classifierObj.score(X_test,y_test))
# +
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Master_File_Housing_Data_LogisticReg2.csv')
#dataset = pd.read_csv('Master_File_Housing_Data.csv')
df= dataset.dropna(how='any', subset=['CONSTRUCTIONTYPE'])
df['BELOWGROUNDAREA'].fillna(0,inplace=True)
X = df.iloc[:,2:-2].values
y = df.iloc[:,14].values
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values=np.nan, strategy='mean')
imputer.fit(X[:,[1,3,5,6,7,8,10]])
X[:,[1,3,5,6,7,8,10]]= imputer.transform(X[:,[1,3,5,6,7,8,10]])
#print(X[0])
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder = LabelEncoder()
X[:, 0] = labelencoder.fit_transform(X[:, 0])
X[:, 9] = labelencoder.fit_transform(X[:, 9])
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [0,9])
data = onehotencoder.fit_transform(X).toarray()
#print(data[0])
NewData = data[:,[0,1,2,3,4,5,6,8,9,10,11,12,14,15,16,17,18,19,20,21,22,23,24,25]]
X_sig = NewData[:,[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,17,19,21,22,23]]
print(X_sig[0])
import statsmodels.api as sm
#Splitting the data into Training Set and Test Set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_sig,y,test_size=0.3,random_state=0)
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
#Applying PCA
from sklearn.decomposition import PCA
pcaObj = PCA(n_components=None)
X_train = pcaObj.fit_transform(X_train)
X_test = pcaObj.transform(X_test)
components_variance = pcaObj.explained_variance_ratio_
#Fitting Logistic Regression to Training Set
from sklearn.linear_model import LogisticRegression
classifierObj = LogisticRegression(random_state=0)
classifierObj.fit(X_train, y_train)
#Making predictions on the Test Set
y_pred = classifierObj.predict(X_test)
#Evaluating the predictions using a Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
#Evaluating the predictions using a Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
#plt.scatter(X_test,y_test*0, c=y_pred, cmap = ListedColormap(('red', 'blue')))
#plt.title('Logistic Regression (Test set)')
#plt.xlabel('PCA')
#plt.show()
y_pred = classifierObj.predict(X_test)
print('Model Accuracy:', classifierObj.score(X_test,y_test))
# -
# PCA results
# 2 components: 57.68% 0.5767878077373975
# 1 Component: 58.09% 0.570926143024619
# None: 60.72% 0.6072684642438453
| PCA_LogisticReg.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # LAB 1a: Exploring natality dataset.
#
# **Learning Objectives**
#
# 1. Use BigQuery to explore natality dataset
# 1. Use Cloud AI Platform Notebooks to plot data explorations
#
#
# ## Introduction
# In this notebook, we will explore the natality dataset before we begin model development and training to predict the weight of a baby before it is born. We will use BigQuery to explore the data and use Cloud AI Platform Notebooks to plot data explorations.
#
# Each learning objective will correspond to a __#TODO__ in this student lab notebook -- try to complete this notebook first and then review the [solution notebook](../solutions/1a_explore_data_babyweight.ipynb).
# + [markdown] colab_type="text" id="hJ7ByvoXzpVI"
# ## Load necessary libraries
# + [markdown] colab_type="text" id="mC9K9Dpx1ztf"
# Check that the Google BigQuery library is installed and if not, install it.
# + colab={"base_uri": "https://localhost:8080/", "height": 609} colab_type="code" id="RZUQtASG10xO" outputId="5612d6b0-9730-476a-a28f-8fdc14f4ecde" language="bash"
# sudo pip3 freeze | grep google-cloud-bigquery==1.6.1 || \
# sudo pip3 install google-cloud-bigquery==1.6.1
# -
from google.cloud import bigquery
# + [markdown] colab_type="text" id="L0-vOB4y2BJM"
# ## The source dataset
#
# Our dataset is hosted in [BigQuery](https://cloud.google.com/bigquery/). The CDC's Natality data has details on US births from 1969 to 2008 and is a publically available dataset, meaning anyone with a GCP account has access. Click [here](https://console.cloud.google.com/bigquery?project=bigquery-public-data&p=publicdata&d=samples&t=natality&page=table) to access the dataset.
#
# The natality dataset is relatively large at almost 138 million rows and 31 columns, but simple to understand. `weight_pounds` is the target, the continuous value we’ll train a model to predict.
# + [markdown] deletable=true editable=true
# <h2> Explore data </h2>
#
# The data is natality data (record of births in the US). The goal is to predict the baby's weight given a number of factors about the pregnancy and the baby's mother. Later, we will want to split the data into training and eval datasets. The hash of the year-month will be used for that -- this way, twins born on the same day won't end up in different cuts of the data. We'll first create a SQL query using the natality data after the year 2000.
# + deletable=true editable=true
query = """
SELECT
weight_pounds,
is_male,
mother_age,
plurality,
gestation_weeks,
FARM_FINGERPRINT(
CONCAT(
CAST(YEAR AS STRING),
CAST(month AS STRING)
)
) AS hashmonth
FROM
publicdata.samples.natality
WHERE
year > 2000
"""
# -
# Let's create a BigQuery client that we can use throughout the notebook.
bq = bigquery.Client()
# Let's now examine the result of a BiqQuery call in a Pandas DataFrame using our newly created client.
# + deletable=true editable=true jupyter={"outputs_hidden": false}
# Call BigQuery and examine in dataframe
df = bigquery.Client().query(query + " LIMIT 1000").to_dataframe()
df.head()
# -
# First, let's get the set of all valid column names in the natality dataset. We can do this by accessing the `INFORMATION_SCHEMA` for the table from the dataset.
# +
# Query to get all column names within table schema
sql = """
SELECT
column_name
FROM
publicdata.samples.INFORMATION_SCHEMA.COLUMNS
WHERE
table_name = "natality"
"""
# Send query through BigQuery client and store output to a dataframe
valid_columns_df = bq.query(sql).to_dataframe()
# Convert column names in dataframe to a set
valid_columns_set = valid_columns_df["column_name"].tolist()
# -
# We can print our valid columns set to see all of the possible columns we have available in the dataset. Of course, you could also find this information by going to the `Schema` tab when selecting the table in the [BigQuery UI](https://console.cloud.google.com/bigquery?project=bigquery-public-data&p=publicdata&d=samples&t=natality&page=table).
print(valid_columns_set)
# ## Lab Task #1: Use BigQuery to explore natality dataset.
# Using the above code as an example, write a query to find the unique values for each of the columns and the count of those values for babies born after the year 2000.
# For example, we want to get these values:
# <pre>
# is_male num_babies avg_wt
# False 16245054 7.104715
# True 17026860 7.349797
# </pre>
# This is important to ensure that we have enough examples of each data value, and to verify our hunch that the parameter has predictive value.
#
# Hint (highlight to see): <p style='color:white'>Use COUNT(), AVG() and GROUP BY. For example:
# <pre style='color:white'>
# SELECT
# is_male,
# COUNT(1) AS num_babies,
# AVG(weight_pounds) AS avg_wt
# FROM
# publicdata.samples.natality
# WHERE
# year > 2000
# GROUP BY
# is_male
# </pre>
# </p>
# + deletable=true editable=true
# TODO: Create function that gets distinct value statistics from BigQuery
def get_distinct_values(valid_columns_set, column_name):
"""Gets distinct value statistics of BigQuery data column.
Args:
valid_columns_set: set, the set of all possible valid column names in
table.
column_name: str, name of column in BigQuery.
Returns:
Dataframe of unique values, their counts, and averages.
"""
assert column_name in valid_columns_set, (
"{column_name} is not a valid column_name".format(
column_name=column_name))
sql = """
SELECT
{column_name},
COUNT(1) AS num_babies,
AVG(weight_pounds) AS avg_wt
FROM
publicdata.samples.natality
WHERE
year > 1990
GROUP BY
{column_name}
""".format(column_name=column_name)
return bq.query(sql).to_dataframe()
#pass
# -
# ## Lab Task #2: Use Cloud AI Platform Notebook to plot explorations.
#
# Which factors seem to play a part in the baby's weight?
#
# <b>Bonus:</b> Draw graphs to illustrate your conclusions
#
# Hint (highlight to see):
# <p style='color:white'># TODO: Reusing the get_distinct_values function you just implemented, create function that plots distinct value statistics from BigQuery
#
# Hint (highlight to see): <p style='color:white'> The simplest way to plot is to use Pandas' built-in plotting capability
# <pre style='color:white'>
# df = get_distinct_values(valid_columns_set, column_name)
# df = df.sort_values(column_name)
# df.plot(x=column_name, y="num_babies", kind="bar", figsize=(12, 5))
# df.plot(x=column_name, y="avg_wt", kind="bar", figsize=(12, 5))
# </pre>
# TODO: Create function that plots distinct value statistics from BigQuery
def plot_distinct_values(valid_columns_set, column_name, logy=False):
"""Plots distinct value statistics of BigQuery data column.
Args:
valid_columns_set: set, the set of all possible valid column names in
table.
column_name: str, name of column in BigQuery.
logy: bool, if plotting counts in log scale or not.
"""
df = get_distinct_values(valid_columns_set, column_name)
df = df.sort_values(column_name)
df.plot(
x=column_name, y="num_babies", logy=logy, kind="bar", figsize=(12, 5))
df.plot(x=column_name, y="avg_wt", kind="bar", figsize=(12, 5))
#pass
# Make a bar plot to see `is_male` with `avg_wt` linearly scaled and `num_babies` logarithmically scaled.
# + deletable=true editable=true jupyter={"outputs_hidden": false}
plot_distinct_values(valid_columns_set, column_name="is_male", logy=False) # TODO: Plot is_male
# -
# Make a bar plot to see `mother_age` with `avg_wt` linearly scaled and `num_babies` linearly scaled.
# + deletable=true editable=true jupyter={"outputs_hidden": false}
plot_distinct_values(valid_columns_set, column_name="mother_age", logy=False) # TODO: Plot mother_age
# -
# Make a bar plot to see `plurality` with `avg_wt` linearly scaled and `num_babies` logarithmically scaled.
# + deletable=true editable=true jupyter={"outputs_hidden": false}
plot_distinct_values(valid_columns_set, column_name="plurality", logy=True) # TODO: Plot plurality
# -
# Make a bar plot to see `gestation_weeks` with `avg_wt` linearly scaled and `num_babies` logarithmically scaled.
# + deletable=true editable=true jupyter={"outputs_hidden": false}
plot_distinct_values(
valid_columns_set, column_name="gestation_weeks", logy=True) # TODO: Plot gestation_weeks
# + [markdown] deletable=true editable=true
# All these factors seem to play a part in the baby's weight. Male babies are heavier on average than female babies. Teenaged and older moms tend to have lower-weight babies. Twins, triplets, etc. are lower weight than single births. Preemies weigh in lower as do babies born to single moms. In addition, it is important to check whether you have enough data (number of babies) for each input value. Otherwise, the model prediction against input values that doesn't have enough data may not be reliable.
# <p>
# In the next notebooks, we will develop a machine learning model to combine all of these factors to come up with a prediction of a baby's weight.
# -
# ## Lab Summary:
# In this lab, we used BigQuery to explore the data and used Cloud AI Platform Notebooks to plot data explorations.
# + [markdown] deletable=true editable=true
# Copyright 2019 Google Inc. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License
| courses/machine_learning/deepdive2/structured/labs/1a_explore_data_babyweight.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
#importing libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
# reading datafile
df_1 = pd.read_excel("E:\capestone project\HRAnalytics\HR Analytics\staff utlz latest 16-17_masked.xlsx")
df_2 = pd.read_excel("E:\capestone project\HRAnalytics\HR Analytics\staff utlz latest 17-18_masked.xlsx")
df_1.head()
df_2.head()
# resetting header
df_1.columns = df_1.iloc[0]
df_2.columns = df_2.iloc[0]
df_1.head()
# now we remove the row.
df_1 = df_1.drop(0)
df_2 = df_2.drop(0)
df_1.head()
#setting index from Employee No
df_1 = df_1.set_index('Employee No')
df_2 = df_2.set_index('Employee No')
df_2.head()
#saving the file
file_name="E:\capestone project\HRAnalytics\HR Analytics\2016.xlsx"
df_1.to_csv(file_name,sep=',',encoding='utf-8')
file_name="E:\capestone project\HRAnalytics\HR Analytics\2018.xlsx"
df_2.to_csv(file_name,sep=',',encoding='utf-8')
df_1 = pd.read_csv("E:\capestone project\HRAnalytics\HR Analytics\2016.xlsx")
df_2 = pd.read_csv("E:\capestone project\HRAnalytics\HR Analytics\2018.xlsx")
df_1.head()
df_1.shape
df_2.shape
# combine botht the data files.
df = pd.concat([df_1,df_2]).reset_index(drop=True)
df.head()
df.shape
# +
#drop duplicates
df = df.drop_duplicates(subset='Employee No')
# -
df = df.drop_duplicates(subset='Employee Name')
df.shape
# removing columns which are not necessary for this dataset
df=df.drop(df.columns[11:107], axis=1)
df.head()
#check the types of columns
df.dtypes
df.info()
#check for missing values"
df.isna().sum()
msno.matrix(df)
msno.bar(df, color='b', figsize = (7,7))
# setting employee No as index
df=df.set_index('Employee No')
#unique values
# we can see that below few columns have categorical variables, we will do label encodeing.
{column: len(df[column].unique()) for column in df.columns}
# we can remove join date and termination date, as the current status is there.
df=df.drop(df.columns[7], axis=1)
# we can remove join date and termination date, as the current status is there.
df=df.drop(df.columns[8], axis=1)
df.head()
# converted utilization column from object dtype to float data type
df['Utilization%.12'] = pd.to_numeric(df['Utilization%.12'],errors='coerce')
#label encoding categorical variables.
from sklearn import preprocessing
from sklearn.preprocessing import LabelEncoder
labelencoder = LabelEncoder()
df['Profit Center'] = labelencoder.fit_transform(df['Profit Center'])
df['Employee Location'] = labelencoder.fit_transform(df['Employee Location'])
df.head()
# current status has 4 categories, where 2 categories comes under active. hence, we can do it as 0 and 1
df['Current Status']=df['Current Status'].replace({'Active':0,'Secondment':0,'Sabbatical':0,'New Joiner':0,'Resigned':1})
# converting employee position to numerical categories
df['Employee Position']=df['Employee Position'].replace({'Level 1':1,'Level A1':1,'Level 2':2,'Level A2':2,'Level 3':3,
'Level A3':3,'Level 4':4,'Level 5':5,'Level 6':6,'Level 7':7,'Level 8':8,
'Level 10':10,'-':0
})
df['People Group'].value_counts()
# get dummies for people group, concat the columns and drop the column people group
people = pd.get_dummies(df['People Group'])
df = pd.concat((df, people), axis = 1)
df.head()
# additionally supervisor name can be dropped.
df = df.drop(df.columns[6], axis=1)
df.head()
#people group also removed.
df = df.drop(df.columns[4], axis=1)
df.head()
df['Employee Category'].unique()
# maping with numeric variables in employee category.
df['Employee Category'] = df['Employee Category'].map({'Confirmed Staff':0,'Level 1/2':1,'Serving Notice Period':2,
'Secondee-Outward-Without Pay':3, 'Awaiting Termination':2,
'Staff on Probation':1,'Secondee-Outward-With Pay':3,'Resigned':2,'Fixed term Staff':1})
# assigned confirmed staff as 0, level 1/2, staff on probation and fixed term staff as 1, serving notice,
#awaiting termination and resinged as 2, Secondee-outward-without pay and with pay as 3
df['Employee Category'].value_counts()
sns.countplot(df['Employee Category'])
sns.countplot(y='Employee Category', hue='Current Status', data=df, palette='magma')
# graphical representation of numeric data distribution among data groups.
df.hist(edgecolor='black', linewidth=1.2, figsize=(15,15))
# +
dfFilter = df[df['Total Available Hours.12'] > 2000]
dfFilter.loc[:,['Work Hours.12','Total Available Hours.12'] ].plot.bar(stacked=False)
# -
df['Training Hours.12'].plot(kind='density')
#finding correlation of data.
df.corr()
#graphical representation
plt.figure(figsize=(16,8))
sns.heatmap(df.corr(),annot=True, cmap='Wistia_r',annot_kws={"size":15})
df.describe()
#recheck columns for which we can use labelencode or onehot encodder.
for column in df.columns:
if df[column].dtype == object:
print(str(column) + ' : '+ str(df[column].unique()))
print(df[column].value_counts())
print('**************************************')
| HR analytics_1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="jwzym_rIk4_C"
#
# ## *Data Science Unit 4 Sprint 3 Assignment 1*
#
# # Recurrent Neural Networks and Long Short Term Memory (LSTM)
#
# 
#
# It is said that [**infinite monkeys typing for an infinite amount of time**](https://en.wikipedia.org/wiki/Infinite_monkey_theorem) will eventually type, among other things, the complete works of <NAME>. Let's see if we can get there a bit faster, with the power of Recurrent Neural Networks and LSTM.
#
# We will focus specifically on Shakespeare's Sonnets in order to improve our model's ability to learn from the data.
# + colab={"resources": {"http://localhost:8080/nbextensions/google.colab/files.js": {"data": "<KEY>K", "ok": true, "headers": [["content-type", "application/javascript"]], "status": 200, "status_text": ""}}, "base_uri": "https://localhost:8080/", "height": 109} id="xktqehW0mWEk" outputId="6bf06777-7109-4328-bbc4-4b682fbc58a9"
from google.colab import files
files.upload()
# + id="EwMRVvN6k4_K"
import random
import sys
import os
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import LambdaCallback
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, Bidirectional
from tensorflow.keras.layers import LSTM
# %matplotlib inline
# a custom data prep class that we'll be using
from data_cleaning_toolkit_class import data_cleaning_toolkit
# + [markdown] id="Wb8WAxQ2k4_N"
# ### Use request to pull data from a URL
#
# [**Read through the request documentation**](https://requests.readthedocs.io/en/master/user/quickstart/#make-a-request) in order to learn how to download the Shakespeare Sonnets from the Gutenberg website.
#
# **Protip:** Do not over think it.
# + deletable=false nbgrader={"cell_type": "code", "checksum": "6ac79c2e9a53d747ebf8fb41f4b39340", "grade": false, "grade_id": "cell-b8ececfad1f60557", "locked": false, "schema_version": 3, "solution": true, "task": false} id="L9wSCXqDk4_O"
# download all of Shakespears Sonnets from the Project Gutenberg website
import requests
# here's the link for the sonnets
url_shakespeare_sonnets = "https://www.gutenberg.org/cache/epub/1041/pg1041.txt"
# use request and the url to download all of the sonnets - save the result to `r`
r = requests.get(url_shakespeare_sonnets)
# + deletable=false nbgrader={"cell_type": "code", "checksum": "4ab4f4f14188a9f3703d43d223bfa150", "grade": false, "grade_id": "cell-0cd0c8509bc8e8cf", "locked": false, "schema_version": 3, "solution": true, "task": false} id="YAcjW6r0k4_P"
# move the downloaded text out of the request object - save the result to `raw_text_data`
# hint: take at look at the attributes of `r`
raw_text_data = r.text
# + [markdown] id="Jfne-CYlo9QW"
# Q: what's the difference between r.text and r.content? r.content is bytes
# ---
#
#
# + colab={"base_uri": "https://localhost:8080/"} id="kjNTX4xDk4_Q" outputId="1faa0aff-11e3-4eac-9958-36763dbe378f"
# check the data type of `raw_text_data`
type(raw_text_data)
# + colab={"base_uri": "https://localhost:8080/"} id="Z4PygjfXpEuw" outputId="3327c042-50b0-46be-a79d-42a6192ef770"
test = r.content
type(test)
# + [markdown] id="LSeSvA5ck4_S"
# ### Data Cleaning
# + colab={"base_uri": "https://localhost:8080/", "height": 103} id="KmzszJSDk4_T" outputId="d19b0be2-3686-4973-b7bc-51247c6257fe"
# as usual, we are tasked with cleaning up messy data
# Question: Do you see any characters that we could use to split up the text?
raw_text_data[:3000]
# + deletable=false nbgrader={"cell_type": "code", "checksum": "13b66e41cc64459f0757f6f53a78e08f", "grade": false, "grade_id": "cell-916f742d2cea299a", "locked": false, "schema_version": 3, "solution": true, "task": false} colab={"base_uri": "https://localhost:8080/"} id="-LDSm5Nvk4_U" outputId="56fb5c74-3e85-4d35-a6f6-3af8d78ffe4f"
# split the text into lines and save the result to `split_data`
split_data = raw_text_data.split('\r\n')
split_data #type: list
# + colab={"base_uri": "https://localhost:8080/"} id="ofNPfit_k4_U" outputId="3dd90bcf-c626-4b17-d220-1a2373e78f3f"
# we need to drop all the boiler plate text (i.e. titles and descriptions) as well as white spaces
# so that we are left with only the sonnets themselves
split_data[:20]
# + [markdown] id="xV-eUiT2k4_V"
# **Use list index slicing in order to remove the titles and descriptions so we are only left with the sonnets.**
#
# + deletable=false nbgrader={"cell_type": "code", "checksum": "00ead0a1024ff72116c24f6b473c1aac", "grade": false, "grade_id": "cell-1f388b88b0eec24a", "locked": false, "schema_version": 3, "solution": true, "task": false} id="HW7Cd3mIk4_W"
# sonnets exists between these indicies
# titles and descriptions exist outside of these indicies
# use index slicing to isolate the sonnet lines - save the result to `sonnets`
#Delete the first 43 lines of descriptions
del split_data[:43]
# + id="E8zzR2Fs2CoI"
#Delete the last non-sonnet description
del split_data[-369:]
# + colab={"base_uri": "https://localhost:8080/"} id="8PNrvTXt1dcs" outputId="d9166f43-f2cc-4f3e-a706-1a4425a46ea2"
#Save the sonnet text to 'sonnets'
sonnets = split_data
sonnets
# + colab={"base_uri": "https://localhost:8080/"} id="uqSVufp5k4_X" outputId="000d4eb0-6994-415b-ae7c-fab62feb91d3"
# notice how all non-sonnet lines have far less characters than the actual sonnet lines?
# well, let's use that observation to filter out all the non-sonnet lines
sonnets[200:240]
# + deletable=false nbgrader={"cell_type": "code", "checksum": "649cf52260448a5faf539ad6b6e8e6e8", "grade": false, "grade_id": "cell-84c4b3cf1f3c032a", "locked": false, "schema_version": 3, "solution": true, "task": false} colab={"base_uri": "https://localhost:8080/"} id="jCJYwhnxk4_Y" outputId="6c850b95-8093-48e1-bf29-47da5f2842b4"
# any string with less than n_chars characters will be filtered out - save results to `filtered_sonnets`
filtered_sonnets = list(filter(lambda x: len(x) > 9, sonnets))
filtered_sonnets[-100:]
# + colab={"base_uri": "https://localhost:8080/"} id="ePH8qHRwk4_Z" outputId="4dd54463-aeae-4ba2-85bc-fb7d29fc8dee"
# ok - much better!
# but we still need to remove all the punctuation and case normalize the text
# import re
# def clean(text):
# filtered = re.sub('[^a-zA-Z 0-9]', '', text)
# filtered = filtered.lower()
# return filtered
# filtered_sonnets = filtered_sonnets.apply(clean)
# filtered_sonnets
for i in range(len(filtered_sonnets)):
filtered_sonnets[i] = filtered_sonnets[i].lower()
filtered_sonnets[i] = re.sub('[^a-zA-Z 0-9]', '', filtered_sonnets[i])
filtered_sonnets
# + [markdown] id="ruVit1gck4_a"
# ### Use custom data cleaning tool
#
# Use one of the methods in `data_cleaning_toolkit` to clean your data.
#
# There is an example of this in the guided project.
# + deletable=false nbgrader={"cell_type": "code", "checksum": "a722083a29139936744ff9a341e1c9a3", "grade": false, "grade_id": "cell-775c14b456d8a724", "locked": false, "schema_version": 3, "solution": true, "task": false} id="_3a1zVI0k4_b"
# instantiate the data_cleaning_toolkit class - save result to `dctk`
dctk = data_cleaning_toolkit()
# + deletable=false nbgrader={"cell_type": "code", "checksum": "ab91e612cd08068f3a36172979157d5d", "grade": false, "grade_id": "cell-684010b6a7360876", "locked": false, "schema_version": 3, "solution": true, "task": false} id="8aU1FJeEk4_b"
# use data_cleaning_toolkit to remove punctuation and to case normalize - save results to `clean_sonnets`
clean_sonnets = dctk.clean_data(str(sonnets))
# + colab={"base_uri": "https://localhost:8080/", "height": 103} id="meLX486sk4_c" outputId="c5b06736-88a8-42de-8de7-4c2acc519bd9"
# much better!
clean_sonnets
# + colab={"base_uri": "https://localhost:8080/"} id="R0zVqV05H1FN" outputId="08062284-e66d-4321-d904-27a992b1aae2"
print(type(clean_sonnets))
print(len(clean_sonnets))
# + [markdown] id="81t4UULsk4_c"
# ### Use your data tool to create character sequences
#
# We'll need the `create_char_sequenes` method for this task. However this method requires a parameter call `maxlen` which is responsible for setting the maximum sequence length.
#
# So what would be a good sequence length, exactly?
#
# In order to answer that question, let's do some statistics!
# + deletable=false nbgrader={"cell_type": "code", "checksum": "1deebea2ada0a7dc7d2eb08295ee1e2b", "grade": false, "grade_id": "cell-9ebdaa2654dd29ab", "locked": false, "schema_version": 3, "solution": true, "task": false} id="xzChGvG_k4_d"
def calc_stats(corpus):
"""
Calculates statisics on the length of every line in the sonnets
"""
# write a list comprehension that calculates each sonnets line length - save the results to `doc_lens`
# use numpy to calculate and return the mean, median, std, max, min of the doc lens - all in one line of code
doc_lens = []
for i in range(len(corpus)):
doc_lens.append(len(corpus[i]))
mean = np.mean(doc_lens)
med = np.median(doc_lens)
std = np.std(doc_lens)
max_ = max(doc_lens)
min_ = min(doc_lens)
return mean, med, std, max_, min_
# + colab={"base_uri": "https://localhost:8080/"} id="yGkLCzWHk4_e" outputId="929f956a-e905-45ef-ac6a-a9cf0de6ac03"
# sonnet line length statistics
mean ,med, std, max_, min_ = calc_stats(clean_sonnets)
mean, med, std, max_, min_
# + colab={"base_uri": "https://localhost:8080/"} id="CVLph_J7JPhY" outputId="5c6a5f8d-42cf-44f0-e903-616739e880d5"
# sonnet line length statistics
mean ,med, std, max_, min_ = calc_stats(filtered_sonnets)
mean, med, std, max_, min_
# + deletable=false nbgrader={"cell_type": "code", "checksum": "690957e46b6f2f32c1f17756d8ceab5b", "grade": false, "grade_id": "cell-35185e26897aad7e", "locked": false, "schema_version": 3, "solution": true, "task": false} colab={"base_uri": "https://localhost:8080/"} id="ZuuKt1x3k4_f" outputId="1d789fe2-480b-4865-be10-67a5b087d706"
# using the results of the sonnet line length statistics, use your judgement and select a value for maxlen
# use .create_char_sequences() to create sequences
sequences = dctk.create_char_sequenes(filtered_sonnets, maxlen=47, step=10)
# + [markdown] id="iCkI86pKk4_g"
# Take a look at the `data_cleaning_toolkit_class.py` file.
#
# In the first 4 lines of code in the `create_char_sequences` method, class attributes `n_features` and `unique_chars` are created. Let's call them in the cells below.
# + colab={"base_uri": "https://localhost:8080/"} id="OyUCmhTVk4_g" outputId="061fa3bd-ec41-411c-8bb7-a3d527b3882f"
# number of input features for our LSTM model
dctk.n_features
# + colab={"base_uri": "https://localhost:8080/"} id="NTZU2nzZk4_h" outputId="973300f1-5e2a-4c96-cd62-38f216ee5d25"
# unique charactes that appear in our sonnets
len(dctk.chars)
# + [markdown] id="4pa6BjVxk4_h"
# ## Time for Questions
#
# ----
# **Question 1:**
#
# Why are the `number of unique characters` (i.e. **dctk.unique_chars**) and the `number of model input features` (i.e. **dctk.n_features**) the same?
#
# **Hint:** The model that we will shortly be building here is very similar to the text generation model that we built in the guided project.
# + [markdown] id="CDtHjjRak4_i"
# **Answer 1:**
#
# Every character that appears in the sonnets will be input into the LSTM model, so the number of both is the same.
# + [markdown] id="xZTpFrN_k4_j"
#
# **Question 2:**
#
# Take a look at the print out of `dctk.unique_chars` one more time. Notice that there is a white space.
#
# Why is it desirable to have a white space as a possible character to predict?
# + [markdown] id="MCIQQN7Xk4_k"
# **Answer 2:**
#
# White space is valuable because it signals the end and beginning of words.
# + [markdown] id="E62Y4n91k4_k"
# ----
# + [markdown] id="whVOHh0Ik4_l"
# ### Use our data tool to create X and Y splits
#
# You'll need the `create_X_and_Y` method for this task.
# + id="0FgVvbVMk4_l"
# TODO: provide a walk through of data_cleaning_toolkit with unit tests that check for understanding
X, y = dctk.create_X_and_Y()
# + [markdown] id="r_Gtcq1Id_QK"
# # Q: why did I not have to call the object sequences in the above function? It's written in the .py object, it's referencing the self.init. Not a recommended way to architect it.
# + [markdown] id="KnCFaXZzk4_m"
# 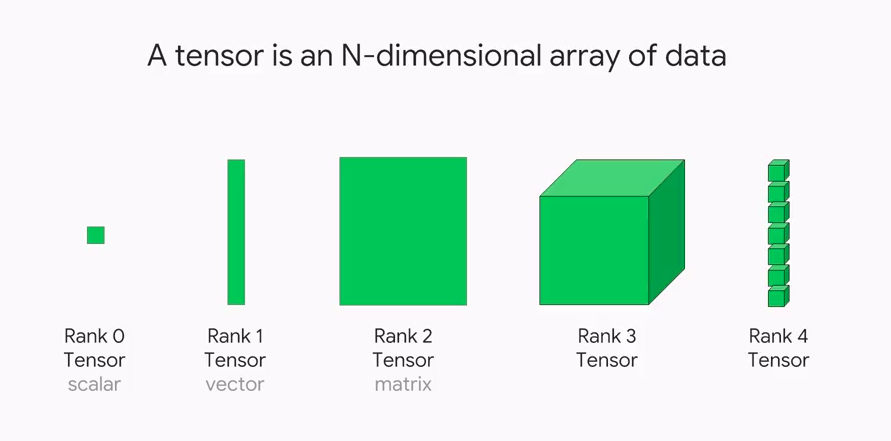
# + colab={"base_uri": "https://localhost:8080/"} id="JSy1d3wNk4_n" outputId="f73b1051-1525-41e9-e8aa-1cad85b13903"
# notice that our input matrix isn't actually a matrix - it's a rank 3 tensor
X.shape
# + colab={"base_uri": "https://localhost:8080/"} id="YV5IU9BleEP9" outputId="bdbb8321-2eae-4e59-c917-d136327730bb"
y.shape
# + [markdown] id="nPMimgdvk4_n"
# In $X$.shape we see three numbers (*n1*, *n2*, *n3*). What do these numbers mean?
#
# Well, *n1* tells us the number of samples that we have. But what about the other two?
# + colab={"base_uri": "https://localhost:8080/"} id="obsIP2hNk4_o" outputId="7b0522c0-4da5-4b9a-8be8-bd4edf87dbeb"
# first index returns a single sample, which we can see is a sequence
first_sample_index = 0
X[first_sample_index]
# + [markdown] id="ActUfCgQk4_o"
# Notice that each sequence (i.e. $X[i]$ where $i$ is some index value) is `maxlen` long and has `dctk.n_features` number of features. Let's try to better understand this shape.
# + colab={"base_uri": "https://localhost:8080/"} id="m44mWwvkk4_p" outputId="a8974e1e-1f86-44b2-f6e7-39c7471b865d"
# each sequence is maxlen long and has dctk.n_features number of features
X[first_sample_index].shape
# + [markdown] id="i9M3QhL3k4_p"
# **Each row corresponds to a character vector** and there are `maxlen` number of character vectors.
#
# **Each column corresponds to a unique character** and there are `dctk.n_features` number of features.
#
# + colab={"base_uri": "https://localhost:8080/"} id="zrR-0fuXk4_q" outputId="8e56ce05-6155-4ea4-c7d6-dd8347e38358"
# let's index for a single character vector
first_char_vect_index = 0
X[first_sample_index][first_char_vect_index]
# + [markdown] id="lnbOmg9lk4_q"
# Notice that there is a single `TRUE` value and all the rest of the values are `FALSE`.
#
# This is a one-hot encoding for which character appears at each index within a sequence. Specifically, the cell above is looking at the first character in the sequence.
#
# Only a single character can appear as the first character in a sequence, so there will necessarily be a single `TRUE` value and the rest will be `FALSE`.
#
# Let's say that `TRUE` appears in the $ith$ index; by $ith$ index we simply mean some index in the general case. How can we find out which character that actually corresponds to?
#
# To answer this question, we need to use the character-to-integer look up dictionaries.
# + colab={"base_uri": "https://localhost:8080/"} id="YQciMPYzk4_r" outputId="11f2e43f-c897-45c2-f46f-e8201e85385e"
# take a look at the index to character dictionary
# if a TRUE appears in the 0th index of a character vector,
# then we know that whatever char you see below next to the 0th key
# is the character that that character vector is endcoding for
dctk.int_char
# + colab={"base_uri": "https://localhost:8080/"} id="Hwl4l21Wk4_r" outputId="8c4d926c-b8b2-4468-dd57-737400d659e7"
# let's look at an example to tie it all together
seq_len_counter = 0
# index for a single sample
for seq_of_char_vects in X[first_sample_index]:
# get index with max value, which will be the one TRUE value
index_with_TRUE_val = np.argmax(seq_of_char_vects)
print (dctk.int_char[index_with_TRUE_val])
seq_len_counter+=1
print ("Sequence length: {}".format(seq_len_counter))
# + [markdown] id="Hlm6aqsPk4_s"
# ## Time for Questions
#
# ----
# **Question 1:**
#
# In your own words, how would you describe the numbers from the shape print out of `X.shape` to a fellow classmate?
#
# + [markdown] id="qNIwly-Mk4_s"
# **Answer 1:**
#
# 9515, 47, 27
#
# 9515 - the number of lines there are in the corpus, which are now vectors.
#
# 47 - the length of each line, how many characters there are in it.
#
# 27 - the number of unique characters in the entire corpus, each letter represents a feature/column for one hot encoding.
# + [markdown] id="lOwj0i7Hk4_t"
# ----
#
# + [markdown] id="tjTnb9oFk4_t"
# ### Build a Text Generation model
#
# Now that we have prepped our data (and understood that process) let's finally build out our character generation model, similar to what we did in the guided project.
# + id="2Pw4Wlo4k4_t"
def sample(preds, temperature=1.0):
"""
Helper function to sample an index from a probability array
"""
# convert preds to array
preds = np.asarray(preds).astype('float64')
# scale values
preds = np.log(preds) / temperature
# exponentiate values
exp_preds = np.exp(preds)
# this equation should look familar to you (hint: it's an activation function)
preds = exp_preds / np.sum(exp_preds)
# Draw samples from a multinomial distribution
probas = np.random.multinomial(1, preds, 1)
# return the index that corresponds to the max probability
return np.argmax(probas)
def on_epoch_end(epoch, _):
""""
Function invoked at end of each epoch. Prints the text generated by our model.
"""
print()
print('----- Generating text after Epoch: %d' % epoch)
# randomly pick a starting index
# will be used to take a random sequence of chars from `text`
start_index = random.randint(0, len(text) - dctk.maxlen - 1)
# this is our seed string (i.e. input seqeunce into the model)
generated = ''
# start the sentence at index `start_index` and include the next` dctk.maxlen` number of chars
sentence = text[start_index: start_index + dctk.maxlen]
# add to generated
generated += sentence
print('----- Generating with seed: "' + sentence + '"')
sys.stdout.write(generated)
# use model to predict what the next 40 chars should be that follow the seed string
for i in range(40):
# shape of a single sample in a rank 3 tensor
x_dims = (1, dctk.maxlen, dctk.n_features)
# create an array of zeros with shape x_dims
# recall that python considers zeros and boolean FALSE as the same
x_pred = np.zeros(x_dims)
# create a seq vector for our randomly select sequence
# i.e. create a numerical encoding for each char in the sequence
for t, char in enumerate(sentence):
# for sample 0 in seq index t and character `char` encode a 1 (which is the same as a TRUE)
x_pred[0, t, dctk.char_int[char]] = 1
# next, take the seq vector and pass into model to get a prediction of what the next char should be
preds = model.predict(x_pred, verbose=0)[0]
# use the sample helper function to get index for next char
next_index = sample(preds)
# use look up dict to get next char
next_char = dctk.int_char[next_index]
# append next char to sequence
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
print()
# + id="JLqlmgKuk4_v"
# need this for on_epoch_end()
text = " ".join(filtered_sonnets)
# + id="eAE0pNDRk4_v"
# create callback object that will print out text generation at the end of each epoch
# use for real-time monitoring of model performance
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
# + [markdown] id="nrEWrrGfk4_v"
# ----
# ### Train Model
#
# Build a text generation model using LSTMs. Feel free to reference the model used in the guided project.
#
# It is recommended that you train this model to at least 50 epochs (but more if you're computer can handle it).
#
# You are free to change up the architecture as you wish.
#
# Just in case you have difficultly training a model, there is a pre-trained model saved to a file called `trained_text_gen_model.h5` that you can load in (the same way that you learned how to load in Keras models in Sprint 2 Module 4).
# + deletable=false nbgrader={"cell_type": "code", "checksum": "e17312b57e17284124ce562dff81b00d", "grade": false, "grade_id": "cell-f34be90367fd9071", "locked": false, "schema_version": 3, "solution": true, "task": false} colab={"base_uri": "https://localhost:8080/"} id="0o3L49hNk4_w" outputId="f757cbac-4678-4089-ff31-c5b6ecf87719"
# build text generation model layer by layer
# fit model
model = Sequential()
model.add(LSTM(128, input_shape=(47, 27)))
model.add(Dense(27, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
model.fit(X, y,
batch_size=32,
epochs=50,
callbacks=[print_callback])
# + id="iPQ0xsvxk4_w"
# save trained model to file
model.save("trained_text_gen_model.h5")
# + [markdown] id="nx6k9w6xk4_x"
# ### Let's play with our trained model
#
# Now that we have a trained model that, though far from perfect, is able to generate actual English words, we can take a look at the predictions to continue to learn more about how a text generation model works.
#
# We can also take this as an opportunity to unpack the `def on_epoch_end` function to better understand how it works.
# + colab={"base_uri": "https://localhost:8080/", "height": 103} id="Ck9oXfZ6k4_x" outputId="a3aa58e0-ab31-4d59-9512-bfbe60159466"
# this is our joinned clean sonnet data
text
# + colab={"base_uri": "https://localhost:8080/"} id="WF3J6G22k4_y" outputId="96066a80-f097-49e6-9ed8-00007dfb735f"
# randomly pick a starting index
# will be used to take a random sequence of chars from `text`
# run this cell a few times and you'll see `start_index` is random
start_index = random.randint(0, len(text) - dctk.maxlen - 1)
start_index
# + colab={"base_uri": "https://localhost:8080/", "height": 35} id="QOpFVajek4_y" outputId="15d7db33-0df7-44bd-fcb0-870291a094c7"
# next use the randomly selected starting index to sample a sequence from the `text`
# this is our seed string (i.e. input seqeunce into the model)
generated = ''
# start the sentence at index `start_index` and include the next` dctk.maxlen` number of chars
sentence = text[start_index: start_index + dctk.maxlen]
# add to generated
generated += sentence
generated
# + colab={"base_uri": "https://localhost:8080/"} id="6-kRBUU9k4_z" outputId="9007540b-18e4-482b-b27d-2a6eea8f3ca3"
# this block of code let's us know what the seed string is
# i.e. the input seqeunce into the model
print('----- Generating with seed: "' + sentence + '"')
sys.stdout.write(generated)
# + id="iZgdGM7ek4_z"
# use model to predict what the next 40 chars should be that follow the seed string
for i in range(40):
# shape of a single sample in a rank 3 tensor
x_dims = (1, dctk.maxlen, dctk.n_features)
# create an array of zeros with shape x_dims
# recall that python considers zeros and boolean FALSE as the same
x_pred = np.zeros(x_dims)
# create a seq vector for our randomly select sequence
# i.e. create a numerical encoding for each char in the sequence
for t, char in enumerate(sentence):
# for sample 0 in seq index t and character `char` encode a 1 (which is the same as a TRUE)
x_pred[0, t, dctk.char_int[char]] = 1
# next, take the seq vector and pass into model to get a prediction of what the next char should be
preds = model.predict(x_pred, verbose=0)[0]
# use the sample helper function to get index for next char
next_index = sample(preds)
# use look up dict to get next char
next_char = dctk.int_char[next_index]
# append next char to sequence
sentence = sentence[1:] + next_char
# + colab={"base_uri": "https://localhost:8080/", "height": 35} id="QhWR_-Xnk4_0" outputId="0e9247db-d8f2-4311-91ff-b3e88c19f6fb"
# this is the seed string
generated
# + colab={"base_uri": "https://localhost:8080/", "height": 35} id="G2Ezaqnck4_1" outputId="8cb5a31e-5260-4876-86bd-f2970949d207"
# these are the 40 chars that the model thinks should come after the seed stirng
sentence
# + colab={"base_uri": "https://localhost:8080/", "height": 35} id="Sst83WTok4_1" outputId="781ac454-ac00-4ce1-c002-c4c11fce4571"
# how put it all together
generated + sentence
# + [markdown] id="zE4a4O7Bp5x1"
# # Resources and Stretch Goals
# + [markdown] id="uT3UV3gap9H6"
# ## Stretch goals:
# - Refine the training and generation of text to be able to ask for different genres/styles of Shakespearean text (e.g. plays versus sonnets)
# - Train a classification model that takes text and returns which work of Shakespeare it is most likely to be from
# - Make it more performant! Many possible routes here - lean on Keras, optimize the code, and/or use more resources (AWS, etc.)
# - Revisit the news example from class, and improve it - use categories or tags to refine the model/generation, or train a news classifier
# - Run on bigger, better data
#
# ## Resources:
# - [The Unreasonable Effectiveness of Recurrent Neural Networks](https://karpathy.github.io/2015/05/21/rnn-effectiveness/) - a seminal writeup demonstrating a simple but effective character-level NLP RNN
# - [Simple NumPy implementation of RNN](https://github.com/JY-Yoon/RNN-Implementation-using-NumPy/blob/master/RNN%20Implementation%20using%20NumPy.ipynb) - Python 3 version of the code from "Unreasonable Effectiveness"
# - [TensorFlow RNN Tutorial](https://github.com/tensorflow/models/tree/master/tutorials/rnn) - code for training a RNN on the Penn Tree Bank language dataset
# - [4 part tutorial on RNN](http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/) - relates RNN to the vanishing gradient problem, and provides example implementation
# - [RNN training tips and tricks](https://github.com/karpathy/char-rnn#tips-and-tricks) - some rules of thumb for parameterizing and training your RNN
| module1-rnn-and-lstm/LS_DS_431_RNN_and_LSTM_Assignment.ipynb |
// -*- coding: utf-8 -*-
// ---
// jupyter:
// jupytext:
// text_representation:
// extension: .scala
// format_name: light
// format_version: '1.5'
// jupytext_version: 1.14.4
// kernelspec:
// display_name: Scala
// language: scala
// name: scala
// ---
// + [markdown] slideshow={"slide_type": "slide"}
// <div style="text-align:center">
// <h1>Scala - Structuring Programs</h1>
// <h3><NAME> <br/> Departement of Mathematics and Computer Science</h3>
// </div>
// + [markdown] slideshow={"slide_type": "slide"}
// # Outline
//
// - Repetition: The basic building blocks
// - Scala - the simple parts
// - Objects
// - Groups
// - Collections
// - For-loops
// - Algebraic data types
// - Case study: Scalismo's IO Methods and ```Try```
// + [markdown] slideshow={"slide_type": "slide"}
// # Expression, types and values
//
// 
// + [markdown] slideshow={"slide_type": "slide"}
// # Functions and Methods
//
//
// Functions
//
// ```scala
// val add = (x : Int, y : Int) => {
// x + y
// }
// ```
//
// Methods
//
// ```scala
// def add(x : Int, y : Int) = {
// x + y
// }
// ```
// + [markdown] slideshow={"slide_type": "slide"}
// # Classes and Objects
//
// Declaring classes
//
// ```scala
// class Fraction(numerator : Int, denumerator : Int) {
// override def toString() : String = {
// numerator.toString() + "/" +denumerator.toString()
// }
// }
//
// val oneHalf = new Fraction(1, 2)
// oneHalf.toString()
// ```
//
// Objects
// ```scala
// object Calculator {
// def plus(a : Int, b : Int) = a + b
// }
//
// Calculator.plus(3, 4)
// ```
//
// + [markdown] slideshow={"slide_type": "slide"}
// # Simple Scala
//
// + [markdown] slideshow={"slide_type": "fragment"}
// > Simple is often erroneously mistaken for easy.
// >
// > * "Easy" means "to be at hand", "to be approachable".
// > * "Simple" is the opposite of "complex" which means "being intertwined", "being tied together".
// >
// > <NAME> (from the talk [Simple Made Easy](https://www.infoq.com/presentations/Simple-Made-Easy)
//
// + [markdown] slideshow={"slide_type": "slide"}
// # (almost) Everything is an expression
//
// * Everything evaluates to a value
// * Everything can be composed
// * Everything can be named
// +
val res = if (a == 3) "abc" else "cde"
val someComputation = {
val a = 3
a + 5
}
val newSeq = for (i <- 0 until 10) yield i + 1
// + [markdown] slideshow={"slide_type": "slide"}
// # Everything is an object
//
// * We always interact with any value by
// * Calling methods
// * Accessing fields
//
// Example:
// ```scala
// 1 + 3
// ```
//
// * 1 is object
// * ```+``` is method
// * 3 is Argument
//
// + [markdown] slideshow={"slide_type": "slide"}
// # Mini exercises
//
//
// Create a class Complex for representing complex numbers
//
// ```scala
// case class Complex(re : Double, imag : Double)
// ```
//
// * Implement a method called ```+``` to add two complex numbers
// * Try out the method:
// * Do you need the ```.``` to call it?
// * Do you need the paranthesis?
//
// * Implement a method called ```#*--!```
//
//
// +
// type your solution here
// + [markdown] slideshow={"slide_type": "slide"}
// # Groups
//
// * Everything can be grouped and nested
// * Static uniform scoping rules
// * Allows naming of thing
// * Allows keeping local things in local context
//
// +
def foo() : Unit = {
import collection.immutable.List
case class KeyValue(key : String, value : Int)
val list = List(KeyValue("A", 3), KeyValue("B", 2))
def keyIsA(kv : KeyValue) : Boolean = { kv.key == "A" }
list.count(keyIsA)
}
// + [markdown] slideshow={"slide_type": "slide"}
// # Collections
//
// * Collections aggregate data
// * Transformed to manipulate data
// * updates not possible with default collections
// * Uniform interface - Learn once, use everywhere
// + [markdown] slideshow={"slide_type": "slide"}
// # Collections - Basic operations
// + slideshow={"slide_type": "fragment"}
val people = Seq("<NAME>", "<NAME>", "<NAME>")
// + slideshow={"slide_type": "fragment"}
people.map(name => name.toUpperCase)
// + slideshow={"slide_type": "fragment"}
people.filter(name => name.startsWith("b"))
// + slideshow={"slide_type": "fragment"}
people.flatMap(name => name.split(" "))
// + [markdown] slideshow={"slide_type": "slide"}
// # Tuples, zip and unzip
//
// * Tuples represent a immutable sequence of fixed length
// -
val t : Tuple2[Int, String] = (1, "abc")
// + [markdown] slideshow={"slide_type": "fragment"}
// * Zip creates a sequence of tuples from two sequences
// * Unzip create two sequences from a sequence of tuples
// +
val a = Seq(1, 2, 3, 4)
val b = Seq("a", "b", "c", "d")
val zippedSeq : Seq[(Int, String)] = a.zip(b)
println("zipped list: " +zippedSeq)
val (aUnzipped, bUnzipped) : (Seq[Int], Seq[String]) = zippedSeq.unzip
// + [markdown] slideshow={"slide_type": "slide"}
// # Mini exercise
//
// * Create a sequence of values from 1 to 10
// * Double each value in the sequence
// * Filter out the values that can be divided by 7
// * Create a sequence of values like this:
// ```1, 2, 3, 2, 3, 4, 3, 4, 5, ...```
// * Create the cartesian product of the numbers 1 to 10 using only map and flatmap
//
// + [markdown] slideshow={"slide_type": "slide"}
// # For - loops
//
// > Scala has also for loops
// + slideshow={"slide_type": "fragment"}
for (i <- 0 until 10) {
print(i + " ")
}
// + slideshow={"slide_type": "fragment"}
val evenNumbers = for (i <- 0 until 10) yield {
i * 2
}
// + [markdown] slideshow={"slide_type": "slide"}
// # Not your father's for loops
//
// > For loops are only syntactic sugar
//
// The two expressions are the same:
// ```scala
// (0 until 10).map(i => i * 2)
// ```
// ```scala
// for (i <- 0 until 10) yield {
// i * 2
// }
// ```
//
// + [markdown] slideshow={"slide_type": "slide"}
// # Not your father's for loops
//
// > For loops are only syntactic sugar
//
// The two expressions are the same:
// ```scala
// (0 until 10).filter(i => i % 2 == 0)
// ```
// ```scala
// for (i <- 0 until 10 if i % 2 == 0) yield {
// i
// }
// ```
//
// + [markdown] slideshow={"slide_type": "slide"}
// # Not your father's for loops
//
// > For loops are only syntactic sugar
//
// The two expressions are the same:
// ```scala
// (0 until 10).flatMap(i =>(i until i + 2))
// ```
// ```scala
// for (i <- (0 until 10;
// iSeq <- i until i + 2) yield iSeq
// ```
//
//
// + [markdown] slideshow={"slide_type": "slide"}
// # Not your father's for loops
//
// > For loops are only syntactic sugar
//
// Makes complicated expressions look simple
// ```scala
// for (i <- 0 until 10;
// j <- 0 until 10;
// if (i + j) == 7) yield (i , j)
// ```
//
//
| notebooks/Scala-structuring.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Quick Setup
# Create a SystemML MLContext object
from systemml import MLContext, dml
ml = MLContext(sc)
# ## Download Data - MNIST
# The MNIST dataset contains labeled images of handwritten digits, where each example is a 28x28 pixel image of grayscale values in the range [0,255] stretched out as 784 pixels, and each label is one of 10 possible digits in [0,9]. Here, we download 60,000 training examples, and 10,000 test examples, where the format is "label, pixel_1, pixel_2, ..., pixel_n".
# + language="sh"
# mkdir -p data/mnist/
# cd data/mnist/
# curl -O http://pjreddie.com/media/files/mnist_train.csv
# curl -O http://pjreddie.com/media/files/mnist_test.csv
# -
# ## SystemML "LeNet" Neural Network
# ### 1. Train
script_string = """
source("mnist_lenet.dml") as mnist_lenet
# Read training data
data = read($data, format="csv")
n = nrow(data)
# Extract images and labels
images = data[,2:ncol(data)]
labels = data[,1]
# Scale images to [-1,1], and one-hot encode the labels
images = (images / 255.0) * 2 - 1
labels = table(seq(1, n), labels+1, n, 10)
# Split into training (55,000 examples) and validation (5,000 examples)
X = images[5001:nrow(images),]
X_val = images[1:5000,]
y = labels[5001:nrow(images),]
y_val = labels[1:5000,]
# Train
[W1, b1, W2, b2, W3, b3, W4, b4] = mnist_lenet::train(X, y, X_val, y_val, C, Hin, Win)
"""
script = (dml(script_string).input("$data", "data/mnist/mnist_train.csv")
.input(C=1, Hin=28, Win=28)
.output("W1", "b1", "W2", "b2", "W3", "b3", "W4", "b4"))
W1, b1, W2, b2, W3, b3, W4, b4 = (ml.execute(script)
.get("W1", "b1", "W2", "b2", "W3", "b3", "W4", "b4"))
# ### 2. Compute Test Accuracy
script_string = """
source("mnist_lenet.dml") as mnist_lenet
# Read test data
data = read($data, format="csv")
n = nrow(data)
# Extract images and labels
X_test = data[,2:ncol(data)]
y_test = data[,1]
# Scale images to [-1,1], and one-hot encode the labels
X_test = (X_test / 255.0) * 2 - 1
y_test = table(seq(1, n), y_test+1, n, 10)
# Eval on test set
probs = mnist_lenet::predict(X_test, C, Hin, Win, W1, b1, W2, b2, W3, b3, W4, b4)
[loss, accuracy] = mnist_lenet::eval(probs, y_test)
print("Test Accuracy: " + accuracy)
"""
script = dml(script_string).input(**{"$data": "data/mnist/mnist_train.csv",
"C": 1, "Hin": 28, "Win": 28,
"W1": W1, "b1": b1,
"W2": W2, "b2": b2,
"W3": W3, "b3": b3,
"W4": W4, "b4": b4})
ml.execute(script)
# ### 3. Extract Model Into Spark DataFrames For Future Use
W1_df = W1.toDF()
b1_df = b1.toDF()
W2_df = W2.toDF()
b2_df = b2.toDF()
W3_df = W3.toDF()
b3_df = b3.toDF()
W4_df = W4.toDF()
b4_df = b4.toDF()
W1_df, b1_df, W2_df, b2_df, W3_df, b3_df, W4_df, b4_df
| scripts/staging/SystemML-NN/examples/Example - MNIST LeNet.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] slideshow={"slide_type": "slide"}
# <center>
#
# # dask-image: distributed image processing for large data
#
# ## Presenter: <NAME>
#
# <img src="imgs/dask-icon.svg#thumbnail" alt="dask logo" width="100"/>
# </center>
#
# + [markdown] slideshow={"slide_type": "slide"}
# # Who needs dask-image?
#
# If you're using `numpy` and/or `scipy.ndimage` and are running out of RAM, dask-image is for you.
#
# ## Two main use cases
# 1. Batch processing
# 2. Large field of view
# + [markdown] slideshow={"slide_type": "slide"}
# # Motivating examples
#
# * Sentinel satellite data
# * Individual neurons within the brain
#
# <img src="imgs/motivating-examples.png#thumbnail" alt="Satellite data and brain neurons" width="1000"/>
#
# + [markdown] slideshow={"slide_type": "slide"}
# # Getting started
# https://github.com/dask/dask-image/
#
# ## conda
# ```
# conda install -c conda-forge dask-image
# ```
#
# ## pip
#
# ```
# pip install dask-image
# ```
#
# + [markdown] slideshow={"slide_type": "slide"}
# # What's included?
#
# * imread
# * ndfilters
# * ndfourier
# * ndmorph
# * ndmeasure
#
#
# + [markdown] slideshow={"slide_type": "slide"}
# # Function coverage
#
# <img src="imgs/function-coverage-table.png#thumbnail" alt="Table of function coverage: scipy.ndimage compared to dask-image http://image.dask.org/en/latest/coverage.html" width="900"/>
#
# + [markdown] slideshow={"slide_type": "slide"}
# # GPU support
#
# Latest release includes GPU support for the modules:
# * ndfilters
# * imread
#
# Still to do: ndfourier, ndmeasure, ndmorph*
#
# *Done, pending cupy PR #3907
# + [markdown] slideshow={"slide_type": "slide"}
# # GPU benchmarking
#
# | Architecture | Time |
# |-----------------|-----------|
# | Single CPU Core | 2hr 39min |
# | Forty CPU Cores | 11min 30s |
# | One GPU | 1min 37s |
# | Eight GPUs | 19s |
#
# https://blog.dask.org/2019/01/03/dask-array-gpus-first-steps
#
# + [markdown] slideshow={"slide_type": "slide"}
# # Let's build a pipeline!
#
# 1. Reading in data
# 2. Filtering images
# 3. Segmenting objects
# 4. Morphological operations
# 5. Measuring objects
# + slideshow={"slide_type": "fragment"}
# %gui qt
# + [markdown] slideshow={"slide_type": "slide"}
# We used image set [BBBC039v1](https://bbbc.broadinstitute.org/bbbc/BBBC039) Caicedo et al. 2018, available from the Broad Bioimage Benchmark Collection [Ljosa et al., Nature Methods, 2012](http://dx.doi.org/10.1038/nmeth.2083).
#
# https://bbbc.broadinstitute.org/BBBC039
#
# <img src="imgs/BBBC039-example-image.png#thumbnail" alt="BBBC039 image of flourescent nuclei" width="700"/>
#
# + [markdown] slideshow={"slide_type": "slide"}
# # 1. Reading in data
#
# + slideshow={"slide_type": "fragment"}
from dask_image.imread import imread
images = imread('data/BBBC039/images/*.tif')
# images_on_gpu = imread('data/BBBC039/images/*.tif', arraytype="cupy")
images
# + [markdown] slideshow={"slide_type": "slide"}
# # 2. Filtering images
# Denoising images with a small blur can improve segmentation later on.
# + slideshow={"slide_type": "fragment"}
from dask_image import ndfilters
smoothed = ndfilters.gaussian_filter(images, sigma=[0, 1, 1])
# + [markdown] slideshow={"slide_type": "slide"}
# # 3. Segmenting objects
# Pixels below the threshold value are background.
# + slideshow={"slide_type": "fragment"}
absolute_threshold = smoothed > 160
# + slideshow={"slide_type": "fragment"}
# Let's have a look at the images
import napari
viewer = napari.Viewer()
viewer.add_image(absolute_threshold)
viewer.add_image(images, contrast_limits=[0, 2000])
# + [markdown] slideshow={"slide_type": "subslide"}
# # 3. Segmenting objects (continued)
#
# A better segmentation using local thresholding.
#
# + slideshow={"slide_type": "fragment"}
thresh = ndfilters.threshold_local(smoothed, images.chunksize)
threshold_images = smoothed > thresh
# + slideshow={"slide_type": "fragment"}
# Let's take a look at the images
viewer.add_image(threshold_images)
# + [markdown] slideshow={"slide_type": "slide"}
# # 4. Morphological operations
#
# These are operations on the shape of a binary image.
#
# https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_imgproc/py_morphological_ops/py_morphological_ops.html
#
#
# + [markdown] slideshow={"slide_type": "subslide"}
# ## Erosion
#
# <img src="imgs/erosion.png#thumbnail" alt="Erosion, binary morphological operation
# https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_imgproc/py_morphological_ops/py_morphological_ops.html
# " width="500"/>
# + [markdown] slideshow={"slide_type": "subslide"}
# ## Dilation
#
# <img src="imgs/dilation.png#thumbnail" alt="Dilation, binary morphological operation
# https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_imgproc/py_morphological_ops/py_morphological_ops.html
# " width="500"/>
#
# + [markdown] slideshow={"slide_type": "subslide"}
# A morphological opening operation is an erosion, followed by a dilation.
#
# <img src="imgs/opening.png#thumbnail" alt="Opening, binary morphological operation
# https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_imgproc/py_morphological_ops/py_morphological_ops.html
# " width="500"/>
#
# + slideshow={"slide_type": "subslide"}
from dask_image import ndmorph
import numpy as np
structuring_element = np.array([
[[0, 0, 0], [0, 0, 0], [0, 0, 0]],
[[0, 1, 0], [1, 1, 1], [0, 1, 0]],
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]])
binary_images = ndmorph.binary_opening(threshold_images, structure=structuring_element)
# + [markdown] slideshow={"slide_type": "slide"}
# # 5. Measuring objects
# Each image has many individual nuclei, so for the sake of time we'll measure a small subset of the data.
# + slideshow={"slide_type": "fragment"}
from dask_image import ndmeasure
# Create labelled mask
label_images, num_features = ndmeasure.label(binary_images[:3], structuring_element)
index = np.arange(num_features - 1) + 1 # [1, 2, 3, ...num_features]
print("Number of nuclei:", num_features.compute())
# + slideshow={"slide_type": "subslide"}
# Let's look at the labels
viewer.add_labels(label_images)
viewer.dims.set_point(0, 0)
# + [markdown] slideshow={"slide_type": "subslide"}
# # Measuring objects (continued)
# + slideshow={"slide_type": "fragment"}
# Measure objects in images
area = ndmeasure.area(images[:3], label_images, index)
mean_intensity = ndmeasure.mean(images[:3], label_images, index)
# + slideshow={"slide_type": "subslide"}
# Run computation and plot results
import matplotlib.pyplot as plt
plt.scatter(area, mean_intensity, alpha=0.5)
plt.gca().update(dict(title="Area vs mean intensity", xlabel='Area (pixels)', ylabel='Mean intensity'))
plt.show()
# + [markdown] slideshow={"slide_type": "slide"}
# # The full pipeline
#
# ```python
# import numpy as np
# from dask_image.imread import imread
# from dask_image import ndfilters, ndmorph, ndmeasure
#
# images = imread('data/BBBC039/images/*.tif')
# smoothed = ndfilters.gaussian_filter(images, sigma=[0, 1, 1])
# thresh = ndfilters.threshold_local(smoothed, blocksize=images.chunksize)
# threshold_images = smoothed > thresh
# structuring_element = np.array([[[0, 0, 0], [0, 0, 0], [0, 0, 0]], [[0, 1, 0], [1, 1, 1], [0, 1, 0]], [[0, 0, 0], [0, 0, 0], [0, 0, 0]]])
# binary_images = ndmorph.binary_closing(threshold_image, structure=structuring_element)
# label_images, num_features = ndmeasure.label(binary_image)
# index = np.arange(num_features)
# area = ndmeasure.area(images, label_images, index)
# mean_intensity = ndmeasure.mean(images, label_images, index)
# ```
# + [markdown] hideOutput=true slideshow={"slide_type": "slide"}
# # Custom functions
#
# What if you want to do something that isn't included?
#
# * scikit-image [apply_parallel()](https://scikit-image.org/docs/dev/api/skimage.util.html#skimage.util.apply_parallel)
# * dask [map_overlap](https://docs.dask.org/en/latest/array-overlap.html?highlight=map_overlap#dask.array.map_overlap) / [map_blocks](https://docs.dask.org/en/latest/array-api.html?highlight=map_blocks#dask.array.map_blocks)
# * dask [delayed](https://docs.dask.org/en/latest/delayed.html)
# + [markdown] slideshow={"slide_type": "slide"}
# # Scaling up computation
#
# Use [dask-distributed](https://distributed.dask.org/en/latest/) to scale up from a laptop onto a supercomputing cluster.
# + [markdown] slideshow={"slide_type": "fragment"}
# ```python
# from dask.distributed import Client
#
# # Setup a local cluster
# # By default this sets up 1 worker per core
# client = Client()
# client.cluster
#
# ```
# + [markdown] slideshow={"slide_type": "slide"}
# # dask-image
#
# * Install: `conda` or `pip install dask-image`
# * Documentation: https://dask-image.readthedocs.io
# * GitHub: https://github.com/dask/dask-image/
# + [markdown] slideshow={"slide_type": "slide"}
# <center>
# <img src="imgs/dask-icon.svg#thumbnail" alt="dask logo" width="300"/>
# </center>
#
# + [markdown] slideshow={"slide_type": "slide"}
# # Bonus content
# ## Example using arrays on GPU
# + [markdown] slideshow={"slide_type": "subslide"}
# ```python
# # CPU example
# import numpy as np
# import dask.array as da
# from dask_image.ndfilters import convolve
#
# s = (10, 10)
# a = da.from_array(np.arange(int(np.prod(s))).reshape(s), chunks=5)
# w = np.ones(a.ndim * (3,), dtype=np.float32)
# result = convolve(a, w)
# result.compute()
# ```
# + [markdown] slideshow={"slide_type": "subslide"}
# ```python
# # Same example moved to the GPU
# import cupy # <- import cupy instead of numpy (version >=7.7.0)
# import dask.array as da
# from dask_image.ndfilters import convolve
#
# s = (10, 10)
# a = da.from_array(cupy.arange(int(cupy.prod(cupy.array(s)))).reshape(s), chunks=5) # <- cupy dask array
# w = cupy.ones(a.ndim * (3,)) # <- cupy dask array
# result = convolve(a, w)
# result.compute()
# ```
# -
| presentation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: visualization-curriculum-gF8wUgMm
# language: python
# name: visualization-curriculum-gf8wugmm
# ---
# # Collecting metrics and logs from on-premises servers with the CloudWatch agent
# > A detailed guide on using cloudwatch agent to collect logs and metrics from an on-premises Ubuntu server.
#
# - toc: true
# - badges: false
# - comments: true
# - categories: [aws, cloudwatch]
# - keywords: [logs, aws, cloudwatch]
# - image: images/copied_from_nb/images/2022-05-21-cloudwatch-agent-onprem.jpeg
# 
# # About
# This post is a detailed guide on using [AWS CloudWatch](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/WhatIsCloudWatch.html) Agent to collect logs and metrics from on-premises Ubuntu server.
# * The CloudWatch agent is open-source tool under the MIT license, and is hosted on GitHub [amazon-cloudwatch-agent](https://github.com/aws/amazon-cloudwatch-agent/)
# * With this agent you can collect more system-level metrics from Amazon EC2 instances or onprem servers across operating systems. You can retrieve custom metrics from your applications or services using the StatsD and collectd protocols. **StatsD** is supported on both Linux servers and servers running Windows Server. **collectd** is supported only on Linux servers
# * For the list of metrics that can be collected by CloudWatch agent follow this link [metrics-collected-by-CloudWatch-agent](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/metrics-collected-by-CloudWatch-agent.html)
# # Environment Details
#
# For on-premises Ubuntu server, we will use an EC2 machine with Ubuntu OS. Enable Auto-assign public IP and keep all the default settings. Once the instance is in a running state use SSH Key to connect to it.
#
# If you are using Windows OS and while connecting to Ubuntu machine you are getting "Permissions for 'ssh-key.pem' are too open." then take help from this post to resolve it [windows-ssh-permissions-for-private-key-are-too-open](https://superuser.com/questions/1296024/windows-ssh-permissions-for-private-key-are-too-open)
#
# 
#
# Once you are successfully connected to EC2 Ubuntu machine you will get the following message on the terminal.
# 
# # CloudWatch Agent Installation and Configuration Steps
# ## Create IAM roles and users for use with CloudWatch agent
# Access to AWS resources requires permissions. You create an IAM role, an IAM user, or both to grant permissions that the CloudWatch agent needs to write metrics to CloudWatch.
# * If you're going to use the agent on Amazon EC2 instances, you should create an IAM role.
# * f you're going to use the agent on on-premises servers, you should create an IAM user.
#
# Since we want to use EC2 machine as an on-premises machine so we will create an IAM user.
#
# **To create the IAM user necessary for the CloudWatch agent to run on on-premises servers follow these steps**
# 1. Sign in to the AWS Management Console and open the IAM console at https://console.aws.amazon.com/iam/.
# 2. In the navigation pane on the left, choose **Users** and then **Add users**.
# 3. Enter the user name for the new user.
# 4. Select **Access key - Programmatic access** and choose **Next: Permissions**.
# 5. Choose **Attach existing policies directly**.
# 6. In the list of policies, select the check box next to **CloudWatchAgentServerPolicy**. If necessary, use the search box to find the policy.
# 7. Choose **Next: Tags**.
# 8. Optionally create tags for the new IAM user, and then choose **Next:Review**.
# 9. Confirm that the correct policy is listed, and choose **Create user**.
# 10. Next to the name of the new user, choose **Show**. Copy the access key and secret key to a file so that you can use them when installing the agent. Choose **Close**.
# ## Install and configure AWS CLI on Ubuntu server
# Connect to the Ubuntu server using any SSH client. We need to first download and install AWS CLI. Follow the below commands to download and install it. For installing AWS CLI on macOS and Windows take help from this post [awscli-getting-started-install](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html)
#
# ### 1. Download AWS CLI package
#
# ```
# curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
# ```
#
# ### 2. Install UNZIP package
#
# ```
# sudo apt install unzip
# ```
#
# ### 3. Unzip AWSCLI Package
#
# ```
# unzip awscliv2.zip
# ```
#
# ### 4. Install AWS CLI
#
# ```
# sudo ./aws/install
# ```
#
# **5. Verify AWS CLI Installation**
#
# ```
# aws --version
# ```
#
# 
#
# ### 6. Configure AWS CLI
# Make sure that you use **AmazonCloudWatchAgent** profile name as this is used by the `OnPremise` case by default. For more details, you may take help from this post [install-CloudWatch-Agent-commandline-fleet](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/install-CloudWatch-Agent-commandline-fleet.html)
# ```
# aws configure --profile AmazonCloudWatchAgent
# ```
# 
#
# ### 7. Verify credentials in User home directory
#
# ```
# # cat /home/ubuntu/.aws/credentials
# ```
# ## Install and run the CloudWatch agent on Ubuntu server
#
# ### 1. Download the agent
# The following download link is for Ubuntu. For any other OS you can take help from this post for downloaded agent [download-cloudwatch-agent-commandline](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/download-cloudwatch-agent-commandline.html)
# ```
# wget https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb
# ```
#
# ### 2. Install the agent
# ```
# sudo dpkg -i -E ./amazon-cloudwatch-agent.deb
# ```
#
# ### 3. Prepare agent configuration file
# Prepare agent configuration file. This config file will be provided to the agent in the run command. One such sample is provided below. For more details on this config file you may take help from this link [create-cloudwatch-agent-configuration-file](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/create-cloudwatch-agent-configuration-file.html). Note the path of this config file (**agent config**) as we will need it in later commands.
# + vscode={"languageId": "json"}
// config-cloudwatchagent.json
{
"agent": {
"metrics_collection_interval": 10,
"logfile": "/opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log",
"run_as_user": "ubuntu",
"debug": false
},
"metrics": {
"namespace": "myblog/cloudwatchagent/demo",
"metrics_collected": {
"cpu": {
"resources": [
"*"
],
"measurement": [
{"name": "cpu_usage_idle", "rename": "CPU_USAGE_IDLE", "unit": "Percent"},
{"name": "cpu_usage_nice", "unit": "Percent"},
"cpu_usage_guest",
"cpu_usage_active"
],
"totalcpu": true,
"metrics_collection_interval": 10
},
"disk": {
"resources": [
"/",
"/tmp"
],
"measurement": [
{"name": "free", "rename": "DISK_FREE", "unit": "Gigabytes"},
"total",
"used"
],
"ignore_file_system_types": [
"sysfs", "devtmpfs"
],
"metrics_collection_interval": 60
},
"diskio": {
"resources": [
"*"
],
"measurement": [
"reads",
"writes",
"read_time",
"write_time",
"io_time"
],
"metrics_collection_interval": 60
},
"swap": {
"measurement": [
"swap_used",
"swap_free",
"swap_used_percent"
]
},
"mem": {
"measurement": [
"mem_used",
"mem_cached",
"mem_total"
],
"metrics_collection_interval": 1
},
"net": {
"resources": [
"eth0"
],
"measurement": [
"bytes_sent",
"bytes_recv",
"drop_in",
"drop_out"
]
},
"netstat": {
"measurement": [
"tcp_established",
"tcp_syn_sent",
"tcp_close"
],
"metrics_collection_interval": 60
},
"processes": {
"measurement": [
"running",
"sleeping",
"dead"
]
}
},
"force_flush_interval" : 30
},
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log",
"log_group_name": "myblog/onprem/ubuntu/amazon-cloudwatch-agent",
"log_stream_name": "myblog-cloudwatchagent-demo.log",
"timezone": "UTC"
}
]
}
},
"log_stream_name": "my_log_stream_name",
"force_flush_interval" : 15
}
}
# -
# Some important parts of this config file
#
# **logfile**
# ```
# "logfile": "/opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log"
# ```
# CloudWatch agent log file location on on-premise server is specified by this tag. After running the agent you can check this log file for any exception messages.
#
# **log_group_name**
# ```
# "log_group_name": "myblog/onprem/ubuntu/amazon-cloudwatch-agent"
# ```
# An on-premise logfile is also uploaded to CloudWatch under `log-group-name` specified by this tag.
#
# **log_stream_name**
# ```
# "log_stream_name": "myblog-cloudwatchagent-demo.log"
# ```
# Log stream name of the CloudWatch where logfile log steam will be uploaded.
#
# **namespace**
# ```
# "namespace": "myblog/cloudwatchagent/demo"
# ```
# On CloudWatch console you find the uploaded metrics under the custom namespace specified by this tag. In our case, it is "myblog/cloudwatchagent/demo"
# ### 4. Update shared configuration file
# From the config file
# 1. Uncomment the `[credentails]` tag
# 2. Update `shared_credentails_profile` name. This is the profile name with which we have configured our AWS CLI 'AmazonCloudWatchAgent'. If you have used any other name then use that name here.
# 3. Update `shared_credentials_file` path. This is the path for AWS user credentails file created by AWS CLI. '/home/`username`/.aws/credentials' and in our case it is `/home/ubuntu/.aws/credentials`
#
# Configuration file is located at `/opt/aws/amazon-cloudwatch-agent/etc/common-config.toml`. For more details on this shared configuration file follow this link [CloudWatch-Agent-profile-instance-first](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/install-CloudWatch-Agent-commandline-fleet.html#CloudWatch-Agent-profile-instance-first)
# ```
# sudo vim /opt/aws/amazon-cloudwatch-agent/etc/common-config.toml
# ```
# 
#
# ### 5. Start the agent
# ```
# sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m onPremise -s -c file:/home/ubuntu/config-cloudwatchagent.json
# ```
# Make sure that you provide the correct path to the JSON config file. In our case, it is **file:/home/ubuntu/config-cloudwatchagent.json**. For more details check this link [start-CloudWatch-Agent-on-premise-SSM-onprem](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/install-CloudWatch-Agent-on-premise.html#start-CloudWatch-Agent-on-premise-SSM-onprem)
#
# 
#
# ### 6. Check agent status
# ```
# sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status
# ```
# If the agent is running you will get **status : running** otherwise you will get **status : stopped**
#
# 
#
# ### 7. Check agent logs
# The agent generates a log while it runs. This log includes troubleshooting information. This log is the `amazon-cloudwatch-agent.log` file. This file is located in `/opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log` on Linux servers. This is the same logfile path we also defined in the JSON config file. If you are using multiple agents on the machine then you can give them separate log file paths using their JSON configurations.
# ```
# sudo tail -f /var/log/amazon/amazon-cloudwatch-agent/amazon-cloudwatch-agent.log
# ```
# Check the logs if there is an exception message or not.
#
# 
#
# Please note that both the log files are the same. It could be that agent is keeping multiple copies for internal processing.
#
# ```
# /opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log
# ```
# or
# ```
# /var/log/amazon/amazon-cloudwatch-agent/amazon-cloudwatch-agent.log
# ```
# ## Check the agent logs on AWS CloudWatch console
# Agent logs are also uploaded to CloudWatch console under log **group** and **stream** that we mentioned in JSON config file. In our case it is
# ```
# "log_group_name": "myblog/onprem/ubuntu/amazon-cloudwatch-agent"
# "log_stream_name": "myblog-cloudwatchagent-demo.log"
# ```
# 
# ## Check the machine metrics on CloudWatch console
#
# Now finally we can check the metrics uploaded by the agent on CloudWatch console under `CloudWatch > Metrics > ALL metrics > Custom namespaces`
#
# The name of the metrics namespace is the same as what we defined in our JSON config file
# ```
# "metrics": {
# "namespace": "myblog/cloudwatchagent/demo"
# ```
#
# 
# # Common scenarios with the CloudWatch agent
#
# For more trouble shooting scenerios follow these link
# * [troubleshooting-CloudWatch-Agent](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/troubleshooting-CloudWatch-Agent.html)
# * [CloudWatch-Agent-common-scenarios](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-Agent-common-scenarios.html)
#
# ## To stop the CloudWatch agent locally using the command line
#
# On a Linux server, enter the following
# ```
# sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a stop
# ```
#
# ## I updated my agent configuration but don’t see the new metrics or logs in the CloudWatch console
# If you update your CloudWatch agent configuration file, the next time that you start the agent, you need to use the fetch-config option. For example, if you stored the updated file on the local computer, enter the following command. Replace `<configuration-file-path>` with the actual config file path.
# ```
# sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -s -m ec2 -c file:<configuration-file-path>
# ```
| _notebooks/2022-05-21-cloudwatch-agent-onprem.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:py37]
# language: python
# name: conda-env-py37-py
# ---
# # Thinking in tensors, writing in PyTorch
#
# Hands-on training by [<NAME>](https://p.migdal.pl) (2019). Version for ML in PL 2019.
#
#
# ## Extra: matrix factorization
#
# See:
#
# * [Matrix decomposition viz](http://p.migdal.pl/matrix-decomposition-viz/) for some inspiration.
# * Section 4 from [From Customer Segmentation to Recommendation Systems](https://www.aitrends.com/machine-learning/ai-customer-targeting-levels/).
#
# To do: turn it into an exercise.
# +
# %matplotlib inline
import pandas as pd
import seaborn as sns
import numpy as np
import torch
from torch import nn
from torch.nn import Parameter
# -
months = ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"]
cities = ["Toronto", "Warsaw", "Boston", "London", "San Francisco", "Jerusalem", "Mexico", "Cape Town", "Sydney"]
avg_temp = np.array([
[-5.8, -3.1, 4.5, 6.7, 14.3, 18.2, 20.1, 20.6, 15.9, 11.2, 3.6, -7.2],
[-2.9, 3.6, 4.2, 9.7, 16.1, 19.5, 20.0, 18.8, 16.4, 7.6, 3.2, 1.3],
[0.3, 1.5, 5.9, 8.4, 14.8, 20.2, 24.5, 24.7, 19.7, 13.0, 7.9, 1.9],
[2.3, 6.5, 8.7, 9.2, 12.3, 15.4, 17.3, 20.0, 14.8, 10.8, 8.7, 6.4],
[11.5, 13.9, 14.3, 15.7, 16.3, 17.4, 17.2, 17.7, 18.2, 17.4, 14.6, 10.4],
[9.7, 10.3, 12.7, 15.5, 21.2, 22.1, 24.1, 25.3, 23.5, 20.1, 15.7, 11.8],
[14.0, 15.6, 17.5, 20.3, 20.6, 18.1, 17.6, 18.2, 17.8, 16.8, 14.9, 16.0],
[23.1, 23.3, 21.4, 19.0, 17.1, 15.5, 15.4, 15.6, 15.4, 18.6, 20.9, 21.3],
[23.8, 24.6, 23.4, 20.8, 18.1, 15.1, 14.4, 14.5, 17.3, 19.0, 21.8, 24.3]
])
df = pd.DataFrame(avg_temp, index=cities, columns=months)
sns.heatmap(df, annot=True, fmt='.0f')
# ## Exercise
#
# Using PyTorch, perform a matrix decomposition, i.e. $M = A B$.
#
# Hints:
#
# * NumPy to PyTorch: `torch.from_numpy(x)`
# * PyTorch to NumPy: `x.numpy()` or `x.detach().numpy()`
# * make sure or floats are `float32` (for Torch tensors use: `x = x.float()`)
# * view results and the training curve
import matplotlib.pyplot as plt
avg_temp_tensor = torch.from_numpy(avg_temp).float()
def show_loss(losses, logy=False):
print("Minimal loss: {:.3f}".format(losses[-1]))
if logy:
plt.semilogy(range(len(losses)), losses)
else:
plt.plot(range(len(losses)), losses);
plt.xlabel("Step")
plt.ylabel("Loss")
# # %load hint_matrix_1.py
class Factorize(nn.Module):
def __init__(self, factors=2):
super().__init__()
self.A = Parameter(torch.randn(9, factors))
self.B = Parameter(torch.randn(factors, 12))
def forward(self):
output = self.A.matmul(self.B)
return output
class FactorizeBiasA(nn.Module):
def __init__(self, factors=2):
super().__init__()
self.A = Parameter(torch.randn(9, factors))
self.B = Parameter(torch.randn(factors, 12))
self.bias_A = Parameter(torch.randn(9, 1))
def forward(self):
output = self.A.matmul(self.B) + self.bias_A
return output
# # %load hint_matrix_2.py
model = Factorize(factors=2)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
# +
# load hint 3... oh, no - actually, go to the previous notebooks :)
# +
losses = []
for i in range(10000):
output = model()
loss = criterion(output, avg_temp_tensor)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
show_loss(losses, logy=True)
# -
df_pred = pd.DataFrame(model().detach().numpy(), index=cities, columns=months)
sns.heatmap(df_pred, annot=True, fmt='.0f')
sns.heatmap(df_pred - df, annot=True, fmt='.0f')
torch.randint_like(avg_temp_tensor, 0, 2)
def train_cv(model, optimizer, epochs=10000):
losses = []
losses_val = []
mask = torch.randint_like(avg_temp_tensor, 0, 2)
for i in range(epochs):
output = model()
loss = (output - avg_temp_tensor).mul(mask).pow(2).sum() / mask.sum()
losses.append(loss.item())
loss_val = (output - avg_temp_tensor).mul(1 - mask).pow(2).sum() / (1 - mask).sum()
losses_val.append(loss_val.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
return losses, losses_val
model = Factorize(factors=2)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
losses, losses_val = train_cv(model, optimizer, epochs=10000)
print(losses[-1], losses_val[-1])
# +
dims = [1, 2, 3, 4]
res = []
for d in dims:
model = Factorize(factors=d)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
losses, losses_val = train_cv(model, optimizer, epochs=10000)
res.append({
'd': d,
'loss': losses[-1],
'losses_val': losses_val[-1]
})
pd.DataFrame(res).set_index('d').plot.bar(logy=True)
# +
dims = [1, 2, 3, 4]
res = []
for d in dims:
model = FactorizeBiasA(factors=d)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
losses, losses_val = train_cv(model, optimizer, epochs=10000)
res.append({
'd': d,
'loss': losses[-1],
'losses_val': losses_val[-1]
})
pd.DataFrame(res).set_index('d').plot.bar(logy=True)
# -
| extra/Matrix exercise.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import os
import json
import glob
import dateutil.parser as dparser
import imageio
import numpy as np
import moviepy.editor as mp
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.backends.backend_pgf import FigureCanvasPgf
mpl.backend_bases.register_backend("pdf", FigureCanvasPgf)
mpl.use("pgf")
# %matplotlib inline
# %config InlineBackend.figure_format="retina"
# Matplotlib plotting options
plt.style.use("seaborn-paper")
plt.rcParams.update({
"axes.labelsize": 16, # label size (x- and y-axis)
"axes.titlesize": 20, # title size on (most) axes
"figure.titlesize": 20, # title size for fig.sup_title()
"legend.fontsize": "large", # font size for legend
"lines.markersize": 6, # marker size for points and lines
"lines.markeredgewidth": 2, # marker edgewidth for points
"xtick.labelsize": 14, # label size for x-ticks
"ytick.labelsize": 14, # label size for y-ticks
"font.family": "serif", # use serif/main font for text elements
"text.usetex": True, # use inline math for ticks
"pgf.rcfonts": False, # don't setup fonts from rc params
"pgf.preamble": [
# Syling
r"\usepackage{color}", # special colors
r"\setmainfont{DejaVu Serif}", # serif font via preamble
# Math
r"\usepackage{xfrac}", # side fractions
r"\usepackage{amsthm}", # theorems
r"\usepackage{amsmath}", # misc math
r"\usepackage{amssymb}", # blackboard math symbols
r"\usepackage{mathtools}", # enhance the appearance of math
],
})
# -
def corner(data):
"""Corner plot of latent distribution :math:`z`."""
num_latent = data.shape[-1]
figsize = (num_latent*3, num_latent*3)
fig, axarr = plt.subplots(nrows=num_latent, ncols=num_latent, sharex=True,
sharey=False, figsize=figsize)
for i in range(axarr.shape[0]):
# Plot latent vector (z) for each param
for j in range(i+1):
ax = axarr[i,j]
if i == j:
ax.hist(data[:, j], bins=20, color="mediumseagreen", density=True)
else:
ax.scatter(data[:, i], data[:, j], c="mediumseagreen", marker="o",
alpha=1.0, edgecolors="black")
ax.set_xlim([-5, 5])
ax.set_ylim([-5, 5])
# Make unused plots white
for j in range(i+1, axarr.shape[1]):
axarr[i,j].axis('off')
# Cleanup
for i, row in enumerate(axarr):
for j, cell in enumerate(row):
# Display labels on edge plots only
if i == len(axarr) - 1:
cell.set_xlabel("$q(z_{%d}|x)$" % j)
if j == 0:
cell.set_ylabel("$q(z_{%d}|x)$" % i)
# Remove tick labels on inner subplots
if i != len(axarr) - 1:
cell.set_xticklabels([])
if j != 0:
cell.set_yticklabels([])
return fig
epoch = 0
rootdir = "../../results/"
files = sorted(glob.glob("../../dumps/3gb1/vae/*/*.json"))
for file in files:
# Epoch number
epoch += 1
# Parse datetime from the file
for _str in file.split("/"):
try:
dt = dparser.parse(_str, fuzzy=True)
except ValueError:
pass
ts = dt.strftime("%Y-%b-%d-%H:%M:%S")
savedir = os.path.join(rootdir, f"3gb1/vae/{ts}")
os.makedirs(savedir, exist_ok=True)
with open(file, "r") as fp:
dump = json.load(fp)
# Obtain original (encoded) data and latent (z) space
z = np.array(dump["z"])
fig = corner(z[:, :5])
# Cleanup and save fig
fig.tight_layout()
fig.suptitle(f"Latent vector (epoch {epoch:04d})")
fig.subplots_adjust(top=0.95)
fig.savefig(os.path.join(savedir, f"E{epoch:04d}.png"),
bbox_inches="tight", dpi=150)
plt.close()
# +
filenames = sorted(glob.glob(os.path.join(savedir, "E*.png")))
with imageio.get_writer(os.path.join(savedir, 'latent.gif'), mode='I', duration=0.2) as writer:
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
clip = mp.VideoFileClip(os.path.join(savedir, 'latent.gif'))
clip.write_videofile(os.path.join(savedir, 'latent.mp4'))
| examples/gb1/visualize_latent.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + _cell_guid="b1076dfc-b9ad-4769-8c92-a6c4dae69d19" _uuid="8f2839f25d086af736a60e9eeb907d3b93b6e0e5"
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# -
# # Task 1
# ## WHO Covid-19 dataset
# This dataset provided by WHO describes the number of deaths, cumulative deaths, confirmed cases, and cumulative confirmed cases per Country and per day. This dataset was downloaded from [WHO](https://covid19.who.int/) and uploaded to Kaggle notebook. <br>
# To load data set *pd.read_csv()* is used.
# + _cell_guid="79c7e3d0-c299-4dcb-8224-4455121ee9b0" _uuid="d629ff2d2480ee46fbb7e2d37f6b5fab8052498a"
df = pd.read_csv('/kaggle/input/WHO-COVID-19-global-data.csv')
df.head(10)
# -
# ## Dimension of the data (rows, columns)
print(df.shape)
# ## Date range of the data
df_range = df.sort_values(by=['day'])
print(df_range['day'].unique())
# The date range is from 2020-01-08 to 2020-04-26
# # Task 2
# ## Number of countries in the dataset
print(df['Country Name'].unique())
print('Number of Countries: ',len(df['Country'].unique()))
# ## First country to report confirmed case (according to data)
df.sort_values(by=['day'])
# According to this data, the first case reported on Jan 08th 2020 was in Thailand. In actual, China was the first country with a confirmed case. By Jan 11th 2020, there were already 41 reported confirmed cases in China.
# ## Line chart showing growth of confirmed cases in China, Thailand, and USA.
df_china = df[df['Country Name'] == 'China']
df_china.head()
# ### Line chart for China
df_china.plot.line(x= 'day', y = 'Cumulative Confirmed')
df_thailand = df[df['Country Name'] == 'Thailand']
df_thailand.head()
# ### Line chart for Thailand
df_thailand.plot.line(x= 'day', y = 'Cumulative Confirmed')
df_usa = df[df['Country Name'] == 'United States of America']
df_usa.head()
# ### Line chart for USA
df_usa.plot.line(x= 'day', y = 'Cumulative Confirmed')
# ## Comparison of cumulative confirmed cases by Country
df2 = df.sort_values(by=['Country'])
df2.drop_duplicates(subset ="Country",
keep = 'first', inplace = True)
df2.head()
import matplotlib.pyplot as plt
df2.plot.area(y = 'Cumulative Confirmed', x='Country', figsize=(15,5))
# # Task 3
# ## Predict confirmed cases by target country
# For this task Linear Regression model is used.
# ### Find minimum and maximum values for confirmed cases
min_con = df['Confirmed'].min()
min_con
max_con = df['Confirmed'].max()
max_con
# ### Normalize the values to be between 0 and 1
# +
def t_normalized(origin):
if origin is None:
return None
else:
return ((origin-min_con)/(max_con-min_con))
normalized_confirmed = t_normalized(df['Confirmed'])
# -
# ### Find the min and max for cumulative confirmed cases
min_cumulative_con = df['Cumulative Confirmed'].min()
min_cumulative_con
max_cumulative_con = df['Cumulative Confirmed'].max()
max_cumulative_con
# ### Normalize the values to be between 0 and 1
# +
def t_normalized(origin):
if origin is None:
return None
else:
return ((origin-min_cumulative_con)/(max_cumulative_con-min_cumulative_con))
normalized_cumulative_confirmed = t_normalized(df['Cumulative Confirmed'])
# -
# ### Reshape the values
y = normalized_confirmed.values.reshape(-1,1)
X = normalized_cumulative_confirmed.values.reshape(-1,1)
# ### Split into train and test sets
# +
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# -
# ### Import the model and fit
from sklearn.linear_model import LinearRegression
from sklearn import metrics
regressor = LinearRegression()
regressor.fit(X_train, y_train)
# ### Perform prediction on the test set
y_pred = regressor.predict(X_test)
# ### The result. Actual vs Predicted
result_df = pd.DataFrame({'Actual': y_test.flatten(), 'Predicted': y_pred.flatten()})
result_df
# ### Visual representation of Actual vs Predicted
df1 = result_df.head(25)
df1.plot(kind='bar',figsize=(16,10))
plt.grid(which='major', linestyle='-', linewidth='0.5', color='green')
plt.grid(which='minor', linestyle=':', linewidth='0.5', color='black')
plt.show()
# ### Perform prediction on a target country.
df_france = df[df['Country Name'] == 'France']
x_test = df_france['Confirmed'].values.reshape(-1,1)
y_pred = regressor.predict(x_test)
res_df = pd.DataFrame({'Actual': x_test.flatten(), 'Predicted': y_pred.flatten()})
res_df
# ### Visual representation of Actual vs Predicted
df1 = res_df.head(25)
df1.plot(kind='bar',figsize=(16,10))
plt.grid(which='major', linestyle='-', linewidth='0.5', color='green')
plt.grid(which='minor', linestyle=':', linewidth='0.5', color='black')
plt.show()
| finalexam-5938122.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
import sys
import math
# %matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
RANDOM_STATE = 42
np.random.seed(RANDOM_STATE)
# +
## Folder Locations
TEST_IMAGE_FOLDER = '../data/raw/Test/testset/'
TEST_CSV = '../data/raw/Test/testset.csv'
TRAIN_IMAGE_FOLDER = '../data/raw/Train/testset/'
TRAIN_CSV = '../data/raw/Train/testset.csv'
# VALID_IMAGE_FOLDER = '../data/raw/Train/testset/'
# VALID_CSV = '../data/raw/Valid/new_valid_set.csv'
# -
train_set = pd.read_csv(TRAIN_CSV)
test_set = pd.read_csv(TEST_CSV)
train_set.head()
test_set.head()
test_set['Label'] = test_set['Label'].apply(str)
train_set['Label'] = train_set['Label'].apply(str)
test_set.info()
CLASSES = len(train_set['Label'].unique())
# # Image Data generator
from keras_preprocessing.image import ImageDataGenerator
datagen=ImageDataGenerator(rescale=1./255.,validation_split=0.25)
# +
TARGET_SIZE=(425, 618)
train_generator=datagen.flow_from_dataframe(
dataframe=train_set,
directory=TRAIN_IMAGE_FOLDER,
x_col="Data",
y_col="Label",
subset="training",
batch_size=32,
seed=RANDOM_STATE,
shuffle=True,
class_mode="categorical",
target_size=TARGET_SIZE)
valid_generator=datagen.flow_from_dataframe(
dataframe=train_set,
directory=TRAIN_IMAGE_FOLDER,
x_col="Data",
y_col="Label",
subset="validation",
batch_size=32,
seed=RANDOM_STATE,
shuffle=True,
class_mode="categorical",
target_size=TARGET_SIZE)
test_datagen=ImageDataGenerator(rescale=1./255.)
test_generator=test_datagen.flow_from_dataframe(
dataframe=test_set,
directory=TEST_IMAGE_FOLDER,
x_col="Data",
y_col=None,
batch_size=32,
seed=RANDOM_STATE,
shuffle=False,
class_mode=None,
target_size=TARGET_SIZE)
# -
TARGET_SIZE[1]
# ## Custom CNN
from tensorflow.keras.layers import Dense, Activation, Flatten, Dropout, BatchNormalization
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import regularizers, optimizers
from tensorflow.keras.models import Sequential
# +
# model = Sequential()
# model.add(Conv2D(32, (3, 3), padding='same',
# input_shape=(TARGET_SIZE[0],TARGET_SIZE[1],3)))
# model.add(Activation('relu'))
# model.add(Conv2D(32, (3, 3)))
# model.add(Activation('relu'))
# model.add(MaxPooling2D(pool_size=(2, 2)))
# model.add(Dropout(0.25))
# model.add(Conv2D(64, (3, 3), padding='same'))
# model.add(Activation('relu'))
# model.add(Conv2D(64, (3, 3)))
# model.add(Activation('relu'))
# model.add(MaxPooling2D(pool_size=(2, 2)))
# model.add(Dropout(0.25))
# model.add(Flatten())
# model.add(Dense(512))
# model.add(Activation('relu'))
# model.add(Dropout(0.5))
# model.add(Dense(CLASSES, activation='softmax'))
# model.compile(optimizers.RMSprop(lr=0.0001, decay=1e-6),loss="categorical_crossentropy",metrics=["accuracy"])
# +
# # STEP_SIZE_TRAIN=train_generator.n//train_generator.batch_size
# # STEP_SIZE_VALID=valid_generator.n//valid_generator.batch_size
# # STEP_SIZE_TEST=test_generator.n//test_generator.batch_size
# STEP_SIZE_TRAIN = 50
# STEP_SIZE_VALID = 10
# STEP_SIZE_TEST =10
# model.fit_generator(generator=train_generator,
# steps_per_epoch=STEP_SIZE_TRAIN,
# validation_data=valid_generator,
# validation_steps=STEP_SIZE_VALID,
# epochs=10
# )
# +
from tensorflow.keras.applications.inception_v3 import InceptionV3
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
# create the base pre-trained model
base_model = InceptionV3(weights='imagenet', include_top=False)
# add a global spatial average pooling layer
x = base_model.output
x = GlobalAveragePooling2D()(x)
# let's add a fully-connected layer
x = Dense(1024, activation='relu')(x)
# and a logistic layer -- let's say we have 200 classes
predictions = Dense(CLASSES, activation='softmax')(x)
# this is the model we will train
model = Model(inputs=base_model.input, outputs=predictions)
# first: train only the top layers (which were randomly initialized)
# i.e. freeze all convolutional InceptionV3 layers
for layer in base_model.layers[:300]:
layer.trainable = False
# compile the model (should be done *after* setting layers to non-trainable)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# train the model on the new data for a few epochs
# model.fit(...)
# +
EPOCHS = 5
BATCH_SIZE = 32
STEPS_PER_EPOCH = train_generator.n//train_generator.batch_size
# VALIDATION_STEPS = 64
STEP_SIZE_VALID=valid_generator.n//valid_generator.batch_size
MODEL_FILE = 'filename.model'
history = model.fit_generator(
train_generator,
epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_data=valid_generator,
validation_steps=STEP_SIZE_VALID)
model.save(MODEL_FILE)
# -
len(model.layers)
# +
# # at this point, the top layers are well trained and we can start fine-tuning
# # convolutional layers from inception V3. We will freeze the bottom N layers
# # and train the remaining top layers.
# # let's visualize layer names and layer indices to see how many layers
# # we should freeze:
# for i, layer in enumerate(base_model.layers):
# print(i, layer.name)
# # we chose to train the top 2 inception blocks, i.e. we will freeze
# # the first 249 layers and unfreeze the rest:
# for layer in model.layers[:249]:
# layer.trainable = False
# for layer in model.layers[249:]:
# layer.trainable = True
# # we need to recompile the model for these modifications to take effect
# # we use SGD with a low learning rate
# from tensorflow.keras.optimizers import SGD
# model.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss='categorical_crossentropy')
# # we train our model again (this time fine-tuning the top 2 inception blocks
# # alongside the top Dense layers
# model.fit(...)
| notebooks/01.01_bb_MODEL_ballot_paper-v2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
import numpy as np
from sklearn.svm import SVR
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
# %matplotlib inline
from matplotlib import pyplot as plt
# -
# # Q1.
# ## Q1.1
# Using make_regression to generate data, create and train the following models:
# - Linear Regression
# - Support Vector Regression ([see here](https://scikit-learn.org/stable/modules/svm.html#regression))
# - Decision Tree Regression ([see here](https://scikit-learn.org/stable/modules/tree.html#regression))
#
# Make sure to use the same data for each model. Plot the data labels and overlay model predictions. Which model performs better? For the SVR, change the `kernel` parameter between 'rbf','linear', and 'poly'.
#
# ## Q1.2
# Create a new function, similar to "create_data" in Section 1 exercises. Instead of a weighted sum, implement the following:
#
# \begin{equation}
# y = A*sin(f x) + V*noise
# \end{equation}
#
# The function should meet the following specifications:
# - x is a user-specified [n by 1] array, where n is the number of elements.
# - A is a user-specified scalar. It corresponds to the amplitude of the sine.
# - f is a user-specified scalar. It corresponds to the frequency of the sine.
# - V is a user-specified sclar. It corresponds to the variance of the noise.
# - noise is a normally-distributed random value added to each sample.
# - y is the returned [n by 1] array.
#
# Re-initialize models from Q1.1 and train them on (x, y). Plot the data labels and overlay predictions. Which models perform better?
# Hint: numpy.sin ; numpy.random.randn
#
# ## Q1.3
# Using the noisy sine function from Q1.2, generate new data. Use `PolynomialFeatures` as we did in Section 1 to create powers of our features (`x`). Training the models from Q1.2 using our new `x_poly` features, how do the models trained on `x_poly` compare to the ones trained on `x` in Q1.2?
#
# +
# Generate new data using make_regression
'''
x_data, y_label, coef = make_regression(n_samples=500, n_features=10, n_informative=7,
noise=50, coef=True, random_state=50)
x_train, x_test, y_train, y_test = train_test_split(x_data, y_label, random_state=42)
print(x_train.shape)
print(x_test.shape)
'''
def create_data(X_n_1, A, f, V):
y_list = []
for i in X_n_1:
rand = numpy.random.randn()
sin = numpy.sin(i*f)
y = A*sin + V*rand
y_list.append(y)
return y_list
x_data = list(numpy.random.random((500,1)))
A = 5
f = 2
V = 3
y_label = create_data(x_data, A, f, V)
assert len(y_label) == len(x_data)
poly_feat_maker = PolynomialFeatures(degree=3) # Initialize object
x_data = poly_feat_maker.fit_transform(x_data) # Apply transformation
plt.plot(x_data[:,0], 'k')
plt.plot(x_data[:,1], 'b')
plt.plot(x_data[:,2], 'r')
plt.plot(x_data[:,3], 'y')
plt.legend(['degree 0','degree 1 ','degree 2','degree 3'])
x_train, x_test, y_train, y_test = train_test_split(x_data, y_label, random_state=42)
print(len(x_train))
print(len(x_test))
print(len(y_train))
print(len(y_test))
# -
# Plot data using different colors
plt.figure()
plt.plot(x_train, y_train, '.', color='blue')
plt.plot(x_test, y_test, '.', color='red')
plt.xlabel('feature value')
plt.ylabel('label value')
mdl = LinearRegression()
mdl.fit(x_train, y_train)
print(mdl.coef_)
print(mdl.intercept_)
plt.figure()
plt.plot(x_train, y_train,'.')
# +
import sklearn.metrics
y_train_pred = mdl.predict(x_train)
r2 = sklearn.metrics.r2_score(y_train, y_train_pred)
mse = sklearn.metrics.mean_squared_error(y_train, y_train_pred)
print("Trained")
print(r2)
print(mse)
print()
plt.figure()
plt.plot(y_train_pred, y_train,'.')
print()
y_test_pred = mdl.predict(x_test)
r2 = sklearn.metrics.r2_score(y_test, y_test_pred)
mse = sklearn.metrics.mean_squared_error(y_test, y_test_pred)
print("Predicted")
print(r2)
print(mse)
plt.figure()
plt.plot(y_test_pred, y_test,'.')
print()
# -
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=.1)
svr_lin = SVR(kernel='linear', C=100, gamma='auto')
svr_poly = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=.1, coef0=1)
svr_models = [svr_rbf, svr_lin, svr_poly]
for m in svr_models:
m.fit(numpy.array(x_train), numpy.array(y_train).ravel())
r2 = sklearn.metrics.r2_score(y_train, y_train_pred)
mse = sklearn.metrics.mean_squared_error(y_train, y_train_pred)
print("Trained")
print(r2)
print(mse)
plt.figure()
plt.plot(y_train_pred, y_train,'.')
y_pred_test = m.predict(x_test)
r2 = sklearn.metrics.r2_score(y_test, y_pred_test)
mse = sklearn.metrics.mean_squared_error(y_test, y_pred_test)
print("Predicted")
print(r2)
print(mse)
print()
plt.figure()
plt.plot(y_pred_test,y_test,'.')
| SKLearn/excercise.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Getting familiar with deep Q-networks
# > Notes on the seminal Deep Q-Networks *Nature* paper from Deepmind.
#
# - branch: 2020-04-03-deep-q-networks
# - badges: true
# - image: images/q-network-architecture.jpg
# - comments: true
# - author: <NAME>
# - categories: [pytorch, deep-reinforcement-learning, deep-q-networks]
# ## Motivation
#
# I am currently using my COVID-19 imposed quarantine to expand my deep learning skills by completing the [*Deep Reinforcement Learning Nanodegree*](https://www.udacity.com/course/deep-reinforcement-learning-nanodegree--nd893) from [Udacity](https://www.udacity.com/). This past week I have been working my way through the seminal 2015 *Nature* paper from researchers at [Deepmind](https://deepmind.com/) [*Human-level control through deep reinforcement learning*](https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf) (Minh et al 2015).
#
# ### Why is Minh et al 2015 important?
#
# While Minh et al 2015 was not the first paper to use neural networks to approximate the action-value function, this paper was the first to demonstrate that the same neural network architecture could be trained in a computationally efficient manner to "solve" a large number or different tasks.
#
# The paper also contributed several practical "tricks" for getting deep neural networks to consistently converge during training. This was a non-trivial contribution as issues with training convergence had plaugued previous attempts to use neural networks as function approximators in reinforcement learning tasks and were blocking widespread adoption of deep learning techniques within the reinforcemnt learning community.
#
# ## Summary of the paper
#
# Minh et al 2015 uses deep (convolutional) neural network to approximate the optimal action-value function
#
# $$ Q^*(s, a) = \max_{\pi} \mathbb{E}\Bigg[\sum_{s=0}^{\infty} \gamma^s r_{t+s} | s_t=s, a_t=a, \pi \Bigg] $$
#
# which is the maximum sum of rewards $r_t$ discounted by $\gamma$ at each time-step $t$ achievable by a behaviour policy $\pi = P(a|s)$, after making an observation of the state $s$ and taking an action $a$.
#
# Prior to this seminal paper it was well known that standard reinforcement learning algorithms were unstable or even diverged when a non-linear function approximators such as a neural networks were used to represent the action-value function $Q$. Why?
#
# Minh et al 2015 discuss several reasons.
#
# 1. Correlations present in the sequence of observations of the state $s$. In reinforcement learning applications the sequence state observations is a time-series which will almost surely be auto-correlated. But surely this would also be true of any application of deep neural networks to model time series data.
# 2. Small updates to $Q$ may significantly change the policy, $\pi$ and therefore change the data distribution.
# 3. Correlations between the action-values, $Q$, and the target values $r + \gamma \max_{a'} Q(s', a')$
#
# In the paper the authors address these issues by using...
#
# * a biologically inspired mechanism they refer to as *experience replay* that randomizes over the data which removes correlations in the sequence of observations of the state $s$ and smoothes over changes in the data distribution (issues 1 and 2 above).
# * an iterative update rule that adjusts the action-values, $Q$, towards target values, $Q'$ that are only periodically updated thereby reducing correlations with the target (issue 3 above).
# ### Approximating the action-value function, $Q(s,a)$
#
# There are several possible ways of approximating the action-value function $Q$ using a neural network. The only input to the DQN architecture is the state representation and the output layer has a separate output for each possible action. The output units correspond to the predicted $Q$-values of the individual actions for the input state. A representaion of the DQN architecture from the paper is reproduced in the figure below.
# 
# The input to the neural network consists of an 84 x 84 x 4 image produced by the preprocessing map $\phi$. The network has four hidden layers:
#
# * Convolutional layer with 32 filters (each of which uses an 8 x 8 kernel and a stride of 4) and a ReLU activation function.
# * Convolutional layer with 64 filters (each of which using a 4 x 4 kernel with stride of 2) and a ReLU activation function.
# * Convolutional layer with 64 filters (each of which uses a 3 x 3 kernel and a stride of 1) and a ReLU activation function.
# * Fully-connected (i.e., dense) layer with 512 neurons followed by a ReLU activation function.
#
# The output layer is another fully-connected layer with a single output for each action. A PyTorch implementation of the DQN architecture would look something like the following.
# +
import typing
import torch
from torch import nn
QNetwork = nn.Module
class LambdaLayer(nn.Module):
def __init__(self, f):
super().__init__()
self._f = f
def forward(self, X):
return self._f(X)
def make_deep_q_network_fn(action_size: int) -> typing.Callable[[], QNetwork]:
def deep_q_network_fn() -> QNetwork:
q_network = nn.Sequential(
nn.Conv2d(in_channels=4, out_channels=32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=2, stride=1),
nn.ReLU(),
LambdaLayer(lambda tensor: tensor.view(tensor.size(0), -1)),
nn.Linear(in_features=25024, out_features=512),
nn.ReLU(),
nn.Linear(in_features=512, out_features=action_size)
)
return q_network
return deep_q_network_fn
# -
# ### The Loss Function
#
# The $Q$-learning update at iteration $i$ uses the following loss function
#
# $$ \mathcal{L_i}(\theta_i) = \mathbb{E}_{(s, a, r, s') \sim U(D)} \Bigg[\bigg(r + \gamma \max_{a'} Q\big(s', a'; \theta_i^{-}\big) - Q\big(s, a; \theta_i\big)\bigg)^2\Bigg] $$
#
# where $\gamma$ is the discount factor determining the agent’s horizon, $\theta_i$ are the parameters of the $Q$-network at iteration $i$ and $\theta_i^{-}$ are the $Q$-network parameters used to compute the target at iteration $i$. The target network parameters $\theta_i^{-}$ are only updated with the $Q$-network parameters $\theta_i$ every $C$ steps and are held fixed between individual updates.
# ### Experience Replay
#
# To perform *experience replay* the authors store the agent's experiences $e_t$ as represented by the tuple
#
# $$ e_t = (s_t, a_t, r_t, s_{t+1}) $$
#
# consisting of the observed state in period $t$, the reward received in period $t$, the action taken in period $t$, and the resulting state in period $t+1$. The dataset of agent experiences at period $t$ consists of the set of past experiences.
#
# $$ D_t = \{e1, e2, ..., e_t \} $$
#
# Depending on the task it may note be feasible for the agent to store the entire history of past experiences.
#
# During learning Q-learning updates are computed based on samples (or minibatches) of experience $(s,a,r,s')$, drawn uniformly at random from the pool of stored samples $D_t$.
#
# The following is my Python implmentation of these ideas.
# +
import collections
import typing
import numpy as np
_field_names = [
"state",
"action",
"reward",
"next_state",
"done"
]
Experience = collections.namedtuple("Experience", field_names=_field_names)
class ExperienceReplayBuffer:
"""Fixed-size buffer to store experience tuples."""
def __init__(self,
batch_size: int,
buffer_size: int = None,
random_state: np.random.RandomState = None) -> None:
"""
Initialize an ExperienceReplayBuffer object.
Parameters:
-----------
buffer_size (int): maximum size of buffer
batch_size (int): size of each training batch
seed (int): random seed
"""
self._batch_size = batch_size
self._buffer_size = buffer_size
self._buffer = collections.deque(maxlen=buffer_size)
self._random_state = np.random.RandomState() if random_state is None else random_state
def __len__(self) -> int:
return len(self._buffer)
@property
def batch_size(self) -> int:
return self._batch_size
@property
def buffer_size(self) -> int:
return self._buffer_size
def is_full(self) -> bool:
return len(self._buffer) == self._buffer_size
def append(self, experience: Experience) -> None:
"""Add a new experience to memory."""
self._buffer.append(experience)
def sample(self) -> typing.List[Experience]:
"""Randomly sample a batch of experiences from memory."""
idxs = self._random_state.randint(len(self._buffer), size=self._batch_size)
experiences = [self._buffer[idx] for idx in idxs]
return experiences
# -
# ### The Deep Q-Network Algorithm
#
# The following is Python pseudo-code for the Deep Q-Network (DQN) algorithm. For more fine-grained details of the DQN algorithm see the methods section of [Minh et al 2015](https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf).
#
# ```python
#
# # hyper-parameters
# batch_size = 32 # number of experience tuples used in computing the gradient descent parameter update.
# buffer_size = 10000 # number of experience tuples stored in the replay buffer
# gamma = 0.99 # discount factor used in the Q-learning update
# target_network_update_frequency = 4 # frequency (measured in parameter updates) with which target network is updated.
# update_frequency = 4 # frequency (measured in number of timesteps) with which q-network parameters are updated.
#
# # initilizing the various data structures
# replay_buffer = ExperienceReplayBuffer(batch_size, buffer_size, seed)
# local_q_network = initialize_q_network()
# target_q_network = initialize_q_network()
# synchronize_q_networks(target_q_network, local_q_network)
#
# for i in range(number_episodes)
#
# # initialize the environment state
# state = env.reset()
#
# # simulate a single training episode
# done = False
# timesteps = 0
# parameter_updates = 0
# while not done:
#
# # greedy action based on Q(s, a; theta)
# action = agent.choose_epsilon_greedy_action(state)
#
# # update the environment based on the chosen action
# next_state, reward, done = env.step(action)
#
# # agent records experience in its replay buffer
# experience = (state, action, reward, next_state, done)
# agent.replay_buffer.append(experience)
#
# # agent samples a mini-batch of experiences from its replay buffer
# experiences = agent.replay_buffer.sample()
# states, actions, rewards, next_states, dones = experiences
#
# # agent learns every update_frequency timesteps
# if timesteps % update_frequency == 0:
#
# # compute the Q^- values using the Q-learning formula
# target_q_values = q_learning_update(target_q_network, rewards, next_states, dones)
#
# # compute the Q values
# local_q_values = local_q_network(states, actions)
#
# # agent updates the parameters theta using gradient descent
# loss = mean_squared_error(target_q_values, local_q_values)
# gradient_descent_update(loss)
#
# parameter_updates += 1
#
# # every target_network_update_frequency timesteps set theta^- = theta
# if parameter_updates % target_network_update_frequency == 0:
# synchronize_q_networks(target_q_network, local_q_network)
# ```
#
# ## Solving the `LunarLander-v2` environment
#
# In the rest of this blog post I will use the DQN algorithm to train an agent to solve the [LunarLander-v2](https://gym.openai.com/envs/LunarLander-v2/) environment from [OpenAI](https://openai.com/).
#
# In this environment the landing pad is always at coordinates (0,0). The reward for moving the lander from the top of the screen to landing pad and arriving at zero speed is typically between 100 and 140 points. Firing the main engine is -0.3 points each frame (so the lander is incentivized to fire the engine as few times possible). If the lander moves away from landing pad it loses reward (so the lander is incentived to land in the designated landing area). The lander is also incentived to land "gracefully" (and not crash in the landing area!).
#
# A training episode finishes if the lander crashes (-100 points) or comes to rest (+100 points). Each leg with ground contact receives and additional +10 points. The task is considered "solved" if the lander is able to achieve 200 points (I will actually be more stringent and define "solved" as achieving over 200 points on average in the most recent 100 training episodes).
#
# ### Action Space
#
# There are four discrete actions available:
#
# 0. Do nothing.
# 1. Fire the left orientation engine.
# 2. Fire main engine.
# 3. Fire the right orientation engine.
# ### Google Colab Preamble
#
# If you are playing around with this notebook on Google Colab, then you will need to run the following cell in order to install the required OpenAI dependencies into the environment.
# + language="bash"
#
# # install required system dependencies
# apt-get install -y xvfb x11-utils
#
# # install required python dependencies (might need to install additional gym extras depending)
# pip install gym[box2d]==0.17.* pyvirtualdisplay==0.2.* PyOpenGL==3.1.* PyOpenGL-accelerate==3.1.*
#
# -
# The code in the cell below creates a virtual display in the background that your Gym Envs can connect to for rendering. You can adjust the size of the virtual buffer as you like but you must set `visible=False`.
#
# **This code only needs to be run once per session to start the display.**
# +
import pyvirtualdisplay
_display = pyvirtualdisplay.Display(visible=False, # use False with Xvfb
size=(1400, 900))
_ = _display.start()
# -
# ### Binder Preamble
#
# If you are running this code on Binder, then there isn't really much to do as all the software is pre-installed. However you do still need to run the code in the cell below to creates a virtual display in the background that your Gym Envs can connect to for rendering. You can adjust the size of the virtual buffer as you like but you must set `visible=False`.
#
# *This code only needs to be run once per session to start the display.*
# +
import pyvirtualdisplay
_display = pyvirtualdisplay.Display(visible=False, # use False with Xvfb
size=(1400, 900))
_ = _display.start()
# -
# ### Creating the Gym environment
# +
import gym
env = gym.make('LunarLander-v2')
_ = env.seed(42)
# -
# ### Defining a generic `Agent` and `train` loop
#
# In the cell below I define a fairly generic training loop for training and `Agent` to solve a task in a given `gym.Env` environment. In working through the hands-on portions of the [Udacity](https://www.udacity.com/) [*Deep Reinforcement Learning Nanodegree*](https://www.udacity.com/course/deep-reinforcement-learning-nanodegree--nd893) I found myself writing similar code over and over again to train the agent to solve a task. This is my first attempt to write something that I might be able to reuse on the course going forward.
class Agent:
def choose_action(self, state: np.array) -> int:
"""Rule for choosing an action given the current state of the environment."""
raise NotImplementedError
def save(self, filepath) -> None:
"""Save any important agent state to a file."""
raise NotImplementedError
def step(self,
state: np.array,
action: int,
reward: float,
next_state: np.array,
done: bool) -> None:
"""Update agent's state after observing the effect of its action on the environment."""
raise NotImplmentedError
# +
def _train_for_at_most(agent: Agent, env: gym.Env, max_timesteps: int) -> int:
"""Train agent for a maximum number of timesteps."""
state = env.reset()
score = 0
for t in range(max_timesteps):
action = agent.choose_action(state)
next_state, reward, done, _ = env.step(action)
agent.step(state, action, reward, next_state, done)
state = next_state
score += reward
if done:
break
return score
def _train_until_done(agent: Agent, env: gym.Env) -> float:
"""Train the agent until the current episode is complete."""
state = env.reset()
score = 0
done = False
while not done:
action = agent.choose_action(state)
next_state, reward, done, _ = env.step(action)
agent.step(state, action, reward, next_state, done)
state = next_state
score += reward
return score
def train(agent: Agent,
env: gym.Env,
checkpoint_filepath: str,
target_score: float,
number_episodes: int,
maximum_timesteps=None) -> typing.List[float]:
"""
Reinforcement learning training loop.
Parameters:
-----------
agent (Agent): an agent to train.
env (gym.Env): an environment in which to train the agent.
checkpoint_filepath (str): filepath used to save the state of the trained agent.
number_episodes (int): maximum number of training episodes.
maximum_timsteps (int): maximum number of timesteps per episode.
Returns:
--------
scores (list): collection of episode scores from training.
"""
scores = []
most_recent_scores = collections.deque(maxlen=100)
for i in range(number_episodes):
if maximum_timesteps is None:
score = _train_until_done(agent, env)
else:
score = _train_for_at_most(agent, env, maximum_timesteps)
scores.append(score)
most_recent_scores.append(score)
average_score = sum(most_recent_scores) / len(most_recent_scores)
if average_score >= target_score:
print(f"\nEnvironment solved in {i:d} episodes!\tAverage Score: {average_score:.2f}")
agent.save(checkpoint_filepath)
break
if (i + 1) % 100 == 0:
print(f"\rEpisode {i + 1}\tAverage Score: {average_score:.2f}")
return scores
# -
# ### Creating a `DeepQAgent`
#
# The code in the cell below encapsulates much of the logic of the DQN algorithm in a `DeepQAgent` class. Since the `LunarLander-v2` task is not well suited for convolutional neural networks, the agent uses a simple three layer dense neural network with ReLU activation functions to approximate the action-value function $Q$.
# +
from torch import optim
from torch.nn import functional as F
class DeepQAgent(Agent):
def __init__(self,
state_size: int,
action_size: int,
number_hidden_units: int,
optimizer_fn: typing.Callable[[typing.Iterable[torch.nn.Parameter]], optim.Optimizer],
batch_size: int,
buffer_size: int,
epsilon_decay_schedule: typing.Callable[[int], float],
alpha: float,
gamma: float,
update_frequency: int,
seed: int = None) -> None:
"""
Initialize a DeepQAgent.
Parameters:
-----------
state_size (int): the size of the state space.
action_size (int): the size of the action space.
number_hidden_units (int): number of units in the hidden layers.
optimizer_fn (callable): function that takes Q-network parameters and returns an optimizer.
batch_size (int): number of experience tuples in each mini-batch.
buffer_size (int): maximum number of experience tuples stored in the replay buffer.
epsilon_decay_schdule (callable): function that takes episode number and returns epsilon.
alpha (float): rate at which the target q-network parameters are updated.
gamma (float): Controls how much that agent discounts future rewards (0 < gamma <= 1).
update_frequency (int): frequency (measured in time steps) with which q-network parameters are updated.
seed (int): random seed
"""
self._state_size = state_size
self._action_size = action_size
self._device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# set seeds for reproducibility
self._random_state = np.random.RandomState() if seed is None else np.random.RandomState(seed)
if seed is not None:
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# initialize agent hyperparameters
self._experience_replay_buffer = ExperienceReplayBuffer(batch_size, buffer_size, seed)
self._epsilon_decay_schedule = epsilon_decay_schedule
self._alpha = alpha
self._gamma = gamma
# initialize Q-Networks
self._update_frequency = update_frequency
self._local_q_network = self._initialize_q_network(number_hidden_units)
self._target_q_network = self._initialize_q_network(number_hidden_units)
self._synchronize_q_networks()
# send the networks to the device
self._local_q_network.to(self._device)
self._target_q_network.to(self._device)
# initialize the optimizer
self._optimizer = optimizer_fn(self._local_q_network.parameters())
# initialize some counters
self._number_episodes = 0
self._number_timesteps = 0
self._number_parameter_updates = 0
def _initialize_q_network(self, number_hidden_units: int) -> nn.Module:
"""Create a neural network for approximating the action-value function."""
q_network = nn.Sequential(
nn.Linear(in_features=self._state_size, out_features=number_hidden_units),
nn.ReLU(),
nn.Linear(in_features=number_hidden_units, out_features=number_hidden_units),
nn.ReLU(),
nn.Linear(in_features=number_hidden_units, out_features=self._action_size)
)
return q_network
def _learn_from(self, experiences: typing.List[Experience]) -> None:
"""Heart of the Deep Q-learning algorithm."""
states, actions, rewards, next_states, dones = (torch.Tensor(vs).to(self._device) for vs in zip(*experiences))
# get max predicted Q values (for next states) from target model
next_target_q_values, _ = (self._target_q_network(next_states)
.detach()
.max(dim=1))
# compute the new Q' values using the Q-learning formula
target_q_values = rewards + (self._gamma * next_target_q_values * (1 - dones))
# get expected Q values from local model
_index = (actions.long()
.unsqueeze(dim=1))
expected_q_values = (self._local_q_network(states)
.gather(dim=1, index=_index))
# compute the mean squared loss
loss = F.mse_loss(expected_q_values, target_q_values.unsqueeze(dim=1))
# agent updates the parameters theta of Q using gradient descent
self._optimizer.zero_grad()
loss.backward()
self._optimizer.step()
self._soft_update_target_q_network_parameters()
def _soft_update_target_q_network_parameters(self) -> None:
"""Soft-update of target q-network parameters with the local q-network parameters."""
for target_param, local_param in zip(self._target_q_network.parameters(), self._local_q_network.parameters()):
target_param.data.copy_(self._alpha * local_param.data + (1 - self._alpha) * target_param.data)
def _synchronize_q_networks(self) -> None:
"""Synchronize the target_q_network and the local_q_network."""
_ = self._target_q_network.load_state_dict(self._local_q_network.state_dict())
def _uniform_random_policy(self, state: torch.Tensor) -> int:
"""Choose an action uniformly at random."""
return self._random_state.randint(self._action_size)
def _greedy_policy(self, state: torch.Tensor) -> int:
"""Choose an action that maximizes the action_values given the current state."""
# evaluate the network to compute the action values
self._local_q_network.eval()
with torch.no_grad():
action_values = self._local_q_network(state)
self._local_q_network.train()
# choose the greedy action
action = (action_values.cpu() # action_values might reside on the GPU!
.argmax()
.item())
return action
def _epsilon_greedy_policy(self, state: torch.Tensor, epsilon: float) -> int:
"""With probability epsilon explore randomly; otherwise exploit knowledge optimally."""
if self._random_state.random() < epsilon:
action = self._uniform_random_policy(state)
else:
action = self._greedy_policy(state)
return action
def choose_action(self, state: np.array) -> int:
"""
Return the action for given state as per current policy.
Parameters:
-----------
state (np.array): current state of the environment.
Return:
--------
action (int): an integer representing the chosen action.
"""
# need to reshape state array and convert to tensor
state_tensor = (torch.from_numpy(state)
.unsqueeze(dim=0)
.to(self._device))
# choose uniform at random if agent has insufficient experience
if not self.has_sufficient_experience():
action = self._uniform_random_policy(state_tensor)
else:
epsilon = self._epsilon_decay_schedule(self._number_episodes)
action = self._epsilon_greedy_policy(state_tensor, epsilon)
return action
def has_sufficient_experience(self) -> bool:
"""True if agent has enough experience to train on a batch of samples; False otherwise."""
return len(self._experience_replay_buffer) >= self._experience_replay_buffer.batch_size
def save(self, filepath: str) -> None:
"""
Saves the state of the DeepQAgent.
Parameters:
-----------
filepath (str): filepath where the serialized state should be saved.
Notes:
------
The method uses `torch.save` to serialize the state of the q-network,
the optimizer, as well as the dictionary of agent hyperparameters.
"""
checkpoint = {
"q-network-state": self._local_q_network.state_dict(),
"optimizer-state": self._optimizer.state_dict(),
"agent-hyperparameters": {
"alpha": self._alpha,
"batch_size": self._experience_replay_buffer.batch_size,
"buffer_size": self._experience_replay_buffer.buffer_size,
"gamma": self._gamma,
"update_frequency": self._update_frequency
}
}
torch.save(checkpoint, filepath)
def step(self, state: np.array, action: int, reward: float, next_state: np.array, done: bool) -> None:
"""
Updates the agent's state based on feedback received from the environment.
Parameters:
-----------
state (np.array): the previous state of the environment.
action (int): the action taken by the agent in the previous state.
reward (float): the reward received from the environment.
next_state (np.array): the resulting state of the environment following the action.
done (bool): True is the training episode is finised; false otherwise.
"""
# save experience in the experience replay buffer
experience = Experience(state, action, reward, next_state, done)
self._experience_replay_buffer.append(experience)
if done:
self._number_episodes += 1
else:
self._number_timesteps += 1
# every so often the agent should learn from experiences
if self._number_timesteps % self._update_frequency == 0 and self.has_sufficient_experience():
experiences = self._experience_replay_buffer.sample()
self._learn_from(experiences)
# -
# #### Epsilon decay schedule
#
# In the DQN algorithm the agent chooses its action using an $\epsilon$-greedy policy. When using an $\epsilon$-greedy policy, with probability $\epsilon$, the agent explores the state space by choosing an action uniformly at random from the set of feasible actions; with probability $1-\epsilon$, the agent exploits its current knowledge by choosing the optimal action given that current state.
#
# As the agent learns and acquires additional knowledge about it environment it makes sense to *decrease* exploration and *increase* exploitation by decreasing $\epsilon$. In practice, it isn't a good idea to decrease $\epsilon$ to zero; instead one typically decreases $\epsilon$ over time according to some schedule until it reaches some minimum value.
#
# The Deepmind researchers used a simple linear decay schedule and set a minimum value of $\epsilon=0.1$. In the cell below I code up a linear decay schedule as well as a power decay schedule that I have seen used in many other practical applications.
# +
def linear_decay_schedule(episode_number: int,
slope: float,
minimum_epsilon: float) -> float:
"""Simple linear decay schedule used in the Deepmind paper."""
return max(1 - slope * episode_number, minimum_epsilon)
def power_decay_schedule(episode_number: int,
decay_factor: float,
minimum_epsilon: float) -> float:
"""Power decay schedule found in other practical applications."""
return max(decay_factor**episode_number, minimum_epsilon)
_epsilon_decay_schedule_kwargs = {
"decay_factor": 0.995,
"minimum_epsilon": 1e-2,
}
epsilon_decay_schedule = lambda n: power_decay_schedule(n, **_epsilon_decay_schedule_kwargs)
# -
# #### Choosing an optimizer
#
# As is the case in training any neural network, the choice of optimizer and the tuning of its hyper-parameters (in particular the learning rate) is important. Here I am going to more or less follow the Minh et al 2015 paper and use the [RMSProp](https://pytorch.org/docs/stable/optim.html#torch.optim.RMSprop) optimizer.
_optimizer_kwargs = {
"lr": 1e-2,
"alpha": 0.99,
"eps": 1e-08,
"weight_decay": 0,
"momentum": 0,
"centered": False
}
optimizer_fn = lambda parameters: optim.RMSprop(parameters, **_optimizer_kwargs)
# At this point I am ready to create an instance of the `DeepQAgent`.
_agent_kwargs = {
"state_size": env.observation_space.shape[0],
"action_size": env.action_space.n,
"number_hidden_units": 64,
"optimizer_fn": optimizer_fn,
"epsilon_decay_schedule": epsilon_decay_schedule,
"batch_size": 64,
"buffer_size": 100000,
"alpha": 1e-3,
"gamma": 0.99,
"update_frequency": 4,
"seed": None,
}
deep_q_agent = DeepQAgent(**_agent_kwargs)
# ### Performance of an un-trained `DeepQAgent`
#
# The function `simulate` defined in the cell below can be used to simuate an agent interacting with and environment for one episode.
# +
import matplotlib.pyplot as plt
from IPython import display
def simulate(agent: Agent, env: gym.Env, ax: plt.Axes) -> None:
state = env.reset()
img = ax.imshow(env.render(mode='rgb_array'))
done = False
while not done:
action = agent.choose_action(state)
img.set_data(env.render(mode='rgb_array'))
plt.axis('off')
display.display(plt.gcf())
display.clear_output(wait=True)
state, reward, done, _ = env.step(action)
env.close()
# -
# The untrained agent behaves erratically (not quite randomly!) and performs poorly. Lots of room for improvement!
_, ax = plt.subplots(1, 1, figsize=(10, 8))
simulate(deep_q_agent, env, ax)
# ### Training the `DeepQAgent`
#
# Now I am finally ready to train the `deep_q_agent`. The target score for the `LunarLander-v2` environment is 200 points on average for at least 100 consecutive episodes. If the `deep_q_agent` is able to "solve" the environment, then training will terminate early.
scores = train(deep_q_agent, env, "checkpoint.pth", number_episodes=2000, target_score=200)
# ### Analyzing `DeepQAgent` performance
#
# Now that I have trained the agent, let's re-run the simulation to see the difference in performance. You should see that the agent is able to pilot the lunar lander to successful landing inside the landing area (or nearby).
_, ax = plt.subplots(1, 1, figsize=(10, 8))
simulate(deep_q_agent, env, ax)
# #### Plotting the time series of scores
#
# I can use [Pandas](https://pandas.pydata.org/) to quickly plot the time series of scores along with a 100 episode moving average. Note that training stops as soon as the rolling average crosses the target score.
import pandas as pd
import matplotlib.pyplot as plt
# %matplotlib inline
scores = pd.Series(scores, name="scores")
scores.describe()
fig, ax = plt.subplots(1, 1)
_ = scores.plot(ax=ax, label="Scores")
_ = (scores.rolling(window=100)
.mean()
.rename("Rolling Average")
.plot(ax=ax))
ax.axhline(200, color='k', linestyle="dashed", label="Target Score")
ax.legend()
_ = ax.set_xlabel("Episode Number")
_ = ax.set_ylabel("Score")
# #### Kernel density plot of the scores
#
# Kernel density plot of scores is bimodal with one mode less than -100 and a second mode greater than 200. The negative mode corresponds to those training episodes where the agent crash landed and thus scored at most -100; the positive mode corresponds to those training episodes where the agent "solved" the task. The kernel density or scores typically exhibits negative skewness (i.e., a fat left tail): there are lots of ways in which landing the lander can go horribly wrong (resulting in the agent getting a very low score) and only relatively few paths to a gentle landing (and a high score).
fig, ax = plt.subplots(1,1)
_ = scores.plot(kind="kde", ax=ax)
_ = ax.set_xlabel("Score")
# ## Where to go from here?
#
# I am a bit frustrated by lack of stability that I am seeing in my implmentation of the Deep Q algorithm: sometimes the algorithm converges and sometimes not. Perhaps more tuning of hyper-parameters or use of a different optimization algorithm would exhibit better convergence. I have already spent more time than I had allocated on playing around with this agorithm so I am not going to try and fine-tune the hyperparamters or explore alternative optimization algorithms for now.
#
# Rather than spending time tuning hyperparameters I think it would be better use of my time to explore algorithmic improvements. In future posts I plan to cover the following extensions of the DQN algorithm: [Double Q-Learning](https://arxiv.org/abs/1509.06461), [Prioritized Experience Replay](https://arxiv.org/abs/1509.06461), and [Dueling Network Architectures](https://arxiv.org/abs/1511.06581)
| _notebooks/2020-04-03-deep-q-networks.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .jl
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Julia 1.5.2
# language: julia
# name: julia-1.5
# ---
# # Discrete Data and the Multinomial Distribution
#
# - **[1]** (##) We consider IID data $D = \{x_1,x_2,\ldots,x_N\}$ obtained from tossing a $K$-sided die. We use a *binary selection variable*
# $$x_{nk} \equiv \begin{cases} 1 & \text{if $x_n$ lands on $k$th face}\\
# 0 & \text{otherwise}
# \end{cases}
# $$
# with probabilities $p(x_{nk} = 1)=\theta_k$.
# (a) Write down the probability for the $n$th observation $p(x_n|\theta)$ and derive the log-likelihood $\log p(D|\theta)$.
# (b) Derive the maximum likelihood estimate for $\theta$.
# > See lecture notes (on class homepage).
# (a) $p(x_n|\theta) = \prod_k \theta_k^{x_{nk}} \quad \text{subject to} \quad \sum_k \theta_k = 1$.
# $$\ell(\theta) = \sum_k m_k \log \theta_k$$
# where $m_k = \sum_n x_{nk}$.
# (b) $\hat \theta = \frac{m_k}{N}$, the *sample proportion*.
#
# - **[2]** (#) In the notebook, Laplace's generalized rule of succession (the probability that we throw the $k$th face at the next toss) was derived as
# $$\begin{align*}
# p(x_{\bullet,k}=1|D) = \frac{m_k + \alpha_k }{ N+ \sum_k \alpha_k}
# \end{align*}$$
# Provide an interpretation of the variables $m_k,N,\alpha_k,\sum_k\alpha_k$.
#
# > $m_k$ is the total number of occurances that we threw $k$ eyes, $\alpha_k$ is the prior pseudo counts representing the number of observations in the $k$th that we assume to have seen already. $\sum_k m_k = N $ is the total number of rolls and $\sum_k \alpha_k $ is the total number of prior pseudo rolls.
#
#
#
# - **[3]** (##) Show that Laplace's generalized rule of succession can be worked out to a prediction that is composed of a prior prediction and data-based correction term.
#
# > $$\begin{align*}
# p(x_{\bullet,k}=1|D) &= \frac{m_k + \alpha_k }{ N+ \sum_k \alpha_k} \\
# &= \frac{N}{N+\sum_k \alpha_k} \frac{m_k}{N} + \frac{\sum_k \alpha_k}{N+\sum_k \alpha_k}\frac{\alpha_k}{\sum_k\alpha_k} \\
# &= \underbrace{\frac{\alpha_k}{\sum_k\alpha_k}}_{\text{prior prediction}} + \underbrace{\frac{N}{N+\sum_k \alpha_k} \cdot \underbrace{\left(\frac{m_k}{N} - \frac{\alpha_k}{\sum_k\alpha_k}\right)}_{\text{prediction error}}}_{\text{data-based correction}}
# \end{align*}$$
#
# - **[4]** (#) Verify that
# (a) the categorial distribution is a special case of the multinomial for $N=1$.
# (b) the Bernoulli is a special case of the categorial distribution for $K=2$.
# (c) the binomial is a special case of the multinomial for $K=2$.
#
# > (a) The probability mass function of a multinomial distribution is $p(D_m|\mu) =\frac{N!}{m_1! m_2!\ldots m_K!} \,\prod_k \mu_k^{m_k}$ over the data frequencies $D_m=\{m_1,\ldots,m_K\}$ with the constraint that $\sum_k \mu_k = 1$ and $\sum_k m_k=N$. Setting $N=1$ we see that $p(D_m|\mu) \propto \prod_k \mu_k^{m_k}$ with $\sum_k m_k=1$, making the sample space one-hot coded given by the categorical distribution.
# > (b) When $K=2$, the constraint for the categorical distribution takes the form $m_1=1-m_2$ leading to $p(D_m|\mu) \propto \mu_1^{m_1}(1-\mu_1)^{1-m_1}$ which is associated with the Bernoulli distribution.
# > (c) Plugging $K=2$ into the multinomial distribution leads to $p(D_m|\mu) =\frac{N!}{m_1! m_2!}\mu_1^{m_1}\left(\mu_2^{m_2}\right)$ with the constraints $m_1+m_2=N$ and $\mu_1+\mu_2=1$. Then plugging the constraints back in we obtain $p(D_m|\mu) = \frac{N!}{m_1! (N-m1)!}\mu_1^{m_1}\left(1-\mu_1\right)^{N-m_1}$ as the binomial distribution.
#
#
# - **[5]** (###) Determine the mean, variance and mode of a Beta distribution.
# > The Beta distribution is given by $\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}x^{\alpha-1}(1-x)^{\beta-1}$. Define $\frac{\Gamma(\alpha)\Gamma(\beta)}{\Gamma(\alpha+\beta)} \triangleq \mathcal{B}(\alpha,\beta)$, which is the normalization constant. Notice that this definition makes $\int_0^1 x^{\alpha-1}(1-x)^{\beta-1}\mathrm{d}x = \mathcal{B}(\alpha,\beta)$. Together with $\Gamma(x+1) = x\Gamma(x)$ we can use these identities to obtain the requested statistics:
# $$\begin{align*}
# \mathbb{E}[x] &= \frac{1}{\mathcal{B}(\alpha,\beta)}\int_0^1 x x^{\alpha-1}(1-x)^{\beta-1}\mathrm{d}x \\
# &= \frac{1}{\mathcal{B}(\alpha,\beta)}\int_0^1x^{\alpha}(1-x)^{\beta-1}\mathrm{d}x \\
# &= \frac{\mathcal{B}(\alpha+1,\beta)}{\mathcal{B}(\alpha,\beta)} \\
# &= \frac{\Gamma(\alpha+1)\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\alpha+\beta+1)}\\
# &= \frac{\alpha \Gamma(\alpha)\Gamma(\alpha+\beta) }{(\alpha+\beta)\Gamma(\alpha)\Gamma(\alpha+\beta)}\\
# &= \frac{\alpha}{\alpha+\beta} \\
# \mathbb{V}[x] &= \mathbb{E}[x^2] - \mathbb{E}[x]^2 \\
# &= \frac{1}{\mathcal{B}(\alpha,\beta)}\int_0^1 x^2 x^{\alpha-1}(1-x)^{\beta-1}\mathrm{d}x - \frac{\alpha^2}{(\alpha+\beta)^2} \\
# &= \frac{\mathcal{B}(\alpha+2,\beta)}{\mathcal{B}(\alpha,\beta)} - \frac{\alpha^2}{(\alpha+\beta)^2} \\
# &= \frac{\alpha}{\alpha+\beta}\left(\frac{\alpha+1}{\alpha+\beta+1} - \frac{\alpha}{\alpha+\beta}\right) \\
# &= \frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)}
# \end{align*}$$
# If $\alpha=\beta$, then the Beta distribution is identical to a uniform distribution, which doesn't have a unique mode. If one of the parameters is $<1$, then the mode is at one of the edges. When both parameters are $>1$, then the mode is well-defined and is within the interior of the distribution. Assuming the parameters are $>1$ we can evaluate the mode as
# $$\begin{align*}
# \nabla_x x^{\alpha-1}(1-x)^{\beta-1} &= 0\\
# \frac{\alpha-1}{\beta-1} &= \frac{x}{1-x} \\
# \alpha-1 &= x(\alpha+\beta-2) \\
# \Rightarrow x_{mode} &= \frac{\alpha-1}{\alpha+\beta-2}.
# \end{align*}$$
#
# - **[6]** (###) Consider a data set of binary variables $D=\{x_1,x_2,\ldots,x_N\}$ with a Bernoulli distribution $\mathrm{Ber}(x_k|\mu)$ as data generating distribution and a Beta prior for $\mu$. Assume that you make $n$ observations with $x=1$ and $N-n$ observations with $x=0$. Now consider a new draw $x_\bullet$. We are interested in computing $p(x_\bullet|D)$. Show that the mean value for $p(x_\bullet|D)$ lies in between the prior mean and Maximum Likelihood estimate.
#
# > In the lectures we have seen that $p(x_\bullet =1|D) = \frac{a+n}{a+b+N}$, where $a$ and $b$ are parameters of the Beta prior. The ML estimate is $\frac{n}{N}$ and the prior mean is $\frac{a}{a+b}$. To show that the prediction lies in between ML and prior estimate, we will try to write the prediction as a convex combination of the latter two. That is we want to solve for $\lambda$
# $$\begin{align*}
# (1-\lambda) \frac{n}{N} + \lambda\frac{a}{a+b} &= \frac{a+n}{a+b+N} \\
# \lambda &= \frac{1}{1+\frac{N}{a+b}}
# \end{align*}$$
# Since $a,b$ and $N$ are positive, it follows that $0<\lambda <1$. This means the prediction is a convex combination of prior and ML estimates and thus lies in between the two.
#
# - **[7]** Consider a data set $D = \{(x_1,y_1), (x_2,y_2),\dots,(x_N,y_N)\}$ with 1-of-$K$ notation for the discrete classes, i.e.,
# \begin{equation*} y_{nk} = \begin{cases} 1 & \text{if $y_n$ in $k$th class} \\
# 0 & \text{otherwise}
# \end{cases}
# \end{equation*}
# together with class-conditional distribution $p(x_n| y_{nk}=1,\theta) = \mathcal{N}(x_n|\mu_k,\Sigma)$ and multinomial prior $p(y_{nk}=1) = \pi_k$.
# (a) Proof that the joint log-likelihood is given by
# $$\begin{equation*}
# \log p(D|\theta) = \sum_{n,k} y_{nk} \log \mathcal{N}(x_n|\mu_k,\Sigma) + \sum_{n,k} y_{nk} \log \pi_k
# \end{equation*}$$
# > $$\begin{align*}
# \log p(D|\theta) &= \sum_n \log \prod_k p(x_n,y_{nk}|\theta)^{y_{nk}} \\
# &= \sum_{n,k} y_{nk} \log p(x_n,y_{nk}|\theta)\\
# &= \sum_{n,k} y_{nk} \log \mathcal{N}(x_n|\mu_k,\Sigma) + \sum_{n,k} y_{nk} \log \pi_k
# \end{align*}$$
#
# (b) Show now that the MLE of the *class-conditional* mean is given by
# $$\begin{equation*}
# \hat \mu_k = \frac{\sum_n y_{nk} x_n}{\sum_n y_{nk}}
# \end{equation*}
# $$
#
# <!---
# - Show that the beta, categorical, multinomial and Dirichlet distributions are normalized.
# --->
#
# <!---
# - Show that the beta, categorical, multinomial and Dirichlet distributions are normalized.
# --->
| lessons/exercises/Solutions-The-Multinomial-Distribution.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: BMRS
# language: python
# name: bmrs
# ---
# +
#hide
#default_exp vis.lolp
# -
# # Loss of Load Probability
#
# <br>
#
# ### Imports
# +
#exports
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from collections.abc import Iterable
from sklearn import linear_model
from ElexonDataPortal.api import Client
# -
#exports
def get_latest_lolpdrm_df(api_key: str=None):
start_date = pd.Timestamp.now(tz='Europe/London').strftime('%Y-%m-%d')
end_date = pd.Timestamp.now(tz='Europe/London') + pd.Timedelta(days=3)
client = Client(api_key=api_key)
df_lolpdrm = client.get_LOLPDRM(start_date, end_date)
return df_lolpdrm
# +
df_lolpdrm = get_latest_lolpdrm_df()
df_lolpdrm.head()
# -
# <br>
#
# N.b. The 12:00 forecast is made every day at mid-day and overwites the previous values, the 8/4/2/1 hour forecasts are not over-written
#exports
def clean_fcst_df(
df_lolpdrm: pd.DataFrame,
fcst_type: str='lolp',
fcst_horizons: list=[8, 4, 2, 1]
):
cols_renaming_map = {f'{fcst_type}12Forecast': '12:00'}
cols_renaming_map.update({
f'{fcst_type}{fcst_horizon}HourForecast': f"{fcst_horizon} Hour{'s' if fcst_horizon>1 else ''} Ahead"
for fcst_horizon
in fcst_horizons
})
df_clean_fcst = (df_lolpdrm
.set_index('local_datetime')
[cols_renaming_map.keys()]
.rename(columns=cols_renaming_map)
.astype(float)
)
return df_clean_fcst
# +
df_clean_lolp = clean_fcst_df(df_lolpdrm)
df_clean_lolp.head()
# -
# +
df_clean_drm = clean_fcst_df(df_lolpdrm, 'drm')
df_clean_drm.head()
# -
df_clean_drm.plot()
# +
#exports
class AxTransformer:
def __init__(self, datetime_vals=False):
self.datetime_vals = datetime_vals
self.lr = linear_model.LinearRegression()
return
def process_tick_vals(self, tick_vals):
if not isinstance(tick_vals, Iterable) or isinstance(tick_vals, str):
tick_vals = [tick_vals]
if self.datetime_vals == True:
tick_vals = pd.to_datetime(tick_vals).astype(int).values
tick_vals = np.array(tick_vals)
return tick_vals
def fit(self, ax, axis='x'):
axis = getattr(ax, f'get_{axis}axis')()
tick_locs = axis.get_ticklocs()
tick_vals = self.process_tick_vals([label._text for label in axis.get_ticklabels()])
self.lr.fit(tick_vals.reshape(-1, 1), tick_locs)
return
def transform(self, tick_vals):
tick_vals = self.process_tick_vals(tick_vals)
tick_locs = self.lr.predict(np.array(tick_vals).reshape(-1, 1))
return tick_locs
def set_date_ticks(ax, start_date, end_date, axis='y', date_format='%Y-%m-%d', **date_range_kwargs):
dt_rng = pd.date_range(start_date, end_date, **date_range_kwargs)
ax_transformer = AxTransformer(datetime_vals=True)
ax_transformer.fit(ax, axis=axis)
getattr(ax, f'set_{axis}ticks')(ax_transformer.transform(dt_rng))
getattr(ax, f'set_{axis}ticklabels')(dt_rng.strftime(date_format))
ax.tick_params(axis=axis, which='both', bottom=True, top=False, labelbottom=True)
return ax
# -
#exports
def create_fcst_htmp(
df_clean: pd.DataFrame,
img_fp: str='docs/img/vis/drm_fcst_htmp.png'
):
# Plotting
fig, ax = plt.subplots(dpi=250)
htmp = sns.heatmap(df_clean, vmin=0, ax=ax)
set_date_ticks(ax, df_clean.index.min(), df_clean.index.max(), freq='6H', date_format='%Y-%m-%d %H:%M')
ax.set_xticklabels(ax.get_xticklabels(), rotation=25)
ax.xaxis.tick_top()
ax.set_ylabel('')
cbar = htmp.collections[0].colorbar
cbar.set_label('De-Rated Margin (MW)', labelpad=20, rotation=270)
# Saving
fig.tight_layout()
fig.savefig(img_fp)
create_fcst_htmp(df_clean_drm, img_fp='../docs/img/vis/drm_fcst_htmp.png')
#exports
def create_fcst_delta_htmp(
df_clean_drm: pd.DataFrame,
img_fp: str='docs/img/vis/drm_fcst_delta_htmp.png'
):
# Preparing data
df_drm_delta = df_clean_drm.iloc[:, 2:].apply(lambda col: col-df_clean_drm.iloc[:, 1]).dropna(how='all', axis=1).dropna(how='all')
# Plotting
fig, ax = plt.subplots(dpi=150)
htmp = sns.heatmap(df_drm_delta, center=0, cmap='bwr_r', ax=ax)
set_date_ticks(ax, df_drm_delta.index.min(), df_drm_delta.index.max(), freq='3H', date_format='%Y-%m-%d %H:%M')
ax.set_xticklabels(ax.get_xticklabels(), rotation=25)
ax.xaxis.tick_top()
ax.set_ylabel('')
cbar = htmp.collections[0].colorbar
cbar.set_label('Delta to the 8 Hour-\nAhead Forecast Horizon', labelpad=25, rotation=270)
# Saving
fig.tight_layout()
fig.savefig(img_fp)
create_fcst_delta_htmp(df_clean_drm, img_fp='../docs/img/vis/drm_fcst_delta_htmp.png')
#exports
def save_lolpdrm_imgs(
docs_dir: str='docs',
api_key: str=None,
fcst_type: str='lolp',
fcst_horizons: list=[8, 4, 2, 1]
):
df_lolpdrm = get_latest_lolpdrm_df(api_key=api_key)
df_clean = clean_fcst_df(df_lolpdrm, fcst_type=fcst_type, fcst_horizons=fcst_horizons)
create_fcst_htmp(df_clean, img_fp=f'{docs_dir}/img/vis/{fcst_type}_fcst_htmp.png')
plt.close()
create_fcst_delta_htmp(df_clean, img_fp=f'{docs_dir}/img/vis/{fcst_type}_fcst_delta_htmp.png')
plt.close()
save_lolpdrm_imgs(docs_dir='../docs', fcst_type='drm')
#exports
def construct_drm_md_txt(
update_time: str=None
):
if update_time is None:
update_time = pd.Timestamp.now().round('5min').strftime('%Y-%m-%d %H:%M')
md_txt = f"""### De-Rated Margin
In each settlement period the system operator publishes the de-rated margin forecast calculated in accordance with the [Loss of Load Probability Calculation Statement](https://www.elexon.co.uk/documents/bsc-codes/lolp/loss-of-load-probability-calculation-statement/) at the following times:
* At 1200 hours on each calendar day for all Settlement Periods for which Gate Closure has not yet passed and which occur within the current Operational Day or the following Operational Day; and
* At eight, four, two and one hour(s) prior to the beginning of the Settlement Period to which the De-Rated Margin Forecast relates.
These figures will be updated on an hourly basis, the last update was at: {update_time}
<br>
#### Forecasts
The following heatmap shows the evolving de-rated margin forecast across the different forecast horizons.

<br>
#### Forecast Deltas
The following heatmap shows how the more recent de-rated margin forecasts deviate from the 8 hours ahead forecast.

"""
return md_txt
#exports
def generate_lolpdrm_imgs_text(
docs_dir: str='docs',
api_key: str=None,
fcst_horizons: list=[8, 4, 2, 1],
update_time: str=None
):
for fcst_type in ['drm', 'lolp']:
save_lolpdrm_imgs(docs_dir=docs_dir, api_key=api_key, fcst_type=fcst_type, fcst_horizons=fcst_horizons)
md_txt = construct_drm_md_txt(update_time=update_time)
return md_txt
# +
md_txt = generate_lolpdrm_imgs_text('../docs')
print(md_txt)
# -
#hide
from ElexonDataPortal.dev.nbdev import notebook2script
notebook2script('vis-03-lolp.ipynb')
| nbs/vis-03-lolp.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Setup
# # SQLAlchemy Joins
# Python SQL toolkit and Object Relational Mapper
import pandas as pd
from sqlalchemy import create_engine
from splinter import Browser
from bs4 import BeautifulSoup as bs
import time
from sql_keys import username, password
executable_path = {'executable_path': 'chromedriver.exe'}
browser = Browser('chrome', **executable_path, headless=False)
# +
time.sleep(1)
url = "https://www.n2yo.com/satellites/?c=&t=country"
browser.visit(url)
# sloth_img= soup.find("img", class_="img-fluid animals").get_text()'
# +
#a_all = avg_temps.find_all('a')[1].text
#td_all = avg_temps.find_all('td')[3].text
datetime='2020-10-23'
data_symbol = {
"country": "",
"country_code": "",
"number_of_satellites": ""
}
offsetVal=0
# -
html = browser.html
soup = bs(html, "html.parser")
data_array = []
avg_temps = soup.find("table", class_="footable")
data_array = []
paragraphs = avg_temps.find_all('tr')
for para in paragraphs:
data_symbol={}
try:
data_symbol["country"] = para.find_all('td')[0].text
data_symbol["country_code"] = para.find_all('td')[2].text
data_symbol["number_of_satellites"] = para.find_all('td')[3].text
data_array.append(data_symbol)
except:
pass
data_array
# html = browser.html
# soup = bs(html, "html.parser")
# data_array = []
# avg_temps = soup.find("table", class_="footable")
# data_array = []
# paragraphs = avg_temps.find_all('tr')
# for para in paragraphs:
# data_symbol={}
# data_symbol["country"] = para.find_all('td')[0].text
# data_symbol["country_code"] = para.find_all('td')[1].text
# data_symbol["number_of_satellites"] = para.find_all('td')[2].text
# data_array.append(data_symbol)
#
data_array_df = pd.DataFrame(data_array)
data_array_df
#rds_connection_string = "postgres:bootcamp@localhost:5432/satellite"
#<insert password>@localhost:5432/customer_db"
engine = create_engine(f'postgresql://{username}:{password}@localhost:5432/satellite')
engine.table_names()
data_array_df.to_sql(name='country', con=engine, if_exists='append', index=False)
pd.read_sql_query('select * from country', con=engine).head()
browser.quit()
| country.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from transformers import pipeline, set_seed
from debiased_gpt2 import generate_sentences
generator = pipeline('text-generation', model='gpt2')
generator('My dad is a computer programmer and my mom is a', max_length=30, num_return_sequences=5)#[0]['generated_text']
generate_sentences('My dad is a computer programmer and my mom is a')
| Debiased GPT2 Demo.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/JSJeong-me/KOSA-Python_Algorithm/blob/main/linear_search.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + id="m8I5E-a0Q3Qu"
data = [38, 27, 49, 3, 9, 82, 10]
# + id="1ZNOAwXJQ5In"
def linear_search(arr, x):
# Linear Search:
# arr --> array
# x --> searched value
for i in range(len(arr)):
if arr[i] == x:
return i
return -1
# + id="acRZpNyARJvT"
found_index = linear_search(data, 9)
# + colab={"base_uri": "https://localhost:8080/"} id="NfIBi5k1RRoo" outputId="d37f8923-af92-4052-89e7-119d7813bb17"
data[found_index]
# + id="htF3xFf9RVgJ"
| linear_search.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Introduction
#
# In this notebook I will train a Neural Process on a set of regression tasks:
# the aim of each task is to asppoximate a function. The common traint of all
# tasks (i.e. functions to approximate) is that they are generated by a sine
# function. What varies across tasks is the amplitude and the period
#
# <img src="https://www.mathsisfun.com/algebra/images/period-amplitude.svg" alt="period and amplitude">
#
# using the formula
#
# $$y = a \cdot \text{sin}\left(bx\right)$$
#
# where $a$ is the amplitude and $2\pi/b$ is the period.
# ### Load required packages
import neural_process_model as nep
import numpy as np
import torch
import matplotlib.pyplot as plt
# %matplotlib inline
# ### Create the training datasets
# +
datasets = {}
n_tasks = 20
period = []
amplitude = []
x_np = np.arange(-4, 4, 0.1).reshape(-1, 1).astype(np.float32)
#plt.subplot(3,1,1)
for i in range(n_tasks):
a = np.random.uniform(1, 5)
period.append(a)
b = np.random.uniform(1, 5)
amplitude.append(b)
y_np = a * np.sin(b * x_np)
datasets['task_{}'.format(i)] = y_np
plt.plot(x_np, y_np)
plt.title('Tasks')
plt.ylabel('y = a sin(bx)')
plt.xlabel('x')
print('Sizes\n', ' x:', x_np.shape, '\n y:', y_np.shape, '\nfor each task')
plt.show()
#plt.subplot(3,1,2)
plt.hist(period, 30, alpha=0.5)
plt.hist(amplitude, 30, alpha=0.5)
plt.legend(['Period', 'Amplitude'])
plt.title('Distribution of period and amplitude')
plt.show()
# -
# ### Parameter initialization
r_dim = 7
z_dim = 5
encoder_specs = [(8, torch.nn.ReLU()), (8, torch.nn.ReLU()), (8, torch.nn.ReLU()), (r_dim, None)]
decoder_specs = [(20, torch.nn.ReLU()), (15, torch.nn.Sigmoid()), (y_np.shape[1], None)]
encoder_input_dim = x_np.shape[1] + y_np.shape[1]
decoder_input_dim = x_np.shape[1] + z_dim
h = nep.Encoder(encoder_input_dim, encoder_specs)
r_to_z = nep.Zparams(r_dim, z_dim)
g = nep.Decoder(decoder_input_dim, decoder_specs)
optimizer = torch.optim.Adam(params=list(g.parameters()) + list(h.parameters()) + list(r_to_z.parameters()), lr=1e-3)
# ### Training
#
# A crucial property of NPs is their flexibility at test time, as they can model
# a whole range of functions and narrow down their prediction as we condition on
# an increasing number of context observations. This behaviour is a result of the
# training regime of NPs which is reflected in our datasets.
#
# <img src="https://bit.ly/2O2Lq8c" alt="drawing" width="600"/>
#
# Rather than training using observations from a single function as it is often
# the case in machine learning (for example value functions in reinforcement
# learning) we will use a dataset that consists of many different functions that
# *share* some underlying characteristics. This is visualized in the figure above.
#
# The example on the left corresponds to a classic training regime: we have a
# single underlying ground truth function (eg. our value function for an agent) in
# grey and at each learning iteration we are provided with a handful of examples from
# this function that we have visualized in different colours for batches of different
# iterations. On the right we show an example of a dataset that could be used for
# training neural processes. Instead of a single function, it consists of a large number
# of functions of a function-class that we are interested in modeling. At each iteration
# we randomly choose one from the dataset and provide some observations from that function
# for training.
# For the next iteration we put that function back and pick a new one from our dataset and
# use this new function to select the training data. This type of dataset ensures that our
# model can't overfit to a single function but rather learns a distribution over functions.
# This idea of a hierarchical dataset also lies at the core of current meta-learning methods.
# Examples of such datasets could be:
#
# We have chosen GPs for the data generation of this example because they
# constitute an easy way of sampling smooth curves that share some underlying
# characteristic (in this case the kernel). Other than for data generation of this
# particular example neural processes do not make use of kernels or GPs as they
# are implemented as neural networks.
# $\mathrm{ELBO} = \mathrm{E}_{q(z|x_T,y_T)}\left[\sum_{i=1}^{N} \log p(y_i|g_z(x_i))\right] - \mathrm{KL}\Big[q(z|x_T, y_T) \Big\Vert q(z|x_C,y_C)\Big]$
#
# $\mathrm{KL} = \frac{1}{2} \left[\sum_{i=1}^N \log \sigma_2^{(i)} - \log \sigma_1^{(i)} + \frac{\sigma_2^{2,(i)}}{\sigma_1^{2,(i)}} + \frac{(\mu_2^{(i)} - \mu_1^{(i)})^2} { \sigma_2^{(i)}} - 1 \right]$
# +
epochs = 5000
log_lik = []
kl = []
elbo = []
#TRAINING
for epoch in range(epochs):
optimizer.zero_grad()
# select a task randomly
task_id = 'task_' + str(np.random.randint(n_tasks))
y_np = datasets[task_id]
# select number of context points randomly
n_context = np.random.randint(1, y_np.shape[0])
# select `n_context` points and create the context set and target set
context_indeces = np.sort(np.random.randint(y_np.shape[0], size=n_context))
x_c = torch.from_numpy(x_np[context_indeces])
y_c = torch.from_numpy(y_np[context_indeces])
x_t = torch.from_numpy(x_np)
y_t = torch.from_numpy(y_np)
# variational parameters (mean, std) of approximate prior
z_mean_c, z_std_c = r_to_z(h(x_c, y_c))
# variational parameters (mean, std) of approximate posterior
z_mean_t, z_std_t = r_to_z(h(x_t, y_t))
# Monte Carlo estimate of log-likelihood (expectation wrt approximate posterior)
log_likelihood = nep.MC_loglikelihood(x_t, y_t, g, z_mean_t, z_std_t, 10)
# compute KL divergence analytically
KL = nep.KL_div(z_mean_t, z_std_t, z_mean_c, z_std_c)
# compute negative ELBO
ELBO = - log_likelihood + KL
log_lik.append(log_likelihood)
kl.append(KL)
elbo.append(ELBO)
# compute gradient of ELBO and take a gradient step
ELBO.backward()
optimizer.step()
# +
# DIAGNOSTICS
plt.subplot(2,1,1)
plt.plot(elbo)
plt.title('Diagnostics')
plt.ylabel('ELBO')
plt.subplot(2, 1, 2)
plt.plot(kl)
plt.ylabel('KL divergence')
plt.xlabel('epochs')
plt.show()
# -
# ## Learned prior over functions
# +
y_pred = nep.predict(x_t, g, z_mean_t, z_std_t, 100)
quantile_05, median, quantile_95 = np.quantile(y_pred, [0.05, 0.5, 0.95], axis=0)
# Plot of sample functions
for i in y_pred:
plt.plot(x_np, i, alpha=0.4)
plt.show()
# Plot of distribution over functions
plt.plot(x_np.flatten(), median.flatten(), '--', 'k')
plt.fill_between(x_np.flatten(), quantile_05.flatten(), quantile_95.flatten(), alpha=0.15, facecolor='#089FFF')
plt.show()
# -
# ## New task
x_new = x_np[[1,2,19,26,35,44,48,59,69,78]]
y_new = np.sin(2*x_new)
epochs = 100
for epoch in range(epochs):
optimizer.zero_grad()
# select number of context points randomly
n_context = np.random.randint(1, y_new.shape[0])
# select `n_context` points and create the context set and target set
context_indeces = np.sort(np.random.randint(y_new.shape[0], size=n_context))
x_c = torch.from_numpy(x_new[context_indeces])
y_c = torch.from_numpy(y_new[context_indeces])
x_t = torch.from_numpy(x_new)
y_t = torch.from_numpy(y_new)
# variational parameters (mean, std) of approximate prior
z_mean_c, z_std_c = r_to_z(h(x_c, y_c))
# variational parameters (mean, std) of approximate posterior
z_mean_t, z_std_t = r_to_z(h(x_t, y_t))
# Monte Carlo estimate of log-likelihood (expectation wrt approximate posterior)
log_likelihood = nep.MC_loglikelihood(x_t, y_t, g, z_mean_t, z_std_t, 10)
# compute KL divergence analytically
KL = nep.KL_div(z_mean_t, z_std_t, z_mean_c, z_std_c)
# compute negative ELBO
ELBO = - log_likelihood + KL
log_lik.append(log_likelihood)
kl.append(KL)
elbo.append(ELBO)
# compute gradient of ELBO and take a gradient step
ELBO.backward()
optimizer.step()
# +
y_pred = nep.predict(torch.from_numpy(x_np), g, z_mean_t, z_std_t, 1000)
quantile_05, median, quantile_95 = np.quantile(y_pred, [0.05, 0.5, 0.95], axis=0)
#plt.plot(x_np.flatten(), np.sin(15*x_np).flatten())
plt.plot(x_new.flatten(), y_new.flatten(), 'o-')
plt.plot(x_np.flatten(), median.flatten(), '--', 'k')
plt.fill_between(x_np.flatten(), quantile_05.flatten(), quantile_95.flatten(), alpha=0.15, facecolor='#089FFF')
plt.show()
# -
| Code/.ipynb_checkpoints/NeuralProcess-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Data Visualization
# In the Python world, there are multiple tools for data visualizing:
# * [**matplotlib**](http://matplotlib.org) produces publication quality figures in a variety of hardcopy formats and interactive environments across platforms; you can generate plots, histograms, power spectra, bar charts, errorcharts, scatterplots, etc., with just a few lines of code;
# * [**Seaborn**](http://stanford.edu/~mwaskom/software/seaborn/index.html) is a library for making attractive and informative statistical graphics in Python;
# * [**Bokeh**](http://bokeh.pydata.org/en/latest/) targets modern web browsers for presentation; its goal is to provide elegant, concise construction of novel graphics in the style of D3.js, but also deliver this capability with high-performance interactivity over very large or streaming datasets;
# * [**plotly**](https://plot.ly) generates the most interactive graphs; allows saving them offline and create very rich web-based visualizations;
#
# and others (particularly, pandas also possesses with its own visualization funtionality). Many of above libraries contains various and powerful tools for geovisualization (using maps or globes).
#
# Here, we will consider preferably matplotlib. Matplotlib is an excellent 2D and 3D graphics library for generating scientific, statistics, etc. figures. Some of the many advantages of this library include:
#
# * Easy to get started
# * Support for $\LaTeX$ formatted labels and texts
# * Great control of every element in a figure, including figure size and DPI.
# * High-quality output in many formats, including PNG, PDF, SVG, EPS, and PGF.
# * GUI for interactively exploring figures *and* support for headless generation of figure files (useful for batch jobs).
# ## Working with Matplotlib
import matplotlib.pyplot as plt
# This line configures matplotlib to show figures embedded in the notebook,
# instead of opening a new window for each figure. More about that later.
# %matplotlib inline
import numpy as np
# To create a simple line `matplotlib` plot you need to set two arrays for `x` and `y` coordinates of drawing points and them call the `plt.plot()` function.
# pyplot is a part of the Matplotlib Package.
# It can be imported like :
# ```python
# import matplotlib.pyplot as plt
# ```
# Let's start with something cool and then move to the boring stuff, shall we?
#
# ### <em>The Waves</em>
import numpy as np
import matplotlib.pyplot as plt
"""
numpy.arange([start, ]stop, [step, ]dtype=None)
Return evenly spaced values within a given interval.
Only stop value is required to be given.
Default start = 0 and step = 1
"""
x = np.arange(0,5,0.1)
y = np.sin(x)
y2 = np.cos(x)
plt.plot(x, y)
plt.plot(x,y2)
plt.show()
# ## <em>Back to The Basics </em>
# ### Bar Charts
#
# A diagram in which the numerical values of variables are represented by the height or length of lines or rectangles of equal width.
# +
objects = ('Python', 'C++', 'Java', 'Perl', 'Scala', 'Lisp')
x_pos = np.arange(len(objects)) # Like the enumerate function.
performance = [10,8,6,4,2,1] # Y values for the plot
# Plots the valueswith x_pos as X axis and Performance as Y axis
plt.bar(x_pos, performance)
# Change X axis values to names from objects
plt.xticks(x_pos, objects)
# Assigns Label to Y axis
plt.ylabel('Usage')
plt.title('Programming Language Usage')
plt.show()
# -
# ### Pie Chart
#
# A pie chart (or a circle chart) is a circular statistical graphic, which is divided into slices to illustrate numerical proportion.
# +
import matplotlib.pyplot as plt
# Data to plot
labels = ('Python', 'C++', 'Ruby', 'Java')
sizes = [10,16,14,11]
# Predefined color values
colors = ['gold', 'yellowgreen', 'lightcoral', 'lightskyblue']
# Highlights a particular Value in plot
explode = (0.1, 0, 0, 0) # Explode 1st slice
# Plot
plt.pie(sizes, explode=explode, labels=labels, colors=colors)
plt.show()
# -
# ### Line Chart
# The statement:
# ```python
# t = arange(0.0, 20.0, 1)
# ```
# defines start from 0, plot 20 items (length of our array) with steps of 1.
# We'll use this to get our X-Values for few examples.
# +
import matplotlib.pyplot as plt
t = np.arange(0.0, 20.0, 1)
s = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]
plt.plot(t, s)
plt.xlabel('Item (s)')
plt.ylabel('Value')
plt.title('Python Line Chart')
plt.grid(True)
plt.show()
# +
import matplotlib.pyplot as plt
t = np.arange(0.0, 20.0, 1)
s = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]
s2 = [4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23]
plt.plot(t, s)
plt.plot(t,s2)
plt.xlabel('Item (s)')
plt.ylabel('Value')
plt.title('Python Line Chart')
plt.grid(True)
plt.show()
# -
# Okay, now that that's taken care of, let's try something like $y =x^2$
# +
import matplotlib.pyplot as plt
a=[]
b=[]
# Try changing the range values to very small values
# Notice the change in output then
for x in range(-25000,25000):
y=x**2
a.append(x)
b.append(y)
plt.plot(a,b)
plt.show()
# -
# ## Subplots
# Matplotlib allows for subplots to be added to each figure using it's Object Oriented API. All long we've been using a global figure instance. We're going to change that now and save the instance to a variable `fig`. From it we create a new axis instance `axes` using the `add_axes` method in the `Figure` class instance `fig`.
#
# Too much theory? Try it out yourself below.
#
# +
fig = plt.figure()
x = np.arange(0,5,0.1)
y = np.sin(x)
# main axes
axes1 = fig.add_axes([0.1, 0.1, 0.9, 0.9]) # left, bottom, width, height (range 0 to 1)
# inner axes
axes2 = fig.add_axes([0.2, 0.2, 0.4, 0.4])
# main figure
axes1.plot(x, y, 'r') # 'r' = red line
axes1.set_xlabel('x')
axes1.set_ylabel('y')
axes1.set_title('Sine Wave')
# inner figure
x2 = np.arange(-5,5,0.1)
y2 = x2 ** 2
axes2.plot(x2,y2, 'g') # 'g' = green line
axes2.set_xlabel('x2')
axes2.set_ylabel('y2')
axes2.set_title('Square Wave')
plt.show()
# -
# If you don't care about the specific location of second graph, try:
# +
fig, axes = plt.subplots(nrows=1, ncols=3)
x = np.arange(-5,5,0.1)
y = x**2
i=1
for ax in axes:
ax.plot(x, y, 'r')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Square Wave '+str(i))
i+=1
# -
# That was easy, but it isn't so pretty with overlapping figure axes and labels, right?
#
# We can deal with that by using the `fig.tight_layout` method, which automatically adjusts the positions of the axes on the figure canvas so that there is no overlapping content. Moreover, the size of figure is fixed by default, i.e. it does not change depending on the subplots amount on the figure.
# +
fig, axes = plt.subplots(nrows=1, ncols=3)
x = np.arange(0,5,0.1)
y = x**2
i=1
for ax in axes:
ax.plot(x, y**(i+1), 'r')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Wave '+str(i))
i+=1
fig.tight_layout()
# -
# Above set of plots can be obtained also using `add_subplot` method of `figure` object.
# +
fig = plt.figure()
for i in range(1,4):
ax = fig.add_subplot(1, 3, i) # (rows amount, columns amount, subplot number)
ax.plot(x, y**(i+1), 'r')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Wave '+str(i))
# clear x and y ticks
# ax.set_xticks([])
# ax.set_yticks([])
fig.tight_layout()
plt.show()
# +
ncols, nrows = 3, 3
fig, axes = plt.subplots(nrows, ncols)
for m in range(nrows):
for n in range(ncols):
axes[m, n].set_xticks([])
axes[m, n].set_yticks([])
axes[m, n].text(0.5, 0.5, "axes[{}, {}]".format(m, n),
horizontalalignment='center')
# -
# `subplot2grid` is a helper function that is similar to `plt.subplot` but uses 0-based indexing and let subplot to occupy multiple cells. Let's to see how it works.
# +
fig = plt.figure()
# Let's remove all labels on the axes
def clear_ticklabels(ax):
ax.set_yticklabels([])
ax.set_xticklabels([])
ax0 = plt.subplot2grid((3, 3), (0, 0))
ax1 = plt.subplot2grid((3, 3), (0, 1))
ax2 = plt.subplot2grid((3, 3), (1, 0), colspan=2)
ax3 = plt.subplot2grid((3, 3), (2, 0), colspan=3)
ax4 = plt.subplot2grid((3, 3), (0, 2), rowspan=2)
axes = (ax0, ax1, ax2, ax3, ax4)
# Add all sublots
[ax.text(0.5, 0.5, "ax{}".format(n), horizontalalignment='center') for n, ax in enumerate(axes)]
# Cleare labels on axes
[clear_ticklabels(ax) for ax in axes]
plt.show()
# -
# ### Figure size, aspect ratio and DPI
# Matplotlib allows the aspect ratio, DPI and figure size to be specified when the `Figure` object is created, using the `figsize` and `dpi` keyword arguments. `figsize` is a tuple of the width and height of the figure in inches, and `dpi` is the dots-per-inch (pixel per inch). To create an 800x400 pixel, 100 dots-per-inch figure, we can do:
fig = plt.figure(figsize=(8,4), dpi=100)
# +
fig, axes = plt.subplots(figsize=(12,3))
axes.plot(x, y, 'r')
axes.set_xlabel('x')
axes.set_ylabel('y')
axes.set_title('title')
| Data Visualization/Matplotlib Explained.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # "My Title"
# > "Awesome summary"
#
# - toc:true
# - branch: master
# - badges: true
# - comments: true
# - author: <NAME> & <NAME>
# - categories: [fastpages, jupyter]
# + [markdown] tags=[]
# # Assignment 3
# -
# ## Pandas and plotting exercises
# + tags=[]
#hide
# Import the pandas library
import pandas as pd
# -
# In Week 2, you used a dataset from the CORGIS website. You may have used either the Python, CSV, or JSON data files.
#
# For this assignment, use the CSV file format for the same category of data that you used previously.
# +
# Use pandas read_csv function to import the data into a dataframe variable
emissions_df = pd.read_csv('emissions.csv')
# +
# How many rows and columns does the dataframe have?
emissions_df.shape
# +
# the dataframe has 8385 rows and 12 columns
# +
# What are the column names of the dataframe?
emissions_df.columns
# +
# What are the datatypes of each column?
emissions_df.dtypes
# +
# Look at the first 2 rows of the dataframe
emissions_df.head(2)
# +
# Look at the last 2 rows of the dataframe
emissions_df.tail(2)
# +
# Print out summary statistics about the dataframe
emissions_df.describe()
# +
# Choose a column and print out the column (it's ok if the output is abbreviated)
emissions_df['Ratio.Per GDP']
# +
# Choose a column that has numeric values and make a line plot of the values
r = emissions_df['Ratio.Per GDP']
r.plot(kind='line')
# +
# Use "loc" to print out the first 10 elements of the plotted column
r.loc[0:9]
# +
# Use "loc" to print out the first 10 elements of the plotted column
# as well as the matching 10 elements of a different column that has interesting text
emissions_df.loc[0:9,['Country','Year','Ratio.Per GDP']]
# +
# Assign the dataframe values from the previous cell into a new dataframe variable
# and make a bar plot with the text values horizontally and the numeric values as the bar heights
new_df = emissions_df.loc[0:9,['Country','Ratio.Per GDP']]
new_df.plot(kind='bar', x='Country', y='Ratio.Per GDP')
# +
# Re-do the plot from the previous cell as a horizontal bar plot
new_df.plot(kind='barh', x='Country')
# +
# Re-do the plot from the previous cell
# and change at least two aesthetic elements (colors, labels, titles, ...)
a = new_df.plot(kind='barh', x='Country', y= 'Ratio.Per GDP')
a.set_xlabel('Emissions per GDP', fontsize=12)
a.set_ylabel('Country', fontsize=12)
a.set_title('Afghanistan Emissions per GDP from 1970-1979')
# -
# # Free form section
# * Choose another type of plot that interests you from the [pandas.DataFrame.plot documentation](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.html#) [look at the 'kind' parameter] and make a new plot of your dataset values using the plot type
# +
emissions_with_year = emissions_df.loc[0:9,['Country', 'Year','Ratio.Per GDP']]
b = emissions_with_year.plot(kind='line', x='Year', y= 'Ratio.Per GDP', figsize=(10,5))
b.set_xlabel('Year', fontsize=12)
b.set_ylabel('Emissions per GDP', fontsize=12)
b.set_title('Afghanistan Emissions per GDP from 1970-1979')
b.legend(['Afghanistan'], fontsize=13)
# -
# * Copy some of your analysis from the Week 2 assignment into new cells below
# * Clean them up if desired, and make sure that you translate them to work with your new pandas dataframe structure here if needed
# * Create several plots to complement and extend your analysis
# +
# evaluating the emissions per GDP in Afghanistan from 1970 vs 2012
# + tags=[]
#collapse-output
x = emissions_df.loc[0:42,['Country','Year','Ratio.Per GDP']]
x
# +
# plotting emissions per GDP in Afghanistan from 1970 to 2012 to show change over the years
# +
y = x.plot(kind='line', x='Year', y= 'Ratio.Per GDP', figsize=(10,5))
y.set_xlabel('Year', fontsize=12)
y.set_ylabel('Emissions per GDP', fontsize=12)
y.set_title('Afghanistan Emissions per GDP from 1970-2012')
y.legend(['Afghanistan'], loc='upper center', fontsize=13)
# +
# emissions per GDP in Afghanistan has decreased significantly since 1970
# +
# plotting the same data above in a bar graph
# + tags=[]
y = x.plot(kind='bar', x='Year', y= 'Ratio.Per GDP', figsize=(10,5))
y.set_xlabel('Year', fontsize=12)
y.set_ylabel('Emissions per GDP', fontsize=12)
y.set_title('Afghanistan Emissions per GDP from 1970-2012')
y.legend(['Afghanistan'], loc='upper center', fontsize=13)
# +
# creating a list of all the data from 2012
# +
year_entries = emissions_df[emissions_df['Year'] == 2012]
year_entries
# +
# plotting the data from 2012 to see which countries had the highest emissions per GPD that year
# + tags=[]
z = year_entries.plot(kind='barh', x='Country', y='Ratio.Per GDP', figsize=(7,40))
z.set_xlabel('Emissions per GDP', fontsize=16)
z.set_ylabel('Country', fontsize=16)
z.set_title('Emissions per GDP in 2012 by Country')
# +
# As shown above, Qatar had the highest level of emissions per GDP in 2012.
# +
#collapse-hide
qatar_emissions = emissions_df[emissions_df['Country'] == 'Qatar']
qatar_emissions
# +
q = qatar_emissions.plot(kind='line', x='Year', y='Ratio.Per GDP', figsize=(10,7))
q.set_xlabel('Year', fontsize=13)
q.set_ylabel('Emissions per GDP')
q.set_title('Qatar Emissions per GDP from 1970-2012')
q.legend(['Qatar'])
# +
# Qatar's emissions per GDP have significantly decreased since 1970
| _notebooks/2022-03-05-Assignment 3.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Midiendo rendimiento y riesgo con datos históricos
#
# <img style="float: right; margin: 0px 0px 15px 15px;" src="https://upload.wikimedia.org/wikipedia/commons/7/7d/Copper_Price_History_USD.png" width="600px" height="400px" />
#
# > Ya sabemos que podemos caracterizar la distribución de rendimientos de un activo mediante una medida de tendencia central (media: rendimiento esperado) y una medida de dispersión (desviación estándar: volatilidad).
#
# > En la clase pasada vimos como obtener reportes históricos de precios de activos. ¿Cómo usamos estos históricos para medir el rendimiento esperado y la volatilidad de los rendimientos?
# *Objetivos:*
# - Calcular los rendimientos a partir de históricos de precios.
# - Estimar rendimiento esperado y riesgo a partir de históricos de rendimientos.
# - Anualizar rendimiento y volatilidad cuando los datos están en una base de tiempo menor.
# - Verificar la relación entre rendimiento y riesgo a través de datos reales.
#
# **Referencias:**
# - http://pandas.pydata.org/
# - https://pandas-datareader.readthedocs.io/en/latest/
# - Notas del curso "Portfolio Selection and Risk Management", Rice University, disponible en Coursera.
# ___
# ## 1. Cálculo de los rendimientos
#
# Muy bien, ya entonces sabemos descargar históricos de precios...
# **Ejemplo:** trabajaremos esta clase con activos que se encuentran en el top-10 del índice S&P500. Descargar precios ajustados en el cierre de Microsoft (MSFT), Apple (AAPL), Amazon (AMZN), Facebook (FB) y Alphabet Inc. (GOOGL) desde el primero de enero del 2015 hasta hoy.
# Importar paquetes
import pandas_datareader.data as web
import pandas as pd
import numpy as np
# %matplotlib inline
# Función para descargar precios de cierre ajustados:
def get_adj_closes(tickers, start_date=None, end_date=None):
# Fecha inicio por defecto (start_date='2010-01-01') y fecha fin por defecto (end_date=today)
# Descargamos DataFrame con todos los datos
closes = web.DataReader(name=tickers, data_source='yahoo', start=start_date, end=end_date)
# Solo necesitamos los precios ajustados en el cierre
closes = closes['Adj Close']
# Se ordenan los índices de manera ascendente
closes.sort_index(inplace=True)
return closes
# Información
names = ['MSFT', 'AAPL', 'AMZN', 'FB', 'GOOGL', '^GSPC']
start_date = '2015-01-01'
# Precios diarios
closes = get_adj_closes(tickers=names,
start_date=start_date
)
closes.tail(10)
# Gráfico de histórico de precios diarios
closes.plot(figsize=(6,4), grid=True)
# ### 1.1. Rendimientos porcentuales
# Muy bien, pero para el análisis no trabajamos con los precios sino con los rendimientos... **¿porqué?**
# Para una sucesión de precios $\{S_t\}_{t=0}^{n}$, el rendimiento simple $R_t$ se define como el el cambio porcentual
# $$
# R_t=\frac{S_t-S_{t-1}}{S_{t-1}}
# $$
# para $t=1,\ldots,n$.
# *¡Cuidado!* los rendimientos son de acuerdo a la base de tiempo en que se reportan los precios. Por ejemplo:
# - si los precios se reportan en una base diaria, los rendimientos también son diarios;
# - si los precios se reportan en una base mensual, los rendimientos también son mensuales.
# Método shift() de un DataFrame...
help(closes.shift)
closes.shift()
# Calcular los rendimientos
ret = ((closes - closes.shift()) / closes.shift()).dropna()
ret.head()
# Otra forma (más fácil)
ret = closes.pct_change().dropna()
# Graficar...
ret.plot(figsize=(6, 4), grid=True)
# **¿Qué se observa respecto a los precios?**
#
# Respuestas:
# - Los rendimientos parecen conservar tendecias estadísticas constantes (por ejemplo, oscilan al rededor de números cercanos a cero).
# ### 1.2. Rendimientos logarítmicos (log-rendimientos)
# Otro rendimiento usado con frecuencia es el rendimiento continuamente compuesto o rendimiento logaritmico. Éste, está definido como
#
# $$
# r_t=\ln\left(\frac{S_t}{S_{t-1}}\right).
# $$
#
# Es fácil darse cuenta que $r_t=\ln(1+R_t)$.
#
# <font color=blue>Ver en el tablero</font> que si $0\leq|x|\ll 1$, entonces $\ln(1+x)\approx x$.
# Calcular rendimientos continuamente compuestos
log_ret = np.log(closes / closes.shift()).dropna()
log_ret.head(2)
# Recordar rendimientos porcentuales. Ver que son similares
ret.head(2)
# Veamos el valor absoluto de la diferencia
np.abs(ret - log_ret).head(3)
# Por lo anterior, muchas veces se usan para el análisis los rendimientos continuamente compuestos.
# ___
# ## 2. Caracterización de la distribución de los rendimientos
#
# Entonces:
# - partimos de que tenemos los rendimientos porcentuales diarios de Apple, Walmart, IBM y Nike desde inicios del 2011 a finales del 2015;
# - ¿cómo resumirían estos datos?
# Rendimiento medio diario (media aritmética)
mean_ret = ret.mean()
mean_ret
# Volatilidad diaria (desviación estándar)
vol = ret.std()
vol
# Podemos resumir en un DataFrame
ret_summary = pd.DataFrame({'Mean': mean_ret, 'Vol': vol})
ret_summary
# Normalmente se reportan rendimientos esperados y volatilidades en una base anual. Para anualizar:
#
# $$E[r_a]=12E[r_m]=252E[r_d]=52E[r_w],\text{ y}$$
#
# $$\sigma_{r_a}=\sqrt{12}\sigma_{r_m}=\sqrt{252}\sigma_{r_d}=\sqrt{52}\sigma_{r_w}$$
# Resumen en base anual
annual_ret_summary = pd.DataFrame({'Mean': mean_ret * 252,
'Vol': vol * np.sqrt(252)
})
annual_ret_summary
# Gráfico rendimiento esperado vs. volatilidad
import matplotlib.pyplot as plt
# Puntos a graficar
x_points = annual_ret_summary.loc[:, 'Vol']
y_points = annual_ret_summary.loc[:, 'Mean']
# Ventana para graficar
plt.figure(figsize=(6, 4))
# Graficar puntos
plt.plot(x_points, y_points, 'o', ms=10)
plt.grid()
# Etiquetas de los ejes
plt.xlabel('Volatilidad ($\sigma$)')
plt.ylabel('Rendimiento esperado ($E[r]$)')
# Etiqueta de cada instrumento
plt.text(x_points[0], y_points[0], annual_ret_summary.index[0])
plt.text(x_points[1], y_points[1], annual_ret_summary.index[1])
plt.text(x_points[2], y_points[2], annual_ret_summary.index[2])
plt.text(x_points[3], y_points[3], annual_ret_summary.index[3])
plt.text(x_points[4], y_points[4], annual_ret_summary.index[4])
plt.text(x_points[5], y_points[5], annual_ret_summary.index[5])
plt.show()
# ### 2.1 Ajuste de curvas con mínimos cuadrados
# Consideramos que tenemos un conjunto de n pares ordenados de datos $(\sigma_{r_i},E[r_i])$, para $i=1,2,3,\dots,n$... **en este caso corresponden a volatilidad y rendimiento esperado**
#
# #### ¿Cuál es la recta que mejor se ajusta a estos datos?
# Consideramos entonces ajustes de la forma $\hat{f}(\sigma) = \beta_0+\beta_1 \sigma = \left[1 \quad \sigma\right]\left[\begin{array}{c} \beta_0 \\ \beta_1 \end{array}\right]=\left[1 \quad \sigma\right]\boldsymbol{\beta}$ (lineas rectas).
#
# Para decir '*mejor*', tenemos que definir algún sentido en que una recta se ajuste *mejor* que otra.
#
# **Mínimos cuadrados**: el objetivo es seleccionar los coeficientes $\boldsymbol{\beta}=\left[\beta_0 \quad \beta_1 \right]^T$, de forma que la función evaluada en los puntos $\sigma_{r_i}$ ($\hat{f}(\sigma_{r_i})$) aproxime los valores correspondientes $E[r_i]$.
#
# La formulación por mínimos cuadrados, encuentra los $\boldsymbol{\beta}=\left[\beta_0 \quad \beta_1 \right]^T$ que minimiza
# $$\sum_{i=1}^{n}(E[r_i]-\hat{f}(\sigma_{r_i}))^2$$
# Importar el módulo optimize de la librería scipy
from scipy.optimize import minimize
# Funcion minimize
help(minimize)
# Funcion objetivo y condicion inicial
def objetivo(beta, vol, mean_ret):
recta = beta[0] + beta[1] * vol
return ((mean_ret - recta) ** 2).sum()
# Resolver problema de optimizacion
beta_ini = [0, 0]
solucion = minimize(fun=objetivo,
x0=beta_ini,
args=(annual_ret_summary['Vol'],
annual_ret_summary['Mean']
)
)
solucion
beta_opt = solucion.x
beta_opt
# +
# Puntos a graficar
x_points = annual_ret_summary.loc[:, 'Vol']
y_points = annual_ret_summary.loc[:, 'Mean']
# Ventana para graficar
plt.figure(figsize=(6, 4))
# Graficar puntos
plt.plot(x_points, y_points, 'o', ms=10)
plt.grid()
# Etiquetas de los ejes
plt.xlabel('Volatilidad ($\sigma$)')
plt.ylabel('Rendimiento esperado ($E[r]$)')
# Etiqueta de cada instrumento
plt.text(x_points[0], y_points[0], annual_ret_summary.index[0])
plt.text(x_points[1], y_points[1], annual_ret_summary.index[1])
plt.text(x_points[2], y_points[2], annual_ret_summary.index[2])
plt.text(x_points[3], y_points[3], annual_ret_summary.index[3])
plt.text(x_points[4], y_points[4], annual_ret_summary.index[4])
plt.text(x_points[5], y_points[5], annual_ret_summary.index[5])
# Grafica de recta ajustada
x_recta = np.linspace(0.1, 0.3, 100)
y_recta = beta_opt[1] * x_recta + beta_opt[0]
plt.plot(x_recta, y_recta, 'r', lw=3, label='Recta ajustada')
plt.legend(loc='best')
plt.show()
# -
# **¿Qué se puede concluir acerca de la relación entre riesgo (medido con la volatilidad) y el rendimiento esperado (medido con la media)?**
#
# Respuestas:
# - Para un rendimiento esperado más alto, se necesita asumir más riesgo.
# - La relación entre rendimiento esperado y riesgo es positiva (de acuerdo a los datos).
# ## 3. Comentarios finales acerca del uso de datos históricos.
#
# ### ¡Cuidado!
# - Es cierto que los patrones que vemos sobre periodos largos de tiempo en diferentes tipos de intrumentos son muy robustos en términos de la relación rendimiento/riesgo (positiva).
# - Por tanto, esperamos rendimientos más altos en el futuro cuando asumimos cierto riesgo.
# - ¿Cómo encontramos ese 'rendimiento esperado' en el futuro'? Datos históricos (humanos: tendencia a generalizar)
# - Entonces, la idea es que si los rendimientos esperados son un p.e. estacionario, el promedio de muchos rendimientos pasados es una buena estimación del rendimiento esperado futuro (Teorema del límite central).
# - ¿Deberíamos pensarlo dos veces?
#
# ## SI
# Problemas:
# - La muestra de datos en el periodo específico de tiempo puede estar sesgada.
# - Ventanas de tiempo más grandes reducen especificidad de la muestra y estimados más precisos.
# - Aún así, datos muy viejos pueden ser no representativos.
# - Nuevos fondos o estrategias de inversión están a menudo sesgados positivamente:
# - reporte de resultados en tiempos voluntarios;
# - las que mueren (no funcionan), no se reportan;
# # Anuncios parroquiales:
# ## 1. Fin Módulo 1. Revisar que se hayan cumplido los objetivos del módulo (Clase0)
# ## 2. Tarea: revisar archivo "Tarea3_MidiendoRendimientoRiesgo" en clase. Para el viernes 14 de Febrero.
# ## 3. Recordar quiz la siguiente clase.
# <script>
# $(document).ready(function(){
# $('div.prompt').hide();
# $('div.back-to-top').hide();
# $('nav#menubar').hide();
# $('.breadcrumb').hide();
# $('.hidden-print').hide();
# });
# </script>
#
# <footer id="attribution" style="float:right; color:#808080; background:#fff;">
# Created with Jupyter by <NAME>.
# </footer>
| Modulo1/Clase5_MidiendoConHistoricos.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
import numpy as np
import pickle
import time
import os
os.chdir('..')
from config import mfp
from src.data_loader import load_ctd
import src.tools.chemidr.id_map as id_map
hdata = load_ctd()
# +
ctd_mesh = hdata.drop_duplicates('ChemicalID').copy().reset_index(drop=True)
mesh_cid_map = []
start = time.time()
for mesh in ctd_mesh.ChemicalID.tolist():
mesh_cid_map.append(id_map.mesh2pid(mesh))
if not i % 400:
print(i, 'loops done in', (time.time() - start) / 60, 'min')
i+=1
# uncomment to re-run, or load saved id's below
# pickle.dump( mesh_cid_map, open( "misc_save/ctd_mesh_cid_map.pkl", "wb" ) )
# +
with open(mfp("misc_save/ctd_mesh_cid_map.pkl"), "rb") as f:
ids = pickle.load(f)
ids_dict = {}
for d in ids:
ids_dict.update(d)
cids = [float(v['cid']) for _, v in ids_dict.items()]
hchems = pd.DataFrame({'chem_id_p' : cids, 'ChemicalName' : [np.nan] * len(cids)})
hchems['chem_id'] = np.nan
hchems['chem_id'] = hchems['chem_id'].astype(object)
hchems.at[hchems[hchems.chem_id_p.notnull()].index, 'chem_id'] = id_map.cids2inchis(hchems[hchems.chem_id_p.notnull()].chem_id_p.tolist(), use_prefix=True)
# -
def disambiguation_table(fm_q, fm_uq, fdb_d_q, fdb_d_uq, usda):
fm_ids = list(set( fm_q[fm_q['chem_id'].notnull()].chem_id.tolist() + fm_uq[fm_uq['chem_id'].notnull()].chem_id.tolist() ))
fdb_ids = list(set( fdb_d_q[fdb_d_q['chem_id'].notnull()].chem_id.tolist() + fdb_d_uq[fdb_d_uq['chem_id'].notnull()].chem_id.tolist() ))
usda_ids = list(set( usda[(usda['chem_id'].notnull()) & (usda.Nutr_Val > 0)].chem_id.tolist() ))
disp = pd.DataFrame({
'' : ['foodmine', 'foodb', 'usda'],
'quant' : [
len( fm_q[fm_q.average_mean > 0].merge(hchems, how='inner', on='chem_id').dropna(subset=['chem_id'], axis=0).drop_duplicates('chem_id') ),
len( fdb_d_q[fdb_d_q.standard_content > 0].merge(hchems, how='inner', on='chem_id').dropna(subset=['chem_id'], axis=0).drop_duplicates('chem_id') ),
len( usda[usda.Nutr_Val > 0].merge(hchems, how='inner', on='chem_id').dropna(subset=['chem_id'], axis=0).drop_duplicates('chem_id') )
],
'unquant' : [
len( fm_uq.merge(hchems, how='inner', on='chem_id').dropna(subset=['chem_id'], axis=0).drop_duplicates('chem_id') ),
len( fdb_d_uq.merge(hchems, how='inner', on='chem_id').dropna(subset=['chem_id'], axis=0).drop_duplicates('chem_id') ),
0
],
'absent' : [
len( hchems[~hchems.chem_id.isin(fm_ids)].dropna(subset=['chem_id'], axis=0).drop_duplicates('chem_id') )
+ len( hchems[hchems.chem_id.isnull()].ChemicalName.drop_duplicates() ),
len( hchems[~hchems.chem_id.isin(fdb_ids)].dropna(subset=['chem_id'], axis=0).drop_duplicates('chem_id') )
+ len( hchems[hchems.chem_id.isnull()].ChemicalName.drop_duplicates() ),
len( hchems[~hchems.chem_id.isin(usda_ids)].dropna(subset=['chem_id'], axis=0).drop_duplicates('chem_id') )
+ len( hchems[hchems.chem_id.isnull()].ChemicalName.drop_duplicates() )
]
})
disp['total'] = disp.sum(axis=1)
display(disp)
# ### Load data related to garlic
# +
fdb_d = pd.read_pickle('misc_save/garlic_foodb_food_dump.pkl')
fdb_d.rename(columns={'pubchem_id' : 'chem_id_p', 'foodb_id' : 'chem_id_f'}, inplace=True)
# Creates a list of the unique chemicals in garlic from FooDB
foodb_food_lower = list(set( fdb_d.chem_id.tolist() ))
# Creates a separate dataframe that holds chemicals for garlic in foodb with a real quantification
fdb_d_q = fdb_d[fdb_d.standard_content.notnull()][['chem_id', 'chem_id_p', 'chem_id_f', 'orig_source_id','name', 'standard_content']].drop_duplicates()
# Creates a separate dataframe that holds chemicals for garlic in foodb without a real quantification
fdb_d_uq = fdb_d[fdb_d.standard_content.isnull()][['chem_id', 'chem_id_p', 'chem_id_f', 'orig_source_id', 'name', 'standard_content']].reset_index()
q_ids = list(set( fdb_d_q.chem_id.tolist() ))
q_names = list(set( fdb_d_q.name.tolist() ))
fdb_d_uq = fdb_d_uq[(~fdb_d_uq.chem_id.fillna('-').isin(q_ids)) & (~fdb_d_uq.name.fillna('-').isin(q_names))]
# Load FoodMine data
fm = pd.read_pickle('misc_save/garlic_fm.pkl')
fm_q = pd.read_pickle('misc_save/garlic_fm_quant.pkl')
fm_uq = pd.read_pickle('misc_save/garlic_fm_unquant.pkl')
fm.rename(columns={'pubchem_id' : 'chem_id_p', 'foodb_id' : 'chem_id_f'}, inplace=True)
fm_q.rename(columns={'pubchem_id' : 'chem_id_p', 'foodb_id' : 'chem_id_f'}, inplace=True)
fm_uq.rename(columns={'pubchem_id' : 'chem_id_p', 'foodb_id' : 'chem_id_f'}, inplace=True)
# Load USDA data
usda = pd.read_pickle('misc_save/garlic_usda.pkl')
usda.rename(columns={'pubchem_id' : 'chem_id_p', 'foodb_id' : 'chem_id_f'}, inplace=True)
# -
disambiguation_table(fm_q, fm_uq, fdb_d_q, fdb_d_uq, usda)
# ### Load data related to cocoa
# +
fdb_d = pd.read_pickle('misc_save/cocoa_foodb_food_dump.pkl')
fdb_d.rename(columns={'pubchem_id' : 'chem_id_p', 'foodb_id' : 'chem_id_f'}, inplace=True)
# Creates a list of the unique chemicals in cocoa from FooDB
foodb_food_lower = list(set( fdb_d.chem_id.tolist() ))
# Creates a separate dataframe that holds chemicals for cocoa in foodb with a real quantification
fdb_d_q = fdb_d[fdb_d.standard_content.notnull()][['chem_id', 'chem_id_p', 'chem_id_f', 'orig_source_id','name', 'standard_content']].drop_duplicates()
# Creates a separate dataframe that holds chemicals for cocoa in foodb without a real quantification
fdb_d_uq = fdb_d[fdb_d.standard_content.isnull()][['chem_id', 'chem_id_p', 'chem_id_f', 'orig_source_id', 'name', 'standard_content']].reset_index()
q_ids = list(set( fdb_d_q.chem_id.tolist() ))
q_names = list(set( fdb_d_q.name.tolist() ))
fdb_d_uq = fdb_d_uq[(~fdb_d_uq.chem_id.fillna('-').isin(q_ids)) & (~fdb_d_uq.name.fillna('-').isin(q_names))]
# Loads FoodMine data
fm = pd.read_pickle('misc_save/cocoa_fm.pkl')
fm_q = pd.read_pickle('misc_save/cocoa_fm_quant.pkl')
fm_uq = pd.read_pickle('misc_save/cocoa_fm_unquant.pkl')
fm.rename(columns={'pubchem_id' : 'chem_id_p', 'foodb_id' : 'chem_id_f'}, inplace=True)
fm_q.rename(columns={'pubchem_id' : 'chem_id_p', 'foodb_id' : 'chem_id_f'}, inplace=True)
fm_uq.rename(columns={'pubchem_id' : 'chem_id_p', 'foodb_id' : 'chem_id_f'}, inplace=True)
# Load USDA data
usda = pd.read_pickle('misc_save/cocoa_usda.pkl')
usda.rename(columns={'pubchem_id' : 'chem_id_p', 'foodb_id' : 'chem_id_f'}, inplace=True)
# -
disambiguation_table(fm_q, fm_uq, fdb_d_q, fdb_d_uq, usda)
| Nature_Food_Perspective/Perspective_Analysis.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Using SageMaker Debugger and SageMaker Experiments for iterative model pruning
#
# This notebook demonstrates how we can use [SageMaker Debugger](https://docs.aws.amazon.com/sagemaker/latest/dg/train-debugger.html) and [SageMaker Experiments](https://docs.aws.amazon.com/sagemaker/latest/dg/experiments.html) to perform iterative model pruning. Let's start first with a quick introduction into model pruning.
#
# State of the art deep learning models consist of millions of parameters and are trained on very large datasets. For transfer learning we take a pre-trained model and fine-tune it on a new and typically much smaller dataset. The new dataset may even consist of different classes, so the model is basically learning a new task. This process allows us to quickly achieve state of the art results without having to design and train our own model from scratch. However, it may happen that a much smaller and simpler model would also perform well on our dataset. With model pruning we identify the importance of weights during training and remove the weights that are contributing very little to the learning process. We can do this in an iterative way where we remove a small percentage of weights in each iteration. Removing means to eliminate the entries in the tensor so its size shrinks.
#
# We use SageMaker Debugger to get weights, activation outputs and gradients during training. These tensors are used to compute the importance of weights. We will use SageMaker Experiments to keep track of each pruning iteration: if we prune too much we may degrade model accuracy, so we will monitor number of parameters versus validation accuracy.
#
# ! pip -q install sagemaker
# ! pip -q install sagemaker-experiments
# ### Get training dataset
# Next we get the [Caltech101](http://www.vision.caltech.edu/Image_Datasets/Caltech101/) dataset. This dataset consists of 101 image categories.
# +
import tarfile
import requests
import os
filename = '101_ObjectCategories.tar.gz'
data_url = os.path.join("https://s3.us-east-2.amazonaws.com/mxnet-public", filename)
r = requests.get(data_url, stream=True)
with open(filename, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print('Extracting {} ...'.format(filename))
tar = tarfile.open(filename, "r:gz")
tar.extractall('.')
tar.close()
print('Data extracted.')
# -
# And upload it to our SageMaker default bucket:
# +
import sagemaker
import boto3
def upload_to_s3(path, directory_name, bucket, counter=-1):
print("Upload files from" + path + " to " + bucket)
client = boto3.client('s3')
for path, subdirs, files in os.walk(path):
path = path.replace("\\","/")
print(path)
for file in files[0:counter]:
client.upload_file(os.path.join(path, file), bucket, directory_name+'/'+path.split("/")[-1]+'/'+file)
boto_session = boto3.Session()
sagemaker_session = sagemaker.Session(boto_session=boto_session)
bucket = sagemaker_session.default_bucket()
upload_to_s3("101_ObjectCategories", directory_name="101_ObjectCategories_train", bucket=bucket)
#we will compute saliency maps for all images in the test dataset, so we will only upload 4 images
upload_to_s3("101_ObjectCategories_test", directory_name="101_ObjectCategories_test", bucket=bucket, counter=4)
# -
# ### Load and save AlexNet model
#
# First we load a pre-trained [AlexNet](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks) model from PyTorch model zoo.
# +
import torch
from torchvision import models
from torch import nn
model = models.alexnet(pretrained=True)
# -
# [AlexNet](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks) is a convolutional neural network and won the [ImageNet Large Scale Visual Recognition Challenge](http://www.image-net.org/challenges/LSVRC/) in 2012.
# The model has two main parts:
# - A feature extraction part, made of five convolution/pooling blocks,
# - A classification part, made of three fully connected (aka 'Linear') layers.
#
# Let's have a look on the model architecture:
model
# As we can see above, the last Linear layer outputs 1000 values, which is the number of classes the model has originally been trained on. Here, we will fine-tune the model on the Caltech101 dataset: as it has only 101 classes, we need to set the number of output classes to 101.
model.classifier[6] = nn.Linear(4096, 101)
# Next we store the model definition and weights in an output file.
# +
checkpoint = {'model': model,
'state_dict': model.state_dict()}
torch.save(checkpoint, 'src/model_checkpoint')
# -
# The following code cell creates a SageMaker experiment:
# +
import boto3
from datetime import datetime
from smexperiments.experiment import Experiment
sagemaker_boto_client = boto3.client("sagemaker")
#name of experiment
timestep = datetime.now()
timestep = timestep.strftime("%d-%m-%Y-%H-%M-%S")
experiment_name = timestep + "-model-pruning-experiment"
#create experiment
Experiment.create(
experiment_name=experiment_name,
description="Iterative model pruning of AlexNet trained on Caltech101",
sagemaker_boto_client=sagemaker_boto_client)
# -
# The following code cell defines a list of tensor names that are considered for pruning. The list contains all convolutional layers and their biases. It also includes the fully-connected layers of the classifier. The lists are defined in the Python script `model_alexnet`.
# +
import model_alexnet
activation_outputs = model_alexnet.activation_outputs
gradients = model_alexnet.gradients
weights = model_alexnet.weights
biases = model_alexnet.biases
classifier_weights = model_alexnet.classifier_weights
classifier_biases = model_alexnet.classifier_biases
# -
# ### Iterative model pruning: step by step
#
# Before we jump into the code for running the iterative model pruning we will walk through the code step by step.
#
# #### Step 0: Create trial and debugger hook coonfiguration
# First we create a new trial for each pruning iteration. That allows us to track our training jobs and see which models have the lowest number of parameters and best accuracy. We use the `smexperiments` library to create a trial within our experiment.
# +
from smexperiments.trial import Trial
trial = Trial.create(
experiment_name=experiment_name,
sagemaker_boto_client=sagemaker_boto_client
)
# -
# Next we define the experiment_config which is a dictionary that will be passed to the SageMaker training.
experiment_config = { "ExperimentName": experiment_name,
"TrialName": trial.trial_name,
"TrialComponentDisplayName": "Training"}
# We create a debugger hook configuration to define a custom collection of tensors to be emitted. The custom collection contains all weights and biases of the model. It also includes individual layer outputs and their gradients which will be used to compute filter ranks. Tensors are saved every 100th iteration where an iteration represents one forward and backward pass.
# +
from sagemaker.debugger import DebuggerHookConfig, CollectionConfig
debugger_hook_config = DebuggerHookConfig(
collection_configs=[
CollectionConfig(
name="custom_collection",
parameters={ "include_regex": ".*output|.*weight|.*bias",
"save_interval": "100" })])
# -
# #### Step 1: Start training job
# Now we define the SageMaker PyTorch Estimator. We will train the model on an `ml.p2.xlarge` instance. The model definition plus training code is defined in the entry_point file `train.py`.
# +
import sagemaker
from sagemaker.pytorch import PyTorch
estimator = PyTorch(role=sagemaker.get_execution_role(),
instance_count=1,
instance_type='ml.p2.xlarge',
volume_size=400,
source_dir='src',
entry_point='train.py',
framework_version='1.3.1',
py_version='py3',
metric_definitions=[ {'Name':'train:loss', 'Regex':'loss:(.*?)'}, {'Name':'eval:acc', 'Regex':'acc:(.*?)'} ],
enable_sagemaker_metrics=True,
hyperparameters = {'epochs': 15},
debugger_hook_config=debugger_hook_config
)
# -
# Once we have defined the estimator object we can call `fit` which creates a ml.p2.xlarge instance on which it starts the training. We pass the experiment_config which associates the training job with a trial and an experiment. If we don't specify an `experiment_config` the training job will appear in SageMaker Experiments under `Unassigned trial components`
estimator.fit(inputs={'train': 's3://{}/101_ObjectCategories_train'.format(bucket),
'test': 's3://{}/101_ObjectCategories_test'.format(bucket)},
experiment_config=experiment_config)
# #### Step 2: Get gradients, weights, biases
#
# Once the training job has finished, we will retrieve its tensors, such as gradients, weights and biases. We use the `smdebug` library which provides functions to read and filter tensors. First we create a [trial](https://github.com/awslabs/sagemaker-debugger/blob/master/docs/analysis.md#Trial) that is reading the tensors from S3.
#
# For clarification: in the context of SageMaker Debugger a trial is an object that lets you query tensors for a given training job. In the context of SageMaker Experiments a trial is part of an experiment and it presents a collection of training steps involved in a single training job.
# +
from smdebug.trials import create_trial
path = estimator.latest_job_debugger_artifacts_path()
smdebug_trial = create_trial(path)
# -
# To access tensor values, we only need to call `smdebug_trial.tensor()`. For instance to get the value of the first fully connected layer at step 0 we run `smdebug_trial.tensor('AlexNet_classifier.1.weight').value(0, mode=modes.TRAIN)`. Next we compute a filter rank for the convolutions.
#
# Some defintions: a filter is a collection of kernels (one kernel for every single input channel) and a filter produces one feature map (output channel). In the image below the convolution creates 64 feature maps (output channels) and uses a kernel of 5x5. By pruning a filter, an entire feature map will be removed. So in the example image below the number of feature maps (output channels) would shrink to 63 and the number of learnable parameters (weights) would be reduced by 1x5x5.
#
# 
#
#
# #### Step 3: Compute filter ranks
#
# In this notebook we compute filter ranks as described in the article ["Pruning Convolutional Neural Networks for Resource Efficient Inference"](https://arxiv.org/pdf/1611.06440.pdf) We basically identify filters that are less important for the final prediction of the model. The product of weights and gradients can be seen as a measure of importance. The product has the dimension `(batch_size, out_channels, width, height)` and we get the average over `axis=0,2,3` to have a single value (rank) for each filter.
#
# In the following code we retrieve activation outputs and gradients and compute the filter rank.
# +
import numpy as np
from smdebug import modes
def compute_filter_ranks(smdebug_trial, activation_outputs, gradients):
filters = {}
for activation_output_name, gradient_name in zip(activation_outputs, gradients):
for step in smdebug_trial.steps(mode=modes.TRAIN):
activation_output = smdebug_trial.tensor(activation_output_name).value(step, mode=modes.TRAIN)
gradient = smdebug_trial.tensor(gradient_name).value(step, mode=modes.TRAIN)
rank = activation_output * gradient
rank = np.mean(rank, axis=(0,2,3))
if activation_output_name not in filters:
filters[activation_output_name] = 0
filters[activation_output_name] += rank
return filters
filters = compute_filter_ranks(smdebug_trial, activation_outputs, gradients)
# -
# Next we normalize the filters:
# +
def normalize_filter_ranks(filters):
for activation_output_name in filters:
rank = np.abs(filters[activation_output_name])
rank = rank / np.sqrt(np.sum(rank * rank))
filters[activation_output_name] = rank
return filters
filters = normalize_filter_ranks(filters)
# -
# We create a list of filters, sort it by rank and retrieve the smallest values:
# +
def get_smallest_filters(filters, n):
filters_list = []
for layer_name in sorted(filters.keys()):
for channel in range(filters[layer_name].shape[0]):
filters_list.append((layer_name, channel, filters[layer_name][channel], ))
filters_list.sort(key = lambda x: x[2])
filters_list = filters_list[:n]
print("The", n, "smallest filters", filters_list)
return filters_list
filters_list = get_smallest_filters(filters, 100)
# -
# #### Step 4 and step 5: Prune low ranking filters and set new weights
#
# Next we prune the model, where we remove filters and their corresponding weights.
# +
step = smdebug_trial.steps(mode=modes.TRAIN)[-1]
model = model_alexnet.prune(model,
activation_outputs,
weights,
biases,
classifier_weights,
classifier_biases,
filters_list,
smdebug_trial,
step)
# -
# #### Step 6: Start next pruning iteration
# Once we have pruned the model, the new architecture and pruned weights will be saved under src and will be used by the next training job in the next pruning iteration.
# +
# save pruned model
checkpoint = {'model': model,
'state_dict': model.state_dict()}
torch.save(checkpoint, 'src/model_checkpoint')
#clean up
del model
# -
# #### Overall workflow
# The overall workflow looks like the following:
# 
# ### Run iterative model pruning
#
# After having gone through the code step by step, we are ready to run the full worfklow. The following cell runs 10 pruning iterations: in each iteration of the pruning a new SageMaker training job is started, where it emits gradients and activation outputs to Amazon S3. Once the job has finished, filter ranks are computed and the 100 smallest filters are removed.
#
#
# +
# start iterative pruning
for pruning_step in range(10):
#create new trial for this pruning step
smexperiments_trial = Trial.create(
experiment_name=experiment_name,
sagemaker_boto_client=sagemaker_boto_client
)
experiment_config["TrialName"] = smexperiments_trial.trial_name
print("Created new trial", smexperiments_trial.trial_name, "for pruning step", pruning_step)
#start training job
estimator = PyTorch(role=sagemaker.get_execution_role(),
train_instance_count=1,
train_instance_type='ml.p2.xlarge',
train_volume_size=400,
source_dir='src',
entry_point='train.py',
framework_version='1.3.1',
py_version='py3',
metric_definitions=[ {'Name':'train:loss', 'Regex':'loss:(.*?)'}, {'Name':'eval:acc', 'Regex':'acc:(.*?)'} ],
enable_sagemaker_metrics=True,
hyperparameters = {'epochs': 10},
debugger_hook_config = debugger_hook_config
)
#start training job
estimator.fit(inputs={'train': 's3://{}/101_ObjectCategories_train'.format(bucket),
'test': 's3://{}/101_ObjectCategories_test'.format(bucket)},
experiment_config=experiment_config)
print("Training job", estimator.latest_training_job.name, " finished.")
# read tensors
path = estimator.latest_job_debugger_artifacts_path()
smdebug_trial = create_trial(path)
# compute filter ranks and get 100 smallest filters
filters = compute_filter_ranks(smdebug_trial, activation_outputs, gradients)
filters_normalized = normalize_filter_ranks(filters)
filters_list = get_smallest_filters(filters_normalized, 100)
#load previous model
checkpoint = torch.load("src/model_checkpoint")
model = checkpoint['model']
model.load_state_dict(checkpoint['state_dict'])
#prune model
step = smdebug_trial.steps(mode=modes.TRAIN)[-1]
model = model_alexnet.prune(model,
activation_outputs,
weights,
biases,
classifier_weights,
classifier_biases,
filters_list,
smdebug_trial,
step)
print("Saving pruned model")
# save pruned model
checkpoint = {'model': model,
'state_dict': model.state_dict()}
torch.save(checkpoint, 'src/model_checkpoint')
#clean up
del model
# -
# As the iterative model pruning is running, we can track and visualize our experiment in SageMaker Studio. In our training script we use SageMaker debugger's `save_scalar` method to store the number of parameters in the model and the model accuracy. So we can visualize those in Studio as shown in the image below.
#
# Initially the model consisted of 57 million parameters. After 11 iterations the number of parameters was reduced to 18 million, while accuracy started at 85% and it significantly dropped after the 8 pruning iteration.
#
# 
# ### Results
# The following animation shows the number of parameters per layer for each pruning iteration. We can see that most of the parameters are pruned in the last convolutional layers. The model starts with 57 million parameters and a size of 218 MB. After 10 iterations it consists of only 18 million parameters and 70 MB. Less parameters means smaller model size, and hence, faster training and inference.
#
# 
# ### Additional: run iterative model pruning with custom rule
#
# In the previous example, we have seen that accuracy drops when the model has less than 22 million parameters. Clearly, we want to stop our experiment once we reach this point. We can define a custom rule that returns `True` if the accuracy drops by a certain percentage. You can find an example implementation in `custom_rule/check_accuracy.py`. Before we can use the rule we have to define a custom rule configuration:
#
# ```python
#
# from sagemaker.debugger import Rule, CollectionConfig, rule_configs
#
# check_accuracy_rule = Rule.custom(
# name='CheckAccuracy',
# image_uri='759209512951.dkr.ecr.us-west-2.amazonaws.com/sagemaker-debugger-rule-evaluator:latest',
# instance_type='ml.c4.xlarge',
# volume_size_in_gb=400,
# source='custom_rule/check_accuracy.py',
# rule_to_invoke='check_accuracy',
# rule_parameters={"previous_accuracy": "0.0",
# "threshold": "0.05",
# "predictions": "CrossEntropyLoss_0_input_0",
# "labels":"CrossEntropyLoss_0_input_1"},
# )
# ```
#
# The rule reads the inputs to the loss function, which are the model predictions and the labels. It computes the accuracy and returns `True` if its value has dropped by more than 5% otherwise `False`.
#
# In each pruning iteration, we need to pass the accuracy of the previous training job to the rule, which can be retrieved via the `ExperimentAnalytics` module.
#
# ```python
# from sagemaker.analytics import ExperimentAnalytics
#
# trial_component_analytics = ExperimentAnalytics(experiment_name=experiment_name)
# accuracy = trial_component_analytics.dataframe()['scalar/accuracy_EVAL - Max'][0]
# ```
# And overwrite the value in the rule configuration:
#
# ```python
# check_accuracy_rule.rule_parameters["previous_accuracy"] = str(accuracy)
# ```
#
# In the PyTorch estimator we need to add the argument `rules = [check_accuracy_rule]`.
# We can create a CloudWatch alarm and use a Lambda function to stop the training. Detailed instructions can be found [here](https://github.com/awslabs/amazon-sagemaker-examples/tree/master/sagemaker-debugger/tensorflow_action_on_rule). In each iteration we check the job status and if the previous job has been stopped, we exit the loop:
#
# ```python
# job_name = estimator.latest_training_job.name
# client = estimator.sagemaker_session.sagemaker_client
# description = client.describe_training_job(TrainingJobName=job_name)
#
# if description['TrainingJobStatus'] == 'Stopped':
# break
# ```
#
#
| sagemaker-debugger/pytorch_iterative_model_pruning/iterative_model_pruning_alexnet.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
import numpy as np
import pandas as pd
df = pd.read_csv("../../data/jx_duty.csv")
df.head(5)
df.shape
df = df.sample(20000)
import jieba
# +
# Need to be length greater than 10;
def length_bigger_than_10(text):
if len(text)>=10:
return True
else:
return False
#新建length列
df['length'] = df.agg({'duty': length_bigger_than_10})
#根据length列来保留长度大于10的文本,并将其放入新的dataframe中
df = df[df['length']==True]
# -
import nltk
import jieba
nltk.download('stopwords')
# +
#停止词
from nltk.corpus import stopwords
stopwords = stopwords.words("chinese")
def clean_text(text):
wordlist = jieba.lcut(text)
#去除停用词和长度小于2的词语
wordlist = [w for w in wordlist if w not in stopwords and len(w)>2]
#将中文数据组织成类似西方于洋那样,词语之间以空格间隔
document = " ".join(wordlist)
return document
#使用dataframe.agg对content列实行clean_text方法
df['duty'] = df.agg({'duty': clean_text})
corpus = df['duty']
corpus.head()
# +
## jieba 分词包
def chinese_word_cut(mytext):
return " ".join(jieba.cut(mytext))
# -
df["duty_cutted"] = df.duty.apply(chinese_word_cut)
df.duty_cutted.head()
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
stpwrdpath = "../../data/stopwords.txt"
stpwrd_dic = open(stpwrdpath, 'rb')
stpwrd_content = stpwrd_dic.read().decode('utf-8')#将停用词表转换为list
stpwrdlst = stpwrd_content.splitlines()
stpwrd_dic.close()
n_features = 1000
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
max_features=n_features,
#stop_words='english',
stop_words=stpwrdlst,
max_df = 0.5,
min_df = 10)
tf = tf_vectorizer.fit_transform(df.duty_cutted)
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
max_features=n_features,
#stop_words='english',
stop_words=stpwrdlst,
max_df = 0.5,
min_df = 10)
tf = tf_vectorizer.fit_transform(corpus)
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_components = 15,max_iter=50,
learning_method='online',
learning_offset=50,
random_state=0)
lda.fit(tf)
import pyLDAvis
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)
p = pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)
# +
# pyLDAvis.save_html(p, 'lda_10_jx.html')
# -
| code/May6/DataViz_lda_jx.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:venv]
# language: python
# name: conda-env-venv-py
# ---
# + colab={"base_uri": "https://localhost:8080/", "height": 109} colab_type="code" executionInfo={"elapsed": 3245, "status": "ok", "timestamp": 1543933930279, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07095926276735907293"}, "user_tz": -60} id="EPqKXh4Fl5C2" outputId="057c5422-ad45-4b96-d17d-c775271c8b4d"
import pandas as pd
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
from sklearn.linear_model import LogisticRegressionCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
import matplotlib as mpl
mpl.rc('font',family='Segoe UI Emoji')
from sklearn import metrics
import itertools
import nltk
nltk.download('twitter_samples')
nltk.download('stopwords')
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 446, "status": "ok", "timestamp": 1543933937359, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07095926276735907293"}, "user_tz": -60} id="ia_FYw6El5DB" outputId="8d0c6e63-29b3-41e2-e38b-aec79dbedbd5"
import string
import re
from nltk.corpus import stopwords
stopwords_german = stopwords.words('german')
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer('german')
from nltk.tokenize import TweetTokenizer
# Happy Emoticons
emoticons_happy = set([
':-)', ':)', ';)', ':o)', ':]', ':3', ':c)', ':>', '=]', '8)', '=)', ':}',
':^)', ':-D', ':D', '8-D', '8D', 'x-D', 'xD', 'X-D', 'XD', '=-D', '=D',
'=-3', '=3', ':-))', ":'-)", ":')", ':*', ':^*', '>:P', ':-P', ':P', 'X-P',
'x-p', 'xp', 'XP', ':-p', ':p', '=p', ':-b', ':b', '>:)', '>;)', '>:-)',
'<3'
])
# Sad Emoticons
emoticons_sad = set([
':L', ':-/', '>:/', ':S', '>:[', ':@', ':-(', ':[', ':-||', '=L', ':<',
':-[', ':-<', '=\\', '=/', '>:(', ':(', '>.<', ":'-(", ":'(", ':\\', ':-c',
':c', ':{', '>:\\', ';('
])
# all emoticons (happy + sad)
emoticons = emoticons_happy.union(emoticons_sad)
def clean_tweets(tweet):
# remove stock market tickers like $GE
tweet = re.sub(r'\$\w*', '', tweet)
# remove old style retweet text "RT"
tweet = re.sub(r'^RT[\s]+', '', tweet)
# remove hyperlinks
tweet = re.sub(r'https?:\/\/[^\s]*', '', tweet)
# remove hashtags
# only removing the hash # sign from the word
tweet = re.sub(r'#', '', tweet)
# replace years with 'ayearzzz'-Token
tweet = re.sub(r'([1-2][0-9]{3})', r'ayearzzz', tweet)
# replace numbers with 'anumberzzz'-Token, only numbers outside of words
tweet = re.sub(r'(?<![0-9a-zA-Z])[0-9]+(?![0-9a-zA-Z])', r'anumberzzz', tweet)
# tokenize tweets
tokenizer = TweetTokenizer(preserve_case=False, strip_handles=True, reduce_len=True)
tweet_tokens = tokenizer.tokenize(tweet)
tweets_clean = []
for word in tweet_tokens:
if (word not in stopwords_german and # remove stopwords
word not in emoticons and # remove emoticons
word not in string.punctuation): # remove punctuation
#tweets_clean.append(word)
stem_word = stemmer.stem(word) # stemming word
tweets_clean.append(stem_word)
tweets_clean=" ".join(tweets_clean)
# remove numbers that were pulled out of words by tokenizer
tweets_clean = re.sub(r'(?<![0-9a-zA-Z])[0-9]+(?![0-9a-zA-Z])', r'', tweets_clean)
return tweets_clean
custom_tweet = "RT @Twitter @chapagain Hello There! Have a great day. :) #good #morning http://chapagain.com.np"
# print cleaned tweet
print (clean_tweets(custom_tweet))
# + colab={} colab_type="code" id="vdvMnGwloGs4"
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, fontname='Segoe UI Emoji')
plt.yticks(tick_marks, classes, fontname='Segoe UI Emoji')
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
# + colab={} colab_type="code" id="gkCzf9iCoGs-"
def get_most_important_features(vectorizer, model, n=5):
index_to_word = {v:k for k,v in vectorizer.vocabulary_.items()}
# loop for each class
classes ={}
for class_index in range(model.coef_.shape[0]):
word_importances = [(el, index_to_word[i]) for i,el in enumerate(model.coef_[class_index])]
sorted_coeff = sorted(word_importances, key = lambda x : x[0], reverse=True)
tops = sorted(sorted_coeff[:n], key = lambda x : x[0])
bottom = sorted_coeff[-n:]
classes[class_index] = {
'tops':tops,
'bottom':bottom
}
return classes
# + colab={} colab_type="code" id="OLPAVQStoGtE"
def plot_important_words_binary(importance, labels, name):
top_scores = [a[0] for a in importance[0]['tops']]
top_words = [a[1] for a in importance[0]['tops']]
bottom_scores = [a[0] for a in importance[0]['bottom']]
bottom_words = [a[1] for a in importance[0]['bottom']]
fig = plt.figure(figsize=(10, 10))
y_pos = np.arange(len(top_words))
plt.subplot(121)
plt.barh(y_pos,bottom_scores, align='center', alpha=0.5)
plt.title(labels[0], fontsize=20)
plt.yticks(y_pos, bottom_words, fontsize=14)
plt.suptitle('Key words', fontsize=16)
plt.xlabel('Importance', fontsize=20)
plt.subplot(122)
plt.barh(y_pos,top_scores, align='center', alpha=0.5)
plt.title(labels[1], fontsize=20)
plt.yticks(y_pos, top_words, fontsize=14)
plt.suptitle(name, fontsize=16)
plt.xlabel('Importance', fontsize=20)
plt.subplots_adjust(wspace=0.8)
# + colab={} colab_type="code" id="eGdZbm1zoGtH"
def plot_important_words_multi_class(importance, class_labels, name):
for i in range(len(importance)):
top_scores = [a[0] for a in importance[i]['tops']]
top_words = [a[1] for a in importance[i]['tops']]
y_pos = np.arange(len(top_words))
top_pairs = [(a,b) for a,b in zip(top_words, top_scores)]
top_pairs = sorted(top_pairs, key=lambda x: x[1])
top_words = [a[0] for a in top_pairs]
top_scores = [a[1] for a in top_pairs]
subplot = str(int(len(importance)/2)+1)+str(2)+str(i + 1)
plt.subplot(int(len(importance)/2)+1, 2, i + 1)
plt.barh(y_pos,top_scores, align='center', alpha=0.5)
plt.title(class_labels[i], fontsize=20, fontname='Segoe UI Emoji')
plt.yticks(y_pos, top_words, fontsize=14)
plt.suptitle(name, fontsize=16)
plt.xlabel('Importance', fontsize=14)
plt.subplots_adjust(wspace=0.8, hspace=0.6)
# + colab={"base_uri": "https://localhost:8080/", "height": 246} colab_type="code" executionInfo={"elapsed": 686, "status": "error", "timestamp": 1543933969136, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07095926276735907293"}, "user_tz": -60} id="RATwLCnyoGtL" outputId="940c60ee-7393-4f34-db49-6808528772d2"
from sklearn.decomposition import PCA, TruncatedSVD
import matplotlib.patches as mpatches
def plot_LSA(test_data, test_labels, savepath="PCA_demo.csv", plot=True):
lsa = TruncatedSVD(n_components=2)
lsa.fit(test_data)
lsa_scores = lsa.transform(test_data)
color_mapper = {label:idx for idx,label in enumerate(set(test_labels))}
color_column = [color_mapper[label] for label in test_labels]
colors = ['orange','blue','red','yellow','green']
if plot:
plt.scatter(lsa_scores[:,0], lsa_scores[:,1], s=8, alpha=.8, c=color_column, cmap=mpl.colors.ListedColormap(colors))
orange_patch = mpatches.Patch(color='orange', label='😂')
blue_patch = mpatches.Patch(color='blue', label='♥️')
red_patch = mpatches.Patch(color='red', label='🤔')
yellow_patch = mpatches.Patch(color='yellow', label='💪')
green_patch = mpatches.Patch(color='green', label='🙄')
plt.legend(handles=[orange_patch, blue_patch,red_patch,yellow_patch,green_patch], prop={'size': 30})
# + [markdown] colab_type="text" id="aW9ijrb_oGtQ"
# End of definitions
#
# ------------------
#
# Start data preparation
#
#
# + colab={"base_uri": "https://localhost:8080/", "height": 945} colab_type="code" executionInfo={"elapsed": 476, "status": "error", "timestamp": 1543934022818, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "07095926276735907293"}, "user_tz": -60} id="mtwNe-JBl5C5" outputId="881ff009-54f5-42e5-9653-b825d8e1f5f0"
importdf=pd.read_csv('../data/trainingssets/all_emoji_tweets_03_12_18_7_labels_excluded.csv', sep =';', usecols=['tweet_full_text', 'target'])
importdf.dropna(inplace=True)
importdf.reset_index(inplace=True, drop=True)
# + colab={} colab_type="code" id="U2P_7rw0oGtZ"
all_targets = importdf['target'].astype(str).values.tolist()
# + colab={} colab_type="code" id="b3xsAa4n_peh"
y=[]
for i in range(len(all_targets)):
#Only use first emoji per tweet for now
y.append(all_targets[i].split(',')[0])
# for filtering in conversion to binary classification later on
dfy=pd.DataFrame(y)
dfx=pd.DataFrame(importdf['tweet_full_text'])
dfx.columns = range(dfx.shape[1])
# + colab={} colab_type="code" id="_UnBKLvwoGto"
# convert to binary classification
binary_labels=['😭','♥️'] # two Labels chosen for binary classification
multi_class_labels=['😂','♥️','🤔','💪','🙄']
dfy=dfy[dfy.isin(multi_class_labels)]
dfy.dropna(inplace=True)
dfx=dfx[dfy.isin(multi_class_labels)]
dfx.dropna(inplace=True)
df=dfx.copy()
df.rename(inplace=True, columns={0: "tweet"})
df['target'] = dfy
'''# BINARY CASE: balance classes to 50:50 by dropping appropriate (randomized) fraction of majority class
majority_class='♥️'
class_freq=df['target'].value_counts()
df = df.drop(df[df['target'] == majority_class].sample(frac=(1-class_freq[1]/class_freq[0]), random_state=123).index)'''
# MULTICLASS CASE: balance classes by dropping rows from all majority classes to length of minority class
minority_class_len=(df['target'].value_counts())[-1] # set to id of minority class
majority_classes=(df['target'].value_counts()).index[0:4]
for label in majority_classes:
df = df.drop(df[df['target'] == label].sample(n=(df['target'].value_counts().loc[label]-minority_class_len), random_state=123).index)
# prepare data for following steps
our_tweets=df['tweet'].astype(str).values.tolist()
y=df['target'].astype(str).values.tolist()
# + colab={} colab_type="code" id="h_TnWRs6l5DF"
corpus=[]
for i in range(len(our_tweets)):
corpus.append(clean_tweets(our_tweets[i]))
corpus
# + [markdown] colab_type="text" id="GPhEM6ivoGtw"
# End Data preparation
#
# -----------------------------
#
# Start data visualisation
# + colab={} colab_type="code" id="v9I1XPeToGty"
X_train, X_test, y_train, y_test = train_test_split(corpus, y, test_size=0.4, random_state=0)
pipe_transformer = Pipeline([
('vect', CountVectorizer(max_df=0.9, min_df=5, ngram_range=(1,2))),
])
pipe_transformer.fit(X_train, y_train);
# + colab={} colab_type="code" id="4qp5jXHLoGt3"
fig = plt.figure(figsize=(16, 16))
plot_LSA(pipe_transformer.transform(X_train), y_train)
plt.savefig('../figures/tweets_from_03_12_18/multiclass/countvectorizer_lsa')
plt.show()
# + colab={} colab_type="code" id="xKLIo7n4oGt7"
# + colab={} colab_type="code" id="UMnda56MoGt9"
X_train, X_test, y_train, y_test = train_test_split(corpus, y, test_size=0.4, random_state=0)
pipe_transformer = Pipeline([
('vect', CountVectorizer(max_df=0.9, min_df=5, ngram_range=(1,2))),
('tfidf', TfidfTransformer(use_idf=True)),
])
pipe_transformer.fit(X_train, y_train);
# + colab={} colab_type="code" id="nZ1OlBo6oGuD"
fig = plt.figure(figsize=(16, 16))
plot_LSA(pipe_transformer.transform(X_train), y_train)
plt.savefig('../figures/tweets_from_03_12_18/multiclass/tfidf_lsa')
plt.show()
# + colab={} colab_type="code" id="THHiErBfoGuI"
# + colab={} colab_type="code" id="Im345gzroGuM"
# For use after arbitrary GridSearch
# Needs to be run twice to work? Probably some mistake here
#fig = plt.figure(figsize=(16, 16))
#clf = gs_clf.best_estimator_.steps.pop(1)
#plot_LSA(gs_clf.best_estimator_.transform(X_train), y_train)
#gs_clf.best_estimator_.steps.append(clf)
#plt.show()
# + [markdown] colab_type="text" id="FnUO5FYroGuS"
# End data visualisation
#
# -----------------------
#
# Start simple MultinomialNB
# + colab={} colab_type="code" id="SgFYVnOLl5DK"
X_train, X_test, y_train, y_test = train_test_split(corpus, y, test_size=0.4, random_state=0)
pipe_clf = Pipeline([
('vect', CountVectorizer(min_df=5)),
('clf', MultinomialNB()),
])
pipe_clf.fit(X_train, y_train)
predicted = pipe_clf.predict(X_test)
np.mean(predicted == y_test)
# -
# Test runs: all_emoji_tweets_29_11_18_7_labels_excluded
#
# Run1:
# * CountVectorizer min_df=20
#
# Score 0.4678792976553464
#
# Run2:
# * CountVectorizer min_df=5
#
# Score 0.4807591210177689
# + colab={} colab_type="code" id="moau7XWToGu7"
plt.figure()
cnf_matrix = confusion_matrix(y_test, predicted)
plot_confusion_matrix(cnf_matrix, classes=multi_class_labels, normalize=True,
title='Confusion matrix, with normalization')
plt.savefig('../figures/tweets_from_03_12_18/multiclass/countvectorizer_multinomialnb_confusion_matrix')
plt.show()
# + colab={} colab_type="code" id="VoJmM4h4oGvG"
plt.figure(figsize=(10,10))
importance = get_most_important_features(pipe_clf.get_params()['vect'], pipe_clf.get_params()['clf'], 10)
plot_important_words_multi_class(importance, pipe_clf.get_params()['clf'].classes_, "Most important words")
plt.savefig('../figures/tweets_from_03_12_18/multiclass/countvectorizer_multinomialnb_feature_importance')
plt.show()
#plot_important_words_one_vs_one(importance, pipe_clf.get_params()['clf'].classes_, "Most important words")
# + [markdown] colab_type="text" id="mcHoJ3AgoGvN"
# End Simple MultinomialNB
#
# ----------------------------
#
# AB <NAME>USFÜHREN. Das Trainieren einiger Modelle nimmt enorm viel Zeit in Anspruch.
#
# Start Advanced MultinomialNB
# + colab={} colab_type="code" id="u3qnPxzp93PX"
pipe_clf = Pipeline([
('vect', CountVectorizer(max_df=0.9, min_df=5, ngram_range=(1,2))),
('tfidf', TfidfTransformer(use_idf=False)),
('clf', MultinomialNB(alpha=0.1))
])
parameters = {
#'vect__min_df': (40,60),
#'vect__max_df': (0.8,0.81),
}
gs_clf = GridSearchCV(pipe_clf, parameters, cv=3, iid=False, n_jobs=-1)
gs_clf.fit(X_train, y_train)
predicted = gs_clf.predict(X_test)
np.mean(predicted == y_test)
# + [markdown] colab={} colab_type="code" id="NfgqtevIoGvi"
# Test runs: all_emoji_tweets_29_11_18_7_labels_excluded
#
# Run1:
# * max_df=0.9
# * min_df=1
# * ngram_range=(1,2)
# * use_idf=True
# * 'clf__loss': ['modified_huber'],
# * 'clf__penalty': ['elasticnet'],
# * 'clf__alpha': [1e-5],
# * 'clf__epsilon': [0.01],
# * 'clf__learning_rate': ['invscaling'],
# * 'clf__eta0': [10]
#
# Score 0.4866733256229629
#
# Run2:
# * max_df=0.9
# * min_df=5
# * ngram_range=(1,2)
# * use_idf=True
# * 'clf__loss': ['modified_huber'],
# * 'clf__penalty': ['elasticnet'],
# * 'clf__alpha': [1e-5],
# * 'clf__epsilon': [0.01],
# * 'clf__learning_rate': ['invscaling'],
# * 'clf__eta0': [10]
#
# Score 0.4799968457575439for param_name in sorted(parameters.keys()):
# print("%s: %r" % (param_name, gs_clf.best_params_[param_name]))
# + colab={} colab_type="code" id="NgKpfh61oGvU"
for param_name in sorted(parameters.keys()):
print("%s: %r" % (param_name, gs_clf.best_params_[param_name]))
# + colab={} colab_type="code" id="URzpXhVCoGva"
plt.figure()
cnf_matrix = confusion_matrix(y_test, predicted)
plot_confusion_matrix(cnf_matrix, classes=multi_class_labels, normalize=True,
title='Confusion matrix, with normalization')
plt.savefig('../figures/tweets_from_03_12_18/multiclass/tfidftransformer_multinomialnb_confusion_matrix')
plt.show()
# + colab={} colab_type="code" id="E3AXTZUUoGvc"
plt.figure(figsize=(10,10))
importance = get_most_important_features(gs_clf.best_estimator_.get_params()['vect'], gs_clf.best_estimator_.get_params()['clf'], 10)
plot_important_words_multi_class(importance, gs_clf.best_estimator_.get_params()['clf'].classes_, "Most important words")
plt.savefig('../figures/tweets_from_03_12_18/multiclass/tfidftransformer_multinomialnb_feature_importances')
plt.show()
# + [markdown] colab_type="text" id="_Iz4My7moGve"
# End Advanced MultinomialNB
#
# ----------------------------
#
# Start Advanced SGDClassifier
# + colab={} colab_type="code" id="gZld7gMcoGvf"
X_train, X_test, y_train, y_test = train_test_split(corpus, y, test_size=0.4, random_state=0)
pipe_clf = Pipeline([
('vect', CountVectorizer(max_df=0.9, min_df=5, ngram_range=(1,2))),
('tfidf', TfidfTransformer(use_idf=True)),
('clf', SGDClassifier(random_state=0,
max_iter=100, tol=None))
])
parameters = {
'clf__loss': ['modified_huber', 'log'],
'clf__penalty': ['elasticnet', 'l2'],
'clf__alpha': [1e-5],
'clf__epsilon': [0.01],
'clf__learning_rate': ['invscaling', 'optimal'],
'clf__eta0': [10]
#'clf__eta0': [1e-4, 0.1],
}
gs_clf = GridSearchCV(pipe_clf, parameters, cv=3, iid=False, n_jobs=-1)
gs_clf.fit(X_train, y_train)
predicted = gs_clf.predict(X_test)
np.mean(predicted == y_test)
# -
# Test runs: all_emoji_tweets_29_11_18_7_labels_excluded
#
# Run1:
# * max_df=0.9
# * min_df=1
# * ngram_range=(1,2)
# * use_idf=True
# * 'clf__loss': ['modified_huber'],
# * 'clf__penalty': ['elasticnet'],
# * 'clf__alpha': [1e-5],
# * 'clf__epsilon': [0.01],
# * 'clf__learning_rate': ['invscaling'],
# * 'clf__eta0': [10]
#
# Score 0.49285038376616547
#
# Run2:
# * max_df=0.9
# * min_df=5
# * ngram_range=(1,2)
# * use_idf=True
# * 'clf__loss': ['modified_huber'],
# * 'clf__penalty': ['elasticnet'],
# * 'clf__alpha': [1e-5],
# * 'clf__epsilon': [0.01],
# * 'clf__learning_rate': ['invscaling'],
# * 'clf__eta0': [10]
#
# Score 0.463568499632005
# + colab={} colab_type="code" id="0E9TJSkUoGvl"
plt.figure()
cnf_matrix = confusion_matrix(y_test, predicted)
plot_confusion_matrix(cnf_matrix, classes=multi_class_labels, normalize=True,
title='Confusion matrix, with normalization')
plt.savefig('../figures/tweets_from_03_12_18/multiclass/tfidftransformer_sgdclassifier_confusion_matrix')
plt.show()
# + colab={} colab_type="code" id="VKnTxzgCoGvp"
plt.figure(figsize=(10,10))
importance = get_most_important_features(gs_clf.best_estimator_.get_params()['vect'], gs_clf.best_estimator_.get_params()['clf'], 10)
plot_important_words_multi_class(importance, gs_clf.best_estimator_.get_params()['clf'].classes_, "Most important words")
plt.savefig('../figures/tweets_from_03_12_18/multiclass/tfidftransformer_sgdclassifier_feature_importances')
plt.show()
# + [markdown] colab_type="text" id="j6CSljUooGvr"
# End Advanced SGDClassifier
#
# ----------------------------
#
# Start Advanced RandomForest
# + colab={} colab_type="code" id="ogjZgzMuoGvs"
X_train, X_test, y_train, y_test = train_test_split(corpus, y, test_size=0.4, random_state=0)
pipe_clf = Pipeline([
('vect', CountVectorizer(max_df=0.9, min_df=5, ngram_range=(1,2))),
('tfidf', TfidfTransformer(use_idf=True)),
('clf', RandomForestClassifier(n_estimators=100, n_jobs=-1, random_state=0))
])
parameters = {
#'vect__ngram_range': [(1, 1), (1, 2)],
#'vect__max_df': [0.9, 1.0],
#'tfidf__use_idf': (True, False)''
#'clf__criterion': ['gini', 'entropy'],
#'clf__max_features': ['log2', 'auto', 0.5],
}
gs_clf = GridSearchCV(pipe_clf, parameters, cv=3, iid=False, n_jobs=-1)
gs_clf.fit(X_train, y_train)
predicted = gs_clf.predict(X_test)
np.mean(predicted == y_test)
# -
# Test runs: all_emoji_tweets_29_11_18_7_labels_excluded
#
# Run1:
# * max_df=0.9
# * min_df=1
# * ngram_range=(1,2)
# * use_idf=True
# * n_estimators=10
#
# Score 0.38960151403637894
#
# Run2:
# * max_df=0.9
# * min_df=5
# * ngram_range=(1,2)
# * use_idf=True
# * n_estimators=100
#
# Score 0.43959625696561877
# + colab={} colab_type="code" id="o4B06fY6oGvu"
for param_name in sorted(parameters.keys()):
print("%s: %r" % (param_name, gs_clf.best_params_[param_name]))
# + colab={} colab_type="code" id="xTL67RLToGvz"
plt.figure()
cnf_matrix = confusion_matrix(y_test, predicted)
plot_confusion_matrix(cnf_matrix, classes=multi_class_labels, normalize=True,
title='Confusion matrix, with normalization')
plt.savefig('../figures/tweets_from_03_12_18/multiclass/tfidftransformer_randomforestclassifier_confusion_matrix')
plt.show()
# + [markdown] colab_type="text" id="9VBWegDqoGv2"
# End Advanced Random Forest
#
# ----------------------------
#
# Start Logistic Regression
# + colab={} colab_type="code" id="SAg_69NioGv3"
X_train, X_test, y_train, y_test = train_test_split(corpus, y, test_size=0.4, random_state=0)
pipe = Pipeline([
('vect', CountVectorizer(max_df=0.9, min_df=5, ngram_range=(1,2))),
('tfidf', TfidfTransformer(use_idf=True))
])
parameters = {
#'vect__ngram_range': [(1, 1), (1, 2)],
#'vect__max_df': [0.9, 1.0],
#'tfidf__use_idf': (True, False)''
# 'clf__solver': ['newton-cg', 'lbfgs', 'sag', 'saga'],
# 'clf__C': [0.1, 1, 10, 30, 100],
}
pipe.fit(X_train)
gs_clf = LogisticRegressionCV(multi_class='auto', cv=3, n_jobs=-1)
gs_clf.fit(pipe.transform(X_train), y_train)
predicted = gs_clf.predict(pipe.transform(X_test))
np.mean(predicted == y_test)
# -
# Test runs: all_emoji_tweets_29_11_18_7_labels_excluded
#
# Run1:
# * max_df=0.9
# * min_df=1
# * ngram_range=(1,2)
# * use_idf=True
# * Cs=5
#
# Score 0.4909841236463043
#
# Run2:
# * max_df=0.9
# * min_df=5
# * ngram_range=(1,2)
# * use_idf=True
# * Cs=5
#
# Score 0.48386079276627064
# + colab={} colab_type="code" id="Cdn1yGaSoGv7"
for param_name in sorted(parameters.keys()):
print("%s: %r" % (param_name, gs_clf.best_params_[param_name]))
# + colab={} colab_type="code" id="QpT7721LoGwA"
plt.figure()
cnf_matrix = confusion_matrix(y_test, predicted)
plot_confusion_matrix(cnf_matrix, classes=multi_class_labels, normalize=True,
title='Confusion matrix, with normalization')
plt.show()
# + colab={} colab_type="code" id="yGwUrYR_oGwB"
plt.figure(figsize=(10,10))
importance = get_most_important_features(pipe.get_params()['vect'], gs_clf, 10)
plot_important_words_multi_class(importance, gs_clf.classes_, "Most important words")
plt.show()
# + [markdown] colab_type="text" id="p2-Qq8WSoGwD"
# End Logistic Regression
#
# ----------------------------
#
# Start AdaBoost
# + colab={} colab_type="code" id="SjJ8_Wn6oGwE"
X_train, X_test, y_train, y_test = train_test_split(corpus, y, test_size=0.4, random_state=0)
pipe_clf = Pipeline([
('vect', CountVectorizer(max_df=0.9, min_df=5, ngram_range=(1,2))),
('tfidf', TfidfTransformer(use_idf=True)),
('clf', AdaBoostClassifier(n_estimators=1000))
])
parameters = {
#'vect__ngram_range': [(1, 1), (1, 2)],
#'vect__max_df': [0.9, 1.0],
#'tfidf__use_idf': (True, False)''
'clf__base_estimator': [DecisionTreeClassifier(max_depth=1)],
#'clf__C': [0.1, 1, 10, 30, 100],
}
gs_clf = RandomizedSearchCV(pipe_clf, parameters, cv=3, n_jobs=-1)
gs_clf.fit(X_train, y_train)
predicted = gs_clf.predict(X_test)
np.mean(predicted == y_test)
# -
# Test runs: all_emoji_tweets_29_11_18_7_labels_excluded
#
# Run1:
# * max_df=0.9
# * min_df=1
# * ngram_range=(1,2)
# * use_idf=True
# * n_estimators=100
# * 'clf__base_estimator': [DecisionTreeClassifier(max_depth=1)]
#
# 0.3838975922615918
#
# Run2:
# * max_df=0.9
# * min_df=5
# * ngram_range=(1,2)
# * use_idf=True
# * n_estimators=100
# * 'clf__base_estimator': [DecisionTreeClassifier(max_depth=1)]
#
# 0.3837135947849858
# + colab={} colab_type="code" id="nBasCe0GoGwG"
for param_name in sorted(parameters.keys()):
print("%s: %r" % (param_name, gs_clf.best_params_[param_name]))
# + colab={} colab_type="code" id="W5b0opCZoGwQ"
plt.figure()
cnf_matrix = confusion_matrix(y_test, predicted)
plot_confusion_matrix(cnf_matrix, classes=multi_class_labels, normalize=True,
title='Confusion matrix, with normalization')
plt.show()
# + [markdown] colab_type="text" id="oBFfCtXMoGwR"
# End AdaBoost
#
# ----------------------------
#
# Start GradientBoosting
# + colab={} colab_type="code" id="L_x5qfXfoGwR"
X_train, X_test, y_train, y_test = train_test_split(corpus, y, test_size=0.4, random_state=0)
pipe_clf = Pipeline([
('vect', CountVectorizer(max_df=0.9, min_df=5, ngram_range=(1,2))),
('tfidf', TfidfTransformer(use_idf=True)),
('clf', GradientBoostingClassifier(n_estimators=100, random_state=0, verbose=1))
])
parameters = {
#'vect__ngram_range': [(1, 1), (1, 2)],
#'vect__max_df': [0.9, 1.0],
#'tfidf__use_idf': (True, False)''
'clf__learning_rate': [0.001, 0.01, 0.1, 1],
'clf__max_depth': [1, 3, 5],
'clf__loss' : ['deviance', 'exponential']
}
gs_clf = RandomizedSearchCV(pipe_clf, parameters, cv=3, n_jobs=-1, verbose=2)
gs_clf.fit(X_train, y_train)
predicted = gs_clf.predict(X_test)
np.mean(predicted == y_test)
# -
# Test runs: all_emoji_tweets_29_11_18_7_labels_excluded
#
# Run1:
# * max_df=0.9
# * min_df=1
# * ngram_range=(1,2)
# * use_idf=True
# * n_estimators=100
# * 'clf__learning_rate': [0.001, 0.01, 0.1, 1],
# * 'clf__max_depth': [1, 3, 5],
# * 'clf__loss' : ['deviance']
#
# Score: 0.4189359688781411
# + colab={} colab_type="code" id="yfXsgLOkoGwU"
for param_name in sorted(parameters.keys()):
print("%s: %r" % (param_name, gs_clf.best_params_[param_name]))
# + colab={} colab_type="code" id="V45OyMgkoGwW"
plt.figure()
cnf_matrix = confusion_matrix(y_test, predicted)
plot_confusion_matrix(cnf_matrix, classes=multi_class_labels, normalize=True,
title='Confusion matrix, with normalization')
plt.show()
# + colab={} colab_type="code" id="eCqVVvkBoGwX"
| python/skripte_klassifikation/multiclass_classification.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# <img src="../logo/logo_ev2017.png">
# # Table of Contents
# * [1. Elementos básicos del lenguaje](#1.-Elementos-básicos-del-lenguaje)
# * [1.1 Estructuras de datos: tuplas, listas y diccionarios](#1.1-Estructuras-de-datos:-tuplas,-listas-y-diccionarios)
# * [1.1.1 Tuplas](#1.1.1-Tuplas)
# * [1.1.2 Listas](#1.1.2-Listas)
# * [1.1.3 Diccionarios](#1.1.3-Diccionarios)
# *
# * [Ejercicios](#Ejercicios)
# * [1.2 Funciones y estructuras de control](#1.2-Funciones-y-estructuras-de-control)
#
# # Elementos básicos del lenguaje
# Jupyter notebook ofrece una herramienta de ejecución interactiva con la cual es posible dar órdenes directamente al intérprete y obtener una respuesta inmediata para cada una de ellas.
#
# __Ejemplos__
2 + 4 - 5
2.3 + 8 # la coma decimal se representa como un punto en Python
total = 2 ** 3 # operación potencia
total # muestra el resultado de la variable total
print (total)
# ## Estructuras de datos: tuplas, listas y diccionarios
# ### Tuplas
# Se trata de un tipo de dato inmutable.
# * Tienen longitud fija
# * Las cadenas de caracteres son un caso particular de las tuplas
# +
# Tuplas
tup = ( 8, 4 ) # colección de elementos (posiblemente de distintos tipos)
tup = ( 'Ana', 10, 'Alberto', 7 )
tup
# -
# LAS cadenas de caracteres TAMBIÉN SON TUPLAS
nombre = 'Pedro'
# ### Listas
# Una lista es similar a una tupla con la diferencia fundamental de que puede ser modificada una vez creada. Se trata de un tipo de datos mutable.
# * Estructura multidimensional
# * Contiene datos heterogéneos
# listas
data = [2, 3, 4] # colección de elementos (posiblemente de distintos tipos)
data = ['Ana', 10, 'Alberto', 7, [ 7 ,8 ]]
data
# insertar elementos en listas
data = [1, -9, 4, 1, 9]
data.append(0) # inserción al final de la lista
data
data.extend([8, 7, 9])
data
data
type(data)
data * 2
data.pop(0)
data
'Ana' + ' ' + 'Maria'
# __Acceso a los elementos de una lista o tupla __
#
# * Los elementos de las secuencias pueden ser accedidos mediante el uso de corchetes `[ ]`, como en otros lenguajes de programación.
# * Podemos *indexar* las secuencias utilizando la sintaxis:
#
# ```
# [<inicio>:<final>:<salto>]
# ```
# * En Python, la indexación empieza por CERO
data, data[0:2:1], len(data[::])
# Acceso a los elementos: indexación comenzando desde 0
data[0]
# modificación de los elementos
data[1] = 9 * 3
data
#longitud de una lista
len(data)
data[1:4] # elementos en el rango [1, 4)
data
data[::2] # desde el principio hasta el final con salto 2
data[-1] # recorrido en orden inverso
data[-3:]
data
data[:5] # 5 primeros elementos
data[4:] # Excluyendo los 5 primeros elementos
# __La función `range`__
# generación de listas de enteros en un rango
list(range(-5, 5))
# generación de listas de enteros en un rango
tuple(range(-5, 5))
list(range(5)) # escoge 0 como ini por default
# ### Diccionarios
# En Python, un diccionario es una colección __no ordenada__ de pares __clave - valor__ donde la clave y el valor son objetos Python.
#
# * Los elementos del diccionario son de la forma __clave : valor__ y cada uno de los elementos se separan por comas.
# * El acceso a los elementos de un diccionario se realiza a través de la clave.
# * En otros lenguajes se les conoce como _tablas hash_.
# * Los diccionarios se crean utilizando llaves __{ }__.
#
# Su uso es imprescindible en el proceso de datasets en formato __Json__.
dic = { } # diccionario vacío
# diccionario con 3 elementos
dic = {1:'Lunes', 2:'Martes', 3:'Miercoles' }
dic
dic
# Acceso a las claves
dic.keys()
# Aceeso a los valores
dic.values()
dic
# Acceso al valor de una clave
dic[3] = 'Domingo'
# añadir / modificar elementos de un diccionario
dic[4] = 'Jueves'
dic
dic.get(3)
# ##### Ejercicios
# Ejecutar el siguiente bloque de código para leer una lista de tweets almacenada en el documento [./Tweets/Oct24.json](./Tweets/Oct24.json).
import json
with open('./Tweets/Oct24.json') as data_file:
lista_tweets = json.load(data_file)
type(lista_tweets), len(lista_tweets)
print( json.dumps(lista_tweets[0], indent=4) )
# __* Recupera el primer tweet de la lista.__
# Solución:
primer_tweet = lista_tweets[0]
primer_tweet
# __* Obtener la lista de claves del primer tweet.__
# +
# Sol
primer_tweet.keys()
# -
primer_tweet['user'].keys()
# __* Obtener la fecha de creación del tercer tweet.__
# +
# Sol
lista_tweets[2]['created_at']
# -
lista_tweets[2]['user']['name']
lista_tweets[2]['text']
lista_tweets[2]['text'] # Texto del tercer tweet
lista_tweets[2]['entities']['hashtags'][0]['text'] # Texto del primer hashtag usado en el tercer tweet
# imprime el texto de todos los tweets recogidos
for ind, tweet in enumerate(lista_tweets):
print('Tweet n', ind + 1, '\n', tweet['text'], '\n')
# ## Funciones y estructuras de control
# Las funciones tienen un _nombre_ y se declaran con la palabra reservada __def__ y devuelve un valor usando la palabra reservada __return__.
# Los bloques se representan con los tabuladores.
# función que suma 3 números y devuelve el resultado
def suma_tres(x, y, z): # 3 argumentos posicionales.
m1 = x + y
m2 = m1 + z
return m2, [m1, m2]
who
# invocación de la función
total, _ = suma_tres(1, 2, 3)
print(total, _)
# instrucción if (Ojo a los bloques)
def orden(x = 0, y = 0):
if x < y :
print('primera rama')
return x
elif x > y:
print('segunda rama')
return y
else:
print('tercera rama')
return 'Son iguales'
orden(2,9)
orden()
orden([2,4],[5]) # comparacion de listas
# + active=""
# orden({'Ana':0},{'Ana':0})
# -
def recorrido(lista):
for elemento in lista: # Bucle FOR :itera soble los elementos de m
print(elemento)
recorrido([9, 8, 7, 6, 4])
# +
def imprime_pares(n = 0):
for elem in range(0, n+1, 2):
print(elem)
imprime_pares(10)
# -
def suma_pares(n):
suma = 0
for elem in range(0, n+1, 2):
suma = suma + elem
return suma
suma_pares(100)
# +
# iterar sobre los elementos de un diccionario
dic = {1:'Lunes', 2:'Martes', 3:'Miércoles' }
for (clave, valor) in dic.items():
print("La clave es: " + str(clave) + " y el valor es: " + valor)
# +
# iterar sobre los elementos de un diccionario
dic = {1:'Lunes', 2:'Martes', 3:'Miércoles' }
for elemento in dic.items():
print( elemento)
# +
# iterar sobre los elementos de un diccionario
dic = {1:'Lunes', 2:'Martes', 3:'Miércoles' }
for _ , v in dic.items():
print('El valor es: ' + v)
# +
i = 0
while i < 5: # bucle WHILE: itera mientras la condición sea cierta
print(i)
i = i + 1
print("Estoy fuera del while")
# -
#
#
# -----
| module2_Python/day1/elementos_Basicos.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="XLwKiZtPD236"
from bs4 import BeautifulSoup, Comment
from urllib.request import urlopen
import pandas as pd
import re
import warnings
warnings.filterwarnings('ignore')
from google.colab import drive # Import only if you are using Google Colab
# + id="LTbGfR1GrQ32"
seasons = list(range(1980, 2022))
# + id="pAslO8rGFGay"
basic_stats_per_season = []
for season in seasons:
url = 'https://www.basketball-reference.com/leagues/NBA_{}_per_game.html'.format(season)
html = urlopen(url)
soup = BeautifulSoup(html)
headers = [th.getText() for th in soup.findAll('tr', limit = 2)[0].findAll('th')][1:]
rows = soup.findAll('tr', class_ = lambda x: x != 'thead')[1:]
players_stats = [[td.getText() for td in rows[i].findAll('td')] for i in range(len(rows))]
stats = pd.DataFrame(players_stats, columns = headers)
stats['Season'] = season
basic_stats_per_season.append(stats)
basic_stats = pd.concat(basic_stats_per_season)
# + id="loIim3itLhyR" colab={"base_uri": "https://localhost:8080/", "height": 248} outputId="98f04bb4-1426-4b2d-cb77-5c22abde7a9a"
basic_stats.tail()
# + id="Ua0W482kLq2t"
advanced_stats_per_season = []
for season in seasons:
url = 'https://www.basketball-reference.com/leagues/NBA_{}_advanced.html'.format(season)
html = urlopen(url)
soup = BeautifulSoup(html)
headers = [th.getText() for th in soup.findAll('tr', limit = 2)[0].findAll('th')][1:]
rows = soup.findAll('tr', class_ = lambda x: x != 'thead')[1:]
players_stats = [[td.getText() for td in rows[i].findAll('td')] for i in range(len(rows))]
stats = pd.DataFrame(players_stats, columns = headers)
stats['Season'] = season
advanced_stats_per_season.append(stats)
advanced_stats = pd.concat(advanced_stats_per_season)
# + id="eDVzKNgsLtO7" colab={"base_uri": "https://localhost:8080/", "height": 282} outputId="cc0c998a-a7da-4091-d41f-f27cca49538f"
advanced_stats.tail()
# + id="TH_s0TEMLw8S"
mvp_award_voting_per_season = []
for season in seasons[:-1]:
url = 'https://www.basketball-reference.com/awards/awards_{}.html'.format(season)
html = urlopen(url)
soup = BeautifulSoup(html)
headers = [th.getText() for th in soup.findAll('tr', limit = 2)[1].findAll('th')][1:]
table = soup.find(lambda tag: tag.has_attr('id') and tag['id'] == 'mvp')
rows = table.findAll('tr', class_ = lambda x: x != 'thead')[1:]
players_stats = [[td.getText() for td in rows[i].findAll('td')] for i in range(len(rows))]
stats = pd.DataFrame(players_stats, columns = headers)
stats['Season'] = season
mvp_award_voting_per_season.append(stats)
mvp_award_voting = pd.concat(mvp_award_voting_per_season)
# + id="TBS_T6WoL5nZ" colab={"base_uri": "https://localhost:8080/", "height": 204} outputId="b0c81c8b-7b4c-4874-9ff1-e37bc0c2b8db"
mvp_award_voting.tail()
# + id="iZdfP-pEL8fl"
standings_per_season = []
for season in seasons:
url = 'https://www.basketball-reference.com/leagues/NBA_{}_standings.html'.format(season)
html = urlopen(url)
soup = BeautifulSoup(html)
commented_html = []
for comments in soup.findAll(text = lambda text:isinstance(text, Comment)):
commented_html.append(comments.extract())
commented_soup = BeautifulSoup(commented_html[28])
headers = [th.getText() for th in commented_soup.findAll('tr', limit = 2)[1].findAll('th')][:3]
rows = commented_soup.findAll('tr')[2:]
teams_stats = [[td.getText() for td in rows[i].findAll(lambda tag: tag.has_attr('data-stat') and tag['data-stat'] == 'ranker' or 'team_name' or 'Overall')][:4] for i in range(len(rows))]
for team_stat in teams_stats:
team_stat.pop(2)
stats = pd.DataFrame(teams_stats, columns = headers)
stats['Season'] = season
standings_per_season.append(stats)
standings_stats = pd.concat(standings_per_season)
# + id="H4_qfNRaL-x5" colab={"base_uri": "https://localhost:8080/", "height": 204} outputId="30254e4d-496a-4518-a8e3-4524e1d73e24"
standings_stats.tail()
# + id="IkyGqYsoMD6W"
teams = {'Atlanta Hawks': 'ATL',
'Boston Celtics': 'BOS',
'Brooklyn Nets': 'BRK',
'Charlotte Bobcats': 'CHA',
'Charlotte Hornets': 'CHH/CHO',
'Chicago Bulls': 'CHI',
'Cleveland Cavaliers': 'CLE',
'Dallas Mavericks': 'DAL',
'Denver Nuggets': 'DEN',
'Detroit Pistons': 'DET',
'Golden State Warriors': 'GSW',
'Houston Rockets': 'HOU',
'Indiana Pacers': 'IND',
'Kansas City Kings': 'KCK',
'Los Angeles Clippers': 'LAC',
'Los Angeles Lakers': 'LAL',
'Memphis Grizzlies': 'MEM',
'Miami Heat': 'MIA',
'Milwaukee Bucks': 'MIL',
'Minnesota Timberwolves': 'MIN',
'New Jersey Nets': 'NJN',
'New Orleans Hornets': 'NOH',
'New Orleans/Oklahoma City Hornets': 'NOK',
'New Orleans Pelicans': 'NOP',
'New York Knicks': 'NYK',
'Oklahoma City Thunder': 'OKC',
'Orlando Magic': 'ORL',
'Philadelphia 76ers': 'PHI',
'Phoenix Suns': 'PHO',
'Portland Trail Blazers': 'POR',
'Sacramento Kings': 'SAC',
'San Antonio Spurs': 'SAS',
'San Diego Clippers': 'SDC',
'Seattle SuperSonics': 'SEA',
'Toronto Raptors': 'TOR',
'Utah Jazz': 'UTA',
'Vancouver Grizzlies': 'VAN',
'Washington Wizards': 'WAS',
'Washington Bullets': 'WSB'}
# + id="0kBtZn57MIWS"
def transform_team_column(x: str) -> str:
return teams[x]
standings_stats.Team = standings_stats.Team.apply(transform_team_column)
# + id="XFvbSW5BMLTL"
maskChh = (standings_stats.Team == 'CHH/CHO') & (standings_stats.Season <= 2002)
standings_stats.Team[maskChh] = 'CHH'
maskCho = (standings_stats.Team == 'CHH/CHO') & (standings_stats.Season >= 2015)
standings_stats.Team[maskCho] = 'CHO'
# + id="JVokBeFCMO9S"
def transform_player_column(x: str) -> str:
return x.replace('*', '')
basic_stats.Player = basic_stats.Player.apply(transform_player_column)
advanced_stats.Player = advanced_stats.Player.apply(transform_player_column)
# + id="-YfQN_kwR4Jc"
basic_stats['PlayerTmSeason'] = basic_stats.Player.map(str) + basic_stats.Tm.map(str) + basic_stats.Season.map(str)
basic_stats['TmSeason'] = basic_stats.Tm.map(str) + basic_stats.Season.map(str)
advanced_stats['PlayerTmSeason'] = advanced_stats.Player.map(str) + advanced_stats.Tm.map(str) + advanced_stats.Season.map(str)
mvp_award_voting['PlayerTmSeason'] = mvp_award_voting.Player.map(str) + mvp_award_voting.Tm.map(str) + mvp_award_voting.Season.map(str)
standings_stats['TmSeason'] = standings_stats.Team.map(str) + standings_stats.Season.map(str)
# + id="EkVBmX0sMZXb"
df = basic_stats.merge(advanced_stats, on = 'PlayerTmSeason', how = 'left')
df = df.merge(mvp_award_voting, on = 'PlayerTmSeason', how = 'left')
df = df.merge(standings_stats, on = 'TmSeason', how = 'left')
# + colab={"base_uri": "https://localhost:8080/"} id="piEykrNMVf9H" outputId="018cfad6-6526-4723-9ea4-2e3cc12d47b0"
df.info()
# + id="81gu1dIuMdHP"
df = df.loc[:, ~df.columns.duplicated()]
# + id="_crgPUWiMfO5"
df.drop(columns = ['\xa0', 'PlayerTmSeason', 'TmSeason', 'Player_y', 'Pos_y', 'Age_y', 'Tm_y', 'G_y', 'MP_y', 'Season_y', 'Player', 'Age', 'Tm',
'G', 'MP', 'PTS_y', 'TRB_y', 'AST_y', 'STL_y', 'BLK_y', 'FG%_y', '3P%_y', 'FT%_y', 'WS_y', 'WS/48_y', 'Team'],
inplace = True)
# + id="DwI0RAyWMh7p"
df.rename(columns = {'Player_x': 'Player', 'Pos_x': 'Pos', 'Age_x': 'Age', 'Tm_x': 'Tm', 'G_x': 'G', 'MP_x': 'MP',
'FG%_x': 'FG%', '3P%_x': '3P%', 'FT%_x': 'FT%', 'TRB_x': 'TRB', 'AST_x': 'AST', 'STL_x': 'STL',
'BLK_x': 'BLK', 'PTS_x': 'PTS', 'Season_x': 'Season', 'WS_x': 'WS', 'WS/48_x': 'WS/48'},
inplace = True)
# + id="wGQzHWyMMkhk"
df.fillna({'G': 0, 'GS': 0, 'MP': 0, 'FG': 0, 'FGA': 0, 'FG%': 0, '3P': 0, '3PA': 0, '3P%': 0, '2P': 0,
'2PA': 0, '2P%': 0, 'eFG%': 0, 'FT': 0, 'FTA': 0, 'FT%': 0, 'ORB': 0, 'DRB': 0, 'TRB': 0, 'AST': 0,
'STL': 0, 'BLK': 0, 'TOV': 0, 'PF': 0, 'PTS': 0, 'PER': 0, 'TS%': 0, '3PAr': 0, 'FTr': 0, 'ORB%': 0,
'DRB%': 0, 'TRB%': 0, 'AST%': 0, 'STL%': 0, 'BLK%': 0, 'TOV%': 0, 'USG%': 0, 'OWS': 0, 'DWS': 0, 'WS': 0,
'WS/48': 0, 'OBPM': 0, 'DBPM': 0, 'BPM': 0, 'VORP': 0, 'First': 0, 'Pts Won': 0, 'Pts Max': 0, 'Share': 0},
inplace = True)
# + id="Q0UWKBmfMnZ-"
df = df[df.Tm != 'TOT']
# + id="od2oDvgZMq3t"
int_columns = ['Age', 'G', 'GS', 'First', 'Pts Won', 'Pts Max', 'Rk']
percentage_float_columns = ['FG%', '3P%', '2P%', 'eFG%', 'FT%', 'TS%', '3PAr', 'FTr', 'WS/48', 'Share']
float_columns = ['MP', 'FG', 'FGA', '3P', '3PA', '2P', '2PA', 'FT', 'FTA', 'ORB', 'DRB', 'TRB', 'AST', 'STL', 'BLK', 'TOV', 'PF',
'PTS', 'PER', 'ORB%', 'DRB%', 'TRB%', 'AST%', 'STL%', 'BLK%', 'TOV%', 'USG%', 'OWS', 'DWS', 'WS', 'OBPM', 'DBPM', 'BPM', 'VORP']
for column in int_columns:
if column == 'GS':
df[column] = df[column].astype(str).apply(lambda x: '0' if x == '' else x)
if column == 'First' or 'Pts Won':
df[column] = df[column].astype(str).apply(lambda x: x[:-2] if '.' in x else x)
df[column] = df[column].astype(int)
for column in percentage_float_columns:
if column == 'Share':
df[column] = df[column].astype(str).apply(lambda x: '0.0' if x == '0' else x).astype(float)
else:
df[column] = df[column].apply(lambda x: x.zfill(1)).astype(float)
for column in float_columns:
if column == 'MP' or 'PER' or 'USG%':
df[column] = df[column].astype(str).apply(lambda x: '0.0' if x == '' else x)
df[column] = df[column].astype(float)
# + id="9XDhbzzcMSwB"
df_train = df[df.Season <= 2020]
df_production = df[df.Season == 2021]
# + colab={"base_uri": "https://localhost:8080/"} id="BPp_JIguVrbi" outputId="b53c6aea-1288-4384-dca1-ebe74a589df9"
df_train.info()
# + colab={"base_uri": "https://localhost:8080/"} id="-lFx18kpVr5r" outputId="23362efe-ac2f-44ed-da05-936c69e5c5a7"
df_production.info()
# + id="MyCbxda6MuQP" colab={"base_uri": "https://localhost:8080/"} outputId="fa96d478-3a0f-4fe5-cfb0-6d843a2548df"
drive.mount('drive')
df_train.to_csv('df_1980_2020.csv', index = False)
# !cp df_1980_2020.csv 'drive/My Drive/'
df_production.to_csv('df_2021.csv', index = False)
# !cp df_2021.csv 'drive/My Drive/'
| Notebook/NBA_MVP_Award_Share_Scrap.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# +
from threeML import *
from hawc_hal import HAL, HealpixConeROI
import os
os.environ['OMP_NUM_THREADS'] = "1"
os.environ['MKL_NUM_THREADS'] = "1"
# %matplotlib notebook
# +
ra_crab, dec_crab = 83.633083, 22.014500
roi = HealpixConeROI(3.0, 12.0, ra=ra_crab, dec=dec_crab)
hawc = HAL("HAWC",
"/home/giacomov/science/hawc/data/maptree_1024.root",
"/home/giacomov/science/hawc/data/response.root",
roi)
hawc.set_active_measurements(1, 9)
hawc.display()
# +
spectrum = Log_parabola()
source = PointSource("CrabNebula", ra=ra_crab, dec=dec_crab, spectral_shape=spectrum)
# NOTE: if you use units, you have to set up the values for the parameters
# AFTER you create the source, because during creation the function Log_parabola
# gets its units
source.position.ra.bounds = (ra_crab - 0.5, ra_crab + 0.5)
source.position.dec.bounds = (dec_crab - 0.5, dec_crab + 0.5)
spectrum.piv = 10 * u.TeV # Pivot energy
spectrum.piv.fix = True
spectrum.K = 1e-14 / (u.TeV * u.cm**2 * u.s) # norm (in 1/(keV cm2 s))
spectrum.K.bounds = (1e-25, 1e-19) # without units energies are in keV
spectrum.beta = 0 # log parabolic beta
spectrum.beta.bounds = (-4., 2.)
spectrum.alpha = -2.5 # log parabolic alpha (index)
spectrum.alpha.bounds = (-4., 2.)
model = Model(source)
data = DataList(hawc)
# -
jl = JointLikelihood(model, data, verbose=False)
# +
jl.set_minimizer("minuit")
# #%lprun -f FlatSkyToHealpixTransform.__call__
# #%lprun -f hawc.get_log_like _ = jl.fit(quiet=False)
# %prun _ = jl.fit()
# 12 s
# CrabNebula.spectrum.main.Log_parabola.K (1.044 +/- 0.017) x 10^-22 1 / (cm2 keV s)
# CrabNebula.spectrum.main.Log_parabola.alpha -2.807 +/- 0.018
# CrabNebula.spectrum.main.Log_parabola.beta (1.750 +/- 0.11) x 10^-1
# -
gf = GoodnessOfFit(jl)
# %load_ext line_profiler
from hawc_hal.convolved_source import ConvolvedPointSource
from hawc_hal.response.response import HAWCResponse, ResponseBin
from hawc_hal.psf_fast import PSFWrapper
# +
import cProfile
command = """gf.by_mc(100)"""
cProfile.runctx( command, globals(), locals(), filename="profiling.profile" )
# #%lprun -f PSFWrapper.__init__ gof, param, likes = gf.by_mc(10)
# +
#print(gof)
#likes.plot()
# +
#param.loc[(slice(None), ['CrabNebula.spectrum.main.Log_parabola.alpha']), 'value'].plot()
# -
# %load_ext line_profiler
# +
source.position.ra.free = True
source.position.dec.free = True
jl.set_minimizer("minuit")
command = """jl.fit()"""
cProfile.runctx( command, globals(), locals(), filename="freepos.profile" )
#best_fit, like_frame = jl.fit()
# CrabNebula.position.ra (8.362 +/- 0.00026) x 10 deg
# CrabNebula.position.dec (2.202 +/- 0.00024) x 10 deg
# CrabNebula.spectrum.main.Log_parabola.K (9.970 +/- 0.17) x 10^-23 1 / (cm2 keV s)
# CrabNebula.spectrum.main.Log_parabola.alpha -2.798 +/- 0.021
# CrabNebula.spectrum.main.Log_parabola.beta (1.590 +/- 0.13) x 10^-1
# +
_ = jl.get_errors()
# CrabNebula.position.ra (8.36201 -0.00027 +0.00026) x 10 deg
# CrabNebula.position.dec (2.20206 -0.00025 +0.00023) x 10 deg
# CrabNebula.spectrum.main.Log_parabola.K (1.010 +/- 0.017) x 10^-22 1 / (cm2 keV s)
# CrabNebula.spectrum.main.Log_parabola.alpha -2.797 +/- 0.019
# CrabNebula.spectrum.main.Log_parabola.beta (1.630 +/- 0.11) x 10^-1
# +
# %prun -D contour.profile jl.get_contours(model.CrabNebula.position.ra, 83.610, 83.630, 16, model.CrabNebula.position.dec, 22.010, 22.030, 16)
import matplotlib.pyplot as plt
plt.plot([dec_crab], [ra_crab], 'x')
# Parallel: 183.5
# 225 / 225 in 249.2 s (0:00:00 remaining)
# -
print spectrum(1.0 * u.TeV).to(1/(u.TeV * u.cm**2 * u.s))
# +
source.position.ra = ra_crab
source.position.ra.free = True
source.position.dec = dec_crab
source.position.dec.free = True
for parameter in model.parameters.values():
if parameter.fix:
continue
if parameter.is_normalization:
parameter.set_uninformative_prior(Log_uniform_prior)
else:
parameter.set_uninformative_prior(Uniform_prior)
bs = BayesianAnalysis(model, data)
# %prun -D bayes.profile bs.sample(30, 10, 10)
# 71.3
# 38.3
# -
_ = bs.corner_plot()
| notebooks/test_like.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import sys
sys.path.append('../') # or just install the module
sys.path.append('../../fuzzy-torch') # or just install the module
sys.path.append('../../fuzzy-tools') # or just install the module
sys.path.append('../../astro-lightcurves-handler') # or just install the module
# +
# %load_ext autoreload
# %autoreload 2
from lcclassifier.results.utils import filter_models
condition_dict = {
#'cell':['GRU', 'LSTM'],
'aggr':['max', 'avg'],
#'mdl':['ParallelTimeSelfAttn', 'SerialTimeSelfAttn'],
#'mdl':['ParallelTimeSelfAttn', 'SerialTimeSelfAttn'],
#'mdl':['ParallelTimeSelfAttn', 'SerialTimeSelfAttn', 'ParallelTimeErrorSelfAttn', 'SerialTimeErrorSelfAttn'],
'rsc':['0'],
}
new_model_names = [
'mdl=ParallelRNN~in-dims=3~te-dims=0~enc-emb=g32-g32-g32.r32-r32-r32~dec-emb=g32-g32.r32-r32~cell=GRU~rsc=0',
'mdl=SerialRNN~in-dims=3~te-dims=0~enc-emb=32-32-32~dec-emb=g32-g32.r32-r32~cell=GRU~rsc=0',
'mdl=ParallelTCNN~in-dims=3~te-dims=0~enc-emb=g32-g32-g32.r32-r32-r32~dec-emb=g32-g32.r32-r32~aggr=avg~rsc=0',
'mdl=SerialTCNN~in-dims=3~te-dims=0~enc-emb=32-32-32~dec-emb=g32-g32.r32-r32~aggr=avg~rsc=0',
'mdl=ParallelTimeSelfAttn~in-dims=2~te-dims=4~enc-emb=g32-g32-g32.r32-r32-r32~dec-emb=g32-g32.r32-r32~rsc=0',
'mdl=SerialTimeSelfAttn~in-dims=2~te-dims=4~enc-emb=32-32-32~dec-emb=g32-g32.r32-r32~rsc=0',
'mdl=ParallelTimeSelfAttn~in-dims=2~te-dims=4~enc-emb=g32-g32-g32.r32-r32-r32~dec-emb=g32-g32.r32-r32~rsc=1',
'mdl=SerialTimeSelfAttn~in-dims=2~te-dims=4~enc-emb=32-32-32~dec-emb=g32-g32.r32-r32~rsc=1',
]
new_model_names = model_names
#new_model_names = filter_models(model_names, condition_dict)
for kmn,model_name in enumerate(new_model_names):
print(f'[{kmn}] {model_name}')
# +
# %load_ext autoreload
# %autoreload 2
from lcclassifier.results.utils import get_models_from_rootdir
method = 'spm-mcmc-estw'
cfilename = f'survey=alerceZTFv7.1~bands=gr~mode=onlySNe~method={method}'
rootdir = f''
survey_name = 'alerceZTFv7.1'
set_name = f'{kf}@r_test' # s_train r_train s_val r_val r_test
rootdir = f'../save/experiments/{set_name}'
cset_name = set_name.split('@')[-1]
model_names = get_models_from_rootdir(f'{rootdir}/{mode}')
for kmn,model_name in enumerate(model_names):
print(f'[{kmn}] {model_name}')
# -
# # metrics v/s days
baselines_dict = {
'r_val':{
'b-accuracy':65.86,
'b-f1score':.43,
},
'r_test':{
'b-accuracy':60.38,
'b-f1score':.45,
},
}
# +
# %load_ext autoreload
# %autoreload 2
from lcclassifier.results.plots import plot_metric
kwargs = {
'label_keys':label_keys,
'set_name':set_name,
}
metric_name = 'b-accuracy' # b-accuracy b-f1score
plot_metric(rootdir, metric_name, new_model_names, baselines_dict.get(cset_name, None), **kwargs)
# +
# %load_ext autoreload
# %autoreload 2
from lcclassifier.results.tables import get_query_df_table
from fuzzytools.latex.latex_tables import LatexTable
kwargs = {
'arch_modes':['Parallel', 'Serial'],
#'arch_modes':['Serial'],
}
metric_names = ['b-accuracy', 'b-f1score', 'b-gmean', 'b-xentropy']
day_to_metric = 150
#query_key = 'cell'; query_values = ['GRU', 'LSTM']
query_key = 'aggr'; query_values = ['avg', 'max']
#query_key = 'te-dims'; query_values = [str(i) for i in [4, 8, 16]]
info_df = get_query_df_table(rootdir, metric_names, new_model_names, day_to_metric, query_key, query_values, **kwargs)
latex_kwargs = {
'caption':f'{query_key} {day_to_metric} {set_name}'.replace('_', '\\_'),
'label':'?',
#'bold_criteriums':'max',
#'custom_tabular_align':'l|'+'c'*sum([m.split('-')[-1]=='fstw' for m in methods])+'|'+'c'*sum([m.split('-')[-1]=='estw' for m in methods]),
#'custom_tabular_align':'l|cc|cc|cc',
'hline_k':2,
}
latex_table = LatexTable(info_df, **latex_kwargs)
print(latex_table)
info_df
# +
# %load_ext autoreload
# %autoreload 2
from lcclassifier.results.tables import get_df_table
from fuzzytools.latex.latex_tables import LatexTable
import fuzzytools.strings as strings
def format_f(model_name):
model_name = model_name.replace('Parallel', '')
model_name = model_name.replace('Serial', '')
mn_dict = strings.get_dict_from_string(model_name)
return mn_dict['mdl']
kwargs = {
'arch_modes':['Parallel', 'Serial'],
#'arch_modes':['Serial'],
}
metric_names = ['b-accuracy', 'b-f1score', 'b-gmean', 'b-xentropy']
day_to_metric = 150
info_df = get_df_table(rootdir, metric_names, new_model_names, day_to_metric, format_f, **kwargs)
latex_kwargs = {
'caption':f'max day={day_to_metric} - eval={set_name}'.replace('_', '\\_'),
'label':'?',
#'bold_criteriums':'max',
#'custom_tabular_align':'l|'+'c'*sum([m.split('-')[-1]=='fstw' for m in methods])+'|'+'c'*sum([m.split('-')[-1]=='estw' for m in methods]),
#'custom_tabular_align':'l|cc|cc|cc',
'hline_k':2,
}
latex_table = LatexTable(info_df, **latex_kwargs)
print(latex_table)
info_df
# +
# %load_ext autoreload
# %autoreload 2
from lcclassifier.results.plots import plot_cm
kwargs = {
'lcset_name':set_name,
'export_animation':True,
}
day_to_metric = 150 # 150
plot_cm(rootdir, new_model_names, day_to_metric, **kwargs)
# -
# # mse v/s days
# +
# %load_ext autoreload
# %autoreload 2
from lcclassifier.results.plots import plot_mse
plot_mse(rootdir, new_model_names)
# -
# # f1score vs mse
# +
# %load_ext autoreload
# %autoreload 2
from lcclassifier.results.plots import plot_f1score_mse
plot_f1score_mse(root_folder)
# -
# # Temporal encoding
# +
# %load_ext autoreload
# %autoreload 2
from lcclassifier.results.plots import plot_te_scores
plot_te_scores(root_folder, error_scale=1.5)
# -
# # Precision & recall
# +
# %matplotlib inline
# %load_ext autoreload
# %autoreload 2
from ipywidgets import interact, fixed
from fuzzytools.myUtils.files import search_for_filedirs
from src.results.plots import plot_precision_recall_classes
def interact_f(model_name):
return plot_precision_recall_classes(root_folder, model_name)
filedirs = search_for_filedirs(root_folder, fext='expmet', verbose=0)
model_names = list(set([fd.split('/')[-2] for fd in filedirs]))
interact(interact_f, model_name=model_names)
# +
# %load_ext autoreload
# %autoreload 2
from src.results.plots import plot_training_losses
plot_training_losses(root_folder)
# -
# # metrics & training times table
# +
# %load_ext autoreload
# %autoreload 2
from src.results.latex_tables import latex_table_metrics_days
target_days = [15, 30, 60]
latex_table_metrics_days(root_folder, target_days)
# +
# %load_ext autoreload
# %autoreload 2
from src.results.latex_tables import latex_table_metrics_mean
latex_table_metrics_mean(root_folder)
# +
# %load_ext autoreload
# %autoreload 2
from src.results.latex_tables import latex_table_parameters
latex_table_parameters(root_folder)
# -
# # confusion matrix plot
# +
# %matplotlib inline
# %load_ext autoreload
# %autoreload 2
from ipywidgets import interact, fixed
from fuzzytools.myUtils.files import search_for_filedirs, load_pickle
from src.results.plots import plot_cm
def interact_f(model_name, target_day):
return plot_cm(root_folder, model_name, target_day)
filedirs = search_for_filedirs(root_folder, fext='expmet', verbose=0)
model_names = list(set([fd.split('/')[-2] for fd in filedirs]))
target_days = load_pickle(filedirs[0])['days'][::-1]
interact(interact_f, model_name=model_names, target_day=target_days)
# +
# %load_ext autoreload
# %autoreload 2
from ipywidgets import interact, fixed
from fuzzytools.myUtils.files import search_for_filedirs, load_pickle
from src.results.plots import animation_cm
filedirs = search_for_filedirs(root_folder, fext='expmet', verbose=0)
model_names = list(set([fd.split('/')[-2] for fd in filedirs]))
target_days = load_pickle(filedirs[0])['days']
animation_cm(root_folder, model_names[0], target_days)
| experiments/.ipynb_checkpoints/metrics_results (copy)-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.6
# language: python
# name: python36
# ---
# Copyright (c) Microsoft Corporation. All rights reserved.
#
# Licensed under the MIT License.
# # Automated ML on Azure Databricks
#
# In this example we use the scikit-learn's <a href="http://scikit-learn.org/stable/datasets/index.html#optical-recognition-of-handwritten-digits-dataset" target="_blank">digit dataset</a> to showcase how you can use AutoML for a simple classification problem.
#
# In this notebook you will learn how to:
# 1. Create Azure Machine Learning Workspace object and initialize your notebook directory to easily reload this object from a configuration file.
# 2. Create an `Experiment` in an existing `Workspace`.
# 3. Configure Automated ML using `AutoMLConfig`.
# 4. Train the model using Azure Databricks.
# 5. Explore the results.
# 6. Test the best fitted model.
#
# Before running this notebook, please follow the <a href="https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/azure-databricks" target="_blank">readme for using Automated ML on Azure Databricks</a> for installing necessary libraries to your cluster.
# We support installing AML SDK with Automated ML as library from GUI. When attaching a library follow <a href="https://docs.databricks.com/user-guide/libraries.html" target="_blank">this link</a> and add the below string as your PyPi package. You can select the option to attach the library to all clusters or just one cluster.
#
# **azureml-sdk with automated ml**
# * Source: Upload Python Egg or PyPi
# * PyPi Name: `azureml-sdk[automl_databricks]`
# * Select Install Library
# ### Check the Azure ML Core SDK Version to Validate Your Installation
# +
import azureml.core
print("SDK Version:", azureml.core.VERSION)
# -
# ## Initialize an Azure ML Workspace
# ### What is an Azure ML Workspace and Why Do I Need One?
#
# An Azure ML workspace is an Azure resource that organizes and coordinates the actions of many other Azure resources to assist in executing and sharing machine learning workflows. In particular, an Azure ML workspace coordinates storage, databases, and compute resources providing added functionality for machine learning experimentation, operationalization, and the monitoring of operationalized models.
#
#
# ### What do I Need?
#
# To create or access an Azure ML workspace, you will need to import the Azure ML library and specify following information:
# * A name for your workspace. You can choose one.
# * Your subscription id. Use the `id` value from the `az account show` command output above.
# * The resource group name. The resource group organizes Azure resources and provides a default region for the resources in the group. The resource group will be created if it doesn't exist. Resource groups can be created and viewed in the [Azure portal](https://portal.azure.com)
# * Supported regions include `eastus2`, `eastus`,`westcentralus`, `southeastasia`, `westeurope`, `australiaeast`, `westus2`, `southcentralus`.
subscription_id = "<Your SubscriptionId>" #you should be owner or contributor
resource_group = "<Resource group - new or existing>" #you should be owner or contributor
workspace_name = "<workspace to be created>" #your workspace name
workspace_region = "<azureregion>" #your region
# ## Creating a Workspace
# If you already have access to an Azure ML workspace you want to use, you can skip this cell. Otherwise, this cell will create an Azure ML workspace for you in the specified subscription, provided you have the correct permissions for the given `subscription_id`.
#
# This will fail when:
# 1. The workspace already exists.
# 2. You do not have permission to create a workspace in the resource group.
# 3. You are not a subscription owner or contributor and no Azure ML workspaces have ever been created in this subscription.
#
# If workspace creation fails for any reason other than already existing, please work with your IT administrator to provide you with the appropriate permissions or to provision the required resources.
#
# **Note:** Creation of a new workspace can take several minutes.
# +
# Import the Workspace class and check the Azure ML SDK version.
from azureml.core import Workspace
ws = Workspace.create(name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group,
location = workspace_region,
exist_ok=True)
ws.get_details()
# -
# ## Configuring Your Local Environment
# You can validate that you have access to the specified workspace and write a configuration file to the default configuration location, `./aml_config/config.json`.
# +
from azureml.core import Workspace
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
# Persist the subscription id, resource group name, and workspace name in aml_config/config.json.
ws.write_config()
# -
# ## Create a Folder to Host Sample Projects
# Finally, create a folder where all the sample projects will be hosted.
# +
import os
sample_projects_folder = './sample_projects'
if not os.path.isdir(sample_projects_folder):
os.mkdir(sample_projects_folder)
print('Sample projects will be created in {}.'.format(sample_projects_folder))
# -
# ## Create an Experiment
#
# As part of the setup you have already created an Azure ML `Workspace` object. For Automated ML you will need to create an `Experiment` object, which is a named object in a `Workspace` used to run experiments.
# +
import logging
import os
import random
import time
from matplotlib import pyplot as plt
from matplotlib.pyplot import imshow
import numpy as np
import pandas as pd
import azureml.core
from azureml.core.experiment import Experiment
from azureml.core.workspace import Workspace
from azureml.train.automl import AutoMLConfig
from azureml.train.automl.run import AutoMLRun
# +
# Choose a name for the experiment and specify the project folder.
experiment_name = 'automl-local-classification'
project_folder = './sample_projects/automl-local-classification'
experiment = Experiment(ws, experiment_name)
output = {}
output['SDK version'] = azureml.core.VERSION
output['Subscription ID'] = ws.subscription_id
output['Workspace Name'] = ws.name
output['Resource Group'] = ws.resource_group
output['Location'] = ws.location
output['Project Directory'] = project_folder
output['Experiment Name'] = experiment.name
pd.set_option('display.max_colwidth', -1)
pd.DataFrame(data = output, index = ['']).T
# -
# ## Diagnostics
#
# Opt-in diagnostics for better experience, quality, and security of future releases.
from azureml.telemetry import set_diagnostics_collection
set_diagnostics_collection(send_diagnostics = True)
# ## Registering Datastore
# Datastore is the way to save connection information to a storage service (e.g. Azure Blob, Azure Data Lake, Azure SQL) information to your workspace so you can access them without exposing credentials in your code. The first thing you will need to do is register a datastore, you can refer to our [python SDK documentation](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.datastore.datastore?view=azure-ml-py) on how to register datastores. __Note: for best security practices, please do not check in code that contains registering datastores with secrets into your source control__
#
# The code below registers a datastore pointing to a publicly readable blob container.
# +
from azureml.core import Datastore
datastore_name = 'demo_training'
container_name = 'digits'
account_name = 'automlpublicdatasets'
Datastore.register_azure_blob_container(
workspace = ws,
datastore_name = datastore_name,
container_name = container_name,
account_name = account_name,
overwrite = True
)
# -
# Below is an example on how to register a private blob container
# ```python
# datastore = Datastore.register_azure_blob_container(
# workspace = ws,
# datastore_name = 'example_datastore',
# container_name = 'example-container',
# account_name = 'storageaccount',
# account_key = 'accountkey'
# )
# ```
# The example below shows how to register an Azure Data Lake store. Please make sure you have granted the necessary permissions for the service principal to access the data lake.
# ```python
# datastore = Datastore.register_azure_data_lake(
# workspace = ws,
# datastore_name = 'example_datastore',
# store_name = 'adlsstore',
# tenant_id = 'tenant-id-of-service-principal',
# client_id = 'client-id-of-service-principal',
# client_secret = 'client-secret-of-service-principal'
# )
# ```
# ## Load Training Data Using DataPrep
# Automated ML takes a Dataflow as input.
#
# If you are familiar with Pandas and have done your data preparation work in Pandas already, you can use the `read_pandas_dataframe` method in dprep to convert the DataFrame to a Dataflow.
# ```python
# df = pd.read_csv(...)
# # apply some transforms
# dprep.read_pandas_dataframe(df, temp_folder='/path/accessible/by/both/driver/and/worker')
# ```
#
# If you just need to ingest data without doing any preparation, you can directly use AzureML Data Prep (Data Prep) to do so. The code below demonstrates this scenario. Data Prep also has data preparation capabilities, we have many [sample notebooks](https://github.com/Microsoft/AMLDataPrepDocs) demonstrating the capabilities.
#
# You will get the datastore you registered previously and pass it to Data Prep for reading. The data comes from the digits dataset: `sklearn.datasets.load_digits()`. `DataPath` points to a specific location within a datastore.
# +
import azureml.dataprep as dprep
from azureml.data.datapath import DataPath
datastore = Datastore.get(workspace = ws, datastore_name = datastore_name)
X_train = dprep.read_csv(datastore.path('X.csv'))
y_train = dprep.read_csv(datastore.path('y.csv')).to_long(dprep.ColumnSelector(term='.*', use_regex = True))
# -
# ## Review the Data Preparation Result
# You can peek the result of a Dataflow at any range using `skip(i)` and `head(j)`. Doing so evaluates only j records for all the steps in the Dataflow, which makes it fast even against large datasets.
X_train.get_profile()
y_train.get_profile()
# ## Configure AutoML
#
# Instantiate an `AutoMLConfig` object to specify the settings and data used to run the experiment.
#
# |Property|Description|
# |-|-|
# |**task**|classification or regression|
# |**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>average_precision_score_weighted</i><br><i>norm_macro_recall</i><br><i>precision_score_weighted</i>|
# |**primary_metric**|This is the metric that you want to optimize. Regression supports the following primary metrics: <br><i>spearman_correlation</i><br><i>normalized_root_mean_squared_error</i><br><i>r2_score</i><br><i>normalized_mean_absolute_error</i>|
# |**iteration_timeout_minutes**|Time limit in minutes for each iteration.|
# |**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|
# |**n_cross_validations**|Number of cross validation splits.|
# |**spark_context**|Spark Context object. for Databricks, use spark_context=sc|
# |**max_concurrent_iterations**|Maximum number of iterations to execute in parallel. This should be <= number of worker nodes in your Azure Databricks cluster.|
# |**X**|(sparse) array-like, shape = [n_samples, n_features]|
# |**y**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]<br>Multi-class targets. An indicator matrix turns on multilabel classification. This should be an array of integers.|
# |**path**|Relative path to the project folder. AutoML stores configuration files for the experiment under this folder. You can specify a new empty folder.|
# |**preprocess**|set this to True to enable pre-processing of data eg. string to numeric using one-hot encoding|
# |**exit_score**|Target score for experiment. It is associated with the metric. eg. exit_score=0.995 will exit experiment after that|
automl_config = AutoMLConfig(task = 'classification',
debug_log = 'automl_errors.log',
primary_metric = 'AUC_weighted',
iteration_timeout_minutes = 10,
iterations = 3,
preprocess = True,
n_cross_validations = 10,
max_concurrent_iterations = 2, #change it based on number of worker nodes
verbosity = logging.INFO,
spark_context=sc, #databricks/spark related
X = X_train,
y = y_train,
path = project_folder)
# ## Train the Models
#
# Call the `submit` method on the experiment object and pass the run configuration. Execution of local runs is synchronous. Depending on the data and the number of iterations this can run for a while.
local_run = experiment.submit(automl_config, show_output = True)
# ## Continue experiment
local_run.continue_experiment(iterations=2,
X=X_train,
y=y_train,
spark_context=sc,
show_output=True)
# ## Explore the Results
# #### Portal URL for Monitoring Runs
#
# The following will provide a link to the web interface to explore individual run details and status. In the future we might support output displayed in the notebook.
displayHTML("<a href={} target='_blank'>Your experiment in Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))
# The following will show the child runs and waits for the parent run to complete.
# #### Retrieve All Child Runs after the experiment is completed (in portal)
# You can also use SDK methods to fetch all the child runs and see individual metrics that we log.
# +
children = list(local_run.get_children())
metricslist = {}
for run in children:
properties = run.get_properties()
metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)}
metricslist[int(properties['iteration'])] = metrics
rundata = pd.DataFrame(metricslist).sort_index(1)
rundata
# -
# ### Retrieve the Best Model after the above run is complete
#
# Below we select the best pipeline from our iterations. The `get_output` method returns the best run and the fitted model. The Model includes the pipeline and any pre-processing. Overloads on `get_output` allow you to retrieve the best run and fitted model for *any* logged metric or for a particular *iteration*.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
# #### Best Model Based on Any Other Metric after the above run is complete based on the child run
# Show the run and the model that has the smallest `log_loss` value:
lookup_metric = "log_loss"
best_run, fitted_model = local_run.get_output(metric = lookup_metric)
print(best_run)
print(fitted_model)
# ### Test the Best Fitted Model
#
# #### Load Test Data - you can split the dataset beforehand & pass Train dataset to AutoML and use Test dataset to evaluate the best model.
blob_location = "https://{}.blob.core.windows.net/{}".format(account_name, container_name)
X_test = pd.read_csv("{}./X_valid.csv".format(blob_location), header=0)
y_test = pd.read_csv("{}/y_valid.csv".format(blob_location), header=0)
images = pd.read_csv("{}/images.csv".format(blob_location), header=None)
images = np.reshape(images.values, (100,8,8))
# #### Testing Our Best Fitted Model
# We will try to predict digits and see how our model works. This is just an example to show you.
# Randomly select digits and test.
for index in np.random.choice(len(y_test), 2, replace = False):
print(index)
predicted = fitted_model.predict(X_test[index:index + 1])[0]
label = y_test.values[index]
title = "Label value = %d Predicted value = %d " % (label, predicted)
fig = plt.figure(3, figsize = (5,5))
ax1 = fig.add_axes((0,0,.8,.8))
ax1.set_title(title)
plt.imshow(images[index], cmap = plt.cm.gray_r, interpolation = 'nearest')
display(fig)
# When deploying an automated ML trained model, please specify _pippackages=['azureml-sdk[automl]']_ in your CondaDependencies.
#
# Please refer to only the **Deploy** section in this notebook - <a href="https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/automated-machine-learning/classification-with-deployment" target="_blank">Deployment of Automated ML trained model</a>
| how-to-use-azureml/azure-databricks/automl/automl-databricks-local-01.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Circos running in Binder
# NOT READY YET. CONTENTS BELOW MOVED ELSEWEHERE. WON'T WORK.
# Run the first step in this notebook to install Circos.
# Run the second and third step to run a demo to verify it is installed.
# + language="bash"
# curl -O http://circos.ca/distribution/circos-0.69-6.tgz
# tar xvfz circos-0.69-6.tgz
# rm circos-0.69-6.tgz
# -
# ### Demonstrate it works by running example code
# + language="bash"
# cd circos-0.69-6/example
# ./run
# -
# ### View generated demo image
from IPython.display import Image
Image("circos-0.69-6/example/circos.png")
# Once it is verified working, use it to develop Circos plots. (Should `!cd circos-0.69-6` first.)
#
# WAITTT... that won't test it is working because image already there when unpacked?!?! IF you check `Run.out` in the example directory, you'll see a report like below because things are presently missing.
# (Maybe to test when I fix things, I delete the `circos.png` file in exampe before the demo run?? That would really test.)
# + language="bash"
# cd circos-0.69-6/example
# ../bin/circos
# -
# So there are a bunch missing. I just followed instructions [here](http://circos.ca/tutorials/lessons/configuration/distribution_and_installation/) to see what was missing and I got:
# + language="bash"
# cd circos-0.69-6/example
# ../bin/circos -modules
# -
| notebooks/Quick_Start_Part1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # QA Sentiment Analysis: Critical Thinking 6.2.1
# # Random Forest
# ### By <NAME>
# # Introduction
# Question: "Recently, we observed a strong negative correlation between depression and self-esteem. Explain what this means. Make sure you avoid the misinterpretations described previously in this chapter."
# Answer: "A strong negative between depression and self-esteem means that individuals who are more depressed also tend to have lower self-esteen, whereas individuals who are less depressed tend to have higher self-esteem. It does not mean that one variable causes changes in the other, but simply that the variables tend to move together in a certain manner."
# ***
# # Importing Packages
import numpy as np
import pandas as pd
import os
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.metrics import (f1_score,precision_score,recall_score, confusion_matrix)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV, train_test_split # for hyperparameter tuning
# ***
# # Loading and Preprocessing the Data
CTC_6_2_1 = pd.read_excel("/Users/jeffreyblack/Desktop/NLPProject/QA_CTC.xlsx", sheet_name = 'CTC_6_2_1')
CTC_6_2_1
X_train, X_test, y_train, y_test = train_test_split(CTC_6_2_1['Answers'] , CTC_6_2_1['Grade'], test_size=0.20, random_state=42)
# ***
# # Feature Extraction
# ### Convert reviews into vectors using the TF-IDF feature extraction
# Note: I did not remove stop-words
def extract_features(x_train, x_test):
# This function extracts document features for input documents, x
# Source:
# https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html#sklearn.feature_extraction.text.CountVectorizer
vectorizer = TfidfVectorizer(max_features=10000, ngram_range = (1,3))
train = vectorizer.fit_transform(x_train)
test = vectorizer.transform(x_test)
test.toarray()
print((vectorizer.get_feature_names()))
return train, test
# Calling the TF-IDF Vectorizer to extract the features for the training and test predictors.
feats_train, feats_test = extract_features(X_train, X_test) # training and test set features
# ***
# # Model Training: Random Forest
# ### Fit the training data using Random Forest classifier
def build_RF_classifier(x, y):
# This function builds a Random Forest classifier with input (x,y):
# Source:
# https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
clf = RandomForestClassifier()
clf.fit(x, y)
return clf
rf_clf = build_RF_classifier(feats_train, y_train)
# ## Hyperparameter Tuning
# I decided to use Random Search Cross Validation in Scikit-Learn to determine the best hyperparameters needed for tuning the Random Forest classifier model. The RandomizedSearchCV allowed me to define a grid of hyperparameter randes and randomly sample from the grid, while performing K-fold cross validation with each combination of values.
# Number of trees in random forest
n_estimators = [int(x) for x in np.linspace(start = 200, stop = 2000, num = 10)]
# Number of features to consider at every split
max_features = ['auto', 'sqrt']
# Maximum number of levels in tree
max_depth = [int(x) for x in np.linspace(10, 110, num = 11)]
max_depth.append(None)
# Minimum number of samples required to split a node
min_samples_split = [2, 5, 10]
# Minimum number of samples required at each leaf node
min_samples_leaf = [1, 2, 4]
# Method of selecting samples for training each tree
bootstrap = [True, False]
# Create the random grid
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
print(random_grid)
# Use the random grid to search for best hyperparameters
# First create the base model to tune
rf = RandomForestClassifier()
# Random search of parameters, using 3 fold cross validation,
# search across 100 different combinations, and use all available cores
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 3, verbose=2, random_state=42, n_jobs = -1)
# Fit the random search model
rf_random.fit(feats_train, y_train)
# finding the best parameters
best = rf_random.best_params_
best
# Using the output above, I tuned the Random Forest classifier below.
def build_RF_classifier_tuned(x, y):
# This function builds a Random Forest classifier with input (x,y):
# Source:
# https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
clf = RandomForestClassifier(n_estimators = best.get('n_estimators'),
min_samples_split = best.get('min_samples_split'),
min_samples_leaf = best.get('min_samples_leaf'),
max_features = best.get('max_features'),
max_depth = best.get('max_depth'),
bootstrap = best.get('bootstrap'))
clf.fit(x, y)
return clf
rf_clf_tuned = build_RF_classifier_tuned(feats_train, y_train)
# ***
# # Model Evaluation Functions
# I used 3 evaluation metrics: recall, precision, and F1-score. I also used a confusion matrix to visualize false-positive, false-negative, true-positive, and true-negative.
def recall_evaluator(x, y_truth, clf):
# Function to evalute model performance, using recall:
# Source:
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html#sklearn.metrics.recall_score
result = 0.0
result = recall_score(y_true = y_truth, y_pred = clf.predict(x), average='weighted')
return result
def precision_evaluator(x, y_truth, clf):
# Function to evalute model performance, using precision:
# Source:
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html#sklearn.metrics.precision_score
result = 0.0
result = precision_score(y_true = y_truth, y_pred = clf.predict(x), average='weighted')
return result
def f1_evaluator(x, y_truth, clf):
# Function to evalute model performance, using F1-score:
# Source:
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html#sklearn.metrics.f1_score
result = 0.0
result = f1_score(y_true = y_truth, y_pred = clf.predict(x), average='weighted')
return result
# ***
# ## Summary Results of Random Forest
# ### Original model evaluation:
recall_rf_score = recall_evaluator(feats_test, y_test, rf_clf)
precision_rf_score = precision_evaluator(feats_test, y_test, rf_clf)
f1_rf_score = f1_evaluator(feats_test, y_test, rf_clf)
pred_rf = rf_clf.predict(feats_test)
print('Random Forest Recall: ', recall_rf_score)
print('Random Forest Precision: ', precision_rf_score)
print('Random Forest F1: ', f1_rf_score)
print("Confusion Matrix for Random Forest Classifier:")
print(confusion_matrix(y_test, pred_rf))
# ### After hyperparameter tuning:
recall_rf_tuned_score = recall_evaluator(feats_test, y_test, rf_clf_tuned)
precision_rf_tuned_score = precision_evaluator(feats_test, y_test, rf_clf_tuned)
f1_rf_tuned_score = f1_evaluator(feats_test, y_test, rf_clf_tuned)
pred_rf_tuned = rf_clf_tuned.predict(feats_test)
print('Random Forest Recall: ', recall_rf_tuned_score)
print('Random Forest Precision: ', precision_rf_tuned_score)
print('Random Forest F1: ', f1_rf_tuned_score)
print("Confusion Matrix for Random Forest Classifier:")
print(confusion_matrix(y_test, pred_rf_tuned))
| RandomForests/RF_6_2_1_QA_Sentiment_Analysis.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Twoja własna wirtualna kamera - czyli sieci neuronowe dla każdego.
# Abstrakt: *Naucz się tworzyć swoje własne doświadczenia ze Sztuczną Inteligencją. Na warsztacie spojrzymy na obecny krajobraz SI z czysto pragmatycznego punktu widzenia, oraz pokażemy jak używać gotowych modeli w celu tworzenia nowych produktów, niezwłocznie przechodząc do budowy Waszego pierwszego narzędzia. Wirtualnej kamery nafaszerowanej sieciami neuronowymi.*
# ## Wykrywanie twarzy
#
# W pierwszej kolejności, spróbujmy wykryć twarz na różne sposoby.
# + [markdown] tags=[]
# ### Instalacja zależności i importy
# `!` pozwala na uruchomienie linii komend i zainstalowanie zależności wprost z notatnika. Alternatywą byłoby dołączenie `requirements.txt`, ale zgodnie z zasadą *Reproducible Research*, starajmy się pisać notatniki tak, aby były w jak największym stopniu samowystarczalne.
# + tags=[]
# !pip install numpy opencv-python matplotlib
# + tags=[]
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# %matplotlib inline
# + [markdown] tags=[]
# ### Pobranie obrazu z kamerki
# Przy sporej większości przypadków związanych z *Computer Vision* używa się OpenCV. Nie inaczej postąpimy tutaj.
# + tags=[]
cap = cv.VideoCapture(0)
if not cap.isOpened():
raise "Nie można otworzyć kamerki"
ret, frame = cap.read()
plt.imshow(frame)
# -
# Obraz w OpenCV jest domyślnie trzymany jako BGR, czyli opisuje go kolejno Niebieski, Zielony i Czerwony, w przeciwieństwie do RGB powszechnego w grafice komputerowej. Powód, jak zazwyczaj, jest historyczny. Format BGR był popularny w swoim czasie wśród producentów kamer oraz oprogramowania do obróbki obrazu.
# + tags=[]
plt.imshow(cv.cvtColor(frame, cv.COLOR_BGR2RGB))
# + [markdown] tags=[]
# ### Rozpoznawanie twarzy
# + [markdown] tags=[]
# #### Kaskady Haar-a
#
# Nazwa wzięła się od tego że jądro splotu (*Convolution Kernel*) w algorytmie przypomina [falki Haar'a](https://en.wikipedia.org/wiki/Haar_wavelet) właśnie. Algorytm opisuje praca [*Rapid Object Detection using a Boosted Cascade of Simple Features*](https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf) z 2001. Sposób działania algorytmu możecie prześledzić na wideo poniżej:
# -
# %%HTML
<iframe src="https://player.vimeo.com/video/12774628?title=0&byline=0&portrait=0" width="700" height="394" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe>
# Kaskady Haar'a są wbudowane w OpenCV. To jest pierwszy, i w oczywiście najprostszy, sposób w jaki możemy używać *Machine Learning*. Sporo bibliotek ma popularne funkcjonalności już wbudowane. Najważniejsze w tym wypadku jest doczytać dokumentację, jakich danych model oczekuje na wejściu. W tym przypadku, musimy mieć obrazek w odcieniach szarości, o wyrównanym histogramie.
#
# Pliki modelu w tym wypadku są rozprowadzane z OpenCV, ale możemy je też pobrać bezpośrednio ze [strony](https://github.com/opencv/opencv/tree/master/data/haarcascades) i wersjonować lokalnie.
# + tags=[]
haar_img = frame.copy()
haar_img_gray = cv.cvtColor(haar_img, cv.COLOR_BGR2GRAY)
haar_img_gray = cv.equalizeHist(haar_img_gray)
face_cascade = cv.CascadeClassifier('haarcascade_frontalface_alt.xml')
faces = face_cascade.detectMultiScale(haar_img_gray)
for (x,y,w,h) in faces:
center = (x + w//2, y + h//2)
haar_img = cv.rectangle(haar_img, (x, y), (x+w, y+h), (255, 0, 0), 2)
plt.imshow(cv.cvtColor(haar_img, cv.COLOR_BGR2RGB))
# -
# Kaskady Haar'a możemy wykorzystywać nie tylko do wykrywania twarzy. Są też modele do wykrywania oczu, części ciała, czy nawet rosyjskich tablic rejestracyjnych...
# + tags=[]
eyes_cascade = cv.CascadeClassifier('haarcascade_eye_tree_eyeglasses.xml')
for (x,y,w,h) in faces:
faceROI = haar_img_gray[y:y+h,x:x+w]
eyes = eyes_cascade.detectMultiScale(faceROI)
for (x2,y2,w2,h2) in eyes:
eye_center = (x + x2 + w2//2, y + y2 + h2//2)
radius = int(round((w2 + h2)*0.25))
haar_img = cv.circle(haar_img, eye_center, radius, (255, 0, 0 ), 4)
plt.imshow(cv.cvtColor(haar_img, cv.COLOR_BGR2RGB))
# -
# ### Dlib
#
# Dlib jest biblioteką algorytmów uczenia maszynowego, napisaną w C++. Posiada natomiast wiązania do pythona. Jest to bardzo popularne rozwiązanie: kod implementujący algorytmy, którego wydajność jest kluczowa, pisany jest w C/C++, CUDA czy częściowo w assemblerze, a API wystawiane jest do języka wyższego poziomu za pomocą tzw. *bindings*.
#
# Dlib posiada algorytm wykrywania twarzy oparty o konwolucyjne sieci neuronowe (*Convolutional Neural Networks*), ale nie nadaje się on do pracy w czasie rzeczywistym, dlatego przyjrzymy się innemu - wykrywaniu twarzy za pomocą Histogramu Gradientu Kierunkowego czyli *Histogram of Oriented Gradients*. Algorytm po raz pierwszy został opisany w [patencie](https://patents.google.com/patent/US4567610) z 1986, ale metoda nie zyskała popularności do czasu publikacji pracy [*Histograms of Oriented Gradients for Human Detection*](http://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf) w 2005.
# !pip install dlib
import dlib
dlib_img = frame.copy()
detector = dlib.get_frontal_face_detector()
dlib_img_gray = cv.cvtColor(dlib_img, cv.COLOR_BGR2GRAY)
faces = detector(dlib_img_gray, 1)
for result in faces:
x = result.left()
y = result.top()
x1 = result.right()
y1 = result.bottom()
dlib_img = cv.rectangle(dlib_img, (x, y), (x1, y1), (0, 0, 255), 2)
plt.imshow(cv.cvtColor(dlib_img, cv.COLOR_BGR2RGB))
# ## Multi-task Cascaded Convolutional Networks
#
# MTCCN opublikował po raz pierwszy <NAME> wraz z innymi, w artykule z 2016 pt. [“Joint Face Detection and Alignment Using Multi-task Cascaded Convolutional Networks”](https://arxiv.org/abs/1604.02878). Wykyrwa on nie tylko twarze, ale także 5 kluczowych punktów tzw. *facial landmarks*.
from mtcnn.mtcnn import MTCNN
mtcnn_img = frame.copy()
detector = MTCNN()
faces = detector.detect_faces(mtcnn_img)
for result in faces:
x, y, w, h = result['box']
x1, y1 = x + w, y + h
mtcnn_img = cv.rectangle(mtcnn_img, (x, y), (x1, y1), (0, 0, 255), 2)
plt.imshow(cv.cvtColor(mtcnn_img, cv.COLOR_BGR2RGB))
# ### OpenCV DNN
#
# Stosunkowo niedawno OpenCV otrzymał swój własny moduł głębokiego uczenia. Dołączony model rozpoznawania twarzy, największą dokładność ma na obrazach w formacie BGR, pomniejszonych do rozmiaru 300x300 pikseli.
#
# Wszystkie modele dostępne w module DNN opisane są [tu](https://github.com/opencv/opencv/blob/master/samples/dnn/models.yml).
#
# My będziemy używać 10 warstwowego modelu ResNET, z [opisem](https://github.com/opencv/opencv/blob/master/samples/dnn/face_detector/deploy.prototxt) i [wagami](https://github.com/opencv/opencv_3rdparty/raw/dnn_samples_face_detector_20170830/res10_300x300_ssd_iter_140000.caffemodel).
dnn_img = frame.copy()
net = cv.dnn.readNetFromCaffe("deploy.prototxt", "res10_300x300_ssd_iter_140000.caffemodel")
h, w = dnn_img.shape[:2]
blob = cv.dnn.blobFromImage(cv.resize(dnn_img, (300, 300)), 1.0, (300, 300), (104.0, 117.0, 123.0))
net.setInput(blob)
faces = net.forward()
for i in range(faces.shape[2]):
confidence = faces[0, 0, i, 2]
if confidence > 0.5:
box = faces[0, 0, i, 3:7] * np.array([w, h, w, h])
(x, y, x1, y1) = box.astype("int")
dnn_img = cv.rectangle(dnn_img, (x, y), (x1, y1), (0, 0, 255), 2)
plt.imshow(cv.cvtColor(dnn_img, cv.COLOR_BGR2RGB))
# ### BodyPix
#
# W 2019 roku, Google [wypuściło w świat](https://medium.com/tensorflow/introducing-bodypix-real-time-person-segmentation-in-the-browser-with-tensorflow-js-f1948126c2a0) swój model BodyPix. Nie dość, że potrafi on działać w czasie rzeczywistym, osiągając powyżej 20fps nawet na starszych sprzętach, to wykrywa nie tylko twarz, ale segmentuje całe ciało na aż 24 części!
#
# Używa albo MobileNetV1 albo ResNet50. Różnica między nimi jest głównie w rozmiarze, a co za tym idzie, wymaganiach sprzętowych i szybkości działania.
#
#
# | Architecture | quantBytes=4 | quantBytes=2 | quantBytes=1 |
# |--------------|:------------:|:------------:|:------------:|
# |ResNet50 | ~90MB | ~45MB | ~22MB|
# |MobileNetV1 (1.00) | ~13MB | ~6MB | ~3MB|
# |MobileNetV1 (0.75) | ~5MB | ~2MB | ~1MB|
# |MobileNetV1 (0.50) | ~2MB | ~1MB | ~0.6MB|
#
# Model do ściągnięcia [tu](https://storage.googleapis.com/tfjs-models/savedmodel/bodypix/mobilenet/float/050/model-stride16.json), a wagi [tu](https://storage.googleapis.com/tfjs-models/savedmodel/bodypix/mobilenet/float/050/group1-shard1of1.bin).
#
# !pip install tf_bodypix[all]==0.3.5 tensorflow-gpu==2.4.1 tfjs_graph_converter
import tensorflow as tf
from tf_bodypix.api import load_model
bodypix_model = load_model('mobilenet-float-50-model-stride16.json')
bodypix_img = frame.copy()
result = bodypix_model.predict_single(bodypix_img)
mask = result.get_mask(threshold=0.5).numpy().astype(np.uint8)
masked_image = result.get_colored_part_mask(mask, part_names=['left_face', 'right_face']).astype(np.uint8)
final = cv.addWeighted(bodypix_img, 0.6, masked_image, 0.4, 2.0)
plt.imshow(final)
contours, hierarchy = cv.findContours(cv.cvtColor(masked_image, cv.COLOR_RGB2GRAY), cv.RETR_EXTERNAL, cv.CHAIN_APPROX_NONE)
for contour in contours:
box = cv.boundingRect(contour)
(x, y, w, h) = box
final = cv.rectangle(final, (x, y), (x+w, y+h), (0, 0, 255), 2)
plt.imshow(final)
# #### Podsumowanie
#
# Kaskady Haara są dość przestarzałe i, gdyby zrobić takie porządne porównanie, z różnorodnym zbiorem testowym, to dawałyby najgorsze rezultaty. Dlib nie wykrywa twarzy na obrazkach mniejszych niż 80x80. Można je oczywiście powiększyć, ale to pogorszy jednocześnie wydajność, która nie jest mocną stroną Dliba i raczej nie nadaje się do pracy w czasie rzeczywistym poza komputerami stacjonarnymi. Moduł DNN z OpenCV i MTCNN radzą sobie podobnie, choć ten ostatni lepiej wypada gdy obrazy są duże.
#
# BodyPix wypada równie dobrze, a przy okazji oferuje dużo więcej informacji.
# ## Wirtualne tło
#
# Jednym z przykładów, gdzie ta większa ilość informacji oferowana przez BodyPix może się przydać, to wirtualne tło, albo tzw. *virtual greenscreen*. Mając informację o korpusie postaci i twarzy, możemy jej użyć do usunięcia wszystkiego co znajduje się poza.
#
# W tym celu, załadujmy najpierw obraz, który będzie stanowił nasze tło.
# +
(fh, fw, fc) = frame.shape
background = cv.imread('wawel-noca.jpg')
(bh, bw, bc) = background.shape
dif = bw if bh > bw else bh
fdif = fw if fh > fw else fh
x_pos = (bw - dif)//2
y_pos = (bh - dif)//2
background_mask = np.zeros((dif, dif, bc), dtype=background.dtype)
background_mask[:dif, :dif, :] = background[y_pos:y_pos+dif, x_pos:x_pos+dif, :]
background_squared = cv.resize(background_mask, (int(fdif*2), int(fdif*2)), cv.INTER_CUBIC)
plt.imshow(cv.cvtColor(background_squared, cv.COLOR_BGR2RGB))
# -
# Następnie pobierzemy maskę z BodyPix'a. Maska będzie miała `0` tam gdzie nie ma postaci, oraz `1` tam gdzie BodyPix postać wykrył. Możemy jej użyć do wycięcia postaci z naszej ramki z kamery. Do wymaskowania tła, będziemy musieli wykonać negację maski, a następnie dodamy tło i ramkę do siebie.
# +
(bh, bw, bc) = background_squared.shape
x_pos = (bw - fw)//2
y_pos = (bh - fh)//2
background = background_squared[y_pos:y_pos+fh, x_pos:x_pos+fw,:]
mask = result.get_mask(threshold=0.5).numpy().astype(np.uint8)
masked_image = cv.bitwise_and(frame, frame, mask=mask)
neg = np.add(mask, -1)
inverse = np.where(neg == -1, 1, neg).astype(np.uint8)
masked_background = cv.bitwise_and(background, background, mask=inverse)
final = cv.add(masked_image, masked_background)
plt.imshow(cv.cvtColor(final, cv.COLOR_BGR2RGB))
# -
# ## Żywa kamera
#
# Spróbujmy teraz zrobić to samo, ale zamiast pracować na pojedynczym ujęciu z kamery, nałóżmy to na podgląd na żywo.
cap = cv.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
result = bodypix_model.predict_single(frame)
(bh, bw, bc) = background_squared.shape
x_pos = (bw - fw)//2
y_pos = (bh - fh)//2
background = background_squared[y_pos:y_pos+fh, x_pos:x_pos+fw,:]
mask = result.get_mask(threshold=0.5).numpy().astype(np.uint8)
masked_image = cv.bitwise_and(frame, frame, mask=mask)
neg = np.add(mask, -1)
inverse = np.where(neg == -1, 1, neg).astype(np.uint8)
masked_background = cv.bitwise_and(background, background, mask=inverse)
final = cv.add(masked_image, masked_background)
cv.imshow("Kamera", final)
if cv.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv.destroyAllWindows()
# ## Paralaksa
#
# Kolejną rzeczą którą chciałbym zaproponować, jest efekt tzw. paralaksy. W skrócie polega on na ożywieniu tła za kamerą, tak, że wygląda ono jak trójwymiarowe. Przesuwając twarz, jakby oglądamy je z pod trochę innym kątem.
#
# W tym celu, będziemy śledzić twarz i jej pozycję. Do śledzenia, wybierzemy twarz o największej obwiedni. W rzeczywistości, algorym powinien być bardziej złożony. Przydatne byłoby choćby uchwycenie twarzy, aby w wypadku gdy aktualnie śledzona twarz oddali się i pojawi się kandydat o większej obwiedni, mimo wszystko śledzić dalej poprzednią, unikając widocznego przeskoku.
#
# Dla uchwyconej twarzy, obliczymy jej odchylenie od środka obrazu, żeby odpowiednio przesunąć tło.
#
# +
import functools
cap = cv.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
result = bodypix_model.predict_single(frame)
(bh, bw, bc) = background_squared.shape
mask = result.get_mask(threshold=0.5).numpy().astype(np.uint8)
face_masked_image = result.get_colored_part_mask(mask, part_names=['left_face', 'right_face']).astype(np.uint8)
contours, hierarchy = cv.findContours(cv.cvtColor(face_masked_image, cv.COLOR_RGB2GRAY), cv.RETR_EXTERNAL, cv.CHAIN_APPROX_NONE)
face = functools.reduce(lambda a,b: a if a[2]+a[3] > b[2]+b[3] else b, list(map(lambda a: cv.boundingRect(a), contours)))
x_pos = (bw - fw)//2
y_pos = (bh - fh)//2
if face:
(x, y, w, h) = face
face_x = x+w//2
face_y = y+h//2
x_pos -= int((fw-face_x)*0.25)
y_pos -= int((fh-face_y)*0.25)
background = background_squared[y_pos:y_pos+fh, x_pos:x_pos+fw,:]
masked_image = cv.bitwise_and(frame, frame, mask=mask)
neg = np.add(mask, -1)
inverse = np.where(neg == -1, 1, neg).astype(np.uint8)
masked_background = cv.bitwise_and(background, background, mask=inverse)
final = cv.add(masked_image, masked_background)
if face:
(x, y, w, h) = face
final = cv.rectangle(final, (x, y), (x+w, y+h), (0, 0, 255), 2)
final = cv.circle(final, (x+w//2, y+h//2), 5, (255, 0, 0 ), 4)
cv.imshow("Kamera", final)
if cv.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv.destroyAllWindows()
# -
# ## Podsumowanie
#
# Pierwszą rzeczą którą zuważyliście zapewne uruchamiając przykład jest fakt, że obwiednia twarzy, a co za tym idzie wyliczony środek ciężkości, co ramkę zmienia delikatnie rozmiar. Wpływa to niestety na płynność przesuwania tła. Następnym krokiem, mogłoby być policzenie ważonej średniej ruchomej.
#
# Co jeszcze dalej? Mając powyższe modele, oraz moduł `pyvirtualcam`, możecie choćby spróbować sami zaimplementować swoją własną [Snap Kamerę](https://snapcamera.snapchat.com/).
#
# Owocnej zabawy!
#
# W razie pytań, nie obawiajcie się zagadnąć :) Znaleźć możecie mnie tu:
#
# - https://twitter.com/unjello
# - http://poly.work/unjello
# - https://www.linkedin.com/in/andrzejlichnerowicz/
| Warsztat.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # State Estimation:Induction Motor
# <span style="color:darkorchid">
#
# ### <NAME>
# ### Department of Electrical Engineering, IIT Bombay
#
# </span>
#
# ## Objective
# Given a state space and measurement model of a plant, an Induction Motor in our case, evaluate performance of estimators under noisy conditions
#
# ## State Space Model
#
# Let $X, Z, Y, W, V$ denote the states, input, measurements, model noise and measurement noise respectively, then state space model is given by
#
# $\frac{dX}{dt}=f(X, Z)+W$
#
# $Y=g(X)+V$
#
# Here, $f, g$ are specific to the system, $W$ ~ $N(0, Q)$ and $V$ ~ $N(0, R)$
#
# ### Induction Motor Model
# For our system, dimensions of $X, Z, Y, W, V$ are $5, 3, 2, 5, 2$ respectively and they are related as
#
# <span style="color:Purple">
#
# $\frac{dx_1}{dt}= k_1 x_1 + z_1 x_2+k_2 x_3+z_2$
#
# $\frac{dx_2}{dt}= -z_1x_1+k_1x_2+k_2x_4$
#
# $\frac{dx_3}{dt}= k_3 x_1 + k_4x_3+(z_1-x_5)x_4$
#
# $\frac{dx_4}{dt}= k_3 x_2 - (z_1-x_5)x_3+k_4x_4$
#
# $\frac{dx_5}{dt}= k_5 (x_1x_4-x_2x_3)+k_6z_3$
#
# </span>
#
# <span style="color:maroon">
#
# $y_1=k_7x_1+k_8x_3$
#
# $y_2=k_7x_2+k_8x_4$
#
# </span>
#
# Values of constants
#
#
# | $k_1$ | $k_2$ | $k_3$ | $k_4$ | $k_5$ | $k_6$ | $k_7$ | $k_8$ | $z_1$ | $z_2$ | $z_3$ |
# |--------|---------|---------|---------|---------|---------|---------|---------|---------|---------|---------|
# |-0.186 |0.178 |0.225 |-0.234 |-0.081 |4.643 | -4.448| 1 | 1 | 1 | 0 |
#
#
#
# <span style="color:blue">
#
# $Q=10^{-4}I_{5x5}$ : Model Noise
#
# $R=10^{-2}I_{2x2}$ : Measurement Noise
#
# </span>
#Import Libraries
import numpy as np
import matplotlib.pyplot as plt
from math import *
import random
random.seed(1)
import scipy.linalg as sp
import scipy.stats
# ### Python Model
#
# To implement the model in python, we use Range-Kutta 4th order method for the integration step which has local truncation error of order $O$~$(h^5)$, where $h$ is time step.
#
# A python class "IMotor" with the following attributes x1, x2, x3, x4, x5, k1, k2, k3, k4, k5, k6, k7, k8 denoting the state and constants of the model. The states are initiliased to [0.2, -0.6, -0.4, 0.1, 0.3]
#
# The associated methods of the class are as:
#
# 1. y1 : returns measurement $Y_1$
# 2. y2 : returns measurement $Y_2$
# 3. dxdt: takes in argument z, a vector denoting inputs and returns a 5x1 array $\frac{dX}{dt}$
# 4. setState: takes in argument x, 5x1 array and sets the current state to X
# 5. getState: returns the current state of the system, a 5x1 array
# 6. update: takes in argument delt, z and a boolean noise. Performs Integration step for one time step using RK-4th order method, with time step delt, input z and adds noise if boolen noise is True
# 7. update2: same as update except integration is performed with Euler Method
# 8. linMod: takes in argument Z and returns Jacobian matrices $\frac{\partial f}{\partial X}, \frac{\partial f}{\partial Z}$, which are 5x5 and 5x3 matrices respectively
# 9. meas: takes in bool noise. If noise is true then adds noise and returns measurements $Y_1, Y_2$ as 2x1 array
# 10. linMeas: returns a 2x5 matrice $\frac{\partial g}{\partial X}$
#
class IMotor(object):
def __init__(self):
#States
self.x1 = 0.2
self.x2 = -0.6
self.x3 = -0.4
self.x4 = 0.1
self.x5 = 0.3
#Constants
self.k1 = -0.186
self.k2 = 0.178
self.k3 = 0.225
self.k4 = -0.234
self.k5 = -0.081
self.k6 = 4.643
self.k7 = -4.448
self.k8 = 1
def y1(self):
#return y1
return self.k7*self.x1 + self.k8*self.x3
def y2(self):
#return y2
return self.k7*self.x2 + self.k8*self.x4
def dxdt(self, z):
#compute dx/dt at current X and input z
z1 = z[0]
z2 = z[1]
z3 = z[2]
dx1dt = self.k1*self.x1 + z1*self.x2 + self.k2*self.x3 + z2
dx2dt = -z1*self.x1 + self.k1*self.x2 + self.k2*self.x4
dx3dt = self.k3*self.x1 + self.k4*self.x3 + (z1-self.x5)*self.x4
dx4dt = self.k3*self.x2 - (z1-self.x5)*self.x3 + self.k4*self.x4
dx5dt = self.k5*(self.x1*self.x4-self.x2*self.x3)+self.k6*z3
#return as numpy array
return np.array([dx1dt, dx2dt, dx3dt, dx4dt, dx5dt])
def setState(self, X):
#set current state to X
self.x1 = X[0]
self.x2 = X[1]
self.x3 = X[2]
self.x4 = X[3]
self.x5 = X[4]
def getState(self):
#return the states
return np.array([self.x1, self.x2, self.x3, self.x4, self.x5])
def update(self, delt, z, noise=False):
#Use RK4 method to integrate
#Initialise
h = delt
X0 = self.getState()
#K1 terms
K1 = h*self.dxdt(z)
X1 = X0+K1/2
self.setState(X1)
#K2 terms
K2 = h*self.dxdt(z)
X2 = X0+K2/2
self.setState(X2)
#K3 terms
K3 = h*self.dxdt(z)
X3 = X0+K3
self.setState(X3)
#K4 terms
K4 = h*self.dxdt(z)
X = X0 + K1/6 + K2/3 + K3/3 + K4/6
if noise == True:
#Add noise
R = np.identity(5)*1e-4
X += np.random.multivariate_normal([0, 0, 0, 0, 0], R)
self.setState(X)
def update2(self, delt, z, noise=False):
X = self.getState()
#Euler Interation
X += delt*self.dxdt(Z)
if noise == True:
#Add noise
R = np.identity(5)*1e-4
X += np.random.multivariate_normal([0, 0, 0, 0, 0], R)
self.setState(X)
def linMod(self, Z):
Z1 = Z[0]
Z2 = Z[1]
Z3 = Z[2]
X = self.getState()
X1 = X[0]
X2 = X[1]
X3 = X[2]
X4 = X[3]
X5 = X[4]
#Jacobian df/dX, obtained analytically
a1 = [self.k1, Z1, self.k2, 0, 0]
a2 = [-Z1, self.k1, 0, self.k2, 0]
a3 = [self.k3, 0, self.k4, (Z1-X5), -X4]
a4 = [0, self.k3, -(Z1-X5), self.k4, X3]
a5 = [self.k5*X4, -self.k5*X3, -self.k5*X2, self.k5*X1, 0]
#form a matrice
A = [a1, a2, a3, a4, a5]
A = np.array(A)
#Jacobian df/dZ, obtained analytically
c1 = [X2, 1, 0]
c2 = [-X1, 0, 0]
c3 = [X4, 0, 0]
c4 = [-X3, 0, 0]
c5 = [0, 0, self.k6]
#return as matrice
D = [c1, c2, c3, c4, c5]
D = np.array(D)
return A, D
def meas(self, noise=True):
x = self.getState()
y1 = self.k7*x[0]+self.k8*x[2]
y2 = self.k7*x[1]+self.k8*x[3]
Y = np.array([y1, y2])
if noise:
R = np.identity(2)*1e-2
Y += np.random.multivariate_normal([0, 0], R)
return Y
def linMeas(self):
y1 = [self.k7, 0, self.k8, 0, 0]
y2 = [0, self.k7, 0, self.k8, 0]
C = [y1, y2]
return np.array(C)
# ## Simulation of Motor
#
# Dynamic Input is provided: For first 600 time instants, U=[1, 1, 0], then U=[1.2, 1, 0] for k=600 to k=900, Then U=[0.8, 1, 0] for next 300 instants and U=[1, 1.2, 0] for next 300 instants.
# +
#Simulation Code
a = IMotor() #Create an instance of induction motor
Xall = [] #Store all states
U1 = [] #Input Y1
U2 = [] #Input Y2
Y1 = [] #Measurement Y1
Y2 = [] #Measurement Y2
#Input is [1, 1, 0]
for i in range(0, 600):
#Store Input
U1.append(1)
U2.append(1)
#Perform Update, with noise
a.update(0.1, [U1[i], U2[i], 0], True)
#Store actual states and measurements with noise
X = a.getState()
Xall.append(X)
y = a.meas(True)
Y1.append(y[0])
Y2.append(y[1])
#Input is [1.2, 1, 0]
for i in range(600, 900):
U1.append(1.2)
U2.append(1)
a.update(0.1, [U1[i], U2[i], 0], True)
X = a.getState()
Xall.append(X)
y = a.meas(True)
Y1.append(y[0])
Y2.append(y[1])
#Input is [0.8, 1, 0]
for i in range(900, 1200):
U1.append(0.8)
U2.append(1)
a.update(0.1, [U1[i], U2[i], 0], True)
X = a.getState()
Xall.append(X)
y = a.meas(True)
Y1.append(y[0])
Y2.append(y[1])
#Input is [1, 1.2, 0]
for i in range(1200, 1500):
U1.append(1)
U2.append(1.2)
a.update(0.1, [U1[i], U2[i], 0], True)
X = a.getState()
Xall.append(X)
y = a.meas(True)
Y1.append(y[0])
Y2.append(y[1])
#Convert to numpy as its easier to manipulate and deal with
Xall = np.array(Xall)
#Plot states
#X1
plt.plot(Xall[:, 0], 'violet')
plt.xlabel('Time Step k')
plt.ylabel('$X_1$')
#plt.savefig('X1s.png')
plt.show()
#X2
plt.plot(Xall[:, 1], 'mediumslateblue')
plt.xlabel('Time Step k')
plt.ylabel('$X_2$')
#plt.savefig('X2s.png')
plt.show()
#X3
plt.plot(Xall[:, 2], 'lime')
plt.xlabel('Time Step k')
plt.ylabel('$X_3$')
#plt.savefig('X3s.png')
plt.show()
#X4
plt.plot(Xall[:, 3], 'gold')
plt.xlabel('Time Step k')
plt.ylabel('$X_4$')
#plt.savefig('X4s.png')
plt.show()
#X5
plt.plot(Xall[:, 4], 'yellow')
plt.xlabel('Time Step k')
plt.ylabel('$X_5$')
#plt.savefig('X5s.png')
plt.show()
#Plot Measurementes
#Y1
plt.plot(Y1, 'darkorange')
plt.xlabel('Time Step k')
plt.ylabel('$y_1$')
plt.savefig('Y1.png')
plt.show()
#Y2
plt.plot(Y2, 'firebrick')
plt.xlabel('Time Step k')
plt.ylabel('$y_2$')
plt.savefig('Y2.png')
plt.show()
# -
# ### Helpful Functions
#
# Some functions are developed for use in Kalman Filters
#
# 1. dxdt: takes in X, z and a default parameter t=0, (to make code more generic t is used though in our case dxdt is dependednt only upon input X and z). Returns $f(X, Z)$ for our model without noise
#
# 2. Gx: takes in argument X and returns $Y$ i.e measurement
# +
#dX/dt takes in argument X, Z and returns dX/dt for motor model
def dxdt(X, z, t=0):
k1 = -0.186
k2 = 0.178
k3 = 0.225
k4 = -0.234
k5 = -0.081
k6 = 4.643
z1 = z[0]
z2 = z[1]
z3 = z[2]
x1 = X[0]
x2 = X[1]
x3 = X[2]
x4 = X[3]
x5 = X[4]
dx1dt = k1*x1 + z1*x2 + k2*x3 + z2
dx2dt = -z1*x1 + k1*x2 + k2*x4
dx3dt = k3*x1 + k4*x3 + (z1-x5)*x4
dx4dt = k3*x2 - (z1-x5)*x3 + k4*x4
dx5dt = k5*(x1*x4-x2*x3)+k6*z3
return np.array([dx1dt, dx2dt, dx3dt, dx4dt, dx5dt])
#Returns measurement on State input X
def Gx(X):
x1 = X[0]
x2 = X[1]
x3 = X[2]
x4 = X[3]
k7 = -4.448
k8 = 1
y1 = k7*x1 + k8*x3
y2 = k7*x2 + k8*x4
return np.array([y1, y2])
# -
# 3. IMlin: takes in arguments x, z and returns jacobian matrices $\frac{\partial f}{\partial X}, \frac{\partial f}{\partial Z}$ and $\frac{\partial \Gamma W}{\partial W}$ i.e. identity (in our case $\Gamma$ is identity)
#
# 10. IMeas: takes in x and returns a 2x5 matrice $\frac{\partial g}{\partial X}$. Though in our case this value is independent of x but that may not always be the case
# +
#Returns Jacobian Matrices, df(X, Z)/dX, df(X, Z)/dZ and dW/dW which is identity in our case
def IMlin(x, z):
k1 = -0.186
k2 = 0.178
k3 = 0.225
k4 = -0.23
k5 = -0.081
k6 = 4.643
dx1 = np.array([k1, z[0], k2, 0, 0])
dx2 = np.array([-z[0], k1, 0, k2, 0])
dx3 = np.array([k3, 0, k4, z[0]-x[4], -x[3]])
dx4 = np.array([0, k3, -(z[0]-x[4]), k4, x[2]])
dx5 = np.array([k5*x[3], -k5*x[2], -k5*x[1], k5*x[0], 0])
A = np.array([dx1, dx2, dx3, dx4, dx5])
dz1 = np.array([x[1], 1, 0])
dz2 = np.array([-x[0], 0, 0])
dz3 = np.array([x[3], 0, 0])
dz4 = np.array([-x[2], 0, 0])
dz5 = np.array([0, 0, k6])
B = [dz1, dz2, dz3, dz4, dz5]
B = np.array(B)
C = np.identity(5)
return A, B, C
#Returns the measurement Jacobian i.e dG(X)/dx, actually in our case its constant independent of x
def IMeas(x):
k7 = -4.448
k8 = 1
y1 = np.array([k7, 0, k8, 0, 0])
y2 = np.array([0, k7, 0, k8, 0])
C = [y1, y2]
return np.array(C)
# -
# 5. genSigma: takes in two arguments X and P and computes the sigma points and returns them.
#
# 6. Fx: takes in arguments X, dt and Z. ie current state X, time step and input. It performs integration with RK-4 method and returns new $X(t+dt)$ which is very close to $X(t)+\int_t^{t+dt}f(X(t), Z)$
#
# 7. festimate: takes in Xs (the sigma points as matrice), dt (time step) and input Z and performs the above integration function Fx on each of the sigma points to generate new propagated sigma points.
#
# 8. xPx: takes in Xs, the sigma points matrix and computes the weighted statistics (mean and Variance Matrice) of the points.
#
# 9. gestimate: takes in Xs, the sigma points as matrice and performs the function Gx on each of them. ie. generates measurements and returns them as matrice
#
# 10. yPy: takes in Ys, the sigma points measurement matric and computes its weighted statistics (mean and Variance Matrice)
#
# 11. xPy: takes in two matrices X, Y-the sigma points matric and sigma points measurements mattice and computes the weighted Co-variance matrice
#
# 12. getWeights: takes in M, an integer denoting dimension of the state vector and returns output a weights array.
# +
def genSigma(X, P):
#Given X, P generat
M=len(X)
if M>=3:
K=1
else:
K=3-M
p=sqrt(M+K)
x=np.zeros([M, 2*M+1])
x[:, 0]=X
for i in range(0, M):
a=P[i]
for j in range(0, len(a)):
if a[j]<0:
a[j]=0
x[:, i+1]=X+p*np.sqrt(a)
x[:, i+M+1]=X-p*np.sqrt(a)
return np.array(x)
def Fx(X, dt, Z):
a=IMotor()
a.setState(X)
a.update(dt, Z)
return a.getState()
def festimate(Xs, t, Z):
Xn=np.zeros([5, 11])
for i in range(0, 11):
Xn[:, i]=Fx(Xs[:, i], t, Z)
return Xn
def xPx(X):
W=getWeights(5)
xmean=np.zeros(5)
for i in range(0, 11):
xmean+=W[i]*X[:, i]
P=np.zeros([5, 5])
for i in range(0, 11):
e=X[:, i]-xmean
P+=W[i]*np.outer(e, e)
xmean=np.around(xmean, decimals=12)
P=np.around(P, decimals=12)
return xmean, P
def gestimate(Xs):
Ys=np.zeros([2, 11])
for i in range(11):
Ys[:, i]=Gx(Xs[:, i])
return Ys
def yPy(Y):
W=getWeights(5)
ymean=np.zeros(2)
for i in range(11):
ymean+=W[i]*Y[:, i]
P=np.zeros([2, 2])
for i in range(0, 11):
e=Y[:, i]-ymean
P+=W[i]*np.outer(e, e)
ymean=np.around(ymean, decimals=12)
P=np.around(P, decimals=12)
#P+=R
return ymean, P
def xPy(X, Y):
W=getWeights(5)
xmean=np.zeros(5)
ymean=np.zeros(2)
for i in range(0, 11):
xmean+=W[i]*X[:, i]
ymean+=W[i]*Y[:, i]
C=np.zeros([5, 2])
for i in range(11):
ex=X[:, i]-xmean
ey=Y[:, i]-ymean
C+=W[i]*np.outer(ex, ey)
C=np.around(C, decimals=12)
return C
def getWeights(M):
if M>=3:
K=0.95 #This parameter can be tweaked according to model
else:
K=3-M
W=np.ones(2*M+1)
W=W*(1/2/(K+M))
W[0]=K/(K+M)
return W
# -
# ## Kalman Filter
# First we initialise a dummy motor model i.e. using IMotor and reach a steady state by running it for 500 instants with input [1, 1, 0]. Then we use linMod function to get Jacobian matrices with which we linearise the model about this steady state. Thereafter using the measurements we estimate the states and store them for plotting. We also compute Estimation error, innovation, spectral radii of predicted and updated variance matrices and also normalised mean square error
#
# +
#A dummy motor named S
S=IMotor()
for i in range(500):
S.update(0.1, [1, 1, 0]) # Running the motor, actually quite literally here :)
Xsteady=S.getState() #Obtain the steady state
A, B=a.linMod([1, 1, 0]) #Jacobian matrices
Phi=np.identity(5)+A*0.1 #Phi
Tau=0.1*B #delta T times B
C=IMeas(0) #dg/dx
Qd=np.identity(5)*1e-4 #variance matrice of model noise
R=np.identity(2)*1e-2 #variance matrice of measurement noise
xest=S.getState() #Initial estimate, taken as steady state value
Pest=np.identity(5) #Initial estimate of co-varaiunce
Xstore=[] #Store all the estimated states
Ey=[] #Innovation
Ex=[] #Actual Error
Bk=[] #Bk
Rp=[] #Spectral Radii-Predicted
Ru=[] #Spectral Radii-Updated
E=[]
T=0.1 #Time Step
for i in range(0, 1500):
#Model Propagation
xest+=T*dxdt(xest, [U1[i], U2[i], 0])
Pest=np.linalg.multi_dot([Phi, Pest, np.transpose(Phi)])+Qd
#Spectral Radius of predicted variance
Gara, dump=np.linalg.eig(Pest)
Rp.append(max(Gara))
#Compute Kalman Gain Matrix
t1=np.linalg.multi_dot([C, Pest, np.transpose(C)])+R
t1=np.linalg.inv(t1)
L=np.linalg.multi_dot([Pest, np.transpose(C), t1])
#Compute Innovation
Y=np.array([Y1[i], Y2[i]])
e=Y-np.dot(C, xest)
Ey.append(e)
#Update Estimates
xest=xest+np.dot(L, e)
t1=np.identity(5)-np.dot(L, C)
Pest=np.dot(t1, Pest)
#Spectral Radius of Updated Variance
Gara, dump=np.linalg.eig(Pest)
Ru.append(max(Gara))
#Storing estimated results
Xstore.append(xest)
ex=Xall[i]-xest
Ex.append(ex)
Pinverse=sp.inv(Pest)
#Normalised Mean Square Error
bk=np.dot(ex, np.dot(Pinverse, ex))
Bk.append(bk)
# -
#KF Data Storings
Xstorekf=np.array(Xstore)
Exkf=np.array(Ex)
Eykf=np.array(Ey)
Rpkf=np.array(Rp)
Rukf=np.array(Ru)
Bkkf=np.array(Bk)
# ## Extended Kalman Filter
#
# Instead of linearising about steady point, we linearise about current state estimate
# +
x=np.array([0.2, -0.6, -0.4, 0.1, 0.3]) #initial estimate of state
P=np.identity(5) #initial estimate of variance
Qd=np.identity(5)*1e-4 #model uncertainity variance
R=np.identity(2)*1e-2 #measurement uncertainity variance
T=0.1 #Time Step
Xstore=[] #All estimated data
Ey=[] #Innovation
Ex=[] #Actual Error
Bk=[] #Bk
Rp=[] #Spectral Radii-Predicted
Ru=[] #Spectral Radii-Updated
for i in range(0, 1500):
Z=[U1[i], U2[i], 0]
#Form the linear model
A, dump, B=IMlin(x0, Z)
Phi=sp.expm(A*T)
Tau=np.linalg.multi_dot([Phi-np.identity(5), np.linalg.inv(A), B])
#Prediction
x+=T*dxdt(x, Z)
P=np.linalg.multi_dot([Phi, P, np.transpose(Phi)])+np.linalg.multi_dot([Tau, Qd, np.transpose(Tau)])
#Spectral Radius of Predicted Variance
Gara, dump=np.linalg.eig(P)
Rp.append(max(Gara))
#Kalman Gain Matrix
C=IMeas(x)
t1=np.linalg.multi_dot([C, P, np.transpose(C)])+R
t2=np.linalg.inv(t1)
L=np.linalg.multi_dot([P, np.transpose(C), t2])
#Update Step
Y=[Y1[i], Y2[i]]
e=np.array(Y)-Gx(x)
Ey.append(e)
x+=np.dot(L, e)
P=np.dot(np.identity(5)-np.dot(L, C), P)
#Store data for plotting
Xstore.append(list(x))
ex=Xall[i]-x
Ex.append(ex)
#Normalised Mean Square Error
Pinverse=sp.inv(P)
bk=np.dot(ex, np.dot(Pinverse, ex))
Bk.append(bk)
#Spectral Radius of Updated Variance
Gara, dump=np.linalg.eig(P)
Ru.append(max(Gara))
# -
#Store EKF Values
Xstoreekf = np.array(Xstore)
Exekf = np.array(Ex)
Eyekf = np.array(Ey)
Rpekf = np.array(Rp)
Ruekf = np.array(Ru)
Bkekf = np.array(Bk)
# ## Unscented Kalman Filter
#
# We use the 'helpful functions' in our algorithm. First generate sigma points based on current state and variance estimate, then propagate the points through the model, then compute new statistics i.e. mean and new variance (predicted variance) and compute new sigma points. Obtain measurements from measurement model to generate sigma points of measurements. Then compute the new statistics from sigma measurements to get Kalman Gain and innovation
# +
#Same symbols with usual meaning
X = np.zeros(5)
P = np.identity(5)
Q = np.identity(5)*1e-4
R = np.identity(2)*1e-2
Xstore = [] #All estimated data
Ey = [] #Innovation
Ex = [] #Actual Error
Bk = [] #Bk
Rp = [] #Spectral Radii-Predicted
Ru = [] #Spectral Radii-Updated
for i in range(0, len(U1)):
#Obtain the input for this time step and sigma points from current estimated X and P
Z = np.array([U1[i], U2[i], 0])
Xs = genSigma(X, P)
#Propagate the sigma points throught the model and obtain stats
Xn = festimate(Xs, T, Z)
X, P = xPx(Xn)
#Obtain spectral Radius of Predicted variance
Gara, dump = np.linalg.eig(P)
Rp.append(max(Gara))
#generate new sigma points from propagated model
Xin = genSigma(X, P)
#Generate measurement sigma points and their stats
Ys = gestimate(Xin)
Y, Py = yPy(Ys)
Py += R
#Compute Kalman Gain
c = xPy(Xin, Ys)
Pyi = sp.inv(Py)
L = np.dot(c, Pyi)
y = np.array([Y1[i], Y2[i]])
e =y-Y
Ey.append(e)
#Update Step
X = X+np.dot(L, e)
P = P-np.linalg.multi_dot([L, Py, np.transpose(L)])+Q
Xstore.append(X)
ex = Xall[i]-X
Ex.append(ex)
#Commpute Normalised Mean Square Error
Pinverse = sp.inv(P)
bk = abs(np.dot(np.transpose(ex), np.dot(Pinverse, ex)))
Bk.append(bk)
#Compute spectral radius of updated variance
Gara, dump = np.linalg.eig(P)
Ru.append(max(Gara))
# -
#Store UKF Values
Xstoreukf = np.array(Xstore)
Exukf = np.array(Ex)
Eyukf = np.array(Ey)
Rpukf = np.array(Rp)
Ruukf = np.array(Ru)
Bkukf = np.array(Bk)
# ## Plot Results
#
# First Plot all the States and their estimates from all three filters
# +
plt.plot(Xall[:, 0])
plt.plot(Xstorekf[:, 0])
plt.plot(Xstoreekf[:, 0])
plt.plot(Xstoreukf[:, 0])
plt.ylabel('Estimated $X_1$')
plt.xlabel('Time Step')
plt.legend(['True Value', 'Kalman Filer', 'Extended Kalman Filter', 'Unsendted Kalman Filter'])
plt.savefig('x1.png')
plt.show()
plt.plot(Xall[:, 1])
plt.plot(Xstorekf[:, 1])
plt.plot(Xstoreekf[:, 1])
plt.plot(Xstoreukf[:, 1])
plt.ylabel('Estimated $X_2$')
plt.xlabel('Time Step')
plt.legend(['True Value', 'Kalman Filer', 'Extended Kalman Filter', 'Unscented Kalman Filter'])
plt.savefig('x2.png')
plt.show()
plt.plot(Xall[:, 2])
plt.plot(Xstorekf[:, 2])
plt.plot(Xstoreekf[:, 2])
plt.plot(Xstoreukf[:, 2])
plt.ylabel('Estimated $X_3$')
plt.xlabel('Time Step')
plt.legend(['True Value', 'Kalman Filer', 'Extended Kalman Filter', 'Unsendted Kalman Filter'])
plt.savefig('x3.png')
plt.show()
plt.plot(Xall[:, 3])
plt.plot(Xstorekf[:, 3])
plt.plot(Xstoreekf[:, 3])
plt.plot(Xstoreukf[:, 3])
plt.ylabel('Estimated $X_4$')
plt.xlabel('Time Step')
plt.legend(['True Value', 'Kalman Filer', 'Extended Kalman Filter', 'Unsendted Kalman Filter'])
plt.savefig('x4.png')
plt.show()
plt.plot(Xall[:, 4])
plt.plot(Xstorekf[:, 4])
plt.plot(Xstoreekf[:, 4])
plt.plot(Xstoreukf[:, 4])
plt.ylabel('Estimated $X_5$')
plt.xlabel('Time Step')
plt.legend(['True Value', 'Kalman Filer', 'Extended Kalman Filter', 'Unscented Kalman Filter'])
plt.savefig('x5.png')
plt.show()
# -
# Now, Plot the innovations i.e. Measurement vs Predicted Measurement
# +
plt.plot(Eykf[:500, 0])
plt.plot(Eyekf[:500, 0])
plt.plot(Eyukf[:500, 0])
plt.ylabel('Estimated $e_1(k)$')
plt.xlabel('Time Step $k$')
plt.legend(['Kalman Filer', 'Extended Kalman Filter', 'Unscented Kalman Filter'])
plt.savefig('e1y.png')
plt.show()
plt.plot(Eykf[:500, 1])
plt.plot(Eyekf[:500, 1])
plt.plot(Eyukf[:500, 1])
plt.ylabel('Estimated $e_2(k)$')
plt.xlabel('Time Step $k$')
plt.legend(['Kalman Filer', 'Extended Kalman Filter', 'Unscented Kalman Filter'])
plt.savefig('e2y.png')
plt.show()
# -
# Plot the Spectral Radii for all the three filters
# +
plt.plot(Rpkf[:50])
plt.plot(Rukf[:50])
plt.xlabel('Time Step k')
plt.ylabel('Spectral Radius')
plt.legend(['Predicted', 'Updated'])
plt.title('Kalman Filter Spectral Radius')
plt.savefig('srkf.png')
plt.show()
plt.plot(Rpekf[:50])
plt.plot(Ruekf[:50])
plt.xlabel('Time Step k')
plt.ylabel('Spectral Radius')
plt.legend(['Predicted', 'Updated'])
plt.title('Extended Kalman Filter Spectral Radius')
plt.savefig('srekf.png')
plt.show()
plt.plot(Rpukf[:50])
plt.plot(Ruukf[:50])
plt.xlabel('Time Step k')
plt.ylabel('Spectral Radius')
plt.legend(['Predicted', 'Updated'])
plt.title('Unscented Kalman Filter Spectral Radius')
plt.savefig('srukf.png')
plt.show()
# -
# Plot the Estimation Errors of states from time instant 500 onwards, along with their $\pm 3 \sigma$ (std deviations)
# +
n=500
plt.plot(Exkf[:n, 0], 'b')
plt.plot(Exekf[:n, 0], 'r')
plt.plot(Exukf[:n, 0], 'g')
dkf=np.std(Exkf[:, 0])
mkf=np.average(Exkf[:, 0])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'b-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'b-', lw=2)
dkf=np.std(Exekf[:, 0])
mkf=np.average(Exekf[:, 0])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'r-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'r-', lw=2)
dkf=np.std(Exukf[:, 0])
mkf=np.average(Exukf[:, 0])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'g-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'g-', lw=2)
plt.xlabel('Time Step k')
plt.ylabel('$\epsilon_1(k|k)$')
plt.legend(['Kalman Filer','Extended Kalman Filter', 'Unsendted Kalman Filter'])
plt.savefig('ex1.png')
plt.show()
plt.plot(Exkf[:n, 1], 'b')
plt.plot(Exekf[:n, 1], 'r')
plt.plot(Exukf[:n, 1], 'g')
dkf=np.std(Exkf[:, 1])
mkf=np.average(Exkf[:, 1])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'b-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'b-', lw=2)
dkf=np.std(Exekf[:, 1])
mkf=np.average(Exekf[:, 1])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'r-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'r-', lw=2)
dkf=np.std(Exukf[:, 1])
mkf=np.average(Exukf[:, 1])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'g-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'g-', lw=2)
plt.xlabel('Time Step k')
plt.ylabel('$\epsilon_2(k|k)$')
plt.legend(['Kalman Filer','Extended Kalman Filter', 'Unsendted Kalman Filter'])
plt.savefig('ex2.png')
plt.show()
plt.plot(Exkf[:n, 2], 'b')
plt.plot(Exekf[:n, 2], 'r')
plt.plot(Exukf[:n, 2], 'g')
dkf=np.std(Exkf[:, 2])
mkf=np.average(Exkf[:, 2])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'b-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'b-', lw=2)
dkf=np.std(Exekf[:, 2])
mkf=np.average(Exekf[:, 2])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'r-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'r-', lw=2)
dkf=np.std(Exukf[:, 2])
mkf=np.average(Exukf[:, 2])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'g-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'g-', lw=2)
plt.xlabel('Time Step k')
plt.ylabel('$\epsilon_3(k|k)$')
plt.legend(['Kalman Filer','Extended Kalman Filter', 'Unsendted Kalman Filter'])
plt.savefig('ex3.png')
plt.show()
plt.plot(Exkf[:n, 3], 'b')
plt.plot(Exekf[:n, 3], 'r')
plt.plot(Exukf[:n, 3], 'g')
dkf=np.std(Exkf[:, 3])
mkf=np.average(Exkf[:, 3])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'b-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'b-', lw=2)
dkf=np.std(Exekf[:, 3])
mkf=np.average(Exekf[:, 3])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'r-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'r-', lw=2)
dkf=np.std(Exukf[:, 3])
mkf=np.average(Exukf[:, 3])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'g-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'g-', lw=2)
plt.xlabel('Time Step k')
plt.ylabel('$\epsilon_4(k|k)$')
plt.legend(['Kalman Filer','Extended Kalman Filter', 'Unsendted Kalman Filter'])
plt.savefig('ex4.png')
plt.show()
plt.plot(Exkf[:n, 4], 'b')
plt.plot(Exekf[:n, 4], 'r')
plt.plot(Exukf[:n, 4], 'g')
dkf=np.std(Exkf[:, 4])
mkf=np.average(Exkf[:, 4])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'b-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'b-', lw=2)
dkf=np.std(Exekf[:, 4])
mkf=np.average(Exekf[:, 4])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'r-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'r-', lw=2)
dkf=np.std(Exukf[:, 4])
mkf=np.average(Exukf[:, 4])
plt.plot([0, n], [mkf-3*dkf, mkf-3*dkf], 'g-', lw=2)
plt.plot([0, n], [mkf+3*dkf, mkf+3*dkf], 'g-', lw=2)
plt.xlabel('Time Step k')
plt.ylabel('$\epsilon_5(k|k)$')
plt.legend(['Kalman Filer','Extended Kalman Filter', 'Unsendted Kalman Filter'])
plt.savefig('ex5.png')
plt.show()
# -
# Print the average Innovation errors and Standard Deviations
print('Average Ey1 KF:'+str(np.average(Eykf[:, 0])))
print('Average Ey2 KF:'+str(np.average(Eykf[:, 1])))
print('Average Ey1 EKF:'+str(np.average(Eyekf[:, 0])))
print('Average Ey2 EKF:'+str(np.average(Eyekf[:, 1])))
print('Average Ey1 UKF:'+str(np.average(Eyukf[:, 0])))
print('Average Ey2 UKF:'+str(np.average(Eyukf[:, 1])))
print()
print('Std Ey1 KF:'+str(np.std(Eykf[:, 0])))
print('Std Ey2 KF:'+str(np.std(Eykf[:, 1])))
print('Std Ey1 EKF:'+str(np.std(Eyekf[:, 0])))
print('Std Ey2 EKF:'+str(np.std(Eyekf[:, 1])))
print('Std Ey1 UKF:'+str(np.std(Eyukf[:, 0])))
print('Std Ey2 UKF:'+str(np.std(Eyukf[:, 1])))
# Print the RMS eestimation errors and standard deviations
def RMSp(E):
s=0
xm=np.average(X)
for i in E:
s+=i**2
s=s/len(E)
return sqrt(s)
print('For KF')
print('For X1 '+str(RMSp(Exkf[:, 0])))
print('For X2 '+str(RMSp(Exkf[:, 1])))
print('For X3 '+str(RMSp(Exkf[:, 2])))
print('For X4 '+str(RMSp(Exkf[:, 3])))
print('For X5 '+str(RMSp(Exkf[:, 4])))
print()
print('For EKF')
print('For X1 '+str(RMSp(Exekf[:, 0])))
print('For X2 '+str(RMSp(Exekf[:, 1])))
print('For X3 '+str(RMSp(Exekf[:, 2])))
print('For X4 '+str(RMSp(Exekf[:, 3])))
print('For X5 '+str(RMSp(Exekf[:, 4])))
print()
print('For UKF')
print('For X1 '+str(RMSp(Exukf[:, 0])))
print('For X2 '+str(RMSp(Exukf[:, 1])))
print('For X3 '+str(RMSp(Exukf[:, 2])))
print('For X4 '+str(RMSp(Exukf[:, 3])))
print('For X5 '+str(RMSp(Exukf[:, 4])))
# Lets see the significance level of filters
#
# First we have the normalised estimation error squared for each filter stored as 'Bkkf', 'Bkekf' and 'Bkukf' for Kalman, EK and UK filters repectively. Let $\zeta_1, \zeta_2$ be threshold derived from chi-aquared density with n degrees of freedom (n=5) and $\alpha=0.05$ (the significance level)
c1 = scipy.stats.chi2.ppf(0.05, df=5)
c2 = scipy.stats.chi2.ppf(0.95, df=5)
# A function PA that takes in Bk an array and computes the fraction of values in Bk within the range $[\zeta_1, \zeta_2]$
# +
def PA(Bk):
n = 0
for i in Bk:
if c1>=i or i>=c2:
n+=1
return n/len(Bk)
plt.plot(Bkkf)
plt.plot(Bkekf)
plt.plot(Bkukf)
plt.plot([0, 1500], [c1, c1], '-g')
plt.plot([0, 1500], [c2, c2], '-y')
plt.xlabel('Time Instant k')
plt.ylabel('$\\beta_k$')
plt.legend(['Kalman Filter', 'Extended Kalman Filter', 'Unscented Kalman Filter'])
plt.savefig('Allbk.png')
plt.show()
plt.plot(Bkkf)
plt.xlabel('Time Instant k')
plt.ylabel('$\\beta_k$')
plt.title('Kalman Filter')
plt.plot([0, 1500], [c1, c1], '-g')
plt.plot([0, 1500], [c2, c2], '-y')
plt.savefig('kfbk.png')
plt.show()
plt.plot(Bkekf)
plt.xlabel('Time Instant k')
plt.ylabel('$\\beta_k$')
plt.title('Extended Kalman Filter')
plt.plot([0, 1500], [c1, c1], '-g')
plt.plot([0, 1500], [c2, c2], '-y')
plt.savefig('ekfbk.png')
plt.show()
plt.plot(Bkukf[500:])
plt.xlabel('Time Instant k')
plt.ylabel('$\\beta_k$')
plt.title('Unscented Kalman Filter')
plt.plot([0, 1000], [c1, c1], '-g')
plt.plot([0, 1000], [c2, c2], '-y')
plt.savefig('ukfbk.png')
plt.show()
# -
print('For KF, fraction not in limits is '+str(PA(Bkkf)))
print('For EKF, fraction not in limits is '+str(PA(Bkekf)))
print('For UKF, fraction not in limits is '+str(PA(Bkukf)))
print('For KF in steady state, fraction not in limits is '+str(PA(Bkkf[500:])))
print('For EKF in steady state, fraction not in limits is '+str(PA(Bkekf[500:])))
print('For UKF in steady state, fraction not in limits is '+str(PA(Bkukf[500:])))
| GitIMKF.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="7VXiHLhLElJB"
# # Exercise 1: Try Linear Regression just using numpy (Without Tensorflow/Pytorch or other torch library).
# + id="WxOmdPTLElJC"
import numpy as np
# + id="R3CfqQEtElJF"
# Input (temp, rainfall, humidity)
inputs = np.array([[73, 67, 43],
[91, 88, 64],
[87, 134, 58],
[102, 43, 37],
[69, 96, 70]], dtype='float32')
# + id="L47a5poHElJI"
# Target (apples)
targets = np.array([[56],
[81],
[119],
[22],
[103]], dtype='float32')
# + id="6WuudXcAElJK" colab={"base_uri": "https://localhost:8080/", "height": 199} outputId="f1d52e62-883d-4347-cb12-bc20b33469c5"
print("Inputs:",inputs)
print("Targets:",targets)
# + id="wXxnkHQoElJN" colab={"base_uri": "https://localhost:8080/", "height": 54} outputId="8d674ff8-d6c3-4869-df2e-2b69518eb204"
from numpy import random
w = random.rand(1, 3)
b=random.rand(1,1)
print(w)
print(b)
# + id="FmiFhxOoElJP"
# Define the model
# @=FOR DOT PRODUCT
def model(x):
return x @ w.transpose()+b
# + id="m2IqV9WgElJS" colab={"base_uri": "https://localhost:8080/", "height": 108} outputId="7ff5c34d-36b6-4f4a-8066-10e0653c2ea0"
# Generate predictions
pred=model(inputs)
print(pred)
# + id="oH2b7i8kElJU" colab={"base_uri": "https://localhost:8080/", "height": 108} outputId="8eaf659c-79c4-441f-9103-9262dabd6f87"
# Compare with targets
print(targets)
# + [markdown] id="fYrCGoMjElJY"
# ## Loss Function
#
# We can compare the predictions with the actual targets, using the following method:
# * Calculate the difference between the two matrices (`preds` and `targets`).
# * Square all elements of the difference matrix to remove negative values.
# * Calculate the average of the elements in the resulting matrix.
#
# The result is a single number, known as the **mean squared error** (MSE).
# + id="Qz1Q4GbOElJZ"
# MSE loss
def mse(t1,t2):
diff=(t1-t2)**2
_sum_=np.sum(diff)
return _sum_/diff.size
# + id="Xuj-u6GTElJb" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="88820474-82b4-4baf-b327-e9faf9d87d38"
# Compute loss
loss=mse(pred,targets)
print(loss)
l_rate=1e-4
# + [markdown] id="nMAqW4hCElJd"
# ## Gradient Descent Algorithm
# + id="KNFmmIVZElJd"
def grad_desc(w,b):
m=len(targets)
b_de=(l_rate * ((1/m) * np.sum(model(inputs) - targets)))
for i in range(len(w)):
w_de=(l_rate * ((1/m) * np.sum(model(inputs) - targets)))
return w_de,b_de
# + [markdown] id="ombsStQrElJg"
# ## Training for 200 epochs
# + id="IhOGUsFVElJg"
# Train for 200 epochs
for i in range(200):
pred=model(inputs)
loss=mse(pred,targets)
w_de,b_de=grad_desc(w,b)
w=w-w_de
b=b-b_de
# + id="KU7-7pf0ElJi" colab={"base_uri": "https://localhost:8080/", "height": 108} outputId="bede70ae-6675-4327-a01a-65f3d774be82"
print(model(inputs))
# + id="RdaUfLGUElJk" colab={"base_uri": "https://localhost:8080/", "height": 108} outputId="4f351a73-93e3-4cdb-bc84-96377a359484"
print(targets)
# + id="80VUx85VElJm" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="92b1d33d-fd5d-45cc-9b85-1d61105eff13"
loss=mse(pred,targets)
print(loss)
# + id="dia_xO8DElJq"
| CE019_Lab5/019_lab5_linear_regression.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# ---
# Most examples work across multiple plotting backends, this example is also available for:
#
# * [Bokeh - boxplot_chart](../bokeh/boxplot_chart.ipynb)
import holoviews as hv
hv.extension('matplotlib')
hv.output(fig='svg')
# ## Declaring data
# +
from bokeh.sampledata.autompg import autompg as df
title = "MPG by Cylinders and Data Source, Colored by Cylinders"
boxwhisker = hv.BoxWhisker(df, ['cyl', 'origin'], 'mpg', label=title)
# -
# ## Plot
boxwhisker.opts(bgcolor='white', aspect=2, fig_size=200)
| examples/gallery/demos/matplotlib/boxplot_chart.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.7.4 64-bit
# name: python374jvsc74a57bd07945e9a82d7512fbf96246d9bbc29cd2f106c1a4a9cf54c9563dadf10f2237d4
# ---
# # Tips **
# ### Step 1. Import the necessary libraries:
# +
# print the graphs in the notebook
% matplotlib inline
# set seaborn style to white
sns.set_style("white")
# -
from matplotlib.pyplot import *
import scipy.stats as stats
import seaborn as sns
sns.set_context('notebook')
sns.set_style('darkgrid')
import pandas as pd
# ### Step 2. Import the dataset from this [address](https://raw.githubusercontent.com/guipsamora/pandas_exercises/master/07_Visualization/Tips/tips.csv).
# ### Step 3. Assign it to a variable called tips
# +
tips = pd.read_csv("https://raw.githubusercontent.com/guipsamora/pandas_exercises/master/07_Visualization/Tips/tips.csv",sep = ",")
tips
# -
# ### Step 4. Delete the Unnamed 0 column
tips.columns = tips.columns.str.replace(' ', '_')
tips
tips = tips.drop("Unnamed:_0", axis="columns")
tips
# ### Step 5. Plot the total_bill column histogram
sns.histplot(x = "total_bill",data = tips,kde = True)
# ### Step 6. Create a scatter plot presenting the relationship between total_bill and tip
sns.scatterplot(x = "total_bill", y = "tip", data = tips)
# ### Step 7. Create one image with the relationship of `total_bill`, `tip` and `size`.
# #### Hint: It is just one function.
gra = sns.PairGrid(data = tips)
gra.map_diag(sns.histplot)
gra.map_offdiag(sns.scatterplot)
# ### Step 8. Present the relationship between days and total_bill value
sns.catplot(x = "day", y = "total_bill", data = tips)
# ### Step 9. Create a scatter plot with the day as the y-axis and tip as the x-axis, differ the dots by sex
sns.scatterplot(x = "tip", y = "day", data = tips,hue = "sex",)
# ### Step 10. Create a box plot presenting the total_bill per day differetiation the time (Dinner or Lunch)
sns.boxplot(x = "size", y = "tip", data = tips)
# ### Step 11. Create two histograms of the tip value based for Dinner and Lunch. They must be side by side.
gra1 = sns.FacetGrid(tips, col="time")
gra1.map(sns.histplot, "tip")
# ### Step 12. Create two scatterplots graphs, one for Male and another for Female, presenting the total_bill value and tip relationship, differing by smoker or no smoker
# ### They must be side by side.
gra2 = sns.FacetGrid(tips, col="sex",hue="smoker")
gra2.map(sns.scatterplot, "total_bill", "tip")
| week6_EDA_streamlit/day2_ds_presentation_flask_individual_project/visualizacion/Tips_viz.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Lecture 4-2
# ## Loading data from file
#
import tensorflow as tf
import numpy as np
xy = np.loadtxt('data-01-test-score.csv', delimiter=',', dtype="float32")
# +
# Slicing
x_data = xy[:,0:3] # xy[:,:-1] xy[:,0:-1]
y_data = xy[:,[-1]]
#print(x_data.shape, x_data, len(x_data))
#print(y_data.shape, y_data, len(y_data))
# +
tf.set_random_seed(777) # for reproducibility
X = tf.placeholder("float32", shape=[None, 3])
Y = tf.placeholder("float32", shape=[None, 1])
W = tf.Variable(tf.random_normal([3, 1]), name = "weight")
b = tf.Variable(tf.random_normal([1]), name = 'bias')
hypothesis = tf.matmul(X,W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(2001):
hy_var, cost_var, _ = sess.run([hypothesis, cost, train],
feed_dict = {X: x_data, Y: y_data})
if step % 10 == 0:
print(step, "Cost: ",cost_var,"\nPrediction:\n",hy_var)
# +
# Ask my score
print("Your score will be ", sess.run(hypothesis,
feed_dict={X:[[100, 70, 101]]}))
print("Other scores will be ", sess.run(hypothesis,
feed_dict={X:[[60, 70, 88], [100, 70, 101]]}))
# -
| Lecture4-2 Loading data from file.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="2Xi0CMM2clAj"
# Importing the Dependencies
# + id="6PbZXKDQZEWJ"
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from xgboost import XGBRegressor
from sklearn import metrics
# + [markdown] id="rcfuz4bXdg1I"
# Data Collection & Processing
# + id="455T_ehLc9LM"
# loading the data from csv file to a Pandas DataFrame
calories = pd.read_csv('/content/calories.csv')
# + colab={"base_uri": "https://localhost:8080/", "height": 206} id="afZUOcwbemJc" outputId="f87a3cab-6d3f-40d0-e0d4-b25e7adcf5b6"
# print the first 5 rows of the dataframe
calories.head()
# + id="alQtMyM6etdl"
exercise_data = pd.read_csv('/content/exercise.csv')
# + colab={"base_uri": "https://localhost:8080/", "height": 206} id="5lA2LmJUe3kA" outputId="6b23b059-a42a-4285-e118-63df6015745c"
exercise_data.head()
# + [markdown] id="Iid8PMjmfqvX"
# Combining the two Dataframes
# + id="kAHQrky8e6VP"
calories_data = pd.concat([exercise_data, calories['Calories']], axis=1)
# + colab={"base_uri": "https://localhost:8080/", "height": 206} id="RO-DGhIdgPrG" outputId="9f657249-c0df-4bb2-b679-98e299697aaf"
calories_data.head()
# + colab={"base_uri": "https://localhost:8080/"} id="kB0hwwMHgS7x" outputId="aa70d65a-416b-4178-f659-99ed4d84301c"
# checking the number of rows and columns
calories_data.shape
# + colab={"base_uri": "https://localhost:8080/"} id="siYE6fU7gbi3" outputId="005d2ecb-0bef-4fe1-a801-606c7b53011c"
# getting some informations about the data
calories_data.info()
# + colab={"base_uri": "https://localhost:8080/"} id="XhKisO0pgwXd" outputId="4ecb312d-1a26-4015-d24a-a5cf3c45501e"
# checking for missing values
calories_data.isnull().sum()
# + [markdown] id="oY-QcmsVhSBV"
# Data Analysis
# + colab={"base_uri": "https://localhost:8080/", "height": 300} id="95cmeAWZhFa4" outputId="5907ee40-2b63-403a-c5fb-dc5c7e03d9d2"
# get some statistical measures about the data
calories_data.describe()
# + [markdown] id="0t8EoEUaiHeZ"
# Data Visualization
# + id="xU4y4ZsIhiKE"
sns.set()
# + colab={"base_uri": "https://localhost:8080/", "height": 357} id="MuzLivXSiMwi" outputId="2ddbc0ef-9a27-4149-d56b-f14151c54937"
# plotting the gender column in count plot
sns.countplot(calories_data['Gender'])
# + colab={"base_uri": "https://localhost:8080/", "height": 357} id="UhcoOmdRihmk" outputId="e90cd7c4-078a-4516-9b0e-d605084c65e0"
# finding the distribution of "Age" column
sns.distplot(calories_data['Age'])
# + [markdown] id="CjbuwRPDk0jT"
# Distribution plot for Heart Rate
# + colab={"base_uri": "https://localhost:8080/", "height": 357} id="CpgQf5wLk_tz" outputId="7010728a-876b-4377-cb08-d1ebdc7e5625"
sns.distplot(calories_data['Heart_Rate'])
# + [markdown] id="gkCeXaL0lLwi"
# Distribution plot for Body temp.
# + colab={"base_uri": "https://localhost:8080/", "height": 357} id="xTASy8UalSvL" outputId="e7ba7681-8190-44c0-83d0-95ea04e246dd"
sns.distplot(calories_data['Body_Temp'])
# + colab={"base_uri": "https://localhost:8080/", "height": 357} id="FZDTaUmfjBzk" outputId="85a265d0-5fa2-4d25-ba83-e2e67fedff39"
# finding the distribution of "Height" column
sns.distplot(calories_data['Height'])
# + colab={"base_uri": "https://localhost:8080/", "height": 358} id="PdYeSvs5mNWz" outputId="c6d31ace-527e-4136-a27f-1a3c9f876ca0"
#distribution for Duration column
sns.distplot(calories_data['Duration'])
# + colab={"base_uri": "https://localhost:8080/", "height": 357} id="JhP8EIrqjV_e" outputId="97e79351-0f0e-4874-92d8-e7b074498546"
# finding the distribution of "Weight" column
sns.distplot(calories_data['Weight'])
# + [markdown] id="N9TJtsGnjrZs"
# Finding the Correlation in the dataset
# + [markdown] id="f6cFMyI3jzPb"
# 1. Positive Correlation
# 2. Negative Correlation
# + id="2UFA5ZOujfbh"
correlation = calories_data.corr()
# + colab={"base_uri": "https://localhost:8080/", "height": 619} id="dtp36oCBjyQI" outputId="95d6d56d-e647-4b9b-d90d-e95f706bf46a"
# constructing a heatmap to understand the correlation
plt.figure(figsize=(10,10))
sns.heatmap(correlation, cbar=True, square=True, fmt='.1f', annot=True, annot_kws={'size':8}, cmap='Blues')
# + [markdown] id="PNxKhdn_lxOC"
# Converting the text data to numerical values
# + id="lvlWPvd_k2hw"
calories_data.replace({"Gender":{'male':0,'female':1}}, inplace=True)
# + colab={"base_uri": "https://localhost:8080/", "height": 206} id="Co_h1CUZmMB0" outputId="b1df5074-9d2f-410a-bde6-aedb66ac01ec"
calories_data.head()
# + [markdown] id="zDrUQynrm5OZ"
# Separating features and Target
# + id="yNX7qV5dmh-o"
X = calories_data.drop(columns=['User_ID','Calories'], axis=1)
Y = calories_data['Calories']
# + colab={"base_uri": "https://localhost:8080/"} id="l9_t_RaknWMS" outputId="56c7e14c-2f67-4c0f-dbe5-a662a1f1459b"
print(X)
# + colab={"base_uri": "https://localhost:8080/"} id="Up5-uH0qnXdD" outputId="afcdcbc5-a611-43c4-c68c-1fa5dcf834e8"
print(Y)
# + [markdown] id="mzj0j0m-nfS7"
# Splitting the data into training data and Test data
# + id="lVpEUea_naiH"
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=2)
# + colab={"base_uri": "https://localhost:8080/"} id="b5bBE7wRoPw9" outputId="4875b085-5e71-49ee-febf-4377b55f5f54"
print(X.shape, X_train.shape, X_test.shape)
# + [markdown] id="TV84xw6Goeh6"
# Model Training
# + [markdown] id="VnB7kvETogu1"
# XGBoost Regressor
# + id="9C4PUD9noX10"
# loading the model
model = XGBRegressor()
# + colab={"base_uri": "https://localhost:8080/"} id="nSNxHXUBowJ4" outputId="25f84a6e-bcfc-4ee6-bb19-b3d894c885e4"
# training the model with X_train
model.fit(X_train, Y_train)
# + [markdown] id="YmzboOlDpOBV"
# Evaluation
# + [markdown] id="uWyeJ2B0pTjl"
# Prediction on Test Data
# + id="6fwoa12gpD1A"
test_data_prediction = model.predict(X_test)
# + colab={"base_uri": "https://localhost:8080/"} id="elvZfEW_pnwa" outputId="c4db84ed-2afc-4e15-dc53-fec2b6479be7"
print(test_data_prediction)
# + [markdown] id="AvAOAtW3p3KU"
# Mean Absolute Error
# + id="e32ffB4Opshq"
mae = metrics.mean_absolute_error(Y_test, test_data_prediction)
# + colab={"base_uri": "https://localhost:8080/"} id="MWJQ0yJtqell" outputId="577e5bb9-bcdb-4744-d19b-d683adbf2cda"
print("Mean Absolute Error = ", mae)
# + id="yVo9E_U_qkpK"
| Calories_Burnt_Prediction.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # File for plotting the susceptiblility plot for the paper
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# ### Load the data
# +
flat_d = np.loadtxt("/media/data/Data/FirstOrder/Susceptibility/Dataset2Figures/flat_sus_duty.txt")
flat_t = np.loadtxt("/media/data/Data/FirstOrder/Susceptibility/Dataset2Figures/flat_sus_torder.txt")
flat_h = np.loadtxt("/media/data/Data/FirstOrder/Susceptibility/Dataset2Figures/flat_sus_horder.txt")
dimple_d = np.loadtxt("/media/data/Data/FirstOrder/Susceptibility/Dataset2Figures/dimpled_sus_duty.txt")
dimple_t = np.loadtxt("/media/data/Data/FirstOrder/Susceptibility/Dataset2Figures/dimpled_sus_torder.txt")
dimple_h = np.loadtxt("/media/data/Data/FirstOrder/Susceptibility/Dataset2Figures/dimpled_sus_horder.txt")
# -
# ### Convert duty to acceleration
# +
g = 9.81
v2a = 42.46
def d2a(d):
"""Converts duty cycle to acceleration ms^-2"""
a = v2a * 0.003 * d - v2a * 1.5
return a
def d2G(d):
"""Converts duty cycle to dimensionless acceleration"""
return d2a(d) / g
# -
flat_a = d2G(flat_d)
dimple_a = d2G(dimple_d)
# ### Change matplotlib rcparams
# %matplotlib auto
plt.rcParams.update(
{
'lines.linewidth': 2,
'axes.labelsize': 12,
'figure.figsize': (3.375, 5),
'figure.dpi': 100 # change this to 600
}
)
# ### Setup the plot
# +
fig, (flat_t_ax, dimple_t_ax) = plt.subplots(2, 1, sharex=True, figsize=(3.375, 4))
flat_h_ax = flat_t_ax.twinx()
dimple_h_ax = dimple_t_ax.twinx()
dimple_t_ax.set_xlabel('$\Gamma$')
dimple_t_ax.set_ylabel(r'$\chi_T (\times 10^{-3})$')
dimple_h_ax.set_ylabel(r'$\chi_6 (\times 10^{-3})$')
flat_t_ax.set_ylabel(r'$\chi_T (\times 10^{-2})$')
flat_h_ax.set_ylabel(r'$\chi_6 (\times 10^{-2})$')
dimple_t_ax.set_title('Dimpled Plate')
flat_t_ax.set_title('Flat Plate')
dimple_t_ax.yaxis.label.set_color('g')
dimple_t_ax.tick_params(axis='y', colors='g')
dimple_h_ax.yaxis.label.set_color('m')
dimple_h_ax.tick_params(axis='y', colors='m')
flat_t_ax.yaxis.label.set_color('g')
flat_t_ax.tick_params(axis='y', colors='g')
flat_h_ax.yaxis.label.set_color('m')
flat_h_ax.tick_params(axis='y', colors='m')
flat_t_ax.set_ylim([0, 1.05*max(flat_t)*100])
flat_h_ax.set_ylim([0, 1.05*max(flat_h)*100])
dimple_t_ax.set_ylim([0, 1.05*max(dimple_t)*1000])
dimple_h_ax.set_ylim([0, 1.05*max(dimple_h)*1000])
flat_t_ax.ticklabel_format(axis='x', style='sci', scilimits=(0,0))
dimple_t_ax.ticklabel_format(axis='x', style='sci', scilimits=(0,0))
flat_h_ax.ticklabel_format(axis='x', style='sci', scilimits=(0,0))
dimple_h_ax.ticklabel_format(axis='x', style='sci', scilimits=(0,0))
flat_t_ax.plot(flat_a, flat_t*100, 'gx')
flat_h_ax.plot(flat_a, flat_h*100, 'mo')
dimple_t_ax.plot(dimple_a, dimple_t*1000, 'gx')
dimple_h_ax.plot(dimple_a, dimple_h*1000, 'mo')
fig.subplots_adjust(left=0.15, right=0.80)
plt.savefig(
"/media/data/Data/FirstOrder/Susceptibility/Dataset2Figures/susceptibility_figure.png",
dpi=600,
pad_inches=0.1
)
# -
| first_order/Susceptibilities/SusceptibilityPlot.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Imports
import numpy as np
import os
from collections import OrderedDict
import io
import pdb
import csls as csls
from data import Language, WordDictionary
from utils import to_numpy, read_from_yaml, setup_output_dir
import evaluate as evl
import json
import logging
logger = logging.getLogger(__name__)
# # Load Config File
# +
config_file = "Configs/GeoMM/ru-en.yaml"
gpu = 0
config = read_from_yaml(config_file)
base_dir = config["base_dir"]
loglevel = "INFO"
output_dir, config = setup_output_dir(base_dir, config, loglevel)
src = config["src_lang"]
tgt = config["tgt_lang"]
BASE_DIR = config["base_data_dir"]
CROSSLINGUAL = os.path.join(BASE_DIR, "crosslingual", "dictionaries")
logger.info(f"Computing between language pairs {src} - {tgt}")
languages = OrderedDict()
for lang in config["languages"]:
name = lang.pop("name")
filename = lang.pop("filename")
lang_obj = Language(name, gpu, **lang)
lang_obj.load(filename, BASE_DIR)
languages[name] = lang_obj
train_file = os.path.join(CROSSLINGUAL, f"{src}-{tgt}.0-5000.txt")
training_mapping = WordDictionary(
languages[src], languages[tgt], train_file)
# -
# # Training
import pytorch_backend as prob
import numpy as np
from pymanopt.solvers import SteepestDescent, ConjugateGradient
import torch
from torch.autograd import Variable
from torch import Tensor
unique_src, src_indices = np.unique(training_mapping.word_map[:, 0], return_inverse=True)
unique_tgt, tgt_indices = np.unique(training_mapping.word_map[:, 1], return_inverse=True)
A = np.zeros((unique_src.shape[0], unique_tgt.shape[0]))
for six, tix in zip(src_indices, tgt_indices):
A[six, tix] = 1
# A : number of unique src tgt pairs.
# A[i, j] is 1 unique_src[i] and unique_tgt[j] are aligned, 0 otherwise
Xs = languages[src].get_embeddings(unique_src)
Xt = languages[tgt].get_embeddings(unique_tgt)
A = Variable(torch.FloatTensor(A))
if gpu >= 0:
A = A.cuda(gpu)
training_params = config["training_params"]
for param in training_params:
value = training_params[param]
logger.info(f"{param}\t{value}")
lbda = training_params["lambda"]
manifold_learner = prob.GeomManifold(Xs, Xt, A, lbda, Xs.size(1), device=gpu)
problem = prob.Problem(
manifold=manifold_learner.manifold,
cost=manifold_learner.cost,
egrad=manifold_learner.egrad)
max_opt_time = training_params["max_opt_time"]
max_opt_iter = training_params["max_opt_iter"]
solver = ConjugateGradient(
maxtime=max_opt_time, maxiter=max_opt_iter)
theta = solver.solve(problem)
Us, B, Ut = theta
# # Save the matrices
np.save(os.path.join(output_dir, "Us.npy"), arr=Us)
np.save(os.path.join(output_dir, "B.npy"), arr=B)
np.save(os.path.join(output_dir, "Ut.npy"), arr=Ut)
# # Transform to different spaces
u,s,vh = np.linalg.svd(B, full_matrices=True)
b_sqrt = np.dot(u, np.dot(np.diag(np.sqrt(s)), vh))
src_embeddings = to_numpy(languages[src].embeddings, gpu >= 0)
tgt_embeddings = to_numpy(languages[tgt].embeddings, gpu >= 0)
src_transform = np.dot(np.dot(src_embeddings, Us), b_sqrt)
tgt_transform = np.dot(np.dot(tgt_embeddings, Ut), b_sqrt)
# # NN Evaluation using CSLS
csls_object = csls.CSLS(src_transform, tgt_transform, gpu_device=gpu)
evaluator = evl.Evaluator(languages[src], languages[tgt], data_dir="data")
metrics = evaluator.supervised(csls_object, {})
metrics_file = os.path.join(output_dir, "metrics.json")
logger.info(f"Writing metrics to {metrics_file}")
json.dump(metrics, open(metrics_file, "w"))
logger.info("Done")
# # Done
| GeoMM.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/connorpheraty/DS-Unit-1-Sprint-3-Data-Storytelling/blob/master/Connor_Heraty_LS_DS_223_Make_explanatory_visualizations.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] colab_type="text" id="-8-trVo__vRE"
# _Lambda School Data Science_
#
# # Make explanatory visualizations
#
#
#
#
# Tody we will reproduce this [example by FiveThirtyEight:](https://fivethirtyeight.com/features/al-gores-new-movie-exposes-the-big-flaw-in-online-movie-ratings/)
# + colab_type="code" id="ya_w5WORGs-n" outputId="32d67539-06b5-4f84-c7bf-670f2462097b" colab={"base_uri": "https://localhost:8080/", "height": 355}
from IPython.display import display, Image
url = 'https://fivethirtyeight.com/wp-content/uploads/2017/09/mehtahickey-inconvenient-0830-1.png'
example = Image(url=url, width=400)
display(example)
# + [markdown] colab_type="text" id="HP4DALiRG3sC"
# Using this data: https://github.com/fivethirtyeight/data/tree/master/inconvenient-sequel
# + [markdown] colab_type="text" id="HioPkYtUG03B"
# Objectives
# - add emphasis and annotations to transform visualizations from exploratory to explanatory
# - remove clutter from visualizations
#
# Links
# - [Strong Titles Are The Biggest Bang for Your Buck](http://stephanieevergreen.com/strong-titles/)
# - [Remove to improve (the data-ink ratio)](https://www.darkhorseanalytics.com/blog/data-looks-better-naked)
# - [How to Generate FiveThirtyEight Graphs in Python](https://www.dataquest.io/blog/making-538-plots/)
# + [markdown] colab_type="text" id="0w_iMnQ6-VoQ"
# ## Make prototypes
#
# This helps us understand the problem
# + colab_type="code" id="5uz0eEaEN-GO" outputId="390ed31a-fb43-4878-8d20-5b3bf93f08de" colab={"base_uri": "https://localhost:8080/", "height": 282}
# %matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.style.use('fivethirtyeight')
fake = pd.Series([38, 3, 2, 1, 2, 4, 6, 5, 5, 33],
index=range(1,11))
fake.plot.bar(color='C1', width=0.9);
# + colab_type="code" id="KZ0VLOV8OyRr" outputId="726db331-b326-4e6e-8434-151ae47c1903" colab={"base_uri": "https://localhost:8080/", "height": 285}
fake2 = pd.Series(
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
2, 2, 2,
3, 3, 3,
4, 4,
5, 5, 5,
6, 6, 6, 6,
7, 7, 7, 7, 7,
8, 8, 8, 8,
9, 9, 9, 9,
10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10])
fake2.value_counts().sort_index().plot.bar(color='C1', width=0.9);
# + [markdown] colab_type="text" id="mZb3UZWO-q05"
# ## Annotate with text
# + colab_type="code" id="f6U1vswr_uWp" outputId="ea4e8b53-bcaf-4563-d2ff-b64c2d59dcbe" colab={"base_uri": "https://localhost:8080/", "height": 335}
plt.style.use('fivethirtyeight')
fake = pd.Series([38, 3, 2, 1, 2, 4, 6, 5, 5, 33],
index=range(1,11))
#plt.title("An Inconventient Sequel: Truth to Power' is divisive", fontsize =15)
plt.ylabel('Percent of Total Votes', fontsize=10, fontweight='bold')
plt.xlabel('Rating', fontsize=10, fontweight='bold')
ax = fake.plot.bar(color='#ef7030', width=0.9);
ax.set(xlabel='Rating', ylabel='Percent of total votes',
yticks=range(0, 50, 10))
ax.text(x=-2, y=45, s="'An Inconventient Sequel: Truth to Power' is divisive", fontsize=15, fontweight='bold')
ax.text(x=-2, y=42, s="IMDB ratings for the film as of Aug. 29", fontsize=12)
ax.tick_params(labelrotation=0)
ax.set_facecolor('white');
# + id="O30A-zuIBQuZ" colab_type="code" outputId="749f4f65-bb66-4c80-84e1-4edafc439170" colab={"base_uri": "https://localhost:8080/", "height": 355}
display(example)
# + [markdown] colab_type="text" id="x8jRZkpB_MJ6"
# ## Reproduce with real data
# + colab_type="code" id="3SOHJckDUPI8" colab={}
df = pd.read_csv('https://raw.githubusercontent.com/fivethirtyeight/data/master/inconvenient-sequel/ratings.csv')
pd.set_option('display.max_columns', 500)
pd.set_option('display.max_rows', 500)
# + [markdown] id="69dbaerbGjMl" colab_type="text"
#
# + colab_type="code" id="cDltXxhC_yG-" outputId="74134fb2-028e-4f2d-b73c-5ad4ca26e5c8" colab={"base_uri": "https://localhost:8080/", "height": 34}
df.shape
# + id="1iR1jegoGllc" colab_type="code" colab={}
df.info()
# + id="C1i32qSFGlnw" colab_type="code" outputId="14f76e6d-aa93-4701-c206-d145d7249615" colab={"base_uri": "https://localhost:8080/", "height": 309}
df.head()
# + id="Ioa49l24Glp_" colab_type="code" outputId="47fa2aff-3bcd-400c-f2a4-537abf6871cc" colab={"base_uri": "https://localhost:8080/", "height": 886}
df.sample(1).T
# + id="zVxX2hCoGlsW" colab_type="code" colab={}
df['timestamp'] = pd.to_datetime(df['timestamp'])
# + id="VttltSqHGluu" colab_type="code" outputId="1ef6dbf1-ddbf-4c75-d3ff-d0d26fa4fe45" colab={"base_uri": "https://localhost:8080/", "height": 136}
df['timestamp'].describe()
# + id="bUQz_Sm2I48G" colab_type="code" colab={}
df = df.set_index('timestamp')
# + id="b7JdqZjlI9Bh" colab_type="code" colab={}
df.head()
# + id="yiCamoFrJLnK" colab_type="code" colab={}
lastday = df['2017-08-29']
# + id="Y-qcDh3wJLpl" colab_type="code" colab={}
lastday[lastday['category'] == 'IMDb users']
# + id="n3Dsic3rJLrs" colab_type="code" colab={}
lastday[lastday['category'] =='IMDb users'].respondents.plot();
# + id="Bi-fmdwUJLt4" colab_type="code" colab={}
final = lastday[lastday['category'] =='IMDb users'].tail(1)
# + id="qYpAxLzhJLv8" colab_type="code" outputId="484d8725-a131-4bb5-c37d-4aaa9868c9d5" colab={"base_uri": "https://localhost:8080/", "height": 148}
final
# + id="yPz8UA3_JLyB" colab_type="code" outputId="ab0ff1d9-8e8b-414c-fa8f-f6f6a379b6d4" colab={"base_uri": "https://localhost:8080/", "height": 111}
pct_columns = ['1_pct', '2_pct', '3_pct', '4_pct', '5_pct',
'6_pct', '7_pct', '8_pct', '9_pct', '10_pct']
final[pct_columns]
# + id="VXQ5-5yYJLzi" colab_type="code" colab={}
data = final[pct_columns].T
data.index = range(1, 11)
# + id="_eTJQnKgN0TY" colab_type="code" colab={}
# + id="6NXkZIz7N0Vm" colab_type="code" outputId="fbba95ba-4548-4449-e431-7d1ceddb7074" colab={"base_uri": "https://localhost:8080/", "height": 335}
plt.style.use('fivethirtyeight')
fake = pd.Series([38, 3, 2, 1, 2, 4, 6, 5, 5, 33],
index=range(1,11))
#plt.title("An Inconventient Sequel: Truth to Power' is divisive", fontsize =15)
plt.ylabel('Percent of Total Votes', fontsize=10, fontweight='bold')
plt.xlabel('Rating', fontsize=10, fontweight='bold')
ax = fake.plot.bar(color='#ef7030', width=0.9);
ax.set(xlabel='Rating', ylabel='Percent of total votes',
yticks=range(0, 50, 10))
ax.text(x=-2, y=45, s="'An Inconventient Sequel: Truth to Power' is divisive", fontsize=15, fontweight='bold')
ax.text(x=-2, y=42, s="IMDB ratings for the film as of Aug. 29", fontsize=12)
ax.tick_params(labelrotation=0)
ax.set_facecolor('white');
# + id="6a9nInMXN0Zs" colab_type="code" colab={}
# + [markdown] colab_type="text" id="NMEswXWh9mqw"
# # ASSIGNMENT
#
# Replicate the lesson code. I recommend that you [do not copy-paste](https://docs.google.com/document/d/1ubOw9B3Hfip27hF2ZFnW3a3z9xAgrUDRReOEo-FHCVs/edit).
#
# # STRETCH OPTIONS
#
# #### Reproduce another example from [FiveThityEight's shared data repository](https://data.fivethirtyeight.com/).
#
# For example:
# - [thanksgiving-2015](https://fivethirtyeight.com/features/heres-what-your-part-of-america-eats-on-thanksgiving/) (try the [`altair`](https://altair-viz.github.io/gallery/index.html#maps) library)
# - [candy-power-ranking](https://fivethirtyeight.com/features/the-ultimate-halloween-candy-power-ranking/) (try the [`statsmodels`](https://www.statsmodels.org/stable/index.html) library)
# - or another example of your choice!
#
# #### Make more charts!
#
# Choose a chart you want to make, from [Visual Vocabulary - Vega Edition](http://ft.com/vocabulary).
#
# Find the chart in an example gallery of a Python data visualization library:
# - [Seaborn](http://seaborn.pydata.org/examples/index.html)
# - [Altair](https://altair-viz.github.io/gallery/index.html)
# - [Matplotlib](https://matplotlib.org/gallery.html)
# - [Pandas](https://pandas.pydata.org/pandas-docs/stable/visualization.html)
#
# Reproduce the chart. [Optionally, try the "Ben Franklin Method."](https://docs.google.com/document/d/1ubOw9B3Hfip27hF2ZFnW3a3z9xAgrUDRReOEo-FHCVs/edit) If you want, experiment and make changes.
#
# Take notes. Consider sharing your work with your cohort!
#
#
#
#
#
#
#
#
# + id="UyUYuQunq7Od" colab_type="code" outputId="5bab56b0-b589-4684-c65d-8ad5bd0920cd" colab={"resources": {"http://localhost:8080/nbextensions/google.colab/files.js": {"data": "<KEY> "ok": true, "headers": [["content-type", "application/javascript"]], "status": 200, "status_text": ""}}, "base_uri": "https://localhost:8080/", "height": 71}
from google.colab import files
uploaded = files.upload()
# + id="xl5MVzhlq7gO" colab_type="code" colab={}
df = pd.read_csv('raw_anonymized_data.csv')
# + id="sKiqzMWKq7i4" colab_type="code" outputId="a8f23a9e-754a-4777-9938-931cf12da665" colab={"base_uri": "https://localhost:8080/", "height": 253}
df.head()
# + id="SFGmcut0q7l1" colab_type="code" outputId="dcb93262-af57-4b79-8482-20be5735fb8b" colab={"base_uri": "https://localhost:8080/", "height": 34}
df.shape
# + id="Ys6mlONquxzx" colab_type="code" colab={}
| Connor_Heraty_LS_DS_223_Make_explanatory_visualizations.ipynb |