+
+
+ -
+
+
+
+
+ Influence Guided Sampling for Domain Adaptation of Text Retrievers
+
+
+
+ Authors:
+
+ Meet Doshi,
+
+ Vishwajeet Kumar,
+
+ Yulong Li,
+
+ Jaydeep Sen
+
+
+
+
+ Abstract:
+
+ General-purpose open-domain dense retrieval systems are usually trained with a large, eclectic mix of corpora and search tasks. How should these diverse corpora and tasks be sampled for training? Conventional approaches…
+ ▽ More
+
+
+ General-purpose open-domain dense retrieval systems are usually trained with a large, eclectic mix of corpora and search tasks. How should these diverse corpora and tasks be sampled for training? Conventional approaches sample them uniformly, proportional to their instance population sizes, or depend on human-level expert supervision. It is well known that the training data sampling strategy can greatly impact model performance. However, how to find the optimal strategy has not been adequately studied in the context of embedding models. We propose Inf-DDS, a novel reinforcement learning driven sampling framework that adaptively reweighs training datasets guided by influence-based reward signals and is much more lightweight with respect to GPU consumption. Our technique iteratively refines the sampling policy, prioritizing datasets that maximize model performance on a target development set. We evaluate the efficacy of our sampling strategy on a wide range of text retrieval tasks, demonstrating strong improvements in retrieval performance and better adaptation compared to existing gradient-based sampling methods, while also being 1.5x to 4x cheaper in GPU compute. Our sampling strategy achieves a 5.03 absolute NDCG@10 improvement while training a multilingual bge-m3 model and an absolute NDCG@10 improvement of 0.94 while training all-MiniLM-L6-v2, even when starting from expert-assigned weights on a large pool of training datasets.
+ △ Less
+
+
+
+
+ Submitted 29 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ ILRR: Inference-Time Steering Method for Masked Diffusion Language Models
+
+
+
+ Authors:
+
+ Eden Avrahami,
+
+ Eliya Nachmani
+
+
+
+
+ Abstract:
+
+ Discrete Diffusion Language Models (DLMs) offer a promising non-autoregressive alternative for text generation, yet effective mechanisms for inference-time control remain relatively underexplored. Existing approaches include…
+ ▽ More
+
+
+ Discrete Diffusion Language Models (DLMs) offer a promising non-autoregressive alternative for text generation, yet effective mechanisms for inference-time control remain relatively underexplored. Existing approaches include sampling-level guidance procedures or trajectory optimization mechanisms. In this work, we introduce Iterative Latent Representation Refinement (ILRR), a learning-free framework for steering DLMs using a single reference sequence. ILRR guides generation by dynamically aligning the internal activations of the generated sequence with those of a given reference throughout the denoising process. This approach captures and transfers high-level semantic properties, with a tunable steering scale enabling flexible control over attributes such as sentiment. We further introduce Spatially Modulated Steering, an extension that enables steering long texts using shorter references by regulating guidance intensity across the sequence. Empirically, we demonstrate that ILRR achieves effective attribute steering on LLaDA and MDLM architectures with a minor computational overhead, requiring only one additional parallel forward pass per denoising step. Under the same compute budget, ILRR improves attribute accuracy over comparable baselines by 10\% to 60\% points, while maintaining high generation quality.
+ △ Less
+
+
+
+
+ Submitted 29 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ inversedMixup: Data Augmentation via Inverting Mixed Embeddings
+
+
+
+ Authors:
+
+ Fanshuang Kong,
+
+ Richong Zhang,
+
+ Qiyu Sun,
+
+ Zhijie Nie,
+
+ Ting Deng,
+
+ Chunming Hu
+
+
+
+
+ Abstract:
+
+ Mixup generates augmented samples by linearly interpolating inputs and labels with a controllable ratio. However, since it operates in the latent embedding level, the resulting…
+ ▽ More
+
+
+ Mixup generates augmented samples by linearly interpolating inputs and labels with a controllable ratio. However, since it operates in the latent embedding level, the resulting samples are not human-interpretable. In contrast, LLM-based augmentation methods produce sentences via prompts at the token level, yielding readable outputs but offering limited control over the generation process. Inspired by recent advances in LLM inversion, which reconstructs natural language from embeddings and helps bridge the gap between latent embedding space and discrete token space, we propose inversedMixup, a unified framework that combines the controllability of Mixup with the interpretability of LLM-based generation. Specifically, inversedMixup adopts a three-stage training procedure to align the output embedding space of a task-specific model with the input embedding space of an LLM. Upon successful alignment, inversedMixup can reconstruct mixed embeddings with a controllable mixing ratio into human-interpretable augmented sentences, thereby improving the augmentation performance. Additionally, inversedMixup provides the first empirical evidence of the manifold intrusion phenomenon in text Mixup and introduces a simple yet effective strategy to mitigate it. Extensive experiments demonstrate the effectiveness and generalizability of our approach in both few-shot and fully supervised scenarios.
+ △ Less
+
+
+
+
+ Submitted 29 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ A Poisson Factor Mixture Model for the Analysis of Linguistic Competence in Italian University Students' Writing
+
+
+
+ Authors:
+
+ Silvia Dallari,
+
+ Laura Anderlucci,
+
+ Nicola Grandi,
+
+ Angela Montanari
+
+
+
+
+ Abstract:
+
+ …students and whether systematic patterns of competence and heterogeneity can be identified. The analysis is based on data from the UniversITA project, which collected formal texts written by a large and nationally representative sample of Italian university students. Texts were a…
+ ▽ More
+
+
+ Public debate on the alleged decline of language skills among younger generations often focuses on university students, the most highly educated segment of the population. Rather than addressing the ill posed question of linguistic decline, this paper examines how formal written Italian is currently used by university students and whether systematic patterns of competence and heterogeneity can be identified. The analysis is based on data from the UniversITA project, which collected formal texts written by a large and nationally representative sample of Italian university students. Texts were annotated for linguistically motivated features covering orthography, lexicon, syntax, morphosyntax, coherence, register, and sentence structure, yielding low frequency multivariate count data. To analyse these data, we propose a novel model-based clustering approach based on a Poisson factor mixture model that accounts for dependence among linguistic features and unobserved population heterogeneity. The results identify two correlated dimensions of writing competence, interpretable as communicative competence and linguistic grammatical competence. When educational and socio demographic information is incorporated, distinct student profiles emerge that are associated with field of study and educational background. These findings provide quantitative evidence on contemporary writing and offer insights relevant for language education and higher education policy.
+ △ Less
+
+
+
+
+ Submitted 29 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Topeax -- An Improved Clustering Topic Model with Density Peak Detection and Lexical-Semantic Term Importance
+
+
+
+ Authors:
+
+ Márton Kardos
+
+
+
+
+ Abstract:
+
+ Text clustering is today the most popular paradigm for topic modelling, both in academia and industry. Despite clustering topic models' apparent success, we identify a number of issues in Top2Vec and BERTopic, which remain largely unsolved. Firstly, these approaches are unreliable at discovering natural clusters in corpora, due to extreme sensitivity to…
+ ▽ More
+
+
+ Text clustering is today the most popular paradigm for topic modelling, both in academia and industry. Despite clustering topic models' apparent success, we identify a number of issues in Top2Vec and BERTopic, which remain largely unsolved. Firstly, these approaches are unreliable at discovering natural clusters in corpora, due to extreme sensitivity to sample size and hyperparameters, the default values of which result in suboptimal behaviour. Secondly, when estimating term importance, BERTopic ignores the semantic distance of keywords to topic vectors, while Top2Vec ignores word counts in the corpus. This results in, on the one hand, less coherent topics due to the presence of stop words and junk words, and lack of variety and trust on the other. In this paper, I introduce a new approach, \textbf{Topeax}, which discovers the number of clusters from peaks in density estimates, and combines lexical and semantic indices of term importance to gain high-quality topic keywords. Topeax is demonstrated to be better at both cluster recovery and cluster description than Top2Vec and BERTopic, while also exhibiting less erratic behaviour in response to changing sample size and hyperparameters.
+ △ Less
+
+
+
+
+ Submitted 29 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Bulk-Calibrated Credal Ambiguity Sets: Fast, Tractable Decision Making under Out-of-Sample Contamination
+
+
+
+ Authors:
+
+ Mengqi Chen,
+
+ Thomas B. Berrett,
+
+ Theodoros Damoulas,
+
+ Michele Caprio
+
+
+
+
+ Abstract:
+
+ Distributionally robust optimisation (DRO) minimises the worst-case expected loss over an ambiguity set that can capture distributional shifts in out-of-sample environments. While Huber (linear-vacuous) contamination is a classical minimal-assumption model for an \varepsilon-fraction of arbitrary perturbations, including it in an ambiguity set can make the…
+ ▽ More
+
+
+ Distributionally robust optimisation (DRO) minimises the worst-case expected loss over an ambiguity set that can capture distributional shifts in out-of-sample environments. While Huber (linear-vacuous) contamination is a classical minimal-assumption model for an \varepsilon-fraction of arbitrary perturbations, including it in an ambiguity set can make the worst-case risk infinite and the DRO objective vacuous unless one imposes strong boundedness or support assumptions. We address these challenges by introducing bulk-calibrated credal ambiguity sets: we learn a high-mass bulk set from data while considering contamination inside the bulk and bounding the remaining tail contribution separately. This leads to a closed-form, finite \mathrm{mean}+\sup robust objective and tractable linear or second-order cone programs for common losses and bulk geometries. Through this framework, we highlight and exploit the equivalence between the imprecise probability (IP) notion of upper expectation and the worst-case risk, demonstrating how IP credal sets translate into DRO objectives with interpretable tolerance levels. Experiments on heavy-tailed inventory control, geographically shifted house-price regression, and demographically shifted text classification show competitive robustness-accuracy trade-offs and efficient optimisation times, using Bayesian, frequentist, or empirical reference distributions.
+ △ Less
+
+
+
+
+ Submitted 29 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Early results in the search for extreme coronal line emitters with the Dark Energy Spectroscopic Instrument
+
+
+
+ Authors:
+
+ Peter Clark,
+
+ Joseph Callow,
+
+ Or Graur,
+
+ Alexei V. Filippenko,
+
+ Thomas G. Brink,
+
+ WeiKang Zheng,
+
+ Jessica Aguilar,
+
+ Steven Ahlen,
+
+ Segev BenZvi,
+
+ Davide Bianchi,
+
+ David Brooks,
+
+ Todd Claybaugh,
+
+ Andrei Cuceu,
+
+ Axel de la Macorra,
+
+ Arjun Dey,
+
+ Peter Doel,
+
+ Jaime E. Forero-Romero,
+
+ Enrique Gaztañaga,
+
+ Satya Gontcho A Gontcho,
+
+ Gaston Gutierrez,
+
+ Victoria Fawcett,
+
+ Mustapha Ishak,
+
+ Jorge Jimenez,
+
+ Dick Joyce,
+
+ Stephanie Juneau
+ , et al. (22 additional authors not shown)
+
+
+
+ Abstract:
+
+ …to both active galactic nuclei (AGNs) and tidal disruption events (TDEs). We focus our search on identifying TDE-linked ECLEs. We identify three such objects within the EDR sample, highlighting DESI's effectiveness for discovering new nuclear transients, and determine a galaxy-normalized TDE-linked ECLE rate of…
+ ▽ More
+
+
+ Here we present the results of our search through the Early Data Release (EDR) of the Dark Energy Spectroscopic Instrument (DESI) for extreme coronal line emitters (ECLEs) - a rare classification of galaxies displaying strong, high-ionization iron coronal emission lines within their spectra. With the requirement of a strong X-ray continuum to generate the coronal emission, ECLEs have been linked to both active galactic nuclei (AGNs) and tidal disruption events (TDEs). We focus our search on identifying TDE-linked ECLEs. We identify three such objects within the EDR sample, highlighting DESI's effectiveness for discovering new nuclear transients, and determine a galaxy-normalized TDE-linked ECLE rate of R_\mathrm{G}=5~^{+5}_{-3}\times10^{-6}~\mathrm{galaxy}^{-1}~\mathrm{yr}^{-1} at a median redshift of z = 0.2 - broadly consistent with previous works. Additionally, we also identify more than 200 AGNs displaying coronal emission lines, which serve as the primary astrophysical contaminants in searches for TDE-related events. We also include an outline of the custom python code developed for this search.
+ △ Less
+
+
+
+
+ Submitted 28 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Say Cheese! Detail-Preserving Portrait Collection Generation via Natural Language Edits
+
+
+
+ Authors:
+
+ Zelong Sun,
+
+ Jiahui Wu,
+
+ Ying Ba,
+
+ Dong Jing,
+
+ Zhiwu Lu
+
+
+
+
+ Abstract:
+
+ …including identity, clothing, and accessories. To address these challenges, we propose CHEESE, the first large-scale PCG dataset containing 24K portrait collections and 573K samples with high-quality modification…
+ ▽ More
+
+
+ As social media platforms proliferate, users increasingly demand intuitive ways to create diverse, high-quality portrait collections. In this work, we introduce Portrait Collection Generation (PCG), a novel task that generates coherent portrait collections by editing a reference portrait image through natural language instructions. This task poses two unique challenges to existing methods: (1) complex multi-attribute modifications such as pose, spatial layout, and camera viewpoint; and (2) high-fidelity detail preservation including identity, clothing, and accessories. To address these challenges, we propose CHEESE, the first large-scale PCG dataset containing 24K portrait collections and 573K samples with high-quality modification text annotations, constructed through an Large Vison-Language Model-based pipeline with inversion-based verification. We further propose SCheese, a framework that combines text-guided generation with hierarchical identity and detail preservation. SCheese employs adaptive feature fusion mechanism to maintain identity consistency, and ConsistencyNet to inject fine-grained features for detail consistency. Comprehensive experiments validate the effectiveness of CHEESE in advancing PCG, with SCheese achieving state-of-the-art performance.
+ △ Less
+
+
+
+
+ Submitted 28 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Audio Deepfake Detection in the Age of Advanced Text-to-Speech models
+
+
+
+ Authors:
+
+ Robin Singh,
+
+ Aditya Yogesh Nair,
+
+ Fabio Palumbo,
+
+ Florian Barbaro,
+
+ Anna Dyka,
+
+ Lohith Rachakonda
+
+
+
+
+ Abstract:
+
+ Recent advances in Text-to-Speech (TTS) systems have substantially increased the realism of synthetic speech, raising new challenges for audio deepfake detection. This work presents a comparative evaluation of three state-of-the-art TTS models--Dia2, Maya1, and MeloTTS--representing streaming, LLM-based, and non-autoregressive architectures. A corpus of 12,0…
+ ▽ More
+
+
+ Recent advances in Text-to-Speech (TTS) systems have substantially increased the realism of synthetic speech, raising new challenges for audio deepfake detection. This work presents a comparative evaluation of three state-of-the-art TTS models--Dia2, Maya1, and MeloTTS--representing streaming, LLM-based, and non-autoregressive architectures. A corpus of 12,000 synthetic audio samples was generated using the Daily-Dialog dataset and evaluated against four detection frameworks, including semantic, structural, and signal-level approaches. The results reveal significant variability in detector performance across generative mechanisms: models effective against one TTS architecture may fail against others, particularly LLM-based synthesis. In contrast, a multi-view detection approach combining complementary analysis levels demonstrates robust performance across all evaluated models. These findings highlight the limitations of single-paradigm detectors and emphasize the necessity of integrated detection strategies to address the evolving landscape of audio deepfake threats.
+ △ Less
+
+
+
+
+ Submitted 28 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Let's Roll a BiFTA: Bi-refinement for Fine-grained Text-visual Alignment in Vision-Language Models
+
+
+
+ Authors:
+
+ Yuhao Sun,
+
+ Chengyi Cai,
+
+ Jiacheng Zhang,
+
+ Zesheng Ye,
+
+ Xingliang Yuan,
+
+ Feng Liu
+
+
+
+
+ Abstract:
+
+ Recent research has shown that aligning fine-grained text descriptions with localized image patches can significantly improve the zero-shot performance of pre-trained vision-language models (e.g., CLIP). However, we find that both fine-grained…
+ ▽ More
+
+
+ Recent research has shown that aligning fine-grained text descriptions with localized image patches can significantly improve the zero-shot performance of pre-trained vision-language models (e.g., CLIP). However, we find that both fine-grained text descriptions and localized image patches often contain redundant information, making text-visual alignment less effective. In this paper, we tackle this issue from two perspectives: \emph{View Refinement} and \emph{Description refinement}, termed as \textit{\textbf{Bi}-refinement for \textbf{F}ine-grained \textbf{T}ext-visual \textbf{A}lignment} (BiFTA). \emph{View refinement} removes redundant image patches with high \emph{Intersection over Union} (IoU) ratios, resulting in more distinctive visual samples. \emph{Description refinement} removes redundant text descriptions with high pairwise cosine similarity, ensuring greater diversity in the remaining descriptions. BiFTA achieves superior zero-shot performance on 6 benchmark datasets for both ViT-based and ResNet-based CLIP, justifying the necessity to remove redundant information in visual-text alignment.
+ △ Less
+
+
+
+
+ Submitted 28 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ DeRaDiff: Denoising Time Realignment of Diffusion Models
+
+
+
+ Authors:
+
+ Ratnavibusena Don Shahain Manujith,
+
+ Yang Zhang,
+
+ Teoh Tze Tzun,
+
+ Kenji Kawaguchi
+
+
+
+
+ Abstract:
+
+ …expensive. We introduce DeRaDiff, a denoising time realignment procedure that, after aligning a pretrained model once, modulates the regularization strength during sampling to emulate models trained at other regularization strengths without any additional training or finetuning. Extending decoding-time realignment from language to diffusion models, DeRaDiff…
+ ▽ More
+
+
+ Recent advances align diffusion models with human preferences to increase aesthetic appeal and mitigate artifacts and biases. Such methods aim to maximize a conditional output distribution aligned with higher rewards whilst not drifting far from a pretrained prior. This is commonly enforced by KL (Kullback Leibler) regularization. As such, a central issue still remains: how does one choose the right regularization strength? Too high of a strength leads to limited alignment and too low of a strength leads to "reward hacking". This renders the task of choosing the correct regularization strength highly non-trivial. Existing approaches sweep over this hyperparameter by aligning a pretrained model at multiple regularization strengths and then choose the best strength. Unfortunately, this is prohibitively expensive. We introduce DeRaDiff, a denoising time realignment procedure that, after aligning a pretrained model once, modulates the regularization strength during sampling to emulate models trained at other regularization strengths without any additional training or finetuning. Extending decoding-time realignment from language to diffusion models, DeRaDiff operates over iterative predictions of continuous latents by replacing the reverse step reference distribution by a geometric mixture of an aligned and reference posterior, thus giving rise to a closed form update under common schedulers and a single tunable parameter, lambda, for on the fly control. Our experiments show that across multiple text image alignment and image-quality metrics, our method consistently provides a strong approximation for models aligned entirely from scratch at different regularization strengths. Thus, our method yields an efficient way to search for the optimal strength, eliminating the need for expensive alignment sweeps and thereby substantially reducing computational costs.
+ △ Less
+
+
+
+
+ Submitted 27 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ BengaliSent140: A Large-Scale Bengali Binary Sentiment Dataset for Hate and Non-Hate Speech Classification
+
+
+
+ Authors:
+
+ Akif Islam,
+
+ Sujan Kumar Roy,
+
+ Md. Ekramul Hamid
+
+
+
+
+ Abstract:
+
+ …and generalizable representations. In this work, we introduce BengaliSent140, a large-scale Bengali binary sentiment dataset constructed by consolidating seven existing Bengali text datasets into a unified corpus. To ensure consistency across sources, heterogeneous annotation schemes are systematically harmonized into a binary sentiment formulation with two…
+ ▽ More
+
+
+ Sentiment analysis for the Bengali language has attracted increasing research interest in recent years. However, progress remains constrained by the scarcity of large-scale and diverse annotated datasets. Although several Bengali sentiment and hate speech datasets are publicly available, most are limited in size or confined to a single domain, such as social media comments. Consequently, these resources are often insufficient for training modern deep learning based models, which require large volumes of heterogeneous data to learn robust and generalizable representations. In this work, we introduce BengaliSent140, a large-scale Bengali binary sentiment dataset constructed by consolidating seven existing Bengali text datasets into a unified corpus. To ensure consistency across sources, heterogeneous annotation schemes are systematically harmonized into a binary sentiment formulation with two classes: Not Hate (0) and Hate (1). The resulting dataset comprises 139,792 unique text samples, including 68,548 hate and 71,244 not-hate instances, yielding a relatively balanced class distribution. By integrating data from multiple sources and domains, BengaliSent140 offers broader linguistic and contextual coverage than existing Bengali sentiment datasets and provides a strong foundation for training and benchmarking deep learning models. Baseline experimental results are also reported to demonstrate the practical usability of the dataset. The dataset is publicly available at https://www.kaggle.com/datasets/akifislam/bengalisent140/
+ △ Less
+
+
+
+
+ Submitted 27 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ DuwatBench: Bridging Language and Visual Heritage through an Arabic Calligraphy Benchmark for Multimodal Understanding
+
+
+
+ Authors:
+
+ Shubham Patle,
+
+ Sara Ghaboura,
+
+ Hania Tariq,
+
+ Mohammad Usman Khan,
+
+ Omkar Thawakar,
+
+ Rao Muhammad Anwer,
+
+ Salman Khan
+
+
+
+
+ Abstract:
+
+ …Arabic script, especially in artistic and stylized calligraphic forms, remains largely unexplored. To address this gap, we present DuwatBench, a benchmark of 1,272 curated samples containing about 1,475 unique words across six classical and modern calligraphic styles, each paired with sentence-level detection annotations. The dataset reflects real-world chal…
+ ▽ More
+
+
+ Arabic calligraphy represents one of the richest visual traditions of the Arabic language, blending linguistic meaning with artistic form. Although multimodal models have advanced across languages, their ability to process Arabic script, especially in artistic and stylized calligraphic forms, remains largely unexplored. To address this gap, we present DuwatBench, a benchmark of 1,272 curated samples containing about 1,475 unique words across six classical and modern calligraphic styles, each paired with sentence-level detection annotations. The dataset reflects real-world challenges in Arabic writing, such as complex stroke patterns, dense ligatures, and stylistic variations that often challenge standard text recognition systems. Using DuwatBench, we evaluated 13 leading Arabic and multilingual multimodal models and showed that while they perform well on clean text, they struggle with calligraphic variation, artistic distortions, and precise visual-text alignment. By publicly releasing DuwatBench and its annotations, we aim to advance culturally grounded multimodal research, foster fair inclusion of the Arabic language and visual heritage in AI systems, and support continued progress in this area. Our dataset (https://huggingface.co/datasets/MBZUAI/DuwatBench) and evaluation suit (https://github.com/mbzuai-oryx/DuwatBench) are publicly available.
+ △ Less
+
+
+
+
+ Submitted 27 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Generative Latent Alignment for Interpretable Radar Based Occupancy Detection in Ambient Assisted Living
+
+
+
+ Authors:
+
+ Huy Trinh
+
+
+
+
+ Abstract:
+
+ …sensing raises privacy concerns. We propose a Generative Latent Alignment (GLA) framework that combines a lightweight convolutional variational autoencoder with a frozen CLIP text encoder to learn a low-dimensional latent representation of radar Range-Angle (RA) heatmaps. The latent space is softly aligned with two semantic anchors corresponding to "empt…
+ ▽ More
+
+
+ In this work, we study how to make mmWave radar presence detection more interpretable for Ambient Assisted Living (AAL) settings, where camera-based sensing raises privacy concerns. We propose a Generative Latent Alignment (GLA) framework that combines a lightweight convolutional variational autoencoder with a frozen CLIP text encoder to learn a low-dimensional latent representation of radar Range-Angle (RA) heatmaps. The latent space is softly aligned with two semantic anchors corresponding to "empty room" and "person present", and Grad-CAM is applied in this aligned latent space to visualize which spatial regions support each presence decision. On our mmWave radar dataset, we qualitatively observe that the "person present" class produces compact Grad-CAM blobs that coincide with strong RA returns, whereas "empty room" samples yield diffuse or no evidence. We also conduct an ablation study using unrelated text prompts, which degrades both reconstruction and localization, suggesting that radar-specific anchors are important for meaningful explanations in this setting.
+ △ Less
+
+
+
+
+ Submitted 27 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Spectroscopy of ^4He at 0.25 ppt Uncertainty and Improved Alpha-Helion Charge-Radius Difference Determination
+
+
+
+ Authors:
+
+ K. Steinebach,
+
+ J. C. J. Koelemeij,
+
+ H. L. Bethlem,
+
+ K. S. E. Eikema
+
+
+
+
+ Abstract:
+
+ …He with 48 Hz uncertainty (0.25 ppt), using a Bose-Einstein condensed sample confined in a magic-wavelength optical dipole trap. A systematic Doppler shift from condensate motion is suppressed by time-resolved ion detection, and the transition frequency is calibrated via a White Rabbit link to a remote active hydrogen maser clock. Combined with previous…
+ ▽ More
+
+
+ High-precision spectroscopy of simple atomic systems can be used to advance the theory of atomic energy levels but can also serve as a sensitive probe of nuclear charge radii. For this last purpose, we report an improved measurement of the 2\,^3{S}_1 \to 2\,^1{S}_0 transition frequency in ^4He with 48 Hz uncertainty (0.25 ppt), using a Bose-Einstein condensed sample confined in a magic-wavelength optical dipole trap. A systematic Doppler shift from condensate motion is suppressed by time-resolved ion detection, and the transition frequency is calibrated via a White Rabbit link to a remote active hydrogen maser clock. Combined with previous ^3He measurements and improved theory, we obtain the most precise determination to date of the charge-radius difference between the alpha and helion particles of r_{h}^2 -r_α^2 of 1.0676(10)\text{fm}^2. This is consistent with other recent determinations and confirms that the current discrepancy between QED theory and experimentally observed ionization energies of excited states in helium is not apparent in the isotope shift.
+ △ Less
+
+
+
+
+ Submitted 27 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Interpretable and Perceptually-Aligned Music Similarity with Pretrained Embeddings
+
+
+
+ Authors:
+
+ Arhan Vohra,
+
+ Taketo Akama
+
+
+
+
+ Abstract:
+
+ …metric learning show promising alignment with human judgment, but are difficult to interpret or generalize due to limited dataset availability. We show that pretrained text-audio embeddings (CLAP and MuQ-MuLan) offer comparable perceptual alignment on similarity tasks without any additional fine-tuning. To surpass this baseline, we introduce a novel method t…
+ ▽ More
+
+
+ Perceptual similarity representations enable music retrieval systems to determine which songs sound most similar to listeners. State-of-the-art approaches based on task-specific training via self-supervised metric learning show promising alignment with human judgment, but are difficult to interpret or generalize due to limited dataset availability. We show that pretrained text-audio embeddings (CLAP and MuQ-MuLan) offer comparable perceptual alignment on similarity tasks without any additional fine-tuning. To surpass this baseline, we introduce a novel method to perceptually align pretrained embeddings with source separation and linear optimization on ABX preference data from listening tests. Our model provides interpretable and controllable instrument-wise weights, allowing music producers to retrieve stem-level loops and samples based on mixed reference songs.
+ △ Less
+
+
+
+
+ Submitted 26 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Beyond Pairwise Comparisons: A Distributional Test of Distinctiveness for Machine-Generated Works in Intellectual Property Law
+
+
+
+ Authors:
+
+ Anirban Mukherjee,
+
+ Hannah Hanwen Chang
+
+
+
+
+ Abstract:
+
+ …where the object of evaluation is not a fixed set of works but a generative process with an effectively unbounded output space. We propose a distributional alternative: a two-sample test based on maximum mean discrepancy computed on semantic embeddings to determine if two creative processes-whether human or machine-produce statistically distinguishable outp…
+ ▽ More
+
+
+ Key doctrines, including novelty (patent), originality (copyright), and distinctiveness (trademark), turn on a shared empirical question: whether a body of work is meaningfully distinct from a relevant reference class. Yet analyses typically operationalize this set-level inquiry using item-level evidence: pairwise comparisons among exemplars. That unit-of-analysis mismatch may be manageable for finite corpora of human-created works, where it can be bridged by ad hoc aggregations. But it becomes acute for machine-generated works, where the object of evaluation is not a fixed set of works but a generative process with an effectively unbounded output space. We propose a distributional alternative: a two-sample test based on maximum mean discrepancy computed on semantic embeddings to determine if two creative processes-whether human or machine-produce statistically distinguishable output distributions. The test requires no task-specific training-obviating the need for discovery of proprietary training data to characterize the generative process-and is sample-efficient, often detecting differences with as few as 5-10 images and 7-20 texts. We validate the framework across three domains: handwritten digits (controlled images), patent abstracts (text), and AI-generated art (real-world images). We reveal a perceptual paradox: even when human evaluators distinguish AI outputs from human-created art with only about 58% accuracy, our method detects distributional distinctiveness. Our results present evidence contrary to the view that generative models act as mere regurgitators of training data. Rather than producing outputs statistically indistinguishable from a human baseline-as simple regurgitation would predict-they produce outputs that are semantically human-like yet stochastically distinct, suggesting their dominant function is as a semantic interpolator within a learned latent space.
+ △ Less
+
+
+
+
+ Submitted 26 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ AmbER^2: Dual Ambiguity-Aware Emotion Recognition Applied to Speech and Text
+
+
+
+ Authors:
+
+ Jingyao Wu,
+
+ Grace Lin,
+
+ Yinuo Song,
+
+ Rosalind Picard
+
+
+
+
+ Abstract:
+
+ Emotion recognition is inherently ambiguous, with uncertainty arising both from rater disagreement and from discrepancies across modalities such as speech and text. There is growing interest in modeling rater ambiguity using label distributions. However, modality ambiguity remains underexplored, and multimodal approaches often rely on simple feature fusion w…
+ ▽ More
+
+
+ Emotion recognition is inherently ambiguous, with uncertainty arising both from rater disagreement and from discrepancies across modalities such as speech and text. There is growing interest in modeling rater ambiguity using label distributions. However, modality ambiguity remains underexplored, and multimodal approaches often rely on simple feature fusion without explicitly addressing conflicts between modalities. In this work, we propose AmbER^2, a dual ambiguity-aware framework that simultaneously models rater-level and modality-level ambiguity through a teacher-student architecture with a distribution-wise training objective. Evaluations on IEMOCAP and MSP-Podcast show that AmbER^2 consistently improves distributional fidelity over conventional cross-entropy baselines and achieves performance competitive with, or superior to, recent state-of-the-art systems. For example, on IEMOCAP, AmbER^2 achieves relative improvements of 20.3% on Bhattacharyya coefficient (0.83 vs. 0.69), 13.6% on R^2 (0.67 vs. 0.59), 3.8% on accuracy (0.683 vs. 0.658), and 4.5% on F1 (0.675 vs. 0.646). Further analysis across ambiguity levels shows that explicitly modeling ambiguity is particularly beneficial for highly uncertain samples. These findings highlight the importance of jointly addressing rater and modality ambiguity when building robust emotion recognition systems.
+ △ Less
+
+
+
+
+ Submitted 25 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Federated learning for unpaired multimodal data through a homogeneous transformer model
+
+
+
+ Authors:
+
+ Anders Eklund
+
+
+
+
+ Abstract:
+
+ Training of multimodal foundation models is currently restricted to centralized data centers containing massive, aligned datasets (e.g., image-text pairs). However, in realistic federated environments, data is often unpaired and fragmented across disjoint nodes; one node may hold sensor data, while another holds textual logs. These datasets are strictly priv…
+ ▽ More
+
+
+ Training of multimodal foundation models is currently restricted to centralized data centers containing massive, aligned datasets (e.g., image-text pairs). However, in realistic federated environments, data is often unpaired and fragmented across disjoint nodes; one node may hold sensor data, while another holds textual logs. These datasets are strictly private and share no common samples. Current federated learning (FL) methods fail in this regime, as they assume local clients possess aligned pairs or require sharing raw feature embeddings, which violates data sovereignty. We propose a novel framework to train a global multimodal transformer across decentralized nodes with disjoint modalities. We introduce a small public anchor set to align disjoint private manifolds. Using Gram matrices calculated from these public anchors, we enforce semantic alignment across modalities through centered kernel alignment without ever transmitting private samples, offering a mathematically superior privacy guarantee compared to prototype sharing. Further, we introduce a subspace-stabilized fine-tuning method to handle FL with huge transformer models. We strictly decouple domain-specific magnitude shifts from semantic direction, ensuring that nodes with varying sensor characteristics align geometrically to the global consensus. Lastly, we propose precision weighted averaging, where efficiently obtained uncertainty estimates are used to downweight uncertain nodes. This paper establishes the mathematical backbone for federated unpaired foundation models, enabling a global model to learn a unified representation of the world from fragmented, disjoint, and private data silos without requiring centralized storage or paired samples.
+ △ Less
+
+
+
+
+ Submitted 25 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Training-Free Text-to-Image Compositional Food Generation via Prompt Grafting
+
+
+
+ Authors:
+
+ Xinyue Pan,
+
+ Yuhao Chen,
+
+ Fengqing Zhu
+
+
+
+
+ Abstract:
+
+ …food image generation important for applications such as image-based dietary assessment, where multi-food data augmentation is needed, and recipe visualization. However, modern text-to-image diffusion models struggle to generate accurate multi-food images due to object entanglement, where adjacent foods (e.g., rice and soup) fuse together because many foods…
+ ▽ More
+
+
+ Real-world meal images often contain multiple food items, making reliable compositional food image generation important for applications such as image-based dietary assessment, where multi-food data augmentation is needed, and recipe visualization. However, modern text-to-image diffusion models struggle to generate accurate multi-food images due to object entanglement, where adjacent foods (e.g., rice and soup) fuse together because many foods do not have clear boundaries. To address this challenge, we introduce Prompt Grafting (PG), a training-free framework that combines explicit spatial cues in text with implicit layout guidance during sampling. PG runs a two-stage process where a layout prompt first establishes distinct regions and the target prompt is grafted once layout formation stabilizes. The framework enables food entanglement control: users can specify which food items should remain separated or be intentionally mixed by editing the arrangement of layouts. Across two food datasets, our method significantly improves the presence of target objects and provides qualitative evidence of controllable separation.
+ △ Less
+
+
+
+
+ Submitted 24 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ DiffusionCinema: Text-to-Aerial Cinematography
+
+
+
+ Authors:
+
+ Valerii Serpiva,
+
+ Artem Lykov,
+
+ Jeffrin Sam,
+
+ Aleksey Fedoseev,
+
+ Dzmitry Tsetserukou
+
+
+
+
+ Abstract:
+
+ …from the right and reveal the background waterfall"). Our system encodes the prompt along with an initial visual snapshot from the onboard camera, and a diffusion model samples plausible spatio-temporal motion plans that satisfy both the scene geometry and shot semantics. The generated flight trajectory is then executed autonomously by the UAV to record…
+ ▽ More
+
+
+ We propose a novel Unmanned Aerial Vehicles (UAV) assisted creative capture system that leverages diffusion models to interpret high-level natural language prompts and automatically generate optimal flight trajectories for cinematic video recording. Instead of manually piloting the drone, the user simply describes the desired shot (e.g., "orbit around me slowly from the right and reveal the background waterfall"). Our system encodes the prompt along with an initial visual snapshot from the onboard camera, and a diffusion model samples plausible spatio-temporal motion plans that satisfy both the scene geometry and shot semantics. The generated flight trajectory is then executed autonomously by the UAV to record smooth, repeatable video clips that match the prompt. User evaluation using NASA-TLX showed a significantly lower overall workload with our interface (M = 21.6) compared to a traditional remote controller (M = 58.1), demonstrating a substantial reduction in perceived effort. Mental demand (M = 11.5 vs. 60.5) and frustration (M = 14.0 vs. 54.5) were also markedly lower for our system, confirming clear usability advantages in autonomous text-driven flight control. This project demonstrates a new interaction paradigm: text-to-cinema flight, where diffusion models act as the "creative operator" converting story intentions directly into aerial motion.
+ △ Less
+
+
+
+
+ Submitted 24 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ TEXTS-Diff: TEXTS-Aware Diffusion Model for Real-World Text Image Super-Resolution
+
+
+
+ Authors:
+
+ Haodong He,
+
+ Xin Zhan,
+
+ Yancheng Bai,
+
+ Rui Lan,
+
+ Lei Sun,
+
+ Xiangxiang Chu
+
+
+
+
+ Abstract:
+
+ Real-world text image super-resolution aims to restore overall visual quality and…
+ ▽ More
+
+
+ Real-world text image super-resolution aims to restore overall visual quality and text legibility in images suffering from diverse degradations and text distortions. However, the scarcity of text image data in existing datasets results in poor performance on text regions. In addition, datasets consisting of isolated text samples limit the quality of background reconstruction. To address these limitations, we construct Real-Texts, a large-scale, high-quality dataset collected from real-world images, which covers diverse scenarios and contains natural text instances in both Chinese and English. Additionally, we propose the TEXTS-Aware Diffusion Model (TEXTS-Diff) to achieve high-quality generation in both background and textual regions. This approach leverages abstract concepts to improve the understanding of textual elements within visual scenes and concrete text regions to enhance textual details. It mitigates distortions and hallucination artifacts commonly observed in text regions, while preserving high-quality visual scene fidelity. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple evaluation metrics, exhibiting superior generalization ability and text restoration accuracy in complex scenarios. All the code, model, and dataset will be released.
+ △ Less
+
+
+
+
+ Submitted 24 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ On the Insecurity of Keystroke-Based AI Authorship Detection: Timing-Forgery Attacks Against Motor-Signal Verification
+
+
+
+ Authors:
+
+ David Condrey
+
+
+
+
+ Abstract:
+
+ …) of inter-keystroke intervals, to distinguish human-composed text from AI-generated content. We demonstrate that this class of defenses is insecure against two practical attack classes: the copy-type attack, in which a human transcribes LLM-generated…
+ ▽ More
+
+
+ Recent proposals advocate using keystroke timing signals, specifically the coefficient of variation (δ) of inter-keystroke intervals, to distinguish human-composed text from AI-generated content. We demonstrate that this class of defenses is insecure against two practical attack classes: the copy-type attack, in which a human transcribes LLM-generated text producing authentic motor signals, and timing-forgery attacks, in which automated agents sample inter-keystroke intervals from empirical human distributions. Using 13,000 sessions from the SBU corpus and three timing-forgery variants (histogram sampling, statistical impersonation, and generative LSTM), we show all attacks achieve \ge99.8% evasion rates against five classifiers. While detectors achieve AUC=1.000 against fully-automated injection, they classify \ge99.8% of attack samples as human with mean confidence \ge0.993. We formalize a non-identifiability result: when the detector observes only timing, the mutual information between features and content provenance is zero for copy-type attacks. Although composition and transcription produce statistically distinguishable motor patterns (Cohen's d=1.28), both yield δ values 2-4x above detection thresholds, rendering the distinction security-irrelevant. These systems confirm a human operated the keyboard, but not whether that human originated the text. Securing provenance requires architectures that bind the writing process to semantic content.
+ △ Less
+
+
+
+
+ Submitted 23 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Latent-Space Contrastive Reinforcement Learning for Stable and Efficient LLM Reasoning
+
+
+
+ Authors:
+
+ Lianlei Shan,
+
+ Han Chen,
+
+ Yixuan Wang,
+
+ Zhenjie Liu,
+
+ Wei Li
+
+
+
+
+ Abstract:
+
+ While Large Language Models (LLMs) demonstrate exceptional performance in surface-level text generation, their nature in handling complex multi-step reasoning tasks often remains one of ``statistical fitting'' rather than systematic logical deduction. Traditional Reinforcement Learning (RL) attempts to mitigate this by introducing a ``think-before-sp…
+ ▽ More
+
+
+ While Large Language Models (LLMs) demonstrate exceptional performance in surface-level text generation, their nature in handling complex multi-step reasoning tasks often remains one of ``statistical fitting'' rather than systematic logical deduction. Traditional Reinforcement Learning (RL) attempts to mitigate this by introducing a ``think-before-speak'' paradigm. However, applying RL directly in high-dimensional, discrete token spaces faces three inherent challenges: sample-inefficient rollouts, high gradient estimation variance, and the risk of catastrophic forgetting. To fundamentally address these structural bottlenecks, we propose \textbf{DeepLatent Reasoning (DLR)}, a latent-space bidirectional contrastive reinforcement learning framework. This framework shifts the trial-and-error cost from expensive token-level full sequence generation to the continuous latent manifold. Specifically, we introduce a lightweight assistant model to efficiently sample K reasoning chain encodings within the latent space. These encodings are filtered via a dual reward mechanism based on correctness and formatting; only high-value latent trajectories are fed into a \textbf{frozen main model} for single-pass decoding. To maximize reasoning diversity while maintaining coherence, we design a contrastive learning objective to enable directed exploration within the latent space. Since the main model parameters remain frozen during optimization, this method mathematically eliminates catastrophic forgetting. Experiments demonstrate that under comparable GPU computational budgets, DLR achieves more stable training convergence, supports longer-horizon reasoning chains, and facilitates the sustainable accumulation of reasoning capabilities, providing a viable path toward reliable and scalable reinforcement learning for LLMs.
+ △ Less
+
+
+
+
+ Submitted 23 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Boltzmann-GPT: Bridging Energy-Based World Models and Language Generation
+
+
+
+ Authors:
+
+ Junichiro Niimi
+
+
+
+
+ Abstract:
+
+ Large Language Models (LLMs) generate fluent text, yet whether they truly understand the world or merely produce plausible language about it remains contested. We propose an architectural principle, the mouth is not the brain, that explicitly separates world models from language models. Our architecture comprises three components: a Deep Boltzmann Machine (D…
+ ▽ More
+
+
+ Large Language Models (LLMs) generate fluent text, yet whether they truly understand the world or merely produce plausible language about it remains contested. We propose an architectural principle, the mouth is not the brain, that explicitly separates world models from language models. Our architecture comprises three components: a Deep Boltzmann Machine (DBM) that captures domain structure as an energy-based world model, an adapter that projects latent belief states into embedding space, and a frozen GPT-2 that provides linguistic competence without domain knowledge. We instantiate this framework in the consumer review domain using Amazon smartphone reviews. Experiments demonstrate that (1) conditioning through the world model yields significantly higher sentiment correlation, lower perplexity, and greater semantic similarity compared to prompt-based generation alone; (2) the DBM's energy function distinguishes coherent from incoherent market configurations, assigning higher energy to implausible brand-price combinations; and (3) interventions on specific attributes propagate causally to generated text with intervened outputs exhibiting distributions statistically consistent with naturally occurring samples sharing the target configuration. These findings suggest that even small-scale language models can achieve consistent, controllable generation when connected to an appropriate world model, providing empirical support for separating linguistic competence from world understanding.
+ △ Less
+
+
+
+
+ Submitted 23 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ BibAgent: An Agentic Framework for Traceable Miscitation Detection in Scientific Literature
+
+
+
+ Authors:
+
+ Peiran Li,
+
+ Fangzhou Lin,
+
+ Shuo Xing,
+
+ Xiang Zheng,
+
+ Xi Hong,
+
+ Jiashuo Sun,
+
+ Zhengzhong Tu,
+
+ Chaoqun Ni
+
+
+
+
+ Abstract:
+
+ …volumes, while existing automated tools are restricted by abstract-only analysis or small-scale, domain-specific datasets in part due to the "paywall barrier" of full-text access. We introduce BibAgent, a scalable, end-to-end agentic framework for automated citation verification. BibAgent integrates retrieval, reasoning, and adaptive evidence aggrega…
+ ▽ More
+
+
+ Citations are the bedrock of scientific authority, yet their integrity is compromised by widespread miscitations: ranging from nuanced distortions to fabricated references. Systematic citation verification is currently unfeasible; manual review cannot scale to modern publishing volumes, while existing automated tools are restricted by abstract-only analysis or small-scale, domain-specific datasets in part due to the "paywall barrier" of full-text access. We introduce BibAgent, a scalable, end-to-end agentic framework for automated citation verification. BibAgent integrates retrieval, reasoning, and adaptive evidence aggregation, applying distinct strategies for accessible and paywalled sources. For paywalled references, it leverages a novel Evidence Committee mechanism that infers citation validity via downstream citation consensus. To support systematic evaluation, we contribute a 5-category Miscitation Taxonomy and MisciteBench, a massive cross-disciplinary benchmark comprising 6,350 miscitation samples spanning 254 fields. Our results demonstrate that BibAgent outperforms state-of-the-art Large Language Model (LLM) baselines in citation verification accuracy and interpretability, providing scalable, transparent detection of citation misalignments across the scientific literature.
+ △ Less
+
+
+
+
+ Submitted 12 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Recovering Communities in Structured Random Graphs
+
+
+
+ Authors:
+
+ Michael Kapralov,
+
+ Luca Trevisan,
+
+ Weronika Wrzos-Kaminska
+
+
+
+
+ Abstract:
+
+ …edges induced by communities. The communities themselves form a collection of vertex-disjoint sparse cuts in the expected graph, and can be recovered, often exactly, from a sample as long as a separation condition on the intra- and inter-community edge probabilities is satisfied.
+ In this paper, we ask whether the presence of a large number of overlapping s…
+ ▽ More
+
+
+ The problem of recovering planted community structure in random graphs has received a lot of attention in the literature on the stochastic block model, where the input is a random graph in which edges crossing between different communities appear with smaller probability than edges induced by communities. The communities themselves form a collection of vertex-disjoint sparse cuts in the expected graph, and can be recovered, often exactly, from a sample as long as a separation condition on the intra- and inter-community edge probabilities is satisfied.
+ In this paper, we ask whether the presence of a large number of overlapping sparsest cuts in the expected graph still allows recovery. For example, the d-dimensional hypercube graph admits d distinct (balanced) sparsest cuts, one for every coordinate. Can these cuts be identified given a random sample of the edges of the hypercube where each edge is present independently with some probability p\in (0, 1)? We show that this is the case, in a very strong sense: the sparsest balanced cut in a sample of the hypercube at rate p=C\log d/d for a sufficiently large constant C is 1/\text{poly}(d)-close to a coordinate cut with high probability. This is asymptotically optimal and allows approximate recovery of all d cuts simultaneously. Furthermore, for an appropriate sample of hypercube-like graphs recovery can be made exact. The proof is essentially a strong hypercube cut sparsification bound that combines a theorem of Friedgut, Kalai and Naor on boolean functions whose Fourier transform concentrates on the first level of the Fourier spectrum with Karger's cut counting argument.
+ △ Less
+
+
+
+
+ Submitted 23 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Quantum correlation of neutral charmed mesons at BESIII
+
+
+
+ Authors:
+
+ Alex Gilman
+
+
+
+
+ Abstract:
+
+ BESIII has recently accumulated a large data sample near the ψ(3770) production threshold corresponding to an integrated luminosity of 20\text{ fb}^{-1}. Neutral D^0\bar{D}^0 pairs produced at the ψ(3770) are in a C-odd correlated state, providing a unique laboratory to measure the strong-phase differences be…
+ ▽ More
+
+
+ BESIII has recently accumulated a large data sample near the ψ(3770) production threshold corresponding to an integrated luminosity of 20\text{ fb}^{-1}. Neutral D^0\bar{D}^0 pairs produced at the ψ(3770) are in a C-odd correlated state, providing a unique laboratory to measure the strong-phase differences between D^0 and \bar{D}^0 decays. These parameters are essential inputs to the study of CP violation in heavy-flavor physics, primarily in the determinations of the CKM angle gamma and charm-mixing parameters. These proceedings report new measurements of strong-phase differences in different neutral D decays at BESIII, including new measurements of the strong phases in D\to K^+K^-π^+π^- decays. Additionally reported is the first observation of correlated DD pairs produced at e^+e^- center-of-mass energies above the ψ(3770) threshold, where e^+e^-\to D^{*}\bar{D} and e^+e^-\to D^{*}\bar{D}^{*} processes also occur. These processes produce both C-odd and C-even correlated D^0\bar{D}^0 pairs, which allow for new measurement techniques to determine strong-phases from previously unused datasets.
+ △ Less
+
+
+
+
+ Submitted 23 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ CER-HV: A CER-Based Human-in-the-Loop Framework for Cleaning Datasets Applied to Arabic-Script HTR
+
+
+
+ Authors:
+
+ Sana Al-azzawi,
+
+ Elisa Barney,
+
+ Marcus Liwicki
+
+
+
+
+ Abstract:
+
+ Handwritten text recognition (HTR) for Arabic-script languages still lags behind Latin-script HTR, despite recent advances in model architectures, datasets, and benchmarks. We show that data quality is a significant limiting factor in many published datasets and propose CER-HV (CER-based Ranking with Human Verification) as a framework to detect and clean lab…
+ ▽ More
+
+
+ Handwritten text recognition (HTR) for Arabic-script languages still lags behind Latin-script HTR, despite recent advances in model architectures, datasets, and benchmarks. We show that data quality is a significant limiting factor in many published datasets and propose CER-HV (CER-based Ranking with Human Verification) as a framework to detect and clean label errors. CER-HV combines a CER-based noise detector, built on a carefully configured Convolutional Recurrent Neural Network (CRNN) with early stopping to avoid overfitting noisy samples, and a human-in-the-loop (HITL) step that verifies high-ranking samples. The framework reveals that several existing datasets contain previously underreported problems, including transcription, segmentation, orientation, and non-text content errors. These have been identified with up to 90 percent precision in the Muharaf and 80-86 percent in the PHTI datasets.
+ We also show that our CRNN achieves state-of-the-art performance across five of the six evaluated datasets, reaching 8.45 percent Character Error Rate (CER) on KHATT (Arabic), 8.26 percent on PHTI (Pashto), 10.66 percent on Ajami, and 10.11 percent on Muharaf (Arabic), all without any data cleaning. We establish a new baseline of 11.3 percent CER on the PHTD (Persian) dataset. Applying CER-HV improves the evaluation CER by 0.3-0.6 percent on the cleaner datasets and 1.0-1.8 percent on the noisier ones. Although our experiments focus on documents written in an Arabic-script language, including Arabic, Persian, Urdu, Ajami, and Pashto, the framework is general and can be applied to other text recognition datasets.
+ △ Less
+
+
+
+
+ Submitted 23 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ CORD: Bridging the Audio-Text Reasoning Gap via Weighted On-policy Cross-modal Distillation
+
+
+
+ Authors:
+
+ Jing Hu,
+
+ Danxiang Zhu,
+
+ Xianlong Luo,
+
+ Dan Zhang,
+
+ Shuwei He,
+
+ Yishu Lei,
+
+ Haitao Zheng,
+
+ Shikun Feng,
+
+ Jingzhou He,
+
+ Yu Sun,
+
+ Hua Wu,
+
+ Haifeng Wang
+
+
+
+
+ Abstract:
+
+ Large Audio Language Models (LALMs) have garnered significant research interest. Despite being built upon text-based large language models (LLMs), LALMs frequently exhibit a degradation in knowledge and reasoning capabilities. We hypothesize that this limitation stems from the failure of current training paradigms to effectively bridge the acoustic-semantic…
+ ▽ More
+
+
+ Large Audio Language Models (LALMs) have garnered significant research interest. Despite being built upon text-based large language models (LLMs), LALMs frequently exhibit a degradation in knowledge and reasoning capabilities. We hypothesize that this limitation stems from the failure of current training paradigms to effectively bridge the acoustic-semantic gap within the feature representation space. To address this challenge, we propose CORD, a unified alignment framework that performs online cross-modal self-distillation. Specifically, it aligns audio-conditioned reasoning with its text-conditioned counterpart within a unified model. Leveraging the text modality as an internal teacher, CORD performs multi-granularity alignment throughout the audio rollout process. At the token level, it employs on-policy reverse KL divergence with importance-aware weighting to prioritize early and semantically critical tokens. At the sequence level, CORD introduces a judge-based global reward to optimize complete reasoning trajectories via Group Relative Policy Optimization (GRPO). Empirical results across multiple benchmarks demonstrate that CORD consistently enhances audio-conditioned reasoning and substantially bridges the audio-text performance gap with only 80k synthetic training samples, validating the efficacy and data efficiency of our on-policy, multi-level cross-modal alignment approach.
+ △ Less
+
+
+
+
+ Submitted 23 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Towards Latent Diffusion Suitable For Text
+
+
+
+ Authors:
+
+ Nesta Midavaine,
+
+ Christian A. Naesseth,
+
+ Grigory Bartosh
+
+
+
+
+ Abstract:
+
+ Language diffusion models aim to improve sampling speed and coherence over autoregressive LLMs. We introduce Neural Flow Diffusion Models for language generation, an extension of NFDM that enables the straightforward application of continuous diffusion models to discrete state spaces. NFDM learns a multivariate forward process from the data, ensuring that th…
+ ▽ More
+
+
+ Language diffusion models aim to improve sampling speed and coherence over autoregressive LLMs. We introduce Neural Flow Diffusion Models for language generation, an extension of NFDM that enables the straightforward application of continuous diffusion models to discrete state spaces. NFDM learns a multivariate forward process from the data, ensuring that the forward process and generative trajectory are a good fit for language modeling. Our model substantially reduces the likelihood gap with autoregressive models of the same size, while achieving sample quality comparable to that of previous latent diffusion models.
+ △ Less
+
+
+
+
+ Submitted 7 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ synthocr-gen: A synthetic ocr dataset generator for low-resource languages- breaking the data barrier
+
+
+
+ Authors:
+
+ Haq Nawaz Malik,
+
+ Kh Mohmad Shafi,
+
+ Tanveer Ahmad Reshi
+
+
+
+
+ Abstract:
+
+ …Manual dataset creation for such languages is prohibitively expensive, time-consuming, and error-prone, often requiring word by word transcription of printed or handwritten text.
+ We present SynthOCR-Gen, an open-source synthetic OCR dataset generator specifically designed for low-resource languages. Our tool addresses the fundamental bottleneck in OCR dev…
+ ▽ More
+
+
+ Optical Character Recognition (OCR) for low-resource languages remains a significant challenge due to the scarcity of large-scale annotated training datasets. Languages such as Kashmiri, with approximately 7 million speakers and a complex Perso-Arabic script featuring unique diacritical marks, currently lack support in major OCR systems including Tesseract, TrOCR, and PaddleOCR. Manual dataset creation for such languages is prohibitively expensive, time-consuming, and error-prone, often requiring word by word transcription of printed or handwritten text.
+ We present SynthOCR-Gen, an open-source synthetic OCR dataset generator specifically designed for low-resource languages. Our tool addresses the fundamental bottleneck in OCR development by transforming digital Unicode text corpora into ready-to-use training datasets. The system implements a comprehensive pipeline encompassing text segmentation (character, word, n-gram, sentence, and line levels), Unicode normalization with script purity enforcement, multi-font rendering with configurable distribution, and 25+ data augmentation techniques simulating real-world document degradations including rotation, blur, noise, and scanner artifacts.
+ We demonstrate the efficacy of our approach by generating a 600,000-sample word-segmented Kashmiri OCR dataset, which we release publicly on HuggingFace. This work provides a practical pathway for bringing low-resource languages into the era of vision-language AI models, and the tool is openly available for researchers and practitioners working with underserved writing systems worldwide.
+ △ Less
+
+
+
+
+ Submitted 22 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Mecellem Models: Turkish Models Trained from Scratch and Continually Pre-trained for the Legal Domain
+
+
+
+ Authors:
+
+ Özgür Uğur,
+
+ Mahmut Göksu,
+
+ Mahmut Çimen,
+
+ Musa Yılmaz,
+
+ Esra Şavirdi,
+
+ Alp Talha Demir,
+
+ Rumeysa Güllüce,
+
+ İclal Çetin,
+
+ Ömer Can Sağbaş
+
+
+
+
+ Abstract:
+
+ …Model with Continual Pre-training (CPT): Qwen3-1.7B and Qwen3-4B models adapted to Turkish legal domain through controlled curriculum learning. Four-phase CPT with optimal sample ratios enables gradual transition from general language knowledge to specialized legal terminology and long-context reasoning. This approach achieves 36.2% perplexity reduction on T…
+ ▽ More
+
+
+ This paper presents Mecellem models, a framework for developing specialized language models for the Turkish legal domain through domain adaptation strategies. We make two contributions: (1)Encoder Model Pre-trained from Scratch: ModernBERT-based bidirectional encoders pre-trained on a Turkish-dominant corpus of 112.7 billion tokens. We implement a checkpoint selection strategy that evaluates downstream retrieval performance throughout training, revealing that optimal checkpoints achieve best retrieval scores before pre-training loss reaches its minimum. Our encoder models achieve top-3 rankings on the Turkish retrieval leaderboard, with smaller models (155M parameters) achieving comparable performance to larger reference models (307M-567M parameters). Our approach achieves 92.36% production efficiency compared to state-of-the-art models (embeddinggemma-300m: 100.00%, BAAI/bge-m3: 99.54%, newmindai/bge-m3-stsb: 94.38%), ranking fourth overall despite requiring less computational resources. SOTA models rely on multi-stage, computationally intensive training pipelines, making our single-stage pre-training followed by efficient post-training approach a cost-effective alternative; (2)Decoder Model with Continual Pre-training (CPT): Qwen3-1.7B and Qwen3-4B models adapted to Turkish legal domain through controlled curriculum learning. Four-phase CPT with optimal sample ratios enables gradual transition from general language knowledge to specialized legal terminology and long-context reasoning. This approach achieves 36.2% perplexity reduction on Turkish legal text, demonstrating domain adaptation gains.
+ △ Less
+
+
+
+
+ Submitted 22 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ STAR: Semantic Table Representation with Header-Aware Clustering and Adaptive Weighted Fusion
+
+
+
+ Authors:
+
+ Shui-Hsiang Hsu,
+
+ Tsung-Hsiang Chou,
+
+ Chen-Jui Yu,
+
+ Yao-Chung Fan
+
+
+
+
+ Abstract:
+
+ …is the task of retrieving the most relevant tables from large-scale corpora given natural language queries. However, structural and semantic discrepancies between unstructured text and structured tables make embedding alignment particularly challenging. Recent methods such as QGpT attempt to enrich table semantics by generating synthetic queries, yet they st…
+ ▽ More
+
+
+ Table retrieval is the task of retrieving the most relevant tables from large-scale corpora given natural language queries. However, structural and semantic discrepancies between unstructured text and structured tables make embedding alignment particularly challenging. Recent methods such as QGpT attempt to enrich table semantics by generating synthetic queries, yet they still rely on coarse partial-table sampling and simple fusion strategies, which limit semantic diversity and hinder effective query-table alignment. We propose STAR (Semantic Table Representation), a lightweight framework that improves semantic table representation through semantic clustering and weighted fusion. STAR first applies header-aware K-means clustering to group semantically similar rows and selects representative centroid instances to construct a diverse partial table. It then generates cluster-specific synthetic queries to comprehensively cover the table's semantic space. Finally, STAR employs weighted fusion strategies to integrate table and query embeddings, enabling fine-grained semantic alignment. This design enables STAR to capture complementary information from structured and textual sources, improving the expressiveness of table representations. Experiments on five benchmarks show that STAR achieves consistently higher Recall than QGpT on all datasets, demonstrating the effectiveness of semantic clustering and adaptive weighted fusion for robust table representation. Our code is available at https://github.com/adsl135789/STAR.
+ △ Less
+
+
+
+
+ Submitted 22 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ CGPT: Cluster-Guided Partial Tables with LLM-Generated Supervision for Table Retrieval
+
+
+
+ Authors:
+
+ Tsung-Hsiang Chou,
+
+ Chen-Jui Yu,
+
+ Shui-Hsiang Hsu,
+
+ Yao-Chung Fan
+
+
+
+
+ Abstract:
+
+ General-purpose embedding models have demonstrated strong performance in text retrieval but remain suboptimal for table retrieval, where highly structured content leads to semantic compression and query-table mismatch. Recent LLM-based retrieval augmentation methods mitigate this issue by generating synthetic queries, yet they often rely on heuristic partial…
+ ▽ More
+
+
+ General-purpose embedding models have demonstrated strong performance in text retrieval but remain suboptimal for table retrieval, where highly structured content leads to semantic compression and query-table mismatch. Recent LLM-based retrieval augmentation methods mitigate this issue by generating synthetic queries, yet they often rely on heuristic partial-table selection and seldom leverage these synthetic queries as supervision to improve the embedding model. We introduce CGPT, a training framework that enhances table retrieval through LLM-generated supervision. CGPT constructs semantically diverse partial tables by clustering table instances using K-means and sampling across clusters to broaden semantic coverage. An LLM then generates synthetic queries for these partial tables, which are used in hard-negative contrastive fine-tuning to refine the embedding model. Experiments across four public benchmarks (MimoTable, OTTQA, FetaQA, and E2E-WTQ) show that CGPT consistently outperforms retrieval baselines, including QGpT, with an average R@1 improvement of 16.54 percent. In a unified multi-domain corpus setting, CGPT further demonstrates strong cross-domain generalization and remains effective even when using smaller LLMs for synthetic query generation. These results indicate that semantically guided partial-table construction, combined with contrastive training from LLM-generated supervision, provides an effective and scalable paradigm for large-scale table retrieval. Our code is available at https://github.com/yumeow0122/CGPT.
+ △ Less
+
+
+
+
+ Submitted 22 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Determinants of Training Corpus Size for Clinical Text Classification
+
+
+
+ Authors:
+
+ Jaya Chaturvedi,
+
+ Saniya Deshpande,
+
+ Chenkai Ma,
+
+ Robert Cobb,
+
+ Angus Roberts,
+
+ Robert Stewart,
+
+ Daniel Stahl,
+
+ Diana Shamsutdinova
+
+
+
+
+ Abstract:
+
+ Introduction: Clinical text classification using natural language processing (NLP) models requires adequate training data to achieve optimal performance. For that, 200-500 documents are typically annotated. The number is constrained by time and costs and lacks justification of the…
+ ▽ More
+
+
+ Introduction: Clinical text classification using natural language processing (NLP) models requires adequate training data to achieve optimal performance. For that, 200-500 documents are typically annotated. The number is constrained by time and costs and lacks justification of the sample size requirements and their relationship to text vocabulary properties.
+ Methods: Using the publicly available MIMIC-III dataset containing hospital discharge notes with ICD-9 diagnoses as labels, we employed pre-trained BERT embeddings followed by Random Forest classifiers to identify 10 randomly selected diagnoses, varying training corpus sizes from 100 to 10,000 documents, and analyzed vocabulary properties by identifying strong and noisy predictive words through Lasso logistic regression on bag-of-words embeddings.
+ Results: Learning curves varied significantly across the 10 classification tasks despite identical preprocessing and algorithms, with 600 documents sufficient to achieve 95% of the performance attainable with 10,000 documents for all tasks. Vocabulary analysis revealed that more strong predictors and fewer noisy predictors were associated with steeper learning curves, where every 100 additional noisy words decreased accuracy by approximately 0.02 while 100 additional strong predictors increased maximum accuracy by approximately 0.04.
+ △ Less
+
+
+
+
+ Submitted 22 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Towards Realistic Remote Sensing Dataset Distillation with Discriminative Prototype-guided Diffusion
+
+
+
+ Authors:
+
+ Yonghao Xu,
+
+ Pedram Ghamisi,
+
+ Qihao Weng
+
+
+
+
+ Abstract:
+
+ …these challenges, this study introduces the concept of dataset distillation into the field of remote sensing image interpretation for the first time. Specifically, we train a text-to-image diffusion model to condense a large-scale remote sensing dataset into a compact and representative distilled dataset. To improve the discriminative quality of the synthesi…
+ ▽ More
+
+
+ Recent years have witnessed the remarkable success of deep learning in remote sensing image interpretation, driven by the availability of large-scale benchmark datasets. However, this reliance on massive training data also brings two major challenges: (1) high storage and computational costs, and (2) the risk of data leakage, especially when sensitive categories are involved. To address these challenges, this study introduces the concept of dataset distillation into the field of remote sensing image interpretation for the first time. Specifically, we train a text-to-image diffusion model to condense a large-scale remote sensing dataset into a compact and representative distilled dataset. To improve the discriminative quality of the synthesized samples, we propose a classifier-driven guidance by injecting a classification consistency loss from a pre-trained model into the diffusion training process. Besides, considering the rich semantic complexity of remote sensing imagery, we further perform latent space clustering on training samples to select representative and diverse prototypes as visual style guidance, while using a visual language model to provide aggregated text descriptions. Experiments on three high-resolution remote sensing scene classification benchmarks show that the proposed method can distill realistic and diverse samples for downstream model training. Code and pre-trained models are available online (https://github.com/YonghaoXu/DPD).
+ △ Less
+
+
+
+
+ Submitted 22 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Off-Policy Actor-Critic with Sigmoid-Bounded Entropy for Real-World Robot Learning
+
+
+
+ Authors:
+
+ Xiefeng Wu,
+
+ Mingyu Hu,
+
+ Shu Zhang
+
+
+
+
+ Abstract:
+
+ Deploying reinforcement learning in the real world remains challenging due to sample inefficiency, sparse rewards, and noisy visual observations. Prior work leverages demonstrations and human feedback to improve learning efficiency and robustness. However, offline-to-online methods need large datasets and can be unstable, while VLA-assisted RL relies on larg…
+ ▽ More
+
+
+ Deploying reinforcement learning in the real world remains challenging due to sample inefficiency, sparse rewards, and noisy visual observations. Prior work leverages demonstrations and human feedback to improve learning efficiency and robustness. However, offline-to-online methods need large datasets and can be unstable, while VLA-assisted RL relies on large-scale pretraining and fine-tuning. As a result, a low-cost real-world RL method with minimal data requirements has yet to emerge. We introduce \textbf{SigEnt-SAC}, an off-policy actor-critic method that learns from scratch using a single expert trajectory. Our key design is a sigmoid-bounded entropy term that prevents negative-entropy-driven optimization toward out-of-distribution actions and reduces Q-function oscillations. We benchmark SigEnt-SAC on D4RL tasks against representative baselines. Experiments show that SigEnt-SAC substantially alleviates Q-function oscillations and reaches a 100\% success rate faster than prior methods. Finally, we validate SigEnt-SAC on four real-world robotic tasks across multiple embodiments, where agents learn from raw images and sparse rewards; results demonstrate that SigEnt-SAC can learn successful policies with only a small number of real-world interactions, suggesting a low-cost and practical pathway for real-world RL deployment.
+ △ Less
+
+
+
+
+ Submitted 22 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Observation of CP violation in B^{0}\!\to{J\mskip-3mu/\mskip-2muψ}ρ(770)^0 decays
+
+
+
+ Authors:
+
+ LHCb collaboration,
+
+ R. Aaij,
+
+ A. S. W. Abdelmotteleb,
+
+ C. Abellan Beteta,
+
+ F. Abudinén,
+
+ T. Ackernley,
+
+ A. A. Adefisoye,
+
+ B. Adeva,
+
+ M. Adinolfi,
+
+ P. Adlarson,
+
+ C. Agapopoulou,
+
+ C. A. Aidala,
+
+ Z. Ajaltouni,
+
+ S. Akar,
+
+ K. Akiba,
+
+ M. Akthar,
+
+ P. Albicocco,
+
+ J. Albrecht,
+
+ R. Aleksiejunas,
+
+ F. Alessio,
+
+ P. Alvarez Cartelle,
+
+ R. Amalric,
+
+ S. Amato,
+
+ J. L. Amey,
+
+ Y. Amhis
+ , et al. (1169 additional authors not shown)
+
+
+
+ Abstract:
+
+ …decays is measured using proton-proton collision data corresponding to an integrated luminosity of 6\,\text{fb}^{-1}, collected with the LHCb detector at a center-of-mass energy of 13\,\text{TeV} during the years 2015-2018. The CP-violation parameters for this process are determined to be…
+ ▽ More
+
+
+ The time-dependent CP asymmetry in B^{0}\!\to{J\mskip-3mu/\mskip-2muψ}ρ(770)^0 decays is measured using proton-proton collision data corresponding to an integrated luminosity of 6\,\text{fb}^{-1}, collected with the LHCb detector at a center-of-mass energy of 13\,\text{TeV} during the years 2015-2018. The CP-violation parameters for this process are determined to be 2β^{\rm eff}_{c\bar{c}d} = 0.710 \pm 0.084 \pm 0.028\,\text{rad} and |λ| = 1.019 \pm 0.034 \pm 0.009, where the first uncertainty is statistical and the second systematic. This constitutes the first observation of time-dependent CP violation in B meson decays to charmonium final states mediated by a b\!\to{c\bar{c}d} transition. These results are consistent with, and two times more precise than, the previous LHCb measurement based on a data sample collected at 7 and 8\,\text{TeV} corresponding to an integrated luminosity of 3\,\text{fb}^{-1}. Assuming approximate SU(3) flavor symmetry, these two measurements are combined to set the most stringent constraint on the enguin contribution, Δφ_{s}, to the CP-violating phase φ_{s} in B^{0}_{s}\!\to{J\mskip-3mu/\mskip-2muψ}φ(1020) decays, yielding Δφ_{s} = 5.0 \pm 4.2\,\text{mrad}.
+ △ Less
+
+
+
+
+ Submitted 23 January, 2026; v1 submitted 21 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Low-Dimensional Adaptation of Rectified Flow: A New Perspective through the Lens of Diffusion and Stochastic Localization
+
+
+
+ Authors:
+
+ Saptarshi Roy,
+
+ Alessandro Rinaldo,
+
+ Purnamrita Sarkar
+
+
+
+
+ Abstract:
+
+ …In this paper, we investigate the degree to which RF automatically adapts to the intrinsic low dimensionality of the support of the target distribution to accelerate sampling. We show that, using a carefully designed choice of the time-discretization scheme and with sufficiently accurate drift estimates, the RF sampler enjoys an iteration complexity of orde…
+ ▽ More
+
+
+ In recent years, Rectified flow (RF) has gained considerable popularity largely due to its generation efficiency and state-of-the-art performance. In this paper, we investigate the degree to which RF automatically adapts to the intrinsic low dimensionality of the support of the target distribution to accelerate sampling. We show that, using a carefully designed choice of the time-discretization scheme and with sufficiently accurate drift estimates, the RF sampler enjoys an iteration complexity of order O(k/\varepsilon) (up to log factors), where \varepsilon is the precision in total variation distance and k is the intrinsic dimension of
+ the target distribution. In addition, we show that the denoising diffusion probabilistic model (DDPM) procedure is equivalent to a stochastic version of RF by establishing a novel connection between these processes and stochastic localization. Building on this connection, we further design a stochastic RF sampler that also adapts to the low-dimensionality of the target distribution under milder requirements on the accuracy of the drift estimates, and also with a specific time schedule. We illustrate with simulations on the synthetic data and text-to-image data experiments the improved performance of the proposed samplers implementing the newly designed time-discretization schedules.
+ △ Less
+
+
+
+
+ Submitted 21 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ DevPrompt: Deviation-Based Prompt Learning for One-Normal ShotImage Anomaly Detection
+
+
+
+ Authors:
+
+ Morteza Poudineh,
+
+ Marc Lalonde
+
+
+
+
+ Abstract:
+
+ Few-normal shot anomaly detection (FNSAD) aims to detect abnormal regions in images using only a few normal training samples, making the task highly challenging due to limited supervision and the diversity of potential defects. Recent approaches leverage vision-language models such as CLIP with prompt-based learning to align image and…
+ ▽ More
+
+
+ Few-normal shot anomaly detection (FNSAD) aims to detect abnormal regions in images using only a few normal training samples, making the task highly challenging due to limited supervision and the diversity of potential defects. Recent approaches leverage vision-language models such as CLIP with prompt-based learning to align image and text features. However, existing methods often exhibit weak discriminability between normal and abnormal prompts and lack principled scoring mechanisms for patch-level anomalies. We propose a deviation-guided prompt learning framework that integrates the semantic power of vision-language models with the statistical reliability of deviation-based scoring. Specifically, we replace fixed prompt prefixes with learnable context vectors shared across normal and abnormal prompts, while anomaly-specific suffix tokens enable class-aware alignment. To enhance separability, we introduce a deviation loss with Top-K Multiple Instance Learning (MIL), modeling patch-level features as Gaussian deviations from the normal distribution. This allows the network to assign higher anomaly scores to patches with statistically significant deviations, improving localization and interpretability. Experiments on the MVTecAD and VISA benchmarks demonstrate superior pixel-level detection performance compared to PromptAD and other baselines. Ablation studies further validate the effectiveness of learnable prompts, deviation-based scoring, and the Top-K MIL strategy.
+ △ Less
+
+
+
+
+ Submitted 21 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Ambient Dataloops: Generative Models for Dataset Refinement
+
+
+
+ Authors:
+
+ Adrián Rodríguez-Muñoz,
+
+ William Daspit,
+
+ Adam Klivans,
+
+ Antonio Torralba,
+
+ Constantinos Daskalakis,
+
+ Giannis Daras
+
+
+
+
+ Abstract:
+
+ …Ambient Dataloops, an iterative framework for refining datasets that makes it easier for diffusion models to learn the underlying data distribution. Modern datasets contain samples of highly varying quality, and training directly on such heterogeneous data often yields suboptimal models. We propose a dataset-model co-evolution process; at each iteration of o…
+ ▽ More
+
+
+ We propose Ambient Dataloops, an iterative framework for refining datasets that makes it easier for diffusion models to learn the underlying data distribution. Modern datasets contain samples of highly varying quality, and training directly on such heterogeneous data often yields suboptimal models. We propose a dataset-model co-evolution process; at each iteration of our method, the dataset becomes progressively higher quality, and the model improves accordingly. To avoid destructive self-consuming loops, at each generation, we treat the synthetically improved samples as noisy, but at a slightly lower noisy level than the previous iteration, and we use Ambient Diffusion techniques for learning under corruption. Empirically, Ambient Dataloops achieve state-of-the-art performance in unconditional and text-conditional image generation and de novo protein design. We further provide a theoretical justification for the proposed framework that captures the benefits of the data looping procedure.
+ △ Less
+
+
+
+
+ Submitted 21 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Solar twins in Gaia DR3 GSP-Spec I. Building a large catalog of Solar twins with ages
+
+
+
+ Authors:
+
+ Daisuke Taniguchi,
+
+ Patrick de Laverny,
+
+ Alejandra Recio-Blanco,
+
+ Takuji Tsujimoto,
+
+ Pedro A. Palicio
+
+
+
+
+ Abstract:
+
+ …confirmed the age--[X/Fe] relations for several species (e.g., Al, Si, Ca, and Y), demonstrating that trends previously identified in small but very high-precision samples persist in a much larger, independent…
+ ▽ More
+
+
+ [Abbreviated] Context. Solar twins, stars whose stellar parameters (Teff, log g, and [M/H]) are very close to the Solar ones, offer a unique opportunity to investigate Galactic archaeology with very high accuracy and precision. However, most previous catalogs of Solar twins contain only a small number of objects (typically a few tens), and their selection functions are poorly characterized. Aims. We aim at building a large catalog of Solar twins from Gaia DR3 GSP-Spec, providing model-driven, rather than data-driven, stellar parameters including ages, together with a well-characterized selection function. Methods. Using stellar parameters from the Gaia DR3 GSP-Spec catalog, we selected Solar-twin candidates whose parameters lie within +- 200 K in Teff, +- 0.2 in log g, and +- 0.1 dex in [M/H] of the Solar values. Candidates unlikely to be genuine Solar twins were removed using Gaia flags and photometric constraints. We determined accurate ages for individual twins with a Bayesian isochrone-projection method, considering three combinations of parameters: Teff, [M/H], and either log g, M_G, or M_Ks. We also constructed a mock catalog to characterize the selection function. Results. Our final GSP-Spec Solar-twin catalog contains 6,594 stars. The mock catalog consisting of 75,588 artificial twins well reproduces the main characteristics of the observed catalog, especially for ages determined with M_G or M_Ks. To demonstrate the usefulness of our catalog, we compared chemical abundances [X/Fe] with age. We statistically confirmed the age--[X/Fe] relations for several species (e.g., Al, Si, Ca, and Y), demonstrating that trends previously identified in small but very high-precision samples persist in a much larger, independent sample. Conclusions. Our study bridges small high-precision Solar-twin samples and large data-driven ones, enabling demographic studies of Solar twins.
+ △ Less
+
+
+
+
+ Submitted 21 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Iterative Refinement Improves Compositional Image Generation
+
+
+
+ Authors:
+
+ Shantanu Jaiswal,
+
+ Mihir Prabhudesai,
+
+ Nikash Bhardwaj,
+
+ Zheyang Qin,
+
+ Amir Zadeh,
+
+ Chuan Li,
+
+ Katerina Fragkiadaki,
+
+ Deepak Pathak
+
+
+
+
+ Abstract:
+
+ Text-to-image (T2I) models have achieved remarkable progress, yet they continue to struggle with complex prompts that require simultaneously handling multiple objects, relations, and attributes. Existing inference-time strategies, such as parallel…
+ ▽ More
+
+
+ Text-to-image (T2I) models have achieved remarkable progress, yet they continue to struggle with complex prompts that require simultaneously handling multiple objects, relations, and attributes. Existing inference-time strategies, such as parallel sampling with verifiers or simply increasing denoising steps, can improve prompt alignment but remain inadequate for richly compositional settings where many constraints must be satisfied. Inspired by the success of chain-of-thought reasoning in large language models, we propose an iterative test-time strategy in which a T2I model progressively refines its generations across multiple steps, guided by feedback from a vision-language model as the critic in the loop. Our approach is simple, requires no external tools or priors, and can be flexibly applied to a wide range of image generators and vision-language models. Empirically, we demonstrate consistent gains on image generation across benchmarks: a 16.9% improvement in all-correct rate on ConceptMix (k=7), a 13.8% improvement on T2I-CompBench (3D-Spatial category) and a 12.5% improvement on Visual Jenga scene decomposition compared to compute-matched parallel sampling. Beyond quantitative gains, iterative refinement produces more faithful generations by decomposing complex prompts into sequential corrections, with human evaluators preferring our method 58.7% of the time over 41.3% for the parallel baseline. Together, these findings highlight iterative self-correction as a broadly applicable principle for compositional image generation. Results and visualizations are available at https://iterative-img-gen.github.io/
+ △ Less
+
+
+
+
+ Submitted 21 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Probing Late-Stage Hadronic Interactions at High Baryon Density via K^{*0} Production in the RHIC Beam Energy Scan Program
+
+
+
+ Authors:
+
+ The STAR Collaboration
+
+
+
+
+ Abstract:
+
+ …using the high-statistics data sample collected by the STAR experiment during the Beam Energy Scan II (BES-II) program at RHIC. The transeverse momentum (p_{T})-integrated yield ratios (K^{*0} + \overline{K^{*0}})/(K^{+} + K^{-}) in central collisions show a suppression relative to peripheral collisions at the…
+ ▽ More
+
+
+ A precision measurement of the K^{*0} meson yield is reported in Au+Au collisions at \sqrt{s_{NN}} = 7.7,\; 11.5,\; 14.6,\; 19.6, and 27~\mathrm{GeV} using the high-statistics data sample collected by the STAR experiment during the Beam Energy Scan II (BES-II) program at RHIC. The transeverse momentum (p_{T})-integrated yield ratios (K^{*0} + \overline{K^{*0}})/(K^{+} + K^{-}) in central collisions show a suppression relative to peripheral collisions at the (1.7\text{-}3.6)\,σ level, while a thermal model without final-stage rescattering overpredicts this ratio with a deviation of (6.9\text{-}8.2)\,σ. These results indicate a loss of the measured K^{*0} signal in central collisions due to re-scattering of its hadronic decay products in the hadronic phase. The p_{T}-integrated yield of charged kaons exhibits an approximate scaling with charged-particle multiplicity, independent of collision energy and system size. A similar trend is observed for the short-lived K^{*0} resonance, although significant deviations emerge at lower energies. At BES energies, the K^{*0}/K ratio shows stronger suppression than at the highest RHIC and LHC energies within a given multiplicity bin, particularly in central and mid-central collisions. This behavior is consistent with changes in the effective hadronic interaction cross section and is supported by transport model calculations, which indicate dominant meson-baryon interactions at lower energies and meson-meson interactions at higher energies.
+ △ Less
+
+
+
+
+ Submitted 21 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ LURE: Latent Space Unblocking for Multi-Concept Reawakening in Diffusion Models
+
+
+
+ Authors:
+
+ Mengyu Sun,
+
+ Ziyuan Yang,
+
+ Andrew Beng Jin Teoh,
+
+ Junxu Liu,
+
+ Haibo Hu,
+
+ Yi Zhang
+
+
+
+
+ Abstract:
+
+ …that erased concepts can still be reawakened, revealing vulnerabilities in erasure methods. Existing reawakening methods mainly rely on prompt-level optimization to manipulate sampling trajectories, neglecting other generative factors, which limits a comprehensive understanding of the underlying dynamics. In this paper, we model the generation process as an…
+ ▽ More
+
+
+ Concept erasure aims to suppress sensitive content in diffusion models, but recent studies show that erased concepts can still be reawakened, revealing vulnerabilities in erasure methods. Existing reawakening methods mainly rely on prompt-level optimization to manipulate sampling trajectories, neglecting other generative factors, which limits a comprehensive understanding of the underlying dynamics. In this paper, we model the generation process as an implicit function to enable a comprehensive theoretical analysis of multiple factors, including text conditions, model parameters, and latent states. We theoretically show that perturbing each factor can reawaken erased concepts. Building on this insight, we propose a novel concept reawakening method: Latent space Unblocking for concept REawakening (LURE), which reawakens erased concepts by reconstructing the latent space and guiding the sampling trajectory. Specifically, our semantic re-binding mechanism reconstructs the latent space by aligning denoising predictions with target distributions to reestablish severed text-visual associations. However, in multi-concept scenarios, naive reconstruction can cause gradient conflicts and feature entanglement. To address this, we introduce Gradient Field Orthogonalization, which enforces feature orthogonality to prevent mutual interference. Additionally, our Latent Semantic Identification-Guided Sampling (LSIS) ensures stability of the reawakening process via posterior density verification. Extensive experiments demonstrate that LURE enables simultaneous, high-fidelity reawakening of multiple erased concepts across diverse erasure tasks and methods.
+ △ Less
+
+
+
+
+ Submitted 20 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Guided by the Plan: Enhancing Faithful Autoregressive Text-to-Audio Generation with Guided Decoding
+
+
+
+ Authors:
+
+ Juncheng Wang,
+
+ Zhe Hu,
+
+ Chao Xu,
+
+ Siyue Ren,
+
+ Yuxiang Feng,
+
+ Yang Liu,
+
+ Baigui Sun,
+
+ Shujun Wang
+
+
+
+
+ Abstract:
+
+ …exploration: it evaluates candidate prefixes early, prunes low-fidelity trajectories, and reallocates computation to high-potential planning seeds. Our Plan-Critic-guided sampling achieves up to a 10-point improvement in CLAP score over the AR baseline-establishing a new state of the art in AR text-to-audio generation-…
+ ▽ More
+
+
+ Autoregressive (AR) models excel at generating temporally coherent audio by producing tokens sequentially, yet they often falter in faithfully following complex textual prompts, especially those describing complex sound events. We uncover a surprising capability in AR audio generators: their early prefix tokens implicitly encode global semantic attributes of the final output, such as event count and sound-object category, revealing a form of implicit planning. Building on this insight, we propose Plan-Critic, a lightweight auxiliary model trained with a Generalized Advantage Estimation (GAE)-inspired objective to predict final instruction-following quality from partial generations. At inference time, Plan-Critic enables guided exploration: it evaluates candidate prefixes early, prunes low-fidelity trajectories, and reallocates computation to high-potential planning seeds. Our Plan-Critic-guided sampling achieves up to a 10-point improvement in CLAP score over the AR baseline-establishing a new state of the art in AR text-to-audio generation-while maintaining computational parity with standard best-of-N decoding. This work bridges the gap between causal generation and global semantic alignment, demonstrating that even strictly autoregressive models can plan ahead.
+ △ Less
+
+
+
+
+ Submitted 18 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Vision Also You Need: Navigating Out-of-Distribution Detection with Multimodal Large Language Model
+
+
+
+ Authors:
+
+ Haoran Xu,
+
+ Yanlin Liu,
+
+ Zizhao Tong,
+
+ Jiaze Li,
+
+ Kexue Fu,
+
+ Yuyang Zhang,
+
+ Longxiang Gao,
+
+ Shuaiguang Li,
+
+ Xingyu Li,
+
+ Yanran Xu,
+
+ Changwei Wang
+
+
+
+
+ Abstract:
+
+ …Current methods leverage expert knowledge from large language models (LLMs) to identify potential outliers. However, these approaches tend to over-rely on knowledge in the text space, neglecting the inherent challenges involved in detecting out-of-distribution…
+ ▽ More
+
+
+ Out-of-Distribution (OOD) detection is a critical task that has garnered significant attention. The emergence of CLIP has spurred extensive research into zero-shot OOD detection, often employing a training-free approach. Current methods leverage expert knowledge from large language models (LLMs) to identify potential outliers. However, these approaches tend to over-rely on knowledge in the text space, neglecting the inherent challenges involved in detecting out-of-distribution samples in the image space. In this paper, we propose a novel pipeline, MM-OOD, which leverages the multimodal reasoning capabilities of MLLMs and their ability to conduct multi-round conversations for enhanced outlier detection. Our method is designed to improve performance in both near OOD and far OOD tasks. Specifically, (1) for near OOD tasks, we directly feed ID images and corresponding text prompts into MLLMs to identify potential outliers; and (2) for far OOD tasks, we introduce the sketch-generate-elaborate framework: first, we sketch outlier exposure using text prompts, then generate corresponding visual OOD samples, and finally elaborate by using multimodal prompts. Experiments demonstrate that our method achieves significant improvements on widely used multimodal datasets such as Food-101, while also validating its scalability on ImageNet-1K.
+ △ Less
+
+
+
+
+ Submitted 20 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Component systems: do null models explain everything?
+
+
+
+ Authors:
+
+ Andrea Mazzolini,
+
+ Mattia Corigliano,
+
+ Rossana Droghetti,
+
+ Matteo Osella,
+
+ Marco Cosentino-Lagomarsino
+
+
+
+
+ Abstract:
+
+ …ensembles of realizations built from a shared repertoire of modular parts - are ubiquitous in biological, ecological, technological, and socio-cultural domains. From genomes to texts, cities, and software, these systems exhibit statistical regularities that often meet the "bona fide" requirements of laws in the physical sciences. Here, we argue that…
+ ▽ More
+
+
+ Component systems - ensembles of realizations built from a shared repertoire of modular parts - are ubiquitous in biological, ecological, technological, and socio-cultural domains. From genomes to texts, cities, and software, these systems exhibit statistical regularities that often meet the "bona fide" requirements of laws in the physical sciences. Here, we argue that the generality and simplicity of those laws are often due to basic combinatorial or sampling constraints, raising the question of whether such patterns are actually revealing system-specific mechanisms and how we might move beyond them. To this end, we first present a unifying mathematical framework, which allows us to compare modular systems in different fields and highlights the common "null" trends as well as the system-specific uniqueness, which, arguably, are signatures of the underlying generative dynamics. Next, we can exploit the framework with statistical mechanics and modern machine-learning tools for a twofold objective. (i) Explaining why the general regularities emerge, highlighting the constraints between them and the general principles at their origins, and (ii) "subtracting" them from data, which will isolate the informative features for inferring hidden system-specific generative processes, mechanistic and causal aspects.
+ △ Less
+
+
+
+
+ Submitted 20 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+ Correlated domain and crystallographic orientation mapping in uniaxial ferroelectric polycrystals by interferometric vector piezoresponse force microscopy
+
+
+
+ Authors:
+
+ Ruben Dragland,
+
+ Jan Schultheiß,
+
+ Ivan N. Ushakov,
+
+ Roger Proksch,
+
+ Dennis Meier
+
+
+
+
+ Abstract:
+
+ …shifting the laser beam position on the cantilever, direction-dependent piezoresponse signals are acquired analogous to classical vector PFM, but without the need to rotate the sample. Using polycrystalline ErMnO_{3} as a model system, we demonstrate that the reconstructed piezoresponse vectors correlate one-to-one with the crystallographic orientations of…
+ ▽ More
+
+
+ Ongoing advances in scanning probe microscopy techniques are continually expanding the possibilities for nanoscale characterization and correlated studies of functional materials. Here, we demonstrate how a recent extension of piezoresponse force microscopy (PFM), known as interferometric vector PFM, can be utilized for simultaneously mapping the local crystallographic orientations and the domain structure of distributed grains in uniaxial ferroelectric polycrystals. By shifting the laser beam position on the cantilever, direction-dependent piezoresponse signals are acquired analogous to classical vector PFM, but without the need to rotate the sample. Using polycrystalline ErMnO_{3} as a model system, we demonstrate that the reconstructed piezoresponse vectors correlate one-to-one with the crystallographic orientations of the micrometer-sized grains, carrying grain-orientation and domain-related information. We establish a versatile approach for rapid, multimodal characterization of polycrystalline uniaxial ferroelectrics, enabling automated, high-throughput reconstruction of polarization and grain orientations with nanoscale precision.
+ △ Less
+
+
+
+
+ Submitted 20 January, 2026;
+ originally announced January 2026.
+
+
+
+
+
+
+
+
+
+
+
+
 +
+ 

 +
+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+ +
+
+
+
+
+ +
+
+
+
+
+
 +
+
+
+
+
+ +
+
+
+
+
+ +
+
+
+
+
+ +
+  +
+ 
 Searching...
Searching...

 Google
Google Google Scholar
Google Scholar Semantic Scholar
Semantic Scholar Internet Archive Scholar
Internet Archive Scholar CiteSeerX
CiteSeerX ORCID
ORCID



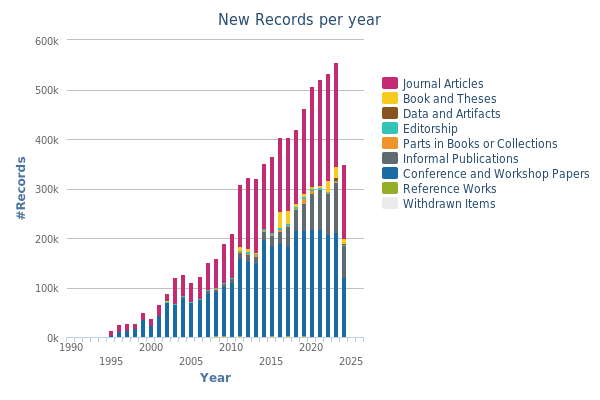

![[rss]](https://dblp.org/img/rss.dark.16x16.png)


 retrieved on 2026-01-30 18:20 CET from data curated by the
retrieved on 2026-01-30 18:20 CET from data curated by the 






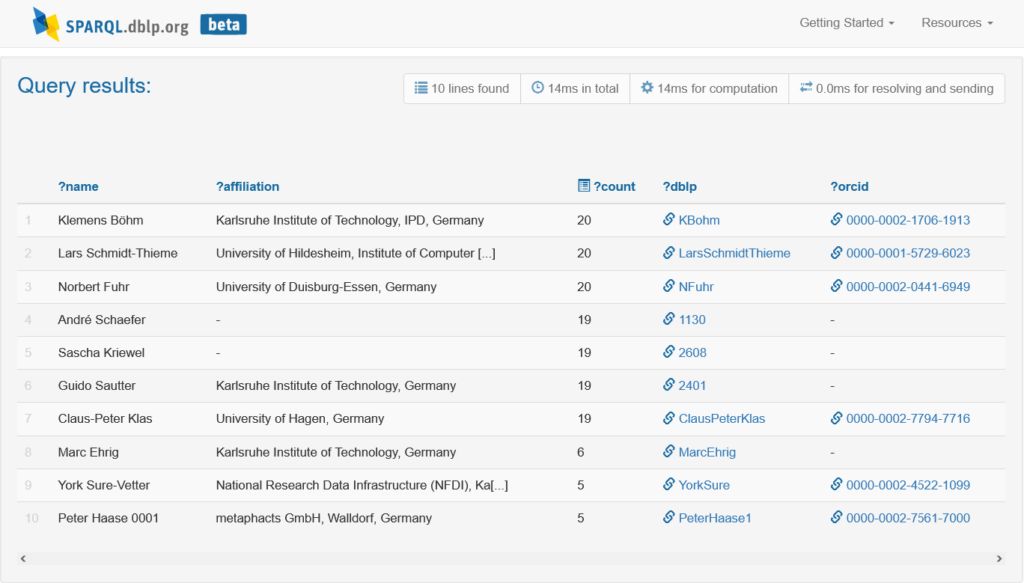

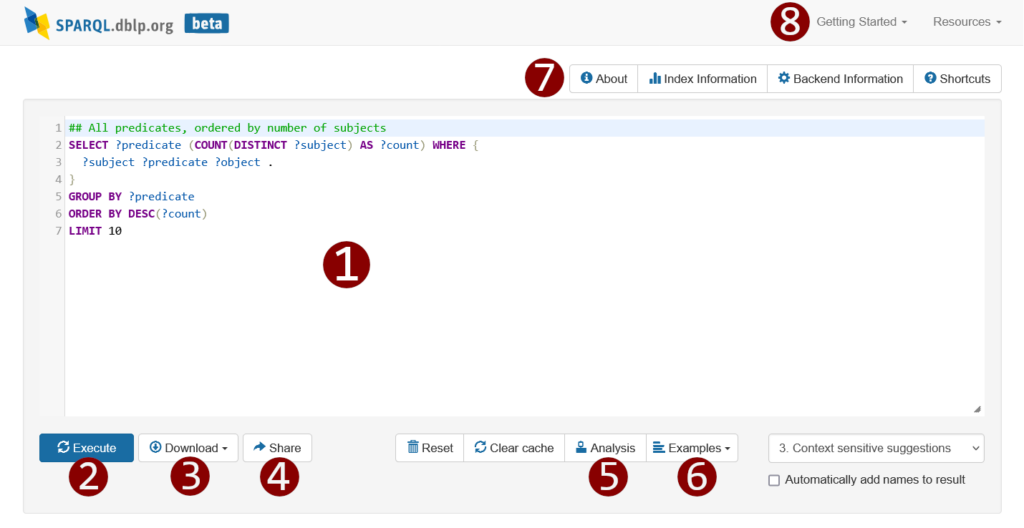
 +
+ +
+ +
+ +
+ +
+ +
+ +
+








































Social media links