

task_categories:
- image-text-to-text
language:
- en
tags:
- visual-reasoning
- symbolic-reasoning
- math
- matchstick-puzzles
- benchmark
MathSticks: A Benchmark for Visual Symbolic Compositional Reasoning with Matchstick Puzzles
Paper: MathSticks: A Benchmark for Visual Symbolic Compositional Reasoning with Matchstick Puzzles Code: https://github.com/Yuheng2000/MathSticks
Overview
MathSticks is a benchmark for Visual Symbolic Compositional Reasoning (VSCR) that unifies visual perception, symbolic manipulation, and arithmetic consistency. Each task presents an incorrect matchstick equation in a seven-segment style. The goal is to move exactly one or two sticks—under strict stick-conservation and digit-legibility constraints—to make the equation mathematically correct.
- Two evaluation regimes:
- Text-guided: the equation string is provided to the model.
- Pure-visual: only the rendered puzzle image is provided.
- Systematic coverage: digit scale (Levels 1–4), move complexity (1/2 sticks), solution multiplicity, and operator variation.
- Scale: 1.4M generated instances; a curated test set of 400 items is released.
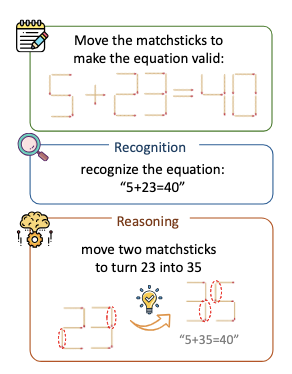
Example: input puzzle, reasoning trace, and move-format predictions.
Evaluations across 14 VLMs reveal substantial limitations: closed-source models succeed only on simple cases, open-source models fail in the pure-visual regime, while humans exceed 90% accuracy. These results establish MathSticks as a rigorous, diagnostic testbed for advancing compositional reasoning across vision and symbols.
Task Definition
- Input: a rendered image of an incorrect equation composed of matchsticks (seven-segment digits). Optionally, a text equation string (text-guided regime).
- Constraints: move one or two sticks only; no addition/removal; preserve digit legibility.
- Objective: reach a valid arithmetic equation (addition or subtraction). Operator flips may be required by the minimal-move constraint in some cases.
- Output format: a boxed sequence of Move operations, e.g.
\boxed{Move(A0, C3)}or\boxed{Move(A0, C3), Move(E1, F4)}.
Data Format (Benchmark JSONL)
Each line is one sample with the following fields:
id(string): unique sample identifier, e.g.,"00075585".level(int): difficulty level (1–4) indicating digit scale.image(string): image path relative to repo root, e.g.,level1/00075585_8-9=3.png.problem(string): the displayed (incorrect) equation string, e.g.,8-9=3.solution_num(list[int, int]): counts of solvable solutions by move budget[one_move_count, two_move_count].mode_1_solution(list): list of one-move solutions. Empty whensolution_num[0] == 0.mode_2_solution(list): list of two-move solutions. Each item has:solution(string): corrected equation (e.g.,"8 - 6 = 2").moves(list[string]): standardized move format strings, e.g.,["Move(B2, B5)", "Move(C3, C5)"].
option_answer(object): order-invariant representation of moves, for robust parsing:mode_1(list): each one-move answer as{ "pick": [from_label], "place": [to_label] }.mode_2(list): each two-move answer as{ "pick": [from_label_1, from_label_2], "place": [to_label_1, to_label_2] }.
Example:
{
"id": "00075585",
"level": 1,
"problem": "8-9=3",
"image": "level1/00075585_8-9=3.png",
"solution_num": [0, 4],
"mode_1_solution": [],
"mode_2_solution": [
{"solution": "8 - 6 = 2", "moves": ["Move(B2, B5)", "Move(C3, C5)"]},
{"solution": "9 - 9 = 0", "moves": ["Move(A5, C5)", "Move(C0, C6)"]},
{"solution": "6 + 3 = 9", "moves": ["Move(A2, G0)", "Move(B6, C6)"]},
{"solution": "9 - 0 = 9", "moves": ["Move(A5, B5)", "Move(B0, C6)"]}
],
"option_answer": {
"mode_1": [],
"mode_2": [
{"pick": ["B2", "C3"], "place": ["B5", "C5"]},
{"pick": ["A5", "C0"], "place": ["C5", "C6"]},
{"pick": ["A2", "B6"], "place": ["G0", "C6"]},
{"pick": ["A5", "B0"], "place": ["B5", "C6"]}
]
}
}
Notes:
- Pure-visual regime uses only
imagefor model input; text-guided may also useproblem. - The string move format is strict for parsing;
option_answerprovides an order-invariant equivalent when needed.
Sample Usage
1) Run evaluation
python eval.py \
--input MathSticks_bench_400.jsonl \
--image-dir ./image \
--output predictions.jsonl
2) Score predictions
python cal_score.py \
--pred predictions.jsonl \
--label MathSticks_bench_400.jsonl \
--output score.json
3) Generate data (research use only)
python match_gen_flt.py
This enumerates positional encodings and writes the discovered solvable cases to match_gen.jsonl. It is computationally intensive and may take a long time.
Citation
If you find MathSticks useful, please cite the paper:
@article{mathsticks2025,
title = {MathSticks: A Benchmark for Visual Symbolic Compositional Reasoning with Matchstick Puzzles},
author = {Anonymous},
journal = {arXiv preprint arXiv:TODO},
year = {2025},
url = {https://huggingface.co/papers/2510.00483}
}