|
|
--- |
|
|
license: mit |
|
|
datasets: |
|
|
- zer0int/CLIP-KO-Adversarial-Train-Typo-Attack |
|
|
- SPRIGHT-T2I/spright_coco |
|
|
base_model: |
|
|
- openai/clip-vit-large-patch14 |
|
|
--- |
|
|
# CLIP-KO: Knocking Out Typographic Attacks in CLIP 💪🤖 |
|
|
### Finally, a CLIP without a 'text obsession'! 🤗 |
|
|
❤️ this CLIP? [Donate](https://ko-fi.com/zer0int) if you can / want. TY! |
|
|
|
|
|
# 🌱 CLIP-KO-LITE is slightly less robust, but the Text Encoder won't produce OOD embeddings. |
|
|
- 📝 Read the [paper](https://github.com/zer0int/CLIP-fine-tune/blob/CLIP-vision/KO-CLIP-teaser/KO-CLIP-paper-final.pdf) (PDF) here. |
|
|
- If you're looking for a a Text Encoder, you'll probably want these: |
|
|
- 🖼️ Download [The Text Encoder for generative AI](https://huggingface.co/zer0int/CLIP-KO-LITE-TypoAttack-Attn-Dropout-ViT-L-14/resolve/main/ViT-L-14-KO-LITE-HuggingFace-TE-only.safetensors?download=true) |
|
|
- 🖼️ Download an [alternatve Text Encoder without Adversarial Training](https://huggingface.co/zer0int/CLIP-KO-LITE-TypoAttack-Attn-Dropout-ViT-L-14/resolve/main/ViT-L-14-KO___NO-ADV___HF-TE-only.safetensors?download=true) |
|
|
- 🤓 Wanna fine-tune yourself? Get the [code](https://github.com/zer0int/CLIP-fine-tune) on my GitHub. |
|
|
- Included: Code for fine-tuning and all benchmarks / claims (as per the paper) |
|
|
|
|
|
## 👉 Check out the [KO variant ](https://huggingface.co/zer0int/CLIP-KO-TypoAttack-Attn-Dropout-ViT-L-14) of this model (strict) |
|
|
|
|
|
---- |
|
|
<details> |
|
|
<summary>👉 CLICK ME to expand example benchmark code ⚡💻</summary> |
|
|
|
|
|
``` |
|
|
from datasets import load_dataset |
|
|
from transformers import CLIPModel, CLIPProcessor |
|
|
import torch |
|
|
from PIL import Image |
|
|
from tqdm import tqdm |
|
|
import pandas as pd |
|
|
|
|
|
device = "cuda" if torch.cuda.is_available() else "cpu" |
|
|
|
|
|
# BLISS / SCAM Typographic Attack Dataset |
|
|
# https://huggingface.co/datasets/BLISS-e-V/SCAM |
|
|
ds = load_dataset("BLISS-e-V/SCAM", split="train") |
|
|
|
|
|
# Benchmark pre-trained model against my fine-tune |
|
|
model_variants = [ |
|
|
("OpenAI ", "openai/clip-vit-large-patch14", "openai/clip-vit-large-patch14"), |
|
|
("KO-CLIP", "zer0int/CLIP-KO-LITE-TypoAttack-Attn-Dropout-ViT-L-14", "zer0int/CLIP-KO-LITE-TypoAttack-Attn-Dropout-ViT-L-14"), |
|
|
] |
|
|
|
|
|
models = {} |
|
|
for name, model_path, processor_path in model_variants: |
|
|
model = CLIPModel.from_pretrained(model_path).to(device).float() |
|
|
processor = CLIPProcessor.from_pretrained(processor_path) |
|
|
models[name] = (model, processor) |
|
|
|
|
|
for variant in ["NoSCAM", "SCAM", "SynthSCAM"]: |
|
|
print(f"\n=== Evaluating var.: {variant} ===") |
|
|
idxs = [i for i, v in enumerate(ds['id']) if v.startswith(variant)] |
|
|
if not idxs: |
|
|
print(f" No samples for {variant}") |
|
|
continue |
|
|
subset = [ds[i] for i in idxs] |
|
|
|
|
|
for model_name, (model, processor) in models.items(): |
|
|
results = [] |
|
|
for entry in tqdm(subset, desc=f"{model_name}", ncols=30, bar_format="{l_bar}{bar}| {n_fmt}/{total_fmt} |"): |
|
|
img = entry['image'] |
|
|
object_label = entry['object_label'] |
|
|
attack_word = entry['attack_word'] |
|
|
|
|
|
texts = [f"a photo of a {object_label}", f"a photo of a {attack_word}"] |
|
|
inputs = processor( |
|
|
text=texts, |
|
|
images=img, |
|
|
return_tensors="pt", |
|
|
padding=True |
|
|
) |
|
|
for k in inputs: |
|
|
if isinstance(inputs[k], torch.Tensor): |
|
|
inputs[k] = inputs[k].to(device) |
|
|
|
|
|
with torch.no_grad(): |
|
|
outputs = model(**inputs) |
|
|
image_features = outputs.image_embeds |
|
|
text_features = outputs.text_embeds |
|
|
|
|
|
logits = image_features @ text_features.T |
|
|
probs = logits.softmax(dim=-1).cpu().numpy().flatten() |
|
|
pred_idx = probs.argmax() |
|
|
pred_label = [object_label, attack_word][pred_idx] |
|
|
is_correct = (pred_label == object_label) |
|
|
|
|
|
results.append({ |
|
|
"id": entry['id'], |
|
|
"object_label": object_label, |
|
|
"attack_word": attack_word, |
|
|
"pred_label": pred_label, |
|
|
"is_correct": is_correct, |
|
|
"type": entry['type'], |
|
|
"model": model_name |
|
|
}) |
|
|
|
|
|
n_total = len(results) |
|
|
n_correct = sum(r['is_correct'] for r in results) |
|
|
acc = n_correct / n_total if n_total else float('nan') |
|
|
print(f"| > > > > Zero-shot accuracy for {variant}, {model_name}: {n_correct}/{n_total} = {acc:.4f}") |
|
|
``` |
|
|
</details> |
|
|
|
|
|
---- |
|
|
# Typographic Attack / adversarial robustness: |
|
|
|
|
|
 |
|
|
--------- |
|
|
## Attention Heatmaps without artifacts: |
|
|
|
|
|
 |
|
|
|
|
|
--------- |
|
|
## 🍂 ALL: Flux.1-dev, NO T5 - CLIP only! CFG=5, Heun, fixed seed. Prompts, in order: |
|
|
|
|
|
1. "bumblewordoooooooo bumblefeelmbles blbeinbumbleghue" (weird CLIP words / text obsession / prompt injection) |
|
|
2. "a photo of a disintegrimpressionism rag hermit" (one weird CLIP word only) |
|
|
3. "a photo of a breakfast table with a highly detailed iridescent mandelbrot sitting on a plate that says 'maths for life!'" (note: "mandelbrot" literally means "almond bread" in German) |
|
|
4. "mathematflake tessswirl psychedsphere zanziflake aluminmathematdeeply mathematzanzirender methylmathematrender detailed mandelmicroscopy mathematfluctucarved iridescent mandelsurface mandeltrippy mandelhallucinpossessed pbr" (Complete CLIP gibberish math rant) |
|
|
5. "spiderman in the moshpit, berlin fashion, wearing punk clothing, they are fighting very angry" (CLIP Interrogator / BLIP) |
|
|
6. "epstein mattypixelart crying epilepsy pixelart dannypixelart mattyteeth trippy talladepixelart retarphotomedit hallucincollage gopro destroyed mathematzanzirender mathematgopro" (CLIP rant) |
|
|
|
|
|
 |
|
|
------ |
|
|
# Evaluation Results |
|
|
| Section | Measurement / Task | Pre-Trained | KO-CLIP | KO-LITE | |
|
|
|-----------------------------|-----------------------------------|-------------|----------|----------| |
|
|
| **RTA 100 Typographic** | Zero-Shot Acc | 0.4330 | **0.7210**🎖️ | 0.6260 | |
|
|
| | | | | | |
|
|
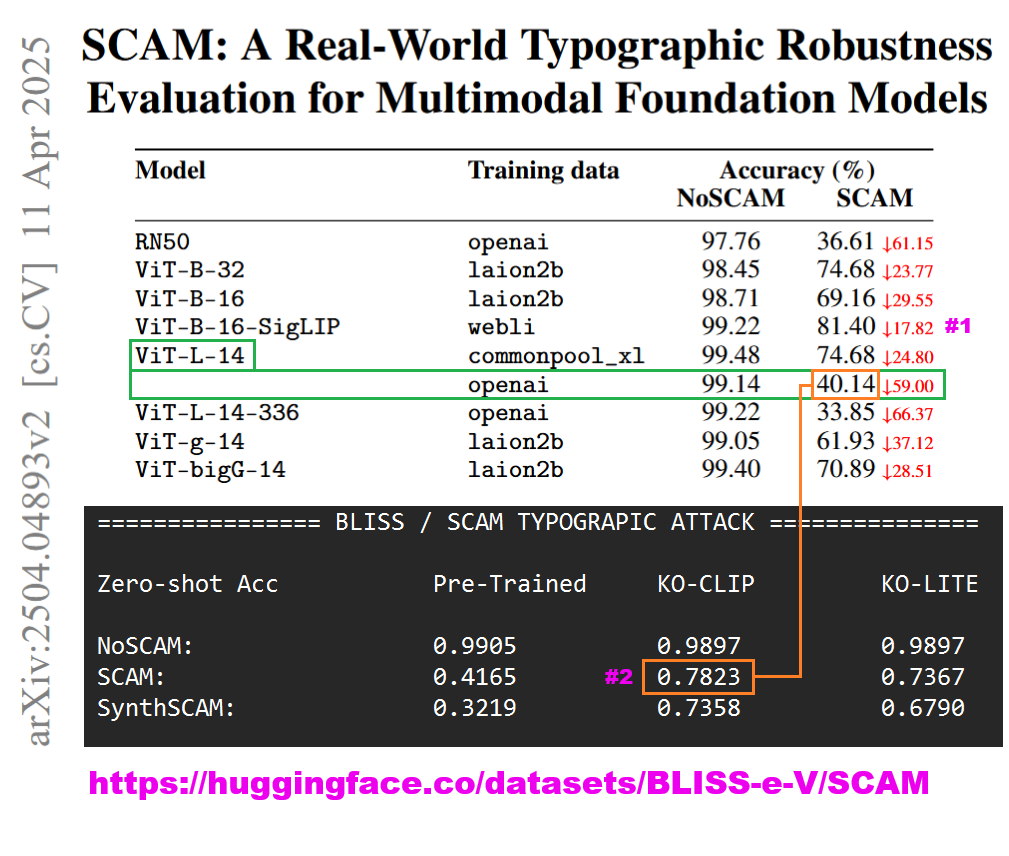
| **BLISS / SCAM** | NoSCAM | 0.9905 | **0.9897** | **0.9897** | |
|
|
| | SCAM | 0.4165 | **0.7823**🎖️ | 0.7367 | |
|
|
| | SynthSCAM | 0.3219 | **0.7358**🎖️ | 0.6790 | |
|
|
| | | | | | |
|
|
| **ILSVRC2012 Linear Probe** | Top-1 | 69.86% | 70.58% | **72.65%** | |
|
|
| | Top-5 | 92.70% | 93.79% | **94.08%** | |
|
|
| | | | | | |
|
|
| **ObjectNet (ZS)** | Accuracy | 0.846 | 0.898 | **0.9029**🎖️ | |
|
|
| | | | | | |
|
|
| **ImageNet 1k (ZS)** | acc1 | 0.32696 | 0.43440 | **0.46882** | |
|
|
| | acc5 | 0.52997 | 0.65297 | **0.68845**🎖️ | |
|
|
| | mean_per_class_recall | 0.32609 | 0.43252 | **0.46695** | |
|
|
| | | | | | |
|
|
| **VoC-2007 (ZS)** | mAP | 0.7615 | 0.8579 | **0.8626**🎖️ | |
|
|
| | | | | | |
|
|
| **mscoco ZS Retrieval** | image_retrieval_recall@5 | 0.2196 | 0.3296 | **0.3385** | |
|
|
| | text_retrieval_recall@5 | 0.3032 | 0.4396 | **0.4745** | |
|
|
| | | | | | |
|
|
| **xm3600 ZS Retrieval** | image_retrieval_recall@5 | 0.30593 | 0.43338 | **0.43700** | |
|
|
| | text_retrieval_recall@5 | 0.24293 | 0.38884 | **0.42324** | |
|
|
| | | | | | |
|
|
| **Sugar_Crepe (PT)** | Add ATT: acc | 0.77745 | 0.84537 | **0.87427** | |
|
|
| | Add OBJ: acc | 0.80358 | 0.84093 | **0.84772** | |
|
|
| | Replace ATT: acc | 0.76903 | 0.81091 | **0.82106** | |
|
|
| | Replace OBJ: acc | 0.87832 | 0.90617 | **0.91162** | |
|
|
| | Replace REL: acc | 0.71550 | 0.73470 | **0.74253** | |
|
|
| | Swap ATT: acc | 0.58558 | 0.62912 | **0.63363** | |
|
|
| | Swap OBJ: acc | 0.57959 | 0.60816 | **0.62040** | |
|
|
| | | | | | |
|
|
| **Flickr-8k Cross-modal** | Euclidean Gap ↓ | 0.8276 | **0.8657** | 0.8182 | |
|
|
| | JSD ↓ | 0.5200 | 0.2863 | **0.1455** | |
|
|
| | Wasserstein Distance ↓ | 0.4084 | 0.4166 | **0.3889** | |
|
|
| | Img-Text Cos Sim (mean) ↑ | 0.2723 | 0.3077 | **0.3300** | |
|
|
| | Img-Text Cos Sim (std) | 0.0362 | 0.0645 | **0.0690** | |
|
|
| | Text-Text Cos Sim (mean) | 0.6807 | **0.7243** | 0.7189 | |
|
|
| | Text-Text Cos Sim (std) | 0.1344 | 0.1377 | **0.1387** | |
