
Model Card for gpt-oss-20b-FAQ-MES
This model is a fine-tuned version of openai/gpt-oss-20b on the fenyo/FAQ-MES dataset. It has been trained using TRL on a virtual machine running Ubuntu 24.04 with 2x Nvidia L40S GPUs.
Ce modèle est comparé à d'autres modèles ici : https://huggingface.co/fenyo/MonEspaceSante-FAQ-Mistral-Small-24B-GGUF/blob/main/REPORT.md
🔬 Comparaison complémentaire — CPT synthétique. Ce modèle est également comparé, sur un protocole closed-book identique (696 questions au phrasing inédit, juge
Qwen3-32B), à fenyo/L40S-Qwen3-8B-MonEspaceSante-CPT-SFT — un Qwen3-8B (2,5× plus petit) enrichi par continued pre-training synthétique (NVIDIA NeMo Curator + EntiGraph). Sur les positives held-out, ce dernier atteint 86,9 % contre 70,8 % pourgpt-oss-20b-FAQ-MES. Méthode complète, tableaux et reproduction dans sa carte.
Look at the branches in this repository to download the checkpoints.
Quick start
from transformers import pipeline
question = "Qu'est-ce que Mon espace santé ?"
generator = pipeline("text-generation", model="fenyo/gpt-oss-20b-FAQ-MES", device="cuda")
output = generator([{"role": "system", "content": "You are a helpful chatbot assistant for the Mon Espace Santé website."}, {"role": "user", "content": question}], max_new_tokens=4096, return_full_text=False)[0]
print(output["generated_text"])
To query a specific checkpoint:
from transformers import pipeline
question = "Qu'est-ce que Mon espace santé ?"
generator = pipeline("text-generation", model="fenyo/gpt-oss-20b-FAQ-MES", revision="ckpt-1500", device="cuda")
output = generator([{"role": "system", "content": "You are a helpful chatbot assistant for the Mon Espace Santé website."}, {"role": "user", "content": question}], max_new_tokens=4096, return_full_text=False)[0]
print(output["generated_text"])
Quick run
https://huggingface.co/fenyo/gpt-oss-20b-FAQ-MES-mxfp4
Running on Ollama
Low-end GPU with 16 Gb VRAM supported: see https://ollama.com/eowyneowyn/gpt-oss-20b-FAQ-MES
Training procedure
![]()
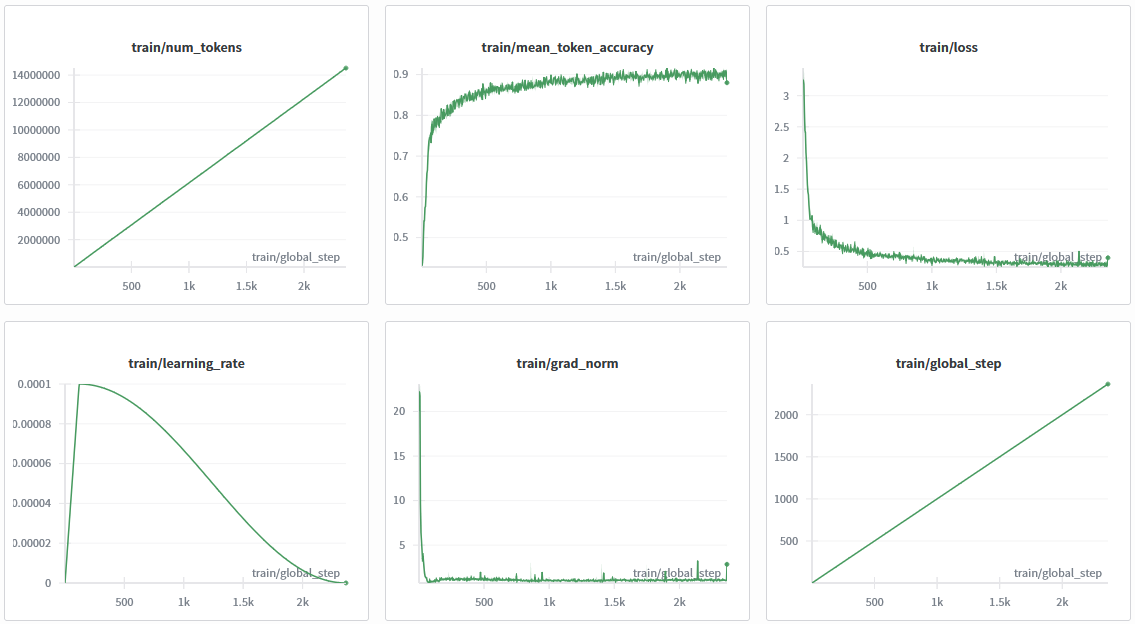
This model was trained with SFT.
Training script and parameters
import wandb
from huggingface_hub import login
from datasets import load_dataset
from transformers import AutoTokenizer
import torch
from transformers import AutoModelForCausalLM, Mxfp4Config
from peft import LoraConfig, get_peft_model
from trl import SFTConfig
from trl import SFTTrainer
wandb.init(project="fenyo-FAQ-MES", entity="alexandre-fenyo-fenyonet", name="finetune-gpt-oss-20b-FAQ-MES")
login(token="[Hugging Face Token]")
dataset = load_dataset("fenyo/FAQ-MES", split="train")
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")
quantization_config = Mxfp4Config(dequantize=True)
model_kwargs = dict(
attn_implementation="eager",
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
use_cache=False,
device_map="auto",
)
model = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs)
peft_config = LoraConfig(
r=32,
lora_alpha=64,
lora_dropout=0.05,
bias="all",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
)
peft_model = get_peft_model(model, peft_config)
peft_model.print_trainable_parameters()
training_args = SFTConfig(
learning_rate=1e-4,
gradient_checkpointing=True,
num_train_epochs=5,
logging_steps=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
max_length=2048,
warmup_ratio=0.05,
lr_scheduler_type="cosine",
output_dir="gpt-oss-20b-finetune",
push_to_hub=True,
report_to="wandb",
)
trainer = SFTTrainer(
model=peft_model,
args=training_args,
train_dataset=dataset,
processing_class=tokenizer,
)
trainer.train()
trainer.save_model(training_args.output_dir)
Framework versions
- TRL: 0.27.1
- Transformers: 5.0.0
- Pytorch: 2.10.0+cu128
- Datasets: 4.5.0
- Tokenizers: 0.22.2
- Downloads last month
- 40
Model tree for fenyo/gpt-oss-20b-FAQ-MES
Base model
openai/gpt-oss-20b