
base_model:
- Qwen/Qwen3.5-4B
language:
- en
license: apache-2.0
pipeline_tag: image-text-to-text
library_name: transformers
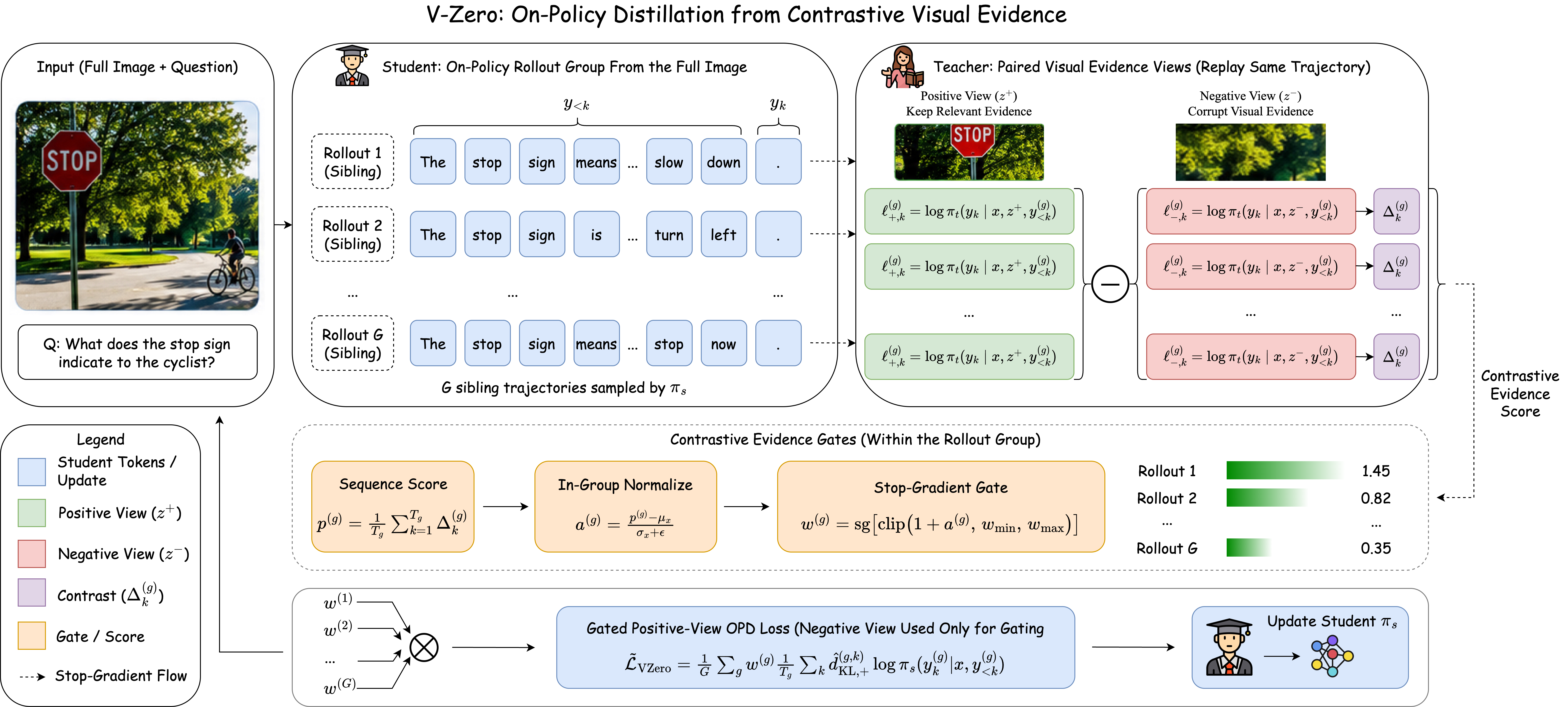
V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning
This repository contains the V-Zero 4B checkpoint, introduced in the paper V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning.
- Code Repository: GitHub - eVI-group-SCU/V-Zero
Overview
V-Zero is an answer-label-free framework designed to improve fine-grained visual reasoning in multimodal large language models (MLLMs). It bypasses the need for costly external answer labels or manual verification rules by utilizing on-policy distillation combined with contrastive evidence gating. During training, the student model samples trajectories on the full image, while a teacher model replays those trajectories under paired positive (task-relevant) and negative (task-irrelevant) crops to evaluate student-sampled reasoning paths.
Citation
If you find this work useful for your research, please cite the paper:
@article{sun2026vzero,
title={V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning},
author={Sun, Haoxiang and Yi, Zhihang and Deng, Langxuan and Zhou, Yuhao and Jia, Peiqi and Zhao, Jian and Yuan, Li and Lv, Jiancheng and Wang, Tao},
journal={arXiv preprint arXiv:2606.25319},
year={2026}
}