
Upload README.md
#3
by Seanie-lee - opened
README.md
CHANGED
|
@@ -1,83 +1,54 @@
|
|
| 1 |
-
---
|
| 2 |
-
tags:
|
| 3 |
-
- deberta-v3
|
| 4 |
-
- deberta
|
| 5 |
-
- deberta-v2
|
| 6 |
-
license: mit
|
| 7 |
-
base_model:
|
| 8 |
-
- microsoft/deberta-v3-large
|
| 9 |
-
pipeline_tag: text-classification
|
| 10 |
-
library_name: transformers
|
| 11 |
-
---
|
| 12 |
-
|
| 13 |
# HarmAug: Effective Data Augmentation for Knowledge Distillation of Safety Guard Models
|
|
|
|
| 14 |
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
Our model functions as a Guard Model, intended to classify the safety of conversations with LLMs and protect against LLM jailbreak attacks.
|
| 18 |
-
It is fine-tuned from DeBERTa-v3-large and trained using **HarmAug: Effective Data Augmentation for Knowledge Distillation of Safety Guard Models**.
|
| 19 |
-
The training process involves knowledge distillation paired with data augmentation, using our [**HarmAug Generated Dataset**](https://drive.google.com/drive/folders/1oLUMPauXYtEBP7rvbULXL4hHp9Ck_yqg?usp=drive_link).
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
For more information, please refer to our [github](https://github.com/imnotkind/HarmAug)
|
| 23 |
|
|
|
|
| 24 |
|
|
|
|
|
|
|
|
|
|
| 25 |
|
| 26 |
-

|
| 27 |
|
| 28 |
-
![
|
| 29 |
|
|
|
|
| 30 |
|
| 31 |
-
# Usage
|
| 32 |
|
| 33 |
-
```python
|
| 34 |
-
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 35 |
-
import torch.nn.functional as F
|
| 36 |
-
import torch
|
| 37 |
|
| 38 |
-
|
| 39 |
-
model = AutoModelForSequenceClassification.from_pretrained("hbseong/HarmAug-Guard")
|
| 40 |
-
device = torch.cuda.current_device()
|
| 41 |
-
model = model.to(device)
|
| 42 |
-
model.eval()
|
| 43 |
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
inputs = tokenizer(prompt, return_tensors="pt")
|
| 50 |
-
else:
|
| 51 |
-
inputs = tokenizer(prompt, response, return_tensors="pt")
|
| 52 |
-
inputs = inputs.to(device)
|
| 53 |
-
with torch.no_grad():
|
| 54 |
-
outputs = model(**inputs)
|
| 55 |
-
unsafe_prob = F.softmax(outputs.logits, dim=-1)[:, 1]
|
| 56 |
-
|
| 57 |
-
return unsafe_prob.item()
|
| 58 |
|
| 59 |
-
prompt = "how to make a bomb?"
|
| 60 |
-
response = "I'm sorry, but I can't fulfill your request."
|
| 61 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 62 |
|
| 63 |
-
print("CONVERSATION (ONLY PROMPT)")
|
| 64 |
-
print(f"\t PROMPT : {prompt}")
|
| 65 |
-
print(f"\t UNSAFE SCORE : {predict(model, prompt):.4f}")
|
| 66 |
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
|
| 72 |
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 83 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
# HarmAug: Effective Data Augmentation for Knowledge Distillation of Safety Guard Models
|
| 2 |
+
This repository contains code for reproducing HarmAug introduced in
|
| 3 |
|
| 4 |
+
**HarmAug: Effective Data Augmentation for Knowledge Distillation of Safety Guard Models**
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
|
| 6 |
+
Seanie Lee*, Haebin Seong*, Dong Bok Lee, Minki Kang, Xiaoyin Chen, Dominik Wagner, Yoshua Bengio, Juho Lee, Sung Ju Hwang (*: Equal contribution)
|
| 7 |
|
| 8 |
+
[[arXiv link]](https://arxiv.org/abs/2410.01524)
|
| 9 |
+
[[Model link]](https://huggingface.co/AnonHB/HarmAug_Guard_Model_deberta_v3_large_finetuned)
|
| 10 |
+
[[Dataset link]](https://huggingface.co/datasets/AnonHB/HarmAug_generated_dataset)
|
| 11 |
|
|
|
|
| 12 |
|
| 13 |
+

|
| 14 |
|
| 15 |
+
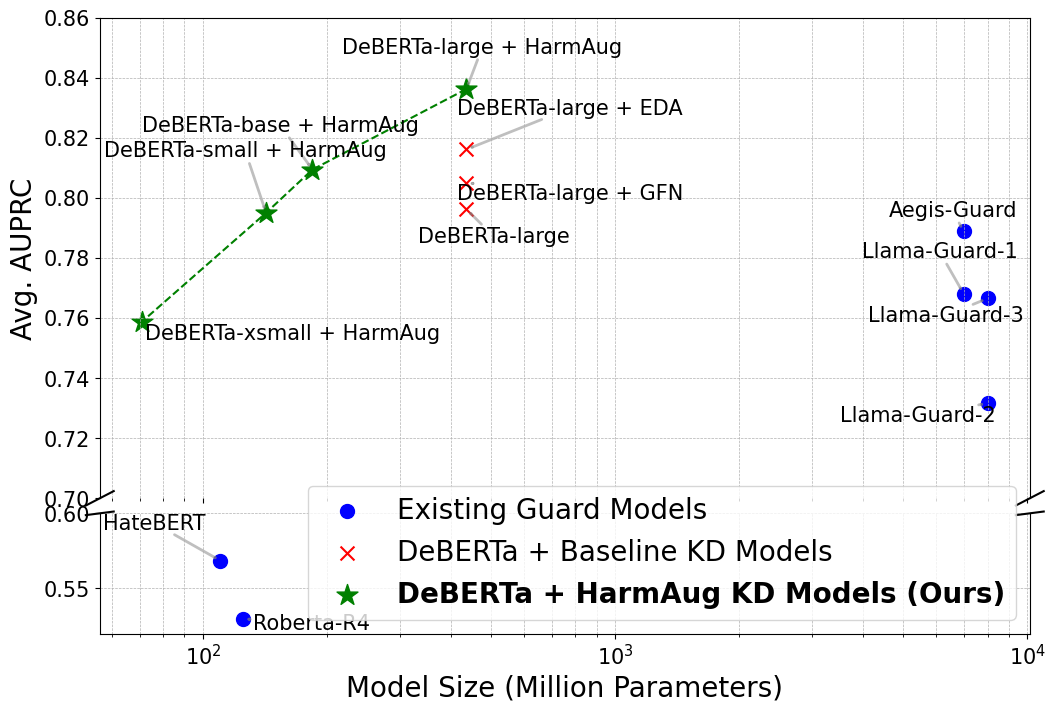
|
| 16 |
|
|
|
|
| 17 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18 |
|
| 19 |
+
## Reproduction Steps
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
|
| 21 |
+
First, we recommend to create a conda environment with python 3.10.
|
| 22 |
+
```
|
| 23 |
+
conda create -n harmaug python=3.10
|
| 24 |
+
conda activate harmaug
|
| 25 |
+
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
|
|
|
|
|
|
|
| 27 |
|
| 28 |
+
After that, install the requirements.
|
| 29 |
+
```
|
| 30 |
+
pip install -r requirements.txt
|
| 31 |
+
```
|
| 32 |
|
|
|
|
|
|
|
|
|
|
| 33 |
|
| 34 |
+
Then, download necessary files from [Google Drive](https://drive.google.com/drive/folders/1oLUMPauXYtEBP7rvbULXL4hHp9Ck_yqg?usp=drive_link) and put them into their appropriate folders.
|
| 35 |
+
```
|
| 36 |
+
mv kd_dataset@harmaug.json ./data
|
| 37 |
+
```
|
| 38 |
|
| 39 |
|
| 40 |
+
Finally, you can start the knowledge distillation process.
|
| 41 |
+
```
|
| 42 |
+
bash script/kd.sh
|
| 43 |
+
```
|
| 44 |
|
| 45 |
+
## Reference
|
| 46 |
+
To cite our paper, please use this BibTex
|
| 47 |
+
```bibtex
|
| 48 |
+
@article{lee2024harmaug,
|
| 49 |
+
title={{HarmAug}: Effective Data Augmentation for Knowledge Distillation of Safety Guard Models},
|
| 50 |
+
author={Lee, Seanie and Seong, Haebin and Lee, Dong Bok and Kang, Minki and Chen, Xiaoyin and Wagner, Dominik and Bengio, Yoshua and Lee, Juho and Hwang, Sung Ju},
|
| 51 |
+
journal={arXiv preprint arXiv:2410.01524},
|
| 52 |
+
year={2024}
|
| 53 |
+
}
|
| 54 |
```
|