| --- |
| license: apache-2.0 |
| language: |
| - en |
| base_model: |
| - meta-llama/Llama-3.1-8B-Instruct |
| - google/siglip-large-patch16-384 |
| pipeline_tag: visual-question-answering |
| --- |
| |
| # Falcon-8B |
|
|
| ## Description |
|
|
| \[[Paper](https://arxiv.org/abs/2501.16297)\] \[[GitHub](https://github.com/JiuTian-VL/FALCON)\] \[[Project Page](https://jiutian-vl.github.io/FALCON.github.io/)\] |
|
|
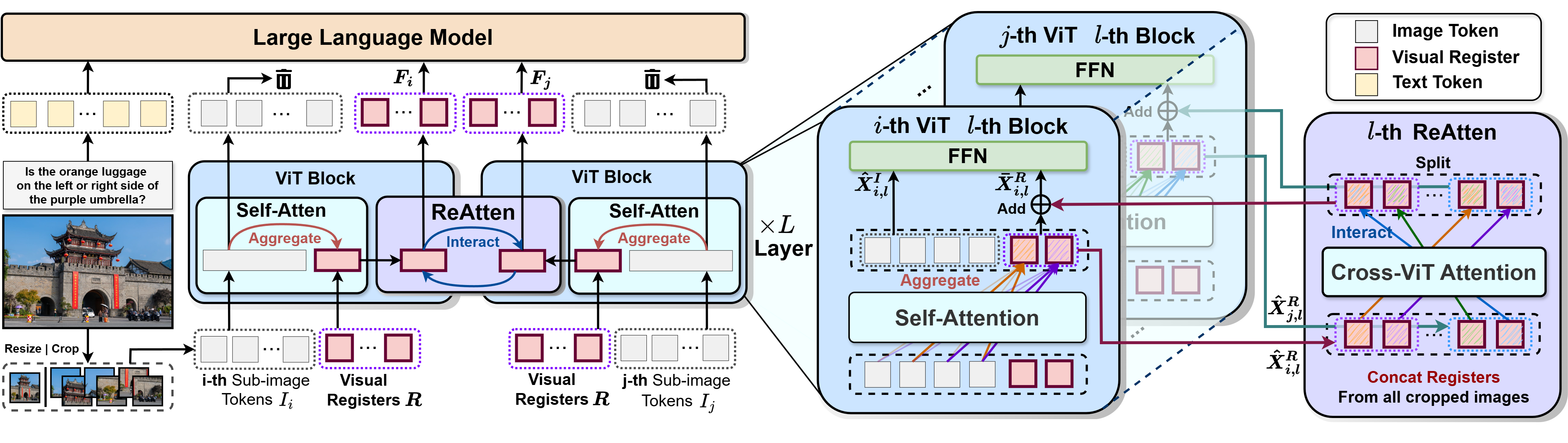
| This is the official model weights of *FALCON: Resolving Visual Redundancy and Fragmentation in High-resolution Multimodal Large Language Models via Visual Registers*. In this work, we propose the FALCON model, which introduces a novel visual register technique to simultaneously address the issues of visual redundancy and fragmentation in the high-resolution visual encoding of MLLMs. |
|
|
|  |
|
|
| ## How to Run? |
|
|
| Please refer to the instructions in the [Githhub repository](https://github.com/JiuTian-VL/FALCON). |
|
|
| ## Citation |
|
|
| If you find this work useful for your research, please kindly cite our paper: |
|
|
| ```BibTeX |
| @InProceedings{zhang2025falcon, |
| author={Zhang, Renshan and Shao, Rui and Chen, Gongwei and Zhang, Miao and Zhou, Kaiwen and Guan, Weili and Nie, Liqiang}, |
| title={FALCON: Resolving Visual Redundancy and Fragmentation in High-resolution Multimodal Large Language Models via Visual Registers}, |
| booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, |
| month= {October}, |
| year={2025}, |
| } |
| ``` |

