

upload checkpoints
Browse files
README.md
CHANGED
|
@@ -1,4 +1,4 @@
|
|
| 1 |
-
<h1 align="center">JoyAI-Image<br><sub><sup>Awakening Spatial Intelligence in Unified Multimodal Understanding and Generation</sup></sub></h1>
|
| 2 |
|
| 3 |
<div align="center">
|
| 4 |
|
|
@@ -7,49 +7,12 @@
|
|
| 7 |
[](https://huggingface.co/jdopensource/JoyAI-Image-Edit) 
|
| 8 |
[](LICENSE)
|
| 9 |
|
| 10 |
-
Welcome to the official project page for **JoyAI-Image**.
|
| 11 |
|
| 12 |
</div>
|
| 13 |
|
| 14 |
-
## 🐶 JoyAI-Image
|
| 15 |
-
|
| 16 |
-
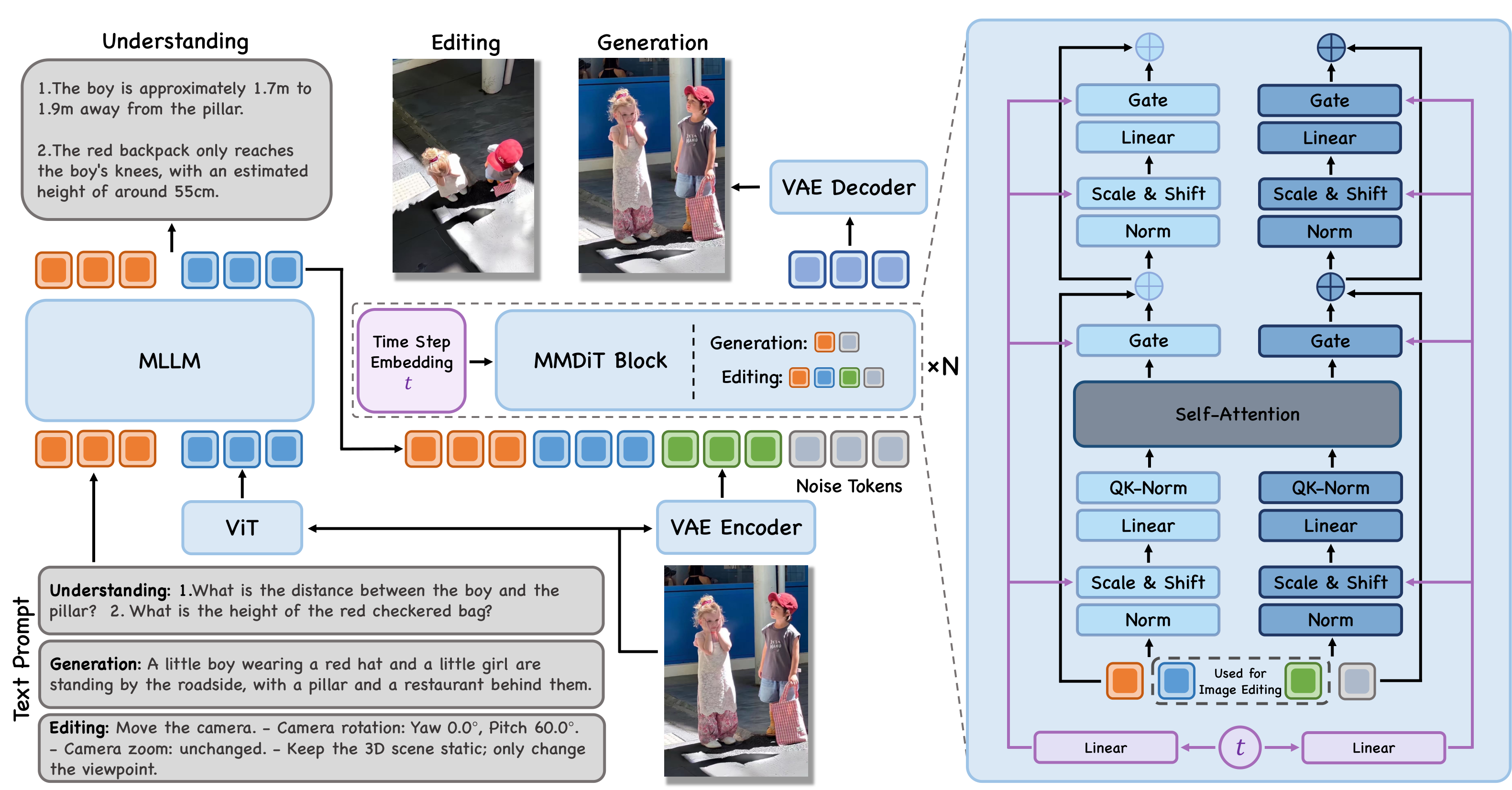
JoyAI-Image is a **unified multimodal foundation model** for image understanding, text-to-image generation, and instruction-guided image editing. It combines an 8B Multimodal Large Language Model (MLLM) with a 16B Multimodal Diffusion Transformer (MMDiT). A central principle of JoyAI-Image is the **closed-loop collaboration between understanding, generation, and editing**. Stronger spatial understanding improves grounded generation and controllable editing through better scene parsing, relational grounding, and instruction decomposition, while generative transformations such as viewpoint changes provide complementary evidence for spatial reasoning.
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
## 💎 Highlights
|
| 21 |
-
|
| 22 |
-
- **Unified multimodal foundation**: one model family for understanding, generation, and editing through a shared MLLM-MMDiT interface.
|
| 23 |
-
- **Practical data and training recipe**: a scalable pipeline with spatial understanding data ([OpenSpatial](https://github.com/VINHYU/OpenSpatial)), long-text rendering data, editing data, and multi-stage optimization strategies.
|
| 24 |
-
- **Awakened spatial intelligence**: stronger spatial understanding, controllable spatial editing, and novel-view-assisted reasoning through a bidirectional loop between understanding and generation.
|
| 25 |
-
- **Advanced visual generation**: strong long-text typography, layout fidelity, multi-view generation, and controllable editing with better preservation of scene structure.
|
| 26 |
-
|
| 27 |
-
## 🔍 Visual Overview
|
| 28 |
-
|
| 29 |
-
### Capability Profile
|
| 30 |
-
|
| 31 |
-
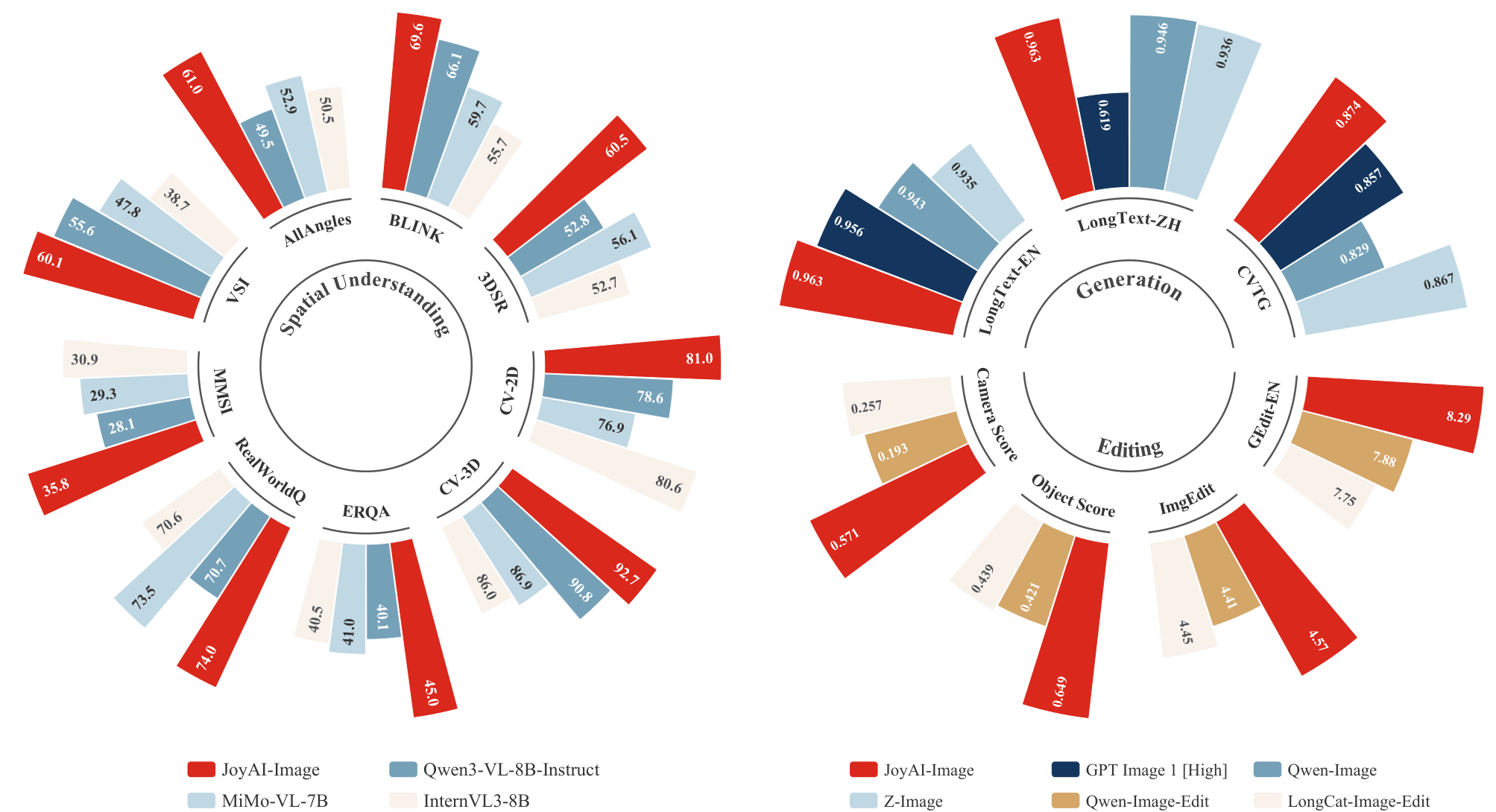
JoyAI-Image demonstrates broad multimodal performance across understanding, synthesis, and editing, with particular strengths in spatial reasoning, long-text rendering, multi-view generation, and controllable editing.
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
### Advanced Text Rendering Showcase
|
| 36 |
-
|
| 37 |
-
JoyAI-Image is optimized for challenging text-heavy scenarios, including multi-panel comics, dense multi-line text, multilingual typography, long-form layouts, real-world scene text, and handwritten styles.
|
| 38 |
-
|
| 39 |
-

|
| 40 |
-
|
| 41 |
-
### Multi-view Generation and Spatial Editing Showcase
|
| 42 |
-
|
| 43 |
-
JoyAI-Image showcases a spatially grounded generation and editing pipeline that supports multi-view generation, geometry-aware transformations, camera control, object rotation, and precise location-specific object editing. Across these settings, it preserves scene content, structure, and visual consistency while following viewpoint-sensitive instructions more accurately.
|
| 44 |
-
|
| 45 |
-

|
| 46 |
-
|
| 47 |
-
### Spatial Editing for Spatial Reasoning Showcase
|
| 48 |
-
|
| 49 |
-
JoyAI-Image poses high-fidelity spatial editing, serving as a powerful catalyst for enhancing spatial reasoning. Compared with Qwen-Image-Edit and Nano Banana Pro, JoyAI-Image-Edit synthesizes the most diagnostic viewpoints by faithfully executing camera motions. These high-fidelity novel views effectively disambiguate complex spatial relations, providing clearer visual evidence for downstream reasoning.
|
| 50 |
-
|
| 51 |
-

|
| 52 |
|
|
|
|
| 53 |
|
| 54 |
## 🚀 Quick Start
|
| 55 |
|
|
@@ -60,34 +23,27 @@ JoyAI-Image poses high-fidelity spatial editing, serving as a powerful catalyst
|
|
| 60 |
Create a virtual environment and install:
|
| 61 |
|
| 62 |
```bash
|
|
|
|
|
|
|
| 63 |
conda create -n joyai python=3.10 -y
|
| 64 |
conda activate joyai
|
| 65 |
|
| 66 |
pip install -e .
|
| 67 |
-
```
|
| 68 |
|
| 69 |
> **Note on Flash Attention**: `flash-attn >= 2.8.0` is listed as a dependency for best performance.
|
| 70 |
|
| 71 |
#### Core Dependencies
|
| 72 |
|
| 73 |
-
| Package
|
| 74 |
-
|
|
| 75 |
-
| `torch`
|
| 76 |
-
| `transformers` | >= 4.57.0, < 4.58.0 | Text encoder
|
| 77 |
-
| `diffusers`
|
| 78 |
-
| `flash-attn`
|
| 79 |
-
|
| 80 |
-
### 2. Inference
|
| 81 |
|
| 82 |
-
#### Image Understanding
|
| 83 |
|
| 84 |
-
|
| 85 |
-
python inference_und.py \
|
| 86 |
-
--ckpt-root /path/to/ckpts_infer \
|
| 87 |
-
--image "test_images/test_1.jpg,test_images/test3.png" \
|
| 88 |
-
--prompt "Compare these two images." \
|
| 89 |
-
--max-new-tokens 1024
|
| 90 |
-
```
|
| 91 |
|
| 92 |
#### Image Editing
|
| 93 |
|
|
@@ -107,34 +63,22 @@ python inference.py \
|
|
| 107 |
|
| 108 |
### CLI Reference (`inference.py`)
|
| 109 |
|
| 110 |
-
| Argument
|
| 111 |
-
|
|
| 112 |
-
| `--ckpt-root`
|
| 113 |
-
| `--prompt`
|
| 114 |
-
| `--image`
|
| 115 |
-
| `--output`
|
| 116 |
-
| `--steps`
|
| 117 |
-
| `--guidance-scale` | float | 5.0
|
| 118 |
-
| `--seed`
|
| 119 |
-
| `--neg-prompt`
|
| 120 |
-
| `--basesize`
|
| 121 |
-
| `--config`
|
| 122 |
-
| `--rewrite-prompt` | flag
|
| 123 |
-
| `--rewrite-model`
|
| 124 |
-
| `--hsdp-shard-dim` | int
|
| 125 |
-
|
| 126 |
-
### CLI Reference (`inference_und.py`)
|
| 127 |
-
|
| 128 |
-
| Argument | Type | Default | Description |
|
| 129 |
-
| ------------------ | ----- | ---------------------------------- | ------------------------------------------------------------------------ |
|
| 130 |
-
| `--ckpt-root` | str | *required* | Checkpoint root containing `text_encoder/` |
|
| 131 |
-
| `--image` | str | *required* | Input image path, or comma-separated paths for multiple images |
|
| 132 |
-
| `--prompt` | str | `"Describe this image in detail."` | User question or instruction. When omitted, defaults to image captioning |
|
| 133 |
-
| `--max-new-tokens` | int | 2048 | Maximum number of tokens to generate |
|
| 134 |
-
| `--temperature` | float | 0.7 | Sampling temperature. Use `0` for greedy decoding |
|
| 135 |
-
| `--top-p` | float | 0.8 | Top-p (nucleus) sampling threshold |
|
| 136 |
-
| `--top-k` | int | 50 | Top-k sampling threshold |
|
| 137 |
-
| `--output` | str | None | Optional output file to save the response text |
|
| 138 |
|
| 139 |
### Spatial Editing Reference
|
| 140 |
|
|
@@ -242,4 +186,5 @@ JoyAI-Image is licensed under Apache 2.0.
|
|
| 242 |
|
| 243 |
## ☎️ We're Hiring!
|
| 244 |
|
| 245 |
-
We are actively hiring Research Scientists, Engineers, and Interns to join us in building next-generation generative foundation models and bringing them into real-world applications. If you’re interested, please send your resume to: [huanghaoyang.ocean@jd.com](mailto:huanghaoyang.ocean@jd.com)
|
|
|
|
|
|
| 1 |
+
<h1 align="center">JoyAI-Image-Edit<br><sub><sup>Awakening Spatial Intelligence in Unified Multimodal Understanding and Generation</sup></sub></h1>
|
| 2 |
|
| 3 |
<div align="center">
|
| 4 |
|
|
|
|
| 7 |
[](https://huggingface.co/jdopensource/JoyAI-Image-Edit) 
|
| 8 |
[](LICENSE)
|
| 9 |
|
|
|
|
| 10 |
|
| 11 |
</div>
|
| 12 |
|
| 13 |
+
## 🐶 JoyAI-Image-Edit
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
|
| 15 |
+
JoyAI-Image-Edit is a multimodal foundation model specialized in instruction-guided image editing. It enables precise and controllable edits by leveraging strong spatial understanding, including scene parsing, relational grounding, and instruction decomposition, allowing complex modifications to be applied accurately to specified regions.
|
| 16 |
|
| 17 |
## 🚀 Quick Start
|
| 18 |
|
|
|
|
| 23 |
Create a virtual environment and install:
|
| 24 |
|
| 25 |
```bash
|
| 26 |
+
git clone https://github.com/jd-opensource/JoyAI-Image
|
| 27 |
+
cd JoyAI-Image
|
| 28 |
conda create -n joyai python=3.10 -y
|
| 29 |
conda activate joyai
|
| 30 |
|
| 31 |
pip install -e .
|
| 32 |
+
```
|
| 33 |
|
| 34 |
> **Note on Flash Attention**: `flash-attn >= 2.8.0` is listed as a dependency for best performance.
|
| 35 |
|
| 36 |
#### Core Dependencies
|
| 37 |
|
| 38 |
+
| Package | Version | Purpose |
|
| 39 |
+
|---------|---------|---------|
|
| 40 |
+
| `torch` | >= 2.8 | PyTorch |
|
| 41 |
+
| `transformers` | >= 4.57.0, < 4.58.0 | Text encoder |
|
| 42 |
+
| `diffusers` | >= 0.34.0 | Pipeline utilities |
|
| 43 |
+
| `flash-attn` | >= 2.8.0 | Fast attention kernel |
|
|
|
|
|
|
|
| 44 |
|
|
|
|
| 45 |
|
| 46 |
+
### 2. Inference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 47 |
|
| 48 |
#### Image Editing
|
| 49 |
|
|
|
|
| 63 |
|
| 64 |
### CLI Reference (`inference.py`)
|
| 65 |
|
| 66 |
+
| Argument | Type | Default | Description |
|
| 67 |
+
|----------|------|---------|-------------|
|
| 68 |
+
| `--ckpt-root` | str | *required* | Checkpoint root |
|
| 69 |
+
| `--prompt` | str | *required* | Edit instruction or T2I prompt |
|
| 70 |
+
| `--image` | str | None | Input image path (required for editing, omit for T2I) |
|
| 71 |
+
| `--output` | str | `example.png` | Output image path |
|
| 72 |
+
| `--steps` | int | 50 | Denoising steps |
|
| 73 |
+
| `--guidance-scale` | float | 5.0 | Classifier-free guidance scale |
|
| 74 |
+
| `--seed` | int | 42 | Random seed for reproducibility |
|
| 75 |
+
| `--neg-prompt` | str | `""` | Negative prompt |
|
| 76 |
+
| `--basesize` | int | 1024 | Bucket base size for input image resizing (256/512/768/1024) |
|
| 77 |
+
| `--config` | str | auto | Config path; defaults to `<ckpt-root>/infer_config.py` |
|
| 78 |
+
| `--rewrite-prompt` | flag | off | Enable LLM-based prompt rewriting |
|
| 79 |
+
| `--rewrite-model` | str | `gpt-5` | Model name for prompt rewriting |
|
| 80 |
+
| `--hsdp-shard-dim` | int | 1 | FSDP shard dimension for multi-GPU (set to GPU count) |
|
| 81 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 82 |
|
| 83 |
### Spatial Editing Reference
|
| 84 |
|
|
|
|
| 186 |
|
| 187 |
## ☎️ We're Hiring!
|
| 188 |
|
| 189 |
+
We are actively hiring Research Scientists, Engineers, and Interns to join us in building next-generation generative foundation models and bringing them into real-world applications. If you’re interested, please send your resume to: [huanghaoyang.ocean@jd.com](mailto:huanghaoyang.ocean@jd.com)
|
| 190 |
+
|