
polyglot-lion
Collection
Efficient Multilingual ASR for Singapore • 4 items • Updated
Polyglot-Lion-0.6B: Compact multilingual ASR for Singapore — English, Mandarin, Tamil & Malay
![]()
![]()
![]()
![]()
Polyglot-Lion-0.6B is a compact multilingual automatic speech recognition (ASR) model tailored for the linguistic landscape of Singapore, covering English, Mandarin, Tamil, and Malay. Developed by Quy-Anh Dang and Chris Ngo at Knovel Engineering, the model is presented in the report "Polyglot-Lion: Efficient Multilingual ASR for Singapore via Balanced Fine-Tuning of Qwen3-ASR".
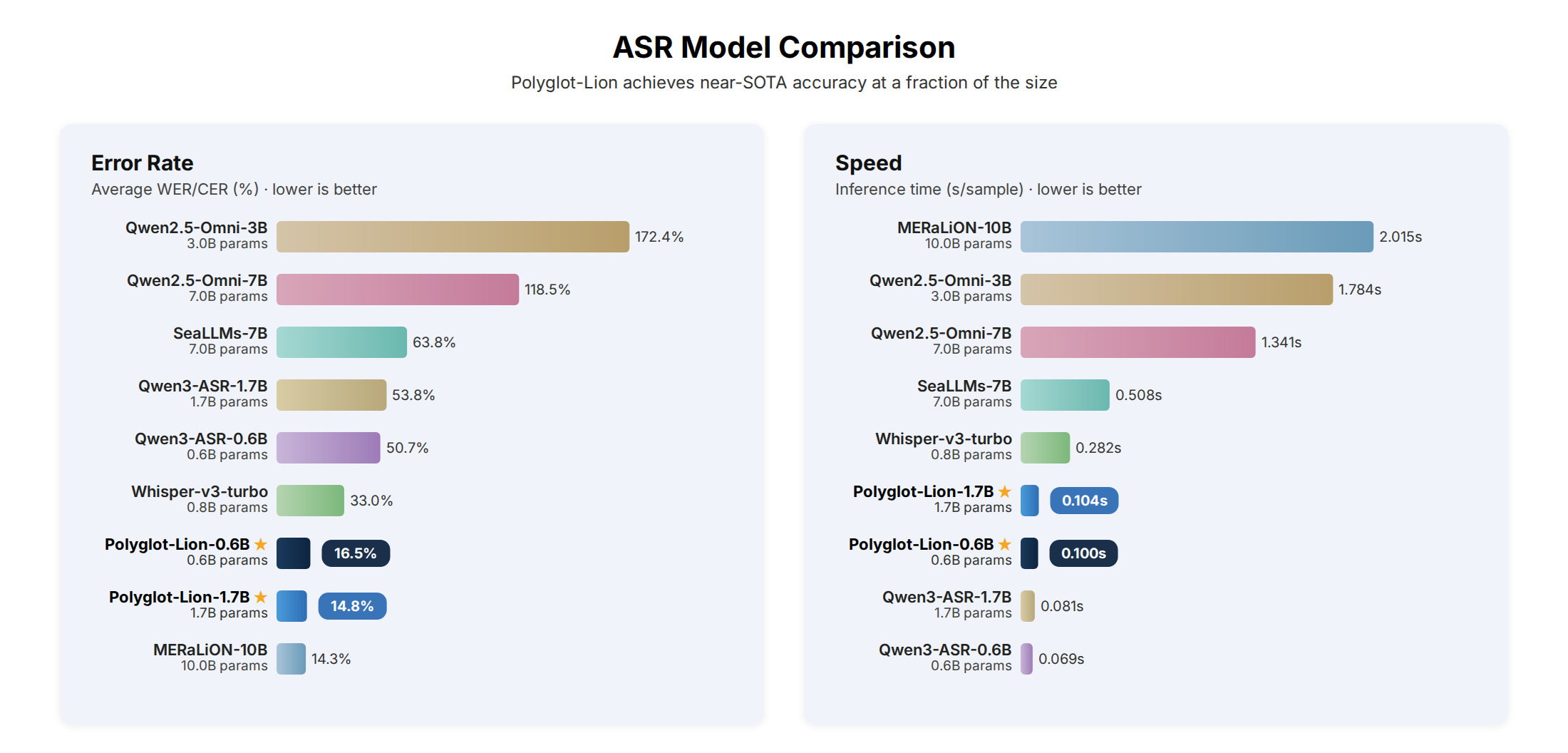
The model is fine-tuned from Qwen3-ASR-0.6B exclusively on publicly available speech corpora. It achieves an average error rate of 16.52 — halving the base model's error (50.68) and outperforming Whisper-large-v3-turbo (33.04) — and 20× faster inference.
Polyglot-Lion employs a two-stage balanced upsampling strategy to handle severe class imbalance across languages and datasets:
The model deliberately omits language-tag conditioning during training, allowing it to learn to identify languages implicitly from the audio signal, which is critical for deployment-ready multilingual ASR in diverse linguistic environments.
| Model | Params | English (LS) | English (NSC) | Mandarin (CV) | Mandarin (AISH1) | Mandarin (AISH3) | Mandarin (Fleurs) | Tamil (CV) | Tamil (SLR65) | Tamil (SLR127) | Tamil (Fleurs) | Malay (Meso.) | Malay (Fleurs) | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Whisper-large-v3-turbo | 0.8B | 3.04 | 32.02 | 17.91 | 9.64 | 16.81 | 10.63 | 74.50 | 58.13 | 69.56 | 66.90 | 28.47 | 8.88 | 33.04 |
| SeaLLMs-Audio-7B | 7B | 94.74 | 9.53 | 8.68 | 9.65 | 9.76 | 37.09 | 126.70 | 127.24 | 138.65 | 105.31 | 71.34 | 26.25 | 63.75 |
| Qwen2.5-Omni-3B | 3B | 29.21 | 34.79 | 46.36 | 28.25 | 44.55 | 54.74 | 318.36 | 465.58 | 448.82 | 311.67 | 211.90 | 74.69 | 172.37 |
| Qwen2.5-Omni-7B | 7B | 13.80 | 22.96 | 14.49 | 7.33 | 22.58 | 16.68 | 252.06 | 239.15 | 303.96 | 326.43 | 158.06 | 43.92 | 118.45 |
| Qwen3-ASR-0.6B | 0.6B | 2.74 | 7.64 | 10.06 | 2.08 | 2.59 | 9.75 | 121.10 | 127.00 | 129.12 | 130.09 | 47.29 | 18.71 | 50.68 |
| Qwen3-ASR-1.7B | 1.7B | 2.31 | 6.22 | 7.50 | 1.52 | 2.08 | 9.33 | 139.96 | 134.63 | 144.49 | 147.23 | 39.00 | 10.87 | 53.76 |
| MERaLiON-2-10B-ASR | 10B | 2.54 | 4.62 | 8.83 | 3.09 | 4.07 | 11.99 | 31.78 | 19.29 | 22.42 | 28.68 | 25.90 | 8.55 | 14.32 |
| Polyglot-Lion-0.6B | 0.6B | 2.67 | 6.09 | 6.16 | 1.93 | 2.32 | 9.19 | 42.16 | 23.07 | 28.14 | 37.68 | 24.33 | 14.45 | 16.52 |
| Polyglot-Lion-1.7B | 1.7B | 2.10 | 5.28 | 4.91 | 1.45 | 1.86 | 8.00 | 39.19 | 19.75 | 26.83 | 37.28 | 21.51 | 9.98 | 14.85 |
WER (%) for English, Tamil, and Malay; CER (%) for Mandarin. Lower is better. Bold = best overall.
Polyglot-Lion uses the qwen-asr package for inference.
# Install uv (if not already installed)
curl -LsSf https://astral.sh/uv/install.sh | sh
# Create environment and install
uv venv --python 3.12 && source .venv/bin/activate
uv pip install qwen-asr hf_transfer
import torch
from qwen_asr import Qwen3ASRModel
model = Qwen3ASRModel.from_pretrained(
"knoveleng/polyglot-lion-0.6b",
dtype=torch.bfloat16,
device_map="cuda:0",
max_new_tokens=256,
)
results = model.transcribe(audio="path/to/audio.wav", language=None)
print(results[0].language, results[0].text)
from qwen_asr import Qwen3ASRModel
if __name__ == "__main__":
model = Qwen3ASRModel.LLM(
model="knoveleng/polyglot-lion-0.6b",
gpu_memory_utilization=0.7,
max_new_tokens=4096,
)
results = model.transcribe(audio=["audio1.wav", "audio2.wav"], language=None)
for r in results:
print(r.language, r.text)
For batch inference, timestamps, streaming, and server deployment, see the Qwen3-ASR documentation.
@misc{dang2026polyglotlion,
title={Polyglot-Lion: Efficient Multilingual ASR for Singapore via Balanced Fine-Tuning of Qwen3-ASR},
author={Quy-Anh Dang and Chris Ngo},
year={2026},
eprint={2603.16184},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2603.16184},
}