
Semantic Textual Similarity
Semantic Textual Similarity (STS) assigns a score on the similarity of two texts. In this example, we use the `stsb <https://huggingface.co/datasets/sentence-transformers/stsb>`_ dataset as training data to fine-tune a :class:`~sentence_transformers.cross_encoder.CrossEncoder` model. See the following example script how to tune :class:`~sentence_transformers.cross_encoder.CrossEncoder` models on STS data:
- training_stsbenchmark.py - This example shows how to create and finetune a CrossEncoder model from a pre-trained transformer model (e.g.
distilroberta-base).
You can also train and use :class:`~sentence_transformers.SentenceTransformer` models for this task. See `Sentence Transformer > Training Examples > Semantic Textual Similarity <../../../sentence_transformer/training/sts/README.html>`_ for more details.
Training data
In STS, we have sentence pairs annotated together with a score indicating the similarity. In the original STSbenchmark dataset, the scores range from 0 to 5. We have normalized these scores to range between 0 and 1 in `stsb <https://huggingface.co/datasets/sentence-transformers/stsb>`_, as that is required for :class:`~sentence_transformers.cross_encoder.losses.BinaryCrossEntropyLoss` as you can see in the `Loss Overiew <../../../../docs/cross_encoder/loss_overview.html>`_.
Here is a simplified version of our training data:
from datasets import Dataset
sentence1_list = ["My first sentence", "Another pair"]
sentence2_list = ["My second sentence", "Unrelated sentence"]
labels_list = [0.8, 0.3]
train_dataset = Dataset.from_dict({
"sentence1": sentence1_list,
"sentence2": sentence2_list,
"label": labels_list,
})
# => Dataset({
# features: ['sentence1', 'sentence2', 'label'],
# num_rows: 2
# })
print(train_dataset[0])
# => {'sentence1': 'My first sentence', 'sentence2': 'My second sentence', 'label': 0.8}
print(train_dataset[1])
# => {'sentence1': 'Another pair', 'sentence2': 'Unrelated sentence', 'label': 0.3}
In the aforementioned scripts, we directly load the stsb dataset:
from datasets import load_dataset
train_dataset = load_dataset("sentence-transformers/stsb", split="train")
# => Dataset({
# features: ['sentence1', 'sentence2', 'score'],
# num_rows: 5749
# })
Loss Function
We use :class:`~sentence_transformers.cross_encoder.losses.BinaryCrossEntropyLoss` as our loss function.
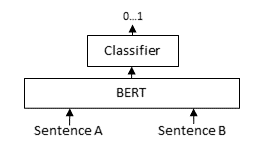
For each sentence pair, we pass sentence A and sentence B through the BERT-based model, after which a classifier head converts the intermediary representation from the BERT-based model into a similarity score. With this loss, we apply :class:`torch.nn.BCEWithLogitsLoss` which accepts logits (a.k.a. outputs, raw predictions) and gold similarity scores to compute a loss denoting how well the model has done on this batch. This loss can be minimized to improve the performance of the model.
Inference
You can perform inference using any of the pre-trained CrossEncoder models for STS like so:
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/stsb-roberta-base")
scores = model.predict([("It's a wonderful day outside.", "It's so sunny today!"), ("It's a wonderful day outside.", "He drove to work earlier.")])
# => array([0.60443085, 0.00240758], dtype=float32)