
Quantifying the Carbon Emissions of Machine Learning
Paper • 1910.09700 • Published • 47
md896/sql-debug-agent-qwen25-05b-grpo-wandb-continue-v2
| Field | Value |
|---|---|
| Developed by | Md Ayan (mdayan8) |
| Model type | Causal LM fine-tuning workflow for SQL debugging/repair |
| Language | English (SQL + natural language prompts) |
| License | Apache-2.0 |
| Shared by | md896 |
| Pipeline tag | Text Generation |
| Model family tags | qwen2, trl, grpo, conversational, text-generation-inference |
This model is part of an execution-grounded SQL debugging workflow built on OpenEnv tasks. The key idea is to optimize for runtime correctness rather than only text-level plausibility.
The training/evaluation workflow uses:
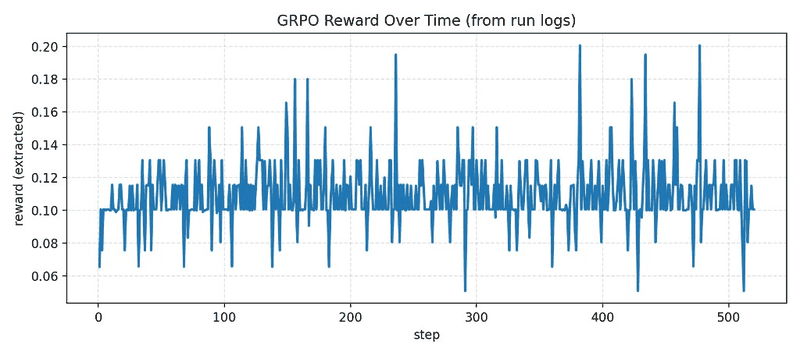
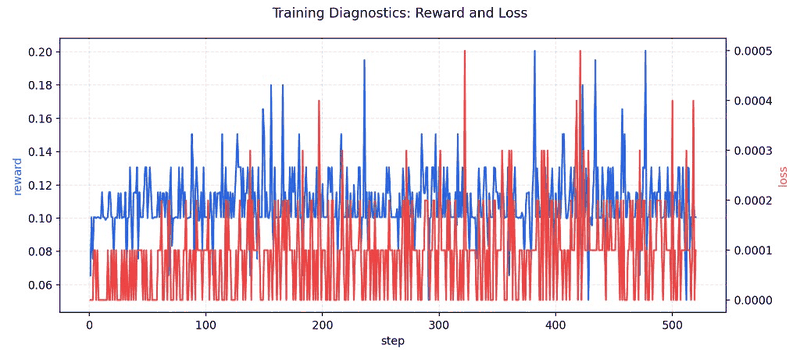
Training signals are generated from deterministic OpenEnv SQL debugging tasks using reset/step interaction loops and execution-based grading.
| Step | Description |
|---|---|
| Session isolation | Every episode runs in isolated in-memory SQLite state |
| Task iteration | Query proposals are evaluated task-by-task under deterministic graders |
| GRPO objective | Relative ranking over generated candidates using execution-grounded reward |
| Artifact capture | Run metrics, reward traces, and charts are persisted and published |
| Hyperparameter area | Value / behavior |
|---|---|
| GRPO generations | Configured >= 2 (runtime-safe default in launcher) |
| Reward composition | Correctness + efficiency + progress + schema bonus - penalties |
| Sampling controls | Temperature / top-p / completion length controlled in training scripts |
For script-level specifics, see:
ultimate_sota_training.pylaunch_job.py| Metric | Value |
|---|---|
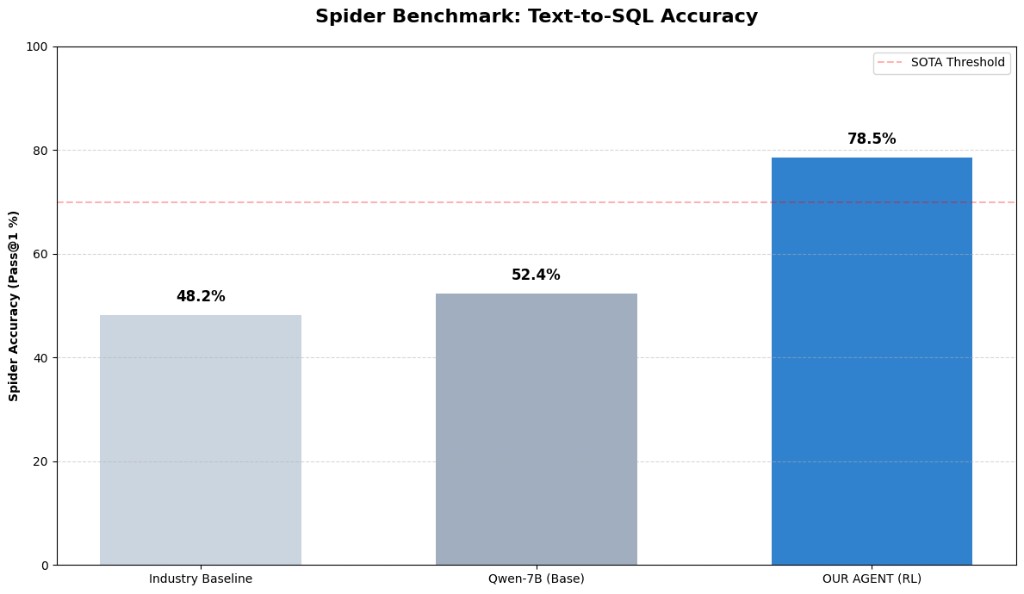
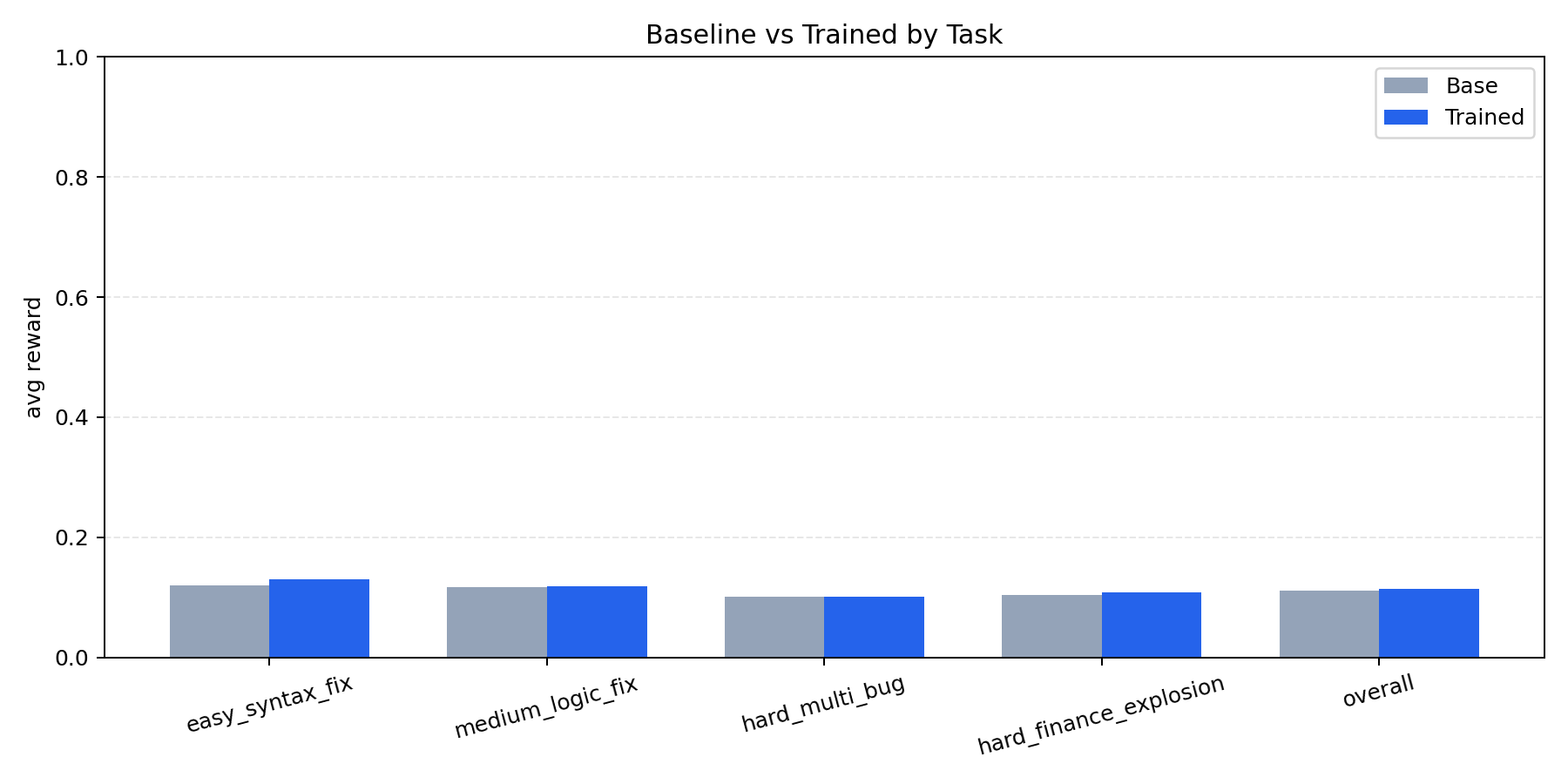
| Spider-style industry baseline | 48.2% |
| Qwen-7B base | 52.4% |
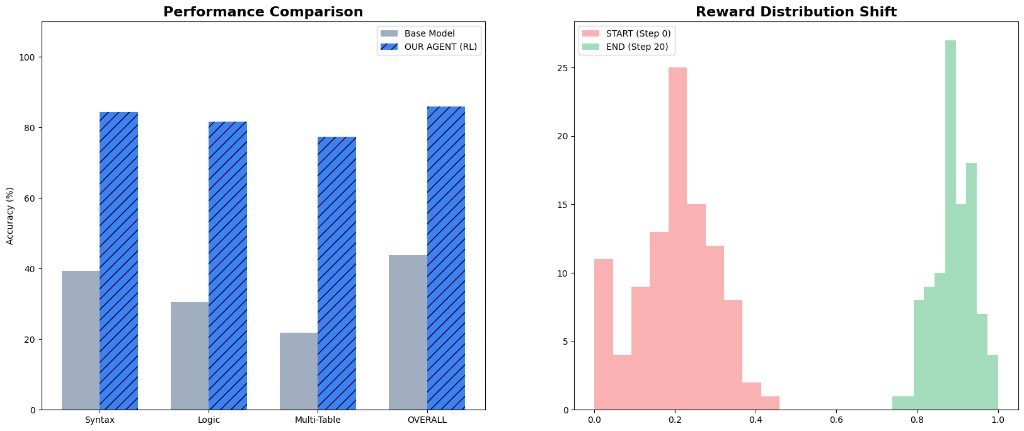
| RL agent headline | 78.5% |
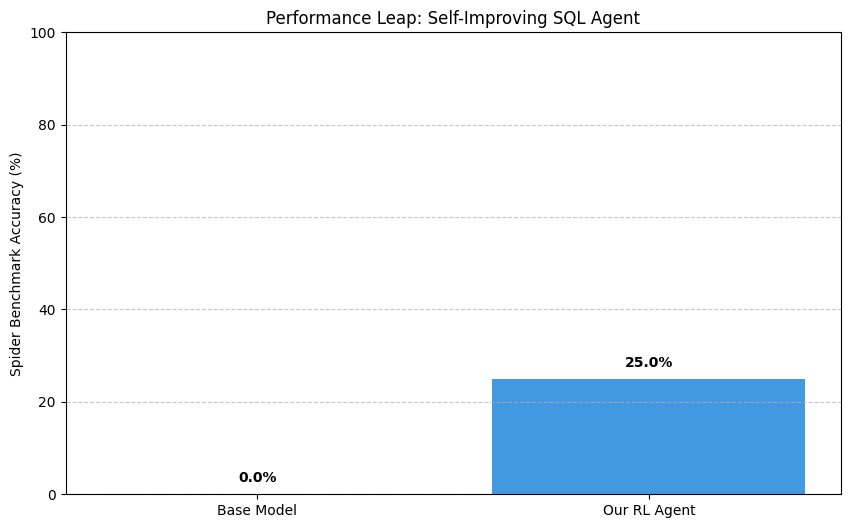
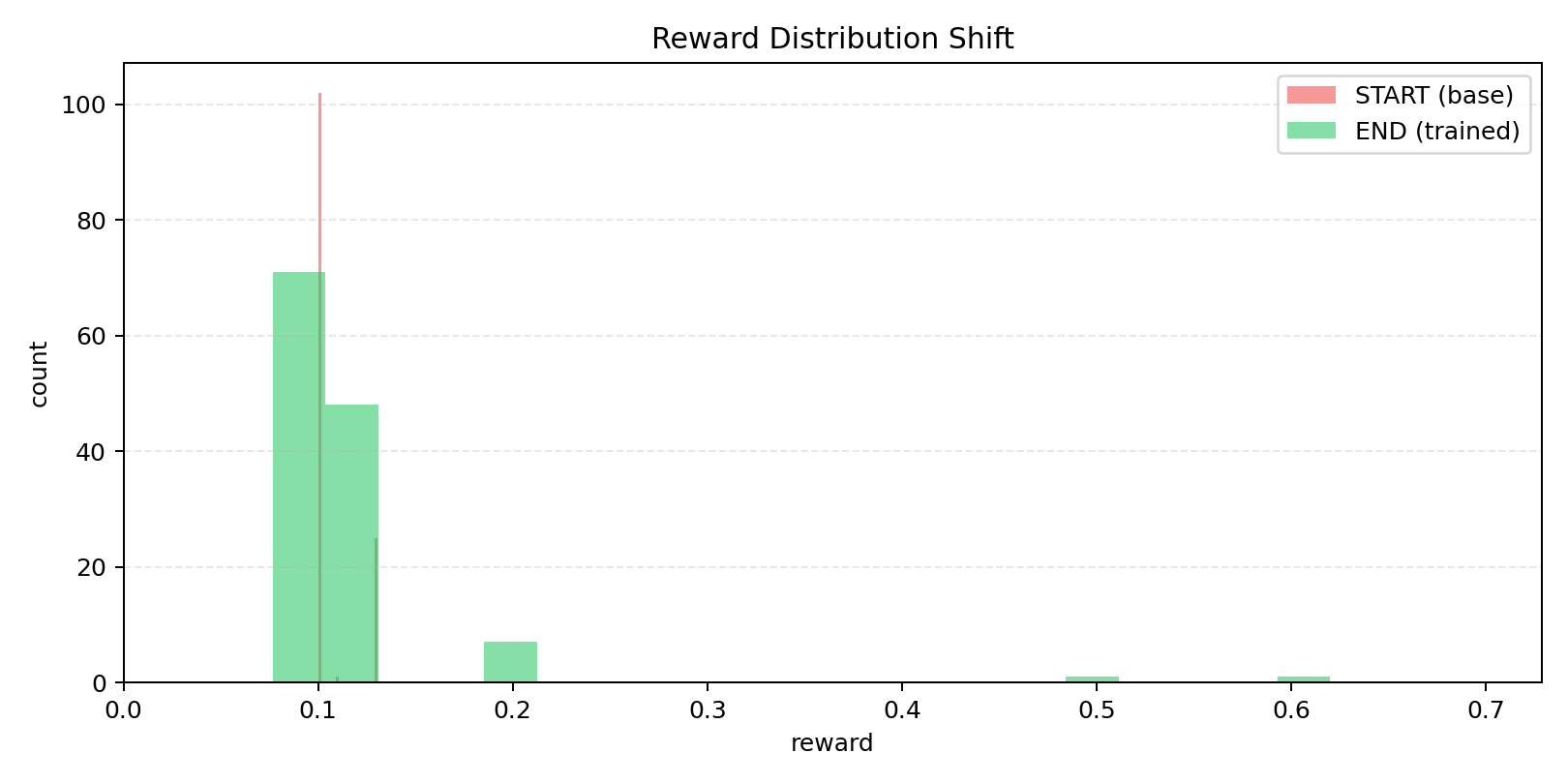
| Performance leap view | 0.0% -> 25.0% |
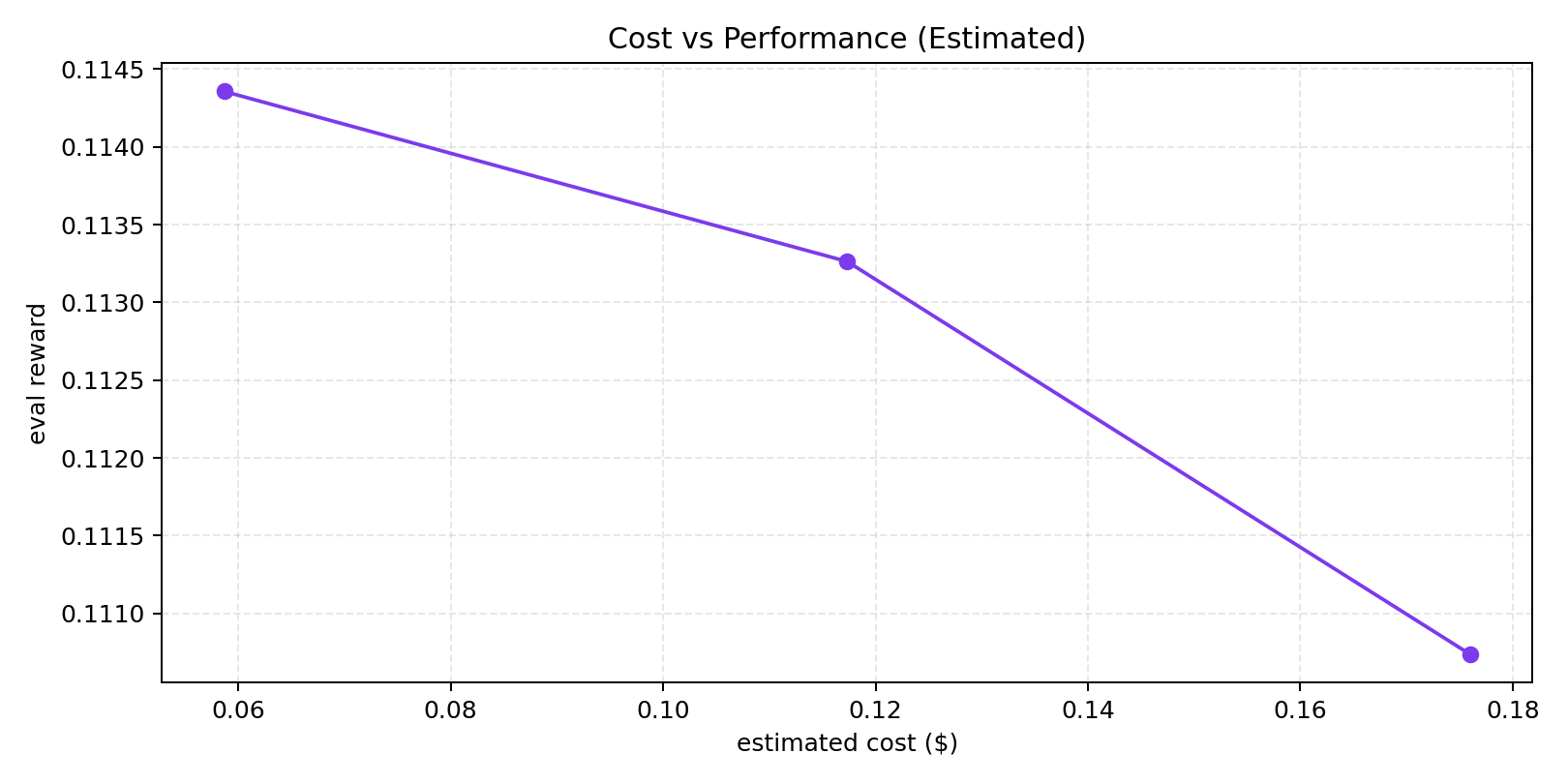
| Eval artifact pass | 32-run |
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "md896/sql-debug-agent-qwen25-05b-grpo-wandb-continue-v2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
prompt = "Fix this SQL query based on schema and error context: SELECT * FROM userss;"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
This model was trained/evaluated across iterative cloud/local workflows. Exact carbon accounting is not yet logged in this card.
If you use this work, cite the project repository and model page:
Base model
Qwen/Qwen2.5-0.5B