
Model Card for MNIST Eraser Repair U-Net
This is a PyTorch-based U-Net Autoencoder designed to reconstruct partially erased handwritten digits from the MNIST dataset. It was created as a submission for the Slovak AI Olympics 2025/26.
Model Details
Model Description
The model takes a damaged 28x28 grayscale image of a handwritten digit (where parts have been synthetically "erased") and restores it to its original form. It uses a U-Net inspired Autoencoder architecture with skip connections to preserve high-resolution spatial details during reconstruction.
- Developed by: mrtineu
- Model type: U-Net Autoencoder (Convolutional Neural Network)
- Language(s): Python (PyTorch)
- License: MIT
Model Architecture
- Encoder: Reduces the 28x28 input image to a 7x7 latent representation using Convolutional layers and Max Pooling.
- Bottleneck: A deep layer with 128 channels capturing the abstract structure of the digit.
- Decoder: Upsamples the latent representation back to 28x28 using Transpose Convolutions. Skip connections link the encoder and decoder to retain fine structural details.
Uses
Direct Use
The primary use of this model is to fulfill the second home assignment of the Slovak AI Olympics 2025/26 challenge. It can be used for restoring damaged, corrupted, or partially missing single-digit handwritten character data.
Out-of-Scope Use
This model is tightly coupled to the standard 28x28 MNIST dataset format. It is not intended for use on real-world, high-resolution document restoration, or general-purpose inpainting tasks outside of the specific characteristics of MNIST digits.
Bias, Risks, and Limitations
- Dataset Dependency: The model only understands digits 0-9 matching the handwriting styles found in MNIST.
- Damage Constraints: If a digit is too heavily erased (to the point where all distinguishing context is lost, such as the entire top of a '7' or '9'), the model may misinterpret the underlying digit.
- Resolution Limit: It exclusively processes 28x28 grayscale images.
Training Details
Training Data
The model was trained on the foundation MNIST dataset. Because the task required pairs of (damaged, clean) images, a synthetic damage generator was used during training. The generator creates random Bézier curves and draws them in black over the white digits, mimicking realistic eraser swipes.
Training Procedure
- Optimizer: Adam
- Learning Rate: 1e-3
- Loss Function: L1 Loss (Mean Absolute Error - MAE). MAE was chosen over MSE to encourage sharper edges and reduce sensitivity to outliers.
- Epochs: 16
- Hardware Setup: Trained using a GPU via Google Colab.
Evaluation
Testing Data & Metrics
The model was evaluated using a challenge test set of 2,000 erased digits. The primary quantitative metric used during both training validation and testing was L1 Loss (Mean Absolute Error).
Results
- The model successfully learned to infer missing segments of characters by utilizing the surrounding context.
- Visual inspection confirms strong qualitative performance; the model restores digits plausibly even when major loops or structural lines are missing.
- Most reconstruction errors are highly localized and low in magnitude (as shown by the very concentrated, low-error distribution in the training records).
Visual Performance
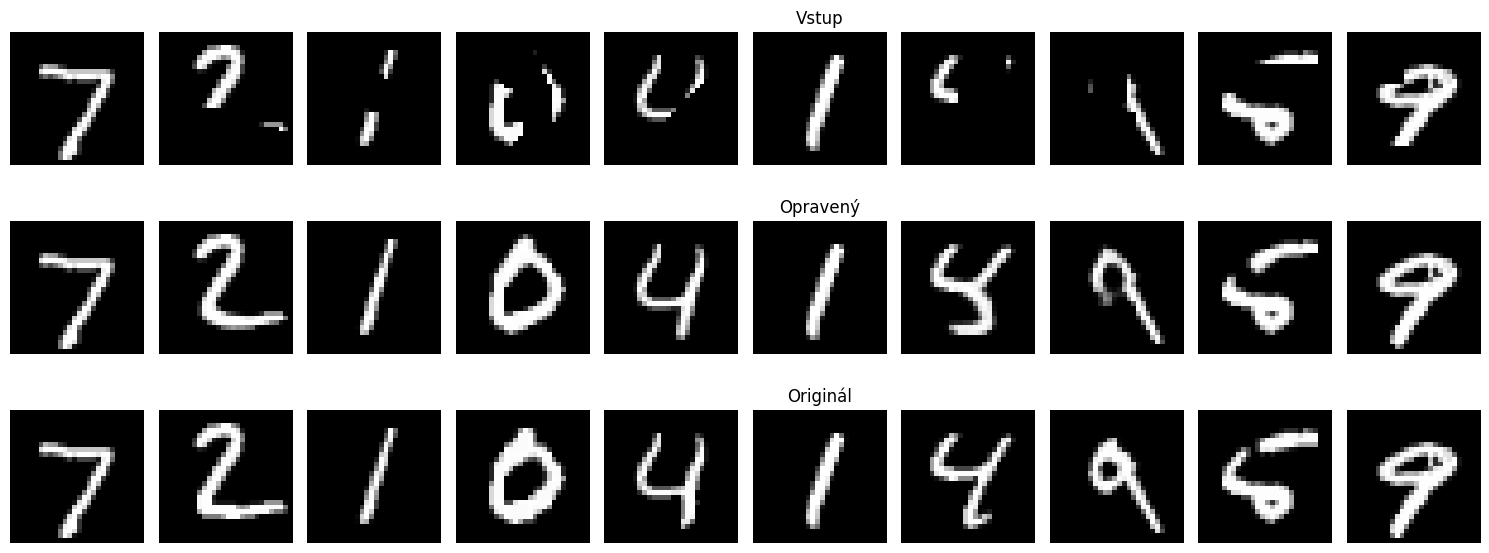 Top: Input (Rubbered), Middle: Output (Fixed), Bottom: Ground Truth
Top: Input (Rubbered), Middle: Output (Fixed), Bottom: Ground Truth
 Top: Input (Rubbered), Bottom: Output (Fixed) from the challenge dataset
Top: Input (Rubbered), Bottom: Output (Fixed) from the challenge dataset
Performance Charts
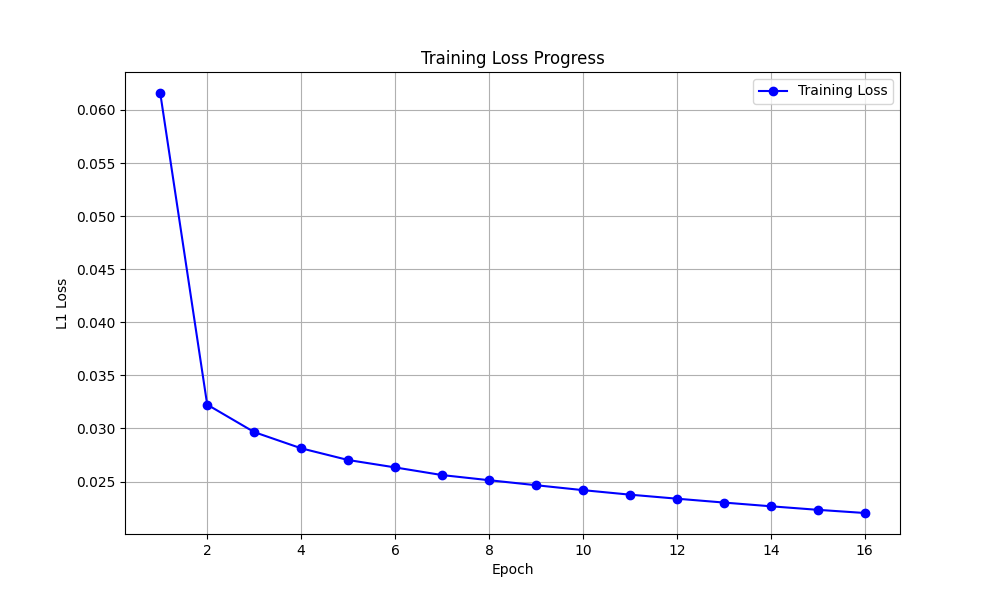 Shows the decrease in L1 Loss over 16 epochs.
Shows the decrease in L1 Loss over 16 epochs.
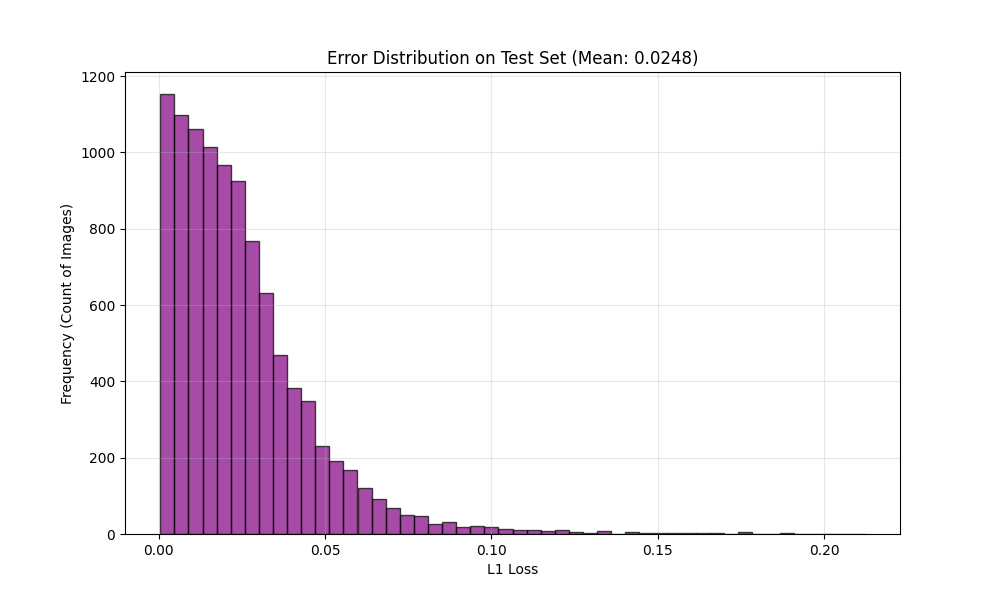 Histogram of the L1 Loss on the test set, showing most errors are very low.
Histogram of the L1 Loss on the test set, showing most errors are very low.