
Update README.md
Browse files
README.md
CHANGED
|
@@ -14,7 +14,6 @@ language:
|
|
| 14 |
metrics:
|
| 15 |
- mae
|
| 16 |
---
|
| 17 |
-
|
| 18 |
# Model Card for MNIST Eraser Repair U-Net
|
| 19 |
|
| 20 |
This is a PyTorch-based U-Net Autoencoder designed to reconstruct partially erased handwritten digits from the MNIST dataset. It was created as a submission for the Slovak AI Olympics 2025/26.
|
|
@@ -59,7 +58,7 @@ Because the task required pairs of (damaged, clean) images, a synthetic damage g
|
|
| 59 |
- **Learning Rate:** 1e-3
|
| 60 |
- **Loss Function:** L1 Loss (Mean Absolute Error - MAE). MAE was chosen over MSE to encourage sharper edges and reduce sensitivity to outliers.
|
| 61 |
- **Epochs:** 16
|
| 62 |
-
- **Hardware Setup:** Trained using a
|
| 63 |
|
| 64 |
## Evaluation
|
| 65 |
|
|
@@ -69,4 +68,20 @@ The model was evaluated using a challenge test set of 2,000 erased digits. The p
|
|
| 69 |
### Results
|
| 70 |
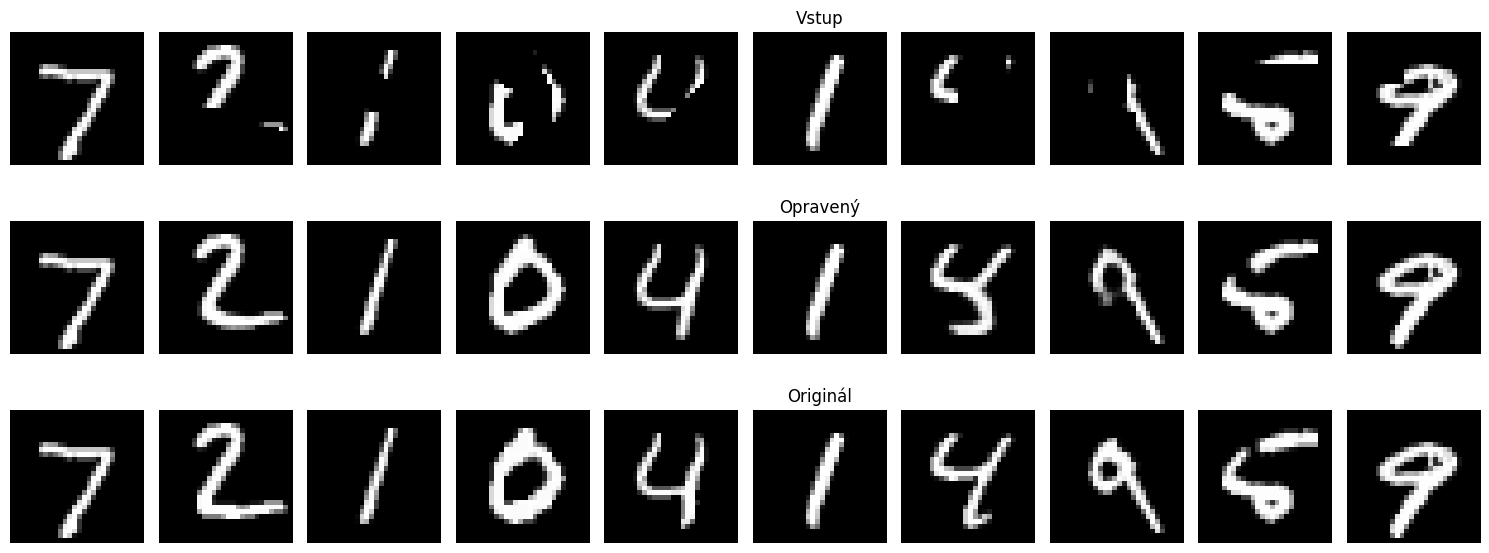
- The model successfully learned to infer missing segments of characters by utilizing the surrounding context.
|
| 71 |
- Visual inspection confirms strong qualitative performance; the model restores digits plausibly even when major loops or structural lines are missing.
|
| 72 |
-
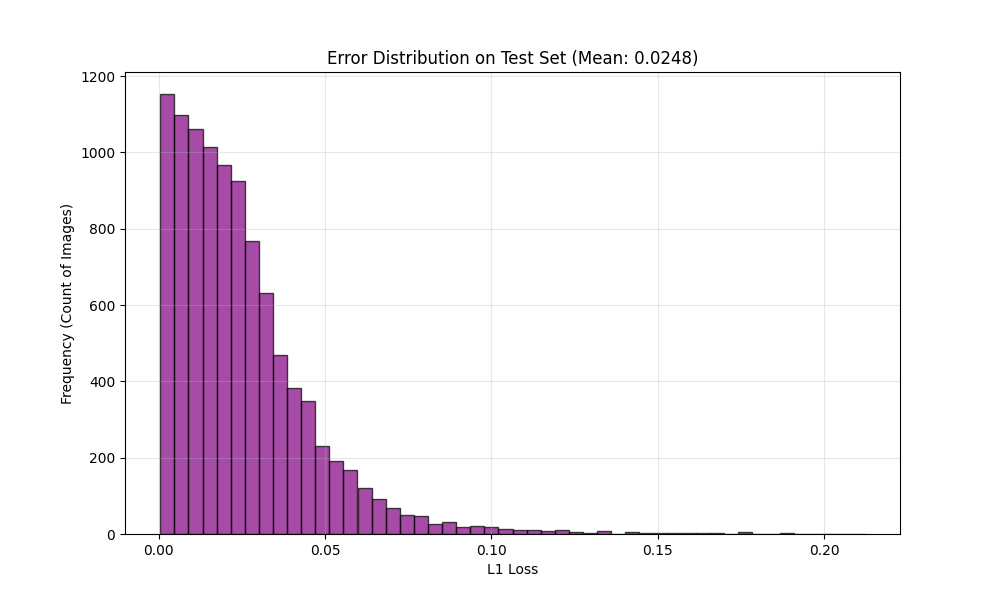
- Most reconstruction errors are highly localized and low in magnitude (as shown by the very concentrated, low-error distribution in the training records).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
metrics:
|
| 15 |
- mae
|
| 16 |
---
|
|
|
|
| 17 |
# Model Card for MNIST Eraser Repair U-Net
|
| 18 |
|
| 19 |
This is a PyTorch-based U-Net Autoencoder designed to reconstruct partially erased handwritten digits from the MNIST dataset. It was created as a submission for the Slovak AI Olympics 2025/26.
|
|
|
|
| 58 |
- **Learning Rate:** 1e-3
|
| 59 |
- **Loss Function:** L1 Loss (Mean Absolute Error - MAE). MAE was chosen over MSE to encourage sharper edges and reduce sensitivity to outliers.
|
| 60 |
- **Epochs:** 16
|
| 61 |
+
- **Hardware Setup:** Trained using a GPU via Google Colab.
|
| 62 |
|
| 63 |
## Evaluation
|
| 64 |
|
|
|
|
| 68 |
### Results
|
| 69 |
- The model successfully learned to infer missing segments of characters by utilizing the surrounding context.
|
| 70 |
- Visual inspection confirms strong qualitative performance; the model restores digits plausibly even when major loops or structural lines are missing.
|
| 71 |
+
- Most reconstruction errors are highly localized and low in magnitude (as shown by the very concentrated, low-error distribution in the training records).
|
| 72 |
+
|
| 73 |
+
#### Visual Performance
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
*Top: Input (Rubbered), Middle: Output (Fixed), Bottom: Ground Truth*
|
| 77 |
+
|
| 78 |
+

|
| 79 |
+
*Top: Input (Rubbered), Bottom: Output (Fixed) from the challenge dataset*
|
| 80 |
+
|
| 81 |
+
#### Performance Charts
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
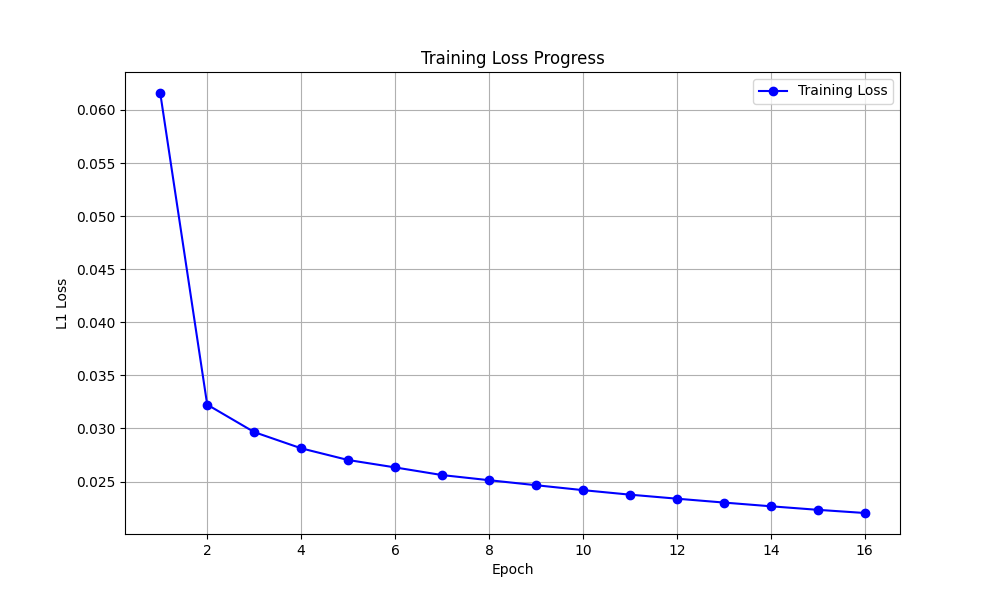
*Shows the decrease in L1 Loss over 16 epochs.*
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
*Histogram of the L1 Loss on the test set, showing most errors are very low.*
|