

metadata
license: mit
base_model: Qwen/Qwen2.5-VL-7B
tags:
- vision-language
- document-to-markdown
- reinforcement-learning
- grpo
- qwen2.5
- markdown
model_name: NuMarkdown-Qwen2.5-VL
datasets:
- NM-dev/markdown-input_output-v3
- NM-dev/markdown-grpo-images3
library_name: transformers
pipeline_tag: text-generation

🖥️ API / Platform | 📑 Blog | 🗣️ Discord
NuMarkdown-Qwen2.5-VL 🖋️📄 → 📝
NuMarkdown-reasoning is the first reasoning vision-language model trained to converts documents into clean GitHub-flavoured Markdown. It is a fine-tune of Qwen 2.5-VL-7B using ~10 k synthetic doc-to-Markdown pairs, followed by a RL phase (GRPO) with a layout-centric reward.
(note: the number of thinking tokens can vary from 20% to 2X the number of token of the final answers)
Results
(we plan to realease a markdown arena -similar to llmArena- for complex document to markdown task)
Arena ranking (using trueskill-2 ranking system)
| Rank | Model | μ | σ | μ − 3σ |
|---|---|---|---|---|
| 🥇 1 | gemini-flash-reasoning | 26.75 | 0.80 | 24.35 |
| 🥈 2 | NuMarkdown-reasoning | 26.10 | 0.79 | 23.72 |
| 🥉 3 | NuMarkdown-reasoning-w/o_reasoning | 25.32 | 0.80 | 22.93 |
| 4 | OCRFlux-3B | 24.63 | 0.80 | 22.22 |
| 5 | gpt-4o | 24.48 | 0.80 | 22.08 |
| 6 | gemini-flash-w/o_reasoning | 24.11 | 0.79 | 21.74 |
| 7 | RolmoOCR | 23.53 | 0.82 | 21.07 |
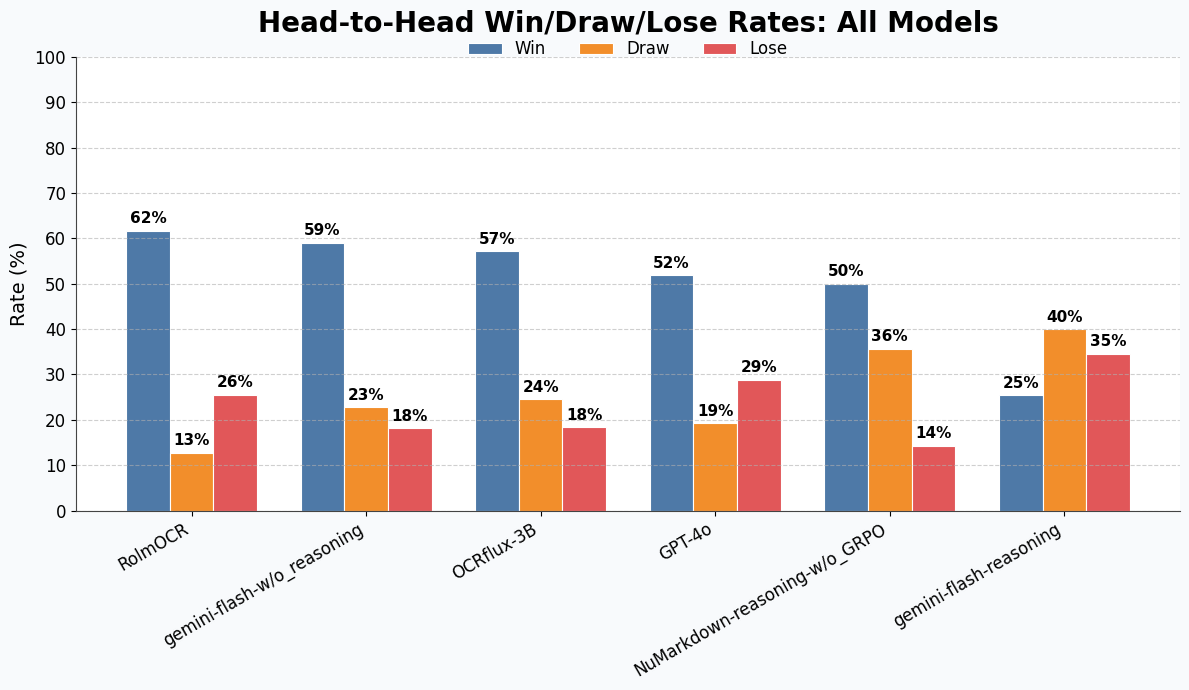
Win-rate of our model against others models:
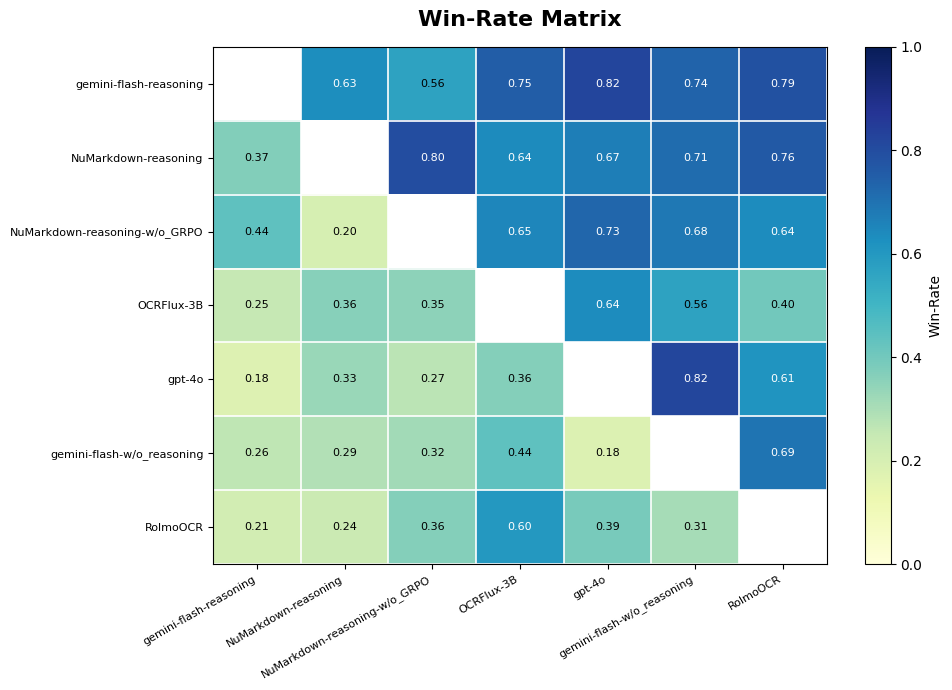
Matrix Win-rate:
Training
- SFT: One-epoch supervised fine-tune on synthetic reasoning trace generated from public PDFs (10K input/output pairs).
- RL (GRPO): RL pahse using a structure-aware reward (5K difficults image examples).
Quick start: 🤗 Transformers
from __future__ import annotations
import torch
from PIL import Image
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
model_id = "NM-dev/NuMarkdown-Qwen2.5-VL"
processor = AutoProcessor.from_pretrained(
model_id,
trust_remote_code=True,
)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto",
trust_remote_code=True,
)
img = Image.open("invoice_scan.png").convert("RGB")
messages = [{
"role": "user",
"content": [
{"type": "image"},
],
}]
prompt = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
enc = processor(text=prompt, images=[img], return_tensors="pt").to(model.device)
with torch.no_grad():
out = model.generate(**enc, max_new_tokens=5000)
print(processor.decode(out[0].split("<answer>")[1].split("</answer>")[0], skip_special_tokens=True))
VLLM:
from PIL import Image
from vllm import LLM, SamplingParameters
from transformers import AutoProcessor
model_id = "NM-dev/NuMarkdown-Qwen2.5-VL"
llm = LLM(model=model_id, trust_remote_code=True, dtype="bfloat16")
proc = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
img = Image.open("invoice_scan.png")
prompt = proc(text="Convert this to Markdown with reasoning.", image=img,
return_tensors="np") # numpy arrays for vLLM
params = SamplingParameters(max_tokens=1024, temperature=0.8, top_p=0.95)
result = llm.generate([{"prompt": prompt}], params)[0].outputs[0].text.split("<answer>")[1].split("</answer>")[0]
print(result)