
Cosmos-Embed1
Collection
Joint video-text embedding for physical AI • 5 items • Updated • 7
Cosmos-Embed1 is a joint video-text embedder tailored for physical AI. It can be used for text-to-video retrieval, inverse video search, semantic deduplication, zero-shot and k-nearest-neighbors (kNN) classification, and as a base model for video curation tasks. It has state-of-the-art (SOTA) performance on autonomous vehicle (AV) and robotics datasets, while maintaining competitive performance in general domains. A fine-tuned variant is also provided for video anomaly detection and classification. This model is ready for commercial use.
The Cosmos-Embed1 release includes the following embedders:
| Variant | Resolution | Frames | Embedding Dim |
|---|---|---|---|
| Cosmos-Embed1-224p | 224×224 | 8 | 256 |
| Cosmos-Embed1-336p | 336×336 | 8 | 768 |
| Cosmos-Embed1-448p | 448×448 | 8 | 768 |
Note: while each checkpoint was optimized at a specific fixed resolution (and default to these), they all support arbitrary non-square resolutions.
In addition, a fine-tuned variant is provided for anomaly detection applications:
| Variant | Base Model | Resolution | Frames | Fine-tuning Dataset | Embedding Dim |
|---|---|---|---|---|---|
| Cosmos-Embed1-448p-anomaly-detection | Cosmos-Embed1-448p | 448×448 | 8 | Vad-Reasoning (training set) | 768 |
The Cosmos-Embed1-448p-anomaly-detection model is fine-tuned from Cosmos-Embed1-448p using LoRA (Low-Rank Adaptation) on the training set of the Vad-Reasoning dataset, a video anomaly detection and reasoning dataset covering traffic, campus, urban, and other real-world scenarios. LoRA is applied to preserve the base model's generalizability while adapting it for anomaly detection, anomaly classification, and video retrieval in diverse video understanding applications.

GOVERNING TERMS: Use of this model is governed by the NVIDIA Open Model License. Additional Information: Apache 2.0 and MIT.
Global
Physical AI developers and engineers for video-text embedding tasks including text-to-video retrieval, video-to-video search, zero-shot classification, and semantic deduplication across robotics, autonomous vehicles (AV), video anomaly detection, and diverse video understanding domains.
Hugging Face 06/15/2025 Model Link
Li, Junnan, et al. "BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models." International conference on machine learning. PMLR, 2023.
Huang, Chao, et al. "Vad-R1: Towards Video Anomaly Reasoning via Perception-to-Cognition Chain-of-Thought." arXiv:2505.19877, 2025.
NVIDIA Cosmos-Embed1 Research Page: https://research.nvidia.com/labs/dir/cosmos-embed1/.
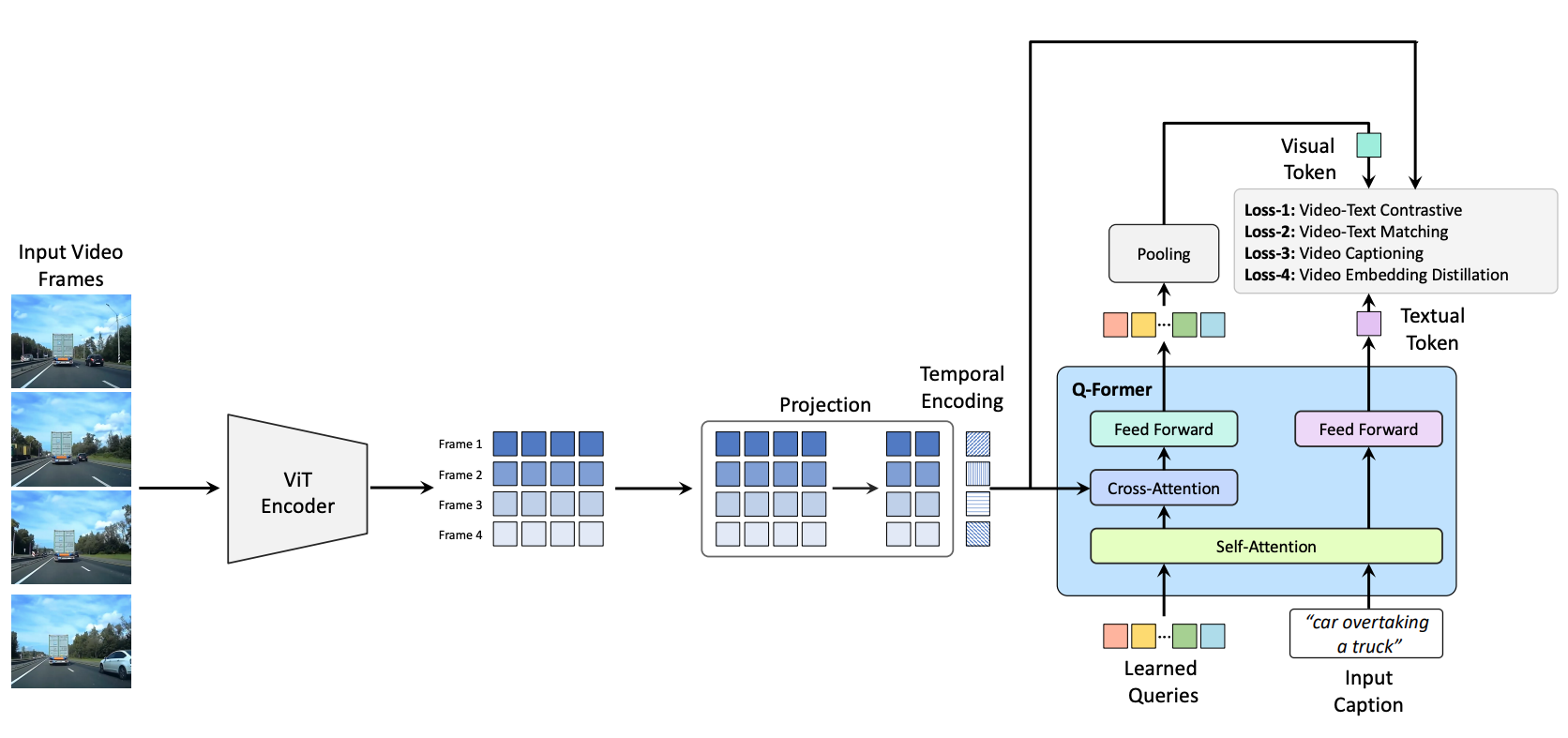
Architecture Type: Transformer
Network Architecture: QFormer-based video-text embedder with EVA-ViT-G visual backbone
** The architecture is based on QFormer, with modifications for processing video inputs. The video embedder processes frames individually with a ViT backbone. The per-frame ViT features are concatenated in the temporal dimension and augmented with temporal embeddings. These are then passed into the QFormer which summarizes via cross-attention a compact set of visual query tokens from the provided frames. The visual query tokens are then pooled into a single video embedding.
The text embedder processes tokenized text via the self-attention branch of the QFormer to produce a text embedding. The normalized text and video embeddings are aligned via a contrastive video-text loss, as well as auxiliary losses such as video-text matching and video captioning. For the 336p and 448p variants, additional summary and dense distillation losses are used.
** Number of model parameters: ~1.0×10^9
The model operates in one of two modes per forward pass — text encoding or video encoding — not both simultaneously. Each mode accepts a single input type and produces a corresponding embedding.
Input Type(s): Text or Video (one per forward pass)
Input Format(s):
Input Parameters:
Other Properties Related to Input:
[batch_size, channels, num_frames, height, width] For each forward pass, the model produces a single 1D embedding — either a text embedding or a video embedding, depending on the input mode. The two embedding types live in a shared vector space, enabling cross-modal similarity (e.g., ranking videos by relevance to a text query via cosine similarity).
Output Type(s): Text embedding or Video embedding (one per forward pass)
Output Format(s):
Output Parameters:
Other Properties Related to Output: Continuous-valued L2-normalized feature vectors with a dimensionality of 256 (224p variant) or 768 (336p and 448p variants). A distance can be calculated between embeddings using cosine similarity. Dense intermediate feature maps are also provided for convenience.
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA's hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
Runtime Engine(s):
Supported Hardware Microarchitecture Compatibility:
Note: Cosmos-Embed1 has been tested with BF16 precision on NVIDIA Ampere and Hopper GPUs. Older GPU architectures (e.g., NVIDIA Volta) may require switching to FP32 precision.
Preferred/Supported Operating System(s):
The integration of foundation and fine-tuned models into AI systems requires additional testing using use-case-specific data to ensure safe and effective deployment. Following the V-model methodology, iterative testing and validation at both unit and system levels are essential to mitigate risks, meet technical and functional requirements, and ensure compliance with safety and ethical standards before deployment.
This AI model can be embedded as an Application Programming Interface (API) call into the software environment described above.
** Total Size: 2,193 videos used (1,755 training + 438 test), from the Vad-Reasoning dataset (8,641 total)
** Total Number of Datasets: 7 source datasets (UCF-Crime, XD-Violence, TAD, ShanghaiTech, UBnormal, ECVA, and internet videos) aggregated into the Vad-Reasoning dataset
The Cosmos-Embed1-448p-anomaly-detection variant is fine-tuned and evaluated on the Vad-Reasoning dataset, introduced in Vad-R1: Towards Video Anomaly Reasoning via Perception-to-Cognition Chain-of-Thought (Huang et al., 2025). The dataset covers diverse real-world traffic, campus, urban, and similar scenarios with a fine-grained anomaly taxonomy: Human Activity Anomaly, Environments Anomaly, and Objects Anomaly — each further divided into subcategories.
** Data Modality
** Video Training Data Size
Vad-Reasoning-SFT Training Set: 1,755 videos with high-quality Chain-of-Thought annotations, sourced from multiple public video anomaly detection datasets (only the SFT subset was used; the 6,448-video RL subset was not used). The original videos are split into 5-second chunks for training. Each chunk is paired with a text caption derived from the anomaly_type field in the dataset annotations.
| Source Dataset | Scenario |
|---|---|
| UCF-Crime | Real-world crime and anomaly footage |
| XD-Violence | Violent events |
| TAD | Traffic anomalies |
| ShanghaiTech | Campus scenes |
| UBnormal | Urban/city scenes |
| ECVA | Multi-scene benchmark |
| Internet videos | Additional anomaly categories |
The dataset contains 24 unique anomaly categories used as text captions for contrastive training and zero-shot evaluation. Video chunks that do not contain an anomaly event are labeled as "Normal" during fine-tuning:
| # | Anomaly Type | # | Anomaly Type | # | Anomaly Type |
|---|---|---|---|---|---|
| 1 | Abuse | 9 | Fighting | 17 | Riot |
| 2 | Animals Obstructing Traffic | 10 | Fire | 18 | Robbery |
| 3 | Arson | 11 | Flooding or Tsunami | 19 | Shooting |
| 4 | Avalanche and Landslide | 12 | Illegal Lane Changing | 20 | Stealing |
| 5 | Dangerous Items | 13 | Illegal Parking | 21 | Tornado |
| 6 | Explosion | 14 | Obstacles on Road | 22 | Traffic Accidents |
| 7 | Falling | 15 | Pedestrian Jaywalking | 23 | Vandalism |
| 8 | Falling Objects | 16 | Red Light Violation | 24 | Wrong-Way Driving |
** Data Collection Method by dataset
** Labeling Method by dataset
Properties: 1,755 video clips (Vad-Reasoning-SFT subset) covering public spaces, traffic, campus, and urban environments. Content includes anomaly categories (Human Activity, Environments, Objects) with fine-grained subcategories. No personal data or copyright-protected content is directly used; source datasets are publicly available research datasets.
Data Collection Method by dataset:
Labeling Method by dataset:
Properties: The Vad-Reasoning test set was used for testing during fine-tuning. See Evaluation Dataset below for details.
Vad-Reasoning Test Set: 438 videos from the same distribution as the training set, used for evaluating anomaly classification and retrieval performance. As with training, the original videos are split into 5-second chunks, and each chunk's ground-truth label is the anomaly_type from the dataset annotations.
Data Collection Method by dataset:
Labeling Method by dataset:
Properties: 438 video clips from public cameras and general-purpose cameras for anomaly classification and retrieval tasks. Same anomaly taxonomy as training set (Human Activity Anomaly, Environments Anomaly, Objects Anomaly).
Kinetics-400: A large-scale human action recognition dataset containing ~400 human action classes sourced from publicly available internet scale data. Each clip is approximately 10 seconds long and annotated with a single action class. The validation set contains 19,877 video clips and is used to evaluate the base Cosmos-Embed1-448p model on general-domain zero-shot action classification.
Data Collection Method by dataset:
Labeling Method by dataset:
Properties: 19,877 video clips (~10s each) covering 400 human action classes including human-object interactions (e.g., playing instruments) and human-human interactions (e.g., shaking hands, hugging).
Benchmark Scores:
Evaluated on the Vad-Reasoning test set (438 videos) using zero-shot classification via video-text similarity.
The key performance indicators are:
| Metric | Cosmos-Embed1-448p | Cosmos-Embed1-448p-anomaly-detection |
|---|---|---|
| Top-1 Hit Rate | 23.21% | 46.44% |
| Top-3 Hit Rate | 34.81% | 73.95% |
| Top-5 Hit Rate | 45.98% | 83.71% |
| Top-10 Hit Rate | 67.24% | 94.50% |
| MRR | 0.3557 | 0.6299 |
| Macro F1 | 19.51% | 38.94% |
Evaluated on the Kinetics-400 validation set (19,877 videos) using zero-shot action classification via video-text similarity.
The key performance indicators are:
| Metric | Cosmos-Embed1-448p | Cosmos-Embed1-448p-anomaly-detection |
|---|---|---|
| Top-1 Accuracy | 87.96% | 85.18% |
| Top-5 Accuracy | 97.58% | 96.47% |
| Recall (macro) | 87.95% | 85.17% |
| F1 (macro) | 87.89% | 85.36% |
Acceleration Engine: PyTorch, ONNX Runtime
Test Hardware:
import decord
import numpy as np
import torch
from transformers import AutoProcessor, AutoModel
model = AutoModel.from_pretrained(
"nvidia/Cosmos-Embed1-448p", trust_remote_code=True
).to("cuda", dtype=torch.bfloat16)
preprocess = AutoProcessor.from_pretrained(
"nvidia/Cosmos-Embed1-448p", trust_remote_code=True
)
# Load video frames
reader = decord.VideoReader("/path/to/video.mp4")
frame_ids = np.linspace(0, len(reader) - 1, 8, dtype=int).tolist()
frames = reader.get_batch(frame_ids).asnumpy()
batch = np.transpose(np.expand_dims(frames, 0), (0, 1, 4, 2, 3)) # BTCHW
captions = ["a person walking", "a car driving on a highway"]
# Compute embeddings
video_inputs = preprocess(videos=batch).to("cuda", dtype=torch.bfloat16)
video_out = model.get_video_embeddings(**video_inputs)
text_inputs = preprocess(text=captions).to("cuda", dtype=torch.bfloat16)
text_out = model.get_text_embeddings(**text_inputs)
# Rank captions by similarity
probs = torch.softmax(
model.logit_scale.exp() * video_out.visual_proj @ text_out.text_proj.T,
dim=-1,
)[0]
print(captions[probs.argmax()])
Cosmos-Embed1 supports fine-tuning via the TAO Toolkit. The model can be fine-tuned using full training or LoRA (Low-Rank Adaptation) for parameter-efficient training. TAO also supports:
video, text, or combined mode.transformers library.A Jupyter notebook with end-to-end workflow is available at
Example training spec:
model:
pretrained_model_path: /model/Cosmos-Embed1-224p
precision: bf16
network:
embed_dim: 256
num_video_frames: 8
train:
num_gpus: 1
max_iter: 1000
freeze_visual_encoder: true
optim:
lr: 1.0e-05
The model can be exported to ONNX in three modes:
| Mode | ONNX Inputs | ONNX Outputs |
|---|---|---|
video |
videos (B,3,T,H,W) |
video_embedding (B, embed_dim) |
text |
input_ids (B,seq_len), attention_mask (B,seq_len) |
text_embedding (B, embed_dim) |
combined |
all of above | both of above |
export:
checkpoint: /results/train/cosmos_embed1_model_latest.pth
mode: combined # video + text
onnx_file: /results/export/cosmos_embed1_video.onnx
batch_size: -1
simplify: true
The exported ONNX file can be further converted to a TensorRT engine for optimized inference on NVIDIA GPUs using trtexec or the TensorRT Python API.
The trained model can be exported to HuggingFace format, producing a self-contained directory with sharded safetensors weights, config.json compatible with AutoModel.from_pretrained(), and tokenizer files. This allows loading with the transformers library or uploading to the HuggingFace Hub.
export:
checkpoint: /results/train/cosmos_embed1_model_latest.pth
mode: huggingface
hf_output_dir: /results/export_hf/cosmos_embed1_hf
on_cpu: true
Once exported, the model can be loaded directly:
from transformers import AutoModel
model = AutoModel.from_pretrained(
"/results/export_hf/cosmos_embed1_hf",
trust_remote_code=True,
)
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Users are responsible for model inputs and outputs. Users are responsible for ensuring safe integration of this model, including implementing guardrails as well as other safety mechanisms, prior to deployment.
For more detailed information on ethical considerations for this model, please see the Model Card++ Bias, Explainability, Safety & Security, and Privacy Subcards.
Please report model quality, risk, security vulnerabilities or NVIDIA AI Concerns here.
| Field | Response |
|---|---|
| Participation considerations from adversely impacted groups protected classes in model design and testing: | None |
| Measures taken to mitigate against unwanted bias: | None |
| Field | Response |
|---|---|
| Intended Task/Domain: | Joint video-text embedding for physical AI applications (robotics, autonomous vehicles (AV), search, general video understanding) and video anomaly detection and classification. |
| Model Type: | Transformer |
| Intended Users: | Physical AI developers working on robotics, autonomous vehicles (AV), search, video understanding, and video anomaly detection tasks. |
| Output: | L2-normalized text and video embedding vectors (256 dimensions for 224p inputs; 768 dimensions for 336p/448p inputs). |
| Describe how the model works: | Video frames are individually processed by a ViT backbone, temporally augmented, and compressed via QFormer cross-attention into a single video embedding. Text is processed by the QFormer self-attention branch into a text embedding. Both embeddings are aligned via contrastive learning. |
| Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable |
| Technical Limitations & Mitigation: | Due to the training datasets being predominantly composed of short action-focused English captions, different text prompts may not be properly aligned to video data, producing suboptimal matching. The model has been optimized for 8 frames at 1–2 FPS; significantly different frame rates or video lengths may degrade performance. Fine-tuning on domain-specific data can mitigate these limitations. |
| Verified to have met prescribed NVIDIA quality standards: | Yes |
| Performance Metrics: | Retrieval metrics (top-K hit rate, mean reciprocal rank) and classification metrics (precision, recall, F1) |
| Potential Known Risks: | The model may produce suboptimal embeddings to unsafe text prompts. |
| Licensing: | GOVERNING TERMS: Use of this model is governed by the NVIDIA Open Model License. Additional Information: Apache 2.0 and MIT. |
| Field | Response |
|---|---|
| Generatable or reverse engineerable personal data? | No |
| Personal data used to create this model? | Yes. |
| Was consent obtained for any personal data used? | Unknown |
| How often is dataset reviewed? | Before Release |
| Is a mechanism in place to honor data subject right of access or deletion of personal data? | No, not possible with externally sourced-data |
| If personal data was collected for the development of the model, was it collected directly by NVIDIA? | No |
| If personal data was collected for the development of the model by NVIDIA, do you maintain or have access to disclosures made to data subjects? | Not Applicable |
| If personal data was collected for the development of this AI model, was it minimized to only what was required? | Not Applicable |
| Was data from user interactions with the AI model (e.g. user input and prompts) used to train the model? | No |
| Is there provenance for all datasets used in training? | Yes |
| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |
| Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data. |
| Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/ |
| Field | Response |
|---|---|
| Model Application Field(s): | Industrial/Machinery and Robotics, Video Understanding |
| Describe the life critical impact (if present). | This model produces video and text embeddings for tasks such as text-to-video retrieval, video-to-video search, zero-shot classification, and semantic deduplication. It is intended for use in physical AI applications encompassing robotics, autonomous vehicles (AV), and anomaly detection. The fine-tuned variant (Cosmos-Embed1-448p-finetuned_anomaly_detection) is additionally optimized for video anomaly detection and classification. |
| Use Case Restrictions: | Abide by the NVIDIA Open Model License. Additional Information: Apache 2.0 and MIT. |
| Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to. Model checkpoints are made available on Hugging Face, and may become available on cloud providers' model catalog. |