

| Trove | |
| ===== | |
| Trove is a CUDA library that provides efficient vector loads and | |
| stores. It works for CUDA architectures 3.0 and above, and uses no | |
| CUDA shared memory, making it easy to integrate. It is useful for | |
| working with data in an Array of Structures format, and also when | |
| writing code that consumes or produces an array of data per CUDA | |
| thread. | |
| How it Works | |
| ============ | |
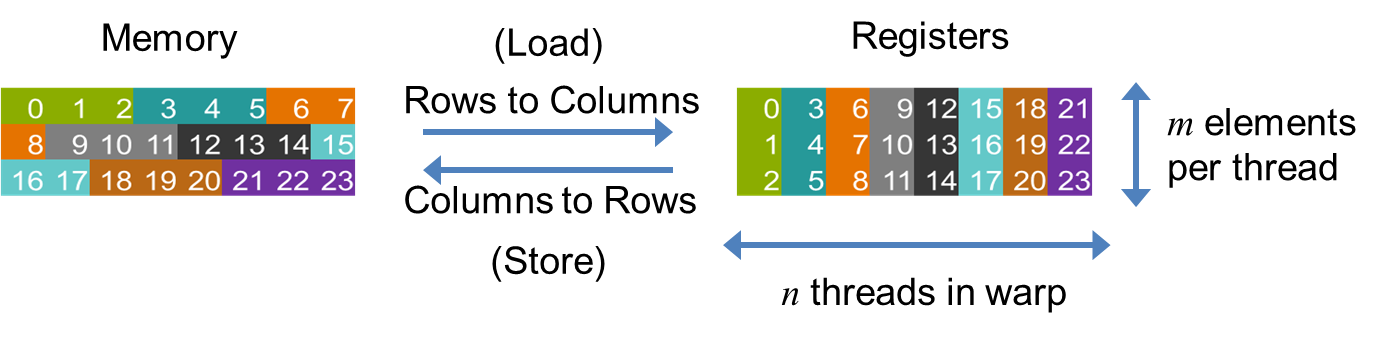
| This functionality is built out of a transposition routine that uses | |
| the warp shuffle intrinsic to redistribute data amongst threads in the | |
| CUDA warp. For example, when every thread in | |
| the warp is loading contiguous structures from an array, the threads | |
| collaboratively load all the data needed by the warp, using coalesced | |
| memory accesses, then transpose the data to redistribute it to the | |
| correct thread. | |
| The following cartoon illustrates how this works, for a notional warp | |
| with eight threads. | |
|  | |
| Performance | |
| =========== | |
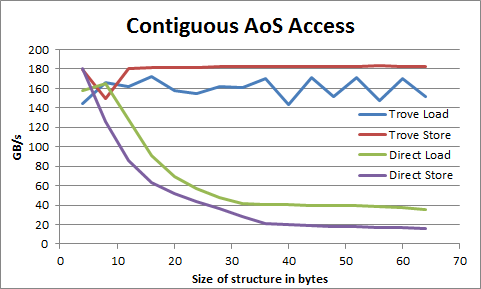
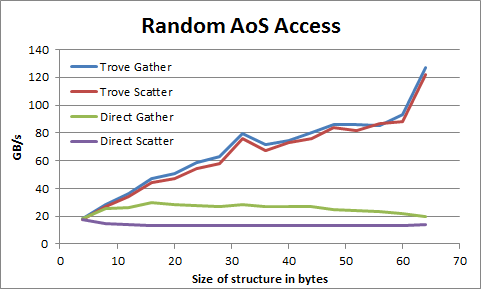
| Accesses to arrays of structures can be 6X faster than direct memory | |
| accesses using compiler generated loads and stores. The following | |
| benchmarks were taken on a Tesla K20c. The structure `T` being loaded | |
| and stored in these benchmarks is made of one to sixteen 32-bit integers. | |
|  | |
|  | |
| High-level Interface | |
| ==================== | |
| ```c++ | |
| #include <trove/ptr.h> | |
| template<typename T> | |
| __global__ void | |
| trove_gather(const int length, const int* indices, | |
| trove::coalesced_ptr<T> src, //Wrapped pointer | |
| trove::coalesced_ptr<T> dst) { | |
| int global_index = threadIdx.x + blockDim.x * blockIdx.x; | |
| if (global_index < length) { | |
| int index = indices[global_index]; | |
| T data = src[index]; | |
| dst[global_index] = data; | |
| } | |
| } | |
| ``` | |
| The high-level interface allows you to load and store structures | |
| directly. Just wrap the pointers of your arrays in | |
| `trove::coalesced_ptr<T>`. You don't need to worry if the warp is | |
| converged, or if the addresses you're accessing are contiguous. This | |
| interface loses some performance, since it has to dynamically check | |
| whether the warp is converged, and also broadcast all pointers from | |
| all threads in each warp to all other threads in the warp, but it is | |
| simple to use. | |
| There are two restrictions on `T`: | |
| * `sizeof(T)` must be divisible by 4 | |
| * `T` must have a default constructor | |
| Block Interface | |
| =============== | |
| It's common for CUDA code to process or produce several values per thread. For | |
| example, a merge operation may process 7 values per thread, to increase the | |
| amount of serial work. For these cases, we provide a blocked interface | |
| that enables efficient block-wise vector loads and stores. | |
| This interface relies on an array type `trove::array<T, s>`, where `T` | |
| is the type of each element of the array, and `s` is an integer that | |
| statically determines the length of the array. `trove::array` types | |
| can be converted to and from standard C arrays (see | |
| [array.h](http://github.com/BryanCatanzaro/trove/blob/master/trove/array.h) | |
| ), but they have value | |
| semantics rather than reference semantics, and they can only be | |
| indexed statically. | |
| With this interface, each thread is assumed to be reading or writing | |
| from contiguous locations in the input or output array. The user is | |
| responsible for checking for convergence, which they probably do | |
| anyway for functional reasons. If the warp is not converged, we | |
| provide fallback functions that load and store arrays using compiler | |
| generated code. | |
| ```c++ | |
| #include <trove/block.h> | |
| template<typename T, int s> | |
| __global__ void test_block_copy(const T* x, T* r, int l) { | |
| typedef trove::array<T, s> s_ary; | |
| int global_index = threadIdx.x + blockIdx.x * blockDim.x; | |
| for(int index = global_index; index < l; index += gridDim.x * blockDim.x) { | |
| //The block memory accesses only function | |
| //correctly if the warp is converged. Here we check. | |
| if (trove::warp_converged()) { | |
| //Warp converged, indices are contiguous, call the fast | |
| //load and store | |
| s_ary d = trove::load_array_warp_contiguous<s>(x, index); | |
| trove::store_array_warp_contiguous(r, index, d); | |
| } else { | |
| //Warp not converged, call the slow load and store | |
| s_ary d = trove::load_array<s>(x, index); | |
| trove::store_array(r, index, d); | |
| } | |
| } | |
| } | |
| ``` | |
| Low-level Interface | |
| =================== | |
| If you know your warp is converged, and that your threads are all | |
| accessing contiguous locations in your array, you can use the | |
| low-level interface for maximum performance. By contiguous, we mean | |
| that if threads with indices *i* and thread *j* are in the same warp, | |
| the pointers *pi* and *pj* you pass to the library must obey the | |
| relation *pj* - *pi* == *j* - *i*. The low-level interface has the | |
| following functions in `<trove/aos.h>`: | |
| `template<typename T> __device__ T load_warp_contiguous(const T* | |
| src);` | |
| `template<typename T> __device__ void store_warp_contiguous(const T& | |
| data, T* dest);` | |