| | --- |
| | license: apache-2.0 |
| | language: |
| | - zh |
| | - en |
| | pipeline_tag: text-generation |
| | library_name: transformers |
| | --- |
| | <div align="center"> |
| | <img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img> |
| | </div> |
| |
|
| | <p align="center"> |
| | <a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> | |
| | <a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a> |
| | </p> |
| | <p align="center"> |
| | 👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a> |
| | </p> |
| |
|
| | ## What's New |
| | - [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥 |
| |
|
| | ## MiniCPM4 Series |
| | MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. |
| | - [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens. |
| | - [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens. |
| | - [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B. |
| | - [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B. |
| | - [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B. |
| | - [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B. |
| | - [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width. |
| | - [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width. |
| | - [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers. |
| | - [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements. |
| | - [BitCPM4-0.5B-GGUF](https://huggingface.co/openbmb/BitCPM4-0.5B-GGUF): GGUF version of BitCPM4-0.5B. (**<-- you are here**) |
| | - [BitCPM4-1B-GGUF](https://huggingface.co/openbmb/BitCPM4-1B-GGUF): GGUF version of BitCPM4-1B. |
| | ## Introduction |
| | BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency. |
| | - Improvements of the training method |
| | - Searching hyperparameters with a wind-tunnel on a small model. |
| | - Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase. |
| | - High parameter efficiency |
| | - Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency. |
| |
|
| | ## Usage |
| | ### Inference with [llama.cpp](https://github.com/ggml-org/llama.cpp) |
| |
|
| | ```bash |
| | ./llama-cli -c 1024 -m BitCPM4-0.5B-q4_0.gguf -n 1024 --top-p 0.7 --temp 0.7 --prompt "请写一篇关于人工智能的文章,详细介绍人工智能的未来发展和隐患。" |
| | ``` |
| |
|
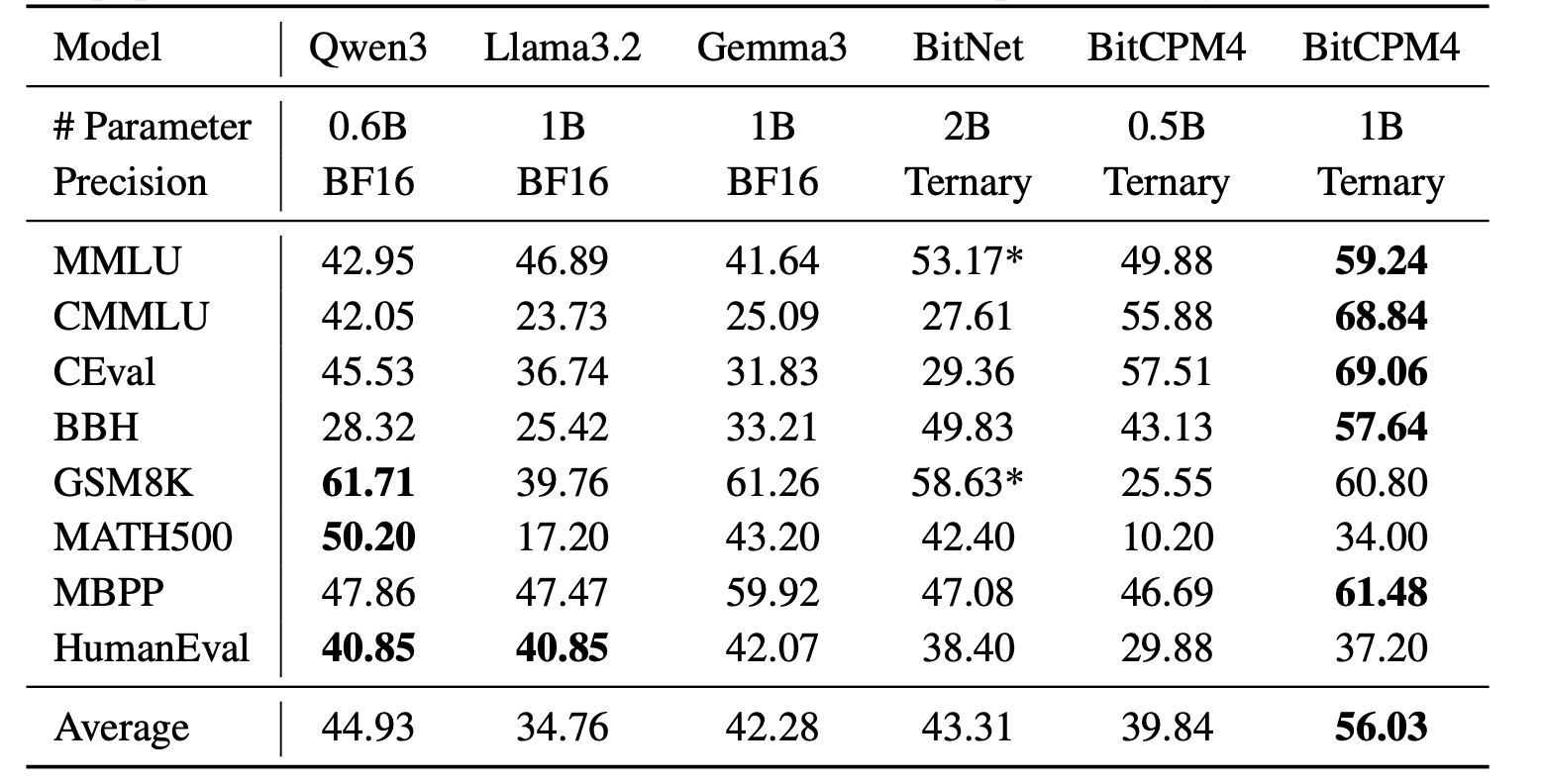
| | ## Evaluation Results |
| | BitCPM4's performance is comparable with other full-precision models in same model size. |
| |  |
| |
|
| | ## Statement |
| | - As a language model, MiniCPM generates content by learning from a vast amount of text. |
| | - However, it does not possess the ability to comprehend or express personal opinions or value judgments. |
| | - Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers. |
| | - Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own. |
| |
|
| | ## LICENSE |
| | - This repository and MiniCPM models are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License. |
| |
|
| | ## Citation |
| | - Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable. |
| |
|
| | ```bibtex |
| | @article{minicpm4, |
| | title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices}, |
| | author={MiniCPM Team}, |
| | year={2025} |
| | } |
| | ``` |
| |
|

