
{kind=link}
MiniCPM4
Collection
MiniCPM4: Ultra-Efficient LLMs on End Devices • 30 items • Updated • 84
winget install llama.cpp
# Start a local OpenAI-compatible server with a web UI:
llama serve -hf openbmb/BitCPM4-1B-GGUF:Q2_K_S# Run inference directly in the terminal:
llama cli -hf openbmb/BitCPM4-1B-GGUF:Q2_K_S# Download pre-built binary from:
# https://github.com/ggerganov/llama.cpp/releases# Start a local OpenAI-compatible server with a web UI:
./llama-server -hf openbmb/BitCPM4-1B-GGUF:Q2_K_S# Run inference directly in the terminal:
./llama-cli -hf openbmb/BitCPM4-1B-GGUF:Q2_K_Sgit clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
cmake -B build
cmake --build build -j --target llama-server llama-cli# Start a local OpenAI-compatible server with a web UI:
./build/bin/llama-server -hf openbmb/BitCPM4-1B-GGUF:Q2_K_S# Run inference directly in the terminal:
./build/bin/llama-cli -hf openbmb/BitCPM4-1B-GGUF:Q2_K_Sdocker model run hf.co/openbmb/BitCPM4-1B-GGUF:Q2_K_SGitHub Repo | Technical Report
👋 Join us on Discord and WeChat
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency.
./llama-cli -c 1024 -m BitCPM4-1B-q4_0.gguf -n 1024 --top-p 0.7 --temp 0.7 --prompt "请写一篇关于人工智能的文章,详细介绍人工智能的未来发展和隐患。"
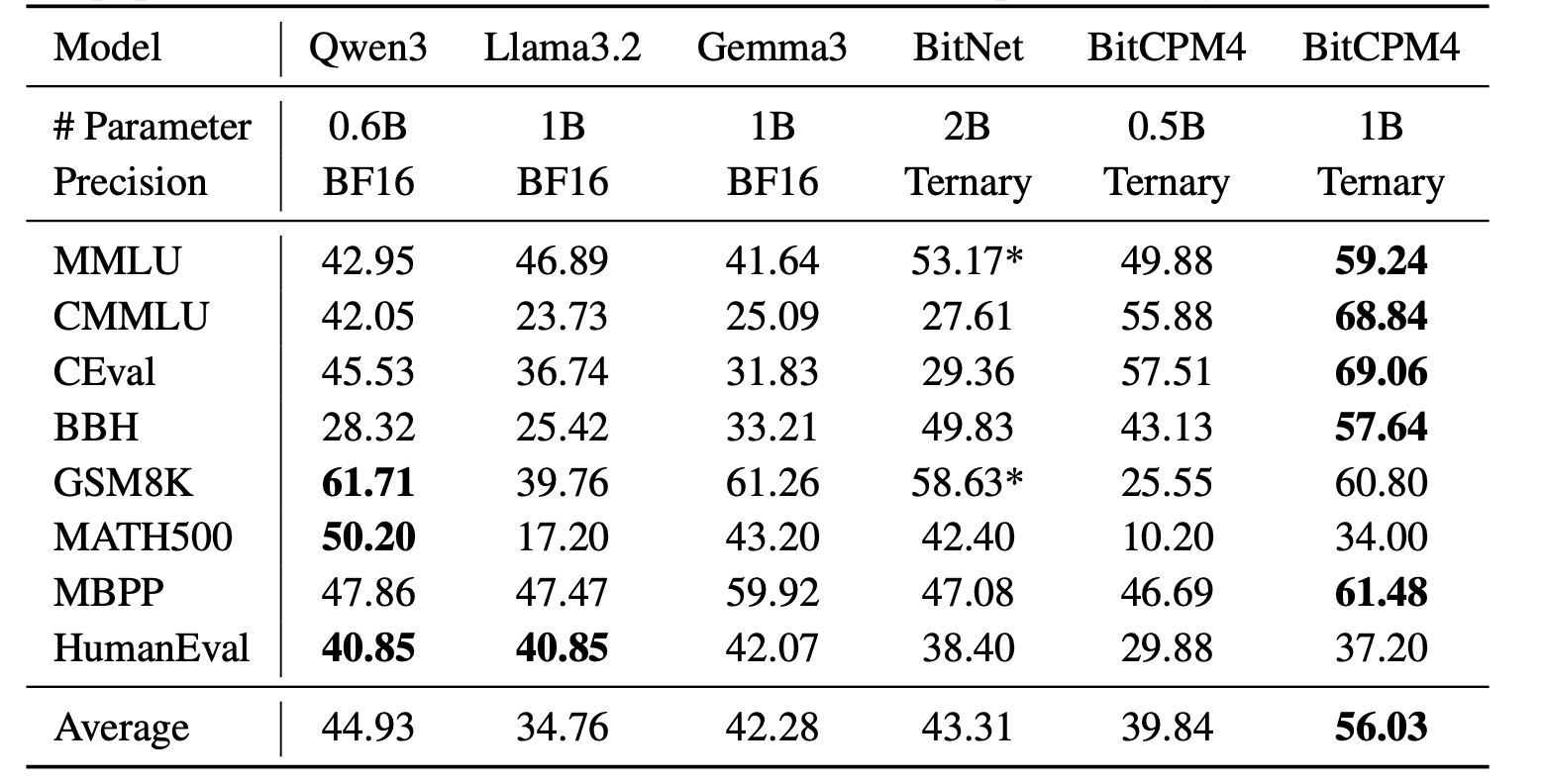
BitCPM4's performance is comparable with other full-precision models in same model size.
@article{minicpm4,
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
2-bit
4-bit
Install (macOS, Linux)
# Start a local OpenAI-compatible server with a web UI: llama serve -hf openbmb/BitCPM4-1B-GGUF:Q2_K_S# Run inference directly in the terminal: llama cli -hf openbmb/BitCPM4-1B-GGUF:Q2_K_S