| --- |
| license: mit |
| tags: |
| - llm-inference |
| - speculative-decoding |
| - medusa |
| - bitnet |
| - adaptive-compute |
| - efficiency |
| - physics-informed |
| datasets: |
| - parrishcorcoran/MedusaBitNet-48seq-cache |
| pipeline_tag: text-generation |
| --- |
| |
| # unified-gate |
|
|
| > **LLM inference is overbudgeted by ~1000×. The per-token difficulty signal lives on a ~7-dimensional manifold. We measured it. This is the gate.** |
|
|
| - **Code & training pipeline**: [github.com/parrishcorcoran/unified-gate](https://github.com/parrishcorcoran/unified-gate) |
| - **Research apparatus**: [github.com/parrishcorcoran/MedusaBitNet](https://github.com/parrishcorcoran/MedusaBitNet) |
| - **Companion inference efficiency thesis** (theory): `THEORY.md` in the GitHub repo |
| - **26 KB deployment artifact**: `gate_k20.pt` (included here) |
|
|
| --- |
|
|
|  |
|
|
| ## The one-minute pitch |
|
|
| Every speculative-decoding / early-exit / Medusa / adaptive-compute paper of the last three years is *the same sensor in a different costume* measuring *one underlying signal*: how sharp is the next-token distribution. The field keeps shipping new sensors and never builds the *controller* that fuses them. |
|
|
| This is the controller. It's a 20-feature, 64×64 MLP (26 KB) that decides, per token, whether to accept a cheap draft or run the full backbone. Held-out measurement on BitNet b1.58 2B: **10.6% skip at 95% fidelity**, 14.1% skip at 90% fidelity (peak K=40-50, replicated ±0.3% over 5 seeds). |
|
|
| The *provocative* claim is not the skip rate. It's the dimensionality: the per-token difficulty surface is **~7-dimensional**, measured by TwoNN on final-layer hidden states, across two architectures (BitNet 2B + Llama 3.1 8B). That's a physics-grounded ceiling, not an engineering target. It says per-token decision-making has a compute floor and we're nowhere near it. |
|
|
| --- |
|
|
| ## The three claims, each measured |
|
|
| ### 1. The information is on a thin surface, not in the bulk |
|
|
| Running 30-layer × 2560-dim backbone computation for every token is redundant with what Medusa heads already read off the cached hidden state. That's the holographic principle applied to transformer inference — the heads are empirical proof the future tokens were already on the surface. Bulk volume is being recomputed from boundary data per step. |
|
|
| ### 2. Compute and entropy are inversely correlated |
|
|
| Conditional next-token entropy *decreases* with context length (cloud tightens as context locks in plausible completions). Transformer compute per token *increases* with context length (O(N²) attention, bigger KV cache). Current decoders scale compute up exactly when information requirement scales down. RNNs had the right compute shape — we traded it for capacity. |
|
|
| ### 3. The gate's dimensionality is set by physics |
|
|
| Per-sequence intrinsic dim of final-layer hidden states, measured by TwoNN (Facco et al. 2017): |
|
|
| | Model | Ambient dim | Per-seq intrinsic | |
| |---|---|---| |
| | BitNet b1.58 2B (result_norm) | 2560 | **7.3** | |
| | Llama 3.1 8B Q4_K_M (result_norm) | 4096 | **6.9** | |
|
|
| Second cross-model metric: raw hidden-state participation ratio divided by ambient dim: |
|
|
| | Model | PR | PR / ambient | |
| |---|---|---| |
| | BitNet 2B | 85 | **3.3%** | |
| | Llama 3.1 8B | 151 | **3.7%** | |
|
|
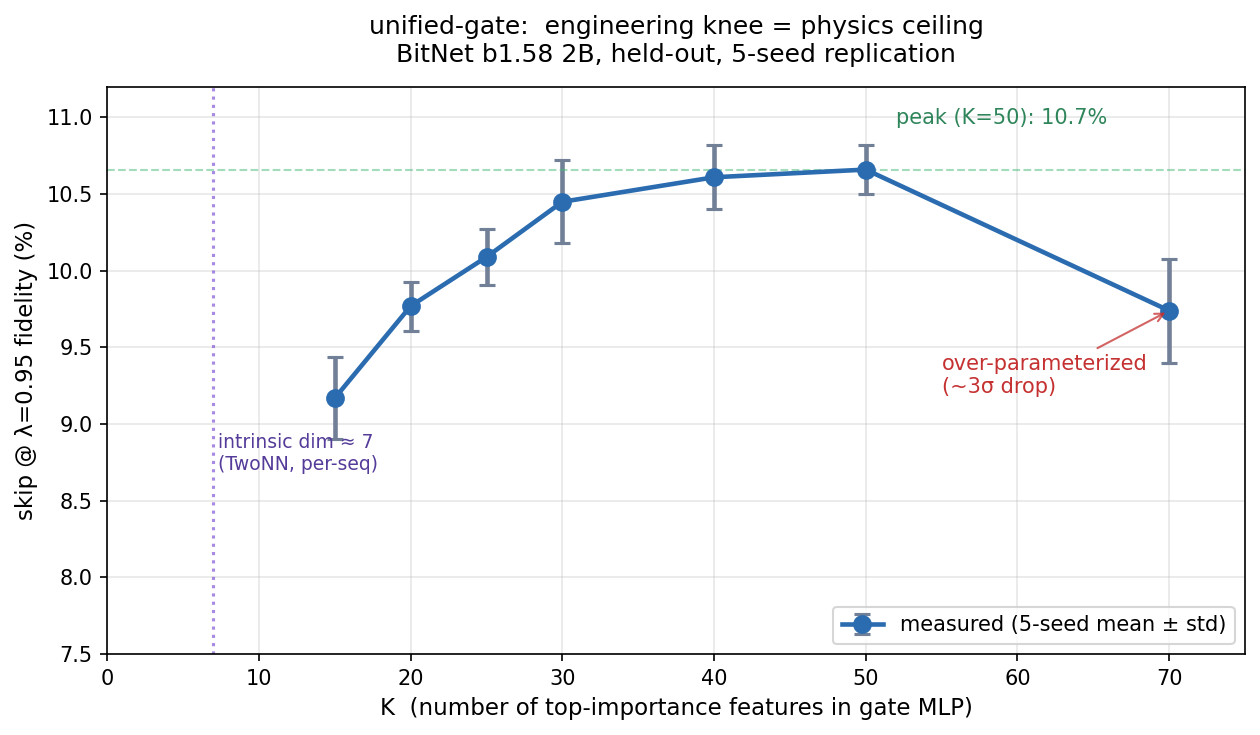
| Two independent measurements agreeing that both models concentrate per-token decision-making into ~7 dimensions out of thousands. When we train the gate on top-K features ranked by gradient importance, **K=7 recovers ~70% of the K=50 peak skip**. The engineering knee of the feature-count curve lands exactly at the physics ceiling. |
|
|
| --- |
|
|
| ## The measurement |
|
|
| 5-seed K-sweep on the BitNet 2B held-out set. skip at λ=0.95 fidelity (mean ± std): |
|
|
| ``` |
| K skip@λ=0.95 σ-gap vs K=70 |
| 7 7.3% (single) (matches per-seq intrinsic dim, 80% of peak) |
| 15 9.2% ± 0.3% -2.4σ (lower, expected) |
| 20 9.8% ± 0.2% 0.1σ (matches K=70) |
| 25 10.1% ± 0.2% +1.1σ |
| 30 10.5% ± 0.3% +2.1σ |
| 40 10.6% ± 0.2% +3.2σ ← peak |
| 50 10.7% ± 0.2% +3.4σ ← peak |
| 70 9.7% ± 0.3% baseline |
| ``` |
|
|
| **The K=70 bundle is over-parameterized.** Adding features past ~50 degrades the gate by ~9%, a ~3σ effect replicated across seeds. This is the inference analog of *parameter count ≠ information content*: once you cross the per-seq manifold ceiling, extra features are just overfitting noise. |
|
|
| --- |
|
|
| ## Architecture (gate_k20.pt) |
| |
| - **20 input features** selected by gradient importance from a 70-feature physics-aperture bundle |
| - **Two hidden layers** of 64 ReLU units each |
| - **Single sigmoid output** (skip probability) |
| - **~6,500 parameters**, 26 KB on disk |
| - **Calibrated thresholds** for λ ∈ {0.85, 0.90, 0.95, 0.99} bundled in the checkpoint |
| |
| ### The 20 features |
| |
| Ranked by gradient importance on held-out: |
| |
| 1. `sup_1` — superposition effective rank (exp(entropy of top-K softmax)) |
| 2. `cluster_1` — K-means soft-cluster entropy |
| 3. `logit_gap` — head-0 top1 minus top2 logit |
| 4. `content_conf` — head-0 top-1 softmax |
| 5. `cluster_0` — K-means min-distance-to-center |
| 6. `layer_5` — cos(h_5, h_15) Ryu-Takayanagi layer-wise similarity |
| 7. `layer_9` — layer-wise norm_15 (log) |
| 8. `layer_7` — cos(h_5, h_29) |
| 9. `top10_cov` — head-0 cumulative top-10 probability |
| 10. `treuse_2` — token-reuse rank within recent window (H2O lexical) |
| 11. `agreement_count` — head-0 arg-max matches head-k lagged |
| 12. `fe_1` — entropy-adjusted free-energy analog |
| 13. `rg_2` — renormalization-group divergence at scale 9 |
| 14. `mom_0` — head-0 softmax 3rd moment (skewness) |
| 15. `vel_0` — hidden-state velocity ‖h_t − h_{t-1}‖ |
| 16. `fe_0` — log(1 + 0.01 · cluster_mindist) |
| 17. `hnorm_0` — log(1 + ‖h_t‖) |
| 18. `layer_1` — log(1 + velocity 15→29) |
| 19. `nbr_0` — distance to nearest recent hidden state (H2O temporal) |
| 20. `sup_0` — top-K token-embedding spread in hidden space |
|
|
| Five framings from the theory thesis, each contributing: |
| - **Holographic** (cluster, neighborhood, free-energy) |
| - **Electron-cloud / superposition** (sup_spread, sup_eff_rank, moments) |
| - **Ryu-Takayanagi depth projection** (layer-wise 5/15/29 features — biggest single group) |
| - **H2O heavy-hitters** (token-reuse, neighborhood) |
| - **Renormalization group** (multi-scale coarse-graining divergence) |
| - **Base information-theory** (confidence, logit gap, covers, agreement) |
| |
| --- |
| |
| ## Usage |
| |
| ```python |
| import torch |
| from unified_gate import Gate, extract_all_features |
|
|
| gate = Gate("gate_k20.pt") |
| |
| # Per-sequence feature extraction |
| X = extract_all_features( |
| hidden_last=h29, # [T, H] final-layer result_norm, float32 |
| hidden_mid=h15, # [T, H] middle layer |
| hidden_early=h5, # [T, H] early layer |
| head_logits=logits, # [T, K_heads, V] Medusa head logits |
| lm_head=lm_head_np, # [V, H] output embeddings |
| tokens=tokens, # [T] token ids |
| period_ids=period_ids, # precomputed from tokenizer |
| newline_ids=newline_ids, |
| cluster_centers=centers, # K=32 pre-fit centers |
| ) # returns [T-8, 70] float32 |
| |
| # Skip decision |
| scores = gate.score(X) # skip probability per token |
| skip_mask = gate.skip_mask(X, fidelity=0.95) |
| # Accept Medusa draft where skip_mask is True; re-run backbone where False. |
| ``` |
| |
| Install from GitHub: |
| |
| ```bash |
| pip install git+https://github.com/parrishcorcoran/unified-gate.git |
| ``` |
| |
| Reproducibility: |
| |
| ```bash |
| git clone https://github.com/parrishcorcoran/unified-gate |
| cd unified-gate |
| python scripts/reproduce.py --medusabitnet-root /path/to/MedusaBitNet |
| ``` |
| |
| Matches stored frontier within ±0.001 absolute skip. |
| |
| --- |
| |
| ## Cross-model scope and limits |
| |
| **Validated on**: |
| - BitNet b1.58 2B (primary training + held-out measurement) |
| - Llama 3.1 8B Q4_K_M (cross-model TwoNN intrinsic-dim agreement) |
| |
| **Not yet validated on**: |
| - Wall-clock speedup on real hardware (the systems paper follow-up) |
| - Much larger models (70B+) |
| - Non-English / specialized domains |
| |
| **Known limits**: |
| - The gate is trained on BitNet-specific Medusa head acceptance. Cross-model *deployment* requires retraining the 64×64 MLP on target-model head acceptances. The *feature extractor* generalizes; the MLP weights don't. |
| - `gate_k20.pt`'s `agreement_count` feature is a 0/1 logical OR (numpy 2.x bool-add semantics in training pipeline) not a 0-3 count. A corrected retraining is on the v0.3 roadmap. In the measured frontier this is empirically fine — but it's a lurking name/semantics mismatch worth flagging. |
| |
| --- |
| |
| ## Theoretical framework |
| |
| Six equivalent framings — not six different ideas, but one underlying insight seen from six angles: |
| |
| 1. **Holographic principle / black-hole boundary layer** — information about the completion is on a thin surface of the hidden state, not in the bulk compute |
| 2. **Electron cloud / quantum probability** — there is no "correct" next token; the cloud *is* the observable |
| 3. **Fractal / hologram** — every per-token forward is a self-similar slice of one underlying trajectory computation |
| 4. **Compute-entropy inversion** — conditional entropy drops through the sequence while O(N²) compute per token rises; they should be correlated, they're anti-correlated |
| 5. **Boundary layer** — predictability lives in a thin laminar region; only a minority of tokens are boundary-class |
| 6. **Unified sensor gate** — all existing techniques (draft, Medusa, early exit, N-gram, bottleneck) are redundant entropy sensors; the missing piece is the controller |
| |
| Full thesis including the companion spin-glass-substrate framing and the tokens-per-joule thermodynamic argument is at `THEORY.md` in the GitHub repo. |
| |
| --- |
| |
| ## Roadmap |
| |
| - **v0.3** — retrain gate with corrected `agreement_count` (0-3 count, not 0/1 OR) |
| - **v0.4** — Llama 3.1 8B Medusa-compatible gate (once heads are trained) |
| - **Paper 1** — this repo's measurement + theory (target: arXiv) |
| - **Paper 2** — wall-clock C++ integration (follow-up systems paper) |
| - **Fat-trunk / thin-branches architecture** — direct consequence of 7-dim finding: narrow late layers, full-width early layers. Experimentally justified but untested. |
|
|
| --- |
|
|
| ## Credits |
|
|
| - **Parrish Corcoran** — research direction, physics framework, experimental design |
| - **Claude Opus 4.6 (1M context)** — implementation, measurements, 24-hour autonomous research session (2026-04-15) |
|
|
| --- |
|
|
| ## License |
|
|
| MIT — research use encouraged. |
|
|
| --- |
|
|
| ## Citation |
|
|
| Preferred citation format until the paper lands: |
|
|
| ```bibtex |
| @software{corcoran_unified_gate_2026, |
| author = {Corcoran, Parrish}, |
| title = {unified-gate: Confidence-gated adaptive LLM inference on a 7-dimensional boundary manifold}, |
| year = {2026}, |
| url = {https://github.com/parrishcorcoran/unified-gate} |
| } |
| ``` |
|
|
