
Commit ·
554b184
1
Parent(s): 2d5fab1
Update README.md
Browse files
README.md
CHANGED
|
@@ -10,41 +10,62 @@ model-index:
|
|
| 10 |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 11 |
should probably proofread and complete it, then remove this comment. -->
|
| 12 |
|
| 13 |
-
# ArtPrompter
|
| 14 |
|
| 15 |
-
|
| 16 |
|
| 17 |
-
|
| 18 |
|
| 19 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
|
| 21 |
## Intended uses & limitations
|
| 22 |
|
| 23 |
-
|
|
|
|
|
|
|
|
|
|
| 24 |
|
| 25 |
-
##
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
|
| 27 |
-
More information needed
|
| 28 |
|
| 29 |
## Training procedure
|
| 30 |
|
|
|
|
|
|
|
| 31 |
### Training hyperparameters
|
| 32 |
|
| 33 |
The following hyperparameters were used during training:
|
| 34 |
- learning_rate: 5e-05
|
| 35 |
-
- train_batch_size:
|
| 36 |
-
- eval_batch_size:
|
| 37 |
- seed: 42
|
| 38 |
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 39 |
- lr_scheduler_type: linear
|
| 40 |
-
- num_epochs:
|
| 41 |
-
|
| 42 |
-
### Training results
|
| 43 |
-
|
| 44 |
-
|
| 45 |
|
| 46 |
### Framework versions
|
| 47 |
|
| 48 |
- Transformers 4.26.0
|
| 49 |
- Pytorch 1.13.1
|
| 50 |
-
- Tokenizers 0.13.2
|
|
|
|
| 10 |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 11 |
should probably proofread and complete it, then remove this comment. -->
|
| 12 |
|
| 13 |
+
# [ArtPrompter](https://pearsonkyle.github.io/Art-Prompter/)
|
| 14 |
|
| 15 |
+
A [gpt2](https://huggingface.co/gpt2) powered predictive algorithm for making descriptive text prompts for A.I. image generators (e.g. MidJourney, Stable Diffusion, ArtBot, etc). The model was trained on a custom dataset containing 666K unique prompts from MidJourney. Simply start a prompt and let the algorithm suggest ways to finish it.
|
| 16 |
|
| 17 |
+

|
| 18 |
|
| 19 |
+
[](https://colab.research.google.com/drive/1HQOtD2LENTeXEaxHUfIhDKUaPIGd6oTR?usp=sharing)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
from transformers import pipeline
|
| 25 |
+
|
| 26 |
+
prompter = pipeline('text-generation',model='pearsonkyle/ArtPrompter', tokenizer='gpt2')
|
| 27 |
+
|
| 28 |
+
texts = prompter('A portal to a galaxy, view with', max_length=30, num_return_sequences=5)
|
| 29 |
+
|
| 30 |
+
for i in range(5):
|
| 31 |
+
print(texts[i]['generated_text']+'\n')
|
| 32 |
+
```
|
| 33 |
|
| 34 |
## Intended uses & limitations
|
| 35 |
|
| 36 |
+
Build sick prompts and lots of them.. use it to [make animations](https://colab.research.google.com/drive/1Ooe7c87xGMa9oG5BDrFVzYqJLvnoKcyZ?usp=sharing) or a discord bot that can interact with MidJourney.
|
| 37 |
+
|
| 38 |
+
[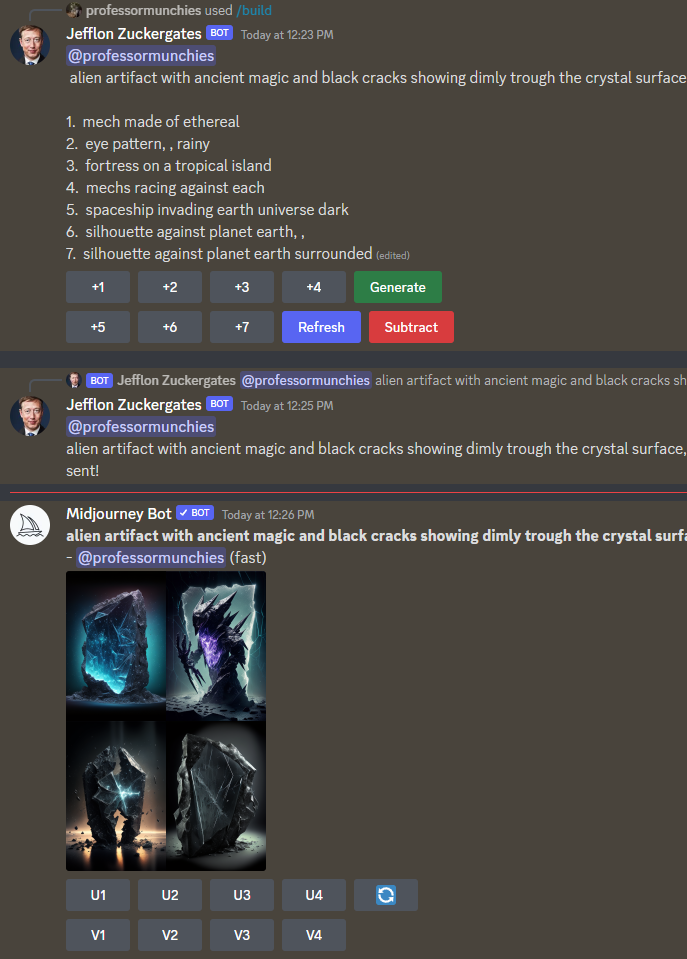](https://discord.gg/3S8Taqa2Xy)
|
| 39 |
+
|
| 40 |
|
| 41 |
+
## Examples
|
| 42 |
+
|
| 43 |
+
- *The entire universe is a simulation,a confessional with a smiling guy fawkes mask, symmetrical, inviting,hyper realistic*
|
| 44 |
+
|
| 45 |
+
- *a pug disguised as a teacher. Setting is a class room*
|
| 46 |
+
|
| 47 |
+
- *I wish I had an angel For one moment of love I wish I had your angel Your Virgin Mary undone Im in love with my desire Burning angelwings to dust*
|
| 48 |
+
|
| 49 |
+
- *The heart of a galaxy, surrounded by stars, magnetic fields, big bang, cinestill 800T,black background, hyper detail, 8k, black*
|
| 50 |
|
|
|
|
| 51 |
|
| 52 |
## Training procedure
|
| 53 |
|
| 54 |
+
~30 hours of finetune on RTX3070 with 666K unique prompts
|
| 55 |
+
|
| 56 |
### Training hyperparameters
|
| 57 |
|
| 58 |
The following hyperparameters were used during training:
|
| 59 |
- learning_rate: 5e-05
|
| 60 |
+
- train_batch_size: 16
|
| 61 |
+
- eval_batch_size: 4
|
| 62 |
- seed: 42
|
| 63 |
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 64 |
- lr_scheduler_type: linear
|
| 65 |
+
- num_epochs: 50
|
|
|
|
|
|
|
|
|
|
|
|
|
| 66 |
|
| 67 |
### Framework versions
|
| 68 |
|
| 69 |
- Transformers 4.26.0
|
| 70 |
- Pytorch 1.13.1
|
| 71 |
+
- Tokenizers 0.13.2
|