|
|
--- |
|
|
library_name: pytorch |
|
|
license: other |
|
|
tags: |
|
|
- bu_auto |
|
|
- android |
|
|
pipeline_tag: image-classification |
|
|
|
|
|
--- |
|
|
|
|
|
 |
|
|
|
|
|
# EfficientFormer: Optimized for Qualcomm Devices |
|
|
|
|
|
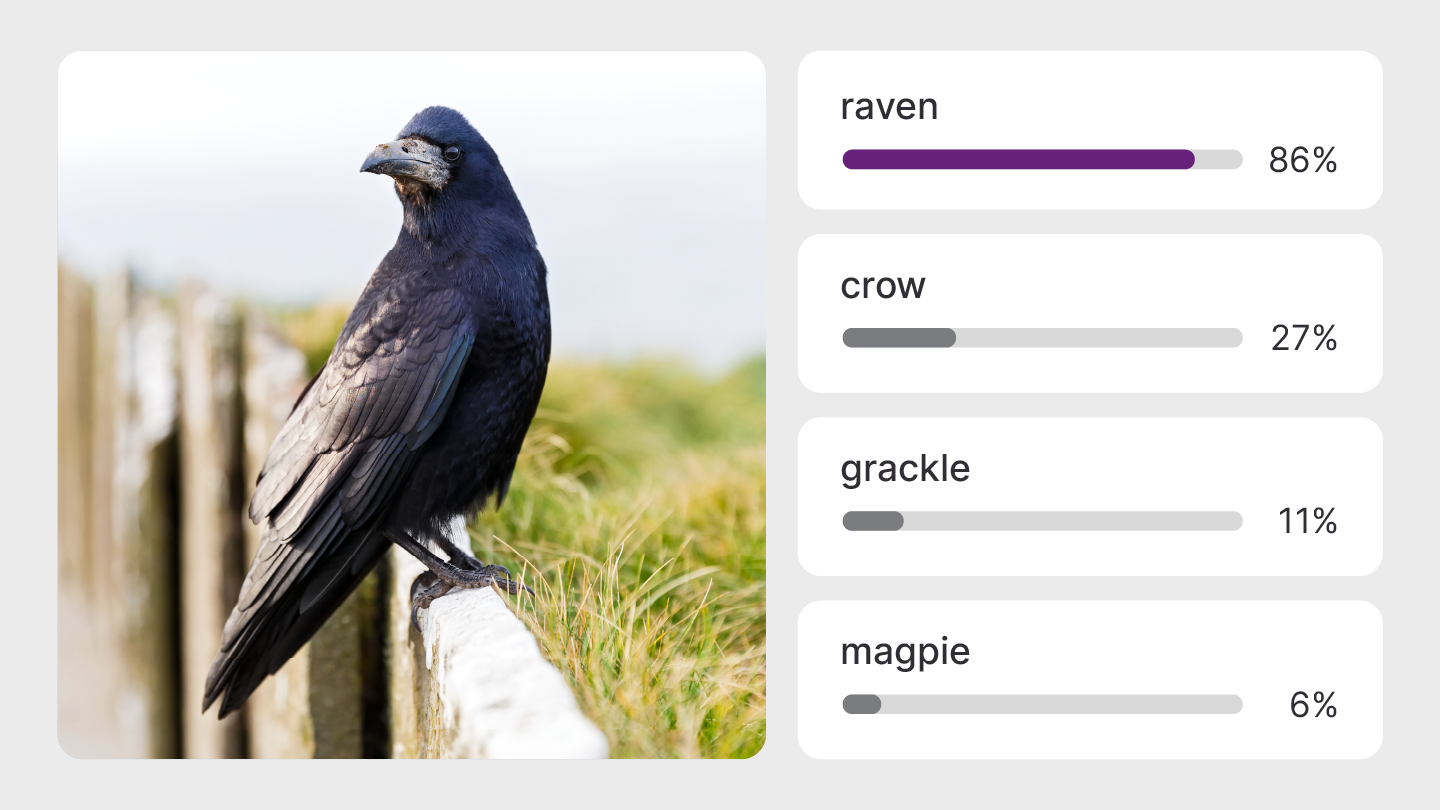
EfficientFormer is a vision transformer model that can classify images from the Imagenet dataset. |
|
|
|
|
|
This is based on the implementation of EfficientFormer found [here](https://github.com/snap-research/EfficientFormer). |
|
|
This repository contains pre-exported model files optimized for Qualcomm® devices. You can use the [Qualcomm® AI Hub Models](https://github.com/quic/ai-hub-models/blob/main/qai_hub_models/models/efficientformer) library to export with custom configurations. More details on model performance across various devices, can be found [here](#performance-summary). |
|
|
|
|
|
Qualcomm AI Hub Models uses [Qualcomm AI Hub Workbench](https://workbench.aihub.qualcomm.com) to compile, profile, and evaluate this model. [Sign up](https://myaccount.qualcomm.com/signup) to run these models on a hosted Qualcomm® device. |
|
|
|
|
|
## Getting Started |
|
|
There are two ways to deploy this model on your device: |
|
|
|
|
|
### Option 1: Download Pre-Exported Models |
|
|
|
|
|
Below are pre-exported model assets ready for deployment. |
|
|
|
|
|
| Runtime | Precision | Chipset | SDK Versions | Download | |
|
|
|---|---|---|---|---| |
|
|
| ONNX | float | Universal | QAIRT 2.37, ONNX Runtime 1.23.0 | [Download](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/models/efficientformer/releases/v0.46.0/efficientformer-onnx-float.zip) |
|
|
| ONNX | w8a16 | Universal | QAIRT 2.37, ONNX Runtime 1.23.0 | [Download](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/models/efficientformer/releases/v0.46.0/efficientformer-onnx-w8a16.zip) |
|
|
| QNN_DLC | float | Universal | QAIRT 2.42 | [Download](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/models/efficientformer/releases/v0.46.0/efficientformer-qnn_dlc-float.zip) |
|
|
| QNN_DLC | w8a16 | Universal | QAIRT 2.42 | [Download](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/models/efficientformer/releases/v0.46.0/efficientformer-qnn_dlc-w8a16.zip) |
|
|
| TFLITE | float | Universal | QAIRT 2.42, TFLite 2.17.0 | [Download](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/models/efficientformer/releases/v0.46.0/efficientformer-tflite-float.zip) |
|
|
|
|
|
For more device-specific assets and performance metrics, visit **[EfficientFormer on Qualcomm® AI Hub](https://aihub.qualcomm.com/models/efficientformer)**. |
|
|
|
|
|
|
|
|
### Option 2: Export with Custom Configurations |
|
|
|
|
|
Use the [Qualcomm® AI Hub Models](https://github.com/quic/ai-hub-models/blob/main/qai_hub_models/models/efficientformer) Python library to compile and export the model with your own: |
|
|
- Custom weights (e.g., fine-tuned checkpoints) |
|
|
- Custom input shapes |
|
|
- Target device and runtime configurations |
|
|
|
|
|
This option is ideal if you need to customize the model beyond the default configuration provided here. |
|
|
|
|
|
See our repository for [EfficientFormer on GitHub](https://github.com/quic/ai-hub-models/blob/main/qai_hub_models/models/efficientformer) for usage instructions. |
|
|
|
|
|
## Model Details |
|
|
|
|
|
**Model Type:** Model_use_case.image_classification |
|
|
|
|
|
**Model Stats:** |
|
|
- Model checkpoint: efficientformer_l1_300d |
|
|
- Input resolution: 224x224 |
|
|
- Number of parameters: 12.3M |
|
|
- Model size (float): 46.9 MB |
|
|
- Model size (w8a16): 12.2 MB |
|
|
|
|
|
## Performance Summary |
|
|
| Model | Runtime | Precision | Chipset | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit |
|
|
|---|---|---|---|---|---|--- |
|
|
| EfficientFormer | ONNX | float | Snapdragon® X Elite | 1.634 ms | 24 - 24 MB | NPU |
|
|
| EfficientFormer | ONNX | float | Snapdragon® 8 Gen 3 Mobile | 1.166 ms | 0 - 148 MB | NPU |
|
|
| EfficientFormer | ONNX | float | Qualcomm® QCS8550 (Proxy) | 1.713 ms | 0 - 63 MB | NPU |
|
|
| EfficientFormer | ONNX | float | Qualcomm® QCS9075 | 2.101 ms | 1 - 3 MB | NPU |
|
|
| EfficientFormer | ONNX | float | Snapdragon® 8 Elite For Galaxy Mobile | 0.963 ms | 0 - 114 MB | NPU |
|
|
| EfficientFormer | ONNX | float | Snapdragon® 8 Elite Gen 5 Mobile | 0.869 ms | 0 - 113 MB | NPU |
|
|
| EfficientFormer | ONNX | w8a16 | Snapdragon® X Elite | 6.347 ms | 10 - 10 MB | NPU |
|
|
| EfficientFormer | ONNX | w8a16 | Snapdragon® 8 Gen 3 Mobile | 5.97 ms | 5 - 151 MB | NPU |
|
|
| EfficientFormer | ONNX | w8a16 | Qualcomm® QCS6490 | 144.626 ms | 19 - 25 MB | CPU |
|
|
| EfficientFormer | ONNX | w8a16 | Qualcomm® QCS8550 (Proxy) | 7.312 ms | 5 - 11 MB | NPU |
|
|
| EfficientFormer | ONNX | w8a16 | Qualcomm® QCS9075 | 9.286 ms | 5 - 8 MB | NPU |
|
|
| EfficientFormer | ONNX | w8a16 | Qualcomm® QCM6690 | 63.675 ms | 22 - 30 MB | CPU |
|
|
| EfficientFormer | ONNX | w8a16 | Snapdragon® 8 Elite For Galaxy Mobile | 5.362 ms | 5 - 123 MB | NPU |
|
|
| EfficientFormer | ONNX | w8a16 | Snapdragon® 7 Gen 4 Mobile | 60.202 ms | 21 - 30 MB | CPU |
|
|
| EfficientFormer | ONNX | w8a16 | Snapdragon® 8 Elite Gen 5 Mobile | 4.916 ms | 0 - 121 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | float | Snapdragon® X Elite | 1.728 ms | 1 - 1 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | float | Snapdragon® 8 Gen 3 Mobile | 1.038 ms | 0 - 80 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | float | Qualcomm® QCS8275 (Proxy) | 4.975 ms | 1 - 46 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | float | Qualcomm® QCS8550 (Proxy) | 1.553 ms | 1 - 3 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | float | Qualcomm® QCS9075 | 1.999 ms | 3 - 5 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | float | Qualcomm® QCS8450 (Proxy) | 5.62 ms | 0 - 82 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | float | Snapdragon® 8 Elite For Galaxy Mobile | 0.79 ms | 0 - 48 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | float | Snapdragon® 8 Elite Gen 5 Mobile | 0.649 ms | 1 - 49 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | w8a16 | Snapdragon® X Elite | 1.845 ms | 0 - 0 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | w8a16 | Snapdragon® 8 Gen 3 Mobile | 1.084 ms | 0 - 78 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | w8a16 | Qualcomm® QCS8275 (Proxy) | 3.253 ms | 0 - 57 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | w8a16 | Qualcomm® QCS8550 (Proxy) | 1.604 ms | 0 - 2 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | w8a16 | Qualcomm® QCS9075 | 1.775 ms | 2 - 4 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | w8a16 | Qualcomm® QCM6690 | 7.064 ms | 0 - 177 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | w8a16 | Snapdragon® 8 Elite For Galaxy Mobile | 0.711 ms | 0 - 49 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | w8a16 | Snapdragon® 7 Gen 4 Mobile | 1.701 ms | 0 - 60 MB | NPU |
|
|
| EfficientFormer | QNN_DLC | w8a16 | Snapdragon® 8 Elite Gen 5 Mobile | 0.579 ms | 0 - 58 MB | NPU |
|
|
| EfficientFormer | TFLITE | float | Snapdragon® 8 Gen 3 Mobile | 1.035 ms | 0 - 104 MB | NPU |
|
|
| EfficientFormer | TFLITE | float | Qualcomm® QCS8275 (Proxy) | 4.928 ms | 0 - 66 MB | NPU |
|
|
| EfficientFormer | TFLITE | float | Qualcomm® QCS8550 (Proxy) | 1.47 ms | 0 - 3 MB | NPU |
|
|
| EfficientFormer | TFLITE | float | Qualcomm® QCS9075 | 1.954 ms | 0 - 27 MB | NPU |
|
|
| EfficientFormer | TFLITE | float | Qualcomm® QCS8450 (Proxy) | 5.589 ms | 0 - 103 MB | NPU |
|
|
| EfficientFormer | TFLITE | float | Snapdragon® 8 Elite For Galaxy Mobile | 0.784 ms | 0 - 71 MB | NPU |
|
|
| EfficientFormer | TFLITE | float | Snapdragon® 8 Elite Gen 5 Mobile | 0.634 ms | 0 - 69 MB | NPU |
|
|
|
|
|
## License |
|
|
* The license for the original implementation of EfficientFormer can be found |
|
|
[here](https://github.com/snap-research/EfficientFormer?tab=License-1-ov-file#readme). |
|
|
|
|
|
## References |
|
|
* [Rethinking Vision Transformers for MobileNet Size and Speed](https://arxiv.org/abs/2212.08059) |
|
|
* [Source Model Implementation](https://github.com/snap-research/EfficientFormer) |
|
|
|
|
|
## Community |
|
|
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI. |
|
|
* For questions or feedback please [reach out to us](mailto:ai-hub-support@qti.qualcomm.com). |
|
|
|

