
OpusMT-En-Es: Optimized for Qualcomm Devices
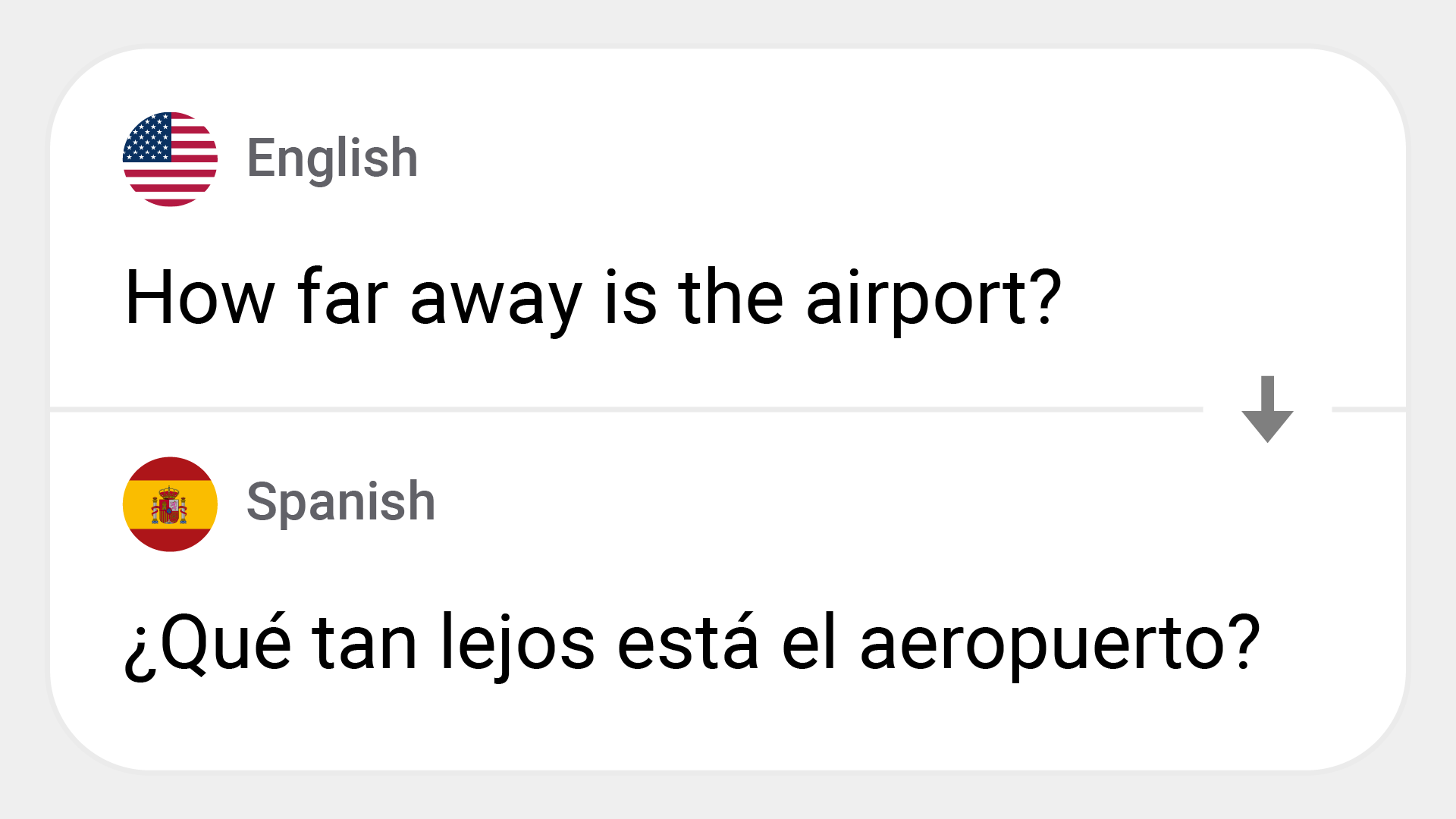
OpusMT English to Spanish translation model is a state-of-the-art neural machine translation system designed for translating English text into Spanish. This model is based on the Marian transformer architecture and has been optimized for edge inference by splitting into encoder and decoder components with modified attention mechanisms. It exhibits robust performance for real-world translation tasks, making it highly reliable for practical applications. The model supports input sequences up to 256 tokens and can generate Spanish translations with high accuracy.
This is based on the implementation of OpusMT-En-Es found here. This repository contains pre-exported model files optimized for Qualcomm® devices. You can use the Qualcomm® AI Hub Models library to export with custom configurations. More details on model performance across various devices, can be found here.
Qualcomm AI Hub Models uses Qualcomm AI Hub Workbench to compile, profile, and evaluate this model. Sign up to run these models on a hosted Qualcomm® device.
Deploying OpusMT-En-Es on-device
This model is compatible with the Qualcomm Voice AI SDK. Download the SDK from the Qualcomm Package Manager to deploy this model on-device.
Getting Started
There are two ways to deploy this model on your device:
Option 1: Download Pre-Exported Models
Below are pre-exported model assets ready for deployment.
| Runtime | Precision | Chipset | SDK Versions | Download |
|---|---|---|---|---|
| VOICE_AI | float | Snapdragon® X2 Elite | QAIRT 2.45 | Download |
| VOICE_AI | float | Snapdragon® X Elite | QAIRT 2.45 | Download |
| VOICE_AI | float | Snapdragon® 8 Gen 3 Mobile | QAIRT 2.45 | Download |
| VOICE_AI | float | Snapdragon® 8 Gen 1 Mobile | QAIRT 2.45 | Download |
| VOICE_AI | float | Qualcomm® QCS8550 (Proxy) | QAIRT 2.45 | Download |
| VOICE_AI | float | Qualcomm® SA8775P | QAIRT 2.45 | Download |
| VOICE_AI | float | Snapdragon® 8 Elite Mobile | QAIRT 2.45 | Download |
| VOICE_AI | float | Snapdragon® 8 Elite Gen 5 Mobile | QAIRT 2.45 | Download |
| VOICE_AI | float | Qualcomm® SA7255P | QAIRT 2.45 | Download |
| VOICE_AI | float | Qualcomm® SA8295P | QAIRT 2.45 | Download |
| VOICE_AI | float | Qualcomm® QCS9075 | QAIRT 2.45 | Download |
For more device-specific assets and performance metrics, visit OpusMT-En-Es on Qualcomm® AI Hub.
Option 2: Export with Custom Configurations
Use the Qualcomm® AI Hub Models Python library to compile and export the model with your own:
- Custom weights (e.g., fine-tuned checkpoints)
- Custom input shapes
- Target device and runtime configurations
This option is ideal if you need to customize the model beyond the default configuration provided here.
See our repository for OpusMT-En-Es on GitHub for usage instructions.
Model Details
Model Type: Model_use_case.text_generation
Model Stats:
- Model checkpoint: Helsinki-NLP/opus-mt-en-es
- Input resolution: 256 tokens (English text)
- Max input sequence length: 256 tokens
- Max output sequence length: 256 tokens
- Number of parameters (encoder): ~74M
- Model size (encoder) (float): ~280 MB
- Number of parameters (decoder): ~74M
- Model size (decoder) (float): ~280 MB
- Number of encoder layers: 6
- Number of decoder layers: 6
- Attention heads: 8
- Hidden dimension: 512
Performance Summary
| Model | Runtime | Precision | Chipset | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit |
|---|---|---|---|---|---|---|
| decoder | VOICE_AI | float | Snapdragon® X2 Elite | 2.206 ms | 12 - 12 MB | NPU |
| decoder | VOICE_AI | float | Snapdragon® X Elite | 3.183 ms | 12 - 12 MB | NPU |
| decoder | VOICE_AI | float | Snapdragon® 8 Gen 3 Mobile | 2.808 ms | 0 - 8 MB | NPU |
| decoder | VOICE_AI | float | Snapdragon® 8 Gen 1 Mobile | 4.517 ms | 11 - 21 MB | NPU |
| decoder | VOICE_AI | float | Qualcomm® QCS8275 | 6.743 ms | 12 - 19 MB | NPU |
| decoder | VOICE_AI | float | Qualcomm® QCS8550 (Proxy) | 3.456 ms | 12 - 14 MB | NPU |
| decoder | VOICE_AI | float | Qualcomm® QCS8450 | 4.517 ms | 11 - 21 MB | NPU |
| decoder | VOICE_AI | float | Qualcomm® SA7255P | 6.743 ms | 12 - 19 MB | NPU |
| decoder | VOICE_AI | float | Snapdragon® 8 Elite Mobile | 2.416 ms | 0 - 9 MB | NPU |
| decoder | VOICE_AI | float | Qualcomm® SA8295P | 4.428 ms | 12 - 18 MB | NPU |
| decoder | VOICE_AI | float | Snapdragon® 8 Elite Gen 5 Mobile | 2.176 ms | 1 - 9 MB | NPU |
| decoder | VOICE_AI | float | Qualcomm® QCS9075 | 3.943 ms | 14 - 28 MB | NPU |
| decoder | VOICE_AI | float | Qualcomm® QCS8750 | 2.416 ms | 0 - 9 MB | NPU |
| decoder | VOICE_AI | float | Qualcomm® QCS7181 | 3.183 ms | 12 - 12 MB | NPU |
| encoder | VOICE_AI | float | Snapdragon® X2 Elite | 2.167 ms | 0 - 0 MB | NPU |
| encoder | VOICE_AI | float | Snapdragon® X Elite | 3.985 ms | 0 - 0 MB | NPU |
| encoder | VOICE_AI | float | Snapdragon® 8 Gen 3 Mobile | 2.646 ms | 0 - 7 MB | NPU |
| encoder | VOICE_AI | float | Snapdragon® 8 Gen 1 Mobile | 5.021 ms | 0 - 10 MB | NPU |
| encoder | VOICE_AI | float | Qualcomm® QCS8275 | 12.662 ms | 0 - 7 MB | NPU |
| encoder | VOICE_AI | float | Qualcomm® QCS8550 (Proxy) | 3.629 ms | 0 - 1 MB | NPU |
| encoder | VOICE_AI | float | Qualcomm® QCS8450 | 5.021 ms | 0 - 10 MB | NPU |
| encoder | VOICE_AI | float | Qualcomm® SA7255P | 12.662 ms | 0 - 7 MB | NPU |
| encoder | VOICE_AI | float | Snapdragon® 8 Elite Mobile | 2.238 ms | 0 - 9 MB | NPU |
| encoder | VOICE_AI | float | Qualcomm® SA8295P | 5.372 ms | 0 - 6 MB | NPU |
| encoder | VOICE_AI | float | Snapdragon® 8 Elite Gen 5 Mobile | 1.772 ms | 0 - 9 MB | NPU |
| encoder | VOICE_AI | float | Qualcomm® QCS9075 | 4.559 ms | 0 - 8 MB | NPU |
| encoder | VOICE_AI | float | Qualcomm® QCS8750 | 2.238 ms | 0 - 9 MB | NPU |
| encoder | VOICE_AI | float | Qualcomm® QCS7181 | 3.985 ms | 0 - 0 MB | NPU |
License
- The license for the original implementation of OpusMT-En-Es can be found here.
References
Community
- Join our AI Hub Slack community to collaborate, post questions and learn more about on-device AI.
- For questions or feedback please reach out to us.