
Scalable In-context Ranking with Generative Models
Paper • 2510.05396 • Published • 10
![]()
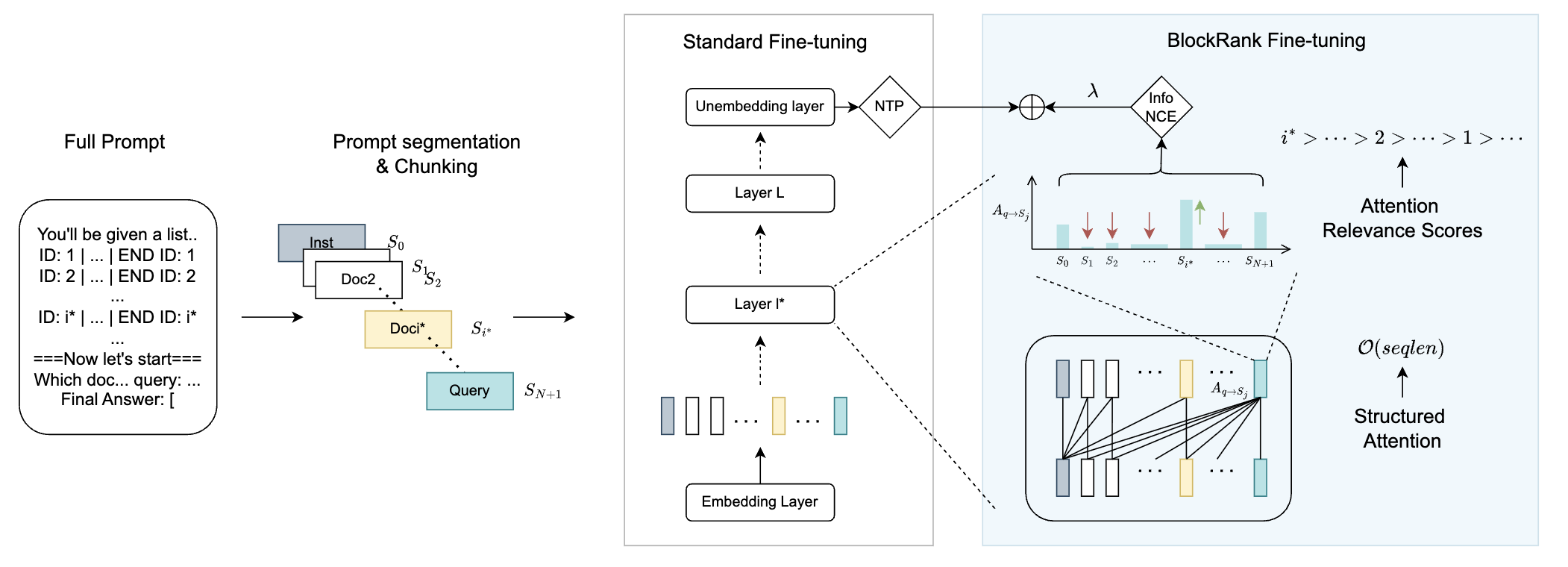
BlockRank-Mistral-7B is a fine-tuned version of Mistral-7B-Instruct-v0.3 optimized for efficient in-context document ranking. It implements BlockRank, a method that makes LLMs efficient and scalable for ranking by aligning their internal attention mechanisms with the structure of the ranking task.
If you use this model, please cite:
@article{gupta2025blockrank,
title={Scalable In-context Ranking with Generative Models},
author={Gupta, Nilesh and You, Chong and Bhojanapalli, Srinadh and Kumar, Sanjiv and Dhillon, Inderjit and Yu, Felix},
journal={arXiv preprint arXiv:2510.05396},
year={2025}
}
For questions or issues, please open an issue on GitHub.
This model is released under the MIT License. See LICENSE for details.