
PrefixGrouper Examples
This directory contains examples for using PrefixGrouper, an optimization technique that groups samples by shared prompts to reduce redundant computations in GRPO.
Introduction
Official Repository: https://github.com/johncaged/PrefixGrouper
PrefixGrouper is a plug-and-play efficient GRPO training tool that requires minimal modifications to existing codebases to achieve reduced computation, lower device memory consumption, and accelerated training.
In current mainstream GRPO training pipelines, policy model training primarily involves copying prefixes (typically questions, multimodal inputs, etc.) G times. Consequently, when training data prefixes are sufficiently long (e.g., long-context reasoning, image/long-video inference), redundant computation during training becomes non-negligible.
PrefixGrouper decomposes the original redundant self-attention operation into prefix self-attention + suffix concat-attention.
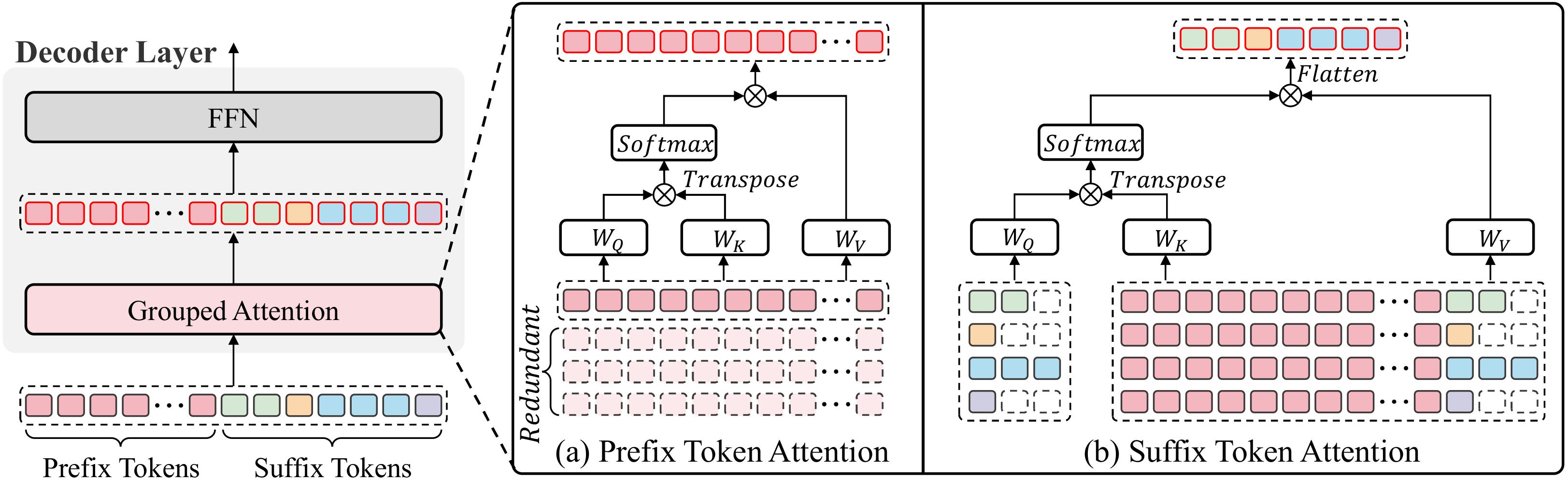
Installation
pip install prefix_grouper
Limitations
- Currently only supports FSDP worker (Megatron worker is not supported yet).
- Incompatible with
use_dynamic_bsz=True. - Incompatible with
use_remove_padding=True(Flash Attention V2 variable length). - Incompatible with
use_fused_kernels=True. - Incompatible with Ulysses sequence parallelism (
use_ulysses_sp=True) and ring-attention.
Note: balance_batch=True is now supported with group-level balancing, which keeps samples with the same uid together on the same rank. However, this requires batch_size % (world_size * rollout.n) == 0. For example, with world_size=8 and rollout.n=4, you need batch_size to be a multiple of 32.
How to Use
1. Enable PrefixGrouper in Config
Simply set use_prefix_grouper=True in your training config:
actor_rollout_ref:
actor:
use_prefix_grouper: True
model:
use_remove_padding: False
Optionally enable balance_batch for better load distribution:
trainer:
balance_batch: True # Now supported with group-level balancing
2. Run Training
Use the provided script run_qwen3_prefix_grouper.sh as an example:
bash examples/prefix_grouper/run_qwen3_prefix_grouper.sh
How It Works
When use_prefix_grouper=True, verl automatically patches the attention functions in transformers.modeling_utils.ALL_ATTENTION_FUNCTIONS to support the prefix_grouper parameter. No model code modifications are needed.
The patch wraps each attention function to:
- Extract
prefix_grouperfrom kwargs - If
prefix_grouperis None, call original attention - If
prefix_grouperis provided, use PrefixGrouper's optimized attention computation
Performance
Benchmark Results (Qwen3-4B, 4×H800, rollout.n=4):
| Context Length | Metric | PG | No PG | Speedup |
|---|---|---|---|---|
| 4K | old_log_prob |
1.31s | 1.70s | 1.30x |
update_actor |
4.80s | 6.07s | 1.26x | |
step |
17.08s | 19.40s | 1.14x | |
| 8K | old_log_prob |
1.69s | 2.63s | 1.56x |
update_actor |
5.98s | 10.18s | 1.70x | |
step |
19.48s | 24.71s | 1.27x |
As context length increases, the speedup becomes more pronounced.