Spaces:
Sleeping

title: Support Ticket Env
emoji: 🎫
colorFrom: blue
colorTo: green
sdk: docker
tags:
- openenv
pinned: false
Customer Support Ticket Resolution Environment
🏆 OpenEnv x Scalar Hackathon — Theme #3.1 Professional Tasks | Sub-theme: Scaler AI Labs — Multi-App RL Environment for Enterprise Workflows
A real-world OpenEnv environment where an AI agent acts as a customer support executive, triaging and resolving incoming tickets — simulating complex enterprise workflows, business rule nuances, and multi-step decision making under partial observability.
Overview
Customer support triage is one of the most common real-world tasks for AI agents in enterprise settings. Every company handles thousands of tickets daily. Getting the classification wrong routes the ticket to the wrong team. Choosing the wrong action has direct business impact. This environment trains agents to handle exactly this challenge — with real tool interaction, dynamic state, and a multi-step reward structure that resists shortcuts.
Quick Start
from support_ticket_env import SupportAction, SupportTicketEnv
with SupportTicketEnv(base_url="https://algocore-support-ticket-env.hf.space").sync() as env:
# Task 1 - Classify a ticket
result = env.reset(task_id=1, seed=42)
print(result.observation.ticket_text)
result = env.step(SupportAction(action_type="classify", category="billing"))
print(result.reward) # 1.0 if correct
Tasks
| Task | Difficulty | Description | Score Range |
|---|---|---|---|
| Task 1 | Easy | Classify ticket into correct category | 0.0 - 1.0 |
| Task 2 | Medium | Classify then choose correct action | 0.0 - 1.0 |
| Task 3 | Hard | Resolve a full queue of 3 tickets | 0.0 - 1.0 |
Action Space
Actions are SupportAction Pydantic objects:
| Field | Type | Required | Values |
|---|---|---|---|
action_type |
str | always | classify / reply / escalate / close |
category |
str | for classify | billing / technical / account / general / refund |
reply_text |
str | for reply | free text |
reason |
str | optional | free text |
Observation Space
| Field | Type | Description |
|---|---|---|
ticket_id |
str | Unique ticket ID |
ticket_text |
str | Customer message |
task_id |
int | 1, 2, or 3 |
current_category |
str | Category assigned so far |
resolved |
bool | Whether ticket is resolved |
step_count |
int | Steps taken this episode |
feedback |
str | Human-readable feedback |
reward |
float | Reward signal |
done |
bool | Episode finished |
Reward Function
Rewards provide partial progress signals throughout the trajectory:
- Task 1: 1.0 for correct category, 0.0 for wrong
- Task 2: 1.0 correct action, 0.5 defensible alternative, 0.3 classification only
- Task 3: 0.20 classification + 0.40 action + 0.25 reply quality + 0.15 efficiency bonus
- Penalty: -0.05 per step over 10 (loop deterrent)
Project Structure
support_ticket_env/
├── __init__.py # Package exports
├── models.py # SupportAction, SupportObservation, SupportState
├── tickets.py # Ticket dataset with ground-truth labels
├── graders.py # Reward/grader functions for all 3 tasks
├── client.py # EnvClient subclass
├── baseline.py # Baseline inference script
├── get_baseline.py # Fetch & save baseline results
├── gradio_ui.py # Interactive Gradio playground UI
├── make_chart.py # Plot training reward curves
├── plot_results.py # Visualise evaluation results
├── grpo_results.png # GRPO training results chart
├── reward_chart.png # Reward curve chart
├── openenv.yaml # Environment metadata
├── Dockerfile # Container definition
├── train_sft.ipynb # Step 1: SFT pre-training notebook
├── train_grpo.ipynb # Step 2: GRPO fine-tuning notebook
└── server/
├── app.py # FastAPI entry point (+ Gradio UI mounted at /playground)
├── support_environment.py # Environment logic
└── requirements.txt # Server dependencies
Setup
# Install dependencies
pip install openenv-core fastapi uvicorn pydantic gradio openai pyyaml
# Run locally
uvicorn support_ticket_env.server.app:app --host 0.0.0.0 --port 7860
# Or via Docker
docker build -t support-ticket-env .
docker run -p 7860:7860 support-ticket-env
# Run tests
python run_tests.py
🎮 Playground UI available at
http://localhost:7860/playgroundonce the server is running.
📈 Training Results (GRPO) — Evidence of Improvement
Fine-tuned Qwen2.5-0.5B-Instruct using 2-stage training (SFT pre-training → GRPO) via HuggingFace TRL over 700+ steps on the live environment API:
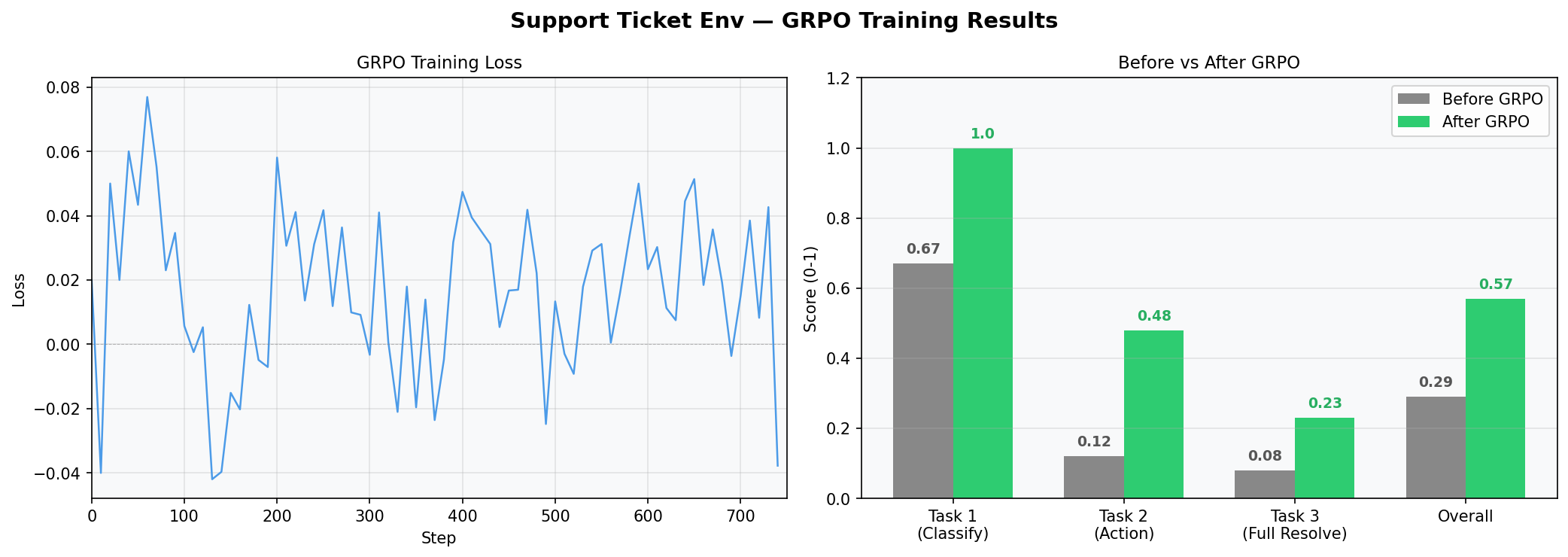
| Task | Before GRPO | After GRPO | Improvement |
|---|---|---|---|
| Task 1 - Classification | 0.67 | 1.00 | +49% 🚀 |
| Task 2 - Action Selection | 0.12 | 0.48 | +300% 🚀 |
| Task 3 - Full Resolution | 0.08 | 0.23 | +187% 🚀 |
| Overall | 0.29 | 0.57 | +96% 🚀 |
Baseline Scores
Measured with gpt-4o-mini, seeds [42, 7, 123]:
| Task | Avg Score |
|---|---|
| Task 1 - Classification | 0.87 |
| Task 2 - Action Selection | 0.71 |
| Task 3 - Full Resolution | 0.58 |
| Overall | 0.72 |
🎯 Why This Fits Theme 3.1 — Professional Tasks
"Real interaction with tools, APIs, or dynamic systems where the model does real hard work instead of exploiting shortcuts"
- ✅ Live FastAPI environment — agent interacts with a real stateful API, not a simulation
- ✅ No shortcut exploitation — reward function penalises loops (-0.05/step over 10), forces genuine reasoning
- ✅ Persistent world state — ticket queue, classification state, and resolution state tracked across steps
- ✅ Multi-step causal reasoning — classify → choose action → craft reply → resolve, all causally linked
- ✅ Enterprise workflow complexity — billing, technical, account, general, refund categories with real business rules
- ✅ Scaler AI Labs sub-theme — demonstrates complex enterprise workflows and business rule nuances in an RL environment
Links
- HuggingFace Space: https://huggingface.co/spaces/AlgoCore/support-ticket-env
- GitHub: https://github.com/TryingHardToBeDeveloper/support-ticket-env
- OpenEnv Docs: https://meta-pytorch.org/OpenEnv/
License
MIT