Spaces:
Running

title: WhisperX API
sdk: docker
app_port: 7860
WhisperX API with Web UI
一键在本地部署一个带 Web 界面的 WhisperX 服务,提供高精度的语音转录和说话人分离功能,同时兼容 OpenAI API。
✨ 项目亮点
- 🚀 一键启动: 使用
uv工具,一条命令即可完成环境配置和启动。 - 💻 简洁 Web UI: 提供开箱即用的网页界面,通过拖拽即可完成音频/视频转录。
- 🗣️ 说话人分离: 基于
pyannote.audio,自动识别并标注对话中的不同说话人。 - ⚡ OpenAI 兼容 API: 可作为 OpenAI Whisper API 的本地平替,无缝集成到现有项目中。
- 🔒 完全本地化: 所有计算都在你的电脑上完成,确保数据隐私和安全。
- 🎯 高精度转录: 基于强大的 WhisperX (FasterWhisper),提供快速且准确的转录结果。
🛠️ 准备工作
在开始之前,请确保您的系统已安装以下必备软件:
硬件要求:
- 强烈推荐: 拥有一块 NVIDIA 显卡 (GPU) 并安装 CUDA,6GB 以上显存。
- 最低要求: 现代多核 CPU,但处理速度会较慢。
软件依赖:
网络环境:
- 首次运行时需要从 Hugging Face 下载模型,请确保您的网络可以访问
huggingface.co。
- 首次运行时需要从 Hugging Face 下载模型,请确保您的网络可以访问
🚀 快速开始
第 1 步:克隆项目
git clone https://github.com/jianchang512/whisperx-api.git
cd whisperx-api
第 2 步:配置说话人分离 (可选)
登录 Hugging Face: 访问 huggingface.co 并注册/登录。
同意模型协议:
- 访问 pyannote/speaker-diarization-3.1
- 访问 pyannote/segmentation-3.0
- 在这两个页面同意并接受用户协议。
获取并配置 Token:
- 在 Hugging Face Tokens 页面 创建一个新的 read 权限的访问令牌。
- 在项目根目录下创建一个名为
token.txt的文件,并将复制的令牌粘贴进去。
第 3 步:一键启动!
确保终端位于项目根目录,然后运行:
uv run app.py
uv 会自动处理所有 Python 依赖的安装。首次运行会下载模型,请耐心等待。当看到以下日志时,表示服务已成功启动:
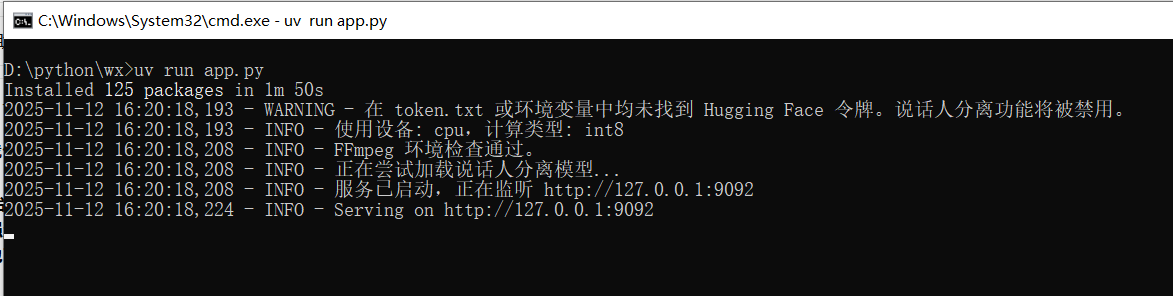
服务启动后,它会自动在浏览器中打开 **http://127.0.0.1:9092**。
☁️ 部署到 Hugging Face Spaces(免费 CPU,API 对外)
- 新建 Space,选择
Docker。 - 直接上传本仓库代码(或用
chouxiang/deploy.py自动上传)。 - Space 会自动构建并对外提供:
- Web UI:
https://<your-space>.hf.space/ - OpenAI 兼容 API:
https://<your-space>.hf.space/v1/audio/transcriptions
- Web UI:
可选环境变量(Space Settings -> Secrets):
HUGGING_FACE_TOKEN: 启用说话人分离(pyannote)所需;不设置则自动禁用。DEFAULT_MODEL: CPU 建议用tiny|base|small(默认 CPU 为small)。ALLOW_LARGE_ON_CPU=1: 允许在 CPU 上请求large-*(不推荐,容易超时/内存不足)。VAD_METHOD: 语音端点检测方法;CPU 建议silero(默认 CPU 即为silero,避免 pyannote checkpoint 的 torch.load 兼容问题)。
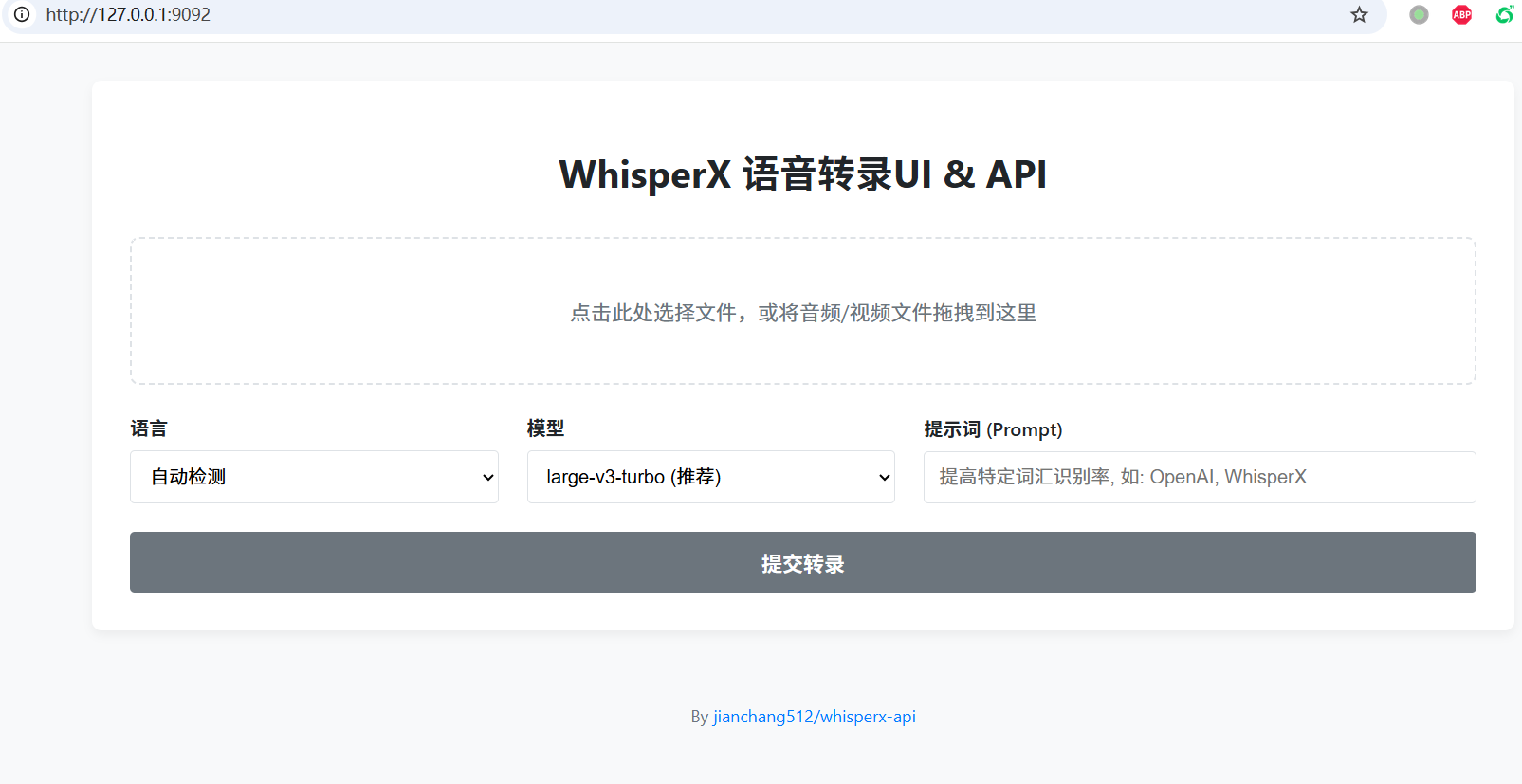
📖 使用指南
方式一:Web 界面 (推荐)
- 上传文件: 点击或拖拽音频/视频文件到上传区域。
- 配置参数:
- 语言: 选择音频语言或保持“自动检测”。
- 模型: 模型越大,效果越好但速度越慢。
large-v3-turbo是推荐的平衡点。 - 提示词 (Prompt): 提供专业术语、人名等可以提高识别准确率 (例如
OpenAI, WhisperX, PyTorch)。
- 开始转录: 点击“提交转录”按钮。
- 查看和下载: 结果会以 SRT 字幕格式显示在下方文本框中,可直接编辑并下载。
方式二:OpenAI 兼容 API
您可以将此服务作为 OpenAI Whisper API 的本地替代品。
model: tiny|base|small|medium|large-v2|large-v3|large-v3-turbo
response_format: 固定值 diarized_json
extra_body:
max_speakers: 最大说话人数量,-1:不启用,0:启用说话人并且不限制最大说话人数量,>0:最大说话人数量
min_speakers: 最小说话人数量,=0:不指定最小说话人数量,>0:最小说话人数量
示例 Python 代码:
from openai import OpenAI
# base_url 指向本地服务地址,api_key 可任意填写
client = OpenAI(base_url='http://127.0.0.1:9092/v1', api_key='dummy-key')
audio_path = "path/to/your/audio.wav"
with open(audio_path, "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="large-v3", # 可选 'tiny', 'base', 'large-v3' 等
file=audio_file,
response_format="diarized_json", # 固定值
extra_body={
"max_speakers": 4, # -1=不启用说话人识别,0=启用说话人并且不指定最大说话人数量,>0=最大说话人数量
"min_speakers": 2 # =0 不指定最小说话人数量,>0=最小说话人数量
},
)
# 打印带说话人信息的字幕片段
for segment in transcript.segments:
speaker = segment.get('speaker', 'Unknown')
start_time = segment['start']
end_time = segment['end']
text = segment['text']
print(f"[{start_time:.2f}s -> {end_time:.2f}s] {speaker}: {text}")
# output: [TranscriptionDiarizedSegment(id=None, end=24.283, speaker=None, start=0.031, text='五老星系中發訊的有機分子我們林第三類接觸還有多人微博 真是展開拍攝任務已經進來中年最近也傳過來許多過去難以拍攝到的照片又越出天文學家在自然期看上發表了這場照片在藍色核心外環繞著一圈橘黃色的光 芒這是一個星系規模的甜甜圈', type=None), TranscriptionDiarizedSegment(id=None, end=40.821, speaker=None, start=24.263, text='這是一個傳送門這是外星文明的代生環其實這是一個還有有幾五多環方向聽的古老星系他的名字是SPT 臨四一巴 带選四十七因為名字很長以下我們就檢稱為SPT 臨四一巴吧', type=None), TranscriptionDiarizedSegment(id=None, end=57.544, speaker=None, start=40.801, text='這個結果有什麼特殊意義這代表我們發現外形生命的嗎?本集節目是販唐會員選題紅每個月都會製作由會員投票出來的題目如果你有好題目希望我們做一集來講解或討論哪上點擊加入按鈕成為我們的會員吧', type=None),...]
❓ 常见问题 (FAQ)
Q: 启动时提示
FFmpeg not found? A: 说明 FFmpeg 未正确安装或未添加到系统环境变量(PATH)。请参考 准备工作 中的安装指南。Q: 点击“提交转录”后长时间无响应或报错? A: 首次运行需要下载模型,请耐心等待。如果报错,请检查终端日志。最常见的原因是网络问题导致模型下载失败。
Q: 结果中为何没有
[Speaker1],[Speaker2]标记? A: 1) 音频中只有单人说话,程序会自动判断。2) 您未配置说话人分离功能(第 2 步),或 Hugging Face 上的模型协议申请还未通过审核。Q: 处理速度很慢怎么办? A: 这是因为您在使用 CPU 进行计算。使用 NVIDIA GPU 会极大提升处理速度。