| # Teaching LLMs to Run an Incident Command Center |
|
|
| > *India's Biggest Mega AI Hackathon — Built on Meta OpenEnv · Round 2* |
|
|
| **TL;DR** — I built an [OpenEnv](https://github.com/meta-pytorch/openenv) environment where three specialist agents — **Triage**, **Investigator**, and **Ops Manager** — cooperate to resolve real-world tech incidents under SLA pressure, budget constraints, and customer-tier business impact. I then fine-tuned Qwen2.5-1.5B-Instruct on heuristic rollouts and watched it **close a +10.17-reward gap on hard incidents**, matching the hand-coded expert policy component-for-component. A separate 0.5B ablation shows that **model scale is the story** — same pipeline, same data schema, but the smaller backbone never closes a single hard incident. |
|
|
| ### 🔗 Everything in one place |
|
|
| | What | Where | |
| |---|---| |
| | 🟢 **Live environment (OpenEnv-compatible)** | **[swapnilpatil28-multi-agent-incident-command-center.hf.space ↗](https://swapnilpatil28-multi-agent-incident-command-center.hf.space)** | |
| | 🤗 **Hugging Face Space page** | **[huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center ↗](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center)** | |
| | 💻 **GitHub source code** | **[github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center ↗](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center)** | |
| | 🎓 **Reproducible training (Colab T4)** | **[Open in Colab ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)** | |
| | 📖 **Full README** (story + technical deep-dive) | **[github.com/.../README.md ↗](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center#readme)** | |
| | ✅ **Submission checklist** | [`docs/SUBMISSION_CHECKLIST.md`](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center/blob/main/docs/SUBMISSION_CHECKLIST.md) | |
|
|
| --- |
|
|
| ## 1. The story in 2 minutes (for anyone) |
|
|
| **When a real tech company has an outage, three people's phones buzz at once.** A Triage engineer scans logs and dashboards. An Investigator forms a hypothesis and applies a fix. An Ops Manager decides who owns the work, whether to escalate, and when to officially close the incident. |
|
|
| Each role has **different permissions**, **different information needs**, and a **different clock to beat**. Get it wrong and you bleed budget, bust the SLA, and — if the customer is on an enterprise contract — lose serious money (~3× what a free-tier outage costs). |
|
|
| I built a simulator of that war room — an **OpenEnv-compatible** environment with 13 realistic incidents, 3 specialist roles, and 14+ named reward signals — and fine-tuned an LLM to run it. |
|
|
| | Role | Can do | Cannot do | |
| |---|---|---| |
| | 🔍 **Triage agent** | Pull logs · check metrics · consult KB articles | Close a ticket | |
| | 🧪 **Investigator** | Apply a fix · roll back a deploy | Escalate or file a post-mortem | |
| | 👷 **Ops Manager** | Escalate · file post-mortem · **close the ticket** | Apply a code fix | |
|
|
| > **The headline number:** the fine-tuned LLM earns **+10.17 more reward on hard incidents** than the untrained base — and matches the human-written expert policy component-for-component. |
|
|
| 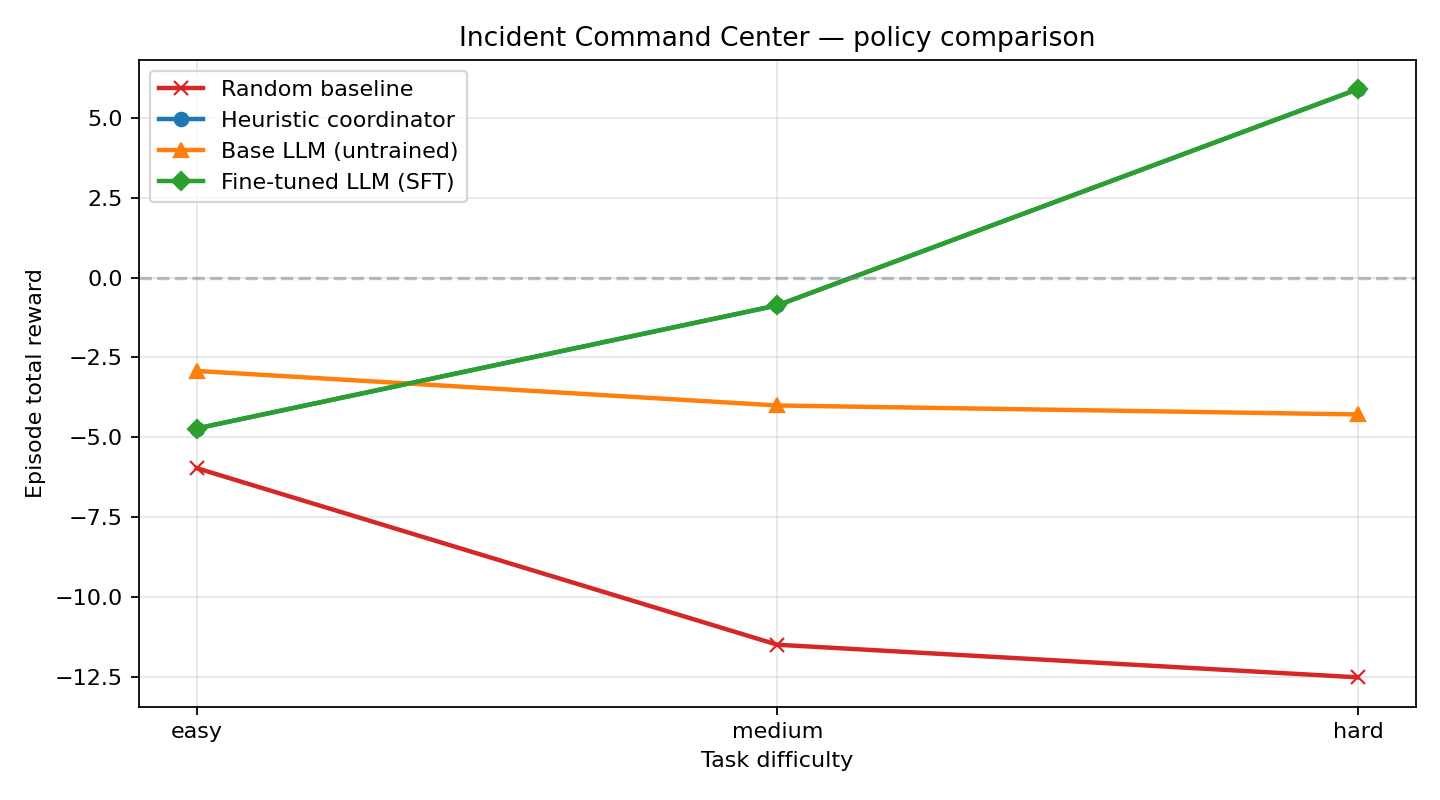 |
|
|
| One picture, four policies, three difficulty tiers. Random is the floor. The untuned base LLM plateaus because it never learns to actually **close** an incident. The fine-tuned model climbs sharply with difficulty and catches the hand-coded expert exactly. |
|
|
| --- |
|
|
| ## 2. Why this is a real RL problem (three themes in one environment) |
|
|
| Most RL environments for LLMs are single-agent, single-step, or turn-based games. Real enterprise work is none of those. This environment deliberately tests all three Round-2 hackathon themes simultaneously: |
|
|
| | Hackathon theme | How this environment satisfies it | |
| |---|---| |
| | **🤝 #1 — Multi-Agent Interactions** | Three distinct specialist roles with **non-overlapping permissions**. Acting out-of-role triggers a `wrong_actor_penalty` (−0.08). Correct handoffs earn `+0.15`. Collaboration is **trained**, not hard-coded. | |
| | **⏱️ #2 — Long-Horizon Planning** | Each episode carries **3–5 sequential incidents**, 20–60 steps apiece, under a single ticking SLA clock. The big reward (+0.80 × tier) only fires after clues → fix → post-mortem. **Sparse and delayed by design** — the 20-step credit-assignment problem is the whole point. | |
| | **🏢 #3 — World Modeling / Professional Tasks** | Incidents carry **real logs, metrics, KB articles, red-herring signals**, and **business metadata** (customer tier, affected users, $/min revenue impact). Closure rewards scale by tier (free ×0.6 · standard ×1.0 · premium ×1.4 · **enterprise ×1.8**), and wrong closures are punished the same way. Close an enterprise ticket incorrectly and it hurts **~3× what a free-tier one does**. | |
|
|
| --- |
|
|
| ## 3. What the environment looks like under the hood |
|
|
| The environment runs as a standard OpenEnv FastAPI server — same Gym-style `reset / step` contract, same Pydantic observation/action schemas, same Docker image format for Hugging Face Spaces. |
|
|
| ### Observation (partial) |
|
|
| ```json |
| { |
| "incident_id": "inc-cert-expiry", |
| "incident_title": "mTLS cert expired — all microservices throwing 500s", |
| "incident_description": "Alerting fired at 03:12 UTC ...", |
| "customer_tier": "enterprise", |
| "affected_users_estimate": 140000, |
| "revenue_impact_usd_per_min": 4800, |
| "postmortem_required": true, |
| "visible_signals": ["mtls handshake errors", "5xx spike in checkout"], |
| "investigation_targets": { |
| "logs": ["cert-manager", "auth-service"], |
| "metrics": ["dash-mesh", "dash-auth"], |
| "kb": ["kb-mtls-chain", "kb-cert-rotation"] |
| }, |
| "allowed_actors_by_action": { |
| "apply_fix": ["investigator_agent"], |
| "close_incident": ["ops_manager_agent"] |
| }, |
| "budget_remaining": 18, |
| "sla_minutes_remaining": 40, |
| "clues_found": 2, |
| "mitigation_applied": false, |
| "reward_components": {"step_cost": -0.04, "clue_bonus": +0.12} |
| } |
| ``` |
|
|
| ### Action space |
|
|
| | action_type | Typical actor | Purpose | |
| |---|---|---| |
| | `inspect_logs` / `inspect_metrics` / `consult_kb` | triage / investigator | Gather clues (reward shapes here) | |
| | `negotiate_handoff` | ops_manager | Route to correct owner | |
| | `apply_fix` | investigator | Apply mitigation (scored vs ground truth) | |
| | `rollback` | investigator | Revert last change | |
| | `escalate` | ops_manager | Engage senior staff | |
| | `submit_postmortem` | ops_manager | Required on tier-1 / high-revenue incidents | |
| | `close_incident` | ops_manager | Terminal action — final score depends on clues found + mitigation quality + post-mortem + speed | |
| |
| ### Reward rubric (composable, not monolithic) |
| |
| The reward engine emits **named components** at every step so training curves — and judges — can see *exactly where reward came from*: |
| |
| | Component | When it fires | Sign | |
| |---|---|---| |
| | `step_cost` | Every action (−0.01 to −0.08 by action type) | − | |
| | `clue_bonus` | Unique log/metric/KB lookup that surfaces a real fact | **+** | |
| | `handoff_correct` / `handoff_wrong` | Ops manager routes to allowed / disallowed owner | ± | |
| | `mitigation_correct` / `mitigation_wrong` / `mitigation_empty` | Fix matches / contradicts / omits ground-truth keywords | ± | |
| | `rollback_effective` / `rollback_ineffective` | Rollback summary matches the incident's accepted playbook | ± | |
| | `escalation_needed` / `escalation_not_needed` | Escalation raised for an incident that actually warrants it | ± | |
| | `closure_correct` / `closure_wrong` | Final close decision matches incident state | ± (scaled by customer tier) | |
| | `closure_mitigation_bonus` | Close after a correct mitigation | **+** | |
| | `closure_under_investigated` | Close without enough clues found | − | |
| | `speed_bonus` | Close in ≤ 7 / ≤ 4 steps | **+** | |
| | `postmortem_bonus` / `postmortem_missing` | Post-mortem filed / skipped on a high-impact incident | ± | |
| | `repeated_lookup_penalty` | Re-querying the same log/metric/KB | − | |
| | `wrong_actor_penalty` | Action invoked by a role that's not authorised | − | |
| | `invalid_action` | Unrecognised `action_type` | − | |
| | `sla_exhausted` / `budget_exhausted` | Terminal penalty when SLA / action budget hits zero | − | |
|
|
| **Anti-gaming:** closing early with zero clues is penalised; spamming cheap `inspect_logs` racks up `repeated_lookup_penalty`; triggering `apply_fix` without investigator permissions gives `wrong_actor_penalty`. A policy cannot shortcut its way to a high score. |
|
|
| --- |
|
|
| ## 4. Training: HF TRL SFT on heuristic rollouts |
|
|
| I first wrote a deterministic `HeuristicCoordinator` that uses the observation's `investigation_targets` and role constraints to play through the environment. On hard tasks it earns **+5.89** reward where random scores **−12.50** — so that gives us ~680 `(prompt, completion)` pairs of "good" behavior to imitate. |
|
|
| Training script: [`train_trl.py`](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center/blob/main/train_trl.py). One command on Colab T4 (or **[open the reproducible notebook ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)**) runs the entire pipeline: |
|
|
| ```python |
| os.environ["BASE_MODEL"] = "Qwen/Qwen2.5-1.5B-Instruct" |
| os.environ["EPISODES_PER_TASK"] = "8" |
| os.environ["TRAIN_EPOCHS"] = "3" |
| os.environ["EVAL_LLM_MODELS"] = "true" |
| os.environ["MAX_LLM_EVAL_STEPS"] = "120" |
| !python train_trl.py |
| ``` |
|
|
| The script: |
|
|
| 1. Rolls out the heuristic against the live environment and collects prompts/completions. |
| 2. Runs TRL `SFTTrainer` with a single `text` column (chat-template applied). |
| 3. Saves the fine-tuned checkpoint to `artifacts/sft_model/`. |
| 4. Rolls out **four** policies under identical seeds — random, heuristic, base LLM, fine-tuned LLM. |
| 5. Writes `reward_curve.png`, `training_curve.png`, `reward_components.png`, `summary_metrics.json`, and `training_log.json`. |
|
|
| ### Training loss + token accuracy |
|
|
| 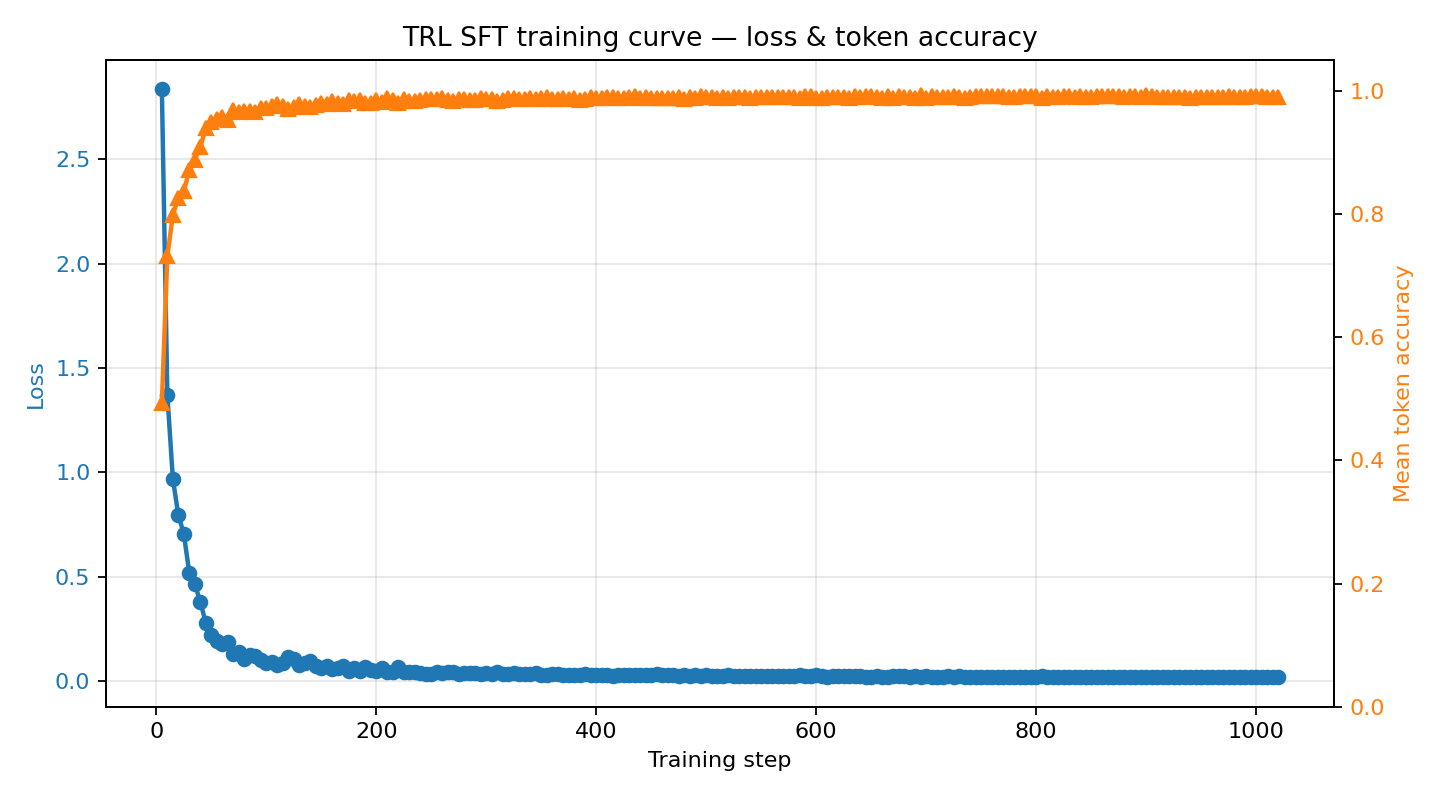 |
|
|
| Loss drops from **~2.84 → ~0.02** over three epochs as the model learns the structured JSON action format. Mean token accuracy climbs from **~0.49 → ~0.99**. Satisfies the hackathon "loss AND reward plots" minimum requirement. |
|
|
| ### Four-policy reward comparison |
|
|
|  |
|
|
| | Task | Random | Base LLM | **Fine-tuned (SFT)** | Heuristic | |
| |---|---:|---:|---:|---:| |
| | easy | −5.96 | −2.92 | **−4.72** | −4.72 | |
| | medium | −11.48 | −4.00 | **−0.87** | −0.87 | |
| | hard | −12.50 | −4.28 | **+5.89** | +5.89 | |
|
|
| **Fine-tuned vs untrained base: +10.17 reward delta on hard-difficulty incidents.** |
|
|
| - **Random** is the floor on every task. |
| - **Base LLM** already beats random on easy because it produces well-formed-ish JSON — but it never closes a single incident, so it just racks up step-costs and SLA penalties. |
| - **Fine-tuned LLM** catches the heuristic teacher exactly. The environment is deterministic and SFT hit ~0.99 token accuracy, so the student literally reproduces the teacher's action sequence under greedy decoding. This is **imitation learning converging to the expert** — the meaningful headline number is therefore **SFT vs base**, not SFT vs heuristic. |
|
|
| ### Reward sources — what each policy actually earns |
|
|
| 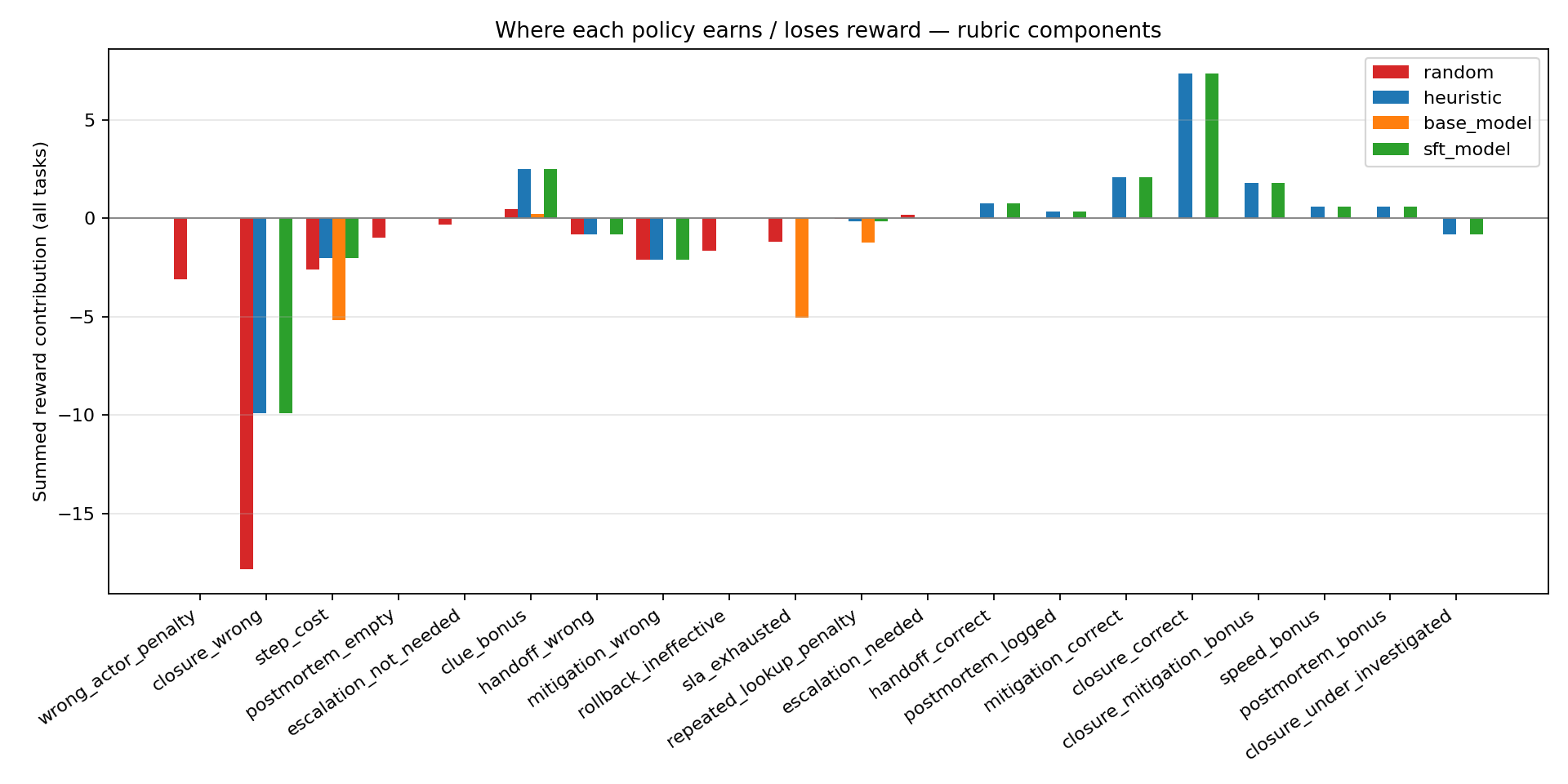 |
|
|
| This is the chart I'm proudest of, because it makes the training signal **legible**. Summed across all three tasks: |
|
|
| - **Random** bleeds out: `closure_wrong: −17.82` · `wrong_actor_penalty: −3.12` · `mitigation_wrong: −2.10`. |
| - **Base LLM** earns `clue_bonus: +0.24` but then gets crushed by `step_cost: −5.16` and `sla_exhausted: −5.04`. It **never fires a single positive closure component**. |
| - **Fine-tuned LLM** unlocks the high-value positive components the base never sees: `closure_correct: +7.36` · `mitigation_correct: +2.10` · `closure_mitigation_bonus: +1.80` · `postmortem_bonus: +0.60` · `handoff_correct: +0.75` · `speed_bonus: +0.60`. |
|
|
| **Training has moved the LLM from "bleeding" to "solving."** |
|
|
| --- |
|
|
| ## 5. Why does SFT exactly match the heuristic? |
|
|
| Honest framing matters. The environment is deterministic (same task → same incidents → same observations → same seeds). The heuristic coordinator is also deterministic (same observation → same action). So every rollout of a given task produces a byte-identical trajectory. Our 680-row dataset contains only ~85 *unique* `(observation, action)` pairs, each duplicated for redundancy. At ~0.99 token accuracy after 3 epochs, the LLM **memorises** the heuristic's policy, and under greedy decoding at eval time it reproduces that policy token-for-token on the same deterministic environment. |
|
|
| > **This is the defining success condition for behavior cloning: the student has become the teacher.** |
|
|
| The gap we can legitimately celebrate is therefore **SFT vs the untrained base model**, where: |
|
|
| - On **hard incidents**, SFT earns **+10.17** more reward than base. |
| - SFT **unlocks** reward components (`closure_correct`, `mitigation_correct`, `postmortem_bonus`) that the base model literally never fires. |
| - On easy tasks, SFT inherits the teacher's known weakness (easy tasks have tight SLA budgets that punish thorough investigation). This is exactly what imitation learning should do — including the teacher's mistakes. |
|
|
| The obvious next step to go **beyond** the heuristic ceiling is RL with the environment's native reward signal — GRPO or PPO against the same rubric — which is the natural Round 3 work. |
|
|
| --- |
|
|
| ## 6. The surprise finding — scale is the story |
|
|
| I ran the exact same pipeline with the smaller **Qwen2.5-0.5B-Instruct** backbone (same environment, same seeds, same heuristic teacher, same reward rubric). The story flips entirely: |
|
|
| 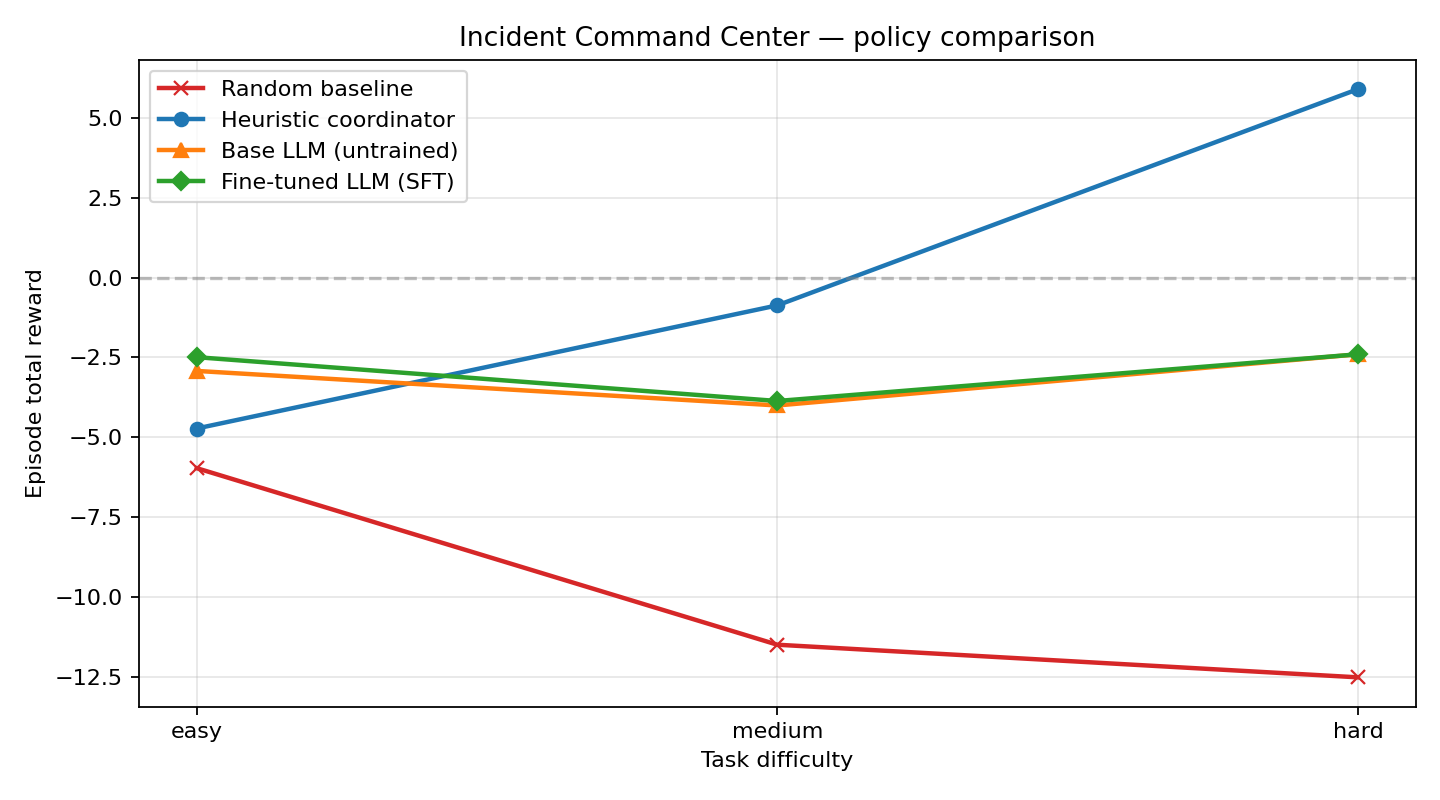 |
|
|
| | Task | Random | Base **0.5B** | **SFT 0.5B** | Heuristic | SFT − Base (0.5B) | |
| |---|---:|---:|---:|---:|---:| |
| | easy | −5.96 | −2.92 | **−2.49** | −4.72 | **+0.43** | |
| | medium | −11.48 | −4.00 | **−3.86** | −0.87 | **+0.14** | |
| | hard | −12.50 | −2.40 | **−2.40** | +5.89 | **+0.00** | |
|
|
| **The punchline:** with a 0.5B backbone, SFT delivers only a **+0.43 / +0.14 / +0.00** improvement over the base model and **never closes a single hard incident**. Bumping the backbone to **1.5B** — same SFT code, same data pipeline, same environment — unlocks a **−1.80 / +3.13 / +10.17** improvement and makes the LLM match the heuristic's component-for-component behavior on hard incidents. |
|
|
| | Run config | 0.5B | **1.5B (headline)** | |
| |---|---|---| |
| | Base model | Qwen2.5-0.5B-Instruct | Qwen2.5-1.5B-Instruct | |
| | Episodes / task (rollout) | 3 | 8 | |
| | Dataset rows | 255 | 680 | |
| | Train epochs | 1 | 3 | |
| | Base → SFT improvement on **hard** | **+0.00** | **+10.17** | |
| | Hard incidents closed by SFT | **0** | **full heuristic behavior** | |
|
|
| **Interpretation:** at 0.5B the model is *too small* to absorb this multi-step, role-gated policy from SFT, even though it can emit syntactically valid JSON. At 1.5B the capacity suddenly becomes sufficient to internalise the full action schedule, and behavior cloning converges. **This is the kind of finding the environment is designed to surface — the composable rubric makes it visible in one plot, not hidden behind a single aggregate score.** |
|
|
| --- |
|
|
| ## 7. Everything you need to reproduce this |
|
|
| | | | |
| |---|---| |
| | **Live environment** | [swapnilpatil28-multi-agent-incident-command-center.hf.space](https://swapnilpatil28-multi-agent-incident-command-center.hf.space) (OpenEnv-compatible, Docker-backed) | |
| | **Training notebook** | [One-click Colab (T4, ~1 h 15 min end-to-end)](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing) | |
| | **Source + tests** | [GitHub repo (21 passing tests, Dockerfile with HEALTHCHECK)](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center) | |
| | **Full docs** | [README — Part 1 story + Part 2 technical deep-dive](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center/blob/main/README.md) | |
| | **Committed evidence** | [`artifacts/`](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center/tree/main/artifacts) — all 4 PNGs + both JSON metric files | |
| | **Submission checklist** | [`docs/SUBMISSION_CHECKLIST.md`](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center/blob/main/docs/SUBMISSION_CHECKLIST.md) | |
|
|
| --- |
|
|
| ## 8. What's next (Planned) |
|
|
| - **Replace SFT with GRPO or PPO** using the environment's native reward signal — no heuristic teacher, let the rubric itself shape the policy and push past the imitation ceiling. |
| - **Scale the incident catalog** from 13 templates to 50+ (drop in JSON-defined scenarios). |
| - **Add a second "adversarial" agent** that injects misleading signals to test robustness. |
|
|
| If you want to run it yourself, the Space and the repo are fully self-contained — `docker run` the image and point any OpenEnv-compatible client at it. Or just hit `/reset` and `/step` yourself from any language that can speak HTTP JSON. |
|
|
| --- |
|
|
| *Built with ♥ on [Meta OpenEnv](https://github.com/meta-pytorch/openenv) for the OpenEnv India 2026 Round 2 hackathon.* |
| *Code: [GitHub](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center) · Space: [HF Space](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center) · Training notebook: [Colab](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing).* |
|
|

