Spaces:
Running

Running
| title: Vision Coder OpenEnv | |
| emoji: 🖼️ | |
| colorFrom: blue | |
| colorTo: purple | |
| sdk: docker | |
| app_port: 7860 | |
| pinned: false | |
| models: | |
| - Qwen/Qwen3.5-2B | |
| tags: | |
| - reinforcement-learning | |
| - html-generation | |
| - computer-vision | |
| - grpo | |
| short_description: RL environment for screenshot-to-HTML generation | |
| # VisionCoder OpenEnv | |
| An RL environment for screenshot-to-HTML generation. An agent receives a UI screenshot and iteratively refines HTML until the rendered output visually matches the reference. | |
| **[Live environment with interactive demo](https://huggingface.co/spaces/amaljoe88/vision-coder-openenv) · [Blog](https://github.com/amaljoe/vision-coder-openenv/blob/main/blog.md)** | |
| --- | |
| ## The Problem | |
| A single LLM call can produce structurally valid HTML that looks nothing like the reference — the model has no way to see its own rendered output and no feedback loop to improve. We frame this as RL: generate HTML, render in a real browser, compute visual reward, iterate. | |
| --- | |
| ## How It Works | |
| ### API | |
| ``` | |
| POST /reset?difficulty=easy|medium|hard&max_steps=5 → { session_id, screenshot_b64 } | |
| POST /step { html, session_id } → { reward, render_low, render_full, done } | |
| POST /render { html } → { image_b64 } | |
| ``` | |
| `max_steps` defaults to 5. Render resolutions default to `320×240` (low) and `640×480` (full) and can be overridden at startup via `LOW_RES=WxH` and `FULL_RES=WxH` env vars. | |
| Episodes run for up to 5 steps. Every submission is rendered by Playwright (headless Chromium) at `320×240` (low-res preview) and `640×480` (full-res, used for reward and Critic). | |
| ### Two-Agent Loop | |
| A **Developer** generates HTML; a **Critic** compares the render against the reference and produces selector-specific CSS fix instructions. | |
| 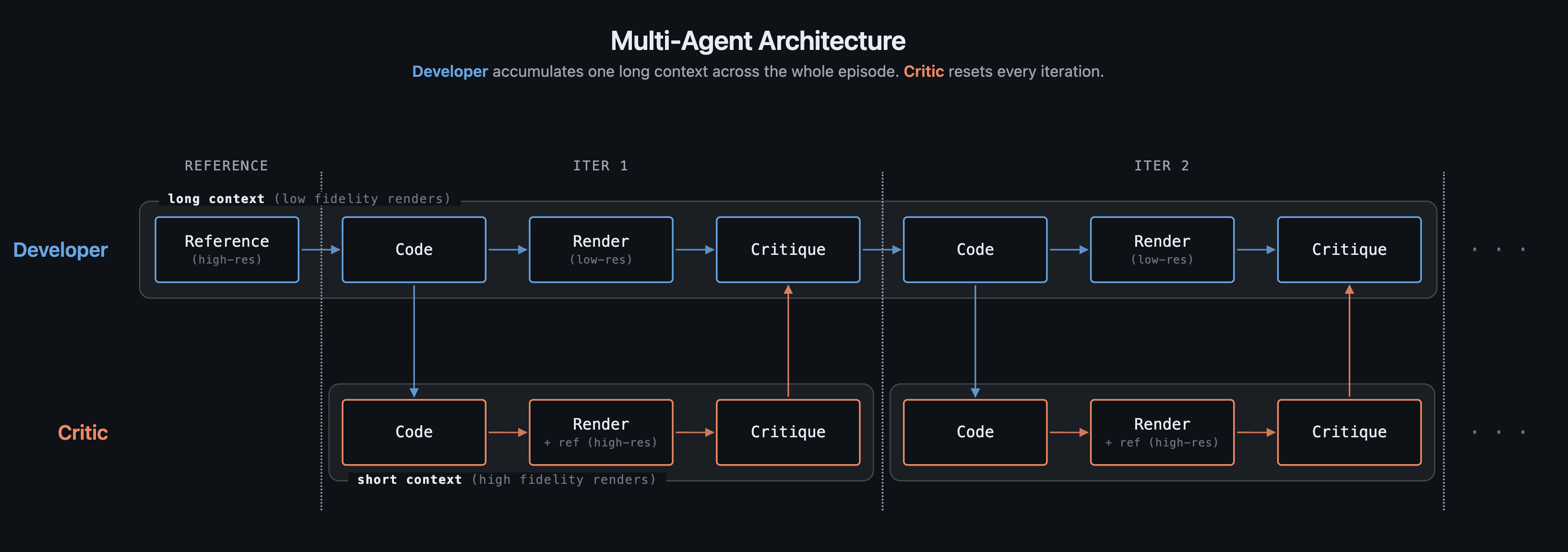 | |
| The Critic compresses ~5,000 tokens of visual+code context into ~200 tokens of actionable fix instructions the Developer can apply directly. | |
| ### Reward Function | |
| 8 sub-rewards weighted by discriminativeness (weight sum = 11.0): | |
| | Signal | Weight | | |
| |---|---| | |
| | `format` + `validity` + `structural` | 0.5 each — saturate early | | |
| | `position` | 1.0 | | |
| | `color` + `ssim` | 1.5 each | | |
| | `clip` | 2.5 | | |
| | `text_block` | **3.0** | | |
| A content multiplier forces blank renders to score 0.0 regardless of sub-reward values. | |
| **Spearman ρ = 0.955** vs human quality rankings across 15 test cases. | |
| The reward test suite runs across all 15 cases. Browse all renders, scores, and per-sub-reward breakdowns in the **[interactive demo](https://amaljoe.github.io/vision-coder-openenv/)**. | |
| --- | |
| ## Results | |
| Training Qwen3.5-2B with full-episode GRPO for 20 episodes on 2× A100 80GB (~2h): | |
| 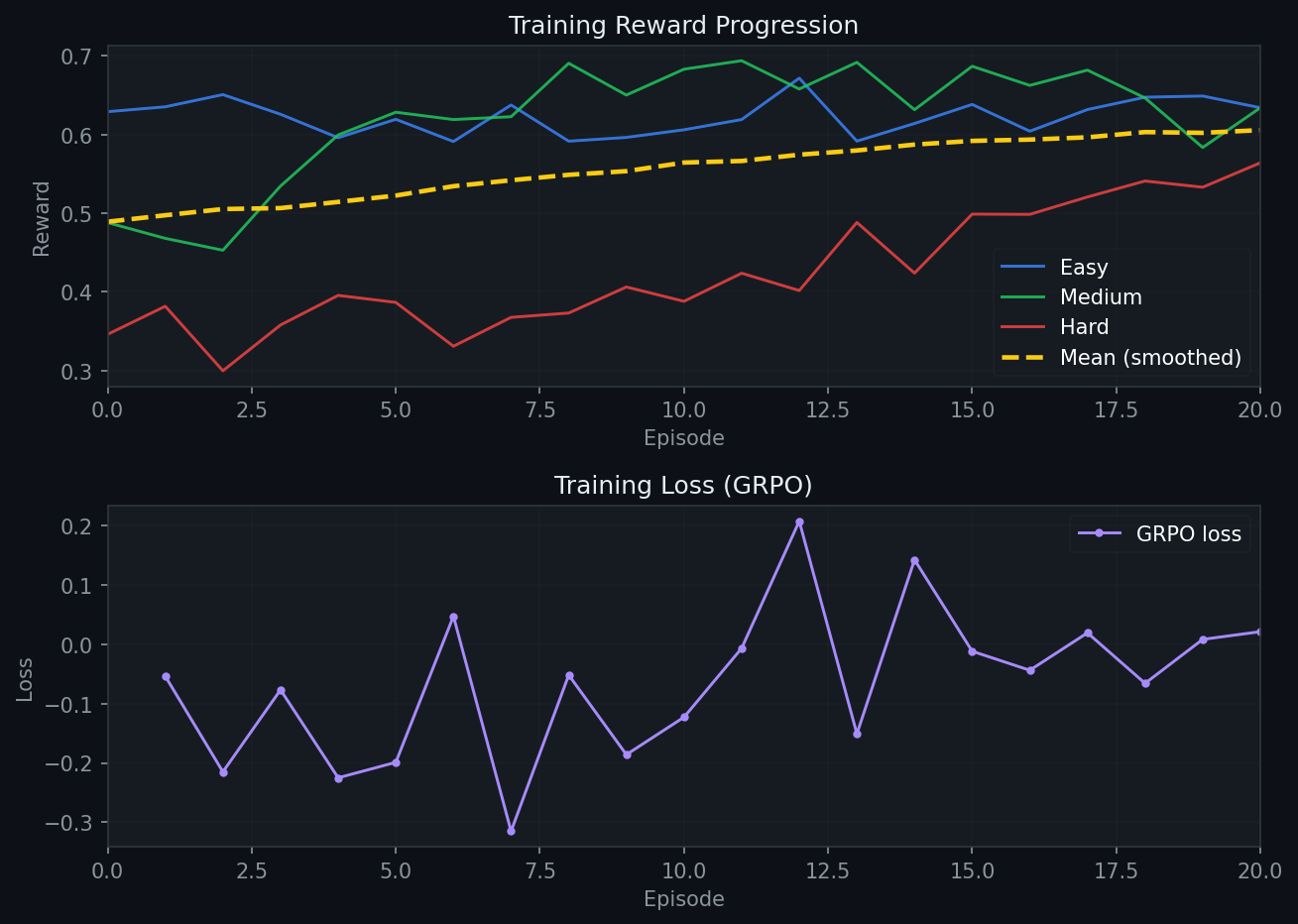 | |
| | Difficulty | Base | Trained | Delta | | |
| |---|---|---|---| | |
| | easy | 0.629 | 0.634 | +0.005 | | |
| | medium | 0.488 | 0.634 | +0.146 | | |
| | hard | 0.346 | 0.564 | +0.218 | | |
| | **mean** | **0.488** | **0.611** | **+25.2%** | | |
| Hard tasks improve the most — complex layouts have the most to gain from the Critic's structured feedback. | |
| 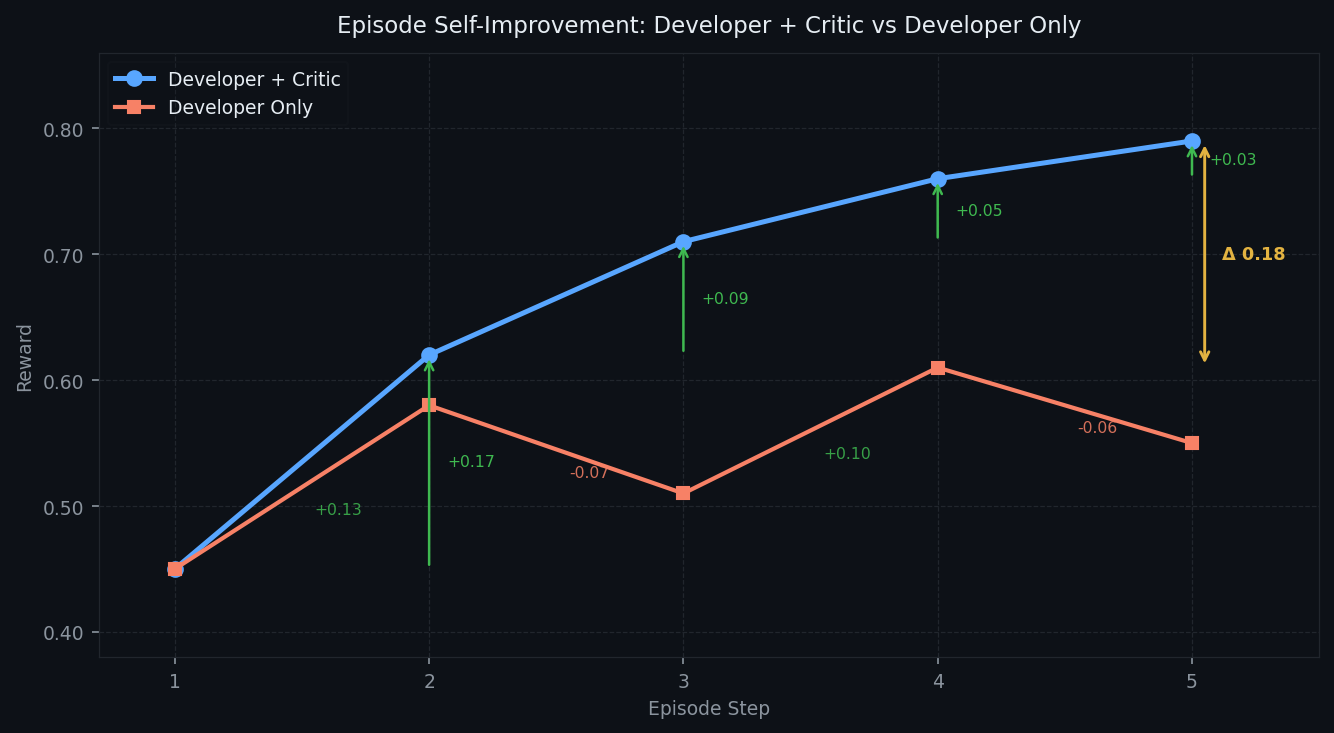 | |
| --- | |
| ## Quickstart | |
| ```bash | |
| pip install -e . | |
| uvicorn openenv.server.app:app --host 0.0.0.0 --port 7860 | |
| ``` | |
| ```bash | |
| export API_BASE_URL=https://router.huggingface.co/v1 | |
| export MODEL_NAME=Qwen/Qwen3.5-35B-A3B | |
| export HF_TOKEN=hf_... | |
| python inference.py | |
| ``` | |