|
|
--- |
|
|
title: Zoo3D (VGGT + open-vocabulary 3D detection) |
|
|
sdk: gradio |
|
|
sdk_version: 5.17.1 |
|
|
app_file: app.py |
|
|
pinned: false |
|
|
--- |
|
|
|
|
|
<div align="center"> |
|
|
<h1>VGGT: Visual Geometry Grounded Transformer</h1> |
|
|
|
|
|
<a href="https://jytime.github.io/data/VGGT_CVPR25.pdf" target="_blank" rel="noopener noreferrer"> |
|
|
<img src="https://img.shields.io/badge/Paper-VGGT" alt="Paper PDF"> |
|
|
</a> |
|
|
<a href="https://arxiv.org/abs/2503.11651"><img src="https://img.shields.io/badge/arXiv-2503.11651-b31b1b" alt="arXiv"></a> |
|
|
<a href="https://vgg-t.github.io/"><img src="https://img.shields.io/badge/Project_Page-green" alt="Project Page"></a> |
|
|
<a href='https://huggingface.co/spaces/facebook/vggt'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Demo-blue'></a> |
|
|
|
|
|
|
|
|
**[Visual Geometry Group, University of Oxford](https://www.robots.ox.ac.uk/~vgg/)**; **[Meta AI](https://ai.facebook.com/research/)** |
|
|
|
|
|
|
|
|
[Jianyuan Wang](https://jytime.github.io/), [Minghao Chen](https://silent-chen.github.io/), [Nikita Karaev](https://nikitakaraevv.github.io/), [Andrea Vedaldi](https://www.robots.ox.ac.uk/~vedaldi/), [Christian Rupprecht](https://chrirupp.github.io/), [David Novotny](https://d-novotny.github.io/) |
|
|
</div> |
|
|
|
|
|
```bibtex |
|
|
@inproceedings{wang2025vggt, |
|
|
title={VGGT: Visual Geometry Grounded Transformer}, |
|
|
author={Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, Andrea and Rupprecht, Christian and Novotny, David}, |
|
|
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, |
|
|
year={2025} |
|
|
} |
|
|
``` |
|
|
|
|
|
## Updates |
|
|
- [June 2, 2025] Added a script to run VGGT and save predictions in COLMAP format, with bundle adjustment support optional. The saved COLMAP files can be directly used with [gsplat](https://github.com/nerfstudio-project/gsplat) or other NeRF/Gaussian splatting libraries. |
|
|
|
|
|
|
|
|
- [May 3, 2025] Evaluation code for reproducing our camera pose estimation results on Co3D is now available in the [evaluation](https://github.com/facebookresearch/vggt/tree/evaluation) branch. |
|
|
|
|
|
|
|
|
- [Apr 13, 2025] Training code is being gradually cleaned and uploaded to the [training](https://github.com/facebookresearch/vggt/tree/training) branch. It will be merged into the main branch once finalized. |
|
|
|
|
|
## Overview |
|
|
|
|
|
Visual Geometry Grounded Transformer (VGGT, CVPR 2025) is a feed-forward neural network that directly infers all key 3D attributes of a scene, including extrinsic and intrinsic camera parameters, point maps, depth maps, and 3D point tracks, **from one, a few, or hundreds of its views, within seconds**. |
|
|
|
|
|
|
|
|
## Quick Start |
|
|
|
|
|
First, clone this repository to your local machine, and install the dependencies (torch, torchvision, numpy, Pillow, and huggingface_hub). |
|
|
|
|
|
```bash |
|
|
git clone git@github.com:facebookresearch/vggt.git |
|
|
cd vggt |
|
|
pip install -r requirements.txt |
|
|
``` |
|
|
|
|
|
Alternatively, you can install VGGT as a package (<a href="docs/package.md">click here</a> for details). |
|
|
|
|
|
|
|
|
Now, try the model with just a few lines of code: |
|
|
|
|
|
```python |
|
|
import torch |
|
|
from vggt.models.vggt import VGGT |
|
|
from vggt.utils.load_fn import load_and_preprocess_images |
|
|
|
|
|
device = "cuda" if torch.cuda.is_available() else "cpu" |
|
|
# bfloat16 is supported on Ampere GPUs (Compute Capability 8.0+) |
|
|
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16 |
|
|
|
|
|
# Initialize the model and load the pretrained weights. |
|
|
# This will automatically download the model weights the first time it's run, which may take a while. |
|
|
model = VGGT.from_pretrained("facebook/VGGT-1B").to(device) |
|
|
|
|
|
# Load and preprocess example images (replace with your own image paths) |
|
|
image_names = ["path/to/imageA.png", "path/to/imageB.png", "path/to/imageC.png"] |
|
|
images = load_and_preprocess_images(image_names).to(device) |
|
|
|
|
|
with torch.no_grad(): |
|
|
with torch.cuda.amp.autocast(dtype=dtype): |
|
|
# Predict attributes including cameras, depth maps, and point maps. |
|
|
predictions = model(images) |
|
|
``` |
|
|
|
|
|
The model weights will be automatically downloaded from Hugging Face. If you encounter issues such as slow loading, you can manually download them [here](https://huggingface.co/facebook/VGGT-1B/blob/main/model.pt) and load, or: |
|
|
|
|
|
```python |
|
|
model = VGGT() |
|
|
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt" |
|
|
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL)) |
|
|
``` |
|
|
|
|
|
## Detailed Usage |
|
|
|
|
|
<details> |
|
|
<summary>Click to expand</summary> |
|
|
|
|
|
You can also optionally choose which attributes (branches) to predict, as shown below. This achieves the same result as the example above. This example uses a batch size of 1 (processing a single scene), but it naturally works for multiple scenes. |
|
|
|
|
|
```python |
|
|
from vggt.utils.pose_enc import pose_encoding_to_extri_intri |
|
|
from vggt.utils.geometry import unproject_depth_map_to_point_map |
|
|
|
|
|
with torch.no_grad(): |
|
|
with torch.cuda.amp.autocast(dtype=dtype): |
|
|
images = images[None] # add batch dimension |
|
|
aggregated_tokens_list, ps_idx = model.aggregator(images) |
|
|
|
|
|
# Predict Cameras |
|
|
pose_enc = model.camera_head(aggregated_tokens_list)[-1] |
|
|
# Extrinsic and intrinsic matrices, following OpenCV convention (camera from world) |
|
|
extrinsic, intrinsic = pose_encoding_to_extri_intri(pose_enc, images.shape[-2:]) |
|
|
|
|
|
# Predict Depth Maps |
|
|
depth_map, depth_conf = model.depth_head(aggregated_tokens_list, images, ps_idx) |
|
|
|
|
|
# Predict Point Maps |
|
|
point_map, point_conf = model.point_head(aggregated_tokens_list, images, ps_idx) |
|
|
|
|
|
# Construct 3D Points from Depth Maps and Cameras |
|
|
# which usually leads to more accurate 3D points than point map branch |
|
|
point_map_by_unprojection = unproject_depth_map_to_point_map(depth_map.squeeze(0), |
|
|
extrinsic.squeeze(0), |
|
|
intrinsic.squeeze(0)) |
|
|
|
|
|
# Predict Tracks |
|
|
# choose your own points to track, with shape (N, 2) for one scene |
|
|
query_points = torch.FloatTensor([[100.0, 200.0], |
|
|
[60.72, 259.94]]).to(device) |
|
|
track_list, vis_score, conf_score = model.track_head(aggregated_tokens_list, images, ps_idx, query_points=query_points[None]) |
|
|
``` |
|
|
|
|
|
|
|
|
Furthermore, if certain pixels in the input frames are unwanted (e.g., reflective surfaces, sky, or water), you can simply mask them by setting the corresponding pixel values to 0 or 1. Precise segmentation masks aren't necessary - simple bounding box masks work effectively (check this [issue](https://github.com/facebookresearch/vggt/issues/47) for an example). |
|
|
|
|
|
</details> |
|
|
|
|
|
|
|
|
## Interactive Demo |
|
|
|
|
|
We provide multiple ways to visualize your 3D reconstructions. Before using these visualization tools, install the required dependencies: |
|
|
|
|
|
```bash |
|
|
pip install -r requirements_demo.txt |
|
|
``` |
|
|
|
|
|
### Interactive 3D Visualization |
|
|
|
|
|
**Please note:** VGGT typically reconstructs a scene in less than 1 second. However, visualizing 3D points may take tens of seconds due to third-party rendering, independent of VGGT's processing time. The visualization is slow especially when the number of images is large. |
|
|
|
|
|
|
|
|
#### Gradio Web Interface |
|
|
|
|
|
Our Gradio-based interface allows you to upload images/videos, run reconstruction, and interactively explore the 3D scene in your browser. You can launch this in your local machine or try it on [Hugging Face](https://huggingface.co/spaces/facebook/vggt). |
|
|
|
|
|
|
|
|
```bash |
|
|
python demo_gradio.py |
|
|
``` |
|
|
|
|
|
<details> |
|
|
<summary>Click to preview the Gradio interactive interface</summary> |
|
|
|
|
|
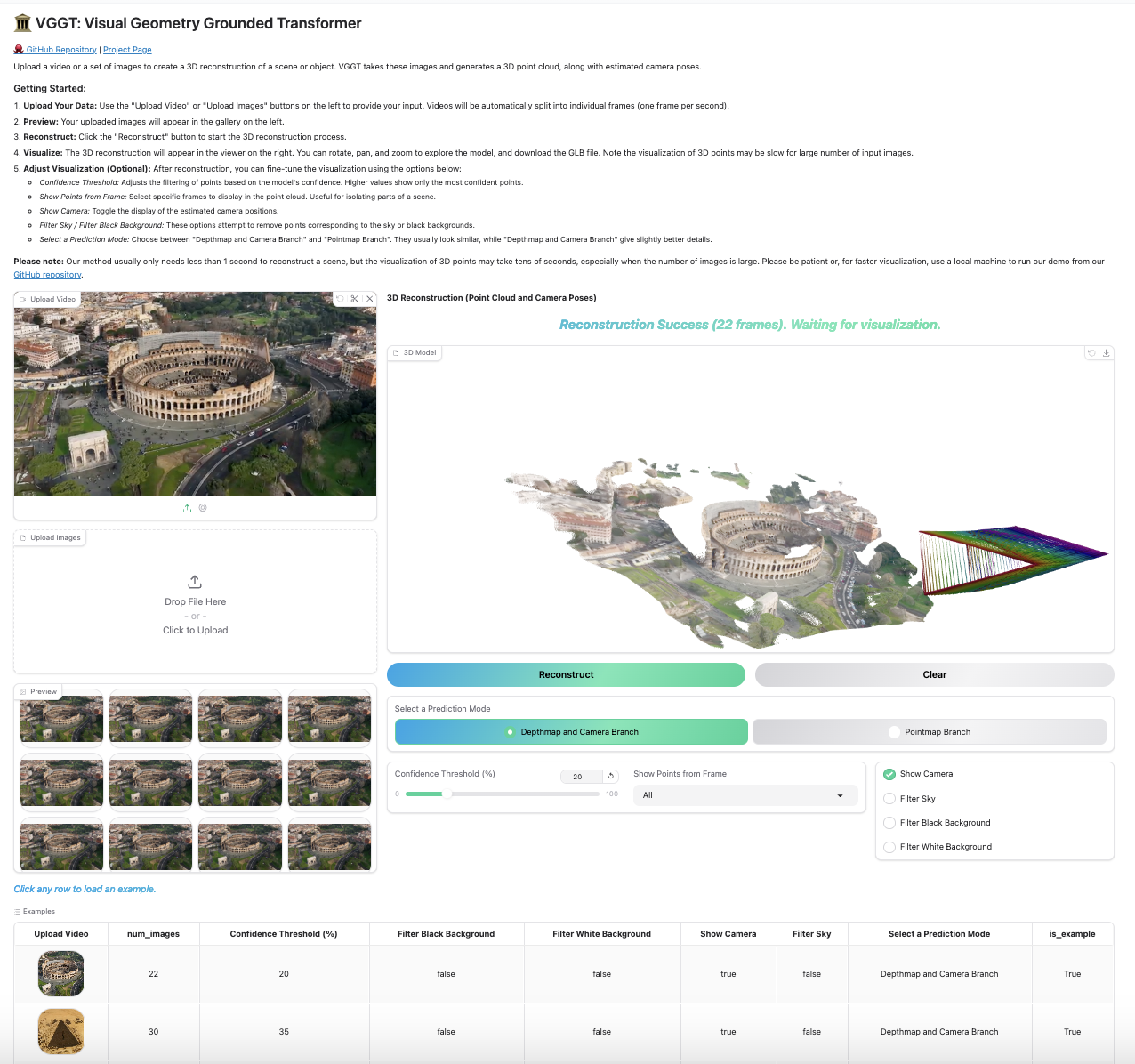 |
|
|
</details> |
|
|
|
|
|
|
|
|
#### Viser 3D Viewer |
|
|
|
|
|
Run the following command to run reconstruction and visualize the point clouds in viser. Note this script requires a path to a folder containing images. It assumes only image files under the folder. You can set `--use_point_map` to use the point cloud from the point map branch, instead of the depth-based point cloud. |
|
|
|
|
|
```bash |
|
|
python demo_viser.py --image_folder path/to/your/images/folder |
|
|
``` |
|
|
|
|
|
## Exporting to COLMAP Format |
|
|
|
|
|
We also support exporting VGGT's predictions directly to COLMAP format, by: |
|
|
|
|
|
```bash |
|
|
# Feedforward prediction only |
|
|
python demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/ |
|
|
|
|
|
# With bundle adjustment |
|
|
python demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/ --use_ba |
|
|
# check the file for additional bundle adjustment configuration options |
|
|
``` |
|
|
|
|
|
Please ensure that the images are stored in `/YOUR/SCENE_DIR/images/`. This folder should contain only the images. Check the examples folder for the desired data structure. |
|
|
|
|
|
The reconstruction result (camera parameters and 3D points) will be automatically saved under `/YOUR/SCENE_DIR/sparse/` in the COLMAP format, such as: |
|
|
|
|
|
``` |
|
|
SCENE_DIR/ |
|
|
├── images/ |
|
|
└── sparse/ |
|
|
├── cameras.bin |
|
|
├── images.bin |
|
|
└── points3D.bin |
|
|
``` |
|
|
|
|
|
## Integration with Gaussian Splatting |
|
|
|
|
|
|
|
|
The exported COLMAP files can be directly used with [gsplat](https://github.com/nerfstudio-project/gsplat) for Gaussian Splatting training. Install `gsplat` following their official instructions (we recommend `gsplat==1.3.0`): |
|
|
|
|
|
An example command to train the model is: |
|
|
``` |
|
|
cd gsplat |
|
|
python examples/simple_trainer.py default --data_factor 1 --data_dir /YOUR/SCENE_DIR/ --result_dir /YOUR/RESULT_DIR/ |
|
|
``` |
|
|
|
|
|
|
|
|
|
|
|
## Zero-shot Single-view Reconstruction |
|
|
|
|
|
Our model shows surprisingly good performance on single-view reconstruction, although it was never trained for this task. The model does not need to duplicate the single-view image to a pair, instead, it can directly infer the 3D structure from the tokens of the single view image. Feel free to try it with our demos above, which naturally works for single-view reconstruction. |
|
|
|
|
|
|
|
|
We did not quantitatively test monocular depth estimation performance ourselves, but [@kabouzeid](https://github.com/kabouzeid) generously provided a comparison of VGGT to recent methods [here](https://github.com/facebookresearch/vggt/issues/36). VGGT shows competitive or better results compared to state-of-the-art monocular approaches such as DepthAnything v2 or MoGe, despite never being explicitly trained for single-view tasks. |
|
|
|
|
|
|
|
|
|
|
|
## Runtime and GPU Memory |
|
|
|
|
|
We benchmark the runtime and GPU memory usage of VGGT's aggregator on a single NVIDIA H100 GPU across various input sizes. |
|
|
|
|
|
| **Input Frames** | 1 | 2 | 4 | 8 | 10 | 20 | 50 | 100 | 200 | |
|
|
|:----------------:|:-:|:-:|:-:|:-:|:--:|:--:|:--:|:---:|:---:| |
|
|
| **Time (s)** | 0.04 | 0.05 | 0.07 | 0.11 | 0.14 | 0.31 | 1.04 | 3.12 | 8.75 | |
|
|
| **Memory (GB)** | 1.88 | 2.07 | 2.45 | 3.23 | 3.63 | 5.58 | 11.41 | 21.15 | 40.63 | |
|
|
|
|
|
Note that these results were obtained using Flash Attention 3, which is faster than the default Flash Attention 2 implementation while maintaining almost the same memory usage. Feel free to compile Flash Attention 3 from source to get better performance. |
|
|
|
|
|
|
|
|
## Research Progression |
|
|
|
|
|
Our work builds upon a series of previous research projects. If you're interested in understanding how our research evolved, check out our previous works: |
|
|
|
|
|
|
|
|
<table border="0" cellspacing="0" cellpadding="0"> |
|
|
<tr> |
|
|
<td align="left"> |
|
|
<a href="https://github.com/jytime/Deep-SfM-Revisited">Deep SfM Revisited</a> |
|
|
</td> |
|
|
<td style="white-space: pre;">──┐</td> |
|
|
<td></td> |
|
|
</tr> |
|
|
<tr> |
|
|
<td align="left"> |
|
|
<a href="https://github.com/facebookresearch/PoseDiffusion">PoseDiffusion</a> |
|
|
</td> |
|
|
<td style="white-space: pre;">─────►</td> |
|
|
<td> |
|
|
<a href="https://github.com/facebookresearch/vggsfm">VGGSfM</a> ──► |
|
|
<a href="https://github.com/facebookresearch/vggt">VGGT</a> |
|
|
</td> |
|
|
</tr> |
|
|
<tr> |
|
|
<td align="left"> |
|
|
<a href="https://github.com/facebookresearch/co-tracker">CoTracker</a> |
|
|
</td> |
|
|
<td style="white-space: pre;">──┘</td> |
|
|
<td></td> |
|
|
</tr> |
|
|
</table> |
|
|
|
|
|
|
|
|
## Acknowledgements |
|
|
|
|
|
Thanks to these great repositories: [PoseDiffusion](https://github.com/facebookresearch/PoseDiffusion), [VGGSfM](https://github.com/facebookresearch/vggsfm), [CoTracker](https://github.com/facebookresearch/co-tracker), [DINOv2](https://github.com/facebookresearch/dinov2), [Dust3r](https://github.com/naver/dust3r), [Moge](https://github.com/microsoft/moge), [PyTorch3D](https://github.com/facebookresearch/pytorch3d), [Sky Segmentation](https://github.com/xiongzhu666/Sky-Segmentation-and-Post-processing), [Depth Anything V2](https://github.com/DepthAnything/Depth-Anything-V2), [Metric3D](https://github.com/YvanYin/Metric3D) and many other inspiring works in the community. |
|
|
|
|
|
## Checklist |
|
|
|
|
|
- [ ] Release the training code |
|
|
- [ ] Release VGGT-500M and VGGT-200M |
|
|
|
|
|
|
|
|
## License |
|
|
See the [LICENSE](./LICENSE.txt) file for details about the license under which this code is made available. |
|
|
|
