Spaces:
Configuration error

Configuration error

| title: Interfaze | |
| thumbnail: >- | |
| https://cdn-uploads.huggingface.co/production/uploads/62fb53b572a7ab50b4b06fca/II4KdeJkepE_NOg9HNnq_.jpeg | |
| short_description: The AI model built for deterministic developer tasks | |
|  | |
| # The AI model built for deterministic developer tasks | |
| Interfaze is an AI model built on a new architecture that merges specialized DNN/CNN models with LLMs for developer tasks that require deterministic output and high consistency like OCR, scraping, classification, web search and more. | |
| [Try now](https://interfaze.ai/dashboard) or [Read paper](https://www.arxiv.org/abs/2602.04101) | |
| - OCR, web scraping, web search, classification and more | |
| - OpenAI chat completion API compatible | |
| - High accuracy structured output consistency | |
| - Built-in code execution and sandboxing | |
| - Custom web engine for scraping and web research capabilities | |
| - Auto reasoning when needed | |
| - Controllable guardrails | |
| - Fully managed and scalable | |
| - Globally distributed fallback system with high uptime | |
| ### Model Comparison | |
| | Benchmark | interfaze-beta | GPT-4.1 | Claude Sonnet 4 | Gemini 2.5 Flash | Claude Sonnet 4 (Thinking) | Claude Opus 4 (Thinking) | GPT-5-Minimal | Gemini-2.5-Pro | | |
| | --- | --- | --- | --- | --- | --- | --- | --- | --- | | |
| | MMLU-Pro | 83.6 | 80.6 | 83.7 | 80.9 | 83.7 | 86 | 80.6 | 86.2 | | |
| | MMLU | 91.38 | 90.2 | - | - | 88.8 | 89 | - | 89.2 | | |
| | MMMU | 77.33 | 74.8 | - | 79.7 | 74.4 | 76.5 | - | 82 | | |
| | AIME-2025 | 90 | 34.7 | 38 | 60.3 | 74.3 | 73.3 | 31.7 | 87.7 | | |
| | GPQA-Diamond | 81.31 | 66.3 | 68.3 | 68.3 | 77.7 | 79.6 | 67.3 | 84.4 | | |
| | LiveCodeBench | 57.77 | 45.7 | 44.9 | 49.5 | 65.5 | 63.6 | 55.8 | 75.9 | | |
| | ChartQA | 90.88 | - | - | - | - | - | - | - | | |
| | AI2D | 91.51 | 85.9 | - | - | - | - | - | 89.5 | | |
| | Common-Voice-v16 | 90.8 | - | - | - | - | - | - | - | | |
| \*Results for Non-Interfaze models are sourced from model providers, leaderboards, and evaluation providers such as Artificial Analysis. | |
| ### Works like any other LLM | |
| OpenAI API compatible, works with every AI SDK out of the box | |
| ``` | |
| import OpenAI from "openai"; | |
| const interfaze = new OpenAI({ | |
| baseURL: "https://api.interfaze.ai/v1", | |
| apiKey: "<your-api-key>" | |
| }); | |
| const completion = await interfaze.chat.completions.create({ | |
| model: "interfaze-beta", | |
| messages: [\ | |
| {\ | |
| role: "user",\ | |
| content: "Get the company description of JigsawStack from their linkedin page",\ | |
| },\ | |
| ], | |
| }); | |
| console.log(completion.choices[0].message.content); | |
| ``` | |
| ### OCR & Document Extraction | |
| [vision docs ->](https://interfaze.ai/docs/vision) | |
| ``` | |
| prompt = "Get the person information from the following ID." | |
| schema = z.object({ | |
| first_name: z.string(), | |
| last_name: z.string(), | |
| dob: z.string(), | |
| expiry: z.string(), | |
| }); | |
| ``` | |
|  | |
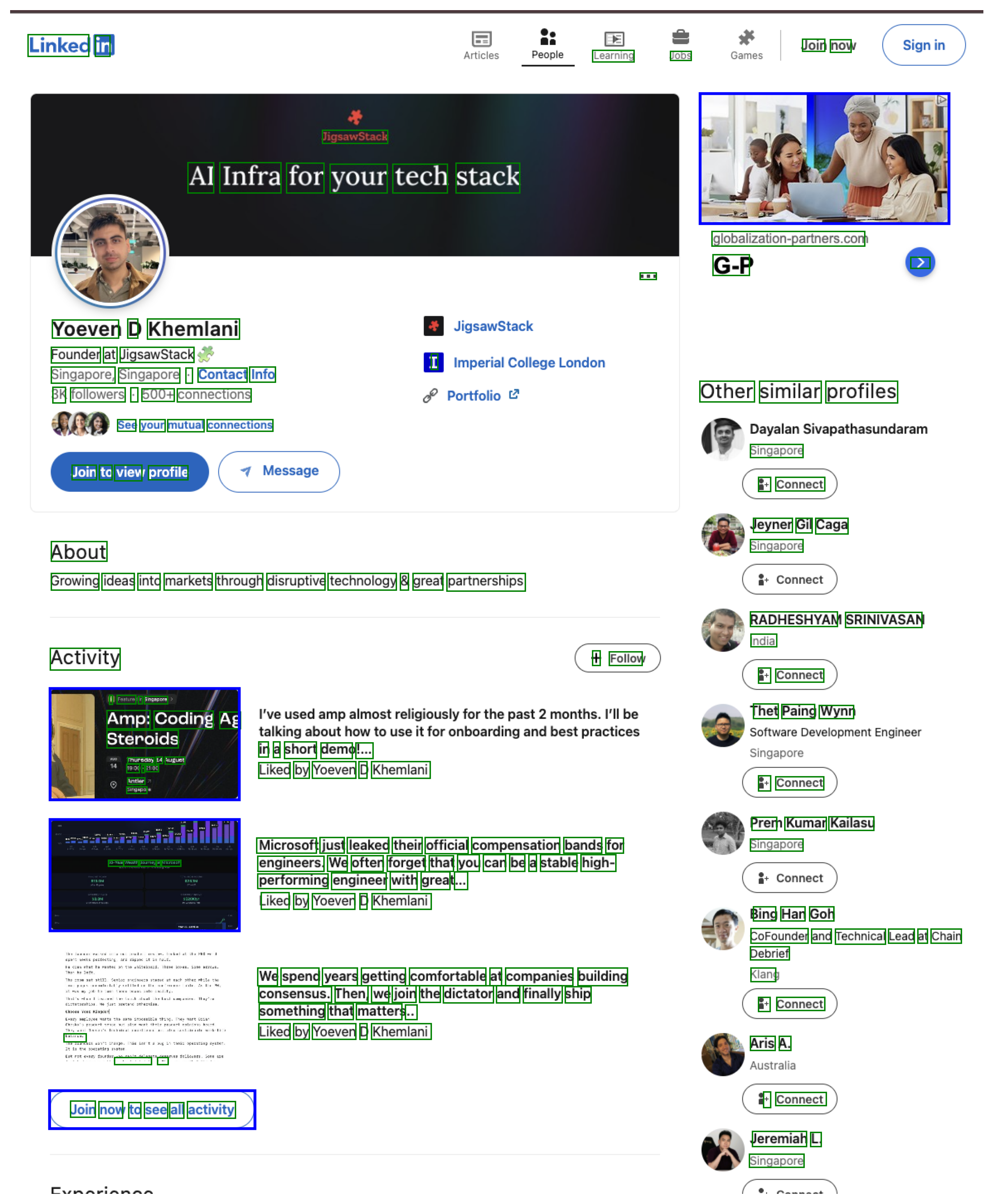
| ### Smart Web Scraping | |
| [web docs ->](https://interfaze.ai/docs/web) | |
| ``` | |
| prompt = "Extract the information from Yoeven D Khemlani's linkedin page based on the schema." | |
| schema = z.object({ | |
| first_name: z.string(), | |
| last_name: z.string(), | |
| about: z.string(), | |
| current_company: z.string(), | |
| current_position: z.string(), | |
| }); | |
| ``` | |
|  | |
| ### Translation | |
| [translation docs ->](https://interfaze.ai/docs/translation) | |
| ``` | |
| prompt = "The UK drinks about 100–160 million cups of tea every day, and 98% of tea drinkers add milk to their tea." | |
| schema = z.object({ | |
| zh: z.string(), | |
| hi: z.string(), | |
| es: z.string(), | |
| fr: z.string(), | |
| de: z.string(), | |
| it: z.string(), | |
| ja: z.string(), | |
| ko: z.string(), | |
| }); | |
| ``` | |
| ``` | |
| zh: 英国每天饮用约100–160百万杯茶,有98%的茶饮者在茶中加入牛奶。 | |
| hi: यूके हर दिन लगभग 100–160 मिलियन कप चाय पीता है, और 98% चाय पीने वाले अपनी चाय में दूध मिलाते हैं। | |
| es: El Reino Unido bebe alrededor de 100–160 millones de tazas de té cada día, y el 98 % de los consumidores de té añade leche a su té. | |
| fr: Le Royaume-Uni boit environ 100–160 millions de tasses de thé chaque jour, et 98 % des buveurs de thé ajoutent du lait à leur thé. | |
| de: Das Vereinigte Königreich trinkt etwa 100–160 Millionen Tassen Tee pro Tag, und 98 % der Teetrinker fügen ihrem Tee Milch hinzu. | |
| it: Il Regno Unito beve circa 100–160 milioni di tazze di tè ogni giorno e il 98% degli amanti del tè aggiunge latte al proprio tè. | |
| ja: イギリスでは毎日約100~160百万杯の紅茶が飲まれており、紅茶を飲む人の98%が紅茶に牛乳を加えます。 | |
| ko: 영국에서는 매일 약 1억 ~ 1억 6천만 잔의 차를 마시며, 차를 마시는 사람의 98%가 차에 우유를 넣습니다. | |
| ``` | |
| ### Speech-to-text (STT) and diarization | |
| [stt docs ->](https://interfaze.ai/docs/speech-to-text) | |
| ``` | |
| prompt = "Transcribe https://jigsawstack.com/preview/stt-example.wav" | |
| schema = z.object({ | |
| text: z.string(), | |
| speakers: z.object({ | |
| id: z.string(), | |
| start: z.number(), | |
| end: z.number() | |
| }) | |
| }); | |
| ``` | |
| ``` | |
| { | |
| "text": " The little tales they tell are false The door was barred, locked and bolted as well Ripe pears are fit for a queen's table A big wet stain was on the round carpet The kite dipped and swayed but stayed aloft The pleasant hours fly by much too soon The room was crowded with a mild wob The room was crowded with a wild mob This strong arm shall shield your honour She blushed when he gave her a white orchid The beetle droned in the hot June sun", | |
| "speakers": [\ | |
| {\ | |
| "start":0,\ | |
| "end":4.78,\ | |
| "id": "SPEAKER_00"\ | |
| },\ | |
| {\ | |
| "start":4.78,\ | |
| "end":9.48,\ | |
| "id": "SPEAKER_00"\ | |
| },\ | |
| {\ | |
| "start":9.48,\ | |
| "end":13.06,\ | |
| "id": "SPEAKER_00"\ | |
| },\ | |
| {\ | |
| "start":13.06,\ | |
| "end":17.24,\ | |
| "id": "SPEAKER_00"\ | |
| },\ | |
| {\ | |
| "start":17.24,\ | |
| "end":21.78,\ | |
| "id": "SPEAKER_00"\ | |
| },\ | |
| {\ | |
| "start":21.78,\ | |
| "end":26.3,\ | |
| "id": "SPEAKER_00"\ | |
| },\ | |
| {\ | |
| "start":26.3,\ | |
| "end":30.76,\ | |
| "id": "SPEAKER_00"\ | |
| },\ | |
| {\ | |
| "start":30.76,\ | |
| "end":35.08,\ | |
| "id": "SPEAKER_00"\ | |
| },\ | |
| {\ | |
| "start":35.08,\ | |
| "end":39.24,\ | |
| "id": "SPEAKER_00"\ | |
| },\ | |
| {\ | |
| "start":39.24,\ | |
| "end":43.94,\ | |
| "id": "SPEAKER_00"\ | |
| },\ | |
| {\ | |
| "start":43.94,\ | |
| "end":48.5,\ | |
| "id": "SPEAKER_00"\ | |
| }\ | |
| ] | |
| } | |
| ``` | |
| ### Configurable guardrails and NSFW checks | |
| [guardrails docs ->](https://interfaze.ai/docs/guard-rails) | |
| Fully configurable guardrails for text and images | |
| ``` | |
| S1: Violent Crimes | |
| S2: Non-Violent Crimes | |
| S3: Sex-Related Crimes | |
| S4: Child Sexual Exploitation | |
| S5: Defamation | |
| S6: Specialized Advice | |
| S7: Privacy | |
| S8: Intellectual Property | |
| S9: Indiscriminate Weapons | |
| S10: Hate | |
| S11: Suicide & Self-Harm | |
| S12: Sexual Content | |
| S12_IMAGE: Sexual Content (Image) | |
| S13: Elections | |
| S14: Code Interpreter Abuse | |
| ``` | |
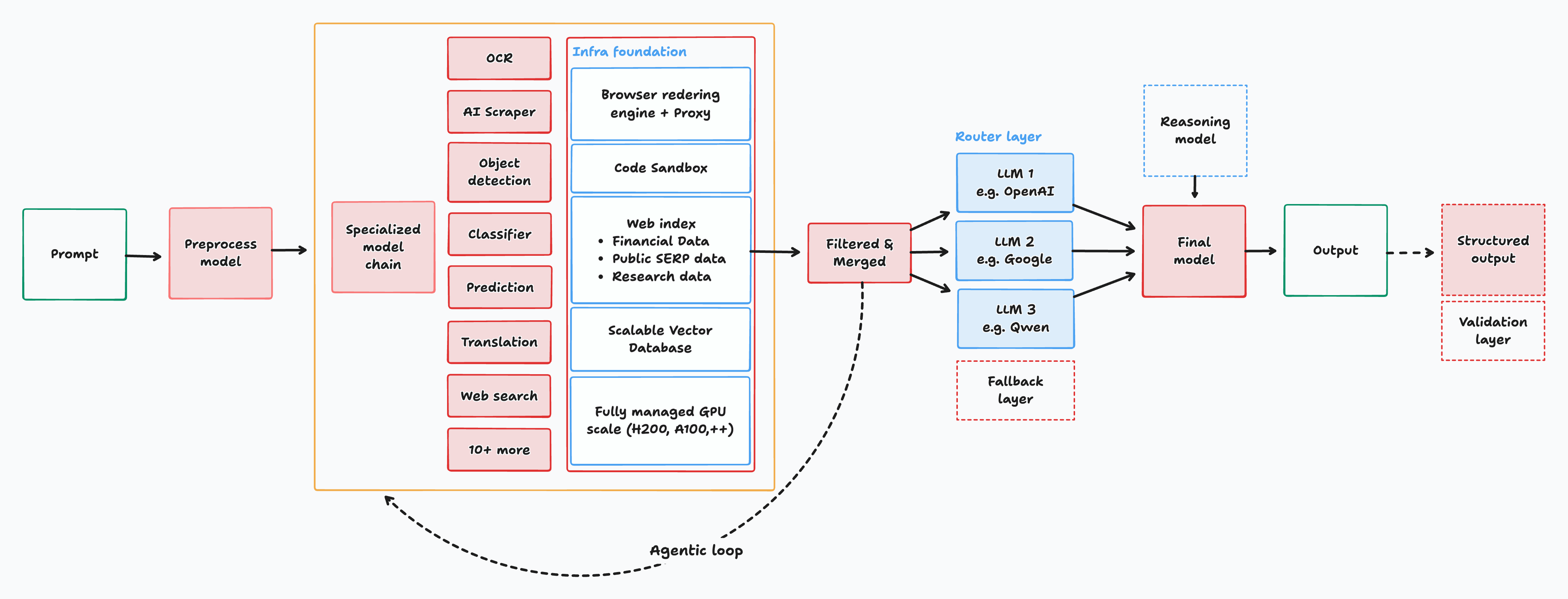
| ### Architecture | |
| [read paper ->](https://www.arxiv.org/abs/2602.04101) | |
| This architecture combines a suite of small specialized models supported with custom tools and infrastructure while automatically routing to the best model for the task that prioritizes accuracy and speed. | |
|  | |
| ### Specs | |
| - Context window: 1m tokens | |
| - Max output tokens: 32k tokens | |
| - Input modalities: Text, Images, Audio, File, Video | |
| - Reasoning: Available | |
| ### Research references | |
| - [Interfaze: The Future of AI is built on Task-Specific Small Models](https://www.arxiv.org/abs/2602.04101) | |
| - [Agentic Context Engineering](https://www.arxiv.org/pdf/2510.04618) | |
| - [Small Language Models are the Future of Agentic AI](https://arxiv.org/pdf/2506.02153) | |
| - [The Sparsely-Gated Mixture-of-Experts Layer](https://arxiv.org/pdf/1701.06538) | |
| - [DeepSeekMoE](https://arxiv.org/pdf/2401.06066) | |
| - [Confronting LLMs with Traditional ML](https://arxiv.org/pdf/2310.14607) | |
| ### Who are we? | |
| We are a small team of ML, Software and Infrastructure engineers engrossed in the fact that a small model can do a lot more when specialized. Allowing us to make AI available in every dev workflow. |