Spaces:
Runtime error

title: Credit scoring MLOps
emoji: 🤖
colorFrom: indigo
colorTo: green
sdk: docker
app_port: 7860
pinned: false
Credit scoring MLOps



Structure rapide
app/API FastAPI + preprocessing inferencemonitoring/rapport drift + Streamlitnotebooks/exploration + modelisationsrc/utilitaires ML (feature engineering / pipeline)docs/preuves & rapports (monitoring, perf)tests/tests unitaires/integration
Le feature engineering est factorise dans src/features.py et reutilise
par le notebook et l'API pour eviter le training-serving skew.
Lancer MLFlow
Le notebook est configure pour utiliser un serveur MLflow local (http://127.0.0.1:5000).
Pour voir les runs et creer l'experiment, demarrer le serveur avec le meme backend :
mlflow server \
--host 127.0.0.1 \
--port 5000 \
--backend-store-uri "file:${PWD}/mlruns" \
--default-artifact-root "file:${PWD}/mlruns"
Seulement l'interface (sans API), lancer :
mlflow ui --backend-store-uri "file:${PWD}/mlruns" --port 5000
Pour tester le serving du modele en staging :
mlflow models serve -m "models:/credit_scoring_model/Staging" -p 5001 --no-conda
API FastAPI
L'API attend un payload JSON avec une cle data. La valeur peut etre un objet unique (un client) ou une liste d'objets (plusieurs clients). La liste des features requises (jeu reduit) est disponible via l'endpoint /features. Les autres champs sont optionnels et seront completes par des valeurs par defaut.
Inputs minimums (10 + SK_ID_CURR) derives d'une selection par correlation (voir /features) :
EXT_SOURCE_2EXT_SOURCE_3AMT_ANNUITYEXT_SOURCE_1CODE_GENDERDAYS_EMPLOYEDAMT_CREDITAMT_GOODS_PRICEDAYS_BIRTHFLAG_OWN_CAR
Parametres utiles (selection des features) :
FEATURE_SELECTION_METHOD(defaut:correlation)FEATURE_SELECTION_TOP_N(defaut:8)FEATURE_SELECTION_MIN_CORR(defaut:0.02)
Environnement pip (dev)
Le developpement local utilise pip et requirements.txt (versions figees),
avec Python 3.11+.
python3 -m venv .venv
source .venv/bin/activate
python -m pip install -r requirements.txt
pytest -q
uvicorn app.main:app --reload --port 7860
Workflow DEV (notebooks)
Ordre recommande (dev uniquement) :
notebooks/P6_MANET_Stephane_notebook_exploration.ipynb→ generedata/data_final.parquet(ecrase).notebooks/P6_MANET_Stephane_notebook_compare_tuning_mlflow.ipynb→ compare+tuning, log MLflow, ecritreports/best_model.json.notebooks/P6_MANET_Stephane_notebook_modélisation.ipynb→ rebuild preprocessor, entraine le modele final, exportedata/<model>_final_model.pkl.- Lancer manuellement le workflow
deploy-assets.ymlpour pousserdata/*_final_model.pkl.
Note : ces notebooks restent dev-only. Le code prod reste dans app/ et monitoring/.
Configuration (.env)
Dupliquez .env.example en .env si vous voulez surcharger les chemins,
seuils ou sources Hugging Face.
Le seuil MISSING_INDICATOR_MIN_RATE limite les colonnes is_missing_*
aux features avec un taux de NaN >= 5% (par defaut).
cp .env.example .env
Environnement Poetry (livrable)
Le livrable inclut pyproject.toml, aligne sur requirements.txt. Si besoin :
poetry install --with dev
poetry run pytest -q
poetry run uvicorn app.main:app --reload --port 7860
Important : le modele *_final_model.pkl doit etre regenere avec la
version de scikit-learn definie dans requirements.txt / pyproject.toml
(re-execution de notebooks/P6_MANET_Stephane_notebook_modélisation.ipynb, cellule de
sauvegarde pickle).
Exemple d'input (schema + valeurs)
Schema :
{
"data": {
"SK_ID_CURR": "int",
"EXT_SOURCE_2": "float",
"EXT_SOURCE_3": "float",
"AMT_ANNUITY": "float",
"EXT_SOURCE_1": "float",
"CODE_GENDER": "str",
"DAYS_EMPLOYED": "int",
"AMT_CREDIT": "float",
"AMT_GOODS_PRICE": "float",
"DAYS_BIRTH": "int",
"FLAG_OWN_CAR": "str"
}
}
Valeurs d'exemple :
{
"data": {
"SK_ID_CURR": 100002,
"EXT_SOURCE_2": 0.61,
"EXT_SOURCE_3": 0.75,
"AMT_ANNUITY": 24700.5,
"EXT_SOURCE_1": 0.45,
"CODE_GENDER": "M",
"DAYS_EMPLOYED": -637,
"AMT_CREDIT": 406597.5,
"AMT_GOODS_PRICE": 351000.0,
"DAYS_BIRTH": -9461,
"FLAG_OWN_CAR": "N"
}
}
Prediction minimale (client existant)
Endpoint POST /predict-minimal : l'utilisateur fournit un identifiant client,
un montant de credit et une duree. Les autres features sont prises depuis la
reference clients (CUSTOMER_DATA_PATH, par defaut data/data_final.parquet).
Si la reference est absente, l'API renvoie 503.
curl -s -X POST "${BASE_URL}/predict-minimal" \
-H "Content-Type: application/json" \
-d '{
"sk_id_curr": 100001,
"amt_credit": 200000,
"duration_months": 60
}'
Variables utiles :
CUSTOMER_LOOKUP_ENABLED=1active la recherche client (defaut: 1)CUSTOMER_DATA_PATH=data/data_final.parquetCUSTOMER_LOOKUP_CACHE=1garde la reference en memoire
Data contract (validation)
- Types numeriques stricts (invalides -> 422).
- Ranges numeriques (min/max entrainement) controles, hors
SK_ID_CURR(ID). - Categoriels normalises:
CODE_GENDER-> {F,M},FLAG_OWN_CAR-> {Y,N}. - Sentinelle
DAYS_EMPLOYED=365243remplacee par NaN + flagDAYS_EMPLOYED_ANOM. - Ratios securises (division par zero) + flags
DENOM_ZERO_*. - Outliers clippees (p1/p99) + flags
is_outlier_*. - Missingness indicators
is_missing_*pour les numeriques avec taux de NaN >= 5%. - Logs enrichis via
data_qualityetsourcepour distinguer drift vs qualite de donnees.
Interface Gradio (scoring)
python gradio_app.py
Sur Hugging Face Spaces, app.py lance l'UI Gradio automatiquement.
Note : l'API valide strictement les champs requis (/features). Pour afficher
toutes les colonnes possibles : /features?include_all=true.
Hugging Face (assets lourds)
Les fichiers binaires (modele, preprocessor, data_final) ne sont pas pushes dans le Space. Ils sont telecharges a l'execution via Hugging Face Hub si les variables suivantes sont definies :
HF_MODEL_REPO_ID+HF_MODEL_FILENAME+HF_MODEL_REPO_TYPEHF_PREPROCESSOR_REPO_ID+HF_PREPROCESSOR_FILENAME+HF_PREPROCESSOR_REPO_TYPEHF_CUSTOMER_REPO_ID+HF_CUSTOMER_FILENAME+HF_CUSTOMER_REPO_TYPE
Exemple (un seul repo dataset avec 3 fichiers) :
HF_MODEL_REPO_ID=stephmnt/assets-credit-scoring-mlopsHF_MODEL_REPO_TYPE=datasetHF_MODEL_FILENAME=histgb_final_model.pkl(oulgbm_final_model.pkl/xgb_final_model.pkl)HF_PREPROCESSOR_REPO_ID=stephmnt/assets-credit-scoring-mlopsHF_PREPROCESSOR_REPO_TYPE=datasetHF_PREPROCESSOR_FILENAME=preprocessor.joblibHF_CUSTOMER_REPO_ID=stephmnt/assets-credit-scoring-mlopsHF_CUSTOMER_REPO_TYPE=datasetHF_CUSTOMER_FILENAME=data_final.parquet
Demo live (commandes cles en main)
Lancer l'API (sans UI) :
uvicorn app.main:app --reload --port 7860
Lancer l'UI Gradio + API (chemin /api) :
uvicorn app:app --reload --port 7860
Verifier le service (HF) :
BASE_URL="https://stephmnt-credit-scoring-mlops.hf.space"
API_BASE="${BASE_URL}/api"
curl -s "${API_BASE}/health"
Note : sur HF Spaces, l'UI Gradio est a la racine, l'API est sous /api.
Voir les features attendues (HF) :
curl -s "${API_BASE}/features"
Predire un client (HF) :
curl -s -X POST "${API_BASE}/predict?threshold=0.5" \
-H "Content-Type: application/json" \
-d '{
"data": {
"SK_ID_CURR": 100002,
"EXT_SOURCE_2": 0.61,
"EXT_SOURCE_3": 0.75,
"AMT_ANNUITY": 24700.5,
"EXT_SOURCE_1": 0.45,
"CODE_GENDER": "M",
"DAYS_EMPLOYED": -637,
"AMT_CREDIT": 406597.5,
"AMT_GOODS_PRICE": 351000.0,
"DAYS_BIRTH": -9461,
"FLAG_OWN_CAR": "N"
}
}'
Predire plusieurs clients (batch, HF) :
curl -s -X POST "${API_BASE}/predict?threshold=0.45" \
-H "Content-Type: application/json" \
-d '{
"data": [
{
"SK_ID_CURR": 100002,
"EXT_SOURCE_2": 0.61,
"EXT_SOURCE_3": 0.75,
"AMT_ANNUITY": 24700.5,
"EXT_SOURCE_1": 0.45,
"CODE_GENDER": "M",
"DAYS_EMPLOYED": -637,
"AMT_CREDIT": 406597.5,
"AMT_GOODS_PRICE": 351000.0,
"DAYS_BIRTH": -9461,
"FLAG_OWN_CAR": "N"
},
{
"SK_ID_CURR": 100003,
"EXT_SOURCE_2": 0.52,
"EXT_SOURCE_3": 0.64,
"AMT_ANNUITY": 19000.0,
"EXT_SOURCE_1": 0.33,
"CODE_GENDER": "F",
"DAYS_EMPLOYED": -1200,
"AMT_CREDIT": 320000.0,
"AMT_GOODS_PRICE": 280000.0,
"DAYS_BIRTH": -12000,
"FLAG_OWN_CAR": "Y"
}
]
}'
Exemple d'erreur (champ requis manquant, HF) :
curl -s -X POST "${API_BASE}/predict" \
-H "Content-Type: application/json" \
-d '{
"data": {
"EXT_SOURCE_2": 0.61
}
}'
Monitoring & Data Drift (Etape 3)
L'API enregistre les appels /predict en JSONL (inputs, outputs, latence).
Par defaut, les logs sont stockes dans logs/predictions.jsonl.
Variables utiles :
LOG_PREDICTIONS=1active l'ecriture des logs (defaut: 1)LOG_DIR=logsLOG_FILE=predictions.jsonlLOGS_ACCESS_TOKENpour proteger l'endpoint/logsLOG_HASH_SK_ID=1pour anonymiserSK_ID_CURR
Les logs incluent un bloc data_quality par requete (champs manquants,
types invalides, out-of-range, outliers, categories inconnues, sentinelle
DAYS_EMPLOYED) et un champ source (api/gradio/etc.).
Astuce : vous pouvez passer un header X-Client-Source pour tagger la source
des requetes (ex: gradio, test, batch).
Exemple local :
LOG_PREDICTIONS=1 LOG_DIR=logs uvicorn app.main:app --reload --port 7860
Recuperer les logs (HF) :
Configurer LOGS_ACCESS_TOKEN dans les secrets du Space, puis :
curl -s -H "X-Logs-Token: $LOGS_ACCESS_TOKEN" "${API_BASE}/logs?tail=200"
Alternative :
curl -s -H "Authorization: Bearer $LOGS_ACCESS_TOKEN" "${API_BASE}/logs?tail=200"
Apres quelques requêtes, générer le rapport de drift :
python monitoring/drift_report.py \
--logs logs/predictions.jsonl \
--reference data/data_final.parquet \
--output-dir reports \
--min-prod-samples 50 \
--fdr-alpha 0.05 \
--prod-since "2024-01-01T00:00:00Z" \
--prod-until "2024-01-31T23:59:59Z"
Le rapport HTML est généré dans reports/drift_report.html (avec des plots dans
reports/plots/). Sur Hugging Face, le disque est éphemère : télécharger les logs
avant d'analyser.
Le drift est calcule uniquement si n_prod >= --min-prod-samples (defaut 50).
Sinon, un badge "Sample insuffisant" est affiche et les alertes sont desactivees.
Robustesse integree:
- Categoriels: PSI avec lissage (
--psi-eps) + categories rares regroupees (OTHER). - Numeriques: KS corrige par FDR (Benjamini-Hochberg,
--fdr-alpha). - Sentinel
DAYS_EMPLOYED: converti en NaN + taux suivi. - Outliers: clipping p1/p99 + taux via
data_quality.
Le rapport inclut aussi la distribution des scores predits et le taux de prediction
(option --score-bins pour ajuster le nombre de bins), ainsi qu'une section
Data Quality si les logs contiennent data_quality (types, NaN, out-of-range,
categories inconnues).
Pour simuler des fenetres glissantes, utiliser --prod-since / --prod-until
avec les timestamps des logs.
Runbook drift: docs/monitoring/runbook.md.
Captures (snapshot local du reporting + stockage):
- Rapport:
docs/monitoring/drift_report.html+docs/monitoring/plots/ - Stockage des logs:
docs/monitoring/logs_storage.png
Profiling & Optimisation (Etape 4)
Profiling et benchmark d'inference (cProfile + latence):
- Notebook:
notebooks/P6_MANET_Stephane_notebook_modélisation.ipynb(section TODO 5). - Resultats:
docs/performance/benchmark_results.json,docs/performance/profile_summary.txt,docs/performance/performance_report.md.
Dashboard local Streamlit (monitoring + drift):
streamlit run monitoring/streamlit_app.py
# ou
python -m streamlit run monitoring/streamlit_app.py
Contenu de la release
- Preparation + pipeline : nettoyage / preparation, encodage, imputation et pipeline d'entrainement presentes.
- Gestion du desequilibre : un sous-echantillonnage est applique sur le jeu d'entrainement final.
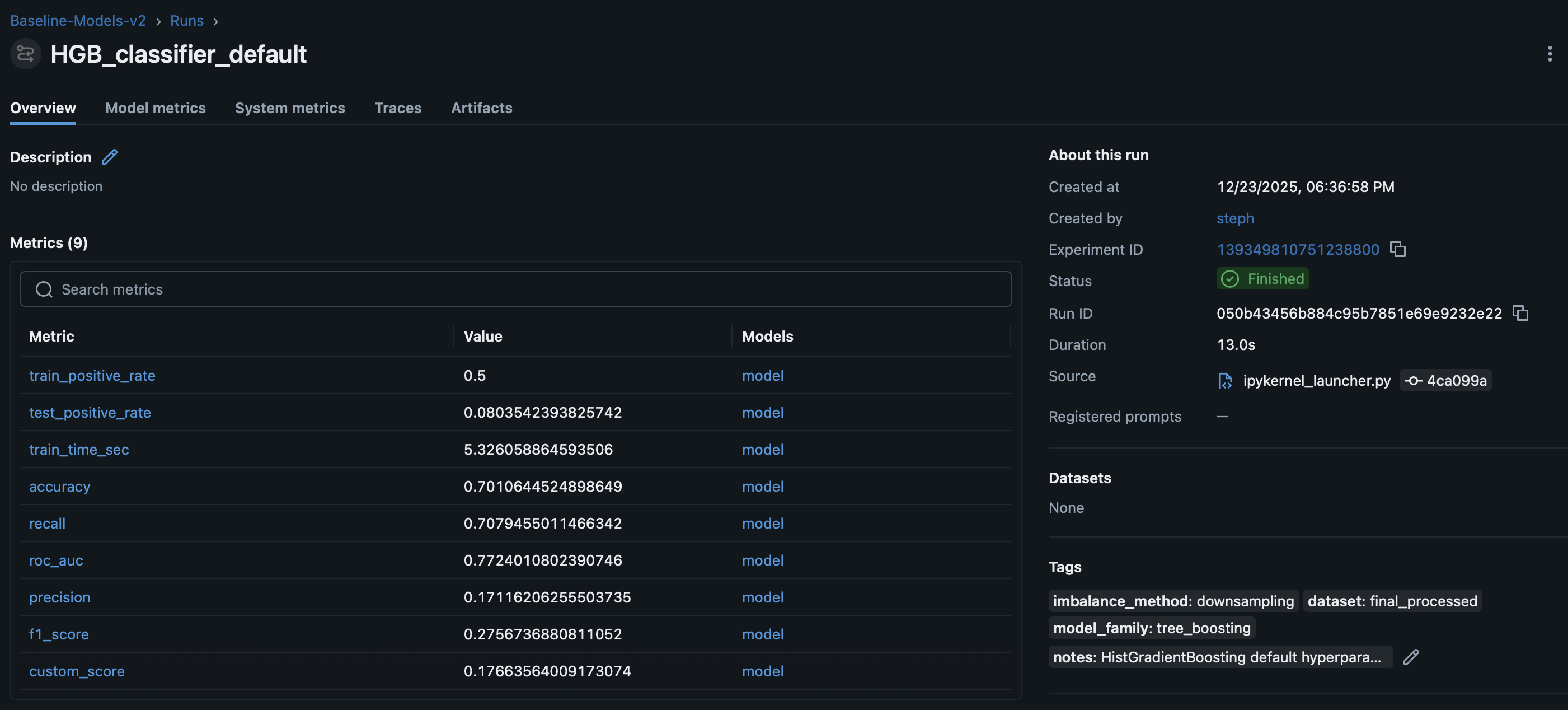
- Comparaison multi-modeles : baseline, Naive Bayes, Logistic Regression, Decision Tree, Random Forest, HistGradientBoosting, LGBM, XGB sont compares.
- Validation croisee + tuning :
StratifiedKFold,GridSearchCVet Hyperopt sont utilises. - Score metier + seuil optimal : le
custom_scoreest la metrique principale des tableaux de comparaison et de la CV, avec unbest_thresholdcalcule. - Explicabilite : feature importance, SHAP et LIME sont inclus.
- Selection de features par correlation : top‑N numeriques + un petit set categoriel, expose via
/features. - Interface Gradio : formulaire minimal (id client + montant + duree) base sur la reference clients.
- Monitoring & drift : rapport HTML avec gating par volume, PSI robuste, KS + FDR, data quality et
distribution des scores (snapshots dans
docs/monitoring/). - Profiling & optimisation : benchmark d'inference + profil cProfile (dossier
docs/performance/). - CI/CD : tests avec couverture (
pytest-cov), build Docker et deploy vers Hugging Face Spaces.