
PaCoRe
Collection
Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning • 4 items • Updated • 12
We introduce PaCoRe (Parallel Coordinated Reasoning), a framework that shifts the driver of inference from sequential depth to coordinated parallel breadth, breaking the model context limitation and massively scaling test time compute:
Trained via large-scale, outcome-based reinforcement learning, PaCoRe masters the Reasoning Synthesis capabilities required to reconcile diverse parallel insights.
The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5’s 93.2% by scaling effective TTC to roughly two million tokens.
We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work!
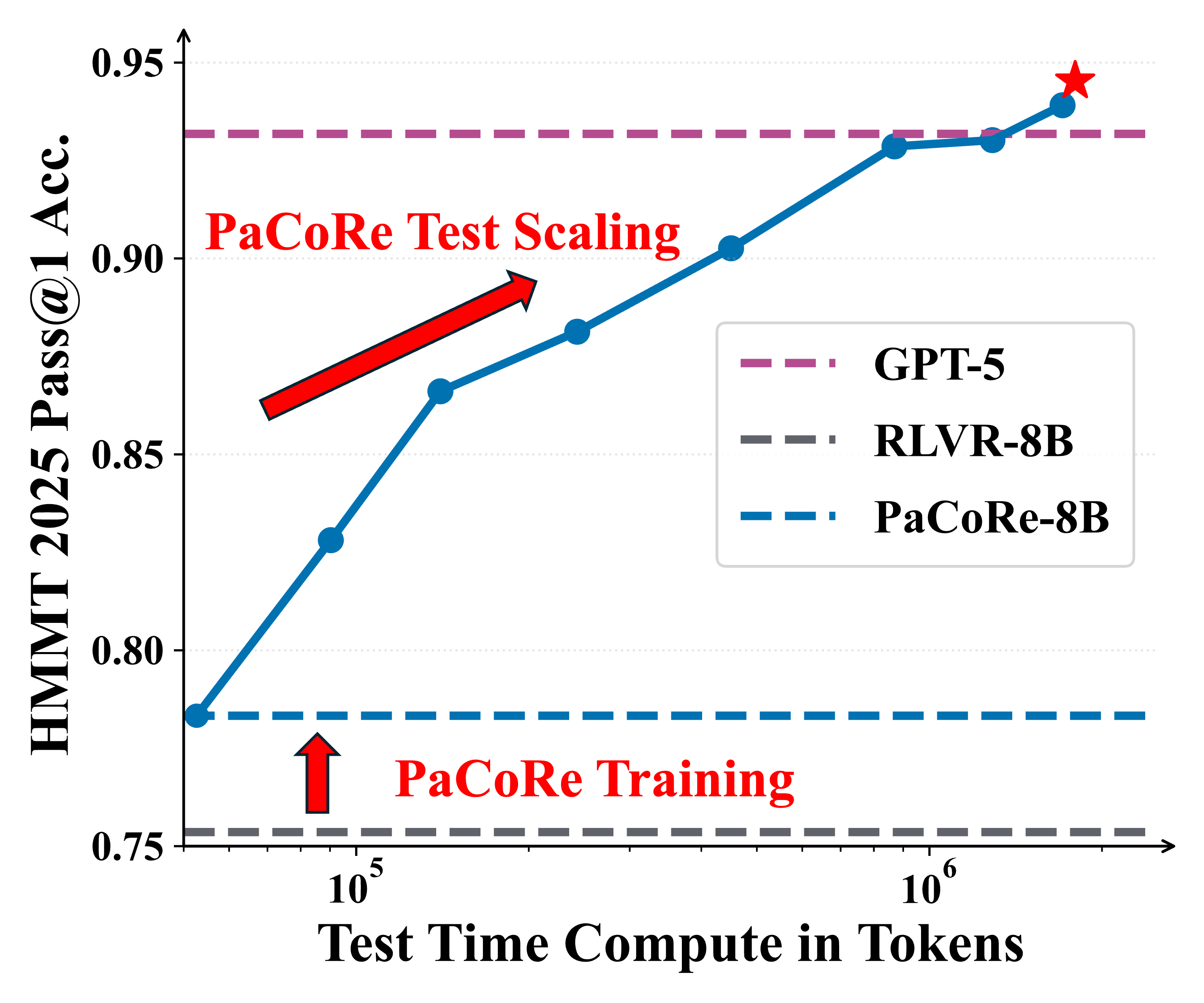
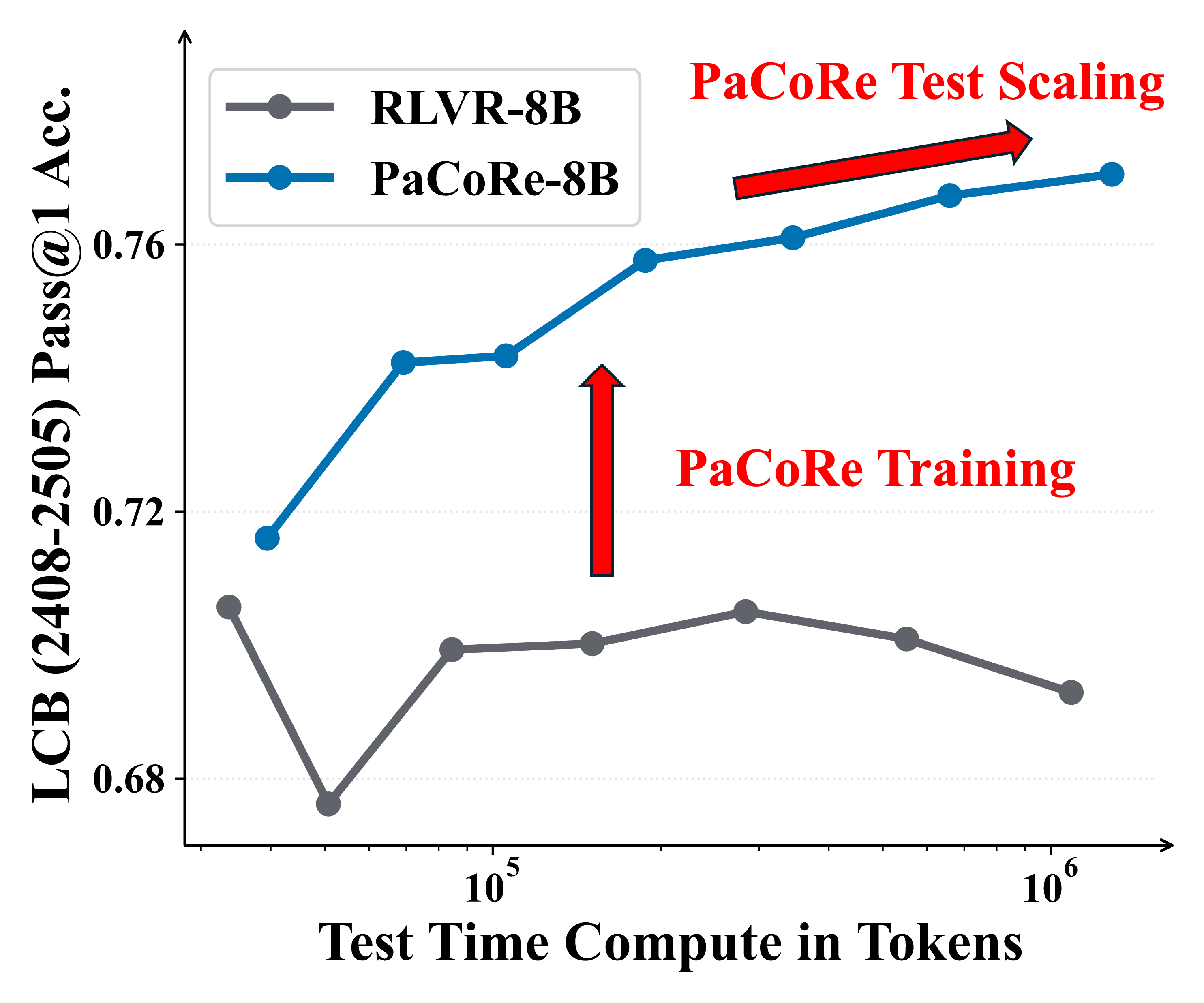
Figure 1 | Parallel Coordinated Reasoning (PaCoRe) performance. Left: On HMMT 2025, PaCoRe-8B demonstrates remarkable test-time scaling, yielding steady gains and ultimately surpassing GPT-5. Right: On LiveCodeBench, the RLVR-8B model fails to leverage increased test-time compute, while PaCoRe-8B model effectively unlocks substantial gains as the test-time compute increases.
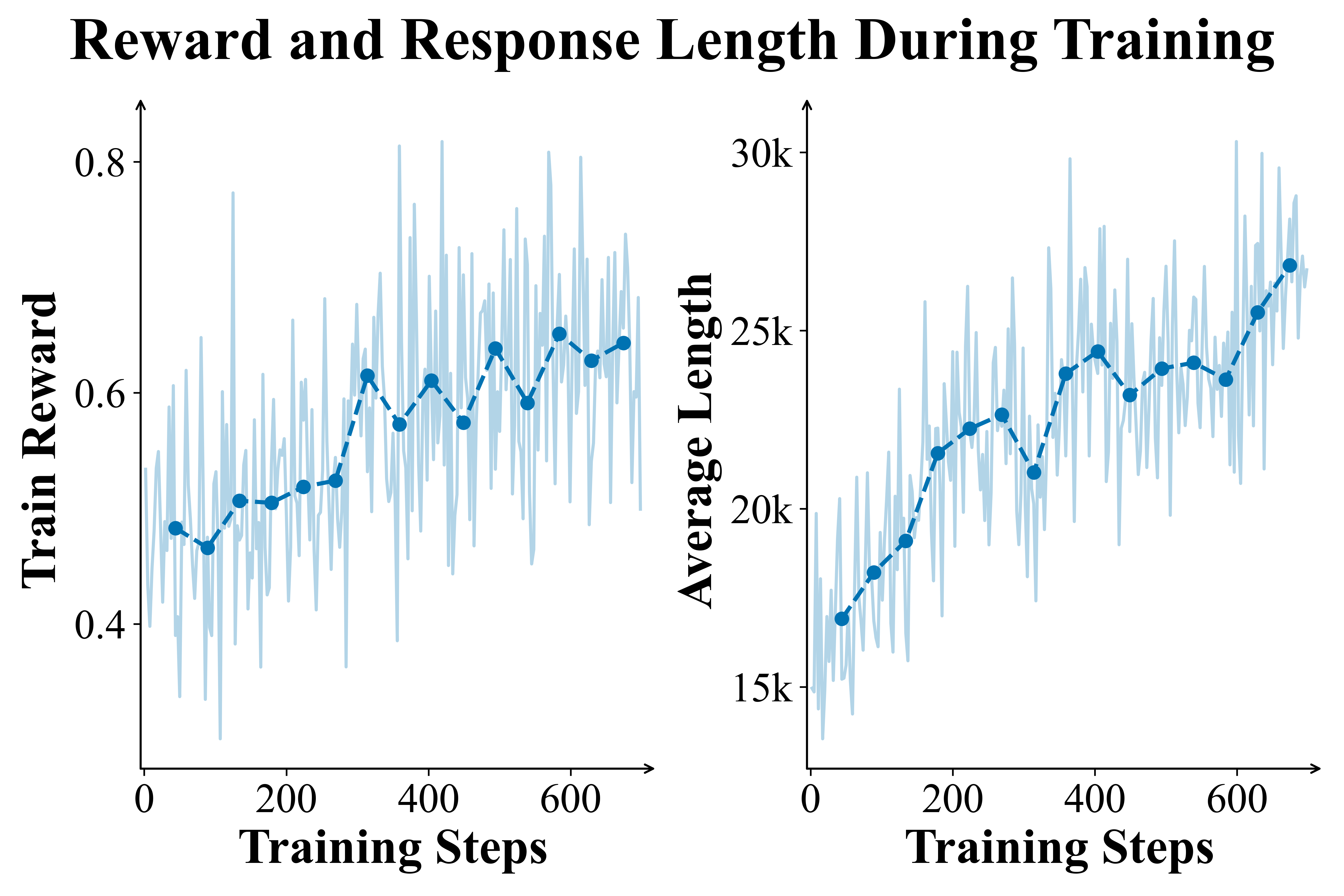
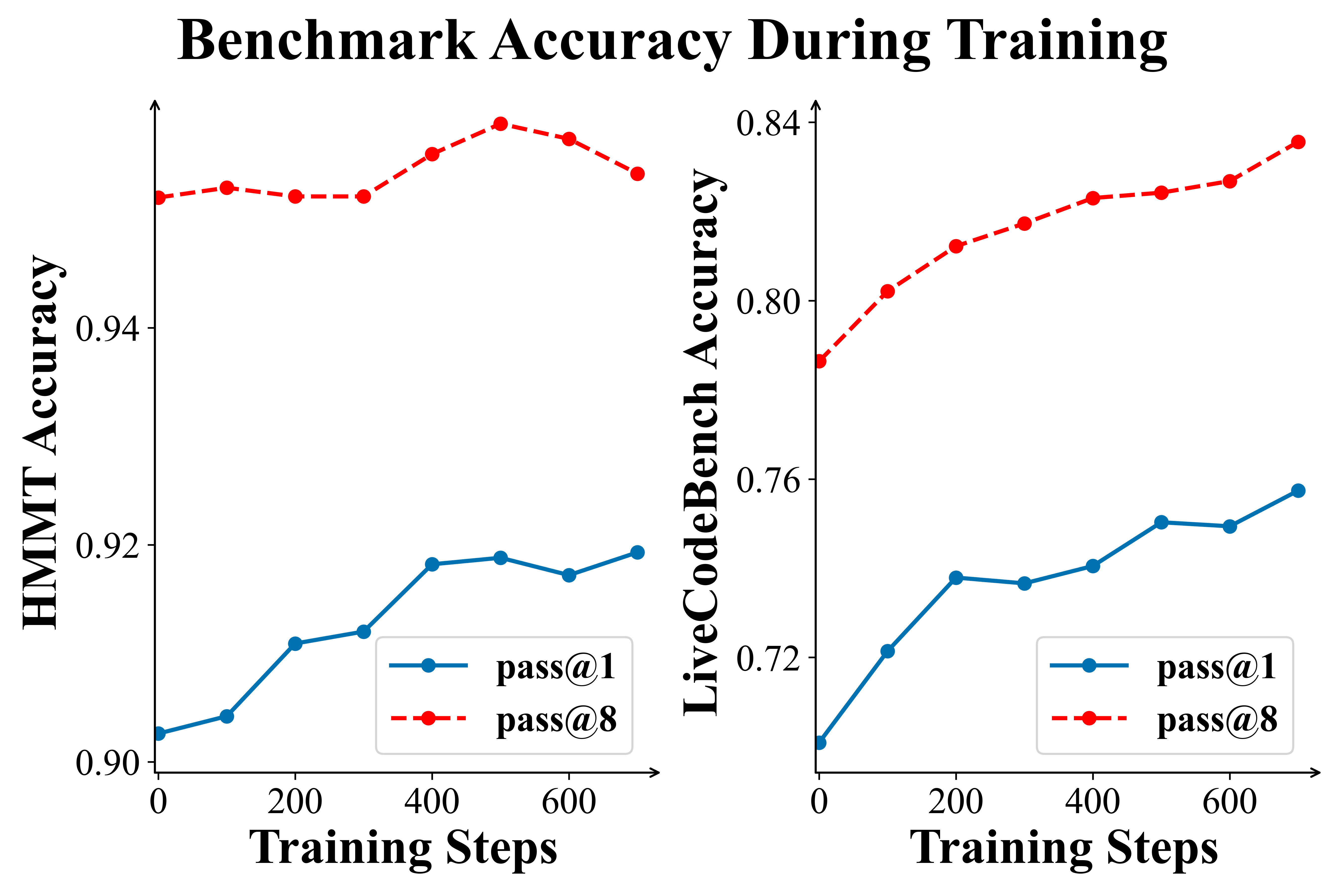
Figure 2 | PaCoRe Training dynamics. Left panels: The Training Reward and Response Length steadily increase, demonstrating the training stability and effectiveness. Right panels: Evaluation on HMMT 2025 and LiveCodeBench (2408-2505). Performance is reported using single round coordinated reasoning in PaCoRe inference setting with $\vec{K} = [16]$.
[2025/12/09] We are excited to release the PaCoRe-8B ecosystem:
opensource_math, public_mathcontest, synthetic_math and code: | HMMT 2025 | LiveCodeBench (2408-2505) | HLEtext | MultiChallenge | |
|---|---|---|---|---|
| GPT-5 | 93.2 (16k) | 83.5 (13k) | 26.0 (14k) | 71.1 (5.0k) |
| Qwen3-235B-Thinking | 82.3 (32k) | 74.5 (21k) | 18.2 (23k) | 60.3 (1.6k) |
| GLM-4.6 | 88.7 (25k) | 79.5 (19k) | 17.2 (21k) | 54.9 (2.2k) |
| DeepSeek-v3.1-Terminus | 86.1 (20k) | 74.9 (11k) | 19.3 (18k) | 54.4 (1.1k) |
| Kimi-K2-Thinking | 86.5 (33k) | 79.2 (25k) | 23.9 (29k) | 66.4 (1.7k) |
| RLVR-8B | 75.4 (48k) | 70.6 (34k) | 9.3 (35k) | 33.3 (1.7k) |
| PaCoRe-8B (low) | 88.2 (243k) | 75.8 (188k) | 13.0 (196k) | 41.8 (13k) |
| PaCoRe-8B (medium) | 92.9 (869k) | 76.7 (659k) | 14.6 (694k) | 45.7 (45k) |
| PaCoRe-8B (high) | 94.5 (1796k) | 78.2 (1391k) | 16.2 (1451k) | 47.0 (95k) |
Table 1 | For each benchmark, we report accuracy together with total TTC (in thousands). For Low, Medium, and High, we apply the inference trajectory configuration as $\vec{K}=[4]$, $[16]$, and $[32, 4]$ separately.
First, install the package from the official repository:
pip install -e .
You can directly use vllm serve to serve the model:
vllm serve stepfun-ai/PaCoRe-8B
Next, you can run our example inference code with PaCoRe-low inference setting:
python playground/example_batch_inference_pacore_low_1210.py
@misc{pacore2025,
title={PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning},
author={Jingcheng Hu and Yinmin Zhang and Shijie Shang and Xiaobo Yang and Yue Peng and Zhewei Huang and Hebin Zhou and Xin Wu and Jie Cheng and Fanqi Wan and Xiangwen Kong and Chengyuan Yao and Kaiwen Yan and Ailin Huang and Hongyu Zhou and Qi Han and Zheng Ge and Daxin Jiang and Xiangyu Zhang and Heung-Yeung Shum},
year={2026},
eprint={2601.05593},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2601.05593},
}